/// Generate call to a character comparison for two ssa-values of type
/// `boxchar`.
mlir::Value genBoxCharCompare(AbstractConverter &converter, mlir::Location loc,
- mlir::CmpIPredicate cmp, mlir::Value lhs,
+ mlir::arith::CmpIPredicate cmp, mlir::Value lhs,
mlir::Value rhs);
/// Generate call to a character comparison op for two unboxed variables. There
/// reference to its buffer (`ref<char<K>>`) and its LEN type parameter (some
/// integral type).
mlir::Value genRawCharCompare(AbstractConverter &converter, mlir::Location loc,
- mlir::CmpIPredicate cmp, mlir::Value lhsBuff,
- mlir::Value lhsLen, mlir::Value rhsBuff,
- mlir::Value rhsLen);
+ mlir::arith::CmpIPredicate cmp,
+ mlir::Value lhsBuff, mlir::Value lhsLen,
+ mlir::Value rhsBuff, mlir::Value rhsLen);
} // namespace lower
} // namespace Fortran
}
namespace fir {
-/// Return the integer value of a ConstantOp.
-inline std::int64_t toInt(mlir::ConstantOp cop) {
- return cop.getValue().cast<mlir::IntegerAttr>().getValue().getSExtValue();
+/// Return the integer value of a arith::ConstantOp.
+inline std::int64_t toInt(mlir::arith::ConstantOp cop) {
+ return cop.value().cast<mlir::IntegerAttr>().getValue().getSExtValue();
}
} // namespace fir
#define FORTRAN_OPTIMIZER_DIALECT_FIROPS_H
#include "flang/Optimizer/Dialect/FIRType.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Interfaces/LoopLikeInterface.h"
#include "mlir/Interfaces/SideEffectInterfaces.h"
class RealAttr;
void buildCmpCOp(mlir::OpBuilder &builder, mlir::OperationState &result,
- mlir::CmpFPredicate predicate, mlir::Value lhs,
+ mlir::arith::CmpFPredicate predicate, mlir::Value lhs,
mlir::Value rhs);
unsigned getCaseArgumentOffset(llvm::ArrayRef<mlir::Attribute> cases,
unsigned dest);
argument. The length of the !fir.char type is ignored.
```mlir
- fir.char_convert %1 for %2 to %3 : !fir.ref<!fir.char<1,?>>, i32,
+ fir.char_convert %1 for %2 to %3 : !fir.ref<!fir.char<1,?>>, i32,
!fir.ref<!fir.char<2,20>>
```
let printer = "printCmpcOp(p, *this);";
- let builders = [OpBuilder<(ins "mlir::CmpFPredicate":$predicate,
+ let builders = [OpBuilder<(ins "mlir::arith::CmpFPredicate":$predicate,
"mlir::Value":$lhs, "mlir::Value":$rhs), [{
buildCmpCOp($_builder, $_state, predicate, lhs, rhs);
}]>];
return "predicate";
}
- CmpFPredicate getPredicate() {
- return (CmpFPredicate)(*this)->getAttrOfType<mlir::IntegerAttr>(
+ arith::CmpFPredicate getPredicate() {
+ return (arith::CmpFPredicate)(*this)->getAttrOfType<mlir::IntegerAttr>(
getPredicateAttrName()).getInt();
}
- static CmpFPredicate getPredicateByName(llvm::StringRef name);
+ static arith::CmpFPredicate getPredicateByName(llvm::StringRef name);
}];
}
operations with a single FMA operation.
```mlir
- %98 = mulf %96, %97 : f32
+ %98 = arith.mulf %96, %97 : f32
%99 = fir.no_reassoc %98 : f32
- %a0 = addf %99, %95 : f32
+ %a0 = arith.addf %99, %95 : f32
```
}];
#ifndef FORTRAN_OPTIMIZER_SUPPORT_INITFIR_H
#define FORTRAN_OPTIMIZER_SUPPORT_INITFIR_H
+#include "flang/Optimizer/CodeGen/CodeGen.h"
#include "flang/Optimizer/Dialect/FIRDialect.h"
#include "mlir/Conversion/Passes.h"
#include "mlir/Dialect/Affine/Passes.h"
#define FLANG_NONCODEGEN_DIALECT_LIST \
mlir::AffineDialect, FIROpsDialect, mlir::acc::OpenACCDialect, \
mlir::omp::OpenMPDialect, mlir::scf::SCFDialect, \
- mlir::StandardOpsDialect, mlir::vector::VectorDialect
+ mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect, \
+ mlir::vector::VectorDialect
// The definitive list of dialects used by flang.
#define FLANG_DIALECT_LIST \
#include "mlir/IR/BuiltinAttributes.h"
namespace fir {
-/// Return the integer value of a ConstantOp.
-inline std::int64_t toInt(mlir::ConstantOp cop) {
- return cop.getValue().cast<mlir::IntegerAttr>().getValue().getSExtValue();
+/// Return the integer value of a arith::ConstantOp.
+inline std::int64_t toInt(mlir::arith::ConstantOp cop) {
+ return cop.value().cast<mlir::IntegerAttr>().getValue().getSExtValue();
}
} // namespace fir
#define FORTRAN_FIR_REWRITE_PATTERNS
include "mlir/IR/OpBase.td"
+include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.td"
include "mlir/Dialect/StandardOps/IR/Ops.td"
include "flang/Optimizer/Dialect/FIROps.td"
,(SmallerWidthPred $arg, $irm)]>;
def createConstantOp
- : NativeCodeCall<"$_builder.create<mlir::ConstantOp>"
+ : NativeCodeCall<"$_builder.create<mlir::arith::ConstantOp>"
"($_loc, $_builder.getIndexType(), "
"rewriter.getIndexAttr($1.dyn_cast<IntegerAttr>().getInt()))">;
def ForwardConstantConvertPattern
- : Pat<(fir_ConvertOp:$res (ConstantOp:$cnt $attr)),
+ : Pat<(fir_ConvertOp:$res (Arith_ConstantOp:$cnt $attr)),
(createConstantOp $res, $attr),
[(IndexTypePred $res)
,(IntegerTypePred $cnt)]>;
// Pad if needed.
if (!compileTimeSameLength) {
auto one = builder.createIntegerConstant(loc, lhs.getLen().getType(), 1);
- auto maxPadding = builder.create<mlir::SubIOp>(loc, lhs.getLen(), one);
+ auto maxPadding =
+ builder.create<mlir::arith::SubIOp>(loc, lhs.getLen(), one);
createPadding(lhs, copyCount, maxPadding);
}
}
fir::CharBoxValue Fortran::lower::CharacterExprHelper::createConcatenate(
const fir::CharBoxValue &lhs, const fir::CharBoxValue &rhs) {
mlir::Value len =
- builder.create<mlir::AddIOp>(loc, lhs.getLen(), rhs.getLen());
+ builder.create<mlir::arith::AddIOp>(loc, lhs.getLen(), rhs.getLen());
auto temp = createTemp(getCharacterType(rhs), len);
createCopy(temp, lhs, lhs.getLen());
auto one = builder.createIntegerConstant(loc, len.getType(), 1);
- auto upperBound = builder.create<mlir::SubIOp>(loc, len, one);
+ auto upperBound = builder.create<mlir::arith::SubIOp>(loc, len, one);
auto lhsLen =
builder.createConvert(loc, builder.getIndexType(), lhs.getLen());
Fortran::lower::DoLoopHelper{builder, loc}.createLoop(
lhs.getLen(), upperBound, one,
[&](Fortran::lower::FirOpBuilder &bldr, mlir::Value index) {
- auto rhsIndex = bldr.create<mlir::SubIOp>(loc, index, lhsLen);
+ auto rhsIndex = bldr.create<mlir::arith::SubIOp>(loc, index, lhsLen);
auto charVal = createLoadCharAt(rhs, rhsIndex);
createStoreCharAt(temp, index, charVal);
});
auto lowerBound = castBounds[0];
// FIR CoordinateOp is zero based but Fortran substring are one based.
auto one = builder.createIntegerConstant(loc, lowerBound.getType(), 1);
- auto offset = builder.create<mlir::SubIOp>(loc, lowerBound, one).getResult();
+ auto offset =
+ builder.create<mlir::arith::SubIOp>(loc, lowerBound, one).getResult();
auto idxType = builder.getIndexType();
if (offset.getType() != idxType)
offset = builder.createConvert(loc, idxType, offset);
mlir::Value substringLen{};
if (nbounds < 2) {
substringLen =
- builder.create<mlir::SubIOp>(loc, str.getLen(), castBounds[0]);
+ builder.create<mlir::arith::SubIOp>(loc, str.getLen(), castBounds[0]);
} else {
substringLen =
- builder.create<mlir::SubIOp>(loc, castBounds[1], castBounds[0]);
+ builder.create<mlir::arith::SubIOp>(loc, castBounds[1], castBounds[0]);
}
- substringLen = builder.create<mlir::AddIOp>(loc, substringLen, one);
+ substringLen = builder.create<mlir::arith::AddIOp>(loc, substringLen, one);
// Set length to zero if bounds were reversed (Fortran 2018 9.4.1)
auto zero = builder.createIntegerConstant(loc, substringLen.getType(), 0);
- auto cdt = builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::slt,
- substringLen, zero);
+ auto cdt = builder.create<mlir::arith::CmpIOp>(
+ loc, mlir::arith::CmpIPredicate::slt, substringLen, zero);
substringLen = builder.create<mlir::SelectOp>(loc, cdt, zero, substringLen);
return {substringRef, substringLen};
// Lower character operations
//===----------------------------------------------------------------------===//
-mlir::Value
-Fortran::lower::genRawCharCompare(Fortran::lower::AbstractConverter &converter,
- mlir::Location loc, mlir::CmpIPredicate cmp,
- mlir::Value lhsBuff, mlir::Value lhsLen,
- mlir::Value rhsBuff, mlir::Value rhsLen) {
+mlir::Value Fortran::lower::genRawCharCompare(
+ Fortran::lower::AbstractConverter &converter, mlir::Location loc,
+ mlir::arith::CmpIPredicate cmp, mlir::Value lhsBuff, mlir::Value lhsLen,
+ mlir::Value rhsBuff, mlir::Value rhsLen) {
auto &builder = converter.getFirOpBuilder();
mlir::FuncOp beginFunc;
switch (discoverKind(lhsBuff.getType())) {
llvm::SmallVector<mlir::Value, 4> args = {lptr, rptr, llen, rlen};
auto tri = builder.create<mlir::CallOp>(loc, beginFunc, args).getResult(0);
auto zero = builder.createIntegerConstant(loc, tri.getType(), 0);
- return builder.create<mlir::CmpIOp>(loc, cmp, tri, zero);
+ return builder.create<mlir::arith::CmpIOp>(loc, cmp, tri, zero);
}
-mlir::Value
-Fortran::lower::genBoxCharCompare(Fortran::lower::AbstractConverter &converter,
- mlir::Location loc, mlir::CmpIPredicate cmp,
- mlir::Value lhs, mlir::Value rhs) {
+mlir::Value Fortran::lower::genBoxCharCompare(
+ Fortran::lower::AbstractConverter &converter, mlir::Location loc,
+ mlir::arith::CmpIPredicate cmp, mlir::Value lhs, mlir::Value rhs) {
auto &builder = converter.getFirOpBuilder();
Fortran::lower::CharacterExprHelper helper{builder, loc};
auto lhsPair = helper.materializeCharacter(lhs);
auto imag1 = extract<Part::Imag>(cplx1);
auto imag2 = extract<Part::Imag>(cplx2);
- mlir::CmpFPredicate predicate =
- eq ? mlir::CmpFPredicate::UEQ : mlir::CmpFPredicate::UNE;
+ mlir::arith::CmpFPredicate predicate =
+ eq ? mlir::arith::CmpFPredicate::UEQ : mlir::arith::CmpFPredicate::UNE;
mlir::Value realCmp =
- builder.create<mlir::CmpFOp>(loc, predicate, real1, real2);
+ builder.create<mlir::arith::CmpFOp>(loc, predicate, real1, real2);
mlir::Value imagCmp =
- builder.create<mlir::CmpFOp>(loc, predicate, imag1, imag2);
+ builder.create<mlir::arith::CmpFOp>(loc, predicate, imag1, imag2);
- return eq ? builder.create<mlir::AndOp>(loc, realCmp, imagCmp).getResult()
- : builder.create<mlir::OrOp>(loc, realCmp, imagCmp).getResult();
+ return eq ? builder.create<mlir::arith::AndIOp>(loc, realCmp, imagCmp)
+ .getResult()
+ : builder.create<mlir::arith::OrIOp>(loc, realCmp, imagCmp)
+ .getResult();
}
auto indexType = builder.getIndexType();
auto zero = builder.createIntegerConstant(loc, indexType, 0);
auto one = builder.createIntegerConstant(loc, count.getType(), 1);
- auto up = builder.create<mlir::SubIOp>(loc, count, one);
+ auto up = builder.create<mlir::arith::SubIOp>(loc, count, one);
createLoop(zero, up, one, bodyGenerator);
}
mlir::Value Fortran::lower::FirOpBuilder::createIntegerConstant(
mlir::Location loc, mlir::Type ty, std::int64_t cst) {
- return create<mlir::ConstantOp>(loc, ty, getIntegerAttr(ty, cst));
+ return create<mlir::arith::ConstantOp>(loc, ty, getIntegerAttr(ty, cst));
}
mlir::Value Fortran::lower::FirOpBuilder::createRealConstant(
mlir::Location loc, mlir::Type realType, const llvm::APFloat &val) {
- return create<mlir::ConstantOp>(loc, realType, getFloatAttr(realType, val));
+ return create<mlir::arith::ConstantOp>(loc, realType,
+ getFloatAttr(realType, val));
}
mlir::Value
} else { // mlir::FloatType.
attr = getZeroAttr(realType);
}
- return create<mlir::ConstantOp>(loc, realType, attr);
+ return create<mlir::arith::ConstantOp>(loc, realType, attr);
}
mlir::Value Fortran::lower::FirOpBuilder::allocateLocal(
auto complexPartAddr = [&](int index) {
return builder.create<fir::CoordinateOp>(
loc, complexPartType, originalItemAddr,
- llvm::SmallVector<mlir::Value, 1>{builder.create<mlir::ConstantOp>(
- loc, builder.getI32IntegerAttr(index))});
+ llvm::SmallVector<mlir::Value, 1>{
+ builder.create<mlir::arith::ConstantOp>(
+ loc, builder.getI32IntegerAttr(index))});
};
if (complexPartType)
itemAddr = complexPartAddr(0); // real part
inputFuncArgs.push_back(
builder.createConvert(loc, inputFunc.getType().getInput(2), len));
} else if (itemType.isa<mlir::IntegerType>()) {
- inputFuncArgs.push_back(builder.create<mlir::ConstantOp>(
+ inputFuncArgs.push_back(builder.create<mlir::arith::ConstantOp>(
loc, builder.getI32IntegerAttr(
itemType.cast<mlir::IntegerType>().getWidth() / 8)));
}
auto upperValue = genFIRLoopIndex(control.upper);
auto stepValue = control.step.has_value()
? genFIRLoopIndex(*control.step)
- : builder.create<mlir::ConstantIndexOp>(loc, 1);
+ : builder.create<mlir::arith::ConstantIndexOp>(loc, 1);
auto genItemList = [&](const D &ioImpliedDo, bool inIterWhileLoop) {
if constexpr (std::is_same_v<D, Fortran::parser::InputImpliedDo>)
genInputItemList(converter, cookie, itemList, insertPt, checkResult, ok,
static mlir::Value getDefaultFilename(Fortran::lower::FirOpBuilder &builder,
mlir::Location loc, mlir::Type toType) {
- mlir::Value null =
- builder.create<mlir::ConstantOp>(loc, builder.getI64IntegerAttr(0));
+ mlir::Value null = builder.create<mlir::arith::ConstantOp>(
+ loc, builder.getI64IntegerAttr(0));
return builder.createConvert(loc, toType, null);
}
static mlir::Value getDefaultLineNo(Fortran::lower::FirOpBuilder &builder,
mlir::Location loc, mlir::Type toType) {
- return builder.create<mlir::ConstantOp>(loc,
- builder.getIntegerAttr(toType, 0));
+ return builder.create<mlir::arith::ConstantOp>(
+ loc, builder.getIntegerAttr(toType, 0));
}
static mlir::Value getDefaultScratch(Fortran::lower::FirOpBuilder &builder,
mlir::Location loc, mlir::Type toType) {
- mlir::Value null =
- builder.create<mlir::ConstantOp>(loc, builder.getI64IntegerAttr(0));
+ mlir::Value null = builder.create<mlir::arith::ConstantOp>(
+ loc, builder.getI64IntegerAttr(0));
return builder.createConvert(loc, toType, null);
}
static mlir::Value getDefaultScratchLen(Fortran::lower::FirOpBuilder &builder,
mlir::Location loc, mlir::Type toType) {
- return builder.create<mlir::ConstantOp>(loc,
- builder.getIntegerAttr(toType, 0));
+ return builder.create<mlir::arith::ConstantOp>(
+ loc, builder.getIntegerAttr(toType, 0));
}
/// Lower a string literal. Many arguments to the runtime are conveyed as
auto len = builder.createConvert(loc, lenTy, dataLen.second);
if (ty2) {
auto kindVal = helper.getCharacterKind(str.getType());
- auto kind = builder.create<mlir::ConstantOp>(
+ auto kind = builder.create<mlir::arith::ConstantOp>(
loc, builder.getIntegerAttr(ty2, kindVal));
return {buff, len, kind};
}
getIORuntimeFunc<mkIOKey(EnableHandlers)>(loc, builder);
mlir::Type boolType = enableHandlers.getType().getInput(1);
auto boolValue = [&](bool specifierIsPresent) {
- return builder.create<mlir::ConstantOp>(
+ return builder.create<mlir::arith::ConstantOp>(
loc, builder.getIntegerAttr(boolType, specifierIsPresent));
};
llvm::SmallVector<mlir::Value, 6> ioArgs = {
auto ex = converter.genExprValue(Fortran::semantics::GetExpr(*e), loc);
return builder.createConvert(loc, ty, ex);
}
- return builder.create<mlir::ConstantOp>(
+ return builder.create<mlir::arith::ConstantOp>(
loc, builder.getIntegerAttr(ty, Fortran::runtime::io::DefaultUnit));
}
ioArgs.push_back(std::get<1>(pair));
}
// unit (always last)
- ioArgs.push_back(builder.create<mlir::ConstantOp>(
+ ioArgs.push_back(builder.create<mlir::arith::ConstantOp>(
loc, builder.getIntegerAttr(ioFuncTy.getInput(ioArgs.size()),
Fortran::runtime::io::DefaultUnit)));
}
auto arg = args[0];
auto type = arg.getType();
if (fir::isa_real(type)) {
- // Runtime call to fp abs. An alternative would be to use mlir AbsFOp
+ // Runtime call to fp abs. An alternative would be to use mlir math::AbsOp
// but it does not support all fir floating point types.
return genRuntimeCall("abs", resultType, args);
}
// So, implement abs here without branching.
auto shift =
builder.createIntegerConstant(loc, intType, intType.getWidth() - 1);
- auto mask = builder.create<mlir::SignedShiftRightOp>(loc, arg, shift);
- auto xored = builder.create<mlir::XOrOp>(loc, arg, mask);
- return builder.create<mlir::SubIOp>(loc, xored, mask);
+ auto mask = builder.create<mlir::arith::ShRSIOp>(loc, arg, shift);
+ auto xored = builder.create<mlir::arith::XOrIOp>(loc, arg, mask);
+ return builder.create<mlir::arith::SubIOp>(loc, xored, mask);
}
if (fir::isa_complex(type)) {
// Use HYPOT to fulfill the no underflow/overflow requirement.
auto imag =
Fortran::lower::ComplexExprHelper{builder, loc}.extractComplexPart(
cplx, /*isImagPart=*/true);
- auto negImag = builder.create<mlir::NegFOp>(loc, imag);
+ auto negImag = builder.create<mlir::arith::NegFOp>(loc, imag);
return Fortran::lower::ComplexExprHelper{builder, loc}.insertComplexPart(
cplx, negImag, /*isImagPart=*/true);
}
assert(args.size() == 2);
if (resultType.isa<mlir::IntegerType>()) {
auto zero = builder.createIntegerConstant(loc, resultType, 0);
- auto diff = builder.create<mlir::SubIOp>(loc, args[0], args[1]);
- auto cmp =
- builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::sgt, diff, zero);
+ auto diff = builder.create<mlir::arith::SubIOp>(loc, args[0], args[1]);
+ auto cmp = builder.create<mlir::arith::CmpIOp>(
+ loc, mlir::arith::CmpIPredicate::sgt, diff, zero);
return builder.create<mlir::SelectOp>(loc, cmp, diff, zero);
}
assert(fir::isa_real(resultType) && "Only expects real and integer in DIM");
auto zero = builder.createRealZeroConstant(loc, resultType);
- auto diff = builder.create<mlir::SubFOp>(loc, args[0], args[1]);
- auto cmp =
- builder.create<mlir::CmpFOp>(loc, mlir::CmpFPredicate::OGT, diff, zero);
+ auto diff = builder.create<mlir::arith::SubFOp>(loc, args[0], args[1]);
+ auto cmp = builder.create<mlir::arith::CmpFOp>(
+ loc, mlir::arith::CmpFPredicate::OGT, diff, zero);
return builder.create<mlir::SelectOp>(loc, cmp, diff, zero);
}
"Result must be double precision in DPROD");
auto a = builder.createConvert(loc, resultType, args[0]);
auto b = builder.createConvert(loc, resultType, args[1]);
- return builder.create<mlir::MulFOp>(loc, a, b);
+ return builder.create<mlir::arith::MulFOp>(loc, a, b);
}
// FLOOR
llvm::ArrayRef<mlir::Value> args) {
assert(args.size() == 2);
- return builder.create<mlir::AndOp>(loc, args[0], args[1]);
+ return builder.create<mlir::arith::AndIOp>(loc, args[0], args[1]);
}
// ICHAR
mlir::Value IntrinsicLibrary::genIEOr(mlir::Type resultType,
llvm::ArrayRef<mlir::Value> args) {
assert(args.size() == 2);
- return builder.create<mlir::XOrOp>(loc, args[0], args[1]);
+ return builder.create<mlir::arith::XOrIOp>(loc, args[0], args[1]);
}
// IOR
mlir::Value IntrinsicLibrary::genIOr(mlir::Type resultType,
llvm::ArrayRef<mlir::Value> args) {
assert(args.size() == 2);
- return builder.create<mlir::OrOp>(loc, args[0], args[1]);
+ return builder.create<mlir::arith::OrIOp>(loc, args[0], args[1]);
}
// LEN
llvm::ArrayRef<mlir::Value> args) {
assert(args.size() == 2);
if (resultType.isa<mlir::IntegerType>())
- return builder.create<mlir::SignedRemIOp>(loc, args[0], args[1]);
+ return builder.create<mlir::arith::RemSIOp>(loc, args[0], args[1]);
- // Use runtime. Note that mlir::RemFOp implements floating point
+ // Use runtime. Note that mlir::arith::RemFOp implements floating point
// remainder, but it does not work with fir::Real type.
- // TODO: consider using mlir::RemFOp when possible, that may help folding
- // and optimizations.
+ // TODO: consider using mlir::arith::RemFOp when possible, that may help
+ // folding and optimizations.
return genRuntimeCall("mod", resultType, args);
}
auto abs = genAbs(resultType, {args[0]});
if (resultType.isa<mlir::IntegerType>()) {
auto zero = builder.createIntegerConstant(loc, resultType, 0);
- auto neg = builder.create<mlir::SubIOp>(loc, zero, abs);
- auto cmp = builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::slt,
- args[1], zero);
+ auto neg = builder.create<mlir::arith::SubIOp>(loc, zero, abs);
+ auto cmp = builder.create<mlir::arith::CmpIOp>(
+ loc, mlir::arith::CmpIPredicate::slt, args[1], zero);
return builder.create<mlir::SelectOp>(loc, cmp, neg, abs);
}
// TODO: Requirements when second argument is +0./0.
auto zeroAttr = builder.getZeroAttr(resultType);
- auto zero = builder.create<mlir::ConstantOp>(loc, resultType, zeroAttr);
- auto neg = builder.create<mlir::NegFOp>(loc, abs);
- auto cmp = builder.create<mlir::CmpFOp>(loc, mlir::CmpFPredicate::OLT,
- args[1], zero);
+ auto zero =
+ builder.create<mlir::arith::ConstantOp>(loc, resultType, zeroAttr);
+ auto neg = builder.create<mlir::arith::NegFOp>(loc, abs);
+ auto cmp = builder.create<mlir::arith::CmpFOp>(
+ loc, mlir::arith::CmpFPredicate::OLT, args[1], zero);
return builder.create<mlir::SelectOp>(loc, cmp, neg, abs);
}
static mlir::Value createExtremumCompare(mlir::Location loc,
Fortran::lower::FirOpBuilder &builder,
mlir::Value left, mlir::Value right) {
- static constexpr auto integerPredicate = extremum == Extremum::Max
- ? mlir::CmpIPredicate::sgt
- : mlir::CmpIPredicate::slt;
+ static constexpr auto integerPredicate =
+ extremum == Extremum::Max ? mlir::arith::CmpIPredicate::sgt
+ : mlir::arith::CmpIPredicate::slt;
static constexpr auto orderedCmp = extremum == Extremum::Max
- ? mlir::CmpFPredicate::OGT
- : mlir::CmpFPredicate::OLT;
+ ? mlir::arith::CmpFPredicate::OGT
+ : mlir::arith::CmpFPredicate::OLT;
auto type = left.getType();
mlir::Value result;
if (fir::isa_real(type)) {
// Return the number if one of the inputs is NaN and the other is
// a number.
auto leftIsResult =
- builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
- auto rightIsNan = builder.create<mlir::CmpFOp>(
- loc, mlir::CmpFPredicate::UNE, right, right);
- result = builder.create<mlir::OrOp>(loc, leftIsResult, rightIsNan);
+ builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
+ auto rightIsNan = builder.create<mlir::arith::CmpFOp>(
+ loc, mlir::arith::CmpFPredicate::UNE, right, right);
+ result =
+ builder.create<mlir::arith::OrIOp>(loc, leftIsResult, rightIsNan);
} else if constexpr (behavior == ExtremumBehavior::IeeeMinMaximum) {
// Always return NaNs if one the input is NaNs
auto leftIsResult =
- builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
- auto leftIsNan = builder.create<mlir::CmpFOp>(
- loc, mlir::CmpFPredicate::UNE, left, left);
- result = builder.create<mlir::OrOp>(loc, leftIsResult, leftIsNan);
+ builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
+ auto leftIsNan = builder.create<mlir::arith::CmpFOp>(
+ loc, mlir::arith::CmpFPredicate::UNE, left, left);
+ result = builder.create<mlir::arith::OrIOp>(loc, leftIsResult, leftIsNan);
} else if constexpr (behavior == ExtremumBehavior::MinMaxss) {
// If the left is a NaN, return the right whatever it is.
- result = builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
+ result =
+ builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
} else if constexpr (behavior == ExtremumBehavior::PgfortranLlvm) {
// If one of the operand is a NaN, return left whatever it is.
- static constexpr auto unorderedCmp = extremum == Extremum::Max
- ? mlir::CmpFPredicate::UGT
- : mlir::CmpFPredicate::ULT;
- result = builder.create<mlir::CmpFOp>(loc, unorderedCmp, left, right);
+ static constexpr auto unorderedCmp =
+ extremum == Extremum::Max ? mlir::arith::CmpFPredicate::UGT
+ : mlir::arith::CmpFPredicate::ULT;
+ result =
+ builder.create<mlir::arith::CmpFOp>(loc, unorderedCmp, left, right);
} else {
// TODO: ieeeMinNum/ieeeMaxNum
static_assert(behavior == ExtremumBehavior::IeeeMinMaxNum,
"ieeeMinNum/ieeeMaxNum behavior not implemented");
}
} else if (fir::isa_integer(type)) {
- result = builder.create<mlir::CmpIOp>(loc, integerPredicate, left, right);
+ result =
+ builder.create<mlir::arith::CmpIOp>(loc, integerPredicate, left, right);
} else if (type.isa<fir::CharacterType>()) {
// TODO: ! character min and max is tricky because the result
// length is the length of the longest argument!
/// ```
/// %1 = fir.shape_shift %4, %5 : (index, index) -> !fir.shapeshift<1>
/// %2 = fir.slice %6, %7, %8 : (index, index, index) -> !fir.slice<1>
-/// %3 = fir.embox %0 (%1) [%2] : (!fir.ref<!fir.array<?xi32>>, !fir.shapeshift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xi32>>
+/// %3 = fir.embox %0 (%1) [%2] : (!fir.ref<!fir.array<?xi32>>,
+/// !fir.shapeshift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xi32>>
/// ```
/// can be rewritten as
/// ```
-/// %1 = fircg.ext_embox %0(%5) origin %4[%6, %7, %8] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
+/// %1 = fircg.ext_embox %0(%5) origin %4[%6, %7, %8] :
+/// (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) ->
+/// !fir.box<!fir.array<?xi32>>
/// ```
class EmboxConversion : public mlir::OpRewritePattern<EmboxOp> {
public:
auto idxTy = rewriter.getIndexType();
for (auto ext : seqTy.getShape()) {
auto iAttr = rewriter.getIndexAttr(ext);
- auto extVal = rewriter.create<mlir::ConstantOp>(loc, idxTy, iAttr);
+ auto extVal = rewriter.create<mlir::arith::ConstantOp>(loc, idxTy, iAttr);
shapeOpers.push_back(extVal);
}
auto xbox = rewriter.create<cg::XEmboxOp>(
///
/// For example,
/// ```
-/// %5 = fir.rebox %3(%1) : (!fir.box<!fir.array<?xi32>>, !fir.shapeshift<1>) -> !fir.box<!fir.array<?xi32>>
+/// %5 = fir.rebox %3(%1) : (!fir.box<!fir.array<?xi32>>, !fir.shapeshift<1>) ->
+/// !fir.box<!fir.array<?xi32>>
/// ```
/// converted to
/// ```
-/// %5 = fircg.ext_rebox %3(%13) origin %12 : (!fir.box<!fir.array<?xi32>>, index, index) -> !fir.box<!fir.array<?xi32>>
+/// %5 = fircg.ext_rebox %3(%13) origin %12 : (!fir.box<!fir.array<?xi32>>,
+/// index, index) -> !fir.box<!fir.array<?xi32>>
/// ```
class ReboxConversion : public mlir::OpRewritePattern<ReboxOp> {
public:
///
/// For example,
/// ```
-/// %4 = fir.array_coor %addr (%1) [%2] %0 : (!fir.ref<!fir.array<?xi32>>, !fir.shapeshift<1>, !fir.slice<1>, index) -> !fir.ref<i32>
+/// %4 = fir.array_coor %addr (%1) [%2] %0 : (!fir.ref<!fir.array<?xi32>>,
+/// !fir.shapeshift<1>, !fir.slice<1>, index) -> !fir.ref<i32>
/// ```
/// converted to
/// ```
-/// %40 = fircg.ext_array_coor %addr(%9) origin %8[%4, %5, %6<%39> : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index, index) -> !fir.ref<i32>
+/// %40 = fircg.ext_array_coor %addr(%9) origin %8[%4, %5, %6<%39> :
+/// (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index, index) ->
+/// !fir.ref<i32>
/// ```
class ArrayCoorConversion : public mlir::OpRewritePattern<ArrayCoorOp> {
public:
auto &context = getContext();
mlir::OpBuilder rewriter(&context);
mlir::ConversionTarget target(context);
- target.addLegalDialect<FIROpsDialect, FIRCodeGenDialect,
- mlir::StandardOpsDialect>();
+ target.addLegalDialect<mlir::arith::ArithmeticDialect, FIROpsDialect,
+ FIRCodeGenDialect, mlir::StandardOpsDialect>();
target.addIllegalOp<ArrayCoorOp>();
target.addIllegalOp<ReboxOp>();
target.addDynamicallyLegalOp<EmboxOp>([](EmboxOp embox) {
LINK_LIBS
FIRSupport
+ MLIRArithmetic
MLIROpenMPToLLVM
MLIRLLVMToLLVMIRTranslation
MLIRTargetLLVMIRExport
template <typename OPTY>
static void printCmpOp(OpAsmPrinter &p, OPTY op) {
p << ' ';
- auto predSym = mlir::symbolizeCmpFPredicate(
+ auto predSym = mlir::arith::symbolizeCmpFPredicate(
op->template getAttrOfType<mlir::IntegerAttr>(
OPTY::getPredicateAttrName())
.getInt());
assert(predSym.hasValue() && "invalid symbol value for predicate");
- p << '"' << mlir::stringifyCmpFPredicate(predSym.getValue()) << '"' << ", ";
+ p << '"' << mlir::arith::stringifyCmpFPredicate(predSym.getValue()) << '"'
+ << ", ";
p.printOperand(op.lhs());
p << ", ";
p.printOperand(op.rhs());
//===----------------------------------------------------------------------===//
void fir::buildCmpCOp(OpBuilder &builder, OperationState &result,
- CmpFPredicate predicate, Value lhs, Value rhs) {
+ arith::CmpFPredicate predicate, Value lhs, Value rhs) {
result.addOperands({lhs, rhs});
result.types.push_back(builder.getI1Type());
result.addAttribute(
builder.getI64IntegerAttr(static_cast<int64_t>(predicate)));
}
-mlir::CmpFPredicate fir::CmpcOp::getPredicateByName(llvm::StringRef name) {
- auto pred = mlir::symbolizeCmpFPredicate(name);
+mlir::arith::CmpFPredicate
+fir::CmpcOp::getPredicateByName(llvm::StringRef name) {
+ auto pred = mlir::arith::symbolizeCmpFPredicate(name);
assert(pred.hasValue() && "invalid predicate name");
return pred.getValue();
}
static void appendAsAttribute(llvm::SmallVectorImpl<mlir::Attribute> &attrs,
mlir::Value val) {
if (auto *op = val.getDefiningOp()) {
- if (auto cop = mlir::dyn_cast<mlir::ConstantOp>(op)) {
+ if (auto cop = mlir::dyn_cast<mlir::arith::ConstantOp>(op)) {
// append the integer constant value
- if (auto iattr = cop.getValue().dyn_cast<mlir::IntegerAttr>()) {
+ if (auto iattr = cop.value().dyn_cast<mlir::IntegerAttr>()) {
attrs.push_back(iattr);
return;
}
void fir::InsertValueOp::getCanonicalizationPatterns(
mlir::OwningRewritePatternList &results, mlir::MLIRContext *context) {
- results.insert<UndoComplexPattern<mlir::AddFOp, fir::AddcOp>,
- UndoComplexPattern<mlir::SubFOp, fir::SubcOp>>(context);
+ results.insert<UndoComplexPattern<mlir::arith::AddFOp, fir::AddcOp>,
+ UndoComplexPattern<mlir::arith::SubFOp, fir::SubcOp>>(context);
}
//===----------------------------------------------------------------------===//
if (auto *op = (*i++).getDefiningOp()) {
if (auto off = mlir::dyn_cast<fir::FieldIndexOp>(op))
return ty.getType(off.getFieldName());
- if (auto off = mlir::dyn_cast<mlir::ConstantOp>(op))
+ if (auto off = mlir::dyn_cast<mlir::arith::ConstantOp>(op))
return ty.getType(fir::toInt(off));
}
return mlir::Type{};
})
.Case<mlir::TupleType>([&](mlir::TupleType ty) {
if (auto *op = (*i++).getDefiningOp())
- if (auto off = mlir::dyn_cast<mlir::ConstantOp>(op))
+ if (auto off = mlir::dyn_cast<mlir::arith::ConstantOp>(op))
return ty.getType(fir::toInt(off));
return mlir::Type{};
})
return;
// Convert the calls and, if needed, the ReturnOp in the function body.
- target.addLegalDialect<fir::FIROpsDialect, mlir::StandardOpsDialect>();
+ target.addLegalDialect<fir::FIROpsDialect, mlir::arith::ArithmeticDialect,
+ mlir::StandardOpsDialect>();
target.addIllegalOp<fir::SaveResultOp>();
target.addDynamicallyLegalOp<fir::CallOp>([](fir::CallOp call) {
return !mustConvertCallOrFunc(call.getFunctionType());
return true;
});
target.addLegalDialect<FIROpsDialect, mlir::scf::SCFDialect,
+ mlir::arith::ArithmeticDialect,
mlir::StandardOpsDialect>();
if (mlir::failed(mlir::applyPartialConversion(function, target,
using MaybeAffineExpr = llvm::Optional<mlir::AffineExpr>;
explicit AffineIfCondition(mlir::Value fc) : firCondition(fc) {
- if (auto condDef = firCondition.getDefiningOp<mlir::CmpIOp>())
+ if (auto condDef = firCondition.getDefiningOp<mlir::arith::CmpIOp>())
fromCmpIOp(condDef);
}
/// in an affine expression, this includes -, +, *, rem, constant.
/// block arguments of a loopOp or forOp are used as dimensions
MaybeAffineExpr toAffineExpr(mlir::Value value) {
- if (auto op = value.getDefiningOp<mlir::SubIOp>())
+ if (auto op = value.getDefiningOp<mlir::arith::SubIOp>())
return affineBinaryOp(mlir::AffineExprKind::Add, toAffineExpr(op.lhs()),
affineBinaryOp(mlir::AffineExprKind::Mul,
toAffineExpr(op.rhs()),
toAffineExpr(-1)));
- if (auto op = value.getDefiningOp<mlir::AddIOp>())
+ if (auto op = value.getDefiningOp<mlir::arith::AddIOp>())
return affineBinaryOp(mlir::AffineExprKind::Add, op.lhs(), op.rhs());
- if (auto op = value.getDefiningOp<mlir::MulIOp>())
+ if (auto op = value.getDefiningOp<mlir::arith::MulIOp>())
return affineBinaryOp(mlir::AffineExprKind::Mul, op.lhs(), op.rhs());
- if (auto op = value.getDefiningOp<mlir::UnsignedRemIOp>())
+ if (auto op = value.getDefiningOp<mlir::arith::RemUIOp>())
return affineBinaryOp(mlir::AffineExprKind::Mod, op.lhs(), op.rhs());
- if (auto op = value.getDefiningOp<mlir::ConstantOp>())
- if (auto intConstant = op.getValue().dyn_cast<IntegerAttr>())
+ if (auto op = value.getDefiningOp<mlir::arith::ConstantOp>())
+ if (auto intConstant = op.value().dyn_cast<IntegerAttr>())
return toAffineExpr(intConstant.getInt());
if (auto blockArg = value.dyn_cast<mlir::BlockArgument>()) {
affineArgs.push_back(value);
return {};
}
- void fromCmpIOp(mlir::CmpIOp cmpOp) {
+ void fromCmpIOp(mlir::arith::CmpIOp cmpOp) {
auto lhsAffine = toAffineExpr(cmpOp.lhs());
auto rhsAffine = toAffineExpr(cmpOp.rhs());
if (!lhsAffine.hasValue() || !rhsAffine.hasValue())
}
llvm::Optional<std::pair<AffineExpr, bool>>
- constraint(mlir::CmpIPredicate predicate, mlir::AffineExpr basic) {
+ constraint(mlir::arith::CmpIPredicate predicate, mlir::AffineExpr basic) {
switch (predicate) {
- case mlir::CmpIPredicate::slt:
+ case mlir::arith::CmpIPredicate::slt:
return {std::make_pair(basic - 1, false)};
- case mlir::CmpIPredicate::sle:
+ case mlir::arith::CmpIPredicate::sle:
return {std::make_pair(basic, false)};
- case mlir::CmpIPredicate::sgt:
+ case mlir::arith::CmpIPredicate::sgt:
return {std::make_pair(1 - basic, false)};
- case mlir::CmpIPredicate::sge:
+ case mlir::arith::CmpIPredicate::sge:
return {std::make_pair(0 - basic, false)};
- case mlir::CmpIPredicate::eq:
+ case mlir::arith::CmpIPredicate::eq:
return {std::make_pair(basic, true)};
default:
return {};
}
static Optional<int64_t> constantIntegerLike(const mlir::Value value) {
- if (auto definition = value.getDefiningOp<ConstantOp>())
- if (auto stepAttr = definition.getValue().dyn_cast<IntegerAttr>())
+ if (auto definition = value.getDefiningOp<mlir::arith::ConstantOp>())
+ if (auto stepAttr = definition.value().dyn_cast<IntegerAttr>())
return stepAttr.getInt();
return {};
}
static void populateIndexArgs(fir::ArrayCoorOp acoOp, fir::ShapeOp shape,
SmallVectorImpl<mlir::Value> &indexArgs,
mlir::PatternRewriter &rewriter) {
- auto one = rewriter.create<mlir::ConstantOp>(
+ auto one = rewriter.create<mlir::arith::ConstantOp>(
acoOp.getLoc(), rewriter.getIndexType(), rewriter.getIndexAttr(1));
auto extents = shape.extents();
for (auto i = extents.begin(); i < extents.end(); i++) {
static void populateIndexArgs(fir::ArrayCoorOp acoOp, fir::ShapeShiftOp shape,
SmallVectorImpl<mlir::Value> &indexArgs,
mlir::PatternRewriter &rewriter) {
- auto one = rewriter.create<mlir::ConstantOp>(
+ auto one = rewriter.create<mlir::arith::ConstantOp>(
acoOp.getLoc(), rewriter.getIndexType(), rewriter.getIndexAttr(1));
auto extents = shape.pairs();
for (auto i = extents.begin(); i < extents.end();) {
patterns.insert<AffineIfConversion>(context, functionAnalysis);
patterns.insert<AffineLoopConversion>(context, functionAnalysis);
mlir::ConversionTarget target = *context;
- target.addLegalDialect<mlir::AffineDialect, FIROpsDialect,
- mlir::scf::SCFDialect, mlir::StandardOpsDialect>();
+ target.addLegalDialect<
+ mlir::AffineDialect, FIROpsDialect, mlir::scf::SCFDialect,
+ mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect>();
target.addDynamicallyLegalOp<IfOp>([&functionAnalysis](fir::IfOp op) {
return !(functionAnalysis.getChildIfAnalysis(op).canPromoteToAffine());
});
<< "running character conversion on " << conv << '\n');
// Establish a loop that executes count iterations.
- auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
- auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
+ auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
+ auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
auto idxTy = rewriter.getIndexType();
auto castCnt = rewriter.create<fir::ConvertOp>(loc, idxTy, conv.count());
- auto countm1 = rewriter.create<mlir::SubIOp>(loc, castCnt, one);
+ auto countm1 = rewriter.create<mlir::arith::SubIOp>(loc, castCnt, one);
auto loop = rewriter.create<fir::DoLoopOp>(loc, zero, countm1, one);
auto insPt = rewriter.saveInsertionPoint();
rewriter.setInsertionPointToStart(loop.getBody());
mlir::Value icast =
(fromBits >= toBits)
? rewriter.create<fir::ConvertOp>(loc, toTy, load).getResult()
- : rewriter.create<mlir::ZeroExtendIOp>(loc, toTy, load).getResult();
+ : rewriter.create<mlir::arith::ExtUIOp>(loc, toTy, load)
+ .getResult();
rewriter.replaceOpWithNewOp<fir::StoreOp>(conv, icast, toi);
rewriter.restoreInsertionPoint(insPt);
return mlir::success();
patterns.insert<CharacterConvertConversion>(context);
mlir::ConversionTarget target(*context);
target.addLegalDialect<mlir::AffineDialect, fir::FIROpsDialect,
+ mlir::arith::ArithmeticDialect,
mlir::StandardOpsDialect>();
// apply the patterns
// Initalization block
rewriter.setInsertionPointToEnd(initBlock);
- auto diff = rewriter.create<mlir::SubIOp>(loc, high, low);
- auto distance = rewriter.create<mlir::AddIOp>(loc, diff, step);
+ auto diff = rewriter.create<mlir::arith::SubIOp>(loc, high, low);
+ auto distance = rewriter.create<mlir::arith::AddIOp>(loc, diff, step);
mlir::Value iters =
- rewriter.create<mlir::SignedDivIOp>(loc, distance, step);
+ rewriter.create<mlir::arith::DivSIOp>(loc, distance, step);
if (forceLoopToExecuteOnce) {
- auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
- auto cond =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, iters, zero);
- auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
+ auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
+ auto cond = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sle, iters, zero);
+ auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
iters = rewriter.create<mlir::SelectOp>(loc, cond, one, iters);
}
auto *terminator = lastBlock->getTerminator();
rewriter.setInsertionPointToEnd(lastBlock);
auto iv = conditionalBlock->getArgument(0);
- mlir::Value steppedIndex = rewriter.create<mlir::AddIOp>(loc, iv, step);
+ mlir::Value steppedIndex =
+ rewriter.create<mlir::arith::AddIOp>(loc, iv, step);
assert(steppedIndex && "must be a Value");
auto lastArg = conditionalBlock->getNumArguments() - 1;
auto itersLeft = conditionalBlock->getArgument(lastArg);
- auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
+ auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
mlir::Value itersMinusOne =
- rewriter.create<mlir::SubIOp>(loc, itersLeft, one);
+ rewriter.create<mlir::arith::SubIOp>(loc, itersLeft, one);
llvm::SmallVector<mlir::Value> loopCarried;
loopCarried.push_back(steppedIndex);
// Conditional block
rewriter.setInsertionPointToEnd(conditionalBlock);
- auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
- auto comparison =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt, itersLeft, zero);
+ auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
+ auto comparison = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sgt, itersLeft, zero);
rewriter.create<mlir::CondBranchOp>(loc, comparison, firstBlock,
llvm::ArrayRef<mlir::Value>(), endBlock,
auto *terminator = lastBodyBlock->getTerminator();
rewriter.setInsertionPointToEnd(lastBodyBlock);
auto step = whileOp.step();
- mlir::Value stepped = rewriter.create<mlir::AddIOp>(loc, iv, step);
+ mlir::Value stepped = rewriter.create<mlir::arith::AddIOp>(loc, iv, step);
assert(stepped && "must be a Value");
llvm::SmallVector<mlir::Value> loopCarried;
// The comparison depends on the sign of the step value. We fully expect
// this expression to be folded by the optimizer or LLVM. This expression
// is written this way so that `step == 0` always returns `false`.
- auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
- auto compl0 =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt, zero, step);
- auto compl1 =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, iv, upperBound);
- auto compl2 =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt, step, zero);
- auto compl3 =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, upperBound, iv);
- auto cmp0 = rewriter.create<mlir::AndOp>(loc, compl0, compl1);
- auto cmp1 = rewriter.create<mlir::AndOp>(loc, compl2, compl3);
- auto cmp2 = rewriter.create<mlir::OrOp>(loc, cmp0, cmp1);
+ auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
+ auto compl0 = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, zero, step);
+ auto compl1 = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sle, iv, upperBound);
+ auto compl2 = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, step, zero);
+ auto compl3 = rewriter.create<mlir::arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sle, upperBound, iv);
+ auto cmp0 = rewriter.create<mlir::arith::AndIOp>(loc, compl0, compl1);
+ auto cmp1 = rewriter.create<mlir::arith::AndIOp>(loc, compl2, compl3);
+ auto cmp2 = rewriter.create<mlir::arith::OrIOp>(loc, cmp0, cmp1);
// Remember to AND in the early-exit bool.
- auto comparison = rewriter.create<mlir::AndOp>(loc, iterateVar, cmp2);
+ auto comparison =
+ rewriter.create<mlir::arith::AndIOp>(loc, iterateVar, cmp2);
rewriter.create<mlir::CondBranchOp>(loc, comparison, firstBodyBlock,
llvm::ArrayRef<mlir::Value>(), endBlock,
llvm::ArrayRef<mlir::Value>());
func private @arrayfunc_callee(%n : index) -> !fir.array<?xf32> {
%buffer = fir.alloca !fir.array<?xf32>, %n
// Do something with result (res(4) = 42.)
- %c4 = constant 4 : i64
+ %c4 = arith.constant 4 : i64
%coor = fir.coordinate_of %buffer, %c4 : (!fir.ref<!fir.array<?xf32>>, i64) -> !fir.ref<f32>
- %cst = constant 4.200000e+01 : f32
+ %cst = arith.constant 4.200000e+01 : f32
fir.store %cst to %coor : !fir.ref<f32>
%res = fir.load %buffer : !fir.ref<!fir.array<?xf32>>
return %res : !fir.array<?xf32>
// CHECK-LABEL: func @call_arrayfunc() {
// CHECK-BOX-LABEL: func @call_arrayfunc() {
func @call_arrayfunc() {
- %c100 = constant 100 : index
+ %c100 = arith.constant 100 : index
%buffer = fir.alloca !fir.array<?xf32>, %c100
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
%res = fir.call @arrayfunc_callee(%c100) : (index) -> !fir.array<?xf32>
fir.save_result %res to %buffer(%shape) : !fir.array<?xf32>, !fir.ref<!fir.array<?xf32>>, !fir.shape<1>
return
- // CHECK: %[[c100:.*]] = constant 100 : index
+ // CHECK: %[[c100:.*]] = arith.constant 100 : index
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
// CHECK: fir.call @arrayfunc_callee(%[[buffer]], %[[c100]]) : (!fir.ref<!fir.array<?xf32>>, index) -> ()
// CHECK-NOT: fir.save_result
- // CHECK-BOX: %[[c100:.*]] = constant 100 : index
+ // CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]](%[[shape]]) : (!fir.ref<!fir.array<?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
// CHECK-BOX-LABEL: func @call_derivedfunc() {
func @call_derivedfunc() {
%buffer = fir.alloca !fir.type<t{x:f32}>
- %cst = constant 4.200000e+01 : f32
+ %cst = arith.constant 4.200000e+01 : f32
%res = fir.call @derivedfunc_callee(%cst) : (f32) -> !fir.type<t{x:f32}>
fir.save_result %res to %buffer : !fir.type<t{x:f32}>, !fir.ref<!fir.type<t{x:f32}>>
return
// CHECK: %[[buffer:.*]] = fir.alloca !fir.type<t{x:f32}>
- // CHECK: %[[cst:.*]] = constant {{.*}} : f32
+ // CHECK: %[[cst:.*]] = arith.constant {{.*}} : f32
// CHECK: fir.call @derivedfunc_callee(%[[buffer]], %[[cst]]) : (!fir.ref<!fir.type<t{x:f32}>>, f32) -> ()
// CHECK-NOT: fir.save_result
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.type<t{x:f32}>
- // CHECK-BOX: %[[cst:.*]] = constant {{.*}} : f32
+ // CHECK-BOX: %[[cst:.*]] = arith.constant {{.*}} : f32
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]] : (!fir.ref<!fir.type<t{x:f32}>>) -> !fir.box<!fir.type<t{x:f32}>>
// CHECK-BOX: fir.call @derivedfunc_callee(%[[box]], %[[cst]]) : (!fir.box<!fir.type<t{x:f32}>>, f32) -> ()
// CHECK-BOX-NOT: fir.save_result
// CHECK-BOX-LABEL: func @call_derived_lparams_func(
// CHECK-BOX-SAME: %[[buffer:.*]]: !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>
func @call_derived_lparams_func(%buffer: !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) {
- %l1 = constant 3 : i32
- %l2 = constant 5 : i32
+ %l1 = arith.constant 3 : i32
+ %l2 = arith.constant 5 : i32
%res = fir.call @derived_lparams_func() : () -> !fir.type<t2(l1:i32,l2:i32){x:f32}>
fir.save_result %res to %buffer typeparams %l1, %l2 : !fir.type<t2(l1:i32,l2:i32){x:f32}>, !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>, i32, i32
return
- // CHECK: %[[l1:.*]] = constant 3 : i32
- // CHECK: %[[l2:.*]] = constant 5 : i32
+ // CHECK: %[[l1:.*]] = arith.constant 3 : i32
+ // CHECK: %[[l2:.*]] = arith.constant 5 : i32
// CHECK: fir.call @derived_lparams_func(%[[buffer]]) : (!fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) -> ()
// CHECK-NOT: fir.save_result
- // CHECK-BOX: %[[l1:.*]] = constant 3 : i32
- // CHECK-BOX: %[[l2:.*]] = constant 5 : i32
+ // CHECK-BOX: %[[l1:.*]] = arith.constant 3 : i32
+ // CHECK-BOX: %[[l2:.*]] = arith.constant 5 : i32
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]] typeparams %[[l1]], %[[l2]] : (!fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>, i32, i32) -> !fir.box<!fir.type<t2(l1:i32,l2:i32){x:f32}>>
// CHECK-BOX: fir.call @derived_lparams_func(%[[box]]) : (!fir.box<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) -> ()
// CHECK-BOX-NOT: fir.save_result
// CHECK-LABEL: func @call_chararrayfunc() {
// CHECK-BOX-LABEL: func @call_chararrayfunc() {
func @call_chararrayfunc() {
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%buffer = fir.alloca !fir.array<?x!fir.char<1,?>>(%c100 : index), %c50
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
%res = fir.call @chararrayfunc(%c100, %c50) : (index, index) -> !fir.array<?x!fir.char<1,?>>
fir.save_result %res to %buffer(%shape) typeparams %c50 : !fir.array<?x!fir.char<1,?>>, !fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index
return
- // CHECK: %[[c100:.*]] = constant 100 : index
- // CHECK: %[[c50:.*]] = constant 50 : index
+ // CHECK: %[[c100:.*]] = arith.constant 100 : index
+ // CHECK: %[[c50:.*]] = arith.constant 50 : index
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?x!fir.char<1,?>>(%[[c100]] : index), %[[c50]]
// CHECK: fir.call @chararrayfunc(%[[buffer]], %[[c100]], %[[c50]]) : (!fir.ref<!fir.array<?x!fir.char<1,?>>>, index, index) -> ()
// CHECK-NOT: fir.save_result
- // CHECK-BOX: %[[c100:.*]] = constant 100 : index
- // CHECK-BOX: %[[c50:.*]] = constant 50 : index
+ // CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
+ // CHECK-BOX: %[[c50:.*]] = arith.constant 50 : index
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?x!fir.char<1,?>>(%[[c100]] : index), %[[c50]]
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]](%[[shape]]) typeparams %[[c50]] : (!fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index) -> !fir.box<!fir.array<?x!fir.char<1,?>>>
// CHECK-BOX-LABEL: func @test_indirect_calls(
// CHECK-BOX-SAME: %[[arg0:.*]]: () -> ()) {
func @test_indirect_calls(%arg0: () -> ()) {
- %c100 = constant 100 : index
+ %c100 = arith.constant 100 : index
%buffer = fir.alloca !fir.array<?xf32>, %c100
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
%0 = fir.convert %arg0 : (() -> ()) -> ((index) -> !fir.array<?xf32>)
fir.save_result %res to %buffer(%shape) : !fir.array<?xf32>, !fir.ref<!fir.array<?xf32>>, !fir.shape<1>
return
- // CHECK: %[[c100:.*]] = constant 100 : index
+ // CHECK: %[[c100:.*]] = arith.constant 100 : index
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
// CHECK: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
// CHECK: %[[original_conv:.*]] = fir.convert %[[arg0]] : (() -> ()) -> ((index) -> !fir.array<?xf32>)
// CHECK: fir.call %[[conv]](%[[buffer]], %c100) : (!fir.ref<!fir.array<?xf32>>, index) -> ()
// CHECK-NOT: fir.save_result
- // CHECK-BOX: %[[c100:.*]] = constant 100 : index
+ // CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
// CHECK-BOX: %[[original_conv:.*]] = fir.convert %[[arg0]] : (() -> ()) -> ((index) -> !fir.array<?xf32>)
#map2 = affine_map<(d0)[s0, s1, s2] -> (d0 * s2 - s0)>
module {
func @calc(%arg0: !fir.ref<!fir.array<?xf32>>, %arg1: !fir.ref<!fir.array<?xf32>>, %arg2: !fir.ref<!fir.array<?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
%0 = fir.shape %c100 : (index) -> !fir.shape<1>
%1 = affine.apply #map0()[%c1, %c100]
%2 = fir.alloca !fir.array<?xf32>, %1
%7 = affine.apply #map2(%arg3)[%c1, %c100, %c1]
%8 = affine.load %3[%7] : memref<?xf32>
%9 = affine.load %4[%7] : memref<?xf32>
- %10 = addf %8, %9 : f32
+ %10 = arith.addf %8, %9 : f32
affine.store %10, %5[%7] : memref<?xf32>
}
%6 = fir.convert %arg2 : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
%7 = affine.apply #map2(%arg3)[%c1, %c100, %c1]
%8 = affine.load %5[%7] : memref<?xf32>
%9 = affine.load %4[%7] : memref<?xf32>
- %10 = mulf %8, %9 : f32
+ %10 = arith.mulf %8, %9 : f32
affine.store %10, %6[%7] : memref<?xf32>
}
return
}
// CHECK: func @calc(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_2:.*]]: !fir.ref<!fir.array<?xf32>>) {
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
-// CHECK: %[[VAL_4:.*]] = constant 100 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 100 : index
// CHECK: %[[VAL_5:.*]] = fir.shape %[[VAL_4]] : (index) -> !fir.shape<1>
-// CHECK: %[[VAL_6:.*]] = constant 100 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 100 : index
// CHECK: %[[VAL_7:.*]] = fir.alloca !fir.array<?xf32>, %[[VAL_6]]
// CHECK: %[[VAL_8:.*]] = fir.convert %[[VAL_0]] : (!fir.ref<!fir.array<?xf32>>) -> !fir.ref<!fir.array<?xf32>>
// CHECK: %[[VAL_9:.*]] = fir.convert %[[VAL_1]] : (!fir.ref<!fir.array<?xf32>>) -> !fir.ref<!fir.array<?xf32>>
// CHECK: %[[VAL_14:.*]] = fir.load %[[VAL_13]] : !fir.ref<f32>
// CHECK: %[[VAL_15:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_12]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
// CHECK: %[[VAL_16:.*]] = fir.load %[[VAL_15]] : !fir.ref<f32>
-// CHECK: %[[VAL_17:.*]] = addf %[[VAL_14]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.addf %[[VAL_14]], %[[VAL_16]] : f32
// CHECK: %[[VAL_18:.*]] = fir.coordinate_of %[[VAL_10]], %[[VAL_12]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
// CHECK: fir.store %[[VAL_17]] to %[[VAL_18]] : !fir.ref<f32>
// CHECK: }
// CHECK: %[[VAL_23:.*]] = fir.load %[[VAL_22]] : !fir.ref<f32>
// CHECK: %[[VAL_24:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_21]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
// CHECK: %[[VAL_25:.*]] = fir.load %[[VAL_24]] : !fir.ref<f32>
-// CHECK: %[[VAL_26:.*]] = mulf %[[VAL_23]], %[[VAL_25]] : f32
+// CHECK: %[[VAL_26:.*]] = arith.mulf %[[VAL_23]], %[[VAL_25]] : f32
// CHECK: %[[VAL_27:.*]] = fir.coordinate_of %[[VAL_19]], %[[VAL_21]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
// CHECK: fir.store %[[VAL_26]] to %[[VAL_27]] : !fir.ref<f32>
// CHECK: }
#arr_len = affine_map<()[j1,k1] -> (k1 - j1 + 1)>
func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %len = constant 100 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %len = arith.constant 100 : index
%dims = fir.shape %len : (index) -> !fir.shape<1>
%siz = affine.apply #arr_len()[%c1,%len]
%t1 = fir.alloca !fir.array<?xf32>, %siz
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
%a2_v = fir.load %a2_idx : !fir.ref<f32>
- %v = addf %a1_v, %a2_v : f32
+ %v = arith.addf %a1_v, %a2_v : f32
%t1_idx = fir.array_coor %t1(%dims) %i
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
%a2_v = fir.load %a2_idx : !fir.ref<f32>
- %v = mulf %t1_v, %a2_v : f32
+ %v = arith.mulf %t1_v, %a2_v : f32
%a3_idx = fir.array_coor %a3(%dims) %i
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
}
// CHECK: func @loop_with_load_and_store(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_2:.*]]: !fir.ref<!fir.array<?xf32>>) {
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
-// CHECK: %[[VAL_4:.*]] = constant 100 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 100 : index
// CHECK: %[[VAL_5:.*]] = fir.shape %[[VAL_4]] : (index) -> !fir.shape<1>
// CHECK: %[[VAL_6:.*]] = affine.apply #map0(){{\[}}%[[VAL_3]], %[[VAL_4]]]
// CHECK: %[[VAL_7:.*]] = fir.alloca !fir.array<?xf32>, %[[VAL_6]]
// CHECK: %[[VAL_12:.*]] = affine.apply #map2(%[[VAL_11]]){{\[}}%[[VAL_3]], %[[VAL_4]], %[[VAL_3]]]
// CHECK: %[[VAL_13:.*]] = affine.load %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<?xf32>
// CHECK: %[[VAL_14:.*]] = affine.load %[[VAL_9]]{{\[}}%[[VAL_12]]] : memref<?xf32>
-// CHECK: %[[VAL_15:.*]] = addf %[[VAL_13]], %[[VAL_14]] : f32
+// CHECK: %[[VAL_15:.*]] = arith.addf %[[VAL_13]], %[[VAL_14]] : f32
// CHECK: affine.store %[[VAL_15]], %[[VAL_10]]{{\[}}%[[VAL_12]]] : memref<?xf32>
// CHECK: }
// CHECK: %[[VAL_16:.*]] = fir.convert %[[VAL_2]] : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
// CHECK: %[[VAL_18:.*]] = affine.apply #map2(%[[VAL_17]]){{\[}}%[[VAL_3]], %[[VAL_4]], %[[VAL_3]]]
// CHECK: %[[VAL_19:.*]] = affine.load %[[VAL_10]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: %[[VAL_20:.*]] = affine.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf32>
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_19]], %[[VAL_20]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_19]], %[[VAL_20]] : f32
// CHECK: affine.store %[[VAL_21]], %[[VAL_16]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: }
// CHECK: return
#arr_len = affine_map<()[j1,k1] -> (k1 - j1 + 1)>
func @loop_with_if(%a: !arr_d1, %v: f32) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %len = constant 100 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %len = arith.constant 100 : index
%dims = fir.shape %len : (index) -> !fir.shape<1>
fir.do_loop %i = %c1 to %len step %c1 {
fir.do_loop %j = %c1 to %len step %c1 {
fir.do_loop %k = %c1 to %len step %c1 {
- %im2 = subi %i, %c2 : index
- %cond = cmpi "sgt", %im2, %c0 : index
+ %im2 = arith.subi %i, %c2 : index
+ %cond = arith.cmpi "sgt", %im2, %c0 : index
fir.if %cond {
%a_idx = fir.array_coor %a(%dims) %i
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
}
// CHECK: func @loop_with_if(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: f32) {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
-// CHECK: %[[VAL_4:.*]] = constant 2 : index
-// CHECK: %[[VAL_5:.*]] = constant 100 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 2 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 100 : index
// CHECK: %[[VAL_6:.*]] = fir.shape %[[VAL_5]] : (index) -> !fir.shape<1>
// CHECK: %[[VAL_7:.*]] = fir.convert %[[VAL_0]] : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
// CHECK: affine.for %[[VAL_8:.*]] = %[[VAL_3]] to #map0(){{\[}}%[[VAL_5]]] {
// CHECK: affine.store %[[VAL_1]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xf32>
// CHECK: }
// CHECK: affine.for %[[VAL_12:.*]] = %[[VAL_3]] to #map0(){{\[}}%[[VAL_5]]] {
-// CHECK: %[[VAL_13:.*]] = subi %[[VAL_12]], %[[VAL_4]] : index
+// CHECK: %[[VAL_13:.*]] = arith.subi %[[VAL_12]], %[[VAL_4]] : index
// CHECK: affine.if #set(%[[VAL_12]]) {
// CHECK: %[[VAL_14:.*]] = affine.apply #map1(%[[VAL_12]]){{\[}}%[[VAL_3]], %[[VAL_5]], %[[VAL_3]]]
// CHECK: affine.store %[[VAL_1]], %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xf32>
// CHECK-LABEL: func @codegen(
// CHECK-SAME: %[[arg:.*]]: !fir
func @codegen(%addr : !fir.ref<!fir.array<?xi32>>) {
- // CHECK: %[[zero:.*]] = constant 0 : index
- %0 = constant 0 : index
+ // CHECK: %[[zero:.*]] = arith.constant 0 : index
+ %0 = arith.constant 0 : index
%1 = fir.shape_shift %0, %0 : (index, index) -> !fir.shapeshift<1>
%2 = fir.slice %0, %0, %0 : (index, index, index) -> !fir.slice<1>
// CHECK: %[[box:.*]] = fircg.ext_embox %[[arg]](%[[zero]]) origin %[[zero]][%[[zero]], %[[zero]], %[[zero]]] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
fir.global @box_global : !fir.box<!fir.array<?xi32>> {
// CHECK: %[[arr:.*]] = fir.zero_bits !fir.ref
%arr = fir.zero_bits !fir.ref<!fir.array<?xi32>>
- // CHECK: %[[zero:.*]] = constant 0 : index
- %0 = constant 0 : index
+ // CHECK: %[[zero:.*]] = arith.constant 0 : index
+ %0 = arith.constant 0 : index
%1 = fir.shape_shift %0, %0 : (index, index) -> !fir.shapeshift<1>
%2 = fir.slice %0, %0, %0 : (index, index, index) -> !fir.slice<1>
// CHECK: fircg.ext_embox %[[arr]](%[[zero]]) origin %[[zero]][%[[zero]], %[[zero]], %[[zero]]] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
// CHECK: %[[VAL_0:.*]] = fir.undefined i32
// CHECK: %[[VAL_1:.*]] = fir.undefined !fir.ref<!fir.char<1>>
// CHECK: %[[VAL_2:.*]] = fir.undefined !fir.ref<!fir.array<?x!fir.char<2,?>>>
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = fir.convert %[[VAL_0]] : (i32) -> index
-// CHECK: %[[VAL_6:.*]] = subi %[[VAL_5]], %[[VAL_4]] : index
+// CHECK: %[[VAL_6:.*]] = arith.subi %[[VAL_5]], %[[VAL_4]] : index
// CHECK: fir.do_loop %[[VAL_7:.*]] = %[[VAL_3]] to %[[VAL_6]] step %[[VAL_4]] {
// CHECK: %[[VAL_8:.*]] = fir.convert %[[VAL_1]] : (!fir.ref<!fir.char<1>>) -> !fir.ref<!fir.array<?xi8>>
// CHECK: %[[VAL_9:.*]] = fir.convert %[[VAL_2]] : (!fir.ref<!fir.array<?x!fir.char<2,?>>>) -> !fir.ref<!fir.array<?xi16>>
// CHECK: %[[VAL_10:.*]] = fir.coordinate_of %[[VAL_8]], %[[VAL_7]] : (!fir.ref<!fir.array<?xi8>>, index) -> !fir.ref<i8>
// CHECK: %[[VAL_11:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_7]] : (!fir.ref<!fir.array<?xi16>>, index) -> !fir.ref<i16>
// CHECK: %[[VAL_12:.*]] = fir.load %[[VAL_10]] : !fir.ref<i8>
-// CHECK: %[[VAL_13:.*]] = zexti %[[VAL_12]] : i8 to i16
+// CHECK: %[[VAL_13:.*]] = arith.extui %[[VAL_12]] : i8 to i16
// CHECK: fir.store %[[VAL_13]] to %[[VAL_11]] : !fir.ref<i16>
// CHECK: }
// CHECK: return
// CHECK-LABEL: @ctest
func @ctest() -> index {
- %1 = constant 10 : i32
+ %1 = arith.constant 10 : i32
%2 = fir.convert %1 : (i32) -> index
- // CHECK-NEXT: %{{.*}} = constant 10 : index
+ // CHECK-NEXT: %{{.*}} = arith.constant 10 : index
// CHECK-NEXT: return %{{.*}} : index
return %2 : index
}
// RUN: fir-opt --external-name-interop %s | FileCheck %s
func @_QPfoo() {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = fir.address_of(@_QBa) : !fir.ref<!fir.array<4xi8>>
%1 = fir.convert %0 : (!fir.ref<!fir.array<4xi8>>) -> !fir.ref<!fir.array<?xi8>>
%2 = fir.coordinate_of %1, %c0 : (!fir.ref<!fir.array<?xi8>>, index) -> !fir.ref<i8>
// CHECK: [[VAL_0:%.*]] = fir.alloca !fir.array<10xi32>
// CHECK: [[VAL_1:%.*]] = fir.load [[VAL_0]] : !fir.ref<!fir.array<10xi32>>
// CHECK: [[VAL_2:%.*]] = fir.alloca i32
-// CHECK: [[VAL_3:%.*]] = constant 22 : i32
+// CHECK: [[VAL_3:%.*]] = arith.constant 22 : i32
%0 = fir.alloca !fir.array<10xi32>
%1 = fir.load %0 : !fir.ref<!fir.array<10xi32>>
%2 = fir.alloca i32
- %3 = constant 22 : i32
+ %3 = arith.constant 22 : i32
// CHECK: fir.store [[VAL_3]] to [[VAL_2]] : !fir.ref<i32>
// CHECK: [[VAL_4:%.*]] = fir.undefined i32
%6 = fir.embox %5 : (!fir.heap<!fir.array<100xf32>>) -> !fir.box<!fir.array<100xf32>>
// CHECK: [[VAL_7:%.*]] = fir.box_addr [[VAL_6]] : (!fir.box<!fir.array<100xf32>>) -> !fir.ref<!fir.array<100xf32>>
-// CHECK: [[VAL_8:%.*]] = constant 0 : index
+// CHECK: [[VAL_8:%.*]] = arith.constant 0 : index
// CHECK: [[VAL_9:%.*]]:3 = fir.box_dims [[VAL_6]], [[VAL_8]] : (!fir.box<!fir.array<100xf32>>, index) -> (index, index, index)
// CHECK: fir.call @print_index3([[VAL_9]]#0, [[VAL_9]]#1, [[VAL_9]]#2) : (index, index, index) -> ()
// CHECK: [[VAL_10:%.*]] = fir.call @it1() : () -> !fir.int<4>
%7 = fir.box_addr %6 : (!fir.box<!fir.array<100xf32>>) -> !fir.ref<!fir.array<100xf32>>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%d1:3 = fir.box_dims %6, %c0 : (!fir.box<!fir.array<100xf32>>, index) -> (index, index, index)
fir.call @print_index3(%d1#0, %d1#1, %d1#2) : (index, index, index) -> ()
%8 = fir.call @it1() : () -> !fir.int<4>
%17 = fir.call @box2() : () -> !fir.boxproc<(i32, i32) -> i64>
%18 = fir.boxproc_host %17 : (!fir.boxproc<(i32, i32) -> i64>) -> !fir.ref<i32>
-// CHECK: [[VAL_21:%.*]] = constant 10 : i32
+// CHECK: [[VAL_21:%.*]] = arith.constant 10 : i32
// CHECK: [[VAL_22:%.*]] = fir.coordinate_of [[VAL_5]], [[VAL_21]] : (!fir.heap<!fir.array<100xf32>>, i32) -> !fir.ref<f32>
// CHECK: [[VAL_23:%.*]] = fir.field_index f, !fir.type<derived{f:f32}>
// CHECK: [[VAL_24:%.*]] = fir.undefined !fir.type<derived{f:f32}>
// CHECK: [[VAL_25:%.*]] = fir.extract_value [[VAL_24]], ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>) -> f32
- %19 = constant 10 : i32
+ %19 = arith.constant 10 : i32
%20 = fir.coordinate_of %5, %19 : (!fir.heap<!fir.array<100xf32>>, i32) -> !fir.ref<f32>
%21 = fir.field_index f, !fir.type<derived{f:f32}>
%22 = fir.undefined !fir.type<derived{f:f32}>
%23 = fir.extract_value %22, ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>) -> f32
-// CHECK: [[VAL_26:%.*]] = constant 1 : i32
+// CHECK: [[VAL_26:%.*]] = arith.constant 1 : i32
// CHECK: [[VAL_27:%.*]] = fir.shape [[VAL_21]] : (i32) -> !fir.shape<1>
-// CHECK: [[VAL_28:%.*]] = constant 1.0
+// CHECK: [[VAL_28:%.*]] = arith.constant 1.0
// CHECK: [[VAL_29:%.*]] = fir.insert_value [[VAL_24]], [[VAL_28]], ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>, f32) -> !fir.type<derived{f:f32}>
// CHECK: [[VAL_30:%.*]] = fir.len_param_index f, !fir.type<derived3{f:f32}>
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
%24 = fir.shape %19 : (i32) -> !fir.shape<1>
- %cf1 = constant 1.0 : f32
+ %cf1 = arith.constant 1.0 : f32
%25 = fir.insert_value %22, %cf1, ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>, f32) -> !fir.type<derived{f:f32}>
%26 = fir.len_param_index f, !fir.type<derived3{f:f32}>
// CHECK: [[VAL_41:%.*]] = fir.alloca tuple<i32, f64>
// CHECK: [[VAL_42:%.*]] = fir.embox [[VAL_38]] : (!fir.ref<i32>) -> !fir.box<i32>
// CHECK: [[VAL_43:%.*]]:6 = fir.unbox [[VAL_42]] : (!fir.box<i32>) -> (!fir.ref<i32>, i32, i32, !fir.tdesc<i32>, i32, !fir.array<3x?xindex>)
-// CHECK: [[VAL_44:%.*]] = constant 8 : i32
+// CHECK: [[VAL_44:%.*]] = arith.constant 8 : i32
// CHECK: [[VAL_45:%.*]] = fir.undefined !fir.char<1>
// CHECK: [[VAL_46:%.*]] = fir.emboxchar [[VAL_40]], [[VAL_44]] : (!fir.ref<!fir.char<1>>, i32) -> !fir.boxchar<1>
// CHECK: [[VAL_47:%.*]]:2 = fir.unboxchar [[VAL_46]] : (!fir.boxchar<1>) -> (!fir.ref<!fir.char<1>>, i32)
// CHECK: [[VAL_48:%.*]] = fir.undefined !fir.type<qq2{f1:i32,f2:f64}>
-// CHECK: [[VAL_49:%.*]] = constant 0 : i32
-// CHECK: [[VAL_50:%.*]] = constant 12 : i32
+// CHECK: [[VAL_49:%.*]] = arith.constant 0 : i32
+// CHECK: [[VAL_50:%.*]] = arith.constant 12 : i32
// CHECK: [[VAL_51:%.*]] = fir.insert_value [[VAL_48]], [[VAL_50]], [0 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, i32) -> !fir.type<qq2{f1:i32,f2:f64}>
-// CHECK: [[VAL_52:%.*]] = constant 1 : i32
-// CHECK: [[VAL_53:%.*]] = constant 4.213000e+01 : f64
+// CHECK: [[VAL_52:%.*]] = arith.constant 1 : i32
+// CHECK: [[VAL_53:%.*]] = arith.constant 4.213000e+01 : f64
// CHECK: [[VAL_54:%.*]] = fir.insert_value [[VAL_48]], [[VAL_53]], [1 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, f64) -> !fir.type<qq2{f1:i32,f2:f64}>
// CHECK: fir.store [[VAL_54]] to [[VAL_39]] : !fir.ref<!fir.type<qq2{f1:i32,f2:f64}>>
// CHECK: [[VAL_55:%.*]] = fir.emboxproc @method_impl, [[VAL_41]] : ((!fir.box<!fir.type<derived3{f:f32}>>) -> (), !fir.ref<tuple<i32, f64>>) -> !fir.boxproc<(!fir.box<!fir.type<derived3{f:f32}>>) -> ()>
%e6 = fir.alloca tuple<i32,f64>
%1 = fir.embox %0 : (!fir.ref<i32>) -> !fir.box<i32>
%2:6 = fir.unbox %1 : (!fir.box<i32>) -> (!fir.ref<i32>,i32,i32,!fir.tdesc<i32>,i32,!fir.array<3x?xindex>)
- %c8 = constant 8 : i32
+ %c8 = arith.constant 8 : i32
%3 = fir.undefined !fir.char<1>
%4 = fir.emboxchar %d3, %c8 : (!fir.ref<!fir.char<1>>, i32) -> !fir.boxchar<1>
%5:2 = fir.unboxchar %4 : (!fir.boxchar<1>) -> (!fir.ref<!fir.char<1>>, i32)
%6 = fir.undefined !fir.type<qq2{f1:i32,f2:f64}>
- %z = constant 0 : i32
- %c12 = constant 12 : i32
+ %z = arith.constant 0 : i32
+ %c12 = arith.constant 12 : i32
%a2 = fir.insert_value %6, %c12, [0 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, i32) -> !fir.type<qq2{f1:i32,f2:f64}>
- %z1 = constant 1 : i32
- %c42 = constant 42.13 : f64
+ %z1 = arith.constant 1 : i32
+ %c42 = arith.constant 42.13 : f64
%a3 = fir.insert_value %6, %c42, [1 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, f64) -> !fir.type<qq2{f1:i32,f2:f64}>
fir.store %a3 to %d6 : !fir.ref<!fir.type<qq2{f1:i32,f2:f64}>>
%7 = fir.emboxproc @method_impl, %e6 : ((!fir.box<!fir.type<derived3{f:f32}>>) -> (), !fir.ref<tuple<i32,f64>>) -> !fir.boxproc<(!fir.box<!fir.type<derived3{f:f32}>>) -> ()>
// CHECK-LABEL: func @loop() {
func @loop() {
-// CHECK: [[VAL_62:%.*]] = constant 1 : index
-// CHECK: [[VAL_63:%.*]] = constant 10 : index
-// CHECK: [[VAL_64:%.*]] = constant true
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- %ct = constant true
+// CHECK: [[VAL_62:%.*]] = arith.constant 1 : index
+// CHECK: [[VAL_63:%.*]] = arith.constant 10 : index
+// CHECK: [[VAL_64:%.*]] = arith.constant true
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %ct = arith.constant true
// CHECK: fir.do_loop [[VAL_65:%.*]] = [[VAL_62]] to [[VAL_63]] step [[VAL_62]] {
// CHECK: fir.if [[VAL_64]] {
// CHECK: func @bar_select([[VAL_66:%.*]]: i32, [[VAL_67:%.*]]: i32) -> i32 {
func @bar_select(%arg : i32, %arg2 : i32) -> i32 {
-// CHECK: [[VAL_68:%.*]] = constant 1 : i32
-// CHECK: [[VAL_69:%.*]] = constant 2 : i32
-// CHECK: [[VAL_70:%.*]] = constant 3 : i32
-// CHECK: [[VAL_71:%.*]] = constant 4 : i32
- %0 = constant 1 : i32
- %1 = constant 2 : i32
- %2 = constant 3 : i32
- %3 = constant 4 : i32
+// CHECK: [[VAL_68:%.*]] = arith.constant 1 : i32
+// CHECK: [[VAL_69:%.*]] = arith.constant 2 : i32
+// CHECK: [[VAL_70:%.*]] = arith.constant 3 : i32
+// CHECK: [[VAL_71:%.*]] = arith.constant 4 : i32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 3 : i32
+ %3 = arith.constant 4 : i32
// CHECK: fir.select [[VAL_66]] : i32 [1, ^bb1([[VAL_68]] : i32), 2, ^bb2([[VAL_70]], [[VAL_66]], [[VAL_67]] : i32, i32, i32), -3, ^bb3([[VAL_67]], [[VAL_70]] : i32, i32), 4, ^bb4([[VAL_69]] : i32), unit, ^bb5]
// CHECK: ^bb1([[VAL_72:%.*]]: i32):
// CHECK: return [[VAL_72]] : i32
// CHECK: ^bb2([[VAL_73:%.*]]: i32, [[VAL_74:%.*]]: i32, [[VAL_75:%.*]]: i32):
-// CHECK: [[VAL_76:%.*]] = addi [[VAL_73]], [[VAL_74]] : i32
-// CHECK: [[VAL_77:%.*]] = addi [[VAL_76]], [[VAL_75]] : i32
+// CHECK: [[VAL_76:%.*]] = arith.addi [[VAL_73]], [[VAL_74]] : i32
+// CHECK: [[VAL_77:%.*]] = arith.addi [[VAL_76]], [[VAL_75]] : i32
// CHECK: return [[VAL_77]] : i32
// CHECK: ^bb3([[VAL_78:%.*]]: i32, [[VAL_79:%.*]]: i32):
-// CHECK: [[VAL_80:%.*]] = addi [[VAL_78]], [[VAL_79]] : i32
+// CHECK: [[VAL_80:%.*]] = arith.addi [[VAL_78]], [[VAL_79]] : i32
// CHECK: return [[VAL_80]] : i32
// CHECK: ^bb4([[VAL_81:%.*]]: i32):
// CHECK: return [[VAL_81]] : i32
// CHECK: ^bb5:
-// CHECK: [[VAL_82:%.*]] = constant 0 : i32
+// CHECK: [[VAL_82:%.*]] = arith.constant 0 : i32
// CHECK: return [[VAL_82]] : i32
// CHECK: }
fir.select %arg:i32 [ 1,^bb1(%0:i32), 2,^bb2(%2,%arg,%arg2:i32,i32,i32), -3,^bb3(%arg2,%2:i32,i32), 4,^bb4(%1:i32), unit,^bb5 ]
^bb1(%a : i32) :
return %a : i32
^bb2(%b : i32, %b2 : i32, %b3:i32) :
- %4 = addi %b, %b2 : i32
- %5 = addi %4, %b3 : i32
+ %4 = arith.addi %b, %b2 : i32
+ %5 = arith.addi %4, %b3 : i32
return %5 : i32
^bb3(%c:i32, %c2:i32) :
- %6 = addi %c, %c2 : i32
+ %6 = arith.addi %c, %c2 : i32
return %6 : i32
^bb4(%d : i32) :
return %d : i32
^bb5 :
- %zero = constant 0 : i32
+ %zero = arith.constant 0 : i32
return %zero : i32
}
// CHECK-LABEL: func @bar_select_rank(
// CHECK-SAME: [[VAL_83:%.*]]: i32, [[VAL_84:%.*]]: i32) -> i32 {
func @bar_select_rank(%arg : i32, %arg2 : i32) -> i32 {
-// CHECK: [[VAL_85:%.*]] = constant 1 : i32
-// CHECK: [[VAL_86:%.*]] = constant 2 : i32
-// CHECK: [[VAL_87:%.*]] = constant 3 : i32
-// CHECK: [[VAL_88:%.*]] = constant 4 : i32
- %0 = constant 1 : i32
- %1 = constant 2 : i32
- %2 = constant 3 : i32
- %3 = constant 4 : i32
+// CHECK: [[VAL_85:%.*]] = arith.constant 1 : i32
+// CHECK: [[VAL_86:%.*]] = arith.constant 2 : i32
+// CHECK: [[VAL_87:%.*]] = arith.constant 3 : i32
+// CHECK: [[VAL_88:%.*]] = arith.constant 4 : i32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 3 : i32
+ %3 = arith.constant 4 : i32
// CHECK: fir.select_rank [[VAL_83]] : i32 [1, ^bb1([[VAL_85]] : i32), 2, ^bb2([[VAL_87]], [[VAL_83]], [[VAL_84]] : i32, i32, i32), 3, ^bb3([[VAL_84]], [[VAL_87]] : i32, i32), -1, ^bb4([[VAL_86]] : i32), unit, ^bb5]
// CHECK: ^bb1([[VAL_89:%.*]]: i32):
// CHECK: return [[VAL_89]] : i32
// CHECK: ^bb2([[VAL_90:%.*]]: i32, [[VAL_91:%.*]]: i32, [[VAL_92:%.*]]: i32):
-// CHECK: [[VAL_93:%.*]] = addi [[VAL_90]], [[VAL_91]] : i32
-// CHECK: [[VAL_94:%.*]] = addi [[VAL_93]], [[VAL_92]] : i32
+// CHECK: [[VAL_93:%.*]] = arith.addi [[VAL_90]], [[VAL_91]] : i32
+// CHECK: [[VAL_94:%.*]] = arith.addi [[VAL_93]], [[VAL_92]] : i32
// CHECK: return [[VAL_94]] : i32
fir.select_rank %arg:i32 [ 1,^bb1(%0:i32), 2,^bb2(%2,%arg,%arg2:i32,i32,i32), 3,^bb3(%arg2,%2:i32,i32), -1,^bb4(%1:i32), unit,^bb5 ]
^bb1(%a : i32) :
return %a : i32
^bb2(%b : i32, %b2 : i32, %b3:i32) :
- %4 = addi %b, %b2 : i32
- %5 = addi %4, %b3 : i32
+ %4 = arith.addi %b, %b2 : i32
+ %5 = arith.addi %4, %b3 : i32
return %5 : i32
// CHECK: ^bb3([[VAL_95:%.*]]: i32, [[VAL_96:%.*]]: i32):
-// CHECK: [[VAL_97:%.*]] = addi [[VAL_95]], [[VAL_96]] : i32
+// CHECK: [[VAL_97:%.*]] = arith.addi [[VAL_95]], [[VAL_96]] : i32
// CHECK: return [[VAL_97]] : i32
// CHECK: ^bb4([[VAL_98:%.*]]: i32):
// CHECK: return [[VAL_98]] : i32
^bb3(%c:i32, %c2:i32) :
- %6 = addi %c, %c2 : i32
+ %6 = arith.addi %c, %c2 : i32
return %6 : i32
^bb4(%d : i32) :
return %d : i32
// CHECK: ^bb5:
-// CHECK: [[VAL_99:%.*]] = constant 0 : i32
+// CHECK: [[VAL_99:%.*]] = arith.constant 0 : i32
// CHECK: [[VAL_100:%.*]] = fir.call @get_method_box() : () -> !fir.box<!fir.type<derived3{f:f32}>>
// CHECK: fir.dispatch "method"([[VAL_100]]) : (!fir.box<!fir.type<derived3{f:f32}>>) -> ()
^bb5 :
- %zero = constant 0 : i32
+ %zero = arith.constant 0 : i32
%7 = fir.call @get_method_box() : () -> !fir.box<!fir.type<derived3{f:f32}>>
fir.dispatch method(%7) : (!fir.box<!fir.type<derived3{f:f32}>>) -> ()
// CHECK-SAME: [[VAL_101:%.*]]: !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>>) -> i32 {
func @bar_select_type(%arg : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>>) -> i32 {
-// CHECK: [[VAL_102:%.*]] = constant 1 : i32
-// CHECK: [[VAL_103:%.*]] = constant 2 : i32
-// CHECK: [[VAL_104:%.*]] = constant 3 : i32
-// CHECK: [[VAL_105:%.*]] = constant 4 : i32
- %0 = constant 1 : i32
- %1 = constant 2 : i32
- %2 = constant 3 : i32
- %3 = constant 4 : i32
+// CHECK: [[VAL_102:%.*]] = arith.constant 1 : i32
+// CHECK: [[VAL_103:%.*]] = arith.constant 2 : i32
+// CHECK: [[VAL_104:%.*]] = arith.constant 3 : i32
+// CHECK: [[VAL_105:%.*]] = arith.constant 4 : i32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 3 : i32
+ %3 = arith.constant 4 : i32
// CHECK: fir.select_type [[VAL_101]] : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>> [#fir.instance<!fir.int<4>>, ^bb1([[VAL_102]] : i32), #fir.instance<!fir.int<8>>, ^bb2([[VAL_104]] : i32), #fir.subsumed<!fir.int<2>>, ^bb3([[VAL_104]] : i32), #fir.instance<!fir.int<1>>, ^bb4([[VAL_103]] : i32), unit, ^bb5]
fir.select_type %arg : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>> [ #fir.instance<!fir.int<4>>,^bb1(%0:i32), #fir.instance<!fir.int<8>>,^bb2(%2:i32), #fir.subsumed<!fir.int<2>>,^bb3(%2:i32), #fir.instance<!fir.int<1>>,^bb4(%1:i32), unit,^bb5 ]
return %d : i32
// CHECK: ^bb5:
-// CHECK: [[VAL_110:%.*]] = constant 0 : i32
+// CHECK: [[VAL_110:%.*]] = arith.constant 0 : i32
// CHECK: return [[VAL_110]] : i32
// CHECK: }
^bb5 :
- %zero = constant 0 : i32
+ %zero = arith.constant 0 : i32
return %zero : i32
}
// CHECK-LABEL: func @bar_select_case(
// CHECK-SAME: [[VAL_111:%.*]]: i32, [[VAL_112:%.*]]: i32) -> i32 {
-// CHECK: [[VAL_113:%.*]] = constant 1 : i32
-// CHECK: [[VAL_114:%.*]] = constant 2 : i32
-// CHECK: [[VAL_115:%.*]] = constant 3 : i32
-// CHECK: [[VAL_116:%.*]] = constant 4 : i32
+// CHECK: [[VAL_113:%.*]] = arith.constant 1 : i32
+// CHECK: [[VAL_114:%.*]] = arith.constant 2 : i32
+// CHECK: [[VAL_115:%.*]] = arith.constant 3 : i32
+// CHECK: [[VAL_116:%.*]] = arith.constant 4 : i32
func @bar_select_case(%arg : i32, %arg2 : i32) -> i32 {
- %0 = constant 1 : i32
- %1 = constant 2 : i32
- %2 = constant 3 : i32
- %3 = constant 4 : i32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 3 : i32
+ %3 = arith.constant 4 : i32
// CHECK: fir.select_case [[VAL_111]] : i32 [#fir.point, [[VAL_113]], ^bb1([[VAL_113]] : i32), #fir.lower, [[VAL_114]], ^bb2([[VAL_115]], [[VAL_111]], [[VAL_112]], [[VAL_114]] : i32, i32, i32, i32), #fir.interval, [[VAL_115]], [[VAL_116]], ^bb3([[VAL_115]], [[VAL_112]] : i32, i32), #fir.upper, [[VAL_111]], ^bb4([[VAL_114]] : i32), unit, ^bb5]
fir.select_case %arg : i32 [#fir.point, %0, ^bb1(%0:i32), #fir.lower, %1, ^bb2(%2,%arg,%arg2,%1:i32,i32,i32,i32), #fir.interval, %2, %3, ^bb3(%2,%arg2:i32,i32), #fir.upper, %arg, ^bb4(%1:i32), unit, ^bb5]
// CHECK: ^bb1([[VAL_117:%.*]]: i32):
// CHECK: return [[VAL_117]] : i32
// CHECK: ^bb2([[VAL_118:%.*]]: i32, [[VAL_119:%.*]]: i32, [[VAL_120:%.*]]: i32, [[VAL_121:%.*]]: i32):
-// CHECK: [[VAL_122:%.*]] = addi [[VAL_118]], [[VAL_119]] : i32
-// CHECK: [[VAL_123:%.*]] = muli [[VAL_122]], [[VAL_120]] : i32
-// CHECK: [[VAL_124:%.*]] = addi [[VAL_123]], [[VAL_121]] : i32
+// CHECK: [[VAL_122:%.*]] = arith.addi [[VAL_118]], [[VAL_119]] : i32
+// CHECK: [[VAL_123:%.*]] = arith.muli [[VAL_122]], [[VAL_120]] : i32
+// CHECK: [[VAL_124:%.*]] = arith.addi [[VAL_123]], [[VAL_121]] : i32
// CHECK: return [[VAL_124]] : i32
// CHECK: ^bb3([[VAL_125:%.*]]: i32, [[VAL_126:%.*]]: i32):
-// CHECK: [[VAL_127:%.*]] = addi [[VAL_125]], [[VAL_126]] : i32
+// CHECK: [[VAL_127:%.*]] = arith.addi [[VAL_125]], [[VAL_126]] : i32
// CHECK: return [[VAL_127]] : i32
// CHECK: ^bb4([[VAL_128:%.*]]: i32):
// CHECK: return [[VAL_128]] : i32
^bb1(%a : i32) :
return %a : i32
^bb2(%b : i32, %b2:i32, %b3:i32, %b4:i32) :
- %4 = addi %b, %b2 : i32
- %5 = muli %4, %b3 : i32
- %6 = addi %5, %b4 : i32
+ %4 = arith.addi %b, %b2 : i32
+ %5 = arith.muli %4, %b3 : i32
+ %6 = arith.addi %5, %b4 : i32
return %6 : i32
^bb3(%c : i32, %c2 : i32) :
- %7 = addi %c, %c2 : i32
+ %7 = arith.addi %c, %c2 : i32
return %7 : i32
^bb4(%d : i32) :
return %d : i32
// CHECK: ^bb5:
-// CHECK: [[VAL_129:%.*]] = constant 0 : i32
+// CHECK: [[VAL_129:%.*]] = arith.constant 0 : i32
// CHECK: return [[VAL_129]] : i32
// CHECK: }
^bb5 :
- %zero = constant 0 : i32
+ %zero = arith.constant 0 : i32
return %zero : i32
}
// CHECK-LABEL: fir.global @global_var : i32 {
-// CHECK: [[VAL_130:%.*]] = constant 1 : i32
+// CHECK: [[VAL_130:%.*]] = arith.constant 1 : i32
// CHECK: fir.has_value [[VAL_130]] : i32
// CHECK: }
fir.global @global_var : i32 {
- %0 = constant 1 : i32
+ %0 = arith.constant 1 : i32
fir.has_value %0 : i32
}
// CHECK-LABEL: fir.global @global_constant constant : i32 {
-// CHECK: [[VAL_131:%.*]] = constant 934 : i32
+// CHECK: [[VAL_131:%.*]] = arith.constant 934 : i32
// CHECK: fir.has_value [[VAL_131]] : i32
// CHECK: }
fir.global @global_constant constant : i32 {
- %0 = constant 934 : i32
+ %0 = arith.constant 934 : i32
fir.has_value %0 : i32
}
// CHECK-SAME: [[VAL_169:%.*]]: f128, [[VAL_170:%.*]]: f128) -> f128 {
func @arith_real(%a : f128, %b : f128) -> f128 {
-// CHECK: [[VAL_171:%.*]] = constant 1.0
+// CHECK: [[VAL_171:%.*]] = arith.constant 1.0
// CHECK: [[VAL_172:%.*]] = fir.convert [[VAL_171]] : (f32) -> f128
-// CHECK: [[VAL_173:%.*]] = negf [[VAL_169]] : f128
-// CHECK: [[VAL_174:%.*]] = addf [[VAL_172]], [[VAL_173]] : f128
-// CHECK: [[VAL_175:%.*]] = subf [[VAL_174]], [[VAL_170]] : f128
-// CHECK: [[VAL_176:%.*]] = mulf [[VAL_173]], [[VAL_175]] : f128
-// CHECK: [[VAL_177:%.*]] = divf [[VAL_176]], [[VAL_169]] : f128
- %c1 = constant 1.0 : f32
+// CHECK: [[VAL_173:%.*]] = arith.negf [[VAL_169]] : f128
+// CHECK: [[VAL_174:%.*]] = arith.addf [[VAL_172]], [[VAL_173]] : f128
+// CHECK: [[VAL_175:%.*]] = arith.subf [[VAL_174]], [[VAL_170]] : f128
+// CHECK: [[VAL_176:%.*]] = arith.mulf [[VAL_173]], [[VAL_175]] : f128
+// CHECK: [[VAL_177:%.*]] = arith.divf [[VAL_176]], [[VAL_169]] : f128
+ %c1 = arith.constant 1.0 : f32
%0 = fir.convert %c1 : (f32) -> f128
- %1 = negf %a : f128
- %2 = addf %0, %1 : f128
- %3 = subf %2, %b : f128
- %4 = mulf %1, %3 : f128
- %5 = divf %4, %a : f128
+ %1 = arith.negf %a : f128
+ %2 = arith.addf %0, %1 : f128
+ %3 = arith.subf %2, %b : f128
+ %4 = arith.mulf %1, %3 : f128
+ %5 = arith.divf %4, %a : f128
// CHECK: return [[VAL_177]] : f128
// CHECK: }
return %5 : f128
// CHECK-LABEL: func @early_exit(
// CHECK-SAME: [[VAL_187:%.*]]: i1, [[VAL_188:%.*]]: i32) -> i1 {
func @early_exit(%ok : i1, %k : i32) -> i1 {
-// CHECK: [[VAL_189:%.*]] = constant 1 : index
-// CHECK: [[VAL_190:%.*]] = constant 100 : index
- %c1 = constant 1 : index
- %c100 = constant 100 : index
+// CHECK: [[VAL_189:%.*]] = arith.constant 1 : index
+// CHECK: [[VAL_190:%.*]] = arith.constant 100 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
// CHECK: %[[VAL_191:.*]]:2 = fir.iterate_while ([[VAL_192:%.*]] = [[VAL_189]] to [[VAL_190]] step [[VAL_189]]) and ([[VAL_193:%.*]] = [[VAL_187]]) iter_args([[VAL_194:%.*]] = [[VAL_188]]) -> (i32) {
// CHECK: [[VAL_195:%.*]] = call @earlyexit2([[VAL_194]]) : (i32) -> i1
// CHECK-LABEL: @array_access
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- // CHECK-DAG: %[[c1:.*]] = constant 100
- // CHECK-DAG: %[[c2:.*]] = constant 50
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ // CHECK-DAG: %[[c1:.*]] = arith.constant 100
+ // CHECK-DAG: %[[c2:.*]] = arith.constant 50
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
// CHECK: %[[sh:.*]] = fir.shape %[[c1]], %[[c2]] : {{.*}} -> !fir.shape<2>
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
- %c47 = constant 47 : index
- %c78 = constant 78 : index
- %c3 = constant 3 : index
- %c18 = constant 18 : index
- %c36 = constant 36 : index
- %c4 = constant 4 : index
+ %c47 = arith.constant 47 : index
+ %c78 = arith.constant 78 : index
+ %c3 = arith.constant 3 : index
+ %c18 = arith.constant 18 : index
+ %c36 = arith.constant 36 : index
+ %c4 = arith.constant 4 : index
// CHECK: %[[sl:.*]] = fir.slice {{.*}} -> !fir.slice<2>
%slice = fir.slice %c47, %c78, %c3, %c18, %c36, %c4 : (index,index,index,index,index,index) -> !fir.slice<2>
- %c0 = constant 0 : index
- %c99 = constant 99 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c99 = arith.constant 99 : index
+ %c1 = arith.constant 1 : index
fir.do_loop %i = %c0 to %c99 step %c1 {
- %c49 = constant 49 : index
+ %c49 = arith.constant 49 : index
fir.do_loop %j = %c0 to %c49 step %c1 {
// CHECK: fir.array_coor %{{.*}}(%[[sh]]) [%[[sl]]] %{{.*}}, %{{.*}} :
%p = fir.array_coor %arr(%shape)[%slice] %i, %j : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, !fir.slice<2>, index, index) -> !fir.ref<f32>
- %x = constant 42.0 : f32
+ %x = arith.constant 42.0 : f32
fir.store %x to %p : !fir.ref<f32>
}
}
// CHECK-LABEL: @test_misc_ops(
// CHECK-SAME: [[ARR1:%.*]]: !fir.ref<!fir.array<?x?xf32>>, [[INDXM:%.*]]: index, [[INDXN:%.*]]: index, [[INDXO:%.*]]: index, [[INDXP:%.*]]: index)
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
- // CHECK: [[I10:%.*]] = constant 10 : index
- // CHECK: [[J20:%.*]] = constant 20 : index
- // CHECK: [[C2:%.*]] = constant 2 : index
- // CHECK: [[C9:%.*]] = constant 9 : index
- // CHECK: [[C1_I32:%.*]] = constant 9 : i32
- %i10 = constant 10 : index
- %j20 = constant 20 : index
- %c2 = constant 2 : index
- %c9 = constant 9 : index
- %c1_i32 = constant 9 : i32
+ // CHECK: [[I10:%.*]] = arith.constant 10 : index
+ // CHECK: [[J20:%.*]] = arith.constant 20 : index
+ // CHECK: [[C2:%.*]] = arith.constant 2 : index
+ // CHECK: [[C9:%.*]] = arith.constant 9 : index
+ // CHECK: [[C1_I32:%.*]] = arith.constant 9 : i32
+ %i10 = arith.constant 10 : index
+ %j20 = arith.constant 20 : index
+ %c2 = arith.constant 2 : index
+ %c9 = arith.constant 9 : index
+ %c1_i32 = arith.constant 9 : i32
// CHECK: [[ARR2:%.*]] = fir.zero_bits !fir.array<10xi32>
// CHECK: [[ARR3:%.*]] = fir.insert_on_range [[ARR2]], [[C1_I32]], [2 : index, 9 : index] : (!fir.array<10xi32>, i32) -> !fir.array<10xi32>
// CHECK-LABEL: @test_shift
func @test_shift(%arg0: !fir.box<!fir.array<?xf32>>) -> !fir.ref<f32> {
- %c4 = constant 4 : index
- %c100 = constant 100 : index
+ %c4 = arith.constant 4 : index
+ %c100 = arith.constant 100 : index
// CHECK: fir.shift %{{.*}} : (index) -> !fir.shift<1>
%0 = fir.shift %c4 : (index) -> !fir.shift<1>
%1 = fir.array_coor %arg0(%0) %c100 : (!fir.box<!fir.array<?xf32>>, !fir.shift<1>, index) -> !fir.ref<f32>
func private @bar_rebox_test(!fir.box<!fir.array<?x?xf32>>)
// CHECK-LABEL: @test_rebox(
func @test_rebox(%arg0: !fir.box<!fir.array<?xf32>>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c10 = constant 10 : index
- %c33 = constant 33 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c10 = arith.constant 10 : index
+ %c33 = arith.constant 33 : index
%0 = fir.slice %c10, %c33, %c2 : (index, index, index) -> !fir.slice<1>
%1 = fir.shift %c0 : (index) -> !fir.shift<1>
// CHECK: fir.rebox %{{.*}}(%{{.*}}) [%{{.*}}] : (!fir.box<!fir.array<?xf32>>, !fir.shift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xf32>>
// CHECK-LABEL: @test_save_result(
func @test_save_result(%buffer: !fir.ref<!fir.array<?x!fir.char<1,?>>>) {
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
%res = fir.call @array_func() : () -> !fir.array<?x!fir.char<1,?>>
// CHECK: fir.save_result %{{.*}} to %{{.*}}(%{{.*}}) typeparams %{{.*}} : !fir.array<?x!fir.char<1,?>>, !fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index
// -----
func @bad_rebox_1(%arg0: !fir.ref<!fir.array<?x?xf32>>) {
- %c10 = constant 10 : index
+ %c10 = arith.constant 10 : index
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
// expected-error@+1{{op operand #0 must be The type of a Fortran descriptor, but got '!fir.ref<!fir.array<?x?xf32>>'}}
%1 = fir.rebox %arg0(%0) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
// -----
func @bad_rebox_2(%arg0: !fir.box<!fir.array<?x?xf32>>) {
- %c10 = constant 10 : index
+ %c10 = arith.constant 10 : index
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
// expected-error@+1{{op result #0 must be The type of a Fortran descriptor, but got '!fir.ref<!fir.array<?xf32>>'}}
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.ref<!fir.array<?xf32>>
// -----
func @bad_rebox_3(%arg0: !fir.box<!fir.array<*:f32>>) {
- %c10 = constant 10 : index
+ %c10 = arith.constant 10 : index
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
// expected-error@+1{{op box operand must not have unknown rank or type}}
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<*:f32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
// -----
func @bad_rebox_5(%arg0: !fir.box<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
// expected-error@+1{{op slice operand rank must match box operand rank}}
%1 = fir.rebox %arg0 [%0] : (!fir.box<!fir.array<?x?xf32>>, !fir.slice<1>) -> !fir.box<!fir.array<?xf32>>
// -----
func @bad_rebox_6(%arg0: !fir.box<!fir.array<?xf32>>) {
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
%1 = fir.shift %c1, %c1 : (index, index) -> !fir.shift<2>
// expected-error@+1{{shape operand and input box ranks must match when there is a slice}}
// -----
func @bad_rebox_7(%arg0: !fir.box<!fir.array<?xf32>>) {
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
%1 = fir.shape %c10 : (index) -> !fir.shape<1>
// expected-error@+1{{shape operand must absent or be a fir.shift when there is a slice}}
// -----
func @bad_rebox_8(%arg0: !fir.box<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%undef = fir.undefined index
%0 = fir.slice %c1, %undef, %undef, %c1, %c10, %c1 : (index, index, index, index, index, index) -> !fir.slice<2>
// expected-error@+1{{result type rank and rank after applying slice operand must match}}
// -----
func @bad_rebox_9(%arg0: !fir.box<!fir.array<?xf32>>) {
- %c10 = constant 10 : index
+ %c10 = arith.constant 10 : index
%0 = fir.shift %c10, %c10 : (index, index) -> !fir.shift<2>
// expected-error@+1{{shape operand and input box ranks must match when the shape is a fir.shift}}
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?xf32>>, !fir.shift<2>) -> !fir.box<!fir.array<?x?xf32>>
// -----
func @bad_rebox_10(%arg0: !fir.box<!fir.array<?xf32>>) {
- %c10 = constant 10 : index
+ %c10 = arith.constant 10 : index
%0 = fir.shape %c10, %c10 : (index, index) -> !fir.shape<2>
// expected-error@+1{{result type and shape operand ranks must match}}
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?xf32>>, !fir.shape<2>) -> !fir.box<!fir.array<?xf32>>
// -----
func @bad_rebox_11(%arg0: !fir.box<!fir.array<?x?xf32>>) {
- %c42 = constant 42 : index
+ %c42 = arith.constant 42 : index
%0 = fir.shape %c42 : (index) -> !fir.shape<1>
// expected-error@+1{{op input and output element types must match for intrinsic types}}
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf64>>
// -----
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
// expected-error@+1 {{'fir.array_coor' op operand #0 must be any reference or box, but got 'index'}}
%p = fir.array_coor %c100(%shape) %c1, %c1 : (index, !fir.shape<2>, index, index) -> !fir.ref<f32>
// -----
func @array_access(%arr : !fir.ref<f32>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
// expected-error@+1 {{'fir.array_coor' op must be a reference to an array}}
%p = fir.array_coor %arr(%shape) %c1, %c1 : (!fir.ref<f32>, !fir.shape<2>, index, index) -> !fir.ref<f32>
// -----
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
- %c47 = constant 47 : index
- %c78 = constant 78 : index
- %c3 = constant 3 : index
+ %c47 = arith.constant 47 : index
+ %c78 = arith.constant 78 : index
+ %c3 = arith.constant 3 : index
%slice = fir.slice %c47, %c78, %c3 : (index,index,index) -> !fir.slice<1>
// expected-error@+1 {{'fir.array_coor' op rank of dimension in slice mismatched}}
%p = fir.array_coor %arr(%shape)[%slice] %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, !fir.slice<1>, index, index) -> !fir.ref<f32>
// -----
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
// expected-error@+1 {{'fir.array_coor' op rank of dimension mismatched}}
%p = fir.array_coor %arr(%shape) %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<1>, index, index) -> !fir.ref<f32>
// -----
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
%shift = fir.shift %c1 : (index) -> !fir.shift<1>
// expected-error@+1 {{'fir.array_coor' op shift can only be provided with fir.box memref}}
%p = fir.array_coor %arr(%shift) %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shift<1>, index, index) -> !fir.ref<f32>
// -----
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %c1 = constant 1 : index
- %c100 = constant 100 : index
- %c50 = constant 50 : index
+ %c1 = arith.constant 1 : index
+ %c100 = arith.constant 100 : index
+ %c50 = arith.constant 50 : index
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
// expected-error@+1 {{'fir.array_coor' op number of indices do not match dim rank}}
%p = fir.array_coor %arr(%shape) %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, index) -> !fir.ref<f32>
// -----
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
// expected-error@+1 {{'fir.array_load' op operand #0 must be any reference or box, but got 'index'}}
%av1 = fir.array_load %c2(%s) : (index, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
// -----
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%shift = fir.shift %c2 : (index) -> !fir.shift<1>
// expected-error@+1 {{'fir.array_load' op shift can only be provided with fir.box memref}}
%av1 = fir.array_load %arr1(%shift) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shift<1>) -> !fir.array<?x?xf32>
// -----
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
- %c47 = constant 47 : index
- %c78 = constant 78 : index
- %c3 = constant 3 : index
+ %c47 = arith.constant 47 : index
+ %c78 = arith.constant 78 : index
+ %c3 = arith.constant 3 : index
%slice = fir.slice %c47, %c78, %c3 : (index,index,index) -> !fir.slice<1>
%s = fir.shape_shift %m, %n, %o, %p: (index, index, index, index) -> !fir.shapeshift<2>
// expected-error@+1 {{'fir.array_load' op rank of dimension in slice mismatched}}
// -----
func @test_coordinate_of(%arr : !fir.ref<!fir.array<?x?xf32>>) {
- %1 = constant 10 : i32
+ %1 = arith.constant 10 : i32
// expected-error@+1 {{'fir.coordinate_of' op cannot find coordinate with unknown extents}}
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.array<?x?xf32>>, i32) -> !fir.ref<f32>
return
// -----
func @test_coordinate_of(%arr : !fir.ref<!fir.array<*:f32>>) {
- %1 = constant 10 : i32
+ %1 = arith.constant 10 : i32
// expected-error@+1 {{'fir.coordinate_of' op cannot find coordinate in unknown shape}}
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.array<*:f32>>, i32) -> !fir.ref<f32>
return
// -----
func @test_coordinate_of(%arr : !fir.ref<!fir.char<10>>) {
- %1 = constant 10 : i32
+ %1 = arith.constant 10 : i32
// expected-error@+1 {{'fir.coordinate_of' op cannot apply coordinate_of to this type}}
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.char<10>>, i32) -> !fir.ref<f32>
return
// -----
-%0 = constant 22 : i32
+%0 = arith.constant 22 : i32
// expected-error@+1 {{'fir.embox' op operand #0 must be any reference, but got 'i32'}}
%1 = fir.embox %0 : (i32) -> !fir.box<i32>
// -----
func @fun(%0 : !fir.ref<i32>) {
- %c_100 = constant 100 : index
+ %c_100 = arith.constant 100 : index
%1 = fir.shape %c_100 : (index) -> !fir.shape<1>
// expected-error@+1 {{'fir.embox' op shape must not be provided for a scalar}}
%2 = fir.embox %0(%1) : (!fir.ref<i32>, !fir.shape<1>) -> !fir.box<i32>
// -----
func @fun(%0 : !fir.ref<i32>) {
- %c_100 = constant 100 : index
+ %c_100 = arith.constant 100 : index
%1 = fir.slice %c_100, %c_100, %c_100 : (index, index, index) -> !fir.slice<1>
// expected-error@+1 {{'fir.embox' op operand #1 must be any legal shape type, but got '!fir.slice<1>'}}
%2 = fir.embox %0(%1) : (!fir.ref<i32>, !fir.slice<1>) -> !fir.box<i32>
// -----
func @fun(%0 : !fir.ref<i32>) {
- %c_100 = constant 100 : index
+ %c_100 = arith.constant 100 : index
%1 = fir.shape %c_100 : (index) -> !fir.shape<1>
// expected-error@+1 {{'fir.embox' op operand #1 must be FIR slice, but got '!fir.shape<1>'}}
%2 = fir.embox %0[%1] : (!fir.ref<i32>, !fir.shape<1>) -> !fir.box<i32>
// -----
func @fun(%0 : !fir.ref<i32>) {
- %c_100 = constant 100 : index
+ %c_100 = arith.constant 100 : index
%1 = fir.slice %c_100, %c_100, %c_100 : (index, index, index) -> !fir.slice<1>
// expected-error@+1 {{'fir.embox' op slice must not be provided for a scalar}}
%2 = fir.embox %0[%1] : (!fir.ref<i32>, !fir.slice<1>) -> !fir.box<i32>
// -----
-%lo = constant 1 : index
-%c1 = constant 1 : index
-%up = constant 10 : index
-%okIn = constant 1 : i1
-%shIn = constant 1 : i16
+%lo = arith.constant 1 : index
+%c1 = arith.constant 1 : index
+%up = arith.constant 10 : index
+%okIn = arith.constant 1 : i1
+%shIn = arith.constant 1 : i16
// expected-error@+1 {{'fir.iterate_while' op expected body first argument to be an index argument for the induction variable}}
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok = %okIn) iter_args(%sh = %shIn) -> (i16, i1, i16) {
%shNew = fir.call @bar(%sh) : (i16) -> i16
// -----
-%lo = constant 1 : index
-%c1 = constant 1 : index
-%up = constant 10 : index
-%okIn = constant 1 : i1
-%shIn = constant 1 : i16
+%lo = arith.constant 1 : index
+%c1 = arith.constant 1 : index
+%up = arith.constant 10 : index
+%okIn = arith.constant 1 : i1
+%shIn = arith.constant 1 : i16
// expected-error@+1 {{'fir.iterate_while' op expected body second argument to be an index argument for the induction variable}}
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok = %okIn) iter_args(%sh = %shIn) -> (index, f32, i16) {
%shNew = fir.call @bar(%sh) : (i16) -> i16
// -----
-%c1 = constant 1 : index
-%c10 = constant 10 : index
+%c1 = arith.constant 1 : index
+%c10 = arith.constant 10 : index
// expected-error@+1 {{'fir.do_loop' op unordered loop has no final value}}
fir.do_loop %i = %c1 to %c10 step %c1 unordered -> index {
}
// -----
-%c1 = constant 1 : index
-%c10 = constant 10 : index
+%c1 = arith.constant 1 : index
+%c10 = arith.constant 10 : index
fir.do_loop %i = %c1 to %c10 step %c1 -> index {
- %f1 = constant 1.0 : f32
+ %f1 = arith.constant 1.0 : f32
// expected-error@+1 {{'fir.result' op types mismatch between result op and its parent}}
fir.result %f1 : f32
}
// -----
-%c1 = constant 1 : index
-%c10 = constant 10 : index
+%c1 = arith.constant 1 : index
+%c10 = arith.constant 10 : index
// expected-error@+1 {{'fir.result' op parent of result must have same arity}}
fir.do_loop %i = %c1 to %c10 step %c1 -> index {
}
// -----
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
- %c0_i32 = constant 1 : i32
+ %c0_i32 = arith.constant 1 : i32
%0 = fir.undefined !fir.array<32x32xi32>
// expected-error@+1 {{'fir.insert_on_range' op has uneven number of values in ranges}}
%2 = fir.insert_on_range %0, %c0_i32, [0 : index, 31 : index, 0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
// -----
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
- %c0_i32 = constant 1 : i32
+ %c0_i32 = arith.constant 1 : i32
%0 = fir.undefined !fir.array<32x32xi32>
// expected-error@+1 {{'fir.insert_on_range' op has uneven number of values in ranges}}
%2 = fir.insert_on_range %0, %c0_i32, [0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
// -----
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
- %c0_i32 = constant 1 : i32
+ %c0_i32 = arith.constant 1 : i32
%0 = fir.undefined !fir.array<32x32xi32>
// expected-error@+1 {{'fir.insert_on_range' op negative range bound}}
%2 = fir.insert_on_range %0, %c0_i32, [-1 : index, 0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
// -----
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
- %c0_i32 = constant 1 : i32
+ %c0_i32 = arith.constant 1 : i32
%0 = fir.undefined !fir.array<32x32xi32>
// expected-error@+1 {{'fir.insert_on_range' op empty range}}
%2 = fir.insert_on_range %0, %c0_i32, [10 : index, 9 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
%av1 = fir.array_load %arr1(%s) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
// expected-error@+1 {{'fir.array_update' op merged value does not have element type}}
%av2 = fir.array_update %av1, %c0, %m, %n : (!fir.array<?x?xf32>, i32, index, index) -> !fir.array<?x?xf32>
return
// -----
func @bad_array_modify(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index, %f : f32) {
- %i10 = constant 10 : index
- %j20 = constant 20 : index
+ %i10 = arith.constant 10 : index
+ %j20 = arith.constant 20 : index
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
%av1 = fir.array_load %arr1(%s) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
// expected-error@+1 {{'fir.array_modify' op number of indices must match array dimension}}
fir.if %b {
fir.store %iv to %addr : !fir.ref<index>
} else {
- %zero = constant 0 : index
+ %zero = arith.constant 0 : index
fir.store %zero to %addr : !fir.ref<index>
}
}
func private @f2() -> i1
// CHECK: func @x(%[[VAL_0:.*]]: index, %[[VAL_1:.*]]: index, %[[VAL_2:.*]]: index, %[[VAL_3:.*]]: i1, %[[VAL_4:.*]]: !fir.ref<index>) {
-// CHECK: %[[VAL_5:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
-// CHECK: %[[VAL_6:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
-// CHECK: %[[VAL_7:.*]] = divi_signed %[[VAL_6]], %[[VAL_2]] : index
+// CHECK: %[[VAL_5:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
+// CHECK: %[[VAL_6:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
+// CHECK: %[[VAL_7:.*]] = arith.divsi %[[VAL_6]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_7]] : index, index)
// CHECK: ^bb1(%[[VAL_8:.*]]: index, %[[VAL_9:.*]]: index):
-// CHECK: %[[VAL_10:.*]] = constant 0 : index
-// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
+// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb6
// CHECK: ^bb2:
// CHECK: cond_br %[[VAL_3]], ^bb3, ^bb4
// CHECK: fir.store %[[VAL_8]] to %[[VAL_4]] : !fir.ref<index>
// CHECK: br ^bb5
// CHECK: ^bb4:
-// CHECK: %[[VAL_12:.*]] = constant 0 : index
+// CHECK: %[[VAL_12:.*]] = arith.constant 0 : index
// CHECK: fir.store %[[VAL_12]] to %[[VAL_4]] : !fir.ref<index>
// CHECK: br ^bb5
// CHECK: ^bb5:
-// CHECK: %[[VAL_13:.*]] = addi %[[VAL_8]], %[[VAL_2]] : index
-// CHECK: %[[VAL_14:.*]] = constant 1 : index
-// CHECK: %[[VAL_15:.*]] = subi %[[VAL_9]], %[[VAL_14]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_8]], %[[VAL_2]] : index
+// CHECK: %[[VAL_14:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_15:.*]] = arith.subi %[[VAL_9]], %[[VAL_14]] : index
// CHECK: br ^bb1(%[[VAL_13]], %[[VAL_15]] : index, index)
// CHECK: ^bb6:
// CHECK: return
// -----
func @x2(%lo : index, %up : index, %ok : i1) {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%unused = fir.iterate_while (%i = %lo to %up step %c1) and (%ok1 = %ok) {
%ok2 = fir.call @f2() : () -> i1
fir.result %ok2 : i1
func private @f3(i16)
// CHECK: func @x2(%[[VAL_0:.*]]: index, %[[VAL_1:.*]]: index, %[[VAL_2:.*]]: i1) {
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_2]] : index, i1)
// CHECK: ^bb1(%[[VAL_4:.*]]: index, %[[VAL_5:.*]]: i1):
-// CHECK: %[[VAL_6:.*]] = constant 0 : index
-// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_3]] : index
-// CHECK: %[[VAL_8:.*]] = cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
-// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_3]], %[[VAL_6]] : index
-// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
-// CHECK: %[[VAL_11:.*]] = and %[[VAL_7]], %[[VAL_8]] : i1
-// CHECK: %[[VAL_12:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
-// CHECK: %[[VAL_13:.*]] = or %[[VAL_11]], %[[VAL_12]] : i1
-// CHECK: %[[VAL_14:.*]] = and %[[VAL_5]], %[[VAL_13]] : i1
+// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_3]] : index
+// CHECK: %[[VAL_8:.*]] = arith.cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
+// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_3]], %[[VAL_6]] : index
+// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
+// CHECK: %[[VAL_11:.*]] = arith.andi %[[VAL_7]], %[[VAL_8]] : i1
+// CHECK: %[[VAL_12:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
+// CHECK: %[[VAL_13:.*]] = arith.ori %[[VAL_11]], %[[VAL_12]] : i1
+// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_5]], %[[VAL_13]] : i1
// CHECK: cond_br %[[VAL_14]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_15:.*]] = fir.call @f2() : () -> i1
-// CHECK: %[[VAL_16:.*]] = addi %[[VAL_4]], %[[VAL_3]] : index
+// CHECK: %[[VAL_16:.*]] = arith.addi %[[VAL_4]], %[[VAL_3]] : index
// CHECK: br ^bb1(%[[VAL_16]], %[[VAL_15]] : index, i1)
// CHECK: ^bb3:
// CHECK: return
// do_loop with an extra loop-carried value
func @x3(%lo : index, %up : index) -> i1 {
- %c1 = constant 1 : index
- %ok1 = constant true
+ %c1 = arith.constant 1 : index
+ %ok1 = arith.constant true
%ok2 = fir.do_loop %i = %lo to %up step %c1 iter_args(%j = %ok1) -> i1 {
%ok = fir.call @f2() : () -> i1
fir.result %ok : i1
// CHECK-LABEL: func @x3(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> i1 {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = constant true
-// CHECK: %[[VAL_4:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
-// CHECK: %[[VAL_5:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
-// CHECK: %[[VAL_6:.*]] = divi_signed %[[VAL_5]], %[[VAL_2]] : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant true
+// CHECK: %[[VAL_4:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
+// CHECK: %[[VAL_5:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
+// CHECK: %[[VAL_6:.*]] = arith.divsi %[[VAL_5]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_6]] : index, i1, index)
// CHECK: ^bb1(%[[VAL_7:.*]]: index, %[[VAL_8:.*]]: i1, %[[VAL_9:.*]]: index):
-// CHECK: %[[VAL_10:.*]] = constant 0 : index
-// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
+// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_12:.*]] = fir.call @f2() : () -> i1
-// CHECK: %[[VAL_13:.*]] = addi %[[VAL_7]], %[[VAL_2]] : index
-// CHECK: %[[VAL_14:.*]] = constant 1 : index
-// CHECK: %[[VAL_15:.*]] = subi %[[VAL_9]], %[[VAL_14]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_7]], %[[VAL_2]] : index
+// CHECK: %[[VAL_14:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_15:.*]] = arith.subi %[[VAL_9]], %[[VAL_14]] : index
// CHECK: br ^bb1(%[[VAL_13]], %[[VAL_12]], %[[VAL_15]] : index, i1, index)
// CHECK: ^bb3:
// CHECK: return %[[VAL_8]] : i1
// iterate_while with an extra loop-carried value
func @y3(%lo : index, %up : index) -> i1 {
- %c1 = constant 1 : index
- %ok1 = constant true
+ %c1 = arith.constant 1 : index
+ %ok1 = arith.constant true
%ok4 = fir.call @f2() : () -> i1
%ok2:2 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok3 = %ok1) iter_args(%j = %ok4) -> i1 {
%ok = fir.call @f2() : () -> i1
fir.result %ok3, %ok : i1, i1
}
- %andok = and %ok2#0, %ok2#1 : i1
+ %andok = arith.andi %ok2#0, %ok2#1 : i1
return %andok : i1
}
// CHECK-LABEL: func @y3(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> i1 {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = constant true
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant true
// CHECK: %[[VAL_4:.*]] = fir.call @f2() : () -> i1
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_4]] : index, i1, i1)
// CHECK: ^bb1(%[[VAL_5:.*]]: index, %[[VAL_6:.*]]: i1, %[[VAL_7:.*]]: i1):
-// CHECK: %[[VAL_8:.*]] = constant 0 : index
-// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
-// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
-// CHECK: %[[VAL_11:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
-// CHECK: %[[VAL_12:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
-// CHECK: %[[VAL_13:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
-// CHECK: %[[VAL_14:.*]] = and %[[VAL_11]], %[[VAL_12]] : i1
-// CHECK: %[[VAL_15:.*]] = or %[[VAL_13]], %[[VAL_14]] : i1
-// CHECK: %[[VAL_16:.*]] = and %[[VAL_6]], %[[VAL_15]] : i1
+// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
+// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
+// CHECK: %[[VAL_11:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
+// CHECK: %[[VAL_12:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
+// CHECK: %[[VAL_13:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
+// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_11]], %[[VAL_12]] : i1
+// CHECK: %[[VAL_15:.*]] = arith.ori %[[VAL_13]], %[[VAL_14]] : i1
+// CHECK: %[[VAL_16:.*]] = arith.andi %[[VAL_6]], %[[VAL_15]] : i1
// CHECK: cond_br %[[VAL_16]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_17:.*]] = fir.call @f2() : () -> i1
-// CHECK: %[[VAL_18:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
+// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_18]], %[[VAL_6]], %[[VAL_17]] : index, i1, i1)
// CHECK: ^bb3:
-// CHECK: %[[VAL_19:.*]] = and %[[VAL_6]], %[[VAL_7]] : i1
+// CHECK: %[[VAL_19:.*]] = arith.andi %[[VAL_6]], %[[VAL_7]] : i1
// CHECK: return %[[VAL_19]] : i1
// CHECK: }
// CHECK: func private @f4(i32) -> i1
// do_loop that returns the final value of the induction
func @x4(%lo : index, %up : index) -> index {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%v = fir.do_loop %i = %lo to %up step %c1 -> index {
%i1 = fir.convert %i : (index) -> i32
%ok = fir.call @f4(%i1) : (i32) -> i1
// CHECK-LABEL: func @x4(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
-// CHECK: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
-// CHECK: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
+// CHECK: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
+// CHECK: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_5]] : index, index)
// CHECK: ^bb1(%[[VAL_6:.*]]: index, %[[VAL_7:.*]]: index):
-// CHECK: %[[VAL_8:.*]] = constant 0 : index
-// CHECK: %[[VAL_9:.*]] = cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
+// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_9:.*]] = arith.cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
// CHECK: cond_br %[[VAL_9]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_10:.*]] = fir.convert %[[VAL_6]] : (index) -> i32
// CHECK: %[[VAL_11:.*]] = fir.call @f4(%[[VAL_10]]) : (i32) -> i1
-// CHECK: %[[VAL_12:.*]] = addi %[[VAL_6]], %[[VAL_2]] : index
-// CHECK: %[[VAL_13:.*]] = constant 1 : index
-// CHECK: %[[VAL_14:.*]] = subi %[[VAL_7]], %[[VAL_13]] : index
+// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_6]], %[[VAL_2]] : index
+// CHECK: %[[VAL_13:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_14:.*]] = arith.subi %[[VAL_7]], %[[VAL_13]] : index
// CHECK: br ^bb1(%[[VAL_12]], %[[VAL_14]] : index, index)
// CHECK: ^bb3:
// CHECK: return %[[VAL_6]] : index
// iterate_while that returns the final value of both inductions
func @y4(%lo : index, %up : index) -> index {
- %c1 = constant 1 : index
- %ok1 = constant true
+ %c1 = arith.constant 1 : index
+ %ok1 = arith.constant true
%v:2 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok2 = %ok1) -> (index, i1) {
%i1 = fir.convert %i : (index) -> i32
%ok = fir.call @f4(%i1) : (i32) -> i1
// CHECK-LABEL: func @y4(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = constant true
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant true
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]] : index, i1)
// CHECK: ^bb1(%[[VAL_4:.*]]: index, %[[VAL_5:.*]]: i1):
-// CHECK: %[[VAL_6:.*]] = constant 0 : index
-// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_2]] : index
-// CHECK: %[[VAL_8:.*]] = cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
-// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_6]] : index
-// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
-// CHECK: %[[VAL_11:.*]] = and %[[VAL_7]], %[[VAL_8]] : i1
-// CHECK: %[[VAL_12:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
-// CHECK: %[[VAL_13:.*]] = or %[[VAL_11]], %[[VAL_12]] : i1
-// CHECK: %[[VAL_14:.*]] = and %[[VAL_5]], %[[VAL_13]] : i1
+// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_2]] : index
+// CHECK: %[[VAL_8:.*]] = arith.cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
+// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_6]] : index
+// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
+// CHECK: %[[VAL_11:.*]] = arith.andi %[[VAL_7]], %[[VAL_8]] : i1
+// CHECK: %[[VAL_12:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
+// CHECK: %[[VAL_13:.*]] = arith.ori %[[VAL_11]], %[[VAL_12]] : i1
+// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_5]], %[[VAL_13]] : i1
// CHECK: cond_br %[[VAL_14]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_15:.*]] = fir.convert %[[VAL_4]] : (index) -> i32
// CHECK: %[[VAL_16:.*]] = fir.call @f4(%[[VAL_15]]) : (i32) -> i1
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_17]], %[[VAL_16]] : index, i1)
// CHECK: ^bb3:
// CHECK: return %[[VAL_4]] : index
// do_loop that returns the final induction value
// and an extra loop-carried value
func @x5(%lo : index, %up : index) -> index {
- %c1 = constant 1 : index
- %s1 = constant 42 : i16
+ %c1 = arith.constant 1 : index
+ %s1 = arith.constant 42 : i16
%v:2 = fir.do_loop %i = %lo to %up step %c1 iter_args(%s = %s1) -> (index, i16) {
%ok = fir.call @f2() : () -> i1
%s2 = fir.convert %ok : (i1) -> i16
// CHECK-LABEL: func @x5(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = constant 42 : i16
-// CHECK: %[[VAL_4:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
-// CHECK: %[[VAL_5:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
-// CHECK: %[[VAL_6:.*]] = divi_signed %[[VAL_5]], %[[VAL_2]] : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 42 : i16
+// CHECK: %[[VAL_4:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
+// CHECK: %[[VAL_5:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
+// CHECK: %[[VAL_6:.*]] = arith.divsi %[[VAL_5]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_6]] : index, i16, index)
// CHECK: ^bb1(%[[VAL_7:.*]]: index, %[[VAL_8:.*]]: i16, %[[VAL_9:.*]]: index):
-// CHECK: %[[VAL_10:.*]] = constant 0 : index
-// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
+// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_12:.*]] = fir.call @f2() : () -> i1
// CHECK: %[[VAL_13:.*]] = fir.convert %[[VAL_12]] : (i1) -> i16
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_7]], %[[VAL_2]] : index
-// CHECK: %[[VAL_15:.*]] = constant 1 : index
-// CHECK: %[[VAL_16:.*]] = subi %[[VAL_9]], %[[VAL_15]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_7]], %[[VAL_2]] : index
+// CHECK: %[[VAL_15:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_16:.*]] = arith.subi %[[VAL_9]], %[[VAL_15]] : index
// CHECK: br ^bb1(%[[VAL_14]], %[[VAL_13]], %[[VAL_16]] : index, i16, index)
// CHECK: ^bb3:
// CHECK: fir.call @f3(%[[VAL_8]]) : (i16) -> ()
// iterate_while that returns the both induction values
// and an extra loop-carried value
func @y5(%lo : index, %up : index) -> index {
- %c1 = constant 1 : index
- %s1 = constant 42 : i16
- %ok1 = constant true
+ %c1 = arith.constant 1 : index
+ %s1 = arith.constant 42 : i16
+ %ok1 = arith.constant true
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok2 = %ok1) iter_args(%s = %s1) -> (index, i1, i16) {
%ok = fir.call @f2() : () -> i1
%s2 = fir.convert %ok : (i1) -> i16
fir.result %i, %ok, %s2 : index, i1, i16
}
fir.if %v#1 {
- %arg = constant 0 : i32
+ %arg = arith.constant 0 : i32
%ok4 = fir.call @f4(%arg) : (i32) -> i1
}
fir.call @f3(%v#2) : (i16) -> ()
// CHECK-LABEL: func @y5(
// CHECK-SAME: %[[VAL_0:.*]]: index,
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = constant 42 : i16
-// CHECK: %[[VAL_4:.*]] = constant true
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 42 : i16
+// CHECK: %[[VAL_4:.*]] = arith.constant true
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_4]], %[[VAL_3]] : index, i1, i16)
// CHECK: ^bb1(%[[VAL_5:.*]]: index, %[[VAL_6:.*]]: i1, %[[VAL_7:.*]]: i16):
-// CHECK: %[[VAL_8:.*]] = constant 0 : index
-// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
-// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
-// CHECK: %[[VAL_11:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
-// CHECK: %[[VAL_12:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
-// CHECK: %[[VAL_13:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
-// CHECK: %[[VAL_14:.*]] = and %[[VAL_11]], %[[VAL_12]] : i1
-// CHECK: %[[VAL_15:.*]] = or %[[VAL_13]], %[[VAL_14]] : i1
-// CHECK: %[[VAL_16:.*]] = and %[[VAL_6]], %[[VAL_15]] : i1
+// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
+// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
+// CHECK: %[[VAL_11:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
+// CHECK: %[[VAL_12:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
+// CHECK: %[[VAL_13:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
+// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_11]], %[[VAL_12]] : i1
+// CHECK: %[[VAL_15:.*]] = arith.ori %[[VAL_13]], %[[VAL_14]] : i1
+// CHECK: %[[VAL_16:.*]] = arith.andi %[[VAL_6]], %[[VAL_15]] : i1
// CHECK: cond_br %[[VAL_16]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: %[[VAL_17:.*]] = fir.call @f2() : () -> i1
// CHECK: %[[VAL_18:.*]] = fir.convert %[[VAL_17]] : (i1) -> i16
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
// CHECK: br ^bb1(%[[VAL_19]], %[[VAL_17]], %[[VAL_18]] : index, i1, i16)
// CHECK: ^bb3:
// CHECK: cond_br %[[VAL_6]], ^bb4, ^bb5
// CHECK: ^bb4:
-// CHECK: %[[VAL_20:.*]] = constant 0 : i32
+// CHECK: %[[VAL_20:.*]] = arith.constant 0 : i32
// CHECK: %[[VAL_21:.*]] = fir.call @f4(%[[VAL_20]]) : (i32) -> i1
// CHECK: br ^bb5
// CHECK: ^bb5:
// RUN: fir-opt --cfg-conversion %s | FileCheck %s --check-prefix=NOOPT
func @x(%addr : !fir.ref<index>) {
- %bound = constant 452 : index
- %step = constant 1 : index
+ %bound = arith.constant 452 : index
+ %step = arith.constant 1 : index
fir.do_loop %iv = %bound to %bound step %step {
fir.call @y(%addr) : (!fir.ref<index>) -> ()
}
// CHECK-LABEL: func @x(
// CHECK-SAME: %[[VAL_0:.*]]: !fir.ref<index>) {
-// CHECK: %[[VAL_1:.*]] = constant 452 : index
-// CHECK: %[[VAL_2:.*]] = constant 1 : index
-// CHECK: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_1]] : index
-// CHECK: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
-// CHECK: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
-// CHECK: %[[VAL_6:.*]] = constant 0 : index
-// CHECK: %[[VAL_7:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_6]] : index
-// CHECK: %[[VAL_8:.*]] = constant 1 : index
+// CHECK: %[[VAL_1:.*]] = arith.constant 452 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_1]] : index
+// CHECK: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
+// CHECK: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_7:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_6]] : index
+// CHECK: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = select %[[VAL_7]], %[[VAL_8]], %[[VAL_5]] : index
// CHECK: br ^bb1(%[[VAL_1]], %[[VAL_9]] : index, index)
// CHECK: ^bb1(%[[VAL_10:.*]]: index, %[[VAL_11:.*]]: index):
-// CHECK: %[[VAL_12:.*]] = constant 0 : index
-// CHECK: %[[VAL_13:.*]] = cmpi sgt, %[[VAL_11]], %[[VAL_12]] : index
+// CHECK: %[[VAL_12:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_13:.*]] = arith.cmpi sgt, %[[VAL_11]], %[[VAL_12]] : index
// CHECK: cond_br %[[VAL_13]], ^bb2, ^bb3
// CHECK: ^bb2:
// CHECK: fir.call @y(%[[VAL_0]]) : (!fir.ref<index>) -> ()
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_10]], %[[VAL_2]] : index
-// CHECK: %[[VAL_15:.*]] = constant 1 : index
-// CHECK: %[[VAL_16:.*]] = subi %[[VAL_11]], %[[VAL_15]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_10]], %[[VAL_2]] : index
+// CHECK: %[[VAL_15:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_16:.*]] = arith.subi %[[VAL_11]], %[[VAL_15]] : index
// CHECK: br ^bb1(%[[VAL_14]], %[[VAL_16]] : index, index)
// CHECK: ^bb3:
// CHECK: return
// NOOPT-LABEL: func @x(
// NOOPT-SAME: %[[VAL_0:.*]]: !fir.ref<index>) {
-// NOOPT: %[[VAL_1:.*]] = constant 452 : index
-// NOOPT: %[[VAL_2:.*]] = constant 1 : index
-// NOOPT: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_1]] : index
-// NOOPT: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
-// NOOPT: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
+// NOOPT: %[[VAL_1:.*]] = arith.constant 452 : index
+// NOOPT: %[[VAL_2:.*]] = arith.constant 1 : index
+// NOOPT: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_1]] : index
+// NOOPT: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
+// NOOPT: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
// NOOPT: br ^bb1(%[[VAL_1]], %[[VAL_5]] : index, index)
// NOOPT: ^bb1(%[[VAL_6:.*]]: index, %[[VAL_7:.*]]: index):
-// NOOPT: %[[VAL_8:.*]] = constant 0 : index
-// NOOPT: %[[VAL_9:.*]] = cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
+// NOOPT: %[[VAL_8:.*]] = arith.constant 0 : index
+// NOOPT: %[[VAL_9:.*]] = arith.cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
// NOOPT: cond_br %[[VAL_9]], ^bb2, ^bb3
// NOOPT: ^bb2:
// NOOPT: fir.call @y(%[[VAL_0]]) : (!fir.ref<index>) -> ()
-// NOOPT: %[[VAL_10:.*]] = addi %[[VAL_6]], %[[VAL_2]] : index
-// NOOPT: %[[VAL_11:.*]] = constant 1 : index
-// NOOPT: %[[VAL_12:.*]] = subi %[[VAL_7]], %[[VAL_11]] : index
+// NOOPT: %[[VAL_10:.*]] = arith.addi %[[VAL_6]], %[[VAL_2]] : index
+// NOOPT: %[[VAL_11:.*]] = arith.constant 1 : index
+// NOOPT: %[[VAL_12:.*]] = arith.subi %[[VAL_7]], %[[VAL_11]] : index
// NOOPT: br ^bb1(%[[VAL_10]], %[[VAL_12]] : index, index)
// NOOPT: ^bb3:
// NOOPT: return
### Pre-requisites
-* A relatively recent Python3 installation
-* Installation of python dependencies as specified in
- `mlir/python/requirements.txt`
+* A relatively recent Python3 installation
+* Installation of python dependencies as specified in
+ `mlir/python/requirements.txt`
### CMake variables
-* **`MLIR_ENABLE_BINDINGS_PYTHON`**`:BOOL`
+* **`MLIR_ENABLE_BINDINGS_PYTHON`**`:BOOL`
- Enables building the Python bindings. Defaults to `OFF`.
+ Enables building the Python bindings. Defaults to `OFF`.
-* **`Python3_EXECUTABLE`**:`STRING`
+* **`Python3_EXECUTABLE`**:`STRING`
- Specifies the `python` executable used for the LLVM build, including for
- determining header/link flags for the Python bindings. On systems with
- multiple Python implementations, setting this explicitly to the preferred
- `python3` executable is strongly recommended.
+ Specifies the `python` executable used for the LLVM build, including for
+ determining header/link flags for the Python bindings. On systems with
+ multiple Python implementations, setting this explicitly to the preferred
+ `python3` executable is strongly recommended.
### Recommended development practices
export PYTHONPATH=$(cd build && pwd)/tools/mlir/python_packages/mlir_core
```
-Note that if you have installed (i.e. via `ninja install`, et al), then
-python packages for all enabled projects will be in your install tree under
+Note that if you have installed (i.e. via `ninja install`, et al), then python
+packages for all enabled projects will be in your install tree under
`python_packages/` (i.e. `python_packages/mlir_core`). Official distributions
are built with a more specialized setup.
There are likely two primary use cases for the MLIR python bindings:
-1. Support users who expect that an installed version of LLVM/MLIR will yield
- the ability to `import mlir` and use the API in a pure way out of the box.
+1. Support users who expect that an installed version of LLVM/MLIR will yield
+ the ability to `import mlir` and use the API in a pure way out of the box.
-1. Downstream integrations will likely want to include parts of the API in their
- private namespace or specially built libraries, probably mixing it with other
- python native bits.
+1. Downstream integrations will likely want to include parts of the API in
+ their private namespace or specially built libraries, probably mixing it
+ with other python native bits.
### Composable modules
composable modules that downstream integrators can include and re-export into
their own namespace if desired. This forces several design points:
-* Separate the construction/populating of a `py::module` from `PYBIND11_MODULE`
- global constructor.
+* Separate the construction/populating of a `py::module` from
+ `PYBIND11_MODULE` global constructor.
-* Introduce headers for C++-only wrapper classes as other related C++ modules
- will need to interop with it.
+* Introduce headers for C++-only wrapper classes as other related C++ modules
+ will need to interop with it.
-* Separate any initialization routines that depend on optional components into
- its own module/dependency (currently, things like `registerAllDialects` fall
- into this category).
+* Separate any initialization routines that depend on optional components into
+ its own module/dependency (currently, things like `registerAllDialects` fall
+ into this category).
There are a lot of co-related issues of shared library linkage, distribution
concerns, etc that affect such things. Organizing the code into composable
Examples:
-* `mlir.ir`
-* `mlir.passes` (`pass` is a reserved word :( )
-* `mlir.dialect`
-* `mlir.execution_engine` (aside from namespacing, it is important that
- "bulky"/optional parts like this are isolated)
+* `mlir.ir`
+* `mlir.passes` (`pass` is a reserved word :( )
+* `mlir.dialect`
+* `mlir.execution_engine` (aside from namespacing, it is important that
+ "bulky"/optional parts like this are isolated)
-In addition, initialization functions that imply optional dependencies should
-be in underscored (notionally private) modules such as `_init` and linked
+In addition, initialization functions that imply optional dependencies should be
+in underscored (notionally private) modules such as `_init` and linked
separately. This allows downstream integrators to completely customize what is
-included "in the box" and covers things like dialect registration,
-pass registration, etc.
+included "in the box" and covers things like dialect registration, pass
+registration, etc.
### Loader
other non-trivial native extensions. As such, the native extension (i.e. the
`.so`/`.pyd`/`.dylib`) is exported as a notionally private top-level symbol
(`_mlir`), while a small set of Python code is provided in
-`mlir/_cext_loader.py` and siblings which loads and re-exports it. This
-split provides a place to stage code that needs to prepare the environment
-*before* the shared library is loaded into the Python runtime, and also
-provides a place that one-time initialization code can be invoked apart from
-module constructors.
+`mlir/_cext_loader.py` and siblings which loads and re-exports it. This split
+provides a place to stage code that needs to prepare the environment *before*
+the shared library is loaded into the Python runtime, and also provides a place
+that one-time initialization code can be invoked apart from module constructors.
It is recommended to avoid using `__init__.py` files to the extent possible,
-until reaching a leaf package that represents a discrete component. The rule
-to keep in mind is that the presence of an `__init__.py` file prevents the
-ability to split anything at that level or below in the namespace into
-different directories, deployment packages, wheels, etc.
+until reaching a leaf package that represents a discrete component. The rule to
+keep in mind is that the presence of an `__init__.py` file prevents the ability
+to split anything at that level or below in the namespace into different
+directories, deployment packages, wheels, etc.
See the documentation for more information and advice:
https://packaging.python.org/guides/packaging-namespace-packages/
### Ownership in the Core IR
-There are several top-level types in the core IR that are strongly owned by their python-side reference:
+There are several top-level types in the core IR that are strongly owned by
+their python-side reference:
-* `PyContext` (`mlir.ir.Context`)
-* `PyModule` (`mlir.ir.Module`)
-* `PyOperation` (`mlir.ir.Operation`) - but with caveats
+* `PyContext` (`mlir.ir.Context`)
+* `PyModule` (`mlir.ir.Module`)
+* `PyOperation` (`mlir.ir.Operation`) - but with caveats
All other objects are dependent. All objects maintain a back-reference
(keep-alive) to their closest containing top-level object. Further, dependent
### Optionality and argument ordering in the Core IR
-The following types support being bound to the current thread as a context manager:
+The following types support being bound to the current thread as a context
+manager:
-* `PyLocation` (`loc: mlir.ir.Location = None`)
-* `PyInsertionPoint` (`ip: mlir.ir.InsertionPoint = None`)
-* `PyMlirContext` (`context: mlir.ir.Context = None`)
+* `PyLocation` (`loc: mlir.ir.Location = None`)
+* `PyInsertionPoint` (`ip: mlir.ir.InsertionPoint = None`)
+* `PyMlirContext` (`context: mlir.ir.Context = None`)
In order to support composability of function arguments, when these types appear
as arguments, they should always be the last and appear in the above order and
m.def("getContext", ...)
```
-### __repr__ methods
+### **repr** methods
-Things that have nice printed representations are really great :) If there is a
+Things that have nice printed representations are really great :) If there is a
reasonable printed form, it can be a significant productivity boost to wire that
to the `__repr__` method (and verify it with a [doctest](#sample-doctest)).
We use `lit` and `FileCheck` based tests:
-* For generative tests (those that produce IR), define a Python module that
- constructs/prints the IR and pipe it through `FileCheck`.
-* Parsing should be kept self-contained within the module under test by use of
- raw constants and an appropriate `parse_asm` call.
-* Any file I/O code should be staged through a tempfile vs relying on file
- artifacts/paths outside of the test module.
-* For convenience, we also test non-generative API interactions with the same
- mechanisms, printing and `CHECK`ing as needed.
+* For generative tests (those that produce IR), define a Python module that
+ constructs/prints the IR and pipe it through `FileCheck`.
+* Parsing should be kept self-contained within the module under test by use of
+ raw constants and an appropriate `parse_asm` call.
+* Any file I/O code should be staged through a tempfile vs relying on file
+ artifacts/paths outside of the test module.
+* For convenience, we also test non-generative API interactions with the same
+ mechanisms, printing and `CHECK`ing as needed.
### Sample FileCheck test
## Integration with ODS
The MLIR Python bindings integrate with the tablegen-based ODS system for
-providing user-friendly wrappers around MLIR dialects and operations. There
-are multiple parts to this integration, outlined below. Most details have
-been elided: refer to the build rules and python sources under `mlir.dialects`
-for the canonical way to use this facility.
+providing user-friendly wrappers around MLIR dialects and operations. There are
+multiple parts to this integration, outlined below. Most details have been
+elided: refer to the build rules and python sources under `mlir.dialects` for
+the canonical way to use this facility.
-Users are responsible for providing a `{DIALECT_NAMESPACE}.py` (or an
-equivalent directory with `__init__.py` file) as the entrypoint.
+Users are responsible for providing a `{DIALECT_NAMESPACE}.py` (or an equivalent
+directory with `__init__.py` file) as the entrypoint.
### Generating `_{DIALECT_NAMESPACE}_ops_gen.py` wrapper modules
### Extending the search path for wrapper modules
When the python bindings need to locate a wrapper module, they consult the
-`dialect_search_path` and use it to find an appropriately named module. For
-the main repository, this search path is hard-coded to include the
-`mlir.dialects` module, which is where wrappers are emitted by the abobe build
-rule. Out of tree dialects and add their modules to the search path by calling:
+`dialect_search_path` and use it to find an appropriately named module. For the
+main repository, this search path is hard-coded to include the `mlir.dialects`
+module, which is where wrappers are emitted by the abobe build rule. Out of tree
+dialects and add their modules to the search path by calling:
```python
mlir._cext.append_dialect_search_prefix("myproject.mlir.dialects")
The wrapper module tablegen emitter outputs:
-* A `_Dialect` class (extending `mlir.ir.Dialect`) with a `DIALECT_NAMESPACE`
- attribute.
-* An `{OpName}` class for each operation (extending `mlir.ir.OpView`).
-* Decorators for each of the above to register with the system.
+* A `_Dialect` class (extending `mlir.ir.Dialect`) with a `DIALECT_NAMESPACE`
+ attribute.
+* An `{OpName}` class for each operation (extending `mlir.ir.OpView`).
+* Decorators for each of the above to register with the system.
Note: In order to avoid naming conflicts, all internal names used by the wrapper
module are prefixed by `_ods_`.
Each concrete `OpView` subclass further defines several public-intended
attributes:
-* `OPERATION_NAME` attribute with the `str` fully qualified operation name
- (i.e. `std.absf`).
-* An `__init__` method for the *default builder* if one is defined or inferred
- for the operation.
-* `@property` getter for each operand or result (using an auto-generated name
- for unnamed of each).
-* `@property` getter, setter and deleter for each declared attribute.
+* `OPERATION_NAME` attribute with the `str` fully qualified operation name
+ (i.e. `math.abs`).
+* An `__init__` method for the *default builder* if one is defined or inferred
+ for the operation.
+* `@property` getter for each operand or result (using an auto-generated name
+ for unnamed of each).
+* `@property` getter, setter and deleter for each declared attribute.
It further emits additional private-intended attributes meant for subclassing
-and customization (default cases omit these attributes in favor of the
-defaults on `OpView`):
-
-* `_ODS_REGIONS`: A specification on the number and types of regions.
- Currently a tuple of (min_region_count, has_no_variadic_regions). Note that
- the API does some light validation on this but the primary purpose is to
- capture sufficient information to perform other default building and region
- accessor generation.
-* `_ODS_OPERAND_SEGMENTS` and `_ODS_RESULT_SEGMENTS`: Black-box value which
- indicates the structure of either the operand or results with respect to
- variadics. Used by `OpView._ods_build_default` to decode operand and result
- lists that contain lists.
+and customization (default cases omit these attributes in favor of the defaults
+on `OpView`):
+
+* `_ODS_REGIONS`: A specification on the number and types of regions.
+ Currently a tuple of (min_region_count, has_no_variadic_regions). Note that
+ the API does some light validation on this but the primary purpose is to
+ capture sufficient information to perform other default building and region
+ accessor generation.
+* `_ODS_OPERAND_SEGMENTS` and `_ODS_RESULT_SEGMENTS`: Black-box value which
+ indicates the structure of either the operand or results with respect to
+ variadics. Used by `OpView._ods_build_default` to decode operand and result
+ lists that contain lists.
#### Default Builder
Presently, only a single, default builder is mapped to the `__init__` method.
-The intent is that this `__init__` method represents the *most specific* of
-the builders typically generated for C++; however currently it is just the
-generic form below.
-
-* One argument for each declared result:
- * For single-valued results: Each will accept an `mlir.ir.Type`.
- * For variadic results: Each will accept a `List[mlir.ir.Type]`.
-* One argument for each declared operand or attribute:
- * For single-valued operands: Each will accept an `mlir.ir.Value`.
- * For variadic operands: Each will accept a `List[mlir.ir.Value]`.
- * For attributes, it will accept an `mlir.ir.Attribute`.
-* Trailing usage-specific, optional keyword arguments:
- * `loc`: An explicit `mlir.ir.Location` to use. Defaults to the location
- bound to the thread (i.e. `with Location.unknown():`) or an error if none
- is bound nor specified.
- * `ip`: An explicit `mlir.ir.InsertionPoint` to use. Default to the insertion
- point bound to the thread (i.e. `with InsertionPoint(...):`).
+The intent is that this `__init__` method represents the *most specific* of the
+builders typically generated for C++; however currently it is just the generic
+form below.
+
+* One argument for each declared result:
+ * For single-valued results: Each will accept an `mlir.ir.Type`.
+ * For variadic results: Each will accept a `List[mlir.ir.Type]`.
+* One argument for each declared operand or attribute:
+ * For single-valued operands: Each will accept an `mlir.ir.Value`.
+ * For variadic operands: Each will accept a `List[mlir.ir.Value]`.
+ * For attributes, it will accept an `mlir.ir.Attribute`.
+* Trailing usage-specific, optional keyword arguments:
+ * `loc`: An explicit `mlir.ir.Location` to use. Defaults to the location
+ bound to the thread (i.e. `with Location.unknown():`) or an error if
+ none is bound nor specified.
+ * `ip`: An explicit `mlir.ir.InsertionPoint` to use. Default to the
+ insertion point bound to the thread (i.e. `with InsertionPoint(...):`).
In addition, each `OpView` inherits a `build_generic` method which allows
construction via a (nested in the case of variadic) sequence of `results` and
`operands`. This can be used to get some default construction semantics for
-operations that are otherwise unsupported in Python, at the expense of having
-a very generic signature.
+operations that are otherwise unsupported in Python, at the expense of having a
+very generic signature.
#### Extending Generated Op Classes
provides some relatively simple examples.
As mentioned above, the build system generates Python sources like
-`_{DIALECT_NAMESPACE}_ops_gen.py` for each dialect with Python bindings. It
-is often desirable to to use these generated classes as a starting point for
-further customization, so an extension mechanism is provided to make this
-easy (you are always free to do ad-hoc patching in your `{DIALECT_NAMESPACE}.py`
-file but we prefer a more standard mechanism that is applied uniformly).
+`_{DIALECT_NAMESPACE}_ops_gen.py` for each dialect with Python bindings. It is
+often desirable to to use these generated classes as a starting point for
+further customization, so an extension mechanism is provided to make this easy
+(you are always free to do ad-hoc patching in your `{DIALECT_NAMESPACE}.py` file
+but we prefer a more standard mechanism that is applied uniformly).
To provide extensions, add a `_{DIALECT_NAMESPACE}_ops_ext.py` file to the
-`dialects` module (i.e. adjacent to your `{DIALECT_NAMESPACE}.py` top-level
-and the `*_ops_gen.py` file). Using the `builtin` dialect and `FuncOp` as an
+`dialects` module (i.e. adjacent to your `{DIALECT_NAMESPACE}.py` top-level and
+the `*_ops_gen.py` file). Using the `builtin` dialect and `FuncOp` as an
example, the generated code will include an import like this:
```python
See the `_ods_common.py` `extend_opview_class` function for details of the
mechanism. At a high level:
-* If the extension module exists, locate an extension class for the op (in
- this example, `FuncOp`):
- * First by looking for an attribute with the exact name in the extension
- module.
- * Falling back to calling a `select_opview_mixin(parent_opview_cls)`
- function defined in the extension module.
-* If a mixin class is found, a new subclass is dynamically created that multiply
- inherits from `({_builtin_ops_ext.FuncOp}, _builtin_ops_gen.FuncOp)`.
-
-The mixin class should not inherit from anything (i.e. directly extends
-`object` only). The facility is typically used to define custom `__init__`
-methods, properties, instance methods and static methods. Due to the
-inheritance ordering, the mixin class can act as though it extends the
-generated `OpView` subclass in most contexts (i.e.
-`issubclass(_builtin_ops_ext.FuncOp, OpView)` will return `False` but usage
-generally allows you treat it as duck typed as an `OpView`).
-
-There are a couple of recommendations, given how the class hierarchy is
-defined:
-
-* For static methods that need to instantiate the actual "leaf" op (which
- is dynamically generated and would result in circular dependencies to try
- to reference by name), prefer to use `@classmethod` and the concrete
- subclass will be provided as your first `cls` argument. See
- `_builtin_ops_ext.FuncOp.from_py_func` as an example.
-* If seeking to replace the generated `__init__` method entirely, you may
- actually want to invoke the super-super-class `mlir.ir.OpView` constructor
- directly, as it takes an `mlir.ir.Operation`, which is likely what you
- are constructing (i.e. the generated `__init__` method likely adds more
- API constraints than you want to expose in a custom builder).
+* If the extension module exists, locate an extension class for the op (in
+ this example, `FuncOp`):
+ * First by looking for an attribute with the exact name in the extension
+ module.
+ * Falling back to calling a `select_opview_mixin(parent_opview_cls)`
+ function defined in the extension module.
+* If a mixin class is found, a new subclass is dynamically created that
+ multiply inherits from `({_builtin_ops_ext.FuncOp},
+ _builtin_ops_gen.FuncOp)`.
+
+The mixin class should not inherit from anything (i.e. directly extends `object`
+only). The facility is typically used to define custom `__init__` methods,
+properties, instance methods and static methods. Due to the inheritance
+ordering, the mixin class can act as though it extends the generated `OpView`
+subclass in most contexts (i.e. `issubclass(_builtin_ops_ext.FuncOp, OpView)`
+will return `False` but usage generally allows you treat it as duck typed as an
+`OpView`).
+
+There are a couple of recommendations, given how the class hierarchy is defined:
+
+* For static methods that need to instantiate the actual "leaf" op (which is
+ dynamically generated and would result in circular dependencies to try to
+ reference by name), prefer to use `@classmethod` and the concrete subclass
+ will be provided as your first `cls` argument. See
+ `_builtin_ops_ext.FuncOp.from_py_func` as an example.
+* If seeking to replace the generated `__init__` method entirely, you may
+ actually want to invoke the super-super-class `mlir.ir.OpView` constructor
+ directly, as it takes an `mlir.ir.Operation`, which is likely what you are
+ constructing (i.e. the generated `__init__` method likely adds more API
+ constraints than you want to expose in a custom builder).
A pattern that comes up frequently is wanting to provide a sugared `__init__`
method which has optional or type-polymorphism/implicit conversions but to
-otherwise want to invoke the default op building logic. For such cases,
-it is recommended to use an idiom such as:
+otherwise want to invoke the default op building logic. For such cases, it is
+recommended to use an idiom such as:
```python
def __init__(self, sugar, spice, *, loc=None, ip=None):
## Requirements
-In order to use BufferDeallocation on an arbitrary dialect, several
-control-flow interfaces have to be implemented when using custom operations.
-This is particularly important to understand the implicit control-flow
-dependencies between different parts of the input program. Without implementing
-the following interfaces, control-flow relations cannot be discovered properly
-and the resulting program can become invalid:
-
-* Branch-like terminators should implement the `BranchOpInterface` to query and
-manipulate associated operands.
-* Operations involving structured control flow have to implement the
-`RegionBranchOpInterface` to model inter-region control flow.
-* Terminators yielding values to their parent operation (in particular in the
-scope of nested regions within `RegionBranchOpInterface`-based operations),
-should implement the `ReturnLike` trait to represent logical “value returns”.
-
-Example dialects that are fully compatible are the “std” and “scf” dialects
-with respect to all implemented interfaces.
+In order to use BufferDeallocation on an arbitrary dialect, several control-flow
+interfaces have to be implemented when using custom operations. This is
+particularly important to understand the implicit control-flow dependencies
+between different parts of the input program. Without implementing the following
+interfaces, control-flow relations cannot be discovered properly and the
+resulting program can become invalid:
+
+* Branch-like terminators should implement the `BranchOpInterface` to query
+ and manipulate associated operands.
+* Operations involving structured control flow have to implement the
+ `RegionBranchOpInterface` to model inter-region control flow.
+* Terminators yielding values to their parent operation (in particular in the
+ scope of nested regions within `RegionBranchOpInterface`-based operations),
+ should implement the `ReturnLike` trait to represent logical “value
+ returns”.
+
+Example dialects that are fully compatible are the “std” and “scf” dialects with
+respect to all implemented interfaces.
During Bufferization, we convert immutable value types (tensors) to mutable
types (memref). This conversion is done in several steps and in all of these
-steps the IR has to fulfill SSA like properties. The usage of memref has
-to be in the following consecutive order: allocation, write-buffer, read-
-buffer.
-In this case, there are only buffer reads allowed after the initial full
-buffer write is done. In particular, there must be no partial write to a
-buffer after the initial write has been finished. However, partial writes in
-the initializing is allowed (fill buffer step by step in a loop e.g.). This
-means, all buffer writes needs to dominate all buffer reads.
+steps the IR has to fulfill SSA like properties. The usage of memref has to be
+in the following consecutive order: allocation, write-buffer, read- buffer. In
+this case, there are only buffer reads allowed after the initial full buffer
+write is done. In particular, there must be no partial write to a buffer after
+the initial write has been finished. However, partial writes in the initializing
+is allowed (fill buffer step by step in a loop e.g.). This means, all buffer
+writes needs to dominate all buffer reads.
Example for breaking the invariant:
particular result value while not using the resource
`SideEffects::AutomaticAllocationScopeResource` (since it is currently reserved
for allocations, like `Alloca` that will be automatically deallocated by a
-parent scope). Allocations that have not been detected in this phase will not
-be tracked internally, and thus, not deallocated automatically. However,
-BufferDeallocation is fully compatible with “hybrid” setups in which tracked
-and untracked allocations are mixed:
+parent scope). Allocations that have not been detected in this phase will not be
+tracked internally, and thus, not deallocated automatically. However,
+BufferDeallocation is fully compatible with “hybrid” setups in which tracked and
+untracked allocations are mixed:
```mlir
func @mixedAllocation(%arg0: i1) {
- %0 = alloca() : memref<2xf32> // aliases: %2
- %1 = alloc() : memref<2xf32> // aliases: %2
+ %0 = memref.alloca() : memref<2xf32> // aliases: %2
+ %1 = memref.alloc() : memref<2xf32> // aliases: %2
cond_br %arg0, ^bb1, ^bb2
^bb1:
use(%0)
some cases, it can be useful to use such stack-based buffers instead of
heap-based buffers. The conversion is restricted to several constraints like:
-* Control flow
-* Buffer Size
-* Dynamic Size
+* Control flow
+* Buffer Size
+* Dynamic Size
-If a buffer is leaving a block, we are not allowed to convert it into an
-alloca. If the size of the buffer is large, we could convert it, but regarding
-stack overflow, it makes sense to limit the size of these buffers and only
-convert small ones. The size can be set via a pass option. The current default
-value is 1KB. Furthermore, we can not convert buffers with dynamic size, since
-the dimension is not known a priori.
+If a buffer is leaving a block, we are not allowed to convert it into an alloca.
+If the size of the buffer is large, we could convert it, but regarding stack
+overflow, it makes sense to limit the size of these buffers and only convert
+small ones. The size can be set via a pass option. The current default value is
+1KB. Furthermore, we can not convert buffers with dynamic size, since the
+dimension is not known a priori.
## Movement and Placement of Allocations
Using the buffer hoisting pass, all buffer allocations are moved as far upwards
as possible in order to group them and make upcoming optimizations easier by
-limiting the search space. Such a movement is shown in the following graphs.
-In addition, we are able to statically free an alloc, if we move it into a
-dominator of all of its uses. This simplifies further optimizations (e.g.
-buffer fusion) in the future. However, movement of allocations is limited by
-external data dependencies (in particular in the case of allocations of
-dynamically shaped types). Furthermore, allocations can be moved out of nested
-regions, if necessary. In order to move allocations to valid locations with
-respect to their uses only, we leverage Liveness information.
+limiting the search space. Such a movement is shown in the following graphs. In
+addition, we are able to statically free an alloc, if we move it into a
+dominator of all of its uses. This simplifies further optimizations (e.g. buffer
+fusion) in the future. However, movement of allocations is limited by external
+data dependencies (in particular in the case of allocations of dynamically
+shaped types). Furthermore, allocations can be moved out of nested regions, if
+necessary. In order to move allocations to valid locations with respect to their
+uses only, we leverage Liveness information.
The following code snippets shows a conditional branch before running the
BufferHoisting pass:
The alloc is moved from bb2 to the beginning and it is passed as an argument to
bb3.
-The following example demonstrates an allocation using dynamically shaped
-types. Due to the data dependency of the allocation to %0, we cannot move the
+The following example demonstrates an allocation using dynamically shaped types.
+Due to the data dependency of the allocation to %0, we cannot move the
allocation out of bb2 in this case:
```mlir
```
The first alloc can be safely freed after the live range of its post-dominator
-block (bb3). The alloc in bb1 has an alias %2 in bb3 that also keeps this
-buffer alive until the end of bb3. Since we cannot determine the actual
-branches that will be taken at runtime, we have to ensure that all buffers are
-freed correctly in bb3 regardless of the branches we will take to reach the
-exit block. This makes it necessary to introduce a copy for %2, which allows us
-to free %alloc0 in bb0 and %alloc1 in bb1. Afterwards, we can continue
-processing all aliases of %2 (none in this case) and we can safely free %2 at
-the end of the sample program. This sample demonstrates that not all
-allocations can be safely freed in their associated post-dominator blocks.
-Instead, we have to pay attention to all of their aliases.
+block (bb3). The alloc in bb1 has an alias %2 in bb3 that also keeps this buffer
+alive until the end of bb3. Since we cannot determine the actual branches that
+will be taken at runtime, we have to ensure that all buffers are freed correctly
+in bb3 regardless of the branches we will take to reach the exit block. This
+makes it necessary to introduce a copy for %2, which allows us to free %alloc0
+in bb0 and %alloc1 in bb1. Afterwards, we can continue processing all aliases of
+%2 (none in this case) and we can safely free %2 at the end of the sample
+program. This sample demonstrates that not all allocations can be safely freed
+in their associated post-dominator blocks. Instead, we have to pay attention to
+all of their aliases.
Applying the BufferDeallocation pass to the program above yields the following
result:
Note that a temporary buffer for %2 was introduced to free all allocations
properly. Note further that the unnecessary allocation of %3 can be easily
-removed using one of the post-pass transformations or the canonicalization
-pass.
+removed using one of the post-pass transformations or the canonicalization pass.
The presented example also works with dynamically shaped types.
tracked allocations into account. We initialize the general iteration process
using all tracked allocations and their associated aliases. As soon as we
encounter an alias that is not properly dominated by our allocation, we mark
-this alias as _critical_ (needs to be freed and tracked by the internal
-fix-point iteration). The following sample demonstrates the presence of
-critical and non-critical aliases:
+this alias as *critical* (needs to be freed and tracked by the internal
+fix-point iteration). The following sample demonstrates the presence of critical
+and non-critical aliases:

operation. Copies for block arguments are handled by analyzing all predecessor
blocks. This is primarily done by querying the `BranchOpInterface` of the
associated branch terminators that can jump to the current block. Consider the
-following example which involves a simple branch and the critical block
-argument %2:
+following example which involves a simple branch and the critical block argument
+%2:
```mlir
custom.br ^bb1(..., %0, : ...)
The `BranchOpInterface` allows us to determine the actual values that will be
passed to block bb1 and its argument %2 by analyzing its predecessor blocks.
Once we have resolved the values %0 and %1 (that are associated with %2 in this
-sample), we can introduce a temporary buffer and clone its contents into the
-new buffer. Afterwards, we rewire the branch operands to use the newly
-allocated buffer instead. However, blocks can have implicitly defined
-predecessors by parent ops that implement the `RegionBranchOpInterface`. This
-can be the case if this block argument belongs to the entry block of a region.
-In this setting, we have to identify all predecessor regions defined by the
-parent operation. For every region, we need to get all terminator operations
-implementing the `ReturnLike` trait, indicating that they can branch to our
-current block. Finally, we can use a similar functionality as described above
-to add the temporary copy. This time, we can modify the terminator operands
-directly without touching a high-level interface.
+sample), we can introduce a temporary buffer and clone its contents into the new
+buffer. Afterwards, we rewire the branch operands to use the newly allocated
+buffer instead. However, blocks can have implicitly defined predecessors by
+parent ops that implement the `RegionBranchOpInterface`. This can be the case if
+this block argument belongs to the entry block of a region. In this setting, we
+have to identify all predecessor regions defined by the parent operation. For
+every region, we need to get all terminator operations implementing the
+`ReturnLike` trait, indicating that they can branch to our current block.
+Finally, we can use a similar functionality as described above to add the
+temporary copy. This time, we can modify the terminator operands directly
+without touching a high-level interface.
Consider the following inner-region control-flow sample that uses an imaginary
-“custom.region_if” operation. It either executes the “then” or “else” region
-and always continues to the “join” region. The “custom.region_if_yield”
-operation returns a result to the parent operation. This sample demonstrates
-the use of the `RegionBranchOpInterface` to determine predecessors in order to
-infer the high-level control flow:
+“custom.region_if” operation. It either executes the “then” or “else” region and
+always continues to the “join” region. The “custom.region_if_yield” operation
+returns a result to the parent operation. This sample demonstrates the use of
+the `RegionBranchOpInterface` to determine predecessors in order to infer the
+high-level control flow:
```mlir
func @inner_region_control_flow(
```mlir
func @nested_region_control_flow(%arg0 : index, %arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi "eq", %arg0, %arg1 : index
+ %0 = arith.cmpi "eq", %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32> // %2 will be an alias of %1
```
In this example, a dealloc is inserted to release the buffer within the else
-block since it cannot be accessed by the remainder of the program. Accessing
-the `RegionBranchOpInterface`, allows us to infer that %2 is a non-critical
-alias of %1 which does not need to be tracked.
+block since it cannot be accessed by the remainder of the program. Accessing the
+`RegionBranchOpInterface`, allows us to infer that %2 is a non-critical alias of
+%1 which does not need to be tracked.
```mlir
func @nested_region_control_flow(%arg0: index, %arg1: index) -> memref<?x?xf32> {
- %0 = cmpi "eq", %arg0, %arg1 : index
+ %0 = arith.cmpi "eq", %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
Analogous to the previous case, we have to detect all terminator operations in
all attached regions of “scf.if” that provides a value to its parent operation
-(in this sample via scf.yield). Querying the `RegionBranchOpInterface` allows
-us to determine the regions that “return” a result to their parent operation.
-Like before, we have to update all `ReturnLike` terminators as described above.
+(in this sample via scf.yield). Querying the `RegionBranchOpInterface` allows us
+to determine the regions that “return” a result to their parent operation. Like
+before, we have to update all `ReturnLike` terminators as described above.
Reconsider a slightly adapted version of the “custom.region_if” example from
above that uses a nested allocation:
Since the allocation %2 happens in a divergent branch and cannot be safely
deallocated in a post-dominator, %arg4 will be considered a critical alias.
-Furthermore, %arg4 is returned to its parent operation and has an alias %1.
-This causes BufferDeallocation to introduce additional copies:
+Furthermore, %arg4 is returned to its parent operation and has an alias %1. This
+causes BufferDeallocation to introduce additional copies:
```mlir
func @inner_region_control_flow_div(
after the last use of the given value. The position can be determined by
calculating the common post-dominator of all values using their remaining
non-critical aliases. A special-case is the presence of back edges: since such
-edges can cause memory leaks when a newly allocated buffer flows back to
-another part of the program. In these cases, we need to free the associated
-buffer instances from the previous iteration by inserting additional deallocs.
+edges can cause memory leaks when a newly allocated buffer flows back to another
+part of the program. In these cases, we need to free the associated buffer
+instances from the previous iteration by inserting additional deallocs.
Consider the following “scf.for” use case containing a nested structured
control-flow if:
%res: memref<2xf32>) {
%0 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %1 = cmpi "eq", %i, %ub : index
+ %1 = arith.cmpi "eq", %i, %ub : index
%2 = scf.if %1 -> (memref<2xf32>) {
%3 = memref.alloc() : memref<2xf32> // makes %2 a critical alias due to a
// divergent allocation
}
```
-In this example, the _then_ branch of the nested “scf.if” operation returns a
+In this example, the *then* branch of the nested “scf.if” operation returns a
newly allocated buffer.
Since this allocation happens in the scope of a divergent branch, %2 becomes a
-critical alias that needs to be handled. As before, we have to insert
-additional copies to eliminate this alias using copies of %3 and %iterBuf. This
-guarantees that %2 will be a newly allocated buffer that is returned in each
-iteration. However, “returning” %2 to its alias %iterBuf turns %iterBuf into a
-critical alias as well. In other words, we have to create a copy of %2 to pass
-it to %iterBuf. Since this jump represents a back edge, and %2 will always be a
-new buffer, we have to free the buffer from the previous iteration to avoid
-memory leaks:
+critical alias that needs to be handled. As before, we have to insert additional
+copies to eliminate this alias using copies of %3 and %iterBuf. This guarantees
+that %2 will be a newly allocated buffer that is returned in each iteration.
+However, “returning” %2 to its alias %iterBuf turns %iterBuf into a critical
+alias as well. In other words, we have to create a copy of %2 to pass it to
+%iterBuf. Since this jump represents a back edge, and %2 will always be a new
+buffer, we have to free the buffer from the previous iteration to avoid memory
+leaks:
```mlir
func @loop_nested_if(
%4 = memref.clone %buf : (memref<2xf32>) -> (memref<2xf32>)
%0 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %4) -> memref<2xf32> {
- %1 = cmpi "eq", %i, %ub : index
+ %1 = arith.cmpi "eq", %i, %ub : index
%2 = scf.if %1 -> (memref<2xf32>) {
%3 = memref.alloc() : memref<2xf32> // makes %2 a critical alias
use(%3)
If these clones appear with their corresponding dealloc operation within the
same block, we can use the canonicalizer to remove these unnecessary operations.
Note, that this step needs to take place after the insertion of clones and
-deallocs in the buffer deallocation step. The canonicalization inludes both,
-the newly created target value from the clone operation and the source
-operation.
+deallocs in the buffer deallocation step. The canonicalization inludes both, the
+newly created target value from the clone operation and the source operation.
## Canonicalization of the Source Buffer of the Clone Operation
operation is also removed.
Consider the following example where a generic test operation writes the result
-to %temp and then copies %temp to %result. However, these two operations
-can be merged into a single step. Canonicalization removes the clone operation
-and %temp, and replaces the uses of %temp with %result:
+to %temp and then copies %temp to %result. However, these two operations can be
+merged into a single step. Canonicalization removes the clone operation and
+%temp, and replaces the uses of %temp with %result:
```mlir
func @reuseTarget(%arg0: memref<2xf32>, %result: memref<2xf32>){
indexing_maps = [#map0, #map0],
iterator_types = ["parallel"]} %arg0, %temp {
^bb0(%gen2_arg0: f32, %gen2_arg1: f32):
- %tmp2 = exp %gen2_arg0 : f32
+ %tmp2 = math.exp %gen2_arg0 : f32
test.yield %tmp2 : f32
}: memref<2xf32>, memref<2xf32>
%result = memref.clone %temp : (memref<2xf32>) -> (memref<2xf32>)
indexing_maps = [#map0, #map0],
iterator_types = ["parallel"]} %arg0, %result {
^bb0(%gen2_arg0: f32, %gen2_arg1: f32):
- %tmp2 = exp %gen2_arg0 : f32
+ %tmp2 = math.exp %gen2_arg0 : f32
test.yield %tmp2 : f32
}: memref<2xf32>, memref<2xf32>
return
BufferDeallocation introduces additional clones from “memref” dialect
(“memref.clone”). Analogous, all deallocations use the “memref” dialect-free
operation “memref.dealloc”. The actual copy process is realized using
-“test.copy”. Furthermore, buffers are essentially immutable after their
-creation in a block. Another limitations are known in the case using
-unstructered control flow.
+“test.copy”. Furthermore, buffers are essentially immutable after their creation
+in a block. Another limitations are known in the case using unstructered control
+flow.
Bufferization in MLIR is the process of converting the `tensor` type to the
`memref` type. MLIR provides a composable system that allows dialects to
-systematically bufferize a program. This system is a simple application
-of MLIR's [dialect conversion](DialectConversion.md) infrastructure. The bulk of
+systematically bufferize a program. This system is a simple application of
+MLIR's [dialect conversion](DialectConversion.md) infrastructure. The bulk of
the code related to bufferization is a set of ordinary `ConversionPattern`'s
that dialect authors write for converting ops that operate on `tensor`'s to ops
that operate on `memref`'s. A set of conventions and best practices are followed
w.r.t. control flow. Thus, a realistic compilation pipeline will usually consist
of:
-1. Bufferization
-1. Buffer optimizations such as `buffer-hoisting`, `buffer-loop-hoisting`, and
- `promote-buffers-to-stack`, which do optimizations that are only exposed
- after bufferization.
-1. Finally, running the [buffer deallocation](BufferDeallocationInternals.md) pass.
+1. Bufferization
+1. Buffer optimizations such as `buffer-hoisting`, `buffer-loop-hoisting`, and
+ `promote-buffers-to-stack`, which do optimizations that are only exposed
+ after bufferization.
+1. Finally, running the [buffer deallocation](BufferDeallocationInternals.md)
+ pass.
After buffer deallocation has been completed, the program will be quite
difficult to transform due to the presence of the deallocation ops. Thus, other
## General structure of the bufferization process
-Bufferization consists of running multiple _partial_ bufferization passes,
-followed by one _finalizing_ bufferization pass.
+Bufferization consists of running multiple *partial* bufferization passes,
+followed by one *finalizing* bufferization pass.
There is typically one partial bufferization pass per dialect (though other
subdivisions are possible). For example, for a dialect `X` there will typically
in the program are incrementally bufferized.
Partial bufferization passes create programs where only some ops have been
-bufferized. These passes will create _materializations_ (also sometimes called
+bufferized. These passes will create *materializations* (also sometimes called
"casts") that convert between the `tensor` and `memref` type, which allows
bridging between ops that have been bufferized and ops that have not yet been
bufferized.
```
The pass has all the hallmarks of a dialect conversion pass that does type
-conversions: a `TypeConverter`, a `RewritePatternSet`, and a
-`ConversionTarget`, and a call to `applyPartialConversion`. Note that a function
+conversions: a `TypeConverter`, a `RewritePatternSet`, and a `ConversionTarget`,
+and a call to `applyPartialConversion`. Note that a function
`populateTensorBufferizePatterns` is separated, so that power users can use the
patterns independently, if necessary (such as to combine multiple sets of
conversion patterns into a single conversion call, for performance).
`BufferizeTypeConverter`, which comes pre-loaded with the necessary conversions
and materializations between `tensor` and `memref`.
-In this case, the `MemRefOpsDialect` is marked as legal, so the `tensor_load`
-and `buffer_cast` ops, which are inserted automatically by the dialect
-conversion framework as materializations, are legal. There is a helper
-`populateBufferizeMaterializationLegality`
+In this case, the `MemRefOpsDialect` is marked as legal, so the
+`memref.tensor_load` and `memref.buffer_cast` ops, which are inserted
+automatically by the dialect conversion framework as materializations, are
+legal. There is a helper `populateBufferizeMaterializationLegality`
([code](https://github.com/llvm/llvm-project/blob/a0b65a7bcd6065688189b3d678c42ed6af9603db/mlir/include/mlir/Transforms/Bufferize.h#L53))
which helps with this in general.
### Other partial bufferization examples
-- `linalg-bufferize`
- ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L1),
- [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Linalg/bufferize.mlir#L1))
-
- - Bufferizes the `linalg` dialect.
- - This is an example of how to simultaneously bufferize all the ops that
- satisfy a certain OpInterface with a single pattern. Specifically,
- `BufferizeAnyLinalgOp`
- ([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L170))
- bufferizes any ops that implements the `LinalgOp` interface.
-
-- `scf-bufferize`
- ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/SCF/Transforms/Bufferize.cpp#L1),
- [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/SCF/bufferize.mlir#L1))
-
- - Bufferizes ops from the `scf` dialect.
- - This is an example of how to bufferize ops that implement
- `RegionBranchOpInterface` (that is, they use regions to represent control
- flow).
- - The bulk of the work is done by
- `lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp`
- ([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp#L1)),
- which is well-commented and covers how to correctly convert ops that contain
- regions.
-
-- `func-bufferize`
- ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/FuncBufferize.cpp#L1),
- [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/func-bufferize.mlir#L1))
-
- - Bufferizes `func`, `call`, and `BranchOpInterface` ops.
- - This is an example of how to bufferize ops that have multi-block regions.
- - This is an example of a pass that is not split along dialect subdivisions.
-
-- `tensor-constant-bufferize`
- ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/TensorConstantBufferize.cpp#L1),
- [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/tensor-constant-bufferize.mlir#L1))
- - Bufferizes only `std.constant` ops of `tensor` type.
- - This is an example of setting up the legality so that only a subset of
- `std.constant` ops get bufferized.
- - This is an example of a pass that is not split along dialect subdivisions.
+- `linalg-bufferize`
+ ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L1),
+ [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Linalg/bufferize.mlir#L1))
+
+ - Bufferizes the `linalg` dialect.
+ - This is an example of how to simultaneously bufferize all the ops that
+ satisfy a certain OpInterface with a single pattern. Specifically,
+ `BufferizeAnyLinalgOp`
+ ([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L170))
+ bufferizes any ops that implements the `LinalgOp` interface.
+
+- `scf-bufferize`
+ ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/SCF/Transforms/Bufferize.cpp#L1),
+ [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/SCF/bufferize.mlir#L1))
+
+ - Bufferizes ops from the `scf` dialect.
+ - This is an example of how to bufferize ops that implement
+ `RegionBranchOpInterface` (that is, they use regions to represent
+ control flow).
+ - The bulk of the work is done by
+ `lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp`
+ ([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp#L1)),
+ which is well-commented and covers how to correctly convert ops that
+ contain regions.
+
+- `func-bufferize`
+ ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/FuncBufferize.cpp#L1),
+ [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/func-bufferize.mlir#L1))
+
+ - Bufferizes `func`, `call`, and `BranchOpInterface` ops.
+ - This is an example of how to bufferize ops that have multi-block
+ regions.
+ - This is an example of a pass that is not split along dialect
+ subdivisions.
+
+- `tensor-constant-bufferize`
+ ([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/TensorConstantBufferize.cpp#L1),
+ [test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/tensor-constant-bufferize.mlir#L1))
+
+ - Bufferizes only `arith.constant` ops of `tensor` type.
+ - This is an example of setting up the legality so that only a subset of
+ `std.constant` ops get bufferized.
+ - This is an example of a pass that is not split along dialect
+ subdivisions.
## How to write a finalizing bufferization pass
from the program.
The easiest way to write a finalizing bufferize pass is to not write one at all!
-MLIR provides a pass `finalizing-bufferize` which eliminates the `tensor_load` /
-`buffer_cast` materialization ops inserted by partial bufferization passes
-and emits an error if that is not sufficient to remove all tensors from the
-program.
+MLIR provides a pass `finalizing-bufferize` which eliminates the
+`memref.tensor_load` / `memref.buffer_cast` materialization ops inserted by
+partial bufferization passes and emits an error if that is not sufficient to
+remove all tensors from the program.
This pass is sufficient when partial bufferization passes have bufferized all
the ops in the program, leaving behind only the materializations. When possible,
unbufferized op.
However, before the current bufferization infrastructure was put in place,
-bufferization could only be done as a single finalizing bufferization
-mega-pass that used the `populate*BufferizePatterns` functions from multiple
-dialects to simultaneously bufferize everything at once. Thus, one might see
-code in downstream projects structured this way. This structure is not
-recommended in new code. A helper,
-`populateEliminateBufferizeMaterializationsPatterns`
+bufferization could only be done as a single finalizing bufferization mega-pass
+that used the `populate*BufferizePatterns` functions from multiple dialects to
+simultaneously bufferize everything at once. Thus, one might see code in
+downstream projects structured this way. This structure is not recommended in
+new code. A helper, `populateEliminateBufferizeMaterializationsPatterns`
([code](https://github.com/llvm/llvm-project/blob/a0b65a7bcd6065688189b3d678c42ed6af9603db/mlir/include/mlir/Transforms/Bufferize.h#L58))
-is available for such passes to provide patterns that eliminate `tensor_load`
-and `buffer_cast`.
+is available for such passes to provide patterns that eliminate
+`memref.tensor_load` and `memref.buffer_cast`.
## Changes since [the talk](#the-talk)
-- `func-bufferize` was changed to be a partial conversion pass, and there is a
- new `finalizing-bufferize` which serves as a general finalizing bufferization
- pass.
+- `func-bufferize` was changed to be a partial conversion pass, and there is a
+ new `finalizing-bufferize` which serves as a general finalizing
+ bufferization pass.
A declarative rewrite rule contains two main components:
-* A _source pattern_, which is used for matching a DAG of operations.
-* One or more _result patterns_, which are used for generating DAGs of
+* A *source pattern*, which is used for matching a DAG of operations.
+* One or more *result patterns*, which are used for generating DAGs of
operations to replace the matched DAG of operations.
We allow multiple result patterns to support
##### `NativeCodeCall` placeholders
In `NativeCodeCall`, we can use placeholders like `$_builder`, `$N` and `$N...`.
-The former is called _special placeholder_, while the latter is called
-_positional placeholder_ and _positional range placeholder_.
+The former is called *special placeholder*, while the latter is called
+*positional placeholder* and *positional range placeholder*.
`NativeCodeCall` right now only supports three special placeholders:
`$_builder`, `$_loc`, and `$_self`:
```
In the above, `$_self` is substituted by the defining operation of the first
-operand of OneAttrOp. Note that we don't support binding name to `NativeCodeCall`
-in the source pattern. To carry some return values from a helper function, put the
-names (constraint is optional) in the parameter list and they will be bound to
-the variables with correspoding type. Then these names must be either passed by
-reference or pointer to the variable used as argument so that the matched value
-can be returned. In the same example, `$val` will be bound to a variable with
-`Attribute` type (as `I32Attr`) and the type of the second argument in `Foo()`
-could be `Attribute&` or `Attribute*`. Names with attribute constraints will be
-captured as `Attribute`s while everything else will be treated as `Value`s.
+operand of OneAttrOp. Note that we don't support binding name to
+`NativeCodeCall` in the source pattern. To carry some return values from a
+helper function, put the names (constraint is optional) in the parameter list
+and they will be bound to the variables with correspoding type. Then these names
+must be either passed by reference or pointer to the variable used as argument
+so that the matched value can be returned. In the same example, `$val` will be
+bound to a variable with `Attribute` type (as `I32Attr`) and the type of the
+second argument in `Foo()` could be `Attribute&` or `Attribute*`. Names with
+attribute constraints will be captured as `Attribute`s while everything else
+will be treated as `Value`s.
Positional placeholders will be substituted by the `dag` object parameters at
the `NativeCodeCall` use site. For example, if we define `SomeCall :
The correct number of returned value specified in NativeCodeCall is important.
It will be used to verify the consistency of the number of return values.
Additionally, `mlir-tblgen` will try to capture the return values of
-`NativeCodeCall` in the generated code so that it will trigger a later compilation
-error if a `NativeCodeCall` that doesn't return any result isn't labeled with 0
-returns.
+`NativeCodeCall` in the generated code so that it will trigger a later
+compilation error if a `NativeCodeCall` that doesn't return any result isn't
+labeled with 0 returns.
##### Customizing entire op building
### Supporting auxiliary ops
A declarative rewrite rule supports multiple result patterns. One of the
-purposes is to allow generating _auxiliary ops_. Auxiliary ops are operations
+purposes is to allow generating *auxiliary ops*. Auxiliary ops are operations
used for building the replacement ops; but they are not directly used for
replacement themselves.
want to allocate memory and store some computation (in pseudocode):
```mlir
-%dst = addi %lhs, %rhs
+%dst = arith.addi %lhs, %rhs
```
into
```mlir
%shape = shape %lhs
-%mem = alloc %shape
-%sum = addi %lhs, %rhs
-store %mem, %sum
-%dst = load %mem
+%mem = memref.alloc %shape
+%sum = arith.addi %lhs, %rhs
+memref.store %mem, %sum
+%dst = memref.load %mem
```
We cannot fit in with just one result pattern given `store` does not return a
Before going into details on variadic op support, we need to define a few terms
regarding an op's values.
-* _Value_: either an operand or a result
-* _Declared operand/result/value_: an operand/result/value statically declared
+* *Value*: either an operand or a result
+* *Declared operand/result/value*: an operand/result/value statically declared
in ODS of the op
-* _Actual operand/result/value_: an operand/result/value of an op instance at
+* *Actual operand/result/value*: an operand/result/value of an op instance at
runtime
The above terms are needed because ops can have multiple results, and some of
The `returnType` directive must be used as a trailing argument to a node
describing a replacement op. The directive comes in three forms:
-* `(returnType $value)`: copy the type of the operand or result bound to
- `value`.
-* `(returnType "$_builder.getI32Type()")`: a string literal embedding C++. The
- embedded snippet is expected to return a `Type` or a `TypeRange`.
-* `(returnType (NativeCodeCall<"myFunc($0)"> $value))`: a DAG node with a native
- code call that can be passed any bound variables arguments.
+* `(returnType $value)`: copy the type of the operand or result bound to
+ `value`.
+* `(returnType "$_builder.getI32Type()")`: a string literal embedding C++. The
+ embedded snippet is expected to return a `Type` or a `TypeRange`.
+* `(returnType (NativeCodeCall<"myFunc($0)"> $value))`: a DAG node with a
+ native code call that can be passed any bound variables arguments.
Specify multiple return types with a mix of any of the above. Example:
// Expect an error on an adjacent line.
func @foo(%a : f32) {
// expected-error@+1 {{unknown comparison predicate "foo"}}
- %result = cmpf "foo", %a, %a : f32
+ %result = arith.cmpf "foo", %a, %a : f32
return
}
- This action signals that only some instances of a given operation are
legal. This allows for defining fine-tune constraints, e.g. saying that
- `addi` is only legal when operating on 32-bit integers.
+ `arith.addi` is only legal when operating on 32-bit integers.
* Illegal
### Dimensions and Symbols
Dimensions and symbols are the two kinds of identifiers that can appear in the
-polyhedral structures, and are always of [`index`](Builtin.md/#indextype)
-type. Dimensions are declared in parentheses and symbols are declared in square
+polyhedral structures, and are always of [`index`](Builtin.md/#indextype) type.
+Dimensions are declared in parentheses and symbols are declared in square
brackets.
Examples:
```mlir
#affine_map2to3 = affine_map<(d0, d1)[s0] -> (d0, d1 + s0, d1 - s0)>
// Binds %N to the s0 symbol in affine_map2to3.
-%x = alloc()[%N] : memref<40x50xf32, #affine_map2to3>
+%x = memref.alloc()[%N] : memref<40x50xf32, #affine_map2to3>
```
### Restrictions on Dimensions and Symbols
The affine dialect imposes certain restrictions on dimension and symbolic
identifiers to enable powerful analysis and transformation. An SSA value's use
-can be bound to a symbolic identifier if that SSA value is either
-1. a region argument for an op with trait `AffineScope` (eg. `FuncOp`),
-2. a value defined at the top level of an `AffineScope` op (i.e., immediately
-enclosed by the latter),
-3. a value that dominates the `AffineScope` op enclosing the value's use,
-4. the result of a [`constant` operation](Standard.md/#stdconstant-constantop),
-5. the result of an [`affine.apply`
-operation](#affineapply-affineapplyop) that recursively takes as arguments any valid
-symbolic identifiers, or
-6. the result of a [`dim` operation](MemRef.md/#memrefdim-mlirmemrefdimop) on either a
-memref that is an argument to a `AffineScope` op or a memref where the
-corresponding dimension is either static or a dynamic one in turn bound to a
-valid symbol.
+can be bound to a symbolic identifier if that SSA value is either 1. a region
+argument for an op with trait `AffineScope` (eg. `FuncOp`), 2. a value defined
+at the top level of an `AffineScope` op (i.e., immediately enclosed by the
+latter), 3. a value that dominates the `AffineScope` op enclosing the value's
+use, 4. the result of a
+[`constant` operation](Standard.md/#stdconstant-constantop), 5. the result of an
+[`affine.apply` operation](#affineapply-affineapplyop) that recursively takes as
+arguments any valid symbolic identifiers, or 6. the result of a
+[`dim` operation](MemRef.md/#memrefdim-mlirmemrefdimop) on either a memref that
+is an argument to a `AffineScope` op or a memref where the corresponding
+dimension is either static or a dynamic one in turn bound to a valid symbol.
*Note:* if the use of an SSA value is not contained in any op with the
`AffineScope` trait, only the rules 4-6 can be applied.
Note that as a result of rule (3) above, symbol validity is sensitive to the
-location of the SSA use. Dimensions may be bound not only to anything that a
+location of the SSA use. Dimensions may be bound not only to anything that a
symbol is bound to, but also to induction variables of enclosing
[`affine.for`](#affinefor-affineforop) and
-[`affine.parallel`](#affineparallel-affineparallelop) operations, and the result of an
-[`affine.apply` operation](#affineapply-affineapplyop) (which recursively may use
-other dimensions and symbols).
+[`affine.parallel`](#affineparallel-affineparallelop) operations, and the result
+of an [`affine.apply` operation](#affineapply-affineapplyop) (which recursively
+may use other dimensions and symbols).
### Affine Expressions
ceildiv, and (4) addition and subtraction. All of these operators associate from
left to right.
-A _multidimensional affine expression_ is a comma separated list of
+A *multidimensional affine expression* is a comma separated list of
one-dimensional affine expressions, with the entire list enclosed in
parentheses.
**Context:** An affine function, informally, is a linear function plus a
constant. More formally, a function f defined on a vector $\vec{v} \in
-\mathbb{Z}^n$ is a multidimensional affine function of $\vec{v}$ if
-$f(\vec{v})$ can be expressed in the form $M \vec{v} + \vec{c}$ where $M$
-is a constant matrix from $\mathbb{Z}^{m \times n}$ and $\vec{c}$ is a
-constant vector from $\mathbb{Z}$. $m$ is the dimensionality of such an
-affine function. MLIR further extends the definition of an affine function to
-allow 'floordiv', 'ceildiv', and 'mod' with respect to positive integer
-constants. Such extensions to affine functions have often been referred to as
-quasi-affine functions by the polyhedral compiler community. MLIR uses the term
-'affine map' to refer to these multidimensional quasi-affine functions. As
-examples, $(i+j+1, j)$, $(i \mod 2, j+i)$, $(j, i/4, i \mod 4)$, $(2i+1,
-j)$ are two-dimensional affine functions of $(i, j)$, but $(i \cdot j,
-i^2)$, $(i \mod j, i/j)$ are not affine functions of $(i, j)$.
+\mathbb{Z}^n$ is a multidimensional affine function of $\vec{v}$ if $f(\vec{v})$
+can be expressed in the form $M \vec{v} + \vec{c}$ where $M$ is a constant
+matrix from $\mathbb{Z}^{m \times n}$ and $\vec{c}$ is a constant vector from
+$\mathbb{Z}$. $m$ is the dimensionality of such an affine function. MLIR further
+extends the definition of an affine function to allow 'floordiv', 'ceildiv', and
+'mod' with respect to positive integer constants. Such extensions to affine
+functions have often been referred to as quasi-affine functions by the
+polyhedral compiler community. MLIR uses the term 'affine map' to refer to these
+multidimensional quasi-affine functions. As examples, $(i+j+1, j)$, $(i \mod 2,
+j+i)$, $(j, i/4, i \mod 4)$, $(2i+1, j)$ are two-dimensional affine functions of
+$(i, j)$, but $(i \cdot j, i^2)$, $(i \mod j, i/j)$ are not affine functions of
+$(i, j)$.
### Affine Maps
combining the indices and symbols. Affine maps distinguish between
[indices and symbols](#dimensions-and-symbols) because indices are inputs to the
affine map when the map is called (through an operation such as
-[affine.apply](#affineapply-affineapplyop)), whereas symbols are bound when
-the map is established (e.g. when a memref is formed, establishing a
-memory [layout map](Builtin.md/#layout-map)).
+[affine.apply](#affineapply-affineapplyop)), whereas symbols are bound when the
+map is established (e.g. when a memref is formed, establishing a memory
+[layout map](Builtin.md/#layout-map)).
Affine maps are used for various core structures in MLIR. The restrictions we
impose on their form allows powerful analysis and transformation, while keeping
// Use an affine mapping definition in an alloc operation, binding the
// SSA value %N to the symbol s0.
-%a = alloc()[%N] : memref<4x4xf32, #affine_map42>
+%a = memref.alloc()[%N] : memref<4x4xf32, #affine_map42>
// Same thing with an inline affine mapping definition.
-%b = alloc()[%N] : memref<4x4xf32, affine_map<(d0, d1)[s0] -> (d0, d0 + d1 + s0 floordiv 2)>>
+%b = memref.alloc()[%N] : memref<4x4xf32, affine_map<(d0, d1)[s0] -> (d0, d0 + d1 + s0 floordiv 2)>>
```
### Semi-affine maps
The `affine.dma_start` op starts a non-blocking DMA operation that transfers
data from a source memref to a destination memref. The source and destination
memref need not be of the same dimensionality, but need to have the same
-elemental type. The operands include the source and destination memref's
-each followed by its indices, size of the data transfer in terms of the
-number of elements (of the elemental type of the memref), a tag memref with
-its indices, and optionally at the end, a stride and a
-number_of_elements_per_stride arguments. The tag location is used by an
-AffineDmaWaitOp to check for completion. The indices of the source memref,
-destination memref, and the tag memref have the same restrictions as any
-affine.load/store. In particular, index for each memref dimension must be an
-affine expression of loop induction variables and symbols.
-The optional stride arguments should be of 'index' type, and specify a
-stride for the slower memory space (memory space with a lower memory space
-id), transferring chunks of number_of_elements_per_stride every stride until
-%num_elements are transferred. Either both or no stride arguments should be
-specified. The value of 'num_elements' must be a multiple of
+elemental type. The operands include the source and destination memref's each
+followed by its indices, size of the data transfer in terms of the number of
+elements (of the elemental type of the memref), a tag memref with its indices,
+and optionally at the end, a stride and a number_of_elements_per_stride
+arguments. The tag location is used by an AffineDmaWaitOp to check for
+completion. The indices of the source memref, destination memref, and the tag
+memref have the same restrictions as any affine.load/store. In particular, index
+for each memref dimension must be an affine expression of loop induction
+variables and symbols. The optional stride arguments should be of 'index' type,
+and specify a stride for the slower memory space (memory space with a lower
+memory space id), transferring chunks of number_of_elements_per_stride every
+stride until %num_elements are transferred. Either both or no stride arguments
+should be specified. The value of 'num_elements' must be a multiple of
'number_of_elements_per_stride'.
-
Example:
```mlir
space 1 at indices [%k + 7, %l], would be specified as follows:
%num_elements = constant 256
- %idx = constant 0 : index
- %tag = alloc() : memref<1xi32, 4>
+ %idx = arith.constant 0 : index
+ %tag = memref.alloc() : memref<1xi32, 4>
affine.dma_start %src[%i + 3, %j], %dst[%k + 7, %l], %tag[%idx],
%num_elements :
memref<40x128xf32, 0>, memref<2x1024xf32, 1>, memref<1xi32, 2>
```
The `affine.dma_start` op blocks until the completion of a DMA operation
-associated with the tag element '%tag[%index]'. %tag is a memref, and %index
-has to be an index with the same restrictions as any load/store index.
-In particular, index for each memref dimension must be an affine expression of
-loop induction variables and symbols. %num_elements is the number of elements
+associated with the tag element '%tag[%index]'. %tag is a memref, and %index has
+to be an index with the same restrictions as any load/store index. In
+particular, index for each memref dimension must be an affine expression of loop
+induction variables and symbols. %num_elements is the number of elements
associated with the DMA operation. For example:
Example:
#map0 = affine_map<(d0) -> (d0 * 2 + 1)>
func @example(%arg0: memref<?xf32>, %arg1: memref<?xvector<4xf32>, #map0>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %0 = dim %arg0, %c0 : memref<?xf32>
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %0 = memref.dim %arg0, %c0 : memref<?xf32>
scf.for %arg2 = %c0 to %0 step %c1 {
- %1 = load %arg0[%arg2] : memref<?xf32>
- %2 = load %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
+ %1 = memref.load %arg0[%arg2] : memref<?xf32>
+ %2 = memref.load %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
- store %3, %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
+ memref.store %3, %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
}
return
}
#map0 = affine_map<(d0, d1) -> (d0 * 2 + d1 * 2)>
func @example(%arg0: memref<8x?xf32, #map0>, %arg1: memref<?xvector<4xf32>>) {
- %c8 = constant 8 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %0 = dim %arg0, %c1 : memref<8x?xf32, #map0>
+ %c8 = arith.constant 8 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %0 = memref.dim %arg0, %c1 : memref<8x?xf32, #map0>
scf.for %arg2 = %c0 to %0 step %c1 {
scf.for %arg3 = %c0 to %c8 step %c1 {
- %1 = load %arg0[%arg3, %arg2] : memref<8x?xf32, #map0>
- %2 = load %arg1[%arg3] : memref<?xvector<4xf32>>
+ %1 = memref.load %arg0[%arg3, %arg2] : memref<8x?xf32, #map0>
+ %2 = memref.load %arg1[%arg3] : memref<?xvector<4xf32>>
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
- store %3, %arg1[%arg3] : memref<?xvector<4xf32>>
+ memref.store %3, %arg1[%arg3] : memref<?xvector<4xf32>>
}
}
return
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
outs(%C: memref<?x?xf32>) {
^bb0(%a: f32, %b: f32, %c: f32):
- %d = addf %a, %b : f32
+ %d = arith.addf %a, %b : f32
linalg.yield %d : f32
}
```mlir
func @example(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %0 = dim %arg0, %c0 : memref<?x?xf32>
- %1 = dim %arg0, %c1 : memref<?x?xf32>
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %0 = memref.dim %arg0, %c0 : memref<?x?xf32>
+ %1 = memref.dim %arg0, %c1 : memref<?x?xf32>
scf.for %arg3 = %c0 to %0 step %c1 {
scf.for %arg4 = %c0 to %1 step %c1 {
- %2 = load %arg0[%arg3, %arg4] : memref<?x?xf32>
- %3 = load %arg1[%arg3, %arg4] : memref<?x?xf32>
- %4 = addf %2, %3 : f32
- store %4, %arg2[%arg3, %arg4] : memref<?x?xf32>
+ %2 = memref.load %arg0[%arg3, %arg4] : memref<?x?xf32>
+ %3 = memref.load %arg1[%arg3, %arg4] : memref<?x?xf32>
+ %4 = arith.addf %2, %3 : f32
+ memref.store %4, %arg2[%arg3, %arg4] : memref<?x?xf32>
}
}
return
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
outs(%C: memref<?x?xf32>) {
^bb0(%a: f32, %b: f32, %c: f32):
- %d = addf %a, %b : f32
+ %d = arith.addf %a, %b : f32
linalg.yield %d : f32
}
return
```
* `memref.view`,
-* `std.subview`,
+* `memref.subview`,
* `memref.transpose`.
* `linalg.range`,
* `linalg.slice`,
Syntax:
```
-operation ::= `dma_start` ssa-use`[`ssa-use-list`]` `,`
+operation ::= `memref.dma_start` ssa-use`[`ssa-use-list`]` `,`
ssa-use`[`ssa-use-list`]` `,` ssa-use `,`
ssa-use`[`ssa-use-list`]` (`,` ssa-use `,` ssa-use)?
`:` memref-type `,` memref-type `,` memref-type
destination memref need not be of the same dimensionality, but need to have the
same elemental type.
-For example, a `dma_start` operation that transfers 32 vector elements from a
-memref `%src` at location `[%i, %j]` to memref `%dst` at `[%k, %l]` would be
-specified as shown below.
+For example, a `memref.dma_start` operation that transfers 32 vector elements
+from a memref `%src` at location `[%i, %j]` to memref `%dst` at `[%k, %l]` would
+be specified as shown below.
Example:
```mlir
-%size = constant 32 : index
-%tag = alloc() : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
-%idx = constant 0 : index
-dma_start %src[%i, %j], %dst[%k, %l], %size, %tag[%idx] :
+%size = arith.constant 32 : index
+%tag = memref.alloc() : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
+%idx = arith.constant 0 : index
+memref.dma_start %src[%i, %j], %dst[%k, %l], %size, %tag[%idx] :
memref<40 x 8 x vector<16xf32>, affine_map<(d0, d1) -> (d0, d1)>, 0>,
memref<2 x 4 x vector<16xf32>, affine_map<(d0, d1) -> (d0, d1)>, 2>,
memref<1 x i32>, affine_map<(d0) -> (d0)>, 4>
Syntax:
```
-operation ::= `dma_wait` ssa-use`[`ssa-use-list`]` `,` ssa-use `:` memref-type
+operation ::= `memref.dma_wait` ssa-use`[`ssa-use-list`]` `,` ssa-use `:` memref-type
```
Blocks until the completion of a DMA operation associated with the tag element
Example:
```mlir
-dma_wait %tag[%idx], %size : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
+memref.dma_wait %tag[%idx], %size : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
```
[TOC]
MLIR supports multi-dimensional `vector` types and custom operations on those
-types. A generic, retargetable, higher-order ``vector`` type (`n-D` with `n >
-1`) is a structured type, that carries semantic information useful for
-transformations. This document discusses retargetable abstractions that exist
-in MLIR today and operate on ssa-values of type `vector` along with pattern
+types. A generic, retargetable, higher-order `vector` type (`n-D` with `n > 1`)
+is a structured type, that carries semantic information useful for
+transformations. This document discusses retargetable abstractions that exist in
+MLIR today and operate on ssa-values of type `vector` along with pattern
rewrites and lowerings that enable targeting specific instructions on concrete
targets. These abstractions serve to separate concerns between operations on
-`memref` (a.k.a buffers) and operations on ``vector`` values. This is not a
-new proposal but rather a textual documentation of existing MLIR components
-along with a rationale.
+`memref` (a.k.a buffers) and operations on `vector` values. This is not a new
+proposal but rather a textual documentation of existing MLIR components along
+with a rationale.
## Positioning in the Codegen Infrastructure
-The following diagram, recently presented with the [StructuredOps
-abstractions](https://drive.google.com/corp/drive/u/0/folders/1sRAsgsd8Bvpm_IxREmZf2agsGU2KvrK-),
+
+The following diagram, recently presented with the
+[StructuredOps abstractions](https://drive.google.com/corp/drive/u/0/folders/1sRAsgsd8Bvpm_IxREmZf2agsGU2KvrK-),
captures the current codegen paths implemented in MLIR in the various existing
lowering paths.
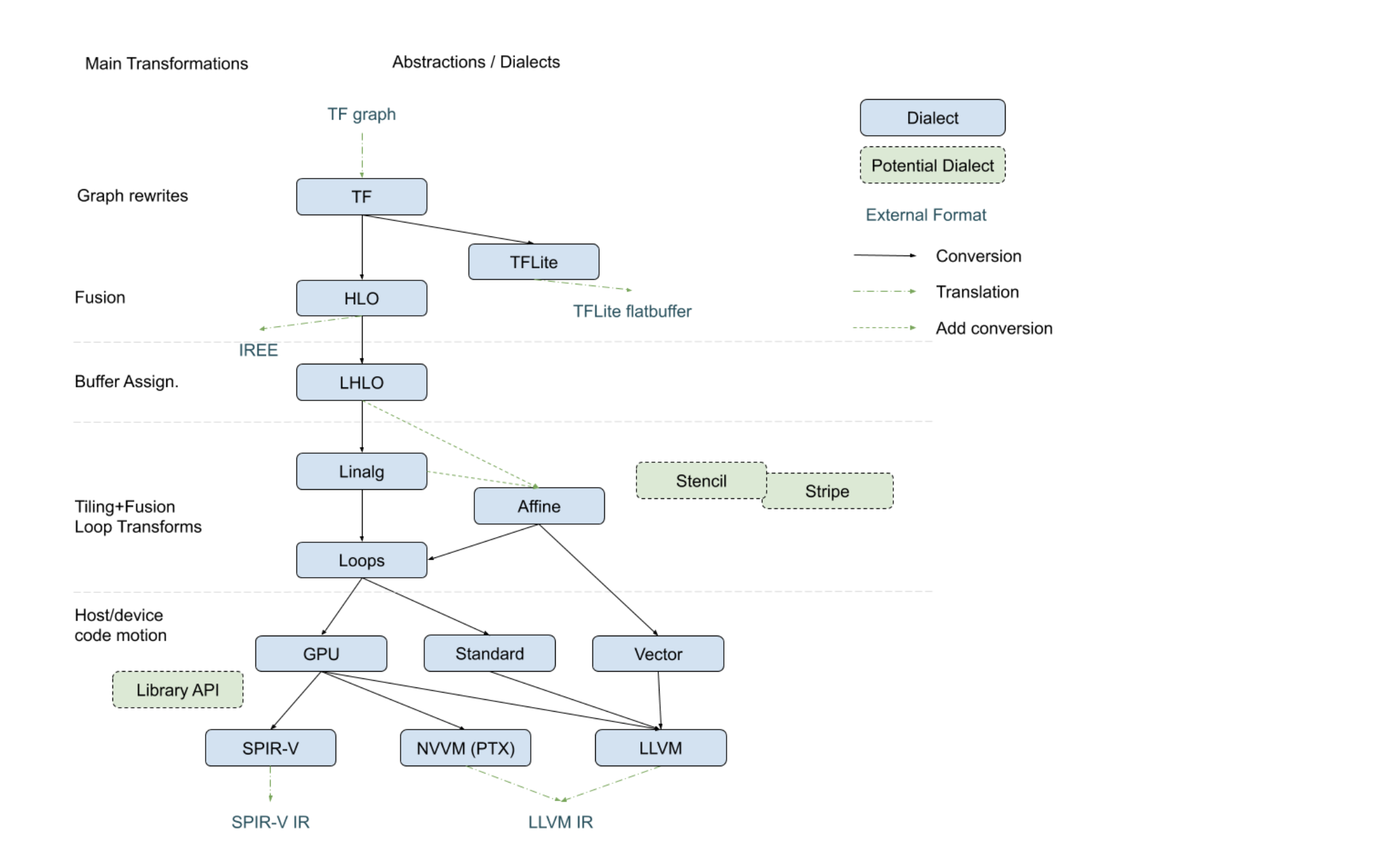
-The following diagram seeks to isolate `vector` dialects from the complexity
-of the codegen paths and focus on the payload-carrying ops that operate on std
-and `vector` types. This diagram is not to be taken as set in stone and
+The following diagram seeks to isolate `vector` dialects from the complexity of
+the codegen paths and focus on the payload-carrying ops that operate on std and
+`vector` types. This diagram is not to be taken as set in stone and
representative of what exists today but rather illustrates the layering of
abstractions in MLIR.
This separates concerns related to (a) defining efficient operations on
`vector` types from (b) program analyses + transformations on `memref`, loops
and other types of structured ops (be they `HLO`, `LHLO`, `Linalg` or other ).
-Looking a bit forward in time, we can put a stake in the ground and venture
-that the higher level of `vector`-level primitives we build and target from
-codegen (or some user/language level), the simpler our task will be, the more
-complex patterns can be expressed and the better performance will be.
+Looking a bit forward in time, we can put a stake in the ground and venture that
+the higher level of `vector`-level primitives we build and target from codegen
+(or some user/language level), the simpler our task will be, the more complex
+patterns can be expressed and the better performance will be.
## Components of a Generic Retargetable Vector-Level Dialect
-The existing MLIR `vector`-level dialects are related to the following
-bottom-up abstractions:
-
-1. Representation in `LLVMIR` via data structures, instructions and
-intrinsics. This is referred to as the `LLVM` level.
-2. Set of machine-specific operations and types that are built to translate
-almost 1-1 with the HW ISA. This is referred to as the Hardware Vector level;
-a.k.a `HWV`. For instance, we have (a) the `NVVM` dialect (for `CUDA`) with
-tensor core ops, (b) accelerator-specific dialects (internal), a potential
-(future) `CPU` dialect to capture `LLVM` intrinsics more closely and other
-dialects for specific hardware. Ideally this should be auto-generated as much
-as possible from the `LLVM` level.
-3. Set of virtual, machine-agnostic, operations that are informed by costs at
-the `HWV`-level. This is referred to as the Virtual Vector level; a.k.a
-`VV`. This is the level that higher-level abstractions (codegen, automatic
-vectorization, potential vector language, ...) targets.
+
+The existing MLIR `vector`-level dialects are related to the following bottom-up
+abstractions:
+
+1. Representation in `LLVMIR` via data structures, instructions and intrinsics.
+ This is referred to as the `LLVM` level.
+2. Set of machine-specific operations and types that are built to translate
+ almost 1-1 with the HW ISA. This is referred to as the Hardware Vector
+ level; a.k.a `HWV`. For instance, we have (a) the `NVVM` dialect (for
+ `CUDA`) with tensor core ops, (b) accelerator-specific dialects (internal),
+ a potential (future) `CPU` dialect to capture `LLVM` intrinsics more closely
+ and other dialects for specific hardware. Ideally this should be
+ auto-generated as much as possible from the `LLVM` level.
+3. Set of virtual, machine-agnostic, operations that are informed by costs at
+ the `HWV`-level. This is referred to as the Virtual Vector level; a.k.a
+ `VV`. This is the level that higher-level abstractions (codegen, automatic
+ vectorization, potential vector language, ...) targets.
The existing generic, retargetable, `vector`-level dialect is related to the
following top-down rewrites and conversions:
-1. MLIR Rewrite Patterns applied by the MLIR `PatternRewrite` infrastructure
-to progressively lower to implementations that match closer and closer to the
-`HWV`. Some patterns are "in-dialect" `VV -> VV` and some are conversions `VV
--> HWV`.
-2. `Virtual Vector -> Hardware Vector` lowering is specified as a set of MLIR
-lowering patterns that are specified manually for now.
-3. `Hardware Vector -> LLVM` lowering is a mechanical process that is written
-manually at the moment and that should be automated, following the `LLVM ->
-Hardware Vector` ops generation as closely as possible.
+1. MLIR Rewrite Patterns applied by the MLIR `PatternRewrite` infrastructure to
+ progressively lower to implementations that match closer and closer to the
+ `HWV`. Some patterns are "in-dialect" `VV -> VV` and some are conversions
+ `VV -> HWV`.
+2. `Virtual Vector -> Hardware Vector` lowering is specified as a set of MLIR
+ lowering patterns that are specified manually for now.
+3. `Hardware Vector -> LLVM` lowering is a mechanical process that is written
+ manually at the moment and that should be automated, following the `LLVM ->
+ Hardware Vector` ops generation as closely as possible.
## Short Description of the Existing Infrastructure
### LLVM level
-On CPU, the `n-D` `vector` type currently lowers to
-`!llvm<array<vector>>`. More concretely, `vector<4x8x128xf32>` lowers to
-`!llvm<[4 x [ 8 x [ 128 x float ]]]>`.
-There are tradeoffs involved related to how one can access subvectors and how
-one uses `llvm.extractelement`, `llvm.insertelement` and
-`llvm.shufflevector`. A [deeper dive section](#DeeperDive) discusses the
-current lowering choices and tradeoffs.
+
+On CPU, the `n-D` `vector` type currently lowers to `!llvm<array<vector>>`. More
+concretely, `vector<4x8x128xf32>` lowers to `!llvm<[4 x [ 8 x [ 128 x float
+]]]>`. There are tradeoffs involved related to how one can access subvectors and
+how one uses `llvm.extractelement`, `llvm.insertelement` and
+`llvm.shufflevector`. A [deeper dive section](#DeeperDive) discusses the current
+lowering choices and tradeoffs.
### Hardware Vector Ops
-Hardware Vector Ops are implemented as one dialect per target.
-For internal hardware, we are auto-generating the specific HW dialects.
-For `GPU`, the `NVVM` dialect adds operations such as `mma.sync`, `shfl` and
-tests.
-For `CPU` things are somewhat in-flight because the abstraction is close to
-`LLVMIR`. The jury is still out on whether a generic `CPU` dialect is
-concretely needed, but it seems reasonable to have the same levels of
-abstraction for all targets and perform cost-based lowering decisions in MLIR
-even for `LLVM`.
-Specialized `CPU` dialects that would capture specific features not well
-captured by LLVM peephole optimizations of on different types that core MLIR
-supports (e.g. Scalable Vectors) are welcome future extensions.
+
+Hardware Vector Ops are implemented as one dialect per target. For internal
+hardware, we are auto-generating the specific HW dialects. For `GPU`, the `NVVM`
+dialect adds operations such as `mma.sync`, `shfl` and tests. For `CPU` things
+are somewhat in-flight because the abstraction is close to `LLVMIR`. The jury is
+still out on whether a generic `CPU` dialect is concretely needed, but it seems
+reasonable to have the same levels of abstraction for all targets and perform
+cost-based lowering decisions in MLIR even for `LLVM`. Specialized `CPU`
+dialects that would capture specific features not well captured by LLVM peephole
+optimizations of on different types that core MLIR supports (e.g. Scalable
+Vectors) are welcome future extensions.
### Virtual Vector Ops
-Some existing Standard and Vector Dialect on `n-D` `vector` types comprise:
-```
-%2 = std.addf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
-%2 = std.mulf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
-%2 = std.splat %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
-
-%1 = vector.extract %0[1]: vector<3x7x8xf32> // -> vector<7x8xf32>
-%1 = vector.extract %0[1, 5]: vector<3x7x8xf32> // -> vector<8xf32>
-%2 = vector.outerproduct %0, %1: vector<4xf32>, vector<8xf32> // -> vector<4x8xf32>
-%3 = vector.outerproduct %0, %1, %2: vector<4xf32>, vector<8xf32> // fma when adding %2
-%3 = vector.strided_slice %0 {offsets = [2, 2], sizes = [2, 2], strides = [1, 1]}:
- vector<4x8x16xf32> // Returns a slice of type vector<2x2x16xf32>
-
-%2 = vector.transfer_read %A[%0, %1]
- {permutation_map = (d0, d1) -> (d0)}: memref<7x?xf32>, vector<4xf32>
-
-vector.transfer_write %f1, %A[%i0, %i1, %i2, %i3]
- {permutation_map = (d0, d1, d2, d3) -> (d3, d1, d0)} :
- vector<5x4x3xf32>, memref<?x?x?x?xf32>
-```
-
-The list of Vector is currently undergoing evolutions and is best kept
-track of by following the evolution of the
+
+Some existing Standard and Vector Dialect on `n-D` `vector` types comprise: ```
+%2 = arith.addf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32> %2 =
+arith.mulf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32> %2 = std.splat
+%1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
+
+%1 = vector.extract %0[1]: vector<3x7x8xf32> // -> vector<7x8xf32> %1 =
+vector.extract %0[1, 5]: vector<3x7x8xf32> // -> vector<8xf32> %2 =
+vector.outerproduct %0, %1: vector<4xf32>, vector<8xf32> // -> vector<4x8xf32>
+%3 = vector.outerproduct %0, %1, %2: vector<4xf32>, vector<8xf32> // fma when
+adding %2 %3 = vector.strided_slice %0 {offsets = [2, 2], sizes = [2, 2],
+strides = [1, 1]}: vector<4x8x16xf32> // Returns a slice of type
+vector<2x2x16xf32>
+
+%2 = vector.transfer_read %A[%0, %1] {permutation_map = (d0, d1) -> (d0)}:
+memref<7x?xf32>, vector<4xf32>
+
+vector.transfer_write %f1, %A[%i0, %i1, %i2, %i3] {permutation_map = (d0, d1,
+d2, d3) -> (d3, d1, d0)} : vector<5x4x3xf32>, memref<?x?x?x?xf32> ```
+
+The list of Vector is currently undergoing evolutions and is best kept track of
+by following the evolution of the
[VectorOps.td](https://github.com/llvm/llvm-project/blob/main/mlir/include/mlir/Dialect/Vector/VectorOps.td)
ODS file (markdown documentation is automatically generated locally when
-building and populates the [Vector
-doc](https://github.com/llvm/llvm-project/blob/main/mlir/docs/Dialects/Vector.md)). Recent
-extensions are driven by concrete use cases of interest. A notable such use
-case is the `vector.contract` op which applies principles of the StructuredOps
-abstraction to `vector` types.
+building and populates the
+[Vector doc](https://github.com/llvm/llvm-project/blob/main/mlir/docs/Dialects/Vector.md)).
+Recent extensions are driven by concrete use cases of interest. A notable such
+use case is the `vector.contract` op which applies principles of the
+StructuredOps abstraction to `vector` types.
### Virtual Vector Rewrite Patterns
The following rewrite patterns exist at the `VV->VV` level:
-1. The now retired `MaterializeVector` pass used to legalize ops on a
-coarse-grained virtual `vector` to a finer-grained virtual `vector` by
-unrolling. This has been rewritten as a retargetable unroll-and-jam pattern on
-`vector` ops and `vector` types.
-2. The lowering of `vector_transfer` ops legalizes `vector` load/store ops to
-permuted loops over scalar load/stores. This should evolve to loops over
-`vector` load/stores + `mask` operations as they become available `vector` ops
-at the `VV` level.
-
-The general direction is to add more Virtual Vector level ops and implement
-more useful `VV -> VV` rewrites as composable patterns that the PatternRewrite
+1. The now retired `MaterializeVector` pass used to legalize ops on a
+ coarse-grained virtual `vector` to a finer-grained virtual `vector` by
+ unrolling. This has been rewritten as a retargetable unroll-and-jam pattern
+ on `vector` ops and `vector` types.
+2. The lowering of `vector_transfer` ops legalizes `vector` load/store ops to
+ permuted loops over scalar load/stores. This should evolve to loops over
+ `vector` load/stores + `mask` operations as they become available `vector`
+ ops at the `VV` level.
+
+The general direction is to add more Virtual Vector level ops and implement more
+useful `VV -> VV` rewrites as composable patterns that the PatternRewrite
infrastructure can apply iteratively.
### Virtual Vector to Hardware Vector Lowering
-For now, `VV -> HWV` are specified in C++ (see for instance the
-[SplatOpLowering for n-D
-vectors](https://github.com/tensorflow/mlir/commit/0a0c4867c6a6fcb0a2f17ef26a791c1d551fe33d)
-or the [VectorOuterProductOp
-lowering](https://github.com/tensorflow/mlir/commit/957b1ca9680b4aacabb3a480fbc4ebd2506334b8)).
-
-Simple [conversion
-tests](https://github.com/llvm/llvm-project/blob/main/mlir/test/Conversion/VectorToLLVM/vector-to-llvm.mlir)
+
+For now, `VV -> HWV` are specified in C++ (see for instance the
+[SplatOpLowering for n-D vectors](https://github.com/tensorflow/mlir/commit/0a0c4867c6a6fcb0a2f17ef26a791c1d551fe33d)
+or the
+[VectorOuterProductOp lowering](https://github.com/tensorflow/mlir/commit/957b1ca9680b4aacabb3a480fbc4ebd2506334b8)).
+
+Simple
+[conversion tests](https://github.com/llvm/llvm-project/blob/main/mlir/test/Conversion/VectorToLLVM/vector-to-llvm.mlir)
are available for the `LLVM` target starting from the Virtual Vector Level.
## Rationale
+
### Hardware as `vector` Machines of Minimum Granularity
Higher-dimensional `vector`s are ubiquitous in modern HPC hardware. One way to
think about Generic Retargetable `vector`-Level Dialect is that it operates on
`vector` types that are multiples of a "good" `vector` size so the HW can
-efficiently implement a set of high-level primitives
-(e.g. `vector<8x8x8x16xf32>` when HW `vector` size is say `vector<4x8xf32>`).
+efficiently implement a set of high-level primitives (e.g.
+`vector<8x8x8x16xf32>` when HW `vector` size is say `vector<4x8xf32>`).
Some notable `vector` sizes of interest include:
-1. CPU: `vector<HW_vector_size * k>`, `vector<core_count * k’ x
-HW_vector_size * k>` and `vector<socket_count x core_count * k’ x
-HW_vector_size * k>`
-2. GPU: `vector<warp_size * k>`, `vector<warp_size * k x float4>` and
-`vector<warp_size * k x 4 x 4 x 4>` for tensor_core sizes,
-3. Other accelerators: n-D `vector` as first-class citizens in the HW.
+1. CPU: `vector<HW_vector_size * k>`, `vector<core_count * k’ x
+ HW_vector_size * k>` and `vector<socket_count x core_count * k’ x
+ HW_vector_size * k>`
+2. GPU: `vector<warp_size * k>`, `vector<warp_size * k x float4>` and
+ `vector<warp_size * k x 4 x 4 x 4>` for tensor_core sizes,
+3. Other accelerators: n-D `vector` as first-class citizens in the HW.
-Depending on the target, ops on sizes that are not multiples of the HW
-`vector` size may either produce slow code (e.g. by going through `LLVM`
-legalization) or may not legalize at all (e.g. some unsupported accelerator X
-combination of ops and types).
+Depending on the target, ops on sizes that are not multiples of the HW `vector`
+size may either produce slow code (e.g. by going through `LLVM` legalization) or
+may not legalize at all (e.g. some unsupported accelerator X combination of ops
+and types).
### Transformations Problems Avoided
+
A `vector<16x32x64xf32>` virtual `vector` is a coarse-grained type that can be
“unrolled” to HW-specific sizes. The multi-dimensional unrolling factors are
carried in the IR by the `vector` type. After unrolling, traditional
instruction-level scheduling can be run.
The following key transformations (along with the supporting analyses and
-structural constraints) are completely avoided by operating on a ``vector``
+structural constraints) are completely avoided by operating on a `vector`
`ssa-value` abstraction:
-1. Loop unroll and unroll-and-jam.
-2. Loop and load-store restructuring for register reuse.
-3. Load to store forwarding and Mem2reg.
-4. Coarsening (raising) from finer-grained `vector` form.
+1. Loop unroll and unroll-and-jam.
+2. Loop and load-store restructuring for register reuse.
+3. Load to store forwarding and Mem2reg.
+4. Coarsening (raising) from finer-grained `vector` form.
Note that “unrolling” in the context of `vector`s corresponds to partial loop
unroll-and-jam and not full unrolling. As a consequence this is expected to
up.
### The Big Out-Of-Scope Piece: Automatic Vectorization
-One important piece not discussed here is automatic vectorization
-(automatically raising from scalar to n-D `vector` ops and types). The TL;DR
-is that when the first "super-vectorization" prototype was implemented, MLIR
-was nowhere near as mature as it is today. As we continue building more
-abstractions in `VV -> HWV`, there is an opportunity to revisit vectorization
-in MLIR.
+
+One important piece not discussed here is automatic vectorization (automatically
+raising from scalar to n-D `vector` ops and types). The TL;DR is that when the
+first "super-vectorization" prototype was implemented, MLIR was nowhere near as
+mature as it is today. As we continue building more abstractions in `VV -> HWV`,
+there is an opportunity to revisit vectorization in MLIR.
Since this topic touches on codegen abstractions, it is technically out of the
scope of this survey document but there is a lot to discuss in light of
-structured op type representations and how a vectorization transformation can
-be reused across dialects. In particular, MLIR allows the definition of
-dialects at arbitrary levels of granularity and lends itself favorably to
-progressive lowering. The argument can be made that automatic vectorization on
-a loops + ops abstraction is akin to raising structural information that has
-been lost. Instead, it is possible to revisit vectorization as simple pattern
-rewrites, provided the IR is in a suitable form. For instance, vectorizing a
-`linalg.generic` op whose semantics match a `matmul` can be done [quite easily
-with a
-pattern](https://github.com/tensorflow/mlir/commit/bff722d6b59ab99b998f0c2b9fccd0267d9f93b5). In
-fact this pattern is trivial to generalize to any type of contraction when
+structured op type representations and how a vectorization transformation can be
+reused across dialects. In particular, MLIR allows the definition of dialects at
+arbitrary levels of granularity and lends itself favorably to progressive
+lowering. The argument can be made that automatic vectorization on a loops + ops
+abstraction is akin to raising structural information that has been lost.
+Instead, it is possible to revisit vectorization as simple pattern rewrites,
+provided the IR is in a suitable form. For instance, vectorizing a
+`linalg.generic` op whose semantics match a `matmul` can be done
+[quite easily with a pattern](https://github.com/tensorflow/mlir/commit/bff722d6b59ab99b998f0c2b9fccd0267d9f93b5).
+In fact this pattern is trivial to generalize to any type of contraction when
targeting the `vector.contract` op, as well as to any field (`+/*`, `min/+`,
-`max/+`, `or/and`, `logsumexp/+` ...) . In other words, by operating on a
-higher level of generic abstractions than affine loops, non-trivial
-transformations become significantly simpler and composable at a finer
-granularity.
+`max/+`, `or/and`, `logsumexp/+` ...) . In other words, by operating on a higher
+level of generic abstractions than affine loops, non-trivial transformations
+become significantly simpler and composable at a finer granularity.
Irrespective of the existence of an auto-vectorizer, one can build a notional
-vector language based on the VectorOps dialect and build end-to-end models
-with expressing `vector`s in the IR directly and simple
-pattern-rewrites. [EDSC](https://github.com/llvm/llvm-project/blob/main/mlir/docs/EDSC.md)s
+vector language based on the VectorOps dialect and build end-to-end models with
+expressing `vector`s in the IR directly and simple pattern-rewrites.
+[EDSC](https://github.com/llvm/llvm-project/blob/main/mlir/docs/EDSC.md)s
provide a simple way of driving such a notional language directly in C++.
## Bikeshed Naming Discussion
-There are arguments against naming an n-D level of abstraction `vector`
-because most people associate it with 1-D `vector`s. On the other hand,
-`vector`s are first-class n-D values in MLIR.
-The alternative name Tile has been proposed, which conveys higher-D
-meaning. But it also is one of the most overloaded terms in compilers and
-hardware.
-For now, we generally use the `n-D` `vector` name and are open to better
-suggestions.
+
+There are arguments against naming an n-D level of abstraction `vector` because
+most people associate it with 1-D `vector`s. On the other hand, `vector`s are
+first-class n-D values in MLIR. The alternative name Tile has been proposed,
+which conveys higher-D meaning. But it also is one of the most overloaded terms
+in compilers and hardware. For now, we generally use the `n-D` `vector` name and
+are open to better suggestions.
## DeeperDive
This section describes the tradeoffs involved in lowering the MLIR n-D vector
-type and operations on it to LLVM-IR. Putting aside the [LLVM
-Matrix](http://lists.llvm.org/pipermail/llvm-dev/2018-October/126871.html)
-proposal for now, this assumes LLVM only has built-in support for 1-D
-vector. The relationship with the LLVM Matrix proposal is discussed at the end
-of this document.
+type and operations on it to LLVM-IR. Putting aside the
+[LLVM Matrix](http://lists.llvm.org/pipermail/llvm-dev/2018-October/126871.html)
+proposal for now, this assumes LLVM only has built-in support for 1-D vector.
+The relationship with the LLVM Matrix proposal is discussed at the end of this
+document.
MLIR does not currently support dynamic vector sizes (i.e. SVE style) so the
-discussion is limited to static rank and static vector sizes
-(e.g. `vector<4x8x16x32xf32>`). This section discusses operations on vectors
-in LLVM and MLIR.
-
-LLVM instructions are prefixed by the `llvm.` dialect prefix
-(e.g. `llvm.insertvalue`). Such ops operate exclusively on 1-D vectors and
-aggregates following the [LLVM LangRef](https://llvm.org/docs/LangRef.html).
-MLIR operations are prefixed by the `vector.` dialect prefix
-(e.g. `vector.insertelement`). Such ops operate exclusively on MLIR `n-D`
-`vector` types.
+discussion is limited to static rank and static vector sizes (e.g.
+`vector<4x8x16x32xf32>`). This section discusses operations on vectors in LLVM
+and MLIR.
+
+LLVM instructions are prefixed by the `llvm.` dialect prefix (e.g.
+`llvm.insertvalue`). Such ops operate exclusively on 1-D vectors and aggregates
+following the [LLVM LangRef](https://llvm.org/docs/LangRef.html). MLIR
+operations are prefixed by the `vector.` dialect prefix (e.g.
+`vector.insertelement`). Such ops operate exclusively on MLIR `n-D` `vector`
+types.
### Alternatives For Lowering an n-D Vector Type to LLVM
-Consider a vector of rank n with static sizes `{s_0, ... s_{n-1}}` (i.e. an
-MLIR `vector<s_0x...s_{n-1}xf32>`). Lowering such an `n-D` MLIR vector type to
-an LLVM descriptor can be done by either:
+
+Consider a vector of rank n with static sizes `{s_0, ... s_{n-1}}` (i.e. an MLIR
+`vector<s_0x...s_{n-1}xf32>`). Lowering such an `n-D` MLIR vector type to an
+LLVM descriptor can be done by either:
1. Flattening to a `1-D` vector: `!llvm<"(s_0*...*s_{n-1})xfloat">` in the MLIR
LLVM dialect.
"k" minor dimensions.
### Constraints Inherited from LLVM (see LangRef)
+
The first constraint was already mentioned: LLVM only supports `1-D` `vector`
-types natively.
-Additional constraints are related to the difference in LLVM between vector
-and aggregate types:
-```
- “Aggregate Types are a subset of derived types that can contain multiple
- member types. Arrays and structs are aggregate types. Vectors are not
- considered to be aggregate types.”.
-```
-
-This distinction is also reflected in some of the operations. For `1-D`
-vectors, the operations `llvm.extractelement`, `llvm.insertelement`, and
+types natively. Additional constraints are related to the difference in LLVM
+between vector and aggregate types: `“Aggregate Types are a subset of derived
+types that can contain multiple member types. Arrays and structs are aggregate
+types. Vectors are not considered to be aggregate types.”.`
+
+This distinction is also reflected in some of the operations. For `1-D` vectors,
+the operations `llvm.extractelement`, `llvm.insertelement`, and
`llvm.shufflevector` apply, with direct support for dynamic indices. For `n-D`
-vectors with `n>1`, and thus aggregate types at LLVM level, the more
-restrictive operations `llvm.extractvalue` and `llvm.insertvalue` apply, which
-only accept static indices. There is no direct shuffling support for aggregate
-types.
+vectors with `n>1`, and thus aggregate types at LLVM level, the more restrictive
+operations `llvm.extractvalue` and `llvm.insertvalue` apply, which only accept
+static indices. There is no direct shuffling support for aggregate types.
-The next sentence illustrates a recurrent tradeoff, also found in MLIR,
-between “value types” (subject to SSA use-def chains) and “memory types”
-(subject to aliasing and side-effects):
-```
-“Structures in memory are accessed using ‘load’ and ‘store’ by getting a
-pointer to a field with the llvm.getelementptr instruction. Structures in
-registers are accessed using the llvm.extractvalue and llvm.insertvalue
-instructions.”
-```
+The next sentence illustrates a recurrent tradeoff, also found in MLIR, between
+“value types” (subject to SSA use-def chains) and “memory types” (subject to
+aliasing and side-effects): `“Structures in memory are accessed using ‘load’ and
+‘store’ by getting a pointer to a field with the llvm.getelementptr instruction.
+Structures in registers are accessed using the llvm.extractvalue and
+llvm.insertvalue instructions.”`
When transposing this to MLIR, `llvm.getelementptr` works on pointers to `n-D`
vectors in memory. For `n-D`, vectors values that live in registers we can use
are discussed in the following sections.
### Nested Aggregate
+
Pros:
-1. Natural encoding n-D vector -> (n-1)-D aggregate over 1-D vector.
-2. No need for linearization / delinearization logic inserted everywhere.
-3. `llvm.insertvalue`, `llvm.extractvalue` of `(n-k)-D` aggregate is natural.
-4. `llvm.insertelement`, `llvm.extractelement`, `llvm.shufflevector` over
-`1-D` vector type is natural.
+1. Natural encoding n-D vector -> (n-1)-D aggregate over 1-D vector.
+2. No need for linearization / delinearization logic inserted everywhere.
+3. `llvm.insertvalue`, `llvm.extractvalue` of `(n-k)-D` aggregate is natural.
+4. `llvm.insertelement`, `llvm.extractelement`, `llvm.shufflevector` over `1-D`
+ vector type is natural.
Cons:
-1. `llvm.insertvalue` / `llvm.extractvalue` does not accept dynamic indices
-but only static ones.
-2. Dynamic indexing on the non-most-minor dimension requires roundtrips to
-memory.
-3. Special intrinsics and native instructions in LLVM operate on `1-D`
-vectors. This is not expected to be a practical limitation thanks to a
-`vector.cast %0: vector<4x8x16x32xf32> to vector<4x4096xf32>` operation, that
-flattens the most minor dimensions (see the bigger picture in implications on
-codegen).
+1. `llvm.insertvalue` / `llvm.extractvalue` does not accept dynamic indices but
+ only static ones.
+2. Dynamic indexing on the non-most-minor dimension requires roundtrips to
+ memory.
+3. Special intrinsics and native instructions in LLVM operate on `1-D` vectors.
+ This is not expected to be a practical limitation thanks to a `vector.cast
+ %0: vector<4x8x16x32xf32> to vector<4x4096xf32>` operation, that flattens
+ the most minor dimensions (see the bigger picture in implications on
+ codegen).
### Flattened 1-D Vector Type
Pros:
-1. `insertelement` / `extractelement` / `shufflevector` with dynamic indexing
-is possible over the whole lowered `n-D` vector type.
-2. Supports special intrinsics and native operations.
+1. `insertelement` / `extractelement` / `shufflevector` with dynamic indexing
+ is possible over the whole lowered `n-D` vector type.
+2. Supports special intrinsics and native operations.
-Cons:
-1. Requires linearization/delinearization logic everywhere, translations are
-complex.
-2. Hides away the real HW structure behind dynamic indexing: at the end of the
-day, HW vector sizes are generally fixed and multiple vectors will be needed
-to hold a vector that is larger than the HW.
-3. Unlikely peephole optimizations will result in good code: arbitrary dynamic
-accesses, especially at HW vector boundaries unlikely to result in regular
-patterns.
+Cons: 1. Requires linearization/delinearization logic everywhere, translations
+are complex. 2. Hides away the real HW structure behind dynamic indexing: at the
+end of the day, HW vector sizes are generally fixed and multiple vectors will be
+needed to hold a vector that is larger than the HW. 3. Unlikely peephole
+optimizations will result in good code: arbitrary dynamic accesses, especially
+at HW vector boundaries unlikely to result in regular patterns.
### Discussion
+
#### HW Vectors and Implications on the SW and the Programming Model
+
As of today, the LLVM model only support `1-D` vector types. This is
unsurprising because historically, the vast majority of HW only supports `1-D`
vector registers. We note that multiple HW vendors are in the process of
evolving to higher-dimensional physical vectors.
-In the following discussion, let's assume the HW vector size is `1-D` and the
-SW vector size is `n-D`, with `n >= 1`. The same discussion would apply with
-`2-D` HW `vector` size and `n >= 2`. In this context, most HW exhibit a vector
-register file. The number of such vectors is fixed.
-Depending on the rank and sizes of the SW vector abstraction and the HW vector
-sizes and number of registers, an `n-D` SW vector type may be materialized by
-a mix of multiple `1-D` HW vector registers + memory locations at a given
-point in time.
-
-The implication of the physical HW constraints on the programming model are
-that one cannot index dynamically across hardware registers: a register file
-can generally not be indexed dynamically. This is because the register number
-is fixed and one either needs to unroll explicitly to obtain fixed register
-numbers or go through memory. This is a constraint familiar to CUDA
-programmers: when declaring a `private float a[4]`; and subsequently indexing
-with a *dynamic* value results in so-called **local memory** usage
-(i.e. roundtripping to memory).
+In the following discussion, let's assume the HW vector size is `1-D` and the SW
+vector size is `n-D`, with `n >= 1`. The same discussion would apply with `2-D`
+HW `vector` size and `n >= 2`. In this context, most HW exhibit a vector
+register file. The number of such vectors is fixed. Depending on the rank and
+sizes of the SW vector abstraction and the HW vector sizes and number of
+registers, an `n-D` SW vector type may be materialized by a mix of multiple
+`1-D` HW vector registers + memory locations at a given point in time.
+
+The implication of the physical HW constraints on the programming model are that
+one cannot index dynamically across hardware registers: a register file can
+generally not be indexed dynamically. This is because the register number is
+fixed and one either needs to unroll explicitly to obtain fixed register numbers
+or go through memory. This is a constraint familiar to CUDA programmers: when
+declaring a `private float a[4]`; and subsequently indexing with a *dynamic*
+value results in so-called **local memory** usage (i.e. roundtripping to
+memory).
#### Implication on codegen
+
MLIR `n-D` vector types are currently represented as `(n-1)-D` arrays of `1-D`
-vectors when lowered to LLVM.
-This introduces the consequences on static vs dynamic indexing discussed
-previously: `extractelement`, `insertelement` and `shufflevector` on `n-D`
-vectors in MLIR only support static indices. Dynamic indices are only
-supported on the most minor `1-D` vector but not the outer `(n-1)-D`.
-For other cases, explicit load / stores are required.
+vectors when lowered to LLVM. This introduces the consequences on static vs
+dynamic indexing discussed previously: `extractelement`, `insertelement` and
+`shufflevector` on `n-D` vectors in MLIR only support static indices. Dynamic
+indices are only supported on the most minor `1-D` vector but not the outer
+`(n-1)-D`. For other cases, explicit load / stores are required.
The implications on codegen are as follows:
-1. Loops around `vector` values are indirect addressing of vector values, they
-must operate on explicit load / store operations over `n-D` vector types.
-2. Once an `n-D` `vector` type is loaded into an SSA value (that may or may
-not live in `n` registers, with or without spilling, when eventually lowered),
-it may be unrolled to smaller `k-D` `vector` types and operations that
-correspond to the HW. This level of MLIR codegen is related to register
-allocation and spilling that occur much later in the LLVM pipeline.
-3. HW may support >1-D vectors with intrinsics for indirect addressing within
-these vectors. These can be targeted thanks to explicit `vector_cast`
-operations from MLIR `k-D` vector types and operations to LLVM `1-D` vectors +
-intrinsics.
-
-Alternatively, we argue that directly lowering to a linearized abstraction
-hides away the codegen complexities related to memory accesses by giving a
-false impression of magical dynamic indexing across registers. Instead we
-prefer to make those very explicit in MLIR and allow codegen to explore
-tradeoffs.
-Different HW will require different tradeoffs in the sizes involved in steps
-1., 2. and 3.
-
-Decisions made at the MLIR level will have implications at a much later stage
-in LLVM (after register allocation). We do not envision to expose concerns
-related to modeling of register allocation and spilling to MLIR
-explicitly. Instead, each target will expose a set of "good" target operations
-and `n-D` vector types, associated with costs that `PatterRewriters` at the
-MLIR level will be able to target. Such costs at the MLIR level will be
-abstract and used for ranking, not for accurate performance modeling. In the
-future such costs will be learned.
+1. Loops around `vector` values are indirect addressing of vector values, they
+ must operate on explicit load / store operations over `n-D` vector types.
+2. Once an `n-D` `vector` type is loaded into an SSA value (that may or may not
+ live in `n` registers, with or without spilling, when eventually lowered),
+ it may be unrolled to smaller `k-D` `vector` types and operations that
+ correspond to the HW. This level of MLIR codegen is related to register
+ allocation and spilling that occur much later in the LLVM pipeline.
+3. HW may support >1-D vectors with intrinsics for indirect addressing within
+ these vectors. These can be targeted thanks to explicit `vector_cast`
+ operations from MLIR `k-D` vector types and operations to LLVM `1-D`
+ vectors + intrinsics.
+
+Alternatively, we argue that directly lowering to a linearized abstraction hides
+away the codegen complexities related to memory accesses by giving a false
+impression of magical dynamic indexing across registers. Instead we prefer to
+make those very explicit in MLIR and allow codegen to explore tradeoffs.
+Different HW will require different tradeoffs in the sizes involved in steps 1.,
+2. and 3.
+
+Decisions made at the MLIR level will have implications at a much later stage in
+LLVM (after register allocation). We do not envision to expose concerns related
+to modeling of register allocation and spilling to MLIR explicitly. Instead,
+each target will expose a set of "good" target operations and `n-D` vector
+types, associated with costs that `PatterRewriters` at the MLIR level will be
+able to target. Such costs at the MLIR level will be abstract and used for
+ranking, not for accurate performance modeling. In the future such costs will be
+learned.
#### Implication on Lowering to Accelerators
-To target accelerators that support higher dimensional vectors natively, we
-can start from either `1-D` or `n-D` vectors in MLIR and use `vector.cast` to
+
+To target accelerators that support higher dimensional vectors natively, we can
+start from either `1-D` or `n-D` vectors in MLIR and use `vector.cast` to
flatten the most minor dimensions to `1-D` `vector<Kxf32>` where `K` is an
appropriate constant. Then, the existing lowering to LLVM-IR immediately
applies, with extensions for accelerator-specific intrinsics.
It is the role of an Accelerator-specific vector dialect (see codegen flow in
-the figure above) to lower the `vector.cast`. Accelerator -> LLVM lowering
-would then consist of a bunch of `Accelerator -> Accelerator` rewrites to
-perform the casts composed with `Accelerator -> LLVM` conversions + intrinsics
-that operate on `1-D` `vector<Kxf32>`.
+the figure above) to lower the `vector.cast`. Accelerator -> LLVM lowering would
+then consist of a bunch of `Accelerator -> Accelerator` rewrites to perform the
+casts composed with `Accelerator -> LLVM` conversions + intrinsics that operate
+on `1-D` `vector<Kxf32>`.
Some of those rewrites may need extra handling, especially if a reduction is
-involved. For example, `vector.cast %0: vector<K1x...xKnxf32> to
-vector<Kxf32>` when `K != K1 * … * Kn` and some arbitrary irregular
-`vector.cast %0: vector<4x4x17xf32> to vector<Kxf32>` may introduce masking
-and intra-vector shuffling that may not be worthwhile or even feasible,
-i.e. infinite cost.
+involved. For example, `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>`
+when `K != K1 * … * Kn` and some arbitrary irregular `vector.cast %0:
+vector<4x4x17xf32> to vector<Kxf32>` may introduce masking and intra-vector
+shuffling that may not be worthwhile or even feasible, i.e. infinite cost.
-However `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>` when `K =
-K1 * … * Kn` should be close to a noop.
+However `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>` when `K = K1 *
+… * Kn` should be close to a noop.
As we start building accelerator-specific abstractions, we hope to achieve
-retargetable codegen: the same infra is used for CPU, GPU and accelerators
-with extra MLIR patterns and costs.
+retargetable codegen: the same infra is used for CPU, GPU and accelerators with
+extra MLIR patterns and costs.
#### Implication on calling external functions that operate on vectors
+
It is possible (likely) that we additionally need to linearize when calling an
external function.
### Relationship to LLVM matrix type proposal.
+
The LLVM matrix proposal was formulated 1 year ago but seemed to be somewhat
stalled until recently. In its current form, it is limited to 2-D matrix types
-and operations are implemented with LLVM intrinsics.
-In contrast, MLIR sits at a higher level of abstraction and allows the
-lowering of generic operations on generic n-D vector types from MLIR to
-aggregates of 1-D LLVM vectors.
-In the future, it could make sense to lower to the LLVM matrix abstraction
-also for CPU even though MLIR will continue needing higher level abstractions.
-
-On the other hand, one should note that as MLIR is moving to LLVM, this
-document could become the unifying abstraction that people should target for
->1-D vectors and the LLVM matrix proposal can be viewed as a subset of this
-work.
+and operations are implemented with LLVM intrinsics. In contrast, MLIR sits at a
+higher level of abstraction and allows the lowering of generic operations on
+generic n-D vector types from MLIR to aggregates of 1-D LLVM vectors. In the
+future, it could make sense to lower to the LLVM matrix abstraction also for CPU
+even though MLIR will continue needing higher level abstractions.
+
+On the other hand, one should note that as MLIR is moving to LLVM, this document
+could become the unifying abstraction that people should target for
+
+> 1-D vectors and the LLVM matrix proposal can be viewed as a subset of this
+> work.
### Conclusion
+
The flattened 1-D vector design in the LLVM matrix proposal is good in a
HW-specific world with special intrinsics. This is a good abstraction for
register allocation, Instruction-Level-Parallelism and
SoftWare-Pipelining/Modulo Scheduling optimizations at the register level.
-However MLIR codegen operates at a higher level of abstraction where we want
-to target operations on coarser-grained vectors than the HW size and on which
+However MLIR codegen operates at a higher level of abstraction where we want to
+target operations on coarser-grained vectors than the HW size and on which
unroll-and-jam is applied and patterns across multiple HW vectors can be
matched.
This makes “nested aggregate type of 1-D vector” an appealing abstraction for
lowering from MLIR because:
-1. it does not hide complexity related to the buffer vs value semantics and
-the memory subsystem and
-2. it does not rely on LLVM to magically make all the things work from a too
-low-level abstraction.
+1. it does not hide complexity related to the buffer vs value semantics and the
+ memory subsystem and
+2. it does not rely on LLVM to magically make all the things work from a too
+ low-level abstraction.
-The use of special intrinsics in a `1-D` LLVM world is still available thanks
-to an explicit `vector.cast` op.
+The use of special intrinsics in a `1-D` LLVM world is still available thanks to
+an explicit `vector.cast` op.
## Operations
-The EmitC dialect allows to convert operations from other MLIR dialects to
-EmitC ops. Those can be translated to C/C++ via the Cpp emitter.
+The EmitC dialect allows to convert operations from other MLIR dialects to EmitC
+ops. Those can be translated to C/C++ via the Cpp emitter.
The following convention is followed:
-* If template arguments are passed to an `emitc.call` operation,
- C++ is generated.
-* If tensors are used, C++ is generated.
-* If multiple return values are used within in a functions or an
- `emitc.call` operation, C++11 is required.
-* If floating-point type template arguments are passed to an `emitc.call`
- operation, C++20 is required.
-* Else the generated code is compatible with C99.
+* If template arguments are passed to an `emitc.call` operation, C++ is
+ generated.
+* If tensors are used, C++ is generated.
+* If multiple return values are used within in a functions or an `emitc.call`
+ operation, C++11 is required.
+* If floating-point type template arguments are passed to an `emitc.call`
+ operation, C++20 is required.
+* Else the generated code is compatible with C99.
These restrictions are neither inherent to the EmitC dialect itself nor to the
Cpp emitter and therefore need to be considered while implementing conversions.
After the conversion, C/C++ code can be emitted with `mlir-translate`. The tool
-supports translating MLIR to C/C++ by passing `-mlir-to-cpp`.
-Furthermore, code with variables declared at top can be generated by passing
-the additional argument `-declare-variables-at-top`.
+supports translating MLIR to C/C++ by passing `-mlir-to-cpp`. Furthermore, code
+with variables declared at top can be generated by passing the additional
+argument `-declare-variables-at-top`.
Besides operations part of the EmitC dialect, the Cpp targets supports
translating the following operations:
-* 'std' Dialect
- * `std.br`
- * `std.call`
- * `std.cond_br`
- * `std.constant`
- * `std.return`
-* 'scf' Dialect
- * `scf.for`
- * `scf.if`
- * `scf.yield`
+* 'std' Dialect
+ * `std.br`
+ * `std.call`
+ * `std.cond_br`
+ * `std.constant`
+ * `std.return`
+* 'scf' Dialect
+ * `scf.for`
+ * `scf.if`
+ * `scf.yield`
+* 'arith' Dialect
+ * 'arith.constant'
continuous design provides a framework to lower from dataflow graphs to
high-performance target-specific code.
-This document defines and describes the key concepts in MLIR, and is intended
-to be a dry reference document - the [rationale
-documentation](Rationale/Rationale.md),
+This document defines and describes the key concepts in MLIR, and is intended to
+be a dry reference document - the
+[rationale documentation](Rationale/Rationale.md),
[glossary](../getting_started/Glossary.md), and other content are hosted
elsewhere.
MLIR is designed to be used in three different forms: a human-readable textual
form suitable for debugging, an in-memory form suitable for programmatic
-transformations and analysis, and a compact serialized form suitable for
-storage and transport. The different forms all describe the same semantic
-content. This document describes the human-readable textual form.
+transformations and analysis, and a compact serialized form suitable for storage
+and transport. The different forms all describe the same semantic content. This
+document describes the human-readable textual form.
[TOC]
MLIR is fundamentally based on a graph-like data structure of nodes, called
*Operations*, and edges, called *Values*. Each Value is the result of exactly
-one Operation or Block Argument, and has a *Value Type* defined by the [type
-system](#type-system). [Operations](#operations) are contained in
+one Operation or Block Argument, and has a *Value Type* defined by the
+[type system](#type-system). [Operations](#operations) are contained in
[Blocks](#blocks) and Blocks are contained in [Regions](#regions). Operations
are also ordered within their containing block and Blocks are ordered in their
-containing region, although this order may or may not be semantically
-meaningful in a given [kind of region](Interfaces.md/#regionkindinterfaces)).
-Operations may also contain regions, enabling hierarchical structures to be
-represented.
+containing region, although this order may or may not be semantically meaningful
+in a given [kind of region](Interfaces.md/#regionkindinterfaces)). Operations
+may also contain regions, enabling hierarchical structures to be represented.
Operations can represent many different concepts, from higher-level concepts
-like function definitions, function calls, buffer allocations, view or slices
-of buffers, and process creation, to lower-level concepts like
-target-independent arithmetic, target-specific instructions, configuration
-registers, and logic gates. These different concepts are represented by
-different operations in MLIR and the set of operations usable in MLIR can be
-arbitrarily extended.
+like function definitions, function calls, buffer allocations, view or slices of
+buffers, and process creation, to lower-level concepts like target-independent
+arithmetic, target-specific instructions, configuration registers, and logic
+gates. These different concepts are represented by different operations in MLIR
+and the set of operations usable in MLIR can be arbitrarily extended.
MLIR also provides an extensible framework for transformations on operations,
using familiar concepts of compiler [Passes](Passes.md). Enabling an arbitrary
-set of passes on an arbitrary set of operations results in a significant
-scaling challenge, since each transformation must potentially take into
-account the semantics of any operation. MLIR addresses this complexity by
-allowing operation semantics to be described abstractly using
-[Traits](Traits.md) and [Interfaces](Interfaces.md), enabling transformations
-to operate on operations more generically. Traits often describe verification
-constraints on valid IR, enabling complex invariants to be captured and
-checked. (see [Op vs
-Operation](Tutorials/Toy/Ch-2.md/#op-vs-operation-using-mlir-operations))
+set of passes on an arbitrary set of operations results in a significant scaling
+challenge, since each transformation must potentially take into account the
+semantics of any operation. MLIR addresses this complexity by allowing operation
+semantics to be described abstractly using [Traits](Traits.md) and
+[Interfaces](Interfaces.md), enabling transformations to operate on operations
+more generically. Traits often describe verification constraints on valid IR,
+enabling complex invariants to be captured and checked. (see
+[Op vs Operation](Tutorials/Toy/Ch-2.md/#op-vs-operation-using-mlir-operations))
One obvious application of MLIR is to represent an
[SSA-based](https://en.wikipedia.org/wiki/Static_single_assignment_form) IR,
// known. The shapes are assumed to match.
func @mul(%A: tensor<100x?xf32>, %B: tensor<?x50xf32>) -> (tensor<100x50xf32>) {
// Compute the inner dimension of %A using the dim operation.
- %n = dim %A, 1 : tensor<100x?xf32>
+ %n = memref.dim %A, 1 : tensor<100x?xf32>
// Allocate addressable "buffers" and copy tensors %A and %B into them.
- %A_m = alloc(%n) : memref<100x?xf32>
- tensor_store %A to %A_m : memref<100x?xf32>
+ %A_m = memref.alloc(%n) : memref<100x?xf32>
+ memref.tensor_store %A to %A_m : memref<100x?xf32>
- %B_m = alloc(%n) : memref<?x50xf32>
- tensor_store %B to %B_m : memref<?x50xf32>
+ %B_m = memref.alloc(%n) : memref<?x50xf32>
+ memref.tensor_store %B to %B_m : memref<?x50xf32>
// Call function @multiply passing memrefs as arguments,
// and getting returned the result of the multiplication.
%C_m = call @multiply(%A_m, %B_m)
: (memref<100x?xf32>, memref<?x50xf32>) -> (memref<100x50xf32>)
- dealloc %A_m : memref<100x?xf32>
- dealloc %B_m : memref<?x50xf32>
+ memref.dealloc %A_m : memref<100x?xf32>
+ memref.dealloc %B_m : memref<?x50xf32>
// Load the buffer data into a higher level "tensor" value.
- %C = tensor_load %C_m : memref<100x50xf32>
- dealloc %C_m : memref<100x50xf32>
+ %C = memref.tensor_load %C_m : memref<100x50xf32>
+ memref.dealloc %C_m : memref<100x50xf32>
// Call TensorFlow built-in function to print the result tensor.
"tf.Print"(%C){message: "mul result"}
func @multiply(%A: memref<100x?xf32>, %B: memref<?x50xf32>)
-> (memref<100x50xf32>) {
// Compute the inner dimension of %A.
- %n = dim %A, 1 : memref<100x?xf32>
+ %n = memref.dim %A, 1 : memref<100x?xf32>
// Allocate memory for the multiplication result.
- %C = alloc() : memref<100x50xf32>
+ %C = memref.alloc() : memref<100x50xf32>
// Multiplication loop nest.
affine.for %i = 0 to 100 {
affine.for %j = 0 to 50 {
- store 0 to %C[%i, %j] : memref<100x50xf32>
+ memref.store 0 to %C[%i, %j] : memref<100x50xf32>
affine.for %k = 0 to %n {
- %a_v = load %A[%i, %k] : memref<100x?xf32>
- %b_v = load %B[%k, %j] : memref<?x50xf32>
- %prod = mulf %a_v, %b_v : f32
- %c_v = load %C[%i, %j] : memref<100x50xf32>
- %sum = addf %c_v, %prod : f32
- store %sum, %C[%i, %j] : memref<100x50xf32>
+ %a_v = memref.load %A[%i, %k] : memref<100x?xf32>
+ %b_v = memref.load %B[%k, %j] : memref<?x50xf32>
+ %prod = arith.mulf %a_v, %b_v : f32
+ %c_v = memref.load %C[%i, %j] : memref<100x50xf32>
+ %sum = arith.addf %c_v, %prod : f32
+ memref.store %sum, %C[%i, %j] : memref<100x50xf32>
}
}
}
## Notation
MLIR has a simple and unambiguous grammar, allowing it to reliably round-trip
-through a textual form. This is important for development of the compiler -
-e.g. for understanding the state of code as it is being transformed and
-writing test cases.
+through a textual form. This is important for development of the compiler - e.g.
+for understanding the state of code as it is being transformed and writing test
+cases.
This document describes the grammar using
[Extended Backus-Naur Form (EBNF)](https://en.wikipedia.org/wiki/Extended_Backus%E2%80%93Naur_form).
value-use-list ::= value-use (`,` value-use)*
```
-Identifiers name entities such as values, types and functions, and are
-chosen by the writer of MLIR code. Identifiers may be descriptive (e.g.
-`%batch_size`, `@matmul`), or may be non-descriptive when they are
-auto-generated (e.g. `%23`, `@func42`). Identifier names for values may be
-used in an MLIR text file but are not persisted as part of the IR - the printer
-will give them anonymous names like `%42`.
+Identifiers name entities such as values, types and functions, and are chosen by
+the writer of MLIR code. Identifiers may be descriptive (e.g. `%batch_size`,
+`@matmul`), or may be non-descriptive when they are auto-generated (e.g. `%23`,
+`@func42`). Identifier names for values may be used in an MLIR text file but are
+not persisted as part of the IR - the printer will give them anonymous names
+like `%42`.
MLIR guarantees identifiers never collide with keywords by prefixing identifiers
with a sigil (e.g. `%`, `#`, `@`, `^`, `!`). In certain unambiguous contexts
keywords may be added to future versions of MLIR without danger of collision
with existing identifiers.
-Value identifiers are only [in scope](#value-scoping) for the (nested)
-region in which they are defined and cannot be accessed or referenced
-outside of that region. Argument identifiers in mapping functions are
-in scope for the mapping body. Particular operations may further limit
-which identifiers are in scope in their regions. For instance, the
-scope of values in a region with [SSA control flow
-semantics](#control-flow-and-ssacfg-regions) is constrained according
-to the standard definition of [SSA
-dominance](https://en.wikipedia.org/wiki/Dominator_\(graph_theory\)). Another
-example is the [IsolatedFromAbove trait](Traits.md/#isolatedfromabove),
-which restricts directly accessing values defined in containing
-regions.
+Value identifiers are only [in scope](#value-scoping) for the (nested) region in
+which they are defined and cannot be accessed or referenced outside of that
+region. Argument identifiers in mapping functions are in scope for the mapping
+body. Particular operations may further limit which identifiers are in scope in
+their regions. For instance, the scope of values in a region with
+[SSA control flow semantics](#control-flow-and-ssacfg-regions) is constrained
+according to the standard definition of
+[SSA dominance](https://en.wikipedia.org/wiki/Dominator_\(graph_theory\)).
+Another example is the [IsolatedFromAbove trait](Traits.md/#isolatedfromabove),
+which restricts directly accessing values defined in containing regions.
Function identifiers and mapping identifiers are associated with
-[Symbols](SymbolsAndSymbolTables.md) and have scoping rules dependent on
-symbol attributes.
+[Symbols](SymbolsAndSymbolTables.md) and have scoping rules dependent on symbol
+attributes.
## Dialects
operations directly through to MLIR. As an example, some targets go through
LLVM. LLVM has a rich set of intrinsics for certain target-independent
operations (e.g. addition with overflow check) as well as providing access to
-target-specific operations for the targets it supports (e.g. vector
-permutation operations). LLVM intrinsics in MLIR are represented via
-operations that start with an "llvm." name.
+target-specific operations for the targets it supports (e.g. vector permutation
+operations). LLVM intrinsics in MLIR are represented via operations that start
+with an "llvm." name.
Example:
trailing-location ::= (`loc` `(` location `)`)?
```
-MLIR introduces a uniform concept called _operations_ to enable describing
-many different levels of abstractions and computations. Operations in MLIR are
-fully extensible (there is no fixed list of operations) and have
-application-specific semantics. For example, MLIR supports [target-independent
-operations](Dialects/Standard.md#memory-operations), [affine
-operations](Dialects/Affine.md), and [target-specific machine
-operations](#target-specific-operations).
+MLIR introduces a uniform concept called *operations* to enable describing many
+different levels of abstractions and computations. Operations in MLIR are fully
+extensible (there is no fixed list of operations) and have application-specific
+semantics. For example, MLIR supports
+[target-independent operations](Dialects/Standard.md#memory-operations),
+[affine operations](Dialects/Affine.md), and
+[target-specific machine operations](#target-specific-operations).
The internal representation of an operation is simple: an operation is
identified by a unique string (e.g. `dim`, `tf.Conv2d`, `x86.repmovsb`,
-`ppc.eieio`, etc), can return zero or more results, take zero or more
-operands, has a dictionary of [attributes](#attributes), has zero or more
-successors, and zero or more enclosed [regions](#regions). The generic printing
-form includes all these elements literally, with a function type to indicate the
-types of the results and operands.
+`ppc.eieio`, etc), can return zero or more results, take zero or more operands,
+has a dictionary of [attributes](#attributes), has zero or more successors, and
+zero or more enclosed [regions](#regions). The generic printing form includes
+all these elements literally, with a function type to indicate the types of the
+results and operands.
Example:
```
In addition to the basic syntax above, dialects may register known operations.
-This allows those dialects to support _custom assembly form_ for parsing and
+This allows those dialects to support *custom assembly form* for parsing and
printing operations. In the operation sets listed below, we show both forms.
### Builtin Operations
block-arg-list ::= `(` value-id-and-type-list? `)`
```
-A *Block* is a list of operations. In [SSACFG
-regions](#control-flow-and-ssacfg-regions), each block represents a compiler
-[basic block](https://en.wikipedia.org/wiki/Basic_block) where instructions
-inside the block are executed in order and terminator operations implement
-control flow branches between basic blocks.
-
-A region with a single block may not include a [terminator
-operation](#terminator-operations). The enclosing op can opt-out of this
-requirement with the `NoTerminator` trait. The top-level `ModuleOp` is an
-example of such operation which defined this trait and whose block body does
-not have a terminator.
-
-Blocks in MLIR take a list of block arguments, notated in a function-like
-way. Block arguments are bound to values specified by the semantics of
-individual operations. Block arguments of the entry block of a region are also
-arguments to the region and the values bound to these arguments are determined
-by the semantics of the containing operation. Block arguments of other blocks
-are determined by the semantics of terminator operations, e.g. Branches, which
-have the block as a successor. In regions with [control
-flow](#control-flow-and-ssacfg-regions), MLIR leverages this structure to
-implicitly represent the passage of control-flow dependent values without the
+A *Block* is a list of operations. In
+[SSACFG regions](#control-flow-and-ssacfg-regions), each block represents a
+compiler [basic block](https://en.wikipedia.org/wiki/Basic_block) where
+instructions inside the block are executed in order and terminator operations
+implement control flow branches between basic blocks.
+
+A region with a single block may not include a
+[terminator operation](#terminator-operations). The enclosing op can opt-out of
+this requirement with the `NoTerminator` trait. The top-level `ModuleOp` is an
+example of such operation which defined this trait and whose block body does not
+have a terminator.
+
+Blocks in MLIR take a list of block arguments, notated in a function-like way.
+Block arguments are bound to values specified by the semantics of individual
+operations. Block arguments of the entry block of a region are also arguments to
+the region and the values bound to these arguments are determined by the
+semantics of the containing operation. Block arguments of other blocks are
+determined by the semantics of terminator operations, e.g. Branches, which have
+the block as a successor. In regions with
+[control flow](#control-flow-and-ssacfg-regions), MLIR leverages this structure
+to implicitly represent the passage of control-flow dependent values without the
complex nuances of PHI nodes in traditional SSA representations. Note that
values which are not control-flow dependent can be referenced directly and do
not need to be passed through block arguments.
br ^bb3(%a: i64) // Branch passes %a as the argument
^bb2:
- %b = addi %a, %a : i64
+ %b = arith.addi %a, %a : i64
br ^bb3(%b: i64) // Branch passes %b as the argument
// ^bb3 receives an argument, named %c, from predecessors
br ^bb4(%c, %a : i64, i64)
^bb4(%d : i64, %e : i64):
- %0 = addi %d, %e : i64
+ %0 = arith.addi %d, %e : i64
return %0 : i64 // Return is also a terminator.
}
```
-**Context:** The "block argument" representation eliminates a number
-of special cases from the IR compared to traditional "PHI nodes are
-operations" SSA IRs (like LLVM). For example, the [parallel copy
-semantics](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.524.5461&rep=rep1&type=pdf)
-of SSA is immediately apparent, and function arguments are no longer a
-special case: they become arguments to the entry block [[more
-rationale](Rationale/Rationale.md/#block-arguments-vs-phi-nodes)]. Blocks
-are also a fundamental concept that cannot be represented by
-operations because values defined in an operation cannot be accessed
-outside the operation.
+**Context:** The "block argument" representation eliminates a number of special
+cases from the IR compared to traditional "PHI nodes are operations" SSA IRs
+(like LLVM). For example, the
+[parallel copy semantics](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.524.5461&rep=rep1&type=pdf)
+of SSA is immediately apparent, and function arguments are no longer a special
+case: they become arguments to the entry block
+[[more rationale](Rationale/Rationale.md/#block-arguments-vs-phi-nodes)]. Blocks
+are also a fundamental concept that cannot be represented by operations because
+values defined in an operation cannot be accessed outside the operation.
## Regions
semantics of the regions it contains. MLIR currently defines two kinds of
regions: [SSACFG regions](#control-flow-and-ssacfg-regions), which describe
control flow between blocks, and [Graph regions](#graph-regions), which do not
-require control flow between block. The kinds of regions within an operation
-are described using the
-[RegionKindInterface](Interfaces.md/#regionkindinterfaces).
+require control flow between block. The kinds of regions within an operation are
+described using the [RegionKindInterface](Interfaces.md/#regionkindinterfaces).
-Regions do not have a name or an address, only the blocks contained in a
-region do. Regions must be contained within operations and have no type or
-attributes. The first block in the region is a special block called the 'entry
-block'. The arguments to the entry block are also the arguments of the region
-itself. The entry block cannot be listed as a successor of any other
-block. The syntax for a region is as follows:
+Regions do not have a name or an address, only the blocks contained in a region
+do. Regions must be contained within operations and have no type or attributes.
+The first block in the region is a special block called the 'entry block'. The
+arguments to the entry block are also the arguments of the region itself. The
+entry block cannot be listed as a successor of any other block. The syntax for a
+region is as follows:
```
region ::= `{` block* `}`
has additional semantic restrictions that other types of regions may not have.
For example, in a function body, block terminators must either branch to a
different block, or return from a function where the types of the `return`
-arguments must match the result types of the function signature. Similarly,
-the function arguments must match the types and count of the region arguments.
-In general, operations with regions can define these correspondances
-arbitrarily.
+arguments must match the result types of the function signature. Similarly, the
+function arguments must match the types and count of the region arguments. In
+general, operations with regions can define these correspondances arbitrarily.
### Value Scoping
Regions provide hierarchical encapsulation of programs: it is impossible to
-reference, i.e. branch to, a block which is not in the same region as the
-source of the reference, i.e. a terminator operation. Similarly, regions
-provides a natural scoping for value visibility: values defined in a region
-don't escape to the enclosing region, if any. By default, operations inside a
-region can reference values defined outside of the region whenever it would
-have been legal for operands of the enclosing operation to reference those
-values, but this can be restricted using traits, such as
+reference, i.e. branch to, a block which is not in the same region as the source
+of the reference, i.e. a terminator operation. Similarly, regions provides a
+natural scoping for value visibility: values defined in a region don't escape to
+the enclosing region, if any. By default, operations inside a region can
+reference values defined outside of the region whenever it would have been legal
+for operands of the enclosing operation to reference those values, but this can
+be restricted using traits, such as
[OpTrait::IsolatedFromAbove](Traits.md/#isolatedfromabove), or a custom
verifier.
```mlir
"any_op"(%a) ({ // if %a is in-scope in the containing region...
- // then %a is in-scope here too.
+ // then %a is in-scope here too.
%new_value = "another_op"(%a) : (i64) -> (i64)
}) : (i64) -> (i64)
```
-MLIR defines a generalized 'hierarchical dominance' concept that operates
-across hierarchy and defines whether a value is 'in scope' and can be used by
-a particular operation. Whether a value can be used by another operation in
-the same region is defined by the kind of region. A value defined in a region
-can be used by an operation which has a parent in the same region, if and only
-if the parent could use the value. A value defined by an argument to a region
-can always be used by any operation deeply contained in the region. A value
-defined in a region can never be used outside of the region.
+MLIR defines a generalized 'hierarchical dominance' concept that operates across
+hierarchy and defines whether a value is 'in scope' and can be used by a
+particular operation. Whether a value can be used by another operation in the
+same region is defined by the kind of region. A value defined in a region can be
+used by an operation which has a parent in the same region, if and only if the
+parent could use the value. A value defined by an argument to a region can
+always be used by any operation deeply contained in the region. A value defined
+in a region can never be used outside of the region.
### Control Flow and SSACFG Regions
In MLIR, control flow semantics of a region is indicated by
-[RegionKind::SSACFG](Interfaces.md/#regionkindinterfaces). Informally, these
-regions support semantics where operations in a region 'execute
-sequentially'. Before an operation executes, its operands have well-defined
-values. After an operation executes, the operands have the same values and
-results also have well-defined values. After an operation executes, the next
-operation in the block executes until the operation is the terminator operation
-at the end of a block, in which case some other operation will execute. The
-determination of the next instruction to execute is the 'passing of control
-flow'.
-
-In general, when control flow is passed to an operation, MLIR does not
-restrict when control flow enters or exits the regions contained in that
-operation. However, when control flow enters a region, it always begins in the
-first block of the region, called the *entry* block. Terminator operations
-ending each block represent control flow by explicitly specifying the
-successor blocks of the block. Control flow can only pass to one of the
-specified successor blocks as in a `branch` operation, or back to the
-containing operation as in a `return` operation. Terminator operations without
-successors can only pass control back to the containing operation. Within
-these restrictions, the particular semantics of terminator operations is
-determined by the specific dialect operations involved. Blocks (other than the
-entry block) that are not listed as a successor of a terminator operation are
-defined to be unreachable and can be removed without affecting the semantics
-of the containing operation.
+[RegionKind::SSACFG](Interfaces.md/#regionkindinterfaces). Informally, these
+regions support semantics where operations in a region 'execute sequentially'.
+Before an operation executes, its operands have well-defined values. After an
+operation executes, the operands have the same values and results also have
+well-defined values. After an operation executes, the next operation in the
+block executes until the operation is the terminator operation at the end of a
+block, in which case some other operation will execute. The determination of the
+next instruction to execute is the 'passing of control flow'.
+
+In general, when control flow is passed to an operation, MLIR does not restrict
+when control flow enters or exits the regions contained in that operation.
+However, when control flow enters a region, it always begins in the first block
+of the region, called the *entry* block. Terminator operations ending each block
+represent control flow by explicitly specifying the successor blocks of the
+block. Control flow can only pass to one of the specified successor blocks as in
+a `branch` operation, or back to the containing operation as in a `return`
+operation. Terminator operations without successors can only pass control back
+to the containing operation. Within these restrictions, the particular semantics
+of terminator operations is determined by the specific dialect operations
+involved. Blocks (other than the entry block) that are not listed as a successor
+of a terminator operation are defined to be unreachable and can be removed
+without affecting the semantics of the containing operation.
Although control flow always enters a region through the entry block, control
flow may exit a region through any block with an appropriate terminator. The
standard dialect leverages this capability to define operations with
Single-Entry-Multiple-Exit (SEME) regions, possibly flowing through different
-blocks in the region and exiting through any block with a `return`
-operation. This behavior is similar to that of a function body in most
-programming languages. In addition, control flow may also not reach the end of
-a block or region, for example if a function call does not return.
+blocks in the region and exiting through any block with a `return` operation.
+This behavior is similar to that of a function body in most programming
+languages. In addition, control flow may also not reach the end of a block or
+region, for example if a function call does not return.
Example:
An operation containing multiple regions also completely determines the
semantics of those regions. In particular, when control flow is passed to an
operation, it may transfer control flow to any contained region. When control
-flow exits a region and is returned to the containing operation, the
-containing operation may pass control flow to any region in the same
-operation. An operation may also pass control flow to multiple contained
-regions concurrently. An operation may also pass control flow into regions
-that were specified in other operations, in particular those that defined the
-values or symbols the given operation uses as in a call operation. This
-passage of control is generally independent of passage of control flow through
-the basic blocks of the containing region.
+flow exits a region and is returned to the containing operation, the containing
+operation may pass control flow to any region in the same operation. An
+operation may also pass control flow to multiple contained regions concurrently.
+An operation may also pass control flow into regions that were specified in
+other operations, in particular those that defined the values or symbols the
+given operation uses as in a call operation. This passage of control is
+generally independent of passage of control flow through the basic blocks of the
+containing region.
#### Closure
completely determined by its containing operation. Graph regions may only
contain a single basic block (the entry block).
-**Rationale:** Currently graph regions are arbitrarily limited to a single
-basic block, although there is no particular semantic reason for this
-limitation. This limitation has been added to make it easier to stabilize the
-pass infrastructure and commonly used passes for processing graph regions to
-properly handle feedback loops. Multi-block regions may be allowed in the
-future if use cases that require it arise.
+**Rationale:** Currently graph regions are arbitrarily limited to a single basic
+block, although there is no particular semantic reason for this limitation. This
+limitation has been added to make it easier to stabilize the pass infrastructure
+and commonly used passes for processing graph regions to properly handle
+feedback loops. Multi-block regions may be allowed in the future if use cases
+that require it arise.
In graph regions, MLIR operations naturally represent nodes, while each MLIR
value represents a multi-edge connecting a single source node and multiple
-destination nodes. All values defined in the region as results of operations
-are in scope within the region and can be accessed by any other operation in
-the region. In graph regions, the order of operations within a block and the
-order of blocks in a region is not semantically meaningful and non-terminator
+destination nodes. All values defined in the region as results of operations are
+in scope within the region and can be accessed by any other operation in the
+region. In graph regions, the order of operations within a block and the order
+of blocks in a region is not semantically meaningful and non-terminator
operations may be freely reordered, for instance, by canonicalization. Other
kinds of graphs, such as graphs with multiple source nodes and multiple
destination nodes, can also be represented by representing graph edges as MLIR
"test.graph_region"() ({ // A Graph region
%1 = "op1"(%1, %3) : (i32, i32) -> (i32) // OK: %1, %3 allowed here
%2 = "test.ssacfg_region"() ({
- %5 = "op2"(%1, %2, %3, %4) : (i32, i32, i32, i32) -> (i32) // OK: %1, %2, %3, %4 all defined in the containing region
+ %5 = "op2"(%1, %2, %3, %4) : (i32, i32, i32, i32) -> (i32) // OK: %1, %2, %3, %4 all defined in the containing region
}) : () -> (i32)
%3 = "op2"(%1, %4) : (i32, i32) -> (i32) // OK: %4 allowed here
%4 = "op3"(%1) : (i32) -> (i32)
semantics. The attribute entries are considered to be of two different kinds
based on whether their dictionary key has a dialect prefix:
-- *inherent attributes* are inherent to the definition of an operation's
- semantics. The operation itself is expected to verify the consistency of these
- attributes. An example is the `predicate` attribute of the `std.cmpi` op.
- These attributes must have names that do not start with a dialect prefix.
-
-- *discardable attributes* have semantics defined externally to the operation
- itself, but must be compatible with the operations's semantics. These
- attributes must have names that start with a dialect prefix. The dialect
- indicated by the dialect prefix is expected to verify these attributes. An
- example is the `gpu.container_module` attribute.
+- *inherent attributes* are inherent to the definition of an operation's
+ semantics. The operation itself is expected to verify the consistency of
+ these attributes. An example is the `predicate` attribute of the
+ `arith.cmpi` op. These attributes must have names that do not start with a
+ dialect prefix.
+
+- *discardable attributes* have semantics defined externally to the operation
+ itself, but must be compatible with the operations's semantics. These
+ attributes must have names that start with a dialect prefix. The dialect
+ indicated by the dialect prefix is expected to verify these attributes. An
+ example is the `gpu.container_module` attribute.
Note that attribute values are allowed to themselves be dictionary attributes,
but only the top-level dictionary attribute attached to the operation is subject
fixed in place?
This document explains that adoption of MLIR to solve graph based problems
-_isn't_ a revolutionary change: it is an incremental series of steps which build
+*isn't* a revolutionary change: it is an incremental series of steps which build
on each other, each of which delivers local value. This document also addresses
some points of confusion that keep coming up.
```mlir
// RUN: mlir-opt %s -canonicalize | FileCheck %s
func @test_subi_zero_cfg(%arg0: i32) -> i32 {
- %y = subi %arg0, %arg0 : i32
+ %y = arith.subi %arg0, %arg0 : i32
return %y: i32
}
// CHECK-LABEL: func @test_subi_zero_cfg(%arg0: i32)
```mlir
// RUN: mlir-opt %s -memref-dependence-check -verify-diagnostics
func @different_memrefs() {
- %m.a = alloc() : memref<100xf32>
- %m.b = alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %c1 = constant 1.0 : f32
- store %c1, %m.a[%c0] : memref<100xf32>
+ %m.a = memref.alloc() : memref<100xf32>
+ %m.b = memref.alloc() : memref<100xf32>
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1.0 : f32
+ memref.store %c1, %m.a[%c0] : memref<100xf32>
// expected-note@-1 {{dependence from memref access 0 to access 1 = false}}
- %v0 = load %m.b[%c0] : memref<100xf32>
+ %v0 = memref.load %m.b[%c0] : memref<100xf32>
return
}
```
capture this (e.g. serialize it to proto), passes have to recompute it on demand
with ShapeRefiner.
-The [MLIR Tensor Type](../Dialects/Builtin.md/#rankedtensortype) directly captures shape
-information, so you can have things like:
+The [MLIR Tensor Type](../Dialects/Builtin.md/#rankedtensortype) directly
+captures shape information, so you can have things like:
```mlir
%x = tf.Add %x, %y : tensor<128 x 8 x ? x f32>
### Unified Graph Rewriting Infrastructure
This is still a work in progress, but we have sightlines towards a
-[general rewriting infrastructure](RationaleGenericDAGRewriter.md) for transforming DAG
-tiles into other DAG tiles, using a declarative pattern format. DAG to DAG
-rewriting is a generalized solution for many common compiler optimizations,
-lowerings, and other rewrites and having an IR enables us to invest in building
-a single high-quality implementation.
+[general rewriting infrastructure](RationaleGenericDAGRewriter.md) for
+transforming DAG tiles into other DAG tiles, using a declarative pattern format.
+DAG to DAG rewriting is a generalized solution for many common compiler
+optimizations, lowerings, and other rewrites and having an IR enables us to
+invest in building a single high-quality implementation.
Declarative pattern rules are preferable to imperative C++ code for a number of
reasons: they are more compact, easier to reason about, can have checkers
Maps, sets, and relations with affine constraints are the core structures
underlying a polyhedral representation of high-dimensional loop nests and
-multidimensional arrays. These structures are represented as textual
-expressions in a form close to their mathematical form. These structures are
-used to capture loop nests, tensor data structures, and how they are reordered
-and mapped for a target architecture. All structured or "conforming" loops are
-captured as part of the polyhedral information, and so are tensor variables,
-their layouts, and subscripted accesses to these tensors in memory.
+multidimensional arrays. These structures are represented as textual expressions
+in a form close to their mathematical form. These structures are used to capture
+loop nests, tensor data structures, and how they are reordered and mapped for a
+target architecture. All structured or "conforming" loops are captured as part
+of the polyhedral information, and so are tensor variables, their layouts, and
+subscripted accesses to these tensors in memory.
The information captured in the IR allows a compact expression of all loop
transformations, data remappings, explicit copying necessary for explicitly
ability to index into the same memref in other ways (something which C arrays
allow for example). Furthermore, for the affine constructs, the compiler can
follow use-def chains (e.g. through
-[affine.apply operations](../Dialects/Affine.md/#affineapply-affineapplyop)) or through
-the map attributes of [affine operations](../Dialects/Affine.md/#operations)) to
-precisely analyze references at compile-time using polyhedral techniques. This
-is possible because of the [restrictions on dimensions and symbols](../Dialects/Affine.md/#restrictions-on-dimensions-and-symbols).
+[affine.apply operations](../Dialects/Affine.md/#affineapply-affineapplyop)) or
+through the map attributes of
+[affine operations](../Dialects/Affine.md/#operations)) to precisely analyze
+references at compile-time using polyhedral techniques. This is possible because
+of the
+[restrictions on dimensions and symbols](../Dialects/Affine.md/#restrictions-on-dimensions-and-symbols).
A scalar of element-type (a primitive type or a vector type) that is stored in
memory is modeled as a 0-d memref. This is also necessary for scalars that are
live out of for loops and if conditionals in a function, for which we don't yet
have an SSA representation --
-[an extension](#affineif-and-affinefor-extensions-for-escaping-scalars) to allow that is
-described later in this doc.
+[an extension](#affineif-and-affinefor-extensions-for-escaping-scalars) to allow
+that is described later in this doc.
### Symbols and types
```mlir
func foo(...) {
- %A = alloc <8x?xf32, #lmap> (%N)
+ %A = memref.alloc <8x?xf32, #lmap> (%N)
...
call bar(%A) : (memref<8x?xf32, #lmap>)
}
// Type of %A indicates that %A has dynamic shape with 8 rows
// and unknown number of columns. The number of columns is queried
// dynamically using dim instruction.
- %N = dim %A, 1 : memref<8x?xf32, #lmap>
+ %N = memref.dim %A, 1 : memref<8x?xf32, #lmap>
affine.for %i = 0 to 8 {
affine.for %j = 0 to %N {
### Block Arguments vs PHI nodes
-MLIR Regions represent SSA using "[block arguments](../LangRef.md/#blocks)" rather
-than [PHI instructions](http://llvm.org/docs/LangRef.html#i-phi) used in LLVM.
-This choice is representationally identical (the same constructs can be
+MLIR Regions represent SSA using "[block arguments](../LangRef.md/#blocks)"
+rather than [PHI instructions](http://llvm.org/docs/LangRef.html#i-phi) used in
+LLVM. This choice is representationally identical (the same constructs can be
represented in either form) but block arguments have several advantages:
1. LLVM PHI nodes always have to be kept at the top of a block, and
Data layout information such as the bit width or the alignment of types may be
target and ABI-specific and thus should be configurable rather than imposed by
the compiler. Especially, the layout of compound or `index` types may vary. MLIR
-specifies default bit widths for certain primitive _types_, in particular for
+specifies default bit widths for certain primitive *types*, in particular for
integers and floats. It is equal to the number that appears in the type
definition, e.g. the bit width of `i32` is `32`, so is the bit width of `f32`.
-The bit width is not _necessarily_ related to the amount of memory (in bytes) or
+The bit width is not *necessarily* related to the amount of memory (in bytes) or
the register size (in bits) that is necessary to store the value of the given
type. For example, `vector<3xi57>` is likely to be lowered to a vector of four
64-bit integers, so that its storage requirement is `4 x 64 / 8 = 32` bytes,
For the standard dialect, the choice is to have signless integer types. An
integer value does not have an intrinsic sign, and it's up to the specific op
-for interpretation. For example, ops like `addi` and `muli` do two's complement
-arithmetic, but some other operations get a sign, e.g. `divis` vs `diviu`.
+for interpretation. For example, ops like `arith.addi` and `arith.muli` do two's
+complement arithmetic, but some other operations get a sign, e.g. `arith.divsi`
+vs `arith.divui`.
LLVM uses the [same design](http://llvm.org/docs/LangRef.html#integer-type),
which was introduced in a revamp rolled out
### Splitting floating point vs integer operations
-The MLIR "standard" operation set splits many integer and floating point
-operations into different categories, for example `addf` vs `addi` and `cmpf` vs
-`cmpi`
+The MLIR "Arithmetic" dialect splits many integer and floating point operations
+into different categories, for example `arith.addf` vs `arith.addi` and
+`arith.cmpf` vs `arith.cmpi`
([following the design of LLVM](http://llvm.org/docs/LangRef.html#binary-operations)).
-These instructions _are_ polymorphic on the number of elements in the type
+These instructions *are* polymorphic on the number of elements in the type
though, for example `addf` is used with scalar floats, vectors of floats, and
tensors of floats (LLVM does the same thing with its scalar/vector types).
### Specifying sign in integer comparison operations
-Since integers are [signless](#integer-signedness-semantics), it is necessary to define the
-sign for integer comparison operations. This sign indicates how to treat the
-foremost bit of the integer: as sign bit or as most significant bit. For
-example, comparing two `i4` values `0b1000` and `0b0010` yields different
+Since integers are [signless](#integer-signedness-semantics), it is necessary to
+define the sign for integer comparison operations. This sign indicates how to
+treat the foremost bit of the integer: as sign bit or as most significant bit.
+For example, comparing two `i4` values `0b1000` and `0b0010` yields different
results for unsigned (`8 > 3`) and signed (`-8 < 3`) interpretations. This
-difference is only significant for _order_ comparisons, but not for _equality_
+difference is only significant for *order* comparisons, but not for *equality*
comparisons. Indeed, for the latter all bits must have the same value
independently of the sign. Since both arguments have exactly the same bit width
and cannot be padded by this operation, it is impossible to compare two values
### Tuple types
The MLIR type system provides first class support for defining
-[tuple types](../Dialects/Builtin/#tupletype). This is due to the fact that `Tuple`
-represents a universal concept that is likely to, and has already begun to,
-present itself in many different dialects. Though this type is first class in
-the type system, it merely serves to provide a common mechanism in which to
+[tuple types](../Dialects/Builtin/#tupletype). This is due to the fact that
+`Tuple` represents a universal concept that is likely to, and has already begun
+to, present itself in many different dialects. Though this type is first class
+in the type system, it merely serves to provide a common mechanism in which to
represent this concept in MLIR. As such, MLIR provides no standard operations
for interfacing with `tuple` types. It is up to dialect authors to provide
operations, e.g. extract_tuple_element, to interpret and manipulate them. When
```mlir
func @search(%A: memref<?x?xi32>, %S: <?xi32>, %key : i32) {
- %ni = dim %A, 0 : memref<?x?xi32>
+ %ni = memref.dim %A, 0 : memref<?x?xi32>
// This loop can be parallelized
affine.for %i = 0 to %ni {
call @search_body (%A, %S, %key, %i) : (memref<?x?xi32>, memref<?xi32>, i32, i32)
}
func @search_body(%A: memref<?x?xi32>, %S: memref<?xi32>, %key: i32, %i : i32) {
- %nj = dim %A, 1 : memref<?x?xi32>
+ %nj = memref.dim %A, 1 : memref<?x?xi32>
br ^bb1(0)
^bb1(%j: i32)
- %p1 = cmpi "lt", %j, %nj : i32
+ %p1 = arith.cmpi "lt", %j, %nj : i32
cond_br %p1, ^bb2, ^bb5
^bb2:
%v = affine.load %A[%i, %j] : memref<?x?xi32>
- %p2 = cmpi "eq", %v, %key : i32
+ %p2 = arith.cmpi "eq", %v, %key : i32
cond_br %p2, ^bb3(%j), ^bb4
^bb3(%j: i32)
br ^bb5
^bb4:
- %jinc = addi %j, 1 : i32
+ %jinc = arith.addi %j, 1 : i32
br ^bb1(%jinc)
^bb5:
explicitly propagate the schedule into domains and model all the cleanup
code. An example and more detail on the schedule tree form is in the next
section.
-1. Having two different forms of "affine regions": an affine loop tree form
- and a polyhedral schedule tree form. In the latter, ops could carry
- attributes capturing domain, scheduling, and other polyhedral code
- generation options with IntegerSet, AffineMap, and other attributes.
+1. Having two different forms of "affine regions": an affine loop tree form and
+ a polyhedral schedule tree form. In the latter, ops could carry attributes
+ capturing domain, scheduling, and other polyhedral code generation options
+ with IntegerSet, AffineMap, and other attributes.
#### Schedule Tree Representation for Affine Regions
### Affine Relations
-The current MLIR spec includes affine maps and integer sets, but not
-affine relations. Affine relations are a natural way to model read and
-write access information, which can be very useful to capture the
-behavior of external library calls where no implementation is
-available, high-performance vendor libraries, or user-provided /
-user-tuned routines.
+The current MLIR spec includes affine maps and integer sets, but not affine
+relations. Affine relations are a natural way to model read and write access
+information, which can be very useful to capture the behavior of external
+library calls where no implementation is available, high-performance vendor
+libraries, or user-provided / user-tuned routines.
An affine relation is a relation between input and output dimension identifiers
while being symbolic on a list of symbolic identifiers and with affine
bb0 (%0, %1: memref<128xf32>, i64):
%val = affine.load %A [%pos]
%val = affine.load %A [%pos + 1]
- %p = mulf %val, %val : f32
+ %p = arith.mulf %val, %val : f32
return %p : f32
}
```
strides (based on [`VulkanLayoutUtils`][VulkanLayoutUtils]) are supported. They
are also mapped to LLVM array.
-SPIR-V Dialect | LLVM Dialect
-:-----------------------------------: | :-----------------------------------:
-`!spv.array<<count> x <element-type>>`| `!llvm.array<<count> x <element-type>>`
-`!spv.rtarray< <element-type> >` | `!llvm.array<0 x <element-type>>`
+SPIR-V Dialect | LLVM Dialect
+:------------------------------------: | :-------------------------------------:
+`!spv.array<<count> x <element-type>>` | `!llvm.array<<count> x <element-type>>`
+`!spv.rtarray< <element-type> >` | `!llvm.array<0 x <element-type>>`
### Struct types
Members of SPIR-V struct types may have decorations and offset information.
Currently, there is **no** support of member decorations conversion for structs.
-For more information see section on [Decorations](#Decorations-conversion).
+For more information see section on [Decorations](#Decorations-conversion).
Usually we expect that each struct member has a natural size and alignment.
-However, there are cases (*e.g.* in graphics) where one would place struct
-members explicitly at particular offsets. This case is **not** supported
-at the moment. Hence, we adhere to the following mapping:
+However, there are cases (*e.g.* in graphics) where one would place struct
+members explicitly at particular offsets. This case is **not** supported at the
+moment. Hence, we adhere to the following mapping:
* Structs with no offset are modelled as LLVM packed structures.
a design would require index recalculation in the conversion of ops that
involve memory addressing.
-Examples of SPIR-V struct conversion are:
-```mlir
-!spv.struct<i8, i32> => !llvm.struct<packed (i8, i32)>
-!spv.struct<i8 [0], i32 [4]> => !llvm.struct<(i8, i32)>
+Examples of SPIR-V struct conversion are: ```mlir !spv.struct<i8, i32> =>
+!llvm.struct<packed (i8, i32)> !spv.struct<i8 [0], i32 [4]> => !llvm.struct<(i8,
+i32)>
-// error
-!spv.struct<i8 [0], i32 [8]>
-```
+// error !spv.struct<i8 [0], i32 [8]> ```
### Not implemented types
This section describes how SPIR-V Dialect operations are converted to LLVM
Dialect. It lists already working conversion patterns, as well as those that are
-an ongoing work.
+an ongoing work.
There are also multiple ops for which there is no clear mapping in LLVM.
-Conversion for those have to be discussed within the community on the
+Conversion for those have to be discussed within the community on the
case-by-case basis.
### Arithmetic ops
SPIR-V arithmetic ops mostly have a direct equivalent in LLVM Dialect. Such
exceptions as `spv.SMod` and `spv.FMod` are rare.
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.FAdd` | `llvm.fadd`
-`spv.FDiv` | `llvm.fdiv`
-`spv.FNegate` | `llvm.fneg`
-`spv.FMul` | `llvm.fmul`
-`spv.FRem` | `llvm.frem`
-`spv.FSub` | `llvm.fsub`
-`spv.IAdd` | `llvm.add`
-`spv.IMul` | `llvm.mul`
-`spv.ISub` | `llvm.sub`
-`spv.SDiv` | `llvm.sdiv`
-`spv.SRem` | `llvm.srem`
-`spv.UDiv` | `llvm.udiv`
-`spv.UMod` | `llvm.urem`
+SPIR-V Dialect op | LLVM Dialect op
+:---------------: | :-------------:
+`spv.FAdd` | `llvm.fadd`
+`spv.FDiv` | `llvm.fdiv`
+`spv.FNegate` | `llvm.fneg`
+`spv.FMul` | `llvm.fmul`
+`spv.FRem` | `llvm.frem`
+`spv.FSub` | `llvm.fsub`
+`spv.IAdd` | `llvm.add`
+`spv.IMul` | `llvm.mul`
+`spv.ISub` | `llvm.sub`
+`spv.SDiv` | `llvm.sdiv`
+`spv.SRem` | `llvm.srem`
+`spv.UDiv` | `llvm.udiv`
+`spv.UMod` | `llvm.urem`
### Bitwise ops
As with arithmetic ops, most of bitwise ops have a semantically equivalent op in
LLVM:
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.BitwiseAnd` | `llvm.and`
-`spv.BitwiseOr` | `llvm.or`
-`spv.BitwiseXor` | `llvm.xor`
+SPIR-V Dialect op | LLVM Dialect op
+:---------------: | :-------------:
+`spv.BitwiseAnd` | `llvm.and`
+`spv.BitwiseOr` | `llvm.or`
+`spv.BitwiseXor` | `llvm.xor`
Also, some of bitwise ops can be modelled with LLVM intrinsics:
-SPIR-V Dialect op | LLVM Dialect intrinsic
-:-----------------------------------: | :-----------------------------------:
-`spv.BitCount` | `llvm.intr.ctpop`
-`spv.BitReverse` | `llvm.intr.bitreverse`
+SPIR-V Dialect op | LLVM Dialect intrinsic
+:---------------: | :--------------------:
+`spv.BitCount` | `llvm.intr.ctpop`
+`spv.BitReverse` | `llvm.intr.bitreverse`
#### `spv.Not`
outline the general design of conversion patterns for this ops, and then
describe each of them.
-All of these ops take `base`, `offset` and `count` (`insert` for
-`spv.BitFieldInsert`) as arguments. There are two important things
-to note:
+All of these ops take `base`, `offset` and `count` (`insert` for
+`spv.BitFieldInsert`) as arguments. There are two important things to note:
* `offset` and `count` are always scalar. This means that we can have the
following case:
##### `spv.BitFieldInsert`
This operation is implemented as a series of LLVM Dialect operations. First step
-would be to create a mask with bits set outside
-[`offset`, `offset` + `count` - 1]. Then, unchanged bits are extracted from
-`base` that are outside of [`offset`, `offset` + `count` - 1]. The result is
-`or`ed with shifted `insert`.
+would be to create a mask with bits set outside [`offset`, `offset` + `count` -
+1]. Then, unchanged bits are extracted from `base` that are outside of
+[`offset`, `offset` + `count` - 1]. The result is `or`ed with shifted `insert`.
```mlir
// Create mask
#### Direct conversions
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.ConvertFToS` | `llvm.fptosi`
-`spv.ConvertFToU` | `llvm.fptoui`
-`spv.ConvertSToF` | `llvm.sitofp`
-`spv.ConvertUToF` | `llvm.uitofp`
+SPIR-V Dialect op | LLVM Dialect op
+:---------------: | :-------------:
+`spv.ConvertFToS` | `llvm.fptosi`
+`spv.ConvertFToU` | `llvm.fptoui`
+`spv.ConvertSToF` | `llvm.sitofp`
+`spv.ConvertUToF` | `llvm.uitofp`
#### spv.Bitcast
+
This operation has a direct counterpart in LLVM: `llvm.bitcast`. It is treated
separately since it also supports pointer to pointer bit pattern-preserving type
conversion, apart from regular scalar or vector of numerical type.
#### Special cases
+
Special cases include `spv.FConvert`, `spv.SConvert` and `spv.UConvert`. These
operations are either a truncate or extend. Let's denote the operand component
width as A, and result component width as R. Then, the following mappings are
used:
-##### `spv.FConvert`
-Case | LLVM Dialect op
-:-------------: | :-----------------------------------:
-A < R | `llvm.fpext`
-A > R | `llvm.fptrunc`
+##### `spv.FConvert`
+
+Case | LLVM Dialect op
+:---: | :-------------:
+A < R | `llvm.fpext`
+A > R | `llvm.fptrunc`
-##### `spv.SConvert`
-Case | LLVM Dialect op
-:-------------: | :-----------------------------------:
-A < R | `llvm.sext`
-A > R | `llvm.trunc`
+##### `spv.SConvert`
-##### `spv.UConvert`
-Case | LLVM Dialect op
-:-------------: | :-----------------------------------:
-A < R | `llvm.zext`
-A > R | `llvm.trunc`
+Case | LLVM Dialect op
+:---: | :-------------:
+A < R | `llvm.sext`
+A > R | `llvm.trunc`
+
+##### `spv.UConvert`
+
+Case | LLVM Dialect op
+:---: | :-------------:
+A < R | `llvm.zext`
+A > R | `llvm.trunc`
The case when A = R is not possible, based on SPIR-V Dialect specification:
+
> The component width cannot equal the component width in Result Type.
### Comparison ops
SPIR-V comparison ops are mapped to LLVM `icmp` and `fcmp` operations.
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.IEqual` | `llvm.icmp "eq"`
-`spv.INotEqual` | `llvm.icmp "ne"`
-`spv.FOrdEqual` | `llvm.fcmp "oeq"`
-`spv.FOrdGreaterThan` | `llvm.fcmp "ogt"`
-`spv.FOrdGreaterThanEqual` | `llvm.fcmp "oge"`
-`spv.FOrdLessThan` | `llvm.fcmp "olt"`
-`spv.FOrdLessThanEqual` | `llvm.fcmp "ole"`
-`spv.FOrdNotEqual` | `llvm.fcmp "one"`
-`spv.FUnordEqual` | `llvm.fcmp "ueq"`
-`spv.FUnordGreaterThan` | `llvm.fcmp "ugt"`
-`spv.FUnordGreaterThanEqual` | `llvm.fcmp "uge"`
-`spv.FUnordLessThan` | `llvm.fcmp "ult"`
-`spv.FUnordLessThanEqual` | `llvm.fcmp "ule"`
-`spv.FUnordNotEqual` | `llvm.fcmp "une"`
-`spv.SGreaterThan` | `llvm.icmp "sgt"`
-`spv.SGreaterThanEqual` | `llvm.icmp "sge"`
-`spv.SLessThan` | `llvm.icmp "slt"`
-`spv.SLessThanEqual` | `llvm.icmp "sle"`
-`spv.UGreaterThan` | `llvm.icmp "ugt"`
-`spv.UGreaterThanEqual` | `llvm.icmp "uge"`
-`spv.ULessThan` | `llvm.icmp "ult"`
-`spv.ULessThanEqual` | `llvm.icmp "ule"`
+SPIR-V Dialect op | LLVM Dialect op
+:--------------------------: | :---------------:
+`spv.IEqual` | `llvm.icmp "eq"`
+`spv.INotEqual` | `llvm.icmp "ne"`
+`spv.FOrdEqual` | `llvm.fcmp "oeq"`
+`spv.FOrdGreaterThan` | `llvm.fcmp "ogt"`
+`spv.FOrdGreaterThanEqual` | `llvm.fcmp "oge"`
+`spv.FOrdLessThan` | `llvm.fcmp "olt"`
+`spv.FOrdLessThanEqual` | `llvm.fcmp "ole"`
+`spv.FOrdNotEqual` | `llvm.fcmp "one"`
+`spv.FUnordEqual` | `llvm.fcmp "ueq"`
+`spv.FUnordGreaterThan` | `llvm.fcmp "ugt"`
+`spv.FUnordGreaterThanEqual` | `llvm.fcmp "uge"`
+`spv.FUnordLessThan` | `llvm.fcmp "ult"`
+`spv.FUnordLessThanEqual` | `llvm.fcmp "ule"`
+`spv.FUnordNotEqual` | `llvm.fcmp "une"`
+`spv.SGreaterThan` | `llvm.icmp "sgt"`
+`spv.SGreaterThanEqual` | `llvm.icmp "sge"`
+`spv.SLessThan` | `llvm.icmp "slt"`
+`spv.SLessThanEqual` | `llvm.icmp "sle"`
+`spv.UGreaterThan` | `llvm.icmp "ugt"`
+`spv.UGreaterThanEqual` | `llvm.icmp "uge"`
+`spv.ULessThan` | `llvm.icmp "ult"`
+`spv.ULessThanEqual` | `llvm.icmp "ule"`
### Composite ops
composite object is a vector, and when the composite object is of a non-vector
type (*i.e.* struct, array or runtime array).
-Composite type | SPIR-V Dialect op | LLVM Dialect op
-:-------------: | :--------------------: | :--------------------:
-vector | `spv.CompositeExtract` | `llvm.extractelement`
-vector | `spv.CompositeInsert` | `llvm.insertelement`
-non-vector | `spv.CompositeExtract` | `llvm.extractvalue`
-non-vector | `spv.CompositeInsert` | `llvm.insertvalue`
+Composite type | SPIR-V Dialect op | LLVM Dialect op
+:------------: | :--------------------: | :-------------------:
+vector | `spv.CompositeExtract` | `llvm.extractelement`
+vector | `spv.CompositeInsert` | `llvm.insertelement`
+non-vector | `spv.CompositeExtract` | `llvm.extractvalue`
+non-vector | `spv.CompositeInsert` | `llvm.insertvalue`
### `spv.EntryPoint` and `spv.ExecutionMode`
struct global variable that stores the execution mode id and any variables
associated with it. In C, the struct has the structure shown below.
- ```C
+ ```c
// No values are associated // There are values that are associated
// with this entry point. // with this entry point.
struct { struct {
they operate on `i1` or vector of `i1` values. The following mapping is used to
emulate SPIR-V ops behaviour:
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.LogicalAnd` | `llvm.and`
-`spv.LogicalOr` | `llvm.or`
-`spv.LogicalEqual` | `llvm.icmp "eq"`
-`spv.LogicalNotEqual` | `llvm.icmp "ne"`
+SPIR-V Dialect op | LLVM Dialect op
+:-------------------: | :--------------:
+`spv.LogicalAnd` | `llvm.and`
+`spv.LogicalOr` | `llvm.or`
+`spv.LogicalEqual` | `llvm.icmp "eq"`
+`spv.LogicalNotEqual` | `llvm.icmp "ne"`
`spv.LogicalNot` has the same conversion pattern as bitwise `spv.Not`. It is
modelled with `xor` operation with a mask with all bits set.
#### `spv.GlobalVariable` and `spv.mlir.addressof`
-`spv.GlobalVariable` is modelled with `llvm.mlir.global` op. However, there
-is a difference that has to be pointed out.
+`spv.GlobalVariable` is modelled with `llvm.mlir.global` op. However, there is a
+difference that has to be pointed out.
In SPIR-V dialect, the global variable returns a pointer, whereas in LLVM
dialect the global holds an actual value. This difference is handled by
-`spv.mlir.addressof` and `llvm.mlir.addressof` ops that both return a pointer and
-are used to reference the global.
+`spv.mlir.addressof` and `llvm.mlir.addressof` ops that both return a pointer
+and are used to reference the global.
```mlir
// Original SPIR-V module
}
```
-The SPIR-V to LLVM conversion does not involve modelling of workgroups.
-Hence, we say that only current invocation is in conversion's scope. This means
-that global variables with pointers of `Input`, `Output`, and `Private` storage
+The SPIR-V to LLVM conversion does not involve modelling of workgroups. Hence,
+we say that only current invocation is in conversion's scope. This means that
+global variables with pointers of `Input`, `Output`, and `Private` storage
classes are supported. Also, `StorageBuffer` storage class is allowed for
executing [`mlir-spirv-cpu-runner`](#mlir-spirv-cpu-runner).
storage class and `External` for other storage classes, based on SPIR-V spec:
> By default, functions and global variables are private to a module and cannot
-be accessed by other modules. However, a module may be written to export or
-import functions and global (module scope) variables.
+> be accessed by other modules. However, a module may be written to export or
+> import functions and global (module scope) variables.
If the global variable's pointer has `Input` storage class, then a `constant`
flag is added to LLVM op:
converted directly to LLVM dialect. Their conversion is addressed in this
section.
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.Select` | `llvm.select`
-`spv.Undef` | `llvm.mlir.undef`
+SPIR-V Dialect op | LLVM Dialect op
+:---------------: | :---------------:
+`spv.Select` | `llvm.select`
+`spv.Undef` | `llvm.mlir.undef`
### Shift ops
### `spv.mlir.selection` and `spv.mlir.loop`
-Control flow within `spv.mlir.selection` and `spv.mlir.loop` is lowered directly to LLVM
-via branch ops. The conversion can only be applied to selection or loop with all
-blocks being reachable. Moreover, selection and loop control attributes (such as
-`Flatten` or `Unroll`) are not supported at the moment.
+Control flow within `spv.mlir.selection` and `spv.mlir.loop` is lowered directly
+to LLVM via branch ops. The conversion can only be applied to selection or loop
+with all blocks being reachable. Moreover, selection and loop control attributes
+(such as `Flatten` or `Unroll`) are not supported at the moment.
```mlir
// Conversion of selection
### Direct conversions
-SPIR-V Dialect op | LLVM Dialect op
-:-----------------------------------: | :-----------------------------------:
-`spv.GLSL.Ceil` | `llvm.intr.ceil`
-`spv.GLSL.Cos` | `llvm.intr.cos`
-`spv.GLSL.Exp` | `llvm.intr.exp`
-`spv.GLSL.FAbs` | `llvm.intr.fabs`
-`spv.GLSL.Floor` | `llvm.intr.floor`
-`spv.GLSL.FMax` | `llvm.intr.maxnum`
-`spv.GLSL.FMin` | `llvm.intr.minnum`
-`spv.GLSL.Log` | `llvm.intr.log`
-`spv.GLSL.Sin` | `llvm.intr.sin`
-`spv.GLSL.Sqrt` | `llvm.intr.sqrt`
-`spv.GLSL.SMax` | `llvm.intr.smax`
-`spv.GLSL.SMin` | `llvm.intr.smin`
+SPIR-V Dialect op | LLVM Dialect op
+:---------------: | :----------------:
+`spv.GLSL.Ceil` | `llvm.intr.ceil`
+`spv.GLSL.Cos` | `llvm.intr.cos`
+`spv.GLSL.Exp` | `llvm.intr.exp`
+`spv.GLSL.FAbs` | `llvm.intr.fabs`
+`spv.GLSL.Floor` | `llvm.intr.floor`
+`spv.GLSL.FMax` | `llvm.intr.maxnum`
+`spv.GLSL.FMin` | `llvm.intr.minnum`
+`spv.GLSL.Log` | `llvm.intr.log`
+`spv.GLSL.Sin` | `llvm.intr.sin`
+`spv.GLSL.Sqrt` | `llvm.intr.sqrt`
+`spv.GLSL.SMax` | `llvm.intr.smax`
+`spv.GLSL.SMin` | `llvm.intr.smin`
### Special cases
%res = fdiv %sin, %cos : f32
```
-`spv.Tanh` is modelled using the equality `tanh(x) = {exp(2x) - 1}/{exp(2x) + 1}`:
+`spv.Tanh` is modelled using the equality `tanh(x) = {exp(2x) - 1}/{exp(2x) +
+1}`:
```mlir
%two = llvm.mlir.constant(2.0: f32) : f32
to LLVM dialect.
### `spv.func`
-This op declares or defines a SPIR-V function and it is converted to `llvm.func`.
-This conversion handles signature conversion, and function control attributes
-remapping to LLVM dialect function [`passthrough` attribute](Dialects/LLVM.md/#attribute-pass-through).
-The following mapping is used to map [SPIR-V function control][SPIRVFunctionAttributes] to
+This op declares or defines a SPIR-V function and it is converted to
+`llvm.func`. This conversion handles signature conversion, and function control
+attributes remapping to LLVM dialect function
+[`passthrough` attribute](Dialects/LLVM.md/#attribute-pass-through).
+
+The following mapping is used to map
+[SPIR-V function control][SPIRVFunctionAttributes] to
[LLVM function attributes][LLVMFunctionAttributes]:
-SPIR-V Function Control Attributes | LLVM Function Attributes
-:-----------------------------------: | :-----------------------------------:
-None | No function attributes passed
-Inline | `alwaysinline`
-DontInline | `noinline`
-Pure | `readonly`
-Const | `readnone`
+SPIR-V Function Control Attributes | LLVM Function Attributes
+:--------------------------------: | :---------------------------:
+None | No function attributes passed
+Inline | `alwaysinline`
+DontInline | `noinline`
+Pure | `readonly`
+Const | `readnone`
### `spv.Return` and `spv.ReturnValue`
SPIR-V to LLVM dialect conversion. Currently, only single-threaded kernel is
supported.
-To build the runner, add the following option to `cmake`:
-```bash
--DMLIR_ENABLE_SPIRV_CPU_RUNNER=1
-```
+To build the runner, add the following option to `cmake`: `bash
+-DMLIR_ENABLE_SPIRV_CPU_RUNNER=1`
### Pipeline
func @main() {
// Fill the buffer with some data
- %buffer = alloc : memref<8xi32>
+ %buffer = memref.alloc : memref<8xi32>
%data = ...
call fillBuffer(%buffer, %data)
func @main() {
// Fill the buffer with some data.
- %buffer = alloc : memref<8xi32>
+ %buffer = memref.alloc : memref<8xi32>
%data = ...
call fillBuffer(%buffer, %data)
[TOC]
-With [Regions](LangRef.md/#regions), the multi-level aspect of MLIR is structural
-in the IR. A lot of infrastructure within the compiler is built around this
-nesting structure; including the processing of operations within the
-[pass manager](PassManagement.md/#pass-manager). One advantage of the MLIR design
-is that it is able to process operations in parallel, utilizing multiple
+With [Regions](LangRef.md/#regions), the multi-level aspect of MLIR is
+structural in the IR. A lot of infrastructure within the compiler is built
+around this nesting structure; including the processing of operations within the
+[pass manager](PassManagement.md/#pass-manager). One advantage of the MLIR
+design is that it is able to process operations in parallel, utilizing multiple
threads. This is possible due to a property of the IR known as
[`IsolatedFromAbove`](Traits.md/#isolatedfromabove).
different trade offs depending on the situation. A function call may directly
use a `SymbolRef` as the callee, whereas a reference to a global variable might
use a materialization operation so that the variable can be used in other
-operations like `std.addi`.
-[`llvm.mlir.addressof`](Dialects/LLVM.md/#llvmmliraddressof-mlirllvmaddressofop) is one example of
-such an operation.
+operations like `arith.addi`.
+[`llvm.mlir.addressof`](Dialects/LLVM.md/#llvmmliraddressof-mlirllvmaddressofop)
+is one example of such an operation.
See the `LangRef` definition of the
-[`SymbolRefAttr`](Dialects/Builtin.md/#symbolrefattr) for more information
-about the structure of this attribute.
+[`SymbolRefAttr`](Dialects/Builtin.md/#symbolrefattr) for more information about
+the structure of this attribute.
Operations that reference a `Symbol` and want to perform verification and
general mutation of the symbol should implement the `SymbolUserOpInterface` to
return %arg0, %arg1 : i32, i64
}
func @bar() {
- %0 = constant 42 : i32
- %1 = constant 17 : i64
+ %0 = arith.constant 42 : i32
+ %1 = arith.constant 17 : i64
%2:2 = call @foo(%0, %1) : (i32, i64) -> (i32, i64)
"use_i32"(%2#0) : (i32) -> ()
"use_i64"(%2#1) : (i64) -> ()
An access to a memref with indices:
```mlir
-%0 = load %m[%1,%2,%3,%4] : memref<?x?x4x8xf32, offset: ?>
+%0 = memref.load %m[%1,%2,%3,%4] : memref<?x?x4x8xf32, offset: ?>
```
is transformed into the equivalent of the following code:
// dynamic, extract the stride value from the descriptor.
%stride1 = llvm.extractvalue[4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
array<4xi64>, array<4xi64>)>
-%addr1 = muli %stride1, %1 : i64
+%addr1 = arith.muli %stride1, %1 : i64
// When the stride or, in absence of explicit strides, the trailing sizes are
// known statically, this value is used as a constant. The natural value of
// strides is the product of all sizes following the current dimension.
%stride2 = llvm.mlir.constant(32 : index) : i64
-%addr2 = muli %stride2, %2 : i64
-%addr3 = addi %addr1, %addr2 : i64
+%addr2 = arith.muli %stride2, %2 : i64
+%addr3 = arith.addi %addr1, %addr2 : i64
%stride3 = llvm.mlir.constant(8 : index) : i64
-%addr4 = muli %stride3, %3 : i64
-%addr5 = addi %addr3, %addr4 : i64
+%addr4 = arith.muli %stride3, %3 : i64
+%addr5 = arith.addi %addr3, %addr4 : i64
// Multiplication with the known unit stride can be omitted.
-%addr6 = addi %addr5, %4 : i64
+%addr6 = arith.addi %addr5, %4 : i64
// If the linear offset is known to be zero, it can also be omitted. If it is
// dynamic, it is extracted from the descriptor.
%offset = llvm.extractvalue[2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
array<4xi64>, array<4xi64>)>
-%addr7 = addi %addr6, %offset : i64
+%addr7 = arith.addi %addr6, %offset : i64
// All accesses are based on the aligned pointer.
%aligned = llvm.extractvalue[1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
`verifyTrait` hook out-of-line as a free function when possible to avoid
instantiating the implementation for every concrete operation type.
-Operation traits may also provide a `foldTrait` hook that is called when
-folding the concrete operation. The trait folders will only be invoked if
-the concrete operation fold is either not implemented, fails, or performs
-an in-place fold.
+Operation traits may also provide a `foldTrait` hook that is called when folding
+the concrete operation. The trait folders will only be invoked if the concrete
+operation fold is either not implemented, fails, or performs an in-place fold.
-The following signature of fold will be called if it is implemented
-and the op has a single result.
+The following signature of fold will be called if it is implemented and the op
+has a single result.
```c++
template <typename ConcreteType>
};
```
-Otherwise, if the operation has a single result and the above signature is
-not implemented, or the operation has multiple results, then the following signature
+Otherwise, if the operation has a single result and the above signature is not
+implemented, or the operation has multiple results, then the following signature
will be used (if implemented):
```c++
such operations automatically become valid symbols for the polyhedral scope
defined by that operation. As a result, such SSA values could be used as the
operands or index operands of various affine dialect operations like affine.for,
-affine.load, and affine.store. The polyhedral scope defined by an operation
-with this trait includes all operations in its region excluding operations that
-are nested inside of other operations that themselves have this trait.
+affine.load, and affine.store. The polyhedral scope defined by an operation with
+this trait includes all operations in its region excluding operations that are
+nested inside of other operations that themselves have this trait.
### AutomaticAllocationScope
This trait is carried by region holding operations that define a new scope for
automatic allocation. Such allocations are automatically freed when control is
transferred back from the regions of such operations. As an example, allocations
-performed by [`memref.alloca`](Dialects/MemRef.md/#memrefalloca-mlirmemrefallocaop) are
+performed by
+[`memref.alloca`](Dialects/MemRef.md/#memrefalloca-mlirmemrefallocaop) are
automatically freed when control leaves the region of its closest surrounding op
that has the trait AutomaticAllocationScope.
### ElementwiseMappable
-* `OpTrait::ElementwiseMappable` -- `ElementwiseMappable`
+* `OpTrait::ElementwiseMappable` -- `ElementwiseMappable`
This trait tags scalar ops that also can be applied to vectors/tensors, with
their semantics on vectors/tensors being elementwise application. This trait
`IsolatedFromAbove`:
```mlir
-%result = constant 10 : i32
+%result = arith.constant 10 : i32
foo.region_op {
foo.yield %result : i32
}
### MemRefsNormalizable
-* `OpTrait::MemRefsNormalizable` -- `MemRefsNormalizable`
+* `OpTrait::MemRefsNormalizable` -- `MemRefsNormalizable`
-This trait is used to flag operations that consume or produce
-values of `MemRef` type where those references can be 'normalized'.
-In cases where an associated `MemRef` has a
-non-identity memory-layout specification, such normalizable operations can be
-modified so that the `MemRef` has an identity layout specification.
-This can be implemented by associating the operation with its own
+This trait is used to flag operations that consume or produce values of `MemRef`
+type where those references can be 'normalized'. In cases where an associated
+`MemRef` has a non-identity memory-layout specification, such normalizable
+operations can be modified so that the `MemRef` has an identity layout
+specification. This can be implemented by associating the operation with its own
index expression that can express the equivalent of the memory-layout
specification of the MemRef type. See [the -normalize-memrefs pass].
(https://mlir.llvm.org/docs/Passes/#-normalize-memrefs-normalize-memrefs)
`Affine` for the computation heavy part of Toy, and in the
[next chapter](Ch-6.md) directly target the `LLVM IR` dialect for lowering
`print`. As part of this lowering, we will be lowering from the
-[TensorType](../../Dialects/Builtin.md/#rankedtensortype) that `Toy`
-operates on to the [MemRefType](../../Dialects/Builtin.md/#memreftype) that is
-indexed via an affine loop-nest. Tensors represent an abstract value-typed
-sequence of data, meaning that they don't live in any memory. MemRefs, on the
-other hand, represent lower level buffer access, as they are concrete
-references to a region of memory.
+[TensorType](../../Dialects/Builtin.md/#rankedtensortype) that `Toy` operates on
+to the [MemRefType](../../Dialects/Builtin.md/#memreftype) that is indexed via
+an affine loop-nest. Tensors represent an abstract value-typed sequence of data,
+meaning that they don't live in any memory. MemRefs, on the other hand,
+represent lower level buffer access, as they are concrete references to a region
+of memory.
# Dialect Conversions
MLIR has many different dialects, so it is important to have a unified framework
-for [converting](../../../getting_started/Glossary.md/#conversion) between them. This is where the
-`DialectConversion` framework comes into play. This framework allows for
-transforming a set of *illegal* operations to a set of *legal* ones. To use this
-framework, we need to provide two things (and an optional third):
+for [converting](../../../getting_started/Glossary.md/#conversion) between them.
+This is where the `DialectConversion` framework comes into play. This framework
+allows for transforming a set of *illegal* operations to a set of *legal* ones.
+To use this framework, we need to provide two things (and an optional third):
* A [Conversion Target](../../DialectConversion.md/#conversion-target)
* A set of
[Rewrite Patterns](../../DialectConversion.md/#rewrite-pattern-specification)
- - This is the set of [patterns](../QuickstartRewrites.md) used to
- convert *illegal* operations into a set of zero or more *legal* ones.
+ - This is the set of [patterns](../QuickstartRewrites.md) used to convert
+ *illegal* operations into a set of zero or more *legal* ones.
* Optionally, a [Type Converter](../../DialectConversion.md/#type-conversion).
// We define the specific operations, or dialects, that are legal targets for
// this lowering. In our case, we are lowering to a combination of the
- // `Affine`, `MemRef` and `Standard` dialects.
- target.addLegalDialect<mlir::AffineDialect, mlir::memref::MemRefDialect,
- mlir::StandardOpsDialect>();
+ // `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
+ target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
+ memref::MemRefDialect, StandardOpsDialect>();
// We also define the Toy dialect as Illegal so that the conversion will fail
// if any of these operations are *not* converted. Given that we actually want
}
```
-Above, we first set the toy dialect to illegal, and then the print operation
-as legal. We could have done this the other way around.
-Individual operations always take precedence over the (more generic) dialect
-definitions, so the order doesn't matter. See `ConversionTarget::getOpInfo`
-for the details.
+Above, we first set the toy dialect to illegal, and then the print operation as
+legal. We could have done this the other way around. Individual operations
+always take precedence over the (more generic) dialect definitions, so the order
+doesn't matter. See `ConversionTarget::getOpInfo` for the details.
## Conversion Patterns
remapped/replaced. This is used when dealing with type conversions, as the
pattern will want to operate on values of the new type but match against the
old. For our lowering, this invariant will be useful as it translates from the
-[TensorType](../../Dialects/Builtin.md/#rankedtensortype) currently
-being operated on to the [MemRefType](../../Dialects/Builtin.md/#memreftype).
-Let's look at a snippet of lowering the `toy.transpose` operation:
+[TensorType](../../Dialects/Builtin.md/#rankedtensortype) currently being
+operated on to the [MemRefType](../../Dialects/Builtin.md/#memreftype). Let's
+look at a snippet of lowering the `toy.transpose` operation:
```c++
/// Lower the `toy.transpose` operation to an affine loop nest.
* Generate `load` operations from the buffer
- One option is to generate `load` operations from the buffer type to materialize
- an instance of the value type. This allows for the definition of the `toy.print`
- operation to remain unchanged. The downside to this approach is that the
- optimizations on the `affine` dialect are limited, because the `load` will
- actually involve a full copy that is only visible *after* our optimizations have
- been performed.
+ One option is to generate `load` operations from the buffer type to
+ materialize an instance of the value type. This allows for the definition of
+ the `toy.print` operation to remain unchanged. The downside to this approach
+ is that the optimizations on the `affine` dialect are limited, because the
+ `load` will actually involve a full copy that is only visible *after* our
+ optimizations have been performed.
* Generate a new version of `toy.print` that operates on the lowered type
- Another option would be to have another, lowered, variant of `toy.print` that
- operates on the lowered type. The benefit of this option is that there is no
- hidden, unnecessary copy to the optimizer. The downside is that another
- operation definition is needed that may duplicate many aspects of the first.
- Defining a base class in [ODS](../../OpDefinitions.md) may simplify this, but
- you still need to treat these operations separately.
+ Another option would be to have another, lowered, variant of `toy.print`
+ that operates on the lowered type. The benefit of this option is that there
+ is no hidden, unnecessary copy to the optimizer. The downside is that
+ another operation definition is needed that may duplicate many aspects of
+ the first. Defining a base class in [ODS](../../OpDefinitions.md) may
+ simplify this, but you still need to treat these operations separately.
* Update `toy.print` to allow for operating on the lowered type
- A third option is to update the current definition of `toy.print` to allow for
- operating the on the lowered type. The benefit of this approach is that it is
- simple, does not introduce an additional hidden copy, and does not require
- another operation definition. The downside to this option is that it requires
- mixing abstraction levels in the `Toy` dialect.
