vishwakftw [Mon, 25 Feb 2019 18:32:48 +0000 (10:32 -0800)]
Fix reduction='none' in poisson_nll_loss (#17358)
Summary:
Changelog:
- Modify `if` to `elif` in reduction mode comparison
- Add error checking for reduction mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17358
Differential Revision:
D14190523
Pulled By: zou3519
fbshipit-source-id:
2b734d284dc4c40679923606a1aa148e6a0abeb8
Michael Liu [Mon, 25 Feb 2019 16:10:14 +0000 (08:10 -0800)]
Apply modernize-use-override (4)
Summary:
Use C++11’s override and remove virtual where applicable.
Change are automatically generated.
bypass-lint
drop-conflicts
Reviewed By: ezyang
Differential Revision:
D14191981
fbshipit-source-id:
1f3421335241cbbc0cc763b8c1e85393ef2fdb33
Gregory Chanan [Mon, 25 Feb 2019 16:08:15 +0000 (08:08 -0800)]
Fix nonzero for scalars on cuda, to_sparse for scalars on cpu/cuda. (#17406)
Summary:
I originally set out to fix to_sparse for scalars, which had some overly restrictive checking (sparse_dim > 0, which is impossible for a scalar).
This fix uncovered an issue with nonzero: it didn't properly return a size (z, 0) tensor for an input scalar, where z is the number of nonzero elements (i.e. 0 or 1).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17406
Differential Revision:
D14185393
Pulled By: gchanan
fbshipit-source-id:
f37a6e1e3773fd9cbf69eeca7fdebb3caa192a19
Tongliang Liao [Mon, 25 Feb 2019 16:07:56 +0000 (08:07 -0800)]
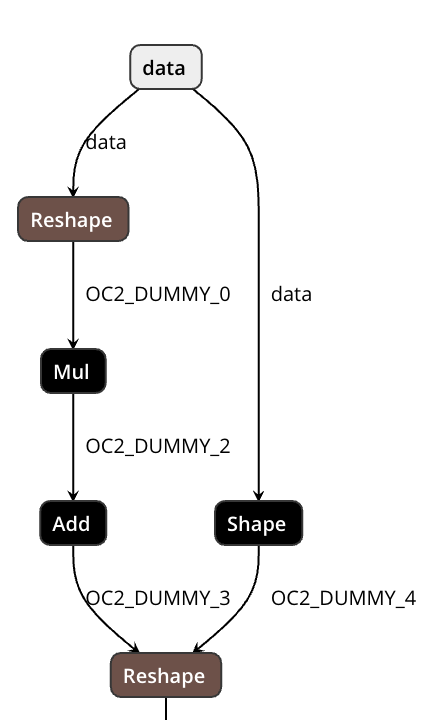
Export ElementwiseLinear to ONNX (Mul + Add). (#17411)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17411
Reshape-based approach to support dynamic shape.
The first Reshape flatten inner dimensions and the second one recover the actual shape.
No Shape/Reshape will be generated unless necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16716
Reviewed By: zrphercule
Differential Revision:
D14094532
Pulled By: houseroad
fbshipit-source-id:
bad6a1fbf5963ef3dd034ef4bf440f5a5d6980bc
Lu Fang [Mon, 25 Feb 2019 15:57:21 +0000 (07:57 -0800)]
Add foxi submodule (ONNXIFI facebook extension)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17178
Reviewed By: yinghai
Differential Revision:
D14197987
Pulled By: houseroad
fbshipit-source-id:
c21d7235e40c2ca4925a10c467c2b4da2f1024ad
Michael Liu [Mon, 25 Feb 2019 15:26:27 +0000 (07:26 -0800)]
Fix remaining -Wreturn-std-move violations in fbcode (#17308)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17308
In some cases there is still no RVO/NRVO and std::move is still needed. Latest
Clang gained -Wreturn-std-move warning to detect cases like this (see
https://reviews.llvm.org/D43322).
Reviewed By: igorsugak
Differential Revision:
D14150915
fbshipit-source-id:
0df158f0b2874f1e16f45ba9cf91c56e9cb25066
Michael Suo [Mon, 25 Feb 2019 07:01:32 +0000 (23:01 -0800)]
add debug/release tip to cpp docs (#17452)
Summary:
as title. These were already added to the tutorials, but I didn't add them to the cpp docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17452
Differential Revision:
D14206501
Pulled By: suo
fbshipit-source-id:
89b5c8aaac22d05381bc4a7ab60d0bb35e43f6f5
Michael Suo [Mon, 25 Feb 2019 07:00:10 +0000 (23:00 -0800)]
add pointer to windows FAQ in contributing.md (#17450)
Summary:
" ProTip! Great commit summaries contain fewer than 50 characters. Place extra information in the extended description."
lol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17450
Differential Revision:
D14206500
Pulled By: suo
fbshipit-source-id:
af7ffe299f8c8f04fa8e720847a1f6d576ebafc1
Thomas Viehmann [Sun, 24 Feb 2019 04:57:28 +0000 (20:57 -0800)]
Remove ROIPooling (#17434)
Summary:
Fixes: #17399
It's undocumented, unused and, according to the issue, not actually working.
