Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Expose GenerateProposals to PyTorch
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16880
Reviewed By: bwasti
Differential Revision:
D13998092
fbshipit-source-id:
23ab886ba137377312557fa718f262f4c8149cc7
Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Expose BBoxTransform to pytorch
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16879
Reviewed By: bwasti
Differential Revision:
D13998093
fbshipit-source-id:
ddfe4bff83e9a1a4cedf1e520e6d2977b21cb3af
Sebastian Messmer [Mon, 11 Feb 2019 22:03:45 +0000 (14:03 -0800)]
Minimize templated code in caffe2 operator wrapper (#16965)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16965
Instead of having one large templated function to wrap the caffe2 op, minimize the amount of templated code.
Non-templated code can be reused between different operators and decreases binary size.
Reviewed By: orionr
Differential Revision:
D14018806
fbshipit-source-id:
bedd4152eec21dd8c5778446963826316d210543
Adam Paszke [Mon, 11 Feb 2019 21:31:06 +0000 (13:31 -0800)]
Don't keep unnecessary saved_inputs alive (#16583)
Summary:
Fixes #16577.
This greatly improves memory efficiency of certain ops like Dropout2d. Previously, they were implemented as `input * mask` where mask never requires_grad, but we didn't use that knowledge in forward, and (in case of a in-place dropout) kept input.clone() for the backward, when it would simply get ignored.
This patch tries to address this situation by emitting some guards for stores like this, but only if they are as simple, as checking if a single value requires_grad.
Interestingly, the same optimizations apply to methods like bmm, baddmm, etc., but _not to mm nor addmm_, because of how their derivatives are defined. Apparently they unnecessarily use `mat1` to compute the derivative of `mat1` just to improve the error message in case `mat1` was sparse. I'd like to apply this optimization to that case, but I don't want to loose the nicer error message, so if anyone has any ideas for solutions, please let me know...
Full list of operators affected by this patch:
* _nnpack_spatial_convolution
* addbmm
* addcdiv
* addcmul
* addmv
* addr
* baddbmm
* bmm
* cross
* div
* dot
* fmod
* ger
* index_add_
* mul
* mv
* scatter_add_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16583
Differential Revision:
D13900881
Pulled By: gchanan
fbshipit-source-id:
dd0aeb2ab58c4b6aa95b37b46d3255b3e014291c
Will Feng [Mon, 11 Feb 2019 20:48:17 +0000 (12:48 -0800)]
Enforce same input tensor storage in VariableType functions (#16305)
Summary:
In VariableType.cpp, when a function modifies its input tensors, it should only change the input tensors' storage data in-place, and should never change the input tensors' storage pointers. This PR adds checks for this, and also fixes functions that fail this test.
This is part of the Variable/Tensor merge work (https://github.com/pytorch/pytorch/issues/13638).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16305
Differential Revision:
D13897855
Pulled By: yf225
fbshipit-source-id:
0c4fc7eb530d30db88037b1f0981f6f8454d3b79
Sebastian Messmer [Mon, 11 Feb 2019 20:29:47 +0000 (12:29 -0800)]
Revert unneeded fixes in flat_hash_map (#16907)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16907
The begin()/end() fix actually doesn't make sense, see my comment on https://github.com/skarupke/flat_hash_map/pull/8
This diff removes it.
Reviewed By: ezyang
Differential Revision:
D13985779
fbshipit-source-id:
f08b02c941069e2a4e728e02a19b65dc72f96b41
Sebastian Messmer [Mon, 11 Feb 2019 20:29:47 +0000 (12:29 -0800)]
Fix constexpr in KernelRegistrationBuilder (#16906)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16906
In C++11, constexpr implies const, so these methods actually wouldn't be rvalue overloads as intended but const rvalue overloads.
Let's only apply the constexpr flag in C++14 to be safe.
Reviewed By: bddppq
Differential Revision:
D13998486
fbshipit-source-id:
a04d17ef0cc8f45e3d0a1ca9843d194f4f0f6f7f
Xiaodong Wang [Mon, 11 Feb 2019 20:27:12 +0000 (12:27 -0800)]
Catch cudaError_t return val (nodiscard in rocm) (#16399)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16399
Catching cudaError_t return values in a few places, because it's nodiscard in rocm. Unless we add -Wno-unused-result, it'll end up with a compilation error.
Also in c10/cuda/test, check whether a host has GPU or not. We were silently throwing out the error before (so not really testing the cuda api).
Reviewed By: bddppq
Differential Revision:
D13828281
fbshipit-source-id:
587d1cc31c20b836ce9594e3c18f067d322b2934
Thomas Viehmann [Mon, 11 Feb 2019 20:26:47 +0000 (12:26 -0800)]
optionally zero infinite losses in CTCLoss (#16199)
Summary:
Here is a stab at implementing an option to zero out infinite losses (and NaN gradients).
It might be nicer to move the zeroing to the respective kernels.
The default is currently `False` to mimic the old behaviour, but I'd be half inclined to set the default to `True`, because the behaviour wasn't consistent between CuDNN and Native anyways and the NaN gradients aren't terribly useful.
This topic seems to come up regularly, e.g. in #14335
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16199
Differential Revision:
D14020462
Pulled By: ezyang
fbshipit-source-id:
5ba8936c66ec6e61530aaf01175dc49f389ae428
Zhizhen Qin [Mon, 11 Feb 2019 20:24:10 +0000 (12:24 -0800)]
Merge binaries "convert_image_to_tensor" and "caffe2_benchmark" (#16875)
Summary:
Merge binaries "convert_image_to_tensor" and "caffe2_benchmark" to remove the overhead of writing to/reading from Tensor file.
*TODO next: TensorProtos is another overhead. No need for de-serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16875
Reviewed By: sf-wind
Differential Revision:
D13997726
Pulled By: ZhizhenQin
fbshipit-source-id:
4dec17f0ebb59cf1438b9aba5421db2b41c47a9f
SsnL [Mon, 11 Feb 2019 19:59:17 +0000 (11:59 -0800)]
Fix missing CircleCI GPG key (#16961)
Summary:
I'm seeing a bunch of apt gpg key errors on CI with the following message:
```
An error occurred during the signature verification. The repository is not
updated and the previous index files will be used. GPG error:
https://packagecloud.io trusty InRelease: The following signatures couldn't
be verified because the public key is not available:
NO_PUBKEY
4E6910DFCB68C9CD
```
Most of the times apt will reuse the old cached version, but sometimes this results in a build failure: https://circleci.com/gh/pytorch/pytorch/758366?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link.
