CaoE [Tue, 10 Aug 2021 20:21:22 +0000 (13:21 -0700)]
Add BFloat16 support for unique and unique_consecutive on CPU (#62559)
Summary:
Add BFloat16 support for unique and unique_consecutive on CPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62559
Reviewed By: anjali411
Differential Revision:
D30199482
Pulled By: ngimel
fbshipit-source-id:
6f2d9cc1a528bea7c723139a4f1b14e4b2213601
Jerry Zhang [Tue, 10 Aug 2021 19:16:00 +0000 (12:16 -0700)]
[quant][refactor] Checking activation_dtype instead of activation_post_process (#62489)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62489
Addressing comment from previous PR: https://github.com/pytorch/pytorch/pull/62374#discussion_r679354145
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: iramazanli
Differential Revision:
D30053980
fbshipit-source-id:
79c216410282eccd6f0a8f24e38c55c4d18ec0d0
Raghav Kansal [Tue, 10 Aug 2021 17:59:43 +0000 (10:59 -0700)]
LU solve uses cuBLAS and cuSOLVER for matrices with dim > 1024 (#61815)
Summary:
This PR builds off of https://github.com/pytorch/pytorch/issues/59148 and modifies the `lu_solve` routine to avoid MAGMA for `b` or `lu_data` matrices with any dimension > 1024, since MAGMA has a bug when dealing with such matrices (https://bitbucket.org/icl/magma/issues/19/dgesv_batched-dgetrs_batched-fails-for).
Fixes https://github.com/pytorch/pytorch/issues/36921
Fixes https://github.com/pytorch/pytorch/issues/61929
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61815
Reviewed By: anjali411
Differential Revision:
D30199618
Pulled By: ngimel
fbshipit-source-id:
06870793f697e9c35aaaa8254b8a8b1a38bd3aa9
Wanchao Liang [Tue, 10 Aug 2021 17:56:41 +0000 (10:56 -0700)]
[sharded_tensor] add default fields to ShardedTensorMetadata (#62867)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62867
This add default fields for ShardedTensorMetadata, to allow easy construction and modification afterwards.
ghstack-source-id:
135284133
Test Plan: ShardedTensorMetadata validity should be guarded with `init_from_local_shards` API and its tests.
Reviewed By: pritamdamania87
Differential Revision:
D30148481
fbshipit-source-id:
0d99f41f23dbeb4201a36109556ba23b9a6c6fb1
Rohan Varma [Tue, 10 Aug 2021 17:46:50 +0000 (10:46 -0700)]
[DDP] Dont set thread local state in reducer autograd hook. (#62996)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62996
No need to set this because autograd engine already propagates TLS
states.
ghstack-source-id:
135438220
Test Plan: CI
Reviewed By: albanD
Differential Revision:
D30202078
fbshipit-source-id:
e5e917269a03afd7a6b8e61f28b45cdb71ac3e64
Pyre Bot Jr [Tue, 10 Aug 2021 17:22:43 +0000 (10:22 -0700)]
[typing] suppress errors in `fbcode/caffe2` - batch 2
Test Plan: Sandcastle
Differential Revision:
D30222378
fbshipit-source-id:
6a0a5d210266f19de63273240a080365c9143eb0
Elias Ellison [Tue, 10 Aug 2021 16:40:41 +0000 (09:40 -0700)]
Test shape analysis with opinfos (#59814)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59814
Using opinfos to test shape analysis. By default, we just check that we don't give incorrect answers, and then if `assert_jit_shape_analysis` is true, tests that we correctly propagates the full shape. and it found a couple bugs {emoji:1f603}
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision:
D30200058
Pulled By: eellison
fbshipit-source-id:
6226be87f5390277cfa5a1fffaa1b072d4bc8803
Elias Ellison [Tue, 10 Aug 2021 16:40:41 +0000 (09:40 -0700)]
add ssupport for a few more opinfos in jit (#59812)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59812
This is sort of a half measure: we can successfully trace through opinfos which are registered as lambdas, we just can't script them. This tests if the op is a lambda in which case bails... see the next PR to get resize_ to work, maybe this should be consolidated with that...
Test Plan: Imported from OSS
Reviewed By: pbelevich, zhxchen17
Differential Revision:
D30200061
Pulled By: eellison
fbshipit-source-id:
7e3c9b0be746b16f0f57ece49f6fbe20bf6535ec
Elias Ellison [Tue, 10 Aug 2021 16:40:41 +0000 (09:40 -0700)]
Don't substitute in symbolic shapes to shape compute graph (#59811)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59811
We don't want to actually substitute in symbolic shapes, because it invalidates the partially evaluated graph for further use.
Test Plan: Imported from OSS
Reviewed By: pbelevich, zhxchen17
Differential Revision:
D30200059
Pulled By: eellison
fbshipit-source-id:
267ed97d8421fe480dec494cdf0dec9cf9ed3ba2
Elias Ellison [Tue, 10 Aug 2021 16:40:41 +0000 (09:40 -0700)]
small cleanups (#59810)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59810
Rephrasings and cleanup of dead code
Test Plan: Imported from OSS
Reviewed By: pbelevich, zhxchen17
Differential Revision:
D30200062
Pulled By: eellison
fbshipit-source-id:
b03e5adb928aa46bee6685667cad43333b6e6016
Elias Ellison [Tue, 10 Aug 2021 16:40:41 +0000 (09:40 -0700)]
Only optimize after change (redo) (#59809)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59809
Some how this didnt get landed previously in ghstack mixup
Test Plan: Imported from OSS
Reviewed By: pbelevich, zhxchen17
Differential Revision:
D30200060
Pulled By: eellison
fbshipit-source-id:
47f256421a1fe1a005cd11fcc4d7f023b5990834
Michael Suo [Tue, 10 Aug 2021 16:21:24 +0000 (09:21 -0700)]
[jit] warn if _check_overload_body fails to find source
Summary:
Under certain conditions (particularly if a module is frozen, like with
PyInstaller or torch::deploy), we will not have source code available for
functions. `import torch` should still work in this case, but this check is
currently causing it to raise an exception.
Since this is an initial check (if an overload is actually exercised there will
be hard failure), raise a warning and move on.
Test Plan: unit tests
Reviewed By: eellison
Differential Revision:
D30214271
fbshipit-source-id:
eb021503e416268e8585e0708d6271c1e7b91e95
Supriya Rao [Tue, 10 Aug 2021 15:40:53 +0000 (08:40 -0700)]
[quant] Update get_default_qat_qconfig to return the fused observer+fake_quant module (#62702)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62702
Expose the qconfig to the user to speed up training by leveraging the fused module.
The module currently supports per-tensor/per-channel moving avg observer and fake-quantize.
For details on perf benefits, refer to https://github.com/pytorch/pytorch/pull/61691
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision:
D30093719
fbshipit-source-id:
b78deb7810f5b597474b9b9a0395d361d04eb46a
Supriya Rao [Tue, 10 Aug 2021 15:40:53 +0000 (08:40 -0700)]
[quant] add reduce_range option to FusedMovingAvgFakeQuantize module (#62863)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62863
To make this consistent with other observers, add reduce_range option that can be used to update quant_min/max
Test Plan:
python test/test_quantization.py test_fused_mod_reduce_range
Imported from OSS
Reviewed By: raghuramank100
Differential Revision:
D30146602
fbshipit-source-id:
a2015f095766f9c884611e9ab6942528bc9bc972
Peter Bell [Tue, 10 Aug 2021 14:57:04 +0000 (07:57 -0700)]
Codegen: Fix operator::name on windows (#62278)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62278
In `Operators.h` we're using `str(BaseOperatorName)`, while in
`OperatorsEverything.cpp` we're using `str(OperatorName)`. e.g.
