Huan Gui [Fri, 1 Mar 2019 07:17:35 +0000 (23:17 -0800)]
add dropout during eval (#17549)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17549
Currently Dropout is only enabled in training, we enable the option of having dropout in Eval.
This is to follow [1]. This functionality would be used for uncertainty estimation in exploration project.
[1] Gal, Yarin, and Zoubin Ghahramani. "Dropout as a bayesian approximation: Representing model uncertainty in deep learning." international conference on machine learning. 2016.
Reviewed By: Wakeupbuddy
Differential Revision:
D14216216
fbshipit-source-id:
87c8c9cc522a82df467b685805f0775c86923d8b
Johannes M Dieterich [Fri, 1 Mar 2019 06:53:34 +0000 (22:53 -0800)]
Adjust launch_bounds annotation for AMD hardware. (#17555)
Summary:
The max pooling backwards kernel is currently annotated with launch bounds (256,8).
Adjust the number of waves to 4 (4 times 64 is 256) for ROCm. This improves training performance for torchvision models by up to 15% (AlexNet) on a gfx906 GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17555
Differential Revision:
D14277744
Pulled By: bddppq
fbshipit-source-id:
2a62088f7b8a87d1e350c432bf655288967c7883
Sebastian Messmer [Fri, 1 Mar 2019 00:26:49 +0000 (16:26 -0800)]
Fix verbose compiler warning in flat_hash_map (#17562)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17562
fixes https://github.com/pytorch/pytorch/issues/17332
Reviewed By: ezyang
Differential Revision:
D14254499
fbshipit-source-id:
9d5d7408c2ce510ac20cd438c6514dc2bbe3a854
Sebastian Messmer [Fri, 1 Mar 2019 00:26:49 +0000 (16:26 -0800)]
Fix diagnostic pragmas (#17561)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17561
The push at the top of the file was missing a corresponding pop
Reviewed By: ezyang
Differential Revision:
D14254500
fbshipit-source-id:
ff20359b563d6d6dcc68273dc754ab31aa8fad12
Sebastian Messmer [Fri, 1 Mar 2019 00:25:37 +0000 (16:25 -0800)]
Allow dispatch based on tensor list args (#17522)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17522
Dispatch is still based on the first tensor arg, but that first "tensor arg" is now allowed to be a tensor list.
That is, the first argument that is either Tensor or TensorList will be the deciding factor for dispatch.
If it is a TensorList, then that TensorList must not be empty or dispatch will fail.
Reviewed By: ezyang
Differential Revision:
D14235840
fbshipit-source-id:
266c18912d56ce77aa84306c5605c4191f3d882b
Sebastian Messmer [Fri, 1 Mar 2019 00:25:37 +0000 (16:25 -0800)]
Allow exposing caffe2 operators with variable number of input tensors to c10 (#17491)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17491
Before, there was no way to expose a caffe2 operator that had a variable number of inputs.
Now, this is allowed by giving the operator one tensor list input.
Note that the tensor list must be the first input, and that any other tensor inputs will be ignored and inaccessible in this case.
Reviewed By: ezyang
Differential Revision:
D14220705
fbshipit-source-id:
7f921bfb581caf46b229888c409bbcc40f7dda80
Syed Tousif Ahmed [Fri, 1 Mar 2019 00:17:37 +0000 (16:17 -0800)]
blacklist fft algorithms for strided dgrad (#17016)
Summary:
Applies https://github.com/pytorch/pytorch/pull/16626 from v1.0.1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17016
Differential Revision:
D14270100
Pulled By: ezyang
fbshipit-source-id:
1137899dd1551d33d16f39e8dde76cad8192af46
Sebastian Messmer [Thu, 28 Feb 2019 22:58:12 +0000 (14:58 -0800)]
Revert
D14078519: [codemod][caffe2] [clangr] refactor caffe2 operator constructors - 5/9
Differential Revision:
D14078519
Original commit changeset:
b0ca31a52e4a
fbshipit-source-id:
713ae108d3dd6f33abdbf98a5f213e57e2b64642
David Riazati [Thu, 28 Feb 2019 22:43:05 +0000 (14:43 -0800)]
Add generic list/dict custom op bindings (#17587)
Summary:
Fixes #17017
Sandcastle refuses to land #17037, so trying fresh here
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17587
Differential Revision:
D14265402
Pulled By: driazati
fbshipit-source-id:
b942721aa9360ac6b3862f552ac95529eb0cf52c
Sebastian Messmer [Thu, 28 Feb 2019 22:12:37 +0000 (14:12 -0800)]
refactor caffe2 operator constructors - 8/9 (#17089)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17089
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078539
fbshipit-source-id:
9ca196af4af7f26fc82e6cf82b35d478d0597752
Sebastian Messmer [Thu, 28 Feb 2019 22:12:14 +0000 (14:12 -0800)]
refactor caffe2 operator constructors - 6/9 (#17087)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17087
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078525
fbshipit-source-id:
7cc03b30b0d4eb99818e35406be4119b27bdb1bc
Sebastian Messmer [Thu, 28 Feb 2019 22:06:51 +0000 (14:06 -0800)]
refactor caffe2 operator constructors - 2/9 (#17083)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17083
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078504
fbshipit-source-id:
34dddb035eee2fca3150e47c57489614b91b6725
Sebastian Messmer [Thu, 28 Feb 2019 22:04:06 +0000 (14:04 -0800)]
refactor caffe2 operator constructors - 7/9 (#17088)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17088
clangr codemod
also manually moved the constructor of a class from the .cpp file to the .h file.
Reviewed By: ezyang
Differential Revision:
D14078531
fbshipit-source-id:
2adb4ac0ce523742da6cce3bc3b6c177b816c299
Sebastian Messmer [Thu, 28 Feb 2019 22:03:34 +0000 (14:03 -0800)]
refactor caffe2 operator constructors - 4/9 (#17085)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17085
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078515
fbshipit-source-id:
aaa48ae10892e3f47063f2133e026fea46f3240b
Sebastian Messmer [Thu, 28 Feb 2019 22:01:30 +0000 (14:01 -0800)]
refactor caffe2 operator constructors - 3/9 (#17084)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17084
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078507
fbshipit-source-id:
ed02d772890b30196302b6830f541f054b7e95c8
Edward Yang [Thu, 28 Feb 2019 21:32:22 +0000 (13:32 -0800)]
Make HIPStream also masquerade as CUDA. (#17469)
Summary:
HIPGuard interfaces that interacted with HIPStream were previously
totally busted (because the streams had the wrong device type).
This fixes it, following along the same lines of MasqueardingAsCUDA.