Differential Revision:
D14200088
Pulled By: soumith
fbshipit-source-id:
a81f0d0f5516faea2bd6aef5667b92c7dd012dbd
Krishna Kalyan [Sun, 24 Feb 2019 04:24:21 +0000 (20:24 -0800)]
Add example to WeightedRandomSampler doc string (#17432)
Summary: Example for the weighted random sampler are missing [here](https://pytorch.org/docs/stable/data.html#torch.utils.data.WeightedRandomSampler)
Differential Revision:
D14198642
Pulled By: soumith
fbshipit-source-id:
af6d8445d31304011002dd4308faaf40b0c1b609
Michael Suo [Sat, 23 Feb 2019 23:52:38 +0000 (15:52 -0800)]
Revert
D14095703: [pytorch][PR] [jit] Add generic list/dict custom op bindings
Differential Revision:
D14095703
Original commit changeset:
2b5ae20d42ad
fbshipit-source-id:
85b23fe4ce0090922da953403c95691bf3e28710
svcscm [Sat, 23 Feb 2019 20:43:01 +0000 (12:43 -0800)]
Updating submodules
Reviewed By: zpao
fbshipit-source-id:
8fa0be05e7410a863febb98b18be55ab723a41db
Jaliya Ekanayake [Sat, 23 Feb 2019 16:46:24 +0000 (08:46 -0800)]
Jaliyae/chunk buffer fix (#17409)
Summary:
The chunk buffer had a possibility to hang when no data is read and the buffer size is lower than chunk size. We detected this while running with larger dataset and hence the fix. I added a test to mimic the situation and validated that the fix is working. Thank you Xueyun for finding this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17409
Differential Revision:
D14198546
Pulled By: soumith
fbshipit-source-id:
b8ca43b0400deaae2ebb6601fdc65b47f32b0554
Stefan Krah [Sat, 23 Feb 2019 16:24:05 +0000 (08:24 -0800)]
Skip test_event_handle_multi_gpu() on a single GPU system (#17402)
Summary:
This fixes the following test failure:
```
======================================================================
ERROR: test_event_handle_multi_gpu (__main__.TestMultiprocessing)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_multiprocessing.py", line 445, in test_event_handle_multi_gpu
with torch.cuda.device(d1):
File "/home/stefan/rel/lib/python3.7/site-packages/torch/cuda/__init__.py", line 229, in __enter__
torch._C._cuda_setDevice(self.idx)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /home/stefan/pytorch/torch/csrc/cuda/Module.cpp:33
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17402
Differential Revision:
D14195190
Pulled By: soumith
fbshipit-source-id:
e911f3782875856de3cfbbd770b6d0411d750279
Olen ANDONI [Sat, 23 Feb 2019 16:19:09 +0000 (08:19 -0800)]
fix(typo): Change 'integeral' to 'integer'
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17396
Differential Revision:
D14195023
Pulled By: soumith
fbshipit-source-id:
300ab68c24bfbf10768fefac44fad64784463c8f
Lu Fang [Sat, 23 Feb 2019 07:56:21 +0000 (23:56 -0800)]
Fix the ONNX expect file (#17430)
Summary:
The CI is broken now, this diff should fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17430
Differential Revision:
D14198045
Pulled By: houseroad
fbshipit-source-id:
a1c8cb5ccff66f32488702bf72997f634360eb5b
Karl Ostmo [Sat, 23 Feb 2019 04:10:22 +0000 (20:10 -0800)]
order caffe2 ubuntu configs contiguously (#17427)
Summary:
This involves another purely cosmetic (ordering) change to the `config.yml` to facilitate simpler logic.
Other changes:
* add some review feedback as comments
* exit with nonzero status on config.yml mismatch
* produce a diagram for pytorch builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17427
Differential Revision:
D14197618
Pulled By: kostmo
fbshipit-source-id:
267439d3aa4c0a80801adcde2fa714268865900e
Jongsoo Park [Sat, 23 Feb 2019 04:03:09 +0000 (20:03 -0800)]
remove redundant inference functions for FC (#17407)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17407
As title says
Reviewed By: csummersea
Differential Revision:
D14177921
fbshipit-source-id:
e48e1086d37de2c290922d1f498e2d2dad49708a
Jongsoo Park [Sat, 23 Feb 2019 03:38:38 +0000 (19:38 -0800)]
optimize max pool 2d (#17418)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17418
Retry of
D14181620 this time with CMakeLists.txt changes
Reviewed By: jianyuh
Differential Revision:
D14190538
fbshipit-source-id:
c59b1bd474edf6376f4c2767a797b041a2ddf742
Roy Li [Sat, 23 Feb 2019 02:33:18 +0000 (18:33 -0800)]
Generate derived extension backend Type classes for each scalar type (#17278)
Summary:
Previously we only generate one class for each extension backend. This caused issues with scalarType() calls and mapping from variable Types to non-variable types. With this change we generate one Type for each scalar type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17278
Reviewed By: ezyang
Differential Revision:
D14161489
Pulled By: li-roy
fbshipit-source-id:
91e6a8f73d19a45946c43153ea1d7bc9d8fb2409
Ilia Cherniavskii [Sat, 23 Feb 2019 02:30:58 +0000 (18:30 -0800)]
Better handling of net errors in prof_dag counters (#17384)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17384
Better handling of possible net run errors in prof_dag counters.
Reviewed By: yinghai
Differential Revision:
D14177619
fbshipit-source-id:
51bc952c684c53136ce97e22281b1af5706f871e
eellison [Sat, 23 Feb 2019 01:54:09 +0000 (17:54 -0800)]
Batch of Expect Files removal (#17414)
Summary:
Batch of removing expect files, and some tests that no longer test anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17414
Differential Revision:
D14196342
Pulled By: eellison
fbshipit-source-id:
75c45649d1dd1ce39958fb02f5b7a2622c1d1d01
Arthur Crippa Búrigo [Sat, 23 Feb 2019 01:11:06 +0000 (17:11 -0800)]
Fix target name.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17365
Differential Revision:
D14195831
Pulled By: soumith
fbshipit-source-id:
fdf03f086f650148c34f4c548c66ef1eee698f05
Zachary DeVito [Sat, 23 Feb 2019 01:10:19 +0000 (17:10 -0800)]
jit technical docs - parts 1, 2, and most of 3 (#16887)
Summary:
This will evolve into complete technical docs for the jit. Posting what I have so far so people can start reading it and offering suggestions. Goto to Files Changed and click 'View File' to see markdown formatted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16887
Differential Revision:
D14191219
Pulled By: zdevito
fbshipit-source-id:
071a0e7db05e4f2eb657fbb99bcd903e4f46d84a
Vishwak Srinivasan [Sat, 23 Feb 2019 01:03:49 +0000 (17:03 -0800)]
USE_ --> BUILD_ for CAFFE2_OPS and TEST (#17390)
Differential Revision:
D14195572
Pulled By: soumith
fbshipit-source-id:
28e4ff3fe03a151cd4ed014c64253389cb85de3e
Gemfield [Sat, 23 Feb 2019 00:56:06 +0000 (16:56 -0800)]
Fix install libcaffe2_protos.a issue mentioned in #14317 (#17393)
Summary:
Fix install libcaffe2_protos.a issue mentioned in #14317.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17393
Differential Revision:
D14195359
Pulled By: soumith
fbshipit-source-id:
ed4da594905d708d03fcd719dc50aec6811d5d3f
Yinghai Lu [Sat, 23 Feb 2019 00:53:32 +0000 (16:53 -0800)]
Improve onnxifi backend init time (#17375)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17375
Previously we create the onnxGraph first and take it to the onnx manager for registration. It doesn't work well in practice. This diff takes "bring your own constructor" approach to reduce the resource spent doing backend compilation.