```
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(name, "aten::abs")
```
vs
```
STATIC_CONST_STR_OUT_OF_LINE_FOR_WIN_CUDA(abs_out, name, "aten::abs.out")
```
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision:
D29962047
Pulled By: albanD
fbshipit-source-id:
5a05b898fc734a4751c2b0187e4eeea4efb0502b
Edward Yang [Tue, 10 Aug 2021 14:13:24 +0000 (07:13 -0700)]
Reject kwonly arguments passed positionally in torch.ops (#62981)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62981
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision:
D30211030
Pulled By: ezyang
fbshipit-source-id:
aae426592e92bf3a50076f470e153a4ae7d6f101
Sameer Deshmukh [Tue, 10 Aug 2021 13:53:43 +0000 (06:53 -0700)]
Allow LocalResponseNorm to accept 0 dim batch sizes (#62801)
Summary:
This issue fixes a part of https://github.com/pytorch/pytorch/issues/12013, which is summarized concretely in https://github.com/pytorch/pytorch/issues/38115.
This PR allows `LocalResponseNorm` to accept tensors with 0 dimensional batch size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62801
Reviewed By: zou3519
Differential Revision:
D30165282
Pulled By: jbschlosser
fbshipit-source-id:
cce0b2d12dbf47dc8ed6247c267bf2f2305f858a
Luca Wehrstedt [Tue, 10 Aug 2021 12:44:50 +0000 (05:44 -0700)]
Update TensorPipe submodule
Test Plan: CI ran as part of https://github.com/pytorch/pytorch/pull/60938.
Reviewed By: beauby
Differential Revision:
D30219343
fbshipit-source-id:
531338f912fee488d312d23da8bda63ceb862aa9
Rohan Varma [Tue, 10 Aug 2021 05:27:49 +0000 (22:27 -0700)]
[Reland][DDP] Support not all outputs used in loss calculation (#61753)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61753
Reland of https://github.com/pytorch/pytorch/pull/57081.
Main difference is that the former diff moved `prepare_for_backward` check into `DDPSink` backward, but that resulted in issues due to potential autograd engine races. The original diff moved `prepare_for_backward` into `DDPSink` as part of a long-term plan to always call it within `DDPSink`.
In particular this doesn't work because `prepare_for_backward` sets `expect_autograd_hooks=true` which enables autograd hooks to fire, but there were several use cases internally where autograd hooks were called before DDPSink called `prepare_for_backward`, resulting in errors/regression.
We instead keep the call to `prepare_for_backward` in the forward pass, but still run outputs through `DDPSink` when find_unused_parameters=True. As a result, outputs that are not used when computing loss have `None` gradients and we don't touch them if they are globally `None`. Note that the hooks still fire with a undefined gradient which is how we avoid the Reducer erroring out with the message that some hooks did not fire.
Added the unittests that were part of the reverted diff.
ghstack-source-id:
135388925
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision:
D29726179
fbshipit-source-id:
54c8819e0aa72c61554104723a5b9c936501e719
Ilqar Ramazanli [Tue, 10 Aug 2021 00:53:11 +0000 (17:53 -0700)]
To fix variance computation for complex Adam (#62946)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/59998
It has been discussed in the issue that the variance term of Adam optimizer currently doesn't compute correctly for complex domain. As it has been stated in the Generalization to Complex numbers section in https://en.wikipedia.org/wiki/Variance variance is computed as E[(X - mu)(X-mu)*] (where mu = E[X] and * stands for conjugate) for complex random variable X.
However, currently the computation method in implementation of Adam is via E[(X - mu)(X-mu)] which doesn't return right variance value, in particular it returns complex number. Variance is defined to be real number even though underlying random variable is complex.
We fix this issue here, and testing that resulting variance is indeed real number.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62946
Reviewed By: albanD
Differential Revision:
D30196038
Pulled By: iramazanli
fbshipit-source-id:
ab0a6f31658aeb56bdcb211ff86eaa29f3f0d718
Jerry Zhang [Mon, 9 Aug 2021 23:46:45 +0000 (16:46 -0700)]
[quant][graphmode][fx] Attach a weight qparam dict to linear and conv in reference quantized model (#62488)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62488
Instead of attaching weight observer/fake_quant to the float linear and conv, we can
compute the quantization parameters and attach that as a dictionary to these modules so
that we can reduce the model size and make the reference module clearer
TODO: the numerics for linear and conv in reference quantized model is still not correct since
we did not quantize weight, we may explore things like parameterization to implement this support
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision:
D30053979
fbshipit-source-id:
b5f8497cf6cf65eec924df2d8fb10a9e154b8cab
zhouzhuojie [Mon, 9 Aug 2021 23:42:38 +0000 (16:42 -0700)]
Simplify the logic of running ci workflow codegen (#62853)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62853
wanted to simplify the logic in the `__post_int__`, and delegate the settings back to individual workflows, this gives us more flexibility in changing individual workflows, as well as reducing the complexity of understanding the mutation conditions.
Test Plan: Imported from OSS
Reviewed By: walterddr, seemethere
Differential Revision:
D30149190
Pulled By: zhouzhuojie
fbshipit-source-id:
44df5b1e14184f3a81cb8004151525d0e0fb20d9
Richard Barnes [Mon, 9 Aug 2021 23:39:32 +0000 (16:39 -0700)]
irange-ify 12b (#62484)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62484
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision:
D30015528
fbshipit-source-id:
c4e1a5425a73f100102a97dcec1579f1049c9c1d
Peter Bell [Mon, 9 Aug 2021 23:15:54 +0000 (16:15 -0700)]
Shard Operators.cpp (#62185)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62185
This file can take 5 minutes on its own to compile, and is the single limiting
factor for compile time of `libtorch_cpu` on a 32-core threadripper. Instead,
sharding into 5 files that take around 1 minute each cuts a full minute off the
overall build time.
This also factors out the `.findSchemaOrThrow(...).typed` step so the code can
be shared between `call` and `redispatch`.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision:
D29962049
Pulled By: albanD
fbshipit-source-id:
be5df05fbea09ada0d825855f1618c25a11abbd8
Richard Barnes [Mon, 9 Aug 2021 23:14:35 +0000 (16:14 -0700)]
irange-ify 13d (#62477)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62477
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision:
D30001499
fbshipit-source-id:
993eb2b39f332ff0ae6c663792bd04734cfc262b
peterjc123 [Mon, 9 Aug 2021 22:54:17 +0000 (15:54 -0700)]
Enable rebuilds for Ninja on Windows (#62948)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/59859.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62948
Reviewed By: seemethere, tktrungna
Differential Revision:
D30192246
Pulled By: janeyx99
fbshipit-source-id:
af25cc4bf0db67a1304d9971cfa0ff6831bb3b48
Marjan Fariborz [Mon, 9 Aug 2021 22:45:43 +0000 (15:45 -0700)]
BFP16 quantization/dequantization (#62974)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62974
Testing the functionality of `tensor.to` approach.
Comparing `tensor.to` and `torch.ops.fb.FloatToBfloat16Quantized` approach and testing if they match for 2d tensors.
