Mikhail Zolotukhin [Thu, 14 Feb 2019 02:15:57 +0000 (18:15 -0800)]
Implement NetDef <--> JIT IR converters. (#16967)
Summary:
Currently the converters are very straightforward, i.e. there is no code for trying to
preserve semantics, we're purely perform conversion from one format to another.
Two things that we might want to add/change:
1. Add semantic conversion as well (but probably it would be a good idea to keep
it separate as a temporary thing).
2. Make sure we don't mess with value names, as they are crucial for current
uses of NetDefs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16967
Differential Revision:
D14062537
Pulled By: ZolotukhinM
fbshipit-source-id:
88b184ee7276779e5e9152b149d69857515ad98a
David Riazati [Thu, 14 Feb 2019 01:56:52 +0000 (17:56 -0800)]
Remove IgnoredPythonOp sugared value
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17042
Differential Revision:
D14072497
Pulled By: driazati
fbshipit-source-id:
68fe3fa89c22e60142d758c8cbe0e6e258e7d5c2
Xiaomeng Yang [Thu, 14 Feb 2019 01:47:49 +0000 (17:47 -0800)]
Separate reduce functions from math (#16929)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16929
Separate CPU reduce functions from math
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision:
D13999469
fbshipit-source-id:
bd628b15a6e3c1f04cc62aefffb0110690e1c0d1
Junjie Bai [Thu, 14 Feb 2019 01:12:01 +0000 (17:12 -0800)]
Skip test_cudnn_multiple_threads_same_device on ROCm (flaky) (#17061)
Summary:
cc iotamudelta
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py2-clang7-rocmdeb-ubuntu16.04-test/10722//console
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py2-clang7-rocmdeb-ubuntu16.04-test/10710//console
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py2-clang7-rocmdeb-ubuntu16.04-test/10753//console
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py2-devtoolset7-rocmrpm-centos7.5-test/1756//console
```
19:07:18 ======================================================================
19:07:18 FAIL: test_cudnn_multiple_threads_same_device (test_nn.TestNN)
19:07:18 ----------------------------------------------------------------------
19:07:18 Traceback (most recent call last):
19:07:18 File "/var/lib/jenkins/workspace/test/test_nn.py", line 3905, in test_cudnn_multiple_threads_same_device
19:07:18 (2048 - test_iters) * (2048 - test_iters))
19:07:18 File "/var/lib/jenkins/workspace/test/common_utils.py", line 453, in assertEqual
19:07:18 super(TestCase, self).assertLessEqual(abs(x - y), prec, message)
19:07:18 AssertionError: 3794704.0 not less than or equal to 1e-05 :
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17061
Differential Revision:
D14069324
Pulled By: bddppq
fbshipit-source-id:
e33b09abca217a62a8b577f9c332ea22985ef4ff
Tongliang Liao [Thu, 14 Feb 2019 01:08:40 +0000 (17:08 -0800)]
Support FC (Caffe2) -> Gemm (ONNX) with variable input shape. (#16184)
Summary:
For >2D input, previously the code uses static shape captured during tracing and reshape before/after `Gemm`.
Now we add `-1` to the first `Reshape`, and uses `Shape(X) => Slice(outer) => Concat(with -1 for inner) => Reshape` for the second.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16184
Differential Revision:
D14070754
Pulled By: ezyang
fbshipit-source-id:
86c69e9b254945b3406c07e122e57a00dfeba3df
Junjie Bai [Thu, 14 Feb 2019 00:57:30 +0000 (16:57 -0800)]
Make timeout in resnet50_trainer configurable (#17058)
Summary:
xw285cornell petrex dagamayank
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17058
Differential Revision:
D14068458
Pulled By: bddppq
fbshipit-source-id:
15df4007859067a22df4c6c407df4121e19aaf97
Boris Daskalov [Wed, 13 Feb 2019 23:30:39 +0000 (15:30 -0800)]
Make mkldnn Stream object thread_local and enable mkldnn thread-safe (#17022)
Summary:
This PR fixes following issue: https://github.com/pytorch/pytorch/issues/16828
It is a combination of two things:
1) MKLDNN streams are not thread-safe but are currently shared between different threads. This change makes them thread_local
2) By default MKLDNN primitives can share global memory and can't be invoked from multiple threads. This PR enables the MKLDNN_ENABLE_CONCURRENT_EXEC cmake configuration option that makes them thread-safe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17022
Differential Revision:
D14069052
Pulled By: ezyang
fbshipit-source-id:
f8f7fcb86c40f5d751fb35dfccc2f802b6e137c6
Tongliang Liao [Wed, 13 Feb 2019 22:57:27 +0000 (14:57 -0800)]
Support conversion from Caffe2 MergeDim to ONNX Reshape + Squeeze. (#16189)
Summary:
`MergeDim` can be done by `Reshape([1, -1, 0, 0, ...]) + Squeeze`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16189
Differential Revision:
D14070676
Pulled By: ezyang
fbshipit-source-id:
28d7e9b35cc2c1dcbd4afb3fbdf7383e219b1777
vishwakftw [Wed, 13 Feb 2019 21:35:40 +0000 (13:35 -0800)]
Fix mvlgamma doc (#17045)
Summary:
Changelog:
- Fix the constant in the docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17045
Differential Revision:
D14068698
Pulled By: ezyang
fbshipit-source-id:
af040b9a9badea213785f5bf3b6daf4d90050eb2
Mikhail Zolotukhin [Wed, 13 Feb 2019 18:32:38 +0000 (10:32 -0800)]
Change IR graph print format to make it look more pythonic (#16986)
Summary:
This removes curly braces from the outputs (we have indentation to indicate scopes), also adds ':' after graph and blocks declaration and removes ';' from the return line. ".expect" tests are updated to keep up with it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16986
Differential Revision:
D14062540
Pulled By: ZolotukhinM
fbshipit-source-id:
7f8e2d11619152a21ef7f1f7f8579c49392c3eca
Gregory Chanan [Wed, 13 Feb 2019 18:27:23 +0000 (10:27 -0800)]
Turn off the ability for Declarations.cwrap entries to be methods.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17053
Differential Revision:
D14065887
Pulled By: gchanan
fbshipit-source-id:
5d06ac66d27d28d48c2aff2b0d911f34ea0cd6fd
Jaliya Ekanayake [Wed, 13 Feb 2019 18:26:15 +0000 (10:26 -0800)]
Remove chunk count check on the ChunkBuffer (#16868)
Summary:
Previously, the ChunkBuffer depends on the remaining chunk count to signal end of dataloading. This does not work with distributed samplers where each sampler only loads a subset of chunks. This refactor remove the dependency on the remaining chunk count at the ChunkBuffer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16868
Differential Revision:
D14066517
Pulled By: goldsborough
fbshipit-source-id:
293dfe282ceff326dff0876c2f75c2ee4f4463e2
Stefan Krah [Wed, 13 Feb 2019 17:24:04 +0000 (09:24 -0800)]
Use IndexError instead of RuntimeError in ATen CPU kernels
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17049
Reviewed By: ezyang
Differential Revision:
D14064700
Pulled By: fmassa
fbshipit-source-id:
3575db103bba5a7d82f574cbb082beca419151ec
Edward Yang [Wed, 13 Feb 2019 16:44:43 +0000 (08:44 -0800)]
Mark IntList as deprecated; add C10_DEPRECATED_USING (#16824)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16824
There was a big wooly yak getting the deprecated macros to work.