Reviewed By: kimishpatel, rdzhabarov
Differential Revision:
D14173793
fbshipit-source-id:
cbc4fe99fc522f017466b2fce88ffc67ae6757cf
vfdev [Sat, 23 Feb 2019 00:18:17 +0000 (16:18 -0800)]
fix code block typo
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17421
Differential Revision:
D14194877
Pulled By: soumith
fbshipit-source-id:
6173835d833ce9e9c02ac7bd507cd424a20f2738
Junjie Bai [Fri, 22 Feb 2019 23:01:46 +0000 (15:01 -0800)]
Double resnet50 batch size in benchmark script (#17416)
Summary:
The benchmarks are now running on gpu cards with more memory
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17416
Differential Revision:
D14190493
Pulled By: bddppq
fbshipit-source-id:
66db1ca1fa693d24c24b9bc0185a6dd8a3337103
Mikhail Zolotukhin [Fri, 22 Feb 2019 22:56:02 +0000 (14:56 -0800)]
Preserve names when converting to/from NetDef.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17378
Differential Revision:
D14176515
Pulled By: ZolotukhinM
fbshipit-source-id:
da9ea28310250ab3ca3a99cdc210fd8d1fbbc82b
David Riazati [Fri, 22 Feb 2019 22:38:33 +0000 (14:38 -0800)]
Add generic list/dict custom op bindings (#17037)
Summary:
Fixes #17017
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17037
Differential Revision:
D14095703
Pulled By: driazati
fbshipit-source-id:
2b5ae20d42ad21c98c86a8f1cd7f1de175510507
Elias Ellison [Fri, 22 Feb 2019 22:30:44 +0000 (14:30 -0800)]
fix test
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17304
Differential Revision:
D14151545
Pulled By: eellison
fbshipit-source-id:
d85535b709c58e2630b505ba57e9823d5a59c1d5
Ailing Zhang [Fri, 22 Feb 2019 22:19:04 +0000 (14:19 -0800)]
Improvements for current AD (#17187)
Summary:
This PR removes a few size of `self` that passed from forward pass to backward pass when `self` is already required in backward pass. This could be reason that cause the potential slow down in #16689 . I will attach a few perf numbers (still a bit volatile among runs tho) I got in the comment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17187
Differential Revision:
D14179512
Pulled By: ailzhang
fbshipit-source-id:
5f3b1f6f26a3fef6dec15623b940380cc13656fa
Lu Fang [Fri, 22 Feb 2019 22:05:33 +0000 (14:05 -0800)]
Bump up the producer version in ONNX exporter
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17410
Reviewed By: zrphercule
Differential Revision:
D14187821
Pulled By: houseroad
fbshipit-source-id:
a8c1d2f7b6ef63e7e92cba638e90922ef98b8702
Michael Kösel [Fri, 22 Feb 2019 21:58:08 +0000 (13:58 -0800)]
list add insert and remove (#17200)
Summary:
See https://github.com/pytorch/pytorch/issues/16662
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17200
Differential Revision:
D14144020
Pulled By: driazati
fbshipit-source-id:
c9a52954fd5f4fb70e3a0dc02d2768e0de237142
Jesse Hellemn [Fri, 22 Feb 2019 21:53:11 +0000 (13:53 -0800)]
Pin nightly builds to last commit before 5am UTC (#17381)
Summary:
This fell through the cracks from the migration from pytorch/builder to circleci. It's technically still racey, but is much less likely now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17381
Differential Revision:
D14190137
Pulled By: pjh5
fbshipit-source-id:
2d4cd04ee874cacce47d1d50b87a054b0503bb82
Zachary DeVito [Fri, 22 Feb 2019 21:37:26 +0000 (13:37 -0800)]
Lazily load libcuda libnvrtc from c++ (#17317)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/16860
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17317
Differential Revision:
D14157877
Pulled By: zdevito
fbshipit-source-id:
c37aec2d77c2e637d4fc6ceffe2bd32901c70317
Elias Ellison [Fri, 22 Feb 2019 21:34:48 +0000 (13:34 -0800)]
Refactor Type Parser b/w Schemas & IRParser into a type common parser (#17383)
Summary:
Creates a new shared type parser to be shared between the IR parser and the Schema Parser.
Also adds parsing of CompleteTensorType and DimensionedTensorType, and feature-gates that for the IRParser.
Renames the existing type_parser for python annotations, python_type_parser, and names the new one jit_type_parser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17383
Differential Revision:
D14186438
Pulled By: eellison
fbshipit-source-id:
bbd5e337917d8862c7c6fa0a0006efa101c76afe
Lu Fang [Fri, 22 Feb 2019 19:57:38 +0000 (11:57 -0800)]
add the support for stable ONNX opsets in exporter (#16068)
Summary:
Still wip, need more tests and correct handling for opset 8 in symbolics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16068
Reviewed By: zrphercule
Differential Revision:
D14185855
Pulled By: houseroad
fbshipit-source-id:
55200be810c88317c6e80a46bdbeb22e0b6e5f9e
Karl Ostmo [Fri, 22 Feb 2019 19:22:14 +0000 (11:22 -0800)]
add readme and notice at the top of config.yml (#17323)
Summary:
reorder some envars for consistency
add readme and notice at the top of config.yml
generate more yaml from Python
closes #17322
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17323
Differential Revision:
D14186734
Pulled By: kostmo
fbshipit-source-id:
23b2b2c1960df6f387f1730c8df1ec24a30433fd
Lu Fang [Fri, 22 Feb 2019 19:15:11 +0000 (11:15 -0800)]
Revert
D14181620: [caffe2/int8] optimize max pool 2d
Differential Revision:
D14181620
Original commit changeset:
ffc6c4412bd1
fbshipit-source-id:
4391703164a672c9a8daecb24a46578765df67c6
Gu, Jinghui [Fri, 22 Feb 2019 18:32:07 +0000 (10:32 -0800)]
fallback operators to CPU for onnx support (#15270)
Summary:
fallback operators to CPU for onnx support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15270
Differential Revision:
D14099496
Pulled By: yinghai
fbshipit-source-id:
52b744aa5917700a802bdf19f7007cdcaa6e640a
Jongsoo Park [Fri, 22 Feb 2019 18:20:24 +0000 (10:20 -0800)]
optimize max pool 2d (#17391)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17391
Optimize 2D max pool using AVX2 intrinsics.