Test Plan: buck test //torchrec/fb/distributed/tests:test_quantized_comms
Reviewed By: wanchaol
Differential Revision:
D30079121
fbshipit-source-id:
612e92baeb2245449637faa9bc31686353d67033
Xiang Gao [Mon, 9 Aug 2021 22:28:35 +0000 (15:28 -0700)]
Migrate Embedding thrust sort to cub sort (#62495)
Summary:
This PR only migrates sort. Other thrust operations will be migrated in followup PRs
Benchmark `num_embeddings` pulled from https://github.com/huggingface/transformers/tree/master/examples by
```
grep -P 'vocab_size.*(=|:)\s*[0-9]+' -r transformers/examples/
grep -P 'hidden_size.*(=|:)\s*[0-9]+' -r transformers/examples/
```
to get `vocab_size = 119547, 50265, 32000, 8000, 3052` (similar size omitted) and `hidden_size = 512, 768`
Code:
```python
import torch
import itertools
num_embeddings = (119547, 50265, 32000, 8000, 3052)
num_tokens = (4096, 16384)
hidden_sizes = (512, 768)
for ne, nt, nh in itertools.product(num_embeddings, num_tokens, hidden_sizes):
print(f"Embedding size: {ne}, Tokens: {nt}, Hidden size: {nh}")
embedding = torch.nn.Embedding(ne, nh).cuda()
input_ = torch.randint(ne, (nt,), device='cuda')
out = embedding(input_)
torch.cuda.synchronize()
%timeit out.backward(out, retain_graph=True); torch.cuda.synchronize()
```
## On CUDA 11.3.1
Before:
```
Embedding size: 119547, Tokens: 4096, Hidden size: 512
1.43 ms ± 11.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 4096, Hidden size: 768
2.07 ms ± 56.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 512
1.61 ms ± 2.29 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 768
2.32 ms ± 8.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 512
738 µs ± 1.38 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 768
1.02 ms ± 1.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 512
913 µs ± 3.89 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 768
1.27 ms ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 512
559 µs ± 860 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 768
743 µs ± 630 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 512
713 µs ± 969 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 768
977 µs ± 884 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 512
301 µs ± 8.02 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 768
383 µs ± 4.36 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 512
409 µs ± 1.39 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 768
515 µs ± 766 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 512
215 µs ± 1.16 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 768
250 µs ± 320 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 512
271 µs ± 888 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 768
325 µs ± 1.14 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After:
```
Embedding size: 119547, Tokens: 4096, Hidden size: 512
1.42 ms ± 1.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 4096, Hidden size: 768
2.05 ms ± 9.93 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 512
1.6 ms ± 3.19 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 768
2.3 ms ± 3.67 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 512
730 µs ± 811 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 768
1.01 ms ± 2.71 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 512
887 µs ± 1.08 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 768
1.25 ms ± 2.74 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 512
556 µs ± 1.86 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 768
744 µs ± 4.44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 512
691 µs ± 570 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 768
957 µs ± 2.02 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 512
309 µs ± 2.84 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 768
376 µs ± 2.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 512
381 µs ± 1.49 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 768
487 µs ± 2.42 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 512
202 µs ± 383 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 768
239 µs ± 1.05 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 512
243 µs ± 1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 768
340 µs ± 2.28 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
## On CUDA 11.1
Before:
```
Embedding size: 119547, Tokens: 4096, Hidden size: 512
1.41 ms ± 14.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 4096, Hidden size: 768
2.05 ms ± 7.61 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 512
1.61 ms ± 1.95 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 768
2.32 ms ± 2.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 512
743 µs ± 1.03 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 768
1.02 ms ± 2.16 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 512
912 µs ± 5.91 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 768
1.28 ms ± 6.17 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 512
555 µs ± 2.61 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 768
743 µs ± 655 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 512
714 µs ± 1.89 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 768
980 µs ± 1.52 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 512
312 µs ± 396 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 768
386 µs ± 2.32 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 512
413 µs ± 3.19 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 768
512 µs ± 1.03 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 512
209 µs ± 585 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 768
271 µs ± 776 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 512
297 µs ± 1.11 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 768
377 µs ± 3.87 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After:
```
Embedding size: 119547, Tokens: 4096, Hidden size: 512
1.46 ms ± 12 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 4096, Hidden size: 768
2.09 ms ± 4.31 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 512
1.64 ms ± 4.48 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 119547, Tokens: 16384, Hidden size: 768
2.35 ms ± 2.54 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 512
782 µs ± 2.12 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 4096, Hidden size: 768
1.06 ms ± 596 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 512
945 µs ± 2.19 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 50265, Tokens: 16384, Hidden size: 768
1.31 ms ± 553 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 512
603 µs ± 856 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 4096, Hidden size: 768
789 µs ± 500 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 512
752 µs ± 7.56 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 32000, Tokens: 16384, Hidden size: 768
1.01 ms ± 4.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 512
323 µs ± 7.23 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 4096, Hidden size: 768
398 µs ± 765 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 512
412 µs ± 544 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 8000, Tokens: 16384, Hidden size: 768
519 µs ± 614 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 512
229 µs ± 1.17 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 4096, Hidden size: 768
263 µs ± 417 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 512
274 µs ± 576 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Embedding size: 3052, Tokens: 16384, Hidden size: 768
354 µs ± 1.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62495
Reviewed By: gchanan
Differential Revision:
D30176833
Pulled By: ngimel
fbshipit-source-id:
44148ebb53a0abfc1e5ab8b986865555bf326ad1
= [Mon, 9 Aug 2021 22:28:00 +0000 (15:28 -0700)]
Use output memory format based on input for cudnn_convolution_relu (#62482)
Summary:
Currently when cudnn_convolution_relu is passed a channels last Tensor it will return a contiguous Tensor. This PR changes this behavior and bases the output format on the input format.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62482
Reviewed By: ngimel
Differential Revision:
D30049905
Pulled By: cpuhrsch
fbshipit-source-id:
98521d14ee03466e7128a1912b9f754ffe10b448
Richard Barnes [Mon, 9 Aug 2021 22:27:14 +0000 (15:27 -0700)]
irange-ify 12 (#62120)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62120
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision:
D29879713
fbshipit-source-id:
3084a5eacb722f7fb0a630d47bf694f4d6831136
Richard Barnes [Mon, 9 Aug 2021 22:26:54 +0000 (15:26 -0700)]
irange-ify 1 (#62193)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62193
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision:
D29879504
fbshipit-source-id:
adc86adcd1e7dcdfa2d7adf4d576f081430d52ec
zhouzhuojie [Mon, 9 Aug 2021 22:25:59 +0000 (15:25 -0700)]
Fix render_test_results if condition on always() (#62997)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62997
Fixes #62979, changed the condition to listen on the previous'
job's result to be either 'success' or 'failure'.
Notice that 'skipped' will also skip this job, which is what
we want.
Test Plan: Imported from OSS
Reviewed By: driazati, seemethere
Differential Revision:
D30202598
Pulled By: zhouzhuojie
fbshipit-source-id:
f3c0f715c39a5c8119b528b66e45f594a54b49d1
Rohan Varma [Mon, 9 Aug 2021 21:39:19 +0000 (14:39 -0700)]
[reland] Gate DistributedOptimizers on RPC availability (#62937)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62937
reland due to windows + cuda failure, fix by running it on gloo on windows even with cuda.
ghstack-source-id:
135306176
Test Plan: ci
Reviewed By: mrshenli
Differential Revision:
D30177734
fbshipit-source-id:
7625746984c8f858648c1b3632394b98bd4518d2
Richard Barnes [Mon, 9 Aug 2021 20:13:14 +0000 (13:13 -0700)]
irange-ify 8d (#62505)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62505
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision:
D29971891
fbshipit-source-id:
7dcbe27221788695f320c7238f5fe81e32823802
Bradley Davis [Mon, 9 Aug 2021 20:06:05 +0000 (13:06 -0700)]
[fx] store Tracer class on Graph and GraphModule for package deserialization (#62497)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62497
Previously named: add support for custom tracer in __reduce_package__
Stores a Tracer class on a Graph created by Tracer, and copies the Tracer class into the GraphModule's state so that when a GraphModule is packaged by torch package, it can be reconstructed with the same Tracer and GraphModule class name.
Reviewed By: suo
Differential Revision:
D30019214
fbshipit-source-id:
eca09424ad30feb93524d481268b066ea55b892a
Nikita Shulga [Mon, 9 Aug 2021 19:57:05 +0000 (12:57 -0700)]
Mark unused functions with `C10_UNUSED` (#62929)
Summary:
Which fixes number of warnings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62929
Reviewed By: walterddr, albanD
Differential Revision:
D30171953
Pulled By: malfet
fbshipit-source-id:
f82475289ff4aebb0c97794114e94a24d00d2ff4
peterjc123 [Mon, 9 Aug 2021 19:50:52 +0000 (12:50 -0700)]
Stop exporting symbols in anonymous namespaces (#62952)
Summary:
The cases are found out by compiling against clang on Windows.
Those functions will still be exported under this case, which is a waste of space in the symbol table.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62952
Reviewed By: gchanan
Differential Revision:
D30191291
Pulled By: ezyang
fbshipit-source-id:
3319b0ec4f5fb02e0fe1b81dbbcedcf12a0c795e
Mike Iovine [Mon, 9 Aug 2021 19:07:55 +0000 (12:07 -0700)]
[Static Runtime] Add tests for all aten ops (#62347)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62347
This diff includes tests for all `aten` ops that did not already have test coverage.