Gory details are in Deprecated.h
Reviewed By: smessmer
Differential Revision:
D13978429
fbshipit-source-id:
f148e5935ac36eacc481789d22c7a9443164fe95
Yinghai Lu [Wed, 13 Feb 2019 07:59:40 +0000 (23:59 -0800)]
Add more debugging facilities to ONNXIFI transform (#17043)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17043
Add more debugging facilities for ONXNIFI transform.
Reviewed By: ipiszy
Differential Revision:
D14019492
fbshipit-source-id:
8c258ccba2f8ce77db096031fc8a61e15bd8af93
svcscm [Wed, 13 Feb 2019 05:45:34 +0000 (21:45 -0800)]
Updating submodules
Reviewed By: cdelahousse
fbshipit-source-id:
399afdc341075c383227d0d410a30eeb6c1d3b08
svcscm [Wed, 13 Feb 2019 05:20:09 +0000 (21:20 -0800)]
Updating submodules
Reviewed By: cdelahousse
fbshipit-source-id:
edb216d2eca7120d0f7729b2e4640096a0341154
Dmytro Dzhulgakov [Wed, 13 Feb 2019 05:13:25 +0000 (21:13 -0800)]
unify c2 and TH allocator (#16892)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16892
Replaces https://github.com/pytorch/pytorch/pull/14517
Merged caffe2 and TH CPU Allocators. Mostly using the code from caffe2 allocators.
`memset` of caffe2 allocator is gone now. These two allocators should be almost the same.
Baseline:
```
Running ./tensor_allocation
Run on (48 X 2501 MHz CPU s)
CPU Caches:
L1 Data 32K (x24)
L1 Instruction 32K (x24)
L2 Unified 256K (x24)
L3 Unified 30720K (x2)
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
BM_MakeStorageImpl 148 ns 148 ns 4676594
BM_StorageImplCtor 54 ns 54 ns
12957810
BM_MallocStorageImpl 62 ns 62 ns
11254745
BM_TensorImplCtor 22 ns 22 ns
31939472
BM_MallocTensorImpl 105 ns 105 ns 6505661
BM_Malloc_1 43 ns 43 ns
16464905
BM_MakeTensorFromStorage 126 ns 126 ns 5586116
BM_MakeVariableFromTensor 236 ns 236 ns 2995528
BM_ATenCPUTensorAllocationSmall1 319 ns 319 ns 2268884
BM_ATenCPUTensorAllocationSmall2 318 ns 318 ns 2163332
BM_ATenCPUTensorAllocationMedium1 403 ns 403 ns 1663228
BM_ATenCPUTensorAllocationMedium2 448 ns 448 ns 1595004
BM_ATenCPUTensorAllocationBig1 532 ns 532 ns 1352634
BM_ATenCPUTensorAllocationBig2 4486 ns 4486 ns 160978
```
Changed:
```
Running ./tensor_allocation
Run on (48 X 2501 MHz CPU s)
CPU Caches:
L1 Data 32K (x24)
L1 Instruction 32K (x24)
L2 Unified 256K (x24)
L3 Unified 30720K (x2)
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
BM_MakeStorageImpl 141 ns 141 ns 4803576
BM_StorageImplCtor 55 ns 55 ns
13129391
BM_MallocStorageImpl 64 ns 64 ns
11088143
BM_TensorImplCtor 23 ns 23 ns
31616273
BM_MallocTensorImpl 101 ns 101 ns 7017585
BM_Malloc_1 39 ns 39 ns
18523954
BM_MakeTensorFromStorage 118 ns 118 ns 5877919
BM_MakeVariableFromTensor 452 ns 452 ns 1565722
BM_ATenCPUTensorAllocationSmall1 384 ns 384 ns 1819763
BM_ATenCPUTensorAllocationSmall2 389 ns 389 ns 1857483
BM_ATenCPUTensorAllocationMedium1 425 ns 425 ns 1646284
BM_ATenCPUTensorAllocationMedium2 430 ns 430 ns 1561319
BM_ATenCPUTensorAllocationBig1 508 ns 508 ns 1309969
BM_ATenCPUTensorAllocationBig2 3799 ns 3799 ns 173674
```
lstm benchmark:
Before:
```
INFO:lstm_bench:Iter: 1 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 21 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 41 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 61 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 81 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 101 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 121 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 141 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 161 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 181 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 201 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 221 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 241 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 261 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 281 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 301 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 321 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 341 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 361 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 381 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Done. Total EPS excluding 1st iteration: 0.8k
```
After:
```
INFO:lstm_bench:Iter: 1 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 21 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 41 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 61 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 81 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 101 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 121 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 141 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 161 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 181 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 201 / 390. Entries Per Second: 0.8k.
INFO:lstm_bench:Iter: 221 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 241 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 261 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 281 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 301 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 321 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 341 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 361 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Iter: 381 / 390. Entries Per Second: 0.7k.
INFO:lstm_bench:Done. Total EPS excluding 1st iteration: 0.8k
```
Reviewed By: ezyang
Differential Revision:
D13202632
fbshipit-source-id:
db6d2ec756ed15b0732b15396c82ad42302bb79d
svcscm [Wed, 13 Feb 2019 04:42:10 +0000 (20:42 -0800)]
Updating submodules
Reviewed By: cdelahousse
fbshipit-source-id:
7d730945dbdd7bb7d10192061229ee6e759a1a7f
Yinghai Lu [Wed, 13 Feb 2019 02:21:09 +0000 (18:21 -0800)]
Remove second output of Reshape during ONNXIFI transform (#17027)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17027
Glow doesn't support second output of Reshape right now and it's useless. For correctness, we do make sure that the second output of Reshape is of Constant type during bound shape inference.
Reviewed By: ipiszy
Differential Revision:
D14056555
fbshipit-source-id:
f39cca7ba941bf5a5cc3adc96e2b1f943cc0be93
Johannes M Dieterich [Wed, 13 Feb 2019 01:41:24 +0000 (17:41 -0800)]
enable more unit tests in test_nn (#16994)
Summary:
These tests work with ROCm 2.1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16994
Differential Revision:
D14059802
Pulled By: bddppq
fbshipit-source-id:
8e2cbb13196c2e0283d3e02b7f761374bc580751
Johannes M Dieterich [Wed, 13 Feb 2019 01:18:40 +0000 (17:18 -0800)]
fix bicubic upsampling and enable tests (#17020)
Summary:
Fix macro name in ifdef guard, enable upsampling tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17020
Differential Revision:
D14059780
Pulled By: bddppq
fbshipit-source-id:
82c57d17d5bccdccb548c65d2b7a1ff8ab05af30
Jongsoo Park [Wed, 13 Feb 2019 01:00:33 +0000 (17:00 -0800)]
Fold col offsets into bias; optimize A symmetric quant (#16942)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16942
We can fold col offsets into bias if zero point of activation is constant.
fbgemm still needs to provide an option to pass col offsets in case zero point of activation keep changes (e.g., dynamic quantization).