Reviewed By: jianyuh
Differential Revision:
D14181620
fbshipit-source-id:
ffc6c4412bd1c1d7839fe06226921df40d9cab83
Iurii Zdebskyi [Fri, 22 Feb 2019 17:40:17 +0000 (09:40 -0800)]
Fixed the script for the THC generated files (#17370)
Summary:
As of tight now, the script will produce a new generated file which will be inconsistent with the rest.
Test Result:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17370
Differential Revision:
D14184943
Pulled By: izdeby
fbshipit-source-id:
5d3b956867bee661256cb4f38f086f33974a1c8b
Gregory Chanan [Fri, 22 Feb 2019 16:59:53 +0000 (08:59 -0800)]
Fix coalesce, clone, to_dense for sparse scalars.
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17379
Differential Revision:
D14183641
Pulled By: gchanan
fbshipit-source-id:
dbd071b648695d51502ed34ab204a1aee7e6259b
Tongzhou Wang [Fri, 22 Feb 2019 16:27:04 +0000 (08:27 -0800)]
Fix DataParallel(cpu_m).cuda() not working by checking at forward (#17363)
Summary:
Fixes #17362
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17363
Differential Revision:
D14175151
Pulled By: soumith
fbshipit-source-id:
7b7e2335d553ed2133287deeaca3f6b6254aea4a
Will Feng [Fri, 22 Feb 2019 15:54:47 +0000 (07:54 -0800)]
Rename BatchNorm running_variance to running_var (#17371)
Summary:
Currently there is a mismatch in naming between Python BatchNorm `running_var` and C++ BatchNorm `running_variance`, which causes JIT model parameters loading to fail (https://github.com/pytorch/vision/pull/728#issuecomment-
466067138):
```
terminate called after throwing an instance of 'c10::Error'
what(): No such serialized tensor 'running_variance' (read at /home/shahriar/Build/pytorch/torch/csrc/api/src/serialize/input-archive.cpp:27)
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 0x85 (0x7f2d92d32f95 in /usr/local/lib/libc10.so)
frame #1: torch::serialize::InputArchive::read(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, at::Tensor&, bool) + 0xdeb (0x7f2d938551ab in /usr/local/lib/libtorch.so.1)
frame #2: torch::nn::Module::load(torch::serialize::InputArchive&) + 0x98 (0x7f2d9381cd08 in /usr/local/lib/libtorch.so.1)
frame #3: torch::nn::Module::load(torch::serialize::InputArchive&) + 0xf9 (0x7f2d9381cd69 in /usr/local/lib/libtorch.so.1)
frame #4: torch::nn::Module::load(torch::serialize::InputArchive&) + 0xf9 (0x7f2d9381cd69 in /usr/local/lib/libtorch.so.1)
frame #5: torch::nn::operator>>(torch::serialize::InputArchive&, std::shared_ptr<torch::nn::Module> const&) + 0x32 (0x7f2d9381c7b2 in /usr/local/lib/libtorch.so.1)
frame #6: <unknown function> + 0x2b16c (0x5645f4d1916c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #7: <unknown function> + 0x27a3c (0x5645f4d15a3c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #8: <unknown function> + 0x2165c (0x5645f4d0f65c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #9: <unknown function> + 0x1540b (0x5645f4d0340b in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #10: __libc_start_main + 0xf3 (0x7f2d051dd223 in /usr/lib/libc.so.6)
frame #11: <unknown function> + 0x1381e (0x5645f4d0181e in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
```
Renaming C++ BatchNorm `running_variance` to `running_var` should fix this problem.
This is a BC-breaking change, but it should be easy for end user to rename `running_variance` to `running_var` in their call sites.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17371
Reviewed By: goldsborough
Differential Revision:
D14172775
Pulled By: yf225
fbshipit-source-id:
b9d3729ec79272a8084269756f28a8f7c4dd16b6
svcscm [Fri, 22 Feb 2019 06:46:32 +0000 (22:46 -0800)]
Updating submodules
Reviewed By: zpao
fbshipit-source-id:
ac16087a2b27b028d8e9def81369008c4723d70f
Chandler Zuo [Fri, 22 Feb 2019 03:31:21 +0000 (19:31 -0800)]
Fix concat dimension check bug (#17343)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17343
See [post](https://fb.workplace.com/groups/
1405155842844877/permalink/
2630764056950710/)
Reviewed By: dzhulgakov
Differential Revision:
D14163001
fbshipit-source-id:
038f15d6a58b3bc31910e7bfa47c335e25739f12
David Riazati [Fri, 22 Feb 2019 01:37:22 +0000 (17:37 -0800)]
Add dict to docs
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/16640
Differential Revision:
D14178270
Pulled By: driazati
fbshipit-source-id:
581040abd0b7f8636c53fd97c7365df99a2446cf
David Riazati [Fri, 22 Feb 2019 00:11:37 +0000 (16:11 -0800)]
Add LSTM to standard library (#15744)
Summary:
**WIP**
Attempt 2 at #14831
This adds `nn.LSTM` to the jit standard library. Necessary changes to the module itself are detailed in comments. The main limitation is the lack of a true `PackedSequence`, instead this PR uses an ordinary `tuple` to stand in for `PackedSequence`.