Test Plan: `buck test //caffe2/benchmarks/static_runtime/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision:
D29968280
fbshipit-source-id:
768655ca535f9e37422711673168dce193de45d2
Zeina Migeed [Mon, 9 Aug 2021 18:45:34 +0000 (11:45 -0700)]
handle get_attr opearations in typechecker (#62682)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62682
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision:
D30107789
Pulled By: migeed-z
fbshipit-source-id:
0b21b2893e2dc7cfaf5b5f5990f662e051a981b4
Bert Maher [Mon, 9 Aug 2021 18:22:24 +0000 (11:22 -0700)]
Linker version script to hide LLVM symbols (#62906)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62906
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision:
D30193893
Pulled By: bertmaher
fbshipit-source-id:
9b189bfd8d4c52e8dc4296a4bed517ff44994ba0
Andrew Gu [Mon, 9 Aug 2021 18:15:35 +0000 (11:15 -0700)]
Add ``allow_empty_param_list`` to functional optimizers (#62522)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62522
Addresses https://github.com/pytorch/pytorch/issues/62481
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision:
D30072074
Pulled By: andwgu
fbshipit-source-id:
1a5da21f9636b8d74a6b00c0f029427f0edff0e3
Sangbaek Park [Mon, 9 Aug 2021 17:48:39 +0000 (10:48 -0700)]
[Vulkan] Added Hardshrink op (#62870)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62870
Added Hardshrink operator for Vulkan
Added tests for Hardshrink op
Reference: [Hardshrink](https://pytorch.org/docs/stable/generated/torch.nn.Hardshrink.html#torch.nn.Hardshrink)
Test Plan: Imported from OSS
Reviewed By: SS-JIA
Differential Revision:
D30174950
Pulled By: beback4u
fbshipit-source-id:
3e192390eb9f92abecae966e84bbfae356bfd7c8
Zeina Migeed [Mon, 9 Aug 2021 17:45:47 +0000 (10:45 -0700)]
Change output node handling for typechecker to deal with tuples (#62582)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62582
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision:
D30050004
Pulled By: migeed-z
fbshipit-source-id:
9b81b10d24e1e8165cdc18c820ea314349b463cb
Edward Yang [Mon, 9 Aug 2021 16:59:01 +0000 (09:59 -0700)]
__torch_dispatch__: Populate kwargs dictionary with keyword-only arguments (#62822)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62822
This is BC breaking for people who were using the old integration,
although only if you had been writing bindings for functions with
keyword-only arguments (that includes functorch). Other than that,
the patch was pretty straightforward.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision:
D30134552
Pulled By: ezyang
fbshipit-source-id:
a47f536fb030994a07c9386069b8f800ac86d731
Jane Xu [Mon, 9 Aug 2021 16:47:26 +0000 (09:47 -0700)]
Modify GHA CI to use PYTORCH_IGNORE_DISABLED_ISSUES based on PR body (#62851)
Summary:
Another step forward in fixing https://github.com/pytorch/pytorch/issues/62359
Disclaimer: this only works with GHA for now, as circleci would require changes in probot.
Test plan can be seen a previous description where I modified the description to include linked issues. I've removed them now since the actual PR doesn't fix any of them.
It works! In the [periodic 11.3 test1](https://github.com/pytorch/pytorch/pull/62851/checks?check_run_id=
3263109970), we get this in the logs and we see that PYTORCH_IGNORE_DISABLED_ISSUES is properly set:
```
test_jit_cuda_extension (__main__.TestCppExtensionJIT) ... Using /var/lib/jenkins/.cache/torch_extensions/py36_cu113 as PyTorch extensions root...
Creating extension directory /var/lib/jenkins/.cache/torch_extensions/py36_cu113/torch_test_cuda_extension...
Detected CUDA files, patching ldflags
Emitting ninja build file /var/lib/jenkins/.cache/torch_extensions/py36_cu113/torch_test_cuda_extension/build.ninja...
Building extension module torch_test_cuda_extension...
Using envvar MAX_JOBS (30) as the number of workers...
[1/3] c++ -MMD -MF cuda_extension.o.d -DTORCH_EXTENSION_NAME=torch_test_cuda_extension -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_COMPILER_TYPE=\"_gcc\" -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_STDLIB=\"_libstdcpp\" -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_BUILD_ABI=\"_cxxabi1011\" -isystem /opt/conda/lib/python3.6/site-packages/torch/include -isystem /opt/conda/lib/python3.6/site-packages/torch/include/torch/csrc/api/include -isystem /opt/conda/lib/python3.6/site-packages/torch/include/TH -isystem /opt/conda/lib/python3.6/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /opt/conda/include/python3.6m -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++14 -c /var/lib/jenkins/workspace/test/cpp_extensions/cuda_extension.cpp -o cuda_extension.o
[2/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=torch_test_cuda_extension -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_COMPILER_TYPE=\"_gcc\" -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_STDLIB=\"_libstdcpp\" -DPYBIND11 (https://github.com/pytorch/pytorch/commit/
d55b25a633b7e2e6122becf6dbdf0528df6e8b13)_BUILD_ABI=\"_cxxabi1011\" -isystem /opt/conda/lib/python3.6/site-packages/torch/include -isystem /opt/conda/lib/python3.6/site-packages/torch/include/torch/csrc/api/include -isystem /opt/conda/lib/python3.6/site-packages/torch/include/TH -isystem /opt/conda/lib/python3.6/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /opt/conda/include/python3.6m -D_GLIBCXX_USE_CXX11_ABI=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_52,code=compute_52 -gencode=arch=compute_52,code=sm_52 --compiler-options '-fPIC' -O2 -std=c++14 -c /var/lib/jenkins/workspace/test/cpp_extensions/cuda_extension.cu -o cuda_extension.cuda.o
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
[3/3] c++ cuda_extension.o cuda_extension.cuda.o -shared -L/opt/conda/lib/python3.6/site-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda_cu -ltorch_cuda_cpp -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o torch_test_cuda_extension.so
Loading extension module torch_test_cuda_extension...
ok (26.161s)
```
whereas on the latest master periodic 11.1 windows [test](https://github.com/pytorch/pytorch/runs/
3263762478?check_suite_focus=true), we see
```
test_jit_cuda_extension (__main__.TestCppExtensionJIT) ... skip (0.000s)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62851
Reviewed By: walterddr, tktrungna
Differential Revision:
D30192029
Pulled By: janeyx99
fbshipit-source-id:
fd2ecc59d2b2bb5c31522a630dd805070d59f584
Raghavan Raman [Mon, 9 Aug 2021 16:27:01 +0000 (09:27 -0700)]
[Static Runtime] Added a cache for NNC generated code across different calls to the same ops (#62921)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62921
Added a cache for NNC generated code across different calls to the same ops.
Before this diff:
```
ProcessedNode time 13402.9 ms
Static Module initialization took 30964.8 ms
```
After this diff:
```
ProcessedNode time 85.4195 ms
Static Module initialization took 4348.42 ms
```
There is one global cache for all the ops. It is guarded with a reader-writer lock. This is necessary because we could have multiple threads loading different models in parallel. Note that this locking does not guarantee that there will be exactly one code generated for each op. There could be more than one thread generating code for the same op simultaneously and all of them will update the cache in some order. But that should be small number bounded by the number of threads. Also, there is no correctness issue, since the generated code is always the same and the one generated by the last thread is retained in the cache and reused later while running the model.