Along the way I beefed up the explanatory comment.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc jithunnair-amd iotamudelta bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17469
Differential Revision:
D14243396
Pulled By: ezyang
fbshipit-source-id:
972455753a62f8584ba9ab194f9c785db7bb9bde
Alex Şuhan [Thu, 28 Feb 2019 21:28:17 +0000 (13:28 -0800)]
Fix Python device type property for XLA and MSNPU
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17361
Differential Revision:
D14243546
Pulled By: soumith
fbshipit-source-id:
b7498968f72e3d97de5bf6e5b44c5a59b6913acb
Morgan Funtowicz [Thu, 28 Feb 2019 21:27:27 +0000 (13:27 -0800)]
Rely on numel() == 1 to check if distribution parameters are scalar. (#17503)
Summary:
As discussed here #16952, this PR aims at improving the __repr__ for distribution when the provided parameters are torch.Tensor with only one element.
Currently, __repr__() relies on dim() == 0 leading to the following behaviour :
```
>>> torch.distributions.Normal(torch.tensor([1.0]), torch.tensor([0.1]))
Normal(loc: torch.Size([1]), scale: torch.Size([1]))
```
With this PR, the output looks like the following:
```
>>> torch.distributions.Normal(torch.tensor([1.0]), torch.tensor([0.1]))
Normal(loc: 1.0, scale: 0.
10000000149011612)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17503
Differential Revision:
D14245439
Pulled By: soumith
fbshipit-source-id:
a440998905fd60cf2ac9a94f75706021dd9ce5bf
Zachary DeVito [Thu, 28 Feb 2019 21:06:10 +0000 (13:06 -0800)]
fix reordering of inlines (#17557)
Summary:
See comment inside of code. This fixes a bug where sometimes we would try to avoid printing long lines but would inadvertently reorder the expressions, which can change the semantics of the program
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17557
Differential Revision:
D14250608
Pulled By: zdevito
fbshipit-source-id:
d44996af4e90fe9ab9508d13cd04adbfc7bb5d1c
Xiang Gao [Thu, 28 Feb 2019 20:59:34 +0000 (12:59 -0800)]
Customize the printing of namedtuple return (#17136)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/17112
```python
print("good", torch.randn(5,5,5).max(1))
print("terrible", torch.randn(5,5,10).max(1))
print("not as good", torch.randn(5,5,500).max(1))
print ("old behaviour = gold standard")
print(tuple(torch.randn(5,5,5).max(1)))
print(tuple(torch.randn(5,5,10).max(1)))
print(tuple(torch.randn(5,5,500).max(1)))
```
now gives
```
>>> import torch
>>> print("good", torch.randn(5,5,5).max(1))
good torch.return_types.max(
values=tensor([[ 1.2821, 1.8063, 1.8075, 1.3082, -0.1267],
[ 0.3437, 0.7353, 1.2619, 0.7557, 1.6662],
[ 0.8583, 1.8906, 1.0246, 1.7598, 1.1184],
[ 1.7821, 0.0230, 0.9452, 1.0318, 1.0823],
[ 0.4116, -0.0379, -0.1843, 1.4129, 1.8796]]),
indices=tensor([[4, 4, 3, 2, 1],
[1, 2, 4, 1, 1],
[2, 4, 0, 2, 1],
[0, 2, 0, 3, 1],
[0, 4, 4, 4, 4]]))
>>> print("terrible", torch.randn(5,5,10).max(1))
terrible torch.return_types.max(
values=tensor([[ 2.1272, 1.3664, 2.2067, 1.3974, -0.0883, 1.2505, 1.0074, 1.1217,
0.3849, 0.6936],
[ 0.6288, -0.4560, 1.2748, 1.5482, 1.2777, 1.6874, 0.7151, 0.6041,
1.3572, 1.6232],
[ 1.6703, 1.0075, 1.6480, 2.2839, 1.3390, 0.4938, 1.6449, 1.7628,
0.8141, 2.5714],
[ 0.7079, 1.8677, 3.2478, 1.5591, 2.4870, 0.8635, -0.1450, 1.6923,
1.4924, 1.6298],
[ 2.4056, 0.8002, 0.9317, 0.7455, 0.7866, 2.1191, 0.3492, 1.2095,
1.8637, 1.7470]]),
indices=tensor([[1, 1, 0, 0, 0, 0, 3, 4, 4, 4],
[4, 2, 2, 1, 2, 2, 3, 1, 1, 3],
[0, 3, 3, 0, 2, 1, 4, 1, 0, 1],
[4, 1, 3, 0, 3, 2, 0, 1, 4, 3],
[1, 0, 3, 2, 1, 0, 0, 1, 0, 1]]))
>>> print("not as good", torch.randn(5,5,500).max(1))
not as good torch.return_types.max(
values=tensor([[ 0.3877, 0.7873, 1.8701, ..., 0.5971, 1.6103, -0.3435],
[ 1.1300, 2.2418, 1.4239, ..., 1.3943, 0.3872, 1.6475],
[ 2.0656, 1.3136, 0.9896, ..., 2.3918, 0.8226, 1.0517],
[ 1.1054, 0.9945, 1.0561, ..., 2.1039, 1.1524, 3.0304],
[ 1.5041, 2.2809, 1.0883, ..., 0.8504, 2.4774, 1.1041]]),
indices=tensor([[4, 3, 1, ..., 1, 4, 0],
[4, 4, 4, ..., 3, 0, 3],
[3, 0, 1, ..., 2, 2, 4],
[0, 1, 1, ..., 4, 2, 2],
[1, 0, 4, ..., 2, 0, 2]]))
>>> print ("old behaviour = gold standard")
old behaviour = gold standard
>>> print(tuple(torch.randn(5,5,5).max(1)))
(tensor([[ 1.1908, 1.1807, 1.3151, 1.7184, 0.3556],
[ 0.3798, 0.9213, 0.3001, 1.3087, 2.2419],
[ 1.4233, 1.4814, 1.9900, 1.7744, 1.3059],
[ 1.0026, -0.0330, 1.3061, 1.8730, 2.0685],
[ 1.3041, 1.6458, 1.3449, 1.8948, 3.6206]]), tensor([[0, 4, 3, 4, 0],
[1, 1, 4, 0, 4],
[4, 1, 0, 3, 3],
[1, 2, 1, 4, 0],
[3, 3, 0, 3, 3]]))
>>> print(tuple(torch.randn(5,5,10).max(1)))
(tensor([[-0.1232, 0.8275, 0.6732, 1.1223, 0.8247, 1.2851, 1.6009, 1.9979,
1.9109, 0.7313],
[ 0.2260, 0.5922, 1.6928, 0.6024, 2.1158, 3.0619, 0.5653, 0.7426,
0.8316, 0.6346],
[ 0.4319, 0.2231, 0.5255, 1.7620, 1.1657, 0.8875, 0.5782, 0.6506,
0.5032, 1.7097],
[ 0.4137, 1.7265, 1.4260, 2.0301, 1.2244, 0.7128, 2.6345, 0.7230,
1.3553, 1.6508],
[ 1.0684, 1.7195, 1.4068, 0.7076, -0.0242, 0.8474, 0.8754, 1.7108,
0.2188, 1.1584]]), tensor([[0, 1, 3, 4, 2, 3, 4, 2, 1, 0],
[1, 4, 0, 0, 3, 2, 0, 0, 3, 3],
[2, 3, 1, 1, 4, 0, 1, 4, 4, 4],
[0, 4, 1, 3, 2, 0, 2, 0, 3, 1],
[1, 0, 0, 0, 0, 3, 3, 3, 2, 0]]))
>>> print(tuple(torch.randn(5,5,500).max(1)))
(tensor([[0.9395, 1.5572, 1.8797, ..., 2.0494, 0.8202, 0.9623],