Most of the new code in `rnn.py` is copied to `nn.LSTM` from `nn.RNNBase` to specialize it for LSTM since `hx` is a `Tuple[Tensor, Tensor]` (rather than just a `Tensor` as in the other RNN modules) for LSTM.
As a hack it adds an internal annotation `@_parameter_list` to mark that a function returns all the parameters of a module. The weights for `RNN` modules are passed to the corresponding op as a `List[Tensor]`. In Python this has to be gathered dynamically since Parameters could be moved from CPU to GPU or be deleted and replaced (i.e. if someone calls `weight_norm` on their module, #15766), but in the JIT parameter lists are immutable, hence a builtin to handle this differently in Python/JIT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15744
Differential Revision:
D14173198
Pulled By: driazati
fbshipit-source-id:
4ee8113159b3a8f29a9f56fe661cfbb6b30dffcd
David Riazati [Fri, 22 Feb 2019 00:09:43 +0000 (16:09 -0800)]
Dict mutability (#16884)
Summary:
Adds `aten::_set_item` for `dict[key]` calls
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16884
Differential Revision:
D14000488
Pulled By: driazati
fbshipit-source-id:
ea1b46e0a736d095053effb4bc52753f696617b2
Soumith Chintala [Fri, 22 Feb 2019 00:05:16 +0000 (16:05 -0800)]
Fix static linkage cases and NO_DISTRIBUTED=1 + CUDA (#16705) (#17337)
Summary:
Attempt #2 (attempt 1 is https://github.com/pytorch/pytorch/pull/16705 and got reverted because of CI failures)
Fixes https://github.com/pytorch/pytorch/issues/14805
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17337
Differential Revision:
D14175626
Pulled By: soumith
fbshipit-source-id:
66f2e10e219a1bf88ed342ec5c89da6f2994d8eb
Elias Ellison [Thu, 21 Feb 2019 23:50:08 +0000 (15:50 -0800)]
Fix Insert Constant Lint Fail (#17316)
Summary:
The test I added was failing lint because a constant was being created that wasn't being destroyed.
It was being inserted to all_nodes, then failing the check
` AT_ASSERT(std::includes(ALL_OF(sum_set), ALL_OF(all_nodes_set)));`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17316
Differential Revision:
D14172548
Pulled By: eellison
fbshipit-source-id:
0922db21b7660e0c568c0811ebf09b22081991a4
Zachary DeVito [Thu, 21 Feb 2019 23:24:23 +0000 (15:24 -0800)]
Partial support for kwarg_only arguments in script (#17339)
Summary:
This provides the minimum necessary to allow derivative formulas for things that have a kwarg only specifier in their schema. Support for non-parser frontend default arguments for kwargs is not completed.
Fixes #16921
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17339
Differential Revision:
D14160923
Pulled By: zdevito
fbshipit-source-id:
822e964c5a3fe2806509cf24d9f51c6dc01711c3
Natalia Gimelshein [Thu, 21 Feb 2019 22:35:20 +0000 (14:35 -0800)]
fix double backward for half softmax/logsoftmax (#17330)
Summary:
Fix for #17261, SsnL do you have tests for it in your other PR? If not, I'll add to this. Example from #17261 now does not error out (and same for log_softmax).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17330
Differential Revision:
D14171529
Pulled By: soumith
fbshipit-source-id:
ee925233feb1b44ef9f1d757db59ca3601aadef2
Christian Puhrsch [Thu, 21 Feb 2019 22:31:24 +0000 (14:31 -0800)]
Revisit some native functions to increase number of jit matches (#17340)
Summary:
Adds about 30 matches due to new functions / misuse of double.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17340
Differential Revision:
D14161109
Pulled By: cpuhrsch
fbshipit-source-id:
bb3333446b32551f7469206509b480db290f28ee
Mikhail Zolotukhin [Thu, 21 Feb 2019 22:18:21 +0000 (14:18 -0800)]
Add Value::isValidName method. (#17372)
Summary:
The method will be used in IRParser and in NetDef converter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17372
Differential Revision:
D14172494
Pulled By: ZolotukhinM
fbshipit-source-id:
96cae8422bc73c3c2eb27524f44ec1ee8cae92f3
Bharat123Rox [Thu, 21 Feb 2019 22:06:24 +0000 (14:06 -0800)]
Fix #17218 by updating documentation (#17258)
Summary:
Fix Issue #17218 by updating the corresponding documentation in [BCEWithLogitsLoss](https://pytorch.org/docs/stable/nn.html#torch.nn.BCEWithLogitsLoss)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17258
Differential Revision:
D14157336
Pulled By: ezyang
fbshipit-source-id:
fb474d866464faeaae560ab58214cccaa8630f08
Soumith Chintala [Thu, 21 Feb 2019 21:37:00 +0000 (13:37 -0800)]
fix lint (#17366)
Summary:
fix lint
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17366
Differential Revision:
D14171702
Pulled By: soumith
fbshipit-source-id:
5d8ecfac442e93b11bf4095f9977fd3302d033eb
Nikolay Korovaiko [Thu, 21 Feb 2019 20:35:23 +0000 (12:35 -0800)]
switch to Operation in register_prim_ops.cpp (#17183)
Summary:
This PR switches from `OperationCreator` to `Operation` to simplify the logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17183
Differential Revision:
D14169829
Pulled By: Krovatkin
fbshipit-source-id:
27f40a30c92e29651cea23f08b5b1f13d7eced8c
Karl Ostmo [Thu, 21 Feb 2019 19:38:28 +0000 (11:38 -0800)]
Use standard docker image for XLA build
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17287
Differential Revision:
D14169689
Pulled By: kostmo
fbshipit-source-id:
24e255be23936542093008ed51d2c061b2924993
Gregory Chanan [Thu, 21 Feb 2019 19:00:05 +0000 (11:00 -0800)]
Modernize test_sparse. (#17324)
Summary:
Our sparse tests still almost exclusively use legacy constructors. This means you can't, for example, easily test scalars (because the legacy constructors don't allow them), and not surprisingly, many operations are broken with sparse scalars.