+ A third option is to update the current definition of `toy.print` to allow
+ for operating the on the lowered type. The benefit of this approach is that
+ it is simple, does not introduce an additional hidden copy, and does not
+ require another operation definition. The downside to this option is that it
+ requires mixing abstraction levels in the `Toy` dialect.
For the sake of simplicity, we will use the third option for this lowering. This
involves updating the type constraints on the PrintOp in the operation
```mlir
func @main() {
- %cst = constant 1.000000e+00 : f64
- %cst_0 = constant 2.000000e+00 : f64
- %cst_1 = constant 3.000000e+00 : f64
- %cst_2 = constant 4.000000e+00 : f64
- %cst_3 = constant 5.000000e+00 : f64
- %cst_4 = constant 6.000000e+00 : f64
+ %cst = arith.constant 1.000000e+00 : f64
+ %cst_0 = arith.constant 2.000000e+00 : f64
+ %cst_1 = arith.constant 3.000000e+00 : f64
+ %cst_2 = arith.constant 4.000000e+00 : f64
+ %cst_3 = arith.constant 5.000000e+00 : f64
+ %cst_4 = arith.constant 6.000000e+00 : f64
// Allocating buffers for the inputs and outputs.
- %0 = alloc() : memref<3x2xf64>
- %1 = alloc() : memref<3x2xf64>
- %2 = alloc() : memref<2x3xf64>
+ %0 = memref.alloc() : memref<3x2xf64>
+ %1 = memref.alloc() : memref<3x2xf64>
+ %2 = memref.alloc() : memref<2x3xf64>
// Initialize the input buffer with the constant values.
affine.store %cst, %2[0, 0] : memref<2x3xf64>
affine.for %arg1 = 0 to 2 {
%3 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
%4 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
- %5 = mulf %3, %4 : f64
+ %5 = arith.mulf %3, %4 : f64
affine.store %5, %0[%arg0, %arg1] : memref<3x2xf64>
}
}
// Print the value held by the buffer.
toy.print %0 : memref<3x2xf64>
- dealloc %2 : memref<2x3xf64>
- dealloc %1 : memref<3x2xf64>
- dealloc %0 : memref<3x2xf64>
+ memref.dealloc %2 : memref<2x3xf64>
+ memref.dealloc %1 : memref<3x2xf64>
+ memref.dealloc %0 : memref<3x2xf64>
return
}
```
```mlir
func @main() {
- %cst = constant 1.000000e+00 : f64
- %cst_0 = constant 2.000000e+00 : f64
- %cst_1 = constant 3.000000e+00 : f64
- %cst_2 = constant 4.000000e+00 : f64
- %cst_3 = constant 5.000000e+00 : f64
- %cst_4 = constant 6.000000e+00 : f64
+ %cst = arith.constant 1.000000e+00 : f64
+ %cst_0 = arith.constant 2.000000e+00 : f64
+ %cst_1 = arith.constant 3.000000e+00 : f64
+ %cst_2 = arith.constant 4.000000e+00 : f64
+ %cst_3 = arith.constant 5.000000e+00 : f64
+ %cst_4 = arith.constant 6.000000e+00 : f64
// Allocating buffers for the inputs and outputs.
- %0 = alloc() : memref<3x2xf64>
- %1 = alloc() : memref<2x3xf64>
+ %0 = memref.alloc() : memref<3x2xf64>
+ %1 = memref.alloc() : memref<2x3xf64>
// Initialize the input buffer with the constant values.
affine.store %cst, %1[0, 0] : memref<2x3xf64>
%2 = affine.load %1[%arg1, %arg0] : memref<2x3xf64>
// Multiply and store into the output buffer.
- %3 = mulf %2, %2 : f64
+ %3 = arith.mulf %2, %2 : f64
affine.store %3, %0[%arg0, %arg1] : memref<3x2xf64>
}
}
// Print the value held by the buffer.
toy.print %0 : memref<3x2xf64>
- dealloc %1 : memref<2x3xf64>
- dealloc %0 : memref<3x2xf64>
+ memref.dealloc %1 : memref<2x3xf64>
+ memref.dealloc %0 : memref<3x2xf64>
return
}
```
Before going over the conversion to LLVM, let's lower the `toy.print` operation.
We will lower this operation to a non-affine loop nest that invokes `printf` for
each element. Note that, because the dialect conversion framework supports
-[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering), we don't need to
-directly emit operations in the LLVM dialect. By transitive lowering, we mean
-that the conversion framework may apply multiple patterns to fully legalize an
-operation. In this example, we are generating a structured loop nest instead of
-the branch-form in the LLVM dialect. As long as we then have a lowering from the
-loop operations to LLVM, the lowering will still succeed.
+[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering),
+we don't need to directly emit operations in the LLVM dialect. By transitive
+lowering, we mean that the conversion framework may apply multiple patterns to
+fully legalize an operation. In this example, we are generating a structured
+loop nest instead of the branch-form in the LLVM dialect. As long as we then
+have a lowering from the loop operations to LLVM, the lowering will still
+succeed.
During lowering we can get, or build, the declaration for printf as so:
Now that the conversion target has been defined, we need to provide the patterns
used for lowering. At this point in the compilation process, we have a
-combination of `toy`, `affine`, and `std` operations. Luckily, the `std` and
-`affine` dialects already provide the set of patterns needed to transform them
-into LLVM dialect. These patterns allow for lowering the IR in multiple stages
-by relying on [transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering).
+combination of `toy`, `affine`, `arith`, and `std` operations. Luckily, the
+`affine`, `arith`, and `std` dialects already provide the set of patterns needed
+to transform them into LLVM dialect. These patterns allow for lowering the IR in
+multiple stages by relying on
+[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering).
```c++
mlir::RewritePatternSet patterns(&getContext());
mlir::populateAffineToStdConversionPatterns(patterns, &getContext());
mlir::populateLoopToStdConversionPatterns(patterns, &getContext());
+ mlir::populateArithmeticToLLVMConversionPatterns(typeConverter, patterns);
mlir::populateStdToLLVMConversionPatterns(typeConverter, patterns);
// The only remaining operation, to lower from the `toy` dialect, is the
%106 = mul i64 %100, 1
%107 = add i64 %105, %106
%108 = getelementptr double, double* %103, i64 %107
- %109 = load double, double* %108
+ %109 = memref.load double, double* %108
%110 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @frmt_spec, i64 0, i64 0), double %109)
%111 = add i64 %100, 1
br label %99
[`--print-ir-after-all`](../../PassManagement.md/#ir-printing) to track the
evolution of the IR throughout the pipeline.
-The example code used throughout this section can be found in
+The example code used throughout this section can be found in
test/Examples/Toy/Ch6/llvm-lowering.mlir.
So far, we have worked with primitive data types. In the
id="tspan3407"
x="21.911886"
y="15.884925"
- style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%0 = alloc()</tspan></text>
+ style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%0 = memref.alloc()</tspan></text>
</g>
</svg>
transform="translate(8.4353227,-0.28369449)"><tspan
x="73.476562"
y="74.182797"><tspan
- style="fill:#d40000;fill-opacity:1">%0 = alloc()</tspan><tspan
+ style="fill:#d40000;fill-opacity:1">%0 = memref.alloc()</tspan><tspan
style="font-size:5.64444px">
</tspan></tspan><tspan
x="73.476562"
id="tspan9336"
x="137.07773"
y="78.674141"
- style="font-size:5.64444px;fill:#999999;stroke-width:0.264583">%1 = alloc(%0)</tspan><tspan
+ style="font-size:5.64444px;fill:#999999;stroke-width:0.264583">%1 = memref.alloc(%0)</tspan><tspan
sodipodi:role="line"
x="137.07773"
y="85.729691"
id="tspan9336-0"
x="-45.424786"
y="77.928955"
- style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%5 = alloc(%d0)</tspan><tspan
+ style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%5 = memref.alloc(%d0)</tspan><tspan
sodipodi:role="line"
x="-45.424786"
y="84.984505"
id="tspan9336-2"
x="135.37999"
y="198.54033"
- style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%6 = alloc(%d1)</tspan><tspan
+ style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%6 = memref.alloc(%d1)</tspan><tspan
sodipodi:role="line"
x="135.37999"
y="205.59589"
id="tspan9336"
x="137.07773"
y="78.674141"
- style="font-size:5.64444px;fill:#d40000;stroke-width:0.264583">%1 = alloc(%0)</tspan><tspan
+ style="font-size:5.64444px;fill:#d40000;stroke-width:0.264583">%1 = memref.alloc(%0)</tspan><tspan
sodipodi:role="line"
x="137.07773"
y="85.729691"
set(LIBS
${dialect_libs}
${conversion_libs}
+ MLIRArithmetic
MLIROptLib
MLIRStandalone
)
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/Dialect.h"
#include "mlir/IR/MLIRContext.h"
#include "mlir/InitAllDialects.h"
// TODO: Register standalone passes here.
mlir::DialectRegistry registry;
- registry.insert<mlir::standalone::StandaloneDialect>();
- registry.insert<mlir::StandardOpsDialect>();
+ registry.insert<mlir::standalone::StandaloneDialect,
+ mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect>();
// Add the following to include *all* MLIR Core dialects, or selectively
// include what you need like above. You only need to register dialects that
// will be *parsed* by the tool, not the one generated
module {
// CHECK-LABEL: func @bar()
func @bar() {
- %0 = constant 1 : i32
+ %0 = arith.constant 1 : i32
// CHECK: %{{.*}} = standalone.foo %{{.*}} : i32
%res = standalone.foo %0 : i32
return
#include "toy/Passes.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Pass/Pass.h"
return success();
}
};
-using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
-using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
+using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
+using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
//===----------------------------------------------------------------------===//
// ToyToAffine RewritePatterns: Constant operations
if (!valueShape.empty()) {
for (auto i : llvm::seq<int64_t>(
0, *std::max_element(valueShape.begin(), valueShape.end())))
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, i));
} else {
// This is the case of a tensor of rank 0.
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, 0));
}
// The constant operation represents a multi-dimensional constant, so we
// we store the element at the given index.
if (dimension == valueShape.size()) {
rewriter.create<AffineStoreOp>(
- loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
+ loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
llvm::makeArrayRef(indices));
return;
}
// We define the specific operations, or dialects, that are legal targets for
// this lowering. In our case, we are lowering to a combination of the
- // `Affine`, `MemRef` and `Standard` dialects.
- target.addLegalDialect<AffineDialect, memref::MemRefDialect,
- StandardOpsDialect>();
+ // `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
+ target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
+ memref::MemRefDialect, StandardOpsDialect>();
// We also define the Toy dialect as Illegal so that the conversion will fail
// if any of these operations are *not* converted. Given that we actually want
#include "toy/Passes.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Pass/Pass.h"
return success();
}
};
-using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
-using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
+using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
+using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
//===----------------------------------------------------------------------===//
// ToyToAffine RewritePatterns: Constant operations
if (!valueShape.empty()) {
for (auto i : llvm::seq<int64_t>(
0, *std::max_element(valueShape.begin(), valueShape.end())))
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, i));
} else {
// This is the case of a tensor of rank 0.
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, 0));
}
// The constant operation represents a multi-dimensional constant, so we
// will need to generate a store for each of the elements. The following
// we store the element at the given index.
if (dimension == valueShape.size()) {
rewriter.create<AffineStoreOp>(
- loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
+ loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
llvm::makeArrayRef(indices));
return;
}
// We define the specific operations, or dialects, that are legal targets for
// this lowering. In our case, we are lowering to a combination of the
- // `Affine`, `MemRef` and `Standard` dialects.
- target.addLegalDialect<AffineDialect, memref::MemRefDialect,
- StandardOpsDialect>();
+ // `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
+ target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
+ memref::MemRefDialect, StandardOpsDialect>();
// We also define the Toy dialect as Illegal so that the conversion will fail
// if any of these operations are *not* converted. Given that we actually want
#include "toy/Passes.h"
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
// Create a loop for each of the dimensions within the shape.
SmallVector<Value, 4> loopIvs;
for (unsigned i = 0, e = memRefShape.size(); i != e; ++i) {
- auto lowerBound = rewriter.create<ConstantIndexOp>(loc, 0);
- auto upperBound = rewriter.create<ConstantIndexOp>(loc, memRefShape[i]);
- auto step = rewriter.create<ConstantIndexOp>(loc, 1);
+ auto lowerBound = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ auto upperBound =
+ rewriter.create<arith::ConstantIndexOp>(loc, memRefShape[i]);
+ auto step = rewriter.create<arith::ConstantIndexOp>(loc, 1);
auto loop =
rewriter.create<scf::ForOp>(loc, lowerBound, upperBound, step);
for (Operation &nested : *loop.getBody())
RewritePatternSet patterns(&getContext());
populateAffineToStdConversionPatterns(patterns);
populateLoopToStdConversionPatterns(patterns);
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
+ patterns);
populateMemRefToLLVMConversionPatterns(typeConverter, patterns);
populateStdToLLVMConversionPatterns(typeConverter, patterns);
#include "toy/Passes.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Pass/Pass.h"
return success();
}
};
-using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
-using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
+using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
+using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
//===----------------------------------------------------------------------===//
// ToyToAffine RewritePatterns: Constant operations
if (!valueShape.empty()) {
for (auto i : llvm::seq<int64_t>(
0, *std::max_element(valueShape.begin(), valueShape.end())))
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, i));
} else {
// This is the case of a tensor of rank 0.
- constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
+ constantIndices.push_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, 0));
}
// The constant operation represents a multi-dimensional constant, so we
// we store the element at the given index.
if (dimension == valueShape.size()) {
rewriter.create<AffineStoreOp>(
- loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
+ loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
llvm::makeArrayRef(indices));
return;
}
// We define the specific operations, or dialects, that are legal targets for
// this lowering. In our case, we are lowering to a combination of the
- // `Affine`, `MemRef` and `Standard` dialects.
- target.addLegalDialect<AffineDialect, memref::MemRefDialect,
- StandardOpsDialect>();
+ // `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
+ target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
+ memref::MemRefDialect, StandardOpsDialect>();
// We also define the Toy dialect as Illegal so that the conversion will fail
// if any of these operations are *not* converted. Given that we actually want
#include "toy/Passes.h"
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
// Create a loop for each of the dimensions within the shape.
SmallVector<Value, 4> loopIvs;
for (unsigned i = 0, e = memRefShape.size(); i != e; ++i) {
- auto lowerBound = rewriter.create<ConstantIndexOp>(loc, 0);
- auto upperBound = rewriter.create<ConstantIndexOp>(loc, memRefShape[i]);
- auto step = rewriter.create<ConstantIndexOp>(loc, 1);
+ auto lowerBound = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ auto upperBound =
+ rewriter.create<arith::ConstantIndexOp>(loc, memRefShape[i]);
+ auto step = rewriter.create<arith::ConstantIndexOp>(loc, 1);
auto loop =
rewriter.create<scf::ForOp>(loc, lowerBound, upperBound, step);
for (Operation &nested : *loop.getBody())
RewritePatternSet patterns(&getContext());
populateAffineToStdConversionPatterns(patterns);
populateLoopToStdConversionPatterns(patterns);
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
+ patterns);
populateMemRefToLLVMConversionPatterns(typeConverter, patterns);
populateStdToLLVMConversionPatterns(typeConverter, patterns);
--- /dev/null
+//===- ArithmeticToLLVM.h - Arith to LLVM dialect conversion ----*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
+#define MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
+
+#include <memory>
+
+namespace mlir {
+
+class LLVMTypeConverter;
+class RewritePatternSet;
+class Pass;
+
+namespace arith {
+void populateArithmeticToLLVMConversionPatterns(LLVMTypeConverter &converter,
+ RewritePatternSet &patterns);
+
+std::unique_ptr<Pass> createConvertArithmeticToLLVMPass();
+} // end namespace arith
+} // end namespace mlir
+
+#endif // MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
--- /dev/null
+//===- ArithmeticToSPIRV.h - Convert Arith to SPIRV dialect -----*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
+#define MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
+
+#include <memory>
+
+namespace mlir {
+
+class SPIRVTypeConverter;
+class RewritePatternSet;
+class Pass;
+
+namespace arith {
+void populateArithmeticToSPIRVPatterns(SPIRVTypeConverter &typeConverter,
+ RewritePatternSet &patterns);
+
+std::unique_ptr<Pass> createConvertArithmeticToSPIRVPass();
+} // end namespace arith
+} // end namespace mlir
+
+#endif // MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
#define MLIR_CONVERSION_PASSES_H
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
+#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
#include "mlir/Conversion/ArmNeon2dToIntr/ArmNeon2dToIntr.h"
#include "mlir/Conversion/AsyncToLLVM/AsyncToLLVM.h"
#include "mlir/Conversion/ComplexToLLVM/ComplexToLLVM.h"
%d0 = <...>
%d1 = <...>
%s0 = <...>
- %0 = constant 2 : index
- %1 = muli %0, %d1
- %2 = addi %d0, %1
- %r = addi %2, %s0
+ %0 = arith.constant 2 : index
+ %1 = arith.muli %0, %d1
+ %2 = arith.addi %d0, %1
+ %r = arith.addi %2, %s0
```
#### Input invariant
}
//===----------------------------------------------------------------------===//
+// ArithmeticToLLVM
+//===----------------------------------------------------------------------===//
+
+def ConvertArithmeticToLLVM : FunctionPass<"convert-arith-to-llvm"> {
+ let summary = "Convert Arithmetic dialect to LLVM dialect";
+ let description = [{
+ This pass converts supported Arithmetic ops to LLVM dialect instructions.
+ }];
+ let constructor = "mlir::arith::createConvertArithmeticToLLVMPass()";
+ let dependentDialects = ["LLVM::LLVMDialect"];
+ let options = [
+ Option<"indexBitwidth", "index-bitwidth", "unsigned",
+ /*default=kDeriveIndexBitwidthFromDataLayout*/"0",
+ "Bitwidth of the index type, 0 to use size of machine word">,
+ ];
+}
+
+//===----------------------------------------------------------------------===//
+// ArithmeticToSPIRV
+//===----------------------------------------------------------------------===//
+
+def ConvertArithmeticToSPIRV : FunctionPass<"convert-arith-to-spirv"> {
+ let summary = "Convert Arithmetic dialect to SPIR-V dialect";
+ let constructor = "mlir::arith::createConvertArithmeticToSPIRVPass()";
+ let dependentDialects = ["spirv::SPIRVDialect"];
+ let options = [
+ Option<"emulateNon32BitScalarTypes", "emulate-non-32-bit-scalar-types",
+ "bool", /*default=*/"true",
+ "Emulate non-32-bit scalar types with 32-bit ones if "
+ "missing native support">
+ ];
+}
+
+//===----------------------------------------------------------------------===//
// AsyncToLLVM
//===----------------------------------------------------------------------===//
API to execute them.
}];
let constructor = "mlir::createConvertAsyncToLLVMPass()";
- let dependentDialects = ["LLVM::LLVMDialect"];
+ let dependentDialects = [
+ "arith::ArithmeticDialect",
+ "LLVM::LLVMDialect",
+ ];
}
//===----------------------------------------------------------------------===//
def ConvertComplexToStandard : FunctionPass<"convert-complex-to-standard"> {
let summary = "Convert Complex dialect to standard dialect";
let constructor = "mlir::createConvertComplexToStandardPass()";
- let dependentDialects = [
- "complex::ComplexDialect",
- "math::MathDialect",
- "StandardOpsDialect"
- ];
+ let dependentDialects = ["math::MathDialect"];
}
//===----------------------------------------------------------------------===//
def ConvertGpuOpsToNVVMOps : Pass<"convert-gpu-to-nvvm", "gpu::GPUModuleOp"> {
let summary = "Generate NVVM operations for gpu operations";
let constructor = "mlir::createLowerGpuOpsToNVVMOpsPass()";
- let dependentDialects = ["NVVM::NVVMDialect", "memref::MemRefDialect"];
+ let dependentDialects = [
+ "memref::MemRefDialect",
+ "NVVM::NVVMDialect",
+ "StandardOpsDialect",
+ ];
let options = [
Option<"indexBitwidth", "index-bitwidth", "unsigned",
/*default=kDeriveIndexBitwidthFromDataLayout*/"0",
This pass converts supported Math ops to libm calls.
}];
let constructor = "mlir::createConvertMathToLibmPass()";
- let dependentDialects = ["StandardOpsDialect", "vector::VectorDialect"];
+ let dependentDialects = [
+ "arith::ArithmeticDialect",
+ "StandardOpsDialect",
+ "vector::VectorDialect",
+ ];
}
//===----------------------------------------------------------------------===//
let dependentDialects = [
"StandardOpsDialect",
"scf::SCFDialect",
- "tensor::TensorDialect"
];
}
def TosaToStandard : Pass<"tosa-to-standard"> {
let summary = "Lower TOSA to the Standard dialect";
- let dependentDialects = ["StandardOpsDialect", "tensor::TensorDialect"];
+ let dependentDialects = [
+ "arith::ArithmeticDialect",
+ "StandardOpsDialect",
+ "tensor::TensorDialect",
+ ];
let description = [{
Pass that converts TOSA operations to the equivalent operations using the
operations in the Standard dialect.
/// affine.for %I = 0 to 9 {
/// %dim = dim %A, 0 : memref<?x?x?xf32>
/// %add = affine.apply %I + %a
-/// %cmp = cmpi "slt", %add, %dim : index
+/// %cmp = arith.cmpi "slt", %add, %dim : index
/// scf.if %cmp {
/// %vec_2d = load %1[%I] : memref<9xvector<17x15xf32>>
/// vector.transfer_write %vec_2d, %A[%add, %b, %c] :
let name = "affine";
let cppNamespace = "mlir";
let hasConstantMaterializer = 1;
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
// Base class for Affine dialect ops.
%sum = affine.for %i = 0 to 10 step 2
iter_args(%sum_iter = %sum_0) -> (f32) {
%t = affine.load %buffer[%i] : memref<1024xf32>
- %sum_next = addf %sum_iter, %t : f32
+ %sum_next = arith.addf %sum_iter, %t : f32
// Yield current iteration sum to next iteration %sum_iter or to %sum
// if final iteration.
affine.yield %sum_next : f32
```mlir
%res:2 = affine.for %i = 0 to 128 iter_args(%arg0 = %init0, %arg1 = %init1)
-> (index, index) {
- %y0 = addi %arg0, %c1 : index
- %y1 = addi %arg1, %c2 : index
+ %y0 = arith.addi %arg0, %c1 : index
+ %y1 = arith.addi %arg1, %c2 : index
affine.yield %y0, %y1 : index, index
}
```
%0 = affine.parallel (%kx, %ky) = (0, 0) to (2, 2) reduce ("addf") {
%1 = affine.load %D[%x + %kx, %y + %ky] : memref<100x100xf32>
%2 = affine.load %K[%kx, %ky] : memref<3x3xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
affine.yield %3 : f32
}
affine.store %0, O[%x, %y] : memref<98x98xf32>
affine.for %i1 = 0 to 10 {
affine.store %cf7, %m[%i0, %i1] : memref<10x10xf32>
%v0 = affine.load %m[%i0, %i1] : memref<10x10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
return %m : memref<10x10xf32>
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.store %cst, %0[%arg0, %arg1] : memref<10x10xf32>
- %1 = addf %cst, %cst : f32
+ %1 = arith.addf %cst, %cst : f32
}
}
return %0 : memref<10x10xf32>
add_subdirectory(IR)
+add_subdirectory(Transforms)
#include "mlir/IR/Dialect.h"
#include "mlir/IR/OpDefinition.h"
+#include "mlir/IR/OpImplementation.h"
#include "mlir/Interfaces/CastInterfaces.h"
#include "mlir/Interfaces/SideEffectInterfaces.h"
#include "mlir/Interfaces/VectorInterfaces.h"
#define GET_OP_CLASSES
#include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.h.inc"
+namespace mlir {
+namespace arith {
+
+/// Specialization of `arith.constant` op that returns an integer value.
+class ConstantIntOp : public arith::ConstantOp {
+public:
+ using arith::ConstantOp::ConstantOp;
+
+ /// Build a constant int op that produces an integer of the specified width.
+ static void build(OpBuilder &builder, OperationState &result, int64_t value,
+ unsigned width);
+
+ /// Build a constant int op that produces an integer of the specified type,
+ /// which must be an integer type.
+ static void build(OpBuilder &builder, OperationState &result, int64_t value,
+ Type type);
+
+ inline int64_t value() {
+ return arith::ConstantOp::value().cast<IntegerAttr>().getInt();
+ }
+
+ static bool classof(Operation *op);
+};
+
+/// Specialization of `arith.constant` op that returns a floating point value.
+class ConstantFloatOp : public arith::ConstantOp {
+public:
+ using arith::ConstantOp::ConstantOp;
+
+ /// Build a constant float op that produces a float of the specified type.
+ static void build(OpBuilder &builder, OperationState &result,
+ const APFloat &value, FloatType type);
+
+ inline APFloat value() {
+ return arith::ConstantOp::value().cast<FloatAttr>().getValue();
+ }
+
+ static bool classof(Operation *op);
+};
+
+/// Specialization of `arith.constant` op that returns an integer of index type.
+class ConstantIndexOp : public arith::ConstantOp {
+public:
+ using arith::ConstantOp::ConstantOp;
+
+ /// Build a constant int op that produces an index.
+ static void build(OpBuilder &builder, OperationState &result, int64_t value);
+
+ inline int64_t value() {
+ return arith::ConstantOp::value().cast<IntegerAttr>().getInt();
+ }
+
+ static bool classof(Operation *op);
+};
+
+} // end namespace arith
+} // end namespace mlir
+
//===----------------------------------------------------------------------===//
// Utility Functions
//===----------------------------------------------------------------------===//
ops, bitwise and shift ops, cast ops, and compare ops. Operations in this
dialect also accept vectors and tensors of integers or floats.
}];
+
+ let hasConstantMaterializer = 1;
}
// The predicate indicates the type of the comparison to perform:
include "mlir/Interfaces/CastInterfaces.td"
include "mlir/Interfaces/SideEffectInterfaces.td"
include "mlir/Interfaces/VectorInterfaces.td"
+include "mlir/IR/OpAsmInterface.td"
// Base class for Arithmetic dialect ops. Ops in this dialect have no side
// effects and can be applied element-wise to vectors and tensors.
//===----------------------------------------------------------------------===//
def Arith_ConstantOp : Op<Arithmetic_Dialect, "constant",
- [ConstantLike, NoSideEffect, TypesMatchWith<
- "result type has same type as the attribute value",
+ [ConstantLike, NoSideEffect,
+ DeclareOpInterfaceMethods<OpAsmOpInterface, ["getAsmResultNames"]>,
+ TypesMatchWith<
+ "result and attribute have the same type",
"value", "result", "$_self">]> {
let summary = "integer or floating point constant";
let description = [{
- The `const` operation produces an SSA value equal to some integer or
+ The `constant` operation produces an SSA value equal to some integer or
floating-point constant specified by an attribute. This is the way MLIR
forms simple integer and floating point constants.
}];
let arguments = (ins AnyAttr:$value);
- let results = (outs SignlessIntegerOrFloatLike:$result);
+ // TODO: Disallow arith.constant to return anything other than a signless
+ // integer or float like. Downstream users of Arithmetic should only be
+ // working with signless integers, floats, or vectors/tensors thereof.
+ // However, it is necessary to allow arith.constant to return vectors/tensors
+ // of strings and signed/unsigned integers (for now) as an artefact of
+ // splitting the Standard dialect.
+ let results = (outs /*SignlessIntegerOrFloatLike*/AnyType:$result);
+ let verifier = [{ return ::verify(*this); }];
let builders = [
OpBuilder<(ins "Attribute":$value),
[{ build($_builder, $_state, type, value); }]>,
];
+ let extraClassDeclaration = [{
+ /// Whether the constant op can be constructed with a particular value and
+ /// type.
+ static bool isBuildableWith(Attribute value, Type type);
+ }];
+
let hasFolder = 1;
let assemblyFormat = "attr-dict $value";
}
```mlir
// Scalar signed integer division remainder.
- %a = remsi %b, %c : i64
+ %a = arith.remsi %b, %c : i64
// SIMD vector element-wise division remainder.
- %f = remsi %g, %h : vector<4xi32>
+ %f = arith.remsi %g, %h : vector<4xi32>
// Tensor element-wise integer division remainder.
- %x = remsi %y, %z : tensor<4x?xi8>
+ %x = arith.remsi %y, %z : tensor<4x?xi8>
```
}];
let hasFolder = 1;
```mlir
%1 = arith.constant 21 : i5 // %1 is 0b10101
- %2 = trunci %1 : i5 to i4 // %2 is 0b0101
- %3 = trunci %1 : i5 to i3 // %3 is 0b101
+ %2 = arith.trunci %1 : i5 to i4 // %2 is 0b0101
+ %3 = arith.trunci %1 : i5 to i3 // %3 is 0b101
- %5 = trunci %0 : vector<2 x i32> to vector<2 x i16>
+ %5 = arith.trunci %0 : vector<2 x i32> to vector<2 x i16>
```
}];
// IndexCastOp
//===----------------------------------------------------------------------===//
-def Arith_IndexCastOp : Arith_IToICastOp<"index_cast"> {
+// Index cast can convert between memrefs of signless integers and indices too.
+def IndexCastTypeConstraint : TypeConstraint<Or<[
+ SignlessIntegerLike.predicate,
+ MemRefOf<[AnySignlessInteger, Index]>.predicate]>,
+ "signless-integer-like or memref of signless-integer">;
+
+def Arith_IndexCastOp : Arith_CastOp<"index_cast", IndexCastTypeConstraint,
+ IndexCastTypeConstraint> {
let summary = "cast between index and integer types";
let description = [{
Casts between scalar or vector integers and corresponding 'index' scalar or
// BitcastOp
//===----------------------------------------------------------------------===//
-def Arith_BitcastOp : Arith_CastOp<"bitcast", SignlessIntegerOrFloatLike,
- SignlessIntegerOrFloatLike> {
+// Bitcast can convert between memrefs of signless integers, indices, and
+// floats too.
+def BitcastTypeConstraint : TypeConstraint<Or<[
+ SignlessIntegerOrFloatLike.predicate,
+ MemRefOf<[AnySignlessInteger, Index, AnyFloat]>.predicate]>,
+ "signless-integer-or-float-like or memref of signless-integer or float">;
+
+def Arith_BitcastOp : Arith_CastOp<"bitcast", BitcastTypeConstraint,
+ BitcastTypeConstraint> {
let summary = "bitcast between values of equal bit width";
let description = [{
Bitcast an integer or floating point value to an integer or floating point
let extraClassDeclaration = [{
static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpIPredicate getPredicateByName(StringRef name);
+ static arith::CmpIPredicate getPredicateByName(StringRef name);
- CmpIPredicate getPredicate() {
- return (CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
+ arith::CmpIPredicate getPredicate() {
+ return (arith::CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
getPredicateAttrName()).getInt();
}
}];
let extraClassDeclaration = [{
static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpFPredicate getPredicateByName(StringRef name);
+ static arith::CmpFPredicate getPredicateByName(StringRef name);
- CmpFPredicate getPredicate() {
- return (CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
+ arith::CmpFPredicate getPredicate() {
+ return (arith::CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
getPredicateAttrName()).getInt();
}
}];
--- /dev/null
+set(LLVM_TARGET_DEFINITIONS Passes.td)
+mlir_tablegen(Passes.h.inc -gen-pass-decls -name Arithmetic)
+add_public_tablegen_target(MLIRArithmeticTransformsIncGen)
+
+add_mlir_doc(Passes ArithmeticPasses ./ -gen-pass-doc)
--- /dev/null
+//===- Passes.h - Pass Entrypoints ------------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
+#define MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
+
+#include "mlir/Pass/Pass.h"
+#include "mlir/Transforms/Bufferize.h"
+
+namespace mlir {
+namespace arith {
+
+/// Add patterns to bufferize Arithmetic ops.
+void populateArithmeticBufferizePatterns(BufferizeTypeConverter &typeConverter,
+ RewritePatternSet &patterns);
+
+/// Create a pass to bufferize Arithmetic ops.
+std::unique_ptr<Pass> createArithmeticBufferizePass();
+
+/// Add patterns to expand Arithmetic ops for LLVM lowering.
+void populateArithmeticExpandOpsPatterns(RewritePatternSet &patterns);
+
+/// Create a pass to legalize Arithmetic ops for LLVM lowering.
+std::unique_ptr<Pass> createArithmeticExpandOpsPass();
+
+//===----------------------------------------------------------------------===//
+// Registration
+//===----------------------------------------------------------------------===//
+
+/// Generate the code for registering passes.
+#define GEN_PASS_REGISTRATION
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h.inc"
+
+} // end namespace arith
+} // end namespace mlir
+
+#endif // MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
--- /dev/null
+//===-- Passes.td - Arithmetic pass definition file --------*- tablegen -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
+#define MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
+
+include "mlir/Pass/PassBase.td"
+
+def ArithmeticBufferize : FunctionPass<"arith-bufferize"> {
+ let summary = "Bufferize Arithmetic dialect ops.";
+ let constructor = "mlir::arith::createArithmeticBufferizePass()";
+ let dependentDialects = ["memref::MemRefDialect"];
+}
+
+def ArithmeticExpandOps : FunctionPass<"arith-expand"> {
+ let summary = "Legalize Arithmetic ops to be convertible to LLVM.";
+ let constructor = "mlir::arith::createArithmeticExpandOpsPass()";
+ let dependentDialects = ["StandardOpsDialect"];
+}
+
+#endif // MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
include "mlir/Interfaces/SideEffectInterfaces.td"
include "mlir/Dialect/LLVMIR/LLVMOpBase.td"
-include "mlir/Dialect/StandardOps/IR/StandardOpsBase.td"
+include "mlir/Dialect/Arithmetic/IR/ArithmeticBase.td"
include "mlir/Dialect/ArmSVE/ArmSVEOpBase.td"
//===----------------------------------------------------------------------===//
```
}];
let arguments = (ins
- CmpFPredicateAttr:$predicate,
+ Arith_CmpFPredicateAttr:$predicate,
ScalableVectorOf<[AnyFloat]>:$lhs,
ScalableVectorOf<[AnyFloat]>:$rhs // TODO: This should support a simple scalar
);
let results = (outs ScalableVectorOf<[I1]>:$result);
let builders = [
- OpBuilder<(ins "CmpFPredicate":$predicate, "Value":$lhs,
+ OpBuilder<(ins "arith::CmpFPredicate":$predicate, "Value":$lhs,
"Value":$rhs), [{
buildScalableCmpFOp($_builder, $_state, predicate, lhs, rhs);
}]>];
let extraClassDeclaration = [{
static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpFPredicate getPredicateByName(StringRef name);
+ static arith::CmpFPredicate getPredicateByName(StringRef name);
- CmpFPredicate getPredicate() {
- return (CmpFPredicate)(*this)->getAttrOfType<IntegerAttr>(
+ arith::CmpFPredicate getPredicate() {
+ return (arith::CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
getPredicateAttrName()).getInt();
}
}];
}];
let arguments = (ins
- CmpIPredicateAttr:$predicate,
+ Arith_CmpIPredicateAttr:$predicate,
ScalableVectorOf<[I8, I16, I32, I64]>:$lhs,
ScalableVectorOf<[I8, I16, I32, I64]>:$rhs
);
let results = (outs ScalableVectorOf<[I1]>:$result);
let builders = [
- OpBuilder<(ins "CmpIPredicate":$predicate, "Value":$lhs,
+ OpBuilder<(ins "arith::CmpIPredicate":$predicate, "Value":$lhs,
"Value":$rhs), [{
buildScalableCmpIOp($_builder, $_state, predicate, lhs, rhs);
}]>];
let extraClassDeclaration = [{
static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpIPredicate getPredicateByName(StringRef name);
+ static arith::CmpIPredicate getPredicateByName(StringRef name);
- CmpIPredicate getPredicate() {
- return (CmpIPredicate)(*this)->getAttrOfType<IntegerAttr>(
+ arith::CmpIPredicate getPredicate() {
+ return (arith::CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
getPredicateAttrName()).getInt();
}
}];
"The minimum task size for sharding parallel operation.">
];
- let dependentDialects = ["async::AsyncDialect", "scf::SCFDialect"];
+ let dependentDialects = [
+ "arith::ArithmeticDialect",
+ "async::AsyncDialect",
+ "scf::SCFDialect"
+ ];
}
def AsyncToAsyncRuntime : Pass<"async-to-async-runtime", "ModuleOp"> {
#ifndef MLIR_DIALECT_COMPLEX_IR_COMPLEX_H_
#define MLIR_DIALECT_COMPLEX_IR_COMPLEX_H_
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
+#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/BuiltinTypes.h"
#include "mlir/IR/Dialect.h"
#include "mlir/IR/OpDefinition.h"
The complex dialect is intended to hold complex numbers creation and
arithmetic ops.
}];
+
+ let dependentDialects = ["arith::ArithmeticDialect", "StandardOpsDialect"];
+ let hasConstantMaterializer = 1;
}
#endif // COMPLEX_BASE
/// space.
static unsigned getPrivateAddressSpace() { return 5; }
}];
+
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
def GPU_AsyncToken : DialectType<
#ifndef MLIR_DIALECT_GPU_GPUDIALECT_H
#define MLIR_DIALECT_GPU_GPUDIALECT_H
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/DLTI/Traits.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinTypes.h"
%1 = "gpu.all_reduce"(%0) ({}) { op = "add" } : (f32) -> (f32)
%2 = "gpu.all_reduce"(%0) ({
^bb(%lhs : f32, %rhs : f32):
- %sum = addf %lhs, %rhs : f32
+ %sum = arith.addf %lhs, %rhs : f32
"gpu.yield"(%sum) : (f32) -> ()
}) : (f32) -> (f32)
```
}];
let cppNamespace = "::mlir::linalg";
let dependentDialects = [
- "AffineDialect", "math::MathDialect", "memref::MemRefDialect",
- "StandardOpsDialect", "tensor::TensorDialect"
+ "arith::ArithmeticDialect",
+ "AffineDialect",
+ "math::MathDialect",
+ "memref::MemRefDialect",
+ "StandardOpsDialect",
+ "tensor::TensorDialect",
];
let hasCanonicalizer = 1;
let hasOperationAttrVerify = 1;
+ let hasConstantMaterializer = 1;
let extraClassDeclaration = [{
/// Attribute name used to to memoize indexing maps for named ops.
constexpr const static ::llvm::StringLiteral
outs(%C : memref<?x?xf32, stride_specification>)
{other-optional-attributes} {
^bb0(%a: f32, %b: f32, %c: f32) :
- %d = mulf %a, %b: f32
- %e = addf %c, %d: f32
+ %d = arith.mulf %a, %b: f32
+ %e = arith.addf %c, %d: f32
linalg.yield %e : f32
}
```
%a = load %A[%m, %k] : memref<?x?xf32, stride_specification>
%b = load %B[%k, %n] : memref<?x?xf32, stride_specification>
%c = load %C[%m, %n] : memref<?x?xf32, stride_specification>
- %d = mulf %a, %b: f32
- %e = addf %c, %d: f32
+ %d = arith.mulf %a, %b: f32
+ %e = arith.addf %c, %d: f32
store %e, %C[%m, %n] : memref<?x?x?xf32, stride_specification>
}
}
#define MLIR_DIALECT_LINALG_LINALGTYPES_H_
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
let dependentDialects = [
"linalg::LinalgDialect",
"AffineDialect",
- "memref::MemRefDialect"
+ "memref::MemRefDialect",
];
}
/// to
///
/// %iv = %lb + %procId * %step
- /// %cond = cmpi "slt", %iv, %ub
+ /// %cond = arith.cmpi "slt", %iv, %ub
/// scf.if %cond {
/// ...
/// }
#ifndef MLIR_DIALECT_MEMREF_IR_MEMREF_H_
#define MLIR_DIALECT_MEMREF_IR_MEMREF_H_
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Utils/ReshapeOpsUtils.h"
#include "mlir/IR/Dialect.h"
manipulation ops, which are not strongly associated with any particular
other dialect or domain abstraction.
}];
- let dependentDialects = ["tensor::TensorDialect"];
+ let dependentDialects = ["arith::ArithmeticDialect", "tensor::TensorDialect"];
let hasConstantMaterializer = 1;
}
omp.wsloop (%i1, %i2) : index = (%c0, %c0) to (%c10, %c10) step (%c1, %c1) {
%a = load %arrA[%i1, %i2] : memref<?x?xf32>
%b = load %arrB[%i1, %i2] : memref<?x?xf32>
- %sum = addf %a, %b : f32
+ %sum = arith.addf %a, %b : f32
store %sum, %arrC[%i1, %i2] : memref<?x?xf32>
omp.yield
}
```mlir
# Before:
scf.for %i = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %arg2 : i32
+ %0 = arith.addi %arg2, %arg2 : i32
memref.store %0, %arg0[%i] : memref<?xi32>
}
# After:
%0 = scf.while (%i = %c0) : (index) -> index {
- %1 = cmpi slt, %i, %arg1 : index
+ %1 = arith.cmpi slt, %i, %arg1 : index
scf.condition(%1) %i : index
} do {
^bb0(%i: index): // no predecessors
- %1 = addi %i, %c1 : index
- %2 = addi %arg2, %arg2 : i32
+ %1 = arith.addi %i, %c1 : index
+ %2 = arith.addi %arg2, %arg2 : i32
memref.store %2, %arg0[%i] : memref<?xi32>
scf.yield %1 : index
}
#ifndef MLIR_DIALECT_SCF_H_
#define MLIR_DIALECT_SCF_H_
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/Attributes.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/Dialect.h"
/// expect the body building functions to return their current value.
/// The built nested scf::For are captured in `capturedLoops` when non-null.
LoopNest buildLoopNest(OpBuilder &builder, Location loc, ValueRange lbs,
- ValueRange ubs, ValueRange steps,
- function_ref<void(OpBuilder &, Location, ValueRange)>
- bodyBuilder = nullptr);
+ ValueRange ubs, ValueRange steps,
+ function_ref<void(OpBuilder &, Location, ValueRange)>
+ bodyBuilder = nullptr);
} // end namespace scf
} // end namespace mlir
def SCF_Dialect : Dialect {
let name = "scf";
let cppNamespace = "::mlir::scf";
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
// Base class for SCF dialect ops.
%sum = scf.for %iv = %lb to %ub step %step
iter_args(%sum_iter = %sum_0) -> (f32) {
%t = load %buffer[%iv] : memref<1024xf32>
- %sum_next = addf %sum_iter, %t : f32
+ %sum_next = arith.addf %sum_iter, %t : f32
// Yield current iteration sum to next iteration %sum_iter or to %sum
// if final iteration.
scf.yield %sum_next : f32
%sum = scf.for %iv = %lb to %ub step %step
iter_args(%sum_iter = %sum_0) -> (f32) {
%t = load %buffer[%iv] : memref<1024xf32>
- %cond = cmpf "ugt", %t, %c0 : f32
+ %cond = arith.cmpf "ugt", %t, %c0 : f32
%sum_next = scf.if %cond -> (f32) {
- %new_sum = addf %sum_iter, %t : f32
+ %new_sum = arith.addf %sum_iter, %t : f32
scf.yield %new_sum : f32
} else {
scf.yield %sum_iter : f32
%elem_to_reduce = load %buffer[%iv] : memref<100xf32>
scf.reduce(%elem_to_reduce) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %res = addf %lhs, %rhs : f32
+ %res = arith.addf %lhs, %rhs : f32
scf.reduce.return %res : f32
}
}
%operand = constant 1.0 : f32
scf.reduce(%operand) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %res = addf %lhs, %rhs : f32
+ %res = arith.addf %lhs, %rhs : f32
scf.reduce.return %res : f32
}
```
#ifndef MLIR_SHAPE_IR_SHAPE_H
#define MLIR_SHAPE_IR_SHAPE_H
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/IR/BuiltinOps.h"
#include "mlir/IR/Dialect.h"
}];
let cppNamespace = "::mlir::shape";
- let dependentDialects = ["tensor::TensorDialect"];
+ let dependentDialects = ["arith::ArithmeticDialect", "tensor::TensorDialect"];
let hasConstantMaterializer = 1;
let hasOperationAttrVerify = 1;
ins(%arga, %argb: tensor<?x?xf64, #SparseMatrix>, tensor<?xf64>)
outs(%argx: tensor<?xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %a, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<?xf64>
return %0 : tensor<?xf64>
let constructor = "mlir::createSparsificationPass()";
let dependentDialects = [
"AffineDialect",
+ "arith::ArithmeticDialect",
"LLVM::LLVMDialect",
"memref::MemRefDialect",
"scf::SCFDialect",
}];
let constructor = "mlir::createSparseTensorConversionPass()";
let dependentDialects = [
+ "arith::ArithmeticDialect",
"LLVM::LLVMDialect",
"memref::MemRefDialect",
"scf::SCFDialect",
#ifndef MLIR_DIALECT_STANDARDOPS_IR_OPS_H
#define MLIR_DIALECT_STANDARDOPS_IR_OPS_H
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinTypes.h"
#include "mlir/IR/Dialect.h"
#include "mlir/Dialect/StandardOps/IR/OpsDialect.h.inc"
namespace mlir {
-/// This is a refinement of the "constant" op for the case where it is
-/// returning a float value of FloatType.
-///
-/// %1 = "std.constant"(){value: 42.0} : bf16
-///
-class ConstantFloatOp : public ConstantOp {
-public:
- using ConstantOp::ConstantOp;
-
- /// Builds a constant float op producing a float of the specified type.
- static void build(OpBuilder &builder, OperationState &result,
- const APFloat &value, FloatType type);
-
- APFloat getValue() {
- return (*this)->getAttrOfType<FloatAttr>("value").getValue();
- }
-
- static bool classof(Operation *op);
-};
-
-/// This is a refinement of the "constant" op for the case where it is
-/// returning an integer value of IntegerType.
-///
-/// %1 = "std.constant"(){value: 42} : i32
-///
-class ConstantIntOp : public ConstantOp {
-public:
- using ConstantOp::ConstantOp;
- /// Build a constant int op producing an integer of the specified width.
- static void build(OpBuilder &builder, OperationState &result, int64_t value,
- unsigned width);
-
- /// Build a constant int op producing an integer with the specified type,
- /// which must be an integer type.
- static void build(OpBuilder &builder, OperationState &result, int64_t value,
- Type type);
-
- int64_t getValue() {
- return (*this)->getAttrOfType<IntegerAttr>("value").getInt();
- }
-
- static bool classof(Operation *op);
-};
-
-/// This is a refinement of the "constant" op for the case where it is
-/// returning an integer value of Index type.
-///
-/// %1 = "std.constant"(){value: 99} : () -> index
-///
-class ConstantIndexOp : public ConstantOp {
-public:
- using ConstantOp::ConstantOp;
-
- /// Build a constant int op producing an index.
- static void build(OpBuilder &builder, OperationState &result, int64_t value);
-
- int64_t getValue() {
- return (*this)->getAttrOfType<IntegerAttr>("value").getInt();
- }
-
- static bool classof(Operation *op);
-};
/// Compute `lhs` `pred` `rhs`, where `pred` is one of the known integer
/// comparison predicates.
-bool applyCmpPredicate(CmpIPredicate predicate, const APInt &lhs,
+bool applyCmpPredicate(arith::CmpIPredicate predicate, const APInt &lhs,
const APInt &rhs);
/// Compute `lhs` `pred` `rhs`, where `pred` is one of the known floating point
/// comparison predicates.
-bool applyCmpPredicate(CmpFPredicate predicate, const APFloat &lhs,
+bool applyCmpPredicate(arith::CmpFPredicate predicate, const APFloat &lhs,
const APFloat &rhs);
/// Returns the identity value attribute associated with an AtomicRMWKind op.
def StandardOps_Dialect : Dialect {
let name = "std";
let cppNamespace = "::mlir";
+ let dependentDialects = ["arith::ArithmeticDialect"];
let hasConstantMaterializer = 1;
}
Arguments<(ins FloatLike:$a, FloatLike:$b, FloatLike:$c)>;
//===----------------------------------------------------------------------===//
-// AbsFOp
-//===----------------------------------------------------------------------===//
-
-def AbsFOp : FloatUnaryOp<"absf"> {
- let summary = "floating point absolute-value operation";
- let description = [{
- The `absf` operation computes the absolute value. It takes one operand and
- returns one result of the same type. This type may be a float scalar type,
- a vector whose element type is float, or a tensor of floats.
-
- Example:
-
- ```mlir
- // Scalar absolute value.
- %a = absf %b : f64
-
- // SIMD vector element-wise absolute value.
- %f = absf %g : vector<4xf32>
-
- // Tensor element-wise absolute value.
- %x = absf %y : tensor<4x?xf8>
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// AddFOp
-//===----------------------------------------------------------------------===//
-
-def AddFOp : FloatBinaryOp<"addf"> {
- let summary = "floating point addition operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.addf` ssa-use `,` ssa-use `:` type
- ```
-
- The `addf` operation takes two operands and returns one result, each of
- these is required to be the same type. This type may be a floating point
- scalar type, a vector whose element type is a floating point type, or a
- floating point tensor.
-
- Example:
-
- ```mlir
- // Scalar addition.
- %a = addf %b, %c : f64
-
- // SIMD vector addition, e.g. for Intel SSE.
- %f = addf %g, %h : vector<4xf32>
-
- // Tensor addition.
- %x = addf %y, %z : tensor<4x?xbf16>
- ```
-
- TODO: In the distant future, this will accept optional attributes for fast
- math, contraction, rounding mode, and other controls.
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// AddIOp
-//===----------------------------------------------------------------------===//
-
-def AddIOp : IntBinaryOp<"addi", [Commutative]> {
- let summary = "integer addition operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.addi` ssa-use `,` ssa-use `:` type
- ```
-
- The `addi` operation takes two operands and returns one result, each of
- these is required to be the same type. This type may be an integer scalar
- type, a vector whose element type is integer, or a tensor of integers. It
- has no standard attributes.
-
- Example:
-
- ```mlir
- // Scalar addition.
- %a = addi %b, %c : i64
-
- // SIMD vector element-wise addition, e.g. for Intel SSE.
- %f = addi %g, %h : vector<4xi32>
-
- // Tensor element-wise addition.
- %x = addi %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
- let hasCanonicalizer = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// AndOp
-//===----------------------------------------------------------------------===//
-
-def AndOp : IntBinaryOp<"and", [Commutative]> {
- let summary = "integer binary and";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.and` ssa-use `,` ssa-use `:` type
- ```
-
- The `and` operation takes two operands and returns one result, each of these
- is required to be the same type. This type may be an integer scalar type, a
- vector whose element type is integer, or a tensor of integers. It has no
- standard attributes.
-
- Example:
-
- ```mlir
- // Scalar integer bitwise and.
- %a = and %b, %c : i64
-
- // SIMD vector element-wise bitwise integer and.
- %f = and %g, %h : vector<4xi32>
-
- // Tensor element-wise bitwise integer and.
- %x = and %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
// AssertOp
//===----------------------------------------------------------------------===//
%x = generic_atomic_rmw %I[%i] : memref<10xf32> {
^bb0(%current_value : f32):
%c1 = constant 1.0 : f32
- %inc = addf %c1, %current_value : f32
+ %inc = arith.addf %c1, %current_value : f32
atomic_yield %inc : f32
}
```
}
//===----------------------------------------------------------------------===//
-// BitcastOp
-//===----------------------------------------------------------------------===//
-
-def BitcastOp : ArithmeticCastOp<"bitcast"> {
- let summary = "bitcast between values of equal bit width";
- let description = [{
- Bitcast an integer or floating point value to an integer or floating point
- value of equal bit width. When operating on vectors, casts elementwise.
-
- Note that this implements a logical bitcast independent of target
- endianness. This allows constant folding without target information and is
- consitent with the bitcast constant folders in LLVM (see
- https://github.com/llvm/llvm-project/blob/18c19414eb/llvm/lib/IR/ConstantFold.cpp#L168)
- For targets where the source and target type have the same endianness (which
- is the standard), this cast will also change no bits at runtime, but it may
- still require an operation, for example if the machine has different
- floating point and integer register files. For targets that have a different
- endianness for the source and target types (e.g. float is big-endian and
- integer is little-endian) a proper lowering would add operations to swap the
- order of words in addition to the bitcast.
- }];
- let hasFolder = 1;
-}
-
-
-//===----------------------------------------------------------------------===//
// BranchOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// CeilFOp
-//===----------------------------------------------------------------------===//
-
-def CeilFOp : FloatUnaryOp<"ceilf"> {
- let summary = "ceiling of the specified value";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.ceilf` ssa-use `:` type
- ```
-
- The `ceilf` operation computes the ceiling of a given value. It takes one
- operand and returns one result of the same type. This type may be a float
- scalar type, a vector whose element type is float, or a tensor of floats.
- It has no standard attributes.
-
- Example:
-
- ```mlir
- // Scalar ceiling value.
- %a = ceilf %b : f64
-
- // SIMD vector element-wise ceiling value.
- %f = ceilf %g : vector<4xf32>
-
- // Tensor element-wise ceiling value.
- %x = ceilf %y : tensor<4x?xf8>
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// FloorFOp
-//===----------------------------------------------------------------------===//
-
-def FloorFOp : FloatUnaryOp<"floorf"> {
- let summary = "floor of the specified value";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.floorf` ssa-use `:` type
- ```
-
- The `floorf` operation computes the floor of a given value. It takes one
- operand and returns one result of the same type. This type may be a float
- scalar type, a vector whose element type is float, or a tensor of floats.
- It has no standard attributes.
-
- Example:
-
- ```mlir
- // Scalar floor value.
- %a = floorf %b : f64
-
- // SIMD vector element-wise floor value.
- %f = floorf %g : vector<4xf32>
-
- // Tensor element-wise floor value.
- %x = floorf %y : tensor<4x?xf8>
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// CmpFOp
-//===----------------------------------------------------------------------===//
-
-def CmpFOp : Std_Op<"cmpf", [NoSideEffect, SameTypeOperands,
- DeclareOpInterfaceMethods<VectorUnrollOpInterface>, TypesMatchWith<
- "result type has i1 element type and same shape as operands",
- "lhs", "result", "getI1SameShape($_self)">] # ElementwiseMappable.traits> {
- let summary = "floating-point comparison operation";
- let description = [{
- The `cmpf` operation compares its two operands according to the float
- comparison rules and the predicate specified by the respective attribute.
- The predicate defines the type of comparison: (un)orderedness, (in)equality
- and signed less/greater than (or equal to) as well as predicates that are
- always true or false. The operands must have the same type, and this type
- must be a float type, or a vector or tensor thereof. The result is an i1,
- or a vector/tensor thereof having the same shape as the inputs. Unlike cmpi,
- the operands are always treated as signed. The u prefix indicates
- *unordered* comparison, not unsigned comparison, so "une" means unordered or
- not equal. For the sake of readability by humans, custom assembly form for
- the operation uses a string-typed attribute for the predicate. The value of
- this attribute corresponds to lower-cased name of the predicate constant,
- e.g., "one" means "ordered not equal". The string representation of the
- attribute is merely a syntactic sugar and is converted to an integer
- attribute by the parser.
-
- Example:
-
- ```mlir
- %r1 = cmpf "oeq" %0, %1 : f32
- %r2 = cmpf "ult" %0, %1 : tensor<42x42xf64>
- %r3 = "std.cmpf"(%0, %1) {predicate: 0} : (f8, f8) -> i1
- ```
- }];
-
- let arguments = (ins
- CmpFPredicateAttr:$predicate,
- FloatLike:$lhs,
- FloatLike:$rhs
- );
- let results = (outs BoolLike:$result);
-
- let builders = [
- OpBuilder<(ins "CmpFPredicate":$predicate, "Value":$lhs,
- "Value":$rhs), [{
- ::buildCmpFOp($_builder, $_state, predicate, lhs, rhs);
- }]>];
-
- let extraClassDeclaration = [{
- static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpFPredicate getPredicateByName(StringRef name);
-
- CmpFPredicate getPredicate() {
- return (CmpFPredicate)(*this)->getAttrOfType<IntegerAttr>(
- getPredicateAttrName()).getInt();
- }
- }];
-
- let verifier = [{ return success(); }];
-
- let hasFolder = 1;
-
- let assemblyFormat = "$predicate `,` $lhs `,` $rhs attr-dict `:` type($lhs)";
-}
-
-//===----------------------------------------------------------------------===//
-// CmpIOp
-//===----------------------------------------------------------------------===//
-
-def CmpIOp : Std_Op<"cmpi", [NoSideEffect, SameTypeOperands,
- DeclareOpInterfaceMethods<VectorUnrollOpInterface>, TypesMatchWith<
- "result type has i1 element type and same shape as operands",
- "lhs", "result", "getI1SameShape($_self)">] # ElementwiseMappable.traits> {
- let summary = "integer comparison operation";
- let description = [{
- The `cmpi` operation is a generic comparison for integer-like types. Its two
- arguments can be integers, vectors or tensors thereof as long as their types
- match. The operation produces an i1 for the former case, a vector or a
- tensor of i1 with the same shape as inputs in the other cases.
-
- Its first argument is an attribute that defines which type of comparison is
- performed. The following comparisons are supported:
-
- - equal (mnemonic: `"eq"`; integer value: `0`)
- - not equal (mnemonic: `"ne"`; integer value: `1`)
- - signed less than (mnemonic: `"slt"`; integer value: `2`)
- - signed less than or equal (mnemonic: `"sle"`; integer value: `3`)
- - signed greater than (mnemonic: `"sgt"`; integer value: `4`)
- - signed greater than or equal (mnemonic: `"sge"`; integer value: `5`)
- - unsigned less than (mnemonic: `"ult"`; integer value: `6`)
- - unsigned less than or equal (mnemonic: `"ule"`; integer value: `7`)
- - unsigned greater than (mnemonic: `"ugt"`; integer value: `8`)
- - unsigned greater than or equal (mnemonic: `"uge"`; integer value: `9`)
-
- The result is `1` if the comparison is true and `0` otherwise. For vector or
- tensor operands, the comparison is performed elementwise and the element of
- the result indicates whether the comparison is true for the operand elements
- with the same indices as those of the result.
-
- Note: while the custom assembly form uses strings, the actual underlying
- attribute has integer type (or rather enum class in C++ code) as seen from
- the generic assembly form. String literals are used to improve readability
- of the IR by humans.
-
- This operation only applies to integer-like operands, but not floats. The
- main reason being that comparison operations have diverging sets of
- attributes: integers require sign specification while floats require various
- floating point-related particularities, e.g., `-ffast-math` behavior,
- IEEE754 compliance, etc
- ([rationale](../Rationale/Rationale.md#splitting-floating-point-vs-integer-operations)).
- The type of comparison is specified as attribute to avoid introducing ten
- similar operations, taking into account that they are often implemented
- using the same operation downstream
- ([rationale](../Rationale/Rationale.md#specifying-comparison-kind-as-attribute)). The
- separation between signed and unsigned order comparisons is necessary
- because of integers being signless. The comparison operation must know how
- to interpret values with the foremost bit being set: negatives in two's
- complement or large positives
- ([rationale](../Rationale/Rationale.md#specifying-sign-in-integer-comparison-operations)).
-
- Example:
-
- ```mlir
- // Custom form of scalar "signed less than" comparison.
- %x = cmpi "slt", %lhs, %rhs : i32
-
- // Generic form of the same operation.
- %x = "std.cmpi"(%lhs, %rhs) {predicate = 2 : i64} : (i32, i32) -> i1
-
- // Custom form of vector equality comparison.
- %x = cmpi "eq", %lhs, %rhs : vector<4xi64>
-
- // Generic form of the same operation.
- %x = "std.cmpi"(%lhs, %rhs) {predicate = 0 : i64}
- : (vector<4xi64>, vector<4xi64>) -> vector<4xi1>
- ```
- }];
-
- let arguments = (ins
- CmpIPredicateAttr:$predicate,
- SignlessIntegerLike:$lhs,
- SignlessIntegerLike:$rhs
- );
- let results = (outs BoolLike:$result);
-
- let builders = [
- OpBuilder<(ins "CmpIPredicate":$predicate, "Value":$lhs,
- "Value":$rhs), [{
- ::buildCmpIOp($_builder, $_state, predicate, lhs, rhs);
- }]>];
-
- let extraClassDeclaration = [{
- static StringRef getPredicateAttrName() { return "predicate"; }
- static CmpIPredicate getPredicateByName(StringRef name);
-
- CmpIPredicate getPredicate() {
- return (CmpIPredicate)(*this)->getAttrOfType<IntegerAttr>(
- getPredicateAttrName()).getInt();
- }
- }];
-
- let verifier = [{ return success(); }];
-
- let hasFolder = 1;
-
- let assemblyFormat = "$predicate `,` $lhs `,` $rhs attr-dict `:` type($lhs)";
-}
-
-//===----------------------------------------------------------------------===//
// CondBranchOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// CopySignOp
+// MaxFOp
//===----------------------------------------------------------------------===//
-def CopySignOp : FloatBinaryOp<"copysign"> {
- let summary = "A copysign operation";
+def MaxFOp : FloatBinaryOp<"maxf"> {
+ let summary = "floating-point maximum operation";
let description = [{
Syntax:
```
- operation ::= ssa-id `=` `std.copysign` ssa-use `,` ssa-use `:` type
+ operation ::= ssa-id `=` `maxf` ssa-use `,` ssa-use `:` type
```
- The `copysign` returns a value with the magnitude of the first operand and
- the sign of the second operand. It takes two operands and returns one
- result of the same type. This type may be a float scalar type, a vector
- whose element type is float, or a tensor of floats. It has no standard
- attributes.
+ Returns the maximum of the two arguments, treating -0.0 as less than +0.0.
+ If one of the arguments is NaN, then the result is also NaN.
Example:
```mlir
- // Scalar copysign value.
- %a = copysign %b, %c : f64
-
- // SIMD vector element-wise copysign value.
- %f = copysign %g, %h : vector<4xf32>
-
- // Tensor element-wise copysign value.
- %x = copysign %y, %z : tensor<4x?xf8>
+ // Scalar floating-point maximum.
+ %a = maxf %b, %c : f64
```
}];
}
//===----------------------------------------------------------------------===//
-// DivFOp
-//===----------------------------------------------------------------------===//
-
-def DivFOp : FloatBinaryOp<"divf"> {
- let summary = "floating point division operation";
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// FmaFOp
+// MaxSIOp
//===----------------------------------------------------------------------===//
-def FmaFOp : FloatTernaryOp<"fmaf"> {
- let summary = "floating point fused multipy-add operation";
+def MaxSIOp : IntBinaryOp<"maxsi"> {
+ let summary = "signed integer maximum operation";
let description = [{
Syntax:
```
- operation ::= ssa-id `=` `std.fmaf` ssa-use `,` ssa-use `,` ssa-use `:` type
+ operation ::= ssa-id `=` `maxsi` ssa-use `,` ssa-use `:` type
```
- The `fmaf` operation takes three operands and returns one result, each of
- these is required to be the same type. This type may be a floating point
- scalar type, a vector whose element type is a floating point type, or a
- floating point tensor.
+ Returns the larger of %a and %b comparing the values as signed integers.
Example:
```mlir
- // Scalar fused multiply-add: d = a*b + c
- %d = fmaf %a, %b, %c : f64
-
- // SIMD vector fused multiply-add, e.g. for Intel SSE.
- %i = fmaf %f, %g, %h : vector<4xf32>
-
- // Tensor fused multiply-add.
- %w = fmaf %x, %y, %z : tensor<4x?xbf16>
+ // Scalar signed integer maximum.
+ %a = maxsi %b, %c : i64
```
-
- The semantics of the operation correspond to those of the `llvm.fma`
- [intrinsic](https://llvm.org/docs/LangRef.html#llvm-fma-intrinsic). In the
- particular case of lowering to LLVM, this is guaranteed to lower
- to the `llvm.fma.*` intrinsic.
}];
}
//===----------------------------------------------------------------------===//
-// FPExtOp
+// MaxUIOp
//===----------------------------------------------------------------------===//
-def FPExtOp : ArithmeticCastOp<"fpext"> {
- let summary = "cast from floating-point to wider floating-point";
+def MaxUIOp : IntBinaryOp<"maxui"> {
+ let summary = "unsigned integer maximum operation";
let description = [{
- Cast a floating-point value to a larger floating-point-typed value.
- The destination type must to be strictly wider than the source type.
- When operating on vectors, casts elementwise.
- }];
-}
+ Syntax:
-//===----------------------------------------------------------------------===//
-// FPToSIOp
-//===----------------------------------------------------------------------===//
+ ```
+ operation ::= ssa-id `=` `maxui` ssa-use `,` ssa-use `:` type
+ ```
-def FPToSIOp : ArithmeticCastOp<"fptosi"> {
- let summary = "cast from floating-point type to integer type";
- let description = [{
- Cast from a value interpreted as floating-point to the nearest (rounding
- towards zero) signed integer value. When operating on vectors, casts
- elementwise.
- }];
-}
+ Returns the larger of %a and %b comparing the values as unsigned integers.
-//===----------------------------------------------------------------------===//
-// FPToUIOp
-//===----------------------------------------------------------------------===//
+ Example:
-def FPToUIOp : ArithmeticCastOp<"fptoui"> {
- let summary = "cast from floating-point type to integer type";
- let description = [{
- Cast from a value interpreted as floating-point to the nearest (rounding
- towards zero) unsigned integer value. When operating on vectors, casts
- elementwise.
+ ```mlir
+ // Scalar unsigned integer maximum.
+ %a = maxui %b, %c : i64
+ ```
}];
}
//===----------------------------------------------------------------------===//
-// FPTruncOp
+// MinFOp
//===----------------------------------------------------------------------===//
-def FPTruncOp : ArithmeticCastOp<"fptrunc"> {
- let summary = "cast from floating-point to narrower floating-point";
+def MinFOp : FloatBinaryOp<"minf"> {
+ let summary = "floating-point minimum operation";
let description = [{
- Truncate a floating-point value to a smaller floating-point-typed value.
- The destination type must be strictly narrower than the source type.
- If the value cannot be exactly represented, it is rounded using the default
- rounding mode. When operating on vectors, casts elementwise.
- }];
+ Syntax:
- let hasFolder = 1;
+ ```
+ operation ::= ssa-id `=` `minf` ssa-use `,` ssa-use `:` type
+ ```
+
+ Returns the minimum of the two arguments, treating -0.0 as less than +0.0.
+ If one of the arguments is NaN, then the result is also NaN.
+
+ Example:
+
+ ```mlir
+ // Scalar floating-point minimum.
+ %a = minf %b, %c : f64
+ ```
+ }];
}
//===----------------------------------------------------------------------===//
-// IndexCastOp
+// MinSIOp
//===----------------------------------------------------------------------===//
-def IndexCastOp : ArithmeticCastOp<"index_cast"> {
- let summary = "cast between index and integer types";
+def MinSIOp : IntBinaryOp<"minsi"> {
+ let summary = "signed integer minimum operation";
let description = [{
- Casts between scalar or vector integers and corresponding 'index' scalar or
- vectors. Index is an integer of platform-specific bit width. If casting to
- a wider integer, the value is sign-extended. If casting to a narrower
- integer, the value is truncated.
- }];
-
- let hasFolder = 1;
- let hasCanonicalizer = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// MaxFOp
-//===----------------------------------------------------------------------===//
-
-def MaxFOp : FloatBinaryOp<"maxf"> {
- let summary = "floating-point maximum operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `maxf` ssa-use `,` ssa-use `:` type
- ```
-
- Returns the maximum of the two arguments, treating -0.0 as less than +0.0.
- If one of the arguments is NaN, then the result is also NaN.
-
- Example:
-
- ```mlir
- // Scalar floating-point maximum.
- %a = maxf %b, %c : f64
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// MaxSIOp
-//===----------------------------------------------------------------------===//
-
-def MaxSIOp : IntBinaryOp<"maxsi"> {
- let summary = "signed integer maximum operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `maxsi` ssa-use `,` ssa-use `:` type
- ```
-
- Returns the larger of %a and %b comparing the values as signed integers.
-
- Example:
-
- ```mlir
- // Scalar signed integer maximum.
- %a = maxsi %b, %c : i64
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// MaxUIOp
-//===----------------------------------------------------------------------===//
-
-def MaxUIOp : IntBinaryOp<"maxui"> {
- let summary = "unsigned integer maximum operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `maxui` ssa-use `,` ssa-use `:` type
- ```
-
- Returns the larger of %a and %b comparing the values as unsigned integers.
-
- Example:
-
- ```mlir
- // Scalar unsigned integer maximum.
- %a = maxui %b, %c : i64
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// MinFOp
-//===----------------------------------------------------------------------===//
-
-def MinFOp : FloatBinaryOp<"minf"> {
- let summary = "floating-point minimum operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `minf` ssa-use `,` ssa-use `:` type
- ```
-
- Returns the minimum of the two arguments, treating -0.0 as less than +0.0.
- If one of the arguments is NaN, then the result is also NaN.
-
- Example:
-
- ```mlir
- // Scalar floating-point minimum.
- %a = minf %b, %c : f64
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// MinSIOp
-//===----------------------------------------------------------------------===//
-
-def MinSIOp : IntBinaryOp<"minsi"> {
- let summary = "signed integer minimum operation";
- let description = [{
- Syntax:
+ Syntax:
```
operation ::= ssa-id `=` `minsi` ssa-use `,` ssa-use `:` type
}
//===----------------------------------------------------------------------===//
-// MulFOp
-//===----------------------------------------------------------------------===//
-
-def MulFOp : FloatBinaryOp<"mulf"> {
- let summary = "floating point multiplication operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.mulf` ssa-use `,` ssa-use `:` type
- ```
-
- The `mulf` operation takes two operands and returns one result, each of
- these is required to be the same type. This type may be a floating point
- scalar type, a vector whose element type is a floating point type, or a
- floating point tensor.
-
- Example:
-
- ```mlir
- // Scalar multiplication.
- %a = mulf %b, %c : f64
-
- // SIMD pointwise vector multiplication, e.g. for Intel SSE.
- %f = mulf %g, %h : vector<4xf32>
-
- // Tensor pointwise multiplication.
- %x = mulf %y, %z : tensor<4x?xbf16>
- ```
-
- TODO: In the distant future, this will accept optional attributes for fast
- math, contraction, rounding mode, and other controls.
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// MulIOp
-//===----------------------------------------------------------------------===//
-
-def MulIOp : IntBinaryOp<"muli", [Commutative]> {
- let summary = "integer multiplication operation";
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// NegFOp
-//===----------------------------------------------------------------------===//
-
-def NegFOp : FloatUnaryOp<"negf"> {
- let summary = "floating point negation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `negf` ssa-use `:` type
- ```
-
- The `negf` operation computes the negation of a given value. It takes one
- operand and returns one result of the same type. This type may be a float
- scalar type, a vector whose element type is float, or a tensor of floats.
- It has no standard attributes.
-
- Example:
-
- ```mlir
- // Scalar negation value.
- %a = negf %b : f64
-
- // SIMD vector element-wise negation value.
- %f = negf %g : vector<4xf32>
-
- // Tensor element-wise negation value.
- %x = negf %y : tensor<4x?xf8>
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// OrOp
-//===----------------------------------------------------------------------===//
-
-def OrOp : IntBinaryOp<"or", [Commutative]> {
- let summary = "integer binary or";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `or` ssa-use `,` ssa-use `:` type
- ```
-
- The `or` operation takes two operands and returns one result, each of these
- is required to be the same type. This type may be an integer scalar type, a
- vector whose element type is integer, or a tensor of integers. It has no
- standard attributes.
-
- Example:
-
- ```mlir
- // Scalar integer bitwise or.
- %a = or %b, %c : i64
-
- // SIMD vector element-wise bitwise integer or.
- %f = or %g, %h : vector<4xi32>
-
- // Tensor element-wise bitwise integer or.
- %x = or %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
// RankOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// RemFOp
-//===----------------------------------------------------------------------===//
-
-def RemFOp : FloatBinaryOp<"remf"> {
- let summary = "floating point division remainder operation";
-}
-
-//===----------------------------------------------------------------------===//
// ReturnOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// ShiftLeftOp
-//===----------------------------------------------------------------------===//
-
-def ShiftLeftOp : IntBinaryOp<"shift_left"> {
- let summary = "integer left-shift";
- let description = [{
- The shift_left operation shifts an integer value to the left by a variable
- amount. The low order bits are filled with zeros.
-
- Example:
-
- ```mlir
- %1 = constant 5 : i8 // %1 is 0b00000101
- %2 = constant 3 : i8
- %3 = shift_left %1, %2 : (i8, i8) -> i8 // %3 is 0b00101000
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// SignedDivIOp
-//===----------------------------------------------------------------------===//
-
-def SignedDivIOp : IntBinaryOp<"divi_signed"> {
- let summary = "signed integer division operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `divi_signed` ssa-use `,` ssa-use `:` type
- ```
-
- Signed integer division. Rounds towards zero. Treats the leading bit as
- sign, i.e. `6 / -2 = -3`.
-
- Note: the semantics of division by zero or signed division overflow (minimum
- value divided by -1) is TBD; do NOT assume any specific behavior.
-
- Example:
-
- ```mlir
- // Scalar signed integer division.
- %a = divi_signed %b, %c : i64
-
- // SIMD vector element-wise division.
- %f = divi_signed %g, %h : vector<4xi32>
-
- // Tensor element-wise integer division.
- %x = divi_signed %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedFloorDivIOp
-//===----------------------------------------------------------------------===//
-
-def SignedFloorDivIOp : IntBinaryOp<"floordivi_signed"> {
- let summary = "signed floor integer division operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `floordivi_signed` ssa-use `,` ssa-use `:` type
- ```
-
- Signed integer division. Rounds towards negative infinity, i.e. `5 / -2 = -3`.
-
- Note: the semantics of division by zero or signed division overflow (minimum
- value divided by -1) is TBD; do NOT assume any specific behavior.
-
- Example:
-
- ```mlir
- // Scalar signed integer division.
- %a = floordivi_signed %b, %c : i64
-
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedCeilDivIOp
-//===----------------------------------------------------------------------===//
-
-def SignedCeilDivIOp : IntBinaryOp<"ceildivi_signed"> {
- let summary = "signed ceil integer division operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `ceildivi_signed` ssa-use `,` ssa-use `:` type
- ```
-
- Signed integer division. Rounds towards positive infinity, i.e. `7 / -2 = -3`.
-
- Note: the semantics of division by zero or signed division overflow (minimum
- value divided by -1) is TBD; do NOT assume any specific behavior.
-
- Example:
-
- ```mlir
- // Scalar signed integer division.
- %a = ceildivi_signed %b, %c : i64
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedRemIOp
-//===----------------------------------------------------------------------===//
-
-def SignedRemIOp : IntBinaryOp<"remi_signed"> {
- let summary = "signed integer division remainder operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.remi_signed` ssa-use `,` ssa-use `:` type
- ```
-
- Signed integer division remainder. Treats the leading bit as sign, i.e. `6 %
- -2 = 0`.
-
- Note: the semantics of division by zero is TBD; do NOT assume any specific
- behavior.
-
- Example:
-
- ```mlir
- // Scalar signed integer division remainder.
- %a = remi_signed %b, %c : i64
-
- // SIMD vector element-wise division remainder.
- %f = remi_signed %g, %h : vector<4xi32>
-
- // Tensor element-wise integer division remainder.
- %x = remi_signed %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedShiftRightOp
-//===----------------------------------------------------------------------===//
-
-def SignedShiftRightOp : IntBinaryOp<"shift_right_signed"> {
- let summary = "signed integer right-shift";
- let description = [{
- The shift_right_signed operation shifts an integer value to the right by
- a variable amount. The integer is interpreted as signed. The high order
- bits in the output are filled with copies of the most-significant bit
- of the shifted value (which means that the sign of the value is preserved).
-
- Example:
-
- ```mlir
- %1 = constant 160 : i8 // %1 is 0b10100000
- %2 = constant 3 : i8
- %3 = shift_right_signed %1, %2 : (i8, i8) -> i8 // %3 is 0b11110100
- %4 = constant 96 : i8 // %4 is 0b01100000
- %5 = shift_right_signed %4, %2 : (i8, i8) -> i8 // %5 is 0b00001100
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// SignExtendIOp
-//===----------------------------------------------------------------------===//
-
-def SignExtendIOp : Std_Op<"sexti", [NoSideEffect,
- DeclareOpInterfaceMethods<VectorUnrollOpInterface>] #
- ElementwiseMappable.traits> {
- let summary = "integer sign extension operation";
- let description = [{
- The integer sign extension operation takes an integer input of
- width M and an integer destination type of width N. The destination
- bit-width must be larger than the input bit-width (N > M).
- The top-most (N - M) bits of the output are filled with copies
- of the most-significant bit of the input.
-
- Example:
-
- ```mlir
- %1 = constant 5 : i3 // %1 is 0b101
- %2 = sexti %1 : i3 to i6 // %2 is 0b111101
- %3 = constant 2 : i3 // %3 is 0b010
- %4 = sexti %3 : i3 to i6 // %4 is 0b000010
-
- %5 = sexti %0 : vector<2 x i32> to vector<2 x i64>
- ```
- }];
-
- let arguments = (ins SignlessIntegerLike:$value);
- let results = (outs SignlessIntegerLike);
-
- let builders = [
- OpBuilder<(ins "Value":$value, "Type":$destType), [{
- $_state.addOperands(value);
- $_state.addTypes(destType);
- }]>];
-
- let parser = [{
- return impl::parseCastOp(parser, result);
- }];
- let printer = [{
- return printStandardCastOp(this->getOperation(), p);
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SIToFPOp
-//===----------------------------------------------------------------------===//
-
-def SIToFPOp : ArithmeticCastOp<"sitofp"> {
- let summary = "cast from integer type to floating-point";
- let description = [{
- Cast from a value interpreted as a signed integer to the corresponding
- floating-point value. If the value cannot be exactly represented, it is
- rounded using the default rounding mode. When operating on vectors, casts
- elementwise.
- }];
-}
-
-//===----------------------------------------------------------------------===//
// SplatOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// SubFOp
-//===----------------------------------------------------------------------===//
-
-def SubFOp : FloatBinaryOp<"subf"> {
- let summary = "floating point subtraction operation";
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// SubIOp
-//===----------------------------------------------------------------------===//
-
-def SubIOp : IntBinaryOp<"subi"> {
- let summary = "integer subtraction operation";
- let hasFolder = 1;
- let hasCanonicalizer = 1;
-}
-
-//===----------------------------------------------------------------------===//
// SwitchOp
//===----------------------------------------------------------------------===//
let hasCanonicalizer = 1;
}
-//===----------------------------------------------------------------------===//
-// TruncateIOp
-//===----------------------------------------------------------------------===//
-
-def TruncateIOp : Std_Op<"trunci", [NoSideEffect,
- DeclareOpInterfaceMethods<VectorUnrollOpInterface>] #
- ElementwiseMappable.traits> {
- let summary = "integer truncation operation";
- let description = [{
- The integer truncation operation takes an integer input of
- width M and an integer destination type of width N. The destination
- bit-width must be smaller than the input bit-width (N < M).
- The top-most (N - M) bits of the input are discarded.
-
- Example:
-
- ```mlir
- %1 = constant 21 : i5 // %1 is 0b10101
- %2 = trunci %1 : i5 to i4 // %2 is 0b0101
- %3 = trunci %1 : i5 to i3 // %3 is 0b101
-
- %5 = trunci %0 : vector<2 x i32> to vector<2 x i16>
- ```
- }];
-
- let arguments = (ins SignlessIntegerLike:$value);
- let results = (outs SignlessIntegerLike);
-
- let builders = [
- OpBuilder<(ins "Value":$value, "Type":$destType), [{
- $_state.addOperands(value);
- $_state.addTypes(destType);
- }]>];
-
- let parser = [{
- return impl::parseCastOp(parser, result);
- }];
- let printer = [{
- return printStandardCastOp(this->getOperation(), p);
- }];
-
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// UIToFPOp
-//===----------------------------------------------------------------------===//
-
-def UIToFPOp : ArithmeticCastOp<"uitofp"> {
- let summary = "cast from unsigned integer type to floating-point";
- let description = [{
- Cast from a value interpreted as unsigned integer to the corresponding
- floating-point value. If the value cannot be exactly represented, it is
- rounded using the default rounding mode. When operating on vectors, casts
- elementwise.
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// UnsignedDivIOp
-//===----------------------------------------------------------------------===//
-
-def UnsignedDivIOp : IntBinaryOp<"divi_unsigned"> {
- let summary = "unsigned integer division operation";
- let description = [{
- Syntax:
- ```
- operation ::= ssa-id `=` `std.divi_unsigned` ssa-use `,` ssa-use `:` type
- ```
-
- Unsigned integer division. Rounds towards zero. Treats the leading bit as
- the most significant, i.e. for `i16` given two's complement representation,
- `6 / -2 = 6 / (2^16 - 2) = 0`.
-
- Note: the semantics of division by zero is TBD; do NOT assume any specific
- behavior.
-
- Example:
-
- ```mlir
- // Scalar unsigned integer division.
- %a = divi_unsigned %b, %c : i64
-
- // SIMD vector element-wise division.
- %f = divi_unsigned %g, %h : vector<4xi32>
-
- // Tensor element-wise integer division.
- %x = divi_unsigned %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// UnsignedRemIOp
-//===----------------------------------------------------------------------===//
-
-def UnsignedRemIOp : IntBinaryOp<"remi_unsigned"> {
- let summary = "unsigned integer division remainder operation";
- let description = [{
- Syntax:
-
- ```
- operation ::= ssa-id `=` `std.remi_unsigned` ssa-use `,` ssa-use `:` type
- ```
-
- Unsigned integer division remainder. Treats the leading bit as the most
- significant, i.e. for `i16`, `6 % -2 = 6 % (2^16 - 2) = 6`.
-
- Note: the semantics of division by zero is TBD; do NOT assume any specific
- behavior.
-
- Example:
-
- ```mlir
- // Scalar unsigned integer division remainder.
- %a = remi_unsigned %b, %c : i64
-
- // SIMD vector element-wise division remainder.
- %f = remi_unsigned %g, %h : vector<4xi32>
-
- // Tensor element-wise integer division remainder.
- %x = remi_unsigned %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// UnsignedShiftRightOp
-//===----------------------------------------------------------------------===//
-
-def UnsignedShiftRightOp : IntBinaryOp<"shift_right_unsigned"> {
- let summary = "unsigned integer right-shift";
- let description = [{
- The shift_right_unsigned operation shifts an integer value to the right by
- a variable amount. The integer is interpreted as unsigned. The high order
- bits are always filled with zeros.
-
- Example:
-
- ```mlir
- %1 = constant 160 : i8 // %1 is 0b10100000
- %2 = constant 3 : i8
- %3 = shift_right_unsigned %1, %2 : (i8, i8) -> i8 // %3 is 0b00010100
- ```
- }];
-}
-
-//===----------------------------------------------------------------------===//
-// XOrOp
-//===----------------------------------------------------------------------===//
-
-def XOrOp : IntBinaryOp<"xor", [Commutative]> {
- let summary = "integer binary xor";
- let description = [{
- The `xor` operation takes two operands and returns one result, each of these
- is required to be the same type. This type may be an integer scalar type, a
- vector whose element type is integer, or a tensor of integers. It has no
- standard attributes.
-
- Example:
-
- ```mlir
- // Scalar integer bitwise xor.
- %a = xor %b, %c : i64
-
- // SIMD vector element-wise bitwise integer xor.
- %f = xor %g, %h : vector<4xi32>
-
- // Tensor element-wise bitwise integer xor.
- %x = xor %y, %z : tensor<4x?xi8>
- ```
- }];
- let hasFolder = 1;
- let hasCanonicalizer = 1;
-}
-
-//===----------------------------------------------------------------------===//
-// ZeroExtendIOp
-//===----------------------------------------------------------------------===//
-
-def ZeroExtendIOp : Std_Op<"zexti", [NoSideEffect,
- DeclareOpInterfaceMethods<VectorUnrollOpInterface>] #
- ElementwiseMappable.traits> {
- let summary = "integer zero extension operation";
- let description = [{
- The integer zero extension operation takes an integer input of
- width M and an integer destination type of width N. The destination
- bit-width must be larger than the input bit-width (N > M).
- The top-most (N - M) bits of the output are filled with zeros.
-
- Example:
-
- ```mlir
- %1 = constant 5 : i3 // %1 is 0b101
- %2 = zexti %1 : i3 to i6 // %2 is 0b000101
- %3 = constant 2 : i3 // %3 is 0b010
- %4 = zexti %3 : i3 to i6 // %4 is 0b000010
-
- %5 = zexti %0 : vector<2 x i32> to vector<2 x i64>
- ```
- }];
-
- let arguments = (ins SignlessIntegerLike:$value);
- let results = (outs SignlessIntegerLike);
-
- let builders = [
- OpBuilder<(ins "Value":$value, "Type":$destType), [{
- $_state.addOperands(value);
- $_state.addTypes(destType);
- }]>];
-
- let parser = [{
- return impl::parseCastOp(parser, result);
- }];
- let printer = [{
- return printStandardCastOp(this->getOperation(), p);
- }];
-}
-
#endif // STANDARD_OPS
let cppNamespace = "::mlir";
}
-// The predicate indicates the type of the comparison to perform:
-// (un)orderedness, (in)equality and less/greater than (or equal to) as
-// well as predicates that are always true or false.
-def CMPF_P_FALSE : I64EnumAttrCase<"AlwaysFalse", 0, "false">;
-def CMPF_P_OEQ : I64EnumAttrCase<"OEQ", 1, "oeq">;
-def CMPF_P_OGT : I64EnumAttrCase<"OGT", 2, "ogt">;
-def CMPF_P_OGE : I64EnumAttrCase<"OGE", 3, "oge">;
-def CMPF_P_OLT : I64EnumAttrCase<"OLT", 4, "olt">;
-def CMPF_P_OLE : I64EnumAttrCase<"OLE", 5, "ole">;
-def CMPF_P_ONE : I64EnumAttrCase<"ONE", 6, "one">;
-def CMPF_P_ORD : I64EnumAttrCase<"ORD", 7, "ord">;
-def CMPF_P_UEQ : I64EnumAttrCase<"UEQ", 8, "ueq">;
-def CMPF_P_UGT : I64EnumAttrCase<"UGT", 9, "ugt">;
-def CMPF_P_UGE : I64EnumAttrCase<"UGE", 10, "uge">;
-def CMPF_P_ULT : I64EnumAttrCase<"ULT", 11, "ult">;
-def CMPF_P_ULE : I64EnumAttrCase<"ULE", 12, "ule">;
-def CMPF_P_UNE : I64EnumAttrCase<"UNE", 13, "une">;
-def CMPF_P_UNO : I64EnumAttrCase<"UNO", 14, "uno">;
-def CMPF_P_TRUE : I64EnumAttrCase<"AlwaysTrue", 15, "true">;
-
-def CmpFPredicateAttr : I64EnumAttr<
- "CmpFPredicate", "",
- [CMPF_P_FALSE, CMPF_P_OEQ, CMPF_P_OGT, CMPF_P_OGE, CMPF_P_OLT, CMPF_P_OLE,
- CMPF_P_ONE, CMPF_P_ORD, CMPF_P_UEQ, CMPF_P_UGT, CMPF_P_UGE, CMPF_P_ULT,
- CMPF_P_ULE, CMPF_P_UNE, CMPF_P_UNO, CMPF_P_TRUE]> {
- let cppNamespace = "::mlir";
-}
-
-def CMPI_P_EQ : I64EnumAttrCase<"eq", 0>;
-def CMPI_P_NE : I64EnumAttrCase<"ne", 1>;
-def CMPI_P_SLT : I64EnumAttrCase<"slt", 2>;
-def CMPI_P_SLE : I64EnumAttrCase<"sle", 3>;
-def CMPI_P_SGT : I64EnumAttrCase<"sgt", 4>;
-def CMPI_P_SGE : I64EnumAttrCase<"sge", 5>;
-def CMPI_P_ULT : I64EnumAttrCase<"ult", 6>;
-def CMPI_P_ULE : I64EnumAttrCase<"ule", 7>;
-def CMPI_P_UGT : I64EnumAttrCase<"ugt", 8>;
-def CMPI_P_UGE : I64EnumAttrCase<"uge", 9>;
-
-def CmpIPredicateAttr : I64EnumAttr<
- "CmpIPredicate", "",
- [CMPI_P_EQ, CMPI_P_NE, CMPI_P_SLT, CMPI_P_SLE, CMPI_P_SGT,
- CMPI_P_SGE, CMPI_P_ULT, CMPI_P_ULE, CMPI_P_UGT, CMPI_P_UGE]> {
- let cppNamespace = "::mlir";
-}
-
#endif // STANDARD_OPS_BASE
/// Creates an instance of the StdExpand pass that legalizes Std
/// dialect ops to be convertible to LLVM. For example,
-/// `std.ceildivi_signed` gets transformed to a number of std operations,
+/// `std.arith.ceildivsi` gets transformed to a number of std operations,
/// which can be lowered to LLVM; `memref.reshape` gets converted to
/// `memref_reinterpret_cast`.
std::unique_ptr<Pass> createStdExpandOpsPass();
#ifndef MLIR_DIALECT_STANDARDOPS_UTILS_UTILS_H
#define MLIR_DIALECT_STANDARDOPS_UTILS_UTILS_H
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Matchers.h"
#include "mlir/IR/PatternMatch.h"
namespace mlir {
/// Matches a ConstantIndexOp.
-detail::op_matcher<ConstantIndexOp> matchConstantIndex();
+detail::op_matcher<arith::ConstantIndexOp> matchConstantIndex();
/// Detects the `values` produced by a ConstantIndexOp and places the new
/// constant in place of the corresponding sentinel value.
#ifndef MLIR_DIALECT_TENSOR_IR_TENSOR_H_
#define MLIR_DIALECT_TENSOR_IR_TENSOR_H_
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/BuiltinTypes.h"
#include "mlir/IR/Dialect.h"
#include "mlir/IR/OpDefinition.h"
}];
let hasConstantMaterializer = 1;
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
#endif // TENSOR_BASE
let name = "vector";
let cppNamespace = "::mlir::vector";
let hasConstantMaterializer = 1;
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
// Base class for Vector dialect ops.
%idx0 = ... : index
// dynamic computation producing the value 1 of index type
%idx1 = ... : index
- %0 = constant dense<0, 1, 2, 3>: vector<4xi32>
+ %0 = arith.constant dense<0, 1, 2, 3>: vector<4xi32>
// extracts values [0, 1]
%1 = vector.extract_map %0[%idx0] : vector<4xi32> to vector<2xi32>
// extracts values [1, 2]
%idx0 = ... : index
// dynamic computation producing the value 1 of index type
%idx1 = ... : index /
- %0 = constant dense<0, 1, 2, 3>: vector<4xi32>
+ %0 = arith.constant dense<0, 1, 2, 3>: vector<4xi32>
// extracts values [0, 1]
%1 = vector.extract_map %0[%idx0] : vector<4xi32> to vector<2xi32>
// extracts values [1, 2]
/// canonicalizations pattern to propagate and fold the vector
/// insert_map/extract_map operations.
/// Transforms:
-// %v = addf %a, %b : vector<32xf32>
+// %v = arith.addf %a, %b : vector<32xf32>
/// to:
-/// %v = addf %a, %b : vector<32xf32>
+/// %v = arith.addf %a, %b : vector<32xf32>
/// %ev = vector.extract_map %v, %id, 32 : vector<32xf32> into vector<1xf32>
/// %nv = vector.insert_map %ev, %id, 32 : vector<1xf32> into vector<32xf32>
Optional<DistributeOps>
%0 = x86vector.avx.intr.dot %a, %b : vector<8xf32>
%1 = vector.extractelement %0[%i0 : i32]: vector<8xf32>
%2 = vector.extractelement %0[%i4 : i32]: vector<8xf32>
- %d = addf %1, %2 : f32
+ %d = arith.addf %1, %2 : f32
```
}];
let arguments = (ins VectorOfLengthAndType<[8], [F32]>:$a,
///
/// Examples:
/// ```
-/// %scalar = "std.addf"(%a, %b) : (f32, f32) -> f32
+/// %scalar = "arith.addf"(%a, %b) : (f32, f32) -> f32
/// ```
/// can be tensorized to
/// ```
-/// %tensor = "std.addf"(%a, %b) : (tensor<?xf32>, tensor<?xf32>)
+/// %tensor = "arith.addf"(%a, %b) : (tensor<?xf32>, tensor<?xf32>)
/// -> tensor<?xf32>
/// ```
///
#include "mlir/Dialect/AMX/AMXDialect.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/ArmNeon/ArmNeonDialect.h"
#include "mlir/Dialect/ArmSVE/ArmSVEDialect.h"
#include "mlir/Dialect/Async/IR/Async.h"
// clang-format off
registry.insert<acc::OpenACCDialect,
AffineDialect,
+ arith::ArithmeticDialect,
amx::AMXDialect,
arm_neon::ArmNeonDialect,
async::AsyncDialect,
#include "mlir/Conversion/Passes.h"
#include "mlir/Dialect/Affine/Passes.h"
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h"
#include "mlir/Dialect/Async/Passes.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/LLVMIR/Transforms/Passes.h"
// Dialect passes
registerAffinePasses();
registerAsyncPasses();
+ arith::registerArithmeticPasses();
registerGPUPasses();
registerGpuSerializeToCubinPass();
registerGpuSerializeToHsacoPass();
#include "mlir/Analysis/BufferViewFlowAnalysis.h"
#include "mlir/Analysis/Liveness.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinOps.h"
public:
GlobalCreator(ModuleOp module, unsigned alignment = 0)
: moduleOp(module), alignment(alignment) {}
- memref::GlobalOp getGlobalFor(ConstantOp constantOp);
+ memref::GlobalOp getGlobalFor(arith::ConstantOp constantOp);
private:
ModuleOp moduleOp;
}
affine.for %arg2 = 0 to 10 {
%2 = affine.load %0[%arg2] : memref<10xf32>
- %3 = addf %2, %2 : f32
+ %3 = arith.addf %2, %2 : f32
affine.store %3, %arg0[%arg2] : memref<10xf32>
}
affine.for %arg2 = 0 to 10 {
%2 = affine.load %1[%arg2] : memref<10xf32>
- %3 = mulf %2, %2 : f32
+ %3 = arith.mulf %2, %2 : f32
affine.store %3, %arg1[%arg2] : memref<10xf32>
}
return
affine.store %cst, %0[0] : memref<1xf32>
affine.store %cst, %1[0] : memref<1xf32>
%2 = affine.load %1[0] : memref<1xf32>
- %3 = mulf %2, %2 : f32
+ %3 = arith.mulf %2, %2 : f32
affine.store %3, %arg1[%arg2] : memref<10xf32>
%4 = affine.load %0[0] : memref<1xf32>
- %5 = addf %4, %4 : f32
+ %5 = arith.addf %4, %4 : f32
affine.store %5, %arg0[%arg2] : memref<10xf32>
}
return
affine.for %arg6 = 0 to 3 {
%0 = affine.load %arg0[%arg5, %arg6] : memref<10x10xf32>
%1 = affine.load %arg1[%arg5, %arg6] : memref<10x10xf32>
- %2 = mulf %0, %1 : f32
+ %2 = arith.mulf %0, %1 : f32
affine.store %2, %arg3[%arg5, %arg6] : memref<10x10xf32>
}
}
affine.for %arg6 = 0 to 3 {
%0 = affine.load %arg0[%arg5, %arg6] : memref<10x10xf32>
%1 = affine.load %arg2[%arg5, %arg6] : memref<10x10xf32>
- %2 = addf %0, %1 : f32
+ %2 = arith.addf %0, %1 : f32
affine.store %2, %arg4[%arg5, %arg6] : memref<10x10xf32>
}
}
affine.for %arg6 = 0 to 3 {
%0 = affine.load %arg0[%arg5, %arg6] : memref<10x10xf32>
%1 = affine.load %arg1[%arg5, %arg6] : memref<10x10xf32>
- %2 = mulf %0, %1 : f32
+ %2 = arith.mulf %0, %1 : f32
affine.store %2, %arg3[%arg5, %arg6] : memref<10x10xf32>
%3 = affine.load %arg0[%arg5, %arg6] : memref<10x10xf32>
%4 = affine.load %arg2[%arg5, %arg6] : memref<10x10xf32>
- %5 = addf %3, %4 : f32
+ %5 = arith.addf %3, %4 : f32
affine.store %5, %arg4[%arg5, %arg6] : memref<10x10xf32>
}
}
let summary = "Coalesce nested loops with independent bounds into a single "
"loop";
let constructor = "mlir::createLoopCoalescingPass()";
+ let dependentDialects = ["arith::ArithmeticDialect"];
}
def LoopInvariantCodeMotion : Pass<"loop-invariant-code-motion"> {
%B: index, %C: memref<16xf64>) -> (memref<16xf64, #tile>) {
affine.for %arg3 = 0 to 16 {
%a = affine.load %A[%arg3] : memref<16xf64, #tile>
- %p = mulf %a, %a : f64
+ %p = arith.mulf %a, %a : f64
affine.store %p, %A[%arg3] : memref<16xf64, #tile>
}
%c = alloc() : memref<16xf64, #tile>
-> memref<4x4xf64> {
affine.for %arg3 = 0 to 16 {
%3 = affine.load %arg0[%arg3 floordiv 4, %arg3 mod 4]: memref<4x4xf64>
- %4 = mulf %3, %3 : f64
+ %4 = arith.mulf %3, %3 : f64
affine.store %4, %arg0[%arg3 floordiv 4, %arg3 mod 4]: memref<4x4xf64>
}
%0 = alloc() : memref<4x4xf64>
%0 = affine.load %arg0[%arg3, %arg5] : memref<8x8xi32, #linear8>
%1 = affine.load %arg1[%arg5, %arg4] : memref<8x8xi32, #linear8>
%2 = affine.load %arg2[%arg3, %arg4] : memref<8x8xi32, #linear8>
- %3 = muli %0, %1 : i32
- %4 = addi %2, %3 : i32
+ %3 = arith.muli %0, %1 : i32
+ %4 = arith.addi %2, %3 : i32
affine.store %4, %arg2[%arg3, %arg4] : memref<8x8xi32, #linear8>
}
}
%0 = affine.load %arg0[%arg3 * 8 + %arg5] : memref<64xi32>
%1 = affine.load %arg1[%arg5 * 8 + %arg4] : memref<64xi32>
%2 = affine.load %arg2[%arg3 * 8 + %arg4] : memref<64xi32>
- %3 = muli %0, %1 : i32
- %4 = addi %2, %3 : i32
+ %3 = arith.muli %0, %1 : i32
+ %4 = arith.addi %2, %3 : i32
affine.store %4, %arg2[%arg3 * 8 + %arg4] : memref<64xi32>
}
}
#include "mlir/Analysis/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/AffineExprVisitor.h"
#include "mlir/IR/BuiltinOps.h"
Operation *combinerOp = combinerOps.back();
Optional<AtomicRMWKind> maybeKind =
TypeSwitch<Operation *, Optional<AtomicRMWKind>>(combinerOp)
- .Case<AddFOp>([](Operation *) { return AtomicRMWKind::addf; })
- .Case<MulFOp>([](Operation *) { return AtomicRMWKind::mulf; })
- .Case<AddIOp>([](Operation *) { return AtomicRMWKind::addi; })
- .Case<MulIOp>([](Operation *) { return AtomicRMWKind::muli; })
+ .Case([](arith::AddFOp) { return AtomicRMWKind::addf; })
+ .Case([](arith::MulFOp) { return AtomicRMWKind::mulf; })
+ .Case([](arith::AddIOp) { return AtomicRMWKind::addi; })
+ .Case([](arith::MulIOp) { return AtomicRMWKind::muli; })
.Default([](Operation *) -> Optional<AtomicRMWKind> {
// TODO: AtomicRMW supports other kinds of reductions this is
// currently not detecting, add those when the need arises.
auto symbol = operands[i];
assert(isValidSymbol(symbol));
// Check if the symbol is a constant.
- if (auto cOp = symbol.getDefiningOp<ConstantIndexOp>())
+ if (auto cOp = symbol.getDefiningOp<arith::ConstantIndexOp>())
dependenceDomain->addBound(FlatAffineConstraints::EQ,
- valuePosMap.getSymPos(symbol),
- cOp.getValue());
+ valuePosMap.getSymPos(symbol), cOp.value());
}
};
#include "mlir/Analysis/Presburger/Simplex.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/AffineExprVisitor.h"
#include "mlir/IR/IntegerSet.h"
// Add top level symbol.
appendSymbolId(val);
// Check if the symbol is a constant.
- if (auto constOp = val.getDefiningOp<ConstantIndexOp>())
- addBound(BoundType::EQ, val, constOp.getValue());
+ if (auto constOp = val.getDefiningOp<arith::ConstantIndexOp>())
+ addBound(BoundType::EQ, val, constOp.value());
}
LogicalResult
mlir-headers
LINK_LIBS PUBLIC
- MLIRAffine
MLIRCallInterfaces
MLIRControlFlowInterfaces
MLIRDataLayoutInterfaces
MLIRInferTypeOpInterface
- MLIRLinalg
- MLIRSCF
+ MLIRSideEffectInterfaces
+ MLIRViewLikeInterface
)
add_mlir_library(MLIRLoopAnalysis
//===----------------------------------------------------------------------===//
#include "mlir/Analysis/NumberOfExecutions.h"
-#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Matchers.h"
#include "mlir/IR/RegionKindInterface.h"
#include "mlir/Interfaces/ControlFlowInterfaces.h"
//===----------------------------------------------------------------------===//
#include "mlir/Analysis/SliceAnalysis.h"
-#include "mlir/Dialect/Affine/IR/AffineOps.h"
-#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
-#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/IR/BuiltinOps.h"
#include "mlir/IR/Operation.h"
#include "mlir/Support/LLVM.h"
#include "mlir/Analysis/PresburgerSet.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/IntegerSet.h"
#include "llvm/ADT/SmallPtrSet.h"
assert(cst->containsId(value) && "value expected to be present");
if (isValidSymbol(value)) {
// Check if the symbol is a constant.
- if (auto cOp = value.getDefiningOp<ConstantIndexOp>())
- cst->addBound(FlatAffineConstraints::EQ, value, cOp.getValue());
+ if (auto cOp = value.getDefiningOp<arith::ConstantIndexOp>())
+ cst->addBound(FlatAffineConstraints::EQ, value, cOp.value());
} else if (auto loop = getForInductionVarOwner(value)) {
if (failed(cst->addAffineForOpDomain(loop)))
return failure();
assert(isValidSymbol(symbol));
// Check if the symbol is a constant.
if (auto *op = symbol.getDefiningOp()) {
- if (auto constOp = dyn_cast<ConstantIndexOp>(op)) {
- cst.addBound(FlatAffineConstraints::EQ, symbol, constOp.getValue());
+ if (auto constOp = dyn_cast<arith::ConstantIndexOp>(op)) {
+ cst.addBound(FlatAffineConstraints::EQ, symbol, constOp.value());
}
}
}
#include "../PassDetail.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
}
Value visitAddExpr(AffineBinaryOpExpr expr) {
- return buildBinaryExpr<AddIOp>(expr);
+ return buildBinaryExpr<arith::AddIOp>(expr);
}
Value visitMulExpr(AffineBinaryOpExpr expr) {
- return buildBinaryExpr<MulIOp>(expr);
+ return buildBinaryExpr<arith::MulIOp>(expr);
}
/// Euclidean modulo operation: negative RHS is not allowed.
auto rhs = visit(expr.getRHS());
assert(lhs && rhs && "unexpected affine expr lowering failure");
- Value remainder = builder.create<SignedRemIOp>(loc, lhs, rhs);
- Value zeroCst = builder.create<ConstantIndexOp>(loc, 0);
- Value isRemainderNegative =
- builder.create<CmpIOp>(loc, CmpIPredicate::slt, remainder, zeroCst);
- Value correctedRemainder = builder.create<AddIOp>(loc, remainder, rhs);
+ Value remainder = builder.create<arith::RemSIOp>(loc, lhs, rhs);
+ Value zeroCst = builder.create<arith::ConstantIndexOp>(loc, 0);
+ Value isRemainderNegative = builder.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, remainder, zeroCst);
+ Value correctedRemainder =
+ builder.create<arith::AddIOp>(loc, remainder, rhs);
Value result = builder.create<SelectOp>(loc, isRemainderNegative,
correctedRemainder, remainder);
return result;
auto rhs = visit(expr.getRHS());
assert(lhs && rhs && "unexpected affine expr lowering failure");
- Value zeroCst = builder.create<ConstantIndexOp>(loc, 0);
- Value noneCst = builder.create<ConstantIndexOp>(loc, -1);
- Value negative =
- builder.create<CmpIOp>(loc, CmpIPredicate::slt, lhs, zeroCst);
- Value negatedDecremented = builder.create<SubIOp>(loc, noneCst, lhs);
+ Value zeroCst = builder.create<arith::ConstantIndexOp>(loc, 0);
+ Value noneCst = builder.create<arith::ConstantIndexOp>(loc, -1);
+ Value negative = builder.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, lhs, zeroCst);
+ Value negatedDecremented = builder.create<arith::SubIOp>(loc, noneCst, lhs);
Value dividend =
builder.create<SelectOp>(loc, negative, negatedDecremented, lhs);
- Value quotient = builder.create<SignedDivIOp>(loc, dividend, rhs);
- Value correctedQuotient = builder.create<SubIOp>(loc, noneCst, quotient);
+ Value quotient = builder.create<arith::DivSIOp>(loc, dividend, rhs);
+ Value correctedQuotient =
+ builder.create<arith::SubIOp>(loc, noneCst, quotient);
Value result =
builder.create<SelectOp>(loc, negative, correctedQuotient, quotient);
return result;
auto rhs = visit(expr.getRHS());
assert(lhs && rhs && "unexpected affine expr lowering failure");
- Value zeroCst = builder.create<ConstantIndexOp>(loc, 0);
- Value oneCst = builder.create<ConstantIndexOp>(loc, 1);
- Value nonPositive =
- builder.create<CmpIOp>(loc, CmpIPredicate::sle, lhs, zeroCst);
- Value negated = builder.create<SubIOp>(loc, zeroCst, lhs);
- Value decremented = builder.create<SubIOp>(loc, lhs, oneCst);
+ Value zeroCst = builder.create<arith::ConstantIndexOp>(loc, 0);
+ Value oneCst = builder.create<arith::ConstantIndexOp>(loc, 1);
+ Value nonPositive = builder.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sle, lhs, zeroCst);
+ Value negated = builder.create<arith::SubIOp>(loc, zeroCst, lhs);
+ Value decremented = builder.create<arith::SubIOp>(loc, lhs, oneCst);
Value dividend =
builder.create<SelectOp>(loc, nonPositive, negated, decremented);
- Value quotient = builder.create<SignedDivIOp>(loc, dividend, rhs);
- Value negatedQuotient = builder.create<SubIOp>(loc, zeroCst, quotient);
- Value incrementedQuotient = builder.create<AddIOp>(loc, quotient, oneCst);
+ Value quotient = builder.create<arith::DivSIOp>(loc, dividend, rhs);
+ Value negatedQuotient =
+ builder.create<arith::SubIOp>(loc, zeroCst, quotient);
+ Value incrementedQuotient =
+ builder.create<arith::AddIOp>(loc, quotient, oneCst);
Value result = builder.create<SelectOp>(loc, nonPositive, negatedQuotient,
incrementedQuotient);
return result;
}
Value visitConstantExpr(AffineConstantExpr expr) {
- auto valueAttr =
- builder.getIntegerAttr(builder.getIndexType(), expr.getValue());
- auto op =
- builder.create<ConstantOp>(loc, builder.getIndexType(), valueAttr);
+ auto op = builder.create<arith::ConstantIndexOp>(loc, expr.getValue());
return op.getResult();
}
/// comparison to perform, "lt" for "min", "gt" for "max" and is used for the
/// `cmpi` operation followed by the `select` operation:
///
-/// %cond = cmpi "predicate" %v0, %v1
+/// %cond = arith.cmpi "predicate" %v0, %v1
/// %result = select %cond, %v0, %v1
///
/// Multiple values are scanned in a linear sequence. This creates a data
/// dependences that wouldn't exist in a tree reduction, but is easier to
/// recognize as a reduction by the subsequent passes.
-static Value buildMinMaxReductionSeq(Location loc, CmpIPredicate predicate,
+static Value buildMinMaxReductionSeq(Location loc,
+ arith::CmpIPredicate predicate,
ValueRange values, OpBuilder &builder) {
assert(!llvm::empty(values) && "empty min/max chain");
auto valueIt = values.begin();
Value value = *valueIt++;
for (; valueIt != values.end(); ++valueIt) {
- auto cmpOp = builder.create<CmpIOp>(loc, predicate, value, *valueIt);
+ auto cmpOp = builder.create<arith::CmpIOp>(loc, predicate, value, *valueIt);
value = builder.create<SelectOp>(loc, cmpOp.getResult(), value, *valueIt);
}
static Value lowerAffineMapMax(OpBuilder &builder, Location loc, AffineMap map,
ValueRange operands) {
if (auto values = expandAffineMap(builder, loc, map, operands))
- return buildMinMaxReductionSeq(loc, CmpIPredicate::sgt, *values, builder);
+ return buildMinMaxReductionSeq(loc, arith::CmpIPredicate::sgt, *values,
+ builder);
return nullptr;
}
static Value lowerAffineMapMin(OpBuilder &builder, Location loc, AffineMap map,
ValueRange operands) {
if (auto values = expandAffineMap(builder, loc, map, operands))
- return buildMinMaxReductionSeq(loc, CmpIPredicate::slt, *values, builder);
+ return buildMinMaxReductionSeq(loc, arith::CmpIPredicate::slt, *values,
+ builder);
return nullptr;
}
Location loc = op.getLoc();
Value lowerBound = lowerAffineLowerBound(op, rewriter);
Value upperBound = lowerAffineUpperBound(op, rewriter);
- Value step = rewriter.create<ConstantIndexOp>(loc, op.getStep());
+ Value step = rewriter.create<arith::ConstantIndexOp>(loc, op.getStep());
auto scfForOp = rewriter.create<scf::ForOp>(loc, lowerBound, upperBound,
step, op.getIterOperands());
rewriter.eraseBlock(scfForOp.getBody());
}
steps.reserve(op.steps().size());
for (Attribute step : op.steps())
- steps.push_back(rewriter.create<ConstantIndexOp>(
+ steps.push_back(rewriter.create<arith::ConstantIndexOp>(
loc, step.cast<IntegerAttr>().getInt()));
// Get the terminator op.
// Now we just have to handle the condition logic.
auto integerSet = op.getIntegerSet();
- Value zeroConstant = rewriter.create<ConstantIndexOp>(loc, 0);
+ Value zeroConstant = rewriter.create<arith::ConstantIndexOp>(loc, 0);
SmallVector<Value, 8> operands(op.getOperands());
auto operandsRef = llvm::makeArrayRef(operands);
operandsRef.drop_front(numDims));
if (!affResult)
return failure();
- auto pred = isEquality ? CmpIPredicate::eq : CmpIPredicate::sge;
+ auto pred =
+ isEquality ? arith::CmpIPredicate::eq : arith::CmpIPredicate::sge;
Value cmpVal =
- rewriter.create<CmpIOp>(loc, pred, affResult, zeroConstant);
- cond =
- cond ? rewriter.create<AndOp>(loc, cond, cmpVal).getResult() : cmpVal;
+ rewriter.create<arith::CmpIOp>(loc, pred, affResult, zeroConstant);
+ cond = cond
+ ? rewriter.create<arith::AndIOp>(loc, cond, cmpVal).getResult()
+ : cmpVal;
}
cond = cond ? cond
- : rewriter.create<ConstantIntOp>(loc, /*value=*/1, /*width=*/1);
+ : rewriter.create<arith::ConstantIntOp>(loc, /*value=*/1,
+ /*width=*/1);
bool hasElseRegion = !op.elseRegion().empty();
auto ifOp = rewriter.create<scf::IfOp>(loc, op.getResultTypes(), cond,
populateAffineToStdConversionPatterns(patterns);
populateAffineToVectorConversionPatterns(patterns);
ConversionTarget target(getContext());
- target.addLegalDialect<memref::MemRefDialect, scf::SCFDialect,
- StandardOpsDialect, VectorDialect>();
+ target
+ .addLegalDialect<arith::ArithmeticDialect, memref::MemRefDialect,
+ scf::SCFDialect, StandardOpsDialect, VectorDialect>();
if (failed(applyPartialConversion(getOperation(), target,
std::move(patterns))))
signalPassFailure();
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRMemRef
MLIRSCF
MLIRPass
--- /dev/null
+//===- ArithmeticToLLVM.cpp - Arithmetic to LLVM dialect conversion -------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
+#include "../PassDetail.h"
+#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
+#include "mlir/Conversion/LLVMCommon/VectorPattern.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
+#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
+#include "mlir/IR/TypeUtilities.h"
+
+using namespace mlir;
+
+namespace {
+
+//===----------------------------------------------------------------------===//
+// Straightforward Op Lowerings
+//===----------------------------------------------------------------------===//
+
+using AddIOpLowering = VectorConvertToLLVMPattern<arith::AddIOp, LLVM::AddOp>;
+using SubIOpLowering = VectorConvertToLLVMPattern<arith::SubIOp, LLVM::SubOp>;
+using MulIOpLowering = VectorConvertToLLVMPattern<arith::MulIOp, LLVM::MulOp>;
+using DivUIOpLowering =
+ VectorConvertToLLVMPattern<arith::DivUIOp, LLVM::UDivOp>;
+using DivSIOpLowering =
+ VectorConvertToLLVMPattern<arith::DivSIOp, LLVM::SDivOp>;
+using RemUIOpLowering =
+ VectorConvertToLLVMPattern<arith::RemUIOp, LLVM::URemOp>;
+using RemSIOpLowering =
+ VectorConvertToLLVMPattern<arith::RemSIOp, LLVM::SRemOp>;
+using AndIOpLowering = VectorConvertToLLVMPattern<arith::AndIOp, LLVM::AndOp>;
+using OrIOpLowering = VectorConvertToLLVMPattern<arith::OrIOp, LLVM::OrOp>;
+using XOrIOpLowering = VectorConvertToLLVMPattern<arith::XOrIOp, LLVM::XOrOp>;
+using ShLIOpLowering = VectorConvertToLLVMPattern<arith::ShLIOp, LLVM::ShlOp>;
+using ShRUIOpLowering =
+ VectorConvertToLLVMPattern<arith::ShRUIOp, LLVM::LShrOp>;
+using ShRSIOpLowering =
+ VectorConvertToLLVMPattern<arith::ShRSIOp, LLVM::AShrOp>;
+using NegFOpLowering = VectorConvertToLLVMPattern<arith::NegFOp, LLVM::FNegOp>;
+using AddFOpLowering = VectorConvertToLLVMPattern<arith::AddFOp, LLVM::FAddOp>;
+using SubFOpLowering = VectorConvertToLLVMPattern<arith::SubFOp, LLVM::FSubOp>;
+using MulFOpLowering = VectorConvertToLLVMPattern<arith::MulFOp, LLVM::FMulOp>;
+using DivFOpLowering = VectorConvertToLLVMPattern<arith::DivFOp, LLVM::FDivOp>;
+using RemFOpLowering = VectorConvertToLLVMPattern<arith::RemFOp, LLVM::FRemOp>;
+using ExtUIOpLowering =
+ VectorConvertToLLVMPattern<arith::ExtUIOp, LLVM::ZExtOp>;
+using ExtSIOpLowering =
+ VectorConvertToLLVMPattern<arith::ExtSIOp, LLVM::SExtOp>;
+using ExtFOpLowering = VectorConvertToLLVMPattern<arith::ExtFOp, LLVM::FPExtOp>;
+using TruncIOpLowering =
+ VectorConvertToLLVMPattern<arith::TruncIOp, LLVM::TruncOp>;
+using TruncFOpLowering =
+ VectorConvertToLLVMPattern<arith::TruncFOp, LLVM::FPTruncOp>;
+using UIToFPOpLowering =
+ VectorConvertToLLVMPattern<arith::UIToFPOp, LLVM::UIToFPOp>;
+using SIToFPOpLowering =
+ VectorConvertToLLVMPattern<arith::SIToFPOp, LLVM::SIToFPOp>;
+using FPToUIOpLowering =
+ VectorConvertToLLVMPattern<arith::FPToUIOp, LLVM::FPToUIOp>;
+using FPToSIOpLowering =
+ VectorConvertToLLVMPattern<arith::FPToSIOp, LLVM::FPToSIOp>;
+using BitcastOpLowering =
+ VectorConvertToLLVMPattern<arith::BitcastOp, LLVM::BitcastOp>;
+
+//===----------------------------------------------------------------------===//
+// Op Lowering Patterns
+//===----------------------------------------------------------------------===//
+
+/// Directly lower to LLVM op.
+struct ConstantOpLowering : public ConvertOpToLLVMPattern<arith::ConstantOp> {
+ using ConvertOpToLLVMPattern<arith::ConstantOp>::ConvertOpToLLVMPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// The lowering of index_cast becomes an integer conversion since index
+/// becomes an integer. If the bit width of the source and target integer
+/// types is the same, just erase the cast. If the target type is wider,
+/// sign-extend the value, otherwise truncate it.
+struct IndexCastOpLowering : public ConvertOpToLLVMPattern<arith::IndexCastOp> {
+ using ConvertOpToLLVMPattern<arith::IndexCastOp>::ConvertOpToLLVMPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::IndexCastOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+struct CmpIOpLowering : public ConvertOpToLLVMPattern<arith::CmpIOp> {
+ using ConvertOpToLLVMPattern<arith::CmpIOp>::ConvertOpToLLVMPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+struct CmpFOpLowering : public ConvertOpToLLVMPattern<arith::CmpFOp> {
+ using ConvertOpToLLVMPattern<arith::CmpFOp>::ConvertOpToLLVMPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+} // end anonymous namespace
+
+//===----------------------------------------------------------------------===//
+// ConstantOpLowering
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+ConstantOpLowering::matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ return LLVM::detail::oneToOneRewrite(op, LLVM::ConstantOp::getOperationName(),
+ adaptor.getOperands(),
+ *getTypeConverter(), rewriter);
+}
+
+//===----------------------------------------------------------------------===//
+// IndexCastOpLowering
+//===----------------------------------------------------------------------===//
+
+LogicalResult IndexCastOpLowering::matchAndRewrite(
+ arith::IndexCastOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto targetType = typeConverter->convertType(op.getResult().getType());
+ auto targetElementType =
+ typeConverter->convertType(getElementTypeOrSelf(op.getResult()))
+ .cast<IntegerType>();
+ auto sourceElementType =
+ getElementTypeOrSelf(adaptor.in()).cast<IntegerType>();
+ unsigned targetBits = targetElementType.getWidth();
+ unsigned sourceBits = sourceElementType.getWidth();
+
+ if (targetBits == sourceBits)
+ rewriter.replaceOp(op, adaptor.in());
+ else if (targetBits < sourceBits)
+ rewriter.replaceOpWithNewOp<LLVM::TruncOp>(op, targetType, adaptor.in());
+ else
+ rewriter.replaceOpWithNewOp<LLVM::SExtOp>(op, targetType, adaptor.in());
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpIOpLowering
+//===----------------------------------------------------------------------===//
+
+// Convert arith.cmp predicate into the LLVM dialect CmpPredicate. The two enums
+// share numerical values so just cast.
+template <typename LLVMPredType, typename PredType>
+static LLVMPredType convertCmpPredicate(PredType pred) {
+ return static_cast<LLVMPredType>(pred);
+}
+
+LogicalResult
+CmpIOpLowering::matchAndRewrite(arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto operandType = adaptor.lhs().getType();
+ auto resultType = op.getResult().getType();
+
+ // Handle the scalar and 1D vector cases.
+ if (!operandType.isa<LLVM::LLVMArrayType>()) {
+ rewriter.replaceOpWithNewOp<LLVM::ICmpOp>(
+ op, typeConverter->convertType(resultType),
+ convertCmpPredicate<LLVM::ICmpPredicate>(op.getPredicate()),
+ adaptor.lhs(), adaptor.rhs());
+ return success();
+ }
+
+ auto vectorType = resultType.dyn_cast<VectorType>();
+ if (!vectorType)
+ return rewriter.notifyMatchFailure(op, "expected vector result type");
+
+ return LLVM::detail::handleMultidimensionalVectors(
+ op.getOperation(), adaptor.getOperands(), *getTypeConverter(),
+ [&](Type llvm1DVectorTy, ValueRange operands) {
+ OpAdaptor adaptor(operands);
+ return rewriter.create<LLVM::ICmpOp>(
+ op.getLoc(), llvm1DVectorTy,
+ convertCmpPredicate<LLVM::ICmpPredicate>(op.getPredicate()),
+ adaptor.lhs(), adaptor.rhs());
+ },
+ rewriter);
+
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpFOpLowering
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+CmpFOpLowering::matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto operandType = adaptor.lhs().getType();
+ auto resultType = op.getResult().getType();
+
+ // Handle the scalar and 1D vector cases.
+ if (!operandType.isa<LLVM::LLVMArrayType>()) {
+ rewriter.replaceOpWithNewOp<LLVM::FCmpOp>(
+ op, typeConverter->convertType(resultType),
+ convertCmpPredicate<LLVM::FCmpPredicate>(op.getPredicate()),
+ adaptor.lhs(), adaptor.rhs());
+ return success();
+ }
+
+ auto vectorType = resultType.dyn_cast<VectorType>();
+ if (!vectorType)
+ return rewriter.notifyMatchFailure(op, "expected vector result type");
+
+ return LLVM::detail::handleMultidimensionalVectors(
+ op.getOperation(), adaptor.getOperands(), *getTypeConverter(),
+ [&](Type llvm1DVectorTy, ValueRange operands) {
+ OpAdaptor adaptor(operands);
+ return rewriter.create<LLVM::FCmpOp>(
+ op.getLoc(), llvm1DVectorTy,
+ convertCmpPredicate<LLVM::FCmpPredicate>(op.getPredicate()),
+ adaptor.lhs(), adaptor.rhs());
+ },
+ rewriter);
+}
+
+//===----------------------------------------------------------------------===//
+// Pass Definition
+//===----------------------------------------------------------------------===//
+
+namespace {
+struct ConvertArithmeticToLLVMPass
+ : public ConvertArithmeticToLLVMBase<ConvertArithmeticToLLVMPass> {
+ ConvertArithmeticToLLVMPass() = default;
+
+ void runOnFunction() override {
+ LLVMConversionTarget target(getContext());
+ RewritePatternSet patterns(&getContext());
+
+ LowerToLLVMOptions options(&getContext());
+ if (indexBitwidth != kDeriveIndexBitwidthFromDataLayout)
+ options.overrideIndexBitwidth(indexBitwidth);
+
+ LLVMTypeConverter converter(&getContext(), options);
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(converter,
+ patterns);
+
+ if (failed(
+ applyPartialConversion(getFunction(), target, std::move(patterns))))
+ signalPassFailure();
+ }
+};
+} // end anonymous namespace
+
+//===----------------------------------------------------------------------===//
+// Pattern Population
+//===----------------------------------------------------------------------===//
+
+void mlir::arith::populateArithmeticToLLVMConversionPatterns(
+ LLVMTypeConverter &converter, RewritePatternSet &patterns) {
+ // clang-format off
+ patterns.add<
+ ConstantOpLowering,
+ AddIOpLowering,
+ SubIOpLowering,
+ MulIOpLowering,
+ DivUIOpLowering,
+ DivSIOpLowering,
+ RemUIOpLowering,
+ RemSIOpLowering,
+ AndIOpLowering,
+ OrIOpLowering,
+ XOrIOpLowering,
+ ShLIOpLowering,
+ ShRUIOpLowering,
+ ShRSIOpLowering,
+ NegFOpLowering,
+ AddFOpLowering,
+ SubFOpLowering,
+ MulFOpLowering,
+ DivFOpLowering,
+ RemFOpLowering,
+ ExtUIOpLowering,
+ ExtSIOpLowering,
+ ExtFOpLowering,
+ TruncIOpLowering,
+ TruncFOpLowering,
+ UIToFPOpLowering,
+ SIToFPOpLowering,
+ FPToUIOpLowering,
+ FPToSIOpLowering,
+ IndexCastOpLowering,
+ BitcastOpLowering,
+ CmpIOpLowering,
+ CmpFOpLowering
+ >(converter);
+ // clang-format on
+}
+
+std::unique_ptr<Pass> mlir::arith::createConvertArithmeticToLLVMPass() {
+ return std::make_unique<ConvertArithmeticToLLVMPass>();
+}
--- /dev/null
+add_mlir_conversion_library(MLIRArithmeticToLLVM
+ ArithmeticToLLVM.cpp
+
+ ADDITIONAL_HEADER_DIRS
+ ${MLIR_MAIN_INCLUDE_DIR}/mlir/Conversion/ArithmeticToLLVM
+
+ DEPENDS
+ MLIRConversionPassIncGen
+
+ LINK_COMPONENTS
+ Core
+
+ LINK_LIBS PUBLIC
+ MLIRLLVMCommonConversion
+ MLIRLLVMIR
+ )
--- /dev/null
+//===- ArithmeticToSPIRV.cpp - Arithmetic to SPIRV dialect conversion -----===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
+#include "../PassDetail.h"
+#include "../SPIRVCommon/Pattern.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
+#include "mlir/Dialect/SPIRV/IR/SPIRVDialect.h"
+#include "mlir/Dialect/SPIRV/IR/SPIRVOps.h"
+#include "mlir/Dialect/SPIRV/Transforms/SPIRVConversion.h"
+#include "llvm/Support/Debug.h"
+
+#define DEBUG_TYPE "arith-to-spirv-pattern"
+
+using namespace mlir;
+
+//===----------------------------------------------------------------------===//
+// Operation Conversion
+//===----------------------------------------------------------------------===//
+
+namespace {
+
+/// Converts composite arith.constant operation to spv.Constant.
+struct ConstantCompositeOpPattern final
+ : public OpConversionPattern<arith::ConstantOp> {
+ using OpConversionPattern<arith::ConstantOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts scalar arith.constant operation to spv.Constant.
+struct ConstantScalarOpPattern final
+ : public OpConversionPattern<arith::ConstantOp> {
+ using OpConversionPattern<arith::ConstantOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.remsi to SPIR-V ops.
+///
+/// This cannot be merged into the template unary/binary pattern due to Vulkan
+/// restrictions over spv.SRem and spv.SMod.
+struct RemSIOpPattern final : public OpConversionPattern<arith::RemSIOp> {
+ using OpConversionPattern<arith::RemSIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::RemSIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts bitwise operations to SPIR-V operations. This is a special pattern
+/// other than the BinaryOpPatternPattern because if the operands are boolean
+/// values, SPIR-V uses different operations (`SPIRVLogicalOp`). For
+/// non-boolean operands, SPIR-V should use `SPIRVBitwiseOp`.
+template <typename Op, typename SPIRVLogicalOp, typename SPIRVBitwiseOp>
+struct BitwiseOpPattern final : public OpConversionPattern<Op> {
+ using OpConversionPattern<Op>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(Op op, typename Op::Adaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.xori to SPIR-V operations.
+struct XOrIOpLogicalPattern final : public OpConversionPattern<arith::XOrIOp> {
+ using OpConversionPattern<arith::XOrIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::XOrIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.xori to SPIR-V operations if the type of source is i1 or
+/// vector of i1.
+struct XOrIOpBooleanPattern final : public OpConversionPattern<arith::XOrIOp> {
+ using OpConversionPattern<arith::XOrIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::XOrIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.uitofp to spv.Select if the type of source is i1 or vector of
+/// i1.
+struct UIToFPI1Pattern final : public OpConversionPattern<arith::UIToFPOp> {
+ using OpConversionPattern<arith::UIToFPOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::UIToFPOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.extui to spv.Select if the type of source is i1 or vector of
+/// i1.
+struct ExtUII1Pattern final : public OpConversionPattern<arith::ExtUIOp> {
+ using OpConversionPattern<arith::ExtUIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::ExtUIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts arith.trunci to spv.Select if the type of result is i1 or vector of
+/// i1.
+struct TruncII1Pattern final : public OpConversionPattern<arith::TruncIOp> {
+ using OpConversionPattern<arith::TruncIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::TruncIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts type-casting standard operations to SPIR-V operations.
+template <typename Op, typename SPIRVOp>
+struct TypeCastingOpPattern final : public OpConversionPattern<Op> {
+ using OpConversionPattern<Op>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(Op op, typename Op::Adaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts integer compare operation on i1 type operands to SPIR-V ops.
+class CmpIOpBooleanPattern final : public OpConversionPattern<arith::CmpIOp> {
+public:
+ using OpConversionPattern<arith::CmpIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts integer compare operation to SPIR-V ops.
+class CmpIOpPattern final : public OpConversionPattern<arith::CmpIOp> {
+public:
+ using OpConversionPattern<arith::CmpIOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts floating-point comparison operations to SPIR-V ops.
+class CmpFOpPattern final : public OpConversionPattern<arith::CmpFOp> {
+public:
+ using OpConversionPattern<arith::CmpFOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts floating point NaN check to SPIR-V ops. This pattern requires
+/// Kernel capability.
+class CmpFOpNanKernelPattern final : public OpConversionPattern<arith::CmpFOp> {
+public:
+ using OpConversionPattern<arith::CmpFOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+/// Converts floating point NaN check to SPIR-V ops. This pattern does not
+/// require additional capability.
+class CmpFOpNanNonePattern final : public OpConversionPattern<arith::CmpFOp> {
+public:
+ using OpConversionPattern<arith::CmpFOp>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override;
+};
+
+} // end anonymous namespace
+
+//===----------------------------------------------------------------------===//
+// Conversion Helpers
+//===----------------------------------------------------------------------===//
+
+/// Converts the given `srcAttr` into a boolean attribute if it holds an
+/// integral value. Returns null attribute if conversion fails.
+static BoolAttr convertBoolAttr(Attribute srcAttr, Builder builder) {
+ if (auto boolAttr = srcAttr.dyn_cast<BoolAttr>())
+ return boolAttr;
+ if (auto intAttr = srcAttr.dyn_cast<IntegerAttr>())
+ return builder.getBoolAttr(intAttr.getValue().getBoolValue());
+ return BoolAttr();
+}
+
+/// Converts the given `srcAttr` to a new attribute of the given `dstType`.
+/// Returns null attribute if conversion fails.
+static IntegerAttr convertIntegerAttr(IntegerAttr srcAttr, IntegerType dstType,
+ Builder builder) {
+ // If the source number uses less active bits than the target bitwidth, then
+ // it should be safe to convert.
+ if (srcAttr.getValue().isIntN(dstType.getWidth()))
+ return builder.getIntegerAttr(dstType, srcAttr.getInt());
+
+ // XXX: Try again by interpreting the source number as a signed value.
+ // Although integers in the standard dialect are signless, they can represent
+ // a signed number. It's the operation decides how to interpret. This is
+ // dangerous, but it seems there is no good way of handling this if we still
+ // want to change the bitwidth. Emit a message at least.
+ if (srcAttr.getValue().isSignedIntN(dstType.getWidth())) {
+ auto dstAttr = builder.getIntegerAttr(dstType, srcAttr.getInt());
+ LLVM_DEBUG(llvm::dbgs() << "attribute '" << srcAttr << "' converted to '"
+ << dstAttr << "' for type '" << dstType << "'\n");
+ return dstAttr;
+ }
+
+ LLVM_DEBUG(llvm::dbgs() << "attribute '" << srcAttr
+ << "' illegal: cannot fit into target type '"
+ << dstType << "'\n");
+ return IntegerAttr();
+}
+
+/// Converts the given `srcAttr` to a new attribute of the given `dstType`.
+/// Returns null attribute if `dstType` is not 32-bit or conversion fails.
+static FloatAttr convertFloatAttr(FloatAttr srcAttr, FloatType dstType,
+ Builder builder) {
+ // Only support converting to float for now.
+ if (!dstType.isF32())
+ return FloatAttr();
+
+ // Try to convert the source floating-point number to single precision.
+ APFloat dstVal = srcAttr.getValue();
+ bool losesInfo = false;
+ APFloat::opStatus status =
+ dstVal.convert(APFloat::IEEEsingle(), APFloat::rmTowardZero, &losesInfo);
+ if (status != APFloat::opOK || losesInfo) {
+ LLVM_DEBUG(llvm::dbgs()
+ << srcAttr << " illegal: cannot fit into converted type '"
+ << dstType << "'\n");
+ return FloatAttr();
+ }
+
+ return builder.getF32FloatAttr(dstVal.convertToFloat());
+}
+
+/// Returns true if the given `type` is a boolean scalar or vector type.
+static bool isBoolScalarOrVector(Type type) {
+ if (type.isInteger(1))
+ return true;
+ if (auto vecType = type.dyn_cast<VectorType>())
+ return vecType.getElementType().isInteger(1);
+ return false;
+}
+
+//===----------------------------------------------------------------------===//
+// ConstantOp with composite type
+//===----------------------------------------------------------------------===//
+
+LogicalResult ConstantCompositeOpPattern::matchAndRewrite(
+ arith::ConstantOp constOp, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto srcType = constOp.getType().dyn_cast<ShapedType>();
+ if (!srcType)
+ return failure();
+
+ // std.constant should only have vector or tenor types.
+ assert((srcType.isa<VectorType, RankedTensorType>()));
+
+ auto dstType = getTypeConverter()->convertType(srcType);
+ if (!dstType)
+ return failure();
+
+ auto dstElementsAttr = constOp.value().dyn_cast<DenseElementsAttr>();
+ ShapedType dstAttrType = dstElementsAttr.getType();
+ if (!dstElementsAttr)
+ return failure();
+
+ // If the composite type has more than one dimensions, perform linearization.
+ if (srcType.getRank() > 1) {
+ if (srcType.isa<RankedTensorType>()) {
+ dstAttrType = RankedTensorType::get(srcType.getNumElements(),
+ srcType.getElementType());
+ dstElementsAttr = dstElementsAttr.reshape(dstAttrType);
+ } else {
+ // TODO: add support for large vectors.
+ return failure();
+ }
+ }
+
+ Type srcElemType = srcType.getElementType();
+ Type dstElemType;
+ // Tensor types are converted to SPIR-V array types; vector types are
+ // converted to SPIR-V vector/array types.
+ if (auto arrayType = dstType.dyn_cast<spirv::ArrayType>())
+ dstElemType = arrayType.getElementType();
+ else
+ dstElemType = dstType.cast<VectorType>().getElementType();
+
+ // If the source and destination element types are different, perform
+ // attribute conversion.
+ if (srcElemType != dstElemType) {
+ SmallVector<Attribute, 8> elements;
+ if (srcElemType.isa<FloatType>()) {
+ for (FloatAttr srcAttr : dstElementsAttr.getValues<FloatAttr>()) {
+ FloatAttr dstAttr =
+ convertFloatAttr(srcAttr, dstElemType.cast<FloatType>(), rewriter);
+ if (!dstAttr)
+ return failure();
+ elements.push_back(dstAttr);
+ }
+ } else if (srcElemType.isInteger(1)) {
+ return failure();
+ } else {
+ for (IntegerAttr srcAttr : dstElementsAttr.getValues<IntegerAttr>()) {
+ IntegerAttr dstAttr = convertIntegerAttr(
+ srcAttr, dstElemType.cast<IntegerType>(), rewriter);
+ if (!dstAttr)
+ return failure();
+ elements.push_back(dstAttr);
+ }
+ }
+
+ // Unfortunately, we cannot use dialect-specific types for element
+ // attributes; element attributes only works with builtin types. So we need
+ // to prepare another converted builtin types for the destination elements
+ // attribute.
+ if (dstAttrType.isa<RankedTensorType>())
+ dstAttrType = RankedTensorType::get(dstAttrType.getShape(), dstElemType);
+ else
+ dstAttrType = VectorType::get(dstAttrType.getShape(), dstElemType);
+
+ dstElementsAttr = DenseElementsAttr::get(dstAttrType, elements);
+ }
+
+ rewriter.replaceOpWithNewOp<spirv::ConstantOp>(constOp, dstType,
+ dstElementsAttr);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// ConstantOp with scalar type
+//===----------------------------------------------------------------------===//
+
+LogicalResult ConstantScalarOpPattern::matchAndRewrite(
+ arith::ConstantOp constOp, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ Type srcType = constOp.getType();
+ if (!srcType.isIntOrIndexOrFloat())
+ return failure();
+
+ Type dstType = getTypeConverter()->convertType(srcType);
+ if (!dstType)
+ return failure();
+
+ // Floating-point types.
+ if (srcType.isa<FloatType>()) {
+ auto srcAttr = constOp.value().cast<FloatAttr>();
+ auto dstAttr = srcAttr;
+
+ // Floating-point types not supported in the target environment are all
+ // converted to float type.
+ if (srcType != dstType) {
+ dstAttr = convertFloatAttr(srcAttr, dstType.cast<FloatType>(), rewriter);
+ if (!dstAttr)
+ return failure();
+ }
+
+ rewriter.replaceOpWithNewOp<spirv::ConstantOp>(constOp, dstType, dstAttr);
+ return success();
+ }
+
+ // Bool type.
+ if (srcType.isInteger(1)) {
+ // std.constant can use 0/1 instead of true/false for i1 values. We need to
+ // handle that here.
+ auto dstAttr = convertBoolAttr(constOp.value(), rewriter);
+ if (!dstAttr)
+ return failure();
+ rewriter.replaceOpWithNewOp<spirv::ConstantOp>(constOp, dstType, dstAttr);
+ return success();
+ }
+
+ // IndexType or IntegerType. Index values are converted to 32-bit integer
+ // values when converting to SPIR-V.
+ auto srcAttr = constOp.value().cast<IntegerAttr>();
+ auto dstAttr =
+ convertIntegerAttr(srcAttr, dstType.cast<IntegerType>(), rewriter);
+ if (!dstAttr)
+ return failure();
+ rewriter.replaceOpWithNewOp<spirv::ConstantOp>(constOp, dstType, dstAttr);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// RemSIOpPattern
+//===----------------------------------------------------------------------===//
+
+/// Returns signed remainder for `lhs` and `rhs` and lets the result follow
+/// the sign of `signOperand`.
+///
+/// Note that this is needed for Vulkan. Per the Vulkan's SPIR-V environment
+/// spec, "for the OpSRem and OpSMod instructions, if either operand is negative
+/// the result is undefined." So we cannot directly use spv.SRem/spv.SMod
+/// if either operand can be negative. Emulate it via spv.UMod.
+static Value emulateSignedRemainder(Location loc, Value lhs, Value rhs,
+ Value signOperand, OpBuilder &builder) {
+ assert(lhs.getType() == rhs.getType());
+ assert(lhs == signOperand || rhs == signOperand);
+
+ Type type = lhs.getType();
+
+ // Calculate the remainder with spv.UMod.
+ Value lhsAbs = builder.create<spirv::GLSLSAbsOp>(loc, type, lhs);
+ Value rhsAbs = builder.create<spirv::GLSLSAbsOp>(loc, type, rhs);
+ Value abs = builder.create<spirv::UModOp>(loc, lhsAbs, rhsAbs);
+
+ // Fix the sign.
+ Value isPositive;
+ if (lhs == signOperand)
+ isPositive = builder.create<spirv::IEqualOp>(loc, lhs, lhsAbs);
+ else
+ isPositive = builder.create<spirv::IEqualOp>(loc, rhs, rhsAbs);
+ Value absNegate = builder.create<spirv::SNegateOp>(loc, type, abs);
+ return builder.create<spirv::SelectOp>(loc, type, isPositive, abs, absNegate);
+}
+
+LogicalResult
+RemSIOpPattern::matchAndRewrite(arith::RemSIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ Value result = emulateSignedRemainder(op.getLoc(), adaptor.getOperands()[0],
+ adaptor.getOperands()[1],
+ adaptor.getOperands()[0], rewriter);
+ rewriter.replaceOp(op, result);
+
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// BitwiseOpPattern
+//===----------------------------------------------------------------------===//
+
+template <typename Op, typename SPIRVLogicalOp, typename SPIRVBitwiseOp>
+LogicalResult
+BitwiseOpPattern<Op, SPIRVLogicalOp, SPIRVBitwiseOp>::matchAndRewrite(
+ Op op, typename Op::Adaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ assert(adaptor.getOperands().size() == 2);
+ auto dstType =
+ this->getTypeConverter()->convertType(op.getResult().getType());
+ if (!dstType)
+ return failure();
+ if (isBoolScalarOrVector(adaptor.getOperands().front().getType())) {
+ rewriter.template replaceOpWithNewOp<SPIRVLogicalOp>(op, dstType,
+ adaptor.getOperands());
+ } else {
+ rewriter.template replaceOpWithNewOp<SPIRVBitwiseOp>(op, dstType,
+ adaptor.getOperands());
+ }
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// XOrIOpLogicalPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult XOrIOpLogicalPattern::matchAndRewrite(
+ arith::XOrIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ assert(adaptor.getOperands().size() == 2);
+
+ if (isBoolScalarOrVector(adaptor.getOperands().front().getType()))
+ return failure();
+
+ auto dstType = getTypeConverter()->convertType(op.getType());
+ if (!dstType)
+ return failure();
+ rewriter.replaceOpWithNewOp<spirv::BitwiseXorOp>(op, dstType,
+ adaptor.getOperands());
+
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// XOrIOpBooleanPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult XOrIOpBooleanPattern::matchAndRewrite(
+ arith::XOrIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ assert(adaptor.getOperands().size() == 2);
+
+ if (!isBoolScalarOrVector(adaptor.getOperands().front().getType()))
+ return failure();
+
+ auto dstType = getTypeConverter()->convertType(op.getType());
+ if (!dstType)
+ return failure();
+ rewriter.replaceOpWithNewOp<spirv::LogicalNotEqualOp>(op, dstType,
+ adaptor.getOperands());
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// UIToFPI1Pattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+UIToFPI1Pattern::matchAndRewrite(arith::UIToFPOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto srcType = adaptor.getOperands().front().getType();
+ if (!isBoolScalarOrVector(srcType))
+ return failure();
+
+ auto dstType =
+ this->getTypeConverter()->convertType(op.getResult().getType());
+ Location loc = op.getLoc();
+ Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
+ Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
+ rewriter.template replaceOpWithNewOp<spirv::SelectOp>(
+ op, dstType, adaptor.getOperands().front(), one, zero);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// ExtUII1Pattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+ExtUII1Pattern::matchAndRewrite(arith::ExtUIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto srcType = adaptor.getOperands().front().getType();
+ if (!isBoolScalarOrVector(srcType))
+ return failure();
+
+ auto dstType =
+ this->getTypeConverter()->convertType(op.getResult().getType());
+ Location loc = op.getLoc();
+ Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
+ Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
+ rewriter.template replaceOpWithNewOp<spirv::SelectOp>(
+ op, dstType, adaptor.getOperands().front(), one, zero);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// TruncII1Pattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+TruncII1Pattern::matchAndRewrite(arith::TruncIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ auto dstType =
+ this->getTypeConverter()->convertType(op.getResult().getType());
+ if (!isBoolScalarOrVector(dstType))
+ return failure();
+
+ Location loc = op.getLoc();
+ auto srcType = adaptor.getOperands().front().getType();
+ // Check if (x & 1) == 1.
+ Value mask = spirv::ConstantOp::getOne(srcType, loc, rewriter);
+ Value maskedSrc = rewriter.create<spirv::BitwiseAndOp>(
+ loc, srcType, adaptor.getOperands()[0], mask);
+ Value isOne = rewriter.create<spirv::IEqualOp>(loc, maskedSrc, mask);
+
+ Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
+ Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
+ rewriter.replaceOpWithNewOp<spirv::SelectOp>(op, dstType, isOne, one, zero);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// TypeCastingOpPattern
+//===----------------------------------------------------------------------===//
+
+template <typename Op, typename SPIRVOp>
+LogicalResult TypeCastingOpPattern<Op, SPIRVOp>::matchAndRewrite(
+ Op op, typename Op::Adaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ assert(adaptor.getOperands().size() == 1);
+ auto srcType = adaptor.getOperands().front().getType();
+ auto dstType =
+ this->getTypeConverter()->convertType(op.getResult().getType());
+ if (isBoolScalarOrVector(srcType) || isBoolScalarOrVector(dstType))
+ return failure();
+ if (dstType == srcType) {
+ // Due to type conversion, we are seeing the same source and target type.
+ // Then we can just erase this operation by forwarding its operand.
+ rewriter.replaceOp(op, adaptor.getOperands().front());
+ } else {
+ rewriter.template replaceOpWithNewOp<SPIRVOp>(op, dstType,
+ adaptor.getOperands());
+ }
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpIOpBooleanPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult CmpIOpBooleanPattern::matchAndRewrite(
+ arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ Type operandType = op.lhs().getType();
+ if (!isBoolScalarOrVector(operandType))
+ return failure();
+
+ switch (op.getPredicate()) {
+#define DISPATCH(cmpPredicate, spirvOp) \
+ case cmpPredicate: \
+ rewriter.replaceOpWithNewOp<spirvOp>(op, op.getResult().getType(), \
+ adaptor.lhs(), adaptor.rhs()); \
+ return success();
+
+ DISPATCH(arith::CmpIPredicate::eq, spirv::LogicalEqualOp);
+ DISPATCH(arith::CmpIPredicate::ne, spirv::LogicalNotEqualOp);
+
+#undef DISPATCH
+ default:;
+ }
+ return failure();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpIOpPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+CmpIOpPattern::matchAndRewrite(arith::CmpIOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ Type operandType = op.lhs().getType();
+ if (isBoolScalarOrVector(operandType))
+ return failure();
+
+ switch (op.getPredicate()) {
+#define DISPATCH(cmpPredicate, spirvOp) \
+ case cmpPredicate: \
+ if (spirvOp::template hasTrait<OpTrait::spirv::UnsignedOp>() && \
+ operandType != this->getTypeConverter()->convertType(operandType)) { \
+ return op.emitError( \
+ "bitwidth emulation is not implemented yet on unsigned op"); \
+ } \
+ rewriter.replaceOpWithNewOp<spirvOp>(op, op.getResult().getType(), \
+ adaptor.lhs(), adaptor.rhs()); \
+ return success();
+
+ DISPATCH(arith::CmpIPredicate::eq, spirv::IEqualOp);
+ DISPATCH(arith::CmpIPredicate::ne, spirv::INotEqualOp);
+ DISPATCH(arith::CmpIPredicate::slt, spirv::SLessThanOp);
+ DISPATCH(arith::CmpIPredicate::sle, spirv::SLessThanEqualOp);
+ DISPATCH(arith::CmpIPredicate::sgt, spirv::SGreaterThanOp);
+ DISPATCH(arith::CmpIPredicate::sge, spirv::SGreaterThanEqualOp);
+ DISPATCH(arith::CmpIPredicate::ult, spirv::ULessThanOp);
+ DISPATCH(arith::CmpIPredicate::ule, spirv::ULessThanEqualOp);
+ DISPATCH(arith::CmpIPredicate::ugt, spirv::UGreaterThanOp);
+ DISPATCH(arith::CmpIPredicate::uge, spirv::UGreaterThanEqualOp);
+
+#undef DISPATCH
+ }
+ return failure();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpFOpPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult
+CmpFOpPattern::matchAndRewrite(arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ switch (op.getPredicate()) {
+#define DISPATCH(cmpPredicate, spirvOp) \
+ case cmpPredicate: \
+ rewriter.replaceOpWithNewOp<spirvOp>(op, op.getResult().getType(), \
+ adaptor.lhs(), adaptor.rhs()); \
+ return success();
+
+ // Ordered.
+ DISPATCH(arith::CmpFPredicate::OEQ, spirv::FOrdEqualOp);
+ DISPATCH(arith::CmpFPredicate::OGT, spirv::FOrdGreaterThanOp);
+ DISPATCH(arith::CmpFPredicate::OGE, spirv::FOrdGreaterThanEqualOp);
+ DISPATCH(arith::CmpFPredicate::OLT, spirv::FOrdLessThanOp);
+ DISPATCH(arith::CmpFPredicate::OLE, spirv::FOrdLessThanEqualOp);
+ DISPATCH(arith::CmpFPredicate::ONE, spirv::FOrdNotEqualOp);
+ // Unordered.
+ DISPATCH(arith::CmpFPredicate::UEQ, spirv::FUnordEqualOp);
+ DISPATCH(arith::CmpFPredicate::UGT, spirv::FUnordGreaterThanOp);
+ DISPATCH(arith::CmpFPredicate::UGE, spirv::FUnordGreaterThanEqualOp);
+ DISPATCH(arith::CmpFPredicate::ULT, spirv::FUnordLessThanOp);
+ DISPATCH(arith::CmpFPredicate::ULE, spirv::FUnordLessThanEqualOp);
+ DISPATCH(arith::CmpFPredicate::UNE, spirv::FUnordNotEqualOp);
+
+#undef DISPATCH
+
+ default:
+ break;
+ }
+ return failure();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpFOpNanKernelPattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult CmpFOpNanKernelPattern::matchAndRewrite(
+ arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ if (op.getPredicate() == arith::CmpFPredicate::ORD) {
+ rewriter.replaceOpWithNewOp<spirv::OrderedOp>(op, adaptor.lhs(),
+ adaptor.rhs());
+ return success();
+ }
+
+ if (op.getPredicate() == arith::CmpFPredicate::UNO) {
+ rewriter.replaceOpWithNewOp<spirv::UnorderedOp>(op, adaptor.lhs(),
+ adaptor.rhs());
+ return success();
+ }
+
+ return failure();
+}
+
+//===----------------------------------------------------------------------===//
+// CmpFOpNanNonePattern
+//===----------------------------------------------------------------------===//
+
+LogicalResult CmpFOpNanNonePattern::matchAndRewrite(
+ arith::CmpFOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const {
+ if (op.getPredicate() != arith::CmpFPredicate::ORD &&
+ op.getPredicate() != arith::CmpFPredicate::UNO)
+ return failure();
+
+ Location loc = op.getLoc();
+
+ Value lhsIsNan = rewriter.create<spirv::IsNanOp>(loc, adaptor.lhs());
+ Value rhsIsNan = rewriter.create<spirv::IsNanOp>(loc, adaptor.rhs());
+
+ Value replace = rewriter.create<spirv::LogicalOrOp>(loc, lhsIsNan, rhsIsNan);
+ if (op.getPredicate() == arith::CmpFPredicate::ORD)
+ replace = rewriter.create<spirv::LogicalNotOp>(loc, replace);
+
+ rewriter.replaceOp(op, replace);
+ return success();
+}
+
+//===----------------------------------------------------------------------===//
+// Pattern Population
+//===----------------------------------------------------------------------===//
+
+void mlir::arith::populateArithmeticToSPIRVPatterns(
+ SPIRVTypeConverter &typeConverter, RewritePatternSet &patterns) {
+ // clang-format off
+ patterns.add<
+ ConstantCompositeOpPattern,
+ ConstantScalarOpPattern,
+ spirv::UnaryAndBinaryOpPattern<arith::AddIOp, spirv::IAddOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::SubIOp, spirv::ISubOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::MulIOp, spirv::IMulOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::DivUIOp, spirv::UDivOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::DivSIOp, spirv::SDivOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::RemUIOp, spirv::UModOp>,
+ RemSIOpPattern,
+ BitwiseOpPattern<arith::AndIOp, spirv::LogicalAndOp, spirv::BitwiseAndOp>,
+ BitwiseOpPattern<arith::OrIOp, spirv::LogicalOrOp, spirv::BitwiseOrOp>,
+ XOrIOpLogicalPattern, XOrIOpBooleanPattern,
+ spirv::UnaryAndBinaryOpPattern<arith::ShLIOp, spirv::ShiftLeftLogicalOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::ShRUIOp, spirv::ShiftRightLogicalOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::ShRSIOp, spirv::ShiftRightArithmeticOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::NegFOp, spirv::FNegateOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::AddFOp, spirv::FAddOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::SubFOp, spirv::FSubOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::MulFOp, spirv::FMulOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::DivFOp, spirv::FDivOp>,
+ spirv::UnaryAndBinaryOpPattern<arith::RemFOp, spirv::FRemOp>,
+ TypeCastingOpPattern<arith::ExtUIOp, spirv::UConvertOp>, ExtUII1Pattern,
+ TypeCastingOpPattern<arith::ExtSIOp, spirv::SConvertOp>,
+ TypeCastingOpPattern<arith::ExtFOp, spirv::FConvertOp>,
+ TypeCastingOpPattern<arith::TruncIOp, spirv::SConvertOp>, TruncII1Pattern,
+ TypeCastingOpPattern<arith::TruncFOp, spirv::FConvertOp>,
+ TypeCastingOpPattern<arith::UIToFPOp, spirv::ConvertUToFOp>, UIToFPI1Pattern,
+ TypeCastingOpPattern<arith::SIToFPOp, spirv::ConvertSToFOp>,
+ TypeCastingOpPattern<arith::FPToSIOp, spirv::ConvertFToSOp>,
+ TypeCastingOpPattern<arith::IndexCastOp, spirv::SConvertOp>,
+ CmpIOpBooleanPattern, CmpIOpPattern,
+ CmpFOpNanNonePattern, CmpFOpPattern
+ >(typeConverter, patterns.getContext());
+ // clang-format on
+
+ // Give CmpFOpNanKernelPattern a higher benefit so it can prevail when Kernel
+ // capability is available.
+ patterns.add<CmpFOpNanKernelPattern>(typeConverter, patterns.getContext(),
+ /*benefit=*/2);
+}
+
+//===----------------------------------------------------------------------===//
+// Pass Definition
+//===----------------------------------------------------------------------===//
+
+namespace {
+struct ConvertArithmeticToSPIRVPass
+ : public ConvertArithmeticToSPIRVBase<ConvertArithmeticToSPIRVPass> {
+ void runOnFunction() override {
+ auto module = getOperation()->getParentOfType<ModuleOp>();
+ auto targetAttr = spirv::lookupTargetEnvOrDefault(module);
+ auto target = SPIRVConversionTarget::get(targetAttr);
+
+ SPIRVTypeConverter::Options options;
+ options.emulateNon32BitScalarTypes = this->emulateNon32BitScalarTypes;
+ SPIRVTypeConverter typeConverter(targetAttr, options);
+
+ RewritePatternSet patterns(&getContext());
+ mlir::arith::populateArithmeticToSPIRVPatterns(typeConverter, patterns);
+
+ if (failed(applyPartialConversion(getOperation(), *target,
+ std::move(patterns))))
+ signalPassFailure();
+ }
+};
+} // end anonymous namespace
+
+std::unique_ptr<Pass> mlir::arith::createConvertArithmeticToSPIRVPass() {
+ return std::make_unique<ConvertArithmeticToSPIRVPass>();
+}
--- /dev/null
+add_mlir_conversion_library(MLIRArithmeticToSPIRV
+ ArithmeticToSPIRV.cpp
+
+ ADDITIONAL_HEADER_DIRS
+ ${MLIR_MAIN_INCLUDE_DIR}/mlir/Conversion/ArithmeticToSPIRV
+
+ DEPENDS
+ MLIRConversionPassIncGen
+
+ LINK_COMPONENTS
+ Core
+
+ LINK_LIBS PUBLIC
+ MLIRSPIRVConversion
+ MLIRSPIRV
+ )
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Async/IR/Async.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
LogicalResult
matchAndRewrite(RefCountingOp op, typename RefCountingOp::Adaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
- auto count =
- rewriter.create<ConstantOp>(op->getLoc(), rewriter.getI64Type(),
- rewriter.getI64IntegerAttr(op.count()));
+ auto count = rewriter.create<arith::ConstantOp>(
+ op->getLoc(), rewriter.getI64Type(),
+ rewriter.getI64IntegerAttr(op.count()));
auto operand = adaptor.operand();
rewriter.replaceOpWithNewOp<CallOp>(op, TypeRange(), apiFunctionName,
converter, ctx);
ConversionTarget target(*ctx);
- target.addLegalOp<ConstantOp, UnrealizedConversionCastOp>();
+ target
+ .addLegalOp<arith::ConstantOp, ConstantOp, UnrealizedConversionCastOp>();
target.addLegalDialect<LLVM::LLVMDialect>();
// All operations from Async dialect must be lowered to the runtime API and
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRAsync
MLIRLLVMCommonConversion
MLIRLLVMIR
add_subdirectory(AffineToStandard)
+add_subdirectory(ArithmeticToLLVM)
+add_subdirectory(ArithmeticToSPIRV)
add_subdirectory(ArmNeon2dToIntr)
add_subdirectory(AsyncToLLVM)
add_subdirectory(ComplexToLLVM)
#include "../PassDetail.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Complex/IR/Complex.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
+#include "mlir/Dialect/StandardOps/IR/Ops.h"
using namespace mlir;
using namespace mlir::LLVM;
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRComplex
MLIRIR
MLIRMath
#include <type_traits>
#include "../PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Complex/IR/Complex.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
Value real = rewriter.create<complex::ReOp>(loc, type, adaptor.complex());
Value imag = rewriter.create<complex::ImOp>(loc, type, adaptor.complex());
- Value realSqr = rewriter.create<MulFOp>(loc, real, real);
- Value imagSqr = rewriter.create<MulFOp>(loc, imag, imag);
- Value sqNorm = rewriter.create<AddFOp>(loc, realSqr, imagSqr);
+ Value realSqr = rewriter.create<arith::MulFOp>(loc, real, real);
+ Value imagSqr = rewriter.create<arith::MulFOp>(loc, imag, imag);
+ Value sqNorm = rewriter.create<arith::AddFOp>(loc, realSqr, imagSqr);
rewriter.replaceOpWithNewOp<math::SqrtOp>(op, sqNorm);
return success();
}
};
-template <typename ComparisonOp, CmpFPredicate p>
+template <typename ComparisonOp, arith::CmpFPredicate p>
struct ComparisonOpConversion : public OpConversionPattern<ComparisonOp> {
using OpConversionPattern<ComparisonOp>::OpConversionPattern;
using ResultCombiner =
std::conditional_t<std::is_same<ComparisonOp, complex::EqualOp>::value,
- AndOp, OrOp>;
+ arith::AndIOp, arith::OrIOp>;
LogicalResult
matchAndRewrite(ComparisonOp op, typename ComparisonOp::Adaptor adaptor,
Value imagLhs = rewriter.create<complex::ImOp>(loc, type, adaptor.lhs());
Value realRhs = rewriter.create<complex::ReOp>(loc, type, adaptor.rhs());
Value imagRhs = rewriter.create<complex::ImOp>(loc, type, adaptor.rhs());
- Value realComparison = rewriter.create<CmpFOp>(loc, p, realLhs, realRhs);
- Value imagComparison = rewriter.create<CmpFOp>(loc, p, imagLhs, imagRhs);
+ Value realComparison =
+ rewriter.create<arith::CmpFOp>(loc, p, realLhs, realRhs);
+ Value imagComparison =
+ rewriter.create<arith::CmpFOp>(loc, p, imagLhs, imagRhs);
rewriter.replaceOpWithNewOp<ResultCombiner>(op, realComparison,
imagComparison);
// resultImag = (lhsImag - lhsReal * rhsImagRealRatio) / rhsImagRealDenom
//
// See https://dl.acm.org/citation.cfm?id=368661 for more details.
- Value rhsRealImagRatio = rewriter.create<DivFOp>(loc, rhsReal, rhsImag);
- Value rhsRealImagDenom = rewriter.create<AddFOp>(
- loc, rhsImag, rewriter.create<MulFOp>(loc, rhsRealImagRatio, rhsReal));
- Value realNumerator1 = rewriter.create<AddFOp>(
- loc, rewriter.create<MulFOp>(loc, lhsReal, rhsRealImagRatio), lhsImag);
+ Value rhsRealImagRatio =
+ rewriter.create<arith::DivFOp>(loc, rhsReal, rhsImag);
+ Value rhsRealImagDenom = rewriter.create<arith::AddFOp>(
+ loc, rhsImag,
+ rewriter.create<arith::MulFOp>(loc, rhsRealImagRatio, rhsReal));
+ Value realNumerator1 = rewriter.create<arith::AddFOp>(
+ loc, rewriter.create<arith::MulFOp>(loc, lhsReal, rhsRealImagRatio),
+ lhsImag);
Value resultReal1 =
- rewriter.create<DivFOp>(loc, realNumerator1, rhsRealImagDenom);
- Value imagNumerator1 = rewriter.create<SubFOp>(
- loc, rewriter.create<MulFOp>(loc, lhsImag, rhsRealImagRatio), lhsReal);
+ rewriter.create<arith::DivFOp>(loc, realNumerator1, rhsRealImagDenom);
+ Value imagNumerator1 = rewriter.create<arith::SubFOp>(
+ loc, rewriter.create<arith::MulFOp>(loc, lhsImag, rhsRealImagRatio),
+ lhsReal);
Value resultImag1 =
- rewriter.create<DivFOp>(loc, imagNumerator1, rhsRealImagDenom);
-
- Value rhsImagRealRatio = rewriter.create<DivFOp>(loc, rhsImag, rhsReal);
- Value rhsImagRealDenom = rewriter.create<AddFOp>(
- loc, rhsReal, rewriter.create<MulFOp>(loc, rhsImagRealRatio, rhsImag));
- Value realNumerator2 = rewriter.create<AddFOp>(
- loc, lhsReal, rewriter.create<MulFOp>(loc, lhsImag, rhsImagRealRatio));
+ rewriter.create<arith::DivFOp>(loc, imagNumerator1, rhsRealImagDenom);
+
+ Value rhsImagRealRatio =
+ rewriter.create<arith::DivFOp>(loc, rhsImag, rhsReal);
+ Value rhsImagRealDenom = rewriter.create<arith::AddFOp>(
+ loc, rhsReal,
+ rewriter.create<arith::MulFOp>(loc, rhsImagRealRatio, rhsImag));
+ Value realNumerator2 = rewriter.create<arith::AddFOp>(
+ loc, lhsReal,
+ rewriter.create<arith::MulFOp>(loc, lhsImag, rhsImagRealRatio));
Value resultReal2 =
- rewriter.create<DivFOp>(loc, realNumerator2, rhsImagRealDenom);
- Value imagNumerator2 = rewriter.create<SubFOp>(
- loc, lhsImag, rewriter.create<MulFOp>(loc, lhsReal, rhsImagRealRatio));
+ rewriter.create<arith::DivFOp>(loc, realNumerator2, rhsImagRealDenom);
+ Value imagNumerator2 = rewriter.create<arith::SubFOp>(
+ loc, lhsImag,
+ rewriter.create<arith::MulFOp>(loc, lhsReal, rhsImagRealRatio));
Value resultImag2 =
- rewriter.create<DivFOp>(loc, imagNumerator2, rhsImagRealDenom);
+ rewriter.create<arith::DivFOp>(loc, imagNumerator2, rhsImagRealDenom);
// Consider corner cases.
// Case 1. Zero denominator, numerator contains at most one NaN value.
- Value zero = rewriter.create<ConstantOp>(loc, elementType,
- rewriter.getZeroAttr(elementType));
- Value rhsRealAbs = rewriter.create<AbsFOp>(loc, rhsReal);
- Value rhsRealIsZero =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, rhsRealAbs, zero);
- Value rhsImagAbs = rewriter.create<AbsFOp>(loc, rhsImag);
- Value rhsImagIsZero =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, rhsImagAbs, zero);
- Value lhsRealIsNotNaN =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ORD, lhsReal, zero);
- Value lhsImagIsNotNaN =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ORD, lhsImag, zero);
+ Value zero = rewriter.create<arith::ConstantOp>(
+ loc, elementType, rewriter.getZeroAttr(elementType));
+ Value rhsRealAbs = rewriter.create<math::AbsOp>(loc, rhsReal);
+ Value rhsRealIsZero = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, rhsRealAbs, zero);
+ Value rhsImagAbs = rewriter.create<math::AbsOp>(loc, rhsImag);
+ Value rhsImagIsZero = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, rhsImagAbs, zero);
+ Value lhsRealIsNotNaN = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ORD, lhsReal, zero);
+ Value lhsImagIsNotNaN = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ORD, lhsImag, zero);
Value lhsContainsNotNaNValue =
- rewriter.create<OrOp>(loc, lhsRealIsNotNaN, lhsImagIsNotNaN);
- Value resultIsInfinity = rewriter.create<AndOp>(
+ rewriter.create<arith::OrIOp>(loc, lhsRealIsNotNaN, lhsImagIsNotNaN);
+ Value resultIsInfinity = rewriter.create<arith::AndIOp>(
loc, lhsContainsNotNaNValue,
- rewriter.create<AndOp>(loc, rhsRealIsZero, rhsImagIsZero));
- Value inf = rewriter.create<ConstantOp>(
+ rewriter.create<arith::AndIOp>(loc, rhsRealIsZero, rhsImagIsZero));
+ Value inf = rewriter.create<arith::ConstantOp>(
loc, elementType,
rewriter.getFloatAttr(
elementType, APFloat::getInf(elementType.getFloatSemantics())));
- Value infWithSignOfRhsReal = rewriter.create<CopySignOp>(loc, inf, rhsReal);
+ Value infWithSignOfRhsReal =
+ rewriter.create<math::CopySignOp>(loc, inf, rhsReal);
Value infinityResultReal =
- rewriter.create<MulFOp>(loc, infWithSignOfRhsReal, lhsReal);
+ rewriter.create<arith::MulFOp>(loc, infWithSignOfRhsReal, lhsReal);
Value infinityResultImag =
- rewriter.create<MulFOp>(loc, infWithSignOfRhsReal, lhsImag);
+ rewriter.create<arith::MulFOp>(loc, infWithSignOfRhsReal, lhsImag);
// Case 2. Infinite numerator, finite denominator.
- Value rhsRealFinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ONE, rhsRealAbs, inf);
- Value rhsImagFinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ONE, rhsImagAbs, inf);
- Value rhsFinite = rewriter.create<AndOp>(loc, rhsRealFinite, rhsImagFinite);
- Value lhsRealAbs = rewriter.create<AbsFOp>(loc, lhsReal);
- Value lhsRealInfinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, lhsRealAbs, inf);
- Value lhsImagAbs = rewriter.create<AbsFOp>(loc, lhsImag);
- Value lhsImagInfinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, lhsImagAbs, inf);
+ Value rhsRealFinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ONE, rhsRealAbs, inf);
+ Value rhsImagFinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ONE, rhsImagAbs, inf);
+ Value rhsFinite =
+ rewriter.create<arith::AndIOp>(loc, rhsRealFinite, rhsImagFinite);
+ Value lhsRealAbs = rewriter.create<math::AbsOp>(loc, lhsReal);
+ Value lhsRealInfinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, lhsRealAbs, inf);
+ Value lhsImagAbs = rewriter.create<math::AbsOp>(loc, lhsImag);
+ Value lhsImagInfinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, lhsImagAbs, inf);
Value lhsInfinite =
- rewriter.create<OrOp>(loc, lhsRealInfinite, lhsImagInfinite);
+ rewriter.create<arith::OrIOp>(loc, lhsRealInfinite, lhsImagInfinite);
Value infNumFiniteDenom =
- rewriter.create<AndOp>(loc, lhsInfinite, rhsFinite);
- Value one = rewriter.create<ConstantOp>(
+ rewriter.create<arith::AndIOp>(loc, lhsInfinite, rhsFinite);
+ Value one = rewriter.create<arith::ConstantOp>(
loc, elementType, rewriter.getFloatAttr(elementType, 1));
- Value lhsRealIsInfWithSign = rewriter.create<CopySignOp>(
+ Value lhsRealIsInfWithSign = rewriter.create<math::CopySignOp>(
loc, rewriter.create<SelectOp>(loc, lhsRealInfinite, one, zero),
lhsReal);
- Value lhsImagIsInfWithSign = rewriter.create<CopySignOp>(
+ Value lhsImagIsInfWithSign = rewriter.create<math::CopySignOp>(
loc, rewriter.create<SelectOp>(loc, lhsImagInfinite, one, zero),
lhsImag);
Value lhsRealIsInfWithSignTimesRhsReal =
- rewriter.create<MulFOp>(loc, lhsRealIsInfWithSign, rhsReal);
+ rewriter.create<arith::MulFOp>(loc, lhsRealIsInfWithSign, rhsReal);
Value lhsImagIsInfWithSignTimesRhsImag =
- rewriter.create<MulFOp>(loc, lhsImagIsInfWithSign, rhsImag);
- Value resultReal3 = rewriter.create<MulFOp>(
+ rewriter.create<arith::MulFOp>(loc, lhsImagIsInfWithSign, rhsImag);
+ Value resultReal3 = rewriter.create<arith::MulFOp>(
loc, inf,
- rewriter.create<AddFOp>(loc, lhsRealIsInfWithSignTimesRhsReal,
- lhsImagIsInfWithSignTimesRhsImag));
+ rewriter.create<arith::AddFOp>(loc, lhsRealIsInfWithSignTimesRhsReal,
+ lhsImagIsInfWithSignTimesRhsImag));
Value lhsRealIsInfWithSignTimesRhsImag =
- rewriter.create<MulFOp>(loc, lhsRealIsInfWithSign, rhsImag);
+ rewriter.create<arith::MulFOp>(loc, lhsRealIsInfWithSign, rhsImag);
Value lhsImagIsInfWithSignTimesRhsReal =
- rewriter.create<MulFOp>(loc, lhsImagIsInfWithSign, rhsReal);
- Value resultImag3 = rewriter.create<MulFOp>(
+ rewriter.create<arith::MulFOp>(loc, lhsImagIsInfWithSign, rhsReal);
+ Value resultImag3 = rewriter.create<arith::MulFOp>(
loc, inf,
- rewriter.create<SubFOp>(loc, lhsImagIsInfWithSignTimesRhsReal,
- lhsRealIsInfWithSignTimesRhsImag));
+ rewriter.create<arith::SubFOp>(loc, lhsImagIsInfWithSignTimesRhsReal,
+ lhsRealIsInfWithSignTimesRhsImag));
// Case 3: Finite numerator, infinite denominator.
- Value lhsRealFinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ONE, lhsRealAbs, inf);
- Value lhsImagFinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::ONE, lhsImagAbs, inf);
- Value lhsFinite = rewriter.create<AndOp>(loc, lhsRealFinite, lhsImagFinite);
- Value rhsRealInfinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, rhsRealAbs, inf);
- Value rhsImagInfinite =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OEQ, rhsImagAbs, inf);
+ Value lhsRealFinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ONE, lhsRealAbs, inf);
+ Value lhsImagFinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::ONE, lhsImagAbs, inf);
+ Value lhsFinite =
+ rewriter.create<arith::AndIOp>(loc, lhsRealFinite, lhsImagFinite);
+ Value rhsRealInfinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, rhsRealAbs, inf);
+ Value rhsImagInfinite = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OEQ, rhsImagAbs, inf);
Value rhsInfinite =
- rewriter.create<OrOp>(loc, rhsRealInfinite, rhsImagInfinite);
+ rewriter.create<arith::OrIOp>(loc, rhsRealInfinite, rhsImagInfinite);
Value finiteNumInfiniteDenom =
- rewriter.create<AndOp>(loc, lhsFinite, rhsInfinite);
- Value rhsRealIsInfWithSign = rewriter.create<CopySignOp>(
+ rewriter.create<arith::AndIOp>(loc, lhsFinite, rhsInfinite);
+ Value rhsRealIsInfWithSign = rewriter.create<math::CopySignOp>(
loc, rewriter.create<SelectOp>(loc, rhsRealInfinite, one, zero),
rhsReal);
- Value rhsImagIsInfWithSign = rewriter.create<CopySignOp>(
+ Value rhsImagIsInfWithSign = rewriter.create<math::CopySignOp>(
loc, rewriter.create<SelectOp>(loc, rhsImagInfinite, one, zero),
rhsImag);
Value rhsRealIsInfWithSignTimesLhsReal =
- rewriter.create<MulFOp>(loc, lhsReal, rhsRealIsInfWithSign);
+ rewriter.create<arith::MulFOp>(loc, lhsReal, rhsRealIsInfWithSign);
Value rhsImagIsInfWithSignTimesLhsImag =
- rewriter.create<MulFOp>(loc, lhsImag, rhsImagIsInfWithSign);
- Value resultReal4 = rewriter.create<MulFOp>(
+ rewriter.create<arith::MulFOp>(loc, lhsImag, rhsImagIsInfWithSign);
+ Value resultReal4 = rewriter.create<arith::MulFOp>(
loc, zero,
- rewriter.create<AddFOp>(loc, rhsRealIsInfWithSignTimesLhsReal,
- rhsImagIsInfWithSignTimesLhsImag));
+ rewriter.create<arith::AddFOp>(loc, rhsRealIsInfWithSignTimesLhsReal,
+ rhsImagIsInfWithSignTimesLhsImag));
Value rhsRealIsInfWithSignTimesLhsImag =
- rewriter.create<MulFOp>(loc, lhsImag, rhsRealIsInfWithSign);
+ rewriter.create<arith::MulFOp>(loc, lhsImag, rhsRealIsInfWithSign);
Value rhsImagIsInfWithSignTimesLhsReal =
- rewriter.create<MulFOp>(loc, lhsReal, rhsImagIsInfWithSign);
- Value resultImag4 = rewriter.create<MulFOp>(
+ rewriter.create<arith::MulFOp>(loc, lhsReal, rhsImagIsInfWithSign);
+ Value resultImag4 = rewriter.create<arith::MulFOp>(
loc, zero,
- rewriter.create<SubFOp>(loc, rhsRealIsInfWithSignTimesLhsImag,
- rhsImagIsInfWithSignTimesLhsReal));
+ rewriter.create<arith::SubFOp>(loc, rhsRealIsInfWithSignTimesLhsImag,
+ rhsImagIsInfWithSignTimesLhsReal));
- Value realAbsSmallerThanImagAbs = rewriter.create<CmpFOp>(
- loc, CmpFPredicate::OLT, rhsRealAbs, rhsImagAbs);
+ Value realAbsSmallerThanImagAbs = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OLT, rhsRealAbs, rhsImagAbs);
Value resultReal = rewriter.create<SelectOp>(loc, realAbsSmallerThanImagAbs,
resultReal1, resultReal2);
Value resultImag = rewriter.create<SelectOp>(loc, realAbsSmallerThanImagAbs,
Value resultImagSpecialCase1 = rewriter.create<SelectOp>(
loc, resultIsInfinity, infinityResultImag, resultImagSpecialCase2);
- Value resultRealIsNaN =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::UNO, resultReal, zero);
- Value resultImagIsNaN =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::UNO, resultImag, zero);
+ Value resultRealIsNaN = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::UNO, resultReal, zero);
+ Value resultImagIsNaN = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::UNO, resultImag, zero);
Value resultIsNaN =
- rewriter.create<AndOp>(loc, resultRealIsNaN, resultImagIsNaN);
+ rewriter.create<arith::AndIOp>(loc, resultRealIsNaN, resultImagIsNaN);
Value resultRealWithSpecialCases = rewriter.create<SelectOp>(
loc, resultIsNaN, resultRealSpecialCase1, resultReal);
Value resultImagWithSpecialCases = rewriter.create<SelectOp>(
rewriter.create<complex::ImOp>(loc, elementType, adaptor.complex());
Value expReal = rewriter.create<math::ExpOp>(loc, real);
Value cosImag = rewriter.create<math::CosOp>(loc, imag);
- Value resultReal = rewriter.create<MulFOp>(loc, expReal, cosImag);
+ Value resultReal = rewriter.create<arith::MulFOp>(loc, expReal, cosImag);
Value sinImag = rewriter.create<math::SinOp>(loc, imag);
- Value resultImag = rewriter.create<MulFOp>(loc, expReal, sinImag);
+ Value resultImag = rewriter.create<arith::MulFOp>(loc, expReal, sinImag);
rewriter.replaceOpWithNewOp<complex::CreateOp>(op, type, resultReal,
resultImag);
Value real = b.create<complex::ReOp>(elementType, adaptor.complex());
Value imag = b.create<complex::ImOp>(elementType, adaptor.complex());
- Value one =
- b.create<ConstantOp>(elementType, b.getFloatAttr(elementType, 1));
- Value realPlusOne = b.create<AddFOp>(real, one);
+ Value one = b.create<arith::ConstantOp>(elementType,
+ b.getFloatAttr(elementType, 1));
+ Value realPlusOne = b.create<arith::AddFOp>(real, one);
Value newComplex = b.create<complex::CreateOp>(type, realPlusOne, imag);
rewriter.replaceOpWithNewOp<complex::LogOp>(op, type, newComplex);
return success();
auto elementType = type.getElementType().cast<FloatType>();
Value lhsReal = b.create<complex::ReOp>(elementType, adaptor.lhs());
- Value lhsRealAbs = b.create<AbsFOp>(lhsReal);
+ Value lhsRealAbs = b.create<math::AbsOp>(lhsReal);
Value lhsImag = b.create<complex::ImOp>(elementType, adaptor.lhs());
- Value lhsImagAbs = b.create<AbsFOp>(lhsImag);
+ Value lhsImagAbs = b.create<math::AbsOp>(lhsImag);
Value rhsReal = b.create<complex::ReOp>(elementType, adaptor.rhs());
- Value rhsRealAbs = b.create<AbsFOp>(rhsReal);
+ Value rhsRealAbs = b.create<math::AbsOp>(rhsReal);
Value rhsImag = b.create<complex::ImOp>(elementType, adaptor.rhs());
- Value rhsImagAbs = b.create<AbsFOp>(rhsImag);
+ Value rhsImagAbs = b.create<math::AbsOp>(rhsImag);
- Value lhsRealTimesRhsReal = b.create<MulFOp>(lhsReal, rhsReal);
- Value lhsRealTimesRhsRealAbs = b.create<AbsFOp>(lhsRealTimesRhsReal);
- Value lhsImagTimesRhsImag = b.create<MulFOp>(lhsImag, rhsImag);
- Value lhsImagTimesRhsImagAbs = b.create<AbsFOp>(lhsImagTimesRhsImag);
- Value real = b.create<SubFOp>(lhsRealTimesRhsReal, lhsImagTimesRhsImag);
+ Value lhsRealTimesRhsReal = b.create<arith::MulFOp>(lhsReal, rhsReal);
+ Value lhsRealTimesRhsRealAbs = b.create<math::AbsOp>(lhsRealTimesRhsReal);
+ Value lhsImagTimesRhsImag = b.create<arith::MulFOp>(lhsImag, rhsImag);
+ Value lhsImagTimesRhsImagAbs = b.create<math::AbsOp>(lhsImagTimesRhsImag);
+ Value real =
+ b.create<arith::SubFOp>(lhsRealTimesRhsReal, lhsImagTimesRhsImag);
- Value lhsImagTimesRhsReal = b.create<MulFOp>(lhsImag, rhsReal);
- Value lhsImagTimesRhsRealAbs = b.create<AbsFOp>(lhsImagTimesRhsReal);
- Value lhsRealTimesRhsImag = b.create<MulFOp>(lhsReal, rhsImag);
- Value lhsRealTimesRhsImagAbs = b.create<AbsFOp>(lhsRealTimesRhsImag);
- Value imag = b.create<AddFOp>(lhsImagTimesRhsReal, lhsRealTimesRhsImag);
+ Value lhsImagTimesRhsReal = b.create<arith::MulFOp>(lhsImag, rhsReal);
+ Value lhsImagTimesRhsRealAbs = b.create<math::AbsOp>(lhsImagTimesRhsReal);
+ Value lhsRealTimesRhsImag = b.create<arith::MulFOp>(lhsReal, rhsImag);
+ Value lhsRealTimesRhsImagAbs = b.create<math::AbsOp>(lhsRealTimesRhsImag);
+ Value imag =
+ b.create<arith::AddFOp>(lhsImagTimesRhsReal, lhsRealTimesRhsImag);
// Handle cases where the "naive" calculation results in NaN values.
- Value realIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, real, real);
- Value imagIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, imag, imag);
- Value isNan = b.create<AndOp>(realIsNan, imagIsNan);
+ Value realIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, real, real);
+ Value imagIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, imag, imag);
+ Value isNan = b.create<arith::AndIOp>(realIsNan, imagIsNan);
- Value inf = b.create<ConstantOp>(
+ Value inf = b.create<arith::ConstantOp>(
elementType,
b.getFloatAttr(elementType,
APFloat::getInf(elementType.getFloatSemantics())));
// Case 1. `lhsReal` or `lhsImag` are infinite.
- Value lhsRealIsInf = b.create<CmpFOp>(CmpFPredicate::OEQ, lhsRealAbs, inf);
- Value lhsImagIsInf = b.create<CmpFOp>(CmpFPredicate::OEQ, lhsImagAbs, inf);
- Value lhsIsInf = b.create<OrOp>(lhsRealIsInf, lhsImagIsInf);
- Value rhsRealIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, rhsReal, rhsReal);
- Value rhsImagIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, rhsImag, rhsImag);
- Value zero = b.create<ConstantOp>(elementType, b.getZeroAttr(elementType));
- Value one =
- b.create<ConstantOp>(elementType, b.getFloatAttr(elementType, 1));
+ Value lhsRealIsInf =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, lhsRealAbs, inf);
+ Value lhsImagIsInf =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, lhsImagAbs, inf);
+ Value lhsIsInf = b.create<arith::OrIOp>(lhsRealIsInf, lhsImagIsInf);
+ Value rhsRealIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, rhsReal, rhsReal);
+ Value rhsImagIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, rhsImag, rhsImag);
+ Value zero =
+ b.create<arith::ConstantOp>(elementType, b.getZeroAttr(elementType));
+ Value one = b.create<arith::ConstantOp>(elementType,
+ b.getFloatAttr(elementType, 1));
Value lhsRealIsInfFloat = b.create<SelectOp>(lhsRealIsInf, one, zero);
lhsReal = b.create<SelectOp>(
- lhsIsInf, b.create<CopySignOp>(lhsRealIsInfFloat, lhsReal), lhsReal);
+ lhsIsInf, b.create<math::CopySignOp>(lhsRealIsInfFloat, lhsReal),
+ lhsReal);
Value lhsImagIsInfFloat = b.create<SelectOp>(lhsImagIsInf, one, zero);
lhsImag = b.create<SelectOp>(
- lhsIsInf, b.create<CopySignOp>(lhsImagIsInfFloat, lhsImag), lhsImag);
- Value lhsIsInfAndRhsRealIsNan = b.create<AndOp>(lhsIsInf, rhsRealIsNan);
- rhsReal = b.create<SelectOp>(lhsIsInfAndRhsRealIsNan,
- b.create<CopySignOp>(zero, rhsReal), rhsReal);
- Value lhsIsInfAndRhsImagIsNan = b.create<AndOp>(lhsIsInf, rhsImagIsNan);
- rhsImag = b.create<SelectOp>(lhsIsInfAndRhsImagIsNan,
- b.create<CopySignOp>(zero, rhsImag), rhsImag);
+ lhsIsInf, b.create<math::CopySignOp>(lhsImagIsInfFloat, lhsImag),
+ lhsImag);
+ Value lhsIsInfAndRhsRealIsNan =
+ b.create<arith::AndIOp>(lhsIsInf, rhsRealIsNan);
+ rhsReal =
+ b.create<SelectOp>(lhsIsInfAndRhsRealIsNan,
+ b.create<math::CopySignOp>(zero, rhsReal), rhsReal);
+ Value lhsIsInfAndRhsImagIsNan =
+ b.create<arith::AndIOp>(lhsIsInf, rhsImagIsNan);
+ rhsImag =
+ b.create<SelectOp>(lhsIsInfAndRhsImagIsNan,
+ b.create<math::CopySignOp>(zero, rhsImag), rhsImag);
// Case 2. `rhsReal` or `rhsImag` are infinite.
- Value rhsRealIsInf = b.create<CmpFOp>(CmpFPredicate::OEQ, rhsRealAbs, inf);
- Value rhsImagIsInf = b.create<CmpFOp>(CmpFPredicate::OEQ, rhsImagAbs, inf);
- Value rhsIsInf = b.create<OrOp>(rhsRealIsInf, rhsImagIsInf);
- Value lhsRealIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, lhsReal, lhsReal);
- Value lhsImagIsNan = b.create<CmpFOp>(CmpFPredicate::UNO, lhsImag, lhsImag);
+ Value rhsRealIsInf =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, rhsRealAbs, inf);
+ Value rhsImagIsInf =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, rhsImagAbs, inf);
+ Value rhsIsInf = b.create<arith::OrIOp>(rhsRealIsInf, rhsImagIsInf);
+ Value lhsRealIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, lhsReal, lhsReal);
+ Value lhsImagIsNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNO, lhsImag, lhsImag);
Value rhsRealIsInfFloat = b.create<SelectOp>(rhsRealIsInf, one, zero);
rhsReal = b.create<SelectOp>(
- rhsIsInf, b.create<CopySignOp>(rhsRealIsInfFloat, rhsReal), rhsReal);
+ rhsIsInf, b.create<math::CopySignOp>(rhsRealIsInfFloat, rhsReal),
+ rhsReal);
Value rhsImagIsInfFloat = b.create<SelectOp>(rhsImagIsInf, one, zero);
rhsImag = b.create<SelectOp>(
- rhsIsInf, b.create<CopySignOp>(rhsImagIsInfFloat, rhsImag), rhsImag);
- Value rhsIsInfAndLhsRealIsNan = b.create<AndOp>(rhsIsInf, lhsRealIsNan);
- lhsReal = b.create<SelectOp>(rhsIsInfAndLhsRealIsNan,
- b.create<CopySignOp>(zero, lhsReal), lhsReal);
- Value rhsIsInfAndLhsImagIsNan = b.create<AndOp>(rhsIsInf, lhsImagIsNan);
- lhsImag = b.create<SelectOp>(rhsIsInfAndLhsImagIsNan,
- b.create<CopySignOp>(zero, lhsImag), lhsImag);
- Value recalc = b.create<OrOp>(lhsIsInf, rhsIsInf);
+ rhsIsInf, b.create<math::CopySignOp>(rhsImagIsInfFloat, rhsImag),
+ rhsImag);
+ Value rhsIsInfAndLhsRealIsNan =
+ b.create<arith::AndIOp>(rhsIsInf, lhsRealIsNan);
+ lhsReal =
+ b.create<SelectOp>(rhsIsInfAndLhsRealIsNan,
+ b.create<math::CopySignOp>(zero, lhsReal), lhsReal);
+ Value rhsIsInfAndLhsImagIsNan =
+ b.create<arith::AndIOp>(rhsIsInf, lhsImagIsNan);
+ lhsImag =
+ b.create<SelectOp>(rhsIsInfAndLhsImagIsNan,
+ b.create<math::CopySignOp>(zero, lhsImag), lhsImag);
+ Value recalc = b.create<arith::OrIOp>(lhsIsInf, rhsIsInf);
// Case 3. One of the pairwise products of left hand side with right hand
// side is infinite.
- Value lhsRealTimesRhsRealIsInf =
- b.create<CmpFOp>(CmpFPredicate::OEQ, lhsRealTimesRhsRealAbs, inf);
- Value lhsImagTimesRhsImagIsInf =
- b.create<CmpFOp>(CmpFPredicate::OEQ, lhsImagTimesRhsImagAbs, inf);
- Value isSpecialCase =
- b.create<OrOp>(lhsRealTimesRhsRealIsInf, lhsImagTimesRhsImagIsInf);
- Value lhsRealTimesRhsImagIsInf =
- b.create<CmpFOp>(CmpFPredicate::OEQ, lhsRealTimesRhsImagAbs, inf);
- isSpecialCase = b.create<OrOp>(isSpecialCase, lhsRealTimesRhsImagIsInf);
- Value lhsImagTimesRhsRealIsInf =
- b.create<CmpFOp>(CmpFPredicate::OEQ, lhsImagTimesRhsRealAbs, inf);
- isSpecialCase = b.create<OrOp>(isSpecialCase, lhsImagTimesRhsRealIsInf);
+ Value lhsRealTimesRhsRealIsInf = b.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, lhsRealTimesRhsRealAbs, inf);
+ Value lhsImagTimesRhsImagIsInf = b.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, lhsImagTimesRhsImagAbs, inf);
+ Value isSpecialCase = b.create<arith::OrIOp>(lhsRealTimesRhsRealIsInf,
+ lhsImagTimesRhsImagIsInf);
+ Value lhsRealTimesRhsImagIsInf = b.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, lhsRealTimesRhsImagAbs, inf);
+ isSpecialCase =
+ b.create<arith::OrIOp>(isSpecialCase, lhsRealTimesRhsImagIsInf);
+ Value lhsImagTimesRhsRealIsInf = b.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, lhsImagTimesRhsRealAbs, inf);
+ isSpecialCase =
+ b.create<arith::OrIOp>(isSpecialCase, lhsImagTimesRhsRealIsInf);
Type i1Type = b.getI1Type();
- Value notRecalc = b.create<XOrOp>(
- recalc, b.create<ConstantOp>(i1Type, b.getIntegerAttr(i1Type, 1)));
- isSpecialCase = b.create<AndOp>(isSpecialCase, notRecalc);
+ Value notRecalc = b.create<arith::XOrIOp>(
+ recalc,
+ b.create<arith::ConstantOp>(i1Type, b.getIntegerAttr(i1Type, 1)));
+ isSpecialCase = b.create<arith::AndIOp>(isSpecialCase, notRecalc);
Value isSpecialCaseAndLhsRealIsNan =
- b.create<AndOp>(isSpecialCase, lhsRealIsNan);
- lhsReal = b.create<SelectOp>(isSpecialCaseAndLhsRealIsNan,
- b.create<CopySignOp>(zero, lhsReal), lhsReal);
+ b.create<arith::AndIOp>(isSpecialCase, lhsRealIsNan);
+ lhsReal =
+ b.create<SelectOp>(isSpecialCaseAndLhsRealIsNan,
+ b.create<math::CopySignOp>(zero, lhsReal), lhsReal);
Value isSpecialCaseAndLhsImagIsNan =
- b.create<AndOp>(isSpecialCase, lhsImagIsNan);
- lhsImag = b.create<SelectOp>(isSpecialCaseAndLhsImagIsNan,
- b.create<CopySignOp>(zero, lhsImag), lhsImag);
+ b.create<arith::AndIOp>(isSpecialCase, lhsImagIsNan);
+ lhsImag =
+ b.create<SelectOp>(isSpecialCaseAndLhsImagIsNan,
+ b.create<math::CopySignOp>(zero, lhsImag), lhsImag);
Value isSpecialCaseAndRhsRealIsNan =
- b.create<AndOp>(isSpecialCase, rhsRealIsNan);
- rhsReal = b.create<SelectOp>(isSpecialCaseAndRhsRealIsNan,
- b.create<CopySignOp>(zero, rhsReal), rhsReal);
+ b.create<arith::AndIOp>(isSpecialCase, rhsRealIsNan);
+ rhsReal =
+ b.create<SelectOp>(isSpecialCaseAndRhsRealIsNan,
+ b.create<math::CopySignOp>(zero, rhsReal), rhsReal);
Value isSpecialCaseAndRhsImagIsNan =
- b.create<AndOp>(isSpecialCase, rhsImagIsNan);
- rhsImag = b.create<SelectOp>(isSpecialCaseAndRhsImagIsNan,
- b.create<CopySignOp>(zero, rhsImag), rhsImag);
- recalc = b.create<OrOp>(recalc, isSpecialCase);
- recalc = b.create<AndOp>(isNan, recalc);
+ b.create<arith::AndIOp>(isSpecialCase, rhsImagIsNan);
+ rhsImag =
+ b.create<SelectOp>(isSpecialCaseAndRhsImagIsNan,
+ b.create<math::CopySignOp>(zero, rhsImag), rhsImag);
+ recalc = b.create<arith::OrIOp>(recalc, isSpecialCase);
+ recalc = b.create<arith::AndIOp>(isNan, recalc);
// Recalculate real part.
- lhsRealTimesRhsReal = b.create<MulFOp>(lhsReal, rhsReal);
- lhsImagTimesRhsImag = b.create<MulFOp>(lhsImag, rhsImag);
- Value newReal = b.create<SubFOp>(lhsRealTimesRhsReal, lhsImagTimesRhsImag);
- real = b.create<SelectOp>(recalc, b.create<MulFOp>(inf, newReal), real);
+ lhsRealTimesRhsReal = b.create<arith::MulFOp>(lhsReal, rhsReal);
+ lhsImagTimesRhsImag = b.create<arith::MulFOp>(lhsImag, rhsImag);
+ Value newReal =
+ b.create<arith::SubFOp>(lhsRealTimesRhsReal, lhsImagTimesRhsImag);
+ real =
+ b.create<SelectOp>(recalc, b.create<arith::MulFOp>(inf, newReal), real);
// Recalculate imag part.
- lhsImagTimesRhsReal = b.create<MulFOp>(lhsImag, rhsReal);
- lhsRealTimesRhsImag = b.create<MulFOp>(lhsReal, rhsImag);
- Value newImag = b.create<AddFOp>(lhsImagTimesRhsReal, lhsRealTimesRhsImag);
- imag = b.create<SelectOp>(recalc, b.create<MulFOp>(inf, newImag), imag);
+ lhsImagTimesRhsReal = b.create<arith::MulFOp>(lhsImag, rhsReal);
+ lhsRealTimesRhsImag = b.create<arith::MulFOp>(lhsReal, rhsImag);
+ Value newImag =
+ b.create<arith::AddFOp>(lhsImagTimesRhsReal, lhsRealTimesRhsImag);
+ imag =
+ b.create<SelectOp>(recalc, b.create<arith::MulFOp>(inf, newImag), imag);
rewriter.replaceOpWithNewOp<complex::CreateOp>(op, type, real, imag);
return success();
rewriter.create<complex::ReOp>(loc, elementType, adaptor.complex());
Value imag =
rewriter.create<complex::ImOp>(loc, elementType, adaptor.complex());
- Value negReal = rewriter.create<NegFOp>(loc, real);
- Value negImag = rewriter.create<NegFOp>(loc, imag);
+ Value negReal = rewriter.create<arith::NegFOp>(loc, real);
+ Value negImag = rewriter.create<arith::NegFOp>(loc, imag);
rewriter.replaceOpWithNewOp<complex::CreateOp>(op, type, negReal, negImag);
return success();
}
Value real = b.create<complex::ReOp>(elementType, adaptor.complex());
Value imag = b.create<complex::ImOp>(elementType, adaptor.complex());
- Value zero = b.create<ConstantOp>(elementType, b.getZeroAttr(elementType));
- Value realIsZero = b.create<CmpFOp>(CmpFPredicate::OEQ, real, zero);
- Value imagIsZero = b.create<CmpFOp>(CmpFPredicate::OEQ, imag, zero);
- Value isZero = b.create<AndOp>(realIsZero, imagIsZero);
+ Value zero =
+ b.create<arith::ConstantOp>(elementType, b.getZeroAttr(elementType));
+ Value realIsZero =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, real, zero);
+ Value imagIsZero =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, imag, zero);
+ Value isZero = b.create<arith::AndIOp>(realIsZero, imagIsZero);
auto abs = b.create<complex::AbsOp>(elementType, adaptor.complex());
- Value realSign = b.create<DivFOp>(real, abs);
- Value imagSign = b.create<DivFOp>(imag, abs);
+ Value realSign = b.create<arith::DivFOp>(real, abs);
+ Value imagSign = b.create<arith::DivFOp>(imag, abs);
Value sign = b.create<complex::CreateOp>(type, realSign, imagSign);
rewriter.replaceOpWithNewOp<SelectOp>(op, isZero, adaptor.complex(), sign);
return success();
// clang-format off
patterns.add<
AbsOpConversion,
- ComparisonOpConversion<complex::EqualOp, CmpFPredicate::OEQ>,
- ComparisonOpConversion<complex::NotEqualOp, CmpFPredicate::UNE>,
- BinaryComplexOpConversion<complex::AddOp, AddFOp>,
- BinaryComplexOpConversion<complex::SubOp, SubFOp>,
+ ComparisonOpConversion<complex::EqualOp, arith::CmpFPredicate::OEQ>,
+ ComparisonOpConversion<complex::NotEqualOp, arith::CmpFPredicate::UNE>,
+ BinaryComplexOpConversion<complex::AddOp, arith::AddFOp>,
+ BinaryComplexOpConversion<complex::SubOp, arith::SubFOp>,
DivOpConversion,
ExpOpConversion,
LogOpConversion,
populateComplexToStandardConversionPatterns(patterns);
ConversionTarget target(getContext());
- target.addLegalDialect<StandardOpsDialect, math::MathDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, StandardOpsDialect,
+ math::MathDialect>();
target.addLegalOp<complex::CreateOp, complex::ImOp, complex::ReOp>();
if (failed(applyPartialConversion(function, target, std::move(patterns))))
signalPassFailure();
${NVPTX_LIBS}
LINK_LIBS PUBLIC
+ MLIRArithmeticToLLVM
MLIRAsyncToLLVM
MLIRGPUTransforms
MLIRIR
#include "mlir/Conversion/GPUCommon/GPUCommonPass.h"
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/AsyncToLLVM/AsyncToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
target.addIllegalDialect<gpu::GPUDialect>();
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(converter, patterns);
populateVectorToLLVMConversionPatterns(converter, patterns);
populateMemRefToLLVMConversionPatterns(converter, patterns);
populateStdToLLVMConversionPatterns(converter, patterns);
MLIRGPUToNVVMIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticToLLVM
MLIRGPUOps
MLIRGPUToGPURuntimeTransforms
MLIRLLVMCommonConversion
MLIRLLVMIR
- MLIRMemRef
MLIRMemRefToLLVM
MLIRNVVMIR
MLIRPass
#include "mlir/Conversion/GPUToNVVM/GPUToNVVMPass.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/LoweringOptions.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/LLVMIR/NVVMDialect.h"
populateGpuRewritePatterns(patterns);
(void)applyPatternsAndFoldGreedily(m, std::move(patterns));
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(converter,
+ llvmPatterns);
populateStdToLLVMConversionPatterns(converter, llvmPatterns);
populateMemRefToLLVMConversionPatterns(converter, llvmPatterns);
populateGpuToNVVMConversionPatterns(converter, llvmPatterns);
Identifier::get(NVVM::NVVMDialect::getKernelFuncAttrName(),
&converter.getContext()));
- patterns.add<OpToFuncCallLowering<AbsFOp>>(converter, "__nv_fabsf",
- "__nv_fabs");
+ patterns.add<OpToFuncCallLowering<math::AbsOp>>(converter, "__nv_fabsf",
+ "__nv_fabs");
patterns.add<OpToFuncCallLowering<math::AtanOp>>(converter, "__nv_atanf",
"__nv_atan");
patterns.add<OpToFuncCallLowering<math::Atan2Op>>(converter, "__nv_atan2f",
"__nv_atan2");
- patterns.add<OpToFuncCallLowering<CeilFOp>>(converter, "__nv_ceilf",
- "__nv_ceil");
+ patterns.add<OpToFuncCallLowering<math::CeilOp>>(converter, "__nv_ceilf",
+ "__nv_ceil");
patterns.add<OpToFuncCallLowering<math::CosOp>>(converter, "__nv_cosf",
"__nv_cos");
patterns.add<OpToFuncCallLowering<math::ExpOp>>(converter, "__nv_expf",
"__nv_exp2");
patterns.add<OpToFuncCallLowering<math::ExpM1Op>>(converter, "__nv_expm1f",
"__nv_expm1");
- patterns.add<OpToFuncCallLowering<FloorFOp>>(converter, "__nv_floorf",
- "__nv_floor");
+ patterns.add<OpToFuncCallLowering<math::FloorOp>>(converter, "__nv_floorf",
+ "__nv_floor");
patterns.add<OpToFuncCallLowering<math::LogOp>>(converter, "__nv_logf",
"__nv_log");
patterns.add<OpToFuncCallLowering<math::Log1pOp>>(converter, "__nv_log1pf",
MLIRGPUToROCDLIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticToLLVM
MLIRGPUOps
MLIRGPUToGPURuntimeTransforms
MLIRLLVMCommonConversion
#include "mlir/Conversion/GPUToROCDL/GPUToROCDLPass.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/LoweringOptions.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
populateGpuRewritePatterns(patterns);
(void)applyPatternsAndFoldGreedily(m, std::move(patterns));
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(converter,
+ llvmPatterns);
populateVectorToLLVMConversionPatterns(converter, llvmPatterns);
populateVectorToROCDLConversionPatterns(converter, llvmPatterns);
populateStdToLLVMConversionPatterns(converter, llvmPatterns);
converter, /*allocaAddrSpace=*/5,
Identifier::get(ROCDL::ROCDLDialect::getKernelFuncAttrName(),
&converter.getContext()));
- patterns.add<OpToFuncCallLowering<AbsFOp>>(converter, "__ocml_fabs_f32",
- "__ocml_fabs_f64");
+ patterns.add<OpToFuncCallLowering<math::AbsOp>>(converter, "__ocml_fabs_f32",
+ "__ocml_fabs_f64");
patterns.add<OpToFuncCallLowering<math::AtanOp>>(converter, "__ocml_atan_f32",
"__ocml_atan_f64");
patterns.add<OpToFuncCallLowering<math::Atan2Op>>(
converter, "__ocml_atan2_f32", "__ocml_atan2_f64");
- patterns.add<OpToFuncCallLowering<CeilFOp>>(converter, "__ocml_ceil_f32",
- "__ocml_ceil_f64");
+ patterns.add<OpToFuncCallLowering<math::CeilOp>>(converter, "__ocml_ceil_f32",
+ "__ocml_ceil_f64");
patterns.add<OpToFuncCallLowering<math::CosOp>>(converter, "__ocml_cos_f32",
"__ocml_cos_f64");
patterns.add<OpToFuncCallLowering<math::ExpOp>>(converter, "__ocml_exp_f32",
"__ocml_exp2_f64");
patterns.add<OpToFuncCallLowering<math::ExpM1Op>>(
converter, "__ocml_expm1_f32", "__ocml_expm1_f64");
- patterns.add<OpToFuncCallLowering<FloorFOp>>(converter, "__ocml_floor_f32",
- "__ocml_floor_f64");
+ patterns.add<OpToFuncCallLowering<math::FloorOp>>(
+ converter, "__ocml_floor_f32", "__ocml_floor_f64");
patterns.add<OpToFuncCallLowering<math::LogOp>>(converter, "__ocml_log_f32",
"__ocml_log_f64");
patterns.add<OpToFuncCallLowering<math::Log10Op>>(
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticToSPIRV
MLIRGPUOps
MLIRIR
MLIRPass
MLIRSCFToSPIRV
MLIRSPIRV
MLIRSPIRVConversion
- MLIRStandard
MLIRStandardToSPIRV
MLIRSupport
MLIRTransforms
#include "mlir/Conversion/GPUToSPIRV/GPUToSPIRVPass.h"
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
#include "mlir/Conversion/GPUToSPIRV/GPUToSPIRV.h"
#include "mlir/Conversion/MemRefToSPIRV/MemRefToSPIRV.h"
#include "mlir/Conversion/StandardToSPIRV/StandardToSPIRV.h"
// TODO: Change SPIR-V conversion to be progressive and remove the following
// patterns.
+ mlir::arith::populateArithmeticToSPIRVPatterns(typeConverter, patterns);
populateMemRefToSPIRVPatterns(typeConverter, patterns);
populateStandardToSPIRVPatterns(typeConverter, patterns);
void ConvertLinalgToStandardPass::runOnOperation() {
auto module = getOperation();
ConversionTarget target(getContext());
- target.addLegalDialect<AffineDialect, memref::MemRefDialect, scf::SCFDialect,
+ target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
+ memref::MemRefDialect, scf::SCFDialect,
StandardOpsDialect>();
target.addLegalOp<ModuleOp, FuncOp, ReturnOp, linalg::RangeOp>();
RewritePatternSet patterns(&getContext());
using namespace mlir;
namespace {
+using AbsOpLowering = VectorConvertToLLVMPattern<math::AbsOp, LLVM::FAbsOp>;
+using CeilOpLowering = VectorConvertToLLVMPattern<math::CeilOp, LLVM::FCeilOp>;
+using CopySignOpLowering =
+ VectorConvertToLLVMPattern<math::CopySignOp, LLVM::CopySignOp>;
using CosOpLowering = VectorConvertToLLVMPattern<math::CosOp, LLVM::CosOp>;
using ExpOpLowering = VectorConvertToLLVMPattern<math::ExpOp, LLVM::ExpOp>;
using Exp2OpLowering = VectorConvertToLLVMPattern<math::Exp2Op, LLVM::Exp2Op>;
+using FloorOpLowering =
+ VectorConvertToLLVMPattern<math::FloorOp, LLVM::FFloorOp>;
+using FmaOpLowering = VectorConvertToLLVMPattern<math::FmaOp, LLVM::FMAOp>;
using Log10OpLowering =
VectorConvertToLLVMPattern<math::Log10Op, LLVM::Log10Op>;
using Log2OpLowering = VectorConvertToLLVMPattern<math::Log2Op, LLVM::Log2Op>;
RewritePatternSet &patterns) {
// clang-format off
patterns.add<
+ AbsOpLowering,
+ CeilOpLowering,
+ CopySignOpLowering,
CosOpLowering,
ExpOpLowering,
Exp2OpLowering,
ExpM1OpLowering,
+ FloorOpLowering,
+ FmaOpLowering,
Log10OpLowering,
Log1pOpLowering,
Log2OpLowering,
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRMath
MLIRStandardOpsTransforms
)
#include "mlir/Conversion/MathToLibm/MathToLibm.h"
#include "../PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Vector/VectorOps.h"
if (shape.size() != 1)
return failure();
- Value result = rewriter.create<ConstantOp>(
+ Value result = rewriter.create<arith::ConstantOp>(
loc, DenseElementsAttr::get(
vecType, FloatAttr::get(vecType.getElementType(), 0.0)));
for (auto i = 0; i < shape.front(); ++i) {
populateMathToLibmConversionPatterns(patterns, /*benefit=*/1);
ConversionTarget target(getContext());
- target.addLegalDialect<BuiltinDialect, StandardOpsDialect,
- vector::VectorDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, BuiltinDialect,
+ StandardOpsDialect, vector::VectorDialect>();
target.addIllegalDialect<math::MathDialect>();
if (failed(applyPartialConversion(module, target, std::move(patterns))))
signalPassFailure();
//
//===----------------------------------------------------------------------===//
+#include "../SPIRVCommon/Pattern.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/SPIRV/IR/SPIRVDialect.h"
#include "mlir/Dialect/SPIRV/IR/SPIRVOps.h"
// normal RewritePattern.
namespace {
-
-/// Converts unary and binary standard operations to SPIR-V operations.
-template <typename StdOp, typename SPIRVOp>
-class UnaryAndBinaryOpPattern final : public OpConversionPattern<StdOp> {
-public:
- using OpConversionPattern<StdOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(StdOp operation, typename StdOp::Adaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- assert(adaptor.getOperands().size() <= 2);
- auto dstType = this->getTypeConverter()->convertType(operation.getType());
- if (!dstType)
- return failure();
- if (SPIRVOp::template hasTrait<OpTrait::spirv::UnsignedOp>() &&
- dstType != operation.getType()) {
- return operation.emitError(
- "bitwidth emulation is not implemented yet on unsigned op");
- }
- rewriter.template replaceOpWithNewOp<SPIRVOp>(operation, dstType,
- adaptor.getOperands());
- return success();
- }
-};
-
/// Converts math.log1p to SPIR-V ops.
///
/// SPIR-V does not have a direct operations for log(1+x). Explicitly lower to
return success();
}
};
-
} // namespace
//===----------------------------------------------------------------------===//
namespace mlir {
void populateMathToSPIRVPatterns(SPIRVTypeConverter &typeConverter,
RewritePatternSet &patterns) {
- patterns.add<Log1pOpPattern,
- UnaryAndBinaryOpPattern<math::CosOp, spirv::GLSLCosOp>,
- UnaryAndBinaryOpPattern<math::ExpOp, spirv::GLSLExpOp>,
- UnaryAndBinaryOpPattern<math::LogOp, spirv::GLSLLogOp>,
- UnaryAndBinaryOpPattern<math::RsqrtOp, spirv::GLSLInverseSqrtOp>,
- UnaryAndBinaryOpPattern<math::PowFOp, spirv::GLSLPowOp>,
- UnaryAndBinaryOpPattern<math::SinOp, spirv::GLSLSinOp>,
- UnaryAndBinaryOpPattern<math::SqrtOp, spirv::GLSLSqrtOp>,
- UnaryAndBinaryOpPattern<math::TanhOp, spirv::GLSLTanhOp>>(
+ patterns.add<
+ Log1pOpPattern,
+ spirv::UnaryAndBinaryOpPattern<math::AbsOp, spirv::GLSLFAbsOp>,
+ spirv::UnaryAndBinaryOpPattern<math::CeilOp, spirv::GLSLCeilOp>,
+ spirv::UnaryAndBinaryOpPattern<math::CosOp, spirv::GLSLCosOp>,
+ spirv::UnaryAndBinaryOpPattern<math::ExpOp, spirv::GLSLExpOp>,
+ spirv::UnaryAndBinaryOpPattern<math::FloorOp, spirv::GLSLFloorOp>,
+ spirv::UnaryAndBinaryOpPattern<math::LogOp, spirv::GLSLLogOp>,
+ spirv::UnaryAndBinaryOpPattern<math::PowFOp, spirv::GLSLPowOp>,
+ spirv::UnaryAndBinaryOpPattern<math::RsqrtOp, spirv::GLSLInverseSqrtOp>,
+ spirv::UnaryAndBinaryOpPattern<math::SinOp, spirv::GLSLSinOp>,
+ spirv::UnaryAndBinaryOpPattern<math::SqrtOp, spirv::GLSLSqrtOp>,
+ spirv::UnaryAndBinaryOpPattern<math::TanhOp, spirv::GLSLTanhOp>>(
typeConverter, patterns.getContext());
}
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIROpenACC
- MLIRTransforms
MLIRSCF
+ MLIRTransforms
)
#include "../PassDetail.h"
#include "mlir/Conversion/OpenACCToSCF/ConvertOpenACCToSCF.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/OpenACC/OpenACC.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
return success();
// Condition is not a constant.
- if (!op.ifCond().template getDefiningOp<ConstantOp>()) {
+ if (!op.ifCond().template getDefiningOp<arith::ConstantOp>()) {
auto ifOp = rewriter.create<scf::IfOp>(op.getLoc(), TypeRange(),
op.ifCond(), false);
rewriter.updateRootInPlace(op, [&]() { op.ifCondMutable().erase(0); });
Core
LINK_LIBS PUBLIC
+ MLIRArithmeticToLLVM
MLIRIR
MLIRLLVMCommonConversion
MLIRLLVMIR
#include "mlir/Conversion/OpenMPToLLVM/ConvertOpenMPToLLVM.h"
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
// Convert to OpenMP operations with LLVM IR dialect
RewritePatternSet patterns(&getContext());
LLVMTypeConverter converter(&getContext());
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(converter, patterns);
populateMemRefToLLVMConversionPatterns(converter, patterns);
populateStdToLLVMConversionPatterns(converter, patterns);
populateOpenMPToLLVMConversionPatterns(converter, patterns);
class OpenACCDialect;
} // end namespace acc
+namespace arith {
+class ArithmeticDialect;
+} // end namespace arith
+
namespace complex {
class ComplexDialect;
} // end namespace complex
LINK_LIBS PUBLIC
MLIRAffine
MLIRAffineToStandard
+ MLIRArithmetic
MLIRComplex
MLIRGPUTransforms
MLIRIR
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/ParallelLoopMapper.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
// Get a Value that corresponds to the loop step. If the step is an attribute,
// materialize a corresponding constant using builder.
static Value getOrCreateStep(AffineForOp forOp, OpBuilder &builder) {
- return builder.create<ConstantIndexOp>(forOp.getLoc(), forOp.getStep());
+ return builder.create<arith::ConstantIndexOp>(forOp.getLoc(),
+ forOp.getStep());
}
// Get a Value for the loop lower bound. If the value requires computation,
// Return true if the value is obviously a constant "one".
static bool isConstantOne(Value value) {
- if (auto def = value.getDefiningOp<ConstantIndexOp>())
- return def.getValue() == 1;
+ if (auto def = value.getDefiningOp<arith::ConstantIndexOp>())
+ return def.value() == 1;
return false;
}
return llvm::None;
}
- Value range =
- builder.create<SubIOp>(currentLoop.getLoc(), upperBound, lowerBound);
+ Value range = builder.create<arith::SubIOp>(currentLoop.getLoc(),
+ upperBound, lowerBound);
Value step = getOrCreateStep(currentLoop, builder);
if (!isConstantOne(step))
- range = builder.create<SignedDivIOp>(currentLoop.getLoc(), range, step);
+ range = builder.create<arith::DivSIOp>(currentLoop.getLoc(), range, step);
dims.push_back(range);
lbs.push_back(lowerBound);
OpBuilder builder(rootForOp.getOperation());
// Prepare the grid and block sizes for the launch operation. If there is
// no loop mapped to a specific dimension, use constant "1" as its size.
- Value constOne = (numBlockDims < 3 || numThreadDims < 3)
- ? builder.create<ConstantIndexOp>(rootForOp.getLoc(), 1)
- : nullptr;
+ Value constOne =
+ (numBlockDims < 3 || numThreadDims < 3)
+ ? builder.create<arith::ConstantIndexOp>(rootForOp.getLoc(), 1)
+ : nullptr;
Value gridSizeX = numBlockDims > 0 ? dims[0] : constOne;
Value gridSizeY = numBlockDims > 1 ? dims[1] : constOne;
Value gridSizeZ = numBlockDims > 2 ? dims[2] : constOne;
: getDim3Value(launchOp.getThreadIds(), en.index() - numBlockDims);
Value step = steps[en.index()];
if (!isConstantOne(step))
- id = builder.create<MulIOp>(rootForOp.getLoc(), step, id);
+ id = builder.create<arith::MulIOp>(rootForOp.getLoc(), step, id);
Value ivReplacement =
- builder.create<AddIOp>(rootForOp.getLoc(), *lbArgumentIt, id);
+ builder.create<arith::AddIOp>(rootForOp.getLoc(), *lbArgumentIt, id);
en.value().replaceAllUsesWith(ivReplacement);
std::advance(lbArgumentIt, 1);
std::advance(stepArgumentIt, 1);
/// `upperBound`.
static Value deriveStaticUpperBound(Value upperBound,
PatternRewriter &rewriter) {
- if (auto op = upperBound.getDefiningOp<ConstantIndexOp>()) {
+ if (auto op = upperBound.getDefiningOp<arith::ConstantIndexOp>()) {
return op;
}
if (auto minOp = upperBound.getDefiningOp<AffineMinOp>()) {
for (const AffineExpr &result : minOp.map().getResults()) {
if (auto constExpr = result.dyn_cast<AffineConstantExpr>()) {
- return rewriter.create<ConstantIndexOp>(minOp.getLoc(),
- constExpr.getValue());
+ return rewriter.create<arith::ConstantIndexOp>(minOp.getLoc(),
+ constExpr.getValue());
}
}
}
- if (auto multiplyOp = upperBound.getDefiningOp<MulIOp>()) {
- if (auto lhs = dyn_cast_or_null<ConstantIndexOp>(
+ if (auto multiplyOp = upperBound.getDefiningOp<arith::MulIOp>()) {
+ if (auto lhs = dyn_cast_or_null<arith::ConstantIndexOp>(
deriveStaticUpperBound(multiplyOp.getOperand(0), rewriter)
.getDefiningOp()))
- if (auto rhs = dyn_cast_or_null<ConstantIndexOp>(
+ if (auto rhs = dyn_cast_or_null<arith::ConstantIndexOp>(
deriveStaticUpperBound(multiplyOp.getOperand(1), rewriter)
.getDefiningOp())) {
// Assumptions about the upper bound of minimum computations no longer
// work if multiplied by a negative value, so abort in this case.
- if (lhs.getValue() < 0 || rhs.getValue() < 0)
+ if (lhs.value() < 0 || rhs.value() < 0)
return {};
- return rewriter.create<ConstantIndexOp>(
- multiplyOp.getLoc(), lhs.getValue() * rhs.getValue());
+ return rewriter.create<arith::ConstantIndexOp>(
+ multiplyOp.getLoc(), lhs.value() * rhs.value());
}
}
launchIndependent](Value val) -> Value {
if (launchIndependent(val))
return val;
- if (ConstantOp constOp = val.getDefiningOp<ConstantOp>())
- return rewriter.create<ConstantOp>(constOp.getLoc(), constOp.getValue());
+ if (auto constOp = val.getDefiningOp<arith::ConstantOp>())
+ return rewriter.create<arith::ConstantOp>(constOp.getLoc(),
+ constOp.value());
return {};
};
// conditional. If the lower-bound is constant or defined before the
// launch, we can use it in the launch bounds. Otherwise fail.
if (!launchIndependent(lowerBound) &&
- !isa_and_nonnull<ConstantOp>(lowerBound.getDefiningOp()))
+ !isa_and_nonnull<arith::ConstantOp>(lowerBound.getDefiningOp()))
return failure();
// The step must also be constant or defined outside of the loop nest.
if (!launchIndependent(step) &&
- !isa_and_nonnull<ConstantOp>(step.getDefiningOp()))
+ !isa_and_nonnull<arith::ConstantOp>(step.getDefiningOp()))
return failure();
// If the upper-bound is constant or defined before the launch, we can
// use it in the launch bounds directly. Otherwise try derive a bound.
bool boundIsPrecise =
launchIndependent(upperBound) ||
- isa_and_nonnull<ConstantOp>(upperBound.getDefiningOp());
+ isa_and_nonnull<arith::ConstantOp>(upperBound.getDefiningOp());
{
PatternRewriter::InsertionGuard guard(rewriter);
rewriter.setInsertionPoint(launchOp);
if (!boundIsPrecise) {
// We are using an approximation, create a surrounding conditional.
Value originalBound = std::get<3>(config);
- CmpIOp pred = rewriter.create<CmpIOp>(
- loc, CmpIPredicate::slt, newIndex,
+ arith::CmpIOp pred = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, newIndex,
cloningMap.lookupOrDefault(originalBound));
scf::IfOp ifOp = rewriter.create<scf::IfOp>(loc, pred, false);
rewriter.setInsertionPointToStart(&ifOp.thenRegion().front());
// Create a launch operation. We start with bound one for all grid/block
// sizes. Those will be refined later as we discover them from mappings.
Location loc = parallelOp.getLoc();
- Value constantOne = rewriter.create<ConstantIndexOp>(parallelOp.getLoc(), 1);
+ Value constantOne =
+ rewriter.create<arith::ConstantIndexOp>(parallelOp.getLoc(), 1);
gpu::LaunchOp launchOp = rewriter.create<gpu::LaunchOp>(
parallelOp.getLoc(), constantOne, constantOne, constantOne, constantOne,
constantOne, constantOne);
#include "../PassDetail.h"
#include "mlir/Conversion/SCFToGPU/SCFToGPU.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Complex/IR/Complex.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/SCF/SCF.h"
LINK_LIBS PUBLIC
MLIRAnalysis
+ MLIRArithmetic
MLIRLLVMIR
MLIROpenMP
MLIRSCF
#include "mlir/Conversion/SCFToOpenMP/SCFToOpenMP.h"
#include "../PassDetail.h"
#include "mlir/Analysis/LoopAnalysis.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/OpenMP/OpenMPDialect.h"
#include "mlir/Dialect/SCF/SCF.h"
// Match simple binary reductions that can be expressed with atomicrmw.
Type type = reduce.operand().getType();
Block &reduction = reduce.getRegion().front();
- if (matchSimpleReduction<AddFOp, LLVM::FAddOp>(reduction)) {
+ if (matchSimpleReduction<arith::AddFOp, LLVM::FAddOp>(reduction)) {
omp::ReductionDeclareOp decl = createDecl(builder, symbolTable, reduce,
builder.getFloatAttr(type, 0.0));
return addAtomicRMW(builder, LLVM::AtomicBinOp::fadd, decl, reduce);
}
- if (matchSimpleReduction<AddIOp, LLVM::AddOp>(reduction)) {
+ if (matchSimpleReduction<arith::AddIOp, LLVM::AddOp>(reduction)) {
omp::ReductionDeclareOp decl = createDecl(builder, symbolTable, reduce,
builder.getIntegerAttr(type, 0));
return addAtomicRMW(builder, LLVM::AtomicBinOp::add, decl, reduce);
}
- if (matchSimpleReduction<OrOp, LLVM::OrOp>(reduction)) {
+ if (matchSimpleReduction<arith::OrIOp, LLVM::OrOp>(reduction)) {
omp::ReductionDeclareOp decl = createDecl(builder, symbolTable, reduce,
builder.getIntegerAttr(type, 0));
return addAtomicRMW(builder, LLVM::AtomicBinOp::_or, decl, reduce);
}
- if (matchSimpleReduction<XOrOp, LLVM::XOrOp>(reduction)) {
+ if (matchSimpleReduction<arith::XOrIOp, LLVM::XOrOp>(reduction)) {
omp::ReductionDeclareOp decl = createDecl(builder, symbolTable, reduce,
builder.getIntegerAttr(type, 0));
return addAtomicRMW(builder, LLVM::AtomicBinOp::_xor, decl, reduce);
}
- if (matchSimpleReduction<AndOp, LLVM::AndOp>(reduction)) {
+ if (matchSimpleReduction<arith::AndIOp, LLVM::AndOp>(reduction)) {
omp::ReductionDeclareOp decl = createDecl(
builder, symbolTable, reduce,
builder.getIntegerAttr(
// Match simple binary reductions that cannot be expressed with atomicrmw.
// TODO: add atomic region using cmpxchg (which needs atomic load to be
// available as an op).
- if (matchSimpleReduction<MulFOp, LLVM::FMulOp>(reduction)) {
+ if (matchSimpleReduction<arith::MulFOp, LLVM::FMulOp>(reduction)) {
return createDecl(builder, symbolTable, reduce,
builder.getFloatAttr(type, 1.0));
}
// Match select-based min/max reductions.
bool isMin;
- if (matchSelectReduction<CmpFOp, SelectOp>(
- reduction, {CmpFPredicate::OLT, CmpFPredicate::OLE},
- {CmpFPredicate::OGT, CmpFPredicate::OGE}, isMin) ||
+ if (matchSelectReduction<arith::CmpFOp, SelectOp>(
+ reduction, {arith::CmpFPredicate::OLT, arith::CmpFPredicate::OLE},
+ {arith::CmpFPredicate::OGT, arith::CmpFPredicate::OGE}, isMin) ||
matchSelectReduction<LLVM::FCmpOp, LLVM::SelectOp>(
reduction, {LLVM::FCmpPredicate::olt, LLVM::FCmpPredicate::ole},
{LLVM::FCmpPredicate::ogt, LLVM::FCmpPredicate::oge}, isMin)) {
return createDecl(builder, symbolTable, reduce,
minMaxValueForFloat(type, !isMin));
}
- if (matchSelectReduction<CmpIOp, SelectOp>(
- reduction, {CmpIPredicate::slt, CmpIPredicate::sle},
- {CmpIPredicate::sgt, CmpIPredicate::sge}, isMin) ||
+ if (matchSelectReduction<arith::CmpIOp, SelectOp>(
+ reduction, {arith::CmpIPredicate::slt, arith::CmpIPredicate::sle},
+ {arith::CmpIPredicate::sgt, arith::CmpIPredicate::sge}, isMin) ||
matchSelectReduction<LLVM::ICmpOp, LLVM::SelectOp>(
reduction, {LLVM::ICmpPredicate::slt, LLVM::ICmpPredicate::sle},
{LLVM::ICmpPredicate::sgt, LLVM::ICmpPredicate::sge}, isMin)) {
isMin ? LLVM::AtomicBinOp::min : LLVM::AtomicBinOp::max,
decl, reduce);
}
- if (matchSelectReduction<CmpIOp, SelectOp>(
- reduction, {CmpIPredicate::ult, CmpIPredicate::ule},
- {CmpIPredicate::ugt, CmpIPredicate::uge}, isMin) ||
+ if (matchSelectReduction<arith::CmpIOp, SelectOp>(
+ reduction, {arith::CmpIPredicate::ult, arith::CmpIPredicate::ule},
+ {arith::CmpIPredicate::ugt, arith::CmpIPredicate::uge}, isMin) ||
matchSelectReduction<LLVM::ICmpOp, LLVM::SelectOp>(
reduction, {LLVM::ICmpPredicate::ugt, LLVM::ICmpPredicate::ule},
{LLVM::ICmpPredicate::ugt, LLVM::ICmpPredicate::uge}, isMin)) {
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticToSPIRV
MLIRMemRefToSPIRV
MLIRSPIRV
MLIRSPIRVConversion
#include "mlir/Conversion/SCFToSPIRV/SCFToSPIRVPass.h"
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
#include "mlir/Conversion/MemRefToSPIRV/MemRefToSPIRV.h"
#include "mlir/Conversion/SCFToSPIRV/SCFToSPIRV.h"
#include "mlir/Conversion/StandardToSPIRV/StandardToSPIRV.h"
// TODO: Change SPIR-V conversion to be progressive and remove the following
// patterns.
+ mlir::arith::populateArithmeticToSPIRVPatterns(typeConverter, patterns);
populateStandardToSPIRVPatterns(typeConverter, patterns);
populateMemRefToSPIRVPatterns(typeConverter, patterns);
populateBuiltinFuncToSPIRVPatterns(typeConverter, patterns);
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRSCF
MLIRTransforms
)
#include "mlir/Conversion/SCFToStandard/SCFToStandard.h"
#include "../PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/BlockAndValueMapping.h"
Operation *terminator = lastBodyBlock->getTerminator();
rewriter.setInsertionPointToEnd(lastBodyBlock);
auto step = forOp.step();
- auto stepped = rewriter.create<AddIOp>(loc, iv, step).getResult();
+ auto stepped = rewriter.create<arith::AddIOp>(loc, iv, step).getResult();
if (!stepped)
return failure();
// With the body block done, we can fill in the condition block.
rewriter.setInsertionPointToEnd(conditionBlock);
- auto comparison =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, iv, upperBound);
+ auto comparison = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, iv, upperBound);
rewriter.create<CondBranchOp>(loc, comparison, firstBodyBlock,
ArrayRef<Value>(), endBlock, ArrayRef<Value>());
--- /dev/null
+//===- Pattern.h - SPIRV Common Conversion Patterns -----------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef MLIR_CONVERSION_SPIRVCOMMON_PATTERN_H
+#define MLIR_CONVERSION_SPIRVCOMMON_PATTERN_H
+
+#include "mlir/Dialect/SPIRV/IR/SPIRVOpTraits.h"
+#include "mlir/Transforms/DialectConversion.h"
+
+namespace mlir {
+namespace spirv {
+
+/// Converts unary and binary standard operations to SPIR-V operations.
+template <typename Op, typename SPIRVOp>
+class UnaryAndBinaryOpPattern final : public OpConversionPattern<Op> {
+public:
+ using OpConversionPattern<Op>::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(Op op, typename Op::Adaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override {
+ assert(adaptor.getOperands().size() <= 2);
+ auto dstType = this->getTypeConverter()->convertType(op.getType());
+ if (!dstType)
+ return failure();
+ if (SPIRVOp::template hasTrait<OpTrait::spirv::UnsignedOp>() &&
+ dstType != op.getType()) {
+ return op.emitError(
+ "bitwidth emulation is not implemented yet on unsigned op");
+ }
+ rewriter.template replaceOpWithNewOp<SPIRVOp>(op, dstType,
+ adaptor.getOperands());
+ return success();
+ }
+};
+
+} // end namespace spirv
+} // end namespace mlir
+
+#endif // MLIR_CONVERSION_SPIRVCOMMON_PATTERN_H
intrinsics_gen
LINK_LIBS PUBLIC
+ MLIRArithmeticToLLVM
MLIRGPUOps
MLIRSPIRV
MLIRSPIRVUtils
//===----------------------------------------------------------------------===//
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/LoweringOptions.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
auto *context = module.getContext();
RewritePatternSet patterns(context);
LLVMTypeConverter typeConverter(context, options);
+ mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
+ patterns);
populateMemRefToLLVMConversionPatterns(typeConverter, patterns);
populateStdToLLVMConversionPatterns(typeConverter, patterns);
patterns.add<GPULaunchLowering>(typeConverter);
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRShape
MLIRTensor
#include "mlir/Conversion/ShapeToStandard/ShapeToStandard.h"
#include "../PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/Shape/IR/Shape.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
// number of extent tensors and shifted offsets into them.
Value getBroadcastedDim(ImplicitLocOpBuilder lb, ValueRange extentTensors,
ValueRange rankDiffs, Value outputDimension) {
- Value one = lb.create<ConstantIndexOp>(1);
+ Value one = lb.create<arith::ConstantIndexOp>(1);
Value broadcastedDim = one;
for (auto tup : llvm::zip(extentTensors, rankDiffs)) {
Value shape = std::get<0>(tup);
Value rankDiff = std::get<1>(tup);
- Value outOfBounds =
- lb.create<CmpIOp>(CmpIPredicate::ult, outputDimension, rankDiff);
+ Value outOfBounds = lb.create<arith::CmpIOp>(arith::CmpIPredicate::ult,
+ outputDimension, rankDiff);
Type indexTy = lb.getIndexType();
broadcastedDim =
lb.create<IfOp>(
// - otherwise, take the extent as-is.
// Note that this logic remains correct in the presence
// of dimensions of zero extent.
- Value lesserRankOperandDimension =
- b.create<SubIOp>(loc, indexTy, outputDimension, rankDiff);
+ Value lesserRankOperandDimension = b.create<arith::SubIOp>(
+ loc, indexTy, outputDimension, rankDiff);
Value lesserRankOperandExtent = b.create<tensor::ExtractOp>(
loc, shape, ValueRange{lesserRankOperandDimension});
- Value dimIsOne = b.create<CmpIOp>(loc, CmpIPredicate::eq,
- lesserRankOperandExtent, one);
+ Value dimIsOne =
+ b.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ lesserRankOperandExtent, one);
Value dim = b.create<SelectOp>(loc, dimIsOne, broadcastedDim,
lesserRankOperandExtent);
b.create<scf::YieldOp>(loc, dim);
auto loc = op.getLoc();
ImplicitLocOpBuilder lb(loc, rewriter);
- Value zero = lb.create<ConstantIndexOp>(0);
+ Value zero = lb.create<arith::ConstantIndexOp>(0);
Type indexTy = lb.getIndexType();
// Save all the ranks for bounds checking. Because this is a tensor
// Find the maximum rank
Value maxRank = ranks.front();
for (Value v : llvm::drop_begin(ranks, 1)) {
- Value rankIsGreater = lb.create<CmpIOp>(CmpIPredicate::ugt, v, maxRank);
+ Value rankIsGreater =
+ lb.create<arith::CmpIOp>(arith::CmpIPredicate::ugt, v, maxRank);
maxRank = lb.create<SelectOp>(rankIsGreater, v, maxRank);
}
// Calculate the difference of ranks and the maximum rank for later offsets.
llvm::append_range(rankDiffs, llvm::map_range(ranks, [&](Value v) {
- return lb.create<SubIOp>(indexTy, maxRank, v);
+ return lb.create<arith::SubIOp>(indexTy, maxRank, v);
}));
Value replacement = lb.create<tensor::GenerateOp>(
SmallVector<Value, 4> extentOperands;
for (auto extent : op.shape()) {
extentOperands.push_back(
- rewriter.create<ConstantIndexOp>(loc, extent.getLimitedValue()));
+ rewriter.create<arith::ConstantIndexOp>(loc, extent.getLimitedValue()));
}
Type indexTy = rewriter.getIndexType();
Value tensor =
LogicalResult ConstSizeOpConversion::matchAndRewrite(
ConstSizeOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const {
- rewriter.replaceOpWithNewOp<ConstantIndexOp>(op, op.value().getSExtValue());
+ rewriter.replaceOpWithNewOp<arith::ConstantIndexOp>(
+ op, op.value().getSExtValue());
return success();
}
auto loc = op.getLoc();
ImplicitLocOpBuilder lb(loc, rewriter);
- Value zero = lb.create<ConstantIndexOp>(0);
- Value one = lb.create<ConstantIndexOp>(1);
+ Value zero = lb.create<arith::ConstantIndexOp>(0);
+ Value one = lb.create<arith::ConstantIndexOp>(1);
Type indexTy = lb.getIndexType();
// Save all the ranks for bounds checking. Because this is a tensor
// Find the maximum rank
Value maxRank = ranks.front();
for (Value v : llvm::drop_begin(ranks, 1)) {
- Value rankIsGreater = lb.create<CmpIOp>(CmpIPredicate::ugt, v, maxRank);
+ Value rankIsGreater =
+ lb.create<arith::CmpIOp>(arith::CmpIPredicate::ugt, v, maxRank);
maxRank = lb.create<SelectOp>(rankIsGreater, v, maxRank);
}
// Calculate the difference of ranks and the maximum rank for later offsets.
llvm::append_range(rankDiffs, llvm::map_range(ranks, [&](Value v) {
- return lb.create<SubIOp>(indexTy, maxRank, v);
+ return lb.create<arith::SubIOp>(indexTy, maxRank, v);
}));
Type i1Ty = rewriter.getI1Type();
Value trueVal =
- rewriter.create<ConstantOp>(loc, i1Ty, rewriter.getBoolAttr(true));
+ rewriter.create<arith::ConstantOp>(loc, i1Ty, rewriter.getBoolAttr(true));
auto reduceResult = lb.create<ForOp>(
loc, zero, maxRank, one, ValueRange{trueVal},
for (auto tup : llvm::zip(adaptor.shapes(), rankDiffs)) {
Value shape, rankDiff;
std::tie(shape, rankDiff) = tup;
- Value outOfBounds =
- b.create<CmpIOp>(loc, CmpIPredicate::ult, iv, rankDiff);
+ Value outOfBounds = b.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::ult, iv, rankDiff);
broadcastable =
b.create<IfOp>(
loc, TypeRange{i1Ty}, outOfBounds,
// Every value needs to be either 1, or the same non-1
// value to be broadcastable in this dim.
Value operandDimension =
- b.create<SubIOp>(loc, indexTy, iv, rankDiff);
+ b.create<arith::SubIOp>(loc, indexTy, iv, rankDiff);
Value dimensionExtent = b.create<tensor::ExtractOp>(
loc, shape, ValueRange{operandDimension});
- Value equalOne = b.create<CmpIOp>(loc, CmpIPredicate::eq,
- dimensionExtent, one);
- Value equalBroadcasted =
- b.create<CmpIOp>(loc, CmpIPredicate::eq,
- dimensionExtent, broadcastedDim);
- Value result = b.create<AndOp>(
+ Value equalOne = b.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::eq, dimensionExtent, one);
+ Value equalBroadcasted = b.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::eq, dimensionExtent,
+ broadcastedDim);
+ Value result = b.create<arith::AndIOp>(
loc, broadcastable,
- b.create<OrOp>(loc, equalOne, equalBroadcasted));
+ b.create<arith::OrIOp>(loc, equalOne,
+ equalBroadcasted));
b.create<scf::YieldOp>(loc, result);
})
.getResult(0);
auto loc = op.getLoc();
- Value zero = rewriter.create<ConstantIndexOp>(loc, 0);
- Value one = rewriter.create<ConstantIndexOp>(loc, 1);
+ Value zero = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ Value one = rewriter.create<arith::ConstantIndexOp>(loc, 1);
Type indexTy = rewriter.getIndexType();
Value rank =
rewriter.create<tensor::DimOp>(loc, indexTy, adaptor.shape(), zero);
/// %c0 = constant 0 : index
/// %0 = dim %arg0, %c0 : tensor<?xindex>
/// %1 = dim %arg1, %c0 : tensor<?xindex>
-/// %2 = cmpi "eq", %0, %1 : index
+/// %2 = arith.cmpi "eq", %0, %1 : index
/// %result = scf.if %2 -> (i1) {
-/// %c1 = constant 1 : index
-/// %true = constant true
+/// %c1 = arith.constant 1 : index
+/// %true = arith.constant true
/// %4 = scf.for %arg2 = %c0 to %0 step %c1 iter_args(%arg3 = %true) -> (i1) {
/// %5 = tensor.extract %arg0[%arg2] : tensor<?xindex>
/// %6 = tensor.extract %arg1[%arg2] : tensor<?xindex>
-/// %7 = cmpi "eq", %5, %6 : index
-/// %8 = and %arg3, %7 : i1
+/// %7 = arith.cmpi "eq", %5, %6 : index
+/// %8 = arith.andi %arg3, %7 : i1
/// scf.yield %8 : i1
/// }
/// scf.yield %4 : i1
/// } else {
-/// %false = constant false
+/// %false = arith.constant false
/// scf.yield %false : i1
/// }
///
Type i1Ty = rewriter.getI1Type();
if (op.shapes().size() <= 1) {
- rewriter.replaceOpWithNewOp<ConstantOp>(op, i1Ty,
- rewriter.getBoolAttr(true));
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(op, i1Ty,
+ rewriter.getBoolAttr(true));
return success();
}
auto loc = op.getLoc();
Type indexTy = rewriter.getIndexType();
- Value zero = rewriter.create<ConstantIndexOp>(loc, 0);
+ Value zero = rewriter.create<arith::ConstantIndexOp>(loc, 0);
Value firstShape = adaptor.shapes().front();
Value firstRank =
rewriter.create<tensor::DimOp>(loc, indexTy, firstShape, zero);
// Generate a linear sequence of compares, all with firstShape as lhs.
for (Value shape : adaptor.shapes().drop_front(1)) {
Value rank = rewriter.create<tensor::DimOp>(loc, indexTy, shape, zero);
- Value eqRank =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::eq, firstRank, rank);
+ Value eqRank = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ firstRank, rank);
auto same = rewriter.create<IfOp>(
loc, i1Ty, eqRank,
[&](OpBuilder &b, Location loc) {
- Value one = b.create<ConstantIndexOp>(loc, 1);
- Value init = b.create<ConstantOp>(loc, i1Ty, b.getBoolAttr(true));
+ Value one = b.create<arith::ConstantIndexOp>(loc, 1);
+ Value init =
+ b.create<arith::ConstantOp>(loc, i1Ty, b.getBoolAttr(true));
auto loop = b.create<scf::ForOp>(
loc, zero, firstRank, one, ValueRange{init},
[&](OpBuilder &b, Location nestedLoc, Value iv, ValueRange args) {
Value lhsExtent =
b.create<tensor::ExtractOp>(loc, firstShape, iv);
Value rhsExtent = b.create<tensor::ExtractOp>(loc, shape, iv);
- Value eqExtent = b.create<CmpIOp>(loc, CmpIPredicate::eq,
- lhsExtent, rhsExtent);
- Value conjNext = b.create<AndOp>(loc, conj, eqExtent);
+ Value eqExtent = b.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::eq, lhsExtent, rhsExtent);
+ Value conjNext = b.create<arith::AndIOp>(loc, conj, eqExtent);
b.create<scf::YieldOp>(loc, ValueRange({conjNext}));
});
b.create<scf::YieldOp>(loc, loop.getResults());
},
[&](OpBuilder &b, Location loc) {
- Value result = b.create<ConstantOp>(loc, i1Ty, b.getBoolAttr(false));
+ Value result =
+ b.create<arith::ConstantOp>(loc, i1Ty, b.getBoolAttr(false));
b.create<scf::YieldOp>(loc, result);
});
result = !result ? same.getResult(0)
- : rewriter.create<AndOp>(loc, result, same.getResult(0));
+ : rewriter.create<arith::AndIOp>(loc, result,
+ same.getResult(0));
}
rewriter.replaceOp(op, result);
return success();
Value extent = rewriter.create<tensor::DimOp>(loc, tensor, i);
extentValues.push_back(extent);
} else {
- Value extent =
- rewriter.create<ConstantIndexOp>(loc, rankedTensorTy.getDimSize(i));
+ Value extent = rewriter.create<arith::ConstantIndexOp>(
+ loc, rankedTensorTy.getDimSize(i));
extentValues.push_back(extent);
}
}
return failure();
ImplicitLocOpBuilder b(op.getLoc(), rewriter);
- Value zero = b.create<ConstantIndexOp>(0);
+ Value zero = b.create<arith::ConstantIndexOp>(0);
Value rank = b.create<tensor::DimOp>(adaptor.operand(), zero);
// index < 0 ? index + rank : index
Value originalIndex = adaptor.index();
- Value add = b.create<AddIOp>(originalIndex, rank);
+ Value add = b.create<arith::AddIOp>(originalIndex, rank);
Value indexIsNegative =
- b.create<CmpIOp>(CmpIPredicate::slt, originalIndex, zero);
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::slt, originalIndex, zero);
Value index = b.create<SelectOp>(indexIsNegative, add, originalIndex);
- Value one = b.create<ConstantIndexOp>(1);
+ Value one = b.create<arith::ConstantIndexOp>(1);
Value head =
b.create<tensor::ExtractSliceOp>(adaptor.operand(), zero, index, one);
- Value tailSize = b.create<SubIOp>(rank, index);
+ Value tailSize = b.create<arith::SubIOp>(rank, index);
Value tail =
b.create<tensor::ExtractSliceOp>(adaptor.operand(), index, tailSize, one);
rewriter.replaceOp(op, {head, tail});
// Setup target legality.
MLIRContext &ctx = getContext();
ConversionTarget target(ctx);
- target
- .addLegalDialect<StandardOpsDialect, SCFDialect, tensor::TensorDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, StandardOpsDialect,
+ SCFDialect, tensor::TensorDialect>();
target.addLegalOp<CstrRequireOp, FuncOp, ModuleOp>();
// Setup conversion patterns.
populateWithGenerated(patterns);
patterns.add<
AnyOpConversion,
- BinaryOpConversion<AddOp, AddIOp>,
- BinaryOpConversion<MulOp, MulIOp>,
+ BinaryOpConversion<AddOp, arith::AddIOp>,
+ BinaryOpConversion<MulOp, arith::MulIOp>,
BroadcastOpConverter,
ConstShapeOpConverter,
ConstSizeOpConversion,
LINK_LIBS PUBLIC
MLIRAnalysis
+ MLIRArithmeticToLLVM
MLIRDataLayoutInterfaces
MLIRLLVMCommonConversion
MLIRLLVMIR
#include "../PassDetail.h"
#include "mlir/Analysis/DataLayoutAnalysis.h"
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
#include "mlir/Conversion/LLVMCommon/VectorPattern.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
#include "mlir/Dialect/LLVMIR/FunctionCallUtils.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
-#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Utils/StaticValueUtils.h"
#include "mlir/IR/Attributes.h"
#include "mlir/IR/BlockAndValueMapping.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinOps.h"
-#include "mlir/IR/MLIRContext.h"
#include "mlir/IR/PatternMatch.h"
#include "mlir/IR/TypeUtilities.h"
#include "mlir/Support/LogicalResult.h"
};
// Straightforward lowerings.
-using AbsFOpLowering = VectorConvertToLLVMPattern<AbsFOp, LLVM::FAbsOp>;
-using AddFOpLowering = VectorConvertToLLVMPattern<AddFOp, LLVM::FAddOp>;
-using AddIOpLowering = VectorConvertToLLVMPattern<AddIOp, LLVM::AddOp>;
-using AndOpLowering = VectorConvertToLLVMPattern<AndOp, LLVM::AndOp>;
-using BitcastOpLowering =
- VectorConvertToLLVMPattern<BitcastOp, LLVM::BitcastOp>;
-using CeilFOpLowering = VectorConvertToLLVMPattern<CeilFOp, LLVM::FCeilOp>;
-using CopySignOpLowering =
- VectorConvertToLLVMPattern<CopySignOp, LLVM::CopySignOp>;
-using DivFOpLowering = VectorConvertToLLVMPattern<DivFOp, LLVM::FDivOp>;
-using FPExtOpLowering = VectorConvertToLLVMPattern<FPExtOp, LLVM::FPExtOp>;
-using FPToSIOpLowering = VectorConvertToLLVMPattern<FPToSIOp, LLVM::FPToSIOp>;
-using FPToUIOpLowering = VectorConvertToLLVMPattern<FPToUIOp, LLVM::FPToUIOp>;
-using FPTruncOpLowering =
- VectorConvertToLLVMPattern<FPTruncOp, LLVM::FPTruncOp>;
-using FloorFOpLowering = VectorConvertToLLVMPattern<FloorFOp, LLVM::FFloorOp>;
-using FmaFOpLowering = VectorConvertToLLVMPattern<FmaFOp, LLVM::FMAOp>;
-using MulFOpLowering = VectorConvertToLLVMPattern<MulFOp, LLVM::FMulOp>;
-using MulIOpLowering = VectorConvertToLLVMPattern<MulIOp, LLVM::MulOp>;
-using NegFOpLowering = VectorConvertToLLVMPattern<NegFOp, LLVM::FNegOp>;
-using OrOpLowering = VectorConvertToLLVMPattern<OrOp, LLVM::OrOp>;
-using RemFOpLowering = VectorConvertToLLVMPattern<RemFOp, LLVM::FRemOp>;
-using SIToFPOpLowering = VectorConvertToLLVMPattern<SIToFPOp, LLVM::SIToFPOp>;
using SelectOpLowering = VectorConvertToLLVMPattern<SelectOp, LLVM::SelectOp>;
-using SignExtendIOpLowering =
- VectorConvertToLLVMPattern<SignExtendIOp, LLVM::SExtOp>;
-using ShiftLeftOpLowering =
- VectorConvertToLLVMPattern<ShiftLeftOp, LLVM::ShlOp>;
-using SignedDivIOpLowering =
- VectorConvertToLLVMPattern<SignedDivIOp, LLVM::SDivOp>;
-using SignedRemIOpLowering =
- VectorConvertToLLVMPattern<SignedRemIOp, LLVM::SRemOp>;
-using SignedShiftRightOpLowering =
- VectorConvertToLLVMPattern<SignedShiftRightOp, LLVM::AShrOp>;
-using SubFOpLowering = VectorConvertToLLVMPattern<SubFOp, LLVM::FSubOp>;
-using SubIOpLowering = VectorConvertToLLVMPattern<SubIOp, LLVM::SubOp>;
-using TruncateIOpLowering =
- VectorConvertToLLVMPattern<TruncateIOp, LLVM::TruncOp>;
-using UIToFPOpLowering = VectorConvertToLLVMPattern<UIToFPOp, LLVM::UIToFPOp>;
-using UnsignedDivIOpLowering =
- VectorConvertToLLVMPattern<UnsignedDivIOp, LLVM::UDivOp>;
-using UnsignedRemIOpLowering =
- VectorConvertToLLVMPattern<UnsignedRemIOp, LLVM::URemOp>;
-using UnsignedShiftRightOpLowering =
- VectorConvertToLLVMPattern<UnsignedShiftRightOp, LLVM::LShrOp>;
-using XOrOpLowering = VectorConvertToLLVMPattern<XOrOp, LLVM::XOrOp>;
-using ZeroExtendIOpLowering =
- VectorConvertToLLVMPattern<ZeroExtendIOp, LLVM::ZExtOp>;
/// Lower `std.assert`. The default lowering calls the `abort` function if the
/// assertion is violated and has no effect otherwise. The failure message is
}
};
-// The lowering of index_cast becomes an integer conversion since index becomes
-// an integer. If the bit width of the source and target integer types is the
-// same, just erase the cast. If the target type is wider, sign-extend the
-// value, otherwise truncate it.
-struct IndexCastOpLowering : public ConvertOpToLLVMPattern<IndexCastOp> {
- using ConvertOpToLLVMPattern<IndexCastOp>::ConvertOpToLLVMPattern;
-
- LogicalResult
- matchAndRewrite(IndexCastOp indexCastOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto targetType =
- typeConverter->convertType(indexCastOp.getResult().getType());
- auto targetElementType =
- typeConverter
- ->convertType(getElementTypeOrSelf(indexCastOp.getResult()))
- .cast<IntegerType>();
- auto sourceElementType =
- getElementTypeOrSelf(adaptor.in()).cast<IntegerType>();
- unsigned targetBits = targetElementType.getWidth();
- unsigned sourceBits = sourceElementType.getWidth();
-
- if (targetBits == sourceBits)
- rewriter.replaceOp(indexCastOp, adaptor.in());
- else if (targetBits < sourceBits)
- rewriter.replaceOpWithNewOp<LLVM::TruncOp>(indexCastOp, targetType,
- adaptor.in());
- else
- rewriter.replaceOpWithNewOp<LLVM::SExtOp>(indexCastOp, targetType,
- adaptor.in());
- return success();
- }
-};
-
-// Convert std.cmp predicate into the LLVM dialect CmpPredicate. The two
-// enums share the numerical values so just cast.
-template <typename LLVMPredType, typename StdPredType>
-static LLVMPredType convertCmpPredicate(StdPredType pred) {
- return static_cast<LLVMPredType>(pred);
-}
-
-struct CmpIOpLowering : public ConvertOpToLLVMPattern<CmpIOp> {
- using ConvertOpToLLVMPattern<CmpIOp>::ConvertOpToLLVMPattern;
-
- LogicalResult
- matchAndRewrite(CmpIOp cmpiOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto operandType = adaptor.lhs().getType();
- auto resultType = cmpiOp.getResult().getType();
-
- // Handle the scalar and 1D vector cases.
- if (!operandType.isa<LLVM::LLVMArrayType>()) {
- rewriter.replaceOpWithNewOp<LLVM::ICmpOp>(
- cmpiOp, typeConverter->convertType(resultType),
- convertCmpPredicate<LLVM::ICmpPredicate>(cmpiOp.getPredicate()),
- adaptor.lhs(), adaptor.rhs());
- return success();
- }
-
- auto vectorType = resultType.dyn_cast<VectorType>();
- if (!vectorType)
- return rewriter.notifyMatchFailure(cmpiOp, "expected vector result type");
-
- return LLVM::detail::handleMultidimensionalVectors(
- cmpiOp.getOperation(), adaptor.getOperands(), *getTypeConverter(),
- [&](Type llvm1DVectorTy, ValueRange operands) {
- CmpIOpAdaptor adaptor(operands);
- return rewriter.create<LLVM::ICmpOp>(
- cmpiOp.getLoc(), llvm1DVectorTy,
- convertCmpPredicate<LLVM::ICmpPredicate>(cmpiOp.getPredicate()),
- adaptor.lhs(), adaptor.rhs());
- },
- rewriter);
-
- return success();
- }
-};
-
-struct CmpFOpLowering : public ConvertOpToLLVMPattern<CmpFOp> {
- using ConvertOpToLLVMPattern<CmpFOp>::ConvertOpToLLVMPattern;
-
- LogicalResult
- matchAndRewrite(CmpFOp cmpfOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto operandType = adaptor.lhs().getType();
- auto resultType = cmpfOp.getResult().getType();
-
- // Handle the scalar and 1D vector cases.
- if (!operandType.isa<LLVM::LLVMArrayType>()) {
- rewriter.replaceOpWithNewOp<LLVM::FCmpOp>(
- cmpfOp, typeConverter->convertType(resultType),
- convertCmpPredicate<LLVM::FCmpPredicate>(cmpfOp.getPredicate()),
- adaptor.lhs(), adaptor.rhs());
- return success();
- }
-
- auto vectorType = resultType.dyn_cast<VectorType>();
- if (!vectorType)
- return rewriter.notifyMatchFailure(cmpfOp, "expected vector result type");
-
- return LLVM::detail::handleMultidimensionalVectors(
- cmpfOp.getOperation(), adaptor.getOperands(), *getTypeConverter(),
- [&](Type llvm1DVectorTy, ValueRange operands) {
- CmpFOpAdaptor adaptor(operands);
- return rewriter.create<LLVM::FCmpOp>(
- cmpfOp.getLoc(), llvm1DVectorTy,
- convertCmpPredicate<LLVM::FCmpPredicate>(cmpfOp.getPredicate()),
- adaptor.lhs(), adaptor.rhs());
- },
- rewriter);
- }
-};
-
// Base class for LLVM IR lowering terminator operations with successors.
template <typename SourceOp, typename TargetOp>
struct OneToOneLLVMTerminatorLowering
populateStdToLLVMFuncOpConversionPattern(converter, patterns);
// clang-format off
patterns.add<
- AbsFOpLowering,
- AddFOpLowering,
- AddIOpLowering,
- AndOpLowering,
AssertOpLowering,
AtomicRMWOpLowering,
- BitcastOpLowering,
BranchOpLowering,
CallIndirectOpLowering,
CallOpLowering,
- CeilFOpLowering,
- CmpFOpLowering,
- CmpIOpLowering,
CondBranchOpLowering,
- CopySignOpLowering,
ConstantOpLowering,
- DivFOpLowering,
- FloorFOpLowering,
- FmaFOpLowering,
GenericAtomicRMWOpLowering,
- FPExtOpLowering,
- FPToSIOpLowering,
- FPToUIOpLowering,
- FPTruncOpLowering,
- IndexCastOpLowering,
- MulFOpLowering,
- MulIOpLowering,
- NegFOpLowering,
- OrOpLowering,
- RemFOpLowering,
RankOpLowering,
ReturnOpLowering,
- SIToFPOpLowering,
SelectOpLowering,
- ShiftLeftOpLowering,
- SignExtendIOpLowering,
- SignedDivIOpLowering,
- SignedRemIOpLowering,
- SignedShiftRightOpLowering,
SplatOpLowering,
SplatNdOpLowering,
- SubFOpLowering,
- SubIOpLowering,
- SwitchOpLowering,
- TruncateIOpLowering,
- UIToFPOpLowering,
- UnsignedDivIOpLowering,
- UnsignedRemIOpLowering,
- UnsignedShiftRightOpLowering,
- XOrOpLowering,
- ZeroExtendIOpLowering>(converter);
+ SwitchOpLowering>(converter);
// clang-format on
}
RewritePatternSet patterns(&getContext());
populateStdToLLVMConversionPatterns(typeConverter, patterns);
+ arith::populateArithmeticToLLVMConversionPatterns(typeConverter, patterns);
LLVMConversionTarget target(getContext());
if (failed(applyPartialConversion(m, target, std::move(patterns))))
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticToSPIRV
MLIRIR
- MLIRMath
+ MLIRMathToSPIRV
MLIRMemRef
MLIRPass
MLIRSPIRV
//
//===----------------------------------------------------------------------===//
+#include "../SPIRVCommon/Pattern.h"
#include "mlir/Dialect/SPIRV/IR/SPIRVDialect.h"
#include "mlir/Dialect/SPIRV/IR/SPIRVOps.h"
#include "mlir/Dialect/SPIRV/Transforms/SPIRVConversion.h"
// Utility functions
//===----------------------------------------------------------------------===//
-/// Returns true if the given `type` is a boolean scalar or vector type.
-static bool isBoolScalarOrVector(Type type) {
- if (type.isInteger(1))
- return true;
- if (auto vecType = type.dyn_cast<VectorType>())
- return vecType.getElementType().isInteger(1);
- return false;
-}
-
/// Converts the given `srcAttr` into a boolean attribute if it holds an
/// integral value. Returns null attribute if conversion fails.
static BoolAttr convertBoolAttr(Attribute srcAttr, Builder builder) {
return builder.getF32FloatAttr(dstVal.convertToFloat());
}
-/// Returns signed remainder for `lhs` and `rhs` and lets the result follow
-/// the sign of `signOperand`.
-///
-/// Note that this is needed for Vulkan. Per the Vulkan's SPIR-V environment
-/// spec, "for the OpSRem and OpSMod instructions, if either operand is negative
-/// the result is undefined." So we cannot directly use spv.SRem/spv.SMod
-/// if either operand can be negative. Emulate it via spv.UMod.
-static Value emulateSignedRemainder(Location loc, Value lhs, Value rhs,
- Value signOperand, OpBuilder &builder) {
- assert(lhs.getType() == rhs.getType());
- assert(lhs == signOperand || rhs == signOperand);
-
- Type type = lhs.getType();
-
- // Calculate the remainder with spv.UMod.
- Value lhsAbs = builder.create<spirv::GLSLSAbsOp>(loc, type, lhs);
- Value rhsAbs = builder.create<spirv::GLSLSAbsOp>(loc, type, rhs);
- Value abs = builder.create<spirv::UModOp>(loc, lhsAbs, rhsAbs);
-
- // Fix the sign.
- Value isPositive;
- if (lhs == signOperand)
- isPositive = builder.create<spirv::IEqualOp>(loc, lhs, lhsAbs);
- else
- isPositive = builder.create<spirv::IEqualOp>(loc, rhs, rhsAbs);
- Value absNegate = builder.create<spirv::SNegateOp>(loc, type, abs);
- return builder.create<spirv::SelectOp>(loc, type, isPositive, abs, absNegate);
-}
-
//===----------------------------------------------------------------------===//
// Operation conversion
//===----------------------------------------------------------------------===//
namespace {
-/// Converts unary and binary standard operations to SPIR-V operations.
-template <typename StdOp, typename SPIRVOp>
-class UnaryAndBinaryOpPattern final : public OpConversionPattern<StdOp> {
-public:
- using OpConversionPattern<StdOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(StdOp operation, typename StdOp::Adaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- assert(adaptor.getOperands().size() <= 2);
- auto dstType = this->getTypeConverter()->convertType(operation.getType());
- if (!dstType)
- return failure();
- if (SPIRVOp::template hasTrait<OpTrait::spirv::UnsignedOp>() &&
- dstType != operation.getType()) {
- return operation.emitError(
- "bitwidth emulation is not implemented yet on unsigned op");
- }
- rewriter.template replaceOpWithNewOp<SPIRVOp>(operation, dstType,
- adaptor.getOperands());
- return success();
- }
-};
-
-/// Converts std.remi_signed to SPIR-V ops.
-///
-/// This cannot be merged into the template unary/binary pattern due to
-/// Vulkan restrictions over spv.SRem and spv.SMod.
-class SignedRemIOpPattern final : public OpConversionPattern<SignedRemIOp> {
-public:
- using OpConversionPattern<SignedRemIOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(SignedRemIOp remOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts bitwise standard operations to SPIR-V operations. This is a special
-/// pattern other than the BinaryOpPatternPattern because if the operands are
-/// boolean values, SPIR-V uses different operations (`SPIRVLogicalOp`). For
-/// non-boolean operands, SPIR-V should use `SPIRVBitwiseOp`.
-template <typename StdOp, typename SPIRVLogicalOp, typename SPIRVBitwiseOp>
-class BitwiseOpPattern final : public OpConversionPattern<StdOp> {
-public:
- using OpConversionPattern<StdOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(StdOp operation, typename StdOp::Adaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- assert(adaptor.getOperands().size() == 2);
- auto dstType =
- this->getTypeConverter()->convertType(operation.getResult().getType());
- if (!dstType)
- return failure();
- if (isBoolScalarOrVector(adaptor.getOperands().front().getType())) {
- rewriter.template replaceOpWithNewOp<SPIRVLogicalOp>(
- operation, dstType, adaptor.getOperands());
- } else {
- rewriter.template replaceOpWithNewOp<SPIRVBitwiseOp>(
- operation, dstType, adaptor.getOperands());
- }
- return success();
- }
-};
-
/// Converts composite std.constant operation to spv.Constant.
class ConstantCompositeOpPattern final
: public OpConversionPattern<ConstantOp> {
ConversionPatternRewriter &rewriter) const override;
};
-/// Converts floating-point comparison operations to SPIR-V ops.
-class CmpFOpPattern final : public OpConversionPattern<CmpFOp> {
-public:
- using OpConversionPattern<CmpFOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts floating point NaN check to SPIR-V ops. This pattern requires
-/// Kernel capability.
-class CmpFOpNanKernelPattern final : public OpConversionPattern<CmpFOp> {
-public:
- using OpConversionPattern<CmpFOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts floating point NaN check to SPIR-V ops. This pattern does not
-/// require additional capability.
-class CmpFOpNanNonePattern final : public OpConversionPattern<CmpFOp> {
-public:
- using OpConversionPattern<CmpFOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts integer compare operation on i1 type operands to SPIR-V ops.
-class BoolCmpIOpPattern final : public OpConversionPattern<CmpIOp> {
-public:
- using OpConversionPattern<CmpIOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(CmpIOp cmpIOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts integer compare operation to SPIR-V ops.
-class CmpIOpPattern final : public OpConversionPattern<CmpIOp> {
-public:
- using OpConversionPattern<CmpIOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(CmpIOp cmpIOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
/// Converts std.return to spv.Return.
class ReturnOpPattern final : public OpConversionPattern<ReturnOp> {
public:
ConversionPatternRewriter &rewriter) const override;
};
-/// Converts std.zexti to spv.Select if the type of source is i1 or vector of
-/// i1.
-class ZeroExtendI1Pattern final : public OpConversionPattern<ZeroExtendIOp> {
-public:
- using OpConversionPattern<ZeroExtendIOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(ZeroExtendIOp op, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto srcType = adaptor.getOperands().front().getType();
- if (!isBoolScalarOrVector(srcType))
- return failure();
-
- auto dstType =
- this->getTypeConverter()->convertType(op.getResult().getType());
- Location loc = op.getLoc();
- Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
- Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
- rewriter.template replaceOpWithNewOp<spirv::SelectOp>(
- op, dstType, adaptor.getOperands().front(), one, zero);
- return success();
- }
-};
-
/// Converts tensor.extract into loading using access chains from SPIR-V local
/// variables.
class TensorExtractPattern final
int64_t byteCountThreshold;
};
-/// Converts std.trunci to spv.Select if the type of result is i1 or vector of
-/// i1.
-class TruncI1Pattern final : public OpConversionPattern<TruncateIOp> {
-public:
- using OpConversionPattern<TruncateIOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(TruncateIOp op, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto dstType =
- this->getTypeConverter()->convertType(op.getResult().getType());
- if (!isBoolScalarOrVector(dstType))
- return failure();
-
- Location loc = op.getLoc();
- auto srcType = adaptor.getOperands().front().getType();
- // Check if (x & 1) == 1.
- Value mask = spirv::ConstantOp::getOne(srcType, loc, rewriter);
- Value maskedSrc = rewriter.create<spirv::BitwiseAndOp>(
- loc, srcType, adaptor.getOperands()[0], mask);
- Value isOne = rewriter.create<spirv::IEqualOp>(loc, maskedSrc, mask);
-
- Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
- Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
- rewriter.replaceOpWithNewOp<spirv::SelectOp>(op, dstType, isOne, one, zero);
- return success();
- }
-};
-
-/// Converts std.uitofp to spv.Select if the type of source is i1 or vector of
-/// i1.
-class UIToFPI1Pattern final : public OpConversionPattern<UIToFPOp> {
-public:
- using OpConversionPattern<UIToFPOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(UIToFPOp op, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto srcType = adaptor.getOperands().front().getType();
- if (!isBoolScalarOrVector(srcType))
- return failure();
-
- auto dstType =
- this->getTypeConverter()->convertType(op.getResult().getType());
- Location loc = op.getLoc();
- Value zero = spirv::ConstantOp::getZero(dstType, loc, rewriter);
- Value one = spirv::ConstantOp::getOne(dstType, loc, rewriter);
- rewriter.template replaceOpWithNewOp<spirv::SelectOp>(
- op, dstType, adaptor.getOperands().front(), one, zero);
- return success();
- }
-};
-
-/// Converts type-casting standard operations to SPIR-V operations.
-template <typename StdOp, typename SPIRVOp>
-class TypeCastingOpPattern final : public OpConversionPattern<StdOp> {
-public:
- using OpConversionPattern<StdOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(StdOp operation, typename StdOp::Adaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- assert(adaptor.getOperands().size() == 1);
- auto srcType = adaptor.getOperands().front().getType();
- auto dstType =
- this->getTypeConverter()->convertType(operation.getResult().getType());
- if (isBoolScalarOrVector(srcType) || isBoolScalarOrVector(dstType))
- return failure();
- if (dstType == srcType) {
- // Due to type conversion, we are seeing the same source and target type.
- // Then we can just erase this operation by forwarding its operand.
- rewriter.replaceOp(operation, adaptor.getOperands().front());
- } else {
- rewriter.template replaceOpWithNewOp<SPIRVOp>(operation, dstType,
- adaptor.getOperands());
- }
- return success();
- }
-};
-
-/// Converts std.xor to SPIR-V operations.
-class XOrOpPattern final : public OpConversionPattern<XOrOp> {
-public:
- using OpConversionPattern<XOrOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(XOrOp xorOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
-/// Converts std.xor to SPIR-V operations if the type of source is i1 or vector
-/// of i1.
-class BoolXOrOpPattern final : public OpConversionPattern<XOrOp> {
-public:
- using OpConversionPattern<XOrOp>::OpConversionPattern;
-
- LogicalResult
- matchAndRewrite(XOrOp xorOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override;
-};
-
} // namespace
//===----------------------------------------------------------------------===//
-// SignedRemIOpPattern
-//===----------------------------------------------------------------------===//
-
-LogicalResult SignedRemIOpPattern::matchAndRewrite(
- SignedRemIOp remOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- Value result = emulateSignedRemainder(
- remOp.getLoc(), adaptor.getOperands()[0], adaptor.getOperands()[1],
- adaptor.getOperands()[0], rewriter);
- rewriter.replaceOp(remOp, result);
-
- return success();
-}
-
-//===----------------------------------------------------------------------===//
// ConstantOp with composite type.
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// CmpFOp
-//===----------------------------------------------------------------------===//
-
-LogicalResult
-CmpFOpPattern::matchAndRewrite(CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- switch (cmpFOp.getPredicate()) {
-#define DISPATCH(cmpPredicate, spirvOp) \
- case cmpPredicate: \
- rewriter.replaceOpWithNewOp<spirvOp>(cmpFOp, cmpFOp.getResult().getType(), \
- adaptor.lhs(), adaptor.rhs()); \
- return success();
-
- // Ordered.
- DISPATCH(CmpFPredicate::OEQ, spirv::FOrdEqualOp);
- DISPATCH(CmpFPredicate::OGT, spirv::FOrdGreaterThanOp);
- DISPATCH(CmpFPredicate::OGE, spirv::FOrdGreaterThanEqualOp);
- DISPATCH(CmpFPredicate::OLT, spirv::FOrdLessThanOp);
- DISPATCH(CmpFPredicate::OLE, spirv::FOrdLessThanEqualOp);
- DISPATCH(CmpFPredicate::ONE, spirv::FOrdNotEqualOp);
- // Unordered.
- DISPATCH(CmpFPredicate::UEQ, spirv::FUnordEqualOp);
- DISPATCH(CmpFPredicate::UGT, spirv::FUnordGreaterThanOp);
- DISPATCH(CmpFPredicate::UGE, spirv::FUnordGreaterThanEqualOp);
- DISPATCH(CmpFPredicate::ULT, spirv::FUnordLessThanOp);
- DISPATCH(CmpFPredicate::ULE, spirv::FUnordLessThanEqualOp);
- DISPATCH(CmpFPredicate::UNE, spirv::FUnordNotEqualOp);
-
-#undef DISPATCH
-
- default:
- break;
- }
- return failure();
-}
-
-LogicalResult CmpFOpNanKernelPattern::matchAndRewrite(
- CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- if (cmpFOp.getPredicate() == CmpFPredicate::ORD) {
- rewriter.replaceOpWithNewOp<spirv::OrderedOp>(cmpFOp, adaptor.lhs(),
- adaptor.rhs());
- return success();
- }
-
- if (cmpFOp.getPredicate() == CmpFPredicate::UNO) {
- rewriter.replaceOpWithNewOp<spirv::UnorderedOp>(cmpFOp, adaptor.lhs(),
- adaptor.rhs());
- return success();
- }
-
- return failure();
-}
-
-LogicalResult CmpFOpNanNonePattern::matchAndRewrite(
- CmpFOp cmpFOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- if (cmpFOp.getPredicate() != CmpFPredicate::ORD &&
- cmpFOp.getPredicate() != CmpFPredicate::UNO)
- return failure();
-
- Location loc = cmpFOp.getLoc();
-
- Value lhsIsNan = rewriter.create<spirv::IsNanOp>(loc, adaptor.lhs());
- Value rhsIsNan = rewriter.create<spirv::IsNanOp>(loc, adaptor.rhs());
-
- Value replace = rewriter.create<spirv::LogicalOrOp>(loc, lhsIsNan, rhsIsNan);
- if (cmpFOp.getPredicate() == CmpFPredicate::ORD)
- replace = rewriter.create<spirv::LogicalNotOp>(loc, replace);
-
- rewriter.replaceOp(cmpFOp, replace);
- return success();
-}
-
-//===----------------------------------------------------------------------===//
-// CmpIOp
-//===----------------------------------------------------------------------===//
-
-LogicalResult
-BoolCmpIOpPattern::matchAndRewrite(CmpIOp cmpIOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- Type operandType = cmpIOp.lhs().getType();
- if (!isBoolScalarOrVector(operandType))
- return failure();
-
- switch (cmpIOp.getPredicate()) {
-#define DISPATCH(cmpPredicate, spirvOp) \
- case cmpPredicate: \
- rewriter.replaceOpWithNewOp<spirvOp>(cmpIOp, cmpIOp.getResult().getType(), \
- adaptor.lhs(), adaptor.rhs()); \
- return success();
-
- DISPATCH(CmpIPredicate::eq, spirv::LogicalEqualOp);
- DISPATCH(CmpIPredicate::ne, spirv::LogicalNotEqualOp);
-
-#undef DISPATCH
- default:;
- }
- return failure();
-}
-
-LogicalResult
-CmpIOpPattern::matchAndRewrite(CmpIOp cmpIOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- Type operandType = cmpIOp.lhs().getType();
- if (isBoolScalarOrVector(operandType))
- return failure();
-
- switch (cmpIOp.getPredicate()) {
-#define DISPATCH(cmpPredicate, spirvOp) \
- case cmpPredicate: \
- if (spirvOp::template hasTrait<OpTrait::spirv::UnsignedOp>() && \
- operandType != this->getTypeConverter()->convertType(operandType)) { \
- return cmpIOp.emitError( \
- "bitwidth emulation is not implemented yet on unsigned op"); \
- } \
- rewriter.replaceOpWithNewOp<spirvOp>(cmpIOp, cmpIOp.getResult().getType(), \
- adaptor.lhs(), adaptor.rhs()); \
- return success();
-
- DISPATCH(CmpIPredicate::eq, spirv::IEqualOp);
- DISPATCH(CmpIPredicate::ne, spirv::INotEqualOp);
- DISPATCH(CmpIPredicate::slt, spirv::SLessThanOp);
- DISPATCH(CmpIPredicate::sle, spirv::SLessThanEqualOp);
- DISPATCH(CmpIPredicate::sgt, spirv::SGreaterThanOp);
- DISPATCH(CmpIPredicate::sge, spirv::SGreaterThanEqualOp);
- DISPATCH(CmpIPredicate::ult, spirv::ULessThanOp);
- DISPATCH(CmpIPredicate::ule, spirv::ULessThanEqualOp);
- DISPATCH(CmpIPredicate::ugt, spirv::UGreaterThanOp);
- DISPATCH(CmpIPredicate::uge, spirv::UGreaterThanEqualOp);
-
-#undef DISPATCH
- }
- return failure();
-}
-
-//===----------------------------------------------------------------------===//
// ReturnOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// XorOp
-//===----------------------------------------------------------------------===//
-
-LogicalResult
-XOrOpPattern::matchAndRewrite(XOrOp xorOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- assert(adaptor.getOperands().size() == 2);
-
- if (isBoolScalarOrVector(adaptor.getOperands().front().getType()))
- return failure();
-
- auto dstType = getTypeConverter()->convertType(xorOp.getType());
- if (!dstType)
- return failure();
- rewriter.replaceOpWithNewOp<spirv::BitwiseXorOp>(xorOp, dstType,
- adaptor.getOperands());
-
- return success();
-}
-
-LogicalResult
-BoolXOrOpPattern::matchAndRewrite(XOrOp xorOp, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const {
- assert(adaptor.getOperands().size() == 2);
-
- if (!isBoolScalarOrVector(adaptor.getOperands().front().getType()))
- return failure();
-
- auto dstType = getTypeConverter()->convertType(xorOp.getType());
- if (!dstType)
- return failure();
- rewriter.replaceOpWithNewOp<spirv::LogicalNotEqualOp>(xorOp, dstType,
- adaptor.getOperands());
- return success();
-}
-
-//===----------------------------------------------------------------------===//
// Pattern population
//===----------------------------------------------------------------------===//
patterns.add<
// Unary and binary patterns
- BitwiseOpPattern<AndOp, spirv::LogicalAndOp, spirv::BitwiseAndOp>,
- BitwiseOpPattern<OrOp, spirv::LogicalOrOp, spirv::BitwiseOrOp>,
- UnaryAndBinaryOpPattern<AbsFOp, spirv::GLSLFAbsOp>,
- UnaryAndBinaryOpPattern<AddFOp, spirv::FAddOp>,
- UnaryAndBinaryOpPattern<AddIOp, spirv::IAddOp>,
- UnaryAndBinaryOpPattern<CeilFOp, spirv::GLSLCeilOp>,
- UnaryAndBinaryOpPattern<DivFOp, spirv::FDivOp>,
- UnaryAndBinaryOpPattern<FloorFOp, spirv::GLSLFloorOp>,
- UnaryAndBinaryOpPattern<MaxFOp, spirv::GLSLFMaxOp>,
- UnaryAndBinaryOpPattern<MaxSIOp, spirv::GLSLSMaxOp>,
- UnaryAndBinaryOpPattern<MaxUIOp, spirv::GLSLUMaxOp>,
- UnaryAndBinaryOpPattern<MinFOp, spirv::GLSLFMinOp>,
- UnaryAndBinaryOpPattern<MinSIOp, spirv::GLSLSMinOp>,
- UnaryAndBinaryOpPattern<MinUIOp, spirv::GLSLUMinOp>,
- UnaryAndBinaryOpPattern<MulFOp, spirv::FMulOp>,
- UnaryAndBinaryOpPattern<MulIOp, spirv::IMulOp>,
- UnaryAndBinaryOpPattern<NegFOp, spirv::FNegateOp>,
- UnaryAndBinaryOpPattern<RemFOp, spirv::FRemOp>,
- UnaryAndBinaryOpPattern<ShiftLeftOp, spirv::ShiftLeftLogicalOp>,
- UnaryAndBinaryOpPattern<SignedDivIOp, spirv::SDivOp>,
- UnaryAndBinaryOpPattern<SignedShiftRightOp,
- spirv::ShiftRightArithmeticOp>,
- UnaryAndBinaryOpPattern<SubIOp, spirv::ISubOp>,
- UnaryAndBinaryOpPattern<SubFOp, spirv::FSubOp>,
- UnaryAndBinaryOpPattern<UnsignedDivIOp, spirv::UDivOp>,
- UnaryAndBinaryOpPattern<UnsignedRemIOp, spirv::UModOp>,
- UnaryAndBinaryOpPattern<UnsignedShiftRightOp, spirv::ShiftRightLogicalOp>,
- SignedRemIOpPattern, XOrOpPattern, BoolXOrOpPattern,
-
- // Comparison patterns
- BoolCmpIOpPattern, CmpFOpPattern, CmpFOpNanNonePattern, CmpIOpPattern,
+ spirv::UnaryAndBinaryOpPattern<MaxFOp, spirv::GLSLFMaxOp>,
+ spirv::UnaryAndBinaryOpPattern<MaxSIOp, spirv::GLSLSMaxOp>,
+ spirv::UnaryAndBinaryOpPattern<MaxUIOp, spirv::GLSLUMaxOp>,
+ spirv::UnaryAndBinaryOpPattern<MinFOp, spirv::GLSLFMinOp>,
+ spirv::UnaryAndBinaryOpPattern<MinSIOp, spirv::GLSLSMinOp>,
+ spirv::UnaryAndBinaryOpPattern<MinUIOp, spirv::GLSLUMinOp>,
// Constant patterns
ConstantCompositeOpPattern, ConstantScalarOpPattern,
- ReturnOpPattern, SelectOpPattern, SplatPattern,
-
- // Type cast patterns
- UIToFPI1Pattern, ZeroExtendI1Pattern, TruncI1Pattern,
- TypeCastingOpPattern<IndexCastOp, spirv::SConvertOp>,
- TypeCastingOpPattern<SIToFPOp, spirv::ConvertSToFOp>,
- TypeCastingOpPattern<UIToFPOp, spirv::ConvertUToFOp>,
- TypeCastingOpPattern<SignExtendIOp, spirv::SConvertOp>,
- TypeCastingOpPattern<ZeroExtendIOp, spirv::UConvertOp>,
- TypeCastingOpPattern<TruncateIOp, spirv::SConvertOp>,
- TypeCastingOpPattern<FPToSIOp, spirv::ConvertFToSOp>,
- TypeCastingOpPattern<FPExtOp, spirv::FConvertOp>,
- TypeCastingOpPattern<FPTruncOp, spirv::FConvertOp>>(typeConverter,
- context);
-
- // Give CmpFOpNanKernelPattern a higher benefit so it can prevail when Kernel
- // capability is available.
- patterns.add<CmpFOpNanKernelPattern>(typeConverter, context,
- /*benefit=*/2);
+ ReturnOpPattern, SelectOpPattern, SplatPattern>(typeConverter, context);
}
void populateTensorToSPIRVPatterns(SPIRVTypeConverter &typeConverter,
#include "mlir/Conversion/StandardToSPIRV/StandardToSPIRVPass.h"
#include "../PassDetail.h"
+#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
+#include "mlir/Conversion/MathToSPIRV/MathToSPIRV.h"
#include "mlir/Conversion/StandardToSPIRV/StandardToSPIRV.h"
#include "mlir/Dialect/SPIRV/IR/SPIRVDialect.h"
#include "mlir/Dialect/SPIRV/Transforms/SPIRVConversion.h"
options.emulateNon32BitScalarTypes = this->emulateNon32BitScalarTypes;
SPIRVTypeConverter typeConverter(targetAttr, options);
+ // TODO ArithmeticToSPIRV cannot be applied separately to StandardToSPIRV
RewritePatternSet patterns(context);
+ arith::populateArithmeticToSPIRVPatterns(typeConverter, patterns);
+ populateMathToSPIRVPatterns(typeConverter, patterns);
populateStandardToSPIRVPatterns(typeConverter, patterns);
- populateTensorToSPIRVPatterns(typeConverter,
- /*byteCountThreshold=*/64, patterns);
+ populateTensorToSPIRVPatterns(typeConverter, /*byteCountThreshold=*/64,
+ patterns);
populateBuiltinFuncToSPIRVPatterns(typeConverter, patterns);
if (failed(applyPartialConversion(module, *target, std::move(patterns))))
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDialectUtils
MLIRIR
MLIRLinalg
//===----------------------------------------------------------------------===//
#include "mlir/Conversion/TosaToLinalg/TosaToLinalg.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/SCF/SCF.h"
}
template <typename T>
-static mlir::ConstantOp
+static arith::ConstantOp
createConstFromIntAttribute(Operation *op, std::string attrName,
Type requiredAttrType, OpBuilder &rewriter) {
auto castedN = static_cast<T>(
op->getAttr(attrName).cast<IntegerAttr>().getValue().getSExtValue());
- return rewriter.create<mlir::ConstantOp>(
+ return rewriter.create<arith::ConstantOp>(
op->getLoc(), IntegerAttr::get(requiredAttrType, castedN));
}
}
template <typename T, typename P>
-static mlir::SelectOp clampHelper(Location loc, Value arg, mlir::ConstantOp min,
- mlir::ConstantOp max, P pred,
- OpBuilder &rewriter) {
+static mlir::SelectOp clampHelper(Location loc, Value arg,
+ arith::ConstantOp min, arith::ConstantOp max,
+ P pred, OpBuilder &rewriter) {
auto smallerThanMin = rewriter.create<T>(loc, pred, arg, min);
auto minOrArg =
rewriter.create<mlir::SelectOp>(loc, smallerThanMin, min, arg);
highIndices.push_back(rewriter.getIndexAttr(highPad));
}
- Value padValue = rewriter.create<ConstantOp>(loc, padAttr);
+ Value padValue = rewriter.create<arith::ConstantOp>(loc, padAttr);
return linalg::PadTensorOp::createPadScalarOp(
RankedTensorType::get(paddedShape, inputETy), input, padValue,
// tosa::AbsOp
if (isa<tosa::AbsOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::AbsFOp>(loc, resultTypes, args);
+ return rewriter.create<math::AbsOp>(loc, resultTypes, args);
if (isa<tosa::AbsOp>(op) && elementTy.isa<IntegerType>()) {
- auto zero =
- rewriter.create<mlir::ConstantOp>(loc, rewriter.getZeroAttr(elementTy));
- auto cmp =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt, args[0], zero);
- auto neg = rewriter.create<mlir::SubIOp>(loc, zero, args[0]);
+ auto zero = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getZeroAttr(elementTy));
+ auto cmp = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt,
+ args[0], zero);
+ auto neg = rewriter.create<arith::SubIOp>(loc, zero, args[0]);
return rewriter.create<mlir::SelectOp>(loc, cmp, args[0], neg);
}
// tosa::AddOp
if (isa<tosa::AddOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::AddFOp>(loc, resultTypes, args);
+ return rewriter.create<arith::AddFOp>(loc, resultTypes, args);
if (isa<tosa::AddOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::AddIOp>(loc, resultTypes, args);
+ return rewriter.create<arith::AddIOp>(loc, resultTypes, args);
// tosa::SubOp
if (isa<tosa::SubOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::SubFOp>(loc, resultTypes, args);
+ return rewriter.create<arith::SubFOp>(loc, resultTypes, args);
if (isa<tosa::SubOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::SubIOp>(loc, resultTypes, args);
+ return rewriter.create<arith::SubIOp>(loc, resultTypes, args);
// tosa::MulOp
if (isa<tosa::MulOp>(op) && elementTy.isa<FloatType>()) {
"Cannot have shift value for float");
return nullptr;
}
- return rewriter.create<mlir::MulFOp>(loc, resultTypes, args);
+ return rewriter.create<arith::MulFOp>(loc, resultTypes, args);
}
// tosa::DivOp
if (isa<tosa::DivOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::SignedDivIOp>(loc, resultTypes, args);
+ return rewriter.create<arith::DivSIOp>(loc, resultTypes, args);
// tosa::ReciprocalOp
if (isa<tosa::ReciprocalOp>(op) && elementTy.isa<FloatType>()) {
auto one =
- rewriter.create<mlir::ConstantOp>(loc, FloatAttr::get(elementTy, 1));
- return rewriter.create<mlir::DivFOp>(loc, resultTypes, one, args[0]);
+ rewriter.create<arith::ConstantOp>(loc, FloatAttr::get(elementTy, 1));
+ return rewriter.create<arith::DivFOp>(loc, resultTypes, one, args[0]);
}
if (isa<tosa::MulOp>(op) && elementTy.isa<IntegerType>()) {
op->getAttr("shift").cast<IntegerAttr>().getValue().getSExtValue();
if (shift > 0) {
auto shiftConst =
- rewriter.create<ConstantIntOp>(loc, shift, /*bitwidth=*/8);
+ rewriter.create<arith::ConstantIntOp>(loc, shift, /*bitwidth=*/8);
if (!a.getType().isInteger(32))
- a = rewriter.create<SignExtendIOp>(loc, rewriter.getI32Type(), a);
+ a = rewriter.create<arith::ExtSIOp>(loc, rewriter.getI32Type(), a);
if (!b.getType().isInteger(32))
- b = rewriter.create<SignExtendIOp>(loc, rewriter.getI32Type(), b);
+ b = rewriter.create<arith::ExtSIOp>(loc, rewriter.getI32Type(), b);
auto result = rewriter.create<tosa::ApplyScaleOp>(
loc, rewriter.getI32Type(), a, b, shiftConst,
if (elementTy.isInteger(32))
return result;
- return rewriter.create<TruncateIOp>(loc, elementTy, result);
+ return rewriter.create<arith::TruncIOp>(loc, elementTy, result);
}
int aWidth = a.getType().getIntOrFloatBitWidth();
int cWidth = resultTypes[0].getIntOrFloatBitWidth();
if (aWidth < cWidth)
- a = rewriter.create<SignExtendIOp>(loc, resultTypes[0], a);
+ a = rewriter.create<arith::ExtSIOp>(loc, resultTypes[0], a);
if (bWidth < cWidth)
- b = rewriter.create<SignExtendIOp>(loc, resultTypes[0], b);
+ b = rewriter.create<arith::ExtSIOp>(loc, resultTypes[0], b);
- return rewriter.create<mlir::MulIOp>(loc, resultTypes, a, b);
+ return rewriter.create<arith::MulIOp>(loc, resultTypes, a, b);
}
// tosa::NegateOp
if (isa<tosa::NegateOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::NegFOp>(loc, resultTypes, args);
+ return rewriter.create<arith::NegFOp>(loc, resultTypes, args);
if (isa<tosa::NegateOp>(op) && elementTy.isa<IntegerType>() &&
!cast<tosa::NegateOp>(op).quantization_info()) {
auto constant =
- rewriter.create<ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
- return rewriter.create<SubIOp>(loc, resultTypes, constant, args[0]);
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
+ return rewriter.create<arith::SubIOp>(loc, resultTypes, constant, args[0]);
}
if (isa<tosa::NegateOp>(op) && elementTy.isa<IntegerType>() &&
}
Type intermediateType = rewriter.getIntegerType(intermediateBitWidth);
- Value zpAddValue = rewriter.create<ConstantOp>(
+ Value zpAddValue = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(intermediateType, zpAdd));
// The negation can be applied by doing:
// outputValue = inZp + outZp - inputValue
- auto ext = rewriter.create<SignExtendIOp>(loc, intermediateType, args[0]);
- auto sub = rewriter.create<SubIOp>(loc, zpAddValue, ext);
+ auto ext = rewriter.create<arith::ExtSIOp>(loc, intermediateType, args[0]);
+ auto sub = rewriter.create<arith::SubIOp>(loc, zpAddValue, ext);
// Clamp to the negation range.
- auto min = rewriter.create<ConstantOp>(
- loc, rewriter.getIntegerAttr(
- intermediateType,
- APInt::getSignedMinValue(inputBitWidth).getSExtValue()));
- auto max = rewriter.create<ConstantOp>(
- loc, rewriter.getIntegerAttr(
- intermediateType,
- APInt::getSignedMaxValue(inputBitWidth).getSExtValue()));
- auto clamp = clampHelper<mlir::CmpIOp>(loc, sub, min, max,
- CmpIPredicate::slt, rewriter);
+ auto min = rewriter.create<arith::ConstantIntOp>(
+ loc, APInt::getSignedMinValue(inputBitWidth).getSExtValue(),
+ intermediateType);
+ auto max = rewriter.create<arith::ConstantIntOp>(
+ loc, APInt::getSignedMaxValue(inputBitWidth).getSExtValue(),
+ intermediateType);
+ auto clamp = clampHelper<arith::CmpIOp>(
+ loc, sub, min, max, arith::CmpIPredicate::slt, rewriter);
// Truncate to the final value.
- return rewriter.create<TruncateIOp>(loc, elementTy, clamp);
+ return rewriter.create<arith::TruncIOp>(loc, elementTy, clamp);
}
// tosa::BitwiseAndOp
if (isa<tosa::BitwiseAndOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::AndOp>(loc, resultTypes, args);
+ return rewriter.create<arith::AndIOp>(loc, resultTypes, args);
// tosa::BitwiseOrOp
if (isa<tosa::BitwiseOrOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::OrOp>(loc, resultTypes, args);
+ return rewriter.create<arith::OrIOp>(loc, resultTypes, args);
// tosa::BitwiseNotOp
if (isa<tosa::BitwiseNotOp>(op) && elementTy.isa<IntegerType>()) {
auto allOnesAttr = rewriter.getIntegerAttr(
elementTy, APInt::getAllOnes(elementTy.getIntOrFloatBitWidth()));
- auto allOnes = rewriter.create<ConstantOp>(loc, allOnesAttr);
- return rewriter.create<mlir::XOrOp>(loc, resultTypes, args[0], allOnes);
+ auto allOnes = rewriter.create<arith::ConstantOp>(loc, allOnesAttr);
+ return rewriter.create<arith::XOrIOp>(loc, resultTypes, args[0], allOnes);
}
// tosa::BitwiseXOrOp
if (isa<tosa::BitwiseXorOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::XOrOp>(loc, resultTypes, args);
+ return rewriter.create<arith::XOrIOp>(loc, resultTypes, args);
// tosa::LogicalLeftShiftOp
if (isa<tosa::LogicalLeftShiftOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::ShiftLeftOp>(loc, resultTypes, args);
+ return rewriter.create<arith::ShLIOp>(loc, resultTypes, args);
// tosa::LogicalRightShiftOp
if (isa<tosa::LogicalRightShiftOp>(op) && elementTy.isa<IntegerType>())
- return rewriter.create<mlir::UnsignedShiftRightOp>(loc, resultTypes, args);
+ return rewriter.create<arith::ShRUIOp>(loc, resultTypes, args);
// tosa::ArithmeticRightShiftOp
if (isa<tosa::ArithmeticRightShiftOp>(op) && elementTy.isa<IntegerType>()) {
- auto result =
- rewriter.create<mlir::SignedShiftRightOp>(loc, resultTypes, args);
+ auto result = rewriter.create<arith::ShRSIOp>(loc, resultTypes, args);
auto round = op->getAttr("round").cast<BoolAttr>().getValue();
if (!round) {
return result;
Type i1Ty = IntegerType::get(rewriter.getContext(), /*width=*/1);
auto one =
- rewriter.create<mlir::ConstantOp>(loc, IntegerAttr::get(elementTy, 1));
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(elementTy, 1));
auto zero =
- rewriter.create<mlir::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
auto i1one =
- rewriter.create<mlir::ConstantOp>(loc, IntegerAttr::get(i1Ty, 1));
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(i1Ty, 1));
// Checking that input2 != 0
- auto shiftValueGreaterThanZero =
- rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt, args[1], zero);
+ auto shiftValueGreaterThanZero = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sgt, args[1], zero);
// Checking for the last bit of input1 to be 1
auto subtract =
- rewriter.create<mlir::SubIOp>(loc, resultTypes, args[1], one);
- auto shifted = rewriter
- .create<mlir::SignedShiftRightOp>(loc, resultTypes,
- args[0], subtract)
- ->getResults();
+ rewriter.create<arith::SubIOp>(loc, resultTypes, args[1], one);
+ auto shifted =
+ rewriter.create<arith::ShRSIOp>(loc, resultTypes, args[0], subtract)
+ ->getResults();
auto truncated =
- rewriter.create<mlir::TruncateIOp>(loc, i1Ty, shifted, mlir::None);
- auto isInputOdd = rewriter.create<mlir::AndOp>(loc, i1Ty, truncated, i1one);
+ rewriter.create<arith::TruncIOp>(loc, i1Ty, shifted, mlir::None);
+ auto isInputOdd =
+ rewriter.create<arith::AndIOp>(loc, i1Ty, truncated, i1one);
- auto shouldRound = rewriter.create<mlir::AndOp>(
+ auto shouldRound = rewriter.create<arith::AndIOp>(
loc, i1Ty, shiftValueGreaterThanZero, isInputOdd);
auto extended =
- rewriter.create<ZeroExtendIOp>(loc, resultTypes, shouldRound);
- return rewriter.create<mlir::AddIOp>(loc, resultTypes, result, extended);
+ rewriter.create<arith::ExtUIOp>(loc, resultTypes, shouldRound);
+ return rewriter.create<arith::AddIOp>(loc, resultTypes, result, extended);
}
// tosa::ClzOp
if (isa<tosa::ClzOp>(op) && elementTy.isa<IntegerType>()) {
int bitWidth = elementTy.getIntOrFloatBitWidth();
auto zero =
- rewriter.create<mlir::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
- auto leadingZeros = rewriter.create<mlir::ConstantOp>(
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
+ auto leadingZeros = rewriter.create<arith::ConstantOp>(
loc, IntegerAttr::get(elementTy, bitWidth));
SmallVector<Value> operands = {args[0], leadingZeros, zero};
Value input = before->getArgument(0);
Value zero = before->getArgument(2);
- Value inputLargerThanZero =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::ne, input, zero);
+ Value inputLargerThanZero = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::ne, input, zero);
rewriter.create<scf::ConditionOp>(loc, inputLargerThanZero,
before->getArguments());
}
Value input = after->getArgument(0);
Value leadingZeros = after->getArgument(1);
- auto one = rewriter.create<mlir::ConstantOp>(
+ auto one = rewriter.create<arith::ConstantOp>(
loc, IntegerAttr::get(elementTy, 1));
- auto shifted = rewriter.create<mlir::UnsignedShiftRightOp>(
- loc, resultTypes, input, one);
+ auto shifted =
+ rewriter.create<arith::ShRUIOp>(loc, resultTypes, input, one);
auto leadingZerosMinusOne =
- rewriter.create<mlir::SubIOp>(loc, resultTypes, leadingZeros, one);
+ rewriter.create<arith::SubIOp>(loc, resultTypes, leadingZeros, one);
rewriter.create<scf::YieldOp>(
loc,
// tosa::LogicalAnd
if (isa<tosa::LogicalAndOp>(op) && elementTy.isInteger(1))
- return rewriter.create<mlir::AndOp>(loc, resultTypes, args);
+ return rewriter.create<arith::AndIOp>(loc, resultTypes, args);
// tosa::LogicalNot
if (isa<tosa::LogicalNotOp>(op) && elementTy.isInteger(1)) {
- auto one = rewriter.create<mlir::ConstantOp>(
+ auto one = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(elementTy, 1));
- return rewriter.create<mlir::XOrOp>(loc, resultTypes, args[0], one);
+ return rewriter.create<arith::XOrIOp>(loc, resultTypes, args[0], one);
}
// tosa::LogicalOr
if (isa<tosa::LogicalOrOp>(op) && elementTy.isInteger(1))
- return rewriter.create<mlir::OrOp>(loc, resultTypes, args);
+ return rewriter.create<arith::OrIOp>(loc, resultTypes, args);
// tosa::LogicalXor
if (isa<tosa::LogicalXorOp>(op) && elementTy.isInteger(1))
- return rewriter.create<mlir::XOrOp>(loc, resultTypes, args);
+ return rewriter.create<arith::XOrIOp>(loc, resultTypes, args);
// tosa::PowOp
if (isa<tosa::PowOp>(op) && elementTy.isa<FloatType>())
// tosa::GreaterOp
if (isa<tosa::GreaterOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGT, args[0],
- args[1]);
+ return rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGT,
+ args[0], args[1]);
if (isa<tosa::GreaterOp>(op) && elementTy.isSignlessInteger())
- return rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt, args[0],
- args[1]);
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt,
+ args[0], args[1]);
// tosa::GreaterEqualOp
if (isa<tosa::GreaterEqualOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGE, args[0],
- args[1]);
+ return rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGE,
+ args[0], args[1]);
if (isa<tosa::GreaterEqualOp>(op) && elementTy.isSignlessInteger())
- return rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sge, args[0],
- args[1]);
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sge,
+ args[0], args[1]);
// tosa::EqualOp
if (isa<tosa::EqualOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OEQ, args[0],
- args[1]);
+ return rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OEQ,
+ args[0], args[1]);
if (isa<tosa::EqualOp>(op) && elementTy.isSignlessInteger())
- return rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::eq, args[0],
- args[1]);
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ args[0], args[1]);
// tosa::SelectOp
if (isa<tosa::SelectOp>(op)) {
// tosa::MaximumOp
if (isa<tosa::MaximumOp>(op) && elementTy.isa<FloatType>()) {
- auto predicate = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGT,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OGT, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::MaximumOp>(op) && elementTy.isSignlessInteger()) {
- auto predicate = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sgt, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
// tosa::MinimumOp
if (isa<tosa::MinimumOp>(op) && elementTy.isa<FloatType>()) {
- auto predicate = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OLT,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OLT, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::MinimumOp>(op) && elementTy.isSignlessInteger()) {
- auto predicate = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
// tosa::CeilOp
if (isa<tosa::CeilOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::CeilFOp>(loc, resultTypes, args);
+ return rewriter.create<math::CeilOp>(loc, resultTypes, args);
// tosa::FloorOp
if (isa<tosa::FloorOp>(op) && elementTy.isa<FloatType>())
- return rewriter.create<mlir::FloorFOp>(loc, resultTypes, args);
+ return rewriter.create<math::FloorOp>(loc, resultTypes, args);
// tosa::ClampOp
if (isa<tosa::ClampOp>(op) && elementTy.isa<FloatType>()) {
- auto min = rewriter.create<mlir::ConstantOp>(loc, elementTy,
- op->getAttr("min_fp"));
- auto max = rewriter.create<mlir::ConstantOp>(loc, elementTy,
- op->getAttr("max_fp"));
- return clampHelper<mlir::CmpFOp>(loc, args[0], min, max, CmpFPredicate::OLT,
- rewriter);
+ auto min = rewriter.create<arith::ConstantOp>(loc, elementTy,
+ op->getAttr("min_fp"));
+ auto max = rewriter.create<arith::ConstantOp>(loc, elementTy,
+ op->getAttr("max_fp"));
+ return clampHelper<arith::CmpFOp>(loc, args[0], min, max,
+ arith::CmpFPredicate::OLT, rewriter);
}
if (isa<tosa::ClampOp>(op) && elementTy.isa<IntegerType>()) {
.getSExtValue());
}
- auto minVal =
- rewriter.create<ConstantIntOp>(loc, min, intTy.getIntOrFloatBitWidth());
- auto maxVal =
- rewriter.create<ConstantIntOp>(loc, max, intTy.getIntOrFloatBitWidth());
- return clampHelper<mlir::CmpIOp>(loc, args[0], minVal, maxVal,
- CmpIPredicate::slt, rewriter);
+ auto minVal = rewriter.create<arith::ConstantIntOp>(
+ loc, min, intTy.getIntOrFloatBitWidth());
+ auto maxVal = rewriter.create<arith::ConstantIntOp>(
+ loc, max, intTy.getIntOrFloatBitWidth());
+ return clampHelper<arith::CmpIOp>(loc, args[0], minVal, maxVal,
+ arith::CmpIPredicate::slt, rewriter);
}
// tosa::ReluNOp
if (isa<tosa::ReluNOp>(op) && elementTy.isa<FloatType>()) {
auto zero =
- rewriter.create<mlir::ConstantOp>(loc, FloatAttr::get(elementTy, 0));
- auto n = rewriter.create<mlir::ConstantOp>(loc, elementTy,
- op->getAttr("max_fp"));
- return clampHelper<mlir::CmpFOp>(loc, args[0], zero, n, CmpFPredicate::OLT,
- rewriter);
+ rewriter.create<arith::ConstantOp>(loc, FloatAttr::get(elementTy, 0));
+ auto n = rewriter.create<arith::ConstantOp>(loc, elementTy,
+ op->getAttr("max_fp"));
+ return clampHelper<arith::CmpFOp>(loc, args[0], zero, n,
+ arith::CmpFPredicate::OLT, rewriter);
}
if (isa<tosa::ReluNOp>(op) && elementTy.isa<IntegerType>()) {
auto zero =
- rewriter.create<mlir::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
+ rewriter.create<arith::ConstantOp>(loc, IntegerAttr::get(elementTy, 0));
auto n = createConstFromIntAttribute<int32_t>(op, "max_int", elementTy,
rewriter);
- return clampHelper<mlir::CmpIOp>(loc, args[0], zero, n, CmpIPredicate::slt,
- rewriter);
+ return clampHelper<arith::CmpIOp>(loc, args[0], zero, n,
+ arith::CmpIPredicate::slt, rewriter);
}
// tosa::SigmoidOp
if (isa<tosa::SigmoidOp>(op) && elementTy.isa<FloatType>()) {
auto one =
- rewriter.create<mlir::ConstantOp>(loc, FloatAttr::get(elementTy, 1));
- auto negate = rewriter.create<mlir::NegFOp>(loc, resultTypes, args[0]);
+ rewriter.create<arith::ConstantOp>(loc, FloatAttr::get(elementTy, 1));
+ auto negate = rewriter.create<arith::NegFOp>(loc, resultTypes, args[0]);
auto exp = rewriter.create<mlir::math::ExpOp>(loc, resultTypes, negate);
- auto added = rewriter.create<mlir::AddFOp>(loc, resultTypes, exp, one);
- return rewriter.create<mlir::DivFOp>(loc, resultTypes, one, added);
+ auto added = rewriter.create<arith::AddFOp>(loc, resultTypes, exp, one);
+ return rewriter.create<arith::DivFOp>(loc, resultTypes, one, added);
}
// tosa::CastOp
return args.front();
if (srcTy.isa<FloatType>() && dstTy.isa<FloatType>() && bitExtend)
- return rewriter.create<mlir::FPExtOp>(loc, resultTypes, args, mlir::None);
+ return rewriter.create<arith::ExtFOp>(loc, resultTypes, args, mlir::None);
if (srcTy.isa<FloatType>() && dstTy.isa<FloatType>() && !bitExtend)
- return rewriter.create<mlir::FPTruncOp>(loc, resultTypes, args,
+ return rewriter.create<arith::TruncFOp>(loc, resultTypes, args,
mlir::None);
// 1-bit integers need to be treated as signless.
- if (srcTy.isInteger(1) && mlir::UIToFPOp::areCastCompatible(srcTy, dstTy))
- return rewriter.create<mlir::UIToFPOp>(loc, resultTypes, args,
- mlir::None);
+ if (srcTy.isInteger(1) && arith::UIToFPOp::areCastCompatible(srcTy, dstTy))
+ return rewriter.create<arith::UIToFPOp>(loc, resultTypes, args,
+ mlir::None);
if (srcTy.isInteger(1) && dstTy.isa<IntegerType>() && bitExtend)
- return rewriter.create<mlir::ZeroExtendIOp>(loc, resultTypes, args,
- mlir::None);
+ return rewriter.create<arith::ExtUIOp>(loc, resultTypes, args,
+ mlir::None);
// All other si-to-fp conversions should be handled by SIToFP.
- if (mlir::SIToFPOp::areCastCompatible(srcTy, dstTy))
- return rewriter.create<mlir::SIToFPOp>(loc, resultTypes, args,
- mlir::None);
+ if (arith::SIToFPOp::areCastCompatible(srcTy, dstTy))
+ return rewriter.create<arith::SIToFPOp>(loc, resultTypes, args,
+ mlir::None);
// Unsigned integers need an unrealized cast so that they can be passed
// to UIToFP.
loc, rewriter.getIntegerType(srcTy.getIntOrFloatBitWidth()),
args[0])
.getResult(0);
- return rewriter.create<mlir::UIToFPOp>(loc, resultTypes[0],
- unrealizedCast);
+ return rewriter.create<arith::UIToFPOp>(loc, resultTypes[0],
+ unrealizedCast);
}
// Casting to boolean, floats need to only be checked as not-equal to zero.
if (srcTy.isa<FloatType>() && dstTy.isInteger(1)) {
- Value zero =
- rewriter.create<ConstantOp>(loc, rewriter.getFloatAttr(srcTy, 0.0));
- return rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::UNE,
- args.front(), zero);
+ Value zero = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getFloatAttr(srcTy, 0.0));
+ return rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::UNE,
+ args.front(), zero);
}
- if (mlir::FPToSIOp::areCastCompatible(srcTy, dstTy)) {
- auto zero =
- rewriter.create<ConstantOp>(loc, rewriter.getF32FloatAttr(0.0f));
- auto half =
- rewriter.create<ConstantOp>(loc, rewriter.getF32FloatAttr(0.5f));
+ if (arith::FPToSIOp::areCastCompatible(srcTy, dstTy)) {
+ auto zero = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getF32FloatAttr(0.0f));
+ auto half = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getF32FloatAttr(0.5f));
- auto intMin = rewriter.create<ConstantOp>(
+ auto intMin = rewriter.create<arith::ConstantOp>(
loc, rewriter.getF32FloatAttr(
APInt::getSignedMinValue(dstTy.getIntOrFloatBitWidth())
.getSExtValue()));
- auto intMax = rewriter.create<ConstantOp>(
+ auto intMax = rewriter.create<arith::ConstantOp>(
loc, rewriter.getF32FloatAttr(
APInt::getSignedMaxValue(dstTy.getIntOrFloatBitWidth())
.getSExtValue()));
- auto added = rewriter.create<AddFOp>(loc, args[0], half);
- auto subbed = rewriter.create<SubFOp>(loc, args[0], half);
- auto negative =
- rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OLT, args[0], zero);
+ auto added = rewriter.create<arith::AddFOp>(loc, args[0], half);
+ auto subbed = rewriter.create<arith::SubFOp>(loc, args[0], half);
+ auto negative = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OLT, args[0], zero);
auto rounded =
rewriter.create<mlir::SelectOp>(loc, negative, subbed, added);
- auto clamped = clampHelper<mlir::CmpFOp>(loc, rounded, intMin, intMax,
- CmpFPredicate::OLT, rewriter);
+ auto clamped = clampHelper<arith::CmpFOp>(
+ loc, rounded, intMin, intMax, arith::CmpFPredicate::OLT, rewriter);
- return rewriter.create<mlir::FPToSIOp>(loc, dstTy, clamped);
+ return rewriter.create<arith::FPToSIOp>(loc, dstTy, clamped);
}
// Casting to boolean, integers need to only be checked as not-equal to
// zero.
if (srcTy.isa<IntegerType>() && dstTy.isInteger(1)) {
- Value zero =
- rewriter.create<ConstantIntOp>(loc, 0, srcTy.getIntOrFloatBitWidth());
- return rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::ne, args.front(),
- zero);
+ Value zero = rewriter.create<arith::ConstantIntOp>(
+ loc, 0, srcTy.getIntOrFloatBitWidth());
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::ne,
+ args.front(), zero);
}
if (srcTy.isa<IntegerType>() && dstTy.isa<IntegerType>() && bitExtend)
- return rewriter.create<mlir::SignExtendIOp>(loc, resultTypes, args,
- mlir::None);
+ return rewriter.create<arith::ExtSIOp>(loc, resultTypes, args,
+ mlir::None);
if (srcTy.isa<IntegerType>() && dstTy.isa<IntegerType>() && !bitExtend) {
- auto intMin = rewriter.create<ConstantIntOp>(
+ auto intMin = rewriter.create<arith::ConstantIntOp>(
loc,
APInt::getSignedMinValue(dstTy.getIntOrFloatBitWidth())
.getSExtValue(),
srcTy.getIntOrFloatBitWidth());
- auto intMax = rewriter.create<ConstantIntOp>(
+ auto intMax = rewriter.create<arith::ConstantIntOp>(
loc,
APInt::getSignedMaxValue(dstTy.getIntOrFloatBitWidth())
.getSExtValue(),
srcTy.getIntOrFloatBitWidth());
- auto clamped = clampHelper<mlir::CmpIOp>(loc, args[0], intMin, intMax,
- CmpIPredicate::slt, rewriter);
- return rewriter.create<mlir::TruncateIOp>(loc, dstTy, clamped);
+ auto clamped = clampHelper<arith::CmpIOp>(
+ loc, args[0], intMin, intMax, arith::CmpIPredicate::slt, rewriter);
+ return rewriter.create<arith::TruncIOp>(loc, dstTy, clamped);
}
}
PatternRewriter &rewriter) {
Location loc = op->getLoc();
if (isa<tosa::ReduceSumOp>(op) && elementTy.isa<FloatType>()) {
- return rewriter.create<AddFOp>(loc, args);
+ return rewriter.create<arith::AddFOp>(loc, args);
}
if (isa<tosa::ReduceSumOp>(op) && elementTy.isa<IntegerType>()) {
- return rewriter.create<AddIOp>(loc, args);
+ return rewriter.create<arith::AddIOp>(loc, args);
}
if (isa<tosa::ReduceProdOp>(op) && elementTy.isa<FloatType>()) {
- return rewriter.create<MulFOp>(loc, args);
+ return rewriter.create<arith::MulFOp>(loc, args);
}
if (isa<tosa::ReduceProdOp>(op) && elementTy.isa<IntegerType>()) {
- return rewriter.create<MulIOp>(loc, args);
+ return rewriter.create<arith::MulIOp>(loc, args);
}
if (isa<tosa::ReduceMinOp>(op) && elementTy.isa<FloatType>()) {
- auto predicate = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OLT,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OLT, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::ReduceMinOp>(op) && elementTy.isa<IntegerType>()) {
- auto predicate = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::ReduceMaxOp>(op) && elementTy.isa<FloatType>()) {
- auto predicate = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGT,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpFOp>(
+ loc, arith::CmpFPredicate::OGT, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::ReduceMaxOp>(op) && elementTy.isa<IntegerType>()) {
- auto predicate = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt,
- args[0], args[1]);
+ auto predicate = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sgt, args[0], args[1]);
return rewriter.create<mlir::SelectOp>(loc, predicate, args[0], args[1]);
}
if (isa<tosa::ReduceAllOp>(op) && elementTy.isInteger(1))
- return rewriter.create<mlir::AndOp>(loc, args);
+ return rewriter.create<arith::AndIOp>(loc, args);
if (isa<tosa::ReduceAnyOp>(op) && elementTy.isInteger(1))
- return rewriter.create<mlir::OrOp>(loc, args);
+ return rewriter.create<arith::OrIOp>(loc, args);
return {};
}
return rewriter.notifyMatchFailure(
op, "No initial value found for reduction operation");
- auto fillValue = rewriter.create<ConstantOp>(loc, fillValueAttr);
+ auto fillValue = rewriter.create<arith::ConstantOp>(loc, fillValueAttr);
auto filledTensor =
rewriter.create<linalg::FillOp>(loc, fillValue, initTensor).result();
weightShape[3], weightShape[0]};
auto weightPermAttr = DenseIntElementsAttr::get(
RankedTensorType::get({4}, rewriter.getI64Type()), weightPerm);
- Value weightPermValue = rewriter.create<ConstantOp>(loc, weightPermAttr);
+ Value weightPermValue =
+ rewriter.create<arith::ConstantOp>(loc, weightPermAttr);
Type newWeightTy =
RankedTensorType::get(newWeightShape, weightTy.getElementType());
weight = rewriter.create<tosa::TransposeOp>(loc, newWeightTy, weight,
Attribute resultZeroAttr = rewriter.getZeroAttr(resultETy);
Value initTensor = rewriter.create<linalg::InitTensorOp>(
loc, resultTy.getShape(), resultETy);
- Value zero = rewriter.create<ConstantOp>(loc, resultZeroAttr);
+ Value zero = rewriter.create<arith::ConstantOp>(loc, resultZeroAttr);
Value zeroTensor =
rewriter.create<linalg::FillOp>(loc, zero, initTensor).getResult(0);
auto kZp = rewriter.getI32IntegerAttr(
quantizationInfo.weight_zp().getValue().getSExtValue());
- auto iZpVal = rewriter.create<ConstantOp>(loc, iZp);
- auto kZpVal = rewriter.create<ConstantOp>(loc, kZp);
+ auto iZpVal = rewriter.create<arith::ConstantOp>(loc, iZp);
+ auto kZpVal = rewriter.create<arith::ConstantOp>(loc, kZp);
Value conv =
rewriter
.create<linalg::Conv2DNhwcHwcfQOp>(
indexingMaps, getNParallelLoopsAttrs(resultTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddIOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddIOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
indexingMaps, getNParallelLoopsAttrs(resultTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddFOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddFOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
Attribute resultZeroAttr = rewriter.getZeroAttr(resultETy);
Value initTensor = rewriter.create<linalg::InitTensorOp>(
loc, linalgConvTy.getShape(), resultETy);
- Value zero = rewriter.create<ConstantOp>(loc, resultZeroAttr);
+ Value zero = rewriter.create<arith::ConstantOp>(loc, resultZeroAttr);
Value zeroTensor =
rewriter.create<linalg::FillOp>(loc, zero, initTensor).getResult(0);
getNParallelLoopsAttrs(resultTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddFOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddFOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
rewriter.replaceOp(op, result);
} else {
- auto iZpVal = rewriter.create<ConstantOp>(loc, iZp);
- auto kZpVal = rewriter.create<ConstantOp>(loc, kZp);
+ auto iZpVal = rewriter.create<arith::ConstantOp>(loc, iZp);
+ auto kZpVal = rewriter.create<arith::ConstantOp>(loc, kZp);
Value conv =
rewriter
.create<linalg::DepthwiseConv2DNhwcQOp>(
getNParallelLoopsAttrs(resultTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddIOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddIOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
SmallVector<Value> filteredDims = filterDynamicDims(dynDims);
auto zeroAttr = rewriter.getZeroAttr(outputElementTy);
- Value zero = rewriter.create<ConstantOp>(loc, zeroAttr);
+ Value zero = rewriter.create<arith::ConstantOp>(loc, zeroAttr);
auto initTensor = rewriter.create<linalg::InitTensorOp>(
loc, filteredDims, outputTy.getShape(), outputTy.getElementType());
Value zeroTensor =
}
auto quantizationInfo = op.quantization_info().getValue();
- auto aZp = rewriter.create<ConstantOp>(
+ auto aZp = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(
quantizationInfo.a_zp().getValue().getSExtValue()));
- auto bZp = rewriter.create<ConstantOp>(
+ auto bZp = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(
quantizationInfo.b_zp().getValue().getSExtValue()));
rewriter.replaceOpWithNewOp<linalg::QuantizedBatchMatmulOp>(
// When quantized, the input elemeny type is not the same as the output
Attribute resultZeroAttr = rewriter.getZeroAttr(outputETy);
- Value zero = rewriter.create<ConstantOp>(loc, resultZeroAttr);
+ Value zero = rewriter.create<arith::ConstantOp>(loc, resultZeroAttr);
Value zeroTensor =
rewriter.create<linalg::FillOp>(loc, zero, initTensor).getResult(0);
SmallVector<int64_t> permutation{1, 0};
auto permutationAttr = DenseIntElementsAttr::get(
RankedTensorType::get({2}, rewriter.getI64Type()), permutation);
- Value permutationValue = rewriter.create<ConstantOp>(loc, permutationAttr);
+ Value permutationValue =
+ rewriter.create<arith::ConstantOp>(loc, permutationAttr);
SmallVector<int64_t> newWeightShape{weightShape[1], weightShape[0]};
Type newWeightTy =
indexingMaps, getNParallelLoopsAttrs(outputTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddFOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddFOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
}
auto quantizationInfo = op.quantization_info().getValue();
- auto inputZp = rewriter.create<ConstantOp>(
+ auto inputZp = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(
quantizationInfo.input_zp().getValue().getSExtValue()));
- auto outputZp = rewriter.create<ConstantOp>(
+ auto outputZp = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(
quantizationInfo.weight_zp().getValue().getSExtValue()));
Value matmul =
indexingMaps, getNParallelLoopsAttrs(outputTy.getRank()),
[&](OpBuilder &nestedBuilder, Location nestedLoc,
ValueRange args) {
- Value added =
- nestedBuilder.create<AddIOp>(loc, args[0], args[1]);
+ Value added = nestedBuilder.create<arith::AddIOp>(
+ loc, args[0], args[1]);
nestedBuilder.create<linalg::YieldOp>(nestedLoc, added);
})
.getResult(0);
Value multiplierConstant;
int64_t multiplierArg = 0;
if (multiplierValues.size() == 1) {
- multiplierConstant = rewriter.create<ConstantOp>(
+ multiplierConstant = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(multiplierValues.front()));
} else {
SmallVector<AffineExpr, 2> multiplierExprs{
auto multiplierType =
RankedTensorType::get({static_cast<int64_t>(multiplierValues.size())},
rewriter.getI32Type());
- genericInputs.push_back(rewriter.create<ConstantOp>(
+ genericInputs.push_back(rewriter.create<arith::ConstantOp>(
loc, DenseIntElementsAttr::get(multiplierType, multiplierValues)));
indexingMaps.push_back(AffineMap::get(/*dimCount=*/rank,
Value shiftConstant;
int64_t shiftArg = 0;
if (shiftValues.size() == 1) {
- shiftConstant = rewriter.create<ConstantOp>(
+ shiftConstant = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI8IntegerAttr(shiftValues.front()));
} else {
SmallVector<AffineExpr, 2> shiftExprs = {
auto shiftType =
RankedTensorType::get({static_cast<int64_t>(shiftValues.size())},
rewriter.getIntegerType(8));
- genericInputs.push_back(rewriter.create<ConstantOp>(
+ genericInputs.push_back(rewriter.create<arith::ConstantOp>(
loc, DenseIntElementsAttr::get(shiftType, shiftValues)));
indexingMaps.push_back(AffineMap::get(/*dimCount=*/rank,
/*symbolCount=*/0, shiftExprs,
valueTy.getIntOrFloatBitWidth()),
value)
.getResult(0);
- value = nestedBuilder.create<ZeroExtendIOp>(
+ value = nestedBuilder.create<arith::ExtUIOp>(
nestedLoc, nestedBuilder.getI32Type(), value);
} else {
- value = nestedBuilder.create<SignExtendIOp>(
+ value = nestedBuilder.create<arith::ExtSIOp>(
nestedLoc, nestedBuilder.getI32Type(), value);
}
}
- value = nestedBuilder.create<SubIOp>(nestedLoc, value, inputZp);
+ value =
+ nestedBuilder.create<arith::SubIOp>(nestedLoc, value, inputZp);
value = nestedBuilder.create<tosa::ApplyScaleOp>(
loc, nestedBuilder.getI32Type(), value, multiplier, shift,
nestedBuilder.getBoolAttr(doubleRound));
// Move to the new zero-point.
- value = nestedBuilder.create<AddIOp>(nestedLoc, value, outputZp);
+ value =
+ nestedBuilder.create<arith::AddIOp>(nestedLoc, value, outputZp);
// Saturate to the output size.
IntegerType outIntType =
intMax = APInt::getMaxValue(outBitWidth).getZExtValue();
}
- auto intMinVal = nestedBuilder.create<ConstantOp>(
- loc,
- nestedBuilder.getIntegerAttr(nestedBuilder.getI32Type(), intMin));
- auto intMaxVal = nestedBuilder.create<ConstantOp>(
- loc,
- nestedBuilder.getIntegerAttr(nestedBuilder.getI32Type(), intMax));
+ auto intMinVal = nestedBuilder.create<arith::ConstantOp>(
+ loc, nestedBuilder.getI32IntegerAttr(intMin));
+ auto intMaxVal = nestedBuilder.create<arith::ConstantOp>(
+ loc, nestedBuilder.getI32IntegerAttr(intMax));
- value =
- clampHelper<mlir::CmpIOp>(nestedLoc, value, intMinVal, intMaxVal,
- CmpIPredicate::slt, nestedBuilder);
+ value = clampHelper<arith::CmpIOp>(
+ nestedLoc, value, intMinVal, intMaxVal, arith::CmpIPredicate::slt,
+ nestedBuilder);
if (outIntType.getWidth() < 32) {
- value = nestedBuilder.create<TruncateIOp>(
+ value = nestedBuilder.create<arith::TruncIOp>(
nestedLoc, rewriter.getIntegerType(outIntType.getWidth()),
value);
Value x = rewriter.create<linalg::IndexOp>(loc, 2);
Value channel = rewriter.create<linalg::IndexOp>(loc, 3);
- auto hwMin =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(0));
- auto hMax = rewriter.create<ConstantOp>(
+ auto hwMin = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(0));
+ auto hMax = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(imageH - 1));
- auto wMax = rewriter.create<ConstantOp>(
+ auto wMax = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(imageW - 1));
- Value inY = rewriter.create<IndexCastOp>(loc, rewriter.getI32Type(), y);
- Value inX = rewriter.create<IndexCastOp>(loc, rewriter.getI32Type(), x);
+ Value inY =
+ rewriter.create<arith::IndexCastOp>(loc, rewriter.getI32Type(), y);
+ Value inX =
+ rewriter.create<arith::IndexCastOp>(loc, rewriter.getI32Type(), x);
int32_t shift = op.shift();
bool floatingPointMode = shift == 0;
Value yStride, xStride, yOffset, xOffset;
if (floatingPointMode) {
- yStride = rewriter.create<ConstantOp>(loc, op.stride_fp()[0]);
- xStride = rewriter.create<ConstantOp>(loc, op.stride_fp()[1]);
- yOffset = rewriter.create<ConstantOp>(loc, op.offset_fp()[0]);
- xOffset = rewriter.create<ConstantOp>(loc, op.offset_fp()[1]);
+ yStride = rewriter.create<arith::ConstantOp>(loc, op.stride_fp()[0]);
+ xStride = rewriter.create<arith::ConstantOp>(loc, op.stride_fp()[1]);
+ yOffset = rewriter.create<arith::ConstantOp>(loc, op.offset_fp()[0]);
+ xOffset = rewriter.create<arith::ConstantOp>(loc, op.offset_fp()[1]);
} else {
SmallVector<int32_t> stride, offset;
getValuesFromIntArrayAttribute(op.stride(), stride);
getValuesFromIntArrayAttribute(op.offset(), offset);
- yStride = rewriter.create<ConstantOp>(
+ yStride = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(stride[0]));
- xStride = rewriter.create<ConstantOp>(
+ xStride = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(stride[1]));
- yOffset = rewriter.create<ConstantOp>(
+ yOffset = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(offset[0]));
- xOffset = rewriter.create<ConstantOp>(
+ xOffset = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(offset[1]));
}
// dx = x - ix
Value ix, iy, dx, dy;
if (floatingPointMode) {
- Value y = rewriter.create<UIToFPOp>(loc, rewriter.getF32Type(), inY);
- Value x = rewriter.create<UIToFPOp>(loc, rewriter.getF32Type(), inX);
+ Value y =
+ rewriter.create<arith::UIToFPOp>(loc, rewriter.getF32Type(), inY);
+ Value x =
+ rewriter.create<arith::UIToFPOp>(loc, rewriter.getF32Type(), inX);
- y = rewriter.create<MulFOp>(loc, y, yStride);
- x = rewriter.create<MulFOp>(loc, x, xStride);
+ y = rewriter.create<arith::MulFOp>(loc, y, yStride);
+ x = rewriter.create<arith::MulFOp>(loc, x, xStride);
- y = rewriter.create<AddFOp>(loc, y, yOffset);
- x = rewriter.create<AddFOp>(loc, x, xOffset);
+ y = rewriter.create<arith::AddFOp>(loc, y, yOffset);
+ x = rewriter.create<arith::AddFOp>(loc, x, xOffset);
- iy = rewriter.create<FloorFOp>(loc, y);
- ix = rewriter.create<FloorFOp>(loc, x);
+ iy = rewriter.create<math::FloorOp>(loc, y);
+ ix = rewriter.create<math::FloorOp>(loc, x);
- dy = rewriter.create<SubFOp>(loc, y, iy);
- dx = rewriter.create<SubFOp>(loc, x, ix);
+ dy = rewriter.create<arith::SubFOp>(loc, y, iy);
+ dx = rewriter.create<arith::SubFOp>(loc, x, ix);
- iy = rewriter.create<FPToSIOp>(loc, rewriter.getI32Type(), iy);
- ix = rewriter.create<FPToSIOp>(loc, rewriter.getI32Type(), ix);
+ iy = rewriter.create<arith::FPToSIOp>(loc, rewriter.getI32Type(), iy);
+ ix = rewriter.create<arith::FPToSIOp>(loc, rewriter.getI32Type(), ix);
} else {
- Value shiftVal =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(shift));
+ Value shiftVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(shift));
- Value y = rewriter.create<MulIOp>(loc, inY, yStride);
- Value x = rewriter.create<MulIOp>(loc, inX, xStride);
+ Value y = rewriter.create<arith::MulIOp>(loc, inY, yStride);
+ Value x = rewriter.create<arith::MulIOp>(loc, inX, xStride);
- y = rewriter.create<AddIOp>(loc, y, yOffset);
- x = rewriter.create<AddIOp>(loc, x, xOffset);
+ y = rewriter.create<arith::AddIOp>(loc, y, yOffset);
+ x = rewriter.create<arith::AddIOp>(loc, x, xOffset);
- iy = rewriter.create<SignedShiftRightOp>(loc, y, shiftVal);
- ix = rewriter.create<SignedShiftRightOp>(loc, x, shiftVal);
+ iy = rewriter.create<arith::ShRSIOp>(loc, y, shiftVal);
+ ix = rewriter.create<arith::ShRSIOp>(loc, x, shiftVal);
- Value yTrunc = rewriter.create<ShiftLeftOp>(loc, iy, shiftVal);
- Value xTrunc = rewriter.create<ShiftLeftOp>(loc, ix, shiftVal);
+ Value yTrunc = rewriter.create<arith::ShLIOp>(loc, iy, shiftVal);
+ Value xTrunc = rewriter.create<arith::ShLIOp>(loc, ix, shiftVal);
- dy = rewriter.create<SubIOp>(loc, y, yTrunc);
- dx = rewriter.create<SubIOp>(loc, x, xTrunc);
+ dy = rewriter.create<arith::SubIOp>(loc, y, yTrunc);
+ dx = rewriter.create<arith::SubIOp>(loc, x, xTrunc);
}
if (op.mode() == "NEAREST_NEIGHBOR") {
Value yPred, xPred;
// Round the index position towards the closest pixel location.
if (floatingPointMode) {
- auto halfVal =
- rewriter.create<ConstantOp>(loc, rewriter.getF32FloatAttr(0.5f));
- yPred = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGE, dy,
- halfVal);
- xPred = rewriter.create<mlir::CmpFOp>(loc, CmpFPredicate::OGE, dx,
- halfVal);
+ auto halfVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getF32FloatAttr(0.5f));
+ yPred = rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGE,
+ dy, halfVal);
+ xPred = rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGE,
+ dx, halfVal);
} else {
- auto halfVal = rewriter.create<ConstantOp>(
+ auto halfVal = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(1 << (shift - 1)));
- yPred = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sge, dy,
- halfVal);
- xPred = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sge, dx,
- halfVal);
+ yPred = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sge,
+ dy, halfVal);
+ xPred = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sge,
+ dx, halfVal);
}
- auto zeroVal =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(0));
- auto oneVal =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(1));
+ auto zeroVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(0));
+ auto oneVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(1));
auto yOffset =
rewriter.create<mlir::SelectOp>(loc, yPred, oneVal, zeroVal);
auto xOffset =
rewriter.create<mlir::SelectOp>(loc, xPred, oneVal, zeroVal);
- iy = rewriter.create<AddIOp>(loc, iy, yOffset);
- ix = rewriter.create<AddIOp>(loc, ix, xOffset);
+ iy = rewriter.create<arith::AddIOp>(loc, iy, yOffset);
+ ix = rewriter.create<arith::AddIOp>(loc, ix, xOffset);
// Clamp the to be within the bounds of the input image.