A trick to optimize static quantization case is setting A zero point to 0 after folding into bias.
This diff also optimizes when weights use symmetric quantization. When B zero point is 0, we use PackAMatrix instead of PackAWithRowOffset .
TODO:
Ideally, PackAWithRowOffset should perform as fast as PackAMatrix when B_zero_point is 0 to make client code simpler
Same in PackAWithIm2Col and depth-wise convolution (group convolution is already doing this)
Reviewed By: csummersea
Differential Revision:
D14013931
fbshipit-source-id:
e4d313343e2a16a451eb910beed30e35de02a40c
Johannes M Dieterich [Wed, 13 Feb 2019 00:48:51 +0000 (16:48 -0800)]
enable unit tests in test_cuda that now pass with ROCm 2.1
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17012
Differential Revision:
D14059761
Pulled By: bddppq
fbshipit-source-id:
8309c3ffe1efed42b5db69fdec26427413c3f224
Sebastian Messmer [Wed, 13 Feb 2019 00:47:53 +0000 (16:47 -0800)]
Register CUDA kernels for caffe2 operators (#16691)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16691
Previous diffs already introduced a macro that registers caffe2 CPU kernels with c10.
This now also registers the CUDA kernels with it.
Reviewed By: bwasti
Differential Revision:
D13901619
fbshipit-source-id:
c15e5b7081ff10e5219af460779b88d6e091a6a6
Johannes M Dieterich [Wed, 13 Feb 2019 00:45:09 +0000 (16:45 -0800)]
Enable test_jit tests that work on ROCm 2.1
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17010
Differential Revision:
D14059748
Pulled By: bddppq
fbshipit-source-id:
7a1f7eee4f818dba91e741437415370973e4d429
Ying Zhang [Wed, 13 Feb 2019 00:37:50 +0000 (16:37 -0800)]
Extract ShapeInfo and some util functions into a separate file. (#17025)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17025
Extract ShapeInfo and some util functions into a separate file.
Reviewed By: yinghai
Differential Revision:
D14017432
fbshipit-source-id:
201db46bce6d52d9355a1a86925aa6206d0336bf
Yinghai Lu [Tue, 12 Feb 2019 22:43:44 +0000 (14:43 -0800)]
Allow customization of blob node in net_drawer (#16915)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16915
TSIA
Reviewed By: ipiszy
Differential Revision:
D14018010
fbshipit-source-id:
df5ccc06fa37f08e7a02a8acc466c4ad47afe04e
Yinghai Lu [Tue, 12 Feb 2019 22:43:43 +0000 (14:43 -0800)]
Ignore unknown_shaped tensor in bound shape inference (#16916)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16916
Two fixes for maximum effort bound shape inference
1. Ignore failed and unknown shape
2. Add specialization for `SparseLengthsWeightedSumFused8BitRowwise`.
Reviewed By: ipiszy
Differential Revision:
D14017810
fbshipit-source-id:
25cd68d35aa20b9ed077bdb562eb7f9deff0ab96
Pearu Peterson [Tue, 12 Feb 2019 22:14:30 +0000 (14:14 -0800)]
Workarounds to the lack of nvidia-smi and ldconfig programs in macosx (was PR 16968) (#16999)
Summary:
Fix issue #12174 for Mac OSX.
PS: This is a duplicate of PR #16968 that got messed up. Sorry for the confusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16999
Differential Revision:
D14050669
Pulled By: zou3519
fbshipit-source-id:
a4594c03ae8e0ca91a4836408b6c588720162c9f
vishwakftw [Tue, 12 Feb 2019 21:34:44 +0000 (13:34 -0800)]
Dispatch the correct legacy function for geqrf_out and ormqr_out (#16964)
Summary:
This fixes the segfault.
Changelog:
- Modify the function calls in LegacyDefinitions for `geqrf_out` and `ormqr_out`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16964
Differential Revision:
D14025985
Pulled By: gchanan
fbshipit-source-id:
aa50e2c1694cbf3642273ee14b09ba12625c7d33
Davide Libenzi [Tue, 12 Feb 2019 21:34:11 +0000 (13:34 -0800)]
Register layout for XLA backend.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16946
Differential Revision:
D14054716
Pulled By: gchanan
fbshipit-source-id:
063495b99b9f7d29ca3ad2020a6bc90d36ba0d7d
Tongliang Liao [Tue, 12 Feb 2019 21:18:13 +0000 (13:18 -0800)]
Export ReduceMean/ReduceFrontMean/ReduceBackMean (Caffe2) to ReduceMean (ONNX). (#16727)
Summary:
The second input (`lengths`) is not supported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16727
Differential Revision:
D14054105
Pulled By: houseroad
fbshipit-source-id:
36b8d00460f9623696439e1bd2a6bc60b7bb263c
James Reed [Tue, 12 Feb 2019 20:18:54 +0000 (12:18 -0800)]
Clean up allocations in FBGEMM linear (#16985)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16985
These statements were causing some redundant allocations + copying, so I cleaned
them up
Reviewed By: zdevito, wanchaol
Differential Revision:
D14031067
fbshipit-source-id:
f760fb29a2561894d52a2663f557b3e9ab1653de
Gregory Chanan [Tue, 12 Feb 2019 20:13:11 +0000 (12:13 -0800)]
Properly dispatch s_copy__cpu.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16974
Differential Revision:
D14030516
Pulled By: gchanan
fbshipit-source-id:
ba4cde5ebf2898d207efbc9117c1f1d6ccae861b
Gregory Chanan [Tue, 12 Feb 2019 20:11:45 +0000 (12:11 -0800)]
Get rid of unused THPStorage defines related to accreal.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16973
Differential Revision:
D14029538
Pulled By: gchanan
fbshipit-source-id:
b51f203ccff97695bf228772bb13e3e6b9bb6d1a
Yinghai Lu [Tue, 12 Feb 2019 19:18:52 +0000 (11:18 -0800)]
Fix AddAdjustBatchOp (#16997)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16997
1. Don't create multiple AdjustBatch ops for the same input name. We create it once and hook input to abc_post_adjust_batch.
2. Dangling tensor. The problem for such an error is still with AttachAdjustBatchOp. Considering such as net
```
op {
type : "Relu"
input: "X"
outpu: "Y"
}
op {
type : "Relu"
input: "Y"
output: "Y2"
}
external_output: "Y"
external_output: "Y2"
```
In this the output of first Relu will be used as an internal node as well as output. We cannot simply rename Y into Y_pre_batch_adjust. Basically, we need another pass in to check all the input of the ops in the net and rename Y into Y_pre_batch_adjust.