[1.7937, 0.7225, 1.8836, ..., 0.7927, 1.4976, 1.1813],
[0.8558, 1.6943, 1.4192, ..., 0.8327, 1.9661, 0.4197],
[1.2993, 1.4995, 0.9357, ..., 0.7810, 1.3030, 2.6216],
[1.4206, 1.8315, 1.0338, ..., 1.4312, 1.3198, 1.5233]]), tensor([[0, 4, 3, ..., 3, 0, 2],
[0, 1, 0, ..., 0, 4, 3],
[3, 4, 3, ..., 3, 0, 0],
[3, 2, 3, ..., 1, 2, 1],
[1, 2, 4, ..., 3, 1, 3]]))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17136
Differential Revision:
D14250021
Pulled By: VitalyFedyunin
fbshipit-source-id:
aae72f03b35980063b1ac1f07b8353eddb0c8b93
Michael Suo [Thu, 28 Feb 2019 20:49:31 +0000 (12:49 -0800)]
Revert
D14231251: [jit] alias_analysis refactor
Differential Revision:
D14231251
Original commit changeset:
6cd98ae6fced
fbshipit-source-id:
96189f47daf7cc4cf4ef5cd343022d56a2296b39
Sebastian Messmer [Thu, 28 Feb 2019 19:43:29 +0000 (11:43 -0800)]
refactor caffe2 operator constructors - 5/9 (#17086)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17086
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078519
fbshipit-source-id:
b0ca31a52e4ab97b145a1490461d59f8fa93874a
Michael Suo [Thu, 28 Feb 2019 19:28:16 +0000 (11:28 -0800)]
alias_analysis refactor (#17511)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17511
AliasTracker was doing bookkeeping for three concepts: the points-to graph,
writes, and wildcards.
This PR makes AliasTracker's job clearer: it keeps track of the points-to
graph. Thus it has been renamed MemoryDAG. Write and wildcard information were
pulled back into AliasDb as part of this—I may decide to pull them into their
own little modules since I don't want the alias analysis stuff to get too
bloated.
This refactor is necessary because we want to start tracking information for
aliasing elements that _aren't_ first-class IR Values (e.g. the "stuff" inside
a list). So MemoryDAG can't know too much about Values
Reviewed By: houseroad
Differential Revision:
D14231251
fbshipit-source-id:
6cd98ae6fced8d6c1522c2454da77c3c1b2b0504
Michael Suo [Thu, 28 Feb 2019 19:28:16 +0000 (11:28 -0800)]
allow "before" and "after" alias annotations (#17480)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17480
This was always part of our "spec" but not implemented
Reviewed By: houseroad
Differential Revision:
D14214301
fbshipit-source-id:
118db320b43ec099dc3e730c67d39487474c23ea
Rui Zhu [Thu, 28 Feb 2019 19:22:20 +0000 (11:22 -0800)]
ONNXIFI extension & e2e tests. (#17478)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17478
Enable onnxifi_ext in glow and build an e2e test in caffe2.
Reviewed By: yinghai
Differential Revision:
D14190136
fbshipit-source-id:
26245278b487b551623109b14432f675279b17b5
Soumith Chintala [Thu, 28 Feb 2019 19:21:23 +0000 (11:21 -0800)]
update slack invite instructions
Summary: update slack invite instructions
Reviewed By: pjh5
Differential Revision:
D14255348
fbshipit-source-id:
564fed0d44a6a68f80d1894fed40c3ddb360aa52
Evgeny Mankov [Thu, 28 Feb 2019 18:31:46 +0000 (10:31 -0800)]
Fix errors in the description for installation on Windows (#17475)
Summary:
+ All quotes for ENV VARS are erroneous;
+ Toolset hasn't be specified;
+ Provide paths for all 3 Visual Studio 2017 products: Community/Professional/Enterprise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17475
Differential Revision:
D14262968
Pulled By: soumith
fbshipit-source-id:
c0504e0a6be9c697ead83b06b0c5cf569b5c8625
Sebastian Messmer [Thu, 28 Feb 2019 17:50:19 +0000 (09:50 -0800)]
refactor caffe2 operator constructors - 9/9 (#17090)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17090
clangr codemod
Reviewed By: ezyang
Differential Revision:
D14078550
fbshipit-source-id:
68e6de4298e55ce83039b7806c1a275c4d6593c8
Gemfield [Thu, 28 Feb 2019 17:37:48 +0000 (09:37 -0800)]
Fix the false generated_comment (#17563)
Summary:
The generated_comments are wrong to below generated files:
```bash
./torch/csrc/autograd/generated/VariableType_0.cpp:3:// generated from tools/autograd/templates/VariableType_0.cpp
./torch/csrc/autograd/generated/VariableType_1.cpp:3:// generated from tools/autograd/templates/VariableType_1.cpp
./torch/csrc/autograd/generated/VariableType_2.cpp:3:// generated from tools/autograd/templates/VariableType_2.cpp
./torch/csrc/autograd/generated/VariableType_3.cpp:3:// generated from tools/autograd/templates/VariableType_3.cpp
./torch/csrc/autograd/generated/VariableType_4.cpp:3:// generated from tools/autograd/templates/VariableType_4.cpp
./torch/csrc/autograd/generated/VariableTypeEverything.cpp:3:// generated from tools/autograd/templates/VariableTypeEverything.cpp
./torch/csrc/jit/generated/register_aten_ops_0.cpp:23:// generated from tools/autograd/templates/register_aten_ops_0.cpp
./torch/csrc/jit/generated/register_aten_ops_1.cpp:23:// generated from tools/autograd/templates/register_aten_ops_1.cpp
./torch/csrc/jit/generated/register_aten_ops_2.cpp:23:// generated from tools/autograd/templates/register_aten_ops_2.cpp
```
These generated files were split to speed the compile, however, the template files are not.
After this fix, the comments will look like below:
```bash
./torch/csrc/autograd/generated/VariableType_0.cpp:3:// generated from tools/autograd/templates/VariableType.cpp
./torch/csrc/autograd/generated/VariableType_1.cpp:3:// generated from tools/autograd/templates/VariableType.cpp
......