- iy = clampHelper<mlir::CmpIOp>(loc, iy, hwMin, hMax, CmpIPredicate::slt,
- rewriter);
- ix = clampHelper<mlir::CmpIOp>(loc, ix, hwMin, wMax, CmpIPredicate::slt,
- rewriter);
+ iy = clampHelper<arith::CmpIOp>(loc, iy, hwMin, hMax,
+ arith::CmpIPredicate::slt, rewriter);
+ ix = clampHelper<arith::CmpIOp>(loc, ix, hwMin, wMax,
+ arith::CmpIPredicate::slt, rewriter);
// Read the value from the input array.
- iy = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), iy);
- ix = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), ix);
+ iy = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ iy);
+ ix = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ ix);
Value result = rewriter.create<tensor::ExtractOp>(
loc, input, ValueRange{batch, iy, ix, channel});
Value y0 = iy;
Value x0 = ix;
- auto oneVal =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(1));
- Value y1 = rewriter.create<AddIOp>(loc, y0, oneVal);
- Value x1 = rewriter.create<AddIOp>(loc, x0, oneVal);
-
- y0 = clampHelper<mlir::CmpIOp>(loc, y0, hwMin, hMax, CmpIPredicate::slt,
- rewriter);
- y1 = clampHelper<mlir::CmpIOp>(loc, y1, hwMin, hMax, CmpIPredicate::slt,
- rewriter);
-
- x0 = clampHelper<mlir::CmpIOp>(loc, x0, hwMin, wMax, CmpIPredicate::slt,
- rewriter);
- x1 = clampHelper<mlir::CmpIOp>(loc, x1, hwMin, wMax, CmpIPredicate::slt,
- rewriter);
-
- y0 = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), y0);
- y1 = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), y1);
- x0 = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), x0);
- x1 = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), x1);
+ auto oneVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(1));
+ Value y1 = rewriter.create<arith::AddIOp>(loc, y0, oneVal);
+ Value x1 = rewriter.create<arith::AddIOp>(loc, x0, oneVal);
+
+ y0 = clampHelper<arith::CmpIOp>(loc, y0, hwMin, hMax,
+ arith::CmpIPredicate::slt, rewriter);
+ y1 = clampHelper<arith::CmpIOp>(loc, y1, hwMin, hMax,
+ arith::CmpIPredicate::slt, rewriter);
+
+ x0 = clampHelper<arith::CmpIOp>(loc, x0, hwMin, wMax,
+ arith::CmpIPredicate::slt, rewriter);
+ x1 = clampHelper<arith::CmpIOp>(loc, x1, hwMin, wMax,
+ arith::CmpIPredicate::slt, rewriter);
+
+ y0 = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ y0);
+ y1 = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ y1);
+ x0 = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ x0);
+ x1 = rewriter.create<arith::IndexCastOp>(loc, rewriter.getIndexType(),
+ x1);
Value y0x0 = rewriter.create<tensor::ExtractOp>(
loc, input, ValueRange{batch, y0, x0, channel});
loc, input, ValueRange{batch, y1, x1, channel});
if (floatingPointMode) {
- auto oneVal =
- rewriter.create<ConstantOp>(loc, rewriter.getF32FloatAttr(1.f));
+ auto oneVal = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getF32FloatAttr(1.f));
Value rightPart = dx;
- Value leftPart = rewriter.create<SubFOp>(loc, oneVal, dx);
+ Value leftPart = rewriter.create<arith::SubFOp>(loc, oneVal, dx);
- y0x0 = rewriter.create<MulFOp>(loc, y0x0, leftPart);
- y0x1 = rewriter.create<MulFOp>(loc, y0x1, rightPart);
- Value topAcc = rewriter.create<AddFOp>(loc, y0x0, y0x1);
+ y0x0 = rewriter.create<arith::MulFOp>(loc, y0x0, leftPart);
+ y0x1 = rewriter.create<arith::MulFOp>(loc, y0x1, rightPart);
+ Value topAcc = rewriter.create<arith::AddFOp>(loc, y0x0, y0x1);
- y1x0 = rewriter.create<MulFOp>(loc, y1x0, leftPart);
- y1x1 = rewriter.create<MulFOp>(loc, y1x1, rightPart);
- Value bottomAcc = rewriter.create<AddFOp>(loc, y1x0, y1x1);
+ y1x0 = rewriter.create<arith::MulFOp>(loc, y1x0, leftPart);
+ y1x1 = rewriter.create<arith::MulFOp>(loc, y1x1, rightPart);
+ Value bottomAcc = rewriter.create<arith::AddFOp>(loc, y1x0, y1x1);
Value bottomPart = dy;
- Value topPart = rewriter.create<SubFOp>(loc, oneVal, dy);
- topAcc = rewriter.create<MulFOp>(loc, topAcc, topPart);
- bottomAcc = rewriter.create<MulFOp>(loc, bottomAcc, bottomPart);
- Value result = rewriter.create<AddFOp>(loc, topAcc, bottomAcc);
+ Value topPart = rewriter.create<arith::SubFOp>(loc, oneVal, dy);
+ topAcc = rewriter.create<arith::MulFOp>(loc, topAcc, topPart);
+ bottomAcc =
+ rewriter.create<arith::MulFOp>(loc, bottomAcc, bottomPart);
+ Value result = rewriter.create<arith::AddFOp>(loc, topAcc, bottomAcc);
rewriter.create<linalg::YieldOp>(loc, result);
return success();
} else {
- y0x0 = rewriter.create<SignExtendIOp>(loc, resultElementTy, y0x0);
- y0x1 = rewriter.create<SignExtendIOp>(loc, resultElementTy, y0x1);
- y1x0 = rewriter.create<SignExtendIOp>(loc, resultElementTy, y1x0);
- y1x1 = rewriter.create<SignExtendIOp>(loc, resultElementTy, y1x1);
+ y0x0 = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, y0x0);
+ y0x1 = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, y0x1);
+ y1x0 = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, y1x0);
+ y1x1 = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, y1x1);
if (resultElementTy.getIntOrFloatBitWidth() > 32) {
- dx = rewriter.create<SignExtendIOp>(loc, resultElementTy, dx);
- dy = rewriter.create<SignExtendIOp>(loc, resultElementTy, dy);
+ dx = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, dx);
+ dy = rewriter.create<arith::ExtSIOp>(loc, resultElementTy, dy);
}
- auto unitVal = rewriter.create<ConstantOp>(
+ auto unitVal = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(resultElementTy, 1 << shift));
Value rightPart = dx;
- Value leftPart = rewriter.create<SubIOp>(loc, unitVal, dx);
+ Value leftPart = rewriter.create<arith::SubIOp>(loc, unitVal, dx);
- y0x0 = rewriter.create<MulIOp>(loc, y0x0, leftPart);
- y0x1 = rewriter.create<MulIOp>(loc, y0x1, rightPart);
- Value topAcc = rewriter.create<AddIOp>(loc, y0x0, y0x1);
+ y0x0 = rewriter.create<arith::MulIOp>(loc, y0x0, leftPart);
+ y0x1 = rewriter.create<arith::MulIOp>(loc, y0x1, rightPart);
+ Value topAcc = rewriter.create<arith::AddIOp>(loc, y0x0, y0x1);
- y1x0 = rewriter.create<MulIOp>(loc, y1x0, leftPart);
- y1x1 = rewriter.create<MulIOp>(loc, y1x1, rightPart);
- Value bottomAcc = rewriter.create<AddIOp>(loc, y1x0, y1x1);
+ y1x0 = rewriter.create<arith::MulIOp>(loc, y1x0, leftPart);
+ y1x1 = rewriter.create<arith::MulIOp>(loc, y1x1, rightPart);
+ Value bottomAcc = rewriter.create<arith::AddIOp>(loc, y1x0, y1x1);
Value bottomPart = dy;
- Value topPart = rewriter.create<SubIOp>(loc, unitVal, dy);
- topAcc = rewriter.create<MulIOp>(loc, topAcc, topPart);
- bottomAcc = rewriter.create<MulIOp>(loc, bottomAcc, bottomPart);
- Value result = rewriter.create<AddIOp>(loc, topAcc, bottomAcc);
+ Value topPart = rewriter.create<arith::SubIOp>(loc, unitVal, dy);
+ topAcc = rewriter.create<arith::MulIOp>(loc, topAcc, topPart);
+ bottomAcc =
+ rewriter.create<arith::MulIOp>(loc, bottomAcc, bottomPart);
+ Value result = rewriter.create<arith::AddIOp>(loc, topAcc, bottomAcc);
rewriter.create<linalg::YieldOp>(loc, result);
return success();
Location loc = op.getLoc();
int axis = op.axis();
Value axisValue =
- rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(axis));
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(axis));
int rank = resultType.getRank();
SmallVector<Value, 3> offsets, sizes, strides;
sizes.reserve(rank);
- strides.resize(rank, rewriter.create<ConstantIndexOp>(loc, 1));
- offsets.resize(rank, rewriter.create<ConstantIndexOp>(loc, 0));
+ strides.resize(rank, rewriter.create<arith::ConstantIndexOp>(loc, 1));
+ offsets.resize(rank, rewriter.create<arith::ConstantIndexOp>(loc, 0));
for (int i = 0; i < rank; ++i) {
sizes.push_back(
Value resultDimSize = sizes[axis];
for (auto arg : adaptor.getOperands().drop_front()) {
auto size = rewriter.create<tensor::DimOp>(loc, arg, axisValue);
- resultDimSize = rewriter.create<AddIOp>(loc, resultDimSize, size);
+ resultDimSize = rewriter.create<arith::AddIOp>(loc, resultDimSize, size);
}
sizes[axis] = resultDimSize;
Value init = rewriter.create<linalg::InitTensorOp>(
loc, resultType.getShape(), resultType.getElementType());
- Value zeroVal = rewriter.create<ConstantOp>(
+ Value zeroVal = rewriter.create<arith::ConstantOp>(
loc, rewriter.getZeroAttr(resultType.getElementType()));
Value result =
rewriter.create<linalg::FillOp>(loc, zeroVal, init).getResult(0);
sizes[axis] = rewriter.create<tensor::DimOp>(loc, arg, axisValue);
result = rewriter.create<tensor::InsertSliceOp>(loc, arg, result, offsets,
sizes, strides);
- offsets[axis] = rewriter.create<AddIOp>(loc, offsets[axis], sizes[axis]);
+ offsets[axis] =
+ rewriter.create<arith::AddIOp>(loc, offsets[axis], sizes[axis]);
}
rewriter.replaceOp(op, result);
return success();
auto index =
rewriter.create<linalg::IndexOp>(nestedLoc, i).getResult();
if (i == axis) {
- auto one = rewriter.create<ConstantIndexOp>(nestedLoc, 1);
+ auto one = rewriter.create<arith::ConstantIndexOp>(nestedLoc, 1);
auto sizeMinusOne =
- rewriter.create<SubIOp>(nestedLoc, axisDimSize, one);
- index = rewriter.create<SubIOp>(nestedLoc, sizeMinusOne, index);
+ rewriter.create<arith::SubIOp>(nestedLoc, axisDimSize, one);
+ index = rewriter.create<arith::SubIOp>(nestedLoc, sizeMinusOne,
+ index);
}
indices.push_back(index);
"tosa.pad to linalg lowering encountered an unknown element type");
}
- Value lowIndex = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(0));
+ Value lowIndex =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(0));
Value highIndex =
- rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(1));
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(1));
SmallVector<OpFoldResult, 3> lowValues;
SmallVector<OpFoldResult, 3> highValues;
highValues.reserve(rank);
for (int i = 0; i < rank; i++) {
- Value inputIndex = rewriter.createOrFold<ConstantIndexOp>(loc, i);
+ Value inputIndex = rewriter.createOrFold<arith::ConstantIndexOp>(loc, i);
Value lowVal = rewriter.createOrFold<tensor::ExtractOp>(
loc, padding, ValueRange({inputIndex, lowIndex}));
Value highVal = rewriter.createOrFold<tensor::ExtractOp>(
loc, padding, ValueRange({inputIndex, highIndex}));
- lowVal = rewriter.createOrFold<IndexCastOp>(loc, rewriter.getIndexType(),
- lowVal);
- highVal = rewriter.createOrFold<IndexCastOp>(loc, rewriter.getIndexType(),
- highVal);
+ lowVal = rewriter.createOrFold<arith::IndexCastOp>(
+ loc, rewriter.getIndexType(), lowVal);
+ highVal = rewriter.createOrFold<arith::IndexCastOp>(
+ loc, rewriter.getIndexType(), highVal);
lowValues.push_back(lowVal);
highValues.push_back(highVal);
}
- Value constant = rewriter.create<ConstantOp>(loc, constantAttr);
+ Value constant = rewriter.create<arith::ConstantOp>(loc, constantAttr);
auto newPadOp = linalg::PadTensorOp::createPadScalarOp(
padOp.getType(), input, constant, lowValues, highValues,
.create<linalg::InitTensorOp>(loc, ArrayRef<Value>({}),
resultTy.getShape(), outElementTy)
.result();
- auto fillValueIdx = rewriter.create<ConstantOp>(
+ auto fillValueIdx = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(outElementTy, 0));
auto filledTensorIdx =
rewriter.create<linalg::FillOp>(loc, fillValueIdx, initTensorIdx)
return rewriter.notifyMatchFailure(
argmaxOp, "unsupported tosa.argmax element type");
- auto fillValueMax = rewriter.create<ConstantOp>(loc, fillValueMaxAttr);
+ auto fillValueMax =
+ rewriter.create<arith::ConstantOp>(loc, fillValueMaxAttr);
auto filledTensorMax =
rewriter.create<linalg::FillOp>(loc, fillValueMax, initTensorMax)
.result();
auto oldIndex = blockArgs[1];
auto oldValue = blockArgs[2];
- Value newIndex = rewriter.create<IndexCastOp>(
+ Value newIndex = rewriter.create<arith::IndexCastOp>(
nestedLoc, oldIndex.getType(),
rewriter.create<linalg::IndexOp>(loc, axis));
Value predicate;
if (inElementTy.isa<FloatType>()) {
- predicate = rewriter.create<mlir::CmpFOp>(
- nestedLoc, CmpFPredicate::OGT, newValue, oldValue);
+ predicate = rewriter.create<arith::CmpFOp>(
+ nestedLoc, arith::CmpFPredicate::OGT, newValue, oldValue);
} else if (inElementTy.isa<IntegerType>()) {
- predicate = rewriter.create<mlir::CmpIOp>(
- nestedLoc, CmpIPredicate::sgt, newValue, oldValue);
+ predicate = rewriter.create<arith::CmpIOp>(
+ nestedLoc, arith::CmpIPredicate::sgt, newValue, oldValue);
} else {
didEncounterError = true;
return;
[&](OpBuilder &b, Location loc, ValueRange args) {
auto indexValue = args[0];
auto index0 = rewriter.create<linalg::IndexOp>(loc, 0);
- Value index1 = rewriter.create<IndexCastOp>(
+ Value index1 = rewriter.create<arith::IndexCastOp>(
loc, rewriter.getIndexType(), indexValue);
auto index2 = rewriter.create<linalg::IndexOp>(loc, 2);
Value extract = rewriter.create<tensor::ExtractOp>(
rewriter.setInsertionPointToStart(block);
if (inputElementTy.isInteger(8) && tableElementTy.isInteger(8) &&
resultElementTy.isInteger(8)) {
- Value index = rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(),
- inputValue);
- Value offset = rewriter.create<ConstantIndexOp>(loc, 128);
- index = rewriter.create<AddIOp>(loc, rewriter.getIndexType(), index,
- offset);
+ Value index = rewriter.create<arith::IndexCastOp>(
+ loc, rewriter.getIndexType(), inputValue);
+ Value offset = rewriter.create<arith::ConstantIndexOp>(loc, 128);
+ index = rewriter.create<arith::AddIOp>(loc, rewriter.getIndexType(),
+ index, offset);
Value extract =
rewriter.create<tensor::ExtractOp>(loc, table, ValueRange{index});
rewriter.create<linalg::YieldOp>(loc, extract);
if (inputElementTy.isInteger(16) && tableElementTy.isInteger(16) &&
resultElementTy.isInteger(32)) {
- Value extend = rewriter.create<SignExtendIOp>(
+ Value extend = rewriter.create<arith::ExtSIOp>(
loc, rewriter.getI32Type(), inputValue);
- auto offset =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(32768));
- auto seven =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(7));
- auto one =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(1));
- auto b1111111 =
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(127));
+ auto offset = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(32768));
+ auto seven = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(7));
+ auto one = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(1));
+ auto b1111111 = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(127));
// Compute the index and fractional part from the input value:
// value = value + 32768
// index = value >> 7;
// fraction = 0x01111111 & value
- auto extendAdd = rewriter.create<AddIOp>(loc, extend, offset);
- Value index =
- rewriter.create<UnsignedShiftRightOp>(loc, extendAdd, seven);
- Value fraction = rewriter.create<mlir::AndOp>(loc, extendAdd, b1111111);
+ auto extendAdd = rewriter.create<arith::AddIOp>(loc, extend, offset);
+ Value index = rewriter.create<arith::ShRUIOp>(loc, extendAdd, seven);
+ Value fraction =
+ rewriter.create<arith::AndIOp>(loc, extendAdd, b1111111);
// Extract the base and next values from the table.
// base = (int32_t) table[index];
// next = (int32_t) table[index + 1];
- Value indexPlusOne = rewriter.create<AddIOp>(loc, index, one);
+ Value indexPlusOne = rewriter.create<arith::AddIOp>(loc, index, one);
- index =
- rewriter.create<IndexCastOp>(loc, rewriter.getIndexType(), index);
- indexPlusOne = rewriter.create<IndexCastOp>(
+ index = rewriter.create<arith::IndexCastOp>(
+ loc, rewriter.getIndexType(), index);
+ indexPlusOne = rewriter.create<arith::IndexCastOp>(
loc, rewriter.getIndexType(), indexPlusOne);
Value base =
Value next = rewriter.create<tensor::ExtractOp>(
loc, table, ValueRange{indexPlusOne});
- base = rewriter.create<SignExtendIOp>(loc, rewriter.getI32Type(), base);
- next = rewriter.create<SignExtendIOp>(loc, rewriter.getI32Type(), next);
+ base =
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI32Type(), base);
+ next =
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI32Type(), next);
// Use the fractional part to interpolate between the input values:
// result = (base << 7) + (next - base) * fraction
- Value baseScaled = rewriter.create<ShiftLeftOp>(loc, base, seven);
- Value diff = rewriter.create<SubIOp>(loc, next, base);
- Value diffScaled = rewriter.create<MulIOp>(loc, diff, fraction);
- Value result = rewriter.create<AddIOp>(loc, baseScaled, diffScaled);
+ Value baseScaled = rewriter.create<arith::ShLIOp>(loc, base, seven);
+ Value diff = rewriter.create<arith::SubIOp>(loc, next, base);
+ Value diffScaled = rewriter.create<arith::MulIOp>(loc, diff, fraction);
+ Value result =
+ rewriter.create<arith::AddIOp>(loc, baseScaled, diffScaled);
rewriter.create<linalg::YieldOp>(loc, result);
pad.resize(pad.size() + 2, 0);
Value paddedInput = applyPad(loc, input, pad, initialAttr, rewriter);
- Value initialValue = rewriter.create<ConstantOp>(loc, initialAttr);
+ Value initialValue = rewriter.create<arith::ConstantOp>(loc, initialAttr);
SmallVector<int64_t> kernel, stride;
getValuesFromIntArrayAttribute(op.kernel(), kernel);
Value paddedInput = applyPad(loc, input, pad, padAttr, rewriter);
Attribute initialAttr = rewriter.getZeroAttr(accETy);
- Value initialValue = rewriter.create<ConstantOp>(loc, initialAttr);
+ Value initialValue = rewriter.create<arith::ConstantOp>(loc, initialAttr);
SmallVector<int64_t> kernel, stride;
getValuesFromIntArrayAttribute(op.kernel(), kernel);
ArrayRef<AffineMap>({affineMap, affineMap}),
getNParallelLoopsAttrs(resultTy.getRank()),
[&](OpBuilder &b, Location loc, ValueRange args) {
- auto zero = rewriter.create<ConstantIndexOp>(loc, 0);
- auto one = rewriter.create<ConstantIndexOp>(loc, 1);
- auto iH = rewriter.create<ConstantIndexOp>(
+ auto zero = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ auto one = rewriter.create<arith::ConstantIndexOp>(loc, 1);
+ auto iH = rewriter.create<arith::ConstantIndexOp>(
loc, poolingOpTy.getDimSize(1) - 1);
- auto iW = rewriter.create<ConstantIndexOp>(
+ auto iW = rewriter.create<arith::ConstantIndexOp>(
loc, poolingOpTy.getDimSize(2) - 1);
// Compute the indices from either end.
auto y0 = rewriter.create<linalg::IndexOp>(loc, 1);
auto x0 = rewriter.create<linalg::IndexOp>(loc, 2);
- auto y1 = rewriter.create<SubIOp>(loc, iH, y0);
- auto x1 = rewriter.create<SubIOp>(loc, iW, x0);
+ auto y1 = rewriter.create<arith::SubIOp>(loc, iH, y0);
+ auto x1 = rewriter.create<arith::SubIOp>(loc, iW, x0);
// Determines what the portion of valid input is covered by the
// kernel.
if (pad == 0)
return v;
- auto padVal = rewriter.create<ConstantIndexOp>(loc, pad);
- Value dx = rewriter.create<SubIOp>(loc, x, padVal);
+ auto padVal = rewriter.create<arith::ConstantIndexOp>(loc, pad);
+ Value dx = rewriter.create<arith::SubIOp>(loc, x, padVal);
- Value cmp = rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt,
- dx, zero);
+ Value cmp = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, dx, zero);
Value offset = rewriter.create<mlir::SelectOp>(loc, cmp, dx, zero);
- return rewriter.create<mlir::AddIOp>(loc, v, offset)->getResult(0);
+ return rewriter.create<arith::AddIOp>(loc, v, offset)->getResult(0);
};
// Compute the vertical component of coverage.
- auto kH0 = rewriter.create<ConstantIndexOp>(loc, kernel[0]);
+ auto kH0 = rewriter.create<arith::ConstantIndexOp>(loc, kernel[0]);
auto kH1 = padFn(kH0, y0, pad[2]);
auto kH2 = padFn(kH1, y1, pad[3]);
- auto kHCmp =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, kH2, one);
+ auto kHCmp = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, kH2, one);
auto kH3 = rewriter.create<SelectOp>(loc, kHCmp, one, kH2);
// compute the horizontal component of coverage.
- auto kW0 = rewriter.create<ConstantIndexOp>(loc, kernel[1]);
+ auto kW0 = rewriter.create<arith::ConstantIndexOp>(loc, kernel[1]);
auto kW1 = padFn(kW0, x0, pad[4]);
auto kW2 = padFn(kW1, x1, pad[5]);
- auto kWCmp =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, kW2, one);
+ auto kWCmp = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::slt, kW2, one);
auto kW3 = rewriter.create<SelectOp>(loc, kWCmp, one, kW2);
// Compute the total number of elements and normalize.
- Value count = rewriter.create<MulIOp>(loc, kH3, kW3);
- auto countI = rewriter.create<mlir::IndexCastOp>(
+ Value count = rewriter.create<arith::MulIOp>(loc, kH3, kW3);
+ auto countI = rewriter.create<arith::IndexCastOp>(
loc, rewriter.getI32Type(), count);
// Divide by the number of summed values. For floats this is just
// to be applied.
Value poolVal = args[0];
if (accETy.isa<FloatType>()) {
- auto countF = rewriter.create<mlir::SIToFPOp>(loc, accETy, countI);
- poolVal =
- rewriter.create<DivFOp>(loc, poolVal, countF)->getResult(0);
+ auto countF = rewriter.create<arith::SIToFPOp>(loc, accETy, countI);
+ poolVal = rewriter.create<arith::DivFOp>(loc, poolVal, countF)
+ ->getResult(0);
} else {
// If we have quantization information we need to apply an offset
// for the input zp value.
if (op.quantization_info()) {
auto quantizationInfo = op.quantization_info().getValue();
- auto inputZp = rewriter.create<mlir::ConstantOp>(
+ auto inputZp = rewriter.create<arith::ConstantOp>(
loc, quantizationInfo.input_zp());
Value offset =
- rewriter.create<mlir::MulIOp>(loc, accETy, countI, inputZp);
- poolVal = rewriter.create<SubIOp>(loc, accETy, poolVal, offset);
+ rewriter.create<arith::MulIOp>(loc, accETy, countI, inputZp);
+ poolVal =
+ rewriter.create<arith::SubIOp>(loc, accETy, poolVal, offset);
}
// Compute the multiplier and shift values for the quantization
int64_t numerator = ((1 << 30) + 1);
int64_t shift = 30;
- Value numeratorVal = rewriter.create<ConstantOp>(
+ Value numeratorVal = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32IntegerAttr(numerator));
Value multiplierVal =
rewriter
- .create<UnsignedDivIOp>(loc, rewriter.getI32Type(),
+ .create<arith::DivUIOp>(loc, rewriter.getI32Type(),
numeratorVal, countI)
.getResult();
- Value shiftVal = rewriter.create<ConstantOp>(
+ Value shiftVal = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI8IntegerAttr(shift));
auto scaled =
// zeropoint.
if (op.quantization_info()) {
auto quantizationInfo = op.quantization_info().getValue();
- auto outputZp = rewriter.create<mlir::ConstantOp>(
+ auto outputZp = rewriter.create<arith::ConstantOp>(
loc, quantizationInfo.output_zp());
- scaled =
- rewriter.create<AddIOp>(loc, scaled, outputZp).getResult();
+ scaled = rewriter.create<arith::AddIOp>(loc, scaled, outputZp)
+ .getResult();
}
// Apply Clip.
int64_t outBitwidth = resultETy.getIntOrFloatBitWidth();
- auto min = rewriter.create<ConstantOp>(
- loc, rewriter.getIntegerAttr(
- accETy,
- APInt::getSignedMinValue(outBitwidth).getSExtValue()));
- auto max = rewriter.create<ConstantOp>(
- loc, rewriter.getIntegerAttr(
- accETy,
- APInt::getSignedMaxValue(outBitwidth).getSExtValue()));
- auto clamp = clampHelper<mlir::CmpIOp>(
- loc, scaled, min, max, CmpIPredicate::slt, rewriter);
+ auto min = rewriter.create<arith::ConstantIntOp>(
+ loc, APInt::getSignedMinValue(outBitwidth).getSExtValue(),
+ accETy);
+ auto max = rewriter.create<arith::ConstantIntOp>(
+ loc, APInt::getSignedMaxValue(outBitwidth).getSExtValue(),
+ accETy);
+ auto clamp = clampHelper<arith::CmpIOp>(
+ loc, scaled, min, max, arith::CmpIPredicate::slt, rewriter);
poolVal = clamp;
// Convert type.
if (resultETy != clamp.getType()) {
- poolVal = rewriter.create<TruncateIOp>(loc, resultETy, poolVal);
+ poolVal =
+ rewriter.create<arith::TruncIOp>(loc, resultETy, poolVal);
}
}
#include "../PassDetail.h"
#include "mlir/Conversion/TosaToLinalg/TosaToLinalg.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/SCF/SCF.h"
: public TosaToLinalgOnTensorsBase<TosaToLinalgOnTensors> {
public:
void getDependentDialects(DialectRegistry ®istry) const override {
- registry
- .insert<linalg::LinalgDialect, math::MathDialect, StandardOpsDialect,
- tensor::TensorDialect, scf::SCFDialect>();
+ registry.insert<arith::ArithmeticDialect, linalg::LinalgDialect,
+ math::MathDialect, StandardOpsDialect,
+ tensor::TensorDialect, scf::SCFDialect>();
}
void runOnFunction() override {
MLIRConversionPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRStandard
MLIRPass
//===----------------------------------------------------------------------===//
#include "mlir/Conversion/TosaToStandard/TosaToStandard.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Tosa/IR/TosaOps.h"
LogicalResult matchAndRewrite(tosa::ConstOp op,
PatternRewriter &rewriter) const final {
- rewriter.replaceOpWithNewOp<::ConstantOp>(op, op.value());
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(op, op.value());
return success();
}
};
bool doubleRound = op.double_round();
Type inType = op.value().getType();
- Value one8 = rewriter.create<ConstantOp>(
+ Value one8 = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(rewriter.getIntegerType(8), 1));
- Value one64 = rewriter.create<ConstantOp>(
+ Value one64 = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(rewriter.getI64Type(), 1));
- Value shiftSubOne8 = rewriter.create<SubIOp>(loc, shift8, one8);
+ Value shiftSubOne8 = rewriter.create<arith::SubIOp>(loc, shift8, one8);
// The rounding value semantics below equate to the following code:
// int64_t round = 1 << (shift - 1);
//
// Note that minimal bitwidth operators are used throughout the block.
- Value round64 = rewriter.create<mlir::ShiftLeftOp>(
+ Value round64 = rewriter.create<arith::ShLIOp>(
loc, one64,
- rewriter.create<SignExtendIOp>(loc, rewriter.getI64Type(),
- shiftSubOne8));
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI64Type(),
+ shiftSubOne8));
// Double rounding is performing a round operation before the shift
if (doubleRound) {
- Value one32 = rewriter.create<ConstantOp>(
+ Value one32 = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(rewriter.getI32Type(), 1));
- Value shift32 = rewriter.create<mlir::SignExtendIOp>(
- loc, rewriter.getI32Type(), shift8);
- Value thirty32 = rewriter.create<ConstantOp>(
+ Value shift32 =
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI32Type(), shift8);
+ Value thirty32 = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(rewriter.getI32Type(), 30));
Value shiftThirty32 =
- rewriter.create<mlir::ShiftLeftOp>(loc, one32, thirty32);
- Value shiftThirty64 = rewriter.create<mlir::SignExtendIOp>(
+ rewriter.create<arith::ShLIOp>(loc, one32, thirty32);
+ Value shiftThirty64 = rewriter.create<arith::ExtSIOp>(
loc, rewriter.getI64Type(), shiftThirty32);
// Round value needs to with be added or subtracted depending on the sign
// of the input value.
Value roundAdd64 =
- rewriter.create<mlir::AddIOp>(loc, round64, shiftThirty64);
+ rewriter.create<arith::AddIOp>(loc, round64, shiftThirty64);
Value roundSub64 =
- rewriter.create<mlir::SubIOp>(loc, round64, shiftThirty64);
+ rewriter.create<arith::SubIOp>(loc, round64, shiftThirty64);
Value zero32 =
- rewriter.create<ConstantOp>(loc, rewriter.getZeroAttr(inType));
- Value valueGreaterThanZero = rewriter.create<mlir::CmpIOp>(
- loc, CmpIPredicate::sge, value32, zero32);
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getZeroAttr(inType));
+ Value valueGreaterThanZero = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sge, value32, zero32);
Value doubleRound64 = rewriter.create<mlir::SelectOp>(
loc, valueGreaterThanZero, roundAdd64, roundSub64);
// We only perform double rounding if the shift value is greater than 32.
- Value thirtyTwo32 = rewriter.create<ConstantOp>(
+ Value thirtyTwo32 = rewriter.create<arith::ConstantOp>(
loc, rewriter.getIntegerAttr(rewriter.getI32Type(), 32));
- Value shiftGreaterThanThirtyTwo = rewriter.create<mlir::CmpIOp>(
- loc, CmpIPredicate::sge, shift32, thirtyTwo32);
+ Value shiftGreaterThanThirtyTwo = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::sge, shift32, thirtyTwo32);
round64 = rewriter.create<mlir::SelectOp>(loc, shiftGreaterThanThirtyTwo,
doubleRound64, round64);
}
// Note that multiply and shift need to be perform in i64 to preserve bits.
Value value64 =
- rewriter.create<SignExtendIOp>(loc, rewriter.getI64Type(), value32);
- Value multiplier64 = rewriter.create<SignExtendIOp>(
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI64Type(), value32);
+ Value multiplier64 = rewriter.create<arith::ExtSIOp>(
loc, rewriter.getI64Type(), multiplier32);
Value shift64 =
- rewriter.create<SignExtendIOp>(loc, rewriter.getI64Type(), shift8);
+ rewriter.create<arith::ExtSIOp>(loc, rewriter.getI64Type(), shift8);
// Multiply as a pair of i64 values to guarantee the end value fits.
- Value result64 = rewriter.create<MulIOp>(loc, value64, multiplier64);
- result64 = rewriter.create<AddIOp>(loc, result64, round64);
- result64 =
- rewriter.create<mlir::SignedShiftRightOp>(loc, result64, shift64);
+ Value result64 = rewriter.create<arith::MulIOp>(loc, value64, multiplier64);
+ result64 = rewriter.create<arith::AddIOp>(loc, result64, round64);
+ result64 = rewriter.create<arith::ShRSIOp>(loc, result64, shift64);
- Value result32 = rewriter.create<mlir::TruncateIOp>(
- loc, rewriter.getI32Type(), result64);
+ Value result32 =
+ rewriter.create<arith::TruncIOp>(loc, rewriter.getI32Type(), result64);
rewriter.replaceOp(op, result32);
return success();
#include "../PassDetail.h"
#include "mlir/Conversion/TosaToStandard/TosaToStandard.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Tosa/IR/TosaOps.h"
target.addIllegalOp<tosa::ConstOp>();
target.addIllegalOp<tosa::SliceOp>();
target.addIllegalOp<tosa::ApplyScaleOp>();
+ target.addLegalDialect<arith::ArithmeticDialect>();
target.addLegalDialect<StandardOpsDialect>();
target.addLegalDialect<tensor::TensorDialect>();
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRGPUOps
MLIRLLVMIR
MLIRMemRef
#include "../PassDetail.h"
#include "mlir/Analysis/SliceAnalysis.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
/// Return true if the constant is a splat to a 2D vector so that it can be
/// converted to a MMA constant matrix op.
-static bool constantSupportsMMAMatrixType(ConstantOp constantOp) {
+static bool constantSupportsMMAMatrixType(arith::ConstantOp constantOp) {
auto vecType = constantOp.getType().dyn_cast<VectorType>();
if (!vecType || vecType.getRank() != 2)
return false;
return transferWriteSupportsMMAMatrixType(transferWrite);
if (auto contract = dyn_cast<vector::ContractionOp>(op))
return contractSupportsMMAMatrixType(contract);
- if (auto constant = dyn_cast<ConstantOp>(op))
+ if (auto constant = dyn_cast<arith::ConstantOp>(op))
return constantSupportsMMAMatrixType(constant);
if (auto broadcast = dyn_cast<vector::BroadcastOp>(op))
return broadcastSupportsMMAMatrixType(broadcast);
}
/// Convert a 2D splat ConstantOp to a SubgroupMmaConstantMatrix op.
-static void convertConstantOp(ConstantOp op,
+static void convertConstantOp(arith::ConstantOp op,
llvm::DenseMap<Value, Value> &valueMapping) {
assert(constantSupportsMMAMatrixType(op));
OpBuilder b(op);
- Attribute splat = op.getValue().cast<SplatElementsAttr>().getSplatValue();
+ Attribute splat = op.value().cast<SplatElementsAttr>().getSplatValue();
auto scalarConstant =
- b.create<ConstantOp>(op.getLoc(), splat.getType(), splat);
+ b.create<arith::ConstantOp>(op.getLoc(), splat.getType(), splat);
const char *fragType = inferFragType(op);
auto vecType = op.getType().cast<VectorType>();
gpu::MMAMatrixType type = gpu::MMAMatrixType::get(
convertTransferWriteOp(transferWrite, valueMapping);
} else if (auto contractOp = dyn_cast<vector::ContractionOp>(op)) {
convertContractOp(contractOp, valueMapping);
- } else if (auto constantOp = dyn_cast<ConstantOp>(op)) {
+ } else if (auto constantOp = dyn_cast<arith::ConstantOp>(op)) {
convertConstantOp(constantOp, valueMapping);
} else if (auto broadcastOp = dyn_cast<vector::BroadcastOp>(op)) {
convertBroadcastOp(broadcastOp, valueMapping);
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRArmNeon
MLIRArmSVE
MLIRArmSVETransforms
#include "mlir/Conversion/VectorToLLVM/ConvertVectorToLLVM.h"
#include "mlir/Conversion/LLVMCommon/VectorPattern.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/FunctionCallUtils.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
return rewriter.create<InsertOp>(loc, from, into, offset);
return rewriter.create<vector::InsertElementOp>(
loc, vectorType, from, into,
- rewriter.create<ConstantIndexOp>(loc, offset));
+ rewriter.create<arith::ConstantIndexOp>(loc, offset));
}
// Helper that picks the proper sequence for extracting.
return rewriter.create<ExtractOp>(loc, vector, offset);
return rewriter.create<vector::ExtractElementOp>(
loc, vectorType.getElementType(), vector,
- rewriter.create<ConstantIndexOp>(loc, offset));
+ rewriter.create<arith::ConstantIndexOp>(loc, offset));
}
// Helper that returns a subset of `arrayAttr` as a vector of int64_t.
auto loc = op.getLoc();
auto elemType = vType.getElementType();
- Value zero = rewriter.create<ConstantOp>(loc, elemType,
- rewriter.getZeroAttr(elemType));
+ Value zero = rewriter.create<arith::ConstantOp>(
+ loc, elemType, rewriter.getZeroAttr(elemType));
Value desc = rewriter.create<SplatOp>(loc, vType, zero);
for (int64_t i = 0, e = vType.getShape().front(); i != e; ++i) {
Value extrLHS = rewriter.create<ExtractOp>(loc, op.lhs(), i);
if (rank == 0) {
switch (conversion) {
case PrintConversion::ZeroExt64:
- value = rewriter.create<ZeroExtendIOp>(
+ value = rewriter.create<arith::ExtUIOp>(
loc, value, IntegerType::get(rewriter.getContext(), 64));
break;
case PrintConversion::SignExt64:
- value = rewriter.create<SignExtendIOp>(
+ value = rewriter.create<arith::ExtSIOp>(
loc, value, IntegerType::get(rewriter.getContext(), 64));
break;
case PrintConversion::None:
}
// Extract/insert on a lower ranked extract strided slice op.
- Value zero = rewriter.create<ConstantOp>(loc, elemType,
- rewriter.getZeroAttr(elemType));
+ Value zero = rewriter.create<arith::ConstantOp>(
+ loc, elemType, rewriter.getZeroAttr(elemType));
Value res = rewriter.create<SplatOp>(loc, dstType, zero);
for (int64_t off = offset, e = offset + size * stride, idx = 0; off < e;
off += stride, ++idx) {
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
#include "mlir/Dialect/AMX/AMXDialect.h"
#include "mlir/Dialect/AMX/Transforms.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/ArmNeon/ArmNeonDialect.h"
#include "mlir/Dialect/ArmSVE/ArmSVEDialect.h"
#include "mlir/Dialect/ArmSVE/Transforms.h"
// Override explicitly to allow conditional dialect dependence.
void getDependentDialects(DialectRegistry ®istry) const override {
registry.insert<LLVM::LLVMDialect>();
+ registry.insert<arith::ArithmeticDialect>();
registry.insert<memref::MemRefDialect>();
if (enableArmNeon)
registry.insert<arm_neon::ArmNeonDialect>();
// Architecture specific augmentations.
LLVMConversionTarget target(getContext());
+ target.addLegalDialect<arith::ArithmeticDialect>();
target.addLegalDialect<memref::MemRefDialect>();
target.addLegalDialect<StandardOpsDialect>();
target.addLegalOp<UnrealizedConversionCastOp>();
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRLLVMIR
MLIRMemRef
MLIRTransforms
#include "../PassDetail.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/Utils.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/Vector/VectorOps.h"
return Value();
Location loc = xferOp.getLoc();
- Value ivI32 =
- b.create<IndexCastOp>(loc, IntegerType::get(b.getContext(), 32), iv);
+ Value ivI32 = b.create<arith::IndexCastOp>(
+ loc, IntegerType::get(b.getContext(), 32), iv);
return b.create<vector::ExtractElementOp>(loc, xferOp.mask(), ivI32);
}
bindDims(xferOp.getContext(), d0, d1);
Value base = xferOp.indices()[dim.getValue()];
Value memrefIdx = makeComposedAffineApply(b, loc, d0 + d1, {base, iv});
- cond = lb.create<CmpIOp>(CmpIPredicate::sgt, memrefDim, memrefIdx);
+ cond = lb.create<arith::CmpIOp>(arith::CmpIPredicate::sgt, memrefDim,
+ memrefIdx);
}
// Condition check 2: Masked in?
if (auto maskCond = generateMaskCheck(b, xferOp, iv)) {
if (cond)
- cond = lb.create<AndOp>(cond, maskCond);
+ cond = lb.create<arith::AndIOp>(cond, maskCond);
else
cond = maskCond;
}
}
// Loop bounds and step.
- auto lb = locB.create<ConstantIndexOp>(0);
- auto ub = locB.create<ConstantIndexOp>(
+ auto lb = locB.create<arith::ConstantIndexOp>(0);
+ auto ub = locB.create<arith::ConstantIndexOp>(
castedDataType.getDimSize(castedDataType.getRank() - 1));
- auto step = locB.create<ConstantIndexOp>(1);
+ auto step = locB.create<arith::ConstantIndexOp>(1);
// TransferWriteOps that operate on tensors return the modified tensor and
// require a loop state.
auto loopState = Strategy<OpTy>::initialLoopState(xferOp);
// Generate fully unrolled loop of transfer ops.
Location loc = xferOp.getLoc();
for (int64_t i = 0; i < dimSize; ++i) {
- Value iv = rewriter.create<ConstantIndexOp>(loc, i);
+ Value iv = rewriter.create<arith::ConstantIndexOp>(loc, i);
vec = generateInBoundsCheck(
rewriter, xferOp, iv, unpackedDim(xferOp), TypeRange(vecType),
// Generate fully unrolled loop of transfer ops.
Location loc = xferOp.getLoc();
for (int64_t i = 0; i < dimSize; ++i) {
- Value iv = rewriter.create<ConstantIndexOp>(loc, i);
+ Value iv = rewriter.create<arith::ConstantIndexOp>(loc, i);
auto updatedSource = generateInBoundsCheck(
rewriter, xferOp, iv, unpackedDim(xferOp),
ValueRange loopState) {
SmallVector<Value, 8> indices;
auto dim = get1dMemrefIndices(b, xferOp, iv, indices);
- Value ivI32 =
- b.create<IndexCastOp>(loc, IntegerType::get(b.getContext(), 32), iv);
+ Value ivI32 = b.create<arith::IndexCastOp>(
+ loc, IntegerType::get(b.getContext(), 32), iv);
auto vec = loopState[0];
// In case of out-of-bounds access, leave `vec` as is (was initialized with
ValueRange /*loopState*/) {
SmallVector<Value, 8> indices;
auto dim = get1dMemrefIndices(b, xferOp, iv, indices);
- Value ivI32 =
- b.create<IndexCastOp>(loc, IntegerType::get(b.getContext(), 32), iv);
+ Value ivI32 = b.create<arith::IndexCastOp>(
+ loc, IntegerType::get(b.getContext(), 32), iv);
// Nothing to do in case of out-of-bounds access.
generateInBoundsCheck(
// Loop bounds, step, state...
Location loc = xferOp.getLoc();
auto vecType = xferOp.getVectorType();
- auto lb = rewriter.create<ConstantIndexOp>(loc, 0);
- auto ub = rewriter.create<ConstantIndexOp>(loc, vecType.getDimSize(0));
- auto step = rewriter.create<ConstantIndexOp>(loc, 1);
+ auto lb = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ auto ub =
+ rewriter.create<arith::ConstantIndexOp>(loc, vecType.getDimSize(0));
+ auto step = rewriter.create<arith::ConstantIndexOp>(loc, 1);
auto loopState = Strategy1d<OpTy>::initialLoopState(rewriter, xferOp);
// Generate for loop.
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/BlockAndValueMapping.h"
Operation *AffineDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
- return builder.create<ConstantOp>(loc, type, value);
+ return builder.create<arith::ConstantOp>(loc, type, value);
}
/// A utility function to check if a value is defined at the top level of an
buildAffineLoopFromValues(OpBuilder &builder, Location loc, Value lb, Value ub,
int64_t step,
AffineForOp::BodyBuilderFn bodyBuilderFn) {
- auto lbConst = lb.getDefiningOp<ConstantIndexOp>();
- auto ubConst = ub.getDefiningOp<ConstantIndexOp>();
+ auto lbConst = lb.getDefiningOp<arith::ConstantIndexOp>();
+ auto ubConst = ub.getDefiningOp<arith::ConstantIndexOp>();
if (lbConst && ubConst)
- return buildAffineLoopFromConstants(builder, loc, lbConst.getValue(),
- ubConst.getValue(), step,
- bodyBuilderFn);
+ return buildAffineLoopFromConstants(builder, loc, lbConst.value(),
+ ubConst.value(), step, bodyBuilderFn);
return builder.create<AffineForOp>(loc, lb, builder.getDimIdentityMap(), ub,
builder.getDimIdentityMap(), step,
/*iterArgs=*/llvm::None, bodyBuilderFn);
MLIRAffineOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRLoopLikeInterface
MLIRMemRef
#include "mlir/Analysis/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/Passes.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Transforms/GreedyPatternRewriteDriver.h"
void AffineDataCopyGeneration::runOnFunction() {
FuncOp f = getFunction();
OpBuilder topBuilder(f.getBody());
- zeroIndex = topBuilder.create<ConstantIndexOp>(f.getLoc(), 0);
+ zeroIndex = topBuilder.create<arith::ConstantIndexOp>(f.getLoc(), 0);
// Nests that are copy-in's or copy-out's; the root AffineForOps of those
// nests are stored herein.
#include "mlir/Analysis/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/Passes.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/AffineExpr.h"
#include "mlir/IR/AffineMap.h"
#include "mlir/IR/Builders.h"
} else if (isa<AffineDmaStartOp, AffineDmaWaitOp>(op)) {
// TODO: Support DMA ops.
return false;
- } else if (!isa<ConstantOp>(op)) {
+ } else if (!isa<arith::ConstantOp, ConstantOp>(op)) {
// Register op in the set of ops that have users.
opsWithUsers.insert(&op);
if (isa<AffineMapAccessInterface>(op)) {
LINK_LIBS PUBLIC
MLIRAffine
MLIRAffineUtils
+ MLIRArithmetic
MLIRIR
MLIRMemRef
MLIRPass
#include "mlir/Analysis/NestedMatcher.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/Utils.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Vector/VectorOps.h"
#include "mlir/Dialect/Vector/VectorUtils.h"
#include "mlir/IR/BlockAndValueMapping.h"
/// %A = alloc (%M, %N) : memref<?x?xf32, 0>
/// %B = alloc (%M, %N) : memref<?x?xf32, 0>
/// %C = alloc (%M, %N) : memref<?x?xf32, 0>
-/// %f1 = constant 1.0 : f32
-/// %f2 = constant 2.0 : f32
+/// %f1 = arith.constant 1.0 : f32
+/// %f2 = arith.constant 2.0 : f32
/// affine.for %i0 = 0 to %M {
/// affine.for %i1 = 0 to %N {
/// // non-scoped %f1
/// affine.for %i5 = 0 to %N {
/// %a5 = affine.load %A[%i4, %i5] : memref<?x?xf32, 0>
/// %b5 = affine.load %B[%i4, %i5] : memref<?x?xf32, 0>
-/// %s5 = addf %a5, %b5 : f32
+/// %s5 = arith.addf %a5, %b5 : f32
/// // non-scoped %f1
-/// %s6 = addf %s5, %f1 : f32
+/// %s6 = arith.addf %s5, %f1 : f32
/// // non-scoped %f2
-/// %s7 = addf %s5, %f2 : f32
+/// %s7 = arith.addf %s5, %f2 : f32
/// // diamond dependency.
-/// %s8 = addf %s7, %s6 : f32
+/// %s8 = arith.addf %s7, %s6 : f32
/// affine.store %s8, %C[%i4, %i5] : memref<?x?xf32, 0>
/// }
/// }
-/// %c7 = constant 7 : index
-/// %c42 = constant 42 : index
+/// %c7 = arith.constant 7 : index
+/// %c42 = arith.constant 42 : index
/// %res = load %C[%c7, %c42] : memref<?x?xf32, 0>
/// return %res : f32
/// }
/// %0 = alloc(%arg0, %arg1) : memref<?x?xf32>
/// %1 = alloc(%arg0, %arg1) : memref<?x?xf32>
/// %2 = alloc(%arg0, %arg1) : memref<?x?xf32>
-/// %cst = constant 1.0 : f32
-/// %cst_0 = constant 2.0 : f32
+/// %cst = arith.constant 1.0 : f32
+/// %cst_0 = arith.constant 2.0 : f32
/// affine.for %i0 = 0 to %arg0 {
/// affine.for %i1 = 0 to %arg1 step 256 {
-/// %cst_1 = constant dense<vector<256xf32>, 1.0> :
+/// %cst_1 = arith.constant dense<vector<256xf32>, 1.0> :
/// vector<256xf32>
/// vector.transfer_write %cst_1, %0[%i0, %i1] :
/// vector<256xf32>, memref<?x?xf32>
/// }
/// affine.for %i2 = 0 to %arg0 {
/// affine.for %i3 = 0 to %arg1 step 256 {
-/// %cst_2 = constant dense<vector<256xf32>, 2.0> :
+/// %cst_2 = arith.constant dense<vector<256xf32>, 2.0> :
/// vector<256xf32>
/// vector.transfer_write %cst_2, %1[%i2, %i3] :
/// vector<256xf32>, memref<?x?xf32>
/// memref<?x?xf32>, vector<256xf32>
/// %4 = vector.transfer_read %1[%i4, %i5] :
/// memref<?x?xf32>, vector<256xf32>
-/// %5 = addf %3, %4 : vector<256xf32>
-/// %cst_3 = constant dense<vector<256xf32>, 1.0> :
+/// %5 = arith.addf %3, %4 : vector<256xf32>
+/// %cst_3 = arith.constant dense<vector<256xf32>, 1.0> :
/// vector<256xf32>
-/// %6 = addf %5, %cst_3 : vector<256xf32>
-/// %cst_4 = constant dense<vector<256xf32>, 2.0> :
+/// %6 = arith.addf %5, %cst_3 : vector<256xf32>
+/// %cst_4 = arith.constant dense<vector<256xf32>, 2.0> :
/// vector<256xf32>
-/// %7 = addf %5, %cst_4 : vector<256xf32>
-/// %8 = addf %7, %6 : vector<256xf32>
+/// %7 = arith.addf %5, %cst_4 : vector<256xf32>
+/// %8 = arith.addf %7, %6 : vector<256xf32>
/// vector.transfer_write %8, %2[%i4, %i5] :
/// vector<256xf32>, memref<?x?xf32>
/// }
/// }
-/// %c7 = constant 7 : index
-/// %c42 = constant 42 : index
+/// %c7 = arith.constant 7 : index
+/// %c42 = arith.constant 42 : index
/// %9 = load %2[%c7, %c42] : memref<?x?xf32>
/// return %9 : f32
/// }
/// %0 = alloc(%arg0, %arg1) : memref<?x?xf32>
/// %1 = alloc(%arg0, %arg1) : memref<?x?xf32>
/// %2 = alloc(%arg0, %arg1) : memref<?x?xf32>
-/// %cst = constant 1.0 : f32
-/// %cst_0 = constant 2.0 : f32
+/// %cst = arith.constant 1.0 : f32
+/// %cst_0 = arith.constant 2.0 : f32
/// affine.for %i0 = 0 to %arg0 step 32 {
/// affine.for %i1 = 0 to %arg1 step 256 {
-/// %cst_1 = constant dense<vector<32x256xf32>, 1.0> :
+/// %cst_1 = arith.constant dense<vector<32x256xf32>, 1.0> :
/// vector<32x256xf32>
/// vector.transfer_write %cst_1, %0[%i0, %i1] :
/// vector<32x256xf32>, memref<?x?xf32>
/// }
/// affine.for %i2 = 0 to %arg0 step 32 {
/// affine.for %i3 = 0 to %arg1 step 256 {
-/// %cst_2 = constant dense<vector<32x256xf32>, 2.0> :
+/// %cst_2 = arith.constant dense<vector<32x256xf32>, 2.0> :
/// vector<32x256xf32>
/// vector.transfer_write %cst_2, %1[%i2, %i3] :
/// vector<32x256xf32>, memref<?x?xf32>
/// memref<?x?xf32> vector<32x256xf32>
/// %4 = vector.transfer_read %1[%i4, %i5] :
/// memref<?x?xf32>, vector<32x256xf32>
-/// %5 = addf %3, %4 : vector<32x256xf32>
-/// %cst_3 = constant dense<vector<32x256xf32>, 1.0> :
+/// %5 = arith.addf %3, %4 : vector<32x256xf32>
+/// %cst_3 = arith.constant dense<vector<32x256xf32>, 1.0> :
/// vector<32x256xf32>
-/// %6 = addf %5, %cst_3 : vector<32x256xf32>
-/// %cst_4 = constant dense<vector<32x256xf32>, 2.0> :
+/// %6 = arith.addf %5, %cst_3 : vector<32x256xf32>
+/// %cst_4 = arith.constant dense<vector<32x256xf32>, 2.0> :
/// vector<32x256xf32>
-/// %7 = addf %5, %cst_4 : vector<32x256xf32>
-/// %8 = addf %7, %6 : vector<32x256xf32>
+/// %7 = arith.addf %5, %cst_4 : vector<32x256xf32>
+/// %8 = arith.addf %7, %6 : vector<32x256xf32>
/// vector.transfer_write %8, %2[%i4, %i5] :
/// vector<32x256xf32>, memref<?x?xf32>
/// }
/// }
-/// %c7 = constant 7 : index
-/// %c42 = constant 42 : index
+/// %c7 = arith.constant 7 : index
+/// %c42 = arith.constant 42 : index
/// %9 = load %2[%c7, %c42] : memref<?x?xf32>
/// return %9 : f32
/// }
/// Consider the following example:
/// ```mlir
/// func @vecred(%in: memref<512xf32>) -> f32 {
-/// %cst = constant 0.000000e+00 : f32
+/// %cst = arith.constant 0.000000e+00 : f32
/// %sum = affine.for %i = 0 to 500 iter_args(%part_sum = %cst) -> (f32) {
/// %ld = affine.load %in[%i] : memref<512xf32>
/// %cos = math.cos %ld : f32
-/// %add = addf %part_sum, %cos : f32
+/// %add = arith.addf %part_sum, %cos : f32
/// affine.yield %add : f32
/// }
/// return %sum : f32
/// ```mlir
/// #map = affine_map<(d0) -> (-d0 + 500)>
/// func @vecred(%arg0: memref<512xf32>) -> f32 {
-/// %cst = constant 0.000000e+00 : f32
-/// %cst_0 = constant dense<0.000000e+00> : vector<128xf32>
+/// %cst = arith.constant 0.000000e+00 : f32
+/// %cst_0 = arith.constant dense<0.000000e+00> : vector<128xf32>
/// %0 = affine.for %arg1 = 0 to 500 step 128 iter_args(%arg2 = %cst_0)
/// -> (vector<128xf32>) {
/// // %2 is the number of iterations left in the original loop.
/// %2 = affine.apply #map(%arg1)
/// %3 = vector.create_mask %2 : vector<128xi1>
-/// %cst_1 = constant 0.000000e+00 : f32
+/// %cst_1 = arith.constant 0.000000e+00 : f32
/// %4 = vector.transfer_read %arg0[%arg1], %cst_1 :
/// memref<512xf32>, vector<128xf32>
/// %5 = math.cos %4 : vector<128xf32>
-/// %6 = addf %arg2, %5 : vector<128xf32>
+/// %6 = arith.addf %arg2, %5 : vector<128xf32>
/// // We filter out the effect of last 12 elements using the mask.
/// %7 = select %3, %6, %arg2 : vector<128xi1>, vector<128xf32>
/// affine.yield %7 : vector<128xf32>
/// the vectorized operations.
///
/// Example:
- /// * 'replaced': %0 = addf %1, %2 : f32
- /// * 'replacement': %0 = addf %1, %2 : vector<128xf32>
+ /// * 'replaced': %0 = arith.addf %1, %2 : f32
+ /// * 'replacement': %0 = arith.addf %1, %2 : vector<128xf32>
void registerOpVectorReplacement(Operation *replaced, Operation *replacement);
/// Registers the vector replacement of a scalar value. The replacement
/// the vectorized operations.
///
/// Example:
-/// * 'replaced': %0 = addf %1, %2 : f32
-/// * 'replacement': %0 = addf %1, %2 : vector<128xf32>
+/// * 'replaced': %0 = arith.addf %1, %2 : f32
+/// * 'replacement': %0 = arith.addf %1, %2 : vector<128xf32>
void VectorizationState::registerOpVectorReplacement(Operation *replaced,
Operation *replacement) {
LLVM_DEBUG(dbgs() << "\n[early-vect]+++++ commit vectorized op:\n");
/// Tries to transform a scalar constant into a vector constant. Returns the
/// vector constant if the scalar type is valid vector element type. Returns
/// nullptr, otherwise.
-static ConstantOp vectorizeConstant(ConstantOp constOp,
- VectorizationState &state) {
+static arith::ConstantOp vectorizeConstant(arith::ConstantOp constOp,
+ VectorizationState &state) {
Type scalarTy = constOp.getType();
if (!VectorType::isValidElementType(scalarTy))
return nullptr;
auto vecTy = getVectorType(scalarTy, state.strategy);
- auto vecAttr = DenseElementsAttr::get(vecTy, constOp.getValue());
+ auto vecAttr = DenseElementsAttr::get(vecTy, constOp.value());
OpBuilder::InsertionGuard guard(state.builder);
Operation *parentOp = state.builder.getInsertionBlock()->getParentOp();
isa<AffineForOp>(parentOp) && "Expected a vectorized for op");
auto vecForOp = cast<AffineForOp>(parentOp);
state.builder.setInsertionPointToStart(vecForOp.getBody());
- auto newConstOp = state.builder.create<ConstantOp>(constOp.getLoc(), vecAttr);
+ auto newConstOp =
+ state.builder.create<arith::ConstantOp>(constOp.getLoc(), vecAttr);
// Register vector replacement for future uses in the scope.
state.registerOpVectorReplacement(constOp, newConstOp);
/// Creates a constant vector filled with the neutral elements of the given
/// reduction. The scalar type of vector elements will be taken from
/// `oldOperand`.
-static ConstantOp createInitialVector(AtomicRMWKind reductionKind,
- Value oldOperand,
- VectorizationState &state) {
+static arith::ConstantOp createInitialVector(AtomicRMWKind reductionKind,
+ Value oldOperand,
+ VectorizationState &state) {
Type scalarTy = oldOperand.getType();
if (!VectorType::isValidElementType(scalarTy))
return nullptr;
auto vecTy = getVectorType(scalarTy, state.strategy);
auto vecAttr = DenseElementsAttr::get(vecTy, valueAttr);
auto newConstOp =
- state.builder.create<ConstantOp>(oldOperand.getLoc(), vecAttr);
+ state.builder.create<arith::ConstantOp>(oldOperand.getLoc(), vecAttr);
return newConstOp;
}
"Vector op not found in replacement map");
// Vectorize constant.
- if (auto constOp = operand.getDefiningOp<ConstantOp>()) {
- ConstantOp vecConstant = vectorizeConstant(constOp, state);
+ if (auto constOp = operand.getDefiningOp<arith::ConstantOp>()) {
+ auto vecConstant = vectorizeConstant(constOp, state);
LLVM_DEBUG(dbgs() << "-> constant: " << vecConstant);
return vecConstant.getResult();
}
return false;
Attribute valueAttr = getIdentityValueAttr(reductionKind, scalarTy,
state.builder, value.getLoc());
- if (auto constOp = dyn_cast_or_null<ConstantOp>(value.getDefiningOp()))
+ if (auto constOp = dyn_cast_or_null<arith::ConstantOp>(value.getDefiningOp()))
return constOp.value() == valueAttr;
return false;
}
// being added to the accumulator by inserting `select` operations, for
// example:
//
- // %res = addf %acc, %val : vector<128xf32>
+ // %res = arith.addf %acc, %val : vector<128xf32>
// %res_masked = select %mask, %res, %acc : vector<128xi1>, vector<128xf32>
// affine.yield %res_masked : vector<128xf32>
//
return vectorizeAffineForOp(forOp, state);
if (auto yieldOp = dyn_cast<AffineYieldOp>(op))
return vectorizeAffineYieldOp(yieldOp, state);
- if (auto constant = dyn_cast<ConstantOp>(op))
+ if (auto constant = dyn_cast<arith::ConstantOp>(op))
return vectorizeConstant(constant, state);
// Other ops with regions are not supported.
add_subdirectory(IR)
+add_subdirectory(Transforms)
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
+#include "mlir/IR/Builders.h"
#include "mlir/Transforms/InliningUtils.h"
using namespace mlir;
};
} // end anonymous namespace
-void mlir::arith::ArithmeticDialect::initialize() {
+void arith::ArithmeticDialect::initialize() {
addOperations<
#define GET_OP_LIST
#include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.cpp.inc"
>();
addInterfaces<ArithmeticInlinerInterface>();
}
+
+/// Materialize an integer or floating point constant.
+Operation *arith::ArithmeticDialect::materializeConstant(OpBuilder &builder,
+ Attribute value,
+ Type type,
+ Location loc) {
+ return builder.create<arith::ConstantOp>(loc, value, type);
+}
} // end anonymous namespace
//===----------------------------------------------------------------------===//
+// ConstantOp
+//===----------------------------------------------------------------------===//
+
+void arith::ConstantOp::getAsmResultNames(
+ function_ref<void(Value, StringRef)> setNameFn) {
+ auto type = getType();
+ if (auto intCst = value().dyn_cast<IntegerAttr>()) {
+ auto intType = type.dyn_cast<IntegerType>();
+
+ // Sugar i1 constants with 'true' and 'false'.
+ if (intType && intType.getWidth() == 1)
+ return setNameFn(getResult(), (intCst.getInt() ? "true" : "false"));
+
+ // Otherwise, build a compex name with the value and type.
+ SmallString<32> specialNameBuffer;
+ llvm::raw_svector_ostream specialName(specialNameBuffer);
+ specialName << 'c' << intCst.getInt();
+ if (intType)
+ specialName << '_' << type;
+ setNameFn(getResult(), specialName.str());
+ } else {
+ setNameFn(getResult(), "cst");
+ }
+}
+
+/// TODO: disallow arith.constant to return anything other than signless integer
+/// or float like.
+static LogicalResult verify(arith::ConstantOp op) {
+ auto type = op.getType();
+ // The value's type must match the return type.
+ if (op.value().getType() != type) {
+ return op.emitOpError() << "value type " << op.value().getType()
+ << " must match return type: " << type;
+ }
+ // Integer values must be signless.
+ if (type.isa<IntegerType>() && !type.cast<IntegerType>().isSignless())
+ return op.emitOpError("integer return type must be signless");
+ // Any float or elements attribute are acceptable.
+ if (!op.value().isa<IntegerAttr, FloatAttr, ElementsAttr>()) {
+ return op.emitOpError(
+ "value must be an integer, float, or elements attribute");
+ }
+ return success();
+}
+
+bool arith::ConstantOp::isBuildableWith(Attribute value, Type type) {
+ // The value's type must be the same as the provided type.
+ if (value.getType() != type)
+ return false;
+ // Integer values must be signless.
+ if (type.isa<IntegerType>() && !type.cast<IntegerType>().isSignless())
+ return false;
+ // Integer, float, and element attributes are buildable.
+ return value.isa<IntegerAttr, FloatAttr, ElementsAttr>();
+}
+
+OpFoldResult arith::ConstantOp::fold(ArrayRef<Attribute> operands) {
+ return value();
+}
+
+void arith::ConstantIntOp::build(OpBuilder &builder, OperationState &result,
+ int64_t value, unsigned width) {
+ auto type = builder.getIntegerType(width);
+ arith::ConstantOp::build(builder, result, type,
+ builder.getIntegerAttr(type, value));
+}
+
+void arith::ConstantIntOp::build(OpBuilder &builder, OperationState &result,
+ int64_t value, Type type) {
+ assert(type.isSignlessInteger() &&
+ "ConstantIntOp can only have signless integer type values");
+ arith::ConstantOp::build(builder, result, type,
+ builder.getIntegerAttr(type, value));
+}
+
+bool arith::ConstantIntOp::classof(Operation *op) {
+ if (auto constOp = dyn_cast_or_null<arith::ConstantOp>(op))
+ return constOp.getType().isSignlessInteger();
+ return false;
+}
+
+void arith::ConstantFloatOp::build(OpBuilder &builder, OperationState &result,
+ const APFloat &value, FloatType type) {
+ arith::ConstantOp::build(builder, result, type,
+ builder.getFloatAttr(type, value));
+}
+
+bool arith::ConstantFloatOp::classof(Operation *op) {
+ if (auto constOp = dyn_cast_or_null<arith::ConstantOp>(op))
+ return constOp.getType().isa<FloatType>();
+ return false;
+}
+
+void arith::ConstantIndexOp::build(OpBuilder &builder, OperationState &result,
+ int64_t value) {
+ arith::ConstantOp::build(builder, result, builder.getIndexType(),
+ builder.getIndexAttr(value));
+}
+
+bool arith::ConstantIndexOp::classof(Operation *op) {
+ if (auto constOp = dyn_cast_or_null<arith::ConstantOp>(op))
+ return constOp.getType().isIndex();
+ return false;
+}
+
+//===----------------------------------------------------------------------===//
// AddIOp
//===----------------------------------------------------------------------===//
/// or(x, x) -> x
if (lhs() == rhs())
return rhs();
+ /// or(x, <all ones>) -> <all ones>
+ if (auto rhsAttr = operands[1].dyn_cast_or_null<IntegerAttr>())
+ if (rhsAttr.getValue().isAllOnes())
+ return rhsAttr;
return constFoldBinaryOp<IntegerAttr>(operands,
[](APInt a, APInt b) { return a | b; });
}
//===----------------------------------------------------------------------===//
+// Utility functions for verifying cast ops
+//===----------------------------------------------------------------------===//
+
+template <typename... Types>
+using type_list = std::tuple<Types...> *;
+
+/// Returns a non-null type only if the provided type is one of the allowed
+/// types or one of the allowed shaped types of the allowed types. Returns the
+/// element type if a valid shaped type is provided.
+template <typename... ShapedTypes, typename... ElementTypes>
+static Type getUnderlyingType(Type type, type_list<ShapedTypes...>,
+ type_list<ElementTypes...>) {
+ if (type.isa<ShapedType>() && !type.isa<ShapedTypes...>())
+ return {};
+
+ auto underlyingType = getElementTypeOrSelf(type);
+ if (!underlyingType.isa<ElementTypes...>())
+ return {};
+
+ return underlyingType;
+}
+
+/// Get allowed underlying types for vectors and tensors.
+template <typename... ElementTypes>
+static Type getTypeIfLike(Type type) {
+ return getUnderlyingType(type, type_list<VectorType, TensorType>(),
+ type_list<ElementTypes...>());
+}
+
+/// Get allowed underlying types for vectors, tensors, and memrefs.
+template <typename... ElementTypes>
+static Type getTypeIfLikeOrMemRef(Type type) {
+ return getUnderlyingType(type,
+ type_list<VectorType, TensorType, MemRefType>(),
+ type_list<ElementTypes...>());
+}
+
+static bool areValidCastInputsAndOutputs(TypeRange inputs, TypeRange outputs) {
+ return inputs.size() == 1 && outputs.size() == 1 &&
+ succeeded(verifyCompatibleShapes(inputs.front(), outputs.front()));
+}
+
+//===----------------------------------------------------------------------===//
// Verifiers for integer and floating point extension/truncation ops
//===----------------------------------------------------------------------===//
return success();
}
+/// Validate a cast that changes the width of a type.
+template <template <typename> class WidthComparator, typename... ElementTypes>
+static bool checkWidthChangeCast(TypeRange inputs, TypeRange outputs) {
+ if (!areValidCastInputsAndOutputs(inputs, outputs))
+ return false;
+
+ auto srcType = getTypeIfLike<ElementTypes...>(inputs.front());
+ auto dstType = getTypeIfLike<ElementTypes...>(outputs.front());
+ if (!srcType || !dstType)
+ return false;
+
+ return WidthComparator<unsigned>()(dstType.getIntOrFloatBitWidth(),
+ srcType.getIntOrFloatBitWidth());
+}
+
//===----------------------------------------------------------------------===//
// ExtUIOp
//===----------------------------------------------------------------------===//
return {};
}
+bool arith::ExtUIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkWidthChangeCast<std::greater, IntegerType>(inputs, outputs);
+}
+
//===----------------------------------------------------------------------===//
// ExtSIOp
//===----------------------------------------------------------------------===//
return {};
}
-// TODO temporary fixes until second patch is in
-OpFoldResult arith::TruncFOp::fold(ArrayRef<Attribute> operands) {
- return {};
+bool arith::ExtSIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkWidthChangeCast<std::greater, IntegerType>(inputs, outputs);
}
-bool arith::TruncFOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+//===----------------------------------------------------------------------===//
+// ExtFOp
+//===----------------------------------------------------------------------===//
+
+bool arith::ExtFOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkWidthChangeCast<std::greater, FloatType>(inputs, outputs);
}
+//===----------------------------------------------------------------------===//
+// TruncIOp
+//===----------------------------------------------------------------------===//
+
OpFoldResult arith::TruncIOp::fold(ArrayRef<Attribute> operands) {
+ // trunci(zexti(a)) -> a
+ // trunci(sexti(a)) -> a
+ if (matchPattern(getOperand(), m_Op<arith::ExtUIOp>()) ||
+ matchPattern(getOperand(), m_Op<arith::ExtSIOp>()))
+ return getOperand().getDefiningOp()->getOperand(0);
+
+ assert(operands.size() == 1 && "unary operation takes one operand");
+
+ if (!operands[0])
+ return {};
+
+ if (auto lhs = operands[0].dyn_cast<IntegerAttr>()) {
+ return IntegerAttr::get(
+ getType(), lhs.getValue().trunc(getType().getIntOrFloatBitWidth()));
+ }
+
return {};
}
bool arith::TruncIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+ return checkWidthChangeCast<std::less, IntegerType>(inputs, outputs);
}
-bool arith::ExtUIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
-}
+//===----------------------------------------------------------------------===//
+// TruncFOp
+//===----------------------------------------------------------------------===//
-bool arith::ExtSIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
-}
+/// Perform safe const propagation for truncf, i.e. only propagate if FP value
+/// can be represented without precision loss or rounding.
+OpFoldResult arith::TruncFOp::fold(ArrayRef<Attribute> operands) {
+ assert(operands.size() == 1 && "unary operation takes one operand");
-bool arith::ExtFOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
-}
+ auto constOperand = operands.front();
+ if (!constOperand || !constOperand.isa<FloatAttr>())
+ return {};
+
+ // Convert to target type via 'double'.
+ double sourceValue =
+ constOperand.dyn_cast<FloatAttr>().getValue().convertToDouble();
+ auto targetAttr = FloatAttr::get(getType(), sourceValue);
+
+ // Propagate if constant's value does not change after truncation.
+ if (sourceValue == targetAttr.getValue().convertToDouble())
+ return targetAttr;
-OpFoldResult arith::ConstantOp::fold(ArrayRef<Attribute> operands) {
return {};
}
-bool arith::SIToFPOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+bool arith::TruncFOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkWidthChangeCast<std::less, FloatType>(inputs, outputs);
}
+//===----------------------------------------------------------------------===//
+// Verifiers for casts between integers and floats.
+//===----------------------------------------------------------------------===//
+
+template <typename From, typename To>
+static bool checkIntFloatCast(TypeRange inputs, TypeRange outputs) {
+ if (!areValidCastInputsAndOutputs(inputs, outputs))
+ return false;
+
+ auto srcType = getTypeIfLike<From>(inputs.front());
+ auto dstType = getTypeIfLike<To>(outputs.back());
+
+ return srcType && dstType;
+}
+
+//===----------------------------------------------------------------------===//
+// UIToFPOp
+//===----------------------------------------------------------------------===//
+
bool arith::UIToFPOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+ return checkIntFloatCast<IntegerType, FloatType>(inputs, outputs);
}
-bool arith::FPToSIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+//===----------------------------------------------------------------------===//
+// SIToFPOp
+//===----------------------------------------------------------------------===//
+
+bool arith::SIToFPOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkIntFloatCast<IntegerType, FloatType>(inputs, outputs);
}
+//===----------------------------------------------------------------------===//
+// FPToUIOp
+//===----------------------------------------------------------------------===//
+
bool arith::FPToUIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- return true;
+ return checkIntFloatCast<FloatType, IntegerType>(inputs, outputs);
+}
+
+//===----------------------------------------------------------------------===//
+// FPToSIOp
+//===----------------------------------------------------------------------===//
+
+bool arith::FPToSIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
+ return checkIntFloatCast<FloatType, IntegerType>(inputs, outputs);
}
//===----------------------------------------------------------------------===//
bool arith::IndexCastOp::areCastCompatible(TypeRange inputs,
TypeRange outputs) {
- assert(inputs.size() == 1 && outputs.size() == 1 &&
- "index_cast op expects one result and one result");
+ if (!areValidCastInputsAndOutputs(inputs, outputs))
+ return false;
- // Shape equivalence is guaranteed by op traits.
- auto srcType = getElementTypeOrSelf(inputs.front());
- auto dstType = getElementTypeOrSelf(outputs.front());
+ auto srcType = getTypeIfLikeOrMemRef<IntegerType, IndexType>(inputs.front());
+ auto dstType = getTypeIfLikeOrMemRef<IntegerType, IndexType>(outputs.front());
+ if (!srcType || !dstType)
+ return false;
return (srcType.isIndex() && dstType.isSignlessInteger()) ||
(srcType.isSignlessInteger() && dstType.isIndex());
//===----------------------------------------------------------------------===//
bool arith::BitcastOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- assert(inputs.size() == 1 && outputs.size() == 1 &&
- "bitcast op expects one operand and one result");
+ if (!areValidCastInputsAndOutputs(inputs, outputs))
+ return false;
- // Shape equivalence is guaranteed by op traits.
- auto srcType = getElementTypeOrSelf(inputs.front());
- auto dstType = getElementTypeOrSelf(outputs.front());
+ auto srcType =
+ getTypeIfLikeOrMemRef<IntegerType, IndexType, FloatType>(inputs.front());
+ auto dstType =
+ getTypeIfLikeOrMemRef<IntegerType, IndexType, FloatType>(outputs.front());
+ if (!srcType || !dstType)
+ return false;
- // Types are guarnateed to be integers or floats by constraints.
return srcType.getIntOrFloatBitWidth() == dstType.getIntOrFloatBitWidth();
}
--- /dev/null
+//===- Bufferize.cpp - Bufferization for Arithmetic ops ---------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "mlir/Transforms/Bufferize.h"
+#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h"
+#include "mlir/Dialect/MemRef/IR/MemRef.h"
+
+using namespace mlir;
+
+namespace {
+
+/// Bufferize arith.index_cast.
+struct BufferizeIndexCastOp : public OpConversionPattern<arith::IndexCastOp> {
+ using OpConversionPattern::OpConversionPattern;
+
+ LogicalResult
+ matchAndRewrite(arith::IndexCastOp op, OpAdaptor adaptor,
+ ConversionPatternRewriter &rewriter) const override {
+ auto tensorType = op.getType().cast<RankedTensorType>();
+ rewriter.replaceOpWithNewOp<arith::IndexCastOp>(
+ op, adaptor.in(),
+ MemRefType::get(tensorType.getShape(), tensorType.getElementType()));
+ return success();
+ }
+};
+
+/// Pass to bufferize Arithmetic ops.
+struct ArithmeticBufferizePass
+ : public ArithmeticBufferizeBase<ArithmeticBufferizePass> {
+ void runOnFunction() override {
+ BufferizeTypeConverter typeConverter;
+ RewritePatternSet patterns(&getContext());
+ ConversionTarget target(getContext());
+
+ target.addLegalDialect<arith::ArithmeticDialect, memref::MemRefDialect>();
+
+ arith::populateArithmeticBufferizePatterns(typeConverter, patterns);
+
+ target.addDynamicallyLegalOp<arith::IndexCastOp>(
+ [&](arith::IndexCastOp op) {
+ return typeConverter.isLegal(op.getType());
+ });
+
+ if (failed(
+ applyPartialConversion(getFunction(), target, std::move(patterns))))
+ signalPassFailure();
+ }
+};
+
+} // end anonymous namespace
+
+void mlir::arith::populateArithmeticBufferizePatterns(
+ BufferizeTypeConverter &typeConverter, RewritePatternSet &patterns) {
+ patterns.add<BufferizeIndexCastOp>(typeConverter, patterns.getContext());
+}
+
+std::unique_ptr<Pass> mlir::arith::createArithmeticBufferizePass() {
+ return std::make_unique<ArithmeticBufferizePass>();
+}
--- /dev/null
+add_mlir_dialect_library(MLIRArithmeticTransforms
+ Bufferize.cpp
+ ExpandOps.cpp
+
+ ADDITIONAL_HEADER_DIRS
+ {$MLIR_MAIN_INCLUDE_DIR}/mlir/Dialect/Arithmetic/Transforms
+
+ DEPENDS
+ MLIRArithmeticTransformsIncGen
+
+ LINK_LIBS PUBLIC
+ MLIRArithmetic
+ MLIRIR
+ MLIRMemRef
+ MLIRPass
+ MLIRTransforms
+ )
--- /dev/null
+//===- ExpandOps.cpp - Pass to legalize Arithmetic ops for LLVM lowering --===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h"
+
+using namespace mlir;
+
+namespace {
+
+/// Expands CeilDivSIOp (n, m) into
+/// 1) x = (m > 0) ? -1 : 1
+/// 2) (n*m>0) ? ((n+x) / m) + 1 : - (-n / m)
+struct CeilDivSIOpConverter : public OpRewritePattern<arith::CeilDivSIOp> {
+ using OpRewritePattern::OpRewritePattern;
+ LogicalResult matchAndRewrite(arith::CeilDivSIOp op,
+ PatternRewriter &rewriter) const final {
+ Location loc = op.getLoc();
+ auto signedCeilDivIOp = cast<arith::CeilDivSIOp>(op);
+ Type type = signedCeilDivIOp.getType();
+ Value a = signedCeilDivIOp.lhs();
+ Value b = signedCeilDivIOp.rhs();
+ Value plusOne = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getIntegerAttr(type, 1));
+ Value zero = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getIntegerAttr(type, 0));
+ Value minusOne = rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getIntegerAttr(type, -1));
+ // Compute x = (b>0) ? -1 : 1.
+ Value compare =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, b, zero);
+ Value x = rewriter.create<SelectOp>(loc, compare, minusOne, plusOne);
+ // Compute positive res: 1 + ((x+a)/b).
+ Value xPlusA = rewriter.create<arith::AddIOp>(loc, x, a);
+ Value xPlusADivB = rewriter.create<arith::DivSIOp>(loc, xPlusA, b);
+ Value posRes = rewriter.create<arith::AddIOp>(loc, plusOne, xPlusADivB);
+ // Compute negative res: - ((-a)/b).
+ Value minusA = rewriter.create<arith::SubIOp>(loc, zero, a);
+ Value minusADivB = rewriter.create<arith::DivSIOp>(loc, minusA, b);
+ Value negRes = rewriter.create<arith::SubIOp>(loc, zero, minusADivB);
+ // Result is (a*b>0) ? pos result : neg result.
+ // Note, we want to avoid using a*b because of possible overflow.
+ // The case that matters are a>0, a==0, a<0, b>0 and b<0. We do
+ // not particuliarly care if a*b<0 is true or false when b is zero
+ // as this will result in an illegal divide. So `a*b<0` can be reformulated
+ // as `(a<0 && b<0) || (a>0 && b>0)' or `(a<0 && b<0) || (a>0 && b>=0)'.
+ // We pick the first expression here.
+ Value aNeg =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, a, zero);
+ Value aPos =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, a, zero);
+ Value bNeg =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, b, zero);
+ Value bPos =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, b, zero);
+ Value firstTerm = rewriter.create<arith::AndIOp>(loc, aNeg, bNeg);
+ Value secondTerm = rewriter.create<arith::AndIOp>(loc, aPos, bPos);
+ Value compareRes =
+ rewriter.create<arith::OrIOp>(loc, firstTerm, secondTerm);
+ Value res = rewriter.create<SelectOp>(loc, compareRes, posRes, negRes);
+ // Perform substitution and return success.
+ rewriter.replaceOp(op, {res});
+ return success();
+ }
+};
+
+/// Expands FloorDivSIOp (n, m) into
+/// 1) x = (m<0) ? 1 : -1
+/// 2) return (n*m<0) ? - ((-n+x) / m) -1 : n / m
+struct FloorDivSIOpConverter : public OpRewritePattern<arith::FloorDivSIOp> {
+ using OpRewritePattern::OpRewritePattern;
+ LogicalResult matchAndRewrite(arith::FloorDivSIOp op,
+ PatternRewriter &rewriter) const final {
+ Location loc = op.getLoc();
+ arith::FloorDivSIOp signedFloorDivIOp = cast<arith::FloorDivSIOp>(op);
+ Type type = signedFloorDivIOp.getType();
+ Value a = signedFloorDivIOp.lhs();
+ Value b = signedFloorDivIOp.rhs();
+ Value plusOne = rewriter.create<arith::ConstantIntOp>(loc, 1, type);
+ Value zero = rewriter.create<arith::ConstantIntOp>(loc, 0, type);
+ Value minusOne = rewriter.create<arith::ConstantIntOp>(loc, -1, type);
+ // Compute x = (b<0) ? 1 : -1.
+ Value compare =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, b, zero);
+ Value x = rewriter.create<SelectOp>(loc, compare, plusOne, minusOne);
+ // Compute negative res: -1 - ((x-a)/b).
+ Value xMinusA = rewriter.create<arith::SubIOp>(loc, x, a);
+ Value xMinusADivB = rewriter.create<arith::DivSIOp>(loc, xMinusA, b);
+ Value negRes = rewriter.create<arith::SubIOp>(loc, minusOne, xMinusADivB);
+ // Compute positive res: a/b.
+ Value posRes = rewriter.create<arith::DivSIOp>(loc, a, b);
+ // Result is (a*b<0) ? negative result : positive result.
+ // Note, we want to avoid using a*b because of possible overflow.
+ // The case that matters are a>0, a==0, a<0, b>0 and b<0. We do
+ // not particuliarly care if a*b<0 is true or false when b is zero
+ // as this will result in an illegal divide. So `a*b<0` can be reformulated
+ // as `(a>0 && b<0) || (a>0 && b<0)' or `(a>0 && b<0) || (a>0 && b<=0)'.
+ // We pick the first expression here.
+ Value aNeg =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, a, zero);
+ Value aPos =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, a, zero);
+ Value bNeg =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, b, zero);
+ Value bPos =
+ rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, b, zero);
+ Value firstTerm = rewriter.create<arith::AndIOp>(loc, aNeg, bPos);
+ Value secondTerm = rewriter.create<arith::AndIOp>(loc, aPos, bNeg);
+ Value compareRes =
+ rewriter.create<arith::OrIOp>(loc, firstTerm, secondTerm);
+ Value res = rewriter.create<SelectOp>(loc, compareRes, negRes, posRes);
+ // Perform substitution and return success.
+ rewriter.replaceOp(op, {res});
+ return success();
+ }
+};
+
+struct ArithmeticExpandOpsPass
+ : public ArithmeticExpandOpsBase<ArithmeticExpandOpsPass> {
+ void runOnFunction() override {
+ RewritePatternSet patterns(&getContext());
+ ConversionTarget target(getContext());
+
+ arith::populateArithmeticExpandOpsPatterns(patterns);
+
+ target.addLegalDialect<arith::ArithmeticDialect, StandardOpsDialect>();
+ target.addIllegalOp<arith::CeilDivSIOp, arith::FloorDivSIOp>();
+
+ if (failed(
+ applyPartialConversion(getFunction(), target, std::move(patterns))))
+ signalPassFailure();
+ }
+};
+
+} // end anonymous namespace
+
+void mlir::arith::populateArithmeticExpandOpsPatterns(
+ RewritePatternSet &patterns) {
+ patterns.add<CeilDivSIOpConverter, FloorDivSIOpConverter>(
+ patterns.getContext());
+}
+
+std::unique_ptr<Pass> mlir::arith::createArithmeticExpandOpsPass() {
+ return std::make_unique<ArithmeticExpandOpsPass>();
+}
--- /dev/null
+//===- PassDetail.h - Arithmetic Pass details -------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef DIALECT_ARITHMETIC_TRANSFORMS_PASSDETAIL_H_
+#define DIALECT_ARITHMETIC_TRANSFORMS_PASSDETAIL_H_
+
+#include "mlir/Pass/Pass.h"
+
+namespace mlir {
+
+class StandardOpsDialect;
+
+namespace memref {
+class MemRefDialect;
+} // end namespace memref
+
+#define GEN_PASS_CLASSES
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h.inc"
+
+} // end namespace mlir
+
+#endif // DIALECT_ARITHMETIC_TRANSFORMS_PASSDETAIL_H_
static Type getI1SameShape(Type type);
static void buildScalableCmpIOp(OpBuilder &build, OperationState &result,
- CmpIPredicate predicate, Value lhs, Value rhs);
+ arith::CmpIPredicate predicate, Value lhs,
+ Value rhs);
static void buildScalableCmpFOp(OpBuilder &build, OperationState &result,
- CmpFPredicate predicate, Value lhs, Value rhs);
+ arith::CmpFPredicate predicate, Value lhs,
+ Value rhs);
#define GET_OP_CLASSES
#include "mlir/Dialect/ArmSVE/ArmSVE.cpp.inc"
//===----------------------------------------------------------------------===//
static void buildScalableCmpFOp(OpBuilder &build, OperationState &result,
- CmpFPredicate predicate, Value lhs, Value rhs) {
+ arith::CmpFPredicate predicate, Value lhs,
+ Value rhs) {
result.addOperands({lhs, rhs});
result.types.push_back(getI1SameShape(lhs.getType()));
result.addAttribute(ScalableCmpFOp::getPredicateAttrName(),
}
static void buildScalableCmpIOp(OpBuilder &build, OperationState &result,
- CmpIPredicate predicate, Value lhs, Value rhs) {
+ arith::CmpIPredicate predicate, Value lhs,
+ Value rhs) {
result.addOperands({lhs, rhs});
result.types.push_back(getI1SameShape(lhs.getType()));
result.addAttribute(ScalableCmpIOp::getPredicateAttrName(),
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Async/IR/Async.h"
#include "mlir/Dialect/Async/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
assert(!tripCounts.empty() && "tripCounts must be not empty");
for (ssize_t i = tripCounts.size() - 1; i >= 0; --i) {
- coords[i] = b.create<SignedRemIOp>(index, tripCounts[i]);
- index = b.create<SignedDivIOp>(index, tripCounts[i]);
+ coords[i] = b.create<arith::RemSIOp>(index, tripCounts[i]);
+ index = b.create<arith::DivSIOp>(index, tripCounts[i]);
}
return coords;
Value blockSize = block->getArgument(offset++);
// Constants used below.
- Value c0 = b.create<ConstantIndexOp>(0);
- Value c1 = b.create<ConstantIndexOp>(1);
+ Value c0 = b.create<arith::ConstantIndexOp>(0);
+ Value c1 = b.create<arith::ConstantIndexOp>(1);
// Multi-dimensional parallel iteration space defined by the loop trip counts.
ArrayRef<Value> tripCounts = getArguments(op.getNumLoops());
// one-dimensional iteration space.
Value tripCount = tripCounts[0];
for (unsigned i = 1; i < tripCounts.size(); ++i)
- tripCount = b.create<MulIOp>(tripCount, tripCounts[i]);
+ tripCount = b.create<arith::MulIOp>(tripCount, tripCounts[i]);
// Parallel operation lower bound and step.
ArrayRef<Value> lowerBound = getArguments(op.getNumLoops());
// Find one-dimensional iteration bounds: [blockFirstIndex, blockLastIndex]:
// blockFirstIndex = blockIndex * blockSize
- Value blockFirstIndex = b.create<MulIOp>(blockIndex, blockSize);
+ Value blockFirstIndex = b.create<arith::MulIOp>(blockIndex, blockSize);
// The last one-dimensional index in the block defined by the `blockIndex`:
// blockLastIndex = max(blockFirstIndex + blockSize, tripCount) - 1
- Value blockEnd0 = b.create<AddIOp>(blockFirstIndex, blockSize);
- Value blockEnd1 = b.create<CmpIOp>(CmpIPredicate::sge, blockEnd0, tripCount);
+ Value blockEnd0 = b.create<arith::AddIOp>(blockFirstIndex, blockSize);
+ Value blockEnd1 =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::sge, blockEnd0, tripCount);
Value blockEnd2 = b.create<SelectOp>(blockEnd1, tripCount, blockEnd0);
- Value blockLastIndex = b.create<SubIOp>(blockEnd2, c1);
+ Value blockLastIndex = b.create<arith::SubIOp>(blockEnd2, c1);
// Convert one-dimensional indices to multi-dimensional coordinates.
auto blockFirstCoord = delinearize(b, blockFirstIndex, tripCounts);
// dimension when inner compute dimension contains multiple blocks.
SmallVector<Value> blockEndCoord(op.getNumLoops());
for (size_t i = 0; i < blockLastCoord.size(); ++i)
- blockEndCoord[i] = b.create<AddIOp>(blockLastCoord[i], c1);
+ blockEndCoord[i] = b.create<arith::AddIOp>(blockLastCoord[i], c1);
// Construct a loop nest out of scf.for operations that will iterate over
// all coordinates in [blockFirstCoord, blockLastCoord] range.
ImplicitLocOpBuilder nb(loc, nestedBuilder);
// Compute induction variable for `loopIdx`.
- computeBlockInductionVars[loopIdx] = nb.create<AddIOp>(
- lowerBound[loopIdx], nb.create<MulIOp>(iv, step[loopIdx]));
+ computeBlockInductionVars[loopIdx] = nb.create<arith::AddIOp>(
+ lowerBound[loopIdx], nb.create<arith::MulIOp>(iv, step[loopIdx]));
// Check if we are inside first or last iteration of the loop.
- isBlockFirstCoord[loopIdx] =
- nb.create<CmpIOp>(CmpIPredicate::eq, iv, blockFirstCoord[loopIdx]);
- isBlockLastCoord[loopIdx] =
- nb.create<CmpIOp>(CmpIPredicate::eq, iv, blockLastCoord[loopIdx]);
+ isBlockFirstCoord[loopIdx] = nb.create<arith::CmpIOp>(
+ arith::CmpIPredicate::eq, iv, blockFirstCoord[loopIdx]);
+ isBlockLastCoord[loopIdx] = nb.create<arith::CmpIOp>(
+ arith::CmpIPredicate::eq, iv, blockLastCoord[loopIdx]);
// Check if the previous loop is in its first or last iteration.
if (loopIdx > 0) {
- isBlockFirstCoord[loopIdx] = nb.create<AndOp>(
+ isBlockFirstCoord[loopIdx] = nb.create<arith::AndIOp>(
isBlockFirstCoord[loopIdx], isBlockFirstCoord[loopIdx - 1]);
- isBlockLastCoord[loopIdx] = nb.create<AndOp>(
+ isBlockLastCoord[loopIdx] = nb.create<arith::AndIOp>(
isBlockLastCoord[loopIdx], isBlockLastCoord[loopIdx - 1]);
}
b.setInsertionPointToEnd(block);
Type indexTy = b.getIndexType();
- Value c1 = b.create<ConstantIndexOp>(1);
- Value c2 = b.create<ConstantIndexOp>(2);
+ Value c1 = b.create<arith::ConstantIndexOp>(1);
+ Value c2 = b.create<arith::ConstantIndexOp>(2);
// Get the async group that will track async dispatch completion.
Value group = block->getArgument(0);
b.setInsertionPointToEnd(before);
Value start = before->getArgument(0);
Value end = before->getArgument(1);
- Value distance = b.create<SubIOp>(end, start);
- Value dispatch = b.create<CmpIOp>(CmpIPredicate::sgt, distance, c1);
+ Value distance = b.create<arith::SubIOp>(end, start);
+ Value dispatch =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::sgt, distance, c1);
b.create<scf::ConditionOp>(dispatch, before->getArguments());
}
b.setInsertionPointToEnd(after);
Value start = after->getArgument(0);
Value end = after->getArgument(1);
- Value distance = b.create<SubIOp>(end, start);
- Value halfDistance = b.create<SignedDivIOp>(distance, c2);
- Value midIndex = b.create<AddIOp>(start, halfDistance);
+ Value distance = b.create<arith::SubIOp>(end, start);
+ Value halfDistance = b.create<arith::DivSIOp>(distance, c2);
+ Value midIndex = b.create<arith::AddIOp>(start, halfDistance);
// Call parallel compute function inside the async.execute region.
auto executeBodyBuilder = [&](OpBuilder &executeBuilder,
FuncOp asyncDispatchFunction =
createAsyncDispatchFunction(parallelComputeFunction, rewriter);
- Value c0 = b.create<ConstantIndexOp>(0);
- Value c1 = b.create<ConstantIndexOp>(1);
+ Value c0 = b.create<arith::ConstantIndexOp>(0);
+ Value c1 = b.create<arith::ConstantIndexOp>(1);
// Appends operands shared by async dispatch and parallel compute functions to
// the given operands vector.
// Check if the block size is one, in this case we can skip the async dispatch
// completely. If this will be known statically, then canonicalization will
// erase async group operations.
- Value isSingleBlock = b.create<CmpIOp>(CmpIPredicate::eq, blockCount, c1);
+ Value isSingleBlock =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::eq, blockCount, c1);
auto syncDispatch = [&](OpBuilder &nestedBuilder, Location loc) {
ImplicitLocOpBuilder nb(loc, nestedBuilder);
// Create an async.group to wait on all async tokens from the concurrent
// execution of multiple parallel compute function. First block will be
// executed synchronously in the caller thread.
- Value groupSize = b.create<SubIOp>(blockCount, c1);
+ Value groupSize = b.create<arith::SubIOp>(blockCount, c1);
Value group = b.create<CreateGroupOp>(GroupType::get(ctx), groupSize);
ImplicitLocOpBuilder nb(loc, nestedBuilder);
FuncOp compute = parallelComputeFunction.func;
- Value c0 = b.create<ConstantIndexOp>(0);
- Value c1 = b.create<ConstantIndexOp>(1);
+ Value c0 = b.create<arith::ConstantIndexOp>(0);
+ Value c1 = b.create<arith::ConstantIndexOp>(1);
// Create an async.group to wait on all async tokens from the concurrent
// execution of multiple parallel compute function. First block will be
// executed synchronously in the caller thread.
- Value groupSize = b.create<SubIOp>(blockCount, c1);
+ Value groupSize = b.create<arith::SubIOp>(blockCount, c1);
Value group = b.create<CreateGroupOp>(GroupType::get(ctx), groupSize);
// Call parallel compute function for all blocks.
auto lb = op.lowerBound()[i];
auto ub = op.upperBound()[i];
auto step = op.step()[i];
- auto range = b.create<SubIOp>(ub, lb);
- tripCounts[i] = b.create<SignedCeilDivIOp>(range, step);
+ auto range = b.create<arith::SubIOp>(ub, lb);
+ tripCounts[i] = b.create<arith::CeilDivSIOp>(range, step);
}
// Compute a product of trip counts to get the 1-dimensional iteration space
// for the scf.parallel operation.
Value tripCount = tripCounts[0];
for (size_t i = 1; i < tripCounts.size(); ++i)
- tripCount = b.create<MulIOp>(tripCount, tripCounts[i]);
+ tripCount = b.create<arith::MulIOp>(tripCount, tripCounts[i]);
// Short circuit no-op parallel loops (zero iterations) that can arise from
// the memrefs with dynamic dimension(s) equal to zero.
- Value c0 = b.create<ConstantIndexOp>(0);
- Value isZeroIterations = b.create<CmpIOp>(CmpIPredicate::eq, tripCount, c0);
+ Value c0 = b.create<arith::ConstantIndexOp>(0);
+ Value isZeroIterations =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::eq, tripCount, c0);
// Do absolutely nothing if the trip count is zero.
auto noOp = [&](OpBuilder &nestedBuilder, Location loc) {
: 0.6;
// Do not overload worker threads with too many compute blocks.
- Value maxComputeBlocks = b.create<ConstantIndexOp>(
+ Value maxComputeBlocks = b.create<arith::ConstantIndexOp>(
std::max(1, static_cast<int>(numWorkerThreads * overshardingFactor)));
// Target block size from the pass parameters.
- Value minTaskSizeCst = b.create<ConstantIndexOp>(minTaskSize);
+ Value minTaskSizeCst = b.create<arith::ConstantIndexOp>(minTaskSize);
// Compute parallel block size from the parallel problem size:
// blockSize = min(tripCount,
// max(ceil_div(tripCount, maxComputeBlocks),
// ceil_div(minTaskSize, bodySize)))
- Value bs0 = b.create<SignedCeilDivIOp>(tripCount, maxComputeBlocks);
- Value bs1 = b.create<CmpIOp>(CmpIPredicate::sge, bs0, minTaskSizeCst);
+ Value bs0 = b.create<arith::DivSIOp>(tripCount, maxComputeBlocks);
+ Value bs1 =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::sge, bs0, minTaskSizeCst);
Value bs2 = b.create<SelectOp>(bs1, bs0, minTaskSizeCst);
- Value bs3 = b.create<CmpIOp>(CmpIPredicate::sle, tripCount, bs2);
+ Value bs3 =
+ b.create<arith::CmpIOp>(arith::CmpIPredicate::sle, tripCount, bs2);
Value blockSize0 = b.create<SelectOp>(bs3, tripCount, bs2);
- Value blockCount0 = b.create<SignedCeilDivIOp>(tripCount, blockSize0);
+ Value blockCount0 = b.create<arith::CeilDivSIOp>(tripCount, blockSize0);
// Compute balanced block size for the estimated block count.
- Value blockSize = b.create<SignedCeilDivIOp>(tripCount, blockCount0);
- Value blockCount = b.create<SignedCeilDivIOp>(tripCount, blockSize);
+ Value blockSize = b.create<arith::CeilDivSIOp>(tripCount, blockCount0);
+ Value blockCount = b.create<arith::CeilDivSIOp>(tripCount, blockSize);
// Create a parallel compute function that takes a block id and computes the
// parallel operation body for a subset of iteration space.
#include "PassDetail.h"
#include "mlir/Conversion/SCFToStandard/SCFToStandard.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Async/IR/Async.h"
#include "mlir/Dialect/Async/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
// Assert that the awaited operands is not in the error state.
Value isError = builder.create<RuntimeIsErrorOp>(i1, operand);
- Value notError = builder.create<XOrOp>(
- isError,
- builder.create<ConstantOp>(loc, i1, builder.getIntegerAttr(i1, 1)));
+ Value notError = builder.create<arith::XOrIOp>(
+ isError, builder.create<arith::ConstantOp>(
+ loc, i1, builder.getIntegerAttr(i1, 1)));
builder.create<AssertOp>(notError,
"Awaited async operand is in error state");
});
return !walkResult.wasInterrupted();
});
- runtimeTarget
- .addLegalOp<AssertOp, XOrOp, ConstantOp, BranchOp, CondBranchOp>();
+ runtimeTarget.addLegalOp<AssertOp, arith::XOrIOp, arith::ConstantOp,
+ ConstantOp, BranchOp, CondBranchOp>();
// Assertions must be converted to runtime errors inside async functions.
runtimeTarget.addDynamicallyLegalOp<AssertOp>([&](AssertOp op) -> bool {
MLIRAsyncPassIncGen
LINK_LIBS PUBLIC
- MLIRIR
+ MLIRArithmetic
MLIRAsync
+ MLIRIR
MLIRPass
MLIRSCF
MLIRSCFToStandard
namespace mlir {
+namespace arith {
+class ArithmeticDialect;
+} // end namespace arith
+
namespace async {
class AsyncDialect;
} // namespace async
MLIRComplexOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDialect
MLIRIR
+ MLIRStandard
)
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Complex/IR/Complex.h"
+#include "mlir/Dialect/StandardOps/IR/Ops.h"
+
+using namespace mlir;
#include "mlir/Dialect/Complex/IR/ComplexOpsDialect.cpp.inc"
-void mlir::complex::ComplexDialect::initialize() {
+void complex::ComplexDialect::initialize() {
addOperations<
#define GET_OP_LIST
#include "mlir/Dialect/Complex/IR/ComplexOps.cpp.inc"
>();
}
+
+Operation *complex::ComplexDialect::materializeConstant(OpBuilder &builder,
+ Attribute value,
+ Type type,
+ Location loc) {
+ // TODO complex.constant
+ if (type.isa<ComplexType>())
+ return builder.create<ConstantOp>(loc, type, value);
+ if (arith::ConstantOp::isBuildableWith(value, type))
+ return builder.create<arith::ConstantOp>(loc, type, value);
+ return nullptr;
+}
Operation *EmitCDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
- return builder.create<ConstantOp>(loc, type, value);
+ return builder.create<emitc::ConstantOp>(loc, type, value);
}
//===----------------------------------------------------------------------===//
MLIRGPUOpInterfacesIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDLTI
MLIRIR
MLIRMemRef
MLIRParallelLoopMapperEnumsGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRAsync
MLIRDataLayoutInterfaces
MLIRGPUOps
#include "mlir/Dialect/GPU/GPUDialect.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
// Create a zero value the first time.
OpBuilder::InsertionGuard guard(rewriter);
rewriter.setInsertionPointToStart(&op.body().front());
- zero = rewriter.create<ConstantIndexOp>(op.getLoc(), /*value=*/0);
+ zero =
+ rewriter.create<arith::ConstantIndexOp>(op.getLoc(), /*value=*/0);
}
id.replaceAllUsesWith(zero);
simplified = true;
LogicalResult matchAndRewrite(memref::DimOp dimOp,
PatternRewriter &rewriter) const override {
- auto index = dimOp.index().getDefiningOp<ConstantIndexOp>();
+ auto index = dimOp.index().getDefiningOp<arith::ConstantIndexOp>();
if (!index)
return failure();
auto memrefType = dimOp.source().getType().dyn_cast<MemRefType>();
- if (!memrefType || !memrefType.isDynamicDim(index.getValue()))
+ if (!memrefType || !memrefType.isDynamicDim(index.value()))
return failure();
auto alloc = dimOp.source().getDefiningOp<AllocOp>();
return failure();
Value substituteOp = *(alloc.dynamicSizes().begin() +
- memrefType.getDynamicDimIndex(index.getValue()));
+ memrefType.getDynamicDimIndex(index.value()));
rewriter.replaceOp(dimOp, substituteOp);
return success();
}
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
/// br ^continue1
/// ^continue1:
/// gpu.barrier
- /// %is_valid_subgroup = cmpi "slt" %invocation_idx, %num_subgroups
+ /// %is_valid_subgroup = arith.cmpi "slt" %invocation_idx, %num_subgroups
/// cond_br %is_valid_subgroup, ^then2, ^continue2
/// ^then2:
/// %partial_reduce = load %workgroup_buffer[%invocation_idx]
Value tidX = getDimOp<gpu::ThreadIdOp>("x");
Value tidY = getDimOp<gpu::ThreadIdOp>("y");
Value tidZ = getDimOp<gpu::ThreadIdOp>("z");
- Value tmp1 = create<MulIOp>(int32Type, tidZ, dimY);
- Value tmp2 = create<AddIOp>(int32Type, tmp1, tidY);
- Value tmp3 = create<MulIOp>(int32Type, tmp2, dimX);
- Value tmp4 = create<MulIOp>(int32Type, dimX, dimY);
- Value invocationIdx = create<AddIOp>(int32Type, tmp3, tidX);
- Value workgroupSize = create<MulIOp>(int32Type, tmp4, dimZ);
+ Value tmp1 = create<arith::MulIOp>(int32Type, tidZ, dimY);
+ Value tmp2 = create<arith::AddIOp>(int32Type, tmp1, tidY);
+ Value tmp3 = create<arith::MulIOp>(int32Type, tmp2, dimX);
+ Value tmp4 = create<arith::MulIOp>(int32Type, dimX, dimY);
+ Value invocationIdx = create<arith::AddIOp>(int32Type, tmp3, tidX);
+ Value workgroupSize = create<arith::MulIOp>(int32Type, tmp4, dimZ);
// Compute lane id (invocation id withing the subgroup).
- Value subgroupMask = create<ConstantIntOp>(kSubgroupSize - 1, int32Type);
- Value laneId = create<AndOp>(invocationIdx, subgroupMask);
- Value isFirstLane = create<CmpIOp>(CmpIPredicate::eq, laneId,
- create<ConstantIntOp>(0, int32Type));
+ Value subgroupMask =
+ create<arith::ConstantIntOp>(kSubgroupSize - 1, int32Type);
+ Value laneId = create<arith::AndIOp>(invocationIdx, subgroupMask);
+ Value isFirstLane =
+ create<arith::CmpIOp>(arith::CmpIPredicate::eq, laneId,
+ create<arith::ConstantIntOp>(0, int32Type));
Value numThreadsWithSmallerSubgroupId =
- create<SubIOp>(invocationIdx, laneId);
+ create<arith::SubIOp>(invocationIdx, laneId);
// The number of active invocations starting from the current subgroup.
// The consumers do not require the value to be clamped to the size of the
// subgroup.
Value activeWidth =
- create<SubIOp>(workgroupSize, numThreadsWithSmallerSubgroupId);
+ create<arith::SubIOp>(workgroupSize, numThreadsWithSmallerSubgroupId);
// Create factory for op which accumulates to values.
AccumulatorFactory accumFactory = getFactory();
// of each subgroup.
createPredicatedBlock(isFirstLane, [&] {
Value subgroupId = getDivideBySubgroupSize(invocationIdx);
- Value index = create<IndexCastOp>(indexType, subgroupId);
+ Value index = create<arith::IndexCastOp>(indexType, subgroupId);
create<memref::StoreOp>(subgroupReduce, buffer, index);
});
create<gpu::BarrierOp>();
// Compute number of active subgroups.
Value biasedBlockSize =
- create<AddIOp>(int32Type, workgroupSize, subgroupMask);
+ create<arith::AddIOp>(int32Type, workgroupSize, subgroupMask);
Value numSubgroups = getDivideBySubgroupSize(biasedBlockSize);
- Value isValidSubgroup =
- create<CmpIOp>(CmpIPredicate::slt, invocationIdx, numSubgroups);
+ Value isValidSubgroup = create<arith::CmpIOp>(arith::CmpIPredicate::slt,
+ invocationIdx, numSubgroups);
// Use the first numSubgroups invocations to reduce the intermediate results
// from workgroup memory. The final result is written to workgroup memory
// again.
- Value zero = create<ConstantIndexOp>(0);
+ Value zero = create<arith::ConstantIndexOp>(0);
createPredicatedBlock(isValidSubgroup, [&] {
- Value index = create<IndexCastOp>(indexType, invocationIdx);
+ Value index = create<arith::IndexCastOp>(indexType, invocationIdx);
Value value = create<memref::LoadOp>(valueType, buffer, index);
Value result =
createSubgroupReduce(numSubgroups, laneId, value, accumFactory);
template <typename T>
Value getDimOp(StringRef dimension) {
Value dim = create<T>(indexType, rewriter.getStringAttr(dimension));
- return create<IndexCastOp>(int32Type, dim);
+ return create<arith::IndexCastOp>(int32Type, dim);
}
/// Adds type to funcOp's workgroup attributions.
AccumulatorFactory getFactory(StringRef opName) {
bool isFloatingPoint = valueType.isa<FloatType>();
if (opName == "add")
- return isFloatingPoint ? getFactory<AddFOp>() : getFactory<AddIOp>();
+ return isFloatingPoint ? getFactory<arith::AddFOp>()
+ : getFactory<arith::AddIOp>();
if (opName == "mul")
- return isFloatingPoint ? getFactory<MulFOp>() : getFactory<MulIOp>();
+ return isFloatingPoint ? getFactory<arith::MulFOp>()
+ : getFactory<arith::MulIOp>();
if (opName == "and") {
- return getFactory<AndOp>();
+ return getFactory<arith::AndIOp>();
}
if (opName == "or") {
- return getFactory<OrOp>();
+ return getFactory<arith::OrIOp>();
}
if (opName == "xor") {
- return getFactory<XOrOp>();
+ return getFactory<arith::XOrIOp>();
}
if (opName == "max") {
return isFloatingPoint
- ? getCmpFactory<CmpFOp, CmpFPredicate, CmpFPredicate::UGT>()
- : getCmpFactory<CmpIOp, CmpIPredicate, CmpIPredicate::ugt>();
+ ? getCmpFactory<arith::CmpFOp, arith::CmpFPredicate,
+ arith::CmpFPredicate::UGT>()
+ : getCmpFactory<arith::CmpIOp, arith::CmpIPredicate,
+ arith::CmpIPredicate::ugt>();
}
if (opName == "min") {
return isFloatingPoint
- ? getCmpFactory<CmpFOp, CmpFPredicate, CmpFPredicate::ULT>()
- : getCmpFactory<CmpIOp, CmpIPredicate, CmpIPredicate::ult>();
+ ? getCmpFactory<arith::CmpFOp, arith::CmpFPredicate,
+ arith::CmpFPredicate::ULT>()
+ : getCmpFactory<arith::CmpIOp, arith::CmpIPredicate,
+ arith::CmpIPredicate::ult>();
}
return AccumulatorFactory();
}
/// The first lane returns the result, all others return values are undefined.
Value createSubgroupReduce(Value activeWidth, Value laneId, Value operand,
AccumulatorFactory &accumFactory) {
- Value subgroupSize = create<ConstantIntOp>(kSubgroupSize, int32Type);
- Value isPartialSubgroup =
- create<CmpIOp>(CmpIPredicate::slt, activeWidth, subgroupSize);
+ Value subgroupSize = create<arith::ConstantIntOp>(kSubgroupSize, int32Type);
+ Value isPartialSubgroup = create<arith::CmpIOp>(arith::CmpIPredicate::slt,
+ activeWidth, subgroupSize);
std::array<Type, 2> shuffleType = {valueType, rewriter.getI1Type()};
auto xorAttr = rewriter.getStringAttr("xor");
// lane is within the active range. The accumulated value is available
// in the first lane.
for (int i = 1; i < kSubgroupSize; i <<= 1) {
- Value offset = create<ConstantIntOp>(i, int32Type);
+ Value offset = create<arith::ConstantIntOp>(i, int32Type);
auto shuffleOp = create<gpu::ShuffleOp>(shuffleType, value, offset,
activeWidth, xorAttr);
// Skip the accumulation if the shuffle op read from a lane outside
[&] {
Value value = operand;
for (int i = 1; i < kSubgroupSize; i <<= 1) {
- Value offset = create<ConstantIntOp>(i, int32Type);
+ Value offset = create<arith::ConstantIntOp>(i, int32Type);
auto shuffleOp = create<gpu::ShuffleOp>(shuffleType, value, offset,
subgroupSize, xorAttr);
value = accumFactory(value, shuffleOp.getResult(0));
/// Returns value divided by the subgroup size (i.e. 32).
Value getDivideBySubgroupSize(Value value) {
- Value subgroupSize = create<ConstantIntOp>(kSubgroupSize, int32Type);
- return create<SignedDivIOp>(int32Type, value, subgroupSize);
+ Value subgroupSize = create<arith::ConstantIntOp>(kSubgroupSize, int32Type);
+ return create<arith::DivSIOp>(int32Type, value, subgroupSize);
}
gpu::GPUFuncOp funcOp;
Location loc;
Type valueType;
Type indexType;
- Type int32Type;
+ IntegerType int32Type;
static constexpr int kSubgroupSize = 32;
};
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/GPU/Utils.h"
/// operations may not have side-effects, as otherwise sinking (and hence
/// duplicating them) is not legal.
static bool isSinkingBeneficiary(Operation *op) {
- return isa<ConstantOp, memref::DimOp, SelectOp, CmpIOp>(op);
+ return isa<arith::ConstantOp, ConstantOp, memref::DimOp, SelectOp,
+ arith::CmpIOp>(op);
}
/// For a given operation `op`, computes whether it is beneficial to sink the
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/GPU/MemoryPromotion.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
auto rank = memRefType.getRank();
SmallVector<Value, 4> lbs, ubs, steps;
- Value zero = b.create<ConstantIndexOp>(0);
- Value one = b.create<ConstantIndexOp>(1);
+ Value zero = b.create<arith::ConstantIndexOp>(0);
+ Value one = b.create<arith::ConstantIndexOp>(1);
// Make sure we have enough loops to use all thread dimensions, these trivial
// loops should be outermost and therefore inserted first.
ubs.reserve(lbs.size());
steps.reserve(lbs.size());
for (auto idx = 0; idx < rank; ++idx) {
- ubs.push_back(
- b.createOrFold<memref::DimOp>(from, b.create<ConstantIndexOp>(idx)));
+ ubs.push_back(b.createOrFold<memref::DimOp>(
+ from, b.create<arith::ConstantIndexOp>(idx)));
steps.push_back(one);
}
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRDialectUtils
MLIRInferTypeOpInterface
MLIRIR
#include "mlir/Dialect/Linalg/IR/LinalgInterfaces.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/IR/AffineExprVisitor.h"
#include "mlir/IR/AffineMap.h"
[](AffineMap m) { return !m.isProjectedPermutation(); }))
return MatchContractionResult::NotProjectedPermutations;
// TODO: more fields than add/mul.
- if (!isAddMul<AddFOp, MulFOp>(linalgOp->getRegion(0).front()) &&
- !isAddMul<AddIOp, MulIOp>(linalgOp->getRegion(0).front()))
+ if (!isAddMul<arith::AddFOp, arith::MulFOp>(linalgOp->getRegion(0).front()) &&
+ !isAddMul<arith::AddIOp, arith::MulIOp>(linalgOp->getRegion(0).front()))
return MatchContractionResult::NotAddMul;
return MatchContractionResult::Success;
}
unsigned numDims = map.getNumDims(), numRes = map.getNumResults();
auto viewSizes = createFlatListOfOperandDims(b, loc);
SmallVector<Range, 4> res(numDims);
- Value zeroVal = b.create<ConstantIndexOp>(loc, 0);
- Value oneVal = b.create<ConstantIndexOp>(loc, 1);
+ Value zeroVal = b.create<arith::ConstantIndexOp>(loc, 0);
+ Value oneVal = b.create<arith::ConstantIndexOp>(loc, 1);
for (unsigned idx = 0; idx < numRes; ++idx) {
auto result = map.getResult(idx);
if (auto d = result.dyn_cast<AffineDimExpr>()) {
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
-#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
-#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
-#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/StandardOps/Utils/Utils.h"
-#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Utils/ReshapeOpsUtils.h"
#include "mlir/Dialect/Utils/StaticValueUtils.h"
#include "mlir/IR/AffineExprVisitor.h"
// If operand is floating point, cast directly to the int type.
if (operand.getType().isa<FloatType>()) {
if (isUnsignedCast)
- return builder.create<FPToUIOp>(loc, toType, operand);
- return builder.create<FPToSIOp>(loc, toType, operand);
+ return builder.create<arith::FPToUIOp>(loc, toType, operand);
+ return builder.create<arith::FPToSIOp>(loc, toType, operand);
}
// Cast index operands directly to the int type.
if (operand.getType().isIndex())
- return builder.create<IndexCastOp>(loc, toType, operand);
+ return builder.create<arith::IndexCastOp>(loc, toType, operand);
if (auto fromIntType = operand.getType().dyn_cast<IntegerType>()) {
// Either extend or truncate.
if (toIntType.getWidth() > fromIntType.getWidth()) {
if (isUnsignedCast)
- return builder.create<ZeroExtendIOp>(loc, toType, operand);
- return builder.create<SignExtendIOp>(loc, toType, operand);
+ return builder.create<arith::ExtUIOp>(loc, toType, operand);
+ return builder.create<arith::ExtSIOp>(loc, toType, operand);
}
if (toIntType.getWidth() < fromIntType.getWidth())
- return builder.create<TruncateIOp>(loc, toType, operand);
+ return builder.create<arith::TruncIOp>(loc, toType, operand);
}
} else if (auto toFloatType = toType.dyn_cast<FloatType>()) {
// If operand is integer, cast directly to the float type.
// Note that it is unclear how to cast from BF16<->FP16.
if (operand.getType().isa<IntegerType>()) {
if (isUnsignedCast)
- return builder.create<UIToFPOp>(loc, toFloatType, operand);
- return builder.create<SIToFPOp>(loc, toFloatType, operand);
+ return builder.create<arith::UIToFPOp>(loc, toFloatType, operand);
+ return builder.create<arith::SIToFPOp>(loc, toFloatType, operand);
}
if (auto fromFloatType = operand.getType().dyn_cast<FloatType>()) {
if (toFloatType.getWidth() > fromFloatType.getWidth())
- return builder.create<FPExtOp>(loc, toFloatType, operand);
+ return builder.create<arith::ExtFOp>(loc, toFloatType, operand);
if (toFloatType.getWidth() < fromFloatType.getWidth())
- return builder.create<FPTruncOp>(loc, toFloatType, operand);
+ return builder.create<arith::TruncFOp>(loc, toFloatType, operand);
}
}
Value applyfn__add(Value lhs, Value rhs) {
OpBuilder builder = getBuilder();
if (isFloatingPoint(lhs))
- return builder.create<AddFOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::AddFOp>(lhs.getLoc(), lhs, rhs);
if (isInteger(lhs))
- return builder.create<AddIOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::AddIOp>(lhs.getLoc(), lhs, rhs);
llvm_unreachable("unsupported non numeric type");
}
Value applyfn__sub(Value lhs, Value rhs) {
OpBuilder builder = getBuilder();
if (isFloatingPoint(lhs))
- return builder.create<SubFOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::SubFOp>(lhs.getLoc(), lhs, rhs);
if (isInteger(lhs))
- return builder.create<SubIOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::SubIOp>(lhs.getLoc(), lhs, rhs);
llvm_unreachable("unsupported non numeric type");
}
Value applyfn__mul(Value lhs, Value rhs) {
OpBuilder builder = getBuilder();
if (isFloatingPoint(lhs))
- return builder.create<MulFOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::MulFOp>(lhs.getLoc(), lhs, rhs);
if (isInteger(lhs))
- return builder.create<MulIOp>(lhs.getLoc(), lhs, rhs);
+ return builder.create<arith::MulIOp>(lhs.getLoc(), lhs, rhs);
llvm_unreachable("unsupported non numeric type");
}
OpBuilder builder = getBuilder();
Location loc = builder.getUnknownLoc();
Attribute valueAttr = parseAttribute(value, builder.getContext());
- return builder.create<ConstantOp>(loc, valueAttr.getType(), valueAttr);
+ return builder.create<arith::ConstantOp>(loc, valueAttr.getType(),
+ valueAttr);
}
Value index(int64_t dim) {
// constant value to find the static size to use.
unsigned operandNum = op.getIndexOfDynamicSize(i);
Value sizeOperand = op.getOperand(operandNum);
- if (auto constantIndexOp = sizeOperand.getDefiningOp<ConstantIndexOp>()) {
- staticSizes.push_back(constantIndexOp.getValue());
+ if (auto constantIndexOp =
+ sizeOperand.getDefiningOp<arith::ConstantIndexOp>()) {
+ staticSizes.push_back(constantIndexOp.value());
continue;
}
llvm::seq<int64_t>(0, getType().getRank()), [&](int64_t dim) -> Value {
if (isDynamicSize(dim))
return getDynamicSize(dim);
- return builder.create<ConstantIndexOp>(getLoc(), getStaticSize(dim));
+ return builder.create<arith::ConstantIndexOp>(getLoc(),
+ getStaticSize(dim));
}));
reifiedReturnShapes.emplace_back(std::move(shapes));
return success();
int rank = rankedTensorType.getRank();
for (int i = 0; i < rank; ++i) {
auto dimOp = builder.createOrFold<tensor::DimOp>(loc, source, i);
- auto resultDimSize = builder.createOrFold<ConstantIndexOp>(
+ auto resultDimSize = builder.createOrFold<arith::ConstantIndexOp>(
loc, rankedTensorType.getDimSize(i));
- auto highValue = builder.createOrFold<SubIOp>(loc, resultDimSize, dimOp);
+ auto highValue =
+ builder.createOrFold<arith::SubIOp>(loc, resultDimSize, dimOp);
high.push_back(highValue);
- low.push_back(builder.createOrFold<ConstantIndexOp>(loc, 0));
+ low.push_back(builder.createOrFold<arith::ConstantIndexOp>(loc, 0));
}
return PadTensorOp::createPadScalarOp(type, source, pad, low, high, nofold,
loc, builder);
SmallVector<Range> PadTensorOp::getLoopBounds(OpBuilder &b) {
ReifiedRankedShapedTypeDims reifiedShapes;
(void)reifyResultShapes(b, reifiedShapes);
- Value zero = b.create<ConstantIndexOp>(getLoc(), 0);
- Value one = b.create<ConstantIndexOp>(getLoc(), 1);
+ Value zero = b.create<arith::ConstantIndexOp>(getLoc(), 0);
+ Value one = b.create<arith::ConstantIndexOp>(getLoc(), 1);
// Initialize all the ranges to {zero, one, one}. All the `ub`s are
// overwritten.
SmallVector<Range> loopRanges(reifiedShapes[0].size(), {zero, one, one});
return b.createOrFold<AffineMaxOp>(loc, idMap, ValueRange{v1, v2});
};
// Zero index-typed integer.
- auto zero = b.create<ConstantIndexOp>(loc, 0);
+ auto zero = b.create<arith::ConstantIndexOp>(loc, 0);
// Helper function for filling static/dynamic low/high padding indices vectors
// of PadTensorOp.
if (auto newLengthInt = getConstantIntValue(newLength)) {
hasZeroLen |= *newLengthInt == 0;
} else {
- Value check = b.create<CmpIOp>(loc, CmpIPredicate::eq, newLength, zero);
- dynHasZeroLenCond = dynHasZeroLenCond
- ? b.create<OrOp>(loc, check, dynHasZeroLenCond)
- : check;
+ Value check = b.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ newLength, zero);
+ dynHasZeroLenCond =
+ dynHasZeroLenCond
+ ? b.create<arith::OrIOp>(loc, check, dynHasZeroLenCond)
+ : check;
}
// The amount of high padding is simply the number of elements remaining,
return failure();
DenseElementsAttr newAttr = DenseElementsAttr::getFromRawBuffer(
reshapeOp.getResultType(), attr.getRawData(), true);
- rewriter.replaceOpWithNewOp<ConstantOp>(reshapeOp, newAttr);
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(reshapeOp, newAttr);
return success();
}
};
results.add<EraseDeadLinalgOp, FoldTensorCastOp, SimplifyDepthwiseConvOp,
SimplifyDepthwiseConvQOp>(getContext());
}
+
+Operation *LinalgDialect::materializeConstant(OpBuilder &builder,
+ Attribute value, Type type,
+ Location loc) {
+ return builder.create<arith::ConstantOp>(loc, type, value);
+}
#include "mlir/Transforms/Bufferize.h"
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Passes.h"
#include "mlir/Dialect/Linalg/Transforms/Transforms.h"
BufferizeTypeConverter typeConverter;
// Mark all Standard operations legal.
- target.addLegalDialect<AffineDialect, memref::MemRefDialect,
- StandardOpsDialect, tensor::TensorDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, AffineDialect,
+ memref::MemRefDialect, StandardOpsDialect,
+ tensor::TensorDialect>();
target.addIllegalOp<InitTensorOp, tensor::ExtractSliceOp,
tensor::InsertSliceOp, PadTensorOp>();
MLIRAffine
MLIRAffineUtils
MLIRAnalysis
+ MLIRArithmetic
MLIRComplex
MLIRIR
MLIRMemRef
.Case([&](vector::TransferWriteOp op) {
r.push_back(&op->getOpOperand(1));
})
- .Case<ConstantOp, CallOpInterface, InitTensorOp>([&](auto op) {})
+ .Case<arith::ConstantOp, ConstantOp, CallOpInterface, InitTensorOp>(
+ [&](auto op) {})
.Default([&](Operation *op) {
op->dump();
llvm_unreachable("unexpected defining op");
}
if (Operation *op = v.getDefiningOp()) {
- if (isa<ConstantOp>(op) || !hasKnownBufferizationAliasingBehavior(op)) {
+ if (isa<arith::ConstantOp>(op) ||
+ !hasKnownBufferizationAliasingBehavior(op)) {
LDBG("-----------notWritable op\n");
return true;
}
return success();
}
-static LogicalResult bufferize(OpBuilder &b, ConstantOp constantOp,
+static LogicalResult bufferize(OpBuilder &b, arith::ConstantOp constantOp,
BlockAndValueMapping &bvm,
BufferizationAliasInfo &aliasInfo,
GlobalCreator &globalCreator) {
"null bufferizedFunctionTypes when bufferizing CallOpInterface");
return bufferize(b, op, bvm, aliasInfo, *bufferizedFunctionTypes);
})
- .Case([&](ConstantOp op) {
+ .Case([&](arith::ConstantOp op) {
if (!isaTensor(op.getResult().getType()))
return success();
LDBG("Begin bufferize:\n" << op << '\n');
/// ins(%6, %6 : tensor<i32>, tensor<i32>)
/// outs(%7 : tensor<i32>) {
/// ^bb0(%arg0: i32, %arg1: i32, %arg2: i32):
- /// %9 = addi %arg0, %arg1 : i32
+ /// %9 = arith.addi %arg0, %arg1 : i32
/// linalg.yield %9 : i32
/// } -> tensor<i32>
/// %10 = "some.op"(%9)
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
#include "mlir/Dialect/Linalg/Passes.h"
/// tensor<5xf32> into tensor<5x1xf32>
/// %2 = linalg.generic #trait %0, %1 {
/// ^bb0(%arg2: f32, %arg3: f32):
-/// %3 = addf %arg2, %arg3 : f32
+/// %3 = arith.addf %arg2, %arg3 : f32
/// linalg.yield %3 : f32
/// } : tensor<1x5xf32>, tensor<5x1xf32> -> tensor<5x5xf32>
/// return %2 : tensor<5x5xf32>
/// {
/// %0 = linalg.generic #trait %arg0, %arg1 {
/// ^bb0(%arg2: f32, %arg3: f32):
-/// %3 = addf %arg2, %arg3 : f32
+/// %3 = arith.addf %arg2, %arg3 : f32
/// linalg.yield %3 : f32
/// } : tensor<5xf32>, tensor<5xf32> -> tensor<5x5xf32>
/// return %0 : tensor<5x5xf32>
OpBuilder::InsertionGuard guard(rewriter);
rewriter.setInsertionPoint(indexOp);
if (unitDims.count(indexOp.dim()) != 0) {
- rewriter.replaceOpWithNewOp<ConstantIndexOp>(indexOp, 0);
+ rewriter.replaceOpWithNewOp<arith::ConstantIndexOp>(indexOp, 0);
} else {
// Update the dimension of the index operation if needed.
unsigned droppedDims = llvm::count_if(
}
// Create a constant scalar value from the splat constant.
- Value scalarConstant = rewriter.create<ConstantOp>(
+ Value scalarConstant = rewriter.create<arith::ConstantOp>(
def->getLoc(), constantAttr, constantAttr.getType());
SmallVector<Value> outputOperands = genericOp.getOutputOperands();
#include "PassDetail.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/Analysis/DependenceAnalysis.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
SmallVector<Value, 8> ivs, tileSizes, sizeBounds;
SmallVector<Range, 8> loopRanges;
Location loc = producer.getLoc();
- auto zero = b.create<ConstantIndexOp>(loc, 0);
- auto one = b.create<ConstantIndexOp>(loc, 1);
+ auto zero = b.create<arith::ConstantIndexOp>(loc, 0);
+ auto one = b.create<arith::ConstantIndexOp>(loc, 1);
for (unsigned i = 0, e = producer.getNumLoops(); i < e; ++i) {
auto shapeDim = getShapeDefiningLoopRange(producer, i);
const LinalgTilingOptions &options,
const std::set<unsigned> &fusedLoops) {
SmallVector<Value, 4> tileSizes(tileSizeVector.begin(), tileSizeVector.end());
- auto zero = b.create<ConstantIndexOp>(op.getLoc(), 0);
+ auto zero = b.create<arith::ConstantIndexOp>(op.getLoc(), 0);
for (unsigned i = 0, e = tileSizes.size(); i != e; ++i)
if (!fusedLoops.count(i))
tileSizes[i] = zero;
// `tiledSliceDims` and store the tile offset and size for the tiled slice
// dimension. Assumes the mapping from slice dimensions to producer loops is a
// permutation.
- auto zero = b.create<ConstantIndexOp>(loc, 0);
+ auto zero = b.create<arith::ConstantIndexOp>(loc, 0);
SmallVector<Value> tileIvs(producerOp.getNumLoops(), nullptr);
SmallVector<Value> tileSizes(producerOp.getNumLoops(), zero);
SmallVector<Value> allIvs(producerOp.getNumLoops(), nullptr);
auto getConstantIntValue = [](OpFoldResult ofr) -> llvm::Optional<int64_t> {
Attribute attr = ofr.dyn_cast<Attribute>();
// Note: isa+cast-like pattern allows writing the condition below as 1 line.
- if (!attr && ofr.get<Value>().getDefiningOp<ConstantOp>())
- attr = ofr.get<Value>().getDefiningOp<ConstantOp>().getValue();
+ if (!attr && ofr.get<Value>().getDefiningOp<arith::ConstantOp>())
+ attr = ofr.get<Value>().getDefiningOp<arith::ConstantOp>().value();
if (auto intAttr = attr.dyn_cast_or_null<IntegerAttr>())
return intAttr.getValue().getSExtValue();
return llvm::None;
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Passes.h"
#include "mlir/Dialect/Linalg/Transforms/Transforms.h"
SmallVector<int64_t> indices = map.getConstantResults();
SmallVector<Value> indicesValues;
for (auto idx : indices)
- indicesValues.emplace_back(rewriter.create<ConstantIndexOp>(loc, idx));
+ indicesValues.emplace_back(
+ rewriter.create<arith::ConstantIndexOp>(loc, idx));
Value extractedValue = rewriter.create<tensor::ExtractOp>(
loc, opOperand->get(), indicesValues);
body->getArgument(idx).replaceAllUsesWith(extractedValue);
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
#include "mlir/Dialect/Linalg/Passes.h"
AffineExpr expr = map.getResult(0);
if (map.getNumInputs() == 0) {
if (auto val = expr.dyn_cast<AffineConstantExpr>()) {
- rewriter.replaceOpWithNewOp<ConstantIndexOp>(op, val.getValue());
+ rewriter.replaceOpWithNewOp<arith::ConstantIndexOp>(op, val.getValue());
return success();
}
return failure();
template <typename ConcreteDialect>
void registerDialect(DialectRegistry ®istry);
+namespace arith {
+class ArithmeticDialect;
+} // end namespace arith
+
namespace linalg {
class LinalgDialect;
} // end namespace linalg
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Complex/IR/Complex.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
alignmentAttr = b.getI64IntegerAttr(alignment.getValue());
// Static buffer.
- if (auto cst = allocSize.getDefiningOp<ConstantIndexOp>()) {
+ if (auto cst = allocSize.getDefiningOp<arith::ConstantIndexOp>()) {
auto staticBufferType =
- MemRefType::get(width * cst.getValue(), b.getIntegerType(8));
+ MemRefType::get(width * cst.value(), b.getIntegerType(8));
if (options.useAlloca) {
return b.createOrFold<memref::AllocaOp>(staticBufferType, ValueRange{},
alignmentAttr);
// Fallback dynamic buffer.
auto dynamicBufferType = MemRefType::get(-1, b.getIntegerType(8));
- Value mul =
- b.createOrFold<MulIOp>(b.create<ConstantIndexOp>(width), allocSize);
+ Value mul = b.createOrFold<arith::MulIOp>(
+ b.create<arith::ConstantIndexOp>(width), allocSize);
if (options.useAlloca)
return b.create<memref::AllocaOp>(dynamicBufferType, mul, alignmentAttr);
return b.create<memref::AllocOp>(dynamicBufferType, mul, alignmentAttr);
Optional<unsigned> alignment, DataLayout &layout) {
ShapedType viewType = subView.getType();
ImplicitLocOpBuilder b(subView.getLoc(), builder);
- auto zero = b.createOrFold<ConstantIndexOp>(0);
- auto one = b.createOrFold<ConstantIndexOp>(1);
+ auto zero = b.createOrFold<arith::ConstantIndexOp>(0);
+ auto one = b.createOrFold<arith::ConstantIndexOp>(1);
Value allocSize = one;
for (auto size : llvm::enumerate(boundingSubViewSize))
- allocSize = b.createOrFold<MulIOp>(allocSize, size.value());
+ allocSize = b.createOrFold<arith::MulIOp>(allocSize, size.value());
Value buffer = allocBuffer(b, options, viewType.getElementType(), allocSize,
layout, alignment);
SmallVector<int64_t, 4> dynSizes(boundingSubViewSize.size(),
// Try to extract a tight constant.
LLVM_DEBUG(llvm::dbgs() << "Extract tightest: " << rangeValue.size << "\n");
IntegerAttr sizeAttr = getSmallestBoundingIndex(rangeValue.size);
- Value size =
- (!sizeAttr) ? rangeValue.size : b.create<ConstantOp>(loc, sizeAttr);
+ Value size = (!sizeAttr) ? rangeValue.size
+ : b.create<arith::ConstantOp>(loc, sizeAttr);
LLVM_DEBUG(llvm::dbgs() << "Extracted tightest: " << size << "\n");
fullSizes.push_back(size);
partialSizes.push_back(
Value fillVal =
llvm::TypeSwitch<Type, Value>(subviewEltType)
.Case([&](FloatType t) {
- return b.create<ConstantOp>(FloatAttr::get(t, 0.0));
+ return b.create<arith::ConstantOp>(FloatAttr::get(t, 0.0));
})
.Case([&](IntegerType t) {
- return b.create<ConstantOp>(IntegerAttr::get(t, 0));
+ return b.create<arith::ConstantOp>(IntegerAttr::get(t, 0));
})
.Case([&](ComplexType t) {
Value tmp;
if (auto et = t.getElementType().dyn_cast<FloatType>())
- tmp = b.create<ConstantOp>(FloatAttr::get(et, 0.0));
+ tmp = b.create<arith::ConstantOp>(FloatAttr::get(et, 0.0));
else if (auto et = t.getElementType().cast<IntegerType>())
- tmp = b.create<ConstantOp>(IntegerAttr::get(et, 0));
+ tmp = b.create<arith::ConstantOp>(IntegerAttr::get(et, 0));
return b.create<complex::CreateOp>(t, tmp, tmp);
})
.Default([](auto) { return Value(); });
#define DEBUG_TYPE "linalg-tiling"
static bool isZero(Value v) {
- if (auto cst = v.getDefiningOp<ConstantIndexOp>())
- return cst.getValue() == 0;
+ if (auto cst = v.getDefiningOp<arith::ConstantIndexOp>())
+ return cst.value() == 0;
return false;
}
// Create a new range with the applied tile sizes.
SmallVector<Range, 4> res;
for (unsigned idx = 0, e = tileSizes.size(); idx < e; ++idx)
- res.push_back(Range{b.create<ConstantIndexOp>(loc, 0), shapeSizes[idx],
- tileSizes[idx]});
+ res.push_back(Range{b.create<arith::ConstantIndexOp>(loc, 0),
+ shapeSizes[idx], tileSizes[idx]});
return std::make_tuple(res, loopIndexToRangeIndex);
}
// %i = linalg.index 0 : index
// %j = linalg.index 1 : index
// // Indices `k` and `l` are implicitly captured in the body.
-// %transformed_i = addi %i, %k : index // index `i` is offset by %k
-// %transformed_j = addi %j, %l : index // index `j` is offset by %l
+// %transformed_i = arith.addi %i, %k : index // index `i` is offset by %k
+// %transformed_j = arith.addi %j, %l : index // index `j` is offset by %l
// // Every use of %i, %j is replaced with %transformed_i, %transformed_j
// <some operations that use %transformed_i, %transformed_j>
// }: memref<?x?xf32, #strided>, memref<?x?xf32, #strided>
SmallVector<Value, 4> tileSizeVector =
options.tileSizeComputationFunction(b, op);
if (tileSizeVector.size() < nLoops) {
- auto zero = b.create<ConstantIndexOp>(op.getLoc(), 0);
+ auto zero = b.create<arith::ConstantIndexOp>(op.getLoc(), 0);
tileSizeVector.append(nLoops - tileSizeVector.size(), zero);
}
AffineForOp::getCanonicalizationPatterns(patterns, ctx);
AffineMinOp::getCanonicalizationPatterns(patterns, ctx);
AffineMaxOp::getCanonicalizationPatterns(patterns, ctx);
- ConstantIndexOp::getCanonicalizationPatterns(patterns, ctx);
+ arith::ConstantIndexOp::getCanonicalizationPatterns(patterns, ctx);
memref::SubViewOp::getCanonicalizationPatterns(patterns, ctx);
memref::ViewOp::getCanonicalizationPatterns(patterns, ctx);
#include "mlir/Dialect/Linalg/Transforms/Transforms.h"
#include "mlir/Dialect/Affine/Utils.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/Analysis/DependenceAnalysis.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Utils/Utils.h"
b.setInsertionPointToStart(
&op->getParentOfType<FuncOp>().getBody().front());
return llvm::to_vector<4>(map_range(tileSizes, [&](int64_t s) {
- Value v = b.create<ConstantIndexOp>(op->getLoc(), s);
+ Value v = b.create<arith::ConstantIndexOp>(op->getLoc(), s);
return v;
}));
};
// size 0).
for (Value shapeSize : shapeSizes)
tileSizes.push_back(getConstantIntValue(shapeSize).hasValue()
- ? b.create<ConstantIndexOp>(loc, 0)
- : b.create<ConstantIndexOp>(loc, 1));
+ ? b.create<arith::ConstantIndexOp>(loc, 0)
+ : b.create<arith::ConstantIndexOp>(loc, 1));
return tileSizes;
};
return *this;
// Tile the unfused loops;
SmallVector<Value, 4> unfusedLoopTileSizes;
- Value zero = rewriter.create<ConstantIndexOp>(op->getLoc(), 0);
+ Value zero = rewriter.create<arith::ConstantIndexOp>(op->getLoc(), 0);
for (auto tileSize : enumerate(tileSizes)) {
if (tiledAndFusedOps->fusedLoopDims.count(tileSize.index()))
unfusedLoopTileSizes.push_back(zero);
if (unfusedLoopTileSizes.size() > linalgOp.getNumLoops())
unfusedLoopTileSizes.resize(linalgOp.getNumLoops());
if (llvm::any_of(unfusedLoopTileSizes, [](Value val) {
- if (auto cst = val.getDefiningOp<ConstantIndexOp>())
- return cst.getValue() != 0;
+ if (auto cst = val.getDefiningOp<arith::ConstantIndexOp>())
+ return cst.value() != 0;
return true;
})) {
LinalgTilingOptions unfusedTilingOptions = tilingOptions;
// Create tensor with the padded shape
Location loc = padOp.getLoc();
SmallVector<Value> indices(resultShapedType.getRank(),
- rewriter.create<ConstantIndexOp>(loc, 0));
+ rewriter.create<arith::ConstantIndexOp>(loc, 0));
Value initTensor = rewriter.create<InitTensorOp>(
loc, resultShapedType.getShape(), resultShapedType.getElementType());
if (auto val = ofr.dyn_cast<Value>())
return val;
return rewriter
- .create<ConstantIndexOp>(
+ .create<arith::ConstantIndexOp>(
padOp.getLoc(), ofr.get<Attribute>().cast<IntegerAttr>().getInt())
.getResult();
};
auto srcSize = rewriter.createOrFold<tensor::DimOp>(padOp.getLoc(),
padOp.source(), dim);
// Add low and high padding value.
- auto plusLow = rewriter.createOrFold<AddIOp>(
+ auto plusLow = rewriter.createOrFold<arith::AddIOp>(
padOp.getLoc(), srcSize, getIdxValue(padOp.getMixedLowPad()[dim]));
- auto plusHigh = rewriter.createOrFold<AddIOp>(
+ auto plusHigh = rewriter.createOrFold<arith::AddIOp>(
padOp.getLoc(), plusLow, getIdxValue(padOp.getMixedHighPad()[dim]));
dynSizes.push_back(plusHigh);
}
#include "mlir/Analysis/LoopAnalysis.h"
#include "mlir/Analysis/SliceAnalysis.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/Analysis/DependenceAnalysis.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Transforms/Transforms.h"
return llvm::None;
return llvm::TypeSwitch<Operation *, llvm::Optional<vector::CombiningKind>>(
reductionOp)
- .Case<AddIOp, AddFOp>([&](auto op) { return vector::CombiningKind::ADD; })
- .Case<AndOp>([&](auto op) { return vector::CombiningKind::AND; })
+ .Case<arith::AddIOp, arith::AddFOp>(
+ [&](auto op) { return vector::CombiningKind::ADD; })
+ .Case<arith::AndIOp>([&](auto op) { return vector::CombiningKind::AND; })
.Case<MaxSIOp>([&](auto op) { return vector::CombiningKind::MAXSI; })
.Case<MaxFOp>([&](auto op) { return vector::CombiningKind::MAXF; })
.Case<MinSIOp>([&](auto op) { return vector::CombiningKind::MINSI; })
.Case<MinFOp>([&](auto op) { return vector::CombiningKind::MINF; })
- .Case<MulIOp, MulFOp>([&](auto op) { return vector::CombiningKind::MUL; })
- .Case<OrOp>([&](auto op) { return vector::CombiningKind::OR; })
- .Case<XOrOp>([&](auto op) { return vector::CombiningKind::XOR; })
+ .Case<arith::MulIOp, arith::MulFOp>(
+ [&](auto op) { return vector::CombiningKind::MUL; })
+ .Case<arith::OrIOp>([&](auto op) { return vector::CombiningKind::OR; })
+ .Case<arith::XOrIOp>([&](auto op) { return vector::CombiningKind::XOR; })
.Default([&](auto op) { return llvm::None; });
}
Location loc = source.getLoc();
auto shapedType = source.getType().cast<ShapedType>();
SmallVector<Value> indices(shapedType.getRank(),
- b.create<ConstantIndexOp>(loc, 0));
+ b.create<arith::ConstantIndexOp>(loc, 0));
if (auto vectorType = readType.dyn_cast<VectorType>())
return b.create<vector::TransferReadOp>(loc, vectorType, source, indices,
map);
assert(!transposeShape.empty() && "unexpected empty transpose shape");
vectorType = VectorType::get(transposeShape, vectorType.getElementType());
SmallVector<Value> indices(linalgOp.getRank(outputOperand),
- b.create<ConstantIndexOp>(loc, 0));
+ b.create<arith::ConstantIndexOp>(loc, 0));
value = broadcastIfNeeded(b, value, vectorType.getShape());
value = reduceIfNeeded(b, vectorType, value, outputOperand, bvm);
write = b.create<vector::TransferWriteOp>(loc, value, outputOperand->get(),
// Compute a one-dimensional index vector for the index op dimension.
SmallVector<int64_t> constantSeq =
llvm::to_vector<16>(llvm::seq<int64_t>(0, targetShape[indexOp.dim()]));
- ConstantOp constantOp =
- b.create<ConstantOp>(loc, b.getIndexVectorAttr(constantSeq));
+ auto constantOp =
+ b.create<arith::ConstantOp>(loc, b.getIndexVectorAttr(constantSeq));
// Return the one-dimensional index vector if it lives in the trailing
// dimension of the iteration space since the vectorization algorithm in this
// case can handle the broadcast.
// 2. Constant ops don't get vectorized but rather broadcasted at their users.
// Clone so that the constant is not confined to the linalgOp block .
- if (isa<ConstantOp>(op))
+ if (isa<arith::ConstantOp, ConstantOp>(op))
return VectorizationResult{VectorizationStatus::NewOp, b.clone(*op)};
// 3. Only ElementwiseMappable are allowed in the generic vectorization.
if (!llvm::hasSingleElement(r))
return false;
for (Operation &op : r.front()) {
- if (!(isa<ConstantOp, linalg::YieldOp, linalg::IndexOp>(op) ||
+ if (!(isa<arith::ConstantOp, ConstantOp, linalg::YieldOp, linalg::IndexOp>(
+ op) ||
OpTrait::hasElementwiseMappableTraits(&op)) ||
llvm::any_of(op.getResultTypes(),
[](Type type) { return !type.isIntOrIndexOrFloat(); }))
CustomVectorizationHook vectorizeContraction =
[&](Operation *op,
const BlockAndValueMapping &bvm) -> VectorizationResult {
- if (!isa<MulIOp, MulFOp>(op))
+ if (!isa<arith::MulIOp, arith::MulFOp>(op))
return VectorizationResult{VectorizationStatus::Failure, nullptr};
ArrayRef<int64_t> outShape =
linalgOp.getShape(linalgOp.getOutputOperand(0));
outShape);
vType = VectorType::get(resultShape, op->getResult(0).getType());
}
- auto zero = b.create<ConstantOp>(loc, vType, b.getZeroAttr(vType));
+ auto zero = b.create<arith::ConstantOp>(loc, vType, b.getZeroAttr(vType));
// Indexing maps at the time of vector.transfer_read are adjusted to order
// vector dimensions in the same order as the canonical linalg op iteration
// space order.
if (auto val = o.template dyn_cast<Value>()) {
result.push_back(val);
} else {
- result.push_back(builder.create<ConstantIndexOp>(
+ result.push_back(builder.create<arith::ConstantIndexOp>(
loc, getIntFromAttr(o.template get<Attribute>())));
}
});
return failure();
// Create dummy padding value.
auto elemType = sourceType.getElementType();
- padValue = rewriter.create<ConstantOp>(padOp.getLoc(), elemType,
- rewriter.getZeroAttr(elemType));
+ padValue = rewriter.create<arith::ConstantOp>(
+ padOp.getLoc(), elemType, rewriter.getZeroAttr(elemType));
}
SmallVector<int64_t> vecShape;
// Generate TransferReadOp.
SmallVector<Value> readIndices(
- vecType.getRank(), rewriter.create<ConstantIndexOp>(padOp.getLoc(), 0));
+ vecType.getRank(),
+ rewriter.create<arith::ConstantIndexOp>(padOp.getLoc(), 0));
auto read = rewriter.create<vector::TransferReadOp>(
padOp.getLoc(), vecType, padOp.source(), readIndices, padValue,
readInBounds);
// Generate TransferReadOp: Read entire source tensor and add high padding.
SmallVector<Value> readIndices(
- vecRank, rewriter.create<ConstantIndexOp>(padOp.getLoc(), 0));
+ vecRank, rewriter.create<arith::ConstantIndexOp>(padOp.getLoc(), 0));
auto read = rewriter.create<vector::TransferReadOp>(
padOp.getLoc(), vecType, padOp.source(), readIndices, padValue);
Type elemType = getElementTypeOrSelf(input->get());
auto map = AffineMap::get(rank, 0, mapping, context);
- SmallVector<Value, 4> zeros(rank, rewriter.create<ConstantIndexOp>(loc, 0));
+ SmallVector<Value, 4> zeros(rank,
+ rewriter.create<arith::ConstantIndexOp>(loc, 0));
auto vecType = VectorType::get(vectorDims, elemType);
auto inputVec = rewriter.create<vector::TransferReadOp>(
auto kernelVec = rewriter.create<vector::TransferReadOp>(
loc, vecType, kernel->get(), zeros, map);
- auto acc = rewriter.create<ConstantOp>(loc, elemType,
- rewriter.getZeroAttr(elemType));
+ auto acc = rewriter.create<arith::ConstantOp>(loc, elemType,
+ rewriter.getZeroAttr(elemType));
std::array<AffineMap, 3> indexingMaps{
AffineMap::getMultiDimIdentityMap(numDims, context),
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRIR
MLIRLinalg
MLIRSCF
#include "mlir/Dialect/Linalg/Utils/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/IR/LinalgTypes.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
using namespace mlir::scf;
static bool isZero(Value v) {
- if (auto cst = v.getDefiningOp<ConstantIndexOp>())
- return cst.getValue() == 0;
+ if (auto cst = v.getDefiningOp<arith::ConstantIndexOp>())
+ return cst.value() == 0;
return false;
}
auto a = m_Val(block.getArgument(0));
auto b = m_Val(block.getArgument(1));
- auto addPattern = m_Op<linalg::YieldOp>(m_Op<AddIOp>(a, b));
+ auto addPattern = m_Op<linalg::YieldOp>(m_Op<arith::AddIOp>(a, b));
if (addPattern.match(&ops.back()))
return BinaryOpKind::IAdd;
boundingConst = boundingConst
? std::min(boundingConst.getValue(), cst.getValue())
: cst.getValue();
- } else if (auto constIndexOp = size.getDefiningOp<ConstantOp>()) {
+ } else if (auto constIndexOp = size.getDefiningOp<arith::ConstantOp>()) {
if (constIndexOp.getType().isa<IndexType>())
boundingConst = constIndexOp.value().cast<IntegerAttr>().getInt();
} else if (auto affineApplyOp = size.getDefiningOp<AffineApplyOp>()) {
boundingConst = cExpr.getValue();
} else if (auto dimOp = size.getDefiningOp<tensor::DimOp>()) {
auto shape = dimOp.source().getType().dyn_cast<ShapedType>();
- if (auto constOp = dimOp.index().getDefiningOp<ConstantOp>()) {
+ if (auto constOp = dimOp.index().getDefiningOp<arith::ConstantOp>()) {
if (auto indexAttr = constOp.value().dyn_cast<IntegerAttr>()) {
auto dimIndex = indexAttr.getInt();
if (!shape.isDynamicDim(dimIndex)) {
SmallVector<int64_t, 4> constantSteps;
constantSteps.reserve(steps.size());
for (Value v : steps) {
- auto op = v.getDefiningOp<ConstantIndexOp>();
+ auto op = v.getDefiningOp<arith::ConstantIndexOp>();
assert(op && "Affine loops require constant steps");
- constantSteps.push_back(op.getValue());
+ constantSteps.push_back(op.value());
}
mlir::buildAffineLoopNest(b, loc, lbs, ubs, constantSteps,
// b. The subshape size is 1. According to the way the loops are set up,
// tensors with "0" dimensions would never be constructed.
int64_t shapeSize = shape[r];
- auto sizeCst = size.getDefiningOp<ConstantIndexOp>();
- auto hasTileSizeOne = sizeCst && sizeCst.getValue() == 1;
+ auto sizeCst = size.getDefiningOp<arith::ConstantIndexOp>();
+ auto hasTileSizeOne = sizeCst && sizeCst.value() == 1;
auto dividesEvenly = sizeCst && !ShapedType::isDynamic(shapeSize) &&
- ((shapeSize % sizeCst.getValue()) == 0);
+ ((shapeSize % sizeCst.value()) == 0);
if (!hasTileSizeOne && !dividesEvenly) {
LLVM_DEBUG(llvm::dbgs() << "makeTiledShape: shapeSize=" << shapeSize
<< ", size: " << size
for (unsigned idx = 0, idxIvs = 0, e = tileSizes.size(); idx < e; ++idx) {
LLVM_DEBUG(llvm::dbgs() << "makeTiledShapes: for loop#" << idx << "\n");
bool isTiled = !isZero(tileSizes[idx]);
- offsets.push_back(isTiled ? ivs[idxIvs++]
- : b.create<ConstantIndexOp>(loc, 0).getResult());
+ offsets.push_back(
+ isTiled ? ivs[idxIvs++]
+ : b.create<arith::ConstantIndexOp>(loc, 0).getResult());
LLVM_DEBUG(llvm::dbgs()
<< "computeTileOffsets: " << offsets.back() << "\n");
}
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/Math/Transforms/Passes.h"
#include "mlir/Dialect/Vector/VectorOps.h"
// Replace `pow(x, 2.0)` with `x * x`.
if (isExponentValue(2.0)) {
- rewriter.replaceOpWithNewOp<MulFOp>(op, ValueRange({x, x}));
+ rewriter.replaceOpWithNewOp<arith::MulFOp>(op, ValueRange({x, x}));
return success();
}
// Replace `pow(x, 3.0)` with `x * x * x`.
if (isExponentValue(3.0)) {
- Value square = rewriter.create<MulFOp>(op.getLoc(), ValueRange({x, x}));
- rewriter.replaceOpWithNewOp<MulFOp>(op, ValueRange({x, square}));
+ Value square =
+ rewriter.create<arith::MulFOp>(op.getLoc(), ValueRange({x, x}));
+ rewriter.replaceOpWithNewOp<arith::MulFOp>(op, ValueRange({x, square}));
return success();
}
// Replace `pow(x, -1.0)` with `1.0 / x`.
if (isExponentValue(-1.0)) {
- Value one = rewriter.create<ConstantOp>(
+ Value one = rewriter.create<arith::ConstantOp>(
loc, rewriter.getFloatAttr(getElementTypeOrSelf(op.getType()), 1.0));
- rewriter.replaceOpWithNewOp<DivFOp>(op, ValueRange({bcast(one), x}));
+ rewriter.replaceOpWithNewOp<arith::DivFOp>(op, ValueRange({bcast(one), x}));
return success();
}
${MLIR_MAIN_INCLUDE_DIR}/mlir/Dialect/Math/Transforms
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRMath
MLIRPass
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/Math/Transforms/Passes.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/Transforms/DialectConversion.h"
+
using namespace mlir;
/// Expands tanh op into
Location loc = op.getLoc();
auto floatOne = rewriter.getFloatAttr(floatType, 1.0);
auto floatTwo = rewriter.getFloatAttr(floatType, 2.0);
- Value one = rewriter.create<ConstantOp>(loc, floatOne);
- Value two = rewriter.create<ConstantOp>(loc, floatTwo);
- Value doubledX = rewriter.create<MulFOp>(loc, op.operand(), two);
+ Value one = rewriter.create<arith::ConstantOp>(loc, floatOne);
+ Value two = rewriter.create<arith::ConstantOp>(loc, floatTwo);
+ Value doubledX = rewriter.create<arith::MulFOp>(loc, op.operand(), two);
// Case 1: tanh(x) = 1-exp^{-2x} / 1+exp^{-2x}
- Value negDoubledX = rewriter.create<NegFOp>(loc, doubledX);
+ Value negDoubledX = rewriter.create<arith::NegFOp>(loc, doubledX);
Value exp2x = rewriter.create<math::ExpOp>(loc, negDoubledX);
- Value dividend = rewriter.create<SubFOp>(loc, one, exp2x);
- Value divisor = rewriter.create<AddFOp>(loc, one, exp2x);
- Value positiveRes = rewriter.create<DivFOp>(loc, dividend, divisor);
+ Value dividend = rewriter.create<arith::SubFOp>(loc, one, exp2x);
+ Value divisor = rewriter.create<arith::AddFOp>(loc, one, exp2x);
+ Value positiveRes = rewriter.create<arith::DivFOp>(loc, dividend, divisor);
// Case 2: tanh(x) = exp^{2x}-1 / exp^{2x}+1
exp2x = rewriter.create<math::ExpOp>(loc, doubledX);
- dividend = rewriter.create<SubFOp>(loc, exp2x, one);
- divisor = rewriter.create<AddFOp>(loc, exp2x, one);
- Value negativeRes = rewriter.create<DivFOp>(loc, dividend, divisor);
+ dividend = rewriter.create<arith::SubFOp>(loc, exp2x, one);
+ divisor = rewriter.create<arith::AddFOp>(loc, exp2x, one);
+ Value negativeRes = rewriter.create<arith::DivFOp>(loc, dividend, divisor);
// tanh(x) = x >= 0 ? positiveRes : negativeRes
auto floatZero = rewriter.getFloatAttr(floatType, 0.0);
- Value zero = rewriter.create<ConstantOp>(loc, floatZero);
- Value cmpRes =
- rewriter.create<CmpFOp>(loc, CmpFPredicate::OGE, op.operand(), zero);
+ Value zero = rewriter.create<arith::ConstantOp>(loc, floatZero);
+ Value cmpRes = rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGE,
+ op.operand(), zero);
rewriter.replaceOpWithNewOp<SelectOp>(op, cmpRes, positiveRes, negativeRes);
return success();
}
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/Math/Transforms/Passes.h"
#include "mlir/Dialect/Vector/VectorOps.h"
//----------------------------------------------------------------------------//
static Value f32Cst(ImplicitLocOpBuilder &builder, float value) {
- return builder.create<ConstantOp>(builder.getF32Type(),
- builder.getF32FloatAttr(value));
+ return builder.create<arith::ConstantOp>(builder.getF32FloatAttr(value));
}
static Value i32Cst(ImplicitLocOpBuilder &builder, int32_t value) {
- return builder.create<ConstantOp>(builder.getI32Type(),
- builder.getI32IntegerAttr(value));
+ return builder.create<arith::ConstantOp>(builder.getI32IntegerAttr(value));
}
static Value f32FromBits(ImplicitLocOpBuilder &builder, uint32_t bits) {
Value i32Value = i32Cst(builder, static_cast<int32_t>(bits));
- return builder.create<BitcastOp>(builder.getF32Type(), i32Value);
+ return builder.create<arith::BitcastOp>(builder.getF32Type(), i32Value);
}
//----------------------------------------------------------------------------//
static Value min(ImplicitLocOpBuilder &builder, Value a, Value b) {
return builder.create<SelectOp>(
- builder.create<CmpFOp>(CmpFPredicate::OLT, a, b), a, b);
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OLT, a, b), a, b);
}
static Value max(ImplicitLocOpBuilder &builder, Value a, Value b) {
return builder.create<SelectOp>(
- builder.create<CmpFOp>(CmpFPredicate::OGT, a, b), a, b);
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OGT, a, b), a, b);
}
static Value clamp(ImplicitLocOpBuilder &builder, Value value, Value lowerBound,
Value cstInvMantMask = f32FromBits(builder, ~0x7f800000u);
// Bitcast to i32 for bitwise operations.
- Value i32Half = builder.create<BitcastOp>(i32, cstHalf);
- Value i32InvMantMask = builder.create<BitcastOp>(i32, cstInvMantMask);
- Value i32Arg = builder.create<BitcastOp>(i32Vec, arg);
+ Value i32Half = builder.create<arith::BitcastOp>(i32, cstHalf);
+ Value i32InvMantMask = builder.create<arith::BitcastOp>(i32, cstInvMantMask);
+ Value i32Arg = builder.create<arith::BitcastOp>(i32Vec, arg);
// Compute normalized fraction.
- Value tmp0 = builder.create<AndOp>(i32Arg, bcast(i32InvMantMask));
- Value tmp1 = builder.create<OrOp>(tmp0, bcast(i32Half));
- Value normalizedFraction = builder.create<BitcastOp>(f32Vec, tmp1);
+ Value tmp0 = builder.create<arith::AndIOp>(i32Arg, bcast(i32InvMantMask));
+ Value tmp1 = builder.create<arith::OrIOp>(tmp0, bcast(i32Half));
+ Value normalizedFraction = builder.create<arith::BitcastOp>(f32Vec, tmp1);
// Compute exponent.
- Value arg0 = is_positive ? arg : builder.create<AbsFOp>(arg);
- Value biasedExponentBits = builder.create<UnsignedShiftRightOp>(
- builder.create<BitcastOp>(i32Vec, arg0), bcast(i32Cst(builder, 23)));
- Value biasedExponent = builder.create<SIToFPOp>(f32Vec, biasedExponentBits);
- Value exponent = builder.create<SubFOp>(biasedExponent, bcast(cst126f));
+ Value arg0 = is_positive ? arg : builder.create<math::AbsOp>(arg);
+ Value biasedExponentBits = builder.create<arith::ShRUIOp>(
+ builder.create<arith::BitcastOp>(i32Vec, arg0),
+ bcast(i32Cst(builder, 23)));
+ Value biasedExponent =
+ builder.create<arith::SIToFPOp>(f32Vec, biasedExponentBits);
+ Value exponent =
+ builder.create<arith::SubFOp>(biasedExponent, bcast(cst126f));
return {normalizedFraction, exponent};
}
// Set the exponent bias to zero.
auto bias = bcast(i32Cst(builder, 127));
- Value biasedArg = builder.create<AddIOp>(arg, bias);
+ Value biasedArg = builder.create<arith::AddIOp>(arg, bias);
Value exp2ValueInt =
- builder.create<ShiftLeftOp>(biasedArg, exponetBitLocation);
- Value exp2ValueF32 = builder.create<BitcastOp>(f32Vec, exp2ValueInt);
+ builder.create<arith::ShLIOp>(biasedArg, exponetBitLocation);
+ Value exp2ValueF32 = builder.create<arith::BitcastOp>(f32Vec, exp2ValueInt);
return exp2ValueF32;
}
// Mask for tiny values that are approximated with `operand`.
Value tiny = bcast(f32Cst(builder, 0.0004f));
- Value tinyMask = builder.create<CmpFOp>(
- CmpFPredicate::OLT, builder.create<AbsFOp>(op.operand()), tiny);
+ Value tinyMask = builder.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OLT, builder.create<math::AbsOp>(op.operand()),
+ tiny);
// The monomial coefficients of the numerator polynomial (odd).
Value alpha1 = bcast(f32Cst(builder, 4.89352455891786e-03f));
Value beta6 = bcast(f32Cst(builder, 1.19825839466702e-06f));
// Since the polynomials are odd/even, we need x^2.
- Value x2 = builder.create<MulFOp>(x, x);
+ Value x2 = builder.create<arith::MulFOp>(x, x);
// Evaluate the numerator polynomial p.
- Value p = builder.create<FmaFOp>(x2, alpha13, alpha11);
- p = builder.create<FmaFOp>(x2, p, alpha9);
- p = builder.create<FmaFOp>(x2, p, alpha7);
- p = builder.create<FmaFOp>(x2, p, alpha5);
- p = builder.create<FmaFOp>(x2, p, alpha3);
- p = builder.create<FmaFOp>(x2, p, alpha1);
- p = builder.create<MulFOp>(x, p);
+ Value p = builder.create<math::FmaOp>(x2, alpha13, alpha11);
+ p = builder.create<math::FmaOp>(x2, p, alpha9);
+ p = builder.create<math::FmaOp>(x2, p, alpha7);
+ p = builder.create<math::FmaOp>(x2, p, alpha5);
+ p = builder.create<math::FmaOp>(x2, p, alpha3);
+ p = builder.create<math::FmaOp>(x2, p, alpha1);
+ p = builder.create<arith::MulFOp>(x, p);
// Evaluate the denominator polynomial q.
- Value q = builder.create<FmaFOp>(x2, beta6, beta4);
- q = builder.create<FmaFOp>(x2, q, beta2);
- q = builder.create<FmaFOp>(x2, q, beta0);
+ Value q = builder.create<math::FmaOp>(x2, beta6, beta4);
+ q = builder.create<math::FmaOp>(x2, q, beta2);
+ q = builder.create<math::FmaOp>(x2, q, beta0);
// Divide the numerator by the denominator.
- Value res =
- builder.create<SelectOp>(tinyMask, x, builder.create<DivFOp>(p, q));
+ Value res = builder.create<SelectOp>(tinyMask, x,
+ builder.create<arith::DivFOp>(p, q));
rewriter.replaceOp(op, res);
// e -= 1;
// x = x + x - 1.0;
// } else { x = x - 1.0; }
- Value mask = builder.create<CmpFOp>(CmpFPredicate::OLT, x, cstCephesSQRTHF);
+ Value mask = builder.create<arith::CmpFOp>(arith::CmpFPredicate::OLT, x,
+ cstCephesSQRTHF);
Value tmp = builder.create<SelectOp>(mask, x, cstZero);
- x = builder.create<SubFOp>(x, cstOne);
- e = builder.create<SubFOp>(e,
- builder.create<SelectOp>(mask, cstOne, cstZero));
- x = builder.create<AddFOp>(x, tmp);
+ x = builder.create<arith::SubFOp>(x, cstOne);
+ e = builder.create<arith::SubFOp>(
+ e, builder.create<SelectOp>(mask, cstOne, cstZero));
+ x = builder.create<arith::AddFOp>(x, tmp);
- Value x2 = builder.create<MulFOp>(x, x);
- Value x3 = builder.create<MulFOp>(x2, x);
+ Value x2 = builder.create<arith::MulFOp>(x, x);
+ Value x3 = builder.create<arith::MulFOp>(x2, x);
// Evaluate the polynomial approximant of degree 8 in three parts.
Value y0, y1, y2;
- y0 = builder.create<FmaFOp>(cstCephesLogP0, x, cstCephesLogP1);
- y1 = builder.create<FmaFOp>(cstCephesLogP3, x, cstCephesLogP4);
- y2 = builder.create<FmaFOp>(cstCephesLogP6, x, cstCephesLogP7);
- y0 = builder.create<FmaFOp>(y0, x, cstCephesLogP2);
- y1 = builder.create<FmaFOp>(y1, x, cstCephesLogP5);
- y2 = builder.create<FmaFOp>(y2, x, cstCephesLogP8);
- y0 = builder.create<FmaFOp>(y0, x3, y1);
- y0 = builder.create<FmaFOp>(y0, x3, y2);
- y0 = builder.create<MulFOp>(y0, x3);
-
- y0 = builder.create<FmaFOp>(cstNegHalf, x2, y0);
- x = builder.create<AddFOp>(x, y0);
+ y0 = builder.create<math::FmaOp>(cstCephesLogP0, x, cstCephesLogP1);
+ y1 = builder.create<math::FmaOp>(cstCephesLogP3, x, cstCephesLogP4);
+ y2 = builder.create<math::FmaOp>(cstCephesLogP6, x, cstCephesLogP7);
+ y0 = builder.create<math::FmaOp>(y0, x, cstCephesLogP2);
+ y1 = builder.create<math::FmaOp>(y1, x, cstCephesLogP5);
+ y2 = builder.create<math::FmaOp>(y2, x, cstCephesLogP8);
+ y0 = builder.create<math::FmaOp>(y0, x3, y1);
+ y0 = builder.create<math::FmaOp>(y0, x3, y2);
+ y0 = builder.create<arith::MulFOp>(y0, x3);
+
+ y0 = builder.create<math::FmaOp>(cstNegHalf, x2, y0);
+ x = builder.create<arith::AddFOp>(x, y0);
if (base2) {
Value cstLog2e = bcast(f32Cst(builder, static_cast<float>(LOG2E_VALUE)));
- x = builder.create<FmaFOp>(x, cstLog2e, e);
+ x = builder.create<math::FmaOp>(x, cstLog2e, e);
} else {
Value cstLn2 = bcast(f32Cst(builder, static_cast<float>(LN2_VALUE)));
- x = builder.create<FmaFOp>(e, cstLn2, x);
+ x = builder.create<math::FmaOp>(e, cstLn2, x);
}
- Value invalidMask =
- builder.create<CmpFOp>(CmpFPredicate::ULT, op.operand(), cstZero);
- Value zeroMask =
- builder.create<CmpFOp>(CmpFPredicate::OEQ, op.operand(), cstZero);
- Value posInfMask =
- builder.create<CmpFOp>(CmpFPredicate::OEQ, op.operand(), cstPosInf);
+ Value invalidMask = builder.create<arith::CmpFOp>(arith::CmpFPredicate::ULT,
+ op.operand(), cstZero);
+ Value zeroMask = builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ,
+ op.operand(), cstZero);
+ Value posInfMask = builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ,
+ op.operand(), cstPosInf);
// Filter out invalid values:
// • x == 0 -> -INF
// "logLarge" below.
Value cstOne = bcast(f32Cst(builder, 1.0f));
Value x = op.operand();
- Value u = builder.create<AddFOp>(x, cstOne);
- Value uSmall = builder.create<CmpFOp>(CmpFPredicate::OEQ, u, cstOne);
+ Value u = builder.create<arith::AddFOp>(x, cstOne);
+ Value uSmall =
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, u, cstOne);
Value logU = builder.create<math::LogOp>(u);
- Value uInf = builder.create<CmpFOp>(CmpFPredicate::OEQ, u, logU);
- Value logLarge = builder.create<MulFOp>(
- x, builder.create<DivFOp>(logU, builder.create<SubFOp>(u, cstOne)));
- Value approximation =
- builder.create<SelectOp>(builder.create<OrOp>(uSmall, uInf), x, logLarge);
+ Value uInf =
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, u, logU);
+ Value logLarge = builder.create<arith::MulFOp>(
+ x, builder.create<arith::DivFOp>(
+ logU, builder.create<arith::SubFOp>(u, cstOne)));
+ Value approximation = builder.create<SelectOp>(
+ builder.create<arith::OrIOp>(uSmall, uInf), x, logLarge);
rewriter.replaceOp(op, approximation);
return success();
}
return broadcast(builder, value, *width);
};
auto fmla = [&](Value a, Value b, Value c) {
- return builder.create<FmaFOp>(a, b, c);
+ return builder.create<math::FmaOp>(a, b, c);
};
auto mul = [&](Value a, Value b) -> Value {
- return builder.create<MulFOp>(a, b);
+ return builder.create<arith::MulFOp>(a, b);
};
auto sub = [&](Value a, Value b) -> Value {
- return builder.create<SubFOp>(a, b);
+ return builder.create<arith::SubFOp>(a, b);
};
- auto floor = [&](Value a) { return builder.create<FloorFOp>(a); };
+ auto floor = [&](Value a) { return builder.create<math::FloorOp>(a); };
Value cstLn2 = bcast(f32Cst(builder, static_cast<float>(LN2_VALUE)));
Value cstLog2E = bcast(f32Cst(builder, static_cast<float>(LOG2E_VALUE)));
auto i32Vec = broadcast(builder.getI32Type(), *width);
// exp2(k)
- Value k = builder.create<FPToSIOp>(kF32, i32Vec);
+ Value k = builder.create<arith::FPToSIOp>(kF32, i32Vec);
Value exp2KValue = exp2I32(builder, k);
// exp(x) = exp(y) * exp2(k)
Value kMaxConst = bcast(i32Cst(builder, 127));
Value kMaxNegConst = bcast(i32Cst(builder, -127));
- Value rightBound = builder.create<CmpIOp>(CmpIPredicate::sle, k, kMaxConst);
- Value leftBound = builder.create<CmpIOp>(CmpIPredicate::sge, k, kMaxNegConst);
+ Value rightBound =
+ builder.create<arith::CmpIOp>(arith::CmpIPredicate::sle, k, kMaxConst);
+ Value leftBound =
+ builder.create<arith::CmpIOp>(arith::CmpIPredicate::sge, k, kMaxNegConst);
- Value isNegInfinityX =
- builder.create<CmpFOp>(CmpFPredicate::OEQ, x, constNegIfinity);
+ Value isNegInfinityX = builder.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, x, constNegIfinity);
Value isPostiveX =
- builder.create<CmpFOp>(CmpFPredicate::OGT, x, zerof32Const);
- Value isComputable = builder.create<AndOp>(rightBound, leftBound);
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OGT, x, zerof32Const);
+ Value isComputable = builder.create<arith::AndIOp>(rightBound, leftBound);
expY = builder.create<SelectOp>(
isComputable, expY,
Value cstNegOne = bcast(f32Cst(builder, -1.0f));
Value x = op.operand();
Value u = builder.create<math::ExpOp>(x);
- Value uEqOne = builder.create<CmpFOp>(CmpFPredicate::OEQ, u, cstOne);
- Value uMinusOne = builder.create<SubFOp>(u, cstOne);
- Value uMinusOneEqNegOne =
- builder.create<CmpFOp>(CmpFPredicate::OEQ, uMinusOne, cstNegOne);
+ Value uEqOne =
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, u, cstOne);
+ Value uMinusOne = builder.create<arith::SubFOp>(u, cstOne);
+ Value uMinusOneEqNegOne = builder.create<arith::CmpFOp>(
+ arith::CmpFPredicate::OEQ, uMinusOne, cstNegOne);
// logU = log(u) ~= x
Value logU = builder.create<math::LogOp>(u);
// Detect exp(x) = +inf; written this way to avoid having to form +inf.
- Value isInf = builder.create<CmpFOp>(CmpFPredicate::OEQ, logU, u);
+ Value isInf =
+ builder.create<arith::CmpFOp>(arith::CmpFPredicate::OEQ, logU, u);
// (u - 1) * (x / ~x)
- Value expm1 =
- builder.create<MulFOp>(uMinusOne, builder.create<DivFOp>(x, logU));
+ Value expm1 = builder.create<arith::MulFOp>(
+ uMinusOne, builder.create<arith::DivFOp>(x, logU));
expm1 = builder.create<SelectOp>(isInf, u, expm1);
Value approximation = builder.create<SelectOp>(
uEqOne, x, builder.create<SelectOp>(uMinusOneEqNegOne, cstNegOne, expm1));
return broadcast(builder, value, *width);
};
auto mul = [&](Value a, Value b) -> Value {
- return builder.create<MulFOp>(a, b);
+ return builder.create<arith::MulFOp>(a, b);
};
auto sub = [&](Value a, Value b) -> Value {
- return builder.create<SubFOp>(a, b);
+ return builder.create<arith::SubFOp>(a, b);
};
- auto floor = [&](Value a) { return builder.create<FloorFOp>(a); };
+ auto floor = [&](Value a) { return builder.create<math::FloorOp>(a); };
auto i32Vec = broadcast(builder.getI32Type(), *width);
auto fPToSingedInteger = [&](Value a) -> Value {
- return builder.create<FPToSIOp>(a, i32Vec);
+ return builder.create<arith::FPToSIOp>(a, i32Vec);
};
auto modulo4 = [&](Value a) -> Value {
- return builder.create<AndOp>(a, bcast(i32Cst(builder, 3)));
+ return builder.create<arith::AndIOp>(a, bcast(i32Cst(builder, 3)));
};
auto isEqualTo = [&](Value a, Value b) -> Value {
- return builder.create<CmpIOp>(CmpIPredicate::eq, a, b);
+ return builder.create<arith::CmpIOp>(arith::CmpIPredicate::eq, a, b);
};
auto isGreaterThan = [&](Value a, Value b) -> Value {
- return builder.create<CmpIOp>(CmpIPredicate::sgt, a, b);
+ return builder.create<arith::CmpIOp>(arith::CmpIPredicate::sgt, a, b);
};
auto select = [&](Value cond, Value t, Value f) -> Value {
};
auto fmla = [&](Value a, Value b, Value c) {
- return builder.create<FmaFOp>(a, b, c);
+ return builder.create<math::FmaOp>(a, b, c);
};
- auto bitwiseOr = [&](Value a, Value b) { return builder.create<OrOp>(a, b); };
+ auto bitwiseOr = [&](Value a, Value b) {
+ return builder.create<arith::OrIOp>(a, b);
+ };
Value twoOverPi = bcast(f32Cst(builder, TWO_OVER_PI));
Value piOverTwo = bcast(f32Cst(builder, PI_OVER_2));
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDialect
MLIRDialectUtils
MLIRInferTypeOpInterface
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/MemRef/Utils/MemRefUtils.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
Operation *MemRefDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
- return builder.create<mlir::ConstantOp>(loc, type, value);
+ if (arith::ConstantOp::isBuildableWith(value, type))
+ return builder.create<arith::ConstantOp>(loc, value, type);
+ if (ConstantOp::isBuildableWith(value, type))
+ return builder.create<ConstantOp>(loc, value, type);
+ return nullptr;
}
//===----------------------------------------------------------------------===//
}
auto dynamicSize = alloc.dynamicSizes()[dynamicDimPos];
auto *defOp = dynamicSize.getDefiningOp();
- if (auto constantIndexOp = dyn_cast_or_null<ConstantIndexOp>(defOp)) {
+ if (auto constantIndexOp =
+ dyn_cast_or_null<arith::ConstantIndexOp>(defOp)) {
// Dynamic shape dimension will be folded.
- newShapeConstants.push_back(constantIndexOp.getValue());
+ newShapeConstants.push_back(constantIndexOp.value());
} else {
// Dynamic shape dimension not folded; copy dynamicSize from old memref.
newShapeConstants.push_back(-1);
for (int i = 0; i < resultType.getRank(); ++i) {
if (resultType.getShape()[i] != ShapedType::kDynamicSize)
continue;
- auto index = rewriter.createOrFold<ConstantIndexOp>(loc, i);
+ auto index = rewriter.createOrFold<arith::ConstantIndexOp>(loc, i);
Value size = rewriter.create<tensor::DimOp>(loc, tensorLoad, index);
dynamicOperands.push_back(size);
}
void DimOp::build(OpBuilder &builder, OperationState &result, Value source,
int64_t index) {
auto loc = result.location;
- Value indexValue = builder.create<ConstantIndexOp>(loc, index);
+ Value indexValue = builder.create<arith::ConstantIndexOp>(loc, index);
build(builder, result, source, indexValue);
}
}
Optional<int64_t> DimOp::getConstantIndex() {
- if (auto constantOp = index().getDefiningOp<ConstantOp>())
- return constantOp.getValue().cast<IntegerAttr>().getInt();
+ if (auto constantOp = index().getDefiningOp<arith::ConstantOp>())
+ return constantOp.value().cast<IntegerAttr>().getInt();
return {};
}
Location loc = dim.getLoc();
Value load = rewriter.create<LoadOp>(loc, reshape.shape(), dim.index());
if (load.getType() != dim.getType())
- load = rewriter.create<IndexCastOp>(loc, dim.getType(), load);
+ load = rewriter.create<arith::IndexCastOp>(loc, dim.getType(), load);
rewriter.replaceOp(dim, load);
return success();
}
Value offset =
op.isDynamicOffset(idx)
? op.getDynamicOffset(idx)
- : b.create<ConstantIndexOp>(loc, op.getStaticOffset(idx));
- Value size = op.isDynamicSize(idx)
- ? op.getDynamicSize(idx)
- : b.create<ConstantIndexOp>(loc, op.getStaticSize(idx));
+ : b.create<arith::ConstantIndexOp>(loc, op.getStaticOffset(idx));
+ Value size =
+ op.isDynamicSize(idx)
+ ? op.getDynamicSize(idx)
+ : b.create<arith::ConstantIndexOp>(loc, op.getStaticSize(idx));
Value stride =
op.isDynamicStride(idx)
? op.getDynamicStride(idx)
- : b.create<ConstantIndexOp>(loc, op.getStaticStride(idx));
+ : b.create<arith::ConstantIndexOp>(loc, op.getStaticStride(idx));
res.emplace_back(Range{offset, size, stride});
}
return res;
continue;
}
auto *defOp = viewOp.sizes()[dynamicDimPos].getDefiningOp();
- if (auto constantIndexOp = dyn_cast_or_null<ConstantIndexOp>(defOp)) {
+ if (auto constantIndexOp =
+ dyn_cast_or_null<arith::ConstantIndexOp>(defOp)) {
// Dynamic shape dimension will be folded.
- newShapeConstants.push_back(constantIndexOp.getValue());
+ newShapeConstants.push_back(constantIndexOp.value());
} else {
// Dynamic shape dimension not folded; copy operand from old memref.
newShapeConstants.push_back(dimSize);
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRInferTypeOpInterface
MLIRMemRef
MLIRPass
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/MemRef/Transforms/Passes.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
llvm::SmallDenseSet<unsigned> unusedDims = subViewOp.getDroppedDims();
for (auto dim : llvm::seq<unsigned>(0, subViewOp.getSourceType().getRank())) {
if (unusedDims.count(dim))
- useIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
+ useIndices.push_back(rewriter.create<arith::ConstantIndexOp>(loc, 0));
else
useIndices.push_back(indices[resultDim++]);
}
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/MemRef/Transforms/Passes.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
Location loc = dimOp->getLoc();
rewriter.replaceOpWithNewOp<tensor::ExtractOp>(
dimOp, resultShape,
- rewriter.createOrFold<ConstantIndexOp>(loc, *dimIndex));
+ rewriter.createOrFold<arith::ConstantIndexOp>(loc, *dimIndex));
return success();
}
};
MLIROpenACCOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRStandard
)
// =============================================================================
#include "mlir/Dialect/OpenACC/OpenACC.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/OpenACC/OpenACCOpsEnums.cpp.inc"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
if (!op.ifCond())
return success();
- auto constOp = op.ifCond().template getDefiningOp<ConstantOp>();
- if (constOp && constOp.getValue().template cast<IntegerAttr>().getInt())
+ auto constOp = op.ifCond().template getDefiningOp<arith::ConstantOp>();
+ if (constOp && constOp.value().template cast<IntegerAttr>().getInt())
rewriter.updateRootInPlace(op, [&]() { op.ifCondMutable().erase(0); });
else if (constOp)
rewriter.eraseOp(op);
MLIRQuantPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRPass
MLIRSideEffectInterfaces
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Quant/Passes.h"
#include "mlir/Dialect/Quant/QuantOps.h"
#include "mlir/Dialect/Quant/QuantizeUtils.h"
// original const and the qbarrier that led to the quantization.
auto fusedLoc = rewriter.getFusedLoc(
{qbarrier.arg().getDefiningOp()->getLoc(), qbarrier.getLoc()});
- auto newConstOp =
- rewriter.create<ConstantOp>(fusedLoc, newConstValueType, newConstValue);
+ auto newConstOp = rewriter.create<arith::ConstantOp>(
+ fusedLoc, newConstValueType, newConstValue);
rewriter.replaceOpWithNewOp<StorageCastOp>(qbarrier, qbarrier.getType(),
newConstOp);
return success();
MLIRSCFOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRLoopLikeInterface
MLIRMemRef
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/SCF/SCF.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
}
static LogicalResult verify(ForOp op) {
- if (auto cst = op.step().getDefiningOp<ConstantIndexOp>())
- if (cst.getValue() <= 0)
+ if (auto cst = op.step().getDefiningOp<arith::ConstantIndexOp>())
+ if (cst.value() <= 0)
return op.emitOpError("constant step operand must be positive");
// Check that the body defines as single block argument for the induction
return success();
}
- auto lb = op.lowerBound().getDefiningOp<ConstantOp>();
- auto ub = op.upperBound().getDefiningOp<ConstantOp>();
+ auto lb = op.lowerBound().getDefiningOp<arith::ConstantOp>();
+ auto ub = op.upperBound().getDefiningOp<arith::ConstantOp>();
if (!lb || !ub)
return failure();
// If the loop is known to have 0 iterations, remove it.
- llvm::APInt lbValue = lb.getValue().cast<IntegerAttr>().getValue();
- llvm::APInt ubValue = ub.getValue().cast<IntegerAttr>().getValue();
+ llvm::APInt lbValue = lb.value().cast<IntegerAttr>().getValue();
+ llvm::APInt ubValue = ub.value().cast<IntegerAttr>().getValue();
if (lbValue.sge(ubValue)) {
rewriter.replaceOp(op, op.getIterOperands());
return success();
}
- auto step = op.step().getDefiningOp<ConstantOp>();
+ auto step = op.step().getDefiningOp<arith::ConstantOp>();
if (!step)
return failure();
// If the loop is known to have 1 iteration, inline its body and remove the
// loop.
- llvm::APInt stepValue = step.getValue().cast<IntegerAttr>().getValue();
+ llvm::APInt stepValue = step.value().cast<IntegerAttr>().getValue();
if ((lbValue + stepValue).sge(ubValue)) {
SmallVector<Value, 4> blockArgs;
blockArgs.reserve(op.getNumIterOperands() + 1);
LogicalResult matchAndRewrite(IfOp op,
PatternRewriter &rewriter) const override {
- auto constant = op.condition().getDefiningOp<ConstantOp>();
+ auto constant = op.condition().getDefiningOp<arith::ConstantOp>();
if (!constant)
return failure();
- if (constant.getValue().cast<BoolAttr>().getValue())
+ if (constant.value().cast<BoolAttr>().getValue())
replaceOpWithRegion(rewriter, op, op.thenRegion());
else if (!op.elseRegion().empty())
replaceOpWithRegion(rewriter, op, op.elseRegion());
PatternRewriter &rewriter) const override {
// Early exit if the condition is constant since replacing a constant
// in the body with another constant isn't a simplification.
- if (op.condition().getDefiningOp<ConstantOp>())
+ if (op.condition().getDefiningOp<arith::ConstantOp>())
return failure();
bool changed = false;
changed = true;
if (!constantTrue)
- constantTrue = rewriter.create<mlir::ConstantOp>(
+ constantTrue = rewriter.create<arith::ConstantOp>(
op.getLoc(), i1Ty, rewriter.getIntegerAttr(i1Ty, 1));
rewriter.updateRootInPlace(use.getOwner(),
changed = true;
if (!constantFalse)
- constantFalse = rewriter.create<mlir::ConstantOp>(
+ constantFalse = rewriter.create<arith::ConstantOp>(
op.getLoc(), i1Ty, rewriter.getIntegerAttr(i1Ty, 0));
rewriter.updateRootInPlace(use.getOwner(),
continue;
}
- auto trueYield = trueResult.getDefiningOp<ConstantOp>();
+ auto trueYield = trueResult.getDefiningOp<arith::ConstantOp>();
if (!trueYield)
continue;
if (!trueYield.getType().isInteger(1))
continue;
- auto falseYield = falseResult.getDefiningOp<ConstantOp>();
+ auto falseYield = falseResult.getDefiningOp<arith::ConstantOp>();
if (!falseYield)
continue;
- bool trueVal = trueYield.getValue().cast<BoolAttr>().getValue();
- bool falseVal = falseYield.getValue().cast<BoolAttr>().getValue();
+ bool trueVal = trueYield.value().cast<BoolAttr>().getValue();
+ bool falseVal = falseYield.value().cast<BoolAttr>().getValue();
if (!trueVal && falseVal) {
if (!opResult.use_empty()) {
- Value notCond = rewriter.create<XOrOp>(
+ Value notCond = rewriter.create<arith::XOrIOp>(
op.getLoc(), op.condition(),
- rewriter.create<mlir::ConstantOp>(
+ rewriter.create<arith::ConstantOp>(
op.getLoc(), i1Ty, rewriter.getIntegerAttr(i1Ty, 1)));
opResult.replaceAllUsesWith(notCond);
changed = true;
// Check whether all constant step values are positive.
for (Value stepValue : stepValues)
- if (auto cst = stepValue.getDefiningOp<ConstantIndexOp>())
- if (cst.getValue() <= 0)
+ if (auto cst = stepValue.getDefiningOp<arith::ConstantIndexOp>())
+ if (cst.value() <= 0)
return op.emitOpError("constant step operand must be positive");
// Check that the body defines the same number of block arguments as the
std::tie(lowerBound, upperBound, step, iv) = dim;
// Collect the statically known loop bounds.
auto lowerBoundConstant =
- dyn_cast_or_null<ConstantIndexOp>(lowerBound.getDefiningOp());
+ dyn_cast_or_null<arith::ConstantIndexOp>(lowerBound.getDefiningOp());
auto upperBoundConstant =
- dyn_cast_or_null<ConstantIndexOp>(upperBound.getDefiningOp());
+ dyn_cast_or_null<arith::ConstantIndexOp>(upperBound.getDefiningOp());
auto stepConstant =
- dyn_cast_or_null<ConstantIndexOp>(step.getDefiningOp());
+ dyn_cast_or_null<arith::ConstantIndexOp>(step.getDefiningOp());
// Replace the loop induction variable by the lower bound if the loop
// performs a single iteration. Otherwise, copy the loop bounds.
if (lowerBoundConstant && upperBoundConstant && stepConstant &&
- (upperBoundConstant.getValue() - lowerBoundConstant.getValue()) > 0 &&
- (upperBoundConstant.getValue() - lowerBoundConstant.getValue()) <=
- stepConstant.getValue()) {
+ (upperBoundConstant.value() - lowerBoundConstant.value()) > 0 &&
+ (upperBoundConstant.value() - lowerBoundConstant.value()) <=
+ stepConstant.value()) {
mapping.map(iv, lowerBound);
} else {
newLowerBounds.push_back(lowerBound);
if (std::get<0>(yieldedAndBlockArgs) == term.condition()) {
if (!std::get<1>(yieldedAndBlockArgs).use_empty()) {
if (!constantTrue)
- constantTrue = rewriter.create<mlir::ConstantOp>(
+ constantTrue = rewriter.create<arith::ConstantOp>(
op.getLoc(), term.condition().getType(),
rewriter.getBoolAttr(true));
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRIR
MLIRMemRef
MLIRPass
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
auto *beforeBlock = rewriter.createBlock(
&whileOp.before(), whileOp.before().begin(), lcvTypes, {});
rewriter.setInsertionPointToStart(&whileOp.before().front());
- auto cmpOp = rewriter.create<CmpIOp>(whileOp.getLoc(), CmpIPredicate::slt,
- beforeBlock->getArgument(0),
- forOp.upperBound());
+ auto cmpOp = rewriter.create<arith::CmpIOp>(
+ whileOp.getLoc(), arith::CmpIPredicate::slt,
+ beforeBlock->getArgument(0), forOp.upperBound());
rewriter.create<scf::ConditionOp>(whileOp.getLoc(), cmpOp.getResult(),
beforeBlock->getArguments());
// Add induction variable incrementation
rewriter.setInsertionPointToEnd(afterBlock);
- auto ivIncOp = rewriter.create<AddIOp>(
+ auto ivIncOp = rewriter.create<arith::AddIOp>(
whileOp.getLoc(), afterBlock->getArgument(0), forOp.step());
// Rewrite uses of the for-loop block arguments to the new while-loop
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
#include "mlir/Dialect/SCF/Utils.h"
bool LoopPipelinerInternal::initializeLoopInfo(
ForOp op, const PipeliningOption &options) {
forOp = op;
- auto upperBoundCst = forOp.upperBound().getDefiningOp<ConstantIndexOp>();
- auto lowerBoundCst = forOp.lowerBound().getDefiningOp<ConstantIndexOp>();
- auto stepCst = forOp.step().getDefiningOp<ConstantIndexOp>();
+ auto upperBoundCst =
+ forOp.upperBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto lowerBoundCst =
+ forOp.lowerBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto stepCst = forOp.step().getDefiningOp<arith::ConstantIndexOp>();
if (!upperBoundCst || !lowerBoundCst || !stepCst)
return false;
- ub = upperBoundCst.getValue();
- lb = lowerBoundCst.getValue();
- step = stepCst.getValue();
+ ub = upperBoundCst.value();
+ lb = lowerBoundCst.value();
+ step = stepCst.value();
int64_t numIteration = ceilDiv(ub - lb, step);
std::vector<std::pair<Operation *, unsigned>> schedule;
options.getScheduleFn(forOp, schedule);
auto yield = cast<scf::YieldOp>(forOp.getBody()->getTerminator());
for (int64_t i = 0; i < maxStage; i++) {
// special handling for induction variable as the increment is implicit.
- Value iv = rewriter.create<ConstantIndexOp>(forOp.getLoc(), lb + i);
+ Value iv = rewriter.create<arith::ConstantIndexOp>(forOp.getLoc(), lb + i);
setValueMapping(forOp.getInductionVar(), iv, i);
for (Operation *op : opOrder) {
if (stages[op] > i)
// Create the new kernel loop. Since we need to peel `numStages - 1`
// iteration we change the upper bound to remove those iterations.
- Value newUb =
- rewriter.create<ConstantIndexOp>(forOp.getLoc(), ub - maxStage * step);
+ Value newUb = rewriter.create<arith::ConstantIndexOp>(forOp.getLoc(),
+ ub - maxStage * step);
auto newForOp = rewriter.create<scf::ForOp>(
forOp.getLoc(), forOp.lowerBound(), newUb, forOp.step(), newLoopArg);
return newForOp;
// version incremented based on the stage where it is used.
if (operand.get() == forOp.getInductionVar()) {
rewriter.setInsertionPoint(newOp);
- Value offset = rewriter.create<ConstantIndexOp>(
+ Value offset = rewriter.create<arith::ConstantIndexOp>(
forOp.getLoc(), (maxStage - stages[op]) * step);
- Value iv = rewriter.create<AddIOp>(forOp.getLoc(),
- newForOp.getInductionVar(), offset);
+ Value iv = rewriter.create<arith::AddIOp>(
+ forOp.getLoc(), newForOp.getInductionVar(), offset);
newOp->setOperand(operand.getOperandNumber(), iv);
rewriter.setInsertionPointAfter(newOp);
continue;
// Emit different versions of the induction variable. They will be
// removed by dead code if not used.
for (int64_t i = 0; i < maxStage; i++) {
- Value newlastIter = rewriter.create<ConstantIndexOp>(
+ Value newlastIter = rewriter.create<arith::ConstantIndexOp>(
forOp.getLoc(), lb + step * ((((ub - 1) - lb) / step) - i));
setValueMapping(forOp.getInductionVar(), newlastIter, maxStage - i);
}
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
break;
Operation *user = *indVar.getUsers().begin();
- if (!isa<AddIOp, MulIOp>(user))
+ if (!isa<arith::AddIOp, arith::MulIOp>(user))
break;
if (!llvm::all_of(user->getOperands(), canBeFolded))
BlockAndValueMapping stepMap;
stepMap.map(indVar, op.step());
- if (isa<AddIOp>(user)) {
+ if (isa<arith::AddIOp>(user)) {
Operation *lbFold = b.clone(*user, lbMap);
Operation *ubFold = b.clone(*user, ubMap);
op.setLowerBound(lbFold->getResult(0));
op.setUpperBound(ubFold->getResult(0));
- } else if (isa<MulIOp>(user)) {
+ } else if (isa<arith::MulIOp>(user)) {
Operation *ubFold = b.clone(*user, ubMap);
Operation *stepFold = b.clone(*user, stepMap);
#include "PassDetail.h"
#include "mlir/Analysis/AffineStructures.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
BlockAndValueMapping map;
Value cond;
for (auto bound : llvm::zip(op.upperBound(), constantIndices)) {
- Value constant = b.create<ConstantIndexOp>(op.getLoc(), std::get<1>(bound));
- Value cmp = b.create<CmpIOp>(op.getLoc(), CmpIPredicate::eq,
- std::get<0>(bound), constant);
- cond = cond ? b.create<AndOp>(op.getLoc(), cond, cmp) : cmp;
+ Value constant =
+ b.create<arith::ConstantIndexOp>(op.getLoc(), std::get<1>(bound));
+ Value cmp = b.create<arith::CmpIOp>(op.getLoc(), arith::CmpIPredicate::eq,
+ std::get<0>(bound), constant);
+ cond = cond ? b.create<arith::AndIOp>(op.getLoc(), cond, cmp) : cmp;
map.map(std::get<0>(bound), constant);
}
auto ifOp = b.create<scf::IfOp>(op.getLoc(), cond, /*withElseRegion=*/true);
OpBuilder b(op);
BlockAndValueMapping map;
- Value constant = b.create<ConstantIndexOp>(op.getLoc(), minConstant);
- Value cond =
- b.create<CmpIOp>(op.getLoc(), CmpIPredicate::eq, bound, constant);
+ Value constant = b.create<arith::ConstantIndexOp>(op.getLoc(), minConstant);
+ Value cond = b.create<arith::CmpIOp>(op.getLoc(), arith::CmpIPredicate::eq,
+ bound, constant);
map.map(bound, constant);
auto ifOp = b.create<scf::IfOp>(op.getLoc(), cond, /*withElseRegion=*/true);
ifOp.getThenBodyBuilder().clone(*op.getOperation(), map);
#include "PassDetail.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/Passes.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
mlir::scf::tileParallelLoop(ParallelOp op, ArrayRef<int64_t> tileSizes,
bool noMinMaxBounds) {
OpBuilder b(op);
- auto zero = b.create<ConstantIndexOp>(op.getLoc(), 0);
+ auto zero = b.create<arith::ConstantIndexOp>(op.getLoc(), 0);
SmallVector<Value, 2> tileSizeConstants;
tileSizeConstants.reserve(op.upperBound().size());
for (size_t i = 0, end = op.upperBound().size(); i != end; ++i) {
if (i < tileSizes.size())
tileSizeConstants.push_back(
- b.create<ConstantIndexOp>(op.getLoc(), tileSizes[i]));
+ b.create<arith::ConstantIndexOp>(op.getLoc(), tileSizes[i]));
else
// Just pick 1 for the remaining dimensions.
- tileSizeConstants.push_back(b.create<ConstantIndexOp>(op.getLoc(), 1));
+ tileSizeConstants.push_back(
+ b.create<arith::ConstantIndexOp>(op.getLoc(), 1));
}
// Create the outer loop with adjusted steps.
SmallVector<Value, 2> newSteps;
newSteps.reserve(op.step().size());
for (auto step : llvm::zip(op.step(), tileSizeConstants)) {
- newSteps.push_back(
- b.create<MulIOp>(op.getLoc(), std::get<0>(step), std::get<1>(step)));
+ newSteps.push_back(b.create<arith::MulIOp>(op.getLoc(), std::get<0>(step),
+ std::get<1>(step)));
}
auto outerLoop = b.create<ParallelOp>(op.getLoc(), op.lowerBound(),
op.upperBound(), newSteps);
std::tie(lowerBound, upperBound, newStep, iv, step, tileSizeConstant) = dim;
// Collect the statically known loop bounds
auto lowerBoundConstant =
- dyn_cast_or_null<ConstantIndexOp>(lowerBound.getDefiningOp());
+ dyn_cast_or_null<arith::ConstantIndexOp>(lowerBound.getDefiningOp());
auto upperBoundConstant =
- dyn_cast_or_null<ConstantIndexOp>(upperBound.getDefiningOp());
- auto stepConstant = dyn_cast_or_null<ConstantIndexOp>(step.getDefiningOp());
+ dyn_cast_or_null<arith::ConstantIndexOp>(upperBound.getDefiningOp());
+ auto stepConstant =
+ dyn_cast_or_null<arith::ConstantIndexOp>(step.getDefiningOp());
auto tileSize =
- cast<ConstantIndexOp>(tileSizeConstant.getDefiningOp()).getValue();
+ cast<arith::ConstantIndexOp>(tileSizeConstant.getDefiningOp()).value();
// If the loop bounds and the loop step are constant and if the number of
// loop iterations is an integer multiple of the tile size, we use a static
// bound for the inner loop.
if (lowerBoundConstant && upperBoundConstant && stepConstant) {
- auto numIterations = llvm::divideCeil(upperBoundConstant.getValue() -
- lowerBoundConstant.getValue(),
- stepConstant.getValue());
+ auto numIterations = llvm::divideCeil(upperBoundConstant.value() -
+ lowerBoundConstant.value(),
+ stepConstant.value());
if (numIterations % tileSize == 0) {
newBounds.push_back(newStep);
continue;
b.setInsertionPointToStart(innerLoop.getBody());
// Insert in-bound check
Value inbound =
- b.create<ConstantOp>(op.getLoc(), b.getIntegerType(1),
- b.getIntegerAttr(b.getIntegerType(1), 1));
+ b.create<arith::ConstantIntOp>(op.getLoc(), 1, b.getIntegerType(1));
for (auto dim :
llvm::zip(outerLoop.upperBound(), outerLoop.getInductionVars(),
innerLoop.getInductionVars(), innerLoop.step())) {
std::tie(outerUpperBound, outerIV, innerIV, innerStep) = dim;
// %in_bound = %in_bound &&
// (%inner_iv * %inner_step + %outer_iv < %outer_upper_bound)
- Value index = b.create<AddIOp>(
- op.getLoc(), b.create<MulIOp>(op.getLoc(), innerIV, innerStep),
+ Value index = b.create<arith::AddIOp>(
+ op.getLoc(), b.create<arith::MulIOp>(op.getLoc(), innerIV, innerStep),
outerIV);
- Value dimInbound = b.create<CmpIOp>(op.getLoc(), CmpIPredicate::ult,
- index, outerUpperBound);
- inbound = b.create<AndOp>(op.getLoc(), inbound, dimInbound);
+ Value dimInbound = b.create<arith::CmpIOp>(
+ op.getLoc(), arith::CmpIPredicate::ult, index, outerUpperBound);
+ inbound = b.create<arith::AndIOp>(op.getLoc(), inbound, dimInbound);
}
auto ifInbound = b.create<IfOp>(op.getLoc(),
/*resultTypes*/ ArrayRef<Type>{}, inbound,
b.setInsertionPointToStart(innerLoop.getBody());
for (auto ivs : llvm::enumerate(llvm::zip(innerLoop.getInductionVars(),
outerLoop.getInductionVars()))) {
- AddIOp newIndex = b.create<AddIOp>(op.getLoc(), std::get<0>(ivs.value()),
- std::get<1>(ivs.value()));
+ auto newIndex = b.create<arith::AddIOp>(
+ op.getLoc(), std::get<0>(ivs.value()), std::get<1>(ivs.value()));
thenBlock.getArgument(ivs.index())
.replaceAllUsesExcept(newIndex, newIndex);
}
for (auto ivs : llvm::zip(innerLoop.getInductionVars(),
outerLoop.getInductionVars())) {
Value innerIndex = std::get<0>(ivs);
- AddIOp newIndex =
- b.create<AddIOp>(op.getLoc(), std::get<0>(ivs), std::get<1>(ivs));
+ auto newIndex = b.create<arith::AddIOp>(op.getLoc(), std::get<0>(ivs),
+ std::get<1>(ivs));
innerIndex.replaceAllUsesExcept(newIndex, newIndex);
}
}
class AffineDialect;
+namespace arith {
+class ArithmeticDialect;
+} // end namespace arith
+
namespace memref {
class MemRefDialect;
} // end namespace memref
MLIRShapeOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRCastInterfaces
MLIRControlFlowInterfaces
MLIRDialect
#include "mlir/Dialect/Shape/IR/Shape.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Traits.h"
} else if (auto inputOp = input.getDefiningOp<ConstShapeOp>()) {
shapeValues = llvm::to_vector<6>(inputOp.shape().getValues<int64_t>());
return success();
- } else if (auto inputOp = input.getDefiningOp<ConstantOp>()) {
+ } else if (auto inputOp = input.getDefiningOp<arith::ConstantOp>()) {
shapeValues = llvm::to_vector<6>(
inputOp.value().cast<DenseIntElementsAttr>().getValues<int64_t>());
return success();
return builder.create<ConstSizeOp>(loc, type, value.cast<IntegerAttr>());
if (type.isa<WitnessType>())
return builder.create<ConstWitnessOp>(loc, type, value.cast<BoolAttr>());
- if (ConstantOp::isBuildableWith(value, type))
- return builder.create<ConstantOp>(loc, type, value);
+ if (arith::ConstantOp::isBuildableWith(value, type))
+ return builder.create<arith::ConstantOp>(loc, type, value);
return nullptr;
}
Optional<int64_t> GetExtentOp::getConstantDim() {
if (auto constSizeOp = dim().getDefiningOp<ConstSizeOp>())
return constSizeOp.value().getLimitedValue();
- if (auto constantOp = dim().getDefiningOp<ConstantOp>())
+ if (auto constantOp = dim().getDefiningOp<arith::ConstantOp>())
return constantOp.value().cast<IntegerAttr>().getInt();
return llvm::None;
}
build(builder, result, builder.getType<SizeType>(), shape, dim);
} else {
Value dim =
- builder.create<ConstantOp>(loc, builder.getIndexType(), dimAttr);
+ builder.create<arith::ConstantOp>(loc, builder.getIndexType(), dimAttr);
build(builder, result, builder.getIndexType(), shape, dim);
}
}
return failure();
int64_t rank = rankedTensorType.getRank();
if (op.getType().isa<IndexType>()) {
- rewriter.replaceOpWithNewOp<ConstantIndexOp>(op.getOperation(), rank);
+ rewriter.replaceOpWithNewOp<arith::ConstantIndexOp>(op.getOperation(),
+ rank);
} else if (op.getType().isa<shape::SizeType>()) {
rewriter.replaceOpWithNewOp<shape::ConstSizeOp>(op.getOperation(), rank);
} else {
target_link_libraries(MLIRShapeOpsTransforms
PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRMemRef
MLIRPass
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Shape/IR/Shape.h"
#include "mlir/Dialect/Shape/Transforms/Passes.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
populateShapeRewritePatterns(patterns);
ConversionTarget target(getContext());
- target.addLegalDialect<ShapeDialect, StandardOpsDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, ShapeDialect,
+ StandardOpsDialect>();
target.addIllegalOp<NumElementsOp>();
if (failed(mlir::applyPartialConversion(getFunction(), target,
std::move(patterns))))
MLIRSparseTensorOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDialect
MLIRIR
MLIRStandard
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SparseTensor/IR/SparseTensor.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
//===----------------------------------------------------------------------===//
static LogicalResult isInBounds(Value dim, Value tensor) {
- if (auto constantOp = dim.getDefiningOp<ConstantOp>()) {
- unsigned d = constantOp.getValue().cast<IntegerAttr>().getInt();
+ if (auto constantOp = dim.getDefiningOp<arith::ConstantOp>()) {
+ unsigned d = constantOp.value().cast<IntegerAttr>().getInt();
if (d >= tensor.getType().cast<RankedTensorType>().getRank())
return failure();
}
MLIRSparseTensorPassIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRLLVMIR
MLIRLinalg
unsigned sz = values.size();
RankedTensorType tt1 = RankedTensorType::get({sz}, etp);
RankedTensorType tt2 = RankedTensorType::get({ShapedType::kDynamicSize}, etp);
- auto elts =
- rewriter.create<ConstantOp>(loc, DenseElementsAttr::get(tt1, values));
+ auto elts = rewriter.create<arith::ConstantOp>(
+ loc, DenseElementsAttr::get(tt1, values));
return rewriter.create<tensor::CastOp>(loc, tt2, elts);
}
unsigned secInd = getOverheadTypeEncoding(enc.getIndexBitWidth());
unsigned primary = getPrimaryTypeEncoding(resType.getElementType());
assert(primary);
- params.push_back(
- rewriter.create<ConstantOp>(loc, rewriter.getI64IntegerAttr(secPtr)));
- params.push_back(
- rewriter.create<ConstantOp>(loc, rewriter.getI64IntegerAttr(secInd)));
- params.push_back(
- rewriter.create<ConstantOp>(loc, rewriter.getI64IntegerAttr(primary)));
+ params.push_back(rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI64IntegerAttr(secPtr)));
+ params.push_back(rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI64IntegerAttr(secInd)));
+ params.push_back(rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI64IntegerAttr(primary)));
// User action and pointer.
Type pTp = LLVM::LLVMPointerType::get(IntegerType::get(op->getContext(), 8));
if (!ptr)
ptr = rewriter.create<LLVM::NullOp>(loc, pTp);
- params.push_back(
- rewriter.create<ConstantOp>(loc, rewriter.getI32IntegerAttr(action)));
+ params.push_back(rewriter.create<arith::ConstantOp>(
+ loc, rewriter.getI32IntegerAttr(action)));
params.push_back(ptr);
// Generate the call to create new tensor.
StringRef name = "newSparseTensor";
/// Generates a constant zero of the given type.
static Value getZero(ConversionPatternRewriter &rewriter, Location loc,
Type t) {
- return rewriter.create<ConstantOp>(loc, rewriter.getZeroAttr(t));
+ return rewriter.create<arith::ConstantOp>(loc, rewriter.getZeroAttr(t));
}
/// Generates the comparison `v != 0` where `v` is of numeric type `t`.
Type t = v.getType();
Value zero = getZero(rewriter, loc, t);
if (t.isa<FloatType>())
- return rewriter.create<CmpFOp>(loc, CmpFPredicate::UNE, v, zero);
+ return rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::UNE, v,
+ zero);
if (t.isIntOrIndex())
- return rewriter.create<CmpIOp>(loc, CmpIPredicate::ne, v, zero);
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::ne, v,
+ zero);
llvm_unreachable("Unknown element type");
}
rewriter.setInsertionPointToStart(&ifOp.thenRegion().front());
unsigned i = 0;
for (auto iv : ivs) {
- Value idx = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(i++));
+ Value idx =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(i++));
rewriter.create<memref::StoreOp>(loc, iv, ind, idx);
}
return val;
static Optional<std::pair<Value, Value>>
genSplitSparseConstant(ConversionPatternRewriter &rewriter, ConvertOp op,
Value tensor) {
- if (auto constOp = tensor.getDefiningOp<ConstantOp>()) {
+ if (auto constOp = tensor.getDefiningOp<arith::ConstantOp>()) {
if (auto attr = constOp.value().dyn_cast<SparseElementsAttr>()) {
Location loc = op->getLoc();
DenseElementsAttr indicesAttr = attr.getIndices();
- Value indices = rewriter.create<ConstantOp>(loc, indicesAttr);
+ Value indices = rewriter.create<arith::ConstantOp>(loc, indicesAttr);
DenseElementsAttr valuesAttr = attr.getValues();
- Value values = rewriter.create<ConstantOp>(loc, valuesAttr);
+ Value values = rewriter.create<arith::ConstantOp>(loc, valuesAttr);
return std::make_pair(indices, values);
}
}
unsigned rank) {
Location loc = op->getLoc();
for (unsigned i = 0; i < rank; i++) {
- Value idx = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(i));
+ Value idx =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(i));
Value val = rewriter.create<tensor::ExtractOp>(loc, indices,
ValueRange{ivs[0], idx});
- val = rewriter.create<IndexCastOp>(loc, val, rewriter.getIndexType());
+ val =
+ rewriter.create<arith::IndexCastOp>(loc, val, rewriter.getIndexType());
rewriter.create<memref::StoreOp>(loc, val, ind, idx);
}
return rewriter.create<tensor::ExtractOp>(loc, values, ivs[0]);
int64_t rank) {
auto indexTp = rewriter.getIndexType();
auto memTp = MemRefType::get({ShapedType::kDynamicSize}, indexTp);
- Value arg = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(rank));
+ Value arg =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(rank));
return rewriter.create<memref::AllocaOp>(loc, memTp, ValueRange{arg});
}
StringRef name = "sparseDimSize";
SmallVector<Value, 2> params;
params.push_back(adaptor.getOperands()[0]);
- params.push_back(
- rewriter.create<ConstantOp>(op.getLoc(), rewriter.getIndexAttr(idx)));
+ params.push_back(rewriter.create<arith::ConstantOp>(
+ op.getLoc(), rewriter.getIndexAttr(idx)));
rewriter.replaceOpWithNewOp<CallOp>(
op, resType, getFunc(op, name, resType, params), params);
return success();
SmallVector<Value> lo;
SmallVector<Value> hi;
SmallVector<Value> st;
- Value zero = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(0));
- Value one = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(1));
+ Value zero =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(0));
+ Value one =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(1));
auto indicesValues = genSplitSparseConstant(rewriter, op, src);
bool isCOOConstant = indicesValues.hasValue();
Value indices;
}
Type eltType = shape.getElementType();
unsigned rank = shape.getRank();
- scf::buildLoopNest(rewriter, op.getLoc(), lo, hi, st, {},
- [&](OpBuilder &builder, Location loc, ValueRange ivs,
- ValueRange args) -> scf::ValueVector {
- Value val;
- if (isCOOConstant)
- val = genIndexAndValueForSparse(
- rewriter, op, indices, values, ind, ivs, rank);
- else
- val = genIndexAndValueForDense(rewriter, op, src,
- ind, ivs);
- genAddEltCall(rewriter, op, eltType, ptr, val, ind,
- perm);
- return {};
- });
+ scf::buildLoopNest(
+ rewriter, op.getLoc(), lo, hi, st, {},
+ [&](OpBuilder &builder, Location loc, ValueRange ivs,
+ ValueRange args) -> scf::ValueVector {
+ Value val;
+ if (isCOOConstant)
+ val = genIndexAndValueForSparse(rewriter, op, indices, values, ind,
+ ivs, rank);
+ else
+ val = genIndexAndValueForDense(rewriter, op, src, ind, ivs);
+ genAddEltCall(rewriter, op, eltType, ptr, val, ind, perm);
+ return {};
+ });
rewriter.replaceOp(op, genNewCall(rewriter, op, encDst, 1, perm, ptr));
return success();
}
});
// The following operations and dialects may be introduced by the
// rewriting rules, and are therefore marked as legal.
- target.addLegalOp<ConstantOp, IndexCastOp, tensor::CastOp,
- tensor::ExtractOp, CmpFOp, CmpIOp>();
+ target.addLegalOp<arith::ConstantOp, ConstantOp, arith::IndexCastOp,
+ tensor::CastOp, tensor::ExtractOp, arith::CmpFOp,
+ arith::CmpIOp>();
target.addLegalDialect<scf::SCFDialect, LLVM::LLVMDialect,
memref::MemRefDialect>();
// Populate with rules and apply rewriting rules.
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Utils/Utils.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
dynShape, genIntType(rewriter, enc.getPointerBitWidth()));
auto indTp = MemRefType::get(
dynShape, genIntType(rewriter, enc.getIndexBitWidth()));
- Value dim = rewriter.create<ConstantIndexOp>(loc, d);
+ Value dim = rewriter.create<arith::ConstantIndexOp>(loc, d);
// Generate sparse primitives to obtains pointer and indices.
codegen.pointers[tensor][idx] =
rewriter.create<ToPointersOp>(loc, ptrTp, t->get(), dim);
matchPattern(step, m_Constant(&stepInt))) {
if (((hiInt.getInt() - loInt.getInt()) % stepInt.getInt()) == 0)
return rewriter.create<vector::BroadcastOp>(
- loc, mtp, rewriter.create<ConstantIntOp>(loc, 1, 1));
+ loc, mtp, rewriter.create<arith::ConstantIntOp>(loc, 1, 1));
}
// Otherwise, generate a vector mask that avoids overrunning the upperbound
// during vector execution. Here we rely on subsequent loop optimizations to
Value ptr, ArrayRef<Value> args) {
Location loc = ptr.getLoc();
VectorType vtp = vectorType(codegen, ptr);
- Value pass = rewriter.create<ConstantOp>(loc, vtp, rewriter.getZeroAttr(vtp));
+ Value pass =
+ rewriter.create<arith::ConstantOp>(loc, vtp, rewriter.getZeroAttr(vtp));
if (args.back().getType().isa<VectorType>()) {
SmallVector<Value, 4> scalarArgs(args.begin(), args.end());
Value indexVec = args.back();
- scalarArgs.back() = rewriter.create<ConstantIndexOp>(loc, 0);
+ scalarArgs.back() = rewriter.create<arith::ConstantIndexOp>(loc, 0);
return rewriter.create<vector::GatherOp>(
loc, vtp, ptr, scalarArgs, indexVec, codegen.curVecMask, pass);
}
if (args.back().getType().isa<VectorType>()) {
SmallVector<Value, 4> scalarArgs(args.begin(), args.end());
Value indexVec = args.back();
- scalarArgs.back() = rewriter.create<ConstantIndexOp>(loc, 0);
+ scalarArgs.back() = rewriter.create<arith::ConstantIndexOp>(loc, 0);
rewriter.create<vector::ScatterOp>(loc, ptr, scalarArgs, indexVec,
codegen.curVecMask, rhs);
return;
}
case AffineExprKind::Add: {
auto binOp = a.cast<AffineBinaryOpExpr>();
- return rewriter.create<AddIOp>(
+ return rewriter.create<arith::AddIOp>(
loc, genAffine(codegen, rewriter, binOp.getLHS(), loc),
genAffine(codegen, rewriter, binOp.getRHS(), loc));
}
case AffineExprKind::Mul: {
auto binOp = a.cast<AffineBinaryOpExpr>();
- return rewriter.create<MulIOp>(
+ return rewriter.create<arith::MulIOp>(
loc, genAffine(codegen, rewriter, binOp.getLHS(), loc),
genAffine(codegen, rewriter, binOp.getRHS(), loc));
}
case AffineExprKind::Constant: {
int64_t c = a.cast<AffineConstantExpr>().getValue();
- return rewriter.create<ConstantIndexOp>(loc, c);
+ return rewriter.create<arith::ConstantIndexOp>(loc, c);
}
default:
llvm_unreachable("unexpected affine subscript");
Value vload = genVectorLoad(codegen, rewriter, ptr, {s});
if (!etp.isa<IndexType>()) {
if (etp.getIntOrFloatBitWidth() < 32)
- vload = rewriter.create<ZeroExtendIOp>(
+ vload = rewriter.create<arith::ExtUIOp>(
loc, vload, vectorType(codegen, rewriter.getIntegerType(32)));
else if (etp.getIntOrFloatBitWidth() < 64 &&
!codegen.options.enableSIMDIndex32)
- vload = rewriter.create<ZeroExtendIOp>(
+ vload = rewriter.create<arith::ExtUIOp>(
loc, vload, vectorType(codegen, rewriter.getIntegerType(64)));
}
return vload;
Value load = rewriter.create<memref::LoadOp>(loc, ptr, s);
if (!load.getType().isa<IndexType>()) {
if (load.getType().getIntOrFloatBitWidth() < 64)
- load = rewriter.create<ZeroExtendIOp>(loc, load,
- rewriter.getIntegerType(64));
- load = rewriter.create<IndexCastOp>(loc, load, rewriter.getIndexType());
+ load = rewriter.create<arith::ExtUIOp>(loc, load,
+ rewriter.getIntegerType(64));
+ load =
+ rewriter.create<arith::IndexCastOp>(loc, load, rewriter.getIndexType());
}
return load;
}
/// Generates an address computation "sz * p + i".
static Value genAddress(CodeGen &codegen, PatternRewriter &rewriter,
Location loc, Value size, Value p, Value i) {
- Value mul = rewriter.create<MulIOp>(loc, size, p);
+ Value mul = rewriter.create<arith::MulIOp>(loc, size, p);
if (auto vtp = i.getType().dyn_cast<VectorType>()) {
- Value inv = rewriter.create<IndexCastOp>(loc, mul, vtp.getElementType());
+ Value inv =
+ rewriter.create<arith::IndexCastOp>(loc, mul, vtp.getElementType());
mul = genVectorInvariantValue(codegen, rewriter, inv);
}
- return rewriter.create<AddIOp>(loc, mul, i);
+ return rewriter.create<arith::AddIOp>(loc, mul, i);
}
/// Generates start of a reduction.
break;
}
Value ptr = codegen.pointers[tensor][idx];
- Value one = rewriter.create<ConstantIndexOp>(loc, 1);
- Value p0 = (pat == 0) ? rewriter.create<ConstantIndexOp>(loc, 0)
+ Value one = rewriter.create<arith::ConstantIndexOp>(loc, 1);
+ Value p0 = (pat == 0) ? rewriter.create<arith::ConstantIndexOp>(loc, 0)
: codegen.pidxs[tensor][topSort[pat - 1]];
codegen.pidxs[tensor][idx] = genLoad(codegen, rewriter, loc, ptr, p0);
- Value p1 = rewriter.create<AddIOp>(loc, p0, one);
+ Value p1 = rewriter.create<arith::AddIOp>(loc, p0, one);
codegen.highs[tensor][idx] = genLoad(codegen, rewriter, loc, ptr, p1);
} else {
// Dense index still in play.
}
// Initialize the universal dense index.
- codegen.loops[idx] = rewriter.create<ConstantIndexOp>(loc, 0);
+ codegen.loops[idx] = rewriter.create<arith::ConstantIndexOp>(loc, 0);
return needsUniv;
}
Location loc = op.getLoc();
Value lo = isSparse ? codegen.pidxs[tensor][idx] : codegen.loops[idx];
Value hi = isSparse ? codegen.highs[tensor][idx] : codegen.sizes[idx];
- Value step = rewriter.create<ConstantIndexOp>(loc, codegen.curVecLength);
+ Value step =
+ rewriter.create<arith::ConstantIndexOp>(loc, codegen.curVecLength);
// Emit a parallel loop.
if (isParallel) {
assert(idx == merger.index(b));
Value op1 = before->getArgument(o);
Value op2 = codegen.highs[tensor][idx];
- Value opc = rewriter.create<CmpIOp>(loc, CmpIPredicate::ult, op1, op2);
- cond = cond ? rewriter.create<AndOp>(loc, cond, opc) : opc;
+ Value opc = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::ult,
+ op1, op2);
+ cond = cond ? rewriter.create<arith::AndIOp>(loc, cond, opc) : opc;
codegen.pidxs[tensor][idx] = after->getArgument(o++);
}
}
codegen.idxs[tensor][idx] = load;
if (!needsUniv) {
if (min) {
- Value cmp =
- rewriter.create<CmpIOp>(loc, CmpIPredicate::ult, load, min);
+ Value cmp = rewriter.create<arith::CmpIOp>(
+ loc, arith::CmpIPredicate::ult, load, min);
min = rewriter.create<SelectOp>(loc, cmp, load, min);
} else {
min = load;
for (; pat != 0; pat--)
if (codegen.pidxs[tensor][topSort[pat - 1]])
break;
- Value p = (pat == 0) ? rewriter.create<ConstantIndexOp>(loc, 0)
+ Value p = (pat == 0) ? rewriter.create<arith::ConstantIndexOp>(loc, 0)
: codegen.pidxs[tensor][topSort[pat - 1]];
codegen.pidxs[tensor][idx] = genAddress(
codegen, rewriter, loc, codegen.sizes[idx], p, codegen.loops[idx]);
Location loc = op.getLoc();
unsigned o = 0;
SmallVector<Value, 4> operands;
- Value one = rewriter.create<ConstantIndexOp>(loc, 1);
+ Value one = rewriter.create<arith::ConstantIndexOp>(loc, 1);
for (unsigned b = 0, be = induction.size(); b < be; b++) {
if (induction[b] && merger.isDim(b, Dim::kSparse)) {
unsigned tensor = merger.tensor(b);
Value op1 = codegen.idxs[tensor][idx];
Value op2 = codegen.loops[idx];
Value op3 = codegen.pidxs[tensor][idx];
- Value cmp = rewriter.create<CmpIOp>(loc, CmpIPredicate::eq, op1, op2);
- Value add = rewriter.create<AddIOp>(loc, op3, one);
+ Value cmp = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ op1, op2);
+ Value add = rewriter.create<arith::AddIOp>(loc, op3, one);
operands.push_back(rewriter.create<SelectOp>(loc, cmp, add, op3));
codegen.pidxs[tensor][idx] = results[o++];
}
}
if (needsUniv) {
- operands.push_back(rewriter.create<AddIOp>(loc, codegen.loops[idx], one));
+ operands.push_back(
+ rewriter.create<arith::AddIOp>(loc, codegen.loops[idx], one));
codegen.loops[idx] = results[o++];
}
assert(o == operands.size());
if (merger.isDim(b, Dim::kSparse)) {
Value op1 = codegen.idxs[tensor][idx];
Value op2 = codegen.loops[idx];
- clause = rewriter.create<CmpIOp>(loc, CmpIPredicate::eq, op1, op2);
+ clause = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::eq,
+ op1, op2);
} else {
- clause = rewriter.create<ConstantIntOp>(loc, 1, 1); // true
+ clause = rewriter.create<arith::ConstantIntOp>(loc, 1, 1); // true
}
- cond = cond ? rewriter.create<AndOp>(loc, cond, clause) : clause;
+ cond = cond ? rewriter.create<arith::AndIOp>(loc, cond, clause) : clause;
}
}
scf::IfOp ifOp = rewriter.create<scf::IfOp>(loc, cond, /*else*/ true);
${MLIR_MAIN_INCLUDE_DIR}/mlir/Dialect/SparseTensor
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRLinalg
)
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/SparseTensor/Utils/Merger.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/IR/Operation.h"
#include "llvm/Support/Debug.h"
/// Only returns false if we are certain this is a nonzero.
bool Merger::maybeZero(unsigned e) const {
if (tensorExps[e].kind == kInvariant) {
- if (auto c = tensorExps[e].val.getDefiningOp<ConstantIntOp>())
- return c.getValue() == 0;
- if (auto c = tensorExps[e].val.getDefiningOp<ConstantFloatOp>())
- return c.getValue().isZero();
+ if (auto c = tensorExps[e].val.getDefiningOp<arith::ConstantIntOp>())
+ return c.value() == 0;
+ if (auto c = tensorExps[e].val.getDefiningOp<arith::ConstantFloatOp>())
+ return c.value().isZero();
}
return true;
}
auto x = buildTensorExp(op, def->getOperand(0));
if (x.hasValue()) {
unsigned e = x.getValue();
- if (isa<AbsFOp>(def))
+ if (isa<math::AbsOp>(def))
return addExp(kAbsF, e);
- if (isa<CeilFOp>(def))
+ if (isa<math::CeilOp>(def))
return addExp(kCeilF, e);
- if (isa<FloorFOp>(def))
+ if (isa<math::FloorOp>(def))
return addExp(kFloorF, e);
- if (isa<NegFOp>(def))
+ if (isa<arith::NegFOp>(def))
return addExp(kNegF, e); // no negi in std
- if (isa<FPTruncOp>(def))
+ if (isa<arith::TruncFOp>(def))
return addExp(kTruncF, e, v);
- if (isa<FPExtOp>(def))
+ if (isa<arith::ExtFOp>(def))
return addExp(kExtF, e, v);
- if (isa<FPToSIOp>(def))
+ if (isa<arith::FPToSIOp>(def))
return addExp(kCastFS, e, v);
- if (isa<FPToUIOp>(def))
+ if (isa<arith::FPToUIOp>(def))
return addExp(kCastFU, e, v);
- if (isa<SIToFPOp>(def))
+ if (isa<arith::SIToFPOp>(def))
return addExp(kCastSF, e, v);
- if (isa<UIToFPOp>(def))
+ if (isa<arith::UIToFPOp>(def))
return addExp(kCastUF, e, v);
- if (isa<SignExtendIOp>(def))
+ if (isa<arith::ExtSIOp>(def))
return addExp(kCastS, e, v);
- if (isa<ZeroExtendIOp>(def))
+ if (isa<arith::ExtUIOp>(def))
return addExp(kCastU, e, v);
- if (isa<TruncateIOp>(def))
+ if (isa<arith::TruncIOp>(def))
return addExp(kTruncI, e, v);
- if (isa<BitcastOp>(def))
+ if (isa<arith::BitcastOp>(def))
return addExp(kBitCast, e, v);
}
}
if (x.hasValue() && y.hasValue()) {
unsigned e0 = x.getValue();
unsigned e1 = y.getValue();
- if (isa<MulFOp>(def))
+ if (isa<arith::MulFOp>(def))
return addExp(kMulF, e0, e1);
- if (isa<MulIOp>(def))
+ if (isa<arith::MulIOp>(def))
return addExp(kMulI, e0, e1);
- if (isa<DivFOp>(def) && !maybeZero(e1))
+ if (isa<arith::DivFOp>(def) && !maybeZero(e1))
return addExp(kDivF, e0, e1);
- if (isa<SignedDivIOp>(def) && !maybeZero(e1))
+ if (isa<arith::DivSIOp>(def) && !maybeZero(e1))
return addExp(kDivS, e0, e1);
- if (isa<UnsignedDivIOp>(def) && !maybeZero(e1))
+ if (isa<arith::DivUIOp>(def) && !maybeZero(e1))
return addExp(kDivU, e0, e1);
- if (isa<AddFOp>(def))
+ if (isa<arith::AddFOp>(def))
return addExp(kAddF, e0, e1);
- if (isa<AddIOp>(def))
+ if (isa<arith::AddIOp>(def))
return addExp(kAddI, e0, e1);
- if (isa<SubFOp>(def))
+ if (isa<arith::SubFOp>(def))
return addExp(kSubF, e0, e1);
- if (isa<SubIOp>(def))
+ if (isa<arith::SubIOp>(def))
return addExp(kSubI, e0, e1);
- if (isa<AndOp>(def))
+ if (isa<arith::AndIOp>(def))
return addExp(kAndI, e0, e1);
- if (isa<OrOp>(def))
+ if (isa<arith::OrIOp>(def))
return addExp(kOrI, e0, e1);
- if (isa<XOrOp>(def))
+ if (isa<arith::XOrIOp>(def))
return addExp(kXorI, e0, e1);
- if (isa<SignedShiftRightOp>(def) && isInvariant(e1))
+ if (isa<arith::ShRSIOp>(def) && isInvariant(e1))
return addExp(kShrS, e0, e1);
- if (isa<UnsignedShiftRightOp>(def) && isInvariant(e1))
+ if (isa<arith::ShRUIOp>(def) && isInvariant(e1))
return addExp(kShrU, e0, e1);
- if (isa<ShiftLeftOp>(def) && isInvariant(e1))
+ if (isa<arith::ShLIOp>(def) && isInvariant(e1))
return addExp(kShlI, e0, e1);
}
}
llvm_unreachable("unexpected non-op");
// Unary ops.
case kAbsF:
- return rewriter.create<AbsFOp>(loc, v0);
+ return rewriter.create<math::AbsOp>(loc, v0);
case kCeilF:
- return rewriter.create<CeilFOp>(loc, v0);
+ return rewriter.create<math::CeilOp>(loc, v0);
case kFloorF:
- return rewriter.create<FloorFOp>(loc, v0);
+ return rewriter.create<math::FloorOp>(loc, v0);
case kNegF:
- return rewriter.create<NegFOp>(loc, v0);
+ return rewriter.create<arith::NegFOp>(loc, v0);
case kNegI: // no negi in std
- return rewriter.create<SubIOp>(
+ return rewriter.create<arith::SubIOp>(
loc,
- rewriter.create<ConstantOp>(loc, v0.getType(),
- rewriter.getZeroAttr(v0.getType())),
+ rewriter.create<arith::ConstantOp>(loc, v0.getType(),
+ rewriter.getZeroAttr(v0.getType())),
v0);
case kTruncF:
- return rewriter.create<FPTruncOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::TruncFOp>(loc, v0, inferType(e, v0));
case kExtF:
- return rewriter.create<FPExtOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::ExtFOp>(loc, v0, inferType(e, v0));
case kCastFS:
- return rewriter.create<FPToSIOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::FPToSIOp>(loc, v0, inferType(e, v0));
case kCastFU:
- return rewriter.create<FPToUIOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::FPToUIOp>(loc, v0, inferType(e, v0));
case kCastSF:
- return rewriter.create<SIToFPOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::SIToFPOp>(loc, v0, inferType(e, v0));
case kCastUF:
- return rewriter.create<UIToFPOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::UIToFPOp>(loc, v0, inferType(e, v0));
case kCastS:
- return rewriter.create<SignExtendIOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::ExtSIOp>(loc, v0, inferType(e, v0));
case kCastU:
- return rewriter.create<ZeroExtendIOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::ExtUIOp>(loc, v0, inferType(e, v0));
case kTruncI:
- return rewriter.create<TruncateIOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::TruncIOp>(loc, v0, inferType(e, v0));
case kBitCast:
- return rewriter.create<BitcastOp>(loc, v0, inferType(e, v0));
+ return rewriter.create<arith::BitcastOp>(loc, v0, inferType(e, v0));
// Binary ops.
case kMulF:
- return rewriter.create<MulFOp>(loc, v0, v1);
+ return rewriter.create<arith::MulFOp>(loc, v0, v1);
case kMulI:
- return rewriter.create<MulIOp>(loc, v0, v1);
+ return rewriter.create<arith::MulIOp>(loc, v0, v1);
case kDivF:
- return rewriter.create<DivFOp>(loc, v0, v1);
+ return rewriter.create<arith::DivFOp>(loc, v0, v1);
case kDivS:
- return rewriter.create<SignedDivIOp>(loc, v0, v1);
+ return rewriter.create<arith::DivSIOp>(loc, v0, v1);
case kDivU:
- return rewriter.create<UnsignedDivIOp>(loc, v0, v1);
+ return rewriter.create<arith::DivUIOp>(loc, v0, v1);
case kAddF:
- return rewriter.create<AddFOp>(loc, v0, v1);
+ return rewriter.create<arith::AddFOp>(loc, v0, v1);
case kAddI:
- return rewriter.create<AddIOp>(loc, v0, v1);
+ return rewriter.create<arith::AddIOp>(loc, v0, v1);
case kSubF:
- return rewriter.create<SubFOp>(loc, v0, v1);
+ return rewriter.create<arith::SubFOp>(loc, v0, v1);
case kSubI:
- return rewriter.create<SubIOp>(loc, v0, v1);
+ return rewriter.create<arith::SubIOp>(loc, v0, v1);
case kAndI:
- return rewriter.create<AndOp>(loc, v0, v1);
+ return rewriter.create<arith::AndIOp>(loc, v0, v1);
case kOrI:
- return rewriter.create<OrOp>(loc, v0, v1);
+ return rewriter.create<arith::OrIOp>(loc, v0, v1);
case kXorI:
- return rewriter.create<XOrOp>(loc, v0, v1);
+ return rewriter.create<arith::XOrIOp>(loc, v0, v1);
case kShrS:
- return rewriter.create<SignedShiftRightOp>(loc, v0, v1);
+ return rewriter.create<arith::ShRSIOp>(loc, v0, v1);
case kShrU:
- return rewriter.create<UnsignedShiftRightOp>(loc, v0, v1);
+ return rewriter.create<arith::ShRUIOp>(loc, v0, v1);
case kShlI:
- return rewriter.create<ShiftLeftOp>(loc, v0, v1);
+ return rewriter.create<arith::ShLIOp>(loc, v0, v1);
}
llvm_unreachable("unexpected expression kind in build");
}
MLIRStandardOpsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRCallInterfaces
MLIRCastInterfaces
MLIRControlFlowInterfaces
#include "mlir/Dialect/StandardOps/IR/Ops.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/CommonFolders.h"
#include "mlir/Dialect/StandardOps/Utils/Utils.h"
#include "mlir/IR/AffineExpr.h"
// StandardOpsDialect
//===----------------------------------------------------------------------===//
-/// A custom unary operation printer that omits the "std." prefix from the
-/// operation names.
-static void printStandardUnaryOp(Operation *op, OpAsmPrinter &p) {
- assert(op->getNumOperands() == 1 && "unary op should have one operand");
- assert(op->getNumResults() == 1 && "unary op should have one result");
-
- p << ' ' << op->getOperand(0);
- p.printOptionalAttrDict(op->getAttrs());
- p << " : " << op->getOperand(0).getType();
-}
-
/// A custom binary operation printer that omits the "std." prefix from the
/// operation names.
static void printStandardBinaryOp(Operation *op, OpAsmPrinter &p) {
p << " : " << op->getResult(0).getType();
}
-/// A custom ternary operation printer that omits the "std." prefix from the
-/// operation names.
-static void printStandardTernaryOp(Operation *op, OpAsmPrinter &p) {
- assert(op->getNumOperands() == 3 && "ternary op should have three operands");
- assert(op->getNumResults() == 1 && "ternary op should have one result");
-
- // If not all the operand and result types are the same, just use the
- // generic assembly form to avoid omitting information in printing.
- auto resultType = op->getResult(0).getType();
- if (op->getOperand(0).getType() != resultType ||
- op->getOperand(1).getType() != resultType ||
- op->getOperand(2).getType() != resultType) {
- p.printGenericOp(op);
- return;
- }
-
- p << ' ' << op->getOperand(0) << ", " << op->getOperand(1) << ", "
- << op->getOperand(2);
- p.printOptionalAttrDict(op->getAttrs());
-
- // Now we can output only one type for all operands and the result.
- p << " : " << op->getResult(0).getType();
-}
-
-/// A custom cast operation printer that omits the "std." prefix from the
-/// operation names.
-static void printStandardCastOp(Operation *op, OpAsmPrinter &p) {
- p << ' ' << op->getOperand(0) << " : " << op->getOperand(0).getType()
- << " to " << op->getResult(0).getType();
-}
-
void StandardOpsDialect::initialize() {
addOperations<
#define GET_OP_LIST
Operation *StandardOpsDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
+ if (arith::ConstantOp::isBuildableWith(value, type))
+ return builder.create<arith::ConstantOp>(loc, type, value);
return builder.create<ConstantOp>(loc, type, value);
}
//===----------------------------------------------------------------------===//
-// Common cast compatibility check for vector types.
-//===----------------------------------------------------------------------===//
-
-/// This method checks for cast compatibility of vector types.
-/// If 'a' and 'b' are vector types, and they are cast compatible,
-/// it calls the 'areElementsCastCompatible' function to check for
-/// element cast compatibility.
-/// Returns 'true' if the vector types are cast compatible, and 'false'
-/// otherwise.
-static bool areVectorCastSimpleCompatible(
- Type a, Type b,
- function_ref<bool(TypeRange, TypeRange)> areElementsCastCompatible) {
- if (auto va = a.dyn_cast<VectorType>())
- if (auto vb = b.dyn_cast<VectorType>())
- return va.getShape().equals(vb.getShape()) &&
- areElementsCastCompatible(va.getElementType(),
- vb.getElementType());
- return false;
-}
-
-//===----------------------------------------------------------------------===//
-// AddFOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult AddFOp::fold(ArrayRef<Attribute> operands) {
- return constFoldBinaryOp<FloatAttr>(
- operands, [](APFloat a, APFloat b) { return a + b; });
-}
-
-//===----------------------------------------------------------------------===//
-// AddIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult AddIOp::fold(ArrayRef<Attribute> operands) {
- /// addi(x, 0) -> x
- if (matchPattern(rhs(), m_Zero()))
- return lhs();
-
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a + b; });
-}
-
-/// Canonicalize a sum of a constant and (constant - something) to simply be
-/// a sum of constants minus something. This transformation does similar
-/// transformations for additions of a constant with a subtract/add of
-/// a constant. This may result in some operations being reordered (but should
-/// remain equivalent).
-struct AddConstantReorder : public OpRewritePattern<AddIOp> {
- using OpRewritePattern<AddIOp>::OpRewritePattern;
-
- LogicalResult matchAndRewrite(AddIOp addop,
- PatternRewriter &rewriter) const override {
- for (int i = 0; i < 2; i++) {
- APInt origConst;
- APInt midConst;
- if (matchPattern(addop.getOperand(i), m_ConstantInt(&origConst))) {
- if (auto midAddOp = addop.getOperand(1 - i).getDefiningOp<AddIOp>()) {
- for (int j = 0; j < 2; j++) {
- if (matchPattern(midAddOp.getOperand(j),
- m_ConstantInt(&midConst))) {
- auto nextConstant = rewriter.create<ConstantOp>(
- addop.getLoc(), rewriter.getIntegerAttr(
- addop.getType(), origConst + midConst));
- rewriter.replaceOpWithNewOp<AddIOp>(addop, nextConstant,
- midAddOp.getOperand(1 - j));
- return success();
- }
- }
- }
- if (auto midSubOp = addop.getOperand(1 - i).getDefiningOp<SubIOp>()) {
- if (matchPattern(midSubOp.getOperand(0), m_ConstantInt(&midConst))) {
- auto nextConstant = rewriter.create<ConstantOp>(
- addop.getLoc(),
- rewriter.getIntegerAttr(addop.getType(), origConst + midConst));
- rewriter.replaceOpWithNewOp<SubIOp>(addop, nextConstant,
- midSubOp.getOperand(1));
- return success();
- }
- if (matchPattern(midSubOp.getOperand(1), m_ConstantInt(&midConst))) {
- auto nextConstant = rewriter.create<ConstantOp>(
- addop.getLoc(),
- rewriter.getIntegerAttr(addop.getType(), origConst - midConst));
- rewriter.replaceOpWithNewOp<AddIOp>(addop, nextConstant,
- midSubOp.getOperand(0));
- return success();
- }
- }
- }
- }
- return failure();
- }
-};
-
-void AddIOp::getCanonicalizationPatterns(OwningRewritePatternList &results,
- MLIRContext *context) {
- results.insert<AddConstantReorder>(context);
-}
-
-//===----------------------------------------------------------------------===//
-// AndOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult AndOp::fold(ArrayRef<Attribute> operands) {
- /// and(x, 0) -> 0
- if (matchPattern(rhs(), m_Zero()))
- return rhs();
- /// and(x, allOnes) -> x
- APInt intValue;
- if (matchPattern(rhs(), m_ConstantInt(&intValue)) && intValue.isAllOnes())
- return lhs();
- /// and(x,x) -> x
- if (lhs() == rhs())
- return rhs();
-
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a & b; });
-}
-
-//===----------------------------------------------------------------------===//
// AssertOp
//===----------------------------------------------------------------------===//
Value mlir::getIdentityValue(AtomicRMWKind op, Type resultType,
OpBuilder &builder, Location loc) {
Attribute attr = getIdentityValueAttr(op, resultType, builder, loc);
- return builder.create<ConstantOp>(loc, attr);
+ return builder.create<arith::ConstantOp>(loc, attr);
}
/// Return the value obtained by applying the reduction operation kind
Value lhs, Value rhs) {
switch (op) {
case AtomicRMWKind::addf:
- return builder.create<AddFOp>(loc, lhs, rhs);
+ return builder.create<arith::AddFOp>(loc, lhs, rhs);
case AtomicRMWKind::addi:
- return builder.create<AddIOp>(loc, lhs, rhs);
+ return builder.create<arith::AddIOp>(loc, lhs, rhs);
case AtomicRMWKind::mulf:
- return builder.create<MulFOp>(loc, lhs, rhs);
+ return builder.create<arith::MulFOp>(loc, lhs, rhs);
case AtomicRMWKind::muli:
- return builder.create<MulIOp>(loc, lhs, rhs);
+ return builder.create<arith::MulIOp>(loc, lhs, rhs);
case AtomicRMWKind::maxf:
return builder.create<SelectOp>(
- loc, builder.create<CmpFOp>(loc, CmpFPredicate::OGT, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGT, lhs, rhs),
+ lhs, rhs);
case AtomicRMWKind::minf:
return builder.create<SelectOp>(
- loc, builder.create<CmpFOp>(loc, CmpFPredicate::OLT, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OLT, lhs, rhs),
+ lhs, rhs);
case AtomicRMWKind::maxs:
return builder.create<SelectOp>(
- loc, builder.create<CmpIOp>(loc, CmpIPredicate::sgt, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, lhs, rhs),
+ lhs, rhs);
case AtomicRMWKind::mins:
return builder.create<SelectOp>(
- loc, builder.create<CmpIOp>(loc, CmpIPredicate::slt, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, lhs, rhs),
+ lhs, rhs);
case AtomicRMWKind::maxu:
return builder.create<SelectOp>(
- loc, builder.create<CmpIOp>(loc, CmpIPredicate::ugt, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpIOp>(loc, arith::CmpIPredicate::ugt, lhs, rhs),
+ lhs, rhs);
case AtomicRMWKind::minu:
return builder.create<SelectOp>(
- loc, builder.create<CmpIOp>(loc, CmpIPredicate::ult, lhs, rhs), lhs,
- rhs);
+ loc,
+ builder.create<arith::CmpIOp>(loc, arith::CmpIPredicate::ult, lhs, rhs),
+ lhs, rhs);
// TODO: Add remaining reduction operations.
default:
(void)emitOptionalError(loc, "Reduction operation type not supported");
}
//===----------------------------------------------------------------------===//
-// BitcastOp
-//===----------------------------------------------------------------------===//
-
-bool BitcastOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- assert(inputs.size() == 1 && outputs.size() == 1 &&
- "bitcast op expects one operand and result");
- Type a = inputs.front(), b = outputs.front();
- if (a.isSignlessIntOrFloat() && b.isSignlessIntOrFloat())
- return a.getIntOrFloatBitWidth() == b.getIntOrFloatBitWidth();
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-OpFoldResult BitcastOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 1 && "bitcastop expects 1 operand");
-
- // Bitcast of bitcast
- auto *sourceOp = getOperand().getDefiningOp();
- if (auto sourceBitcast = dyn_cast_or_null<BitcastOp>(sourceOp)) {
- setOperand(sourceBitcast.getOperand());
- return getResult();
- }
-
- auto operand = operands[0];
- if (!operand)
- return {};
-
- Type resType = getResult().getType();
-
- if (auto denseAttr = operand.dyn_cast<DenseElementsAttr>())
- return denseAttr.bitcast(resType.cast<ShapedType>().getElementType());
-
- APInt bits;
- if (auto floatAttr = operand.dyn_cast<FloatAttr>())
- bits = floatAttr.getValue().bitcastToAPInt();
- else if (auto intAttr = operand.dyn_cast<IntegerAttr>())
- bits = intAttr.getValue();
- else
- return {};
-
- if (resType.isa<IntegerType>())
- return IntegerAttr::get(resType, bits);
- if (auto resFloatType = resType.dyn_cast<FloatType>())
- return FloatAttr::get(resType,
- APFloat(resFloatType.getFloatSemantics(), bits));
- return {};
-}
-
-//===----------------------------------------------------------------------===//
// BranchOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// CmpIOp
-//===----------------------------------------------------------------------===//
-
-static void buildCmpIOp(OpBuilder &build, OperationState &result,
- CmpIPredicate predicate, Value lhs, Value rhs) {
- result.addOperands({lhs, rhs});
- result.types.push_back(getI1SameShape(lhs.getType()));
- result.addAttribute(CmpIOp::getPredicateAttrName(),
- build.getI64IntegerAttr(static_cast<int64_t>(predicate)));
-}
-
-// Compute `lhs` `pred` `rhs`, where `pred` is one of the known integer
-// comparison predicates.
-bool mlir::applyCmpPredicate(CmpIPredicate predicate, const APInt &lhs,
- const APInt &rhs) {
- switch (predicate) {
- case CmpIPredicate::eq:
- return lhs.eq(rhs);
- case CmpIPredicate::ne:
- return lhs.ne(rhs);
- case CmpIPredicate::slt:
- return lhs.slt(rhs);
- case CmpIPredicate::sle:
- return lhs.sle(rhs);
- case CmpIPredicate::sgt:
- return lhs.sgt(rhs);
- case CmpIPredicate::sge:
- return lhs.sge(rhs);
- case CmpIPredicate::ult:
- return lhs.ult(rhs);
- case CmpIPredicate::ule:
- return lhs.ule(rhs);
- case CmpIPredicate::ugt:
- return lhs.ugt(rhs);
- case CmpIPredicate::uge:
- return lhs.uge(rhs);
- }
- llvm_unreachable("unknown comparison predicate");
-}
-
-// Returns true if the predicate is true for two equal operands.
-static bool applyCmpPredicateToEqualOperands(CmpIPredicate predicate) {
- switch (predicate) {
- case CmpIPredicate::eq:
- case CmpIPredicate::sle:
- case CmpIPredicate::sge:
- case CmpIPredicate::ule:
- case CmpIPredicate::uge:
- return true;
- case CmpIPredicate::ne:
- case CmpIPredicate::slt:
- case CmpIPredicate::sgt:
- case CmpIPredicate::ult:
- case CmpIPredicate::ugt:
- return false;
- }
- llvm_unreachable("unknown comparison predicate");
-}
-
-// Constant folding hook for comparisons.
-OpFoldResult CmpIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "cmpi takes two arguments");
-
- if (lhs() == rhs()) {
- auto val = applyCmpPredicateToEqualOperands(getPredicate());
- return BoolAttr::get(getContext(), val);
- }
-
- auto lhs = operands.front().dyn_cast_or_null<IntegerAttr>();
- auto rhs = operands.back().dyn_cast_or_null<IntegerAttr>();
- if (!lhs || !rhs)
- return {};
-
- auto val = applyCmpPredicate(getPredicate(), lhs.getValue(), rhs.getValue());
- return BoolAttr::get(getContext(), val);
-}
-
-//===----------------------------------------------------------------------===//
-// CmpFOp
-//===----------------------------------------------------------------------===//
-
-static void buildCmpFOp(OpBuilder &build, OperationState &result,
- CmpFPredicate predicate, Value lhs, Value rhs) {
- result.addOperands({lhs, rhs});
- result.types.push_back(getI1SameShape(lhs.getType()));
- result.addAttribute(CmpFOp::getPredicateAttrName(),
- build.getI64IntegerAttr(static_cast<int64_t>(predicate)));
-}
-
-/// Compute `lhs` `pred` `rhs`, where `pred` is one of the known floating point
-/// comparison predicates.
-bool mlir::applyCmpPredicate(CmpFPredicate predicate, const APFloat &lhs,
- const APFloat &rhs) {
- auto cmpResult = lhs.compare(rhs);
- switch (predicate) {
- case CmpFPredicate::AlwaysFalse:
- return false;
- case CmpFPredicate::OEQ:
- return cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::OGT:
- return cmpResult == APFloat::cmpGreaterThan;
- case CmpFPredicate::OGE:
- return cmpResult == APFloat::cmpGreaterThan ||
- cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::OLT:
- return cmpResult == APFloat::cmpLessThan;
- case CmpFPredicate::OLE:
- return cmpResult == APFloat::cmpLessThan || cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::ONE:
- return cmpResult != APFloat::cmpUnordered && cmpResult != APFloat::cmpEqual;
- case CmpFPredicate::ORD:
- return cmpResult != APFloat::cmpUnordered;
- case CmpFPredicate::UEQ:
- return cmpResult == APFloat::cmpUnordered || cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::UGT:
- return cmpResult == APFloat::cmpUnordered ||
- cmpResult == APFloat::cmpGreaterThan;
- case CmpFPredicate::UGE:
- return cmpResult == APFloat::cmpUnordered ||
- cmpResult == APFloat::cmpGreaterThan ||
- cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::ULT:
- return cmpResult == APFloat::cmpUnordered ||
- cmpResult == APFloat::cmpLessThan;
- case CmpFPredicate::ULE:
- return cmpResult == APFloat::cmpUnordered ||
- cmpResult == APFloat::cmpLessThan || cmpResult == APFloat::cmpEqual;
- case CmpFPredicate::UNE:
- return cmpResult != APFloat::cmpEqual;
- case CmpFPredicate::UNO:
- return cmpResult == APFloat::cmpUnordered;
- case CmpFPredicate::AlwaysTrue:
- return true;
- }
- llvm_unreachable("unknown comparison predicate");
-}
-
-// Constant folding hook for comparisons.
-OpFoldResult CmpFOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "cmpf takes two arguments");
-
- auto lhs = operands.front().dyn_cast_or_null<FloatAttr>();
- auto rhs = operands.back().dyn_cast_or_null<FloatAttr>();
-
- // TODO: We could actually do some intelligent things if we know only one
- // of the operands, but it's inf or nan.
- if (!lhs || !rhs)
- return {};
-
- auto val = applyCmpPredicate(getPredicate(), lhs.getValue(), rhs.getValue());
- return IntegerAttr::get(IntegerType::get(getContext(), 1), APInt(1, val));
-}
-
-//===----------------------------------------------------------------------===//
// CondBranchOp
//===----------------------------------------------------------------------===//
replaced = true;
if (!constantTrue)
- constantTrue = rewriter.create<mlir::ConstantOp>(
+ constantTrue = rewriter.create<arith::ConstantOp>(
condbr.getLoc(), ty, rewriter.getBoolAttr(true));
rewriter.updateRootInPlace(use.getOwner(),
replaced = true;
if (!constantFalse)
- constantFalse = rewriter.create<mlir::ConstantOp>(
+ constantFalse = rewriter.create<arith::ConstantOp>(
condbr.getLoc(), ty, rewriter.getBoolAttr(false));
rewriter.updateRootInPlace(use.getOwner(),
}
//===----------------------------------------------------------------------===//
-// Constant*Op
+// ConstantOp
//===----------------------------------------------------------------------===//
static void print(OpAsmPrinter &p, ConstantOp &op) {
return op.emitOpError() << "requires attribute's type (" << value.getType()
<< ") to match op's return type (" << type << ")";
- if (auto intAttr = value.dyn_cast<IntegerAttr>()) {
- if (type.isa<IndexType>() || value.isa<BoolAttr>())
- return success();
- IntegerType intType = type.cast<IntegerType>();
- if (!intType.isSignless())
- return op.emitOpError("requires integer result types to be signless");
-
- // If the type has a known bitwidth we verify that the value can be
- // represented with the given bitwidth.
- unsigned bitwidth = intType.getWidth();
- APInt intVal = intAttr.getValue();
- if (!intVal.isSignedIntN(bitwidth) && !intVal.isIntN(bitwidth))
- return op.emitOpError("requires 'value' to be an integer within the "
- "range of the integer result type");
- return success();
- }
-
if (auto complexTy = type.dyn_cast<ComplexType>()) {
auto arrayAttr = value.dyn_cast<ArrayAttr>();
if (!complexTy || arrayAttr.size() != 2)
return success();
}
- if (type.isa<FloatType>()) {
- if (!value.isa<FloatAttr>())
- return op.emitOpError("requires 'value' to be a floating point constant");
- return success();
- }
-
- if (type.isa<ShapedType>()) {
- if (!value.isa<ElementsAttr>())
- return op.emitOpError("requires 'value' to be a shaped constant");
- return success();
- }
-
if (type.isa<FunctionType>()) {
auto fnAttr = value.dyn_cast<FlatSymbolRefAttr>();
if (!fnAttr)
void ConstantOp::getAsmResultNames(
function_ref<void(Value, StringRef)> setNameFn) {
Type type = getType();
- if (auto intCst = getValue().dyn_cast<IntegerAttr>()) {
- IntegerType intTy = type.dyn_cast<IntegerType>();
-
- // Sugar i1 constants with 'true' and 'false'.
- if (intTy && intTy.getWidth() == 1)
- return setNameFn(getResult(), (intCst.getInt() ? "true" : "false"));
-
- // Otherwise, build a complex name with the value and type.
- SmallString<32> specialNameBuffer;
- llvm::raw_svector_ostream specialName(specialNameBuffer);
- specialName << 'c' << intCst.getInt();
- if (intTy)
- specialName << '_' << type;
- setNameFn(getResult(), specialName.str());
-
- } else if (type.isa<FunctionType>()) {
+ if (type.isa<FunctionType>()) {
setNameFn(getResult(), "f");
} else {
setNameFn(getResult(), "cst");
// The attribute must have the same type as 'type'.
if (!value.getType().isa<NoneType>() && value.getType() != type)
return false;
- // If the type is an integer type, it must be signless.
- if (IntegerType integerTy = type.dyn_cast<IntegerType>())
- if (!integerTy.isSignless())
- return false;
// Finally, check that the attribute kind is handled.
if (auto arrAttr = value.dyn_cast<ArrayAttr>()) {
auto complexTy = type.dyn_cast<ComplexType>();
return arrAttr.size() == 2 && arrAttr[0].getType() == complexEltTy &&
arrAttr[1].getType() == complexEltTy;
}
- return value.isa<IntegerAttr, FloatAttr, ElementsAttr, UnitAttr>();
-}
-
-void ConstantFloatOp::build(OpBuilder &builder, OperationState &result,
- const APFloat &value, FloatType type) {
- ConstantOp::build(builder, result, type, builder.getFloatAttr(type, value));
-}
-
-bool ConstantFloatOp::classof(Operation *op) {
- return ConstantOp::classof(op) && op->getResult(0).getType().isa<FloatType>();
-}
-
-/// ConstantIntOp only matches values whose result type is an IntegerType.
-bool ConstantIntOp::classof(Operation *op) {
- return ConstantOp::classof(op) &&
- op->getResult(0).getType().isSignlessInteger();
-}
-
-void ConstantIntOp::build(OpBuilder &builder, OperationState &result,
- int64_t value, unsigned width) {
- Type type = builder.getIntegerType(width);
- ConstantOp::build(builder, result, type, builder.getIntegerAttr(type, value));
-}
-
-/// Build a constant int op producing an integer with the specified type,
-/// which must be an integer type.
-void ConstantIntOp::build(OpBuilder &builder, OperationState &result,
- int64_t value, Type type) {
- assert(type.isSignlessInteger() &&
- "ConstantIntOp can only have signless integer type");
- ConstantOp::build(builder, result, type, builder.getIntegerAttr(type, value));
-}
-
-/// ConstantIndexOp only matches values whose result type is Index.
-bool ConstantIndexOp::classof(Operation *op) {
- return ConstantOp::classof(op) && op->getResult(0).getType().isIndex();
-}
-
-void ConstantIndexOp::build(OpBuilder &builder, OperationState &result,
- int64_t value) {
- Type type = builder.getIndexType();
- ConstantOp::build(builder, result, type, builder.getIntegerAttr(type, value));
-}
-
-// ---------------------------------------------------------------------------
-// DivFOp
-// ---------------------------------------------------------------------------
-
-OpFoldResult DivFOp::fold(ArrayRef<Attribute> operands) {
- return constFoldBinaryOp<FloatAttr>(
- operands, [](APFloat a, APFloat b) { return a / b; });
-}
-
-//===----------------------------------------------------------------------===//
-// FPExtOp
-//===----------------------------------------------------------------------===//
-
-bool FPExtOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (auto fa = a.dyn_cast<FloatType>())
- if (auto fb = b.dyn_cast<FloatType>())
- return fa.getWidth() < fb.getWidth();
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-//===----------------------------------------------------------------------===//
-// FPToSIOp
-//===----------------------------------------------------------------------===//
-
-bool FPToSIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (a.isa<FloatType>() && b.isSignlessInteger())
- return true;
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-//===----------------------------------------------------------------------===//
-// FPToUIOp
-//===----------------------------------------------------------------------===//
-
-bool FPToUIOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (a.isa<FloatType>() && b.isSignlessInteger())
- return true;
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-//===----------------------------------------------------------------------===//
-// FPTruncOp
-//===----------------------------------------------------------------------===//
-
-bool FPTruncOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (auto fa = a.dyn_cast<FloatType>())
- if (auto fb = b.dyn_cast<FloatType>())
- return fa.getWidth() > fb.getWidth();
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-/// Perform safe const propagation for fptrunc, i.e. only propagate
-/// if FP value can be represented without precision loss or rounding.
-OpFoldResult FPTruncOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 1 && "unary operation takes one operand");
-
- auto constOperand = operands.front();
- if (!constOperand || !constOperand.isa<FloatAttr>())
- return {};
-
- // Convert to target type via 'double'.
- double sourceValue =
- constOperand.dyn_cast<FloatAttr>().getValue().convertToDouble();
- auto targetAttr = FloatAttr::get(getType(), sourceValue);
-
- // Propagate if constant's value does not change after truncation.
- if (sourceValue == targetAttr.getValue().convertToDouble())
- return targetAttr;
-
- return {};
-}
-
-//===----------------------------------------------------------------------===//
-// IndexCastOp
-//===----------------------------------------------------------------------===//
-
-// Index cast is applicable from index to integer and backwards.
-bool IndexCastOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (a.isa<ShapedType>() && b.isa<ShapedType>()) {
- auto aShaped = a.cast<ShapedType>();
- auto bShaped = b.cast<ShapedType>();
-
- return (aShaped.getShape() == bShaped.getShape()) &&
- areCastCompatible(aShaped.getElementType(),
- bShaped.getElementType());
- }
-
- return (a.isIndex() && b.isSignlessInteger()) ||
- (a.isSignlessInteger() && b.isIndex());
-}
-
-OpFoldResult IndexCastOp::fold(ArrayRef<Attribute> cstOperands) {
- // Fold IndexCast(IndexCast(x)) -> x
- auto cast = getOperand().getDefiningOp<IndexCastOp>();
- if (cast && cast.getOperand().getType() == getType())
- return cast.getOperand();
-
- // Fold IndexCast(constant) -> constant
- // A little hack because we go through int. Otherwise, the size
- // of the constant might need to change.
- if (auto value = cstOperands[0].dyn_cast_or_null<IntegerAttr>())
- return IntegerAttr::get(getType(), value.getInt());
-
- return {};
-}
-
-namespace {
-/// index_cast(sign_extend x) => index_cast(x)
-struct IndexCastOfSExt : public OpRewritePattern<IndexCastOp> {
- using OpRewritePattern<IndexCastOp>::OpRewritePattern;
-
- LogicalResult matchAndRewrite(IndexCastOp op,
- PatternRewriter &rewriter) const override {
-
- if (auto extop = op.getOperand().getDefiningOp<SignExtendIOp>()) {
- op.setOperand(extop.getOperand());
- return success();
- }
- return failure();
- }
-};
-
-} // namespace
-
-void IndexCastOp::getCanonicalizationPatterns(OwningRewritePatternList &results,
- MLIRContext *context) {
- results.insert<IndexCastOfSExt>(context);
-}
-
-//===----------------------------------------------------------------------===//
-// MulFOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult MulFOp::fold(ArrayRef<Attribute> operands) {
- return constFoldBinaryOp<FloatAttr>(
- operands, [](APFloat a, APFloat b) { return a * b; });
-}
-
-//===----------------------------------------------------------------------===//
-// MulIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult MulIOp::fold(ArrayRef<Attribute> operands) {
- /// muli(x, 0) -> 0
- if (matchPattern(rhs(), m_Zero()))
- return rhs();
- /// muli(x, 1) -> x
- if (matchPattern(rhs(), m_One()))
- return getOperand(0);
-
- // TODO: Handle the overflow case.
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a * b; });
-}
-
-//===----------------------------------------------------------------------===//
-// OrOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult OrOp::fold(ArrayRef<Attribute> operands) {
- /// or(x, 0) -> x
- if (matchPattern(rhs(), m_Zero()))
- return lhs();
- /// or(x, x) -> x
- if (lhs() == rhs())
- return rhs();
- /// or(x, <all ones>) -> <all ones>
- if (auto rhsAttr = operands[1].dyn_cast_or_null<IntegerAttr>())
- if (rhsAttr.getValue().isAllOnes())
- return rhsAttr;
-
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a | b; });
+ return value.isa<UnitAttr>();
}
//===----------------------------------------------------------------------===//
if (!op.getType().isInteger(1))
return failure();
- rewriter.replaceOpWithNewOp<XOrOp>(op, op.condition(), op.getFalseValue());
+ rewriter.replaceOpWithNewOp<arith::XOrIOp>(op, op.condition(),
+ op.getFalseValue());
return success();
}
};
if (matchPattern(condition, m_Zero()))
return falseVal;
- if (auto cmp = dyn_cast_or_null<CmpIOp>(condition.getDefiningOp())) {
+ if (auto cmp = dyn_cast_or_null<arith::CmpIOp>(condition.getDefiningOp())) {
auto pred = cmp.predicate();
- if (pred == mlir::CmpIPredicate::eq || pred == mlir::CmpIPredicate::ne) {
+ if (pred == arith::CmpIPredicate::eq || pred == arith::CmpIPredicate::ne) {
auto cmpLhs = cmp.lhs();
auto cmpRhs = cmp.rhs();
- // %0 = cmpi eq, %arg0, %arg1
+ // %0 = arith.cmpi eq, %arg0, %arg1
// %1 = select %0, %arg0, %arg1 => %arg1
- // %0 = cmpi ne, %arg0, %arg1
+ // %0 = arith.cmpi ne, %arg0, %arg1
// %1 = select %0, %arg0, %arg1 => %arg0
if ((cmpLhs == trueVal && cmpRhs == falseVal) ||
(cmpRhs == trueVal && cmpLhs == falseVal))
- return pred == mlir::CmpIPredicate::ne ? trueVal : falseVal;
+ return pred == arith::CmpIPredicate::ne ? trueVal : falseVal;
}
}
return nullptr;
}
//===----------------------------------------------------------------------===//
-// SignExtendIOp
-//===----------------------------------------------------------------------===//
-
-static LogicalResult verify(SignExtendIOp op) {
- // Get the scalar type (which is either directly the type of the operand
- // or the vector's/tensor's element type.
- auto srcType = getElementTypeOrSelf(op.getOperand().getType());
- auto dstType = getElementTypeOrSelf(op.getType());
-
- // For now, index is forbidden for the source and the destination type.
- if (srcType.isa<IndexType>())
- return op.emitError() << srcType << " is not a valid operand type";
- if (dstType.isa<IndexType>())
- return op.emitError() << dstType << " is not a valid result type";
-
- if (srcType.cast<IntegerType>().getWidth() >=
- dstType.cast<IntegerType>().getWidth())
- return op.emitError("result type ")
- << dstType << " must be wider than operand type " << srcType;
-
- return success();
-}
-
-OpFoldResult SignExtendIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 1 && "unary operation takes one operand");
-
- if (!operands[0])
- return {};
-
- if (auto lhs = operands[0].dyn_cast<IntegerAttr>()) {
- return IntegerAttr::get(
- getType(), lhs.getValue().sext(getType().getIntOrFloatBitWidth()));
- }
-
- return {};
-}
-
-//===----------------------------------------------------------------------===//
-// SignedDivIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult SignedDivIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "binary operation takes two operands");
-
- // Don't fold if it would overflow or if it requires a division by zero.
- bool overflowOrDiv0 = false;
- auto result = constFoldBinaryOp<IntegerAttr>(operands, [&](APInt a, APInt b) {
- if (overflowOrDiv0 || !b) {
- overflowOrDiv0 = true;
- return a;
- }
- return a.sdiv_ov(b, overflowOrDiv0);
- });
-
- // Fold out division by one. Assumes all tensors of all ones are splats.
- if (auto rhs = operands[1].dyn_cast_or_null<IntegerAttr>()) {
- if (rhs.getValue() == 1)
- return lhs();
- } else if (auto rhs = operands[1].dyn_cast_or_null<SplatElementsAttr>()) {
- if (rhs.getSplatValue<IntegerAttr>().getValue() == 1)
- return lhs();
- }
-
- return overflowOrDiv0 ? Attribute() : result;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedFloorDivIOp
-//===----------------------------------------------------------------------===//
-
-static APInt signedCeilNonnegInputs(APInt a, APInt b, bool &overflow) {
- // Returns (a-1)/b + 1
- APInt one(a.getBitWidth(), 1, true); // Signed value 1.
- APInt val = a.ssub_ov(one, overflow).sdiv_ov(b, overflow);
- return val.sadd_ov(one, overflow);
-}
-
-OpFoldResult SignedFloorDivIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "binary operation takes two operands");
-
- // Don't fold if it would overflow or if it requires a division by zero.
- bool overflowOrDiv0 = false;
- auto result = constFoldBinaryOp<IntegerAttr>(operands, [&](APInt a, APInt b) {
- if (overflowOrDiv0 || !b) {
- overflowOrDiv0 = true;
- return a;
- }
- unsigned bits = a.getBitWidth();
- APInt zero = APInt::getZero(bits);
- if (a.sge(zero) && b.sgt(zero)) {
- // Both positive (or a is zero), return a / b.
- return a.sdiv_ov(b, overflowOrDiv0);
- } else if (a.sle(zero) && b.slt(zero)) {
- // Both negative (or a is zero), return -a / -b.
- APInt posA = zero.ssub_ov(a, overflowOrDiv0);
- APInt posB = zero.ssub_ov(b, overflowOrDiv0);
- return posA.sdiv_ov(posB, overflowOrDiv0);
- } else if (a.slt(zero) && b.sgt(zero)) {
- // A is negative, b is positive, return - ceil(-a, b).
- APInt posA = zero.ssub_ov(a, overflowOrDiv0);
- APInt ceil = signedCeilNonnegInputs(posA, b, overflowOrDiv0);
- return zero.ssub_ov(ceil, overflowOrDiv0);
- } else {
- // A is positive, b is negative, return - ceil(a, -b).
- APInt posB = zero.ssub_ov(b, overflowOrDiv0);
- APInt ceil = signedCeilNonnegInputs(a, posB, overflowOrDiv0);
- return zero.ssub_ov(ceil, overflowOrDiv0);
- }
- });
-
- // Fold out floor division by one. Assumes all tensors of all ones are
- // splats.
- if (auto rhs = operands[1].dyn_cast_or_null<IntegerAttr>()) {
- if (rhs.getValue() == 1)
- return lhs();
- } else if (auto rhs = operands[1].dyn_cast_or_null<SplatElementsAttr>()) {
- if (rhs.getSplatValue<IntegerAttr>().getValue() == 1)
- return lhs();
- }
-
- return overflowOrDiv0 ? Attribute() : result;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedCeilDivIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult SignedCeilDivIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "binary operation takes two operands");
-
- // Don't fold if it would overflow or if it requires a division by zero.
- bool overflowOrDiv0 = false;
- auto result = constFoldBinaryOp<IntegerAttr>(operands, [&](APInt a, APInt b) {
- if (overflowOrDiv0 || !b) {
- overflowOrDiv0 = true;
- return a;
- }
- unsigned bits = a.getBitWidth();
- APInt zero = APInt::getZero(bits);
- if (a.sgt(zero) && b.sgt(zero)) {
- // Both positive, return ceil(a, b).
- return signedCeilNonnegInputs(a, b, overflowOrDiv0);
- } else if (a.slt(zero) && b.slt(zero)) {
- // Both negative, return ceil(-a, -b).
- APInt posA = zero.ssub_ov(a, overflowOrDiv0);
- APInt posB = zero.ssub_ov(b, overflowOrDiv0);
- return signedCeilNonnegInputs(posA, posB, overflowOrDiv0);
- } else if (a.slt(zero) && b.sgt(zero)) {
- // A is negative, b is positive, return - ( -a / b).
- APInt posA = zero.ssub_ov(a, overflowOrDiv0);
- APInt div = posA.sdiv_ov(b, overflowOrDiv0);
- return zero.ssub_ov(div, overflowOrDiv0);
- } else {
- // A is positive (or zero), b is negative, return - (a / -b).
- APInt posB = zero.ssub_ov(b, overflowOrDiv0);
- APInt div = a.sdiv_ov(posB, overflowOrDiv0);
- return zero.ssub_ov(div, overflowOrDiv0);
- }
- });
-
- // Fold out floor division by one. Assumes all tensors of all ones are
- // splats.
- if (auto rhs = operands[1].dyn_cast_or_null<IntegerAttr>()) {
- if (rhs.getValue() == 1)
- return lhs();
- } else if (auto rhs = operands[1].dyn_cast_or_null<SplatElementsAttr>()) {
- if (rhs.getSplatValue<IntegerAttr>().getValue() == 1)
- return lhs();
- }
-
- return overflowOrDiv0 ? Attribute() : result;
-}
-
-//===----------------------------------------------------------------------===//
-// SignedRemIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult SignedRemIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "remi_signed takes two operands");
-
- auto rhs = operands.back().dyn_cast_or_null<IntegerAttr>();
- if (!rhs)
- return {};
- auto rhsValue = rhs.getValue();
-
- // x % 1 = 0
- if (rhsValue.isOneValue())
- return IntegerAttr::get(rhs.getType(), APInt(rhsValue.getBitWidth(), 0));
-
- // Don't fold if it requires division by zero.
- if (rhsValue.isNullValue())
- return {};
-
- auto lhs = operands.front().dyn_cast_or_null<IntegerAttr>();
- if (!lhs)
- return {};
- return IntegerAttr::get(lhs.getType(), lhs.getValue().srem(rhsValue));
-}
-
-//===----------------------------------------------------------------------===//
-// SIToFPOp
-//===----------------------------------------------------------------------===//
-
-// sitofp is applicable from integer types to float types.
-bool SIToFPOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (a.isSignlessInteger() && b.isa<FloatType>())
- return true;
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-//===----------------------------------------------------------------------===//
// SplatOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// SubFOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult SubFOp::fold(ArrayRef<Attribute> operands) {
- return constFoldBinaryOp<FloatAttr>(
- operands, [](APFloat a, APFloat b) { return a - b; });
-}
-
-//===----------------------------------------------------------------------===//
-// SubIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult SubIOp::fold(ArrayRef<Attribute> operands) {
- // subi(x,x) -> 0
- if (getOperand(0) == getOperand(1))
- return Builder(getContext()).getZeroAttr(getType());
- // subi(x,0) -> x
- if (matchPattern(rhs(), m_Zero()))
- return lhs();
-
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a - b; });
-}
-
-/// Canonicalize a sub of a constant and (constant +/- something) to simply be
-/// a single operation that merges the two constants.
-struct SubConstantReorder : public OpRewritePattern<SubIOp> {
- using OpRewritePattern<SubIOp>::OpRewritePattern;
-
- LogicalResult matchAndRewrite(SubIOp subOp,
- PatternRewriter &rewriter) const override {
- APInt origConst;
- APInt midConst;
-
- if (matchPattern(subOp.getOperand(0), m_ConstantInt(&origConst))) {
- if (auto midAddOp = subOp.getOperand(1).getDefiningOp<AddIOp>()) {
- // origConst - (midConst + something) == (origConst - midConst) -
- // something
- for (int j = 0; j < 2; j++) {
- if (matchPattern(midAddOp.getOperand(j), m_ConstantInt(&midConst))) {
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst - midConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, nextConstant,
- midAddOp.getOperand(1 - j));
- return success();
- }
- }
- }
-
- if (auto midSubOp = subOp.getOperand(0).getDefiningOp<SubIOp>()) {
- if (matchPattern(midSubOp.getOperand(0), m_ConstantInt(&midConst))) {
- // (midConst - something) - origConst == (midConst - origConst) -
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), midConst - origConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, nextConstant,
- midSubOp.getOperand(1));
- return success();
- }
-
- if (matchPattern(midSubOp.getOperand(1), m_ConstantInt(&midConst))) {
- // (something - midConst) - origConst == something - (origConst +
- // midConst)
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst + midConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, midSubOp.getOperand(0),
- nextConstant);
- return success();
- }
- }
-
- if (auto midSubOp = subOp.getOperand(1).getDefiningOp<SubIOp>()) {
- if (matchPattern(midSubOp.getOperand(0), m_ConstantInt(&midConst))) {
- // origConst - (midConst - something) == (origConst - midConst) +
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst - midConst));
- rewriter.replaceOpWithNewOp<AddIOp>(subOp, nextConstant,
- midSubOp.getOperand(1));
- return success();
- }
-
- if (matchPattern(midSubOp.getOperand(1), m_ConstantInt(&midConst))) {
- // origConst - (something - midConst) == (origConst + midConst) -
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst + midConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, nextConstant,
- midSubOp.getOperand(0));
- return success();
- }
- }
- }
-
- if (matchPattern(subOp.getOperand(1), m_ConstantInt(&origConst))) {
- if (auto midAddOp = subOp.getOperand(0).getDefiningOp<AddIOp>()) {
- // (midConst + something) - origConst == (midConst - origConst) +
- // something
- for (int j = 0; j < 2; j++) {
- if (matchPattern(midAddOp.getOperand(j), m_ConstantInt(&midConst))) {
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), midConst - origConst));
- rewriter.replaceOpWithNewOp<AddIOp>(subOp, nextConstant,
- midAddOp.getOperand(1 - j));
- return success();
- }
- }
- }
-
- if (auto midSubOp = subOp.getOperand(0).getDefiningOp<SubIOp>()) {
- if (matchPattern(midSubOp.getOperand(0), m_ConstantInt(&midConst))) {
- // (midConst - something) - origConst == (midConst - origConst) -
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), midConst - origConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, nextConstant,
- midSubOp.getOperand(1));
- return success();
- }
-
- if (matchPattern(midSubOp.getOperand(1), m_ConstantInt(&midConst))) {
- // (something - midConst) - origConst == something - (midConst +
- // origConst)
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), midConst + origConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, midSubOp.getOperand(0),
- nextConstant);
- return success();
- }
- }
-
- if (auto midSubOp = subOp.getOperand(1).getDefiningOp<SubIOp>()) {
- if (matchPattern(midSubOp.getOperand(0), m_ConstantInt(&midConst))) {
- // origConst - (midConst - something) == (origConst - midConst) +
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst - midConst));
- rewriter.replaceOpWithNewOp<AddIOp>(subOp, nextConstant,
- midSubOp.getOperand(1));
- return success();
- }
- if (matchPattern(midSubOp.getOperand(1), m_ConstantInt(&midConst))) {
- // origConst - (something - midConst) == (origConst - midConst) -
- // something
- auto nextConstant = rewriter.create<ConstantOp>(
- subOp.getLoc(),
- rewriter.getIntegerAttr(subOp.getType(), origConst - midConst));
- rewriter.replaceOpWithNewOp<SubIOp>(subOp, nextConstant,
- midSubOp.getOperand(0));
- return success();
- }
- }
- }
- return failure();
- }
-};
-
-void SubIOp::getCanonicalizationPatterns(OwningRewritePatternList &results,
- MLIRContext *context) {
- results.insert<SubConstantReorder>(context);
-}
-
-//===----------------------------------------------------------------------===//
-// UIToFPOp
-//===----------------------------------------------------------------------===//
-
-// uitofp is applicable from integer types to float types.
-bool UIToFPOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
- if (inputs.size() != 1 || outputs.size() != 1)
- return false;
- Type a = inputs.front(), b = outputs.front();
- if (a.isSignlessInteger() && b.isa<FloatType>())
- return true;
- return areVectorCastSimpleCompatible(a, b, areCastCompatible);
-}
-
-//===----------------------------------------------------------------------===//
// SwitchOp
//===----------------------------------------------------------------------===//
}
//===----------------------------------------------------------------------===//
-// TruncateIOp
-//===----------------------------------------------------------------------===//
-
-static LogicalResult verify(TruncateIOp op) {
- auto srcType = getElementTypeOrSelf(op.getOperand().getType());
- auto dstType = getElementTypeOrSelf(op.getType());
-
- if (srcType.isa<IndexType>())
- return op.emitError() << srcType << " is not a valid operand type";
- if (dstType.isa<IndexType>())
- return op.emitError() << dstType << " is not a valid result type";
-
- if (srcType.cast<IntegerType>().getWidth() <=
- dstType.cast<IntegerType>().getWidth())
- return op.emitError("operand type ")
- << srcType << " must be wider than result type " << dstType;
-
- return success();
-}
-
-OpFoldResult TruncateIOp::fold(ArrayRef<Attribute> operands) {
- // trunci(zexti(a)) -> a
- // trunci(sexti(a)) -> a
- if (matchPattern(getOperand(), m_Op<ZeroExtendIOp>()) ||
- matchPattern(getOperand(), m_Op<SignExtendIOp>()))
- return getOperand().getDefiningOp()->getOperand(0);
-
- assert(operands.size() == 1 && "unary operation takes one operand");
-
- if (!operands[0])
- return {};
-
- if (auto lhs = operands[0].dyn_cast<IntegerAttr>()) {
-
- return IntegerAttr::get(
- getType(), lhs.getValue().trunc(getType().getIntOrFloatBitWidth()));
- }
-
- return {};
-}
-
-//===----------------------------------------------------------------------===//
-// UnsignedDivIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult UnsignedDivIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "binary operation takes two operands");
-
- // Don't fold if it would require a division by zero.
- bool div0 = false;
- auto result = constFoldBinaryOp<IntegerAttr>(operands, [&](APInt a, APInt b) {
- if (div0 || !b) {
- div0 = true;
- return a;
- }
- return a.udiv(b);
- });
-
- // Fold out division by one. Assumes all tensors of all ones are splats.
- if (auto rhs = operands[1].dyn_cast_or_null<IntegerAttr>()) {
- if (rhs.getValue() == 1)
- return lhs();
- } else if (auto rhs = operands[1].dyn_cast_or_null<SplatElementsAttr>()) {
- if (rhs.getSplatValue<IntegerAttr>().getValue() == 1)
- return lhs();
- }
-
- return div0 ? Attribute() : result;
-}
-
-//===----------------------------------------------------------------------===//
-// UnsignedRemIOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult UnsignedRemIOp::fold(ArrayRef<Attribute> operands) {
- assert(operands.size() == 2 && "remi_unsigned takes two operands");
-
- auto rhs = operands.back().dyn_cast_or_null<IntegerAttr>();
- if (!rhs)
- return {};
- auto rhsValue = rhs.getValue();
-
- // x % 1 = 0
- if (rhsValue.isOneValue())
- return IntegerAttr::get(rhs.getType(), APInt(rhsValue.getBitWidth(), 0));
-
- // Don't fold if it requires division by zero.
- if (rhsValue.isNullValue())
- return {};
-
- auto lhs = operands.front().dyn_cast_or_null<IntegerAttr>();
- if (!lhs)
- return {};
- return IntegerAttr::get(lhs.getType(), lhs.getValue().urem(rhsValue));
-}
-
-//===----------------------------------------------------------------------===//
-// XOrOp
-//===----------------------------------------------------------------------===//
-
-OpFoldResult XOrOp::fold(ArrayRef<Attribute> operands) {
- /// xor(x, 0) -> x
- if (matchPattern(rhs(), m_Zero()))
- return lhs();
- /// xor(x,x) -> 0
- if (lhs() == rhs())
- return Builder(getContext()).getZeroAttr(getType());
-
- return constFoldBinaryOp<IntegerAttr>(operands,
- [](APInt a, APInt b) { return a ^ b; });
-}
-
-namespace {
-/// Replace a not of a comparison operation, for example: not(cmp eq A, B) =>
-/// cmp ne A, B. Note that a logical not is implemented as xor 1, val.
-struct NotICmp : public OpRewritePattern<XOrOp> {
- using OpRewritePattern<XOrOp>::OpRewritePattern;
-
- LogicalResult matchAndRewrite(XOrOp op,
- PatternRewriter &rewriter) const override {
- // Commutative ops (such as xor) have the constant appear second, which
- // we assume here.
-
- APInt constValue;
- if (!matchPattern(op.getOperand(1), m_ConstantInt(&constValue)))
- return failure();
-
- if (constValue != 1)
- return failure();
-
- auto prev = op.getOperand(0).getDefiningOp<CmpIOp>();
- if (!prev)
- return failure();
-
- switch (prev.predicate()) {
- case CmpIPredicate::eq:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::ne, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::ne:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::eq, prev.lhs(),
- prev.rhs());
- return success();
-
- case CmpIPredicate::slt:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::sge, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::sle:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::sgt, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::sgt:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::sle, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::sge:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::slt, prev.lhs(),
- prev.rhs());
- return success();
-
- case CmpIPredicate::ult:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::uge, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::ule:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::ugt, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::ugt:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::ule, prev.lhs(),
- prev.rhs());
- return success();
- case CmpIPredicate::uge:
- rewriter.replaceOpWithNewOp<CmpIOp>(op, CmpIPredicate::ult, prev.lhs(),
- prev.rhs());
- return success();
- }
- return failure();
- }
-};
-} // namespace
-
-void XOrOp::getCanonicalizationPatterns(OwningRewritePatternList &results,
- MLIRContext *context) {
- results.insert<NotICmp>(context);
-}
-
-//===----------------------------------------------------------------------===//
-// ZeroExtendIOp
-//===----------------------------------------------------------------------===//
-
-static LogicalResult verify(ZeroExtendIOp op) {
- auto srcType = getElementTypeOrSelf(op.getOperand().getType());
- auto dstType = getElementTypeOrSelf(op.getType());
-
- if (srcType.isa<IndexType>())
- return op.emitError() << srcType << " is not a valid operand type";
- if (dstType.isa<IndexType>())
- return op.emitError() << dstType << " is not a valid result type";
-
- if (srcType.cast<IntegerType>().getWidth() >=
- dstType.cast<IntegerType>().getWidth())
- return op.emitError("result type ")
- << dstType << " must be wider than operand type " << srcType;
-
- return success();
-}
-
-//===----------------------------------------------------------------------===//
// TableGen'd op method definitions
//===----------------------------------------------------------------------===//
using namespace mlir;
namespace {
-class BufferizeIndexCastOp : public OpConversionPattern<IndexCastOp> {
-public:
- using OpConversionPattern::OpConversionPattern;
- LogicalResult
- matchAndRewrite(IndexCastOp op, OpAdaptor adaptor,
- ConversionPatternRewriter &rewriter) const override {
- auto tensorType = op.getType().cast<RankedTensorType>();
- rewriter.replaceOpWithNewOp<IndexCastOp>(
- op, adaptor.in(),
- MemRefType::get(tensorType.getShape(), tensorType.getElementType()));
- return success();
- }
-};
-
class BufferizeSelectOp : public OpConversionPattern<SelectOp> {
public:
using OpConversionPattern::OpConversionPattern;
void mlir::populateStdBufferizePatterns(BufferizeTypeConverter &typeConverter,
RewritePatternSet &patterns) {
- patterns.add<BufferizeSelectOp, BufferizeIndexCastOp>(typeConverter,
- patterns.getContext());
+ patterns.add<BufferizeSelectOp>(typeConverter, patterns.getContext());
}
namespace {
// We only bufferize the case of tensor selected type and scalar condition,
// as that boils down to a select over memref descriptors (don't need to
// touch the data).
- target.addDynamicallyLegalOp<IndexCastOp>(
- [&](IndexCastOp op) { return typeConverter.isLegal(op.getType()); });
target.addDynamicallyLegalOp<SelectOp>([&](SelectOp op) {
return typeConverter.isLegal(op.getType()) ||
!op.condition().getType().isa<IntegerType>();
MLIRStandardTransformsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmeticTransforms
MLIRIR
MLIRMemRef
MLIRPass
//===----------------------------------------------------------------------===//
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
+#include "mlir/Dialect/Arithmetic/Transforms/Passes.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/StandardOps/Transforms/Passes.h"
#include "mlir/IR/PatternMatch.h"
+#include "mlir/IR/TypeUtilities.h"
using namespace mlir;
///
/// %x = std.generic_atomic_rmw %F[%i] : memref<10xf32> {
/// ^bb0(%current: f32):
-/// %cmp = cmpf "ogt", %current, %fval : f32
+/// %cmp = arith.cmpf "ogt", %current, %fval : f32
/// %new_value = select %cmp, %current, %fval : f32
/// atomic_yield %new_value : f32
/// }
LogicalResult matchAndRewrite(AtomicRMWOp op,
PatternRewriter &rewriter) const final {
- CmpFPredicate predicate;
+ arith::CmpFPredicate predicate;
switch (op.kind()) {
case AtomicRMWKind::maxf:
- predicate = CmpFPredicate::OGT;
+ predicate = arith::CmpFPredicate::OGT;
break;
case AtomicRMWKind::minf:
- predicate = CmpFPredicate::OLT;
+ predicate = arith::CmpFPredicate::OLT;
break;
default:
return failure();
Value lhs = genericOp.getCurrentValue();
Value rhs = op.value();
- Value cmp = bodyBuilder.create<CmpFOp>(loc, predicate, lhs, rhs);
+ Value cmp = bodyBuilder.create<arith::CmpFOp>(loc, predicate, lhs, rhs);
Value select = bodyBuilder.create<SelectOp>(loc, cmp, lhs, rhs);
bodyBuilder.create<AtomicYieldOp>(loc, select);
strides.resize(rank);
Location loc = op.getLoc();
- Value stride = rewriter.create<ConstantIndexOp>(loc, 1);
+ Value stride = rewriter.create<arith::ConstantIndexOp>(loc, 1);
for (int i = rank - 1; i >= 0; --i) {
Value size;
// Load dynamic sizes from the shape input, use constants for static dims.
if (op.getType().isDynamicDim(i)) {
- Value index = rewriter.create<ConstantIndexOp>(loc, i);
+ Value index = rewriter.create<arith::ConstantIndexOp>(loc, i);
size = rewriter.create<memref::LoadOp>(loc, op.shape(), index);
if (!size.getType().isa<IndexType>())
- size =
- rewriter.create<IndexCastOp>(loc, size, rewriter.getIndexType());
+ size = rewriter.create<arith::IndexCastOp>(loc, size,
+ rewriter.getIndexType());
sizes[i] = size;
} else {
sizes[i] = rewriter.getIndexAttr(op.getType().getDimSize(i));
- size = rewriter.create<ConstantOp>(loc, sizes[i].get<Attribute>());
+ size =
+ rewriter.create<arith::ConstantOp>(loc, sizes[i].get<Attribute>());
}
strides[i] = stride;
if (i > 0)
- stride = rewriter.create<MulIOp>(loc, stride, size);
+ stride = rewriter.create<arith::MulIOp>(loc, stride, size);
}
rewriter.replaceOpWithNewOp<memref::ReinterpretCastOp>(
op, op.getType(), op.source(), /*offset=*/rewriter.getIndexAttr(0),
}
};
-/// Expands SignedCeilDivIOP (n, m) into
-/// 1) x = (m > 0) ? -1 : 1
-/// 2) (n*m>0) ? ((n+x) / m) + 1 : - (-n / m)
-struct SignedCeilDivIOpConverter : public OpRewritePattern<SignedCeilDivIOp> {
-public:
- using OpRewritePattern::OpRewritePattern;
- LogicalResult matchAndRewrite(SignedCeilDivIOp op,
- PatternRewriter &rewriter) const final {
- Location loc = op.getLoc();
- SignedCeilDivIOp signedCeilDivIOp = cast<SignedCeilDivIOp>(op);
- Type type = signedCeilDivIOp.getType();
- Value a = signedCeilDivIOp.lhs();
- Value b = signedCeilDivIOp.rhs();
- Value plusOne =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, 1));
- Value zero =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, 0));
- Value minusOne =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, -1));
- // Compute x = (b>0) ? -1 : 1.
- Value compare = rewriter.create<CmpIOp>(loc, CmpIPredicate::sgt, b, zero);
- Value x = rewriter.create<SelectOp>(loc, compare, minusOne, plusOne);
- // Compute positive res: 1 + ((x+a)/b).
- Value xPlusA = rewriter.create<AddIOp>(loc, x, a);
- Value xPlusADivB = rewriter.create<SignedDivIOp>(loc, xPlusA, b);
- Value posRes = rewriter.create<AddIOp>(loc, plusOne, xPlusADivB);
- // Compute negative res: - ((-a)/b).
- Value minusA = rewriter.create<SubIOp>(loc, zero, a);
- Value minusADivB = rewriter.create<SignedDivIOp>(loc, minusA, b);
- Value negRes = rewriter.create<SubIOp>(loc, zero, minusADivB);
- // Result is (a*b>0) ? pos result : neg result.
- // Note, we want to avoid using a*b because of possible overflow.
- // The case that matters are a>0, a==0, a<0, b>0 and b<0. We do
- // not particuliarly care if a*b<0 is true or false when b is zero
- // as this will result in an illegal divide. So `a*b<0` can be reformulated
- // as `(a<0 && b<0) || (a>0 && b>0)' or `(a<0 && b<0) || (a>0 && b>=0)'.
- // We pick the first expression here.
- Value aNeg = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, a, zero);
- Value aPos = rewriter.create<CmpIOp>(loc, CmpIPredicate::sgt, a, zero);
- Value bNeg = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, b, zero);
- Value bPos = rewriter.create<CmpIOp>(loc, CmpIPredicate::sgt, b, zero);
- Value firstTerm = rewriter.create<AndOp>(loc, aNeg, bNeg);
- Value secondTerm = rewriter.create<AndOp>(loc, aPos, bPos);
- Value compareRes = rewriter.create<OrOp>(loc, firstTerm, secondTerm);
- Value res = rewriter.create<SelectOp>(loc, compareRes, posRes, negRes);
- // Perform substitution and return success.
- rewriter.replaceOp(op, {res});
- return success();
- }
-};
-
-/// Expands SignedFloorDivIOP (n, m) into
-/// 1) x = (m<0) ? 1 : -1
-/// 2) return (n*m<0) ? - ((-n+x) / m) -1 : n / m
-struct SignedFloorDivIOpConverter : public OpRewritePattern<SignedFloorDivIOp> {
-public:
- using OpRewritePattern::OpRewritePattern;
- LogicalResult matchAndRewrite(SignedFloorDivIOp op,
- PatternRewriter &rewriter) const final {
- Location loc = op.getLoc();
- SignedFloorDivIOp signedFloorDivIOp = cast<SignedFloorDivIOp>(op);
- Type type = signedFloorDivIOp.getType();
- Value a = signedFloorDivIOp.lhs();
- Value b = signedFloorDivIOp.rhs();
- Value plusOne =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, 1));
- Value zero =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, 0));
- Value minusOne =
- rewriter.create<ConstantOp>(loc, rewriter.getIntegerAttr(type, -1));
- // Compute x = (b<0) ? 1 : -1.
- Value compare = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, b, zero);
- Value x = rewriter.create<SelectOp>(loc, compare, plusOne, minusOne);
- // Compute negative res: -1 - ((x-a)/b).
- Value xMinusA = rewriter.create<SubIOp>(loc, x, a);
- Value xMinusADivB = rewriter.create<SignedDivIOp>(loc, xMinusA, b);
- Value negRes = rewriter.create<SubIOp>(loc, minusOne, xMinusADivB);
- // Compute positive res: a/b.
- Value posRes = rewriter.create<SignedDivIOp>(loc, a, b);
- // Result is (a*b<0) ? negative result : positive result.
- // Note, we want to avoid using a*b because of possible overflow.
- // The case that matters are a>0, a==0, a<0, b>0 and b<0. We do
- // not particuliarly care if a*b<0 is true or false when b is zero
- // as this will result in an illegal divide. So `a*b<0` can be reformulated
- // as `(a>0 && b<0) || (a>0 && b<0)' or `(a>0 && b<0) || (a>0 && b<=0)'.
- // We pick the first expression here.
- Value aNeg = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, a, zero);
- Value aPos = rewriter.create<CmpIOp>(loc, CmpIPredicate::sgt, a, zero);
- Value bNeg = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, b, zero);
- Value bPos = rewriter.create<CmpIOp>(loc, CmpIPredicate::sgt, b, zero);
- Value firstTerm = rewriter.create<AndOp>(loc, aNeg, bPos);
- Value secondTerm = rewriter.create<AndOp>(loc, aPos, bNeg);
- Value compareRes = rewriter.create<OrOp>(loc, firstTerm, secondTerm);
- Value res = rewriter.create<SelectOp>(loc, compareRes, negRes, posRes);
- // Perform substitution and return success.
- rewriter.replaceOp(op, {res});
- return success();
- }
-};
-
-static Type getElementTypeOrSelf(Type type) {
- if (auto st = type.dyn_cast<ShapedType>())
- return st.getElementType();
- return type;
-}
-
-template <typename OpTy, CmpFPredicate pred>
+template <typename OpTy, arith::CmpFPredicate pred>
struct MaxMinFOpConverter : public OpRewritePattern<OpTy> {
public:
using OpRewritePattern<OpTy>::OpRewritePattern;
Value rhs = op.rhs();
Location loc = op.getLoc();
- Value cmp = rewriter.create<CmpFOp>(loc, pred, lhs, rhs);
+ Value cmp = rewriter.create<arith::CmpFOp>(loc, pred, lhs, rhs);
Value select = rewriter.create<SelectOp>(loc, cmp, lhs, rhs);
auto floatType = getElementTypeOrSelf(lhs.getType()).cast<FloatType>();
- Value isNaN = rewriter.create<CmpFOp>(loc, CmpFPredicate::UNO, lhs, rhs);
+ Value isNaN = rewriter.create<arith::CmpFOp>(loc, arith::CmpFPredicate::UNO,
+ lhs, rhs);
- Value nan = rewriter.create<ConstantFloatOp>(
+ Value nan = rewriter.create<arith::ConstantFloatOp>(
loc, APFloat::getQNaN(floatType.getFloatSemantics()), floatType);
if (VectorType vectorType = lhs.getType().dyn_cast<VectorType>())
nan = rewriter.create<SplatOp>(loc, vectorType, nan);
}
};
-template <typename OpTy, CmpIPredicate pred>
+template <typename OpTy, arith::CmpIPredicate pred>
struct MaxMinIOpConverter : public OpRewritePattern<OpTy> {
public:
using OpRewritePattern<OpTy>::OpRewritePattern;
Value rhs = op.rhs();
Location loc = op.getLoc();
- Value cmp = rewriter.create<CmpIOp>(loc, pred, lhs, rhs);
+ Value cmp = rewriter.create<arith::CmpIOp>(loc, pred, lhs, rhs);
rewriter.replaceOpWithNewOp<SelectOp>(op, cmp, lhs, rhs);
return success();
}
RewritePatternSet patterns(&ctx);
populateStdExpandOpsPatterns(patterns);
+ arith::populateArithmeticExpandOpsPatterns(patterns);
ConversionTarget target(getContext());
- target.addLegalDialect<memref::MemRefDialect, StandardOpsDialect>();
+ target.addLegalDialect<arith::ArithmeticDialect, memref::MemRefDialect,
+ StandardOpsDialect>();
+ target.addIllegalOp<arith::CeilDivSIOp, arith::FloorDivSIOp>();
target.addDynamicallyLegalOp<AtomicRMWOp>([](AtomicRMWOp op) {
return op.kind() != AtomicRMWKind::maxf &&
op.kind() != AtomicRMWKind::minf;
MaxUIOp,
MinFOp,
MinSIOp,
- MinUIOp,
- SignedCeilDivIOp,
- SignedFloorDivIOp
+ MinUIOp
>();
// clang-format on
if (failed(
// clang-format off
patterns.add<
AtomicRMWOpConverter,
- MaxMinFOpConverter<MaxFOp, CmpFPredicate::OGT>,
- MaxMinFOpConverter<MinFOp, CmpFPredicate::OLT>,
- MaxMinIOpConverter<MaxSIOp, CmpIPredicate::sgt>,
- MaxMinIOpConverter<MaxUIOp, CmpIPredicate::ugt>,
- MaxMinIOpConverter<MinSIOp, CmpIPredicate::slt>,
- MaxMinIOpConverter<MinUIOp, CmpIPredicate::ult>,
- MemRefReshapeOpConverter,
- SignedCeilDivIOpConverter,
- SignedFloorDivIOpConverter
+ MaxMinFOpConverter<MaxFOp, arith::CmpFPredicate::OGT>,
+ MaxMinFOpConverter<MinFOp, arith::CmpFPredicate::OLT>,
+ MaxMinIOpConverter<MaxSIOp, arith::CmpIPredicate::sgt>,
+ MaxMinIOpConverter<MaxUIOp, arith::CmpIPredicate::ugt>,
+ MaxMinIOpConverter<MinSIOp, arith::CmpIPredicate::slt>,
+ MaxMinIOpConverter<MinUIOp, arith::CmpIPredicate::ult>,
+ MemRefReshapeOpConverter
>(patterns.getContext());
// clang-format on
}
//
//===----------------------------------------------------------------------===//
//
-// This file implements bufferization of tensor-valued std.constant ops.
+// This file implements bufferization of tensor-valued arith.constant ops.
//
//===----------------------------------------------------------------------===//
using namespace mlir;
-memref::GlobalOp GlobalCreator::getGlobalFor(ConstantOp constantOp) {
+memref::GlobalOp GlobalCreator::getGlobalFor(arith::ConstantOp constantOp) {
auto type = constantOp.getType().cast<RankedTensorType>();
BufferizeTypeConverter typeConverter;
// If we already have a global for this constant value, no need to do
// anything else.
- auto it = globals.find(constantOp.getValue());
+ auto it = globals.find(constantOp.value());
if (it != globals.end())
return cast<memref::GlobalOp>(it->second);
constantOp.getLoc(), (Twine("__constant_") + os.str()).str(),
/*sym_visibility=*/globalBuilder.getStringAttr("private"),
/*type=*/typeConverter.convertType(type).cast<MemRefType>(),
- /*initial_value=*/constantOp.getValue().cast<ElementsAttr>(),
+ /*initial_value=*/constantOp.value().cast<ElementsAttr>(),
/*constant=*/true,
/*alignment=*/memrefAlignment);
symbolTable.insert(global);
// The symbol table inserts at the end of the module, but globals are a bit
// nicer if they are at the beginning.
global->moveBefore(&moduleOp.front());
- globals[constantOp.getValue()] = global;
+ globals[constantOp.value()] = global;
return global;
}
namespace {
-class BufferizeTensorConstantOp : public OpConversionPattern<ConstantOp> {
+class BufferizeTensorConstantOp
+ : public OpConversionPattern<arith::ConstantOp> {
public:
BufferizeTensorConstantOp(GlobalCreator &globals,
TypeConverter &typeConverter, MLIRContext *context)
- : OpConversionPattern<ConstantOp>(typeConverter, context, /*benefit=*/1),
+ : OpConversionPattern<arith::ConstantOp>(typeConverter, context,
+ /*benefit=*/1),
globals(globals) {}
LogicalResult
- matchAndRewrite(ConstantOp op, OpAdaptor adaptor,
+ matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
auto type = op.getType().dyn_cast<RankedTensorType>();
if (!type)
target.addLegalDialect<memref::MemRefDialect>();
populateTensorConstantBufferizePatterns(globals, typeConverter, patterns);
- target.addDynamicallyLegalOp<ConstantOp>(
- [&](ConstantOp op) { return typeConverter.isLegal(op.getType()); });
+ target.addDynamicallyLegalOp<arith::ConstantOp>([&](arith::ConstantOp op) {
+ return typeConverter.isLegal(op.getType());
+ });
if (failed(applyPartialConversion(module, target, std::move(patterns))))
signalPassFailure();
}
#include "mlir/Dialect/StandardOps/Utils/Utils.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
using namespace mlir;
/// Matches a ConstantIndexOp.
/// TODO: This should probably just be a general matcher that uses matchConstant
/// and checks the operation for an index type.
-detail::op_matcher<ConstantIndexOp> mlir::matchConstantIndex() {
- return detail::op_matcher<ConstantIndexOp>();
+detail::op_matcher<arith::ConstantIndexOp> mlir::matchConstantIndex() {
+ return detail::op_matcher<arith::ConstantIndexOp>();
}
/// Detects the `values` produced by a ConstantIndexOp and places the new
if (ofr.is<Attribute>())
continue;
// Newly static, move from Value to constant.
- if (auto cstOp = ofr.dyn_cast<Value>().getDefiningOp<ConstantIndexOp>())
- ofr = OpBuilder(cstOp).getIndexAttr(cstOp.getValue());
+ if (auto cstOp =
+ ofr.dyn_cast<Value>().getDefiningOp<arith::ConstantIndexOp>())
+ ofr = OpBuilder(cstOp).getIndexAttr(cstOp.value());
}
}
return value;
auto attr = ofr.dyn_cast<Attribute>().dyn_cast<IntegerAttr>();
assert(attr && "expect the op fold result casts to an integer attribute");
- return b.create<ConstantIndexOp>(loc, attr.getValue().getSExtValue());
+ return b.create<arith::ConstantIndexOp>(loc, attr.getValue().getSExtValue());
}
SmallVector<Value>
}
Value ArithBuilder::_and(Value lhs, Value rhs) {
- return b.create<AndOp>(loc, lhs, rhs);
+ return b.create<arith::AndIOp>(loc, lhs, rhs);
}
Value ArithBuilder::add(Value lhs, Value rhs) {
if (lhs.getType().isa<IntegerType>())
- return b.create<AddIOp>(loc, lhs, rhs);
- return b.create<AddFOp>(loc, lhs, rhs);
+ return b.create<arith::AddIOp>(loc, lhs, rhs);
+ return b.create<arith::AddFOp>(loc, lhs, rhs);
}
Value ArithBuilder::mul(Value lhs, Value rhs) {
if (lhs.getType().isa<IntegerType>())
- return b.create<MulIOp>(loc, lhs, rhs);
- return b.create<MulFOp>(loc, lhs, rhs);
+ return b.create<arith::MulIOp>(loc, lhs, rhs);
+ return b.create<arith::MulFOp>(loc, lhs, rhs);
}
Value ArithBuilder::sgt(Value lhs, Value rhs) {
if (lhs.getType().isa<IndexType, IntegerType>())
- return b.create<CmpIOp>(loc, CmpIPredicate::sgt, lhs, rhs);
- return b.create<CmpFOp>(loc, CmpFPredicate::OGT, lhs, rhs);
+ return b.create<arith::CmpIOp>(loc, arith::CmpIPredicate::sgt, lhs, rhs);
+ return b.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OGT, lhs, rhs);
}
Value ArithBuilder::slt(Value lhs, Value rhs) {
if (lhs.getType().isa<IndexType, IntegerType>())
- return b.create<CmpIOp>(loc, CmpIPredicate::slt, lhs, rhs);
- return b.create<CmpFOp>(loc, CmpFPredicate::OLT, lhs, rhs);
+ return b.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, lhs, rhs);
+ return b.create<arith::CmpFOp>(loc, arith::CmpFPredicate::OLT, lhs, rhs);
}
Value ArithBuilder::select(Value cmp, Value lhs, Value rhs) {
return b.create<SelectOp>(loc, cmp, lhs, rhs);
Core
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRCastInterfaces
MLIRDialectUtils
MLIRIR
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/Utils/Utils.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
#include "mlir/Dialect/Utils/StaticValueUtils.h"
Operation *TensorDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
- return builder.create<mlir::ConstantOp>(loc, type, value);
+ if (arith::ConstantOp::isBuildableWith(value, type))
+ return builder.create<arith::ConstantOp>(loc, value, type);
+ if (ConstantOp::isBuildableWith(value, type))
+ return builder.create<ConstantOp>(loc, value, type);
+ return nullptr;
}
//===----------------------------------------------------------------------===//
void DimOp::build(OpBuilder &builder, OperationState &result, Value source,
int64_t index) {
auto loc = result.location;
- Value indexValue = builder.create<ConstantIndexOp>(loc, index);
+ Value indexValue = builder.create<arith::ConstantIndexOp>(loc, index);
build(builder, result, source, indexValue);
}
Optional<int64_t> DimOp::getConstantIndex() {
- if (auto constantOp = index().getDefiningOp<ConstantOp>())
- return constantOp.getValue().cast<IntegerAttr>().getInt();
+ if (auto constantOp = index().getDefiningOp<arith::ConstantOp>())
+ return constantOp.value().cast<IntegerAttr>().getInt();
return {};
}
if (droppedDims.count(size.index()))
continue;
if (auto attr = size.value().dyn_cast<Attribute>()) {
- reifiedReturnShapes[0].push_back(builder.create<ConstantIndexOp>(
+ reifiedReturnShapes[0].push_back(builder.create<arith::ConstantIndexOp>(
loc, attr.cast<IntegerAttr>().getInt()));
continue;
}
#include "mlir/Transforms/Bufferize.h"
#include "PassDetail.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
Value result = rewriter.create<memref::AllocOp>(op.getLoc(), resultType);
for (auto element : llvm::enumerate(op.elements())) {
Value index =
- rewriter.create<ConstantIndexOp>(op.getLoc(), element.index());
+ rewriter.create<arith::ConstantIndexOp>(op.getLoc(), element.index());
rewriter.create<memref::StoreOp>(op.getLoc(), element.value(), result,
index);
}
// Collect loop bounds.
int64_t rank = tensorType.getRank();
- Value zero = rewriter.create<ConstantIndexOp>(loc, 0);
- Value one = rewriter.create<ConstantIndexOp>(loc, 1);
+ Value zero = rewriter.create<arith::ConstantIndexOp>(loc, 0);
+ Value one = rewriter.create<arith::ConstantIndexOp>(loc, 1);
SmallVector<Value, 4> lowerBounds(rank, zero);
SmallVector<Value, 4> steps(rank, one);
SmallVector<Value, 4> upperBounds;
int nextDynamicIndex = 0;
for (int i = 0; i < rank; i++) {
- Value upperBound =
- tensorType.isDynamicDim(i)
- ? adaptor.dynamicExtents()[nextDynamicIndex++]
- : rewriter.create<ConstantIndexOp>(loc, memrefType.getDimSize(i));
+ Value upperBound = tensorType.isDynamicDim(i)
+ ? adaptor.dynamicExtents()[nextDynamicIndex++]
+ : rewriter.create<arith::ConstantIndexOp>(
+ loc, memrefType.getDimSize(i));
upperBounds.push_back(upperBound);
}
target.addIllegalOp<tensor::CastOp, tensor::ExtractOp,
tensor::FromElementsOp, tensor::GenerateOp>();
target.addLegalDialect<memref::MemRefDialect>();
- target.addDynamicallyLegalDialect<StandardOpsDialect>(
+ target.addDynamicallyLegalDialect<arith::ArithmeticDialect,
+ StandardOpsDialect>(
[&](Operation *op) { return typeConverter.isLegal(op); });
target.addLegalOp<CallOp>();
target.addLegalOp<ReturnOp>();
MLIRTensorTransformsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRIR
MLIRMemRef
MLIRPass
MLIRVectorOpsEnumsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRDialectUtils
MLIRIR
MLIRStandard
switch (multiReductionOp.kind()) {
case vector::CombiningKind::ADD:
if (elementType.isIntOrIndex())
- result = rewriter.create<AddIOp>(loc, operand, result);
+ result = rewriter.create<arith::AddIOp>(loc, operand, result);
else
- result = rewriter.create<AddFOp>(loc, operand, result);
+ result = rewriter.create<arith::AddFOp>(loc, operand, result);
break;
case vector::CombiningKind::MUL:
if (elementType.isIntOrIndex())
- result = rewriter.create<MulIOp>(loc, operand, result);
+ result = rewriter.create<arith::MulIOp>(loc, operand, result);
else
- result = rewriter.create<MulFOp>(loc, operand, result);
+ result = rewriter.create<arith::MulFOp>(loc, operand, result);
break;
case vector::CombiningKind::MINUI:
result = rewriter.create<MinUIOp>(loc, operand, result);
result = rewriter.create<MaxFOp>(loc, operand, result);
break;
case vector::CombiningKind::AND:
- result = rewriter.create<AndOp>(loc, operand, result);
+ result = rewriter.create<arith::AndIOp>(loc, operand, result);
break;
case vector::CombiningKind::OR:
- result = rewriter.create<OrOp>(loc, operand, result);
+ result = rewriter.create<arith::OrIOp>(loc, operand, result);
break;
case vector::CombiningKind::XOR:
- result = rewriter.create<XOrOp>(loc, operand, result);
+ result = rewriter.create<arith::XOrIOp>(loc, operand, result);
break;
}
}
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/Vector/VectorOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/StandardOps/Utils/Utils.h"
/// and a constant mask operation (since the client may be called at
/// various stages during progressive lowering).
static MaskFormat get1DMaskFormat(Value mask) {
- if (auto c = mask.getDefiningOp<ConstantOp>()) {
+ if (auto c = mask.getDefiningOp<arith::ConstantOp>()) {
// Inspect constant dense values. We count up for bits that
// are set, count down for bits that are cleared, and bail
// when a mix is detected.
Operation *VectorDialect::materializeConstant(OpBuilder &builder,
Attribute value, Type type,
Location loc) {
- return builder.create<ConstantOp>(loc, type, value);
+ return builder.create<arith::ConstantOp>(loc, type, value);
}
IntegerType vector::getVectorSubscriptType(Builder &builder) {
maybeContraction.getDefiningOp());
if (!contractionOp)
return vector::ContractionOp();
- if (auto maybeZero = dyn_cast_or_null<ConstantOp>(
+ if (auto maybeZero = dyn_cast_or_null<arith::ConstantOp>(
contractionOp.acc().getDefiningOp())) {
if (maybeZero.value() ==
rewriter.getZeroAttr(contractionOp.acc().getType())) {
void ContractionOp::getCanonicalizationPatterns(RewritePatternSet &results,
MLIRContext *context) {
- results.add<CanonicalizeContractAdd<AddIOp>, CanonicalizeContractAdd<AddFOp>>(
- context);
+ results.add<CanonicalizeContractAdd<arith::AddIOp>,
+ CanonicalizeContractAdd<arith::AddFOp>>(context);
}
//===----------------------------------------------------------------------===//
void vector::ExtractElementOp::build(OpBuilder &builder, OperationState &result,
Value source, int64_t position) {
- Value pos = builder.create<ConstantIntOp>(result.location, position, 32);
+ Value pos =
+ builder.create<arith::ConstantIntOp>(result.location, position, 32);
build(builder, result, source, pos);
}
Value source, ValueRange position) {
SmallVector<int64_t, 4> positionConstants =
llvm::to_vector<4>(llvm::map_range(position, [](Value pos) {
- return pos.getDefiningOp<ConstantIndexOp>().getValue();
+ return pos.getDefiningOp<arith::ConstantIndexOp>().value();
}));
build(builder, result, source, positionConstants);
}
void InsertElementOp::build(OpBuilder &builder, OperationState &result,
Value source, Value dest, int64_t position) {
- Value pos = builder.create<ConstantIntOp>(result.location, position, 32);
+ Value pos =
+ builder.create<arith::ConstantIntOp>(result.location, position, 32);
build(builder, result, source, dest, pos);
}
Value dest, ValueRange position) {
SmallVector<int64_t, 4> positionConstants =
llvm::to_vector<4>(llvm::map_range(position, [](Value pos) {
- return pos.getDefiningOp<ConstantIndexOp>().getValue();
+ return pos.getDefiningOp<arith::ConstantIndexOp>().value();
}));
build(builder, result, source, dest, positionConstants);
}
// If all shape operands are produced by constant ops, verify that product
// of dimensions for input/output shape match.
auto isDefByConstant = [](Value operand) {
- return isa_and_nonnull<ConstantIndexOp>(operand.getDefiningOp());
+ return isa_and_nonnull<arith::ConstantIndexOp>(operand.getDefiningOp());
};
if (llvm::all_of(op.input_shape(), isDefByConstant) &&
llvm::all_of(op.output_shape(), isDefByConstant)) {
int64_t numInputElements = 1;
for (auto operand : op.input_shape())
numInputElements *=
- cast<ConstantIndexOp>(operand.getDefiningOp()).getValue();
+ cast<arith::ConstantIndexOp>(operand.getDefiningOp()).value();
int64_t numOutputElements = 1;
for (auto operand : op.output_shape())
numOutputElements *=
- cast<ConstantIndexOp>(operand.getDefiningOp()).getValue();
+ cast<arith::ConstantIndexOp>(operand.getDefiningOp()).value();
if (numInputElements != numOutputElements)
return op.emitError("product of input and output shape sizes must match");
}
// Return if 'extractStridedSliceOp' operand is not defined by a
// ConstantOp.
auto constantOp =
- extractStridedSliceOp.vector().getDefiningOp<ConstantOp>();
+ extractStridedSliceOp.vector().getDefiningOp<arith::ConstantOp>();
if (!constantOp)
return failure();
auto dense = constantOp.value().dyn_cast<SplatElementsAttr>();
return failure();
auto newAttr = DenseElementsAttr::get(extractStridedSliceOp.getType(),
dense.getSplatValue());
- rewriter.replaceOpWithNewOp<ConstantOp>(extractStridedSliceOp, newAttr);
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(extractStridedSliceOp,
+ newAttr);
return success();
}
};
ValueRange indices, AffineMap permutationMap,
ArrayRef<bool> inBounds) {
Type elemType = source.getType().cast<ShapedType>().getElementType();
- Value padding = builder.create<ConstantOp>(result.location, elemType,
- builder.getZeroAttr(elemType));
+ Value padding = builder.create<arith::ConstantOp>(
+ result.location, elemType, builder.getZeroAttr(elemType));
if (inBounds.empty())
return build(builder, result, vectorType, source, indices, permutationMap,
padding, ArrayAttr());
if (op.getShapedType().isDynamicDim(indicesIdx))
return false;
Value index = op.indices()[indicesIdx];
- auto cstOp = index.getDefiningOp<ConstantIndexOp>();
+ auto cstOp = index.getDefiningOp<arith::ConstantIndexOp>();
if (!cstOp)
return false;
int64_t sourceSize = op.getShapedType().getDimSize(indicesIdx);
int64_t vectorSize = op.getVectorType().getDimSize(resultIdx);
- return cstOp.getValue() + vectorSize <= sourceSize;
+ return cstOp.value() + vectorSize <= sourceSize;
}
template <typename TransferOp>
/// ```
/// is rewritten to:
/// ```
-/// %p0 = addi %a, %e : index
-/// %p1 = addi %b, %f : index
+/// %p0 = arith.addi %a, %e : index
+/// %p1 = arith.addi %b, %f : index
/// %1 = vector.transfer_read %t[%p0, %p1], %cst {in_bounds = [true, true]}
/// : tensor<?x?xf32>, vector<4x5xf32>
/// ```
for (auto it : llvm::enumerate(xferOp.indices())) {
OpFoldResult offset =
extractOp.getMixedOffsets()[it.index() + rankReduced];
- newIndices.push_back(
- rewriter.create<AddIOp>(xferOp->getLoc(), it.value(),
- getValueOrCreateConstantIndexOp(
- rewriter, extractOp.getLoc(), offset)));
+ newIndices.push_back(rewriter.create<arith::AddIOp>(
+ xferOp->getLoc(), it.value(),
+ getValueOrCreateConstantIndexOp(rewriter, extractOp.getLoc(),
+ offset)));
}
SmallVector<bool> inBounds(xferOp.getTransferRank(), true);
rewriter.replaceOpWithNewOp<TransferReadOp>(xferOp, xferOp.getVectorType(),
return failure();
// If any index is nonzero.
auto isNotConstantZero = [](Value v) {
- auto cstOp = v.getDefiningOp<ConstantIndexOp>();
- return !cstOp || cstOp.getValue() != 0;
+ auto cstOp = v.getDefiningOp<arith::ConstantIndexOp>();
+ return !cstOp || cstOp.value() != 0;
};
if (llvm::any_of(read.indices(), isNotConstantZero) ||
llvm::any_of(write.indices(), isNotConstantZero))
LogicalResult matchAndRewrite(ShapeCastOp shapeCastOp,
PatternRewriter &rewriter) const override {
- auto constantOp = shapeCastOp.source().getDefiningOp<ConstantOp>();
+ auto constantOp = shapeCastOp.source().getDefiningOp<arith::ConstantOp>();
if (!constantOp)
return failure();
// Only handle splat for now.
return failure();
auto newAttr = DenseElementsAttr::get(
shapeCastOp.getType().cast<VectorType>(), dense.getSplatValue());
- rewriter.replaceOpWithNewOp<ConstantOp>(shapeCastOp, newAttr);
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(shapeCastOp, newAttr);
return success();
}
};
PatternRewriter &rewriter) const override {
// Return if any of 'createMaskOp' operands are not defined by a constant.
auto is_not_def_by_constant = [](Value operand) {
- return !isa_and_nonnull<ConstantIndexOp>(operand.getDefiningOp());
+ return !isa_and_nonnull<arith::ConstantIndexOp>(operand.getDefiningOp());
};
if (llvm::any_of(createMaskOp.operands(), is_not_def_by_constant))
return failure();
SmallVector<int64_t, 4> maskDimSizes;
for (auto operand : createMaskOp.operands()) {
auto defOp = operand.getDefiningOp();
- maskDimSizes.push_back(cast<ConstantIndexOp>(defOp).getValue());
+ maskDimSizes.push_back(cast<arith::ConstantIndexOp>(defOp).value());
}
// Replace 'createMaskOp' with ConstantMaskOp.
rewriter.replaceOpWithNewOp<ConstantMaskOp>(
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/Utils.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
// Unroll leading dimensions.
VectorType vType = lowType.cast<VectorType>();
VectorType resType = adjustType(type, index).cast<VectorType>();
- Value result =
- rewriter.create<ConstantOp>(loc, resType, rewriter.getZeroAttr(resType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, resType, rewriter.getZeroAttr(resType));
for (int64_t d = 0, e = resType.getDimSize(0); d < e; d++) {
auto posAttr = rewriter.getI64ArrayAttr(d);
Value ext = rewriter.create<vector::ExtractOp>(loc, vType, val, posAttr);
// Compute shape ratio of 'shape' and 'sizes'.
int64_t sliceCount = computeMaxLinearIndex(ratio);
// Prepare the result vector;
- Value result = rewriter.create<ConstantOp>(
+ Value result = rewriter.create<arith::ConstantOp>(
loc, sourceVectorType, rewriter.getZeroAttr(sourceVectorType));
auto targetType =
VectorType::get(*targetShape, sourceVectorType.getElementType());
accCache[dstOffets] = newOp->getResult(0);
}
// Assemble back the accumulator into a single vector.
- Value result = rewriter.create<ConstantOp>(
+ Value result = rewriter.create<arith::ConstantOp>(
loc, dstVecType, rewriter.getZeroAttr(dstVecType));
for (const auto &it : accCache) {
SmallVector<int64_t> dstStrides(it.first.size(), 1);
int64_t sliceCount = computeMaxLinearIndex(ratio);
Location loc = op->getLoc();
// Prepare the result vector.