Reviewed By: bertmaher
Differential Revision:
D14041446
fbshipit-source-id:
f6553e287a8dfb14e4044cc20afaf3f290e5151b
Will Feng [Tue, 12 Feb 2019 18:49:38 +0000 (10:49 -0800)]
Roll back PyTorch DockerVersion to 282
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17013
Differential Revision:
D14052415
Pulled By: yf225
fbshipit-source-id:
df663fb46ee825174fe06b8d395979b3d4e84766
Karl Ostmo [Tue, 12 Feb 2019 18:41:45 +0000 (10:41 -0800)]
fix silent failure on Windows builds (#16984)
Summary:
Closes #16983
Remove backticks that are being interpreted by the shell. Add -e option to bash script to avoid future such failures
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16984
Reviewed By: yf225
Differential Revision:
D14039128
Pulled By: kostmo
fbshipit-source-id:
c31a1895377ca86c1b59e79351843cc8c4fd7de3
Theo [Tue, 12 Feb 2019 17:35:23 +0000 (09:35 -0800)]
Add module and name to func created with _jit_internal.boolean_dispatch (#16922)
Summary:
The use case for making this PR is the following bug :
(with F = torch.nn.functional)
`F.max_pool2d.__module__` is `torch._jit_internal`
`F.max_pool2d.__name__` is `fn`
With this PR you get:
`F.max_pool2d.__module__` is `torch.nn.functional`
`F.max_pool2d.__name__` is `max_pool2d`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16922
Differential Revision:
D14020053
Pulled By: driazati
fbshipit-source-id:
c109c1f04640f3b2b69bc4790b16fef7714025dd
Edward Yang [Tue, 12 Feb 2019 16:02:05 +0000 (08:02 -0800)]
More docs for methods in operator.h
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16826
Reviewed By: izdeby
Differential Revision:
D13979891
fbshipit-source-id:
df8391ffaff0d44845057bb839f05aea6fc5712c
Daniel [Tue, 12 Feb 2019 15:52:55 +0000 (07:52 -0800)]
Minor typo
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16980
Differential Revision:
D14033686
Pulled By: gchanan
fbshipit-source-id:
9f7967defc6795640e14157d0b701b185061741f
SsnL [Tue, 12 Feb 2019 15:49:48 +0000 (07:49 -0800)]
Fix allow_inf in assertEqual (#16959)
Summary:
gchanan pointed out in https://github.com/pytorch/pytorch/pull/16389 that `allow_inf` is treating `-inf` and `inf` as equal. This fixes it.
Also fixing #16448 since it's near and 2.1 has released.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16959
Differential Revision:
D14025297
Pulled By: gchanan
fbshipit-source-id:
95348309492e7ab65aa4d7aabb5a1800de66c5d6
Edward Yang [Tue, 12 Feb 2019 15:22:05 +0000 (07:22 -0800)]
Refine return type Stream to HIPStream in HIPStreamGuardMasqueradingAsCUDA (#16978)
Summary:
Previously, we used the templated class directly to provide
implementations. However, there is a subtle difference
between this, and CUDAStreamGuard: CUDAStreamGuard has refined types
for the Streams it returns. This lead to a compilation failure
of HIPified ddp.cpp. This commit lines them up more closely,
at the cost of copy-paste.
A possible alternate strategy would have been to extend the
InlineDeviceGuard templates to optionally accept refinements
for Stream. I leave this for future work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16978
Differential Revision:
D14045346
Pulled By: ezyang
fbshipit-source-id:
2b101606e62e4db588027c57902ea739a2119410
Edward Yang [Tue, 12 Feb 2019 14:59:36 +0000 (06:59 -0800)]
Revert
D14030665: [pytorch][PR] [HOTFIX] Pin docker-ce version to the one expected by nvidia-docker2
Differential Revision:
D14030665
Original commit changeset:
dece6a5aa4d1
fbshipit-source-id:
885a464ec3d1c23d4e07630fa3b67e69a3eab1b8
Simeon Monov [Tue, 12 Feb 2019 08:12:03 +0000 (00:12 -0800)]
Parse the command line and check the arguments before build_deps() (#16914)
Summary:
This is needed to check for wrong arguments or --help options
before `build_deps()` is executed. Otherwise command line arguments
are not parsed and checked until `setup()` is run.
Fixes: #16707
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16914
Differential Revision:
D14041236
Pulled By: soumith
fbshipit-source-id:
41f635772ccf47f05114775d5a19ae04c495ab3b
Dmytro Dzhulgakov [Tue, 12 Feb 2019 07:15:54 +0000 (23:15 -0800)]
Fix and add testing for nullptr allocator in c2->pt conversion (#16857)
Summary:
Fixes the bug for when tensor is created on Caffe2 side, then passed to PT and resized. Now we just initialize allocator correctly.
Note that the code in raw_mutable_data() is still necessary because of non-resizable tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16857
Reviewed By: houseroad
Differential Revision:
D14019469
Pulled By: dzhulgakov
fbshipit-source-id:
14d3a3b946d718bbab747ea376903646b885706a
Dmytro Dzhulgakov [Tue, 12 Feb 2019 07:04:59 +0000 (23:04 -0800)]
Fix NERPredictor for zero initialization
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16931
Reviewed By: dragonxlwang
Differential Revision:
D14016749
fbshipit-source-id:
b5512c52cef77651bdba1e31f588ea649daacdd9
David Riazati [Tue, 12 Feb 2019 05:48:58 +0000 (21:48 -0800)]
Allow calling a Python function with a dict
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16989
Differential Revision:
D14037896
Pulled By: driazati
fbshipit-source-id:
5f26d2d8fabf0f267909a3383f19d984645f94d0
Kimish Patel [Mon, 11 Feb 2019 22:32:30 +0000 (14:32 -0800)]
Keep weights name unchanged during SsaRewrite (#16932)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16932
During onnxifi transformation net ssa is rewritten. At the last step the weight
names are changed back to what they were before. The diff keeps the weight
names unchanged thru the process.
Reviewed By: yinghai
Differential Revision:
D13972597
fbshipit-source-id:
7c29857f788a674edf625c073b345f2b44267b33
Will Feng [Mon, 11 Feb 2019 22:04:31 +0000 (14:04 -0800)]
Pin docker-ce version to the one expected by nvidia-docker2 (#16976)
Summary:
Fix errors such as https://circleci.com/gh/pytorch/pytorch/760715.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16976
Differential Revision:
D14030665
Pulled By: yf225
fbshipit-source-id:
dece6a5aa4d13ff771c18b4ce02a0b9f9572a379
Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Expose GenerateProposals to PyTorch
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16880
Reviewed By: bwasti
Differential Revision:
D13998092
fbshipit-source-id:
23ab886ba137377312557fa718f262f4c8149cc7
Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Expose BBoxTransform to pytorch
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16879
Reviewed By: bwasti
Differential Revision:
D13998093
fbshipit-source-id:
ddfe4bff83e9a1a4cedf1e520e6d2977b21cb3af
Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Minimize templated code in caffe2 operator wrapper (#16965)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16965
Instead of having one large templated function to wrap the caffe2 op, minimize the amount of templated code.
Non-templated code can be reused between different operators and decreases binary size.