This should hopefully fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16961
Differential Revision:
D14028151
Pulled By: ezyang
fbshipit-source-id:
7648a0a58ece38d8d04916937a9fa17f34f8833e
Edward Yang [Mon, 11 Feb 2019 19:43:45 +0000 (11:43 -0800)]
Disable binary_linux_conda_3.6_cu90_build on PRs. (#16958)
Summary:
Issue tracked at https://github.com/pytorch/pytorch/issues/16710
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16958
Differential Revision:
D14028078
Pulled By: ezyang
fbshipit-source-id:
6c68f79775a156ef4a55ac450a5a0ecacc0e6af5
Xiaodong Wang [Mon, 11 Feb 2019 17:44:17 +0000 (09:44 -0800)]
Install Thrust package and stop patching (#16911)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16911
I think the Thrust package has want we want for /opt/rocm/include/thrust. We probably can stop patching it now.
Reviewed By: bddppq
Differential Revision:
D14015177
fbshipit-source-id:
8d9128783a790c39083a1b8b4771c2c18bd67d46
Eskil Jörgensen [Mon, 11 Feb 2019 16:22:15 +0000 (08:22 -0800)]
Make pin_memory and default_collate preserve namedtuples (#16440)
Summary:
Open issue: https://github.com/pytorch/pytorch/issues/3281
Corresponding PR (conflict): https://github.com/pytorch/pytorch/pull/4577
Another open issue: https://github.com/pytorch/pytorch/issues/14613
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16440
Differential Revision:
D14020901
Pulled By: ezyang
fbshipit-source-id:
4abe817fc43c281a510715d311bad544511995d3
Edward Yang [Mon, 11 Feb 2019 14:02:08 +0000 (06:02 -0800)]
Revert
D14020906: [pytorch][PR] Extend support for exporting reshape to onnx.
Differential Revision:
D14020906
Original commit changeset:
168616873044
fbshipit-source-id:
2730bb6990d41f3a9cef6625ea919c219733433d
Ivan Ogasawara [Mon, 11 Feb 2019 12:52:06 +0000 (04:52 -0800)]
Added scientific notation on set_printoptions (#16876)
Summary:
This PR fixes #15683
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16876
Differential Revision:
D14021703
Pulled By: soumith
fbshipit-source-id:
1f603a7d24e331831d8d389f4a704c6a5b070b0c
BowenBao [Mon, 11 Feb 2019 04:12:45 +0000 (20:12 -0800)]
Extend support for exporting reshape to onnx.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16632
Differential Revision:
D14020906
Pulled By: ezyang
fbshipit-source-id:
168616873044b980145a3554dab942bdec19efb2
eyyub.sari@epitech.eu [Mon, 11 Feb 2019 04:05:32 +0000 (20:05 -0800)]
Int8GivenTensorFill Operator Schema fix typo (#16204)
Summary:
Hi,
caffe2/operators/quantized/int8_given_tensor_fill_op.cc expects the value array to be named "values" but the operator schema describe "value" (no s). I guess it is a little typo but it made me losing a bit of time before understanding why I had this error by passing "value" instead of "values":
```
[F int8_given_tensor_fill_op.h:95] Check failed: output->t.numel() == values_.numel() output size: 3 given size: 0
Aborted (core dumped)
```
Thanks,
Eyyüb Sari
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16204
Differential Revision:
D14020476
Pulled By: ezyang
fbshipit-source-id:
a8a46bfc44ec125e7925ce4b7c79fdf99c890a50
Adam Paszke [Mon, 11 Feb 2019 03:32:15 +0000 (19:32 -0800)]
Add support for fusion of half batch norm with float stats (#16735)
Summary:
Fixes #16642.
cc ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16735
Differential Revision:
D14020310
Pulled By: ezyang
fbshipit-source-id:
ac78726f471d16d188eb998354d52bc79fe2c282
musikisomorphie [Mon, 11 Feb 2019 03:31:38 +0000 (19:31 -0800)]
Improve the Sparse matrix multiplication computational speed #16187 (#16905)
Summary:
Instead of converting coo to csr format of the sparse matrix in the original implementation, in my revision I directly use coo format for sparse dense matrix mutliplication.
On my linux machine it is 5 times faster than the original code:
```
(original code)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.39403 seconds
np: 0.
00496674 seconds
torch/np: 79.3338
----------------------------------------
(my update)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.0812583 seconds
np: 0.
00501871 seconds
torch/np: 16.1911
```
Further code feedback and running time tests are highly welcomed. I will keep revise my code if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16905
Differential Revision:
D14020095
Pulled By: ezyang
fbshipit-source-id:
4ab94075344a55b375f22421e97a690e682baed5
Michael Carilli [Mon, 11 Feb 2019 03:31:23 +0000 (19:31 -0800)]
Allow dataloader to accept a custom memory pinning function (#16743)
Summary:
Renewed attempt at https://github.com/pytorch/pytorch/pull/14171
From the original PR:
> Currently, the pin_memory_batch function in the dataloader will return a batch comprised of any unrecognized type without pinning the data, because it doesn't know how.
>
>This behavior was preventing us from overlapping data prefetching in Mask-RCNN, whose custom collate_fn returns a custom batch type.
The old PR allowed the user to implement batch pinning for custom batch and data types by passing a custom pin function to the dataloader. slayton58 suggested a cleaner approach: allow the user to define a `pin_memory` method on their custom types, and have `pin_memory_batch` [check for the presence of that method](https://github.com/pytorch/pytorch/pull/16743/files#diff-9f154cbd884fe654066b1621fad654f3R56) in the incoming batch as a fallback. I've updated the test and docstrings accordingly.
The old PR was merged but then reverted due to weird cuda OOM errors on windows that may or may not have been related. I have no idea why my changes would cause such errors (then or now) but it's something to keep an eye out for.
fmassa and yf225 who were my POCs on the old PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16743
Differential Revision:
D13991745
Pulled By: ezyang
fbshipit-source-id:
74e71f62a03be453b4caa9f5524e9bc53467fa17
Hameer Abbasi [Mon, 11 Feb 2019 03:28:50 +0000 (19:28 -0800)]
Add abs for ByteTensor and CharTensor. (#16893)
Summary:
Fixes #15089
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16893
Differential Revision:
D14020115
Pulled By: ezyang
fbshipit-source-id:
6f3be6ed28d2d37667159be45959d400bc473451
Xiang Gao [Mon, 11 Feb 2019 02:10:59 +0000 (18:10 -0800)]
Support named tuple return from operators on JIT (#16253)
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/16233
The following changes are made:
- Modify `TupleType` to store optional field names
- Modify schema matching to return fill in those field names when creating `TupleType` as return type.