- Value result = rewriter.create<ConstantOp>(
+ Value result = rewriter.create<arith::ConstantOp>(
loc, dstVecType, rewriter.getZeroAttr(dstVecType));
SmallVector<int64_t, 4> strides(targetShape->size(), 1);
VectorType newVecType =
VectorType::get(dstType.getShape().drop_front(), eltType);
Value bcst =
rewriter.create<vector::BroadcastOp>(loc, resType, op.source());
- Value result = rewriter.create<ConstantOp>(loc, dstType,
- rewriter.getZeroAttr(dstType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, dstType, rewriter.getZeroAttr(dstType));
for (int64_t d = 0, dim = dstType.getDimSize(0); d < dim; ++d)
result = rewriter.create<vector::InsertOp>(loc, bcst, result, d);
rewriter.replaceOp(op, result);
// %x = [%a,%b,%c,%d]
VectorType resType =
VectorType::get(dstType.getShape().drop_front(), eltType);
- Value result = rewriter.create<ConstantOp>(loc, dstType,
- rewriter.getZeroAttr(dstType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, dstType, rewriter.getZeroAttr(dstType));
if (m == 0) {
// Stetch at start.
Value ext = rewriter.create<vector::ExtractOp>(loc, op.source(), 0);
/// One:
/// %x = vector.transpose %y, [1, 0]
/// is replaced by:
-/// %z = constant dense<0.000000e+00>
+/// %z = arith.constant dense<0.000000e+00>
/// %0 = vector.extract %y[0, 0]
/// %1 = vector.insert %0, %z [0, 0]
/// ..
}
// Generate fully unrolled extract/insert ops.
- Value result = rewriter.create<ConstantOp>(loc, resType,
- rewriter.getZeroAttr(resType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, resType, rewriter.getZeroAttr(resType));
SmallVector<int64_t, 4> lhs(transp.size(), 0);
SmallVector<int64_t, 4> rhs(transp.size(), 0);
rewriter.replaceOp(op, expandIndices(loc, resType, 0, transp, lhs, rhs,
return success();
}
- Value result = rewriter.create<ConstantOp>(loc, resType,
- rewriter.getZeroAttr(resType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, resType, rewriter.getZeroAttr(resType));
for (int64_t d = 0, e = resType.getDimSize(0); d < e; ++d) {
auto pos = rewriter.getI64ArrayAttr(d);
Value x = rewriter.create<vector::ExtractOp>(loc, eltType, op.lhs(), pos);
PatternRewriter &rewriter) {
using vector::CombiningKind;
- MulIOp mul = rewriter.create<MulIOp>(loc, x, y);
+ auto mul = rewriter.create<arith::MulIOp>(loc, x, y);
if (!acc)
return Optional<Value>(mul);
Value combinedResult;
switch (kind) {
case CombiningKind::ADD:
- combinedResult = rewriter.create<AddIOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::AddIOp>(loc, mul, acc);
break;
case CombiningKind::MUL:
- combinedResult = rewriter.create<MulIOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::MulIOp>(loc, mul, acc);
break;
case CombiningKind::MINUI:
combinedResult = rewriter.create<MinUIOp>(loc, mul, acc);
combinedResult = rewriter.create<MaxSIOp>(loc, mul, acc);
break;
case CombiningKind::AND:
- combinedResult = rewriter.create<AndOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::AndIOp>(loc, mul, acc);
break;
case CombiningKind::OR:
- combinedResult = rewriter.create<OrOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::OrIOp>(loc, mul, acc);
break;
case CombiningKind::XOR:
- combinedResult = rewriter.create<XOrOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::XOrIOp>(loc, mul, acc);
break;
case CombiningKind::MINF: // Only valid for floating point types.
case CombiningKind::MAXF: // Only valid for floating point types.
return Optional<Value>(rewriter.create<vector::FMAOp>(loc, x, y, acc));
}
- MulFOp mul = rewriter.create<MulFOp>(loc, x, y);
+ auto mul = rewriter.create<arith::MulFOp>(loc, x, y);
if (!acc)
return Optional<Value>(mul);
Value combinedResult;
switch (kind) {
case CombiningKind::MUL:
- combinedResult = rewriter.create<MulFOp>(loc, mul, acc);
+ combinedResult = rewriter.create<arith::MulFOp>(loc, mul, acc);
break;
case CombiningKind::MINF:
combinedResult = rewriter.create<MinFOp>(loc, mul, acc);
SmallVector<bool, 4> values(dstType.getDimSize(0));
for (int64_t d = 0; d < trueDim; d++)
values[d] = true;
- rewriter.replaceOpWithNewOp<ConstantOp>(
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(
op, dstType, rewriter.getBoolVectorAttr(values));
return success();
}
newDimSizes.push_back(dimSizes[r].cast<IntegerAttr>().getInt());
Value trueVal = rewriter.create<vector::ConstantMaskOp>(
loc, lowType, rewriter.getI64ArrayAttr(newDimSizes));
- Value result = rewriter.create<ConstantOp>(loc, dstType,
- rewriter.getZeroAttr(dstType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, dstType, rewriter.getZeroAttr(dstType));
for (int64_t d = 0; d < trueDim; d++) {
auto pos = rewriter.getI64ArrayAttr(d);
result =
/// %x = vector.create_mask %a, ... : vector<dx...>
/// is replaced by:
/// %l = vector.create_mask ... : vector<...> ; one lower rank
-/// %0 = cmpi "slt", %ci, %a |
+/// %0 = arith.cmpi "slt", %ci, %a |
/// %1 = select %0, %l, %zeroes |
/// %r = vector.insert %1, %pr [i] | d-times
/// %x = ....
VectorType::get(dstType.getShape().drop_front(), eltType);
Value trueVal = rewriter.create<vector::CreateMaskOp>(
loc, lowType, op.getOperands().drop_front());
- Value falseVal = rewriter.create<ConstantOp>(loc, lowType,
- rewriter.getZeroAttr(lowType));
- Value result = rewriter.create<ConstantOp>(loc, dstType,
- rewriter.getZeroAttr(dstType));
+ Value falseVal = rewriter.create<arith::ConstantOp>(
+ loc, lowType, rewriter.getZeroAttr(lowType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, dstType, rewriter.getZeroAttr(dstType));
for (int64_t d = 0; d < dim; d++) {
- Value bnd = rewriter.create<ConstantOp>(loc, rewriter.getIndexAttr(d));
- Value val = rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, bnd, idx);
+ Value bnd =
+ rewriter.create<arith::ConstantOp>(loc, rewriter.getIndexAttr(d));
+ Value val = rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt,
+ bnd, idx);
Value sel = rewriter.create<SelectOp>(loc, val, trueVal, falseVal);
auto pos = rewriter.getI64ArrayAttr(d);
result =
return failure();
auto loc = op.getLoc();
- Value desc = rewriter.create<ConstantOp>(
+ Value desc = rewriter.create<arith::ConstantOp>(
loc, resultVectorType, rewriter.getZeroAttr(resultVectorType));
unsigned mostMinorVectorSize = sourceVectorType.getShape()[1];
for (int64_t i = 0, e = sourceVectorType.getShape().front(); i != e; ++i) {
return failure();
auto loc = op.getLoc();
- Value desc = rewriter.create<ConstantOp>(
+ Value desc = rewriter.create<arith::ConstantOp>(
loc, resultVectorType, rewriter.getZeroAttr(resultVectorType));
unsigned mostMinorVectorSize = resultVectorType.getShape()[1];
for (int64_t i = 0, e = resultVectorType.getShape().front(); i != e; ++i) {
// within the source and result shape.
SmallVector<int64_t, 4> srcIdx(srcRank);
SmallVector<int64_t, 4> resIdx(resRank);
- Value result = rewriter.create<ConstantOp>(
+ Value result = rewriter.create<arith::ConstantOp>(
loc, resultVectorType, rewriter.getZeroAttr(resultVectorType));
for (int64_t i = 0; i < numElts; i++) {
if (i != 0) {
} // namespace
-/// Creates an AddIOp if `isInt` is true otherwise create an AddFOp using
+/// Creates an AddIOp if `isInt` is true otherwise create an arith::AddFOp using
/// operands `x` and `y`.
static Value createAdd(Location loc, Value x, Value y, bool isInt,
PatternRewriter &rewriter) {
if (isInt)
- return rewriter.create<AddIOp>(loc, x, y);
- return rewriter.create<AddFOp>(loc, x, y);
+ return rewriter.create<arith::AddIOp>(loc, x, y);
+ return rewriter.create<arith::AddFOp>(loc, x, y);
}
/// Creates a MulIOp if `isInt` is true otherwise create an MulFOp using
static Value createMul(Location loc, Value x, Value y, bool isInt,
PatternRewriter &rewriter) {
if (isInt)
- return rewriter.create<MulIOp>(loc, x, y);
- return rewriter.create<MulFOp>(loc, x, y);
+ return rewriter.create<arith::MulIOp>(loc, x, y);
+ return rewriter.create<arith::MulFOp>(loc, x, y);
}
namespace mlir {
else if (accMap != AffineMap::get(3, 0, {m, n}, ctx))
llvm_unreachable("invalid contraction semantics");
- Value res = elementType.isa<IntegerType>()
- ? static_cast<Value>(rew.create<AddIOp>(loc, op.acc(), mul))
- : static_cast<Value>(rew.create<AddFOp>(loc, op.acc(), mul));
+ Value res =
+ elementType.isa<IntegerType>()
+ ? static_cast<Value>(rew.create<arith::AddIOp>(loc, op.acc(), mul))
+ : static_cast<Value>(rew.create<arith::AddFOp>(loc, op.acc(), mul));
rew.replaceOp(op, res);
return success();
unsigned dstColumns = rank == 1 ? 1 : dstType.getShape()[1];
// ExtractOp does not allow dynamic indexing, we must unroll explicitly.
- Value res =
- rewriter.create<ConstantOp>(loc, dstType, rewriter.getZeroAttr(dstType));
+ Value res = rewriter.create<arith::ConstantOp>(loc, dstType,
+ rewriter.getZeroAttr(dstType));
bool isInt = dstType.getElementType().isa<IntegerType>();
for (unsigned r = 0; r < dstRows; ++r) {
Value a = rewriter.create<vector::ExtractOp>(op.getLoc(), lhs, r);
rewriter.getArrayAttr(adjustIter(op.iterator_types(), iterIndex));
// Unroll into a series of lower dimensional vector.contract ops.
Location loc = op.getLoc();
- Value result =
- rewriter.create<ConstantOp>(loc, resType, rewriter.getZeroAttr(resType));
+ Value result = rewriter.create<arith::ConstantOp>(
+ loc, resType, rewriter.getZeroAttr(resType));
for (int64_t d = 0; d < dimSize; ++d) {
auto lhs = reshapeLoad(loc, op.lhs(), lhsType, lhsIndex, d, rewriter);
auto rhs = reshapeLoad(loc, op.rhs(), rhsType, rhsIndex, d, rewriter);
} // namespace mlir
static Optional<int64_t> extractConstantIndex(Value v) {
- if (auto cstOp = v.getDefiningOp<ConstantIndexOp>())
- return cstOp.getValue();
+ if (auto cstOp = v.getDefiningOp<arith::ConstantIndexOp>())
+ return cstOp.value();
if (auto affineApplyOp = v.getDefiningOp<AffineApplyOp>())
if (affineApplyOp.getAffineMap().isSingleConstant())
return affineApplyOp.getAffineMap().getSingleConstantResult();
auto maybeCstUb = extractConstantIndex(ub);
if (maybeCstV && maybeCstUb && *maybeCstV < *maybeCstUb)
return Value();
- return b.create<CmpIOp>(v.getLoc(), CmpIPredicate::sle, v, ub);
+ return b.create<arith::CmpIOp>(v.getLoc(), arith::CmpIPredicate::sle, v, ub);
}
// Operates under a scoped context to build the condition to ensure that a
return;
// Conjunction over all dims for which we are in-bounds.
if (inBoundsCond)
- inBoundsCond = lb.create<AndOp>(inBoundsCond, cond);
+ inBoundsCond = lb.create<arith::AndIOp>(inBoundsCond, cond);
else
inBoundsCond = cond;
});
TypeRange returnTypes, Value inBoundsCond,
MemRefType compatibleMemRefType, Value alloc) {
Location loc = xferOp.getLoc();
- Value zero = b.create<ConstantIndexOp>(loc, 0);
+ Value zero = b.create<arith::ConstantIndexOp>(loc, 0);
Value memref = xferOp.source();
return b.create<scf::IfOp>(
loc, returnTypes, inBoundsCond,
Value inBoundsCond, MemRefType compatibleMemRefType, Value alloc) {
Location loc = xferOp.getLoc();
scf::IfOp fullPartialIfOp;
- Value zero = b.create<ConstantIndexOp>(loc, 0);
+ Value zero = b.create<arith::ConstantIndexOp>(loc, 0);
Value memref = xferOp.source();
return b.create<scf::IfOp>(
loc, returnTypes, inBoundsCond,
TypeRange returnTypes, Value inBoundsCond,
MemRefType compatibleMemRefType, Value alloc) {
Location loc = xferOp.getLoc();
- Value zero = b.create<ConstantIndexOp>(loc, 0);
+ Value zero = b.create<arith::ConstantIndexOp>(loc, 0);
Value memref = xferOp.source();
return b
.create<scf::IfOp>(
/// 3. it originally wrote to %view
/// Produce IR resembling:
/// ```
-/// %notInBounds = xor %inBounds, %true
+/// %notInBounds = arith.xori %inBounds, %true
/// scf.if (%notInBounds) {
/// %3 = subview %alloc [...][...][...]
/// %4 = subview %view [0, 0][...][...]
vector::TransferWriteOp xferOp,
Value inBoundsCond, Value alloc) {
ImplicitLocOpBuilder lb(xferOp.getLoc(), b);
- auto notInBounds =
- lb.create<XOrOp>(inBoundsCond, lb.create<ConstantIntOp>(true, 1));
+ auto notInBounds = lb.create<arith::XOrIOp>(
+ inBoundsCond, lb.create<arith::ConstantIntOp>(true, 1));
lb.create<scf::IfOp>(notInBounds, [&](OpBuilder &b, Location loc) {
std::pair<Value, Value> copyArgs = createSubViewIntersection(
b, cast<VectorTransferOpInterface>(xferOp.getOperation()), alloc);
/// 3. it originally wrote to %view
/// Produce IR resembling:
/// ```
-/// %notInBounds = xor %inBounds, %true
+/// %notInBounds = arith.xori %inBounds, %true
/// scf.if (%notInBounds) {
/// %2 = load %alloc : memref<vector<...>>
/// vector.transfer_write %2, %view[...] : memref<A...>, vector<...>
Value inBoundsCond,
Value alloc) {
ImplicitLocOpBuilder lb(xferOp.getLoc(), b);
- auto notInBounds =
- lb.create<XOrOp>(inBoundsCond, lb.create<ConstantIntOp>(true, 1));
+ auto notInBounds = lb.create<arith::XOrIOp>(
+ inBoundsCond, lb.create<arith::ConstantIntOp>(true, 1));
lb.create<scf::IfOp>(notInBounds, [&](OpBuilder &b, Location loc) {
BlockAndValueMapping mapping;
Value load = b.create<memref::LoadOp>(
/// Canonicalize an extract_map using the result of a pointwise operation.
/// Transforms:
-/// %v = addf %a, %b : vector32xf32>
+/// %v = arith.addf %a, %b : vector32xf32>
/// %dv = vector.extract_map %v[%id] : vector<32xf32> to vector<1xf32>
/// to:
/// %da = vector.extract_map %a[%id] : vector<32xf32> to vector<1xf32>
/// %db = vector.extract_map %a[%id] : vector<32xf32> to vector<1xf32>
-/// %dv = addf %da, %db : vector<1xf32>
+/// %dv = arith.addf %da, %db : vector<1xf32>
struct PointwiseExtractPattern : public OpRewritePattern<vector::ExtractMapOp> {
using OpRewritePattern<vector::ExtractMapOp>::OpRewritePattern;
LogicalResult matchAndRewrite(vector::ExtractMapOp extract,
Value newRead = lb.create<vector::TransferReadOp>(
extract.getType(), read.source(), indices, read.permutation_map(),
read.padding(), read.in_boundsAttr());
- Value dest = lb.create<ConstantOp>(read.getType(),
- rewriter.getZeroAttr(read.getType()));
+ Value dest = lb.create<arith::ConstantOp>(
+ read.getType(), rewriter.getZeroAttr(read.getType()));
newRead = lb.create<vector::InsertMapOp>(newRead, dest, extract.ids());
rewriter.replaceOp(read, newRead);
return success();
bool targetIsIndex = targetType.isIndex();
bool valueIsIndex = value.getType().isIndex();
if (targetIsIndex ^ valueIsIndex)
- return rewriter.create<IndexCastOp>(loc, targetType, value);
+ return rewriter.create<arith::IndexCastOp>(loc, targetType, value);
auto targetIntegerType = targetType.dyn_cast<IntegerType>();
auto valueIntegerType = value.getType().dyn_cast<IntegerType>();
assert(targetIntegerType.getSignedness() == valueIntegerType.getSignedness());
if (targetIntegerType.getWidth() > valueIntegerType.getWidth())
- return rewriter.create<SignExtendIOp>(loc, targetIntegerType, value);
- return rewriter.create<TruncateIOp>(loc, targetIntegerType, value);
+ return rewriter.create<arith::ExtSIOp>(loc, targetIntegerType, value);
+ return rewriter.create<arith::TruncIOp>(loc, targetIntegerType, value);
}
// Helper that returns a vector comparison that constructs a mask:
Value indices;
Type idxType;
if (enableIndexOptimizations) {
- indices = rewriter.create<ConstantOp>(
+ indices = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI32VectorAttr(
llvm::to_vector<4>(llvm::seq<int32_t>(0, dim))));
idxType = rewriter.getI32Type();
} else {
- indices = rewriter.create<ConstantOp>(
+ indices = rewriter.create<arith::ConstantOp>(
loc, rewriter.getI64VectorAttr(
llvm::to_vector<4>(llvm::seq<int64_t>(0, dim))));
idxType = rewriter.getI64Type();
if (off) {
Value o = createCastToIndexLike(rewriter, loc, idxType, *off);
Value ov = rewriter.create<SplatOp>(loc, indices.getType(), o);
- indices = rewriter.create<AddIOp>(loc, ov, indices);
+ indices = rewriter.create<arith::AddIOp>(loc, ov, indices);
}
// Construct the vector comparison.
Value bound = createCastToIndexLike(rewriter, loc, idxType, b);
Value bounds = rewriter.create<SplatOp>(loc, indices.getType(), bound);
- return rewriter.create<CmpIOp>(loc, CmpIPredicate::slt, indices, bounds);
+ return rewriter.create<arith::CmpIOp>(loc, arith::CmpIPredicate::slt, indices,
+ bounds);
}
template <typename ConcreteOp>
if (xferOp.mask()) {
// Intersect the in-bounds with the mask specified as an op parameter.
- mask = rewriter.create<AndOp>(loc, mask, xferOp.mask());
+ mask = rewriter.create<arith::AndIOp>(loc, mask, xferOp.mask());
}
rewriter.updateRootInPlace(xferOp, [&]() {
#include "mlir/Dialect/Vector/VectorUtils.h"
#include "mlir/Analysis/LoopAnalysis.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
return false;
unsigned rankOffset = transferA.getLeadingShapedRank();
for (unsigned i = 0, e = transferA.indices().size(); i < e; i++) {
- auto indexA = transferA.indices()[i].getDefiningOp<ConstantOp>();
- auto indexB = transferB.indices()[i].getDefiningOp<ConstantOp>();
+ auto indexA = transferA.indices()[i].getDefiningOp<arith::ConstantOp>();
+ auto indexB = transferB.indices()[i].getDefiningOp<arith::ConstantOp>();
// If any of the indices are dynamic we cannot prove anything.
if (!indexA || !indexB)
continue;
if (i < rankOffset) {
// For leading dimensions, if we can prove that index are different we
// know we are accessing disjoint slices.
- if (indexA.getValue().cast<IntegerAttr>().getInt() !=
- indexB.getValue().cast<IntegerAttr>().getInt())
+ if (indexA.value().cast<IntegerAttr>().getInt() !=
+ indexB.value().cast<IntegerAttr>().getInt())
return true;
} else {
// For this dimension, we slice a part of the memref we need to make sure
// the intervals accessed don't overlap.
- int64_t distance =
- std::abs(indexA.getValue().cast<IntegerAttr>().getInt() -
- indexB.getValue().cast<IntegerAttr>().getInt());
+ int64_t distance = std::abs(indexA.value().cast<IntegerAttr>().getInt() -
+ indexB.value().cast<IntegerAttr>().getInt());
if (distance >= transferA.getVectorType().getDimSize(i - rankOffset))
return true;
}
MLIRX86VectorConversionsIncGen
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIRX86Vector
MLIRIR
MLIRLLVMCommonConversion
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
#include "mlir/Conversion/LLVMCommon/Pattern.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/X86Vector/X86VectorDialect.h"
if (op.src()) {
src = adaptor.src();
} else if (op.constant_src()) {
- src = rewriter.create<ConstantOp>(op.getLoc(), opType,
- op.constant_srcAttr());
+ src = rewriter.create<arith::ConstantOp>(op.getLoc(), opType,
+ op.constant_srcAttr());
} else {
Attribute zeroAttr = rewriter.getZeroAttr(opType);
- src = rewriter.create<ConstantOp>(op->getLoc(), opType, zeroAttr);
+ src = rewriter.create<arith::ConstantOp>(op->getLoc(), opType, zeroAttr);
}
rewriter.replaceOpWithNewOp<MaskCompressIntrOp>(op, opType, adaptor.a(),
${EMITC_MAIN_INCLUDE_DIR}/emitc/Target/Cpp
LINK_LIBS PUBLIC
+ MLIRArithmetic
MLIREmitC
MLIRIR
+ MLIRMath
MLIRSCF
MLIRStandard
MLIRSupport
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/EmitC/IR/EmitC.h"
+#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/BuiltinOps.h"
},
[](DialectRegistry ®istry) {
// clang-format off
- registry.insert<emitc::EmitCDialect,
+ registry.insert<arith::ArithmeticDialect,
+ emitc::EmitCDialect,
+ math::MathDialect,
StandardOpsDialect,
scf::SCFDialect>();
// clang-format on
}
static LogicalResult printOperation(CppEmitter &emitter,
+ arith::ConstantOp constantOp) {
+ Operation *operation = constantOp.getOperation();
+ Attribute value = constantOp.value();
+
+ return printConstantOp(emitter, operation, value);
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
mlir::ConstantOp constantOp) {
Operation *operation = constantOp.getOperation();
Attribute value = constantOp.value();
.Case<BranchOp, mlir::CallOp, CondBranchOp, mlir::ConstantOp, FuncOp,
ModuleOp, ReturnOp>(
[&](auto op) { return printOperation(*this, op); })
+ // Arithmetic ops.
+ .Case<arith::ConstantOp>(
+ [&](auto op) { return printOperation(*this, op); })
.Default([&](Operation *) {
return op.emitOpError("unable to find printer for op");
});
#include "PassDetail.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Transforms/LoopUtils.h"
#include "mlir/Transforms/Passes.h"
template <typename ConcreteDialect>
void registerDialect(DialectRegistry ®istry);
+namespace arith {
+class ArithmeticDialect;
+} // end namespace arith
+
namespace memref {
class MemRefDialect;
} // end namespace memref
LINK_LIBS PUBLIC
MLIRAffine
+ MLIRArithmetic
MLIRAnalysis
MLIRLoopAnalysis
MLIRMemRef
#include "mlir/Transforms/FoldUtils.h"
-#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/Matchers.h"
#include "mlir/IR/Operation.h"
return constOp;
}
- // TODO: To facilitate splitting the std dialect (PR48490), have a special
- // case for falling back to std.constant. Eventually, we will have separate
- // ops tensor.constant, int.constant, float.constant, etc. that live in their
- // respective dialects, which will allow each dialect to implement the
- // materializeConstant hook above.
- //
- // The special case is needed because in the interim state while we are
- // splitting out those dialects from std, the std dialect depends on the
- // tensor dialect, which makes it impossible for the tensor dialect to use
- // std.constant (it would be a cyclic dependency) as part of its
- // materializeConstant hook.
- //
- // If the dialect is unable to materialize a constant, check to see if the
- // standard constant can be used.
- if (ConstantOp::isBuildableWith(value, type))
- return builder.create<ConstantOp>(loc, type, value);
return nullptr;
}
#include "mlir/Analysis/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/IR/AffineMap.h"
assert(divisor > 0 && "expected positive divisor");
assert(dividend.getType().isIndex() && "expected index-typed value");
- Value divisorMinusOneCst = builder.create<ConstantIndexOp>(loc, divisor - 1);
- Value divisorCst = builder.create<ConstantIndexOp>(loc, divisor);
- Value sum = builder.create<AddIOp>(loc, dividend, divisorMinusOneCst);
- return builder.create<SignedDivIOp>(loc, sum, divisorCst);
+ Value divisorMinusOneCst =
+ builder.create<arith::ConstantIndexOp>(loc, divisor - 1);
+ Value divisorCst = builder.create<arith::ConstantIndexOp>(loc, divisor);
+ Value sum = builder.create<arith::AddIOp>(loc, dividend, divisorMinusOneCst);
+ return builder.create<arith::DivSIOp>(loc, sum, divisorCst);
}
// Build the IR that performs ceil division of a positive value by another
Value divisor) {
assert(dividend.getType().isIndex() && "expected index-typed value");
- Value cstOne = builder.create<ConstantIndexOp>(loc, 1);
- Value divisorMinusOne = builder.create<SubIOp>(loc, divisor, cstOne);
- Value sum = builder.create<AddIOp>(loc, dividend, divisorMinusOne);
- return builder.create<SignedDivIOp>(loc, sum, divisor);
+ Value cstOne = builder.create<arith::ConstantIndexOp>(loc, 1);
+ Value divisorMinusOne = builder.create<arith::SubIOp>(loc, divisor, cstOne);
+ Value sum = builder.create<arith::AddIOp>(loc, dividend, divisorMinusOne);
+ return builder.create<arith::DivSIOp>(loc, sum, divisor);
}
/// Helper to replace uses of loop carried values (iter_args) and loop
if (!iv.use_empty()) {
if (forOp.hasConstantLowerBound()) {
OpBuilder topBuilder(forOp->getParentOfType<FuncOp>().getBody());
- auto constOp = topBuilder.create<ConstantIndexOp>(
+ auto constOp = topBuilder.create<arith::ConstantIndexOp>(
forOp.getLoc(), forOp.getConstantLowerBound());
iv.replaceAllUsesWith(constOp);
} else {
/// Promotes the loop body of a forOp to its containing block if the forOp
/// it can be determined that the loop has a single iteration.
LogicalResult mlir::promoteIfSingleIteration(scf::ForOp forOp) {
- auto lbCstOp = forOp.lowerBound().getDefiningOp<ConstantIndexOp>();
- auto ubCstOp = forOp.upperBound().getDefiningOp<ConstantIndexOp>();
- auto stepCstOp = forOp.step().getDefiningOp<ConstantIndexOp>();
- if (!lbCstOp || !ubCstOp || !stepCstOp || lbCstOp.getValue() < 0 ||
- ubCstOp.getValue() < 0 || stepCstOp.getValue() < 0)
+ auto lbCstOp = forOp.lowerBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto ubCstOp = forOp.upperBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto stepCstOp = forOp.step().getDefiningOp<arith::ConstantIndexOp>();
+ if (!lbCstOp || !ubCstOp || !stepCstOp || lbCstOp.value() < 0 ||
+ ubCstOp.value() < 0 || stepCstOp.value() < 0)
return failure();
- int64_t tripCount = mlir::ceilDiv(ubCstOp.getValue() - lbCstOp.getValue(),
- stepCstOp.getValue());
+ int64_t tripCount =
+ mlir::ceilDiv(ubCstOp.value() - lbCstOp.value(), stepCstOp.value());
if (tripCount != 1)
return failure();
auto iv = forOp.getInductionVar();
Value stepUnrolled;
bool generateEpilogueLoop = true;
- auto lbCstOp = forOp.lowerBound().getDefiningOp<ConstantIndexOp>();
- auto ubCstOp = forOp.upperBound().getDefiningOp<ConstantIndexOp>();
- auto stepCstOp = forOp.step().getDefiningOp<ConstantIndexOp>();
+ auto lbCstOp = forOp.lowerBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto ubCstOp = forOp.upperBound().getDefiningOp<arith::ConstantIndexOp>();
+ auto stepCstOp = forOp.step().getDefiningOp<arith::ConstantIndexOp>();
if (lbCstOp && ubCstOp && stepCstOp) {
// Constant loop bounds computation.
- int64_t lbCst = lbCstOp.getValue();
- int64_t ubCst = ubCstOp.getValue();
- int64_t stepCst = stepCstOp.getValue();
+ int64_t lbCst = lbCstOp.value();
+ int64_t ubCst = ubCstOp.value();
+ int64_t stepCst = stepCstOp.value();
assert(lbCst >= 0 && ubCst >= 0 && stepCst >= 0 &&
"expected positive loop bounds and step");
int64_t tripCount = mlir::ceilDiv(ubCst - lbCst, stepCst);
// Create constant for 'upperBoundUnrolled' and set epilogue loop flag.
generateEpilogueLoop = upperBoundUnrolledCst < ubCst;
if (generateEpilogueLoop)
- upperBoundUnrolled =
- boundsBuilder.create<ConstantIndexOp>(loc, upperBoundUnrolledCst);
+ upperBoundUnrolled = boundsBuilder.create<arith::ConstantIndexOp>(
+ loc, upperBoundUnrolledCst);
else
upperBoundUnrolled = ubCstOp;
// Create constant for 'stepUnrolled'.
- stepUnrolled =
- stepCst == stepUnrolledCst
- ? step
- : boundsBuilder.create<ConstantIndexOp>(loc, stepUnrolledCst);
+ stepUnrolled = stepCst == stepUnrolledCst
+ ? step
+ : boundsBuilder.create<arith::ConstantIndexOp>(
+ loc, stepUnrolledCst);
} else {
// Dynamic loop bounds computation.
// TODO: Add dynamic asserts for negative lb/ub/step, or
// consider using ceilDiv from AffineApplyExpander.
auto lowerBound = forOp.lowerBound();
auto upperBound = forOp.upperBound();
- Value diff = boundsBuilder.create<SubIOp>(loc, upperBound, lowerBound);
+ Value diff =
+ boundsBuilder.create<arith::SubIOp>(loc, upperBound, lowerBound);
Value tripCount = ceilDivPositive(boundsBuilder, loc, diff, step);
Value unrollFactorCst =
- boundsBuilder.create<ConstantIndexOp>(loc, unrollFactor);
+ boundsBuilder.create<arith::ConstantIndexOp>(loc, unrollFactor);
Value tripCountRem =
- boundsBuilder.create<SignedRemIOp>(loc, tripCount, unrollFactorCst);
+ boundsBuilder.create<arith::RemSIOp>(loc, tripCount, unrollFactorCst);
// Compute tripCountEvenMultiple = tripCount - (tripCount % unrollFactor)
Value tripCountEvenMultiple =
- boundsBuilder.create<SubIOp>(loc, tripCount, tripCountRem);
+ boundsBuilder.create<arith::SubIOp>(loc, tripCount, tripCountRem);
// Compute upperBoundUnrolled = lowerBound + tripCountEvenMultiple * step
- upperBoundUnrolled = boundsBuilder.create<AddIOp>(
+ upperBoundUnrolled = boundsBuilder.create<arith::AddIOp>(
loc, lowerBound,
- boundsBuilder.create<MulIOp>(loc, tripCountEvenMultiple, step));
+ boundsBuilder.create<arith::MulIOp>(loc, tripCountEvenMultiple, step));
// Scale 'step' by 'unrollFactor'.
- stepUnrolled = boundsBuilder.create<MulIOp>(loc, step, unrollFactorCst);
+ stepUnrolled =
+ boundsBuilder.create<arith::MulIOp>(loc, step, unrollFactorCst);
}
// Create epilogue clean up loop starting at 'upperBoundUnrolled'.
forOp.getBody(), forOp.getInductionVar(), unrollFactor,
[&](unsigned i, Value iv, OpBuilder b) {
// iv' = iv + step * i;
- auto stride =
- b.create<MulIOp>(loc, step, b.create<ConstantIndexOp>(loc, i));
- return b.create<AddIOp>(loc, iv, stride);
+ auto stride = b.create<arith::MulIOp>(
+ loc, step, b.create<arith::ConstantIndexOp>(loc, i));
+ return b.create<arith::AddIOp>(loc, iv, stride);
},
annotateFn, iterArgs, yieldedValues);
// Promote the loop body up if this has turned into a single iteration loop.
if (forOp.getNumResults() > 0) {
// Create reduction ops to combine every `unrollJamFactor` related results
// into one value. For example, for %0:2 = affine.for ... and addf, we add
- // %1 = addf %0#0, %0#1, and replace the following uses of %0#0 with %1.
+ // %1 = arith.addf %0#0, %0#1, and replace the following uses of %0#0 with
+ // %1.
builder.setInsertionPointAfter(forOp);
auto loc = forOp.getLoc();
unsigned oldNumResults = forOp.getNumResults() / unrollJamFactor;
auto iv = forOp.getInductionVar();
OpBuilder b(forOp);
- forOp.setStep(b.create<MulIOp>(forOp.getLoc(), originalStep, factor));
+ forOp.setStep(b.create<arith::MulIOp>(forOp.getLoc(), originalStep, factor));
Loops innerLoops;
for (auto t : targets) {
// Insert newForOp before the terminator of `t`.
auto b = OpBuilder::atBlockTerminator((t.getBody()));
- Value stepped = b.create<AddIOp>(t.getLoc(), iv, forOp.step());
- Value less = b.create<CmpIOp>(t.getLoc(), CmpIPredicate::slt,
- forOp.upperBound(), stepped);
+ Value stepped = b.create<arith::AddIOp>(t.getLoc(), iv, forOp.step());
+ Value less = b.create<arith::CmpIOp>(t.getLoc(), arith::CmpIPredicate::slt,
+ forOp.upperBound(), stepped);
Value ub =
b.create<SelectOp>(t.getLoc(), less, forOp.upperBound(), stepped);
auto forOp = forOps[i];
OpBuilder builder(forOp);
auto loc = forOp.getLoc();
- Value diff =
- builder.create<SubIOp>(loc, forOp.upperBound(), forOp.lowerBound());
+ Value diff = builder.create<arith::SubIOp>(loc, forOp.upperBound(),
+ forOp.lowerBound());
Value numIterations = ceilDivPositive(builder, loc, diff, forOp.step());
Value iterationsPerBlock =
ceilDivPositive(builder, loc, numIterations, sizes[i]);
// Check if the loop is already known to have a constant zero lower bound or
// a constant one step.
bool isZeroBased = false;
- if (auto ubCst = lowerBound.getDefiningOp<ConstantIndexOp>())
- isZeroBased = ubCst.getValue() == 0;
+ if (auto ubCst = lowerBound.getDefiningOp<arith::ConstantIndexOp>())
+ isZeroBased = ubCst.value() == 0;
bool isStepOne = false;
- if (auto stepCst = step.getDefiningOp<ConstantIndexOp>())
- isStepOne = stepCst.getValue() == 1;
+ if (auto stepCst = step.getDefiningOp<arith::ConstantIndexOp>())
+ isStepOne = stepCst.value() == 1;
// Compute the number of iterations the loop executes: ceildiv(ub - lb, step)
// assuming the step is strictly positive. Update the bounds and the step
return {/*lowerBound=*/lowerBound, /*upperBound=*/upperBound,
/*step=*/step};
- Value diff = boundsBuilder.create<SubIOp>(loc, upperBound, lowerBound);
+ Value diff = boundsBuilder.create<arith::SubIOp>(loc, upperBound, lowerBound);
Value newUpperBound = ceilDivPositive(boundsBuilder, loc, diff, step);
Value newLowerBound =
- isZeroBased ? lowerBound : boundsBuilder.create<ConstantIndexOp>(loc, 0);
+ isZeroBased ? lowerBound
+ : boundsBuilder.create<arith::ConstantIndexOp>(loc, 0);
Value newStep =
- isStepOne ? step : boundsBuilder.create<ConstantIndexOp>(loc, 1);
+ isStepOne ? step : boundsBuilder.create<arith::ConstantIndexOp>(loc, 1);
// Insert code computing the value of the original loop induction variable
// from the "normalized" one.
Value scaled =
- isStepOne ? inductionVar
- : insideLoopBuilder.create<MulIOp>(loc, inductionVar, step);
+ isStepOne
+ ? inductionVar
+ : insideLoopBuilder.create<arith::MulIOp>(loc, inductionVar, step);
Value shifted =
- isZeroBased ? scaled
- : insideLoopBuilder.create<AddIOp>(loc, scaled, lowerBound);
+ isZeroBased
+ ? scaled
+ : insideLoopBuilder.create<arith::AddIOp>(loc, scaled, lowerBound);
SmallPtrSet<Operation *, 2> preserve{scaled.getDefiningOp(),
shifted.getDefiningOp()};
Location loc = outermost.getLoc();
Value upperBound = outermost.upperBound();
for (auto loop : loops.drop_front())
- upperBound = builder.create<MulIOp>(loc, upperBound, loop.upperBound());
+ upperBound =
+ builder.create<arith::MulIOp>(loc, upperBound, loop.upperBound());
outermost.setUpperBound(upperBound);
builder.setInsertionPointToStart(outermost.getBody());
for (unsigned i = 0, e = loops.size(); i < e; ++i) {
unsigned idx = loops.size() - i - 1;
if (i != 0)
- previous = builder.create<SignedDivIOp>(loc, previous,
- loops[idx + 1].upperBound());
+ previous = builder.create<arith::DivSIOp>(loc, previous,
+ loops[idx + 1].upperBound());
Value iv = (i == e - 1) ? previous
- : builder.create<SignedRemIOp>(
+ : builder.create<arith::RemSIOp>(
loc, previous, loops[idx].upperBound());
replaceAllUsesInRegionWith(loops[idx].getInductionVar(), iv,
loops.back().region());
// Combine iteration spaces.
SmallVector<Value, 3> lowerBounds, upperBounds, steps;
- auto cst0 = outsideBuilder.create<ConstantIndexOp>(loc, 0);
- auto cst1 = outsideBuilder.create<ConstantIndexOp>(loc, 1);
+ auto cst0 = outsideBuilder.create<arith::ConstantIndexOp>(loc, 0);
+ auto cst1 = outsideBuilder.create<arith::ConstantIndexOp>(loc, 1);
for (unsigned i = 0, e = sortedDimensions.size(); i < e; ++i) {
- Value newUpperBound = outsideBuilder.create<ConstantIndexOp>(loc, 1);
+ Value newUpperBound = outsideBuilder.create<arith::ConstantIndexOp>(loc, 1);
for (auto idx : sortedDimensions[i]) {
- newUpperBound = outsideBuilder.create<MulIOp>(loc, newUpperBound,
- normalizedUpperBounds[idx]);
+ newUpperBound = outsideBuilder.create<arith::MulIOp>(
+ loc, newUpperBound, normalizedUpperBounds[idx]);
}
lowerBounds.push_back(cst0);
steps.push_back(cst1);
unsigned idx = combinedDimensions[i][j];
// Determine the current induction value's current loop iteration
- Value iv = insideBuilder.create<SignedRemIOp>(
+ Value iv = insideBuilder.create<arith::RemSIOp>(
loc, previous, normalizedUpperBounds[idx]);
replaceAllUsesInRegionWith(loops.getBody()->getArgument(idx), iv,
loops.region());
// Remove the effect of the current induction value to prepare for
// the next value.
- previous = insideBuilder.create<SignedDivIOp>(
+ previous = insideBuilder.create<arith::DivSIOp>(
loc, previous, normalizedUpperBounds[idx]);
}
FuncOp f = begin->getParentOfType<FuncOp>();
OpBuilder topBuilder(f.getBody());
- Value zeroIndex = topBuilder.create<ConstantIndexOp>(f.getLoc(), 0);
+ Value zeroIndex = topBuilder.create<arith::ConstantIndexOp>(f.getLoc(), 0);
if (begin == end)
return success();
memIndices.push_back(zeroIndex);
} else {
memIndices.push_back(
- top.create<ConstantIndexOp>(loc, indexVal).getResult());
+ top.create<arith::ConstantIndexOp>(loc, indexVal).getResult());
}
} else {
// The coordinate for the start location is just the lower bound along the
}
auto numElementsSSA =
- top.create<ConstantIndexOp>(loc, numElements.getValue());
+ top.create<arith::ConstantIndexOp>(loc, numElements.getValue());
Value dmaStride = nullptr;
Value numEltPerDmaStride = nullptr;
}
if (!dmaStrideInfos.empty()) {
- dmaStride = top.create<ConstantIndexOp>(loc, dmaStrideInfos[0].stride);
- numEltPerDmaStride =
- top.create<ConstantIndexOp>(loc, dmaStrideInfos[0].numEltPerStride);
+ dmaStride =
+ top.create<arith::ConstantIndexOp>(loc, dmaStrideInfos[0].stride);
+ numEltPerDmaStride = top.create<arith::ConstantIndexOp>(
+ loc, dmaStrideInfos[0].numEltPerStride);
}
}
#include "mlir/Analysis/AffineStructures.h"
#include "mlir/Analysis/Utils.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinOps.h"
Attribute constantAttr =
b.getIntegerAttr(b.getIndexType(), oldMemRefShape[d]);
inAffineApply.emplace_back(
- b.create<ConstantOp>(allocOp->getLoc(), constantAttr));
+ b.create<arith::ConstantOp>(allocOp->getLoc(), constantAttr));
}
}
declare_mlir_dialect_python_bindings(
ADD_TO_PARENT MLIRPythonSources.Dialects
ROOT_DIR "${CMAKE_CURRENT_SOURCE_DIR}/mlir"
+ TD_FILE dialects/ArithmeticOps.td
+ SOURCES
+ dialects/arith.py
+ dialects/_arith_ops_ext.py
+ DIALECT_NAME arith)
+
+declare_mlir_dialect_python_bindings(
+ ADD_TO_PARENT MLIRPythonSources.Dialects
+ ROOT_DIR "${CMAKE_CURRENT_SOURCE_DIR}/mlir"
TD_FILE dialects/MemRefOps.td
SOURCES dialects/memref.py
DIALECT_NAME memref)
--- /dev/null
+//===-- ArithmeticOps.td - Entry point for ArithmeticOps bindings ---------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef PYTHON_BINDINGS_ARITHMETIC_OPS
+#define PYTHON_BINDINGS_ARITHMETIC_OPS
+
+include "mlir/Bindings/Python/Attributes.td"
+include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.td"
+
+#endif
--- /dev/null
+# Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+# See https://llvm.org/LICENSE.txt for license information.
+# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+
+try:
+ from ..ir import *
+ from ._ods_common import get_default_loc_context as _get_default_loc_context
+
+ from typing import Any, List, Union
+except ImportError as e:
+ raise RuntimeError("Error loading imports from extension module") from e
+
+
+def _isa(obj: Any, cls: type):
+ try:
+ cls(obj)
+ except ValueError:
+ return False
+ return True
+
+
+def _is_any_of(obj: Any, classes: List[type]):
+ return any(_isa(obj, cls) for cls in classes)
+
+
+def _is_integer_like_type(type: Type):
+ return _is_any_of(type, [IntegerType, IndexType])
+
+
+def _is_float_type(type: Type):
+ return _is_any_of(type, [BF16Type, F16Type, F32Type, F64Type])
+
+
+class ConstantOp:
+ """Specialization for the constant op class."""
+
+ def __init__(self,
+ result: Type,
+ value: Union[int, float, Attribute],
+ *,
+ loc=None,
+ ip=None):
+ if isinstance(value, int):
+ super().__init__(result, IntegerAttr.get(result, value), loc=loc, ip=ip)
+ elif isinstance(value, float):
+ super().__init__(result, FloatAttr.get(result, value), loc=loc, ip=ip)
+ else:
+ super().__init__(result, value, loc=loc, ip=ip)
+
+ @classmethod
+ def create_index(cls, value: int, *, loc=None, ip=None):
+ """Create an index-typed constant."""
+ return cls(
+ IndexType.get(context=_get_default_loc_context(loc)),
+ value,
+ loc=loc,
+ ip=ip)
+
+ @property
+ def type(self):
+ return self.results[0].type
+
+ @property
+ def literal_value(self) -> Union[int, float]:
+ if _is_integer_like_type(self.type):
+ return IntegerAttr(self.value).value
+ elif _is_float_type(self.type):
+ return FloatAttr(self.value).value
+ else:
+ raise ValueError("only integer and float constants have literal values")
raise RuntimeError("Error loading imports from extension module") from e
-def _isa(obj: Any, cls: type):
- try:
- cls(obj)
- except ValueError:
- return False
- return True
-
-
-def _is_any_of(obj: Any, classes: List[type]):
- return any(_isa(obj, cls) for cls in classes)
-
-
-def _is_integer_like_type(type: Type):
- return _is_any_of(type, [IntegerType, IndexType])
-
-
-def _is_float_type(type: Type):
- return _is_any_of(type, [BF16Type, F16Type, F32Type, F64Type])
-
-
class ConstantOp:
"""Specialization for the constant op class."""
- def __init__(self,
- result: Type,
- value: Union[int, float, Attribute],
- *,
- loc=None,
- ip=None):
- if isinstance(value, int):
- super().__init__(result, IntegerAttr.get(result, value), loc=loc, ip=ip)
- elif isinstance(value, float):
- super().__init__(result, FloatAttr.get(result, value), loc=loc, ip=ip)
- else:
- super().__init__(result, value, loc=loc, ip=ip)
-
- @classmethod
- def create_index(cls, value: int, *, loc=None, ip=None):
- """Create an index-typed constant."""
- return cls(
- IndexType.get(context=_get_default_loc_context(loc)),
- value,
- loc=loc,
- ip=ip)
+ def __init__(self, result: Type, value: Attribute, *, loc=None, ip=None):
+ super().__init__(result, value, loc=loc, ip=ip)
@property
def type(self):
return self.results[0].type
- @property
- def literal_value(self) -> Union[int, float]:
- if _is_integer_like_type(self.type):
- return IntegerAttr(self.value).value
- elif _is_float_type(self.type):
- return FloatAttr(self.value).value
- else:
- raise ValueError("only integer and float constants have literal values")
-
class CallOp:
"""Specialization for the call op class."""
--- /dev/null
+# Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+# See https://llvm.org/LICENSE.txt for license information.
+# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+
+from ._arith_ops_gen import *
from .... import linalg
from .... import std
from .... import math
+from .... import arith
from ...._ods_common import get_op_result_or_value as _get_op_result_or_value, get_op_results_or_values as _get_op_results_or_values
from .scalar_expr import *
f"this structured op.")
elif expr.scalar_const:
value_attr = Attribute.parse(expr.scalar_const.value)
- return std.ConstantOp(value_attr.type, value_attr).result
+ return arith.ConstantOp(value_attr.type, value_attr).result
elif expr.scalar_index:
- dim_attr = IntegerAttr.get(IntegerType.get_signless(64),
- expr.scalar_index.dim)
+ dim_attr = IntegerAttr.get(
+ IntegerType.get_signless(64), expr.scalar_index.dim)
return linalg.IndexOp(IndexType.get(), dim_attr).result
elif expr.scalar_apply:
try:
operand_type = operand.type
if _is_floating_point_type(operand_type):
if is_unsigned_cast:
- return std.FPToUIOp(to_type, operand).result
- return std.FPToSIOp(to_type, operand).result
+ return arith.FPToUIOp(to_type, operand).result
+ return arith.FPToSIOp(to_type, operand).result
if _is_index_type(operand_type):
- return std.IndexCastOp(to_type, operand).result
+ return arith.IndexCastOp(to_type, operand).result
# Assume integer.
from_width = IntegerType(operand_type).width
if to_width > from_width:
if is_unsigned_cast:
- return std.ZeroExtendIOp(to_type, operand).result
- return std.SignExtendIOp(to_type, operand).result
+ return arith.ExtUIOp(to_type, operand).result
+ return arith.ExtSIOp(to_type, operand).result
elif to_width < from_width:
- return std.TruncateIOp(to_type, operand).result
+ return arith.TruncIOp(to_type, operand).result
raise ValueError(f"Unable to cast body expression from {operand_type} to "
f"{to_type}")
operand_type = operand.type
if _is_integer_type(operand_type):
if is_unsigned_cast:
- return std.UIToFPOp(to_type, operand).result
- return std.SIToFPOp(to_type, operand).result
+ return arith.UIToFPOp(to_type, operand).result
+ return arith.SIToFPOp(to_type, operand).result
# Assume FloatType.
to_width = _get_floating_point_width(to_type)
from_width = _get_floating_point_width(operand_type)
if to_width > from_width:
- return std.FPExtOp(to_type, operand).result
+ return arith.ExtFOp(to_type, operand).result
elif to_width < from_width:
- return std.FPTruncOp(to_type, operand).result
+ return arith.TruncFOp(to_type, operand).result
raise ValueError(f"Unable to cast body expression from {operand_type} to "
f"{to_type}")
def _eval_add(self, lhs: Value, rhs: Value) -> Value:
if _is_floating_point_type(lhs.type):
- return std.AddFOp(lhs.type, lhs, rhs).result
+ return arith.AddFOp(lhs.type, lhs, rhs).result
if _is_integer_type(lhs.type) or _is_index_type(lhs.type):
- return std.AddIOp(lhs.type, lhs, rhs).result
+ return arith.AddIOp(lhs.type, lhs, rhs).result
raise NotImplementedError("Unsupported 'add' operand: {lhs}")
def _eval_exp(self, x: Value) -> Value:
def _eval_sub(self, lhs: Value, rhs: Value) -> Value:
if _is_floating_point_type(lhs.type):
- return std.SubFOp(lhs.type, lhs, rhs).result
+ return arith.SubFOp(lhs.type, lhs, rhs).result
if _is_integer_type(lhs.type) or _is_index_type(lhs.type):
- return std.SubIOp(lhs.type, lhs, rhs).result
+ return arith.SubIOp(lhs.type, lhs, rhs).result
raise NotImplementedError("Unsupported 'sub' operand: {lhs}")
def _eval_mul(self, lhs: Value, rhs: Value) -> Value:
if _is_floating_point_type(lhs.type):
- return std.MulFOp(lhs.type, lhs, rhs).result
+ return arith.MulFOp(lhs.type, lhs, rhs).result
if _is_integer_type(lhs.type) or _is_index_type(lhs.type):
- return std.MulIOp(lhs.type, lhs, rhs).result
+ return arith.MulIOp(lhs.type, lhs, rhs).result
raise NotImplementedError("Unsupported 'mul' operand: {lhs}")
def _eval_max(self, lhs: Value, rhs: Value) -> Value:
return std.MinUIOp(lhs.type, lhs, rhs).result
raise NotImplementedError("Unsupported 'min_unsigned' operand: {lhs}")
+
def _infer_structured_outs(
op_config: LinalgStructuredOpConfig,
in_arg_defs: Sequence[OperandDefConfig], ins: Sequence[Value],
func @view_like(%arg: memref<2xf32>, %size: index) attributes {test.ptr = "func"} {
%1 = memref.alloc() {test.ptr = "alloc_1"} : memref<8x64xf32>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%2 = memref.alloca (%size) {test.ptr = "alloca_1"} : memref<?xi8>
%3 = memref.view %2[%c0][] {test.ptr = "view"} : memref<?xi8> to memref<8x64xf32>
return
func @constants(%arg: memref<2xf32>) attributes {test.ptr = "func"} {
%1 = memref.alloc() {test.ptr = "alloc_1"} : memref<8x64xf32>
- %c0 = constant {test.ptr = "constant_1"} 0 : index
- %c0_2 = constant {test.ptr = "constant_2"} 0 : index
- %c1 = constant {test.ptr = "constant_3"} 1 : index
+ %c0 = arith.constant {test.ptr = "constant_1"} 0 : index
+ %c0_2 = arith.constant {test.ptr = "constant_2"} 0 : index
+ %c1 = arith.constant {test.ptr = "constant_3"} 1 : index
return
}
func @func_loop(%arg0 : i32, %arg1 : i32) {
br ^loopHeader(%arg0 : i32)
^loopHeader(%counter : i32):
- %lessThan = cmpi slt, %counter, %arg1 : i32
+ %lessThan = arith.cmpi slt, %counter, %arg1 : i32
cond_br %lessThan, ^loopBody, ^exit
^loopBody:
- %const0 = constant 1 : i32
- %inc = addi %counter, %const0 : i32
+ %const0 = arith.constant 1 : i32
+ %inc = arith.addi %counter, %const0 : i32
br ^loopHeader(%inc : i32)
^exit:
return
%arg4 : index) {
br ^loopHeader(%arg0 : i32)
^loopHeader(%counter : i32):
- %lessThan = cmpi slt, %counter, %arg1 : i32
+ %lessThan = arith.cmpi slt, %counter, %arg1 : i32
cond_br %lessThan, ^loopBody, ^exit
^loopBody:
- %const0 = constant 1 : i32
- %inc = addi %counter, %const0 : i32
+ %const0 = arith.constant 1 : i32
+ %inc = arith.addi %counter, %const0 : i32
scf.for %arg5 = %arg2 to %arg3 step %arg4 {
scf.for %arg6 = %arg2 to %arg3 step %arg4 { }
}
// CHECK-NEXT: LiveOut:{{ *$}}
// CHECK-NEXT: BeginLiveness
// CHECK: val_2
- // CHECK-NEXT: %0 = addi
+ // CHECK-NEXT: %0 = arith.addi
// CHECK-NEXT: return
// CHECK-NEXT: EndLiveness
- %result = addi %arg0, %arg1 : i32
+ %result = arith.addi %arg0, %arg1 : i32
return %result : i32
}
// CHECK-NEXT: LiveOut:{{ *$}}
// CHECK-NEXT: BeginLiveness
// CHECK: val_3
- // CHECK-NEXT: %0 = addi
+ // CHECK-NEXT: %0 = arith.addi
// CHECK-NEXT: return
// CHECK-NEXT: EndLiveness
- %result = addi %arg1, %arg2 : i32
+ %result = arith.addi %arg1, %arg2 : i32
return %result : i32
}
// CHECK: Block: 0
// CHECK-NEXT: LiveIn:{{ *$}}
// CHECK-NEXT: LiveOut: arg1@0
- %const0 = constant 0 : i32
+ %const0 = arith.constant 0 : i32
br ^loopHeader(%const0, %arg0 : i32, i32)
^loopHeader(%counter : i32, %i : i32):
// CHECK: Block: 1
// CHECK-NEXT: LiveOut: arg1@0 arg0@1
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_5
- // CHECK-NEXT: %2 = cmpi
+ // CHECK-NEXT: %2 = arith.cmpi
// CHECK-NEXT: cond_br
// CHECK-NEXT: EndLiveness
- %lessThan = cmpi slt, %counter, %arg1 : i32
+ %lessThan = arith.cmpi slt, %counter, %arg1 : i32
cond_br %lessThan, ^loopBody(%i : i32), ^exit(%i : i32)
^loopBody(%val : i32):
// CHECK: Block: 2
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_7
// CHECK-NEXT: %c
- // CHECK-NEXT: %4 = addi
- // CHECK-NEXT: %5 = addi
+ // CHECK-NEXT: %4 = arith.addi
+ // CHECK-NEXT: %5 = arith.addi
// CHECK-NEXT: val_8
- // CHECK-NEXT: %4 = addi
- // CHECK-NEXT: %5 = addi
+ // CHECK-NEXT: %4 = arith.addi
+ // CHECK-NEXT: %5 = arith.addi
// CHECK-NEXT: br
// CHECK: EndLiveness
- %const1 = constant 1 : i32
- %inc = addi %val, %const1 : i32
- %inc2 = addi %counter, %const1 : i32
+ %const1 = arith.constant 1 : i32
+ %inc = arith.addi %val, %const1 : i32
+ %inc2 = arith.addi %counter, %const1 : i32
br ^loopHeader(%inc, %inc2 : i32, i32)
^exit(%sum : i32):
// CHECK: Block: 3
// CHECK-NEXT: LiveIn: arg1@0
// CHECK-NEXT: LiveOut:{{ *$}}
- %result = addi %sum, %arg1 : i32
+ %result = arith.addi %sum, %arg1 : i32
return %result : i32
}
// CHECK-NEXT: LiveOut: arg2@0 val_9 val_10
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_4
- // CHECK-NEXT: %0 = addi
+ // CHECK-NEXT: %0 = arith.addi
// CHECK-NEXT: %c
- // CHECK-NEXT: %1 = addi
- // CHECK-NEXT: %2 = addi
- // CHECK-NEXT: %3 = muli
+ // CHECK-NEXT: %1 = arith.addi
+ // CHECK-NEXT: %2 = arith.addi
+ // CHECK-NEXT: %3 = arith.muli
// CHECK-NEXT: val_5
// CHECK-NEXT: %c
- // CHECK-NEXT: %1 = addi
- // CHECK-NEXT: %2 = addi
- // CHECK-NEXT: %3 = muli
- // CHECK-NEXT: %4 = muli
- // CHECK-NEXT: %5 = addi
+ // CHECK-NEXT: %1 = arith.addi
+ // CHECK-NEXT: %2 = arith.addi
+ // CHECK-NEXT: %3 = arith.muli
+ // CHECK-NEXT: %4 = arith.muli
+ // CHECK-NEXT: %5 = arith.addi
// CHECK-NEXT: val_6
- // CHECK-NEXT: %1 = addi
- // CHECK-NEXT: %2 = addi
- // CHECK-NEXT: %3 = muli
+ // CHECK-NEXT: %1 = arith.addi
+ // CHECK-NEXT: %2 = arith.addi
+ // CHECK-NEXT: %3 = arith.muli
// CHECK-NEXT: val_7
- // CHECK-NEXT %2 = addi
- // CHECK-NEXT %3 = muli
- // CHECK-NEXT %4 = muli
+ // CHECK-NEXT %2 = arith.addi
+ // CHECK-NEXT %3 = arith.muli
+ // CHECK-NEXT %4 = arith.muli
// CHECK: val_8
- // CHECK-NEXT: %3 = muli
- // CHECK-NEXT: %4 = muli
+ // CHECK-NEXT: %3 = arith.muli
+ // CHECK-NEXT: %4 = arith.muli
// CHECK-NEXT: val_9
- // CHECK-NEXT: %4 = muli
- // CHECK-NEXT: %5 = addi
+ // CHECK-NEXT: %4 = arith.muli
+ // CHECK-NEXT: %5 = arith.addi
// CHECK-NEXT: cond_br
// CHECK-NEXT: %c
- // CHECK-NEXT: %6 = muli
- // CHECK-NEXT: %7 = muli
- // CHECK-NEXT: %8 = addi
+ // CHECK-NEXT: %6 = arith.muli
+ // CHECK-NEXT: %7 = arith.muli
+ // CHECK-NEXT: %8 = arith.addi
// CHECK-NEXT: val_10
- // CHECK-NEXT: %5 = addi
+ // CHECK-NEXT: %5 = arith.addi
// CHECK-NEXT: cond_br
// CHECK-NEXT: %7
// CHECK: EndLiveness
- %0 = addi %arg1, %arg2 : i32
- %const1 = constant 1 : i32
- %1 = addi %const1, %arg2 : i32
- %2 = addi %const1, %arg3 : i32
- %3 = muli %0, %1 : i32
- %4 = muli %3, %2 : i32
- %5 = addi %4, %const1 : i32
+ %0 = arith.addi %arg1, %arg2 : i32
+ %const1 = arith.constant 1 : i32
+ %1 = arith.addi %const1, %arg2 : i32
+ %2 = arith.addi %const1, %arg3 : i32
+ %3 = arith.muli %0, %1 : i32
+ %4 = arith.muli %3, %2 : i32
+ %5 = arith.addi %4, %const1 : i32
cond_br %cond, ^bb1, ^bb2
^bb1:
// CHECK: Block: 1
// CHECK-NEXT: LiveIn: arg2@0 val_9
// CHECK-NEXT: LiveOut: arg2@0
- %const4 = constant 4 : i32
- %6 = muli %4, %const4 : i32
+ %const4 = arith.constant 4 : i32
+ %6 = arith.muli %4, %const4 : i32
br ^exit(%6 : i32)
^bb2:
// CHECK: Block: 2
// CHECK-NEXT: LiveIn: arg2@0 val_9 val_10
// CHECK-NEXT: LiveOut: arg2@0
- %7 = muli %4, %5 : i32
- %8 = addi %4, %arg2 : i32
+ %7 = arith.muli %4, %5 : i32
+ %8 = arith.addi %4, %arg2 : i32
br ^exit(%8 : i32)
^exit(%sum : i32):
// CHECK: Block: 3
// CHECK-NEXT: LiveIn: arg2@0
// CHECK-NEXT: LiveOut:{{ *$}}
- %result = addi %sum, %arg2 : i32
+ %result = arith.addi %sum, %arg2 : i32
return %result : i32
}
// CHECK-NEXT: LiveOut:{{ *$}}
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_7
- // CHECK-NEXT: %0 = addi
- // CHECK-NEXT: %1 = addi
+ // CHECK-NEXT: %0 = arith.addi
+ // CHECK-NEXT: %1 = arith.addi
// CHECK-NEXT: scf.for
- // CHECK: // %2 = addi
- // CHECK-NEXT: %3 = addi
+ // CHECK: // %2 = arith.addi
+ // CHECK-NEXT: %3 = arith.addi
// CHECK-NEXT: val_8
- // CHECK-NEXT: %1 = addi
+ // CHECK-NEXT: %1 = arith.addi
// CHECK-NEXT: scf.for
// CHECK: // return %1
// CHECK: EndLiveness
- %0 = addi %arg3, %arg4 : i32
- %1 = addi %arg4, %arg5 : i32
+ %0 = arith.addi %arg3, %arg4 : i32
+ %1 = arith.addi %arg4, %arg5 : i32
scf.for %arg6 = %arg0 to %arg1 step %arg2 {
// CHECK: Block: 1
// CHECK-NEXT: LiveIn: arg5@0 arg6@0 val_7
// CHECK-NEXT: LiveOut:{{ *$}}
- %2 = addi %0, %arg5 : i32
- %3 = addi %2, %0 : i32
+ %2 = arith.addi %0, %arg5 : i32
+ %3 = arith.addi %2, %0 : i32
memref.store %3, %buffer[] : memref<i32>
}
return %1 : i32
// CHECK-NEXT: LiveOut:{{ *$}}
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_7
- // CHECK-NEXT: %0 = addi
- // CHECK-NEXT: %1 = addi
+ // CHECK-NEXT: %0 = arith.addi
+ // CHECK-NEXT: %1 = arith.addi
// CHECK-NEXT: scf.for
- // CHECK: // %2 = addi
+ // CHECK: // %2 = arith.addi
// CHECK-NEXT: scf.for
- // CHECK: // %3 = addi
+ // CHECK: // %3 = arith.addi
// CHECK-NEXT: val_8
- // CHECK-NEXT: %1 = addi
+ // CHECK-NEXT: %1 = arith.addi
// CHECK-NEXT: scf.for
// CHECK: // return %1
// CHECK: EndLiveness
%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : i32, %arg4 : i32, %arg5 : i32,
%buffer : memref<i32>) -> i32 {
- %0 = addi %arg3, %arg4 : i32
- %1 = addi %arg4, %arg5 : i32
+ %0 = arith.addi %arg3, %arg4 : i32
+ %1 = arith.addi %arg4, %arg5 : i32
scf.for %arg6 = %arg0 to %arg1 step %arg2 {
// CHECK: Block: 1
// CHECK-NEXT: LiveIn: arg0@0 arg1@0 arg2@0 arg5@0 arg6@0 val_7
// CHECK-NEXT: LiveOut:{{ *$}}
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_10
- // CHECK-NEXT: %2 = addi
+ // CHECK-NEXT: %2 = arith.addi
// CHECK-NEXT: scf.for
- // CHECK: // %3 = addi
+ // CHECK: // %3 = arith.addi
// CHECK: EndLiveness
- %2 = addi %0, %arg5 : i32
+ %2 = arith.addi %0, %arg5 : i32
scf.for %arg7 = %arg0 to %arg1 step %arg2 {
- %3 = addi %2, %0 : i32
+ %3 = arith.addi %2, %0 : i32
memref.store %3, %buffer[] : memref<i32>
}
}
// CHECK-NEXT: LiveOut: arg0@0 arg1@0 arg2@0 arg6@0 val_7 val_8
// CHECK-NEXT: BeginLiveness
// CHECK-NEXT: val_7
- // CHECK-NEXT: %0 = addi
- // CHECK-NEXT: %1 = addi
+ // CHECK-NEXT: %0 = arith.addi
+ // CHECK-NEXT: %1 = arith.addi
// CHECK-NEXT: scf.for
// CHECK: // br ^bb1
- // CHECK-NEXT: %2 = addi
+ // CHECK-NEXT: %2 = arith.addi
// CHECK-NEXT: scf.for
- // CHECK: // %2 = addi
+ // CHECK: // %2 = arith.addi
// CHECK: EndLiveness
%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : i32, %arg4 : i32, %arg5 : i32,
%buffer : memref<i32>) -> i32 {
- %0 = addi %arg3, %arg4 : i32
- %1 = addi %arg4, %arg5 : i32
+ %0 = arith.addi %arg3, %arg4 : i32
+ %1 = arith.addi %arg4, %arg5 : i32
scf.for %arg6 = %arg0 to %arg1 step %arg2 {
// CHECK: Block: 1
// CHECK-NEXT: LiveIn: arg5@0 arg6@0 val_7
// CHECK-NEXT: LiveOut:{{ *$}}
- %2 = addi %0, %arg5 : i32
+ %2 = arith.addi %0, %arg5 : i32
memref.store %2, %buffer[] : memref<i32>
}
br ^exit
// CHECK: Block: 3
// CHECK-NEXT: LiveIn: arg6@0 val_7 val_8
// CHECK-NEXT: LiveOut:{{ *$}}
- %2 = addi %0, %1 : i32
+ %2 = arith.addi %0, %1 : i32
memref.store %2, %buffer[] : memref<i32>
}
return %1 : i32
func @linalg_red_add(%in0t : tensor<?xf32>, %out0t : tensor<1xf32>) {
// expected-remark@below {{Reduction found in output #0!}}
// expected-remark@below {{Reduced Value: <block argument> of type 'f32' at index: 0}}
- // expected-remark@below {{Combiner Op: %1 = addf %arg2, %arg3 : f32}}
+ // expected-remark@below {{Combiner Op: %1 = arith.addf %arg2, %arg3 : f32}}
%red = linalg.generic {indexing_maps = [affine_map<(d0) -> (d0)>,
affine_map<(d0) -> (0)>],
iterator_types = ["reduction"]}
ins(%in0t : tensor<?xf32>)
outs(%out0t : tensor<1xf32>) {
^bb0(%in0: f32, %out0: f32):
- %add = addf %in0, %out0 : f32
+ %add = arith.addf %in0, %out0 : f32
linalg.yield %add : f32
} -> tensor<1xf32>
return
// expected-remark@below {{Testing function}}
func @affine_red_add(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
// expected-remark@below {{Reduction found in output #0!}}
// expected-remark@below {{Reduced Value: %1 = affine.load %arg0[%arg2, %arg3] : memref<256x512xf32>}}
- // expected-remark@below {{Combiner Op: %2 = addf %arg4, %1 : f32}}
+ // expected-remark@below {{Combiner Op: %2 = arith.addf %arg4, %1 : f32}}
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
ins(%in0t : tensor<4x4xf32>)
outs(%out0t : tensor<4xf32>) {
^bb0(%in0: f32, %out0: f32):
- %cmp = cmpf ogt, %in0, %out0 : f32
+ %cmp = arith.cmpf ogt, %in0, %out0 : f32
%sel = select %cmp, %in0, %out0 : f32
linalg.yield %sel : f32
} -> tensor<4xf32>
// expected-remark@below {{Testing function}}
func @linalg_fused_red_add(%in0t: tensor<4x4xf32>, %out0t: tensor<4xf32>) {
// expected-remark@below {{Reduction found in output #0!}}
- // expected-remark@below {{Reduced Value: %2 = subf %1, %arg2 : f32}}
- // expected-remark@below {{Combiner Op: %3 = addf %2, %arg3 : f32}}
+ // expected-remark@below {{Reduced Value: %2 = arith.subf %1, %arg2 : f32}}
+ // expected-remark@below {{Combiner Op: %3 = arith.addf %2, %arg3 : f32}}
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
affine_map<(d0, d1) -> (d0)>],
iterator_types = ["parallel", "reduction"]}
ins(%in0t : tensor<4x4xf32>)
outs(%out0t : tensor<4xf32>) {
^bb0(%in0: f32, %out0: f32):
- %mul = mulf %in0, %in0 : f32
- %sub = subf %mul, %in0 : f32
- %add = addf %sub, %out0 : f32
+ %mul = arith.mulf %in0, %in0 : f32
+ %sub = arith.subf %mul, %in0 : f32
+ %add = arith.addf %sub, %out0 : f32
linalg.yield %add : f32
} -> tensor<4xf32>
return
// expected-remark@below {{Testing function}}
func @affine_no_red_rec(%in: memref<512xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
// %rec is the value loaded in the previous iteration.
// expected-remark@below {{Reduction NOT found in output #0!}}
%final_val = affine.for %j = 0 to 512 iter_args(%rec = %cst) -> (f32) {
%ld = affine.load %in[%j] : memref<512xf32>
- %add = addf %ld, %rec : f32
+ %add = arith.addf %ld, %rec : f32
affine.yield %ld : f32
}
return
// expected-remark@below {{Testing function}}
func @affine_output_dep(%in: memref<512xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
// Reduction %red is not supported because it depends on another
// loop-carried dependence.
// expected-remark@below {{Reduction NOT found in output #0!}}
%final_red, %final_dep = affine.for %j = 0 to 512
iter_args(%red = %cst, %dep = %cst) -> (f32, f32) {
%ld = affine.load %in[%j] : memref<512xf32>
- %add = addf %dep, %red : f32
+ %add = arith.addf %dep, %red : f32
affine.yield %add, %ld : f32, f32
}
return
func @scf_for_constant_bounds() {
// CHECK: Block: 0
// CHECK-NEXT: Number of executions: 1
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
scf.for %i = %c0 to %c2 step %c1 {
// CHECK: Block: 1
func @propagate_parent_num_executions() {
// CHECK: Block: 0
// CHECK-NEXT: Number of executions: 1
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
scf.for %i = %c0 to %c2 step %c1 {
// CHECK: Block: 1
func @clear_num_executions(%step : index) {
// CHECK: Block: 0
// CHECK-NEXT: Number of executions: 1
- %c0 = constant 0 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
scf.for %i = %c0 to %c2 step %step {
// CHECK: Block: 1
// CHECK-LABEL: Number of executions: propagate_parent_num_executions
func @propagate_parent_num_executions() {
- // CHECK: Operation: std.constant
+ // CHECK: Operation: arith.constant
// CHECK-NEXT: Number of executions: 1
- %c0 = constant 0 : index
- // CHECK: Operation: std.constant
+ %c0 = arith.constant 0 : index
+ // CHECK: Operation: arith.constant
// CHECK-NEXT: Number of executions: 1
- %c1 = constant 1 : index
- // CHECK: Operation: std.constant
+ %c1 = arith.constant 1 : index
+ // CHECK: Operation: arith.constant
// CHECK-NEXT: Number of executions: 1
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
// CHECK-DAG: Operation: scf.for
// CHECK-NEXT: Number of executions: 1
// CHECK-LABEL: Number of executions: clear_num_executions
func @clear_num_executions(%step : index) {
- // CHECK: Operation: std.constant
+ // CHECK: Operation: arith.constant
// CHECK-NEXT: Number of executions: 1
- %c0 = constant 0 : index
- // CHECK: Operation: std.constant
+ %c0 = arith.constant 0 : index
+ // CHECK: Operation: arith.constant
// CHECK-NEXT: Number of executions: 1
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
// CHECK: Operation: scf.for
// CHECK-NEXT: Number of executions: 1
void lowerModuleToLLVM(MlirContext ctx, MlirModule module) {
MlirPassManager pm = mlirPassManagerCreate(ctx);
+ MlirOpPassManager opm = mlirPassManagerGetNestedUnder(
+ pm, mlirStringRefCreateFromCString("builtin.func"));
mlirPassManagerAddOwnedPass(pm, mlirCreateConversionConvertStandardToLLVM());
+ mlirOpPassManagerAddOwnedPass(opm,
+ mlirCreateConversionConvertArithmeticToLLVM());
MlirLogicalResult status = mlirPassManagerRun(pm, module);
if (mlirLogicalResultIsFailure(status)) {
fprintf(stderr, "Unexpected failure running pass pipeline\n");
// clang-format off
"module { \n"
" func @add(%arg0 : i32) -> i32 attributes { llvm.emit_c_interface } { \n"
-" %res = std.addi %arg0, %arg0 : i32 \n"
+" %res = arith.addi %arg0, %arg0 : i32 \n"
" return %res : i32 \n"
" } \n"
"}"));
mlirBlockAppendOwnedOperation(loopBody, loadRHS);
MlirOperationState addState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.addf"), location);
+ mlirStringRefCreateFromCString("arith.addf"), location);
MlirValue addOperands[] = {mlirOperationGetResult(loadLHS, 0),
mlirOperationGetResult(loadRHS, 0)};
mlirOperationStateAddOperands(&addState, 2, addOperands);
mlirIdentifierGet(ctx, mlirStringRefCreateFromCString("value")),
indexZeroLiteral);
MlirOperationState constZeroState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.constant"), location);
+ mlirStringRefCreateFromCString("arith.constant"), location);
mlirOperationStateAddResults(&constZeroState, 1, &indexType);
mlirOperationStateAddAttributes(&constZeroState, 1, &indexZeroValueAttr);
MlirOperation constZero = mlirOperationCreate(&constZeroState);
mlirIdentifierGet(ctx, mlirStringRefCreateFromCString("value")),
indexOneLiteral);
MlirOperationState constOneState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.constant"), location);
+ mlirStringRefCreateFromCString("arith.constant"), location);
mlirOperationStateAddResults(&constOneState, 1, &indexType);
mlirOperationStateAddAttributes(&constOneState, 1, &indexOneValueAttr);
MlirOperation constOne = mlirOperationCreate(&constOneState);
// clang-format off
// CHECK: module {
// CHECK: func @add(%[[ARG0:.*]]: memref<?xf32>, %[[ARG1:.*]]: memref<?xf32>) {
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = memref.dim %[[ARG0]], %[[C0]] : memref<?xf32>
- // CHECK: %[[C1:.*]] = constant 1 : index
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: scf.for %[[I:.*]] = %[[C0]] to %[[DIM]] step %[[C1]] {
// CHECK: %[[LHS:.*]] = memref.load %[[ARG0]][%[[I]]] : memref<?xf32>
// CHECK: %[[RHS:.*]] = memref.load %[[ARG1]][%[[I]]] : memref<?xf32>
- // CHECK: %[[SUM:.*]] = addf %[[LHS]], %[[RHS]] : f32
+ // CHECK: %[[SUM:.*]] = arith.addf %[[LHS]], %[[RHS]] : f32
// CHECK: memref.store %[[SUM]], %[[ARG0]][%[[I]]] : memref<?xf32>
// CHECK: }
// CHECK: return
mlirOperationPrint(operation, printToStderr, NULL);
fprintf(stderr, "\n");
// clang-format off
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = memref.dim %{{.*}}, %[[C0]] : memref<?xf32>
- // CHECK: %[[C1:.*]] = constant 1 : index
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: scf.for %[[I:.*]] = %[[C0]] to %[[DIM]] step %[[C1]] {
// CHECK: %[[LHS:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xf32>
// CHECK: %[[RHS:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xf32>
- // CHECK: %[[SUM:.*]] = addf %[[LHS]], %[[RHS]] : f32
+ // CHECK: %[[SUM:.*]] = arith.addf %[[LHS]], %[[RHS]] : f32
// CHECK: memref.store %[[SUM]], %{{.*}}[%[[I]]] : memref<?xf32>
// CHECK: }
// CHECK: return
- // CHECK: First operation: {{.*}} = constant 0 : index
+ // CHECK: First operation: {{.*}} = arith.constant 0 : index
// clang-format on
// Get the operation name and print it.
for (size_t i = 0; i < identStr.length; ++i)
fputc(identStr.data[i], stderr);
fprintf(stderr, "'\n");
- // CHECK: Operation name: 'std.constant'
+ // CHECK: Operation name: 'arith.constant'
// Get the identifier again and verify equal.
MlirIdentifier identAgain = mlirIdentifierGet(ctx, identStr);
mlirValuePrint(value, printToStderr, NULL);
fprintf(stderr, "\n");
fprintf(stderr, "Value is null: %d\n", mlirValueIsNull(value));
- // CHECK: Result 0: {{.*}} = constant 0 : index
+ // CHECK: Result 0: {{.*}} = arith.constant 0 : index
// CHECK: Value is null: 0
MlirType type = mlirValueGetType(value);
mlirOperationPrintWithFlags(operation, flags, printToStderr, NULL);
fprintf(stderr, "\n");
// clang-format off
- // CHECK: Op print with all flags: %{{.*}} = "std.constant"() {elts = opaque<"_", "0xDEADBEEF"> : tensor<4xi32>, value = 0 : index} : () -> index loc(unknown)
+ // CHECK: Op print with all flags: %{{.*}} = "arith.constant"() {elts = opaque<"_", "0xDEADBEEF"> : tensor<4xi32>, value = 0 : index} : () -> index loc(unknown)
// clang-format on
mlirOpPrintingFlagsDestroy(flags);
mlirIdentifierGet(ctx, mlirStringRefCreateFromCString("value")),
indexZeroLiteral);
MlirOperationState constZeroState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.constant"), loc);
+ mlirStringRefCreateFromCString("arith.constant"), loc);
mlirOperationStateAddResults(&constZeroState, 1, &indexType);
mlirOperationStateAddAttributes(&constZeroState, 1, &indexZeroValueAttr);
MlirOperation constZero = mlirOperationCreate(&constZeroState);
mlirIdentifierGet(ctx, mlirStringRefCreateFromCString("value")),
indexOneLiteral);
MlirOperationState constOneState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.constant"), loc);
+ mlirStringRefCreateFromCString("arith.constant"), loc);
mlirOperationStateAddResults(&constOneState, 1, &indexType);
mlirOperationStateAddAttributes(&constOneState, 1, &indexOneValueAttr);
MlirOperation constOne = mlirOperationCreate(&constOneState);
MlirValue opOperand = mlirOperationGetOperand(op, 0);
fprintf(stderr, "Original operand: ");
mlirValuePrint(opOperand, printToStderr, NULL);
- // CHECK: Original operand: {{.+}} constant 0 : index
+ // CHECK: Original operand: {{.+}} arith.constant 0 : index
mlirOperationSetOperand(op, 0, constOneValue);
opOperand = mlirOperationGetOperand(op, 0);
fprintf(stderr, "Updated operand: ");
mlirValuePrint(opOperand, printToStderr, NULL);
- // CHECK: Updated operand: {{.+}} constant 1 : index
+ // CHECK: Updated operand: {{.+}} arith.constant 1 : index
mlirOperationDestroy(op);
mlirOperationDestroy(constZero);
MlirNamedAttribute indexZeroValueAttr = mlirNamedAttributeGet(
mlirIdentifierGet(ctx, valueStringRef), indexZeroLiteral);
MlirOperationState constZeroState = mlirOperationStateGet(
- mlirStringRefCreateFromCString("std.constant"), loc);
+ mlirStringRefCreateFromCString("arith.constant"), loc);
mlirOperationStateAddResults(&constZeroState, 1, &indexType);
mlirOperationStateAddAttributes(&constZeroState, 1, &indexZeroValueAttr);
MlirOperation constZero = mlirOperationCreate(&constZeroState);
mlirOperationPrint(constZero, printToStderr, NULL);
mlirOperationPrint(constOne, printToStderr, NULL);
- // CHECK: constant 0 : index
- // CHECK: constant 1 : index
+ // CHECK: arith.constant 0 : index
+ // CHECK: arith.constant 1 : index
mlirOperationDestroy(constZero);
mlirOperationDestroy(constOne);
// clang-format off
mlirStringRefCreateFromCString(
"func @foo(%arg0 : i32) -> i32 { \n"
-" %res = addi %arg0, %arg0 : i32 \n"
+" %res = arith.addi %arg0, %arg0 : i32 \n"
" return %res : i32 \n"
"}"));
// clang-format on
// Run the print-op-stats pass on the top-level module:
// CHECK-LABEL: Operations encountered:
+ // CHECK: arith.addi , 1
// CHECK: builtin.func , 1
- // CHECK: std.addi , 1
// CHECK: std.return , 1
{
MlirPassManager pm = mlirPassManagerCreate(ctx);
MlirContext ctx = mlirContextCreate();
mlirRegisterAllDialects(ctx);
- MlirModule module = mlirModuleCreateParse(
- ctx,
- // clang-format off
+ MlirModule module =
+ mlirModuleCreateParse(ctx,
+ // clang-format off
mlirStringRefCreateFromCString(
"func @foo(%arg0 : i32) -> i32 { \n"
-" %res = addi %arg0, %arg0 : i32 \n"
+" %res = arith.addi %arg0, %arg0 : i32 \n"
" return %res : i32 \n"
"} \n"
"module { \n"
" func @bar(%arg0 : f32) -> f32 { \n"
-" %res = addf %arg0, %arg0 : f32 \n"
+" %res = arith.addf %arg0, %arg0 : f32 \n"
" return %res : f32 \n"
" } \n"
"}"));
// Run the print-op-stats pass on functions under the top-level module:
// CHECK-LABEL: Operations encountered:
+ // CHECK: arith.addi , 1
// CHECK: builtin.func , 1
- // CHECK: std.addi , 1
// CHECK: std.return , 1
{
MlirPassManager pm = mlirPassManagerCreate(ctx);
}
// Run the print-op-stats pass on functions under the nested module:
// CHECK-LABEL: Operations encountered:
+ // CHECK: arith.addf , 1
// CHECK: builtin.func , 1
- // CHECK: std.addf , 1
// CHECK: std.return , 1
{
MlirPassManager pm = mlirPassManagerCreate(ctx);
%1 = affine.vector_load %0[%i0 + symbol(%arg0) + 7] : memref<100xf32>, vector<8xf32>
}
// CHECK: %[[buf:.*]] = memref.alloc
-// CHECK: %[[a:.*]] = addi %{{.*}}, %{{.*}} : index
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[b:.*]] = addi %[[a]], %[[c7]] : index
+// CHECK: %[[a:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %[[a]], %[[c7]] : index
// CHECK-NEXT: vector.load %[[buf]][%[[b]]] : memref<100xf32>, vector<8xf32>
return
}
// CHECK-LABEL: func @affine_vector_store
func @affine_vector_store(%arg0 : index) {
%0 = memref.alloc() : memref<100xf32>
- %1 = constant dense<11.0> : vector<4xf32>
+ %1 = arith.constant dense<11.0> : vector<4xf32>
affine.for %i0 = 0 to 16 {
affine.vector_store %1, %0[%i0 - symbol(%arg0) + 7] : memref<100xf32>, vector<4xf32>
}
// CHECK: %[[buf:.*]] = memref.alloc
-// CHECK: %[[val:.*]] = constant dense
-// CHECK: %[[c_1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[a:.*]] = muli %arg0, %[[c_1]] : index
-// CHECK-NEXT: %[[b:.*]] = addi %{{.*}}, %[[a]] : index
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[c:.*]] = addi %[[b]], %[[c7]] : index
+// CHECK: %[[val:.*]] = arith.constant dense
+// CHECK: %[[c_1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[a:.*]] = arith.muli %arg0, %[[c_1]] : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %{{.*}}, %[[a]] : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[c:.*]] = arith.addi %[[b]], %[[c7]] : index
// CHECK-NEXT: vector.store %[[val]], %[[buf]][%[[c]]] : memref<100xf32>, vector<4xf32>
return
}
// CHECK-LABEL: func @vector_store_2d
func @vector_store_2d() {
%0 = memref.alloc() : memref<100x100xf32>
- %1 = constant dense<11.0> : vector<2x8xf32>
+ %1 = arith.constant dense<11.0> : vector<2x8xf32>
affine.for %i0 = 0 to 16 step 2{
affine.for %i1 = 0 to 16 step 8 {
affine.vector_store %1, %0[%i0, %i1] : memref<100x100xf32>, vector<2x8xf32>
// CHECK: %[[buf:.*]] = memref.alloc
-// CHECK: %[[val:.*]] = constant dense
+// CHECK: %[[val:.*]] = arith.constant dense
// CHECK: scf.for %[[i0:.*]] =
// CHECK: scf.for %[[i1:.*]] =
// CHECK-NEXT: vector.store %[[val]], %[[buf]][%[[i0]], %[[i1]]] : memref<100x100xf32>, vector<2x8xf32>
// Simple loops are properly converted.
// CHECK-LABEL: func @simple_loop
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c1_0:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c1_0:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c1]] to %[[c42]] step %[[c1_0]] {
// CHECK-NEXT: call @body(%{{.*}}) : (index) -> ()
// CHECK-NEXT: }
/////////////////////////////////////////////////////////////////////
func @for_with_yield(%buffer: memref<1024xf32>) -> (f32) {
- %sum_0 = constant 0.0 : f32
+ %sum_0 = arith.constant 0.0 : f32
%sum = affine.for %i = 0 to 10 step 2 iter_args(%sum_iter = %sum_0) -> (f32) {
%t = affine.load %buffer[%i] : memref<1024xf32>
- %sum_next = addf %sum_iter, %t : f32
+ %sum_next = arith.addf %sum_iter, %t : f32
affine.yield %sum_next : f32
}
return %sum : f32
}
// CHECK-LABEL: func @for_with_yield
-// CHECK: %[[INIT_SUM:.*]] = constant 0.000000e+00 : f32
-// CHECK-NEXT: %[[LOWER:.*]] = constant 0 : index
-// CHECK-NEXT: %[[UPPER:.*]] = constant 10 : index
-// CHECK-NEXT: %[[STEP:.*]] = constant 2 : index
+// CHECK: %[[INIT_SUM:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[LOWER:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[UPPER:.*]] = arith.constant 10 : index
+// CHECK-NEXT: %[[STEP:.*]] = arith.constant 2 : index
// CHECK-NEXT: %[[SUM:.*]] = scf.for %[[IV:.*]] = %[[LOWER]] to %[[UPPER]] step %[[STEP]] iter_args(%[[SUM_ITER:.*]] = %[[INIT_SUM]]) -> (f32) {
// CHECK-NEXT: memref.load
-// CHECK-NEXT: %[[SUM_NEXT:.*]] = addf
+// CHECK-NEXT: %[[SUM_NEXT:.*]] = arith.addf
// CHECK-NEXT: scf.yield %[[SUM_NEXT]] : f32
// CHECK-NEXT: }
// CHECK-NEXT: return %[[SUM]] : f32
func private @post(index) -> ()
// CHECK-LABEL: func @imperfectly_nested_loops
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0]] to %[[c42]] step %[[c1]] {
// CHECK-NEXT: call @pre(%{{.*}}) : (index) -> ()
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[c56:.*]] = constant 56 : index
-// CHECK-NEXT: %[[c2:.*]] = constant 2 : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[c56:.*]] = arith.constant 56 : index
+// CHECK-NEXT: %[[c2:.*]] = arith.constant 2 : index
// CHECK-NEXT: for %{{.*}} = %[[c7]] to %[[c56]] step %[[c2]] {
// CHECK-NEXT: call @body2(%{{.*}}, %{{.*}}) : (index, index) -> ()
// CHECK-NEXT: }
func private @body3(index, index) -> ()
// CHECK-LABEL: func @more_imperfectly_nested_loops
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0]] to %[[c42]] step %[[c1]] {
// CHECK-NEXT: call @pre(%{{.*}}) : (index) -> ()
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[c56:.*]] = constant 56 : index
-// CHECK-NEXT: %[[c2:.*]] = constant 2 : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[c56:.*]] = arith.constant 56 : index
+// CHECK-NEXT: %[[c2:.*]] = arith.constant 2 : index
// CHECK-NEXT: for %{{.*}} = %[[c7]] to %[[c56]] step %[[c2]] {
// CHECK-NEXT: call @body2(%{{.*}}, %{{.*}}) : (index, index) -> ()
// CHECK-NEXT: }
// CHECK-NEXT: call @mid(%{{.*}}) : (index) -> ()
-// CHECK-NEXT: %[[c18:.*]] = constant 18 : index
-// CHECK-NEXT: %[[c37:.*]] = constant 37 : index
-// CHECK-NEXT: %[[c3:.*]] = constant 3 : index
+// CHECK-NEXT: %[[c18:.*]] = arith.constant 18 : index
+// CHECK-NEXT: %[[c37:.*]] = arith.constant 37 : index
+// CHECK-NEXT: %[[c3:.*]] = arith.constant 3 : index
// CHECK-NEXT: for %{{.*}} = %[[c18]] to %[[c37]] step %[[c3]] {
// CHECK-NEXT: call @body3(%{{.*}}, %{{.*}}) : (index, index) -> ()
// CHECK-NEXT: }
}
// CHECK-LABEL: func @affine_apply_loops_shorthand
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0]] to %{{.*}} step %[[c1]] {
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c1_0:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c1_0:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %{{.*}} to %[[c42]] step %[[c1_0]] {
// CHECK-NEXT: call @body2(%{{.*}}, %{{.*}}) : (index, index) -> ()
// CHECK-NEXT: }
// CHECK-LABEL: func @if_only
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v1:.*]] = muli %[[v0]], %[[cm1]] : index
-// CHECK-NEXT: %[[c20:.*]] = constant 20 : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v1]], %[[c20]] : index
-// CHECK-NEXT: %[[v3:.*]] = cmpi sge, %[[v2]], %[[c0]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.muli %[[v0]], %[[cm1]] : index
+// CHECK-NEXT: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v1]], %[[c20]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.cmpi sge, %[[v2]], %[[c0]] : index
// CHECK-NEXT: if %[[v3]] {
// CHECK-NEXT: call @body(%[[v0:.*]]) : (index) -> ()
// CHECK-NEXT: }
// CHECK-LABEL: func @if_else
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v1:.*]] = muli %[[v0]], %[[cm1]] : index
-// CHECK-NEXT: %[[c20:.*]] = constant 20 : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v1]], %[[c20]] : index
-// CHECK-NEXT: %[[v3:.*]] = cmpi sge, %[[v2]], %[[c0]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.muli %[[v0]], %[[cm1]] : index
+// CHECK-NEXT: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v1]], %[[c20]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.cmpi sge, %[[v2]], %[[c0]] : index
// CHECK-NEXT: if %[[v3]] {
// CHECK-NEXT: call @body(%[[v0:.*]]) : (index) -> ()
// CHECK-NEXT: } else {
// CHECK-LABEL: func @nested_ifs
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v1:.*]] = muli %[[v0]], %[[cm1]] : index
-// CHECK-NEXT: %[[c20:.*]] = constant 20 : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v1]], %[[c20]] : index
-// CHECK-NEXT: %[[v3:.*]] = cmpi sge, %[[v2]], %[[c0]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.muli %[[v0]], %[[cm1]] : index
+// CHECK-NEXT: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v1]], %[[c20]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.cmpi sge, %[[v2]], %[[c0]] : index
// CHECK-NEXT: if %[[v3]] {
-// CHECK-NEXT: %[[c0_0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm10:.*]] = constant -10 : index
-// CHECK-NEXT: %[[v4:.*]] = addi %[[v0]], %[[cm10]] : index
-// CHECK-NEXT: %[[v5:.*]] = cmpi sge, %[[v4]], %[[c0_0]] : index
+// CHECK-NEXT: %[[c0_0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm10:.*]] = arith.constant -10 : index
+// CHECK-NEXT: %[[v4:.*]] = arith.addi %[[v0]], %[[cm10]] : index
+// CHECK-NEXT: %[[v5:.*]] = arith.cmpi sge, %[[v4]], %[[c0_0]] : index
// CHECK-NEXT: if %[[v5]] {
// CHECK-NEXT: call @body(%[[v0:.*]]) : (index) -> ()
// CHECK-NEXT: }
// CHECK-NEXT: } else {
-// CHECK-NEXT: %[[c0_0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm10:.*]] = constant -10 : index
-// CHECK-NEXT: %{{.*}} = addi %[[v0]], %[[cm10]] : index
-// CHECK-NEXT: %{{.*}} = cmpi sge, %{{.*}}, %[[c0_0]] : index
+// CHECK-NEXT: %[[c0_0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm10:.*]] = arith.constant -10 : index
+// CHECK-NEXT: %{{.*}} = arith.addi %[[v0]], %[[cm10]] : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi sge, %{{.*}}, %[[c0_0]] : index
// CHECK-NEXT: if %{{.*}} {
// CHECK-NEXT: call @mid(%[[v0:.*]]) : (index) -> ()
// CHECK-NEXT: }
}
// CHECK-LABEL: func @if_with_yield
-// CHECK-NEXT: %[[c0_i64:.*]] = constant 0 : i64
-// CHECK-NEXT: %[[c1_i64:.*]] = constant 1 : i64
+// CHECK-NEXT: %[[c0_i64:.*]] = arith.constant 0 : i64
+// CHECK-NEXT: %[[c1_i64:.*]] = arith.constant 1 : i64
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm10:.*]] = constant -10 : index
-// CHECK-NEXT: %[[v1:.*]] = addi %[[v0]], %[[cm10]] : index
-// CHECK-NEXT: %[[v2:.*]] = cmpi sge, %[[v1]], %[[c0]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm10:.*]] = arith.constant -10 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.addi %[[v0]], %[[cm10]] : index
+// CHECK-NEXT: %[[v2:.*]] = arith.cmpi sge, %[[v1]], %[[c0]] : index
// CHECK-NEXT: %[[v3:.*]] = scf.if %[[v2]] -> (i64) {
// CHECK-NEXT: scf.yield %[[c0_i64]] : i64
// CHECK-NEXT: } else {
// CHECK-NEXT: return %[[v3]] : i64
// CHECK-NEXT: }
func @if_with_yield() -> (i64) {
- %cst0 = constant 0 : i64
- %cst1 = constant 1 : i64
+ %cst0 = arith.constant 0 : i64
+ %cst1 = arith.constant 1 : i64
%i = call @get_idx() : () -> (index)
%1 = affine.if #set2(%i) -> (i64) {
affine.yield %cst0 : i64
// CHECK-LABEL: func @multi_cond
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v1:.*]] = muli %[[v0]], %[[cm1]] : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v1]], %{{.*}} : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[v3:.*]] = addi %[[v2]], %[[c1]] : index
-// CHECK-NEXT: %[[v4:.*]] = cmpi sge, %[[v3]], %[[c0]] : index
-// CHECK-NEXT: %[[cm1_0:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v5:.*]] = addi %{{.*}}, %[[cm1_0]] : index
-// CHECK-NEXT: %[[v6:.*]] = cmpi sge, %[[v5]], %[[c0]] : index
-// CHECK-NEXT: %[[v7:.*]] = and %[[v4]], %[[v6]] : i1
-// CHECK-NEXT: %[[cm1_1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v8:.*]] = addi %{{.*}}, %[[cm1_1]] : index
-// CHECK-NEXT: %[[v9:.*]] = cmpi sge, %[[v8]], %[[c0]] : index
-// CHECK-NEXT: %[[v10:.*]] = and %[[v7]], %[[v9]] : i1
-// CHECK-NEXT: %[[cm1_2:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v11:.*]] = addi %{{.*}}, %[[cm1_2]] : index
-// CHECK-NEXT: %[[v12:.*]] = cmpi sge, %[[v11]], %[[c0]] : index
-// CHECK-NEXT: %[[v13:.*]] = and %[[v10]], %[[v12]] : i1
-// CHECK-NEXT: %[[cm42:.*]] = constant -42 : index
-// CHECK-NEXT: %[[v14:.*]] = addi %{{.*}}, %[[cm42]] : index
-// CHECK-NEXT: %[[v15:.*]] = cmpi eq, %[[v14]], %[[c0]] : index
-// CHECK-NEXT: %[[v16:.*]] = and %[[v13]], %[[v15]] : i1
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.muli %[[v0]], %[[cm1]] : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v1]], %{{.*}} : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[v3:.*]] = arith.addi %[[v2]], %[[c1]] : index
+// CHECK-NEXT: %[[v4:.*]] = arith.cmpi sge, %[[v3]], %[[c0]] : index
+// CHECK-NEXT: %[[cm1_0:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v5:.*]] = arith.addi %{{.*}}, %[[cm1_0]] : index
+// CHECK-NEXT: %[[v6:.*]] = arith.cmpi sge, %[[v5]], %[[c0]] : index
+// CHECK-NEXT: %[[v7:.*]] = arith.andi %[[v4]], %[[v6]] : i1
+// CHECK-NEXT: %[[cm1_1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v8:.*]] = arith.addi %{{.*}}, %[[cm1_1]] : index
+// CHECK-NEXT: %[[v9:.*]] = arith.cmpi sge, %[[v8]], %[[c0]] : index
+// CHECK-NEXT: %[[v10:.*]] = arith.andi %[[v7]], %[[v9]] : i1
+// CHECK-NEXT: %[[cm1_2:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v11:.*]] = arith.addi %{{.*}}, %[[cm1_2]] : index
+// CHECK-NEXT: %[[v12:.*]] = arith.cmpi sge, %[[v11]], %[[c0]] : index
+// CHECK-NEXT: %[[v13:.*]] = arith.andi %[[v10]], %[[v12]] : i1
+// CHECK-NEXT: %[[cm42:.*]] = arith.constant -42 : index
+// CHECK-NEXT: %[[v14:.*]] = arith.addi %{{.*}}, %[[cm42]] : index
+// CHECK-NEXT: %[[v15:.*]] = arith.cmpi eq, %[[v14]], %[[c0]] : index
+// CHECK-NEXT: %[[v16:.*]] = arith.andi %[[v13]], %[[v15]] : i1
// CHECK-NEXT: if %[[v16]] {
// CHECK-NEXT: call @body(%[[v0:.*]]) : (index) -> ()
// CHECK-NEXT: } else {
func @if_for() {
// CHECK-NEXT: %[[v0:.*]] = call @get_idx() : () -> index
%i = call @get_idx() : () -> (index)
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v1:.*]] = muli %[[v0]], %[[cm1]] : index
-// CHECK-NEXT: %[[c20:.*]] = constant 20 : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v1]], %[[c20]] : index
-// CHECK-NEXT: %[[v3:.*]] = cmpi sge, %[[v2]], %[[c0]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.muli %[[v0]], %[[cm1]] : index
+// CHECK-NEXT: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v1]], %[[c20]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.cmpi sge, %[[v2]], %[[c0]] : index
// CHECK-NEXT: if %[[v3]] {
-// CHECK-NEXT: %[[c0:.*]]{{.*}} = constant 0 : index
-// CHECK-NEXT: %[[c42:.*]]{{.*}} = constant 42 : index
-// CHECK-NEXT: %[[c1:.*]]{{.*}} = constant 1 : index
+// CHECK-NEXT: %[[c0:.*]]{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %[[c42:.*]]{{.*}} = arith.constant 42 : index
+// CHECK-NEXT: %[[c1:.*]]{{.*}} = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0:.*]]{{.*}} to %[[c42:.*]]{{.*}} step %[[c1:.*]]{{.*}} {
-// CHECK-NEXT: %[[c0_:.*]]{{.*}} = constant 0 : index
-// CHECK-NEXT: %[[cm10:.*]] = constant -10 : index
-// CHECK-NEXT: %[[v4:.*]] = addi %{{.*}}, %[[cm10]] : index
-// CHECK-NEXT: %[[v5:.*]] = cmpi sge, %[[v4]], %[[c0_:.*]]{{.*}} : index
+// CHECK-NEXT: %[[c0_:.*]]{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %[[cm10:.*]] = arith.constant -10 : index
+// CHECK-NEXT: %[[v4:.*]] = arith.addi %{{.*}}, %[[cm10]] : index
+// CHECK-NEXT: %[[v5:.*]] = arith.cmpi sge, %[[v4]], %[[c0_:.*]]{{.*}} : index
// CHECK-NEXT: if %[[v5]] {
// CHECK-NEXT: call @body2(%[[v0]], %{{.*}}) : (index, index) -> ()
affine.if #set1(%i) {
}
}
}
-// CHECK: %[[c0:.*]]{{.*}} = constant 0 : index
-// CHECK-NEXT: %[[c42:.*]]{{.*}} = constant 42 : index
-// CHECK-NEXT: %[[c1:.*]]{{.*}} = constant 1 : index
+// CHECK: %[[c0:.*]]{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %[[c42:.*]]{{.*}} = arith.constant 42 : index
+// CHECK-NEXT: %[[c1:.*]]{{.*}} = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0:.*]]{{.*}} to %[[c42:.*]]{{.*}} step %[[c1:.*]]{{.*}} {
-// CHECK-NEXT: %[[c0:.*]]{{.*}} = constant 0 : index
-// CHECK-NEXT: %[[cm10:.*]]{{.*}} = constant -10 : index
-// CHECK-NEXT: %{{.*}} = addi %{{.*}}, %[[cm10:.*]]{{.*}} : index
-// CHECK-NEXT: %{{.*}} = cmpi sge, %{{.*}}, %[[c0:.*]]{{.*}} : index
+// CHECK-NEXT: %[[c0:.*]]{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %[[cm10:.*]]{{.*}} = arith.constant -10 : index
+// CHECK-NEXT: %{{.*}} = arith.addi %{{.*}}, %[[cm10:.*]]{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi sge, %{{.*}}, %[[c0:.*]]{{.*}} : index
// CHECK-NEXT: if %{{.*}} {
-// CHECK-NEXT: %[[c0_:.*]]{{.*}} = constant 0 : index
-// CHECK-NEXT: %[[c42_:.*]]{{.*}} = constant 42 : index
-// CHECK-NEXT: %[[c1_:.*]]{{.*}} = constant 1 : index
+// CHECK-NEXT: %[[c0_:.*]]{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %[[c42_:.*]]{{.*}} = arith.constant 42 : index
+// CHECK-NEXT: %[[c1_:.*]]{{.*}} = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0_:.*]]{{.*}} to %[[c42_:.*]]{{.*}} step %[[c1_:.*]]{{.*}} {
affine.for %k = 0 to 42 {
affine.if #set2(%k) {
#ubMultiMap = affine_map<(d0)[s0] -> (s0, d0 + 10)>
// CHECK-LABEL: func @loop_min_max
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0]] to %[[c42]] step %[[c1]] {
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[a:.*]] = muli %{{.*}}, %[[cm1]] : index
-// CHECK-NEXT: %[[b:.*]] = addi %[[a]], %{{.*}} : index
-// CHECK-NEXT: %[[c:.*]] = cmpi sgt, %{{.*}}, %[[b]] : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[a:.*]] = arith.muli %{{.*}}, %[[cm1]] : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %[[a]], %{{.*}} : index
+// CHECK-NEXT: %[[c:.*]] = arith.cmpi sgt, %{{.*}}, %[[b]] : index
// CHECK-NEXT: %[[d:.*]] = select %[[c]], %{{.*}}, %[[b]] : index
-// CHECK-NEXT: %[[c10:.*]] = constant 10 : index
-// CHECK-NEXT: %[[e:.*]] = addi %{{.*}}, %[[c10]] : index
-// CHECK-NEXT: %[[f:.*]] = cmpi slt, %{{.*}}, %[[e]] : index
+// CHECK-NEXT: %[[c10:.*]] = arith.constant 10 : index
+// CHECK-NEXT: %[[e:.*]] = arith.addi %{{.*}}, %[[c10]] : index
+// CHECK-NEXT: %[[f:.*]] = arith.cmpi slt, %{{.*}}, %[[e]] : index
// CHECK-NEXT: %[[g:.*]] = select %[[f]], %{{.*}}, %[[e]] : index
-// CHECK-NEXT: %[[c1_0:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c1_0:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[d]] to %[[g]] step %[[c1_0]] {
// CHECK-NEXT: call @body2(%{{.*}}, %{{.*}}) : (index, index) -> ()
// CHECK-NEXT: }
// correctly for an affine map with 7 results.
// CHECK-LABEL: func @min_reduction_tree
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c01:.+]] = cmpi slt, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c01:.+]] = arith.cmpi slt, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: %[[r01:.+]] = select %[[c01]], %{{.*}}, %{{.*}} : index
-// CHECK-NEXT: %[[c012:.+]] = cmpi slt, %[[r01]], %{{.*}} : index
+// CHECK-NEXT: %[[c012:.+]] = arith.cmpi slt, %[[r01]], %{{.*}} : index
// CHECK-NEXT: %[[r012:.+]] = select %[[c012]], %[[r01]], %{{.*}} : index
-// CHECK-NEXT: %[[c0123:.+]] = cmpi slt, %[[r012]], %{{.*}} : index
+// CHECK-NEXT: %[[c0123:.+]] = arith.cmpi slt, %[[r012]], %{{.*}} : index
// CHECK-NEXT: %[[r0123:.+]] = select %[[c0123]], %[[r012]], %{{.*}} : index
-// CHECK-NEXT: %[[c01234:.+]] = cmpi slt, %[[r0123]], %{{.*}} : index
+// CHECK-NEXT: %[[c01234:.+]] = arith.cmpi slt, %[[r0123]], %{{.*}} : index
// CHECK-NEXT: %[[r01234:.+]] = select %[[c01234]], %[[r0123]], %{{.*}} : index
-// CHECK-NEXT: %[[c012345:.+]] = cmpi slt, %[[r01234]], %{{.*}} : index
+// CHECK-NEXT: %[[c012345:.+]] = arith.cmpi slt, %[[r01234]], %{{.*}} : index
// CHECK-NEXT: %[[r012345:.+]] = select %[[c012345]], %[[r01234]], %{{.*}} : index
-// CHECK-NEXT: %[[c0123456:.+]] = cmpi slt, %[[r012345]], %{{.*}} : index
+// CHECK-NEXT: %[[c0123456:.+]] = arith.cmpi slt, %[[r012345]], %{{.*}} : index
// CHECK-NEXT: %[[r0123456:.+]] = select %[[c0123456]], %[[r012345]], %{{.*}} : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
// CHECK-NEXT: for %{{.*}} = %[[c0]] to %[[r0123456]] step %[[c1]] {
// CHECK-NEXT: call @body(%{{.*}}) : (index) -> ()
// CHECK-NEXT: }
// CHECK-LABEL: func @affine_applies(
func @affine_applies(%arg0 : index) {
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
%zero = affine.apply #map0()
// Identity maps are just discarded.
-// CHECK-NEXT: %[[c101:.*]] = constant 101 : index
- %101 = constant 101 : index
+// CHECK-NEXT: %[[c101:.*]] = arith.constant 101 : index
+ %101 = arith.constant 101 : index
%symbZero = affine.apply #map1()[%zero]
-// CHECK-NEXT: %[[c102:.*]] = constant 102 : index
- %102 = constant 102 : index
+// CHECK-NEXT: %[[c102:.*]] = arith.constant 102 : index
+ %102 = arith.constant 102 : index
%copy = affine.apply #map2(%zero)
-// CHECK-NEXT: %[[v0:.*]] = addi %[[c0]], %[[c0]] : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[v1:.*]] = addi %[[v0]], %[[c1]] : index
+// CHECK-NEXT: %[[v0:.*]] = arith.addi %[[c0]], %[[c0]] : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.addi %[[v0]], %[[c1]] : index
%one = affine.apply #map3(%symbZero)[%zero]
-// CHECK-NEXT: %[[c2:.*]] = constant 2 : index
-// CHECK-NEXT: %[[v2:.*]] = muli %arg0, %[[c2]] : index
-// CHECK-NEXT: %[[v3:.*]] = addi %arg0, %[[v2]] : index
-// CHECK-NEXT: %[[c3:.*]] = constant 3 : index
-// CHECK-NEXT: %[[v4:.*]] = muli %arg0, %[[c3]] : index
-// CHECK-NEXT: %[[v5:.*]] = addi %[[v3]], %[[v4]] : index
-// CHECK-NEXT: %[[c4:.*]] = constant 4 : index
-// CHECK-NEXT: %[[v6:.*]] = muli %arg0, %[[c4]] : index
-// CHECK-NEXT: %[[v7:.*]] = addi %[[v5]], %[[v6]] : index
-// CHECK-NEXT: %[[c5:.*]] = constant 5 : index
-// CHECK-NEXT: %[[v8:.*]] = muli %arg0, %[[c5]] : index
-// CHECK-NEXT: %[[v9:.*]] = addi %[[v7]], %[[v8]] : index
-// CHECK-NEXT: %[[c6:.*]] = constant 6 : index
-// CHECK-NEXT: %[[v10:.*]] = muli %arg0, %[[c6]] : index
-// CHECK-NEXT: %[[v11:.*]] = addi %[[v9]], %[[v10]] : index
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[v12:.*]] = muli %arg0, %[[c7]] : index
-// CHECK-NEXT: %[[v13:.*]] = addi %[[v11]], %[[v12]] : index
+// CHECK-NEXT: %[[c2:.*]] = arith.constant 2 : index
+// CHECK-NEXT: %[[v2:.*]] = arith.muli %arg0, %[[c2]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.addi %arg0, %[[v2]] : index
+// CHECK-NEXT: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-NEXT: %[[v4:.*]] = arith.muli %arg0, %[[c3]] : index
+// CHECK-NEXT: %[[v5:.*]] = arith.addi %[[v3]], %[[v4]] : index
+// CHECK-NEXT: %[[c4:.*]] = arith.constant 4 : index
+// CHECK-NEXT: %[[v6:.*]] = arith.muli %arg0, %[[c4]] : index
+// CHECK-NEXT: %[[v7:.*]] = arith.addi %[[v5]], %[[v6]] : index
+// CHECK-NEXT: %[[c5:.*]] = arith.constant 5 : index
+// CHECK-NEXT: %[[v8:.*]] = arith.muli %arg0, %[[c5]] : index
+// CHECK-NEXT: %[[v9:.*]] = arith.addi %[[v7]], %[[v8]] : index
+// CHECK-NEXT: %[[c6:.*]] = arith.constant 6 : index
+// CHECK-NEXT: %[[v10:.*]] = arith.muli %arg0, %[[c6]] : index
+// CHECK-NEXT: %[[v11:.*]] = arith.addi %[[v9]], %[[v10]] : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[v12:.*]] = arith.muli %arg0, %[[c7]] : index
+// CHECK-NEXT: %[[v13:.*]] = arith.addi %[[v11]], %[[v12]] : index
%four = affine.apply #map4(%arg0, %arg0, %arg0, %arg0)[%arg0, %arg0, %arg0]
return
}
// --------------------------------------------------------------------------//
// CHECK-LABEL: func @affine_apply_mod
func @affine_apply_mod(%arg0 : index) -> (index) {
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[v0:.*]] = remi_signed %{{.*}}, %[[c42]] : index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[v1:.*]] = cmpi slt, %[[v0]], %[[c0]] : index
-// CHECK-NEXT: %[[v2:.*]] = addi %[[v0]], %[[c42]] : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[v0:.*]] = arith.remsi %{{.*}}, %[[c42]] : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[v1:.*]] = arith.cmpi slt, %[[v0]], %[[c0]] : index
+// CHECK-NEXT: %[[v2:.*]] = arith.addi %[[v0]], %[[c42]] : index
// CHECK-NEXT: %[[v3:.*]] = select %[[v1]], %[[v2]], %[[v0]] : index
%0 = affine.apply #mapmod (%arg0)
return %0 : index
// --------------------------------------------------------------------------//
// CHECK-LABEL: func @affine_apply_floordiv
func @affine_apply_floordiv(%arg0 : index) -> (index) {
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[cm1:.*]] = constant -1 : index
-// CHECK-NEXT: %[[v0:.*]] = cmpi slt, %{{.*}}, %[[c0]] : index
-// CHECK-NEXT: %[[v1:.*]] = subi %[[cm1]], %{{.*}} : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[cm1:.*]] = arith.constant -1 : index
+// CHECK-NEXT: %[[v0:.*]] = arith.cmpi slt, %{{.*}}, %[[c0]] : index
+// CHECK-NEXT: %[[v1:.*]] = arith.subi %[[cm1]], %{{.*}} : index
// CHECK-NEXT: %[[v2:.*]] = select %[[v0]], %[[v1]], %{{.*}} : index
-// CHECK-NEXT: %[[v3:.*]] = divi_signed %[[v2]], %[[c42]] : index
-// CHECK-NEXT: %[[v4:.*]] = subi %[[cm1]], %[[v3]] : index
+// CHECK-NEXT: %[[v3:.*]] = arith.divsi %[[v2]], %[[c42]] : index
+// CHECK-NEXT: %[[v4:.*]] = arith.subi %[[cm1]], %[[v3]] : index
// CHECK-NEXT: %[[v5:.*]] = select %[[v0]], %[[v4]], %[[v3]] : index
%0 = affine.apply #mapfloordiv (%arg0)
return %0 : index
// --------------------------------------------------------------------------//
// CHECK-LABEL: func @affine_apply_ceildiv
func @affine_apply_ceildiv(%arg0 : index) -> (index) {
-// CHECK-NEXT: %[[c42:.*]] = constant 42 : index
-// CHECK-NEXT: %[[c0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[c1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[v0:.*]] = cmpi sle, %{{.*}}, %[[c0]] : index
-// CHECK-NEXT: %[[v1:.*]] = subi %[[c0]], %{{.*}} : index
-// CHECK-NEXT: %[[v2:.*]] = subi %{{.*}}, %[[c1]] : index
+// CHECK-NEXT: %[[c42:.*]] = arith.constant 42 : index
+// CHECK-NEXT: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[v0:.*]] = arith.cmpi sle, %{{.*}}, %[[c0]] : index
+// CHECK-NEXT: %[[v1:.*]] = arith.subi %[[c0]], %{{.*}} : index
+// CHECK-NEXT: %[[v2:.*]] = arith.subi %{{.*}}, %[[c1]] : index
// CHECK-NEXT: %[[v3:.*]] = select %[[v0]], %[[v1]], %[[v2]] : index
-// CHECK-NEXT: %[[v4:.*]] = divi_signed %[[v3]], %[[c42]] : index
-// CHECK-NEXT: %[[v5:.*]] = subi %[[c0]], %[[v4]] : index
-// CHECK-NEXT: %[[v6:.*]] = addi %[[v4]], %[[c1]] : index
+// CHECK-NEXT: %[[v4:.*]] = arith.divsi %[[v3]], %[[c42]] : index
+// CHECK-NEXT: %[[v5:.*]] = arith.subi %[[c0]], %[[v4]] : index
+// CHECK-NEXT: %[[v6:.*]] = arith.addi %[[v4]], %[[c1]] : index
// CHECK-NEXT: %[[v7:.*]] = select %[[v0]], %[[v5]], %[[v6]] : index
%0 = affine.apply #mapceildiv (%arg0)
return %0 : index
affine.for %i0 = 0 to 10 {
%1 = affine.load %0[%i0 + symbol(%arg0) + 7] : memref<10xf32>
}
-// CHECK: %[[a:.*]] = addi %{{.*}}, %{{.*}} : index
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[b:.*]] = addi %[[a]], %[[c7]] : index
+// CHECK: %[[a:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %[[a]], %[[c7]] : index
// CHECK-NEXT: %{{.*}} = memref.load %[[v0:.*]][%[[b]]] : memref<10xf32>
return
}
// CHECK-LABEL: func @affine_store
func @affine_store(%arg0 : index) {
%0 = memref.alloc() : memref<10xf32>
- %1 = constant 11.0 : f32
+ %1 = arith.constant 11.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %1, %0[%i0 - symbol(%arg0) + 7] : memref<10xf32>
}
-// CHECK: %c-1 = constant -1 : index
-// CHECK-NEXT: %[[a:.*]] = muli %arg0, %c-1 : index
-// CHECK-NEXT: %[[b:.*]] = addi %{{.*}}, %[[a]] : index
-// CHECK-NEXT: %c7 = constant 7 : index
-// CHECK-NEXT: %[[c:.*]] = addi %[[b]], %c7 : index
+// CHECK: %c-1 = arith.constant -1 : index
+// CHECK-NEXT: %[[a:.*]] = arith.muli %arg0, %c-1 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %{{.*}}, %[[a]] : index
+// CHECK-NEXT: %c7 = arith.constant 7 : index
+// CHECK-NEXT: %[[c:.*]] = arith.addi %[[b]], %c7 : index
// CHECK-NEXT: store %cst, %0[%[[c]]] : memref<10xf32>
return
}
affine.for %i0 = 0 to 10 {
affine.prefetch %0[%i0 + symbol(%arg0) + 7], read, locality<3>, data : memref<10xf32>
}
-// CHECK: %[[a:.*]] = addi %{{.*}}, %{{.*}} : index
-// CHECK-NEXT: %[[c7:.*]] = constant 7 : index
-// CHECK-NEXT: %[[b:.*]] = addi %[[a]], %[[c7]] : index
+// CHECK: %[[a:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[c7:.*]] = arith.constant 7 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %[[a]], %[[c7]] : index
// CHECK-NEXT: memref.prefetch %[[v0:.*]][%[[b]]], read, locality<3>, data : memref<10xf32>
return
}
%0 = memref.alloc() : memref<100xf32>
%1 = memref.alloc() : memref<100xf32, 2>
%2 = memref.alloc() : memref<1xi32>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.dma_start %0[%i0 + 7], %1[%arg0 + 11], %2[%c0], %c64
: memref<100xf32>, memref<100xf32, 2>, memref<1xi32>
}
-// CHECK: %c7 = constant 7 : index
-// CHECK-NEXT: %[[a:.*]] = addi %{{.*}}, %c7 : index
-// CHECK-NEXT: %c11 = constant 11 : index
-// CHECK-NEXT: %[[b:.*]] = addi %arg0, %c11 : index
+// CHECK: %c7 = arith.constant 7 : index
+// CHECK-NEXT: %[[a:.*]] = arith.addi %{{.*}}, %c7 : index
+// CHECK-NEXT: %c11 = arith.constant 11 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %arg0, %c11 : index
// CHECK-NEXT: dma_start %0[%[[a]]], %1[%[[b]]], %c64, %2[%c0] : memref<100xf32>, memref<100xf32, 2>, memref<1xi32>
return
}
// CHECK-LABEL: func @affine_dma_wait
func @affine_dma_wait(%arg0 : index) {
%2 = memref.alloc() : memref<1xi32>
- %c64 = constant 64 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.dma_wait %2[%i0 + %arg0 + 17], %c64 : memref<1xi32>
}
-// CHECK: %[[a:.*]] = addi %{{.*}}, %arg0 : index
-// CHECK-NEXT: %c17 = constant 17 : index
-// CHECK-NEXT: %[[b:.*]] = addi %[[a]], %c17 : index
+// CHECK: %[[a:.*]] = arith.addi %{{.*}}, %arg0 : index
+// CHECK-NEXT: %c17 = arith.constant 17 : index
+// CHECK-NEXT: %[[b:.*]] = arith.addi %[[a]], %c17 : index
// CHECK-NEXT: dma_wait %0[%[[b]]], %c64 : memref<1xi32>
return
}
// CHECK-LABEL: func @affine_min
// CHECK-SAME: %[[ARG0:.*]]: index, %[[ARG1:.*]]: index
func @affine_min(%arg0: index, %arg1: index) -> index{
- // CHECK: %[[Cm1:.*]] = constant -1
- // CHECK: %[[neg1:.*]] = muli %[[ARG1]], %[[Cm1:.*]]
- // CHECK: %[[first:.*]] = addi %[[ARG0]], %[[neg1]]
- // CHECK: %[[Cm2:.*]] = constant -1
- // CHECK: %[[neg2:.*]] = muli %[[ARG0]], %[[Cm2:.*]]
- // CHECK: %[[second:.*]] = addi %[[ARG1]], %[[neg2]]
- // CHECK: %[[cmp:.*]] = cmpi slt, %[[first]], %[[second]]
+ // CHECK: %[[Cm1:.*]] = arith.constant -1
+ // CHECK: %[[neg1:.*]] = arith.muli %[[ARG1]], %[[Cm1:.*]]
+ // CHECK: %[[first:.*]] = arith.addi %[[ARG0]], %[[neg1]]
+ // CHECK: %[[Cm2:.*]] = arith.constant -1
+ // CHECK: %[[neg2:.*]] = arith.muli %[[ARG0]], %[[Cm2:.*]]
+ // CHECK: %[[second:.*]] = arith.addi %[[ARG1]], %[[neg2]]
+ // CHECK: %[[cmp:.*]] = arith.cmpi slt, %[[first]], %[[second]]
// CHECK: select %[[cmp]], %[[first]], %[[second]]
%0 = affine.min affine_map<(d0,d1) -> (d0 - d1, d1 - d0)>(%arg0, %arg1)
return %0 : index
// CHECK-LABEL: func @affine_max
// CHECK-SAME: %[[ARG0:.*]]: index, %[[ARG1:.*]]: index
func @affine_max(%arg0: index, %arg1: index) -> index{
- // CHECK: %[[Cm1:.*]] = constant -1
- // CHECK: %[[neg1:.*]] = muli %[[ARG1]], %[[Cm1:.*]]
- // CHECK: %[[first:.*]] = addi %[[ARG0]], %[[neg1]]
- // CHECK: %[[Cm2:.*]] = constant -1
- // CHECK: %[[neg2:.*]] = muli %[[ARG0]], %[[Cm2:.*]]
- // CHECK: %[[second:.*]] = addi %[[ARG1]], %[[neg2]]
- // CHECK: %[[cmp:.*]] = cmpi sgt, %[[first]], %[[second]]
+ // CHECK: %[[Cm1:.*]] = arith.constant -1
+ // CHECK: %[[neg1:.*]] = arith.muli %[[ARG1]], %[[Cm1:.*]]
+ // CHECK: %[[first:.*]] = arith.addi %[[ARG0]], %[[neg1]]
+ // CHECK: %[[Cm2:.*]] = arith.constant -1
+ // CHECK: %[[neg2:.*]] = arith.muli %[[ARG0]], %[[Cm2:.*]]
+ // CHECK: %[[second:.*]] = arith.addi %[[ARG1]], %[[neg2]]
+ // CHECK: %[[cmp:.*]] = arith.cmpi sgt, %[[first]], %[[second]]
// CHECK: select %[[cmp]], %[[first]], %[[second]]
%0 = affine.max affine_map<(d0,d1) -> (d0 - d1, d1 - d0)>(%arg0, %arg1)
return %0 : index
return
}
-// CHECK-DAG: %[[C100:.*]] = constant 100
-// CHECK-DAG: %[[C100_1:.*]] = constant 100
-// CHECK-DAG: %[[C0:.*]] = constant 0
-// CHECK-DAG: %[[C0_1:.*]] = constant 0
-// CHECK-DAG: %[[C1:.*]] = constant 1
-// CHECK-DAG: %[[C1_1:.*]] = constant 1
+// CHECK-DAG: %[[C100:.*]] = arith.constant 100
+// CHECK-DAG: %[[C100_1:.*]] = arith.constant 100
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0
+// CHECK-DAG: %[[C0_1:.*]] = arith.constant 0
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1
+// CHECK-DAG: %[[C1_1:.*]] = arith.constant 1
// CHECK-DAG: scf.parallel (%arg2, %arg3) = (%[[C0]], %[[C0_1]]) to (%[[C100]], %[[C100_1]]) step (%[[C1]], %[[C1_1]]) {
// CHECK-LABEL: func @affine_parallel_tiled(
affine.parallel (%i1, %j1, %k1) = (%i0, %j0, %k0) to (%i0 + 10, %j0 + 10, %k0 + 10) {
%0 = affine.load %a[%i1, %k1] : memref<100x100xf32>
%1 = affine.load %b[%k1, %j1] : memref<100x100xf32>
- %2 = mulf %0, %1 : f32
+ %2 = arith.mulf %0, %1 : f32
}
}
return
}
-// CHECK-DAG: %[[C100:.*]] = constant 100
-// CHECK-DAG: %[[C100_0:.*]] = constant 100
-// CHECK-DAG: %[[C100_1:.*]] = constant 100
-// CHECK-DAG: %[[C0:.*]] = constant 0
-// CHECK-DAG: %[[C0_2:.*]] = constant 0
-// CHECK-DAG: %[[C0_3:.*]] = constant 0
-// CHECK-DAG: %[[C10:.*]] = constant 10
-// CHECK-DAG: %[[C10_4:.*]] = constant 10
-// CHECK-DAG: %[[C10_5:.*]] = constant 10
+// CHECK-DAG: %[[C100:.*]] = arith.constant 100
+// CHECK-DAG: %[[C100_0:.*]] = arith.constant 100
+// CHECK-DAG: %[[C100_1:.*]] = arith.constant 100
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0
+// CHECK-DAG: %[[C0_2:.*]] = arith.constant 0
+// CHECK-DAG: %[[C0_3:.*]] = arith.constant 0
+// CHECK-DAG: %[[C10:.*]] = arith.constant 10
+// CHECK-DAG: %[[C10_4:.*]] = arith.constant 10
+// CHECK-DAG: %[[C10_5:.*]] = arith.constant 10
// CHECK: scf.parallel (%[[arg3:.*]], %[[arg4:.*]], %[[arg5:.*]]) = (%[[C0]], %[[C0_2]], %[[C0_3]]) to (%[[C100]], %[[C100_0]], %[[C100_1]]) step (%[[C10]], %[[C10_4]], %[[C10_5]]) {
-// CHECK-DAG: %[[C10_6:.*]] = constant 10
-// CHECK-DAG: %[[A0:.*]] = addi %[[arg3]], %[[C10_6]]
-// CHECK-DAG: %[[C10_7:.*]] = constant 10
-// CHECK-DAG: %[[A1:.*]] = addi %[[arg4]], %[[C10_7]]
-// CHECK-DAG: %[[C10_8:.*]] = constant 10
-// CHECK-DAG: %[[A2:.*]] = addi %[[arg5]], %[[C10_8]]
-// CHECK-DAG: %[[C1:.*]] = constant 1
-// CHECK-DAG: %[[C1_9:.*]] = constant 1
-// CHECK-DAG: %[[C1_10:.*]] = constant 1
+// CHECK-DAG: %[[C10_6:.*]] = arith.constant 10
+// CHECK-DAG: %[[A0:.*]] = arith.addi %[[arg3]], %[[C10_6]]
+// CHECK-DAG: %[[C10_7:.*]] = arith.constant 10
+// CHECK-DAG: %[[A1:.*]] = arith.addi %[[arg4]], %[[C10_7]]
+// CHECK-DAG: %[[C10_8:.*]] = arith.constant 10
+// CHECK-DAG: %[[A2:.*]] = arith.addi %[[arg5]], %[[C10_8]]
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1
+// CHECK-DAG: %[[C1_9:.*]] = arith.constant 1
+// CHECK-DAG: %[[C1_10:.*]] = arith.constant 1
// CHECK: scf.parallel (%[[arg6:.*]], %[[arg7:.*]], %[[arg8:.*]]) = (%[[arg3]], %[[arg4]], %[[arg5]]) to (%[[A0]], %[[A1]], %[[A2]]) step (%[[C1]], %[[C1_9]], %[[C1_10]]) {
// CHECK: %[[A3:.*]] = memref.load %[[ARG1]][%[[arg6]], %[[arg8]]] : memref<100x100xf32>
// CHECK: %[[A4:.*]] = memref.load %[[ARG2]][%[[arg8]], %[[arg7]]] : memref<100x100xf32>
-// CHECK: mulf %[[A3]], %[[A4]] : f32
+// CHECK: arith.mulf %[[A3]], %[[A4]] : f32
// CHECK: scf.yield
/////////////////////////////////////////////////////////////////////
affine.parallel (%kx, %ky) = (0, 0) to (2, 2) {
%1 = affine.load %arg0[%kx, %ky] : memref<3x3xf32>
%2 = affine.load %arg1[%kx, %ky] : memref<3x3xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
affine.store %3, %O[%kx, %ky] : memref<3x3xf32>
}
return %O : memref<3x3xf32>
}
// CHECK-LABEL: func @affine_parallel_simple
-// CHECK: %[[LOWER_1:.*]] = constant 0 : index
-// CHECK-NEXT: %[[UPPER_1:.*]] = constant 2 : index
-// CHECK-NEXT: %[[LOWER_2:.*]] = constant 0 : index
-// CHECK-NEXT: %[[UPPER_2:.*]] = constant 2 : index
-// CHECK-NEXT: %[[STEP_1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[STEP_2:.*]] = constant 1 : index
+// CHECK: %[[LOWER_1:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[UPPER_1:.*]] = arith.constant 2 : index
+// CHECK-NEXT: %[[LOWER_2:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[UPPER_2:.*]] = arith.constant 2 : index
+// CHECK-NEXT: %[[STEP_1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[STEP_2:.*]] = arith.constant 1 : index
// CHECK-NEXT: scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[LOWER_1]], %[[LOWER_2]]) to (%[[UPPER_1]], %[[UPPER_2]]) step (%[[STEP_1]], %[[STEP_2]]) {
// CHECK-NEXT: %[[VAL_1:.*]] = memref.load
// CHECK-NEXT: %[[VAL_2:.*]] = memref.load
-// CHECK-NEXT: %[[PRODUCT:.*]] = mulf
+// CHECK-NEXT: %[[PRODUCT:.*]] = arith.mulf
// CHECK-NEXT: store
// CHECK-NEXT: scf.yield
// CHECK-NEXT: }
/////////////////////////////////////////////////////////////////////
func @affine_parallel_simple_dynamic_bounds(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %c_0 = constant 0 : index
+ %c_0 = arith.constant 0 : index
%output_dim = memref.dim %arg0, %c_0 : memref<?x?xf32>
affine.parallel (%kx, %ky) = (%c_0, %c_0) to (%output_dim, %output_dim) {
%1 = affine.load %arg0[%kx, %ky] : memref<?x?xf32>
%2 = affine.load %arg1[%kx, %ky] : memref<?x?xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
affine.store %3, %arg2[%kx, %ky] : memref<?x?xf32>
}
return
}
// CHECK-LABEL: func @affine_parallel_simple_dynamic_bounds
// CHECK-SAME: %[[ARG_0:.*]]: memref<?x?xf32>, %[[ARG_1:.*]]: memref<?x?xf32>, %[[ARG_2:.*]]: memref<?x?xf32>
-// CHECK: %[[DIM_INDEX:.*]] = constant 0 : index
+// CHECK: %[[DIM_INDEX:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[UPPER:.*]] = memref.dim %[[ARG_0]], %[[DIM_INDEX]] : memref<?x?xf32>
-// CHECK-NEXT: %[[LOWER_1:.*]] = constant 0 : index
-// CHECK-NEXT: %[[LOWER_2:.*]] = constant 0 : index
-// CHECK-NEXT: %[[STEP_1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[STEP_2:.*]] = constant 1 : index
+// CHECK-NEXT: %[[LOWER_1:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[LOWER_2:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[STEP_1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[STEP_2:.*]] = arith.constant 1 : index
// CHECK-NEXT: scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[LOWER_1]], %[[LOWER_2]]) to (%[[UPPER]], %[[UPPER]]) step (%[[STEP_1]], %[[STEP_2]]) {
// CHECK-NEXT: %[[VAL_1:.*]] = memref.load
// CHECK-NEXT: %[[VAL_2:.*]] = memref.load
-// CHECK-NEXT: %[[PRODUCT:.*]] = mulf
+// CHECK-NEXT: %[[PRODUCT:.*]] = arith.mulf
// CHECK-NEXT: store
// CHECK-NEXT: scf.yield
// CHECK-NEXT: }
%0:2 = affine.parallel (%kx, %ky) = (0, 0) to (2, 2) reduce ("addf", "mulf") -> (f32, f32) {
%1 = affine.load %arg0[%kx, %ky] : memref<3x3xf32>
%2 = affine.load %arg1[%kx, %ky] : memref<3x3xf32>
- %3 = mulf %1, %2 : f32
- %4 = addf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
+ %4 = arith.addf %1, %2 : f32
affine.yield %3, %4 : f32, f32
}
return %0#0, %0#1 : f32, f32
}
// CHECK-LABEL: func @affine_parallel_with_reductions
-// CHECK: %[[LOWER_1:.*]] = constant 0 : index
-// CHECK-NEXT: %[[UPPER_1:.*]] = constant 2 : index
-// CHECK-NEXT: %[[LOWER_2:.*]] = constant 0 : index
-// CHECK-NEXT: %[[UPPER_2:.*]] = constant 2 : index
-// CHECK-NEXT: %[[STEP_1:.*]] = constant 1 : index
-// CHECK-NEXT: %[[STEP_2:.*]] = constant 1 : index
-// CHECK-NEXT: %[[INIT_1:.*]] = constant 0.000000e+00 : f32
-// CHECK-NEXT: %[[INIT_2:.*]] = constant 1.000000e+00 : f32
+// CHECK: %[[LOWER_1:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[UPPER_1:.*]] = arith.constant 2 : index
+// CHECK-NEXT: %[[LOWER_2:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[UPPER_2:.*]] = arith.constant 2 : index
+// CHECK-NEXT: %[[STEP_1:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[STEP_2:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[INIT_1:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[INIT_2:.*]] = arith.constant 1.000000e+00 : f32
// CHECK-NEXT: %[[RES:.*]] = scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[LOWER_1]], %[[LOWER_2]]) to (%[[UPPER_1]], %[[UPPER_2]]) step (%[[STEP_1]], %[[STEP_2]]) init (%[[INIT_1]], %[[INIT_2]]) -> (f32, f32) {
// CHECK-NEXT: %[[VAL_1:.*]] = memref.load
// CHECK-NEXT: %[[VAL_2:.*]] = memref.load
-// CHECK-NEXT: %[[PRODUCT:.*]] = mulf
-// CHECK-NEXT: %[[SUM:.*]] = addf
+// CHECK-NEXT: %[[PRODUCT:.*]] = arith.mulf
+// CHECK-NEXT: %[[SUM:.*]] = arith.addf
// CHECK-NEXT: scf.reduce(%[[PRODUCT]]) : f32 {
// CHECK-NEXT: ^bb0(%[[LHS:.*]]: f32, %[[RHS:.*]]: f32):
-// CHECK-NEXT: %[[RES:.*]] = addf
+// CHECK-NEXT: %[[RES:.*]] = arith.addf
// CHECK-NEXT: scf.reduce.return %[[RES]] : f32
// CHECK-NEXT: }
// CHECK-NEXT: scf.reduce(%[[SUM]]) : f32 {
// CHECK-NEXT: ^bb0(%[[LHS:.*]]: f32, %[[RHS:.*]]: f32):
-// CHECK-NEXT: %[[RES:.*]] = mulf
+// CHECK-NEXT: %[[RES:.*]] = arith.mulf
// CHECK-NEXT: scf.reduce.return %[[RES]] : f32
// CHECK-NEXT: }
// CHECK-NEXT: scf.yield
%0:2 = affine.parallel (%kx, %ky) = (0, 0) to (2, 2) reduce ("addf", "mulf") -> (f64, f64) {
%1 = affine.load %arg0[%kx, %ky] : memref<3x3xf64>
%2 = affine.load %arg1[%kx, %ky] : memref<3x3xf64>
- %3 = mulf %1, %2 : f64
- %4 = addf %1, %2 : f64
+ %3 = arith.mulf %1, %2 : f64
+ %4 = arith.addf %1, %2 : f64
affine.yield %3, %4 : f64, f64
}
return %0#0, %0#1 : f64, f64
}
// CHECK-LABEL: @affine_parallel_with_reductions_f64
-// CHECK: %[[LOWER_1:.*]] = constant 0 : index
-// CHECK: %[[UPPER_1:.*]] = constant 2 : index
-// CHECK: %[[LOWER_2:.*]] = constant 0 : index
-// CHECK: %[[UPPER_2:.*]] = constant 2 : index
-// CHECK: %[[STEP_1:.*]] = constant 1 : index
-// CHECK: %[[STEP_2:.*]] = constant 1 : index
-// CHECK: %[[INIT_1:.*]] = constant 0.000000e+00 : f64
-// CHECK: %[[INIT_2:.*]] = constant 1.000000e+00 : f64
+// CHECK: %[[LOWER_1:.*]] = arith.constant 0 : index
+// CHECK: %[[UPPER_1:.*]] = arith.constant 2 : index
+// CHECK: %[[LOWER_2:.*]] = arith.constant 0 : index
+// CHECK: %[[UPPER_2:.*]] = arith.constant 2 : index
+// CHECK: %[[STEP_1:.*]] = arith.constant 1 : index
+// CHECK: %[[STEP_2:.*]] = arith.constant 1 : index
+// CHECK: %[[INIT_1:.*]] = arith.constant 0.000000e+00 : f64
+// CHECK: %[[INIT_2:.*]] = arith.constant 1.000000e+00 : f64
// CHECK: %[[RES:.*]] = scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[LOWER_1]], %[[LOWER_2]]) to (%[[UPPER_1]], %[[UPPER_2]]) step (%[[STEP_1]], %[[STEP_2]]) init (%[[INIT_1]], %[[INIT_2]]) -> (f64, f64) {
// CHECK: %[[VAL_1:.*]] = memref.load
// CHECK: %[[VAL_2:.*]] = memref.load
-// CHECK: %[[PRODUCT:.*]] = mulf
-// CHECK: %[[SUM:.*]] = addf
+// CHECK: %[[PRODUCT:.*]] = arith.mulf
+// CHECK: %[[SUM:.*]] = arith.addf
// CHECK: scf.reduce(%[[PRODUCT]]) : f64 {
// CHECK: ^bb0(%[[LHS:.*]]: f64, %[[RHS:.*]]: f64):
-// CHECK: %[[RES:.*]] = addf
+// CHECK: %[[RES:.*]] = arith.addf
// CHECK: scf.reduce.return %[[RES]] : f64
// CHECK: }
// CHECK: scf.reduce(%[[SUM]]) : f64 {
// CHECK: ^bb0(%[[LHS:.*]]: f64, %[[RHS:.*]]: f64):
-// CHECK: %[[RES:.*]] = mulf
+// CHECK: %[[RES:.*]] = arith.mulf
// CHECK: scf.reduce.return %[[RES]] : f64
// CHECK: }
// CHECK: scf.yield
%0:2 = affine.parallel (%kx, %ky) = (0, 0) to (2, 2) reduce ("addi", "muli") -> (i64, i64) {
%1 = affine.load %arg0[%kx, %ky] : memref<3x3xi64>
%2 = affine.load %arg1[%kx, %ky] : memref<3x3xi64>
- %3 = muli %1, %2 : i64
- %4 = addi %1, %2 : i64
+ %3 = arith.muli %1, %2 : i64
+ %4 = arith.addi %1, %2 : i64
affine.yield %3, %4 : i64, i64
}
return %0#0, %0#1 : i64, i64
}
// CHECK-LABEL: @affine_parallel_with_reductions_i64
-// CHECK: %[[LOWER_1:.*]] = constant 0 : index
-// CHECK: %[[UPPER_1:.*]] = constant 2 : index
-// CHECK: %[[LOWER_2:.*]] = constant 0 : index
-// CHECK: %[[UPPER_2:.*]] = constant 2 : index
-// CHECK: %[[STEP_1:.*]] = constant 1 : index
-// CHECK: %[[STEP_2:.*]] = constant 1 : index
-// CHECK: %[[INIT_1:.*]] = constant 0 : i64
-// CHECK: %[[INIT_2:.*]] = constant 1 : i64
+// CHECK: %[[LOWER_1:.*]] = arith.constant 0 : index
+// CHECK: %[[UPPER_1:.*]] = arith.constant 2 : index
+// CHECK: %[[LOWER_2:.*]] = arith.constant 0 : index
+// CHECK: %[[UPPER_2:.*]] = arith.constant 2 : index
+// CHECK: %[[STEP_1:.*]] = arith.constant 1 : index
+// CHECK: %[[STEP_2:.*]] = arith.constant 1 : index
+// CHECK: %[[INIT_1:.*]] = arith.constant 0 : i64
+// CHECK: %[[INIT_2:.*]] = arith.constant 1 : i64
// CHECK: %[[RES:.*]] = scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[LOWER_1]], %[[LOWER_2]]) to (%[[UPPER_1]], %[[UPPER_2]]) step (%[[STEP_1]], %[[STEP_2]]) init (%[[INIT_1]], %[[INIT_2]]) -> (i64, i64) {
// CHECK: %[[VAL_1:.*]] = memref.load
// CHECK: %[[VAL_2:.*]] = memref.load
-// CHECK: %[[PRODUCT:.*]] = muli
-// CHECK: %[[SUM:.*]] = addi
+// CHECK: %[[PRODUCT:.*]] = arith.muli
+// CHECK: %[[SUM:.*]] = arith.addi
// CHECK: scf.reduce(%[[PRODUCT]]) : i64 {
// CHECK: ^bb0(%[[LHS:.*]]: i64, %[[RHS:.*]]: i64):
-// CHECK: %[[RES:.*]] = addi
+// CHECK: %[[RES:.*]] = arith.addi
// CHECK: scf.reduce.return %[[RES]] : i64
// CHECK: }
// CHECK: scf.reduce(%[[SUM]]) : i64 {
// CHECK: ^bb0(%[[LHS:.*]]: i64, %[[RHS:.*]]: i64):
-// CHECK: %[[RES:.*]] = muli
+// CHECK: %[[RES:.*]] = arith.muli
// CHECK: scf.reduce.return %[[RES]] : i64
// CHECK: }
// CHECK: scf.yield
--- /dev/null
+// RUN: mlir-opt -convert-arith-to-llvm %s -split-input-file | FileCheck %s
+
+// CHECK-LABEL: @vector_ops
+func @vector_ops(%arg0: vector<4xf32>, %arg1: vector<4xi1>, %arg2: vector<4xi64>, %arg3: vector<4xi64>) -> vector<4xf32> {
+// CHECK-NEXT: %0 = llvm.mlir.constant(dense<4.200000e+01> : vector<4xf32>) : vector<4xf32>
+ %0 = arith.constant dense<42.> : vector<4xf32>
+// CHECK-NEXT: %1 = llvm.fadd %arg0, %0 : vector<4xf32>
+ %1 = arith.addf %arg0, %0 : vector<4xf32>
+// CHECK-NEXT: %2 = llvm.sdiv %arg2, %arg2 : vector<4xi64>
+ %3 = arith.divsi %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %3 = llvm.udiv %arg2, %arg2 : vector<4xi64>
+ %4 = arith.divui %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %4 = llvm.srem %arg2, %arg2 : vector<4xi64>
+ %5 = arith.remsi %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %5 = llvm.urem %arg2, %arg2 : vector<4xi64>
+ %6 = arith.remui %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %6 = llvm.fdiv %arg0, %0 : vector<4xf32>
+ %7 = arith.divf %arg0, %0 : vector<4xf32>
+// CHECK-NEXT: %7 = llvm.frem %arg0, %0 : vector<4xf32>
+ %8 = arith.remf %arg0, %0 : vector<4xf32>
+// CHECK-NEXT: %8 = llvm.and %arg2, %arg3 : vector<4xi64>
+ %9 = arith.andi %arg2, %arg3 : vector<4xi64>
+// CHECK-NEXT: %9 = llvm.or %arg2, %arg3 : vector<4xi64>
+ %10 = arith.ori %arg2, %arg3 : vector<4xi64>
+// CHECK-NEXT: %10 = llvm.xor %arg2, %arg3 : vector<4xi64>
+ %11 = arith.xori %arg2, %arg3 : vector<4xi64>
+// CHECK-NEXT: %11 = llvm.shl %arg2, %arg2 : vector<4xi64>
+ %12 = arith.shli %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %12 = llvm.ashr %arg2, %arg2 : vector<4xi64>
+ %13 = arith.shrsi %arg2, %arg2 : vector<4xi64>
+// CHECK-NEXT: %13 = llvm.lshr %arg2, %arg2 : vector<4xi64>
+ %14 = arith.shrui %arg2, %arg2 : vector<4xi64>
+ return %1 : vector<4xf32>
+}
+
+// CHECK-LABEL: @ops
+func @ops(f32, f32, i32, i32, f64) -> (f32, i32) {
+^bb0(%arg0: f32, %arg1: f32, %arg2: i32, %arg3: i32, %arg4: f64):
+// CHECK: = llvm.fsub %arg0, %arg1 : f32
+ %0 = arith.subf %arg0, %arg1: f32
+// CHECK: = llvm.sub %arg2, %arg3 : i32
+ %1 = arith.subi %arg2, %arg3: i32
+// CHECK: = llvm.icmp "slt" %arg2, %1 : i32
+ %2 = arith.cmpi slt, %arg2, %1 : i32
+// CHECK: = llvm.sdiv %arg2, %arg3 : i32
+ %3 = arith.divsi %arg2, %arg3 : i32
+// CHECK: = llvm.udiv %arg2, %arg3 : i32
+ %4 = arith.divui %arg2, %arg3 : i32
+// CHECK: = llvm.srem %arg2, %arg3 : i32
+ %5 = arith.remsi %arg2, %arg3 : i32
+// CHECK: = llvm.urem %arg2, %arg3 : i32
+ %6 = arith.remui %arg2, %arg3 : i32
+// CHECK: = llvm.fdiv %arg0, %arg1 : f32
+ %8 = arith.divf %arg0, %arg1 : f32
+// CHECK: = llvm.frem %arg0, %arg1 : f32
+ %9 = arith.remf %arg0, %arg1 : f32
+// CHECK: = llvm.and %arg2, %arg3 : i32
+ %10 = arith.andi %arg2, %arg3 : i32
+// CHECK: = llvm.or %arg2, %arg3 : i32
+ %11 = arith.ori %arg2, %arg3 : i32
+// CHECK: = llvm.xor %arg2, %arg3 : i32
+ %12 = arith.xori %arg2, %arg3 : i32
+// CHECK: = llvm.mlir.constant(7.900000e-01 : f64) : f64
+ %15 = arith.constant 7.9e-01 : f64
+// CHECK: = llvm.shl %arg2, %arg3 : i32
+ %16 = arith.shli %arg2, %arg3 : i32
+// CHECK: = llvm.ashr %arg2, %arg3 : i32
+ %17 = arith.shrsi %arg2, %arg3 : i32
+// CHECK: = llvm.lshr %arg2, %arg3 : i32
+ %18 = arith.shrui %arg2, %arg3 : i32
+ return %0, %4 : f32, i32
+}
+
+// Checking conversion of index types to integers using i1, assuming no target
+// system would have a 1-bit address space. Otherwise, we would have had to
+// make this test dependent on the pointer size on the target system.
+// CHECK-LABEL: @index_cast
+func @index_cast(%arg0: index, %arg1: i1) {
+// CHECK: = llvm.trunc %0 : i{{.*}} to i1
+ %0 = arith.index_cast %arg0: index to i1
+// CHECK-NEXT: = llvm.sext %arg1 : i1 to i{{.*}}
+ %1 = arith.index_cast %arg1: i1 to index
+ return
+}
+
+// CHECK-LABEL: @vector_index_cast
+func @vector_index_cast(%arg0: vector<2xindex>, %arg1: vector<2xi1>) {
+// CHECK: = llvm.trunc %{{.*}} : vector<2xi{{.*}}> to vector<2xi1>
+ %0 = arith.index_cast %arg0: vector<2xindex> to vector<2xi1>
+// CHECK-NEXT: = llvm.sext %{{.*}} : vector<2xi1> to vector<2xi{{.*}}>
+ %1 = arith.index_cast %arg1: vector<2xi1> to vector<2xindex>
+ return
+}
+
+// Checking conversion of signed integer types to floating point.
+// CHECK-LABEL: @sitofp
+func @sitofp(%arg0 : i32, %arg1 : i64) {
+// CHECK-NEXT: = llvm.sitofp {{.*}} : i32 to f32
+ %0 = arith.sitofp %arg0: i32 to f32
+// CHECK-NEXT: = llvm.sitofp {{.*}} : i32 to f64
+ %1 = arith.sitofp %arg0: i32 to f64
+// CHECK-NEXT: = llvm.sitofp {{.*}} : i64 to f32
+ %2 = arith.sitofp %arg1: i64 to f32
+// CHECK-NEXT: = llvm.sitofp {{.*}} : i64 to f64
+ %3 = arith.sitofp %arg1: i64 to f64
+ return
+}
+
+// Checking conversion of integer vectors to floating point vector types.
+// CHECK-LABEL: @sitofp_vector
+func @sitofp_vector(%arg0 : vector<2xi16>, %arg1 : vector<2xi32>, %arg2 : vector<2xi64>) {
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi16> to vector<2xf32>
+ %0 = arith.sitofp %arg0: vector<2xi16> to vector<2xf32>
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi16> to vector<2xf64>
+ %1 = arith.sitofp %arg0: vector<2xi16> to vector<2xf64>
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi32> to vector<2xf32>
+ %2 = arith.sitofp %arg1: vector<2xi32> to vector<2xf32>
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi32> to vector<2xf64>
+ %3 = arith.sitofp %arg1: vector<2xi32> to vector<2xf64>
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi64> to vector<2xf32>
+ %4 = arith.sitofp %arg2: vector<2xi64> to vector<2xf32>
+// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi64> to vector<2xf64>
+ %5 = arith.sitofp %arg2: vector<2xi64> to vector<2xf64>
+ return
+}
+
+// Checking conversion of unsigned integer types to floating point.
+// CHECK-LABEL: @uitofp
+func @uitofp(%arg0 : i32, %arg1 : i64) {
+// CHECK-NEXT: = llvm.uitofp {{.*}} : i32 to f32
+ %0 = arith.uitofp %arg0: i32 to f32
+// CHECK-NEXT: = llvm.uitofp {{.*}} : i32 to f64
+ %1 = arith.uitofp %arg0: i32 to f64
+// CHECK-NEXT: = llvm.uitofp {{.*}} : i64 to f32
+ %2 = arith.uitofp %arg1: i64 to f32
+// CHECK-NEXT: = llvm.uitofp {{.*}} : i64 to f64
+ %3 = arith.uitofp %arg1: i64 to f64
+ return
+}
+
+// Checking conversion of integer types to floating point.
+// CHECK-LABEL: @fpext
+func @fpext(%arg0 : f16, %arg1 : f32) {
+// CHECK-NEXT: = llvm.fpext {{.*}} : f16 to f32
+ %0 = arith.extf %arg0: f16 to f32
+// CHECK-NEXT: = llvm.fpext {{.*}} : f16 to f64
+ %1 = arith.extf %arg0: f16 to f64
+// CHECK-NEXT: = llvm.fpext {{.*}} : f32 to f64
+ %2 = arith.extf %arg1: f32 to f64
+ return
+}
+
+// Checking conversion of integer types to floating point.
+// CHECK-LABEL: @fpext
+func @fpext_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>) {
+// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf16> to vector<2xf32>
+ %0 = arith.extf %arg0: vector<2xf16> to vector<2xf32>
+// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf16> to vector<2xf64>
+ %1 = arith.extf %arg0: vector<2xf16> to vector<2xf64>
+// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf32> to vector<2xf64>
+ %2 = arith.extf %arg1: vector<2xf32> to vector<2xf64>
+ return
+}
+
+// Checking conversion of floating point to integer types.
+// CHECK-LABEL: @fptosi
+func @fptosi(%arg0 : f32, %arg1 : f64) {
+// CHECK-NEXT: = llvm.fptosi {{.*}} : f32 to i32
+ %0 = arith.fptosi %arg0: f32 to i32
+// CHECK-NEXT: = llvm.fptosi {{.*}} : f32 to i64
+ %1 = arith.fptosi %arg0: f32 to i64
+// CHECK-NEXT: = llvm.fptosi {{.*}} : f64 to i32
+ %2 = arith.fptosi %arg1: f64 to i32
+// CHECK-NEXT: = llvm.fptosi {{.*}} : f64 to i64
+ %3 = arith.fptosi %arg1: f64 to i64
+ return
+}
+
+// Checking conversion of floating point vectors to integer vector types.
+// CHECK-LABEL: @fptosi_vector
+func @fptosi_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>, %arg2 : vector<2xf64>) {
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf16> to vector<2xi32>
+ %0 = arith.fptosi %arg0: vector<2xf16> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf16> to vector<2xi64>
+ %1 = arith.fptosi %arg0: vector<2xf16> to vector<2xi64>
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf32> to vector<2xi32>
+ %2 = arith.fptosi %arg1: vector<2xf32> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf32> to vector<2xi64>
+ %3 = arith.fptosi %arg1: vector<2xf32> to vector<2xi64>
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf64> to vector<2xi32>
+ %4 = arith.fptosi %arg2: vector<2xf64> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf64> to vector<2xi64>
+ %5 = arith.fptosi %arg2: vector<2xf64> to vector<2xi64>
+ return
+}
+
+// Checking conversion of floating point to integer types.
+// CHECK-LABEL: @fptoui
+func @fptoui(%arg0 : f32, %arg1 : f64) {
+// CHECK-NEXT: = llvm.fptoui {{.*}} : f32 to i32
+ %0 = arith.fptoui %arg0: f32 to i32
+// CHECK-NEXT: = llvm.fptoui {{.*}} : f32 to i64
+ %1 = arith.fptoui %arg0: f32 to i64
+// CHECK-NEXT: = llvm.fptoui {{.*}} : f64 to i32
+ %2 = arith.fptoui %arg1: f64 to i32
+// CHECK-NEXT: = llvm.fptoui {{.*}} : f64 to i64
+ %3 = arith.fptoui %arg1: f64 to i64
+ return
+}
+
+// Checking conversion of floating point vectors to integer vector types.
+// CHECK-LABEL: @fptoui_vector
+func @fptoui_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>, %arg2 : vector<2xf64>) {
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf16> to vector<2xi32>
+ %0 = arith.fptoui %arg0: vector<2xf16> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf16> to vector<2xi64>
+ %1 = arith.fptoui %arg0: vector<2xf16> to vector<2xi64>
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf32> to vector<2xi32>
+ %2 = arith.fptoui %arg1: vector<2xf32> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf32> to vector<2xi64>
+ %3 = arith.fptoui %arg1: vector<2xf32> to vector<2xi64>
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf64> to vector<2xi32>
+ %4 = arith.fptoui %arg2: vector<2xf64> to vector<2xi32>
+// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf64> to vector<2xi64>
+ %5 = arith.fptoui %arg2: vector<2xf64> to vector<2xi64>
+ return
+}
+
+// Checking conversion of integer vectors to floating point vector types.
+// CHECK-LABEL: @uitofp_vector
+func @uitofp_vector(%arg0 : vector<2xi16>, %arg1 : vector<2xi32>, %arg2 : vector<2xi64>) {
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi16> to vector<2xf32>
+ %0 = arith.uitofp %arg0: vector<2xi16> to vector<2xf32>
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi16> to vector<2xf64>
+ %1 = arith.uitofp %arg0: vector<2xi16> to vector<2xf64>
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi32> to vector<2xf32>
+ %2 = arith.uitofp %arg1: vector<2xi32> to vector<2xf32>
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi32> to vector<2xf64>
+ %3 = arith.uitofp %arg1: vector<2xi32> to vector<2xf64>
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi64> to vector<2xf32>
+ %4 = arith.uitofp %arg2: vector<2xi64> to vector<2xf32>
+// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi64> to vector<2xf64>
+ %5 = arith.uitofp %arg2: vector<2xi64> to vector<2xf64>
+ return
+}
+
+// Checking conversion of integer types to floating point.
+// CHECK-LABEL: @fptrunc
+func @fptrunc(%arg0 : f32, %arg1 : f64) {
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : f32 to f16
+ %0 = arith.truncf %arg0: f32 to f16
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : f64 to f16
+ %1 = arith.truncf %arg1: f64 to f16
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : f64 to f32
+ %2 = arith.truncf %arg1: f64 to f32
+ return
+}
+
+// Checking conversion of integer types to floating point.
+// CHECK-LABEL: @fptrunc
+func @fptrunc_vector(%arg0 : vector<2xf32>, %arg1 : vector<2xf64>) {
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf32> to vector<2xf16>
+ %0 = arith.truncf %arg0: vector<2xf32> to vector<2xf16>
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf64> to vector<2xf16>
+ %1 = arith.truncf %arg1: vector<2xf64> to vector<2xf16>
+// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf64> to vector<2xf32>
+ %2 = arith.truncf %arg1: vector<2xf64> to vector<2xf32>
+ return
+}
+
+// Check sign and zero extension and truncation of integers.
+// CHECK-LABEL: @integer_extension_and_truncation
+func @integer_extension_and_truncation(%arg0 : i3) {
+// CHECK-NEXT: = llvm.sext %arg0 : i3 to i6
+ %0 = arith.extsi %arg0 : i3 to i6
+// CHECK-NEXT: = llvm.zext %arg0 : i3 to i6
+ %1 = arith.extui %arg0 : i3 to i6
+// CHECK-NEXT: = llvm.trunc %arg0 : i3 to i2
+ %2 = arith.trunci %arg0 : i3 to i2
+ return
+}
+
+// CHECK-LABEL: func @fcmp(%arg0: f32, %arg1: f32) {
+func @fcmp(f32, f32) -> () {
+^bb0(%arg0: f32, %arg1: f32):
+ // CHECK: llvm.fcmp "oeq" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ogt" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "oge" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "olt" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ole" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "one" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ord" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ueq" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ugt" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "uge" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ult" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "ule" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "une" %arg0, %arg1 : f32
+ // CHECK-NEXT: llvm.fcmp "uno" %arg0, %arg1 : f32
+ // CHECK-NEXT: return
+ %1 = arith.cmpf oeq, %arg0, %arg1 : f32
+ %2 = arith.cmpf ogt, %arg0, %arg1 : f32
+ %3 = arith.cmpf oge, %arg0, %arg1 : f32
+ %4 = arith.cmpf olt, %arg0, %arg1 : f32
+ %5 = arith.cmpf ole, %arg0, %arg1 : f32
+ %6 = arith.cmpf one, %arg0, %arg1 : f32
+ %7 = arith.cmpf ord, %arg0, %arg1 : f32
+ %8 = arith.cmpf ueq, %arg0, %arg1 : f32
+ %9 = arith.cmpf ugt, %arg0, %arg1 : f32
+ %10 = arith.cmpf uge, %arg0, %arg1 : f32
+ %11 = arith.cmpf ult, %arg0, %arg1 : f32
+ %12 = arith.cmpf ule, %arg0, %arg1 : f32
+ %13 = arith.cmpf une, %arg0, %arg1 : f32
+ %14 = arith.cmpf uno, %arg0, %arg1 : f32
+
+ return
+}
+
+// -----
+
+// CHECK-LABEL: @index_vector
+func @index_vector(%arg0: vector<4xindex>) {
+ // CHECK: %[[CST:.*]] = llvm.mlir.constant(dense<[0, 1, 2, 3]> : vector<4xindex>) : vector<4xi64>
+ %0 = arith.constant dense<[0, 1, 2, 3]> : vector<4xindex>
+ // CHECK: %[[V:.*]] = llvm.add %1, %[[CST]] : vector<4xi64>
+ %1 = arith.addi %arg0, %0 : vector<4xindex>
+ std.return
+}
+
+// -----
+
+// CHECK-LABEL: @bitcast_1d
+func @bitcast_1d(%arg0: vector<2xf32>) {
+ // CHECK: llvm.bitcast %{{.*}} : vector<2xf32> to vector<2xi32>
+ arith.bitcast %arg0 : vector<2xf32> to vector<2xi32>
+ return
+}
+
+// -----
+
+// CHECK-LABEL: func @cmpf_2dvector(
+func @cmpf_2dvector(%arg0 : vector<4x3xf32>, %arg1 : vector<4x3xf32>) {
+ // CHECK: %[[ARG0:.*]] = builtin.unrealized_conversion_cast
+ // CHECK: %[[ARG1:.*]] = builtin.unrealized_conversion_cast
+ // CHECK: %[[EXTRACT1:.*]] = llvm.extractvalue %[[ARG0]][0] : !llvm.array<4 x vector<3xf32>>
+ // CHECK: %[[EXTRACT2:.*]] = llvm.extractvalue %[[ARG1]][0] : !llvm.array<4 x vector<3xf32>>
+ // CHECK: %[[CMP:.*]] = llvm.fcmp "olt" %[[EXTRACT1]], %[[EXTRACT2]] : vector<3xf32>
+ // CHECK: %[[INSERT:.*]] = llvm.insertvalue %[[CMP]], %2[0] : !llvm.array<4 x vector<3xi1>>
+ %0 = arith.cmpf olt, %arg0, %arg1 : vector<4x3xf32>
+ std.return
+}
+
+// -----
+
+// CHECK-LABEL: func @cmpi_2dvector(
+func @cmpi_2dvector(%arg0 : vector<4x3xi32>, %arg1 : vector<4x3xi32>) {
+ // CHECK: %[[ARG0:.*]] = builtin.unrealized_conversion_cast
+ // CHECK: %[[ARG1:.*]] = builtin.unrealized_conversion_cast
+ // CHECK: %[[EXTRACT1:.*]] = llvm.extractvalue %[[ARG0]][0] : !llvm.array<4 x vector<3xi32>>
+ // CHECK: %[[EXTRACT2:.*]] = llvm.extractvalue %[[ARG1]][0] : !llvm.array<4 x vector<3xi32>>
+ // CHECK: %[[CMP:.*]] = llvm.icmp "ult" %[[EXTRACT1]], %[[EXTRACT2]] : vector<3xi32>
+ // CHECK: %[[INSERT:.*]] = llvm.insertvalue %[[CMP]], %2[0] : !llvm.array<4 x vector<3xi1>>
+ %0 = arith.cmpi ult, %arg0, %arg1 : vector<4x3xi32>
+ std.return
+}
-// RUN: mlir-opt -convert-std-to-llvm %s -split-input-file | FileCheck %s
+// RUN: mlir-opt -convert-arith-to-llvm %s -split-input-file | FileCheck %s
// CHECK-LABEL: @vec_bin
func @vec_bin(%arg0: vector<2x2x2xf32>) -> vector<2x2x2xf32> {
- %0 = addf %arg0, %arg0 : vector<2x2x2xf32>
+ // CHECK: llvm.mlir.undef : !llvm.array<2 x array<2 x vector<2xf32>>>
+
+ // This block appears 2x2 times
+ // CHECK-NEXT: llvm.extractvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK-NEXT: llvm.extractvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK-NEXT: llvm.fadd %{{.*}} : vector<2xf32>
+ // CHECK-NEXT: llvm.insertvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
+
+ // We check the proper indexing of extract/insert in the remaining 3 positions.
+ // CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK: llvm.insertvalue %{{.*}}[0, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK: llvm.extractvalue %{{.*}}[1, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK: llvm.insertvalue %{{.*}}[1, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK: llvm.extractvalue %{{.*}}[1, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ // CHECK: llvm.insertvalue %{{.*}}[1, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
+ %0 = arith.addf %arg0, %arg0 : vector<2x2x2xf32>
return %0 : vector<2x2x2xf32>
-
-// CHECK-NEXT: llvm.mlir.undef : !llvm.array<2 x array<2 x vector<2xf32>>>
-
-// This block appears 2x2 times
-// CHECK-NEXT: llvm.extractvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK-NEXT: llvm.extractvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK-NEXT: llvm.fadd %{{.*}} : vector<2xf32>
-// CHECK-NEXT: llvm.insertvalue %{{.*}}[0, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
-
-// We check the proper indexing of extract/insert in the remaining 3 positions.
-// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK: llvm.insertvalue %{{.*}}[0, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK: llvm.extractvalue %{{.*}}[1, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK: llvm.insertvalue %{{.*}}[1, 0] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK: llvm.extractvalue %{{.*}}[1, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
-// CHECK: llvm.insertvalue %{{.*}}[1, 1] : !llvm.array<2 x array<2 x vector<2xf32>>>
}
// CHECK-LABEL: @sexti
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
// CHECK: llvm.sext %{{.*}} : vector<3xi32> to vector<3xi64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
- %0 = sexti %arg0: vector<1x2x3xi32> to vector<1x2x3xi64>
+ %0 = arith.extsi %arg0: vector<1x2x3xi32> to vector<1x2x3xi64>
return
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
// CHECK: llvm.zext %{{.*}} : vector<3xi32> to vector<3xi64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
- %0 = zexti %arg0: vector<1x2x3xi32> to vector<1x2x3xi64>
+ %0 = arith.extui %arg0: vector<1x2x3xi32> to vector<1x2x3xi64>
return
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
// CHECK: llvm.sitofp %{{.*}} : vector<3xi32> to vector<3xf32>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf32>>>
- %0 = sitofp %arg0: vector<1x2x3xi32> to vector<1x2x3xf32>
+ %0 = arith.sitofp %arg0: vector<1x2x3xi32> to vector<1x2x3xf32>
return %0 : vector<1x2x3xf32>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
// CHECK: llvm.uitofp %{{.*}} : vector<3xi32> to vector<3xf32>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf32>>>
- %0 = uitofp %arg0: vector<1x2x3xi32> to vector<1x2x3xf32>
+ %0 = arith.uitofp %arg0: vector<1x2x3xi32> to vector<1x2x3xf32>
return %0 : vector<1x2x3xf32>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf32>>>
// CHECK: llvm.fptosi %{{.*}} : vector<3xf32> to vector<3xi32>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
- %0 = fptosi %arg0: vector<1x2x3xf32> to vector<1x2x3xi32>
+ %0 = arith.fptosi %arg0: vector<1x2x3xf32> to vector<1x2x3xi32>
return %0 : vector<1x2x3xi32>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf32>>>
// CHECK: llvm.fptoui %{{.*}} : vector<3xf32> to vector<3xi32>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi32>>>
- %0 = fptoui %arg0: vector<1x2x3xf32> to vector<1x2x3xi32>
+ %0 = arith.fptoui %arg0: vector<1x2x3xf32> to vector<1x2x3xi32>
return %0 : vector<1x2x3xi32>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf16>>>
// CHECK: llvm.fpext %{{.*}} : vector<3xf16> to vector<3xf64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf64>>>
- %0 = fpext %arg0: vector<1x2x3xf16> to vector<1x2x3xf64>
+ %0 = arith.extf %arg0: vector<1x2x3xf16> to vector<1x2x3xf64>
return %0 : vector<1x2x3xf64>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf64>>>
// CHECK: llvm.fptrunc %{{.*}} : vector<3xf64> to vector<3xf16>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xf16>>>
- %0 = fptrunc %arg0: vector<1x2x3xf64> to vector<1x2x3xf16>
+ %0 = arith.truncf %arg0: vector<1x2x3xf64> to vector<1x2x3xf16>
return %0 : vector<1x2x3xf16>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
// CHECK: llvm.trunc %{{.*}} : vector<3xi64> to vector<3xi16>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi16>>>
- %0 = trunci %arg0: vector<1x2x3xi64> to vector<1x2x3xi16>
+ %0 = arith.trunci %arg0: vector<1x2x3xi64> to vector<1x2x3xi16>
return %0 : vector<1x2x3xi16>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
// CHECK: llvm.shl %{{.*}}, %{{.*}} : vector<3xi64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
- %c1 = constant dense<1> : vector<1x2x3xi64>
- %0 = shift_left %arg0, %c1 : vector<1x2x3xi64>
+ %c1 = arith.constant dense<1> : vector<1x2x3xi64>
+ %0 = arith.shli %arg0, %c1 : vector<1x2x3xi64>
return %0 : vector<1x2x3xi64>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
// CHECK: llvm.ashr %{{.*}}, %{{.*}} : vector<3xi64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
- %c1 = constant dense<1> : vector<1x2x3xi64>
- %0 = shift_right_signed %arg0, %c1 : vector<1x2x3xi64>
+ %c1 = arith.constant dense<1> : vector<1x2x3xi64>
+ %0 = arith.shrsi %arg0, %c1 : vector<1x2x3xi64>
return %0 : vector<1x2x3xi64>
}
// CHECK: llvm.extractvalue %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
// CHECK: llvm.lshr %{{.*}}, %{{.*}} : vector<3xi64>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0, 1] : !llvm.array<1 x array<2 x vector<3xi64>>>
- %c1 = constant dense<1> : vector<1x2x3xi64>
- %0 = shift_right_unsigned %arg0, %c1 : vector<1x2x3xi64>
+ %c1 = arith.constant dense<1> : vector<1x2x3xi64>
+ %0 = arith.shrui %arg0, %c1 : vector<1x2x3xi64>
return %0 : vector<1x2x3xi64>
}
// CHECK: llvm.extractvalue %{{.*}}[1]
// CHECK: llvm.bitcast %{{.*}} : vector<4xf32> to vector<4xi32>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[1]
- std.bitcast %arg0 : vector<2x4xf32> to vector<2x4xi32>
+ arith.bitcast %arg0 : vector<2x4xf32> to vector<2x4xi32>
return
}
--- /dev/null
+// RUN: mlir-opt -split-input-file -convert-std-to-spirv -verify-diagnostics %s | FileCheck %s
+
+//===----------------------------------------------------------------------===//
+// arithmetic ops
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<
+ #spv.vce<v1.0, [Int8, Int16, Int64, Float16, Float64], []>, {}>
+} {
+
+// Check integer operation conversions.
+// CHECK-LABEL: @int32_scalar
+func @int32_scalar(%lhs: i32, %rhs: i32) {
+ // CHECK: spv.IAdd %{{.*}}, %{{.*}}: i32
+ %0 = arith.addi %lhs, %rhs: i32
+ // CHECK: spv.ISub %{{.*}}, %{{.*}}: i32
+ %1 = arith.subi %lhs, %rhs: i32
+ // CHECK: spv.IMul %{{.*}}, %{{.*}}: i32
+ %2 = arith.muli %lhs, %rhs: i32
+ // CHECK: spv.SDiv %{{.*}}, %{{.*}}: i32
+ %3 = arith.divsi %lhs, %rhs: i32
+ // CHECK: spv.UDiv %{{.*}}, %{{.*}}: i32
+ %4 = arith.divui %lhs, %rhs: i32
+ // CHECK: spv.UMod %{{.*}}, %{{.*}}: i32
+ %5 = arith.remui %lhs, %rhs: i32
+ return
+}
+
+// CHECK-LABEL: @scalar_srem
+// CHECK-SAME: (%[[LHS:.+]]: i32, %[[RHS:.+]]: i32)
+func @scalar_srem(%lhs: i32, %rhs: i32) {
+ // CHECK: %[[LABS:.+]] = spv.GLSL.SAbs %[[LHS]] : i32
+ // CHECK: %[[RABS:.+]] = spv.GLSL.SAbs %[[RHS]] : i32
+ // CHECK: %[[ABS:.+]] = spv.UMod %[[LABS]], %[[RABS]] : i32
+ // CHECK: %[[POS:.+]] = spv.IEqual %[[LHS]], %[[LABS]] : i32
+ // CHECK: %[[NEG:.+]] = spv.SNegate %[[ABS]] : i32
+ // CHECK: %{{.+}} = spv.Select %[[POS]], %[[ABS]], %[[NEG]] : i1, i32
+ %0 = arith.remsi %lhs, %rhs: i32
+ return
+}
+
+// Check float unary operation conversions.
+// CHECK-LABEL: @float32_unary_scalar
+func @float32_unary_scalar(%arg0: f32) {
+ // CHECK: spv.GLSL.FAbs %{{.*}}: f32
+ %0 = math.abs %arg0 : f32
+ // CHECK: spv.GLSL.Ceil %{{.*}}: f32
+ %1 = math.ceil %arg0 : f32
+ // CHECK: spv.FNegate %{{.*}}: f32
+ %5 = arith.negf %arg0 : f32
+ // CHECK: spv.GLSL.Floor %{{.*}}: f32
+ %10 = math.floor %arg0 : f32
+ return
+}
+
+// Check float binary operation conversions.
+// CHECK-LABEL: @float32_binary_scalar
+func @float32_binary_scalar(%lhs: f32, %rhs: f32) {
+ // CHECK: spv.FAdd %{{.*}}, %{{.*}}: f32
+ %0 = arith.addf %lhs, %rhs: f32
+ // CHECK: spv.FSub %{{.*}}, %{{.*}}: f32
+ %1 = arith.subf %lhs, %rhs: f32
+ // CHECK: spv.FMul %{{.*}}, %{{.*}}: f32
+ %2 = arith.mulf %lhs, %rhs: f32
+ // CHECK: spv.FDiv %{{.*}}, %{{.*}}: f32
+ %3 = arith.divf %lhs, %rhs: f32
+ // CHECK: spv.FRem %{{.*}}, %{{.*}}: f32
+ %4 = arith.remf %lhs, %rhs: f32
+ return
+}
+
+// Check int vector types.
+// CHECK-LABEL: @int_vector234
+func @int_vector234(%arg0: vector<2xi8>, %arg1: vector<4xi64>) {
+ // CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<2xi8>
+ %0 = arith.divsi %arg0, %arg0: vector<2xi8>
+ // CHECK: spv.UDiv %{{.*}}, %{{.*}}: vector<4xi64>
+ %1 = arith.divui %arg1, %arg1: vector<4xi64>
+ return
+}
+
+// CHECK-LABEL: @vector_srem
+// CHECK-SAME: (%[[LHS:.+]]: vector<3xi16>, %[[RHS:.+]]: vector<3xi16>)
+func @vector_srem(%arg0: vector<3xi16>, %arg1: vector<3xi16>) {
+ // CHECK: %[[LABS:.+]] = spv.GLSL.SAbs %[[LHS]] : vector<3xi16>
+ // CHECK: %[[RABS:.+]] = spv.GLSL.SAbs %[[RHS]] : vector<3xi16>
+ // CHECK: %[[ABS:.+]] = spv.UMod %[[LABS]], %[[RABS]] : vector<3xi16>
+ // CHECK: %[[POS:.+]] = spv.IEqual %[[LHS]], %[[LABS]] : vector<3xi16>
+ // CHECK: %[[NEG:.+]] = spv.SNegate %[[ABS]] : vector<3xi16>
+ // CHECK: %{{.+}} = spv.Select %[[POS]], %[[ABS]], %[[NEG]] : vector<3xi1>, vector<3xi16>
+ %0 = arith.remsi %arg0, %arg1: vector<3xi16>
+ return
+}
+
+// Check float vector types.
+// CHECK-LABEL: @float_vector234
+func @float_vector234(%arg0: vector<2xf16>, %arg1: vector<3xf64>) {
+ // CHECK: spv.FAdd %{{.*}}, %{{.*}}: vector<2xf16>
+ %0 = arith.addf %arg0, %arg0: vector<2xf16>
+ // CHECK: spv.FMul %{{.*}}, %{{.*}}: vector<3xf64>
+ %1 = arith.mulf %arg1, %arg1: vector<3xf64>
+ return
+}
+
+// CHECK-LABEL: @one_elem_vector
+func @one_elem_vector(%arg0: vector<1xi32>) {
+ // CHECK: spv.IAdd %{{.+}}, %{{.+}}: i32
+ %0 = arith.addi %arg0, %arg0: vector<1xi32>
+ return
+}
+
+// CHECK-LABEL: @unsupported_5elem_vector
+func @unsupported_5elem_vector(%arg0: vector<5xi32>) {
+ // CHECK: arith.subi
+ %1 = arith.subi %arg0, %arg0: vector<5xi32>
+ return
+}
+
+// CHECK-LABEL: @unsupported_2x2elem_vector
+func @unsupported_2x2elem_vector(%arg0: vector<2x2xi32>) {
+ // CHECK: arith.muli
+ %2 = arith.muli %arg0, %arg0: vector<2x2xi32>
+ return
+}
+
+} // end module
+
+// -----
+
+// Check that types are converted to 32-bit when no special capabilities.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @int_vector23
+func @int_vector23(%arg0: vector<2xi8>, %arg1: vector<3xi16>) {
+ // CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<2xi32>
+ %0 = arith.divsi %arg0, %arg0: vector<2xi8>
+ // CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<3xi32>
+ %1 = arith.divsi %arg1, %arg1: vector<3xi16>
+ return
+}
+
+// CHECK-LABEL: @float_scalar
+func @float_scalar(%arg0: f16, %arg1: f64) {
+ // CHECK: spv.FAdd %{{.*}}, %{{.*}}: f32
+ %0 = arith.addf %arg0, %arg0: f16
+ // CHECK: spv.FMul %{{.*}}, %{{.*}}: f32
+ %1 = arith.mulf %arg1, %arg1: f64
+ return
+}
+
+} // end module
+
+// -----
+
+// Check that types are converted to 32-bit when no special capabilities that
+// are not supported.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+func @int_vector4_invalid(%arg0: vector<4xi64>) {
+ // expected-error @+2 {{bitwidth emulation is not implemented yet on unsigned op}}
+ // expected-error @+1 {{op requires the same type for all operands and results}}
+ %0 = arith.divui %arg0, %arg0: vector<4xi64>
+ return
+}
+
+} // end module
+
+// -----
+
+//===----------------------------------------------------------------------===//
+// std bit ops
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @bitwise_scalar
+func @bitwise_scalar(%arg0 : i32, %arg1 : i32) {
+ // CHECK: spv.BitwiseAnd
+ %0 = arith.andi %arg0, %arg1 : i32
+ // CHECK: spv.BitwiseOr
+ %1 = arith.ori %arg0, %arg1 : i32
+ // CHECK: spv.BitwiseXor
+ %2 = arith.xori %arg0, %arg1 : i32
+ return
+}
+
+// CHECK-LABEL: @bitwise_vector
+func @bitwise_vector(%arg0 : vector<4xi32>, %arg1 : vector<4xi32>) {
+ // CHECK: spv.BitwiseAnd
+ %0 = arith.andi %arg0, %arg1 : vector<4xi32>
+ // CHECK: spv.BitwiseOr
+ %1 = arith.ori %arg0, %arg1 : vector<4xi32>
+ // CHECK: spv.BitwiseXor
+ %2 = arith.xori %arg0, %arg1 : vector<4xi32>
+ return
+}
+
+// CHECK-LABEL: @logical_scalar
+func @logical_scalar(%arg0 : i1, %arg1 : i1) {
+ // CHECK: spv.LogicalAnd
+ %0 = arith.andi %arg0, %arg1 : i1
+ // CHECK: spv.LogicalOr
+ %1 = arith.ori %arg0, %arg1 : i1
+ // CHECK: spv.LogicalNotEqual
+ %2 = arith.xori %arg0, %arg1 : i1
+ return
+}
+
+// CHECK-LABEL: @logical_vector
+func @logical_vector(%arg0 : vector<4xi1>, %arg1 : vector<4xi1>) {
+ // CHECK: spv.LogicalAnd
+ %0 = arith.andi %arg0, %arg1 : vector<4xi1>
+ // CHECK: spv.LogicalOr
+ %1 = arith.ori %arg0, %arg1 : vector<4xi1>
+ // CHECK: spv.LogicalNotEqual
+ %2 = arith.xori %arg0, %arg1 : vector<4xi1>
+ return
+}
+
+// CHECK-LABEL: @shift_scalar
+func @shift_scalar(%arg0 : i32, %arg1 : i32) {
+ // CHECK: spv.ShiftLeftLogical
+ %0 = arith.shli %arg0, %arg1 : i32
+ // CHECK: spv.ShiftRightArithmetic
+ %1 = arith.shrsi %arg0, %arg1 : i32
+ // CHECK: spv.ShiftRightLogical
+ %2 = arith.shrui %arg0, %arg1 : i32
+ return
+}
+
+// CHECK-LABEL: @shift_vector
+func @shift_vector(%arg0 : vector<4xi32>, %arg1 : vector<4xi32>) {
+ // CHECK: spv.ShiftLeftLogical
+ %0 = arith.shli %arg0, %arg1 : vector<4xi32>
+ // CHECK: spv.ShiftRightArithmetic
+ %1 = arith.shrsi %arg0, %arg1 : vector<4xi32>
+ // CHECK: spv.ShiftRightLogical
+ %2 = arith.shrui %arg0, %arg1 : vector<4xi32>
+ return
+}
+
+} // end module
+
+// -----
+
+//===----------------------------------------------------------------------===//
+// arith.cmpf
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @cmpf
+func @cmpf(%arg0 : f32, %arg1 : f32) {
+ // CHECK: spv.FOrdEqual
+ %1 = arith.cmpf oeq, %arg0, %arg1 : f32
+ // CHECK: spv.FOrdGreaterThan
+ %2 = arith.cmpf ogt, %arg0, %arg1 : f32
+ // CHECK: spv.FOrdGreaterThanEqual
+ %3 = arith.cmpf oge, %arg0, %arg1 : f32
+ // CHECK: spv.FOrdLessThan
+ %4 = arith.cmpf olt, %arg0, %arg1 : f32
+ // CHECK: spv.FOrdLessThanEqual
+ %5 = arith.cmpf ole, %arg0, %arg1 : f32
+ // CHECK: spv.FOrdNotEqual
+ %6 = arith.cmpf one, %arg0, %arg1 : f32
+ // CHECK: spv.FUnordEqual
+ %7 = arith.cmpf ueq, %arg0, %arg1 : f32
+ // CHECK: spv.FUnordGreaterThan
+ %8 = arith.cmpf ugt, %arg0, %arg1 : f32
+ // CHECK: spv.FUnordGreaterThanEqual
+ %9 = arith.cmpf uge, %arg0, %arg1 : f32
+ // CHECK: spv.FUnordLessThan
+ %10 = arith.cmpf ult, %arg0, %arg1 : f32
+ // CHECK: FUnordLessThanEqual
+ %11 = arith.cmpf ule, %arg0, %arg1 : f32
+ // CHECK: spv.FUnordNotEqual
+ %12 = arith.cmpf une, %arg0, %arg1 : f32
+ return
+}
+
+} // end module
+
+// -----
+
+// With Kernel capability, we can convert NaN check to spv.Ordered/spv.Unordered.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [Kernel], []>, {}>
+} {
+
+// CHECK-LABEL: @cmpf
+func @cmpf(%arg0 : f32, %arg1 : f32) {
+ // CHECK: spv.Ordered
+ %0 = arith.cmpf ord, %arg0, %arg1 : f32
+ // CHECK: spv.Unordered
+ %1 = arith.cmpf uno, %arg0, %arg1 : f32
+ return
+}
+
+} // end module
+
+// -----
+
+// Without Kernel capability, we need to convert NaN check to spv.IsNan.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @cmpf
+// CHECK-SAME: %[[LHS:.+]]: f32, %[[RHS:.+]]: f32
+func @cmpf(%arg0 : f32, %arg1 : f32) {
+ // CHECK: %[[LHS_NAN:.+]] = spv.IsNan %[[LHS]] : f32
+ // CHECK-NEXT: %[[RHS_NAN:.+]] = spv.IsNan %[[RHS]] : f32
+ // CHECK-NEXT: %[[OR:.+]] = spv.LogicalOr %[[LHS_NAN]], %[[RHS_NAN]] : i1
+ // CHECK-NEXT: %{{.+}} = spv.LogicalNot %[[OR]] : i1
+ %0 = arith.cmpf ord, %arg0, %arg1 : f32
+
+ // CHECK-NEXT: %[[LHS_NAN:.+]] = spv.IsNan %[[LHS]] : f32
+ // CHECK-NEXT: %[[RHS_NAN:.+]] = spv.IsNan %[[RHS]] : f32
+ // CHECK-NEXT: %{{.+}} = spv.LogicalOr %[[LHS_NAN]], %[[RHS_NAN]] : i1
+ %1 = arith.cmpf uno, %arg0, %arg1 : f32
+ return
+}
+
+} // end module
+
+// -----
+
+//===----------------------------------------------------------------------===//
+// arith.cmpi
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @cmpi
+func @cmpi(%arg0 : i32, %arg1 : i32) {
+ // CHECK: spv.IEqual
+ %0 = arith.cmpi eq, %arg0, %arg1 : i32
+ // CHECK: spv.INotEqual
+ %1 = arith.cmpi ne, %arg0, %arg1 : i32
+ // CHECK: spv.SLessThan
+ %2 = arith.cmpi slt, %arg0, %arg1 : i32
+ // CHECK: spv.SLessThanEqual
+ %3 = arith.cmpi sle, %arg0, %arg1 : i32
+ // CHECK: spv.SGreaterThan
+ %4 = arith.cmpi sgt, %arg0, %arg1 : i32
+ // CHECK: spv.SGreaterThanEqual
+ %5 = arith.cmpi sge, %arg0, %arg1 : i32
+ // CHECK: spv.ULessThan
+ %6 = arith.cmpi ult, %arg0, %arg1 : i32
+ // CHECK: spv.ULessThanEqual
+ %7 = arith.cmpi ule, %arg0, %arg1 : i32
+ // CHECK: spv.UGreaterThan
+ %8 = arith.cmpi ugt, %arg0, %arg1 : i32
+ // CHECK: spv.UGreaterThanEqual
+ %9 = arith.cmpi uge, %arg0, %arg1 : i32
+ return
+}
+
+// CHECK-LABEL: @boolcmpi
+func @boolcmpi(%arg0 : i1, %arg1 : i1) {
+ // CHECK: spv.LogicalEqual
+ %0 = arith.cmpi eq, %arg0, %arg1 : i1
+ // CHECK: spv.LogicalNotEqual
+ %1 = arith.cmpi ne, %arg0, %arg1 : i1
+ return
+}
+
+// CHECK-LABEL: @vecboolcmpi
+func @vecboolcmpi(%arg0 : vector<4xi1>, %arg1 : vector<4xi1>) {
+ // CHECK: spv.LogicalEqual
+ %0 = arith.cmpi eq, %arg0, %arg1 : vector<4xi1>
+ // CHECK: spv.LogicalNotEqual
+ %1 = arith.cmpi ne, %arg0, %arg1 : vector<4xi1>
+ return
+}
+
+} // end module
+
+// -----
+
+//===----------------------------------------------------------------------===//
+// arith.constant
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<
+ #spv.vce<v1.0, [Int8, Int16, Int64, Float16, Float64], []>, {}>
+} {
+
+// CHECK-LABEL: @constant
+func @constant() {
+ // CHECK: spv.Constant true
+ %0 = arith.constant true
+ // CHECK: spv.Constant 42 : i32
+ %1 = arith.constant 42 : i32
+ // CHECK: spv.Constant 5.000000e-01 : f32
+ %2 = arith.constant 0.5 : f32
+ // CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
+ %3 = arith.constant dense<[2, 3]> : vector<2xi32>
+ // CHECK: spv.Constant 1 : i32
+ %4 = arith.constant 1 : index
+ // CHECK: spv.Constant dense<1> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
+ %5 = arith.constant dense<1> : tensor<2x3xi32>
+ // CHECK: spv.Constant dense<1.000000e+00> : tensor<6xf32> : !spv.array<6 x f32, stride=4>
+ %6 = arith.constant dense<1.0> : tensor<2x3xf32>
+ // CHECK: spv.Constant dense<{{\[}}1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf32> : !spv.array<6 x f32, stride=4>
+ %7 = arith.constant dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf32>
+ // CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
+ %8 = arith.constant dense<[[1, 2, 3], [4, 5, 6]]> : tensor<2x3xi32>
+ // CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
+ %9 = arith.constant dense<[[1, 2], [3, 4], [5, 6]]> : tensor<3x2xi32>
+ // CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
+ %10 = arith.constant dense<[1, 2, 3, 4, 5, 6]> : tensor<6xi32>
+ return
+}
+
+// CHECK-LABEL: @constant_16bit
+func @constant_16bit() {
+ // CHECK: spv.Constant 4 : i16
+ %0 = arith.constant 4 : i16
+ // CHECK: spv.Constant 5.000000e+00 : f16
+ %1 = arith.constant 5.0 : f16
+ // CHECK: spv.Constant dense<[2, 3]> : vector<2xi16>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi16>
+ // CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf16> : !spv.array<5 x f16, stride=2>
+ %3 = arith.constant dense<4.0> : tensor<5xf16>
+ return
+}
+
+// CHECK-LABEL: @constant_64bit
+func @constant_64bit() {
+ // CHECK: spv.Constant 4 : i64
+ %0 = arith.constant 4 : i64
+ // CHECK: spv.Constant 5.000000e+00 : f64
+ %1 = arith.constant 5.0 : f64
+ // CHECK: spv.Constant dense<[2, 3]> : vector<2xi64>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi64>
+ // CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf64> : !spv.array<5 x f64, stride=8>
+ %3 = arith.constant dense<4.0> : tensor<5xf64>
+ return
+}
+
+} // end module
+
+// -----
+
+// Check that constants are converted to 32-bit when no special capability.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [], []>, {}>
+} {
+
+// CHECK-LABEL: @constant_16bit
+func @constant_16bit() {
+ // CHECK: spv.Constant 4 : i32
+ %0 = arith.constant 4 : i16
+ // CHECK: spv.Constant 5.000000e+00 : f32
+ %1 = arith.constant 5.0 : f16
+ // CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi16>
+ // CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf32> : !spv.array<5 x f32, stride=4>
+ %3 = arith.constant dense<4.0> : tensor<5xf16>
+ // CHECK: spv.Constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00]> : tensor<4xf32> : !spv.array<4 x f32, stride=4>
+ %4 = arith.constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
+ return
+}
+
+// CHECK-LABEL: @constant_64bit
+func @constant_64bit() {
+ // CHECK: spv.Constant 4 : i32
+ %0 = arith.constant 4 : i64
+ // CHECK: spv.Constant 5.000000e+00 : f32
+ %1 = arith.constant 5.0 : f64
+ // CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi64>
+ // CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf32> : !spv.array<5 x f32, stride=4>
+ %3 = arith.constant dense<4.0> : tensor<5xf64>
+ // CHECK: spv.Constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00]> : tensor<4xf32> : !spv.array<4 x f32, stride=4>
+ %4 = arith.constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
+ return
+}
+
+// CHECK-LABEL: @corner_cases
+func @corner_cases() {
+ // CHECK: %{{.*}} = spv.Constant -1 : i32
+ %0 = arith.constant 4294967295 : i64 // 2^32 - 1
+ // CHECK: %{{.*}} = spv.Constant 2147483647 : i32
+ %1 = arith.constant 2147483647 : i64 // 2^31 - 1
+ // CHECK: %{{.*}} = spv.Constant -2147483648 : i32
+ %2 = arith.constant 2147483648 : i64 // 2^31
+ // CHECK: %{{.*}} = spv.Constant -2147483648 : i32
+ %3 = arith.constant -2147483648 : i64 // -2^31
+
+ // CHECK: %{{.*}} = spv.Constant -1 : i32
+ %5 = arith.constant -1 : i64
+ // CHECK: %{{.*}} = spv.Constant -2 : i32
+ %6 = arith.constant -2 : i64
+ // CHECK: %{{.*}} = spv.Constant -1 : i32
+ %7 = arith.constant -1 : index
+ // CHECK: %{{.*}} = spv.Constant -2 : i32
+ %8 = arith.constant -2 : index
+
+
+ // CHECK: spv.Constant false
+ %9 = arith.constant false
+ // CHECK: spv.Constant true
+ %10 = arith.constant true
+
+ return
+}
+
+// CHECK-LABEL: @unsupported_cases
+func @unsupported_cases() {
+ // CHECK: %{{.*}} = arith.constant 4294967296 : i64
+ %0 = arith.constant 4294967296 : i64 // 2^32
+ // CHECK: %{{.*}} = arith.constant -2147483649 : i64
+ %1 = arith.constant -2147483649 : i64 // -2^31 - 1
+ // CHECK: %{{.*}} = arith.constant 1.0000000000000002 : f64
+ %2 = arith.constant 0x3FF0000000000001 : f64 // smallest number > 1
+ return
+}
+
+} // end module
+
+// -----
+
+//===----------------------------------------------------------------------===//
+// std cast ops
+//===----------------------------------------------------------------------===//
+
+module attributes {
+ spv.target_env = #spv.target_env<
+ #spv.vce<v1.0, [Int8, Int16, Int64, Float16, Float64], []>, {}>
+} {
+
+// CHECK-LABEL: index_cast1
+func @index_cast1(%arg0: i16) {
+ // CHECK: spv.SConvert %{{.+}} : i16 to i32
+ %0 = arith.index_cast %arg0 : i16 to index
+ return
+}
+
+// CHECK-LABEL: index_cast2
+func @index_cast2(%arg0: index) {
+ // CHECK: spv.SConvert %{{.+}} : i32 to i16
+ %0 = arith.index_cast %arg0 : index to i16
+ return
+}
+
+// CHECK-LABEL: index_cast3
+func @index_cast3(%arg0: i32) {
+ // CHECK-NOT: spv.SConvert
+ %0 = arith.index_cast %arg0 : i32 to index
+ return
+}
+
+// CHECK-LABEL: index_cast4
+func @index_cast4(%arg0: index) {
+ // CHECK-NOT: spv.SConvert
+ %0 = arith.index_cast %arg0 : index to i32
+ return
+}
+
+// CHECK-LABEL: @fpext1
+func @fpext1(%arg0: f16) -> f64 {
+ // CHECK: spv.FConvert %{{.*}} : f16 to f64
+ %0 = arith.extf %arg0 : f16 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: @fpext2
+func @fpext2(%arg0 : f32) -> f64 {
+ // CHECK: spv.FConvert %{{.*}} : f32 to f64
+ %0 = arith.extf %arg0 : f32 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: @fptrunc1
+func @fptrunc1(%arg0 : f64) -> f16 {
+ // CHECK: spv.FConvert %{{.*}} : f64 to f16
+ %0 = arith.truncf %arg0 : f64 to f16
+ return %0 : f16
+}
+
+// CHECK-LABEL: @fptrunc2
+func @fptrunc2(%arg0: f32) -> f16 {
+ // CHECK: spv.FConvert %{{.*}} : f32 to f16
+ %0 = arith.truncf %arg0 : f32 to f16
+ return %0 : f16
+}
+
+// CHECK-LABEL: @sitofp1
+func @sitofp1(%arg0 : i32) -> f32 {
+ // CHECK: spv.ConvertSToF %{{.*}} : i32 to f32
+ %0 = arith.sitofp %arg0 : i32 to f32
+ return %0 : f32
+}
+
+// CHECK-LABEL: @sitofp2
+func @sitofp2(%arg0 : i64) -> f64 {
+ // CHECK: spv.ConvertSToF %{{.*}} : i64 to f64
+ %0 = arith.sitofp %arg0 : i64 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: @uitofp_i16_f32
+func @uitofp_i16_f32(%arg0: i16) -> f32 {
+ // CHECK: spv.ConvertUToF %{{.*}} : i16 to f32
+ %0 = arith.uitofp %arg0 : i16 to f32
+ return %0 : f32
+}
+
+// CHECK-LABEL: @uitofp_i32_f32
+func @uitofp_i32_f32(%arg0 : i32) -> f32 {
+ // CHECK: spv.ConvertUToF %{{.*}} : i32 to f32
+ %0 = arith.uitofp %arg0 : i32 to f32
+ return %0 : f32
+}
+
+// CHECK-LABEL: @uitofp_i1_f32
+func @uitofp_i1_f32(%arg0 : i1) -> f32 {
+ // CHECK: %[[ZERO:.+]] = spv.Constant 0.000000e+00 : f32
+ // CHECK: %[[ONE:.+]] = spv.Constant 1.000000e+00 : f32
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, f32
+ %0 = arith.uitofp %arg0 : i1 to f32
+ return %0 : f32
+}
+
+// CHECK-LABEL: @uitofp_i1_f64
+func @uitofp_i1_f64(%arg0 : i1) -> f64 {
+ // CHECK: %[[ZERO:.+]] = spv.Constant 0.000000e+00 : f64
+ // CHECK: %[[ONE:.+]] = spv.Constant 1.000000e+00 : f64
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, f64
+ %0 = arith.uitofp %arg0 : i1 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: @uitofp_vec_i1_f32
+func @uitofp_vec_i1_f32(%arg0 : vector<4xi1>) -> vector<4xf32> {
+ // CHECK: %[[ZERO:.+]] = spv.Constant dense<0.000000e+00> : vector<4xf32>
+ // CHECK: %[[ONE:.+]] = spv.Constant dense<1.000000e+00> : vector<4xf32>
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xf32>
+ %0 = arith.uitofp %arg0 : vector<4xi1> to vector<4xf32>
+ return %0 : vector<4xf32>
+}
+
+// CHECK-LABEL: @uitofp_vec_i1_f64
+spv.func @uitofp_vec_i1_f64(%arg0: vector<4xi1>) -> vector<4xf64> "None" {
+ // CHECK: %[[ZERO:.+]] = spv.Constant dense<0.000000e+00> : vector<4xf64>
+ // CHECK: %[[ONE:.+]] = spv.Constant dense<1.000000e+00> : vector<4xf64>
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xf64>
+ %0 = spv.Constant dense<0.000000e+00> : vector<4xf64>
+ %1 = spv.Constant dense<1.000000e+00> : vector<4xf64>
+ %2 = spv.Select %arg0, %1, %0 : vector<4xi1>, vector<4xf64>
+ spv.ReturnValue %2 : vector<4xf64>
+}
+
+// CHECK-LABEL: @sexti1
+func @sexti1(%arg0: i16) -> i64 {
+ // CHECK: spv.SConvert %{{.*}} : i16 to i64
+ %0 = arith.extsi %arg0 : i16 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: @sexti2
+func @sexti2(%arg0 : i32) -> i64 {
+ // CHECK: spv.SConvert %{{.*}} : i32 to i64
+ %0 = arith.extsi %arg0 : i32 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: @zexti1
+func @zexti1(%arg0: i16) -> i64 {
+ // CHECK: spv.UConvert %{{.*}} : i16 to i64
+ %0 = arith.extui %arg0 : i16 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: @zexti2
+func @zexti2(%arg0 : i32) -> i64 {
+ // CHECK: spv.UConvert %{{.*}} : i32 to i64
+ %0 = arith.extui %arg0 : i32 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: @zexti3
+func @zexti3(%arg0 : i1) -> i32 {
+ // CHECK: %[[ZERO:.+]] = spv.Constant 0 : i32
+ // CHECK: %[[ONE:.+]] = spv.Constant 1 : i32
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, i32
+ %0 = arith.extui %arg0 : i1 to i32
+ return %0 : i32
+}
+
+// CHECK-LABEL: @zexti4
+func @zexti4(%arg0 : vector<4xi1>) -> vector<4xi32> {
+ // CHECK: %[[ZERO:.+]] = spv.Constant dense<0> : vector<4xi32>
+ // CHECK: %[[ONE:.+]] = spv.Constant dense<1> : vector<4xi32>
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xi32>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi32>
+ return %0 : vector<4xi32>
+}
+
+// CHECK-LABEL: @zexti5
+func @zexti5(%arg0 : vector<4xi1>) -> vector<4xi64> {
+ // CHECK: %[[ZERO:.+]] = spv.Constant dense<0> : vector<4xi64>
+ // CHECK: %[[ONE:.+]] = spv.Constant dense<1> : vector<4xi64>
+ // CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xi64>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi64>
+ return %0 : vector<4xi64>
+}
+
+// CHECK-LABEL: @trunci1
+func @trunci1(%arg0 : i64) -> i16 {
+ // CHECK: spv.SConvert %{{.*}} : i64 to i16
+ %0 = arith.trunci %arg0 : i64 to i16
+ return %0 : i16
+}
+
+// CHECK-LABEL: @trunci2
+func @trunci2(%arg0: i32) -> i16 {
+ // CHECK: spv.SConvert %{{.*}} : i32 to i16
+ %0 = arith.trunci %arg0 : i32 to i16
+ return %0 : i16
+}
+
+// CHECK-LABEL: @trunc_to_i1
+func @trunc_to_i1(%arg0: i32) -> i1 {
+ // CHECK: %[[MASK:.*]] = spv.Constant 1 : i32
+ // CHECK: %[[MASKED_SRC:.*]] = spv.BitwiseAnd %{{.*}}, %[[MASK]] : i32
+ // CHECK: %[[IS_ONE:.*]] = spv.IEqual %[[MASKED_SRC]], %[[MASK]] : i32
+ // CHECK-DAG: %[[TRUE:.*]] = spv.Constant true
+ // CHECK-DAG: %[[FALSE:.*]] = spv.Constant false
+ // CHECK: spv.Select %[[IS_ONE]], %[[TRUE]], %[[FALSE]] : i1, i1
+ %0 = arith.trunci %arg0 : i32 to i1
+ return %0 : i1
+}
+
+// CHECK-LABEL: @trunc_to_veci1
+func @trunc_to_veci1(%arg0: vector<4xi32>) -> vector<4xi1> {
+ // CHECK: %[[MASK:.*]] = spv.Constant dense<1> : vector<4xi32>
+ // CHECK: %[[MASKED_SRC:.*]] = spv.BitwiseAnd %{{.*}}, %[[MASK]] : vector<4xi32>
+ // CHECK: %[[IS_ONE:.*]] = spv.IEqual %[[MASKED_SRC]], %[[MASK]] : vector<4xi32>
+ // CHECK-DAG: %[[TRUE:.*]] = spv.Constant dense<true> : vector<4xi1>
+ // CHECK-DAG: %[[FALSE:.*]] = spv.Constant dense<false> : vector<4xi1>
+ // CHECK: spv.Select %[[IS_ONE]], %[[TRUE]], %[[FALSE]] : vector<4xi1>, vector<4xi1>
+ %0 = arith.trunci %arg0 : vector<4xi32> to vector<4xi1>
+ return %0 : vector<4xi1>
+}
+
+// CHECK-LABEL: @fptosi1
+func @fptosi1(%arg0 : f32) -> i32 {
+ // CHECK: spv.ConvertFToS %{{.*}} : f32 to i32
+ %0 = arith.fptosi %arg0 : f32 to i32
+ return %0 : i32
+}
+
+// CHECK-LABEL: @fptosi2
+func @fptosi2(%arg0 : f16) -> i16 {
+ // CHECK: spv.ConvertFToS %{{.*}} : f16 to i16
+ %0 = arith.fptosi %arg0 : f16 to i16
+ return %0 : i16
+}
+
+} // end module
+
+// -----
+
+// Checks that cast types will be adjusted when missing special capabilities for
+// certain non-32-bit scalar types.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [Float64], []>, {}>
+} {
+
+// CHECK-LABEL: @fpext1
+// CHECK-SAME: %[[ARG:.*]]: f32
+func @fpext1(%arg0: f16) -> f64 {
+ // CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f64
+ %0 = arith.extf %arg0 : f16 to f64
+ return %0: f64
+}
+
+// CHECK-LABEL: @fpext2
+// CHECK-SAME: %[[ARG:.*]]: f32
+func @fpext2(%arg0 : f32) -> f64 {
+ // CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f64
+ %0 = arith.extf %arg0 : f32 to f64
+ return %0: f64
+}
+
+} // end module
+
+// -----
+
+// Checks that cast types will be adjusted when missing special capabilities for
+// certain non-32-bit scalar types.
+module attributes {
+ spv.target_env = #spv.target_env<#spv.vce<v1.0, [Float16], []>, {}>
+} {
+
+// CHECK-LABEL: @fptrunc1
+// CHECK-SAME: %[[ARG:.*]]: f32
+func @fptrunc1(%arg0 : f64) -> f16 {
+ // CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f16
+ %0 = arith.truncf %arg0 : f64 to f16
+ return %0: f16
+}
+
+// CHECK-LABEL: @fptrunc2
+// CHECK-SAME: %[[ARG:.*]]: f32
+func @fptrunc2(%arg0: f32) -> f16 {
+ // CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f16
+ %0 = arith.truncf %arg0 : f32 to f16
+ return %0: f16
+}
+
+// CHECK-LABEL: @sitofp
+func @sitofp(%arg0 : i64) -> f64 {
+ // CHECK: spv.ConvertSToF %{{.*}} : i32 to f32
+ %0 = arith.sitofp %arg0 : i64 to f64
+ return %0: f64
+}
+
+} // end module
// CHECK-LABEL: @create_group
func @create_group() {
- // CHECK: %[[C:.*]] = constant 1 : index
+ // CHECK: %[[C:.*]] = arith.constant 1 : index
// CHECK: %[[S:.*]] = builtin.unrealized_conversion_cast %[[C]] : index to i64
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: %[[GROUP:.*]] = call @mlirAsyncRuntimeCreateGroup(%[[S]])
%0 = async.runtime.create_group %c: !async.group
return
// CHECK-LABEL: @await_group
func @await_group() {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: %[[GROUP:.*]] = call @mlirAsyncRuntimeCreateGroup
%0 = async.runtime.create_group %c: !async.group
// CHECK: call @mlirAsyncRuntimeAwaitAllInGroup(%[[GROUP]])
// CHECK-LABEL: @await_and_resume_group
func @await_and_resume_group() {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
%0 = async.coro.id
// CHECK: %[[HDL:.*]] = llvm.intr.coro.begin
%1 = async.coro.begin %0
// CHECK-LABEL: @store
func @store() {
- // CHECK: %[[CST:.*]] = constant 1.0
- %0 = constant 1.0 : f32
+ // CHECK: %[[CST:.*]] = arith.constant 1.0
+ %0 = arith.constant 1.0 : f32
// CHECK: %[[VALUE:.*]] = call @mlirAsyncRuntimeCreateValue
%1 = async.runtime.create : !async.value<f32>
// CHECK: %[[P0:.*]] = call @mlirAsyncRuntimeGetValueStorage(%[[VALUE]])
// CHECK-LABEL: @add_token_to_group
func @add_token_to_group() {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: %[[TOKEN:.*]] = call @mlirAsyncRuntimeCreateToken
%0 = async.runtime.create : !async.token
// CHECK: %[[GROUP:.*]] = call @mlirAsyncRuntimeCreateGroup
// CHECK-LABEL: reference_counting
func @reference_counting(%arg0: !async.token) {
- // CHECK: %[[C2:.*]] = constant 2 : i64
+ // CHECK: %[[C2:.*]] = arith.constant 2 : i64
// CHECK: call @mlirAsyncRuntimeAddRef(%arg0, %[[C2]])
async.runtime.add_ref %arg0 {count = 2 : i64} : !async.token
- // CHECK: %[[C1:.*]] = constant 1 : i64
+ // CHECK: %[[C1:.*]] = arith.constant 1 : i64
// CHECK: call @mlirAsyncRuntimeDropRef(%arg0, %[[C1]])
async.runtime.drop_ref %arg0 {count = 1 : i64} : !async.token
func @execute_no_async_args(%arg0: f32, %arg1: memref<1xf32>) {
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn(%arg0, %arg1)
%token = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
// CHECK: call @mlirAsyncRuntimeAwaitToken(%[[TOKEN]])
// CHECK: %[[IS_ERROR:.*]] = call @mlirAsyncRuntimeIsTokenError(%[[TOKEN]])
- // CHECK: %[[TRUE:.*]] = constant true
- // CHECK: %[[NOT_ERROR:.*]] = xor %[[IS_ERROR]], %[[TRUE]] : i1
+ // CHECK: %[[TRUE:.*]] = arith.constant true
+ // CHECK: %[[NOT_ERROR:.*]] = arith.xori %[[IS_ERROR]], %[[TRUE]] : i1
// CHECK: assert %[[NOT_ERROR]]
// CHECK-NEXT: return
async.await %token : !async.token
func @nested_async_execute(%arg0: f32, %arg1: f32, %arg2: memref<1xf32>) {
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn_0(%arg0, %arg2, %arg1)
%token0 = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%token1 = async.execute {
- %c1 = constant 1: index
+ %c1 = arith.constant 1: index
memref.store %arg0, %arg2[%c0] : memref<1xf32>
async.yield
}
}
// CHECK: call @mlirAsyncRuntimeAwaitToken(%[[TOKEN]])
// CHECK: %[[IS_ERROR:.*]] = call @mlirAsyncRuntimeIsTokenError(%[[TOKEN]])
- // CHECK: %[[TRUE:.*]] = constant true
- // CHECK: %[[NOT_ERROR:.*]] = xor %[[IS_ERROR]], %[[TRUE]] : i1
+ // CHECK: %[[TRUE:.*]] = arith.constant true
+ // CHECK: %[[NOT_ERROR:.*]] = arith.xori %[[IS_ERROR]], %[[TRUE]] : i1
// CHECK: assert %[[NOT_ERROR]]
async.await %token0 : !async.token
return
// CHECK: %[[HDL_0:.*]] = llvm.intr.coro.begin
// CHECK: call @mlirAsyncRuntimeExecute
// CHECK: llvm.intr.coro.suspend
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: memref.store %arg0, %arg1[%[[C0]]] : memref<1xf32>
// CHECK: call @mlirAsyncRuntimeEmplaceToken(%[[RET_0]])
func @async_execute_token_dependency(%arg0: f32, %arg1: memref<1xf32>) {
// CHECK: %0 = call @async_execute_fn(%arg0, %arg1)
%token = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
// CHECK: %1 = call @async_execute_fn_0(%0, %arg0, %arg1)
%token_0 = async.execute [%token] {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
// CHECK-LABEL: async_group_await_all
func @async_group_await_all(%arg0: f32, %arg1: memref<1xf32>) {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: %[[GROUP:.*]] = call @mlirAsyncRuntimeCreateGroup
%0 = async.create_group %c : !async.group
func @execute_and_return_f32() -> f32 {
// CHECK: %[[RET:.*]]:2 = call @async_execute_fn
%token, %result = async.execute -> !async.value<f32> {
- %c0 = constant 123.0 : f32
+ %c0 = arith.constant 123.0 : f32
async.yield %c0 : f32
}
// CHECK: llvm.intr.coro.suspend
// Emplace result value.
-// CHECK: %[[CST:.*]] = constant 1.230000e+02 : f32
+// CHECK: %[[CST:.*]] = arith.constant 1.230000e+02 : f32
// CHECK: %[[STORAGE:.*]] = call @mlirAsyncRuntimeGetValueStorage(%[[VALUE]])
// CHECK: %[[ST_F32:.*]] = llvm.bitcast %[[STORAGE]]
// CHECK: llvm.store %[[CST]], %[[ST_F32]] : !llvm.ptr<f32>
func @async_value_operands() {
// CHECK: %[[RET:.*]]:2 = call @async_execute_fn
%token, %result = async.execute -> !async.value<f32> {
- %c0 = constant 123.0 : f32
+ %c0 = arith.constant 123.0 : f32
async.yield %c0 : f32
}
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn_0(%[[RET]]#1)
%token0 = async.execute(%result as %value: !async.value<f32>) {
- %0 = addf %value, %value : f32
+ %0 = arith.addf %value, %value : f32
async.yield
}
// CHECK: %[[STORAGE:.*]] = call @mlirAsyncRuntimeGetValueStorage(%arg0)
// CHECK: %[[ST_F32:.*]] = llvm.bitcast %[[STORAGE]]
// CHECK: %[[LOADED:.*]] = llvm.load %[[ST_F32]] : !llvm.ptr<f32>
-// CHECK: addf %[[LOADED]], %[[LOADED]] : f32
+// CHECK: arith.addf %[[LOADED]], %[[LOADED]] : f32
// Emplace result token.
// CHECK: call @mlirAsyncRuntimeEmplaceToken(%[[TOKEN]])
// CHECK: %[[C1:.*]] = llvm.insertvalue %[[C_REAL]], %[[C0]][0] : !llvm.struct<(f64, f64)>
// CHECK: %[[C2:.*]] = llvm.insertvalue %[[C_IMAG]], %[[C1]][1] : !llvm.struct<(f64, f64)>
func @complex_addition() {
- %a_re = constant 1.2 : f64
- %a_im = constant 3.4 : f64
+ %a_re = arith.constant 1.2 : f64
+ %a_im = arith.constant 3.4 : f64
%a = complex.create %a_re, %a_im : complex<f64>
- %b_re = constant 5.6 : f64
- %b_im = constant 7.8 : f64
+ %b_re = arith.constant 5.6 : f64
+ %b_im = arith.constant 7.8 : f64
%b = complex.create %b_re, %b_im : complex<f64>
%c = complex.add %a, %b : complex<f64>
return
// CHECK: %[[C1:.*]] = llvm.insertvalue %[[C_REAL]], %[[C0]][0] : !llvm.struct<(f64, f64)>
// CHECK: %[[C2:.*]] = llvm.insertvalue %[[C_IMAG]], %[[C1]][1] : !llvm.struct<(f64, f64)>
func @complex_substraction() {
- %a_re = constant 1.2 : f64
- %a_im = constant 3.4 : f64
+ %a_re = arith.constant 1.2 : f64
+ %a_im = arith.constant 3.4 : f64
%a = complex.create %a_re, %a_im : complex<f64>
- %b_re = constant 5.6 : f64
- %b_im = constant 7.8 : f64
+ %b_re = arith.constant 5.6 : f64
+ %b_im = arith.constant 7.8 : f64
%b = complex.create %b_re, %b_im : complex<f64>
%c = complex.sub %a, %b : complex<f64>
return
}
// CHECK: %[[REAL:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK-DAG: %[[REAL_SQ:.*]] = mulf %[[REAL]], %[[REAL]] : f32
-// CHECK-DAG: %[[IMAG_SQ:.*]] = mulf %[[IMAG]], %[[IMAG]] : f32
-// CHECK: %[[SQ_NORM:.*]] = addf %[[REAL_SQ]], %[[IMAG_SQ]] : f32
+// CHECK-DAG: %[[REAL_SQ:.*]] = arith.mulf %[[REAL]], %[[REAL]] : f32
+// CHECK-DAG: %[[IMAG_SQ:.*]] = arith.mulf %[[IMAG]], %[[IMAG]] : f32
+// CHECK: %[[SQ_NORM:.*]] = arith.addf %[[REAL_SQ]], %[[IMAG_SQ]] : f32
// CHECK: %[[NORM:.*]] = math.sqrt %[[SQ_NORM]] : f32
// CHECK: return %[[NORM]] : f32
}
// CHECK: %[[REAL_LHS:.*]] = complex.re %[[LHS]] : complex<f32>
// CHECK: %[[REAL_RHS:.*]] = complex.re %[[RHS]] : complex<f32>
-// CHECK: %[[RESULT_REAL:.*]] = addf %[[REAL_LHS]], %[[REAL_RHS]] : f32
+// CHECK: %[[RESULT_REAL:.*]] = arith.addf %[[REAL_LHS]], %[[REAL_RHS]] : f32
// CHECK: %[[IMAG_LHS:.*]] = complex.im %[[LHS]] : complex<f32>
// CHECK: %[[IMAG_RHS:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK: %[[RESULT_IMAG:.*]] = addf %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
+// CHECK: %[[RESULT_IMAG:.*]] = arith.addf %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[RESULT_REAL]], %[[RESULT_IMAG]] : complex<f32>
// CHECK: return %[[RESULT]] : complex<f32>
// CHECK: %[[RHS_REAL:.*]] = complex.re %[[RHS]] : complex<f32>
// CHECK: %[[RHS_IMAG:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK: %[[RHS_REAL_IMAG_RATIO:.*]] = divf %[[RHS_REAL]], %[[RHS_IMAG]] : f32
-// CHECK: %[[RHS_REAL_TIMES_RHS_REAL_IMAG_RATIO:.*]] = mulf %[[RHS_REAL_IMAG_RATIO]], %[[RHS_REAL]] : f32
-// CHECK: %[[RHS_REAL_IMAG_DENOM:.*]] = addf %[[RHS_IMAG]], %[[RHS_REAL_TIMES_RHS_REAL_IMAG_RATIO]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_IMAG_RATIO:.*]] = mulf %[[LHS_REAL]], %[[RHS_REAL_IMAG_RATIO]] : f32
-// CHECK: %[[REAL_NUMERATOR_1:.*]] = addf %[[LHS_REAL_TIMES_RHS_REAL_IMAG_RATIO]], %[[LHS_IMAG]] : f32
-// CHECK: %[[RESULT_REAL_1:.*]] = divf %[[REAL_NUMERATOR_1]], %[[RHS_REAL_IMAG_DENOM]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_IMAG_RATIO:.*]] = mulf %[[LHS_IMAG]], %[[RHS_REAL_IMAG_RATIO]] : f32
-// CHECK: %[[IMAG_NUMERATOR_1:.*]] = subf %[[LHS_IMAG_TIMES_RHS_REAL_IMAG_RATIO]], %[[LHS_REAL]] : f32
-// CHECK: %[[RESULT_IMAG_1:.*]] = divf %[[IMAG_NUMERATOR_1]], %[[RHS_REAL_IMAG_DENOM]] : f32
+// CHECK: %[[RHS_REAL_IMAG_RATIO:.*]] = arith.divf %[[RHS_REAL]], %[[RHS_IMAG]] : f32
+// CHECK: %[[RHS_REAL_TIMES_RHS_REAL_IMAG_RATIO:.*]] = arith.mulf %[[RHS_REAL_IMAG_RATIO]], %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_REAL_IMAG_DENOM:.*]] = arith.addf %[[RHS_IMAG]], %[[RHS_REAL_TIMES_RHS_REAL_IMAG_RATIO]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_IMAG_RATIO:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_REAL_IMAG_RATIO]] : f32
+// CHECK: %[[REAL_NUMERATOR_1:.*]] = arith.addf %[[LHS_REAL_TIMES_RHS_REAL_IMAG_RATIO]], %[[LHS_IMAG]] : f32
+// CHECK: %[[RESULT_REAL_1:.*]] = arith.divf %[[REAL_NUMERATOR_1]], %[[RHS_REAL_IMAG_DENOM]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_IMAG_RATIO:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_REAL_IMAG_RATIO]] : f32
+// CHECK: %[[IMAG_NUMERATOR_1:.*]] = arith.subf %[[LHS_IMAG_TIMES_RHS_REAL_IMAG_RATIO]], %[[LHS_REAL]] : f32
+// CHECK: %[[RESULT_IMAG_1:.*]] = arith.divf %[[IMAG_NUMERATOR_1]], %[[RHS_REAL_IMAG_DENOM]] : f32
-// CHECK: %[[RHS_IMAG_REAL_RATIO:.*]] = divf %[[RHS_IMAG]], %[[RHS_REAL]] : f32
-// CHECK: %[[RHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO:.*]] = mulf %[[RHS_IMAG_REAL_RATIO]], %[[RHS_IMAG]] : f32
-// CHECK: %[[RHS_IMAG_REAL_DENOM:.*]] = addf %[[RHS_REAL]], %[[RHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO:.*]] = mulf %[[LHS_IMAG]], %[[RHS_IMAG_REAL_RATIO]] : f32
-// CHECK: %[[REAL_NUMERATOR_2:.*]] = addf %[[LHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO]] : f32
-// CHECK: %[[RESULT_REAL_2:.*]] = divf %[[REAL_NUMERATOR_2]], %[[RHS_IMAG_REAL_DENOM]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_REAL_RATIO:.*]] = mulf %[[LHS_REAL]], %[[RHS_IMAG_REAL_RATIO]] : f32
-// CHECK: %[[IMAG_NUMERATOR_2:.*]] = subf %[[LHS_IMAG]], %[[LHS_REAL_TIMES_RHS_IMAG_REAL_RATIO]] : f32
-// CHECK: %[[RESULT_IMAG_2:.*]] = divf %[[IMAG_NUMERATOR_2]], %[[RHS_IMAG_REAL_DENOM]] : f32
+// CHECK: %[[RHS_IMAG_REAL_RATIO:.*]] = arith.divf %[[RHS_IMAG]], %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO:.*]] = arith.mulf %[[RHS_IMAG_REAL_RATIO]], %[[RHS_IMAG]] : f32
+// CHECK: %[[RHS_IMAG_REAL_DENOM:.*]] = arith.addf %[[RHS_REAL]], %[[RHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_IMAG_REAL_RATIO]] : f32
+// CHECK: %[[REAL_NUMERATOR_2:.*]] = arith.addf %[[LHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG_REAL_RATIO]] : f32
+// CHECK: %[[RESULT_REAL_2:.*]] = arith.divf %[[REAL_NUMERATOR_2]], %[[RHS_IMAG_REAL_DENOM]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_REAL_RATIO:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_IMAG_REAL_RATIO]] : f32
+// CHECK: %[[IMAG_NUMERATOR_2:.*]] = arith.subf %[[LHS_IMAG]], %[[LHS_REAL_TIMES_RHS_IMAG_REAL_RATIO]] : f32
+// CHECK: %[[RESULT_IMAG_2:.*]] = arith.divf %[[IMAG_NUMERATOR_2]], %[[RHS_IMAG_REAL_DENOM]] : f32
// Case 1. Zero denominator, numerator contains at most one NaN value.
-// CHECK: %[[ZERO:.*]] = constant 0.000000e+00 : f32
-// CHECK: %[[RHS_REAL_ABS:.*]] = absf %[[RHS_REAL]] : f32
-// CHECK: %[[RHS_REAL_ABS_IS_ZERO:.*]] = cmpf oeq, %[[RHS_REAL_ABS]], %[[ZERO]] : f32
-// CHECK: %[[RHS_IMAG_ABS:.*]] = absf %[[RHS_IMAG]] : f32
-// CHECK: %[[RHS_IMAG_ABS_IS_ZERO:.*]] = cmpf oeq, %[[RHS_IMAG_ABS]], %[[ZERO]] : f32
-// CHECK: %[[LHS_REAL_IS_NOT_NAN:.*]] = cmpf ord, %[[LHS_REAL]], %[[ZERO]] : f32
-// CHECK: %[[LHS_IMAG_IS_NOT_NAN:.*]] = cmpf ord, %[[LHS_IMAG]], %[[ZERO]] : f32
-// CHECK: %[[LHS_CONTAINS_NOT_NAN_VALUE:.*]] = or %[[LHS_REAL_IS_NOT_NAN]], %[[LHS_IMAG_IS_NOT_NAN]] : i1
-// CHECK: %[[RHS_IS_ZERO:.*]] = and %[[RHS_REAL_ABS_IS_ZERO]], %[[RHS_IMAG_ABS_IS_ZERO]] : i1
-// CHECK: %[[RESULT_IS_INFINITY:.*]] = and %[[LHS_CONTAINS_NOT_NAN_VALUE]], %[[RHS_IS_ZERO]] : i1
-// CHECK: %[[INF:.*]] = constant 0x7F800000 : f32
-// CHECK: %[[INF_WITH_SIGN_OF_RHS_REAL:.*]] = copysign %[[INF]], %[[RHS_REAL]] : f32
-// CHECK: %[[INFINITY_RESULT_REAL:.*]] = mulf %[[INF_WITH_SIGN_OF_RHS_REAL]], %[[LHS_REAL]] : f32
-// CHECK: %[[INFINITY_RESULT_IMAG:.*]] = mulf %[[INF_WITH_SIGN_OF_RHS_REAL]], %[[LHS_IMAG]] : f32
+// CHECK: %[[ZERO:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK: %[[RHS_REAL_ABS:.*]] = math.abs %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_REAL_ABS_IS_ZERO:.*]] = arith.cmpf oeq, %[[RHS_REAL_ABS]], %[[ZERO]] : f32
+// CHECK: %[[RHS_IMAG_ABS:.*]] = math.abs %[[RHS_IMAG]] : f32
+// CHECK: %[[RHS_IMAG_ABS_IS_ZERO:.*]] = arith.cmpf oeq, %[[RHS_IMAG_ABS]], %[[ZERO]] : f32
+// CHECK: %[[LHS_REAL_IS_NOT_NAN:.*]] = arith.cmpf ord, %[[LHS_REAL]], %[[ZERO]] : f32
+// CHECK: %[[LHS_IMAG_IS_NOT_NAN:.*]] = arith.cmpf ord, %[[LHS_IMAG]], %[[ZERO]] : f32
+// CHECK: %[[LHS_CONTAINS_NOT_NAN_VALUE:.*]] = arith.ori %[[LHS_REAL_IS_NOT_NAN]], %[[LHS_IMAG_IS_NOT_NAN]] : i1
+// CHECK: %[[RHS_IS_ZERO:.*]] = arith.andi %[[RHS_REAL_ABS_IS_ZERO]], %[[RHS_IMAG_ABS_IS_ZERO]] : i1
+// CHECK: %[[RESULT_IS_INFINITY:.*]] = arith.andi %[[LHS_CONTAINS_NOT_NAN_VALUE]], %[[RHS_IS_ZERO]] : i1
+// CHECK: %[[INF:.*]] = arith.constant 0x7F800000 : f32
+// CHECK: %[[INF_WITH_SIGN_OF_RHS_REAL:.*]] = math.copysign %[[INF]], %[[RHS_REAL]] : f32
+// CHECK: %[[INFINITY_RESULT_REAL:.*]] = arith.mulf %[[INF_WITH_SIGN_OF_RHS_REAL]], %[[LHS_REAL]] : f32
+// CHECK: %[[INFINITY_RESULT_IMAG:.*]] = arith.mulf %[[INF_WITH_SIGN_OF_RHS_REAL]], %[[LHS_IMAG]] : f32
// Case 2. Infinite numerator, finite denominator.
-// CHECK: %[[RHS_REAL_FINITE:.*]] = cmpf one, %[[RHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IMAG_FINITE:.*]] = cmpf one, %[[RHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IS_FINITE:.*]] = and %[[RHS_REAL_FINITE]], %[[RHS_IMAG_FINITE]] : i1
-// CHECK: %[[LHS_REAL_ABS:.*]] = absf %[[LHS_REAL]] : f32
-// CHECK: %[[LHS_REAL_INFINITE:.*]] = cmpf oeq, %[[LHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IMAG_ABS:.*]] = absf %[[LHS_IMAG]] : f32
-// CHECK: %[[LHS_IMAG_INFINITE:.*]] = cmpf oeq, %[[LHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IS_INFINITE:.*]] = or %[[LHS_REAL_INFINITE]], %[[LHS_IMAG_INFINITE]] : i1
-// CHECK: %[[INF_NUM_FINITE_DENOM:.*]] = and %[[LHS_IS_INFINITE]], %[[RHS_IS_FINITE]] : i1
-// CHECK: %[[ONE:.*]] = constant 1.000000e+00 : f32
+// CHECK: %[[RHS_REAL_FINITE:.*]] = arith.cmpf one, %[[RHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IMAG_FINITE:.*]] = arith.cmpf one, %[[RHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IS_FINITE:.*]] = arith.andi %[[RHS_REAL_FINITE]], %[[RHS_IMAG_FINITE]] : i1
+// CHECK: %[[LHS_REAL_ABS:.*]] = math.abs %[[LHS_REAL]] : f32
+// CHECK: %[[LHS_REAL_INFINITE:.*]] = arith.cmpf oeq, %[[LHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IMAG_ABS:.*]] = math.abs %[[LHS_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_INFINITE:.*]] = arith.cmpf oeq, %[[LHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IS_INFINITE:.*]] = arith.ori %[[LHS_REAL_INFINITE]], %[[LHS_IMAG_INFINITE]] : i1
+// CHECK: %[[INF_NUM_FINITE_DENOM:.*]] = arith.andi %[[LHS_IS_INFINITE]], %[[RHS_IS_FINITE]] : i1
+// CHECK: %[[ONE:.*]] = arith.constant 1.000000e+00 : f32
// CHECK: %[[LHS_REAL_IS_INF:.*]] = select %[[LHS_REAL_INFINITE]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN:.*]] = copysign %[[LHS_REAL_IS_INF]], %[[LHS_REAL]] : f32
+// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN:.*]] = math.copysign %[[LHS_REAL_IS_INF]], %[[LHS_REAL]] : f32
// CHECK: %[[LHS_IMAG_IS_INF:.*]] = select %[[LHS_IMAG_INFINITE]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN:.*]] = copysign %[[LHS_IMAG_IS_INF]], %[[LHS_IMAG]] : f32
-// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_REAL:.*]] = mulf %[[LHS_REAL_IS_INF_WITH_SIGN]], %[[RHS_REAL]] : f32
-// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_IMAG_IS_INF_WITH_SIGN]], %[[RHS_IMAG]] : f32
-// CHECK: %[[INF_MULTIPLICATOR_1:.*]] = addf %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_REAL]], %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[RESULT_REAL_3:.*]] = mulf %[[INF]], %[[INF_MULTIPLICATOR_1]] : f32
-// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_REAL_IS_INF_WITH_SIGN]], %[[RHS_IMAG]] : f32
-// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_REAL:.*]] = mulf %[[LHS_IMAG_IS_INF_WITH_SIGN]], %[[RHS_REAL]] : f32
-// CHECK: %[[INF_MULTIPLICATOR_2:.*]] = subf %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_REAL]], %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[RESULT_IMAG_3:.*]] = mulf %[[INF]], %[[INF_MULTIPLICATOR_2]] : f32
+// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN:.*]] = math.copysign %[[LHS_IMAG_IS_INF]], %[[LHS_IMAG]] : f32
+// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_REAL_IS_INF_WITH_SIGN]], %[[RHS_REAL]] : f32
+// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_IMAG_IS_INF_WITH_SIGN]], %[[RHS_IMAG]] : f32
+// CHECK: %[[INF_MULTIPLICATOR_1:.*]] = arith.addf %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_REAL]], %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[RESULT_REAL_3:.*]] = arith.mulf %[[INF]], %[[INF_MULTIPLICATOR_1]] : f32
+// CHECK: %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_REAL_IS_INF_WITH_SIGN]], %[[RHS_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_IMAG_IS_INF_WITH_SIGN]], %[[RHS_REAL]] : f32
+// CHECK: %[[INF_MULTIPLICATOR_2:.*]] = arith.subf %[[LHS_IMAG_IS_INF_WITH_SIGN_TIMES_RHS_REAL]], %[[LHS_REAL_IS_INF_WITH_SIGN_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[RESULT_IMAG_3:.*]] = arith.mulf %[[INF]], %[[INF_MULTIPLICATOR_2]] : f32
// Case 3. Finite numerator, infinite denominator.
-// CHECK: %[[LHS_REAL_FINITE:.*]] = cmpf one, %[[LHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IMAG_FINITE:.*]] = cmpf one, %[[LHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IS_FINITE:.*]] = and %[[LHS_REAL_FINITE]], %[[LHS_IMAG_FINITE]] : i1
-// CHECK: %[[RHS_REAL_INFINITE:.*]] = cmpf oeq, %[[RHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IMAG_INFINITE:.*]] = cmpf oeq, %[[RHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IS_INFINITE:.*]] = or %[[RHS_REAL_INFINITE]], %[[RHS_IMAG_INFINITE]] : i1
-// CHECK: %[[FINITE_NUM_INFINITE_DENOM:.*]] = and %[[LHS_IS_FINITE]], %[[RHS_IS_INFINITE]] : i1
+// CHECK: %[[LHS_REAL_FINITE:.*]] = arith.cmpf one, %[[LHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IMAG_FINITE:.*]] = arith.cmpf one, %[[LHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IS_FINITE:.*]] = arith.andi %[[LHS_REAL_FINITE]], %[[LHS_IMAG_FINITE]] : i1
+// CHECK: %[[RHS_REAL_INFINITE:.*]] = arith.cmpf oeq, %[[RHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IMAG_INFINITE:.*]] = arith.cmpf oeq, %[[RHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IS_INFINITE:.*]] = arith.ori %[[RHS_REAL_INFINITE]], %[[RHS_IMAG_INFINITE]] : i1
+// CHECK: %[[FINITE_NUM_INFINITE_DENOM:.*]] = arith.andi %[[LHS_IS_FINITE]], %[[RHS_IS_INFINITE]] : i1
// CHECK: %[[RHS_REAL_IS_INF:.*]] = select %[[RHS_REAL_INFINITE]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN:.*]] = copysign %[[RHS_REAL_IS_INF]], %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN:.*]] = math.copysign %[[RHS_REAL_IS_INF]], %[[RHS_REAL]] : f32
// CHECK: %[[RHS_IMAG_IS_INF:.*]] = select %[[RHS_IMAG_INFINITE]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN:.*]] = copysign %[[RHS_IMAG_IS_INF]], %[[RHS_IMAG]] : f32
-// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_REAL:.*]] = mulf %[[LHS_REAL]], %[[RHS_REAL_IS_INF_WITH_SIGN]] : f32
-// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_IMAG:.*]] = mulf %[[LHS_IMAG]], %[[RHS_IMAG_IS_INF_WITH_SIGN]] : f32
-// CHECK: %[[ZERO_MULTIPLICATOR_1:.*]] = addf %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_REAL]], %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_IMAG]] : f32
-// CHECK: %[[RESULT_REAL_4:.*]] = mulf %[[ZERO]], %[[ZERO_MULTIPLICATOR_1]] : f32
-// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_IMAG:.*]] = mulf %[[LHS_IMAG]], %[[RHS_REAL_IS_INF_WITH_SIGN]] : f32
-// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_REAL:.*]] = mulf %[[LHS_REAL]], %[[RHS_IMAG_IS_INF_WITH_SIGN]] : f32
-// CHECK: %[[ZERO_MULTIPLICATOR_2:.*]] = subf %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_IMAG]], %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_REAL]] : f32
-// CHECK: %[[RESULT_IMAG_4:.*]] = mulf %[[ZERO]], %[[ZERO_MULTIPLICATOR_2]] : f32
+// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN:.*]] = math.copysign %[[RHS_IMAG_IS_INF]], %[[RHS_IMAG]] : f32
+// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_REAL:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_REAL_IS_INF_WITH_SIGN]] : f32
+// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_IMAG:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_IMAG_IS_INF_WITH_SIGN]] : f32
+// CHECK: %[[ZERO_MULTIPLICATOR_1:.*]] = arith.addf %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_REAL]], %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_IMAG]] : f32
+// CHECK: %[[RESULT_REAL_4:.*]] = arith.mulf %[[ZERO]], %[[ZERO_MULTIPLICATOR_1]] : f32
+// CHECK: %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_IMAG:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_REAL_IS_INF_WITH_SIGN]] : f32
+// CHECK: %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_REAL:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_IMAG_IS_INF_WITH_SIGN]] : f32
+// CHECK: %[[ZERO_MULTIPLICATOR_2:.*]] = arith.subf %[[RHS_REAL_IS_INF_WITH_SIGN_TIMES_LHS_IMAG]], %[[RHS_IMAG_IS_INF_WITH_SIGN_TIMES_LHS_REAL]] : f32
+// CHECK: %[[RESULT_IMAG_4:.*]] = arith.mulf %[[ZERO]], %[[ZERO_MULTIPLICATOR_2]] : f32
-// CHECK: %[[REAL_ABS_SMALLER_THAN_IMAG_ABS:.*]] = cmpf olt, %[[RHS_REAL_ABS]], %[[RHS_IMAG_ABS]] : f32
+// CHECK: %[[REAL_ABS_SMALLER_THAN_IMAG_ABS:.*]] = arith.cmpf olt, %[[RHS_REAL_ABS]], %[[RHS_IMAG_ABS]] : f32
// CHECK: %[[RESULT_REAL:.*]] = select %[[REAL_ABS_SMALLER_THAN_IMAG_ABS]], %[[RESULT_REAL_1]], %[[RESULT_REAL_2]] : f32
// CHECK: %[[RESULT_IMAG:.*]] = select %[[REAL_ABS_SMALLER_THAN_IMAG_ABS]], %[[RESULT_IMAG_1]], %[[RESULT_IMAG_2]] : f32
// CHECK: %[[RESULT_REAL_SPECIAL_CASE_3:.*]] = select %[[FINITE_NUM_INFINITE_DENOM]], %[[RESULT_REAL_4]], %[[RESULT_REAL]] : f32
// CHECK: %[[RESULT_IMAG_SPECIAL_CASE_2:.*]] = select %[[INF_NUM_FINITE_DENOM]], %[[RESULT_IMAG_3]], %[[RESULT_IMAG_SPECIAL_CASE_3]] : f32
// CHECK: %[[RESULT_REAL_SPECIAL_CASE_1:.*]] = select %[[RESULT_IS_INFINITY]], %[[INFINITY_RESULT_REAL]], %[[RESULT_REAL_SPECIAL_CASE_2]] : f32
// CHECK: %[[RESULT_IMAG_SPECIAL_CASE_1:.*]] = select %[[RESULT_IS_INFINITY]], %[[INFINITY_RESULT_IMAG]], %[[RESULT_IMAG_SPECIAL_CASE_2]] : f32
-// CHECK: %[[RESULT_REAL_IS_NAN:.*]] = cmpf uno, %[[RESULT_REAL]], %[[ZERO]] : f32
-// CHECK: %[[RESULT_IMAG_IS_NAN:.*]] = cmpf uno, %[[RESULT_IMAG]], %[[ZERO]] : f32
-// CHECK: %[[RESULT_IS_NAN:.*]] = and %[[RESULT_REAL_IS_NAN]], %[[RESULT_IMAG_IS_NAN]] : i1
+// CHECK: %[[RESULT_REAL_IS_NAN:.*]] = arith.cmpf uno, %[[RESULT_REAL]], %[[ZERO]] : f32
+// CHECK: %[[RESULT_IMAG_IS_NAN:.*]] = arith.cmpf uno, %[[RESULT_IMAG]], %[[ZERO]] : f32
+// CHECK: %[[RESULT_IS_NAN:.*]] = arith.andi %[[RESULT_REAL_IS_NAN]], %[[RESULT_IMAG_IS_NAN]] : i1
// CHECK: %[[RESULT_REAL_WITH_SPECIAL_CASES:.*]] = select %[[RESULT_IS_NAN]], %[[RESULT_REAL_SPECIAL_CASE_1]], %[[RESULT_REAL]] : f32
// CHECK: %[[RESULT_IMAG_WITH_SPECIAL_CASES:.*]] = select %[[RESULT_IS_NAN]], %[[RESULT_IMAG_SPECIAL_CASE_1]], %[[RESULT_IMAG]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[RESULT_REAL_WITH_SPECIAL_CASES]], %[[RESULT_IMAG_WITH_SPECIAL_CASES]] : complex<f32>
// CHECK: %[[IMAG_LHS:.*]] = complex.im %[[LHS]] : complex<f32>
// CHECK: %[[REAL_RHS:.*]] = complex.re %[[RHS]] : complex<f32>
// CHECK: %[[IMAG_RHS:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK-DAG: %[[REAL_EQUAL:.*]] = cmpf oeq, %[[REAL_LHS]], %[[REAL_RHS]] : f32
-// CHECK-DAG: %[[IMAG_EQUAL:.*]] = cmpf oeq, %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
-// CHECK: %[[EQUAL:.*]] = and %[[REAL_EQUAL]], %[[IMAG_EQUAL]] : i1
+// CHECK-DAG: %[[REAL_EQUAL:.*]] = arith.cmpf oeq, %[[REAL_LHS]], %[[REAL_RHS]] : f32
+// CHECK-DAG: %[[IMAG_EQUAL:.*]] = arith.cmpf oeq, %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
+// CHECK: %[[EQUAL:.*]] = arith.andi %[[REAL_EQUAL]], %[[IMAG_EQUAL]] : i1
// CHECK: return %[[EQUAL]] : i1
// CHECK-LABEL: func @complex_exp
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
// CHECK-DAG: %[[COS_IMAG:.*]] = math.cos %[[IMAG]] : f32
// CHECK-DAG: %[[EXP_REAL:.*]] = math.exp %[[REAL]] : f32
-// CHECK-DAG: %[[RESULT_REAL:.]] = mulf %[[EXP_REAL]], %[[COS_IMAG]] : f32
+// CHECK-DAG: %[[RESULT_REAL:.]] = arith.mulf %[[EXP_REAL]], %[[COS_IMAG]] : f32
// CHECK-DAG: %[[SIN_IMAG:.*]] = math.sin %[[IMAG]] : f32
-// CHECK-DAG: %[[RESULT_IMAG:.*]] = mulf %[[EXP_REAL]], %[[SIN_IMAG]] : f32
+// CHECK-DAG: %[[RESULT_IMAG:.*]] = arith.mulf %[[EXP_REAL]], %[[SIN_IMAG]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[RESULT_REAL]], %[[RESULT_IMAG]] : complex<f32>
// CHECK: return %[[RESULT]] : complex<f32>
}
// CHECK: %[[REAL:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK: %[[SQR_REAL:.*]] = mulf %[[REAL]], %[[REAL]] : f32
-// CHECK: %[[SQR_IMAG:.*]] = mulf %[[IMAG]], %[[IMAG]] : f32
-// CHECK: %[[SQ_NORM:.*]] = addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
+// CHECK: %[[SQR_REAL:.*]] = arith.mulf %[[REAL]], %[[REAL]] : f32
+// CHECK: %[[SQR_IMAG:.*]] = arith.mulf %[[IMAG]], %[[IMAG]] : f32
+// CHECK: %[[SQ_NORM:.*]] = arith.addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
// CHECK: %[[NORM:.*]] = math.sqrt %[[SQ_NORM]] : f32
// CHECK: %[[RESULT_REAL:.*]] = math.log %[[NORM]] : f32
// CHECK: %[[REAL2:.*]] = complex.re %[[ARG]] : complex<f32>
}
// CHECK: %[[REAL:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK: %[[ONE:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[REAL_PLUS_ONE:.*]] = addf %[[REAL]], %[[ONE]] : f32
+// CHECK: %[[ONE:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[REAL_PLUS_ONE:.*]] = arith.addf %[[REAL]], %[[ONE]] : f32
// CHECK: %[[NEW_COMPLEX:.*]] = complex.create %[[REAL_PLUS_ONE]], %[[IMAG]] : complex<f32>
// CHECK: %[[REAL:.*]] = complex.re %[[NEW_COMPLEX]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[NEW_COMPLEX]] : complex<f32>
-// CHECK: %[[SQR_REAL:.*]] = mulf %[[REAL]], %[[REAL]] : f32
-// CHECK: %[[SQR_IMAG:.*]] = mulf %[[IMAG]], %[[IMAG]] : f32
-// CHECK: %[[SQ_NORM:.*]] = addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
+// CHECK: %[[SQR_REAL:.*]] = arith.mulf %[[REAL]], %[[REAL]] : f32
+// CHECK: %[[SQR_IMAG:.*]] = arith.mulf %[[IMAG]], %[[IMAG]] : f32
+// CHECK: %[[SQ_NORM:.*]] = arith.addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
// CHECK: %[[NORM:.*]] = math.sqrt %[[SQ_NORM]] : f32
// CHECK: %[[RESULT_REAL:.*]] = math.log %[[NORM]] : f32
// CHECK: %[[REAL2:.*]] = complex.re %[[NEW_COMPLEX]] : complex<f32>
return %mul : complex<f32>
}
// CHECK: %[[LHS_REAL:.*]] = complex.re %[[LHS]] : complex<f32>
-// CHECK: %[[LHS_REAL_ABS:.*]] = absf %[[LHS_REAL]] : f32
+// CHECK: %[[LHS_REAL_ABS:.*]] = math.abs %[[LHS_REAL]] : f32
// CHECK: %[[LHS_IMAG:.*]] = complex.im %[[LHS]] : complex<f32>
-// CHECK: %[[LHS_IMAG_ABS:.*]] = absf %[[LHS_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_ABS:.*]] = math.abs %[[LHS_IMAG]] : f32
// CHECK: %[[RHS_REAL:.*]] = complex.re %[[RHS]] : complex<f32>
-// CHECK: %[[RHS_REAL_ABS:.*]] = absf %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_REAL_ABS:.*]] = math.abs %[[RHS_REAL]] : f32
// CHECK: %[[RHS_IMAG:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK: %[[RHS_IMAG_ABS:.*]] = absf %[[RHS_IMAG]] : f32
+// CHECK: %[[RHS_IMAG_ABS:.*]] = math.abs %[[RHS_IMAG]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_REAL:.*]] = mulf %[[LHS_REAL]], %[[RHS_REAL]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_ABS:.*]] = absf %[[LHS_REAL_TIMES_RHS_REAL]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_IMAG]], %[[RHS_IMAG]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_ABS:.*]] = absf %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[REAL:.*]] = subf %[[LHS_REAL_TIMES_RHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_REAL]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_ABS:.*]] = math.abs %[[LHS_REAL_TIMES_RHS_REAL]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_ABS:.*]] = math.abs %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[REAL:.*]] = arith.subf %[[LHS_REAL_TIMES_RHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL:.*]] = mulf %[[LHS_IMAG]], %[[RHS_REAL]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_ABS:.*]] = absf %[[LHS_IMAG_TIMES_RHS_REAL]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_REAL]], %[[RHS_IMAG]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_ABS:.*]] = absf %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[IMAG:.*]] = addf %[[LHS_IMAG_TIMES_RHS_REAL]], %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_IMAG]], %[[RHS_REAL]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_ABS:.*]] = math.abs %[[LHS_IMAG_TIMES_RHS_REAL]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_REAL]], %[[RHS_IMAG]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_ABS:.*]] = math.abs %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[IMAG:.*]] = arith.addf %[[LHS_IMAG_TIMES_RHS_REAL]], %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
// Handle cases where the "naive" calculation results in NaN values.
-// CHECK: %[[REAL_IS_NAN:.*]] = cmpf uno, %[[REAL]], %[[REAL]] : f32
-// CHECK: %[[IMAG_IS_NAN:.*]] = cmpf uno, %[[IMAG]], %[[IMAG]] : f32
-// CHECK: %[[IS_NAN:.*]] = and %[[REAL_IS_NAN]], %[[IMAG_IS_NAN]] : i1
-// CHECK: %[[INF:.*]] = constant 0x7F800000 : f32
+// CHECK: %[[REAL_IS_NAN:.*]] = arith.cmpf uno, %[[REAL]], %[[REAL]] : f32
+// CHECK: %[[IMAG_IS_NAN:.*]] = arith.cmpf uno, %[[IMAG]], %[[IMAG]] : f32
+// CHECK: %[[IS_NAN:.*]] = arith.andi %[[REAL_IS_NAN]], %[[IMAG_IS_NAN]] : i1
+// CHECK: %[[INF:.*]] = arith.constant 0x7F800000 : f32
// Case 1. LHS_REAL or LHS_IMAG are infinite.
-// CHECK: %[[LHS_REAL_IS_INF:.*]] = cmpf oeq, %[[LHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IMAG_IS_INF:.*]] = cmpf oeq, %[[LHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IS_INF:.*]] = or %[[LHS_REAL_IS_INF]], %[[LHS_IMAG_IS_INF]] : i1
-// CHECK: %[[RHS_REAL_IS_NAN:.*]] = cmpf uno, %[[RHS_REAL]], %[[RHS_REAL]] : f32
-// CHECK: %[[RHS_IMAG_IS_NAN:.*]] = cmpf uno, %[[RHS_IMAG]], %[[RHS_IMAG]] : f32
-// CHECK: %[[ZERO:.*]] = constant 0.000000e+00 : f32
-// CHECK: %[[ONE:.*]] = constant 1.000000e+00 : f32
+// CHECK: %[[LHS_REAL_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IMAG_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IS_INF:.*]] = arith.ori %[[LHS_REAL_IS_INF]], %[[LHS_IMAG_IS_INF]] : i1
+// CHECK: %[[RHS_REAL_IS_NAN:.*]] = arith.cmpf uno, %[[RHS_REAL]], %[[RHS_REAL]] : f32
+// CHECK: %[[RHS_IMAG_IS_NAN:.*]] = arith.cmpf uno, %[[RHS_IMAG]], %[[RHS_IMAG]] : f32
+// CHECK: %[[ZERO:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK: %[[ONE:.*]] = arith.constant 1.000000e+00 : f32
// CHECK: %[[LHS_REAL_IS_INF_FLOAT:.*]] = select %[[LHS_REAL_IS_INF]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[TMP:.*]] = copysign %[[LHS_REAL_IS_INF_FLOAT]], %[[LHS_REAL]] : f32
+// CHECK: %[[TMP:.*]] = math.copysign %[[LHS_REAL_IS_INF_FLOAT]], %[[LHS_REAL]] : f32
// CHECK: %[[LHS_REAL1:.*]] = select %[[LHS_IS_INF]], %[[TMP]], %[[LHS_REAL]] : f32
// CHECK: %[[LHS_IMAG_IS_INF_FLOAT:.*]] = select %[[LHS_IMAG_IS_INF]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[TMP:.*]] = copysign %[[LHS_IMAG_IS_INF_FLOAT]], %[[LHS_IMAG]] : f32
+// CHECK: %[[TMP:.*]] = math.copysign %[[LHS_IMAG_IS_INF_FLOAT]], %[[LHS_IMAG]] : f32
// CHECK: %[[LHS_IMAG1:.*]] = select %[[LHS_IS_INF]], %[[TMP]], %[[LHS_IMAG]] : f32
-// CHECK: %[[LHS_IS_INF_AND_RHS_REAL_IS_NAN:.*]] = and %[[LHS_IS_INF]], %[[RHS_REAL_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[RHS_REAL]] : f32
+// CHECK: %[[LHS_IS_INF_AND_RHS_REAL_IS_NAN:.*]] = arith.andi %[[LHS_IS_INF]], %[[RHS_REAL_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[RHS_REAL]] : f32
// CHECK: %[[RHS_REAL1:.*]] = select %[[LHS_IS_INF_AND_RHS_REAL_IS_NAN]], %[[TMP]], %[[RHS_REAL]] : f32
-// CHECK: %[[LHS_IS_INF_AND_RHS_IMAG_IS_NAN:.*]] = and %[[LHS_IS_INF]], %[[RHS_IMAG_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[RHS_IMAG]] : f32
+// CHECK: %[[LHS_IS_INF_AND_RHS_IMAG_IS_NAN:.*]] = arith.andi %[[LHS_IS_INF]], %[[RHS_IMAG_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[RHS_IMAG]] : f32
// CHECK: %[[RHS_IMAG1:.*]] = select %[[LHS_IS_INF_AND_RHS_IMAG_IS_NAN]], %[[TMP]], %[[RHS_IMAG]] : f32
// Case 2. RHS_REAL or RHS_IMAG are infinite.
-// CHECK: %[[RHS_REAL_IS_INF:.*]] = cmpf oeq, %[[RHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IMAG_IS_INF:.*]] = cmpf oeq, %[[RHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[RHS_IS_INF:.*]] = or %[[RHS_REAL_IS_INF]], %[[RHS_IMAG_IS_INF]] : i1
-// CHECK: %[[LHS_REAL_IS_NAN:.*]] = cmpf uno, %[[LHS_REAL1]], %[[LHS_REAL1]] : f32
-// CHECK: %[[LHS_IMAG_IS_NAN:.*]] = cmpf uno, %[[LHS_IMAG1]], %[[LHS_IMAG1]] : f32
+// CHECK: %[[RHS_REAL_IS_INF:.*]] = arith.cmpf oeq, %[[RHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IMAG_IS_INF:.*]] = arith.cmpf oeq, %[[RHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[RHS_IS_INF:.*]] = arith.ori %[[RHS_REAL_IS_INF]], %[[RHS_IMAG_IS_INF]] : i1
+// CHECK: %[[LHS_REAL_IS_NAN:.*]] = arith.cmpf uno, %[[LHS_REAL1]], %[[LHS_REAL1]] : f32
+// CHECK: %[[LHS_IMAG_IS_NAN:.*]] = arith.cmpf uno, %[[LHS_IMAG1]], %[[LHS_IMAG1]] : f32
// CHECK: %[[RHS_REAL_IS_INF_FLOAT:.*]] = select %[[RHS_REAL_IS_INF]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[TMP:.*]] = copysign %[[RHS_REAL_IS_INF_FLOAT]], %[[RHS_REAL1]] : f32
+// CHECK: %[[TMP:.*]] = math.copysign %[[RHS_REAL_IS_INF_FLOAT]], %[[RHS_REAL1]] : f32
// CHECK: %[[RHS_REAL2:.*]] = select %[[RHS_IS_INF]], %[[TMP]], %[[RHS_REAL1]] : f32
// CHECK: %[[RHS_IMAG_IS_INF_FLOAT:.*]] = select %[[RHS_IMAG_IS_INF]], %[[ONE]], %[[ZERO]] : f32
-// CHECK: %[[TMP:.*]] = copysign %[[RHS_IMAG_IS_INF_FLOAT]], %[[RHS_IMAG1]] : f32
+// CHECK: %[[TMP:.*]] = math.copysign %[[RHS_IMAG_IS_INF_FLOAT]], %[[RHS_IMAG1]] : f32
// CHECK: %[[RHS_IMAG2:.*]] = select %[[RHS_IS_INF]], %[[TMP]], %[[RHS_IMAG1]] : f32
-// CHECK: %[[RHS_IS_INF_AND_LHS_REAL_IS_NAN:.*]] = and %[[RHS_IS_INF]], %[[LHS_REAL_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[LHS_REAL1]] : f32
+// CHECK: %[[RHS_IS_INF_AND_LHS_REAL_IS_NAN:.*]] = arith.andi %[[RHS_IS_INF]], %[[LHS_REAL_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[LHS_REAL1]] : f32
// CHECK: %[[LHS_REAL2:.*]] = select %[[RHS_IS_INF_AND_LHS_REAL_IS_NAN]], %[[TMP]], %[[LHS_REAL1]] : f32
-// CHECK: %[[RHS_IS_INF_AND_LHS_IMAG_IS_NAN:.*]] = and %[[RHS_IS_INF]], %[[LHS_IMAG_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[LHS_IMAG1]] : f32
+// CHECK: %[[RHS_IS_INF_AND_LHS_IMAG_IS_NAN:.*]] = arith.andi %[[RHS_IS_INF]], %[[LHS_IMAG_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[LHS_IMAG1]] : f32
// CHECK: %[[LHS_IMAG2:.*]] = select %[[RHS_IS_INF_AND_LHS_IMAG_IS_NAN]], %[[TMP]], %[[LHS_IMAG1]] : f32
-// CHECK: %[[RECALC:.*]] = or %[[LHS_IS_INF]], %[[RHS_IS_INF]] : i1
+// CHECK: %[[RECALC:.*]] = arith.ori %[[LHS_IS_INF]], %[[RHS_IS_INF]] : i1
// Case 3. One of the pairwise products of left hand side with right hand side
// is infinite.
-// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_IS_INF:.*]] = cmpf oeq, %[[LHS_REAL_TIMES_RHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_IS_INF:.*]] = cmpf oeq, %[[LHS_IMAG_TIMES_RHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[IS_SPECIAL_CASE:.*]] = or %[[LHS_REAL_TIMES_RHS_REAL_IS_INF]], %[[LHS_IMAG_TIMES_RHS_IMAG_IS_INF]] : i1
-// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_IS_INF:.*]] = cmpf oeq, %[[LHS_REAL_TIMES_RHS_IMAG_ABS]], %[[INF]] : f32
-// CHECK: %[[IS_SPECIAL_CASE1:.*]] = or %[[IS_SPECIAL_CASE]], %[[LHS_REAL_TIMES_RHS_IMAG_IS_INF]] : i1
-// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_IS_INF:.*]] = cmpf oeq, %[[LHS_IMAG_TIMES_RHS_REAL_ABS]], %[[INF]] : f32
-// CHECK: %[[IS_SPECIAL_CASE2:.*]] = or %[[IS_SPECIAL_CASE1]], %[[LHS_IMAG_TIMES_RHS_REAL_IS_INF]] : i1
-// CHECK: %[[TRUE:.*]] = constant true
-// CHECK: %[[NOT_RECALC:.*]] = xor %[[RECALC]], %[[TRUE]] : i1
-// CHECK: %[[IS_SPECIAL_CASE3:.*]] = and %[[IS_SPECIAL_CASE2]], %[[NOT_RECALC]] : i1
-// CHECK: %[[IS_SPECIAL_CASE_AND_LHS_REAL_IS_NAN:.*]] = and %[[IS_SPECIAL_CASE3]], %[[LHS_REAL_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[LHS_REAL2]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_REAL_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_REAL_TIMES_RHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_IMAG_TIMES_RHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[IS_SPECIAL_CASE:.*]] = arith.ori %[[LHS_REAL_TIMES_RHS_REAL_IS_INF]], %[[LHS_IMAG_TIMES_RHS_IMAG_IS_INF]] : i1
+// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_REAL_TIMES_RHS_IMAG_ABS]], %[[INF]] : f32
+// CHECK: %[[IS_SPECIAL_CASE1:.*]] = arith.ori %[[IS_SPECIAL_CASE]], %[[LHS_REAL_TIMES_RHS_IMAG_IS_INF]] : i1
+// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL_IS_INF:.*]] = arith.cmpf oeq, %[[LHS_IMAG_TIMES_RHS_REAL_ABS]], %[[INF]] : f32
+// CHECK: %[[IS_SPECIAL_CASE2:.*]] = arith.ori %[[IS_SPECIAL_CASE1]], %[[LHS_IMAG_TIMES_RHS_REAL_IS_INF]] : i1
+// CHECK: %[[TRUE:.*]] = arith.constant true
+// CHECK: %[[NOT_RECALC:.*]] = arith.xori %[[RECALC]], %[[TRUE]] : i1
+// CHECK: %[[IS_SPECIAL_CASE3:.*]] = arith.andi %[[IS_SPECIAL_CASE2]], %[[NOT_RECALC]] : i1
+// CHECK: %[[IS_SPECIAL_CASE_AND_LHS_REAL_IS_NAN:.*]] = arith.andi %[[IS_SPECIAL_CASE3]], %[[LHS_REAL_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[LHS_REAL2]] : f32
// CHECK: %[[LHS_REAL3:.*]] = select %[[IS_SPECIAL_CASE_AND_LHS_REAL_IS_NAN]], %[[TMP]], %[[LHS_REAL2]] : f32
-// CHECK: %[[IS_SPECIAL_CASE_AND_LHS_IMAG_IS_NAN:.*]] = and %[[IS_SPECIAL_CASE3]], %[[LHS_IMAG_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[LHS_IMAG2]] : f32
+// CHECK: %[[IS_SPECIAL_CASE_AND_LHS_IMAG_IS_NAN:.*]] = arith.andi %[[IS_SPECIAL_CASE3]], %[[LHS_IMAG_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[LHS_IMAG2]] : f32
// CHECK: %[[LHS_IMAG3:.*]] = select %[[IS_SPECIAL_CASE_AND_LHS_IMAG_IS_NAN]], %[[TMP]], %[[LHS_IMAG2]] : f32
-// CHECK: %[[IS_SPECIAL_CASE_AND_RHS_REAL_IS_NAN:.*]] = and %[[IS_SPECIAL_CASE3]], %[[RHS_REAL_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[RHS_REAL2]] : f32
+// CHECK: %[[IS_SPECIAL_CASE_AND_RHS_REAL_IS_NAN:.*]] = arith.andi %[[IS_SPECIAL_CASE3]], %[[RHS_REAL_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[RHS_REAL2]] : f32
// CHECK: %[[RHS_REAL3:.*]] = select %[[IS_SPECIAL_CASE_AND_RHS_REAL_IS_NAN]], %[[TMP]], %[[RHS_REAL2]] : f32
-// CHECK: %[[IS_SPECIAL_CASE_AND_RHS_IMAG_IS_NAN:.*]] = and %[[IS_SPECIAL_CASE3]], %[[RHS_IMAG_IS_NAN]] : i1
-// CHECK: %[[TMP:.*]] = copysign %[[ZERO]], %[[RHS_IMAG2]] : f32
+// CHECK: %[[IS_SPECIAL_CASE_AND_RHS_IMAG_IS_NAN:.*]] = arith.andi %[[IS_SPECIAL_CASE3]], %[[RHS_IMAG_IS_NAN]] : i1
+// CHECK: %[[TMP:.*]] = math.copysign %[[ZERO]], %[[RHS_IMAG2]] : f32
// CHECK: %[[RHS_IMAG3:.*]] = select %[[IS_SPECIAL_CASE_AND_RHS_IMAG_IS_NAN]], %[[TMP]], %[[RHS_IMAG2]] : f32
-// CHECK: %[[RECALC2:.*]] = or %[[RECALC]], %[[IS_SPECIAL_CASE3]] : i1
-// CHECK: %[[RECALC3:.*]] = and %[[IS_NAN]], %[[RECALC2]] : i1
+// CHECK: %[[RECALC2:.*]] = arith.ori %[[RECALC]], %[[IS_SPECIAL_CASE3]] : i1
+// CHECK: %[[RECALC3:.*]] = arith.andi %[[IS_NAN]], %[[RECALC2]] : i1
// Recalculate real part.
-// CHECK: %[[LHS_REAL_TIMES_RHS_REAL:.*]] = mulf %[[LHS_REAL3]], %[[RHS_REAL3]] : f32
-// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_IMAG3]], %[[RHS_IMAG3]] : f32
-// CHECK: %[[NEW_REAL:.*]] = subf %[[LHS_REAL_TIMES_RHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[NEW_REAL_TIMES_INF:.*]] = mulf %[[INF]], %[[NEW_REAL]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_REAL3]], %[[RHS_REAL3]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_IMAG3]], %[[RHS_IMAG3]] : f32
+// CHECK: %[[NEW_REAL:.*]] = arith.subf %[[LHS_REAL_TIMES_RHS_REAL]], %[[LHS_IMAG_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[NEW_REAL_TIMES_INF:.*]] = arith.mulf %[[INF]], %[[NEW_REAL]] : f32
// CHECK: %[[FINAL_REAL:.*]] = select %[[RECALC3]], %[[NEW_REAL_TIMES_INF]], %[[REAL]] : f32
// Recalculate imag part.
-// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL:.*]] = mulf %[[LHS_IMAG3]], %[[RHS_REAL3]] : f32
-// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG:.*]] = mulf %[[LHS_REAL3]], %[[RHS_IMAG3]] : f32
-// CHECK: %[[NEW_IMAG:.*]] = addf %[[LHS_IMAG_TIMES_RHS_REAL]], %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
-// CHECK: %[[NEW_IMAG_TIMES_INF:.*]] = mulf %[[INF]], %[[NEW_IMAG]] : f32
+// CHECK: %[[LHS_IMAG_TIMES_RHS_REAL:.*]] = arith.mulf %[[LHS_IMAG3]], %[[RHS_REAL3]] : f32
+// CHECK: %[[LHS_REAL_TIMES_RHS_IMAG:.*]] = arith.mulf %[[LHS_REAL3]], %[[RHS_IMAG3]] : f32
+// CHECK: %[[NEW_IMAG:.*]] = arith.addf %[[LHS_IMAG_TIMES_RHS_REAL]], %[[LHS_REAL_TIMES_RHS_IMAG]] : f32
+// CHECK: %[[NEW_IMAG_TIMES_INF:.*]] = arith.mulf %[[INF]], %[[NEW_IMAG]] : f32
// CHECK: %[[FINAL_IMAG:.*]] = select %[[RECALC3]], %[[NEW_IMAG_TIMES_INF]], %[[IMAG]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[FINAL_REAL]], %[[FINAL_IMAG]] : complex<f32>
}
// CHECK: %[[REAL:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK-DAG: %[[NEG_REAL:.*]] = negf %[[REAL]] : f32
-// CHECK-DAG: %[[NEG_IMAG:.*]] = negf %[[IMAG]] : f32
+// CHECK-DAG: %[[NEG_REAL:.*]] = arith.negf %[[REAL]] : f32
+// CHECK-DAG: %[[NEG_IMAG:.*]] = arith.negf %[[IMAG]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[NEG_REAL]], %[[NEG_IMAG]] : complex<f32>
// CHECK: return %[[RESULT]] : complex<f32>
// CHECK: %[[IMAG_LHS:.*]] = complex.im %[[LHS]] : complex<f32>
// CHECK: %[[REAL_RHS:.*]] = complex.re %[[RHS]] : complex<f32>
// CHECK: %[[IMAG_RHS:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK-DAG: %[[REAL_NOT_EQUAL:.*]] = cmpf une, %[[REAL_LHS]], %[[REAL_RHS]] : f32
-// CHECK-DAG: %[[IMAG_NOT_EQUAL:.*]] = cmpf une, %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
-// CHECK: %[[NOT_EQUAL:.*]] = or %[[REAL_NOT_EQUAL]], %[[IMAG_NOT_EQUAL]] : i1
+// CHECK-DAG: %[[REAL_NOT_EQUAL:.*]] = arith.cmpf une, %[[REAL_LHS]], %[[REAL_RHS]] : f32
+// CHECK-DAG: %[[IMAG_NOT_EQUAL:.*]] = arith.cmpf une, %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
+// CHECK: %[[NOT_EQUAL:.*]] = arith.ori %[[REAL_NOT_EQUAL]], %[[IMAG_NOT_EQUAL]] : i1
// CHECK: return %[[NOT_EQUAL]] : i1
// CHECK-LABEL: func @complex_sign
}
// CHECK: %[[REAL:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK: %[[ZERO:.*]] = constant 0.000000e+00 : f32
-// CHECK: %[[REAL_IS_ZERO:.*]] = cmpf oeq, %[[REAL]], %[[ZERO]] : f32
-// CHECK: %[[IMAG_IS_ZERO:.*]] = cmpf oeq, %1, %cst : f32
-// CHECK: %[[IS_ZERO:.*]] = and %[[REAL_IS_ZERO]], %[[IMAG_IS_ZERO]] : i1
+// CHECK: %[[ZERO:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK: %[[REAL_IS_ZERO:.*]] = arith.cmpf oeq, %[[REAL]], %[[ZERO]] : f32
+// CHECK: %[[IMAG_IS_ZERO:.*]] = arith.cmpf oeq, %1, %cst : f32
+// CHECK: %[[IS_ZERO:.*]] = arith.andi %[[REAL_IS_ZERO]], %[[IMAG_IS_ZERO]] : i1
// CHECK: %[[REAL2:.*]] = complex.re %[[ARG]] : complex<f32>
// CHECK: %[[IMAG2:.*]] = complex.im %[[ARG]] : complex<f32>
-// CHECK: %[[SQR_REAL:.*]] = mulf %[[REAL2]], %[[REAL2]] : f32
-// CHECK: %[[SQR_IMAG:.*]] = mulf %[[IMAG2]], %[[IMAG2]] : f32
-// CHECK: %[[SQ_NORM:.*]] = addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
+// CHECK: %[[SQR_REAL:.*]] = arith.mulf %[[REAL2]], %[[REAL2]] : f32
+// CHECK: %[[SQR_IMAG:.*]] = arith.mulf %[[IMAG2]], %[[IMAG2]] : f32
+// CHECK: %[[SQ_NORM:.*]] = arith.addf %[[SQR_REAL]], %[[SQR_IMAG]] : f32
// CHECK: %[[NORM:.*]] = math.sqrt %[[SQ_NORM]] : f32
-// CHECK: %[[REAL_SIGN:.*]] = divf %[[REAL]], %[[NORM]] : f32
-// CHECK: %[[IMAG_SIGN:.*]] = divf %[[IMAG]], %[[NORM]] : f32
+// CHECK: %[[REAL_SIGN:.*]] = arith.divf %[[REAL]], %[[NORM]] : f32
+// CHECK: %[[IMAG_SIGN:.*]] = arith.divf %[[IMAG]], %[[NORM]] : f32
// CHECK: %[[SIGN:.*]] = complex.create %[[REAL_SIGN]], %[[IMAG_SIGN]] : complex<f32>
// CHECK: %[[RESULT:.*]] = select %[[IS_ZERO]], %[[ARG]], %[[SIGN]] : complex<f32>
// CHECK: return %[[RESULT]] : complex<f32>
}
// CHECK: %[[REAL_LHS:.*]] = complex.re %[[LHS]] : complex<f32>
// CHECK: %[[REAL_RHS:.*]] = complex.re %[[RHS]] : complex<f32>
-// CHECK: %[[RESULT_REAL:.*]] = subf %[[REAL_LHS]], %[[REAL_RHS]] : f32
+// CHECK: %[[RESULT_REAL:.*]] = arith.subf %[[REAL_LHS]], %[[REAL_RHS]] : f32
// CHECK: %[[IMAG_LHS:.*]] = complex.im %[[LHS]] : complex<f32>
// CHECK: %[[IMAG_RHS:.*]] = complex.im %[[RHS]] : complex<f32>
-// CHECK: %[[RESULT_IMAG:.*]] = subf %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
+// CHECK: %[[RESULT_IMAG:.*]] = arith.subf %[[IMAG_LHS]], %[[IMAG_RHS]] : f32
// CHECK: %[[RESULT:.*]] = complex.create %[[RESULT_REAL]], %[[RESULT_IMAG]] : complex<f32>
// CHECK: return %[[RESULT]] : complex<f32>
-// RUN: mlir-opt %s -convert-complex-to-standard -convert-complex-to-llvm -convert-math-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | FileCheck %s
+// RUN: mlir-opt %s -convert-complex-to-standard -convert-complex-to-llvm -convert-math-to-llvm -convert-arith-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | FileCheck %s
// CHECK-LABEL: llvm.func @complex_abs
// CHECK-SAME: %[[ARG:.*]]: ![[C_TY:.*]])
}
func @foo(%buffer: memref<?xf32>) {
- %c8 = constant 8 : index
- %c32 = constant 32 : i32
- %c256 = constant 256 : i32
+ %c8 = arith.constant 8 : index
+ %c32 = arith.constant 32 : i32
+ %c256 = arith.constant 256 : i32
gpu.launch_func @kernel_module::@kernel
blocks in (%c8, %c8, %c8)
threads in (%c8, %c8, %c8)
// ROCDL: llvm.extractvalue %[[descr6:.*]]
// ROCDL: llvm.getelementptr
// ROCDL: llvm.store
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<4xf32, 5>
"terminator"() : () -> ()
// ROCDL: llvm.extractvalue %[[descr6:.*]]
// ROCDL: llvm.getelementptr
// ROCDL: llvm.store
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<4xf32, 3>
"terminator"() : () -> ()
// ROCDL: %[[c1:.*]] = llvm.mlir.constant(1 : index) : i64
// ROCDL: %[[descr10:.*]] = llvm.insertvalue %[[c1]], %[[descr9]][4, 2]
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0,%c0,%c0] : memref<4x2x6xf32, 3>
"terminator"() : () -> ()
}
// ROCDL: %[[c4:.*]] = llvm.mlir.constant(4 : i64)
// ROCDL: llvm.alloca %[[c4]] x f32 : (i64) -> !llvm.ptr<f32, 5>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32, 3>
memref.store %arg0, %arg2[%c0] : memref<2xf32, 3>
memref.store %arg0, %arg3[%c0] : memref<3xf32, 5>
builtin.func @gpu_index_comp(%idx : index) -> index {
// CHECK: = llvm.add %{{.*}}, %{{.*}} : i64
// CHECK32: = llvm.add %{{.*}}, %{{.*}} : i32
- %0 = addi %idx, %idx : index
+ %0 = arith.addi %idx, %idx : index
// CHECK: llvm.return %{{.*}} : i64
// CHECK32: llvm.return %{{.*}} : i32
std.return %0 : index
gpu.module @test_module {
// CHECK-LABEL: func @gpu_all_reduce_op()
gpu.func @gpu_all_reduce_op() {
- %arg0 = constant 1.0 : f32
+ %arg0 = arith.constant 1.0 : f32
// TODO: Check full IR expansion once lowering has settled.
// CHECK: nvvm.shfl.sync.bfly
// CHECK: nvvm.barrier0
gpu.module @test_module {
// CHECK-LABEL: func @gpu_all_reduce_region()
gpu.func @gpu_all_reduce_region() {
- %arg0 = constant 1 : i32
+ %arg0 = arith.constant 1 : i32
// TODO: Check full IR expansion once lowering has settled.
// CHECK: nvvm.shfl.sync.bfly
// CHECK: nvvm.barrier0
%result = "gpu.all_reduce"(%arg0) ({
^bb(%lhs : i32, %rhs : i32):
- %xor = xor %lhs, %rhs : i32
+ %xor = arith.xori %lhs, %rhs : i32
"gpu.yield"(%xor) : (i32) -> ()
}) : (i32) -> (i32)
gpu.return
// CHECK-LABEL: func @gpu_shuffle()
builtin.func @gpu_shuffle() -> (f32) {
// CHECK: %[[#VALUE:]] = llvm.mlir.constant(1.000000e+00 : f32) : f32
- %arg0 = constant 1.0 : f32
+ %arg0 = arith.constant 1.0 : f32
// CHECK: %[[#OFFSET:]] = llvm.mlir.constant(4 : i32) : i32
- %arg1 = constant 4 : i32
+ %arg1 = arith.constant 4 : i32
// CHECK: %[[#WIDTH:]] = llvm.mlir.constant(23 : i32) : i32
- %arg2 = constant 23 : i32
+ %arg2 = arith.constant 23 : i32
// CHECK: %[[#ONE:]] = llvm.mlir.constant(1 : i32) : i32
// CHECK: %[[#SHL:]] = llvm.shl %[[#ONE]], %[[#WIDTH]] : i32
// CHECK: %[[#MASK:]] = llvm.sub %[[#SHL]], %[[#ONE]] : i32
// CHECK: llvm.func @__nv_fabs(f64) -> f64
// CHECK-LABEL: func @gpu_fabs
builtin.func @gpu_fabs(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.absf %arg_f32 : f32
+ %result32 = math.abs %arg_f32 : f32
// CHECK: llvm.call @__nv_fabsf(%{{.*}}) : (f32) -> f32
- %result64 = std.absf %arg_f64 : f64
+ %result64 = math.abs %arg_f64 : f64
// CHECK: llvm.call @__nv_fabs(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
// CHECK: llvm.func @__nv_ceil(f64) -> f64
// CHECK-LABEL: func @gpu_ceil
builtin.func @gpu_ceil(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.ceilf %arg_f32 : f32
+ %result32 = math.ceil %arg_f32 : f32
// CHECK: llvm.call @__nv_ceilf(%{{.*}}) : (f32) -> f32
- %result64 = std.ceilf %arg_f64 : f64
+ %result64 = math.ceil %arg_f64 : f64
// CHECK: llvm.call @__nv_ceil(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
// CHECK: llvm.func @__nv_floor(f64) -> f64
// CHECK-LABEL: func @gpu_floor
builtin.func @gpu_floor(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.floorf %arg_f32 : f32
+ %result32 = math.floor %arg_f32 : f32
// CHECK: llvm.call @__nv_floorf(%{{.*}}) : (f32) -> f32
- %result64 = std.floorf %arg_f64 : f64
+ %result64 = math.floor %arg_f64 : f64
// CHECK: llvm.call @__nv_floor(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
// CHECK-SAME: !llvm.struct<(vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>)> {
builtin.func @gpu_wmma_load_op() -> (!gpu.mma_matrix<16x16xf16, "AOp">) {
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
- %j = constant 16 : index
+ %i = arith.constant 16 : index
+ %j = arith.constant 16 : index
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %j] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16xf16, "AOp">
// CHECK: %[[INX:.*]] = llvm.mlir.constant(16 : index) : i32
// CHECK: %{{.*}} = llvm.insertvalue %{{.*}}, %{{.*}}[{{.*}}, {{.*}}]
// CHECK-SAME: (%[[D:.*]]: !llvm.struct<(vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>)>) {
builtin.func @gpu_wmma_store_op(%arg0 : !gpu.mma_matrix<16x16xf16, "COp">) -> () {
%sg = memref.alloca(){alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
- %j = constant 16 : index
+ %i = arith.constant 16 : index
+ %j = arith.constant 16 : index
gpu.subgroup_mma_store_matrix %arg0, %sg[%i,%j] {leadDimension= 32 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<32x32xf16, 3>
// CHECK: %[[INX:.*]] = llvm.mlir.constant(16 : index) : i32
// CHECK: %{{.*}} = llvm.insertvalue %{{.*}}, %{{.*}}[{{.*}}, {{.*}}]
// CHECK: nvvm.wmma.m16n16k16.store.d.f16.row.stride %86, %87, %88, %89, %90, %79 : !llvm.ptr<i32>, vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>, i32
builtin.func @gpu_wmma_mma_loop_op(%arg0: memref<128x128xf16>, %arg1: memref<128x128xf16>, %arg2: memref<128x128xf16>) {
- %c0 = constant 0 : index
- %c128 = constant 128 : index
- %c32 = constant 32 : index
+ %c0 = arith.constant 0 : index
+ %c128 = arith.constant 128 : index
+ %c32 = arith.constant 32 : index
%0 = gpu.subgroup_mma_load_matrix %arg2[%c0, %c0] {leadDimension = 128 : index} : memref<128x128xf16> -> !gpu.mma_matrix<16x16xf16, "COp">
br ^bb1(%c0, %0 : index, !gpu.mma_matrix<16x16xf16, "COp">)
^bb1(%1: index, %2: !gpu.mma_matrix<16x16xf16, "COp">): // 2 preds: ^bb0, ^bb2
- %3 = cmpi slt, %1, %c128 : index
+ %3 = arith.cmpi slt, %1, %c128 : index
cond_br %3, ^bb2, ^bb3
^bb2: // pred: ^bb1
%4 = gpu.subgroup_mma_load_matrix %arg0[%c0, %1] {leadDimension = 128 : index} : memref<128x128xf16> -> !gpu.mma_matrix<16x16xf16, "AOp">
%5 = gpu.subgroup_mma_load_matrix %arg1[%1, %c0] {leadDimension = 128 : index} : memref<128x128xf16> -> !gpu.mma_matrix<16x16xf16, "BOp">
%6 = gpu.subgroup_mma_compute %4, %5, %2 : !gpu.mma_matrix<16x16xf16, "AOp">, !gpu.mma_matrix<16x16xf16, "BOp"> -> !gpu.mma_matrix<16x16xf16, "COp">
- %7 = addi %1, %c32 : index
+ %7 = arith.addi %1, %c32 : index
br ^bb1(%7, %6 : index, !gpu.mma_matrix<16x16xf16, "COp">)
^bb3: // pred: ^bb1
gpu.subgroup_mma_store_matrix %2, %arg2[%c0, %c0] {leadDimension = 128 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<128x128xf16>
// CHECK: %[[M4:.+]] = llvm.insertvalue %[[V2]], %[[M3]][3 : i32] : !llvm.struct<(vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>)>
// CHECK: llvm.return %[[M4]] : !llvm.struct<(vector<2xf16>, vector<2xf16>, vector<2xf16>, vector<2xf16>)>
builtin.func @gpu_wmma_constant_op() ->(!gpu.mma_matrix<16x16xf16, "COp">) {
- %cst = constant 1.0 : f16
+ %cst = arith.constant 1.0 : f16
%C = gpu.subgroup_mma_constant_matrix %cst : !gpu.mma_matrix<16x16xf16, "COp">
return %C : !gpu.mma_matrix<16x16xf16, "COp">
}
builtin.func @gpu_index_comp(%idx : index) -> index {
// CHECK: = llvm.add %{{.*}}, %{{.*}} : i64
// CHECK32: = llvm.add %{{.*}}, %{{.*}} : i32
- %0 = addi %idx, %idx : index
+ %0 = arith.addi %idx, %idx : index
// CHECK: llvm.return %{{.*}} : i64
// CHECK32: llvm.return %{{.*}} : i32
std.return %0 : index
// CHECK: llvm.func @__ocml_fabs_f64(f64) -> f64
// CHECK-LABEL: func @gpu_fabs
builtin.func @gpu_fabs(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.absf %arg_f32 : f32
+ %result32 = math.abs %arg_f32 : f32
// CHECK: llvm.call @__ocml_fabs_f32(%{{.*}}) : (f32) -> f32
- %result64 = std.absf %arg_f64 : f64
+ %result64 = math.abs %arg_f64 : f64
// CHECK: llvm.call @__ocml_fabs_f64(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
// CHECK: llvm.func @__ocml_ceil_f64(f64) -> f64
// CHECK-LABEL: func @gpu_ceil
builtin.func @gpu_ceil(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.ceilf %arg_f32 : f32
+ %result32 = math.ceil %arg_f32 : f32
// CHECK: llvm.call @__ocml_ceil_f32(%{{.*}}) : (f32) -> f32
- %result64 = std.ceilf %arg_f64 : f64
+ %result64 = math.ceil %arg_f64 : f64
// CHECK: llvm.call @__ocml_ceil_f64(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
// CHECK: llvm.func @__ocml_floor_f64(f64) -> f64
// CHECK-LABEL: func @gpu_floor
builtin.func @gpu_floor(%arg_f32 : f32, %arg_f64 : f64) -> (f32, f64) {
- %result32 = std.floorf %arg_f32 : f32
+ %result32 = math.floor %arg_f32 : f32
// CHECK: llvm.call @__ocml_floor_f32(%{{.*}}) : (f32) -> f32
- %result64 = std.floorf %arg_f64 : f64
+ %result64 = math.floor %arg_f64 : f64
// CHECK: llvm.call @__ocml_floor_f64(%{{.*}}) : (f64) -> f64
std.return %result32, %result64 : f32, f64
}
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_workgroup_id_x
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
- %c256 = constant 256 : i32
+ %c0 = arith.constant 1 : index
+ %c256 = arith.constant 256 : i32
gpu.launch_func @kernels::@builtin_workgroup_id_y
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
dynamic_shared_memory_size %c256
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_workgroup_id_z
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_workgroup_size_x
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_workgroup_size_y
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_workgroup_size_z
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_local_id_x
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
module attributes {gpu.container_module} {
func @builtin() {
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
gpu.launch_func @kernels::@builtin_num_workgroups_x
blocks in (%c0, %c0, %c0) threads in (%c0, %c0, %c0)
return
#spv.vce<v1.0, [Shader], [SPV_KHR_storage_buffer_storage_class]>, {}>
} {
func @load_store(%arg0: memref<12x4xf32>, %arg1: memref<12x4xf32>, %arg2: memref<12x4xf32>) {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %0 = subi %c12, %c0 : index
- %c1 = constant 1 : index
- %c0_0 = constant 0 : index
- %c4 = constant 4 : index
- %1 = subi %c4, %c0_0 : index
- %c1_1 = constant 1 : index
- %c1_2 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %0 = arith.subi %c12, %c0 : index
+ %c1 = arith.constant 1 : index
+ %c0_0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %1 = arith.subi %c4, %c0_0 : index
+ %c1_1 = arith.constant 1 : index
+ %c1_2 = arith.constant 1 : index
gpu.launch_func @kernels::@load_store_kernel
blocks in (%0, %c1_2, %c1_2) threads in (%1, %c1_2, %c1_2)
args(%arg0 : memref<12x4xf32>, %arg1 : memref<12x4xf32>, %arg2 : memref<12x4xf32>,
%10 = "gpu.block_dim"() {dimension = "y"} : () -> index
%11 = "gpu.block_dim"() {dimension = "z"} : () -> index
// CHECK: %[[INDEX1:.*]] = spv.IAdd %[[ARG3]], %[[WORKGROUPIDX]]
- %12 = addi %arg3, %0 : index
+ %12 = arith.addi %arg3, %0 : index
// CHECK: %[[INDEX2:.*]] = spv.IAdd %[[ARG4]], %[[LOCALINVOCATIONIDX]]
- %13 = addi %arg4, %3 : index
+ %13 = arith.addi %arg4, %3 : index
// CHECK: %[[ZERO:.*]] = spv.Constant 0 : i32
// CHECK: %[[OFFSET1_0:.*]] = spv.Constant 0 : i32
// CHECK: %[[STRIDE1_1:.*]] = spv.Constant 4 : i32
// CHECK-NEXT: %[[VAL2:.*]] = spv.Load "StorageBuffer" %[[PTR2]]
%15 = memref.load %arg1[%12, %13] : memref<12x4xf32>
// CHECK: %[[VAL3:.*]] = spv.FAdd %[[VAL1]], %[[VAL2]]
- %16 = addf %14, %15 : f32
+ %16 = arith.addf %14, %15 : f32
// CHECK: %[[PTR3:.*]] = spv.AccessChain %[[ARG2]]{{\[}}{{%.*}}, {{%.*}}{{\]}}
// CHECK-NEXT: spv.Store "StorageBuffer" %[[PTR3]], %[[VAL3]]
memref.store %16, %arg2[%12, %13] : memref<12x4xf32>
func @main() {
%0 = "op"() : () -> (f32)
%1 = "op"() : () -> (memref<12xf32, 11>)
- %cst = constant 1 : index
+ %cst = arith.constant 1 : index
gpu.launch_func @kernels::@basic_module_structure
blocks in (%cst, %cst, %cst) threads in (%cst, %cst, %cst)
args(%0 : f32, %1 : memref<12xf32, 11>)
func @main() {
%0 = "op"() : () -> (f32)
%1 = "op"() : () -> (memref<12xf32>)
- %cst = constant 1 : index
+ %cst = arith.constant 1 : index
gpu.launch_func @kernels::@basic_module_structure
blocks in (%cst, %cst, %cst) threads in (%cst, %cst, %cst)
args(%0 : f32, %1 : memref<12xf32>)
func @main() {
%0 = "op"() : () -> (f32)
%1 = "op"() : () -> (memref<12xf32>)
- %cst = constant 1 : index
+ %cst = arith.constant 1 : index
gpu.launch_func @kernels::@missing_entry_point_abi
blocks in (%cst, %cst, %cst) threads in (%cst, %cst, %cst)
args(%0 : f32, %1 : memref<12xf32>)
// RUN: mlir-opt %s -convert-gpu-launch-to-vulkan-launch | FileCheck %s
// CHECK: %[[resource:.*]] = memref.alloc() : memref<12xf32>
-// CHECK: %[[index:.*]] = constant 1 : index
+// CHECK: %[[index:.*]] = arith.constant 1 : index
// CHECK: call @vulkanLaunch(%[[index]], %[[index]], %[[index]], %[[resource]]) {spirv_blob = "{{.*}}", spirv_entry_point = "kernel"}
module attributes {gpu.container_module} {
}
func @foo() {
%0 = memref.alloc() : memref<12xf32>
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
gpu.launch_func @kernels::@kernel
blocks in(%c1, %c1, %c1)
threads in(%c1, %c1, %c1)
ins(%input : memref<16xi32>)
outs(%output : memref<1xi32>) {
^bb(%in: i32, %out: i32):
- %sum = addi %in, %out : i32
+ %sum = arith.addi %in, %out : i32
linalg.yield %sum : i32
}
spv.Return
ins(%input : memref<16xi32>)
outs(%output : memref<1xi32>) {
^bb(%in: i32, %out: i32):
- %sum = addi %in, %out : i32
+ %sum = arith.addi %in, %out : i32
linalg.yield %sum : i32
}
return
ins(%input : memref<16xi32>)
outs(%output : memref<1xi32>) {
^bb(%in: i32, %out: i32):
- %sum = addi %in, %out : i32
+ %sum = arith.addi %in, %out : i32
linalg.yield %sum : i32
}
spv.Return
ins(%input : memref<16x8xi32>)
outs(%output : memref<16xi32>) {
^bb(%in: i32, %out: i32):
- %sum = addi %in, %out : i32
+ %sum = arith.addi %in, %out : i32
linalg.yield %sum : i32
}
spv.Return
// CHECK-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?xf32>
// CHECK-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?xf32
func @conv_1d(%arg0: memref<?xf32>, %arg1: memref<?xf32>, %arg2: memref<?xf32>) {
-// CHECK-DAG: %[[c12:.*]] = constant 12 : index
-// CHECK-DAG: %[[c4:.*]] = constant 4 : index
-// CHECK-DAG: %[[cst:.*]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
+// CHECK-DAG: %[[c12:.*]] = arith.constant 12 : index
+// CHECK-DAG: %[[c4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[cst:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[v0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?xf32>
// CHECK: %[[v1:.*]] = memref.dim %[[arg2]], %[[c0]] : memref<?xf32>
// CHECK: %[[v2:.*]] = memref.dim %[[arg0]], %[[c0]] : memref<?xf32>
// CHECK: %[[v17:.*]] = subview %[[v6]][0] [%[[v13]]] [1] : memref<3xf32> to memref<?xf32>
// CHECK: %[[v19:.*]] = vector.transfer_read %[[v6]][%[[c0]]], %[[cst]] {in_bounds = [true]} : memref<3xf32>, vector<3xf32>
// CHECK: %[[v20:.*]] = vector.transfer_read %[[v7]][%[[c0]]], %[[cst]] {in_bounds = [true]} : memref<3xf32>, vector<3xf32>
-// CHECK: %[[v21:.*]] = mulf %[[v19]], %[[v20]] : vector<3xf32>
+// CHECK: %[[v21:.*]] = arith.mulf %[[v19]], %[[v20]] : vector<3xf32>
// CHECK: %[[v22:.*]] = vector.reduction "add", %[[v21]], %[[cst]] : vector<3xf32> into f32
// CHECK: store %[[v22]], %[[v8]][%[[c0]]] : memref<1xf32>
// CHECK: scf.for %[[arg5:.*]] = %[[c0]] to %[[v9]] step %[[c1]] {
// CHECK-LABEL: func @expm1_vec_caller(
// CHECK-SAME: %[[VAL_0:.*]]: vector<2xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: vector<2xf64>) -> (vector<2xf32>, vector<2xf64>) {
-// CHECK-DAG: %[[CVF:.*]] = constant dense<0.000000e+00> : vector<2xf32>
-// CHECK-DAG: %[[CVD:.*]] = constant dense<0.000000e+00> : vector<2xf64>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : i32
-// CHECK-DAG: %[[C1:.*]] = constant 1 : i32
+// CHECK-DAG: %[[CVF:.*]] = arith.constant dense<0.000000e+00> : vector<2xf32>
+// CHECK-DAG: %[[CVD:.*]] = arith.constant dense<0.000000e+00> : vector<2xf64>
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : i32
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : i32
// CHECK: %[[IN0_F32:.*]] = vector.extractelement %[[VAL_0]]{{\[}}%[[C0]] : i32] : vector<2xf32>
// CHECK: %[[OUT0_F32:.*]] = call @expm1f(%[[IN0_F32]]) : (f32) -> f32
// CHECK: %[[VAL_8:.*]] = vector.insertelement %[[OUT0_F32]], %[[CVF]]{{\[}}%[[C0]] : i32] : vector<2xf32>
// CHECK-LABEL: @returns_nothing
func @returns_nothing(%b: f32) {
- %a = constant 10.0 : f32
+ %a = arith.constant 10.0 : f32
// CHECK: llvm.intr.stacksave
memref.alloca_scope {
- %c = std.addf %a, %b : f32
+ %c = arith.addf %a, %b : f32
memref.alloca_scope.return
}
// CHECK: llvm.intr.stackrestore
// CHECK-LABEL: @returns_one_value
func @returns_one_value(%b: f32) -> f32 {
- %a = constant 10.0 : f32
+ %a = arith.constant 10.0 : f32
// CHECK: llvm.intr.stacksave
%result = memref.alloca_scope -> f32 {
- %c = std.addf %a, %b : f32
+ %c = arith.addf %a, %b : f32
memref.alloca_scope.return %c: f32
}
// CHECK: llvm.intr.stackrestore
// CHECK-LABEL: @returns_multiple_values
func @returns_multiple_values(%b: f32) -> f32 {
- %a = constant 10.0 : f32
+ %a = arith.constant 10.0 : f32
// CHECK: llvm.intr.stacksave
%result1, %result2 = memref.alloca_scope -> (f32, f32) {
- %c = std.addf %a, %b : f32
- %d = std.subf %a, %b : f32
+ %c = arith.addf %a, %b : f32
+ %d = arith.subf %a, %b : f32
memref.alloca_scope.return %c, %d: f32, f32
}
// CHECK: llvm.intr.stackrestore
- %result = std.addf %result1, %result2 : f32
+ %result = arith.addf %result1, %result2 : f32
return %result : f32
}
// CHECK-LABEL: func @mixed_memref_dim
func @mixed_memref_dim(%mixed : memref<42x?x?x13x?xf32>) {
// CHECK: llvm.mlir.constant(42 : index) : i64
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.dim %mixed, %c0 : memref<42x?x?x13x?xf32>
// CHECK: llvm.extractvalue %{{.*}}[3, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<5 x i64>, array<5 x i64>)>
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%1 = memref.dim %mixed, %c1 : memref<42x?x?x13x?xf32>
// CHECK: llvm.extractvalue %{{.*}}[3, 2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<5 x i64>, array<5 x i64>)>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%2 = memref.dim %mixed, %c2 : memref<42x?x?x13x?xf32>
// CHECK: llvm.mlir.constant(13 : index) : i64
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%3 = memref.dim %mixed, %c3 : memref<42x?x?x13x?xf32>
// CHECK: llvm.extractvalue %{{.*}}[3, 4] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<5 x i64>, array<5 x i64>)>
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%4 = memref.dim %mixed, %c4 : memref<42x?x?x13x?xf32>
return
}
// CHECK-LABEL: func @static_memref_dim
func @static_memref_dim(%static : memref<42x32x15x13x27xf32>) {
// CHECK: llvm.mlir.constant(42 : index) : i64
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.dim %static, %c0 : memref<42x32x15x13x27xf32>
// CHECK: llvm.mlir.constant(32 : index) : i64
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%1 = memref.dim %static, %c1 : memref<42x32x15x13x27xf32>
// CHECK: llvm.mlir.constant(15 : index) : i64
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%2 = memref.dim %static, %c2 : memref<42x32x15x13x27xf32>
// CHECK: llvm.mlir.constant(13 : index) : i64
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%3 = memref.dim %static, %c3 : memref<42x32x15x13x27xf32>
// CHECK: llvm.mlir.constant(27 : index) : i64
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%4 = memref.dim %static, %c4 : memref<42x32x15x13x27xf32>
return
}
// a data layout specification.
module attributes { dlti.dl_spec = #dlti.dl_spec<#dlti.dl_entry<index, 32>> } {
func @address() {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc(%c1) : memref<? x vector<2xf32>>
- // CHECK: %[[CST_S:.*]] = constant 1 : index
+ // CHECK: %[[CST_S:.*]] = arith.constant 1 : index
// CHECK: %[[CST:.*]] = builtin.unrealized_conversion_cast
// CHECK: llvm.mlir.null
// CHECK: llvm.getelementptr %{{.*}}[[CST]]
// CHECK-LABEL: func @dim_of_unranked
// CHECK32-LABEL: func @dim_of_unranked
func @dim_of_unranked(%unranked: memref<*xi32>) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%dim = memref.dim %unranked, %c0 : memref<*xi32>
return %dim : index
}
// CHECK-LABEL: func @address_space(
func @address_space(%arg0 : memref<32xf32, affine_map<(d0) -> (d0)>, 7>) {
%0 = memref.alloc() : memref<32xf32, affine_map<(d0) -> (d0)>, 5>
- %1 = constant 7 : index
+ %1 = arith.constant 7 : index
// CHECK: llvm.load %{{.*}} : !llvm.ptr<f32, 5>
%2 = memref.load %0[%1] : memref<32xf32, affine_map<(d0) -> (d0)>, 5>
std.return
// CHECK-SAME: %[[DST:.+]]: memref<4xi1>,
// CHECK-SAME: %[[IDX:.+]]: index
func @store_i1(%dst: memref<4xi1>, %i: index) {
- %true = constant true
+ %true = arith.constant true
// CHECK: %[[DST_CAST:.+]] = builtin.unrealized_conversion_cast %[[DST]] : memref<4xi1> to !spv.ptr<!spv.struct<(!spv.array<4 x i8, stride=1> [0])>, StorageBuffer>
// CHECK: %[[IDX_CAST:.+]] = builtin.unrealized_conversion_cast %[[IDX]]
// CHECK: %[[ZERO_0:.+]] = spv.Constant 0 : i32
// -----
func @testenterdataop(%a: memref<10xf32>, %b: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.enter_data if(%ifCond) copyin(%b : memref<10xf32>) create(%a : memref<10xf32>)
return
}
// -----
func @testexitdataop(%a: memref<10xf32>, %b: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.exit_data if(%ifCond) copyout(%b : memref<10xf32>) delete(%a : memref<10xf32>)
return
}
// -----
func @testupdateop(%a: memref<10xf32>, %b: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.update if(%ifCond) host(%b : memref<10xf32>) device(%a : memref<10xf32>)
return
}
// -----
func @testdataregion(%a: memref<10xf32>, %b: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.data if(%ifCond) copyin_readonly(%b : memref<10xf32>) copyout_zero(%a : memref<10xf32>) {
}
return
// -----
func @testparallelop(%a: memref<10xf32>, %b: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.parallel if(%ifCond) copyin_readonly(%b : memref<10xf32>) copyout_zero(%a : memref<10xf32>) {
}
return
// CHECK-LABEL: llvm.func @branch_loop
func @branch_loop() {
- %start = constant 0 : index
- %end = constant 0 : index
+ %start = arith.constant 0 : index
+ %end = arith.constant 0 : index
// CHECK: omp.parallel
omp.parallel {
// CHECK-NEXT: llvm.br ^[[BB1:.*]](%{{[0-9]+}}, %{{[0-9]+}} : i64, i64
// CHECK-NEXT: ^[[BB1]](%[[ARG1:[0-9]+]]: i64, %[[ARG2:[0-9]+]]: i64):{{.*}}
^bb1(%0: index, %1: index):
// CHECK-NEXT: %[[CMP:[0-9]+]] = llvm.icmp "slt" %[[ARG1]], %[[ARG2]] : i64
- %2 = cmpi slt, %0, %1 : index
+ %2 = arith.cmpi slt, %0, %1 : index
// CHECK-NEXT: llvm.cond_br %[[CMP]], ^[[BB2:.*]](%{{[0-9]+}}, %{{[0-9]+}} : i64, i64), ^[[BB3:.*]]
cond_br %2, ^bb2(%end, %end : index, index), ^bb3
// CHECK-NEXT: ^[[BB2]](%[[ARG3:[0-9]+]]: i64, %[[ARG4:[0-9]+]]: i64):
// CHECK-BLOCKS-LABEL: @one_d_loop
func @one_d_loop(%A : memref<?xf32>, %B : memref<?xf32>) {
// Bounds of the loop, its range and step.
- // CHECK-THREADS-NEXT: %{{.*}} = constant 0 : index
- // CHECK-THREADS-NEXT: %{{.*}} = constant 42 : index
- // CHECK-THREADS-NEXT: %[[BOUND:.*]] = subi %{{.*}}, %{{.*}} : index
- // CHECK-THREADS-NEXT: %{{.*}} = constant 1 : index
- // CHECK-THREADS-NEXT: %[[ONE:.*]] = constant 1 : index
+ // CHECK-THREADS-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-THREADS-NEXT: %{{.*}} = arith.constant 42 : index
+ // CHECK-THREADS-NEXT: %[[BOUND:.*]] = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-THREADS-NEXT: %{{.*}} = arith.constant 1 : index
+ // CHECK-THREADS-NEXT: %[[ONE:.*]] = arith.constant 1 : index
//
- // CHECK-BLOCKS-NEXT: %{{.*}} = constant 0 : index
- // CHECK-BLOCKS-NEXT: %{{.*}} = constant 42 : index
- // CHECK-BLOCKS-NEXT: %[[BOUND:.*]] = subi %{{.*}}, %{{.*}} : index
- // CHECK-BLOCKS-NEXT: %{{.*}} = constant 1 : index
- // CHECK-BLOCKS-NEXT: %[[ONE:.*]] = constant 1 : index
+ // CHECK-BLOCKS-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-BLOCKS-NEXT: %{{.*}} = arith.constant 42 : index
+ // CHECK-BLOCKS-NEXT: %[[BOUND:.*]] = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-BLOCKS-NEXT: %{{.*}} = arith.constant 1 : index
+ // CHECK-BLOCKS-NEXT: %[[ONE:.*]] = arith.constant 1 : index
// CHECK-THREADS-NEXT: gpu.launch blocks(%[[B0:.*]], %[[B1:.*]], %[[B2:.*]]) in (%{{.*}} = %[[ONE]], %{{.*}} = %[[ONE]], %{{.*}}0 = %[[ONE]]) threads(%[[T0:.*]], %[[T1:.*]], %[[T2:.*]]) in (%{{.*}} = %[[BOUND]], %{{.*}} = %[[ONE]], %{{.*}} = %[[ONE]])
// CHECK-BLOCKS-NEXT: gpu.launch blocks(%[[B0:.*]], %[[B1:.*]], %[[B2:.*]]) in (%{{.*}} = %[[BOUND]], %{{.*}} = %[[ONE]], %{{.*}}0 = %[[ONE]]) threads(%[[T0:.*]], %[[T1:.*]], %[[T2:.*]]) in (%{{.*}} = %[[ONE]], %{{.*}} = %[[ONE]], %{{.*}} = %[[ONE]])
affine.for %i = 0 to 42 {
- // CHECK-THREADS-NEXT: %[[INDEX:.*]] = addi %{{.*}}, %[[T0]]
+ // CHECK-THREADS-NEXT: %[[INDEX:.*]] = arith.addi %{{.*}}, %[[T0]]
// CHECK-THREADS-NEXT: memref.load %{{.*}}[%[[INDEX]]]
- // CHECK-BLOCKS-NEXT: %[[INDEX:.*]] = addi %{{.*}}, %[[B0]]
+ // CHECK-BLOCKS-NEXT: %[[INDEX:.*]] = arith.addi %{{.*}}, %[[B0]]
// CHECK-BLOCKS-NEXT: memref.load %{{.*}}[%[[INDEX]]]
%0 = memref.load %A[%i] : memref<?xf32>
memref.store %0, %B[%i] : memref<?xf32>
%arg3 : index, %arg4 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %step = constant 2 : index
+ %step = arith.constant 2 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) {
%val = memref.load %buf[%i0, %i1] : memref<?x?xf32>
// CHECK: module {
// CHECK-LABEL: func @parallel_loop_bidy_bidx(
// CHECK-SAME: [[VAL_0:%.*]]: index, [[VAL_1:%.*]]: index, [[VAL_2:%.*]]: index, [[VAL_3:%.*]]: index, [[VAL_4:%.*]]: index, [[VAL_5:%.*]]: memref<?x?xf32>, [[VAL_6:%.*]]: memref<?x?xf32>) {
-// CHECK: [[VAL_7:%.*]] = constant 2 : index
-// CHECK: [[VAL_8:%.*]] = constant 1 : index
+// CHECK: [[VAL_7:%.*]] = arith.constant 2 : index
+// CHECK: [[VAL_8:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_9:%.*]] = affine.apply #[[$MAP0]]([[VAL_2]]){{\[}}[[VAL_0]], [[VAL_4]]]
// CHECK: [[VAL_10:%.*]] = affine.apply #[[$MAP0]]([[VAL_3]]){{\[}}[[VAL_1]], [[VAL_7]]]
// CHECK: gpu.launch blocks([[VAL_11:%.*]], [[VAL_12:%.*]], [[VAL_13:%.*]]) in ([[VAL_14:%.*]] = [[VAL_10]], [[VAL_15:%.*]] = [[VAL_9]], [[VAL_16:%.*]] = [[VAL_8]]) threads([[VAL_17:%.*]], [[VAL_18:%.*]], [[VAL_19:%.*]]) in ([[VAL_20:%.*]] = [[VAL_8]], [[VAL_21:%.*]] = [[VAL_8]], [[VAL_22:%.*]] = [[VAL_8]]) {
%arg3 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %zero = constant 0 : index
- %one = constant 1 : index
- %four = constant 4 : index
+ %zero = arith.constant 0 : index
+ %one = arith.constant 1 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
scf.parallel (%si0, %si1) = (%zero, %zero) to (%four, %four)
step (%one, %one) {
- %idx0 = addi %i0, %si0 : index
- %idx1 = addi %i1, %si1 : index
+ %idx0 = arith.addi %i0, %si0 : index
+ %idx1 = arith.addi %i1, %si1 : index
%val = memref.load %buf[%idx0, %idx1] : memref<?x?xf32>
memref.store %val, %res[%idx1, %idx0] : memref<?x?xf32>
} { mapping = [
// CHECK: module {
// CHECK-LABEL: func @parallel_loop_tiled(
// CHECK-SAME: [[VAL_26:%.*]]: index, [[VAL_27:%.*]]: index, [[VAL_28:%.*]]: index, [[VAL_29:%.*]]: index, [[VAL_30:%.*]]: memref<?x?xf32>, [[VAL_31:%.*]]: memref<?x?xf32>) {
-// CHECK: [[VAL_32:%.*]] = constant 0 : index
-// CHECK: [[VAL_33:%.*]] = constant 1 : index
-// CHECK: [[VAL_34:%.*]] = constant 4 : index
-// CHECK: [[VAL_35:%.*]] = constant 1 : index
+// CHECK: [[VAL_32:%.*]] = arith.constant 0 : index
+// CHECK: [[VAL_33:%.*]] = arith.constant 1 : index
+// CHECK: [[VAL_34:%.*]] = arith.constant 4 : index
+// CHECK: [[VAL_35:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_36:%.*]] = affine.apply #[[$MAP0]]([[VAL_28]]){{\[}}[[VAL_26]], [[VAL_34]]]
// CHECK: [[VAL_37:%.*]] = affine.apply #[[$MAP0]]([[VAL_29]]){{\[}}[[VAL_27]], [[VAL_34]]]
// CHECK: [[VAL_38:%.*]] = affine.apply #[[$MAP0]]([[VAL_34]]){{\[}}[[VAL_32]], [[VAL_33]]]
// CHECK: [[VAL_53:%.*]] = affine.apply #[[$MAP1]]([[VAL_40]]){{\[}}[[VAL_34]], [[VAL_27]]]
// CHECK: [[VAL_54:%.*]] = affine.apply #[[$MAP1]]([[VAL_47]]){{\[}}[[VAL_33]], [[VAL_32]]]
// CHECK: [[VAL_55:%.*]] = affine.apply #[[$MAP1]]([[VAL_46]]){{\[}}[[VAL_33]], [[VAL_32]]]
-// CHECK: [[VAL_56:%.*]] = addi [[VAL_52]], [[VAL_54]] : index
-// CHECK: [[VAL_57:%.*]] = addi [[VAL_53]], [[VAL_55]] : index
+// CHECK: [[VAL_56:%.*]] = arith.addi [[VAL_52]], [[VAL_54]] : index
+// CHECK: [[VAL_57:%.*]] = arith.addi [[VAL_53]], [[VAL_55]] : index
// CHECK: [[VAL_58:%.*]] = memref.load [[VAL_30]]{{\[}}[[VAL_56]], [[VAL_57]]] : memref<?x?xf32>
// CHECK: memref.store [[VAL_58]], [[VAL_31]]{{\[}}[[VAL_57]], [[VAL_56]]] : memref<?x?xf32>
// CHECK: gpu.terminator
%arg3 : index, %arg4 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %step = constant 2 : index
+ %step = arith.constant 2 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) {
%val = memref.load %buf[%i0, %i1] : memref<?x?xf32>
// CHECK: module {
// CHECK-LABEL: func @parallel_loop_bidy_seq(
// CHECK-SAME: [[VAL_59:%.*]]: index, [[VAL_60:%.*]]: index, [[VAL_61:%.*]]: index, [[VAL_62:%.*]]: index, [[VAL_63:%.*]]: index, [[VAL_64:%.*]]: memref<?x?xf32>, [[VAL_65:%.*]]: memref<?x?xf32>) {
-// CHECK: [[VAL_66:%.*]] = constant 2 : index
-// CHECK: [[VAL_67:%.*]] = constant 1 : index
+// CHECK: [[VAL_66:%.*]] = arith.constant 2 : index
+// CHECK: [[VAL_67:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_68:%.*]] = affine.apply #[[$MAP0]]([[VAL_61]]){{\[}}[[VAL_59]], [[VAL_63]]]
// CHECK: gpu.launch blocks([[VAL_69:%.*]], [[VAL_70:%.*]], [[VAL_71:%.*]]) in ([[VAL_72:%.*]] = [[VAL_67]], [[VAL_73:%.*]] = [[VAL_68]], [[VAL_74:%.*]] = [[VAL_67]]) threads([[VAL_75:%.*]], [[VAL_76:%.*]], [[VAL_77:%.*]]) in ([[VAL_78:%.*]] = [[VAL_67]], [[VAL_79:%.*]] = [[VAL_67]], [[VAL_80:%.*]] = [[VAL_67]]) {
// CHECK: [[VAL_81:%.*]] = affine.apply #[[$MAP1]]([[VAL_70]]){{\[}}[[VAL_63]], [[VAL_59]]]
%arg3 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %zero = constant 0 : index
- %one = constant 1 : index
- %four = constant 4 : index
+ %zero = arith.constant 0 : index
+ %one = arith.constant 1 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
scf.parallel (%si0, %si1) = (%zero, %zero) to (%four, %four)
step (%one, %one) {
- %idx0 = addi %i0, %si0 : index
- %idx1 = addi %i1, %si1 : index
+ %idx0 = arith.addi %i0, %si0 : index
+ %idx1 = arith.addi %i1, %si1 : index
%val = memref.load %buf[%idx0, %idx1] : memref<?x?xf32>
memref.store %val, %res[%idx1, %idx0] : memref<?x?xf32>
} { mapping = [
// CHECK: module {
// CHECK-LABEL: func @parallel_loop_tiled_seq(
// CHECK-SAME: [[VAL_84:%.*]]: index, [[VAL_85:%.*]]: index, [[VAL_86:%.*]]: index, [[VAL_87:%.*]]: index, [[VAL_88:%.*]]: memref<?x?xf32>, [[VAL_89:%.*]]: memref<?x?xf32>) {
-// CHECK: [[VAL_90:%.*]] = constant 0 : index
-// CHECK: [[VAL_91:%.*]] = constant 1 : index
-// CHECK: [[VAL_92:%.*]] = constant 4 : index
-// CHECK: [[VAL_93:%.*]] = constant 1 : index
+// CHECK: [[VAL_90:%.*]] = arith.constant 0 : index
+// CHECK: [[VAL_91:%.*]] = arith.constant 1 : index
+// CHECK: [[VAL_92:%.*]] = arith.constant 4 : index
+// CHECK: [[VAL_93:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_94:%.*]] = affine.apply #[[$MAP0]]([[VAL_86]]){{\[}}[[VAL_84]], [[VAL_92]]]
// CHECK: [[VAL_95:%.*]] = affine.apply #[[$MAP0]]([[VAL_92]]){{\[}}[[VAL_90]], [[VAL_91]]]
// CHECK: gpu.launch blocks([[VAL_96:%.*]], [[VAL_97:%.*]], [[VAL_98:%.*]]) in ([[VAL_99:%.*]] = [[VAL_93]], [[VAL_100:%.*]] = [[VAL_94]], [[VAL_101:%.*]] = [[VAL_93]]) threads([[VAL_102:%.*]], [[VAL_103:%.*]], [[VAL_104:%.*]]) in ([[VAL_105:%.*]] = [[VAL_93]], [[VAL_106:%.*]] = [[VAL_95]], [[VAL_107:%.*]] = [[VAL_93]]) {
// CHECK: scf.for [[VAL_109:%.*]] = [[VAL_85]] to [[VAL_87]] step [[VAL_92]] {
// CHECK: [[VAL_110:%.*]] = affine.apply #[[$MAP1]]([[VAL_103]]){{\[}}[[VAL_91]], [[VAL_90]]]
// CHECK: scf.for [[VAL_111:%.*]] = [[VAL_90]] to [[VAL_92]] step [[VAL_91]] {
-// CHECK: [[VAL_112:%.*]] = addi [[VAL_108]], [[VAL_110]] : index
-// CHECK: [[VAL_113:%.*]] = addi [[VAL_109]], [[VAL_111]] : index
+// CHECK: [[VAL_112:%.*]] = arith.addi [[VAL_108]], [[VAL_110]] : index
+// CHECK: [[VAL_113:%.*]] = arith.addi [[VAL_109]], [[VAL_111]] : index
// CHECK: [[VAL_114:%.*]] = memref.load [[VAL_88]]{{\[}}[[VAL_112]], [[VAL_113]]] : memref<?x?xf32>
// CHECK: memref.store [[VAL_114]], [[VAL_89]]{{\[}}[[VAL_113]], [[VAL_112]]] : memref<?x?xf32>
// CHECK: }
module {
func @sum(%arg0: memref<?x?xf32, #map0>, %arg1: memref<?x?xf32, #map0>, %arg2: memref<?x?xf32, #map0>) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32, #map0>
%1 = memref.dim %arg0, %c1 : memref<?x?xf32, #map0>
scf.parallel (%arg3, %arg4) = (%c0, %c0) to (%0, %1) step (%c2, %c3) {
%2 = memref.dim %arg0, %c0 : memref<?x?xf32, #map0>
%3 = affine.min #map1(%arg3)[%2]
- %squared_min = muli %3, %3 : index
+ %squared_min = arith.muli %3, %3 : index
%4 = memref.dim %arg0, %c1 : memref<?x?xf32, #map0>
%5 = affine.min #map2(%arg4)[%4]
%6 = memref.subview %arg0[%arg3, %arg4][%squared_min, %5][%c1, %c1] : memref<?x?xf32, #map0> to memref<?x?xf32, #map3>
%17 = memref.load %6[%arg5, %arg6] : memref<?x?xf32, #map3>
%18 = memref.load %11[%arg5, %arg6] : memref<?x?xf32, #map3>
%19 = memref.load %16[%arg5, %arg6] : memref<?x?xf32, #map3>
- %20 = addf %17, %18 : f32
+ %20 = arith.addf %17, %18 : f32
memref.store %20, %16[%arg5, %arg6] : memref<?x?xf32, #map3>
scf.yield
} {mapping = [{bound = affine_map<(d0) -> (d0)>, map = affine_map<(d0) -> (d0)>, processor = 3 : i64}, {bound = affine_map<(d0) -> (d0)>, map = affine_map<(d0) -> (d0)>, processor = 4 : i64}]}
// CHECK: module {
// CHECK-LABEL: func @sum(
// CHECK-SAME: [[VAL_0:%.*]]: memref<?x?xf32, #[[$MAP0]]>, [[VAL_1:%.*]]: memref<?x?xf32, #[[$MAP0]]>, [[VAL_2:%.*]]: memref<?x?xf32, #[[$MAP0]]>) {
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C3:.*]] = constant 3 : index
-// CHECK: %[[C2:.*]] = constant 2 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C3:.*]] = arith.constant 3 : index
+// CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: [[VAL_7:%.*]] = memref.dim [[VAL_0]], %[[C0]] : memref<?x?xf32, #[[$MAP0]]>
// CHECK: [[VAL_8:%.*]] = memref.dim [[VAL_0]], %[[C1]] : memref<?x?xf32, #[[$MAP0]]>
-// CHECK: [[VAL_9:%.*]] = constant 1 : index
+// CHECK: [[VAL_9:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_10:%.*]] = affine.apply #[[$MAP1]]([[VAL_7]]){{\[}}%[[C0]], %[[C2]]]
// CHECK: [[VAL_11:%.*]] = affine.apply #[[$MAP1]]([[VAL_8]]){{\[}}%[[C0]], %[[C3]]]
-// CHECK: [[VAL_12:%.*]] = constant 4 : index
+// CHECK: [[VAL_12:%.*]] = arith.constant 4 : index
// CHECK: [[VAL_13:%.*]] = affine.apply #[[$MAP1]]([[VAL_12]]){{\[}}%[[C0]], %[[C1]]]
-// CHECK: [[VAL_14:%.*]] = constant 3 : index
+// CHECK: [[VAL_14:%.*]] = arith.constant 3 : index
// CHECK: [[VAL_15:%.*]] = affine.apply #[[$MAP1]]([[VAL_14]]){{\[}}%[[C0]], %[[C1]]]
// CHECK: gpu.launch blocks([[VAL_16:%.*]], [[VAL_17:%.*]], [[VAL_18:%.*]]) in ([[VAL_19:%.*]] = [[VAL_10]], [[VAL_20:%.*]] = [[VAL_11]], [[VAL_21:%.*]] = [[VAL_9]]) threads([[VAL_22:%.*]], [[VAL_23:%.*]], [[VAL_24:%.*]]) in ([[VAL_25:%.*]] = [[VAL_13]], [[VAL_26:%.*]] = [[VAL_15]], [[VAL_27:%.*]] = [[VAL_9]]) {
// CHECK: [[VAL_28:%.*]] = affine.apply #[[$MAP2]]([[VAL_16]]){{\[}}%[[C2]], %[[C0]]]
// CHECK: [[VAL_29:%.*]] = affine.apply #[[$MAP2]]([[VAL_17]]){{\[}}%[[C3]], %[[C0]]]
// CHECK: [[VAL_30:%.*]] = memref.dim [[VAL_0]], %[[C0]] : memref<?x?xf32, #[[$MAP0]]>
// CHECK: [[VAL_31:%.*]] = affine.min #[[$MAP3]]([[VAL_28]]){{\[}}[[VAL_30]]]
-// CHECK: [[VAL_31_SQUARED:%.*]] = muli [[VAL_31]], [[VAL_31]] : index
+// CHECK: [[VAL_31_SQUARED:%.*]] = arith.muli [[VAL_31]], [[VAL_31]] : index
// CHECK: [[VAL_32:%.*]] = memref.dim [[VAL_0]], %[[C1]] : memref<?x?xf32, #[[$MAP0]]>
// CHECK: [[VAL_33:%.*]] = affine.min #[[$MAP4]]([[VAL_29]]){{\[}}[[VAL_32]]]
// CHECK: [[VAL_34:%.*]] = memref.subview [[VAL_0]]{{\[}}[[VAL_28]], [[VAL_29]]] {{\[}}[[VAL_31_SQUARED]], [[VAL_33]]] {{\[}}%[[C1]], %[[C1]]] : memref<?x?xf32, #[[$MAP0]]> to memref<?x?xf32, #[[$MAP5]]>
// CHECK: [[VAL_43:%.*]] = affine.min #[[$MAP4]]([[VAL_29]]){{\[}}[[VAL_42]]]
// CHECK: [[VAL_44:%.*]] = memref.subview [[VAL_2]]{{\[}}[[VAL_28]], [[VAL_29]]] {{\[}}[[VAL_41]], [[VAL_43]]] {{\[}}%[[C1]], %[[C1]]] : memref<?x?xf32, #[[$MAP0]]> to memref<?x?xf32, #[[$MAP5]]>
// CHECK: [[VAL_45:%.*]] = affine.apply #[[$MAP2]]([[VAL_22]]){{\[}}%[[C1]], %[[C0]]]
-// CHECK: [[VAL_46:%.*]] = cmpi slt, [[VAL_45]], [[VAL_31_SQUARED]] : index
+// CHECK: [[VAL_46:%.*]] = arith.cmpi slt, [[VAL_45]], [[VAL_31_SQUARED]] : index
// CHECK: scf.if [[VAL_46]] {
// CHECK: [[VAL_47:%.*]] = affine.apply #[[$MAP2]]([[VAL_23]]){{\[}}%[[C1]], %[[C0]]]
-// CHECK: [[VAL_48:%.*]] = cmpi slt, [[VAL_47]], [[VAL_33]] : index
+// CHECK: [[VAL_48:%.*]] = arith.cmpi slt, [[VAL_47]], [[VAL_33]] : index
// CHECK: scf.if [[VAL_48]] {
// CHECK: [[VAL_49:%.*]] = memref.load [[VAL_34]]{{\[}}[[VAL_45]], [[VAL_47]]] : memref<?x?xf32, #[[$MAP5]]>
// CHECK: [[VAL_50:%.*]] = memref.load [[VAL_39]]{{\[}}[[VAL_45]], [[VAL_47]]] : memref<?x?xf32, #[[$MAP5]]>
// CHECK: [[VAL_51:%.*]] = memref.load [[VAL_44]]{{\[}}[[VAL_45]], [[VAL_47]]] : memref<?x?xf32, #[[$MAP5]]>
-// CHECK: [[VAL_52:%.*]] = addf [[VAL_49]], [[VAL_50]] : f32
+// CHECK: [[VAL_52:%.*]] = arith.addf [[VAL_49]], [[VAL_50]] : f32
// CHECK: memref.store [[VAL_52]], [[VAL_44]]{{\[}}[[VAL_45]], [[VAL_47]]] : memref<?x?xf32, #[[$MAP5]]>
// CHECK: }
// CHECK: }
// Optional attribute lowering test
func @parallel_loop_optional_attr() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i0) = (%c0) to (%c1) step (%c1) {
} { mapping = [{processor = 0, map = affine_map<(d0) -> (d0)>, bound = affine_map<(d0) -> (d0)>}], optional_attr = 1 }
// CHECK: optional_attr = 1
%arg3 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %four = constant 4 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
} { mapping = [
%arg3 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %zero = constant 0 : index
- %one = constant 1 : index
- %four = constant 4 : index
+ %zero = arith.constant 0 : index
+ %one = arith.constant 1 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
scf.parallel (%si0, %si1) = (%zero, %zero) to (%i0, %i1)
step (%one, %one) {
- %idx0 = addi %i0, %si0 : index
- %idx1 = addi %i1, %si1 : index
+ %idx0 = arith.addi %i0, %si0 : index
+ %idx1 = arith.addi %i1, %si1 : index
%val = memref.load %buf[%idx0, %idx1] : memref<?x?xf32>
memref.store %val, %res[%idx1, %idx0] : memref<?x?xf32>
} { mapping = [
%arg3 : index,
%buf : memref<?x?xf32>,
%res : memref<?x?xf32>) {
- %four = constant 4 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
}
// CHECK-22-LABEL: @step_1
func @step_1(%A : memref<?x?x?x?xf32>, %B : memref<?x?x?x?xf32>) {
// Bounds of the loop, its range and step.
- // CHECK-11-NEXT: %{{.*}} = constant 0 : index
- // CHECK-11-NEXT: %{{.*}} = constant 42 : index
- // CHECK-11-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-11-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 42 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 1 : index
//
- // CHECK-22-NEXT: %{{.*}} = constant 0 : index
- // CHECK-22-NEXT: %{{.*}} = constant 42 : index
- // CHECK-22-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 42 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 1 : index
affine.for %i = 0 to 42 {
// Bounds of the loop, its range and step.
- // CHECK-11-NEXT: %{{.*}} = constant 0 : index
- // CHECK-11-NEXT: %{{.*}} = constant 10 : index
- // CHECK-11-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-11-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 10 : index
+ // CHECK-11-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-11-NEXT: %{{.*}} = arith.constant 1 : index
//
- // CHECK-22-NEXT: %{{.*}} = constant 0 : index
- // CHECK-22-NEXT: %{{.*}} = constant 10 : index
- // CHECK-22-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 0 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 10 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 1 : index
affine.for %j = 0 to 10 {
// CHECK-11: gpu.launch
// CHECK-11-SAME: blocks
// CHECK-11-SAME: threads
// Remapping of the loop induction variables.
- // CHECK-11: %[[i:.*]] = addi %{{.*}}, %{{.*}} : index
- // CHECK-11-NEXT: %[[j:.*]] = addi %{{.*}}, %{{.*}} : index
+ // CHECK-11: %[[i:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+ // CHECK-11-NEXT: %[[j:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// This loop is not converted if mapping to 1, 1 dimensions.
// CHECK-11-NEXT: affine.for %[[ii:.*]] = 2 to 16
//
// Bounds of the loop, its range and step.
- // CHECK-22-NEXT: %{{.*}} = constant 2 : index
- // CHECK-22-NEXT: %{{.*}} = constant 16 : index
- // CHECK-22-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 2 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 16 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 1 : index
affine.for %ii = 2 to 16 {
// This loop is not converted if mapping to 1, 1 dimensions.
// CHECK-11-NEXT: affine.for %[[jj:.*]] = 5 to 17
//
// Bounds of the loop, its range and step.
- // CHECK-22-NEXT: %{{.*}} = constant 5 : index
- // CHECK-22-NEXT: %{{.*}} = constant 17 : index
- // CHECK-22-NEXT: %{{.*}} = subi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %{{.*}} = constant 1 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 5 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 17 : index
+ // CHECK-22-NEXT: %{{.*}} = arith.subi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %{{.*}} = arith.constant 1 : index
affine.for %jj = 5 to 17 {
// CHECK-22: gpu.launch
// CHECK-22-SAME: blocks
// CHECK-22-SAME: threads
// Remapping of the loop induction variables in the last mapped scf.