Reviewed By: orionr
Differential Revision:
D14018806
fbshipit-source-id:
bedd4152eec21dd8c5778446963826316d210543
Adam Paszke [Mon, 11 Feb 2019 21:31:06 +0000 (13:31 -0800)]
Don't keep unnecessary saved_inputs alive (#16583)
Summary:
Fixes #16577.
This greatly improves memory efficiency of certain ops like Dropout2d. Previously, they were implemented as `input * mask` where mask never requires_grad, but we didn't use that knowledge in forward, and (in case of a in-place dropout) kept input.clone() for the backward, when it would simply get ignored.
This patch tries to address this situation by emitting some guards for stores like this, but only if they are as simple, as checking if a single value requires_grad.
Interestingly, the same optimizations apply to methods like bmm, baddmm, etc., but _not to mm nor addmm_, because of how their derivatives are defined. Apparently they unnecessarily use `mat1` to compute the derivative of `mat1` just to improve the error message in case `mat1` was sparse. I'd like to apply this optimization to that case, but I don't want to loose the nicer error message, so if anyone has any ideas for solutions, please let me know...
Full list of operators affected by this patch:
* _nnpack_spatial_convolution
* addbmm
* addcdiv
* addcmul
* addmv
* addr
* baddbmm
* bmm
* cross
* div
* dot
* fmod
* ger
* index_add_
* mul
* mv
* scatter_add_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16583
Differential Revision:
D13900881
Pulled By: gchanan
fbshipit-source-id:
dd0aeb2ab58c4b6aa95b37b46d3255b3e014291c
Will Feng [Mon, 11 Feb 2019 20:48:17 +0000 (12:48 -0800)]
Enforce same input tensor storage in VariableType functions (#16305)
Summary:
In VariableType.cpp, when a function modifies its input tensors, it should only change the input tensors' storage data in-place, and should never change the input tensors' storage pointers. This PR adds checks for this, and also fixes functions that fail this test.
This is part of the Variable/Tensor merge work (https://github.com/pytorch/pytorch/issues/13638).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16305
Differential Revision:
D13897855
Pulled By: yf225
fbshipit-source-id:
0c4fc7eb530d30db88037b1f0981f6f8454d3b79
Sebastian Messmer [Mon, 11 Feb 2019 20:29:47 +0000 (12:29 -0800)]
Revert unneeded fixes in flat_hash_map (#16907)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16907
The begin()/end() fix actually doesn't make sense, see my comment on https://github.com/skarupke/flat_hash_map/pull/8
This diff removes it.
Reviewed By: ezyang
Differential Revision:
D13985779
fbshipit-source-id:
f08b02c941069e2a4e728e02a19b65dc72f96b41
Sebastian Messmer [Mon, 11 Feb 2019 20:29:47 +0000 (12:29 -0800)]
Fix constexpr in KernelRegistrationBuilder (#16906)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16906
In C++11, constexpr implies const, so these methods actually wouldn't be rvalue overloads as intended but const rvalue overloads.
Let's only apply the constexpr flag in C++14 to be safe.
Reviewed By: bddppq
Differential Revision:
D13998486
fbshipit-source-id:
a04d17ef0cc8f45e3d0a1ca9843d194f4f0f6f7f
Xiaodong Wang [Mon, 11 Feb 2019 20:27:12 +0000 (12:27 -0800)]
Catch cudaError_t return val (nodiscard in rocm) (#16399)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16399
Catching cudaError_t return values in a few places, because it's nodiscard in rocm. Unless we add -Wno-unused-result, it'll end up with a compilation error.
Also in c10/cuda/test, check whether a host has GPU or not. We were silently throwing out the error before (so not really testing the cuda api).
Reviewed By: bddppq
Differential Revision:
D13828281
fbshipit-source-id:
587d1cc31c20b836ce9594e3c18f067d322b2934
Thomas Viehmann [Mon, 11 Feb 2019 20:26:47 +0000 (12:26 -0800)]
optionally zero infinite losses in CTCLoss (#16199)
Summary:
Here is a stab at implementing an option to zero out infinite losses (and NaN gradients).
It might be nicer to move the zeroing to the respective kernels.
The default is currently `False` to mimic the old behaviour, but I'd be half inclined to set the default to `True`, because the behaviour wasn't consistent between CuDNN and Native anyways and the NaN gradients aren't terribly useful.
This topic seems to come up regularly, e.g. in #14335
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16199
Differential Revision:
D14020462
Pulled By: ezyang
fbshipit-source-id:
5ba8936c66ec6e61530aaf01175dc49f389ae428
Zhizhen Qin [Mon, 11 Feb 2019 20:24:10 +0000 (12:24 -0800)]
Merge binaries "convert_image_to_tensor" and "caffe2_benchmark" (#16875)
Summary:
Merge binaries "convert_image_to_tensor" and "caffe2_benchmark" to remove the overhead of writing to/reading from Tensor file.
*TODO next: TensorProtos is another overhead. No need for de-serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16875
Reviewed By: sf-wind
Differential Revision:
D13997726
Pulled By: ZhizhenQin
fbshipit-source-id:
4dec17f0ebb59cf1438b9aba5421db2b41c47a9f
SsnL [Mon, 11 Feb 2019 19:59:17 +0000 (11:59 -0800)]
Fix missing CircleCI GPG key (#16961)
Summary:
I'm seeing a bunch of apt gpg key errors on CI with the following message:
```
An error occurred during the signature verification. The repository is not
updated and the previous index files will be used. GPG error:
https://packagecloud.io trusty InRelease: The following signatures couldn't
be verified because the public key is not available:
NO_PUBKEY
4E6910DFCB68C9CD
```
Most of the times apt will reuse the old cached version, but sometimes this results in a build failure: https://circleci.com/gh/pytorch/pytorch/758366?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link.
This should hopefully fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16961
Differential Revision:
D14028151
Pulled By: ezyang
fbshipit-source-id:
7648a0a58ece38d8d04916937a9fa17f34f8833e
Edward Yang [Mon, 11 Feb 2019 19:43:45 +0000 (11:43 -0800)]
Disable binary_linux_conda_3.6_cu90_build on PRs. (#16958)
Summary:
Issue tracked at https://github.com/pytorch/pytorch/issues/16710
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16958
Differential Revision:
D14028078
Pulled By: ezyang
fbshipit-source-id:
6c68f79775a156ef4a55ac450a5a0ecacc0e6af5
Xiaodong Wang [Mon, 11 Feb 2019 17:44:17 +0000 (09:44 -0800)]
Install Thrust package and stop patching (#16911)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16911
I think the Thrust package has want we want for /opt/rocm/include/thrust. We probably can stop patching it now.
Reviewed By: bddppq
Differential Revision:
D14015177
fbshipit-source-id:
8d9128783a790c39083a1b8b4771c2c18bd67d46
Eskil Jörgensen [Mon, 11 Feb 2019 16:22:15 +0000 (08:22 -0800)]
Make pin_memory and default_collate preserve namedtuples (#16440)
Summary:
Open issue: https://github.com/pytorch/pytorch/issues/3281
Corresponding PR (conflict): https://github.com/pytorch/pytorch/pull/4577
Another open issue: https://github.com/pytorch/pytorch/issues/14613
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16440
Differential Revision:
D14020901
Pulled By: ezyang
fbshipit-source-id:
4abe817fc43c281a510715d311bad544511995d3
Edward Yang [Mon, 11 Feb 2019 14:02:08 +0000 (06:02 -0800)]
Revert
D14020906: [pytorch][PR] Extend support for exporting reshape to onnx.