Test Plan: Tested inline_cvr model
Reviewed By: hlu1
Differential Revision:
D30104017
fbshipit-source-id:
32e9af43d7e724ed54b661dfe58a73a14e443ff7
Rong Rong (AI Infra) [Mon, 9 Aug 2021 16:26:47 +0000 (09:26 -0700)]
Enable upper for torch.linalg.cholesky (#62434)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61988
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62434
Reviewed By: seemethere, tktrungna
Differential Revision:
D30079806
Pulled By: walterddr
fbshipit-source-id:
044efb96525155c9bc7953ac4ad47c1b7c12fb20
Raghavan Raman [Mon, 9 Aug 2021 16:11:13 +0000 (09:11 -0700)]
[nnc] Updated IR cloning to create clones of expressions in addition to statements (#62833)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62833
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision:
D30135980
Pulled By: navahgar
fbshipit-source-id:
e557eedec7ecf596a4045756276d25a485fa66fb
peter [Mon, 9 Aug 2021 16:01:45 +0000 (09:01 -0700)]
minor fixes in c10d for Windows (#62953)
Summary:
Found out by triggering builds against clang on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62953
Reviewed By: gchanan
Differential Revision:
D30191300
Pulled By: ezyang
fbshipit-source-id:
d929119768298084c41d70dbc3a78aacd64fb715
Elias Ellison [Mon, 9 Aug 2021 15:49:08 +0000 (08:49 -0700)]
Add handling of list write to remove mutation (#62904)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62904
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision:
D30168493
Pulled By: eellison
fbshipit-source-id:
3b25982b235938cc7439dd3a5236dfce68254c05
Elias Ellison [Mon, 9 Aug 2021 15:49:08 +0000 (08:49 -0700)]
Add tensor-scalar op (#62903)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62903
Test Plan: Imported from OSS
Reviewed By: pbelevich, SplitInfinity
Differential Revision:
D30168338
Pulled By: eellison
fbshipit-source-id:
7dcb34ddd76c6aad4108a4073d3c8a93d974d0ef
Yukio Siraichi [Mon, 9 Aug 2021 15:44:55 +0000 (08:44 -0700)]
Port `sum.dim_IntList` kernel to structured kernels. (#61642)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61642
Tracking issue: #55070
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision:
D29783865
Pulled By: ezyang
fbshipit-source-id:
375d4cd5f915812108367601a610a428762e606d
Marjan Fariborz [Mon, 9 Aug 2021 15:09:49 +0000 (08:09 -0700)]
Adding collective quantization API (#62142)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62142
Created wrapper that takes the collective op and a quantization type as an arguments. It quantize the input, performs the collective op, and and perform dequantization
Test Plan:
Tested through distributed_gloo_fork.
e.g., buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_all_to_all_quantized
Reviewed By: wanchaol
Differential Revision:
D29682812
fbshipit-source-id:
79c39105ff11270008caa9f566361452fe82a92e
Erjia Guan [Mon, 9 Aug 2021 14:34:25 +0000 (07:34 -0700)]
Set mkl thread locally (#62891)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62891
Fixes #60469
We want to land this PR before next release, so soliciting the idea from raven38 in https://github.com/pytorch/pytorch/pull/60471. And, add corresponding test to verify the result.
- Before this PR using this test:
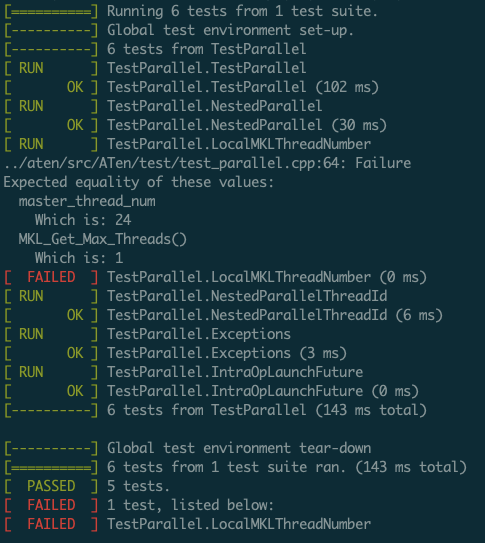
- After this PR the test passed without Error.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision:
D30161483
Pulled By: ejguan
fbshipit-source-id:
800f7204e0e1a19c492b2e556c92a91115f1b69b
Nikita Shulga [Sat, 7 Aug 2021 20:32:20 +0000 (13:32 -0700)]
[BE] irangefy (#62928)
Summary:
Replace for loop with for `irange` loop. Also fix some unused variable warnings in range loop cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62928
Reviewed By: driazati
Differential Revision:
D30171904
Pulled By: malfet
fbshipit-source-id:
1b437a0f7e3515f4a2e324f3450e93312f1933ae
Will Constable [Sat, 7 Aug 2021 05:56:54 +0000 (22:56 -0700)]
Make IMethod cache mutable so getArgument works on const IMethod (#62834)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62834
Test Plan: existing unit tests
Reviewed By: alanwaketan
Differential Revision:
D30135939
fbshipit-source-id:
e19c0ac1af6996e065a18318351265b5c4a01e70
Mikhail Zolotukhin [Sat, 7 Aug 2021 05:42:56 +0000 (22:42 -0700)]
[TensorExpr] Remove more 'const' from IRVisitor methods for *Imm types. (#62932)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62932
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision:
D30172961
Pulled By: ZolotukhinM
fbshipit-source-id:
9b7f45880d356f823364135fe29fc08f6565f827
Natalia Gimelshein [Sat, 7 Aug 2021 05:09:23 +0000 (22:09 -0700)]
Revert
D30117838: [WIP] Gate DistributedOptimizers on RPC availability
Test Plan: revert-hammer
Differential Revision:
D30117838 (https://github.com/pytorch/pytorch/commit/
3f09485d7e0c7466862cd6647b3668e119590716)
Original commit changeset:
e6365a910a3d
fbshipit-source-id:
f276b2b2bdf5f7bd27df473fca0eebaee9f7aef2
Natalia Gimelshein [Sat, 7 Aug 2021 02:13:42 +0000 (19:13 -0700)]
Allow broadcasting along non-reduction dimension for cosine similarity (#62912)
Summary:
Checks introduced by https://github.com/pytorch/pytorch/issues/58559 are too strict and disable correctly working cases that people were relying on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62912
Reviewed By: jbschlosser
Differential Revision:
D30165827
Pulled By: ngimel
fbshipit-source-id:
f9229a9fc70142fe08a42fbf2d18dae12f679646
Peter Bell [Sat, 7 Aug 2021 02:12:34 +0000 (19:12 -0700)]
Refactor codegen file sharding (#62184)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62184
File sharding is currently implemented twice, once for VariableType and once for
TraceType. This refactors the implementation into `FileManager` and also changes
it so template substitution is only done once and shared between the sharded
file and the "Everything" file.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision:
D29962050
Pulled By: albanD
fbshipit-source-id:
7858c3ca9f6e674ad036febd2d1a4ed2323a2861
Rohan Varma [Sat, 7 Aug 2021 01:33:39 +0000 (18:33 -0700)]
[DDP] Add host-side time to CUDATimer (#62770)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62770
Adding timing of forward, backward comp, backward comm, etc will help
detect desynchronization issues.