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17563
Differential Revision:
D14260992
Pulled By: soumith
fbshipit-source-id:
038181367fa43bee87837e4170704ddff7f4d6f2
Dmytro Dzhulgakov [Thu, 28 Feb 2019 07:18:46 +0000 (23:18 -0800)]
Remove useless OpenCV reference
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17564
Differential Revision:
D14255542
Pulled By: dzhulgakov
fbshipit-source-id:
c129f3751ae82deedd258ee16586552b77baaca6
Ailing Zhang [Thu, 28 Feb 2019 05:36:37 +0000 (21:36 -0800)]
convolution/matmul/dropout (#17523)
Summary:
* Add AD formula for _convolution & matmul & dropout
* add prim::range, fixes #17483
Example:
```
dim = 3
x = range(dim)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17523
Differential Revision:
D14254002
Pulled By: ailzhang
fbshipit-source-id:
ba60d77b047db347929b72beca2623fb26aec957
Elias Ellison [Thu, 28 Feb 2019 02:59:19 +0000 (18:59 -0800)]
disallow shape analysis with resize ops (#17518)
Summary:
resize_ and resize_as resize the input tensor. because our shape analysis
is flow invariant, we don't do shape analysis on any op that relies on a Tensor that can alias a resized Tensor.
E.g. in the following graph the x += 10 x may have been resized.
```
torch.jit.script
def test(x, y):
for i in range(10):
x += 10
x.resize_as_([1 for i in int(range(torch.rand())))
return x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17518
Differential Revision:
D14249835
Pulled By: eellison
fbshipit-source-id:
f281b468ccb8c29eeb0f68ca5458cc7246a166d9
Sebastian Messmer [Thu, 28 Feb 2019 01:54:51 +0000 (17:54 -0800)]
Make C10_MOBILE consistent with how feature macros are usually used (#17481)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17481
Usually, feature macros are either defined or undefined and checked accordingly.
C10_MOBILE was a weird special case that was always defined but either defined to 1 or to 0.
This caused a lot of confusion for me when trying to disable something from mobile build and it also disabled it
from the server build (because I was using ifdef). Also, I found a place in the existing code base that made
that wrong assumption and used the macro wrongly, see https://fburl.com/y4icohts
Reviewed By: dzhulgakov
Differential Revision:
D14214825
fbshipit-source-id:
f3a155b6d43d334e8839e2b2e3c40ed2c773eab6
Sebastian Messmer [Thu, 28 Feb 2019 01:54:50 +0000 (17:54 -0800)]
Disable c10 dispatcher on mobile (#17078)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17078
This prevents caffe2 operators from being expsoed to c10 on mobile,
which in turn causes the whole c10 dispatcher to be stripped away
and saves binary size.
We probably want to re-enable the c10 dispatcher for mobile,
but for now this is ok.
Reviewed By: ezyang
Differential Revision:
D14077972
fbshipit-source-id:
e4dd3e3b60cdfbde91fe0d24102c1d9708d3e5c4
Shen Li [Wed, 27 Feb 2019 22:54:30 +0000 (14:54 -0800)]
Always synchronize src and dst streams when copying tensors (#16966)
Summary:
fixes #15568
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16966
Differential Revision:
D14213144
Pulled By: mrshenli
fbshipit-source-id:
2fcf5e07895fde80b4aee72e2736b0def876d21f
Lara Haidar [Wed, 27 Feb 2019 22:52:26 +0000 (14:52 -0800)]
ONNX Export Adaptive Pooling
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17412
Differential Revision:
D14247923
Pulled By: houseroad
fbshipit-source-id:
5530cea8f80da7368bff1e29cf89c45ad53accee
Christian Puhrsch [Wed, 27 Feb 2019 21:48:34 +0000 (13:48 -0800)]
Use name for output variables instead of out in JIT (#17386)
Summary:
This adds 88 matches.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17386
Differential Revision:
D14179139
Pulled By: cpuhrsch
fbshipit-source-id:
2c3263b8e4d084db84791e53290e8c8b1b7aecd5
Jesse Hellemn [Wed, 27 Feb 2019 21:17:16 +0000 (13:17 -0800)]
Forcing UTC on Mac circleci jobs (#17516)
Summary:
And adding timestamps to linux build jobs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17516
Differential Revision:
D14244533
Pulled By: pjh5
fbshipit-source-id:
26c38f59e0284c99f987d69ce6a2c2af9116c3c2
Xiaomeng Yang [Wed, 27 Feb 2019 20:18:52 +0000 (12:18 -0800)]
Fix math::Set for large tensor (#17539)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17539
Fix math::Set for large tensor
i-am-not-moving-c2-to-c10
Reviewed By: dzhulgakov, houseroad
Differential Revision:
D14240756
fbshipit-source-id:
0ade26790be41fb26d2cc193bfa3082c7bd4e69d
Natalia Gimelshein [Wed, 27 Feb 2019 19:39:37 +0000 (11:39 -0800)]
Add sparse gradient option to `gather` operation (#17182)
Summary:
This PR allows `gather` to optionally return sparse gradients, as requested in #16329. It also allows to autograd engine to accumulate sparse gradients in place when it is safe to do so.
I've commented out size.size() check in `SparseTensor.cpp` that also caused #17152, it does not seem to me that check serves a useful purpose, but please correct me if I'm wrong and a better fix is required.
Motivating example:
For this commonly used label smoothing loss function
```
def label_smoothing_opt(x, target):
padding_idx = 0
smoothing = 0.1
logprobs = torch.nn.functional.log_softmax(x, dim=-1, dtype=torch.float32)
pad_mask = (target == padding_idx)
ll_loss = logprobs.gather(dim=-1, index=target.unsqueeze(1), sparse = True).squeeze(1)
smooth_loss = logprobs.mean(dim=-1)
loss = (smoothing - 1.0) * ll_loss - smoothing * smooth_loss
loss.masked_fill_(pad_mask, 0)
return loss.sum()
```
backward goes from 12.6 ms with dense gather gradients to 7.3 ms with sparse gradients, for 9K tokens x 30K vocab, which is some single percent end-to-end improvement, and also improvement in peak memory required.
Shout-out to core devs: adding python-exposed functions with keyword arguments through native_functions.yaml is very easy now!
cc gchanan apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17182
Differential Revision:
D14158431
Pulled By: gchanan
fbshipit-source-id:
c8b654611534198025daaf7a634482b3151fbade
Jane Wang [Wed, 27 Feb 2019 19:26:40 +0000 (11:26 -0800)]
add elastic zeus handler (#16746)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16746
as titled. We use a special url schem elasticzeus for elastic zeus so that we dont need to change the public interface of init_process_group.