- // CHECK-22: %[[i:.*]] = addi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %[[j:.*]] = addi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %[[ii:.*]] = addi %{{.*}}, %{{.*}} : index
- // CHECK-22-NEXT: %[[jj:.*]] = addi %{{.*}}, %{{.*}} : index
+ // CHECK-22: %[[i:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %[[j:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %[[ii:.*]] = arith.addi %{{.*}}, %{{.*}} : index
+ // CHECK-22-NEXT: %[[jj:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// Using remapped values instead of loop iterators.
// CHECK-11: {{.*}} = memref.load %{{.*}}[%[[i]], %[[j]], %[[ii]], %[[jj]]] : memref<?x?x?x?xf32>
// CHECK-LABEL: @step_var
func @step_var(%A : memref<?x?xf32>, %B : memref<?x?xf32>) {
// Check that we divide by step.
- // CHECK: %[[range_i:.*]] = divi_signed {{.*}}, %{{.*}}
- // CHECK: %[[range_j:.*]] = divi_signed {{.*}}, %{{.*}}
+ // CHECK: %[[range_i:.*]] = arith.divsi {{.*}}, %{{.*}}
+ // CHECK: %[[range_j:.*]] = arith.divsi {{.*}}, %{{.*}}
// CHECK: gpu.launch
// CHECK-SAME: blocks(%{{[^)]*}}, %{{[^)]*}}, %{{[^)]*}}) in (%{{[^)]*}} = %[[range_i]], %{{[^)]*}} = %{{[^)]*}}, %{{[^)]*}} = %{{[^)]*}})
affine.for %j = 3 to 19 step 7 {
// Loop induction variable remapping:
// iv = thread(block)_id * step + lower_bound
- // CHECK: %[[prod_i:.*]] = muli %{{.*}}, %{{.*}} : index
- // CHECK-NEXT: %[[i:.*]] = addi %{{.*}}, %[[prod_i]] : index
- // CHECK-NEXT: %[[prod_j:.*]] = muli %{{.*}}, %{{.*}} : index
- // CHECK-NEXT: %[[j:.*]] = addi %{{.*}}, %[[prod_j]] : index
+ // CHECK: %[[prod_i:.*]] = arith.muli %{{.*}}, %{{.*}} : index
+ // CHECK-NEXT: %[[i:.*]] = arith.addi %{{.*}}, %[[prod_i]] : index
+ // CHECK-NEXT: %[[prod_j:.*]] = arith.muli %{{.*}}, %{{.*}} : index
+ // CHECK-NEXT: %[[j:.*]] = arith.addi %{{.*}}, %[[prod_j]] : index
// CHECK: {{.*}} = memref.load %{{.*}}[%[[i]], %[[j]]] : memref<?x?xf32>
%0 = memref.load %A[%i, %j] : memref<?x?xf32>
// CHECK: combiner
// CHECK: ^{{.*}}(%[[ARG0:.*]]: f32, %[[ARG1:.*]]: f32)
-// CHECK: %[[RES:.*]] = addf %[[ARG0]], %[[ARG1]]
+// CHECK: %[[RES:.*]] = arith.addf %[[ARG0]], %[[ARG1]]
// CHECK: omp.yield(%[[RES]] : f32)
// CHECK: atomic
// CHECK-LABEL: @reduction1
func @reduction1(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) {
- // CHECK: %[[CST:.*]] = constant 0.0
+ // CHECK: %[[CST:.*]] = arith.constant 0.0
// CHECK: %[[ONE:.*]] = llvm.mlir.constant(1
// CHECK: llvm.intr.stacksave
// CHECK: %[[BUF:.*]] = llvm.alloca %[[ONE]] x f32
// CHECK: llvm.store %[[CST]], %[[BUF]]
- %step = constant 1 : index
- %zero = constant 0.0 : f32
+ %step = arith.constant 1 : index
+ %zero = arith.constant 0.0 : f32
// CHECK: omp.parallel
// CHECK: omp.wsloop
// CHECK-SAME: reduction(@[[$REDF]] -> %[[BUF]]
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) init (%zero) -> (f32) {
- // CHECK: %[[CST_INNER:.*]] = constant 1.0
- %one = constant 1.0 : f32
+ // CHECK: %[[CST_INNER:.*]] = arith.constant 1.0
+ %one = arith.constant 1.0 : f32
// CHECK: omp.reduction %[[CST_INNER]], %[[BUF]]
scf.reduce(%one) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %res = addf %lhs, %rhs : f32
+ %res = arith.addf %lhs, %rhs : f32
scf.reduce.return %res : f32
}
// CHECK: omp.yield
// CHECK: combiner
// CHECK: ^{{.*}}(%[[ARG0:.*]]: f32, %[[ARG1:.*]]: f32)
-// CHECK: %[[RES:.*]] = mulf %[[ARG0]], %[[ARG1]]
+// CHECK: %[[RES:.*]] = arith.mulf %[[ARG0]], %[[ARG1]]
// CHECK: omp.yield(%[[RES]] : f32)
// CHECK-NOT: atomic
// CHECK-LABEL: @reduction2
func @reduction2(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) {
- %step = constant 1 : index
- %zero = constant 0.0 : f32
+ %step = arith.constant 1 : index
+ %zero = arith.constant 0.0 : f32
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) init (%zero) -> (f32) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
scf.reduce(%one) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %res = mulf %lhs, %rhs : f32
+ %res = arith.mulf %lhs, %rhs : f32
scf.reduce.return %res : f32
}
}
// CHECK: combiner
// CHECK: ^{{.*}}(%[[ARG0:.*]]: f32, %[[ARG1:.*]]: f32)
-// CHECK: %[[CMP:.*]] = cmpf oge, %[[ARG0]], %[[ARG1]]
+// CHECK: %[[CMP:.*]] = arith.cmpf oge, %[[ARG0]], %[[ARG1]]
// CHECK: %[[RES:.*]] = select %[[CMP]], %[[ARG0]], %[[ARG1]]
// CHECK: omp.yield(%[[RES]] : f32)
// CHECK-LABEL: @reduction3
func @reduction3(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) {
- %step = constant 1 : index
- %zero = constant 0.0 : f32
+ %step = arith.constant 1 : index
+ %zero = arith.constant 0.0 : f32
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) init (%zero) -> (f32) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
scf.reduce(%one) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %cmp = cmpf oge, %lhs, %rhs : f32
+ %cmp = arith.cmpf oge, %lhs, %rhs : f32
%res = select %cmp, %lhs, %rhs : f32
scf.reduce.return %res : f32
}
// CHECK: combiner
// CHECK: ^{{.*}}(%[[ARG0:.*]]: f32, %[[ARG1:.*]]: f32)
-// CHECK: %[[CMP:.*]] = cmpf oge, %[[ARG0]], %[[ARG1]]
+// CHECK: %[[CMP:.*]] = arith.cmpf oge, %[[ARG0]], %[[ARG1]]
// CHECK: %[[RES:.*]] = select %[[CMP]], %[[ARG0]], %[[ARG1]]
// CHECK: omp.yield(%[[RES]] : f32)
// CHECK: combiner
// CHECK: ^{{.*}}(%[[ARG0:.*]]: i64, %[[ARG1:.*]]: i64)
-// CHECK: %[[CMP:.*]] = cmpi slt, %[[ARG0]], %[[ARG1]]
+// CHECK: %[[CMP:.*]] = arith.cmpi slt, %[[ARG0]], %[[ARG1]]
// CHECK: %[[RES:.*]] = select %[[CMP]], %[[ARG1]], %[[ARG0]]
// CHECK: omp.yield(%[[RES]] : i64)
// CHECK-LABEL: @reduction4
func @reduction4(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) -> (f32, i64) {
- %step = constant 1 : index
- // CHECK: %[[ZERO:.*]] = constant 0.0
- %zero = constant 0.0 : f32
- // CHECK: %[[IONE:.*]] = constant 1
- %ione = constant 1 : i64
+ %step = arith.constant 1 : index
+ // CHECK: %[[ZERO:.*]] = arith.constant 0.0
+ %zero = arith.constant 0.0 : f32
+ // CHECK: %[[IONE:.*]] = arith.constant 1
+ %ione = arith.constant 1 : i64
// CHECK: %[[BUF1:.*]] = llvm.alloca %{{.*}} x f32
// CHECK: llvm.store %[[ZERO]], %[[BUF1]]
// CHECK: %[[BUF2:.*]] = llvm.alloca %{{.*}} x i64
// CHECK-SAME: @[[$REDF2]] -> %[[BUF2]]
%res:2 = scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) init (%zero, %ione) -> (f32, i64) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
// CHECK: omp.reduction %{{.*}}, %[[BUF1]]
scf.reduce(%one) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %cmp = cmpf oge, %lhs, %rhs : f32
+ %cmp = arith.cmpf oge, %lhs, %rhs : f32
%res = select %cmp, %lhs, %rhs : f32
scf.reduce.return %res : f32
}
- // CHECK: fptosi
- %1 = fptosi %one : f32 to i64
+ // CHECK: arith.fptosi
+ %1 = arith.fptosi %one : f32 to i64
// CHECK: omp.reduction %{{.*}}, %[[BUF2]]
scf.reduce(%1) : i64 {
^bb1(%lhs: i64, %rhs: i64):
- %cmp = cmpi slt, %lhs, %rhs : i64
+ %cmp = arith.cmpi slt, %lhs, %rhs : i64
%res = select %cmp, %rhs, %lhs : i64
scf.reduce.return %res : i64
}
func @loop_kernel(%arg2 : memref<10xf32>, %arg3 : memref<10xf32>) {
// CHECK: %[[LB:.*]] = spv.Constant 4 : i32
- %lb = constant 4 : index
+ %lb = arith.constant 4 : index
// CHECK: %[[UB:.*]] = spv.Constant 42 : i32
- %ub = constant 42 : index
+ %ub = arith.constant 42 : index
// CHECK: %[[STEP:.*]] = spv.Constant 2 : i32
- %step = constant 2 : index
+ %step = arith.constant 2 : index
// CHECK: spv.mlir.loop {
// CHECK-NEXT: spv.Branch ^[[HEADER:.*]](%[[LB]] : i32)
// CHECK: ^[[HEADER]](%[[INDVAR:.*]]: i32):
// CHECK-LABEL: @loop_yield
func @loop_yield(%arg2 : memref<10xf32>, %arg3 : memref<10xf32>) {
// CHECK: %[[LB:.*]] = spv.Constant 4 : i32
- %lb = constant 4 : index
+ %lb = arith.constant 4 : index
// CHECK: %[[UB:.*]] = spv.Constant 42 : i32
- %ub = constant 42 : index
+ %ub = arith.constant 42 : index
// CHECK: %[[STEP:.*]] = spv.Constant 2 : i32
- %step = constant 2 : index
+ %step = arith.constant 2 : index
// CHECK: %[[INITVAR1:.*]] = spv.Constant 0.000000e+00 : f32
- %s0 = constant 0.0 : f32
+ %s0 = arith.constant 0.0 : f32
// CHECK: %[[INITVAR2:.*]] = spv.Constant 1.000000e+00 : f32
- %s1 = constant 1.0 : f32
+ %s1 = arith.constant 1.0 : f32
// CHECK: %[[VAR1:.*]] = spv.Variable : !spv.ptr<f32, Function>
// CHECK: %[[VAR2:.*]] = spv.Variable : !spv.ptr<f32, Function>
// CHECK: spv.mlir.loop {
// CHECK: spv.mlir.merge
// CHECK: }
%result:2 = scf.for %i0 = %lb to %ub step %step iter_args(%si = %s0, %sj = %s1) -> (f32, f32) {
- %sn = addf %si, %si : f32
+ %sn = arith.addf %si, %si : f32
scf.yield %sn, %sn : f32, f32
}
// CHECK-DAG: %[[OUT1:.*]] = spv.Load "Function" %[[VAR1]] : f32
// CHECK-LABEL: @kernel_simple_selection
func @kernel_simple_selection(%arg2 : memref<10xf32>, %arg3 : i1) {
- %value = constant 0.0 : f32
- %i = constant 0 : index
+ %value = arith.constant 0.0 : f32
+ %i = arith.constant 0 : index
// CHECK: spv.mlir.selection {
// CHECK-NEXT: spv.BranchConditional {{%.*}}, [[TRUE:\^.*]], [[MERGE:\^.*]]
// CHECK-LABEL: @kernel_nested_selection
func @kernel_nested_selection(%arg3 : memref<10xf32>, %arg4 : memref<10xf32>, %arg5 : i1, %arg6 : i1) {
- %i = constant 0 : index
- %j = constant 9 : index
+ %i = arith.constant 0 : index
+ %j = arith.constant 9 : index
// CHECK: spv.mlir.selection {
// CHECK-NEXT: spv.BranchConditional {{%.*}}, [[TRUE_TOP:\^.*]], [[FALSE_TOP:\^.*]]
// CHECK: spv.Store "StorageBuffer" {{%.*}}, %[[OUT2]] : f32
// CHECK: spv.Return
%0:2 = scf.if %arg3 -> (f32, f32) {
- %c0 = constant 0.0 : f32
- %c1 = constant 1.0 : f32
+ %c0 = arith.constant 0.0 : f32
+ %c1 = arith.constant 1.0 : f32
scf.yield %c0, %c1 : f32, f32
} else {
- %c0 = constant 2.0 : f32
- %c1 = constant 3.0 : f32
+ %c0 = arith.constant 2.0 : f32
+ %c1 = arith.constant 3.0 : f32
scf.yield %c1, %c0 : f32, f32
}
- %i = constant 0 : index
- %j = constant 1 : index
+ %i = arith.constant 0 : index
+ %j = arith.constant 1 : index
memref.store %0#0, %arg2[%i] : memref<10xf32>
memref.store %0#1, %arg2[%j] : memref<10xf32>
return
// CHECK: %[[ADD:.*]] = spv.AccessChain %[[OUT]][{{%.*}}, {{%.*}}] : !spv.ptr<!spv.struct<(!spv.array<10 x f32, stride=4> [0])>, StorageBuffer>
// CHECK: spv.Store "StorageBuffer" %[[ADD]], {{%.*}} : f32
// CHECK: spv.Return
- %i = constant 0 : index
- %value = constant 0.0 : f32
+ %i = arith.constant 0 : index
+ %value = arith.constant 0.0 : f32
%0 = scf.if %arg4 -> (memref<10xf32>) {
scf.yield %arg2 : memref<10xf32>
} else {
// CHECK-LABEL: func @simple_std_for_loop(%{{.*}}: index, %{{.*}}: index, %{{.*}}: index) {
// CHECK-NEXT: br ^bb1(%{{.*}} : index)
// CHECK-NEXT: ^bb1(%{{.*}}: index): // 2 preds: ^bb0, ^bb2
-// CHECK-NEXT: %{{.*}} = cmpi slt, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi slt, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: cond_br %{{.*}}, ^bb2, ^bb3
// CHECK-NEXT: ^bb2: // pred: ^bb1
-// CHECK-NEXT: %{{.*}} = constant 1 : index
-// CHECK-NEXT: %[[iv:.*]] = addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
+// CHECK-NEXT: %[[iv:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// CHECK-NEXT: br ^bb1(%[[iv]] : index)
// CHECK-NEXT: ^bb3: // pred: ^bb1
// CHECK-NEXT: return
func @simple_std_for_loop(%arg0 : index, %arg1 : index, %arg2 : index) {
scf.for %i0 = %arg0 to %arg1 step %arg2 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
}
return
}
// CHECK-LABEL: func @simple_std_2_for_loops(%{{.*}}: index, %{{.*}}: index, %{{.*}}: index) {
// CHECK-NEXT: br ^bb1(%{{.*}} : index)
// CHECK-NEXT: ^bb1(%[[ub0:.*]]: index): // 2 preds: ^bb0, ^bb5
-// CHECK-NEXT: %[[cond0:.*]] = cmpi slt, %[[ub0]], %{{.*}} : index
+// CHECK-NEXT: %[[cond0:.*]] = arith.cmpi slt, %[[ub0]], %{{.*}} : index
// CHECK-NEXT: cond_br %[[cond0]], ^bb2, ^bb6
// CHECK-NEXT: ^bb2: // pred: ^bb1
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb3(%{{.*}} : index)
// CHECK-NEXT: ^bb3(%[[ub1:.*]]: index): // 2 preds: ^bb2, ^bb4
-// CHECK-NEXT: %[[cond1:.*]] = cmpi slt, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[cond1:.*]] = arith.cmpi slt, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: cond_br %[[cond1]], ^bb4, ^bb5
// CHECK-NEXT: ^bb4: // pred: ^bb3
-// CHECK-NEXT: %{{.*}} = constant 1 : index
-// CHECK-NEXT: %[[iv1:.*]] = addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
+// CHECK-NEXT: %[[iv1:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// CHECK-NEXT: br ^bb3(%[[iv1]] : index)
// CHECK-NEXT: ^bb5: // pred: ^bb3
-// CHECK-NEXT: %[[iv0:.*]] = addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[iv0:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// CHECK-NEXT: br ^bb1(%[[iv0]] : index)
// CHECK-NEXT: ^bb6: // pred: ^bb1
// CHECK-NEXT: return
func @simple_std_2_for_loops(%arg0 : index, %arg1 : index, %arg2 : index) {
scf.for %i0 = %arg0 to %arg1 step %arg2 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
scf.for %i1 = %arg0 to %arg1 step %arg2 {
- %c1_0 = constant 1 : index
+ %c1_0 = arith.constant 1 : index
}
}
return
// CHECK-LABEL: func @simple_std_if(%{{.*}}: i1) {
// CHECK-NEXT: cond_br %{{.*}}, ^bb1, ^bb2
// CHECK-NEXT: ^bb1: // pred: ^bb0
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb2
// CHECK-NEXT: ^bb2: // 2 preds: ^bb0, ^bb1
// CHECK-NEXT: return
func @simple_std_if(%arg0: i1) {
scf.if %arg0 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
}
return
}
// CHECK-LABEL: func @simple_std_if_else(%{{.*}}: i1) {
// CHECK-NEXT: cond_br %{{.*}}, ^bb1, ^bb2
// CHECK-NEXT: ^bb1: // pred: ^bb0
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb3
// CHECK-NEXT: ^bb2: // pred: ^bb0
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb3
// CHECK-NEXT: ^bb3: // 2 preds: ^bb1, ^bb2
// CHECK-NEXT: return
func @simple_std_if_else(%arg0: i1) {
scf.if %arg0 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
} else {
- %c1_0 = constant 1 : index
+ %c1_0 = arith.constant 1 : index
}
return
}
// CHECK-LABEL: func @simple_std_2_ifs(%{{.*}}: i1) {
// CHECK-NEXT: cond_br %{{.*}}, ^bb1, ^bb5
// CHECK-NEXT: ^bb1: // pred: ^bb0
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: cond_br %{{.*}}, ^bb2, ^bb3
// CHECK-NEXT: ^bb2: // pred: ^bb1
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb4
// CHECK-NEXT: ^bb3: // pred: ^bb1
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb4
// CHECK-NEXT: ^bb4: // 2 preds: ^bb2, ^bb3
// CHECK-NEXT: br ^bb5
// CHECK-NEXT: return
func @simple_std_2_ifs(%arg0: i1) {
scf.if %arg0 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
scf.if %arg0 {
- %c1_0 = constant 1 : index
+ %c1_0 = arith.constant 1 : index
} else {
- %c1_1 = constant 1 : index
+ %c1_1 = arith.constant 1 : index
}
}
return
// CHECK-LABEL: func @simple_std_for_loop_with_2_ifs(%{{.*}}: index, %{{.*}}: index, %{{.*}}: index, %{{.*}}: i1) {
// CHECK-NEXT: br ^bb1(%{{.*}} : index)
// CHECK-NEXT: ^bb1(%{{.*}}: index): // 2 preds: ^bb0, ^bb7
-// CHECK-NEXT: %{{.*}} = cmpi slt, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi slt, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: cond_br %{{.*}}, ^bb2, ^bb8
// CHECK-NEXT: ^bb2: // pred: ^bb1
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: cond_br %{{.*}}, ^bb3, ^bb7
// CHECK-NEXT: ^bb3: // pred: ^bb2
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: cond_br %{{.*}}, ^bb4, ^bb5
// CHECK-NEXT: ^bb4: // pred: ^bb3
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb6
// CHECK-NEXT: ^bb5: // pred: ^bb3
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: br ^bb6
// CHECK-NEXT: ^bb6: // 2 preds: ^bb4, ^bb5
// CHECK-NEXT: br ^bb7
// CHECK-NEXT: ^bb7: // 2 preds: ^bb2, ^bb6
-// CHECK-NEXT: %[[iv0:.*]] = addi %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %[[iv0:.*]] = arith.addi %{{.*}}, %{{.*}} : index
// CHECK-NEXT: br ^bb1(%[[iv0]] : index)
// CHECK-NEXT: ^bb8: // pred: ^bb1
// CHECK-NEXT: return
// CHECK-NEXT: }
func @simple_std_for_loop_with_2_ifs(%arg0 : index, %arg1 : index, %arg2 : index, %arg3 : i1) {
scf.for %i0 = %arg0 to %arg1 step %arg2 {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
scf.if %arg3 {
- %c1_0 = constant 1 : index
+ %c1_0 = arith.constant 1 : index
scf.if %arg3 {
- %c1_1 = constant 1 : index
+ %c1_1 = arith.constant 1 : index
} else {
- %c1_2 = constant 1 : index
+ %c1_2 = arith.constant 1 : index
}
}
}
// CHECK: cond_br %{{.*}}, ^[[then:.*]], ^[[else:.*]]
%0:2 = scf.if %arg0 -> (i1, i1) {
// CHECK: ^[[then]]:
-// CHECK: %[[v0:.*]] = constant false
-// CHECK: %[[v1:.*]] = constant true
+// CHECK: %[[v0:.*]] = arith.constant false
+// CHECK: %[[v1:.*]] = arith.constant true
// CHECK: br ^[[dom:.*]](%[[v0]], %[[v1]] : i1, i1)
- %c0 = constant false
- %c1 = constant true
+ %c0 = arith.constant false
+ %c1 = arith.constant true
scf.yield %c0, %c1 : i1, i1
} else {
// CHECK: ^[[else]]:
-// CHECK: %[[v2:.*]] = constant false
-// CHECK: %[[v3:.*]] = constant true
+// CHECK: %[[v2:.*]] = arith.constant false
+// CHECK: %[[v3:.*]] = arith.constant true
// CHECK: br ^[[dom]](%[[v3]], %[[v2]] : i1, i1)
- %c0 = constant false
- %c1 = constant true
+ %c0 = arith.constant false
+ %c1 = arith.constant true
scf.yield %c1, %c0 : i1, i1
}
// CHECK: ^[[dom]](%[[arg1:.*]]: i1, %[[arg2:.*]]: i1):
// CHECK: cond_br %{{.*}}, ^[[first_then:.*]], ^[[first_else:.*]]
%0 = scf.if %arg0 -> i1 {
// CHECK: ^[[first_then]]:
- %1 = constant true
+ %1 = arith.constant true
// CHECK: br ^[[first_dom:.*]]({{.*}})
scf.yield %1 : i1
} else {
// CHECK: ^[[first_else]]:
- %2 = constant false
+ %2 = arith.constant false
// CHECK: br ^[[first_dom]]({{.*}})
scf.yield %2 : i1
}
// CHECK: cond_br %arg0, ^[[second_inner_then:.*]], ^[[second_inner_else:.*]]
%3 = scf.if %arg0 -> index {
// CHECK: ^[[second_inner_then]]:
- %4 = constant 40 : index
+ %4 = arith.constant 40 : index
// CHECK: br ^[[second_inner_dom:.*]]({{.*}})
scf.yield %4 : index
} else {
// CHECK: ^[[second_inner_else]]:
- %5 = constant 41 : index
+ %5 = arith.constant 41 : index
// CHECK: br ^[[second_inner_dom]]({{.*}})
scf.yield %5 : index
}
scf.yield %3 : index
} else {
// CHECK: ^[[second_outer_else]]:
- %6 = constant 42 : index
+ %6 = arith.constant 42 : index
// CHECK: br ^[[second_outer_dom]]({{.*}}
scf.yield %6 : index
}
// CHECK-LABEL: func @parallel_loop(
// CHECK-SAME: [[VAL_0:%.*]]: index, [[VAL_1:%.*]]: index, [[VAL_2:%.*]]: index, [[VAL_3:%.*]]: index, [[VAL_4:%.*]]: index) {
-// CHECK: [[VAL_5:%.*]] = constant 1 : index
+// CHECK: [[VAL_5:%.*]] = arith.constant 1 : index
// CHECK: br ^bb1([[VAL_0]] : index)
// CHECK: ^bb1([[VAL_6:%.*]]: index):
-// CHECK: [[VAL_7:%.*]] = cmpi slt, [[VAL_6]], [[VAL_2]] : index
+// CHECK: [[VAL_7:%.*]] = arith.cmpi slt, [[VAL_6]], [[VAL_2]] : index
// CHECK: cond_br [[VAL_7]], ^bb2, ^bb6
// CHECK: ^bb2:
// CHECK: br ^bb3([[VAL_1]] : index)
// CHECK: ^bb3([[VAL_8:%.*]]: index):
-// CHECK: [[VAL_9:%.*]] = cmpi slt, [[VAL_8]], [[VAL_3]] : index
+// CHECK: [[VAL_9:%.*]] = arith.cmpi slt, [[VAL_8]], [[VAL_3]] : index
// CHECK: cond_br [[VAL_9]], ^bb4, ^bb5
// CHECK: ^bb4:
-// CHECK: [[VAL_10:%.*]] = constant 1 : index
-// CHECK: [[VAL_11:%.*]] = addi [[VAL_8]], [[VAL_5]] : index
+// CHECK: [[VAL_10:%.*]] = arith.constant 1 : index
+// CHECK: [[VAL_11:%.*]] = arith.addi [[VAL_8]], [[VAL_5]] : index
// CHECK: br ^bb3([[VAL_11]] : index)
// CHECK: ^bb5:
-// CHECK: [[VAL_12:%.*]] = addi [[VAL_6]], [[VAL_4]] : index
+// CHECK: [[VAL_12:%.*]] = arith.addi [[VAL_6]], [[VAL_4]] : index
// CHECK: br ^bb1([[VAL_12]] : index)
// CHECK: ^bb6:
// CHECK: return
func @parallel_loop(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) {
- %step = constant 1 : index
+ %step = arith.constant 1 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
}
return
}
// CHECK-LABEL: @for_yield
// CHECK-SAME: (%[[LB:.*]]: index, %[[UB:.*]]: index, %[[STEP:.*]]: index)
-// CHECK: %[[INIT0:.*]] = constant 0
-// CHECK: %[[INIT1:.*]] = constant 1
+// CHECK: %[[INIT0:.*]] = arith.constant 0
+// CHECK: %[[INIT1:.*]] = arith.constant 1
// CHECK: br ^[[COND:.*]](%[[LB]], %[[INIT0]], %[[INIT1]] : index, f32, f32)
//
// CHECK: ^[[COND]](%[[ITER:.*]]: index, %[[ITER_ARG0:.*]]: f32, %[[ITER_ARG1:.*]]: f32):
-// CHECK: %[[CMP:.*]] = cmpi slt, %[[ITER]], %[[UB]] : index
+// CHECK: %[[CMP:.*]] = arith.cmpi slt, %[[ITER]], %[[UB]] : index
// CHECK: cond_br %[[CMP]], ^[[BODY:.*]], ^[[CONTINUE:.*]]
//
// CHECK: ^[[BODY]]:
-// CHECK: %[[SUM:.*]] = addf %[[ITER_ARG0]], %[[ITER_ARG1]] : f32
-// CHECK: %[[STEPPED:.*]] = addi %[[ITER]], %[[STEP]] : index
+// CHECK: %[[SUM:.*]] = arith.addf %[[ITER_ARG0]], %[[ITER_ARG1]] : f32
+// CHECK: %[[STEPPED:.*]] = arith.addi %[[ITER]], %[[STEP]] : index
// CHECK: br ^[[COND]](%[[STEPPED]], %[[SUM]], %[[SUM]] : index, f32, f32)
//
// CHECK: ^[[CONTINUE]]:
// CHECK: return %[[ITER_ARG0]], %[[ITER_ARG1]] : f32, f32
func @for_yield(%arg0 : index, %arg1 : index, %arg2 : index) -> (f32, f32) {
- %s0 = constant 0.0 : f32
- %s1 = constant 1.0 : f32
+ %s0 = arith.constant 0.0 : f32
+ %s1 = arith.constant 1.0 : f32
%result:2 = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %s0, %sj = %s1) -> (f32, f32) {
- %sn = addf %si, %sj : f32
+ %sn = arith.addf %si, %sj : f32
scf.yield %sn, %sn : f32, f32
}
return %result#0, %result#1 : f32, f32
// CHECK-LABEL: @nested_for_yield
// CHECK-SAME: (%[[LB:.*]]: index, %[[UB:.*]]: index, %[[STEP:.*]]: index)
-// CHECK: %[[INIT:.*]] = constant
+// CHECK: %[[INIT:.*]] = arith.constant
// CHECK: br ^[[COND_OUT:.*]](%[[LB]], %[[INIT]] : index, f32)
// CHECK: ^[[COND_OUT]](%[[ITER_OUT:.*]]: index, %[[ARG_OUT:.*]]: f32):
// CHECK: cond_br %{{.*}}, ^[[BODY_OUT:.*]], ^[[CONT_OUT:.*]]
// CHECK: ^[[COND_IN]](%[[ITER_IN:.*]]: index, %[[ARG_IN:.*]]: f32):
// CHECK: cond_br %{{.*}}, ^[[BODY_IN:.*]], ^[[CONT_IN:.*]]
// CHECK: ^[[BODY_IN]]
-// CHECK: %[[RES:.*]] = addf
+// CHECK: %[[RES:.*]] = arith.addf
// CHECK: br ^[[COND_IN]](%{{.*}}, %[[RES]] : index, f32)
// CHECK: ^[[CONT_IN]]:
// CHECK: br ^[[COND_OUT]](%{{.*}}, %[[ARG_IN]] : index, f32)
// CHECK: ^[[CONT_OUT]]:
// CHECK: return %[[ARG_OUT]] : f32
func @nested_for_yield(%arg0 : index, %arg1 : index, %arg2 : index) -> f32 {
- %s0 = constant 1.0 : f32
+ %s0 = arith.constant 1.0 : f32
%r = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%iter = %s0) -> (f32) {
%result = scf.for %i1 = %arg0 to %arg1 step %arg2 iter_args(%si = %iter) -> (f32) {
- %sn = addf %si, %si : f32
+ %sn = arith.addf %si, %si : f32
scf.yield %sn : f32
}
scf.yield %result : f32
// Condition branch takes as arguments the current value of the iteration
// variable and the current partially reduced value.
// CHECK: ^[[COND]](%[[ITER:.*]]: index, %[[ITER_ARG:.*]]: f32
- // CHECK: %[[COMP:.*]] = cmpi slt, %[[ITER]], %[[UB]]
+ // CHECK: %[[COMP:.*]] = arith.cmpi slt, %[[ITER]], %[[UB]]
// CHECK: cond_br %[[COMP]], ^[[BODY:.*]], ^[[CONTINUE:.*]]
// Bodies of scf.reduce operations are folded into the main loop body. The
// result of this partial reduction is passed as argument to the condition
// block.
// CHECK: ^[[BODY]]:
- // CHECK: %[[CST:.*]] = constant 4.2
- // CHECK: %[[PROD:.*]] = mulf %[[ITER_ARG]], %[[CST]]
- // CHECK: %[[INCR:.*]] = addi %[[ITER]], %[[STEP]]
+ // CHECK: %[[CST:.*]] = arith.constant 4.2
+ // CHECK: %[[PROD:.*]] = arith.mulf %[[ITER_ARG]], %[[CST]]
+ // CHECK: %[[INCR:.*]] = arith.addi %[[ITER]], %[[STEP]]
// CHECK: br ^[[COND]](%[[INCR]], %[[PROD]]
// The continuation block has access to the (last value of) reduction.
// CHECK: ^[[CONTINUE]]:
// CHECK: return %[[ITER_ARG]]
%0 = scf.parallel (%i) = (%arg0) to (%arg1) step (%arg2) init(%arg3) -> f32 {
- %cst = constant 42.0 : f32
+ %cst = arith.constant 42.0 : f32
scf.reduce(%cst) : f32 {
^bb0(%lhs: f32, %rhs: f32):
- %1 = mulf %lhs, %rhs : f32
+ %1 = arith.mulf %lhs, %rhs : f32
scf.reduce.return %1 : f32
}
}
%arg3 : index, %arg4 : index, %arg5 : f32) -> (f32, i64) {
// Multiple reduction blocks should be folded in the same body, and the
// reduction value must be forwarded through block structures.
- // CHECK: %[[INIT2:.*]] = constant 42
+ // CHECK: %[[INIT2:.*]] = arith.constant 42
// CHECK: br ^[[COND_OUT:.*]](%{{.*}}, %[[INIT1]], %[[INIT2]]
// CHECK: ^[[COND_OUT]](%{{.*}}: index, %[[ITER_ARG1_OUT:.*]]: f32, %[[ITER_ARG2_OUT:.*]]: i64
// CHECK: cond_br %{{.*}}, ^[[BODY_OUT:.*]], ^[[CONT_OUT:.*]]
// CHECK: ^[[COND_IN]](%{{.*}}: index, %[[ITER_ARG1_IN:.*]]: f32, %[[ITER_ARG2_IN:.*]]: i64
// CHECK: cond_br %{{.*}}, ^[[BODY_IN:.*]], ^[[CONT_IN:.*]]
// CHECK: ^[[BODY_IN]]:
- // CHECK: %[[REDUCE1:.*]] = addf %[[ITER_ARG1_IN]], %{{.*}}
- // CHECK: %[[REDUCE2:.*]] = or %[[ITER_ARG2_IN]], %{{.*}}
+ // CHECK: %[[REDUCE1:.*]] = arith.addf %[[ITER_ARG1_IN]], %{{.*}}
+ // CHECK: %[[REDUCE2:.*]] = arith.ori %[[ITER_ARG2_IN]], %{{.*}}
// CHECK: br ^[[COND_IN]](%{{.*}}, %[[REDUCE1]], %[[REDUCE2]]
// CHECK: ^[[CONT_IN]]:
// CHECK: br ^[[COND_OUT]](%{{.*}}, %[[ITER_ARG1_IN]], %[[ITER_ARG2_IN]]
// CHECK: ^[[CONT_OUT]]:
// CHECK: return %[[ITER_ARG1_OUT]], %[[ITER_ARG2_OUT]]
- %step = constant 1 : index
- %init = constant 42 : i64
+ %step = arith.constant 1 : index
+ %init = arith.constant 42 : i64
%0:2 = scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) init(%arg5, %init) -> (f32, i64) {
- %cf = constant 42.0 : f32
+ %cf = arith.constant 42.0 : f32
scf.reduce(%cf) : f32 {
^bb0(%lhs: f32, %rhs: f32):
- %1 = addf %lhs, %rhs : f32
+ %1 = arith.addf %lhs, %rhs : f32
scf.reduce.return %1 : f32
}
%2 = call @generate() : () -> i64
scf.reduce(%2) : i64 {
^bb0(%lhs: i64, %rhs: i64):
- %3 = or %lhs, %rhs : i64
+ %3 = arith.ori %lhs, %rhs : i64
scf.reduce.return %3 : i64
}
}
func @while_values(%arg0: i32, %arg1: f32) {
// CHECK: %[[COND:.*]] = "test.make_condition"() : () -> i1
%0 = "test.make_condition"() : () -> i1
- %c0_i32 = constant 0 : i32
- %cst = constant 0.000000e+00 : f32
+ %c0_i32 = arith.constant 0 : i32
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK: br ^[[BEFORE:.*]](%[[ARG0]], %[[ARG1]] : i32, f32)
%1:2 = scf.while (%arg2 = %arg0, %arg3 = %arg1) : (i32, f32) -> (i64, f64) {
// CHECK: ^bb1(%[[ARG2:.*]]: i32, %[[ARG3:.]]: f32):
- // CHECK: %[[VAL1:.*]] = zexti %[[ARG0]] : i32 to i64
- %2 = zexti %arg0 : i32 to i64
- // CHECK: %[[VAL2:.*]] = fpext %[[ARG3]] : f32 to f64
- %3 = fpext %arg3 : f32 to f64
+ // CHECK: %[[VAL1:.*]] = arith.extui %[[ARG0]] : i32 to i64
+ %2 = arith.extui %arg0 : i32 to i64
+ // CHECK: %[[VAL2:.*]] = arith.extf %[[ARG3]] : f32 to f64
+ %3 = arith.extf %arg3 : f32 to f64
// CHECK: cond_br %[[COND]],
// CHECK: ^[[AFTER:.*]](%[[VAL1]], %[[VAL2]] : i64, f64),
// CHECK: ^[[CONT:.*]]
func @ifs_in_parallel(%arg1: index, %arg2: index, %arg3: index, %arg4: i1, %arg5: i1) {
// CHECK: br ^[[LOOP_LATCH:.*]](%[[ARG0]] : index)
// CHECK: ^[[LOOP_LATCH]](%[[LOOP_IV:.*]]: index):
- // CHECK: %[[LOOP_COND:.*]] = cmpi slt, %[[LOOP_IV]], %[[ARG1]] : index
+ // CHECK: %[[LOOP_COND:.*]] = arith.cmpi slt, %[[LOOP_IV]], %[[ARG1]] : index
// CHECK: cond_br %[[LOOP_COND]], ^[[LOOP_BODY:.*]], ^[[LOOP_CONT:.*]]
// CHECK: ^[[LOOP_BODY]]:
// CHECK: cond_br %[[ARG3]], ^[[IF1_THEN:.*]], ^[[IF1_CONT:.*]]
// CHECK: ^[[IF2_CONT]]:
// CHECK: br ^[[IF1_CONT]]
// CHECK: ^[[IF1_CONT]]:
- // CHECK: %{{.*}} = addi %[[LOOP_IV]], %[[ARG2]] : index
+ // CHECK: %{{.*}} = arith.addi %[[LOOP_IV]], %[[ARG2]] : index
// CHECK: br ^[[LOOP_LATCH]](%{{.*}} : index)
scf.parallel (%i) = (%arg1) to (%arg2) step (%arg3) {
scf.if %arg4 {
func @main() {
%buffer = memref.alloc() : memref<6xi32>
- %one = constant 1 : index
+ %one = arith.constant 1 : index
gpu.launch_func @foo::@bar blocks in (%one, %one, %one)
threads in (%one, %one, %one) args(%buffer : memref<6xi32>)
return
// CHECK-LABEL: @binary_ops
// CHECK-SAME: (%[[LHS:.*]]: index, %[[RHS:.*]]: index)
func @binary_ops(%lhs : index, %rhs : index) {
- // CHECK: addi %[[LHS]], %[[RHS]] : index
+ // CHECK: arith.addi %[[LHS]], %[[RHS]] : index
%sum = shape.add %lhs, %rhs : index, index -> index
- // CHECK: muli %[[LHS]], %[[RHS]] : index
+ // CHECK: arith.muli %[[LHS]], %[[RHS]] : index
%product = shape.mul %lhs, %rhs : index, index -> index
return
}
// CHECK-LABEL: @rank
// CHECK-SAME: (%[[SHAPE:.*]]: tensor<?xindex>) -> index
func @rank(%shape : tensor<?xindex>) -> index {
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[RESULT:.*]] = tensor.dim %[[SHAPE]], %[[C0]]
// CHECK: return %[[RESULT]] : index
%rank = shape.rank %shape : tensor<?xindex> -> index
// CHECK-LABEL: @const_shape
// CHECK-SAME: () -> tensor<3xindex>
func @const_shape() -> tensor<3xindex> {
- // CHECK: %[[C1:.*]] = constant 1 : index
- // CHECK: %[[C2:.*]] = constant 2 : index
- // CHECK: %[[C3:.*]] = constant 3 : index
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
+ // CHECK: %[[C3:.*]] = arith.constant 3 : index
// CHECK: %[[TENSOR3:.*]] = tensor.from_elements %[[C1]], %[[C2]], %[[C3]]
// CHECK: %[[RESULT:.*]] = tensor.cast %[[TENSOR3]] : tensor<3xindex> to tensor<3xindex>
// CHECK: return %[[RESULT]] : tensor<3xindex>
// -----
-// Lower 'const_size` to `std.constant`
+// Lower 'const_size` to `arith.constant`
// CHECK-LABEL: @const_size
func @const_size() -> index {
- // CHECK: %[[RES:.*]] = constant 42 : index
+ // CHECK: %[[RES:.*]] = arith.constant 42 : index
%size = shape.const_size 42
%result = shape.size_to_index %size : !shape.size
// CHECK: return %[[RES]]
// CHECK-LABEL: @shape_reduce
// CHECK-SAME: (%[[SHAPE:.*]]: tensor<?xindex>) -> index
func @shape_reduce(%shape : tensor<?xindex>) -> index {
- %init = constant 1 : index
+ %init = arith.constant 1 : index
%num_elements = shape.reduce(%shape, %init) : tensor<?xindex> -> index {
^bb0(%index : index, %extent : index, %acc: index):
- %new_acc = muli %acc, %extent : index
+ %new_acc = arith.muli %acc, %extent : index
shape.yield %new_acc : index
}
return %num_elements : index
}
-// CHECK-NEXT: %[[INIT:.*]] = constant 1 : index
-// CHECK-NEXT: %[[C0:.*]] = constant 0 : index
-// CHECK-NEXT: %[[C1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[INIT:.*]] = arith.constant 1 : index
+// CHECK-NEXT: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-NEXT: %[[C1:.*]] = arith.constant 1 : index
// CHECK-NEXT: %[[RANK:.*]] = tensor.dim %[[SHAPE]], %[[C0]] : tensor<?xindex>
// CHECK-NEXT: %[[RESULT:.*]] = scf.for %[[I:.*]] = %[[C0]] to %[[RANK]] step %[[C1]] iter_args(%[[ACC:.*]] = %[[INIT]]) -> (index)
// CHECK-NEXT: %[[EXTENT:.*]] = tensor.extract %[[SHAPE]][%[[I]]]
-// CHECK-NEXT: %[[NEW_ACC:.*]] = muli %[[ACC]], %[[EXTENT]] : index
+// CHECK-NEXT: %[[NEW_ACC:.*]] = arith.muli %[[ACC]], %[[EXTENT]] : index
// CHECK-NEXT: scf.yield %[[NEW_ACC]] : index
// CHECK-NEXT: }
// CHECK-NEXT: return %[[RESULT]] : index
// CHECK-LABEL: @shape_of_stat
// CHECK-SAME: (%[[ARG:.*]]: tensor<1x2x3xf32>)
func @shape_of_stat(%arg : tensor<1x2x3xf32>) {
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C2:.*]] = constant 2 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// CHECK-DAG: %[[SHAPE_UNCASTED:.*]] = tensor.from_elements %[[C1]], %[[C2]], %[[C3]] : tensor<3xindex>
%shape = shape.shape_of %arg : tensor<1x2x3xf32> -> tensor<?xindex>
return
// CHECK-LABEL: @shape_of_dyn
// CHECK-SAME: (%[[ARG:.*]]: tensor<1x5x?xf32>)
func @shape_of_dyn(%arg : tensor<1x5x?xf32>) {
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C5:.*]] = constant 5 : index
- // CHECK-DAG: %[[C2:.*]] = constant 2 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C5:.*]] = arith.constant 5 : index
+ // CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: %[[DYN_DIM:.*]] = tensor.dim %[[ARG]], %[[C2]] : tensor<1x5x?xf32>
// CHECK-DAG: %[[SHAPE_UNCASTED:.*]] = tensor.from_elements %[[C1]], %[[C5]], %[[DYN_DIM]] : tensor<3xindex>
%shape = shape.shape_of %arg : tensor<1x5x?xf32> -> tensor<?xindex>
// CHECK-LABEL: @shape_eq
// CHECK-SAME: (%[[A:.*]]: tensor<?xindex>, %[[B:.*]]: tensor<?xindex>) -> i1
func @shape_eq(%a : tensor<?xindex>, %b : tensor<?xindex>) -> i1 {
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[RANK_A:.*]] = tensor.dim %[[A]], %[[C0]] : tensor<?xindex>
// CHECK: %[[RANK_B:.*]] = tensor.dim %[[B]], %[[C0]] : tensor<?xindex>
- // CHECK: %[[RANK_EQ:.*]] = cmpi eq, %[[RANK_A]], %[[RANK_B]]
+ // CHECK: %[[RANK_EQ:.*]] = arith.cmpi eq, %[[RANK_A]], %[[RANK_B]]
// CHECK: %[[SHAPE_EQ:.*]] = scf.if %[[RANK_EQ]] -> (i1) {
- // CHECK: %[[C1:.*]] = constant 1 : index
- // CHECK: %[[INIT:.*]] = constant true
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK: %[[INIT:.*]] = arith.constant true
// CHECK: %[[SHAPE_EQ_INNER:.*]] = scf.for %[[I:.*]] = %[[C0]] to %[[RANK_A]] step %[[C1]] iter_args(%[[CONJ:.*]] = %[[INIT]]) -> (i1) {
// CHECK: %[[EXTENT_A:.*]] = tensor.extract %[[A]][%[[I]]] : tensor<?xindex>
// CHECK: %[[EXTENT_B:.*]] = tensor.extract %[[B]][%[[I]]] : tensor<?xindex>
- // CHECK: %[[EXTENT_EQ:.*]] = cmpi eq, %[[EXTENT_A]], %[[EXTENT_B]]
- // CHECK: %[[CONJ_NEXT:.*]] = and %[[CONJ]], %[[EXTENT_EQ]]
+ // CHECK: %[[EXTENT_EQ:.*]] = arith.cmpi eq, %[[EXTENT_A]], %[[EXTENT_B]]
+ // CHECK: %[[CONJ_NEXT:.*]] = arith.andi %[[CONJ]], %[[EXTENT_EQ]]
// CHECK: scf.yield %[[CONJ_NEXT]] : i1
// CHECK: }
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: } else {
- // CHECK: %[[SHAPE_EQ_INNER:.*]] = constant false
+ // CHECK: %[[SHAPE_EQ_INNER:.*]] = arith.constant false
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: }
// CHECK: return %[[SHAPE_EQ]] : i1
// CHECK-LABEL: @shape_eq
// CHECK-SAME: (%[[A:.*]]: tensor<?xindex>, %[[B:.*]]: tensor<?xindex>, %[[C:.*]]: tensor<?xindex>) -> i1
func @shape_eq(%a : tensor<?xindex>, %b : tensor<?xindex>, %c : tensor<?xindex>) -> i1 {
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[RANK_A:.*]] = tensor.dim %[[A]], %[[C0]] : tensor<?xindex>
// CHECK: %[[RANK_B:.*]] = tensor.dim %[[B]], %[[C0]] : tensor<?xindex>
- // CHECK: %[[RANK_EQ:.*]] = cmpi eq, %[[RANK_A]], %[[RANK_B]]
+ // CHECK: %[[RANK_EQ:.*]] = arith.cmpi eq, %[[RANK_A]], %[[RANK_B]]
// CHECK: %[[SHAPE_EQ:.*]] = scf.if %[[RANK_EQ]] -> (i1) {
- // CHECK: %[[C1:.*]] = constant 1 : index
- // CHECK: %[[INIT:.*]] = constant true
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK: %[[INIT:.*]] = arith.constant true
// CHECK: %[[SHAPE_EQ_INNER:.*]] = scf.for %[[I:.*]] = %[[C0]] to %[[RANK_A]] step %[[C1]] iter_args(%[[CONJ:.*]] = %[[INIT]]) -> (i1) {
// CHECK: %[[EXTENT_A:.*]] = tensor.extract %[[A]][%[[I]]] : tensor<?xindex>
// CHECK: %[[EXTENT_B:.*]] = tensor.extract %[[B]][%[[I]]] : tensor<?xindex>
- // CHECK: %[[EXTENT_EQ:.*]] = cmpi eq, %[[EXTENT_A]], %[[EXTENT_B]]
- // CHECK: %[[CONJ_NEXT:.*]] = and %[[CONJ]], %[[EXTENT_EQ]]
+ // CHECK: %[[EXTENT_EQ:.*]] = arith.cmpi eq, %[[EXTENT_A]], %[[EXTENT_B]]
+ // CHECK: %[[CONJ_NEXT:.*]] = arith.andi %[[CONJ]], %[[EXTENT_EQ]]
// CHECK: scf.yield %[[CONJ_NEXT]] : i1
// CHECK: }
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: } else {
- // CHECK: %[[SHAPE_EQ_INNER:.*]] = constant false
+ // CHECK: %[[SHAPE_EQ_INNER:.*]] = arith.constant false
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: }
// CHECK: %[[RANK_C:.*]] = tensor.dim %[[C]], %[[C0]] : tensor<?xindex>
- // CHECK: %[[RANK_EQ:.*]] = cmpi eq, %[[RANK_A]], %[[RANK_C]]
+ // CHECK: %[[RANK_EQ:.*]] = arith.cmpi eq, %[[RANK_A]], %[[RANK_C]]
// CHECK: %[[SHAPE_EQ2:.*]] = scf.if %[[RANK_EQ]] -> (i1) {
- // CHECK: %[[C1:.*]] = constant 1 : index
- // CHECK: %[[INIT:.*]] = constant true
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK: %[[INIT:.*]] = arith.constant true
// CHECK: %[[SHAPE_EQ_INNER:.*]] = scf.for %[[I:.*]] = %[[C0]] to %[[RANK_A]] step %[[C1]] iter_args(%[[CONJ:.*]] = %[[INIT]]) -> (i1) {
// CHECK: %[[EXTENT_A:.*]] = tensor.extract %[[A]][%[[I]]] : tensor<?xindex>
// CHECK: %[[EXTENT_C:.*]] = tensor.extract %[[C]][%[[I]]] : tensor<?xindex>
- // CHECK: %[[EXTENT_EQ:.*]] = cmpi eq, %[[EXTENT_A]], %[[EXTENT_C]]
- // CHECK: %[[CONJ_NEXT:.*]] = and %[[CONJ]], %[[EXTENT_EQ]]
+ // CHECK: %[[EXTENT_EQ:.*]] = arith.cmpi eq, %[[EXTENT_A]], %[[EXTENT_C]]
+ // CHECK: %[[CONJ_NEXT:.*]] = arith.andi %[[CONJ]], %[[EXTENT_EQ]]
// CHECK: scf.yield %[[CONJ_NEXT]] : i1
// CHECK: }
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: } else {
- // CHECK: %[[SHAPE_EQ_INNER:.*]] = constant false
+ // CHECK: %[[SHAPE_EQ_INNER:.*]] = arith.constant false
// CHECK: scf.yield %[[SHAPE_EQ_INNER]] : i1
// CHECK: }
- // CHECK: %[[RESULT:.*]] = and %[[SHAPE_EQ]], %[[SHAPE_EQ2]] : i1
+ // CHECK: %[[RESULT:.*]] = arith.andi %[[SHAPE_EQ]], %[[SHAPE_EQ2]] : i1
// CHECK: return %[[RESULT]] : i1
%result = shape.shape_eq %a, %b, %c : tensor<?xindex>, tensor<?xindex>, tensor<?xindex>
return %result : i1
// CHECK-SAME: %[[ARG0:.*]]: tensor<2xindex>,
// CHECK-SAME: %[[ARG1:.*]]: tensor<3xindex>,
// CHECK-SAME: %[[ARG2:.*]]: tensor<2xindex>)
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[RANK0:.*]] = tensor.dim %[[ARG0]], %[[C0]] : tensor<2xindex>
// CHECK: %[[RANK1:.*]] = tensor.dim %[[ARG1]], %[[C0]] : tensor<3xindex>
// CHECK: %[[RANK2:.*]] = tensor.dim %[[ARG2]], %[[C0]] : tensor<2xindex>
-// CHECK: %[[CMP0:.*]] = cmpi ugt, %[[RANK1]], %[[RANK0]] : index
+// CHECK: %[[CMP0:.*]] = arith.cmpi ugt, %[[RANK1]], %[[RANK0]] : index
// CHECK: %[[LARGER_DIM:.*]] = select %[[CMP0]], %[[RANK1]], %[[RANK0]] : index
-// CHECK: %[[CMP1:.*]] = cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
+// CHECK: %[[CMP1:.*]] = arith.cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
// CHECK: %[[MAX_RANK:.*]] = select %[[CMP1]], %[[RANK2]], %[[LARGER_DIM]] : index
-// CHECK: %[[DIM_DIFF0:.*]] = subi %[[MAX_RANK]], %[[RANK0]] : index
-// CHECK: %[[DIM_DIFF1:.*]] = subi %[[MAX_RANK]], %[[RANK1]] : index
-// CHECK: %[[DIM_DIFF2:.*]] = subi %[[MAX_RANK]], %[[RANK2]] : index
-// CHECK: %[[TRUE:.*]] = constant true
+// CHECK: %[[DIM_DIFF0:.*]] = arith.subi %[[MAX_RANK]], %[[RANK0]] : index
+// CHECK: %[[DIM_DIFF1:.*]] = arith.subi %[[MAX_RANK]], %[[RANK1]] : index
+// CHECK: %[[DIM_DIFF2:.*]] = arith.subi %[[MAX_RANK]], %[[RANK2]] : index
+// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ALL_RESULT:.*]] = scf.for %[[IDX:.*]] = %[[C0]] to %[[MAX_RANK]] step %[[C1]] iter_args(%[[ALL_SO_FAR:.*]] = %[[TRUE]]) -> (i1) {
-// CHECK: %[[C1_0:.*]] = constant 1 : index
-// CHECK: %[[OUTBOUNDS0:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[C1_0:.*]] = arith.constant 1 : index
+// CHECK: %[[OUTBOUNDS0:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[DIM0:.*]] = scf.if %[[OUTBOUNDS0]] -> (index) {
// CHECK: scf.yield %[[C1_0]] : index
// CHECK: } else {
-// CHECK: %[[IDX0:.*]] = subi %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[IDX0:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[EXTRACTED_0:.*]] = tensor.extract %[[ARG0]]{{\[}}%[[IDX0]]] : tensor<2xindex>
-// CHECK: %[[DIM0_IS_1:.*]] = cmpi eq, %[[EXTRACTED_0:.*]], %[[C1_0]] : index
+// CHECK: %[[DIM0_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_0:.*]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM0:.*]] = select %[[DIM0_IS_1]], %[[C1_0]], %[[EXTRACTED_0]] : index
// CHECK: }
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[DIM1:.*]] = scf.if %[[VAL_28]] -> (index) {
// CHECK: scf.yield %[[DIM0]] : index
// CHECK: } else {
-// CHECK: %[[IDX1:.*]] = subi %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[IDX1:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[EXTRACTED_1:.*]] = tensor.extract %[[ARG1]]{{\[}}%[[IDX1]]] : tensor<3xindex>
-// CHECK: %[[DIM1_IS_1:.*]] = cmpi eq, %[[EXTRACTED_1:.*]], %[[C1_0]] : index
+// CHECK: %[[DIM1_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_1:.*]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM1:.*]] = select %[[DIM1_IS_1]], %[[DIM0]], %[[EXTRACTED_1]] : index
// CHECK: }
-// CHECK: %[[VAL_36:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[DIM2:.*]] = scf.if %[[VAL_36]] -> (index) {
// CHECK: scf.yield %[[DIM1]] : index
// CHECK: } else {
-// CHECK: %[[IDX2:.*]] = subi %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[IDX2:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[EXTRACTED_2:.*]] = tensor.extract %[[ARG2]]{{\[}}%[[IDX2]]] : tensor<2xindex>
-// CHECK: %[[DIM2_IS_1:.*]] = cmpi eq, %[[EXTRACTED_2]], %[[C1_0]] : index
+// CHECK: %[[DIM2_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_2]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM2:.*]] = select %[[DIM2_IS_1]], %[[DIM1]], %[[EXTRACTED_2]] : index
// CHECK: }
-// CHECK: %[[OUT_BOUND_0:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[OUT_BOUND_0:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[REDUCTION_0:.*]] = scf.if %[[OUT_BOUND_0]] -> (i1) {
// CHECK: scf.yield %[[ALL_SO_FAR]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg0[%[[SHIFTED]]] : tensor<2xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[ALL_SO_FAR]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[ALL_SO_FAR]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
-// CHECK: %[[OUT_BOUND_1:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[OUT_BOUND_1:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[SECOND_REDUCTION:.*]] = scf.if %[[OUT_BOUND_1]] -> (i1) {
// CHECK: scf.yield %[[REDUCTION_0]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg1[%[[SHIFTED]]] : tensor<3xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[REDUCTION_0]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[REDUCTION_0]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
-// CHECK: %[[OUT_BOUND_2:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[OUT_BOUND_2:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[FINAL_RESULT:.*]] = scf.if %[[OUT_BOUND_2]] -> (i1) {
// CHECK: scf.yield %[[SECOND_REDUCTION]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg2[%[[SHIFTED]]] : tensor<2xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED:.*]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED:.*]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1:.*]], %[[EQUALS_BROADCASTED:.*]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[SECOND_REDUCTION]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED:.*]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED:.*]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1:.*]], %[[EQUALS_BROADCASTED:.*]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[SECOND_REDUCTION]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
// CHECK: scf.yield %[[FINAL_RESULT]] : i1
// CHECK-SAME: %[[ARG0:.*]]: tensor<2xindex>,
// CHECK-SAME: %[[ARG1:.*]]: tensor<3xindex>,
// CHECK-SAME: %[[ARG2:.*]]: tensor<2xindex>)
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[RANK0:.*]] = tensor.dim %[[ARG0]], %[[C0]] : tensor<2xindex>
// CHECK: %[[RANK1:.*]] = tensor.dim %[[ARG1]], %[[C0]] : tensor<3xindex>
// CHECK: %[[RANK2:.*]] = tensor.dim %[[ARG2]], %[[C0]] : tensor<2xindex>
-// CHECK: %[[CMP0:.*]] = cmpi ugt, %[[RANK1]], %[[RANK0]] : index
+// CHECK: %[[CMP0:.*]] = arith.cmpi ugt, %[[RANK1]], %[[RANK0]] : index
// CHECK: %[[LARGER_DIM:.*]] = select %[[CMP0]], %[[RANK1]], %[[RANK0]] : index
-// CHECK: %[[CMP1:.*]] = cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
+// CHECK: %[[CMP1:.*]] = arith.cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
// CHECK: %[[MAX_RANK:.*]] = select %[[CMP1]], %[[RANK2]], %[[LARGER_DIM]] : index
-// CHECK: %[[DIM_DIFF0:.*]] = subi %[[MAX_RANK]], %[[RANK0]] : index
-// CHECK: %[[DIM_DIFF1:.*]] = subi %[[MAX_RANK]], %[[RANK1]] : index
-// CHECK: %[[DIM_DIFF2:.*]] = subi %[[MAX_RANK]], %[[RANK2]] : index
-// CHECK: %[[TRUE:.*]] = constant true
+// CHECK: %[[DIM_DIFF0:.*]] = arith.subi %[[MAX_RANK]], %[[RANK0]] : index
+// CHECK: %[[DIM_DIFF1:.*]] = arith.subi %[[MAX_RANK]], %[[RANK1]] : index
+// CHECK: %[[DIM_DIFF2:.*]] = arith.subi %[[MAX_RANK]], %[[RANK2]] : index
+// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ALL_RESULT:.*]] = scf.for %[[IDX:.*]] = %[[C0]] to %[[MAX_RANK]] step %[[C1]] iter_args(%[[ALL_SO_FAR:.*]] = %[[TRUE]]) -> (i1) {
-// CHECK: %[[C1_0:.*]] = constant 1 : index
-// CHECK: %[[OUTBOUNDS0:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[C1_0:.*]] = arith.constant 1 : index
+// CHECK: %[[OUTBOUNDS0:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[DIM0:.*]] = scf.if %[[OUTBOUNDS0]] -> (index) {
// CHECK: scf.yield %[[C1_0]] : index
// CHECK: } else {
-// CHECK: %[[IDX0:.*]] = subi %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[IDX0:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[EXTRACTED_0:.*]] = tensor.extract %[[ARG0]]{{\[}}%[[IDX0]]] : tensor<2xindex>
-// CHECK: %[[DIM0_IS_1:.*]] = cmpi eq, %[[EXTRACTED_0:.*]], %[[C1_0]] : index
+// CHECK: %[[DIM0_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_0:.*]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM0:.*]] = select %[[DIM0_IS_1]], %[[C1_0]], %[[EXTRACTED_0]] : index
// CHECK: }
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[DIM1:.*]] = scf.if %[[VAL_28]] -> (index) {
// CHECK: scf.yield %[[DIM0]] : index
// CHECK: } else {
-// CHECK: %[[IDX1:.*]] = subi %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[IDX1:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[EXTRACTED_1:.*]] = tensor.extract %[[ARG1]]{{\[}}%[[IDX1]]] : tensor<3xindex>
-// CHECK: %[[DIM1_IS_1:.*]] = cmpi eq, %[[EXTRACTED_1:.*]], %[[C1_0]] : index
+// CHECK: %[[DIM1_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_1:.*]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM1:.*]] = select %[[DIM1_IS_1]], %[[DIM0]], %[[EXTRACTED_1]] : index
// CHECK: }
-// CHECK: %[[VAL_36:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[DIM2:.*]] = scf.if %[[VAL_36]] -> (index) {
// CHECK: scf.yield %[[DIM1]] : index
// CHECK: } else {
-// CHECK: %[[IDX2:.*]] = subi %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[IDX2:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[EXTRACTED_2:.*]] = tensor.extract %[[ARG2]]{{\[}}%[[IDX2]]] : tensor<2xindex>
-// CHECK: %[[DIM2_IS_1:.*]] = cmpi eq, %[[EXTRACTED_2]], %[[C1_0]] : index
+// CHECK: %[[DIM2_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_2]], %[[C1_0]] : index
// CHECK: %[[MAX_DIM2:.*]] = select %[[DIM2_IS_1]], %[[DIM1]], %[[EXTRACTED_2]] : index
// CHECK: }
-// CHECK: %[[OUT_BOUND_0:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[OUT_BOUND_0:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[REDUCTION_0:.*]] = scf.if %[[OUT_BOUND_0]] -> (i1) {
// CHECK: scf.yield %[[ALL_SO_FAR]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg0[%[[SHIFTED]]] : tensor<2xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[ALL_SO_FAR]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[ALL_SO_FAR]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
-// CHECK: %[[OUT_BOUND_1:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[OUT_BOUND_1:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[SECOND_REDUCTION:.*]] = scf.if %[[OUT_BOUND_1]] -> (i1) {
// CHECK: scf.yield %[[REDUCTION_0]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg1[%[[SHIFTED]]] : tensor<3xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[REDUCTION_0]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1]], %[[EQUALS_BROADCASTED]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[REDUCTION_0]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
-// CHECK: %[[OUT_BOUND_2:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[OUT_BOUND_2:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[FINAL_RESULT:.*]] = scf.if %[[OUT_BOUND_2]] -> (i1) {
// CHECK: scf.yield %[[SECOND_REDUCTION]] : i1
// CHECK: } else {
-// CHECK: %[[SHIFTED:.*]] = subi %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[SHIFTED:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[EXTRACTED:.*]] = tensor.extract %arg2[%[[SHIFTED]]] : tensor<2xindex>
-// CHECK: %[[EQUALS_1:.*]] = cmpi eq, %[[EXTRACTED:.*]], %c1 : index
-// CHECK: %[[EQUALS_BROADCASTED:.*]] = cmpi eq, %[[EXTRACTED:.*]], %[[DIM2]] : index
-// CHECK: %[[GOOD:.*]] = or %[[EQUALS_1:.*]], %[[EQUALS_BROADCASTED:.*]] : i1
-// CHECK: %[[AND_REDUCTION:.*]] = and %[[SECOND_REDUCTION]], %[[GOOD]] : i1
+// CHECK: %[[EQUALS_1:.*]] = arith.cmpi eq, %[[EXTRACTED:.*]], %c1 : index
+// CHECK: %[[EQUALS_BROADCASTED:.*]] = arith.cmpi eq, %[[EXTRACTED:.*]], %[[DIM2]] : index
+// CHECK: %[[GOOD:.*]] = arith.ori %[[EQUALS_1:.*]], %[[EQUALS_BROADCASTED:.*]] : i1
+// CHECK: %[[AND_REDUCTION:.*]] = arith.andi %[[SECOND_REDUCTION]], %[[GOOD]] : i1
// CHECK: scf.yield %[[AND_REDUCTION]] : i1
// CHECK: }
// CHECK: scf.yield %[[FINAL_RESULT]] : i1
// CHECK-SAME: %[[ARG0:.*]]: tensor<2xindex>,
// CHECK-SAME: %[[ARG1:.*]]: tensor<3xindex>,
// CHECK-SAME: %[[ARG2:.*]]: tensor<2xindex>) {
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[RANK0:.*]] = tensor.dim %[[ARG0]], %[[C0]] : tensor<2xindex>
// CHECK: %[[RANK1:.*]] = tensor.dim %[[ARG1]], %[[C0]] : tensor<3xindex>
// CHECK: %[[RANK2:.*]] = tensor.dim %[[ARG2]], %[[C0]] : tensor<2xindex>
-// CHECK: %[[CMP0:.*]] = cmpi ugt, %[[RANK1]], %[[RANK0]] : index
+// CHECK: %[[CMP0:.*]] = arith.cmpi ugt, %[[RANK1]], %[[RANK0]] : index
// CHECK: %[[LARGER_DIM:.*]] = select %[[CMP0]], %[[RANK1]], %[[RANK0]] : index
-// CHECK: %[[CMP1:.*]] = cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
+// CHECK: %[[CMP1:.*]] = arith.cmpi ugt, %[[RANK2]], %[[LARGER_DIM]] : index
// CHECK: %[[MAX_RANK:.*]] = select %[[CMP1]], %[[RANK2]], %[[LARGER_DIM]] : index
-// CHECK: %[[DIM_DIFF0:.*]] = subi %[[MAX_RANK]], %[[RANK0]] : index
-// CHECK: %[[DIM_DIFF1:.*]] = subi %[[MAX_RANK]], %[[RANK1]] : index
-// CHECK: %[[DIM_DIFF2:.*]] = subi %[[MAX_RANK]], %[[RANK2]] : index
+// CHECK: %[[DIM_DIFF0:.*]] = arith.subi %[[MAX_RANK]], %[[RANK0]] : index
+// CHECK: %[[DIM_DIFF1:.*]] = arith.subi %[[MAX_RANK]], %[[RANK1]] : index
+// CHECK: %[[DIM_DIFF2:.*]] = arith.subi %[[MAX_RANK]], %[[RANK2]] : index
// CHECK: %[[RESULT:.*]] = tensor.generate %[[MAX_RANK]] {
// CHECK: ^bb0(%[[IDX:.*]]: index):
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[OUTBOUNDS0:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[OUTBOUNDS0:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[DIM0:.*]] = scf.if %[[OUTBOUNDS0]] -> (index) {
// CHECK: scf.yield %[[C1]] : index
// CHECK: } else {
-// CHECK: %[[IDX0:.*]] = subi %[[IDX]], %[[DIM_DIFF0]] : index
+// CHECK: %[[IDX0:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF0]] : index
// CHECK: %[[EXTRACTED_0:.*]] = tensor.extract %[[ARG0]]{{\[}}%[[IDX0]]] : tensor<2xindex>
-// CHECK: %[[DIM0_IS_1:.*]] = cmpi eq, %[[EXTRACTED_0:.*]], %[[C1]] : index
+// CHECK: %[[DIM0_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_0:.*]], %[[C1]] : index
// CHECK: %[[MAX_DIM0:.*]] = select %[[DIM0_IS_1]], %[[C1]], %[[EXTRACTED_0]] : index
// CHECK: }
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[DIM1:.*]] = scf.if %[[VAL_28]] -> (index) {
// CHECK: scf.yield %[[DIM0]] : index
// CHECK: } else {
-// CHECK: %[[IDX1:.*]] = subi %[[IDX]], %[[DIM_DIFF1]] : index
+// CHECK: %[[IDX1:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF1]] : index
// CHECK: %[[EXTRACTED_1:.*]] = tensor.extract %[[ARG1]]{{\[}}%[[IDX1]]] : tensor<3xindex>
-// CHECK: %[[DIM1_IS_1:.*]] = cmpi eq, %[[EXTRACTED_1:.*]], %[[C1]] : index
+// CHECK: %[[DIM1_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_1:.*]], %[[C1]] : index
// CHECK: %[[MAX_DIM1:.*]] = select %[[DIM1_IS_1]], %[[DIM0]], %[[EXTRACTED_1]] : index
// CHECK: }
-// CHECK: %[[VAL_36:.*]] = cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi ult, %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[DIM2:.*]] = scf.if %[[VAL_36]] -> (index) {
// CHECK: scf.yield %[[DIM1]] : index
// CHECK: } else {
-// CHECK: %[[IDX2:.*]] = subi %[[IDX]], %[[DIM_DIFF2]] : index
+// CHECK: %[[IDX2:.*]] = arith.subi %[[IDX]], %[[DIM_DIFF2]] : index
// CHECK: %[[EXTRACTED_2:.*]] = tensor.extract %[[ARG2]]{{\[}}%[[IDX2]]] : tensor<2xindex>
-// CHECK: %[[DIM2_IS_1:.*]] = cmpi eq, %[[EXTRACTED_2:.*]], %[[C1]] : index
+// CHECK: %[[DIM2_IS_1:.*]] = arith.cmpi eq, %[[EXTRACTED_2:.*]], %[[C1]] : index
// CHECK: %[[MAX_DIM2:.*]] = select %[[DIM2_IS_1]], %[[DIM1]], %[[EXTRACTED_2]] : index
// CHECK: }
// CHECK: tensor.yield %[[DIM2]] : index
// CHECK-LABEL: @split_at
// CHECK-SAME: %[[SHAPE:.*]]: tensor<?xindex>, %[[INDEX:.*]]: index
func @split_at(%shape: tensor<?xindex>, %index: index) -> (tensor<?xindex>, tensor<?xindex>) {
- // CHECK-NEXT: %[[C0:.*]] = constant 0 : index
+ // CHECK-NEXT: %[[C0:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[RANK:.*]] = tensor.dim %[[SHAPE]], %[[C0]] : tensor<?xindex>
- // CHECK-NEXT: %[[POSINDEX:.*]] = addi %[[INDEX]], %[[RANK]] : index
- // CHECK-NEXT: %[[ISNEG:.*]] = cmpi slt, %[[INDEX]], %[[C0]] : index
+ // CHECK-NEXT: %[[POSINDEX:.*]] = arith.addi %[[INDEX]], %[[RANK]] : index
+ // CHECK-NEXT: %[[ISNEG:.*]] = arith.cmpi slt, %[[INDEX]], %[[C0]] : index
// CHECK-NEXT: %[[SELECT:.*]] = select %[[ISNEG]], %[[POSINDEX]], %[[INDEX]] : index
- // CHECK-NEXT: %[[C1:.*]] = constant 1 : index
+ // CHECK-NEXT: %[[C1:.*]] = arith.constant 1 : index
// CHECK-NEXT: %[[HEAD:.*]] = tensor.extract_slice %[[SHAPE]][%[[C0]]] [%[[SELECT]]] [%[[C1]]] : tensor<?xindex> to tensor<?xindex>
- // CHECK-NEXT: %[[TAIL_SIZE:.*]] = subi %[[RANK]], %[[SELECT]] : index
+ // CHECK-NEXT: %[[TAIL_SIZE:.*]] = arith.subi %[[RANK]], %[[SELECT]] : index
// CHECK-NEXT: %[[TAIL:.*]] = tensor.extract_slice %[[SHAPE]][%[[SELECT]]] [%[[TAIL_SIZE]]] [%[[C1]]] : tensor<?xindex> to tensor<?xindex>
// CHECK-NEXT: return %[[HEAD]], %[[TAIL]] : tensor<?xindex>, tensor<?xindex>
%head, %tail = "shape.split_at"(%shape, %index) : (tensor<?xindex>, index) -> (tensor<?xindex>, tensor<?xindex>)
--- /dev/null
+// RUN: mlir-opt -convert-std-to-llvm -reconcile-unrealized-casts %s | FileCheck %s
+// RUN: mlir-opt -convert-std-to-llvm='use-bare-ptr-memref-call-conv=1' -split-input-file %s | FileCheck %s --check-prefix=BAREPTR
+
+// These tests were separated from func-memref.mlir because applying
+// -reconcile-unrealized-casts resulted in `llvm.extractvalue` ops getting
+// folded away.
+
+// CHECK-LABEL: func @check_static_return
+// CHECK-COUNT-2: !llvm.ptr<f32>
+// CHECK-COUNT-5: i64
+// CHECK-SAME: -> !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-LABEL: func @check_static_return
+// BAREPTR-SAME: (%[[arg:.*]]: !llvm.ptr<f32>) -> !llvm.ptr<f32> {
+func @check_static_return(%static : memref<32x18xf32>) -> memref<32x18xf32> {
+// CHECK: llvm.return %{{.*}} : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+
+// BAREPTR: %[[udf:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[base0:.*]] = llvm.insertvalue %[[arg]], %[[udf]][0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[aligned:.*]] = llvm.insertvalue %[[arg]], %[[base0]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val0:.*]] = llvm.mlir.constant(0 : index) : i64
+// BAREPTR-NEXT: %[[ins0:.*]] = llvm.insertvalue %[[val0]], %[[aligned]][2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val1:.*]] = llvm.mlir.constant(32 : index) : i64
+// BAREPTR-NEXT: %[[ins1:.*]] = llvm.insertvalue %[[val1]], %[[ins0]][3, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val2:.*]] = llvm.mlir.constant(18 : index) : i64
+// BAREPTR-NEXT: %[[ins2:.*]] = llvm.insertvalue %[[val2]], %[[ins1]][4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val3:.*]] = llvm.mlir.constant(18 : index) : i64
+// BAREPTR-NEXT: %[[ins3:.*]] = llvm.insertvalue %[[val3]], %[[ins2]][3, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val4:.*]] = llvm.mlir.constant(1 : index) : i64
+// BAREPTR-NEXT: %[[ins4:.*]] = llvm.insertvalue %[[val4]], %[[ins3]][4, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[base1:.*]] = llvm.extractvalue %[[ins4]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: llvm.return %[[base1]] : !llvm.ptr<f32>
+ return %static : memref<32x18xf32>
+}
+
+// -----
+
+// CHECK-LABEL: func @check_static_return_with_offset
+// CHECK-COUNT-2: !llvm.ptr<f32>
+// CHECK-COUNT-5: i64
+// CHECK-SAME: -> !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-LABEL: func @check_static_return_with_offset
+// BAREPTR-SAME: (%[[arg:.*]]: !llvm.ptr<f32>) -> !llvm.ptr<f32> {
+func @check_static_return_with_offset(%static : memref<32x18xf32, offset:7, strides:[22,1]>) -> memref<32x18xf32, offset:7, strides:[22,1]> {
+// CHECK: llvm.return %{{.*}} : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+
+// BAREPTR: %[[udf:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[base0:.*]] = llvm.insertvalue %[[arg]], %[[udf]][0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[aligned:.*]] = llvm.insertvalue %[[arg]], %[[base0]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val0:.*]] = llvm.mlir.constant(7 : index) : i64
+// BAREPTR-NEXT: %[[ins0:.*]] = llvm.insertvalue %[[val0]], %[[aligned]][2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val1:.*]] = llvm.mlir.constant(32 : index) : i64
+// BAREPTR-NEXT: %[[ins1:.*]] = llvm.insertvalue %[[val1]], %[[ins0]][3, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val2:.*]] = llvm.mlir.constant(22 : index) : i64
+// BAREPTR-NEXT: %[[ins2:.*]] = llvm.insertvalue %[[val2]], %[[ins1]][4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val3:.*]] = llvm.mlir.constant(18 : index) : i64
+// BAREPTR-NEXT: %[[ins3:.*]] = llvm.insertvalue %[[val3]], %[[ins2]][3, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[val4:.*]] = llvm.mlir.constant(1 : index) : i64
+// BAREPTR-NEXT: %[[ins4:.*]] = llvm.insertvalue %[[val4]], %[[ins3]][4, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: %[[base1:.*]] = llvm.extractvalue %[[ins4]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
+// BAREPTR-NEXT: llvm.return %[[base1]] : !llvm.ptr<f32>
+ return %static : memref<32x18xf32, offset:7, strides:[22,1]>
+}
+
+// -----
+
+// BAREPTR: llvm.func @foo(!llvm.ptr<i8>) -> !llvm.ptr<i8>
+func private @foo(memref<10xi8>) -> memref<20xi8>
+
+// BAREPTR-LABEL: func @check_memref_func_call
+// BAREPTR-SAME: %[[in:.*]]: !llvm.ptr<i8>) -> !llvm.ptr<i8>
+func @check_memref_func_call(%in : memref<10xi8>) -> memref<20xi8> {
+ // BAREPTR: %[[inDesc:.*]] = llvm.insertvalue %{{.*}}, %{{.*}}[4, 0]
+ // BAREPTR-NEXT: %[[barePtr:.*]] = llvm.extractvalue %[[inDesc]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[call:.*]] = llvm.call @foo(%[[barePtr]]) : (!llvm.ptr<i8>) -> !llvm.ptr<i8>
+ // BAREPTR-NEXT: %[[desc0:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[desc1:.*]] = llvm.insertvalue %[[call]], %[[desc0]][0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[desc2:.*]] = llvm.insertvalue %[[call]], %[[desc1]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[c0:.*]] = llvm.mlir.constant(0 : index) : i64
+ // BAREPTR-NEXT: %[[desc4:.*]] = llvm.insertvalue %[[c0]], %[[desc2]][2] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[c20:.*]] = llvm.mlir.constant(20 : index) : i64
+ // BAREPTR-NEXT: %[[desc6:.*]] = llvm.insertvalue %[[c20]], %[[desc4]][3, 0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: %[[c1:.*]] = llvm.mlir.constant(1 : index) : i64
+ // BAREPTR-NEXT: %[[outDesc:.*]] = llvm.insertvalue %[[c1]], %[[desc6]][4, 0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ %res = call @foo(%in) : (memref<10xi8>) -> (memref<20xi8>)
+ // BAREPTR-NEXT: %[[res:.*]] = llvm.extractvalue %[[outDesc]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
+ // BAREPTR-NEXT: llvm.return %[[res]] : !llvm.ptr<i8>
+ return %res : memref<20xi8>
+}
-// RUN: mlir-opt -convert-std-to-llvm -split-input-file %s | FileCheck %s
-// RUN: mlir-opt -convert-std-to-llvm='use-bare-ptr-memref-call-conv=1' -split-input-file %s | FileCheck %s --check-prefix=BAREPTR
+// RUN: mlir-opt -convert-arith-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts -split-input-file %s | FileCheck %s
+// RUN: mlir-opt -convert-arith-to-llvm -convert-std-to-llvm='use-bare-ptr-memref-call-conv=1' -reconcile-unrealized-casts -split-input-file %s | FileCheck %s --check-prefix=BAREPTR
// BAREPTR-LABEL: func @check_noalias
// BAREPTR-SAME: %{{.*}}: !llvm.ptr<f32> {llvm.noalias}, %{{.*}}: !llvm.ptr<f32> {llvm.noalias}
// -----
-// CHECK-LABEL: func @check_static_return
-// CHECK-COUNT-2: !llvm.ptr<f32>
-// CHECK-COUNT-5: i64
-// CHECK-SAME: -> !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-LABEL: func @check_static_return
-// BAREPTR-SAME: (%[[arg:.*]]: !llvm.ptr<f32>) -> !llvm.ptr<f32> {
-func @check_static_return(%static : memref<32x18xf32>) -> memref<32x18xf32> {
-// CHECK: llvm.return %{{.*}} : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-
-// BAREPTR: %[[udf:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[base0:.*]] = llvm.insertvalue %[[arg]], %[[udf]][0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[aligned:.*]] = llvm.insertvalue %[[arg]], %[[base0]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val0:.*]] = llvm.mlir.constant(0 : index) : i64
-// BAREPTR-NEXT: %[[ins0:.*]] = llvm.insertvalue %[[val0]], %[[aligned]][2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val1:.*]] = llvm.mlir.constant(32 : index) : i64
-// BAREPTR-NEXT: %[[ins1:.*]] = llvm.insertvalue %[[val1]], %[[ins0]][3, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val2:.*]] = llvm.mlir.constant(18 : index) : i64
-// BAREPTR-NEXT: %[[ins2:.*]] = llvm.insertvalue %[[val2]], %[[ins1]][4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val3:.*]] = llvm.mlir.constant(18 : index) : i64
-// BAREPTR-NEXT: %[[ins3:.*]] = llvm.insertvalue %[[val3]], %[[ins2]][3, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val4:.*]] = llvm.mlir.constant(1 : index) : i64
-// BAREPTR-NEXT: %[[ins4:.*]] = llvm.insertvalue %[[val4]], %[[ins3]][4, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[base1:.*]] = llvm.extractvalue %[[ins4]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: llvm.return %[[base1]] : !llvm.ptr<f32>
- return %static : memref<32x18xf32>
-}
-
-// -----
-
-// CHECK-LABEL: func @check_static_return_with_offset
-// CHECK-COUNT-2: !llvm.ptr<f32>
-// CHECK-COUNT-5: i64
-// CHECK-SAME: -> !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-LABEL: func @check_static_return_with_offset
-// BAREPTR-SAME: (%[[arg:.*]]: !llvm.ptr<f32>) -> !llvm.ptr<f32> {
-func @check_static_return_with_offset(%static : memref<32x18xf32, offset:7, strides:[22,1]>) -> memref<32x18xf32, offset:7, strides:[22,1]> {
-// CHECK: llvm.return %{{.*}} : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-
-// BAREPTR: %[[udf:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[base0:.*]] = llvm.insertvalue %[[arg]], %[[udf]][0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[aligned:.*]] = llvm.insertvalue %[[arg]], %[[base0]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val0:.*]] = llvm.mlir.constant(7 : index) : i64
-// BAREPTR-NEXT: %[[ins0:.*]] = llvm.insertvalue %[[val0]], %[[aligned]][2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val1:.*]] = llvm.mlir.constant(32 : index) : i64
-// BAREPTR-NEXT: %[[ins1:.*]] = llvm.insertvalue %[[val1]], %[[ins0]][3, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val2:.*]] = llvm.mlir.constant(22 : index) : i64
-// BAREPTR-NEXT: %[[ins2:.*]] = llvm.insertvalue %[[val2]], %[[ins1]][4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val3:.*]] = llvm.mlir.constant(18 : index) : i64
-// BAREPTR-NEXT: %[[ins3:.*]] = llvm.insertvalue %[[val3]], %[[ins2]][3, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[val4:.*]] = llvm.mlir.constant(1 : index) : i64
-// BAREPTR-NEXT: %[[ins4:.*]] = llvm.insertvalue %[[val4]], %[[ins3]][4, 1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: %[[base1:.*]] = llvm.extractvalue %[[ins4]][1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64, array<2 x i64>, array<2 x i64>)>
-// BAREPTR-NEXT: llvm.return %[[base1]] : !llvm.ptr<f32>
- return %static : memref<32x18xf32, offset:7, strides:[22,1]>
-}
-
-// -----
-
-// BAREPTR: llvm.func @foo(!llvm.ptr<i8>) -> !llvm.ptr<i8>
-func private @foo(memref<10xi8>) -> memref<20xi8>
-
-// BAREPTR-LABEL: func @check_memref_func_call
-// BAREPTR-SAME: %[[in:.*]]: !llvm.ptr<i8>) -> !llvm.ptr<i8>
-func @check_memref_func_call(%in : memref<10xi8>) -> memref<20xi8> {
- // BAREPTR: %[[inDesc:.*]] = llvm.insertvalue %{{.*}}, %{{.*}}[4, 0]
- // BAREPTR-NEXT: %[[barePtr:.*]] = llvm.extractvalue %[[inDesc]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[call:.*]] = llvm.call @foo(%[[barePtr]]) : (!llvm.ptr<i8>) -> !llvm.ptr<i8>
- // BAREPTR-NEXT: %[[desc0:.*]] = llvm.mlir.undef : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[desc1:.*]] = llvm.insertvalue %[[call]], %[[desc0]][0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[desc2:.*]] = llvm.insertvalue %[[call]], %[[desc1]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[c0:.*]] = llvm.mlir.constant(0 : index) : i64
- // BAREPTR-NEXT: %[[desc4:.*]] = llvm.insertvalue %[[c0]], %[[desc2]][2] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[c20:.*]] = llvm.mlir.constant(20 : index) : i64
- // BAREPTR-NEXT: %[[desc6:.*]] = llvm.insertvalue %[[c20]], %[[desc4]][3, 0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: %[[c1:.*]] = llvm.mlir.constant(1 : index) : i64
- // BAREPTR-NEXT: %[[outDesc:.*]] = llvm.insertvalue %[[c1]], %[[desc6]][4, 0] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- %res = call @foo(%in) : (memref<10xi8>) -> (memref<20xi8>)
- // BAREPTR-NEXT: %[[res:.*]] = llvm.extractvalue %[[outDesc]][1] : !llvm.struct<(ptr<i8>, ptr<i8>, i64, array<1 x i64>, array<1 x i64>)>
- // BAREPTR-NEXT: llvm.return %[[res]] : !llvm.ptr<i8>
- return %res : memref<20xi8>
-}
-
-// -----
-
// Unranked memrefs are currently not supported in the bare-ptr calling
// convention. Check that the conversion to the LLVM-IR dialect doesn't happen
// in the presence of unranked memrefs when using such a calling convention.
// BAREPTR-NEXT: llvm.icmp
// BAREPTR-NEXT: llvm.cond_br %{{.*}}, ^bb2, ^bb3
^bb1(%0: index, %1: memref<64xi32, 201>, %2: memref<64xi32, 201>): // 2 preds: ^bb0, ^bb2
- %3 = cmpi slt, %0, %arg1 : index
+ %3 = arith.cmpi slt, %0, %arg1 : index
cond_br %3, ^bb2, ^bb3
^bb2: // pred: ^bb1
- %4 = addi %0, %arg2 : index
+ %4 = arith.addi %0, %arg2 : index
br ^bb1(%4, %2, %1 : index, memref<64xi32, 201>, memref<64xi32, 201>)
^bb3: // pred: ^bb1
return %1, %2 : memref<64xi32, 201>, memref<64xi32, 201>
--- /dev/null
+// RUN: mlir-opt -convert-std-to-llvm %s -split-input-file | FileCheck %s
+// RUN: mlir-opt -convert-std-to-llvm='index-bitwidth=32' %s -split-input-file | FileCheck --check-prefix=CHECK32 %s
+
+// CHECK-LABEL: func @rank_of_unranked
+// CHECK32-LABEL: func @rank_of_unranked
+func @rank_of_unranked(%unranked: memref<*xi32>) {
+ %rank = rank %unranked : memref<*xi32>
+ return
+}
+// CHECK-NEXT: llvm.mlir.undef
+// CHECK-NEXT: llvm.insertvalue
+// CHECK-NEXT: llvm.insertvalue
+// CHECK-NEXT: llvm.extractvalue %{{.*}}[0] : !llvm.struct<(i64, ptr<i8>)>
+// CHECK32: llvm.extractvalue %{{.*}}[0] : !llvm.struct<(i32, ptr<i8>)>
+
+// CHECK-LABEL: func @rank_of_ranked
+// CHECK32-LABEL: func @rank_of_ranked
+func @rank_of_ranked(%ranked: memref<?xi32>) {
+ %rank = rank %ranked : memref<?xi32>
+ return
+}
+// CHECK: llvm.mlir.constant(1 : index) : i64
+// CHECK32: llvm.mlir.constant(1 : index) : i32
-// RUN: mlir-opt -convert-std-to-llvm %s -split-input-file | FileCheck %s
-// RUN: mlir-opt -convert-std-to-llvm='index-bitwidth=32' %s -split-input-file | FileCheck --check-prefix=CHECK32 %s
+// RUN: mlir-opt -convert-math-to-llvm -convert-arith-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts %s -split-input-file | FileCheck %s
+// RUN: mlir-opt -convert-math-to-llvm -convert-arith-to-llvm='index-bitwidth=32' -convert-std-to-llvm='index-bitwidth=32' -reconcile-unrealized-casts %s -split-input-file | FileCheck --check-prefix=CHECK32 %s
// CHECK-LABEL: func @empty() {
// CHECK-NEXT: llvm.return
// CHECK32-NEXT: {{.*}} = llvm.mlir.constant(42 : index) : i32
// CHECK32-NEXT: llvm.br ^bb2({{.*}} : i32)
^bb1: // pred: ^bb0
- %c1 = constant 1 : index
- %c42 = constant 42 : index
+ %c1 = arith.constant 1 : index
+ %c42 = arith.constant 42 : index
br ^bb2(%c1 : index)
// CHECK: ^bb2({{.*}}: i64): // 2 preds: ^bb1, ^bb3
// CHECK32-NEXT: {{.*}} = llvm.icmp "slt" {{.*}}, {{.*}} : i32
// CHECK32-NEXT: llvm.cond_br {{.*}}, ^bb3, ^bb4
^bb2(%0: index): // 2 preds: ^bb1, ^bb3
- %1 = cmpi slt, %0, %c42 : index
+ %1 = arith.cmpi slt, %0, %c42 : index
cond_br %1, ^bb3, ^bb4
// CHECK: ^bb3: // pred: ^bb2
// CHECK32-NEXT: llvm.br ^bb2({{.*}} : i32)
^bb3: // pred: ^bb2
call @body(%0) : (index) -> ()
- %c1_0 = constant 1 : index
- %2 = addi %0, %c1_0 : index
+ %c1_0 = arith.constant 1 : index
+ %2 = arith.addi %0, %c1_0 : index
br ^bb2(%2 : index)
// CHECK: ^bb4: // pred: ^bb2
// CHECK32-NEXT: llvm.br ^bb1
func @func_args(i32, i32) -> i32 {
^bb0(%arg0: i32, %arg1: i32):
- %c0_i32 = constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
br ^bb1
// CHECK-NEXT: ^bb1: // pred: ^bb0
// CHECK32-NEXT: {{.*}} = llvm.mlir.constant(42 : index) : i32
// CHECK32-NEXT: llvm.br ^bb2({{.*}} : i32)
^bb1: // pred: ^bb0
- %c0 = constant 0 : index
- %c42 = constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c42 = arith.constant 42 : index
br ^bb2(%c0 : index)
// CHECK-NEXT: ^bb2({{.*}}: i64): // 2 preds: ^bb1, ^bb3
// CHECK32-NEXT: {{.*}} = llvm.icmp "slt" {{.*}}, {{.*}} : i32
// CHECK32-NEXT: llvm.cond_br {{.*}}, ^bb3, ^bb4
^bb2(%0: index): // 2 preds: ^bb1, ^bb3
- %1 = cmpi slt, %0, %c42 : index
+ %1 = arith.cmpi slt, %0, %c42 : index
cond_br %1, ^bb3, ^bb4
// CHECK-NEXT: ^bb3: // pred: ^bb2
%3 = call @other(%2, %arg0) : (index, i32) -> i32
%4 = call @other(%2, %3) : (index, i32) -> i32
%5 = call @other(%2, %arg1) : (index, i32) -> i32
- %c1 = constant 1 : index
- %6 = addi %0, %c1 : index
+ %c1 = arith.constant 1 : index
+ %6 = arith.addi %0, %c1 : index
br ^bb2(%6 : index)
// CHECK-NEXT: ^bb4: // pred: ^bb2
// CHECK32-NEXT: {{.*}} = llvm.call @other({{.*}}, {{.*}}) : (i32, i32) -> i32
// CHECK32-NEXT: llvm.return {{.*}} : i32
^bb4: // pred: ^bb2
- %c0_0 = constant 0 : index
+ %c0_0 = arith.constant 0 : index
%7 = call @other(%c0_0, %c0_i32) : (index, i32) -> i32
return %7 : i32
}
// CHECK-NEXT: {{.*}} = llvm.mlir.constant(42 : index) : i64
// CHECK-NEXT: llvm.br ^bb2({{.*}} : i64)
^bb1: // pred: ^bb0
- %c0 = constant 0 : index
- %c42 = constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c42 = arith.constant 42 : index
br ^bb2(%c0 : index)
// CHECK-NEXT: ^bb2({{.*}}: i64): // 2 preds: ^bb1, ^bb7
// CHECK-NEXT: {{.*}} = llvm.icmp "slt" {{.*}}, {{.*}} : i64
// CHECK-NEXT: llvm.cond_br {{.*}}, ^bb3, ^bb8
^bb2(%0: index): // 2 preds: ^bb1, ^bb7
- %1 = cmpi slt, %0, %c42 : index
+ %1 = arith.cmpi slt, %0, %c42 : index
cond_br %1, ^bb3, ^bb8
// CHECK-NEXT: ^bb3:
// CHECK-NEXT: {{.*}} = llvm.mlir.constant(56 : index) : i64
// CHECK-NEXT: llvm.br ^bb5({{.*}} : i64)
^bb4: // pred: ^bb3
- %c7 = constant 7 : index
- %c56 = constant 56 : index
+ %c7 = arith.constant 7 : index
+ %c56 = arith.constant 56 : index
br ^bb5(%c7 : index)
// CHECK-NEXT: ^bb5({{.*}}: i64): // 2 preds: ^bb4, ^bb6
// CHECK-NEXT: {{.*}} = llvm.icmp "slt" {{.*}}, {{.*}} : i64
// CHECK-NEXT: llvm.cond_br {{.*}}, ^bb6, ^bb7
^bb5(%2: index): // 2 preds: ^bb4, ^bb6
- %3 = cmpi slt, %2, %c56 : index
+ %3 = arith.cmpi slt, %2, %c56 : index
cond_br %3, ^bb6, ^bb7
// CHECK-NEXT: ^bb6: // pred: ^bb5
// CHECK-NEXT: llvm.br ^bb5({{.*}} : i64)
^bb6: // pred: ^bb5
call @body2(%0, %2) : (index, index) -> ()
- %c2 = constant 2 : index
- %4 = addi %2, %c2 : index
+ %c2 = arith.constant 2 : index
+ %4 = arith.addi %2, %c2 : index
br ^bb5(%4 : index)
// CHECK-NEXT: ^bb7: // pred: ^bb5
// CHECK-NEXT: llvm.br ^bb2({{.*}} : i64)
^bb7: // pred: ^bb5
call @post(%0) : (index) -> ()
- %c1 = constant 1 : index
- %5 = addi %0, %c1 : index
+ %c1 = arith.constant 1 : index
+ %5 = arith.addi %0, %c1 : index
br ^bb2(%5 : index)
// CHECK-NEXT: ^bb8: // pred: ^bb2
^bb0:
br ^bb1
^bb1: // pred: ^bb0
- %c0 = constant 0 : index
- %c42 = constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c42 = arith.constant 42 : index
br ^bb2(%c0 : index)
^bb2(%0: index): // 2 preds: ^bb1, ^bb11
- %1 = cmpi slt, %0, %c42 : index
+ %1 = arith.cmpi slt, %0, %c42 : index
cond_br %1, ^bb3, ^bb12
^bb3: // pred: ^bb2
call @pre(%0) : (index) -> ()
br ^bb4
^bb4: // pred: ^bb3
- %c7 = constant 7 : index
- %c56 = constant 56 : index
+ %c7 = arith.constant 7 : index
+ %c56 = arith.constant 56 : index
br ^bb5(%c7 : index)
^bb5(%2: index): // 2 preds: ^bb4, ^bb6
- %3 = cmpi slt, %2, %c56 : index
+ %3 = arith.cmpi slt, %2, %c56 : index
cond_br %3, ^bb6, ^bb7
^bb6: // pred: ^bb5
call @body2(%0, %2) : (index, index) -> ()
- %c2 = constant 2 : index
- %4 = addi %2, %c2 : index
+ %c2 = arith.constant 2 : index
+ %4 = arith.addi %2, %c2 : index
br ^bb5(%4 : index)
^bb7: // pred: ^bb5
call @mid(%0) : (index) -> ()
br ^bb8
^bb8: // pred: ^bb7
- %c18 = constant 18 : index
- %c37 = constant 37 : index
+ %c18 = arith.constant 18 : index
+ %c37 = arith.constant 37 : index
br ^bb9(%c18 : index)
^bb9(%5: index): // 2 preds: ^bb8, ^bb10
- %6 = cmpi slt, %5, %c37 : index
+ %6 = arith.cmpi slt, %5, %c37 : index
cond_br %6, ^bb10, ^bb11
^bb10: // pred: ^bb9
call @body3(%0, %5) : (index, index) -> ()
- %c3 = constant 3 : index
- %7 = addi %5, %c3 : index
+ %c3 = arith.constant 3 : index
+ %7 = arith.addi %5, %c3 : index
br ^bb9(%7 : index)
^bb11: // pred: ^bb9
call @post(%0) : (index) -> ()
- %c1 = constant 1 : index
- %8 = addi %0, %c1 : index
+ %c1 = arith.constant 1 : index
+ %8 = arith.addi %0, %c1 : index
br ^bb2(%8 : index)
^bb12: // pred: ^bb2
return
// CHECK32-NEXT: {{.*}} = llvm.extractvalue {{.*}}[1] : !llvm.struct<(i64, f32, struct<(ptr<f32>, ptr<f32>, i32, array<4 x i32>, array<4 x i32>)>)>
// CHECK32-NEXT: {{.*}} = llvm.extractvalue {{.*}}[2] : !llvm.struct<(i64, f32, struct<(ptr<f32>, ptr<f32>, i32, array<4 x i32>, array<4 x i32>)>)>
%0:3 = call @multireturn() : () -> (i64, f32, memref<42x?x10x?xf32>)
- %1 = constant 42 : i64
+ %1 = arith.constant 42 : i64
// CHECK: {{.*}} = llvm.add {{.*}}, {{.*}} : i64
- %2 = addi %0#0, %1 : i64
- %3 = constant 42.0 : f32
+ %2 = arith.addi %0#0, %1 : i64
+ %3 = arith.constant 42.0 : f32
// CHECK: {{.*}} = llvm.fadd {{.*}}, {{.*}} : f32
- %4 = addf %0#1, %3 : f32
- %5 = constant 0 : index
+ %4 = arith.addf %0#1, %3 : f32
+ %5 = arith.constant 0 : index
return
}
-// CHECK-LABEL: llvm.func @vector_ops(%arg0: vector<4xf32>, %arg1: vector<4xi1>, %arg2: vector<4xi64>, %arg3: vector<4xi64>) -> vector<4xf32> {
-func @vector_ops(%arg0: vector<4xf32>, %arg1: vector<4xi1>, %arg2: vector<4xi64>, %arg3: vector<4xi64>) -> vector<4xf32> {
-// CHECK-NEXT: %0 = llvm.mlir.constant(dense<4.200000e+01> : vector<4xf32>) : vector<4xf32>
- %0 = constant dense<42.> : vector<4xf32>
-// CHECK-NEXT: %1 = llvm.fadd %arg0, %0 : vector<4xf32>
- %1 = addf %arg0, %0 : vector<4xf32>
-// CHECK-NEXT: %2 = llvm.sdiv %arg2, %arg2 : vector<4xi64>
- %3 = divi_signed %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %3 = llvm.udiv %arg2, %arg2 : vector<4xi64>
- %4 = divi_unsigned %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %4 = llvm.srem %arg2, %arg2 : vector<4xi64>
- %5 = remi_signed %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %5 = llvm.urem %arg2, %arg2 : vector<4xi64>
- %6 = remi_unsigned %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %6 = llvm.fdiv %arg0, %0 : vector<4xf32>
- %7 = divf %arg0, %0 : vector<4xf32>
-// CHECK-NEXT: %7 = llvm.frem %arg0, %0 : vector<4xf32>
- %8 = remf %arg0, %0 : vector<4xf32>
-// CHECK-NEXT: %8 = llvm.and %arg2, %arg3 : vector<4xi64>
- %9 = and %arg2, %arg3 : vector<4xi64>
-// CHECK-NEXT: %9 = llvm.or %arg2, %arg3 : vector<4xi64>
- %10 = or %arg2, %arg3 : vector<4xi64>
-// CHECK-NEXT: %10 = llvm.xor %arg2, %arg3 : vector<4xi64>
- %11 = xor %arg2, %arg3 : vector<4xi64>
-// CHECK-NEXT: %11 = llvm.shl %arg2, %arg2 : vector<4xi64>
- %12 = shift_left %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %12 = llvm.ashr %arg2, %arg2 : vector<4xi64>
- %13 = shift_right_signed %arg2, %arg2 : vector<4xi64>
-// CHECK-NEXT: %13 = llvm.lshr %arg2, %arg2 : vector<4xi64>
- %14 = shift_right_unsigned %arg2, %arg2 : vector<4xi64>
- return %1 : vector<4xf32>
-}
-
-// CHECK-LABEL: @ops
-func @ops(f32, f32, i32, i32, f64) -> (f32, i32) {
-^bb0(%arg0: f32, %arg1: f32, %arg2: i32, %arg3: i32, %arg4: f64):
-// CHECK: = llvm.fsub %arg0, %arg1 : f32
- %0 = subf %arg0, %arg1: f32
-// CHECK: = llvm.sub %arg2, %arg3 : i32
- %1 = subi %arg2, %arg3: i32
-// CHECK: = llvm.icmp "slt" %arg2, %1 : i32
- %2 = cmpi slt, %arg2, %1 : i32
-// CHECK: = llvm.sdiv %arg2, %arg3 : i32
- %3 = divi_signed %arg2, %arg3 : i32
-// CHECK: = llvm.udiv %arg2, %arg3 : i32
- %4 = divi_unsigned %arg2, %arg3 : i32
-// CHECK: = llvm.srem %arg2, %arg3 : i32
- %5 = remi_signed %arg2, %arg3 : i32
-// CHECK: = llvm.urem %arg2, %arg3 : i32
- %6 = remi_unsigned %arg2, %arg3 : i32
-// CHECK: = llvm.select %2, %arg2, %arg3 : i1, i32
- %7 = select %2, %arg2, %arg3 : i32
-// CHECK: = llvm.fdiv %arg0, %arg1 : f32
- %8 = divf %arg0, %arg1 : f32
-// CHECK: = llvm.frem %arg0, %arg1 : f32
- %9 = remf %arg0, %arg1 : f32
-// CHECK: = llvm.and %arg2, %arg3 : i32
- %10 = and %arg2, %arg3 : i32
-// CHECK: = llvm.or %arg2, %arg3 : i32
- %11 = or %arg2, %arg3 : i32
-// CHECK: = llvm.xor %arg2, %arg3 : i32
- %12 = xor %arg2, %arg3 : i32
-// CHECK: = llvm.mlir.constant(7.900000e-01 : f64) : f64
- %15 = constant 7.9e-01 : f64
-// CHECK: = llvm.shl %arg2, %arg3 : i32
- %16 = shift_left %arg2, %arg3 : i32
-// CHECK: = llvm.ashr %arg2, %arg3 : i32
- %17 = shift_right_signed %arg2, %arg3 : i32
-// CHECK: = llvm.lshr %arg2, %arg3 : i32
- %18 = shift_right_unsigned %arg2, %arg3 : i32
- return %0, %4 : f32, i32
-}
-
-// Checking conversion of index types to integers using i1, assuming no target
-// system would have a 1-bit address space. Otherwise, we would have had to
-// make this test dependent on the pointer size on the target system.
-// CHECK-LABEL: @index_cast
-func @index_cast(%arg0: index, %arg1: i1) {
-// CHECK-NEXT: = llvm.trunc %arg0 : i{{.*}} to i1
- %0 = index_cast %arg0: index to i1
-// CHECK-NEXT: = llvm.sext %arg1 : i1 to i{{.*}}
- %1 = index_cast %arg1: i1 to index
- return
-}
-
-// CHECK-LABEL: @vector_index_cast
-func @vector_index_cast(%arg0: vector<2xindex>, %arg1: vector<2xi1>) {
-// CHECK-NEXT: = llvm.trunc %{{.*}} : vector<2xi{{.*}}> to vector<2xi1>
- %0 = index_cast %arg0: vector<2xindex> to vector<2xi1>
-// CHECK-NEXT: = llvm.sext %{{.*}} : vector<2xi1> to vector<2xi{{.*}}>
- %1 = index_cast %arg1: vector<2xi1> to vector<2xindex>
- return
-}
-
-// Checking conversion of signed integer types to floating point.
-// CHECK-LABEL: @sitofp
-func @sitofp(%arg0 : i32, %arg1 : i64) {
-// CHECK-NEXT: = llvm.sitofp {{.*}} : i32 to f32
- %0 = sitofp %arg0: i32 to f32
-// CHECK-NEXT: = llvm.sitofp {{.*}} : i32 to f64
- %1 = sitofp %arg0: i32 to f64
-// CHECK-NEXT: = llvm.sitofp {{.*}} : i64 to f32
- %2 = sitofp %arg1: i64 to f32
-// CHECK-NEXT: = llvm.sitofp {{.*}} : i64 to f64
- %3 = sitofp %arg1: i64 to f64
- return
-}
-
-// Checking conversion of integer vectors to floating point vector types.
-// CHECK-LABEL: @sitofp_vector
-func @sitofp_vector(%arg0 : vector<2xi16>, %arg1 : vector<2xi32>, %arg2 : vector<2xi64>) {
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi16> to vector<2xf32>
- %0 = sitofp %arg0: vector<2xi16> to vector<2xf32>
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi16> to vector<2xf64>
- %1 = sitofp %arg0: vector<2xi16> to vector<2xf64>
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi32> to vector<2xf32>
- %2 = sitofp %arg1: vector<2xi32> to vector<2xf32>
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi32> to vector<2xf64>
- %3 = sitofp %arg1: vector<2xi32> to vector<2xf64>
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi64> to vector<2xf32>
- %4 = sitofp %arg2: vector<2xi64> to vector<2xf32>
-// CHECK-NEXT: = llvm.sitofp {{.*}} : vector<2xi64> to vector<2xf64>
- %5 = sitofp %arg2: vector<2xi64> to vector<2xf64>
- return
-}
-
-// Checking conversion of unsigned integer types to floating point.
-// CHECK-LABEL: @uitofp
-func @uitofp(%arg0 : i32, %arg1 : i64) {
-// CHECK-NEXT: = llvm.uitofp {{.*}} : i32 to f32
- %0 = uitofp %arg0: i32 to f32
-// CHECK-NEXT: = llvm.uitofp {{.*}} : i32 to f64
- %1 = uitofp %arg0: i32 to f64
-// CHECK-NEXT: = llvm.uitofp {{.*}} : i64 to f32
- %2 = uitofp %arg1: i64 to f32
-// CHECK-NEXT: = llvm.uitofp {{.*}} : i64 to f64
- %3 = uitofp %arg1: i64 to f64
- return
-}
-
-// Checking conversion of integer types to floating point.
-// CHECK-LABEL: @fpext
-func @fpext(%arg0 : f16, %arg1 : f32) {
-// CHECK-NEXT: = llvm.fpext {{.*}} : f16 to f32
- %0 = fpext %arg0: f16 to f32
-// CHECK-NEXT: = llvm.fpext {{.*}} : f16 to f64
- %1 = fpext %arg0: f16 to f64
-// CHECK-NEXT: = llvm.fpext {{.*}} : f32 to f64
- %2 = fpext %arg1: f32 to f64
- return
-}
-
-// Checking conversion of integer types to floating point.
-// CHECK-LABEL: @fpext
-func @fpext_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>) {
-// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf16> to vector<2xf32>
- %0 = fpext %arg0: vector<2xf16> to vector<2xf32>
-// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf16> to vector<2xf64>
- %1 = fpext %arg0: vector<2xf16> to vector<2xf64>
-// CHECK-NEXT: = llvm.fpext {{.*}} : vector<2xf32> to vector<2xf64>
- %2 = fpext %arg1: vector<2xf32> to vector<2xf64>
- return
-}
-
-// Checking conversion of floating point to integer types.
-// CHECK-LABEL: @fptosi
-func @fptosi(%arg0 : f32, %arg1 : f64) {
-// CHECK-NEXT: = llvm.fptosi {{.*}} : f32 to i32
- %0 = fptosi %arg0: f32 to i32
-// CHECK-NEXT: = llvm.fptosi {{.*}} : f32 to i64
- %1 = fptosi %arg0: f32 to i64
-// CHECK-NEXT: = llvm.fptosi {{.*}} : f64 to i32
- %2 = fptosi %arg1: f64 to i32
-// CHECK-NEXT: = llvm.fptosi {{.*}} : f64 to i64
- %3 = fptosi %arg1: f64 to i64
- return
-}
-
-// Checking conversion of floating point vectors to integer vector types.
-// CHECK-LABEL: @fptosi_vector
-func @fptosi_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>, %arg2 : vector<2xf64>) {
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf16> to vector<2xi32>
- %0 = fptosi %arg0: vector<2xf16> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf16> to vector<2xi64>
- %1 = fptosi %arg0: vector<2xf16> to vector<2xi64>
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf32> to vector<2xi32>
- %2 = fptosi %arg1: vector<2xf32> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf32> to vector<2xi64>
- %3 = fptosi %arg1: vector<2xf32> to vector<2xi64>
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf64> to vector<2xi32>
- %4 = fptosi %arg2: vector<2xf64> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptosi {{.*}} : vector<2xf64> to vector<2xi64>
- %5 = fptosi %arg2: vector<2xf64> to vector<2xi64>
- return
-}
-
-// Checking conversion of floating point to integer types.
-// CHECK-LABEL: @fptoui
-func @fptoui(%arg0 : f32, %arg1 : f64) {
-// CHECK-NEXT: = llvm.fptoui {{.*}} : f32 to i32
- %0 = fptoui %arg0: f32 to i32
-// CHECK-NEXT: = llvm.fptoui {{.*}} : f32 to i64
- %1 = fptoui %arg0: f32 to i64
-// CHECK-NEXT: = llvm.fptoui {{.*}} : f64 to i32
- %2 = fptoui %arg1: f64 to i32
-// CHECK-NEXT: = llvm.fptoui {{.*}} : f64 to i64
- %3 = fptoui %arg1: f64 to i64
- return
-}
-
-// Checking conversion of floating point vectors to integer vector types.
-// CHECK-LABEL: @fptoui_vector
-func @fptoui_vector(%arg0 : vector<2xf16>, %arg1 : vector<2xf32>, %arg2 : vector<2xf64>) {
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf16> to vector<2xi32>
- %0 = fptoui %arg0: vector<2xf16> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf16> to vector<2xi64>
- %1 = fptoui %arg0: vector<2xf16> to vector<2xi64>
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf32> to vector<2xi32>
- %2 = fptoui %arg1: vector<2xf32> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf32> to vector<2xi64>
- %3 = fptoui %arg1: vector<2xf32> to vector<2xi64>
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf64> to vector<2xi32>
- %4 = fptoui %arg2: vector<2xf64> to vector<2xi32>
-// CHECK-NEXT: = llvm.fptoui {{.*}} : vector<2xf64> to vector<2xi64>
- %5 = fptoui %arg2: vector<2xf64> to vector<2xi64>
- return
-}
-
-// Checking conversion of integer vectors to floating point vector types.
-// CHECK-LABEL: @uitofp_vector
-func @uitofp_vector(%arg0 : vector<2xi16>, %arg1 : vector<2xi32>, %arg2 : vector<2xi64>) {
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi16> to vector<2xf32>
- %0 = uitofp %arg0: vector<2xi16> to vector<2xf32>
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi16> to vector<2xf64>
- %1 = uitofp %arg0: vector<2xi16> to vector<2xf64>
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi32> to vector<2xf32>
- %2 = uitofp %arg1: vector<2xi32> to vector<2xf32>
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi32> to vector<2xf64>
- %3 = uitofp %arg1: vector<2xi32> to vector<2xf64>
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi64> to vector<2xf32>
- %4 = uitofp %arg2: vector<2xi64> to vector<2xf32>
-// CHECK-NEXT: = llvm.uitofp {{.*}} : vector<2xi64> to vector<2xf64>
- %5 = uitofp %arg2: vector<2xi64> to vector<2xf64>
- return
-}
-
-// Checking conversion of integer types to floating point.
-// CHECK-LABEL: @fptrunc
-func @fptrunc(%arg0 : f32, %arg1 : f64) {
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : f32 to f16
- %0 = fptrunc %arg0: f32 to f16
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : f64 to f16
- %1 = fptrunc %arg1: f64 to f16
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : f64 to f32
- %2 = fptrunc %arg1: f64 to f32
- return
-}
-
-// Checking conversion of integer types to floating point.
-// CHECK-LABEL: @fptrunc
-func @fptrunc_vector(%arg0 : vector<2xf32>, %arg1 : vector<2xf64>) {
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf32> to vector<2xf16>
- %0 = fptrunc %arg0: vector<2xf32> to vector<2xf16>
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf64> to vector<2xf16>
- %1 = fptrunc %arg1: vector<2xf64> to vector<2xf16>
-// CHECK-NEXT: = llvm.fptrunc {{.*}} : vector<2xf64> to vector<2xf32>
- %2 = fptrunc %arg1: vector<2xf64> to vector<2xf32>
- return
-}
-
-// Check sign and zero extension and truncation of integers.
-// CHECK-LABEL: @integer_extension_and_truncation
-func @integer_extension_and_truncation(%arg0 : i3) {
-// CHECK-NEXT: = llvm.sext %arg0 : i3 to i6
- %0 = sexti %arg0 : i3 to i6
-// CHECK-NEXT: = llvm.zext %arg0 : i3 to i6
- %1 = zexti %arg0 : i3 to i6
-// CHECK-NEXT: = llvm.trunc %arg0 : i3 to i2
- %2 = trunci %arg0 : i3 to i2
- return
+// CHECK-LABEL: @select
+func @select(%arg0 : i1, %arg1 : i32, %arg2 : i32) -> i32 {
+// CHECK: = llvm.select %arg0, %arg1, %arg2 : i1, i32
+ %0 = select %arg0, %arg1, %arg2 : i32
+ return %0 : i32
}
// CHECK-LABEL: @dfs_block_order
func @dfs_block_order(%arg0: i32) -> (i32) {
// CHECK-NEXT: %[[CST:.*]] = llvm.mlir.constant(42 : i32) : i32
- %0 = constant 42 : i32
+ %0 = arith.constant 42 : i32
// CHECK-NEXT: llvm.br ^bb2
br ^bb2
// CHECK-NEXT: %[[ADD:.*]] = llvm.add %arg0, %[[CST]] : i32
// CHECK-NEXT: llvm.return %[[ADD]] : i32
^bb1:
- %2 = addi %arg0, %0 : i32
+ %2 = arith.addi %arg0, %0 : i32
return %2 : i32
// CHECK-NEXT: ^bb2:
br ^bb1
}
-// CHECK-LABEL: func @fcmp(%arg0: f32, %arg1: f32) {
-func @fcmp(f32, f32) -> () {
-^bb0(%arg0: f32, %arg1: f32):
- // CHECK: llvm.fcmp "oeq" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ogt" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "oge" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "olt" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ole" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "one" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ord" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ueq" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ugt" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "uge" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ult" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "ule" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "une" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.fcmp "uno" %arg0, %arg1 : f32
- // CHECK-NEXT: llvm.return
- %1 = cmpf oeq, %arg0, %arg1 : f32
- %2 = cmpf ogt, %arg0, %arg1 : f32
- %3 = cmpf oge, %arg0, %arg1 : f32
- %4 = cmpf olt, %arg0, %arg1 : f32
- %5 = cmpf ole, %arg0, %arg1 : f32
- %6 = cmpf one, %arg0, %arg1 : f32
- %7 = cmpf ord, %arg0, %arg1 : f32
- %8 = cmpf ueq, %arg0, %arg1 : f32
- %9 = cmpf ugt, %arg0, %arg1 : f32
- %10 = cmpf uge, %arg0, %arg1 : f32
- %11 = cmpf ult, %arg0, %arg1 : f32
- %12 = cmpf ule, %arg0, %arg1 : f32
- %13 = cmpf une, %arg0, %arg1 : f32
- %14 = cmpf uno, %arg0, %arg1 : f32
-
- return
-}
-
// CHECK-LABEL: @splat
// CHECK-SAME: %[[A:arg[0-9]+]]: vector<4xf32>
// CHECK-SAME: %[[ELT:arg[0-9]+]]: f32
func @splat(%a: vector<4xf32>, %b: f32) -> vector<4xf32> {
%vb = splat %b : vector<4xf32>
- %r = mulf %a, %vb : vector<4xf32>
+ %r = arith.mulf %a, %vb : vector<4xf32>
return %r : vector<4xf32>
}
// CHECK-NEXT: %[[UNDEF:[0-9]+]] = llvm.mlir.undef : vector<4xf32>
func @generic_atomic_rmw(%I : memref<10xi32>, %i : index) -> i32 {
%x = generic_atomic_rmw %I[%i] : memref<10xi32> {
^bb0(%old_value : i32):
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
atomic_yield %c1 : i32
}
// CHECK: [[init:%.*]] = llvm.load %{{.*}} : !llvm.ptr<i32>
// CHECK-NEXT: [[ok:%.*]] = llvm.extractvalue [[pair]][1]
// CHECK-NEXT: llvm.cond_br [[ok]], ^bb2, ^bb1([[new]] : i32)
// CHECK-NEXT: ^bb2:
- %c2 = constant 2 : i32
- %add = addi %c2, %x : i32
+ %c2 = arith.constant 2 : i32
+ %add = arith.addi %c2, %x : i32
return %add : i32
// CHECK-NEXT: [[c2:%.*]] = llvm.mlir.constant(2 : i32)
// CHECK-NEXT: [[add:%.*]] = llvm.add [[c2]], [[new]] : i32
// -----
-// CHECK-LABEL: func @rank_of_unranked
-// CHECK32-LABEL: func @rank_of_unranked
-func @rank_of_unranked(%unranked: memref<*xi32>) {
- %rank = rank %unranked : memref<*xi32>
- return
-}
-// CHECK-NEXT: llvm.mlir.undef
-// CHECK-NEXT: llvm.insertvalue
-// CHECK-NEXT: llvm.insertvalue
-// CHECK-NEXT: llvm.extractvalue %{{.*}}[0] : !llvm.struct<(i64, ptr<i8>)>
-// CHECK32: llvm.extractvalue %{{.*}}[0] : !llvm.struct<(i32, ptr<i8>)>
-
-// CHECK-LABEL: func @rank_of_ranked
-// CHECK32-LABEL: func @rank_of_ranked
-func @rank_of_ranked(%ranked: memref<?xi32>) {
- %rank = rank %ranked : memref<?xi32>
- return
-}
-// CHECK: llvm.mlir.constant(1 : index) : i64
-// CHECK32: llvm.mlir.constant(1 : index) : i32
-
-// -----
-
// CHECK-LABEL: func @ceilf(
// CHECK-SAME: f32
func @ceilf(%arg0 : f32) {
// CHECK: "llvm.intr.ceil"(%arg0) : (f32) -> f32
- %0 = ceilf %arg0 : f32
+ %0 = math.ceil %arg0 : f32
std.return
}
// CHECK-SAME: f32
func @floorf(%arg0 : f32) {
// CHECK: "llvm.intr.floor"(%arg0) : (f32) -> f32
- %0 = floorf %arg0 : f32
+ %0 = math.floor %arg0 : f32
std.return
}
// CHECK-SAME: %[[ARG1:.*]]: vector<4xf32>
func @fmaf(%arg0: f32, %arg1: vector<4xf32>) {
// CHECK: %[[S:.*]] = "llvm.intr.fma"(%[[ARG0]], %[[ARG0]], %[[ARG0]]) : (f32, f32, f32) -> f32
- %0 = fmaf %arg0, %arg0, %arg0 : f32
+ %0 = math.fma %arg0, %arg0, %arg0 : f32
// CHECK: %[[V:.*]] = "llvm.intr.fma"(%[[ARG1]], %[[ARG1]], %[[ARG1]]) : (vector<4xf32>, vector<4xf32>, vector<4xf32>) -> vector<4xf32>
- %1 = fmaf %arg1, %arg1, %arg1 : vector<4xf32>
- std.return
-}
-
-// -----
-
-// CHECK-LABEL: func @index_vector(
-// CHECK-SAME: %[[ARG0:.*]]: vector<4xi64>
-func @index_vector(%arg0: vector<4xindex>) {
- // CHECK: %[[CST:.*]] = llvm.mlir.constant(dense<[0, 1, 2, 3]> : vector<4xindex>) : vector<4xi64>
- %0 = constant dense<[0, 1, 2, 3]> : vector<4xindex>
- // CHECK: %[[V:.*]] = llvm.add %[[ARG0]], %[[CST]] : vector<4xi64>
- %1 = addi %arg0, %0 : vector<4xindex>
- std.return
-}
-
-// -----
-
-// CHECK-LABEL: @bitcast_1d
-func @bitcast_1d(%arg0: vector<2xf32>) {
- // CHECK: llvm.bitcast %{{.*}} : vector<2xf32> to vector<2xi32>
- std.bitcast %arg0 : vector<2xf32> to vector<2xi32>
- return
-}
-
-// -----
-
-// CHECK-LABEL: func @cmpf_2dvector(
-func @cmpf_2dvector(%arg0 : vector<4x3xf32>, %arg1 : vector<4x3xf32>) {
- // CHECK: %[[EXTRACT1:.*]] = llvm.extractvalue %arg0[0] : !llvm.array<4 x vector<3xf32>>
- // CHECK: %[[EXTRACT2:.*]] = llvm.extractvalue %arg1[0] : !llvm.array<4 x vector<3xf32>>
- // CHECK: %[[CMP:.*]] = llvm.fcmp "olt" %[[EXTRACT1]], %[[EXTRACT2]] : vector<3xf32>
- // CHECK: %[[INSERT:.*]] = llvm.insertvalue %[[CMP]], %0[0] : !llvm.array<4 x vector<3xi1>>
- %0 = cmpf olt, %arg0, %arg1 : vector<4x3xf32>
- std.return
-}
-
-// -----
-
-// CHECK-LABEL: func @cmpi_2dvector(
-func @cmpi_2dvector(%arg0 : vector<4x3xi32>, %arg1 : vector<4x3xi32>) {
- // CHECK: %[[EXTRACT1:.*]] = llvm.extractvalue %arg0[0] : !llvm.array<4 x vector<3xi32>>
- // CHECK: %[[EXTRACT2:.*]] = llvm.extractvalue %arg1[0] : !llvm.array<4 x vector<3xi32>>
- // CHECK: %[[CMP:.*]] = llvm.icmp "ult" %[[EXTRACT1]], %[[EXTRACT2]] : vector<3xi32>
- // CHECK: %[[INSERT:.*]] = llvm.insertvalue %[[CMP]], %0[0] : !llvm.array<4 x vector<3xi1>>
- %0 = cmpi ult, %arg0, %arg1 : vector<4x3xi32>
+ %1 = math.fma %arg1, %arg1, %arg1 : vector<4xf32>
std.return
}
-// RUN: mlir-opt -split-input-file -convert-std-to-spirv -verify-diagnostics %s -o - | FileCheck %s
+// RUN: mlir-opt -split-input-file -convert-std-to-spirv -verify-diagnostics %s | FileCheck %s
//===----------------------------------------------------------------------===//
-// std arithmetic ops
+// std.select
//===----------------------------------------------------------------------===//
module attributes {
// CHECK-LABEL: @int32_scalar
func @int32_scalar(%lhs: i32, %rhs: i32) {
// CHECK: spv.IAdd %{{.*}}, %{{.*}}: i32
- %0 = addi %lhs, %rhs: i32
+ %0 = arith.addi %lhs, %rhs: i32
// CHECK: spv.ISub %{{.*}}, %{{.*}}: i32
- %1 = subi %lhs, %rhs: i32
+ %1 = arith.subi %lhs, %rhs: i32
// CHECK: spv.IMul %{{.*}}, %{{.*}}: i32
- %2 = muli %lhs, %rhs: i32
+ %2 = arith.muli %lhs, %rhs: i32
// CHECK: spv.SDiv %{{.*}}, %{{.*}}: i32
- %3 = divi_signed %lhs, %rhs: i32
+ %3 = arith.divsi %lhs, %rhs: i32
// CHECK: spv.UDiv %{{.*}}, %{{.*}}: i32
- %4 = divi_unsigned %lhs, %rhs: i32
+ %4 = arith.divui %lhs, %rhs: i32
// CHECK: spv.UMod %{{.*}}, %{{.*}}: i32
- %5 = remi_unsigned %lhs, %rhs: i32
+ %5 = arith.remui %lhs, %rhs: i32
// CHECK: spv.GLSL.SMax %{{.*}}, %{{.*}}: i32
%6 = maxsi %lhs, %rhs : i32
// CHECK: spv.GLSL.UMax %{{.*}}, %{{.*}}: i32
// CHECK: %[[POS:.+]] = spv.IEqual %[[LHS]], %[[LABS]] : i32
// CHECK: %[[NEG:.+]] = spv.SNegate %[[ABS]] : i32
// CHECK: %{{.+}} = spv.Select %[[POS]], %[[ABS]], %[[NEG]] : i1, i32
- %0 = remi_signed %lhs, %rhs: i32
+ %0 = arith.remsi %lhs, %rhs: i32
return
}
// CHECK-LABEL: @float32_unary_scalar
func @float32_unary_scalar(%arg0: f32) {
// CHECK: spv.GLSL.FAbs %{{.*}}: f32
- %0 = absf %arg0 : f32
+ %0 = math.abs %arg0 : f32
// CHECK: spv.GLSL.Ceil %{{.*}}: f32
- %1 = ceilf %arg0 : f32
+ %1 = math.ceil %arg0 : f32
// CHECK: spv.FNegate %{{.*}}: f32
- %5 = negf %arg0 : f32
+ %5 = arith.negf %arg0 : f32
// CHECK: spv.GLSL.Floor %{{.*}}: f32
- %10 = floorf %arg0 : f32
+ %10 = math.floor %arg0 : f32
return
}
// CHECK-LABEL: @float32_binary_scalar
func @float32_binary_scalar(%lhs: f32, %rhs: f32) {
// CHECK: spv.FAdd %{{.*}}, %{{.*}}: f32
- %0 = addf %lhs, %rhs: f32
+ %0 = arith.addf %lhs, %rhs: f32
// CHECK: spv.FSub %{{.*}}, %{{.*}}: f32
- %1 = subf %lhs, %rhs: f32
+ %1 = arith.subf %lhs, %rhs: f32
// CHECK: spv.FMul %{{.*}}, %{{.*}}: f32
- %2 = mulf %lhs, %rhs: f32
+ %2 = arith.mulf %lhs, %rhs: f32
// CHECK: spv.FDiv %{{.*}}, %{{.*}}: f32
- %3 = divf %lhs, %rhs: f32
+ %3 = arith.divf %lhs, %rhs: f32
// CHECK: spv.FRem %{{.*}}, %{{.*}}: f32
- %4 = remf %lhs, %rhs: f32
+ %4 = arith.remf %lhs, %rhs: f32
// CHECK: spv.GLSL.FMax %{{.*}}, %{{.*}}: f32
%5 = maxf %lhs, %rhs: f32
// CHECK: spv.GLSL.FMin %{{.*}}, %{{.*}}: f32
// CHECK-LABEL: @int_vector234
func @int_vector234(%arg0: vector<2xi8>, %arg1: vector<4xi64>) {
// CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<2xi8>
- %0 = divi_signed %arg0, %arg0: vector<2xi8>
+ %0 = arith.divsi %arg0, %arg0: vector<2xi8>
// CHECK: spv.UDiv %{{.*}}, %{{.*}}: vector<4xi64>
- %1 = divi_unsigned %arg1, %arg1: vector<4xi64>
+ %1 = arith.divui %arg1, %arg1: vector<4xi64>
return
}
// CHECK: %[[POS:.+]] = spv.IEqual %[[LHS]], %[[LABS]] : vector<3xi16>
// CHECK: %[[NEG:.+]] = spv.SNegate %[[ABS]] : vector<3xi16>
// CHECK: %{{.+}} = spv.Select %[[POS]], %[[ABS]], %[[NEG]] : vector<3xi1>, vector<3xi16>
- %0 = remi_signed %arg0, %arg1: vector<3xi16>
+ %0 = arith.remsi %arg0, %arg1: vector<3xi16>
return
}
// CHECK-LABEL: @float_vector234
func @float_vector234(%arg0: vector<2xf16>, %arg1: vector<3xf64>) {
// CHECK: spv.FAdd %{{.*}}, %{{.*}}: vector<2xf16>
- %0 = addf %arg0, %arg0: vector<2xf16>
+ %0 = arith.addf %arg0, %arg0: vector<2xf16>
// CHECK: spv.FMul %{{.*}}, %{{.*}}: vector<3xf64>
- %1 = mulf %arg1, %arg1: vector<3xf64>
+ %1 = arith.mulf %arg1, %arg1: vector<3xf64>
return
}
// CHECK-LABEL: @one_elem_vector
func @one_elem_vector(%arg0: vector<1xi32>) {
// CHECK: spv.IAdd %{{.+}}, %{{.+}}: i32
- %0 = addi %arg0, %arg0: vector<1xi32>
+ %0 = arith.addi %arg0, %arg0: vector<1xi32>
return
}
// CHECK-LABEL: @unsupported_5elem_vector
func @unsupported_5elem_vector(%arg0: vector<5xi32>) {
// CHECK: subi
- %1 = subi %arg0, %arg0: vector<5xi32>
+ %1 = arith.subi %arg0, %arg0: vector<5xi32>
return
}
// CHECK-LABEL: @unsupported_2x2elem_vector
func @unsupported_2x2elem_vector(%arg0: vector<2x2xi32>) {
// CHECK: muli
- %2 = muli %arg0, %arg0: vector<2x2xi32>
+ %2 = arith.muli %arg0, %arg0: vector<2x2xi32>
return
}
// CHECK-LABEL: @int_vector23
func @int_vector23(%arg0: vector<2xi8>, %arg1: vector<3xi16>) {
// CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<2xi32>
- %0 = divi_signed %arg0, %arg0: vector<2xi8>
+ %0 = arith.divsi %arg0, %arg0: vector<2xi8>
// CHECK: spv.SDiv %{{.*}}, %{{.*}}: vector<3xi32>
- %1 = divi_signed %arg1, %arg1: vector<3xi16>
+ %1 = arith.divsi %arg1, %arg1: vector<3xi16>
return
}
// CHECK-LABEL: @float_scalar
func @float_scalar(%arg0: f16, %arg1: f64) {
// CHECK: spv.FAdd %{{.*}}, %{{.*}}: f32
- %0 = addf %arg0, %arg0: f16
+ %0 = arith.addf %arg0, %arg0: f16
// CHECK: spv.FMul %{{.*}}, %{{.*}}: f32
- %1 = mulf %arg1, %arg1: f64
+ %1 = arith.mulf %arg1, %arg1: f64
return
}
func @int_vector4_invalid(%arg0: vector<4xi64>) {
// expected-error @+2 {{bitwidth emulation is not implemented yet on unsigned op}}
// expected-error @+1 {{op requires the same type for all operands and results}}
- %0 = divi_unsigned %arg0, %arg0: vector<4xi64>
+ %0 = arith.divui %arg0, %arg0: vector<4xi64>
return
}
// CHECK-LABEL: @bitwise_scalar
func @bitwise_scalar(%arg0 : i32, %arg1 : i32) {
// CHECK: spv.BitwiseAnd
- %0 = and %arg0, %arg1 : i32
+ %0 = arith.andi %arg0, %arg1 : i32
// CHECK: spv.BitwiseOr
- %1 = or %arg0, %arg1 : i32
+ %1 = arith.ori %arg0, %arg1 : i32
// CHECK: spv.BitwiseXor
- %2 = xor %arg0, %arg1 : i32
+ %2 = arith.xori %arg0, %arg1 : i32
return
}
// CHECK-LABEL: @bitwise_vector
func @bitwise_vector(%arg0 : vector<4xi32>, %arg1 : vector<4xi32>) {
// CHECK: spv.BitwiseAnd
- %0 = and %arg0, %arg1 : vector<4xi32>
+ %0 = arith.andi %arg0, %arg1 : vector<4xi32>
// CHECK: spv.BitwiseOr
- %1 = or %arg0, %arg1 : vector<4xi32>
+ %1 = arith.ori %arg0, %arg1 : vector<4xi32>
// CHECK: spv.BitwiseXor
- %2 = xor %arg0, %arg1 : vector<4xi32>
+ %2 = arith.xori %arg0, %arg1 : vector<4xi32>
return
}
// CHECK-LABEL: @logical_scalar
func @logical_scalar(%arg0 : i1, %arg1 : i1) {
// CHECK: spv.LogicalAnd
- %0 = and %arg0, %arg1 : i1
+ %0 = arith.andi %arg0, %arg1 : i1
// CHECK: spv.LogicalOr
- %1 = or %arg0, %arg1 : i1
+ %1 = arith.ori %arg0, %arg1 : i1
// CHECK: spv.LogicalNotEqual
- %2 = xor %arg0, %arg1 : i1
+ %2 = arith.xori %arg0, %arg1 : i1
return
}
// CHECK-LABEL: @logical_vector
func @logical_vector(%arg0 : vector<4xi1>, %arg1 : vector<4xi1>) {
// CHECK: spv.LogicalAnd
- %0 = and %arg0, %arg1 : vector<4xi1>
+ %0 = arith.andi %arg0, %arg1 : vector<4xi1>
// CHECK: spv.LogicalOr
- %1 = or %arg0, %arg1 : vector<4xi1>
+ %1 = arith.ori %arg0, %arg1 : vector<4xi1>
// CHECK: spv.LogicalNotEqual
- %2 = xor %arg0, %arg1 : vector<4xi1>
+ %2 = arith.xori %arg0, %arg1 : vector<4xi1>
return
}
// CHECK-LABEL: @shift_scalar
func @shift_scalar(%arg0 : i32, %arg1 : i32) {
// CHECK: spv.ShiftLeftLogical
- %0 = shift_left %arg0, %arg1 : i32
+ %0 = arith.shli %arg0, %arg1 : i32
// CHECK: spv.ShiftRightArithmetic
- %1 = shift_right_signed %arg0, %arg1 : i32
+ %1 = arith.shrsi %arg0, %arg1 : i32
// CHECK: spv.ShiftRightLogical
- %2 = shift_right_unsigned %arg0, %arg1 : i32
+ %2 = arith.shrui %arg0, %arg1 : i32
return
}
// CHECK-LABEL: @shift_vector
func @shift_vector(%arg0 : vector<4xi32>, %arg1 : vector<4xi32>) {
// CHECK: spv.ShiftLeftLogical
- %0 = shift_left %arg0, %arg1 : vector<4xi32>
+ %0 = arith.shli %arg0, %arg1 : vector<4xi32>
// CHECK: spv.ShiftRightArithmetic
- %1 = shift_right_signed %arg0, %arg1 : vector<4xi32>
+ %1 = arith.shrsi %arg0, %arg1 : vector<4xi32>
// CHECK: spv.ShiftRightLogical
- %2 = shift_right_unsigned %arg0, %arg1 : vector<4xi32>
+ %2 = arith.shrui %arg0, %arg1 : vector<4xi32>
return
}
// CHECK-LABEL: @cmpf
func @cmpf(%arg0 : f32, %arg1 : f32) {
// CHECK: spv.FOrdEqual
- %1 = cmpf oeq, %arg0, %arg1 : f32
+ %1 = arith.cmpf oeq, %arg0, %arg1 : f32
// CHECK: spv.FOrdGreaterThan
- %2 = cmpf ogt, %arg0, %arg1 : f32
+ %2 = arith.cmpf ogt, %arg0, %arg1 : f32
// CHECK: spv.FOrdGreaterThanEqual
- %3 = cmpf oge, %arg0, %arg1 : f32
+ %3 = arith.cmpf oge, %arg0, %arg1 : f32
// CHECK: spv.FOrdLessThan
- %4 = cmpf olt, %arg0, %arg1 : f32
+ %4 = arith.cmpf olt, %arg0, %arg1 : f32
// CHECK: spv.FOrdLessThanEqual
- %5 = cmpf ole, %arg0, %arg1 : f32
+ %5 = arith.cmpf ole, %arg0, %arg1 : f32
// CHECK: spv.FOrdNotEqual
- %6 = cmpf one, %arg0, %arg1 : f32
+ %6 = arith.cmpf one, %arg0, %arg1 : f32
// CHECK: spv.FUnordEqual
- %7 = cmpf ueq, %arg0, %arg1 : f32
+ %7 = arith.cmpf ueq, %arg0, %arg1 : f32
// CHECK: spv.FUnordGreaterThan
- %8 = cmpf ugt, %arg0, %arg1 : f32
+ %8 = arith.cmpf ugt, %arg0, %arg1 : f32
// CHECK: spv.FUnordGreaterThanEqual
- %9 = cmpf uge, %arg0, %arg1 : f32
+ %9 = arith.cmpf uge, %arg0, %arg1 : f32
// CHECK: spv.FUnordLessThan
- %10 = cmpf ult, %arg0, %arg1 : f32
+ %10 = arith.cmpf ult, %arg0, %arg1 : f32
// CHECK: FUnordLessThanEqual
- %11 = cmpf ule, %arg0, %arg1 : f32
+ %11 = arith.cmpf ule, %arg0, %arg1 : f32
// CHECK: spv.FUnordNotEqual
- %12 = cmpf une, %arg0, %arg1 : f32
+ %12 = arith.cmpf une, %arg0, %arg1 : f32
return
}
// CHECK-LABEL: @cmpf
func @cmpf(%arg0 : f32, %arg1 : f32) {
// CHECK: spv.Ordered
- %0 = cmpf ord, %arg0, %arg1 : f32
+ %0 = arith.cmpf ord, %arg0, %arg1 : f32
// CHECK: spv.Unordered
- %1 = cmpf uno, %arg0, %arg1 : f32
+ %1 = arith.cmpf uno, %arg0, %arg1 : f32
return
}
// CHECK-NEXT: %[[RHS_NAN:.+]] = spv.IsNan %[[RHS]] : f32
// CHECK-NEXT: %[[OR:.+]] = spv.LogicalOr %[[LHS_NAN]], %[[RHS_NAN]] : i1
// CHECK-NEXT: %{{.+}} = spv.LogicalNot %[[OR]] : i1
- %0 = cmpf ord, %arg0, %arg1 : f32
+ %0 = arith.cmpf ord, %arg0, %arg1 : f32
// CHECK-NEXT: %[[LHS_NAN:.+]] = spv.IsNan %[[LHS]] : f32
// CHECK-NEXT: %[[RHS_NAN:.+]] = spv.IsNan %[[RHS]] : f32
// CHECK-NEXT: %{{.+}} = spv.LogicalOr %[[LHS_NAN]], %[[RHS_NAN]] : i1
- %1 = cmpf uno, %arg0, %arg1 : f32
+ %1 = arith.cmpf uno, %arg0, %arg1 : f32
return
}
// CHECK-LABEL: @cmpi
func @cmpi(%arg0 : i32, %arg1 : i32) {
// CHECK: spv.IEqual
- %0 = cmpi eq, %arg0, %arg1 : i32
+ %0 = arith.cmpi eq, %arg0, %arg1 : i32
// CHECK: spv.INotEqual
- %1 = cmpi ne, %arg0, %arg1 : i32
+ %1 = arith.cmpi ne, %arg0, %arg1 : i32
// CHECK: spv.SLessThan
- %2 = cmpi slt, %arg0, %arg1 : i32
+ %2 = arith.cmpi slt, %arg0, %arg1 : i32
// CHECK: spv.SLessThanEqual
- %3 = cmpi sle, %arg0, %arg1 : i32
+ %3 = arith.cmpi sle, %arg0, %arg1 : i32
// CHECK: spv.SGreaterThan
- %4 = cmpi sgt, %arg0, %arg1 : i32
+ %4 = arith.cmpi sgt, %arg0, %arg1 : i32
// CHECK: spv.SGreaterThanEqual
- %5 = cmpi sge, %arg0, %arg1 : i32
+ %5 = arith.cmpi sge, %arg0, %arg1 : i32
// CHECK: spv.ULessThan
- %6 = cmpi ult, %arg0, %arg1 : i32
+ %6 = arith.cmpi ult, %arg0, %arg1 : i32
// CHECK: spv.ULessThanEqual
- %7 = cmpi ule, %arg0, %arg1 : i32
+ %7 = arith.cmpi ule, %arg0, %arg1 : i32
// CHECK: spv.UGreaterThan
- %8 = cmpi ugt, %arg0, %arg1 : i32
+ %8 = arith.cmpi ugt, %arg0, %arg1 : i32
// CHECK: spv.UGreaterThanEqual
- %9 = cmpi uge, %arg0, %arg1 : i32
+ %9 = arith.cmpi uge, %arg0, %arg1 : i32
return
}
// CHECK-LABEL: @boolcmpi
func @boolcmpi(%arg0 : i1, %arg1 : i1) {
// CHECK: spv.LogicalEqual
- %0 = cmpi eq, %arg0, %arg1 : i1
+ %0 = arith.cmpi eq, %arg0, %arg1 : i1
// CHECK: spv.LogicalNotEqual
- %1 = cmpi ne, %arg0, %arg1 : i1
+ %1 = arith.cmpi ne, %arg0, %arg1 : i1
return
}
// CHECK-LABEL: @vecboolcmpi
func @vecboolcmpi(%arg0 : vector<4xi1>, %arg1 : vector<4xi1>) {
// CHECK: spv.LogicalEqual
- %0 = cmpi eq, %arg0, %arg1 : vector<4xi1>
+ %0 = arith.cmpi eq, %arg0, %arg1 : vector<4xi1>
// CHECK: spv.LogicalNotEqual
- %1 = cmpi ne, %arg0, %arg1 : vector<4xi1>
+ %1 = arith.cmpi ne, %arg0, %arg1 : vector<4xi1>
return
}
// -----
//===----------------------------------------------------------------------===//
-// std.constant
+// arith.constant
//===----------------------------------------------------------------------===//
module attributes {
// CHECK-LABEL: @constant
func @constant() {
// CHECK: spv.Constant true
- %0 = constant true
+ %0 = arith.constant true
// CHECK: spv.Constant 42 : i32
- %1 = constant 42 : i32
+ %1 = arith.constant 42 : i32
// CHECK: spv.Constant 5.000000e-01 : f32
- %2 = constant 0.5 : f32
+ %2 = arith.constant 0.5 : f32
// CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
- %3 = constant dense<[2, 3]> : vector<2xi32>
+ %3 = arith.constant dense<[2, 3]> : vector<2xi32>
// CHECK: spv.Constant 1 : i32
- %4 = constant 1 : index
+ %4 = arith.constant 1 : index
// CHECK: spv.Constant dense<1> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
- %5 = constant dense<1> : tensor<2x3xi32>
+ %5 = arith.constant dense<1> : tensor<2x3xi32>
// CHECK: spv.Constant dense<1.000000e+00> : tensor<6xf32> : !spv.array<6 x f32, stride=4>
- %6 = constant dense<1.0> : tensor<2x3xf32>
+ %6 = arith.constant dense<1.0> : tensor<2x3xf32>
// CHECK: spv.Constant dense<{{\[}}1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf32> : !spv.array<6 x f32, stride=4>
- %7 = constant dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf32>
+ %7 = arith.constant dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf32>
// CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
- %8 = constant dense<[[1, 2, 3], [4, 5, 6]]> : tensor<2x3xi32>
+ %8 = arith.constant dense<[[1, 2, 3], [4, 5, 6]]> : tensor<2x3xi32>
// CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
- %9 = constant dense<[[1, 2], [3, 4], [5, 6]]> : tensor<3x2xi32>
+ %9 = arith.constant dense<[[1, 2], [3, 4], [5, 6]]> : tensor<3x2xi32>
// CHECK: spv.Constant dense<{{\[}}1, 2, 3, 4, 5, 6]> : tensor<6xi32> : !spv.array<6 x i32, stride=4>
- %10 = constant dense<[1, 2, 3, 4, 5, 6]> : tensor<6xi32>
+ %10 = arith.constant dense<[1, 2, 3, 4, 5, 6]> : tensor<6xi32>
return
}
// CHECK-LABEL: @constant_16bit
func @constant_16bit() {
// CHECK: spv.Constant 4 : i16
- %0 = constant 4 : i16
+ %0 = arith.constant 4 : i16
// CHECK: spv.Constant 5.000000e+00 : f16
- %1 = constant 5.0 : f16
+ %1 = arith.constant 5.0 : f16
// CHECK: spv.Constant dense<[2, 3]> : vector<2xi16>
- %2 = constant dense<[2, 3]> : vector<2xi16>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi16>
// CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf16> : !spv.array<5 x f16, stride=2>
- %3 = constant dense<4.0> : tensor<5xf16>
+ %3 = arith.constant dense<4.0> : tensor<5xf16>
return
}
// CHECK-LABEL: @constant_64bit
func @constant_64bit() {
// CHECK: spv.Constant 4 : i64
- %0 = constant 4 : i64
+ %0 = arith.constant 4 : i64
// CHECK: spv.Constant 5.000000e+00 : f64
- %1 = constant 5.0 : f64
+ %1 = arith.constant 5.0 : f64
// CHECK: spv.Constant dense<[2, 3]> : vector<2xi64>
- %2 = constant dense<[2, 3]> : vector<2xi64>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi64>
// CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf64> : !spv.array<5 x f64, stride=8>
- %3 = constant dense<4.0> : tensor<5xf64>
+ %3 = arith.constant dense<4.0> : tensor<5xf64>
return
}
// CHECK-LABEL: @constant_16bit
func @constant_16bit() {
// CHECK: spv.Constant 4 : i32
- %0 = constant 4 : i16
+ %0 = arith.constant 4 : i16
// CHECK: spv.Constant 5.000000e+00 : f32
- %1 = constant 5.0 : f16
+ %1 = arith.constant 5.0 : f16
// CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
- %2 = constant dense<[2, 3]> : vector<2xi16>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi16>
// CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf32> : !spv.array<5 x f32, stride=4>
- %3 = constant dense<4.0> : tensor<5xf16>
+ %3 = arith.constant dense<4.0> : tensor<5xf16>
// CHECK: spv.Constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00]> : tensor<4xf32> : !spv.array<4 x f32, stride=4>
- %4 = constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
+ %4 = arith.constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
return
}
// CHECK-LABEL: @constant_64bit
func @constant_64bit() {
// CHECK: spv.Constant 4 : i32
- %0 = constant 4 : i64
+ %0 = arith.constant 4 : i64
// CHECK: spv.Constant 5.000000e+00 : f32
- %1 = constant 5.0 : f64
+ %1 = arith.constant 5.0 : f64
// CHECK: spv.Constant dense<[2, 3]> : vector<2xi32>
- %2 = constant dense<[2, 3]> : vector<2xi64>
+ %2 = arith.constant dense<[2, 3]> : vector<2xi64>
// CHECK: spv.Constant dense<4.000000e+00> : tensor<5xf32> : !spv.array<5 x f32, stride=4>
- %3 = constant dense<4.0> : tensor<5xf64>
+ %3 = arith.constant dense<4.0> : tensor<5xf64>
// CHECK: spv.Constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00]> : tensor<4xf32> : !spv.array<4 x f32, stride=4>
- %4 = constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
+ %4 = arith.constant dense<[[1.0, 2.0], [3.0, 4.0]]> : tensor<2x2xf16>
return
}
// CHECK-LABEL: @corner_cases
func @corner_cases() {
// CHECK: %{{.*}} = spv.Constant -1 : i32
- %0 = constant 4294967295 : i64 // 2^32 - 1
+ %0 = arith.constant 4294967295 : i64 // 2^32 - 1
// CHECK: %{{.*}} = spv.Constant 2147483647 : i32
- %1 = constant 2147483647 : i64 // 2^31 - 1
+ %1 = arith.constant 2147483647 : i64 // 2^31 - 1
// CHECK: %{{.*}} = spv.Constant -2147483648 : i32
- %2 = constant 2147483648 : i64 // 2^31
+ %2 = arith.constant 2147483648 : i64 // 2^31
// CHECK: %{{.*}} = spv.Constant -2147483648 : i32
- %3 = constant -2147483648 : i64 // -2^31
+ %3 = arith.constant -2147483648 : i64 // -2^31
// CHECK: %{{.*}} = spv.Constant -1 : i32
- %5 = constant -1 : i64
+ %5 = arith.constant -1 : i64
// CHECK: %{{.*}} = spv.Constant -2 : i32
- %6 = constant -2 : i64
+ %6 = arith.constant -2 : i64
// CHECK: %{{.*}} = spv.Constant -1 : i32
- %7 = constant -1 : index
+ %7 = arith.constant -1 : index
// CHECK: %{{.*}} = spv.Constant -2 : i32
- %8 = constant -2 : index
+ %8 = arith.constant -2 : index
// CHECK: spv.Constant false
- %9 = constant false
+ %9 = arith.constant false
// CHECK: spv.Constant true
- %10 = constant true
+ %10 = arith.constant true
return
}
// CHECK-LABEL: @unsupported_cases
func @unsupported_cases() {
- // CHECK: %{{.*}} = constant 4294967296 : i64
- %0 = constant 4294967296 : i64 // 2^32
- // CHECK: %{{.*}} = constant -2147483649 : i64
- %1 = constant -2147483649 : i64 // -2^31 - 1
- // CHECK: %{{.*}} = constant 1.0000000000000002 : f64
- %2 = constant 0x3FF0000000000001 : f64 // smallest number > 1
+ // CHECK: %{{.*}} = arith.constant 4294967296 : i64
+ %0 = arith.constant 4294967296 : i64 // 2^32
+ // CHECK: %{{.*}} = arith.constant -2147483649 : i64
+ %1 = arith.constant -2147483649 : i64 // -2^31 - 1
+ // CHECK: %{{.*}} = arith.constant 1.0000000000000002 : f64
+ %2 = arith.constant 0x3FF0000000000001 : f64 // smallest number > 1
return
}
// CHECK-LABEL: index_cast1
func @index_cast1(%arg0: i16) {
// CHECK: spv.SConvert %{{.+}} : i16 to i32
- %0 = index_cast %arg0 : i16 to index
+ %0 = arith.index_cast %arg0 : i16 to index
return
}
// CHECK-LABEL: index_cast2
func @index_cast2(%arg0: index) {
// CHECK: spv.SConvert %{{.+}} : i32 to i16
- %0 = index_cast %arg0 : index to i16
+ %0 = arith.index_cast %arg0 : index to i16
return
}
// CHECK-LABEL: index_cast3
func @index_cast3(%arg0: i32) {
// CHECK-NOT: spv.SConvert
- %0 = index_cast %arg0 : i32 to index
+ %0 = arith.index_cast %arg0 : i32 to index
return
}
// CHECK-LABEL: index_cast4
func @index_cast4(%arg0: index) {
// CHECK-NOT: spv.SConvert
- %0 = index_cast %arg0 : index to i32
+ %0 = arith.index_cast %arg0 : index to i32
return
}
// CHECK-LABEL: @fpext1
func @fpext1(%arg0: f16) -> f64 {
// CHECK: spv.FConvert %{{.*}} : f16 to f64
- %0 = std.fpext %arg0 : f16 to f64
+ %0 = arith.extf %arg0 : f16 to f64
return %0 : f64
}
// CHECK-LABEL: @fpext2
func @fpext2(%arg0 : f32) -> f64 {
// CHECK: spv.FConvert %{{.*}} : f32 to f64
- %0 = std.fpext %arg0 : f32 to f64
+ %0 = arith.extf %arg0 : f32 to f64
return %0 : f64
}
// CHECK-LABEL: @fptrunc1
func @fptrunc1(%arg0 : f64) -> f16 {
// CHECK: spv.FConvert %{{.*}} : f64 to f16
- %0 = std.fptrunc %arg0 : f64 to f16
+ %0 = arith.truncf %arg0 : f64 to f16
return %0 : f16
}
// CHECK-LABEL: @fptrunc2
func @fptrunc2(%arg0: f32) -> f16 {
// CHECK: spv.FConvert %{{.*}} : f32 to f16
- %0 = std.fptrunc %arg0 : f32 to f16
+ %0 = arith.truncf %arg0 : f32 to f16
return %0 : f16
}
// CHECK-LABEL: @sitofp1
func @sitofp1(%arg0 : i32) -> f32 {
// CHECK: spv.ConvertSToF %{{.*}} : i32 to f32
- %0 = std.sitofp %arg0 : i32 to f32
+ %0 = arith.sitofp %arg0 : i32 to f32
return %0 : f32
}
// CHECK-LABEL: @sitofp2
func @sitofp2(%arg0 : i64) -> f64 {
// CHECK: spv.ConvertSToF %{{.*}} : i64 to f64
- %0 = std.sitofp %arg0 : i64 to f64
+ %0 = arith.sitofp %arg0 : i64 to f64
return %0 : f64
}
// CHECK-LABEL: @uitofp_i16_f32
func @uitofp_i16_f32(%arg0: i16) -> f32 {
// CHECK: spv.ConvertUToF %{{.*}} : i16 to f32
- %0 = std.uitofp %arg0 : i16 to f32
+ %0 = arith.uitofp %arg0 : i16 to f32
return %0 : f32
}
// CHECK-LABEL: @uitofp_i32_f32
func @uitofp_i32_f32(%arg0 : i32) -> f32 {
// CHECK: spv.ConvertUToF %{{.*}} : i32 to f32
- %0 = std.uitofp %arg0 : i32 to f32
+ %0 = arith.uitofp %arg0 : i32 to f32
return %0 : f32
}
// CHECK: %[[ZERO:.+]] = spv.Constant 0.000000e+00 : f32
// CHECK: %[[ONE:.+]] = spv.Constant 1.000000e+00 : f32
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, f32
- %0 = std.uitofp %arg0 : i1 to f32
+ %0 = arith.uitofp %arg0 : i1 to f32
return %0 : f32
}
// CHECK: %[[ZERO:.+]] = spv.Constant 0.000000e+00 : f64
// CHECK: %[[ONE:.+]] = spv.Constant 1.000000e+00 : f64
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, f64
- %0 = std.uitofp %arg0 : i1 to f64
+ %0 = arith.uitofp %arg0 : i1 to f64
return %0 : f64
}
// CHECK: %[[ZERO:.+]] = spv.Constant dense<0.000000e+00> : vector<4xf32>
// CHECK: %[[ONE:.+]] = spv.Constant dense<1.000000e+00> : vector<4xf32>
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xf32>
- %0 = std.uitofp %arg0 : vector<4xi1> to vector<4xf32>
+ %0 = arith.uitofp %arg0 : vector<4xi1> to vector<4xf32>
return %0 : vector<4xf32>
}
// CHECK-LABEL: @sexti1
func @sexti1(%arg0: i16) -> i64 {
// CHECK: spv.SConvert %{{.*}} : i16 to i64
- %0 = std.sexti %arg0 : i16 to i64
+ %0 = arith.extsi %arg0 : i16 to i64
return %0 : i64
}
// CHECK-LABEL: @sexti2
func @sexti2(%arg0 : i32) -> i64 {
// CHECK: spv.SConvert %{{.*}} : i32 to i64
- %0 = std.sexti %arg0 : i32 to i64
+ %0 = arith.extsi %arg0 : i32 to i64
return %0 : i64
}
// CHECK-LABEL: @zexti1
func @zexti1(%arg0: i16) -> i64 {
// CHECK: spv.UConvert %{{.*}} : i16 to i64
- %0 = std.zexti %arg0 : i16 to i64
+ %0 = arith.extui %arg0 : i16 to i64
return %0 : i64
}
// CHECK-LABEL: @zexti2
func @zexti2(%arg0 : i32) -> i64 {
// CHECK: spv.UConvert %{{.*}} : i32 to i64
- %0 = std.zexti %arg0 : i32 to i64
+ %0 = arith.extui %arg0 : i32 to i64
return %0 : i64
}
// CHECK: %[[ZERO:.+]] = spv.Constant 0 : i32
// CHECK: %[[ONE:.+]] = spv.Constant 1 : i32
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : i1, i32
- %0 = std.zexti %arg0 : i1 to i32
+ %0 = arith.extui %arg0 : i1 to i32
return %0 : i32
}
// CHECK: %[[ZERO:.+]] = spv.Constant dense<0> : vector<4xi32>
// CHECK: %[[ONE:.+]] = spv.Constant dense<1> : vector<4xi32>
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xi32>
- %0 = std.zexti %arg0 : vector<4xi1> to vector<4xi32>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi32>
return %0 : vector<4xi32>
}
// CHECK: %[[ZERO:.+]] = spv.Constant dense<0> : vector<4xi64>
// CHECK: %[[ONE:.+]] = spv.Constant dense<1> : vector<4xi64>
// CHECK: spv.Select %{{.*}}, %[[ONE]], %[[ZERO]] : vector<4xi1>, vector<4xi64>
- %0 = std.zexti %arg0 : vector<4xi1> to vector<4xi64>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi64>
return %0 : vector<4xi64>
}
// CHECK-LABEL: @trunci1
func @trunci1(%arg0 : i64) -> i16 {
// CHECK: spv.SConvert %{{.*}} : i64 to i16
- %0 = std.trunci %arg0 : i64 to i16
+ %0 = arith.trunci %arg0 : i64 to i16
return %0 : i16
}
// CHECK-LABEL: @trunci2
func @trunci2(%arg0: i32) -> i16 {
// CHECK: spv.SConvert %{{.*}} : i32 to i16
- %0 = std.trunci %arg0 : i32 to i16
+ %0 = arith.trunci %arg0 : i32 to i16
return %0 : i16
}
// CHECK-DAG: %[[TRUE:.*]] = spv.Constant true
// CHECK-DAG: %[[FALSE:.*]] = spv.Constant false
// CHECK: spv.Select %[[IS_ONE]], %[[TRUE]], %[[FALSE]] : i1, i1
- %0 = std.trunci %arg0 : i32 to i1
+ %0 = arith.trunci %arg0 : i32 to i1
return %0 : i1
}
// CHECK-DAG: %[[TRUE:.*]] = spv.Constant dense<true> : vector<4xi1>
// CHECK-DAG: %[[FALSE:.*]] = spv.Constant dense<false> : vector<4xi1>
// CHECK: spv.Select %[[IS_ONE]], %[[TRUE]], %[[FALSE]] : vector<4xi1>, vector<4xi1>
- %0 = std.trunci %arg0 : vector<4xi32> to vector<4xi1>
+ %0 = arith.trunci %arg0 : vector<4xi32> to vector<4xi1>
return %0 : vector<4xi1>
}
// CHECK-LABEL: @fptosi1
func @fptosi1(%arg0 : f32) -> i32 {
// CHECK: spv.ConvertFToS %{{.*}} : f32 to i32
- %0 = std.fptosi %arg0 : f32 to i32
+ %0 = arith.fptosi %arg0 : f32 to i32
return %0 : i32
}
// CHECK-LABEL: @fptosi2
func @fptosi2(%arg0 : f16) -> i16 {
// CHECK: spv.ConvertFToS %{{.*}} : f16 to i16
- %0 = std.fptosi %arg0 : f16 to i16
+ %0 = arith.fptosi %arg0 : f16 to i16
return %0 : i16
}
// CHECK-SAME: %[[ARG:.*]]: f32
func @fpext1(%arg0: f16) -> f64 {
// CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f64
- %0 = std.fpext %arg0 : f16 to f64
+ %0 = arith.extf %arg0 : f16 to f64
return %0: f64
}
// CHECK-SAME: %[[ARG:.*]]: f32
func @fpext2(%arg0 : f32) -> f64 {
// CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f64
- %0 = std.fpext %arg0 : f32 to f64
+ %0 = arith.extf %arg0 : f32 to f64
return %0: f64
}
// CHECK-SAME: %[[ARG:.*]]: f32
func @fptrunc1(%arg0 : f64) -> f16 {
// CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f16
- %0 = std.fptrunc %arg0 : f64 to f16
+ %0 = arith.truncf %arg0 : f64 to f16
return %0: f16
}
// CHECK-SAME: %[[ARG:.*]]: f32
func @fptrunc2(%arg0: f32) -> f16 {
// CHECK-NEXT: spv.FConvert %[[ARG]] : f32 to f16
- %0 = std.fptrunc %arg0 : f32 to f16
+ %0 = arith.truncf %arg0 : f32 to f16
return %0: f16
}
// CHECK-LABEL: @sitofp
func @sitofp(%arg0 : i64) -> f64 {
// CHECK: spv.ConvertSToF %{{.*}} : i32 to f32
- %0 = std.sitofp %arg0 : i64 to f64
+ %0 = arith.sitofp %arg0 : i64 to f64
return %0: f64
}
[SPV_KHR_storage_buffer_storage_class]>, {}>
} {
-//===----------------------------------------------------------------------===//
-// std.select
-//===----------------------------------------------------------------------===//
-
// CHECK-LABEL: @select
func @select(%arg0 : i32, %arg1 : i32) {
- %0 = cmpi sle, %arg0, %arg1 : i32
+ %0 = arith.cmpi sle, %arg0, %arg1 : i32
// CHECK: spv.Select
%1 = select %0, %arg0, %arg1 : i32
return
// CHECK-SAME: (%[[A:.+]]: i32, %[[B:.+]]: i32, %[[C:.+]]: i32)
func @tensor_extract_constant(%a : index, %b: index, %c: index) -> i32 {
// CHECK: %[[CST:.+]] = spv.Constant dense<[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]>
- %cst = constant dense<[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]> : tensor<2x2x3xi32>
+ %cst = arith.constant dense<[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]> : tensor<2x2x3xi32>
// CHECK: %[[VAR:.+]] = spv.Variable init(%[[CST]]) : !spv.ptr<!spv.array<12 x i32, stride=4>, Function>
// CHECK: %[[C0:.+]] = spv.Constant 0 : i32
// CHECK: %[[C6:.+]] = spv.Constant 6 : i32
// CHECK: [[INIT:%.+]] = linalg.init_tensor [] : tensor<f32>
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = []} ins(%arg0 : tensor<f32>) outs([[INIT]] : tensor<f32>) {
// CHECK: ^bb0(%arg1: f32, %arg2: f32):
- // CHECK: [[ELEMENT:%.+]] = absf %arg1
+ // CHECK: [[ELEMENT:%.+]] = math.abs %arg1
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<f32>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2] : tensor<2xf32>
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0 : tensor<2xf32>) outs([[INIT]] : tensor<2xf32>) {
// CHECK: ^bb0(%arg1: f32, %arg2: f32):
- // CHECK: [[ELEMENT:%.+]] = absf %arg1
+ // CHECK: [[ELEMENT:%.+]] = math.abs %arg1
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<2xf32>
%0 = "tosa.abs"(%arg0) : (tensor<2xf32>) -> tensor<2xf32>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2, 3] : tensor<2x3xf32>
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel", "parallel"]} ins(%arg0 : tensor<2x3xf32>) outs([[INIT]] : tensor<2x3xf32>) {
// CHECK: ^bb0(%arg1: f32, %arg2: f32):
- // CHECK: [[ELEMENT:%.+]] = absf %arg1
+ // CHECK: [[ELEMENT:%.+]] = math.abs %arg1
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<2x3xf32>
%0 = "tosa.abs"(%arg0) : (tensor<2x3xf32>) -> tensor<2x3xf32>
// CHECK-LABEL: @test_abs
func @test_abs(%arg0: tensor<?xf32>) -> tensor<?xf32> {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[DIM:.+]] = tensor.dim %arg0, %[[C0]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [%[[DIM]]]
// CHECK: linalg.generic
- // CHECK: absf
+ // CHECK: math.abs
%0 = "tosa.abs"(%arg0) : (tensor<?xf32>) -> tensor<?xf32>
return %0 : tensor<?xf32>
}
// CHECK-LABEL: @test_abs_dyn
func @test_abs_dyn(%arg0: tensor<2x?xf32>) -> tensor<2x?xf32> {
- // CHECK: %[[C1:.+]] = constant 1
+ // CHECK: %[[C1:.+]] = arith.constant 1
// CHECK: %[[DIM:.+]] = tensor.dim %arg0, %[[C1]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [2, %[[DIM]]]
// CHECK: linalg.generic
- // CHECK: absf
+ // CHECK: math.abs
%0 = "tosa.abs"(%arg0) : (tensor<2x?xf32>) -> tensor<2x?xf32>
return %0 : tensor<2x?xf32>
}
// CHECK: [[RESHAPE:%.+]] = linalg.tensor_collapse_shape %arg0
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel"]} ins([[RESHAPE]], %arg1 : tensor<f32>, tensor<2xf32>) outs([[INIT]] : tensor<2xf32>) {
// CHECK: ^bb0(%arg2: f32, %arg3: f32, %arg4: f32):
- // CHECK: [[ELEMENT:%.+]] = addf %arg2, %arg3 : f32
+ // CHECK: [[ELEMENT:%.+]] = arith.addf %arg2, %arg3 : f32
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<2xf32>
%0 = "tosa.add"(%arg0, %arg1) : (tensor<1xf32>, tensor<2xf32>) -> tensor<2xf32>
// CHECK: [[RESHAPE:%.+]] = linalg.tensor_collapse_shape %arg1
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0, [[RESHAPE]] : tensor<2xf32>, tensor<f32>) outs([[INIT]] : tensor<2xf32>) {
// CHECK: ^bb0(%arg2: f32, %arg3: f32, %arg4: f32):
- // CHECK: [[ELEMENT:%.+]] = addf %arg2, %arg3 : f32
+ // CHECK: [[ELEMENT:%.+]] = arith.addf %arg2, %arg3 : f32
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<2xf32>
%0 = "tosa.add"(%arg0, %arg1) : (tensor<2xf32>, tensor<1xf32>) -> tensor<2xf32>
// CHECK: [[RESHAPE2:%.+]] = linalg.tensor_collapse_shape %arg1 {{\[}}[0, 1]]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP1]], #[[$MAP2]], #[[$MAP0]]], iterator_types = ["parallel", "parallel"]} ins([[RESHAPE1]], [[RESHAPE2]] : tensor<3xf32>, tensor<2xf32>) outs([[INIT]] : tensor<2x3xf32>) {
// CHECK: ^bb0(%arg2: f32, %arg3: f32, %arg4: f32):
- // CHECK: [[ELEMENT:%.+]] = addf %arg2, %arg3 : f32
+ // CHECK: [[ELEMENT:%.+]] = arith.addf %arg2, %arg3 : f32
// CHECK: linalg.yield [[ELEMENT]] : f32
// CHECK: } -> tensor<2x3xf32>
%0 = "tosa.add"(%arg0, %arg1) : (tensor<1x3xf32>, tensor<2x1xf32>) -> tensor<2x3xf32>
%0 = "tosa.tanh"(%arg0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: absf
+ // CHECK: math.abs
%1 = "tosa.abs"(%arg0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: addf
+ // CHECK: arith.addf
%2 = "tosa.add"(%0, %0) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: subf
+ // CHECK: arith.subf
%3 = "tosa.sub"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: mulf
+ // CHECK: arith.mulf
%4 = "tosa.mul"(%0, %1) {shift = 0 : i32} : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: negf
+ // CHECK: arith.negf
%5 = "tosa.negate"(%0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
%9 = "tosa.exp"(%arg0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
%10 = "tosa.greater"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
%11 = "tosa.greater_equal"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
%12 = "tosa.equal"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xi1>
// CHECK: linalg.generic
%13 = "tosa.select"(%10, %0, %1) : (tensor<1xi1>, tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
// CHECK: select
%14 = "tosa.maximum"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
// CHECK: select
%15 = "tosa.minimum"(%0, %1) : (tensor<1xf32>, tensor<1xf32>) -> tensor<1xf32>
%17 = "tosa.floor"(%0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
// CHECK: select
%18 = "tosa.clamp"(%0) {min_int = 1 : i64, max_int = 5 : i64, min_fp = 1.0 : f32, max_fp = 5.0 : f32} : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: cmpf
+ // CHECK: arith.cmpf
// CHECK: select
%19 = "tosa.reluN"(%0) {max_int = 5 : i64, max_fp = 5.0 : f32} : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: negf
+ // CHECK: arith.negf
// CHECK: exp
- // CHECK: addf
- // CHECK: divf
+ // CHECK: arith.addf
+ // CHECK: arith.divf
%20 = "tosa.sigmoid"(%0) : (tensor<1xf32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: constant 0.000000e+00
- // CHECK: constant 5.000000e-01
- // CHECK: constant -2.14748365E+9
- // CHECK: constant 2.14748365E+9
- // CHECK: addf
- // CHECK: subf
- // CHECK: cmpf olt
+ // CHECK: arith.constant 0.000000e+00
+ // CHECK: arith.constant 5.000000e-01
+ // CHECK: arith.constant -2.14748365E+9
+ // CHECK: arith.constant 2.14748365E+9
+ // CHECK: arith.addf
+ // CHECK: arith.subf
+ // CHECK: arith.cmpf olt
// CHECK: select
- // CHECK: cmpf olt
+ // CHECK: arith.cmpf olt
// CHECK: select
- // CHECK: cmpf olt
+ // CHECK: arith.cmpf olt
// CHECK: select
- // CHECK: fptosi
+ // CHECK: arith.fptosi
%21 = "tosa.cast"(%0) : (tensor<1xf32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: constant 0
- // CHECK: cmpf
+ // CHECK: arith.constant 0
+ // CHECK: arith.cmpf
%22 = "tosa.cast"(%0) : (tensor<1xf32>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: fptrunc
+ // CHECK: arith.truncf
%23 = "tosa.cast"(%0) : (tensor<1xf32>) -> tensor<1xf16>
// CHECK: linalg.generic
- // CHECK: divf
+ // CHECK: arith.divf
%24 = "tosa.reciprocal"(%0) : (tensor<1xf32>) -> tensor<1xf32>
return
func @test_simple_f16(%arg0: tensor<1xf16>) -> () {
// CHECK: linalg.generic
- // CHECK: fpext
+ // CHECK: arith.extf
%0 = "tosa.cast"(%arg0) : (tensor<1xf16>) -> tensor<1xf32>
return
// CHECK-LABEL: @test_simple_i16
func @test_simple_i16(%arg0: tensor<1xi16>) -> () {
// CHECK: linalg.generic
- // CHECK: sext
- // CHECK: sext
- // CHECK: muli
+ // CHECK: arith.extsi
+ // CHECK: arith.extsi
+ // CHECK: arith.muli
%0 = "tosa.mul"(%arg0, %arg0) {shift = 0 : i32} : (tensor<1xi16>, tensor<1xi16>) -> tensor<1xi32>
return
// CHECK-LABEL: @test_simple_i32
func @test_simple_i32(%arg0: tensor<1xi32>) -> () {
// CHECK: linalg.generic
- // CHECK: addi
+ // CHECK: arith.addi
%0 = "tosa.add"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: subi
+ // CHECK: arith.subi
%1 = "tosa.sub"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: muli
+ // CHECK: arith.muli
%2 = "tosa.mul"(%arg0, %arg0) {shift = 0 : i32} : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: constant 2
+ // CHECK: arith.constant 2
// CHECK: apply_scale
%3 = "tosa.mul"(%arg0, %arg0) {shift = 2 : i32} : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: divi
+ // CHECK: arith.divsi
%4 = "tosa.div"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: [[ZERO:%.+]] = constant 0
- // CHECK: subi [[ZERO]], %arg1
+ // CHECK: [[ZERO:%.+]] = arith.constant 0
+ // CHECK: arith.subi [[ZERO]], %arg1
%5 = "tosa.negate"(%arg0) : (tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
%7 = "tosa.bitwise_or"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: xor
+ // CHECK: arith.xori
%8 = "tosa.bitwise_xor"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: shift_left
+ // CHECK: arith.shli
%9 = "tosa.logical_left_shift"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: shift_right_unsigned
+ // CHECK: arith.shrui
%10 = "tosa.logical_right_shift"(%arg0, %arg0) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: shift_right_signed
+ // CHECK: arith.shrsi
%11 = "tosa.arithmetic_right_shift"(%arg0, %arg0) {round = 0 : i1} : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: constant 1
- // CHECK: constant 0
- // CHECK: constant true
- // CHECK: cmpi
- // CHECK: subi
- // CHECK: shift_right_signed
- // CHECK: trunci
+ // CHECK: arith.constant 1
+ // CHECK: arith.constant 0
+ // CHECK: arith.constant true
+ // CHECK: arith.cmpi
+ // CHECK: arith.subi
+ // CHECK: arith.shrsi
+ // CHECK: arith.trunci
// CHECK: and
// CHECK: and
- // CHECK: zexti
- // CHECK: addi
+ // CHECK: arith.extui
+ // CHECK: arith.addi
%12 = "tosa.arithmetic_right_shift"(%arg0, %arg0) {round = 1 : i1} : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: scf.while
- // CHECK: cmpi ne
+ // CHECK: arith.cmpi ne
// CHECK: scf.condition
- // CHECK: shift_right_unsigned
- // CHECK: subi
+ // CHECK: arith.shrui
+ // CHECK: arith.subi
// CHECK: scf.yield
%13 = "tosa.clz"(%arg0) : (tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
%14 = "tosa.greater"(%0, %1) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
%15 = "tosa.greater_equal"(%0, %1) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi1>
// CHECK: linalg.generic
%16 = "tosa.select"(%14, %0, %1) : (tensor<1xi1>, tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
// CHECK: select
%17 = "tosa.maximum"(%0, %1) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
// CHECK: select
%18 = "tosa.minimum"(%0, %1) : (tensor<1xi32>, tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
// CHECK: select
%19 = "tosa.clamp"(%0) {min_int = 1 : i64, max_int = 5 : i64, min_fp = 1.0 : f32, max_fp = 5.0 : f32} : (tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: cmpi
+ // CHECK: arith.cmpi
// CHECK: select
%20 = "tosa.reluN"(%0) {max_int = 5 : i64, max_fp = 5.0 : f32} : (tensor<1xi32>) -> tensor<1xi32>
// CHECK: linalg.generic
- // CHECK: constant -32768
- // CHECK: constant 32767
- // CHECK: cmpi slt
+ // CHECK: arith.constant -32768
+ // CHECK: arith.constant 32767
+ // CHECK: arith.cmpi slt
// CHECK: select
- // CHECK: cmpi slt
+ // CHECK: arith.cmpi slt
// CHECK: select
- // CHECK: trunci
+ // CHECK: arith.trunci
%21 = "tosa.cast"(%0) : (tensor<1xi32>) -> tensor<1xi16>
// CHECK: linalg.generic
- // CHECK: sexti
+ // CHECK: arith.extsi
%22 = "tosa.cast"(%0) : (tensor<1xi32>) -> tensor<1xi64>
// CHECK: linalg.generic
- // CHECK: constant 0
- // CHECK: cmpi
+ // CHECK: arith.constant 0
+ // CHECK: arith.cmpi
%23 = "tosa.cast"(%0) : (tensor<1xi32>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: sitofp
+ // CHECK: arith.sitofp
%24 = "tosa.cast"(%0) : (tensor<1xi32>) -> tensor<1xf32>
// CHECK: linalg.generic
- // CHECK: constant 0
- // CHECK: cmpi sgt
- // CHECK: subi
+ // CHECK: arith.constant 0
+ // CHECK: arith.cmpi sgt
+ // CHECK: arith.subi
// CHECK: select
%25 = "tosa.abs"(%arg0) : (tensor<1xi32>) -> tensor<1xi32>
// -----
// CHECK-LABEL: @test_simple_ui8
-func @test_simple_ui8(%arg0: tensor<1xui8>) -> () {
+func @test_simple_ui8(%arg0: tensor<1xi8>) -> () {
// CHECK: linalg.generic
- // CHECK: uitofp
- %0 = "tosa.cast"(%arg0) : (tensor<1xui8>) -> tensor<1xf32>
+ // CHECK: sitofp
+ %0 = "tosa.cast"(%arg0) : (tensor<1xi8>) -> tensor<1xf32>
return
}
// CHECK-LABEL: @test_i8
func @test_i8(%arg0: tensor<1xi8>) -> () {
// CHECK: linalg.generic
- // CHECK-DAG: %[[C127:.+]] = constant -127
- // CHECK-DAG: %[[C126:.+]] = constant 126
- // CHECK-DAG: %[[CMP1:.+]] = cmpi slt, %arg1, %[[C127]]
+ // CHECK-DAG: %[[C127:.+]] = arith.constant -127
+ // CHECK-DAG: %[[C126:.+]] = arith.constant 126
+ // CHECK-DAG: %[[CMP1:.+]] = arith.cmpi slt, %arg1, %[[C127]]
// CHECK-DAG: %[[SEL1:.+]] = select %[[CMP1]], %[[C127]]
- // CHECK-DAG: %[[CMP2:.+]] = cmpi slt, %[[C126]], %arg1
+ // CHECK-DAG: %[[CMP2:.+]] = arith.cmpi slt, %[[C126]], %arg1
// CHECK: %[[SEL2:.+]] = select %[[CMP2]], %[[C126]], %[[SEL1]]
%0 = "tosa.clamp"(%arg0) {min_int = -127 : i64, max_int = 126 : i64, min_fp = 0.0 : f32, max_fp = 0.0 : f32} : (tensor<1xi8>) -> tensor<1xi8>
// CHECK: linalg.generic
- // CHECK-DAG: %[[C128:.+]] = constant -128
- // CHECK-DAG: %[[C127:.+]] = constant 127
- // CHECK-DAG: %[[CMP1:.+]] = cmpi slt, %arg1, %[[C128]]
+ // CHECK-DAG: %[[C128:.+]] = arith.constant -128
+ // CHECK-DAG: %[[C127:.+]] = arith.constant 127
+ // CHECK-DAG: %[[CMP1:.+]] = arith.cmpi slt, %arg1, %[[C128]]
// CHECK-DAG: %[[SEL1:.+]] = select %[[CMP1]], %[[C128]]
- // CHECK-DAG: %[[CMP2:.+]] = cmpi slt, %[[C127]], %arg1
+ // CHECK-DAG: %[[CMP2:.+]] = arith.cmpi slt, %[[C127]], %arg1
// CHECK: %[[SEL2:.+]] = select %[[CMP2]], %[[C127]], %[[SEL1]]
%1 = "tosa.clamp"(%arg0) {min_int = -130 : i64, max_int = 130 : i64, min_fp = 0.0 : f32, max_fp = 0.0 : f32} : (tensor<1xi8>) -> tensor<1xi8>
%1 = "tosa.logical_or"(%arg0, %arg1) : (tensor<1xi1>, tensor<1xi1>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: xor
+ // CHECK: arith.xori
%2 = "tosa.logical_xor"(%arg0, %arg1) : (tensor<1xi1>, tensor<1xi1>) -> tensor<1xi1>
// CHECK: linalg.generic
- // CHECK: constant true
- // CHECK: xor
+ // CHECK: arith.constant true
+ // CHECK: arith.xori
%3 = "tosa.logical_not"(%arg0) : (tensor<1xi1>) -> tensor<1xi1>
return
// CHECK-LABEL: @test_negate_quantized
func @test_negate_quantized(%arg0: tensor<1xi8>) -> () {
// CHECK: linalg.generic
- // CHECK: [[ZERO:%.+]] = constant 0
- // CHECK: [[EXT:%.+]] = sexti %arg1 : i8 to i16
- // CHECK: [[SUB:%.+]] = subi [[ZERO]], [[EXT]]
- // CHECK: [[MIN:%.+]] = constant -128
- // CHECK: [[MAX:%.+]] = constant 127
- // CHECK: [[PRED1:%.+]] = cmpi slt, [[SUB]], [[MIN]]
+ // CHECK: [[ZERO:%.+]] = arith.constant 0
+ // CHECK: [[EXT:%.+]] = arith.extsi %arg1 : i8 to i16
+ // CHECK: [[SUB:%.+]] = arith.subi [[ZERO]], [[EXT]]
+ // CHECK: [[MIN:%.+]] = arith.constant -128
+ // CHECK: [[MAX:%.+]] = arith.constant 127
+ // CHECK: [[PRED1:%.+]] = arith.cmpi slt, [[SUB]], [[MIN]]
// CHECK: [[LBOUND:%.+]] = select [[PRED1]], [[MIN]], [[SUB]]
- // CHECK: [[PRED2:%.+]] = cmpi slt, [[MAX]], [[SUB]]
+ // CHECK: [[PRED2:%.+]] = arith.cmpi slt, [[MAX]], [[SUB]]
// CHECK: [[UBOUND:%.+]] = select [[PRED2]], [[MAX]], [[LBOUND]]
- // CHECK: [[TRUNC:%.+]] = trunci [[UBOUND]]
+ // CHECK: [[TRUNC:%.+]] = arith.trunci [[UBOUND]]
// CHECK: linalg.yield [[TRUNC]]
%0 = "tosa.negate"(%arg0) {quantization_info = { input_zp = 0 : i32, output_zp = 0 : i32}} : (tensor<1xi8>) -> tensor<1xi8>
// CHECK: linalg.generic
- // CHECK: [[EXT:%.+]] = sexti %arg1 : i8 to i16
+ // CHECK: [[EXT:%.+]] = arith.extsi %arg1 : i8 to i16
%1 = "tosa.negate"(%arg0) {quantization_info = { input_zp = 32639 : i32, output_zp = 0 : i32}} : (tensor<1xi8>) -> tensor<1xi8>
// CHECK: linalg.generic
- // CHECK: [[EXT:%.+]] = sexti %arg1 : i8 to i32
+ // CHECK: [[EXT:%.+]] = arith.extsi %arg1 : i8 to i32
%2 = "tosa.negate"(%arg0) {quantization_info = { input_zp = 32640 : i32, output_zp = 0 : i32}} : (tensor<1xi8>) -> tensor<1xi8>
return
// CHECK-LABEL: @test_transpose
// CHECK-SAME: ([[ARG0:%.+]]: tensor<1x2x3xi32>)
func @test_transpose(%arg0: tensor<1x2x3xi32>) -> () {
- %0 = constant dense<[1, 2, 0]> : tensor<3xi32>
+ %0 = arith.constant dense<[1, 2, 0]> : tensor<3xi32>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2, 3, 1]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel"]} ins([[ARG0]] : tensor<1x2x3xi32>) outs([[OUT:%.+]] : tensor<2x3x1xi32>)
// CHECK: ^bb0([[ARG1:%.+]]: i32, [[ARG2:%.+]]: i32)
// CHECK-LABEL: @test_transpose_dyn
// CHECK-SAME: (%[[ARG0:.+]]: tensor<1x?x3x4xi32>)
func @test_transpose_dyn(%arg0: tensor<1x?x3x4xi32>) -> () {
- %0 = constant dense<[1, 3, 0, 2]> : tensor<4xi32>
- // CHECK: %[[C1:.+]] = constant 1
+ %0 = arith.constant dense<[1, 3, 0, 2]> : tensor<4xi32>
+ // CHECK: %[[C1:.+]] = arith.constant 1
// CHECK: %[[DIM:.+]] = tensor.dim %arg0, %[[C1]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [%[[DIM]], 4, 1, 3]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%[[ARG0]] : tensor<1x?x3x4xi32>) outs([[OUT:%.+]] : tensor<?x4x1x3xi32>)
// CHECK-LABEL: @test_transpose_dyn
// CHECK-SAME: (%[[ARG0:.+]]: tensor<?x?xf32>)
func @test_transpose_dyn_multiple(%arg0: tensor<?x?xf32>) -> () {
- %0 = constant dense<[1, 0]> : tensor<2xi32>
- // CHECK: %[[C0:.+]] = constant 0
+ %0 = arith.constant dense<[1, 0]> : tensor<2xi32>
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[DIM0:.+]] = tensor.dim %arg0, %[[C0]]
- // CHECK: %[[C1:.+]] = constant 1
+ // CHECK: %[[C1:.+]] = arith.constant 1
// CHECK: %[[DIM1:.+]] = tensor.dim %arg0, %[[C1]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [%[[DIM1]], %[[DIM0]]]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%[[ARG0]] : tensor<?x?xf32>) outs([[OUT:%.+]] : tensor<?x?xf32>)
// CHECK-SAME: [[ARG0:%.+]]: tensor<5x4xf32>
func @reduce_float(%arg0: tensor<5x4xf32>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [4]
- // CHECK: [[CST0:%.+]] = constant 0.0
+ // CHECK: [[CST0:%.+]] = arith.constant 0.0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["reduction", "parallel"]} ins([[ARG0]] : tensor<5x4xf32>) outs([[FILL]] : tensor<4xf32>)
// CHECK: ^bb0(%arg1: f32, %arg2: f32)
- // CHECK: [[RES:%.+]] = addf %arg1, %arg2 : f32
+ // CHECK: [[RES:%.+]] = arith.addf %arg1, %arg2 : f32
// CHECK: linalg.yield [[RES]] : f32
// CHECK: linalg.tensor_expand_shape [[GENERIC]] {{\[}}[0, 1]] : tensor<4xf32> into tensor<1x4xf32>
%0 = "tosa.reduce_sum"(%arg0) {axis = 0 : i64} : (tensor<5x4xf32>) -> tensor<1x4xf32>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [5]
- // CHECK: [[CST0:%.+]] = constant 0.0
+ // CHECK: [[CST0:%.+]] = arith.constant 0.0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP2]]], iterator_types = ["parallel", "reduction"]} ins([[ARG0]] : tensor<5x4xf32>) outs([[FILL]] : tensor<5xf32>)
// CHECK: ^bb0(%arg1: f32, %arg2: f32)
- // CHECK: [[RES:%.+]] = addf %arg1, %arg2 : f32
+ // CHECK: [[RES:%.+]] = arith.addf %arg1, %arg2 : f32
// CHECK: linalg.yield [[RES]] : f32
// CHECK: linalg.tensor_expand_shape [[GENERIC]] {{\[}}[0, 1]] : tensor<5xf32> into tensor<5x1xf32>
%1 = "tosa.reduce_sum"(%arg0) {axis = 1 : i64} : (tensor<5x4xf32>) -> tensor<5x1xf32>
- // CHECK: constant 1.0
+ // CHECK: arith.constant 1.0
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: mulf
+ // CHECK: arith.mulf
%2 = "tosa.reduce_prod"(%arg0) {axis = 0 : i64} : (tensor<5x4xf32>) -> tensor<1x4xf32>
- // CHECK: constant 3.40282347E+38 : f32
+ // CHECK: arith.constant 3.40282347E+38 : f32
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: cmpf olt
+ // CHECK: arith.cmpf olt
// CHECK: select
%3 = "tosa.reduce_min"(%arg0) {axis = 0 : i64} : (tensor<5x4xf32>) -> tensor<1x4xf32>
- // CHECK: constant -3.40282347E+38 : f32
+ // CHECK: arith.constant -3.40282347E+38 : f32
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: cmpf ogt
+ // CHECK: arith.cmpf ogt
// CHECK: select
%4 = "tosa.reduce_max"(%arg0) {axis = 0 : i64} : (tensor<5x4xf32>) -> tensor<1x4xf32>
return
// CHECK-SAME: [[ARG0:%.+]]: tensor<5x4xi32>
func @reduce_int(%arg0: tensor<5x4xi32>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [4]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["reduction", "parallel"]} ins([[ARG0]] : tensor<5x4xi32>) outs([[FILL]] : tensor<4xi32>)
// CHECK: ^bb0(%arg1: i32, %arg2: i32)
- // CHECK: [[RES:%.+]] = addi %arg1, %arg2 : i32
+ // CHECK: [[RES:%.+]] = arith.addi %arg1, %arg2 : i32
// CHECK: linalg.yield [[RES]] : i32
// CHECK: linalg.tensor_expand_shape [[GENERIC]] {{\[}}[0, 1]] : tensor<4xi32> into tensor<1x4xi32>
%0 = "tosa.reduce_sum"(%arg0) {axis = 0 : i64} : (tensor<5x4xi32>) -> tensor<1x4xi32>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [5]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP2]]], iterator_types = ["parallel", "reduction"]} ins([[ARG0]] : tensor<5x4xi32>) outs([[FILL]] : tensor<5xi32>)
// CHECK: ^bb0(%arg1: i32, %arg2: i32)
- // CHECK: [[RES:%.+]] = addi %arg1, %arg2 : i32
+ // CHECK: [[RES:%.+]] = arith.addi %arg1, %arg2 : i32
// CHECK: linalg.yield [[RES]] : i32
// CHECK: linalg.tensor_expand_shape [[GENERIC]] {{\[}}[0, 1]] : tensor<5xi32> into tensor<5x1xi32>
%1 = "tosa.reduce_sum"(%arg0) {axis = 1 : i64} : (tensor<5x4xi32>) -> tensor<5x1xi32>
- // CHECK: constant 1
+ // CHECK: arith.constant 1
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: muli
+ // CHECK: arith.muli
%2 = "tosa.reduce_prod"(%arg0) {axis = 0 : i64} : (tensor<5x4xi32>) -> tensor<1x4xi32>
- // CHECK: constant 2147483647 : i32
+ // CHECK: arith.constant 2147483647 : i32
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: cmpi slt
+ // CHECK: arith.cmpi slt
// CHECK: select
%3 = "tosa.reduce_min"(%arg0) {axis = 0 : i64} : (tensor<5x4xi32>) -> tensor<1x4xi32>
- // CHECK: constant -2147483648 : i32
+ // CHECK: arith.constant -2147483648 : i32
// CHECK: linalg.fill
// CHECK: linalg.generic
- // CHECK: cmpi sgt
+ // CHECK: arith.cmpi sgt
// CHECK: select
%4 = "tosa.reduce_max"(%arg0) {axis = 0 : i64} : (tensor<5x4xi32>) -> tensor<1x4xi32>
return
// CHECK-SAME: [[ARG0:%.+]]: tensor<5x4xi1>
func @reduce_bool(%arg0: tensor<5x4xi1>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [4]
- // CHECK: [[CST0:%.+]] = constant true
+ // CHECK: [[CST0:%.+]] = arith.constant true
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["reduction", "parallel"]} ins([[ARG0]] : tensor<5x4xi1>) outs([[FILL]] : tensor<4xi1>)
// CHECK: ^bb0(%arg1: i1, %arg2: i1)
- // CHECK: [[RES:%.+]] = and %arg1, %arg2 : i1
+ // CHECK: [[RES:%.+]] = arith.andi %arg1, %arg2 : i1
// CHECK: linalg.yield [[RES]] : i1
// CHECK: linalg.tensor_expand_shape [[GENERIC]] {{\[}}[0, 1]] : tensor<4xi1> into tensor<1x4xi1>
%0 = "tosa.reduce_all"(%arg0) {axis = 0 : i64} : (tensor<5x4xi1>) -> tensor<1x4xi1>
- // CHECK: constant false
+ // CHECK: arith.constant false
// CHECK: linalg.fill
// CHECK: linalg.generic
// CHECK: or
// CHECK-LABEL: @concat
func @concat(%arg0: tensor<5x1xf32>, %arg1: tensor<6x1xf32>) -> () {
- // CHECK: [[AXIS:%.+]] = constant 0
- // CHECK: [[STRIDE:%.+]] = constant 1
- // CHECK: [[OFFSET:%.+]] = constant 0 : index
- // CHECK: [[IDX0:%.+]] = constant 0 : index
+ // CHECK: [[AXIS:%.+]] = arith.constant 0
+ // CHECK: [[STRIDE:%.+]] = arith.constant 1
+ // CHECK: [[OFFSET:%.+]] = arith.constant 0 : index
+ // CHECK: [[IDX0:%.+]] = arith.constant 0 : index
// CHECK: [[ARG0_DIM0:%.+]] = tensor.dim %arg0, [[IDX0]]
- // CHECK: [[IDX1:%.+]] = constant 1 : index
+ // CHECK: [[IDX1:%.+]] = arith.constant 1 : index
// CHECK: [[ARG0_DIM1:%.+]] = tensor.dim %arg0, [[IDX1]]
// CHECK: [[ARG1_AXIS:%.+]] = tensor.dim %arg1, [[AXIS]]
- // CHECK: [[RESULT_AXIS:%.+]] = addi [[ARG0_DIM0]], [[ARG1_AXIS]]
+ // CHECK: [[RESULT_AXIS:%.+]] = arith.addi [[ARG0_DIM0]], [[ARG1_AXIS]]
// CHECK: [[INIT:%.+]] = linalg.init_tensor [11, 1]
- // CHECK: [[CST:%.+]] = constant 0.0
+ // CHECK: [[CST:%.+]] = arith.constant 0.0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST]], [[INIT]])
// CHECK: [[ARG0_DIM0:%.+]] = tensor.dim %arg0, [[AXIS]]
// CHECK: [[INSERT0:%.+]] = tensor.insert_slice %arg0 into [[FILL]]{{\[}}[[OFFSET]], [[OFFSET]]] {{\[}}[[ARG0_DIM0]], [[ARG0_DIM1]]] {{\[}}[[STRIDE]], [[STRIDE]]]
- // CHECK: [[NEW_OFFSET:%.+]] = addi [[OFFSET]], [[ARG0_DIM0]]
+ // CHECK: [[NEW_OFFSET:%.+]] = arith.addi [[OFFSET]], [[ARG0_DIM0]]
// CHECK: [[ARG1_DIM0:%.+]] = tensor.dim %arg1, [[AXIS]]
// CHECK: [[INSERT1:%.+]] = tensor.insert_slice %arg1 into [[INSERT0]]{{\[}}[[NEW_OFFSET]], [[OFFSET]]] {{\[}}[[ARG1_DIM0]], [[ARG0_DIM1]]] {{\[}}[[STRIDE]], [[STRIDE]]]
%0 = "tosa.concat"(%arg0, %arg1) { axis = 0 : i64} : (tensor<5x1xf32>, tensor<6x1xf32>) -> (tensor<11x1xf32>)
- // CHECK: [[AXIS:%.+]] = constant 1
- // CHECK: [[STRIDE:%.+]] = constant 1
- // CHECK: [[OFFSET:%.+]] = constant 0 : index
- // CHECK: [[IDX0:%.+]] = constant 0 : index
+ // CHECK: [[AXIS:%.+]] = arith.constant 1
+ // CHECK: [[STRIDE:%.+]] = arith.constant 1
+ // CHECK: [[OFFSET:%.+]] = arith.constant 0 : index
+ // CHECK: [[IDX0:%.+]] = arith.constant 0 : index
// CHECK: [[ARG0_DIM0:%.+]] = tensor.dim %arg0, [[IDX0]]
- // CHECK: [[IDX1:%.+]] = constant 1 : index
+ // CHECK: [[IDX1:%.+]] = arith.constant 1 : index
// CHECK: [[ARG0_DIM1:%.+]] = tensor.dim %arg0, [[IDX1]]
// CHECK: [[ARG1_AXIS:%.+]] = tensor.dim %arg0, [[AXIS]]
- // CHECK: [[RESULT_AXIS:%.+]] = addi [[ARG0_DIM1]], [[ARG1_AXIS]]
+ // CHECK: [[RESULT_AXIS:%.+]] = arith.addi [[ARG0_DIM1]], [[ARG1_AXIS]]
// CHECK: [[INIT:%.+]] = linalg.init_tensor [5, 2]
- // CHECK: [[CST:%.+]] = constant 0.0
+ // CHECK: [[CST:%.+]] = arith.constant 0.0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST]], [[INIT]])
// CHECK: [[ARG0_DIM1:%.+]] = tensor.dim %arg0, [[AXIS]]
// CHECK: [[INSERT0:%.+]] = tensor.insert_slice %arg0 into [[FILL]]{{\[}}[[OFFSET]], [[OFFSET]]] {{\[}}[[ARG0_DIM0]], [[ARG0_DIM1]]] {{\[}}[[STRIDE]], [[STRIDE]]]
- // CHECK: [[NEW_OFFSET:%.+]] = addi [[OFFSET]], [[ARG0_DIM1]]
+ // CHECK: [[NEW_OFFSET:%.+]] = arith.addi [[OFFSET]], [[ARG0_DIM1]]
// CHECK: [[ARG1_DIM1:%.+]] = tensor.dim %arg0, [[AXIS]]
// CHECK: [[INSERT1:%.+]] = tensor.insert_slice %arg0 into [[INSERT0]]{{\[}}[[OFFSET]], [[NEW_OFFSET]]] {{\[}}[[ARG0_DIM0]], [[ARG1_DIM1]]] {{\[}}[[STRIDE]], [[STRIDE]]]
%1 = "tosa.concat"(%arg0, %arg0) { axis = 1 : i64} : (tensor<5x1xf32>, tensor<5x1xf32>) -> (tensor<5x2xf32>)
// CHECK-LABEL: @rescale_i8
func @rescale_i8(%arg0 : tensor<2xi8>) -> () {
- // CHECK: [[C0:%.+]] = constant 19689
- // CHECK: [[C1:%.+]] = constant 15
+ // CHECK: [[C0:%.+]] = arith.constant 19689
+ // CHECK: [[C1:%.+]] = arith.constant 15
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0 : tensor<2xi8>) outs([[INIT]] : tensor<2xi8>)
// CHECK: ^bb0([[IN:%.+]]: i8, [[UNUSED:%.+]]: i8):
- // CHECK: [[C17:%.+]] = constant 17
- // CHECK: [[C22:%.+]] = constant 22
- // CHECK-DAG: [[IN32:%.+]] = sexti [[IN]]
- // CHECK-DAG: [[IN_ZEROED:%.+]] = subi [[IN32]], [[C17]]
+ // CHECK: [[C17:%.+]] = arith.constant 17
+ // CHECK: [[C22:%.+]] = arith.constant 22
+ // CHECK-DAG: [[IN32:%.+]] = arith.extsi [[IN]]
+ // CHECK-DAG: [[IN_ZEROED:%.+]] = arith.subi [[IN32]], [[C17]]
// CHECK-DAG: [[SCALED:%.+]] = "tosa.apply_scale"([[IN_ZEROED]], [[C0]], [[C1]]) {double_round = false}
- // CHECK-DAG: [[SCALED_ZEROED:%.+]] = addi [[SCALED]], [[C22]]
- // CHECK-DAG: [[CMIN:%.+]] = constant -128
- // CHECK-DAG: [[CMAX:%.+]] = constant 127
- // CHECK-DAG: [[MINLT:%.+]] = cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
- // CHECK-DAG: [[MAXLT:%.+]] = cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
+ // CHECK-DAG: [[SCALED_ZEROED:%.+]] = arith.addi [[SCALED]], [[C22]]
+ // CHECK-DAG: [[CMIN:%.+]] = arith.constant -128
+ // CHECK-DAG: [[CMAX:%.+]] = arith.constant 127
+ // CHECK-DAG: [[MINLT:%.+]] = arith.cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
+ // CHECK-DAG: [[MAXLT:%.+]] = arith.cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
// CHECK-DAG: [[LOWER:%.+]] = select [[MINLT]], [[CMIN]], [[SCALED_ZEROED]]
// CHECK-DAG: [[BOUNDED:%.+]] = select [[MAXLT]], [[CMAX]], [[LOWER]]
- // CHECK-DAG: [[TRUNC:%.+]] = trunci [[BOUNDED]]
+ // CHECK-DAG: [[TRUNC:%.+]] = arith.trunci [[BOUNDED]]
// CHECK-DAG: linalg.yield [[TRUNC]]
%0 = "tosa.rescale"(%arg0) {input_zp = 17 : i32, output_zp = 22 : i32, multiplier = [19689 : i32], shift = [15 : i32], scale32 = false, double_round = false, per_channel = false} : (tensor<2xi8>) -> (tensor<2xi8>)
- // CHECK: [[C0:%.+]] = constant 19689
- // CHECK: [[C1:%.+]] = constant 15
+ // CHECK: [[C0:%.+]] = arith.constant 19689
+ // CHECK: [[C1:%.+]] = arith.constant 15
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0 : tensor<2xi8>) outs([[INIT]] : tensor<2xui8>)
// CHECK: ^bb0([[IN:%.+]]: i8, [[UNUSED:%.+]]: ui8):
- // CHECK: [[C17:%.+]] = constant 17
- // CHECK: [[C22:%.+]] = constant 22
- // CHECK-DAG: [[IN32:%.+]] = sexti [[IN]]
- // CHECK-DAG: [[IN_ZEROED:%.+]] = subi [[IN32]], [[C17]]
+ // CHECK: [[C17:%.+]] = arith.constant 17
+ // CHECK: [[C22:%.+]] = arith.constant 22
+ // CHECK-DAG: [[IN32:%.+]] = arith.extsi [[IN]]
+ // CHECK-DAG: [[IN_ZEROED:%.+]] = arith.subi [[IN32]], [[C17]]
// CHECK-DAG: [[SCALED:%.+]] = "tosa.apply_scale"([[IN_ZEROED]], [[C0]], [[C1]]) {double_round = false}
- // CHECK-DAG: [[SCALED_ZEROED:%.+]] = addi [[SCALED]], [[C22]]
- // CHECK-DAG: [[CMIN:%.+]] = constant 0
- // CHECK-DAG: [[CMAX:%.+]] = constant 255
- // CHECK-DAG: [[MINLT:%.+]] = cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
+ // CHECK-DAG: [[SCALED_ZEROED:%.+]] = arith.addi [[SCALED]], [[C22]]
+ // CHECK-DAG: [[CMIN:%.+]] = arith.constant 0
+ // CHECK-DAG: [[CMAX:%.+]] = arith.constant 255
+ // CHECK-DAG: [[MINLT:%.+]] = arith.cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
// CHECK-DAG: [[LOWER:%.+]] = select [[MINLT]], [[CMIN]], [[SCALED_ZEROED]]
- // CHECK-DAG: [[MAXLT:%.+]] = cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
+ // CHECK-DAG: [[MAXLT:%.+]] = arith.cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
// CHECK-DAG: [[BOUNDED:%.+]] = select [[MAXLT]], [[CMAX]], [[LOWER]]
- // CHECK-DAG: [[TRUNC:%.+]] = trunci [[BOUNDED]]
+ // CHECK-DAG: [[TRUNC:%.+]] = arith.trunci [[BOUNDED]]
// CHECK-DAG: [[CAST:%.+]] = builtin.unrealized_conversion_cast [[TRUNC]] : i8 to ui8
// CHECK: linalg.yield [[CAST]]
%1 = "tosa.rescale"(%arg0) {input_zp = 17 : i32, output_zp = 22 : i32, multiplier = [19689 : i32], shift = [15 : i32], scale32 = false, double_round = false, per_channel = false} : (tensor<2xi8>) -> (tensor<2xui8>)
// CHECK-LABEL: @rescale_ui8
func @rescale_ui8(%arg0 : tensor<2xui8>) -> () {
- // CHECK: [[C0:%.+]] = constant 19689
- // CHECK: [[C1:%.+]] = constant 15
+ // CHECK: [[C0:%.+]] = arith.constant 19689
+ // CHECK: [[C1:%.+]] = arith.constant 15
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0 : tensor<2xui8>) outs([[INIT]] : tensor<2xi8>)
// CHECK: ^bb0([[IN:%.+]]: ui8, [[UNUSED:%.+]]: i8):
- // CHECK: [[C17:%.+]] = constant 17
- // CHECK: [[C22:%.+]] = constant 22
+ // CHECK: [[C17:%.+]] = arith.constant 17
+ // CHECK: [[C22:%.+]] = arith.constant 22
// CHECK-DAG: [[CAST:%.+]] = builtin.unrealized_conversion_cast [[IN]] : ui8 to i8
- // CHECK-DAG: [[IN32:%.+]] = zexti [[CAST]]
- // CHECK-DAG: [[IN_ZEROED:%.+]] = subi [[IN32]], [[C17]]
+ // CHECK-DAG: [[IN32:%.+]] = arith.extui [[CAST]]
+ // CHECK-DAG: [[IN_ZEROED:%.+]] = arith.subi [[IN32]], [[C17]]
// CHECK-DAG: [[SCALED:%.+]] = "tosa.apply_scale"([[IN_ZEROED]], [[C0]], [[C1]]) {double_round = false}
- // CHECK-DAG: [[SCALED_ZEROED:%.+]] = addi [[SCALED]], [[C22]]
- // CHECK-DAG: [[CMIN:%.+]] = constant -128
- // CHECK-DAG: [[CMAX:%.+]] = constant 127
- // CHECK-DAG: [[MINLT:%.+]] = cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
+ // CHECK-DAG: [[SCALED_ZEROED:%.+]] = arith.addi [[SCALED]], [[C22]]
+ // CHECK-DAG: [[CMIN:%.+]] = arith.constant -128
+ // CHECK-DAG: [[CMAX:%.+]] = arith.constant 127
+ // CHECK-DAG: [[MINLT:%.+]] = arith.cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
// CHECK-DAG: [[LOWER:%.+]] = select [[MINLT]], [[CMIN]], [[SCALED_ZEROED]]
- // CHECK-DAG: [[MAXLT:%.+]] = cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
+ // CHECK-DAG: [[MAXLT:%.+]] = arith.cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
// CHECK-DAG: [[BOUNDED:%.+]] = select [[MAXLT]], [[CMAX]], [[LOWER]]
- // CHECK-DAG: [[TRUNC:%.+]] = trunci [[BOUNDED]]
+ // CHECK-DAG: [[TRUNC:%.+]] = arith.trunci [[BOUNDED]]
// CHECK: linalg.yield [[TRUNC]]
%0 = "tosa.rescale"(%arg0) {input_zp = 17 : i32, output_zp = 22 : i32, multiplier = [19689 : i32], shift = [15 : i32], scale32 = false, double_round = false, per_channel = false} : (tensor<2xui8>) -> (tensor<2xi8>)
// CHECK-LABEL: @rescale_per_channel
func @rescale_per_channel(%arg0 : tensor<2xi8>) -> (tensor<2xi8>) {
- // CHECK: [[MULTIPLIERS:%.+]] = constant dense<[42, 43]>
- // CHECK: [[SHIFTS:%.+]] = constant dense<[14, 15]>
+ // CHECK: [[MULTIPLIERS:%.+]] = arith.constant dense<[42, 43]>
+ // CHECK: [[SHIFTS:%.+]] = arith.constant dense<[14, 15]>
// CHECK: [[INIT:%.+]] = linalg.init_tensor [2]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]], #[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%arg0, [[MULTIPLIERS]], [[SHIFTS]] : tensor<2xi8>, tensor<2xi32>, tensor<2xi8>) outs([[INIT]] : tensor<2xi8>)
// CHECK: ^bb0([[IN:%.+]]: i8, [[MULTIPLIER:%.+]]: i32, [[SHIFT:%.+]]: i8, [[UNUSED:%.+]]: i8):
- // CHECK: [[C243:%.+]] = constant 243
- // CHECK: [[C252:%.+]] = constant 252
+ // CHECK: [[C243:%.+]] = arith.constant 243
+ // CHECK: [[C252:%.+]] = arith.constant 252
- // CHECK-DAG: [[IN32:%.+]] = sexti [[IN]]
- // CHECK-DAG: [[IN_ZEROED:%.+]] = subi [[IN32]], [[C243]]
+ // CHECK-DAG: [[IN32:%.+]] = arith.extsi [[IN]]
+ // CHECK-DAG: [[IN_ZEROED:%.+]] = arith.subi [[IN32]], [[C243]]
// CHECK-DAG: [[SCALED:%.+]] = "tosa.apply_scale"([[IN_ZEROED]], [[MULTIPLIER]], [[SHIFT]]) {double_round = false}
- // CHECK-DAG: [[SCALED_ZEROED:%.+]] = addi [[SCALED]], [[C252]]
- // CHECK-DAG: [[CMIN:%.+]] = constant -128
- // CHECK-DAG: [[CMAX:%.+]] = constant 127
- // CHECK-DAG: [[MINLT:%.+]] = cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
- // CHECK-DAG: [[MAXLT:%.+]] = cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
+ // CHECK-DAG: [[SCALED_ZEROED:%.+]] = arith.addi [[SCALED]], [[C252]]
+ // CHECK-DAG: [[CMIN:%.+]] = arith.constant -128
+ // CHECK-DAG: [[CMAX:%.+]] = arith.constant 127
+ // CHECK-DAG: [[MINLT:%.+]] = arith.cmpi slt, [[SCALED_ZEROED]], [[CMIN]]
+ // CHECK-DAG: [[MAXLT:%.+]] = arith.cmpi slt, [[CMAX]], [[SCALED_ZEROED]]
// CHECK-DAG: [[LOWER:%.+]] = select [[MINLT]], [[CMIN]], [[SCALED_ZEROED]]
// CHECK-DAG: [[BOUNDED:%.+]] = select [[MAXLT]], [[CMAX]], [[LOWER]]
- // CHECK-DAG: [[TRUNC:%.+]] = trunci [[BOUNDED]]
+ // CHECK-DAG: [[TRUNC:%.+]] = arith.trunci [[BOUNDED]]
// CHECK-DAG: linalg.yield [[TRUNC]]
%0 = "tosa.rescale"(%arg0) {input_zp = 243 : i32, output_zp = 252 : i32, multiplier = [42 : i32, 43 : i32], shift = [14 : i32, 15 : i32], scale32 = false, double_round = false, per_channel = false} : (tensor<2xi8>) -> (tensor<2xi8>)
// CHECK-LABEL: @reverse
func @reverse(%arg0: tensor<5x4xi32>) -> () {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[RDIM:.+]] = tensor.dim %arg0, %[[C0]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [5, 4]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]]], iterator_types = ["parallel", "parallel"]} outs(%[[INIT]] : tensor<5x4xi32>)
// CHECK-DAG: %[[I0:.+]] = linalg.index 0
// CHECK-DAG: %[[I1:.+]] = linalg.index 1
- // CHECK-DAG: %[[SUB1:.+]] = constant 1
- // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = subi %[[RDIM]], %[[SUB1]]
- // CHECK-DAG: %[[READ_DIM:.+]] = subi %[[RDIM_MINUS_C1]], %[[I0]]
+ // CHECK-DAG: %[[SUB1:.+]] = arith.constant 1
+ // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = arith.subi %[[RDIM]], %[[SUB1]]
+ // CHECK-DAG: %[[READ_DIM:.+]] = arith.subi %[[RDIM_MINUS_C1]], %[[I0]]
// CHECK-DAG: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[READ_DIM]], %[[I1]]] : tensor<5x4xi32>
// CHECK: linalg.yield %[[EXTRACT]]
%0 = "tosa.reverse"(%arg0) {axis = 0 : i64} : (tensor<5x4xi32>) -> tensor<5x4xi32>
- // CHECK: %[[C1:.+]] = constant 1
+ // CHECK: %[[C1:.+]] = arith.constant 1
// CHECK: %[[RDIM:.+]] = tensor.dim %arg0, %[[C1]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [5, 4]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]]], iterator_types = ["parallel", "parallel"]} outs(%[[INIT]] : tensor<5x4xi32>)
// CHECK-DAG: %[[I0:.+]] = linalg.index 0
// CHECK-DAG: %[[I1:.+]] = linalg.index 1
- // CHECK-DAG: %[[SUB1:.+]] = constant 1
- // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = subi %[[RDIM]], %[[SUB1]]
- // CHECK-DAG: %[[READ_DIM:.+]] = subi %[[RDIM_MINUS_C1]], %[[I1]]
+ // CHECK-DAG: %[[SUB1:.+]] = arith.constant 1
+ // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = arith.subi %[[RDIM]], %[[SUB1]]
+ // CHECK-DAG: %[[READ_DIM:.+]] = arith.subi %[[RDIM_MINUS_C1]], %[[I1]]
// CHECK-DAG: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[I0]], %[[READ_DIM]]] : tensor<5x4xi32>
// CHECK: linalg.yield %[[EXTRACT]]
%1 = "tosa.reverse"(%arg0) {axis = 1 : i64} : (tensor<5x4xi32>) -> tensor<5x4xi32>
// CHECK-LABEL: @reverse_dyn
func @reverse_dyn(%arg0: tensor<?xi32>) -> () {
- // CHECK: %[[C0_1:.+]] = constant 0
+ // CHECK: %[[C0_1:.+]] = arith.constant 0
// CHECK: %[[D0_1:.+]] = tensor.dim %arg0, %[[C0_1]]
- // CHECK: %[[C0_2:.+]] = constant 0
+ // CHECK: %[[C0_2:.+]] = arith.constant 0
// CHECK: %[[D0_2:.+]] = tensor.dim %arg0, %[[C0_2]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [%[[D0_1]]]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]]], iterator_types = ["parallel"]} outs(%[[INIT]] : tensor<?xi32>)
// CHECK-DAG: %[[I0:.+]] = linalg.index 0
- // CHECK-DAG: %[[SUB1:.+]] = constant 1
- // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = subi %[[D0_2]], %[[SUB1]]
- // CHECK-DAG: %[[READ_DIM:.+]] = subi %[[RDIM_MINUS_C1]], %[[I0]]
+ // CHECK-DAG: %[[SUB1:.+]] = arith.constant 1
+ // CHECK-DAG: %[[RDIM_MINUS_C1:.+]] = arith.subi %[[D0_2]], %[[SUB1]]
+ // CHECK-DAG: %[[READ_DIM:.+]] = arith.subi %[[RDIM_MINUS_C1]], %[[I0]]
// CHECK-DAG: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[READ_DIM]]] : tensor<?xi32>
// CHECK: linalg.yield %[[EXTRACT]]
%0 = "tosa.reverse"(%arg0) {axis = 0 : i64} : (tensor<?xi32>) -> tensor<?xi32>
// CHECK-LABEL: @matmul
func @matmul(%arg0: tensor<1x5x3xf32>, %arg1: tensor<1x3x6xf32>) -> (tensor<1x5x6xf32>) {
- // CHECK: [[C0:%.+]] = constant 0
+ // CHECK: [[C0:%.+]] = arith.constant 0
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 5, 6]
// CHECK: [[FILLED:%.+]] = linalg.fill([[C0]], [[INIT]]) : f32, tensor<1x5x6xf32> -> tensor<1x5x6xf32>
// CHECK: linalg.batch_matmul ins(%arg0, %arg1 : tensor<1x5x3xf32>, tensor<1x3x6xf32>) outs([[FILLED]] : tensor<1x5x6xf32>) -> tensor<1x5x6xf32>
// CHECK-LABEL: @matmul_quantized
func @matmul_quantized(%arg0: tensor<1x5x3xi8>, %arg1: tensor<1x3x6xi8>) -> (tensor<1x5x6xi32>) {
- // CHECK: [[C0:%.+]] = constant 0
+ // CHECK: [[C0:%.+]] = arith.constant 0
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 5, 6]
// CHECK: [[FILLED:%.+]] = linalg.fill([[C0]], [[INIT]]) : i32, tensor<1x5x6xi32> -> tensor<1x5x6xi32>
- // CHECK: [[ONE:%.+]] = constant 1
- // CHECK: [[TWO:%.+]] = constant 2
+ // CHECK: [[ONE:%.+]] = arith.constant 1
+ // CHECK: [[TWO:%.+]] = arith.constant 2
// CHECK: linalg.quantized_batch_matmul ins(%arg0, %arg1, [[ONE]], [[TWO]] : tensor<1x5x3xi8>, tensor<1x3x6xi8>, i32, i32) outs([[FILLED]] : tensor<1x5x6xi32>) -> tensor<1x5x6xi32>
%0 = "tosa.matmul"(%arg0, %arg1) {quantization_info = {a_zp = 1 : i32, b_zp = 2 : i32}} : (tensor<1x5x3xi8>, tensor<1x3x6xi8>) -> (tensor<1x5x6xi32>)
return %0 : tensor<1x5x6xi32>
// CHECK-LABEL: @matmul_dyn_batch
func @matmul_dyn_batch(%arg0: tensor<?x5x3xf32>, %arg1: tensor<?x3x6xf32>) -> (tensor<?x5x6xf32>) {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[DIM:.+]] = tensor.dim %arg0, %[[C0]]
- // CHECK: %[[C0_0:.+]] = constant 0
+ // CHECK: %[[C0_0:.+]] = arith.constant 0
// CHECK: %[[INIT:.+]] = linalg.init_tensor [%[[DIM]], 5, 6]
// CHECK: %[[FILLED:.+]] = linalg.fill(%[[C0_0]], %[[INIT]]) : f32, tensor<?x5x6xf32> -> tensor<?x5x6xf32>
// CHECK: linalg.batch_matmul ins(%arg0, %arg1 : tensor<?x5x3xf32>, tensor<?x3x6xf32>) outs(%[[FILLED]] : tensor<?x5x6xf32>) -> tensor<?x5x6xf32>
// CHECK-LABEL: @matmul_dyn_independent_dim
func @matmul_dyn_independent_dim(%arg0: tensor<1x5x3xf32>, %arg1: tensor<1x3x?xf32>) -> (tensor<1x5x?xf32>) {
- // CHECK: %[[C2:.+]] = constant 2
+ // CHECK: %[[C2:.+]] = arith.constant 2
// CHECK: %[[DIM:.+]] = tensor.dim %arg1, %[[C2]]
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[INIT:.+]] = linalg.init_tensor [1, 5, %[[DIM]]]
// CHECK: %[[FILLED:.+]] = linalg.fill(%[[C0]], %[[INIT]]) : f32, tensor<1x5x?xf32> -> tensor<1x5x?xf32>
// CHECK: linalg.batch_matmul ins(%arg0, %arg1 : tensor<1x5x3xf32>, tensor<1x3x?xf32>) outs(%[[FILLED]] : tensor<1x5x?xf32>) -> tensor<1x5x?xf32>
// CHECK-LABEL: @matmul_dyn_independent_dim
func @matmul_dyn_independent_dim(%arg0: tensor<1x5x?xf32>, %arg1: tensor<1x?x6xf32>) -> (tensor<1x5x6xf32>) {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[INIT:.+]] = linalg.init_tensor [1, 5, 6]
// CHECK: %[[FILLED:.+]] = linalg.fill(%[[C0]], %[[INIT]]) : f32, tensor<1x5x6xf32> -> tensor<1x5x6xf32>
// CHECK: linalg.batch_matmul ins(%arg0, %arg1 : tensor<1x5x?xf32>, tensor<1x?x6xf32>) outs(%[[FILLED]] : tensor<1x5x6xf32>) -> tensor<1x5x6xf32>
// CHECK-LABEL: @fully_connected
func @fully_connected(%arg0: tensor<5x3xf32>, %arg1: tensor<6x3xf32>, %arg2: tensor<6xf32>) -> (tensor<5x6xf32>) {
// CHECK: [[INITT:%.+]] = linalg.init_tensor [5, 6]
- // CHECK: [[ZERO:%.+]] = constant 0
+ // CHECK: [[ZERO:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[ZERO]], [[INITT]])
- // CHECK: [[PERM:%.+]] = constant dense<[1, 0]>
+ // CHECK: [[PERM:%.+]] = arith.constant dense<[1, 0]>
// CHECK: [[INITT:%.+]] = linalg.init_tensor [3, 6]
// CHECK: [[TRANSPOSE:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg1 : tensor<6x3xf32>) outs([[INITT]] : tensor<3x6xf32>) {
// CHECK: ^bb0([[IN:%.+]]: f32, [[UNUSED:%.+]]: f32):
// CHECK: [[MATMUL:%.+]] = linalg.matmul ins(%arg0, [[TRANSPOSE]] : tensor<5x3xf32>, tensor<3x6xf32>) outs([[FILL]] : tensor<5x6xf32>) -> tensor<5x6xf32>
// CHECK: [[ADDED:%.+]] = linalg.generic {indexing_maps = [#[[$MAP2]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg2, [[MATMUL]] : tensor<6xf32>, tensor<5x6xf32>) outs([[INITB]] : tensor<5x6xf32>) {
// CHECK: ^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
- // CHECK: [[ADD:%.+]] = addf %arg3, %arg4 : f32
+ // CHECK: [[ADD:%.+]] = arith.addf %arg3, %arg4 : f32
// CHECK: linalg.yield [[ADD]] : f32
%0 = "tosa.fully_connected"(%arg0, %arg1, %arg2) : (tensor<5x3xf32>, tensor<6x3xf32>, tensor<6xf32>) -> (tensor<5x6xf32>)
// CHECK-LABEL: @quantized_fully_connected
func @quantized_fully_connected(%arg0: tensor<5x3xi8>, %arg1: tensor<6x3xi8>, %arg2: tensor<6xi32>) -> (tensor<5x6xi32>) {
// CHECK: [[INITT:%.+]] = linalg.init_tensor [5, 6]
- // CHECK: [[ZERO:%.+]] = constant 0
+ // CHECK: [[ZERO:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[ZERO]], [[INITT]])
- // CHECK: [[PERM:%.+]] = constant dense<[1, 0]>
+ // CHECK: [[PERM:%.+]] = arith.constant dense<[1, 0]>
// CHECK: [[INITT:%.+]] = linalg.init_tensor [3, 6]
// CHECK: [[TRANSPOSE:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg1 : tensor<6x3xi8>) outs([[INITT]] : tensor<3x6xi8>) {
// CHECK: ^bb0([[IN:%.+]]: i8, [[UNUSED:%.+]]: i8):
// CHECK: linalg.yield [[IN]] : i8
// CHECK: [[INITB:%.+]] = linalg.init_tensor [5, 6]
- // CHECK: [[ONE:%.+]] = constant 1
- // CHECK: [[TWO:%.+]] = constant 2
+ // CHECK: [[ONE:%.+]] = arith.constant 1
+ // CHECK: [[TWO:%.+]] = arith.constant 2
// CHECK: [[MATMUL:%.+]] = linalg.quantized_matmul ins(%arg0, [[TRANSPOSE]], [[ONE]], [[TWO]] : tensor<5x3xi8>, tensor<3x6xi8>, i32, i32) outs([[FILL]] : tensor<5x6xi32>) -> tensor<5x6xi32>
// CHECK: [[ADDED:%.+]] = linalg.generic {indexing_maps = [#[[$MAP2]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg2, [[MATMUL]] : tensor<6xi32>, tensor<5x6xi32>) outs([[INITB]]
// CHECK: ^bb0([[IN1:%.+]]: i32, [[IN2:%.+]]: i32, [[UNUSED:%.+]]: i32):
- // CHECK: [[ADD:%.+]] = addi
+ // CHECK: [[ADD:%.+]] = arith.addi
// CHECK: linalg.yield [[ADD]] : i32
%0 = "tosa.fully_connected"(%arg0, %arg1, %arg2) {quantization_info = {input_zp = 1:i32, weight_zp = 2:i32}} : (tensor<5x3xi8>, tensor<6x3xi8>, tensor<6xi32>) -> (tensor<5x6xi32>)
return %0 : tensor<5x6xi32>
// CHECK-LABEL: @fully_connected_dyn
func @fully_connected_dyn(%arg0: tensor<?x3xf32>, %arg1: tensor<6x3xf32>, %arg2: tensor<6xf32>) -> (tensor<?x6xf32>) {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: %[[DIM:.+]] = tensor.dim %arg0, %[[C0]]
// CHECK: %[[INITT:.+]] = linalg.init_tensor [%[[DIM]], 6]
- // CHECK: %[[ZERO:.+]] = constant 0
+ // CHECK: %[[ZERO:.+]] = arith.constant 0
// CHECK: %[[FILL:.+]] = linalg.fill(%[[ZERO]], %[[INITT]])
- // CHECK: %[[PERM:.+]] = constant dense<[1, 0]>
+ // CHECK: %[[PERM:.+]] = arith.constant dense<[1, 0]>
// CHECK: %[[INITT:.+]] = linalg.init_tensor [3, 6]
// CHECK: %[[TRANSPOSE:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg1 : tensor<6x3xf32>) outs(%[[INITT]] : tensor<3x6xf32>) {
// CHECK: ^bb0(%[[IN:.+]]: f32, %[[UNUSED:.+]]: f32):
// CHECK: %[[MATMUL:.+]] = linalg.matmul ins(%arg0, %[[TRANSPOSE]] : tensor<?x3xf32>, tensor<3x6xf32>) outs(%[[FILL]] : tensor<?x6xf32>) -> tensor<?x6xf32>
// CHECK: %[[ADDED:.+]] = linalg.generic {indexing_maps = [#[[$MAP2]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel"]} ins(%arg2, %[[MATMUL]] : tensor<6xf32>, tensor<?x6xf32>) outs(%[[INITB]] : tensor<?x6xf32>) {
// CHECK: ^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
- // CHECK: %[[ADD:.+]] = addf %arg3, %arg4 : f32
+ // CHECK: %[[ADD:.+]] = arith.addf %arg3, %arg4 : f32
// CHECK: linalg.yield %[[ADD]] : f32
%0 = "tosa.fully_connected"(%arg0, %arg1, %arg2) : (tensor<?x3xf32>, tensor<6x3xf32>, tensor<6xf32>) -> (tensor<?x6xf32>)
// -----
func @pad_float(%arg0 : tensor<1x2xf32>) -> (tensor<4x9xf32>) {
- %0 = constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
- // TODO: Output contains multiple "constant 1 : index".
- // CHECK: [[INDEX1:%.+]] = constant 1 : index
- // CHECK: [[INDEX2:%.+]] = constant 2 : index
- // CHECK: [[INDEX3:%.+]] = constant 3 : index
- // CHECK: [[INDEX4:%.+]] = constant 4 : index
- // CHECK: [[CST:%.+]] = constant 0.000000e+00 : f32
+ %0 = arith.constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
+ // TODO: Output contains multiple "arith.constant 1 : index".
+ // CHECK: [[INDEX1:%.+]] = arith.constant 1 : index
+ // CHECK: [[INDEX2:%.+]] = arith.constant 2 : index
+ // CHECK: [[INDEX3:%.+]] = arith.constant 3 : index
+ // CHECK: [[INDEX4:%.+]] = arith.constant 4 : index
+ // CHECK: [[CST:%.+]] = arith.constant 0.000000e+00 : f32
// CHECK: linalg.pad_tensor %arg0 low{{\[}}%{{.*}}, [[INDEX3]]] high{{\[}}[[INDEX2]], [[INDEX4]]] {
// CHECK: ^bb0(%arg1: index, %arg2: index): // no predecessors
// CHECK: linalg.yield [[CST]]
}
func @pad_int(%arg0 : tensor<1x2xi32>) -> (tensor<4x9xi32>) {
- %0 = constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
- // CHECK: [[CST:%.+]] = constant 0 : i32
+ %0 = arith.constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
+ // CHECK: [[CST:%.+]] = arith.constant 0 : i32
// CHECK: linalg.pad_tensor
// CHECK: linalg.yield [[CST]]
%1 = "tosa.pad"(%arg0, %0) : (tensor<1x2xi32>, tensor<2x2xi32>) -> (tensor<4x9xi32>)
}
func @pad_quant(%arg0 : tensor<1x2xi32>) -> (tensor<4x9xi32>) {
- %0 = constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
- // CHECK: [[CST:%.+]] = constant 42 : i32
+ %0 = arith.constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
+ // CHECK: [[CST:%.+]] = arith.constant 42 : i32
// CHECK: linalg.pad_tensor
// CHECK: linalg.yield [[CST]]
%1 = "tosa.pad"(%arg0, %0) { quantization_info = { input_zp = 42 : i32}} : (tensor<1x2xi32>, tensor<2x2xi32>) -> (tensor<4x9xi32>)
func @argmax(%arg0 : tensor<3x2xi32>, %arg1 : tensor<6xf32>) -> () {
// CHECK: [[IDX_INIT:%.+]] = linalg.init_tensor [2]
- // CHECK: [[IDX_MIN:%.+]] = constant 0 : i32
+ // CHECK: [[IDX_MIN:%.+]] = arith.constant 0 : i32
// CHECK: [[IDX_FILL:%.+]] = linalg.fill([[IDX_MIN]], [[IDX_INIT]])
// CHECK: [[VAL_INIT:%.+]] = linalg.init_tensor [2]
- // CHECK: [[VAL_MIN:%.+]] = constant -2147483648
+ // CHECK: [[VAL_MIN:%.+]] = arith.constant -2147483648
// CHECK: [[VAL_FILL:%.+]] = linalg.fill([[VAL_MIN]], [[VAL_INIT]])
// CHECK: linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["reduction", "parallel"]} ins(%arg0 : tensor<3x2xi32>) outs([[IDX_FILL]], [[VAL_FILL]] : tensor<2xi32>, tensor<2xi32>)
// CHECK: [[IDX:%.+]] = linalg.index 0
- // CHECK: [[CAST:%.+]] = index_cast [[IDX]]
- // CHECK: [[CMP:%.+]] = cmpi sgt, %arg2, %arg4
+ // CHECK: [[CAST:%.+]] = arith.index_cast [[IDX]]
+ // CHECK: [[CMP:%.+]] = arith.cmpi sgt, %arg2, %arg4
// CHECK: [[SELECT_VAL:%.+]] = select [[CMP]], %arg2, %arg4
// CHECK: [[SELECT_IDX:%.+]] = select [[CMP]], [[CAST]], %arg3
// CHECK: linalg.yield [[SELECT_IDX]], [[SELECT_VAL]]
%0 = "tosa.argmax"(%arg0) { axis = 0 : i64} : (tensor<3x2xi32>) -> (tensor<2xi32>)
// CHECK: [[IDX_INIT:%.+]] = linalg.init_tensor [3]
- // CHECK: [[IDX_MIN:%.+]] = constant 0 : i32
+ // CHECK: [[IDX_MIN:%.+]] = arith.constant 0 : i32
// CHECK: [[IDX_FILL:%.+]] = linalg.fill([[IDX_MIN]], [[IDX_INIT]])
// CHECK: [[VAL_INIT:%.+]] = linalg.init_tensor [3]
- // CHECK: [[VAL_MIN:%.+]] = constant -2147483648
+ // CHECK: [[VAL_MIN:%.+]] = arith.constant -2147483648
// CHECK: [[VAL_FILL:%.+]] = linalg.fill([[VAL_MIN]], [[VAL_INIT]])
// CHECK: linalg.generic {indexing_maps = [#map0, #map2, #map2], iterator_types = ["parallel", "reduction"]} ins(%arg0 : tensor<3x2xi32>) outs([[IDX_FILL]], [[VAL_FILL]] : tensor<3xi32>, tensor<3xi32>)
// CHECK: [[IDX:%.+]] = linalg.index 1
- // CHECK: [[CAST:%.+]] = index_cast [[IDX]]
- // CHECK: [[CMP:%.+]] = cmpi sgt, %arg2, %arg4
+ // CHECK: [[CAST:%.+]] = arith.index_cast [[IDX]]
+ // CHECK: [[CMP:%.+]] = arith.cmpi sgt, %arg2, %arg4
// CHECK: [[SELECT_VAL:%.+]] = select [[CMP]], %arg2, %arg4
// CHECK: [[SELECT_IDX:%.+]] = select [[CMP]], [[CAST]], %arg3
// CHECK: linalg.yield [[SELECT_IDX]], [[SELECT_VAL]]
%1 = "tosa.argmax"(%arg0) { axis = 1 : i64} : (tensor<3x2xi32>) -> (tensor<3xi32>)
- // CHECK: constant -3.40282347E+38 : f32
+ // CHECK: arith.constant -3.40282347E+38 : f32
// CHECK: linalg.index
- // CHECK: index_cast
- // CHECK: cmpf ogt
+ // CHECK: arith.index_cast
+ // CHECK: arith.cmpf ogt
// CHECK: select
// CHECK: select
// CHECK: linalg.yield
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#map0, #map1], iterator_types = ["parallel", "parallel", "parallel"]} ins(%arg1 : tensor<2x3xi32>) outs(%[[INIT]] : tensor<2x3x2xf32>)
// CHECK: ^bb0(%[[ARG0:.+]]: i32, %[[ARG1:.+]]: f32)
// CHECK: %[[IDX0:.+]] = linalg.index 0
- // CHECK: %[[CAST:.+]] = index_cast %[[ARG0]]
+ // CHECK: %[[CAST:.+]] = arith.index_cast %[[ARG0]]
// CHECK: %[[IDX2:.+]] = linalg.index 2
// CHECK: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[IDX0]], %[[CAST]], %[[IDX2]]] : tensor<2x3x2xf32>
// CHECK: linalg.yield %[[EXTRACT]]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#map0, #map1], iterator_types = ["parallel", "parallel", "parallel"]} ins(%arg1 : tensor<2x3xi32>) outs(%[[INIT]] : tensor<2x3x2xi32>)
// CHECK: ^bb0(%[[ARG0:.+]]: i32, %[[ARG1:.+]]: i32)
// CHECK: %[[IDX0:.+]] = linalg.index 0
- // CHECK: %[[CAST:.+]] = index_cast %[[ARG0]]
+ // CHECK: %[[CAST:.+]] = arith.index_cast %[[ARG0]]
// CHECK: %[[IDX2:.+]] = linalg.index 2
// CHECK: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[IDX0]], %[[CAST]], %[[IDX2]]] : tensor<2x3x2xi32>
// CHECK: linalg.yield %[[EXTRACT]]
// CHECK: %[[INIT:.+]] = linalg.init_tensor [6]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#map, #map], iterator_types = ["parallel"]} ins(%arg0 : tensor<6xi8>) outs(%[[INIT]] : tensor<6xi8>)
// CHECK: ^bb0(%[[ARG_IN:.+]]: i8, %[[ARG_INIT:.+]]: i8)
- // CHECK: %[[CAST:.+]] = index_cast %[[ARG_IN]]
- // CHECK: %[[OFFSET:.+]] = constant 128
- // CHECK: %[[ADD:.+]] = addi %[[CAST]], %[[OFFSET]]
+ // CHECK: %[[CAST:.+]] = arith.index_cast %[[ARG_IN]]
+ // CHECK: %[[OFFSET:.+]] = arith.constant 128
+ // CHECK: %[[ADD:.+]] = arith.addi %[[CAST]], %[[OFFSET]]
// CHECK: %[[EXTRACT:.+]] = tensor.extract %arg1[%[[ADD]]]
// CHECK: linalg.yield %[[EXTRACT]]
%0 = "tosa.table"(%arg0, %arg1) : (tensor<6xi8>, tensor<512xi8>) -> (tensor<6xi8>)
// CHECK: %[[INIT:.+]] = linalg.init_tensor [6]
// CHECK: %[[GENERIC:.+]] = linalg.generic {indexing_maps = [#map, #map], iterator_types = ["parallel"]} ins(%arg0 : tensor<6xi16>) outs(%[[INIT]] : tensor<6xi32>)
// CHECK: ^bb0(%arg2: i16, %arg3: i32)
- // CHECK: %[[EXT_IN:.+]] = sexti %arg2
- // CHECK: %[[C32768:.+]] = constant 32768
- // CHECK: %[[C7:.+]] = constant 7
- // CHECK: %[[C1:.+]] = constant 1
- // CHECK: %[[C127:.+]] = constant 127
- // CHECK: %[[INADD:.+]] = addi %[[EXT_IN]], %[[C32768]]
- // CHECK: %[[IDX:.+]] = shift_right_unsigned %[[INADD]], %[[C7]]
- // CHECK: %[[FRACTION:.+]] = and %[[INADD]], %[[C127]]
- // CHECK: %[[IDXPLUS1:.+]] = addi %[[IDX]], %[[C1]]
- // CHECK: %[[IDX_CAST:.+]] = index_cast %[[IDX]]
- // CHECK: %[[IDXPLUS1_CAST:.+]] = index_cast %[[IDXPLUS1]]
+ // CHECK: %[[EXT_IN:.+]] = arith.extsi %arg2
+ // CHECK: %[[C32768:.+]] = arith.constant 32768
+ // CHECK: %[[C7:.+]] = arith.constant 7
+ // CHECK: %[[C1:.+]] = arith.constant 1
+ // CHECK: %[[C127:.+]] = arith.constant 127
+ // CHECK: %[[INADD:.+]] = arith.addi %[[EXT_IN]], %[[C32768]]
+ // CHECK: %[[IDX:.+]] = arith.shrui %[[INADD]], %[[C7]]
+ // CHECK: %[[FRACTION:.+]] = arith.andi %[[INADD]], %[[C127]]
+ // CHECK: %[[IDXPLUS1:.+]] = arith.addi %[[IDX]], %[[C1]]
+ // CHECK: %[[IDX_CAST:.+]] = arith.index_cast %[[IDX]]
+ // CHECK: %[[IDXPLUS1_CAST:.+]] = arith.index_cast %[[IDXPLUS1]]
// CHECK: %[[BASE:.+]] = tensor.extract %arg1[%[[IDX_CAST]]]
// CHECK: %[[NEXT:.+]] = tensor.extract %arg1[%[[IDXPLUS1_CAST]]]
- // CHECK: %[[BASE_EXT:.+]] = sexti %[[BASE]]
- // CHECK: %[[NEXT_EXT:.+]] = sexti %[[NEXT]]
- // CHECK: %[[BASE_MUL:.+]] = shift_left %[[BASE_EXT]], %[[C7]]
- // CHECK: %[[DIFF:.+]] = subi %[[NEXT_EXT]], %[[BASE_EXT]]
- // CHECK: %[[DIFF_MUL:.+]] = muli %[[DIFF]], %[[FRACTION]]
- // CHECK: %[[RESULT:.+]] = addi %[[BASE_MUL]], %[[DIFF_MUL]]
+ // CHECK: %[[BASE_EXT:.+]] = arith.extsi %[[BASE]]
+ // CHECK: %[[NEXT_EXT:.+]] = arith.extsi %[[NEXT]]
+ // CHECK: %[[BASE_MUL:.+]] = arith.shli %[[BASE_EXT]], %[[C7]]
+ // CHECK: %[[DIFF:.+]] = arith.subi %[[NEXT_EXT]], %[[BASE_EXT]]
+ // CHECK: %[[DIFF_MUL:.+]] = arith.muli %[[DIFF]], %[[FRACTION]]
+ // CHECK: %[[RESULT:.+]] = arith.addi %[[BASE_MUL]], %[[DIFF_MUL]]
// CHECK: linalg.yield %[[RESULT]]
%0 = "tosa.table"(%arg0, %arg1) : (tensor<6xi16>, tensor<513xi16>) -> (tensor<6xi32>)
return
// CHECK-LABEL: @max_pool
func @max_pool(%arg0: tensor<1x6x34x62xf32>) -> () {
- // CHECK-DAG: [[CONST:%.+]] = constant -3.40282347E+38
+ // CHECK-DAG: [[CONST:%.+]] = arith.constant -3.40282347E+38
// CHECK-DAG: [[INIT:%.+]] = linalg.init_tensor [1, 4, 32, 62]
// CHECK-DAG: [[FILL:%.+]] = linalg.fill([[CONST]], [[INIT]])
// CHECK-DAG: [[KERNEL:%.+]] = linalg.init_tensor [3, 3]
// CHECK-LABEL: @max_pool_padded
func @max_pool_padded(%arg0: tensor<1x6x34x62xf32>) -> () {
- // CHECK-DAG: [[CONST:%.+]] = constant -3.40282347E+38 : f32
+ // CHECK-DAG: [[CONST:%.+]] = arith.constant -3.40282347E+38 : f32
// CHECK-DAG: [[PAD:%.+]] = linalg.pad_tensor %arg0 low[0, 0, 0, 0] high[0, 0, 1, 0]
// CHECK-DAG: linalg.yield [[CONST]]
- // CHECK-DAG: [[INITVAL:%.+]] = constant -3.40282347E+38 : f32
+ // CHECK-DAG: [[INITVAL:%.+]] = arith.constant -3.40282347E+38 : f32
// CHECK-DAG: [[INIT:%.+]] = linalg.init_tensor [1, 4, 33, 62]
// CHECK-DAG: [[FILL:%.+]] = linalg.fill([[INITVAL]], [[INIT]])
// CHECK-DAG: [[KERNEL:%.+]] = linalg.init_tensor [3, 3]
// CHECK-LABEL: @max_pool_i8
func @max_pool_i8(%arg0: tensor<1x6x34x62xi8>) -> () {
- // CHECK: constant -128
+ // CHECK: arith.constant -128
// CHECK: linalg.pooling_nhwc_max
%0 = "tosa.max_pool2d"(%arg0) {pad = [0, 0, 0, 0], kernel = [3, 3], stride = [1, 1]} : (tensor<1x6x34x62xi8>) -> (tensor<1x4x32x62xi8>)
return
// CHECK-LABEL: @max_pool_i16
func @max_pool_i16(%arg0: tensor<1x6x34x62xi16>) -> () {
- // CHECK: constant -32768
+ // CHECK: arith.constant -32768
// CHECK: linalg.pooling_nhwc_max
%0 = "tosa.max_pool2d"(%arg0) {pad = [0, 0, 0, 0], kernel = [3, 3], stride = [1, 1]} : (tensor<1x6x34x62xi16>) -> (tensor<1x4x32x62xi16>)
return
// CHECK-LABEL: @max_pool_i32
func @max_pool_i32(%arg0: tensor<1x6x34x62xi32>) -> () {
- // CHECK: constant -2147483648
+ // CHECK: arith.constant -2147483648
// CHECK: linalg.pooling_nhwc_max
%0 = "tosa.max_pool2d"(%arg0) {pad = [0, 0, 0, 0], kernel = [3, 3], stride = [1, 1]} : (tensor<1x6x34x62xi32>) -> (tensor<1x4x32x62xi32>)
return
// CHECK-LABEL: @avg_pool
func @avg_pool(%arg0: tensor<1x6x34x62xf32>) -> (tensor<1x5x33x62xf32>) {
// Initial piece computes the sum of the pooling region, with appropriate padding.
- // CHECK: [[CONST:%.+]] = constant 0
+ // CHECK: [[CONST:%.+]] = arith.constant 0
// CHECK: [[PAD:%.+]] = linalg.pad_tensor %arg0 low[0, 1, 1, 0] high[0, 1, 1, 0]
- // CHECK: [[CONST:%.+]] = constant 0
+ // CHECK: [[CONST:%.+]] = arith.constant 0
// CHECK: [[POOLINIT:%.+]] = linalg.init_tensor [1, 5, 33, 62]
// CHECK: [[FILL:%.+]] = linalg.fill([[CONST]], [[POOLINIT]])
// CHECK: [[KERNEL:%.+]] = linalg.init_tensor [4, 4]
// CHECK: [[POOL:%.+]] = linalg.pooling_nhwc_sum {dilations = dense<1> : vector<2xi64>, strides = dense<1> : vector<2xi64>} ins([[PAD]], [[KERNEL]] : tensor<1x8x36x62xf32>, tensor<4x4xf32>) outs([[FILL]] : tensor<1x5x33x62xf32>)
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 5, 33, 62]
// CHECK: [[GENERIC:%.+]] = linalg.generic {indexing_maps = [#map, #map], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins([[POOL]] : tensor<1x5x33x62xf32>) outs([[INIT]] : tensor<1x5x33x62xf32>)
- // CHECK: [[ZERO:%.0]] = constant 0
- // CHECK: [[ONE:%.+]] = constant 1
- // CHECK: [[HEIGHT:%.+]] = constant 4
- // CHECK: [[WIDTH:%.+]] = constant 32
+ // CHECK: [[ZERO:%.0]] = arith.constant 0
+ // CHECK: [[ONE:%.+]] = arith.constant 1
+ // CHECK: [[HEIGHT:%.+]] = arith.constant 4
+ // CHECK: [[WIDTH:%.+]] = arith.constant 32
// CHECK: [[IDX1:%.+]] = linalg.index 1
// CHECK: [[IDX2:%.+]] = linalg.index 2
// The large block below computes what portion of the kernel is within non-padded input.
- // CHECK: [[NY:%.+]] = subi [[HEIGHT]], [[IDX1]]
- // CHECK: [[NX:%.+]] = subi [[WIDTH]], [[IDX2]]
- // CHECK: [[KH:%.+]] = constant 4
- // CHECK: [[PAD0:%.+]] = constant 1
- // CHECK: [[SUBP0:%.+]] = subi [[IDX1]], [[PAD0]]
- // CHECK: [[P0CMP:%.+]] = cmpi slt, [[SUBP0]], [[ZERO]]
+ // CHECK: [[NY:%.+]] = arith.subi [[HEIGHT]], [[IDX1]]
+ // CHECK: [[NX:%.+]] = arith.subi [[WIDTH]], [[IDX2]]
+ // CHECK: [[KH:%.+]] = arith.constant 4
+ // CHECK: [[PAD0:%.+]] = arith.constant 1
+ // CHECK: [[SUBP0:%.+]] = arith.subi [[IDX1]], [[PAD0]]
+ // CHECK: [[P0CMP:%.+]] = arith.cmpi slt, [[SUBP0]], [[ZERO]]
// CHECK: [[SELP0:%.+]] = select [[P0CMP]], [[SUBP0]], [[ZERO]]
- // CHECK: [[ADDP0:%.+]] = addi [[KH]], [[SELP0]]
- // CHECK: [[PAD1:%.+]] = constant 1
- // CHECK: [[SUBP1:%.+]] = subi [[NY]], [[PAD1]]
- // CHECK: [[P1CMP:%.+]] = cmpi slt, [[SUBP1]], [[ZERO]]
+ // CHECK: [[ADDP0:%.+]] = arith.addi [[KH]], [[SELP0]]
+ // CHECK: [[PAD1:%.+]] = arith.constant 1
+ // CHECK: [[SUBP1:%.+]] = arith.subi [[NY]], [[PAD1]]
+ // CHECK: [[P1CMP:%.+]] = arith.cmpi slt, [[SUBP1]], [[ZERO]]
// CHECK: [[SELP1:%.+]] = select [[P1CMP]], [[SUBP1]], [[ZERO]]
- // CHECK: [[ADDP1:%.+]] = addi [[ADDP0]], [[SELP1]]
- // CHECK: [[YCMP:%.+]] = cmpi slt, [[ADDP1]], [[ONE]]
+ // CHECK: [[ADDP1:%.+]] = arith.addi [[ADDP0]], [[SELP1]]
+ // CHECK: [[YCMP:%.+]] = arith.cmpi slt, [[ADDP1]], [[ONE]]
// CHECK: [[YSEL:%.+]] = select [[YCMP]], [[ONE]], [[ADDP1]]
- // CHECK: [[KW:%.+]] = constant 4 : index
- // CHECK: [[PAD2:%.+]] = constant 1 : index
- // CHECK: [[SUBP2:%.+]] = subi [[IDX2]], [[PAD2]]
- // CHECK: [[P2CMP:%.+]] = cmpi slt, [[SUBP2]], [[ZERO]]
+ // CHECK: [[KW:%.+]] = arith.constant 4 : index
+ // CHECK: [[PAD2:%.+]] = arith.constant 1 : index
+ // CHECK: [[SUBP2:%.+]] = arith.subi [[IDX2]], [[PAD2]]
+ // CHECK: [[P2CMP:%.+]] = arith.cmpi slt, [[SUBP2]], [[ZERO]]
// CHECK: [[SELP2:%.+]] = select [[P2CMP]], [[SUBP2]], [[ZERO]]
- // CHECK: [[ADDP2:%.+]] = addi [[KW]], [[SELP2]]
- // CHECK: [[PAD3:%.+]] = constant 1 : index
- // CHECK: [[SUBP3:%.+]] = subi [[NX]], [[PAD3]]
- // CHECK: [[P3CMP:%.+]] = cmpi slt, [[SUBP3]], [[ZERO]]
+ // CHECK: [[ADDP2:%.+]] = arith.addi [[KW]], [[SELP2]]
+ // CHECK: [[PAD3:%.+]] = arith.constant 1 : index
+ // CHECK: [[SUBP3:%.+]] = arith.subi [[NX]], [[PAD3]]
+ // CHECK: [[P3CMP:%.+]] = arith.cmpi slt, [[SUBP3]], [[ZERO]]
// CHECK: [[SELP3:%.+]] = select [[P3CMP]], [[SUBP3]], [[ZERO]]
- // CHECK: [[ADDP3:%.+]] = addi [[ADDP2]], [[SELP3]]
- // CHECK: [[XCMP:%.+]] = cmpi slt, [[ADDP3]], [[ONE]]
+ // CHECK: [[ADDP3:%.+]] = arith.addi [[ADDP2]], [[SELP3]]
+ // CHECK: [[XCMP:%.+]] = arith.cmpi slt, [[ADDP3]], [[ONE]]
// CHECK: [[XSEL:%.+]] = select [[XCMP]], [[ONE]], [[ADDP3]]
// Given the valid coverage of the pooling region, normalize the summation.
- // CHECK: [[C:%.+]] = muli [[YSEL]], [[XSEL]]
- // CHECK: [[CI:%.+]] = index_cast [[C]]
- // CHECK: [[CF:%.+]] = sitofp [[CI]]
- // CHECK: [[RESULT:%.+]] = divf %arg1, [[CF]]
+ // CHECK: [[C:%.+]] = arith.muli [[YSEL]], [[XSEL]]
+ // CHECK: [[CI:%.+]] = arith.index_cast [[C]]
+ // CHECK: [[CF:%.+]] = arith.sitofp [[CI]]
+ // CHECK: [[RESULT:%.+]] = arith.divf %arg1, [[CF]]
// CHECK: linalg.yield [[RESULT]]
%0 = "tosa.avg_pool2d"(%arg0) {pad = [1, 1, 1, 1], kernel = [4, 4], stride = [1, 1]} : (tensor<1x6x34x62xf32>) -> (tensor<1x5x33x62xf32>)
return %0 : tensor<1x5x33x62xf32>
// CHECK: linalg.pooling_nhwc_sum
// CHECK: linalg.generic
- // CHECK: %[[INZP:.+]] = constant -128
- // CHECK: %[[INZP_OFF:.+]] = muli %{{.+}}, %[[INZP]]
- // CHECK: %[[OFFSETED:.+]] = subi %arg1, %[[INZP_OFF]]
- // CHECK: %[[NUMERATOR:.+]] = constant 1073741825
- // CHECK: %[[MULTIPLIER:.+]] = divi_unsigned %[[NUMERATOR]], %{{.+}}
- // CHECK: %[[SHIFT:.+]] = constant 30
+ // CHECK: %[[INZP:.+]] = arith.constant -128
+ // CHECK: %[[INZP_OFF:.+]] = arith.muli %{{.+}}, %[[INZP]]
+ // CHECK: %[[OFFSETED:.+]] = arith.subi %arg1, %[[INZP_OFF]]
+ // CHECK: %[[NUMERATOR:.+]] = arith.constant 1073741825
+ // CHECK: %[[MULTIPLIER:.+]] = arith.divui %[[NUMERATOR]], %{{.+}}
+ // CHECK: %[[SHIFT:.+]] = arith.constant 30
// CHECK: %[[SCALE:.+]] = "tosa.apply_scale"(%{{.+}}, %[[MULTIPLIER]], %[[SHIFT]]) {double_round = false}
- // CHECK: %[[OUTZP:.+]] = constant -128
- // CHECK: %[[OUT:.+]] = addi %[[SCALE]], %[[OUTZP]]
- // CHECK: %[[MIN:.+]] = constant -2147483648
- // CHECK: %[[MAX:.+]] = constant 2147483647
- // CHECK: %[[CMP_MIN:.+]] = cmpi slt, %[[OUT]], %[[MIN]]
+ // CHECK: %[[OUTZP:.+]] = arith.constant -128
+ // CHECK: %[[OUT:.+]] = arith.addi %[[SCALE]], %[[OUTZP]]
+ // CHECK: %[[MIN:.+]] = arith.constant -2147483648
+ // CHECK: %[[MAX:.+]] = arith.constant 2147483647
+ // CHECK: %[[CMP_MIN:.+]] = arith.cmpi slt, %[[OUT]], %[[MIN]]
// CHECK: %[[CLMP_MIN:.+]] = select %[[CMP_MIN]], %[[MIN]], %[[OUT]]
- // CHECK: %[[CMP_MAX:.+]] = cmpi slt, %[[MAX]], %[[OUT]]
+ // CHECK: %[[CMP_MAX:.+]] = arith.cmpi slt, %[[MAX]], %[[OUT]]
// CHECK: %[[CLMP_MAX:.+]] = select %[[CMP_MAX]], %[[MAX]], %[[CLMP_MIN]]
// CHECK: linalg.yield %[[CLMP_MAX]]
%0 = "tosa.avg_pool2d"(%arg0) {kernel = [4, 4], pad = [0, 0, 0, 0], quantization_info = {input_zp = -128 : i32, output_zp = -128 : i32}, stride = [4, 4]} : (tensor<1x128x128x2xi8>) -> tensor<1x32x32x2xi32>
// CHECK: %[[W:.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg1 : tensor<28x3x3x27xf32>) outs(%[[W_IN]] : tensor<3x3x27x28xf32>)
// CHECK: linalg.yield %arg3 : f32
// CHECK: %[[M_IN:.+]] = linalg.init_tensor [1, 45, 40, 28]
- // CHECK: %[[CST:.+]] = constant 0
+ // CHECK: %[[CST:.+]] = arith.constant 0
// CHECK: %[[FILL:.+]] = linalg.fill
// CHECK: %[[B_IN:.+]] = linalg.init_tensor [1, 45, 40, 28]
// CHECK: %[[CONV:.+]] = linalg.conv_2d_nhwc_hwcf {dilations = dense<[2, 1]> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>} ins(%arg0, %[[W]] : tensor<1x49x42x27xf32>, tensor<3x3x27x28xf32>) outs(%[[FILL]] : tensor<1x45x40x28xf32>)
// CHECK: %[[B:.+]] = linalg.generic {indexing_maps = [#[[$MAP2]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg2, %[[CONV]] : tensor<28xf32>, tensor<1x45x40x28xf32>) outs(%[[B_IN]] : tensor<1x45x40x28xf32>)
- // CHECK: addf
+ // CHECK: arith.addf
// CHECK: linalg.yield %7 : f32
%0 = "tosa.conv2d"(%input, %weights, %bias) {pad = [0, 0, 0, 0], stride = [1, 1], dilation = [2, 1]} : (tensor<1x49x42x27xf32>, tensor<28x3x3x27xf32>, tensor<28xf32>) -> (tensor<1x45x40x28xf32>)
return
// CHECK-LABEL: @conv2d_padded_f32
func @conv2d_padded_f32(%input: tensor<1x47x40x28xf32>, %weights: tensor<28x3x3x28xf32>, %bias: tensor<28xf32>) -> () {
- // CHECK: %[[C0:.+]] = constant 0
+ // CHECK: %[[C0:.+]] = arith.constant 0
// CHECK: linalg.pad_tensor %arg0 low[0, 1, 1, 0] high[0, 1, 1, 0]
// CHECK: linalg.yield %[[C0]]
// CHECK: linalg.conv_2d_nhwc_hwcf
// CHECK-LABEL: @conv2d_quant
func @conv2d_quant(%arg0 : tensor<1x12x12x1xi8>, %arg1 : tensor<1024x3x3x1xi8>, %arg2 : tensor<1024xi32>) -> () {
- // CHECK: %[[C22:.+]] = constant -22
+ // CHECK: %[[C22:.+]] = arith.constant -22
// CHECK: linalg.pad_tensor %arg0 low[0, 1, 1, 0] high[0, 1, 1, 0]
// CHECK: linalg.yield %[[C22]]
// CHECK: linalg.conv_2d_nhwc_hwcf_q
// CHECK-LABEL: @depthwise_conv
func @depthwise_conv(%arg0 : tensor<1x7x5x3xf32>, %arg1 : tensor<3x1x3x11xf32>, %arg2 : tensor<33xf32>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 5, 5, 3, 11]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[OUT:%.+]] = linalg.init_tensor [1, 5, 5, 33]
// CHECK: [[DEPTH:%.+]] = linalg.depthwise_conv2D_nhwc {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>} ins(%arg0, %arg1 : tensor<1x7x5x3xf32>, tensor<3x1x3x11xf32>) outs([[FILL]] : tensor<1x5x5x3x11xf32>)
// CHECK: [[COLLAPSED:%.+]] = linalg.tensor_collapse_shape [[DEPTH]] {{\[}}[0], [1], [2], [3, 4]]
// CHECK: [[BIAS:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg2, [[COLLAPSED]] : tensor<33xf32>, tensor<1x5x5x33xf32>) outs([[OUT]] : tensor<1x5x5x33xf32>) {
// CHECK: ^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- // CHECK: [[ADD:%.+]] = addf %arg3, %arg4 : f32
+ // CHECK: [[ADD:%.+]] = arith.addf %arg3, %arg4 : f32
// CHECK: linalg.yield [[ADD]] : f32
// CHECK: } -> tensor<1x5x5x33xf32>
%2 = "tosa.depthwise_conv2d"(%arg0, %arg1, %arg2) { pad = [0, 0, 0, 0], stride = [1, 1], dilation = [1, 1] } : (tensor<1x7x5x3xf32>, tensor<3x1x3x11xf32>, tensor<33xf32>) -> (tensor<1x5x5x33xf32>)
// CHECK-LABEL: @depthwise_conv_strides
func @depthwise_conv_strides(%arg0 : tensor<1x11x9x3xf32>, %arg1 : tensor<3x1x3x11xf32>, %arg2 : tensor<33xf32>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 5, 5, 3, 11]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[OUT:%.+]] = linalg.init_tensor [1, 5, 5, 33]
// CHECK: [[DEPTH:%.+]] = linalg.depthwise_conv2D_nhwc {dilations = dense<1> : tensor<2xi64>, strides = dense<2> : tensor<2xi64>} ins(%arg0, %arg1 : tensor<1x11x9x3xf32>, tensor<3x1x3x11xf32>) outs([[FILL]] : tensor<1x5x5x3x11xf32>)
// CHECK: [[COLLAPSED:%.+]] = linalg.tensor_collapse_shape [[DEPTH]] {{\[}}[0], [1], [2], [3, 4]]
// CHECK: [[BIAS:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg2, [[COLLAPSED]] : tensor<33xf32>, tensor<1x5x5x33xf32>) outs([[OUT]] : tensor<1x5x5x33xf32>) {
// CHECK: ^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- // CHECK: [[ADD:%.+]] = addf %arg3, %arg4 : f32
+ // CHECK: [[ADD:%.+]] = arith.addf %arg3, %arg4 : f32
// CHECK: linalg.yield [[ADD]] : f32
// CHECK: } -> tensor<1x5x5x33xf32>
%2 = "tosa.depthwise_conv2d"(%arg0, %arg1, %arg2) { pad = [0, 0, 0, 0], stride = [2, 2], dilation = [1, 1] } : (tensor<1x11x9x3xf32>, tensor<3x1x3x11xf32>, tensor<33xf32>) -> (tensor<1x5x5x33xf32>)
// CHECK-LABEL: @depthwise_conv_quant
func @depthwise_conv_quant(%arg0 : tensor<1x12x12x4xi8>, %arg1 : tensor<3x3x4x128xi8>, %arg2 : tensor<512xi32>) -> () {
- // CHECK: [[PADV:%.+]] = constant -128
+ // CHECK: [[PADV:%.+]] = arith.constant -128
// CHECK: [[PAD:%.+]] = linalg.pad_tensor %arg0 low[0, 1, 1, 0] high[0, 1, 1, 0]
// CHECK: linalg.yield [[PADV]]
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 12, 12, 4, 128]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[OUT:%.+]] = linalg.init_tensor [1, 12, 12, 512]
- // CHECK: [[C128:%.+]] = constant -128
- // CHECK: [[C42:%.+]] = constant 42
+ // CHECK: [[C128:%.+]] = arith.constant -128
+ // CHECK: [[C42:%.+]] = arith.constant 42
// CHECK: [[DEPTH:%.+]] = linalg.depthwise_conv2D_nhwc_q {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>} ins([[PAD]], %arg1, [[C128]], [[C42]] : tensor<1x14x14x4xi8>, tensor<3x3x4x128xi8>, i32, i32) outs([[FILL]] : tensor<1x12x12x4x128xi32>)
// CHECK: [[COLLAPSED:%.+]] = linalg.tensor_collapse_shape [[DEPTH]] {{\[}}[0], [1], [2], [3, 4]]
// CHECK: [[BIAS:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg2, [[COLLAPSED]] : tensor<512xi32>, tensor<1x12x12x512xi32>) outs([[OUT]] : tensor<1x12x12x512xi32>) {
// CHECK: ^bb0(%arg3: i32, %arg4: i32, %arg5: i32): // no predecessors
- // CHECK: [[ADD:%.+]] = addi %arg3, %arg4 : i32
+ // CHECK: [[ADD:%.+]] = arith.addi %arg3, %arg4 : i32
// CHECK: linalg.yield [[ADD]] : i32
// CHECK: } -> tensor<1x12x12x512xi32>
%0 = "tosa.depthwise_conv2d"(%arg0, %arg1, %arg2) {pad = [1, 1, 1, 1], quantization_info = {input_zp = -128 : i32, weight_zp = 42 : i32}, stride = [1, 1], dilation = [1, 1] } : (tensor<1x12x12x4xi8>, tensor<3x3x4x128xi8>, tensor<512xi32>) -> tensor<1x12x12x512xi32>
// CHECK-LABEL: @depthwise_conv_quant_dilations
func @depthwise_conv_quant_dilations(%arg0 : tensor<1x14x14x4xi8>, %arg1 : tensor<3x3x4x128xi8>, %arg2 : tensor<512xi32>) -> () {
// CHECK: [[INIT:%.+]] = linalg.init_tensor [1, 10, 10, 4, 128]
- // CHECK: [[CST0:%.+]] = constant 0
+ // CHECK: [[CST0:%.+]] = arith.constant 0
// CHECK: [[FILL:%.+]] = linalg.fill([[CST0]], [[INIT]])
// CHECK: [[OUT:%.+]] = linalg.init_tensor [1, 10, 10, 512]
- // CHECK: [[C128:%.+]] = constant -128
- // CHECK: [[C42:%.+]] = constant 42
+ // CHECK: [[C128:%.+]] = arith.constant -128
+ // CHECK: [[C42:%.+]] = arith.constant 42
// CHECK: [[DEPTH:%.+]] = linalg.depthwise_conv2D_nhwc_q {dilations = dense<2> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>} ins(%arg0, %arg1, [[C128]], [[C42]] : tensor<1x14x14x4xi8>, tensor<3x3x4x128xi8>, i32, i32) outs([[FILL]] : tensor<1x10x10x4x128xi32>)
// CHECK: [[COLLAPSED:%.+]] = linalg.tensor_collapse_shape [[DEPTH]] {{\[}}[0], [1], [2], [3, 4]]
// CHECK: [[BIAS:%.+]] = linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP1]]], iterator_types = ["parallel", "parallel", "parallel", "parallel"]} ins(%arg2, [[COLLAPSED]] : tensor<512xi32>, tensor<1x10x10x512xi32>) outs([[OUT]] : tensor<1x10x10x512xi32>) {
// CHECK: ^bb0(%arg3: i32, %arg4: i32, %arg5: i32): // no predecessors
- // CHECK: [[ADD:%.+]] = addi %arg3, %arg4 : i32
+ // CHECK: [[ADD:%.+]] = arith.addi %arg3, %arg4 : i32
// CHECK: linalg.yield [[ADD]] : i32
// CHECK: } -> tensor<1x10x10x512xi32>
%0 = "tosa.depthwise_conv2d"(%arg0, %arg1, %arg2) {pad = [0, 0, 0, 0], quantization_info = {input_zp = -128 : i32, weight_zp = 42 : i32}, stride = [1, 1], dilation = [2, 2] } : (tensor<1x14x14x4xi8>, tensor<3x3x4x128xi8>, tensor<512xi32>) -> tensor<1x10x10x512xi32>
// CHECK: %[[IDX1:.+]] = linalg.index 1
// CHECK: %[[IDX2:.+]] = linalg.index 2
// CHECK: %[[IDX3:.+]] = linalg.index 3
- // CHECK-DAG: %[[XYMIN:.+]] = constant 0
- // CHECK-DAG: %[[YMAX:.+]] = constant 1
- // CHECK-DAG: %[[XMAX:.+]] = constant 1
- // CHECK-DAG: %[[Y:.+]] = index_cast %[[IDX1]]
- // CHECK-DAG: %[[X:.+]] = index_cast %[[IDX2]]
- // CHECK-DAG: %[[STRIDEY:.+]] = constant 5.000000e-01
- // CHECK-DAG: %[[STRIDEX:.+]] = constant 5.000000e-01
- // CHECK-DAG: %[[OFFSETY:.+]] = constant 1.000000e-01
- // CHECK-DAG: %[[OFFSETX:.+]] = constant 2.000000e-01
- // CHECK-DAG: %[[VAL4:.+]] = uitofp %[[Y]]
- // CHECK-DAG: %[[VAL5:.+]] = uitofp %[[X]]
- // CHECK-DAG: %[[VAL6:.+]] = mulf %[[VAL4]], %[[STRIDEY]]
- // CHECK-DAG: %[[VAL7:.+]] = mulf %[[VAL5]], %[[STRIDEX]]
- // CHECK-DAG: %[[VAL8:.+]] = addf %[[VAL6]], %[[OFFSETY]]
- // CHECK-DAG: %[[VAL9:.+]] = addf %[[VAL7]], %[[OFFSETX]]
+ // CHECK-DAG: %[[XYMIN:.+]] = arith.constant 0
+ // CHECK-DAG: %[[YMAX:.+]] = arith.constant 1
+ // CHECK-DAG: %[[XMAX:.+]] = arith.constant 1
+ // CHECK-DAG: %[[Y:.+]] = arith.index_cast %[[IDX1]]
+ // CHECK-DAG: %[[X:.+]] = arith.index_cast %[[IDX2]]
+ // CHECK-DAG: %[[STRIDEY:.+]] = arith.constant 5.000000e-01
+ // CHECK-DAG: %[[STRIDEX:.+]] = arith.constant 5.000000e-01
+ // CHECK-DAG: %[[OFFSETY:.+]] = arith.constant 1.000000e-01
+ // CHECK-DAG: %[[OFFSETX:.+]] = arith.constant 2.000000e-01
+ // CHECK-DAG: %[[VAL4:.+]] = arith.uitofp %[[Y]]
+ // CHECK-DAG: %[[VAL5:.+]] = arith.uitofp %[[X]]
+ // CHECK-DAG: %[[VAL6:.+]] = arith.mulf %[[VAL4]], %[[STRIDEY]]
+ // CHECK-DAG: %[[VAL7:.+]] = arith.mulf %[[VAL5]], %[[STRIDEX]]
+ // CHECK-DAG: %[[VAL8:.+]] = arith.addf %[[VAL6]], %[[OFFSETY]]
+ // CHECK-DAG: %[[VAL9:.+]] = arith.addf %[[VAL7]], %[[OFFSETX]]
// Find the remainder and integer component of the target index.
- // CHECK-DAG: %[[VAL10:.+]] = floorf %[[VAL8]]
- // CHECK-DAG: %[[VAL11:.+]] = floorf %[[VAL9]]
- // CHECK-DAG: %[[VAL12:.+]] = subf %[[VAL8]], %[[VAL10]]
- // CHECK-DAG: %[[VAL13:.+]] = subf %[[VAL9]], %[[VAL11]]
- // CHECK-DAG: %[[VAL14:.+]] = fptosi %[[VAL10]]
- // CHECK-DAG: %[[VAL15:.+]] = fptosi %[[VAL11]]
+ // CHECK-DAG: %[[VAL10:.+]] = math.floor %[[VAL8]]
+ // CHECK-DAG: %[[VAL11:.+]] = math.floor %[[VAL9]]
+ // CHECK-DAG: %[[VAL12:.+]] = arith.subf %[[VAL8]], %[[VAL10]]
+ // CHECK-DAG: %[[VAL13:.+]] = arith.subf %[[VAL9]], %[[VAL11]]
+ // CHECK-DAG: %[[VAL14:.+]] = arith.fptosi %[[VAL10]]
+ // CHECK-DAG: %[[VAL15:.+]] = arith.fptosi %[[VAL11]]
// Round to the nearest index.
- // CHECK-DAG: %[[ROUND:.+]] = constant 5.000000e-01
- // CHECK-DAG: %[[VAL16:.+]] = cmpf oge, %[[VAL12]], %[[ROUND]]
- // CHECK-DAG: %[[VAL17:.+]] = cmpf oge, %[[VAL13]], %[[ROUND]]
- // CHECK-DAG: %[[ZERO:.+]] = constant 0
- // CHECK-DAG: %[[ONE:.+]] = constant 1
+ // CHECK-DAG: %[[ROUND:.+]] = arith.constant 5.000000e-01
+ // CHECK-DAG: %[[VAL16:.+]] = arith.cmpf oge, %[[VAL12]], %[[ROUND]]
+ // CHECK-DAG: %[[VAL17:.+]] = arith.cmpf oge, %[[VAL13]], %[[ROUND]]
+ // CHECK-DAG: %[[ZERO:.+]] = arith.constant 0
+ // CHECK-DAG: %[[ONE:.+]] = arith.constant 1
// CHECK-DAG: %[[VAL18:.+]] = select %[[VAL16]], %[[ONE]], %[[ZERO]]
// CHECK-DAG: %[[VAL19:.+]] = select %[[VAL17]], %[[ONE]], %[[ZERO]]
- // CHECK-DAG: %[[VAL20:.+]] = addi %[[VAL14]], %[[VAL18]]
- // CHECK-DAG: %[[VAL21:.+]] = addi %[[VAL15]], %[[VAL19]]
+ // CHECK-DAG: %[[VAL20:.+]] = arith.addi %[[VAL14]], %[[VAL18]]
+ // CHECK-DAG: %[[VAL21:.+]] = arith.addi %[[VAL15]], %[[VAL19]]
// This section applies bound checking to be within the input image.
- // CHECK-DAG: %[[VAL22:.+]] = cmpi slt, %[[VAL20]], %[[XYMIN]]
+ // CHECK-DAG: %[[VAL22:.+]] = arith.cmpi slt, %[[VAL20]], %[[XYMIN]]
// CHECK-DAG: %[[VAL23:.+]] = select %[[VAL22]], %[[XYMIN]], %[[VAL20]]
- // CHECK-DAG: %[[VAL24:.+]] = cmpi slt, %[[YMAX]], %[[VAL20]]
+ // CHECK-DAG: %[[VAL24:.+]] = arith.cmpi slt, %[[YMAX]], %[[VAL20]]
// CHECK-DAG: %[[VAL25:.+]] = select %[[VAL24]], %[[YMAX]], %[[VAL23]]
- // CHECK-DAG: %[[VAL26:.+]] = cmpi slt, %[[VAL21]], %[[XYMIN]]
+ // CHECK-DAG: %[[VAL26:.+]] = arith.cmpi slt, %[[VAL21]], %[[XYMIN]]
// CHECK-DAG: %[[VAL27:.+]] = select %[[VAL26]], %[[XYMIN]], %[[VAL21]]
- // CHECK-DAG: %[[VAL28:.+]] = cmpi slt, %[[XMAX]], %[[VAL21]]
+ // CHECK-DAG: %[[VAL28:.+]] = arith.cmpi slt, %[[XMAX]], %[[VAL21]]
// CHECK-DAG: %[[VAL29:.+]] = select %[[VAL28]], %[[XMAX]], %[[VAL27]]
// Extract the nearest value using the computed indices.
- // CHECK-DAG: %[[IDY:.+]] = index_cast %[[VAL25]]
- // CHECK-DAG: %[[IDX:.+]] = index_cast %[[VAL29]]
+ // CHECK-DAG: %[[IDY:.+]] = arith.index_cast %[[VAL25]]
+ // CHECK-DAG: %[[IDX:.+]] = arith.index_cast %[[VAL29]]
// CHECK-DAG: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[IDX0]], %[[IDY]], %[[IDX]], %[[IDX3]]]
// CHECK: linalg.yield %[[EXTRACT]]
%output = "tosa.resize"(%input) { output_size = [4, 4], stride = [0, 0], offset = [0, 0], stride_fp = [0.5 : f32, 0.5 : f32], offset_fp = [0.1 : f32, 0.2 : f32], shift = 0 : i32, mode = "NEAREST_NEIGHBOR" } : (tensor<1x2x2x1xf32>) -> (tensor<1x4x4x1xf32>)
// CHECK: %[[IDX1:.+]] = linalg.index 1
// CHECK: %[[IDX2:.+]] = linalg.index 2
// CHECK: %[[IDX3:.+]] = linalg.index 3
- // CHECK: %[[XYMIN:.+]] = constant 0
- // CHECK: %[[YMAX:.+]] = constant 1
- // CHECK: %[[XMAX:.+]] = constant 1
+ // CHECK: %[[XYMIN:.+]] = arith.constant 0
+ // CHECK: %[[YMAX:.+]] = arith.constant 1
+ // CHECK: %[[XMAX:.+]] = arith.constant 1
- // CHECK: %[[VAL10:.+]] = floorf %[[VAL8:.+]]
- // CHECK: %[[VAL11:.+]] = floorf %[[VAL9:.+]]
+ // CHECK: %[[VAL10:.+]] = math.floor %[[VAL8:.+]]
+ // CHECK: %[[VAL11:.+]] = math.floor %[[VAL9:.+]]
- // CHECK: %[[DY:.+]] = subf %[[VAL8:.+]], %[[VAL10]]
- // CHECK: %[[DX:.+]] = subf %[[VAL9:.+]], %[[VAL11]]
+ // CHECK: %[[DY:.+]] = arith.subf %[[VAL8:.+]], %[[VAL10]]
+ // CHECK: %[[DX:.+]] = arith.subf %[[VAL9:.+]], %[[VAL11]]
- // CHECK: %[[Y0:.+]] = fptosi %[[VAL10]]
- // CHECK: %[[X0:.+]] = fptosi %[[VAL11]]
+ // CHECK: %[[Y0:.+]] = arith.fptosi %[[VAL10]]
+ // CHECK: %[[X0:.+]] = arith.fptosi %[[VAL11]]
// Compute the left, right, and top indices for the bilinear interpolation.
- // CHECK: %[[ONE:.+]] = constant 1
- // CHECK: %[[Y1:.+]] = addi %[[Y0]], %[[ONE]]
- // CHECK: %[[X1:.+]] = addi %[[X0]], %[[ONE]]
+ // CHECK: %[[ONE:.+]] = arith.constant 1
+ // CHECK: %[[Y1:.+]] = arith.addi %[[Y0]], %[[ONE]]
+ // CHECK: %[[X1:.+]] = arith.addi %[[X0]], %[[ONE]]
// Bound check each dimension.
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[Y0]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[Y0]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[Y0]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[YMAX]], %[[Y0]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[YMAX]], %[[Y0]]
// CHECK: %[[YLO:.+]] = select %[[PRED]], %[[YMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[Y1]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[Y1]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[Y1]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[YMAX]], %[[Y1]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[YMAX]], %[[Y1]]
// CHECK: %[[YHI:.+]] = select %[[PRED]], %[[YMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[X0]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[X0]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[X0]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[XMAX]], %[[X0]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[XMAX]], %[[X0]]
// CHECK: %[[XLO:.+]] = select %[[PRED]], %[[XMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[X1]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[X1]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[X1]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[XMAX]], %[[X1]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[XMAX]], %[[X1]]
// CHECK: %[[XHI:.+]] = select %[[PRED]], %[[XMAX]], %[[BOUND]]
// Extract each corner of the bilinear interpolation.
- // CHECK: %[[YLOI:.+]] = index_cast %[[YLO]]
- // CHECK: %[[YHII:.+]] = index_cast %[[YHI]]
- // CHECK: %[[XLOI:.+]] = index_cast %[[XLO]]
- // CHECK: %[[XHII:.+]] = index_cast %[[XHI]]
+ // CHECK: %[[YLOI:.+]] = arith.index_cast %[[YLO]]
+ // CHECK: %[[YHII:.+]] = arith.index_cast %[[YHI]]
+ // CHECK: %[[XLOI:.+]] = arith.index_cast %[[XLO]]
+ // CHECK: %[[XHII:.+]] = arith.index_cast %[[XHI]]
// CHECK: %[[LOLO:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YLOI]], %[[XLOI]], %[[IDX3]]]
// CHECK: %[[LOHI:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YLOI]], %[[XHII]], %[[IDX3]]]
// Compute the bilinear interpolation.
- // CHECK: %[[ONE:.+]] = constant 1.000000e+00
- // CHECK: %[[NDX:.+]] = subf %[[ONE]], %[[DX]]
- // CHECK: %[[WLOLO:.+]] = mulf %[[LOLO]], %[[NDX]]
- // CHECK: %[[WLOHI:.+]] = mulf %[[LOHI]], %[[DX]]
- // CHECK: %[[LO:.+]] = addf %[[WLOLO]], %[[WLOHI]]
- // CHECK: %[[WHILO:.+]] = mulf %[[HILO]], %[[NDX]]
- // CHECK: %[[WHIHI:.+]] = mulf %[[HIHI]], %[[DX]]
- // CHECK: %[[HI:.+]] = addf %[[WHILO]], %[[WHIHI]]
- // CHECK: %[[NDY:.+]] = subf %[[ONE]], %[[DY]]
- // CHECK: %[[WLO:.+]] = mulf %[[LO]], %[[NDY]]
- // CHECK: %[[WHI:.+]] = mulf %[[HI]], %[[DY]]
- // CHECK: %[[RESULT:.+]] = addf %[[WLO]], %[[WHI]]
+ // CHECK: %[[ONE:.+]] = arith.constant 1.000000e+00
+ // CHECK: %[[NDX:.+]] = arith.subf %[[ONE]], %[[DX]]
+ // CHECK: %[[WLOLO:.+]] = arith.mulf %[[LOLO]], %[[NDX]]
+ // CHECK: %[[WLOHI:.+]] = arith.mulf %[[LOHI]], %[[DX]]
+ // CHECK: %[[LO:.+]] = arith.addf %[[WLOLO]], %[[WLOHI]]
+ // CHECK: %[[WHILO:.+]] = arith.mulf %[[HILO]], %[[NDX]]
+ // CHECK: %[[WHIHI:.+]] = arith.mulf %[[HIHI]], %[[DX]]
+ // CHECK: %[[HI:.+]] = arith.addf %[[WHILO]], %[[WHIHI]]
+ // CHECK: %[[NDY:.+]] = arith.subf %[[ONE]], %[[DY]]
+ // CHECK: %[[WLO:.+]] = arith.mulf %[[LO]], %[[NDY]]
+ // CHECK: %[[WHI:.+]] = arith.mulf %[[HI]], %[[DY]]
+ // CHECK: %[[RESULT:.+]] = arith.addf %[[WLO]], %[[WHI]]
// CHECK: linalg.yield %[[RESULT]]
%output = "tosa.resize"(%input) { output_size = [4, 4], stride = [0, 0], offset = [0, 0], stride_fp = [0.5 : f32, 0.5 : f32], offset_fp = [0.1 : f32, 0.2 : f32], shift = 0 : i32, mode = "BILINEAR" } : (tensor<1x2x2x1xf32>) -> (tensor<1x4x4x1xf32>)
return
// CHECK: %[[IDX1:.+]] = linalg.index 1
// CHECK: %[[IDX2:.+]] = linalg.index 2
// CHECK: %[[IDX3:.+]] = linalg.index 3
- // CHECK-DAG: %[[XYMIN:.+]] = constant 0
- // CHECK-DAG: %[[YMAX:.+]] = constant 1
- // CHECK-DAG: %[[XMAX:.+]] = constant 1
- // CHECK-DAG: %[[Y:.+]] = index_cast %[[IDX1]]
- // CHECK-DAG: %[[X:.+]] = index_cast %[[IDX2]]
- // CHECK-DAG: %[[STRIDEY:.+]] = constant 128
- // CHECK-DAG: %[[STRIDEX:.+]] = constant 128
- // CHECK-DAG: %[[OFFSETY:.+]] = constant 1
- // CHECK-DAG: %[[OFFSETX:.+]] = constant 2
- // CHECK-DAG: %[[EIGHT:.+]] = constant 8
- // CHECK-DAG: %[[VAL4:.+]] = muli %[[Y]], %[[STRIDEY]]
- // CHECK-DAG: %[[VAL5:.+]] = muli %[[X]], %[[STRIDEX]]
- // CHECK-DAG: %[[VAL6:.+]] = addi %[[VAL4]], %[[OFFSETY]]
- // CHECK-DAG: %[[VAL7:.+]] = addi %[[VAL5]], %[[OFFSETX]]
+ // CHECK-DAG: %[[XYMIN:.+]] = arith.constant 0
+ // CHECK-DAG: %[[YMAX:.+]] = arith.constant 1
+ // CHECK-DAG: %[[XMAX:.+]] = arith.constant 1
+ // CHECK-DAG: %[[Y:.+]] = arith.index_cast %[[IDX1]]
+ // CHECK-DAG: %[[X:.+]] = arith.index_cast %[[IDX2]]
+ // CHECK-DAG: %[[STRIDEY:.+]] = arith.constant 128
+ // CHECK-DAG: %[[STRIDEX:.+]] = arith.constant 128
+ // CHECK-DAG: %[[OFFSETY:.+]] = arith.constant 1
+ // CHECK-DAG: %[[OFFSETX:.+]] = arith.constant 2
+ // CHECK-DAG: %[[EIGHT:.+]] = arith.constant 8
+ // CHECK-DAG: %[[VAL4:.+]] = arith.muli %[[Y]], %[[STRIDEY]]
+ // CHECK-DAG: %[[VAL5:.+]] = arith.muli %[[X]], %[[STRIDEX]]
+ // CHECK-DAG: %[[VAL6:.+]] = arith.addi %[[VAL4]], %[[OFFSETY]]
+ // CHECK-DAG: %[[VAL7:.+]] = arith.addi %[[VAL5]], %[[OFFSETX]]
// Find the remainder and integer component of the target index.
- // CHECK-DAG: %[[VAL8:.+]] = shift_right_signed %[[VAL6]], %[[EIGHT]]
- // CHECK-DAG: %[[VAL9:.+]] = shift_right_signed %[[VAL7]], %[[EIGHT]]
- // CHECK-DAG: %[[VAL10:.+]] = shift_left %[[VAL8]], %[[EIGHT]]
- // CHECK-DAG: %[[VAL11:.+]] = shift_left %[[VAL9]], %[[EIGHT]]
- // CHECK-DAG: %[[VAL12:.+]] = subi %[[VAL6]], %[[VAL10]]
- // CHECK-DAG: %[[VAL13:.+]] = subi %[[VAL7]], %[[VAL11]]
+ // CHECK-DAG: %[[VAL8:.+]] = arith.shrsi %[[VAL6]], %[[EIGHT]]
+ // CHECK-DAG: %[[VAL9:.+]] = arith.shrsi %[[VAL7]], %[[EIGHT]]
+ // CHECK-DAG: %[[VAL10:.+]] = arith.shli %[[VAL8]], %[[EIGHT]]
+ // CHECK-DAG: %[[VAL11:.+]] = arith.shli %[[VAL9]], %[[EIGHT]]
+ // CHECK-DAG: %[[VAL12:.+]] = arith.subi %[[VAL6]], %[[VAL10]]
+ // CHECK-DAG: %[[VAL13:.+]] = arith.subi %[[VAL7]], %[[VAL11]]
// Round to the nearest index.
- // CHECK-DAG: %[[ROUND:.+]] = constant 128
- // CHECK-DAG: %[[VAL16:.+]] = cmpi sge, %[[VAL12]], %[[ROUND]]
- // CHECK-DAG: %[[VAL17:.+]] = cmpi sge, %[[VAL13]], %[[ROUND]]
- // CHECK-DAG: %[[ZERO:.+]] = constant 0
- // CHECK-DAG: %[[ONE:.+]] = constant 1
+ // CHECK-DAG: %[[ROUND:.+]] = arith.constant 128
+ // CHECK-DAG: %[[VAL16:.+]] = arith.cmpi sge, %[[VAL12]], %[[ROUND]]
+ // CHECK-DAG: %[[VAL17:.+]] = arith.cmpi sge, %[[VAL13]], %[[ROUND]]
+ // CHECK-DAG: %[[ZERO:.+]] = arith.constant 0
+ // CHECK-DAG: %[[ONE:.+]] = arith.constant 1
// CHECK-DAG: %[[VAL18:.+]] = select %[[VAL16]], %[[ONE]], %[[ZERO]]
// CHECK-DAG: %[[VAL19:.+]] = select %[[VAL17]], %[[ONE]], %[[ZERO]]
- // CHECK-DAG: %[[VAL20:.+]] = addi %[[VAL8]], %[[VAL18]]
- // CHECK-DAG: %[[VAL21:.+]] = addi %[[VAL9]], %[[VAL19]]
+ // CHECK-DAG: %[[VAL20:.+]] = arith.addi %[[VAL8]], %[[VAL18]]
+ // CHECK-DAG: %[[VAL21:.+]] = arith.addi %[[VAL9]], %[[VAL19]]
// This section applies bound checking to be within the input image.
- // CHECK-DAG: %[[VAL22:.+]] = cmpi slt, %[[VAL20]], %[[XYMIN]]
+ // CHECK-DAG: %[[VAL22:.+]] = arith.cmpi slt, %[[VAL20]], %[[XYMIN]]
// CHECK-DAG: %[[VAL23:.+]] = select %[[VAL22]], %[[XYMIN]], %[[VAL20]]
- // CHECK-DAG: %[[VAL24:.+]] = cmpi slt, %[[YMAX]], %[[VAL20]]
+ // CHECK-DAG: %[[VAL24:.+]] = arith.cmpi slt, %[[YMAX]], %[[VAL20]]
// CHECK-DAG: %[[VAL25:.+]] = select %[[VAL24]], %[[YMAX]], %[[VAL23]]
- // CHECK-DAG: %[[VAL26:.+]] = cmpi slt, %[[VAL21]], %[[XYMIN]]
+ // CHECK-DAG: %[[VAL26:.+]] = arith.cmpi slt, %[[VAL21]], %[[XYMIN]]
// CHECK-DAG: %[[VAL27:.+]] = select %[[VAL26]], %[[XYMIN]], %[[VAL21]]
- // CHECK-DAG: %[[VAL28:.+]] = cmpi slt, %[[XMAX]], %[[VAL21]]
+ // CHECK-DAG: %[[VAL28:.+]] = arith.cmpi slt, %[[XMAX]], %[[VAL21]]
// CHECK-DAG: %[[VAL29:.+]] = select %[[VAL28]], %[[XMAX]], %[[VAL27]]
// Extract the nearest value using the computed indices.
- // CHECK-DAG: %[[IDY:.+]] = index_cast %[[VAL25]]
- // CHECK-DAG: %[[IDX:.+]] = index_cast %[[VAL29]]
+ // CHECK-DAG: %[[IDY:.+]] = arith.index_cast %[[VAL25]]
+ // CHECK-DAG: %[[IDX:.+]] = arith.index_cast %[[VAL29]]
// CHECK: %[[EXTRACT:.+]] = tensor.extract %arg0[%[[IDX0]], %[[IDY]], %[[IDX]], %[[IDX3]]]
// CHECK: linalg.yield %[[EXTRACT]]
%output = "tosa.resize"(%input) { output_size = [4, 4], stride = [128, 128], offset = [1, 2], stride_fp = [0. : f32, 0. : f32], offset_fp = [0. : f32, 0. : f32], shift = 8 : i32, mode = "NEAREST_NEIGHBOR" } : (tensor<1x2x2x1xi32>) -> (tensor<1x4x4x1xi32>)
// CHECK: %[[IDX0:.+]] = linalg.index 0
// CHECK: %[[IDX3:.+]] = linalg.index 3
- // CHECK: %[[XYMIN:.+]] = constant 0
- // CHECK: %[[YMAX:.+]] = constant 1
- // CHECK: %[[XMAX:.+]] = constant 1
+ // CHECK: %[[XYMIN:.+]] = arith.constant 0
+ // CHECK: %[[YMAX:.+]] = arith.constant 1
+ // CHECK: %[[XMAX:.+]] = arith.constant 1
- // CHECK: %[[Y0:.+]] = shift_right_signed
- // CHECK: %[[X0:.+]] = shift_right_signed
- // CHECK: %[[ROUNDY:.+]] = shift_left %[[Y0]]
- // CHECK: %[[ROUNDX:.+]] = shift_left %[[X0]]
- // CHECK: %[[DY:.+]] = subi %10, %[[ROUNDY]]
- // CHECK: %[[DX:.+]] = subi %11, %[[ROUNDX]]
+ // CHECK: %[[Y0:.+]] = arith.shrsi
+ // CHECK: %[[X0:.+]] = arith.shrsi
+ // CHECK: %[[ROUNDY:.+]] = arith.shli %[[Y0]]
+ // CHECK: %[[ROUNDX:.+]] = arith.shli %[[X0]]
+ // CHECK: %[[DY:.+]] = arith.subi %10, %[[ROUNDY]]
+ // CHECK: %[[DX:.+]] = arith.subi %11, %[[ROUNDX]]
// Compute the left, right, and top indices for the bilinear interpolation.
- // CHECK: %[[ONE:.+]] = constant 1
- // CHECK: %[[Y1:.+]] = addi %[[Y0]], %[[ONE]]
- // CHECK: %[[X1:.+]] = addi %[[X0]], %[[ONE]]
+ // CHECK: %[[ONE:.+]] = arith.constant 1
+ // CHECK: %[[Y1:.+]] = arith.addi %[[Y0]], %[[ONE]]
+ // CHECK: %[[X1:.+]] = arith.addi %[[X0]], %[[ONE]]
// Bound check each dimension.
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[Y0]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[Y0]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[Y0]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[YMAX]], %[[Y0]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[YMAX]], %[[Y0]]
// CHECK: %[[YLO:.+]] = select %[[PRED]], %[[YMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[Y1]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[Y1]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[Y1]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[YMAX]], %[[Y1]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[YMAX]], %[[Y1]]
// CHECK: %[[YHI:.+]] = select %[[PRED]], %[[YMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[X0]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[X0]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[X0]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[XMAX]], %[[X0]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[XMAX]], %[[X0]]
// CHECK: %[[XLO:.+]] = select %[[PRED]], %[[XMAX]], %[[BOUND]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[X1]], %[[XYMIN]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[X1]], %[[XYMIN]]
// CHECK: %[[BOUND:.+]] = select %[[PRED]], %[[XYMIN]], %[[X1]]
- // CHECK: %[[PRED:.+]] = cmpi slt, %[[XMAX]], %[[X1]]
+ // CHECK: %[[PRED:.+]] = arith.cmpi slt, %[[XMAX]], %[[X1]]
// CHECK: %[[XHI:.+]] = select %[[PRED]], %[[XMAX]], %[[BOUND]]
// Extract each corner of the bilinear interpolation.
- // CHECK: %[[YLOI:.+]] = index_cast %[[YLO]]
- // CHECK: %[[YHII:.+]] = index_cast %[[YHI]]
- // CHECK: %[[XLOI:.+]] = index_cast %[[XLO]]
- // CHECK: %[[XHII:.+]] = index_cast %[[XHI]]
+ // CHECK: %[[YLOI:.+]] = arith.index_cast %[[YLO]]
+ // CHECK: %[[YHII:.+]] = arith.index_cast %[[YHI]]
+ // CHECK: %[[XLOI:.+]] = arith.index_cast %[[XLO]]
+ // CHECK: %[[XHII:.+]] = arith.index_cast %[[XHI]]
// CHECK: %[[LOLO:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YLOI]], %[[XLOI]], %[[IDX3]]]
// CHECK: %[[LOHI:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YLOI]], %[[XHII]], %[[IDX3]]]
// CHECK: %[[HILO:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YHII]], %[[XLOI]], %[[IDX3]]]
// CHECK: %[[HIHI:.+]] = tensor.extract %arg0[%[[IDX0]], %[[YHII]], %[[XHII]], %[[IDX3]]]
- // CHECK: %[[XLOLO:.+]] = sexti %[[LOLO]]
- // CHECK: %[[XLOHI:.+]] = sexti %[[LOHI]]
- // CHECK: %[[XHILO:.+]] = sexti %[[HILO]]
- // CHECK: %[[XHIHI:.+]] = sexti %[[HIHI]]
+ // CHECK: %[[XLOLO:.+]] = arith.extsi %[[LOLO]]
+ // CHECK: %[[XLOHI:.+]] = arith.extsi %[[LOHI]]
+ // CHECK: %[[XHILO:.+]] = arith.extsi %[[HILO]]
+ // CHECK: %[[XHIHI:.+]] = arith.extsi %[[HIHI]]
// Compute the bilinear interpolation.
- // CHECK: %[[SCALE:.+]] = constant 256
- // CHECK: %[[NDX:.+]] = subi %[[SCALE]], %[[DX]]
- // CHECK: %[[WLOLO:.+]] = muli %[[XLOLO]], %[[NDX]]
- // CHECK: %[[WLOHI:.+]] = muli %[[XLOHI]], %[[DX]]
- // CHECK: %[[LO:.+]] = addi %[[WLOLO]], %[[WLOHI]]
- // CHECK: %[[WHILO:.+]] = muli %[[XHILO]], %[[NDX]]
- // CHECK: %[[WHIHI:.+]] = muli %[[XHIHI]], %[[DX]]
- // CHECK: %[[HI:.+]] = addi %[[WHILO]], %[[WHIHI]]
- // CHECK: %[[NDY:.+]] = subi %[[SCALE]], %[[DY]]
- // CHECK: %[[WLO:.+]] = muli %[[LO]], %[[NDY]]
- // CHECK: %[[WHI:.+]] = muli %[[HI]], %[[DY]]
- // CHECK: %[[RESULT:.+]] = addi %[[WLO]], %[[WHI]]
+ // CHECK: %[[SCALE:.+]] = arith.constant 256
+ // CHECK: %[[NDX:.+]] = arith.subi %[[SCALE]], %[[DX]]
+ // CHECK: %[[WLOLO:.+]] = arith.muli %[[XLOLO]], %[[NDX]]
+ // CHECK: %[[WLOHI:.+]] = arith.muli %[[XLOHI]], %[[DX]]
+ // CHECK: %[[LO:.+]] = arith.addi %[[WLOLO]], %[[WLOHI]]
+ // CHECK: %[[WHILO:.+]] = arith.muli %[[XHILO]], %[[NDX]]
+ // CHECK: %[[WHIHI:.+]] = arith.muli %[[XHIHI]], %[[DX]]
+ // CHECK: %[[HI:.+]] = arith.addi %[[WHILO]], %[[WHIHI]]
+ // CHECK: %[[NDY:.+]] = arith.subi %[[SCALE]], %[[DY]]
+ // CHECK: %[[WLO:.+]] = arith.muli %[[LO]], %[[NDY]]
+ // CHECK: %[[WHI:.+]] = arith.muli %[[HI]], %[[DY]]
+ // CHECK: %[[RESULT:.+]] = arith.addi %[[WLO]], %[[WHI]]
// CHECK: linalg.yield %[[RESULT]]
%output = "tosa.resize"(%input) { output_size = [4, 4], stride = [128, 128], offset = [1, 2], stride_fp = [0. : f32, 0. : f32], offset_fp = [0. : f32, 0. : f32], shift = 8 : i32, mode = "BILINEAR" } : (tensor<1x2x2x1xi8>) -> (tensor<1x4x4x1xi32>)
return
// CHECK-LABEL: func @const_test
func @const_test() -> (tensor<i32>) {
- // CHECK: [[C3:%.+]] = constant dense<3> : tensor<i32>
+ // CHECK: [[C3:%.+]] = arith.constant dense<3> : tensor<i32>
%0 = "tosa.const"() {value = dense<3> : tensor<i32>} : () -> tensor<i32>
// CHECK: return [[C3]]
// CHECK-LABEL: @apply_scale_test_i32
func @apply_scale_test_i32(%arg0 : i32, %arg1 : i32, %arg2 : i8) -> (i32) {
- // CHECK-DAG: [[C1_8:%.+]] = constant 1 : i8
- // CHECK-DAG: [[C1_32:%.+]] = constant 1 : i32
- // CHECK-DAG: [[C1_64:%.+]] = constant 1 : i64
- // CHECK-DAG: [[SHIFT_MINUS_ONE_8:%.+]] = subi %arg2, [[C1_8]]
+ // CHECK-DAG: [[C1_8:%.+]] = arith.constant 1 : i8
+ // CHECK-DAG: [[C1_32:%.+]] = arith.constant 1 : i32
+ // CHECK-DAG: [[C1_64:%.+]] = arith.constant 1 : i64
+ // CHECK-DAG: [[SHIFT_MINUS_ONE_8:%.+]] = arith.subi %arg2, [[C1_8]]
- // CHECK-DAG: [[SHIFT_32:%.+]] = sexti %arg2 : i8 to i32
- // CHECK-DAG: [[SHIFT_MINUS_ONE_64:%.+]] = sexti [[SHIFT_MINUS_ONE_8]] : i8 to i64
- // CHECK-DAG: [[SHIFTED_64:%.+]] = shift_left [[C1_64]], [[SHIFT_MINUS_ONE_64]]
+ // CHECK-DAG: [[SHIFT_32:%.+]] = arith.extsi %arg2 : i8 to i32
+ // CHECK-DAG: [[SHIFT_MINUS_ONE_64:%.+]] = arith.extsi [[SHIFT_MINUS_ONE_8]] : i8 to i64
+ // CHECK-DAG: [[SHIFTED_64:%.+]] = arith.shli [[C1_64]], [[SHIFT_MINUS_ONE_64]]
- // CHECK-DAG: [[C0_32:%.+]] = constant 0 : i32
- // CHECK-DAG: [[C30_32:%.+]] = constant 30 : i32
- // CHECK-DAG: [[SECOND_BIAS:%.+]] = shift_left [[C1_32]], [[C30_32]]
- // CHECK-DAG: [[SECOND_BIAS_64:%.+]] = sexti [[SECOND_BIAS]] : i32 to i64
- // CHECK-DAG: [[POSITIVE_ROUND:%.+]] = addi [[SHIFTED_64]], [[SECOND_BIAS_64]]
- // CHECK-DAG: [[NEGATIVE_ROUND:%.+]] = subi [[SHIFTED_64]], [[SECOND_BIAS_64]]
- // CHECK-DAG: [[VALUE_NEGATIVE:%.+]] = cmpi sge, %arg0, [[C0_32]] : i32
+ // CHECK-DAG: [[C0_32:%.+]] = arith.constant 0 : i32
+ // CHECK-DAG: [[C30_32:%.+]] = arith.constant 30 : i32
+ // CHECK-DAG: [[SECOND_BIAS:%.+]] = arith.shli [[C1_32]], [[C30_32]]
+ // CHECK-DAG: [[SECOND_BIAS_64:%.+]] = arith.extsi [[SECOND_BIAS]] : i32 to i64
+ // CHECK-DAG: [[POSITIVE_ROUND:%.+]] = arith.addi [[SHIFTED_64]], [[SECOND_BIAS_64]]
+ // CHECK-DAG: [[NEGATIVE_ROUND:%.+]] = arith.subi [[SHIFTED_64]], [[SECOND_BIAS_64]]
+ // CHECK-DAG: [[VALUE_NEGATIVE:%.+]] = arith.cmpi sge, %arg0, [[C0_32]] : i32
// CHECK-DAG: [[DOUBLE_ROUNDED:%.+]] = select [[VALUE_NEGATIVE]], [[POSITIVE_ROUND]], [[NEGATIVE_ROUND]] : i64
- // CHECK-DAG: [[C32_32:%.+]] = constant 32 : i32
- // CHECK-DAG: [[IS_32BIT_SHIFT:%.+]] = cmpi sge, [[SHIFT_32]], [[C32_32]]
+ // CHECK-DAG: [[C32_32:%.+]] = arith.constant 32 : i32
+ // CHECK-DAG: [[IS_32BIT_SHIFT:%.+]] = arith.cmpi sge, [[SHIFT_32]], [[C32_32]]
// CHECK-DAG: [[ROUND:%.+]] = select [[IS_32BIT_SHIFT]], [[DOUBLE_ROUNDED]], [[SHIFTED_64]]
- // CHECK-DAG: [[VAL_64:%.+]] = sexti %arg0 : i32 to i64
- // CHECK-DAG: [[MULTIPLY_64:%.+]] = sexti %arg1 : i32 to i64
- // CHECK-DAG: [[SHIFT_64:%.+]] = sexti %arg2 : i8 to i64
- // CHECK-DAG: [[SCALED:%.+]] = muli [[VAL_64]], [[MULTIPLY_64]]
- // CHECK-DAG: [[BIASED:%.+]] = addi [[SCALED]], [[ROUND]]
- // CHECK-DAG: [[DOWNSHIFTED:%.+]] = shift_right_signed [[BIASED]], [[SHIFT_64]]
- // CHECK: [[TRUNCATED:%.+]] = trunci [[DOWNSHIFTED]]
+ // CHECK-DAG: [[VAL_64:%.+]] = arith.extsi %arg0 : i32 to i64
+ // CHECK-DAG: [[MULTIPLY_64:%.+]] = arith.extsi %arg1 : i32 to i64
+ // CHECK-DAG: [[SHIFT_64:%.+]] = arith.extsi %arg2 : i8 to i64
+ // CHECK-DAG: [[SCALED:%.+]] = arith.muli [[VAL_64]], [[MULTIPLY_64]]
+ // CHECK-DAG: [[BIASED:%.+]] = arith.addi [[SCALED]], [[ROUND]]
+ // CHECK-DAG: [[DOWNSHIFTED:%.+]] = arith.shrsi [[BIASED]], [[SHIFT_64]]
+ // CHECK: [[TRUNCATED:%.+]] = arith.trunci [[DOWNSHIFTED]]
%0 = "tosa.apply_scale"(%arg0, %arg1, %arg2) {double_round = true} : (i32, i32, i8) -> i32
return %0 : i32
// CHECK-LABEL: @apply_scale_test_i48
func @apply_scale_test_i48(%arg0 : i48, %arg1 : i32, %arg2 : i8) -> (i32) {
- // CHECK-DAG: [[C1_8:%.+]] = constant 1 : i8
- // CHECK-DAG: [[C1_32:%.+]] = constant 1 : i32
- // CHECK-DAG: [[C1_64:%.+]] = constant 1 : i64
- // CHECK-DAG: [[C30_32:%.+]] = constant 30 : i32
- // CHECK-DAG: [[C0_32:%.+]] = constant 0 : i48
- // CHECK-DAG: [[C32_32:%.+]] = constant 32 : i32
- // CHECK-DAG: [[SHIFT_MINUS_ONE_8:%.+]] = subi %arg2, [[C1_8]]
- // CHECK-DAG: [[SHIFT_32:%.+]] = sexti %arg2 : i8 to i32
- // CHECK-DAG: [[SHIFT_MINUS_ONE_64:%.+]] = sexti [[SHIFT_MINUS_ONE_8]] : i8 to i64
- // CHECK-DAG: [[SHIFTED_64:%.+]] = shift_left [[C1_64]], [[SHIFT_MINUS_ONE_64]]
- // CHECK-DAG: [[SECOND_BIAS:%.+]] = shift_left [[C1_32]], [[C30_32]]
- // CHECK-DAG: [[SECOND_BIAS_64:%.+]] = sexti [[SECOND_BIAS]] : i32 to i64
- // CHECK-DAG: [[POSITIVE_ROUND:%.+]] = addi [[SHIFTED_64]], [[SECOND_BIAS_64]]
- // CHECK-DAG: [[NEGATIVE_ROUND:%.+]] = subi [[SHIFTED_64]], [[SECOND_BIAS_64]]
- // CHECK-DAG: [[VALUE_NEGATIVE:%.+]] = cmpi sge, %arg0, [[C0_32]] : i48
+ // CHECK-DAG: [[C1_8:%.+]] = arith.constant 1 : i8
+ // CHECK-DAG: [[C1_32:%.+]] = arith.constant 1 : i32
+ // CHECK-DAG: [[C1_64:%.+]] = arith.constant 1 : i64
+ // CHECK-DAG: [[C30_32:%.+]] = arith.constant 30 : i32
+ // CHECK-DAG: [[C0_32:%.+]] = arith.constant 0 : i48
+ // CHECK-DAG: [[C32_32:%.+]] = arith.constant 32 : i32
+ // CHECK-DAG: [[SHIFT_MINUS_ONE_8:%.+]] = arith.subi %arg2, [[C1_8]]
+ // CHECK-DAG: [[SHIFT_32:%.+]] = arith.extsi %arg2 : i8 to i32
+ // CHECK-DAG: [[SHIFT_MINUS_ONE_64:%.+]] = arith.extsi [[SHIFT_MINUS_ONE_8]] : i8 to i64
+ // CHECK-DAG: [[SHIFTED_64:%.+]] = arith.shli [[C1_64]], [[SHIFT_MINUS_ONE_64]]
+ // CHECK-DAG: [[SECOND_BIAS:%.+]] = arith.shli [[C1_32]], [[C30_32]]
+ // CHECK-DAG: [[SECOND_BIAS_64:%.+]] = arith.extsi [[SECOND_BIAS]] : i32 to i64
+ // CHECK-DAG: [[POSITIVE_ROUND:%.+]] = arith.addi [[SHIFTED_64]], [[SECOND_BIAS_64]]
+ // CHECK-DAG: [[NEGATIVE_ROUND:%.+]] = arith.subi [[SHIFTED_64]], [[SECOND_BIAS_64]]
+ // CHECK-DAG: [[VALUE_NEGATIVE:%.+]] = arith.cmpi sge, %arg0, [[C0_32]] : i48
// CHECK-DAG: [[DOUBLE_ROUNDED:%.+]] = select [[VALUE_NEGATIVE]], [[POSITIVE_ROUND]], [[NEGATIVE_ROUND]] : i64
- // CHECK-DAG: [[IS_32BIT_SHIFT:%.+]] = cmpi sge, [[SHIFT_32]], [[C32_32]]
+ // CHECK-DAG: [[IS_32BIT_SHIFT:%.+]] = arith.cmpi sge, [[SHIFT_32]], [[C32_32]]
// CHECK-DAG: [[ROUND:%.+]] = select [[IS_32BIT_SHIFT]], [[DOUBLE_ROUNDED]], [[SHIFTED_64]]
- // CHECK-DAG: [[VAL_64:%.+]] = sexti %arg0 : i48 to i64
- // CHECK-DAG: [[MULTIPLY_64:%.+]] = sexti %arg1 : i32 to i64
- // CHECK-DAG: [[SHIFT_64:%.+]] = sexti %arg2 : i8 to i64
- // CHECK-DAG: [[SCALED:%.+]] = muli [[VAL_64]], [[MULTIPLY_64]]
- // CHECK-DAG: [[BIASED:%.+]] = addi [[SCALED]], [[ROUND]]
- // CHECK-DAG: [[DOWNSHIFTED:%.+]] = shift_right_signed [[BIASED]], [[SHIFT_64]]
- // CHECK: [[TRUNCATED:%.+]] = trunci [[DOWNSHIFTED]]
+ // CHECK-DAG: [[VAL_64:%.+]] = arith.extsi %arg0 : i48 to i64
+ // CHECK-DAG: [[MULTIPLY_64:%.+]] = arith.extsi %arg1 : i32 to i64
+ // CHECK-DAG: [[SHIFT_64:%.+]] = arith.extsi %arg2 : i8 to i64
+ // CHECK-DAG: [[SCALED:%.+]] = arith.muli [[VAL_64]], [[MULTIPLY_64]]
+ // CHECK-DAG: [[BIASED:%.+]] = arith.addi [[SCALED]], [[ROUND]]
+ // CHECK-DAG: [[DOWNSHIFTED:%.+]] = arith.shrsi [[BIASED]], [[SHIFT_64]]
+ // CHECK: [[TRUNCATED:%.+]] = arith.trunci [[DOWNSHIFTED]]
%0 = "tosa.apply_scale"(%arg0, %arg1, %arg2) {double_round = true} : (i48, i32, i8) -> i32
return %0 : i32
}
// CHECK: %[[D:.+]] = gpu.subgroup_mma_compute %[[A]], %[[B]], %[[C]] : !gpu.mma_matrix<16x16xf16, "AOp">, !gpu.mma_matrix<16x16xf16, "BOp"> -> !gpu.mma_matrix<16x16xf16, "COp">
// CHECK: gpu.subgroup_mma_store_matrix %[[D]], %{{.*}}[%{{.*}}, %{{.*}}] {leadDimension = 16 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<16x16xf16>
func @matmul(%arg0: memref<16x16xf16>, %arg1: memref<16x16xf16>, %arg2: memref<16x16xf16>) {
- %cst_0 = constant dense<0.000000e+00> : vector<16x16xf16>
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f16
+ %cst_0 = arith.constant dense<0.000000e+00> : vector<16x16xf16>
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f16
%A = vector.transfer_read %arg0[%c0, %c0], %cst {in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%B = vector.transfer_read %arg1[%c0, %c0], %cst {permutation_map = #map0, in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%C = vector.transfer_read %arg2[%c0, %c0], %cst {in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
}
// CHECK-LABEL: func @matmul_cst
-// CHECK-DAG: %[[CST:.+]] = constant 0.000000e+00 : f16
+// CHECK-DAG: %[[CST:.+]] = arith.constant 0.000000e+00 : f16
// CHECK-DAG: %[[A:.+]] = gpu.subgroup_mma_load_matrix %{{.*}}[%{{.*}}, %{{.*}}] {leadDimension = 16 : index} : memref<16x16xf16> -> !gpu.mma_matrix<16x16xf16, "AOp">
// CHECK-DAG: %[[B:.+]] = gpu.subgroup_mma_load_matrix %{{.*}}[%c0, %c0] {leadDimension = 16 : index} : memref<16x16xf16> -> !gpu.mma_matrix<16x16xf16, "BOp">
// CHECK-DAG: %[[C:.+]] = gpu.subgroup_mma_constant_matrix %[[CST]] : !gpu.mma_matrix<16x16xf16, "COp">
// CHECK: %[[D:.+]] = gpu.subgroup_mma_compute %[[A]], %[[B]], %[[C]] : !gpu.mma_matrix<16x16xf16, "AOp">, !gpu.mma_matrix<16x16xf16, "BOp"> -> !gpu.mma_matrix<16x16xf16, "COp">
// CHECK: gpu.subgroup_mma_store_matrix %[[D]], %{{.*}}[%{{.*}}, %{{.*}}] {leadDimension = 16 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<16x16xf16>
func @matmul_cst(%arg0: memref<16x16xf16>, %arg1: memref<16x16xf16>, %arg2: memref<16x16xf16>) {
- %cst_0 = constant dense<0.000000e+00> : vector<16x16xf16>
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f16
+ %cst_0 = arith.constant dense<0.000000e+00> : vector<16x16xf16>
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f16
%A = vector.transfer_read %arg0[%c0, %c0], %cst {in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%B = vector.transfer_read %arg1[%c0, %c0], %cst {permutation_map = #map0, in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%D = vector.contract {indexing_maps = [#map1, #map2, #map3], iterator_types = ["parallel", "parallel", "reduction"], kind = #vector.kind<add>} %A, %B, %cst_0 : vector<16x16xf16>, vector<16x16xf16> into vector<16x16xf16>
// CHECK: gpu.subgroup_mma_store_matrix %[[D]], %{{.*}}[%{{.*}}, %{{.*}}] {leadDimension = 16 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<16x16xf16>
func @matmul_broadcast(%arg0: memref<16x16xf16>, %arg1: memref<16x16xf16>, %arg2: memref<16x16xf16>, %f: f16) {
%C = vector.broadcast %f : f16 to vector<16x16xf16>
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f16
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f16
%A = vector.transfer_read %arg0[%c0, %c0], %cst {in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%B = vector.transfer_read %arg1[%c0, %c0], %cst {permutation_map = #map0, in_bounds = [true, true]} : memref<16x16xf16>, vector<16x16xf16>
%D = vector.contract {indexing_maps = [#map1, #map2, #map3], iterator_types = ["parallel", "parallel", "reduction"], kind = #vector.kind<add>} %A, %B, %C : vector<16x16xf16>, vector<16x16xf16> into vector<16x16xf16>
// CHECK-NEXT: }
// CHECK-NEXT: gpu.subgroup_mma_store_matrix %[[ACC]], %{{.*}}[%{{.*}}, %{{.*}}] {leadDimension = 128 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<128x128xf16>
func @matmul_loop(%arg0: memref<128x128xf16>, %arg1: memref<128x128xf16>, %arg2: memref<128x128xf16>) {
- %c0 = constant 0 : index
- %c128 = constant 128 : index
- %c32 = constant 32 : index
- %cst = constant 0.000000e+00 : f16
+ %c0 = arith.constant 0 : index
+ %c128 = arith.constant 128 : index
+ %c32 = arith.constant 32 : index
+ %cst = arith.constant 0.000000e+00 : f16
%C = vector.transfer_read %arg2[%c0, %c0], %cst {in_bounds = [true, true]} : memref<128x128xf16>, vector<16x16xf16>
%14 = scf.for %arg17 = %c0 to %c128 step %c32 iter_args(%arg18 = %C) -> (vector<16x16xf16>) {
%17 = vector.transfer_read %arg0[%c0, %arg17], %cst {in_bounds = [true, true]} : memref<128x128xf16>, vector<16x16xf16>
// CMP32-LABEL: @genbool_var_1d(
// CMP32-SAME: %[[ARG:.*]]: index)
-// CMP32: %[[T0:.*]] = constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]> : vector<11xi32>
-// CMP32: %[[T1:.*]] = index_cast %[[ARG]] : index to i32
+// CMP32: %[[T0:.*]] = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]> : vector<11xi32>
+// CMP32: %[[T1:.*]] = arith.index_cast %[[ARG]] : index to i32
// CMP32: %[[T2:.*]] = splat %[[T1]] : vector<11xi32>
-// CMP32: %[[T3:.*]] = cmpi slt, %[[T0]], %[[T2]] : vector<11xi32>
+// CMP32: %[[T3:.*]] = arith.cmpi slt, %[[T0]], %[[T2]] : vector<11xi32>
// CMP32: return %[[T3]] : vector<11xi1>
// CMP64-LABEL: @genbool_var_1d(
// CMP64-SAME: %[[ARG:.*]]: index)
-// CMP64: %[[T0:.*]] = constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]> : vector<11xi64>
-// CMP64: %[[T1:.*]] = index_cast %[[ARG]] : index to i64
+// CMP64: %[[T0:.*]] = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]> : vector<11xi64>
+// CMP64: %[[T1:.*]] = arith.index_cast %[[ARG]] : index to i64
// CMP64: %[[T2:.*]] = splat %[[T1]] : vector<11xi64>
-// CMP64: %[[T3:.*]] = cmpi slt, %[[T0]], %[[T2]] : vector<11xi64>
+// CMP64: %[[T3:.*]] = arith.cmpi slt, %[[T0]], %[[T2]] : vector<11xi64>
// CMP64: return %[[T3]] : vector<11xi1>
func @genbool_var_1d(%arg0: index) -> vector<11xi1> {
}
// CMP32-LABEL: @transfer_read_1d
-// CMP32: %[[C:.*]] = constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xi32>
-// CMP32: %[[A:.*]] = addi %{{.*}}, %[[C]] : vector<16xi32>
-// CMP32: %[[M:.*]] = cmpi slt, %[[A]], %{{.*}} : vector<16xi32>
+// CMP32: %[[C:.*]] = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xi32>
+// CMP32: %[[A:.*]] = arith.addi %{{.*}}, %[[C]] : vector<16xi32>
+// CMP32: %[[M:.*]] = arith.cmpi slt, %[[A]], %{{.*}} : vector<16xi32>
// CMP32: %[[L:.*]] = llvm.intr.masked.load %{{.*}}, %[[M]], %{{.*}}
// CMP32: return %[[L]] : vector<16xf32>
// CMP64-LABEL: @transfer_read_1d
-// CMP64: %[[C:.*]] = constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xi64>
-// CMP64: %[[A:.*]] = addi %{{.*}}, %[[C]] : vector<16xi64>
-// CMP64: %[[M:.*]] = cmpi slt, %[[A]], %{{.*}} : vector<16xi64>
+// CMP64: %[[C:.*]] = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xi64>
+// CMP64: %[[A:.*]] = arith.addi %{{.*}}, %[[C]] : vector<16xi64>
+// CMP64: %[[M:.*]] = arith.cmpi slt, %[[A]], %{{.*}} : vector<16xi64>
// CMP64: %[[L:.*]] = llvm.intr.masked.load %{{.*}}, %[[M]], %{{.*}}
// CMP64: return %[[L]] : vector<16xf32>
func @transfer_read_1d(%A : memref<?xf32>, %i: index) -> vector<16xf32> {
- %d = constant -1.0: f32
+ %d = arith.constant -1.0: f32
%f = vector.transfer_read %A[%i], %d {permutation_map = affine_map<(d0) -> (d0)>} : memref<?xf32>, vector<16xf32>
return %f : vector<16xf32>
}
}
// CHECK-LABEL: @broadcast_vec2d_from_vec1d(
// CHECK-SAME: %[[A:.*]]: vector<2xf32>)
-// CHECK: %[[T0:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[T0:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
// CHECK: %[[T1:.*]] = builtin.unrealized_conversion_cast %[[T0]] : vector<3x2xf32> to !llvm.array<3 x vector<2xf32>>
// CHECK: %[[T2:.*]] = llvm.insertvalue %[[A]], %[[T1]][0] : !llvm.array<3 x vector<2xf32>>
// CHECK: %[[T3:.*]] = llvm.insertvalue %[[A]], %[[T2]][1] : !llvm.array<3 x vector<2xf32>>
}
// CHECK-LABEL: @broadcast_vec2d_from_index_vec1d(
// CHECK-SAME: %[[A:.*]]: vector<2xindex>)
-// CHECK: %[[T0:.*]] = constant dense<0> : vector<3x2xindex>
+// CHECK: %[[T0:.*]] = arith.constant dense<0> : vector<3x2xindex>
// CHECK: %[[T1:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<2xindex> to vector<2xi64>
// CHECK: %[[T2:.*]] = builtin.unrealized_conversion_cast %[[T0]] : vector<3x2xindex> to !llvm.array<3 x vector<2xi64>>
// CHECK: %[[T3:.*]] = llvm.insertvalue %[[T1]], %[[T2]][0] : !llvm.array<3 x vector<2xi64>>
}
// CHECK-LABEL: @broadcast_vec3d_from_vec1d(
// CHECK-SAME: %[[A:.*]]: vector<2xf32>)
-// CHECK: %[[T0:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
-// CHECK: %[[T1:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[T0:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[T1:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
// CHECK: %[[T2:.*]] = builtin.unrealized_conversion_cast %[[T0]] : vector<3x2xf32> to !llvm.array<3 x vector<2xf32>>
// CHECK: %[[T3:.*]] = llvm.insertvalue %[[A]], %[[T2]][0] : !llvm.array<3 x vector<2xf32>>
}
// CHECK-LABEL: @broadcast_vec3d_from_vec2d(
// CHECK-SAME: %[[A:.*]]: vector<3x2xf32>)
-// CHECK: %[[T0:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[T0:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
// CHECK: %[[T1:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<3x2xf32> to !llvm.array<3 x vector<2xf32>>
// CHECK: %[[T2:.*]] = builtin.unrealized_conversion_cast %[[T0]] : vector<4x3x2xf32> to !llvm.array<4 x array<3 x vector<2xf32>>>
// CHECK: %[[T3:.*]] = llvm.insertvalue %[[T1]], %[[T2]][0] : !llvm.array<4 x array<3 x vector<2xf32>>>
}
// CHECK-LABEL: @broadcast_stretch_at_start(
// CHECK-SAME: %[[A:.*]]: vector<1x4xf32>)
-// CHECK: %[[T1:.*]] = constant dense<0.000000e+00> : vector<3x4xf32>
+// CHECK: %[[T1:.*]] = arith.constant dense<0.000000e+00> : vector<3x4xf32>
// CHECK: %[[T2:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<1x4xf32> to !llvm.array<1 x vector<4xf32>>
// CHECK: %[[T3:.*]] = llvm.extractvalue %[[T2]][0] : !llvm.array<1 x vector<4xf32>>
// CHECK: %[[T4:.*]] = builtin.unrealized_conversion_cast %[[T1]] : vector<3x4xf32> to !llvm.array<3 x vector<4xf32>>
}
// CHECK-LABEL: @broadcast_stretch_at_end(
// CHECK-SAME: %[[A:.*]]: vector<4x1xf32>)
-// CHECK: %[[T1:.*]] = constant dense<0.000000e+00> : vector<4x3xf32>
+// CHECK: %[[T1:.*]] = arith.constant dense<0.000000e+00> : vector<4x3xf32>
// CHECK: %[[T2:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<4x1xf32> to !llvm.array<4 x vector<1xf32>>
// CHECK: %[[T3:.*]] = llvm.extractvalue %[[T2]][0] : !llvm.array<4 x vector<1xf32>>
// CHECK: %[[T4:.*]] = llvm.mlir.constant(0 : i64) : i64
}
// CHECK-LABEL: @broadcast_stretch_in_middle(
// CHECK-SAME: %[[A:.*]]: vector<4x1x2xf32>) -> vector<4x3x2xf32> {
-// CHECK: %[[T1:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
-// CHECK: %[[T2:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[T1:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[T2:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
// CHECK: %[[T3:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<4x1x2xf32> to !llvm.array<4 x array<1 x vector<2xf32>>>
// CHECK: %[[T4:.*]] = llvm.extractvalue %[[T3]][0, 0] : !llvm.array<4 x array<1 x vector<2xf32>>>
// CHECK: %[[T5:.*]] = builtin.unrealized_conversion_cast %[[T2]] : vector<3x2xf32> to !llvm.array<3 x vector<2xf32>>
// CHECK-LABEL: @outerproduct(
// CHECK-SAME: %[[A:.*]]: vector<2xf32>,
// CHECK-SAME: %[[B:.*]]: vector<3xf32>)
-// CHECK: %[[T2:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// CHECK: %[[T2:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// CHECK: %[[T3:.*]] = llvm.mlir.constant(0 : i64) : i64
// CHECK: %[[T4:.*]] = llvm.extractelement %[[A]]{{\[}}%[[T3]] : i64] : vector<2xf32>
// CHECK: %[[T5:.*]] = splat %[[T4]] : vector<3xf32>
-// CHECK: %[[T6:.*]] = mulf %[[T5]], %[[B]] : vector<3xf32>
+// CHECK: %[[T6:.*]] = arith.mulf %[[T5]], %[[B]] : vector<3xf32>
// CHECK: %[[T7:.*]] = builtin.unrealized_conversion_cast %[[T2]] : vector<2x3xf32> to !llvm.array<2 x vector<3xf32>>
// CHECK: %[[T8:.*]] = llvm.insertvalue %[[T6]], %[[T7]][0] : !llvm.array<2 x vector<3xf32>>
// CHECK: %[[T9:.*]] = llvm.mlir.constant(1 : i64) : i64
// CHECK: %[[T10:.*]] = llvm.extractelement %[[A]]{{\[}}%[[T9]] : i64] : vector<2xf32>
// CHECK: %[[T11:.*]] = splat %[[T10]] : vector<3xf32>
-// CHECK: %[[T12:.*]] = mulf %[[T11]], %[[B]] : vector<3xf32>
+// CHECK: %[[T12:.*]] = arith.mulf %[[T11]], %[[B]] : vector<3xf32>
// CHECK: %[[T13:.*]] = llvm.insertvalue %[[T12]], %[[T8]][1] : !llvm.array<2 x vector<3xf32>>
// CHECK: %[[T14:.*]] = builtin.unrealized_conversion_cast %[[T13]] : !llvm.array<2 x vector<3xf32>> to vector<2x3xf32>
// CHECK: return %[[T14]] : vector<2x3xf32>
// CHECK-LABEL: @outerproduct_index(
// CHECK-SAME: %[[A:.*]]: vector<2xindex>,
// CHECK-SAME: %[[B:.*]]: vector<3xindex>)
-// CHECK: %[[T0:.*]] = constant dense<0> : vector<2x3xindex>
+// CHECK: %[[T0:.*]] = arith.constant dense<0> : vector<2x3xindex>
// CHECK: %[[T1:.*]] = builtin.unrealized_conversion_cast %[[A]] : vector<2xindex> to vector<2xi64>
// CHECK: %[[T2:.*]] = llvm.mlir.constant(0 : i64) : i64
// CHECK: %[[T3:.*]] = llvm.extractelement %[[T1]]{{\[}}%[[T2]] : i64] : vector<2xi64>
// CHECK: %[[T4:.*]] = builtin.unrealized_conversion_cast %[[T3]] : i64 to index
// CHECK: %[[T5:.*]] = splat %[[T4]] : vector<3xindex>
-// CHECK: %[[T6:.*]] = muli %[[T5]], %[[B]] : vector<3xindex>
+// CHECK: %[[T6:.*]] = arith.muli %[[T5]], %[[B]] : vector<3xindex>
// CHECK: %[[T7:.*]] = builtin.unrealized_conversion_cast %[[T6]] : vector<3xindex> to vector<3xi64>
// CHECK: %[[T8:.*]] = builtin.unrealized_conversion_cast %[[T0]] : vector<2x3xindex> to !llvm.array<2 x vector<3xi64>>
// CHECK: %{{.*}} = llvm.insertvalue %[[T7]], %[[T8]][0] : !llvm.array<2 x vector<3xi64>>
// CHECK-SAME: %[[A:.*]]: vector<2xf32>,
// CHECK-SAME: %[[B:.*]]: vector<3xf32>,
// CHECK-SAME: %[[C:.*]]: vector<2x3xf32>) -> vector<2x3xf32>
-// CHECK: %[[T3:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// CHECK: %[[T3:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// CHECK: %[[T4:.*]] = llvm.mlir.constant(0 : i64) : i64
// CHECK: %[[T5:.*]] = llvm.extractelement %[[A]]{{\[}}%[[T4]] : i64] : vector<2xf32>
// CHECK: %[[T6:.*]] = splat %[[T5]] : vector<3xf32>
// -----
func @extract_element(%arg0: vector<16xf32>) -> f32 {
- %0 = constant 15 : i32
+ %0 = arith.constant 15 : i32
%1 = vector.extractelement %arg0[%0 : i32]: vector<16xf32>
return %1 : f32
}
// CHECK-LABEL: @extract_element(
// CHECK-SAME: %[[A:.*]]: vector<16xf32>)
-// CHECK: %[[c:.*]] = constant 15 : i32
+// CHECK: %[[c:.*]] = arith.constant 15 : i32
// CHECK: %[[x:.*]] = llvm.extractelement %[[A]][%[[c]] : i32] : vector<16xf32>
// CHECK: return %[[x]] : f32
// -----
func @insert_element(%arg0: f32, %arg1: vector<4xf32>) -> vector<4xf32> {
- %0 = constant 3 : i32
+ %0 = arith.constant 3 : i32
%1 = vector.insertelement %arg0, %arg1[%0 : i32] : vector<4xf32>
return %1 : vector<4xf32>
}
// CHECK-LABEL: @insert_element(
// CHECK-SAME: %[[A:.*]]: f32,
// CHECK-SAME: %[[B:.*]]: vector<4xf32>)
-// CHECK: %[[c:.*]] = constant 3 : i32
+// CHECK: %[[c:.*]] = arith.constant 3 : i32
// CHECK: %[[x:.*]] = llvm.insertelement %[[A]], %[[B]][%[[c]] : i32] : vector<4xf32>
// CHECK: return %[[x]] : vector<4xf32>
//
// CHECK-LABEL: @vector_print_scalar_i1(
// CHECK-SAME: %[[A:.*]]: i1)
-// CHECK: %[[S:.*]] = zexti %[[A]] : i1 to i64
+// CHECK: %[[S:.*]] = arith.extui %[[A]] : i1 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
}
// CHECK-LABEL: @vector_print_scalar_i4(
// CHECK-SAME: %[[A:.*]]: i4)
-// CHECK: %[[S:.*]] = sexti %[[A]] : i4 to i64
+// CHECK: %[[S:.*]] = arith.extsi %[[A]] : i4 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
// CHECK-LABEL: @vector_print_scalar_si4(
// CHECK-SAME: %[[A:.*]]: si4)
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[A]] : si4 to i4
-// CHECK: %[[S:.*]] = sexti %[[C]] : i4 to i64
+// CHECK: %[[S:.*]] = arith.extsi %[[C]] : i4 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
// CHECK-LABEL: @vector_print_scalar_ui4(
// CHECK-SAME: %[[A:.*]]: ui4)
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[A]] : ui4 to i4
-// CHECK: %[[S:.*]] = zexti %[[C]] : i4 to i64
+// CHECK: %[[S:.*]] = arith.extui %[[C]] : i4 to i64
// CHECK: llvm.call @printU64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
}
// CHECK-LABEL: @vector_print_scalar_i32(
// CHECK-SAME: %[[A:.*]]: i32)
-// CHECK: %[[S:.*]] = sexti %[[A]] : i32 to i64
+// CHECK: %[[S:.*]] = arith.extsi %[[A]] : i32 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
// CHECK-LABEL: @vector_print_scalar_ui32(
// CHECK-SAME: %[[A:.*]]: ui32)
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[A]] : ui32 to i32
-// CHECK: %[[S:.*]] = zexti %[[C]] : i32 to i64
+// CHECK: %[[S:.*]] = arith.extui %[[C]] : i32 to i64
// CHECK: llvm.call @printU64(%[[S]]) : (i64) -> ()
// -----
}
// CHECK-LABEL: @vector_print_scalar_i40(
// CHECK-SAME: %[[A:.*]]: i40)
-// CHECK: %[[S:.*]] = sexti %[[A]] : i40 to i64
+// CHECK: %[[S:.*]] = arith.extsi %[[A]] : i40 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
// CHECK-LABEL: @vector_print_scalar_si40(
// CHECK-SAME: %[[A:.*]]: si40)
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[A]] : si40 to i40
-// CHECK: %[[S:.*]] = sexti %[[C]] : i40 to i64
+// CHECK: %[[S:.*]] = arith.extsi %[[C]] : i40 to i64
// CHECK: llvm.call @printI64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
// CHECK-LABEL: @vector_print_scalar_ui40(
// CHECK-SAME: %[[A:.*]]: ui40)
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[A]] : ui40 to i40
-// CHECK: %[[S:.*]] = zexti %[[C]] : i40 to i64
+// CHECK: %[[S:.*]] = arith.extui %[[C]] : i40 to i64
// CHECK: llvm.call @printU64(%[[S]]) : (i64) -> ()
// CHECK: llvm.call @printNewline() : () -> ()
}
// CHECK-LABEL: @extract_strided_slice3(
// CHECK-SAME: %[[ARG:.*]]: vector<4x8xf32>)
-// CHECK: %[[VAL_1:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[VAL_1:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[VAL_2:.*]] = splat %[[VAL_1]] : vector<2x2xf32>
// CHECK: %[[A:.*]] = builtin.unrealized_conversion_cast %[[ARG]] : vector<4x8xf32> to !llvm.array<4 x vector<8xf32>>
// CHECK: %[[T2:.*]] = llvm.extractvalue %[[A]][2] : !llvm.array<4 x vector<8xf32>>
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : vector<4x4xf32> to !llvm.array<4 x vector<4xf32>>
// CHECK-NEXT: llvm.extractvalue {{.*}}[2] : !llvm.array<4 x vector<4xf32>>
// Element @0 -> element @2
-// CHECK-NEXT: constant 0 : index
+// CHECK-NEXT: arith.constant 0 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.extractelement {{.*}}[{{.*}} : i64] : vector<2xf32>
-// CHECK-NEXT: constant 2 : index
+// CHECK-NEXT: arith.constant 2 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.insertelement {{.*}}, {{.*}}[{{.*}} : i64] : vector<4xf32>
// Element @1 -> element @3
-// CHECK-NEXT: constant 1 : index
+// CHECK-NEXT: arith.constant 1 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.extractelement {{.*}}[{{.*}} : i64] : vector<2xf32>
-// CHECK-NEXT: constant 3 : index
+// CHECK-NEXT: arith.constant 3 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.insertelement {{.*}}, {{.*}}[{{.*}} : i64] : vector<4xf32>
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : vector<4x4xf32> to !llvm.array<4 x vector<4xf32>>
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : vector<4x4xf32> to !llvm.array<4 x vector<4xf32>>
// CHECK-NEXT: llvm.extractvalue {{.*}}[3] : !llvm.array<4 x vector<4xf32>>
// Element @0 -> element @2
-// CHECK-NEXT: constant 0 : index
+// CHECK-NEXT: arith.constant 0 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.extractelement {{.*}}[{{.*}} : i64] : vector<2xf32>
-// CHECK-NEXT: constant 2 : index
+// CHECK-NEXT: arith.constant 2 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.insertelement {{.*}}, {{.*}}[{{.*}} : i64] : vector<4xf32>
// Element @1 -> element @3
-// CHECK-NEXT: constant 1 : index
+// CHECK-NEXT: arith.constant 1 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.extractelement {{.*}}[{{.*}} : i64] : vector<2xf32>
-// CHECK-NEXT: constant 3 : index
+// CHECK-NEXT: arith.constant 3 : index
// CHECK-NEXT: unrealized_conversion_cast %{{.*}} : index to i64
// CHECK-NEXT: llvm.insertelement {{.*}}, {{.*}}[{{.*}} : i64] : vector<4xf32>
// CHECK-NEXT: llvm.insertvalue {{.*}}, {{.*}}[3] : !llvm.array<4 x vector<4xf32>>
// CHECK: %[[s5:.*]] = llvm.extractvalue %[[s4]][0] : !llvm.array<2 x vector<4xf32>>
// CHECK: %[[s6:.*]] = builtin.unrealized_conversion_cast %[[B]] : vector<16x4x8xf32> to !llvm.array<16 x array<4 x vector<8xf32>>>
// CHECK: %[[s7:.*]] = llvm.extractvalue %[[s6]][0, 0] : !llvm.array<16 x array<4 x vector<8xf32>>>
-// CHECK: %[[s8:.*]] = constant 0 : index
+// CHECK: %[[s8:.*]] = arith.constant 0 : index
// CHECK: %[[s9:.*]] = builtin.unrealized_conversion_cast %[[s8]] : index to i64
// CHECK: %[[s10:.*]] = llvm.extractelement %[[s5]]{{\[}}%[[s9]] : i64] : vector<4xf32>
-// CHECK: %[[s11:.*]] = constant 2 : index
+// CHECK: %[[s11:.*]] = arith.constant 2 : index
// CHECK: %[[s12:.*]] = builtin.unrealized_conversion_cast %[[s11]] : index to i64
// CHECK: %[[s13:.*]] = llvm.insertelement %[[s10]], %[[s7]]{{\[}}%[[s12]] : i64] : vector<8xf32>
-// CHECK: %[[s14:.*]] = constant 1 : index
+// CHECK: %[[s14:.*]] = arith.constant 1 : index
// CHECK: %[[s15:.*]] = builtin.unrealized_conversion_cast %[[s14]] : index to i64
// CHECK: %[[s16:.*]] = llvm.extractelement %[[s5]]{{\[}}%[[s15]] : i64] : vector<4xf32>
-// CHECK: %[[s17:.*]] = constant 3 : index
+// CHECK: %[[s17:.*]] = arith.constant 3 : index
// CHECK: %[[s18:.*]] = builtin.unrealized_conversion_cast %[[s17]] : index to i64
// CHECK: %[[s19:.*]] = llvm.insertelement %[[s16]], %[[s13]]{{\[}}%[[s18]] : i64] : vector<8xf32>
-// CHECK: %[[s20:.*]] = constant 2 : index
+// CHECK: %[[s20:.*]] = arith.constant 2 : index
// CHECK: %[[s21:.*]] = builtin.unrealized_conversion_cast %[[s20]] : index to i64
// CHECK: %[[s22:.*]] = llvm.extractelement %[[s5]]{{\[}}%[[s21]] : i64] : vector<4xf32>
-// CHECK: %[[s23:.*]] = constant 4 : index
+// CHECK: %[[s23:.*]] = arith.constant 4 : index
// CHECK: %[[s24:.*]] = builtin.unrealized_conversion_cast %[[s23]] : index to i64
// CHECK: %[[s25:.*]] = llvm.insertelement %[[s22]], %[[s19]]{{\[}}%[[s24]] : i64] : vector<8xf32>
-// CHECK: %[[s26:.*]] = constant 3 : index
+// CHECK: %[[s26:.*]] = arith.constant 3 : index
// CHECK: %[[s27:.*]] = builtin.unrealized_conversion_cast %[[s26]] : index to i64
// CHECK: %[[s28:.*]] = llvm.extractelement %[[s5]]{{\[}}%[[s27]] : i64] : vector<4xf32>
-// CHECK: %[[s29:.*]] = constant 5 : index
+// CHECK: %[[s29:.*]] = arith.constant 5 : index
// CHECK: %[[s30:.*]] = builtin.unrealized_conversion_cast %[[s29]] : index to i64
// CHECK: %[[s31:.*]] = llvm.insertelement %[[s28]], %[[s25]]{{\[}}%[[s30]] : i64] : vector<8xf32>
// CHECK: %[[s32:.*]] = llvm.insertvalue %[[s31]], %[[s3]][0] : !llvm.array<4 x vector<8xf32>>
// CHECK: %[[s34:.*]] = llvm.extractvalue %[[s33]][1] : !llvm.array<2 x vector<4xf32>>
// CHECK: %[[s35:.*]] = builtin.unrealized_conversion_cast %[[B]] : vector<16x4x8xf32> to !llvm.array<16 x array<4 x vector<8xf32>>>
// CHECK: %[[s36:.*]] = llvm.extractvalue %[[s35]][0, 1] : !llvm.array<16 x array<4 x vector<8xf32>>>
-// CHECK: %[[s37:.*]] = constant 0 : index
+// CHECK: %[[s37:.*]] = arith.constant 0 : index
// CHECK: %[[s38:.*]] = builtin.unrealized_conversion_cast %[[s37]] : index to i64
// CHECK: %[[s39:.*]] = llvm.extractelement %[[s34]]{{\[}}%[[s38]] : i64] : vector<4xf32>
-// CHECK: %[[s40:.*]] = constant 2 : index
+// CHECK: %[[s40:.*]] = arith.constant 2 : index
// CHECK: %[[s41:.*]] = builtin.unrealized_conversion_cast %[[s40]] : index to i64
// CHECK: %[[s42:.*]] = llvm.insertelement %[[s39]], %[[s36]]{{\[}}%[[s41]] : i64] : vector<8xf32>
-// CHECK: %[[s43:.*]] = constant 1 : index
+// CHECK: %[[s43:.*]] = arith.constant 1 : index
// CHECK: %[[s44:.*]] = builtin.unrealized_conversion_cast %[[s43]] : index to i64
// CHECK: %[[s45:.*]] = llvm.extractelement %[[s34]]{{\[}}%[[s44]] : i64] : vector<4xf32>
-// CHECK: %[[s46:.*]] = constant 3 : index
+// CHECK: %[[s46:.*]] = arith.constant 3 : index
// CHECK: %[[s47:.*]] = builtin.unrealized_conversion_cast %[[s46]] : index to i64
// CHECK: %[[s48:.*]] = llvm.insertelement %[[s45]], %[[s42]]{{\[}}%[[s47]] : i64] : vector<8xf32>
-// CHECK: %[[s49:.*]] = constant 2 : index
+// CHECK: %[[s49:.*]] = arith.constant 2 : index
// CHECK: %[[s50:.*]] = builtin.unrealized_conversion_cast %[[s49]] : index to i64
// CHECK: %[[s51:.*]] = llvm.extractelement %[[s34]]{{\[}}%[[s50]] : i64] : vector<4xf32>
-// CHECK: %[[s52:.*]] = constant 4 : index
+// CHECK: %[[s52:.*]] = arith.constant 4 : index
// CHECK: %[[s53:.*]] = builtin.unrealized_conversion_cast %[[s52]] : index to i64
// CHECK: %[[s54:.*]] = llvm.insertelement %[[s51]], %[[s48]]{{\[}}%[[s53]] : i64] : vector<8xf32>
-// CHECK: %[[s55:.*]] = constant 3 : index
+// CHECK: %[[s55:.*]] = arith.constant 3 : index
// CHECK: %[[s56:.*]] = builtin.unrealized_conversion_cast %[[s55]] : index to i64
// CHECK: %[[s57:.*]] = llvm.extractelement %[[s34]]{{\[}}%[[s56]] : i64] : vector<4xf32>
-// CHECK: %[[s58:.*]] = constant 5 : index
+// CHECK: %[[s58:.*]] = arith.constant 5 : index
// CHECK: %[[s59:.*]] = builtin.unrealized_conversion_cast %[[s58]] : index to i64
// CHECK: %[[s60:.*]] = llvm.insertelement %[[s57]], %[[s54]]{{\[}}%[[s59]] : i64] : vector<8xf32>
// CHECK: %[[s61:.*]] = llvm.insertvalue %[[s60]], %[[s32]][1] : !llvm.array<4 x vector<8xf32>>
// -----
func @transfer_read_1d(%A : memref<?xf32>, %base: index) -> vector<17xf32> {
- %f7 = constant 7.0: f32
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base], %f7
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<17xf32>
}
// CHECK-LABEL: func @transfer_read_1d
// CHECK-SAME: %[[BASE:[a-zA-Z0-9]*]]: index) -> vector<17xf32>
-// CHECK: %[[c7:.*]] = constant 7.0
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[c7:.*]] = arith.constant 7.0
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = memref.dim %{{.*}}, %[[C0]] : memref<?xf32>
//
// 1. Create a vector with linear indices [ 0 .. vector_length - 1 ].