ghstack-source-id:
135195680
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision:
D30115585
fbshipit-source-id:
509bf341c5c92dcc63bdacd3c1e414da4eb4f321
Will Constable [Fri, 6 Aug 2021 23:42:27 +0000 (16:42 -0700)]
Back out "Enable test_api IMethodTest in OSS" (#62893)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62893
Original commit changeset:
50eb3689cf84
Test Plan: Confirm pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_test2 passes in OSS
Reviewed By: seemethere, alanwaketan
Differential Revision:
D30159999
fbshipit-source-id:
74ff8975328409a3dc8222d3e2707a1bb0ab930c
Alex Suhan [Fri, 6 Aug 2021 22:28:38 +0000 (15:28 -0700)]
Fix reshape for the Lazy key (#62846)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/62846
Test Plan: CI
Reviewed By: zou3519
Differential Revision:
D30162185
Pulled By: asuhan
fbshipit-source-id:
d582dcef35ce7e8bebf161a5c93e470339891e29
Natalia Gimelshein [Fri, 6 Aug 2021 22:11:43 +0000 (15:11 -0700)]
Revert
D30138788: [pytorch][PR] OpInfo for `adaptive_avg_pool2d`
Test Plan: revert-hammer
Differential Revision:
D30138788 (https://github.com/pytorch/pytorch/commit/
5c431981b5b36da6dba61f0e5d5101e72d2fd726)
Original commit changeset:
66735ceaa85b
fbshipit-source-id:
75eb241ef82d32d6480db069c035df0abc6753fe
Angela Yi [Fri, 6 Aug 2021 22:09:08 +0000 (15:09 -0700)]
[quant] Input-Weight Equalization - allow logical evaluation (#61603)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/61603
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision:
D29686878
fbshipit-source-id:
67ca4cab98b3d592ff2bb8db86499789b85bd582
Eli Uriegas [Fri, 6 Aug 2021 22:05:40 +0000 (15:05 -0700)]
.github: Make sure to deep clone on windows (#62907)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62907
Deep clones allow us to use git commands on historical commits so that
we can do things like collect test times correctly
Should fix empty `.pytorch-test-times.json` files that walterddr was observing
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision:
D30166414
Pulled By: seemethere
fbshipit-source-id:
1f9904eeb5a8ebaf0a02d1aa7291fffe1aecd57b
Natalia Gimelshein [Fri, 6 Aug 2021 21:57:19 +0000 (14:57 -0700)]
Revert
D30038175: Improve IMethod::getArgumentNames to deal with empty argument names list
Test Plan: revert-hammer
Differential Revision:
D30038175 (https://github.com/pytorch/pytorch/commit/
64b3ab64078c2400656544a8f4e6ccfc56009a89)
Original commit changeset:
46f08dda9418
fbshipit-source-id:
604735d2300487a0b75890b330d7ba5b3e7145b2
Yi Wang [Fri, 6 Aug 2021 21:49:37 +0000 (14:49 -0700)]
Add GradBucket::parameters() to ddp_comm_hooks.rst (#62877)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62877
as title
ghstack-source-id:
135214612
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision:
D30153490
fbshipit-source-id:
d4cec434a53ef6e65b60c065804884d1a114aa0d
eqy [Fri, 6 Aug 2021 21:03:58 +0000 (14:03 -0700)]
Check contiguous to dispatch to NHWC cuda template (#62839)
Summary:
follow up of https://github.com/pytorch/pytorch/issues/62773
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62839
Reviewed By: H-Huang
Differential Revision:
D30142906
Pulled By: ngimel
fbshipit-source-id:
600a7ad240a4a1827352eab8c8cbc98240d693f0
= [Fri, 6 Aug 2021 21:01:39 +0000 (14:01 -0700)]
[FX] Add torch.memory_format as a BaseArgumentType (#62593)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62498
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62593
Reviewed By: H-Huang
Differential Revision:
D30104091
Pulled By: cpuhrsch
fbshipit-source-id:
25b7a4b308219860c969db54d7b1867b1aa4180a
Rong Rong (AI Infra) [Fri, 6 Aug 2021 18:51:25 +0000 (11:51 -0700)]
use test environment for test phase (#62824)
Summary:
Currently all test generated in test matrix share the same `BUILD_ENVIRONMENT` variable. we should distinguish them because some test scripts uses BUILD_ENVIRONMENT to differentiate what to run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62824
Reviewed By: zhouzhuojie
Differential Revision:
D30162250
Pulled By: walterddr
fbshipit-source-id:
3a99a21e91e02ed8638feed102e7966af01dd175
Jane Xu [Fri, 6 Aug 2021 18:28:40 +0000 (11:28 -0700)]
Adds JOB_BASE_NAME to steps of CircleCI mac workflows (#62892)
Summary:
Upon noticing that we had a job entry named "None" in our S3 stats, I set out to find which test reporting had a JOB_BASE_NAME that wasn't set.
It turns out all non Windows and Linux workflows did not have JOB_BASE_NAME but instead used CIRCLE_JOB. This remedies the current issue by explicitly setting JOB_BASE_NAME in Mac workflows, but doesn't touch anything else as those other jobs (like android) do not report test stats.
This also adds back the CIRCLE_JOB dependency in print_test_stats to be backwards compatible, but the goal is to move off of CIRCLE_JOB dependency to a more CI-platform-agnostic naming of variables.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62892
Test Plan:
Imported from GitHub, without a `Test Plan:` line.
{
F639556801}
None is now the macos!
Reviewed By: walterddr
Differential Revision:
D30160234
Pulled By: janeyx99
fbshipit-source-id:
df868dec5f9b289d3837e927d2bb95acb2d9185b
Rong Rong (AI Infra) [Fri, 6 Aug 2021 18:14:08 +0000 (11:14 -0700)]
[hotfix] fix BC checker direction (#62901)
Summary:
fix https://github.com/pytorch/pytorch/issues/62687 error. should allow listed those that has date time newer than today.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62901
Reviewed By: zhouzhuojie
Differential Revision:
D30163202
Pulled By: walterddr
fbshipit-source-id:
b882975a231249137cb2d252f41e98e133b6f337
Thomas J. Fan [Fri, 6 Aug 2021 18:09:50 +0000 (11:09 -0700)]
BUG Fixes bug in no_batch_dim tests (#62726)
Summary:
The way that Python captures variables for lambdas meant that only the last `input_fn`, etc were captured. This PR adds makes sure the local variable to captured by a lambda.
REF: https://docs.python.org/3/faq/programming.html#why-do-lambdas-defined-in-a-loop-with-different-values-all-return-the-same-result
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62726
Reviewed By: zou3519
Differential Revision:
D30159478
Pulled By: jbschlosser
fbshipit-source-id:
cfef3d9776d2676b2f5bb6d39d569b8ca07b0fe5
Jane Xu [Fri, 6 Aug 2021 18:05:23 +0000 (11:05 -0700)]
Set JOB_BASE_NAME consistently for bazel (#62886)
Summary:
It was manually set incorrectly before to pytorch-linux-xenial-py3.6-gcc7-bazel-test-test, which is inconsistent with the rest of our naming scheme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62886
Reviewed By: driazati
Differential Revision:
D30159860
Pulled By: janeyx99
fbshipit-source-id:
4984ec04ee2bcf68b9a57e241ca9f979bfe6398a
Rohan Varma [Fri, 6 Aug 2021 17:55:44 +0000 (10:55 -0700)]
[WIP] Gate DistributedOptimizers on RPC availability (#62774)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62774
Gates DistributedOptimizer which relies on RRef based on if RPC is available. This should enable ZeRo to work with Windows as Windows should not try to import the DIstributedOptimizer. If this works as expected we can enable the windows tests for functional/local sgd optimizers as well.
ghstack-source-id:
135216642
Test Plan: CI
Reviewed By: pbelevich
Differential Revision:
D30117838
fbshipit-source-id:
e6365a910a3d1ca40d95fa6777a7019c561957db
Rohan Varma [Fri, 6 Aug 2021 17:52:34 +0000 (10:52 -0700)]
Enable step_param for Adam functional optimizer (#62611)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62611
Enables optimizer overlap with backwards in DDP for Adam. Additional optimizers, especially Adagrad will be done in follow up diffs.
1. Implement `step_param` method based on `step` in _FunctionalAdam (perf permitting we can later dedupe `step` to call `step_param`
2. Modify tests to test all current functional optimizers.
ghstack-source-id:
135207143
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision:
D29891783
fbshipit-source-id:
321915982afd5cb0a9c2e43d27550f433bff00d1
Angela Yi [Fri, 6 Aug 2021 16:27:03 +0000 (09:27 -0700)]
[quant] Input-Weight Equalization - selective equalization (#61916)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61916
Functions used to run selective equalization based on the SQNR obtained from running the Numeric Suite. After running the Numeric Suite between the equalized and float model, we will get the SQNR between the two models and construct an equalization_qconfig_dict that specifies to only equalize the layers with the highest quantization errors.
How to run:
```
layer_to_sqnr_dict = get_layer_sqnr_dict(float_model, equalized_model, input)
eq_qconfig_dict = get_equalization_qconfig_dict(layer_to_sqnr_dict, equalized_model, num_layers_to_equalize)
prepared = prepare_fx(float_model, qconfig_dict, eq_qconfig_dict)
...