Differential Revision:
D14020906
Original commit changeset:
168616873044
fbshipit-source-id:
2730bb6990d41f3a9cef6625ea919c219733433d
Ivan Ogasawara [Mon, 11 Feb 2019 12:52:06 +0000 (04:52 -0800)]
Added scientific notation on set_printoptions (#16876)
Summary:
This PR fixes #15683
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16876
Differential Revision:
D14021703
Pulled By: soumith
fbshipit-source-id:
1f603a7d24e331831d8d389f4a704c6a5b070b0c
BowenBao [Mon, 11 Feb 2019 04:12:45 +0000 (20:12 -0800)]
Extend support for exporting reshape to onnx.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16632
Differential Revision:
D14020906
Pulled By: ezyang
fbshipit-source-id:
168616873044b980145a3554dab942bdec19efb2
eyyub.sari@epitech.eu [Mon, 11 Feb 2019 04:05:32 +0000 (20:05 -0800)]
Int8GivenTensorFill Operator Schema fix typo (#16204)
Summary:
Hi,
caffe2/operators/quantized/int8_given_tensor_fill_op.cc expects the value array to be named "values" but the operator schema describe "value" (no s). I guess it is a little typo but it made me losing a bit of time before understanding why I had this error by passing "value" instead of "values":
```
[F int8_given_tensor_fill_op.h:95] Check failed: output->t.numel() == values_.numel() output size: 3 given size: 0
Aborted (core dumped)
```
Thanks,
Eyyüb Sari
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16204
Differential Revision:
D14020476
Pulled By: ezyang
fbshipit-source-id:
a8a46bfc44ec125e7925ce4b7c79fdf99c890a50
Adam Paszke [Mon, 11 Feb 2019 03:32:15 +0000 (19:32 -0800)]
Add support for fusion of half batch norm with float stats (#16735)
Summary:
Fixes #16642.
cc ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16735
Differential Revision:
D14020310
Pulled By: ezyang
fbshipit-source-id:
ac78726f471d16d188eb998354d52bc79fe2c282
musikisomorphie [Mon, 11 Feb 2019 03:31:38 +0000 (19:31 -0800)]
Improve the Sparse matrix multiplication computational speed #16187 (#16905)
Summary:
Instead of converting coo to csr format of the sparse matrix in the original implementation, in my revision I directly use coo format for sparse dense matrix mutliplication.
On my linux machine it is 5 times faster than the original code:
```
(original code)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.39403 seconds
np: 0.
00496674 seconds
torch/np: 79.3338
----------------------------------------
(my update)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.0812583 seconds
np: 0.
00501871 seconds
torch/np: 16.1911
```
Further code feedback and running time tests are highly welcomed. I will keep revise my code if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16905
Differential Revision:
D14020095
Pulled By: ezyang
fbshipit-source-id:
4ab94075344a55b375f22421e97a690e682baed5
Michael Carilli [Mon, 11 Feb 2019 03:31:23 +0000 (19:31 -0800)]
Allow dataloader to accept a custom memory pinning function (#16743)
Summary:
Renewed attempt at https://github.com/pytorch/pytorch/pull/14171
From the original PR:
> Currently, the pin_memory_batch function in the dataloader will return a batch comprised of any unrecognized type without pinning the data, because it doesn't know how.
>
>This behavior was preventing us from overlapping data prefetching in Mask-RCNN, whose custom collate_fn returns a custom batch type.
The old PR allowed the user to implement batch pinning for custom batch and data types by passing a custom pin function to the dataloader. slayton58 suggested a cleaner approach: allow the user to define a `pin_memory` method on their custom types, and have `pin_memory_batch` [check for the presence of that method](https://github.com/pytorch/pytorch/pull/16743/files#diff-9f154cbd884fe654066b1621fad654f3R56) in the incoming batch as a fallback. I've updated the test and docstrings accordingly.
The old PR was merged but then reverted due to weird cuda OOM errors on windows that may or may not have been related. I have no idea why my changes would cause such errors (then or now) but it's something to keep an eye out for.
fmassa and yf225 who were my POCs on the old PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16743
Differential Revision:
D13991745
Pulled By: ezyang
fbshipit-source-id:
74e71f62a03be453b4caa9f5524e9bc53467fa17
Hameer Abbasi [Mon, 11 Feb 2019 03:28:50 +0000 (19:28 -0800)]
Add abs for ByteTensor and CharTensor. (#16893)
Summary:
Fixes #15089
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16893
Differential Revision:
D14020115
Pulled By: ezyang
fbshipit-source-id:
6f3be6ed28d2d37667159be45959d400bc473451
Xiang Gao [Mon, 11 Feb 2019 02:10:59 +0000 (18:10 -0800)]
Support named tuple return from operators on JIT (#16253)
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/16233
The following changes are made:
- Modify `TupleType` to store optional field names
- Modify schema matching to return fill in those field names when creating `TupleType` as return type.
- Modify codegen of JIT to copy field names to schema string
- Modify `SchemaParser` to set field names of returned schema.
- Modify `SimpleValue::attr` to emit tuple indexing for named tuple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16253
Reviewed By: ezyang
Differential Revision:
D13954298
Pulled By: zdevito
fbshipit-source-id:
247d483d78a0c9c12d1ba36e1f1ec6c3f1a3007b
Derek Kim [Sun, 10 Feb 2019 23:52:37 +0000 (15:52 -0800)]
Enhance the documentation for torch.nn.DataParallel (#15993)
Summary:
I found a few sentences in DataParallel docstring confusing, so I suggest this enhancement.
- Arbitrary arguments are allowed to be passed .... *INCLUDING* tensors (Not *EXCLUDING*)
- The original author said that "other types" are shallow-copied but I think actually only some builtin types are (effectively) shallow-copied. And "other types" are shared. Here is an example.
```python
import torch
from torch.nn import Module, DataParallel
from collections import deque
class MyModel(Module):
def forward(self, x):
x.append(None)
model = MyModel(); model.cuda()
model = DataParallel(model)
d = deque()
model.forward(d)
print(d)
```
This is a side note.
As far as I know, copying objects is not a specially frequent operation in python unlike some other languages. Notably, no copying is involved in assignment or function parameter passing. They are only name bindings and it is the whole point of "everything is object" python philosophy, I guess. If one keep this in mind, it may help you dealing with things like multithreading.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15993
Differential Revision:
D14020404
Pulled By: ezyang
fbshipit-source-id:
a38689c94d0b8f77be70447f34962d3a7cd25e2e
ZhuBaohe [Sun, 10 Feb 2019 22:34:31 +0000 (14:34 -0800)]
DOC: correct docstring for torch and torch.Tensor package (#16842)
Summary:
This PR is a simple fix for the mistake in the "tensor" and "torch.Tensor"doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16842
Differential Revision:
D14020300
Pulled By: ezyang
fbshipit-source-id:
3ab04f1223d6e60f8da578d04d759e385d23acbb
Thomas Viehmann [Sun, 10 Feb 2019 21:57:57 +0000 (13:57 -0800)]
find libnvToolsExt instead of using only hardcoded path (#16714)
Summary:
This changes the libnvToolsExt dependency to go through CMake find_library.