Reviewed By: aazzolini, soumith
Differential Revision:
D13948151
fbshipit-source-id:
88939dcfa0ad93467dabedad6905ec32e6ec60e6
Jongsoo Park [Wed, 27 Feb 2019 18:09:53 +0000 (10:09 -0800)]
optimize elementwise sum (#17456)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17456
Using an instruction sequence similar to function in fbgemm/src/QuantUtilAvx2.cc
elementwise_sum_benchmark added
Reviewed By: protonu
Differential Revision:
D14205695
fbshipit-source-id:
84939c9d3551f123deec3baf7086c8d31fbc873e
rohithkrn [Wed, 27 Feb 2019 18:04:33 +0000 (10:04 -0800)]
Enable boolean_mask, adadelta, adagrad fp16 on ROCm (#17235)
Summary:
- Fix bugs, indentation for adadelta and adagrad tests to enable fp16
- Enable boolean_mask fp16 on ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17235
Differential Revision:
D14240828
Pulled By: bddppq
fbshipit-source-id:
ab6e8f38aa7afb83b4b879f2f4cf2277c643198f
Iurii Zdebskyi [Wed, 27 Feb 2019 17:17:04 +0000 (09:17 -0800)]
Enabled HALF for fill() and zero() methods. Moved them into THTensorFill (#17536)
Summary:
For some additional context on this change, please, see this [PR](https://github.com/pytorch/pytorch/pull/17376)
As a part of work on Bool Tensor, we will need to add support for a bool type to _fill() and _zero() methods that are currently located in THTensorMath. As we don't need anything else and those methods are not really math related - we are moving them out into separate THTensorFill for simplicity.
Change:
-moved _fill() and _zero() from THTensorMath.h to THTensorFill
-enabled _fill() and _zero() for HALF type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17536
Differential Revision:
D14242130
Pulled By: izdeby
fbshipit-source-id:
1d8bd806f0f5510723b9299d360b70cc4ab96afb
Tongzhou Wang [Wed, 27 Feb 2019 04:43:11 +0000 (20:43 -0800)]
Fix autograd with buffers requiring grad in DataParallel (#13352)
Summary:
Causing a problem with spectral norm, although SN won't use that anymore after #13350 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13352
Differential Revision:
D14209562
Pulled By: ezyang
fbshipit-source-id:
f5e3183e1e7050ac5a66d203de6f8cf56e775134
Chaitanya Sri Krishna Lolla [Wed, 27 Feb 2019 04:36:45 +0000 (20:36 -0800)]
enable assymetric dilations and stride for miopen conv (#17472)
Summary:
As of MIOpen 1.7.1 as shipped in ROCm 2.1 this works correctly and we can use MIOpen and do not need to fall back
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17472
Differential Revision:
D14210323
Pulled By: ezyang
fbshipit-source-id:
4c08d0d4623e732eda304fe04cb722c835ec70e4
Johannes M Dieterich [Wed, 27 Feb 2019 04:35:28 +0000 (20:35 -0800)]
Enable tests working on ROCm 2.1 dual gfx906
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17473
Reviewed By: bddppq
Differential Revision:
D14210243
Pulled By: ezyang
fbshipit-source-id:
519032a1e73c13ecb260ea93102dc8efb645e070
peter [Wed, 27 Feb 2019 04:33:59 +0000 (20:33 -0800)]
Fix linking errors when building dataloader test binaries on Windows (#17494)
Summary:
Fixes #17489.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17494
Differential Revision:
D14226525
Pulled By: ezyang
fbshipit-source-id:
3dfef9bc6f443d647e9f05a54bc17c5717033723
hysts [Wed, 27 Feb 2019 04:20:32 +0000 (20:20 -0800)]
Fix typo
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17521
Differential Revision:
D14237482
Pulled By: soumith
fbshipit-source-id:
636e0fbe2c667d15fcb649136a65ae64937fa0cb
Christian Puhrsch [Wed, 27 Feb 2019 01:41:56 +0000 (17:41 -0800)]
Remove Bool/IndexTensor from schema for native functions with derivatives (#17193)
Summary:
This only deals with four functions, but is an important first step towards removing BoolTensor and IndexTensor entirely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17193
Differential Revision:
D14157829
Pulled By: cpuhrsch
fbshipit-source-id:
a36f16d1d88171036c44cc7de60ac9dfed9d14f2
Ilia Cherniavskii [Tue, 26 Feb 2019 23:34:04 +0000 (15:34 -0800)]
Fix operator initialization order (#15445)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15445
Initilize task graph after operators (task graph uses ops)
Reviewed By: yinghai
Differential Revision:
D13530864
fbshipit-source-id:
fdc91e9158c1b50fcc96fd1983fd000fdf20c7da
bhushan [Tue, 26 Feb 2019 22:11:18 +0000 (14:11 -0800)]
Make transpose consistent with numpy's behavior (#17462)
Summary:
Pytorch's tensor.t() is now equivalent with Numpy's ndarray.T for 1D tensor
i.e. tensor.t() == tensor
Test case added:
- test_t
fixes #9687
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17462
Differential Revision:
D14214838
Pulled By: soumith
fbshipit-source-id:
c5df1ecc8837be22478e3a82ce4854ccabb35765
Lu Fang [Tue, 26 Feb 2019 20:22:14 +0000 (12:22 -0800)]
Bump up the ONNX default opset version to 10 (#17419)
Summary:
Align with the master of ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17419
Reviewed By: zrphercule
Differential Revision:
D14197985
Pulled By: houseroad
fbshipit-source-id:
13fc1f7786aadbbf5fe83bddf488fee3dedf58ce
liangdzou [Tue, 26 Feb 2019 20:18:42 +0000 (12:18 -0800)]
' ' ==> ' ' (#17498)
Summary:
Fix formatting error for cpp code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17498
Reviewed By: zou3519
Differential Revision:
D14224549
Pulled By: fmassa
fbshipit-source-id:
f1721c4a75908ded759aea8c561f2e1d66859eec
Johannes M Dieterich [Tue, 26 Feb 2019 19:35:26 +0000 (11:35 -0800)]
Support all ROCm supported uarchs simultaneously: gfx803, gfx900, gfx906 (#17367)
Summary:
Correct misspelled flag.
Remove dependency on debug flag (HCC_AMDGPU_TARGET)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17367
Differential Revision:
D14227334
Pulled By: bddppq
fbshipit-source-id:
d838f219a9a1854330b0bc851c40dfbba77a32ef
knightXun [Tue, 26 Feb 2019 18:09:54 +0000 (10:09 -0800)]
refactor: a bit intricate so I refactor it (#16995)
Summary:
this code is a bit intricate so i refactor it
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16995
Differential Revision:
D14050667
Pulled By: ifedan
fbshipit-source-id:
55452339c6518166f3d4bc9898b1fe2f28601dc4
Elias Ellison [Tue, 26 Feb 2019 16:11:47 +0000 (08:11 -0800)]
new batch of expect file removals
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17486
Differential Revision:
D14218963
Pulled By: eellison
fbshipit-source-id:
dadc8bb71e756f47cdb04525d47f66c13ed56d16
Michael Suo [Tue, 26 Feb 2019 09:24:05 +0000 (01:24 -0800)]
user defined types (#17314)
Summary:
First pass at user defined types. The following is contained in this PR:
- `UserType` type, which contains a reference to a module with all methods for the type, and a separate namespace for data attributes (map of name -> TypePtr).
- `UserTypeRegistry`, similar to the operator registry
- `UserObject` which is the runtime representation of the user type (just a map of names -> IValues)
- `UserTypeValue` SugaredValue, to manage getattr and setattr while generating IR, plus compiler.cpp changes to make that work.
- Frontend changes to get `torch.jit.script` to work as a class decorator
- `ClassDef` node in our AST.