```
Test Plan:
`python test/test_quantization.py TestEqualizeFx.test_selective_equalization`
Imported from OSS
Reviewed By: supriyar
Differential Revision:
D29796950
fbshipit-source-id:
91f0f8427d751beaea32d8ffc2f3b8aa8ef7ea95
Yusuo Hu [Fri, 6 Aug 2021 15:43:07 +0000 (08:43 -0700)]
[BF16] Add BF16 support to _aminmax and _anminmax_all operators (#62767)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62767
Add BF16 support to _aminmax_all and _aminmax operators.
Test Plan:
Added unit test:
https://www.internalfb.com/intern/testinfra/testconsole/testrun/
2533274857208373/
Reviewed By: anjali411
Differential Revision:
D30073837
fbshipit-source-id:
9cb4991e644cfdb2f0674ccaff161d223c174150
Stephen Jia [Fri, 6 Aug 2021 15:38:47 +0000 (08:38 -0700)]
[vulkan] Add _reshape_alias (#62858)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62858
D29792126 (https://github.com/pytorch/pytorch/commit/
adb73d3dcffdbcdcb7344413d7e27c8633db030a) changed the behaviour of `reshape()` such that it calls `_reshape_alias()` instead of `view()` in order to avoid duplicating some work such as computing strides.
Vulkan has not yet implemented `_reshape_alias()` so `reshape()` would fail with
```
C++ exception with description "Could not run 'aten::_reshape_alias' with arguments from the 'Vulkan' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions.
```
For Vulkan there is no concept of strides so it's fine to just have `_reshape_alias()` point to `view()`.
Test Plan:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
cd -
```
Reviewed By: kimishpatel
Differential Revision:
D30054706
fbshipit-source-id:
770979fa3a0f99bcc2ddaefa4674e5bd79b17c03
Stephen Jia [Fri, 6 Aug 2021 15:38:47 +0000 (08:38 -0700)]
[vulkan] Throw an exception if device does not support Vulkan (#62859)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62859
If the Vulkan instance cannot be initialized successfully (i.e. no `vkPhysicalDevice` could be found due to missing drivers) then Vulkan ops will not be able to execute. However, currently `api::context()` which is used to access the global Vulkan context simply returns a null pointer if there is a problem initializing the Vulkan instance.
This leads to Segmentation Faults later on because Vulkan ops assume that `api::context()` will not return a `nullptr`. For instance: [this line](https://www.internalfb.com/code/fbsource/xplat/caffe2/aten/src/ATen/native/vulkan/ops/Persistent.cpp?lines=14) will frequently cause a Segmentation Fault when drivers are not present.
Instead of having `api::context()` returning a nullptr when Vulkan cannot be initialized, it should just throw an exception since ops cannot be executed anyway. This results in a more graceful failure as these exceptions can be caught instead of crashing the app with a Seg Fault down the line.
Test Plan:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
cd -
```
On an Omni model portal, I can also remove the vulkan drivers in order to test the functionality when Vulkan is not supported.
Reviewed By: kimishpatel
Differential Revision:
D30139891
fbshipit-source-id:
47fcc8dcd219cb78ab9bec0b6a85b2aa7320ab50
Vitaly Fedyunin [Fri, 6 Aug 2021 15:34:58 +0000 (08:34 -0700)]
Introducing DataChunk for DataPipes batching (#62768)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62768
This is part of TorchArrow DF support preparation, separating it to multiple PRs to simplify review process.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision:
D30149090
Pulled By: VitalyFedyunin
fbshipit-source-id:
a36b5ff56e2ac6b06060014d4cd41b487754acb8
Edward Yang [Fri, 6 Aug 2021 15:19:50 +0000 (08:19 -0700)]
Add getPyInterpreter() API (#62659)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62659
It turns out that it is occasionally useful to be able to access the
PyInterpreter object from other Python bindings (see next diff in the
stack). Make it publicly available.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision:
D30074926
Pulled By: ezyang
fbshipit-source-id:
2f745ab7c7a672ed7215231fdf9eef6af9705511
Eugene Yang [Fri, 6 Aug 2021 15:13:48 +0000 (08:13 -0700)]
fix docstring default value of `last_epoch` for SWALR in torch/optim/… (#62799)
Summary:
…swa_utils
Fixes https://github.com/pytorch/pytorch/issues/62633
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62799
Reviewed By: zou3519
Differential Revision:
D30131929
Pulled By: H-Huang
fbshipit-source-id:
741c077073bbe398492dff0761836acdbba7be78
Michael Shang [Fri, 6 Aug 2021 04:02:59 +0000 (21:02 -0700)]
rename namespace f4d to velox (#61)
Summary:
Pull Request resolved: https://github.com/facebookexternal/torchdata/pull/61
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62860
Pull Request resolved: https://github.com/facebookexternal/presto_cpp/pull/453
Moving all namespace definitions, declarations and references from 'f4d' to 'velox'
Test Plan:
```
buck build //f4d/...
buck test //f4d/...
```
Also monitor the signals from sandcaslte
Reviewed By: pedroerp
Differential Revision:
D30140136
fbshipit-source-id:
5b53ac768bb7e5cd07c93a9b04dfd6363080eb52
Aliaksandr Ivanou [Fri, 6 Aug 2021 02:55:58 +0000 (19:55 -0700)]
[torchelastic][multiprocessing] Print warning message only when child processes are stuck (#62823)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62823
The diff makes sure that the warning message is printed only when the child processes are stuck after sending termination code.
Test Plan:
sandcastle
buck build mode/dev-nosan //caffe2:run
buck-out/gen/caffe2/run.par --nnodes 1 --nproc_per_node 1 main.py
P435691445
Differential Revision:
D30046695
fbshipit-source-id:
c59170b297f4a0e530906fa5069234303deee938
Sameer Deshmukh [Fri, 6 Aug 2021 00:38:06 +0000 (17:38 -0700)]
Allow FractionalMaxPool 2D and 3D layers to accept 0 dim batch size tensors. (#62083)
Summary:
This issue fixes a part of https://github.com/pytorch/pytorch/issues/12013, which is summarized concretely in https://github.com/pytorch/pytorch/issues/38115.
Allow `FractionalMaxPool` 2D and 3D layers to accept 0 dim batch sizes. Also make some minor corrections to error messages to make them more informative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62083
Reviewed By: H-Huang
Differential Revision:
D30134461
Pulled By: jbschlosser
fbshipit-source-id:
0ec50875d36c2083a7f06d9ca6a110fb3ec4f2e2
Andrew Gu [Fri, 6 Aug 2021 00:19:30 +0000 (17:19 -0700)]
Add tutorial link (#62785)
Summary:
Addresses: https://github.com/pytorch/pytorch/pull/62605#discussion_r681380364
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62785
Test Plan: I checked the render, and the link redirects as desired.
Reviewed By: mrshenli
Differential Revision:
D30133229
Pulled By: andwgu
fbshipit-source-id:
baefe0d1f1b78ece44bb42e67629bc130dbf8e9a
kshitij12345 [Fri, 6 Aug 2021 00:06:51 +0000 (17:06 -0700)]
[opinfo] nn.functional.unfold (#62705)
Summary:
Reference: facebookresearch/functorch#78
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62705
Reviewed By: H-Huang
Differential Revision:
D30138807
Pulled By: zou3519
fbshipit-source-id:
1d0b0e58feb13aec7b231c9f632a6d1694b9d272
Rohan Varma [Thu, 5 Aug 2021 23:33:40 +0000 (16:33 -0700)]
[DDP] log gradient ready order and bucket indices (#62751)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62751
This will help us determine whether gradient ready order and bucket
indices are aligned amongst all the ranks. This should always be true for rank
0 as we determine rebuilt bucket order by the gradient ready order on rank 0,
but would be interested to see this on different workloads for other ranks
ghstack-source-id:
135104369
Test Plan: CI
Reviewed By: SciPioneer, wanchaol
Differential Revision:
D30111833
fbshipit-source-id:
a0ab38413a45022d953da76384800bee53cbcf9f
Rohan Varma [Thu, 5 Aug 2021 23:33:40 +0000 (16:33 -0700)]
[DDP] Allow tuning of first bucket (#62748)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62748
Previously after buckets were rebuilt the first bucket size was always
defaulted to 1MB, this diff allows first bucket to be tuned like the rest of
the bucket sizes can.