Note: this doesn't address the SparseTensor constructor itself, because there is a separate incompatibility there that I will address in a follow-on commit, namely, that torch.sparse.FloatTensor() is supported, but torch.sparse_coo_tensor() is not (because the size is ambiguous).
The follow-on PR will explicitly set the size for sparse tensor constructors and add a test for the legacy behavior, so we don't lose it.
Included in this PR are changes to the constituent sparse tensor pieces (indices, values):
1) IndexTensor becomes index_tensor
2) ValueTensor becomes value_tensor if it is a data-based construction, else value_empty.
3) Small changes around using the legacy tensor type directly, e.g. torch.FloatTensor.dtype exists, but torch.tensor isn't a type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17324
Differential Revision:
D14159270
Pulled By: gchanan
fbshipit-source-id:
71ee63e1ea6a4bc98f50be41d138c9c72f5ca651
Soumith Chintala [Thu, 21 Feb 2019 18:55:14 +0000 (10:55 -0800)]
remove nn.Upsample deprecation warnings from tests (#17352)
Differential Revision:
D14168481
Pulled By: soumith
fbshipit-source-id:
63c37c5f04d2529abd4f42558a3d5e81993eecec
Soumith Chintala [Thu, 21 Feb 2019 17:53:24 +0000 (09:53 -0800)]
upgrade documentation in setup.py to NO_ -> USE_ (#17333)
Summary:
fixes https://github.com/pytorch/pytorch/issues/17265
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17333
Differential Revision:
D14168483
Pulled By: soumith
fbshipit-source-id:
a79f4f9d9e18cb64e2f56f777caa69ae92d2fa4b
Dmytro Dzhulgakov [Thu, 21 Feb 2019 17:22:12 +0000 (09:22 -0800)]
Enforce non-negativity of tensor construction (#17077)
Summary:
Apparently, before the only way we enforced it was size>=0 in alloc_cpu. So empty((5,-5)) would fail but empty((-5,-5)) would hang :)
Please suggest better place to enforce it if any.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17077
Differential Revision:
D14077930
Pulled By: dzhulgakov
fbshipit-source-id:
1120513300fd5448e06fa15c2d72f9b0ee5734e4
Igor Macedo Quintanilha [Thu, 21 Feb 2019 16:04:07 +0000 (08:04 -0800)]
Fixing docstring in CTCLoss (#17307)
Summary:
The argument `zero_infinity` is in the wrong place! :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17307
Differential Revision:
D14154850
Pulled By: ezyang
fbshipit-source-id:
7a9fe537483b23041f21ba1b80375b7f44265538
fehiepsi [Thu, 21 Feb 2019 16:01:54 +0000 (08:01 -0800)]
Fix the slowness of mvn's log_prob (#17294)
Summary:
This PR addresses the slowness of MVN's log_prob as reported in #17206.
t-vi I find it complicated to handle permutation dimensions if we squeeze singleton dimensions of bL, so I leave it as-is and keep the old approach. What do you think?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17294
Differential Revision:
D14157292
Pulled By: ezyang
fbshipit-source-id:
f32590b89bf18c9c99b39501dbee0eeb61e130d0
Gao, Xiang [Thu, 21 Feb 2019 15:50:27 +0000 (07:50 -0800)]
Move argsort to C++
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17099
Differential Revision:
D14165671
Pulled By: ezyang
fbshipit-source-id:
3871de6874fe09871ebd9b8943c13c9af325bf33
Tri Dao [Thu, 21 Feb 2019 15:34:27 +0000 (07:34 -0800)]
Include vec256 headers in setup.py (#17220)
Summary:
Fix #16650.
Headers such as `ATen/cpu/vml.h` contain `#include <ATen/cpu/vec256/vec256.h>`
for example, but these vec256 headers aren't included, due to commit e4c0bb1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17220
Differential Revision:
D14165695
Pulled By: ezyang
fbshipit-source-id:
27b2aa2a734b3719ca4af0565f79623b64b2620f
peter [Thu, 21 Feb 2019 12:34:08 +0000 (04:34 -0800)]
Enable MAX_JOBS for using Ninja on Windows
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17341
Differential Revision:
D14164740
Pulled By: soumith
fbshipit-source-id:
7a1c3db0a7c590f72a777fcd32e1c740bb0c6257
Luca Wehrstedt [Thu, 21 Feb 2019 09:24:56 +0000 (01:24 -0800)]
Avoid unnecessary CPU-to-GPU copy of torch.load with CUDA (#17297)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17297
When `torch.load` needs to load a tensor, no matter which device it will be end up being loaded on, it first creates a CPU storage for it of the necessary size. This storage is allocated but it's not "set" yet, hence no data is written to it: it exists in the kernel's memory map, but it's not resident and doesn't take up physical pages. Then, this storage is passed to the `map_location` function (if the parameter is a string, a device or a map, PyTorch builds that function automatically). The default map for CUDA consists effectively in `lambda storage, _: storage.cuda()` (I omitted the code needed to pick the correct device). This creates a GPU storage and copies over the data of the CPU storage. *This step is unnecessary as we're copying uninitialized memory*. (Surprisingly enough, though, it appears the kernel is smart enough that reading from the unpaged CPU memory doesn't cause it to become paged.) Once `map_location` returns a storage residing on the correct target device, `torch.load` resumes reading the file and copying the tensor's content over into the storage. This will overwrite the content that had previously been written to it, which confirms that the above copy was pointless.
A way to avoid this useless copy is to just create and return a new empty storage on the target GPU, instead of "transforming" the original one.
This does indeed increase the performance:
```
In [5]: torch.save(torch.rand(100, 100, 100), "/tmp/tensor")
In [6]: %timeit torch.load("/tmp/tensor", map_location="cuda")
1.55 ms ± 111 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [7]: %timeit torch.load("/tmp/tensor", map_location=lambda storage, _: torch.cuda.FloatStorage(storage.size()))
1.03 ms ± 44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Credit for this diff is shared with adamlerer and fmassa.