- Modify codegen of JIT to copy field names to schema string
- Modify `SchemaParser` to set field names of returned schema.
- Modify `SimpleValue::attr` to emit tuple indexing for named tuple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16253
Reviewed By: ezyang
Differential Revision:
D13954298
Pulled By: zdevito
fbshipit-source-id:
247d483d78a0c9c12d1ba36e1f1ec6c3f1a3007b
Derek Kim [Sun, 10 Feb 2019 23:52:37 +0000 (15:52 -0800)]
Enhance the documentation for torch.nn.DataParallel (#15993)
Summary:
I found a few sentences in DataParallel docstring confusing, so I suggest this enhancement.
- Arbitrary arguments are allowed to be passed .... *INCLUDING* tensors (Not *EXCLUDING*)
- The original author said that "other types" are shallow-copied but I think actually only some builtin types are (effectively) shallow-copied. And "other types" are shared. Here is an example.
```python
import torch
from torch.nn import Module, DataParallel
from collections import deque
class MyModel(Module):
def forward(self, x):
x.append(None)
model = MyModel(); model.cuda()
model = DataParallel(model)
d = deque()
model.forward(d)
print(d)
```
This is a side note.
As far as I know, copying objects is not a specially frequent operation in python unlike some other languages. Notably, no copying is involved in assignment or function parameter passing. They are only name bindings and it is the whole point of "everything is object" python philosophy, I guess. If one keep this in mind, it may help you dealing with things like multithreading.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15993
Differential Revision:
D14020404
Pulled By: ezyang
fbshipit-source-id:
a38689c94d0b8f77be70447f34962d3a7cd25e2e
ZhuBaohe [Sun, 10 Feb 2019 22:34:31 +0000 (14:34 -0800)]
DOC: correct docstring for torch and torch.Tensor package (#16842)
Summary:
This PR is a simple fix for the mistake in the "tensor" and "torch.Tensor"doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16842
Differential Revision:
D14020300
Pulled By: ezyang
fbshipit-source-id:
3ab04f1223d6e60f8da578d04d759e385d23acbb
Thomas Viehmann [Sun, 10 Feb 2019 21:57:57 +0000 (13:57 -0800)]
find libnvToolsExt instead of using only hardcoded path (#16714)
Summary:
This changes the libnvToolsExt dependency to go through CMake find_library.
I have a machine where cuda libs, and libnvToolsExt in particular, are in the "usual library locations". It would be neat if we could find libnvToolsExt and use the path currently hardcoded as default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16714
Differential Revision:
D14020315
Pulled By: ezyang
fbshipit-source-id:
00be27be10b1863ca92fd585f273d50bded850f8
Xiang Gao [Sun, 10 Feb 2019 21:42:49 +0000 (13:42 -0800)]
Clean up autograd method tests
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16790
Differential Revision:
D14020305
Pulled By: ezyang
fbshipit-source-id:
3aa3362830cde35967a3895837a25b3cf3287569
Travis Johnston [Sun, 10 Feb 2019 19:44:54 +0000 (11:44 -0800)]
fixed LogSigmoid math string that wasn't rendering in documentation (#16900)
Summary:
The documentation for LogSigmoid says:
> Applies the element-wise function:
> \<blank\>
Now the documentation properly displays the math string.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16900
Differential Revision:
D14020097
Pulled By: ezyang
fbshipit-source-id:
41e229d0fcc6b9bb53367be548bf85286dc13546
drkw [Sun, 10 Feb 2019 18:41:46 +0000 (10:41 -0800)]
ctc_loss error message bug fix. (#16917)
Summary:
CTCLLoss argument error message is wrong.
Please fix this. (sorry if I made some mistakes.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16917
Differential Revision:
D14019983
Pulled By: ezyang
fbshipit-source-id:
3337a2e86da6f3f7594c73fddb73340494a19ce2
Will Feng [Sun, 10 Feb 2019 17:38:50 +0000 (09:38 -0800)]
Use non-Variable type for callsites that check type equality (#16325)
Summary:
When Variable and Tensor are merged, the dynamic type of the tensors passed to certain functions will become variables, and expecting `type()` on those variables to still return non-Variable types will cause type mismatch error.
One way to fix this problem is to use the thread-local guard `at::AutoNonVariableTypeMode` to force `type()` to return non-Variable type, but ideally we want to limit the use of `at::AutoNonVariableTypeMode` to be only in VariableType.cpp. Another way to fix the problem is to use `at::globalContext().getNonVariableType()` instead to get the non-Variable type of the tensor, which is what this PR is trying to achieve.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16325
Differential Revision:
D14012022
Pulled By: yf225
fbshipit-source-id:
77ef1d2a02f78bff0063bdd72596e34046f1e00d
Jiren Jin [Sun, 10 Feb 2019 04:12:32 +0000 (20:12 -0800)]
Fix the error in the note about `torch.device` documentation. (#16839)
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-
abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
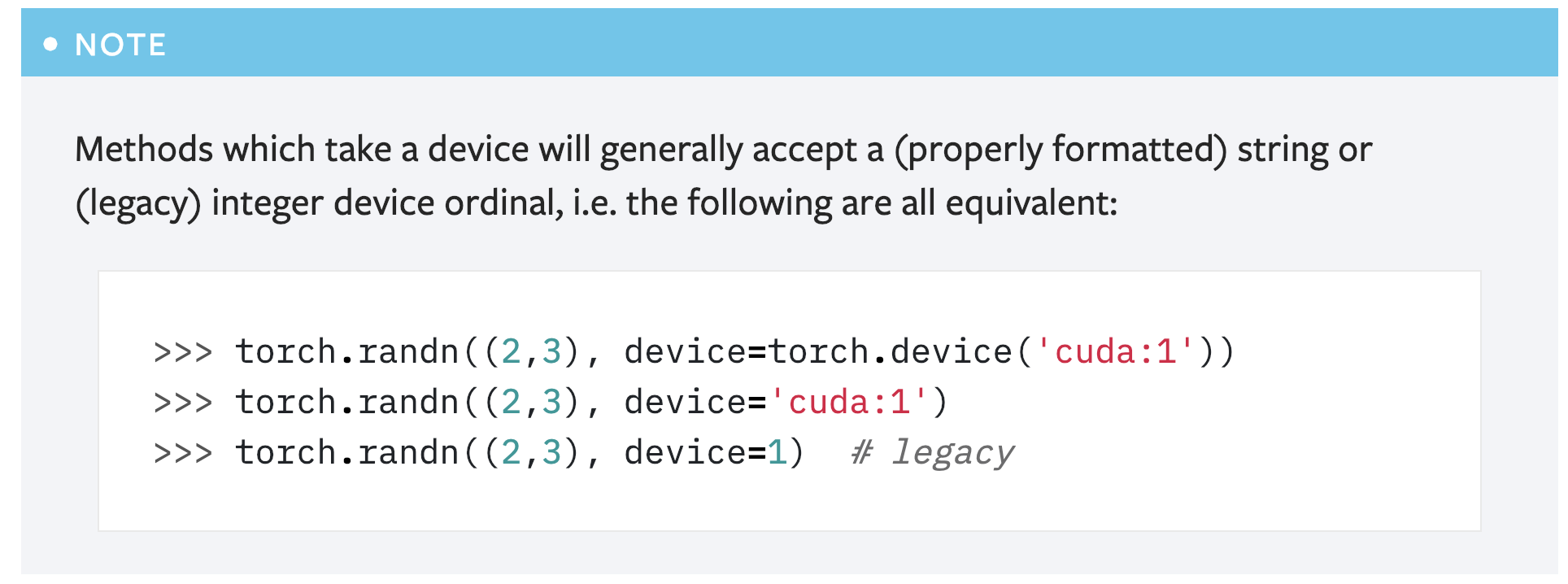
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision:
D13989209
Pulled By: gchanan
fbshipit-source-id:
ac255d52528da053ebfed18125ee6b857865ccaf
Johannes M Dieterich [Sat, 9 Feb 2019 19:20:18 +0000 (11:20 -0800)]
Register coalescer bug was fixed in ROCm 2.1 (#16923)
Summary:
Remove specialization/workaround for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16923