I have a machine where cuda libs, and libnvToolsExt in particular, are in the "usual library locations". It would be neat if we could find libnvToolsExt and use the path currently hardcoded as default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16714
Differential Revision:
D14020315
Pulled By: ezyang
fbshipit-source-id:
00be27be10b1863ca92fd585f273d50bded850f8
Xiang Gao [Sun, 10 Feb 2019 21:42:49 +0000 (13:42 -0800)]
Clean up autograd method tests
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16790
Differential Revision:
D14020305
Pulled By: ezyang
fbshipit-source-id:
3aa3362830cde35967a3895837a25b3cf3287569
Travis Johnston [Sun, 10 Feb 2019 19:44:54 +0000 (11:44 -0800)]
fixed LogSigmoid math string that wasn't rendering in documentation (#16900)
Summary:
The documentation for LogSigmoid says:
> Applies the element-wise function:
> \<blank\>
Now the documentation properly displays the math string.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16900
Differential Revision:
D14020097
Pulled By: ezyang
fbshipit-source-id:
41e229d0fcc6b9bb53367be548bf85286dc13546
drkw [Sun, 10 Feb 2019 18:41:46 +0000 (10:41 -0800)]
ctc_loss error message bug fix. (#16917)
Summary:
CTCLLoss argument error message is wrong.
Please fix this. (sorry if I made some mistakes.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16917
Differential Revision:
D14019983
Pulled By: ezyang
fbshipit-source-id:
3337a2e86da6f3f7594c73fddb73340494a19ce2
Will Feng [Sun, 10 Feb 2019 17:38:50 +0000 (09:38 -0800)]
Use non-Variable type for callsites that check type equality (#16325)
Summary:
When Variable and Tensor are merged, the dynamic type of the tensors passed to certain functions will become variables, and expecting `type()` on those variables to still return non-Variable types will cause type mismatch error.
One way to fix this problem is to use the thread-local guard `at::AutoNonVariableTypeMode` to force `type()` to return non-Variable type, but ideally we want to limit the use of `at::AutoNonVariableTypeMode` to be only in VariableType.cpp. Another way to fix the problem is to use `at::globalContext().getNonVariableType()` instead to get the non-Variable type of the tensor, which is what this PR is trying to achieve.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16325
Differential Revision:
D14012022
Pulled By: yf225
fbshipit-source-id:
77ef1d2a02f78bff0063bdd72596e34046f1e00d
Jiren Jin [Sun, 10 Feb 2019 04:12:32 +0000 (20:12 -0800)]
Fix the error in the note about `torch.device` documentation. (#16839)
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-
abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
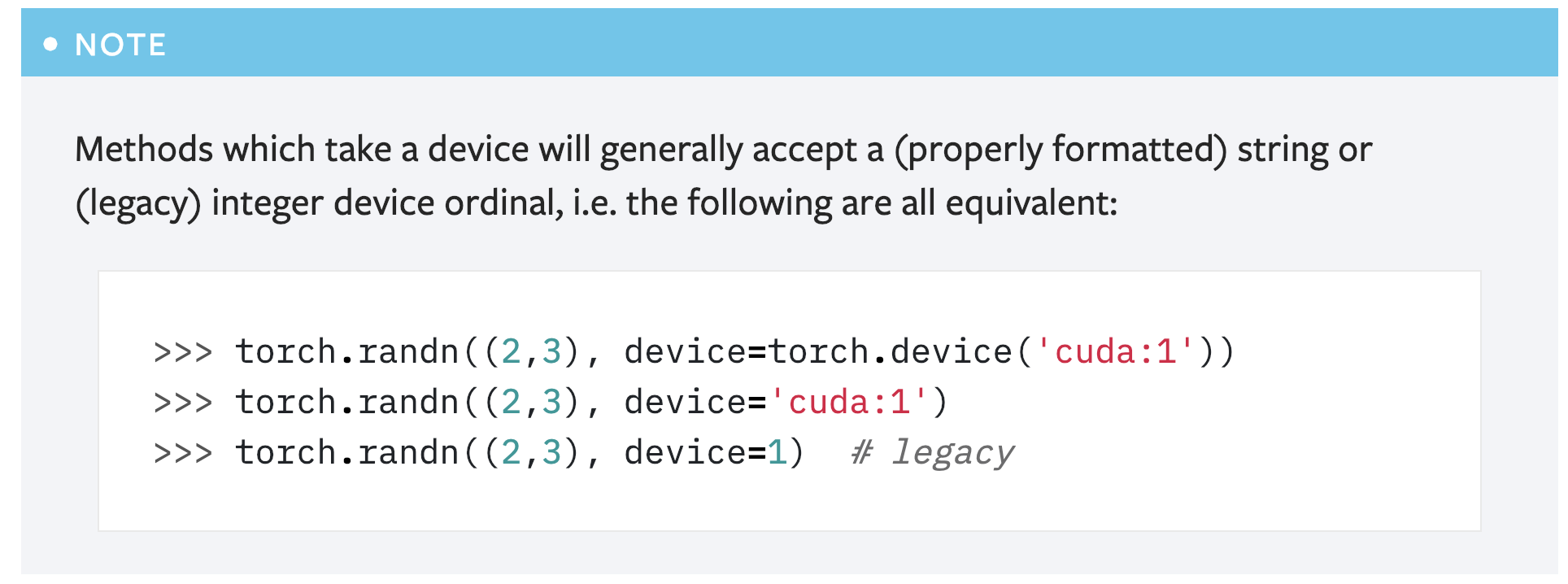
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision:
D13989209
Pulled By: gchanan
fbshipit-source-id:
ac255d52528da053ebfed18125ee6b857865ccaf
Johannes M Dieterich [Sat, 9 Feb 2019 19:20:18 +0000 (11:20 -0800)]
Register coalescer bug was fixed in ROCm 2.1 (#16923)
Summary:
Remove specialization/workaround for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16923
Differential Revision:
D14018521
Pulled By: bddppq
fbshipit-source-id:
d88162740bca6dc8ad37397dfbf8c84408074a00
Johannes M Dieterich [Sat, 9 Feb 2019 19:19:30 +0000 (11:19 -0800)]
Alignas is now correctly handled on ROCm (#16920)
Summary:
Post 2.1 release, packing is fixed and alignas works as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16920
Differential Revision:
D14018539
Pulled By: bddppq
fbshipit-source-id:
0ed4d9e9f36afb9b970812c3870082fd7f905455
Johannes M Dieterich [Sat, 9 Feb 2019 19:16:05 +0000 (11:16 -0800)]
Enable buildin bitonic sort (#16919)
Summary:
It now works post ROCm 2.1 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16919
Differential Revision:
D14018538
Pulled By: bddppq
fbshipit-source-id:
c4e1bafb53204a6d718b2d5054647d5715f23243
Junjie Bai [Sat, 9 Feb 2019 19:15:29 +0000 (11:15 -0800)]
Change the default image size from 227 to 224 in resnet50 trainer (#16924)
Summary:
cc xw285cornell
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16924
Differential Revision:
D14018509
Pulled By: bddppq
fbshipit-source-id:
fdbc9e94816ce6e4b1ca6f7261007bda7b80e1e5
Johannes M Dieterich [Sat, 9 Feb 2019 08:09:33 +0000 (00:09 -0800)]
enable unit tests working on ROCm 2.1 (#16871)
Summary:
This is the first round of enabling unit tests that work on ROCm 2.1 in my tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16871
Differential Revision:
D13997662
Pulled By: bddppq
fbshipit-source-id:
d909a3f7dd5fc8f85f126bf0613751c8e4ef949f
Elias Ellison [Sat, 9 Feb 2019 03:06:41 +0000 (19:06 -0800)]
Add suggest add to __constants__ message on save fail
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16850
Differential Revision:
D14014735
Pulled By: eellison
fbshipit-source-id:
7b6d5d5b64b9b107743cea1548cb4ee1b653977e
Chandler Zuo [Fri, 8 Feb 2019 23:20:15 +0000 (15:20 -0800)]
Make the exception raised from "numpy.dtype(numpy.void, (INT,))" less cryptic (#16809)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16809
https://fb.facebook.com/groups/
582508038765902/permalink/
736710343345670/?comment_id=
824042307945806&reply_comment_id=
824318864584817
numpy.dtype(numpy.void, (<INT>, )) raises a cryptic message "invalid itemsize in generic type tuple" that is hard to debug.