-// CHECK: %[[linearIndex:.*]] = constant dense
+// CHECK: %[[linearIndex:.*]] = arith.constant dense
// CHECK-SAME: <[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]> :
// CHECK-SAME: vector<17xi32>
//
// 2. Create offsetVector = [ offset + 0 .. offset + vector_length - 1 ].
-// CHECK: %[[otrunc:.*]] = index_cast %[[BASE]] : index to i32
+// CHECK: %[[otrunc:.*]] = arith.index_cast %[[BASE]] : index to i32
// CHECK: %[[offsetVec:.*]] = splat %[[otrunc]] : vector<17xi32>
-// CHECK: %[[offsetVec2:.*]] = addi %[[offsetVec]], %[[linearIndex]] : vector<17xi32>
+// CHECK: %[[offsetVec2:.*]] = arith.addi %[[offsetVec]], %[[linearIndex]] : vector<17xi32>
//
// 3. Let dim the memref dimension, compute the vector comparison mask:
// [ offset + 0 .. offset + vector_length - 1 ] < [ dim .. dim ]
-// CHECK: %[[dtrunc:.*]] = index_cast %[[DIM]] : index to i32
+// CHECK: %[[dtrunc:.*]] = arith.index_cast %[[DIM]] : index to i32
// CHECK: %[[dimVec:.*]] = splat %[[dtrunc]] : vector<17xi32>
-// CHECK: %[[mask:.*]] = cmpi slt, %[[offsetVec2]], %[[dimVec]] : vector<17xi32>
+// CHECK: %[[mask:.*]] = arith.cmpi slt, %[[offsetVec2]], %[[dimVec]] : vector<17xi32>
//
// 4. Create pass-through vector.
// CHECK: %[[PASS_THROUGH:.*]] = splat %[[c7]] : vector<17xf32>
// CHECK-SAME: (!llvm.ptr<vector<17xf32>>, vector<17xi1>, vector<17xf32>) -> vector<17xf32>
//
// 1. Create a vector with linear indices [ 0 .. vector_length - 1 ].
-// CHECK: %[[linearIndex_b:.*]] = constant dense
+// CHECK: %[[linearIndex_b:.*]] = arith.constant dense
// CHECK-SAME: <[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]> :
// CHECK-SAME: vector<17xi32>
//
// 2. Create offsetVector = [ offset + 0 .. offset + vector_length - 1 ].
// CHECK: splat %{{.*}} : vector<17xi32>
-// CHECK: addi
+// CHECK: arith.addi
//
// 3. Let dim the memref dimension, compute the vector comparison mask:
// [ offset + 0 .. offset + vector_length - 1 ] < [ dim .. dim ]
// CHECK: splat %{{.*}} : vector<17xi32>
-// CHECK: %[[mask_b:.*]] = cmpi slt, {{.*}} : vector<17xi32>
+// CHECK: %[[mask_b:.*]] = arith.cmpi slt, {{.*}} : vector<17xi32>
//
// 4. Bitcast to vector form.
// CHECK: %[[gep_b:.*]] = llvm.getelementptr {{.*}} :
// -----
func @transfer_read_index_1d(%A : memref<?xindex>, %base: index) -> vector<17xindex> {
- %f7 = constant 7: index
+ %f7 = arith.constant 7: index
%f = vector.transfer_read %A[%base], %f7
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xindex>, vector<17xindex>
}
// CHECK-LABEL: func @transfer_read_index_1d
// CHECK-SAME: %[[BASE:[a-zA-Z0-9]*]]: index) -> vector<17xindex>
-// CHECK: %[[C7:.*]] = constant 7 : index
+// CHECK: %[[C7:.*]] = arith.constant 7 : index
// CHECK: %[[SPLAT:.*]] = splat %[[C7]] : vector<17xindex>
// CHECK: %{{.*}} = builtin.unrealized_conversion_cast %[[SPLAT]] : vector<17xindex> to vector<17xi64>
func @transfer_read_1d_aligned(%A : memref<?xf32>, %base: index) -> vector<17xf32> {
memref.assume_alignment %A, 32 : memref<?xf32>
- %f7 = constant 7.0: f32
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base], %f7
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<17xf32>
// -----
func @transfer_read_2d_to_1d(%A : memref<?x?xf32>, %base0: index, %base1: index) -> vector<17xf32> {
- %f7 = constant 7.0: f32
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base0, %base1], %f7
{permutation_map = affine_map<(d0, d1) -> (d1)>} :
memref<?x?xf32>, vector<17xf32>
}
// CHECK-LABEL: func @transfer_read_2d_to_1d
// CHECK-SAME: %[[BASE_0:[a-zA-Z0-9]*]]: index, %[[BASE_1:[a-zA-Z0-9]*]]: index) -> vector<17xf32>
-// CHECK: %[[c1:.*]] = constant 1 : index
+// CHECK: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[DIM:.*]] = memref.dim %{{.*}}, %[[c1]] : memref<?x?xf32>
//
// Create offsetVector = [ offset + 0 .. offset + vector_length - 1 ].
-// CHECK: %[[trunc:.*]] = index_cast %[[BASE_1]] : index to i32
+// CHECK: %[[trunc:.*]] = arith.index_cast %[[BASE_1]] : index to i32
// CHECK: %[[offsetVec:.*]] = splat %[[trunc]] : vector<17xi32>
//
// Let dim the memref dimension, compute the vector comparison mask:
// [ offset + 0 .. offset + vector_length - 1 ] < [ dim .. dim ]
-// CHECK: %[[dimtrunc:.*]] = index_cast %[[DIM]] : index to i32
+// CHECK: %[[dimtrunc:.*]] = arith.index_cast %[[DIM]] : index to i32
// CHECK: splat %[[dimtrunc]] : vector<17xi32>
// -----
func @transfer_read_1d_non_zero_addrspace(%A : memref<?xf32, 3>, %base: index) -> vector<17xf32> {
- %f7 = constant 7.0: f32
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base], %f7
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32, 3>, vector<17xf32>
// CHECK-SAME: !llvm.ptr<f32, 3> to !llvm.ptr<vector<17xf32>, 3>
//
// 2. Check address space of the memref is correct.
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = memref.dim %{{.*}}, %[[c0]] : memref<?xf32, 3>
//
// 3. Check address space for GEP is correct.
// -----
func @transfer_read_1d_inbounds(%A : memref<?xf32>, %base: index) -> vector<17xf32> {
- %f7 = constant 7.0: f32
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base], %f7 {in_bounds = [true]} :
memref<?xf32>, vector<17xf32>
return %f: vector<17xf32>
// -----
// CHECK-LABEL: func @transfer_read_1d_mask
-// CHECK: %[[mask1:.*]] = constant dense<[false, false, true, false, true]>
-// CHECK: %[[cmpi:.*]] = cmpi slt
-// CHECK: %[[mask2:.*]] = and %[[cmpi]], %[[mask1]]
+// CHECK: %[[mask1:.*]] = arith.constant dense<[false, false, true, false, true]>
+// CHECK: %[[cmpi:.*]] = arith.cmpi slt
+// CHECK: %[[mask2:.*]] = arith.andi %[[cmpi]], %[[mask1]]
// CHECK: %[[r:.*]] = llvm.intr.masked.load %{{.*}}, %[[mask2]]
// CHECK: return %[[r]]
func @transfer_read_1d_mask(%A : memref<?xf32>, %base : index) -> vector<5xf32> {
- %m = constant dense<[0, 0, 1, 0, 1]> : vector<5xi1>
- %f7 = constant 7.0: f32
+ %m = arith.constant dense<[0, 0, 1, 0, 1]> : vector<5xi1>
+ %f7 = arith.constant 7.0: f32
%f = vector.transfer_read %A[%base], %f7, %m : memref<?xf32>, vector<5xf32>
return %f: vector<5xf32>
}
return %0 : vector<8xi1>
}
// CHECK-LABEL: func @genbool_1d
-// CHECK: %[[VAL_0:.*]] = constant dense<[true, true, true, true, false, false, false, false]> : vector<8xi1>
+// CHECK: %[[VAL_0:.*]] = arith.constant dense<[true, true, true, true, false, false, false, false]> : vector<8xi1>
// CHECK: return %[[VAL_0]] : vector<8xi1>
// -----
}
// CHECK-LABEL: func @genbool_2d
-// CHECK: %[[VAL_0:.*]] = constant dense<[true, true, false, false]> : vector<4xi1>
-// CHECK: %[[VAL_1:.*]] = constant dense<false> : vector<4x4xi1>
+// CHECK: %[[VAL_0:.*]] = arith.constant dense<[true, true, false, false]> : vector<4xi1>
+// CHECK: %[[VAL_1:.*]] = arith.constant dense<false> : vector<4x4xi1>
// CHECK: %[[VAL_2:.*]] = builtin.unrealized_conversion_cast %[[VAL_1]] : vector<4x4xi1> to !llvm.array<4 x vector<4xi1>>
// CHECK: %[[VAL_3:.*]] = llvm.insertvalue %[[VAL_0]], %[[VAL_2]][0] : !llvm.array<4 x vector<4xi1>>
// CHECK: %[[VAL_4:.*]] = llvm.insertvalue %[[VAL_0]], %[[VAL_3]][1] : !llvm.array<4 x vector<4xi1>>
// -----
func @vector_store_op(%memref : memref<200x100xf32>, %i : index, %j : index) {
- %val = constant dense<11.0> : vector<4xf32>
+ %val = arith.constant dense<11.0> : vector<4xf32>
vector.store %val, %memref[%i, %j] : memref<200x100xf32>, vector<4xf32>
return
}
// -----
func @vector_store_op_index(%memref : memref<200x100xindex>, %i : index, %j : index) {
- %val = constant dense<11> : vector<4xindex>
+ %val = arith.constant dense<11> : vector<4xindex>
vector.store %val, %memref[%i, %j] : memref<200x100xindex>, vector<4xindex>
return
}
func @vector_store_op_aligned(%memref : memref<200x100xf32>, %i : index, %j : index) {
memref.assume_alignment %memref, 32 : memref<200x100xf32>
- %val = constant dense<11.0> : vector<4xf32>
+ %val = arith.constant dense<11.0> : vector<4xf32>
vector.store %val, %memref[%i, %j] : memref<200x100xf32>, vector<4xf32>
return
}
// -----
func @masked_load_op(%arg0: memref<?xf32>, %arg1: vector<16xi1>, %arg2: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%0 = vector.maskedload %arg0[%c0], %arg1, %arg2 : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
return %0 : vector<16xf32>
}
// CHECK-LABEL: func @masked_load_op
-// CHECK: %[[CO:.*]] = constant 0 : index
+// CHECK: %[[CO:.*]] = arith.constant 0 : index
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[CO]] : index to i64
// CHECK: %[[P:.*]] = llvm.getelementptr %{{.*}}[%[[C]]] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
// CHECK: %[[B:.*]] = llvm.bitcast %[[P]] : !llvm.ptr<f32> to !llvm.ptr<vector<16xf32>>
// -----
func @masked_load_op_index(%arg0: memref<?xindex>, %arg1: vector<16xi1>, %arg2: vector<16xindex>) -> vector<16xindex> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%0 = vector.maskedload %arg0[%c0], %arg1, %arg2 : memref<?xindex>, vector<16xi1>, vector<16xindex> into vector<16xindex>
return %0 : vector<16xindex>
}
// -----
func @masked_store_op(%arg0: memref<?xf32>, %arg1: vector<16xi1>, %arg2: vector<16xf32>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.maskedstore %arg0[%c0], %arg1, %arg2 : memref<?xf32>, vector<16xi1>, vector<16xf32>
return
}
// CHECK-LABEL: func @masked_store_op
-// CHECK: %[[CO:.*]] = constant 0 : index
+// CHECK: %[[CO:.*]] = arith.constant 0 : index
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[CO]] : index to i64
// CHECK: %[[P:.*]] = llvm.getelementptr %{{.*}}[%[[C]]] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
// CHECK: %[[B:.*]] = llvm.bitcast %[[P]] : !llvm.ptr<f32> to !llvm.ptr<vector<16xf32>>
// -----
func @masked_store_op_index(%arg0: memref<?xindex>, %arg1: vector<16xi1>, %arg2: vector<16xindex>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.maskedstore %arg0[%c0], %arg1, %arg2 : memref<?xindex>, vector<16xi1>, vector<16xindex>
return
}
// -----
func @gather_op(%arg0: memref<?xf32>, %arg1: vector<3xi32>, %arg2: vector<3xi1>, %arg3: vector<3xf32>) -> vector<3xf32> {
- %0 = constant 0: index
+ %0 = arith.constant 0: index
%1 = vector.gather %arg0[%0][%arg1], %arg2, %arg3 : memref<?xf32>, vector<3xi32>, vector<3xi1>, vector<3xf32> into vector<3xf32>
return %1 : vector<3xf32>
}
// -----
func @gather_op_index(%arg0: memref<?xindex>, %arg1: vector<3xindex>, %arg2: vector<3xi1>, %arg3: vector<3xindex>) -> vector<3xindex> {
- %0 = constant 0: index
+ %0 = arith.constant 0: index
%1 = vector.gather %arg0[%0][%arg1], %arg2, %arg3 : memref<?xindex>, vector<3xindex>, vector<3xi1>, vector<3xindex> into vector<3xindex>
return %1 : vector<3xindex>
}
func @gather_op_aligned(%arg0: memref<?xf32>, %arg1: vector<3xi32>, %arg2: vector<3xi1>, %arg3: vector<3xf32>) -> vector<3xf32> {
memref.assume_alignment %arg0, 32 : memref<?xf32>
- %0 = constant 0: index
+ %0 = arith.constant 0: index
%1 = vector.gather %arg0[%0][%arg1], %arg2, %arg3 : memref<?xf32>, vector<3xi32>, vector<3xi1>, vector<3xf32> into vector<3xf32>
return %1 : vector<3xf32>
}
// -----
func @gather_2d_op(%arg0: memref<4x4xf32>, %arg1: vector<4xi32>, %arg2: vector<4xi1>, %arg3: vector<4xf32>) -> vector<4xf32> {
- %0 = constant 3 : index
+ %0 = arith.constant 3 : index
%1 = vector.gather %arg0[%0, %0][%arg1], %arg2, %arg3 : memref<4x4xf32>, vector<4xi32>, vector<4xi1>, vector<4xf32> into vector<4xf32>
return %1 : vector<4xf32>
}
// -----
func @scatter_op(%arg0: memref<?xf32>, %arg1: vector<3xi32>, %arg2: vector<3xi1>, %arg3: vector<3xf32>) {
- %0 = constant 0: index
+ %0 = arith.constant 0: index
vector.scatter %arg0[%0][%arg1], %arg2, %arg3 : memref<?xf32>, vector<3xi32>, vector<3xi1>, vector<3xf32>
return
}
// -----
func @scatter_op_index(%arg0: memref<?xindex>, %arg1: vector<3xindex>, %arg2: vector<3xi1>, %arg3: vector<3xindex>) {
- %0 = constant 0: index
+ %0 = arith.constant 0: index
vector.scatter %arg0[%0][%arg1], %arg2, %arg3 : memref<?xindex>, vector<3xindex>, vector<3xi1>, vector<3xindex>
return
}
func @scatter_op_aligned(%arg0: memref<?xf32>, %arg1: vector<3xi32>, %arg2: vector<3xi1>, %arg3: vector<3xf32>) {
memref.assume_alignment %arg0, 32 : memref<?xf32>
- %0 = constant 0: index
+ %0 = arith.constant 0: index
vector.scatter %arg0[%0][%arg1], %arg2, %arg3 : memref<?xf32>, vector<3xi32>, vector<3xi1>, vector<3xf32>
return
}
// -----
func @scatter_2d_op(%arg0: memref<4x4xf32>, %arg1: vector<4xi32>, %arg2: vector<4xi1>, %arg3: vector<4xf32>) {
- %0 = constant 3 : index
+ %0 = arith.constant 3 : index
vector.scatter %arg0[%0, %0][%arg1], %arg2, %arg3 : memref<4x4xf32>, vector<4xi32>, vector<4xi1>, vector<4xf32>
return
}
// -----
func @expand_load_op(%arg0: memref<?xf32>, %arg1: vector<11xi1>, %arg2: vector<11xf32>) -> vector<11xf32> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%0 = vector.expandload %arg0[%c0], %arg1, %arg2 : memref<?xf32>, vector<11xi1>, vector<11xf32> into vector<11xf32>
return %0 : vector<11xf32>
}
// CHECK-LABEL: func @expand_load_op
-// CHECK: %[[CO:.*]] = constant 0 : index
+// CHECK: %[[CO:.*]] = arith.constant 0 : index
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[CO]] : index to i64
// CHECK: %[[P:.*]] = llvm.getelementptr %{{.*}}[%[[C]]] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
// CHECK: %[[E:.*]] = "llvm.intr.masked.expandload"(%[[P]], %{{.*}}, %{{.*}}) : (!llvm.ptr<f32>, vector<11xi1>, vector<11xf32>) -> vector<11xf32>
// -----
func @expand_load_op_index(%arg0: memref<?xindex>, %arg1: vector<11xi1>, %arg2: vector<11xindex>) -> vector<11xindex> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%0 = vector.expandload %arg0[%c0], %arg1, %arg2 : memref<?xindex>, vector<11xi1>, vector<11xindex> into vector<11xindex>
return %0 : vector<11xindex>
}
// -----
func @compress_store_op(%arg0: memref<?xf32>, %arg1: vector<11xi1>, %arg2: vector<11xf32>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.compressstore %arg0[%c0], %arg1, %arg2 : memref<?xf32>, vector<11xi1>, vector<11xf32>
return
}
// CHECK-LABEL: func @compress_store_op
-// CHECK: %[[CO:.*]] = constant 0 : index
+// CHECK: %[[CO:.*]] = arith.constant 0 : index
// CHECK: %[[C:.*]] = builtin.unrealized_conversion_cast %[[CO]] : index to i64
// CHECK: %[[P:.*]] = llvm.getelementptr %{{.*}}[%[[C]]] : (!llvm.ptr<f32>, i64) -> !llvm.ptr<f32>
// CHECK: "llvm.intr.masked.compressstore"(%{{.*}}, %[[P]], %{{.*}}) : (vector<11xf32>, !llvm.ptr<f32>, vector<11xi1>) -> ()
// -----
func @compress_store_op_index(%arg0: memref<?xindex>, %arg1: vector<11xi1>, %arg2: vector<11xindex>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.compressstore %arg0[%c0], %arg1, %arg2 : memref<?xindex>, vector<11xi1>, vector<11xindex>
return
}
gpu.module @test_read{
builtin.func @transfer_readx2(%A : memref<?xf32>, %base: index) -> vector<2xf32> {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
%f = vector.transfer_read %A[%base], %f0
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<2xf32>
// CHECK: rocdl.buffer.load {{.*}} vector<2xf32>
builtin.func @transfer_readx4(%A : memref<?xf32>, %base: index) -> vector<4xf32> {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
%f = vector.transfer_read %A[%base], %f0
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<4xf32>
// CHECK: rocdl.buffer.load {{.*}} vector<4xf32>
builtin.func @transfer_read_dwordConfig(%A : memref<?xf32>, %base: index) -> vector<4xf32> {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
%f = vector.transfer_read %A[%base], %f0
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<4xf32>
// CHECK: return %[[LOADED]] : vector<4x9xf32>
func @transfer_read_2d(%A : tensor<?x?xf32>, %base1 : index, %base2 : index)
-> (vector<4x9xf32>){
- %p = constant -42.0: f32
+ %p = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %p {in_bounds = [true, true]}
: tensor<?x?xf32>, vector<4x9xf32>
return %f : vector<4x9xf32>
// RUN: mlir-opt %s -convert-vector-to-scf='full-unroll=true lower-tensors=true' -split-input-file -allow-unregistered-dialect | FileCheck %s
// CHECK-LABEL: func @transfer_read_2d(
-// CHECK: %[[V_INIT:.*]] = constant dense<-4.200000e+01> : vector<4x9xf32>
+// CHECK: %[[V_INIT:.*]] = arith.constant dense<-4.200000e+01> : vector<4x9xf32>
// CHECK: %[[V0:.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{.*}} {in_bounds = [true]} : tensor<?x?xf32>, vector<9xf32>
// CHECK: %[[I0:.*]] = vector.insert %[[V0]], %[[V_INIT]] [0] : vector<9xf32> into vector<4x9xf32>
// CHECK: %[[V1:.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{.*}} {in_bounds = [true]} : tensor<?x?xf32>, vector<9xf32>
// CHECK: return %[[I3]] : vector<4x9xf32>
func @transfer_read_2d(%A : tensor<?x?xf32>, %base1 : index, %base2 : index)
-> (vector<4x9xf32>){
- %p = constant -42.0: f32
+ %p = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %p {in_bounds = [true, true]}
: tensor<?x?xf32>, vector<4x9xf32>
return %f : vector<4x9xf32>
// CHECK-LABEL: func @transfer_read_inbounds
func @transfer_read_inbounds(%A : memref<?x?x?xf32>) -> (vector<2x3x4xf32>) {
- %f0 = constant 0.0: f32
- %c0 = constant 0: index
+ %f0 = arith.constant 0.0: f32
+ %c0 = arith.constant 0: index
// CHECK: vector.transfer_read {{.*}} : memref<?x?x?xf32>, vector<4xf32>
// CHECK-NEXT: vector.insert {{.*}} [0, 0] : vector<4xf32> into vector<2x3x4xf32>
// CHECK-LABEL: func @transfer_read_out_of_bounds
func @transfer_read_out_of_bounds(%A : memref<?x?x?xf32>) -> (vector<2x3x4xf32>) {
- %f0 = constant 0.0: f32
- %c0 = constant 0: index
+ %f0 = arith.constant 0.0: f32
+ %c0 = arith.constant 0: index
// CHECK: scf.if
// CHECK: scf.if
// -----
func @transfer_read_mask(%A : memref<?x?x?xf32>, %mask : vector<2x3x4xi1>) -> (vector<2x3x4xf32>) {
- %f0 = constant 0.0: f32
- %c0 = constant 0: index
+ %f0 = arith.constant 0.0: f32
+ %c0 = arith.constant 0: index
// CHECK: vector.extract %{{.*}}[0, 0] : vector<2x3x4xi1>
// CHECK-NEXT: vector.transfer_read {{.*}} : memref<?x?x?xf32>, vector<4xf32>
// before lowering the vector.transfer_read.
// CHECK-LABEL: func @transfer_read_2d_mask_transposed(
-// CHECK-DAG: %[[PADDING:.*]] = constant dense<-4.200000e+01> : vector<9xf32>
-// CHECK-DAG: %[[MASK:.*]] = constant dense<{{.*}}> : vector<9x4xi1>
+// CHECK-DAG: %[[PADDING:.*]] = arith.constant dense<-4.200000e+01> : vector<9xf32>
+// CHECK-DAG: %[[MASK:.*]] = arith.constant dense<{{.*}}> : vector<9x4xi1>
// CHECK: %[[MASK_MEM:.*]] = memref.alloca() : memref<vector<4x9xi1>>
// CHECK: %[[MASK_T:.*]] = vector.transpose %[[MASK]], [1, 0] : vector<9x4xi1> to vector<4x9xi1>
// CHECK: memref.store %[[MASK_T]], %[[MASK_MEM]][] : memref<vector<4x9xi1>>
// Vector load with mask + transpose.
func @transfer_read_2d_mask_transposed(
%A : memref<?x?xf32>, %base1: index, %base2: index) -> (vector<9x4xf32>) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[[1, 0, 1, 0], [0, 0, 1, 0],
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[[1, 0, 1, 0], [0, 0, 1, 0],
[1, 1, 1, 1], [0, 1, 1, 0],
[1, 1, 1, 1], [1, 1, 1, 1],
[1, 1, 1, 1], [0, 0, 0, 0],
// CHECK-LABEL: func @vector_transfer_ops_0d(
// CHECK-SAME: %[[MEM:.*]]: memref<f32>) {
func @vector_transfer_ops_0d(%M: memref<f32>) {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
-// CHECK: %[[V0:.*]] = constant dense<0{{.*}}> : vector<1xf32>
+// CHECK: %[[V0:.*]] = arith.constant dense<0{{.*}}> : vector<1xf32>
// CHECK: %[[R0:.*]] = scf.for %[[I:.*]] = {{.*}} iter_args(%[[V0_ITER:.*]] = %[[V0]]) -> (vector<1xf32>) {
-// CHECK: %[[IDX:.*]] = index_cast %[[I]] : index to i32
+// CHECK: %[[IDX:.*]] = arith.index_cast %[[I]] : index to i32
// CHECK: %[[S:.*]] = memref.load %[[MEM]][] : memref<f32>
// CHECK: %[[R_ITER:.*]] = vector.insertelement %[[S]], %[[V0_ITER]][%[[IDX]] : i32] : vector<1xf32>
// CHECK: scf.yield %[[R_ITER]] : vector<1xf32>
memref<f32>, vector<1xf32>
// CHECK: scf.for %[[J:.*]] = %{{.*}}
-// CHECK: %[[JDX:.*]] = index_cast %[[J]] : index to i32
+// CHECK: %[[JDX:.*]] = arith.index_cast %[[J]] : index to i32
// CHECK: %[[SS:.*]] = vector.extractelement %[[R0]][%[[JDX]] : i32] : vector<1xf32>
// CHECK: memref.store %[[SS]], %[[MEM]][] : memref<f32>
vector.transfer_write %0, %M[] {permutation_map = affine_map<()->(0)>} :
// CHECK-LABEL: func @materialize_read_1d() {
func @materialize_read_1d() {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
%A = memref.alloc () : memref<7x42xf32>
affine.for %i0 = 0 to 7 step 4 {
affine.for %i1 = 0 to 42 step 4 {
// CHECK-LABEL: func @materialize_read_1d_partially_specialized
func @materialize_read_1d_partially_specialized(%dyn1 : index, %dyn2 : index, %dyn4 : index) {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
%A = memref.alloc (%dyn1, %dyn2, %dyn4) : memref<7x?x?x42x?xf32>
affine.for %i0 = 0 to 7 {
affine.for %i1 = 0 to %dyn1 {
// CHECK-LABEL: func @materialize_read(%{{.*}}: index, %{{.*}}: index, %{{.*}}: index, %{{.*}}: index) {
func @materialize_read(%M: index, %N: index, %O: index, %P: index) {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
// CHECK-DAG: %[[ALLOC:.*]] = memref.alloca() : memref<vector<5x4x3xf32>>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
- // CHECK-DAG: %[[C4:.*]] = constant 4 : index
- // CHECK-DAG: %[[C5:.*]] = constant 5 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+ // CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+ // CHECK-DAG: %[[C5:.*]] = arith.constant 5 : index
// CHECK: %{{.*}} = memref.alloc(%{{.*}}, %{{.*}}, %{{.*}}, %{{.*}}) : memref<?x?x?x?xf32>
// CHECK-NEXT: affine.for %[[I0:.*]] = 0 to %{{.*}} step 3 {
// CHECK-NEXT: affine.for %[[I1:.*]] = 0 to %{{.*}} {
// CHECK: scf.for %[[I5:.*]] = %[[C0]] to %[[C4]] step %[[C1]] {
// CHECK: %[[VEC:.*]] = scf.for %[[I6:.*]] = %[[C0]] to %[[C3]] step %[[C1]] {{.*}} -> (vector<3xf32>) {
// CHECK: %[[L0:.*]] = affine.apply #[[$ADD]](%[[I0]], %[[I6]])
- // CHECK: %[[VIDX:.*]] = index_cast %[[I6]]
+ // CHECK: %[[VIDX:.*]] = arith.index_cast %[[I6]]
// CHECK: scf.if {{.*}} -> (vector<3xf32>) {
// CHECK-NEXT: %[[SCAL:.*]] = memref.load %{{.*}}[%[[L0]], %[[I1]], %[[I2]], %[[L3]]] : memref<?x?x?x?xf32>
// CHECK-NEXT: %[[RVEC:.*]] = vector.insertelement %[[SCAL]], %{{.*}}[%[[VIDX]] : i32] : vector<3xf32>
// CHECK-LABEL:func @materialize_write(%{{.*}}: index, %{{.*}}: index, %{{.*}}: index, %{{.*}}: index) {
func @materialize_write(%M: index, %N: index, %O: index, %P: index) {
// CHECK-DAG: %[[ALLOC:.*]] = memref.alloca() : memref<vector<5x4x3xf32>>
- // CHECK-DAG: %{{.*}} = constant dense<1.000000e+00> : vector<5x4x3xf32>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
- // CHECK-DAG: %[[C4:.*]] = constant 4 : index
- // CHECK-DAG: %[[C5:.*]] = constant 5 : index
+ // CHECK-DAG: %{{.*}} = arith.constant dense<1.000000e+00> : vector<5x4x3xf32>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+ // CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+ // CHECK-DAG: %[[C5:.*]] = arith.constant 5 : index
// CHECK: %{{.*}} = memref.alloc(%{{.*}}, %{{.*}}, %{{.*}}, %{{.*}}) : memref<?x?x?x?xf32>
// CHECK-NEXT: affine.for %[[I0:.*]] = 0 to %{{.*}} step 3 {
// CHECK-NEXT: affine.for %[[I1:.*]] = 0 to %{{.*}} step 4 {
// CHECK: %[[VEC:.*]] = memref.load %[[VECTOR_VIEW2]][%[[I4]], %[[I5]]] : memref<5x4xvector<3xf32>>
// CHECK: scf.for %[[I6:.*]] = %[[C0]] to %[[C3]] step %[[C1]] {
// CHECK: %[[S0:.*]] = affine.apply #[[$ADD]](%[[I0]], %[[I6]])
- // CHECK: %[[VIDX:.*]] = index_cast %[[I6]]
+ // CHECK: %[[VIDX:.*]] = arith.index_cast %[[I6]]
// CHECK: scf.if
// CHECK: %[[SCAL:.*]] = vector.extractelement %[[VEC]][%[[VIDX]] : i32] : vector<3xf32>
// CHECK: memref.store %[[SCAL]], {{.*}}[%[[S0]], %[[S1]], %[[I2]], %[[S3]]] : memref<?x?x?x?xf32>
// Check that I3 + I6 (of size 5) read from first index load(I6, ...) and write into last index store(..., S3)
// Other dimension is just accessed with I2.
%A = memref.alloc (%M, %N, %O, %P) : memref<?x?x?x?xf32, 0>
- %f1 = constant dense<1.000000e+00> : vector<5x4x3xf32>
+ %f1 = arith.constant dense<1.000000e+00> : vector<5x4x3xf32>
affine.for %i0 = 0 to %M step 3 {
affine.for %i1 = 0 to %N step 4 {
affine.for %i2 = 0 to %O {
// FULL-UNROLL-SAME: %[[base:[a-zA-Z0-9]+]]: index
func @transfer_read_progressive(%A : memref<?x?xf32>, %base: index) -> vector<3x15xf32> {
- %f7 = constant 7.0: f32
- // CHECK-DAG: %[[C7:.*]] = constant 7.000000e+00 : f32
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
- // CHECK-DAG: %[[splat:.*]] = constant dense<7.000000e+00> : vector<15xf32>
+ %f7 = arith.constant 7.0: f32
+ // CHECK-DAG: %[[C7:.*]] = arith.constant 7.000000e+00 : f32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+ // CHECK-DAG: %[[splat:.*]] = arith.constant dense<7.000000e+00> : vector<15xf32>
// CHECK-DAG: %[[alloc:.*]] = memref.alloca() : memref<vector<3x15xf32>>
// CHECK: %[[alloc_casted:.*]] = vector.type_cast %[[alloc]] : memref<vector<3x15xf32>> to memref<3xvector<15xf32>>
// CHECK: scf.for %[[I:.*]] = %[[C0]] to %[[C3]]
// CHECK: %[[dim:.*]] = memref.dim %[[A]], %[[C0]] : memref<?x?xf32>
// CHECK: %[[add:.*]] = affine.apply #[[$MAP0]](%[[I]])[%[[base]]]
- // CHECK: %[[cond1:.*]] = cmpi sgt, %[[dim]], %[[add]] : index
+ // CHECK: %[[cond1:.*]] = arith.cmpi sgt, %[[dim]], %[[add]] : index
// CHECK: scf.if %[[cond1]] {
// CHECK: %[[vec_1d:.*]] = vector.transfer_read %[[A]][%{{.*}}, %[[base]]], %[[C7]] : memref<?x?xf32>, vector<15xf32>
// CHECK: memref.store %[[vec_1d]], %[[alloc_casted]][%[[I]]] : memref<3xvector<15xf32>>
// CHECK: }
// CHECK: %[[cst:.*]] = memref.load %[[alloc]][] : memref<vector<3x15xf32>>
- // FULL-UNROLL: %[[C7:.*]] = constant 7.000000e+00 : f32
- // FULL-UNROLL: %[[VEC0:.*]] = constant dense<7.000000e+00> : vector<3x15xf32>
- // FULL-UNROLL: %[[C0:.*]] = constant 0 : index
+ // FULL-UNROLL: %[[C7:.*]] = arith.constant 7.000000e+00 : f32
+ // FULL-UNROLL: %[[VEC0:.*]] = arith.constant dense<7.000000e+00> : vector<3x15xf32>
+ // FULL-UNROLL: %[[C0:.*]] = arith.constant 0 : index
// FULL-UNROLL: %[[DIM:.*]] = memref.dim %[[A]], %[[C0]] : memref<?x?xf32>
// FULL-UNROLL: cmpi sgt, %[[DIM]], %[[base]] : index
// FULL-UNROLL: %[[VEC1:.*]] = scf.if %{{.*}} -> (vector<3x15xf32>) {
// FULL-UNROLL-SAME: %[[base:[a-zA-Z0-9]+]]: index,
// FULL-UNROLL-SAME: %[[vec:[a-zA-Z0-9]+]]: vector<3x15xf32>
func @transfer_write_progressive(%A : memref<?x?xf32>, %base: index, %vec: vector<3x15xf32>) {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// CHECK: %[[alloc:.*]] = memref.alloca() : memref<vector<3x15xf32>>
// CHECK: memref.store %[[vec]], %[[alloc]][] : memref<vector<3x15xf32>>
// CHECK: %[[vmemref:.*]] = vector.type_cast %[[alloc]] : memref<vector<3x15xf32>> to memref<3xvector<15xf32>>
// CHECK: scf.for %[[I:.*]] = %[[C0]] to %[[C3]]
// CHECK: %[[dim:.*]] = memref.dim %[[A]], %[[C0]] : memref<?x?xf32>
// CHECK: %[[add:.*]] = affine.apply #[[$MAP0]](%[[I]])[%[[base]]]
- // CHECK: %[[cmp:.*]] = cmpi sgt, %[[dim]], %[[add]] : index
+ // CHECK: %[[cmp:.*]] = arith.cmpi sgt, %[[dim]], %[[add]] : index
// CHECK: scf.if %[[cmp]] {
// CHECK: %[[vec_1d:.*]] = memref.load %[[vmemref]][%[[I]]] : memref<3xvector<15xf32>>
// CHECK: vector.transfer_write %[[vec_1d]], %[[A]][{{.*}}, %[[base]]] : vector<15xf32>, memref<?x?xf32>
// CHECK: }
// CHECK: }
- // FULL-UNROLL: %[[C0:.*]] = constant 0 : index
+ // FULL-UNROLL: %[[C0:.*]] = arith.constant 0 : index
// FULL-UNROLL: %[[DIM:.*]] = memref.dim %[[A]], %[[C0]] : memref<?x?xf32>
- // FULL-UNROLL: %[[CMP0:.*]] = cmpi sgt, %[[DIM]], %[[base]] : index
+ // FULL-UNROLL: %[[CMP0:.*]] = arith.cmpi sgt, %[[DIM]], %[[base]] : index
// FULL-UNROLL: scf.if %[[CMP0]] {
// FULL-UNROLL: %[[V0:.*]] = vector.extract %[[vec]][0] : vector<3x15xf32>
// FULL-UNROLL: vector.transfer_write %[[V0]], %[[A]][%[[base]], %[[base]]] : vector<15xf32>, memref<?x?xf32>
// FULL-UNROLL: }
// FULL-UNROLL: %[[I1:.*]] = affine.apply #[[$MAP1]]()[%[[base]]]
- // FULL-UNROLL: %[[CMP1:.*]] = cmpi sgt, %{{.*}}, %[[I1]] : index
+ // FULL-UNROLL: %[[CMP1:.*]] = arith.cmpi sgt, %{{.*}}, %[[I1]] : index
// FULL-UNROLL: scf.if %[[CMP1]] {
// FULL-UNROLL: %[[V1:.*]] = vector.extract %[[vec]][1] : vector<3x15xf32>
// FULL-UNROLL: vector.transfer_write %[[V1]], %[[A]][%{{.*}}, %[[base]]] : vector<15xf32>, memref<?x?xf32>
// FULL-UNROLL: }
// FULL-UNROLL: %[[I2:.*]] = affine.apply #[[$MAP2]]()[%[[base]]]
- // FULL-UNROLL: %[[CMP2:.*]] = cmpi sgt, %{{.*}}, %[[I2]] : index
+ // FULL-UNROLL: %[[CMP2:.*]] = arith.cmpi sgt, %{{.*}}, %[[I2]] : index
// FULL-UNROLL: scf.if %[[CMP2]] {
// FULL-UNROLL: %[[V2:.*]] = vector.extract %[[vec]][2] : vector<3x15xf32>
// FULL-UNROLL: vector.transfer_write %[[V2]], %[[A]][%{{.*}}, %[[base]]] : vector<15xf32>, memref<?x?xf32>
// FULL-UNROLL-SAME: %[[vec:[a-zA-Z0-9]+]]: vector<3x15xf32>
func @transfer_write_progressive_inbounds(%A : memref<?x?xf32>, %base: index, %vec: vector<3x15xf32>) {
// CHECK-NOT: scf.if
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// CHECK: %[[alloc:.*]] = memref.alloca() : memref<vector<3x15xf32>>
// CHECK-NEXT: memref.store %[[vec]], %[[alloc]][] : memref<vector<3x15xf32>>
// CHECK-NEXT: %[[vmemref:.*]] = vector.type_cast %[[alloc]] : memref<vector<3x15xf32>> to memref<3xvector<15xf32>>
// FULL-UNROLL-LABEL: transfer_read_simple
func @transfer_read_simple(%A : memref<2x2xf32>) -> vector<2x2xf32> {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
- // FULL-UNROLL-DAG: %[[VC0:.*]] = constant dense<0.000000e+00> : vector<2x2xf32>
- // FULL-UNROLL-DAG: %[[C0:.*]] = constant 0 : index
- // FULL-UNROLL-DAG: %[[C1:.*]] = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
+ // FULL-UNROLL-DAG: %[[VC0:.*]] = arith.constant dense<0.000000e+00> : vector<2x2xf32>
+ // FULL-UNROLL-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // FULL-UNROLL-DAG: %[[C1:.*]] = arith.constant 1 : index
// FULL-UNROLL: %[[V0:.*]] = vector.transfer_read %{{.*}}[%[[C0]], %[[C0]]]
// FULL-UNROLL: %[[RES0:.*]] = vector.insert %[[V0]], %[[VC0]] [0] : vector<2xf32> into vector<2x2xf32>
// FULL-UNROLL: %[[V1:.*]] = vector.transfer_read %{{.*}}[%[[C1]], %[[C0]]]
}
func @transfer_read_minor_identity(%A : memref<?x?x?x?xf32>) -> vector<3x3xf32> {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %A[%c0, %c0, %c0, %c0], %f0
{ permutation_map = affine_map<(d0, d1, d2, d3) -> (d2, d3)> }
: memref<?x?x?x?xf32>, vector<3x3xf32>
// CHECK-LABEL: transfer_read_minor_identity(
// CHECK-SAME: %[[A:.*]]: memref<?x?x?x?xf32>) -> vector<3x3xf32>
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-DAG: %[[c2:.*]] = constant 2 : index
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
-// CHECK-DAG: %[[f0:.*]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[cst0:.*]] = constant dense<0.000000e+00> : vector<3xf32>
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[c2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[f0:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[cst0:.*]] = arith.constant dense<0.000000e+00> : vector<3xf32>
// CHECK: %[[m:.*]] = memref.alloca() : memref<vector<3x3xf32>>
// CHECK: %[[cast:.*]] = vector.type_cast %[[m]] : memref<vector<3x3xf32>> to memref<3xvector<3xf32>>
// CHECK: scf.for %[[arg1:.*]] = %[[c0]] to %[[c3]]
// CHECK: %[[d:.*]] = memref.dim %[[A]], %[[c2]] : memref<?x?x?x?xf32>
-// CHECK: %[[cmp:.*]] = cmpi sgt, %[[d]], %[[arg1]] : index
+// CHECK: %[[cmp:.*]] = arith.cmpi sgt, %[[d]], %[[arg1]] : index
// CHECK: scf.if %[[cmp]] {
// CHECK: %[[tr:.*]] = vector.transfer_read %[[A]][%c0, %c0, %[[arg1]], %c0], %[[f0]] : memref<?x?x?x?xf32>, vector<3xf32>
// CHECK: memref.store %[[tr]], %[[cast]][%[[arg1]]] : memref<3xvector<3xf32>>
// CHECK: return %[[ret]] : vector<3x3xf32>
func @transfer_write_minor_identity(%A : vector<3x3xf32>, %B : memref<?x?x?x?xf32>) {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
vector.transfer_write %A, %B[%c0, %c0, %c0, %c0]
{ permutation_map = affine_map<(d0, d1, d2, d3) -> (d2, d3)> }
: vector<3x3xf32>, memref<?x?x?x?xf32>
// CHECK-LABEL: transfer_write_minor_identity(
// CHECK-SAME: %[[A:.*]]: vector<3x3xf32>,
// CHECK-SAME: %[[B:.*]]: memref<?x?x?x?xf32>)
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-DAG: %[[c2:.*]] = constant 2 : index
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[c2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
// CHECK: %[[m:.*]] = memref.alloca() : memref<vector<3x3xf32>>
// CHECK: memref.store %[[A]], %[[m]][] : memref<vector<3x3xf32>>
// CHECK: %[[cast:.*]] = vector.type_cast %[[m]] : memref<vector<3x3xf32>> to memref<3xvector<3xf32>>
// CHECK: scf.for %[[arg2:.*]] = %[[c0]] to %[[c3]]
// CHECK: %[[d:.*]] = memref.dim %[[B]], %[[c2]] : memref<?x?x?x?xf32>
-// CHECK: %[[cmp:.*]] = cmpi sgt, %[[d]], %[[arg2]] : index
+// CHECK: %[[cmp:.*]] = arith.cmpi sgt, %[[d]], %[[arg2]] : index
// CHECK: scf.if %[[cmp]] {
// CHECK: %[[tmp:.*]] = memref.load %[[cast]][%[[arg2]]] : memref<3xvector<3xf32>>
// CHECK: vector.transfer_write %[[tmp]], %[[B]][%[[c0]], %[[c0]], %[[arg2]], %[[c0]]] : vector<3xf32>, memref<?x?x?x?xf32>
// -----
func @transfer_read_strided(%A : memref<8x4xf32, affine_map<(d0, d1) -> (d0 + d1 * 8)>>) -> vector<4xf32> {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %A[%c0, %c0], %f0
: memref<8x4xf32, affine_map<(d0, d1) -> (d0 + d1 * 8)>>, vector<4xf32>
return %0 : vector<4xf32>
// CHECK: memref.load
func @transfer_write_strided(%A : vector<4xf32>, %B : memref<8x4xf32, affine_map<(d0, d1) -> (d0 + d1 * 8)>>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
vector.transfer_write %A, %B[%c0, %c0] :
vector<4xf32>, memref<8x4xf32, affine_map<(d0, d1) -> (d0 + d1 * 8)>>
return
// -----
func @memtilesize(%arg0: memref<?x?xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
// expected-error@+1 {{'amx.tile_load' op bad column width: 68}}
%1 = amx.tile_load %arg0[%0, %0] : memref<?x?xf32> into vector<16x17xf32>
}
// -----
func @memindexsize(%arg0: memref<?x?xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
// expected-error@+1 {{'amx.tile_load' op requires 2 indices}}
%1 = amx.tile_load %arg0[%0] : memref<?x?xf32> into vector<16x16xf32>
}
// CHECK: amx.tdpbsud
// CHECK: amx.tilestored64
func @muli(%arg0: memref<?x?xi8>, %arg1: memref<?x?xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_zero : vector<16x64xi8>
%2 = amx.tile_load %arg0[%0, %0] : memref<?x?xi8> into vector<16x64xi8>
%3 = amx.tile_load %arg1[%0, %0] : memref<?x?xi32> into vector<16x16xi32>
// CHECK: amx.tdpbf16ps
// CHECK: amx.tilestored64
func @mulf(%arg0: memref<?x?xbf16>, %arg1: memref<?x?xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_zero : vector<16x32xbf16>
%2 = amx.tile_load %arg0[%0, %0] : memref<?x?xbf16> into vector<16x32xbf16>
%3 = amx.tile_load %arg1[%0, %0] : memref<?x?xf32> into vector<16x16xf32>
// CHECK: amx.tile_zero : vector<16x16xbf16>
// CHECK amx.tile_store %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}} : memref<?x?xbf16>, vector<16x16xbf16>
func @tzero(%arg0: memref<?x?xbf16>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_zero : vector<16x16xbf16>
amx.tile_store %arg0[%0, %0], %1 : memref<?x?xbf16>, vector<16x16xbf16>
return
// CHECK: %[[m:.*]] = amx.tile_mulf %[[x]], %[[x]], %[[z]] : vector<16x32xbf16>, vector<16x32xbf16>, vector<16x16xf32>
// CHECK: amx.tile_store %{{.*}}[%{{.*}}, %{{.*}}], %[[m]] : memref<?x?xf32>, vector<16x16xf32>
func @tmulf(%arg0: memref<?x?xbf16>, %arg1: memref<?x?xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<?x?xbf16> into vector<16x32xbf16>
%2 = amx.tile_load %arg1[%0, %0] : memref<?x?xf32> into vector<16x16xf32>
%3 = amx.tile_mulf %1, %1, %2 : vector<16x32xbf16>, vector<16x32xbf16>, vector<16x16xf32>
// CHECK: amx.tile_muli %{{.*}} zext, %{{.*}}, %{{.*}}
// CHECK: amx.tile_muli %{{.*}}, %{{.*}}, %{{.*}}
func @tmuli(%arg0: memref<?x?xi8>, %arg1: memref<?x?xi8>, %arg2: memref<?x?xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<?x?xi8> into vector<16x64xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<?x?xi8> into vector<16x64xi8>
%3 = amx.tile_load %arg2[%0, %0] : memref<?x?xi32> into vector<16x16xi32>
func @uniform_arg(%in : memref<512xf32>, %uniform : f32) {
affine.for %i = 0 to 512 {
%ld = affine.load %in[%i] : memref<512xf32>
- %add = addf %ld, %uniform : f32
+ %add = arith.addf %ld, %uniform : f32
}
return
}
// CHECK-NEXT: %[[bcast:.*]] = vector.broadcast %[[uniform]] : f32 to vector<128xf32>
// CHECK-NEXT: affine.for
-// CHECK: addf %{{.*}}, %[[bcast]] : vector<128xf32>
+// CHECK: arith.addf %{{.*}}, %[[bcast]] : vector<128xf32>
// -----
func @multi_use_uniform_arg(%in : memref<512xf32>, %uniform : f32) {
affine.for %i = 0 to 512 {
%ld = affine.load %in[%i] : memref<512xf32>
- %user0 = addf %ld, %uniform : f32
- %user1 = addf %ld, %uniform : f32
+ %user0 = arith.addf %ld, %uniform : f32
+ %user1 = arith.addf %ld, %uniform : f32
}
return
}
// CHECK-NEXT: %[[bcast:.*]] = vector.broadcast %[[uniform]] : f32 to vector<128xf32>
// CHECK-NOT: vector.broadcast
// CHECK-NEXT: affine.for
-// CHECK: addf %{{.*}}, %[[bcast]] : vector<128xf32>
-// CHECK: addf %{{.*}}, %[[bcast]] : vector<128xf32>
+// CHECK: arith.addf %{{.*}}, %[[bcast]] : vector<128xf32>
+// CHECK: arith.addf %{{.*}}, %[[bcast]] : vector<128xf32>
// -----
// CHECK-LABEL: @uniform_load
func @uniform_load(%A : memref<?x?xf32>, %C : memref<?x?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%N = memref.dim %A, %c0 : memref<?x?xf32>
affine.for %i = 0 to %N {
%uniform_ld = affine.load %A[%i, %i] : memref<?x?xf32>
affine.for %j = 0 to %N {
%b = affine.load %A[%i, %j] : memref<?x?xf32>
- %c = addf %uniform_ld, %b : f32
+ %c = arith.addf %uniform_ld, %b : f32
}
}
return
// CHECK-NEXT: %[[uniform_ld:.*]] = affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECK-NEXT: %[[bcast:.*]] = vector.broadcast %[[uniform_ld]] : f32 to vector<128xf32>
// CHECK-NEXT: affine.for
-// CHECK: addf %[[bcast]], %{{.*}} : vector<128xf32>
+// CHECK: arith.addf %[[bcast]], %{{.*}} : vector<128xf32>
func @vector_add_2d(%arg0: index, %arg1: index) -> f32 {
// Nothing should be matched in this first block.
// CHECK-NOT:matched: {{.*}} = memref.alloc{{.*}}
- // CHECK-NOT:matched: {{.*}} = constant 0{{.*}}
- // CHECK-NOT:matched: {{.*}} = constant 1{{.*}}
+ // CHECK-NOT:matched: {{.*}} = arith.constant 0{{.*}}
+ // CHECK-NOT:matched: {{.*}} = arith.constant 1{{.*}}
%0 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
%1 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
%2 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
- %c0 = constant 0 : index
- %cst = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 1.000000e+00 : f32
- // CHECK:matched: {{.*}} constant dense{{.*}} with shape ratio: 2, 32
- %cst_1 = constant dense<1.000000e+00> : vector<8x256xf32>
- // CHECK:matched: {{.*}} constant dense{{.*}} with shape ratio: 1, 3, 7, 2, 1
- %cst_a = constant dense<1.000000e+00> : vector<1x3x7x8x8xf32>
- // CHECK-NOT:matched: {{.*}} constant dense{{.*}} with shape ratio: 1, 3, 7, 1{{.*}}
- %cst_b = constant dense<1.000000e+00> : vector<1x3x7x4x4xf32>
- // TEST-3x4x5x8:matched: {{.*}} constant dense{{.*}} with shape ratio: 3, 2, 1, 4
- %cst_c = constant dense<1.000000e+00> : vector<3x4x5x8xf32>
- // TEST-3x4x4x8-NOT:matched: {{.*}} constant dense{{.*}} with shape ratio{{.*}}
- %cst_d = constant dense<1.000000e+00> : vector<3x4x4x8xf32>
- // TEST-3x4x4x8:matched: {{.*}} constant dense{{.*}} with shape ratio: 1, 1, 2, 16
- %cst_e = constant dense<1.000000e+00> : vector<1x2x10x32xf32>
+ // CHECK:matched: {{.*}} arith.constant dense{{.*}} with shape ratio: 2, 32
+ %cst_1 = arith.constant dense<1.000000e+00> : vector<8x256xf32>
+ // CHECK:matched: {{.*}} arith.constant dense{{.*}} with shape ratio: 1, 3, 7, 2, 1
+ %cst_a = arith.constant dense<1.000000e+00> : vector<1x3x7x8x8xf32>
+ // CHECK-NOT:matched: {{.*}} arith.constant dense{{.*}} with shape ratio: 1, 3, 7, 1{{.*}}
+ %cst_b = arith.constant dense<1.000000e+00> : vector<1x3x7x4x4xf32>
+ // TEST-3x4x5x8:matched: {{.*}} arith.constant dense{{.*}} with shape ratio: 3, 2, 1, 4
+ %cst_c = arith.constant dense<1.000000e+00> : vector<3x4x5x8xf32>
+ // TEST-3x4x4x8-NOT:matched: {{.*}} arith.constant dense{{.*}} with shape ratio{{.*}}
+ %cst_d = arith.constant dense<1.000000e+00> : vector<3x4x4x8xf32>
+ // TEST-3x4x4x8:matched: {{.*}} arith.constant dense{{.*}} with shape ratio: 1, 1, 2, 16
+ %cst_e = arith.constant dense<1.000000e+00> : vector<1x2x10x32xf32>
// Nothing should be matched in this last block.
- // CHECK-NOT:matched: {{.*}} = constant 7{{.*}}
- // CHECK-NOT:matched: {{.*}} = constant 42{{.*}}
+ // CHECK-NOT:matched: {{.*}} = arith.constant 7{{.*}}
+ // CHECK-NOT:matched: {{.*}} = arith.constant 42{{.*}}
// CHECK-NOT:matched: {{.*}} = memref.load{{.*}}
// CHECK-NOT:matched: return {{.*}}
- %c7 = constant 7 : index
- %c42 = constant 42 : index
+ %c7 = arith.constant 7 : index
+ %c42 = arith.constant 42 : index
%9 = memref.load %2[%c7, %c42] : memref<?x?xf32>
return %9 : f32
}
// CHECK-LABEL: func @vec1d_1
func @vec1d_1(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK: for {{.*}} step 128
// CHECK-NEXT: %{{.*}} = affine.apply #[[$map_id1]](%[[C0]])
// CHECK-NEXT: %{{.*}} = affine.apply #[[$map_id1]](%[[C0]])
-// CHECK-NEXT: %{{.*}} = constant 0.0{{.*}}: f32
+// CHECK-NEXT: %{{.*}} = arith.constant 0.0{{.*}}: f32
// CHECK-NEXT: {{.*}} = vector.transfer_read %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}} {permutation_map = #[[$map_proj_d0d1_0]]} : memref<?x?xf32>, vector<128xf32>
affine.for %i0 = 0 to %M { // vectorized due to scalar -> vector
%a0 = affine.load %A[%c0, %c0] : memref<?x?xf32>
// CHECK-LABEL: func @vec1d_2
func @vec1d_2(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK:for [[IV3:%[a-zA-Z0-9]+]] = 0 to [[ARG_M]] step 128
-// CHECK-NEXT: %[[CST:.*]] = constant 0.0{{.*}}: f32
+// CHECK-NEXT: %[[CST:.*]] = arith.constant 0.0{{.*}}: f32
// CHECK-NEXT: {{.*}} = vector.transfer_read %{{.*}}[%{{.*}}, %{{.*}}], %[[CST]] : memref<?x?xf32>, vector<128xf32>
affine.for %i3 = 0 to %M { // vectorized
%a3 = affine.load %A[%c0, %i3] : memref<?x?xf32>
// CHECK-LABEL: func @vec1d_3
func @vec1d_3(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %arg0, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %arg0, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %arg1, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-NEXT: for [[IV9:%[arg0-9]*]] = 0 to [[ARG_N]] {
// CHECK-NEXT: %[[APP9_0:[0-9]+]] = affine.apply {{.*}}([[IV9]], [[IV8]])
// CHECK-NEXT: %[[APP9_1:[0-9]+]] = affine.apply {{.*}}([[IV9]], [[IV8]])
-// CHECK-NEXT: %[[CST:.*]] = constant 0.0{{.*}}: f32
+// CHECK-NEXT: %[[CST:.*]] = arith.constant 0.0{{.*}}: f32
// CHECK-NEXT: {{.*}} = vector.transfer_read %{{.*}}[%[[APP9_0]], %[[APP9_1]]], %[[CST]] : memref<?x?xf32>, vector<128xf32>
affine.for %i8 = 0 to %M { // vectorized
affine.for %i9 = 0 to %N {
%A = memref.alloc (%M, %N) : memref<?x?xf32, 0>
%B = memref.alloc (%M, %N) : memref<?x?xf32, 0>
%C = memref.alloc (%M, %N) : memref<?x?xf32, 0>
- %f1 = constant 1.0 : f32
- %f2 = constant 2.0 : f32
+ %f1 = arith.constant 1.0 : f32
+ %f2 = arith.constant 2.0 : f32
affine.for %i0 = 0 to %M {
affine.for %i1 = 0 to %N {
- // CHECK: %[[C1:.*]] = constant dense<1.000000e+00> : vector<128xf32>
+ // CHECK: %[[C1:.*]] = arith.constant dense<1.000000e+00> : vector<128xf32>
// CHECK: vector.transfer_write %[[C1]], {{.*}} : vector<128xf32>, memref<?x?xf32>
// non-scoped %f1
affine.store %f1, %A[%i0, %i1] : memref<?x?xf32, 0>
}
affine.for %i2 = 0 to %M {
affine.for %i3 = 0 to %N {
- // CHECK: %[[C3:.*]] = constant dense<2.000000e+00> : vector<128xf32>
+ // CHECK: %[[C3:.*]] = arith.constant dense<2.000000e+00> : vector<128xf32>
// CHECK: vector.transfer_write %[[C3]], {{.*}} : vector<128xf32>, memref<?x?xf32>
// non-scoped %f2
affine.store %f2, %B[%i2, %i3] : memref<?x?xf32, 0>
}
affine.for %i4 = 0 to %M {
affine.for %i5 = 0 to %N {
- // CHECK: %[[SPLAT2:.*]] = constant dense<2.000000e+00> : vector<128xf32>
- // CHECK: %[[SPLAT1:.*]] = constant dense<1.000000e+00> : vector<128xf32>
+ // CHECK: %[[SPLAT2:.*]] = arith.constant dense<2.000000e+00> : vector<128xf32>
+ // CHECK: %[[SPLAT1:.*]] = arith.constant dense<1.000000e+00> : vector<128xf32>
// CHECK: %[[A5:.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{[a-zA-Z0-9_]*}} : memref<?x?xf32>, vector<128xf32>
// CHECK: %[[B5:.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{[a-zA-Z0-9_]*}} : memref<?x?xf32>, vector<128xf32>
- // CHECK: %[[S5:.*]] = addf %[[A5]], %[[B5]] : vector<128xf32>
- // CHECK: %[[S6:.*]] = addf %[[S5]], %[[SPLAT1]] : vector<128xf32>
- // CHECK: %[[S7:.*]] = addf %[[S5]], %[[SPLAT2]] : vector<128xf32>
- // CHECK: %[[S8:.*]] = addf %[[S7]], %[[S6]] : vector<128xf32>
+ // CHECK: %[[S5:.*]] = arith.addf %[[A5]], %[[B5]] : vector<128xf32>
+ // CHECK: %[[S6:.*]] = arith.addf %[[S5]], %[[SPLAT1]] : vector<128xf32>
+ // CHECK: %[[S7:.*]] = arith.addf %[[S5]], %[[SPLAT2]] : vector<128xf32>
+ // CHECK: %[[S8:.*]] = arith.addf %[[S7]], %[[S6]] : vector<128xf32>
// CHECK: vector.transfer_write %[[S8]], {{.*}} : vector<128xf32>, memref<?x?xf32>
%a5 = affine.load %A[%i4, %i5] : memref<?x?xf32, 0>
%b5 = affine.load %B[%i4, %i5] : memref<?x?xf32, 0>
- %s5 = addf %a5, %b5 : f32
+ %s5 = arith.addf %a5, %b5 : f32
// non-scoped %f1
- %s6 = addf %s5, %f1 : f32
+ %s6 = arith.addf %s5, %f1 : f32
// non-scoped %f2
- %s7 = addf %s5, %f2 : f32
+ %s7 = arith.addf %s5, %f2 : f32
// diamond dependency.
- %s8 = addf %s7, %s6 : f32
+ %s8 = arith.addf %s7, %s6 : f32
affine.store %s8, %C[%i4, %i5] : memref<?x?xf32, 0>
}
}
- %c7 = constant 7 : index
- %c42 = constant 42 : index
+ %c7 = arith.constant 7 : index
+ %c42 = arith.constant 42 : index
%res = affine.load %C[%c7, %c42] : memref<?x?xf32, 0>
return %res : f32
}
func @vec_constant_with_two_users(%M : index, %N : index) -> (f32, f32) {
%A = memref.alloc (%M, %N) : memref<?x?xf32, 0>
%B = memref.alloc (%M) : memref<?xf32, 0>
- %f1 = constant 1.0 : f32
+ %f1 = arith.constant 1.0 : f32
affine.for %i0 = 0 to %M { // vectorized
- // CHECK: %[[C1:.*]] = constant dense<1.000000e+00> : vector<128xf32>
+ // CHECK: %[[C1:.*]] = arith.constant dense<1.000000e+00> : vector<128xf32>
// CHECK-NEXT: affine.for
// CHECK-NEXT: vector.transfer_write %[[C1]], {{.*}} : vector<128xf32>, memref<?x?xf32>
affine.for %i1 = 0 to %N {
// CHECK: vector.transfer_write %[[C1]], {{.*}} : vector<128xf32>, memref<?xf32>
affine.store %f1, %B[%i0] : memref<?xf32, 0>
}
- %c12 = constant 12 : index
+ %c12 = arith.constant 12 : index
%res1 = affine.load %A[%c12, %c12] : memref<?x?xf32, 0>
%res2 = affine.load %B[%c12] : memref<?xf32, 0>
return %res1, %res2 : f32, f32
// CHECK: affine.for %[[IV0:[arg0-9]+]] = 0 to 512 step 128 {
// CHECK-NEXT: affine.for %[[IV1:[arg0-9]+]] = 0 to 32 {
// CHECK-NEXT: %[[BROADCAST:.*]] = vector.broadcast %[[IV1]] : index to vector<128xindex>
- // CHECK-NEXT: %[[CAST:.*]] = index_cast %[[BROADCAST]] : vector<128xindex> to vector<128xi32>
+ // CHECK-NEXT: %[[CAST:.*]] = arith.index_cast %[[BROADCAST]] : vector<128xindex> to vector<128xi32>
// CHECK-NEXT: vector.transfer_write %[[CAST]], {{.*}}[%[[IV1]], %[[IV0]]] : vector<128xi32>, memref<32x512xi32>
affine.for %i = 0 to 512 { // vectorized
affine.for %j = 0 to 32 {
- %idx = std.index_cast %j : index to i32
+ %idx = arith.index_cast %j : index to i32
affine.store %idx, %A[%j, %i] : memref<32x512xi32>
}
}
// CHECK-DAG: #[[$map1:map[0-9]+]] = affine_map<(d0, d1, d2) -> (d2)>
// CHECK-LABEL: func @vec_block_arg_2
func @vec_block_arg_2(%A : memref<?x512xindex>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%N = memref.dim %A, %c0 : memref<?x512xindex>
// CHECK: affine.for %[[IV0:[arg0-9]+]] = 0 to %{{.*}} {
// CHECK-NEXT: %[[BROADCAST1:.*]] = vector.broadcast %[[IV0]] : index to vector<128xindex>
// CHECK-NEXT: %[[INDEX1:.*]] = affine.apply #[[$map0]](%[[IV0]], %[[IV2]], %[[IV1]])
// CHECK-NEXT: %[[INDEX2:.*]] = affine.apply #[[$map1]](%[[IV0]], %[[IV2]], %[[IV1]])
// CHECK: %[[LOAD:.*]] = vector.transfer_read %{{.*}}[%[[INDEX1]], %[[INDEX2]]], %{{.*}} : memref<?x512xindex>, vector<128xindex>
- // CHECK-NEXT: muli %[[BROADCAST1]], %[[LOAD]] : vector<128xindex>
- // CHECK-NEXT: addi %{{.*}}, %[[BROADCAST2]] : vector<128xindex>
+ // CHECK-NEXT: arith.muli %[[BROADCAST1]], %[[LOAD]] : vector<128xindex>
+ // CHECK-NEXT: arith.addi %{{.*}}, %[[BROADCAST2]] : vector<128xindex>
// CHECK: }
affine.for %i0 = 0 to %N {
affine.for %i1 = 0 to 512 { // vectorized
affine.for %i2 = 0 to 2 {
%0 = affine.load %A[%i0 * 2 + %i2 - 1, %i1] : memref<?x512xindex>
- %mul = muli %i0, %0 : index
- %add = addi %mul, %i2 : index
+ %mul = arith.muli %i0, %0 : index
+ %add = arith.addi %mul, %i2 : index
}
- }
- }
+ }
+ }
return
}
// CHECK-LABEL: func @vec_rejected_1
func @vec_rejected_1(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_2
func @vec_rejected_2(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_3
func @vec_rejected_3(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK:for [[IV4:%[arg0-9]+]] = 0 to [[ARG_M]] step 128 {
// CHECK-NEXT: for [[IV5:%[arg0-9]*]] = 0 to [[ARG_N]] {
-// CHECK-NEXT: %{{.*}} = constant 0.0{{.*}}: f32
+// CHECK-NEXT: %{{.*}} = arith.constant 0.0{{.*}}: f32
// CHECK-NEXT: {{.*}} = vector.transfer_read %{{.*}}[%{{.*}}, %{{.*}}], %{{[a-zA-Z0-9_]*}} : memref<?x?xf32>, vector<128xf32>
affine.for %i4 = 0 to %M { // vectorized
affine.for %i5 = 0 to %N { // not vectorized, would vectorize with --test-fastest-varying=1
// CHECK-LABEL: func @vec_rejected_4
func @vec_rejected_4(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_5
func @vec_rejected_5(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_6
func @vec_rejected_6(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_7
func @vec_rejected_7(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_8
func @vec_rejected_8(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK: for [[IV18:%[a-zA-Z0-9]+]] = 0 to [[ARG_M]] step 128
// CHECK: %{{.*}} = affine.apply #[[$map_id1]](%{{.*}})
// CHECK: %{{.*}} = affine.apply #[[$map_id1]](%{{.*}})
-// CHECK: %{{.*}} = constant 0.0{{.*}}: f32
+// CHECK: %{{.*}} = arith.constant 0.0{{.*}}: f32
// CHECK: {{.*}} = vector.transfer_read %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}} {permutation_map = #[[$map_proj_d0d1_0]]} : memref<?x?xf32>, vector<128xf32>
affine.for %i17 = 0 to %M { // not vectorized, the 1-D pattern that matched %{{.*}} in DFS post-order prevents vectorizing %{{.*}}
affine.for %i18 = 0 to %M { // vectorized due to scalar -> vector
// CHECK-LABEL: func @vec_rejected_9
func @vec_rejected_9(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK: for [[IV18:%[a-zA-Z0-9]+]] = 0 to [[ARG_M]] step 128
// CHECK: %{{.*}} = affine.apply #[[$map_id1]](%{{.*}})
// CHECK-NEXT: %{{.*}} = affine.apply #[[$map_id1]](%{{.*}})
-// CHECK-NEXT: %{{.*}} = constant 0.0{{.*}}: f32
+// CHECK-NEXT: %{{.*}} = arith.constant 0.0{{.*}}: f32
// CHECK-NEXT: {{.*}} = vector.transfer_read %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}} {permutation_map = #[[$map_proj_d0d1_0]]} : memref<?x?xf32>, vector<128xf32>
affine.for %i17 = 0 to %M { // not vectorized, the 1-D pattern that matched %i18 in DFS post-order prevents vectorizing %{{.*}}
affine.for %i18 = 0 to %M { // vectorized due to scalar -> vector
// CHECK-LABEL: func @vec_rejected_10
func @vec_rejected_10(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// CHECK-LABEL: func @vec_rejected_11
func @vec_rejected_11(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C2:.*]] = constant 2 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: [[ARG_M:%[0-9]+]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_N:%[0-9]+]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// CHECK-DAG: [[ARG_P:%[0-9]+]] = memref.dim %{{.*}}, %[[C2]] : memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?xf32>
%P = memref.dim %B, %c2 : memref<?x?x?xf32>
// This should not vectorize due to the sequential dependence in the loop.
// CHECK-LABEL: @vec_rejected_sequential
func @vec_rejected_sequential(%A : memref<?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%N = memref.dim %A, %c0 : memref<?xf32>
affine.for %i = 0 to %N {
// CHECK-NOT: vector
// CHECK-LABEL: @vec_no_load_store_ops
func @vec_no_load_store_ops(%a: f32, %b: f32) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 128 {
- %add = addf %a, %b : f32
+ %add = arith.addf %a, %b : f32
}
// CHECK-DAG: %[[bc1:.*]] = vector.broadcast
// CHECK-DAG: %[[bc0:.*]] = vector.broadcast
// CHECK: affine.for %{{.*}} = 0 to 128 step
- // CHECK-NEXT: [[add:.*]] addf %[[bc0]], %[[bc1]]
+ // CHECK-NEXT: [[add:.*]] arith.addf %[[bc0]], %[[bc1]]
return
}
func @vec_rejected_unsupported_block_arg(%A : memref<512xi32>) {
affine.for %i = 0 to 512 {
// CHECK-NOT: vector
- %idx = std.index_cast %i : index to i32
+ %idx = arith.index_cast %i : index to i32
affine.store %idx, %A[%i] : memref<512xi32>
}
return
// '%i' loop is vectorized, including the inner reduction over '%j'.
func @vec_non_vecdim_reduction(%in: memref<128x256xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 128 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%j, %i] : memref<128x256xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK-LABEL: @vec_non_vecdim_reduction
// CHECK: affine.for %{{.*}} = 0 to 256 step 128 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[final_red:.*]] = affine.for %{{.*}} = 0 to 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<128x256xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: affine.yield %[[add]] : vector<128xf32>
// CHECK: }
// CHECK: vector.transfer_write %[[final_red]], %{{.*}} : vector<128xf32>, memref<256xf32>
func @vec_non_vecdim_reductions(%in0: memref<128x256xf32>, %in1: memref<128x256xi32>,
%out0: memref<256xf32>, %out1: memref<256xi32>) {
- %zero = constant 0.000000e+00 : f32
- %one = constant 1 : i32
+ %zero = arith.constant 0.000000e+00 : f32
+ %one = arith.constant 1 : i32
affine.for %i = 0 to 256 {
%red0, %red1 = affine.for %j = 0 to 128
iter_args(%red_iter0 = %zero, %red_iter1 = %one) -> (f32, i32) {
%ld0 = affine.load %in0[%j, %i] : memref<128x256xf32>
- %add = addf %red_iter0, %ld0 : f32
+ %add = arith.addf %red_iter0, %ld0 : f32
%ld1 = affine.load %in1[%j, %i] : memref<128x256xi32>
- %mul = muli %red_iter1, %ld1 : i32
+ %mul = arith.muli %red_iter1, %ld1 : i32
affine.yield %add, %mul : f32, i32
}
affine.store %red0, %out0[%i] : memref<256xf32>
// CHECK-LABEL: @vec_non_vecdim_reductions
// CHECK: affine.for %{{.*}} = 0 to 256 step 128 {
-// CHECK: %[[vone:.*]] = constant dense<1> : vector<128xi32>
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vone:.*]] = arith.constant dense<1> : vector<128xi32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[reds:.*]]:2 = affine.for %{{.*}} = 0 to 128
// CHECK-SAME: iter_args(%[[red_iter0:.*]] = %[[vzero]], %[[red_iter1:.*]] = %[[vone]]) -> (vector<128xf32>, vector<128xi32>) {
// CHECK: %[[ld0:.*]] = vector.transfer_read %{{.*}} : memref<128x256xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter0]], %[[ld0]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter0]], %[[ld0]] : vector<128xf32>
// CHECK: %[[ld1:.*]] = vector.transfer_read %{{.*}} : memref<128x256xi32>, vector<128xi32>
-// CHECK: %[[mul:.*]] = muli %[[red_iter1]], %[[ld1]] : vector<128xi32>
+// CHECK: %[[mul:.*]] = arith.muli %[[red_iter1]], %[[ld1]] : vector<128xi32>
// CHECK: affine.yield %[[add]], %[[mul]] : vector<128xf32>, vector<128xi32>
// CHECK: }
// CHECK: vector.transfer_write %[[reds]]#0, %{{.*}} : vector<128xf32>, memref<256xf32>
// '%i' loop is vectorized, including the inner last value computation over '%j'.
func @vec_no_vecdim_last_value(%in: memref<128x256xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%last_val = affine.for %j = 0 to 128 iter_args(%last_iter = %cst) -> (f32) {
%ld = affine.load %in[%j, %i] : memref<128x256xf32>
// CHECK-LABEL: @vec_no_vecdim_last_value
// CHECK: affine.for %{{.*}} = 0 to 256 step 128 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[last_val:.*]] = affine.for %{{.*}} = 0 to 128 iter_args(%[[last_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<128x256xf32>, vector<128xf32>
// CHECK: affine.yield %[[ld]] : vector<128xf32>
// reduction vectorization.
func @vec_vecdim_reduction_rejected(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// VECT-DAG: #[[$map_proj_d0d1_d0zero:map[0-9]+]] = affine_map<(d0, d1) -> (d0, 0)>
func @vec2d(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?x?xf32>
%P = memref.dim %A, %c2 : memref<?x?x?xf32>
%A = memref.alloc (%M, %N) : memref<?x?xf32, 0>
%B = memref.alloc (%M, %N) : memref<?x?xf32, 0>
%C = memref.alloc (%M, %N) : memref<?x?xf32, 0>
- %f1 = constant 1.0 : f32
- %f2 = constant 2.0 : f32
+ %f1 = arith.constant 1.0 : f32
+ %f2 = arith.constant 2.0 : f32
affine.for %i0 = 0 to %M {
affine.for %i1 = 0 to %N {
- // CHECK: [[C1:%.*]] = constant dense<1.000000e+00> : vector<32x256xf32>
+ // CHECK: [[C1:%.*]] = arith.constant dense<1.000000e+00> : vector<32x256xf32>
// CHECK: vector.transfer_write [[C1]], {{.*}} : vector<32x256xf32>, memref<?x?xf32>
// non-scoped %f1
affine.store %f1, %A[%i0, %i1] : memref<?x?xf32, 0>
}
affine.for %i2 = 0 to %M {
affine.for %i3 = 0 to %N {
- // CHECK: [[C3:%.*]] = constant dense<2.000000e+00> : vector<32x256xf32>
+ // CHECK: [[C3:%.*]] = arith.constant dense<2.000000e+00> : vector<32x256xf32>
// CHECK: vector.transfer_write [[C3]], {{.*}} : vector<32x256xf32>, memref<?x?xf32>
// non-scoped %f2
affine.store %f2, %B[%i2, %i3] : memref<?x?xf32, 0>
}
affine.for %i4 = 0 to %M {
affine.for %i5 = 0 to %N {
- // CHECK: [[SPLAT2:%.*]] = constant dense<2.000000e+00> : vector<32x256xf32>
- // CHECK: [[SPLAT1:%.*]] = constant dense<1.000000e+00> : vector<32x256xf32>
+ // CHECK: [[SPLAT2:%.*]] = arith.constant dense<2.000000e+00> : vector<32x256xf32>
+ // CHECK: [[SPLAT1:%.*]] = arith.constant dense<1.000000e+00> : vector<32x256xf32>
// CHECK: [[A5:%.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{.*}} : memref<?x?xf32>, vector<32x256xf32>
// CHECK: [[B5:%.*]] = vector.transfer_read %{{.*}}[{{.*}}], %{{.*}} : memref<?x?xf32>, vector<32x256xf32>
- // CHECK: [[S5:%.*]] = addf [[A5]], [[B5]] : vector<32x256xf32>
- // CHECK: [[S6:%.*]] = addf [[S5]], [[SPLAT1]] : vector<32x256xf32>
- // CHECK: [[S7:%.*]] = addf [[S5]], [[SPLAT2]] : vector<32x256xf32>
- // CHECK: [[S8:%.*]] = addf [[S7]], [[S6]] : vector<32x256xf32>
+ // CHECK: [[S5:%.*]] = arith.addf [[A5]], [[B5]] : vector<32x256xf32>
+ // CHECK: [[S6:%.*]] = arith.addf [[S5]], [[SPLAT1]] : vector<32x256xf32>
+ // CHECK: [[S7:%.*]] = arith.addf [[S5]], [[SPLAT2]] : vector<32x256xf32>
+ // CHECK: [[S8:%.*]] = arith.addf [[S7]], [[S6]] : vector<32x256xf32>
// CHECK: vector.transfer_write [[S8]], {{.*}} : vector<32x256xf32>, memref<?x?xf32>
//
%a5 = affine.load %A[%i4, %i5] : memref<?x?xf32, 0>
%b5 = affine.load %B[%i4, %i5] : memref<?x?xf32, 0>
- %s5 = addf %a5, %b5 : f32
+ %s5 = arith.addf %a5, %b5 : f32
// non-scoped %f1
- %s6 = addf %s5, %f1 : f32
+ %s6 = arith.addf %s5, %f1 : f32
// non-scoped %f2
- %s7 = addf %s5, %f2 : f32
+ %s7 = arith.addf %s5, %f2 : f32
// diamond dependency.
- %s8 = addf %s7, %s6 : f32
+ %s8 = arith.addf %s7, %s6 : f32
affine.store %s8, %C[%i4, %i5] : memref<?x?xf32, 0>
}
}
- %c7 = constant 7 : index
- %c42 = constant 42 : index
+ %c7 = arith.constant 7 : index
+ %c42 = arith.constant 42 : index
%res = affine.load %C[%c7, %c42] : memref<?x?xf32, 0>
return %res : f32
}
// VECT-LABEL: func @vectorize_matmul
func @vectorize_matmul(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%M = memref.dim %arg0, %c0 : memref<?x?xf32>
%K = memref.dim %arg0, %c1 : memref<?x?xf32>
%N = memref.dim %arg2, %c1 : memref<?x?xf32>
- // VECT: %[[C0:.*]] = constant 0 : index
- // VECT-NEXT: %[[C1:.*]] = constant 1 : index
+ // VECT: %[[C0:.*]] = arith.constant 0 : index
+ // VECT-NEXT: %[[C1:.*]] = arith.constant 1 : index
// VECT-NEXT: %[[M:.*]] = memref.dim %{{.*}}, %[[C0]] : memref<?x?xf32>
// VECT-NEXT: %[[K:.*]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// VECT-NEXT: %[[N:.*]] = memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32>
// VECT: {{.*}} #[[$map_id1]](%[[M]]) step 4 {
// VECT-NEXT: {{.*}} #[[$map_id1]](%[[N]]) step 8 {
- // VECT: %[[VC0:.*]] = constant dense<0.000000e+00> : vector<4x8xf32>
+ // VECT: %[[VC0:.*]] = arith.constant dense<0.000000e+00> : vector<4x8xf32>
// VECT-NEXT: vector.transfer_write %[[VC0]], %{{.*}}[%{{.*}}, %{{.*}}] : vector<4x8xf32>, memref<?x?xf32>
affine.for %i0 = affine_map<(d0) -> (d0)>(%c0) to affine_map<(d0) -> (d0)>(%M) {
affine.for %i1 = affine_map<(d0) -> (d0)>(%c0) to affine_map<(d0) -> (d0)>(%N) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.store %cst, %arg2[%i0, %i1] : memref<?x?xf32>
}
}
// VECT-NEXT: affine.for %[[I4:.*]] = #[[$map_id1]](%[[C0]]) to #[[$map_id1]](%[[K]]) {
// VECT: %[[A:.*]] = vector.transfer_read %{{.*}}[%[[I4]], %[[I3]]], %{{.*}} {permutation_map = #[[$map_proj_d0d1_zerod1]]} : memref<?x?xf32>, vector<4x8xf32>
// VECT: %[[B:.*]] = vector.transfer_read %{{.*}}[%[[I2]], %[[I4]]], %{{.*}} {permutation_map = #[[$map_proj_d0d1_d0zero]]} : memref<?x?xf32>, vector<4x8xf32>
- // VECT-NEXT: %[[C:.*]] = mulf %[[B]], %[[A]] : vector<4x8xf32>
+ // VECT-NEXT: %[[C:.*]] = arith.mulf %[[B]], %[[A]] : vector<4x8xf32>
// VECT: %[[D:.*]] = vector.transfer_read %{{.*}}[%[[I2]], %[[I3]]], %{{.*}} : memref<?x?xf32>, vector<4x8xf32>
- // VECT-NEXT: %[[E:.*]] = addf %[[D]], %[[C]] : vector<4x8xf32>
+ // VECT-NEXT: %[[E:.*]] = arith.addf %[[D]], %[[C]] : vector<4x8xf32>
// VECT: vector.transfer_write %[[E]], %{{.*}}[%[[I2]], %[[I3]]] : vector<4x8xf32>, memref<?x?xf32>
affine.for %i2 = affine_map<(d0) -> (d0)>(%c0) to affine_map<(d0) -> (d0)>(%M) {
affine.for %i3 = affine_map<(d0) -> (d0)>(%c0) to affine_map<(d0) -> (d0)>(%N) {
affine.for %i4 = affine_map<(d0) -> (d0)>(%c0) to affine_map<(d0) -> (d0)>(%K) {
%6 = affine.load %arg1[%i4, %i3] : memref<?x?xf32>
%7 = affine.load %arg0[%i2, %i4] : memref<?x?xf32>
- %8 = mulf %7, %6 : f32
+ %8 = arith.mulf %7, %6 : f32
%9 = affine.load %arg2[%i2, %i3] : memref<?x?xf32>
- %10 = addf %9, %8 : f32
+ %10 = arith.addf %9, %8 : f32
affine.store %10, %arg2[%i2, %i3] : memref<?x?xf32>
}
}
// RUN: mlir-opt %s -affine-super-vectorize="virtual-vector-size=32,64,256 test-fastest-varying=2,1,0" | FileCheck %s
func @vec3d(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %A, %c0 : memref<?x?x?xf32>
%1 = memref.dim %A, %c1 : memref<?x?x?xf32>
%2 = memref.dim %A, %c2 : memref<?x?x?xf32>
// CHECK: #[[map_proj_d0d1d2_d0d2:map[0-9]*]] = affine_map<(d0, d1, d2) -> (d0, d2)>
func @vec2d(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?x?xf32>
%P = memref.dim %A, %c2 : memref<?x?x?xf32>
// CHECK: #[[map_proj_d0d1d2_d2d0:map[0-9]*]] = affine_map<(d0, d1, d2) -> (d2, d0)>
func @vec2d(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?x?xf32>
%P = memref.dim %A, %c2 : memref<?x?x?xf32>
}
func @vec2d_imperfectly_nested(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %A, %c0 : memref<?x?x?xf32>
%1 = memref.dim %A, %c1 : memref<?x?x?xf32>
%2 = memref.dim %A, %c2 : memref<?x?x?xf32>
// The inner reduction loop '%j' is vectorized.
func @vecdim_reduction(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK-LABEL: @vecdim_reduction
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]] = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: affine.yield %[[add]] : vector<128xf32>
// CHECK: }
// CHECK: %[[final_sum:.*]] = vector.reduction "add", %[[vred:.*]] : vector<128xf32> into f32
// different than in the previous test case).
func @vecdim_reduction_comm(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %ld, %red_iter : f32
+ %add = arith.addf %ld, %red_iter : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK-LABEL: @vecdim_reduction_comm
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]] = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[ld]], %[[red_iter]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[ld]], %[[red_iter]] : vector<128xf32>
// CHECK: affine.yield %[[add]] : vector<128xf32>
// CHECK: }
// CHECK: %[[final_sum:.*]] = vector.reduction "add", %[[vred:.*]] : vector<128xf32> into f32
// performing the accumulation doesn't cause any problem.
func @vecdim_reduction_expsin(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
%sin = math.sin %ld : f32
%exp = math.exp %sin : f32
- %add = addf %red_iter, %exp : f32
+ %add = arith.addf %red_iter, %exp : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK-LABEL: @vecdim_reduction_expsin
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]] = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
// CHECK: %[[sin:.*]] = math.sin %[[ld]]
// CHECK: %[[exp:.*]] = math.exp %[[sin]]
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[exp]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[exp]] : vector<128xf32>
// CHECK: affine.yield %[[add]] : vector<128xf32>
// CHECK: }
// CHECK: %[[final_sum:.*]] = vector.reduction "add", %[[vred:.*]] : vector<128xf32> into f32
// Two reductions at the same time. The inner reduction loop '%j' is vectorized.
func @two_vecdim_reductions(%in: memref<256x512xf32>, %out_sum: memref<256xf32>, %out_prod: memref<256xf32>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
affine.for %i = 0 to 256 {
// Note that we pass the same constant '1.0' as initial values for both
// reductions.
%sum, %prod = affine.for %j = 0 to 512 iter_args(%part_sum = %cst, %part_prod = %cst) -> (f32, f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %part_sum, %ld : f32
- %mul = mulf %part_prod, %ld : f32
+ %add = arith.addf %part_sum, %ld : f32
+ %mul = arith.mulf %part_prod, %ld : f32
affine.yield %add, %mul : f32, f32
}
affine.store %sum, %out_sum[%i] : memref<256xf32>
}
// CHECK-LABEL: @two_vecdim_reductions
-// CHECK: %[[cst:.*]] = constant 1.000000e+00 : f32
+// CHECK: %[[cst:.*]] = arith.constant 1.000000e+00 : f32
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
-// CHECK: %[[vone:.*]] = constant dense<1.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vone:.*]] = arith.constant dense<1.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]]:2 = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[part_sum:.*]] = %[[vzero]], %[[part_prod:.*]] = %[[vone]]) -> (vector<128xf32>, vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[part_sum]], %[[ld]] : vector<128xf32>
-// CHECK: %[[mul:.*]] = mulf %[[part_prod]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[part_sum]], %[[ld]] : vector<128xf32>
+// CHECK: %[[mul:.*]] = arith.mulf %[[part_prod]], %[[ld]] : vector<128xf32>
// CHECK: affine.yield %[[add]], %[[mul]] : vector<128xf32>, vector<128xf32>
// CHECK: }
// CHECK: %[[nonfinal_sum:.*]] = vector.reduction "add", %[[vred:.*]]#0 : vector<128xf32> into f32
// Note that to compute the final sum we need to add the original initial value
// (%cst) since it is not zero.
-// CHECK: %[[final_sum:.*]] = addf %[[nonfinal_sum]], %[[cst]] : f32
+// CHECK: %[[final_sum:.*]] = arith.addf %[[nonfinal_sum]], %[[cst]] : f32
// For the final product we don't need to do this additional step because the
// initial value equals to 1 (the neutral element for multiplication).
// CHECK: %[[final_prod:.*]] = vector.reduction "mul", %[[vred:.*]]#1 : vector<128xf32> into f32
// The integer case.
func @two_vecdim_reductions_int(%in: memref<256x512xi64>, %out_sum: memref<256xi64>, %out_prod: memref<256xi64>) {
- %cst0 = constant 0 : i64
- %cst1 = constant 1 : i64
+ %cst0 = arith.constant 0 : i64
+ %cst1 = arith.constant 1 : i64
affine.for %i = 0 to 256 {
%sum, %prod = affine.for %j = 0 to 512 iter_args(%part_sum = %cst0, %part_prod = %cst1) -> (i64, i64) {
%ld = affine.load %in[%i, %j] : memref<256x512xi64>
- %add = addi %part_sum, %ld : i64
- %mul = muli %part_prod, %ld : i64
+ %add = arith.addi %part_sum, %ld : i64
+ %mul = arith.muli %part_prod, %ld : i64
affine.yield %add, %mul : i64, i64
}
affine.store %sum, %out_sum[%i] : memref<256xi64>
// CHECK-LABEL: @two_vecdim_reductions
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0> : vector<128xi64>
-// CHECK: %[[vone:.*]] = constant dense<1> : vector<128xi64>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0> : vector<128xi64>
+// CHECK: %[[vone:.*]] = arith.constant dense<1> : vector<128xi64>
// CHECK: %[[vred:.*]]:2 = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[part_sum:.*]] = %[[vzero]], %[[part_prod:.*]] = %[[vone]]) -> (vector<128xi64>, vector<128xi64>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xi64>, vector<128xi64>
-// CHECK: %[[add:.*]] = addi %[[part_sum]], %[[ld]] : vector<128xi64>
-// CHECK: %[[mul:.*]] = muli %[[part_prod]], %[[ld]] : vector<128xi64>
+// CHECK: %[[add:.*]] = arith.addi %[[part_sum]], %[[ld]] : vector<128xi64>
+// CHECK: %[[mul:.*]] = arith.muli %[[part_prod]], %[[ld]] : vector<128xi64>
// CHECK: affine.yield %[[add]], %[[mul]] : vector<128xi64>, vector<128xi64>
// CHECK: }
// CHECK: %[[final_sum:.*]] = vector.reduction "add", %[[vred:.*]]#0 : vector<128xi64> into i64
// The outer reduction loop '%j' is vectorized.
func @vecdim_reduction_nested(%in: memref<256x512xf32>, %out: memref<1xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%outer_red = affine.for %j = 0 to 512 iter_args(%outer_iter = %cst) -> (f32) {
%inner_red = affine.for %i = 0 to 256 iter_args(%inner_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %inner_iter, %ld : f32
+ %add = arith.addf %inner_iter, %ld : f32
affine.yield %add : f32
}
- %outer_add = addf %outer_iter, %inner_red : f32
+ %outer_add = arith.addf %outer_iter, %inner_red : f32
affine.yield %outer_add : f32
}
affine.store %outer_red, %out[0] : memref<1xf32>
}
// CHECK-LABEL: @vecdim_reduction_nested
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[outer_red:.*]] = affine.for %{{.*}} = 0 to 512 step 128 iter_args(%[[outer_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[inner_red:.*]] = affine.for %{{.*}} = 0 to 256 iter_args(%[[inner_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[inner_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[inner_iter]], %[[ld]] : vector<128xf32>
// CHECK: affine.yield %[[add]] : vector<128xf32>
// CHECK: }
-// CHECK: %[[outer_add:.*]] = addf %[[outer_iter]], %[[inner_red]] : vector<128xf32>
+// CHECK: %[[outer_add:.*]] = arith.addf %[[outer_iter]], %[[inner_red]] : vector<128xf32>
// CHECK: affine.yield %[[outer_add]] : vector<128xf32>
// CHECK: }
// CHECK: %[[final_sum:.*]] = vector.reduction "add", %[[outer_red:.*]] : vector<128xf32> into f32
// is not vectorized.
func @vecdim_partial_sums_1_rejected(%in: memref<256x512xf32>, %out_sum: memref<256xf32>, %out_prod: memref<256xf32>, %out_partsum: memref<256x512xf32>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
affine.for %i = 0 to 256 {
%sum, %prod = affine.for %j = 0 to 512 iter_args(%part_sum = %cst, %part_prod = %cst) -> (f32, f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %part_sum, %ld : f32
- %mul = mulf %part_prod, %ld : f32
+ %add = arith.addf %part_sum, %ld : f32
+ %mul = arith.mulf %part_prod, %ld : f32
affine.store %add, %out_partsum[%i, %j] : memref<256x512xf32>
affine.yield %add, %mul : f32, f32
}
// is not vectorized.
func @vecdim_partial_sums_2_rejected(%in: memref<256x512xf32>, %out_sum: memref<256xf32>, %out_prod: memref<256xf32>, %out_partsum: memref<256x512xf32>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
affine.for %i = 0 to 256 {
%sum, %prod = affine.for %j = 0 to 512 iter_args(%part_sum = %cst, %part_prod = %cst) -> (f32, f32) {
affine.store %part_sum, %out_partsum[%i, %j] : memref<256x512xf32>
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %part_sum, %ld : f32
- %mul = mulf %part_prod, %ld : f32
+ %add = arith.addf %part_sum, %ld : f32
+ %mul = arith.mulf %part_prod, %ld : f32
affine.yield %add, %mul : f32, f32
}
affine.store %sum, %out_sum[%i] : memref<256xf32>
// not vectorized.
func @vecdim_unknown_reduction_rejected(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
- %add = addf %red_iter, %red_iter : f32
+ %add = arith.addf %red_iter, %red_iter : f32
affine.yield %add : f32
}
affine.store %final_red, %out[0] : memref<256xf32>
// recognized as a standard reduction.
func @vecdim_none_reduction_rejected(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
%final_red = affine.for %j = 0 to 512 iter_args(%red_iter = %cst) -> (f32) {
affine.yield %red_iter : f32
}
// to be applied to the last update of the accumulator.
func @vecdim_reduction_masked(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to 500 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK: #[[$map0:.*]] = affine_map<([[d0:.*]]) -> (-[[d0]] + 500)>
// CHECK-LABEL: @vecdim_reduction_masked
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]] = affine.for %[[iv:.*]] = 0 to 500 step 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[elems_left:.*]] = affine.apply #[[$map0]](%[[iv]])
// CHECK: %[[mask:.*]] = vector.create_mask %[[elems_left]] : vector<128xi1>
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: %[[new_acc:.*]] = select %[[mask]], %[[add]], %[[red_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: affine.yield %[[new_acc]] : vector<128xf32>
// CHECK: }
// The number of iteration is not known, so a mask has to be applied.
func @vecdim_reduction_masked_unknown_ub(%in: memref<256x512xf32>, %out: memref<256xf32>, %bnd: index) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to %bnd iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK: #[[$map1:.*]] = affine_map<([[d0:.*]]){{\[}}[[s0:.*]]{{\]}} -> (-[[d0]] + [[s0]])>
// CHECK-LABEL: @vecdim_reduction_masked_unknown_ub
// CHECK: affine.for %{{.*}} = 0 to 256 {
-// CHECK: %[[vzero:.*]] = constant dense<0.000000e+00> : vector<128xf32>
+// CHECK: %[[vzero:.*]] = arith.constant dense<0.000000e+00> : vector<128xf32>
// CHECK: %[[vred:.*]] = affine.for %[[iv:.*]] = 0 to %[[bnd:.*]] step 128 iter_args(%[[red_iter:.*]] = %[[vzero]]) -> (vector<128xf32>) {
// CHECK: %[[elems_left:.*]] = affine.apply #[[$map1]](%[[iv]])[%[[bnd]]]
// CHECK: %[[mask:.*]] = vector.create_mask %[[elems_left]] : vector<128xi1>
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: %[[new_acc:.*]] = select %[[mask]], %[[add]], %[[red_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: affine.yield %[[new_acc]] : vector<128xf32>
// CHECK: }
// vector size, so masking is not needed.
func @vecdim_reduction_nonzero_lb(%in: memref<256x512xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 127 to 511 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// The lower bound is unknown, so we need to create a mask.
func @vecdim_reduction_masked_unknown_lb(%in: memref<256x512xf32>, %out: memref<256xf32>, %lb: index) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = %lb to 512 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK: %[[elems_left:.*]] = affine.apply #[[$map2]](%[[iv]])
// CHECK: %[[mask:.*]] = vector.create_mask %[[elems_left]] : vector<128xi1>
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: %[[new_acc:.*]] = select %[[mask]], %[[add]], %[[red_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: affine.yield %[[new_acc]] : vector<128xf32>
// The upper bound is a minimum expression.
func @vecdim_reduction_complex_ub(%in: memref<256x512xf32>, %out: memref<256xf32>, %M: index, %N: index) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_red = affine.for %j = 0 to min affine_map<(d0, d1) -> (d0, d1*2)>(%M, %N) iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
affine.store %final_red, %out[%i] : memref<256xf32>
// CHECK: %[[elems_left:.*]] = affine.apply #[[$map3_sub]](%[[ub]], %[[iv]])
// CHECK: %[[mask:.*]] = vector.create_mask %[[elems_left]] : vector<128xi1>
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[red_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[red_iter]], %[[ld]] : vector<128xf32>
// CHECK: %[[new_acc:.*]] = select %[[mask]], %[[add]], %[[red_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: affine.yield %[[new_acc]] : vector<128xf32>
// The same mask is applied to both reductions.
func @vecdim_two_reductions_masked(%in: memref<256x512xf32>, %out: memref<512xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%final_sum, %final_expsum = affine.for %j = 0 to 500 iter_args(%sum_iter = %cst, %expsum_iter = %cst) -> (f32, f32) {
%ld = affine.load %in[%i, %j] : memref<256x512xf32>
%exp = math.exp %ld : f32
- %add = addf %sum_iter, %ld : f32
- %eadd = addf %expsum_iter, %exp : f32
+ %add = arith.addf %sum_iter, %ld : f32
+ %eadd = arith.addf %expsum_iter, %exp : f32
affine.yield %add, %eadd : f32, f32
}
affine.store %final_sum, %out[2*%i] : memref<512xf32>
// CHECK: %[[mask:.*]] = vector.create_mask %[[elems_left]] : vector<128xi1>
// CHECK: %[[ld:.*]] = vector.transfer_read %{{.*}} : memref<256x512xf32>, vector<128xf32>
// CHECK: %[[exp:.*]] = math.exp %[[ld]] : vector<128xf32>
-// CHECK: %[[add:.*]] = addf %[[sum_iter]], %[[ld]] : vector<128xf32>
-// CHECK: %[[eadd:.*]] = addf %[[esum_iter]], %[[exp]] : vector<128xf32>
+// CHECK: %[[add:.*]] = arith.addf %[[sum_iter]], %[[ld]] : vector<128xf32>
+// CHECK: %[[eadd:.*]] = arith.addf %[[esum_iter]], %[[exp]] : vector<128xf32>
// CHECK: %[[new_acc:.*]] = select %[[mask]], %[[add]], %[[sum_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: %[[new_eacc:.*]] = select %[[mask]], %[[eadd]], %[[esum_iter]] : vector<128xi1>, vector<128xf32>
// CHECK: affine.yield %[[new_acc]], %[[new_eacc]] : vector<128xf32>
// expected-error@+1 {{Vectorizing reductions is supported only for 1-D vectors}}
func @vecdim_reduction_2d(%in: memref<256x512x1024xf32>, %out: memref<256xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i = 0 to 256 {
%sum_j = affine.for %j = 0 to 512 iter_args(%red_iter_j = %cst) -> (f32) {
%sum_k = affine.for %k = 0 to 1024 iter_args(%red_iter_k = %cst) -> (f32) {
%ld = affine.load %in[%i, %j, %k] : memref<256x512x1024xf32>
- %add = addf %red_iter_k, %ld : f32
+ %add = arith.addf %red_iter_k, %ld : f32
affine.yield %add : f32
}
- %add = addf %red_iter_j, %sum_k : f32
+ %add = arith.addf %red_iter_j, %sum_k : f32
affine.yield %add : f32
}
affine.store %sum_j, %out[%i] : memref<256xf32>
// CHECK-DAG: #[[map_proj_d0d1d2_d2d1:map[0-9]*]] = affine_map<(d0, d1, d2) -> (d2, d1)>
func @vec2d(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %A, %c0 : memref<?x?x?xf32>
%N = memref.dim %A, %c1 : memref<?x?x?xf32>
%P = memref.dim %A, %c2 : memref<?x?x?xf32>
}
func @vec2d_imperfectly_nested(%A : memref<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %A, %c0 : memref<?x?x?xf32>
%1 = memref.dim %A, %c1 : memref<?x?x?xf32>
%2 = memref.dim %A, %c2 : memref<?x?x?xf32>
%5 = affine.load %A[%ii, %kk] : memref<4096x4096xf32>
%6 = affine.load %B[%kk, %jj] : memref<4096x4096xf32>
%7 = affine.load %C[%ii, %jj] : memref<4096x4096xf32>
- %8 = mulf %5, %6 : f32
- %9 = addf %7, %8 : f32
+ %8 = arith.mulf %5, %6 : f32
+ %9 = arith.addf %7, %8 : f32
affine.store %9, %C[%ii, %jj] : memref<4096x4096xf32>
}
}
// CHECK: affine.load [[BUFA]][-%{{.*}} + %{{.*}}, -%{{.*}} + %{{.*}}] : memref<128x128xf32>
// CHECK: affine.load [[BUFB]][-%{{.*}} + %{{.*}}, -%{{.*}} + %{{.*}}] : memref<128x128xf32>
// CHECK: affine.load [[BUFC]][-%{{.*}} + %{{.*}}, -%{{.*}} + %{{.*}}] : memref<128x128xf32>
-// CHECK: mulf %{{.*}}, %{{.*}} : f32
-// CHECK: addf %{{.*}}, %{{.*}} : f32
+// CHECK: arith.mulf %{{.*}}, %{{.*}} : f32
+// CHECK: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK: affine.store %{{.*}}, [[BUFC]][-%{{.*}} + %{{.*}}, -%{{.*}} + %{{.*}}] : memref<128x128xf32>
// CHECK: }
// CHECK: }
affine.for %k = 0 to 1024 {
%6 = affine.load %arg1[%k, %j] : memref<1024x1024xf32>
%7 = affine.load %arg2[%i, %j] : memref<1024x1024xf32>
- %9 = addf %6, %7 : f32
+ %9 = arith.addf %6, %7 : f32
affine.store %9, %arg2[%i, %j] : memref<1024x1024xf32>
}
}
// CHECK-SMALL: affine.store %{{.*}}, %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-SMALL: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-SMALL: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
-// CHECK-SMALL: addf %{{.*}}, %{{.*}} : f32
+// CHECK-SMALL: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-SMALL: affine.store %{{.*}}, %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-SMALL: memref.dealloc %{{.*}} : memref<1x1xf32>
// CHECK-SMALL: }
affine.for %i = 0 to 4096 step 100 {
affine.for %ii = affine_map<(d0) -> (d0)>(%i) to min #map_ub(%i) {
%5 = affine.load %A[%ii] : memref<4096xf32>
- %6 = mulf %5, %5 : f32
+ %6 = arith.mulf %5, %5 : f32
affine.store %6, %A[%ii] : memref<4096xf32>
}
}
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %[[IV2:.*]] = #[[$MAP_IDENTITY]](%[[IV1]]) to min #[[$MAP_MIN_UB2]](%[[IV1]]) {
// CHECK-NEXT: affine.load %[[BUF]][-%[[IV1]] + %[[IV2]]] : memref<100xf32>
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.store %{{.*}}, %[[BUF]][-%[[IV1]] + %[[IV2]]] : memref<100xf32>
// CHECK-NEXT: }
// CHECK: affine.for %[[IV2:.*]] = #[[$MAP_IDENTITY]](%[[IV1]]) to min #[[$MAP_MIN_UB1]](%[[IV1]]) {
func @nested_loops_both_having_invariant_code() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
affine.store %v0, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// dependence information.
// CHECK-LABEL: func @store_affine_apply
func @store_affine_apply() -> memref<10xf32> {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %arg0 = 0 to 10 {
%t0 = affine.apply affine_map<(d1) -> (d1 + 1)>(%arg0)
affine.store %cf7, %m[%t0] : memref<10xf32>
}
return %m : memref<10xf32>
-// CHECK: %cst = constant 7.000000e+00 : f32
+// CHECK: %cst = arith.constant 7.000000e+00 : f32
// CHECK-NEXT: %0 = memref.alloc() : memref<10xf32>
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %1 = affine.apply #map{{[0-9]*}}(%arg0)
func @nested_loops_code_invariant_to_both() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
return
}
affine.for %arg1 = 0 to 30 {
%v0 = affine.for %arg2 = 0 to 10 iter_args (%prevAccum = %arg1) -> index {
%v1 = affine.load %m[%arg2] : memref<10xindex>
- %newAccum = addi %prevAccum, %v1 : index
+ %newAccum = arith.addi %prevAccum, %v1 : index
affine.yield %newAccum : index
}
}
// CHECK: affine.for %{{.*}} = 0 to 30 {
// CHECK-NEXT: %{{.*}} = affine.for %{{.*}} = 0 to 10 iter_args(%{{.*}} = %{{.*}}) -> (index) {
// CHECK-NEXT: %{{.*}} = affine.load %{{.*}}[%{{.*}} : memref<10xindex>
- // CHECK-NEXT: %{{.*}} = addi %{{.*}}, %{{.*}} : index
+ // CHECK-NEXT: %{{.*}} = arith.addi %{{.*}}, %{{.*}} : index
// CHECK-NEXT: affine.yield %{{.*}} : index
// CHECK-NEXT: }
// CHECK-NEXT: }
affine.for %arg0 = 0 to 10 {
%v0 = affine.load %m1[%arg0] : memref<10xf32>
%v1 = affine.load %m2[%arg0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
affine.store %v2, %m1[%arg0] : memref<10xf32>
}
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %2 = affine.load %0[%arg0] : memref<10xf32>
// CHECK-NEXT: %3 = affine.load %1[%arg0] : memref<10xf32>
- // CHECK-NEXT: %4 = addf %2, %3 : f32
+ // CHECK-NEXT: %4 = arith.addf %2, %3 : f32
// CHECK-NEXT: affine.store %4, %0[%arg0] : memref<10xf32>
return
func @invariant_code_inside_affine_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
%t0 = affine.apply affine_map<(d1) -> (d1 + 1)>(%arg0)
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %t0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %1 = affine.apply #map{{[0-9]*}}(%arg0)
// CHECK-NEXT: affine.if #set(%arg0, %1) {
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %2, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: }
func @dependent_stores() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
- %v1 = addf %cf7, %cf7 : f32
+ %v1 = arith.addf %cf7, %cf7 : f32
affine.store %v1, %m[%arg1] : memref<10xf32>
affine.store %v0, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
func @independent_stores() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
- %v1 = addf %cf7, %cf7 : f32
+ %v1 = arith.addf %cf7, %cf7 : f32
affine.store %v0, %m[%arg0] : memref<10xf32>
affine.store %v1, %m[%arg1] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
func @load_dependent_store() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
- %v1 = addf %cf7, %cf7 : f32
+ %v1 = arith.addf %cf7, %cf7 : f32
affine.store %v0, %m[%arg1] : memref<10xf32>
%v2 = affine.load %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.store %1, %0[%arg1] : memref<10xf32>
func @load_after_load() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
- %v1 = addf %cf7, %cf7 : f32
+ %v1 = arith.addf %cf7, %cf7 : f32
%v3 = affine.load %m[%arg1] : memref<10xf32>
%v2 = affine.load %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %3 = affine.load %0[%arg0] : memref<10xf32>
// CHECK-NEXT: }
func @invariant_affine_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: }
func @invariant_affine_if2() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg1] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %1, %0[%arg1] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
func @invariant_affine_nested_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
affine.store %cf9, %m[%arg1] : memref<10xf32>
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
// CHECK-NEXT: affine.store %1, %0[%arg1] : memref<10xf32>
func @invariant_affine_nested_if_else() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
affine.store %cf9, %m[%arg0] : memref<10xf32>
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
func @invariant_affine_nested_if_else2() {
%m = memref.alloc() : memref<10xf32>
%m2 = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
%tload1 = affine.load %m[%arg0] : memref<10xf32>
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
affine.store %cf9, %m2[%arg0] : memref<10xf32>
// CHECK: %0 = memref.alloc() : memref<10xf32>
// CHECK-NEXT: %1 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: %3 = affine.load %0[%arg0] : memref<10xf32>
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
// CHECK-NEXT: affine.store %2, %1[%arg0] : memref<10xf32>
func @invariant_affine_nested_if2() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
%v1 = affine.load %m[%arg0] : memref<10xf32>
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
%v2 = affine.load %m[%arg0] : memref<10xf32>
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: %2 = affine.load %0[%arg0] : memref<10xf32>
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
// CHECK-NEXT: %3 = affine.load %0[%arg0] : memref<10xf32>
func @invariant_affine_for_inside_affine_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
affine.for %arg2 = 0 to 10 {
affine.store %cf9, %m[%arg2] : memref<10xf32>
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
// CHECK-NEXT: affine.if #set(%arg0, %arg0) {
- // CHECK-NEXT: %1 = addf %cst, %cst : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %1, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: affine.for %arg2 = 0 to 10 {
// CHECK-NEXT: affine.store %1, %0[%arg2] : memref<10xf32>
%m = memref.alloc() : memref<100xf32>
%m2 = memref.alloc() : memref<100xf32>
affine.for %arg0 = 0 to 5 {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%v = affine.load %m2[%c0] : memref<100xf32>
affine.store %v, %m[%arg0] : memref<100xf32>
}
// CHECK: %0 = memref.alloc() : memref<100xf32>
// CHECK-NEXT: %1 = memref.alloc() : memref<100xf32>
- // CHECK-NEXT: %c0 = constant 0 : index
+ // CHECK-NEXT: %c0 = arith.constant 0 : index
// CHECK-NEXT: %2 = affine.load %1[%c0] : memref<100xf32>
// CHECK-NEXT: affine.for %arg0 = 0 to 5 {
// CHECK-NEXT: affine.store %2, %0[%arg0] : memref<100xf32>
func @nested_load_store_same_memref() {
%m = memref.alloc() : memref<10xf32>
- %cst = constant 8.0 : f32
- %c0 = constant 0 : index
+ %cst = arith.constant 8.0 : f32
+ %c0 = arith.constant 0 : index
affine.for %arg0 = 0 to 10 {
%v0 = affine.load %m[%c0] : memref<10xf32>
affine.for %arg1 = 0 to 10 {
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
- // CHECK-NEXT: %c0 = constant 0 : index
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %c0 = arith.constant 0 : index
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %1 = affine.load %0[%c0] : memref<10xf32>
// CHECK-NEXT: affine.for %arg1 = 0 to 10 {
func @nested_load_store_same_memref2() {
%m = memref.alloc() : memref<10xf32>
- %cst = constant 8.0 : f32
- %c0 = constant 0 : index
+ %cst = arith.constant 8.0 : f32
+ %c0 = arith.constant 0 : index
affine.for %arg0 = 0 to 10 {
affine.store %cst, %m[%c0] : memref<10xf32>
affine.for %arg1 = 0 to 10 {
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
- // CHECK-NEXT: %c0 = constant 0 : index
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %c0 = arith.constant 0 : index
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-LABEL: func @do_not_hoist_dependent_side_effect_free_op
func @do_not_hoist_dependent_side_effect_free_op(%arg0: memref<10x512xf32>) {
%0 = memref.alloca() : memref<1xf32>
- %cst = constant 8.0 : f32
+ %cst = arith.constant 8.0 : f32
affine.for %i = 0 to 512 {
affine.for %j = 0 to 10 {
%5 = affine.load %arg0[%i, %j] : memref<10x512xf32>
%6 = affine.load %0[0] : memref<1xf32>
- %add = addf %5, %6 : f32
+ %add = arith.addf %5, %6 : f32
affine.store %add, %0[0] : memref<1xf32>
}
%3 = affine.load %0[0] : memref<1xf32>
- %4 = mulf %3, %cst : f32 // It shouldn't be hoisted.
+ %4 = arith.mulf %3, %cst : f32 // It shouldn't be hoisted.
}
return
}
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.load
// CHECK-NEXT: affine.load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// CHECK-NEXT: }
// CHECK-NEXT: affine.load
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: }
// -----
affine.for %arg0 = 0 to 10 {
%v0 = affine.vector_load %m1[%arg0*4] : memref<40xf32>, vector<4xf32>
%v1 = affine.vector_load %m2[%arg0*4] : memref<40xf32>, vector<4xf32>
- %v2 = addf %v0, %v1 : vector<4xf32>
+ %v2 = arith.addf %v0, %v1 : vector<4xf32>
affine.vector_store %v2, %m1[%arg0*4] : memref<40xf32>, vector<4xf32>
}
return
// CHECK: affine.for
// CHECK-NEXT: affine.vector_load
// CHECK-NEXT: affine.vector_load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.vector_store
// CHECK-NEXT: }
affine.for %arg0 = 0 to 10 {
%v0 = affine.vector_load %m1[0] : memref<4xf32>, vector<4xf32>
%v1 = affine.vector_load %m2[0] : memref<4xf32>, vector<4xf32>
- %v2 = addf %v0, %v1 : vector<4xf32>
+ %v2 = arith.addf %v0, %v1 : vector<4xf32>
affine.vector_store %v2, %m3[0] : memref<4xf32>, vector<4xf32>
}
return
// CHECK-NEXT: memref.alloc()
// CHECK-NEXT: affine.vector_load
// CHECK-NEXT: affine.vector_load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.vector_store
// CHECK-NEXT: affine.for
#set = affine_set<(d0): (d0 - 10 >= 0)>
// CHECK-LABEL: func @affine_if_not_invariant(
func @affine_if_not_invariant(%buffer: memref<1024xf32>) -> f32 {
- %sum_init_0 = constant 0.0 : f32
- %sum_init_1 = constant 1.0 : f32
+ %sum_init_0 = arith.constant 0.0 : f32
+ %sum_init_1 = arith.constant 1.0 : f32
%res = affine.for %i = 0 to 10 step 2 iter_args(%sum_iter = %sum_init_0) -> f32 {
%t = affine.load %buffer[%i] : memref<1024xf32>
%sum_next = affine.if #set(%i) -> (f32) {
- %new_sum = addf %sum_iter, %t : f32
+ %new_sum = arith.addf %sum_iter, %t : f32
affine.yield %new_sum : f32
} else {
affine.yield %sum_iter : f32
}
- %modified_sum = addf %sum_next, %sum_init_1 : f32
+ %modified_sum = arith.addf %sum_next, %sum_init_1 : f32
affine.yield %modified_sum : f32
}
return %res : f32
}
-// CHECK: constant 0.000000e+00 : f32
-// CHECK-NEXT: constant 1.000000e+00 : f32
+// CHECK: arith.constant 0.000000e+00 : f32
+// CHECK-NEXT: arith.constant 1.000000e+00 : f32
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.load
// CHECK-NEXT: affine.if
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.yield
// CHECK-NEXT: } else {
// CHECK-NEXT: affine.yield
// CHECK-NEXT: }
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.yield
// CHECK-NEXT: }
// CHECK-LABEL: func @affine_for_not_invariant(
func @affine_for_not_invariant(%in : memref<30x512xf32, 1>,
%out : memref<30x1xf32, 1>) {
- %sum_0 = constant 0.0 : f32
- %cst_0 = constant 1.1 : f32
+ %sum_0 = arith.constant 0.0 : f32
+ %cst_0 = arith.constant 1.1 : f32
affine.for %j = 0 to 30 {
%sum = affine.for %i = 0 to 512 iter_args(%sum_iter = %sum_0) -> (f32) {
%t = affine.load %in[%j,%i] : memref<30x512xf32,1>
- %sum_next = addf %sum_iter, %t : f32
+ %sum_next = arith.addf %sum_iter, %t : f32
affine.yield %sum_next : f32
}
- %mod_sum = mulf %sum, %cst_0 : f32
+ %mod_sum = arith.mulf %sum, %cst_0 : f32
affine.store %mod_sum, %out[%j, 0] : memref<30x1xf32, 1>
}
return
}
-// CHECK: constant 0.000000e+00 : f32
-// CHECK-NEXT: constant 1.100000e+00 : f32
+// CHECK: arith.constant 0.000000e+00 : f32
+// CHECK-NEXT: arith.constant 1.100000e+00 : f32
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.yield
// CHECK-NEXT: }
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.store
// -----
// CHECK-LABEL: func @use_of_iter_operands_invariant
func @use_of_iter_operands_invariant(%m : memref<10xindex>) {
- %sum_1 = constant 0 : index
+ %sum_1 = arith.constant 0 : index
%v0 = affine.for %arg1 = 0 to 11 iter_args (%prevAccum = %sum_1) -> index {
- %prod = muli %sum_1, %sum_1 : index
- %newAccum = addi %prevAccum, %prod : index
+ %prod = arith.muli %sum_1, %sum_1 : index
+ %newAccum = arith.addi %prevAccum, %prod : index
affine.yield %newAccum : index
}
return
// CHECK-LABEL: func @use_of_iter_args_not_invariant
func @use_of_iter_args_not_invariant(%m : memref<10xindex>) {
- %sum_1 = constant 0 : index
+ %sum_1 = arith.constant 0 : index
%v0 = affine.for %arg1 = 0 to 11 iter_args (%prevAccum = %sum_1) -> index {
- %newAccum = addi %prevAccum, %sum_1 : index
+ %newAccum = arith.addi %prevAccum, %sum_1 : index
affine.yield %newAccum : index
}
return
}
-// CHECK: constant
+// CHECK: arith.constant
// CHECK-NEXT: affine.for
-// CHECK-NEXT: addi
+// CHECK-NEXT: arith.addi
// CHECK-NEXT: affine.yield
// CHECK-LABEL: func @normalize_parallel()
func @normalize_parallel() {
- %cst = constant 1.0 : f32
+ %cst = arith.constant 1.0 : f32
%0 = memref.alloc() : memref<2x4xf32>
// CHECK: affine.parallel (%[[i0:.*]], %[[j0:.*]]) = (0, 0) to (4, 2)
affine.parallel (%i, %j) = (0, 1) to (10, 5) step (3, 2) {
// CHECK-LABEL: func @loop_with_unknown_upper_bound
// CHECK-SAME: (%[[ARG0:.*]]: memref<?x?xf32>, %[[ARG1:.*]]: index)
-// CHECK-NEXT: %{{.*}} = constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 0 : index
// CHECK-NEXT: %[[DIM:.*]] = memref.dim %arg0, %c0 : memref<?x?xf32>
// CHECK-NEXT: affine.for %[[I:.*]] = 0 to [[$UB00]]()[%[[DIM]]] {
// CHECK-NEXT: %[[IIV:.*]] = affine.apply [[$IV00]](%[[I]])
// CHECK-NEXT: return
// CHECK-NEXT: }
func @loop_with_unknown_upper_bound(%arg0: memref<?x?xf32>, %arg1: index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
affine.for %i0 = 2 to %0 step 32 {
affine.for %i1 = 0 to %arg1 step 2 {
// CHECK-LABEL: func @loop_with_multiple_upper_bounds
// CHECK-SAME: (%[[ARG0:.*]]: memref<?x?xf32>, %[[ARG1:.*]]: index)
-// CHECK-NEXT: %{{.*}} = constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 0 : index
// CHECK-NEXT: %[[DIM:.*]] = memref.dim %arg0, %c0 : memref<?x?xf32>
// CHECK-NEXT: affine.for %[[I:.*]] = 0 to [[$OUTERUB]]()[%[[DIM]]] {
// CHECK-NEXT: %[[IIV:.*]] = affine.apply [[$OUTERIV]](%[[I]])
// CHECK-NEXT: return
// CHECK-NEXT: }
func @loop_with_multiple_upper_bounds(%arg0: memref<?x?xf32>, %arg1 : index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
affine.for %i0 = 2 to %0 step 32{
affine.for %i1 = 2 to min affine_map<(d0)[] -> (d0, 512)>(%arg1) {
// CHECK-LABEL: func @tiled_matmul
// CHECK-SAME: (%[[ARG0:.*]]: memref<1024x1024xf32>, %[[ARG1:.*]]: memref<1024x1024xf32>, %[[ARG2:.*]]: memref<1024x1024xf32>)
-// CHECK-NEXT: %{{.*}} = constant 0 : index
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: %[[DIM0:.*]] = memref.dim %[[ARG0]], %{{.*}}
// CHECK-NEXT: %[[DIM1:.*]] = memref.dim %[[ARG1]], %{{.*}}
// CHECK-NEXT: %[[DIM2:.*]] = memref.dim %[[ARG0]], %{{.*}}
// CHECK-NEXT: %{{.*}} = affine.load %[[ARG0]][%[[IIIV]], %[[KKIV]]] : memref<1024x1024xf32>
// CHECK-NEXT: %{{.*}} = affine.load %[[ARG1]][%[[KKIV]], %[[JJIV]]] : memref<1024x1024xf32>
// CHECK-NEXT: %{{.*}} = affine.load %[[ARG2]][%[[IIIV]], %[[JJIV]]] : memref<1024x1024xf32>
-// CHECK-NEXT: %{{.*}} = mulf %9, %10 : f32
-// CHECK-NEXT: %{{.*}} = addf %11, %12 : f32
+// CHECK-NEXT: %{{.*}} = arith.mulf %9, %10 : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %11, %12 : f32
// CHECK-NEXT: affine.store %{{.*}}, %[[ARG2]][%6, %7] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
#map4 = affine_map<()[s0] -> (s0)>
func @tiled_matmul(%0: memref<1024x1024xf32>, %1: memref<1024x1024xf32>, %2: memref<1024x1024xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%3 = memref.dim %0, %c0 : memref<1024x1024xf32>
%4 = memref.dim %1, %c1 : memref<1024x1024xf32>
%5 = memref.dim %0, %c1 : memref<1024x1024xf32>
%6 = affine.load %0[%arg3, %arg5] : memref<1024x1024xf32>
%7 = affine.load %1[%arg5, %arg4] : memref<1024x1024xf32>
%8 = affine.load %2[%arg3, %arg4] : memref<1024x1024xf32>
- %9 = mulf %6, %7 : f32
- %10 = addf %8, %9 : f32
+ %9 = arith.mulf %6, %7 : f32
+ %10 = arith.addf %8, %9 : f32
affine.store %10, %2[%arg3, %arg4] : memref<1024x1024xf32>
}
}
affine.for %i0 = 0 to 15 {
// Test load[%x0, %x0] with symbol %c4
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%x0 = affine.apply affine_map<(d0)[s0] -> (d0 - s0)> (%i0)[%c4]
// CHECK: %[[I0:.*]] = affine.apply #[[$MAP4]](%{{.*}})
memref.store %v0, %0[%y2, %y2] : memref<4x4xf32>
// Test store[%x2, %x0] with symbol %c4 from '%x0' and %c5 from '%x2'
- %c5 = constant 5 : index
+ %c5 = arith.constant 5 : index
%x2 = affine.apply affine_map<(d0)[s0] -> (d0 + s0)> (%i0)[%c5]
%y3 = affine.apply affine_map<(d0, d1) -> (d0 + d1)> (%x2, %x0)
// CHECK: %[[I3:.*]] = affine.apply #[[$MAP7a]](%{{.*}})
// CHECK-LABEL: func @compose_affine_maps_2d_tile
func @compose_affine_maps_2d_tile(%0: memref<16x32xf32>, %1: memref<16x32xf32>) {
- %c4 = constant 4 : index
- %c8 = constant 8 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
affine.for %i0 = 0 to 3 {
%x0 = affine.apply affine_map<(d0)[s0] -> (d0 ceildiv s0)> (%i0)[%c4]
affine.for %i0 = 0 to 3 {
affine.for %i1 = 0 to 3 {
affine.for %i2 = 0 to 3 {
- %c3 = constant 3 : index
- %c7 = constant 7 : index
+ %c3 = arith.constant 3 : index
+ %c7 = arith.constant 7 : index
%x00 = affine.apply affine_map<(d0, d1, d2)[s0, s1] -> (d0 + s0)>
(%i0, %i1, %i2)[%c3, %c7]
// CHECK-LABEL: func @arg_used_as_dim_and_symbol
func @arg_used_as_dim_and_symbol(%arg0: memref<100x100xf32>, %arg1: index, %arg2: f32) -> (memref<100x100xf32, 1>, memref<1xi32>) {
- %c9 = constant 9 : index
+ %c9 = arith.constant 9 : index
%1 = memref.alloc() : memref<100x100xf32, 1>
%2 = memref.alloc() : memref<1xi32>
affine.for %i0 = 0 to 100 {
// CHECK-NOT: affine.apply
%0 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i1 = 0 to 10 {
%1 = affine.apply affine_map<()[s0] -> (s0)>()[%c0]
memref.store %cst, %0[%1] : memref<10xf32>
// CHECK-LABEL: func @partial_fold_map
func @partial_fold_map(%arg1: index, %arg2: index) -> index {
// TODO: Constant fold one index into affine.apply
- %c42 = constant 42 : index
+ %c42 = arith.constant 42 : index
%2 = affine.apply affine_map<(d0, d1) -> (d0 - d1)> (%arg1, %c42)
// CHECK: [[X:.*]] = affine.apply #[[$MAP15]]()[%{{.*}}]
return %2 : index
%d = affine.apply affine_map<()[s0] -> (s0 ceildiv 8)> ()[%b]
%e = affine.apply affine_map<(d0) -> (d0 floordiv 3)> (%c)
%f = affine.apply affine_map<(d0, d1)[s0, s1] -> (d0 - s1 + d1 - s0)> (%d, %e)[%e, %d]
- // CHECK: {{.*}} = constant 0 : index
+ // CHECK: {{.*}} = arith.constant 0 : index
return %f : index
}
%res1 = affine.apply affine_map<()[s0, s1] -> (4 * s0)>()[%N, %K]
%res2 = affine.apply affine_map<()[s0, s1] -> (s1)>()[%N, %K]
%res3 = affine.apply affine_map<()[s0, s1] -> (1024)>()[%N, %K]
- // CHECK-DAG: {{.*}} = constant 1024 : index
+ // CHECK-DAG: {{.*}} = arith.constant 1024 : index
// CHECK-DAG: {{.*}} = affine.apply #[[$MAP_symbolic_composition_b]]()[%{{.*}}]
// CHECK-DAG: {{.*}} = affine.apply #[[$MAP_symbolic_composition_b]]()[%{{.*}}]
return %res1, %res2, %res3 : index, index, index
// CHECK-LABEL: func @symbolic_semi_affine(%arg0: index, %arg1: index, %arg2: memref<?xf32>) {
func @symbolic_semi_affine(%M: index, %N: index, %A: memref<?xf32>) {
- %f1 = constant 1.0 : f32
+ %f1 = arith.constant 1.0 : f32
affine.for %i0 = 1 to 100 {
%1 = affine.apply affine_map<()[s0] -> (s0 + 1)> ()[%M]
%2 = affine.apply affine_map<(d0)[s0] -> (d0 floordiv s0)> (%i0)[%1]
// CHECK-LABEL: func @constant_fold_bounds(%arg0: index) {
func @constant_fold_bounds(%N : index) {
- // CHECK: constant 3 : index
+ // CHECK: arith.constant 3 : index
// CHECK-NEXT: "foo"() : () -> index
- %c9 = constant 9 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c9 = arith.constant 9 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%c3 = affine.apply affine_map<(d0, d1) -> (d0 + d1)> (%c1, %c2)
%l = "foo"() : () -> index
// CHECK-LABEL: func @fold_empty_loops()
func @fold_empty_loops() -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
affine.for %i = 0 to 10 {
}
%res = affine.for %i = 0 to 10 iter_args(%arg = %c0) -> index {
affine.yield %arg : index
}
- // CHECK-NEXT: %[[zero:.*]] = constant 0
+ // CHECK-NEXT: %[[zero:.*]] = arith.constant 0
// CHECK-NEXT: return %[[zero]]
return %res : index
}
// CHECK-LABEL: func @fold_zero_iter_loops
// CHECK-SAME: %[[ARG:.*]]: index
func @fold_zero_iter_loops(%in : index) -> index {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
affine.for %i = 0 to 0 {
affine.for %j = 0 to -1 {
}
}
%res = affine.for %i = 0 to 0 iter_args(%loop_arg = %in) -> index {
- %yield = addi %loop_arg, %c1 : index
+ %yield = arith.addi %loop_arg, %c1 : index
affine.yield %yield : index
}
// CHECK-NEXT: return %[[ARG]]
// CHECK-SAME: %[[M:[0-9a-zA-Z]*]]: index,
// CHECK-SAME: %[[N:[0-9a-zA-Z]*]]: index)
func @canonicalize_affine_if(%M : index, %N : index) {
- %c1022 = constant 1022 : index
+ %c1022 = arith.constant 1022 : index
// Drop unused operand %M, propagate %c1022, and promote %N to symbolic.
affine.for %i = 0 to 1024 {
affine.for %j = 0 to %N {
// CHECK-SAME: %[[M:.*]]: index,
// CHECK-SAME: %[[N:.*]]: index)
func @canonicalize_bounds(%M : index, %N : index) {
- %c0 = constant 0 : index
- %c1024 = constant 1024 : index
+ %c0 = arith.constant 0 : index
+ %c1024 = arith.constant 1024 : index
// Drop unused operand %N, drop duplicate operand %M, propagate %c1024, and
// promote %M to a symbolic one.
// CHECK: affine.for %{{.*}} = 0 to min #[[$UBMAP]]()[%[[M]]]
// -----
func @affine_min(%arg0 : index, %arg1 : index, %arg2 : index) {
- %c511 = constant 511 : index
- %c1 = constant 0 : index
+ %c511 = arith.constant 511 : index
+ %c1 = arith.constant 0 : index
%0 = affine.min affine_map<(d0)[s0] -> (1000, d0 + 512, s0 + 1)> (%c1)[%c511]
"op0"(%0) : (index) -> ()
- // CHECK: %[[CST:.*]] = constant 512 : index
+ // CHECK: %[[CST:.*]] = arith.constant 512 : index
// CHECK-NEXT: "op0"(%[[CST]]) : (index) -> ()
// CHECK-NEXT: return
return
// -----
func @affine_min(%arg0 : index, %arg1 : index, %arg2 : index) {
- %c3 = constant 3 : index
- %c20 = constant 20 : index
+ %c3 = arith.constant 3 : index
+ %c20 = arith.constant 20 : index
%0 = affine.min affine_map<(d0)[s0] -> (1000, d0 floordiv 4, (s0 mod 5) + 1)> (%c20)[%c3]
"op0"(%0) : (index) -> ()
- // CHECK: %[[CST:.*]] = constant 4 : index
+ // CHECK: %[[CST:.*]] = arith.constant 4 : index
// CHECK-NEXT: "op0"(%[[CST]]) : (index) -> ()
// CHECK-NEXT: return
return
// -----
func @affine_max(%arg0 : index, %arg1 : index, %arg2 : index) {
- %c511 = constant 511 : index
- %c1 = constant 0 : index
+ %c511 = arith.constant 511 : index
+ %c1 = arith.constant 0 : index
%0 = affine.max affine_map<(d0)[s0] -> (1000, d0 + 512, s0 + 1)> (%c1)[%c511]
"op0"(%0) : (index) -> ()
- // CHECK: %[[CST:.*]] = constant 1000 : index
+ // CHECK: %[[CST:.*]] = arith.constant 1000 : index
// CHECK-NEXT: "op0"(%[[CST]]) : (index) -> ()
// CHECK-NEXT: return
return
// -----
func @affine_max(%arg0 : index, %arg1 : index, %arg2 : index) {
- %c3 = constant 3 : index
- %c20 = constant 20 : index
+ %c3 = arith.constant 3 : index
+ %c20 = arith.constant 20 : index
%0 = affine.max affine_map<(d0)[s0] -> (1000, d0 floordiv 4, (s0 mod 5) + 1)> (%c20)[%c3]
"op0"(%0) : (index) -> ()
- // CHECK: %[[CST:.*]] = constant 1000 : index
+ // CHECK: %[[CST:.*]] = arith.constant 1000 : index
// CHECK-NEXT: "op0"(%[[CST]]) : (index) -> ()
// CHECK-NEXT: return
return
func @affine_min(%arg0: index) {
affine.for %i = 0 to %arg0 {
affine.for %j = 0 to %arg0 {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
// CHECK: affine.min #[[$MAP]]
%0 = affine.min affine_map<(d0,d1,d2)->(d0, d1 - d2)>(%i, %j, %c2)
"consumer"(%0) : (index) -> ()
// CHECK: func @rep(%[[ARG0:.*]]: index, %[[ARG1:.*]]: index)
func @rep(%arg0 : index, %arg1 : index) -> index {
- // CHECK-NOT: constant
- %c0 = constant 0 : index
- %c1024 = constant 1024 : index
+ // CHECK-NOT: arith.constant
+ %c0 = arith.constant 0 : index
+ %c1024 = arith.constant 1024 : index
// CHECK-NOT: affine.apply
%0 = affine.apply #map1(%arg0)[%c1024, %c0]
// CHECK-LABEL: func @affine_parallel_const_bounds
func @affine_parallel_const_bounds() {
- %cst = constant 1.0 : f32
- %c0 = constant 0 : index
- %c4 = constant 4 : index
+ %cst = arith.constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
%0 = memref.alloc() : memref<4xf32>
// CHECK: affine.parallel (%{{.*}}) = (0) to (4)
affine.parallel (%i) = (%c0) to (%c0 + %c4) {
%0 = affine.apply affine_map<()[s0] -> (2 * s0)> ()[%i0]
%1 = affine.apply affine_map<()[s0] -> (3 * s0)> ()[%i0]
%2 = affine.apply affine_map<(d0)[s0, s1] -> (d0 mod s1 + s0 * s1 + s0 * 4)> (%i1)[%0, %1]
- %3 = index_cast %2: index to i64
+ %3 = arith.index_cast %2: index to i64
memref.store %3, %A[]: memref<i64>
affine.for %i2 = 0 to 3 {
%4 = affine.apply affine_map<(d0)[s0, s1] -> (d0 ceildiv s1 + s0 + s0 * 3)> (%i2)[%0, %1]
- %5 = index_cast %4: index to i64
+ %5 = arith.index_cast %4: index to i64
memref.store %5, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @affine_apply
func @affine_apply(%variable : index) -> (index, index, index) {
- %c177 = constant 177 : index
- %c211 = constant 211 : index
- %N = constant 1075 : index
+ %c177 = arith.constant 177 : index
+ %c211 = arith.constant 211 : index
+ %N = arith.constant 1075 : index
- // CHECK:[[C1159:%.+]] = constant 1159 : index
- // CHECK:[[C1152:%.+]] = constant 1152 : index
+ // CHECK:[[C1159:%.+]] = arith.constant 1159 : index
+ // CHECK:[[C1152:%.+]] = arith.constant 1152 : index
%x0 = affine.apply affine_map<(d0, d1)[S0] -> ( (d0 + 128 * S0) floordiv 128 + d1 mod 128)>
(%c177, %c211)[%N]
%x1 = affine.apply affine_map<(d0, d1)[S0] -> (128 * (S0 ceildiv 128))>
(%c177, %c211)[%N]
- // CHECK:[[C42:%.+]] = constant 42 : index
+ // CHECK:[[C42:%.+]] = arith.constant 42 : index
%y = affine.apply affine_map<(d0) -> (42)> (%variable)
// CHECK: return [[C1159]], [[C1152]], [[C42]]
// CHECK: #[[map:.*]] = affine_map<(d0, d1) -> (42, d1)
func @affine_min(%variable: index) -> (index, index) {
- // CHECK: %[[C42:.*]] = constant 42
- %c42 = constant 42 : index
- %c44 = constant 44 : index
+ // CHECK: %[[C42:.*]] = arith.constant 42
+ %c42 = arith.constant 42 : index
+ %c44 = arith.constant 44 : index
// Partial folding will use a different map.
// CHECK: %[[r:.*]] = affine.min #[[map]](%[[C42]], %{{.*}})
%0 = affine.min affine_map<(d0, d1) -> (d0, d1)>(%c42, %variable)
// CHECK: #[[map:.*]] = affine_map<(d0, d1) -> (42, d1)
func @affine_min(%variable: index) -> (index, index) {
- // CHECK: %[[C42:.*]] = constant 42
- %c42 = constant 42 : index
- // CHECK: %[[C44:.*]] = constant 44
- %c44 = constant 44 : index
+ // CHECK: %[[C42:.*]] = arith.constant 42
+ %c42 = arith.constant 42 : index
+ // CHECK: %[[C44:.*]] = arith.constant 44
+ %c44 = arith.constant 44 : index
// Partial folding will use a different map.
// CHECK: %[[r:.*]] = affine.max #[[map]](%[[C42]], %{{.*}})
%0 = affine.max affine_map<(d0, d1) -> (d0, d1)>(%c42, %variable)
// -----
// CHECK-LABEL: func @loop_nest_high_d
-// CHECK: %{{.*}} = constant 16384 : index
+// CHECK: %{{.*}} = arith.constant 16384 : index
// CHECK-DAG: [[BUFB:%[0-9]+]] = memref.alloc() : memref<512x32xf32, 2>
// CHECK-DAG: [[BUFA:%[0-9]+]] = memref.alloc() : memref<512x32xf32, 2>
// CHECK-DAG: [[BUFC:%[0-9]+]] = memref.alloc() : memref<512x32xf32, 2>
// CHECK-LABEL: func @dma_constant_dim_access
func @dma_constant_dim_access(%A : memref<100x100xf32>) {
- %one = constant 1 : index
- %N = constant 100 : index
+ %one = arith.constant 1 : index
+ %N = arith.constant 100 : index
// CHECK: memref.alloc() : memref<1x100xf32, 2>
// CHECK-NEXT: memref.alloc() : memref<1xi32>
// No strided DMA needed here.
// CHECK-LABEL: func @dma_with_symbolic_accesses
func @dma_with_symbolic_accesses(%A : memref<100x100xf32>, %M : index) {
- %N = constant 9 : index
+ %N = arith.constant 9 : index
affine.for %i = 0 to 100 {
affine.for %j = 0 to 100 {
%idy = affine.apply affine_map<(d0, d1) [s0, s1] -> (d1 + s0 + s1)>(%i, %j)[%M, %N]
// CHECK-LABEL: func @dma_with_symbolic_loop_bounds
func @dma_with_symbolic_loop_bounds(%A : memref<100x100xf32>, %M : index, %N: index) {
- %K = constant 9 : index
+ %K = arith.constant 9 : index
// The buffer size can't be bound by a constant smaller than the original
// memref size; so the DMA buffer is the entire 100x100.
// CHECK: memref.alloc() : memref<100x100xf32, 2>
// CHECK-LABEL: func @dma_unknown_size
func @dma_unknown_size(%arg0: memref<?x?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %arg0, %c0 : memref<? x ? x f32>
%N = memref.dim %arg0, %c0 : memref<? x ? x f32>
affine.for %i = 0 to %M {
// CHECK-LABEL: func @dma_loop_straightline_interspersed() {
func @dma_loop_straightline_interspersed() {
- %c0 = constant 0 : index
- %c255 = constant 255 : index
+ %c0 = arith.constant 0 : index
+ %c255 = arith.constant 255 : index
%A = memref.alloc() : memref<256 x f32>
%v = affine.load %A[%c0] : memref<256 x f32>
affine.for %i = 1 to 255 {
// CHECK-LABEL: func @dma_mixed_loop_blocks() {
func @dma_mixed_loop_blocks() {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%A = memref.alloc() : memref<256 x 256 x vector<8 x f32>>
affine.for %i = 0 to 256 {
%v = affine.load %A[%c0, %c0] : memref<256 x 256 x vector<8 x f32>>
func @relative_loop_bounds(%arg0: memref<1027xf32>) {
affine.for %i0 = 0 to 1024 {
affine.for %i2 = affine_map<(d0) -> (d0)>(%i0) to affine_map<(d0) -> (d0 + 4)>(%i0) {
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
affine.store %0, %arg0[%i2] : memref<1027xf32>
}
}
#map_acc = affine_map<(d0) -> (d0 floordiv 8)>
// CHECK-LABEL: func @test_analysis_util
func @test_analysis_util(%arg0: memref<4x4x16x1xf32>, %arg1: memref<144x9xf32>, %arg2: memref<2xf32>) -> (memref<144x9xf32>, memref<2xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<64x1xf32>
%1 = memref.alloc() : memref<144x4xf32>
- %2 = constant 0.0 : f32
+ %2 = arith.constant 0.0 : f32
affine.for %i8 = 0 to 9 step 3 {
affine.for %i9 = #map_lb(%i8) to #map_ub(%i8) {
affine.for %i17 = 0 to 64 {
// Test for test case in b/128303048 #4.
// CHECK-LABEL: func @test_memref_bounds
func @test_memref_bounds(%arg0: memref<4x4x16x1xvector<8x128xf32>>, %arg1: memref<144x9xvector<8x128xf32>>, %arg2: memref<2xvector<8x128xf32>>) -> (memref<144x9xvector<8x128xf32>>, memref<2xvector<8x128xf32>>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
affine.for %i8 = 0 to 9 step 3 {
affine.for %i9 = #map3(%i8) to #map12(%i8) {
affine.for %i10 = 0 to 64 {
// FAST-MEM-16KB: affine.for %{{.*}}
affine.for %i3 = affine_map<(d0) -> (d0)>(%i1) to affine_map<(d0) -> (d0 + 4)>(%i1) {
%3 = affine.load %arg0[%i2, %i3] : memref<256x1024xf32>
- %4 = mulf %3, %3 : f32
+ %4 = arith.mulf %3, %3 : f32
affine.store %4, %arg0[%i2, %i3] : memref<256x1024xf32>
} // FAST-MEM-16KB: }
} // FAST-MEM-16KB: }
%5 = affine.load %arg0[%ii, %kk] : memref<8x8xvector<64xf32>>
%6 = affine.load %arg1[%kk, %jj] : memref<8x8xvector<64xf32>>
%7 = affine.load %arg2[%ii, %jj] : memref<8x8xvector<64xf32>>
- %8 = mulf %5, %6 : vector<64xf32>
- %9 = addf %7, %8 : vector<64xf32>
+ %8 = arith.mulf %5, %6 : vector<64xf32>
+ %9 = arith.addf %7, %8 : vector<64xf32>
affine.store %9, %arg2[%ii, %jj] : memref<8x8xvector<64xf32>>
}
}
%0 = memref.alloc() : memref<100x100xf32>
%1 = memref.alloc() : memref<100x100xf32, affine_map<(d0, d1) -> (d0, d1)>, 2>
%2 = memref.alloc() : memref<1xi32>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.dma_start %0[%i0, %i1], %1[%i0, %i1], %2[%c0], %c64
%0 = memref.alloc() : memref<100x100xf32>
%1 = memref.alloc() : memref<100x100xf32, affine_map<(d0, d1) -> (d0, d1)>, 2>
%2 = memref.alloc() : memref<1xi32>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
- %c128 = constant 128 : index
- %c256 = constant 256 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
+ %c128 = arith.constant 128 : index
+ %c256 = arith.constant 256 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.dma_start %0[%i0, %i1], %1[%i0, %i1], %2[%c0], %c64, %c128, %c256
%0 = memref.alloc() : memref<100x100xf32>
%1 = memref.alloc() : memref<100x100xf32, affine_map<(d0, d1) -> (d0, d1)>, 2>
%2 = memref.alloc() : memref<1xi32>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.dma_start %0[%i0 + %arg0, %i1], %1[%i0, %i1 + %arg1 + 5],
%0 = memref.alloc() : memref<100x100xf32>
%1 = memref.alloc() : memref<100x100xf32, affine_map<(d0, d1) -> (d0, d1)>, 2>
%2 = memref.alloc() : memref<1xi32>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.dma_start %0[%i0 + symbol(%arg0), %i1],
%0 = memref.alloc() : memref<100x100xf32>
%1 = memref.alloc() : memref<100x100xf32, 2>
%2 = memref.alloc() : memref<1xi32>
- %c64 = constant 64 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.dma_start %0[(%i0 + symbol(%arg0)) floordiv 3, %i1],
// Basic test that functions within affine operations are inlined.
func @func_with_affine_ops(%N: index) {
- %c = constant 200 : index
+ %c = arith.constant 200 : index
affine.for %i = 1 to 10 {
affine.if affine_set<(i)[N] : (i - 2 >= 0, 4 - i >= 0)>(%i)[%c] {
%w = affine.apply affine_map<(d0,d1)[s0] -> (d0+d1+s0)> (%i, %i) [%N]
// CHECK-LABEL: func @inline_with_affine_ops
func @inline_with_affine_ops() {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: affine.for
// CHECK-NEXT: affine.if
// CHECK-LABEL: func @not_inline_in_affine_op
func @not_inline_in_affine_op() {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// CHECK-NOT: affine.if
// CHECK: call
func @affine_for_lower_bound_invalid_dim(%arg : index) {
affine.for %n0 = 0 to 7 {
- %dim = addi %arg, %arg : index
+ %dim = arith.addi %arg, %arg : index
// expected-error@+1 {{operand cannot be used as a dimension id}}
affine.for %n1 = 0 to #map(%dim)[%arg] {
func @affine_for_upper_bound_invalid_dim(%arg : index) {
affine.for %n0 = 0 to 7 {
- %dim = addi %arg, %arg : index
+ %dim = arith.addi %arg, %arg : index
// expected-error@+1 {{operand cannot be used as a dimension id}}
affine.for %n1 = #map(%dim)[%arg] to 7 {
func @affine_if_invalid_dim(%arg : index) {
affine.for %n0 = 0 to 7 {
- %dim = addi %arg, %arg : index
+ %dim = arith.addi %arg, %arg : index
// expected-error@+1 {{operand cannot be used as a dimension id}}
affine.if #set0(%dim)[%n0] {}
func @affine_if_invalid_dimop_dim(%arg0: index, %arg1: index, %arg2: index, %arg3: index) {
affine.for %n0 = 0 to 7 {
%0 = memref.alloc(%arg0, %arg1, %arg2, %arg3) : memref<?x?x?x?xf32>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%dim = memref.dim %0, %c0 : memref<?x?x?x?xf32>
// expected-error@+1 {{operand cannot be used as a symbol}}
// -----
func @affine_store_missing_l_square(%C: memref<4096x4096xf32>) {
- %9 = constant 0.0 : f32
+ %9 = arith.constant 0.0 : f32
// expected-error@+1 {{expected '['}}
affine.store %9, %C : memref<4096x4096xf32>
return
func @affine_parallel(%arg0 : index, %arg1 : index, %arg2 : index) {
affine.for %x = 0 to 7 {
- %y = addi %x, %x : index
+ %y = arith.addi %x, %x : index
// expected-error@+1 {{operand cannot be used as a dimension id}}
affine.parallel (%i, %j) = (0, 0) to (%y, 100) step (10, 10) {
}
func @affine_parallel(%arg0 : index, %arg1 : index, %arg2 : index) {
affine.for %x = 0 to 7 {
- %y = addi %x, %x : index
+ %y = arith.addi %x, %x : index
// expected-error@+1 {{operand cannot be used as a symbol}}
affine.parallel (%i, %j) = (0, 0) to (symbol(%y), 100) step (10, 10) {
}
func @vector_store_invalid_vector_type() {
%0 = memref.alloc() : memref<100xf32>
- %1 = constant dense<7.0> : vector<8xf64>
+ %1 = arith.constant dense<7.0> : vector<8xf64>
affine.for %i0 = 0 to 16 step 8 {
// expected-error@+1 {{requires memref and vector types of the same elemental type}}
affine.vector_store %1, %0[%i0] : memref<100xf32>, vector<8xf64>
func @vector_store_vector_memref() {
%0 = memref.alloc() : memref<100xvector<8xf32>>
- %1 = constant dense<7.0> : vector<8xf32>
+ %1 = arith.constant dense<7.0> : vector<8xf32>
affine.for %i0 = 0 to 4 {
// expected-error@+1 {{requires memref and vector types of the same elemental type}}
affine.vector_store %1, %0[%i0] : memref<100xvector<8xf32>>, vector<8xf32>
// -----
func @affine_if_with_then_region_args(%N: index) {
- %c = constant 200 : index
- %i = constant 20: index
+ %c = arith.constant 200 : index
+ %i = arith.constant 20: index
// expected-error@+1 {{affine.if' op region #0 should have no arguments}}
affine.if affine_set<(i)[N] : (i - 2 >= 0, 4 - i >= 0)>(%i)[%c] {
^bb0(%arg:i32):
// -----
func @affine_if_with_else_region_args(%N: index) {
- %c = constant 200 : index
- %i = constant 20: index
+ %c = arith.constant 200 : index
+ %i = arith.constant 20: index
// expected-error@+1 {{affine.if' op region #1 should have no arguments}}
affine.if affine_set<(i)[N] : (i - 2 >= 0, 4 - i >= 0)>(%i)[%c] {
%w = affine.apply affine_map<(d0,d1)[s0] -> (d0+d1+s0)> (%i, %i) [%N]
// -----
func @affine_for_iter_args_mismatch(%buffer: memref<1024xf32>) -> f32 {
- %sum_0 = constant 0.0 : f32
+ %sum_0 = arith.constant 0.0 : f32
// expected-error@+1 {{mismatch between the number of loop-carried values and results}}
%res = affine.for %i = 0 to 10 step 2 iter_args(%sum_iter = %sum_0) -> (f32, f32) {
%t = affine.load %buffer[%i] : memref<1024xf32>
func @load_non_affine_index(%arg0 : index) {
%0 = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
- %1 = muli %i0, %arg0 : index
+ %1 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op index must be a dimension or symbol identifier}}
%v = affine.load %0[%1] : memref<10xf32>
}
func @store_non_affine_index(%arg0 : index) {
%0 = memref.alloc() : memref<10xf32>
- %1 = constant 11.0 : f32
+ %1 = arith.constant 11.0 : f32
affine.for %i0 = 0 to 10 {
- %2 = muli %i0, %arg0 : index
+ %2 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op index must be a dimension or symbol identifier}}
affine.store %1, %0[%2] : memref<10xf32>
}
%0 = memref.alloc() : memref<100xf32>
%1 = memref.alloc() : memref<100xf32, 2>
%2 = memref.alloc() : memref<1xi32, 4>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
- %3 = muli %i0, %arg0 : index
+ %3 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op src index must be a dimension or symbol identifier}}
affine.dma_start %0[%3], %1[%i0], %2[%c0], %c64
: memref<100xf32>, memref<100xf32, 2>, memref<1xi32, 4>
%0 = memref.alloc() : memref<100xf32>
%1 = memref.alloc() : memref<100xf32, 2>
%2 = memref.alloc() : memref<1xi32, 4>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
- %3 = muli %i0, %arg0 : index
+ %3 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op dst index must be a dimension or symbol identifier}}
affine.dma_start %0[%i0], %1[%3], %2[%c0], %c64
: memref<100xf32>, memref<100xf32, 2>, memref<1xi32, 4>
%0 = memref.alloc() : memref<100xf32>
%1 = memref.alloc() : memref<100xf32, 2>
%2 = memref.alloc() : memref<1xi32, 4>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
- %3 = muli %i0, %arg0 : index
+ %3 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op tag index must be a dimension or symbol identifier}}
affine.dma_start %0[%i0], %1[%arg0], %2[%3], %c64
: memref<100xf32>, memref<100xf32, 2>, memref<1xi32, 4>
%0 = memref.alloc() : memref<100xf32>
%1 = memref.alloc() : memref<100xf32, 2>
%2 = memref.alloc() : memref<1xi32, 4>
- %c0 = constant 0 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c64 = arith.constant 64 : index
affine.for %i0 = 0 to 10 {
- %3 = muli %i0, %arg0 : index
+ %3 = arith.muli %i0, %arg0 : index
// expected-error@+1 {{op index must be a dimension or symbol identifier}}
affine.dma_wait %2[%3], %c64 : memref<1xi32, 4>
}
// CHECK: func @tile_loop_with_div_in_upper_bound([[ARG0:%arg[0-9]+]]: index, %{{.*}}: memref<?xi32>, %{{.*}}: index, %{{.*}}: index)
#ub = affine_map<()[s0, s1] -> (s0, 4096 floordiv s1)>
func @tile_loop_with_div_in_upper_bound(%t5 : index, %A : memref<? x i32>, %L : index, %U : index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %A, %c0 : memref<? x i32>
affine.for %i = 0 to min #ub()[%M, %U] {
- addi %i, %i : index
+ arith.addi %i, %i : index
}
// CHECK: affine.for [[ARG1:%arg[0-9]+]] = 0 to min [[UBO0]]()[%{{.*}}, %{{.*}}, [[ARG0]]]
// CHECK-NEXT: affine.for %[[I:.*]] = [[LBI0]]([[ARG1]]){{.*}}[[ARG0]]{{.*}} to min [[UBI0]]({{.*}})[{{.*}}, {{.*}}, [[ARG0]]]
- // CHECK-NEXT: addi %[[I]], %[[I]]
+ // CHECK-NEXT: arith.addi %[[I]], %[[I]]
return
}
// CHECK: func @tile_loop_with_div_in_upper_bound_non_unit_step([[ARG0:%arg[0-9]+]]: index, %{{.*}}: memref<?xi32>, %{{.*}}: index, %{{.*}}: index)
#ub = affine_map<()[s0, s1] -> (s0, 4096 floordiv s1)>
func @tile_loop_with_div_in_upper_bound_non_unit_step(%t5 : index, %A : memref<? x i32>, %L : index, %U : index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %A, %c0 : memref<? x i32>
affine.for %i = 0 to min #ub()[%M, %U] step 4 {
- addi %i, %i : index
+ arith.addi %i, %i : index
}
// CHECK: affine.for [[ARG1:%arg[0-9]+]] = 0 to min [[UBO0]]()[%{{.*}}, %{{.*}}, [[ARG0]]]{{.*}} step 4{{.*}}
// CHECK-NEXT: affine.for %[[I:.*]] = [[LBI0]]([[ARG1]]){{.*}}[[ARG0]]{{.*}} to min [[UBI0]]({{.*}})[{{.*}}, {{.*}}, [[ARG0]]]{{.*}} step 4{{.*}}
- // CHECK-NEXT: addi %[[I]], %[[I]]
+ // CHECK-NEXT: arith.addi %[[I]], %[[I]]
return
}
// CHECK-NEXT: affine.load %{{.*}}[%[[I]], %[[K]]]
// CHECK-NEXT: affine.load %{{.*}}[%[[K]], %[[J]]]
// CHECK-NEXT: affine.load %{{.*}}[%[[I]], %[[J]]]
-// CHECK-NEXT: mulf %{{.*}}
-// CHECK-NEXT: addf %{{.*}}
+// CHECK-NEXT: arith.mulf %{{.*}}
+// CHECK-NEXT: arith.addf %{{.*}}
// CHECK-NEXT: affine.store %{{.*}}[%[[I]], %[[J]]]
func @simple_matmul(%t6 : index, %t7 : index, %t8 : index, %arg0: memref<256x256xvector<64xf32>>, %arg1: memref<256x256xvector<64xf32>>, %arg2: memref<256x256xvector<64xf32>>) -> memref<256x256xvector<64xf32>> {
affine.for %i = 0 to 256 {
%l = affine.load %arg0[%i, %k] : memref<256x256xvector<64xf32>>
%r = affine.load %arg1[%k, %j] : memref<256x256xvector<64xf32>>
%o = affine.load %arg2[%i, %j] : memref<256x256xvector<64xf32>>
- %m = mulf %l, %r : vector<64xf32>
- %a = addf %o, %m : vector<64xf32>
+ %m = arith.mulf %l, %r : vector<64xf32>
+ %a = arith.addf %o, %m : vector<64xf32>
affine.store %a, %arg2[%i, %j] : memref<256x256xvector<64xf32>>
}
}
// CHECK-NEXT: affine.for %[[I2:.*]] = 0 to %{{.*}} {
// CHECK-NEXT: affine.load %{{.*}}%[[I0]], %[[I2]]
// CHECK-NEXT: affine.load %{{.*}}%[[I2]], %[[I1]]
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.load %{{.*}}%[[I0]], %[[I1]]
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store %{{.*}}%[[I0]], %[[I1]]
func @tile_with_symbolic_loop_upper_bounds(%t9 : index, %t10: index, %arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
affine.for %i0 = 0 to %0 {
affine.for %i1 = 0 to %0 {
affine.for %i2 = 0 to %0 {
%1 = affine.load %arg0[%i0, %i2] : memref<?x?xf32>
%2 = affine.load %arg1[%i2, %i1] : memref<?x?xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
%4 = affine.load %arg2[%i0, %i1] : memref<?x?xf32>
- %5 = addf %4, %3 : f32
+ %5 = arith.addf %4, %3 : f32
affine.store %5, %arg2[%i0, %i1] : memref<?x?xf32>
}
}
// CHECK: func @tile_with_loop_upper_bounds_in_two_symbols([[ARG0:%arg[0-9]+]]: index{{.*}}){{.*}}
func @tile_with_loop_upper_bounds_in_two_symbols(%t11 : index, %arg0: memref<?xf32>, %limit: index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%dim0 = memref.dim %arg0, %c0 : memref<?xf32>
affine.for %i0 = 0 to affine_map<()[s0, s1] -> (s0 + s1)> ()[%dim0, %limit] {
%v0 = affine.load %arg0[%i0] : memref<?xf32>
#ub = affine_map<(d0)[s0] -> (d0, s0)>
func @non_hyperrect_loop() {
- %N = constant 128 : index
+ %N = arith.constant 128 : index
// expected-error@+1 {{tiled code generation unimplemented for the non-hyperrectangular case}}
affine.for %i = 0 to %N {
affine.for %j = 0 to min #ub(%i)[%N] {
affine.for %i = 0 to 64 {
%1 = affine.load %0[%i] : memref<64xf32>
- %2 = addf %1, %1 : f32
+ %2 = arith.addf %1, %1 : f32
affine.store %2, %0[%i] : memref<64xf32>
}
affine.for %j = 0 to 64 {
%0 = affine.load %A[%j, %i] : memref<64x64xf32>
%1 = affine.load %A[%i, %j - 1] : memref<64x64xf32>
- %2 = addf %0, %1 : f32
+ %2 = arith.addf %0, %1 : f32
affine.store %2, %A[%i, %j] : memref<64x64xf32>
}
}
#ub = affine_map<()[s0, s1] -> (s0, 4096 floordiv s1)>
// CHECK-LABEL: func @loop_max_min_bound(%{{.*}}: memref<?xi32>, %{{.*}}: index, %{{.*}}: index) {
func @loop_max_min_bound(%A : memref<? x i32>, %L : index, %U : index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %A, %c0 : memref<? x i32>
affine.for %i = max #lb()[%L] to min #ub()[%M, %U] {
- addi %i, %i : index
+ arith.addi %i, %i : index
}
return
// CHECK: affine.for %{{.*}} = max [[$LB]]()[%{{.*}}] to min [[$UB]]()[%{{.*}}, %{{.*}}] step 32 {
// CHECK-NEXT: affine.for %[[I:.*]] = [[$IDENTITY]](%{{.*}}) to min [[$UB_INTRA_TILE]](%{{.*}})[%{{.*}}, %{{.*}}] {
-// CHECK-NEXT: addi %[[I]], %[[I]]
+// CHECK-NEXT: arith.addi %[[I]], %[[I]]
// CHECK-NEXT: }
// CHECK-NEXT: }
}
%l = affine.load %arg0[%i, %k] : memref<256x256xvector<64xf32>>
%r = affine.load %arg1[%k, %j] : memref<256x256xvector<64xf32>>
%o = affine.load %arg2[%i, %j] : memref<256x256xvector<64xf32>>
- %m = mulf %l, %r : vector<64xf32>
- %a = addf %o, %m : vector<64xf32>
+ %m = arith.mulf %l, %r : vector<64xf32>
+ %a = arith.addf %o, %m : vector<64xf32>
affine.store %a, %arg2[%i, %j] : memref<256x256xvector<64xf32>>
}
}
// CHECK-DAG: [[$UBMAP:#map[0-9]+]] = affine_map<(d0)[s0] -> (d0 + 32, s0)>
func @tile_with_symbolic_loop_upper_bounds(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
affine.for %i0 = 0 to %0 {
affine.for %i1 = 0 to %0 {
affine.for %i2 = 0 to %0 {
%1 = affine.load %arg0[%i0, %i2] : memref<?x?xf32>
%2 = affine.load %arg1[%i2, %i1] : memref<?x?xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
%4 = affine.load %arg2[%i0, %i1] : memref<?x?xf32>
- %5 = addf %4, %3 : f32
+ %5 = arith.addf %4, %3 : f32
affine.store %5, %arg2[%i0, %i1] : memref<?x?xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to %{{.*}} {
// CHECK-NEXT: affine.load
// CHECK-NEXT: affine.load
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-DAG: [[$UBMAP:#map[0-9]+]] = affine_map<(d0)[s0, s1] -> (d0 + 32, s0 + s1)>
func @tile_with_loop_upper_bounds_in_two_symbols(%arg0: memref<?xf32>, %limit: index) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%dim0 = memref.dim %arg0, %c0 : memref<?xf32>
affine.for %i0 = 0 to affine_map<()[s0, s1] -> (s0 + s1)> ()[%dim0, %limit] {
%v0 = affine.load %arg0[%i0] : memref<?xf32>
// -----
func @valid_symbols(%arg0: index, %arg1: index, %arg2: index) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
affine.for %arg3 = 0 to %arg2 step 768 {
%13 = memref.dim %0, %c1 : memref<?x?xf32>
// CHECK-LABEL: func @valid_symbol_affine_scope
func @valid_symbol_affine_scope(%n : index, %A : memref<?xf32>) {
test.affine_scope {
- %c1 = constant 1 : index
- %l = subi %n, %c1 : index
+ %c1 = arith.constant 1 : index
+ %l = arith.subi %n, %c1 : index
// %l, %n are valid symbols since test.affine_scope defines a new affine
// scope.
affine.for %i = %l to %n {
- %m = subi %l, %i : index
+ %m = arith.subi %l, %i : index
test.affine_scope {
// %m and %n are valid symbols.
affine.for %j = %m to %n {
// CHECK-LABEL: func @affine_if
func @affine_if() -> f32 {
- // CHECK: %[[ZERO:.*]] = constant {{.*}} : f32
- %zero = constant 0.0 : f32
+ // CHECK: %[[ZERO:.*]] = arith.constant {{.*}} : f32
+ %zero = arith.constant 0.0 : f32
// CHECK: %[[OUT:.*]] = affine.if {{.*}}() -> f32 {
%0 = affine.if affine_set<() : ()> () -> f32 {
// CHECK: affine.yield %[[ZERO]] : f32
// CHECK-LABEL: func @yield_loop
func @yield_loop(%buffer: memref<1024xf32>) -> f32 {
- %sum_init_0 = constant 0.0 : f32
+ %sum_init_0 = arith.constant 0.0 : f32
%res = affine.for %i = 0 to 10 step 2 iter_args(%sum_iter = %sum_init_0) -> f32 {
%t = affine.load %buffer[%i] : memref<1024xf32>
%sum_next = affine.if #set(%i) -> (f32) {
- %new_sum = addf %sum_iter, %t : f32
+ %new_sum = arith.addf %sum_iter, %t : f32
affine.yield %new_sum : f32
} else {
affine.yield %sum_iter : f32
}
return %res : f32
}
-// CHECK: %[[const_0:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[const_0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: %[[output:.*]] = affine.for %{{.*}} = 0 to 10 step 2 iter_args(%{{.*}} = %[[const_0]]) -> (f32) {
// CHECK: affine.if #set(%{{.*}}) -> f32 {
// CHECK: affine.yield %{{.*}} : f32
// CHECK-LABEL: func @affine_for_multiple_yield
func @affine_for_multiple_yield(%buffer: memref<1024xf32>) -> (f32, f32) {
- %init_0 = constant 0.0 : f32
+ %init_0 = arith.constant 0.0 : f32
%res1, %res2 = affine.for %i = 0 to 10 step 2 iter_args(%iter_arg1 = %init_0, %iter_arg2 = %init_0) -> (f32, f32) {
%t = affine.load %buffer[%i] : memref<1024xf32>
- %ret1 = addf %t, %iter_arg1 : f32
- %ret2 = addf %t, %iter_arg2 : f32
+ %ret1 = arith.addf %t, %iter_arg1 : f32
+ %ret2 = arith.addf %t, %iter_arg2 : f32
affine.yield %ret1, %ret2 : f32, f32
}
return %res1, %res2 : f32, f32
}
-// CHECK: %[[const_0:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[const_0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: %[[output:[0-9]+]]:2 = affine.for %{{.*}} = 0 to 10 step 2 iter_args(%[[iter_arg1:.*]] = %[[const_0]], %[[iter_arg2:.*]] = %[[const_0]]) -> (f32, f32) {
-// CHECK: %[[res1:.*]] = addf %{{.*}}, %[[iter_arg1]] : f32
-// CHECK-NEXT: %[[res2:.*]] = addf %{{.*}}, %[[iter_arg2]] : f32
+// CHECK: %[[res1:.*]] = arith.addf %{{.*}}, %[[iter_arg1]] : f32
+// CHECK-NEXT: %[[res2:.*]] = arith.addf %{{.*}}, %[[iter_arg2]] : f32
// CHECK-NEXT: affine.yield %[[res1]], %[[res2]] : f32, f32
// CHECK-NEXT: }
// CHECK-LABEL: func @reduce_window_max() {
func @reduce_window_max() {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = memref.alloc() : memref<1x8x8x64xf32>
%1 = memref.alloc() : memref<1x18x18x64xf32>
affine.for %arg0 = 0 to 1 {
affine.for %arg7 = 0 to 1 {
%2 = affine.load %0[%arg0, %arg1, %arg2, %arg3] : memref<1x8x8x64xf32>
%3 = affine.load %1[%arg0 + %arg4, %arg1 * 2 + %arg5, %arg2 * 2 + %arg6, %arg3 + %arg7] : memref<1x18x18x64xf32>
- %4 = cmpf ogt, %2, %3 : f32
+ %4 = arith.cmpf ogt, %2, %3 : f32
%5 = select %4, %2, %3 : f32
affine.store %5, %0[%arg0, %arg1, %arg2, %arg3] : memref<1x8x8x64xf32>
}
return
}
-// CHECK: %[[cst:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[cst:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[v0:.*]] = memref.alloc() : memref<1x8x8x64xf32>
// CHECK: %[[v1:.*]] = memref.alloc() : memref<1x18x18x64xf32>
// CHECK: affine.parallel (%[[arg0:.*]]) = (0) to (1) {
// CHECK: affine.parallel (%[[a7:.*]]) = (0) to (1) {
// CHECK: %[[lhs:.*]] = affine.load %[[v0]][%[[a0]], %[[a1]], %[[a2]], %[[a3]]] : memref<1x8x8x64xf32>
// CHECK: %[[rhs:.*]] = affine.load %[[v1]][%[[a0]] + %[[a4]], %[[a1]] * 2 + %[[a5]], %[[a2]] * 2 + %[[a6]], %[[a3]] + %[[a7]]] : memref<1x18x18x64xf32>
-// CHECK: %[[res:.*]] = cmpf ogt, %[[lhs]], %[[rhs]] : f32
+// CHECK: %[[res:.*]] = arith.cmpf ogt, %[[lhs]], %[[rhs]] : f32
// CHECK: %[[sel:.*]] = select %[[res]], %[[lhs]], %[[rhs]] : f32
// CHECK: affine.store %[[sel]], %[[v0]][%[[a0]], %[[a1]], %[[a2]], %[[a3]]] : memref<1x8x8x64xf32>
// CHECK: }
affine.for %k = 0 to %N {
%5 = affine.load %0[%i, %k] : memref<1024x1024xvector<64xf32>>
%6 = affine.load %1[%k, %j] : memref<1024x1024xvector<64xf32>>
- %8 = mulf %5, %6 : vector<64xf32>
- %9 = addf %7, %8 : vector<64xf32>
+ %8 = arith.mulf %5, %6 : vector<64xf32>
+ %9 = arith.addf %7, %8 : vector<64xf32>
affine.store %9, %2[%i, %j] : memref<1024x1024xvector<64xf32>>
}
}
%1 = affine.load %arg0[%arg3, %arg5] : memref<4096x4096xf32>
%2 = affine.load %arg1[%arg5, %arg4] : memref<4096x4096xf32>
%3 = affine.load %0[%arg3, %arg4] : memref<4096x4096xf32>
- %4 = mulf %1, %2 : f32
- %5 = addf %3, %4 : f32
+ %4 = arith.mulf %1, %2 : f32
+ %5 = arith.addf %3, %4 : f32
affine.store %5, %0[%arg3, %arg4] : memref<4096x4096xf32>
}
}
// CHECK-LABEL: @iter_args
// REDUCE-LABEL: @iter_args
func @iter_args(%in: memref<10xf32>) {
- // REDUCE: %[[init:.*]] = constant
- %cst = constant 0.000000e+00 : f32
+ // REDUCE: %[[init:.*]] = arith.constant
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK-NOT: affine.parallel
// REDUCE: %[[reduced:.*]] = affine.parallel (%{{.*}}) = (0) to (10) reduce ("addf")
%final_red = affine.for %i = 0 to 10 iter_args(%red_iter = %cst) -> (f32) {
// REDUCE: %[[red_value:.*]] = affine.load
%ld = affine.load %in[%i] : memref<10xf32>
- // REDUCE-NOT: addf
- %add = addf %red_iter, %ld : f32
+ // REDUCE-NOT: arith.addf
+ %add = arith.addf %red_iter, %ld : f32
// REDUCE: affine.yield %[[red_value]]
affine.yield %add : f32
}
- // REDUCE: addf %[[init]], %[[reduced]]
+ // REDUCE: arith.addf %[[init]], %[[reduced]]
return
}
// CHECK-LABEL: @nested_iter_args
// REDUCE-LABEL: @nested_iter_args
func @nested_iter_args(%in: memref<20x10xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK: affine.parallel
affine.for %i = 0 to 20 {
// CHECK-NOT: affine.parallel
// REDUCE: reduce ("addf")
%final_red = affine.for %j = 0 to 10 iter_args(%red_iter = %cst) -> (f32) {
%ld = affine.load %in[%i, %j] : memref<20x10xf32>
- %add = addf %red_iter, %ld : f32
+ %add = arith.addf %red_iter, %ld : f32
affine.yield %add : f32
}
}
// REDUCE-LABEL: @strange_butterfly
func @strange_butterfly() {
- %cst1 = constant 0.0 : f32
- %cst2 = constant 1.0 : f32
+ %cst1 = arith.constant 0.0 : f32
+ %cst2 = arith.constant 1.0 : f32
// REDUCE-NOT: affine.parallel
affine.for %i = 0 to 10 iter_args(%it1 = %cst1, %it2 = %cst2) -> (f32, f32) {
- %0 = addf %it1, %it2 : f32
+ %0 = arith.addf %it1, %it2 : f32
affine.yield %0, %0 : f32, f32
}
return
// should not be parallelized.
// REDUCE-LABEL: @repeated_use
func @repeated_use() {
- %cst1 = constant 0.0 : f32
+ %cst1 = arith.constant 0.0 : f32
// REDUCE-NOT: affine.parallel
affine.for %i = 0 to 10 iter_args(%it1 = %cst1) -> (f32) {
- %0 = addf %it1, %it1 : f32
+ %0 = arith.addf %it1, %it1 : f32
affine.yield %0 : f32
}
return
// reduced, this is not a simple reduction and should not be parallelized.
// REDUCE-LABEL: @use_in_backward_slice
func @use_in_backward_slice() {
- %cst1 = constant 0.0 : f32
- %cst2 = constant 1.0 : f32
+ %cst1 = arith.constant 0.0 : f32
+ %cst2 = arith.constant 1.0 : f32
// REDUCE-NOT: affine.parallel
affine.for %i = 0 to 10 iter_args(%it1 = %cst1, %it2 = %cst2) -> (f32, f32) {
%0 = "test.some_modification"(%it2) : (f32) -> f32
- %1 = addf %it1, %0 : f32
+ %1 = arith.addf %it1, %0 : f32
affine.yield %1, %1 : f32, f32
}
return
// CHECK-LABEL: func @simple_store_load() {
func @simple_store_load() {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
return
-// CHECK: %{{.*}} = constant 7.000000e+00 : f32
+// CHECK: %{{.*}} = arith.constant 7.000000e+00 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: }
// CHECK-NEXT: return
}
// CHECK-LABEL: func @multi_store_load() {
func @multi_store_load() {
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
- %cf9 = constant 9.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
+ %cf9 = arith.constant 9.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
affine.store %cf8, %m[%i0] : memref<10xf32>
affine.store %cf9, %m[%i0] : memref<10xf32>
%v2 = affine.load %m[%i0] : memref<10xf32>
%v3 = affine.load %m[%i0] : memref<10xf32>
- %v4 = mulf %v2, %v3 : f32
+ %v4 = arith.mulf %v2, %v3 : f32
}
return
-// CHECK: %{{.*}} = constant 0 : index
-// CHECK-NEXT: %{{.*}} = constant 7.000000e+00 : f32
-// CHECK-NEXT: %{{.*}} = constant 8.000000e+00 : f32
-// CHECK-NEXT: %{{.*}} = constant 9.000000e+00 : f32
+// CHECK: %{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 7.000000e+00 : f32
+// CHECK-NEXT: %{{.*}} = arith.constant 8.000000e+00 : f32
+// CHECK-NEXT: %{{.*}} = arith.constant 9.000000e+00 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
-// CHECK-NEXT: %{{.*}} = mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: }
// CHECK-NEXT: return
// dependence information.
// CHECK-LABEL: func @store_load_affine_apply
func @store_load_affine_apply() -> memref<10x10xf32> {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10x10xf32>
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.store %cf7, %m[%idx0, %idx1] : memref<10x10xf32>
// CHECK-NOT: affine.load %{{[0-9]+}}
%v0 = affine.load %m[%i0, %i1] : memref<10x10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
// The memref and its stores won't be erased due to this memref return.
return %m : memref<10x10xf32>
-// CHECK: %{{.*}} = constant 7.000000e+00 : f32
+// CHECK: %{{.*}} = arith.constant 7.000000e+00 : f32
// CHECK-NEXT: %{{.*}} = memref.alloc() : memref<10x10xf32>
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: %{{.*}} = affine.apply [[$MAP2]](%{{.*}}, %{{.*}})
// CHECK-NEXT: %{{.*}} = affine.apply [[$MAP3]](%{{.*}}, %{{.*}})
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-NEXT: return %{{.*}} : memref<10x10xf32>
// CHECK-LABEL: func @store_load_nested
func @store_load_nested(%N : index) {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i1 = 0 to %N {
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
return
-// CHECK: %{{.*}} = constant 7.000000e+00 : f32
+// CHECK: %{{.*}} = arith.constant 7.000000e+00 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.for %{{.*}} = 0 to %{{.*}} {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-NEXT: return
// out SSA scalars are available.
// CHECK-LABEL: func @multi_store_load_nested_no_fwd
func @multi_store_load_nested_no_fwd(%N : index) {
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i2 = 0 to %N {
// CHECK: %{{[0-9]+}} = affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
return
// the load.
// CHECK-LABEL: func @store_load_store_nested_no_fwd
func @store_load_store_nested_no_fwd(%N : index) {
- %cf7 = constant 7.0 : f32
- %cf9 = constant 9.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf9 = arith.constant 9.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i1 = 0 to %N {
// CHECK: %{{[0-9]+}} = affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
affine.store %cf9, %m[%i0] : memref<10xf32>
}
}
// and other forwarding criteria are satisfied.
// CHECK-LABEL: func @multi_store_load_nested_fwd
func @multi_store_load_nested_fwd(%N : index) {
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
- %cf9 = constant 9.0 : f32
- %cf10 = constant 10.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
+ %cf9 = arith.constant 9.0 : f32
+ %cf10 = arith.constant 10.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i3 = 0 to %N {
// CHECK-NOT: %{{[0-9]+}} = affine.load
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
return
// There is no unique load location for the store to forward to.
// CHECK-LABEL: func @store_load_no_fwd
func @store_load_no_fwd() {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i2 = 0 to 10 {
// CHECK: affine.load %{{[0-9]+}}
%v0 = affine.load %m[%i2] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
}
// Forwarding happens here as there is a one-to-one store-load correspondence.
// CHECK-LABEL: func @store_load_fwd
func @store_load_fwd() {
- %cf7 = constant 7.0 : f32
- %c0 = constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
+ %c0 = arith.constant 0 : index
%m = memref.alloc() : memref<10xf32>
affine.store %cf7, %m[%c0] : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.for %i2 = 0 to 10 {
// CHECK-NOT: affine.load %{{[0-9]}}+
%v0 = affine.load %m[%c0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
}
}
// satisfied by the outer surrounding loop, and does not prevent the first
// store to be forwarded to the load.
func @store_load_store_nested_fwd(%N : index) -> f32 {
- %cf7 = constant 7.0 : f32
- %cf9 = constant 9.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cf7 = arith.constant 7.0 : f32
+ %cf9 = arith.constant 9.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i1 = 0 to %N {
%v0 = affine.load %m[%i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
%idx = affine.apply affine_map<(d0) -> (d0 + 1)> (%i0)
affine.store %cf9, %m[%idx] : memref<10xf32>
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.for %{{.*}} = 0 to %{{.*}} {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: %{{.*}} = affine.apply [[$MAP4]](%{{.*}})
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-LABEL: func @should_not_fwd
func @should_not_fwd(%A: memref<100xf32>, %M : index, %N : index) -> f32 {
- %cf = constant 0.0 : f32
+ %cf = arith.constant 0.0 : f32
affine.store %cf, %A[%M] : memref<100xf32>
// CHECK: affine.load %{{.*}}[%{{.*}}]
%v = affine.load %A[%N] : memref<100xf32>
// CHECK-LABEL: func @refs_not_known_to_be_equal
func @refs_not_known_to_be_equal(%A : memref<100 x 100 x f32>, %M : index) {
%N = affine.apply affine_map<(d0) -> (d0 + 1)> (%M)
- %cf1 = constant 1.0 : f32
+ %cf1 = arith.constant 1.0 : f32
affine.for %i = 0 to 100 {
// CHECK: affine.for %[[I:.*]] =
affine.for %j = 0 to 100 {
%v0 = affine.load %in[%i0] : memref<10xf32>
// CHECK-NOT: affine.load
%v1 = affine.load %in[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
%v3 = affine.load %in[%i0] : memref<10xf32>
- %v4 = addf %v2, %v3 : f32
+ %v4 = arith.addf %v2, %v3 : f32
}
return
}
// CHECK-LABEL: func @nested_loads_const_index
func @nested_loads_const_index(%in : memref<10xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: affine.load
%v0 = affine.load %in[%c0] : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.for %i2 = 0 to 30 {
// CHECK-NOT: affine.load
%v1 = affine.load %in[%c0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
}
}
affine.for %i1 = 0 to %N {
// CHECK-NOT: affine.load
%v1 = affine.load %in[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
}
return
affine.for %i1 = 0 to 20 {
// CHECK: affine.load
%v1 = affine.load %in[%i1] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
}
return
%v0 = affine.load %m[%i0] : memref<10xf32>
// CHECK-NOT: affine.load
%v1 = affine.load %m[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
affine.store %v2, %m[%i0] : memref<10xf32>
}
return
affine.for %i1 = 0 to %N {
// CHECK: affine.load
%v1 = affine.load %m[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
affine.store %v2, %m[%i0] : memref<10xf32>
}
}
// CHECK-LABEL: func @load_load_store_3_loops_no_cse
func @load_load_store_3_loops_no_cse(%m : memref<10xf32>) {
-%cf1 = constant 1.0 : f32
+%cf1 = arith.constant 1.0 : f32
affine.for %i0 = 0 to 10 {
// CHECK: affine.load
%v0 = affine.load %m[%i0] : memref<10xf32>
affine.for %i2 = 0 to 30 {
// CHECK: affine.load
%v1 = affine.load %m[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
affine.store %cf1, %m[%i0] : memref<10xf32>
}
// CHECK-LABEL: func @load_load_store_3_loops
func @load_load_store_3_loops(%m : memref<10xf32>) {
-%cf1 = constant 1.0 : f32
+%cf1 = arith.constant 1.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 20 {
// CHECK: affine.load
affine.for %i2 = 0 to 30 {
// CHECK-NOT: affine.load
%v1 = affine.load %m[%i0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
}
affine.store %cf1, %m[%i0] : memref<10xf32>
// CHECK-LABEL: func @loads_in_sibling_loops_const_index_no_cse
func @loads_in_sibling_loops_const_index_no_cse(%m : memref<10xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
affine.for %i0 = 0 to 10 {
// CHECK: affine.load
%v0 = affine.load %m[%c0] : memref<10xf32>
affine.for %i1 = 0 to 10 {
// CHECK: affine.load
%v0 = affine.load %m[%c0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
}
return
}
%v0 = affine.load %in[%idx0, %idx1] : memref<10x10xf32>
// CHECK-NOT: affine.load
%v1 = affine.load %in[%i0, %i1] : memref<10x10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
}
}
return
%ld0 = affine.vector_load %in[32*%i] : memref<512xf32>, vector<32xf32>
// CHECK-NOT: affine.vector_load
%ld1 = affine.vector_load %in[32*%i] : memref<512xf32>, vector<32xf32>
- %add = addf %ld0, %ld1 : vector<32xf32>
+ %add = arith.addf %ld0, %ld1 : vector<32xf32>
affine.vector_store %ld1, %out[32*%i] : memref<512xf32>, vector<32xf32>
}
return
affine.vector_store %ld0, %in[16*%i] : memref<512xf32>, vector<32xf32>
// CHECK: affine.vector_load
%ld1 = affine.vector_load %in[32*%i] : memref<512xf32>, vector<32xf32>
- %add = addf %ld0, %ld1 : vector<32xf32>
+ %add = arith.addf %ld0, %ld1 : vector<32xf32>
affine.vector_store %ld1, %out[32*%i] : memref<512xf32>, vector<32xf32>
}
return
// CHECK-LABEL: func @reduction_multi_store
func @reduction_multi_store() -> memref<1xf32> {
%A = memref.alloc() : memref<1xf32>
- %cf0 = constant 0.0 : f32
- %cf5 = constant 5.0 : f32
+ %cf0 = arith.constant 0.0 : f32
+ %cf5 = arith.constant 5.0 : f32
affine.store %cf0, %A[0] : memref<1xf32>
affine.for %i = 0 to 100 step 2 {
%l = affine.load %A[0] : memref<1xf32>
- %s = addf %l, %cf5 : f32
+ %s = arith.addf %l, %cf5 : f32
// Store to load forwarding from this store should happen.
affine.store %s, %A[0] : memref<1xf32>
%m = affine.load %A[0] : memref<1xf32>
// CHECK-LABEL: func @vector_load_affine_apply_store_load
func @vector_load_affine_apply_store_load(%in : memref<512xf32>, %out : memref<512xf32>) {
- %cf1 = constant 1: index
+ %cf1 = arith.constant 1: index
affine.for %i = 0 to 15 {
// CHECK: affine.vector_load
%ld0 = affine.vector_load %in[32*%i] : memref<512xf32>, vector<32xf32>
affine.vector_store %ld0, %in[32*%idx] : memref<512xf32>, vector<32xf32>
// CHECK-NOT: affine.vector_load
%ld1 = affine.vector_load %in[32*%i] : memref<512xf32>, vector<32xf32>
- %add = addf %ld0, %ld1 : vector<32xf32>
+ %add = arith.addf %ld0, %ld1 : vector<32xf32>
affine.vector_store %ld1, %out[32*%i] : memref<512xf32>, vector<32xf32>
}
return
// CHECK-LABEL: func @external_no_forward_store
func @external_no_forward_store(%in : memref<512xf32>, %out : memref<512xf32>) {
- %cf1 = constant 1.0 : f32
+ %cf1 = arith.constant 1.0 : f32
affine.for %i = 0 to 16 {
affine.store %cf1, %in[32*%i] : memref<512xf32>
"memop"(%in, %out) : (memref<512xf32>, memref<512xf32>) -> ()
// CHECK-LABEL: func @no_forward_cast
func @no_forward_cast(%in : memref<512xf32>, %out : memref<512xf32>) {
- %cf1 = constant 1.0 : f32
- %cf2 = constant 2.0 : f32
+ %cf1 = arith.constant 1.0 : f32
+ %cf2 = arith.constant 2.0 : f32
%m2 = memref.cast %in : memref<512xf32> to memref<?xf32>
affine.for %i = 0 to 16 {
affine.store %cf1, %in[32*%i] : memref<512xf32>
// CHECK-LABEL: func @overlap_no_fwd
func @overlap_no_fwd(%N : index) -> f32 {
- %cf7 = constant 7.0 : f32
- %cf9 = constant 9.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cf7 = arith.constant 7.0 : f32
+ %cf9 = arith.constant 9.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 5 {
affine.store %cf7, %m[2 * %i0] : memref<10xf32>
affine.for %i1 = 0 to %N {
%v0 = affine.load %m[2 * %i0] : memref<10xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
affine.store %cf9, %m[%i0 + 1] : memref<10xf32>
}
}
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.for %{{.*}} = 0 to %{{.*}} {
// CHECK-NEXT: %{{.*}} = affine.load
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-LABEL: func @redundant_store_elim
func @redundant_store_elim(%out : memref<512xf32>) {
- %cf1 = constant 1.0 : f32
- %cf2 = constant 2.0 : f32
+ %cf1 = arith.constant 1.0 : f32
+ %cf2 = arith.constant 2.0 : f32
affine.for %i = 0 to 16 {
affine.store %cf1, %out[32*%i] : memref<512xf32>
affine.store %cf2, %out[32*%i] : memref<512xf32>
// CHECK-LABEL: func @redundant_store_elim_fail
func @redundant_store_elim_fail(%out : memref<512xf32>) {
- %cf1 = constant 1.0 : f32
- %cf2 = constant 2.0 : f32
+ %cf1 = arith.constant 1.0 : f32
+ %cf2 = arith.constant 2.0 : f32
affine.for %i = 0 to 16 {
affine.store %cf1, %out[32*%i] : memref<512xf32>
"test.use"(%out) : (memref<512xf32>) -> ()
// CHECK-LABEL: @with_inner_ops
func @with_inner_ops(%arg0: memref<?xf64>, %arg1: memref<?xf64>, %arg2: i1) {
- %cst = constant 0.000000e+00 : f64
- %cst_0 = constant 3.140000e+00 : f64
- %cst_1 = constant 1.000000e+00 : f64
+ %cst = arith.constant 0.000000e+00 : f64
+ %cst_0 = arith.constant 3.140000e+00 : f64
+ %cst_1 = arith.constant 1.000000e+00 : f64
affine.for %arg3 = 0 to 28 {
affine.store %cst, %arg1[%arg3] : memref<?xf64>
affine.store %cst_0, %arg1[%arg3] : memref<?xf64>
return
}
-// CHECK: %[[pi:.+]] = constant 3.140000e+00 : f64
+// CHECK: %[[pi:.+]] = arith.constant 3.140000e+00 : f64
// CHECK: %{{.*}} = scf.if %arg2 -> (f64) {
// CHECK: scf.yield %{{.*}} : f64
// CHECK: } else {
// CHECK-LABEL: func @test_gaussian_elimination_empty_set3() {
func @test_gaussian_elimination_empty_set3() {
- %c7 = constant 7 : index
- %c11 = constant 11 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
affine.for %arg0 = 1 to 10 {
affine.for %arg1 = 1 to 100 {
// CHECK-NOT: affine.if
// CHECK-LABEL: func @test_gaussian_elimination_non_empty_set4() {
func @test_gaussian_elimination_non_empty_set4() {
- %c7 = constant 7 : index
- %c11 = constant 11 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
affine.for %arg0 = 1 to 10 {
affine.for %arg1 = 1 to 100 {
// CHECK: #[[$SET_7_11]](%arg0, %arg1)
// CHECK-LABEL: func @test_gaussian_elimination_empty_set5() {
func @test_gaussian_elimination_empty_set5() {
- %c7 = constant 7 : index
- %c11 = constant 11 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
affine.for %arg0 = 1 to 10 {
affine.for %arg1 = 1 to 100 {
// CHECK-NOT: affine.if
// CHECK-DAG: -> (s0 * 2 + 1)
-// Test "op local" simplification on affine.apply. DCE on addi will not happen.
+// Test "op local" simplification on affine.apply. DCE on arith.addi will not happen.
func @affine.apply(%N : index) -> index {
%v = affine.apply affine_map<(d0, d1) -> (d0 + d1 + 1)>(%N, %N)
- %res = addi %v, %v : index
+ %res = arith.addi %v, %v : index
// CHECK: affine.apply #map{{.*}}()[%arg0]
- // CHECK-NEXT: addi
+ // CHECK-NEXT: arith.addi
return %res: index
}
// CHECK-LABEL: func @semiaffine_mod
func @semiaffine_mod(%arg0: index, %arg1: index) -> index {
%a = affine.apply affine_map<(d0)[s0] ->((-((d0 floordiv s0) * s0) + s0 * s0) mod s0)> (%arg0)[%arg1]
- // CHECK: %[[CST:.*]] = constant 0
+ // CHECK: %[[CST:.*]] = arith.constant 0
return %a : index
}
return %a : index
}
-// Tests the simplification of a semi-affine expression with a ceildiv operation and a division of constant 0 by a symbol.
+// Tests the simplification of a semi-affine expression with a ceildiv operation and a division of arith.constant 0 by a symbol.
// CHECK-LABEL: func @semiaffine_ceildiv
func @semiaffine_ceildiv(%arg0: index, %arg1: index) -> index {
%a = affine.apply affine_map<(d0)[s0] ->((-((d0 floordiv s0) * s0) + s0 * 42 + ((5-5) floordiv s0)) ceildiv s0)> (%arg0)[%arg1]
// CHECK-LABEL: func @semiaffine_composite_floor
func @semiaffine_composite_floor(%arg0: index, %arg1: index) -> index {
%a = affine.apply affine_map<(d0)[s0] ->(((((s0 * 2) ceildiv 4) * 5) + s0 * 42) ceildiv s0)> (%arg0)[%arg1]
- // CHECK: %[[CST:.*]] = constant 47
+ // CHECK: %[[CST:.*]] = arith.constant 47
return %a : index
}
// CHECK-LABEL: func @semiaffine_unsimplified_symbol
func @semiaffine_unsimplified_symbol(%arg0: index, %arg1: index) -> index {
%a = affine.apply affine_map<(d0)[s0] ->(s0 mod (2 * s0 - s0))> (%arg0)[%arg1]
- // CHECK: %[[CST:.*]] = constant 0
+ // CHECK: %[[CST:.*]] = arith.constant 0
return %a : index
}
// Testing: affine.if gets removed.
// CHECK-LABEL: func @test_num_results_if_elimination
func @test_num_results_if_elimination() -> index {
- // CHECK: %[[zero:.*]] = constant 0 : index
- %zero = constant 0 : index
+ // CHECK: %[[zero:.*]] = arith.constant 0 : index
+ %zero = arith.constant 0 : index
%0 = affine.if affine_set<() : ()> () -> index {
affine.yield %zero : index
} else {
// CHECK-LABEL: func @test_trivially_false_returning_two_results
// CHECK-SAME: (%[[arg0:.*]]: index)
func @test_trivially_false_returning_two_results(%arg0: index) -> (index, index) {
- // CHECK: %[[c7:.*]] = constant 7 : index
- // CHECK: %[[c13:.*]] = constant 13 : index
- %c7 = constant 7 : index
- %c13 = constant 13 : index
- // CHECK: %[[c2:.*]] = constant 2 : index
- // CHECK: %[[c3:.*]] = constant 3 : index
+ // CHECK: %[[c7:.*]] = arith.constant 7 : index
+ // CHECK: %[[c13:.*]] = arith.constant 13 : index
+ %c7 = arith.constant 7 : index
+ %c13 = arith.constant 13 : index
+ // CHECK: %[[c2:.*]] = arith.constant 2 : index
+ // CHECK: %[[c3:.*]] = arith.constant 3 : index
%res:2 = affine.if affine_set<(d0, d1) : (5 >= 0, -2 >= 0)> (%c7, %c13) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
affine.yield %c0, %c1 : index, index
} else {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
affine.yield %c7, %arg0 : index, index
}
// CHECK-NEXT: return %[[c7]], %[[arg0]] : index, index
// Testing: affine.if gets removed. `Then` block get promoted.
// CHECK-LABEL: func @test_trivially_true_returning_five_results
func @test_trivially_true_returning_five_results() -> (index, index, index, index, index) {
- // CHECK: %[[c12:.*]] = constant 12 : index
- // CHECK: %[[c13:.*]] = constant 13 : index
- %c12 = constant 12 : index
- %c13 = constant 13 : index
- // CHECK: %[[c0:.*]] = constant 0 : index
- // CHECK: %[[c1:.*]] = constant 1 : index
- // CHECK: %[[c2:.*]] = constant 2 : index
- // CHECK: %[[c3:.*]] = constant 3 : index
- // CHECK: %[[c4:.*]] = constant 4 : index
+ // CHECK: %[[c12:.*]] = arith.constant 12 : index
+ // CHECK: %[[c13:.*]] = arith.constant 13 : index
+ %c12 = arith.constant 12 : index
+ %c13 = arith.constant 13 : index
+ // CHECK: %[[c0:.*]] = arith.constant 0 : index
+ // CHECK: %[[c1:.*]] = arith.constant 1 : index
+ // CHECK: %[[c2:.*]] = arith.constant 2 : index
+ // CHECK: %[[c3:.*]] = arith.constant 3 : index
+ // CHECK: %[[c4:.*]] = arith.constant 4 : index
%res:5 = affine.if affine_set<(d0, d1) : (1 >= 0, 3 >= 0)>(%c12, %c13) -> (index, index, index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
affine.yield %c0, %c1, %c2, %c3, %c4 : index, index, index, index, index
} else {
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c8 = constant 8 : index
- %c9 = constant 9 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c8 = arith.constant 8 : index
+ %c9 = arith.constant 9 : index
affine.yield %c5, %c6, %c7, %c8, %c9 : index, index, index, index, index
}
// CHECK-NEXT: return %[[c0]], %[[c1]], %[[c2]], %[[c3]], %[[c4]] : index, index, index, index, index
// Testing: affine.if doesn't get removed.
// CHECK-LABEL: func @test_not_trivially_true_or_false_returning_three_results
func @test_not_trivially_true_or_false_returning_three_results() -> (index, index, index) {
- // CHECK: %[[c8:.*]] = constant 8 : index
- // CHECK: %[[c13:.*]] = constant 13 : index
- %c8 = constant 8 : index
- %c13 = constant 13 : index
+ // CHECK: %[[c8:.*]] = arith.constant 8 : index
+ // CHECK: %[[c13:.*]] = arith.constant 13 : index
+ %c8 = arith.constant 8 : index
+ %c13 = arith.constant 13 : index
// CHECK: affine.if
%res:3 = affine.if affine_set<(d0, d1) : (d0 - 1 == 0)>(%c8, %c13) -> (index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
affine.yield %c0, %c1, %c2 : index, index, index
// CHECK: } else {
} else {
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
affine.yield %c3, %c4, %c5 : index, index, index
}
return %res#0, %res#1, %res#2 : index, index, index
// BWD-LABEL: slicing_test_2
// FWDBWD-LABEL: slicing_test_2
func @slicing_test_2() {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c16 = constant 16 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c16 = arith.constant 16 : index
affine.for %i0 = %c0 to %c16 {
affine.for %i1 = affine_map<(i)[] -> (i)>(%i0) to 10 {
// BWD: matched: %[[b:.*]] {{.*}} backward static slice:
// BWD-LABEL: slicing_test_3
// FWDBWD-LABEL: slicing_test_3
func @slicing_test_3() {
- %f = constant 1.0 : f32
+ %f = arith.constant 1.0 : f32
%c = "slicing-test-op"(%f): (f32) -> index
// FWD: matched: {{.*}} (f32) -> index forward static slice:
// FWD: scf.for {{.*}}
// CHECK-LABEL: func @unroll_jam_one_iter_arg
func @unroll_jam_one_iter_arg() {
affine.for %i = 0 to 101 {
- %cst = constant 1 : i32
+ %cst = arith.constant 1 : i32
%x = "addi32"(%i, %i) : (index, index) -> i32
%red = affine.for %j = 0 to 17 iter_args(%acc = %cst) -> (i32) {
%y = "bar"(%i, %j, %acc) : (index, index, i32) -> i32
return
}
// CHECK: affine.for [[IV0:%arg[0-9]+]] = 0 to 100 step 2 {
-// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES1:%[0-9]+]] = "addi32"([[IV0]], [[IV0]])
// CHECK-NEXT: [[INC:%[0-9]+]] = affine.apply [[$MAP_PLUS_1]]([[IV0]])
-// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES2:%[0-9]+]] = "addi32"([[INC]], [[INC]])
// CHECK-NEXT: [[RES3:%[0-9]+]]:2 = affine.for [[IV1:%arg[0-9]+]] = 0 to 17 iter_args([[ACC1:%arg[0-9]+]] = [[CONST1]], [[ACC2:%arg[0-9]+]] = [[CONST2]]) -> (i32, i32) {
// CHECK-NEXT: [[RES4:%[0-9]+]] = "bar"([[IV0]], [[IV1]], [[ACC1]])
// CHECK-LABEL: func @unroll_jam_iter_args
func @unroll_jam_iter_args() {
affine.for %i = 0 to 101 {
- %cst = constant 0 : i32
- %cst1 = constant 1 : i32
+ %cst = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
%x = "addi32"(%i, %i) : (index, index) -> i32
%red:2 = affine.for %j = 0 to 17 iter_args(%acc = %cst, %acc1 = %cst1) -> (i32, i32) {
%y = "bar"(%i, %j, %acc) : (index, index, i32) -> i32
return
}
// CHECK: affine.for [[IV0:%arg[0-9]+]] = 0 to 100 step 2 {
-// CHECK-NEXT: [[CONST0:%[a-zA-Z0-9_]*]] = constant 0 : i32
-// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST0:%[a-zA-Z0-9_]*]] = arith.constant 0 : i32
+// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES1:%[0-9]+]] = "addi32"([[IV0]], [[IV0]])
// CHECK-NEXT: [[INC:%[0-9]+]] = affine.apply [[$MAP_PLUS_1]]([[IV0]])
-// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = constant 0 : i32
-// CHECK-NEXT: [[CONST3:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = arith.constant 0 : i32
+// CHECK-NEXT: [[CONST3:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES2:%[0-9]+]] = "addi32"([[INC]], [[INC]])
// CHECK-NEXT: [[RES3:%[0-9]+]]:4 = affine.for [[IV1:%arg[0-9]+]] = 0 to 17 iter_args([[ACC0:%arg[0-9]+]] = [[CONST0]], [[ACC1:%arg[0-9]+]] = [[CONST1]],
// CHECK-SAME: [[ACC2:%arg[0-9]+]] = [[CONST2]], [[ACC3:%arg[0-9]+]] = [[CONST3]]) -> (i32, i32, i32, i32) {
// CHECK-LABEL: func @unroll_jam_iter_args_nested
func @unroll_jam_iter_args_nested() {
affine.for %i = 0 to 101 {
- %cst = constant 1 : i32
+ %cst = arith.constant 1 : i32
%x = "addi32"(%i, %i) : (index, index) -> i32
%red = affine.for %j = 0 to 17 iter_args(%acc = %cst) -> (i32) {
%red1 = affine.for %k = 0 to 35 iter_args(%acc1 = %acc) -> (i32) {
return
}
// CHECK: affine.for [[IV0:%arg[0-9]+]] = 0 to 100 step 2 {
-// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES1:%[0-9]+]] = "addi32"([[IV0]], [[IV0]])
// CHECK-NEXT: [[INC:%[0-9]+]] = affine.apply [[$MAP_PLUS_1]]([[IV0]])
-// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES2:%[0-9]+]] = "addi32"([[INC]], [[INC]])
// CHECK-NEXT: [[RES3:%[0-9]+]]:2 = affine.for [[IV1:%arg[0-9]+]] = 0 to 17 iter_args([[ACC1:%arg[0-9]+]] = [[CONST1]], [[ACC2:%arg[0-9]+]] = [[CONST2]]) -> (i32, i32) {
// CHECK-NEXT: [[RES4:%[0-9]+]]:2 = affine.for [[IV2:%arg[0-9]+]] = 0 to 35 iter_args([[ACC3:%arg[0-9]+]] = [[ACC1]], [[ACC4:%arg[0-9]+]] = [[ACC2]]) -> (i32, i32) {
// CHECK-LABEL: func @unroll_jam_iter_args_nested_affine_for_result
func @unroll_jam_iter_args_nested_affine_for_result() {
affine.for %i = 0 to 101 {
- %cst = constant 1 : i32
+ %cst = arith.constant 1 : i32
%x = "addi32"(%i, %i) : (index, index) -> i32
%red = affine.for %j = 0 to 17 iter_args(%acc = %cst) -> (i32) {
%red1 = affine.for %k = 0 to 35 iter_args(%acc1 = %acc) -> (i32) {
return
}
// CHECK: affine.for [[IV0:%arg[0-9]+]] = 0 to 100 step 2 {
-// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES1:%[0-9]+]] = "addi32"([[IV0]], [[IV0]])
// CHECK-NEXT: [[INC:%[0-9]+]] = affine.apply [[$MAP_PLUS_1]]([[IV0]])
-// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES2:%[0-9]+]] = "addi32"([[INC]], [[INC]])
// CHECK-NEXT: [[RES3:%[0-9]+]]:2 = affine.for [[IV1:%arg[0-9]+]] = 0 to 17 iter_args([[ACC1:%arg[0-9]+]] = [[CONST1]], [[ACC2:%arg[0-9]+]] = [[CONST2]]) -> (i32, i32) {
// CHECK-NEXT: [[RES4:%[0-9]+]]:2 = affine.for [[IV2:%arg[0-9]+]] = 0 to 35 iter_args([[ACC3:%arg[0-9]+]] = [[ACC1]], [[ACC4:%arg[0-9]+]] = [[ACC2]]) -> (i32, i32) {
// CHECK-LABEL: func @unroll_jam_iter_args_nested_yield
func @unroll_jam_iter_args_nested_yield() {
affine.for %i = 0 to 101 {
- %cst = constant 1 : i32
+ %cst = arith.constant 1 : i32
%x = "addi32"(%i, %i) : (index, index) -> i32
%red:3 = affine.for %j = 0 to 17 iter_args(%acc = %cst, %acc1 = %cst, %acc2 = %cst) -> (i32, i32, i32) {
%red1 = affine.for %k = 0 to 35 iter_args(%acc3 = %acc) -> (i32) {
return
}
// CHECK: affine.for [[IV0:%arg[0-9]+]] = 0 to 100 step 2 {
-// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST1:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES1:%[0-9]+]] = "addi32"([[IV0]], [[IV0]])
// CHECK-NEXT: [[INC:%[0-9]+]] = affine.apply [[$MAP_PLUS_1]]([[IV0]])
-// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = constant 1 : i32
+// CHECK-NEXT: [[CONST2:%[a-zA-Z0-9_]*]] = arith.constant 1 : i32
// CHECK-NEXT: [[RES2:%[0-9]+]] = "addi32"([[INC]], [[INC]])
// CHECK-NEXT: [[RES3:%[0-9]+]]:6 = affine.for [[IV1:%arg[0-9]+]] = 0 to 17 iter_args([[ACC1:%arg[0-9]+]] = [[CONST1]], [[ACC2:%arg[0-9]+]] = [[CONST1]],
// CHECK-SAME: [[ACC3:%arg[0-9]+]] = [[CONST1]], [[ACC4:%arg[0-9]+]] = [[CONST2]], [[ACC5:%arg[0-9]+]] = [[CONST2]], [[ACC6:%arg[0-9]+]] = [[CONST2]]) -> (i32, i32, i32, i32, i32, i32) {
%0 = affine.for %arg3 = 0 to 21 iter_args(%arg4 = %init) -> (f32) {
%1 = affine.for %arg5 = 0 to 30 iter_args(%arg6 = %init1) -> (f32) {
%3 = affine.load %arg0[%arg3, %arg5] : memref<21x30xf32, 1>
- %4 = addf %arg6, %3 : f32
+ %4 = arith.addf %arg6, %3 : f32
affine.yield %4 : f32
}
- %2 = mulf %arg4, %1 : f32
+ %2 = arith.mulf %arg4, %1 : f32
affine.yield %2 : f32
}
return
}
-// CHECK: %[[CONST0:[a-zA-Z0-9_]*]] = constant 20 : index
+// CHECK: %[[CONST0:[a-zA-Z0-9_]*]] = arith.constant 20 : index
// CHECK-NEXT: [[RES:%[0-9]+]]:2 = affine.for %[[IV0:arg[0-9]+]] = 0 to 20 step 2 iter_args([[ACC0:%arg[0-9]+]] = [[INIT0]], [[ACC1:%arg[0-9]+]] = [[INIT0]]) -> (f32, f32) {
// CHECK-NEXT: [[RES1:%[0-9]+]]:2 = affine.for %[[IV1:arg[0-9]+]] = 0 to 30 iter_args([[ACC2:%arg[0-9]+]] = [[INIT1]], [[ACC3:%arg[0-9]+]] = [[INIT1]]) -> (f32, f32) {
// CHECK-NEXT: [[LOAD1:%[0-9]+]] = affine.load {{.*}}[%[[IV0]], %[[IV1]]]
-// CHECK-NEXT: [[ADD1:%[0-9]+]] = addf [[ACC2]], [[LOAD1]] : f32
+// CHECK-NEXT: [[ADD1:%[0-9]+]] = arith.addf [[ACC2]], [[LOAD1]] : f32
// CHECK-NEXT: %[[INC1:[0-9]+]] = affine.apply [[$MAP_PLUS_1]](%[[IV0]])
// CHECK-NEXT: [[LOAD2:%[0-9]+]] = affine.load {{.*}}[%[[INC1]], %[[IV1]]]
-// CHECK-NEXT: [[ADD2:%[0-9]+]] = addf [[ACC3]], [[LOAD2]] : f32
+// CHECK-NEXT: [[ADD2:%[0-9]+]] = arith.addf [[ACC3]], [[LOAD2]] : f32
// CHECK-NEXT: affine.yield [[ADD1]], [[ADD2]]
// CHECK-NEXT: }
-// CHECK-NEXT: [[MUL1:%[0-9]+]] = mulf [[ACC0]], [[RES1]]#0 : f32
+// CHECK-NEXT: [[MUL1:%[0-9]+]] = arith.mulf [[ACC0]], [[RES1]]#0 : f32
// CHECK-NEXT: affine.apply
-// CHECK-NEXT: [[MUL2:%[0-9]+]] = mulf [[ACC1]], [[RES1]]#1 : f32
+// CHECK-NEXT: [[MUL2:%[0-9]+]] = arith.mulf [[ACC1]], [[RES1]]#1 : f32
// CHECK-NEXT: affine.yield [[MUL1]], [[MUL2]]
// CHECK-NEXT: }
// Reduction op.
-// CHECK-NEXT: [[MUL3:%[0-9]+]] = mulf [[RES]]#0, [[RES]]#1 : f32
+// CHECK-NEXT: [[MUL3:%[0-9]+]] = arith.mulf [[RES]]#0, [[RES]]#1 : f32
// Cleanup loop (single iteration).
// CHECK-NEXT: [[RES2:%[0-9]+]] = affine.for %[[IV2:arg[0-9]+]] = 0 to 30 iter_args([[ACC4:%arg[0-9]+]] = [[INIT1]]) -> (f32) {
// CHECK-NEXT: [[LOAD3:%[0-9]+]] = affine.load {{.*}}[%[[CONST0]], %[[IV2]]]
-// CHECK-NEXT: [[ADD3:%[0-9]+]] = addf [[ACC4]], [[LOAD3]] : f32
+// CHECK-NEXT: [[ADD3:%[0-9]+]] = arith.addf [[ACC4]], [[LOAD3]] : f32
// CHECK-NEXT: affine.yield [[ADD3]] : f32
// CHECK-NEXT: }
-// CHECK-NEXT: [[MUL4:%[0-9]+]] = mulf [[MUL3]], [[RES2]] : f32
+// CHECK-NEXT: [[MUL4:%[0-9]+]] = arith.mulf [[MUL3]], [[RES2]] : f32
// CHECK-NEXT: return
// CHECK-LABEL: func @unroll_jam_iter_args_addi
func @unroll_jam_iter_args_addi(%arg0: memref<21xi32, 1>, %init : i32) {
%0 = affine.for %arg3 = 0 to 21 iter_args(%arg4 = %init) -> (i32) {
%1 = affine.load %arg0[%arg3] : memref<21xi32, 1>
- %2 = addi %arg4, %1 : i32
+ %2 = arith.addi %arg4, %1 : i32
affine.yield %2 : i32
}
return
}
-// CHECK: %[[CONST0:[a-zA-Z0-9_]*]] = constant 20 : index
+// CHECK: %[[CONST0:[a-zA-Z0-9_]*]] = arith.constant 20 : index
// CHECK-NEXT: [[RES:%[0-9]+]]:2 = affine.for %[[IV0:arg[0-9]+]] = 0 to 20 step 2 iter_args([[ACC0:%arg[0-9]+]] = [[INIT0]], [[ACC1:%arg[0-9]+]] = [[INIT0]]) -> (i32, i32) {
// CHECK-NEXT: [[LOAD1:%[0-9]+]] = affine.load {{.*}}[%[[IV0]]]
-// CHECK-NEXT: [[ADD1:%[0-9]+]] = addi [[ACC0]], [[LOAD1]] : i32
+// CHECK-NEXT: [[ADD1:%[0-9]+]] = arith.addi [[ACC0]], [[LOAD1]] : i32
// CHECK-NEXT: %[[INC1:[0-9]+]] = affine.apply [[$MAP_PLUS_1]](%[[IV0]])
// CHECK-NEXT: [[LOAD2:%[0-9]+]] = affine.load {{.*}}[%[[INC1]]]
-// CHECK-NEXT: [[ADD2:%[0-9]+]] = addi [[ACC1]], [[LOAD2]] : i32
+// CHECK-NEXT: [[ADD2:%[0-9]+]] = arith.addi [[ACC1]], [[LOAD2]] : i32
// CHECK-NEXT: affine.yield [[ADD1]], [[ADD2]]
// CHECK-NEXT: }
// Reduction op.
-// CHECK-NEXT: [[ADD3:%[0-9]+]] = addi [[RES]]#0, [[RES]]#1 : i32
+// CHECK-NEXT: [[ADD3:%[0-9]+]] = arith.addi [[RES]]#0, [[RES]]#1 : i32
// Cleanup loop (single iteration).
// CHECK-NEXT: [[LOAD3:%[0-9]+]] = affine.load {{.*}}[%[[CONST0]]]
-// CHECK-NEXT: [[ADD4:%[0-9]+]] = addi [[ADD3]], [[LOAD3]] : i32
+// CHECK-NEXT: [[ADD4:%[0-9]+]] = arith.addi [[ADD3]], [[LOAD3]] : i32
// CHECK-NEXT: return
func @loop_nest_simplest() {
// UNROLL-FULL: affine.for %arg0 = 0 to 100 step 2 {
affine.for %i = 0 to 100 step 2 {
- // UNROLL-FULL: %c1_i32 = constant 1 : i32
- // UNROLL-FULL-NEXT: %c1_i32_0 = constant 1 : i32
- // UNROLL-FULL-NEXT: %c1_i32_1 = constant 1 : i32
- // UNROLL-FULL-NEXT: %c1_i32_2 = constant 1 : i32
+ // UNROLL-FULL: %c1_i32 = arith.constant 1 : i32
+ // UNROLL-FULL-NEXT: %c1_i32_0 = arith.constant 1 : i32
+ // UNROLL-FULL-NEXT: %c1_i32_1 = arith.constant 1 : i32
+ // UNROLL-FULL-NEXT: %c1_i32_2 = arith.constant 1 : i32
affine.for %j = 0 to 4 {
- %x = constant 1 : i32
+ %x = arith.constant 1 : i32
}
} // UNROLL-FULL: }
return // UNROLL-FULL: return
// UNROLL-FULL-LABEL: func @loop_nest_simple_iv_use() {
func @loop_nest_simple_iv_use() {
- // UNROLL-FULL: %c0 = constant 0 : index
+ // UNROLL-FULL: %c0 = arith.constant 0 : index
// UNROLL-FULL-NEXT: affine.for %arg0 = 0 to 100 step 2 {
affine.for %i = 0 to 100 step 2 {
// UNROLL-FULL: %0 = "addi32"(%c0, %c0) : (index, index) -> i32
// Operations in the loop body have results that are used therein.
// UNROLL-FULL-LABEL: func @loop_nest_body_def_use() {
func @loop_nest_body_def_use() {
- // UNROLL-FULL: %c0 = constant 0 : index
+ // UNROLL-FULL: %c0 = arith.constant 0 : index
// UNROLL-FULL-NEXT: affine.for %arg0 = 0 to 100 step 2 {
affine.for %i = 0 to 100 step 2 {
- // UNROLL-FULL: %c0_0 = constant 0 : index
- %c0 = constant 0 : index
+ // UNROLL-FULL: %c0_0 = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
// UNROLL-FULL: %0 = affine.apply [[$MAP0]](%c0)
// UNROLL-FULL-NEXT: %1 = "addi32"(%0, %c0_0) : (index, index) -> index
// UNROLL-FULL-NEXT: %2 = affine.apply [[$MAP0]](%c0)
// UNROLL-FULL-LABEL: func @loop_nest_strided() {
func @loop_nest_strided() {
- // UNROLL-FULL: %c2 = constant 2 : index
- // UNROLL-FULL-NEXT: %c2_0 = constant 2 : index
+ // UNROLL-FULL: %c2 = arith.constant 2 : index
+ // UNROLL-FULL-NEXT: %c2_0 = arith.constant 2 : index
// UNROLL-FULL-NEXT: affine.for %arg0 = 0 to 100 {
affine.for %i = 0 to 100 {
// UNROLL-FULL: %0 = affine.apply [[$MAP0]](%c2_0)
// UNROLL-FULL-LABEL: func @loop_nest_multiple_results() {
func @loop_nest_multiple_results() {
- // UNROLL-FULL: %c0 = constant 0 : index
+ // UNROLL-FULL: %c0 = arith.constant 0 : index
// UNROLL-FULL-NEXT: affine.for %arg0 = 0 to 100 {
affine.for %i = 0 to 100 {
// UNROLL-FULL: %0 = affine.apply [[$MAP4]](%arg0, %c0)
// Imperfect loop nest. Unrolling innermost here yields a perfect nest.
// UNROLL-FULL-LABEL: func @loop_nest_seq_imperfect(%arg0: memref<128x128xf32>) {
func @loop_nest_seq_imperfect(%a : memref<128x128xf32>) {
- // UNROLL-FULL: %c0 = constant 0 : index
- // UNROLL-FULL-NEXT: %c128 = constant 128 : index
- %c128 = constant 128 : index
+ // UNROLL-FULL: %c0 = arith.constant 0 : index
+ // UNROLL-FULL-NEXT: %c128 = arith.constant 128 : index
+ %c128 = arith.constant 128 : index
// UNROLL-FULL: affine.for %arg1 = 0 to 100 {
affine.for %i = 0 to 100 {
// UNROLL-FULL: %0 = "vld"(%arg1) : (index) -> i32
// UNROLL-FULL-LABEL: func @loop_nest_seq_multiple() {
func @loop_nest_seq_multiple() {
- // UNROLL-FULL: c0 = constant 0 : index
- // UNROLL-FULL-NEXT: %c0_0 = constant 0 : index
+ // UNROLL-FULL: c0 = arith.constant 0 : index
+ // UNROLL-FULL-NEXT: %c0_0 = arith.constant 0 : index
// UNROLL-FULL-NEXT: %0 = affine.apply [[$MAP0]](%c0_0)
// UNROLL-FULL-NEXT: "mul"(%0, %0) : (index, index) -> ()
// UNROLL-FULL-NEXT: %1 = affine.apply [[$MAP0]](%c0_0)
"mul"(%x, %x) : (index, index) -> ()
}
- // UNROLL-FULL: %c99 = constant 99 : index
- %k = constant 99 : index
+ // UNROLL-FULL: %c99 = arith.constant 99 : index
+ %k = arith.constant 99 : index
// UNROLL-FULL: affine.for %arg0 = 0 to 100 step 2 {
affine.for %m = 0 to 100 step 2 {
// UNROLL-FULL: %7 = affine.apply [[$MAP0]](%c0)
%B = memref.alloc() : memref<512 x 512 x i32, affine_map<(d0, d1) -> (d0, d1)>, 2>
%C = memref.alloc() : memref<512 x 512 x i32, affine_map<(d0, d1) -> (d0, d1)>, 2>
- %zero = constant 0 : i32
- %one = constant 1 : i32
- %two = constant 2 : i32
+ %zero = arith.constant 0 : i32
+ %one = arith.constant 1 : i32
+ %two = arith.constant 2 : i32
- %zero_idx = constant 0 : index
+ %zero_idx = arith.constant 0 : index
// CHECK: affine.for %arg0 = 0 to 512
affine.for %n0 = 0 to 512 {
// Both the unrolled loop and the cleanup loop are single iteration loops.
// UNROLL-BY-4-LABEL: func @loop_nest_single_iteration_after_unroll
func @loop_nest_single_iteration_after_unroll(%N: index) {
- // UNROLL-BY-4: %c0 = constant 0 : index
- // UNROLL-BY-4: %c4 = constant 4 : index
+ // UNROLL-BY-4: %c0 = arith.constant 0 : index
+ // UNROLL-BY-4: %c4 = arith.constant 4 : index
// UNROLL-BY-4: affine.for %arg1 = 0 to %arg0 {
affine.for %i = 0 to %N {
// UNROLL-BY-4: %0 = "addi32"(%c0, %c0) : (index, index) -> i32
%x = "foo"(%i) : (index) -> i32
}
return
-// UNROLL-BY-1-NEXT: %c0 = constant 0 : index
+// UNROLL-BY-1-NEXT: %c0 = arith.constant 0 : index
// UNROLL-BY-1-NEXT: %0 = "foo"(%c0) : (index) -> i32
// UNROLL-BY-1-NEXT: return
}
// UNROLL-BY-4-LABEL: loop_unroll_with_iter_args_and_cleanup
func @loop_unroll_with_iter_args_and_cleanup(%arg0 : f32, %arg1 : f32, %n : index) -> (f32,f32) {
- %cf1 = constant 1.0 : f32
- %cf2 = constant 2.0 : f32
+ %cf1 = arith.constant 1.0 : f32
+ %cf2 = arith.constant 2.0 : f32
%sum:2 = affine.for %iv = 0 to 10 iter_args(%i0 = %arg0, %i1 = %arg1) -> (f32, f32) {
- %sum0 = addf %i0, %cf1 : f32
- %sum1 = addf %i1, %cf2 : f32
+ %sum0 = arith.addf %i0, %cf1 : f32
+ %sum1 = arith.addf %i1, %cf2 : f32
affine.yield %sum0, %sum1 : f32, f32
}
return %sum#0, %sum#1 : f32, f32
// UNROLL-BY-4: %[[SUM:.*]]:2 = affine.for {{.*}} = 0 to 8 step 4 iter_args
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: addf
- // UNROLL-BY-4-NEXT: %[[Y1:.*]] = addf
- // UNROLL-BY-4-NEXT: %[[Y2:.*]] = addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: arith.addf
+ // UNROLL-BY-4-NEXT: %[[Y1:.*]] = arith.addf
+ // UNROLL-BY-4-NEXT: %[[Y2:.*]] = arith.addf
// UNROLL-BY-4-NEXT: affine.yield %[[Y1]], %[[Y2]]
// UNROLL-BY-4-NEXT: }
// UNROLL-BY-4-NEXT: %[[SUM1:.*]]:2 = affine.for {{.*}} = 8 to 10 iter_args(%[[V1:.*]] = %[[SUM]]#0, %[[V2:.*]] = %[[SUM]]#1)
// UNROLL-BY-4-LABEL: unroll_with_iter_args_and_promotion
func @unroll_with_iter_args_and_promotion(%arg0 : f32, %arg1 : f32) -> f32 {
- %from = constant 0 : index
- %to = constant 10 : index
- %step = constant 1 : index
+ %from = arith.constant 0 : index
+ %to = arith.constant 10 : index
+ %step = arith.constant 1 : index
%sum = affine.for %iv = 0 to 9 iter_args(%sum_iter = %arg0) -> (f32) {
- %next = addf %sum_iter, %arg1 : f32
+ %next = arith.addf %sum_iter, %arg1 : f32
affine.yield %next : f32
}
// UNROLL-BY-4: %[[SUM:.*]] = affine.for %{{.*}} = 0 to 8 step 4 iter_args(%[[V0:.*]] =
- // UNROLL-BY-4-NEXT: %[[V1:.*]] = addf %[[V0]]
- // UNROLL-BY-4-NEXT: %[[V2:.*]] = addf %[[V1]]
- // UNROLL-BY-4-NEXT: %[[V3:.*]] = addf %[[V2]]
- // UNROLL-BY-4-NEXT: %[[V4:.*]] = addf %[[V3]]
+ // UNROLL-BY-4-NEXT: %[[V1:.*]] = arith.addf %[[V0]]
+ // UNROLL-BY-4-NEXT: %[[V2:.*]] = arith.addf %[[V1]]
+ // UNROLL-BY-4-NEXT: %[[V3:.*]] = arith.addf %[[V2]]
+ // UNROLL-BY-4-NEXT: %[[V4:.*]] = arith.addf %[[V3]]
// UNROLL-BY-4-NEXT: affine.yield %[[V4]]
// UNROLL-BY-4-NEXT: }
- // UNROLL-BY-4-NEXT: %[[RES:.*]] = addf %[[SUM]],
+ // UNROLL-BY-4-NEXT: %[[RES:.*]] = arith.addf %[[SUM]],
// UNROLL-BY-4-NEXT: return %[[RES]]
return %sum : f32
}
--- /dev/null
+// RUN: mlir-opt %s -arith-bufferize | FileCheck %s
+
+// CHECK-LABEL: func @index_cast(
+// CHECK-SAME: %[[TENSOR:.*]]: tensor<i32>, %[[SCALAR:.*]]: i32
+func @index_cast(%tensor: tensor<i32>, %scalar: i32) -> (tensor<index>, index) {
+ %index_tensor = arith.index_cast %tensor : tensor<i32> to tensor<index>
+ %index_scalar = arith.index_cast %scalar : i32 to index
+ return %index_tensor, %index_scalar : tensor<index>, index
+}
+// CHECK: %[[MEMREF:.*]] = memref.buffer_cast %[[TENSOR]] : memref<i32>
+// CHECK-NEXT: %[[INDEX_MEMREF:.*]] = arith.index_cast %[[MEMREF]]
+// CHECK-SAME: memref<i32> to memref<index>
+// CHECK-NEXT: %[[INDEX_TENSOR:.*]] = memref.tensor_load %[[INDEX_MEMREF]]
+// CHECK: return %[[INDEX_TENSOR]]
--- /dev/null
+// RUN: mlir-opt %s -canonicalize --split-input-file | FileCheck %s
+
+// Test case: Folding of comparisons with equal operands.
+// CHECK-LABEL: @cmpi_equal_operands
+// CHECK-DAG: %[[T:.*]] = arith.constant true
+// CHECK-DAG: %[[F:.*]] = arith.constant false
+// CHECK: return %[[T]], %[[T]], %[[T]], %[[T]], %[[T]],
+// CHECK-SAME: %[[F]], %[[F]], %[[F]], %[[F]], %[[F]]
+func @cmpi_equal_operands(%arg0: i64)
+ -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
+ %0 = arith.cmpi eq, %arg0, %arg0 : i64
+ %1 = arith.cmpi sle, %arg0, %arg0 : i64
+ %2 = arith.cmpi sge, %arg0, %arg0 : i64
+ %3 = arith.cmpi ule, %arg0, %arg0 : i64
+ %4 = arith.cmpi uge, %arg0, %arg0 : i64
+ %5 = arith.cmpi ne, %arg0, %arg0 : i64
+ %6 = arith.cmpi slt, %arg0, %arg0 : i64
+ %7 = arith.cmpi sgt, %arg0, %arg0 : i64
+ %8 = arith.cmpi ult, %arg0, %arg0 : i64
+ %9 = arith.cmpi ugt, %arg0, %arg0 : i64
+ return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9
+ : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
+}
+
+// -----
+
+// CHECK-LABEL: @indexCastOfSignExtend
+// CHECK: %[[res:.+]] = arith.index_cast %arg0 : i8 to index
+// CHECK: return %[[res]]
+func @indexCastOfSignExtend(%arg0: i8) -> index {
+ %ext = arith.extsi %arg0 : i8 to i16
+ %idx = arith.index_cast %ext : i16 to index
+ return %idx : index
+}
+
+// CHECK-LABEL: @signExtendConstant
+// CHECK: %[[cres:.+]] = arith.constant -2 : i16
+// CHECK: return %[[cres]]
+func @signExtendConstant() -> i16 {
+ %c-2 = arith.constant -2 : i8
+ %ext = arith.extsi %c-2 : i8 to i16
+ return %ext : i16
+}
+
+// CHECK-LABEL: @truncConstant
+// CHECK: %[[cres:.+]] = arith.constant -2 : i16
+// CHECK: return %[[cres]]
+func @truncConstant(%arg0: i8) -> i16 {
+ %c-2 = arith.constant -2 : i32
+ %tr = arith.trunci %c-2 : i32 to i16
+ return %tr : i16
+}
+
+// CHECK-LABEL: @truncFPConstant
+// CHECK: %[[cres:.+]] = arith.constant 1.000000e+00 : bf16
+// CHECK: return %[[cres]]
+func @truncFPConstant() -> bf16 {
+ %cst = arith.constant 1.000000e+00 : f32
+ %0 = arith.truncf %cst : f32 to bf16
+ return %0 : bf16
+}
+
+// Test that cases with rounding are NOT propagated
+// CHECK-LABEL: @truncFPConstantRounding
+// CHECK: arith.constant 1.444000e+25 : f32
+// CHECK: truncf
+func @truncFPConstantRounding() -> bf16 {
+ %cst = arith.constant 1.444000e+25 : f32
+ %0 = arith.truncf %cst : f32 to bf16
+ return %0 : bf16
+}
+
+// CHECK-LABEL: @tripleAddAdd
+// CHECK: %[[cres:.+]] = arith.constant 59 : index
+// CHECK: %[[add:.+]] = arith.addi %arg0, %[[cres]] : index
+// CHECK: return %[[add]]
+func @tripleAddAdd(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.addi %c17, %arg0 : index
+ %add2 = arith.addi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleAddSub0
+// CHECK: %[[cres:.+]] = arith.constant 59 : index
+// CHECK: %[[add:.+]] = arith.subi %[[cres]], %arg0 : index
+// CHECK: return %[[add]]
+func @tripleAddSub0(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %c17, %arg0 : index
+ %add2 = arith.addi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleAddSub1
+// CHECK: %[[cres:.+]] = arith.constant 25 : index
+// CHECK: %[[add:.+]] = arith.addi %arg0, %[[cres]] : index
+// CHECK: return %[[add]]
+func @tripleAddSub1(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %arg0, %c17 : index
+ %add2 = arith.addi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubAdd0
+// CHECK: %[[cres:.+]] = arith.constant 25 : index
+// CHECK: %[[add:.+]] = arith.subi %[[cres]], %arg0 : index
+// CHECK: return %[[add]]
+func @tripleSubAdd0(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.addi %c17, %arg0 : index
+ %add2 = arith.subi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubAdd1
+// CHECK: %[[cres:.+]] = arith.constant -25 : index
+// CHECK: %[[add:.+]] = arith.addi %arg0, %[[cres]] : index
+// CHECK: return %[[add]]
+func @tripleSubAdd1(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.addi %c17, %arg0 : index
+ %add2 = arith.subi %add1, %c42 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubSub0
+// CHECK: %[[cres:.+]] = arith.constant 25 : index
+// CHECK: %[[add:.+]] = arith.addi %arg0, %[[cres]] : index
+// CHECK: return %[[add]]
+func @tripleSubSub0(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %c17, %arg0 : index
+ %add2 = arith.subi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubSub1
+// CHECK: %[[cres:.+]] = arith.constant -25 : index
+// CHECK: %[[add:.+]] = arith.subi %[[cres]], %arg0 : index
+// CHECK: return %[[add]]
+func @tripleSubSub1(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %c17, %arg0 : index
+ %add2 = arith.subi %add1, %c42 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubSub2
+// CHECK: %[[cres:.+]] = arith.constant 59 : index
+// CHECK: %[[add:.+]] = arith.subi %[[cres]], %arg0 : index
+// CHECK: return %[[add]]
+func @tripleSubSub2(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %arg0, %c17 : index
+ %add2 = arith.subi %c42, %add1 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @tripleSubSub3
+// CHECK: %[[cres:.+]] = arith.constant 59 : index
+// CHECK: %[[add:.+]] = arith.subi %arg0, %[[cres]] : index
+// CHECK: return %[[add]]
+func @tripleSubSub3(%arg0: index) -> index {
+ %c17 = arith.constant 17 : index
+ %c42 = arith.constant 42 : index
+ %add1 = arith.subi %arg0, %c17 : index
+ %add2 = arith.subi %add1, %c42 : index
+ return %add2 : index
+}
+
+// CHECK-LABEL: @notCmpEQ
+// CHECK: %[[cres:.+]] = arith.cmpi ne, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpEQ(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "eq", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpEQ2
+// CHECK: %[[cres:.+]] = arith.cmpi ne, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpEQ2(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "eq", %arg0, %arg1 : i8
+ %ncmp = arith.xori %true, %cmp : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpNE
+// CHECK: %[[cres:.+]] = arith.cmpi eq, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpNE(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "ne", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpSLT
+// CHECK: %[[cres:.+]] = arith.cmpi sge, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpSLT(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "slt", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpSLE
+// CHECK: %[[cres:.+]] = arith.cmpi sgt, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpSLE(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "sle", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpSGT
+// CHECK: %[[cres:.+]] = arith.cmpi sle, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpSGT(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "sgt", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpSGE
+// CHECK: %[[cres:.+]] = arith.cmpi slt, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpSGE(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "sge", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpULT
+// CHECK: %[[cres:.+]] = arith.cmpi uge, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpULT(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "ult", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpULE
+// CHECK: %[[cres:.+]] = arith.cmpi ugt, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpULE(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "ule", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpUGT
+// CHECK: %[[cres:.+]] = arith.cmpi ule, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpUGT(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "ugt", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// CHECK-LABEL: @notCmpUGE
+// CHECK: %[[cres:.+]] = arith.cmpi ult, %arg0, %arg1 : i8
+// CHECK: return %[[cres]]
+func @notCmpUGE(%arg0: i8, %arg1: i8) -> i1 {
+ %true = arith.constant true
+ %cmp = arith.cmpi "uge", %arg0, %arg1 : i8
+ %ncmp = arith.xori %cmp, %true : i1
+ return %ncmp : i1
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastSameType(
+// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
+func @bitcastSameType(%arg : f32) -> f32 {
+ // CHECK: return %[[ARG]]
+ %res = arith.bitcast %arg : f32 to f32
+ return %res : f32
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantFPtoI(
+func @bitcastConstantFPtoI() -> i32 {
+ // CHECK: %[[C0:.+]] = arith.constant 0 : i32
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant 0.0 : f32
+ %res = arith.bitcast %c0 : f32 to i32
+ return %res : i32
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantItoFP(
+func @bitcastConstantItoFP() -> f32 {
+ // CHECK: %[[C0:.+]] = arith.constant 0.0{{.*}} : f32
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant 0 : i32
+ %res = arith.bitcast %c0 : i32 to f32
+ return %res : f32
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantFPtoFP(
+func @bitcastConstantFPtoFP() -> f16 {
+ // CHECK: %[[C0:.+]] = arith.constant 0.0{{.*}} : f16
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant 0.0 : bf16
+ %res = arith.bitcast %c0 : bf16 to f16
+ return %res : f16
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantVecFPtoI(
+func @bitcastConstantVecFPtoI() -> vector<3xf32> {
+ // CHECK: %[[C0:.+]] = arith.constant dense<0.0{{.*}}> : vector<3xf32>
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant dense<0> : vector<3xi32>
+ %res = arith.bitcast %c0 : vector<3xi32> to vector<3xf32>
+ return %res : vector<3xf32>
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantVecItoFP(
+func @bitcastConstantVecItoFP() -> vector<3xi32> {
+ // CHECK: %[[C0:.+]] = arith.constant dense<0> : vector<3xi32>
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant dense<0.0> : vector<3xf32>
+ %res = arith.bitcast %c0 : vector<3xf32> to vector<3xi32>
+ return %res : vector<3xi32>
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastConstantVecFPtoFP(
+func @bitcastConstantVecFPtoFP() -> vector<3xbf16> {
+ // CHECK: %[[C0:.+]] = arith.constant dense<0.0{{.*}}> : vector<3xbf16>
+ // CHECK: return %[[C0]]
+ %c0 = arith.constant dense<0.0> : vector<3xf16>
+ %res = arith.bitcast %c0 : vector<3xf16> to vector<3xbf16>
+ return %res : vector<3xbf16>
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastBackAndForth(
+// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
+func @bitcastBackAndForth(%arg : i32) -> i32 {
+ // CHECK: return %[[ARG]]
+ %f = arith.bitcast %arg : i32 to f32
+ %res = arith.bitcast %f : f32 to i32
+ return %res : i32
+}
+
+// -----
+
+// CHECK-LABEL: @bitcastOfBitcast(
+// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
+func @bitcastOfBitcast(%arg : i16) -> i16 {
+ // CHECK: return %[[ARG]]
+ %f = arith.bitcast %arg : i16 to f16
+ %bf = arith.bitcast %f : f16 to bf16
+ %res = arith.bitcast %bf : bf16 to i16
+ return %res : i16
+}
--- /dev/null
+// RUN: mlir-opt %s -arith-expand -split-input-file | FileCheck %s
+
+// Test ceil divide with signed integer
+// CHECK-LABEL: func @ceildivi
+// CHECK-SAME: ([[ARG0:%.+]]: i32, [[ARG1:%.+]]: i32) -> i32 {
+func @ceildivi(%arg0: i32, %arg1: i32) -> (i32) {
+ %res = arith.ceildivsi %arg0, %arg1 : i32
+ return %res : i32
+
+// CHECK: [[ONE:%.+]] = arith.constant 1 : i32
+// CHECK: [[ZERO:%.+]] = arith.constant 0 : i32
+// CHECK: [[MINONE:%.+]] = arith.constant -1 : i32
+// CHECK: [[CMP1:%.+]] = arith.cmpi sgt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[X:%.+]] = select [[CMP1]], [[MINONE]], [[ONE]] : i32
+// CHECK: [[TRUE1:%.+]] = arith.addi [[X]], [[ARG0]] : i32
+// CHECK: [[TRUE2:%.+]] = arith.divsi [[TRUE1]], [[ARG1]] : i32
+// CHECK: [[TRUE3:%.+]] = arith.addi [[ONE]], [[TRUE2]] : i32
+// CHECK: [[FALSE1:%.+]] = arith.subi [[ZERO]], [[ARG0]] : i32
+// CHECK: [[FALSE2:%.+]] = arith.divsi [[FALSE1]], [[ARG1]] : i32
+// CHECK: [[FALSE3:%.+]] = arith.subi [[ZERO]], [[FALSE2]] : i32
+// CHECK: [[NNEG:%.+]] = arith.cmpi slt, [[ARG0]], [[ZERO]] : i32
+// CHECK: [[NPOS:%.+]] = arith.cmpi sgt, [[ARG0]], [[ZERO]] : i32
+// CHECK: [[MNEG:%.+]] = arith.cmpi slt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[MPOS:%.+]] = arith.cmpi sgt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[TERM1:%.+]] = arith.andi [[NNEG]], [[MNEG]] : i1
+// CHECK: [[TERM2:%.+]] = arith.andi [[NPOS]], [[MPOS]] : i1
+// CHECK: [[CMP2:%.+]] = arith.ori [[TERM1]], [[TERM2]] : i1
+// CHECK: [[RES:%.+]] = select [[CMP2]], [[TRUE3]], [[FALSE3]] : i32
+}
+
+// -----
+
+// Test floor divide with signed integer
+// CHECK-LABEL: func @floordivi
+// CHECK-SAME: ([[ARG0:%.+]]: i32, [[ARG1:%.+]]: i32) -> i32 {
+func @floordivi(%arg0: i32, %arg1: i32) -> (i32) {
+ %res = arith.floordivsi %arg0, %arg1 : i32
+ return %res : i32
+// CHECK: [[ONE:%.+]] = arith.constant 1 : i32
+// CHECK: [[ZERO:%.+]] = arith.constant 0 : i32
+// CHECK: [[MIN1:%.+]] = arith.constant -1 : i32
+// CHECK: [[CMP1:%.+]] = arith.cmpi slt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[X:%.+]] = select [[CMP1]], [[ONE]], [[MIN1]] : i32
+// CHECK: [[TRUE1:%.+]] = arith.subi [[X]], [[ARG0]] : i32
+// CHECK: [[TRUE2:%.+]] = arith.divsi [[TRUE1]], [[ARG1]] : i32
+// CHECK: [[TRUE3:%.+]] = arith.subi [[MIN1]], [[TRUE2]] : i32
+// CHECK: [[FALSE:%.+]] = arith.divsi [[ARG0]], [[ARG1]] : i32
+// CHECK: [[NNEG:%.+]] = arith.cmpi slt, [[ARG0]], [[ZERO]] : i32
+// CHECK: [[NPOS:%.+]] = arith.cmpi sgt, [[ARG0]], [[ZERO]] : i32
+// CHECK: [[MNEG:%.+]] = arith.cmpi slt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[MPOS:%.+]] = arith.cmpi sgt, [[ARG1]], [[ZERO]] : i32
+// CHECK: [[TERM1:%.+]] = arith.andi [[NNEG]], [[MPOS]] : i1
+// CHECK: [[TERM2:%.+]] = arith.andi [[NPOS]], [[MNEG]] : i1
+// CHECK: [[CMP2:%.+]] = arith.ori [[TERM1]], [[TERM2]] : i1
+// CHECK: [[RES:%.+]] = select [[CMP2]], [[TRUE3]], [[FALSE]] : i32
+}
--- /dev/null
+// RUN: mlir-opt -split-input-file %s -verify-diagnostics
+
+func @test_index_cast_shape_error(%arg0 : tensor<index>) -> tensor<2xi64> {
+ // expected-error @+1 {{'arith.index_cast' op requires the same shape for all operands and results}}
+ %0 = arith.index_cast %arg0 : tensor<index> to tensor<2xi64>
+ return %0 : tensor<2xi64>
+}
+
+// -----
+
+func @test_index_cast_tensor_error(%arg0 : tensor<index>) -> i64 {
+ // expected-error @+1 {{'arith.index_cast' op requires the same shape for all operands and results}}
+ %0 = arith.index_cast %arg0 : tensor<index> to i64
+ return %0 : i64
+}
+
+// -----
+
+func @non_signless_constant() {
+ // expected-error @+1 {{'arith.constant' op integer return type must be signless}}
+ %0 = arith.constant 0 : ui32
+ return
+}
+
+// -----
+
+func @complex_constant_wrong_attribute_type() {
+ // expected-error @+1 {{'arith.constant' op failed to verify that result and attribute have the same type}}
+ %0 = "arith.constant" () {value = 1.0 : f32} : () -> complex<f32>
+ return
+}
+
+// -----
+
+func @non_signless_constant() {
+ // expected-error @+1 {{'arith.constant' op integer return type must be signless}}
+ %0 = arith.constant 0 : si32
+ return
+}
+
+// -----
+
+func @bitcast_different_bit_widths(%arg : f16) -> f32 {
+ // expected-error@+1 {{are cast incompatible}}
+ %res = arith.bitcast %arg : f16 to f32
+ return %res : f32
+}
+
+// -----
+
+func @constant() {
+^bb:
+ %x = "arith.constant"(){value = "xyz"} : () -> i32 // expected-error {{'arith.constant' op failed to verify that result and attribute have the same type}}
+ return
+}
+
+// -----
+
+func @constant_out_of_range() {
+^bb:
+ %x = "arith.constant"(){value = 100} : () -> i1 // expected-error {{'arith.constant' op failed to verify that result and attribute have the same type}}
+ return
+}
+
+// -----
+
+func @constant_wrong_type() {
+^bb:
+ %x = "arith.constant"(){value = 10.} : () -> f32 // expected-error {{'arith.constant' op failed to verify that result and attribute have the same type}}
+ return
+}
+
+// -----
+
+func @intlimit2() {
+^bb:
+ %0 = "arith.constant"() {value = 0} : () -> i16777215
+ %1 = "arith.constant"() {value = 1} : () -> i16777216 // expected-error {{integer bitwidth is limited to 16777215 bits}}
+ return
+}
+
+// -----
+
+func @func_with_ops(f32) {
+^bb0(%a : f32):
+ %sf = arith.addf %a, %a, %a : f32 // expected-error {{expected ':'}}
+}
+
+// -----
+
+func @func_with_ops(f32) {
+^bb0(%a : f32):
+ %sf = arith.addf(%a, %a) : f32 // expected-error {{expected SSA operand}}
+}
+
+// -----
+
+func @func_with_ops(f32) {
+^bb0(%a : f32):
+ %sf = arith.addf{%a, %a} : f32 // expected-error {{expected SSA operand}}
+}
+
+// -----
+
+func @func_with_ops(f32) {
+^bb0(%a : f32):
+ // expected-error@+1 {{'arith.addi' op operand #0 must be signless-integer-like}}
+ %sf = arith.addi %a, %a : f32
+}
+
+// -----
+
+func @func_with_ops(i32) {
+^bb0(%a : i32):
+ %sf = arith.addf %a, %a : i32 // expected-error {{'arith.addf' op operand #0 must be floating-point-like}}
+}
+
+// -----
+
+func @func_with_ops(i32) {
+^bb0(%a : i32):
+ // expected-error@+1 {{failed to satisfy constraint: allowed 64-bit signless integer cases: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9}}
+ %r = "arith.cmpi"(%a, %a) {predicate = 42} : (i32, i32) -> i1
+}
+
+// -----
+
+// Comparison are defined for arguments of the same type.
+func @func_with_ops(i32, i64) {
+^bb0(%a : i32, %b : i64): // expected-note {{prior use here}}
+ %r = arith.cmpi eq, %a, %b : i32 // expected-error {{use of value '%b' expects different type than prior uses}}
+}
+
+// -----
+
+// Comparisons must have the "predicate" attribute.
+func @func_with_ops(i32, i32) {
+^bb0(%a : i32, %b : i32):
+ %r = arith.cmpi %a, %b : i32 // expected-error {{expected string or keyword containing one of the following enum values}}
+}
+
+// -----
+
+// Integer comparisons are not recognized for float types.
+func @func_with_ops(f32, f32) {
+^bb0(%a : f32, %b : f32):
+ %r = arith.cmpi eq, %a, %b : f32 // expected-error {{'lhs' must be signless-integer-like, but got 'f32'}}
+}
+
+// -----
+
+// Result type must be boolean like.
+func @func_with_ops(i32, i32) {
+^bb0(%a : i32, %b : i32):
+ %r = "arith.cmpi"(%a, %b) {predicate = 0} : (i32, i32) -> i32 // expected-error {{op result #0 must be bool-like}}
+}
+
+// -----
+
+func @func_with_ops(i32, i32) {
+^bb0(%a : i32, %b : i32):
+ // expected-error@+1 {{requires attribute 'predicate'}}
+ %r = "arith.cmpi"(%a, %b) {foo = 1} : (i32, i32) -> i1
+}
+
+// -----
+
+func @func_with_ops() {
+^bb0:
+ %c = arith.constant dense<0> : vector<42 x i32>
+ // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
+ %r = "arith.cmpi"(%c, %c) {predicate = 0} : (vector<42 x i32>, vector<42 x i32>) -> vector<41 x i1>
+}
+
+// -----
+
+func @invalid_cmp_shape(%idx : () -> ()) {
+ // expected-error@+1 {{'lhs' must be signless-integer-like, but got '() -> ()'}}
+ %cmp = arith.cmpi eq, %idx, %idx : () -> ()
+
+// -----
+
+func @invalid_cmp_attr(%idx : i32) {
+ // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
+ %cmp = arith.cmpi i1, %idx, %idx : i32
+
+// -----
+
+func @cmpf_generic_invalid_predicate_value(%a : f32) {
+ // expected-error@+1 {{attribute 'predicate' failed to satisfy constraint: allowed 64-bit signless integer cases}}
+ %r = "arith.cmpf"(%a, %a) {predicate = 42} : (f32, f32) -> i1
+}
+
+// -----
+
+func @cmpf_canonical_invalid_predicate_value(%a : f32) {
+ // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
+ %r = arith.cmpf foo, %a, %a : f32
+}
+
+// -----
+
+func @cmpf_canonical_invalid_predicate_value_signed(%a : f32) {
+ // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
+ %r = arith.cmpf sge, %a, %a : f32
+}
+
+// -----
+
+func @cmpf_canonical_invalid_predicate_value_no_order(%a : f32) {
+ // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
+ %r = arith.cmpf eq, %a, %a : f32
+}
+
+// -----
+
+func @cmpf_canonical_no_predicate_attr(%a : f32, %b : f32) {
+ %r = arith.cmpf %a, %b : f32 // expected-error {{}}
+}
+
+// -----
+
+func @cmpf_generic_no_predicate_attr(%a : f32, %b : f32) {
+ // expected-error@+1 {{requires attribute 'predicate'}}
+ %r = "arith.cmpf"(%a, %b) {foo = 1} : (f32, f32) -> i1
+}
+
+// -----
+
+func @cmpf_wrong_type(%a : i32, %b : i32) {
+ %r = arith.cmpf oeq, %a, %b : i32 // expected-error {{must be floating-point-like}}
+}
+
+// -----
+
+func @cmpf_generic_wrong_result_type(%a : f32, %b : f32) {
+ // expected-error@+1 {{result #0 must be bool-like}}
+ %r = "arith.cmpf"(%a, %b) {predicate = 0} : (f32, f32) -> f32
+}
+
+// -----
+
+func @cmpf_canonical_wrong_result_type(%a : f32, %b : f32) -> f32 {
+ %r = arith.cmpf oeq, %a, %b : f32 // expected-note {{prior use here}}
+ // expected-error@+1 {{use of value '%r' expects different type than prior uses}}
+ return %r : f32
+}
+
+// -----
+
+func @cmpf_result_shape_mismatch(%a : vector<42xf32>) {
+ // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
+ %r = "arith.cmpf"(%a, %a) {predicate = 0} : (vector<42 x f32>, vector<42 x f32>) -> vector<41 x i1>
+}
+
+// -----
+
+func @cmpf_operand_shape_mismatch(%a : vector<42xf32>, %b : vector<41xf32>) {
+ // expected-error@+1 {{op requires all operands to have the same type}}
+ %r = "arith.cmpf"(%a, %b) {predicate = 0} : (vector<42 x f32>, vector<41 x f32>) -> vector<42 x i1>
+}
+
+// -----
+
+func @cmpf_generic_operand_type_mismatch(%a : f32, %b : f64) {
+ // expected-error@+1 {{op requires all operands to have the same type}}
+ %r = "arith.cmpf"(%a, %b) {predicate = 0} : (f32, f64) -> i1
+}
+
+// -----
+
+func @cmpf_canonical_type_mismatch(%a : f32, %b : f64) { // expected-note {{prior use here}}
+ // expected-error@+1 {{use of value '%b' expects different type than prior uses}}
+ %r = arith.cmpf oeq, %a, %b : f32
+}
+
+// -----
+
+func @index_cast_index_to_index(%arg0: index) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.index_cast %arg0: index to index
+ return
+}
+
+// -----
+
+func @index_cast_float(%arg0: index, %arg1: f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.index_cast %arg0 : index to f32
+ return
+}
+
+// -----
+
+func @index_cast_float_to_index(%arg0: f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.index_cast %arg0 : f32 to index
+ return
+}
+
+// -----
+
+func @sitofp_i32_to_i64(%arg0 : i32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.sitofp %arg0 : i32 to i64
+ return
+}
+
+// -----
+
+func @sitofp_f32_to_i32(%arg0 : f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.sitofp %arg0 : f32 to i32
+ return
+}
+
+// -----
+
+func @fpext_f32_to_f16(%arg0 : f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : f32 to f16
+ return
+}
+
+// -----
+
+func @fpext_f16_to_f16(%arg0 : f16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : f16 to f16
+ return
+}
+
+// -----
+
+func @fpext_i32_to_f32(%arg0 : i32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : i32 to f32
+ return
+}
+
+// -----
+
+func @fpext_f32_to_i32(%arg0 : f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : f32 to i32
+ return
+}
+
+// -----
+
+func @fpext_vec(%arg0 : vector<2xf16>) {
+ // expected-error@+1 {{op requires the same shape for all operands and results}}
+ %0 = arith.extf %arg0 : vector<2xf16> to vector<3xf32>
+ return
+}
+
+// -----
+
+func @fpext_vec_f32_to_f16(%arg0 : vector<2xf32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : vector<2xf32> to vector<2xf16>
+ return
+}
+
+// -----
+
+func @fpext_vec_f16_to_f16(%arg0 : vector<2xf16>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : vector<2xf16> to vector<2xf16>
+ return
+}
+
+// -----
+
+func @fpext_vec_i32_to_f32(%arg0 : vector<2xi32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : vector<2xi32> to vector<2xf32>
+ return
+}
+
+// -----
+
+func @fpext_vec_f32_to_i32(%arg0 : vector<2xf32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extf %arg0 : vector<2xf32> to vector<2xi32>
+ return
+}
+
+// -----
+
+func @fptrunc_f16_to_f32(%arg0 : f16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : f16 to f32
+ return
+}
+
+// -----
+
+func @fptrunc_f32_to_f32(%arg0 : f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : f32 to f32
+ return
+}
+
+// -----
+
+func @fptrunc_i32_to_f32(%arg0 : i32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : i32 to f32
+ return
+}
+
+// -----
+
+func @fptrunc_f32_to_i32(%arg0 : f32) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : f32 to i32
+ return
+}
+
+// -----
+
+func @fptrunc_vec(%arg0 : vector<2xf16>) {
+ // expected-error@+1 {{op requires the same shape for all operands and results}}
+ %0 = arith.truncf %arg0 : vector<2xf16> to vector<3xf32>
+ return
+}
+
+// -----
+
+func @fptrunc_vec_f16_to_f32(%arg0 : vector<2xf16>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : vector<2xf16> to vector<2xf32>
+ return
+}
+
+// -----
+
+func @fptrunc_vec_f32_to_f32(%arg0 : vector<2xf32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : vector<2xf32> to vector<2xf32>
+ return
+}
+
+// -----
+
+func @fptrunc_vec_i32_to_f32(%arg0 : vector<2xi32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : vector<2xi32> to vector<2xf32>
+ return
+}
+
+// -----
+
+func @fptrunc_vec_f32_to_i32(%arg0 : vector<2xf32>) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.truncf %arg0 : vector<2xf32> to vector<2xi32>
+ return
+}
+
+// -----
+
+func @sexti_index_as_operand(%arg0 : index) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extsi %arg0 : index to i128
+ return
+}
+
+// -----
+
+func @zexti_index_as_operand(%arg0 : index) {
+ // expected-error@+1 {{operand type 'index' and result type}}
+ %0 = arith.extui %arg0 : index to i128
+ return
+}
+
+// -----
+
+func @trunci_index_as_operand(%arg0 : index) {
+ // expected-error@+1 {{operand type 'index' and result type}}
+ %2 = arith.trunci %arg0 : index to i128
+ return
+}
+
+// -----
+
+func @sexti_index_as_result(%arg0 : i1) {
+ // expected-error@+1 {{result type 'index' are cast incompatible}}
+ %0 = arith.extsi %arg0 : i1 to index
+ return
+}
+
+// -----
+
+func @zexti_index_as_operand(%arg0 : i1) {
+ // expected-error@+1 {{result type 'index' are cast incompatible}}
+ %0 = arith.extui %arg0 : i1 to index
+ return
+}
+
+// -----
+
+func @trunci_index_as_result(%arg0 : i128) {
+ // expected-error@+1 {{result type 'index' are cast incompatible}}
+ %2 = arith.trunci %arg0 : i128 to index
+ return
+}
+
+// -----
+
+func @sexti_cast_to_narrower(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extsi %arg0 : i16 to i15
+ return
+}
+
+// -----
+
+func @zexti_cast_to_narrower(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extui %arg0 : i16 to i15
+ return
+}
+
+// -----
+
+func @trunci_cast_to_wider(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.trunci %arg0 : i16 to i17
+ return
+}
+
+// -----
+
+func @sexti_cast_to_same_width(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extsi %arg0 : i16 to i16
+ return
+}
+
+// -----
+
+func @zexti_cast_to_same_width(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.extui %arg0 : i16 to i16
+ return
+}
+
+// -----
+
+func @trunci_cast_to_same_width(%arg0 : i16) {
+ // expected-error@+1 {{are cast incompatible}}
+ %0 = arith.trunci %arg0 : i16 to i16
+ return
+}
--- /dev/null
+// RUN: mlir-opt %s | mlir-opt | FileCheck %s
+// RUN: mlir-opt %s --mlir-print-op-generic | mlir-opt | FileCheck %s
+
+// CHECK-LABEL: test_addi
+func @test_addi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.addi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_addi_tensor
+func @test_addi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.addi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_addi_vector
+func @test_addi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.addi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_subi
+func @test_subi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.subi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_subi_tensor
+func @test_subi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.subi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_subi_vector
+func @test_subi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.subi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_muli
+func @test_muli(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.muli %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_muli_tensor
+func @test_muli_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.muli %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_muli_vector
+func @test_muli_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.muli %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_divui
+func @test_divui(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.divui %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_divui_tensor
+func @test_divui_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.divui %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_divui_vector
+func @test_divui_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.divui %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_divsi
+func @test_divsi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.divsi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_divsi_tensor
+func @test_divsi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.divsi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_divsi_vector
+func @test_divsi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.divsi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_remui
+func @test_remui(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.remui %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_remui_tensor
+func @test_remui_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.remui %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_remui_vector
+func @test_remui_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.remui %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_remsi
+func @test_remsi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.remsi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_remsi_tensor
+func @test_remsi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.remsi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_remsi_vector
+func @test_remsi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.remsi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_andi
+func @test_andi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.andi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_andi_tensor
+func @test_andi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.andi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_andi_vector
+func @test_andi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.andi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_ori
+func @test_ori(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.ori %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_ori_tensor
+func @test_ori_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.ori %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_ori_vector
+func @test_ori_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.ori %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_xori
+func @test_xori(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.xori %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_xori_tensor
+func @test_xori_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.xori %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_xori_vector
+func @test_xori_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.xori %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_ceildivsi
+func @test_ceildivsi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.ceildivsi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_ceildivsi_tensor
+func @test_ceildivsi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.ceildivsi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_ceildivsi_vector
+func @test_ceildivsi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.ceildivsi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_floordivsi
+func @test_floordivsi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.floordivsi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_floordivsi_tensor
+func @test_floordivsi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.floordivsi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_floordivsi_vector
+func @test_floordivsi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.floordivsi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_shli
+func @test_shli(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.shli %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_shli_tensor
+func @test_shli_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.shli %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_shli_vector
+func @test_shli_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.shli %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_shrui
+func @test_shrui(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.shrui %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_shrui_tensor
+func @test_shrui_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.shrui %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_shrui_vector
+func @test_shrui_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.shrui %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_shrsi
+func @test_shrsi(%arg0 : i64, %arg1 : i64) -> i64 {
+ %0 = arith.shrsi %arg0, %arg1 : i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_shrsi_tensor
+func @test_shrsi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi64> {
+ %0 = arith.shrsi %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_shrsi_vector
+func @test_shrsi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi64> {
+ %0 = arith.shrsi %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_negf
+func @test_negf(%arg0 : f64) -> f64 {
+ %0 = arith.negf %arg0 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_negf_tensor
+func @test_negf_tensor(%arg0 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.negf %arg0 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_negf_vector
+func @test_negf_vector(%arg0 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.negf %arg0 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_addf
+func @test_addf(%arg0 : f64, %arg1 : f64) -> f64 {
+ %0 = arith.addf %arg0, %arg1 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_addf_tensor
+func @test_addf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.addf %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_addf_vector
+func @test_addf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.addf %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_subf
+func @test_subf(%arg0 : f64, %arg1 : f64) -> f64 {
+ %0 = arith.subf %arg0, %arg1 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_subf_tensor
+func @test_subf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.subf %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_subf_vector
+func @test_subf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.subf %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_mulf
+func @test_mulf(%arg0 : f64, %arg1 : f64) -> f64 {
+ %0 = arith.mulf %arg0, %arg1 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_mulf_tensor
+func @test_mulf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.mulf %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_mulf_vector
+func @test_mulf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.mulf %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_divf
+func @test_divf(%arg0 : f64, %arg1 : f64) -> f64 {
+ %0 = arith.divf %arg0, %arg1 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_divf_tensor
+func @test_divf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.divf %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_divf_vector
+func @test_divf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.divf %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_remf
+func @test_remf(%arg0 : f64, %arg1 : f64) -> f64 {
+ %0 = arith.remf %arg0, %arg1 : f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_remf_tensor
+func @test_remf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xf64> {
+ %0 = arith.remf %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_remf_vector
+func @test_remf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xf64> {
+ %0 = arith.remf %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_extui
+func @test_extui(%arg0 : i32) -> i64 {
+ %0 = arith.extui %arg0 : i32 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_extui_tensor
+func @test_extui_tensor(%arg0 : tensor<8x8xi32>) -> tensor<8x8xi64> {
+ %0 = arith.extui %arg0 : tensor<8x8xi32> to tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_extui_vector
+func @test_extui_vector(%arg0 : vector<8xi32>) -> vector<8xi64> {
+ %0 = arith.extui %arg0 : vector<8xi32> to vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_extsi
+func @test_extsi(%arg0 : i32) -> i64 {
+ %0 = arith.extsi %arg0 : i32 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_extsi_tensor
+func @test_extsi_tensor(%arg0 : tensor<8x8xi32>) -> tensor<8x8xi64> {
+ %0 = arith.extsi %arg0 : tensor<8x8xi32> to tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_extsi_vector
+func @test_extsi_vector(%arg0 : vector<8xi32>) -> vector<8xi64> {
+ %0 = arith.extsi %arg0 : vector<8xi32> to vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_extf
+func @test_extf(%arg0 : f32) -> f64 {
+ %0 = arith.extf %arg0 : f32 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_extf_tensor
+func @test_extf_tensor(%arg0 : tensor<8x8xf32>) -> tensor<8x8xf64> {
+ %0 = arith.extf %arg0 : tensor<8x8xf32> to tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_extf_vector
+func @test_extf_vector(%arg0 : vector<8xf32>) -> vector<8xf64> {
+ %0 = arith.extf %arg0 : vector<8xf32> to vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_trunci
+func @test_trunci(%arg0 : i32) -> i16 {
+ %0 = arith.trunci %arg0 : i32 to i16
+ return %0 : i16
+}
+
+// CHECK-LABEL: test_trunci_tensor
+func @test_trunci_tensor(%arg0 : tensor<8x8xi32>) -> tensor<8x8xi16> {
+ %0 = arith.trunci %arg0 : tensor<8x8xi32> to tensor<8x8xi16>
+ return %0 : tensor<8x8xi16>
+}
+
+// CHECK-LABEL: test_trunci_vector
+func @test_trunci_vector(%arg0 : vector<8xi32>) -> vector<8xi16> {
+ %0 = arith.trunci %arg0 : vector<8xi32> to vector<8xi16>
+ return %0 : vector<8xi16>
+}
+
+// CHECK-LABEL: test_truncf
+func @test_truncf(%arg0 : f32) -> bf16 {
+ %0 = arith.truncf %arg0 : f32 to bf16
+ return %0 : bf16
+}
+
+// CHECK-LABEL: test_truncf_tensor
+func @test_truncf_tensor(%arg0 : tensor<8x8xf32>) -> tensor<8x8xbf16> {
+ %0 = arith.truncf %arg0 : tensor<8x8xf32> to tensor<8x8xbf16>
+ return %0 : tensor<8x8xbf16>
+}
+
+// CHECK-LABEL: test_truncf_vector
+func @test_truncf_vector(%arg0 : vector<8xf32>) -> vector<8xbf16> {
+ %0 = arith.truncf %arg0 : vector<8xf32> to vector<8xbf16>
+ return %0 : vector<8xbf16>
+}
+
+// CHECK-LABEL: test_uitofp
+func @test_uitofp(%arg0 : i32) -> f32 {
+ %0 = arith.uitofp %arg0 : i32 to f32
+ return %0 : f32
+}
+
+// CHECK-LABEL: test_uitofp_tensor
+func @test_uitofp_tensor(%arg0 : tensor<8x8xi32>) -> tensor<8x8xf32> {
+ %0 = arith.uitofp %arg0 : tensor<8x8xi32> to tensor<8x8xf32>
+ return %0 : tensor<8x8xf32>
+}
+
+// CHECK-LABEL: test_uitofp_vector
+func @test_uitofp_vector(%arg0 : vector<8xi32>) -> vector<8xf32> {
+ %0 = arith.uitofp %arg0 : vector<8xi32> to vector<8xf32>
+ return %0 : vector<8xf32>
+}
+
+// CHECK-LABEL: test_sitofp
+func @test_sitofp(%arg0 : i16) -> f64 {
+ %0 = arith.sitofp %arg0 : i16 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_sitofp_tensor
+func @test_sitofp_tensor(%arg0 : tensor<8x8xi16>) -> tensor<8x8xf64> {
+ %0 = arith.sitofp %arg0 : tensor<8x8xi16> to tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_sitofp_vector
+func @test_sitofp_vector(%arg0 : vector<8xi16>) -> vector<8xf64> {
+ %0 = arith.sitofp %arg0 : vector<8xi16> to vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_fptoui
+func @test_fptoui(%arg0 : bf16) -> i8 {
+ %0 = arith.fptoui %arg0 : bf16 to i8
+ return %0 : i8
+}
+
+// CHECK-LABEL: test_fptoui_tensor
+func @test_fptoui_tensor(%arg0 : tensor<8x8xbf16>) -> tensor<8x8xi8> {
+ %0 = arith.fptoui %arg0 : tensor<8x8xbf16> to tensor<8x8xi8>
+ return %0 : tensor<8x8xi8>
+}
+
+// CHECK-LABEL: test_fptoui_vector
+func @test_fptoui_vector(%arg0 : vector<8xbf16>) -> vector<8xi8> {
+ %0 = arith.fptoui %arg0 : vector<8xbf16> to vector<8xi8>
+ return %0 : vector<8xi8>
+}
+
+// CHECK-LABEL: test_fptosi
+func @test_fptosi(%arg0 : f64) -> i64 {
+ %0 = arith.fptosi %arg0 : f64 to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_fptosi_tensor
+func @test_fptosi_tensor(%arg0 : tensor<8x8xf64>) -> tensor<8x8xi64> {
+ %0 = arith.fptosi %arg0 : tensor<8x8xf64> to tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_fptosi_vector
+func @test_fptosi_vector(%arg0 : vector<8xf64>) -> vector<8xi64> {
+ %0 = arith.fptosi %arg0 : vector<8xf64> to vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_index_cast0
+func @test_index_cast0(%arg0 : i32) -> index {
+ %0 = arith.index_cast %arg0 : i32 to index
+ return %0 : index
+}
+
+// CHECK-LABEL: test_index_cast_tensor0
+func @test_index_cast_tensor0(%arg0 : tensor<8x8xi32>) -> tensor<8x8xindex> {
+ %0 = arith.index_cast %arg0 : tensor<8x8xi32> to tensor<8x8xindex>
+ return %0 : tensor<8x8xindex>
+}
+
+// CHECK-LABEL: test_index_cast_vector0
+func @test_index_cast_vector0(%arg0 : vector<8xi32>) -> vector<8xindex> {
+ %0 = arith.index_cast %arg0 : vector<8xi32> to vector<8xindex>
+ return %0 : vector<8xindex>
+}
+
+// CHECK-LABEL: test_index_cast1
+func @test_index_cast1(%arg0 : index) -> i64 {
+ %0 = arith.index_cast %arg0 : index to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_index_cast_tensor1
+func @test_index_cast_tensor1(%arg0 : tensor<8x8xindex>) -> tensor<8x8xi64> {
+ %0 = arith.index_cast %arg0 : tensor<8x8xindex> to tensor<8x8xi64>
+ return %0 : tensor<8x8xi64>
+}
+
+// CHECK-LABEL: test_index_cast_vector1
+func @test_index_cast_vector1(%arg0 : vector<8xindex>) -> vector<8xi64> {
+ %0 = arith.index_cast %arg0 : vector<8xindex> to vector<8xi64>
+ return %0 : vector<8xi64>
+}
+
+// CHECK-LABEL: test_bitcast0
+func @test_bitcast0(%arg0 : i64) -> f64 {
+ %0 = arith.bitcast %arg0 : i64 to f64
+ return %0 : f64
+}
+
+// CHECK-LABEL: test_bitcast_tensor0
+func @test_bitcast_tensor0(%arg0 : tensor<8x8xi64>) -> tensor<8x8xf64> {
+ %0 = arith.bitcast %arg0 : tensor<8x8xi64> to tensor<8x8xf64>
+ return %0 : tensor<8x8xf64>
+}
+
+// CHECK-LABEL: test_bitcast_vector0
+func @test_bitcast_vector0(%arg0 : vector<8xi64>) -> vector<8xf64> {
+ %0 = arith.bitcast %arg0 : vector<8xi64> to vector<8xf64>
+ return %0 : vector<8xf64>
+}
+
+// CHECK-LABEL: test_bitcast1
+func @test_bitcast1(%arg0 : f32) -> i32 {
+ %0 = arith.bitcast %arg0 : f32 to i32
+ return %0 : i32
+}
+
+// CHECK-LABEL: test_bitcast_tensor1
+func @test_bitcast_tensor1(%arg0 : tensor<8x8xf32>) -> tensor<8x8xi32> {
+ %0 = arith.bitcast %arg0 : tensor<8x8xf32> to tensor<8x8xi32>
+ return %0 : tensor<8x8xi32>
+}
+
+// CHECK-LABEL: test_bitcast_vector1
+func @test_bitcast_vector1(%arg0 : vector<8xf32>) -> vector<8xi32> {
+ %0 = arith.bitcast %arg0 : vector<8xf32> to vector<8xi32>
+ return %0 : vector<8xi32>
+}
+
+// CHECK-LABEL: test_cmpi
+func @test_cmpi(%arg0 : i64, %arg1 : i64) -> i1 {
+ %0 = arith.cmpi ne, %arg0, %arg1 : i64
+ return %0 : i1
+}
+
+// CHECK-LABEL: test_cmpi_tensor
+func @test_cmpi_tensor(%arg0 : tensor<8x8xi64>, %arg1 : tensor<8x8xi64>) -> tensor<8x8xi1> {
+ %0 = arith.cmpi slt, %arg0, %arg1 : tensor<8x8xi64>
+ return %0 : tensor<8x8xi1>
+}
+
+// CHECK-LABEL: test_cmpi_vector
+func @test_cmpi_vector(%arg0 : vector<8xi64>, %arg1 : vector<8xi64>) -> vector<8xi1> {
+ %0 = arith.cmpi ult, %arg0, %arg1 : vector<8xi64>
+ return %0 : vector<8xi1>
+}
+
+// CHECK-LABEL: test_cmpf
+func @test_cmpf(%arg0 : f64, %arg1 : f64) -> i1 {
+ %0 = arith.cmpf oeq, %arg0, %arg1 : f64
+ return %0 : i1
+}
+
+// CHECK-LABEL: test_cmpf_tensor
+func @test_cmpf_tensor(%arg0 : tensor<8x8xf64>, %arg1 : tensor<8x8xf64>) -> tensor<8x8xi1> {
+ %0 = arith.cmpf olt, %arg0, %arg1 : tensor<8x8xf64>
+ return %0 : tensor<8x8xi1>
+}
+
+// CHECK-LABEL: test_cmpf_vector
+func @test_cmpf_vector(%arg0 : vector<8xf64>, %arg1 : vector<8xf64>) -> vector<8xi1> {
+ %0 = arith.cmpf ult, %arg0, %arg1 : vector<8xf64>
+ return %0 : vector<8xi1>
+}
+
+// CHECK-LABEL: test_index_cast
+func @test_index_cast(%arg0 : index) -> i64 {
+ %0 = arith.index_cast %arg0 : index to i64
+ return %0 : i64
+}
+
+// CHECK-LABEL: test_index_cast_tensor
+func @test_index_cast_tensor(%arg0 : tensor<index>) -> tensor<i64> {
+ %0 = arith.index_cast %arg0 : tensor<index> to tensor<i64>
+ return %0 : tensor<i64>
+}
+
+// CHECK-LABEL: test_index_cast_tensor_reverse
+func @test_index_cast_tensor_reverse(%arg0 : tensor<i64>) -> tensor<index> {
+ %0 = arith.index_cast %arg0 : tensor<i64> to tensor<index>
+ return %0 : tensor<index>
+}
+
+// CHECK-LABEL: func @bitcast(
+func @bitcast(%arg : f32) -> i32 {
+ %res = arith.bitcast %arg : f32 to i32
+ return %res : i32
+}
+
+// CHECK-LABEL: test_constant
+func @test_constant() -> () {
+ // CHECK: %c42_i32 = arith.constant 42 : i32
+ %0 = "arith.constant"(){value = 42 : i32} : () -> i32
+
+ // CHECK: %c42_i32_0 = arith.constant 42 : i32
+ %1 = arith.constant 42 : i32
+
+ // CHECK: %c43 = arith.constant {crazy = "std.foo"} 43 : index
+ %2 = arith.constant {crazy = "std.foo"} 43: index
+
+ // CHECK: %cst = arith.constant 4.300000e+01 : bf16
+ %3 = arith.constant 43.0 : bf16
+
+ // CHECK: %cst_1 = arith.constant dense<0> : vector<4xi32>
+ %4 = arith.constant dense<0> : vector<4 x i32>
+
+ // CHECK: %cst_2 = arith.constant dense<0> : tensor<42xi32>
+ %5 = arith.constant dense<0> : tensor<42 x i32>
+
+ // CHECK: %cst_3 = arith.constant dense<0> : vector<42xi32>
+ %6 = arith.constant dense<0> : vector<42 x i32>
+
+ // CHECK: %true = arith.constant true
+ %7 = arith.constant true
+
+ // CHECK: %false = arith.constant false
+ %8 = arith.constant false
+
+ return
+}
// CHECK: memcopy([[SRC:%arg[0-9]+]]: memref<?xf32>, [[DST:%arg[0-9]+]]
func @memcopy(%src : memref<?xf32>, %dst : memref<?xf32>, %size : index) {
- %c0 = constant 0 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
%vs = arm_sve.vector_scale : index
- %step = muli %c4, %vs : index
+ %step = arith.muli %c4, %vs : index
// CHECK: scf.for [[LOOPIDX:%arg[0-9]+]] = {{.*}}
scf.for %i0 = %c0 to %size step %step {
func @arm_sve_memory(%v: !arm_sve.vector<4xi32>,
%m: memref<?xi32>)
-> !arm_sve.vector<4xi32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: arm_sve.load {{.*}}: !arm_sve.vector<4xi32> from memref<?xi32>
%0 = arm_sve.load %m[%c0] : !arm_sve.vector<4xi32> from memref<?xi32>
// CHECK: arm_sve.store {{.*}}: !arm_sve.vector<4xi32> to memref<?xi32>
// CHECK-LABEL: @loop_1d(
// CHECK-SAME: %[[LB:.*]]: index, %[[UB:.*]]: index, %[[STEP:.*]]: index
func @loop_1d(%arg0: index, %arg1: index, %arg2: index, %arg3: memref<?xf32>) {
- // CHECK: %[[C0:.*]] = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0 : index
- // CHECK: %[[RANGE:.*]] = subi %[[UB]], %[[LB]]
- // CHECK: %[[TRIP_CNT:.*]] = ceildivi_signed %[[RANGE]], %[[STEP]]
- // CHECK: %[[IS_NOOP:.*]] = cmpi eq, %[[TRIP_CNT]], %[[C0]] : index
+ // CHECK: %[[RANGE:.*]] = arith.subi %[[UB]], %[[LB]]
+ // CHECK: %[[TRIP_CNT:.*]] = arith.ceildivsi %[[RANGE]], %[[STEP]]
+ // CHECK: %[[IS_NOOP:.*]] = arith.cmpi eq, %[[TRIP_CNT]], %[[C0]] : index
// CHECK: scf.if %[[IS_NOOP]] {
// CHECK-NEXT: } else {
// CHECK: }
// CHECK: }
scf.parallel (%i) = (%arg0) to (%arg1) step (%arg2) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
memref.store %one, %arg3[%i] : memref<?xf32>
}
return
// CHECK-SAME: %[[BLOCK_START:arg1]]: index
// CHECK-SAME: %[[BLOCK_END:arg2]]: index
// CHECK-SAME: )
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C2:.*]] = constant 2 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: scf.while (%[[S0:.*]] = %[[BLOCK_START]],
// CHECK-SAME: %[[E0:.*]] = %[[BLOCK_END]])
// While loop `before` block decides if we need to dispatch more tasks.
// CHECK: {
-// CHECK: %[[DIFF0:.*]] = subi %[[E0]], %[[S0]]
-// CHECK: %[[COND:.*]] = cmpi sgt, %[[DIFF0]], %[[C1]]
+// CHECK: %[[DIFF0:.*]] = arith.subi %[[E0]], %[[S0]]
+// CHECK: %[[COND:.*]] = arith.cmpi sgt, %[[DIFF0]], %[[C1]]
// CHECK: scf.condition(%[[COND]])
// While loop `after` block splits the range in half and submits async task
// to process the second half using the call to the same dispatch function.
// CHECK: } do {
// CHECK: ^bb0(%[[S1:.*]]: index, %[[E1:.*]]: index):
-// CHECK: %[[DIFF1:.*]] = subi %[[E1]], %[[S1]]
-// CHECK: %[[HALF:.*]] = divi_signed %[[DIFF1]], %[[C2]]
-// CHECK: %[[MID:.*]] = addi %[[S1]], %[[HALF]]
+// CHECK: %[[DIFF1:.*]] = arith.subi %[[E1]], %[[S1]]
+// CHECK: %[[HALF:.*]] = arith.divsi %[[DIFF1]], %[[C2]]
+// CHECK: %[[MID:.*]] = arith.addi %[[S1]], %[[HALF]]
// CHECK: %[[TOKEN:.*]] = async.execute
// CHECK: call @async_dispatch_fn
// CHECK: async.add_to_group
// CHECK: async.await_all %[[GROUP]]
scf.parallel (%i0, %i1) = (%arg0, %arg3) to (%arg1, %arg4)
step (%arg2, %arg5) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
memref.store %one, %arg6[%i0, %i1] : memref<?x?xf32>
}
return
// CHECK-LABEL: @loop_1d(
// CHECK: %[[MEMREF:.*]]: memref<?xf32>
func @loop_1d(%arg0: memref<?xf32>) {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C100:.*]] = constant 100 : index
- // CHECK-DAG: %[[ONE:.*]] = constant 1.000000e+00 : f32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C100:.*]] = arith.constant 100 : index
+ // CHECK-DAG: %[[ONE:.*]] = arith.constant 1.000000e+00 : f32
// CHECK: scf.for %[[I:.*]] = %[[C0]] to %[[C100]] step %[[C1]]
// CHECK: memref.store %[[ONE]], %[[MEMREF]][%[[I]]]
- %lb = constant 0 : index
- %ub = constant 100 : index
- %st = constant 1 : index
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 100 : index
+ %st = arith.constant 1 : index
scf.parallel (%i) = (%lb) to (%ub) step (%st) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
memref.store %one, %arg0[%i] : memref<?xf32>
}
// CHECK-LABEL: func @clone_constant(
func @clone_constant(%arg0: memref<?xf32>, %lb: index, %ub: index, %st: index) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
scf.parallel (%i) = (%lb) to (%ub) step (%st) {
memref.store %one, %arg0[%i] : memref<?xf32>
// CHECK-SAME: %[[STEP:arg[0-9]+]]: index,
// CHECK-SAME: %[[MEMREF:arg[0-9]+]]: memref<?xf32>
// CHECK-SAME: ) {
-// CHECK: %[[CST:.*]] = constant 1.0{{.*}} : f32
+// CHECK: %[[CST:.*]] = arith.constant 1.0{{.*}} : f32
// CHECK: scf.for
// CHECK: memref.store %[[CST]], %[[MEMREF]]
// CHECK: call @parallel_compute_fn
// CHECK: async.await_all %[[GROUP]]
scf.parallel (%i) = (%arg0) to (%arg1) step (%arg2) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
memref.store %one, %arg3[%i] : memref<?xf32>
}
return
// CHECK: async.await_all %[[GROUP]]
scf.parallel (%i0, %i1) = (%arg0, %arg3) to (%arg1, %arg4)
step (%arg2, %arg5) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
memref.store %one, %arg6[%i0, %i1] : memref<?x?xf32>
}
return
// CHECK: %[[LOADED:.*]] = async.runtime.load %[[VALUE]]
// CHECK: async.runtime.drop_ref %[[VALUE]] {count = 1 : i64}
%0 = async.runtime.load %arg0 : !async.value<f32>
- // CHECK: addf %[[LOADED]], %[[LOADED]]
- %1 = addf %0, %0 : f32
+ // CHECK: arith.addf %[[LOADED]], %[[LOADED]]
+ %1 = arith.addf %0, %0 : f32
br ^cleanup
^cleanup:
async.coro.free %id, %hdl
// CHECK: %[[HDL:.*]] = async.coro.begin %[[ID]]
// CHECK: br ^[[ORIGINAL_ENTRY:.*]]
// CHECK ^[[ORIGINAL_ENTRY]]:
-// CHECK: %[[VAL:.*]] = addf %[[ARG]], %[[ARG]] : f32
- %0 = addf %arg0, %arg0 : f32
+// CHECK: %[[VAL:.*]] = arith.addf %[[ARG]], %[[ARG]] : f32
+ %0 = arith.addf %arg0, %arg0 : f32
// CHECK: %[[VAL_STORAGE:.*]] = async.runtime.create : !async.value<f32>
%1 = async.runtime.create: !async.value<f32>
// CHECK: async.runtime.store %[[VAL]], %[[VAL_STORAGE]] : !async.value<f32>
// CHECK: ^[[BRANCH_OK]]:
// CHECK: %[[LOADED:.*]] = async.runtime.load %[[VAL_STORAGE]] : !async.value<f32>
-// CHECK: %[[RETURNED:.*]] = mulf %[[ARG]], %[[LOADED]] : f32
+// CHECK: %[[RETURNED:.*]] = arith.mulf %[[ARG]], %[[LOADED]] : f32
// CHECK: async.runtime.store %[[RETURNED]], %[[RETURNED_STORAGE]] : !async.value<f32>
// CHECK: async.runtime.set_available %[[RETURNED_STORAGE]]
// CHECK: async.runtime.set_available %[[TOKEN]]
// CHECK: br ^[[CLEANUP]]
- %3 = mulf %arg0, %2 : f32
+ %3 = arith.mulf %arg0, %2 : f32
return %3: f32
// CHECK: ^[[BRANCH_ERROR]]:
// CHECK: br ^[[ORIGINAL_ENTRY:.*]]
// CHECK ^[[ORIGINAL_ENTRY]]:
-// CHECK: %[[CONSTANT:.*]] = constant
- %c = constant 1.0 : f32
+// CHECK: %[[CONSTANT:.*]] = arith.constant
+ %c = arith.constant 1.0 : f32
// CHECK: %[[RETURNED_TO_CALLER:.*]]:2 = call @simple_callee(%[[CONSTANT]]) : (f32) -> (!async.token, !async.value<f32>)
// CHECK: %[[SAVED:.*]] = async.coro.save %[[HDL]]
// CHECK: async.runtime.await_and_resume %[[RETURNED_TO_CALLER]]#0, %[[HDL]]
// CHECK: br ^[[ORIGINAL_ENTRY:.*]]
// CHECK ^[[ORIGINAL_ENTRY]]:
-// CHECK: %[[CONSTANT:.*]] = constant
- %c = constant 1.0 : f32
+// CHECK: %[[CONSTANT:.*]] = arith.constant
+ %c = arith.constant 1.0 : f32
// CHECK: %[[RETURNED_TO_CALLER_1:.*]]:2 = call @simple_callee(%[[CONSTANT]]) : (f32) -> (!async.token, !async.value<f32>)
// CHECK: %[[SAVED_1:.*]] = async.coro.save %[[HDL]]
// CHECK: async.runtime.await_and_resume %[[RETURNED_TO_CALLER_1]]#0, %[[HDL]]
// CHECK-LABEL: func @caller_allowed_to_block
// CHECK-SAME: () -> f32
func @caller_allowed_to_block() -> f32 attributes { async.allowed_to_block } {
-// CHECK: %[[CONSTANT:.*]] = constant
- %c = constant 1.0 : f32
+// CHECK: %[[CONSTANT:.*]] = arith.constant
+ %c = arith.constant 1.0 : f32
// CHECK: %[[RETURNED_TO_CALLER:.*]]:2 = call @simple_callee(%[[CONSTANT]]) : (f32) -> (!async.token, !async.value<f32>)
// CHECK: async.runtime.await %[[RETURNED_TO_CALLER]]#0
// CHECK: async.runtime.await %[[RETURNED_TO_CALLER]]#1
// CHECK-LABEL: @execute_no_async_args
func @execute_no_async_args(%arg0: f32, %arg1: memref<1xf32>) {
%token = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
func @nested_async_execute(%arg0: f32, %arg1: f32, %arg2: memref<1xf32>) {
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn_0(%arg0, %arg2, %arg1)
%token0 = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%token1 = async.execute {
- %c1 = constant 1: index
+ %c1 = arith.constant 1: index
memref.store %arg0, %arg2[%c0] : memref<1xf32>
async.yield
}
}
// CHECK: async.runtime.await %[[TOKEN]]
// CHECK: %[[IS_ERROR:.*]] = async.runtime.is_error %[[TOKEN]]
- // CHECK: %[[TRUE:.*]] = constant true
- // CHECK: %[[NOT_ERROR:.*]] = xor %[[IS_ERROR]], %[[TRUE]] : i1
+ // CHECK: %[[TRUE:.*]] = arith.constant true
+ // CHECK: %[[NOT_ERROR:.*]] = arith.xori %[[IS_ERROR]], %[[TRUE]] : i1
// CHECK: assert %[[NOT_ERROR]]
// CHECK-NEXT: return
async.await %token0 : !async.token
func @async_execute_token_dependency(%arg0: f32, %arg1: memref<1xf32>) {
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn
%token = async.execute {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
// CHECK: call @async_execute_fn_0(%[[TOKEN]], %arg0, %arg1)
%token_0 = async.execute [%token] {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
}
// CHECK-LABEL: @async_group_await_all
func @async_group_await_all(%arg0: f32, %arg1: memref<1xf32>) {
- // CHECK: %[[C:.*]] = constant 1 : index
- %c = constant 1 : index
+ // CHECK: %[[C:.*]] = arith.constant 1 : index
+ %c = arith.constant 1 : index
// CHECK: %[[GROUP:.*]] = async.runtime.create_group %[[C]] : !async.group
%0 = async.create_group %c : !async.group
func @execute_and_return_f32() -> f32 {
// CHECK: %[[RET:.*]]:2 = call @async_execute_fn
%token, %result = async.execute -> !async.value<f32> {
- %c0 = constant 123.0 : f32
+ %c0 = arith.constant 123.0 : f32
async.yield %c0 : f32
}
// Emplace result value.
// CHECK: ^[[RESUME]]:
-// CHECK: %[[CST:.*]] = constant 1.230000e+02 : f32
+// CHECK: %[[CST:.*]] = arith.constant 1.230000e+02 : f32
// CHECK: async.runtime.store %cst, %[[VALUE]]
// CHECK: async.runtime.set_available %[[VALUE]]
// CHECK: async.runtime.set_available %[[TOKEN]]
func @async_value_operands() {
// CHECK: %[[RET:.*]]:2 = call @async_execute_fn
%token, %result = async.execute -> !async.value<f32> {
- %c0 = constant 123.0 : f32
+ %c0 = arith.constant 123.0 : f32
async.yield %c0 : f32
}
// CHECK: %[[TOKEN:.*]] = call @async_execute_fn_0(%[[RET]]#1)
%token0 = async.execute(%result as %value: !async.value<f32>) {
- %0 = addf %value, %value : f32
+ %0 = arith.addf %value, %value : f32
async.yield
}
// // Load from the async.value argument after error checking.