Differential Revision:
D14018521
Pulled By: bddppq
fbshipit-source-id:
d88162740bca6dc8ad37397dfbf8c84408074a00
Johannes M Dieterich [Sat, 9 Feb 2019 19:19:30 +0000 (11:19 -0800)]
Alignas is now correctly handled on ROCm (#16920)
Summary:
Post 2.1 release, packing is fixed and alignas works as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16920
Differential Revision:
D14018539
Pulled By: bddppq
fbshipit-source-id:
0ed4d9e9f36afb9b970812c3870082fd7f905455
Johannes M Dieterich [Sat, 9 Feb 2019 19:16:05 +0000 (11:16 -0800)]
Enable buildin bitonic sort (#16919)
Summary:
It now works post ROCm 2.1 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16919
Differential Revision:
D14018538
Pulled By: bddppq
fbshipit-source-id:
c4e1bafb53204a6d718b2d5054647d5715f23243
Junjie Bai [Sat, 9 Feb 2019 19:15:29 +0000 (11:15 -0800)]
Change the default image size from 227 to 224 in resnet50 trainer (#16924)
Summary:
cc xw285cornell
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16924
Differential Revision:
D14018509
Pulled By: bddppq
fbshipit-source-id:
fdbc9e94816ce6e4b1ca6f7261007bda7b80e1e5
Johannes M Dieterich [Sat, 9 Feb 2019 08:09:33 +0000 (00:09 -0800)]
enable unit tests working on ROCm 2.1 (#16871)
Summary:
This is the first round of enabling unit tests that work on ROCm 2.1 in my tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16871
Differential Revision:
D13997662
Pulled By: bddppq
fbshipit-source-id:
d909a3f7dd5fc8f85f126bf0613751c8e4ef949f
Elias Ellison [Sat, 9 Feb 2019 03:06:41 +0000 (19:06 -0800)]
Add suggest add to __constants__ message on save fail
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16850
Differential Revision:
D14014735
Pulled By: eellison
fbshipit-source-id:
7b6d5d5b64b9b107743cea1548cb4ee1b653977e
Chandler Zuo [Fri, 8 Feb 2019 23:20:15 +0000 (15:20 -0800)]
Make the exception raised from "numpy.dtype(numpy.void, (INT,))" less cryptic (#16809)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16809
https://fb.facebook.com/groups/
582508038765902/permalink/
736710343345670/?comment_id=
824042307945806&reply_comment_id=
824318864584817
numpy.dtype(numpy.void, (<INT>, )) raises a cryptic message "invalid itemsize in generic type tuple" that is hard to debug.
This diff adds the message to ask the user to investigate the error causing blob.
Reviewed By: kennyhorror
Differential Revision:
D13973359
fbshipit-source-id:
43a0c492ffafbabdfd7f7541c08a258e5ac0280f
Bram Wasti [Fri, 8 Feb 2019 22:57:57 +0000 (14:57 -0800)]
Revert
D13970381: [caffe2] Add visibility to registry class to fix ubsan error
Differential Revision:
D13970381
Original commit changeset:
763db24b8a98
fbshipit-source-id:
dda8672ed0bc6fecc4dde5ce73feb99e15205978
Nikita Shulga [Fri, 8 Feb 2019 22:20:31 +0000 (14:20 -0800)]
Extend Net.RunAllOnGPU() to support RecurrentNetwork op (#15713)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15713
[caffe2] Extend Net.RunAllOnGPU() to support RecurrentNetwork op
Reviewed By: dzhulgakov
Differential Revision:
D13576507
fbshipit-source-id:
f517127492c9d516ece663d42fef84338c70344e
James Reed [Fri, 8 Feb 2019 21:45:43 +0000 (13:45 -0800)]
delete critical section in TH*Tensor_addmm (#16889)
Summary:
This was serializing all calls to `addmm` (and any op that used it, in my case `bmm`) in the entire process, and led to downright atrocious performance in the TorchScript threaded runtime. Removing this gives a 2x throughput boost for high-load machine translation inference.
The original justification for this is dubious: there are other `gemm` callsites in the codebase that are not protected by critical sections. And in caffe2 land we never had any issues with nonreentrant BLAS libraries
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16889
Differential Revision:
D14008928
Pulled By: jamesr66a
fbshipit-source-id:
498e2133bd6564dba539a2d9751f4e61afbce608
Bram Wasti [Fri, 8 Feb 2019 19:42:22 +0000 (11:42 -0800)]
Revert
D13806753: [pytorch][PR] TensorIterator cuda launch configs update
Differential Revision:
D13806753
Original commit changeset:
37e45c7767b5
fbshipit-source-id:
74ac9f54f86853287b372ccf21fb37ed0e04a5d3
Elias Ellison [Fri, 8 Feb 2019 19:34:40 +0000 (11:34 -0800)]
Allow sequential modules in module list (#16882)
Summary:
Fix for https://github.com/pytorch/pytorch/issues/16845
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16882
Differential Revision:
D14007746
Pulled By: eellison
fbshipit-source-id:
d7918275cc1de6a67320619c3203463f66783343
Gu, Jinghui [Fri, 8 Feb 2019 19:17:59 +0000 (11:17 -0800)]
Impl ExpandDims op and fallback to CPU if needed (#15264)
Summary:
Impl ExpandDims op and fallback to CPU if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15264
Differential Revision:
D13808797
Pulled By: yinghai
fbshipit-source-id:
7795ec303a46e85f84e5490273db0ec76e8b9374
Bram Wasti [Fri, 8 Feb 2019 18:00:49 +0000 (10:00 -0800)]
Add visibility to registry class to fix ubsan error (#16792)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16792
fix
Reviewed By: ezyang
Differential Revision:
D13970381
fbshipit-source-id:
763db24b8a98a2757a63b77c70c8c68ba47f31e6
Edward Yang [Fri, 8 Feb 2019 17:29:59 +0000 (09:29 -0800)]
Remove Legacy entry point. (#16721)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16721
The very key line is we have to set the stream to the default
stream before calling the allocator. This is very interesting.