- primitive ops for object creation, setattr, and getattr, plus alias analysis changes to make mutation safe.
Things that definitely need to get done:
- Import/export, python_print support
- String frontend doesn't understand class definitions yet
- Python interop (using a user-defined type outside TorchScript) is completely broken
- Static methods (without `self`) don't work
Things that are nice but not essential:
- Method definition shouldn't matter (right now you can only reference a method that's already been defined)
- Class definitions can only contain defs, no other expressions are supported.
Things I definitely won't do initially:
- Polymorphism/inheritance
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17314
Differential Revision:
D14194065
Pulled By: suo
fbshipit-source-id:
c5434afdb9b39f84b7c85a9fdc2891f8250b5025
Michael Suo [Tue, 26 Feb 2019 08:24:15 +0000 (00:24 -0800)]
add mutability to docs (#17454)
Summary:
Not sure the best way to integrate this…I wrote something that focuses on mutability "vertically" through the stack. Should I split it up and distribute it into the various sections, or keep it all together?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17454
Differential Revision:
D14222883
Pulled By: suo
fbshipit-source-id:
3c83f6d53bba9186c32ee443aa9c32901a0951c0
Christian Puhrsch [Tue, 26 Feb 2019 01:44:07 +0000 (17:44 -0800)]
Remove usages of int64_t from native_functions.yaml
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17387
Differential Revision:
D14185458
Pulled By: cpuhrsch
fbshipit-source-id:
5c8b358d36b77b60c3226afcd3443c2b1727cbc2
Michael Suo [Tue, 26 Feb 2019 00:55:55 +0000 (16:55 -0800)]
upload alias tracker graph for docs (#17476)
Summary:
as title
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17476
Differential Revision:
D14218312
Pulled By: suo
fbshipit-source-id:
64df096a3431a6f25cd2373f0959d415591fed15
Ailing Zhang [Tue, 26 Feb 2019 00:22:16 +0000 (16:22 -0800)]
Temporarily disable select/topk/kthvalue AD (#17470)
Summary:
Temporarily disable them for perf consideration. Will figure out a way to do `torch.zeros(sizes, grad.options())` in torchscript before enabling these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17470
Differential Revision:
D14210313
Pulled By: ailzhang
fbshipit-source-id:
efaf44df1192ae42f4fe75998ff0073234bb4204
Elias Ellison [Tue, 26 Feb 2019 00:11:47 +0000 (16:11 -0800)]
Batch of expect file removals Remove dce expect files (#17471)
Summary:
Batch of removing expect test files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17471
Differential Revision:
D14217265
Pulled By: eellison
fbshipit-source-id:
425da022115b7e83aca86ef61d4d41fd046d439e
Dmytro Dzhulgakov [Tue, 26 Feb 2019 00:00:56 +0000 (16:00 -0800)]
Back out part of "Fix NERPredictor for zero initialization"
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17482
Reviewed By: david-y-lam
Differential Revision:
D14216135
fbshipit-source-id:
2ef4cb5dea74fc5c68e9b8cb43fcb180f219cb32
Stefan Krah [Mon, 25 Feb 2019 23:30:59 +0000 (15:30 -0800)]
Followup to #17049: change more instances of RuntimeError to IndexError
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17114
Differential Revision:
D14150890
Pulled By: gchanan
fbshipit-source-id:
579ca71665166c6a904b894598a0b334f0d8acc7
Krishna Kalyan [Mon, 25 Feb 2019 22:32:34 +0000 (14:32 -0800)]
Missing argument description (value) in scatter_ function documentation (#17467)
Summary: Update the docs to include the value parameter that was missing in the `scatter_` function.
Differential Revision:
D14209225
Pulled By: soumith
fbshipit-source-id:
5c65e4d8fbd93fcd11a0a47605bce6d57570f248
Lu Fang [Mon, 25 Feb 2019 22:25:18 +0000 (14:25 -0800)]
Throw exception when foxi is not checked out (#17477)
Summary:
Add check and provide useful warning/error information to user if foxi is not checked out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17477
Reviewed By: zrphercule
Differential Revision:
D14212896
Pulled By: houseroad
fbshipit-source-id:
557247d5d8fdc016b1c24c2a21503e59f874ad09
svcscm [Mon, 25 Feb 2019 21:42:28 +0000 (13:42 -0800)]
Updating submodules
Reviewed By: yns88
fbshipit-source-id:
ae3e05c2ee3af5df171556698ff1469780d739d1
Michael Suo [Mon, 25 Feb 2019 21:27:43 +0000 (13:27 -0800)]
simplify aliasdb interface (#17453)
Summary:
Stack:
:black_circle: **#17453 [jit] simplify aliasdb interface** [:yellow_heart:](https://our.intern.facebook.com/intern/diff/
D14205209/)
The previous "getWrites" API relies on the user to do alias checking, which is confusing and inconsistent with the rest of the interface. So replace it with a higher-level call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17453
Differential Revision:
D14209942
Pulled By: suo
fbshipit-source-id:
d4aff2af6062ab8465ee006fc6dc603296bcb7ab
Elias Ellison [Mon, 25 Feb 2019 21:26:49 +0000 (13:26 -0800)]
fix list type unification (#17424)
Summary:
Previously we were unifying the types of lists across if block outputs. This now fails with Optional subtyping because two types which can be unified have different runtime representations.
```
torch.jit.script
def list_optional_fails(x):
# type: (bool) -> Optional[int]
if x:
y = [1]
else:
y = [None]
return y[0]
```
the indexing op will expect y to be a generic list, but it will find an intlist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17424
Differential Revision:
D14210903
Pulled By: eellison
fbshipit-source-id:
4b8b26ba2e7e5bebf617e40316475f91e9109cc2
Shen Li [Mon, 25 Feb 2019 20:02:35 +0000 (12:02 -0800)]
Restore current streams on dst device after switching streams (#17439)
Summary:
When switching back to `d0` from a stream on a different device `d1`, we need to restore the current streams on both `d0` and `d1`. The current implementation only does that for `d0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17439
Differential Revision:
D14208919
Pulled By: mrshenli
fbshipit-source-id:
89f2565b9977206256efbec42adbd789329ccad8
Lu Fang [Mon, 25 Feb 2019 19:05:10 +0000 (11:05 -0800)]
update of fbcode/onnx to
e18bb41d255a23daf368ffd62a2645db55db4c72 (#17460)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17460
Previous import was
4c091e048ca42682d63ccd3c1811560bc12b732d
Included changes:
- **[e18bb41](https://github.com/onnx/onnx/commit/e18bb41)**: Infer shape of the second output of Dropout op (#1822) <Shinichiro Hamaji>
- **[cb544d0](https://github.com/onnx/onnx/commit/cb544d0)**: Clarify dtype of Dropout's mask output (#1826) <Shinichiro Hamaji>
- **[b60f693](https://github.com/onnx/onnx/commit/b60f693)**: Fix shape inference when auto_pad is notset (#1824) <Li-Wen Chang>
- **[80346bd](https://github.com/onnx/onnx/commit/80346bd)**: update test datat (#1825) <Rui Zhu>
- **[b37fc6d](https://github.com/onnx/onnx/commit/b37fc6d)**: Add stringnormalizer operator to ONNX (#1745) <Dmitri Smirnov>
Reviewed By: zrphercule
Differential Revision:
D14206264
fbshipit-source-id:
0575fa3374ff2b93b2ecee9989cfa4793c599117
Will Feng [Mon, 25 Feb 2019 18:56:03 +0000 (10:56 -0800)]
Fix variable checking in THCPModule_setRNGState (#17474)
Summary:
See https://github.com/pytorch/pytorch/pull/16325/files#r259576901
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17474
Differential Revision:
D14209549
Pulled By: yf225
fbshipit-source-id:
2ae091955ae17f5d1540f7d465739c4809c327f8
vishwakftw [Mon, 25 Feb 2019 18:32:48 +0000 (10:32 -0800)]
Fix reduction='none' in poisson_nll_loss (#17358)
Summary:
Changelog:
- Modify `if` to `elif` in reduction mode comparison
- Add error checking for reduction mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17358
Differential Revision:
D14190523
Pulled By: zou3519
fbshipit-source-id:
2b734d284dc4c40679923606a1aa148e6a0abeb8
Michael Liu [Mon, 25 Feb 2019 16:10:14 +0000 (08:10 -0800)]
Apply modernize-use-override (4)
Summary:
Use C++11’s override and remove virtual where applicable.