Differential Revision:
D14147673
fbshipit-source-id:
a58d4bc0d894ca03a008499334fc2cdd4cc91e9f
Michael Suo [Thu, 21 Feb 2019 08:15:59 +0000 (00:15 -0800)]
allow lists to contain any tensor type (#17321)
Summary:
If something is a TensorList, it should be a list of `TensorType`, not a list of some specialized type.
Fixes #17140, #15642
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17321
Differential Revision:
D14158192
Pulled By: suo
fbshipit-source-id:
ba8fe6ae8d618c73b23cd00cbcb3111c390c5514
Junjie Bai [Thu, 21 Feb 2019 05:05:59 +0000 (21:05 -0800)]
Skip convnets benchmark in rocm CI (#17331)
Summary:
random coredump
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17331
Differential Revision:
D14162018
Pulled By: bddppq
fbshipit-source-id:
3ed15a79b7bca2498c50f6af80cbd6be7229dea8
Edward Yang [Thu, 21 Feb 2019 04:16:50 +0000 (20:16 -0800)]
Don't have malloc-free pairs that cross DLL boundaries. (#17302)
Summary:
See https://blogs.msdn.microsoft.com/oldnewthing/
20060915-04/?p=29723
for more background on this requirement on Windows.
Fixes #17239.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc xkszltl peterjc123
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17302
Differential Revision:
D14150067
Pulled By: ezyang
fbshipit-source-id:
9dc16ca781ff17515b8df1bb55492477e7843d4c
bddppq [Thu, 21 Feb 2019 02:40:31 +0000 (18:40 -0800)]
Add support to build for multiple amd gpu targets (#17329)
Summary:
iotamudelta petrex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17329
Differential Revision:
D14161277
Pulled By: bddppq
fbshipit-source-id:
f3eb9f52e96a8fcd779c57df0f8c9a2c54754e35
Michael Suo [Thu, 21 Feb 2019 02:27:31 +0000 (18:27 -0800)]
batched cleanups (#17288)
Summary:
Bunch of random stuff I came across while doing UDT stuff. Putting in a separate PR to avoid noise
- fix up the alias analysis list ops to include fork/wait
- improve dump() for aliasDb to print writes
- Move BuiltinFunction::call() to sugaredvalue with the rest of the methods
- formatting and includes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17288
Differential Revision:
D14147105
Pulled By: suo
fbshipit-source-id:
62e2a922a1726b684347365dc42c72188f154e9c
Edward Yang [Thu, 21 Feb 2019 01:54:04 +0000 (17:54 -0800)]
(Permanently) fix CI breakage due to new docker version. (#17338)
Summary:
Pull request resolved: https://github.com/pytorch/pytorch/pull/17338
See comment in config.yml for details.
build-break
Reviewed By: orionr
Differential Revision:
D14160934
fbshipit-source-id:
a91160ab15dd6c174a7d946a78a7d2d50ae0a011
Cheng,Penghui [Thu, 21 Feb 2019 00:54:51 +0000 (16:54 -0800)]
Implementation convolutionTranspose operator for mkl-dnn (#12866)
Summary:
the speed-up of a single operation is up to 2-3X on BDW.
This PR depend on https://github.com/pytorch/pytorch/pull/14308
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12866
Differential Revision:
D13936110
Pulled By: ezyang
fbshipit-source-id:
34e3c2ca982a41e8bf556e2aa0477c999fc939d3
Cheng,Penghui [Thu, 21 Feb 2019 00:53:23 +0000 (16:53 -0800)]
Support multi-device configuration for MKL-DNN (#12856)
Summary:
MKL-DNN support multi-node mode,but not support multi-devices mode,this commit will support multi-devices for MKL-DNN.This commit depend on https://github.com/pytorch/pytorch/pull/11330
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12856
Differential Revision:
D13735075
Pulled By: ezyang
fbshipit-source-id:
b63f92b7c792051f5cb22e3dda948013676e109b
Ailing Zhang [Thu, 21 Feb 2019 00:41:33 +0000 (16:41 -0800)]
fix missing std (#17263)
Summary:
add missing std introduced by #16689 . Investigating why this wasn't caught in CI (nor my local dev environment).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17263
Reviewed By: ezyang
Differential Revision:
D14134556
Pulled By: ailzhang
fbshipit-source-id:
6f0753fa858d3997e654924779646228d6d49838
Ilia Cherniavskii [Thu, 21 Feb 2019 00:22:01 +0000 (16:22 -0800)]
Rethrow exceptions from RunAsync (#15034)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15034
Rethrow exception happened during RunAsync, ensure that pending tasks
are not executed after marked as finished
Reviewed By: andrewwdye
Differential Revision:
D13409649
fbshipit-source-id:
3fd12b3dcf32af4752f8b6e55eb7a92812a5c057
Ilia Cherniavskii [Thu, 21 Feb 2019 00:22:01 +0000 (16:22 -0800)]
Reinforce scheduling invariants (#17132)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17132
schedule() function is not supposed to throw exception and is supposed
to succeed in scheduling the full graph of tasks, potential errors (e.g. errors
from underlying thread pool, out of memory exceptions etc) are considered not
recoverable.
The invariant - the graph of tasks is either not executed or
executed in full before the call to finishRun()
Reviewed By: andrewwdye
Differential Revision:
D14092457
fbshipit-source-id:
a3e5d65dfee5ff5e5e71ec72bb9e576180019698
Lukasz Wesolowski [Wed, 20 Feb 2019 23:52:24 +0000 (15:52 -0800)]
Modify TileOp GPU implementation to expose more concurrency and better utilize GPU memory bandwidth (#17275)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17275
Previous implementation used a memcpy inside the kernel. It is more efficient to reduce the data fetched per thread to a single word from memory. This exposes more concurrency and takes advantage of GPU memory coalescing support.