It shouldn't be necessary, but seemingly is!
Reviewed By: dzhulgakov
Differential Revision:
D13943193
fbshipit-source-id:
c21014917d9fe504fab0ad8abbc025787f559287
Edward Yang [Fri, 8 Feb 2019 17:29:59 +0000 (09:29 -0800)]
Deduplicate instances caching allocator, so that we only have one instance. (#16720)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16720
I'm taking the deduplication slowly because there is something here
that is causing problems, and I want to figure out what it is.
Reviewed By: dzhulgakov
Differential Revision:
D13943194
fbshipit-source-id:
cbc08fee5862fdcb393b9dd5b1d2ac7250f77c4b
Edward Yang [Fri, 8 Feb 2019 17:29:58 +0000 (09:29 -0800)]
Delete duplicate copy of THCCachingAllocator (round two). (#16615)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16615
This is another go at landing https://github.com/pytorch/pytorch/pull/16226
Now that the caching allocator is moved to c10_cuda, we can
delete the duplicate copy from Caffe2.
The difference between this and the previous PR is that this
version faithfully maintains the binding code; in particular,
we end up with a SECOND copy of the caching allocator in
this patch. I verified that this code does NOT cause a crash
in the workflow we canaried last time.
In further diffs, I plan to eliminate the second copy, and then
adjust the binding code.
Reviewed By: dzhulgakov
Differential Revision:
D13901067
fbshipit-source-id:
66331fd4eadffd0a5defb3cea532d5cd07287872
Junjie Bai [Fri, 8 Feb 2019 08:32:49 +0000 (00:32 -0800)]
Bump caffe2 docker images to 248 (#16863)
Summary:
Jenkins jobs update will be separate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16863
Differential Revision:
D13994672
Pulled By: bddppq
fbshipit-source-id:
5b27879dc6ac11a42016fe7835e9124345005ebb
Sebastian Messmer [Fri, 8 Feb 2019 04:47:46 +0000 (20:47 -0800)]
Also register op schema when no kernels are registered
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16878
Reviewed By: bwasti
Differential Revision:
D13997959
fbshipit-source-id:
7527a560b03f672f76e95d4f22ae28ce24698cc1
Sebastian Messmer [Fri, 8 Feb 2019 04:47:45 +0000 (20:47 -0800)]
Don't automatically handle context parameter (#16867)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16867
Some caffe2 operators (example: BBoxTransform) have not just one template parameter which is the context, but might have multiple template parameters.
Because of this, we can't handle the context parameter inside the macro.
Reviewed By: bwasti
Differential Revision:
D13995696
fbshipit-source-id:
f55c3be913c8b125445a8d486846fc2fab587a63
Yinghai Lu [Fri, 8 Feb 2019 04:41:18 +0000 (20:41 -0800)]
Support onnxifi with partially shaped inferred net (#16877)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16877
That's it.
Reviewed By: ipiszy
Differential Revision:
D13997771
fbshipit-source-id:
f512c7f30b4a4747aca335a0769712c2a2cc2206
Pearu Peterson [Fri, 8 Feb 2019 04:27:40 +0000 (20:27 -0800)]
Robust determination of cudnn library and relevant conda packages. (#16859)
Summary:
This PR implements:
1. a fix to issue #12174 - determine the location of cudnn library using `ldconfig`
2. a fix to determine the installed conda packages (in recent versions of conda, the command `conda` is a Bash function that cannot be called within a python script, so using CONDA_EXE environment variable instead)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16859
Differential Revision:
D14000399
Pulled By: soumith
fbshipit-source-id:
905658ecacb0ca0587a162fade436de9582d32ab
Yinghai Lu [Fri, 8 Feb 2019 04:08:39 +0000 (20:08 -0800)]
Specialize LengthsRangeFill and SparseLengthsWeightedSum in bound shape inference (#16869)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16869
TSIA.