Change are automatically generated.
bypass-lint
drop-conflicts
Reviewed By: ezyang
Differential Revision:
D14191981
fbshipit-source-id:
1f3421335241cbbc0cc763b8c1e85393ef2fdb33
Gregory Chanan [Mon, 25 Feb 2019 16:08:15 +0000 (08:08 -0800)]
Fix nonzero for scalars on cuda, to_sparse for scalars on cpu/cuda. (#17406)
Summary:
I originally set out to fix to_sparse for scalars, which had some overly restrictive checking (sparse_dim > 0, which is impossible for a scalar).
This fix uncovered an issue with nonzero: it didn't properly return a size (z, 0) tensor for an input scalar, where z is the number of nonzero elements (i.e. 0 or 1).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17406
Differential Revision:
D14185393
Pulled By: gchanan
fbshipit-source-id:
f37a6e1e3773fd9cbf69eeca7fdebb3caa192a19
Tongliang Liao [Mon, 25 Feb 2019 16:07:56 +0000 (08:07 -0800)]
Export ElementwiseLinear to ONNX (Mul + Add). (#17411)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17411
Reshape-based approach to support dynamic shape.
The first Reshape flatten inner dimensions and the second one recover the actual shape.
No Shape/Reshape will be generated unless necessary.
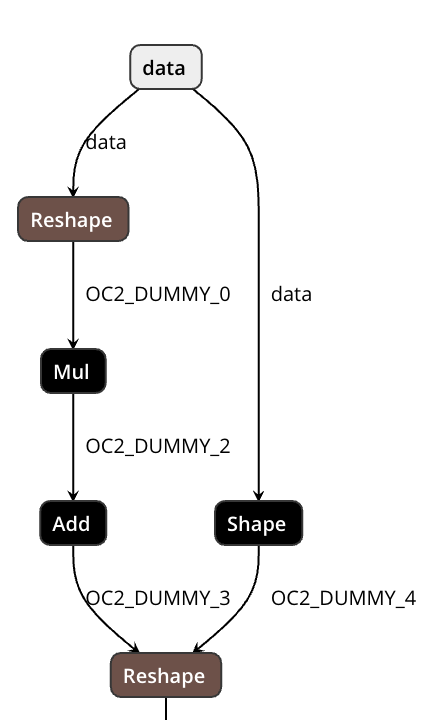
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16716
Reviewed By: zrphercule
Differential Revision:
D14094532
Pulled By: houseroad
fbshipit-source-id:
bad6a1fbf5963ef3dd034ef4bf440f5a5d6980bc
Lu Fang [Mon, 25 Feb 2019 15:57:21 +0000 (07:57 -0800)]
Add foxi submodule (ONNXIFI facebook extension)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17178
Reviewed By: yinghai
Differential Revision:
D14197987
Pulled By: houseroad
fbshipit-source-id:
c21d7235e40c2ca4925a10c467c2b4da2f1024ad
Michael Liu [Mon, 25 Feb 2019 15:26:27 +0000 (07:26 -0800)]
Fix remaining -Wreturn-std-move violations in fbcode (#17308)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17308
In some cases there is still no RVO/NRVO and std::move is still needed. Latest
Clang gained -Wreturn-std-move warning to detect cases like this (see
https://reviews.llvm.org/D43322).
Reviewed By: igorsugak
Differential Revision:
D14150915
fbshipit-source-id:
0df158f0b2874f1e16f45ba9cf91c56e9cb25066
Michael Suo [Mon, 25 Feb 2019 07:01:32 +0000 (23:01 -0800)]
add debug/release tip to cpp docs (#17452)
Summary:
as title. These were already added to the tutorials, but I didn't add them to the cpp docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17452
Differential Revision:
D14206501
Pulled By: suo
fbshipit-source-id:
89b5c8aaac22d05381bc4a7ab60d0bb35e43f6f5
Michael Suo [Mon, 25 Feb 2019 07:00:10 +0000 (23:00 -0800)]
add pointer to windows FAQ in contributing.md (#17450)
Summary:
" ProTip! Great commit summaries contain fewer than 50 characters. Place extra information in the extended description."
lol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17450
Differential Revision:
D14206500
Pulled By: suo
fbshipit-source-id:
af7ffe299f8c8f04fa8e720847a1f6d576ebafc1
Thomas Viehmann [Sun, 24 Feb 2019 04:57:28 +0000 (20:57 -0800)]
Remove ROIPooling (#17434)
Summary:
Fixes: #17399
It's undocumented, unused and, according to the issue, not actually working.