Reviewed By: takatosp1
Differential Revision:
D14120147
fbshipit-source-id:
c4734003d4342e55147c5b858f232a006af60b68
Christian Puhrsch [Wed, 20 Feb 2019 23:37:04 +0000 (15:37 -0800)]
Support str for native_functions.yaml schema
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17276
Differential Revision:
D14154222
Pulled By: cpuhrsch
fbshipit-source-id:
411181da5399608c1d1f3218f8f570bb106c88ec
Xiaomeng Yang [Wed, 20 Feb 2019 22:38:35 +0000 (14:38 -0800)]
Separate gpu reduce functions (#17146)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17146
Separate gpu reduce functions
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision:
D14097564
fbshipit-source-id:
a27de340997111a794b1d083c1673d4263afb9fb
Edward Yang [Wed, 20 Feb 2019 22:25:01 +0000 (14:25 -0800)]
Minor doc updates in c10/core/Allocator.h (#17164)
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17164
Differential Revision:
D14154393
Pulled By: ezyang
fbshipit-source-id:
59d8276d4bb4e7cadb4382769b75e5348ed388de
Xiang Gao [Wed, 20 Feb 2019 21:47:50 +0000 (13:47 -0800)]
Namedtuple return for symeig, eig, pstrf, qr, geqrf (#16950)
Summary: More ops for https://github.com/pytorch/pytorch/issues/394
Differential Revision:
D14118645
Pulled By: ezyang
fbshipit-source-id:
a98646c3ddcbe4e34452aa044951286dcf9df778
Thomas Viehmann [Wed, 20 Feb 2019 21:31:23 +0000 (13:31 -0800)]
Allow PyTorch to be built without NCCL (#17295)
Summary:
With this patch you can use USE_DISTRIBUTED=OFF (possibly in combination with USE_NCCL=OFF (?))
The significance is partly because the NCCL doesn't build with CUDA 8.
This is written under the assumption that NCCL is required for distributed if not, the USE_DISTRIBUTED check in nccl.py should be replaced by a check for the USE_NCCL environment variable.
Fixes: #17274
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17295
Differential Revision:
D14155080
Pulled By: ezyang
fbshipit-source-id:
0d133f7c5b4d118849f041bd4d4cbbd7ffc3c7b4
Lu Fang [Wed, 20 Feb 2019 21:25:05 +0000 (13:25 -0800)]
add foxi submodule (#17184)
Peizhao Zhang [Wed, 20 Feb 2019 21:08:31 +0000 (13:08 -0800)]
Removed obsolete argument correct_transform_coords in bbox_transform op. (#16723)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16723
Removed obsolete argument correct_transform_coords in bbox_transform op.
* It was only for backward compatibility. We should not have models using it now.
Differential Revision:
D13937430
fbshipit-source-id:
504bb066137ce408c12dc9dcc2e0a513bad9b7ee
Hector Yuen [Wed, 20 Feb 2019 21:07:08 +0000 (13:07 -0800)]
make the threshold for acurracy more precise (#17194)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17194
we found that there is a per row absolute error due to int8 quant
and a relative error table-wide in case fp16 is used
Reviewed By: csummersea
Differential Revision:
D14113353
fbshipit-source-id:
c7065aa9d15c453c2e5609f421ad0155145af889
Yinghai Lu [Wed, 20 Feb 2019 20:37:34 +0000 (12:37 -0800)]
Add rule based filtering for ONNXIFI transformation (#17198)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17198
We come to the point that we need to apply some rules to bind certain ops together to avoid un-inferrable intermediate shapes. We either lower them together to backend or neither. This diff adds a pass for us to add rules like this. The first one is to bind `Gather` with `SparseLengthsWeighted*`.
Reviewed By: ipiszy
Differential Revision:
D14118326
fbshipit-source-id:
14bc62e1feddae02a3dd8eae93b8f553d52ac951
svcscm [Wed, 20 Feb 2019 17:23:27 +0000 (09:23 -0800)]
Updating submodules
Reviewed By: zpao
fbshipit-source-id:
4ee15707bcf8c23c2d7feb6987acecef4131d467
Oleg Bogdanov [Wed, 20 Feb 2019 17:15:11 +0000 (09:15 -0800)]
caffe2 | added missing operator source file (#17272)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17272
after windows-specific fixes were applied new file was left out of CMakeLists
Reviewed By: orionr
Differential Revision:
D14140419
fbshipit-source-id:
6a6c652048ed196ec20241bc2a1d08cbe2a4e155
Nikolay Korovaiko [Wed, 20 Feb 2019 17:11:11 +0000 (09:11 -0800)]
add list methods: copy,extend (#17092)
Summary:
This PR adds the following methods to python's list.
* copy
* extend
and tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17092
Differential Revision:
D14141817
Pulled By: Krovatkin
fbshipit-source-id:
c89207f0f25f3d1d4ad903ee634745615d61d576
SsnL [Wed, 20 Feb 2019 16:58:49 +0000 (08:58 -0800)]
Improve error message w/ size inference on empty tensors
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/17255
Differential Revision:
D14143094
Pulled By: soumith
fbshipit-source-id:
f96fa7f8eb6eaac72887d3e837546cbfa505f101
Gemfield [Wed, 20 Feb 2019 14:59:31 +0000 (06:59 -0800)]
add install step and docs for Android build (#17298)
Summary:
This commit did below enhancements:
1, add doc for build_android.sh;
2, add install step for build_android.sh, thus the headers and libraries can be collected together for further usage conveniently;
3, change the default INSTALL_PREFIX from $PYTORCH_ROOT/install to $PYTORCH_ROOT/build_android/install to make the project directory clean.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17298
Differential Revision:
D14149709
Pulled By: soumith
fbshipit-source-id:
a3a38cb41f26377e21aa89e49e57e8f21c9c1a39
Soumith Chintala [Wed, 20 Feb 2019 14:27:17 +0000 (06:27 -0800)]
improve libtorch install docs with GPU note (#17299)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/15702
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17299
Differential Revision:
D14149712
Pulled By: soumith
fbshipit-source-id:
5b83110bb00e4d4dad04c1f293c2b52e41711f11
Thomas Viehmann [Wed, 20 Feb 2019 11:06:53 +0000 (03:06 -0800)]
Add launch bounds for TopK kernel, be more conservative in sorting (#17296)
Summary:
The particular use case reported is Jetson TX2 and maskrcnn.
Fixes #17144
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17296
Differential Revision:
D14147886
Pulled By: soumith
fbshipit-source-id:
44d5a89aaeb4cc07d1b53dd90121013be93c419c