Reviewed By: ipiszy, rdzhabarov
Differential Revision:
D13994946
fbshipit-source-id:
7e507abc5a3c2834c92910e521387085c56e8b2e
Summer Deng [Fri, 8 Feb 2019 03:42:17 +0000 (19:42 -0800)]
Activation histogram net observer with multiple histogram files as output (#16855)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16855
Save the histogram of each net to a separate file
Reviewed By: jspark1105
Differential Revision:
D13991610
fbshipit-source-id:
a5be4e37a5e63567dcd7fdf99f451ee31bb350a5
David Riazati [Fri, 8 Feb 2019 02:21:30 +0000 (18:21 -0800)]
Allow dicts in C++ frontend (#16846)
Summary:
Fixes #16856
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16846
Differential Revision:
D13991103
Pulled By: driazati
fbshipit-source-id:
4830dd6f707fa90429b5d3070eeda0bee53d2f2b
Xiaomeng Yang [Fri, 8 Feb 2019 02:19:46 +0000 (18:19 -0800)]
Separate elementwise level2 math functions (#16753)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16753
Separate elementwise level2 math functions
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision:
D13954928
fbshipit-source-id:
1ca7a5d3da96e32510f502e5e4e79168854bee67
Freddie Mendoza [Fri, 8 Feb 2019 02:15:44 +0000 (18:15 -0800)]
Fix (#2) ppc64le build break on git status --porcelain check (#16852)
Summary:
Add test/.hypothesis/ to .gitignore to pass git status --porcelain check in CI build
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16852
Differential Revision:
D14000206
Pulled By: soumith
fbshipit-source-id:
5da99a4bb242c12aa35776f7254f6399a7fa6d8c
Michael Suo [Fri, 8 Feb 2019 01:56:10 +0000 (17:56 -0800)]
doc updates for TorchScript (#16866)
Summary:
Some batched updates:
1. bool is a type now
2. Early returns are allowed now
3. The beginning of an FAQ section with some guidance on the best way to do GPU training + CPU inference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16866
Differential Revision:
D13996729
Pulled By: suo
fbshipit-source-id:
3b884fd3a4c9632c9697d8f1a5a0e768fc918916
Alex Şuhan [Fri, 8 Feb 2019 01:31:52 +0000 (17:31 -0800)]
Fix autodiff of nll_loss
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16851
Differential Revision:
D13995046
Pulled By: wanchaol
fbshipit-source-id:
557c99f1d1825fa9b6031dd9fa8ba9b54205e8c4
James Reed [Fri, 8 Feb 2019 01:22:00 +0000 (17:22 -0800)]
aten::_convolution now participates in shape analysis (#16837)
Summary:
During tracing, we record `aten::_convolution` rather than `aten::convolution`. The schema for the former was not present in the shape analysis pass, and resulted in some missing shape information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16837
Differential Revision:
D13993831
Pulled By: jamesr66a
fbshipit-source-id:
ebb63bf628d81613258caf773a3af5930303ce5a
peter.yeh@amd.com [Fri, 8 Feb 2019 00:10:50 +0000 (16:10 -0800)]
Enable arg_ops_test/unique_ops_test on AMD/rocm (#16853)
Summary:
Verified both tests are passing on rocm 2.1 env.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16853
Differential Revision:
D13996279
Pulled By: bddppq
fbshipit-source-id:
c0df610d7d9ca8d80ed2d1339cdadef59105a71c
Johannes M Dieterich [Thu, 7 Feb 2019 22:17:14 +0000 (14:17 -0800)]
Update CI to recently released ROCm 2.1 release (#16808)
Summary:
* we do not need EAP packages any longer as the antistatic feature is now in the release
* consistently install the rccl package
* Skip one unit test that has regressed with 2.1
* Follow-up PRs will use 2.1 features once deployed on CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16808
Differential Revision:
D13992645
Pulled By: bddppq
fbshipit-source-id:
37ca9a1f104bb140bd2b56d403e32f04c4fbf4f0
Yinghai Lu [Thu, 7 Feb 2019 22:11:44 +0000 (14:11 -0800)]
Use bound shape inference in SparseNN tests (#16834)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16834
Inserting AdjustBatch ops will possibly change the names of the input/output, so we need to create a mapping and use the renamed names for external_inputs/outputs and input_shape_info for the onnxifi_net.
Reviewed By: ipiszy
Differential Revision:
D13982731
fbshipit-source-id:
c18b8a03d01490162929b2ca30c182d166001626
Davide Libenzi [Thu, 7 Feb 2019 22:11:33 +0000 (14:11 -0800)]
Add recognition for XLA device types.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16844
Differential Revision:
D13988805
Pulled By: gchanan
fbshipit-source-id:
4e89d6d2cde8bdac41739efa65cc91569a360953
Sebastian Messmer [Thu, 7 Feb 2019 21:52:49 +0000 (13:52 -0800)]
Fix and re-enable test case (#16643)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16643
The test was disabled in
D13908117 because it conflicted with another diff that was about to land.
Now fixed the merge conflict and re-landing it.
Reviewed By: ezyang
Differential Revision:
D13911775
fbshipit-source-id:
b790f1c3a3f207916eea41ac93bc104d011f629b
Sebastian Messmer [Thu, 7 Feb 2019 21:52:49 +0000 (13:52 -0800)]
C10_REGISTER_CAFFE2_OPERATOR: Macro for registering c2 kernels (#16548)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16548
With this macro, a caffe2 operator can now directly be registered with c10.
No need to write custom wrapper kernels anymore.
Differential Revision:
D13877076
fbshipit-source-id:
e56846238c5bb4b1989b79855fd44d5ecf089c9c
Jesse Hellemn [Thu, 7 Feb 2019 21:39:18 +0000 (13:39 -0800)]
Fix Anaconda logins on binary builds
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16848
Differential Revision:
D13993614
Pulled By: pjh5
fbshipit-source-id:
16854b06d01460b78d9dbe7bd0341b7332984795
Zhicheng Yan [Thu, 7 Feb 2019 21:08:06 +0000 (13:08 -0800)]
new embedding label type in image input op (#16835)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16835
We were using label type `multi_label_dense` to denote both 1) dense representation of integer label 2) embedding label of data type floating number.
This cause some issues as two cases have different assumption, such as for integer label, we will check whether label value is in [0, number_class - 1]. But such check should be skipped for `embedding label`.
Reviewed By: BIT-silence
Differential Revision:
D13985048
fbshipit-source-id:
1202cdfeea806eb47647e3f4a1ed9c104f72ad2c
Michael Antonov [Thu, 7 Feb 2019 20:42:38 +0000 (12:42 -0800)]
Update ATen internals to use int64_t for dimension indexing (#16739)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16739
Some code ATen locations seemed to use int, etc. inclorrectly where either
int64_t or size_t was required. Update them to use int64_t for dimension indexing where necessary.
Reviewed By: ezyang
Differential Revision:
D13950124
fbshipit-source-id:
aaf1cef783bf3c657aa03490f2616c35c816679f
Will Feng [Thu, 7 Feb 2019 19:58:50 +0000 (11:58 -0800)]
Make JIT attributes t_ and ts_ store Variable instead of Tensor (#16596)
Summary:
Discussed with zdevito and we want to use Variable (with `set_requires_grad(false)`) instead of Tensor in all parts of JIT, to eliminate the distinction and the conceptual overhead when trying to figure out which one to use.
This also helps with the Variable/Tensor merge work tracked at https://github.com/pytorch/pytorch/issues/13638, which will make common functions (such as `numel()` / `sizes()` / `dim()`) on Variable much faster when finished.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16596
Differential Revision:
D13979971
Pulled By: yf225
fbshipit-source-id:
c69119deec5bce0c22809081115f1012fdbb7d5a
David Riazati [Thu, 7 Feb 2019 19:50:27 +0000 (11:50 -0800)]
Better error when using a constant tensor (#16724)
Summary:
Fixes #16284
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16724
Differential Revision:
D13990531
Pulled By: driazati
fbshipit-source-id:
adbf47a07eddb3813fbe1322944abfe5fcff89fa
Richard Zou [Thu, 7 Feb 2019 19:09:10 +0000 (11:09 -0800)]
Backport the stable doc build on v1.0.1 to master (#16503)
Summary:
List of changes:
- Always push the final state of the doc build docker for debugging purposes.