This diff adds the message to ask the user to investigate the error causing blob.
Reviewed By: kennyhorror
Differential Revision:
D13973359
fbshipit-source-id:
43a0c492ffafbabdfd7f7541c08a258e5ac0280f
Bram Wasti [Fri, 8 Feb 2019 22:57:57 +0000 (14:57 -0800)]
Revert
D13970381: [caffe2] Add visibility to registry class to fix ubsan error
Differential Revision:
D13970381
Original commit changeset:
763db24b8a98
fbshipit-source-id:
dda8672ed0bc6fecc4dde5ce73feb99e15205978
Nikita Shulga [Fri, 8 Feb 2019 22:20:31 +0000 (14:20 -0800)]
Extend Net.RunAllOnGPU() to support RecurrentNetwork op (#15713)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15713
[caffe2] Extend Net.RunAllOnGPU() to support RecurrentNetwork op
Reviewed By: dzhulgakov
Differential Revision:
D13576507
fbshipit-source-id:
f517127492c9d516ece663d42fef84338c70344e
James Reed [Fri, 8 Feb 2019 21:45:43 +0000 (13:45 -0800)]
delete critical section in TH*Tensor_addmm (#16889)
Summary:
This was serializing all calls to `addmm` (and any op that used it, in my case `bmm`) in the entire process, and led to downright atrocious performance in the TorchScript threaded runtime. Removing this gives a 2x throughput boost for high-load machine translation inference.
The original justification for this is dubious: there are other `gemm` callsites in the codebase that are not protected by critical sections. And in caffe2 land we never had any issues with nonreentrant BLAS libraries
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16889
Differential Revision:
D14008928
Pulled By: jamesr66a
fbshipit-source-id:
498e2133bd6564dba539a2d9751f4e61afbce608
Bram Wasti [Fri, 8 Feb 2019 19:42:22 +0000 (11:42 -0800)]
Revert
D13806753: [pytorch][PR] TensorIterator cuda launch configs update
Differential Revision:
D13806753
Original commit changeset:
37e45c7767b5
fbshipit-source-id:
74ac9f54f86853287b372ccf21fb37ed0e04a5d3
Elias Ellison [Fri, 8 Feb 2019 19:34:40 +0000 (11:34 -0800)]
Allow sequential modules in module list (#16882)
Summary:
Fix for https://github.com/pytorch/pytorch/issues/16845
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16882
Differential Revision:
D14007746
Pulled By: eellison
fbshipit-source-id:
d7918275cc1de6a67320619c3203463f66783343
Gu, Jinghui [Fri, 8 Feb 2019 19:17:59 +0000 (11:17 -0800)]
Impl ExpandDims op and fallback to CPU if needed (#15264)
Summary:
Impl ExpandDims op and fallback to CPU if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15264
Differential Revision:
D13808797
Pulled By: yinghai
fbshipit-source-id:
7795ec303a46e85f84e5490273db0ec76e8b9374
Bram Wasti [Fri, 8 Feb 2019 18:00:49 +0000 (10:00 -0800)]
Add visibility to registry class to fix ubsan error (#16792)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16792
fix
Reviewed By: ezyang
Differential Revision:
D13970381
fbshipit-source-id:
763db24b8a98a2757a63b77c70c8c68ba47f31e6
Edward Yang [Fri, 8 Feb 2019 17:29:59 +0000 (09:29 -0800)]
Remove Legacy entry point. (#16721)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16721
The very key line is we have to set the stream to the default
stream before calling the allocator. This is very interesting.
It shouldn't be necessary, but seemingly is!
Reviewed By: dzhulgakov
Differential Revision:
D13943193
fbshipit-source-id:
c21014917d9fe504fab0ad8abbc025787f559287
Edward Yang [Fri, 8 Feb 2019 17:29:59 +0000 (09:29 -0800)]
Deduplicate instances caching allocator, so that we only have one instance. (#16720)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16720
I'm taking the deduplication slowly because there is something here
that is causing problems, and I want to figure out what it is.
Reviewed By: dzhulgakov
Differential Revision:
D13943194
fbshipit-source-id:
cbc08fee5862fdcb393b9dd5b1d2ac7250f77c4b
Edward Yang [Fri, 8 Feb 2019 17:29:58 +0000 (09:29 -0800)]
Delete duplicate copy of THCCachingAllocator (round two). (#16615)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16615
This is another go at landing https://github.com/pytorch/pytorch/pull/16226
Now that the caching allocator is moved to c10_cuda, we can
delete the duplicate copy from Caffe2.
The difference between this and the previous PR is that this
version faithfully maintains the binding code; in particular,
we end up with a SECOND copy of the caching allocator in
this patch. I verified that this code does NOT cause a crash
in the workflow we canaried last time.
In further diffs, I plan to eliminate the second copy, and then
adjust the binding code.
Reviewed By: dzhulgakov
Differential Revision:
D13901067
fbshipit-source-id:
66331fd4eadffd0a5defb3cea532d5cd07287872
Junjie Bai [Fri, 8 Feb 2019 08:32:49 +0000 (00:32 -0800)]
Bump caffe2 docker images to 248 (#16863)
Summary:
Jenkins jobs update will be separate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16863
Differential Revision:
D13994672
Pulled By: bddppq
fbshipit-source-id:
5b27879dc6ac11a42016fe7835e9124345005ebb