// CHECK: ^[[CONTINUATION:.*]]:
// CHECK: %[[LOADED:.*]] = async.runtime.load %[[ARG]] : !async.value<f32
-// CHECK: addf %[[LOADED]], %[[LOADED]] : f32
+// CHECK: arith.addf %[[LOADED]], %[[LOADED]] : f32
// CHECK: async.runtime.set_available %[[TOKEN]]
// CHECK: ^[[CLEANUP]]:
// CHECK-LABEL: @clone_constants
func @clone_constants(%arg0: f32, %arg1: memref<1xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%token = async.execute {
memref.store %arg0, %arg1[%c0] : memref<1xf32>
async.yield
// CHECK-SAME: %[[VALUE:arg[0-9]+]]: f32,
// CHECK-SAME: %[[MEMREF:arg[0-9]+]]: memref<1xf32>
// CHECK-SAME: ) -> !async.token
-// CHECK: %[[CST:.*]] = constant 0 : index
+// CHECK: %[[CST:.*]] = arith.constant 0 : index
// CHECK: memref.store %[[VALUE]], %[[MEMREF]][%[[CST]]]
func @return_async_value() -> !async.value<f32> {
// CHECK: async.execute -> !async.value<f32>
%token, %results = async.execute -> !async.value<f32> {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
async.yield %cst : f32
}
// CHECK-LABEL: @return_captured_value
func @return_captured_value() -> !async.token {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
// CHECK: async.execute -> !async.value<f32>
%token, %results = async.execute -> !async.value<f32> {
async.yield %cst : f32
// CHECK-LABEL: @return_async_values
func @return_async_values() -> (!async.value<f32>, !async.value<f32>) {
%token, %results:2 = async.execute -> (!async.value<f32>, !async.value<f32>) {
- %cst1 = constant 1.000000e+00 : f32
- %cst2 = constant 2.000000e+00 : f32
+ %cst1 = arith.constant 1.000000e+00 : f32
+ %cst2 = arith.constant 2.000000e+00 : f32
async.yield %cst1, %cst2 : f32, f32
}
// CHECK-LABEL: @create_group_and_await_all
func @create_group_and_await_all(%arg0: !async.token,
%arg1: !async.value<f32>) -> index {
- %c = constant 2 : index
+ %c = arith.constant 2 : index
%0 = async.create_group %c : !async.group
// CHECK: async.add_to_group %arg0
%2 = async.add_to_group %arg1, %0 : !async.value<f32>
async.await_all %0
- %3 = addi %1, %2 : index
+ %3 = arith.addi %1, %2 : index
return %3 : index
}
// CHECK-LABEL: @create_group
func @create_group() -> !async.group {
- // CHECK: %[[C:.*]] = constant 10 : index
- %c = constant 10 : index
+ // CHECK: %[[C:.*]] = arith.constant 10 : index
+ %c = arith.constant 10 : index
// CHECK: %[[V:.*]] = async.runtime.create_group %[[C]] : !async.group
%0 = async.runtime.create_group %c : !async.group
// CHECK: return %[[V]] : !async.group
// CHECK-LABEL: func @real_of_const(
func @real_of_const() -> f32 {
- // CHECK: %[[CST:.*]] = constant 1.000000e+00 : f32
+ // CHECK: %[[CST:.*]] = arith.constant 1.000000e+00 : f32
// CHECK-NEXT: return %[[CST]] : f32
%complex = constant [1.0 : f32, 0.0 : f32] : complex<f32>
%1 = complex.re %complex : complex<f32>
// CHECK-LABEL: func @real_of_create_op(
func @real_of_create_op() -> f32 {
- // CHECK: %[[CST:.*]] = constant 1.000000e+00 : f32
+ // CHECK: %[[CST:.*]] = arith.constant 1.000000e+00 : f32
// CHECK-NEXT: return %[[CST]] : f32
- %real = constant 1.0 : f32
- %imag = constant 0.0 : f32
+ %real = arith.constant 1.0 : f32
+ %imag = arith.constant 0.0 : f32
%complex = complex.create %real, %imag : complex<f32>
%1 = complex.re %complex : complex<f32>
return %1 : f32
// CHECK-LABEL: func @imag_of_const(
func @imag_of_const() -> f32 {
- // CHECK: %[[CST:.*]] = constant 0.000000e+00 : f32
+ // CHECK: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: return %[[CST]] : f32
%complex = constant [1.0 : f32, 0.0 : f32] : complex<f32>
%1 = complex.im %complex : complex<f32>
// CHECK-LABEL: func @imag_of_create_op(
func @imag_of_create_op() -> f32 {
- // CHECK: %[[CST:.*]] = constant 0.000000e+00 : f32
+ // CHECK: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: return %[[CST]] : f32
- %real = constant 1.0 : f32
- %imag = constant 0.0 : f32
+ %real = arith.constant 1.0 : f32
+ %imag = arith.constant 0.0 : f32
%complex = complex.create %real, %imag : complex<f32>
%1 = complex.im %complex : complex<f32>
return %1 : f32
// CHECK-LABEL: gpu.func @kernel(
// CHECK-SAME: [[VAL_0:%.*]]: f32) workgroup([[VAL_1:%.*]] : memref<32xf32, 3>) kernel {
gpu.func @kernel(%arg0 : f32) kernel {
- // CHECK-DAG: [[VAL_2:%.*]] = constant 31 : i32
- // CHECK-DAG: [[VAL_3:%.*]] = constant 0 : i32
- // CHECK-DAG: [[VAL_4:%.*]] = constant 0 : index
- // CHECK-DAG: [[VAL_5:%.*]] = constant 32 : i32
- // CHECK-DAG: [[VAL_6:%.*]] = constant 1 : i32
- // CHECK-DAG: [[VAL_7:%.*]] = constant 2 : i32
- // CHECK-DAG: [[VAL_8:%.*]] = constant 4 : i32
- // CHECK-DAG: [[VAL_9:%.*]] = constant 8 : i32
- // CHECK-DAG: [[VAL_10:%.*]] = constant 16 : i32
+ // CHECK-DAG: [[VAL_2:%.*]] = arith.constant 31 : i32
+ // CHECK-DAG: [[VAL_3:%.*]] = arith.constant 0 : i32
+ // CHECK-DAG: [[VAL_4:%.*]] = arith.constant 0 : index
+ // CHECK-DAG: [[VAL_5:%.*]] = arith.constant 32 : i32
+ // CHECK-DAG: [[VAL_6:%.*]] = arith.constant 1 : i32
+ // CHECK-DAG: [[VAL_7:%.*]] = arith.constant 2 : i32
+ // CHECK-DAG: [[VAL_8:%.*]] = arith.constant 4 : i32
+ // CHECK-DAG: [[VAL_9:%.*]] = arith.constant 8 : i32
+ // CHECK-DAG: [[VAL_10:%.*]] = arith.constant 16 : i32
// CHECK: [[VAL_11:%.*]] = "gpu.block_dim"() {dimension = "x"} : () -> index
- // CHECK: [[VAL_12:%.*]] = index_cast [[VAL_11]] : index to i32
+ // CHECK: [[VAL_12:%.*]] = arith.index_cast [[VAL_11]] : index to i32
// CHECK: [[VAL_13:%.*]] = "gpu.block_dim"() {dimension = "y"} : () -> index
- // CHECK: [[VAL_14:%.*]] = index_cast [[VAL_13]] : index to i32
+ // CHECK: [[VAL_14:%.*]] = arith.index_cast [[VAL_13]] : index to i32
// CHECK: [[VAL_15:%.*]] = "gpu.block_dim"() {dimension = "z"} : () -> index
- // CHECK: [[VAL_16:%.*]] = index_cast [[VAL_15]] : index to i32
+ // CHECK: [[VAL_16:%.*]] = arith.index_cast [[VAL_15]] : index to i32
// CHECK: [[VAL_17:%.*]] = "gpu.thread_id"() {dimension = "x"} : () -> index
- // CHECK: [[VAL_18:%.*]] = index_cast [[VAL_17]] : index to i32
+ // CHECK: [[VAL_18:%.*]] = arith.index_cast [[VAL_17]] : index to i32
// CHECK: [[VAL_19:%.*]] = "gpu.thread_id"() {dimension = "y"} : () -> index
- // CHECK: [[VAL_20:%.*]] = index_cast [[VAL_19]] : index to i32
+ // CHECK: [[VAL_20:%.*]] = arith.index_cast [[VAL_19]] : index to i32
// CHECK: [[VAL_21:%.*]] = "gpu.thread_id"() {dimension = "z"} : () -> index
- // CHECK: [[VAL_22:%.*]] = index_cast [[VAL_21]] : index to i32
- // CHECK: [[VAL_23:%.*]] = muli [[VAL_22]], [[VAL_14]] : i32
- // CHECK: [[VAL_24:%.*]] = addi [[VAL_23]], [[VAL_20]] : i32
- // CHECK: [[VAL_25:%.*]] = muli [[VAL_24]], [[VAL_12]] : i32
- // CHECK: [[VAL_26:%.*]] = muli [[VAL_12]], [[VAL_14]] : i32
- // CHECK: [[VAL_27:%.*]] = addi [[VAL_25]], [[VAL_18]] : i32
- // CHECK: [[VAL_28:%.*]] = muli [[VAL_26]], [[VAL_16]] : i32
- // CHECK: [[VAL_29:%.*]] = and [[VAL_27]], [[VAL_2]] : i32
- // CHECK: [[VAL_30:%.*]] = cmpi eq, [[VAL_29]], [[VAL_3]] : i32
- // CHECK: [[VAL_31:%.*]] = subi [[VAL_27]], [[VAL_29]] : i32
- // CHECK: [[VAL_32:%.*]] = subi [[VAL_28]], [[VAL_31]] : i32
- // CHECK: [[VAL_33:%.*]] = cmpi slt, [[VAL_32]], [[VAL_5]] : i32
+ // CHECK: [[VAL_22:%.*]] = arith.index_cast [[VAL_21]] : index to i32
+ // CHECK: [[VAL_23:%.*]] = arith.muli [[VAL_22]], [[VAL_14]] : i32
+ // CHECK: [[VAL_24:%.*]] = arith.addi [[VAL_23]], [[VAL_20]] : i32
+ // CHECK: [[VAL_25:%.*]] = arith.muli [[VAL_24]], [[VAL_12]] : i32
+ // CHECK: [[VAL_26:%.*]] = arith.muli [[VAL_12]], [[VAL_14]] : i32
+ // CHECK: [[VAL_27:%.*]] = arith.addi [[VAL_25]], [[VAL_18]] : i32
+ // CHECK: [[VAL_28:%.*]] = arith.muli [[VAL_26]], [[VAL_16]] : i32
+ // CHECK: [[VAL_29:%.*]] = arith.andi [[VAL_27]], [[VAL_2]] : i32
+ // CHECK: [[VAL_30:%.*]] = arith.cmpi eq, [[VAL_29]], [[VAL_3]] : i32
+ // CHECK: [[VAL_31:%.*]] = arith.subi [[VAL_27]], [[VAL_29]] : i32
+ // CHECK: [[VAL_32:%.*]] = arith.subi [[VAL_28]], [[VAL_31]] : i32
+ // CHECK: [[VAL_33:%.*]] = arith.cmpi slt, [[VAL_32]], [[VAL_5]] : i32
// CHECK: cond_br [[VAL_33]], ^bb1, ^bb17
// CHECK: ^bb1:
// CHECK: [[VAL_34:%.*]], [[VAL_35:%.*]] = gpu.shuffle [[VAL_0]], [[VAL_6]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_35]], ^bb2, ^bb3
// CHECK: ^bb2:
- // CHECK: [[VAL_36:%.*]] = cmpf ugt, [[VAL_0]], [[VAL_34]] : f32
+ // CHECK: [[VAL_36:%.*]] = arith.cmpf ugt, [[VAL_0]], [[VAL_34]] : f32
// CHECK: [[VAL_37:%.*]] = select [[VAL_36]], [[VAL_0]], [[VAL_34]] : f32
// CHECK: br ^bb4([[VAL_37]] : f32)
// CHECK: ^bb3:
// CHECK: [[VAL_39:%.*]], [[VAL_40:%.*]] = gpu.shuffle [[VAL_38]], [[VAL_7]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_40]], ^bb5, ^bb6
// CHECK: ^bb5:
- // CHECK: [[VAL_41:%.*]] = cmpf ugt, [[VAL_38]], [[VAL_39]] : f32
+ // CHECK: [[VAL_41:%.*]] = arith.cmpf ugt, [[VAL_38]], [[VAL_39]] : f32
// CHECK: [[VAL_42:%.*]] = select [[VAL_41]], [[VAL_38]], [[VAL_39]] : f32
// CHECK: br ^bb7([[VAL_42]] : f32)
// CHECK: ^bb6:
// CHECK: [[VAL_44:%.*]], [[VAL_45:%.*]] = gpu.shuffle [[VAL_43]], [[VAL_8]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_45]], ^bb8, ^bb9
// CHECK: ^bb8:
- // CHECK: [[VAL_46:%.*]] = cmpf ugt, [[VAL_43]], [[VAL_44]] : f32
+ // CHECK: [[VAL_46:%.*]] = arith.cmpf ugt, [[VAL_43]], [[VAL_44]] : f32
// CHECK: [[VAL_47:%.*]] = select [[VAL_46]], [[VAL_43]], [[VAL_44]] : f32
// CHECK: br ^bb10([[VAL_47]] : f32)
// CHECK: ^bb9:
// CHECK: [[VAL_49:%.*]], [[VAL_50:%.*]] = gpu.shuffle [[VAL_48]], [[VAL_9]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_50]], ^bb11, ^bb12
// CHECK: ^bb11:
- // CHECK: [[VAL_51:%.*]] = cmpf ugt, [[VAL_48]], [[VAL_49]] : f32
+ // CHECK: [[VAL_51:%.*]] = arith.cmpf ugt, [[VAL_48]], [[VAL_49]] : f32
// CHECK: [[VAL_52:%.*]] = select [[VAL_51]], [[VAL_48]], [[VAL_49]] : f32
// CHECK: br ^bb13([[VAL_52]] : f32)
// CHECK: ^bb12:
// CHECK: [[VAL_54:%.*]], [[VAL_55:%.*]] = gpu.shuffle [[VAL_53]], [[VAL_10]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_55]], ^bb14, ^bb15
// CHECK: ^bb14:
- // CHECK: [[VAL_56:%.*]] = cmpf ugt, [[VAL_53]], [[VAL_54]] : f32
+ // CHECK: [[VAL_56:%.*]] = arith.cmpf ugt, [[VAL_53]], [[VAL_54]] : f32
// CHECK: [[VAL_57:%.*]] = select [[VAL_56]], [[VAL_53]], [[VAL_54]] : f32
// CHECK: br ^bb16([[VAL_57]] : f32)
// CHECK: ^bb15:
// CHECK: br ^bb18([[VAL_58]] : f32)
// CHECK: ^bb17:
// CHECK: [[VAL_59:%.*]], [[VAL_60:%.*]] = gpu.shuffle [[VAL_0]], [[VAL_6]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_61:%.*]] = cmpf ugt, [[VAL_0]], [[VAL_59]] : f32
+ // CHECK: [[VAL_61:%.*]] = arith.cmpf ugt, [[VAL_0]], [[VAL_59]] : f32
// CHECK: [[VAL_62:%.*]] = select [[VAL_61]], [[VAL_0]], [[VAL_59]] : f32
// CHECK: [[VAL_63:%.*]], [[VAL_64:%.*]] = gpu.shuffle [[VAL_62]], [[VAL_7]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_65:%.*]] = cmpf ugt, [[VAL_62]], [[VAL_63]] : f32
+ // CHECK: [[VAL_65:%.*]] = arith.cmpf ugt, [[VAL_62]], [[VAL_63]] : f32
// CHECK: [[VAL_66:%.*]] = select [[VAL_65]], [[VAL_62]], [[VAL_63]] : f32
// CHECK: [[VAL_67:%.*]], [[VAL_68:%.*]] = gpu.shuffle [[VAL_66]], [[VAL_8]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_69:%.*]] = cmpf ugt, [[VAL_66]], [[VAL_67]] : f32
+ // CHECK: [[VAL_69:%.*]] = arith.cmpf ugt, [[VAL_66]], [[VAL_67]] : f32
// CHECK: [[VAL_70:%.*]] = select [[VAL_69]], [[VAL_66]], [[VAL_67]] : f32
// CHECK: [[VAL_71:%.*]], [[VAL_72:%.*]] = gpu.shuffle [[VAL_70]], [[VAL_9]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_73:%.*]] = cmpf ugt, [[VAL_70]], [[VAL_71]] : f32
+ // CHECK: [[VAL_73:%.*]] = arith.cmpf ugt, [[VAL_70]], [[VAL_71]] : f32
// CHECK: [[VAL_74:%.*]] = select [[VAL_73]], [[VAL_70]], [[VAL_71]] : f32
// CHECK: [[VAL_75:%.*]], [[VAL_76:%.*]] = gpu.shuffle [[VAL_74]], [[VAL_10]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_77:%.*]] = cmpf ugt, [[VAL_74]], [[VAL_75]] : f32
+ // CHECK: [[VAL_77:%.*]] = arith.cmpf ugt, [[VAL_74]], [[VAL_75]] : f32
// CHECK: [[VAL_78:%.*]] = select [[VAL_77]], [[VAL_74]], [[VAL_75]] : f32
// CHECK: br ^bb18([[VAL_78]] : f32)
// CHECK: ^bb18([[VAL_79:%.*]]: f32):
// CHECK: cond_br [[VAL_30]], ^bb19, ^bb20
// CHECK: ^bb19:
- // CHECK: [[VAL_80:%.*]] = divi_signed [[VAL_27]], [[VAL_5]] : i32
- // CHECK: [[VAL_81:%.*]] = index_cast [[VAL_80]] : i32 to index
+ // CHECK: [[VAL_80:%.*]] = arith.divsi [[VAL_27]], [[VAL_5]] : i32
+ // CHECK: [[VAL_81:%.*]] = arith.index_cast [[VAL_80]] : i32 to index
// CHECK: store [[VAL_79]], [[VAL_1]]{{\[}}[[VAL_81]]] : memref<32xf32, 3>
// CHECK: br ^bb21
// CHECK: ^bb20:
// CHECK: br ^bb21
// CHECK: ^bb21:
// CHECK: gpu.barrier
- // CHECK: [[VAL_82:%.*]] = addi [[VAL_28]], [[VAL_2]] : i32
- // CHECK: [[VAL_83:%.*]] = divi_signed [[VAL_82]], [[VAL_5]] : i32
- // CHECK: [[VAL_84:%.*]] = cmpi slt, [[VAL_27]], [[VAL_83]] : i32
+ // CHECK: [[VAL_82:%.*]] = arith.addi [[VAL_28]], [[VAL_2]] : i32
+ // CHECK: [[VAL_83:%.*]] = arith.divsi [[VAL_82]], [[VAL_5]] : i32
+ // CHECK: [[VAL_84:%.*]] = arith.cmpi slt, [[VAL_27]], [[VAL_83]] : i32
// CHECK: cond_br [[VAL_84]], ^bb22, ^bb41
// CHECK: ^bb22:
- // CHECK: [[VAL_85:%.*]] = index_cast [[VAL_27]] : i32 to index
+ // CHECK: [[VAL_85:%.*]] = arith.index_cast [[VAL_27]] : i32 to index
// CHECK: [[VAL_86:%.*]] = memref.load [[VAL_1]]{{\[}}[[VAL_85]]] : memref<32xf32, 3>
- // CHECK: [[VAL_87:%.*]] = cmpi slt, [[VAL_83]], [[VAL_5]] : i32
+ // CHECK: [[VAL_87:%.*]] = arith.cmpi slt, [[VAL_83]], [[VAL_5]] : i32
// CHECK: cond_br [[VAL_87]], ^bb23, ^bb39
// CHECK: ^bb23:
// CHECK: [[VAL_88:%.*]], [[VAL_89:%.*]] = gpu.shuffle [[VAL_86]], [[VAL_6]], [[VAL_83]] xor : f32
// CHECK: cond_br [[VAL_89]], ^bb24, ^bb25
// CHECK: ^bb24:
- // CHECK: [[VAL_90:%.*]] = cmpf ugt, [[VAL_86]], [[VAL_88]] : f32
+ // CHECK: [[VAL_90:%.*]] = arith.cmpf ugt, [[VAL_86]], [[VAL_88]] : f32
// CHECK: [[VAL_91:%.*]] = select [[VAL_90]], [[VAL_86]], [[VAL_88]] : f32
// CHECK: br ^bb26([[VAL_91]] : f32)
// CHECK: ^bb25:
// CHECK: [[VAL_93:%.*]], [[VAL_94:%.*]] = gpu.shuffle [[VAL_92]], [[VAL_7]], [[VAL_83]] xor : f32
// CHECK: cond_br [[VAL_94]], ^bb27, ^bb28
// CHECK: ^bb27:
- // CHECK: [[VAL_95:%.*]] = cmpf ugt, [[VAL_92]], [[VAL_93]] : f32
+ // CHECK: [[VAL_95:%.*]] = arith.cmpf ugt, [[VAL_92]], [[VAL_93]] : f32
// CHECK: [[VAL_96:%.*]] = select [[VAL_95]], [[VAL_92]], [[VAL_93]] : f32
// CHECK: br ^bb29([[VAL_96]] : f32)
// CHECK: ^bb28:
// CHECK: [[VAL_98:%.*]], [[VAL_99:%.*]] = gpu.shuffle [[VAL_97]], [[VAL_8]], [[VAL_83]] xor : f32
// CHECK: cond_br [[VAL_99]], ^bb30, ^bb31
// CHECK: ^bb30:
- // CHECK: [[VAL_100:%.*]] = cmpf ugt, [[VAL_97]], [[VAL_98]] : f32
+ // CHECK: [[VAL_100:%.*]] = arith.cmpf ugt, [[VAL_97]], [[VAL_98]] : f32
// CHECK: [[VAL_101:%.*]] = select [[VAL_100]], [[VAL_97]], [[VAL_98]] : f32
// CHECK: br ^bb32([[VAL_101]] : f32)
// CHECK: ^bb31:
// CHECK: [[VAL_103:%.*]], [[VAL_104:%.*]] = gpu.shuffle [[VAL_102]], [[VAL_9]], [[VAL_83]] xor : f32
// CHECK: cond_br [[VAL_104]], ^bb33, ^bb34
// CHECK: ^bb33:
- // CHECK: [[VAL_105:%.*]] = cmpf ugt, [[VAL_102]], [[VAL_103]] : f32
+ // CHECK: [[VAL_105:%.*]] = arith.cmpf ugt, [[VAL_102]], [[VAL_103]] : f32
// CHECK: [[VAL_106:%.*]] = select [[VAL_105]], [[VAL_102]], [[VAL_103]] : f32
// CHECK: br ^bb35([[VAL_106]] : f32)
// CHECK: ^bb34:
// CHECK: [[VAL_108:%.*]], [[VAL_109:%.*]] = gpu.shuffle [[VAL_107]], [[VAL_10]], [[VAL_83]] xor : f32
// CHECK: cond_br [[VAL_109]], ^bb36, ^bb37
// CHECK: ^bb36:
- // CHECK: [[VAL_110:%.*]] = cmpf ugt, [[VAL_107]], [[VAL_108]] : f32
+ // CHECK: [[VAL_110:%.*]] = arith.cmpf ugt, [[VAL_107]], [[VAL_108]] : f32
// CHECK: [[VAL_111:%.*]] = select [[VAL_110]], [[VAL_107]], [[VAL_108]] : f32
// CHECK: br ^bb38([[VAL_111]] : f32)
// CHECK: ^bb37:
// CHECK: br ^bb40([[VAL_112]] : f32)
// CHECK: ^bb39:
// CHECK: [[VAL_113:%.*]], [[VAL_114:%.*]] = gpu.shuffle [[VAL_86]], [[VAL_6]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_115:%.*]] = cmpf ugt, [[VAL_86]], [[VAL_113]] : f32
+ // CHECK: [[VAL_115:%.*]] = arith.cmpf ugt, [[VAL_86]], [[VAL_113]] : f32
// CHECK: [[VAL_116:%.*]] = select [[VAL_115]], [[VAL_86]], [[VAL_113]] : f32
// CHECK: [[VAL_117:%.*]], [[VAL_118:%.*]] = gpu.shuffle [[VAL_116]], [[VAL_7]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_119:%.*]] = cmpf ugt, [[VAL_116]], [[VAL_117]] : f32
+ // CHECK: [[VAL_119:%.*]] = arith.cmpf ugt, [[VAL_116]], [[VAL_117]] : f32
// CHECK: [[VAL_120:%.*]] = select [[VAL_119]], [[VAL_116]], [[VAL_117]] : f32
// CHECK: [[VAL_121:%.*]], [[VAL_122:%.*]] = gpu.shuffle [[VAL_120]], [[VAL_8]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_123:%.*]] = cmpf ugt, [[VAL_120]], [[VAL_121]] : f32
+ // CHECK: [[VAL_123:%.*]] = arith.cmpf ugt, [[VAL_120]], [[VAL_121]] : f32
// CHECK: [[VAL_124:%.*]] = select [[VAL_123]], [[VAL_120]], [[VAL_121]] : f32
// CHECK: [[VAL_125:%.*]], [[VAL_126:%.*]] = gpu.shuffle [[VAL_124]], [[VAL_9]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_127:%.*]] = cmpf ugt, [[VAL_124]], [[VAL_125]] : f32
+ // CHECK: [[VAL_127:%.*]] = arith.cmpf ugt, [[VAL_124]], [[VAL_125]] : f32
// CHECK: [[VAL_128:%.*]] = select [[VAL_127]], [[VAL_124]], [[VAL_125]] : f32
// CHECK: [[VAL_129:%.*]], [[VAL_130:%.*]] = gpu.shuffle [[VAL_128]], [[VAL_10]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_131:%.*]] = cmpf ugt, [[VAL_128]], [[VAL_129]] : f32
+ // CHECK: [[VAL_131:%.*]] = arith.cmpf ugt, [[VAL_128]], [[VAL_129]] : f32
// CHECK: [[VAL_132:%.*]] = select [[VAL_131]], [[VAL_128]], [[VAL_129]] : f32
// CHECK: br ^bb40([[VAL_132]] : f32)
// CHECK: ^bb40([[VAL_133:%.*]]: f32):
// CHECK-LABEL: gpu.func @kernel(
// CHECK-SAME: [[VAL_0:%.*]]: f32) workgroup([[VAL_1:%.*]] : memref<32xf32, 3>) kernel {
gpu.func @kernel(%arg0 : f32) kernel {
- // CHECK-DAG: [[VAL_2:%.*]] = constant 31 : i32
- // CHECK-DAG: [[VAL_3:%.*]] = constant 0 : i32
- // CHECK-DAG: [[VAL_4:%.*]] = constant 0 : index
- // CHECK-DAG: [[VAL_5:%.*]] = constant 32 : i32
- // CHECK-DAG: [[VAL_6:%.*]] = constant 1 : i32
- // CHECK-DAG: [[VAL_7:%.*]] = constant 2 : i32
- // CHECK-DAG: [[VAL_8:%.*]] = constant 4 : i32
- // CHECK-DAG: [[VAL_9:%.*]] = constant 8 : i32
- // CHECK-DAG: [[VAL_10:%.*]] = constant 16 : i32
+ // CHECK-DAG: [[VAL_2:%.*]] = arith.constant 31 : i32
+ // CHECK-DAG: [[VAL_3:%.*]] = arith.constant 0 : i32
+ // CHECK-DAG: [[VAL_4:%.*]] = arith.constant 0 : index
+ // CHECK-DAG: [[VAL_5:%.*]] = arith.constant 32 : i32
+ // CHECK-DAG: [[VAL_6:%.*]] = arith.constant 1 : i32
+ // CHECK-DAG: [[VAL_7:%.*]] = arith.constant 2 : i32
+ // CHECK-DAG: [[VAL_8:%.*]] = arith.constant 4 : i32
+ // CHECK-DAG: [[VAL_9:%.*]] = arith.constant 8 : i32
+ // CHECK-DAG: [[VAL_10:%.*]] = arith.constant 16 : i32
// CHECK: [[VAL_11:%.*]] = "gpu.block_dim"() {dimension = "x"} : () -> index
- // CHECK: [[VAL_12:%.*]] = index_cast [[VAL_11]] : index to i32
+ // CHECK: [[VAL_12:%.*]] = arith.index_cast [[VAL_11]] : index to i32
// CHECK: [[VAL_13:%.*]] = "gpu.block_dim"() {dimension = "y"} : () -> index
- // CHECK: [[VAL_14:%.*]] = index_cast [[VAL_13]] : index to i32
+ // CHECK: [[VAL_14:%.*]] = arith.index_cast [[VAL_13]] : index to i32
// CHECK: [[VAL_15:%.*]] = "gpu.block_dim"() {dimension = "z"} : () -> index
- // CHECK: [[VAL_16:%.*]] = index_cast [[VAL_15]] : index to i32
+ // CHECK: [[VAL_16:%.*]] = arith.index_cast [[VAL_15]] : index to i32
// CHECK: [[VAL_17:%.*]] = "gpu.thread_id"() {dimension = "x"} : () -> index
- // CHECK: [[VAL_18:%.*]] = index_cast [[VAL_17]] : index to i32
+ // CHECK: [[VAL_18:%.*]] = arith.index_cast [[VAL_17]] : index to i32
// CHECK: [[VAL_19:%.*]] = "gpu.thread_id"() {dimension = "y"} : () -> index
- // CHECK: [[VAL_20:%.*]] = index_cast [[VAL_19]] : index to i32
+ // CHECK: [[VAL_20:%.*]] = arith.index_cast [[VAL_19]] : index to i32
// CHECK: [[VAL_21:%.*]] = "gpu.thread_id"() {dimension = "z"} : () -> index
- // CHECK: [[VAL_22:%.*]] = index_cast [[VAL_21]] : index to i32
- // CHECK: [[VAL_23:%.*]] = muli [[VAL_22]], [[VAL_14]] : i32
- // CHECK: [[VAL_24:%.*]] = addi [[VAL_23]], [[VAL_20]] : i32
- // CHECK: [[VAL_25:%.*]] = muli [[VAL_24]], [[VAL_12]] : i32
- // CHECK: [[VAL_26:%.*]] = muli [[VAL_12]], [[VAL_14]] : i32
- // CHECK: [[VAL_27:%.*]] = addi [[VAL_25]], [[VAL_18]] : i32
- // CHECK: [[VAL_28:%.*]] = muli [[VAL_26]], [[VAL_16]] : i32
- // CHECK: [[VAL_29:%.*]] = and [[VAL_27]], [[VAL_2]] : i32
- // CHECK: [[VAL_30:%.*]] = cmpi eq, [[VAL_29]], [[VAL_3]] : i32
- // CHECK: [[VAL_31:%.*]] = subi [[VAL_27]], [[VAL_29]] : i32
- // CHECK: [[VAL_32:%.*]] = subi [[VAL_28]], [[VAL_31]] : i32
- // CHECK: [[VAL_33:%.*]] = cmpi slt, [[VAL_32]], [[VAL_5]] : i32
+ // CHECK: [[VAL_22:%.*]] = arith.index_cast [[VAL_21]] : index to i32
+ // CHECK: [[VAL_23:%.*]] = arith.muli [[VAL_22]], [[VAL_14]] : i32
+ // CHECK: [[VAL_24:%.*]] = arith.addi [[VAL_23]], [[VAL_20]] : i32
+ // CHECK: [[VAL_25:%.*]] = arith.muli [[VAL_24]], [[VAL_12]] : i32
+ // CHECK: [[VAL_26:%.*]] = arith.muli [[VAL_12]], [[VAL_14]] : i32
+ // CHECK: [[VAL_27:%.*]] = arith.addi [[VAL_25]], [[VAL_18]] : i32
+ // CHECK: [[VAL_28:%.*]] = arith.muli [[VAL_26]], [[VAL_16]] : i32
+ // CHECK: [[VAL_29:%.*]] = arith.andi [[VAL_27]], [[VAL_2]] : i32
+ // CHECK: [[VAL_30:%.*]] = arith.cmpi eq, [[VAL_29]], [[VAL_3]] : i32
+ // CHECK: [[VAL_31:%.*]] = arith.subi [[VAL_27]], [[VAL_29]] : i32
+ // CHECK: [[VAL_32:%.*]] = arith.subi [[VAL_28]], [[VAL_31]] : i32
+ // CHECK: [[VAL_33:%.*]] = arith.cmpi slt, [[VAL_32]], [[VAL_5]] : i32
// CHECK: cond_br [[VAL_33]], ^bb1, ^bb17
// CHECK: ^bb1:
// CHECK: [[VAL_34:%.*]], [[VAL_35:%.*]] = gpu.shuffle [[VAL_0]], [[VAL_6]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_35]], ^bb2, ^bb3
// CHECK: ^bb2:
- // CHECK: [[VAL_36:%.*]] = addf [[VAL_0]], [[VAL_34]] : f32
+ // CHECK: [[VAL_36:%.*]] = arith.addf [[VAL_0]], [[VAL_34]] : f32
// CHECK: br ^bb4([[VAL_36]] : f32)
// CHECK: ^bb3:
// CHECK: br ^bb4([[VAL_0]] : f32)
// CHECK: [[VAL_38:%.*]], [[VAL_39:%.*]] = gpu.shuffle [[VAL_37]], [[VAL_7]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_39]], ^bb5, ^bb6
// CHECK: ^bb5:
- // CHECK: [[VAL_40:%.*]] = addf [[VAL_37]], [[VAL_38]] : f32
+ // CHECK: [[VAL_40:%.*]] = arith.addf [[VAL_37]], [[VAL_38]] : f32
// CHECK: br ^bb7([[VAL_40]] : f32)
// CHECK: ^bb6:
// CHECK: br ^bb7([[VAL_37]] : f32)
// CHECK: [[VAL_42:%.*]], [[VAL_43:%.*]] = gpu.shuffle [[VAL_41]], [[VAL_8]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_43]], ^bb8, ^bb9
// CHECK: ^bb8:
- // CHECK: [[VAL_44:%.*]] = addf [[VAL_41]], [[VAL_42]] : f32
+ // CHECK: [[VAL_44:%.*]] = arith.addf [[VAL_41]], [[VAL_42]] : f32
// CHECK: br ^bb10([[VAL_44]] : f32)
// CHECK: ^bb9:
// CHECK: br ^bb10([[VAL_41]] : f32)
// CHECK: [[VAL_46:%.*]], [[VAL_47:%.*]] = gpu.shuffle [[VAL_45]], [[VAL_9]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_47]], ^bb11, ^bb12
// CHECK: ^bb11:
- // CHECK: [[VAL_48:%.*]] = addf [[VAL_45]], [[VAL_46]] : f32
+ // CHECK: [[VAL_48:%.*]] = arith.addf [[VAL_45]], [[VAL_46]] : f32
// CHECK: br ^bb13([[VAL_48]] : f32)
// CHECK: ^bb12:
// CHECK: br ^bb13([[VAL_45]] : f32)
// CHECK: [[VAL_50:%.*]], [[VAL_51:%.*]] = gpu.shuffle [[VAL_49]], [[VAL_10]], [[VAL_32]] xor : f32
// CHECK: cond_br [[VAL_51]], ^bb14, ^bb15
// CHECK: ^bb14:
- // CHECK: [[VAL_52:%.*]] = addf [[VAL_49]], [[VAL_50]] : f32
+ // CHECK: [[VAL_52:%.*]] = arith.addf [[VAL_49]], [[VAL_50]] : f32
// CHECK: br ^bb16([[VAL_52]] : f32)
// CHECK: ^bb15:
// CHECK: br ^bb16([[VAL_49]] : f32)
// CHECK: br ^bb18([[VAL_53]] : f32)
// CHECK: ^bb17:
// CHECK: [[VAL_54:%.*]], [[VAL_55:%.*]] = gpu.shuffle [[VAL_0]], [[VAL_6]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_56:%.*]] = addf [[VAL_0]], [[VAL_54]] : f32
+ // CHECK: [[VAL_56:%.*]] = arith.addf [[VAL_0]], [[VAL_54]] : f32
// CHECK: [[VAL_57:%.*]], [[VAL_58:%.*]] = gpu.shuffle [[VAL_56]], [[VAL_7]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_59:%.*]] = addf [[VAL_56]], [[VAL_57]] : f32
+ // CHECK: [[VAL_59:%.*]] = arith.addf [[VAL_56]], [[VAL_57]] : f32
// CHECK: [[VAL_60:%.*]], [[VAL_61:%.*]] = gpu.shuffle [[VAL_59]], [[VAL_8]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_62:%.*]] = addf [[VAL_59]], [[VAL_60]] : f32
+ // CHECK: [[VAL_62:%.*]] = arith.addf [[VAL_59]], [[VAL_60]] : f32
// CHECK: [[VAL_63:%.*]], [[VAL_64:%.*]] = gpu.shuffle [[VAL_62]], [[VAL_9]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_65:%.*]] = addf [[VAL_62]], [[VAL_63]] : f32
+ // CHECK: [[VAL_65:%.*]] = arith.addf [[VAL_62]], [[VAL_63]] : f32
// CHECK: [[VAL_66:%.*]], [[VAL_67:%.*]] = gpu.shuffle [[VAL_65]], [[VAL_10]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_68:%.*]] = addf [[VAL_65]], [[VAL_66]] : f32
+ // CHECK: [[VAL_68:%.*]] = arith.addf [[VAL_65]], [[VAL_66]] : f32
// CHECK: br ^bb18([[VAL_68]] : f32)
// CHECK: ^bb18([[VAL_69:%.*]]: f32):
// CHECK: cond_br [[VAL_30]], ^bb19, ^bb20
// CHECK: ^bb19:
- // CHECK: [[VAL_70:%.*]] = divi_signed [[VAL_27]], [[VAL_5]] : i32
- // CHECK: [[VAL_71:%.*]] = index_cast [[VAL_70]] : i32 to index
+ // CHECK: [[VAL_70:%.*]] = arith.divsi [[VAL_27]], [[VAL_5]] : i32
+ // CHECK: [[VAL_71:%.*]] = arith.index_cast [[VAL_70]] : i32 to index
// CHECK: store [[VAL_69]], [[VAL_1]]{{\[}}[[VAL_71]]] : memref<32xf32, 3>
// CHECK: br ^bb21
// CHECK: ^bb20:
// CHECK: br ^bb21
// CHECK: ^bb21:
// CHECK: gpu.barrier
- // CHECK: [[VAL_72:%.*]] = addi [[VAL_28]], [[VAL_2]] : i32
- // CHECK: [[VAL_73:%.*]] = divi_signed [[VAL_72]], [[VAL_5]] : i32
- // CHECK: [[VAL_74:%.*]] = cmpi slt, [[VAL_27]], [[VAL_73]] : i32
+ // CHECK: [[VAL_72:%.*]] = arith.addi [[VAL_28]], [[VAL_2]] : i32
+ // CHECK: [[VAL_73:%.*]] = arith.divsi [[VAL_72]], [[VAL_5]] : i32
+ // CHECK: [[VAL_74:%.*]] = arith.cmpi slt, [[VAL_27]], [[VAL_73]] : i32
// CHECK: cond_br [[VAL_74]], ^bb22, ^bb41
// CHECK: ^bb22:
- // CHECK: [[VAL_75:%.*]] = index_cast [[VAL_27]] : i32 to index
+ // CHECK: [[VAL_75:%.*]] = arith.index_cast [[VAL_27]] : i32 to index
// CHECK: [[VAL_76:%.*]] = memref.load [[VAL_1]]{{\[}}[[VAL_75]]] : memref<32xf32, 3>
- // CHECK: [[VAL_77:%.*]] = cmpi slt, [[VAL_73]], [[VAL_5]] : i32
+ // CHECK: [[VAL_77:%.*]] = arith.cmpi slt, [[VAL_73]], [[VAL_5]] : i32
// CHECK: cond_br [[VAL_77]], ^bb23, ^bb39
// CHECK: ^bb23:
// CHECK: [[VAL_78:%.*]], [[VAL_79:%.*]] = gpu.shuffle [[VAL_76]], [[VAL_6]], [[VAL_73]] xor : f32
// CHECK: cond_br [[VAL_79]], ^bb24, ^bb25
// CHECK: ^bb24:
- // CHECK: [[VAL_80:%.*]] = addf [[VAL_76]], [[VAL_78]] : f32
+ // CHECK: [[VAL_80:%.*]] = arith.addf [[VAL_76]], [[VAL_78]] : f32
// CHECK: br ^bb26([[VAL_80]] : f32)
// CHECK: ^bb25:
// CHECK: br ^bb26([[VAL_76]] : f32)
// CHECK: [[VAL_82:%.*]], [[VAL_83:%.*]] = gpu.shuffle [[VAL_81]], [[VAL_7]], [[VAL_73]] xor : f32
// CHECK: cond_br [[VAL_83]], ^bb27, ^bb28
// CHECK: ^bb27:
- // CHECK: [[VAL_84:%.*]] = addf [[VAL_81]], [[VAL_82]] : f32
+ // CHECK: [[VAL_84:%.*]] = arith.addf [[VAL_81]], [[VAL_82]] : f32
// CHECK: br ^bb29([[VAL_84]] : f32)
// CHECK: ^bb28:
// CHECK: br ^bb29([[VAL_81]] : f32)
// CHECK: [[VAL_86:%.*]], [[VAL_87:%.*]] = gpu.shuffle [[VAL_85]], [[VAL_8]], [[VAL_73]] xor : f32
// CHECK: cond_br [[VAL_87]], ^bb30, ^bb31
// CHECK: ^bb30:
- // CHECK: [[VAL_88:%.*]] = addf [[VAL_85]], [[VAL_86]] : f32
+ // CHECK: [[VAL_88:%.*]] = arith.addf [[VAL_85]], [[VAL_86]] : f32
// CHECK: br ^bb32([[VAL_88]] : f32)
// CHECK: ^bb31:
// CHECK: br ^bb32([[VAL_85]] : f32)
// CHECK: [[VAL_90:%.*]], [[VAL_91:%.*]] = gpu.shuffle [[VAL_89]], [[VAL_9]], [[VAL_73]] xor : f32
// CHECK: cond_br [[VAL_91]], ^bb33, ^bb34
// CHECK: ^bb33:
- // CHECK: [[VAL_92:%.*]] = addf [[VAL_89]], [[VAL_90]] : f32
+ // CHECK: [[VAL_92:%.*]] = arith.addf [[VAL_89]], [[VAL_90]] : f32
// CHECK: br ^bb35([[VAL_92]] : f32)
// CHECK: ^bb34:
// CHECK: br ^bb35([[VAL_89]] : f32)
// CHECK: [[VAL_94:%.*]], [[VAL_95:%.*]] = gpu.shuffle [[VAL_93]], [[VAL_10]], [[VAL_73]] xor : f32
// CHECK: cond_br [[VAL_95]], ^bb36, ^bb37
// CHECK: ^bb36:
- // CHECK: [[VAL_96:%.*]] = addf [[VAL_93]], [[VAL_94]] : f32
+ // CHECK: [[VAL_96:%.*]] = arith.addf [[VAL_93]], [[VAL_94]] : f32
// CHECK: br ^bb38([[VAL_96]] : f32)
// CHECK: ^bb37:
// CHECK: br ^bb38([[VAL_93]] : f32)
// CHECK: br ^bb40([[VAL_97]] : f32)
// CHECK: ^bb39:
// CHECK: [[VAL_98:%.*]], [[VAL_99:%.*]] = gpu.shuffle [[VAL_76]], [[VAL_6]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_100:%.*]] = addf [[VAL_76]], [[VAL_98]] : f32
+ // CHECK: [[VAL_100:%.*]] = arith.addf [[VAL_76]], [[VAL_98]] : f32
// CHECK: [[VAL_101:%.*]], [[VAL_102:%.*]] = gpu.shuffle [[VAL_100]], [[VAL_7]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_103:%.*]] = addf [[VAL_100]], [[VAL_101]] : f32
+ // CHECK: [[VAL_103:%.*]] = arith.addf [[VAL_100]], [[VAL_101]] : f32
// CHECK: [[VAL_104:%.*]], [[VAL_105:%.*]] = gpu.shuffle [[VAL_103]], [[VAL_8]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_106:%.*]] = addf [[VAL_103]], [[VAL_104]] : f32
+ // CHECK: [[VAL_106:%.*]] = arith.addf [[VAL_103]], [[VAL_104]] : f32
// CHECK: [[VAL_107:%.*]], [[VAL_108:%.*]] = gpu.shuffle [[VAL_106]], [[VAL_9]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_109:%.*]] = addf [[VAL_106]], [[VAL_107]] : f32
+ // CHECK: [[VAL_109:%.*]] = arith.addf [[VAL_106]], [[VAL_107]] : f32
// CHECK: [[VAL_110:%.*]], [[VAL_111:%.*]] = gpu.shuffle [[VAL_109]], [[VAL_10]], [[VAL_5]] xor : f32
- // CHECK: [[VAL_112:%.*]] = addf [[VAL_109]], [[VAL_110]] : f32
+ // CHECK: [[VAL_112:%.*]] = arith.addf [[VAL_109]], [[VAL_110]] : f32
// CHECK: br ^bb40([[VAL_112]] : f32)
// CHECK: ^bb40([[VAL_113:%.*]]: f32):
// CHECK: store [[VAL_113]], [[VAL_1]]{{\[}}[[VAL_4]]] : memref<32xf32, 3>
// CHECK-NEXT: return %[[SIZE]] : index
func @gpu_dim_of_alloc(%size: index) -> index {
%0 = gpu.alloc(%size) : memref<?xindex>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%1 = memref.dim %0, %c0 : memref<?xindex>
return %1 : index
}
// CHECK-LABEL: func @simplify_gpu_launch
func @simplify_gpu_launch() attributes {llvm.emit_c_interface} {
- %cst = constant 0.000000e+00 : f32
- %c1 = constant 1 : index
- %c32 = constant 32 : index
- %c16 = constant 16 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c1 = arith.constant 1 : index
+ %c32 = arith.constant 32 : index
+ %c16 = arith.constant 16 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<2x16x16xf32>
scf.for %arg0 = %c0 to %c2 step %c1 {
scf.for %arg1 = %c0 to %c16 step %c1 {
gpu.wait [%1]
gpu.launch blocks(%arg0, %arg1, %arg2) in (%arg6 = %c1, %arg7 = %c1, %arg8 = %c1)
threads(%arg3, %arg4, %arg5) in (%arg9 = %c32, %arg10 = %c1, %arg11 = %c1) {
- %3 = muli %arg5, %c32 : index
- %4 = muli %arg4, %c32 : index
- %5 = addi %3, %4 : index
- %6 = addi %5, %arg3 : index
- %7 = divi_unsigned %6, %c32 : index
- %8 = muli %arg0, %c16 : index
- %9 = muli %arg1, %c2 : index
- %10 = muli %7, %c2 : index
- %11 = addi %9, %10 : index
+ %3 = arith.muli %arg5, %c32 : index
+ %4 = arith.muli %arg4, %c32 : index
+ %5 = arith.addi %3, %4 : index
+ %6 = arith.addi %5, %arg3 : index
+ %7 = arith.divui %6, %c32 : index
+ %8 = arith.muli %arg0, %c16 : index
+ %9 = arith.muli %arg1, %c2 : index
+ %10 = arith.muli %7, %c2 : index
+ %11 = arith.addi %9, %10 : index
%12 = memref.load %memref[%11, %c0, %8] : memref<2x16x16xf32>
- %13 = addi %11, %c1 : index
+ %13 = arith.addi %11, %c1 : index
%14 = memref.load %memref[%13, %c0, %8] : memref<2x16x16xf32>
memref.store %12, %memref[%11, %c0, %8] : memref<2x16x16xf32>
memref.store %14, %memref[%13, %c0, %8] : memref<2x16x16xf32>
return
}
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: gpu.launch blocks(%{{.*}}, %{{.*}}, %{{.*}}) in (%{{.*}} = %[[C1]], %{{.*}} = %[[C1]], %{{.*}} = %[[C1]]) threads(%[[TIDX:.*]], %{{.*}}, %{{.*}}) in (%{{.*}} = %c32, %{{.*}} = %[[C1]], %{{.*}} = %[[C1]]) {
-// CHECK-NEXT: divi_unsigned %[[TIDX]], %c32 : index
-// CHECK-NEXT: muli %{{.*}}, %c2 : index
+// CHECK-NEXT: arith.divui %[[TIDX]], %c32 : index
+// CHECK-NEXT: arith.muli %{{.*}}, %c2 : index
// CHECK-NEXT: memref.load %memref[%{{.*}}, %[[C0]], %[[C0]]] : memref<2x16x16xf32>
-// CHECK-NEXT: addi %{{.*}}, %[[C1]] : index
+// CHECK-NEXT: arith.addi %{{.*}}, %[[C1]] : index
// CHECK-NEXT: memref.load %memref[%{{.*}}, %[[C0]], %[[C0]]] : memref<2x16x16xf32>
// CHECK-NEXT: memref.store %{{.*}}, %memref[%{{.*}}, %[[C0]], %[[C0]]] : memref<2x16x16xf32>
// CHECK-NEXT: memref.store %{{.*}}, %memref[%{{.*}}, %[[C0]], %[[C0]]] : memref<2x16x16xf32>
// expected-error@+1 {{incorrect gpu.yield type}}
%res = "gpu.all_reduce"(%arg0) ({
^bb(%lhs : f32, %rhs : f32):
- %one = constant 1 : i32
+ %one = arith.constant 1 : i32
"gpu.yield"(%one) : (i32) -> ()
}) : (f32) -> (f32)
return
gpu.module @gpu_funcs {
// expected-note @+1 {{return type declared here}}
gpu.func @kernel() {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
// expected-error @+1 {{'gpu.return' op expected 0 result operands}}
gpu.return %0 : index
}
gpu.module @gpu_funcs {
// expected-error @+1 {{'gpu.func' op expected void return type for kernel function}}
gpu.func @kernel() -> index kernel {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
gpu.return
}
}
func @mmamatrix_invalid_shape(){
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
+ %i = arith.constant 16 : index
// expected-error @+1 {{MMAMatrixType must have exactly two dimensions}}
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16x16xf16, "AOp">
return
func @mmamatrix_operand_type(){
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
+ %i = arith.constant 16 : index
// expected-error @+1 {{operand expected to be one of AOp, BOp or COp}}
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16xf16, "EOp">
return
func @mmamatrix_invalid_element_type(){
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
+ %i = arith.constant 16 : index
// expected-error @+1 {{MMAMatrixType elements must be F16 or F32}}
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16xi32, "AOp">
return
func @mmaLoadOp_identity_layout(){
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, #layout_map_col_major, 3>
- %i = constant 16 : index
+ %i = arith.constant 16 : index
// expected-error @+1 {{expected identity layout map for source memref}}
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, #layout_map_col_major, 3> -> !gpu.mma_matrix<16x16xf16, "AOp">
return
func @mmaLoadOp_invalid_mem_space(){
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 5>
- %i = constant 16 : index
+ %i = arith.constant 16 : index
// expected-error @+1 {{source memorySpace kGenericMemorySpace, kSharedMemorySpace or kGlobalMemorySpace only allowed}}
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, 5> -> !gpu.mma_matrix<16x16xf16, "AOp">
return
func @wmmaStoreOp_invalid_map(%arg0 : !gpu.mma_matrix<16x16xf16, "COp">) -> () {
%sg = memref.alloca(){alignment = 32} : memref<32x32xf16, #layout_map_col_major, 3>
- %i = constant 16 : index
- %j = constant 16 : index
+ %i = arith.constant 16 : index
+ %j = arith.constant 16 : index
// expected-error @+1 {{expected identity layout map for destination memref}}
gpu.subgroup_mma_store_matrix %arg0, %sg[%i,%j] {leadDimension= 32 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<32x32xf16,#layout_map_col_major, 3>
return
func @wmmaStoreOp_invalid_mem_space(%arg0 : !gpu.mma_matrix<16x16xf16, "COp">) -> () {
%sg = memref.alloca(){alignment = 32} : memref<32x32xf16, 5>
- %i = constant 16 : index
- %j = constant 16 : index
+ %i = arith.constant 16 : index
+ %j = arith.constant 16 : index
// expected-error @+1 {{destination memorySpace of kGenericMemorySpace, kGlobalMemorySpace or kSharedMemorySpace only allowed}}
gpu.subgroup_mma_store_matrix %arg0, %sg[%i,%j] {leadDimension= 32 : index} : !gpu.mma_matrix<16x16xf16, "COp">, memref<32x32xf16, 5>
return
func @wmmaStoreOp_invalid_store_operand(%arg0 : !gpu.mma_matrix<16x16xf16, "AOp">) -> () {
%sg = memref.alloca(){alignment = 32} : memref<32x32xf16, 3>
- %i = constant 16 : index
- %j = constant 16 : index
+ %i = arith.constant 16 : index
+ %j = arith.constant 16 : index
// expected-error @+1 {{expected the operand matrix being stored to have 'COp' operand type}}
gpu.subgroup_mma_store_matrix %arg0, %sg[%i,%j] {leadDimension= 32 : index} : !gpu.mma_matrix<16x16xf16, "AOp">, memref<32x32xf16, 3>
return
func @parallel_loop(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index) {
- %zero = constant 0 : index
- %one = constant 1 : index
- %four = constant 4 : index
+ %zero = arith.constant 0 : index
+ %one = arith.constant 1 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%four, %four) {
scf.parallel (%si0, %si1) = (%zero, %zero) to (%four, %four)
func @parallel_loop_4d(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index) {
- %zero = constant 0 : index
- %one = constant 1 : index
- %four = constant 4 : index
+ %zero = arith.constant 0 : index
+ %one = arith.constant 1 : index
+ %four = arith.constant 4 : index
scf.parallel (%i0, %i1, %i2, %i3) = (%zero, %zero, %zero, %zero) to (%arg0, %arg1, %arg2, %arg3)
step (%four, %four, %four, %four) {
scf.parallel (%si0, %si1, %si2, %si3) = (%zero, %zero, %zero, %zero) to (%four, %four, %four, %four)
%data = memref.alloc() : memref<2x6xf32>
%sum = memref.alloc() : memref<2xf32>
%mul = memref.alloc() : memref<2xf32>
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
// ADD + MUL
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
%numSg = gpu.num_subgroups : index
%SgSi = gpu.subgroup_size : index
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
%sum = "gpu.all_reduce"(%one) ({}) {op = "add"} : (f32) -> (f32)
- %width = constant 7 : i32
- %offset = constant 3 : i32
+ %width = arith.constant 7 : i32
+ %offset = arith.constant 3 : i32
// CHECK: gpu.shuffle %{{.*}}, %{{.*}}, %{{.*}} xor : f32
%shfl, %pred = gpu.shuffle %arg0, %offset, %width xor : f32
func @foo() {
%0 = "op"() : () -> (f32)
%1 = "op"() : () -> (memref<?xf32, 1>)
- // CHECK: %{{.*}} = constant 8
- %cst = constant 8 : index
- %c0 = constant 0 : i32
+ // CHECK: %{{.*}} = arith.constant 8
+ %cst = arith.constant 8 : index
+ %c0 = arith.constant 0 : i32
%t0 = gpu.wait async
// CHECK: gpu.launch_func @kernels::@kernel_1 blocks in (%{{.*}}, %{{.*}}, %{{.*}}) threads in (%{{.*}}, %{{.*}}, %{{.*}}) args(%{{.*}} : f32, %{{.*}} : memref<?xf32, 1>)
// CHECK-LABEL: func @mmamatrix_valid_element_type
%wg = memref.alloca() {alignment = 32} : memref<32x32xf16, 3>
// CHECK: %[[wg:.*]] = memref.alloca()
- %i = constant 16 : index
- // CHECK: %[[i:.*]] = constant 16 : index
- %cst = constant 1.000000e+00 : f32
- // CHECK: %[[cst:.*]] = constant 1.000000e+00 : f32
+ %i = arith.constant 16 : index
+ // CHECK: %[[i:.*]] = arith.constant 16 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ // CHECK: %[[cst:.*]] = arith.constant 1.000000e+00 : f32
%0 = gpu.subgroup_mma_load_matrix %wg[%i, %i] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16xf16, "AOp">
// CHECK: gpu.subgroup_mma_load_matrix %[[wg]][%[[i]], %[[i]]] {leadDimension = 32 : index} : memref<32x32xf16, 3> -> !gpu.mma_matrix<16x16xf16, "AOp">
%1 = gpu.subgroup_mma_constant_matrix %cst : !gpu.mma_matrix<16x16xf32, "COp">
%0 = "op"() : () -> (f32)
// CHECK: %[[ARG1:.*]] = "op"() : () -> memref<?xf32, 1>
%1 = "op"() : () -> (memref<?xf32, 1>)
- // CHECK: %[[GDIMX:.*]] = constant 8
- %gDimX = constant 8 : index
- // CHECK: %[[GDIMY:.*]] = constant 12
- %gDimY = constant 12 : index
- // CHECK: %[[GDIMZ:.*]] = constant 16
- %gDimZ = constant 16 : index
- // CHECK: %[[BDIMX:.*]] = constant 20
- %bDimX = constant 20 : index
- // CHECK: %[[BDIMY:.*]] = constant 24
- %bDimY = constant 24 : index
- // CHECK: %[[BDIMZ:.*]] = constant 28
- %bDimZ = constant 28 : index
+ // CHECK: %[[GDIMX:.*]] = arith.constant 8
+ %gDimX = arith.constant 8 : index
+ // CHECK: %[[GDIMY:.*]] = arith.constant 12
+ %gDimY = arith.constant 12 : index
+ // CHECK: %[[GDIMZ:.*]] = arith.constant 16
+ %gDimZ = arith.constant 16 : index
+ // CHECK: %[[BDIMX:.*]] = arith.constant 20
+ %bDimX = arith.constant 20 : index
+ // CHECK: %[[BDIMY:.*]] = arith.constant 24
+ %bDimY = arith.constant 24 : index
+ // CHECK: %[[BDIMZ:.*]] = arith.constant 28
+ %bDimZ = arith.constant 28 : index
// CHECK: gpu.launch_func @launch_kernel::@launch_kernel blocks in (%[[GDIMX]], %[[GDIMY]], %[[GDIMZ]]) threads in (%[[BDIMX]], %[[BDIMY]], %[[BDIMZ]]) args(%[[ARG0]] : f32, %[[ARG1]] : memref<?xf32, 1>)
// CHECK-NOT: gpu.launch blocks
// CHECK: module attributes {gpu.container_module}
// CHECK-LABEL: @multiple_launches
func @multiple_launches() {
- // CHECK: %[[CST:.*]] = constant 8 : index
- %cst = constant 8 : index
+ // CHECK: %[[CST:.*]] = arith.constant 8 : index
+ %cst = arith.constant 8 : index
// CHECK: gpu.launch_func @multiple_launches_kernel::@multiple_launches_kernel blocks in (%[[CST]], %[[CST]], %[[CST]]) threads in (%[[CST]], %[[CST]], %[[CST]])
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst,
%grid_z = %cst)
// CHECK-LABEL: @extra_constants_not_inlined
func @extra_constants_not_inlined(%arg0: memref<?xf32>) {
- // CHECK: %[[CST:.*]] = constant 8 : index
- %cst = constant 8 : index
- %cst2 = constant 2 : index
- %c0 = constant 0 : index
+ // CHECK: %[[CST:.*]] = arith.constant 8 : index
+ %cst = arith.constant 8 : index
+ %cst2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
%cst3 = "secret_constant"() : () -> index
// CHECK: gpu.launch_func @extra_constants_not_inlined_kernel::@extra_constants_not_inlined_kernel blocks in (%[[CST]], %[[CST]], %[[CST]]) threads in (%[[CST]], %[[CST]], %[[CST]]) args({{.*}} : memref<?xf32>, {{.*}} : index)
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst,
}
// CHECK-LABEL: func @extra_constants_not_inlined_kernel(%{{.*}}: memref<?xf32>, %{{.*}}: index)
-// CHECK: constant 2
+// CHECK: arith.constant 2
// -----
// CHECK-LABEL: @extra_constants
// CHECK-SAME: %[[ARG0:.*]]: memref<?xf32>
func @extra_constants(%arg0: memref<?xf32>) {
- // CHECK: %[[CST:.*]] = constant 8 : index
- %cst = constant 8 : index
- %cst2 = constant 2 : index
- %c0 = constant 0 : index
+ // CHECK: %[[CST:.*]] = arith.constant 8 : index
+ %cst = arith.constant 8 : index
+ %cst2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
%cst3 = memref.dim %arg0, %c0 : memref<?xf32>
// CHECK: gpu.launch_func @extra_constants_kernel::@extra_constants_kernel blocks in (%[[CST]], %[[CST]], %[[CST]]) threads in (%[[CST]], %[[CST]], %[[CST]]) args(%[[ARG0]] : memref<?xf32>)
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst,
// CHECK-LABEL: func @extra_constants_kernel(
// CHECK-SAME: %[[KARG0:.*]]: memref<?xf32>
-// CHECK: constant 2
-// CHECK: constant 0
+// CHECK: arith.constant 2
+// CHECK: arith.constant 0
// CHECK: memref.dim %[[KARG0]]
// -----
// CHECK-LABEL: @extra_constants_noarg
// CHECK-SAME: %[[ARG0:.*]]: memref<?xf32>, %[[ARG1:.*]]: memref<?xf32>
func @extra_constants_noarg(%arg0: memref<?xf32>, %arg1: memref<?xf32>) {
- // CHECK: %[[CST:.*]] = constant 8 : index
- %cst = constant 8 : index
- %cst2 = constant 2 : index
- %c0 = constant 0 : index
+ // CHECK: %[[CST:.*]] = arith.constant 8 : index
+ %cst = arith.constant 8 : index
+ %cst2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
// CHECK: memref.dim %[[ARG1]]
%cst3 = memref.dim %arg1, %c0 : memref<?xf32>
// CHECK: gpu.launch_func @extra_constants_noarg_kernel::@extra_constants_noarg_kernel blocks in (%[[CST]], %[[CST]], %[[CST]]) threads in (%[[CST]], %[[CST]], %[[CST]]) args(%[[ARG0]] : memref<?xf32>, {{.*}} : index)
// CHECK-LABEL: func @extra_constants_noarg_kernel(
// CHECK-SAME: %[[KARG0:.*]]: memref<?xf32>, %[[KARG1:.*]]: index
-// CHECK: %[[KCST:.*]] = constant 2
+// CHECK: %[[KCST:.*]] = arith.constant 2
// CHECK: "use"(%[[KCST]], %[[KARG0]], %[[KARG1]])
// -----
// CHECK-LABEL: @multiple_uses
func @multiple_uses(%arg0 : memref<?xf32>) {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
// CHECK: gpu.func {{.*}} {
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: "use1"(%[[C2]], %[[C2]])
// CHECK: "use2"(%[[C2]])
// CHECK: gpu.return
// CHECK-LABEL: @multiple_uses2
func @multiple_uses2(%arg0 : memref<*xf32>) {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%d = memref.dim %arg0, %c2 : memref<*xf32>
// CHECK: gpu.func {{.*}} {
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: %[[D:.*]] = memref.dim %[[ARG:.*]], %[[C2]]
// CHECK: "use1"(%[[D]])
// CHECK: "use2"(%[[C2]], %[[C2]])
//CHECK-LABEL: @function_call
func @function_call(%arg0 : memref<?xf32>) {
- %cst = constant 8 : index
+ %cst = arith.constant 8 : index
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst,
%grid_z = %cst)
threads(%tx, %ty, %tz) in (%block_x = %cst, %block_y = %cst,
// CHECK-SAME: workgroup(%[[promoted:.*]] : memref<5x4xf32, 3>)
gpu.func @memref3d(%arg0: memref<5x4xf32> {gpu.test_promote_workgroup}) kernel {
// Verify that loop bounds are emitted, the order does not matter.
- // CHECK-DAG: %[[c1:.*]] = constant 1
- // CHECK-DAG: %[[c4:.*]] = constant 4
- // CHECK-DAG: %[[c5:.*]] = constant 5
+ // CHECK-DAG: %[[c1:.*]] = arith.constant 1
+ // CHECK-DAG: %[[c4:.*]] = arith.constant 4
+ // CHECK-DAG: %[[c5:.*]] = arith.constant 5
// CHECK-DAG: %[[tx:.*]] = "gpu.thread_id"() {dimension = "x"}
// CHECK-DAG: %[[ty:.*]] = "gpu.thread_id"() {dimension = "y"}
// CHECK-DAG: %[[tz:.*]] = "gpu.thread_id"() {dimension = "z"}
// CHECK-SAME: workgroup(%[[promoted:.*]] : memref<8x7x6x5x4xf32, 3>)
gpu.func @memref5d(%arg0: memref<8x7x6x5x4xf32> {gpu.test_promote_workgroup}) kernel {
// Verify that loop bounds are emitted, the order does not matter.
- // CHECK-DAG: %[[c0:.*]] = constant 0
- // CHECK-DAG: %[[c1:.*]] = constant 1
- // CHECK-DAG: %[[c4:.*]] = constant 4
- // CHECK-DAG: %[[c5:.*]] = constant 5
- // CHECK-DAG: %[[c6:.*]] = constant 6
- // CHECK-DAG: %[[c7:.*]] = constant 7
- // CHECK-DAG: %[[c8:.*]] = constant 8
+ // CHECK-DAG: %[[c0:.*]] = arith.constant 0
+ // CHECK-DAG: %[[c1:.*]] = arith.constant 1
+ // CHECK-DAG: %[[c4:.*]] = arith.constant 4
+ // CHECK-DAG: %[[c5:.*]] = arith.constant 5
+ // CHECK-DAG: %[[c6:.*]] = arith.constant 6
+ // CHECK-DAG: %[[c7:.*]] = arith.constant 7
+ // CHECK-DAG: %[[c8:.*]] = arith.constant 8
// CHECK-DAG: %[[tx:.*]] = "gpu.thread_id"() {dimension = "x"}
// CHECK-DAG: %[[ty:.*]] = "gpu.thread_id"() {dimension = "y"}
// CHECK-DAG: %[[tz:.*]] = "gpu.thread_id"() {dimension = "z"}
// CHECK-LABEL: fold_extractvalue
llvm.func @fold_extractvalue() -> i32 {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : i32
- %c0 = constant 0 : i32
- // CHECK-DAG: %[[C1:.*]] = constant 1 : i32
- %c1 = constant 1 : i32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : i32
+ %c0 = arith.constant 0 : i32
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : i32
+ %c1 = arith.constant 1 : i32
%0 = llvm.mlir.undef : !llvm.struct<(i32, i32)>
// RUN: mlir-opt %s -convert-linalg-to-affine-loops -convert-linalg-to-llvm -o=/dev/null 2>&1
func @matmul(%arg0: memref<?xi8>, %M: index, %N: index, %K: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%A = memref.view %arg0[%c0][%M, %K] : memref<?xi8> to memref<?x?xf32>
%B = memref.view %arg0[%c0][%K, %N] : memref<?xi8> to memref<?x?xf32>
%C = memref.view %arg0[%c0][%M, %N] : memref<?xi8> to memref<?x?xf32>
// CHECK: %[[va:.*]] = affine.load %[[mA]][%[[b]], %[[m]], %[[k]]] : memref<?x?x?xf32>
// CHECK: %[[vb:.*]] = affine.load %[[mB]][%[[b]], %[[k]], %[[n]]] : memref<?x?x?xf32>
// CHECK: %[[vc:.*]] = affine.load %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
-// CHECK: %[[inc:.*]] = mulf %[[va]], %[[vb]] : f32
-// CHECK: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECK: %[[inc:.*]] = arith.mulf %[[va]], %[[vb]] : f32
+// CHECK: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECK: affine.store %[[res]], %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
-
// CHECK-LABEL: func @dynamic_results(
// CHECK-SAME: %[[ARG:.*]]: tensor<?x?xf32>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[MEMREF_ARG:.*]] = memref.buffer_cast %[[ARG]] : memref<?x?xf32>
// CHECK: %[[DIM0:.*]] = tensor.dim %[[ARG]], %[[C0]] : tensor<?x?xf32>
// CHECK: %[[DIM1:.*]] = tensor.dim %[[ARG]], %[[C1]] : tensor<?x?xf32>
// CHECK-SAME: %[[ST1:[0-9a-z]*]]: tensor<2x?xf32>
func @bufferize_insert_slice(%t : tensor<?x?xf32>, %st0 : tensor<2x3xf32>, %st1 : tensor<2x?xf32>) ->
(tensor<?x?xf32>, tensor<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
%i0 = call @make_index() : () -> index
// CHECK: %[[IDX:.*]] = call @make_index() : () -> index
// CHECK-LABEL: func @bufferize_fill(
// CHECK-SAME: %[[IN:.*]]: tensor<?xf32>
func @bufferize_fill(%arg0: tensor<?xf32>) -> tensor<?xf32> {
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
// CHECK: %[[MEMREF:.*]] = memref.buffer_cast %[[IN]] : memref<?xf32>
// CHECK: linalg.fill(%cst, %[[MEMREF]]) : f32, memref<?xf32>
// CHECK: %[[TENSOR:.*]] = memref.tensor_load %[[MEMREF]] : memref<?xf32>
// CHECK-SAME: %[[IN:.*]]: tensor<4x?x2x?xf32>,
// CHECK-SAME: %[[OFFSET:.*]]: index) -> tensor<4x?x?x?xf32> {
func @pad_tensor_dynamic_shape(%arg0: tensor<4x?x2x?xf32>, %arg1: index) -> tensor<4x?x?x?xf32> {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
%out = linalg.pad_tensor %arg0 low[%c0, %c0, %arg1, %c0] high[%c0, %c0, %c0, %arg1] {
^bb0(%gen_arg1: index, %gen_arg2: index, %gen_arg3: index, %gen_arg4: index): // no predecessors
linalg.yield %cst : f32
return %out : tensor<4x?x?x?xf32>
}
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[CST:.*]] = constant 0.000000e+00 : f32
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[DIM1:.*]] = tensor.dim %[[IN]], %[[C1]] : tensor<4x?x2x?xf32>
-// CHECK: %[[OUT_DIM2:.*]] = addi %[[OFFSET]], %[[C2]] : index
+// CHECK: %[[OUT_DIM2:.*]] = arith.addi %[[OFFSET]], %[[C2]] : index
// CHECK: %[[DIM3:.*]] = tensor.dim %[[IN]], %[[C3]] : tensor<4x?x2x?xf32>
-// CHECK: %[[OUT_DIM3:.*]] = addi %[[DIM3]], %[[OFFSET]] : index
+// CHECK: %[[OUT_DIM3:.*]] = arith.addi %[[DIM3]], %[[OFFSET]] : index
// CHECK: %[[FILLED:.*]] = memref.alloc(%[[DIM1]], %[[OUT_DIM2]], %[[OUT_DIM3]]) : memref<4x?x?x?xf32>
// CHECK: linalg.fill(%[[CST]], %[[FILLED]]) : f32, memref<4x?x?x?xf32>
// CHECK: %[[IN_MEMREF:.*]] = memref.buffer_cast %[[IN]] : memref<4x?x2x?xf32>
// CHECK-LABEL: func @vector_transfer
func @vector_transfer(%in: tensor<4xf32>, %out: tensor<4xf32>) {
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
%read = vector.transfer_read %in[%c0], %cst {in_bounds = [true]}
: tensor<4xf32>, vector<4xf32>
%tanh = math.tanh %read : vector<4xf32>
// CHECK: linalg.generic{{.*}}[#[[$MAP]], #[[$MAP]]]
// CHECK: attrs = {someattr}
// CHECK: ^bb0(%[[BBARG:.*]]: f32, %{{.*}}: f32):
- // CHECK: addf %[[BBARG]], %[[BBARG]]
+ // CHECK: arith.addf %[[BBARG]], %[[BBARG]]
%0 = linalg.generic {indexing_maps = [#map, #map, #map], iterator_types = ["parallel"]}
ins(%arg0, %arg0 : tensor<?xf32>, tensor<?xf32>)
outs(%arg0 : tensor<?xf32>) attrs = {someattr} {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
- %1 = addf %arg1, %arg2 : f32
+ %1 = arith.addf %arg1, %arg2 : f32
linalg.yield %1 : f32
} -> tensor<?xf32>
return %0 : tensor<?xf32>
ins(%arg0, %arg0 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arg0 : tensor<?x?xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
- %1 = addf %arg1, %arg2 : f32
+ %1 = arith.addf %arg1, %arg2 : f32
linalg.yield %1 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
// CHECK-LABEL: func @memref_cast(
func @memref_cast(%a: index, %b: index) -> memref<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c8 = constant 8 : index
- %c16 = constant 16 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c8 = arith.constant 8 : index
+ %c16 = arith.constant 16 : index
%1 = memref.alloc (%b) : memref<?xi8>
%2 = memref.view %1[%c0][] : memref<?xi8> to memref<16x16xf32>
%3 = memref.cast %2 : memref<16x16xf32> to memref<?x?xf32>
func @memref_cast_into_tiled_loop(%arg0: memref<192xf32>) {
%0 = memref.cast %arg0
: memref<192xf32> to memref<192xf32, #map>
- %cst = constant 0.000000e+00 : f32
- %c24 = constant 24 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c24 = arith.constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
// CHECK: linalg.tiled_loop
// CHECK-SAME: outs (%{{.*}} = %{{.*}}: memref<192xf32>)
linalg.tiled_loop (%arg3) = (%c0) to (%c192) step (%c24)
func @reshape_splat_constant_int32() -> tensor<2x4x2xi32>
{
- %c0 = constant dense<42> : tensor<2x8xi32>
+ %c0 = arith.constant dense<42> : tensor<2x8xi32>
%0 = linalg.tensor_expand_shape %c0 [[0], [1, 2]]
: tensor<2x8xi32> into tensor<2x4x2xi32>
return %0 : tensor<2x4x2xi32>
}
// CHECK-LABEL: @reshape_splat_constant_int32
-// CHECK: %[[CST:.*]] = constant dense<{{.*}}> : tensor<2x4x2xi32>
+// CHECK: %[[CST:.*]] = arith.constant dense<{{.*}}> : tensor<2x4x2xi32>
// CHECK-NOT: linalg.tensor_expand_shape
// CHECK: return %[[CST]]
func @reshape_splat_constant_int16() -> tensor<2x4x2xi16>
{
- %c0 = constant dense<42> : tensor<2x8xi16>
+ %c0 = arith.constant dense<42> : tensor<2x8xi16>
%0 = linalg.tensor_expand_shape %c0 [[0], [1, 2]]
: tensor<2x8xi16> into tensor<2x4x2xi16>
return %0 : tensor<2x4x2xi16>
}
// CHECK-LABEL: @reshape_splat_constant_int16
-// CHECK: %[[CST:.*]] = constant dense<{{.*}}> : tensor<2x4x2xi16>
+// CHECK: %[[CST:.*]] = arith.constant dense<{{.*}}> : tensor<2x4x2xi16>
// CHECK-NOT: linalg.tensor_expand_shape
// CHECK: return %[[CST]]
func @reshape_splat_constant_float32() -> tensor<2x4x2xf32>
{
- %c0 = constant dense<42.0> : tensor<2x8xf32>
+ %c0 = arith.constant dense<42.0> : tensor<2x8xf32>
%0 = linalg.tensor_expand_shape %c0 [[0], [1, 2]]
: tensor<2x8xf32> into tensor<2x4x2xf32>
return %0 : tensor<2x4x2xf32>
}
// CHECK-LABEL: @reshape_splat_constant_float32
-// CHECK: %[[CST:.*]] = constant dense<{{.*}}> : tensor<2x4x2xf32>
+// CHECK: %[[CST:.*]] = arith.constant dense<{{.*}}> : tensor<2x4x2xf32>
// CHECK-NOT: linalg.tensor_expand_shape
// CHECK: return %[[CST]]
func @reshape_splat_constant_float64() -> tensor<2x4x2xf64>
{
- %c0 = constant dense<42.0> : tensor<2x8xf64>
+ %c0 = arith.constant dense<42.0> : tensor<2x8xf64>
%0 = linalg.tensor_expand_shape %c0 [[0], [1, 2]]
: tensor<2x8xf64> into tensor<2x4x2xf64>
return %0 : tensor<2x4x2xf64>
}
// CHECK-LABEL: @reshape_splat_constant_float64
-// CHECK: %[[CST:.*]] = constant dense<{{.*}}> : tensor<2x4x2xf64>
+// CHECK: %[[CST:.*]] = arith.constant dense<{{.*}}> : tensor<2x4x2xf64>
// CHECK-NOT: linalg.tensor_expand_shape
// CHECK: return %[[CST]]
// -----
func @init_tensor_canonicalize() -> (tensor<4x5x?xf32>) {
- %c6 = constant 6 : index
+ %c6 = arith.constant 6 : index
%0 = linalg.init_tensor [4, 5, %c6] : tensor<4x5x?xf32>
return %0 : tensor<4x5x?xf32>
}
#map = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
func @remove_no_op(%arg0 : tensor<?x?x?xf32>, %arg1 : tensor<?x?x?xf32>)
-> (tensor<?x?x?xf32>, tensor<?x?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
#map = affine_map<(d0, d1) -> (d0, d1)>
func @keep_not_noop(%arg0 : tensor<?x?xf32>) -> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cst = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cst = arith.constant 1.000000e+00 : f32
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
#map = affine_map<(d0, d1) -> (d0, d1)>
func @keep_not_noop(%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>)
-> (tensor<?x?xf32>, tensor<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cst = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cst = arith.constant 1.000000e+00 : f32
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
// CHECK: return
func @dead_linalg_tensor(%arg0 : tensor<7x7xi32>, %arg1 : tensor<7x7xf32>,
%arg2: tensor<?x?xf32>, %high : index) {
- %c0_i32 = constant 0 : i32
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0_i32 = arith.constant 0 : i32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.fill(%c0_i32, %arg0) : i32, tensor<7x7xi32> -> tensor<7x7xi32>
%1 = linalg.matmul ins(%arg1, %arg1: tensor<7x7xf32>, tensor<7x7xf32>)
outs(%arg1: tensor<7x7xf32>) -> tensor<7x7xf32>
// CHECK: return %[[ARG0]]
func @pad_tensor_same_static_shape(%arg0: tensor<5x6xf32>, %a: index)
-> tensor<5x6xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.pad_tensor %arg0 low[%a, 0] high[0, %a] {
^bb0(%arg1: index, %arg2: index):
linalg.yield %cst : f32
// CHECK: return %[[PAD]]
func @pad_tensor_nofold_same_static_shape(%arg0: tensor<5x6xf32>, %a: index)
-> tensor<5x6xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.pad_tensor %arg0 nofold low[%a, 0] high[0, %a] {
^bb0(%arg1: index, %arg2: index):
linalg.yield %cst : f32
// CHECK-LABEL: func @pad_tensor_after_cast_different_shape(
// CHECK-SAME: %[[INPUT:.*]]: tensor<?x64x?x?xf32>) -> tensor<?x?x?x?xf32> {
-// CHECK: %[[CST:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[PADDED:.*]] = linalg.pad_tensor %[[INPUT]]
// CHECK-SAME: low[0, 0, 1, 1] high[0, 0, 1, 1] {
// CHECK: ^bb0(%[[ARG1:.*]]: index, %[[ARG2:.*]]: index, %[[ARG3:.*]]: index, %[[ARG4:.*]]: index):
// CHECK: }
func @pad_tensor_after_cast_different_shape(%arg0: tensor<?x64x?x?xf32>)
-> tensor<?x?x?x?xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%dynamic = tensor.cast %arg0 : tensor<?x64x?x?xf32> to tensor<?x?x?x?xf32>
%padded = linalg.pad_tensor %dynamic low[0, 0, 1, 1] high[0, 0, 1, 1] {
^bb0(%arg1: index, %arg2: index, %arg3: index, %arg4: index): // no predecessors
// CHECK-LABEL: func @pad_tensor_after_cast_same_shape(
// CHECK-SAME: %[[INPUT:.*]]: tensor<?x64x?x?xf32>,
// CHECK-SAME: %[[PADDING:.*]]: index) -> tensor<?x?x?x?xf32> {
-// CHECK: %[[CST:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[PADDED:.*]] = linalg.pad_tensor %[[INPUT]]
// CHECK-SAME: low[0, %[[PADDING]], 1, 1] high[0, %[[PADDING]], 1, 1] {
// CHECK: ^bb0(%[[ARG1:.*]]: index, %[[ARG2:.*]]: index, %[[ARG3:.*]]: index, %[[ARG4:.*]]: index):
// CHECK: }
func @pad_tensor_after_cast_same_shape(%arg0: tensor<?x64x?x?xf32>, %padding : index)
-> tensor<?x?x?x?xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%dynamic = tensor.cast %arg0 : tensor<?x64x?x?xf32> to tensor<?x?x?x?xf32>
%padded = linalg.pad_tensor %dynamic low[0, %padding, 1, 1] high[0, %padding, 1, 1] {
^bb0(%arg1: index, %arg2: index, %arg3: index, %arg4: index): // no predecessors
// CHECK: linalg.pad_tensor
// CHECK: tensor<8x?xf32> to tensor<8x32xf32>
func @pad_tensor_of_cast(%t: tensor<8x?xf32>, %s: index) -> tensor<8x32xf32> {
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = tensor.cast %t : tensor<8x?xf32> to tensor<?x?xf32>
%1 = linalg.pad_tensor %0 low[%c0, %c0] high[%c0, %s] {
^bb0(%arg9: index, %arg10: index): // no predecessors
// CHECK-LABEL: @cast_of_pad_more_static
func @cast_of_pad_more_static(%arg0: tensor<?x?xf32>, %padding: index) -> tensor<32x32xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK: %[[PAD:.*]] = linalg.pad_tensor
// CHECK: tensor<?x?xf32> to tensor<32x32xf32>
%padded = linalg.pad_tensor %arg0 low[%padding, %padding] high[0, 0] {
// CHECK-LABEL: @cast_of_pad_less_static
func @cast_of_pad_less_static(%arg0: tensor<32x?x?xf32>, %padding: index) -> tensor<?x32x32xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK: linalg.pad_tensor
%padded = linalg.pad_tensor %arg0 low[%padding, %padding, %padding] high[0, 0, 0] {
^bb0(%arg1: index, %arg2: index, %arg3: index):
func @propogate_casts(%arg0 : tensor<?x?xf32>, %arg1 : f32, %arg2 : index,
%arg3 : index) -> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c21 = constant 21 : index
- %c42 = constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c21 = arith.constant 21 : index
+ %c42 = arith.constant 42 : index
%0 = linalg.init_tensor [%c21, %c42] : tensor<?x?xf32>
%1 = linalg.fill(%arg1, %0) : f32, tensor<?x?xf32> -> tensor<?x?xf32>
%2 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
// CHECK-LABEL: func @fold_fill_reshape()
func @fold_fill_reshape() -> tensor<6x4xf32> {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
// CHECK: %[[INIT:.+]] = linalg.init_tensor [6, 4] : tensor<6x4xf32>
%init = linalg.init_tensor [1, 2, 3, 4] : tensor<1x2x3x4xf32>
// CHECK: %[[FILL:.+]] = linalg.fill(%cst, %[[INIT]]) : f32, tensor<6x4xf32> -> tensor<6x4xf32>
// CHECK: func @fold_fill_reshape_dynamic
// CHECK-SAME: %[[ARG0:.+]]: tensor<?x?x?x?x?xf32>
func @fold_fill_reshape_dynamic(%arg0 : tensor<?x?x?x?x?xf32>) -> tensor<?x?xf32> {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
// CHECK: %[[RESHAPE:.+]] = linalg.tensor_collapse_shape %[[ARG0]]
%0 = linalg.fill(%zero, %arg0) : f32, tensor<?x?x?x?x?xf32> -> tensor<?x?x?x?x?xf32>
// CHECK: %[[RESULT:.+]] = linalg.fill(%{{.+}}, %[[RESHAPE]])
func @fold_tiled_loop_results(%A: memref<48xf32>, %B: tensor<48xf32>,
%C: memref<48xf32>, %C_tensor: tensor<48xf32>) -> tensor<48xf32> {
- %c0 = constant 0 : index
- %c24 = constant 24 : index
- %c48 = constant 48 : index
+ %c0 = arith.constant 0 : index
+ %c24 = arith.constant 24 : index
+ %c48 = arith.constant 48 : index
%useful, %useless = linalg.tiled_loop (%i) = (%c0) to (%c48) step (%c24)
ins (%A_ = %A: memref<48xf32>)
outs (%B_ = %B: tensor<48xf32>,
// CHECK-SAME: %[[A:.*]]: [[BUF_TY:memref<48xf32>]], %[[B:.*]]: [[TY:tensor<48xf32>]],
// CHECK-SAME: %[[C:.*]]: [[BUF_TY]], %[[C_TENSOR:.*]]: [[TY]]) -> [[TY]] {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C24:.*]] = constant 24 : index
-// CHECK-DAG: %[[C48:.*]] = constant 48 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C24:.*]] = arith.constant 24 : index
+// CHECK-DAG: %[[C48:.*]] = arith.constant 48 : index
// CHECK-NOT: %{{.*}} = linalg.tiled_loop
// CHECK: %[[RESULT:.*]] = linalg.tiled_loop (%{{.*}}) = (%[[C0]])
func @fold_tiled_loop_inputs(%A: memref<192xf32>, %A_tensor: tensor<192xf32>,
%B_tensor: tensor<192xf32>) -> tensor<192xf32> {
- %c0 = constant 0 : index
- %c24 = constant 24 : index
- %c192 = constant 192 : index
+ %c0 = arith.constant 0 : index
+ %c24 = arith.constant 24 : index
+ %c192 = arith.constant 192 : index
%result = linalg.tiled_loop (%i) = (%c0) to (%c192) step (%c24)
ins (%A_ = %A: memref<192xf32>, %AT_ = %A_tensor: tensor<192xf32>)
outs (%BT_ = %B_tensor: tensor<192xf32>) {
// -----
func @tensor_pad_cast_fold(%arg0: tensor<4x4xf32>) -> tensor<4x4xf32> {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
%0 = tensor.cast %arg0 : tensor<4x4xf32> to tensor<?x?xf32>
%1 = linalg.pad_tensor %0 low[%c0, %c0] high[%c0, %c0] {
^bb0(%arg1: index, %arg2: index): // no predecessors
// CHECK-NOT: tensor.cast
// CHECK: %[[RESULT:.*]] = linalg.pad_tensor %[[ARG0]]
func @fold_pad_tensor_source_cast(%arg0: tensor<4x?xf32>) -> tensor<4x4xf32> {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%0 = tensor.cast %arg0 : tensor<4x?xf32> to tensor<?x?xf32>
%1 = linalg.pad_tensor %0 low[0, 0] high[0, 1] {
^bb0(%arg1: index, %arg2: index): // no predecessors
// CHECK: %[[RESULT:.*]] = tensor.cast %[[ARG0]] : tensor<?x?x?xf32> to tensor<2x3x4xf32>
// CHECK: return %[[RESULT]]
func @pad_static_zero_cast(%arg0: tensor<?x?x?xf32>, %pad_value: f32) -> tensor<2x3x4xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = linalg.pad_tensor %arg0 low[0, %c0, 0] high[0, 0, %c0] {
^bb0(%arg1: index, %arg2: index, %arg3: index):
linalg.yield %pad_value : f32
// CHECK: %[[PAD:.*]] = linalg.pad_tensor
// CHECK: return %[[PAD]]
func @pad_nofold_static_zero(%arg0: tensor<?x?x?xf32>, %pad_value: f32) -> tensor<2x3x4xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = linalg.pad_tensor %arg0 nofold low[0, %c0, 0] high[0, 0, %c0] {
^bb0(%arg1: index, %arg2: index, %arg3: index):
linalg.yield %pad_value : f32
// CHECK-LABEL: func @init_canonicalize
// CHECK-SAME: %[[I:.*]]: index
func @init_canonicalize(%i : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// CHECK-NOT: init_tensor
%0 = linalg.init_tensor [%i, 42] : tensor<?x42xf32>
%1 = tensor.dim %0, %c0: tensor<?x42xf32>
%2 = tensor.dim %0, %c1: tensor<?x42xf32>
- // CHECK: %[[c42:.*]] = constant 42 : index
+ // CHECK: %[[c42:.*]] = arith.constant 42 : index
// CHECK: call @some_use(%[[I]], %[[c42]])
call @some_use(%1, %2) : (index, index) -> ()
// CHECK-LABEL: func @dim_of_tiled_loop_input_no_canonicalize(
// CHECK-SAME: %[[arg0:.*]]: tensor<?x?xf32>, %[[arg1:.*]]: tensor<?x?xf32>, %[[arg2:.*]]: tensor<?x?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK: linalg.tiled_loop {{.*}} outs (%[[o:.*]] =
// CHECK: %[[dim:.*]] = tensor.dim %[[o]], %[[c0]]
-// CHECK: index_cast %[[dim]]
+// CHECK: arith.index_cast %[[dim]]
func @dim_of_tiled_loop_input_no_canonicalize(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>, %s: index)
-> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%r = linalg.tiled_loop (%iv0, %iv1) = (%c0, %c0)
ins (%in0 = %arg0 : tensor<?x?xf32>, %in1 = %arg1 : tensor<?x?xf32>)
outs (%out1 = %arg2 : tensor<?x?xf32>) {
%inner_dim = tensor.dim %out1, %c0 : tensor<?x?xf32>
- %cast1 = std.index_cast %inner_dim : index to i32
- %cast2 = std.sitofp %cast1 : i32 to f32
+ %cast1 = arith.index_cast %inner_dim : index to i32
+ %cast2 = arith.sitofp %cast1 : i32 to f32
%fill = linalg.fill(%cast2, %out1) : f32, tensor<?x?xf32> -> tensor<?x?xf32>
%slice = tensor.extract_slice %fill[0, 0][%s, %s][1, 1] : tensor<?x?xf32> to tensor<?x?xf32>
linalg.yield %slice : tensor<?x?xf32>
// CHECK-LABEL: func @dim_of_tiled_loop_input(
// CHECK-SAME: %[[arg0:.*]]: tensor<?x?xf32>, %[[arg1:.*]]: tensor<?x?xf32>, %[[arg2:.*]]: tensor<?x?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK: linalg.tiled_loop
// CHECK: %[[dim:.*]] = tensor.dim %[[arg1]], %[[c0]]
-// CHECK: index_cast %[[dim]]
+// CHECK: arith.index_cast %[[dim]]
func @dim_of_tiled_loop_input(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>)
-> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%r = linalg.tiled_loop (%iv0, %iv1) = (%c0, %c0)
ins (%in0 = %arg0 : tensor<?x?xf32>, %in1 = %arg1 : tensor<?x?xf32>)
outs (%out1 = %arg2 : tensor<?x?xf32>) {
%inner_dim = tensor.dim %in1, %c0 : tensor<?x?xf32>
- %cast1 = std.index_cast %inner_dim : index to i32
- %cast2 = std.sitofp %cast1 : i32 to f32
+ %cast1 = arith.index_cast %inner_dim : index to i32
+ %cast2 = arith.sitofp %cast1 : i32 to f32
%fill = linalg.fill(%cast2, %out1) : f32, tensor<?x?xf32> -> tensor<?x?xf32>
linalg.yield %fill : tensor<?x?xf32>
}
// CHECK-LABEL: func @dim_of_tiled_loop_result(
// CHECK-SAME: %[[arg0:.*]]: tensor<?x?xf32>, %[[arg1:.*]]: tensor<?x?xf32>, %[[arg2:.*]]: tensor<?x?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK: tensor.dim %[[arg2]], %[[c0]]
func @dim_of_tiled_loop_result(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>, %s: index)
-> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%r = linalg.tiled_loop (%iv0, %iv1) = (%c0, %c0)
// CHECK-LABEL: func @dim_of_tiled_loop_result_no_canonicalize(
// CHECK-SAME: %[[arg0:.*]]: tensor<?x?xf32>, %[[arg1:.*]]: tensor<?x?xf32>, %[[arg2:.*]]: tensor<?x?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK: %[[r:.*]] = linalg.tiled_loop
// CHECK: tensor.dim %[[r]], %[[c0]]
func @dim_of_tiled_loop_result_no_canonicalize(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>, %s: index)
-> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%r = linalg.tiled_loop (%iv0, %iv1) = (%c0, %c0)
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
// CHECK: {__inplace_results_attr__ = ["false"]}
%idx : index)
-> (tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>)
{
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
// 2-level matching tensor.extract_slice / tensor.insert_slice into non
// inplaceable %A.
// CHECK-LABEL: dependence_through_call
func @dependence_through_call(%I : tensor<64xf32> {linalg.inplaceable = true}) {
- %f1 = constant 1.000000e+00 : f32
- %f2 = constant 2.000000e+00 : f32
+ %f1 = arith.constant 1.000000e+00 : f32
+ %f2 = arith.constant 2.000000e+00 : f32
// 2. %B already bufferizes inplace, %A would alias and have a different
// value. The calls to `foo` are determined to read conservatively, so %A
func @read_dependence_through_scf_and_call(
%I : tensor<64xf32> {linalg.inplaceable = true},
%I2 : tensor<64xf32> {linalg.inplaceable = true}) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- %f1 = constant 1.000000e+00 : f32
- %f2 = constant 2.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %f1 = arith.constant 1.000000e+00 : f32
+ %f2 = arith.constant 2.000000e+00 : f32
// 5. %B bufferizes inplace, %A would alias and have a different value.
// The calls to `foo` are determined to read conservatively, so %A cannot
func @write_into_constant_via_alias(%v : vector<5xi32>,
%s1 : index, %s2 : index,
%s3 : index) -> tensor<?xi32> {
- %A = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %A = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
// CHECK: tensor.extract_slice
// CHECK-SAME: {__inplace_results_attr__ = ["false"]}
%b = tensor.extract_slice %A[%s1][%s2][1] : tensor<4xi32> to tensor<?xi32>
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst_0 = constant 0.000000e+00 : f32
- %cst_1 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst_0 = arith.constant 0.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
%7 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
%arg2: tensor<256x256xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<256x256xf32>
{
- %c0 = constant 0 : index
- %cst_0 = constant 0.000000e+00 : f32
- %cst_1 = constant 1.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst_0 = arith.constant 0.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
%7 = linalg.init_tensor [256, 256] : tensor<256x256xf32>
%arg2: tensor<62x90xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<62x90xf32> attributes {passthrough = [["target-cpu", "skylake-avx512"], ["prefer-vector-width", "512"]]}
{
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
// CHECK: linalg.fill
// CHECK-SAME: {__inplace_results_attr__ = ["true"]
%x: index, %y: index, %v: vector<5x6xf32>)
-> tensor<10x20xf32>
{
- %c0 = constant 0 : index
- %c256 = constant 256 : index
- %c257 = constant 257 : index
+ %c0 = arith.constant 0 : index
+ %c256 = arith.constant 256 : index
+ %c257 = arith.constant 257 : index
%r = scf.for %arg0 = %c0 to %c257 step %c256 iter_args(%arg1 = %t) -> (tensor<10x20xf32>) {
%t1 = tensor.extract_slice %arg1[%x, 0] [5, %y] [1, 1] : tensor<10x20xf32> to tensor<5x?xf32>
%t11 = tensor.extract_slice %t1[0, 0] [5, %y] [1, 1] : tensor<5x?xf32> to tensor<5x?xf32>
}
func @scf_yield_needs_copy(%A : tensor<?xf32> {linalg.inplaceable = true}, %iters : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%res = scf.for %arg0 = %c0 to %iters step %c1 iter_args(%bbarg = %A) -> (tensor<?xf32>) {
%r = call @foo(%A) : (tensor<?xf32>) -> (tensor<?xf32>)
// expected-error @+1 {{Yield operand #0 does not bufferize to an equivalent buffer}}
// expected-error @+1 {{memref return type is unsupported}}
func @mini_test_case1() -> tensor<10x20xf32> {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
%t = linalg.init_tensor [10, 20] : tensor<10x20xf32>
%r = linalg.fill(%f0, %t) : f32, tensor<10x20xf32> -> tensor<10x20xf32>
return %r : tensor<10x20xf32>
func @main() -> tensor<4xi32> {
// expected-error @+1 {{unsupported op with tensors}}
%r = scf.execute_region -> tensor<4xi32> {
- %A = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %A = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
scf.yield %A: tensor<4xi32>
}
return %r: tensor<4xi32>
// -----
func @main() -> i32 {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
// expected-error @+1 {{expected result-less scf.execute_region containing op}}
%r = scf.execute_region -> i32 {
- %A = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %A = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
%e = tensor.extract %A[%c0]: tensor<4xi32>
scf.yield %e: i32
}
// CHECK-LABEL: func @transfer_read(%{{.*}}: memref<?xf32, #map>) -> vector<4xf32> {
func @transfer_read(%A : tensor<?xf32>) -> (vector<4xf32>) {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
// CHECK: %[[RES:.*]] = vector.transfer_read {{.*}} : memref<?xf32, #{{.*}}>, vector<4xf32>
%0 = vector.transfer_read %A[%c0], %f0 : tensor<?xf32>, vector<4xf32>
// CHECK-LABEL: func @fill_inplace(
// CHECK-SAME: %[[A:[a-zA-Z0-9]*]]: memref<?xf32, #[[$map_1d_dyn]]>
func @fill_inplace(%A : tensor<?xf32> {linalg.inplaceable = true}) -> tensor<?xf32> {
- // CHECK: %[[F0:.*]] = constant 0.000000e+00 : f32
- %f0 = constant 0.0 : f32
+ // CHECK: %[[F0:.*]] = arith.constant 0.000000e+00 : f32
+ %f0 = arith.constant 0.0 : f32
/// Inplaceable, no alloc
// CHECK-NOT: alloc
// CHECK-LABEL: func @tensor_extract(%{{.*}}: memref<?xf32, #{{.*}}>) -> f32 {
func @tensor_extract(%A : tensor<?xf32>) -> (f32) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[RES:.*]] = memref.load {{.*}} : memref<?xf32, #{{.*}}>
%0 = tensor.extract %A[%c0] : tensor<?xf32>
// CHECK-LABEL: func @not_inplace(
// CHECK-SAME: %[[A:[a-zA-Z0-9]*]]: memref<?xf32, #[[$map_1d_dyn]]>) -> memref<?xf32> {
func @not_inplace(%A : tensor<?xf32>) -> tensor<?xf32> {
- // CHECK: %[[F0:.*]] = constant 0.000000e+00 : f32
- %f0 = constant 0.0 : f32
+ // CHECK: %[[F0:.*]] = arith.constant 0.000000e+00 : f32
+ %f0 = arith.constant 0.0 : f32
// CHECK: %[[D0:.*]] = memref.dim %[[A]], {{.*}} : memref<?xf32, #[[$map_1d_dyn]]>
// CHECK: %[[ALLOC:.*]] = memref.alloc(%[[D0]]) {alignment = 128 : i64} : memref<?xf32>
// CHECK-LABEL: func @not_inplace
// CHECK-SAME: %[[A:[a-zA-Z0-9]*]]: memref<?x?xf32, #[[$map_2d_dyn]]>) {
func @not_inplace(%A : tensor<?x?xf32> {linalg.inplaceable = true}) -> tensor<?x?xf32> {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
/// Cross-op multiple uses of %A, the first op which has interfering reads must alloc.
// CHECK: %[[ALLOC:.*]] = memref.alloc
func @vec_inplace(%A : tensor<?xf32> {linalg.inplaceable = true}, %vec : vector<4xf32>)
-> tensor<?xf32>
{
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK-NOT: alloc
%r = vector.transfer_write %vec, %A[%c0] : vector<4xf32>, tensor<?xf32>
func @vec_not_inplace(%A : tensor<?xf32> {linalg.inplaceable = true}, %vec : vector<4xf32>)
-> (tensor<?xf32>, tensor<?xf32>)
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
/// Cross-op multiple uses of %A, the first vector.transfer which has interfering reads must alloc.
// CHECK: %[[ALLOC:.*]] = memref.alloc
func @insert_slice_fun(%A : tensor<?xf32> {linalg.inplaceable = true}, %t : tensor<4xf32>)
-> tensor<?xf32>
{
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
// CHECK-NOT: alloc
// CHECK: %[[SV_A:.*]] = memref.subview %[[A]]
func @insert_slice_fun(%A : tensor<?xf32> {linalg.inplaceable = true}, %t : tensor<4xf32>)
-> tensor<?xf32>
{
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
// CHECK: linalg.fill({{.*}}, %[[A]]
%r0 = linalg.fill(%f0, %A) : f32, tensor<?xf32> -> tensor<?xf32>
// CHECK: func @main()
func @main() {
// CHECK: %[[A:.*]] = memref.get_global @__constant_4xi32 : memref<4xi32>
- %A = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %A = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
// CHECK: %[[B:.*]] = memref.cast %[[A]] : memref<4xi32> to memref<4xi32, #[[$DYN_1D_MAP]]>
// CHECK: call @some_external_func(%[[B]]) : (memref<4xi32, #[[$DYN_1D_MAP]]>) -> ()
// CHECK: func @main()
func @main() {
// CHECK: %[[A:.*]] = memref.get_global @__constant_4xi32 : memref<4xi32>
- %A = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %A = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
// CHECK: %[[B:.*]] = memref.cast %[[A]] : memref<4xi32> to memref<4xi32, #[[$DYN_1D_MAP]]>
// CHECK: call @some_external_func_within_scf_execute(%[[B]]) : (memref<4xi32, #[[$DYN_1D_MAP]]>) -> ()
// CHECK-SAME: %[[B:[a-zA-Z0-9]*]]: memref<64xf32, #[[$DYN_1D_MAP]]>
// CHECK-SAME: %[[C:[a-zA-Z0-9]*]]: memref<f32, #[[$DYN_0D_MAP]]>
func @init_and_dot(%a: tensor<64xf32>, %b: tensor<64xf32>, %c: tensor<f32>) -> tensor<f32> {
- // CHECK-NEXT: %[[C0:.*]] = constant 0{{.*}} : f32
- %v0 = constant 0.0 : f32
+ // CHECK-NEXT: %[[C0:.*]] = arith.constant 0{{.*}} : f32
+ %v0 = arith.constant 0.0 : f32
// CHECK-NEXT: linalg.fill(%[[C0]], %[[C]]) : f32, memref<f32, #[[$DYN_0D_MAP]]>
%d = linalg.fill(%v0, %c) : f32, tensor<f32> -> tensor<f32>
// CHECK: func @main()
func @main() {
- // CHECK-DAG: %[[C0:.*]] = constant 0{{.*}} : f32
- // CHECK-DAG: %[[C1:.*]] = constant 1{{.*}} : f32
- // CHECK-DAG: %[[C2:.*]] = constant 2{{.*}} : f32
- %v0 = constant 0.0 : f32
- %v1 = constant 1.0 : f32
- %v2 = constant 2.0 : f32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0{{.*}} : f32
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1{{.*}} : f32
+ // CHECK-DAG: %[[C2:.*]] = arith.constant 2{{.*}} : f32
+ %v0 = arith.constant 0.0 : f32
+ %v1 = arith.constant 1.0 : f32
+ %v2 = arith.constant 2.0 : f32
// CHECK-NEXT: %[[C:.*]] = memref.alloc() {alignment = 128 : i64} : memref<f32>
// CHECK-NEXT: %[[B:.*]] = memref.alloc() {alignment = 128 : i64} : memref<64xf32>
// CHECK-SAME: %[[c:[a-zA-Z0-9]*]]: memref<f32, #[[$DYN_0D_MAP]]>
func @tiled_dot(%A: tensor<?xf32>, %B: tensor<?xf32>, %c: tensor<f32> {linalg.inplaceable = true},
%effecting: memref<?xf32>) -> tensor<f32> {
- %c3 = constant 3 : index
- %c0 = constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[M:.*]] = memref.dim %[[A]], {{.*}} : memref<?xf32, #[[$DYN_1D_MAP:.*]]>
%0 = tensor.dim %A, %c0 : tensor<?xf32>
// CHECK: func @tiled_fill(
// CHECK-SAME: %[[A:[a-zA-Z0-9]*]]: memref<?xf32, #[[$DYN_MAP]]>
func @tiled_fill(%A: tensor<?xf32> {linalg.inplaceable = true}) -> tensor<?xf32> {
- %c3 = constant 3 : index
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
// CHECK: %[[M:.*]] = memref.dim %[[A]], {{.*}} : memref<?xf32, #[[$DYN_MAP:.*]]>
%0 = tensor.dim %A, %c0 : tensor<?xf32>
%B: tensor<256x192xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = false},
%C: tensor<128x192xf32> {linalg.buffer_layout = affine_map<(d0, d1) -> (d0, d1)>, linalg.inplaceable = true})
-> tensor<128x192xf32> {
- %c0 = constant 0 : index
- %c256 = constant 256 : index
- %c32 = constant 32 : index
- %cst = constant 0.000000e+00 : f32
- %c128 = constant 128 : index
- %c192 = constant 192 : index
- %c8 = constant 8 : index
- %c16 = constant 16 : index
+ %c0 = arith.constant 0 : index
+ %c256 = arith.constant 256 : index
+ %c32 = arith.constant 32 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c128 = arith.constant 128 : index
+ %c192 = arith.constant 192 : index
+ %c8 = arith.constant 8 : index
+ %c16 = arith.constant 16 : index
// Hoisted alloc.
// CHECK: %[[ALLOC:.*]] = memref.alloc() {alignment = 128 : i64} : memref<8x16xf32>
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]]
// CHECK-SAME: outs(%[[ARG0]]
// CHECK: ^bb0(%[[LHS:.*]]: f32, %[[RHS:.*]]: f32, %{{.*}}: f32):
- // CHECK: %[[YIELD:.*]] = addf %[[LHS]], %[[RHS]] : f32
+ // CHECK: %[[YIELD:.*]] = arith.addf %[[LHS]], %[[RHS]] : f32
// CHECK: linalg.yield %[[YIELD]] : f32
// CHECK: } -> tensor<f32>
- %0 = addf %arg0, %arg1 : tensor<f32>
+ %0 = arith.addf %arg0, %arg1 : tensor<f32>
return %0 : tensor<f32>
}
// CHECK-SAME: iterator_types = ["parallel"]
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]]
// CHECK-SAME: outs(%[[ARG0]]
- %0 = addf %arg0, %arg1 : tensor<?xf32>
+ %0 = arith.addf %arg0, %arg1 : tensor<?xf32>
return %0 : tensor<?xf32>
}
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]]
// CHECK-SAME: outs(%[[INIT]]
// CHECK: ^bb0(%{{.*}}: f32, %{{.*}}: f32, %{{.*}}: i1):
- // CHECK: cmpf olt, %{{.*}}, %{{.*}} : f32
- %0 = cmpf olt, %arg0, %arg1 : tensor<f32>
+ // CHECK: arith.cmpf olt, %{{.*}}, %{{.*}} : f32
+ %0 = arith.cmpf olt, %arg0, %arg1 : tensor<f32>
return %0 : tensor<i1>
}
// CHECK-SAME: %[[ARG0:[0-9a-zA-Z]*]]: tensor<4x?x?x8x2x?xf32>
// CHECK-SAME: %[[ARG1:[0-9a-zA-Z]*]]: tensor<4x?x?x8x2x?xf32>
func @cmpf(%arg0: tensor<4x?x?x8x2x?xf32>, %arg1: tensor<4x?x?x8x2x?xf32>) -> tensor<4x?x?x8x2x?xi1> {
- // CHECK: %[[C1:.*]] = constant 1 : index
+ // CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[D1:.*]] = tensor.dim %[[ARG0]], %[[C1]] : tensor<4x?x?x8x2x?xf32>
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: %[[D2:.*]] = tensor.dim %[[ARG0]], %[[C2]] : tensor<4x?x?x8x2x?xf32>
- // CHECK: %[[C5:.*]] = constant 5 : index
+ // CHECK: %[[C5:.*]] = arith.constant 5 : index
// CHECK: %[[D5:.*]] = tensor.dim %[[ARG0]], %[[C5]] : tensor<4x?x?x8x2x?xf32>
// CHECK: %[[INIT:.*]] = linalg.init_tensor [4, %[[D1]], %[[D2]], 8, 2, %[[D5]]] : tensor<4x?x?x8x2x?xi1>
// CHECK: linalg.generic
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]]
// CHECK-SAME: outs(%[[INIT]]
// CHECK: ^bb0(%{{.*}}: f32, %{{.*}}: f32, %{{.*}}: i1):
- // CHECK: cmpf olt, %{{.*}}, %{{.*}} : f32
- %0 = cmpf olt, %arg0, %arg1 : tensor<4x?x?x8x2x?xf32>
+ // CHECK: arith.cmpf olt, %{{.*}}, %{{.*}} : f32
+ %0 = arith.cmpf olt, %arg0, %arg1 : tensor<4x?x?x8x2x?xf32>
return %0 : tensor<4x?x?x8x2x?xi1>
}
ins(%arg1, %arg2 : tensor<f32>, tensor<f32>)
outs(%0 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
linalg.yield %2 : f32
} -> tensor<f32>
return %1: tensor<f32>
// CHECK-SAME: (%[[arg1:.*]]: tensor<f32>, %[[arg2:.*]]: tensor<f32>)
// CHECK-DAG: %[[arg1_val:.*]] = tensor.extract %[[arg1]]
// CHECK-DAG: %[[arg2_val:.*]] = tensor.extract %[[arg2]]
-// CHECK: %[[detensored_res:.*]] = addf %[[arg1_val]], %[[arg2_val]]
+// CHECK: %[[detensored_res:.*]] = arith.addf %[[arg1_val]], %[[arg2_val]]
// CHECK: %[[new_tensor_res:.*]] = tensor.from_elements %[[detensored_res]]
// CHECK: %[[reshaped_tensor_res:.*]] = linalg.tensor_collapse_shape %[[new_tensor_res]]
// CHECK: return %[[reshaped_tensor_res]]
ins(%arg1, %arg2 : tensor<f32>, tensor<f32>)
outs(%0 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
linalg.yield %2 : f32
} -> tensor<f32>
ins(%arg1, %1 : tensor<f32>, tensor<f32>)
outs(%3 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %5 = mulf %arg3, %arg4 : f32
+ %5 = arith.mulf %arg3, %arg4 : f32
linalg.yield %5 : f32
} -> tensor<f32>
ins(%1, %4 : tensor<f32>, tensor<f32>)
outs(%6 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %5 = divf %arg3, %arg4 : f32
+ %5 = arith.divf %arg3, %arg4 : f32
linalg.yield %5 : f32
} -> tensor<f32>
// CHECK-SAME: (%[[arg1:.*]]: tensor<f32>, %[[arg2:.*]]: tensor<f32>)
// CHECK-DAG: %[[arg1_val:.*]] = tensor.extract %[[arg1]]
// CHECK-DAG: %[[arg2_val:.*]] = tensor.extract %[[arg2]]
-// CHECK: %[[detensored_res:.*]] = addf %[[arg1_val]], %[[arg2_val]]
+// CHECK: %[[detensored_res:.*]] = arith.addf %[[arg1_val]], %[[arg2_val]]
// CHECK-DAG: %[[arg1_val2:.*]] = tensor.extract %[[arg1]]
-// CHECK: %[[detensored_res2:.*]] = mulf %[[arg1_val2]], %[[detensored_res]]
-// CHECK: %[[detensored_res3:.*]] = divf %[[detensored_res]], %[[detensored_res2]]
+// CHECK: %[[detensored_res2:.*]] = arith.mulf %[[arg1_val2]], %[[detensored_res]]
+// CHECK: %[[detensored_res3:.*]] = arith.divf %[[detensored_res]], %[[detensored_res2]]
// CHECK: %[[new_tensor_res:.*]] = tensor.from_elements %[[detensored_res3]]
// CHECK: %[[reshaped_tensor_res:.*]] = linalg.tensor_collapse_shape %[[new_tensor_res]]
// CHECK: return %[[reshaped_tensor_res]]
ins(%arg1, %arg2 : tensor<f32>, tensor<f32>)
outs(%0 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
- %3 = mulf %2, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
+ %3 = arith.mulf %2, %arg4 : f32
linalg.yield %3 : f32
} -> tensor<f32>
return %1: tensor<f32>
// CHECK-SAME: (%[[arg1:.*]]: tensor<f32>, %[[arg2:.*]]: tensor<f32>)
// CHECK-DAG: %[[arg1_val:.*]] = tensor.extract %[[arg1]]
// CHECK-DAG: %[[arg2_val:.*]] = tensor.extract %[[arg2]]
-// CHECK: %[[detensored_res:.*]] = addf %[[arg1_val]], %[[arg2_val]]
-// CHECK: %[[detensored_res2:.*]] = mulf %[[detensored_res]], %[[arg2_val]]
+// CHECK: %[[detensored_res:.*]] = arith.addf %[[arg1_val]], %[[arg2_val]]
+// CHECK: %[[detensored_res2:.*]] = arith.mulf %[[detensored_res]], %[[arg2_val]]
// CHECK: %[[new_tensor_res:.*]] = tensor.from_elements %[[detensored_res2]]
// CHECK: %[[reshaped_tensor_res:.*]] = linalg.tensor_collapse_shape %[[new_tensor_res]]
// CHECK: return %[[reshaped_tensor_res]]
%arg1_t = tensor.from_elements %arg1 : tensor<1xi32>
%arg1_t2 = linalg.tensor_collapse_shape %arg1_t [] : tensor<1xi32> into tensor<i32>
- %cst = constant dense<10> : tensor<i32>
+ %cst = arith.constant dense<10> : tensor<i32>
%2 = linalg.init_tensor [] : tensor<i8>
%3 = linalg.generic
{indexing_maps = [affine_map<() -> ()>, affine_map<() -> ()>], iterator_types = []}
ins(%arg0_t2 : tensor<i1>)
outs(%2 : tensor<i8>) {
^bb0(%arg2: i1, %arg3: i8): // no predecessors
- %10 = zexti %arg2 : i1 to i8
+ %10 = arith.extui %arg2 : i1 to i8
linalg.yield %10 : i8
} -> tensor<i8>
%4 = tensor.extract %3[] : tensor<i8>
- %5 = trunci %4 : i8 to i1
+ %5 = arith.trunci %4 : i8 to i1
cond_br %5, ^bb1, ^bb2(%arg1_t2 : tensor<i32>)
^bb1:
%6 = linalg.init_tensor [] : tensor<i32>
ins(%arg1_t2, %cst : tensor<i32>, tensor<i32>)
outs(%6 : tensor<i32>) {
^bb0(%arg2: i32, %arg3: i32, %arg4: i32): // no predecessors
- %10 = addi %arg2, %arg3 : i32
+ %10 = arith.addi %arg2, %arg3 : i32
linalg.yield %10 : i32
} -> tensor<i32>
br ^bb2(%7 : tensor<i32>)
// CHECK-LABEL: func @if_true_test
// CHECK-SAME: (%[[arg0:.*]]: i1, %[[arg1:.*]]: i32)
-// CHECK-NEXT: constant 10 : i32
+// CHECK-NEXT: arith.constant 10 : i32
// CHECK-NEXT: cond_br %[[arg0]], ^[[bb1:.*]], ^[[bb2:.*]](%[[arg1]] : i32)
// CHECK-NEXT: ^[[bb1]]:
-// CHECK-NEXT: %[[add_res:.*]] = addi
+// CHECK-NEXT: %[[add_res:.*]] = arith.addi
// CHECK-NEXT: br ^[[bb2]](%[[add_res]] : i32)
// CHECK-NEXT: ^[[bb2]]
// CHECK-NEXT: tensor.from_elements
}
func @main() -> (tensor<i32>) attributes {} {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%0 = tensor.from_elements %c0 : tensor<1xi32>
%reshaped0 = linalg.tensor_collapse_shape %0 [] : tensor<1xi32> into tensor<i32>
- %c10 = constant 10 : i32
+ %c10 = arith.constant 10 : i32
%1 = tensor.from_elements %c10 : tensor<1xi32>
%reshaped1 = linalg.tensor_collapse_shape %1 [] : tensor<1xi32> into tensor<i32>
br ^bb1(%reshaped0 : tensor<i32>)
ins(%2, %reshaped1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%5 = tensor.extract %4[] : tensor<i1>
ins(%6, %6 : tensor<i32>, tensor<i32>)
outs(%7 : tensor<i32>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i32): // no predecessors
- %9 = addi %arg0, %arg1 : i32
+ %9 = arith.addi %arg0, %arg1 : i32
linalg.yield %9 : i32
} -> tensor<i32>
br ^bb3(%8 : tensor<i32>)
}
// CHECK-LABEL: func @main()
-// CHECK-NEXT: constant 0
-// CHECK-NEXT: constant 10
+// CHECK-NEXT: arith.constant 0
+// CHECK-NEXT: arith.constant 10
// CHECK-NEXT: br ^[[bb1:.*]](%{{.*}}: i32)
// CHECK-NEXT: ^[[bb1]](%{{.*}}: i32):
-// CHECK-NEXT: cmpi slt, %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.cmpi slt, %{{.*}}, %{{.*}}
// CHECK-NEXT: cond_br %{{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^bb3(%{{.*}} : i32)
// CHECK-NEXT: ^[[bb2]](%{{.*}}: i32)
-// CHECK-NEXT: addi %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.addi %{{.*}}, %{{.*}}
// CHECK-NEXT: br ^[[bb3:.*]](%{{.*}} : i32)
// CHECK-NEXT: ^[[bb3]](%{{.*}}: i32)
// CHECK-NEXT: tensor.from_elements %{{.*}} : tensor<1xi32>
}
func @main() -> (tensor<i32>) attributes {} {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%0 = tensor.from_elements %c0 : tensor<1xi32>
%reshaped0 = linalg.tensor_collapse_shape %0 [] : tensor<1xi32> into tensor<i32>
- %c10 = constant 10 : i32
+ %c10 = arith.constant 10 : i32
%1 = tensor.from_elements %c10 : tensor<1xi32>
%reshaped1 = linalg.tensor_collapse_shape %1 [] : tensor<1xi32> into tensor<i32>
br ^bb1(%reshaped0 : tensor<i32>)
ins(%2, %reshaped1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%5 = tensor.extract %4[] : tensor<i1>
ins(%6, %6 : tensor<i32>, tensor<i32>)
outs(%7 : tensor<i32>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i32): // no predecessors
- %9 = addi %arg0, %arg1 : i32
+ %9 = arith.addi %arg0, %arg1 : i32
linalg.yield %9 : i32
} -> tensor<i32>
br ^bb3(%8 : tensor<i32>)
}
// CHECK-LABEL: func @main()
-// CHECK-NEXT: constant 0
-// CHECK-NEXT: constant 10
+// CHECK-NEXT: arith.constant 0
+// CHECK-NEXT: arith.constant 10
// CHECK-NEXT: br ^[[bb1:.*]](%{{.*}}: i32)
// CHECK-NEXT: ^[[bb1]](%{{.*}}: i32):
-// CHECK-NEXT: cmpi slt, %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.cmpi slt, %{{.*}}, %{{.*}}
// CHECK-NEXT: cond_br %{{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^bb3(%{{.*}} : i32)
// CHECK-NEXT: ^[[bb2]](%{{.*}}: i32)
-// CHECK-NEXT: addi %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.addi %{{.*}}, %{{.*}}
// CHECK-NEXT: br ^[[bb3:.*]](%{{.*}} : i32)
// CHECK-NEXT: ^[[bb3]](%{{.*}}: i32)
// CHECK-NEXT: br ^[[bb4:.*]](%{{.*}} : i32)
}
func @main() -> (tensor<i32>) attributes {} {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%0 = tensor.from_elements %c0 : tensor<1xi32>
%reshaped0 = linalg.tensor_collapse_shape %0 [] : tensor<1xi32> into tensor<i32>
- %c10 = constant 10 : i32
+ %c10 = arith.constant 10 : i32
%1 = tensor.from_elements %c10 : tensor<1xi32>
%reshaped1 = linalg.tensor_collapse_shape %1 [] : tensor<1xi32> into tensor<i32>
br ^bb1(%reshaped0 : tensor<i32>)
ins(%2, %reshaped1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%5 = tensor.extract %4[] : tensor<i1>
ins(%6, %reshaped12 : tensor<i32>, tensor<i32>)
outs(%7 : tensor<i32>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i32): // no predecessors
- %9 = addi %arg0, %arg1 : i32
+ %9 = arith.addi %arg0, %arg1 : i32
linalg.yield %9 : i32
} -> tensor<i32>
br ^bb3(%8 : tensor<i32>)
}
// CHECK-LABEL: func @main()
-// CHECK-NEXT: constant 0
-// CHECK-NEXT: constant 10
+// CHECK-NEXT: arith.constant 0
+// CHECK-NEXT: arith.constant 10
// CHECK-NEXT: br ^[[bb1:.*]](%{{.*}}: i32)
// CHECK-NEXT: ^[[bb1]](%{{.*}}: i32):
-// CHECK-NEXT: cmpi slt, %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.cmpi slt, %{{.*}}, %{{.*}}
// CHECK-NEXT: cond_br %{{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^bb2(%{{.*}} : i32)
// CHECK-NEXT: ^[[bb2]](%{{.*}}: i32)
-// CHECK-NEXT: addi %{{.*}}, %{{.*}}
+// CHECK-NEXT: arith.addi %{{.*}}, %{{.*}}
// CHECK-NEXT: br ^[[bb3:.*]](%{{.*}} : i32)
// CHECK-NEXT: ^[[bb3]](%{{.*}}: i32)
// CHECK-NEXT: tensor.from_elements %{{.*}} : tensor<1xi32>
}
func @main(%farg0 : tensor<i32>) -> (tensor<i1>) attributes {} {
- %c10 = constant 10 : i32
+ %c10 = arith.constant 10 : i32
%1 = tensor.from_elements %c10 : tensor<1xi32>
%reshaped1 = linalg.tensor_collapse_shape %1 [] : tensor<1xi32> into tensor<i32>
%3 = linalg.init_tensor [] : tensor<i1>
ins(%farg0, %reshaped1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1):
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
return %4 : tensor<i1>
// DET-ALL-LABEL: func @main(%{{.*}}: tensor<i32>)
-// DET-ALL-NEXT: constant 10
+// DET-ALL-NEXT: arith.constant 10
// DET-ALL-NEXT: tensor.extract %{{.*}}[]
-// DET-ALL-NEXT: cmpi slt, %{{.*}}, %{{.*}}
+// DET-ALL-NEXT: arith.cmpi slt, %{{.*}}, %{{.*}}
// DET-ALL-NEXT: tensor.from_elements %{{.*}}
// DET-ALL-NEXT: linalg.tensor_collapse_shape %{{.*}}
// DET-ALL-NEXT: return %{{.*}} : tensor<i1>
// DET-ALL-NEXT: }
// DET-CF-LABEL: func @main(%{{.*}}: tensor<i32>)
-// DET-CF-NEXT: constant dense<10> : tensor<i32>
+// DET-CF-NEXT: arith.constant dense<10> : tensor<i32>
// DET-CF-NEXT: linalg.init_tensor [] : tensor<i1>
// DET-CF-NEXT: linalg.generic
// DET-CF-NEXT: ^{{.*}}(%{{.*}}: i32, %{{.*}}: i32, %{{.*}}: i1)
-// DET-CF-NEXT: cmpi slt, %{{.*}}, %{{.*}}
+// DET-CF-NEXT: arith.cmpi slt, %{{.*}}, %{{.*}}
// DET-CF-NEXT: linalg.yield %{{.*}}
// DET-CF-NEXT: } -> tensor<i1>
// DET-CF-NEXT: return %{{.*}}
ins(%0, %farg1 : tensor<i32>, tensor<i32>)
outs(%1 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%3 = tensor.extract %2[] : tensor<i1>
ins(%4, %4 : tensor<i32>, tensor<i32>)
outs(%5 : tensor<i32>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i32): // no predecessors
- %8 = addi %arg0, %arg1 : i32
+ %8 = arith.addi %arg0, %arg1 : i32
linalg.yield %8 : i32
} -> tensor<i32>
br ^bb1(%6 : tensor<i32>)
// DET-ALL: tensor.extract {{.*}}
// DET-ALL: br ^[[bb1:.*]](%{{.*}} : i32)
// DET-ALL: ^[[bb1]](%{{.*}}: i32)
-// DET-ALL: cmpi slt, {{.*}}
+// DET-ALL: arith.cmpi slt, {{.*}}
// DET-ALL: cond_br {{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^[[bb3:.*]](%{{.*}} : i32)
// DET-ALL: ^[[bb2]](%{{.*}}: i32)
-// DET-ALL: addi {{.*}}
+// DET-ALL: arith.addi {{.*}}
// DET-ALL: br ^[[bb1]](%{{.*}} : i32)
// DET-ALL: ^[[bb3]](%{{.*}}: i32)
// DET-ALL: tensor.from_elements {{.*}}
// DET-CF: tensor.extract {{.*}}
// DET-CF: br ^[[bb1:.*]](%{{.*}} : i32)
// DET-CF: ^[[bb1]](%{{.*}}: i32)
-// DET-CF: cmpi slt, {{.*}}
+// DET-CF: arith.cmpi slt, {{.*}}
// DET-CF: cond_br {{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^[[bb3:.*]](%{{.*}} : i32)
// DET-CF: ^[[bb2]](%{{.*}}: i32)
-// DET-CF: addi {{.*}}
+// DET-CF: arith.addi {{.*}}
// DET-CF: br ^[[bb1]](%{{.*}} : i32)
// DET-CF: ^[[bb3]](%{{.*}}: i32)
// DET-CF: tensor.from_elements %{{.*}} : tensor<1xi32>
ins(%0: tensor<10xi32>)
outs(%1: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %b = addi %x, %a : i32
+ %b = arith.addi %x, %a : i32
linalg.yield %b : i32
} -> tensor<i32>
ins(%2, %farg1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%5 = tensor.extract %4[] : tensor<i1>
// DET-ALL: linalg.init_tensor [] : tensor<i32>
// DET-ALL: linalg.generic {{{.*}}} ins(%{{.*}} : tensor<10xi32>) outs(%{{.*}} : tensor<i32>) {
// DET-ALL: ^bb0(%{{.*}}: i32, %{{.*}}: i32): // no predecessors
-// DET-ALL: %{{.*}} = addi %{{.*}}, %{{.*}}
+// DET-ALL: %{{.*}} = arith.addi %{{.*}}, %{{.*}}
// DET-ALL: linalg.yield %{{.*}} : i32
// DET-ALL: } -> tensor<i32>
// DET-ALL: tensor.extract %{{.*}}[] : tensor<i32>
// DET-ALL: tensor.extract %{{.*}}[] : tensor<i32>
-// DET-ALL: cmpi slt, %{{.*}}, %{{.*}} : i32
+// DET-ALL: arith.cmpi slt, %{{.*}}, %{{.*}} : i32
// DET-ALL: tensor.extract %{{.*}}[] : tensor<i32>
// DET-ALL: tensor.extract %{{.*}}[] : tensor<i32>
// DET-ALL: cond_br %{{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^[[bb3:.*]](%{{.*}} : i32)
// DET-CF: %{{.*}} = linalg.generic {{{.*}}} ins(%{{.*}} : tensor<10xi32>) outs(%{{.*}} : tensor<i32>) {
// DET-CF: tensor.extract %{{.*}}[] : tensor<i32>
// DET-CF: tensor.extract %{{.*}}[] : tensor<i32>
-// DET-CF: cmpi slt, %{{.*}}, %{{.*}} : i32
+// DET-CF: arith.cmpi slt, %{{.*}}, %{{.*}} : i32
// DET-CF: cond_br %{{.*}}, ^bb2(%{{.*}} : tensor<i32>), ^bb3(%{{.*}} : tensor<i32>)
// DET-CF: ^bb2(%{{.*}}: tensor<i32>)
// DET-CF: %{{.*}} = linalg.generic {{{.*}}} ins(%{{.*}} : tensor<i32>) outs(%{{.*}} : tensor<10xi32>) {
}
func @main() -> () attributes {} {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%0 = tensor.from_elements %c0 : tensor<1xi32>
%reshaped0 = linalg.tensor_collapse_shape %0 [] : tensor<1xi32> into tensor<i32>
- %c10 = constant 10 : i32
+ %c10 = arith.constant 10 : i32
%1 = tensor.from_elements %c10 : tensor<1xi32>
%reshaped1 = linalg.tensor_collapse_shape %1 [] : tensor<1xi32> into tensor<i32>
br ^bb1(%reshaped0 : tensor<i32>)
ins(%2, %reshaped1 : tensor<i32>, tensor<i32>)
outs(%3 : tensor<i1>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i1): // no predecessors
- %8 = cmpi slt, %arg0, %arg1 : i32
+ %8 = arith.cmpi slt, %arg0, %arg1 : i32
linalg.yield %8 : i1
} -> tensor<i1>
%5 = tensor.extract %4[] : tensor<i1>
ins(%6, %6 : tensor<i32>, tensor<i32>)
outs(%7 : tensor<i32>) {
^bb0(%arg0: i32, %arg1: i32, %arg2: i32): // no predecessors
- %9 = addi %arg0, %arg1 : i32
+ %9 = arith.addi %arg0, %arg1 : i32
linalg.yield %9 : i32
} -> tensor<i32>
br ^bb1(%8 : tensor<i32>)
}
// CHECK-LABEL: func @main
-// CHECK-NEXT: constant 0 : i32
-// CHECK-NEXT: constant 10
+// CHECK-NEXT: arith.constant 0 : i32
+// CHECK-NEXT: arith.constant 10
// CHECK-NEXT: br ^[[bb1:.*]](%{{.*}} : i32)
// CHECK-NEXT: ^[[bb1]](%{{.*}}: i32)
-// CHECK-NEXT: %{{.*}} = cmpi slt, %{{.*}}, %{{.*}}
+// CHECK-NEXT: %{{.*}} = arith.cmpi slt, %{{.*}}, %{{.*}}
// CHECK-NEXT: cond_br %{{.*}}, ^[[bb2:.*]](%{{.*}} : i32), ^[[bb3:.*]]
// CHECK-NEXT: ^[[bb2]](%{{.*}}: i32)
-// CHECK-NEXT: %{{.*}} = addi %{{.*}}, %{{.*}}
+// CHECK-NEXT: %{{.*}} = arith.addi %{{.*}}, %{{.*}}
// CHECK-NEXT: br ^[[bb1]](%{{.*}} : i32)
// CHECK-NEXT: ^[[bb3]]:
// CHECK-NEXT: return
func @distribute_for_gpu(%A: tensor<64x64xf32>,
%B: tensor<64x64xf32>) -> tensor<64x64xf32> {
- %c0 = constant 0 : index
- %c16 = constant 16 : index
- %c64 = constant 64 : index
- %c24 = constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c16 = arith.constant 16 : index
+ %c64 = arith.constant 64 : index
+ %c24 = arith.constant 24 : index
%0 = linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c64, %c64) step (%c24, %c16)
ins (%A_ = %A: tensor<64x64xf32>) outs (%B_ = %B:tensor<64x64xf32>)
distribution ["block_x", "block_y"] {
// CHECK-DAG: #[[$MAP1:.+]] = affine_map<()[s0] -> (s0 * 16)>
// CHECK-LABEL: func @distribute_for_gpu
-// CHECK: %[[C64:.*]] = constant 64 : index
+// CHECK: %[[C64:.*]] = arith.constant 64 : index
// CHECK-DAG: %[[GPU_BLOCK_X:.*]] = "gpu.block_id"() {dimension = "x"}
// CHECK-DAG: %[[GPU_GRID_DIM_X:.*]] = "gpu.grid_dim"() {dimension = "x"}
%idx2 = linalg.index 2 : index
%idx3 = linalg.index 3 : index
%idx4 = linalg.index 4 : index
- %1 = addi %idx0, %idx1 : index
- %2 = subi %1, %idx2 : index
- %3 = subi %2, %idx3 : index
- %4 = addi %3, %idx4 : index
- %5 = index_cast %4 : index to i32
- %6 = addi %5, %arg6 : i32
+ %1 = arith.addi %idx0, %idx1 : index
+ %2 = arith.subi %1, %idx2 : index
+ %3 = arith.subi %2, %idx3 : index
+ %4 = arith.addi %3, %idx4 : index
+ %5 = arith.index_cast %4 : index to i32
+ %6 = arith.addi %5, %arg6 : i32
linalg.yield %6 : i32
} -> tensor<?x1x?x1x?xi32>
return %0 : tensor<?x1x?x1x?xi32>
// CHECK: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
// CHECK: %[[IDX2:.+]] = linalg.index 2 : index
-// CHECK: %[[T3:.+]] = addi %[[IDX0]], %[[IDX1]]
-// CHECK: %[[T4:.+]] = addi %[[T3]], %[[IDX2]]
-// CHECK: %[[T5:.+]] = index_cast %[[T4]] : index to i32
-// CHECK: %[[T6:.+]] = addi %[[T5]], %[[ARG4]] : i32
+// CHECK: %[[T3:.+]] = arith.addi %[[IDX0]], %[[IDX1]]
+// CHECK: %[[T4:.+]] = arith.addi %[[T3]], %[[IDX2]]
+// CHECK: %[[T5:.+]] = arith.index_cast %[[T4]] : index to i32
+// CHECK: %[[T6:.+]] = arith.addi %[[T5]], %[[ARG4]] : i32
// CHECK: linalg.yield %[[T6]] : i32
// -----
^bb0(%arg3: i32, %arg4: i32) :
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %1 = addi %idx0, %idx1 : index
- %2 = index_cast %1 : index to i32
- %3 = addi %2, %arg3 : i32
+ %1 = arith.addi %idx0, %idx1 : index
+ %2 = arith.index_cast %1 : index to i32
+ %3 = arith.addi %2, %arg3 : i32
linalg.yield %3 : i32
} -> tensor<1x1xi32>
return %0 : tensor<1x1xi32>
ins(%0, %1 : tensor<1x5xf32>, tensor<5x1xf32>)
outs(%shape : tensor<5x5xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
- %3 = addf %arg3, %arg4 : f32
+ %3 = arith.addf %arg3, %arg4 : f32
linalg.yield %3 : f32
} -> tensor<5x5xf32>
return %2 : tensor<5x5xf32>
// -----
func @fold_unit_dim_for_init_tensor(%input: tensor<1x1000xf32>) -> tensor<1xf32> {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%init = linalg.init_tensor [1] : tensor<1xf32>
%fill = linalg.fill(%cst, %init) : f32, tensor<1xf32> -> tensor<1xf32>
%add = linalg.generic {
iterator_types = ["parallel", "reduction"]}
ins(%input : tensor<1x1000xf32>)outs(%fill : tensor<1xf32>) {
^bb0(%arg1: f32, %arg2: f32):
- %1823 = addf %arg1, %arg2 : f32
+ %1823 = arith.addf %arg1, %arg2 : f32
linalg.yield %1823 : f32
} -> tensor<1xf32>
return %add : tensor<1xf32>
// -----
func @unit_dim_for_reduction(%arg0: tensor<1x?x1x?xf32>) -> tensor<1x?xf32> {
- %cst = constant 1.000000e+00 : f32
- %c3 = constant 3 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ %c3 = arith.constant 3 : index
%0 = tensor.dim %arg0, %c3 : tensor<1x?x1x?xf32>
%1 = linalg.init_tensor [1, %0] : tensor<1x?xf32>
%2 = linalg.fill(%cst, %1) : f32, tensor<1x?xf32> -> tensor<1x?xf32>
ins(%arg0 : tensor<1x?x1x?xf32>)
outs(%2 : tensor<1x?xf32>) {
^bb0(%arg1: f32, %arg2: f32): // no predecessors
- %4 = addf %arg1, %arg2 : f32
+ %4 = arith.addf %arg1, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<1x?xf32>
return %3 : tensor<1x?xf32>
// -----
func @unit_dim_for_both_reduction(%arg0: tensor<1x?x1x1xf32>) -> tensor<1x1xf32> {
- %cst = constant 1.000000e+00 : f32
- %c3 = constant 3 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ %c3 = arith.constant 3 : index
%1 = linalg.init_tensor [1, 1] : tensor<1x1xf32>
%2 = linalg.fill(%cst, %1) : f32, tensor<1x1xf32> -> tensor<1x1xf32>
%3 = linalg.generic {
ins(%arg0 : tensor<1x?x1x1xf32>)
outs(%2 : tensor<1x1xf32>) {
^bb0(%arg1: f32, %arg2: f32): // no predecessors
- %4 = addf %arg1, %arg2 : f32
+ %4 = arith.addf %arg1, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<1x1xf32>
return %3 : tensor<1x1xf32>
// -----
func @unit_dim_for_reduction_inner(%arg0: tensor<?x1x?x1xf32>) -> tensor<?x1xf32> {
- %cst = constant 1.000000e+00 : f32
- %c2 = constant 2 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ %c2 = arith.constant 2 : index
%0 = tensor.dim %arg0, %c2 : tensor<?x1x?x1xf32>
%1 = linalg.init_tensor [%0, 1] : tensor<?x1xf32>
%2 = linalg.fill(%cst, %1) : f32, tensor<?x1xf32> -> tensor<?x1xf32>
ins(%arg0 : tensor<?x1x?x1xf32>)
outs(%2 : tensor<?x1xf32>) {
^bb0(%arg1: f32, %arg2: f32): // no predecessors
- %4 = addf %arg1, %arg2 : f32
+ %4 = arith.addf %arg1, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<?x1xf32>
return %3 : tensor<?x1xf32>
%idx2 = linalg.index 2 : index
%idx3 = linalg.index 3 : index
%idx4 = linalg.index 4 : index
- %1 = addi %idx0, %idx1 : index
- %2 = subi %1, %idx2 : index
- %3 = subi %2, %idx3 : index
- %4 = addi %3, %idx4 : index
- %5 = index_cast %4 : index to i32
- %6 = addi %5, %arg6 : i32
+ %1 = arith.addi %idx0, %idx1 : index
+ %2 = arith.subi %1, %idx2 : index
+ %3 = arith.subi %2, %idx3 : index
+ %4 = arith.addi %3, %idx4 : index
+ %5 = arith.index_cast %4 : index to i32
+ %6 = arith.addi %5, %arg6 : i32
linalg.yield %6 : i32
}
return %shape : memref<?x1x?x1x?xi32>
// CHECK: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
// CHECK: %[[IDX2:.+]] = linalg.index 2 : index
-// CHECK: %[[T3:.+]] = addi %[[IDX0]], %[[IDX1]]
-// CHECK: %[[T4:.+]] = addi %[[T3]], %[[IDX2]]
-// CHECK: %[[T5:.+]] = index_cast %[[T4]] : index to i32
-// CHECK: %[[T6:.+]] = addi %[[T5]], %[[ARG4]] : i32
+// CHECK: %[[T3:.+]] = arith.addi %[[IDX0]], %[[IDX1]]
+// CHECK: %[[T4:.+]] = arith.addi %[[T3]], %[[IDX2]]
+// CHECK: %[[T5:.+]] = arith.index_cast %[[T4]] : index to i32
+// CHECK: %[[T6:.+]] = arith.addi %[[T5]], %[[ARG4]] : i32
// CHECK: linalg.yield %[[T6]] : i32
// -----
^bb0(%arg3: i32, %arg4: i32) :
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %1 = addi %idx0, %idx1 : index
- %2 = index_cast %1 : index to i32
- %3 = addi %2, %arg3 : i32
+ %1 = arith.addi %idx0, %idx1 : index
+ %2 = arith.index_cast %1 : index to i32
+ %3 = arith.addi %2, %arg3 : i32
linalg.yield %3 : i32
}
return %arg0 : memref<1x1xi32>
ins(%0, %1 : memref<1x5xf32>, memref<5x1xf32>)
outs(%shape : memref<5x5xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
- %3 = addf %arg3, %arg4 : f32
+ %3 = arith.addf %arg3, %arg4 : f32
linalg.yield %3 : f32
}
return %shape : memref<5x5xf32>
// -----
func @fold_unit_dim_for_init_memref(%input: memref<1x1000xf32>) -> memref<1xf32> {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%init = memref.alloc() : memref<1xf32>
linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>, affine_map<(d0, d1) -> (d0)>],
iterator_types = ["parallel", "reduction"]}
ins(%input : memref<1x1000xf32>)outs(%init : memref<1xf32>) {
^bb0(%arg1: f32, %arg2: f32):
- %1823 = addf %arg1, %arg2 : f32
+ %1823 = arith.addf %arg1, %arg2 : f32
linalg.yield %1823 : f32
}
return %init : memref<1xf32>
ins(%arg0, %arg1: tensor<8x8xf32, #CSR>, tensor<8xf32>)
outs(%0: tensor<8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %m = mulf %a, %b : f32
- %add = addf %x, %m : f32
+ %m = arith.mulf %a, %b : f32
+ %add = arith.addf %x, %m : f32
linalg.yield %add : f32
} -> tensor<8xf32>
return %1: tensor<8xf32>
// CHECK: vector.transfer_read %[[ARG0]]
// CHECK-NOT: in_bounds
func @testAllocRead(%in: memref<? x f32>) -> vector<32 x f32> {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<32 x f32>
%subview = memref.subview %alloc[0][16][1] : memref<32 x f32> to memref<16 x f32>
linalg.copy(%in, %subview): memref<? x f32>, memref<16 x f32>
// CHECK: vector.transfer_read %[[ARG0]]
// CHECK-NOT: in_bounds
func @testAllocFillRead(%in: memref<? x f32>) -> vector<32 x f32> {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<32 x f32>
linalg.fill(%f0, %alloc) : f32, memref<32 x f32>
%subview = memref.subview %alloc[0][16][1] : memref<32 x f32> to memref<16 x f32>
// CHECK: vector.transfer_read %[[ARG0]]
// CHECK-NOT: in_bounds
func @testViewRead(%in: memref<? x f32>) -> vector<32 x f32> {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<128 x i8>
%view = memref.view %alloc[%c0][] : memref<128 x i8> to memref<32 x f32>
%subview = memref.subview %view[0][16][1] : memref<32 x f32> to memref<16 x f32>
// CHECK: vector.transfer_read %[[ARG0]]
// CHECK-NOT: in_bounds
func @testViewFillRead(%in: memref<? x f32>) -> vector<32 x f32> {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<128 x i8>
%view = memref.view %alloc[%c0][] : memref<128 x i8> to memref<32 x f32>
%subview = memref.subview %view[0][16][1] : memref<32 x f32> to memref<16 x f32>
// CHECK: vector.transfer_write %[[ARG0]], %[[ARG1]]
// CHECK-NOT: in_bounds
func @testAllocWrite(%vec: vector<32 x f32>, %out: memref<? x f32>) {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<32 x f32>
%subview = memref.subview %alloc[0][16][1] : memref<32 x f32> to memref<16 x f32>
vector.transfer_write %vec, %alloc[%c0] {in_bounds = [true]} : vector<32 x f32>, memref<32 x f32>
// CHECK: vector.transfer_write %[[ARG0]], %[[ARG1]]
// CHECK-NOT: in_bounds
func @testViewWrite(%vec: vector<32 x f32>, %out: memref<? x f32>) {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<128 x i8>
%view = memref.view %alloc[%c0][] : memref<128 x i8> to memref<32 x f32>
%subview = memref.subview %view[0][16][1] : memref<32 x f32> to memref<16 x f32>
// CHECK: linalg.copy
// CHECK: vector.transfer_read %[[ALLOC]]
func @failAllocFillRead(%in: memref<? x f32>) -> vector<32 x f32> {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
%alloc = memref.alloc() : memref<32 x f32>
linalg.fill(%f0, %alloc) : f32, memref<32 x f32>
%subview = memref.subview %alloc[0][16][1] : memref<32 x f32> to memref<16 x f32>
// CHECK: vector.transfer_write %[[ARG0]], %[[ALLOC]]
// CHECK: linalg.copy
func @failAllocWrite(%vec: vector<32 x f32>, %out: memref<? x f32>) {
- %c0 = constant 0: index
- %f0 = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %f0 = arith.constant 0.0: f32
%alloc = memref.alloc() : memref<32 x f32>
%subview = memref.subview %alloc[0][16][1] : memref<32 x f32> to memref<16 x f32>
vector.transfer_write %vec, %alloc[%c0] : vector<32 x f32>, memref<32 x f32>
// RUN: mlir-opt %s -test-linalg-greedy-fusion | FileCheck %s
func @f1(%A: memref<?x?xf32, offset: ?, strides: [?, 1]>, %B: memref<?x?xf32, offset: ?, strides: [?, 1]>, %C: memref<?x?xf32, offset: ?, strides: [?, 1]>, %D: memref<?x?xf32, offset: ?, strides: [?, 1]>, %E: memref<?x?xf32, offset: ?, strides: [?, 1]>) -> memref<?x?xf32, offset: ?, strides: [?, 1]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
- %c40 = constant 40 : index
- %c30 = constant 30 : index
- %c20 = constant 20 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c40 = arith.constant 40 : index
+ %c30 = arith.constant 30 : index
+ %c20 = arith.constant 20 : index
%0 = memref.dim %C, %c0 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%1 = memref.dim %C, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%2 = memref.dim %D, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
// CHECK-LABEL: @add_mul_fusion
func @add_mul_fusion(%arg0: tensor<?x?xf32>, %arg1 : tensor<?x?xf32>, %arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %4 = addf %arg3, %arg4 : f32
+ %4 = arith.addf %arg3, %arg4 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
// CHECK: linalg.generic {
// CHECK-SAME: [[ARG1:%[a-zA-Z0-9_]*]]
// CHECK-SAME: [[ARG2:%[a-zA-Z0-9_]*]]
^bb0(%arg5: f32, %arg6: f32, %arg7: f32): // no predecessors
- // CHECK: [[T1:%[a-zA-Z0-9_]*]] = addf [[ARG0]], [[ARG1]]
+ // CHECK: [[T1:%[a-zA-Z0-9_]*]] = arith.addf [[ARG0]], [[ARG1]]
// CHECK-NOT: linalg.yield
- // CHECK: mulf [[T1]], [[ARG2]]
+ // CHECK: arith.mulf [[T1]], [[ARG2]]
// CHECK: linalg.yield
- %5 = mulf %arg5, %arg6 : f32
+ %5 = arith.mulf %arg5, %arg6 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// CHECK-LABEL: @scalar_add_mul_fusion
func @scalar_add_mul_fusion(%arg0: tensor<?x?xf32>, %arg1 : f32, %arg2 : f32) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, f32)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %4 = addf %arg3, %arg4 : f32
+ %4 = arith.addf %arg3, %arg4 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
// CHECK: linalg.generic {
// CHECK-SAME: [[ARG4:%[a-zA-Z0-9_]*]]
// CHECK-SAME: [[ARG5:%[a-zA-Z0-9_]*]]
^bb0(%arg5: f32, %arg6: f32, %arg7: f32): // no predecessors
- // CHECK: [[T1:%[a-zA-Z0-9_]*]] = addf [[ARG3]], [[ARG4]]
+ // CHECK: [[T1:%[a-zA-Z0-9_]*]] = arith.addf [[ARG3]], [[ARG4]]
// CHECK-NOT: linalg.yield
- // CHECK: mulf [[T1]], [[ARG5]]
+ // CHECK: arith.mulf [[T1]], [[ARG5]]
// CHECK: linalg.yield
- %5 = mulf %arg5, %arg6 : f32
+ %5 = arith.mulf %arg5, %arg6 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// CHECK-LABEL: @transpose_add_mul_fusion
func @transpose_add_mul_fusion(%arg0: tensor<?x?xf32>, %arg1 : tensor<?x?xf32>, %arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %4 = addf %arg3, %arg4 : f32
+ %4 = arith.addf %arg3, %arg4 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
// CHECK: linalg.generic {
ins(%3, %arg2 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg5: f32, %arg6: f32, %arg7: f32): // no predecessors
- %5 = mulf %arg5, %arg6 : f32
+ %5 = arith.mulf %arg5, %arg6 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// CHECK-LABEL: @add_transpose_mul_fusion
func @add_transpose_mul_fusion(%arg0: tensor<?x?xf32>, %arg1 : tensor<?x?xf32>, %arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %4 = addf %arg3, %arg4 : f32
+ %4 = arith.addf %arg3, %arg4 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
// CHECK: linalg.generic {
ins(%3, %arg2 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>){
^bb0(%arg5: f32, %arg6: f32, %arg7: f32): // no predecessors
- %5= mulf %arg5, %arg6 : f32
+ %5 = arith.mulf %arg5, %arg6 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// CHECK-LABEL: @add_broadcast_mul_fusion
func @add_broadcast_mul_fusion(%arg0: tensor<?xf32>, %arg1 : tensor<?xf32>, %arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?xf32>
%1 = linalg.init_tensor [%0] : tensor<?xf32>
%2 = linalg.generic {indexing_maps = [#map2, #map2, #map2], iterator_types = ["parallel"]}
ins(%arg0, %arg1 : tensor<?xf32>, tensor<?xf32>)
outs(%1 : tensor<?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %3 = addf %arg3, %arg4 : f32
+ %3 = arith.addf %arg3, %arg4 : f32
linalg.yield %3 : f32
} -> tensor<?xf32>
// CHECK: linalg.generic {
ins(%2, %arg2 : tensor<?xf32>, tensor<?x?xf32>)
outs(%4 : tensor<?x?xf32>){
^bb0(%arg5: f32, %arg6: f32, %arg7: f32): // no predecessors
- %6 = mulf %arg5, %arg6 : f32
+ %6 = arith.mulf %arg5, %arg6 : f32
linalg.yield %6 : f32
} -> tensor<?x?xf32>
return %5 : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<f32>, tensor<f32>)
outs(%0 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
linalg.yield %2 : f32
} -> tensor<f32>
// CHECK: linalg.generic {
- // CHECK: addf
- // CHECK: mulf
+ // CHECK: arith.addf
+ // CHECK: arith.mulf
%2 = linalg.generic {indexing_maps = [#map0, #map0, #map0], iterator_types = []}
ins(%1, %arg2 : tensor<f32>, tensor<f32>)
outs(%0 : tensor<f32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %3 = mulf %arg3, %arg4 : f32
+ %3 = arith.mulf %arg3, %arg4 : f32
linalg.yield %3 : f32
} -> tensor<f32>
#map1 = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
func @generic_op_constant_fusion(%arg0 : tensor<5x?x?xf32>) -> tensor<5x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %cst = constant dense<42.0> : tensor<5xf32>
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %cst = arith.constant dense<42.0> : tensor<5xf32>
%0 = tensor.dim %arg0, %c1 : tensor<5x?x?xf32>
%1 = tensor.dim %arg0, %c2 : tensor<5x?x?xf32>
%2 = linalg.init_tensor [5, %0, %1] : tensor<5x?x?xf32>
ins(%cst, %arg0 : tensor<5xf32>, tensor<5x?x?xf32>)
outs(%2 : tensor<5x?x?xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
- %4 = mulf %arg1, %arg2 : f32
+ %4 = arith.mulf %arg1, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<5x?x?xf32>
return %3 : tensor<5x?x?xf32>
}
// CHECK-DAG: #[[$MAP0:.*]] = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
// CHECK-LABEL: func @generic_op_constant_fusion
-// CHECK: %[[CST:.*]] = constant {{.*}} : f32
+// CHECK: %[[CST:.*]] = arith.constant {{.*}} : f32
// CHECK: linalg.generic
// CHECK: ^{{.+}}(%[[ARG1:[a-zA-Z0-9_]+]]: f32, %{{.+}}: f32):
-// CHECK: mulf %[[CST]], %[[ARG1]]
+// CHECK: arith.mulf %[[CST]], %[[ARG1]]
// -----
func @generic_op_zero_dim_constant_fusion(%arg0 : tensor<5x?x?xf32>)
-> tensor<5x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %cst = constant dense<42.0> : tensor<f32>
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %cst = arith.constant dense<42.0> : tensor<f32>
%0 = tensor.dim %arg0, %c1 : tensor<5x?x?xf32>
%1 = tensor.dim %arg0, %c2 : tensor<5x?x?xf32>
%2 = linalg.init_tensor [5, %0, %1] : tensor<5x?x?xf32>
ins(%cst, %arg0 : tensor<f32>, tensor<5x?x?xf32>)
outs(%2 : tensor<5x?x?xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
- %4 = mulf %arg1, %arg2 : f32
+ %4 = arith.mulf %arg1, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<5x?x?xf32>
return %3 : tensor<5x?x?xf32>
}
// CHECK-DAG: #[[$MAP0:.*]] = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
// CHECK-LABEL: func @generic_op_zero_dim_constant_fusion
-// CHECK: %[[CST:.*]] = constant {{.*}} : f32
+// CHECK: %[[CST:.*]] = arith.constant {{.*}} : f32
// CHECK: linalg.generic
// CHECK: ^{{.*}}(%[[ARG1:[a-zA-Z0-9_]*]]: f32, %{{.*}}: f32)
-// CHECK: mulf %[[CST]], %[[ARG1]]
+// CHECK: arith.mulf %[[CST]], %[[ARG1]]
// -----
#map0 = affine_map<(d0, d1) -> (d0, d1)>
func @producer_indexed_consumer_fusion(%arg0: tensor<?x?xi32>,
%arg1: tensor<?x?xi32>) -> tensor<?x?xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xi32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xi32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xi32>
ins(%arg0, %arg1 : tensor<?x?xi32>, tensor<?x?xi32>)
outs(%2 : tensor<?x?xi32>) {
^bb0(%arg2: i32, %arg3: i32, %arg4: i32): // no predecessors
- %10 = addi %arg2, %arg3 : i32
+ %10 = arith.addi %arg2, %arg3 : i32
linalg.yield %10 : i32
} -> tensor<?x?xi32>
%4 = linalg.generic {
^bb0(%arg2: i32, %arg3: i32): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %5 = index_cast %idx0 : index to i32
- %6 = index_cast %idx1 : index to i32
- %7 = addi %arg2, %5 : i32
- %8 = subi %7, %6 : i32
+ %5 = arith.index_cast %idx0 : index to i32
+ %6 = arith.index_cast %idx1 : index to i32
+ %7 = arith.addi %arg2, %5 : i32
+ %8 = arith.subi %7, %6 : i32
linalg.yield %8 : i32
} -> tensor<?x?xi32>
return %4 : tensor<?x?xi32>
// CHECK: ^{{[a-zA-Z0-9_]*}}
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]*]]: i32
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: i32
-// CHECK: %[[VAL1:.+]] = addi %[[ARG0]], %[[ARG1]] : i32
+// CHECK: %[[VAL1:.+]] = arith.addi %[[ARG0]], %[[ARG1]] : i32
// CHECK: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
-// CHECK: %[[ADD_OPERAND:.+]] = index_cast %[[IDX0]] : index to i32
-// CHECK: %[[SUB_OPERAND:.+]] = index_cast %[[IDX1]] : index to i32
-// CHECK: %[[VAL2:.+]] = addi %[[VAL1]], %[[ADD_OPERAND]] : i32
-// CHECK: %[[VAL3:.+]] = subi %[[VAL2]], %[[SUB_OPERAND]] : i32
+// CHECK: %[[ADD_OPERAND:.+]] = arith.index_cast %[[IDX0]] : index to i32
+// CHECK: %[[SUB_OPERAND:.+]] = arith.index_cast %[[IDX1]] : index to i32
+// CHECK: %[[VAL2:.+]] = arith.addi %[[VAL1]], %[[ADD_OPERAND]] : i32
+// CHECK: %[[VAL3:.+]] = arith.subi %[[VAL2]], %[[SUB_OPERAND]] : i32
// CHECK: linalg.yield %[[VAL3]] : i32
// CHECK-NOT: linalg.generic
#map0 = affine_map<(d0, d1) -> (d0, d1)>
func @indexed_producer_consumer_fusion(%arg0: tensor<?x?xi32>) -> tensor<?x?xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xi32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xi32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xi32>
^bb0(%arg4: i32, %arg5: i32): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %4 = index_cast %idx0 : index to i32
- %5 = index_cast %idx1 : index to i32
- %6 = addi %arg4, %4 : i32
- %7 = subi %6, %5 : i32
+ %4 = arith.index_cast %idx0 : index to i32
+ %5 = arith.index_cast %idx1 : index to i32
+ %6 = arith.addi %arg4, %4 : i32
+ %7 = arith.subi %6, %5 : i32
linalg.yield %7 : i32
} -> tensor<?x?xi32>
%4 = linalg.generic {
ins(%3, %arg0 : tensor<?x?xi32>, tensor<?x?xi32>)
outs(%2 : tensor<?x?xi32>) {
^bb0(%arg2: i32, %arg3: i32, %arg4: i32): // no predecessors
- %10 = addi %arg2, %arg3 : i32
+ %10 = arith.addi %arg2, %arg3 : i32
linalg.yield %10 : i32
} -> tensor<?x?xi32>
return %4 : tensor<?x?xi32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: i32
// CHECK: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
-// CHECK: %[[ADD_OPERAND:.+]] = index_cast %[[IDX0]] : index to i32
-// CHECK: %[[SUB_OPERAND:.+]] = index_cast %[[IDX1]] : index to i32
-// CHECK: %[[VAL1:.+]] = addi %[[ARG0]], %[[ADD_OPERAND]] : i32
-// CHECK: %[[VAL2:.+]] = subi %[[VAL1]], %[[SUB_OPERAND]] : i32
-// CHECK: %[[VAL3:.+]] = addi %[[VAL2]], %[[ARG0]] : i32
+// CHECK: %[[ADD_OPERAND:.+]] = arith.index_cast %[[IDX0]] : index to i32
+// CHECK: %[[SUB_OPERAND:.+]] = arith.index_cast %[[IDX1]] : index to i32
+// CHECK: %[[VAL1:.+]] = arith.addi %[[ARG0]], %[[ADD_OPERAND]] : i32
+// CHECK: %[[VAL2:.+]] = arith.subi %[[VAL1]], %[[SUB_OPERAND]] : i32
+// CHECK: %[[VAL3:.+]] = arith.addi %[[VAL2]], %[[ARG0]] : i32
// CHECK: linalg.yield %[[VAL3]] : i32
// CHECK-NOT: linalg.generic
#map1 = affine_map<(d0, d1) -> (d0, d1)>
func @indexed_producer_indexed_consumer_fusion(%arg0: tensor<?x?xi32>)
-> tensor<?x?xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xi32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xi32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xi32>
^bb0(%arg2: i32, %arg3: i32): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %4 = index_cast %idx0 : index to i32
- %5 = index_cast %idx1 : index to i32
- %6 = addi %arg2, %4 : i32
- %7 = subi %5, %6 : i32
+ %4 = arith.index_cast %idx0 : index to i32
+ %5 = arith.index_cast %idx1 : index to i32
+ %6 = arith.addi %arg2, %4 : i32
+ %7 = arith.subi %5, %6 : i32
linalg.yield %7 : i32
} -> tensor<?x?xi32>
%4= linalg.generic {
^bb0(%arg2: i32, %arg3: i32): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %5 = index_cast %idx0 : index to i32
- %6 = index_cast %idx1 : index to i32
- %7 = addi %arg2, %5 : i32
- %8 = subi %7, %6 : i32
+ %5 = arith.index_cast %idx0 : index to i32
+ %6 = arith.index_cast %idx1 : index to i32
+ %7 = arith.addi %arg2, %5 : i32
+ %8 = arith.subi %7, %6 : i32
linalg.yield %8 : i32
} -> tensor<?x?xi32>
return %4 : tensor<?x?xi32>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]*]]: i32
// CHECK: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
-// CHECK: %[[ADD_OPERAND1:.+]] = index_cast %[[IDX1]] : index to i32
-// CHECK: %[[SUB_OPERAND1:.+]] = index_cast %[[IDX0]] : index to i32
-// CHECK: %[[VAL1:.+]] = addi %[[ARG0]], %[[ADD_OPERAND1]] : i32
-// CHECK: %[[VAL2:.+]] = subi %[[SUB_OPERAND1]], %[[VAL1]] : i32
+// CHECK: %[[ADD_OPERAND1:.+]] = arith.index_cast %[[IDX1]] : index to i32
+// CHECK: %[[SUB_OPERAND1:.+]] = arith.index_cast %[[IDX0]] : index to i32
+// CHECK: %[[VAL1:.+]] = arith.addi %[[ARG0]], %[[ADD_OPERAND1]] : i32
+// CHECK: %[[VAL2:.+]] = arith.subi %[[SUB_OPERAND1]], %[[VAL1]] : i32
// CHECK: %[[IDX2:.+]] = linalg.index 0 : index
// CHECK: %[[IDX3:.+]] = linalg.index 1 : index
-// CHECK: %[[ADD_OPERAND2:.+]] = index_cast %[[IDX2]] : index to i32
-// CHECK: %[[SUB_OPERAND2:.+]] = index_cast %[[IDX3]] : index to i32
-// CHECK: %[[VAL3:.+]] = addi %[[VAL2]], %[[ADD_OPERAND2]] : i32
-// CHECK: %[[VAL4:.+]] = subi %[[VAL3]], %[[SUB_OPERAND2]] : i32
+// CHECK: %[[ADD_OPERAND2:.+]] = arith.index_cast %[[IDX2]] : index to i32
+// CHECK: %[[SUB_OPERAND2:.+]] = arith.index_cast %[[IDX3]] : index to i32
+// CHECK: %[[VAL3:.+]] = arith.addi %[[VAL2]], %[[ADD_OPERAND2]] : i32
+// CHECK: %[[VAL4:.+]] = arith.subi %[[VAL3]], %[[SUB_OPERAND2]] : i32
// CHECK: linalg.yield %[[VAL4]] : i32
// CHECK-NOT: linalg.generic
#map3 = affine_map<(d0, d1) -> (d1)>
func @one_dim_indexed_producer_consumer_fusion(%arg0 : tensor<?xi32>,
%arg1 : tensor<?x?xi32>) -> tensor<?x?xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?xi32>
%0 = linalg.init_tensor [%d0] : tensor<?xi32>
%1 = linalg.generic
ins(%arg0 : tensor<?xi32>) outs(%0 : tensor<?xi32>) {
^bb0(%arg2 : i32, %arg3 : i32):
%2 = linalg.index 0 : index
- %3 = index_cast %2 : index to i32
- %4 = addi %arg2, %3 : i32
+ %3 = arith.index_cast %2 : index to i32
+ %4 = arith.addi %arg2, %3 : i32
linalg.yield %4 : i32
} -> tensor<?xi32>
%2 = tensor.dim %arg1, %c0 : tensor<?x?xi32>
ins(%arg1, %1 : tensor<?x?xi32>, tensor<?xi32>)
outs(%4 : tensor<?x?xi32>) {
^bb0(%arg2 : i32, %arg3 : i32, %arg4: i32):
- %6 = addi %arg2, %arg3 : i32
+ %6 = arith.addi %arg2, %arg3 : i32
linalg.yield %6 : i32
} -> tensor<?x?xi32>
return %5 : tensor<?x?xi32>
// CHECK: ^{{[a-zA-Z0-9_]*}}
// CHECK-SAME: (%[[ARG0:[a-zA-Z0-9_]*]]: i32, %[[ARG1:[a-zA-Z0-9_]*]]: i32
// CHECK: %[[IDX1:.+]] = linalg.index 1 : index
-// CHECK: %[[VAL1:.+]] = index_cast %[[IDX1]] : index to i32
-// CHECK: %[[VAL2:.+]] = addi %[[ARG1]], %[[VAL1]] : i32
-// CHECK: %[[VAL3:.+]] = addi %[[ARG0]], %[[VAL2]] : i32
+// CHECK: %[[VAL1:.+]] = arith.index_cast %[[IDX1]] : index to i32
+// CHECK: %[[VAL2:.+]] = arith.addi %[[ARG1]], %[[VAL1]] : i32
+// CHECK: %[[VAL3:.+]] = arith.addi %[[ARG0]], %[[VAL2]] : i32
// CHECK: linalg.yield %[[VAL3]] : i32
// CHECK-NOT: linalg.generic
func @scalar_generic_fusion
(%arg0: tensor<5x1x1xf32>, %arg1 : tensor<i32>) -> tensor<10xf32>
{
- %c0 = constant 0 : index
- %cst = constant dense<1.000000e+00> : tensor<10xf32>
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant dense<1.000000e+00> : tensor<10xf32>
%0 = linalg.init_tensor [] : tensor<f32>
%1 = linalg.generic
{indexing_maps = [affine_map<() -> ()>, affine_map<() -> ()>],
iterator_types = []}
ins(%arg1 : tensor<i32>) outs(%0 : tensor<f32>) {
^bb0(%arg2: i32, %arg3: f32): // no predecessors
- %3 = index_cast %arg2 : i32 to index
+ %3 = arith.index_cast %arg2 : i32 to index
%4 = tensor.extract %arg0[%3, %c0, %c0] : tensor<5x1x1xf32>
linalg.yield %4 : f32
} -> tensor<f32>
iterator_types = ["parallel"]}
ins(%1, %cst : tensor<f32>, tensor<10xf32>) outs(%2 : tensor<10xf32>) {
^bb0(%arg2: f32, %arg3: f32, %arg4: f32): // no predecessors
- %4 = mulf %arg2, %arg3 : f32
+ %4 = arith.mulf %arg2, %arg3 : f32
linalg.yield %4 : f32
} -> tensor<10xf32>
return %3 : tensor<10xf32>
// -----
func @constant_fusion(%arg0 : tensor<4xf32>) -> (tensor<4xf32>) {
- %cst = constant dense<1.0> : tensor<4xf32>
+ %cst = arith.constant dense<1.0> : tensor<4xf32>
%1 = linalg.init_tensor [4] : tensor<4xf32>
%2 = linalg.generic
{indexing_maps = [affine_map<(d0) -> (d0)>, affine_map<(d0) -> (d0)>,
ins (%arg0, %cst : tensor<4xf32>, tensor<4xf32>)
outs (%1 : tensor<4xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
- %3 = addf %arg1, %arg2 : f32
+ %3 = arith.addf %arg1, %arg2 : f32
linalg.yield %3 : f32
} -> tensor<4xf32>
return %2 : tensor<4xf32>
// CHECK-DAG: #[[MAP:.+]] = affine_map<(d0) -> (d0)>
// CHECK: func @constant_fusion(%[[ARG0:.+]]: tensor<4xf32>)
-// CHECK-DAG: %[[CST:.+]] = constant 1.000000e+00 : f32
+// CHECK-DAG: %[[CST:.+]] = arith.constant 1.000000e+00 : f32
// CHECK-DAG: %[[T0:.+]] = linalg.init_tensor [4] : tensor<4xf32>
// CHECK: %[[T1:.+]] = linalg.generic
// CHECK-SAME: indexing_maps = [#[[MAP]], #[[MAP]]]
// CHECK-SAME: outs(%[[T0]] : tensor<4xf32>)
// CHECK: ^{{.+}}(
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: f32, %[[ARG2:[a-zA-Z0-9_]+]]: f32)
-// CHECK: %[[T2:.+]] = addf %[[ARG1]], %[[CST]]
+// CHECK: %[[T2:.+]] = arith.addf %[[ARG1]], %[[CST]]
// CHECK: linalg.yield %[[T2]]
// CHECK: return %[[T1]]
ins(%arg0, %arg1 : tensor<1x10xf32>, tensor<1x10xf32>)
outs(%init : tensor<1x10xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
linalg.yield %2 : f32
} -> tensor<1x10xf32>
%1 = linalg.generic
ins(%0 : tensor<1x10xf32>)
outs(%arg2 : tensor<1xf32>) {
^bb0(%arg3: f32, %arg4: f32): // no predecessors
- %2 = addf %arg3, %arg4 : f32
+ %2 = arith.addf %arg3, %arg4 : f32
linalg.yield %2 : f32
} -> tensor<1xf32>
return %1 : tensor<1xf32>
// CHECK-SAME: iterator_types = ["reduction"]
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]] : tensor<1x10xf32>, tensor<1x10xf32>)
// CHECK: ^{{.+}}(%[[T0:.+]]: f32, %[[T1:.+]]: f32, %[[T2:.+]]: f32)
-// CHECK: %[[T3:.+]] = addf %[[T0]], %[[T1]] : f32
-// CHECK: %[[T4:.+]] = addf %[[T3]], %[[T2]] : f32
+// CHECK: %[[T3:.+]] = arith.addf %[[T0]], %[[T1]] : f32
+// CHECK: %[[T4:.+]] = arith.addf %[[T3]], %[[T2]] : f32
// CHECK: linalg.yield %[[T4]]
// CHECK: return %[[RES]]
// CHECK-NOT: linalg.generic
// CHECK: return %[[RES]]
func @sigmoid_dynamic_dim(%0: tensor<?x1xf32>) -> tensor<?x1xf32> {
- %cp5 = constant 5.000000e-01 : f32
- %c0 = constant 0 : index
+ %cp5 = arith.constant 5.000000e-01 : f32
+ %c0 = arith.constant 0 : index
%shape = shape.shape_of %0 : tensor<?x1xf32> -> tensor<?xindex>
%extend = shape.to_extent_tensor %shape : tensor<?xindex> -> tensor<2xindex>
%extracted = tensor.extract %extend[%c0] : tensor<2xindex>
ins(%0, %1 : tensor<?x1xf32>, tensor<?x1xf32>)
outs(%init1 : tensor<?x1xf32>) {
^bb0(%a: f32, %b: f32, %c: f32): // no predecessors
- %m = mulf %a, %b : f32
+ %m = arith.mulf %a, %b : f32
linalg.yield %m : f32
} -> tensor<?x1xf32>
return %2 : tensor<?x1xf32>
// CHECK-LABEL: func @no_fuse_constant_with_reduction
func @no_fuse_constant_with_reduction() -> tensor<3xf32>
{
- // CHECK: %[[CONST:.+]] = constant {{.+}} : tensor<3x2xf32>
+ // CHECK: %[[CONST:.+]] = arith.constant {{.+}} : tensor<3x2xf32>
// CHECK: %[[RESULT:.+]] = linalg.generic
// CHECK-SAME: ins(%[[CONST]] : tensor<3x2xf32>)
// CHECK: return %[[RESULT]]
- %three = constant dense<3.0> : tensor<3x2xf32>
+ %three = arith.constant dense<3.0> : tensor<3x2xf32>
%init = linalg.init_tensor [3] : tensor<3xf32>
%result = linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
iterator_types = ["parallel", "reduction"]}
ins(%three : tensor<3x2xf32>) outs(%init : tensor<3xf32>) {
^bb0(%arg0 : f32, %arg1 : f32):
- %0 = addf %arg0, %arg1 : f32
+ %0 = arith.addf %arg0, %arg1 : f32
linalg.yield %0 : f32
} -> tensor<3xf32>
return %result : tensor<3xf32>
{
%0 = linalg.generic #trait ins(%arg0 : tensor<?x?xf32>) outs(%arg0 : tensor<?x?xf32>) {
^bb0(%arg1 : f32, %arg2 : f32) :
- %1 = addf %arg1, %arg1 : f32
+ %1 = arith.addf %arg1, %arg1 : f32
linalg.yield %1 : f32
} -> tensor<?x?xf32>
%2 = linalg.generic #trait ins(%0 : tensor<?x?xf32>) outs(%0 : tensor<?x?xf32>) {
^bb0(%arg1 : f32, %arg2 : f32) :
- %3 = mulf %arg1, %arg1 : f32
+ %3 = arith.mulf %arg1, %arg1 : f32
linalg.yield %3 : f32
} -> tensor<?x?xf32>
return %2 : tensor<?x?xf32>
}
// CHECK: func @break_outs_dependency(
// CHECK-SAME: %[[ARG0:.+]]: tensor<?x?xf32>)
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
// CHECK-DAG: %[[D0:.+]] = tensor.dim %[[ARG0]], %[[C0]]
// CHECK-DAG: %[[D1:.+]] = tensor.dim %[[ARG0]], %[[C1]]
// CHECK-DAG: %[[INIT:.+]] = linalg.init_tensor [%[[D0]], %[[D1]]]
// -----
func @fuse_scalar_constant(%arg0 : tensor<?x?xf32>) -> (tensor<?x?xf32>, tensor<?x?xi32>) {
- %cst = constant 4.0 : f32
- %c42 = constant 42 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cst = arith.constant 4.0 : f32
+ %c42 = arith.constant 42 : i32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%0 = linalg.init_tensor[%d0, %d1] : tensor<?x?xf32>
ins(%arg0, %cst, %c42 : tensor<?x?xf32>, f32, i32)
outs(%0, %1 : tensor<?x?xf32>, tensor<?x?xi32>) {
^bb0(%arg1 : f32, %arg2 : f32, %arg3 : i32, %arg4 : f32, %arg5 : i32) :
- %3 = addf %arg1, %arg2 : f32
+ %3 = arith.addf %arg1, %arg2 : f32
linalg.yield %3, %arg3 : f32, i32
} -> (tensor<?x?xf32>, tensor<?x?xi32>)
return %2#0, %2#1 : tensor<?x?xf32>, tensor<?x?xi32>
}
// CHECK-LABEL: func @fuse_scalar_constant
-// CHECK-DAG: %[[CST:.+]] = constant 4.000000e+00 : f32
-// CHECK-DAG: %[[C42:.+]] = constant 42 : i32
+// CHECK-DAG: %[[CST:.+]] = arith.constant 4.000000e+00 : f32
+// CHECK-DAG: %[[C42:.+]] = arith.constant 42 : i32
// CHECK: linalg.generic
// CHECK-SAME: ins(%{{.+}} : tensor<?x?xf32>)
-// CHECK: %[[YIELD:.+]] = addf %{{.+}}, %[[CST]] : f32
+// CHECK: %[[YIELD:.+]] = arith.addf %{{.+}}, %[[CST]] : f32
// CHECK: linalg.yield %[[YIELD]], %[[C42]] : f32, i32
// -----
// CHECK-LABEL: @transpose_fold_2d_fp32
func @transpose_fold_2d_fp32(%init: tensor<3x2xf32>) -> tensor<3x2xf32> {
- %input = constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
- // CHECK: %[[CST:.+]] = constant
+ %input = arith.constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
+ // CHECK: %[[CST:.+]] = arith.constant
// CHECK-SAME{LITERAL}: dense<[[0.000000e+00, 3.000000e+00], [1.000000e+00, 4.000000e+00], [2.000000e+00, 5.000000e+00]]> : tensor<3x2xf32>
%1 = linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d1, d0)>, affine_map<(d0, d1) -> (d0, d1)>],
// CHECK-LABEL: @transpose_fold_2d_fp64
func @transpose_fold_2d_fp64(%init: tensor<3x2xf64>) -> tensor<3x2xf64> {
- %input = constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf64>
- // CHECK: %[[CST:.+]] = constant
+ %input = arith.constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf64>
+ // CHECK: %[[CST:.+]] = arith.constant
// CHECK-SAME{LITERAL}: dense<[[0.000000e+00, 3.000000e+00], [1.000000e+00, 4.000000e+00], [2.000000e+00, 5.000000e+00]]> : tensor<3x2xf64>
%1 = linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d1, d0)>, affine_map<(d0, d1) -> (d0, d1)>],
// CHECK-LABEL: @transpose_fold_4d_i32
func @transpose_fold_4d_i32(%init: tensor<3x1x4x2xi32>) -> tensor<3x1x4x2xi32> {
- %input = constant dense<[[
+ %input = arith.constant dense<[[
[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]],
[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]
]]> : tensor<1x2x3x4xi32>
- // CHECK: %[[CST:.+]] = constant dense<[
+ // CHECK: %[[CST:.+]] = arith.constant dense<[
// CHECK-SAME{LITERAL}: [[[0, 12], [1, 13], [2, 14], [3, 15]]],
// CHECK-SAME{LITERAL}: [[[4, 16], [5, 17], [6, 18], [7, 19]]],
// CHECK-SAME{LITERAL}: [[[8, 20], [9, 21], [10, 22], [11, 23]]]
// CHECK-LABEL: @transpose_fold_4d_i16
func @transpose_fold_4d_i16(%init: tensor<3x1x4x2xi16>) -> tensor<3x1x4x2xi16> {
- %input = constant dense<[[
+ %input = arith.constant dense<[[
[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]],
[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]
]]> : tensor<1x2x3x4xi16>
- // CHECK: %[[CST:.+]] = constant dense<[
+ // CHECK: %[[CST:.+]] = arith.constant dense<[
// CHECK-SAME{LITERAL}: [[[0, 12], [1, 13], [2, 14], [3, 15]]],
// CHECK-SAME{LITERAL}: [[[4, 16], [5, 17], [6, 18], [7, 19]]],
// CHECK-SAME{LITERAL}: [[[8, 20], [9, 21], [10, 22], [11, 23]]]
// CHECK-LABEL: @transpose_nofold_yield_const
func @transpose_nofold_yield_const(%init: tensor<3x2xf32>) -> tensor<3x2xf32> {
- %input = constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
- %cst = constant 8.0 : f32
+ %input = arith.constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
+ %cst = arith.constant 8.0 : f32
// CHECK: linalg.generic
%1 = linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d1, d0)>, affine_map<(d0, d1) -> (d0, d1)>],
// CHECK-LABEL: @transpose_nofold_multi_ops_in_region
func @transpose_nofold_multi_ops_in_region(%init: tensor<3x2xf32>) -> tensor<3x2xf32> {
- %input = constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
+ %input = arith.constant dense<[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0]]> : tensor<2x3xf32>
// CHECK: linalg.generic
%1 = linalg.generic {
indexing_maps = [affine_map<(d0, d1) -> (d1, d0)>, affine_map<(d0, d1) -> (d0, d1)>],
iterator_types = ["parallel", "parallel"]
} ins(%input : tensor<2x3xf32>) outs(%init : tensor<3x2xf32>) {
^bb0(%arg1: f32, %arg2: f32):
- %add = addf %arg1, %arg1 : f32
+ %add = arith.addf %arg1, %arg1 : f32
linalg.yield %add : f32
} -> tensor<3x2xf32>
return %1 : tensor<3x2xf32>
%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>, %arg2 : tensor<?x?xf32>,
%arg3 : tensor<?x?xf32>, %arg4 : tensor<?x?xf32>, %arg5 : tensor<?x?xf32>)
-> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%init = linalg.init_tensor [%d0, %d1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%init : tensor<?x?xf32>) {
^bb0(%arg6 : f32, %arg7 : f32, %arg8 : f32):
- %1 = mulf %arg6, %arg7 : f32
+ %1 = arith.mulf %arg6, %arg7 : f32
linalg.yield %1 : f32
} -> tensor<?x?xf32>
%2 = linalg.generic #binary2Dpointwise
ins(%arg2, %arg3 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%init : tensor<?x?xf32>) {
^bb0(%arg6 : f32, %arg7 : f32, %arg8 : f32):
- %3 = mulf %arg6, %arg7 : f32
+ %3 = arith.mulf %arg6, %arg7 : f32
linalg.yield %3 : f32
} -> tensor<?x?xf32>
%4 = linalg.generic #binary2Dpointwise
ins(%arg4, %arg5 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%init : tensor<?x?xf32>) {
^bb0(%arg6 : f32, %arg7 : f32, %arg8 : f32):
- %5 = mulf %arg6, %arg7 : f32
+ %5 = arith.mulf %arg6, %arg7 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
%6 = linalg.generic #ternary2Dpointwise
ins(%0, %2, %4 : tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>)
outs(%init : tensor<?x?xf32>) {
^bb0(%arg6 : f32, %arg7 : f32, %arg8 : f32, %arg9 : f32):
- %7 = addf %arg6, %arg7 : f32
- %8 = addf %7, %arg8 : f32
+ %7 = arith.addf %arg6, %arg7 : f32
+ %8 = arith.addf %7, %arg8 : f32
linalg.yield %8 : f32
} -> tensor<?x?xf32>
return %6 : tensor<?x?xf32>
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
outs(%C : memref<?x?xf32>) {
^bb0(%e: f32, %arg5: f32, %arg6: f32): // no predecessors
- %2 = addf %e, %arg5 : f32
+ %2 = arith.addf %e, %arg5 : f32
linalg.yield %2 : f32
}
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c25 = constant 25 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c25 = arith.constant 25 : index
+ %c10 = arith.constant 10 : index
%0 = memref.dim %C, %c0 : memref<?x?xf32>
%1 = memref.dim %C, %c1 : memref<?x?xf32>
%2 = memref.dim %D, %c0 : memref<?x?xf32>
^bb0(%arg4: f32, %arg5: f32):
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %6 = addi %idx0, %arg2 : index
- %7 = addi %idx1, %arg3 : index
- %8 = index_cast %6 : index to i32
- %9 = sitofp %8 : i32 to f32
- %10 = index_cast %7 : index to i32
- %11 = sitofp %10 : i32 to f32
- %12 = addf %9, %11 : f32
+ %6 = arith.addi %idx0, %arg2 : index
+ %7 = arith.addi %idx1, %arg3 : index
+ %8 = arith.index_cast %6 : index to i32
+ %9 = arith.sitofp %8 : i32 to f32
+ %10 = arith.index_cast %7 : index to i32
+ %11 = arith.sitofp %10 : i32 to f32
+ %12 = arith.addf %9, %11 : f32
linalg.yield %12 : f32
}
}
// CHECK-NOT: scf.for
// CHECK: linalg.generic
// CHECK-NOT: affine.apply
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: linalg.generic
-// CHECK: index_cast
+// CHECK: arith.index_cast
// -----
#map = affine_map<(d0, d1)[s0, s1, s2] -> (d0 * s1 + s0 + d1 * s2)>
func @fuse_indexed_producer(%A: memref<?x?xindex>,
%B: memref<?x?xindex>) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c25 = constant 25 : index
- %c10 = constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c25 = arith.constant 25 : index
+ %c10 = arith.constant 10 : index
linalg.generic {
indexing_maps = [affine_map<(i, j) -> (j, i)>],
iterator_types = ["parallel", "parallel"]}
^bb0(%a: index): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %0 = addi %idx0, %idx1 : index
+ %0 = arith.addi %idx0, %idx1 : index
linalg.yield %0 : index
}
%A_X = memref.dim %A, %c0 : memref<?x?xindex>
// CHECK: [[i_new:%.*]] = affine.apply [[$MAP]]([[idx0]], [[J]])
// CHECK: [[idx1:%.*]] = linalg.index 1 : index
// CHECK: [[j_new:%.*]] = affine.apply [[$MAP]]([[idx1]], [[I]])
-// CHECK: [[sum:%.*]] = addi [[i_new]], [[j_new]] : index
+// CHECK: [[sum:%.*]] = arith.addi [[i_new]], [[j_new]] : index
// CHECK: linalg.yield [[sum]] : index
// CHECK: linalg.generic
#map = affine_map<(d0, d1)[s0, s1, s2] -> (d0 * s1 + s0 + d1 * s2)>
func @fuse_indexed_producer_tiled_second_dim_only(%A: memref<?x?xindex>,
%B: memref<?x?xindex>) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c25 = constant 25 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c25 = arith.constant 25 : index
linalg.generic {
indexing_maps = [affine_map<(i, j) -> (i, j)>],
iterator_types = ["parallel", "parallel"]}
^bb0(%a: index): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %0 = addi %idx0, %idx1 : index
+ %0 = arith.addi %idx0, %idx1 : index
linalg.yield %0 : index
}
%A_X = memref.dim %A, %c0 : memref<?x?xindex>
// CHECK: [[idx0:%.*]] = linalg.index 0 : index
// CHECK: [[idx1:%.*]] = linalg.index 1 : index
// CHECK: [[j_new:%.*]] = affine.apply [[$MAP]]([[idx1]], [[J]])
-// CHECK: [[sum:%.*]] = addi [[idx0]], [[j_new]] : index
+// CHECK: [[sum:%.*]] = arith.addi [[idx0]], [[j_new]] : index
// CHECK: linalg.yield [[sum]] : index
// CHECK: linalg.generic
module {
func @basic_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
linalg.fill(%cst, %arg2) : f32, memref<?x?xf32>
linalg.matmul {__internal_linalg_transform__ = "basic_fusion"}
ins(%arg0, %arg1 : memref<?x?xf32>, memref<?x?xf32>)
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C32:.+]] = constant 32 : index
-// CHECK-DAG: %[[C64:.+]] = constant 64 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
-// CHECK-DAG: %[[CST:.+]] = constant 0.0{{.*}} : f32
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C32:.+]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.+]] = arith.constant 64 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
+// CHECK-DAG: %[[CST:.+]] = arith.constant 0.0{{.*}} : f32
// CHECK-DAG: linalg.fill(%[[CST]], %[[ARG2]])
// CHECK-SAME: __internal_linalg_transform__ = "after_basic_fusion_original"
// CHECK-DAG: %[[M:.+]] = memref.dim %[[ARG0]], %[[C0]]
module {
func @rhs_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>, %arg3: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
linalg.copy(%arg1, %arg2) : memref<?x?xf32>, memref<?x?xf32>
linalg.fill(%cst, %arg3) : f32, memref<?x?xf32>
linalg.matmul {__internal_linalg_transform__ = "rhs_fusion"}
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG3:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C32:.+]] = constant 32 : index
-// CHECK-DAG: %[[C64:.+]] = constant 64 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
-// CHECK-DAG: %[[CST:.+]] = constant 0.0{{.*}} : f32
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C32:.+]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.+]] = arith.constant 64 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
+// CHECK-DAG: %[[CST:.+]] = arith.constant 0.0{{.*}} : f32
// CHECK-DAG: linalg.copy(%[[ARG1]], %[[ARG2]])
// CHECK-SAME: __internal_linalg_transform__ = "after_rhs_fusion_original"
// CHECK-DAG: %[[N:.+]] = memref.dim %[[ARG2]], %[[C1]]
module {
func @two_operand_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>, %arg3: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
linalg.copy(%arg0, %arg1) : memref<?x?xf32>, memref<?x?xf32>
linalg.fill(%cst, %arg3) : f32, memref<?x?xf32>
linalg.matmul {__internal_linalg_transform__ = "two_operand_fusion"}
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG3:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C32:.+]] = constant 32 : index
-// CHECK-DAG: %[[C64:.+]] = constant 64 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
-// CHECK-DAG: %[[CST:.+]] = constant 0.0{{.*}} : f32
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C32:.+]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.+]] = arith.constant 64 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
+// CHECK-DAG: %[[CST:.+]] = arith.constant 0.0{{.*}} : f32
// CHECK: linalg.copy(%[[ARG0]], %[[ARG1]])
// CHECK-SAME: __internal_linalg_transform__ = "after_two_operand_fusion_original"
// CHECK: linalg.fill(%[[CST]], %[[ARG3]])
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG3:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG4:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C32:.+]] = constant 32 : index
-// CHECK-DAG: %[[C64:.+]] = constant 64 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C32:.+]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.+]] = arith.constant 64 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
// CHECK: linalg.matmul
// CHECK-SAME: __internal_linalg_transform__ = "after_lhs_fusion_original"
// CHECK-DAG: %[[M:.+]] = memref.dim %[[ARG2]], %[[C0]]
module {
func @matmul_plus_matmul(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.dim %arg2, %c0 : memref<?x?xf32>
%1 = memref.dim %arg2, %c1 : memref<?x?xf32>
%2 = memref.alloc(%0, %1) : memref<?x?xf32>
ins(%2, %2 : memref<?x?xf32>, memref<?x?xf32>)
outs(%arg2 : memref<?x?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32) :
- %3 = addf %arg3, %arg4 : f32
+ %3 = arith.addf %arg3, %arg4 : f32
linalg.yield %3 : f32
}
return
func @matmul_plus_transpose_matmul(%arg0: memref<?x?xf32>,
%arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.dim %arg2, %c0 : memref<?x?xf32>
%1 = memref.dim %arg2, %c1 : memref<?x?xf32>
%2 = memref.alloc(%0, %1) : memref<?x?xf32>
ins(%2, %2 : memref<?x?xf32>, memref<?x?xf32>)
outs(%arg2 : memref<?x?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32) :
- %3 = addf %arg3, %arg4 : f32
+ %3 = arith.addf %arg3, %arg4 : f32
linalg.yield %3 : f32
}
return
module {
func @basic_no_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c32 = constant 32 : index
- %c64 = constant 64 : index
- %c16 = constant 16 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c32 = arith.constant 32 : index
+ %c64 = arith.constant 64 : index
+ %c16 = arith.constant 16 : index
+ %cst = arith.constant 0.000000e+00 : f32
linalg.fill(%cst, %arg2) : f32, memref<?x?xf32>
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
%1 = memref.dim %arg1, %c1 : memref<?x?xf32>
module {
func @basic_conv_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
linalg.fill(%cst, %arg2) : f32, memref<?x?xf32>
linalg.conv_2d {__internal_linalg_transform__ = "basic_fusion"}
ins(%arg1, %arg0 : memref<?x?xf32>, memref<?x?xf32>) outs(%arg2 : memref<?x?xf32>)
ins(%0, %B : tensor<?x112x16xf32>, tensor<16xf32>)
outs(%init : tensor<?x112x16xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32): // no predecessors
- %s = subf %arg1, %arg2 : f32
+ %s = arith.subf %arg1, %arg2 : f32
linalg.yield %s : f32
} -> tensor<?x112x16xf32>
return %2 : tensor<?x112x16xf32>
ins(%0, %1, %C : tensor<112x112x16xf32>, tensor<112x112x16xf32>, tensor<16xf32>)
outs(%2 : tensor<112x112x16xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32, %arg4: f32): // no predecessors
- %s = subf %arg1, %arg2 : f32
- %m = mulf %s, %arg3 : f32
+ %s = arith.subf %arg1, %arg2 : f32
+ %m = arith.mulf %s, %arg3 : f32
linalg.yield %m : f32
} -> tensor<112x112x16xf32>
return %3 : tensor<112x112x16xf32>
ins(%20, %B : tensor<112x112x16xf32>, tensor<112xf32>)
outs(%21 : tensor<112x112x16xf32>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32): // no predecessors
- %s = subf %arg1, %arg2 : f32
+ %s = arith.subf %arg1, %arg2 : f32
linalg.yield %s : f32
} -> tensor<112x112x16xf32>
return %22 : tensor<112x112x16xf32>
func @type_correctness(%arg0 : tensor<6x5xi32>, %arg1 : tensor<5xf32>,
%arg2 : tensor<5xf32>) -> tensor<2x3x5xf32> {
- %cst_6 = constant 1.000000e+00 : f32
- %cst_7 = constant 7.000000e+00 : f32
- %cst_8 = constant 1.1920929E-7 : f32
+ %cst_6 = arith.constant 1.000000e+00 : f32
+ %cst_7 = arith.constant 7.000000e+00 : f32
+ %cst_8 = arith.constant 1.1920929E-7 : f32
%25 = linalg.tensor_expand_shape %arg0 [[0, 1], [2]]
: tensor<6x5xi32> into tensor<2x3x5xi32>
%26 = linalg.init_tensor [2, 3, 5] : tensor<2x3x5xf32>
ins(%25, %arg1, %arg2 : tensor<2x3x5xi32>, tensor<5xf32>, tensor<5xf32>)
outs(%26 : tensor<2x3x5xf32>) {
^bb0(%arg6: i32, %arg7: f32, %arg8: f32, %arg9: f32): // no predecessors
- %29 = sitofp %arg6 : i32 to f32
- %30 = addf %arg7, %cst_8 : f32
- %31 = divf %cst_7, %30 : f32
- %32 = divf %cst_6, %31 : f32
- %33 = mulf %29, %32 : f32
- %34 = addf %33, %arg8 : f32
+ %29 = arith.sitofp %arg6 : i32 to f32
+ %30 = arith.addf %arg7, %cst_8 : f32
+ %31 = arith.divf %cst_7, %30 : f32
+ %32 = arith.divf %cst_6, %31 : f32
+ %33 = arith.mulf %29, %32 : f32
+ %34 = arith.addf %33, %arg8 : f32
linalg.yield %34 : f32
} -> tensor<2x3x5xf32>
return %28 : tensor<2x3x5xf32>
module {
func @three_op_fusion(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?xf32>, %arg3 : memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = memref.dim %arg0, %c0 : memref<?x?xf32>
%d1 = memref.dim %arg1, %c1 : memref<?x?xf32>
%0 = memref.alloc(%d0, %d1) : memref<?x?xf32>
ins(%0, %arg2 : memref<?x?xf32>, memref<?xf32>)
outs(%arg3 : memref<?x?xf32>) {
^bb0(%arg4 : f32, %arg5 : f32, %arg6 : f32) :
- %5 = addf %arg4, %arg5 : f32
+ %5 = arith.addf %arg4, %arg5 : f32
linalg.yield %5 : f32
}
return
func @sequence_of_matmul(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>,
%arg2: memref<?x?xf32>, %arg3: memref<?x?xf32>,
%arg4: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%m = memref.dim %arg0, %c0 : memref<?x?xf32>
%n1 = memref.dim %arg1, %c1 : memref<?x?xf32>
%n2 = memref.dim %arg2, %c1 : memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG3:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG4:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
// CHECK-DAG: %[[M:.+]] = memref.dim %[[ARG0]], %[[C0]]
// CHECK-DAG: %[[N1:.+]] = memref.dim %[[ARG1]], %[[C1]]
// CHECK-DAG: %[[N2:.+]] = memref.dim %[[ARG2]], %[[C1]]
func @tensor_op_fusion(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>,
%arg2: tensor<?x?xf32>, %arg3: tensor<?xf32>)
-> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.matmul ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?xf32>
ins(%0, %arg3 : tensor<?x?xf32>, tensor<?xf32>)
outs(%3 : tensor<?x?xf32>) {
^bb0(%arg4: f32, %arg5: f32, %arg6: f32):
- %5 = addf %arg4, %arg5 : f32
+ %5 = arith.addf %arg4, %arg5 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// CHECK-SAME: %[[ARG4:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG5:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG6:[a-zA-Z0-9_]+]]: tensor<?x?xf32>) -> tensor<?x?xf32> {
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
// CHECK: %[[M:.+]] = tensor.dim %[[ARG0]], %c0 : tensor<?x?xf32>
// CHECK: %[[R0:.+]] = scf.for %[[IV0:[a-zA-Z0-9_]+]] =
// CHECK-SAME: iter_args(%[[ARG8:.+]] = %[[ARG6]]) -> (tensor<?x?xf32>) {
// CHECK-SAME: %[[ARG3:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG4:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C32:.+]] = constant 32 : index
-// CHECK-DAG: %[[C64:.+]] = constant 64 : index
-// CHECK-DAG: %[[C16:.+]] = constant 16 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C32:.+]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.+]] = arith.constant 64 : index
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : index
// CHECK-DAG: %[[M:.+]] = tensor.dim %[[ARG0]], %[[C0]]
// CHECK: %[[RESULT:.+]] = scf.for %[[IV0:[a-zA-Z0-9]+]] =
// CHECK-SAME: %[[C0]] to %[[M]] step %[[C32]]
// TLOOP-SAME: %[[C:[a-zA-Z0-9_]+]]: tensor<?x?xf32>,
// TLOOP-SAME: %[[ABC_INIT:[a-zA-Z0-9_]+]]: tensor<?x?xf32>) -> tensor<?x?xf32> {
-// TLOOP-DAG: %[[C32:.*]] = constant 32 : index
-// TLOOP-DAG: %[[C64:.*]] = constant 64 : index
-// TLOOP-DAG: %[[C16:.*]] = constant 16 : index
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
+// TLOOP-DAG: %[[C32:.*]] = arith.constant 32 : index
+// TLOOP-DAG: %[[C64:.*]] = arith.constant 64 : index
+// TLOOP-DAG: %[[C16:.*]] = arith.constant 16 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
// TLOOP: %[[DIM_A0:.*]] = tensor.dim %[[A]], %[[C0]] : [[TY:.*]]
module {
func @matmul_plus_matmul(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>,
%arg2: tensor<?x?xf32>) -> tensor<?x?xf32>{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg2, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg2, %c1 : tensor<?x?xf32>
%2 = linalg.matmul ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
ins(%2, %2 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%5 : tensor<?x?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32) :
- %7 = addf %arg3, %arg4 : f32
+ %7 = arith.addf %arg3, %arg4 : f32
linalg.yield %7 : f32
} -> tensor<?x?xf32>
return %6 : tensor<?x?xf32>
// TLOOP-SAME: %[[B:[a-zA-Z0-9_]+]]: tensor<?x?xf32>,
// TLOOP-SAME: %[[AB:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// TLOOP-DAG: %[[C32:.*]] = constant 32 : index
-// TLOOP-DAG: %[[C64:.*]] = constant 64 : index
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
+// TLOOP-DAG: %[[C32:.*]] = arith.constant 32 : index
+// TLOOP-DAG: %[[C64:.*]] = arith.constant 64 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
// TLOOP: %[[DIM_A_0:.*]] = tensor.dim %[[A]], %[[C0]] : [[TY:.*]]
// TLOOP: %[[DIM_B_1:.*]] = tensor.dim %[[B]], %[[C1]] : [[TY]]
module {
func @matmul_out_fusion(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>,
%arg2: tensor<?x?xf32>) -> tensor<?x?xf32> {
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
%0 = linalg.fill(%c0, %arg0) : f32, tensor<?x?xf32> -> tensor<?x?xf32>
%1 = linalg.matmul {__internal_linalg_transform__ = "out_fusion"}
ins(%arg1, %arg2 : tensor<?x?xf32>, tensor<?x?xf32>)
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// CHECK: %[[C0:.*]] = constant 0.0{{.*}} : f32
+// CHECK: %[[C0:.*]] = arith.constant 0.0{{.*}} : f32
// CHECK-NOT: fill
// CHECK: scf.for %[[I:.*]]{{.*}}iter_args(%{{.*}} = %[[ARG0]]) -> (tensor<?x?xf32>) {
// CHECK: scf.for %[[J:.*]]
// TLOOP-SAME: %[[A:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// TLOOP-SAME: %[[B:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// TLOOP-DAG: %[[C0_F32:.*]] = constant 0.0
-// TLOOP-DAG: %[[C32:.*]] = constant 32 : index
-// TLOOP-DAG: %[[C64:.*]] = constant 64 : index
-// TLOOP-DAG: %[[C16:.*]] = constant 16 : index
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
+// TLOOP-DAG: %[[C0_F32:.*]] = arith.constant 0.0
+// TLOOP-DAG: %[[C32:.*]] = arith.constant 32 : index
+// TLOOP-DAG: %[[C64:.*]] = arith.constant 64 : index
+// TLOOP-DAG: %[[C16:.*]] = arith.constant 16 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
// TLOOP: %[[DIM_A_0:.*]] = tensor.dim %[[A]], %[[C0]] : [[TY:.*]]
// TLOOP: %[[DIM_B_1:.*]] = tensor.dim %[[B]], %[[C1]] : [[TY]]
module {
func @generic_plus_matmul(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>,
%arg2: tensor<?x?xf32>) -> tensor<?x?xf32> {
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
%0 = linalg.generic {
indexing_maps = [affine_map<(m, n) -> ()>, affine_map<(m, n) -> (m, n)>],
iterator_types = ["parallel", "parallel"]}
// TLOOP-SAME: %[[A:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// TLOOP-SAME: %[[B:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// TLOOP-DAG: %[[C0_F32:.*]] = constant 0.0
-// TLOOP-DAG: %[[C32:.*]] = constant 32 : index
-// TLOOP-DAG: %[[C64:.*]] = constant 64 : index
-// TLOOP-DAG: %[[C16:.*]] = constant 16 : index
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
+// TLOOP-DAG: %[[C0_F32:.*]] = arith.constant 0.0
+// TLOOP-DAG: %[[C32:.*]] = arith.constant 32 : index
+// TLOOP-DAG: %[[C64:.*]] = arith.constant 64 : index
+// TLOOP-DAG: %[[C16:.*]] = arith.constant 16 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
// TLOOP: %[[DIM_A_0:.*]] = tensor.dim %[[A]], %[[C0]] : [[TY:.*]]
// TLOOP: %[[DIM_B_1:.*]] = tensor.dim %[[B]], %[[C1]] : [[TY]]
%D: memref<?x?xf32, offset: 0, strides: [?, 1]>,
%E: memref<?x?xf32, offset: 0, strides: [?, 1]>
) -> memref<?x?xf32, offset: 0, strides: [?, 1]> {
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c1 = arith.constant 1 : index
%0 = memref.dim %A, %c0 : memref<?x?xf32, offset: 0, strides: [?, 1]>
%1 = memref.dim %A, %c1 : memref<?x?xf32, offset: 0, strides: [?, 1]>
%2 = memref.dim %B, %c1 : memref<?x?xf32, offset: 0, strides: [?, 1]>
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
linalg.matmul ins(%A, %B : memref<?x?xf32, offset: 0, strides: [?, ?]>,
memref<?x?xf32, offset: 0, strides: [?, ?]>)
outs(%C: memref<?x?xf32, offset: 0, strides: [?, ?]>)
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
linalg.matmul ins(%A, %B : memref<?x?xf32, offset: 0, strides: [?, ?]>,
memref<?x?xf32, offset: 0, strides: [?, ?]>)
outs(%C : memref<?x?xf32, offset: 0, strides: [?, ?]>)
}
// CHECK-LABEL: func @f3
// CHECK: (%[[A:.*]]:{{.*}}, %[[B:.*]]:{{.*}}, %[[C:.*]]:{{.*}}, %[[D:.*]]:{{.*}}, %[[E:.*]]:{{.*}})
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[D_0:.*]] = memref.dim %[[D]], %[[C0]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[D_1:.*]] = memref.dim %[[D]], %[[C1]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[C_1:.*]] = memref.dim %[[C]], %[[C1]] : memref<?x?xf32, #[[$strided2D]]>
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
linalg.matmul ins(%A, %B : memref<?x?xf32, offset: 0, strides: [?, ?]>,
memref<?x?xf32, offset: 0, strides: [?, ?]>)
outs(%C : memref<?x?xf32, offset: 0, strides: [?, ?]>)
}
// CHECK-LABEL: func @f4
// CHECK: (%[[A:.*]]:{{.*}}, %[[B:.*]]:{{.*}}, %[[C:.*]]:{{.*}}, %[[D:.*]]:{{.*}}, %[[E:.*]]:{{.*}})
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[C_0:.*]] = memref.dim %[[C]], %[[C0:.*]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[C_1:.*]] = memref.dim %[[C]], %[[C1:.*]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[D_1:.*]] = memref.dim %[[D]], %[[C1:.*]] : memref<?x?xf32, #[[$strided2D]]>
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %B, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
%1 = memref.dim %D, %c0 : memref<?x?xf32, offset: 0, strides: [?, ?]>
%2 = memref.dim %D, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
// CHECK-DAG: #[[BOUND_4_MAP:.+]] = affine_map<(d0)[s0] -> (4, -d0 + s0)>
// CHECK: func @f5
// CHECK-SAME: (%[[A:.*]]:{{.*}}, %[[B:.*]]:{{.*}}, %[[C:.*]]:{{.*}}, %[[D:.*]]:{{.*}}, %[[E:.*]]:{{.*}})
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK-DAG: %[[A_0:.*]] = memref.dim %[[A]], %[[C0]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK-DAG: %[[B_1:.*]] = memref.dim %[[B]], %[[C1]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK-DAG: %[[C_0:.*]] = memref.dim %[[C]], %[[C0]] : memref<?x?xf32, #[[$strided2D]]>
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %C, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
linalg.matmul ins(%A, %B : memref<?x?xf32, offset: 0, strides: [?, ?]>,
memref<?x?xf32, offset: 0, strides: [?, ?]>)
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %A, %c0 : memref<?x?xf32, offset: 0, strides: [?, ?]>
%1 = memref.dim %A, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
%2 = memref.dim %C, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
}
// CHECK-LABEL: func @f7
// CHECK: (%[[A:.*]]:{{.*}}, %[[B:.*]]:{{.*}}, %[[C:.*]]:{{.*}}, %[[D:.*]]:{{.*}}, %[[E:.*]]:{{.*}})
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[A_0:.*]] = memref.dim %[[A]], %[[C0:.*]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[A_1:.*]] = memref.dim %[[A]], %[[C1:.*]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[C_1:.*]] = memref.dim %[[C]], %[[C1:.*]] : memref<?x?xf32, #[[$strided2D]]>
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%E: memref<?x?xf32, offset: 0, strides: [?, ?]>
) -> memref<?x?xf32, offset: 0, strides: [?, ?]> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %A, %c0 : memref<?x?xf32, offset: 0, strides: [?, ?]>
%1 = memref.dim %A, %c1 : memref<?x?xf32, offset: 0, strides: [?, ?]>
linalg.matmul ins(%A, %C : memref<?x?xf32, offset: 0, strides: [?, ?]>,
%B: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%C: memref<?x?xf32, offset: 0, strides: [?, ?]>,
%D: memref<?x?xf32, offset: 0, strides: [?, ?]>) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
linalg.generic #pointwise_2d_trait
ins(%A, %A: memref<?x?xf32, offset: 0, strides: [?, ?]>,
memref<?x?xf32, offset: 0, strides: [?, ?]>)
outs(%B : memref<?x?xf32, offset: 0, strides: [?, ?]>) {
^bb0(%E: f32, %arg5: f32, %arg6: f32): // no predecessors
- %2 = addf %E, %arg5 : f32
+ %2 = arith.addf %E, %arg5 : f32
linalg.yield %2 : f32
}
%0 = memref.dim %B, %c0 : memref<?x?xf32, offset: 0, strides: [?, ?]>
memref<?x?xf32, offset: ?, strides: [?, ?]>)
outs(%6 : memref<?x?xf32, offset: ?, strides: [?, ?]>) {
^bb0(%arg6: f32, %arg7: f32, %arg8: f32): // no predecessors
- %7 = mulf %arg6, %arg7 : f32
+ %7 = arith.mulf %arg6, %arg7 : f32
linalg.yield %7 : f32
}
}
// CHECK: scf.for
// CHECK-NOT: scf.for
// CHECK: linalg.generic
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: linalg.generic
-// CHECK: mulf
+// CHECK: arith.mulf
// -----
iterator_types = ["parallel", "parallel"]
}
func @pointwise_no_view(%M: index, %N: index) {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
%A = memref.alloc (%M, %N): memref<?x?xf32>
%B = memref.alloc (%M, %N): memref<?x?xf32>
%C = memref.alloc (%M, %N): memref<?x?xf32>
ins(%A, %A : memref<?x?xf32>, memref<?x?xf32>)
outs(%B : memref<?x?xf32>) {
^bb0(%e: f32, %arg5: f32, %arg6: f32): // no predecessors
- %2 = addf %e, %arg5 : f32
+ %2 = arith.addf %e, %arg5 : f32
linalg.yield %2 : f32
}
%0 = memref.dim %B, %c0 : memref<?x?xf32>
memref<?x?xf32, offset: ?, strides: [?, ?]>)
outs(%6 : memref<?x?xf32, offset: ?, strides: [?, ?]>) {
^bb0(%arg6: f32, %arg7: f32, %arg8: f32): // no predecessors
- %7 = mulf %arg6, %arg7 : f32
+ %7 = arith.mulf %arg6, %arg7 : f32
linalg.yield %7 : f32
}
}
// CHECK: scf.for
// CHECK-NOT: scf.for
// CHECK: linalg.generic
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: linalg.generic
-// CHECK: mulf
+// CHECK: arith.mulf
// -----
func @fusion_of_three(%arg0: memref<100x10xf32>,
%arg1: memref<100xf32>,
%arg2: memref<100x10xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc() {temp = true} : memref<100x10xf32>
linalg.generic {
indexing_maps = [#map0, #map1],
ins(%arg0, %0: memref<100x10xf32>, memref<100x10xf32>)
outs(%1 : memref<100x10xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %2 = subf %arg3, %arg4 : f32
+ %2 = arith.subf %arg3, %arg4 : f32
linalg.yield %2 : f32
}
memref.dealloc %0 : memref<100x10xf32>
// CHECK: linalg.generic
// CHECK: linalg.yield
// CHECK: linalg.generic
-// CHECK: subf
+// CHECK: arith.subf
// CHECK: linalg.yield
// CHECK: linalg.generic
// CHECK: exp
#map4 = affine_map<(d0)[s0, s1] -> (s0 + 2, -d0 + s0 + s1)>
func @fill_and_conv(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
linalg.fill(%cst, %arg0) : f32, memref<?x?xf32>
%2 = memref.dim %arg1, %c0 : memref<?x?xf32>
%3 = memref.dim %arg1, %c1 : memref<?x?xf32>
// Test that different allocation-like ops are recognized and properly handled.
func @accept_different_alloc_ops(%dim: index, %s0 : index, %s1: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
%A = memref.alloca(%dim, %dim)[%s0, %s1] : memref<?x?xf32, offset: 0, strides: [?, ?]>
%B = memref.alloca(%dim, %dim)[%s0, %s1] : memref<?x?xf32, offset: 0, strides: [?, ?]>
// CHECK-SAME: outs(%[[C]]
// CHECK: ^{{.*}}(%[[A_ARG:.+]]: f32, %[[B_ARG:.+]]: f32, %[[C_ARG:.+]]: f32)
-// CHECK: %[[MUL:.+]] = mulf %[[A_ARG]], %[[B_ARG]] : f32
-// CHECK: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+// CHECK: %[[MUL:.+]] = arith.mulf %[[A_ARG]], %[[B_ARG]] : f32
+// CHECK: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
// CHECK: linalg.yield %[[ADD]] : f32
// -----
// CHECK-SAME: outs(%{{.+}} : tensor<16x32xf32>)
// CHECK: ^{{.*}}(%[[A_ARG:.+]]: f32, %[[B_ARG:.+]]: f32, %[[C_ARG:.+]]: f32)
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[A_ARG]], %[[B_ARG]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[A_ARG]], %[[B_ARG]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// CHECK-NEXT: -> tensor<16x32xf32>
// CHECK-SAME: outs(%{{.+}} : memref<2x3x4x2x3xf32>)
// CHECK: ^{{.+}}(%[[BBARG0:.+]]: f32, %[[BBARG1:.+]]: f32, %[[BBARG2:.+]]: f32)
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[BBARG0]], %[[BBARG1]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[BBARG2]], %[[MUL]] : f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[BBARG0]], %[[BBARG1]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[BBARG2]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// -----
// CHECK-SAME: outs(%{{.+}} : memref<2x2x3x2x3xf32>)
// CHECK: ^{{.+}}(%[[BBARG0:.+]]: f32, %[[BBARG1:.+]]: f32, %[[BBARG2:.+]]: f32)
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[BBARG0]], %[[BBARG1]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[BBARG2]], %[[MUL]] : f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[BBARG0]], %[[BBARG1]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[BBARG2]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// -----
// CHECK-SAME: outs(%{{.+}} : memref<1x56x56x96xf32>)
// CHECK: ^{{.+}}(%[[BBARG0:.+]]: f32, %[[BBARG1:.+]]: f32, %[[BBARG2:.+]]: f32)
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[BBARG0]], %[[BBARG1]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[BBARG2]], %[[MUL]] : f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[BBARG0]], %[[BBARG1]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[BBARG2]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// -----
// CHECK-SAME: outs(%{{.+}} : memref<?x?x?xf32>)
// CHECK: ^{{.+}}(%[[BBARG0:.+]]: f32, %[[BBARG1:.+]]: f32, %[[BBARG2:.+]]: f32)
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[BBARG0]], %[[BBARG1]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[BBARG2]], %[[MUL]] : f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[BBARG0]], %[[BBARG1]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[BBARG2]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// -----
// CHECK-SAME: ins(%{{.+}}, %{{.+}} : memref<?x?x?xi8>, memref<?x?xi8>)
// CHECK-SAME: outs(%{{.+}} : memref<?x?xf32>)
// CHECK: ^{{.+}}(%[[BBARG0:.+]]: i8, %[[BBARG1:.+]]: i8, %[[BBARG2:.+]]: f32)
-// CHECK: %[[BBARG0_F32:.+]] = sitofp %[[BBARG0]] : i8 to f32
-// CHECK: %[[BBARG1_F32:.+]] = sitofp %[[BBARG1]] : i8 to f32
-// CHECK: %[[MUL:.+]] = mulf %[[BBARG0_F32]], %[[BBARG1_F32]]
-// CHECK: %[[ADD:.+]] = addf %[[BBARG2]], %[[MUL]]
+// CHECK: %[[BBARG0_F32:.+]] = arith.sitofp %[[BBARG0]] : i8 to f32
+// CHECK: %[[BBARG1_F32:.+]] = arith.sitofp %[[BBARG1]] : i8 to f32
+// CHECK: %[[MUL:.+]] = arith.mulf %[[BBARG0_F32]], %[[BBARG1_F32]]
+// CHECK: %[[ADD:.+]] = arith.addf %[[BBARG2]], %[[MUL]]
// CHECK: linalg.yield %[[ADD]] : f32
// CHECK-LABEL: @generalize_matmul_tensor_f16f64f32
// CHECK: ^{{.*}}(%[[A_ARG:.+]]: f16, %[[B_ARG:.+]]: f64, %[[C_ARG:.+]]: f32)
// Verify floating point extension and truncation.
-// CHECK-NEXT: %[[A_CAST:.+]] = fpext %[[A_ARG]] : f16 to f32
-// CHECK-NEXT: %[[B_CAST:.+]] = fptrunc %[[B_ARG]] : f64 to f32
-// CHECK-NEXT: %[[MUL:.+]] = mulf %[[A_CAST]], %[[B_CAST]] : f32
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+// CHECK-NEXT: %[[A_CAST:.+]] = arith.extf %[[A_ARG]] : f16 to f32
+// CHECK-NEXT: %[[B_CAST:.+]] = arith.truncf %[[B_ARG]] : f64 to f32
+// CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[A_CAST]], %[[B_CAST]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// CHECK-NEXT: -> tensor<16x32xf32>
// CHECK-LABEL: @generalize_matmul_tensor_i16i64i32
// CHECK: ^{{.*}}(%[[A_ARG:.+]]: i16, %[[B_ARG:.+]]: i64, %[[C_ARG:.+]]: i32)
// Verify signed integer extension and truncation.
-// CHECK-NEXT: %[[A_CAST:.+]] = sexti %[[A_ARG]] : i16 to i32
-// CHECK-NEXT: %[[B_CAST:.+]] = trunci %[[B_ARG]] : i64 to i32
-// CHECK-NEXT: %[[MUL:.+]] = muli %[[A_CAST]], %[[B_CAST]] : i32
-// CHECK-NEXT: %[[ADD:.+]] = addi %[[C_ARG]], %[[MUL]] : i32
+// CHECK-NEXT: %[[A_CAST:.+]] = arith.extsi %[[A_ARG]] : i16 to i32
+// CHECK-NEXT: %[[B_CAST:.+]] = arith.trunci %[[B_ARG]] : i64 to i32
+// CHECK-NEXT: %[[MUL:.+]] = arith.muli %[[A_CAST]], %[[B_CAST]] : i32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addi %[[C_ARG]], %[[MUL]] : i32
// CHECK-NEXT: linalg.yield %[[ADD]] : i32
// CHECK-NEXT: -> tensor<16x32xi32>
// CHECK-LABEL: @generalize_matmul_tensor_i16i64f32
// Verify signed integer to floating point cast.
-// CHECK: = sitofp
-// CHECK: = sitofp
+// CHECK: = arith.sitofp
+// CHECK: = arith.sitofp
// -----
// CHECK-LABEL: @generalize_matmul_tensor_f16f64i32
// Verify floating point to signed integer cast.
-// CHECK: = fptosi
-// CHECK: = fptosi
+// CHECK: = arith.fptosi
+// CHECK: = arith.fptosi
// -----
// CHECK-LABEL: @generalize_matmul_unsigned_tensor_i16i64i32
// Verify unsigned integer extension and truncation.
-// CHECK: = zexti
-// CHECK: = trunci
+// CHECK: = arith.extui
+// CHECK: = arith.trunci
// -----
// CHECK-LABEL: @generalize_matmul_unsigned_tensor_i16i64f32
// Verify unsigned integer to floating point cast.
-// CHECK: = uitofp
-// CHECK: = uitofp
+// CHECK: = arith.uitofp
+// CHECK: = arith.uitofp
// -----
// CHECK-LABEL: @generalize_matmul_unsigned_tensor_f16f64i32
// Verify floating point to unsigend integer cast.
-// CHECK: = fptoui
-// CHECK: = fptoui
+// CHECK: = arith.fptoui
+// CHECK: = arith.fptoui
// -----
// CHECK-LABEL: @generalize_pooling_nhwc_sum_f32
// CHECK: ^{{.*}}(%[[IN_ARG:.+]]: f32, %[[SHAPE_ARG:.+]]: f32, %[[OUT_ARG:.+]]: f32)
-// CHECK-NEXT: %[[ADD:.+]] = addf %[[OUT_ARG]], %[[IN_ARG]] : f32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[OUT_ARG]], %[[IN_ARG]] : f32
// CHECK-NEXT: linalg.yield %[[ADD]] : f32
// CHECK-NEXT: -> tensor<1x2x4x1xf32>
// CHECK-LABEL: @generalize_pooling_nhwc_sum_i32
// CHECK: ^{{.*}}(%[[IN_ARG:.+]]: i32, %[[SHAPE_ARG:.+]]: i32, %[[OUT_ARG:.+]]: i32)
-// CHECK-NEXT: %[[ADD:.+]] = addi %[[OUT_ARG]], %[[IN_ARG]] : i32
+// CHECK-NEXT: %[[ADD:.+]] = arith.addi %[[OUT_ARG]], %[[IN_ARG]] : i32
// CHECK-NEXT: linalg.yield %[[ADD]] : i32
// CHECK-NEXT: -> tensor<1x2x4x1xi32>
// CHECK-DAG: ^{{.*}}(%[[MIN:.+]]: f64, %[[MAX:.+]]: f64, %[[SEED:.+]]: i32, %[[O:.+]]: f32
// CHECK-DAG: %[[IDX0:.+]] = linalg.index 0 : index
// CHECK-DAG: %[[IDX1:.+]] = linalg.index 1 : index
-// CHECK-DAG: %[[IDX0_CAST:.+]] = index_cast %[[IDX0]] : index to i32
-// CHECK-DAG: %[[IDX1_CAST:.+]] = index_cast %[[IDX1]] : index to i32
-// CHECK-DAG: %[[VAL0:.+]] = addi %[[IDX0_CAST]], %[[SEED]] : i32
-// CHECK-DAG: %[[CST0:.+]] = constant 1103515245 : i32
-// CHECK-DAG: %[[CST1:.+]] = constant 12345 : i32
-// CHECK-DAG: %[[VAL1:.+]] = muli %[[VAL0]], %[[CST0]] : i32
-// CHECK-DAG: %[[VAL2:.+]] = addi %[[VAL1]], %[[CST1]] : i32
+// CHECK-DAG: %[[IDX0_CAST:.+]] = arith.index_cast %[[IDX0]] : index to i32
+// CHECK-DAG: %[[IDX1_CAST:.+]] = arith.index_cast %[[IDX1]] : index to i32
+// CHECK-DAG: %[[VAL0:.+]] = arith.addi %[[IDX0_CAST]], %[[SEED]] : i32
+// CHECK-DAG: %[[CST0:.+]] = arith.constant 1103515245 : i32
+// CHECK-DAG: %[[CST1:.+]] = arith.constant 12345 : i32
+// CHECK-DAG: %[[VAL1:.+]] = arith.muli %[[VAL0]], %[[CST0]] : i32
+// CHECK-DAG: %[[VAL2:.+]] = arith.addi %[[VAL1]], %[[CST1]] : i32
// Skip random number computation for the second index.
-// CHECK-DAG: %[[DIFF:.+]] = subf %[[MAX]], %[[MIN]] : f64
-// CHECK-DAG: %[[CST2:.+]] = constant 2.3283063999999999E-10 : f64
-// CHECK-DAG: %[[FACT:.+]] = mulf %[[DIFF]], %[[CST2]] : f64
-// CHECK-DAG: %[[VAL4:.+]] = mulf %{{.+}}, %[[FACT]] : f64
-// CHECK-DAG: %[[VAL5:.+]] = addf %[[VAL4]], %[[MIN]] : f64
-// CHECK-DAG: %[[VAL6:.+]] = fptrunc %[[VAL5]] : f64 to f32
+// CHECK-DAG: %[[DIFF:.+]] = arith.subf %[[MAX]], %[[MIN]] : f64
+// CHECK-DAG: %[[CST2:.+]] = arith.constant 2.3283063999999999E-10 : f64
+// CHECK-DAG: %[[FACT:.+]] = arith.mulf %[[DIFF]], %[[CST2]] : f64
+// CHECK-DAG: %[[VAL4:.+]] = arith.mulf %{{.+}}, %[[FACT]] : f64
+// CHECK-DAG: %[[VAL5:.+]] = arith.addf %[[VAL4]], %[[MIN]] : f64
+// CHECK-DAG: %[[VAL6:.+]] = arith.truncf %[[VAL5]] : f64 to f32
// CHECK-NEXT: linalg.yield %[[VAL6]] : f32
// CHECK-NEXT: -> tensor<16x32xf32>
// CHECK-LABEL: @generalize_fill_rng_2d_i32
// CHECK: ^{{.*}}(%[[MIN:.+]]: f64, %[[MAX:.+]]: f64, %[[SEED:.+]]: i32, %[[O:.+]]: i32
// Verifies floating point to integer cast.
-// CHECK: %[[VAL6:.+]] = fptosi %{{.+}} : f64 to i32
+// CHECK: %[[VAL6:.+]] = arith.fptosi %{{.+}} : f64 to i32
// CHECK-NEXT: linalg.yield %[[VAL6]] : i32
// CHECK-NEXT: -> tensor<16x32xi32>
}
// CHECK-LABEL: @generalize_soft_plus_2d_f32
-// CHECK: %[[C1:.+]] = constant 1.000000e+00 : f32
+// CHECK: %[[C1:.+]] = arith.constant 1.000000e+00 : f32
// CHECK: ^{{.*}}(%[[IN:.+]]: f32, %[[OUT:.+]]: f32
// CHECK-NEXT: %[[EXP:.+]] = math.exp %[[IN]] : f32
-// CHECK-NEXT: %[[SUM:.+]] = addf %[[C1]], %[[EXP]] : f32
+// CHECK-NEXT: %[[SUM:.+]] = arith.addf %[[C1]], %[[EXP]] : f32
// CHECK-NEXT: %[[LOG:.+]] = math.log %[[SUM]] : f32
// CHECK-NEXT: linalg.yield %[[LOG]] : f32
// CHECK-NEXT: -> tensor<16x32xf32>
// CHECK-LABEL: func @generalize_pad_tensor_static_shape(
// CHECK-SAME: %[[IN:.*]]: tensor<1x28x28x1xf32>) -> tensor<1x32x32x1xf32> {
-// CHECK: %[[C0:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[C0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[INIT:.*]] = linalg.init_tensor [1, 32, 32, 1] : tensor<1x32x32x1xf32>
// CHECK: %[[FILL:.*]] = linalg.fill(%[[C0]], %[[INIT]]) : f32, tensor<1x32x32x1xf32> -> tensor<1x32x32x1xf32>
// CHECK: %[[PADDED:.*]] = tensor.insert_slice %[[IN]] into %[[FILL]][0, 2, 2, 0] [1, 28, 28, 1] [1, 1, 1, 1] : tensor<1x28x28x1xf32> into tensor<1x32x32x1xf32>
// CHECK: return %[[PADDED]] : tensor<1x32x32x1xf32>
func @generalize_pad_tensor_static_shape(%arg0: tensor<1x28x28x1xf32>) -> tensor<1x32x32x1xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.pad_tensor %arg0 low[0, 2, 2, 0] high[0, 2, 2, 0] {
^bb0(%arg1: index, %arg2: index, %arg3: index, %arg4: index): // no predecessors
linalg.yield %cst : f32
// CHECK-LABEL: func @generalize_pad_tensor_dynamic_shape(
// CHECK-SAME: %[[IN:.*]]: tensor<4x?x2x?xf32>,
// CHECK-SAME: %[[OFFSET:.*]]: index) -> tensor<4x?x?x?xf32> {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[CST:.*]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[CST:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// CHECK: %[[DIM1:.*]] = tensor.dim %[[IN]], %[[C1]] : tensor<4x?x2x?xf32>
-// CHECK: %[[OUT_DIM2:.*]] = addi %[[OFFSET]], %[[C2]] : index
+// CHECK: %[[OUT_DIM2:.*]] = arith.addi %[[OFFSET]], %[[C2]] : index
// CHECK: %[[DIM3:.*]] = tensor.dim %[[IN]], %[[C3]] : tensor<4x?x2x?xf32>
-// CHECK: %[[OUT_DIM3:.*]] = addi %[[DIM3]], %[[OFFSET]] : index
+// CHECK: %[[OUT_DIM3:.*]] = arith.addi %[[DIM3]], %[[OFFSET]] : index
// CHECK: %[[INIT:.*]] = linalg.init_tensor [4, %[[DIM1]], %[[OUT_DIM2]], %[[OUT_DIM3]]] : tensor<4x?x?x?xf32>
// CHECK: %[[FILL:.*]] = linalg.fill(%[[CST]], %[[INIT]]) : f32, tensor<4x?x?x?xf32> -> tensor<4x?x?x?xf32>
// CHECK: %[[DIM1_1:.*]] = tensor.dim %[[IN]], %[[C1]] : tensor<4x?x2x?xf32>
// CHECK: return %[[PADDED]] : tensor<4x?x?x?xf32>
// CHECK: }
func @generalize_pad_tensor_dynamic_shape(%arg0: tensor<4x?x2x?xf32>, %arg1: index) -> tensor<4x?x?x?xf32> {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
%out = linalg.pad_tensor %arg0 low[%c0, %c0, %arg1, %c0] high[%c0, %c0, %c0, %arg1] {
^bb0(%gen_arg1: index, %gen_arg2: index, %gen_arg3: index, %gen_arg4: index): // no predecessors
linalg.yield %cst : f32
%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>)
-> tensor<?x?xf32>
{
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %cst = constant 0.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.000000e+00 : f32
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// CHECK-DAG: %[[dM:.*]] = tensor.dim %[[TA]], %[[C0]] : tensor<?x?xf32>
// CHECK-DAG: %[[dK:.*]] = tensor.dim %[[TA]], %[[C1]] : tensor<?x?xf32>
%18 = tensor.dim %arg8, %c1 : tensor<?x?xf32>
%19 = affine.min #map4(%18, %arg5)
%20 = tensor.extract_slice %arg8[%arg3, %arg5] [%17, %19] [1, 1] : tensor<?x?xf32> to tensor<?x?xf32>
- %21 = subi %c2, %7 : index
- %22 = subi %c4, %9 : index
+ %21 = arith.subi %c2, %7 : index
+ %22 = arith.subi %c4, %9 : index
%23 = linalg.pad_tensor %10 low[%c0, %c0] high[%21, %22] {
^bb0(%arg9: index, %arg10: index): // no predecessors
linalg.yield %cst : f32
} : tensor<?x?xf32> to tensor<2x4xf32>
- %24 = subi %c4, %12 : index
- %25 = subi %c3, %14 : index
+ %24 = arith.subi %c4, %12 : index
+ %25 = arith.subi %c3, %14 : index
%26 = linalg.pad_tensor %15 low[%c0, %c0] high[%24, %25] {
^bb0(%arg9: index, %arg10: index): // no predecessors
linalg.yield %cst : f32
} : tensor<?x?xf32> to tensor<4x3xf32>
- %27 = subi %c2, %17 : index
- %28 = subi %c3, %19 : index
+ %27 = arith.subi %c2, %17 : index
+ %28 = arith.subi %c3, %19 : index
%29 = linalg.pad_tensor %20 low[%c0, %c0] high[%27, %28] {
^bb0(%arg9: index, %arg10: index): // no predecessors
linalg.yield %cst : f32
func @dot(%arg0: tensor<?xf32>, %arg1: tensor<?xf32>, %arg2: tensor<f32>)
-> tensor<f32>
{
- %c8 = constant 8 : index
- %c4 = constant 4 : index
- %cst = constant 0.000000e+00 : f32
- %c2 = constant 2 : index
- %c0 = constant 0 : index
+ %c8 = arith.constant 8 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
%1 = tensor.dim %arg0, %c0 : tensor<?xf32>
%2 = tensor.dim %arg0, %c0 : tensor<?xf32>
%3 = tensor.dim %arg1, %c0 : tensor<?xf32>
%16 = tensor.extract_slice %11[%arg7] [%15] [1] : tensor<?xf32> to tensor<?xf32>
%17 = affine.min #map2(%12, %arg7)
%18 = tensor.extract_slice %13[%arg7] [%17] [1] : tensor<?xf32> to tensor<?xf32>
- %19 = subi %c2, %15 : index
+ %19 = arith.subi %c2, %15 : index
%20 = linalg.pad_tensor %16 low[%c0] high[%19] {
^bb0(%arg9: index): // no predecessors
linalg.yield %cst : f32
} : tensor<?xf32> to tensor<2xf32>
- %21 = subi %c2, %17 : index
+ %21 = arith.subi %c2, %17 : index
%22 = linalg.pad_tensor %18 low[%c0] high[%21] {
^bb0(%arg9: index): // no predecessors
linalg.yield %cst : f32
// CHECK-LABEL: func @matmul_2d_tiling
// VERIFIER-ONLY-LABEL: func @matmul_2d_tiling
func @matmul_2d_tiling(%arg0: tensor<32x128xf32>, %arg1: tensor<128x64xf32>, %arg2: tensor<32x64xf32>) -> tensor<32x64xf32> {
- %c128 = constant 128 : index
- %c64 = constant 64 : index
- %c32 = constant 32 : index
- %c16 = constant 16 : index
- %cst = constant 0.000000e+00 : f32
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c0 = constant 0 : index
+ %c128 = arith.constant 128 : index
+ %c64 = arith.constant 64 : index
+ %c32 = arith.constant 32 : index
+ %c16 = arith.constant 16 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c0 = arith.constant 0 : index
%1 = scf.for %arg3 = %c0 to %c32 step %c16 iter_args(%arg4 = %arg2) -> (tensor<32x64xf32>) {
%2 = scf.for %arg5 = %c0 to %c64 step %c32 iter_args(%arg6 = %arg4) -> (tensor<32x64xf32>) {
%3 = scf.for %arg7 = %c0 to %c128 step %c32 iter_args(%arg8 = %arg6) -> (tensor<32x64xf32>) {
%memref0: memref<?x?xf32>, %memref1: memref<?x?xf32>, %memref2: memref<?x?xf32>,
%memref3: memref<?x?xf32>, %memref4: memref<?x?xf32>, %memref5: memref<?x?xf32>,
%val: index, %lb : index, %ub : index, %step: index, %cmp: i1) {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
// CHECK: vector.transfer_read %{{.*}} : memref<?x?xf32>, vector<1xf32>
// CHECK: scf.for %[[I:.*]] = %[[LB]] to %[[UB]] step %[[STEP]] iter_args({{.*}}) -> (vector<1xf32>) {
%memref0: memref<?x?xf32>, %memref1: memref<?x?xf32>,
%memref2: memref<?x?xf32>, %memref3: memref<?x?xf32>, %val: index, %lb : index, %ub : index,
%step: index, %random_index : index, %cmp: i1) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 0.0 : f32
// CHECK: vector.transfer_read %[[MEMREF2]]{{.*}} : memref<?x?xf32>, vector<3xf32>
// CHECK: vector.transfer_read %[[MEMREF2]]{{.*}} : memref<?x?xf32>, vector<3xf32>
%val: index, %lb : index, %ub : index, %step: index) ->
(tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>,
tensor<?x?xf32>, tensor<?x?xf32>) {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
// CHECK: vector.transfer_read %{{.*}} : tensor<?x?xf32>, vector<1xf32>
// CHECK: scf.for {{.*}} iter_args({{.*}}) ->
%val: index, %lb : index, %ub : index, %step: index,
%random_index : index) ->
(tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 0.0 : f32
// CHECK: vector.transfer_read %[[TENSOR2]]{{.*}} : tensor<?x?xf32>, vector<3xf32>
// CHECK: vector.transfer_read %[[TENSOR2]]{{.*}} : tensor<?x?xf32>, vector<3xf32>
(
tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>//, tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32>
) {
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
// CHECK: scf.for %[[I:.*]] = {{.*}} iter_args(
// CHECK-SAME: %[[TENSOR0_ARG:[0-9a-zA-Z]+]] = %[[TENSOR0]],
// CHECK: ^bb0(%{{.*}}: f32, %{{.*}}: f32)
^bb0(%arg1: f32, %arg2: f32, %arg3: f32): // no predecessors
// CHECK: tensor.extract %[[SCALAR]][]
- %2 = divf %arg1, %arg2 : f32
+ %2 = arith.divf %arg1, %arg2 : f32
linalg.yield %2 : f32
} -> tensor<4xf32>
return %1 : tensor<4xf32>
// CHECK: func @inline_oned(%[[ARG:.*]]: tensor<4xf32>, %[[SCALAR:.*]]: tensor<1xf32>)
func @inline_oned(%arg0: tensor<4xf32>, %scalar: tensor<1xf32>) -> tensor<4xf32> {
- // CHECK: %[[ZERO:.*]] = constant 0 : index
+ // CHECK: %[[ZERO:.*]] = arith.constant 0 : index
%0 = linalg.init_tensor [4] : tensor<4xf32>
// CHECK: linalg.generic {indexing_maps = [#[[MAP]], #[[MAP]]],
// CHECK-SAME: iterator_types = ["parallel"]} ins(%[[ARG]] : tensor<4xf32>)
// CHECK: ^bb0(%{{.*}}: f32, %{{.*}}: f32)
^bb0(%arg1: f32, %arg2: f32, %arg3: f32): // no predecessors
// CHECK: tensor.extract %[[SCALAR]][%[[ZERO]]]
- %2 = divf %arg1, %arg2 : f32
+ %2 = arith.divf %arg1, %arg2 : f32
linalg.yield %2 : f32
} -> tensor<4xf32>
return %1 : tensor<4xf32>
%0 = linalg.index 0 : index
%1 = linalg.index 1 : index
%2 = linalg.index 4 : index
- %3 = subi %0, %1 : index
- %4 = addi %3, %2 : index
- %5 = addi %4, %arg2 : index
+ %3 = arith.subi %0, %1 : index
+ %4 = arith.addi %3, %2 : index
+ %5 = arith.addi %4, %arg2 : index
linalg.yield %5 : index
}
return
// CHECK-DAG: %[[IDX0:.+]] = linalg.index 1 : index
// CHECK-DAG: %[[IDX1:.+]] = linalg.index 3 : index
// CHECK-DAG: %[[IDX4:.+]] = linalg.index 0 : index
-// CHECK: %[[T0:.+]] = subi %[[IDX0]], %[[IDX1]] : index
-// CHECK: %[[T1:.+]] = addi %[[T0]], %[[IDX4]] : index
-// CHECK: %[[T2:.+]] = addi %[[T1]], %{{.*}} : index
+// CHECK: %[[T0:.+]] = arith.subi %[[IDX0]], %[[IDX1]] : index
+// CHECK: %[[T1:.+]] = arith.addi %[[T0]], %[[IDX4]] : index
+// CHECK: %[[T2:.+]] = arith.addi %[[T1]], %{{.*}} : index
// CANCEL-OUT-DAG: #[[MAP0:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d1, d2, d3, d4)>
// CANCEL-OUT-DAG: #[[MAP1:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d1, d3)>
// CANCEL-OUT-DAG: %[[IDX0:.+]] = linalg.index 0 : index
// CANCEL-OUT-DAG: %[[IDX1:.+]] = linalg.index 1 : index
// CANCEL-OUT-DAG: %[[IDX4:.+]] = linalg.index 4 : index
-// CANCEL-OUT: %[[T0:.+]] = subi %[[IDX0]], %[[IDX1]] : index
-// CANCEL-OUT: %[[T1:.+]] = addi %[[T0]], %[[IDX4]] : index
-// CANCEL-OUT: %[[T2:.+]] = addi %[[T1]], %{{.*}} : index
+// CANCEL-OUT: %[[T0:.+]] = arith.subi %[[IDX0]], %[[IDX1]] : index
+// CANCEL-OUT: %[[T1:.+]] = arith.addi %[[T0]], %[[IDX4]] : index
+// CANCEL-OUT: %[[T2:.+]] = arith.addi %[[T1]], %{{.*}} : index
func @load_number_of_indices(%v : memref<f32>) {
// expected-error @+2 {{incorrect number of indices for load}}
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
memref.load %v[%c0] : memref<f32>
}
func @store_number_of_indices(%v : memref<f32>) {
// expected-error @+3 {{store index operand count not equal to memref rank}}
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
memref.store %f0, %v[%c0] : memref<f32>
}
// -----
func @generic_scalar_view(%arg0: memref<?xf32, affine_map<(i)[off]->(off + i)>>) {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
// expected-error @+1 {{expected operand rank (0) to match the result rank of indexing_map #0 (1)}}
linalg.generic {
indexing_maps = [ affine_map<() -> (0)>, affine_map<() -> (0, 0)> ],
iterator_types = ["parallel"]}
outs(%arg0 : memref<?xf32, affine_map<(i)[off]->(off + i)>>) {
^bb(%0: f32):
- %1 = constant 1: i4
+ %1 = arith.constant 1: i4
linalg.yield %1: i4
}
}
// -----
func @generic_empty_region(%arg0: memref<f32>) {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
// expected-error @+1 {{op expected 1 region with 1 block}}
linalg.generic {
indexing_maps = [ affine_map<() -> ()>, affine_map<() -> ()> ],
// -----
func @generic_empty_region(%arg0: memref<f32>) {
- %f0 = constant 0.0: f32
+ %f0 = arith.constant 0.0: f32
// expected-error @+1 {{linalg.generic' op expected 1 region with 1 block}}
linalg.generic {
indexing_maps = [ affine_map<() -> ()> , affine_map<() -> ()> ],
iterator_types = ["parallel"]}
outs(%arg0 : memref<?xf32, affine_map<(i)[off]->(off + i)>>) {
^bb(%i: f32):
- %0 = constant 0: i1
+ %0 = arith.constant 0: i1
linalg.yield %0: i1
}
}
// -----
func @generic(%arg0: memref<?x?xi4>) {
- // expected-error @+2 {{op expects regions to end with 'linalg.yield', found 'std.addf'}}
+ // expected-error @+2 {{op expects regions to end with 'linalg.yield', found 'arith.addf'}}
// expected-note @+1 {{in custom textual format, the absence of terminator implies 'linalg.yield'}}
linalg.generic {
indexing_maps = [ affine_map<(i, j) -> (i, j)> ],
iterator_types = ["parallel", "parallel"]}
outs(%arg0 : memref<?x?xi4>) {
^bb(%0: i4) :
- %1 = std.addf %0, %0: i4
+ %1 = arith.addf %0, %0: i4
}
return
}
func @tiled_loop_incorrent_num_yield_operands(%A: memref<192x192xf32>,
%B: memref<192x192xf32>, %C: memref<192x192xf32>,
%C_tensor: tensor<192x192xf32>) {
- %c24 = constant 24 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
+ %c24 = arith.constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
%0 = linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c192, %c192)
step (%c24, %c24)
ins (%A_ = %A: memref<192x192xf32>, %B_ = %B: memref<192x192xf32>)
func @tiled_loop_incorrent_yield_operand_type(%A: memref<192x192xf32>,
%B: memref<192x192xf32>, %C: memref<192x192xf32>,
%C_tensor: tensor<192x192xf32>) {
- %c24 = constant 24 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
+ %c24 = arith.constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
%0 = linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c192, %c192)
step (%c24, %c24)
ins (%A_ = %A: memref<192x192xf32>, %B_ = %B: memref<192x192xf32>)
func @tiled_loop_incorrent_iterator_types_count(%A: memref<192x192xf32>,
%B: memref<192x192xf32>, %C: memref<192x192xf32>,
%C_tensor: tensor<192x192xf32>) {
- %c24 = constant 24 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
+ %c24 = arith.constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
// expected-error @+1 {{expected iterator types array attribute size = 1 to match the number of loops = 2}}
%0 = "linalg.tiled_loop"(%c0, %c0, %c192, %c192, %c24, %c24, %A, %B, %C_tensor, %C) ( {
^bb0(%arg4: index, %arg5: index, %A_: memref<192x192xf32>,
func private @foo(%A: memref<100xf32>) -> ()
func @tiled_loop_incorrent_block_arg_type(%A: memref<192xf32>) {
- %c0 = constant 0 : index
- %c192 = constant 192 : index
- %c24 = constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
+ %c24 = arith.constant 24 : index
// expected-error @+1 {{expected output arg 0 with type = 'memref<192xf32>' to match region arg 1 type = 'memref<100xf32>'}}
"linalg.tiled_loop"(%c0, %c192, %c24, %A) ( {
^bb0(%arg4: index, %A_: memref<100xf32>):
// CHECK: func private @linalg_matmul_viewsxsxf32_viewsxsxf32_viewsxsxf32(memref<?x?xf32, {{.*}}>, memref<?x?xf32, {{.*}}>, memref<?x?xf32, {{.*}}>) attributes {llvm.emit_c_interface}
func @matmul(%A: memref<?x?xf32>, %B: memref<?x?xf32>) -> (memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %f0 = arith.constant 0.0 : f32
%x = memref.dim %A, %c0 : memref<?x?xf32>
%y = memref.dim %B, %c1 : memref<?x?xf32>
%C = memref.alloc(%x, %y) : memref<?x?xf32>
// RUN: mlir-opt %s -convert-linalg-to-llvm | FileCheck %s
func @range(%arg0: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%R = linalg.range %c0:%arg0:%c1 : !linalg.range
return
}
// CHECK-LABEL: func @range
-// CHECK: constant 0 : index
-// CHECK: constant 1 : index
+// CHECK: arith.constant 0 : index
+// CHECK: arith.constant 1 : index
// CHECK: llvm.mlir.undef : !llvm.struct<(i64, i64, i64)>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[0] : !llvm.struct<(i64, i64, i64)>
// CHECK: llvm.insertvalue %{{.*}}, %{{.*}}[1] : !llvm.struct<(i64, i64, i64)>
// CHECKPARALLEL-DAG: #[[$stride1Dilation1:.*]] = affine_map<(d0, d1) -> (d0 + d1)>
func @matmul(%arg0: memref<?xi8>, %M: index, %N: index, %K: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%A = memref.view %arg0[%c0][%M, %K] : memref<?xi8> to memref<?x?xf32>
%B = memref.view %arg0[%c0][%K, %N] : memref<?xi8> to memref<?x?xf32>
%C = memref.view %arg0[%c0][%M, %N] : memref<?xi8> to memref<?x?xf32>
// CHECK: scf.for {{.*}} to %[[K]]
// CHECK-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECK-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
-// CHECK-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECK-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECK-DAG: %[[c:.*]] = memref.load %[[C]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
-// CHECK-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECK-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECK: store %[[res]], %[[C]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECKPARALLEL-LABEL: func @matmul(%{{.*}}: memref<?xi8>,
// CHECKPARALLEL: scf.for {{.*}} to %[[K]]
// CHECKPARALLEL-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECKPARALLEL-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
-// CHECKPARALLEL-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECKPARALLEL-DAG: %[[c:.*]] = memref.load %[[C]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
-// CHECKPARALLEL-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECKPARALLEL-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[C]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
func @matvec(%arg0: memref<?xi8>, %M: index, %N: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%2 = memref.view %arg0[%c0][%M, %N] : memref<?xi8> to memref<?x?xf32>
%3 = memref.view %arg0[%c0][%M] : memref<?xi8> to memref<?xf32>
%4 = memref.view %arg0[%c0][%N] : memref<?xi8> to memref<?xf32>
// CHECK: scf.for {{.*}} to %[[K]]
// CHECK-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECK-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}] : memref<?xf32>
-// CHECK-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECK-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECK-DAG: %[[c:.*]] = memref.load %[[C]][%{{.*}}] : memref<?xf32>
-// CHECK-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECK-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECK: store %[[res]], %[[C]][%{{.*}}] : memref<?xf32>
// CHECKPARALLEL-LABEL: func @matvec(%{{.*}}: memref<?xi8>,
// CHECKPARALLEL: scf.for {{.*}} to %[[K]]
// CHECKPARALLEL-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}, %{{.*}}] : memref<?x?xf32>
// CHECKPARALLEL-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}] : memref<?xf32>
-// CHECKPARALLEL-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECKPARALLEL-DAG: %[[c:.*]] = memref.load %[[C]][%{{.*}}] : memref<?xf32>
-// CHECKPARALLEL-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECKPARALLEL-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[C]][%{{.*}}] : memref<?xf32>
func @dot(%arg0: memref<?xi8>, %M: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%1 = memref.view %arg0[%c0][%M] : memref<?xi8> to memref<?xf32>
%2 = memref.view %arg0[%c0][%M] : memref<?xi8> to memref<?xf32>
%3 = memref.view %arg0[%c0][] : memref<?xi8> to memref<f32>
// CHECK: scf.for {{.*}} to %[[K]]
// CHECK-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}] : memref<?xf32>
// CHECK-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}] : memref<?xf32>
-// CHECK-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECK-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECK-DAG: %[[c:.*]] = memref.load %[[C]][] : memref<f32>
-// CHECK-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECK-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECK: store %[[res]], %[[C]][] : memref<f32>
// CHECKPARALLEL-LABEL: func @dot(%{{.*}}: memref<?xi8>,
// CHECKPARALLEL: scf.for {{.*}} to %[[K]]
// CHECKPARALLEL-DAG: %[[a:.*]] = memref.load %[[A]][%{{.*}}] : memref<?xf32>
// CHECKPARALLEL-DAG: %[[b:.*]] = memref.load %[[B]][%{{.*}}] : memref<?xf32>
-// CHECKPARALLEL-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECKPARALLEL-DAG: %[[c:.*]] = memref.load %[[C]][] : memref<f32>
-// CHECKPARALLEL-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECKPARALLEL-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[C]][] : memref<f32>
// CHECK: scf.for {{.*}} to %[[K]]
// CHECK-DAG: %[[a:.*]] = memref.load %arg0[%{{.*}}] : memref<?xf32, #[[$strided1D]]>
// CHECK-DAG: %[[b:.*]] = memref.load %{{.*}}[%{{.*}}] : memref<?xf32, #[[$strided1D]]>
-// CHECK-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECK-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECK-DAG: %[[c:.*]] = memref.load %{{.*}}[] : memref<f32>
-// CHECK-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECK-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECK: store %[[res]], %{{.*}}[] : memref<f32>
// CHECKPARALLEL-LABEL: func @dot_view(
// CHECKPARALLEL: scf.for {{.*}} to %[[K]]
// CHECKPARALLEL-DAG: %[[a:.*]] = memref.load %arg0[%{{.*}}] : memref<?xf32, #[[$strided1D]]>
// CHECKPARALLEL-DAG: %[[b:.*]] = memref.load %{{.*}}[%{{.*}}] : memref<?xf32, #[[$strided1D]]>
-// CHECKPARALLEL-DAG: %[[inc:.*]] = mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL-DAG: %[[inc:.*]] = arith.mulf %[[a]], %[[b]] : f32
// CHECKPARALLEL-DAG: %[[c:.*]] = memref.load %{{.*}}[] : memref<f32>
-// CHECKPARALLEL-DAG: %[[res:.*]] = addf %[[c]], %[[inc]] : f32
+// CHECKPARALLEL-DAG: %[[res:.*]] = arith.addf %[[c]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %{{.*}}[] : memref<f32>
func @fill_view(%arg0: memref<?xf32, offset: ?, strides: [1]>, %arg1: f32) {
outs(%arg1, %arg2 : memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>,
memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>) {
^bb0(%a: f32, %b: f32, %c: f32):
- %d = mulf %a, %b : f32
- %e = addf %c, %d : f32
+ %d = arith.mulf %a, %b : f32
+ %e = arith.addf %c, %d : f32
linalg.yield %d, %e : f32, f32
}
return
// CHECK: %[[a:.*]] = memref.load %{{.*}}[%[[i]], %[[j]]] : memref<?x?xf32, #[[$strided2D]]>
// CHECK: %[[b:.*]] = memref.load %{{.*}}[%[[i]], %[[j]], %[[k]]] : memref<?x?x?xf32, #[[$strided3D]]>
// CHECK: %[[c:.*]] = memref.load %{{.*}}[%[[i]], %[[k]], %[[j]]] : memref<?x?x?xf32, #[[$strided3D]]>
-// CHECK: %[[d:.*]] = mulf %[[a]], %[[b]] : f32
-// CHECK: %[[e:.*]] = addf %[[c]], %[[d]] : f32
+// CHECK: %[[d:.*]] = arith.mulf %[[a]], %[[b]] : f32
+// CHECK: %[[e:.*]] = arith.addf %[[c]], %[[d]] : f32
// CHECK: store %[[d]], %{{.*}}[%[[i]], %[[j]], %[[k]]] : memref<?x?x?xf32, #[[$strided3D]]>
// CHECK: store %[[e]], %{{.*}}[%[[i]], %[[k]], %[[j]]] : memref<?x?x?xf32, #[[$strided3D]]>
// CHECKPARALLEL: %[[a:.*]] = memref.load %{{.*}}[%[[i]], %[[j]]] : memref<?x?xf32, #[[$strided2D]]>
// CHECKPARALLEL: %[[b:.*]] = memref.load %{{.*}}[%[[i]], %[[j]], %[[k]]] : memref<?x?x?xf32, #[[$strided3D]]>
// CHECKPARALLEL: %[[c:.*]] = memref.load %{{.*}}[%[[i]], %[[k]], %[[j]]] : memref<?x?x?xf32, #[[$strided3D]]>
-// CHECKPARALLEL: %[[d:.*]] = mulf %[[a]], %[[b]] : f32
-// CHECKPARALLEL: %[[e:.*]] = addf %[[c]], %[[d]] : f32
+// CHECKPARALLEL: %[[d:.*]] = arith.mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL: %[[e:.*]] = arith.addf %[[c]], %[[d]] : f32
// CHECKPARALLEL: store %[[d]], %{{.*}}[%[[i]], %[[j]], %[[k]]] : memref<?x?x?xf32, #[[$strided3D]]>
// CHECKPARALLEL: store %[[e]], %{{.*}}[%[[i]], %[[k]], %[[j]]] : memref<?x?x?xf32, #[[$strided3D]]>
%i = linalg.index 0 : index
%j = linalg.index 1 : index
%k = linalg.index 2 : index
- %result_1 = mulf %a, %b : f32
+ %result_1 = arith.mulf %a, %b : f32
- %ij = addi %i, %j : index
- %ijk = addi %ij, %k : index
- %ijk_int = index_cast %ijk : index to i32
- %ijk_float = sitofp %ijk_int : i32 to f32
+ %ij = arith.addi %i, %j : index
+ %ijk = arith.addi %ij, %k : index
+ %ijk_int = arith.index_cast %ijk : index to i32
+ %ijk_float = arith.sitofp %ijk_int : i32 to f32
- %result_2 = addf %c, %ijk_float : f32
+ %result_2 = arith.addf %c, %ijk_float : f32
linalg.yield %result_1, %result_2 : f32, f32
}
return
// CHECK: %[[a:.*]] = memref.load %{{.*}}[%[[i]], %[[j]]]
// CHECK: %[[b:.*]] = memref.load %{{.*}}[%[[i]], %[[j]], %[[k]]]
// CHECK: %[[c:.*]] = memref.load %{{.*}}[%[[i]], %[[k]], %[[j]]]
-// CHECK: %[[result_1:.*]] = mulf %[[a]], %[[b]] : f32
-// CHECK: %[[ij:.*]] = addi %[[i]], %[[j]] : index
-// CHECK: %[[ijk:.*]] = addi %[[ij]], %[[k]] : index
-// CHECK: %[[ijk_int:.*]] = index_cast %[[ijk]] : index to i32
-// CHECK: %[[ijk_float:.*]] = sitofp %[[ijk_int]] : i32 to f32
-// CHECK: %[[result_2:.*]] = addf %[[c]], %[[ijk_float]] : f32
+// CHECK: %[[result_1:.*]] = arith.mulf %[[a]], %[[b]] : f32
+// CHECK: %[[ij:.*]] = arith.addi %[[i]], %[[j]] : index
+// CHECK: %[[ijk:.*]] = arith.addi %[[ij]], %[[k]] : index
+// CHECK: %[[ijk_int:.*]] = arith.index_cast %[[ijk]] : index to i32
+// CHECK: %[[ijk_float:.*]] = arith.sitofp %[[ijk_int]] : i32 to f32
+// CHECK: %[[result_2:.*]] = arith.addf %[[c]], %[[ijk_float]] : f32
// CHECK: store %[[result_1]], %{{.*}}[%[[i]], %[[j]], %[[k]]]
// CHECK: store %[[result_2]], %{{.*}}[%[[i]], %[[k]], %[[j]]]
// CHECKPARALLEL: %[[a:.*]] = memref.load %{{.*}}[%[[i]], %[[j]]]
// CHECKPARALLEL: %[[b:.*]] = memref.load %{{.*}}[%[[i]], %[[j]], %[[k]]]
// CHECKPARALLEL: %[[c:.*]] = memref.load %{{.*}}[%[[i]], %[[k]], %[[j]]]
-// CHECKPARALLEL: %[[result_1:.*]] = mulf %[[a]], %[[b]] : f32
-// CHECKPARALLEL: %[[ij:.*]] = addi %[[i]], %[[j]] : index
-// CHECKPARALLEL: %[[ijk:.*]] = addi %[[ij]], %[[k]] : index
-// CHECKPARALLEL: %[[ijk_int:.*]] = index_cast %[[ijk]] : index to i32
-// CHECKPARALLEL: %[[ijk_float:.*]] = sitofp %[[ijk_int]] : i32 to f32
-// CHECKPARALLEL: %[[result_2:.*]] = addf %[[c]], %[[ijk_float]] : f32
+// CHECKPARALLEL: %[[result_1:.*]] = arith.mulf %[[a]], %[[b]] : f32
+// CHECKPARALLEL: %[[ij:.*]] = arith.addi %[[i]], %[[j]] : index
+// CHECKPARALLEL: %[[ijk:.*]] = arith.addi %[[ij]], %[[k]] : index
+// CHECKPARALLEL: %[[ijk_int:.*]] = arith.index_cast %[[ijk]] : index to i32
+// CHECKPARALLEL: %[[ijk_float:.*]] = arith.sitofp %[[ijk_int]] : i32 to f32
+// CHECKPARALLEL: %[[result_2:.*]] = arith.addf %[[c]], %[[ijk_float]] : f32
// CHECKPARALLEL: store %[[result_1]], %{{.*}}[%[[i]], %[[j]], %[[k]]]
// CHECKPARALLEL: store %[[result_2]], %{{.*}}[%[[i]], %[[k]], %[[j]]]
^bb(%a: i32, %b: i32) :
%i = linalg.index 0 : index
%j = linalg.index 1 : index
- %ij = addi %i, %j : index
- %ij_int = index_cast %ij : index to i32
- %result = addi %a, %ij_int : i32
+ %ij = arith.addi %i, %j : index
+ %ij_int = arith.index_cast %ij : index to i32
+ %result = arith.addi %a, %ij_int : i32
linalg.yield %result : i32
}
return
// CHECK: scf.for %[[i:.*]] = {{.*}}
// CHECK: scf.for %[[j:.*]] = {{.*}}
// CHECK: %[[a:.*]] = memref.load %[[ARG0]][
-// CHECK: %[[ij:.*]] = addi %[[i]], %[[j]] : index
-// CHECK: %[[ij_int:.*]] = index_cast %[[ij]] : index to i32
-// CHECK: %[[result:.*]] = addi %[[a]], %[[ij_int]] : i32
+// CHECK: %[[ij:.*]] = arith.addi %[[i]], %[[j]] : index
+// CHECK: %[[ij_int:.*]] = arith.index_cast %[[ij]] : index to i32
+// CHECK: %[[result:.*]] = arith.addi %[[a]], %[[ij_int]] : i32
// CHECK: store %[[result]], %[[ARG1]][%[[i]], %[[j]]]
// CHECKPARALLEL-LABEL: @generic_index_op_zero_rank
// CHECKPARALLEL-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: memref<3x4xi32>
// CHECKPARALLEL: scf.parallel (%[[i:[a-zA-Z0-9_]*]], %[[j:[a-zA-Z0-9_]*]])
// CHECKPARALLEL: %[[a:.*]] = memref.load %[[ARG0]][
-// CHECKPARALLEL: %[[ij:.*]] = addi %[[i]], %[[j]] : index
-// CHECKPARALLEL: %[[ij_int:.*]] = index_cast %[[ij]] : index to i32
-// CHECKPARALLEL: %[[result:.*]] = addi %[[a]], %[[ij_int]] : i32
+// CHECKPARALLEL: %[[ij:.*]] = arith.addi %[[i]], %[[j]] : index
+// CHECKPARALLEL: %[[ij_int:.*]] = arith.index_cast %[[ij]] : index to i32
+// CHECKPARALLEL: %[[result:.*]] = arith.addi %[[a]], %[[ij_int]] : i32
// CHECKPARALLEL: store %[[result]], %[[ARG1]][%[[i]], %[[j]]]
#reduce_1D_access = [
ins(%arg0 : memref<?xf32>)
outs(%arg1 : memref<f32>) {
^bb(%a: f32, %b: f32) :
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
}
return
// CHECK: scf.for %[[i:.*]] = {{.*}}
// CHECK: %[[a:.*]] = memref.load %[[ARG0]][%[[i]]]
// CHECK: %[[b:.*]] = memref.load %[[ARG1]][]
-// CHECK: %[[c:.*]] = addf %[[a]], %[[b]] : f32
+// CHECK: %[[c:.*]] = arith.addf %[[a]], %[[b]] : f32
// CHECK: store %[[c]], %[[ARG1]][]
// CHECKPARALLEL-LABEL: @generic_op_1D_reduce
// CHECKPARALLEL: scf.for %[[i:.*]] = {{.*}}
// CHECKPARALLEL: %[[a:.*]] = memref.load %[[ARG0]][%[[i]]]
// CHECKPARALLEL: %[[b:.*]] = memref.load %[[ARG1]][]
-// CHECKPARALLEL: %[[c:.*]] = addf %[[a]], %[[b]] : f32
+// CHECKPARALLEL: %[[c:.*]] = arith.addf %[[a]], %[[b]] : f32
// CHECKPARALLEL: store %[[c]], %[[ARG1]][]
outs(%arg2 : memref<f32>) {
^bb(%a: f32, %b: f32, %c: f32) :
%i = linalg.index 0 : index
- %0 = constant 0 : index
- %1 = cmpi eq, %0, %i : index
+ %0 = arith.constant 0 : index
+ %1 = arith.cmpi eq, %0, %i : index
%2 = select %1, %b, %c : f32
- %3 = addf %a, %2 : f32
+ %3 = arith.addf %a, %2 : f32
linalg.yield %3 : f32
}
return
// CHECK: %[[b:.*]] = memref.load %[[ARG1]][]
// CHECK: %[[c:.*]] = memref.load %[[ARG2]][]
// CHECK: %[[d:.*]] = select %{{.*}}, %[[b]], %[[c]]
-// CHECK: %[[e:.*]] = addf %[[a]], %[[d]]
+// CHECK: %[[e:.*]] = arith.addf %[[a]], %[[d]]
// CHECK: store %[[e]], %[[ARG2]][]
// CHECKPARALLEL-LABEL: @generic_index_op_1D_reduce
// CHECKPARALLEL: %[[b:.*]] = memref.load %[[ARG1]][]
// CHECKPARALLEL: %[[c:.*]] = memref.load %[[ARG2]][]
// CHECKPARALLEL: %[[d:.*]] = select %{{.*}}, %[[b]], %[[c]]
-// CHECKPARALLEL: %[[e:.*]] = addf %[[a]], %[[d]]
+// CHECKPARALLEL: %[[e:.*]] = arith.addf %[[a]], %[[d]]
// CHECKPARALLEL: store %[[e]], %[[ARG2]][]
#trait_const_fill = {
library_call = "some_external_fn"
}
func @generic_const_init(%arg0: memref<?xf32>) {
- %cst = constant 1.0 : f32
+ %cst = arith.constant 1.0 : f32
linalg.generic #trait_const_fill outs(%arg0 : memref<?xf32>) {
^bb0(%arg1: f32): // no predecessors
linalg.yield %cst : f32
}
// CHECK-LABEL: @generic_const_init
// CHECK-SAME: %[[ARG0:.*]]: memref<?xf32>
-// CHECK: %[[CONST:.*]] = constant 1.000000e+00 : f32
+// CHECK: %[[CONST:.*]] = arith.constant 1.000000e+00 : f32
// CHECK: scf.for %[[i:.*]] = {{.*}}
// CHECK: store %[[CONST]], %[[ARG0]]
// CHECKPARALLEL-LABEL: @generic_const_init
// CHECKPARALLEL-SAME: %[[ARG0:.*]]: memref<?xf32>
-// CHECKPARALLEL: %[[CONST:.*]] = constant 1.000000e+00 : f32
+// CHECKPARALLEL: %[[CONST:.*]] = arith.constant 1.000000e+00 : f32
// CHECKPARALLEL: scf.parallel (%[[i:.*]])
// CHECKPARALLEL: store %[[CONST]], %[[ARG0]]
// CHECK: %[[va:.*]] = memref.load %[[mA]][%[[b]], %[[m]], %[[k]]] : memref<?x?x?xf32>
// CHECK: %[[vb:.*]] = memref.load %[[mB]][%[[b]], %[[k]], %[[n]]] : memref<?x?x?xf32>
// CHECK: %[[vc:.*]] = memref.load %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
-// CHECK: %[[inc:.*]] = mulf %[[va]], %[[vb]] : f32
-// CHECK: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECK: %[[inc:.*]] = arith.mulf %[[va]], %[[vb]] : f32
+// CHECK: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECK: store %[[res]], %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
// CHECKPARALLEL-LABEL: @named_batch_matmul
// CHECKPARALLEL: %[[va:.*]] = memref.load %[[mA]][%[[b]], %[[m]], %[[k]]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[vb:.*]] = memref.load %[[mB]][%[[b]], %[[k]], %[[n]]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[vc:.*]] = memref.load %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
-// CHECKPARALLEL: %[[inc:.*]] = mulf %[[va]], %[[vb]] : f32
-// CHECKPARALLEL: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECKPARALLEL: %[[inc:.*]] = arith.mulf %[[va]], %[[vb]] : f32
+// CHECKPARALLEL: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[mC]][%[[b]], %[[m]], %[[n]]] : memref<?x?x?xf32>
// CHECK-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?xf32>
// CHECK-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?xf32>
// CHECK-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
-// CHECK: %[[c1:.*]] = constant 1 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
+// CHECK: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?xf32>
// CHECK: %[[dim1:.*]] = memref.dim %[[arg2]], %[[c0]] : memref<?xf32>
// CHECK: scf.for %[[b:.*]] = %[[c0]] to %[[dim1]] step %[[c1]] {
// CHECK: %[[vb:.*]] = memref.load %[[arg0]][%[[aff]]] : memref<?xf32>
// CHECK: %[[va:.*]] = memref.load %[[arg1]][%[[m]]] : memref<?xf32>
// CHECK: %[[vc:.*]] = memref.load %[[arg2]][%[[b]]] : memref<?xf32>
-// CHECK: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECK: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECK: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECK: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECK: store %[[res]], %[[arg2]][%[[b]]] : memref<?xf32>
// CHECKPARALLEL-LABEL: @conv1d_no_symbols
// CHECKPARALLEL-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?xf32>
// CHECKPARALLEL-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?xf32>
// CHECKPARALLEL-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?xf32>
-// CHECKPARALLEL: %[[c0:.*]] = constant 0 : index
-// CHECKPARALLEL: %[[c1:.*]] = constant 1 : index
+// CHECKPARALLEL: %[[c0:.*]] = arith.constant 0 : index
+// CHECKPARALLEL: %[[c1:.*]] = arith.constant 1 : index
// CHECKPARALLEL: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?xf32>
// CHECKPARALLEL: %[[dim1:.*]] = memref.dim %[[arg2]], %[[c0]] : memref<?xf32>
// CHECKPARALLEL: scf.parallel (%[[b:.*]]) = (%[[c0]]) to (%[[dim1]]) step (%[[c1]]) {
// CHECKPARALLEL: %[[vb:.*]] = memref.load %[[arg0]][%[[aff]]] : memref<?xf32>
// CHECKPARALLEL: %[[va:.*]] = memref.load %[[arg1]][%[[m]]] : memref<?xf32>
// CHECKPARALLEL: %[[vc:.*]] = memref.load %[[arg2]][%[[b]]] : memref<?xf32>
-// CHECKPARALLEL: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECKPARALLEL: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECKPARALLEL: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECKPARALLEL: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[arg2]][%[[b]]] : memref<?xf32>
// CHECK-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?x?xf32>
// CHECK-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?x?xf32>
// CHECK-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?x?xf32>
-// CHECK: %[[c0:.*]] = constant 0 : index
-// CHECK: %[[c1:.*]] = constant 1 : index
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
+// CHECK: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?x?xf32>
// CHECK: %[[dim1:.*]] = memref.dim %[[arg1]], %[[c1]] : memref<?x?xf32>
// CHECK: %[[dim2:.*]] = memref.dim %[[arg2]], %[[c0]] : memref<?x?xf32>
// CHECK: %[[va:.*]] = memref.load %[[arg1]][%[[arg5]], %[[arg6]]] : memref<?x?xf32>
// CHECK: %[[vc:.*]] = memref.load %[[arg2]][%[[arg3]], %[[arg4]]] : memref<?x?xf32>
-// CHECK: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECK: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECK: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECK: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECK: store %[[res]], %[[arg2]][%[[arg3]], %[[arg4]]] : memref<?x?xf32>
// CHECKPARALLEL-LABEL: @conv2d_no_symbols
// CHECKPARALLEL-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?x?xf32>
// CHECKPARALLEL-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?x?xf32>
// CHECKPARALLEL-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?x?xf32>
-// CHECKPARALLEL: %[[c0:.*]] = constant 0 : index
-// CHECKPARALLEL: %[[c1:.*]] = constant 1 : index
+// CHECKPARALLEL: %[[c0:.*]] = arith.constant 0 : index
+// CHECKPARALLEL: %[[c1:.*]] = arith.constant 1 : index
// CHECKPARALLEL: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?x?xf32>
// CHECKPARALLEL: %[[dim1:.*]] = memref.dim %[[arg1]], %[[c1]] : memref<?x?xf32>
// CHECKPARALLEL: %[[dim2:.*]] = memref.dim %[[arg2]], %[[c0]] : memref<?x?xf32>
// CHECKPARALLEL: %[[vb:.*]] = memref.load %[[arg0]][%[[aff]], %[[aff2]]] : memref<?x?xf32>
// CHECKPARALLEL: %[[va:.*]] = memref.load %[[arg1]][%[[arg5]], %[[arg6]]] : memref<?x?xf32>
// CHECKPARALLEL: %[[vc:.*]] = memref.load %[[arg2]][%[[arg3]], %[[arg4]]] : memref<?x?xf32>
-// CHECKPARALLEL: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECKPARALLEL: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECKPARALLEL: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECKPARALLEL: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[arg2]][%[[arg3]], %[[arg4]]] : memref<?x?xf32>
// CHECK-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
// CHECK-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
// CHECK-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
-// CHECK-DAG: %[[c2:.*]] = constant 2 : index
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
+// CHECK-DAG: %[[c2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?x?x?xf32>
// CHECK: %[[dim1:.*]] = memref.dim %[[arg1]], %[[c1]] : memref<?x?x?xf32>
// CHECK: %[[dim2:.*]] = memref.dim %[[arg1]], %[[c2]] : memref<?x?x?xf32>
// CHECK: %[[va:.*]] = memref.load %[[arg1]][%[[arg6]], %[[arg7]], %[[arg8]]] : memref<?x?x?xf32>
// CHECK: %[[vc:.*]] = memref.load %[[arg2]][%[[arg3]], %[[arg4]], %[[arg5]]] : memref<?x?x?xf32>
-// CHECK: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECK: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECK: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECK: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECK: store %[[res]], %[[arg2]][%[[arg3]], %[[arg4]], %[[arg5]]] : memref<?x?x?xf32>
// CHECKPARALLEL-LABEL: @conv3d_no_symbols
// CHECKPARALLEL-SAME: %[[arg0:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
// CHECKPARALLEL-SAME: %[[arg1:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
// CHECKPARALLEL-SAME: %[[arg2:[a-zA-Z0-9]+]]: memref<?x?x?xf32>
-// CHECKPARALLEL-DAG: %[[c2:.*]] = constant 2 : index
-// CHECKPARALLEL-DAG: %[[c0:.*]] = constant 0 : index
-// CHECKPARALLEL-DAG: %[[c1:.*]] = constant 1 : index
+// CHECKPARALLEL-DAG: %[[c2:.*]] = arith.constant 2 : index
+// CHECKPARALLEL-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECKPARALLEL-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECKPARALLEL: %[[dim0:.*]] = memref.dim %[[arg1]], %[[c0]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[dim1:.*]] = memref.dim %[[arg1]], %[[c1]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[dim2:.*]] = memref.dim %[[arg1]], %[[c2]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[vb:.*]] = memref.load %[[arg0]][%[[aff]], %[[aff2]], %[[aff3]]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[va:.*]] = memref.load %[[arg1]][%[[arg6]], %[[arg7]], %[[arg8]]] : memref<?x?x?xf32>
// CHECKPARALLEL: %[[vc:.*]] = memref.load %[[arg2]][%[[arg3]], %[[arg4]], %[[arg5]]] : memref<?x?x?xf32>
-// CHECKPARALLEL: %[[inc:.*]] = mulf %[[vb]], %[[va]] : f32
-// CHECKPARALLEL: %[[res:.*]] = addf %[[vc]], %[[inc]] : f32
+// CHECKPARALLEL: %[[inc:.*]] = arith.mulf %[[vb]], %[[va]] : f32
+// CHECKPARALLEL: %[[res:.*]] = arith.addf %[[vc]], %[[inc]] : f32
// CHECKPARALLEL: store %[[res]], %[[arg2]][%[[arg3]], %[[arg4]], %[[arg5]]] : memref<?x?x?xf32>
// -----
// CHECK-DAG: #[[$MAP1:.*]] = affine_map<(d0, d1, d2, d3) -> (d0 + 1, d1 + 1, d2 + 1, d3 + 2)>
// CHECK-LABEL: func @pad_tensor_with_memrefs
func @pad_tensor_with_memrefs(%arg0: memref<1x28x28x1xf32>) -> memref<2x31x31x3xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = memref.tensor_load %arg0 : memref<1x28x28x1xf32>
%1 = linalg.pad_tensor %0 low[1, 1, 1, 2] high[0, 2, 2, 0] {
^bb0(%arg1: index, %arg2: index, %arg3: index, %arg4: index): // no predecessors
// CHECK-DAG: #[[$MAP3:.*]] = affine_map<(d0, d1, d2) -> (d0 + 1, d1 + 2, d2 + 2)>
// CHECK-LABEL: func @pad_tensor_no_memrefs
func @pad_tensor_no_memrefs(%arg0: tensor<1x28x28xf32>) -> tensor<2x32x32xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.pad_tensor %arg0 low[1, 2, 2] high[0, 2, 2] {
^bb0(%arg1: index, %arg2: index, %arg3: index): // no predecessors
linalg.yield %cst : f32
// CHECK-DAG: #[[$MAP5:.*]] = affine_map<(d0, d1, d2, d3) -> (d0, d1 + 2, d2 + 2, d3)>
// CHECK-LABEL: func @pad_tensor_detailed
func @pad_tensor_detailed(%arg0: tensor<1x28x28x1xf32>) -> tensor<1x32x32x1xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.pad_tensor %arg0 low[0, 2, 2, 0] high[0, 2, 2, 0] {
^bb0(%arg1: index, %arg2: index, %arg3: index, %arg4: index): // no predecessors
linalg.yield %cst : f32
}
// CHECK: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<1x28x28x1xf32>) -> tensor<1x32x32x1xf32>
-// CHECK: %[[CTE:.+]] = constant 0.000000e+00 : f32
+// CHECK: %[[CTE:.+]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[TMP:.+]] = linalg.init_tensor [1, 32, 32, 1] : tensor<1x32x32x1xf32>
// CHECK: %[[R1c:.+]] = linalg.fill
// CHECK: %[[R2c:.+]] = linalg.generic
// CHECK-LABEL: func @depthwise_conv2D_nhwc_tensor
func @depthwise_conv2D_nhwc_tensor(%input: tensor<2x4x5x2xf32>, %filter: tensor<2x2x2x3xf32>) -> tensor<2x3x4x2x3xf32> {
- %zero = constant 0.000000e+00 : f32
+ %zero = arith.constant 0.000000e+00 : f32
%init = linalg.init_tensor [2, 3, 4, 2, 3] : tensor<2x3x4x2x3xf32>
%fill = linalg.fill(%zero, %init) : f32, tensor<2x3x4x2x3xf32> -> tensor<2x3x4x2x3xf32>
// CHECK: %{{.+}} = linalg.depthwise_conv2D_nhwc
}
func @depthwise_conv2D_nhwc_tensor_dilated(%input: tensor<2x8x9x2xf32>, %filter: tensor<2x2x2x3xf32>) -> tensor<2x6x7x2x3xf32> {
- %zero = constant 0.000000e+00 : f32
+ %zero = arith.constant 0.000000e+00 : f32
%init = linalg.init_tensor [2, 6, 7, 2, 3] : tensor<2x6x7x2x3xf32>
%fill = linalg.fill(%zero, %init) : f32, tensor<2x6x7x2x3xf32> -> tensor<2x6x7x2x3xf32>
// CHECK: %{{.+}} = linalg.depthwise_conv2D_nhwc
func @pooling_nhwc_sum_tensor(%input: tensor<1x4x4x1xf32>) -> tensor<1x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x1xf32> -> tensor<1x2x2x1xf32>
%res = linalg.pooling_nhwc_sum {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xf32>, tensor<3x3xf32>)
func @pooling_nhwc_max_tensor(%input: tensor<1x4x4x1xf32>) -> tensor<1x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x1xf32> -> tensor<1x2x2x1xf32>
%res = linalg.pooling_nhwc_max {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xf32>, tensor<3x3xf32>)
func @pooling_nchw_max_tensor(%input: tensor<1x1x4x4xf32>) -> tensor<1x1x2x2xf32> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xf32>
%init = linalg.init_tensor [1, 1, 2, 2] : tensor<1x1x2x2xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x1x2x2xf32> -> tensor<1x1x2x2xf32>
%res = linalg.pooling_nchw_max {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x1x4x4xf32>, tensor<3x3xf32>)
func @pooling_nhwc_i8_max_tensor(%input: tensor<1x4x4x1xi8>) -> tensor<1x2x2x1xi8> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xi8>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xi8>
- %cst = constant 0 : i8
+ %cst = arith.constant 0 : i8
%fill = linalg.fill(%cst, %init) : i8, tensor<1x2x2x1xi8> -> tensor<1x2x2x1xi8>
%res = linalg.pooling_nhwc_max {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xi8>, tensor<3x3xi8>)
func @pooling_nhwc_i16_max_tensor(%input: tensor<1x4x4x1xi16>) -> tensor<1x2x2x1xi16> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xi16>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xi16>
- %cst = constant 0 : i16
+ %cst = arith.constant 0 : i16
%fill = linalg.fill(%cst, %init) : i16, tensor<1x2x2x1xi16> -> tensor<1x2x2x1xi16>
%res = linalg.pooling_nhwc_max {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xi16>, tensor<3x3xi16>)
func @pooling_nhwc_i32_max_tensor(%input: tensor<1x4x4x1xi32>) -> tensor<1x2x2x1xi32> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xi32>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xi32>
- %cst = constant 0 : i32
+ %cst = arith.constant 0 : i32
%fill = linalg.fill(%cst, %init) : i32, tensor<1x2x2x1xi32> -> tensor<1x2x2x1xi32>
%res = linalg.pooling_nhwc_max {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xi32>, tensor<3x3xi32>)
func @pooling_nhwc_min_tensor(%input: tensor<1x4x4x1xf32>) -> tensor<1x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3] : tensor<3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 1] : tensor<1x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x1xf32> -> tensor<1x2x2x1xf32>
%res = linalg.pooling_nhwc_min {dilations = dense<1> : tensor<2xi64>, strides = dense<1> : tensor<2xi64>}
ins(%input, %fake: tensor<1x4x4x1xf32>, tensor<3x3xf32>)
func @pooling_ndhwc_sum_tensor(%input: tensor<1x4x4x4x1xf32>) -> tensor<1x2x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3, 3] : tensor<3x3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 2, 1] : tensor<1x2x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x2x1xf32> -> tensor<1x2x2x2x1xf32>
%res = linalg.pooling_ndhwc_sum {dilations = dense<1> : tensor<3xi64>, strides = dense<1> : tensor<3xi64>}
ins(%input, %fake: tensor<1x4x4x4x1xf32>, tensor<3x3x3xf32>)
func @pooling_ndhwc_max_tensor(%input: tensor<1x4x4x4x1xf32>) -> tensor<1x2x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3, 3] : tensor<3x3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 2, 1] : tensor<1x2x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x2x1xf32> -> tensor<1x2x2x2x1xf32>
%res = linalg.pooling_ndhwc_max {dilations = dense<1> : tensor<3xi64>, strides = dense<1> : tensor<3xi64>}
ins(%input, %fake: tensor<1x4x4x4x1xf32>, tensor<3x3x3xf32>)
func @pooling_ndhwc_min_tensor(%input: tensor<1x4x4x4x1xf32>) -> tensor<1x2x2x2x1xf32> {
%fake = linalg.init_tensor [3, 3, 3] : tensor<3x3x3xf32>
%init = linalg.init_tensor [1, 2, 2, 2, 1] : tensor<1x2x2x2x1xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%fill = linalg.fill(%cst, %init) : f32, tensor<1x2x2x2x1xf32> -> tensor<1x2x2x2x1xf32>
%res = linalg.pooling_ndhwc_min {dilations = dense<1> : tensor<3xi64>, strides = dense<1> : tensor<3xi64>}
ins(%input, %fake: tensor<1x4x4x4x1xf32>, tensor<3x3x3xf32>)
// expected-error @+1 {{unexpected input index map for convolutions}}
%0 = "linalg.conv_2d_nhwc_hwcf"(%arg0, %arg1, %arg2) ( {
^bb0(%arg3: f32, %arg4: f32, %arg5 : f32): // no predecessors
- %1 = "std.mulf"(%arg3, %arg4) : (f32, f32) -> f32
- %2 = "std.addf"(%arg5, %1) : (f32, f32) -> f32
+ %1 = "arith.mulf"(%arg3, %arg4) : (f32, f32) -> f32
+ %2 = "arith.addf"(%arg5, %1) : (f32, f32) -> f32
"linalg.yield"(%2) : (f32) -> ()
}) {dilations = dense<1> : tensor<2xi64>, linalg.memoized_indexing_maps = [#map0, #map1, #map2], operand_segment_sizes = dense<[2, 1]> : vector<2xi32>, strides = dense<2> : tensor<2xi64>} : (tensor<?x?x?x?xf32>, tensor<?x?x?x?xf32>, tensor<?x?x?x?xf32>) -> tensor<?x?x?x?xf32>
return %0 : tensor<?x?x?x?xf32>
// expected-error @+1 {{expected output/filter indexing maps to be projected permutations}}
%0 = "linalg.conv_2d_nhwc_hwcf"(%arg0, %arg1, %arg2) ( {
^bb0(%arg3: f32, %arg4: f32, %arg5 : f32): // no predecessors
- %1 = "std.mulf"(%arg3, %arg4) : (f32, f32) -> f32
- %2 = "std.addf"(%arg5, %1) : (f32, f32) -> f32
+ %1 = "arith.mulf"(%arg3, %arg4) : (f32, f32) -> f32
+ %2 = "arith.addf"(%arg5, %1) : (f32, f32) -> f32
"linalg.yield"(%2) : (f32) -> ()
}) {dilations = dense<1> : tensor<2xi64>, linalg.memoized_indexing_maps = [#map0, #map1, #map2], operand_segment_sizes = dense<[2, 1]> : vector<2xi32>, strides = dense<1> : tensor<2xi64>} : (tensor<?x?x?x?xf32>, tensor<?x?x?x?x?xf32>, tensor<?x?x?x?xf32>) -> tensor<?x?x?x?xf32>
return %0 : tensor<?x?x?x?xf32>
ins(%lhs, %rhs : memref<2x2xf32>, memref<2x2xf32>)
outs(%sum : memref<2x2xf32>) {
^bb0(%lhs_in: f32, %rhs_in: f32, %sum_out: f32): // no predecessors
- %0 = addf %lhs_in, %rhs_in : f32
+ %0 = arith.addf %lhs_in, %rhs_in : f32
linalg.yield %0 : f32
}
return
}
// CHECK-LABEL: @linalg_generic_sum
// CHECK: (%[[LHS:.*]]:{{.*}}, %[[RHS:.*]]:{{.*}}, %[[SUM:.*]]:{{.*}})
-// CHECK-DAG: %[[C2:.*]] = constant 2
-// CHECK-DAG: %[[C0:.*]] = constant 0
-// CHECK-DAG: %[[C1:.*]] = constant 1
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1
// CHECK: scf.parallel (%[[I:.*]], %[[J:.*]]) = {{.*}}
// CHECK: %[[LHS_ELEM:.*]] = memref.load %[[LHS]][%[[I]], %[[J]]]
// CHECK: %[[RHS_ELEM:.*]] = memref.load %[[RHS]][%[[I]], %[[J]]]
-// CHECK: %[[SUM:.*]] = addf %[[LHS_ELEM]], %[[RHS_ELEM]] : f32
+// CHECK: %[[SUM:.*]] = arith.addf %[[LHS_ELEM]], %[[RHS_ELEM]] : f32
// CHECK: store %[[SUM]], %{{.*}}[%[[I]], %[[J]]]
// CHECK: scf.yield
return
}
// CHECK-LABEL: @lower_outer_parallel
-// CHECK-DAG: %[[C0:.*]] = constant 0
-// CHECK-DAG: %[[C1:.*]] = constant 1
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1
// CHECK-DAG: %[[D0:.*]] = memref.dim %{{.*}}, %c0
// CHECK-DAG: %[[D1:.*]] = memref.dim %{{.*}}, %c1
// CHECK-DAG: %[[D2:.*]] = memref.dim %{{.*}}, %c2
return
}
// CHECK-LABEL: @lower_mixed_parallel
-// CHECK-DAG: %[[C0:.*]] = constant 0
-// CHECK-DAG: %[[C1:.*]] = constant 1
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1
// CHECK-DAG: %[[D0:.*]] = memref.dim %{{.*}}, %c0
// CHECK-DAG: %[[D1:.*]] = memref.dim %{{.*}}, %c1
// CHECK-DAG: %[[D2:.*]] = memref.dim %{{.*}}, %c2
// CHECK-DAG: #[[$strided2D:.*]] = affine_map<(d0, d1)[s0, s1] -> (d0 * s1 + s0 + d1)>
func @matmul_f32(%A: memref<?xi8>, %M: index, %N: index, %K: index) {
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%3 = memref.view %A[%c0][%M, %K] : memref<?xi8> to memref<?x?xf32>
%4 = memref.view %A[%c0][%K, %N] : memref<?xi8> to memref<?x?xf32>
%5 = memref.view %A[%c0][%M, %N] : memref<?xi8> to memref<?x?xf32>
// -----
func @matmul_f64(%A: memref<?xi8>, %M: index, %N: index, %K: index) {
- %c4 = constant 4 : index
- %c3 = constant 3 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c3 = arith.constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%3 = memref.view %A[%c0][%M, %K] : memref<?xi8> to memref<?x?xf64>
%4 = memref.view %A[%c0][%K, %N] : memref<?xi8> to memref<?x?xf64>
%5 = memref.view %A[%c0][%M, %N] : memref<?xi8> to memref<?x?xf64>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C42:.+]] = constant 4.200000e+01 : f32
+// CHECK-DAG: %[[C42:.+]] = arith.constant 4.200000e+01 : f32
// CHECK: scf.for
// CHECK: scf.for
// CHECK: scf.for
// RUN: mlir-opt -test-linalg-control-fusion-by-expansion %s -split-input-file | FileCheck %s
func @control_producer_reshape_fusion(%arg0 : tensor<?x?x?xf32>, %arg1 : tensor<?xf32>) -> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.tensor_collapse_shape %arg0 [[0, 1], [2]] : tensor<?x?x?xf32> into tensor<?x?xf32>
%d0 = tensor.dim %0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %0, %c1 : tensor<?x?xf32>
ins(%0, %arg1 : tensor<?x?xf32>, tensor<?xf32>)
outs(%init : tensor<?x?xf32>) {
^bb0(%arg2 : f32, %arg3:f32, %arg4 : f32):
- %2 = addf %arg2, %arg3 : f32
+ %2 = arith.addf %arg2, %arg3 : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
return %1 : tensor<?x?xf32>
// CHECK: func @control_producer_reshape_fusion
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
// CHECK: %[[RESHAPE:.+]] = linalg.tensor_collapse_shape %[[ARG0]]
// CHECK-SAME: {{\[}}[0, 1], [2]{{\]}} : tensor<?x?x?xf32> into tensor<?x?xf32>
// CHECK: %[[RESULT:.+]] = linalg.generic
// -----
func @control_consumer_reshape_fusion(%arg0 : tensor<1x?x?xf32>, %arg1 : tensor<1x?x?xf32>) -> tensor<1x?x?xf32> {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %cst = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %cst = arith.constant 0.0 : f32
%d0 = tensor.dim %arg0, %c1 : tensor<1x?x?xf32>
%d1 = tensor.dim %arg1, %c2 : tensor<1x?x?xf32>
%init = linalg.init_tensor [%d0, %d1] : tensor<?x?xf32>
ins(%0, %arg1, %arg2 : tensor<?x?x?xf32>, tensor<?x?x?xf32>, f32)
outs(%0 : tensor<?x?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32, %s: f32): // no predecessors
- %1 = mulf %arg3, %arg4 : f32
- %2 = addf %1, %arg5 : f32
+ %1 = arith.mulf %arg3, %arg4 : f32
+ %2 = arith.addf %1, %arg5 : f32
linalg.yield %2 : f32
} -> tensor<?x?x?xf32>
return %1 : tensor<?x?x?xf32>
ins(%arg0, %arg1, %arg2 : tensor<?x?xf32>, tensor<?x?xf32>, f32)
outs(%arg0 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32, %s: f32): // no predecessors
- %1 = mulf %arg3, %arg4 : f32
- %2 = addf %1, %arg5 : f32
+ %1 = arith.mulf %arg3, %arg4 : f32
+ %2 = arith.addf %1, %arg5 : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
%1 = linalg.tensor_expand_shape %0 [[0], [1, 2, 3]] :
ins(%a, %b : tensor<?x?x?xf32>, tensor<?x?xf32>)
outs(%a : tensor<?x?x?xf32>) {
^bb0(%arg0 : f32, %arg1: f32, %s: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
linalg.yield %1 : f32
} -> tensor<?x?x?xf32>
%d = linalg.tensor_expand_shape %c [[0, 1], [2], [3, 4, 5]]
func @generic_op_reshape_consumer_static(%arg0: tensor<264x4xf32>)
-> tensor<8x33x4xf32> {
- %cst = constant dense<2.000000e+00> : tensor<264x4xf32>
+ %cst = arith.constant dense<2.000000e+00> : tensor<264x4xf32>
%0 = linalg.init_tensor [264, 4] : tensor<264x4xf32>
%1 = linalg.generic {
indexing_maps = [#map0, #map0, #map0],
ins(%arg0, %cst : tensor<264x4xf32>, tensor<264x4xf32>)
outs(%0 : tensor<264x4xf32>) {
^bb0(%arg1: f32, %arg2: f32, %s: f32): // no predecessors
- %2 = mulf %arg1, %arg2 : f32
+ %2 = arith.mulf %arg1, %arg2 : f32
linalg.yield %2 : f32
} -> tensor<264x4xf32>
%2 = linalg.tensor_expand_shape %1 [[0, 1], [2]] :
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
%idx2 = linalg.index 2 : index
- %1 = muli %arg3, %arg4 : i32
- %2 = index_cast %idx0 : index to i32
- %3 = addi %1, %2 : i32
- %4 = index_cast %idx1 : index to i32
- %5 = addi %3, %4 : i32
- %6 = index_cast %idx2 : index to i32
- %7 = addi %5, %6 : i32
+ %1 = arith.muli %arg3, %arg4 : i32
+ %2 = arith.index_cast %idx0 : index to i32
+ %3 = arith.addi %1, %2 : i32
+ %4 = arith.index_cast %idx1 : index to i32
+ %5 = arith.addi %3, %4 : i32
+ %6 = arith.index_cast %idx2 : index to i32
+ %7 = arith.addi %5, %6 : i32
linalg.yield %7 : i32
} -> tensor<?x?x?xi32>
return %1 : tensor<?x?x?xi32>
// CHECK-DAG: %[[IDX2:.+]] = linalg.index 2 : index
// CHECK-DAG: %[[IDX3:.+]] = linalg.index 3 : index
// CHECK-DAG: %[[T3:.+]] = affine.apply #[[MAP]](%[[IDX1]], %[[IDX0]])
-// CHECK: %[[T4:.+]] = muli %[[ARG3]], %[[ARG4]]
-// CHECK: %[[T5:.+]] = index_cast %[[T3]]
-// CHECK: %[[T6:.+]] = addi %[[T4]], %[[T5]]
-// CHECK: %[[T7:.+]] = index_cast %[[IDX2]]
-// CHECK: %[[T8:.+]] = addi %[[T6]], %[[T7]]
-// CHECK: %[[T9:.+]] = index_cast %[[IDX3]]
-// CHECK: %[[T10:.+]] = addi %[[T8]], %[[T9]]
+// CHECK: %[[T4:.+]] = arith.muli %[[ARG3]], %[[ARG4]]
+// CHECK: %[[T5:.+]] = arith.index_cast %[[T3]]
+// CHECK: %[[T6:.+]] = arith.addi %[[T4]], %[[T5]]
+// CHECK: %[[T7:.+]] = arith.index_cast %[[IDX2]]
+// CHECK: %[[T8:.+]] = arith.addi %[[T6]], %[[T7]]
+// CHECK: %[[T9:.+]] = arith.index_cast %[[IDX3]]
+// CHECK: %[[T10:.+]] = arith.addi %[[T8]], %[[T9]]
// CHECK: linalg.yield %[[T10]]
// -----
^bb0(%arg3: i32, %arg4: i32, %s: i32): // no predecessors
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
- %1 = muli %arg3, %arg4 : i32
- %2 = index_cast %idx0 : index to i32
- %3 = addi %1, %2 : i32
- %4 = index_cast %idx1 : index to i32
- %5 = addi %3, %4 : i32
+ %1 = arith.muli %arg3, %arg4 : i32
+ %2 = arith.index_cast %idx0 : index to i32
+ %3 = arith.addi %1, %2 : i32
+ %4 = arith.index_cast %idx1 : index to i32
+ %5 = arith.addi %3, %4 : i32
linalg.yield %5 : i32
} -> tensor<?x?xi32>
%1 = linalg.tensor_expand_shape %0 [[0], [1, 2, 3]] :
// CHECK-DAG: %[[IDX2:.+]] = linalg.index 2 : index
// CHECK-DAG: %[[IDX3:.+]] = linalg.index 3 : index
// CHECK-DAG: %[[T3:.+]] = affine.apply #[[MAP]](%[[IDX3]], %[[IDX2]], %[[IDX1]])
-// CHECK: %[[T4:.+]] = muli %[[ARG3]], %[[ARG4]]
-// CHECK: %[[T5:.+]] = index_cast %[[IDX0]]
-// CHECK: %[[T6:.+]] = addi %[[T4]], %[[T5]]
-// CHECK: %[[T7:.+]] = index_cast %[[T3]]
-// CHECK: %[[T8:.+]] = addi %[[T6]], %[[T7]]
+// CHECK: %[[T4:.+]] = arith.muli %[[ARG3]], %[[ARG4]]
+// CHECK: %[[T5:.+]] = arith.index_cast %[[IDX0]]
+// CHECK: %[[T6:.+]] = arith.addi %[[T4]], %[[T5]]
+// CHECK: %[[T7:.+]] = arith.index_cast %[[T3]]
+// CHECK: %[[T8:.+]] = arith.addi %[[T6]], %[[T7]]
// CHECK: linalg.yield %[[T8]]
// -----
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
%idx2 = linalg.index 2 : index
- %1 = addi %arg3, %arg4 : i32
- %2 = index_cast %idx0 : index to i32
- %3 = addi %1, %2 : i32
- %4 = index_cast %idx1 : index to i32
- %5 = addi %3, %4 : i32
- %6 = index_cast %idx2 : index to i32
- %7 = addi %5, %6 : i32
+ %1 = arith.addi %arg3, %arg4 : i32
+ %2 = arith.index_cast %idx0 : index to i32
+ %3 = arith.addi %1, %2 : i32
+ %4 = arith.index_cast %idx1 : index to i32
+ %5 = arith.addi %3, %4 : i32
+ %6 = arith.index_cast %idx2 : index to i32
+ %7 = arith.addi %5, %6 : i32
linalg.yield %7 : i32
} -> tensor<6x4x210xi32>
%d = linalg.tensor_expand_shape %c [[0, 1], [2], [3, 4, 5]]
// CHECK-DAG: %[[IDX5:.+]] = linalg.index 5 : index
// CHECK-DAG: %[[T5:.+]] = affine.apply #[[MAP8]](%[[IDX1]], %[[IDX0]])
// CHECK-DAG: %[[T6:.+]] = affine.apply #[[MAP9]](%[[IDX4]], %[[IDX3]], %[[IDX2]])
-// CHECK-DAG: %[[T7:.+]] = addi %[[ARG8]], %[[ARG9]]
-// CHECK: %[[T8:.+]] = index_cast %[[T5]]
-// CHECK: %[[T9:.+]] = addi %[[T7]], %[[T8]]
-// CHECK: %[[T10:.+]] = index_cast %[[T6]]
-// CHECK: %[[T11:.+]] = addi %[[T9]], %[[T10]]
-// CHECK: %[[T12:.+]] = index_cast %[[IDX5]]
-// CHECK: %[[T13:.+]] = addi %[[T11]], %[[T12]]
+// CHECK-DAG: %[[T7:.+]] = arith.addi %[[ARG8]], %[[ARG9]]
+// CHECK: %[[T8:.+]] = arith.index_cast %[[T5]]
+// CHECK: %[[T9:.+]] = arith.addi %[[T7]], %[[T8]]
+// CHECK: %[[T10:.+]] = arith.index_cast %[[T6]]
+// CHECK: %[[T11:.+]] = arith.addi %[[T9]], %[[T10]]
+// CHECK: %[[T12:.+]] = arith.index_cast %[[IDX5]]
+// CHECK: %[[T13:.+]] = arith.addi %[[T11]], %[[T12]]
// -----
%idx0 = linalg.index 0 : index
%idx1 = linalg.index 1 : index
%idx2 = linalg.index 2 : index
- %2 = index_cast %idx0 : index to i32
- %3 = addi %arg1, %2 : i32
- %4 = index_cast %idx1 : index to i32
- %5 = addi %3, %4 : i32
- %6 = index_cast %idx2 : index to i32
- %7 = addi %5, %6 : i32
+ %2 = arith.index_cast %idx0 : index to i32
+ %3 = arith.addi %arg1, %2 : i32
+ %4 = arith.index_cast %idx1 : index to i32
+ %5 = arith.addi %3, %4 : i32
+ %6 = arith.index_cast %idx2 : index to i32
+ %7 = arith.addi %5, %6 : i32
linalg.yield %7 : i32
} -> tensor<264x?x4xi32>
return %1 : tensor<264x?x4xi32>
// CHECK-DAG: %[[IDX2:.+]] = linalg.index 2 : index
// CHECK-DAG: %[[IDX3:.+]] = linalg.index 3 : index
// CHECK-DAG: %[[T0:.+]] = affine.apply #[[MAP2]](%[[IDX1]], %[[IDX0]])
-// CHECK: %[[T1:.+]] = index_cast %[[T0]] : index to i32
-// CHECK: %[[T2:.+]] = addi %[[ARG1]], %[[T1]] : i32
-// CHECK: %[[T3:.+]] = index_cast %[[IDX2]] : index to i32
-// CHECK: %[[T4:.+]] = addi %[[T2]], %[[T3]] : i32
-// CHECK: %[[T5:.+]] = index_cast %[[IDX3]] : index to i32
-// CHECK: %[[T6:.+]] = addi %[[T4]], %[[T5]] : i32
+// CHECK: %[[T1:.+]] = arith.index_cast %[[T0]] : index to i32
+// CHECK: %[[T2:.+]] = arith.addi %[[ARG1]], %[[T1]] : i32
+// CHECK: %[[T3:.+]] = arith.index_cast %[[IDX2]] : index to i32
+// CHECK: %[[T4:.+]] = arith.addi %[[T2]], %[[T3]] : i32
+// CHECK: %[[T5:.+]] = arith.index_cast %[[IDX3]] : index to i32
+// CHECK: %[[T6:.+]] = arith.addi %[[T4]], %[[T5]] : i32
// CHECK: linalg.yield %[[T6]] : i32
// CHECK: %[[RES2:.+]] = linalg.tensor_collapse_shape %[[RES]]
// CHECK-SAME: [0, 1], [2], [3]
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arg0 : tensor<?x?xf32>) {
^bb0(%arg3: f32, %arg4: f32, %s: f32): // no predecessors
- %1 = mulf %arg3, %arg4 : f32
+ %1 = arith.mulf %arg3, %arg4 : f32
linalg.yield %1 : f32
} -> tensor<?x?xf32>
%1 = linalg.tensor_expand_shape %0 [[0], [1, 2, 3]] :
func @unit_dim_reshape_expansion_full
(%arg0 : tensor<1x?x1x2x1x4xf32>, %arg1 : tensor<?x2x4xf32>)
-> tensor<?x2x4xf32> {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.tensor_collapse_shape %arg0 [[0, 1, 2], [3, 4], [5]]
: tensor<1x?x1x2x1x4xf32> into tensor<?x2x4xf32>
%1 = tensor.dim %arg0, %c1 : tensor<1x?x1x2x1x4xf32>
ins(%0, %arg1 : tensor<?x2x4xf32>, tensor<?x2x4xf32>)
outs(%2 : tensor<?x2x4xf32>) {
^bb0(%arg2: f32, %arg3: f32, %arg4: f32): // no predecessors
- %4 = mulf %arg2, %arg3 : f32
+ %4 = arith.mulf %arg2, %arg3 : f32
linalg.yield %4 : f32
} -> tensor<?x2x4xf32>
return %3 : tensor<?x2x4xf32>
outs(%0 : tensor<?x?x4x?xi32>) {
^bb0(%arg6: i32, %arg7 : i32): // no predecessors
%idx = linalg.index 0 : index
- %2 = index_cast %idx : index to i32
- %3 = addi %arg6, %2 : i32
+ %2 = arith.index_cast %idx : index to i32
+ %3 = arith.addi %arg6, %2 : i32
linalg.yield %3 : i32
} -> tensor<?x?x4x?xi32>
return %1 : tensor<?x?x4x?xi32>
// CHECK-SAME: ins(%[[ARG0]] : tensor<?x?x?xi32>)
// CHECK-SAME: outs(%[[T0]] : tensor<?x?x4x?xi32>)
// CHECK: %[[IDX:.+]] = linalg.index 0 : index
-// CHECK-NEXT: %[[IDX_CASTED:.+]] = index_cast %[[IDX]] : index to i32
+// CHECK-NEXT: %[[IDX_CASTED:.+]] = arith.index_cast %[[IDX]] : index to i32
// -----
ins(%arg0 : tensor<?x?x4x5xi32>) outs(%arg0 : tensor<?x?x4x5xi32>) {
^bb0(%arg6: i32, %arg7: i32): // no predecessors
%idx = linalg.index 0 : index
- %2 = index_cast %idx : index to i32
- %3 = addi %arg6, %2 : i32
+ %2 = arith.index_cast %idx : index to i32
+ %3 = arith.addi %arg6, %2 : i32
linalg.yield %3 : i32
} -> tensor<?x?x4x5xi32>
%1 = linalg.tensor_collapse_shape %0 [[0], [1, 2, 3]] :
// CHECK-SAME: indexing_maps = [#[[MAP2]], #[[MAP3]]]
// CHECK-SAME: outs(%[[T0]] : tensor<?x?xi32>)
// CHECK: %[[IDX:.+]] = linalg.index 0 : index
-// CHECK-NEXT: %[[IDX_CASTED:.+]] = index_cast %[[IDX]] : index to i32
+// CHECK-NEXT: %[[IDX_CASTED:.+]] = arith.index_cast %[[IDX]] : index to i32
// CHECK-NOT: linalg.tensor_collapse_shape
// -----
ins(%arg0, %arg1 : tensor<?x?x?x5xf32>, tensor<?x?x?x5xf32>)
outs(%arg0 : tensor<?x?x?x5xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32): // no predecessors
- %1 = mulf %arg3, %arg4 : f32
+ %1 = arith.mulf %arg3, %arg4 : f32
linalg.yield %1 : f32
} -> tensor<?x?x?x5xf32>
%1 = linalg.tensor_collapse_shape %0 [[0], [1, 2, 3]] :
#map = affine_map<(d0, d1) -> (d0, d1)>
func @do_not_fold1(%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>) -> tensor<?x?x1xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?xf32>
%2 = linalg.init_tensor [%0, %1] : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%2 : tensor<?x?xf32>) {
^bb0(%arg2 : f32, %arg3 : f32, %arg4 : f32):
- %4 = addf %arg2, %arg3 : f32
+ %4 = arith.addf %arg2, %arg3 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
%4 = linalg.tensor_expand_shape %3 [[0], [1, 2]] : tensor<?x?xf32> into tensor<?x?x1xf32>
#map = affine_map<(d0, d1) -> (d0, d1)>
func @do_not_fold2(%arg0 : tensor<?x?x1xf32>, %arg1 : tensor<?x?xf32>) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.tensor_collapse_shape %arg0 [[0], [1, 2]] : tensor<?x?x1xf32> into tensor<?x?xf32>
%1 = tensor.dim %arg1, %c0 : tensor<?x?xf32>
%2 = tensor.dim %arg1, %c1 : tensor<?x?xf32>
ins(%0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%3 : tensor<?x?xf32>) {
^bb0(%arg2 : f32, %arg3 : f32, %arg4 : f32):
- %4 = addf %arg2, %arg3 : f32
+ %4 = arith.addf %arg2, %arg3 : f32
linalg.yield %4 : f32
} -> tensor<?x?xf32>
return %4 : tensor<?x?xf32>
// RUN: mlir-opt -resolve-shaped-type-result-dims -split-input-file %s | FileCheck %s
func @init_tensor_static_dim() -> (index, index) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c6 = arith.constant 6 : index
%0 = linalg.init_tensor [4, 5, %c6] : tensor<4x5x?xf32>
%1 = tensor.dim %0, %c2 : tensor<4x5x?xf32>
%2 = tensor.dim %0, %c0 : tensor<4x5x?xf32>
return %1, %2 : index, index
}
// CHECK: func @init_tensor_static_dim
-// CHECK-DAG: %[[C4:.+]] = constant 4 : index
-// CHECK-DAG: %[[C6:.+]] = constant 6 : index
+// CHECK-DAG: %[[C4:.+]] = arith.constant 4 : index
+// CHECK-DAG: %[[C6:.+]] = arith.constant 6 : index
// CHECK: return %[[C6]], %[[C4]]
// -----
func @init_tensor_dynamic_dim(%arg0 : index) -> (index) {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%0 = linalg.init_tensor [4, 5, %arg0] : tensor<4x5x?xf32>
%1 = tensor.dim %0, %c2 : tensor<4x5x?xf32>
return %1 : index
// -----
func @init_tensor_dynamic_dim2(%arg0 : index, %arg1 : index) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.init_tensor [%arg0, %arg1] : tensor<?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?xf32>
%2 = tensor.dim %0, %c1 : tensor<?x?xf32>
func @remove_dim_result_uses
(%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>,
%arg2 : tensor<?x?xf32>) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.generic
{indexing_maps = [affine_map<(d0, d1, d2) -> (d0, d2)>,
affine_map<(d0, d1, d2) -> (d2, d1)>,
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arg2 : tensor<?x?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32):
- %1 = mulf %arg3, %arg4 : f32
- %2 = addf %1, %arg5 : f32
+ %1 = arith.mulf %arg3, %arg4 : f32
+ %2 = arith.addf %1, %arg5 : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
%3 = tensor.dim %0, %c0 : tensor<?x?xf32>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
// CHECK-DAG: %[[T0:.+]] = tensor.dim %[[ARG0]], %[[C0]]
// CHECK-DAG: %[[T1:.+]] = tensor.dim %[[ARG1]], %[[C1]]
// CHECK: %[[T2:.+]] = affine.apply #[[MAP0]]()[%[[T0]], %[[T1]]]
func @remove_dim_result_uses_outs
(%arg0 : tensor<?xf32>, %arg1 : index) -> (index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?xf32>
%0 = linalg.init_tensor [%d0, %arg1] : tensor<?x?xf32>
%1 = linalg.generic
func @remove_dim_result_uses_sequence
(%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>,
%arg2 : tensor<?x?xf32>) -> (index, index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = linalg.matmul ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?xf32>
ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
outs(%0 : tensor<?x?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32):
- %4 = mulf %arg3, %arg4 : f32
- %5 = addf %4, %arg5 : f32
+ %4 = arith.mulf %arg3, %arg4 : f32
+ %5 = arith.addf %4, %arg5 : f32
linalg.yield %5 : f32
} -> tensor<?x?xf32>
%6 = tensor.dim %3, %c0 : tensor<?x?xf32>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
// CHECK-DAG: %[[T0:.+]] = tensor.dim %[[ARG0]], %[[C0]]
// CHECK-DAG: %[[T1:.+]] = tensor.dim %[[ARG1]], %[[C1]]
// CHECK-DAG: %[[T2:.+]] = tensor.dim %[[ARG0]], %[[C1]]
func @keep_result_dim_uses_sequence2
(%arg0 : tensor<?xf32>, %arg1 : index) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?xf32>
%0 = linalg.init_tensor [%d0, %arg1] : tensor<?x?xf32>
%1 = linalg.generic
// CHECK: func @keep_result_dim_uses_sequence2
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: index
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
// CHECK-DAG: %[[T0:.+]] = tensor.dim %[[ARG0]], %[[C0]]
// CHECK: return %[[T0]], %[[ARG1]]
linalg.yield %in, %in : f32, f32
} -> (tensor<?xf32>, tensor<?xf32>)
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%num_elem_0 = tensor.dim %0, %c0 : tensor<?xf32>
%num_elem_1 = tensor.dim %1, %c0 : tensor<?xf32>
func @dim_reshape_expansion(%arg0 : tensor<6x5x?xf32>) -> (index, index, index)
{
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
%0 = linalg.tensor_expand_shape %arg0 [[0, 1], [2], [3, 4, 5]]
: tensor<6x5x?xf32> into tensor<2x3x5x4x?x7xf32>
%1 = tensor.dim %0, %c1 : tensor<2x3x5x4x?x7xf32>
// CHECK: #[[MAP:.+]] = affine_map<()[s0] -> (s0 floordiv 28)>
// CHECK: func @dim_reshape_expansion
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<6x5x?xf32>
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
-// CHECK-DAG: %[[C3:.+]] = constant 3 : index
-// CHECK-DAG: %[[C4:.+]] = constant 4 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.+]] = arith.constant 3 : index
+// CHECK-DAG: %[[C4:.+]] = arith.constant 4 : index
// CHECK: %[[D0:.+]] = tensor.dim %[[ARG0]], %[[C2]]
// CHECK: %[[D1:.+]] = affine.apply #[[MAP]]()[%[[D0]]]
// CHECK: return %[[C3]], %[[C4]], %[[D1]]
func @dim_reshape_collapse(%arg0 : tensor<2x3x5x4x?x7xf32>) -> (index, index)
{
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = linalg.tensor_collapse_shape %arg0 [[0, 1], [2], [3, 4, 5]]
: tensor<2x3x5x4x?x7xf32> into tensor<6x5x?xf32>
%1 = tensor.dim %0, %c1 : tensor<6x5x?xf32>
// CHECK: #[[MAP:.+]] = affine_map<()[s0] -> (s0 * 28)>
// CHECK: func @dim_reshape_collapse
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<2x3x5x4x?x7xf32>
-// CHECK-DAG: %[[C4:.+]] = constant 4 : index
-// CHECK-DAG: %[[C5:.+]] = constant 5 : index
+// CHECK-DAG: %[[C4:.+]] = arith.constant 4 : index
+// CHECK-DAG: %[[C5:.+]] = arith.constant 5 : index
// CHECK: %[[D0:.+]] = tensor.dim %[[ARG0]], %[[C4]]
// CHECK: %[[D1:.+]] = affine.apply #[[MAP]]()[%[[D0]]]
// CHECK: return %[[C5]], %[[D1]]
func @dim_of_pad_op(%arg0 : tensor<2x?x?xf32>, %arg1 : index, %arg2 : index,
%arg3: f32) -> (index, index, index)
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
%0 = linalg.pad_tensor %arg0 low[%c3, %arg1, %c4] high[7, %c5, %arg2] {
^bb0(%arg4: index, %arg5: index, %arg6: index):
linalg.yield %arg3 : f32
// CHECK-SAME: %[[ARG0:[A-Za-z0-9_]+]]: tensor<2x?x?xf32>
// CHECK-SAME: %[[ARG1:[A-Za-z0-9_]+]]: index
// CHECK-SAME: %[[ARG2:[A-Za-z0-9_]+]]: index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
-// CHECK-DAG: %[[C12:.+]] = constant 12 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
+// CHECK-DAG: %[[C12:.+]] = arith.constant 12 : index
// CHECK: %[[IN_DIM1:.+]] = tensor.dim %[[ARG0]], %[[C1]]
// CHECK: %[[OUT_DIM1:.+]] = affine.apply #[[MAP0]]()[%[[ARG1]], %[[IN_DIM1]]]
// CHECK: %[[IN_DIM2:.+]] = tensor.dim %[[ARG0]], %[[C2]]
// -----
func @views(%arg0: index, %arg1: index, %arg2: index, %arg3: index, %arg4: index) {
- %c0 = constant 0 : index
- %0 = muli %arg0, %arg0 : index
+ %c0 = arith.constant 0 : index
+ %0 = arith.muli %arg0, %arg0 : index
%1 = memref.alloc (%0) : memref<?xi8>
%2 = linalg.range %arg0:%arg1:%arg2 : !linalg.range
%3 = memref.view %1[%c0][%arg0, %arg0] : memref<?xi8> to memref<?x?xf32>
return
}
// CHECK-LABEL: func @views
-// CHECK: muli %{{.*}}, %{{.*}} : index
+// CHECK: arith.muli %{{.*}}, %{{.*}} : index
// CHECK-NEXT: memref.alloc(%{{.*}}) : memref<?xi8>
// CHECK-NEXT: range
// CHECK-NEXT: memref.view %{{.*}}[%{{.*}}][%{{.*}}] :
func @generic(%arg0: memref<?x?xvector<3x4xi4>, offset: ?, strides: [?, 1]>,
%arg1: memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>) {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
linalg.generic #trait_0
ins(%arg0, %cst : memref<?x?xvector<3x4xi4>, offset: ?, strides: [?, 1]>, f32)
outs(%arg1 : memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>)
func @generic_with_tensor_input(%arg0: tensor<?x?xvector<3x4xi4>>,
%arg1: memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>) {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
linalg.generic #trait_0
ins(%arg0, %cst : tensor<?x?xvector<3x4xi4>>, f32)
outs(%arg1 : memref<?x?x?xf32, offset: ?, strides: [?, ?, 1]>)
iterator_types = ["parallel", "parallel", "parallel"]}
outs(%arg0 : memref<?x?x?xf32>) {
^bb0(%arg3: f32): // no predecessors
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
linalg.yield %cst : f32
}
return
outs(%arg1 : tensor<?x?x?xf32>)
attrs = {foo = 1} {
^bb(%0: vector<3x4xi4>, %1: f32, %2: f32) :
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
linalg.yield %f0 : f32
} -> tensor<?x?x?xf32>
return %0 : tensor<?x?x?xf32>
func @generic_with_multiple_tensor_outputs(
%arg0: tensor<?xi32>, %arg1: tensor<?xi32>, %arg2: i32)
-> (tensor<i32>, tensor<i32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = linalg.init_tensor [] : tensor<i32>
%1 = linalg.fill(%arg2, %0) : i32, tensor<i32> -> tensor<i32>
%2 = linalg.init_tensor [] : tensor<i32>
ins(%arg0, %arg1 : tensor<?xi32>, tensor<?xi32>)
outs(%1, %3 : tensor<i32>, tensor<i32>) {
^bb0(%arg3: i32, %arg4: i32, %arg5: i32, %arg6: i32): // no predecessors
- %5 = cmpi sge, %arg3, %arg5 : i32
+ %5 = arith.cmpi sge, %arg3, %arg5 : i32
%6 = select %5, %arg3, %arg5 : i32
- %7 = cmpi eq, %arg3, %arg5 : i32
- %8 = cmpi slt, %arg4, %arg6 : i32
+ %7 = arith.cmpi eq, %arg3, %arg5 : i32
+ %8 = arith.cmpi slt, %arg4, %arg6 : i32
%9 = select %8, %arg4, %arg6 : i32
%10 = select %5, %arg4, %arg6 : i32
%11 = select %7, %9, %10 : i32
func @tiled_loop(%lhs: tensor<24x64xi8>, %rhs: tensor<24x64xi8>,
%out: tensor<24x64xi8>) -> tensor<24x64xi8> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c24 = constant 24 : index
- %c64 = constant 64 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c24 = arith.constant 24 : index
+ %c64 = arith.constant 64 : index
%prod = linalg.tiled_loop (%i) = (%c0) to (%c24) step (%c4)
ins(%lhs_ = %lhs: tensor<24x64xi8>, %rhs_ = %rhs: tensor<24x64xi8>)
outs(%out_ = %out: tensor<24x64xi8>) {
ins(%lhs_sub, %rhs_sub : tensor<?x?xi8>, tensor<?x?xi8>)
outs(%out_sub : tensor<?x?xi8>) {
^bb(%l: i8, %r: i8, %o: i8) :
- %s = addi %l, %r : i8
+ %s = arith.addi %l, %r : i8
linalg.yield %s : i8
} -> tensor<?x?xi8>
%input_2d: tensor<16x32xf32>,
%input_1d: tensor<24xf32>,
%output: tensor<24xf32>) -> tensor<24xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
%X = tensor.dim %input_3d, %c0 : tensor<16x24x32xf32>
%Y = tensor.dim %input_3d, %c1 : tensor<16x24x32xf32>
%Z = tensor.dim %input_3d, %c2 : tensor<16x24x32xf32>
: tensor<2x4x8xf32>, tensor<2x8xf32>, tensor<4xf32>)
outs(%sub_out : tensor<4xf32>) {
^bb0(%i3d: f32, %i2d: f32, %i1d: f32, %o: f32):
- %0 = addf %i3d, %i2d : f32
- %1 = addf %0, %i1d : f32
+ %0 = arith.addf %i3d, %i2d : f32
+ %1 = arith.addf %0, %i1d : f32
linalg.yield %1 : f32
} -> tensor<4xf32>
%input_2d: memref<16x32xf32>,
%input_1d: memref<24xf32>,
%output: memref<24xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
%X = memref.dim %input_3d, %c0 : memref<16x24x32xf32>
%Y = memref.dim %input_3d, %c1 : memref<16x24x32xf32>
%Z = memref.dim %input_3d, %c2 : memref<16x24x32xf32>
memref<4xf32, #map_3>)
outs(%sub_out : memref<4xf32, #map_3>) {
^bb0(%i3d: f32, %i2d: f32, %i1d: f32, %o: f32):
- %0 = addf %i3d, %i2d : f32
- %1 = addf %0, %i1d : f32
+ %0 = arith.addf %i3d, %i2d : f32
+ %1 = arith.addf %0, %i1d : f32
linalg.yield %1 : f32
}
linalg.yield
// CHECK-LABEL: @dynamic_high_pad
// CHECK-SAME: %[[ARG0:.*]]: tensor<?x5xf32>
// CHECK-NOT: linalg.pad_tensor
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: tensor.dim %[[ARG0]], %[[C0]]
// CHECK: %[[RESULT:.*]] = scf.if %{{.*}} -> (tensor<3x4xf32>) {
// CHECK: %[[GEN:.*]] = tensor.generate
// CHECK-LABEL: @dynamic_extract_size
// CHECK-SAME: %[[ARG0:.*]]: tensor<?x5xf32>, %[[ARG1:.*]]: index
// CHECK-NOT: linalg.pad_tensor
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: tensor.dim %[[ARG0]], %[[C0]]
// CHECK: %[[RESULT:.*]] = scf.if %{{.*}} -> (tensor<?x4xf32>) {
// CHECK: %[[GEN:.*]] = tensor.generate %[[ARG1]]
// CHECK-DAG: %[[BIDX:.*]] = "gpu.block_id"() {dimension = "x"}
// CHECK: %[[ITERY:.*]] = affine.apply #[[MAP0]]()[%[[BIDY]]]
// CHECK: %[[ITERX:.*]] = affine.apply #[[MAP0]]()[%[[BIDX]]]
-// CHECK: %[[INBOUNDSY:.*]] = cmpi slt, %[[ITERY]], %{{.*}}
-// CHECK: %[[INBOUNDSX:.*]] = cmpi slt, %[[ITERX]], %{{.*}}
-// CHECK: %[[INBOUNDS:.*]] = and %[[INBOUNDSY]], %[[INBOUNDSX]]
+// CHECK: %[[INBOUNDSY:.*]] = arith.cmpi slt, %[[ITERY]], %{{.*}}
+// CHECK: %[[INBOUNDSX:.*]] = arith.cmpi slt, %[[ITERX]], %{{.*}}
+// CHECK: %[[INBOUNDS:.*]] = arith.andi %[[INBOUNDSY]], %[[INBOUNDSX]]
// CHECK: scf.if %[[INBOUNDS]]
// CHECK: scf.for %[[ARG3:.*]] =
// CHECK: %[[OFFSETY:.*]] = affine.apply #[[MAP0]]()[%[[BIDY]]]
// CHECK-DAG: %[[BIDY:.*]] = "gpu.block_id"() {dimension = "y"}
// CHECK-DAG: %[[BIDX:.*]] = "gpu.block_id"() {dimension = "x"}
// CHECK: %[[LBX:.*]] = affine.apply #[[MAP0]]()[%[[BIDX]]]
-// CHECK: %[[INBOUNDS:.*]] = cmpi slt, %[[LBX]], %{{.*}}
+// CHECK: %[[INBOUNDS:.*]] = arith.cmpi slt, %[[LBX]], %{{.*}}
// CHECK: scf.if %[[INBOUNDS]]
// CHECK: scf.for %[[ARG3:.*]] =
// CHECK: %[[OFFSETY:.*]] = affine.apply #[[MAP0]]()[%[[BIDY]]]
// CHECK: %[[LBY:.*]] = affine.apply #[[MAP0]]()[%[[BIDY]]]
// CHECK: %[[LBX:.*]] = affine.apply #[[MAP0]]()[%[[BIDX]]]
// CHECK: %[[STEPX:.*]] = affine.apply #[[MAP0]]()[%[[NBLOCKSX]]]
-// CHECK: %[[INBOUNDS:.*]] = cmpi slt, %[[LBY]], %{{.*}}
+// CHECK: %[[INBOUNDS:.*]] = arith.cmpi slt, %[[LBY]], %{{.*}}
// CHECK: scf.if %[[INBOUNDS]]
// CHECK: scf.parallel (%[[ARG3:.*]]) = (%[[LBX]]) to (%{{.*}}) step (%[[STEPX]])
// CHECK: scf.for %[[ARG4:.*]] =
func @matmul_tensors(
%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>, %arg2: tensor<?x?xf32>)
-> tensor<?x?xf32> {
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK-DAG: %[[BIDY:.*]] = "gpu.block_id"() {dimension = "y"}
// CHECK-DAG: %[[NBLOCKSY:.*]] = "gpu.grid_dim"() {dimension = "y"}
// CHECK-DAG: %[[BIDX:.*]] = "gpu.block_id"() {dimension = "x"}
builtin.func @fuse_input(%arg0: tensor<24x12xf32>,
%arg1: tensor<12x25xf32>,
%arg2: tensor<24x25xf32>) -> tensor<24x25xf32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.fill(%cst, %arg0) : f32, tensor<24x12xf32> -> tensor<24x12xf32>
// CHECK: scf.for %[[IV0:[0-9a-zA-Z]*]] =
builtin.func @fuse_output(%arg0: tensor<24x12xf32>,
%arg1: tensor<12x25xf32>,
%arg2: tensor<24x25xf32>) -> tensor<24x25xf32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.fill(%cst, %arg2) : f32, tensor<24x25xf32> -> tensor<24x25xf32>
// Update the iteration argument of the outermost tile loop.
%arg1: tensor<12x25xf32>,
%arg2: tensor<24x25xf32>,
%arg3: tensor<12x7x25xf32>) -> tensor<24x25xf32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
%0 = linalg.generic {indexing_maps = [#map0, #map1], iterator_types = ["parallel", "reduction", "parallel"]} ins(%arg3 : tensor<12x7x25xf32>) outs(%arg1 : tensor<12x25xf32>) {
^bb0(%arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg4, %arg5 : f32
+ %2 = arith.addf %arg4, %arg5 : f32
linalg.yield %2 : f32
} -> tensor<12x25xf32>
%arg1: tensor<12x25xf32>,
%arg2: tensor<24x25xf32>,
%arg3: tensor<12x24xf32>) -> tensor<24x25xf32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
%0 = linalg.generic {indexing_maps = [#map0, #map1], iterator_types = ["parallel", "parallel"]} ins(%arg3 : tensor<12x24xf32>) outs(%arg0 : tensor<24x12xf32>) {
^bb0(%arg4: f32, %arg5: f32): // no predecessors
- %2 = addf %arg4, %arg5 : f32
+ %2 = arith.addf %arg4, %arg5 : f32
linalg.yield %2 : f32
} -> tensor<24x12xf32>
builtin.func @fuse_input_and_output(%arg0: tensor<24x12xf32>,
%arg1: tensor<12x25xf32>,
%arg2: tensor<24x25xf32>) -> tensor<24x25xf32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.fill(%cst, %arg0) : f32, tensor<24x12xf32> -> tensor<24x12xf32>
%1 = linalg.fill(%cst, %arg2) : f32, tensor<24x25xf32> -> tensor<24x25xf32>
builtin.func @fuse_indexed(%arg0: tensor<24x12xi32>,
%arg1: tensor<12x25xi32>,
%arg2: tensor<24x25xi32>) -> tensor<24x25xi32> {
- %c0 = constant 0 : index
- %c12 = constant 12 : index
- %c25 = constant 25 : index
- %c24 = constant 24 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c12 = arith.constant 12 : index
+ %c25 = arith.constant 25 : index
+ %c24 = arith.constant 24 : index
+ %c4 = arith.constant 4 : index
%0 = linalg.generic {indexing_maps = [#map0], iterator_types = ["parallel", "parallel"]} outs(%arg1 : tensor<12x25xi32>) {
^bb0(%arg3: i32): // no predecessors
%6 = linalg.index 0 : index
%7 = linalg.index 1 : index
- %8 = addi %6, %7 : index
- %9 = index_cast %8 : index to i32
+ %8 = arith.addi %6, %7 : index
+ %9 = arith.index_cast %8 : index to i32
linalg.yield %9 : i32
} -> tensor<12x25xi32>
// CHECK: %[[IDX0_SHIFTED:.*]] = affine.apply #[[MAP0]](%[[IDX0]], %[[IV0]])
// CHECK: %[[IDX1:.*]] = linalg.index 1
// CHECK: %[[IDX1_SHIFTED:.*]] = affine.apply #[[MAP0]](%[[IDX1]], %[[IV2]])
- // CHECK: %{{.*}} = addi %[[IDX0_SHIFTED]], %[[IDX1_SHIFTED]]
+ // CHECK: %{{.*}} = arith.addi %[[IDX0_SHIFTED]], %[[IDX1_SHIFTED]]
%1 = linalg.matmul ins(%arg0, %0 : tensor<24x12xi32>, tensor<12x25xi32>) outs(%arg2 : tensor<24x25xi32>) -> tensor<24x25xi32>
return %1 : tensor<24x25xi32>
}
func @fuse_non_rectangular(%arg0: tensor<10x17xf32>,
%arg1: tensor<10x8xf32>) -> tensor<10x8xf32> {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C4:.*]] = constant 4 : index
- // CHECK-DAG: %[[C5:.*]] = constant 5 : index
- // CHECK-DAG: %[[C8:.*]] = constant 8 : index
- // CHECK-DAG: %[[C10:.*]] = constant 10 : index
- %cst = constant 0.000000e+00 : f32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+ // CHECK-DAG: %[[C5:.*]] = arith.constant 5 : index
+ // CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+ // CHECK-DAG: %[[C10:.*]] = arith.constant 10 : index
+ %cst = arith.constant 0.000000e+00 : f32
%0 = linalg.fill(%cst, %arg0) : f32, tensor<10x17xf32> -> tensor<10x17xf32>
// CHECK: scf.for %[[IV0:[0-9a-zA-Z]*]] = %[[C0]] to %[[C8]] step %[[C4]]
// CHECK: %[[T1:.*]] = linalg.fill(%{{.*}}, %[[T0]])
%1 = linalg.generic {indexing_maps = [#map0, #map1], iterator_types = ["parallel", "parallel"]} ins(%0 : tensor<10x17xf32>) outs(%arg1 : tensor<10x8xf32>) {
^bb0(%arg2: f32, %arg3: f32): // no predecessors
- %2 = addf %arg2, %arg3 : f32
+ %2 = arith.addf %arg2, %arg3 : f32
linalg.yield %2 : f32
} -> tensor<10x8xf32>
return %1 : tensor<10x8xf32>
outs(%arg2: tensor<?x?xf32>)
-> tensor<?x?xf32>
- %c4 = constant 4 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c1 = constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %t0, %c0 : tensor<?x?xf32>
%1 = tensor.dim %t0, %c1 : tensor<?x?xf32>
%2 = tensor.dim %arg1, %c1 : tensor<?x?xf32>
// CHECK-SAME: %[[B:[0-9a-z]*]]: tensor<?x?xf32>
// CHECK-SAME: %[[C:[0-9a-z]*]]: tensor<?x?xf32>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK-DAG: %[[dA0:.*]] = tensor.dim %[[A]], %[[C0]] : tensor<?x?xf32>
// CHECK-DAG: %[[dA1:.*]] = tensor.dim %[[A]], %[[C1]] : tensor<?x?xf32>
// CHECK-DAG: %[[dB0:.*]] = tensor.dim %[[B]], %[[C0]] : tensor<?x?xf32>
// -----
func @conv_tensors_static(%input: tensor<1x225x225x3xf32>, %filter: tensor<3x3x3x32xf32>, %elementwise: tensor<1x112x112x32xf32>) -> tensor<1x112x112x32xf32> {
- %c112 = constant 112 : index
- %c32 = constant 32 : index
- %c16 = constant 16 : index
- %c8 = constant 8 : index
- %c4 = constant 4 : index
- %c0 = constant 0 : index
- %cst = constant 0.0 : f32
+ %c112 = arith.constant 112 : index
+ %c32 = arith.constant 32 : index
+ %c16 = arith.constant 16 : index
+ %c8 = arith.constant 8 : index
+ %c4 = arith.constant 4 : index
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.0 : f32
%init = linalg.init_tensor [1, 112, 112, 32] : tensor<1x112x112x32xf32>
%fill = linalg.fill(%cst, %init) : f32, tensor<1x112x112x32xf32> -> tensor<1x112x112x32xf32>
}
ins(%0, %1 : tensor<1x8x16x4xf32>, tensor<1x8x16x4xf32>) outs(%2 : tensor<1x8x16x4xf32>) {
^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
- %result = addf %arg3, %arg4 : f32
+ %result = arith.addf %arg3, %arg4 : f32
linalg.yield %result : f32
} -> tensor<1x8x16x4xf32>
// -----
func @conv_tensors_dynamic(%input: tensor<?x?x?x?xf32>, %filter: tensor<?x?x?x?xf32>, %elementwise: tensor<?x?x?x?xf32>) -> tensor<?x?x?x?xf32> {
- %cst = constant 0.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c8 = constant 8 : index
- %c16 = constant 16 : index
+ %cst = arith.constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
+ %c16 = arith.constant 16 : index
%n = tensor.dim %elementwise, %c0 : tensor<?x?x?x?xf32>
%oh = tensor.dim %elementwise, %c1 : tensor<?x?x?x?xf32>
}
ins(%0, %1 : tensor<?x?x?x?xf32>, tensor<?x?x?x?xf32>) outs(%2 : tensor<?x?x?x?xf32>) {
^bb0(%arg4: f32, %arg5: f32, %arg6: f32):
- %result = addf %arg4, %arg5 : f32
+ %result = arith.addf %arg4, %arg5 : f32
linalg.yield %result : f32
} -> tensor<?x?x?x?xf32>
// CHECK: func @conv_tensors_dynamic
// CHECK-SAME: (%[[INPUT]]: tensor<?x?x?x?xf32>, %[[FILTER]]: tensor<?x?x?x?xf32>, %[[ELEM]]: tensor<?x?x?x?xf32>)
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
-// CHECK-DAG: %[[C3:.+]] = constant 3 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.+]] = arith.constant 3 : index
// CHECK-DAG: %[[ELEM_N:.+]] = tensor.dim %[[ELEM]], %[[C0]] : tensor<?x?x?x?xf32>
// CHECK-DAG: %[[ELEM_OH:.+]] = tensor.dim %[[ELEM]], %[[C1]] : tensor<?x?x?x?xf32>
#map = affine_map<(d0, d1) -> (d0, d1)>
// CHECK: func @pad_generic_static
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C16:.*]] = constant 16 : index
-// CHECK-DAG: %[[C32:.*]] = constant 32 : index
-// CHECK-DAG: %[[C64:.*]] = constant 64 : index
-// CHECK-DAG: %[[C128:.*]] = constant 128 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C16:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[C32:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[C64:.*]] = arith.constant 64 : index
+// CHECK-DAG: %[[C128:.*]] = arith.constant 128 : index
// CHECK: scf.for %{{.*}} = %[[C0]] to %[[C64]] step %[[C16]]
-// CHECK: %[[CMPI1:.*]] = cmpi eq
+// CHECK: %[[CMPI1:.*]] = arith.cmpi eq
// CHECK: scf.for %{{.*}} = %[[C0]] to %[[C128]] step %[[C32]]
-// CHECK: %[[CMPI2:.*]] = cmpi eq
-// CHECK: %[[HASZERO:.*]] = or %[[CMPI2]], %[[CMPI1]] : i1
+// CHECK: %[[CMPI2:.*]] = arith.cmpi eq
+// CHECK: %[[HASZERO:.*]] = arith.ori %[[CMPI2]], %[[CMPI1]] : i1
// CHECK: scf.if %[[HASZERO]]
// CHECK: tensor.generate
// CHECK: else
// CHECK: linalg.generic
// CHECK: tensor.insert_slice
func @pad_generic_static(%small_input: tensor<58x1xf32>, %large_input: tensor<64x128xf32>) -> tensor<64x128xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c16 = constant 16 : index
- %c32 = constant 32 : index
- %zero = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c16 = arith.constant 16 : index
+ %c32 = arith.constant 32 : index
+ %zero = arith.constant 0.0 : f32
%d0 = tensor.dim %large_input, %c0 : tensor<64x128xf32>
%d1 = tensor.dim %large_input, %c1 : tensor<64x128xf32>
{indexing_maps = [#map, #map, #map], iterator_types = ["parallel", "parallel"]}
ins(%0, %1 : tensor<16x32xf32>, tensor<16x32xf32>) outs(%2 : tensor<16x32xf32>) {
^bb0(%arg4: f32, %arg5: f32, %arg6: f32):
- %result = addf %arg4, %arg5 : f32
+ %result = arith.addf %arg4, %arg5 : f32
linalg.yield %result : f32
} -> tensor<16x32xf32>
func @matmul_tensors(
%arg0: tensor<?x?xi8>, %arg1: tensor<?x?xi8>, %arg2: tensor<?x?xi32>)
-> tensor<?x?xi32> {
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[TD0:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC0:.*]] = %[[TC]]) -> (tensor<?x?xi32>) {
// CHECK: %[[TD1:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC1:.*]] = %[[TC0]]) -> (tensor<?x?xi32>) {
// CHECK: %[[TD2:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC2:.*]] = %[[TC1]]) -> (tensor<?x?xi32>) {
func @generic_scalar_and_tensor(
%arg0: tensor<?x?x?xf32>, %arg1: f32)
-> tensor<?x?x?xf32> {
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[TD0:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC0:.*]] = %[[TC]]) -> (tensor<?x?x?xf32>) {
// CHECK: %[[TD1:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC1:.*]] = %[[TC0]]) -> (tensor<?x?x?xf32>) {
// CHECK: %[[TD2:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC2:.*]] = %[[TC1]]) -> (tensor<?x?x?xf32>) {
// CHECK-1DIM-TILE-SAME: %[[TA:[0-9a-z]+]]: tensor<?x8xi8>
// CHECK-1DIM-TILE-SAME: %[[TB:[0-9a-z]+]]: tensor<8x?xi8>
// CHECK-1DIM-TILE-SAME: %[[TC:[0-9a-z]+]]: tensor<?x?xi32>) -> tensor<?x?xi32> {
-// CHECK-1DIM-TILE: %[[C0:.*]] = constant 0 : index
+// CHECK-1DIM-TILE: %[[C0:.*]] = arith.constant 0 : index
// CHECK-1DIM-TILE: %[[TD0:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC0:.*]] = %[[TC]]) -> (tensor<?x?xi32>) {
// CHECK-1DIM-TILE: %[[TD1:.*]] = scf.for {{.*}} to {{.*}} step {{.*}} iter_args(%[[TC1:.*]] = %[[TC0]]) -> (tensor<?x?xi32>) {
// CHECK-1DIM-TILE: %[[sTA:.*]] = tensor.extract_slice %[[TA]][{{.*}}] : tensor<?x8xi8> to tensor<?x8xi8>
// shapes.