- Adds code for the stable doc build. This code is never actually run on master, only the v1.0.1 branch. There is a big note for this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16503
Differential Revision:
D13972469
Pulled By: zou3519
fbshipit-source-id:
68f459650ef0de200a34edd43fc1372143923972
Wanchao Liang [Thu, 7 Feb 2019 18:32:02 +0000 (10:32 -0800)]
Remove undefined tensor in jit script (#16379)
Summary:
This PR is a follow up of #15460, it did the following things:
* remove the undefined tensor semantic in jit script/tracing mode
* change ATen/JIT schema for at::index and other index related ops with `Tensor?[]` to align with what at::index is really doing and to adopt `optional[tensor]` in JIT
* change python_print to correctly print the exported script
* register both TensorList and ListOfOptionalTensor in JIT ATen ops to support both
* Backward compatibility for `torch.jit.annotate(Tensor, None)`
List of follow ups:
* remove the undefined tensor semantic in jit autograd, autodiff and grad_of
* remove prim::Undefined fully
For easy reviews, please turn on `hide white space changes` in diff settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16379
Differential Revision:
D13855677
Pulled By: wanchaol
fbshipit-source-id:
0e21c14d7de250c62731227c81bfbfb7b7da20ab
Fritz Obermeyer [Thu, 7 Feb 2019 09:33:41 +0000 (01:33 -0800)]
Support multiple inheritance in torch.distributions (#16772)
Summary:
This adds calls to `super().__init__()` in three classes in torch.distributions.
This is needed when `Distribution` and `Transform` objects are used with multiple inheritance, as e.g. combined with `torch.nn.Module`s. For example
```py
class MyModule(torch.distributions.Transform, torch.nn.Module):
...
```
cc martinjankowiak esling who have wanted to use this pattern, e.g. in #16756
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16772
Differential Revision:
D13978633
Pulled By: soumith
fbshipit-source-id:
8bc6cca1747cd74d32135ee2fe588bba2ea796f1
vishwakftw [Thu, 7 Feb 2019 09:10:54 +0000 (01:10 -0800)]
Remove redundant wrappers in torch.distributions (#16807)
Summary:
Changelog:
- Remove torch.distributions.multivariate_normal._batch_diag : same functionality is provided by torch.diagonal
- Remove torch.distributions.lowrank_multivariate_normal._batch_vector_diag : same functionality is provided by torch.diag_embed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16807
Differential Revision:
D13985550
Pulled By: soumith
fbshipit-source-id:
25c7d00c52ff7f85e431134e9ce0d5dda453667b
Ying Zhang [Thu, 7 Feb 2019 08:33:29 +0000 (00:33 -0800)]
Insert AdjustBatchSizeOp into the predict_net. (#16811)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16811
As the title. The AdjustBatch ops will be inserted before and after the Onnxifi op to:
1) adjust batch/seq sizes to the ideal batch/seq size before these tensors are processed by the Onnxifi op;
2) adjust batch size to the original batch size for batches generated by the Onnxifi op.
Reviewed By: yinghai
Differential Revision:
D13967711
fbshipit-source-id:
471b25ae6a60bf5b7ebee1de6449e0389b6cafff
rohithkrn [Thu, 7 Feb 2019 08:21:21 +0000 (00:21 -0800)]
Unify gpu_support variable in python tests (#16748)
Summary:
Assign `has_gpu_support = has_cuda_support or has_hip_support` and make according changes in python tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16748
Differential Revision:
D13983132
Pulled By: bddppq
fbshipit-source-id:
ca496fd8c6ae3549b736bebd3ace7fa20a6dad7f
Mohana Rao [Thu, 7 Feb 2019 07:33:40 +0000 (23:33 -0800)]
Update Docker file section in README.md (#16812)
Summary:
Emphasize on the fact that docker build should be triggered from pytorch repo directory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16812
Differential Revision:
D13985531
Pulled By: soumith
fbshipit-source-id:
c6511d1e81476eb795b37fb0ad23e8951dbca617
Jie [Thu, 7 Feb 2019 07:05:49 +0000 (23:05 -0800)]
TensorIterator cuda launch configs update (#16224)
Summary:
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16224
Differential Revision:
D13806753
Pulled By: soumith
fbshipit-source-id:
37e45c7767b5748cf9ecf894fad306e040e2f79f
Sebastian Messmer [Thu, 7 Feb 2019 05:14:21 +0000 (21:14 -0800)]
Define layer_norm schema in caffe2 (#16535)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16535
There is now no need anymore to define the layer norm schema in a central location.
It can just be defined in caffe2 next to the kernel implementation.
Reviewed By: ezyang
Differential Revision:
D13869503
fbshipit-source-id:
c478153f8fd712ff6d507c794500286eb3583149
Sebastian Messmer [Thu, 7 Feb 2019 05:14:20 +0000 (21:14 -0800)]
Automatically register c10 ops with JIT (#16534)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16534
All c10 ops from the c10 dispatcher are now automatically registered with JIT
Reviewed By: dzhulgakov
Differential Revision:
D13869275
fbshipit-source-id:
5ab5dec5b983fe661f977f9d29d8036768cdcab6
Yinghai Lu [Thu, 7 Feb 2019 03:12:32 +0000 (19:12 -0800)]
Add AdjustBatch Op (#16676)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16676
This op is used for changing batch size (first dimension) of the tensor.
Reviewed By: bertmaher, ipiszy
Differential Revision:
D13929200
fbshipit-source-id:
4f2c3faec072d468be8301bf00c80d33adb3b5b3
bddppq [Thu, 7 Feb 2019 01:52:12 +0000 (17:52 -0800)]
Bring back running pytorch tests in rocm CI
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16829
Differential Revision:
D13982323
Pulled By: bddppq
fbshipit-source-id:
6ffadb96b9e2ebd64a29e38674a51401dfb211db
Zachary DeVito [Thu, 7 Feb 2019 01:22:47 +0000 (17:22 -0800)]
Rename DynamicType -> TensorType (#16787)
Summary:
```
import json
from subprocess import check_call
from pprint import pprint
renames = {
'c10::TensorType': 'DimentionedTensorType',
'c10::DynamicType': 'TensorType',
'c10::TensorTypePtr': 'DimentionedTensorTypePtr',
'c10::DynamicTypePtr': 'TensorTypePtr',
'c10::TypeKind::DynamicType': 'TensorType',
'c10::TypeKind::TensorType': 'DimentionedTensorType',
}
entries = json.loads(open('compile_commands.json', 'r').read())
build = None
sources = []
for e in entries:
name = e['file']
if not ('jit' in name or 'ATen/core' in name):
continue
build = e['directory']
sources.append(name)
args = ['clang-rename', '-i', '-force', '-pl']
for name in sorted(renames.keys()):
args += ['-qualified-name={}'.format(name), '-new-name={}'.format(renames[name])]
for source in sources:
cmd = args + [source]
pprint(args)
check_call(cmd, cwd=build)
check_call(['git', 'stash', 'push', '-m', 'rename'])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16787
Differential Revision:
D13974132
Pulled By: zdevito
fbshipit-source-id:
8368fd53e17cff83707bbe77f2d7aad74f8ce60e
Yinghai Lu [Thu, 7 Feb 2019 00:13:24 +0000 (16:13 -0800)]
Use bound shape inference in onnxifi transform (#16598)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16598
ATT.