Setting `dist._DEFAULT_FIRST_BUCKET_BYTES = 1` results in the following logs as
expected:
I0804 12:31:47.592272 246736 reducer.cpp:1694] 3 buckets rebuilt with size
limits: 1, 1048, 1048 bytes.
ghstack-source-id:
135074696
Test Plan: CI
Reviewed By: SciPioneer, wanchaol
Differential Revision:
D30110041
fbshipit-source-id:
96f76bec012de129d1645e7f50e266d4b255ec66
Kushashwa Ravi Shrimali [Thu, 5 Aug 2021 23:10:02 +0000 (16:10 -0700)]
OpInfo for `adaptive_avg_pool2d` (#62704)
Summary:
Please see https://github.com/facebookresearch/functorch/issues/78 and https://github.com/pytorch/pytorch/issues/54261.
Note regarding sample inputs for this function:
* Checks added for all relevant/interesting cases for `output_size`: `(None, None), (None, width), (height, None), (height, width)`.
cc: mruberry zou3519 Chillee
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62704
Reviewed By: H-Huang
Differential Revision:
D30138788
Pulled By: zou3519
fbshipit-source-id:
66735ceaa85b9e6050d4ec27749fc3a8108cf557
neginraoof [Thu, 5 Aug 2021 22:44:35 +0000 (15:44 -0700)]
Bump protobuf version in CircleCI docker images (#62441)
Summary:
Needed to update ONNX to 1.10 (https://github.com/pytorch/pytorch/issues/62039) because that introduces uses
of the "reserved" protobuf feature.
Also:
* Remove protobuf install code from scripts where it was unused.
* Add `-j` flag to make commands to speed things up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62441
Reviewed By: soulitzer
Differential Revision:
D30072381
Pulled By: malfet
fbshipit-source-id:
f55a4597baf95e3ed8ed987d6874388cab3426b0
Zhengxu Chen [Thu, 5 Aug 2021 21:19:56 +0000 (14:19 -0700)]
[jit] Better checking for overload function declarations. (#59956)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59956
Issue #50175. Basically two things need to be checked and are lacking currently:
1. Overload declarations should always have a single `pass` statement as the body.
2. There should be always an implementation provided for decls which doesn't
have the torch.jit._overload decorator. So in this case we need to check
whether we are actually compiling a function body with decorator ahead.
Test Plan:
python test/test_jit.py TestScript.test_function_overloads
Imported from OSS
Reviewed By: gmagogsfm
Differential Revision:
D29106555
fbshipit-source-id:
2d9d7df2fb51ab6db0e1b726f9644e4cfbf733d6
Will Constable [Thu, 5 Aug 2021 20:58:09 +0000 (13:58 -0700)]
Add batched model to torchdeploy examples (#62836)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62836
Used for upcoming diff that adds support for batching to torchdeploy
Test Plan: Models are used by later diffs, but generation script is verified by CI now and locally.
Reviewed By: gunchu
Differential Revision:
D30135938
fbshipit-source-id:
566a32a3ede56833e41712025e9d47191dfc5f39
mattip [Thu, 5 Aug 2021 18:22:19 +0000 (11:22 -0700)]
test, fix sparse * dense exceptions and corner case (#61723)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/59916
This fixes two problems with sparse multiplication
- 0d-dense * sparse was creating a non-sparse output and failing.
- dense * sparse or sparse * dense is not supported, but would emit an unhelpful error message
<details>
<summary> unhelpful error message </summary>
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NotImplementedError: Could not run 'aten::_nnz' with arguments from the 'CPU' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::_nnz' is only available for these backends: [SparseCPU, SparseCUDA, SparseCsrCPU, SparseCsrCUDA, BackendSelect, Python, Named, Conjugate, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradXPU, AutogradMLC, AutogradHPU, AutogradNestedTensor, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, Tracer, UNKNOWN_TENSOR_TYPE_ID, Autocast, Batched, VmapMode].
SparseCPU: registered at aten/src/ATen/RegisterSparseCPU.cpp:961 [kernel]
SparseCUDA: registered at aten/src/ATen/RegisterSparseCUDA.cpp:1092 [kernel]
SparseCsrCPU: registered at aten/src/ATen/RegisterSparseCsrCPU.cpp:202 [kernel]
SparseCsrCUDA: registered at aten/src/ATen/RegisterSparseCsrCUDA.cpp:229 [kernel]
BackendSelect: fallthrough registered at ../aten/src/ATen/core/BackendSelectFallbackKernel.cpp:3 [backend fallback]
Python: registered at ../aten/src/ATen/core/PythonFallbackKernel.cpp:38 [backend fallback]
Named: registered at ../aten/src/ATen/core/NamedRegistrations.cpp:7 [backend fallback]
Conjugate: registered at ../aten/src/ATen/ConjugateFallback.cpp:118 [backend fallback]
ADInplaceOrView: fallthrough registered at ../aten/src/ATen/core/VariableFallbackKernel.cpp:60 [backend fallback]
AutogradOther: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradCPU: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradCUDA: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradXLA: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradXPU: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradMLC: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradHPU: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradNestedTensor: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradPrivateUse1: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradPrivateUse2: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
AutogradPrivateUse3: registered at ../torch/csrc/autograd/generated/VariableType_2.cpp:11202 [autograd kernel]
Tracer: registered at ../torch/csrc/autograd/generated/TraceType_2.cpp:10254 [kernel]
UNKNOWN_TENSOR_TYPE_ID: fallthrough registered at ../aten/src/ATen/autocast_mode.cpp:446 [backend fallback]
Autocast: fallthrough registered at ../aten/src/ATen/autocast_mode.cpp:285 [backend fallback]
Batched: registered at ../aten/src/ATen/BatchingRegistrations.cpp:1016 [backend fallback]
VmapMode: fallthrough registered at ../aten/src/ATen/VmapModeRegistrations.cpp:33 [backend fallback]
</details>
Also added tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61723
Reviewed By: ezyang
Differential Revision:
D29962639
Pulled By: cpuhrsch
fbshipit-source-id:
5455680ddfa91d5cc9925174d0fd3107c40f5b06
Peter Lin [Thu, 5 Aug 2021 18:13:50 +0000 (11:13 -0700)]
Simplify hardswish ONNX export graph. (#60080)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/58301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60080
Reviewed By: suo
Differential Revision:
D30002939
Pulled By: SplitInfinity
fbshipit-source-id:
8b4ca6f62d51b72e9d86534592e3c82ed6608c9d
Philip Meier [Thu, 5 Aug 2021 17:42:43 +0000 (10:42 -0700)]
add `OpInfo` for `torch.nn.functional.grid_sample` (#62311)
Summary:
Addresses facebookresearch/functorch#78.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62311
Reviewed By: malfet
Differential Revision:
D30013388
Pulled By: zou3519
fbshipit-source-id:
0887ae9935923d928bfeb59054afe1aab954b40b
Kushashwa Ravi Shrimali [Thu, 5 Aug 2021 17:21:28 +0000 (10:21 -0700)]
OpInfo for `nn.functional.avg_pool2d` (#62455)
Summary:
Please see https://github.com/facebookresearch/functorch/issues/78
cc: mruberry zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62455
Reviewed By: soulitzer
Differential Revision:
D30096146
Pulled By: heitorschueroff
fbshipit-source-id:
ef09abee9baa5a9aab403201226d1d9db5af100a
Eddie Yan [Thu, 5 Aug 2021 17:20:09 +0000 (10:20 -0700)]
Preserve memory layout when aten batchnorm is used (#62773)
Summary:
https://github.com/pytorch/pytorch/issues/62594
CC cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62773
Reviewed By: H-Huang
Differential Revision:
D30118658
Pulled By: cpuhrsch
fbshipit-source-id:
bce9e92f5f8710c876a33cccbd1625155496ddea