Differential Revision:
D14200088
Pulled By: soumith
fbshipit-source-id:
a81f0d0f5516faea2bd6aef5667b92c7dd012dbd
Krishna Kalyan [Sun, 24 Feb 2019 04:24:21 +0000 (20:24 -0800)]
Add example to WeightedRandomSampler doc string (#17432)
Summary: Example for the weighted random sampler are missing [here](https://pytorch.org/docs/stable/data.html#torch.utils.data.WeightedRandomSampler)
Differential Revision:
D14198642
Pulled By: soumith
fbshipit-source-id:
af6d8445d31304011002dd4308faaf40b0c1b609
Michael Suo [Sat, 23 Feb 2019 23:52:38 +0000 (15:52 -0800)]
Revert
D14095703: [pytorch][PR] [jit] Add generic list/dict custom op bindings
Differential Revision:
D14095703
Original commit changeset:
2b5ae20d42ad
fbshipit-source-id:
85b23fe4ce0090922da953403c95691bf3e28710
svcscm [Sat, 23 Feb 2019 20:43:01 +0000 (12:43 -0800)]
Updating submodules
Reviewed By: zpao
fbshipit-source-id:
8fa0be05e7410a863febb98b18be55ab723a41db
Jaliya Ekanayake [Sat, 23 Feb 2019 16:46:24 +0000 (08:46 -0800)]
Jaliyae/chunk buffer fix (#17409)
Summary:
The chunk buffer had a possibility to hang when no data is read and the buffer size is lower than chunk size. We detected this while running with larger dataset and hence the fix. I added a test to mimic the situation and validated that the fix is working. Thank you Xueyun for finding this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17409
Differential Revision:
D14198546
Pulled By: soumith
fbshipit-source-id:
b8ca43b0400deaae2ebb6601fdc65b47f32b0554
Stefan Krah [Sat, 23 Feb 2019 16:24:05 +0000 (08:24 -0800)]
Skip test_event_handle_multi_gpu() on a single GPU system (#17402)
Summary:
This fixes the following test failure:
```
======================================================================
ERROR: test_event_handle_multi_gpu (__main__.TestMultiprocessing)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_multiprocessing.py", line 445, in test_event_handle_multi_gpu
with torch.cuda.device(d1):
File "/home/stefan/rel/lib/python3.7/site-packages/torch/cuda/__init__.py", line 229, in __enter__
torch._C._cuda_setDevice(self.idx)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /home/stefan/pytorch/torch/csrc/cuda/Module.cpp:33
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17402
Differential Revision:
D14195190
Pulled By: soumith
fbshipit-source-id:
e911f3782875856de3cfbbd770b6d0411d750279
Olen ANDONI [Sat, 23 Feb 2019 16:19:09 +0000 (08:19 -0800)]
fix(typo): Change 'integeral' to 'integer'
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17396
Differential Revision:
D14195023
Pulled By: soumith
fbshipit-source-id:
300ab68c24bfbf10768fefac44fad64784463c8f
Lu Fang [Sat, 23 Feb 2019 07:56:21 +0000 (23:56 -0800)]
Fix the ONNX expect file (#17430)
Summary:
The CI is broken now, this diff should fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17430
Differential Revision:
D14198045
Pulled By: houseroad
fbshipit-source-id:
a1c8cb5ccff66f32488702bf72997f634360eb5b
Karl Ostmo [Sat, 23 Feb 2019 04:10:22 +0000 (20:10 -0800)]
order caffe2 ubuntu configs contiguously (#17427)
Summary:
This involves another purely cosmetic (ordering) change to the `config.yml` to facilitate simpler logic.
Other changes:
* add some review feedback as comments
* exit with nonzero status on config.yml mismatch
* produce a diagram for pytorch builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17427
Differential Revision:
D14197618
Pulled By: kostmo
fbshipit-source-id:
267439d3aa4c0a80801adcde2fa714268865900e
Jongsoo Park [Sat, 23 Feb 2019 04:03:09 +0000 (20:03 -0800)]
remove redundant inference functions for FC (#17407)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17407
As title says
Reviewed By: csummersea
Differential Revision:
D14177921
fbshipit-source-id:
e48e1086d37de2c290922d1f498e2d2dad49708a
Jongsoo Park [Sat, 23 Feb 2019 03:38:38 +0000 (19:38 -0800)]
optimize max pool 2d (#17418)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17418
Retry of
D14181620 this time with CMakeLists.txt changes
Reviewed By: jianyuh
Differential Revision:
D14190538
fbshipit-source-id:
c59b1bd474edf6376f4c2767a797b041a2ddf742
Roy Li [Sat, 23 Feb 2019 02:33:18 +0000 (18:33 -0800)]
Generate derived extension backend Type classes for each scalar type (#17278)
Summary:
Previously we only generate one class for each extension backend. This caused issues with scalarType() calls and mapping from variable Types to non-variable types. With this change we generate one Type for each scalar type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17278
Reviewed By: ezyang
Differential Revision:
D14161489
Pulled By: li-roy
fbshipit-source-id:
91e6a8f73d19a45946c43153ea1d7bc9d8fb2409
Ilia Cherniavskii [Sat, 23 Feb 2019 02:30:58 +0000 (18:30 -0800)]
Better handling of net errors in prof_dag counters (#17384)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17384
Better handling of possible net run errors in prof_dag counters.
Reviewed By: yinghai
Differential Revision:
D14177619
fbshipit-source-id:
51bc952c684c53136ce97e22281b1af5706f871e
eellison [Sat, 23 Feb 2019 01:54:09 +0000 (17:54 -0800)]
Batch of Expect Files removal (#17414)
Summary:
Batch of removing expect files, and some tests that no longer test anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17414
Differential Revision:
D14196342
Pulled By: eellison
fbshipit-source-id:
75c45649d1dd1ce39958fb02f5b7a2622c1d1d01
Arthur Crippa Búrigo [Sat, 23 Feb 2019 01:11:06 +0000 (17:11 -0800)]
Fix target name.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17365
Differential Revision:
D14195831
Pulled By: soumith
fbshipit-source-id:
fdf03f086f650148c34f4c548c66ef1eee698f05
Zachary DeVito [Sat, 23 Feb 2019 01:10:19 +0000 (17:10 -0800)]
jit technical docs - parts 1, 2, and most of 3 (#16887)
Summary:
This will evolve into complete technical docs for the jit. Posting what I have so far so people can start reading it and offering suggestions. Goto to Files Changed and click 'View File' to see markdown formatted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16887
Differential Revision:
D14191219
Pulled By: zdevito
fbshipit-source-id:
071a0e7db05e4f2eb657fbb99bcd903e4f46d84a
Vishwak Srinivasan [Sat, 23 Feb 2019 01:03:49 +0000 (17:03 -0800)]
USE_ --> BUILD_ for CAFFE2_OPS and TEST (#17390)
Differential Revision:
D14195572
Pulled By: soumith
fbshipit-source-id:
28e4ff3fe03a151cd4ed014c64253389cb85de3e
Gemfield [Sat, 23 Feb 2019 00:56:06 +0000 (16:56 -0800)]
Fix install libcaffe2_protos.a issue mentioned in #14317 (#17393)
Summary:
Fix install libcaffe2_protos.a issue mentioned in #14317.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17393
Differential Revision:
D14195359
Pulled By: soumith
fbshipit-source-id:
ed4da594905d708d03fcd719dc50aec6811d5d3f
Yinghai Lu [Sat, 23 Feb 2019 00:53:32 +0000 (16:53 -0800)]
Improve onnxifi backend init time (#17375)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17375
Previously we create the onnxGraph first and take it to the onnx manager for registration. It doesn't work well in practice. This diff takes "bring your own constructor" approach to reduce the resource spent doing backend compilation.
Reviewed By: kimishpatel, rdzhabarov
Differential Revision:
D14173793
fbshipit-source-id:
cbc4fe99fc522f017466b2fce88ffc67ae6757cf