Reviewed By: bertmaher, rdzhabarov
Differential Revision:
D13893698
fbshipit-source-id:
8d2ad9814fe76924a46b450eb7ebd3601fbdbbc7
Soumith Chintala [Wed, 6 Feb 2019 23:46:39 +0000 (15:46 -0800)]
improve error message (#16719)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/16712
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16719
Differential Revision:
D13978688
Pulled By: ezyang
fbshipit-source-id:
61f8fa4c54c6969a58550e32e18be2eb9254ced7
Jongsoo Park [Wed, 6 Feb 2019 23:14:17 +0000 (15:14 -0800)]
int8 SpatialBN (#16796)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16796
SpatialBN int8 version
Reviewed By: dskhudia
Differential Revision:
D13971224
fbshipit-source-id:
e55fd608c161069daaa4e62c618bc14b01f32cb7
Jongsoo Park [Wed, 6 Feb 2019 23:10:07 +0000 (15:10 -0800)]
call istringstream clear after str (#16820)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16820
Sometimes parsing histogram was not working correctly due to changes in
D13633256
We need to call istringstream clear after str
Reviewed By: csummersea
Differential Revision:
D13977509
fbshipit-source-id:
ce3e8cb390641d8f0b5c9a7d6d6daadffeddbe11
Narine Kokhlikyan [Wed, 6 Feb 2019 22:29:35 +0000 (14:29 -0800)]
Replace resize_dim() with set_sizes_and_strides() (#16732)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16732
Use set_sizes_and_strides instead of resize_dim with.
Reviewed By: ezyang
Differential Revision:
D13947867
fbshipit-source-id:
067b096b1fde14b039690992a5fe3ace386b2789
Jongsoo Park [Wed, 6 Feb 2019 19:52:23 +0000 (11:52 -0800)]
no EIGEN engine for DeformConv (#16785)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16785
There's no EIGEN engine implemented for DeformConv but unit test was checking it.
Reviewed By: BIT-silence
Differential Revision:
D13967306
fbshipit-source-id:
e29c19f59f5700fc0501c59f45d60443b87ffedc
Jongsoo Park [Wed, 6 Feb 2019 19:52:23 +0000 (11:52 -0800)]
format deform_conv_test.py (#16786)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16786
Format to prepare
D13967306
Reviewed By: BIT-silence
Differential Revision:
D13967317
fbshipit-source-id:
2de895f8474b04c55ba067fbf788c553dc010c60
Yinghai Lu [Wed, 6 Feb 2019 18:23:01 +0000 (10:23 -0800)]
Fix/Improve bound shape inference with real net tests (#16597)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16597
This diff fixes some bugs in shape inference for `SparseLengthsSumFused8BitRowwise`. And added input shape inference for `Concat` when `add_axis=1`.
Reviewed By: bertmaher
Differential Revision:
D13892452
fbshipit-source-id:
6cd95697a6fabe6d78a5ce3cb749a3a1e51c68e7
Edward Yang [Wed, 6 Feb 2019 18:19:37 +0000 (10:19 -0800)]
Typofix (#16800)
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16800
Differential Revision:
D13972592
Pulled By: ezyang
fbshipit-source-id:
45c352ac6090c8060bf75f44dec7205556986d88
Oleg Bogdanov [Wed, 6 Feb 2019 17:40:00 +0000 (09:40 -0800)]
caffe2 | MSVS compatibility fixes (#16765)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16765
Code changes required to build caffe2 for windows with toolchain used by FB.
Reviewed By: orionr
Differential Revision:
D13953258
fbshipit-source-id:
651823ec9d81ac70e32d4cce5bc2472434104733
Gu, Jinghui [Wed, 6 Feb 2019 17:25:42 +0000 (09:25 -0800)]
Fallback sum/add to CPU if needed (#15267)
Summary:
Fallback sum/add to CPU if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15267
Differential Revision:
D13935064
Pulled By: yinghai
fbshipit-source-id:
eb228683d00a0462a1970f849d35365bc98340d6
Lu Fang [Wed, 6 Feb 2019 17:17:37 +0000 (09:17 -0800)]
update of fbcode/onnx to
822d8df0a2a32233c6022f50a158817a0f19bdc7 (#16791)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16791
Previous import was
bfa8b335ab6d1ed7b688dc2ec96421a3fe9e644c
Included changes:
- **[822d8df](https://github.com/onnx/onnx/commit/822d8df)**: allow removed experimental ops in the checker for now (#1792) <Lu Fang>
Reviewed By: MisterTea
Differential Revision:
D13970103
fbshipit-source-id:
5feaaa6c65ba10901eeba0b63724d7e451e9b642
Freddie Mendoza [Wed, 6 Feb 2019 17:02:18 +0000 (09:02 -0800)]
Adding torch/lib64 in .gitignore for ppc64le CI build to pass (#16782)
Summary:
Adding torch/lib64 in .gitignore so that a git status --porcelain
check during CI build and test passes for ppc64le. During build
torch/lib64 is created and contains third-party libraries. This
should be ignored by the porcelain check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16782
Differential Revision:
D13972794
Pulled By: ezyang
fbshipit-source-id:
5459c524eca42d396ac46e756a327980b4b1fa53
Edward Yang [Wed, 6 Feb 2019 16:17:55 +0000 (08:17 -0800)]
Revert
D13854304: [redo][c10] LayerNorm Registration Example
Differential Revision:
D13854304
Original commit changeset:
ec463ce22721
fbshipit-source-id:
4262b9a2ef486e1c7c0283ea021331ac97cc5f56
Edward Yang [Wed, 6 Feb 2019 16:17:54 +0000 (08:17 -0800)]
Revert
D13855525: [c10] Expose RoIAlign to torch
Differential Revision:
D13855525
Original commit changeset:
cfee7bb1544d
fbshipit-source-id:
0b4124b78c4082b52e592a1275069c879a9aed39