// CHECK-LABEL: @pad_to_same_static_size
func @pad_to_same_static_size(%arg0: tensor<2x3x4xf32>, %arg1: f32) -> tensor<2x3x4xf32> {
- // CHECK: %[[c0:.*]] = constant 0 : index
+ // CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK-NOT: scf.for
// CHECK: linalg.pad_tensor %{{.*}} nofold low[%[[c0]], %[[c0]], %[[c0]]] high[%[[c0]], %[[c0]], %[[c0]]]
// CHECK: tensor<2x3x4xf32> to tensor<2x3x4xf32>
// CHECK-LABEL: @pad_static_divisible_size
func @pad_static_divisible_size(%arg0: tensor<4x6x8xf32>, %arg1: f32) -> tensor<4x6x8xf32> {
- // CHECK: %[[c0:.*]] = constant 0 : index
+ // CHECK: %[[c0:.*]] = arith.constant 0 : index
// CHECK-COUNT-3: scf.for
// CHECK: linalg.pad_tensor %{{.*}} nofold low[%[[c0]], %[[c0]], %[[c0]]] high[%[[c0]], %[[c0]], %[[c0]]]
// CHECK: tensor<2x3x4xf32> to tensor<2x3x4xf32>
// RUN: FileCheck %s -check-prefix=CHECK-TILED-LOOP-PEEL-01
// CHECK-PEEL-0: func @matmul_static_tensor
-// CHECK-PEEL-0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-PEEL-0-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-PEEL-0-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-PEEL-0-DAG: %[[c512:.*]] = constant 512 : index
-// CHECK-PEEL-0-DAG: %[[c1280:.*]] = constant 1280 : index
-// CHECK-PEEL-0-DAG: %[[c1600:.*]] = constant 1600 : index
-// CHECK-PEEL-0-DAG: %[[c1700:.*]] = constant 1700 : index
+// CHECK-PEEL-0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-PEEL-0-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-PEEL-0-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-PEEL-0-DAG: %[[c512:.*]] = arith.constant 512 : index
+// CHECK-PEEL-0-DAG: %[[c1280:.*]] = arith.constant 1280 : index
+// CHECK-PEEL-0-DAG: %[[c1600:.*]] = arith.constant 1600 : index
+// CHECK-PEEL-0-DAG: %[[c1700:.*]] = arith.constant 1700 : index
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %[[c1280]] step %[[c256]] {{.*}} {
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %[[c1700]] step %[[c128]] {{.*}} {
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %[[c1600]] step %[[c512]] {{.*}} {
// CHECK-PEEL-0: }
// CHECK-PEEL-12: func @matmul_static_tensor
-// CHECK-PEEL-12-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-PEEL-12-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-PEEL-12-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-PEEL-12-DAG: %[[c512:.*]] = constant 512 : index
-// CHECK-PEEL-12-DAG: %[[c1500:.*]] = constant 1500 : index
-// CHECK-PEEL-12-DAG: %[[c1536:.*]] = constant 1536 : index
-// CHECK-PEEL-12-DAG: %[[c1600:.*]] = constant 1600 : index
-// CHECK-PEEL-12-DAG: %[[c1664:.*]] = constant 1664 : index
+// CHECK-PEEL-12-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-PEEL-12-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-PEEL-12-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-PEEL-12-DAG: %[[c512:.*]] = arith.constant 512 : index
+// CHECK-PEEL-12-DAG: %[[c1500:.*]] = arith.constant 1500 : index
+// CHECK-PEEL-12-DAG: %[[c1536:.*]] = arith.constant 1536 : index
+// CHECK-PEEL-12-DAG: %[[c1600:.*]] = arith.constant 1600 : index
+// CHECK-PEEL-12-DAG: %[[c1664:.*]] = arith.constant 1664 : index
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %[[c1500]] step %[[c256]] {{.*}} {
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %[[c1664]] step %[[c128]] {{.*}} {
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %[[c1536]] step %[[c512]] {{.*}} {
// CHECK-PEEL-12: }
// CHECK-TILED-LOOP-PEEL-0: func @matmul_static_tensor
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c512:.*]] = constant 512 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1280:.*]] = constant 1280 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1500:.*]] = constant 1500 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1600:.*]] = constant 1600 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1700:.*]] = constant 1700 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c512:.*]] = arith.constant 512 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1280:.*]] = arith.constant 1280 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1500:.*]] = arith.constant 1500 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1600:.*]] = arith.constant 1600 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c1700:.*]] = arith.constant 1700 : index
// CHECK-TILED-LOOP-PEEL-0: linalg.tiled_loop (%{{.*}}, %{{.*}}, %{{.*}}) = (%[[c0]], %[[c0]], %[[c0]]) to (%[[c1280]], %[[c1700]], %[[c1600]]) step (%[[c256]], %[[c128]], %[[c512]])
// CHECK-TILED-LOOP-PEEL-0: linalg.matmul ins({{.*}} : tensor<256x?xf32>, tensor<?x?xf32>) outs({{.*}} : tensor<256x?xf32>)
// CHECK-TILED-LOOP-PEEL-0: }
// CHECK-TILED-LOOP-PEEL-0: }
// CHECK-TILED-LOOP-PEEL-01: func @matmul_static_tensor
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c512:.*]] = constant 512 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1280:.*]] = constant 1280 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1500:.*]] = constant 1500 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1600:.*]] = constant 1600 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1664:.*]] = constant 1664 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1700:.*]] = constant 1700 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c512:.*]] = arith.constant 512 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1280:.*]] = arith.constant 1280 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1500:.*]] = arith.constant 1500 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1600:.*]] = arith.constant 1600 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1664:.*]] = arith.constant 1664 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c1700:.*]] = arith.constant 1700 : index
// CHECK-TILED-LOOP-PEEL-01: linalg.tiled_loop (%{{.*}}, %{{.*}}, %{{.*}}) = (%[[c0]], %[[c0]], %[[c0]]) to (%[[c1280]], %[[c1664]], %[[c1600]]) step (%[[c256]], %[[c128]], %[[c512]])
// CHECK-TILED-LOOP-PEEL-01: linalg.matmul ins({{.*}} : tensor<256x?xf32>, tensor<?x128xf32>) outs({{.*}} : tensor<256x128xf32>)
// CHECK-TILED-LOOP-PEEL-01: }
// -----
// CHECK-PEEL-0: func @matmul_dynamic_tensor
-// CHECK-PEEL-0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-PEEL-0-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-PEEL-0-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-PEEL-0-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-PEEL-0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-PEEL-0-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-PEEL-0-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-PEEL-0-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c256]] {{.*}} {
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c128]] {{.*}} {
// CHECK-PEEL-0: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c512]] {{.*}} {
// CHECK-PEEL-0: }
// CHECK-PEEL-12: func @matmul_dynamic_tensor
-// CHECK-PEEL-12-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-PEEL-12-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-PEEL-12-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-PEEL-12-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-PEEL-12-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-PEEL-12-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-PEEL-12-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-PEEL-12-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c256]] {{.*}} {
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c128]] {{.*}} {
// CHECK-PEEL-12: scf.for %{{.*}} = %[[c0]] to %{{.*}} step %[[c512]] {{.*}} {
// CHECK-PEEL-12: }
// CHECK-TILED-LOOP-PEEL-0: func @matmul_dynamic_tensor
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-TILED-LOOP-PEEL-0-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-TILED-LOOP-PEEL-0: linalg.tiled_loop (%{{.*}}, %{{.*}}, %{{.*}}) = (%[[c0]], %[[c0]], %[[c0]]) to (%{{.*}}, %{{.*}}, %{{.*}}) step (%[[c256]], %[[c128]], %[[c512]])
// CHECK-TILED-LOOP-PEEL-0: linalg.matmul ins({{.*}} : tensor<256x?xf32>, tensor<?x?xf32>) outs({{.*}} : tensor<256x?xf32>)
// CHECK-TILED-LOOP-PEEL-0: }
// CHECK-TILED-LOOP-PEEL-0: }
// CHECK-TILED-LOOP-PEEL-01: func @matmul_dynamic_tensor
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c128:.*]] = constant 128 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c256:.*]] = constant 256 : index
-// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c128:.*]] = arith.constant 128 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c256:.*]] = arith.constant 256 : index
+// CHECK-TILED-LOOP-PEEL-01-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-TILED-LOOP-PEEL-01: linalg.tiled_loop (%{{.*}}, %{{.*}}, %{{.*}}) = (%[[c0]], %[[c0]], %[[c0]]) to (%{{.*}}, %{{.*}}, %{{.*}}) step (%[[c256]], %[[c128]], %[[c512]])
// CHECK-TILED-LOOP-PEEL-01: linalg.matmul ins({{.*}} : tensor<256x?xf32>, tensor<?x128xf32>) outs({{.*}} : tensor<256x128xf32>)
// CHECK-TILED-LOOP-PEEL-01: }
// CHECK-TILED-LOOP-PEEL-01: }
func @matmul_dynamic_tensor(%arg0: tensor<?x?xf32>, %arg1: tensor<?x?xf32>)
-> tensor<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%d1 = tensor.dim %arg1, %c1 : tensor<?x?xf32>
%out = linalg.init_tensor [%d0, %d1] : tensor<?x?xf32>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]*]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]*]]: memref<?x?xf32>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// CHECK-DAG: %[[T0:.*]] = memref.dim %[[ARG1]], %[[C0]]
// CHECK-DAG: %[[T1:.*]] = memref.dim %[[ARG1]], %[[C1]]
// CHECK-DAG: %[[T2:.*]] = memref.dim %[[ARG2]], %[[C0]]
}
// TILE-10n25-DAG: [[$MAP:#[a-zA-Z0-9_]*]] = affine_map<(d0, d1) -> (d0 + d1)>
// TILE-10n25-LABEL: func @indexed_vector
-// TILE-10n25: %[[C10:.*]] = constant 10 : index
+// TILE-10n25: %[[C10:.*]] = arith.constant 10 : index
// TILE-10n25: scf.for %[[J:.*]] = {{.*}} step %[[C10]]
// TILE-10n25: linalg.generic
// TILE-10n25: %[[I:.*]] = linalg.index 0 : index
// TILE-25n0-DAG: [[$MAP:#[a-zA-Z0-9_]*]] = affine_map<(d0, d1) -> (d0 + d1)>
// TILE-25n0-LABEL: func @indexed_vector
-// TILE-25n0: %[[C25:.*]] = constant 25 : index
+// TILE-25n0: %[[C25:.*]] = arith.constant 25 : index
// TILE-25n0: scf.for %[[J:.*]] = {{.*}} step %[[C25]]
// TILE-25n0: linalg.generic
// TILE-25n0: %[[I:.*]] = linalg.index 0 : index
^bb0(%a: index):
%i = linalg.index 0 : index
%j = linalg.index 1 : index
- %sum = addi %i, %j : index
+ %sum = arith.addi %i, %j : index
linalg.yield %sum : index
}
return
}
// TILE-10n25-DAG: [[$MAP:#[a-zA-Z0-9_]*]] = affine_map<(d0, d1) -> (d0 + d1)>
// TILE-10n25-LABEL: func @indexed_matrix
-// TILE-10n25-DAG: %[[C25:.*]] = constant 25 : index
-// TILE-10n25-DAG: %[[C10:.*]] = constant 10 : index
+// TILE-10n25-DAG: %[[C25:.*]] = arith.constant 25 : index
+// TILE-10n25-DAG: %[[C10:.*]] = arith.constant 10 : index
// TILE-10n25: scf.for %[[K:.*]] = {{.*}} step %[[C10]]
// TILE-10n25: scf.for %[[L:.*]] = {{.*}} step %[[C25]]
// TILE-10n25: linalg.generic
// TILE-10n25: %[[NEW_I:.*]] = affine.apply [[$MAP]](%[[I]], %[[K]])
// TILE-10n25: %[[J:.*]] = linalg.index 1 : index
// TILE-10n25: %[[NEW_J:.*]] = affine.apply [[$MAP]](%[[J]], %[[L]])
-// TILE-10n25: %[[SUM:.*]] = addi %[[NEW_I]], %[[NEW_J]] : index
+// TILE-10n25: %[[SUM:.*]] = arith.addi %[[NEW_I]], %[[NEW_J]] : index
// TILE-10n25: linalg.yield %[[SUM]] : index
// TILE-25n0-DAG: [[$MAP:#[a-zA-Z0-9_]*]] = affine_map<(d0, d1) -> (d0 + d1)>
// TILE-25n0-LABEL: func @indexed_matrix
-// TILE-25n0: %[[C25:.*]] = constant 25 : index
+// TILE-25n0: %[[C25:.*]] = arith.constant 25 : index
// TILE-25n0: scf.for %[[L:.*]] = {{.*}} step %[[C25]]
// TILE-25n0: linalg.generic
// TILE-25n0: %[[I:.*]] = linalg.index 0 : index
// TILE-25n0: %[[NEW_I:.*]] = affine.apply [[$MAP]](%[[I]], %[[L]])
// TILE-25n0: %[[J:.*]] = linalg.index 1 : index
-// TILE-25n0: %[[SUM:.*]] = addi %[[NEW_I]], %[[J]] : index
+// TILE-25n0: %[[SUM:.*]] = arith.addi %[[NEW_I]], %[[J]] : index
// TILE-25n0: linalg.yield %[[SUM]] : index
// TILE-0n25-DAG: [[$MAP:#[a-zA-Z0-9_]*]] = affine_map<(d0, d1) -> (d0 + d1)>
// TILE-0n25-LABEL: func @indexed_matrix
-// TILE-0n25: %[[C25:.*]] = constant 25 : index
+// TILE-0n25: %[[C25:.*]] = arith.constant 25 : index
// TILE-0n25: scf.for %[[L:.*]] = {{.*}} step %[[C25]]
// TILE-0n25: linalg.generic
// TILE-0n25: %[[I:.*]] = linalg.index 0 : index
// TILE-0n25: %[[J:.*]] = linalg.index 1 : index
// TILE-0n25: %[[NEW_J:.*]] = affine.apply [[$MAP]](%[[J]], %[[L]])
-// TILE-0n25: %[[SUM:.*]] = addi %[[I]], %[[NEW_J]] : index
+// TILE-0n25: %[[SUM:.*]] = arith.addi %[[I]], %[[NEW_J]] : index
// TILE-0n25: linalg.yield %[[SUM]] : index
// TILE2-DAG: #[[MAP1:.*]] = affine_map<()[s0] -> (s0 + 7)>
// TILE2: func @dynamic_pad_tensor(
// TILE2-SAME: %[[IN:.*]]: tensor<?x?xf32>
-// TILE2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE2-DAG: %[[C1:.*]] = constant 1 : index
-// TILE2-DAG: %[[C2:.*]] = constant 2 : index
-// TILE2-DAG: %[[C3:.*]] = constant 3 : index
+// TILE2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE2-DAG: %[[C1:.*]] = arith.constant 1 : index
+// TILE2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE2-DAG: %[[C3:.*]] = arith.constant 3 : index
// TILE2: %[[DIM_IN0:.*]] = tensor.dim %[[IN]], %[[C0]]
// TILE2: %[[DIM0:.*]] = affine.apply #[[MAP0]]()[%[[DIM_IN0]]]
// TILE2: %[[DIM_IN1:.*]] = tensor.dim %[[IN]], %[[C1]]
// TILE1-DAG: #[[MAP1:.*]] = affine_map<()[s0] -> (s0 + 8)>
// TILE1: func @dynamic_pad_tensor(
// TILE1-SAME: %[[IN:.*]]: tensor<?x?xf32>
-// TILE1-DAG: %[[C0:.*]] = constant 0 : index
-// TILE1-DAG: %[[C1:.*]] = constant 1 : index
-// TILE1-DAG: %[[C3:.*]] = constant 3 : index
+// TILE1-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE1-DAG: %[[C1:.*]] = arith.constant 1 : index
+// TILE1-DAG: %[[C3:.*]] = arith.constant 3 : index
// TILE1: %[[DIM_IN1:.*]] = tensor.dim %[[IN]], %[[C1]]
// TILE1: %[[DIM1:.*]] = affine.apply #[[MAP0]]()[%[[DIM_IN1]]]
// TILE1: %[[DIM_IN0:.*]] = tensor.dim %[[IN]], %[[C0]]
// TILE2-LABEL: func @static_pad_tensor(
// TILE2-SAME: %[[IN:.*]]: tensor<7x9xf32>
-// TILE2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE2-DAG: %[[C2:.*]] = constant 2 : index
-// TILE2-DAG: %[[C3:.*]] = constant 3 : index
-// TILE2-DAG: %[[C15:.*]] = constant 15 : index
-// TILE2-DAG: %[[C16:.*]] = constant 16 : index
+// TILE2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE2-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TILE2-DAG: %[[C15:.*]] = arith.constant 15 : index
+// TILE2-DAG: %[[C16:.*]] = arith.constant 16 : index
// TILE2: %[[RESULT:.*]] = scf.for {{.*}} = %[[C0]] to %[[C15]] step %[[C2]]
// TILE2: scf.for {{.*}} = %[[C0]] to %[[C16]] step %[[C3]] iter_args(%[[INNER_OUT:.*]] =
// TILE2: %[[SWAP_RESULT:.*]] = scf.if
// TILE1-LABEL: func @static_pad_tensor(
// TILE1-SAME: %[[IN:.*]]: tensor<7x9xf32>
-// TILE1-DAG: %[[C0:.*]] = constant 0 : index
-// TILE1-DAG: %[[C3:.*]] = constant 3 : index
-// TILE1-DAG: %[[C16:.*]] = constant 16 : index
+// TILE1-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE1-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TILE1-DAG: %[[C16:.*]] = arith.constant 16 : index
// TILE1: %[[RESULT:.*]] = scf.for {{.*}} = %[[C0]] to %[[C16]] step %[[C3]] iter_args(%[[INNER_OUT:.*]] =
// TILE1: %[[SWAP_RESULT:.*]] = scf.if
// TILE1: tensor.generate
// TILE1-LABEL: func @static_pad_tile_evenly(
// TILE1-SAME: %[[IN:.*]]: tensor<7x9xf32>, %[[OUT:.*]]: tensor<14x15xf32>
-// TILE1-DAG: %[[C0:.*]] = constant 0 : index
-// TILE1-DAG: %[[C3:.*]] = constant 3 : index
-// TILE1-DAG: %[[C15:.*]] = constant 15 : index
+// TILE1-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE1-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TILE1-DAG: %[[C15:.*]] = arith.constant 15 : index
// TILE1: %[[RESULT:.*]] = scf.for %[[IV:.*]] = %[[C0]] to %[[C15]] step %[[C3]] iter_args(%[[INNER_OUT:.*]] =
// TILE1: %[[R2:.*]] = scf.if
// TILE1: %[[GEN:.*]] = tensor.generate
return
}
// CHECK-LABEL: func @gemm
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
// CHECK: scf.parallel (%[[ARG3:.*]], %[[ARG4:.*]]) =
// CHECK-SAME: step (%[[C2]], %[[C4]])
// CHECK: scf.for %[[ARG5:.*]] =
// CHECK: linalg.matmul ins(%[[SV1]], %[[SV2]]{{.*}} outs(%[[SV3]]
// TILE1-LABEL: func @gemm
-// TILE1-DAG: %[[C2:.*]] = constant 2 : index
+// TILE1-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE1: scf.parallel (%[[ARG3:.*]]) =
// TILE1-SAME: step (%[[C2]])
// TILE1: %[[SV1:.*]] = memref.subview %{{.*}}[%[[ARG3]], 0]
// TILE1: linalg.matmul ins(%[[SV1]], %{{.*}} outs(%[[SV3]]
// TILE2-LABEL: func @gemm
-// TILE2-DAG: %[[C2:.*]] = constant 2 : index
-// TILE2-DAG: %[[C4:.*]] = constant 4 : index
+// TILE2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE2-DAG: %[[C4:.*]] = arith.constant 4 : index
// TILE2: scf.parallel (%[[ARG3:.*]], %[[ARG4:.*]]) =
// TILE2-SAME: step (%[[C2]], %[[C4]])
// TILE2: %[[SV1:.*]] = memref.subview %{{.*}}[%[[ARG3]], 0]
ins(%arg0, %arg1 : memref<?x?x?xf32>, memref<?x?xf32>)
outs(%arg2 : memref<?xf32>) {
^bb0(%arg3 : f32, %arg4 : f32, %arg5 : f32):
- %0 = addf %arg3, %arg4 : f32
- %1 = addf %0, %arg5 : f32
+ %0 = arith.addf %arg3, %arg4 : f32
+ %1 = arith.addf %0, %arg5 : f32
linalg.yield %1 : f32
}
return
}
// CHECK-LABEL: func @reduction
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
// CHECK: scf.for %[[ARG3:.*]] =
// CHECK-SAME: step %[[C2]]
// CHECK: scf.parallel (%[[ARG4:.*]]) =
// CHECK-SAME: outs(%[[SV3]]
// TILE1-LABEL: func @reduction
-// TILE1-DAG: %[[C2:.*]] = constant 2 : index
+// TILE1-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE1: scf.for %[[ARG3:.*]] =
// TILE1-SAME: step %[[C2]]
// TILE1: %[[SV1:.*]] = memref.subview %{{.*}}[%[[ARG3]], 0, 0]
// TILE1-SAME: outs(%{{.*}}
// TILE2-LABEL: func @reduction
-// TILE2-DAG: %[[C2:.*]] = constant 2 : index
-// TILE2-DAG: %[[C4:.*]] = constant 4 : index
+// TILE2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE2-DAG: %[[C4:.*]] = arith.constant 4 : index
// TILE2: scf.for %[[ARG3:.*]] =
// TILE2-SAME: step %[[C2]]
// TILE2: scf.parallel (%[[ARG4:.*]]) =
memref<?x?xf32, offset: ?, strides: [?, 1]>)
outs(%sum : memref<?x?xf32, offset: ?, strides: [?, 1]>) {
^bb0(%lhs_in: f32, %rhs_in: f32, %sum_out: f32):
- %result = addf %lhs_in, %rhs_in : f32
+ %result = arith.addf %lhs_in, %rhs_in : f32
linalg.yield %result : f32
}
return
}
// TILE-2-LABEL: func @sum(
// TILE-2-SAME: [[LHS:%.*]]: {{.*}}, [[RHS:%.*]]: {{.*}}, [[SUM:%.*]]: {{.*}}) {
-// TILE-2-DAG: [[C0:%.*]] = constant 0 : index
-// TILE-2-DAG: [[C2:%.*]] = constant 2 : index
+// TILE-2-DAG: [[C0:%.*]] = arith.constant 0 : index
+// TILE-2-DAG: [[C2:%.*]] = arith.constant 2 : index
// TILE-2: [[LHS_ROWS:%.*]] = memref.dim [[LHS]], %c0
// TILE-2: scf.parallel ([[I:%.*]]) = ([[C0]]) to ([[LHS_ROWS]]) step ([[C2]]) {
// TILE-2-NO: scf.parallel
// TILE-02-LABEL: func @sum(
// TILE-02-SAME: [[LHS:%.*]]: {{.*}}, [[RHS:%.*]]: {{.*}}, [[SUM:%.*]]: {{.*}}) {
-// TILE-02-DAG: [[C0:%.*]] = constant 0 : index
-// TILE-02-DAG: [[C2:%.*]] = constant 2 : index
+// TILE-02-DAG: [[C0:%.*]] = arith.constant 0 : index
+// TILE-02-DAG: [[C2:%.*]] = arith.constant 2 : index
// TILE-02: [[LHS_COLS:%.*]] = memref.dim [[LHS]], %c1
// TILE-02: scf.parallel ([[I:%.*]]) = ([[C0]]) to ([[LHS_COLS]]) step ([[C2]]) {
// TILE-02-NO: scf.parallel
// TILE-234-LABEL: func @sum(
// TILE-234-SAME: [[LHS:%.*]]: {{.*}}, [[RHS:%.*]]: {{.*}}, [[SUM:%.*]]: {{.*}}) {
-// TILE-234-DAG: [[C0:%.*]] = constant 0 : index
-// TILE-234-DAG: [[C2:%.*]] = constant 2 : index
-// TILE-234-DAG: [[C3:%.*]] = constant 3 : index
+// TILE-234-DAG: [[C0:%.*]] = arith.constant 0 : index
+// TILE-234-DAG: [[C2:%.*]] = arith.constant 2 : index
+// TILE-234-DAG: [[C3:%.*]] = arith.constant 3 : index
// TILE-234: [[LHS_ROWS:%.*]] = memref.dim [[LHS]], %c0
// TILE-234: [[LHS_COLS:%.*]] = memref.dim [[LHS]], %c1
// TILE-234: scf.parallel ([[I:%.*]], [[J:%.*]]) = ([[C0]], [[C0]]) to ([[LHS_ROWS]], [[LHS_COLS]]) step ([[C2]], [[C3]]) {
// CHECK-LABEL: func @matmul_partly_dynamic_tensor(
// CHECK-SAME: %[[ARG0:.*]]: tensor<?x?xf32>, %[[ARG1:.*]]: tensor<?x2000xf32>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: tensor.dim %[[ARG0]], %[[C0]] : tensor<?x?xf32>
// CHECK: %[[UB1:.*]] = tensor.dim %[[ARG0]], %[[C0]] : tensor<?x?xf32>
// CHECK: %[[UB2:.*]] = tensor.dim %[[ARG0]], %[[C1]] : tensor<?x?xf32>
// CHECK: linalg.matmul ins(%[[S1]], %[[S2]] : tensor<1x1xf32>, tensor<1x2000xf32>) outs(%[[S3]] : tensor<1x2000xf32>) -> tensor<1x2000xf32>
func @matmul_partly_dynamic_tensor(%arg0: tensor<?x?xf32>, %arg1: tensor<?x2000xf32>)
-> tensor<?x2000xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?xf32>
%out = linalg.init_tensor [%d0, 2000] : tensor<?x2000xf32>
%r = linalg.matmul {__internal_linalg_transform__ = "tile"}
#map2 = affine_map<(d0)[s0] -> (d0 - (s0 floordiv 32) * 32)>
func @tiled_and_peeled_matmul(%arg0: tensor<257x259xf32>, %arg1: tensor<259x258xf32>, %arg2: tensor<257x258xf32>) -> tensor<257x258xf32> {
- %c257 = constant 257 : index
- %c64 = constant 64 : index
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c32 = constant 32 : index
+ %c257 = arith.constant 257 : index
+ %c64 = arith.constant 64 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c32 = arith.constant 32 : index
%0 = linalg.fill(%cst, %arg2) : f32, tensor<257x258xf32> -> tensor<257x258xf32>
%1 = scf.for %arg3 = %c0 to %c257 step %c64 iter_args(%arg4 = %0) -> (tensor<257x258xf32>) {
%2 = affine.min #map0(%arg3)
%13 = tensor.insert_slice %12 into %arg6[%arg5, 0] [32, 258] [1, 1] : tensor<32x258xf32> into tensor<?x258xf32>
scf.yield %13 : tensor<?x258xf32>
}
- %7 = cmpi slt, %5, %2 : index
+ %7 = arith.cmpi slt, %5, %2 : index
%8 = scf.if %7 -> (tensor<?x258xf32>) {
%10 = affine.apply #map2(%2)[%2]
%11 = tensor.extract_slice %3[%5, 0] [%10, 259] [1, 1] : tensor<?x259xf32> to tensor<?x259xf32>
// TLOOP-SAME: (%[[ARG_0:.*]]: [[TY:.*]], %[[ARG_1:.*]]: [[TY]],
// TLOOP-SAME: %[[ARG_2:.*]]: [[TY]]) -> [[TY]] {
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
-// TLOOP-DAG: %[[C2:.*]] = constant 2 : index
-// TLOOP-DAG: %[[C3:.*]] = constant 3 : index
-// TLOOP-DAG: %[[C4:.*]] = constant 4 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
+// TLOOP-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TLOOP-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TLOOP-DAG: %[[C4:.*]] = arith.constant 4 : index
// TLOOP: %[[ARG_0_X:.*]] = tensor.dim %[[ARG_0]], %[[C0]] : [[TY]]
// TLOOP: %[[ARG_0_Y:.*]] = tensor.dim %[[ARG_0]], %[[C1]] : [[TY]]
func @generic_op_tensors(
%arg0 : tensor<?x?x?xf32>, %arg1 : tensor<?x?x?xf32>) -> tensor<?x?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
ins(%arg0, %arg1 : tensor<?x?x?xf32>, tensor<?x?x?xf32>)
outs(%3 : tensor<?x?x?xf32>) {
^bb0(%arg2 : f32, %arg3: f32, %arg4: f32):
- %5 = addf %arg2, %arg3 : f32
+ %5 = arith.addf %arg2, %arg3 : f32
linalg.yield %5 : f32
} -> tensor<?x?x?xf32>
return %4 : tensor<?x?x?xf32>
// TLOOP-SAME: %[[ARG_0:.*]]: [[TY:.*]],
// TLOOP-SAME: %[[ARG_1:.*]]: [[TY]]) -> [[TY]] {
-// TLOOP-DAG: %[[C0:.*]] = constant 0 : index
-// TLOOP-DAG: %[[C1:.*]] = constant 1 : index
-// TLOOP-DAG: %[[C2:.*]] = constant 2 : index
-// TLOOP-DAG: %[[C3:.*]] = constant 3 : index
-// TLOOP-DAG: %[[C4:.*]] = constant 4 : index
+// TLOOP-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TLOOP-DAG: %[[C1:.*]] = arith.constant 1 : index
+// TLOOP-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TLOOP-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TLOOP-DAG: %[[C4:.*]] = arith.constant 4 : index
// TLOOP: %[[INIT:.*]] = linalg.init_tensor
// TLOOP: %[[ARG_0_X:.*]] = tensor.dim %[[ARG_0]], %[[C0]] : [[TY]]
func @fold_extract_slice(
%arg0 : tensor<?x128xf32>, %arg1 : tensor<?x42xf32>, %arg2 : tensor<?x42x?xf32>) -> tensor<?x42xf32> {
- // CHECK: %[[C0:.*]] = constant 0
- %c0 = constant 0 : index
+ // CHECK: %[[C0:.*]] = arith.constant 0
+ %c0 = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = tensor.dim %[[ARG1]], %[[C0]]
%0 = tensor.dim %arg1, %c0 : tensor<?x42xf32>
ins(%1, %arg2 : tensor<?x42xf32>, tensor<?x42x?xf32>)
outs(%arg1 : tensor<?x42xf32>) {
^bb0(%arg3 : f32, %arg4: f32, %arg5: f32):
- %5 = addf %arg3, %arg5 : f32
+ %5 = arith.addf %arg3, %arg5 : f32
linalg.yield %5 : f32
} -> tensor<?x42xf32>
return %2 : tensor<?x42xf32>
return
}
// TILE-2-LABEL: func @matmul(
-// TILE-2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-2-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-2-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-2: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-2: scf.for %[[I:.*]] = %{{.*}}{{.*}} to %[[M]] step %{{.*}} {
// TILE-2: %[[szM:.*]] = affine.min #[[$bound_map]](%[[I]])[%[[M]]]
// TILE-2: linalg.matmul ins(%[[sAi]]{{.*}} outs(%[[sCi]]
// TILE-02-LABEL: func @matmul(
-// TILE-02-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-02-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-02-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-02-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-02: %[[N:.*]] = memref.dim %arg1, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-02: scf.for %[[J:.*]] = %{{.*}} to %[[N]] step %{{.*}} {
// TILE-02: %[[K:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-02: linalg.matmul ins(%{{.*}}, %[[sBj]]{{.*}} outs(%[[sCj]]
// TILE-002-LABEL: func @matmul(
-// TILE-002-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-002-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-002-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-002-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-002: %[[ubK:.*]] = memref.dim %{{.*}}, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-002: scf.for %[[K:.*]] = %{{.*}}{{.*}} to %[[ubK]] step %{{.*}} {
// TILE-002: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-002: linalg.matmul ins(%[[sAj]], %[[sBj]]{{.*}} outs(%{{.*}}
// TILE-234-LABEL: func @matmul(
-// TILE-234-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-234-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-234-DAG: %[[C3:.*]] = constant 3 : index
-// TILE-234-DAG: %[[C4:.*]] = constant 4 : index
+// TILE-234-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-234-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-234-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TILE-234-DAG: %[[C4:.*]] = arith.constant 4 : index
// TILE-234: %[[ubM:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-234: %[[ubK:.*]] = memref.dim %{{.*}}, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-234: %[[ubN:.*]] = memref.dim %{{.*}}, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-2-SAME: %[[ARG0:[0-9a-zA-Z]*]]: memref
// TILE-2-SAME: %[[ARG1:[0-9a-zA-Z]*]]: memref
// TILE-2-SAME: %[[ARG2:[0-9a-zA-Z]*]]: memref
-// TILE-2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-2-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-2-DAG: %[[M:.*]] = constant 10 : index
+// TILE-2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-2-DAG: %[[M:.*]] = arith.constant 10 : index
// TILE-2: scf.for %[[I:.*]] = %{{.*}} to %[[M]] step %{{.*}} {
// TILE-2: %[[sAi:.*]] = memref.subview %{{.*}}[%[[I]], 0] [2, 16] [1, 1] : memref<10x16xf32, #[[$strided2D]]> to memref<2x16xf32, #[[$strided2D]]>
// TILE-2: %[[sCi:.*]] = memref.subview %{{.*}}[%[[I]], 0] [2, 12] [1, 1] : memref<10x12xf32, #[[$strided2D]]> to memref<2x12xf32, #[[$strided2D]]>
// TILE-2: linalg.matmul ins(%[[sAi]], %{{.*}}{{.*}} outs(%[[sCi]]
// TILE-02-LABEL: func @matmul_static(
-// TILE-02-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-02-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-02-DAG: %[[N:.*]] = constant 12 : index
+// TILE-02-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-02-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-02-DAG: %[[N:.*]] = arith.constant 12 : index
// TILE-02: scf.for %[[J:.*]] = %{{.*}} to %[[N]] step %{{.*}} {
// TILE-02: %[[sBj:.*]] = memref.subview %{{.*}}[0, %[[J]]] [16, 2] [1, 1] : memref<16x12xf32, #[[$strided2D]]> to memref<16x2xf32, #[[$strided2D]]>
// TILE-02: %[[sCj:.*]] = memref.subview %{{.*}}[0, %[[J]]] [10, 2] [1, 1] : memref<10x12xf32, #[[$strided2D]]> to memref<10x2xf32, #[[$strided2D]]>
// TILE-02: linalg.matmul ins(%{{.*}}, %[[sBj]]{{.*}} outs(%[[sCj]]
// TILE-002-LABEL: func @matmul_static(
-// TILE-002-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-002-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-002-DAG: %[[C16:.*]] = constant 16 : index
+// TILE-002-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-002-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-002-DAG: %[[C16:.*]] = arith.constant 16 : index
// TILE-002: scf.for %[[K:.*]] = %{{.*}}{{.*}} to %[[C16]] step %{{.*}} {
// TILE-002: %[[sAj:.*]] = memref.subview %{{.*}}[0, %[[K]]] [10, 2] [1, 1] : memref<10x16xf32, #[[$strided2D]]> to memref<10x2xf32, #[[$strided2D]]>
// TILE-002: %[[sBj:.*]] = memref.subview %{{.*}}[%[[K]], 0] [2, 12] [1, 1] : memref<16x12xf32, #[[$strided2D]]> to memref<2x12xf32, #[[$strided2D]]>
// TILE-002: linalg.matmul ins(%[[sAj]], %[[sBj]]{{.*}} outs(%{{.*}}
// TILE-234-LABEL: func @matmul_static(
-// TILE-234-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-234-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-234-DAG: %[[C3:.*]] = constant 3 : index
-// TILE-234-DAG: %[[C4:.*]] = constant 4 : index
-// TILE-234-DAG: %[[C10:.*]] = constant 10 : index
-// TILE-234-DAG: %[[C16:.*]] = constant 16 : index
-// TILE-234-DAG: %[[C12:.*]] = constant 12 : index
+// TILE-234-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-234-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-234-DAG: %[[C3:.*]] = arith.constant 3 : index
+// TILE-234-DAG: %[[C4:.*]] = arith.constant 4 : index
+// TILE-234-DAG: %[[C10:.*]] = arith.constant 10 : index
+// TILE-234-DAG: %[[C16:.*]] = arith.constant 16 : index
+// TILE-234-DAG: %[[C12:.*]] = arith.constant 12 : index
// TILE-234: scf.for %[[I:.*]] = %{{.*}}{{.*}} to %[[C10]] step %{{.*}} {
// TILE-234: scf.for %[[J:.*]] = %{{.*}}{{.*}} to %[[C12]] step %{{.*}} {
// TILE-234: scf.for %[[K:.*]] = %{{.*}}{{.*}} to %[[C16]] step %{{.*}} {
// TILE-2-SAME: %[[ARG0:[0-9a-zA-Z]*]]: memref
// TILE-2-SAME: %[[ARG1:[0-9a-zA-Z]*]]: memref
// TILE-2-SAME: %[[ARG2:[0-9a-zA-Z]*]]: memref
-// TILE-2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-2-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-2-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-2: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-2: scf.for %[[I:.*]] = %{{.*}}{{.*}} to %[[M]] step %{{.*}} {
// TILE-2: %[[szM:.*]] = affine.min #[[$bound_map]](%[[I]])[%[[M]]]
// TILE-02-SAME: %[[ARG0:[0-9a-zA-Z]*]]: memref
// TILE-02-SAME: %[[ARG1:[0-9a-zA-Z]*]]: memref
// TILE-02-SAME: %[[ARG2:[0-9a-zA-Z]*]]: memref
-// TILE-02-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-02-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-02-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-02-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-02: %[[K:.*]] = memref.dim %{{.*}}, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-02: scf.for %[[J:.*]] = %{{.*}}{{.*}} to %[[K]] step %{{.*}} {
// TILE-02: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-234-SAME: %[[ARG0:[0-9a-zA-Z]*]]: memref
// TILE-234-SAME: %[[ARG1:[0-9a-zA-Z]*]]: memref
// TILE-234-SAME: %[[ARG2:[0-9a-zA-Z]*]]: memref
-// TILE-234-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-234-DAG: %[[C2:.*]] = constant 2 : index
-// TILE-234-DAG: %[[C3:.*]] = constant 3 : index
+// TILE-234-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-234-DAG: %[[C2:.*]] = arith.constant 2 : index
+// TILE-234-DAG: %[[C3:.*]] = arith.constant 3 : index
// TILE-234: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?x?xf32, #[[$strided2D]]>
// TILE-234: %[[K:.*]] = memref.dim %{{.*}}, %c1 : memref<?x?xf32, #[[$strided2D]]>
// TILE-234: scf.for %[[I:.*]] = %{{.*}}{{.*}} to %[[M]] step %{{.*}} {
return
}
// TILE-2-LABEL: func @dot(
-// TILE-2-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-2-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-2-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-2: %[[M:.*]] = memref.dim %{{.*}}, %c0 : memref<?xf32, #[[$strided1D]]>
// TILE-2: scf.for %[[I:.*]] = %{{.*}}{{.*}} to %[[M]] step %{{.*}} {
// TILE-2: %[[szM:.*]] = affine.min #[[$bound_map]](%[[I]])[%[[M]]]
// TILE-002-NOT: scf.for
// TILE-234-LABEL: func @dot(
-// TILE-234-DAG: %[[C0:.*]] = constant 0 : index
-// TILE-234-DAG: %[[C2:.*]] = constant 2 : index
+// TILE-234-DAG: %[[C0:.*]] = arith.constant 0 : index
+// TILE-234-DAG: %[[C2:.*]] = arith.constant 2 : index
// TILE-234: %[[ubK:.*]] = memref.dim %{{.*}}, %c0 : memref<?xf32, #[[$strided1D]]>
// TILE-234: scf.for %[[I:.*]] = %{{.*}} to %[[ubK]] step %{{.*}} {
// TILE-234: %[[szM:.*]] = affine.min #[[$bound_map_2]](%[[I]])[%[[ubK]]]
ins(%arg0, %arg1 : memref<?x?xf32, offset: ?, strides: [?, 1]>, memref<?x?xf32, offset: ?, strides: [?, 1]>)
outs(%arg2 : memref<?x?xf32, offset: ?, strides: [?, 1]>) {
^bb0(%arg4: f32, %arg5: f32, %arg6: f32): // no predecessors
- %4 = addf %arg4, %arg5 : f32
+ %4 = arith.addf %arg4, %arg5 : f32
linalg.yield %4 : f32
}
return
// CHECK-TILE-2-LABEL: func @tiled_loop_3d_tensor(
// CHECK-TILE-2-SAME: %[[input:.*]]: tensor<?x?x?xf32>, %[[s0:.*]]: index, %[[s1:.*]]: index, %[[s2:.*]]: index
-// CHECK-TILE-2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILE-2-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-TILE-2-DAG: %[[c2:.*]] = constant 2 : index
+// CHECK-TILE-2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILE-2-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-TILE-2-DAG: %[[c2:.*]] = arith.constant 2 : index
// CHECK-TILE-2: %[[dim0:.*]] = tensor.dim %[[input]], %[[c0]]
// CHECK-TILE-2: %[[dim1:.*]] = tensor.dim %[[input]], %[[c1]]
// CHECK-TILE-2: %[[dim2:.*]] = tensor.dim %[[input]], %[[c2]]
// CHECK-TILE-012-SKIP-PARTIAL: func @tiled_loop_3d_tensor(
// CHECK-TILE-012-SKIP-PARTIAL-SAME: %[[input:.*]]: tensor<?x?x?xf32>
-// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c2:.*]] = constant 2 : index
+// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[c2:.*]] = arith.constant 2 : index
// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[dim0:.*]] = tensor.dim %[[input]], %[[c0]]
// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[dim1:.*]] = tensor.dim %[[input]], %[[c1]]
// CHECK-TILE-012-SKIP-PARTIAL-DAG: %[[dim2:.*]] = tensor.dim %[[input]], %[[c2]]
// CHECK-TILE-012-SKIP-PARTIAL: linalg.tiled_loop {{.*}} = (%[[p0]], %[[c0]], %[[c0]]) to (%[[dim0]], %[[dim1]], %[[dim2]])
func @tiled_loop_3d_tensor(%arg0: tensor<?x?x?xf32>, %s0: index, %s1: index,
%s2: index) -> tensor<?x?x?xf32> {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
%dim0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%dim1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%dim2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
// CHECK-TILE-2-LABEL: func @tiled_loop_3d_memref(
// CHECK-TILE-2-SAME: %[[input:.*]]: memref<?x?x?xf32>, %[[output:.*]]: memref<?x?x?xf32>, %[[s0:.*]]: index, %[[s1:.*]]: index, %[[s2:.*]]: index
-// CHECK-TILE-2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-TILE-2-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-TILE-2-DAG: %[[c2:.*]] = constant 2 : index
+// CHECK-TILE-2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-TILE-2-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-TILE-2-DAG: %[[c2:.*]] = arith.constant 2 : index
// CHECK-TILE-2: %[[dim0:.*]] = memref.dim %[[input]], %[[c0]]
// CHECK-TILE-2: %[[dim1:.*]] = memref.dim %[[input]], %[[c1]]
// CHECK-TILE-2: %[[dim2:.*]] = memref.dim %[[input]], %[[c2]]
func @tiled_loop_3d_memref(%arg0: memref<?x?x?xf32>, %output: memref<?x?x?xf32>,
%s0: index, %s1: index, %s2: index) {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
%dim0 = memref.dim %arg0, %c0 : memref<?x?x?xf32>
%dim1 = memref.dim %arg0, %c1 : memref<?x?x?xf32>
%dim2 = memref.dim %arg0, %c2 : memref<?x?x?xf32>
// CHECK-TILE-012-LABEL: func @step_1_do_not_peel
func @step_1_do_not_peel(%arg0: tensor<?x?x?xf32>) -> tensor<?x?x?xf32> {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
%dim0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%dim1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%dim2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
func @divides_evenly_do_not_peel(%arg0: tensor<?x?x?xf32>, %s: index)
-> tensor<?x?x?xf32> {
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
- %c64 = constant 64 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
+ %c64 = arith.constant 64 : index
%dim0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%dim1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%dim2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
func @tiled_loop(%A: memref<192x192xf32>,
%B: memref<192x192xf32>,
%C: memref<192x192xf32>) {
- %cst = constant 0.000000e+00 : f32
- %c24 = constant 24 : index
- %c16 = constant 16 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c24 = arith.constant 24 : index
+ %c16 = arith.constant 16 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c192, %c192) step (%c24, %c16)
ins (%A_ = %A: memref<192x192xf32>, %B_ = %B: memref<192x192xf32>)
// CHECK-LABEL: @tiled_loop
// CHECK-SAME: %[[A:.*]]: memref<192x192xf32>, %[[B:.*]]: memref<192x192xf32>,
// CHECK-SAME: %[[C:.*]]: memref<192x192xf32>) {
-// CHECK: %[[C24:.*]] = constant 24 : index
-// CHECK: %[[C16:.*]] = constant 16 : index
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C192:.*]] = constant 192 : index
+// CHECK: %[[C24:.*]] = arith.constant 24 : index
+// CHECK: %[[C16:.*]] = arith.constant 16 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C192:.*]] = arith.constant 192 : index
// CHECK: scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[C0]], %[[C0]])
// CHECK-SAME: to (%[[C192]], %[[C192]]) step (%[[C24]], %[[C16]]) {
// CHECK: %[[A_sub:.*]] = memref.subview %[[A]][%[[I]]
func @tiled_loop_reduction(%A: memref<192x192xf32>,
%B: memref<192x192xf32>,
%C: memref<f32>) {
- %c24 = constant 24 : index
- %c16 = constant 16 : index
- %c0 = constant 0 : index
- %c192 = constant 192 : index
- %cst = constant 0.000000e+00 : f32
+ %c24 = arith.constant 24 : index
+ %c16 = arith.constant 16 : index
+ %c0 = arith.constant 0 : index
+ %c192 = arith.constant 192 : index
+ %cst = arith.constant 0.000000e+00 : f32
linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c192, %c192) step (%c24, %c16)
ins (%A_ = %A: memref<192x192xf32>, %B_ = %B: memref<192x192xf32>)
}
// CHECK-LABEL: @tiled_loop_reduction
-// CHECK: %[[C24:.*]] = constant 24 : index
-// CHECK: %[[C16:.*]] = constant 16 : index
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C192:.*]] = constant 192 : index
+// CHECK: %[[C24:.*]] = arith.constant 24 : index
+// CHECK: %[[C16:.*]] = arith.constant 16 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C192:.*]] = arith.constant 192 : index
// CHECK: scf.for %{{.*}} = %[[C0]] to %[[C192]] step %[[C24]]
// CHECK: scf.for %{{.*}} = %[[C0]] to %[[C192]] step %[[C16]]
// CHECK: linalg.fill
func @tiled_loop_row_reduction(%A: memref<10x8xf32>,
%B: memref<8xf32>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c8 = constant 8 : index
- %c10 = constant 10 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
+ %c10 = arith.constant 10 : index
+ %cst = arith.constant 0.000000e+00 : f32
linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c10, %c8) step (%c2, %c4)
ins (%A_ = %A: memref<10x8xf32>)
ins(%A_sub : memref<2x4xf32, #strided_2d>)
outs(%B_sub : memref<4xf32, #strided_1d>) {
^bb(%a: f32, %b: f32) :
- %0 = addf %a, %b: f32
+ %0 = arith.addf %a, %b: f32
linalg.yield %0 : f32
}
linalg.yield
// CHECK-LABEL: @tiled_loop_row_reduction
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C10:.*]] = constant 10 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C10:.*]] = arith.constant 10 : index
// CHECK: scf.parallel (%[[J:.*]]) = (%[[C0]]) to (%[[C8]]) step (%[[C4]])
// CHECK-NEXT: scf.for %[[I:.*]] = %[[C0]] to %[[C10]] step %[[C2]]
func @tiled_loop_col_reduction(%A: memref<10x8xf32>,
%B: memref<10xf32>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c8 = constant 8 : index
- %c10 = constant 10 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c8 = arith.constant 8 : index
+ %c10 = arith.constant 10 : index
+ %cst = arith.constant 0.000000e+00 : f32
linalg.tiled_loop (%i, %j) = (%c0, %c0) to (%c10, %c8) step (%c2, %c4)
ins (%A_ = %A: memref<10x8xf32>)
ins(%A_sub : memref<2x4xf32, #strided_2d>)
outs(%B_sub : memref<2xf32, #strided_1d>) {
^bb(%a: f32, %b: f32) :
- %0 = addf %a, %b: f32
+ %0 = arith.addf %a, %b: f32
linalg.yield %0 : f32
}
linalg.yield
// CHECK-LABEL: @tiled_loop_col_reduction
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C10:.*]] = constant 10 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C10:.*]] = arith.constant 10 : index
// CHECK: scf.parallel (%[[I:.*]]) = (%[[C0]]) to (%[[C10]]) step (%[[C2]])
// CHECK-NEXT: scf.for %[[J:.*]] = %[[C0]] to %[[C8]] step %[[C4]]
return
}
// CHECK-LABEL: func @dot
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-DAG: %[[c8000:.*]] = constant 8000 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[c8000:.*]] = arith.constant 8000 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c8000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c1]] {
// CHECK: load
// CHECK: load
// CHECK: load
-// CHECK: mulf
-// CHECK: addf
+// CHECK: arith.mulf
+// CHECK: arith.addf
// CHECK: store
func @matvec(%A: memref<?x?xf32, offset: ?, strides: [?, 1]>,
return
}
// CHECK-LABEL: func @matvec
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c5:.*]] = constant 5 : index
-// CHECK-DAG: %[[c6:.*]] = constant 6 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c5:.*]] = arith.constant 5 : index
+// CHECK-DAG: %[[c6:.*]] = arith.constant 6 : index
// CHECK: scf.parallel {{.*}} step (%[[c5]])
// CHECK: scf.for {{.*}} step %[[c6]]
// CHECK: linalg.matvec
return
}
// CHECK-LABEL: func @matmul
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c2:.*]] = constant 2 : index
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
-// CHECK-DAG: %[[c4:.*]] = constant 4 : index
-// CHECK-DAG: %[[c20:.*]] = constant 20 : index
-// CHECK-DAG: %[[c30:.*]] = constant 30 : index
-// CHECK-DAG: %[[c40:.*]] = constant 40 : index
-// CHECK-DAG: %[[c200:.*]] = constant 200 : index
-// CHECK-DAG: %[[c300:.*]] = constant 300 : index
-// CHECK-DAG: %[[c400:.*]] = constant 400 : index
-// CHECK-DAG: %[[c2000:.*]] = constant 2000 : index
-// CHECK-DAG: %[[c3000:.*]] = constant 3000 : index
-// CHECK-DAG: %[[c4000:.*]] = constant 4000 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[c4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-DAG: %[[c30:.*]] = arith.constant 30 : index
+// CHECK-DAG: %[[c40:.*]] = arith.constant 40 : index
+// CHECK-DAG: %[[c200:.*]] = arith.constant 200 : index
+// CHECK-DAG: %[[c300:.*]] = arith.constant 300 : index
+// CHECK-DAG: %[[c400:.*]] = arith.constant 400 : index
+// CHECK-DAG: %[[c2000:.*]] = arith.constant 2000 : index
+// CHECK-DAG: %[[c3000:.*]] = arith.constant 3000 : index
+// CHECK-DAG: %[[c4000:.*]] = arith.constant 4000 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c2000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c3000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c4000]] {
memref<?x?xf32, offset: ?, strides: [?, 1]>)
outs(%C : memref<?x?xf32, offset: ?, strides: [?, 1]>) {
^bb(%a: f32, %b: f32, %c: f32):
- %d = mulf %a, %b: f32
- %e = addf %c, %d: f32
+ %d = arith.mulf %a, %b: f32
+ %e = arith.addf %c, %d: f32
linalg.yield %e: f32
}
return
return
}
// CHECK-LABEL: func @matvec_perm
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c5:.*]] = constant 5 : index
-// CHECK-DAG: %[[c6:.*]] = constant 6 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c5:.*]] = arith.constant 5 : index
+// CHECK-DAG: %[[c6:.*]] = arith.constant 6 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c6]]
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c5]]
// CHECK: linalg.matvec
return
}
// CHECK-LABEL: func @matmul_perm
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c20:.*]] = constant 20 : index
-// CHECK-DAG: %[[c30:.*]] = constant 30 : index
-// CHECK-DAG: %[[c40:.*]] = constant 40 : index
-// CHECK-DAG: %[[c200:.*]] = constant 200 : index
-// CHECK-DAG: %[[c300:.*]] = constant 300 : index
-// CHECK-DAG: %[[c400:.*]] = constant 400 : index
-// CHECK-DAG: %[[c2000:.*]] = constant 2000 : index
-// CHECK-DAG: %[[c3000:.*]] = constant 3000 : index
-// CHECK-DAG: %[[c4000:.*]] = constant 4000 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c20:.*]] = arith.constant 20 : index
+// CHECK-DAG: %[[c30:.*]] = arith.constant 30 : index
+// CHECK-DAG: %[[c40:.*]] = arith.constant 40 : index
+// CHECK-DAG: %[[c200:.*]] = arith.constant 200 : index
+// CHECK-DAG: %[[c300:.*]] = arith.constant 300 : index
+// CHECK-DAG: %[[c400:.*]] = arith.constant 400 : index
+// CHECK-DAG: %[[c2000:.*]] = arith.constant 2000 : index
+// CHECK-DAG: %[[c3000:.*]] = arith.constant 3000 : index
+// CHECK-DAG: %[[c4000:.*]] = arith.constant 4000 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c3000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c4000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c2000]] {
func @promote_subview_matmul(%arg0: memref<?x?xf32, offset: ?, strides: [?, 1]>,
%arg1: memref<?x?xf32, offset: ?, strides: [?, 1]>,
%arg2: memref<?x?xf32, offset: ?, strides: [?, 1]>) {
- %c2000 = constant 2000 : index
- %c3000 = constant 3000 : index
- %c4000 = constant 4000 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2000 = arith.constant 2000 : index
+ %c3000 = arith.constant 3000 : index
+ %c4000 = arith.constant 4000 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%1 = memref.dim %arg0, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%2 = memref.dim %arg1, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
return
}
// CHECK-LABEL: func @promote_subview_matmul
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c2000:.*]] = constant 2000 : index
-// CHECK-DAG: %[[c3000:.*]] = constant 3000 : index
-// CHECK-DAG: %[[c4000:.*]] = constant 4000 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c2000:.*]] = arith.constant 2000 : index
+// CHECK-DAG: %[[c3000:.*]] = arith.constant 3000 : index
+// CHECK-DAG: %[[c4000:.*]] = arith.constant 4000 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c2000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c3000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c4000]] {
func @promote_first_subview_matmul(%arg0: memref<?x?xf32, offset: ?, strides: [?, 1]>,
%arg1: memref<?x?xf32, offset: ?, strides: [?, 1]>,
%arg2: memref<?x?xf32, offset: ?, strides: [?, 1]>) {
- %c2000 = constant 2000 : index
- %c3000 = constant 3000 : index
- %c4000 = constant 4000 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2000 = arith.constant 2000 : index
+ %c3000 = arith.constant 3000 : index
+ %c4000 = arith.constant 4000 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.dim %arg0, %c0 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%1 = memref.dim %arg0, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
%2 = memref.dim %arg1, %c1 : memref<?x?xf32, offset: ?, strides: [?, 1]>
return
}
// CHECK-LABEL: func @promote_first_subview_matmul
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c2000:.*]] = constant 2000 : index
-// CHECK-DAG: %[[c3000:.*]] = constant 3000 : index
-// CHECK-DAG: %[[c4000:.*]] = constant 4000 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c2000:.*]] = arith.constant 2000 : index
+// CHECK-DAG: %[[c3000:.*]] = arith.constant 3000 : index
+// CHECK-DAG: %[[c4000:.*]] = arith.constant 4000 : index
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c2000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c3000]] {
// CHECK: scf.for {{.*}} = %[[c0]] to {{.*}} step %[[c4000]] {
// CHECK-SAME: outs(%[[s2]] : memref<?x?xf32, #[[$STRIDED_2D]]>)
func @aligned_promote_fill(%arg0: memref<?x?xf32, offset: ?, strides: [?, 1]>) {
- %c2000 = constant 2000 : index
- %c4000 = constant 4000 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf = constant 1.0 : f32
+ %c2000 = arith.constant 2000 : index
+ %c4000 = arith.constant 4000 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf = arith.constant 1.0 : f32
%3 = memref.subview %arg0[%c0, %c0][%c2000, %c4000][%c1, %c1] :
memref<?x?xf32, offset: ?, strides: [?, 1]> to memref<?x?xf32, offset: ?, strides: [?, ?]>
linalg.fill(%cf, %3) { __internal_linalg_transform__ = "_promote_views_aligned_"}
return
}
// CHECK-LABEL: func @aligned_promote_fill
-// CHECK: %[[cf:.*]] = constant {{.*}} : f32
+// CHECK: %[[cf:.*]] = arith.constant {{.*}} : f32
// CHECK: %[[s0:.*]] = memref.subview {{.*}}: memref<?x?xf32, #map{{.*}}> to memref<?x?xf32, #map{{.*}}>
// CHECK: %[[a0:.*]] = memref.alloc() {alignment = 32 : i64} : memref<32000000xi8>
// CHECK: %[[v0:.*]] = memref.view %[[a0]]{{.*}} : memref<32000000xi8> to memref<?x?xf32>
// CHECK: linalg.fill(%[[cf]], %[[v0]]) : f32, memref<?x?xf32>
func @aligned_promote_fill_complex(%arg0: memref<?x?xcomplex<f32>, offset: ?, strides: [?, 1]>) {
- %c2000 = constant 2000 : index
- %c4000 = constant 4000 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf = constant 1.0 : f32
+ %c2000 = arith.constant 2000 : index
+ %c4000 = arith.constant 4000 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf = arith.constant 1.0 : f32
%cc = complex.create %cf, %cf : complex<f32>
%3 = memref.subview %arg0[%c0, %c0][%c2000, %c4000][%c1, %c1] :
memref<?x?xcomplex<f32>, offset: ?, strides: [?, 1]> to memref<?x?xcomplex<f32>, offset: ?, strides: [?, ?]>
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: memref<?x?xf32>
// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: memref<?x?xf32>
-// CHECK-DAG: %[[C16:.*]] = constant 16 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C16:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK-DAG: %[[D0:.*]] = memref.dim %[[ARG0]], %c0
// CHECK-DAG: %[[D1:.*]] = memref.dim %[[ARG0]], %c1
// CHECK-DAG: %[[D2:.*]] = memref.dim %[[ARG1]], %c1
ins(%A, %B : memref<8x16xf32>, memref<16x32xf32>)
outs(%C : memref<8x32xf32>) {
^bb(%a: f32, %b: f32, %c: f32) :
- %d = mulf %a, %b: f32
- %e = addf %c, %d: f32
+ %d = arith.mulf %a, %b: f32
+ %e = arith.addf %c, %d: f32
linalg.yield %e : f32
}
return
ins(%A, %B : memref<8x16xf32>, memref<16x32xf32>)
outs(%C : memref<32x8xf32>) {
^bb(%a: f32, %b: f32, %c: f32) :
- %d = mulf %a, %b: f32
- %e = addf %c, %d: f32
+ %d = arith.mulf %a, %b: f32
+ %e = arith.addf %c, %d: f32
linalg.yield %e : f32
}
return
ins(%A, %B : memref<8x16xi32>, memref<16x32xi32>)
outs(%C : memref<8x32xi32>) {
^bb(%a: i32, %b: i32, %c: i32) :
- %d = muli %a, %b: i32
- %e = addi %c, %d: i32
+ %d = arith.muli %a, %b: i32
+ %e = arith.addi %c, %d: i32
linalg.yield %e : i32
}
return
// CHECK-LABEL: func @test_vectorize_trailing_index
// CHECK-SAME: (%[[ARG0:.*]]: memref<1x2x4x8xindex>)
func @test_vectorize_trailing_index(%arg0: memref<1x2x4x8xindex>) {
- // CHECK-DAG: %[[CST0:.*]] = constant dense<[0, 1, 2, 3, 4, 5, 6, 7]> : vector<8xindex>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
+ // CHECK-DAG: %[[CST0:.*]] = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7]> : vector<8xindex>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
linalg.generic {
indexing_maps = [
affine_map<(d0, d1, d2, d3) -> (d0, d1, d2, d3)>],
// CHECK-LABEL: func @test_vectorize_inner_index
// CHECK-SAME: (%[[ARG0:.*]]: memref<1x2x4x8xindex>)
func @test_vectorize_inner_index(%arg0: memref<1x2x4x8xindex>) {
- // CHECK-DAG: %[[CST0:.*]] = constant dense<[0, 1]> : vector<2xindex>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
+ // CHECK-DAG: %[[CST0:.*]] = arith.constant dense<[0, 1]> : vector<2xindex>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
linalg.generic {
indexing_maps = [
affine_map<(d0, d1, d2, d3) -> (d0, d1, d2, d3)>],
func @generic_vectorize(%arg0: memref<4x256xf32>,
%arg1: memref<4x256xf32>,
%arg2: memref<256xf32>, %i: f32) {
- // CHECK-DAG: %[[CST0:.*]] = constant dense<2.000000e+00> : vector<4x256xf32>
- // CHECK-DAG: %[[CST1:.*]] = constant dense<1.000000e+00> : vector<4x256xf32>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- %c1_f32 = constant 1.0 : f32
+ // CHECK-DAG: %[[CST0:.*]] = arith.constant dense<2.000000e+00> : vector<4x256xf32>
+ // CHECK-DAG: %[[CST1:.*]] = arith.constant dense<1.000000e+00> : vector<4x256xf32>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ %c1_f32 = arith.constant 1.0 : f32
linalg.generic {
args_in = 0 : i64,
args_out = 10 : i64,
// CHECK: %[[V1:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : memref<4x256xf32>, vector<4x256xf32>
%arg9 : f32, %arg10 : f32, %arg11 : f32, %arg12 : f32, %arg13 : f32,
%arg14 : f32):
- // CHECK: %[[ADD:.*]] = addf %[[V0]], %[[V1]] : vector<4x256xf32>
- %6 = addf %arg4, %arg6 : f32
- // CHECK: %[[CMP:.*]] = cmpf ogt, %[[V2]], %[[V1]] : vector<4x256xf32>
- %7 = cmpf ogt, %arg3, %arg6 : f32
+ // CHECK: %[[ADD:.*]] = arith.addf %[[V0]], %[[V1]] : vector<4x256xf32>
+ %6 = arith.addf %arg4, %arg6 : f32
+ // CHECK: %[[CMP:.*]] = arith.cmpf ogt, %[[V2]], %[[V1]] : vector<4x256xf32>
+ %7 = arith.cmpf ogt, %arg3, %arg6 : f32
// CHECK: %[[ARG3B:.*]] = vector.broadcast %[[ARG3]] : f32 to vector<4x256xf32>
- %8 = constant 2.0 : f32
- // CHECK: %[[DIV:.*]] = divf %[[V3]], %[[ARG3B]] : vector<4x256xf32>
- %9 = divf %arg5, %i : f32
+ %8 = arith.constant 2.0 : f32
+ // CHECK: %[[DIV:.*]] = arith.divf %[[V3]], %[[ARG3B]] : vector<4x256xf32>
+ %9 = arith.divf %arg5, %i : f32
// CHECK: %[[EXP:.*]] = math.exp2 %[[V3]] : vector<4x256xf32>
%10 = math.exp2 %arg5 : f32
- // CHECK: %[[MUL:.*]] = mulf %[[V3]], %[[CST0]] : vector<4x256xf32>
- %11 = mulf %arg5, %8 : f32
+ // CHECK: %[[MUL:.*]] = arith.mulf %[[V3]], %[[CST0]] : vector<4x256xf32>
+ %11 = arith.mulf %arg5, %8 : f32
// CHECK: %[[RSQRT:.*]] = math.rsqrt %[[V3]] : vector<4x256xf32>
%12 = math.rsqrt %arg5 : f32
// CHECK: %[[SEL:.*]] = select %[[CMP]], %[[V3]], %[[V1]] : vector<4x256xi1>, vector<4x256xf32>
%13 = select %7, %arg5, %arg6 : f32
- // CHECK: %[[SUB:.*]] = subf %[[V3]], %[[V0]] : vector<4x256xf32>
- %14 = subf %arg5, %arg4 : f32
+ // CHECK: %[[SUB:.*]] = arith.subf %[[V3]], %[[V0]] : vector<4x256xf32>
+ %14 = arith.subf %arg5, %arg4 : f32
// CHECK: %[[TAN:.*]] = math.tanh %[[V3]] : vector<4x256xf32>
%15 = math.tanh %arg5 : f32
// CHECK: vector.transfer_write %[[ADD]], %[[ARG0]][%[[C0]], %[[C0]]] {{.*}} : vector<4x256xf32>, memref<4x256xf32>
%i: f32) -> (tensor<4x256xf32>, tensor<4x256xf32>, tensor<4x256xf32>,
tensor<4x256xf32>, tensor<4x256xf32>, tensor<4x256xf32>, tensor<4x256xf32>,
tensor<4x256xf32>, tensor<4x256xf32>, tensor<4x256xf32>) {
- %c1_f32 = constant 1.0 : f32
+ %c1_f32 = arith.constant 1.0 : f32
%r:10 = linalg.generic {
indexing_maps = [
affine_map<(d0, d1) -> (d0, d1)>,
^bb0(%arg3 : f32, %arg4 : f32, %arg5: f32, %arg6: f32, %arg7: f32, %arg8: f32,
%arg9 : f32, %arg10 : f32, %arg11 : f32, %arg12 : f32, %arg13 : f32,
%arg14 : f32):
- // CHECK-DAG: %[[CST0:.*]] = constant dense<2.000000e+00> : vector<4x256xf32>
- // CHECK-DAG: %[[CST1:.*]] = constant dense<1.000000e+00> : vector<4x256xf32>
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
+ // CHECK-DAG: %[[CST0:.*]] = arith.constant dense<2.000000e+00> : vector<4x256xf32>
+ // CHECK-DAG: %[[CST1:.*]] = arith.constant dense<1.000000e+00> : vector<4x256xf32>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[V2:.*]] = vector.transfer_read %[[ARG1]][%[[C0]], %[[C0]]], {{.*}} : tensor<4x256xf32>, vector<4x256xf32>
// CHECK: %[[V0:.*]] = vector.transfer_read %[[ARG2]][%[[C0]]], {{.*}} : tensor<256xf32>, vector<4x256xf32>
// CHECK: %[[V3:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : tensor<4x256xf32>, vector<4x256xf32>
// CHECK: %[[V1:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : tensor<4x256xf32>, vector<4x256xf32>
- // CHECK: %[[ADD:.*]] = addf %[[V0]], %[[V1]] : vector<4x256xf32>
- %6 = addf %arg4, %arg6 : f32
- // CHECK: %[[CMP:.*]] = cmpf ogt, %[[V2]], %[[V1]] : vector<4x256xf32>
- %7 = cmpf ogt, %arg3, %arg6 : f32
+ // CHECK: %[[ADD:.*]] = arith.addf %[[V0]], %[[V1]] : vector<4x256xf32>
+ %6 = arith.addf %arg4, %arg6 : f32
+ // CHECK: %[[CMP:.*]] = arith.cmpf ogt, %[[V2]], %[[V1]] : vector<4x256xf32>
+ %7 = arith.cmpf ogt, %arg3, %arg6 : f32
// CHECK: %[[ARG3B:.*]] = vector.broadcast %[[ARG3]] : f32 to vector<4x256xf32>
- %8 = constant 2.0 : f32
- // CHECK: %[[DIV:.*]] = divf %[[V3]], %[[ARG3B]] : vector<4x256xf32>
- %9 = divf %arg5, %i : f32
+ %8 = arith.constant 2.0 : f32
+ // CHECK: %[[DIV:.*]] = arith.divf %[[V3]], %[[ARG3B]] : vector<4x256xf32>
+ %9 = arith.divf %arg5, %i : f32
// CHECK: %[[EXP:.*]] = math.exp2 %[[V3]] : vector<4x256xf32>
%10 = math.exp2 %arg5 : f32
- // CHECK: %[[MUL:.*]] = mulf %[[V3]], %[[CST0]] : vector<4x256xf32>
- %11 = mulf %arg5, %8 : f32
+ // CHECK: %[[MUL:.*]] = arith.mulf %[[V3]], %[[CST0]] : vector<4x256xf32>
+ %11 = arith.mulf %arg5, %8 : f32
// CHECK: %[[RSQRT:.*]] = math.rsqrt %[[V3]] : vector<4x256xf32>
%12 = math.rsqrt %arg5 : f32
// CHECK: %[[SEL:.*]] = select %[[CMP]], %[[V3]], %[[V1]] : vector<4x256xi1>, vector<4x256xf32>
%13 = select %7, %arg5, %arg6 : f32
- // CHECK: %[[SUB:.*]] = subf %[[V3]], %[[V0]] : vector<4x256xf32>
- %14 = subf %arg5, %arg4 : f32
+ // CHECK: %[[SUB:.*]] = arith.subf %[[V3]], %[[V0]] : vector<4x256xf32>
+ %14 = arith.subf %arg5, %arg4 : f32
// CHECK: %[[TAN:.*]] = math.tanh %[[V3]] : vector<4x256xf32>
%15 = math.tanh %arg5 : f32
// CHECK: %[[R0:.*]] = vector.transfer_write %[[ADD]], %[[ARG0]][%[[C0]], %[[C0]]] {{.*}} : vector<4x256xf32>, tensor<4x256xf32>
// CHECK-DAG: #[[$MAP2:.*]] = affine_map<(d0) -> (0, 0, d0, 0)>
// CHECK-DAG: #[[$MAP3:.*]] = affine_map<(d0, d1) -> (d1, 0, d0, 0)>
// CHECK: func @generic_vectorize_broadcast_transpose
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[CF:.*]] = constant 0.000000e+00 : f32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[CF:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[V0:.*]] = vector.transfer_read %{{.*}}[%[[C0]], %[[C0]]], %[[CF]] {in_bounds = [true, true, true, true], permutation_map = #[[$MAP0]]} : memref<4x4xf32>, vector<4x4x4x4xf32>
// CHECK: %[[V1:.*]] = vector.transfer_read %{{.*}}[%[[C0]]], %[[CF]] {in_bounds = [true, true, true, true], permutation_map = #[[$MAP1]]} : memref<4xf32>, vector<4x4x4x4xf32>
// CHECK: %[[V2:.*]] = vector.transfer_read %{{.*}}[%[[C0]]], %[[CF]] {in_bounds = [true, true, true, true], permutation_map = #[[$MAP2]]} : memref<4xf32>, vector<4x4x4x4xf32>
// CHECK: %[[V3:.*]] = vector.transfer_read %{{.*}}[%[[C0]], %[[C0]]], %[[CF]] {in_bounds = [true, true, true, true], permutation_map = #[[$MAP3]]} : memref<4x4xf32>, vector<4x4x4x4xf32>
-// CHECK: %[[SUB:.*]] = subf %[[V0]], %[[V1]] : vector<4x4x4x4xf32>
-// CHECK: %[[ADD0:.*]] = addf %[[V2]], %[[SUB]] : vector<4x4x4x4xf32>
-// CHECK: %[[ADD1:.*]] = addf %[[V3]], %[[ADD0]] : vector<4x4x4x4xf32>
+// CHECK: %[[SUB:.*]] = arith.subf %[[V0]], %[[V1]] : vector<4x4x4x4xf32>
+// CHECK: %[[ADD0:.*]] = arith.addf %[[V2]], %[[SUB]] : vector<4x4x4x4xf32>
+// CHECK: %[[ADD1:.*]] = arith.addf %[[V3]], %[[ADD0]] : vector<4x4x4x4xf32>
// CHECK: vector.transfer_write %[[ADD1]], {{.*}} : vector<4x4x4x4xf32>, memref<4x4x4x4xf32>
func @generic_vectorize_broadcast_transpose(
%A: memref<4xf32>, %B: memref<4x4xf32>, %C: memref<4x4x4x4xf32>) {
ins(%B, %A, %A, %B: memref<4x4xf32>, memref<4xf32>, memref<4xf32>, memref<4x4xf32>)
outs(%C : memref<4x4x4x4xf32>) {
^bb0(%arg0: f32, %arg1: f32, %arg2: f32, %arg3: f32, %arg4: f32): // no predecessors
- %s = subf %arg0, %arg1 : f32
- %a = addf %arg2, %s : f32
- %b = addf %arg3, %a : f32
+ %s = arith.subf %arg0, %arg1 : f32
+ %a = arith.addf %arg2, %s : f32
+ %b = arith.addf %arg3, %a : f32
linalg.yield %b : f32
}
return
// CHECK: vector.transfer_read {{.*}}{in_bounds = [true, true, true, true], permutation_map = #[[MAP0]]} : memref<14x7xf32>, vector<7x14x8x16xf32>
// CHECK: vector.transfer_read {{.*}}{in_bounds = [true, true, true, true], permutation_map = #[[MAP1]]} : memref<16x14xf32>, vector<7x14x8x16xf32>
// CHECK: vector.transfer_read {{.*}}{in_bounds = [true, true, true, true], permutation_map = #[[MAP2]]} : memref<16x14x7x8xf32>, vector<7x14x8x16xf32>
-// CHECK: addf {{.*}} : vector<7x14x8x16xf32>
-// CHECK: addf {{.*}} : vector<7x14x8x16xf32>
+// CHECK: arith.addf {{.*}} : vector<7x14x8x16xf32>
+// CHECK: arith.addf {{.*}} : vector<7x14x8x16xf32>
// CHECK: vector.transfer_write {{.*}} : vector<7x14x8x16xf32>, memref<7x14x8x16xf32>
func @vectorization_transpose(%A: memref<14x7xf32>, %B: memref<16x14xf32>,
%C: memref<16x14x7x8xf32>, %D: memref<7x14x8x16xf32>) {
ins(%A, %B, %C : memref<14x7xf32>, memref<16x14xf32>, memref<16x14x7x8xf32>)
outs(%D : memref<7x14x8x16xf32>) {
^bb(%a: f32, %b: f32, %c: f32, %d: f32) :
- %e = addf %a, %b: f32
- %f = addf %e, %c: f32
+ %e = arith.addf %a, %b: f32
+ %f = arith.addf %e, %c: f32
linalg.yield %f : f32
}
return
func @matmul_tensors(
%arg0: tensor<8x4xf32>, %arg1: tensor<4x12xf32>, %arg2: tensor<8x12xf32>)
-> tensor<8x12xf32> {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[VEC_C0:.*]] = constant dense<0.000000e+00> : vector<8x12xf32>
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[VEC_C0:.*]] = arith.constant dense<0.000000e+00> : vector<8x12xf32>
// CHECK-DAG: %[[V0:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : tensor<8x4xf32>, vector<8x4xf32>
// CHECK-DAG: %[[V1:.*]] = vector.transfer_read %[[ARG1]][%[[C0]], %[[C0]]], {{.*}} : tensor<4x12xf32>, vector<12x4xf32>
// CHECK-DAG: %[[V2:.*]] = vector.transfer_read %[[ARG2]][%[[C0]], %[[C0]]], {{.*}} : tensor<8x12xf32>, vector<8x12xf32>
// CHECK-SAME: iterator_types = ["parallel", "parallel", "reduction"], kind = #vector.kind<add>}
// CHECK-SAME: %[[V0]], %[[V1]], %[[VEC_C0]] :
// CHECK-SAME: vector<8x4xf32>, vector<12x4xf32> into vector<8x12xf32>
- // CHECK: %[[C2:.*]] = addf %[[V2]], %[[C]] : vector<8x12xf32>
+ // CHECK: %[[C2:.*]] = arith.addf %[[V2]], %[[C]] : vector<8x12xf32>
// CHECK: %[[W:.*]] = vector.transfer_write %[[C2]], %[[ARG2]][%[[C0]], %[[C0]]] {in_bounds = [true, true]} : vector<8x12xf32>, tensor<8x12xf32>
%0 = linalg.matmul ins(%arg0, %arg1: tensor<8x4xf32>, tensor<4x12xf32>)
outs(%arg2: tensor<8x12xf32>)
// CHECK-LABEL: func @pad_static(
// CHECK-SAME: %[[ARG0:.*]]: tensor<2x?x2xf32>, %[[PAD:.*]]: f32
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-DAG: %[[INIT:.*]] = linalg.init_tensor [2, 3, 4] : tensor<2x3x4xf32>
// CHECK-DAG: %[[VEC:.*]] = vector.broadcast %[[PAD]] : f32 to vector<2x3x4xf32>
// CHECK: %[[FILL:.*]] = vector.transfer_write %[[VEC]], %[[INIT]]{{.*}} : vector<2x3x4xf32>, tensor<2x3x4xf32>
// CHECK-LABEL: func @pad_static_source(
// CHECK-SAME: %[[ARG0:.*]]: tensor<2x5x2xf32>, %[[PAD:.*]]: f32
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK: %[[INIT:.*]] = linalg.init_tensor [2, 6, 4] : tensor<2x6x4xf32>
// CHECK: %[[VEC:.*]] = vector.broadcast %[[PAD]] : f32 to vector<2x6x4xf32>
// CHECK: %[[FILL:.*]] = vector.transfer_write %[[VEC]], %[[INIT]][%[[C0]], %[[C0]], %[[C0]]] {in_bounds = [true, true, true]} : vector<2x6x4xf32>, tensor<2x6x4xf32>
// CHECK-LABEL: func @pad_static_dynamic(
// CHECK-SAME: %[[SRC:.*]]: tensor<1x2x2x?xf32>, %[[LOW:.*]]: index, %[[HIGH:.*]]: index
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[C5:.*]] = constant 5 : index
-// CHECK: %[[V0:.*]] = addi %[[LOW]], %[[C2]] : index
-// CHECK: %[[V1:.*]] = addi %[[V0]], %[[C3]] : index
-// CHECK: %[[V2:.*]] = addi %[[HIGH]], %[[C5]] : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[C5:.*]] = arith.constant 5 : index
+// CHECK: %[[V0:.*]] = arith.addi %[[LOW]], %[[C2]] : index
+// CHECK: %[[V1:.*]] = arith.addi %[[V0]], %[[C3]] : index
+// CHECK: %[[V2:.*]] = arith.addi %[[HIGH]], %[[C5]] : index
// CHECK: %[[DIM3:.*]] = tensor.dim %[[SRC]], %[[C3]] : tensor<1x2x2x?xf32>
-// CHECK: %[[V4:.*]] = addi %[[DIM3]], %[[C3]] : index
-// CHECK: %[[V5:.*]] = addi %[[V4]], %[[C2]] : index
+// CHECK: %[[V4:.*]] = arith.addi %[[DIM3]], %[[C3]] : index
+// CHECK: %[[V5:.*]] = arith.addi %[[V4]], %[[C2]] : index
// CHECK: %[[INIT:.*]] = linalg.init_tensor [6, %[[V1]], %[[V2]], %[[V5]]] : tensor<6x?x?x?xf32>
// CHECK: %[[FILL:.*]] = linalg.fill(%{{.*}}, %[[INIT]]) : f32, tensor<6x?x?x?xf32> -> tensor<6x?x?x?xf32>
// CHECK: %[[SRCDIM:.*]] = tensor.dim %[[SRC]], %[[C3]] : tensor<1x2x2x?xf32>
// CHECK-LABEL: func @pad_and_transfer_read
// CHECK-SAME: %[[ARG0:.*]]: tensor<5x6xf32>
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C5:.*]] = constant 5.0
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C5:.*]] = arith.constant 5.0
// CHECK: %[[RESULT:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], %[[C5]] : tensor<5x6xf32>, vector<7x9xf32>
// CHECK: return %[[RESULT]]
func @pad_and_transfer_read(%arg0: tensor<5x6xf32>) -> vector<7x9xf32> {
- %c0 = constant 0 : index
- %c5 = constant 5.0 : f32
- %c6 = constant 6.0 : f32
+ %c0 = arith.constant 0 : index
+ %c5 = arith.constant 5.0 : f32
+ %c6 = arith.constant 6.0 : f32
%0 = linalg.pad_tensor %arg0 low[0, 0] high[5, 7] {
^bb0(%arg1: index, %arg2: index):
linalg.yield %c5 : f32
// CHECK-LABEL: func @pad_and_transfer_write_static
// CHECK-SAME: %[[ARG0:.*]]: tensor<5x6xf32>
// CHECK-NOT: linalg.pad_tensor
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VEC0:.*]] = call @make_vector() : () -> vector<7x9xf32>
// CHECK: %[[RESULT:.*]] = vector.transfer_write %[[VEC0]], %[[ARG0]][%[[C0]], %[[C0]]] : vector<7x9xf32>, tensor<5x6xf32>
// CHECK: return %[[RESULT]]
func @pad_and_transfer_write_static(
%arg0: tensor<5x6xf32>) -> tensor<5x6xf32> {
- %c0 = constant 0 : index
- %c5 = constant 5.0 : f32
+ %c0 = arith.constant 0 : index
+ %c5 = arith.constant 5.0 : f32
%0 = linalg.pad_tensor %arg0 low[0, 0] high[5, 7] {
^bb0(%arg2: index, %arg3: index):
linalg.yield %c5 : f32
// CHECK-LABEL: func @pad_and_transfer_write_dynamic_static
// CHECK-SAME: %[[ARG0:.*]]: tensor<?x?xf32>, %[[SIZE:.*]]: index, %[[PADDING:.*]]: index
// CHECK-NOT: linalg.pad_tensor
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[SUB:.*]] = tensor.extract_slice %[[ARG0]][0, 0] [%[[SIZE]], 6] [1, 1] : tensor<?x?xf32> to tensor<?x6xf32>
// CHECK: %[[VEC0:.*]] = call @make_vector() : () -> vector<7x9xf32>
// CHECK: %[[RESULT:.*]] = vector.transfer_write %[[VEC0]], %[[SUB]][%[[C0]], %[[C0]]] : vector<7x9xf32>, tensor<?x6xf32>
// CHECK: return %[[RESULT]]
func @pad_and_transfer_write_dynamic_static(
%arg0: tensor<?x?xf32>, %size: index, %padding: index) -> tensor<?x6xf32> {
- %c0 = constant 0 : index
- %c5 = constant 5.0 : f32
+ %c0 = arith.constant 0 : index
+ %c5 = arith.constant 5.0 : f32
%s = tensor.extract_slice %arg0[0, 0] [%size, 6] [1, 1]
: tensor<?x?xf32> to tensor<?x6xf32>
%0 = linalg.pad_tensor %s low[0, 0] high[%padding, 7] {
// CHECK-LABEL: func @pad_and_insert_slice
// CHECK-SAME: %[[ARG0:.*]]: tensor<5x6xf32>
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C5:.*]] = constant 5.0
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C5:.*]] = arith.constant 5.0
// CHECK: %[[VEC0:.*]] = call @make_vector() : () -> tensor<12x13xf32>
// CHECK: %[[READ:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], %[[C5]] : tensor<5x6xf32>, vector<7x9xf32>
// CHECK: %[[WRITE:.*]] = vector.transfer_write %[[READ]], %[[VEC0]][%[[C0]], %[[C0]]] {in_bounds = [true, true]} : vector<7x9xf32>, tensor<12x13xf32>
// CHECK: return %[[WRITE]]
func @pad_and_insert_slice(
%arg0: tensor<5x6xf32>) -> tensor<12x13xf32> {
- %c0 = constant 0 : index
- %c5 = constant 5.0 : f32
+ %c0 = arith.constant 0 : index
+ %c5 = arith.constant 5.0 : f32
%0 = linalg.pad_tensor %arg0 low[0, 0] high[2, 3] {
^bb0(%arg2: index, %arg3: index):
linalg.yield %c5 : f32
// CHECK-LABEL: func @pad_tensor_non_const_pad_value
// CHECK-SAME: %[[ARG0:.*]]: tensor<5x6xf32>
// CHECK-NOT: linalg.pad_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
// CHECK: %[[FILL:.*]] = tensor.generate
-// CHECK: %[[RES:.*]] = mulf
+// CHECK: %[[RES:.*]] = arith.mulf
// CHECK: tensor.yield %[[RES]] : f32
// CHECK: %[[READ:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], %{{.*}} {in_bounds = [true, true]} : tensor<5x6xf32>, vector<5x6xf32>
// CHECK: %[[WRITE:.*]] = vector.transfer_write %[[READ]], %[[FILL]][%[[C3]], %[[C4]]] {in_bounds = [true, true]} : vector<5x6xf32>, tensor<12x13xf32>
// CHECK: return %[[WRITE]]
func @pad_tensor_non_const_pad_value(%arg0: tensor<5x6xf32>) -> tensor<12x13xf32> {
- %c0 = constant 0 : index
- %c5 = constant 5.0 : f32
+ %c0 = arith.constant 0 : index
+ %c5 = arith.constant 5.0 : f32
%0 = linalg.pad_tensor %arg0 low[3, 4] high[4, 3] {
^bb0(%arg1: index, %arg2: index):
- %i1 = index_cast %arg1 : index to i32
- %i2 = index_cast %arg2 : index to i32
- %f1 = sitofp %i1 : i32 to f32
- %f2 = sitofp %i2 : i32 to f32
- %m = mulf %f1, %f2 : f32
+ %i1 = arith.index_cast %arg1 : index to i32
+ %i2 = arith.index_cast %arg2 : index to i32
+ %f1 = arith.sitofp %i1 : i32 to f32
+ %f2 = arith.sitofp %i2 : i32 to f32
+ %m = arith.mulf %f1, %f2 : f32
linalg.yield %m : f32
} : tensor<5x6xf32> to tensor<12x13xf32>
return %0 : tensor<12x13xf32>
} ins(%input : tensor<4x16x8xf32>) outs(%output : tensor<4x16xf32>) {
^bb0(%arg0: f32, %arg1: f32): // no predecessors
%1 = math.exp %arg0 : f32
- %2 = addf %1, %arg1 : f32
+ %2 = arith.addf %1, %arg1 : f32
linalg.yield %2 : f32
} -> tensor<4x16xf32>
return %0 : tensor<4x16xf32>
^bb0(%arg0: f32, %arg1: f32, %arg2: f32): // no predecessors
%1 = math.exp %arg0 : f32
%2 = math.exp %arg1 : f32
- %3 = addf %1, %2 : f32
- %4 = addf %3, %arg2 : f32
+ %3 = arith.addf %1, %2 : f32
+ %4 = arith.addf %3, %arg2 : f32
linalg.yield %4 : f32
} -> tensor<5x2xf32>
return %0 : tensor<5x2xf32>
// CHECK-LABEL: func @red_max_2d(
func @red_max_2d(%arg0: tensor<4x4xf32>) -> tensor<4xf32> {
- // CHECK: %[[CMINF:.+]] = constant dense<-3.402820e+38> : vector<4xf32>
+ // CHECK: %[[CMINF:.+]] = arith.constant dense<-3.402820e+38> : vector<4xf32>
// CHECK: linalg.init_tensor [4] : tensor<4xf32>
// CHECK: vector.transfer_write {{.*}} : vector<4xf32>, tensor<4xf32>
// CHECK: %[[R:.+]] = vector.multi_reduction #vector.kind<maxf>, {{.*}} [1] : vector<4x4xf32> to vector<4xf32>
// CHECK: maxf %[[R]], %[[CMINF]] : vector<4xf32>
// CHECK: vector.transfer_write {{.*}} : vector<4xf32>, tensor<4xf32>
- %ident = constant -3.40282e+38 : f32
+ %ident = arith.constant -3.40282e+38 : f32
%init = linalg.init_tensor [4] : tensor<4xf32>
%fill = linalg.fill(%ident, %init) : f32, tensor<4xf32> -> tensor<4xf32>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
// CHECK-LABEL: func @red_min_2d(
func @red_min_2d(%arg0: tensor<4x4xf32>) -> tensor<4xf32> {
- // CHECK: %[[CMAXF:.+]] = constant dense<3.402820e+38> : vector<4xf32>
+ // CHECK: %[[CMAXF:.+]] = arith.constant dense<3.402820e+38> : vector<4xf32>
// CHECK: linalg.init_tensor [4] : tensor<4xf32>
// CHECK: vector.transfer_write {{.*}} : vector<4xf32>, tensor<4xf32>
// CHECK: vector.transfer_read {{.*}} : tensor<4x4xf32>, vector<4x4xf32>
// CHECK: %[[R:.+]] = vector.multi_reduction #vector.kind<minf>, {{.*}} [1] : vector<4x4xf32> to vector<4xf32>
// CHECK: minf %[[R]], %[[CMAXF]] : vector<4xf32>
// CHECK: vector.transfer_write {{.*}} : vector<4xf32>, tensor<4xf32>
- %maxf32 = constant 3.40282e+38 : f32
+ %maxf32 = arith.constant 3.40282e+38 : f32
%init = linalg.init_tensor [4] : tensor<4xf32>
%fill = linalg.fill(%maxf32, %init) : f32, tensor<4xf32> -> tensor<4xf32>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
// CHECK: vector.multi_reduction #vector.kind<mul>, {{.*}} [1] : vector<4x4xf32> to vector<4xf32>
// CHECK: mulf {{.*}} : vector<4xf32>
// CHECK: vector.transfer_write {{.*}} : vector<4xf32>, tensor<4xf32>
- %ident = constant 1.0 : f32
+ %ident = arith.constant 1.0 : f32
%init = linalg.init_tensor [4] : tensor<4xf32>
%fill = linalg.fill(%ident, %init) : f32, tensor<4xf32> -> tensor<4xf32>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
iterator_types = ["parallel", "reduction"]}
ins(%arg0 : tensor<4x4xf32>) outs(%fill : tensor<4xf32>) {
^bb0(%in0: f32, %out0: f32): // no predecessors
- %mul = mulf %in0, %out0 : f32
+ %mul = arith.mulf %in0, %out0 : f32
linalg.yield %mul : f32
} -> tensor<4xf32>
return %red : tensor<4xf32>
// CHECK: vector.transfer_read {{.*}} : tensor<4x4xi1>, vector<4x4xi1>
// CHECK: vector.multi_reduction #vector.kind<or>, {{.*}} [1] : vector<4x4xi1> to vector<4xi1>
// CHECK: vector.transfer_write {{.*}} : vector<4xi1>, tensor<4xi1>
- %ident = constant false
+ %ident = arith.constant false
%init = linalg.init_tensor [4] : tensor<4xi1>
%fill = linalg.fill(%ident, %init) : i1, tensor<4xi1> -> tensor<4xi1>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
iterator_types = ["parallel", "reduction"]}
ins(%arg0 : tensor<4x4xi1>) outs(%fill : tensor<4xi1>) {
^bb0(%in0: i1, %out0: i1): // no predecessors
- %or = or %in0, %out0 : i1
+ %or = arith.ori %in0, %out0 : i1
linalg.yield %or : i1
} -> tensor<4xi1>
return %red : tensor<4xi1>
// CHECK: vector.transfer_read {{.*}} : tensor<4x4xi1>, vector<4x4xi1>
// CHECK: vector.multi_reduction #vector.kind<and>, {{.*}} [1] : vector<4x4xi1> to vector<4xi1>
// CHECK: vector.transfer_write {{.*}} : vector<4xi1>, tensor<4xi1>
- %ident = constant true
+ %ident = arith.constant true
%init = linalg.init_tensor [4] : tensor<4xi1>
%fill = linalg.fill(%ident, %init) : i1, tensor<4xi1> -> tensor<4xi1>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
iterator_types = ["parallel", "reduction"]}
ins(%arg0 : tensor<4x4xi1>) outs(%fill : tensor<4xi1>) {
^bb0(%in0: i1, %out0: i1): // no predecessors
- %and = and %in0, %out0 : i1
+ %and = arith.andi %in0, %out0 : i1
linalg.yield %and : i1
} -> tensor<4xi1>
return %red : tensor<4xi1>
// CHECK: vector.transfer_read {{.*}} : tensor<4x4xi1>, vector<4x4xi1>
// CHECK: vector.multi_reduction #vector.kind<xor>, {{.*}} [1] : vector<4x4xi1> to vector<4xi1>
// CHECK: vector.transfer_write {{.*}} : vector<4xi1>, tensor<4xi1>
- %ident = constant false
+ %ident = arith.constant false
%init = linalg.init_tensor [4] : tensor<4xi1>
%fill = linalg.fill(%ident, %init) : i1, tensor<4xi1> -> tensor<4xi1>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
iterator_types = ["parallel", "reduction"]}
ins(%arg0 : tensor<4x4xi1>) outs(%fill : tensor<4xi1>) {
^bb0(%in0: i1, %out0: i1): // no predecessors
- %xor = xor %in0, %out0 : i1
+ %xor = arith.xori %in0, %out0 : i1
linalg.yield %xor : i1
} -> tensor<4xi1>
return %red : tensor<4xi1>
// CHECK: vector.transfer_read {{.*}} {in_bounds = [true, true], permutation_map = #[[$M5]]} : tensor<4x1xf32>, vector<4x4xf32>
// CHECK: subf {{.*}} : vector<4x4xf32>
// CHECK: vector.transfer_write {{.*}} {in_bounds = [true, true]} : vector<4x4xf32>, tensor<4x4xf32>
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
%init = linalg.init_tensor [4, 4] : tensor<4x4xf32>
%fill = linalg.fill(%c0, %init) : f32, tensor<4x4xf32> -> tensor<4x4xf32>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
ins(%arg0, %arg1 : tensor<4x4xf32>, tensor<4x1xf32>)
outs(%fill : tensor<4x4xf32>) {
^bb0(%arg7: f32, %arg8: f32, %arg9: f32):
- %40 = subf %arg7, %arg8 : f32
+ %40 = arith.subf %arg7, %arg8 : f32
linalg.yield %40 : f32
} -> tensor<4x4xf32>
return %red : tensor<4x4xf32>
// CHECK: vector.multi_reduction #vector.kind<add>, {{.*}} : vector<4x4xf32> to vector<4xf32>
// CHECK: addf {{.*}} : vector<4xf32>
// CHECK: vector.transfer_write {{.*}} {in_bounds = [true]} : vector<4xf32>, tensor<4xf32>
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
%init = linalg.init_tensor [4] : tensor<4xf32>
%fill = linalg.fill(%c0, %init) : f32, tensor<4xf32> -> tensor<4xf32>
%red = linalg.generic {indexing_maps = [affine_map<(d0, d1) -> (d0, d1)>,
ins(%arg0, %arg1 : tensor<4x4xf32>, tensor<4x1xf32>)
outs(%fill : tensor<4xf32>) {
^bb0(%arg7: f32, %arg8: f32, %arg9: f32):
- %40 = subf %arg7, %arg8 : f32
+ %40 = arith.subf %arg7, %arg8 : f32
%41 = math.exp %40 : f32
- %42 = addf %41, %arg9 : f32
+ %42 = arith.addf %41, %arg9 : f32
linalg.yield %42 : f32
} -> tensor<4xf32>
return %red : tensor<4xf32>
// CHECK-LABEL: func @reduce_1d(
// CHECK-SAME: %[[A:.*]]: tensor<32xf32>
func @reduce_1d(%arg0: tensor<32xf32>) -> tensor<f32> {
- // CHECK-DAG: %[[F0_v1:.*]] = constant dense<0.000000e+00> : vector<1xf32>
- // CHECK-DAG: %[[F0:.*]] = constant 0.000000e+00 : f32
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- %f0 = constant 0.000000e+00 : f32
+ // CHECK-DAG: %[[F0_v1:.*]] = arith.constant dense<0.000000e+00> : vector<1xf32>
+ // CHECK-DAG: %[[F0:.*]] = arith.constant 0.000000e+00 : f32
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ %f0 = arith.constant 0.000000e+00 : f32
// CHECK: %[[init:.*]] = linalg.init_tensor [] : tensor<f32>
%0 = linalg.init_tensor [] : tensor<f32>
// CHECK-SAME: : tensor<32xf32>, vector<32xf32>
// CHECK: %[[red:.*]] = vector.multi_reduction #vector.kind<add>, %[[r]] [0]
// CHECK-SAME: : vector<32xf32> to f32
- // CHECK: %[[a:.*]] = addf %[[red]], %[[F0]] : f32
+ // CHECK: %[[a:.*]] = arith.addf %[[red]], %[[F0]] : f32
// CHECK: %[[red_v1:.*]] = vector.broadcast %[[a]] : f32 to vector<1xf32>
// CHECK: %[[res:.*]] = vector.transfer_write %[[red_v1]], %[[f]][]
// CHECK-SAME: : vector<1xf32>, tensor<f32>
ins(%arg0 : tensor<32xf32>)
outs(%1 : tensor<f32>) {
^bb0(%a: f32, %b: f32): // no predecessors
- %3 = addf %a, %b : f32
+ %3 = arith.addf %a, %b : f32
linalg.yield %3 : f32
} -> tensor<f32>
// CHECK-LABEL: @pow_noop
func @pow_noop(%arg0: f32, %arg1 : vector<4xf32>) -> (f32, vector<4xf32>) {
// CHECK: return %arg0, %arg1
- %c = constant 1.0 : f32
- %v = constant dense <1.0> : vector<4xf32>
+ %c = arith.constant 1.0 : f32
+ %v = arith.constant dense <1.0> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK-LABEL: @pow_square
func @pow_square(%arg0: f32, %arg1 : vector<4xf32>) -> (f32, vector<4xf32>) {
- // CHECK: %[[SCALAR:.*]] = mulf %arg0, %arg0
- // CHECK: %[[VECTOR:.*]] = mulf %arg1, %arg1
+ // CHECK: %[[SCALAR:.*]] = arith.mulf %arg0, %arg0
+ // CHECK: %[[VECTOR:.*]] = arith.mulf %arg1, %arg1
// CHECK: return %[[SCALAR]], %[[VECTOR]]
- %c = constant 2.0 : f32
- %v = constant dense <2.0> : vector<4xf32>
+ %c = arith.constant 2.0 : f32
+ %v = arith.constant dense <2.0> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK-LABEL: @pow_cube
func @pow_cube(%arg0: f32, %arg1 : vector<4xf32>) -> (f32, vector<4xf32>) {
- // CHECK: %[[TMP_S:.*]] = mulf %arg0, %arg0
- // CHECK: %[[SCALAR:.*]] = mulf %arg0, %[[TMP_S]]
- // CHECK: %[[TMP_V:.*]] = mulf %arg1, %arg1
- // CHECK: %[[VECTOR:.*]] = mulf %arg1, %[[TMP_V]]
+ // CHECK: %[[TMP_S:.*]] = arith.mulf %arg0, %arg0
+ // CHECK: %[[SCALAR:.*]] = arith.mulf %arg0, %[[TMP_S]]
+ // CHECK: %[[TMP_V:.*]] = arith.mulf %arg1, %arg1
+ // CHECK: %[[VECTOR:.*]] = arith.mulf %arg1, %[[TMP_V]]
// CHECK: return %[[SCALAR]], %[[VECTOR]]
- %c = constant 3.0 : f32
- %v = constant dense <3.0> : vector<4xf32>
+ %c = arith.constant 3.0 : f32
+ %v = arith.constant dense <3.0> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK-LABEL: @pow_recip
func @pow_recip(%arg0: f32, %arg1 : vector<4xf32>) -> (f32, vector<4xf32>) {
- // CHECK: %[[CST_S:.*]] = constant 1.0{{.*}} : f32
- // CHECK: %[[CST_V:.*]] = constant dense<1.0{{.*}}> : vector<4xf32>
- // CHECK: %[[SCALAR:.*]] = divf %[[CST_S]], %arg0
- // CHECK: %[[VECTOR:.*]] = divf %[[CST_V]], %arg1
+ // CHECK: %[[CST_S:.*]] = arith.constant 1.0{{.*}} : f32
+ // CHECK: %[[CST_V:.*]] = arith.constant dense<1.0{{.*}}> : vector<4xf32>
+ // CHECK: %[[SCALAR:.*]] = arith.divf %[[CST_S]], %arg0
+ // CHECK: %[[VECTOR:.*]] = arith.divf %[[CST_V]], %arg1
// CHECK: return %[[SCALAR]], %[[VECTOR]]
- %c = constant -1.0 : f32
- %v = constant dense <-1.0> : vector<4xf32>
+ %c = arith.constant -1.0 : f32
+ %v = arith.constant dense <-1.0> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK: %[[SCALAR:.*]] = math.sqrt %arg0
// CHECK: %[[VECTOR:.*]] = math.sqrt %arg1
// CHECK: return %[[SCALAR]], %[[VECTOR]]
- %c = constant 0.5 : f32
- %v = constant dense <0.5> : vector<4xf32>
+ %c = arith.constant 0.5 : f32
+ %v = arith.constant dense <0.5> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK: %[[SCALAR:.*]] = math.rsqrt %arg0
// CHECK: %[[VECTOR:.*]] = math.rsqrt %arg1
// CHECK: return %[[SCALAR]], %[[VECTOR]]
- %c = constant -0.5 : f32
- %v = constant dense <-0.5> : vector<4xf32>
+ %c = arith.constant -0.5 : f32
+ %v = arith.constant dense <-0.5> : vector<4xf32>
%0 = math.powf %arg0, %c : f32
%1 = math.powf %arg1, %v : vector<4xf32>
return %0, %1 : f32, vector<4xf32>
// CHECK-LABEL: func @exp_scalar(
// CHECK-SAME: %[[VAL_0:.*]]: f32) -> f32 {
-// CHECK-DAG: %[[VAL_1:.*]] = constant 0.693147182 : f32
-// CHECK-DAG: %[[VAL_2:.*]] = constant 1.44269502 : f32
-// CHECK-DAG: %[[VAL_3:.*]] = constant 1.000000e+00 : f32
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0.499705136 : f32
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0.168738902 : f32
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0.0366896503 : f32
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1.314350e-02 : f32
-// CHECK-DAG: %[[VAL_8:.*]] = constant 23 : i32
-// CHECK-DAG: %[[VAL_9:.*]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[VAL_10:.*]] = constant 0x7F800000 : f32
-// CHECK-DAG: %[[VAL_11:.*]] = constant 0xFF800000 : f32
-// CHECK-DAG: %[[VAL_12:.*]] = constant 1.17549435E-38 : f32
-// CHECK-DAG: %[[VAL_13:.*]] = constant 127 : i32
-// CHECK-DAG: %[[VAL_14:.*]] = constant -127 : i32
-// CHECK: %[[VAL_15:.*]] = mulf %[[VAL_0]], %[[VAL_2]] : f32
-// CHECK: %[[VAL_16:.*]] = floorf %[[VAL_15]] : f32
-// CHECK: %[[VAL_17:.*]] = mulf %[[VAL_16]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_18:.*]] = subf %[[VAL_0]], %[[VAL_17]] : f32
-// CHECK: %[[VAL_19:.*]] = mulf %[[VAL_18]], %[[VAL_18]] : f32
-// CHECK: %[[VAL_20:.*]] = mulf %[[VAL_19]], %[[VAL_19]] : f32
-// CHECK: %[[VAL_21:.*]] = fmaf %[[VAL_3]], %[[VAL_18]], %[[VAL_3]] : f32
-// CHECK: %[[VAL_22:.*]] = fmaf %[[VAL_5]], %[[VAL_18]], %[[VAL_4]] : f32
-// CHECK: %[[VAL_23:.*]] = fmaf %[[VAL_7]], %[[VAL_18]], %[[VAL_6]] : f32
-// CHECK: %[[VAL_24:.*]] = fmaf %[[VAL_22]], %[[VAL_19]], %[[VAL_21]] : f32
-// CHECK: %[[VAL_25:.*]] = fmaf %[[VAL_23]], %[[VAL_20]], %[[VAL_24]] : f32
-// CHECK: %[[VAL_26:.*]] = fptosi %[[VAL_16]] : f32 to i32
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_26]], %[[VAL_13]] : i32
-// CHECK: %[[VAL_28:.*]] = shift_left %[[VAL_27]], %[[VAL_8]] : i32
-// CHECK: %[[VAL_29:.*]] = bitcast %[[VAL_28]] : i32 to f32
-// CHECK: %[[VAL_30:.*]] = mulf %[[VAL_25]], %[[VAL_29]] : f32
-// CHECK: %[[VAL_31:.*]] = cmpi sle, %[[VAL_26]], %[[VAL_13]] : i32
-// CHECK: %[[VAL_32:.*]] = cmpi sge, %[[VAL_26]], %[[VAL_14]] : i32
-// CHECK: %[[VAL_33:.*]] = cmpf oeq, %[[VAL_0]], %[[VAL_11]] : f32
-// CHECK: %[[VAL_34:.*]] = cmpf ogt, %[[VAL_0]], %[[VAL_9]] : f32
-// CHECK: %[[VAL_35:.*]] = and %[[VAL_31]], %[[VAL_32]] : i1
+// CHECK-DAG: %[[VAL_1:.*]] = arith.constant 0.693147182 : f32
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 1.44269502 : f32
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0.499705136 : f32
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0.168738902 : f32
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0.0366896503 : f32
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1.314350e-02 : f32
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 23 : i32
+// CHECK-DAG: %[[VAL_9:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[VAL_10:.*]] = arith.constant 0x7F800000 : f32
+// CHECK-DAG: %[[VAL_11:.*]] = arith.constant 0xFF800000 : f32
+// CHECK-DAG: %[[VAL_12:.*]] = arith.constant 1.17549435E-38 : f32
+// CHECK-DAG: %[[VAL_13:.*]] = arith.constant 127 : i32
+// CHECK-DAG: %[[VAL_14:.*]] = arith.constant -127 : i32
+// CHECK: %[[VAL_15:.*]] = arith.mulf %[[VAL_0]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_16:.*]] = math.floor %[[VAL_15]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.mulf %[[VAL_16]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_18:.*]] = arith.subf %[[VAL_0]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_19:.*]] = arith.mulf %[[VAL_18]], %[[VAL_18]] : f32
+// CHECK: %[[VAL_20:.*]] = arith.mulf %[[VAL_19]], %[[VAL_19]] : f32
+// CHECK: %[[VAL_21:.*]] = math.fma %[[VAL_3]], %[[VAL_18]], %[[VAL_3]] : f32
+// CHECK: %[[VAL_22:.*]] = math.fma %[[VAL_5]], %[[VAL_18]], %[[VAL_4]] : f32
+// CHECK: %[[VAL_23:.*]] = math.fma %[[VAL_7]], %[[VAL_18]], %[[VAL_6]] : f32
+// CHECK: %[[VAL_24:.*]] = math.fma %[[VAL_22]], %[[VAL_19]], %[[VAL_21]] : f32
+// CHECK: %[[VAL_25:.*]] = math.fma %[[VAL_23]], %[[VAL_20]], %[[VAL_24]] : f32
+// CHECK: %[[VAL_26:.*]] = arith.fptosi %[[VAL_16]] : f32 to i32
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_26]], %[[VAL_13]] : i32
+// CHECK: %[[VAL_28:.*]] = arith.shli %[[VAL_27]], %[[VAL_8]] : i32
+// CHECK: %[[VAL_29:.*]] = arith.bitcast %[[VAL_28]] : i32 to f32
+// CHECK: %[[VAL_30:.*]] = arith.mulf %[[VAL_25]], %[[VAL_29]] : f32
+// CHECK: %[[VAL_31:.*]] = arith.cmpi sle, %[[VAL_26]], %[[VAL_13]] : i32
+// CHECK: %[[VAL_32:.*]] = arith.cmpi sge, %[[VAL_26]], %[[VAL_14]] : i32
+// CHECK: %[[VAL_33:.*]] = arith.cmpf oeq, %[[VAL_0]], %[[VAL_11]] : f32
+// CHECK: %[[VAL_34:.*]] = arith.cmpf ogt, %[[VAL_0]], %[[VAL_9]] : f32
+// CHECK: %[[VAL_35:.*]] = arith.andi %[[VAL_31]], %[[VAL_32]] : i1
// CHECK: %[[VAL_36:.*]] = select %[[VAL_33]], %[[VAL_9]], %[[VAL_12]] : f32
// CHECK: %[[VAL_37:.*]] = select %[[VAL_34]], %[[VAL_10]], %[[VAL_36]] : f32
// CHECK: %[[VAL_38:.*]] = select %[[VAL_35]], %[[VAL_30]], %[[VAL_37]] : f32
// CHECK-LABEL: func @exp_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[VAL_1:.*]] = constant dense<0.693147182> : vector<8xf32>
+// CHECK: %[[VAL_1:.*]] = arith.constant dense<0.693147182> : vector<8xf32>
// CHECK-NOT: exp
// CHECK-COUNT-2: select
// CHECK: %[[VAL_38:.*]] = select
// CHECK-LABEL: func @expm1_scalar(
// CHECK-SAME: %[[X:.*]]: f32) -> f32 {
-// CHECK-DAG: %[[CST_MINUSONE:.*]] = constant -1.000000e+00 : f32
-// CHECK-DAG: %[[CST_LOG2E:.*]] = constant 1.44269502 : f32
-// CHECK-DAG: %[[CST_ONE:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[BEGIN_EXP_X:.*]] = mulf %[[X]], %[[CST_LOG2E]] : f32
+// CHECK-DAG: %[[CST_MINUSONE:.*]] = arith.constant -1.000000e+00 : f32
+// CHECK-DAG: %[[CST_LOG2E:.*]] = arith.constant 1.44269502 : f32
+// CHECK-DAG: %[[CST_ONE:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[BEGIN_EXP_X:.*]] = arith.mulf %[[X]], %[[CST_LOG2E]] : f32
// CHECK-NOT: exp
// CHECK-COUNT-2: select
// CHECK: %[[EXP_X:.*]] = select
-// CHECK: %[[VAL_58:.*]] = cmpf oeq, %[[EXP_X]], %[[CST_ONE]] : f32
-// CHECK: %[[VAL_59:.*]] = subf %[[EXP_X]], %[[CST_ONE]] : f32
-// CHECK: %[[VAL_60:.*]] = cmpf oeq, %[[VAL_59]], %[[CST_MINUSONE]] : f32
+// CHECK: %[[VAL_58:.*]] = arith.cmpf oeq, %[[EXP_X]], %[[CST_ONE]] : f32
+// CHECK: %[[VAL_59:.*]] = arith.subf %[[EXP_X]], %[[CST_ONE]] : f32
+// CHECK: %[[VAL_60:.*]] = arith.cmpf oeq, %[[VAL_59]], %[[CST_MINUSONE]] : f32
// CHECK-NOT: log
// CHECK-COUNT-5: select
// CHECK: %[[LOG_U:.*]] = select
-// CHECK: %[[VAL_104:.*]] = cmpf oeq, %[[LOG_U]], %[[EXP_X]] : f32
-// CHECK: %[[VAL_105:.*]] = divf %[[X]], %[[LOG_U]] : f32
-// CHECK: %[[VAL_106:.*]] = mulf %[[VAL_59]], %[[VAL_105]] : f32
+// CHECK: %[[VAL_104:.*]] = arith.cmpf oeq, %[[LOG_U]], %[[EXP_X]] : f32
+// CHECK: %[[VAL_105:.*]] = arith.divf %[[X]], %[[LOG_U]] : f32
+// CHECK: %[[VAL_106:.*]] = arith.mulf %[[VAL_59]], %[[VAL_105]] : f32
// CHECK: %[[VAL_107:.*]] = select %[[VAL_104]], %[[EXP_X]], %[[VAL_106]] : f32
// CHECK: %[[VAL_108:.*]] = select %[[VAL_60]], %[[CST_MINUSONE]], %[[VAL_107]] : f32
// CHECK: %[[VAL_109:.*]] = select %[[VAL_58]], %[[X]], %[[VAL_108]] : f32
// CHECK-LABEL: func @expm1_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[VAL_1:.*]] = constant dense<-1.000000e+00> : vector<8xf32>
+// CHECK: %[[VAL_1:.*]] = arith.constant dense<-1.000000e+00> : vector<8xf32>
// CHECK-NOT: exp
// CHECK-COUNT-3: select
// CHECK-NOT: log
// CHECK-LABEL: func @log_scalar(
// CHECK-SAME: %[[X:.*]]: f32) -> f32 {
-// CHECK: %[[VAL_1:.*]] = constant 0.000000e+00 : f32
-// CHECK: %[[VAL_2:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[VAL_3:.*]] = constant -5.000000e-01 : f32
-// CHECK: %[[VAL_4:.*]] = constant 1.17549435E-38 : f32
-// CHECK: %[[VAL_5:.*]] = constant 0xFF800000 : f32
-// CHECK: %[[VAL_6:.*]] = constant 0x7F800000 : f32
-// CHECK: %[[VAL_7:.*]] = constant 0x7FC00000 : f32
-// CHECK: %[[VAL_8:.*]] = constant 0.707106769 : f32
-// CHECK: %[[VAL_9:.*]] = constant 0.0703768358 : f32
-// CHECK: %[[VAL_10:.*]] = constant -0.115146101 : f32
-// CHECK: %[[VAL_11:.*]] = constant 0.116769984 : f32
-// CHECK: %[[VAL_12:.*]] = constant -0.12420141 : f32
-// CHECK: %[[VAL_13:.*]] = constant 0.142493233 : f32
-// CHECK: %[[VAL_14:.*]] = constant -0.166680574 : f32
-// CHECK: %[[VAL_15:.*]] = constant 0.200007141 : f32
-// CHECK: %[[VAL_16:.*]] = constant -0.24999994 : f32
-// CHECK: %[[VAL_17:.*]] = constant 0.333333313 : f32
-// CHECK: %[[VAL_18:.*]] = constant 1.260000e+02 : f32
-// CHECK: %[[VAL_19:.*]] = constant -2139095041 : i32
-// CHECK: %[[VAL_20:.*]] = constant 1056964608 : i32
-// CHECK: %[[VAL_21:.*]] = constant 23 : i32
-// CHECK: %[[VAL_22:.*]] = constant 0.693147182 : f32
-// CHECK: %[[VAL_23:.*]] = cmpf ogt, %[[X]], %[[VAL_4]] : f32
+// CHECK: %[[VAL_1:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK: %[[VAL_2:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant -5.000000e-01 : f32
+// CHECK: %[[VAL_4:.*]] = arith.constant 1.17549435E-38 : f32
+// CHECK: %[[VAL_5:.*]] = arith.constant 0xFF800000 : f32
+// CHECK: %[[VAL_6:.*]] = arith.constant 0x7F800000 : f32
+// CHECK: %[[VAL_7:.*]] = arith.constant 0x7FC00000 : f32
+// CHECK: %[[VAL_8:.*]] = arith.constant 0.707106769 : f32
+// CHECK: %[[VAL_9:.*]] = arith.constant 0.0703768358 : f32
+// CHECK: %[[VAL_10:.*]] = arith.constant -0.115146101 : f32
+// CHECK: %[[VAL_11:.*]] = arith.constant 0.116769984 : f32
+// CHECK: %[[VAL_12:.*]] = arith.constant -0.12420141 : f32
+// CHECK: %[[VAL_13:.*]] = arith.constant 0.142493233 : f32
+// CHECK: %[[VAL_14:.*]] = arith.constant -0.166680574 : f32
+// CHECK: %[[VAL_15:.*]] = arith.constant 0.200007141 : f32
+// CHECK: %[[VAL_16:.*]] = arith.constant -0.24999994 : f32
+// CHECK: %[[VAL_17:.*]] = arith.constant 0.333333313 : f32
+// CHECK: %[[VAL_18:.*]] = arith.constant 1.260000e+02 : f32
+// CHECK: %[[VAL_19:.*]] = arith.constant -2139095041 : i32
+// CHECK: %[[VAL_20:.*]] = arith.constant 1056964608 : i32
+// CHECK: %[[VAL_21:.*]] = arith.constant 23 : i32
+// CHECK: %[[VAL_22:.*]] = arith.constant 0.693147182 : f32
+// CHECK: %[[VAL_23:.*]] = arith.cmpf ogt, %[[X]], %[[VAL_4]] : f32
// CHECK: %[[VAL_24:.*]] = select %[[VAL_23]], %[[X]], %[[VAL_4]] : f32
// CHECK-NOT: frexp
-// CHECK: %[[VAL_25:.*]] = bitcast %[[VAL_24]] : f32 to i32
-// CHECK: %[[VAL_26:.*]] = and %[[VAL_25]], %[[VAL_19]] : i32
-// CHECK: %[[VAL_27:.*]] = or %[[VAL_26]], %[[VAL_20]] : i32
-// CHECK: %[[VAL_28:.*]] = bitcast %[[VAL_27]] : i32 to f32
-// CHECK: %[[VAL_29:.*]] = bitcast %[[VAL_24]] : f32 to i32
-// CHECK: %[[VAL_30:.*]] = shift_right_unsigned %[[VAL_29]], %[[VAL_21]] : i32
-// CHECK: %[[VAL_31:.*]] = sitofp %[[VAL_30]] : i32 to f32
-// CHECK: %[[VAL_32:.*]] = subf %[[VAL_31]], %[[VAL_18]] : f32
-// CHECK: %[[VAL_33:.*]] = cmpf olt, %[[VAL_28]], %[[VAL_8]] : f32
+// CHECK: %[[VAL_25:.*]] = arith.bitcast %[[VAL_24]] : f32 to i32
+// CHECK: %[[VAL_26:.*]] = arith.andi %[[VAL_25]], %[[VAL_19]] : i32
+// CHECK: %[[VAL_27:.*]] = arith.ori %[[VAL_26]], %[[VAL_20]] : i32
+// CHECK: %[[VAL_28:.*]] = arith.bitcast %[[VAL_27]] : i32 to f32
+// CHECK: %[[VAL_29:.*]] = arith.bitcast %[[VAL_24]] : f32 to i32
+// CHECK: %[[VAL_30:.*]] = arith.shrui %[[VAL_29]], %[[VAL_21]] : i32
+// CHECK: %[[VAL_31:.*]] = arith.sitofp %[[VAL_30]] : i32 to f32
+// CHECK: %[[VAL_32:.*]] = arith.subf %[[VAL_31]], %[[VAL_18]] : f32
+// CHECK: %[[VAL_33:.*]] = arith.cmpf olt, %[[VAL_28]], %[[VAL_8]] : f32
// CHECK: %[[VAL_34:.*]] = select %[[VAL_33]], %[[VAL_28]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_35:.*]] = subf %[[VAL_28]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_35:.*]] = arith.subf %[[VAL_28]], %[[VAL_2]] : f32
// CHECK: %[[VAL_36:.*]] = select %[[VAL_33]], %[[VAL_2]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_37:.*]] = subf %[[VAL_32]], %[[VAL_36]] : f32
-// CHECK: %[[VAL_38:.*]] = addf %[[VAL_35]], %[[VAL_34]] : f32
-// CHECK: %[[VAL_39:.*]] = mulf %[[VAL_38]], %[[VAL_38]] : f32
-// CHECK: %[[VAL_40:.*]] = mulf %[[VAL_39]], %[[VAL_38]] : f32
-// CHECK: %[[VAL_41:.*]] = fmaf %[[VAL_9]], %[[VAL_38]], %[[VAL_10]] : f32
-// CHECK: %[[VAL_42:.*]] = fmaf %[[VAL_12]], %[[VAL_38]], %[[VAL_13]] : f32
-// CHECK: %[[VAL_43:.*]] = fmaf %[[VAL_15]], %[[VAL_38]], %[[VAL_16]] : f32
-// CHECK: %[[VAL_44:.*]] = fmaf %[[VAL_41]], %[[VAL_38]], %[[VAL_11]] : f32
-// CHECK: %[[VAL_45:.*]] = fmaf %[[VAL_42]], %[[VAL_38]], %[[VAL_14]] : f32
-// CHECK: %[[VAL_46:.*]] = fmaf %[[VAL_43]], %[[VAL_38]], %[[VAL_17]] : f32
-// CHECK: %[[VAL_47:.*]] = fmaf %[[VAL_44]], %[[VAL_40]], %[[VAL_45]] : f32
-// CHECK: %[[VAL_48:.*]] = fmaf %[[VAL_47]], %[[VAL_40]], %[[VAL_46]] : f32
-// CHECK: %[[VAL_49:.*]] = mulf %[[VAL_48]], %[[VAL_40]] : f32
-// CHECK: %[[VAL_50:.*]] = fmaf %[[VAL_3]], %[[VAL_39]], %[[VAL_49]] : f32
-// CHECK: %[[VAL_51:.*]] = addf %[[VAL_38]], %[[VAL_50]] : f32
-// CHECK: %[[VAL_52:.*]] = fmaf %[[VAL_37]], %[[VAL_22]], %[[VAL_51]] : f32
-// CHECK: %[[VAL_53:.*]] = cmpf ult, %[[X]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_54:.*]] = cmpf oeq, %[[X]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_55:.*]] = cmpf oeq, %[[X]], %[[VAL_6]] : f32
+// CHECK: %[[VAL_37:.*]] = arith.subf %[[VAL_32]], %[[VAL_36]] : f32
+// CHECK: %[[VAL_38:.*]] = arith.addf %[[VAL_35]], %[[VAL_34]] : f32
+// CHECK: %[[VAL_39:.*]] = arith.mulf %[[VAL_38]], %[[VAL_38]] : f32
+// CHECK: %[[VAL_40:.*]] = arith.mulf %[[VAL_39]], %[[VAL_38]] : f32
+// CHECK: %[[VAL_41:.*]] = math.fma %[[VAL_9]], %[[VAL_38]], %[[VAL_10]] : f32
+// CHECK: %[[VAL_42:.*]] = math.fma %[[VAL_12]], %[[VAL_38]], %[[VAL_13]] : f32
+// CHECK: %[[VAL_43:.*]] = math.fma %[[VAL_15]], %[[VAL_38]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_44:.*]] = math.fma %[[VAL_41]], %[[VAL_38]], %[[VAL_11]] : f32
+// CHECK: %[[VAL_45:.*]] = math.fma %[[VAL_42]], %[[VAL_38]], %[[VAL_14]] : f32
+// CHECK: %[[VAL_46:.*]] = math.fma %[[VAL_43]], %[[VAL_38]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_47:.*]] = math.fma %[[VAL_44]], %[[VAL_40]], %[[VAL_45]] : f32
+// CHECK: %[[VAL_48:.*]] = math.fma %[[VAL_47]], %[[VAL_40]], %[[VAL_46]] : f32
+// CHECK: %[[VAL_49:.*]] = arith.mulf %[[VAL_48]], %[[VAL_40]] : f32
+// CHECK: %[[VAL_50:.*]] = math.fma %[[VAL_3]], %[[VAL_39]], %[[VAL_49]] : f32
+// CHECK: %[[VAL_51:.*]] = arith.addf %[[VAL_38]], %[[VAL_50]] : f32
+// CHECK: %[[VAL_52:.*]] = math.fma %[[VAL_37]], %[[VAL_22]], %[[VAL_51]] : f32
+// CHECK: %[[VAL_53:.*]] = arith.cmpf ult, %[[X]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_54:.*]] = arith.cmpf oeq, %[[X]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_55:.*]] = arith.cmpf oeq, %[[X]], %[[VAL_6]] : f32
// CHECK: %[[VAL_56:.*]] = select %[[VAL_55]], %[[VAL_6]], %[[VAL_52]] : f32
// CHECK: %[[VAL_57:.*]] = select %[[VAL_53]], %[[VAL_7]], %[[VAL_56]] : f32
// CHECK: %[[VAL_58:.*]] = select %[[VAL_54]], %[[VAL_5]], %[[VAL_57]] : f32
// CHECK-LABEL: func @log_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[CST_LN2:.*]] = constant dense<0.693147182> : vector<8xf32>
+// CHECK: %[[CST_LN2:.*]] = arith.constant dense<0.693147182> : vector<8xf32>
// CHECK-COUNT-5: select
// CHECK: %[[VAL_71:.*]] = select
// CHECK: return %[[VAL_71]] : vector<8xf32>
// CHECK-LABEL: func @log2_scalar(
// CHECK-SAME: %[[VAL_0:.*]]: f32) -> f32 {
-// CHECK: %[[CST_LOG2E:.*]] = constant 1.44269502 : f32
+// CHECK: %[[CST_LOG2E:.*]] = arith.constant 1.44269502 : f32
// CHECK-COUNT-5: select
// CHECK: %[[VAL_65:.*]] = select
// CHECK: return %[[VAL_65]] : f32
// CHECK-LABEL: func @log2_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[CST_LOG2E:.*]] = constant dense<1.44269502> : vector<8xf32>
+// CHECK: %[[CST_LOG2E:.*]] = arith.constant dense<1.44269502> : vector<8xf32>
// CHECK-COUNT-5: select
// CHECK: %[[VAL_71:.*]] = select
// CHECK: return %[[VAL_71]] : vector<8xf32>
// CHECK-LABEL: func @log1p_scalar(
// CHECK-SAME: %[[X:.*]]: f32) -> f32 {
-// CHECK: %[[CST_ONE:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[U:.*]] = addf %[[X]], %[[CST_ONE]] : f32
-// CHECK: %[[U_SMALL:.*]] = cmpf oeq, %[[U]], %[[CST_ONE]] : f32
+// CHECK: %[[CST_ONE:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[U:.*]] = arith.addf %[[X]], %[[CST_ONE]] : f32
+// CHECK: %[[U_SMALL:.*]] = arith.cmpf oeq, %[[U]], %[[CST_ONE]] : f32
// CHECK-NOT: log
// CHECK-COUNT-5: select
// CHECK: %[[LOG_U:.*]] = select
-// CHECK: %[[U_INF:.*]] = cmpf oeq, %[[U]], %[[LOG_U]] : f32
-// CHECK: %[[VAL_69:.*]] = subf %[[U]], %[[CST_ONE]] : f32
-// CHECK: %[[VAL_70:.*]] = divf %[[LOG_U]], %[[VAL_69]] : f32
-// CHECK: %[[LOG_LARGE:.*]] = mulf %[[X]], %[[VAL_70]] : f32
-// CHECK: %[[VAL_72:.*]] = or %[[U_SMALL]], %[[U_INF]] : i1
+// CHECK: %[[U_INF:.*]] = arith.cmpf oeq, %[[U]], %[[LOG_U]] : f32
+// CHECK: %[[VAL_69:.*]] = arith.subf %[[U]], %[[CST_ONE]] : f32
+// CHECK: %[[VAL_70:.*]] = arith.divf %[[LOG_U]], %[[VAL_69]] : f32
+// CHECK: %[[LOG_LARGE:.*]] = arith.mulf %[[X]], %[[VAL_70]] : f32
+// CHECK: %[[VAL_72:.*]] = arith.ori %[[U_SMALL]], %[[U_INF]] : i1
// CHECK: %[[APPROX:.*]] = select %[[VAL_72]], %[[X]], %[[LOG_LARGE]] : f32
// CHECK: return %[[APPROX]] : f32
// CHECK: }
// CHECK-LABEL: func @log1p_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[CST_ONE:.*]] = constant dense<1.000000e+00> : vector<8xf32>
+// CHECK: %[[CST_ONE:.*]] = arith.constant dense<1.000000e+00> : vector<8xf32>
// CHECK-COUNT-6: select
// CHECK: %[[VAL_79:.*]] = select
// CHECK: return %[[VAL_79]] : vector<8xf32>
// CHECK-LABEL: func @tanh_scalar(
// CHECK-SAME: %[[VAL_0:.*]]: f32) -> f32 {
-// CHECK: %[[VAL_1:.*]] = constant -7.90531111 : f32
-// CHECK: %[[VAL_2:.*]] = constant 7.90531111 : f32
-// CHECK: %[[VAL_3:.*]] = constant 4.000000e-04 : f32
-// CHECK: %[[VAL_4:.*]] = constant 0.00489352457 : f32
-// CHECK: %[[VAL_5:.*]] = constant 6.37261954E-4 : f32
-// CHECK: %[[VAL_6:.*]] = constant 1.48572235E-5 : f32
-// CHECK: %[[VAL_7:.*]] = constant 5.12229725E-8 : f32
-// CHECK: %[[VAL_8:.*]] = constant -8.60467184E-11 : f32
-// CHECK: %[[VAL_9:.*]] = constant 2.00018794E-13 : f32
-// CHECK: %[[VAL_10:.*]] = constant -2.76076837E-16 : f32
-// CHECK: %[[VAL_11:.*]] = constant 0.00489352504 : f32
-// CHECK: %[[VAL_12:.*]] = constant 0.00226843474 : f32
-// CHECK: %[[VAL_13:.*]] = constant 1.18534706E-4 : f32
-// CHECK: %[[VAL_14:.*]] = constant 1.19825836E-6 : f32
-// CHECK: %[[VAL_15:.*]] = cmpf olt, %[[VAL_0]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_1:.*]] = arith.constant -7.90531111 : f32
+// CHECK: %[[VAL_2:.*]] = arith.constant 7.90531111 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant 4.000000e-04 : f32
+// CHECK: %[[VAL_4:.*]] = arith.constant 0.00489352457 : f32
+// CHECK: %[[VAL_5:.*]] = arith.constant 6.37261954E-4 : f32
+// CHECK: %[[VAL_6:.*]] = arith.constant 1.48572235E-5 : f32
+// CHECK: %[[VAL_7:.*]] = arith.constant 5.12229725E-8 : f32
+// CHECK: %[[VAL_8:.*]] = arith.constant -8.60467184E-11 : f32
+// CHECK: %[[VAL_9:.*]] = arith.constant 2.00018794E-13 : f32
+// CHECK: %[[VAL_10:.*]] = arith.constant -2.76076837E-16 : f32
+// CHECK: %[[VAL_11:.*]] = arith.constant 0.00489352504 : f32
+// CHECK: %[[VAL_12:.*]] = arith.constant 0.00226843474 : f32
+// CHECK: %[[VAL_13:.*]] = arith.constant 1.18534706E-4 : f32
+// CHECK: %[[VAL_14:.*]] = arith.constant 1.19825836E-6 : f32
+// CHECK: %[[VAL_15:.*]] = arith.cmpf olt, %[[VAL_0]], %[[VAL_2]] : f32
// CHECK: %[[VAL_16:.*]] = select %[[VAL_15]], %[[VAL_0]], %[[VAL_2]] : f32
-// CHECK: %[[VAL_17:.*]] = cmpf ogt, %[[VAL_16]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.cmpf ogt, %[[VAL_16]], %[[VAL_1]] : f32
// CHECK: %[[VAL_18:.*]] = select %[[VAL_17]], %[[VAL_16]], %[[VAL_1]] : f32
-// CHECK: %[[VAL_19:.*]] = absf %[[VAL_0]] : f32
-// CHECK: %[[VAL_20:.*]] = cmpf olt, %[[VAL_19]], %[[VAL_3]] : f32
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_18]], %[[VAL_18]] : f32
-// CHECK: %[[VAL_22:.*]] = fmaf %[[VAL_21]], %[[VAL_10]], %[[VAL_9]] : f32
-// CHECK: %[[VAL_23:.*]] = fmaf %[[VAL_21]], %[[VAL_22]], %[[VAL_8]] : f32
-// CHECK: %[[VAL_24:.*]] = fmaf %[[VAL_21]], %[[VAL_23]], %[[VAL_7]] : f32
-// CHECK: %[[VAL_25:.*]] = fmaf %[[VAL_21]], %[[VAL_24]], %[[VAL_6]] : f32
-// CHECK: %[[VAL_26:.*]] = fmaf %[[VAL_21]], %[[VAL_25]], %[[VAL_5]] : f32
-// CHECK: %[[VAL_27:.*]] = fmaf %[[VAL_21]], %[[VAL_26]], %[[VAL_4]] : f32
-// CHECK: %[[VAL_28:.*]] = mulf %[[VAL_18]], %[[VAL_27]] : f32
-// CHECK: %[[VAL_29:.*]] = fmaf %[[VAL_21]], %[[VAL_14]], %[[VAL_13]] : f32
-// CHECK: %[[VAL_30:.*]] = fmaf %[[VAL_21]], %[[VAL_29]], %[[VAL_12]] : f32
-// CHECK: %[[VAL_31:.*]] = fmaf %[[VAL_21]], %[[VAL_30]], %[[VAL_11]] : f32
-// CHECK: %[[VAL_32:.*]] = divf %[[VAL_28]], %[[VAL_31]] : f32
+// CHECK: %[[VAL_19:.*]] = math.abs %[[VAL_0]] : f32
+// CHECK: %[[VAL_20:.*]] = arith.cmpf olt, %[[VAL_19]], %[[VAL_3]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_18]], %[[VAL_18]] : f32
+// CHECK: %[[VAL_22:.*]] = math.fma %[[VAL_21]], %[[VAL_10]], %[[VAL_9]] : f32
+// CHECK: %[[VAL_23:.*]] = math.fma %[[VAL_21]], %[[VAL_22]], %[[VAL_8]] : f32
+// CHECK: %[[VAL_24:.*]] = math.fma %[[VAL_21]], %[[VAL_23]], %[[VAL_7]] : f32
+// CHECK: %[[VAL_25:.*]] = math.fma %[[VAL_21]], %[[VAL_24]], %[[VAL_6]] : f32
+// CHECK: %[[VAL_26:.*]] = math.fma %[[VAL_21]], %[[VAL_25]], %[[VAL_5]] : f32
+// CHECK: %[[VAL_27:.*]] = math.fma %[[VAL_21]], %[[VAL_26]], %[[VAL_4]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.mulf %[[VAL_18]], %[[VAL_27]] : f32
+// CHECK: %[[VAL_29:.*]] = math.fma %[[VAL_21]], %[[VAL_14]], %[[VAL_13]] : f32
+// CHECK: %[[VAL_30:.*]] = math.fma %[[VAL_21]], %[[VAL_29]], %[[VAL_12]] : f32
+// CHECK: %[[VAL_31:.*]] = math.fma %[[VAL_21]], %[[VAL_30]], %[[VAL_11]] : f32
+// CHECK: %[[VAL_32:.*]] = arith.divf %[[VAL_28]], %[[VAL_31]] : f32
// CHECK: %[[VAL_33:.*]] = select %[[VAL_20]], %[[VAL_18]], %[[VAL_32]] : f32
// CHECK: return %[[VAL_33]] : f32
// CHECK: }
// CHECK-LABEL: func @tanh_vector(
// CHECK-SAME: %[[VAL_0:.*]]: vector<8xf32>) -> vector<8xf32> {
-// CHECK: %[[VAL_1:.*]] = constant dense<-7.90531111> : vector<8xf32>
+// CHECK: %[[VAL_1:.*]] = arith.constant dense<-7.90531111> : vector<8xf32>
// CHECK-NOT: tanh
// CHECK-COUNT-2: select
// CHECK: %[[VAL_33:.*]] = select
// CHECK-SAME: -> memref<?xf32, #[[$OFF_3]]> {
// CHECK-NOT: memref.tensor_load
// CHECK-NOT: memref.buffer_cast
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[DIM:.*]] = memref.dim %[[M]], %[[C0]] : memref<?xf32, #[[$OFF_UNK]]>
// CHECK: %[[ALLOC:.*]] = memref.alloc(%[[DIM]]) : memref<?xf32, #[[$OFF_3]]>
// CHECK: memref.copy %[[M]], %[[ALLOC]]
func @subview_canonicalize(%arg0 : memref<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> memref<?x?x?xf32, #map0>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = memref.subview %arg0[%c0, %arg1, %c1] [%c4, %c1, %arg2] [%c1, %c1, %c1] : memref<?x?x?xf32> to memref<?x?x?xf32, #map0>
return %0 : memref<?x?x?xf32, #map0>
}
func @rank_reducing_subview_canonicalize(%arg0 : memref<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> memref<?x?xf32, #map0>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = memref.subview %arg0[%c0, %arg1, %c1] [%c4, 1, %arg2] [%c1, %c1, %c1] : memref<?x?x?xf32> to memref<?x?xf32, #map0>
return %0 : memref<?x?xf32, #map0>
}
func @multiple_reducing_dims(%arg0 : memref<1x384x384xf32>,
%arg1 : index, %arg2 : index, %arg3 : index) -> memref<?xf32, offset: ?, strides: [1]>
{
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.subview %arg0[0, %arg1, %arg2] [1, %c1, %arg3] [1, 1, 1] : memref<1x384x384xf32> to memref<?x?xf32, offset: ?, strides: [384, 1]>
%1 = memref.subview %0[0, 0] [1, %arg3] [1, 1] : memref<?x?xf32, offset: ?, strides: [384, 1]> to memref<?xf32, offset: ?, strides: [1]>
return %1 : memref<?xf32, offset: ?, strides: [1]>
func @multiple_reducing_dims_dynamic(%arg0 : memref<?x?x?xf32>,
%arg1 : index, %arg2 : index, %arg3 : index) -> memref<?xf32, offset: ?, strides: [1]>
{
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.subview %arg0[0, %arg1, %arg2] [1, %c1, %arg3] [1, 1, 1] : memref<?x?x?xf32> to memref<?x?xf32, offset: ?, strides: [?, 1]>
%1 = memref.subview %0[0, 0] [1, %arg3] [1, 1] : memref<?x?xf32, offset: ?, strides: [?, 1]> to memref<?xf32, offset: ?, strides: [1]>
return %1 : memref<?xf32, offset: ?, strides: [1]>
func @multiple_reducing_dims_all_dynamic(%arg0 : memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]>,
%arg1 : index, %arg2 : index, %arg3 : index) -> memref<?xf32, offset: ?, strides: [?]>
{
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.subview %arg0[0, %arg1, %arg2] [1, %c1, %arg3] [1, 1, 1]
: memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]> to memref<?x?xf32, offset: ?, strides: [?, ?]>
%1 = memref.subview %0[0, 0] [1, %arg3] [1, 1] : memref<?x?xf32, offset: ?, strides: [?, ?]> to memref<?xf32, offset: ?, strides: [?]>
// CHECK-SAME: %[[SIZE:.[a-z0-9A-Z_]+]]: index
// CHECK: return %[[SIZE]] : index
func @dim_of_sized_view(%arg : memref<?xi8>, %size: index) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.reinterpret_cast %arg to offset: [0], sizes: [%size], strides: [0] : memref<?xi8> to memref<?xi8>
%1 = memref.dim %0, %c0 : memref<?xi8>
return %1 : index
// Test case: Basic folding of tensor.dim(memref.tensor_load(m)) -> memref.dim(m).
// CHECK-LABEL: func @dim_of_tensor_load(
// CHECK-SAME: %[[MEMREF:[0-9a-z]*]]: memref<?xf32>
-// CHECK: %[[C0:.*]] = constant 0
+// CHECK: %[[C0:.*]] = arith.constant 0
// CHECK: %[[D:.*]] = memref.dim %[[MEMREF]], %[[C0]]
// CHECK: return %[[D]] : index
func @dim_of_tensor_load(%arg0: memref<?xf32>) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.tensor_load %arg0 : memref<?xf32>
%1 = tensor.dim %0, %c0 : tensor<?xf32>
return %1 : index
// CHECK-NEXT: return %[[SIZE]] : index
func @dim_of_alloca(%size: index) -> index {
%0 = memref.alloca(%size) : memref<?xindex>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%1 = memref.dim %0, %c0 : memref<?xindex>
return %1 : index
}
func @dim_of_alloca_with_dynamic_size(%arg0: memref<*xf32>) -> index {
%0 = rank %arg0 : memref<*xf32>
%1 = memref.alloca(%0) : memref<?xindex>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%2 = memref.dim %1, %c0 : memref<?xindex>
return %2 : index
}
// CHECK-LABEL: func @dim_of_memref_reshape(
// CHECK-SAME: %[[MEM:[0-9a-z]+]]: memref<*xf32>,
// CHECK-SAME: %[[SHP:[0-9a-z]+]]: memref<?xindex>
-// CHECK-NEXT: %[[IDX:.*]] = constant 3
+// CHECK-NEXT: %[[IDX:.*]] = arith.constant 3
// CHECK-NEXT: %[[DIM:.*]] = memref.load %[[SHP]][%[[IDX]]]
// CHECK-NEXT: memref.store
// CHECK-NOT: memref.dim
// CHECK: return %[[DIM]] : index
func @dim_of_memref_reshape(%arg0: memref<*xf32>, %arg1: memref<?xindex>)
-> index {
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%0 = memref.reshape %arg0(%arg1)
: (memref<*xf32>, memref<?xindex>) -> memref<*xf32>
// Update the shape to test that he load ends up in the right place.
// CHECK-LABEL: func @dim_of_memref_reshape_i32(
// CHECK-SAME: %[[MEM:[0-9a-z]+]]: memref<*xf32>,
// CHECK-SAME: %[[SHP:[0-9a-z]+]]: memref<?xi32>
-// CHECK-NEXT: %[[IDX:.*]] = constant 3
+// CHECK-NEXT: %[[IDX:.*]] = arith.constant 3
// CHECK-NEXT: %[[DIM:.*]] = memref.load %[[SHP]][%[[IDX]]]
-// CHECK-NEXT: %[[CAST:.*]] = index_cast %[[DIM]]
+// CHECK-NEXT: %[[CAST:.*]] = arith.index_cast %[[DIM]]
// CHECK-NOT: memref.dim
// CHECK: return %[[CAST]] : index
func @dim_of_memref_reshape_i32(%arg0: memref<*xf32>, %arg1: memref<?xi32>)
-> index {
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%0 = memref.reshape %arg0(%arg1)
: (memref<*xf32>, memref<?xi32>) -> memref<*xf32>
%1 = memref.dim %0, %c3 : memref<*xf32>
// CHECK-LABEL: func @alloc_const_fold
func @alloc_const_fold() -> memref<?xf32> {
// CHECK-NEXT: %0 = memref.alloc() : memref<4xf32>
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloc(%c4) : memref<?xf32>
// CHECK-NEXT: %1 = memref.cast %0 : memref<4xf32> to memref<?xf32>
// CHECK-LABEL: func @alloc_alignment_const_fold
func @alloc_alignment_const_fold() -> memref<?xf32> {
// CHECK-NEXT: %0 = memref.alloc() {alignment = 4096 : i64} : memref<4xf32>
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloc(%c4) {alignment = 4096 : i64} : memref<?xf32>
// CHECK-NEXT: %1 = memref.cast %0 : memref<4xf32> to memref<?xf32>
// -----
// CHECK-LABEL: func @alloc_const_fold_with_symbols1(
-// CHECK: %[[c1:.+]] = constant 1 : index
+// CHECK: %[[c1:.+]] = arith.constant 1 : index
// CHECK: %[[mem1:.+]] = memref.alloc({{.*}})[%[[c1]], %[[c1]]] : memref<?xi32, #map>
// CHECK: return %[[mem1]] : memref<?xi32, #map>
#map0 = affine_map<(d0)[s0, s1] -> (d0 * s1 + s0)>
func @alloc_const_fold_with_symbols1(%arg0 : index) -> memref<?xi32, #map0> {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc(%arg0)[%c1, %c1] : memref<?xi32, #map0>
return %0 : memref<?xi32, #map0>
}
// -----
// CHECK-LABEL: func @alloc_const_fold_with_symbols2(
-// CHECK: %[[c1:.+]] = constant 1 : index
+// CHECK: %[[c1:.+]] = arith.constant 1 : index
// CHECK: %[[mem1:.+]] = memref.alloc()[%[[c1]], %[[c1]]] : memref<1xi32, #map>
// CHECK: %[[mem2:.+]] = memref.cast %[[mem1]] : memref<1xi32, #map> to memref<?xi32, #map>
// CHECK: return %[[mem2]] : memref<?xi32, #map>
#map0 = affine_map<(d0)[s0, s1] -> (d0 * s1 + s0)>
func @alloc_const_fold_with_symbols2() -> memref<?xi32, #map0> {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc(%c1)[%c1, %c1] : memref<?xi32, #map0>
return %0 : memref<?xi32, #map0>
}
// -----
func @fold_subview_with_transfer_read(%arg0 : memref<12x32xf32>, %arg1 : index, %arg2 : index, %arg3 : index, %arg4 : index, %arg5 : index, %arg6 : index) -> vector<4xf32> {
- %f1 = constant 1.0 : f32
+ %f1 = arith.constant 1.0 : f32
%0 = memref.subview %arg0[%arg1, %arg2][4, 4][%arg5, %arg6] : memref<12x32xf32> to memref<4x4xf32, offset:?, strides: [?, ?]>
%1 = vector.transfer_read %0[%arg3, %arg4], %f1 {in_bounds = [true]} : memref<4x4xf32, offset:?, strides: [?, ?]>, vector<4xf32>
return %1 : vector<4xf32>
// CHECK-SAME: %[[ARG14:[a-zA-Z0-9_]+]]: index
// CHECK-SAME: %[[ARG15:[a-zA-Z0-9_]+]]: index
// CHECK-SAME: %[[ARG16:[a-zA-Z0-9_]+]]: index
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
// CHECK-DAG: %[[I1:.+]] = affine.apply #[[MAP]](%[[ARG13]])[%[[ARG7]], %[[ARG1]]]
// CHECK-DAG: %[[I2:.+]] = affine.apply #[[MAP]](%[[ARG14]])[%[[ARG8]], %[[ARG2]]]
// CHECK-DAG: %[[I3:.+]] = affine.apply #[[MAP]](%[[C0]])[%[[ARG9]], %[[ARG3]]]
%arg0 : memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]>,
%arg1: index, %arg2 : index, %arg3 : index, %arg4: index, %arg5 : index,
%arg6 : index) -> vector<4xf32> {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%0 = memref.subview %arg0[0, %arg1, %arg2] [1, %arg3, %arg4] [1, 1, 1]
: memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]> to
memref<?x?xf32, offset: ?, strides: [?, ?]>
// CHECK-SAME: %[[ARG4:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG5:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG6:[a-zA-Z0-9]+]]: index
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
// CHECK-DAG: %[[IDX0:.+]] = affine.apply #[[MAP1]](%[[ARG5]])[%[[ARG1]]]
// CHECK-DAG: %[[IDX1:.+]] = affine.apply #[[MAP1]](%[[ARG6]])[%[[ARG2]]]
// CHECK: vector.transfer_read %[[ARG0]][%[[C0]], %[[IDX0]], %[[IDX1]]], %{{.*}} : memref<?x?x?xf32
%arg0 : memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]>,
%arg1 : vector<4xf32>, %arg2: index, %arg3 : index, %arg4 : index,
%arg5: index, %arg6 : index, %arg7 : index) {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%0 = memref.subview %arg0[0, %arg2, %arg3] [1, %arg4, %arg5] [1, 1, 1]
: memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]> to
memref<?x?xf32, offset: ?, strides: [?, ?]>
// CHECK-SAME: %[[ARG5:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG6:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG7:[a-zA-Z0-9]+]]: index
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
// CHECK-DAG: %[[IDX0:.+]] = affine.apply #[[MAP1]](%[[ARG6]])[%[[ARG2]]]
// CHECK-DAG: %[[IDX1:.+]] = affine.apply #[[MAP1]](%[[ARG7]])[%[[ARG3]]]
// CHECK-DAG: vector.transfer_write %[[ARG1]], %[[ARG0]][%[[C0]], %[[IDX0]], %[[IDX1]]] {in_bounds = [true]} : vector<4xf32>, memref<?x?x?xf32
%arg0 : memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]>,
%arg1 : vector<4xf32>, %arg2: index, %arg3 : index, %arg4 : index,
%arg5: index, %arg6 : index, %arg7 : index) {
- %cst = constant 0.0 : f32
+ %cst = arith.constant 0.0 : f32
%0 = memref.subview %arg0[%arg2, %arg3, 0] [%arg4, %arg5, 1] [1, 1, 1]
: memref<?x?x?xf32, offset: ?, strides: [?, ?, ?]> to
memref<?x?xf32, offset: ?, strides: [?, ?]>
// CHECK-SAME: %[[ARG5:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG6:[a-zA-Z0-9]+]]: index
// CHECK-SAME: %[[ARG7:[a-zA-Z0-9]+]]: index
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
// CHECK-DAG: %[[IDX0:.+]] = affine.apply #[[MAP1]](%[[ARG6]])[%[[ARG2]]]
// CHECK-DAG: %[[IDX1:.+]] = affine.apply #[[MAP1]](%[[ARG7]])[%[[ARG3]]]
// CHECK-DAG: vector.transfer_write %[[ARG1]], %[[ARG0]][%[[IDX0]], %[[IDX1]], %[[C0]]]
// -----
func @memref_reinterpret_cast_offset_mismatch(%in: memref<?xf32>) {
- %c0 = constant 0 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c10 = arith.constant 10 : index
// expected-error @+1 {{expected result type with size = 10 instead of -1 in dim = 0}}
%out = memref.reinterpret_cast %in to
offset: [%c0], sizes: [10, %c10], strides: [%c10, 1]
// CHECK-LABEL: func @memref_reinterpret_cast
func @memref_reinterpret_cast(%in: memref<?xf32>)
-> memref<10x?xf32, offset: ?, strides: [?, 1]> {
- %c0 = constant 0 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c10 = arith.constant 10 : index
%out = memref.reinterpret_cast %in to
offset: [%c0], sizes: [10, %c10], strides: [%c10, 1]
: memref<?xf32> to memref<10x?xf32, offset: ?, strides: [?, 1]>
// CHECK-LABEL: func @write_global_memref
func @write_global_memref() {
%0 = memref.get_global @memref0 : memref<2xf32>
- %1 = constant dense<[1.0, 2.0]> : tensor<2xf32>
+ %1 = arith.constant dense<[1.0, 2.0]> : tensor<2xf32>
memref.tensor_store %1, %0 : memref<2xf32>
return
}
// RUN: mlir-opt %s -canonicalize -split-input-file | FileCheck %s
func @testenterdataop(%a: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.enter_data if(%ifCond) create(%a: memref<10xf32>)
return
}
// -----
func @testenterdataop(%a: memref<10xf32>) -> () {
- %ifCond = constant false
+ %ifCond = arith.constant false
acc.enter_data if(%ifCond) create(%a: memref<10xf32>)
return
}
// -----
func @testexitdataop(%a: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.exit_data if(%ifCond) delete(%a: memref<10xf32>)
return
}
// -----
func @testexitdataop(%a: memref<10xf32>) -> () {
- %ifCond = constant false
+ %ifCond = arith.constant false
acc.exit_data if(%ifCond) delete(%a: memref<10xf32>)
return
}
// -----
func @testupdateop(%a: memref<10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.update if(%ifCond) host(%a: memref<10xf32>)
return
}
// -----
func @testupdateop(%a: memref<10xf32>) -> () {
- %ifCond = constant false
+ %ifCond = arith.constant false
acc.update if(%ifCond) host(%a: memref<10xf32>)
return
}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{wait_devnum cannot appear without waitOperands}}
acc.update wait_devnum(%cst: index) host(%value: memref<10xf32>)
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{async attribute cannot appear with asyncOperand}}
acc.update async(%cst: index) host(%value: memref<10xf32>) attributes {async}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{wait attribute cannot appear with waitOperands}}
acc.update wait(%cst: index) host(%value: memref<10xf32>) attributes {wait}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
// expected-error@+1 {{wait_devnum cannot appear without waitOperands}}
acc.wait wait_devnum(%cst: index)
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
// expected-error@+1 {{async attribute cannot appear with asyncOperand}}
acc.wait async(%cst: index) attributes {async}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{async attribute cannot appear with asyncOperand}}
acc.exit_data async(%cst: index) delete(%value : memref<10xf32>) attributes {async}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{wait_devnum cannot appear without waitOperands}}
acc.exit_data wait_devnum(%cst: index) delete(%value : memref<10xf32>)
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{async attribute cannot appear with asyncOperand}}
acc.enter_data async(%cst: index) create(%value : memref<10xf32>) attributes {async}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{wait attribute cannot appear with waitOperands}}
acc.enter_data wait(%cst: index) create(%value : memref<10xf32>) attributes {wait}
// -----
-%cst = constant 1 : index
+%cst = arith.constant 1 : index
%value = memref.alloc() : memref<10xf32>
// expected-error@+1 {{wait_devnum cannot appear without waitOperands}}
acc.enter_data wait_devnum(%cst: index) create(%value : memref<10xf32>)
// RUN: mlir-opt -split-input-file -mlir-print-op-generic %s | mlir-opt -allow-unregistered-dialect | FileCheck %s
func @compute1(%A: memref<10x10xf32>, %B: memref<10x10xf32>, %C: memref<10x10xf32>) -> memref<10x10xf32> {
- %c0 = constant 0 : index
- %c10 = constant 10 : index
- %c1 = constant 1 : index
- %async = constant 1 : i64
+ %c0 = arith.constant 0 : index
+ %c10 = arith.constant 10 : index
+ %c1 = arith.constant 1 : index
+ %async = arith.constant 1 : i64
acc.parallel async(%async: i64) {
acc.loop gang vector {
%a = memref.load %A[%arg3, %arg5] : memref<10x10xf32>
%b = memref.load %B[%arg5, %arg4] : memref<10x10xf32>
%cij = memref.load %C[%arg3, %arg4] : memref<10x10xf32>
- %p = mulf %a, %b : f32
- %co = addf %cij, %p : f32
+ %p = arith.mulf %a, %b : f32
+ %co = arith.addf %cij, %p : f32
memref.store %co, %C[%arg3, %arg4] : memref<10x10xf32>
}
}
}
// CHECK-LABEL: func @compute1(
-// CHECK-NEXT: %{{.*}} = constant 0 : index
-// CHECK-NEXT: %{{.*}} = constant 10 : index
-// CHECK-NEXT: %{{.*}} = constant 1 : index
-// CHECK-NEXT: [[ASYNC:%.*]] = constant 1 : i64
+// CHECK-NEXT: %{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 10 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
+// CHECK-NEXT: [[ASYNC:%.*]] = arith.constant 1 : i64
// CHECK-NEXT: acc.parallel async([[ASYNC]]: i64) {
// CHECK-NEXT: acc.loop gang vector {
// CHECK-NEXT: scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} {
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: %{{.*}} = mulf %{{.*}}, %{{.*}} : f32
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: memref.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// -----
func @compute2(%A: memref<10x10xf32>, %B: memref<10x10xf32>, %C: memref<10x10xf32>) -> memref<10x10xf32> {
- %c0 = constant 0 : index
- %c10 = constant 10 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c10 = arith.constant 10 : index
+ %c1 = arith.constant 1 : index
acc.parallel {
acc.loop {
%a = memref.load %A[%arg3, %arg5] : memref<10x10xf32>
%b = memref.load %B[%arg5, %arg4] : memref<10x10xf32>
%cij = memref.load %C[%arg3, %arg4] : memref<10x10xf32>
- %p = mulf %a, %b : f32
- %co = addf %cij, %p : f32
+ %p = arith.mulf %a, %b : f32
+ %co = arith.addf %cij, %p : f32
memref.store %co, %C[%arg3, %arg4] : memref<10x10xf32>
}
}
}
// CHECK-LABEL: func @compute2(
-// CHECK-NEXT: %{{.*}} = constant 0 : index
-// CHECK-NEXT: %{{.*}} = constant 10 : index
-// CHECK-NEXT: %{{.*}} = constant 1 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 0 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 10 : index
+// CHECK-NEXT: %{{.*}} = arith.constant 1 : index
// CHECK-NEXT: acc.parallel {
// CHECK-NEXT: acc.loop {
// CHECK-NEXT: scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} {
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: %{{.*}} = mulf %{{.*}}, %{{.*}} : f32
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: memref.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// -----
func @compute3(%a: memref<10x10xf32>, %b: memref<10x10xf32>, %c: memref<10xf32>, %d: memref<10xf32>) -> memref<10xf32> {
- %lb = constant 0 : index
- %st = constant 1 : index
- %c10 = constant 10 : index
- %numGangs = constant 10 : i64
- %numWorkers = constant 10 : i64
+ %lb = arith.constant 0 : index
+ %st = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %numGangs = arith.constant 10 : i64
+ %numWorkers = arith.constant 10 : i64
acc.data present(%a, %b, %c, %d: memref<10x10xf32>, memref<10x10xf32>, memref<10xf32>, memref<10xf32>) {
acc.parallel num_gangs(%numGangs: i64) num_workers(%numWorkers: i64) private(%c : memref<10xf32>) {
scf.for %y = %lb to %c10 step %st {
%axy = memref.load %a[%x, %y] : memref<10x10xf32>
%bxy = memref.load %b[%x, %y] : memref<10x10xf32>
- %tmp = addf %axy, %bxy : f32
+ %tmp = arith.addf %axy, %bxy : f32
memref.store %tmp, %c[%y] : memref<10xf32>
}
acc.yield
scf.for %i = %lb to %c10 step %st {
%ci = memref.load %c[%i] : memref<10xf32>
%dx = memref.load %d[%x] : memref<10xf32>
- %z = addf %ci, %dx : f32
+ %z = arith.addf %ci, %dx : f32
memref.store %z, %d[%x] : memref<10xf32>
}
acc.yield
}
// CHECK: func @compute3({{.*}}: memref<10x10xf32>, {{.*}}: memref<10x10xf32>, [[ARG2:%.*]]: memref<10xf32>, {{.*}}: memref<10xf32>) -> memref<10xf32> {
-// CHECK-NEXT: [[C0:%.*]] = constant 0 : index
-// CHECK-NEXT: [[C1:%.*]] = constant 1 : index
-// CHECK-NEXT: [[C10:%.*]] = constant 10 : index
-// CHECK-NEXT: [[NUMGANG:%.*]] = constant 10 : i64
-// CHECK-NEXT: [[NUMWORKERS:%.*]] = constant 10 : i64
+// CHECK-NEXT: [[C0:%.*]] = arith.constant 0 : index
+// CHECK-NEXT: [[C1:%.*]] = arith.constant 1 : index
+// CHECK-NEXT: [[C10:%.*]] = arith.constant 10 : index
+// CHECK-NEXT: [[NUMGANG:%.*]] = arith.constant 10 : i64
+// CHECK-NEXT: [[NUMWORKERS:%.*]] = arith.constant 10 : i64
// CHECK-NEXT: acc.data present(%{{.*}}, %{{.*}}, %{{.*}}, %{{.*}} : memref<10x10xf32>, memref<10x10xf32>, memref<10xf32>, memref<10xf32>) {
// CHECK-NEXT: acc.parallel num_gangs([[NUMGANG]]: i64) num_workers([[NUMWORKERS]]: i64) private([[ARG2]]: memref<10xf32>) {
// CHECK-NEXT: acc.loop gang {
// CHECK-NEXT: scf.for %{{.*}} = [[C0]] to [[C10]] step [[C1]] {
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: memref.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: acc.yield
// CHECK-NEXT: scf.for %{{.*}} = [[C0]] to [[C10]] step [[C1]] {
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: %{{.*}} = memref.load %{{.*}}[%{{.*}}] : memref<10xf32>
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: memref.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: acc.yield
// -----
func @testloopop() -> () {
- %i64Value = constant 1 : i64
- %i32Value = constant 128 : i32
- %idxValue = constant 8 : index
+ %i64Value = arith.constant 1 : i64
+ %i32Value = arith.constant 128 : i32
+ %idxValue = arith.constant 8 : index
acc.loop gang worker vector {
"test.openacc_dummy_op"() : () -> ()
return
}
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK-NEXT: [[I32VALUE:%.*]] = constant 128 : i32
-// CHECK-NEXT: [[IDXVALUE:%.*]] = constant 8 : index
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK-NEXT: [[I32VALUE:%.*]] = arith.constant 128 : i32
+// CHECK-NEXT: [[IDXVALUE:%.*]] = arith.constant 8 : index
// CHECK: acc.loop gang worker vector {
// CHECK-NEXT: "test.openacc_dummy_op"() : () -> ()
// CHECK-NEXT: acc.yield
// -----
func @testparallelop(%a: memref<10xf32>, %b: memref<10xf32>, %c: memref<10x10xf32>) -> () {
- %i64value = constant 1 : i64
- %i32value = constant 1 : i32
- %idxValue = constant 1 : index
+ %i64value = arith.constant 1 : i64
+ %i32value = arith.constant 1 : i32
+ %idxValue = arith.constant 1 : index
acc.parallel async(%i64value: i64) {
}
acc.parallel async(%i32value: i32) {
}
// CHECK: func @testparallelop([[ARGA:%.*]]: memref<10xf32>, [[ARGB:%.*]]: memref<10xf32>, [[ARGC:%.*]]: memref<10x10xf32>) {
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
// CHECK: acc.parallel async([[I64VALUE]]: i64) {
// CHECK-NEXT: }
// CHECK: acc.parallel async([[I32VALUE]]: i32) {
// -----
func @testdataop(%a: memref<10xf32>, %b: memref<10xf32>, %c: memref<10x10xf32>) -> () {
- %ifCond = constant true
+ %ifCond = arith.constant true
acc.data if(%ifCond) present(%a : memref<10xf32>) {
}
acc.data present(%a, %b, %c : memref<10xf32>, memref<10xf32>, memref<10x10xf32>) {
}
// CHECK: func @testdataop([[ARGA:%.*]]: memref<10xf32>, [[ARGB:%.*]]: memref<10xf32>, [[ARGC:%.*]]: memref<10x10xf32>) {
-// CHECK: [[IFCOND1:%.*]] = constant true
+// CHECK: [[IFCOND1:%.*]] = arith.constant true
// CHECK: acc.data if([[IFCOND1]]) present([[ARGA]] : memref<10xf32>) {
// CHECK-NEXT: }
// CHECK: acc.data present([[ARGA]], [[ARGB]], [[ARGC]] : memref<10xf32>, memref<10xf32>, memref<10x10xf32>) {
// -----
func @testupdateop(%a: memref<10xf32>, %b: memref<10xf32>, %c: memref<10x10xf32>) -> () {
- %i64Value = constant 1 : i64
- %i32Value = constant 1 : i32
- %idxValue = constant 1 : index
- %ifCond = constant true
+ %i64Value = arith.constant 1 : i64
+ %i32Value = arith.constant 1 : i32
+ %idxValue = arith.constant 1 : index
+ %ifCond = arith.constant true
acc.update async(%i64Value: i64) host(%a: memref<10xf32>)
acc.update async(%i32Value: i32) host(%a: memref<10xf32>)
acc.update async(%idxValue: index) host(%a: memref<10xf32>)
}
// CHECK: func @testupdateop([[ARGA:%.*]]: memref<10xf32>, [[ARGB:%.*]]: memref<10xf32>, [[ARGC:%.*]]: memref<10x10xf32>) {
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
-// CHECK: [[IFCOND:%.*]] = constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
+// CHECK: [[IFCOND:%.*]] = arith.constant true
// CHECK: acc.update async([[I64VALUE]] : i64) host([[ARGA]] : memref<10xf32>)
// CHECK: acc.update async([[I32VALUE]] : i32) host([[ARGA]] : memref<10xf32>)
// CHECK: acc.update async([[IDXVALUE]] : index) host([[ARGA]] : memref<10xf32>)
// -----
-%i64Value = constant 1 : i64
-%i32Value = constant 1 : i32
-%idxValue = constant 1 : index
-%ifCond = constant true
+%i64Value = arith.constant 1 : i64
+%i32Value = arith.constant 1 : i32
+%idxValue = arith.constant 1 : index
+%ifCond = arith.constant true
acc.wait
acc.wait(%i64Value: i64)
acc.wait(%i32Value: i32)
acc.wait(%i64Value: i64) async(%idxValue: index) wait_devnum(%i32Value: i32)
acc.wait if(%ifCond)
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
-// CHECK: [[IFCOND:%.*]] = constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
+// CHECK: [[IFCOND:%.*]] = arith.constant true
// CHECK: acc.wait
// CHECK: acc.wait([[I64VALUE]] : i64)
// CHECK: acc.wait([[I32VALUE]] : i32)
// -----
-%i64Value = constant 1 : i64
-%i32Value = constant 1 : i32
-%i32Value2 = constant 2 : i32
-%idxValue = constant 1 : index
-%ifCond = constant true
+%i64Value = arith.constant 1 : i64
+%i32Value = arith.constant 1 : i32
+%i32Value2 = arith.constant 2 : i32
+%idxValue = arith.constant 1 : index
+%ifCond = arith.constant true
acc.init
acc.init device_type(%i32Value : i32)
acc.init device_type(%i32Value, %i32Value2 : i32, i32)
acc.init device_num(%idxValue : index)
acc.init if(%ifCond)
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[I32VALUE2:%.*]] = constant 2 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
-// CHECK: [[IFCOND:%.*]] = constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[I32VALUE2:%.*]] = arith.constant 2 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
+// CHECK: [[IFCOND:%.*]] = arith.constant true
// CHECK: acc.init
// CHECK: acc.init device_type([[I32VALUE]] : i32)
// CHECK: acc.init device_type([[I32VALUE]], [[I32VALUE2]] : i32, i32)
// -----
-%i64Value = constant 1 : i64
-%i32Value = constant 1 : i32
-%i32Value2 = constant 2 : i32
-%idxValue = constant 1 : index
-%ifCond = constant true
+%i64Value = arith.constant 1 : i64
+%i32Value = arith.constant 1 : i32
+%i32Value2 = arith.constant 2 : i32
+%idxValue = arith.constant 1 : index
+%ifCond = arith.constant true
acc.shutdown
acc.shutdown device_type(%i32Value : i32)
acc.shutdown device_type(%i32Value, %i32Value2 : i32, i32)
acc.shutdown device_num(%idxValue : index)
acc.shutdown if(%ifCond)
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[I32VALUE2:%.*]] = constant 2 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
-// CHECK: [[IFCOND:%.*]] = constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[I32VALUE2:%.*]] = arith.constant 2 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
+// CHECK: [[IFCOND:%.*]] = arith.constant true
// CHECK: acc.shutdown
// CHECK: acc.shutdown device_type([[I32VALUE]] : i32)
// CHECK: acc.shutdown device_type([[I32VALUE]], [[I32VALUE2]] : i32, i32)
// -----
func @testexitdataop(%a: memref<10xf32>, %b: memref<10xf32>, %c: memref<10x10xf32>) -> () {
- %ifCond = constant true
- %i64Value = constant 1 : i64
- %i32Value = constant 1 : i32
- %idxValue = constant 1 : index
+ %ifCond = arith.constant true
+ %i64Value = arith.constant 1 : i64
+ %i32Value = arith.constant 1 : i32
+ %idxValue = arith.constant 1 : index
acc.exit_data copyout(%a : memref<10xf32>)
acc.exit_data delete(%a : memref<10xf32>)
}
// CHECK: func @testexitdataop([[ARGA:%.*]]: memref<10xf32>, [[ARGB:%.*]]: memref<10xf32>, [[ARGC:%.*]]: memref<10x10xf32>) {
-// CHECK: [[IFCOND1:%.*]] = constant true
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
+// CHECK: [[IFCOND1:%.*]] = arith.constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
// CHECK: acc.exit_data copyout([[ARGA]] : memref<10xf32>)
// CHECK: acc.exit_data delete([[ARGA]] : memref<10xf32>)
// CHECK: acc.exit_data delete([[ARGA]] : memref<10xf32>) attributes {async, finalize}
func @testenterdataop(%a: memref<10xf32>, %b: memref<10xf32>, %c: memref<10x10xf32>) -> () {
- %ifCond = constant true
- %i64Value = constant 1 : i64
- %i32Value = constant 1 : i32
- %idxValue = constant 1 : index
+ %ifCond = arith.constant true
+ %i64Value = arith.constant 1 : i64
+ %i32Value = arith.constant 1 : i32
+ %idxValue = arith.constant 1 : index
acc.enter_data copyin(%a : memref<10xf32>)
acc.enter_data create(%a : memref<10xf32>) create_zero(%b, %c : memref<10xf32>, memref<10x10xf32>)
}
// CHECK: func @testenterdataop([[ARGA:%.*]]: memref<10xf32>, [[ARGB:%.*]]: memref<10xf32>, [[ARGC:%.*]]: memref<10x10xf32>) {
-// CHECK: [[IFCOND1:%.*]] = constant true
-// CHECK: [[I64VALUE:%.*]] = constant 1 : i64
-// CHECK: [[I32VALUE:%.*]] = constant 1 : i32
-// CHECK: [[IDXVALUE:%.*]] = constant 1 : index
+// CHECK: [[IFCOND1:%.*]] = arith.constant true
+// CHECK: [[I64VALUE:%.*]] = arith.constant 1 : i64
+// CHECK: [[I32VALUE:%.*]] = arith.constant 1 : i32
+// CHECK: [[IDXVALUE:%.*]] = arith.constant 1 : index
// CHECK: acc.enter_data copyin([[ARGA]] : memref<10xf32>)
// CHECK: acc.enter_data create([[ARGA]] : memref<10xf32>) create_zero([[ARGB]], [[ARGC]] : memref<10xf32>, memref<10x10xf32>)
// CHECK: acc.enter_data attach([[ARGA]] : memref<10xf32>)
omp.reduction.declare @add_f32 : f64
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f64
+ %0 = arith.constant 0.0 : f64
omp.yield (%0 : f64)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f64, %arg1: f64):
- %1 = addf %arg0, %arg1 : f64
+ %1 = arith.addf %arg0, %arg1 : f64
omp.yield (%1 : f64)
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
- %2 = fpext %1 : f32 to f64
+ %1 = arith.addf %arg0, %arg1 : f32
+ %2 = arith.extf %1 : f32 to f64
omp.yield (%2 : f64)
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
atomic {
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
atomic {
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
func @foo(%lb : index, %ub : index, %step : index) {
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
%0 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
%1 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@add_f32 -> %0 : !llvm.ptr<f32>) {
- %2 = constant 2.0 : f32
+ %2 = arith.constant 2.0 : f32
// expected-error @below {{accumulator is not used by the parent}}
omp.reduction %2, %1 : !llvm.ptr<f32>
omp.yield
// -----
func @foo(%lb : index, %ub : index, %step : index) {
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
%0 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
%1 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
// expected-error @below {{expected symbol reference @foo to point to a reduction declaration}}
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@foo -> %0 : !llvm.ptr<f32>) {
- %2 = constant 2.0 : f32
+ %2 = arith.constant 2.0 : f32
omp.reduction %2, %1 : !llvm.ptr<f32>
omp.yield
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
func @foo(%lb : index, %ub : index, %step : index) {
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
%0 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
// expected-error @below {{accumulator variable used more than once}}
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@add_f32 -> %0 : !llvm.ptr<f32>, @add_f32 -> %0 : !llvm.ptr<f32>) {
- %2 = constant 2.0 : f32
+ %2 = arith.constant 2.0 : f32
omp.reduction %2, %0 : !llvm.ptr<f32>
omp.yield
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
atomic {
}
func @foo(%lb : index, %ub : index, %step : index, %mem : memref<1xf32>) {
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
// expected-error @below {{expected accumulator ('memref<1xf32>') to be the same type as reduction declaration ('!llvm.ptr<f32>')}}
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@add_f32 -> %mem : memref<1xf32>) {
- %2 = constant 2.0 : f32
+ %2 = arith.constant 2.0 : f32
omp.reduction %2, %mem : memref<1xf32>
omp.yield
}
omp.reduction.declare @add_f32 : f32
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
atomic {
}
func @reduction(%lb : index, %ub : index, %step : index) {
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
%0 = llvm.alloca %c1 x i32 : (i32) -> !llvm.ptr<f32>
// CHECK: reduction(@add_f32 -> %{{.+}} : !llvm.ptr<f32>)
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@add_f32 -> %0 : !llvm.ptr<f32>) {
- %1 = constant 2.0 : f32
+ %1 = arith.constant 2.0 : f32
// CHECK: omp.reduction %{{.+}}, %{{.+}}
omp.reduction %1, %0 : !llvm.ptr<f32>
omp.yield
// CHECK: init
init {
^bb0(%arg: f32):
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
omp.yield (%0 : f32)
}
// CHECK: combiner
combiner {
^bb1(%arg0: f32, %arg1: f32):
- %1 = addf %arg0, %arg1 : f32
+ %1 = arith.addf %arg0, %arg1 : f32
omp.yield (%1 : f32)
}
// CHECK-NOT: atomic
// CHECK: reduction
omp.wsloop (%iv) : index = (%lb) to (%ub) step (%step)
reduction(@add2_f32 -> %0 : memref<1xf32>) {
- %1 = constant 2.0 : f32
+ %1 = arith.constant 2.0 : f32
// CHECK: omp.reduction
omp.reduction %1, %0 : memref<1xf32>
omp.yield
// -----
// CHECK-LABEL: redundant_scast
func @redundant_scast() -> tensor<4xi8> {
- // CHECK-NEXT: constant dense<10> : tensor<4xi8>
+ // CHECK-NEXT: arith.constant dense<10> : tensor<4xi8>
// CHECK-NEXT: return
- %cst = constant dense<5> : tensor<4xi8>
+ %cst = arith.constant dense<5> : tensor<4xi8>
%1 = "quant.scast"(%cst) : (tensor<4xi8>) -> tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>
%2 = "quant.scast"(%1) : (tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>) -> tensor<4xi8>
- %3 = addi %2, %2 : tensor<4xi8>
+ %3 = arith.addi %2, %2 : tensor<4xi8>
return %3 : tensor<4xi8>
}
// -----
// CHECK-LABEL: non_redundant_scast
func @non_redundant_scast() -> tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>> {
- // CHECK-NEXT: constant dense<5> : tensor<4xi8>
+ // CHECK-NEXT: arith.constant dense<5> : tensor<4xi8>
// CHECK-NEXT: scast
// CHECK-NEXT: return
- %cst = constant dense<5> : tensor<4xi8>
+ %cst = arith.constant dense<5> : tensor<4xi8>
%1 = "quant.scast"(%cst) : (tensor<4xi8>) -> tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>
return %1 : tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>
}
// (-64 signed == 192 unsigned).
// CHECK-LABEL: constant_splat_tensor_u8_affine
func @constant_splat_tensor_u8_affine() -> tensor<4xf32> {
- // CHECK: %cst = constant dense<-64> : tensor<4xi8>
+ // CHECK: %cst = arith.constant dense<-64> : tensor<4xi8>
// CHECK-NEXT: %0 = "quant.scast"(%cst) : (tensor<4xi8>) -> tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>
- %cst = constant dense<0.5> : tensor<4xf32>
+ %cst = arith.constant dense<0.5> : tensor<4xf32>
%1 = "quant.qcast"(%cst) : (tensor<4xf32>) -> tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>
%2 = "quant.dcast"(%1) : (tensor<4x!quant.uniform<u8:f32, 7.812500e-03:128>>) -> (tensor<4xf32>)
return %2 : tensor<4xf32>
// Verifies i8 affine quantization on a splat tensor.
// CHECK-LABEL: constant_splat_tensor_i8_affine
func @constant_splat_tensor_i8_affine() -> tensor<4xf32> {
- // CHECK: %cst = constant dense<63> : tensor<4xi8>
+ // CHECK: %cst = arith.constant dense<63> : tensor<4xi8>
// CHECK-NEXT: %0 = "quant.scast"(%cst) : (tensor<4xi8>) -> tensor<4x!quant.uniform<i8:f32, 7.812500e-03:-1>>
- %cst = constant dense<0.5> : tensor<4xf32>
+ %cst = arith.constant dense<0.5> : tensor<4xf32>
%1 = "quant.qcast"(%cst) : (tensor<4xf32>) -> tensor<4x!quant.uniform<i8:f32, 7.812500e-03:-1>>
%2 = "quant.dcast"(%1) : (tensor<4x!quant.uniform<i8:f32, 7.812500e-03:-1>>) -> (tensor<4xf32>)
return %2 : tensor<4xf32>
// Verifies i8 fixedpoint quantization on a splat tensor.
// CHECK-LABEL: const_splat_tensor_i8_fixedpoint
func @const_splat_tensor_i8_fixedpoint() -> tensor<4xf32> {
- // CHECK: %cst = constant dense<64> : tensor<4xi8>
+ // CHECK: %cst = arith.constant dense<64> : tensor<4xi8>
// CHECK-NEXT: %0 = "quant.scast"(%cst) : (tensor<4xi8>) -> tensor<4x!quant.uniform<i8:f32, 7.812500e-03>>
- %cst = constant dense<0.5> : tensor<4xf32>
+ %cst = arith.constant dense<0.5> : tensor<4xf32>
%1 = "quant.qcast"(%cst) : (tensor<4xf32>) -> tensor<4x!quant.uniform<i8:f32, 7.812500e-03>>
%2 = "quant.dcast"(%1) : (tensor<4x!quant.uniform<i8:f32, 7.812500e-03>>) -> (tensor<4xf32>)
return %2 : tensor<4xf32>
// Verifies i8 fixedpoint quantization on a splat tensor resulting in a negative storage value.
// CHECK-LABEL: const_splat_tensor_i8_fixedpoint_neg
func @const_splat_tensor_i8_fixedpoint_neg() -> tensor<4xf32> {
- // CHECK: %cst = constant dense<-64> : tensor<4xi8>
- %cst = constant dense<-0.5> : tensor<4xf32>
+ // CHECK: %cst = arith.constant dense<-64> : tensor<4xi8>
+ %cst = arith.constant dense<-0.5> : tensor<4xf32>
%1 = "quant.qcast"(%cst) : (tensor<4xf32>) -> tensor<4x!quant.uniform<i8:f32, 7.812500e-03>>
%2 = "quant.dcast"(%1) : (tensor<4x!quant.uniform<i8:f32, 7.812500e-03>>) -> (tensor<4xf32>)
return %2 : tensor<4xf32>
// Verifies i8 fixedpoint quantization on a dense tensor, sweeping values.
// CHECK-LABEL: const_dense_tensor_i8_fixedpoint
func @const_dense_tensor_i8_fixedpoint() -> tensor<7xf32> {
- // CHECK: %cst = constant dense<[-128, -128, -64, 0, 64, 127, 127]> : tensor<7xi8>
- %cst = constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
+ // CHECK: %cst = arith.constant dense<[-128, -128, -64, 0, 64, 127, 127]> : tensor<7xi8>
+ %cst = arith.constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i8:f32, 7.812500e-03>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<i8:f32, 7.812500e-03>>) -> (tensor<7xf32>)
return %2 : tensor<7xf32>
// CHECK-LABEL: const_sparse_tensor_i8_fixedpoint
func @const_sparse_tensor_i8_fixedpoint() -> tensor<2x7xf32> {
// NOTE: Ugly regex match pattern for opening "[[" of indices tensor.
- // CHECK: %cst = constant sparse<{{\[}}[0, 0], [0, 1], [0, 2], [0, 3], [0, 4], [0, 5], [0, 6]], [-128, -128, -64, 0, 64, 127, 127]> : tensor<2x7xi8>
- %cst = constant sparse<
+ // CHECK: %cst = arith.constant sparse<{{\[}}[0, 0], [0, 1], [0, 2], [0, 3], [0, 4], [0, 5], [0, 6]], [-128, -128, -64, 0, 64, 127, 127]> : tensor<2x7xi8>
+ %cst = arith.constant sparse<
[[0, 0], [0, 1], [0, 2], [0, 3], [0, 4], [0, 5], [0, 6]],
[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<2x7xf32>
%1 = "quant.qcast"(%cst) : (tensor<2x7xf32>) -> tensor<2x7x!quant.uniform<i8:f32, 7.812500e-03>>
// Verifies i8 fixedpoint quantization on a primitive const.
// CHECK-LABEL: const_primitive_float_i8_fixedpoint
func @const_primitive_float_i8_fixedpoint() -> f32 {
- // CHECK: %c64_i8 = constant 64 : i8
+ // CHECK: %c64_i8 = arith.constant 64 : i8
// CHECK-NEXT: %0 = "quant.scast"(%c64_i8) : (i8) -> !quant.uniform<i8:f32, 7.812500e-03>
- %cst = constant 0.5 : f32
+ %cst = arith.constant 0.5 : f32
%1 = "quant.qcast"(%cst) : (f32) -> !quant.uniform<i8:f32, 7.812500e-03>
%2 = "quant.dcast"(%1) : (!quant.uniform<i8:f32, 7.812500e-03>) -> (f32)
return %2 : f32
// CHECK-LABEL: const_dense_tensor_u4_affine
func @const_dense_tensor_u4_affine() -> tensor<7xf32> {
// NOTE: Unsigned quantities printed by MLIR as signed.
- // CHECK: %cst = constant dense<[0, 0, 4, -8, -4, -1, -1]> : tensor<7xi4>
- %cst = constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
+ // CHECK: %cst = arith.constant dense<[0, 0, 4, -8, -4, -1, -1]> : tensor<7xi4>
+ %cst = arith.constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<u4:f32, 1.250000e-01:8>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<u4:f32, 1.250000e-01:8>>) -> (tensor<7xf32>)
return %2 : tensor<7xf32>
// CHECK-LABEL: const_dense_tensor_i4_affine
func @const_dense_tensor_i4_affine() -> tensor<7xf32> {
// NOTE: Unsigned quantities printed by MLIR as signed.
- // CHECK: %cst = constant dense<[-8, -8, -5, -1, 3, 7, 7]> : tensor<7xi4>
- %cst = constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
+ // CHECK: %cst = arith.constant dense<[-8, -8, -5, -1, 3, 7, 7]> : tensor<7xi4>
+ %cst = arith.constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i4:f32, 1.250000e-01:-1>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<i4:f32, 1.250000e-01:-1>>) -> (tensor<7xf32>)
return %2 : tensor<7xf32>
// Verifies i4 fixed point quantization on a dense tensor, sweeping values.
// CHECK-LABEL: const_dense_tensor_i4_fixedpoint
func @const_dense_tensor_i4_fixedpoint() -> tensor<7xf32> {
- // CHECK: %cst = constant dense<[-8, -8, -4, 0, 4, 7, 7]> : tensor<7xi4>
- %cst = constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
+ // CHECK: %cst = arith.constant dense<[-8, -8, -4, 0, 4, 7, 7]> : tensor<7xi4>
+ %cst = arith.constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i4:f32, 1.250000e-01>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<i4:f32, 1.250000e-01>>) -> (tensor<7xf32>)
return %2 : tensor<7xf32>
// be clamped to 100).
// CHECK-LABEL: const_custom_storage_range_i8_fixedpoint
func @const_custom_storage_range_i8_fixedpoint() -> tensor<7xf32> {
- // CHECK: %cst = constant dense<[-100, -100, -64, 0, 64, 100, 100]> : tensor<7xi8>
- %cst = constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
+ // CHECK: %cst = arith.constant dense<[-100, -100, -64, 0, 64, 100, 100]> : tensor<7xi8>
+ %cst = arith.constant dense<[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i8<-100:100>:f32, 7.812500e-03>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<i8<-100:100>:f32, 7.812500e-03>>) -> (tensor<7xf32>)
return %2 : tensor<7xf32>
// CHECK-LABEL: zero_tensors_to_zero_points
func @zero_tensors_to_zero_points() -> (tensor<7xf32>, tensor<7xf32>, tensor<7xf32>, tensor<7xf32>) {
-// CHECK-DAG: %[[cst1:.*]] = constant dense<1> : tensor<7xi8>
-// CHECK-DAG: %[[cst:.*]] = constant dense<-127> : tensor<7xi8>
-// CHECK-DAG: %[[cst0:.*]] = constant dense<0> : tensor<7xi8>
+// CHECK-DAG: %[[cst1:.*]] = arith.constant dense<1> : tensor<7xi8>
+// CHECK-DAG: %[[cst:.*]] = arith.constant dense<-127> : tensor<7xi8>
+// CHECK-DAG: %[[cst0:.*]] = arith.constant dense<0> : tensor<7xi8>
// CHECK: "quant.scast"(%[[cst0]]) : (tensor<7xi8>) -> tensor<7x!quant.uniform<i8:f32, 1.000000e+00>>
// CHECK: "quant.scast"(%[[cst]]) : (tensor<7xi8>) -> tensor<7x!quant.uniform<i8<-127:127>:f32, 1.000000e+00:-127>>
// CHECK: "quant.scast"(%[[cst0]]) : (tensor<7xi8>) -> tensor<7x!quant.uniform<u8:f32, 1.000000e+00>>
// CHECK: "quant.scast"(%[[cst1]]) : (tensor<7xi8>) -> tensor<7x!quant.uniform<u8<1:255>:f32, 1.000000e+00:1>>
- %cst = constant dense<0.0> : tensor<7xf32>
+ %cst = arith.constant dense<0.0> : tensor<7xf32>
%1 = "quant.qcast"(%cst) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i8:f32, 1.0>>
%2 = "quant.dcast"(%1) : (tensor<7x!quant.uniform<i8:f32, 1.0>>) -> (tensor<7xf32>)
- %cst0 = constant dense<0.0> : tensor<7xf32>
+ %cst0 = arith.constant dense<0.0> : tensor<7xf32>
%3 = "quant.qcast"(%cst0) : (tensor<7xf32>) -> tensor<7x!quant.uniform<i8<-127:127>:f32, 1.0:-127>>
%4 = "quant.dcast"(%3) : (tensor<7x!quant.uniform<i8<-127:127>:f32, 1.0:-127>>) -> (tensor<7xf32>)
- %cst1 = constant dense<0.0> : tensor<7xf32>
+ %cst1 = arith.constant dense<0.0> : tensor<7xf32>
%5 = "quant.qcast"(%cst1) : (tensor<7xf32>) -> tensor<7x!quant.uniform<u8:f32, 1.0>>
%6 = "quant.dcast"(%5) : (tensor<7x!quant.uniform<u8:f32, 1.0>>) -> (tensor<7xf32>)
- %cst2 = constant dense<0.0> : tensor<7xf32>
+ %cst2 = arith.constant dense<0.0> : tensor<7xf32>
%7 = "quant.qcast"(%cst2) : (tensor<7xf32>) -> tensor<7x!quant.uniform<u8<1:255>:f32, 1.0:1>>
%8 = "quant.dcast"(%7) : (tensor<7x!quant.uniform<u8<1:255>:f32, 1.0:1>>) -> (tensor<7xf32>)
// CHECK-LABEL: per_axis_dense_quantization
func @per_axis_dense_quantization() -> (tensor<2x3xf32>, tensor<2x3xf32>) {
-// CHECK-DAG: %[[cst0:.*]] = constant dense<{{\[}}[-128, -1, 1], [127, 1, 3]]> : tensor<2x3xi8>
-// CHECK-DAG: %[[cst:.*]] = constant dense<{{\[}}[-128, 64, 127], [0, 1, 2]]> : tensor<2x3xi8>
+// CHECK-DAG: %[[cst0:.*]] = arith.constant dense<{{\[}}[-128, -1, 1], [127, 1, 3]]> : tensor<2x3xi8>
+// CHECK-DAG: %[[cst:.*]] = arith.constant dense<{{\[}}[-128, 64, 127], [0, 1, 2]]> : tensor<2x3xi8>
// CHECK: "quant.scast"(%[[cst]]) : (tensor<2x3xi8>) -> tensor<2x3x!quant.uniform<i8:f32:0, {7.812500e-03:128,1.000000e+00}>>
// CHECK: "quant.scast"(%[[cst0]]) : (tensor<2x3xi8>) -> tensor<2x3x!quant.uniform<i8:f32:1, {7.812500e-03:128,1.000000e+00,1.000000e+00:1}>>
- %cst = constant dense<[[-2.0, -0.5, 0.0], [0.0, 1.0, 2.0]]> : tensor<2x3xf32>
+ %cst = arith.constant dense<[[-2.0, -0.5, 0.0], [0.0, 1.0, 2.0]]> : tensor<2x3xf32>
%1 = "quant.qcast"(%cst) : (tensor<2x3xf32>) -> tensor<2x3x!quant.uniform<i8:f32:0, {7.812500e-03:128, 1.0}>>
%2 = "quant.dcast"(%1) : (tensor<2x3x!quant.uniform<i8:f32:0, {7.812500e-03:128, 1.0}>>) -> (tensor<2x3xf32>)
- %cst0 = constant dense<[[-2.0, -0.5, 0.0], [0.0, 1.0, 2.0]]> : tensor<2x3xf32>
+ %cst0 = arith.constant dense<[[-2.0, -0.5, 0.0], [0.0, 1.0, 2.0]]> : tensor<2x3xf32>
%3 = "quant.qcast"(%cst0) : (tensor<2x3xf32>) -> tensor<2x3x!quant.uniform<i8:f32:1, {7.812500e-03:128, 1.0, 1.0:1}>>
%4 = "quant.dcast"(%3) : (tensor<2x3x!quant.uniform<i8:f32:1, {7.812500e-03:128, 1.0, 1.0:1}>>) -> (tensor<2x3xf32>)
// CHECK: %[[RES2:.*]] = memref.tensor_load %[[RES1]]#2 : memref<f32>
// CHECK: return %[[RES1]]#1, %[[RES2]] : i64, tensor<f32>
func @bufferize_while(%arg0: i64, %arg1: i64, %arg2: tensor<f32>) -> (i64, tensor<f32>) {
- %c2_i64 = constant 2 : i64
+ %c2_i64 = arith.constant 2 : i64
%0:3 = scf.while (%arg3 = %arg0, %arg4 = %arg2) : (i64, tensor<f32>) -> (i64, i64, tensor<f32>) {
- %1 = cmpi slt, %arg3, %arg1 : i64
+ %1 = arith.cmpi slt, %arg3, %arg1 : i64
scf.condition(%1) %arg3, %arg3, %arg4 : i64, i64, tensor<f32>
} do {
^bb0(%arg5: i64, %arg6: i64, %arg7: tensor<f32>):
- %1 = muli %arg6, %c2_i64 : i64
+ %1 = arith.muli %arg6, %c2_i64 : i64
scf.yield %1, %arg7 : i64, tensor<f32>
}
return %0#1, %0#2 : i64, tensor<f32>
// -----
func @single_iteration_some(%A: memref<?x?x?xi32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c10 = arith.constant 10 : index
scf.parallel (%i0, %i1, %i2) = (%c0, %c3, %c7) to (%c1, %c6, %c10) step (%c1, %c2, %c3) {
- %c42 = constant 42 : i32
+ %c42 = arith.constant 42 : i32
memref.store %c42, %A[%i0, %i1, %i2] : memref<?x?x?xi32>
scf.yield
}
// CHECK-LABEL: func @single_iteration_some(
// CHECK-SAME: [[ARG0:%.*]]: memref<?x?x?xi32>) {
-// CHECK-DAG: [[C42:%.*]] = constant 42 : i32
-// CHECK-DAG: [[C7:%.*]] = constant 7 : index
-// CHECK-DAG: [[C6:%.*]] = constant 6 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
-// CHECK-DAG: [[C2:%.*]] = constant 2 : index
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
+// CHECK-DAG: [[C42:%.*]] = arith.constant 42 : i32
+// CHECK-DAG: [[C7:%.*]] = arith.constant 7 : index
+// CHECK-DAG: [[C6:%.*]] = arith.constant 6 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
+// CHECK-DAG: [[C2:%.*]] = arith.constant 2 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
// CHECK: scf.parallel ([[V0:%.*]]) = ([[C3]]) to ([[C6]]) step ([[C2]]) {
// CHECK: memref.store [[C42]], [[ARG0]]{{\[}}[[C0]], [[V0]], [[C7]]] : memref<?x?x?xi32>
// CHECK: scf.yield
// -----
func @single_iteration_all(%A: memref<?x?x?xi32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c10 = arith.constant 10 : index
scf.parallel (%i0, %i1, %i2) = (%c0, %c3, %c7) to (%c1, %c6, %c10) step (%c1, %c3, %c3) {
- %c42 = constant 42 : i32
+ %c42 = arith.constant 42 : i32
memref.store %c42, %A[%i0, %i1, %i2] : memref<?x?x?xi32>
scf.yield
}
// CHECK-LABEL: func @single_iteration_all(
// CHECK-SAME: [[ARG0:%.*]]: memref<?x?x?xi32>) {
-// CHECK-DAG: [[C42:%.*]] = constant 42 : i32
-// CHECK-DAG: [[C7:%.*]] = constant 7 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
+// CHECK-DAG: [[C42:%.*]] = arith.constant 42 : i32
+// CHECK-DAG: [[C7:%.*]] = arith.constant 7 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
// CHECK-NOT: scf.parallel
// CHECK: memref.store [[C42]], [[ARG0]]{{\[}}[[C0]], [[C3]], [[C7]]] : memref<?x?x?xi32>
// CHECK-NOT: scf.yield
// -----
func @single_iteration_reduce(%A: index, %B: index) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
%0:2 = scf.parallel (%i0, %i1) = (%c1, %c3) to (%c2, %c6) step (%c1, %c3) init(%A, %B) -> (index, index) {
scf.reduce(%i0) : index {
^bb0(%lhs: index, %rhs: index):
- %1 = addi %lhs, %rhs : index
+ %1 = arith.addi %lhs, %rhs : index
scf.reduce.return %1 : index
}
scf.reduce(%i1) : index {
^bb0(%lhs: index, %rhs: index):
- %2 = muli %lhs, %rhs : index
+ %2 = arith.muli %lhs, %rhs : index
scf.reduce.return %2 : index
}
scf.yield
// CHECK-LABEL: func @single_iteration_reduce(
// CHECK-SAME: [[ARG0:%.*]]: index, [[ARG1:%.*]]: index)
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
// CHECK-NOT: scf.parallel
// CHECK-NOT: scf.reduce
// CHECK-NOT: scf.reduce.return
// CHECK-NOT: scf.yield
-// CHECK: [[V0:%.*]] = addi [[ARG0]], [[C1]]
-// CHECK: [[V1:%.*]] = muli [[ARG1]], [[C3]]
+// CHECK: [[V0:%.*]] = arith.addi [[ARG0]], [[C1]]
+// CHECK: [[V1:%.*]] = arith.muli [[ARG1]], [[C3]]
// CHECK: return [[V0]], [[V1]]
// -----
func @nested_parallel(%0: memref<?x?x?xf64>) -> memref<?x?x?xf64> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%1 = memref.dim %0, %c0 : memref<?x?x?xf64>
%2 = memref.dim %0, %c1 : memref<?x?x?xf64>
%3 = memref.dim %0, %c2 : memref<?x?x?xf64>
}
// CHECK-LABEL: func @nested_parallel(
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
-// CHECK-DAG: [[C2:%.*]] = constant 2 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C2:%.*]] = arith.constant 2 : index
// CHECK: [[B0:%.*]] = memref.dim {{.*}}, [[C0]]
// CHECK: [[B1:%.*]] = memref.dim {{.*}}, [[C1]]
// CHECK: [[B2:%.*]] = memref.dim {{.*}}, [[C2]]
func private @side_effect()
func @one_unused(%cond: i1) -> (index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
%0, %1 = scf.if %cond -> (index, index) {
call @side_effect() : () -> ()
scf.yield %c0, %c1 : index, index
}
// CHECK-LABEL: func @one_unused
-// CHECK-DAG: [[C0:%.*]] = constant 1 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
// CHECK: [[V0:%.*]] = scf.if %{{.*}} -> (index) {
// CHECK: call @side_effect() : () -> ()
// CHECK: scf.yield [[C0]] : index
func private @side_effect()
func @nested_unused(%cond1: i1, %cond2: i1) -> (index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
%0, %1 = scf.if %cond1 -> (index, index) {
%2, %3 = scf.if %cond2 -> (index, index) {
call @side_effect() : () -> ()
}
// CHECK-LABEL: func @nested_unused
-// CHECK-DAG: [[C0:%.*]] = constant 1 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
// CHECK: [[V0:%.*]] = scf.if {{.*}} -> (index) {
// CHECK: [[V1:%.*]] = scf.if {{.*}} -> (index) {
// CHECK: call @side_effect() : () -> ()
func private @side_effect()
func @all_unused(%cond: i1) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0, %1 = scf.if %cond -> (index, index) {
call @side_effect() : () -> ()
scf.yield %c0, %c1 : index, index
// -----
func @to_select1(%cond: i1) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = scf.if %cond -> index {
scf.yield %c0 : index
} else {
}
// CHECK-LABEL: func @to_select1
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[V0:%.*]] = select {{.*}}, [[C0]], [[C1]]
// CHECK: return [[V0]] : index
// -----
func @to_select_same_val(%cond: i1) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0, %1 = scf.if %cond -> (index, index) {
scf.yield %c0, %c1 : index, index
} else {
}
// CHECK-LABEL: func @to_select_same_val
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[V0:%.*]] = select {{.*}}, [[C0]], [[C1]]
// CHECK: return [[V0]], [[C1]] : index, index
// -----
func @to_select2(%cond: i1) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
%0, %1 = scf.if %cond -> (index, index) {
scf.yield %c0, %c1 : index, index
} else {
}
// CHECK-LABEL: func @to_select2
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
-// CHECK-DAG: [[C2:%.*]] = constant 2 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C2:%.*]] = arith.constant 2 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
// CHECK: [[V0:%.*]] = select {{.*}}, [[C0]], [[C2]]
// CHECK: [[V1:%.*]] = select {{.*}}, [[C1]], [[C3]]
// CHECK: return [[V0]], [[V1]] : index
// CHECK-LABEL: @replace_true_if
func @replace_true_if() {
- %true = constant true
+ %true = arith.constant true
// CHECK-NOT: scf.if
// CHECK: "test.op"
scf.if %true {
// CHECK-LABEL: @remove_false_if
func @remove_false_if() {
- %false = constant false
+ %false = arith.constant false
// CHECK-NOT: scf.if
// CHECK-NOT: "test.op"
scf.if %false {
// CHECK-LABEL: @replace_true_if_with_values
func @replace_true_if_with_values() {
- %true = constant true
+ %true = arith.constant true
// CHECK-NOT: scf.if
// CHECK: %[[VAL:.*]] = "test.op"
%0 = scf.if %true -> (i32) {
// CHECK-LABEL: @replace_false_if_with_values
func @replace_false_if_with_values() {
- %false = constant false
+ %false = arith.constant false
// CHECK-NOT: scf.if
// CHECK: %[[VAL:.*]] = "test.other_op"
%0 = scf.if %false -> (i32) {
// CHECK-LABEL: @remove_zero_iteration_loop
func @remove_zero_iteration_loop() {
- %c42 = constant 42 : index
- %c1 = constant 1 : index
+ %c42 = arith.constant 42 : index
+ %c1 = arith.constant 1 : index
// CHECK: %[[INIT:.*]] = "test.init"
%init = "test.init"() : () -> i32
// CHECK-NOT: scf.for
// CHECK-LABEL: @remove_zero_iteration_loop_vals
func @remove_zero_iteration_loop_vals(%arg0: index) {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
// CHECK: %[[INIT:.*]] = "test.init"
%init = "test.init"() : () -> i32
// CHECK-NOT: scf.for
// CHECK-LABEL: @replace_single_iteration_loop_1
func @replace_single_iteration_loop_1() {
- // CHECK: %[[LB:.*]] = constant 42
- %c42 = constant 42 : index
- %c43 = constant 43 : index
- %c1 = constant 1 : index
+ // CHECK: %[[LB:.*]] = arith.constant 42
+ %c42 = arith.constant 42 : index
+ %c43 = arith.constant 43 : index
+ %c1 = arith.constant 1 : index
// CHECK: %[[INIT:.*]] = "test.init"
%init = "test.init"() : () -> i32
// CHECK-NOT: scf.for
// CHECK-LABEL: @replace_single_iteration_loop_2
func @replace_single_iteration_loop_2() {
- // CHECK: %[[LB:.*]] = constant 5
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %c11 = constant 11 : index
+ // CHECK: %[[LB:.*]] = arith.constant 5
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %c11 = arith.constant 11 : index
// CHECK: %[[INIT:.*]] = "test.init"
%init = "test.init"() : () -> i32
// CHECK-NOT: scf.for
// CHECK-LABEL: @replace_single_iteration_loop_non_unit_step
func @replace_single_iteration_loop_non_unit_step() {
- // CHECK: %[[LB:.*]] = constant 42
- %c42 = constant 42 : index
- %c47 = constant 47 : index
- %c5 = constant 5 : index
+ // CHECK: %[[LB:.*]] = arith.constant 42
+ %c42 = arith.constant 42 : index
+ %c47 = arith.constant 47 : index
+ %c5 = arith.constant 5 : index
// CHECK: %[[INIT:.*]] = "test.init"
%init = "test.init"() : () -> i32
// CHECK-NOT: scf.for
// CHECK-SAME: %[[A0:[0-9a-z]*]]: i32
func @fold_away_iter_with_no_use_and_yielded_input(%arg0 : i32,
%ub : index, %lb : index, %step : index) -> (i32, i32) {
- // CHECK-NEXT: %[[C32:.*]] = constant 32 : i32
- %cst = constant 32 : i32
+ // CHECK-NEXT: %[[C32:.*]] = arith.constant 32 : i32
+ %cst = arith.constant 32 : i32
// CHECK-NEXT: %[[FOR_RES:.*]] = scf.for {{.*}} iter_args({{.*}} = %[[A0]]) -> (i32) {
%0:2 = scf.for %arg1 = %lb to %ub step %step iter_args(%arg2 = %arg0, %arg3 = %cst)
-> (i32, i32) {
- %1 = addi %arg2, %cst : i32
+ %1 = arith.addi %arg2, %cst : i32
scf.yield %1, %cst : i32, i32
}
// CHECK-SAME: %[[A0:[0-9a-z]*]]: i32
func @fold_away_iter_and_result_with_no_use(%arg0 : i32,
%ub : index, %lb : index, %step : index) -> (i32) {
- %cst = constant 32 : i32
+ %cst = arith.constant 32 : i32
// CHECK: %[[FOR_RES:.*]] = scf.for {{.*}} iter_args({{.*}} = %[[A0]]) -> (i32) {
%0:2 = scf.for %arg1 = %lb to %ub step %step iter_args(%arg2 = %arg0, %arg3 = %cst)
-> (i32, i32) {
- %1 = addi %arg2, %cst : i32
+ %1 = arith.addi %arg2, %cst : i32
scf.yield %1, %1 : i32, i32
}
// CHECK-SAME: %[[T0:[0-9a-z]*]]: tensor<32x1024xf32>
// CHECK-SAME: %[[T1:[0-9a-z]*]]: tensor<1024x1024xf32>
func @matmul_on_tensors(%t0: tensor<32x1024xf32>, %t1: tensor<1024x1024xf32>) -> tensor<1024x1024xf32> {
- %c0 = constant 0 : index
- %c32 = constant 32 : index
- %c1024 = constant 1024 : index
+ %c0 = arith.constant 0 : index
+ %c32 = arith.constant 32 : index
+ %c1024 = arith.constant 1024 : index
// CHECK-NOT: tensor.cast
// CHECK: %[[FOR_RES:.*]] = scf.for {{.*}} iter_args(%[[ITER_T0:.*]] = %[[T0]]) -> (tensor<32x1024xf32>) {
// CHECK: %[[CAST:.*]] = tensor.cast %[[ITER_T0]] : tensor<32x1024xf32> to tensor<?x?xf32>
// CHECK-LABEL: @cond_prop
func @cond_prop(%arg0 : i1) -> index {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
%res = scf.if %arg0 -> index {
%res1 = scf.if %arg0 -> index {
%v1 = "test.get_some_value"() : () -> i32
}
return %res : index
}
-// CHECK-DAG: %[[c1:.+]] = constant 1 : index
-// CHECK-DAG: %[[c4:.+]] = constant 4 : index
+// CHECK-DAG: %[[c1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[c4:.+]] = arith.constant 4 : index
// CHECK-NEXT: %[[if:.+]] = scf.if %arg0 -> (index) {
// CHECK-NEXT: %{{.+}} = "test.get_some_value"() : () -> i32
// CHECK-NEXT: scf.yield %[[c1]] : index
// CHECK-LABEL: @replace_if_with_cond1
func @replace_if_with_cond1(%arg0 : i1) -> (i32, i1) {
- %true = constant true
- %false = constant false
+ %true = arith.constant true
+ %false = arith.constant false
%res:2 = scf.if %arg0 -> (i32, i1) {
%v = "test.get_some_value"() : () -> i32
scf.yield %v, %true : i32, i1
// CHECK-LABEL: @replace_if_with_cond2
func @replace_if_with_cond2(%arg0 : i1) -> (i32, i1) {
- %true = constant true
- %false = constant false
+ %true = arith.constant true
+ %false = arith.constant false
%res:2 = scf.if %arg0 -> (i32, i1) {
%v = "test.get_some_value"() : () -> i32
scf.yield %v, %false : i32, i1
}
return %res#0, %res#1 : i32, i1
}
-// CHECK-NEXT: %true = constant true
-// CHECK-NEXT: %[[toret:.+]] = xor %arg0, %true : i1
+// CHECK-NEXT: %true = arith.constant true
+// CHECK-NEXT: %[[toret:.+]] = arith.xori %arg0, %true : i1
// CHECK-NEXT: %[[if:.+]] = scf.if %arg0 -> (i32) {
// CHECK-NEXT: %[[sv1:.+]] = "test.get_some_value"() : () -> i32
// CHECK-NEXT: scf.yield %[[sv1]] : i32
}
return
}
-// CHECK-NEXT: %[[true:.+]] = constant true
+// CHECK-NEXT: %[[true:.+]] = arith.constant true
// CHECK-NEXT: %{{.+}} = scf.while : () -> i1 {
// CHECK-NEXT: %[[cmp:.+]] = "test.condition"() : () -> i1
// CHECK-NEXT: scf.condition(%[[cmp]]) %[[cmp]] : i1
// CHECK-LABEL: func @propagate_into_execute_region
func @propagate_into_execute_region() {
- %cond = constant 0 : i1
+ %cond = arith.constant 0 : i1
affine.for %i = 0 to 100 {
"test.foo"() : () -> ()
%v = scf.execute_region -> i64 {
cond_br %cond, ^bb1, ^bb2
^bb1:
- %c1 = constant 1 : i64
+ %c1 = arith.constant 1 : i64
br ^bb3(%c1 : i64)
^bb2:
- %c2 = constant 2 : i64
+ %c2 = arith.constant 2 : i64
br ^bb3(%c2 : i64)
^bb3(%x : i64):
scf.yield %x : i64
}
"test.bar"(%v) : (i64) -> ()
- // CHECK: %[[C2:.*]] = constant 2 : i64
+ // CHECK: %[[C2:.*]] = arith.constant 2 : i64
// CHECK: "test.foo"
// CHECK-NEXT: "test.bar"(%[[C2]]) : (i64) -> ()
}
// RUN: mlir-opt %s -for-loop-canonicalization -split-input-file | FileCheck %s
// CHECK-LABEL: func @scf_for_canonicalize_min
-// CHECK: %[[C2:.*]] = constant 2 : i64
+// CHECK: %[[C2:.*]] = arith.constant 2 : i64
// CHECK: scf.for
// CHECK: memref.store %[[C2]], %{{.*}}[] : memref<i64>
func @scf_for_canonicalize_min(%A : memref<i64>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c0 to %c4 step %c2 {
%1 = affine.min affine_map<(d0, d1)[] -> (2, d1 - d0)> (%i, %c4)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// -----
// CHECK-LABEL: func @scf_for_canonicalize_max
-// CHECK: %[[Cneg2:.*]] = constant -2 : i64
+// CHECK: %[[Cneg2:.*]] = arith.constant -2 : i64
// CHECK: scf.for
// CHECK: memref.store %[[Cneg2]], %{{.*}}[] : memref<i64>
func @scf_for_canonicalize_max(%A : memref<i64>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c0 to %c4 step %c2 {
%1 = affine.max affine_map<(d0, d1)[] -> (-2, -(d1 - d0))> (%i, %c4)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @scf_for_max_not_canonicalizable
// CHECK: scf.for
// CHECK: affine.max
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_max_not_canonicalizable(%A : memref<i64>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c0 to %c4 step %c2 {
%1 = affine.max affine_map<(d0, d1)[] -> (-2, -(d1 - d0))> (%i, %c3)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// -----
// CHECK-LABEL: func @scf_for_loop_nest_canonicalize_min
-// CHECK: %[[C5:.*]] = constant 5 : i64
+// CHECK: %[[C5:.*]] = arith.constant 5 : i64
// CHECK: scf.for
// CHECK: scf.for
// CHECK: memref.store %[[C5]], %{{.*}}[] : memref<i64>
func @scf_for_loop_nest_canonicalize_min(%A : memref<i64>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c6 = arith.constant 6 : index
scf.for %i = %c0 to %c4 step %c2 {
scf.for %j = %c0 to %c6 step %c3 {
%1 = affine.min affine_map<(d0, d1, d2, d3)[] -> (5, d1 + d3 - d0 - d2)> (%i, %c4, %j, %c6)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
}
// CHECK-LABEL: func @scf_for_not_canonicalizable_1
// CHECK: scf.for
// CHECK: affine.min
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_not_canonicalizable_1(%A : memref<i64>) {
// This should not canonicalize because: 4 - %i may take the value 1 < 2.
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c1 to %c4 step %c2 {
%1 = affine.min affine_map<(d0)[s0] -> (2, s0 - d0)> (%i)[%c4]
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @scf_for_canonicalize_partly
// CHECK: scf.for
// CHECK: affine.apply
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_canonicalize_partly(%A : memref<i64>) {
// This should canonicalize only partly: 256 - %i <= 256.
- %c1 = constant 1 : index
- %c16 = constant 16 : index
- %c256 = constant 256 : index
+ %c1 = arith.constant 1 : index
+ %c16 = arith.constant 16 : index
+ %c256 = arith.constant 256 : index
scf.for %i = %c1 to %c256 step %c16 {
%1 = affine.min affine_map<(d0) -> (256, 256 - d0)> (%i)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @scf_for_not_canonicalizable_2
// CHECK: scf.for
// CHECK: affine.min
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_not_canonicalizable_2(%A : memref<i64>, %step : index) {
// This example should simplify but affine_map is currently missing
// semi-affine canonicalizations: `((s0 * 42 - 1) floordiv s0) * s0`
// should evaluate to 41 * s0.
// Note that this may require positivity assumptions on `s0`.
// Revisit when support is added.
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%ub = affine.apply affine_map<(d0) -> (42 * d0)> (%step)
scf.for %i = %c0 to %ub step %step {
%1 = affine.min affine_map<(d0, d1, d2) -> (d0, d1 - d2)> (%step, %ub, %i)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @scf_for_not_canonicalizable_3
// CHECK: scf.for
// CHECK: affine.min
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_not_canonicalizable_3(%A : memref<i64>, %step : index) {
// This example should simplify but affine_map is currently missing
// semi-affine canonicalizations: `-(((s0 * s0 - 1) floordiv s0) * s0)`
// should evaluate to (s0 - 1) * s0.
// Note that this may require positivity assumptions on `s0`.
// Revisit when support is added.
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%ub2 = affine.apply affine_map<(d0)[s0] -> (s0 * d0)> (%step)[%step]
scf.for %i = %c0 to %ub2 step %step {
%1 = affine.min affine_map<(d0, d1, d2) -> (d0, d2 - d1)> (%step, %i, %ub2)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK-LABEL: func @scf_for_invalid_loop
// CHECK: scf.for
// CHECK: affine.min
-// CHECK: index_cast
+// CHECK: arith.index_cast
func @scf_for_invalid_loop(%A : memref<i64>, %step : index) {
// This is an invalid loop. It should not be touched by the canonicalization
// pattern.
- %c1 = constant 1 : index
- %c7 = constant 7 : index
- %c256 = constant 256 : index
+ %c1 = arith.constant 1 : index
+ %c7 = arith.constant 7 : index
+ %c256 = arith.constant 256 : index
scf.for %i = %c256 to %c1 step %c1 {
%1 = affine.min affine_map<(d0)[s0] -> (s0 + d0, 0)> (%i)[%c7]
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// -----
// CHECK-LABEL: func @scf_parallel_canonicalize_min_1
-// CHECK: %[[C2:.*]] = constant 2 : i64
+// CHECK: %[[C2:.*]] = arith.constant 2 : i64
// CHECK: scf.parallel
// CHECK-NEXT: memref.store %[[C2]], %{{.*}}[] : memref<i64>
func @scf_parallel_canonicalize_min_1(%A : memref<i64>) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
scf.parallel (%i) = (%c0) to (%c4) step (%c2) {
%1 = affine.min affine_map<(d0, d1)[] -> (2, d1 - d0)> (%i, %c4)
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// -----
// CHECK-LABEL: func @scf_parallel_canonicalize_min_2
-// CHECK: %[[C2:.*]] = constant 2 : i64
+// CHECK: %[[C2:.*]] = arith.constant 2 : i64
// CHECK: scf.parallel
// CHECK-NEXT: memref.store %[[C2]], %{{.*}}[] : memref<i64>
func @scf_parallel_canonicalize_min_2(%A : memref<i64>) {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c7 = constant 7 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c7 = arith.constant 7 : index
scf.parallel (%i) = (%c1) to (%c7) step (%c2) {
%1 = affine.min affine_map<(d0)[s0] -> (2, s0 - d0)> (%i)[%c7]
- %2 = index_cast %1: index to i64
+ %2 = arith.index_cast %1: index to i64
memref.store %2, %A[]: memref<i64>
}
return
// CHECK: scf.for
// CHECK: tensor.dim %[[t]]
func @tensor_dim_of_iter_arg(%t : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0, %1 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t, %arg1 = %c0)
-> (tensor<?x?xf32>, index) {
%dim = tensor.dim %arg0, %c0 : tensor<?x?xf32>
// CHECK: tensor.dim %[[t]]
func @tensor_dim_of_iter_arg_insertslice(%t : tensor<?x?xf32>,
%t2 : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0, %1 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t, %arg1 = %c0)
-> (tensor<?x?xf32>, index) {
%dim = tensor.dim %arg0, %c0 : tensor<?x?xf32>
// CHECK: tensor.dim %[[t]]
func @tensor_dim_of_iter_arg_nested_for(%t : tensor<?x?xf32>,
%t2 : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0, %1 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t, %arg1 = %c0)
-> (tensor<?x?xf32>, index) {
%2, %3 = scf.for %j = %c0 to %c10 step %c1 iter_args(%arg2 = %arg0, %arg3 = %arg1)
// CHECK: tensor.dim %[[arg0]]
func @tensor_dim_of_iter_arg_no_canonicalize(%t : tensor<?x?xf32>,
%t2 : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0, %1 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t, %arg1 = %c0)
-> (tensor<?x?xf32>, index) {
%dim = tensor.dim %arg0, %c0 : tensor<?x?xf32>
// CHECK-SAME: %[[t:.*]]: tensor<?x?xf32>
// CHECK: tensor.dim %[[t]]
func @tensor_dim_of_loop_result(%t : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t)
-> (tensor<?x?xf32>) {
scf.yield %arg0 : tensor<?x?xf32>
// CHECK: tensor.dim %[[loop]]#1
func @tensor_dim_of_loop_result_no_canonicalize(%t : tensor<?x?xf32>,
%u : tensor<?x?xf32>) -> index {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
%0, %1 = scf.for %i = %c0 to %c10 step %c1 iter_args(%arg0 = %t, %arg1 = %u)
-> (tensor<?x?xf32>, tensor<?x?xf32>) {
scf.yield %arg0, %u : tensor<?x?xf32>, tensor<?x?xf32>
// CHECK-DAG: #[[MAP1:.*]] = affine_map<(d0)[s0] -> (-d0 + s0)>
// CHECK: func @fully_dynamic_bounds(
// CHECK-SAME: %[[LB:.*]]: index, %[[UB:.*]]: index, %[[STEP:.*]]: index
-// CHECK: %[[C0_I32:.*]] = constant 0 : i32
+// CHECK: %[[C0_I32:.*]] = arith.constant 0 : i32
// CHECK: %[[NEW_UB:.*]] = affine.apply #[[MAP0]]()[%[[LB]], %[[UB]], %[[STEP]]]
// CHECK: %[[LOOP:.*]] = scf.for %[[IV:.*]] = %[[LB]] to %[[NEW_UB]]
// CHECK-SAME: step %[[STEP]] iter_args(%[[ACC:.*]] = %[[C0_I32]]) -> (i32) {
-// CHECK: %[[CAST:.*]] = index_cast %[[STEP]] : index to i32
-// CHECK: %[[ADD:.*]] = addi %[[ACC]], %[[CAST]] : i32
+// CHECK: %[[CAST:.*]] = arith.index_cast %[[STEP]] : index to i32
+// CHECK: %[[ADD:.*]] = arith.addi %[[ACC]], %[[CAST]] : i32
// CHECK: scf.yield %[[ADD]]
// CHECK: }
// CHECK: %[[RESULT:.*]] = scf.for %[[IV2:.*]] = %[[NEW_UB]] to %[[UB]]
// CHECK-SAME: step %[[STEP]] iter_args(%[[ACC2:.*]] = %[[LOOP]]) -> (i32) {
// CHECK: %[[REM:.*]] = affine.apply #[[MAP1]](%[[IV2]])[%[[UB]]]
-// CHECK: %[[CAST2:.*]] = index_cast %[[REM]]
-// CHECK: %[[ADD2:.*]] = addi %[[ACC2]], %[[CAST2]]
+// CHECK: %[[CAST2:.*]] = arith.index_cast %[[REM]]
+// CHECK: %[[ADD2:.*]] = arith.addi %[[ACC2]], %[[CAST2]]
// CHECK: scf.yield %[[ADD2]]
// CHECK: }
// CHECK: return %[[RESULT]]
#map = affine_map<(d0, d1)[s0] -> (s0, d0 - d1)>
func @fully_dynamic_bounds(%lb : index, %ub: index, %step: index) -> i32 {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%r = scf.for %iv = %lb to %ub step %step iter_args(%arg = %c0) -> i32 {
%s = affine.min #map(%ub, %iv)[%step]
- %casted = index_cast %s : index to i32
- %0 = addi %arg, %casted : i32
+ %casted = arith.index_cast %s : index to i32
+ %0 = arith.addi %arg, %casted : i32
scf.yield %0 : i32
}
return %r : i32
// -----
// CHECK: func @fully_static_bounds(
-// CHECK-DAG: %[[C0_I32:.*]] = constant 0 : i32
-// CHECK-DAG: %[[C1_I32:.*]] = constant 1 : i32
-// CHECK-DAG: %[[C4_I32:.*]] = constant 4 : i32
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C16:.*]] = constant 16 : index
+// CHECK-DAG: %[[C0_I32:.*]] = arith.constant 0 : i32
+// CHECK-DAG: %[[C1_I32:.*]] = arith.constant 1 : i32
+// CHECK-DAG: %[[C4_I32:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C16:.*]] = arith.constant 16 : index
// CHECK: %[[LOOP:.*]] = scf.for %[[IV:.*]] = %[[C0]] to %[[C16]]
// CHECK-SAME: step %[[C4]] iter_args(%[[ACC:.*]] = %[[C0_I32]]) -> (i32) {
-// CHECK: %[[ADD:.*]] = addi %[[ACC]], %[[C4_I32]] : i32
+// CHECK: %[[ADD:.*]] = arith.addi %[[ACC]], %[[C4_I32]] : i32
// CHECK: scf.yield %[[ADD]]
// CHECK: }
-// CHECK: %[[RESULT:.*]] = addi %[[LOOP]], %[[C1_I32]] : i32
+// CHECK: %[[RESULT:.*]] = arith.addi %[[LOOP]], %[[C1_I32]] : i32
// CHECK: return %[[RESULT]]
#map = affine_map<(d0, d1)[s0] -> (s0, d0 - d1)>
func @fully_static_bounds() -> i32 {
- %c0_i32 = constant 0 : i32
- %lb = constant 0 : index
- %step = constant 4 : index
- %ub = constant 17 : index
+ %c0_i32 = arith.constant 0 : i32
+ %lb = arith.constant 0 : index
+ %step = arith.constant 4 : index
+ %ub = arith.constant 17 : index
%r = scf.for %iv = %lb to %ub step %step
iter_args(%arg = %c0_i32) -> i32 {
%s = affine.min #map(%ub, %iv)[%step]
- %casted = index_cast %s : index to i32
- %0 = addi %arg, %casted : i32
+ %casted = arith.index_cast %s : index to i32
+ %0 = arith.addi %arg, %casted : i32
scf.yield %0 : i32
}
return %r : i32
// CHECK-DAG: #[[MAP1:.*]] = affine_map<(d0)[s0] -> (-d0 + s0)>
// CHECK: func @dynamic_upper_bound(
// CHECK-SAME: %[[UB:.*]]: index
-// CHECK-DAG: %[[C0_I32:.*]] = constant 0 : i32
-// CHECK-DAG: %[[C4_I32:.*]] = constant 4 : i32
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
+// CHECK-DAG: %[[C0_I32:.*]] = arith.constant 0 : i32
+// CHECK-DAG: %[[C4_I32:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
// CHECK: %[[NEW_UB:.*]] = affine.apply #[[MAP0]]()[%[[UB]]]
// CHECK: %[[LOOP:.*]] = scf.for %[[IV:.*]] = %[[C0]] to %[[NEW_UB]]
// CHECK-SAME: step %[[C4]] iter_args(%[[ACC:.*]] = %[[C0_I32]]) -> (i32) {
-// CHECK: %[[ADD:.*]] = addi %[[ACC]], %[[C4_I32]] : i32
+// CHECK: %[[ADD:.*]] = arith.addi %[[ACC]], %[[C4_I32]] : i32
// CHECK: scf.yield %[[ADD]]
// CHECK: }
// CHECK: %[[RESULT:.*]] = scf.for %[[IV2:.*]] = %[[NEW_UB]] to %[[UB]]
// CHECK-SAME: step %[[C4]] iter_args(%[[ACC2:.*]] = %[[LOOP]]) -> (i32) {
// CHECK: %[[REM:.*]] = affine.apply #[[MAP1]](%[[IV2]])[%[[UB]]]
-// CHECK: %[[CAST2:.*]] = index_cast %[[REM]]
-// CHECK: %[[ADD2:.*]] = addi %[[ACC2]], %[[CAST2]]
+// CHECK: %[[CAST2:.*]] = arith.index_cast %[[REM]]
+// CHECK: %[[ADD2:.*]] = arith.addi %[[ACC2]], %[[CAST2]]
// CHECK: scf.yield %[[ADD2]]
// CHECK: }
// CHECK: return %[[RESULT]]
#map = affine_map<(d0, d1)[s0] -> (s0, d0 - d1)>
func @dynamic_upper_bound(%ub : index) -> i32 {
- %c0_i32 = constant 0 : i32
- %lb = constant 0 : index
- %step = constant 4 : index
+ %c0_i32 = arith.constant 0 : i32
+ %lb = arith.constant 0 : index
+ %step = arith.constant 4 : index
%r = scf.for %iv = %lb to %ub step %step
iter_args(%arg = %c0_i32) -> i32 {
%s = affine.min #map(%ub, %iv)[%step]
- %casted = index_cast %s : index to i32
- %0 = addi %arg, %casted : i32
+ %casted = arith.index_cast %s : index to i32
+ %0 = arith.addi %arg, %casted : i32
scf.yield %0 : i32
}
return %r : i32
// CHECK-DAG: #[[MAP1:.*]] = affine_map<(d0)[s0] -> (-d0 + s0)>
// CHECK: func @no_loop_results(
// CHECK-SAME: %[[UB:.*]]: index, %[[MEMREF:.*]]: memref<i32>
-// CHECK-DAG: %[[C4_I32:.*]] = constant 4 : i32
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
+// CHECK-DAG: %[[C4_I32:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
// CHECK: %[[NEW_UB:.*]] = affine.apply #[[MAP0]]()[%[[UB]]]
// CHECK: scf.for %[[IV:.*]] = %[[C0]] to %[[NEW_UB]] step %[[C4]] {
// CHECK: %[[LOAD:.*]] = memref.load %[[MEMREF]][]
-// CHECK: %[[ADD:.*]] = addi %[[LOAD]], %[[C4_I32]] : i32
+// CHECK: %[[ADD:.*]] = arith.addi %[[LOAD]], %[[C4_I32]] : i32
// CHECK: memref.store %[[ADD]], %[[MEMREF]]
// CHECK: }
// CHECK: scf.for %[[IV2:.*]] = %[[NEW_UB]] to %[[UB]] step %[[C4]] {
// CHECK: %[[REM:.*]] = affine.apply #[[MAP1]](%[[IV2]])[%[[UB]]]
// CHECK: %[[LOAD2:.*]] = memref.load %[[MEMREF]][]
-// CHECK: %[[CAST2:.*]] = index_cast %[[REM]]
-// CHECK: %[[ADD2:.*]] = addi %[[LOAD2]], %[[CAST2]]
+// CHECK: %[[CAST2:.*]] = arith.index_cast %[[REM]]
+// CHECK: %[[ADD2:.*]] = arith.addi %[[LOAD2]], %[[CAST2]]
// CHECK: memref.store %[[ADD2]], %[[MEMREF]]
// CHECK: }
// CHECK: return
#map = affine_map<(d0, d1)[s0] -> (s0, d0 - d1)>
func @no_loop_results(%ub : index, %d : memref<i32>) {
- %c0_i32 = constant 0 : i32
- %lb = constant 0 : index
- %step = constant 4 : index
+ %c0_i32 = arith.constant 0 : i32
+ %lb = arith.constant 0 : index
+ %step = arith.constant 4 : index
scf.for %iv = %lb to %ub step %step {
%s = affine.min #map(%ub, %iv)[%step]
%r = memref.load %d[] : memref<i32>
- %casted = index_cast %s : index to i32
- %0 = addi %r, %casted : i32
+ %casted = arith.index_cast %s : index to i32
+ %0 = arith.addi %r, %casted : i32
memref.store %0, %d[] : memref<i32>
}
return
func @test_affine_op_rewrite(%lb : index, %ub: index,
%step: index, %d : memref<?xindex>,
%some_val: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
scf.for %iv = %lb to %ub step %step {
// Most common case: Rewrite min(%ub - %iv, %step) to %step.
%m0 = affine.min #map0(%ub, %iv)[%step]
#map = affine_map<(d0, d1)[s0] -> (s0, d0 - d1)>
func @nested_loops(%lb0: index, %lb1 : index, %ub0: index, %ub1: index,
%step: index) -> i32 {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%r0 = scf.for %iv0 = %lb0 to %ub0 step %step iter_args(%arg0 = %c0) -> i32 {
%r1 = scf.for %iv1 = %lb1 to %ub1 step %step iter_args(%arg1 = %arg0) -> i32 {
%s = affine.min #map(%ub1, %iv1)[%step]
- %casted = index_cast %s : index to i32
- %0 = addi %arg1, %casted : i32
+ %casted = arith.index_cast %s : index to i32
+ %0 = arith.addi %arg1, %casted : i32
scf.yield %0 : i32
}
- %1 = addi %arg0, %r1 : i32
+ %1 = arith.addi %arg0, %r1 : i32
scf.yield %1 : i32
}
return %r0 : i32
func @for(%outer: index, %A: memref<?xf32>, %B: memref<?xf32>,
%C: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = memref.dim %A, %c0 : memref<?xf32>
%b0 = affine.min #map0()[%d0, %outer]
scf.for %i0 = %c0 to %b0 step %c1 {
%B_elem = memref.load %B[%i0] : memref<?xf32>
%C_elem = memref.load %C[%i0] : memref<?xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %result[%i0] : memref<?xf32>
}
return
// CHECK-LABEL: func @for(
// CHECK-SAME: [[ARG0:%.*]]: index, [[ARG1:%.*]]: memref<?xf32>, [[ARG2:%.*]]: memref<?xf32>, [[ARG3:%.*]]: memref<?xf32>, [[ARG4:%.*]]: memref<?xf32>) {
-// CHECK: [[CST_0:%.*]] = constant 0 : index
-// CHECK: [[CST_1:%.*]] = constant 1 : index
+// CHECK: [[CST_0:%.*]] = arith.constant 0 : index
+// CHECK: [[CST_1:%.*]] = arith.constant 1 : index
// CHECK: [[DIM_0:%.*]] = memref.dim [[ARG1]], [[CST_0]] : memref<?xf32>
// CHECK: [[MIN:%.*]] = affine.min #map(){{\[}}[[DIM_0]], [[ARG0]]]
-// CHECK: [[CST_1024:%.*]] = constant 1024 : index
-// CHECK: [[PRED:%.*]] = cmpi eq, [[MIN]], [[CST_1024]] : index
+// CHECK: [[CST_1024:%.*]] = arith.constant 1024 : index
+// CHECK: [[PRED:%.*]] = arith.cmpi eq, [[MIN]], [[CST_1024]] : index
// CHECK: scf.if [[PRED]] {
// CHECK: scf.for [[IDX0:%.*]] = [[CST_0]] to [[CST_1024]] step [[CST_1]] {
// CHECK: memref.store
// CHECK-SAME: %[[VAL_0:.*]]: memref<?xi32>,
// CHECK-SAME: %[[VAL_1:.*]]: index,
// CHECK-SAME: %[[VAL_2:.*]]: i32) {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = scf.while (%[[VAL_6:.*]] = %[[VAL_3]]) : (index) -> index {
-// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
+// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
// CHECK: scf.condition(%[[VAL_7]]) %[[VAL_6]] : index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_8:.*]]: index):
-// CHECK: %[[VAL_9:.*]] = addi %[[VAL_8]], %[[VAL_4]] : index
-// CHECK: %[[VAL_10:.*]] = addi %[[VAL_2]], %[[VAL_2]] : i32
+// CHECK: %[[VAL_9:.*]] = arith.addi %[[VAL_8]], %[[VAL_4]] : index
+// CHECK: %[[VAL_10:.*]] = arith.addi %[[VAL_2]], %[[VAL_2]] : i32
// CHECK: memref.store %[[VAL_10]], %[[VAL_0]]{{\[}}%[[VAL_8]]] : memref<?xi32>
// CHECK: scf.yield %[[VAL_9]] : index
// CHECK: }
// CHECK: return
// CHECK: }
func @single_loop(%arg0: memref<?xi32>, %arg1: index, %arg2: i32) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.for %i = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %arg2 : i32
+ %0 = arith.addi %arg2, %arg2 : i32
memref.store %0, %arg0[%i] : memref<?xi32>
}
return
// CHECK-SAME: %[[VAL_0:.*]]: memref<?xi32>,
// CHECK-SAME: %[[VAL_1:.*]]: index,
// CHECK-SAME: %[[VAL_2:.*]]: i32) {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = scf.while (%[[VAL_6:.*]] = %[[VAL_3]]) : (index) -> index {
-// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
+// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
// CHECK: scf.condition(%[[VAL_7]]) %[[VAL_6]] : index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_8:.*]]: index):
-// CHECK: %[[VAL_9:.*]] = addi %[[VAL_8]], %[[VAL_4]] : index
+// CHECK: %[[VAL_9:.*]] = arith.addi %[[VAL_8]], %[[VAL_4]] : index
// CHECK: %[[VAL_10:.*]] = scf.while (%[[VAL_11:.*]] = %[[VAL_3]]) : (index) -> index {
-// CHECK: %[[VAL_12:.*]] = cmpi slt, %[[VAL_11]], %[[VAL_1]] : index
+// CHECK: %[[VAL_12:.*]] = arith.cmpi slt, %[[VAL_11]], %[[VAL_1]] : index
// CHECK: scf.condition(%[[VAL_12]]) %[[VAL_11]] : index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_13:.*]]: index):
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_4]] : index
-// CHECK: %[[VAL_15:.*]] = addi %[[VAL_2]], %[[VAL_2]] : i32
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_4]] : index
+// CHECK: %[[VAL_15:.*]] = arith.addi %[[VAL_2]], %[[VAL_2]] : i32
// CHECK: memref.store %[[VAL_15]], %[[VAL_0]]{{\[}}%[[VAL_8]]] : memref<?xi32>
// CHECK: memref.store %[[VAL_15]], %[[VAL_0]]{{\[}}%[[VAL_13]]] : memref<?xi32>
// CHECK: scf.yield %[[VAL_14]] : index
// CHECK: return
// CHECK: }
func @nested_loop(%arg0: memref<?xi32>, %arg1: index, %arg2: i32) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.for %i = %c0 to %arg1 step %c1 {
scf.for %j = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %arg2 : i32
+ %0 = arith.addi %arg2, %arg2 : i32
memref.store %0, %arg0[%i] : memref<?xi32>
memref.store %0, %arg0[%j] : memref<?xi32>
}
// CHECK-LABEL: func @for_iter_args(
// CHECK-SAME: %[[VAL_0:.*]]: index, %[[VAL_1:.*]]: index,
// CHECK-SAME: %[[VAL_2:.*]]: index) -> f32 {
-// CHECK: %[[VAL_3:.*]] = constant 0.000000e+00 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant 0.000000e+00 : f32
// CHECK: %[[VAL_4:.*]]:3 = scf.while (%[[VAL_5:.*]] = %[[VAL_0]], %[[VAL_6:.*]] = %[[VAL_3]], %[[VAL_7:.*]] = %[[VAL_3]]) : (index, f32, f32) -> (index, f32, f32) {
-// CHECK: %[[VAL_8:.*]] = cmpi slt, %[[VAL_5]], %[[VAL_1]] : index
+// CHECK: %[[VAL_8:.*]] = arith.cmpi slt, %[[VAL_5]], %[[VAL_1]] : index
// CHECK: scf.condition(%[[VAL_8]]) %[[VAL_5]], %[[VAL_6]], %[[VAL_7]] : index, f32, f32
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_9:.*]]: index, %[[VAL_10:.*]]: f32, %[[VAL_11:.*]]: f32):
-// CHECK: %[[VAL_12:.*]] = addi %[[VAL_9]], %[[VAL_2]] : index
-// CHECK: %[[VAL_13:.*]] = addf %[[VAL_10]], %[[VAL_11]] : f32
+// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_9]], %[[VAL_2]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addf %[[VAL_10]], %[[VAL_11]] : f32
// CHECK: scf.yield %[[VAL_12]], %[[VAL_13]], %[[VAL_13]] : index, f32, f32
// CHECK: }
// CHECK: return %[[VAL_14:.*]]#2 : f32
// CHECK: }
func @for_iter_args(%arg0 : index, %arg1: index, %arg2: index) -> f32 {
- %s0 = constant 0.0 : f32
+ %s0 = arith.constant 0.0 : f32
%result:2 = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%iarg0 = %s0, %iarg1 = %s0) -> (f32, f32) {
- %sn = addf %iarg0, %iarg1 : f32
+ %sn = arith.addf %iarg0, %iarg1 : f32
scf.yield %sn, %sn : f32, f32
}
return %result#1 : f32
// CHECK-SAME: %[[VAL_0:.*]]: i32,
// CHECK-SAME: %[[VAL_1:.*]]: index,
// CHECK-SAME: %[[VAL_2:.*]]: i32) -> i32 {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]]:2 = scf.while (%[[VAL_6:.*]] = %[[VAL_3]], %[[VAL_7:.*]] = %[[VAL_0]]) : (index, i32) -> (index, i32) {
-// CHECK: %[[VAL_8:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
+// CHECK: %[[VAL_8:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_1]] : index
// CHECK: scf.condition(%[[VAL_8]]) %[[VAL_6]], %[[VAL_7]] : index, i32
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_9:.*]]: index, %[[VAL_10:.*]]: i32):
-// CHECK: %[[VAL_11:.*]] = addi %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_11:.*]] = arith.addi %[[VAL_9]], %[[VAL_4]] : index
// CHECK: %[[VAL_12:.*]] = scf.execute_region -> i32 {
-// CHECK: %[[VAL_13:.*]] = cmpi slt, %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_13:.*]] = arith.cmpi slt, %[[VAL_9]], %[[VAL_4]] : index
// CHECK: cond_br %[[VAL_13]], ^bb1, ^bb2
// CHECK: ^bb1:
-// CHECK: %[[VAL_14:.*]] = subi %[[VAL_10]], %[[VAL_0]] : i32
+// CHECK: %[[VAL_14:.*]] = arith.subi %[[VAL_10]], %[[VAL_0]] : i32
// CHECK: scf.yield %[[VAL_14]] : i32
// CHECK: ^bb2:
-// CHECK: %[[VAL_15:.*]] = muli %[[VAL_10]], %[[VAL_2]] : i32
+// CHECK: %[[VAL_15:.*]] = arith.muli %[[VAL_10]], %[[VAL_2]] : i32
// CHECK: scf.yield %[[VAL_15]] : i32
// CHECK: }
// CHECK: scf.yield %[[VAL_11]], %[[VAL_16:.*]] : index, i32
// CHECK: return %[[VAL_17:.*]]#1 : i32
// CHECK: }
func @exec_region_multiple_yields(%arg0: i32, %arg1: index, %arg2: i32) -> i32 {
- %c1_i32 = constant 1 : i32
- %c2_i32 = constant 2 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c5 = constant 5 : index
+ %c1_i32 = arith.constant 1 : i32
+ %c2_i32 = arith.constant 2 : i32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c5 = arith.constant 5 : index
%0 = scf.for %i = %c0 to %arg1 step %c1 iter_args(%iarg0 = %arg0) -> i32 {
%2 = scf.execute_region -> i32 {
- %1 = cmpi slt, %i, %c1 : index
+ %1 = arith.cmpi slt, %i, %c1 : index
cond_br %1, ^bb1, ^bb2
^bb1:
- %2 = subi %iarg0, %arg0 : i32
+ %2 = arith.subi %iarg0, %arg0 : i32
scf.yield %2 : i32
^bb2:
- %3 = muli %iarg0, %arg2 : i32
+ %3 = arith.muli %iarg0, %arg2 : i32
scf.yield %3 : i32
}
scf.yield %2 : i32
func @loop_for_step_positive(%arg0: index) {
// expected-error@+2 {{constant step operand must be positive}}
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
"scf.for"(%arg0, %arg0, %c0) ({
^bb0(%arg1: index):
scf.yield
func @parallel_step_not_positive(
%arg0: index, %arg1: index, %arg2: index, %arg3: index) {
// expected-error@+3 {{constant step operand must be positive}}
- %c0 = constant 1 : index
- %c1 = constant 0 : index
+ %c0 = arith.constant 1 : index
+ %c1 = arith.constant 0 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3) step (%c0, %c1) {
}
return
%arg0 : index, %arg1: index, %arg2: index) {
// expected-error@+1 {{expects number of results: 0 to be the same as number of reductions: 1}}
scf.parallel (%i0) = (%arg0) to (%arg1) step (%arg2) {
- %c0 = constant 1.0 : f32
+ %c0 = arith.constant 1.0 : f32
scf.reduce(%c0) : f32 {
^bb0(%lhs: f32, %rhs: f32):
scf.reduce.return %lhs : f32
func @parallel_more_results_than_reduces(
%arg0 : index, %arg1 : index, %arg2 : index) {
// expected-error@+2 {{expects number of results: 1 to be the same as number of reductions: 0}}
- %zero = constant 1.0 : f32
+ %zero = arith.constant 1.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg1) step (%arg2) init (%zero) -> f32 {
}
func @parallel_different_types_of_results_and_reduces(
%arg0 : index, %arg1: index, %arg2: index) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg1)
step (%arg2) init (%zero) -> f32 {
// expected-error@+1 {{expects type of reduce: 'index' to be the same as result type: 'f32'}}
// -----
func @reduce_empty_block(%arg0 : index, %arg1 : f32) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg0)
step (%arg0) init (%zero) -> f32 {
// expected-error@+1 {{the block inside reduce should not be empty}}
// -----
func @reduce_too_many_args(%arg0 : index, %arg1 : f32) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg0)
step (%arg0) init (%zero) -> f32 {
// expected-error@+1 {{expects two arguments to reduce block of type 'f32'}}
// -----
func @reduce_wrong_args(%arg0 : index, %arg1 : f32) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg0)
step (%arg0) init (%zero) -> f32 {
// expected-error@+1 {{expects two arguments to reduce block of type 'f32'}}
// -----
func @reduce_wrong_terminator(%arg0 : index, %arg1 : f32) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg0)
step (%arg0) init (%zero) -> f32 {
// expected-error@+1 {{the block inside reduce should be terminated with a 'scf.reduce.return' op}}
// -----
func @reduceReturn_wrong_type(%arg0 : index, %arg1: f32) {
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%res = scf.parallel (%i0) = (%arg0) to (%arg0)
step (%arg0) init (%zero) -> f32 {
scf.reduce(%arg1) : f32 {
^bb0(%lhs : f32, %rhs : f32):
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
// expected-error@+1 {{needs to have type 'f32' (the type of the enclosing ReduceOp)}}
scf.reduce.return %c0 : index
}
{
// expected-error@+1 {{region control flow edge from Region #0 to parent results: source has 1 operands, but target successor needs 2}}
%x, %y = scf.if %arg0 -> (f32, f32) {
- %0 = addf %arg1, %arg1 : f32
+ %0 = arith.addf %arg1, %arg1 : f32
scf.yield %0 : f32
} else {
- %0 = subf %arg1, %arg1 : f32
+ %0 = arith.subf %arg1, %arg1 : f32
scf.yield %0, %0 : f32, f32
}
return
{
// expected-error@+1 {{must have an else block if defining values}}
%x = scf.if %arg0 -> (f32) {
- %0 = addf %arg1, %arg1 : f32
+ %0 = arith.addf %arg1, %arg1 : f32
scf.yield %0 : f32
}
return
// -----
func @std_for_operands_mismatch(%arg0 : index, %arg1 : index, %arg2 : index) {
- %s0 = constant 0.0 : f32
- %t0 = constant 1 : i32
+ %s0 = arith.constant 0.0 : f32
+ %t0 = arith.constant 1 : i32
// expected-error@+1 {{mismatch in number of loop-carried values and defined values}}
%result1:3 = scf.for %i0 = %arg0 to %arg1 step %arg2
iter_args(%si = %s0, %ti = %t0) -> (f32, i32, f32) {
- %sn = addf %si, %si : f32
- %tn = addi %ti, %ti : i32
+ %sn = arith.addf %si, %si : f32
+ %tn = arith.addi %ti, %ti : i32
scf.yield %sn, %tn, %sn : f32, i32, f32
}
return
// -----
func @std_for_operands_mismatch_2(%arg0 : index, %arg1 : index, %arg2 : index) {
- %s0 = constant 0.0 : f32
- %t0 = constant 1 : i32
- %u0 = constant 1.0 : f32
+ %s0 = arith.constant 0.0 : f32
+ %t0 = arith.constant 1 : i32
+ %u0 = arith.constant 1.0 : f32
// expected-error@+1 {{mismatch in number of loop-carried values and defined values}}
%result1:2 = scf.for %i0 = %arg0 to %arg1 step %arg2
iter_args(%si = %s0, %ti = %t0, %ui = %u0) -> (f32, i32) {
- %sn = addf %si, %si : f32
- %tn = addi %ti, %ti : i32
- %un = subf %ui, %ui : f32
+ %sn = arith.addf %si, %si : f32
+ %tn = arith.addi %ti, %ti : i32
+ %un = arith.subf %ui, %ui : f32
scf.yield %sn, %tn, %un : f32, i32, f32
}
return
func @std_for_operands_mismatch_3(%arg0 : index, %arg1 : index, %arg2 : index) {
// expected-note@+1 {{prior use here}}
- %s0 = constant 0.0 : f32
- %t0 = constant 1.0 : f32
+ %s0 = arith.constant 0.0 : f32
+ %t0 = arith.constant 1.0 : f32
// expected-error@+2 {{expects different type than prior uses: 'i32' vs 'f32'}}
%result1:2 = scf.for %i0 = %arg0 to %arg1 step %arg2
iter_args(%si = %s0, %ti = %t0) -> (i32, i32) {
- %sn = addf %si, %si : i32
- %tn = addf %ti, %ti : i32
+ %sn = arith.addf %si, %si : i32
+ %tn = arith.addf %ti, %ti : i32
scf.yield %sn, %tn : i32, i32
}
return
// -----
func @std_for_operands_mismatch_4(%arg0 : index, %arg1 : index, %arg2 : index) {
- %s0 = constant 0.0 : f32
- %t0 = constant 1.0 : f32
+ %s0 = arith.constant 0.0 : f32
+ %t0 = arith.constant 1.0 : f32
// expected-error @+1 {{along control flow edge from Region #0 to Region #0: source type #1 'i32' should match input type #1 'f32'}}
%result1:2 = scf.for %i0 = %arg0 to %arg1 step %arg2
iter_args(%si = %s0, %ti = %t0) -> (f32, f32) {
- %sn = addf %si, %si : f32
- %ic = constant 1 : i32
+ %sn = arith.addf %si, %si : f32
+ %ic = arith.constant 1 : i32
scf.yield %sn, %ic : f32, i32
}
return
func @parallel_invalid_yield(
%arg0: index, %arg1: index, %arg2: index) {
scf.parallel (%i0) = (%arg0) to (%arg1) step (%arg2) {
- %c0 = constant 1.0 : f32
+ %c0 = arith.constant 1.0 : f32
// expected-error@+1 {{'scf.yield' op not allowed to have operands inside 'scf.parallel'}}
scf.yield %c0 : f32
}
// -----
func @while_parser_type_mismatch() {
- %true = constant true
+ %true = arith.constant true
// expected-error@+1 {{expected as many input types as operands (expected 0 got 1)}}
scf.while : (i32) -> () {
scf.condition(%true)
// -----
func @while_cross_region_type_mismatch() {
- %true = constant true
+ %true = arith.constant true
// expected-error@+1 {{'scf.while' op region control flow edge from Region #0 to Region #1: source has 0 operands, but target successor needs 1}}
scf.while : () -> () {
scf.condition(%true)
// -----
func @while_cross_region_type_mismatch() {
- %true = constant true
+ %true = arith.constant true
// expected-error@+1 {{'scf.while' op along control flow edge from Region #0 to Region #1: source type #0 'i1' should match input type #0 'i32'}}
scf.while : () -> () {
scf.condition(%true) %true : i1
// -----
func @while_result_type_mismatch() {
- %true = constant true
+ %true = arith.constant true
// expected-error@+1 {{'scf.while' op region control flow edge from Region #0 to parent results: source has 1 operands, but target successor needs 0}}
scf.while : () -> () {
scf.condition(%true) %true : i1
// -----
func @while_bad_terminator() {
- %true = constant true
+ %true = arith.constant true
// expected-error@+1 {{expects the 'after' region to terminate with 'scf.yield'}}
scf.while : () -> () {
scf.condition(%true)
// CHECK-LABEL: simple_pipeline(
// CHECK-SAME: %[[A:.*]]: memref<?xf32>, %[[R:.*]]: memref<?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[L1:.*]] = scf.for %[[IV:.*]] = %[[C0]] to %[[C3]]
// CHECK-SAME: step %[[C1]] iter_args(%[[LARG:.*]] = %[[L0]]) -> (f32) {
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[LARG]], %{{.*}} : f32
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[LARG]], %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD0]], %[[R]][%[[IV]]] : memref<?xf32>
-// CHECK-NEXT: %[[IV1:.*]] = addi %[[IV]], %[[C1]] : index
+// CHECK-NEXT: %[[IV1:.*]] = arith.addi %[[IV]], %[[C1]] : index
// CHECK-NEXT: %[[LR:.*]] = memref.load %[[A]][%[[IV1]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[LR]] : f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[L1]], %{{.*}} : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[L1]], %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD1]], %[[R]][%[[C3]]] : memref<?xf32>
func @simple_pipeline(%A: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf = arith.constant 1.0 : f32
scf.for %i0 = %c0 to %c4 step %c1 {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 2 } : memref<?xf32>
- %A1_elem = addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
+ %A1_elem = arith.addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
memref.store %A1_elem, %result[%i0] { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : memref<?xf32>
} { __test_pipelining_loop__ }
return
// CHECK-LABEL: three_stage(
// CHECK-SAME: %[[A:.*]]: memref<?xf32>, %[[R:.*]]: memref<?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[L0]], %{{.*}} : f32
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[L0]], %{{.*}} : f32
// CHECK-NEXT: %[[L1:.*]] = memref.load %[[A]][%[[C1]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[LR:.*]]:2 = scf.for %[[IV:.*]] = %[[C0]] to %[[C2]]
// CHECK-SAME: step %[[C1]] iter_args(%[[ADDARG:.*]] = %[[ADD0]],
// CHECK-SAME: %[[LARG:.*]] = %[[L1]]) -> (f32, f32) {
// CHECK-NEXT: memref.store %[[ADDARG]], %[[R]][%[[IV]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[LARG]], %{{.*}} : f32
-// CHECK-NEXT: %[[IV2:.*]] = addi %[[IV]], %[[C2]] : index
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[LARG]], %{{.*}} : f32
+// CHECK-NEXT: %[[IV2:.*]] = arith.addi %[[IV]], %[[C2]] : index
// CHECK-NEXT: %[[L3:.*]] = memref.load %[[A]][%[[IV2]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[ADD1]], %[[L3]] : f32, f32
// CHECK-NEXT: }
// Epilogue:
// CHECK-NEXT: memref.store %[[LR]]#0, %[[R]][%[[C2]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD2:.*]] = addf %[[LR]]#1, %{{.*}} : f32
+// CHECK-NEXT: %[[ADD2:.*]] = arith.addf %[[LR]]#1, %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD2]], %[[R]][%[[C3]]] : memref<?xf32>
func @three_stage(%A: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf = arith.constant 1.0 : f32
scf.for %i0 = %c0 to %c4 step %c1 {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 2 } : memref<?xf32>
- %A1_elem = addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
+ %A1_elem = arith.addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
memref.store %A1_elem, %result[%i0] { __test_pipelining_stage__ = 2, __test_pipelining_op_order__ = 0 } : memref<?xf32>
} { __test_pipelining_loop__ }
return
// -----
// CHECK-LABEL: long_liverange(
// CHECK-SAME: %[[A:.*]]: memref<?xf32>, %[[R:.*]]: memref<?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C6:.*]] = constant 6 : index
-// CHECK-DAG: %[[C7:.*]] = constant 7 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C9:.*]] = constant 9 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C6:.*]] = arith.constant 6 : index
+// CHECK-DAG: %[[C7:.*]] = arith.constant 7 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C9:.*]] = arith.constant 9 : index
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
// CHECK-NEXT: %[[L1:.*]] = memref.load %[[A]][%[[C1]]] : memref<?xf32>
// CHECK-SAME: step %[[C1]] iter_args(%[[LA0:.*]] = %[[L0]],
// CHECK-SAME: %[[LA1:.*]] = %[[L1]], %[[LA2:.*]] = %[[L2]],
// CHECK-SAME: %[[LA3:.*]] = %[[L3]]) -> (f32, f32, f32, f32) {
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[LA0]], %{{.*}} : f32
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[LA0]], %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD0]], %[[R]][%[[IV]]] : memref<?xf32>
-// CHECK-NEXT: %[[IV4:.*]] = addi %[[IV]], %[[C4]] : index
+// CHECK-NEXT: %[[IV4:.*]] = arith.addi %[[IV]], %[[C4]] : index
// CHECK-NEXT: %[[L4:.*]] = memref.load %[[A]][%[[IV4]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[LA1]], %[[LA2]], %[[LA3]], %[[L4]] : f32, f32, f32, f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[LR]]#0, %{{.*}} : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[LR]]#0, %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD1]], %[[R]][%[[C6]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD2:.*]] = addf %[[LR]]#1, %{{.*}} : f32
+// CHECK-NEXT: %[[ADD2:.*]] = arith.addf %[[LR]]#1, %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD2]], %[[R]][%[[C7]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD3:.*]] = addf %[[LR]]#2, %{{.*}} : f32
+// CHECK-NEXT: %[[ADD3:.*]] = arith.addf %[[LR]]#2, %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD3]], %[[R]][%[[C8]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD4:.*]] = addf %[[LR]]#3, %{{.*}} : f32
+// CHECK-NEXT: %[[ADD4:.*]] = arith.addf %[[LR]]#3, %{{.*}} : f32
// CHECK-NEXT: memref.store %[[ADD4]], %[[R]][%[[C9]]] : memref<?xf32>
func @long_liverange(%A: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %cf = arith.constant 1.0 : f32
scf.for %i0 = %c0 to %c10 step %c1 {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 2 } : memref<?xf32>
- %A1_elem = addf %A_elem, %cf { __test_pipelining_stage__ = 4, __test_pipelining_op_order__ = 0 } : f32
+ %A1_elem = arith.addf %A_elem, %cf { __test_pipelining_stage__ = 4, __test_pipelining_op_order__ = 0 } : f32
memref.store %A1_elem, %result[%i0] { __test_pipelining_stage__ = 4, __test_pipelining_op_order__ = 1 } : memref<?xf32>
} { __test_pipelining_loop__ }
return
// CHECK-LABEL: multiple_uses(
// CHECK-SAME: %[[A:.*]]: memref<?xf32>, %[[R:.*]]: memref<?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[C7:.*]] = constant 7 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C9:.*]] = constant 9 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[C7:.*]] = arith.constant 7 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C9:.*]] = arith.constant 9 : index
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[L0]], %{{.*}} : f32
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[L0]], %{{.*}} : f32
// CHECK-NEXT: %[[L1:.*]] = memref.load %[[A]][%[[C1]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[L1]], %{{.*}} : f32
-// CHECK-NEXT: %[[MUL0:.*]] = mulf %[[ADD0]], %[[L0]] : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[L1]], %{{.*}} : f32
+// CHECK-NEXT: %[[MUL0:.*]] = arith.mulf %[[ADD0]], %[[L0]] : f32
// CHECK-NEXT: %[[L2:.*]] = memref.load %[[A]][%[[C2]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[LR:.*]]:4 = scf.for %[[IV:.*]] = %[[C0]] to %[[C7]]
// CHECK-SAME: step %[[C1]] iter_args(%[[LA1:.*]] = %[[L1]],
// CHECK-SAME: %[[LA2:.*]] = %[[L2]], %[[ADDARG1:.*]] = %[[ADD1]],
// CHECK-SAME: %[[MULARG0:.*]] = %[[MUL0]]) -> (f32, f32, f32, f32) {
-// CHECK-NEXT: %[[ADD2:.*]] = addf %[[LA2]], %{{.*}} : f32
-// CHECK-NEXT: %[[MUL1:.*]] = mulf %[[ADDARG1]], %[[LA1]] : f32
+// CHECK-NEXT: %[[ADD2:.*]] = arith.addf %[[LA2]], %{{.*}} : f32
+// CHECK-NEXT: %[[MUL1:.*]] = arith.mulf %[[ADDARG1]], %[[LA1]] : f32
// CHECK-NEXT: memref.store %[[MULARG0]], %[[R]][%[[IV]]] : memref<?xf32>
-// CHECK-NEXT: %[[IV3:.*]] = addi %[[IV]], %[[C3]] : index
+// CHECK-NEXT: %[[IV3:.*]] = arith.addi %[[IV]], %[[C3]] : index
// CHECK-NEXT: %[[L3:.*]] = memref.load %[[A]][%[[IV3]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[LA2]], %[[L3]], %[[ADD2]], %[[MUL1]] : f32, f32, f32, f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[ADD3:.*]] = addf %[[LR]]#1, %{{.*}} : f32
-// CHECK-NEXT: %[[MUL2:.*]] = mulf %[[LR]]#2, %[[LR]]#0 : f32
+// CHECK-NEXT: %[[ADD3:.*]] = arith.addf %[[LR]]#1, %{{.*}} : f32
+// CHECK-NEXT: %[[MUL2:.*]] = arith.mulf %[[LR]]#2, %[[LR]]#0 : f32
// CHECK-NEXT: memref.store %[[LR]]#3, %[[R]][%[[C7]]] : memref<?xf32>
-// CHECK-NEXT: %[[MUL3:.*]] = mulf %[[ADD3]], %[[LR]]#1 : f32
+// CHECK-NEXT: %[[MUL3:.*]] = arith.mulf %[[ADD3]], %[[LR]]#1 : f32
// CHECK-NEXT: memref.store %[[MUL2]], %[[R]][%[[C8]]] : memref<?xf32>
// CHECK-NEXT: memref.store %[[MUL3]], %[[R]][%[[C9]]] : memref<?xf32>
func @multiple_uses(%A: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %cf = arith.constant 1.0 : f32
scf.for %i0 = %c0 to %c10 step %c1 {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 3 } : memref<?xf32>
- %A1_elem = addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
- %A2_elem = mulf %A1_elem, %A_elem { __test_pipelining_stage__ = 2, __test_pipelining_op_order__ = 1 } : f32
+ %A1_elem = arith.addf %A_elem, %cf { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
+ %A2_elem = arith.mulf %A1_elem, %A_elem { __test_pipelining_stage__ = 2, __test_pipelining_op_order__ = 1 } : f32
memref.store %A2_elem, %result[%i0] { __test_pipelining_stage__ = 3, __test_pipelining_op_order__ = 2 } : memref<?xf32>
} { __test_pipelining_loop__ }
return
// CHECK-LABEL: loop_carried(
// CHECK-SAME: %[[A:.*]]: memref<?xf32>, %[[R:.*]]: memref<?xf32>) {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[CSTF:.*]] = constant 1.000000e+00 : f32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[CSTF:.*]] = arith.constant 1.000000e+00 : f32
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[LR:.*]]:2 = scf.for %[[IV:.*]] = %[[C0]] to %[[C3]]
// CHECK-SAME: step %[[C1]] iter_args(%[[C:.*]] = %[[CSTF]],
// CHECK-SAME: %[[LARG:.*]] = %[[L0]]) -> (f32, f32) {
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[LARG]], %[[C]] : f32
-// CHECK-NEXT: %[[IV1:.*]] = addi %[[IV]], %[[C1]] : index
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[LARG]], %[[C]] : f32
+// CHECK-NEXT: %[[IV1:.*]] = arith.addi %[[IV]], %[[C1]] : index
// CHECK-NEXT: %[[L1:.*]] = memref.load %[[A]][%[[IV1]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[ADD0]], %[[L1]] : f32, f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[LR]]#1, %[[LR]]#0 : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[LR]]#1, %[[LR]]#0 : f32
// CHECK-NEXT: memref.store %[[ADD1]], %[[R]][%[[C0]]] : memref<?xf32>
func @loop_carried(%A: memref<?xf32>, %result: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf = arith.constant 1.0 : f32
%r = scf.for %i0 = %c0 to %c4 step %c1 iter_args(%arg0 = %cf) -> (f32) {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 1 } : memref<?xf32>
- %A1_elem = addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
+ %A1_elem = arith.addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
scf.yield %A1_elem : f32
} { __test_pipelining_loop__ }
memref.store %r, %result[%c0] : memref<?xf32>
// CHECK-LABEL: backedge_different_stage
// CHECK-SAME: (%[[A:.*]]: memref<?xf32>) -> f32 {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[CSTF:.*]] = constant 1.000000e+00 : f32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[CSTF:.*]] = arith.constant 1.000000e+00 : f32
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[L0]], %[[CSTF]] : f32
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[L0]], %[[CSTF]] : f32
// CHECK-NEXT: %[[L1:.*]] = memref.load %[[A]][%[[C1]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[R:.*]]:3 = scf.for %[[IV:.*]] = %[[C0]] to %[[C2]]
// CHECK-SAME: step %[[C1]] iter_args(%[[C:.*]] = %[[CSTF]],
// CHECK-SAME: %[[ADDARG:.*]] = %[[ADD0]], %[[LARG:.*]] = %[[L1]]) -> (f32, f32, f32) {
-// CHECK-NEXT: %[[MUL0:.*]] = mulf %[[CSTF]], %[[ADDARG]] : f32
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[LARG]], %[[MUL0]] : f32
-// CHECK-NEXT: %[[IV2:.*]] = addi %[[IV]], %[[C2]] : index
+// CHECK-NEXT: %[[MUL0:.*]] = arith.mulf %[[CSTF]], %[[ADDARG]] : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[LARG]], %[[MUL0]] : f32
+// CHECK-NEXT: %[[IV2:.*]] = arith.addi %[[IV]], %[[C2]] : index
// CHECK-NEXT: %[[L2:.*]] = memref.load %[[A]][%[[IV2]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[MUL0]], %[[ADD1]], %[[L2]] : f32, f32, f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[MUL1:.*]] = mulf %[[CSTF]], %[[R]]#1 : f32
-// CHECK-NEXT: %[[ADD2:.*]] = addf %[[R]]#2, %[[MUL1]] : f32
-// CHECK-NEXT: %[[MUL2:.*]] = mulf %[[CSTF]], %[[ADD2]] : f32
+// CHECK-NEXT: %[[MUL1:.*]] = arith.mulf %[[CSTF]], %[[R]]#1 : f32
+// CHECK-NEXT: %[[ADD2:.*]] = arith.addf %[[R]]#2, %[[MUL1]] : f32
+// CHECK-NEXT: %[[MUL2:.*]] = arith.mulf %[[CSTF]], %[[ADD2]] : f32
// CHECK-NEXT: return %[[MUL2]] : f32
func @backedge_different_stage(%A: memref<?xf32>) -> f32 {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf = arith.constant 1.0 : f32
%r = scf.for %i0 = %c0 to %c4 step %c1 iter_args(%arg0 = %cf) -> (f32) {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 2 } : memref<?xf32>
- %A1_elem = addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
- %A2_elem = mulf %cf, %A1_elem { __test_pipelining_stage__ = 2, __test_pipelining_op_order__ = 0 } : f32
+ %A1_elem = arith.addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
+ %A2_elem = arith.mulf %cf, %A1_elem { __test_pipelining_stage__ = 2, __test_pipelining_op_order__ = 0 } : f32
scf.yield %A2_elem : f32
} { __test_pipelining_loop__ }
return %r : f32
// CHECK-LABEL: backedge_same_stage
// CHECK-SAME: (%[[A:.*]]: memref<?xf32>) -> f32 {
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C3:.*]] = constant 3 : index
-// CHECK-DAG: %[[CSTF:.*]] = constant 1.000000e+00 : f32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[CSTF:.*]] = arith.constant 1.000000e+00 : f32
// Prologue:
// CHECK: %[[L0:.*]] = memref.load %[[A]][%[[C0]]] : memref<?xf32>
// Kernel:
// CHECK-NEXT: %[[R:.*]]:2 = scf.for %[[IV:.*]] = %[[C0]] to %[[C3]]
// CHECK-SAME: step %[[C1]] iter_args(%[[C:.*]] = %[[CSTF]],
// CHECK-SAME: %[[LARG:.*]] = %[[L0]]) -> (f32, f32) {
-// CHECK-NEXT: %[[ADD0:.*]] = addf %[[LARG]], %[[C]] : f32
-// CHECK-NEXT: %[[MUL0:.*]] = mulf %[[CSTF]], %[[ADD0]] : f32
-// CHECK-NEXT: %[[IV1:.*]] = addi %[[IV]], %[[C1]] : index
+// CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[LARG]], %[[C]] : f32
+// CHECK-NEXT: %[[MUL0:.*]] = arith.mulf %[[CSTF]], %[[ADD0]] : f32
+// CHECK-NEXT: %[[IV1:.*]] = arith.addi %[[IV]], %[[C1]] : index
// CHECK-NEXT: %[[L2:.*]] = memref.load %[[A]][%[[IV1]]] : memref<?xf32>
// CHECK-NEXT: scf.yield %[[MUL0]], %[[L2]] : f32, f32
// CHECK-NEXT: }
// Epilogue:
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[R]]#1, %[[R]]#0 : f32
-// CHECK-NEXT: %[[MUL1:.*]] = mulf %[[CSTF]], %[[ADD1]] : f32
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[R]]#1, %[[R]]#0 : f32
+// CHECK-NEXT: %[[MUL1:.*]] = arith.mulf %[[CSTF]], %[[ADD1]] : f32
// CHECK-NEXT: return %[[MUL1]] : f32
func @backedge_same_stage(%A: memref<?xf32>) -> f32 {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf = arith.constant 1.0 : f32
%r = scf.for %i0 = %c0 to %c4 step %c1 iter_args(%arg0 = %cf) -> (f32) {
%A_elem = memref.load %A[%i0] { __test_pipelining_stage__ = 0, __test_pipelining_op_order__ = 2 } : memref<?xf32>
- %A1_elem = addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
- %A2_elem = mulf %cf, %A1_elem { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
+ %A1_elem = arith.addf %A_elem, %arg0 { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 0 } : f32
+ %A2_elem = arith.mulf %cf, %A1_elem { __test_pipelining_stage__ = 1, __test_pipelining_op_order__ = 1 } : f32
scf.yield %A2_elem : f32
} { __test_pipelining_loop__ }
return %r : f32
// RUN: mlir-opt %s -pass-pipeline='builtin.func(for-loop-range-folding)' -split-input-file | FileCheck %s
func @fold_one_loop(%arg0: memref<?xi32>, %arg1: index, %arg2: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %i : index
- %1 = muli %0, %c4 : index
+ %0 = arith.addi %arg2, %i : index
+ %1 = arith.muli %0, %c4 : index
%2 = memref.load %arg0[%1] : memref<?xi32>
- %3 = muli %2, %2 : i32
+ %3 = arith.muli %2, %2 : i32
memref.store %3, %arg0[%1] : memref<?xi32>
}
return
// CHECK-LABEL: func @fold_one_loop
// CHECK-SAME: (%[[ARG0:.*]]: {{.*}}, %[[ARG1:.*]]: {{.*}}, %[[ARG2:.*]]: {{.*}}
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C4:.*]] = constant 4 : index
-// CHECK: %[[I0:.*]] = addi %[[ARG2]], %[[C0]] : index
-// CHECK: %[[I1:.*]] = addi %[[ARG2]], %[[ARG1]] : index
-// CHECK: %[[I2:.*]] = muli %[[I1]], %[[C4]] : index
-// CHECK: %[[I3:.*]] = muli %[[C1]], %[[C4]] : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C4:.*]] = arith.constant 4 : index
+// CHECK: %[[I0:.*]] = arith.addi %[[ARG2]], %[[C0]] : index
+// CHECK: %[[I1:.*]] = arith.addi %[[ARG2]], %[[ARG1]] : index
+// CHECK: %[[I2:.*]] = arith.muli %[[I1]], %[[C4]] : index
+// CHECK: %[[I3:.*]] = arith.muli %[[C1]], %[[C4]] : index
// CHECK: scf.for %[[I:.*]] = %[[I0]] to %[[I2]] step %[[I3]] {
// CHECK: %[[I4:.*]] = memref.load %[[ARG0]]{{\[}}%[[I]]
-// CHECK: %[[I5:.*]] = muli %[[I4]], %[[I4]] : i32
+// CHECK: %[[I5:.*]] = arith.muli %[[I4]], %[[I4]] : i32
// CHECK: memref.store %[[I5]], %[[ARG0]]{{\[}}%[[I]]
func @fold_one_loop2(%arg0: memref<?xi32>, %arg1: index, %arg2: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c10 = arith.constant 10 : index
scf.for %j = %c0 to %c10 step %c1 {
scf.for %i = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %i : index
- %1 = muli %0, %c4 : index
+ %0 = arith.addi %arg2, %i : index
+ %1 = arith.muli %0, %c4 : index
%2 = memref.load %arg0[%1] : memref<?xi32>
- %3 = muli %2, %2 : i32
+ %3 = arith.muli %2, %2 : i32
memref.store %3, %arg0[%1] : memref<?xi32>
}
}
// CHECK-LABEL: func @fold_one_loop2
// CHECK-SAME: (%[[ARG0:.*]]: {{.*}}, %[[ARG1:.*]]: {{.*}}, %[[ARG2:.*]]: {{.*}}
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C4:.*]] = constant 4 : index
-// CHECK: %[[C10:.*]] = constant 10 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C4:.*]] = arith.constant 4 : index
+// CHECK: %[[C10:.*]] = arith.constant 10 : index
// CHECK: scf.for %[[J:.*]] = %[[C0]] to %[[C10]] step %[[C1]] {
-// CHECK: %[[I0:.*]] = addi %[[ARG2]], %[[C0]] : index
-// CHECK: %[[I1:.*]] = addi %[[ARG2]], %[[ARG1]] : index
-// CHECK: %[[I2:.*]] = muli %[[I1]], %[[C4]] : index
-// CHECK: %[[I3:.*]] = muli %[[C1]], %[[C4]] : index
+// CHECK: %[[I0:.*]] = arith.addi %[[ARG2]], %[[C0]] : index
+// CHECK: %[[I1:.*]] = arith.addi %[[ARG2]], %[[ARG1]] : index
+// CHECK: %[[I2:.*]] = arith.muli %[[I1]], %[[C4]] : index
+// CHECK: %[[I3:.*]] = arith.muli %[[C1]], %[[C4]] : index
// CHECK: scf.for %[[I:.*]] = %[[I0]] to %[[I2]] step %[[I3]] {
// CHECK: %[[I4:.*]] = memref.load %[[ARG0]]{{\[}}%[[I]]
-// CHECK: %[[I5:.*]] = muli %[[I4]], %[[I4]] : i32
+// CHECK: %[[I5:.*]] = arith.muli %[[I4]], %[[I4]] : i32
// CHECK: memref.store %[[I5]], %[[ARG0]]{{\[}}%[[I]]
func @fold_two_loops(%arg0: memref<?xi32>, %arg1: index, %arg2: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c10 = arith.constant 10 : index
scf.for %j = %c0 to %c10 step %c1 {
scf.for %i = %j to %arg1 step %c1 {
- %0 = addi %arg2, %i : index
- %1 = muli %0, %c4 : index
+ %0 = arith.addi %arg2, %i : index
+ %1 = arith.muli %0, %c4 : index
%2 = memref.load %arg0[%1] : memref<?xi32>
- %3 = muli %2, %2 : i32
+ %3 = arith.muli %2, %2 : i32
memref.store %3, %arg0[%1] : memref<?xi32>
}
}
// CHECK-LABEL: func @fold_two_loops
// CHECK-SAME: (%[[ARG0:.*]]: {{.*}}, %[[ARG1:.*]]: {{.*}}, %[[ARG2:.*]]: {{.*}}
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C4:.*]] = constant 4 : index
-// CHECK: %[[C10:.*]] = constant 10 : index
-// CHECK: %[[I0:.*]] = addi %[[ARG2]], %[[C0]] : index
-// CHECK: %[[I1:.*]] = addi %[[ARG2]], %[[C10]] : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C4:.*]] = arith.constant 4 : index
+// CHECK: %[[C10:.*]] = arith.constant 10 : index
+// CHECK: %[[I0:.*]] = arith.addi %[[ARG2]], %[[C0]] : index
+// CHECK: %[[I1:.*]] = arith.addi %[[ARG2]], %[[C10]] : index
// CHECK: scf.for %[[J:.*]] = %[[I0]] to %[[I1]] step %[[C1]] {
-// CHECK: %[[I1:.*]] = addi %[[ARG2]], %[[ARG1]] : index
-// CHECK: %[[I2:.*]] = muli %[[I1]], %[[C4]] : index
-// CHECK: %[[I3:.*]] = muli %[[C1]], %[[C4]] : index
+// CHECK: %[[I1:.*]] = arith.addi %[[ARG2]], %[[ARG1]] : index
+// CHECK: %[[I2:.*]] = arith.muli %[[I1]], %[[C4]] : index
+// CHECK: %[[I3:.*]] = arith.muli %[[C1]], %[[C4]] : index
// CHECK: scf.for %[[I:.*]] = %[[J]] to %[[I2]] step %[[I3]] {
// CHECK: %[[I4:.*]] = memref.load %[[ARG0]]{{\[}}%[[I]]
-// CHECK: %[[I5:.*]] = muli %[[I4]], %[[I4]] : i32
+// CHECK: %[[I5:.*]] = arith.muli %[[I4]], %[[I4]] : i32
// CHECK: memref.store %[[I5]], %[[ARG0]]{{\[}}%[[I]]
// If an instruction's operands are not defined outside the loop, we cannot
-// perform the optimization, as is the case with the muli below. (If paired
-// with loop invariant code motion we can continue.)
+// perform the optimization, as is the case with the arith.muli below. (If
+// paired with loop invariant code motion we can continue.)
func @fold_only_first_add(%arg0: memref<?xi32>, %arg1: index, %arg2: index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
scf.for %i = %c0 to %arg1 step %c1 {
- %0 = addi %arg2, %i : index
- %1 = addi %arg2, %c4 : index
- %2 = muli %0, %1 : index
+ %0 = arith.addi %arg2, %i : index
+ %1 = arith.addi %arg2, %c4 : index
+ %2 = arith.muli %0, %1 : index
%3 = memref.load %arg0[%2] : memref<?xi32>
- %4 = muli %3, %3 : i32
+ %4 = arith.muli %3, %3 : i32
memref.store %4, %arg0[%2] : memref<?xi32>
}
return
// CHECK-LABEL: func @fold_only_first_add
// CHECK-SAME: (%[[ARG0:.*]]: {{.*}}, %[[ARG1:.*]]: {{.*}}, %[[ARG2:.*]]: {{.*}}
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C4:.*]] = constant 4 : index
-// CHECK: %[[I0:.*]] = addi %[[ARG2]], %[[C0]] : index
-// CHECK: %[[I1:.*]] = addi %[[ARG2]], %[[ARG1]] : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C4:.*]] = arith.constant 4 : index
+// CHECK: %[[I0:.*]] = arith.addi %[[ARG2]], %[[C0]] : index
+// CHECK: %[[I1:.*]] = arith.addi %[[ARG2]], %[[ARG1]] : index
// CHECK: scf.for %[[I:.*]] = %[[I0]] to %[[I1]] step %[[C1]] {
-// CHECK: %[[I2:.*]] = addi %[[ARG2]], %[[C4]] : index
-// CHECK: %[[I3:.*]] = muli %[[I]], %[[I2]] : index
+// CHECK: %[[I2:.*]] = arith.addi %[[ARG2]], %[[C4]] : index
+// CHECK: %[[I3:.*]] = arith.muli %[[I]], %[[I2]] : index
// CHECK: %[[I4:.*]] = memref.load %[[ARG0]]{{\[}}%[[I3]]
-// CHECK: %[[I5:.*]] = muli %[[I4]], %[[I4]] : i32
+// CHECK: %[[I5:.*]] = arith.muli %[[I4]], %[[I4]] : i32
// CHECK: memref.store %[[I5]], %[[ARG0]]{{\[}}%[[I3]]
func @dynamic_loop_unroll(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3: memref<?xf32>) {
- %0 = constant 7.0 : f32
+ %0 = arith.constant 7.0 : f32
scf.for %i0 = %arg0 to %arg1 step %arg2 {
memref.store %0, %arg3[%i0] : memref<?xf32>
}
// UNROLL-BY-2-SAME: %[[STEP:.*2]]: index,
// UNROLL-BY-2-SAME: %[[MEM:.*3]]: memref<?xf32>
//
-// UNROLL-BY-2-DAG: %[[V0:.*]] = subi %[[UB]], %[[LB]] : index
-// UNROLL-BY-2-DAG: %[[C1:.*]] = constant 1 : index
-// UNROLL-BY-2-DAG: %[[V1:.*]] = subi %[[STEP]], %[[C1]] : index
-// UNROLL-BY-2-DAG: %[[V2:.*]] = addi %[[V0]], %[[V1]] : index
+// UNROLL-BY-2-DAG: %[[V0:.*]] = arith.subi %[[UB]], %[[LB]] : index
+// UNROLL-BY-2-DAG: %[[C1:.*]] = arith.constant 1 : index
+// UNROLL-BY-2-DAG: %[[V1:.*]] = arith.subi %[[STEP]], %[[C1]] : index
+// UNROLL-BY-2-DAG: %[[V2:.*]] = arith.addi %[[V0]], %[[V1]] : index
// Compute trip count in V3.
-// UNROLL-BY-2-DAG: %[[V3:.*]] = divi_signed %[[V2]], %[[STEP]] : index
+// UNROLL-BY-2-DAG: %[[V3:.*]] = arith.divsi %[[V2]], %[[STEP]] : index
// Store unroll factor in C2.
-// UNROLL-BY-2-DAG: %[[C2:.*]] = constant 2 : index
-// UNROLL-BY-2-DAG: %[[V4:.*]] = remi_signed %[[V3]], %[[C2]] : index
-// UNROLL-BY-2-DAG: %[[V5:.*]] = subi %[[V3]], %[[V4]] : index
-// UNROLL-BY-2-DAG: %[[V6:.*]] = muli %[[V5]], %[[STEP]] : index
+// UNROLL-BY-2-DAG: %[[C2:.*]] = arith.constant 2 : index
+// UNROLL-BY-2-DAG: %[[V4:.*]] = arith.remsi %[[V3]], %[[C2]] : index
+// UNROLL-BY-2-DAG: %[[V5:.*]] = arith.subi %[[V3]], %[[V4]] : index
+// UNROLL-BY-2-DAG: %[[V6:.*]] = arith.muli %[[V5]], %[[STEP]] : index
// Compute upper bound of unrolled loop in V7.
-// UNROLL-BY-2-DAG: %[[V7:.*]] = addi %[[LB]], %[[V6]] : index
+// UNROLL-BY-2-DAG: %[[V7:.*]] = arith.addi %[[LB]], %[[V6]] : index
// Compute step of unrolled loop in V8.
-// UNROLL-BY-2-DAG: %[[V8:.*]] = muli %[[STEP]], %[[C2]] : index
+// UNROLL-BY-2-DAG: %[[V8:.*]] = arith.muli %[[STEP]], %[[C2]] : index
// UNROLL-BY-2: scf.for %[[IV:.*]] = %[[LB]] to %[[V7]] step %[[V8]] {
// UNROLL-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV]]] : memref<?xf32>
-// UNROLL-BY-2-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-BY-2-NEXT: %[[V9:.*]] = muli %[[STEP]], %[[C1_IV]] : index
-// UNROLL-BY-2-NEXT: %[[V10:.*]] = addi %[[IV]], %[[V9]] : index
+// UNROLL-BY-2-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-BY-2-NEXT: %[[V9:.*]] = arith.muli %[[STEP]], %[[C1_IV]] : index
+// UNROLL-BY-2-NEXT: %[[V10:.*]] = arith.addi %[[IV]], %[[V9]] : index
// UNROLL-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V10]]] : memref<?xf32>
// UNROLL-BY-2-NEXT: }
// UNROLL-BY-2-NEXT: scf.for %[[IV:.*]] = %[[V7]] to %[[UB]] step %[[STEP]] {
// UNROLL-BY-3-SAME: %[[STEP:.*2]]: index,
// UNROLL-BY-3-SAME: %[[MEM:.*3]]: memref<?xf32>
//
-// UNROLL-BY-3-DAG: %[[V0:.*]] = subi %[[UB]], %[[LB]] : index
-// UNROLL-BY-3-DAG: %[[C1:.*]] = constant 1 : index
-// UNROLL-BY-3-DAG: %[[V1:.*]] = subi %[[STEP]], %[[C1]] : index
-// UNROLL-BY-3-DAG: %[[V2:.*]] = addi %[[V0]], %[[V1]] : index
+// UNROLL-BY-3-DAG: %[[V0:.*]] = arith.subi %[[UB]], %[[LB]] : index
+// UNROLL-BY-3-DAG: %[[C1:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-DAG: %[[V1:.*]] = arith.subi %[[STEP]], %[[C1]] : index
+// UNROLL-BY-3-DAG: %[[V2:.*]] = arith.addi %[[V0]], %[[V1]] : index
// Compute trip count in V3.
-// UNROLL-BY-3-DAG: %[[V3:.*]] = divi_signed %[[V2]], %[[STEP]] : index
+// UNROLL-BY-3-DAG: %[[V3:.*]] = arith.divsi %[[V2]], %[[STEP]] : index
// Store unroll factor in C3.
-// UNROLL-BY-3-DAG: %[[C3:.*]] = constant 3 : index
-// UNROLL-BY-3-DAG: %[[V4:.*]] = remi_signed %[[V3]], %[[C3]] : index
-// UNROLL-BY-3-DAG: %[[V5:.*]] = subi %[[V3]], %[[V4]] : index
-// UNROLL-BY-3-DAG: %[[V6:.*]] = muli %[[V5]], %[[STEP]] : index
+// UNROLL-BY-3-DAG: %[[C3:.*]] = arith.constant 3 : index
+// UNROLL-BY-3-DAG: %[[V4:.*]] = arith.remsi %[[V3]], %[[C3]] : index
+// UNROLL-BY-3-DAG: %[[V5:.*]] = arith.subi %[[V3]], %[[V4]] : index
+// UNROLL-BY-3-DAG: %[[V6:.*]] = arith.muli %[[V5]], %[[STEP]] : index
// Compute upper bound of unrolled loop in V7.
-// UNROLL-BY-3-DAG: %[[V7:.*]] = addi %[[LB]], %[[V6]] : index
+// UNROLL-BY-3-DAG: %[[V7:.*]] = arith.addi %[[LB]], %[[V6]] : index
// Compute step of unrolled loop in V8.
-// UNROLL-BY-3-DAG: %[[V8:.*]] = muli %[[STEP]], %[[C3]] : index
+// UNROLL-BY-3-DAG: %[[V8:.*]] = arith.muli %[[STEP]], %[[C3]] : index
// UNROLL-BY-3: scf.for %[[IV:.*]] = %[[LB]] to %[[V7]] step %[[V8]] {
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-BY-3-NEXT: %[[V9:.*]] = muli %[[STEP]], %[[C1_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V10:.*]] = addi %[[IV]], %[[V9]] : index
+// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-NEXT: %[[V9:.*]] = arith.muli %[[STEP]], %[[C1_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V10:.*]] = arith.addi %[[IV]], %[[V9]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V10]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = constant 2 : index
-// UNROLL-BY-3-NEXT: %[[V11:.*]] = muli %[[STEP]], %[[C2_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V12:.*]] = addi %[[IV]], %[[V11]] : index
+// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = arith.constant 2 : index
+// UNROLL-BY-3-NEXT: %[[V11:.*]] = arith.muli %[[STEP]], %[[C2_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V12:.*]] = arith.addi %[[IV]], %[[V11]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V12]]] : memref<?xf32>
// UNROLL-BY-3-NEXT: }
// UNROLL-BY-3-NEXT: scf.for %[[IV:.*]] = %[[V7]] to %[[UB]] step %[[STEP]] {
func @dynamic_loop_unroll_outer_by_2(
%arg0 : index, %arg1 : index, %arg2 : index, %arg3 : index, %arg4 : index,
%arg5 : index, %arg6: memref<?xf32>) {
- %0 = constant 7.0 : f32
+ %0 = arith.constant 7.0 : f32
scf.for %i0 = %arg0 to %arg1 step %arg2 {
scf.for %i1 = %arg3 to %arg4 step %arg5 {
memref.store %0, %arg6[%i1] : memref<?xf32>
func @dynamic_loop_unroll_inner_by_2(
%arg0 : index, %arg1 : index, %arg2 : index, %arg3 : index, %arg4 : index,
%arg5 : index, %arg6: memref<?xf32>) {
- %0 = constant 7.0 : f32
+ %0 = arith.constant 7.0 : f32
scf.for %i0 = %arg0 to %arg1 step %arg2 {
scf.for %i1 = %arg3 to %arg4 step %arg5 {
memref.store %0, %arg6[%i1] : memref<?xf32>
// UNROLL-INNER-BY-2: scf.for %[[IV0:.*]] = %[[LB0]] to %[[UB0]] step %[[STEP0]] {
// UNROLL-INNER-BY-2: scf.for %[[IV1:.*]] = %[[LB1]] to %{{.*}} step %{{.*}} {
// UNROLL-INNER-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV1]]] : memref<?xf32>
-// UNROLL-INNER-BY-2-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-INNER-BY-2-NEXT: %[[V0:.*]] = muli %[[STEP1]], %[[C1_IV]] : index
-// UNROLL-INNER-BY-2-NEXT: %[[V1:.*]] = addi %[[IV1]], %[[V0]] : index
+// UNROLL-INNER-BY-2-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-INNER-BY-2-NEXT: %[[V0:.*]] = arith.muli %[[STEP1]], %[[C1_IV]] : index
+// UNROLL-INNER-BY-2-NEXT: %[[V1:.*]] = arith.addi %[[IV1]], %[[V0]] : index
// UNROLL-INNER-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V1]]] : memref<?xf32>
// UNROLL-INNER-BY-2-NEXT: }
// UNROLL-INNER-BY-2-NEXT: scf.for %[[IV1:.*]] = %{{.*}} to %[[UB1]] step %[[STEP1]] {
// Test that no epilogue clean-up loop is generated because the trip count is
// a multiple of the unroll factor.
func @static_loop_unroll_by_2(%arg0 : memref<?xf32>) {
- %0 = constant 7.0 : f32
- %lb = constant 0 : index
- %ub = constant 20 : index
- %step = constant 1 : index
+ %0 = arith.constant 7.0 : f32
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 20 : index
+ %step = arith.constant 1 : index
scf.for %i0 = %lb to %ub step %step {
memref.store %0, %arg0[%i0] : memref<?xf32>
}
// UNROLL-BY-2-LABEL: func @static_loop_unroll_by_2
// UNROLL-BY-2-SAME: %[[MEM:.*0]]: memref<?xf32>
//
-// UNROLL-BY-2-DAG: %[[C0:.*]] = constant 0 : index
-// UNROLL-BY-2-DAG: %[[C1:.*]] = constant 1 : index
-// UNROLL-BY-2-DAG: %[[C20:.*]] = constant 20 : index
-// UNROLL-BY-2-DAG: %[[C2:.*]] = constant 2 : index
+// UNROLL-BY-2-DAG: %[[C0:.*]] = arith.constant 0 : index
+// UNROLL-BY-2-DAG: %[[C1:.*]] = arith.constant 1 : index
+// UNROLL-BY-2-DAG: %[[C20:.*]] = arith.constant 20 : index
+// UNROLL-BY-2-DAG: %[[C2:.*]] = arith.constant 2 : index
// UNROLL-BY-2: scf.for %[[IV:.*]] = %[[C0]] to %[[C20]] step %[[C2]] {
// UNROLL-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV]]] : memref<?xf32>
-// UNROLL-BY-2-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-BY-2-NEXT: %[[V0:.*]] = muli %[[C1]], %[[C1_IV]] : index
-// UNROLL-BY-2-NEXT: %[[V1:.*]] = addi %[[IV]], %[[V0]] : index
+// UNROLL-BY-2-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-BY-2-NEXT: %[[V0:.*]] = arith.muli %[[C1]], %[[C1_IV]] : index
+// UNROLL-BY-2-NEXT: %[[V1:.*]] = arith.addi %[[IV]], %[[V0]] : index
// UNROLL-BY-2-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V1]]] : memref<?xf32>
// UNROLL-BY-2-NEXT: }
// UNROLL-BY-2-NEXT: return
// Test that epilogue clean up loop is generated (trip count is not
// a multiple of unroll factor).
func @static_loop_unroll_by_3(%arg0 : memref<?xf32>) {
- %0 = constant 7.0 : f32
- %lb = constant 0 : index
- %ub = constant 20 : index
- %step = constant 1 : index
+ %0 = arith.constant 7.0 : f32
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 20 : index
+ %step = arith.constant 1 : index
scf.for %i0 = %lb to %ub step %step {
memref.store %0, %arg0[%i0] : memref<?xf32>
}
// UNROLL-BY-3-LABEL: func @static_loop_unroll_by_3
// UNROLL-BY-3-SAME: %[[MEM:.*0]]: memref<?xf32>
//
-// UNROLL-BY-3-DAG: %[[C0:.*]] = constant 0 : index
-// UNROLL-BY-3-DAG: %[[C1:.*]] = constant 1 : index
-// UNROLL-BY-3-DAG: %[[C20:.*]] = constant 20 : index
-// UNROLL-BY-3-DAG: %[[C18:.*]] = constant 18 : index
-// UNROLL-BY-3-DAG: %[[C3:.*]] = constant 3 : index
+// UNROLL-BY-3-DAG: %[[C0:.*]] = arith.constant 0 : index
+// UNROLL-BY-3-DAG: %[[C1:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-DAG: %[[C20:.*]] = arith.constant 20 : index
+// UNROLL-BY-3-DAG: %[[C18:.*]] = arith.constant 18 : index
+// UNROLL-BY-3-DAG: %[[C3:.*]] = arith.constant 3 : index
// UNROLL-BY-3: scf.for %[[IV:.*]] = %[[C0]] to %[[C18]] step %[[C3]] {
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-BY-3-NEXT: %[[V0:.*]] = muli %[[C1]], %[[C1_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V1:.*]] = addi %[[IV]], %[[V0]] : index
+// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-NEXT: %[[V0:.*]] = arith.muli %[[C1]], %[[C1_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V1:.*]] = arith.addi %[[IV]], %[[V0]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V1]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = constant 2 : index
-// UNROLL-BY-3-NEXT: %[[V2:.*]] = muli %[[C1]], %[[C2_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V3:.*]] = addi %[[IV]], %[[V2]] : index
+// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = arith.constant 2 : index
+// UNROLL-BY-3-NEXT: %[[V2:.*]] = arith.muli %[[C1]], %[[C2_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V3:.*]] = arith.addi %[[IV]], %[[V2]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V3]]] : memref<?xf32>
// UNROLL-BY-3-NEXT: }
// UNROLL-BY-3-NEXT: scf.for %[[IV:.*]] = %[[C18]] to %[[C20]] step %[[C1]] {
// Test that the single iteration epilogue loop body is promoted to the loops
// containing block.
func @static_loop_unroll_by_3_promote_epilogue(%arg0 : memref<?xf32>) {
- %0 = constant 7.0 : f32
- %lb = constant 0 : index
- %ub = constant 10 : index
- %step = constant 1 : index
+ %0 = arith.constant 7.0 : f32
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 10 : index
+ %step = arith.constant 1 : index
scf.for %i0 = %lb to %ub step %step {
memref.store %0, %arg0[%i0] : memref<?xf32>
}
// UNROLL-BY-3-LABEL: func @static_loop_unroll_by_3_promote_epilogue
// UNROLL-BY-3-SAME: %[[MEM:.*0]]: memref<?xf32>
//
-// UNROLL-BY-3-DAG: %[[C0:.*]] = constant 0 : index
-// UNROLL-BY-3-DAG: %[[C1:.*]] = constant 1 : index
-// UNROLL-BY-3-DAG: %[[C10:.*]] = constant 10 : index
-// UNROLL-BY-3-DAG: %[[C9:.*]] = constant 9 : index
-// UNROLL-BY-3-DAG: %[[C3:.*]] = constant 3 : index
+// UNROLL-BY-3-DAG: %[[C0:.*]] = arith.constant 0 : index
+// UNROLL-BY-3-DAG: %[[C1:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-DAG: %[[C10:.*]] = arith.constant 10 : index
+// UNROLL-BY-3-DAG: %[[C9:.*]] = arith.constant 9 : index
+// UNROLL-BY-3-DAG: %[[C3:.*]] = arith.constant 3 : index
// UNROLL-BY-3: scf.for %[[IV:.*]] = %[[C0]] to %[[C9]] step %[[C3]] {
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[IV]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = constant 1 : index
-// UNROLL-BY-3-NEXT: %[[V0:.*]] = muli %[[C1]], %[[C1_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V1:.*]] = addi %[[IV]], %[[V0]] : index
+// UNROLL-BY-3-NEXT: %[[C1_IV:.*]] = arith.constant 1 : index
+// UNROLL-BY-3-NEXT: %[[V0:.*]] = arith.muli %[[C1]], %[[C1_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V1:.*]] = arith.addi %[[IV]], %[[V0]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V1]]] : memref<?xf32>
-// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = constant 2 : index
-// UNROLL-BY-3-NEXT: %[[V2:.*]] = muli %[[C1]], %[[C2_IV]] : index
-// UNROLL-BY-3-NEXT: %[[V3:.*]] = addi %[[IV]], %[[V2]] : index
+// UNROLL-BY-3-NEXT: %[[C2_IV:.*]] = arith.constant 2 : index
+// UNROLL-BY-3-NEXT: %[[V2:.*]] = arith.muli %[[C1]], %[[C2_IV]] : index
+// UNROLL-BY-3-NEXT: %[[V3:.*]] = arith.addi %[[IV]], %[[V2]] : index
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[V3]]] : memref<?xf32>
// UNROLL-BY-3-NEXT: }
// UNROLL-BY-3-NEXT: memref.store %{{.*}}, %[[MEM]][%[[C9]]] : memref<?xf32>
// Test unroll-up-to functionality.
func @static_loop_unroll_up_to_factor(%arg0 : memref<?xf32>) {
- %0 = constant 7.0 : f32
- %lb = constant 0 : index
- %ub = constant 2 : index
+ %0 = arith.constant 7.0 : f32
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 2 : index
affine.for %i0 = %lb to %ub {
affine.store %0, %arg0[%i0] : memref<?xf32>
}
// UNROLL-UP-TO-LABEL: func @static_loop_unroll_up_to_factor
// UNROLL-UP-TO-SAME: %[[MEM:.*0]]: memref<?xf32>
//
-// UNROLL-UP-TO-DAG: %[[C0:.*]] = constant 0 : index
-// UNROLL-UP-TO-DAG: %[[C2:.*]] = constant 2 : index
+// UNROLL-UP-TO-DAG: %[[C0:.*]] = arith.constant 0 : index
+// UNROLL-UP-TO-DAG: %[[C2:.*]] = arith.constant 2 : index
// UNROLL-UP-TO-NEXT: %[[V0:.*]] = affine.apply {{.*}}
// UNROLL-UP-TO-NEXT: store %{{.*}}, %[[MEM]][%[[V0]]] : memref<?xf32>
// UNROLL-UP-TO-NEXT: %[[V1:.*]] = affine.apply {{.*}}
func @std_for(%arg0 : index, %arg1 : index, %arg2 : index) {
scf.for %i0 = %arg0 to %arg1 step %arg2 {
scf.for %i1 = %arg0 to %arg1 step %arg2 {
- %min_cmp = cmpi slt, %i0, %i1 : index
+ %min_cmp = arith.cmpi slt, %i0, %i1 : index
%min = select %min_cmp, %i0, %i1 : index
- %max_cmp = cmpi sge, %i0, %i1 : index
+ %max_cmp = arith.cmpi sge, %i0, %i1 : index
%max = select %max_cmp, %i0, %i1 : index
scf.for %i2 = %min to %max step %i1 {
}
// CHECK-LABEL: func @std_for(
// CHECK-NEXT: scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} {
// CHECK-NEXT: scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} {
-// CHECK-NEXT: %{{.*}} = cmpi slt, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi slt, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: %{{.*}} = select %{{.*}}, %{{.*}}, %{{.*}} : index
-// CHECK-NEXT: %{{.*}} = cmpi sge, %{{.*}}, %{{.*}} : index
+// CHECK-NEXT: %{{.*}} = arith.cmpi sge, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: %{{.*}} = select %{{.*}}, %{{.*}}, %{{.*}} : index
// CHECK-NEXT: scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} {
func @std_if(%arg0: i1, %arg1: f32) {
scf.if %arg0 {
- %0 = addf %arg1, %arg1 : f32
+ %0 = arith.addf %arg1, %arg1 : f32
}
return
}
// CHECK-LABEL: func @std_if(
// CHECK-NEXT: scf.if %{{.*}} {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
func @std_if_else(%arg0: i1, %arg1: f32) {
scf.if %arg0 {
- %0 = addf %arg1, %arg1 : f32
+ %0 = arith.addf %arg1, %arg1 : f32
} else {
- %1 = addf %arg1, %arg1 : f32
+ %1 = arith.addf %arg1, %arg1 : f32
}
return
}
// CHECK-LABEL: func @std_if_else(
// CHECK-NEXT: scf.if %{{.*}} {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: } else {
-// CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
func @std_parallel_loop(%arg0 : index, %arg1 : index, %arg2 : index,
%arg3 : index, %arg4 : index) {
- %step = constant 1 : index
+ %step = arith.constant 1 : index
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3)
step (%arg4, %step) {
- %min_cmp = cmpi slt, %i0, %i1 : index
+ %min_cmp = arith.cmpi slt, %i0, %i1 : index
%min = select %min_cmp, %i0, %i1 : index
- %max_cmp = cmpi sge, %i0, %i1 : index
+ %max_cmp = arith.cmpi sge, %i0, %i1 : index
%max = select %max_cmp, %i0, %i1 : index
- %zero = constant 0.0 : f32
- %int_zero = constant 0 : i32
+ %zero = arith.constant 0.0 : f32
+ %int_zero = arith.constant 0 : i32
%red:2 = scf.parallel (%i2) = (%min) to (%max) step (%i1)
init (%zero, %int_zero) -> (f32, i32) {
- %one = constant 1.0 : f32
+ %one = arith.constant 1.0 : f32
scf.reduce(%one) : f32 {
^bb0(%lhs : f32, %rhs: f32):
- %res = addf %lhs, %rhs : f32
+ %res = arith.addf %lhs, %rhs : f32
scf.reduce.return %res : f32
}
- %int_one = constant 1 : i32
+ %int_one = arith.constant 1 : i32
scf.reduce(%int_one) : i32 {
^bb0(%lhs : i32, %rhs: i32):
- %res = muli %lhs, %rhs : i32
+ %res = arith.muli %lhs, %rhs : i32
scf.reduce.return %res : i32
}
}
// CHECK-SAME: %[[ARG2:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG3:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG4:[A-Za-z0-9]+]]:
-// CHECK: %[[STEP:.*]] = constant 1 : index
+// CHECK: %[[STEP:.*]] = arith.constant 1 : index
// CHECK-NEXT: scf.parallel (%[[I0:.*]], %[[I1:.*]]) = (%[[ARG0]], %[[ARG1]]) to
// CHECK: (%[[ARG2]], %[[ARG3]]) step (%[[ARG4]], %[[STEP]]) {
-// CHECK-NEXT: %[[MIN_CMP:.*]] = cmpi slt, %[[I0]], %[[I1]] : index
+// CHECK-NEXT: %[[MIN_CMP:.*]] = arith.cmpi slt, %[[I0]], %[[I1]] : index
// CHECK-NEXT: %[[MIN:.*]] = select %[[MIN_CMP]], %[[I0]], %[[I1]] : index
-// CHECK-NEXT: %[[MAX_CMP:.*]] = cmpi sge, %[[I0]], %[[I1]] : index
+// CHECK-NEXT: %[[MAX_CMP:.*]] = arith.cmpi sge, %[[I0]], %[[I1]] : index
// CHECK-NEXT: %[[MAX:.*]] = select %[[MAX_CMP]], %[[I0]], %[[I1]] : index
-// CHECK-NEXT: %[[ZERO:.*]] = constant 0.000000e+00 : f32
-// CHECK-NEXT: %[[INT_ZERO:.*]] = constant 0 : i32
+// CHECK-NEXT: %[[ZERO:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[INT_ZERO:.*]] = arith.constant 0 : i32
// CHECK-NEXT: scf.parallel (%{{.*}}) = (%[[MIN]]) to (%[[MAX]])
// CHECK-SAME: step (%[[I1]])
// CHECK-SAME: init (%[[ZERO]], %[[INT_ZERO]]) -> (f32, i32) {
-// CHECK-NEXT: %[[ONE:.*]] = constant 1.000000e+00 : f32
+// CHECK-NEXT: %[[ONE:.*]] = arith.constant 1.000000e+00 : f32
// CHECK-NEXT: scf.reduce(%[[ONE]]) : f32 {
// CHECK-NEXT: ^bb0(%[[LHS:.*]]: f32, %[[RHS:.*]]: f32):
-// CHECK-NEXT: %[[RES:.*]] = addf %[[LHS]], %[[RHS]] : f32
+// CHECK-NEXT: %[[RES:.*]] = arith.addf %[[LHS]], %[[RHS]] : f32
// CHECK-NEXT: scf.reduce.return %[[RES]] : f32
// CHECK-NEXT: }
-// CHECK-NEXT: %[[INT_ONE:.*]] = constant 1 : i32
+// CHECK-NEXT: %[[INT_ONE:.*]] = arith.constant 1 : i32
// CHECK-NEXT: scf.reduce(%[[INT_ONE]]) : i32 {
// CHECK-NEXT: ^bb0(%[[LHS:.*]]: i32, %[[RHS:.*]]: i32):
-// CHECK-NEXT: %[[RES:.*]] = muli %[[LHS]], %[[RHS]] : i32
+// CHECK-NEXT: %[[RES:.*]] = arith.muli %[[LHS]], %[[RHS]] : i32
// CHECK-NEXT: scf.reduce.return %[[RES]] : i32
// CHECK-NEXT: }
// CHECK-NEXT: scf.yield
func @std_if_yield(%arg0: i1, %arg1: f32)
{
%x, %y = scf.if %arg0 -> (f32, f32) {
- %0 = addf %arg1, %arg1 : f32
- %1 = subf %arg1, %arg1 : f32
+ %0 = arith.addf %arg1, %arg1 : f32
+ %1 = arith.subf %arg1, %arg1 : f32
scf.yield %0, %1 : f32, f32
} else {
- %0 = subf %arg1, %arg1 : f32
- %1 = addf %arg1, %arg1 : f32
+ %0 = arith.subf %arg1, %arg1 : f32
+ %1 = arith.addf %arg1, %arg1 : f32
scf.yield %0, %1 : f32, f32
}
return
// CHECK-SAME: %[[ARG0:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG1:[A-Za-z0-9]+]]:
// CHECK-NEXT: %{{.*}}:2 = scf.if %[[ARG0]] -> (f32, f32) {
-// CHECK-NEXT: %[[T1:.*]] = addf %[[ARG1]], %[[ARG1]]
-// CHECK-NEXT: %[[T2:.*]] = subf %[[ARG1]], %[[ARG1]]
+// CHECK-NEXT: %[[T1:.*]] = arith.addf %[[ARG1]], %[[ARG1]]
+// CHECK-NEXT: %[[T2:.*]] = arith.subf %[[ARG1]], %[[ARG1]]
// CHECK-NEXT: scf.yield %[[T1]], %[[T2]] : f32, f32
// CHECK-NEXT: } else {
-// CHECK-NEXT: %[[T3:.*]] = subf %[[ARG1]], %[[ARG1]]
-// CHECK-NEXT: %[[T4:.*]] = addf %[[ARG1]], %[[ARG1]]
+// CHECK-NEXT: %[[T3:.*]] = arith.subf %[[ARG1]], %[[ARG1]]
+// CHECK-NEXT: %[[T4:.*]] = arith.addf %[[ARG1]], %[[ARG1]]
// CHECK-NEXT: scf.yield %[[T3]], %[[T4]] : f32, f32
// CHECK-NEXT: }
func @std_for_yield(%arg0 : index, %arg1 : index, %arg2 : index) {
- %s0 = constant 0.0 : f32
+ %s0 = arith.constant 0.0 : f32
%result = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %s0) -> (f32) {
- %sn = addf %si, %si : f32
+ %sn = arith.addf %si, %si : f32
scf.yield %sn : f32
}
return
// CHECK-SAME: %[[ARG0:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG1:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG2:[A-Za-z0-9]+]]:
-// CHECK-NEXT: %[[INIT:.*]] = constant
+// CHECK-NEXT: %[[INIT:.*]] = arith.constant
// CHECK-NEXT: %{{.*}} = scf.for %{{.*}} = %[[ARG0]] to %[[ARG1]] step %[[ARG2]]
// CHECK-SAME: iter_args(%[[ITER:.*]] = %[[INIT]]) -> (f32) {
-// CHECK-NEXT: %[[NEXT:.*]] = addf %[[ITER]], %[[ITER]] : f32
+// CHECK-NEXT: %[[NEXT:.*]] = arith.addf %[[ITER]], %[[ITER]] : f32
// CHECK-NEXT: scf.yield %[[NEXT]] : f32
// CHECK-NEXT: }
func @std_for_yield_multi(%arg0 : index, %arg1 : index, %arg2 : index) {
- %s0 = constant 0.0 : f32
- %t0 = constant 1 : i32
- %u0 = constant 1.0 : f32
+ %s0 = arith.constant 0.0 : f32
+ %t0 = arith.constant 1 : i32
+ %u0 = arith.constant 1.0 : f32
%result1:3 = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %s0, %ti = %t0, %ui = %u0) -> (f32, i32, f32) {
- %sn = addf %si, %si : f32
- %tn = addi %ti, %ti : i32
- %un = subf %ui, %ui : f32
+ %sn = arith.addf %si, %si : f32
+ %tn = arith.addi %ti, %ti : i32
+ %un = arith.subf %ui, %ui : f32
scf.yield %sn, %tn, %un : f32, i32, f32
}
return
// CHECK-SAME: %[[ARG0:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG1:[A-Za-z0-9]+]]:
// CHECK-SAME: %[[ARG2:[A-Za-z0-9]+]]:
-// CHECK-NEXT: %[[INIT1:.*]] = constant
-// CHECK-NEXT: %[[INIT2:.*]] = constant
-// CHECK-NEXT: %[[INIT3:.*]] = constant
+// CHECK-NEXT: %[[INIT1:.*]] = arith.constant
+// CHECK-NEXT: %[[INIT2:.*]] = arith.constant
+// CHECK-NEXT: %[[INIT3:.*]] = arith.constant
// CHECK-NEXT: %{{.*}}:3 = scf.for %{{.*}} = %[[ARG0]] to %[[ARG1]] step %[[ARG2]]
// CHECK-SAME: iter_args(%[[ITER1:.*]] = %[[INIT1]], %[[ITER2:.*]] = %[[INIT2]], %[[ITER3:.*]] = %[[INIT3]]) -> (f32, i32, f32) {
-// CHECK-NEXT: %[[NEXT1:.*]] = addf %[[ITER1]], %[[ITER1]] : f32
-// CHECK-NEXT: %[[NEXT2:.*]] = addi %[[ITER2]], %[[ITER2]] : i32
-// CHECK-NEXT: %[[NEXT3:.*]] = subf %[[ITER3]], %[[ITER3]] : f32
+// CHECK-NEXT: %[[NEXT1:.*]] = arith.addf %[[ITER1]], %[[ITER1]] : f32
+// CHECK-NEXT: %[[NEXT2:.*]] = arith.addi %[[ITER2]], %[[ITER2]] : i32
+// CHECK-NEXT: %[[NEXT3:.*]] = arith.subf %[[ITER3]], %[[ITER3]] : f32
// CHECK-NEXT: scf.yield %[[NEXT1]], %[[NEXT2]], %[[NEXT3]] : f32, i32, f32
func @conditional_reduce(%buffer: memref<1024xf32>, %lb: index, %ub: index, %step: index) -> (f32) {
- %sum_0 = constant 0.0 : f32
- %c0 = constant 0.0 : f32
+ %sum_0 = arith.constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
%sum = scf.for %iv = %lb to %ub step %step iter_args(%sum_iter = %sum_0) -> (f32) {
%t = memref.load %buffer[%iv] : memref<1024xf32>
- %cond = cmpf ugt, %t, %c0 : f32
+ %cond = arith.cmpf ugt, %t, %c0 : f32
%sum_next = scf.if %cond -> (f32) {
- %new_sum = addf %sum_iter, %t : f32
+ %new_sum = arith.addf %sum_iter, %t : f32
scf.yield %new_sum : f32
} else {
scf.yield %sum_iter : f32
// CHECK-SAME: %[[ARG1:[A-Za-z0-9]+]]
// CHECK-SAME: %[[ARG2:[A-Za-z0-9]+]]
// CHECK-SAME: %[[ARG3:[A-Za-z0-9]+]]
-// CHECK-NEXT: %[[INIT:.*]] = constant
-// CHECK-NEXT: %[[ZERO:.*]] = constant
+// CHECK-NEXT: %[[INIT:.*]] = arith.constant
+// CHECK-NEXT: %[[ZERO:.*]] = arith.constant
// CHECK-NEXT: %[[RESULT:.*]] = scf.for %[[IV:.*]] = %[[ARG1]] to %[[ARG2]] step %[[ARG3]]
// CHECK-SAME: iter_args(%[[ITER:.*]] = %[[INIT]]) -> (f32) {
// CHECK-NEXT: %[[T:.*]] = memref.load %[[ARG0]][%[[IV]]]
-// CHECK-NEXT: %[[COND:.*]] = cmpf ugt, %[[T]], %[[ZERO]]
+// CHECK-NEXT: %[[COND:.*]] = arith.cmpf ugt, %[[T]], %[[ZERO]]
// CHECK-NEXT: %[[IFRES:.*]] = scf.if %[[COND]] -> (f32) {
-// CHECK-NEXT: %[[THENRES:.*]] = addf %[[ITER]], %[[T]]
+// CHECK-NEXT: %[[THENRES:.*]] = arith.addf %[[ITER]], %[[T]]
// CHECK-NEXT: scf.yield %[[THENRES]] : f32
// CHECK-NEXT: } else {
// CHECK-NEXT: scf.yield %[[ITER]] : f32
// CHECK-LABEL: @infinite_while
func @infinite_while() {
- %true = constant true
+ %true = arith.constant true
// CHECK: scf.while : () -> () {
scf.while : () -> () {
// CHECK-LABEL: func @execute_region
func @execute_region() -> i64 {
// CHECK: scf.execute_region -> i64 {
- // CHECK-NEXT: constant
+ // CHECK-NEXT: arith.constant
// CHECK-NEXT: scf.yield
// CHECK-NEXT: }
%res = scf.execute_region -> i64 {
- %c1 = constant 1 : i64
+ %c1 = arith.constant 1 : i64
scf.yield %c1 : i64
}
// CHECK: scf.execute_region -> (i64, i64) {
%res2:2 = scf.execute_region -> (i64, i64) {
- %c1 = constant 1 : i64
+ %c1 = arith.constant 1 : i64
scf.yield %c1, %c1 : i64, i64
}
// RUN: mlir-opt -allow-unregistered-dialect %s -pass-pipeline='builtin.func(parallel-loop-fusion)' -split-input-file | FileCheck %s
func @fuse_empty_loops() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
}
return
}
// CHECK-LABEL: func @fuse_empty_loops
-// CHECK: [[C2:%.*]] = constant 2 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C2:%.*]] = arith.constant 2 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: scf.parallel ([[I:%.*]], [[J:%.*]]) = ([[C0]], [[C0]])
// CHECK-SAME: to ([[C2]], [[C2]]) step ([[C1]], [[C1]]) {
// CHECK: scf.yield
func @fuse_two(%A: memref<2x2xf32>, %B: memref<2x2xf32>,
%C: memref<2x2xf32>, %result: memref<2x2xf32>) {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%sum = memref.alloc() : memref<2x2xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%B_elem = memref.load %B[%i, %j] : memref<2x2xf32>
%C_elem = memref.load %C[%i, %j] : memref<2x2xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %sum[%i, %j] : memref<2x2xf32>
scf.yield
}
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%sum_elem = memref.load %sum[%i, %j] : memref<2x2xf32>
%A_elem = memref.load %A[%i, %j] : memref<2x2xf32>
- %product_elem = mulf %sum_elem, %A_elem : f32
+ %product_elem = arith.mulf %sum_elem, %A_elem : f32
memref.store %product_elem, %result[%i, %j] : memref<2x2xf32>
scf.yield
}
// CHECK-LABEL: func @fuse_two
// CHECK-SAME: ([[A:%.*]]: {{.*}}, [[B:%.*]]: {{.*}}, [[C:%.*]]: {{.*}},
// CHECK-SAME: [[RESULT:%.*]]: {{.*}}) {
-// CHECK: [[C2:%.*]] = constant 2 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C2:%.*]] = arith.constant 2 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[SUM:%.*]] = memref.alloc()
// CHECK: scf.parallel ([[I:%.*]], [[J:%.*]]) = ([[C0]], [[C0]])
// CHECK-SAME: to ([[C2]], [[C2]]) step ([[C1]], [[C1]]) {
// CHECK: [[B_ELEM:%.*]] = memref.load [[B]]{{\[}}[[I]], [[J]]]
// CHECK: [[C_ELEM:%.*]] = memref.load [[C]]{{\[}}[[I]], [[J]]]
-// CHECK: [[SUM_ELEM:%.*]] = addf [[B_ELEM]], [[C_ELEM]]
+// CHECK: [[SUM_ELEM:%.*]] = arith.addf [[B_ELEM]], [[C_ELEM]]
// CHECK: memref.store [[SUM_ELEM]], [[SUM]]{{\[}}[[I]], [[J]]]
// CHECK: [[SUM_ELEM_:%.*]] = memref.load [[SUM]]{{\[}}[[I]], [[J]]]
// CHECK: [[A_ELEM:%.*]] = memref.load [[A]]{{\[}}[[I]], [[J]]]
-// CHECK: [[PRODUCT_ELEM:%.*]] = mulf [[SUM_ELEM_]], [[A_ELEM]]
+// CHECK: [[PRODUCT_ELEM:%.*]] = arith.mulf [[SUM_ELEM_]], [[A_ELEM]]
// CHECK: memref.store [[PRODUCT_ELEM]], [[RESULT]]{{\[}}[[I]], [[J]]]
// CHECK: scf.yield
// CHECK: }
func @fuse_three(%lhs: memref<100x10xf32>, %rhs: memref<100xf32>,
%result: memref<100x10xf32>) {
- %c100 = constant 100 : index
- %c10 = constant 10 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c100 = arith.constant 100 : index
+ %c10 = arith.constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%broadcast_rhs = memref.alloc() : memref<100x10xf32>
%diff = memref.alloc() : memref<100x10xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%c100, %c10) step (%c1, %c1) {
scf.parallel (%i, %j) = (%c0, %c0) to (%c100, %c10) step (%c1, %c1) {
%lhs_elem = memref.load %lhs[%i, %j] : memref<100x10xf32>
%broadcast_rhs_elem = memref.load %broadcast_rhs[%i, %j] : memref<100x10xf32>
- %diff_elem = subf %lhs_elem, %broadcast_rhs_elem : f32
+ %diff_elem = arith.subf %lhs_elem, %broadcast_rhs_elem : f32
memref.store %diff_elem, %diff[%i, %j] : memref<100x10xf32>
scf.yield
}
// CHECK-LABEL: func @fuse_three
// CHECK-SAME: ([[LHS:%.*]]: memref<100x10xf32>, [[RHS:%.*]]: memref<100xf32>,
// CHECK-SAME: [[RESULT:%.*]]: memref<100x10xf32>) {
-// CHECK: [[C100:%.*]] = constant 100 : index
-// CHECK: [[C10:%.*]] = constant 10 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C100:%.*]] = arith.constant 100 : index
+// CHECK: [[C10:%.*]] = arith.constant 10 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[BROADCAST_RHS:%.*]] = memref.alloc()
// CHECK: [[DIFF:%.*]] = memref.alloc()
// CHECK: scf.parallel ([[I:%.*]], [[J:%.*]]) = ([[C0]], [[C0]])
// CHECK: memref.store [[RHS_ELEM]], [[BROADCAST_RHS]]{{\[}}[[I]], [[J]]]
// CHECK: [[LHS_ELEM:%.*]] = memref.load [[LHS]]{{\[}}[[I]], [[J]]]
// CHECK: [[BROADCAST_RHS_ELEM:%.*]] = memref.load [[BROADCAST_RHS]]
-// CHECK: [[DIFF_ELEM:%.*]] = subf [[LHS_ELEM]], [[BROADCAST_RHS_ELEM]]
+// CHECK: [[DIFF_ELEM:%.*]] = arith.subf [[LHS_ELEM]], [[BROADCAST_RHS_ELEM]]
// CHECK: memref.store [[DIFF_ELEM]], [[DIFF]]{{\[}}[[I]], [[J]]]
// CHECK: [[DIFF_ELEM_:%.*]] = memref.load [[DIFF]]{{\[}}[[I]], [[J]]]
// CHECK: [[EXP_ELEM:%.*]] = math.exp [[DIFF_ELEM_]]
// -----
func @do_not_fuse_nested_ploop1() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.parallel (%k, %l) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
// -----
func @do_not_fuse_nested_ploop2() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
}
// -----
func @do_not_fuse_loops_unmatching_num_loops() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
}
// -----
func @do_not_fuse_loops_with_side_effecting_ops_in_between() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
}
// -----
func @do_not_fuse_loops_unmatching_iteration_space() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c4, %c4) step (%c2, %c2) {
scf.yield
}
func @do_not_fuse_unmatching_write_read_patterns(
%A: memref<2x2xf32>, %B: memref<2x2xf32>,
%C: memref<2x2xf32>, %result: memref<2x2xf32>) {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%common_buf = memref.alloc() : memref<2x2xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%B_elem = memref.load %B[%i, %j] : memref<2x2xf32>
%C_elem = memref.load %C[%i, %j] : memref<2x2xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %common_buf[%i, %j] : memref<2x2xf32>
scf.yield
}
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
- %k = addi %i, %c1 : index
+ %k = arith.addi %i, %c1 : index
%sum_elem = memref.load %common_buf[%k, %j] : memref<2x2xf32>
%A_elem = memref.load %A[%i, %j] : memref<2x2xf32>
- %product_elem = mulf %sum_elem, %A_elem : f32
+ %product_elem = arith.mulf %sum_elem, %A_elem : f32
memref.store %product_elem, %result[%i, %j] : memref<2x2xf32>
scf.yield
}
func @do_not_fuse_unmatching_read_write_patterns(
%A: memref<2x2xf32>, %B: memref<2x2xf32>, %common_buf: memref<2x2xf32>) {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%sum = memref.alloc() : memref<2x2xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%B_elem = memref.load %B[%i, %j] : memref<2x2xf32>
%C_elem = memref.load %common_buf[%i, %j] : memref<2x2xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %sum[%i, %j] : memref<2x2xf32>
scf.yield
}
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
- %k = addi %i, %c1 : index
+ %k = arith.addi %i, %c1 : index
%sum_elem = memref.load %sum[%k, %j] : memref<2x2xf32>
%A_elem = memref.load %A[%i, %j] : memref<2x2xf32>
- %product_elem = mulf %sum_elem, %A_elem : f32
+ %product_elem = arith.mulf %sum_elem, %A_elem : f32
memref.store %product_elem, %common_buf[%j, %i] : memref<2x2xf32>
scf.yield
}
// -----
func @do_not_fuse_loops_with_memref_defined_in_loop_bodies() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%buffer = memref.alloc() : memref<2x2xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.yield
func @nested_fuse(%A: memref<2x2xf32>, %B: memref<2x2xf32>,
%C: memref<2x2xf32>, %result: memref<2x2xf32>) {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%sum = memref.alloc() : memref<2x2xf32>
scf.parallel (%k) = (%c0) to (%c2) step (%c1) {
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%B_elem = memref.load %B[%i, %j] : memref<2x2xf32>
%C_elem = memref.load %C[%i, %j] : memref<2x2xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %sum[%i, %j] : memref<2x2xf32>
scf.yield
}
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
%sum_elem = memref.load %sum[%i, %j] : memref<2x2xf32>
%A_elem = memref.load %A[%i, %j] : memref<2x2xf32>
- %product_elem = mulf %sum_elem, %A_elem : f32
+ %product_elem = arith.mulf %sum_elem, %A_elem : f32
memref.store %product_elem, %result[%i, %j] : memref<2x2xf32>
scf.yield
}
// CHECK-LABEL: func @nested_fuse
// CHECK-SAME: ([[A:%.*]]: {{.*}}, [[B:%.*]]: {{.*}}, [[C:%.*]]: {{.*}},
// CHECK-SAME: [[RESULT:%.*]]: {{.*}}) {
-// CHECK: [[C2:%.*]] = constant 2 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C2:%.*]] = arith.constant 2 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[SUM:%.*]] = memref.alloc()
// CHECK: scf.parallel
// CHECK: scf.parallel ([[I:%.*]], [[J:%.*]]) = ([[C0]], [[C0]])
// CHECK-SAME: to ([[C2]], [[C2]]) step ([[C1]], [[C1]]) {
// CHECK: [[B_ELEM:%.*]] = memref.load [[B]]{{\[}}[[I]], [[J]]]
// CHECK: [[C_ELEM:%.*]] = memref.load [[C]]{{\[}}[[I]], [[J]]]
-// CHECK: [[SUM_ELEM:%.*]] = addf [[B_ELEM]], [[C_ELEM]]
+// CHECK: [[SUM_ELEM:%.*]] = arith.addf [[B_ELEM]], [[C_ELEM]]
// CHECK: memref.store [[SUM_ELEM]], [[SUM]]{{\[}}[[I]], [[J]]]
// CHECK: [[SUM_ELEM_:%.*]] = memref.load [[SUM]]{{\[}}[[I]], [[J]]]
// CHECK: [[A_ELEM:%.*]] = memref.load [[A]]{{\[}}[[I]], [[J]]]
-// CHECK: [[PRODUCT_ELEM:%.*]] = mulf [[SUM_ELEM_]], [[A_ELEM]]
+// CHECK: [[PRODUCT_ELEM:%.*]] = arith.mulf [[SUM_ELEM_]], [[A_ELEM]]
// CHECK: memref.store [[PRODUCT_ELEM]], [[RESULT]]{{\[}}[[I]], [[J]]]
// CHECK: scf.yield
// CHECK: }
func @parallel_loop(%outer_i0: index, %outer_i1: index, %A: memref<?x?xf32>, %B: memref<?x?xf32>,
%C: memref<?x?xf32>, %result: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = memref.dim %A, %c0 : memref<?x?xf32>
%d1 = memref.dim %A, %c1 : memref<?x?xf32>
%b0 = affine.min #map0()[%d0, %outer_i0]
scf.parallel (%i0, %i1) = (%c0, %c0) to (%b0, %b1) step (%c1, %c1) {
%B_elem = memref.load %B[%i0, %i1] : memref<?x?xf32>
%C_elem = memref.load %C[%i0, %i1] : memref<?x?xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %result[%i0, %i1] : memref<?x?xf32>
}
return
// CHECK-LABEL: func @parallel_loop(
// CHECK-SAME: [[VAL_0:%.*]]: index, [[VAL_1:%.*]]: index, [[VAL_2:%.*]]: memref<?x?xf32>, [[VAL_3:%.*]]: memref<?x?xf32>, [[VAL_4:%.*]]: memref<?x?xf32>, [[VAL_5:%.*]]: memref<?x?xf32>) {
-// CHECK: [[VAL_6:%.*]] = constant 0 : index
-// CHECK: [[VAL_7:%.*]] = constant 1 : index
+// CHECK: [[VAL_6:%.*]] = arith.constant 0 : index
+// CHECK: [[VAL_7:%.*]] = arith.constant 1 : index
// CHECK: [[VAL_8:%.*]] = memref.dim [[VAL_2]], [[VAL_6]] : memref<?x?xf32>
// CHECK: [[VAL_9:%.*]] = memref.dim [[VAL_2]], [[VAL_7]] : memref<?x?xf32>
// CHECK: [[VAL_10:%.*]] = affine.min #map0(){{\[}}[[VAL_8]], [[VAL_0]]]
// CHECK: [[VAL_11:%.*]] = affine.min #map1(){{\[}}[[VAL_9]], [[VAL_1]]]
-// CHECK: [[VAL_12:%.*]] = constant 1024 : index
-// CHECK: [[VAL_13:%.*]] = cmpi eq, [[VAL_10]], [[VAL_12]] : index
-// CHECK: [[VAL_14:%.*]] = constant 64 : index
-// CHECK: [[VAL_15:%.*]] = cmpi eq, [[VAL_11]], [[VAL_14]] : index
-// CHECK: [[VAL_16:%.*]] = and [[VAL_13]], [[VAL_15]] : i1
+// CHECK: [[VAL_12:%.*]] = arith.constant 1024 : index
+// CHECK: [[VAL_13:%.*]] = arith.cmpi eq, [[VAL_10]], [[VAL_12]] : index
+// CHECK: [[VAL_14:%.*]] = arith.constant 64 : index
+// CHECK: [[VAL_15:%.*]] = arith.cmpi eq, [[VAL_11]], [[VAL_14]] : index
+// CHECK: [[VAL_16:%.*]] = arith.andi [[VAL_13]], [[VAL_15]] : i1
// CHECK: scf.if [[VAL_16]] {
// CHECK: scf.parallel ([[VAL_17:%.*]], [[VAL_18:%.*]]) = ([[VAL_6]], [[VAL_6]]) to ([[VAL_12]], [[VAL_14]]) step ([[VAL_7]], [[VAL_7]]) {
// CHECK: memref.store
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3) step (%arg4, %arg5) {
%B_elem = memref.load %B[%i0, %i1] : memref<?x?xf32>
%C_elem = memref.load %C[%i0, %i1] : memref<?x?xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %result[%i0, %i1] : memref<?x?xf32>
}
return
// CHECK-LABEL: func @parallel_loop(
// CHECK-SAME: [[ARG1:%.*]]: index, [[ARG2:%.*]]: index, [[ARG3:%.*]]: index, [[ARG4:%.*]]: index, [[ARG5:%.*]]: index, [[ARG6:%.*]]: index, [[ARG7:%.*]]: memref<?x?xf32>, [[ARG8:%.*]]: memref<?x?xf32>, [[ARG9:%.*]]: memref<?x?xf32>, [[ARG10:%.*]]: memref<?x?xf32>) {
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V1:%.*]] = muli [[ARG5]], [[C1]] : index
-// CHECK: [[V2:%.*]] = muli [[ARG6]], [[C4]] : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V1:%.*]] = arith.muli [[ARG5]], [[C1]] : index
+// CHECK: [[V2:%.*]] = arith.muli [[ARG6]], [[C4]] : index
// CHECK: scf.parallel ([[V3:%.*]], [[V4:%.*]]) = ([[ARG1]], [[ARG2]]) to ([[ARG3]], [[ARG4]]) step ([[V1]], [[V2]]) {
// CHECK: scf.parallel ([[V7:%.*]], [[V8:%.*]]) = ([[C0]], [[C0]]) to ([[V1]], [[V2]]) step ([[ARG5]], [[ARG6]]) {
-// CHECK: [[V9:%.*]] = addi [[V7]], [[V3]] : index
-// CHECK: [[V10:%.*]] = addi [[V8]], [[V4]] : index
-// CHECK: %true = constant true
-// CHECK: [[V11:%.*]] = muli [[V7]], [[ARG5]] : index
-// CHECK: [[V12:%.*]] = addi [[V11]], [[V3]] : index
-// CHECK: [[V13:%.*]] = cmpi ult, [[V12]], [[ARG3]] : index
-// CHECK: [[V14:%.*]] = and %true, [[V13]] : i1
-// CHECK: [[V15:%.*]] = muli [[V8]], [[ARG6]] : index
-// CHECK: [[V16:%.*]] = addi [[V15]], [[V4]] : index
-// CHECK: [[V17:%.*]] = cmpi ult, [[V16]], [[ARG4]] : index
-// CHECK: [[V18:%.*]] = and [[V14]], [[V17]] : i1
+// CHECK: [[V9:%.*]] = arith.addi [[V7]], [[V3]] : index
+// CHECK: [[V10:%.*]] = arith.addi [[V8]], [[V4]] : index
+// CHECK: %true = arith.constant true
+// CHECK: [[V11:%.*]] = arith.muli [[V7]], [[ARG5]] : index
+// CHECK: [[V12:%.*]] = arith.addi [[V11]], [[V3]] : index
+// CHECK: [[V13:%.*]] = arith.cmpi ult, [[V12]], [[ARG3]] : index
+// CHECK: [[V14:%.*]] = arith.andi %true, [[V13]] : i1
+// CHECK: [[V15:%.*]] = arith.muli [[V8]], [[ARG6]] : index
+// CHECK: [[V16:%.*]] = arith.addi [[V15]], [[V4]] : index
+// CHECK: [[V17:%.*]] = arith.cmpi ult, [[V16]], [[ARG4]] : index
+// CHECK: [[V18:%.*]] = arith.andi [[V14]], [[V17]] : i1
// CHECK: scf.if [[V18]] {
// CHECK: [[V19:%.*]] = memref.load [[ARG8]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
// CHECK: [[V20:%.*]] = memref.load [[ARG9]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
-// CHECK: [[V21:%.*]] = addf [[V19]], [[V20]] : f32
+// CHECK: [[V21:%.*]] = arith.addf [[V19]], [[V20]] : f32
// CHECK: memref.store [[V21]], [[ARG10]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
// CHECK: }
// CHECK: }
// -----
func @static_loop_with_step() {
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c22 = constant 22 : index
- %c24 = constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c22 = arith.constant 22 : index
+ %c24 = arith.constant 24 : index
scf.parallel (%i0, %i1) = (%c0, %c0) to (%c22, %c24) step (%c3, %c3) {
}
return
}
// CHECK-LABEL: func @static_loop_with_step() {
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C3:%.*]] = constant 3 : index
-// CHECK: [[C22:%.*]] = constant 22 : index
-// CHECK: [[C24:%.*]] = constant 24 : index
-// CHECK: [[C0_1:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V1:%.*]] = muli [[C3]], [[C1]] : index
-// CHECK: [[V2:%.*]] = muli [[C3]], [[C4]] : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C3:%.*]] = arith.constant 3 : index
+// CHECK: [[C22:%.*]] = arith.constant 22 : index
+// CHECK: [[C24:%.*]] = arith.constant 24 : index
+// CHECK: [[C0_1:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V1:%.*]] = arith.muli [[C3]], [[C1]] : index
+// CHECK: [[V2:%.*]] = arith.muli [[C3]], [[C4]] : index
// CHECK: scf.parallel ([[V3:%.*]], [[V4:%.*]]) = ([[C0]], [[C0]]) to ([[C22]], [[C24]]) step ([[V1]], [[V2]]) {
// CHECK: scf.parallel ([[V5:%.*]], [[V6:%.*]]) = ([[C0_1]], [[C0_1]]) to ([[V1]], [[V2]]) step ([[C3]], [[C3]]) {
// CHECK-NOT: scf.if
-// CHECK: = addi [[V5]], [[V3]] : index
-// CHECK: = addi [[V6]], [[V4]] : index
+// CHECK: = arith.addi [[V5]], [[V3]] : index
+// CHECK: = arith.addi [[V6]], [[V4]] : index
// CHECK: }
// CHECK: }
// CHECK: return
// -----
func @tile_nested_innermost() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.parallel (%k, %l) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
}
}
// CHECK-LABEL: func @tile_nested_innermost() {
-// CHECK: [[C2:%.*]] = constant 2 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C2:%.*]] = arith.constant 2 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: scf.parallel ([[V1:%.*]], [[V2:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[C1]], [[C1]]) {
-// CHECK: [[C0_1:%.*]] = constant 0 : index
-// CHECK: [[C1_1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V3:%.*]] = muli [[C1]], [[C1_1]] : index
-// CHECK: [[V4:%.*]] = muli [[C1]], [[C4]] : index
+// CHECK: [[C0_1:%.*]] = arith.constant 0 : index
+// CHECK: [[C1_1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V3:%.*]] = arith.muli [[C1]], [[C1_1]] : index
+// CHECK: [[V4:%.*]] = arith.muli [[C1]], [[C4]] : index
// CHECK: scf.parallel ([[V5:%.*]], [[V6:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[V3]], [[V4]]) {
// CHECK: scf.parallel ([[V8:%.*]], [[V9:%.*]]) = ([[C0_1]], [[C0_1]]) to ([[V3]], [[V4]]) step ([[C1]], [[C1]]) {
-// CHECK: = addi [[V8]], [[V5]] : index
-// CHECK: = addi [[V9]], [[V6]] : index
+// CHECK: = arith.addi [[V8]], [[V5]] : index
+// CHECK: = arith.addi [[V9]], [[V6]] : index
// CHECK: scf.if
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: [[C0_2:%.*]] = constant 0 : index
-// CHECK: [[C1_2:%.*]] = constant 1 : index
-// CHECK: [[C4_1:%.*]] = constant 4 : index
-// CHECK: [[V10:%.*]] = muli [[C1]], [[C1_2]] : index
-// CHECK: [[V11:%.*]] = muli [[C1]], [[C4_1]] : index
+// CHECK: [[C0_2:%.*]] = arith.constant 0 : index
+// CHECK: [[C1_2:%.*]] = arith.constant 1 : index
+// CHECK: [[C4_1:%.*]] = arith.constant 4 : index
+// CHECK: [[V10:%.*]] = arith.muli [[C1]], [[C1_2]] : index
+// CHECK: [[V11:%.*]] = arith.muli [[C1]], [[C4_1]] : index
// CHECK: scf.parallel ([[V12:%.*]], [[V13:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[V10]], [[V11]]) {
// CHECK: scf.parallel ([[V15:%.*]], [[V16:%.*]]) = ([[C0_2]], [[C0_2]]) to ([[V10]], [[V11]]) step ([[C1]], [[C1]]) {
-// CHECK: = addi [[V15]], [[V12]] : index
-// CHECK: = addi [[V16]], [[V13]] : index
+// CHECK: = arith.addi [[V15]], [[V12]] : index
+// CHECK: = arith.addi [[V16]], [[V13]] : index
// CHECK: scf.if
// CHECK: }
// CHECK: }
// -----
func @tile_nested_in_non_ploop() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
scf.for %i = %c0 to %c2 step %c1 {
scf.for %j = %c0 to %c2 step %c1 {
scf.parallel (%k, %l) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.parallel (%i0, %i1) = (%arg0, %arg1) to (%arg2, %arg3) step (%arg4, %arg5) {
%B_elem = memref.load %B[%i0, %i1] : memref<?x?xf32>
%C_elem = memref.load %C[%i0, %i1] : memref<?x?xf32>
- %sum_elem = addf %B_elem, %C_elem : f32
+ %sum_elem = arith.addf %B_elem, %C_elem : f32
memref.store %sum_elem, %result[%i0, %i1] : memref<?x?xf32>
}
return
// CHECK: #map = affine_map<(d0, d1, d2) -> (d0, d1 - d2)>
// CHECK-LABEL: func @parallel_loop(
// CHECK-SAME: [[ARG1:%.*]]: index, [[ARG2:%.*]]: index, [[ARG3:%.*]]: index, [[ARG4:%.*]]: index, [[ARG5:%.*]]: index, [[ARG6:%.*]]: index, [[ARG7:%.*]]: memref<?x?xf32>, [[ARG8:%.*]]: memref<?x?xf32>, [[ARG9:%.*]]: memref<?x?xf32>, [[ARG10:%.*]]: memref<?x?xf32>) {
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V1:%.*]] = muli [[ARG5]], [[C1]] : index
-// CHECK: [[V2:%.*]] = muli [[ARG6]], [[C4]] : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V1:%.*]] = arith.muli [[ARG5]], [[C1]] : index
+// CHECK: [[V2:%.*]] = arith.muli [[ARG6]], [[C4]] : index
// CHECK: scf.parallel ([[V3:%.*]], [[V4:%.*]]) = ([[ARG1]], [[ARG2]]) to ([[ARG3]], [[ARG4]]) step ([[V1]], [[V2]]) {
// CHECK: [[V5:%.*]] = affine.min #map([[V1]], [[ARG3]], [[V3]])
// CHECK: [[V6:%.*]] = affine.min #map([[V2]], [[ARG4]], [[V4]])
// CHECK: scf.parallel ([[V7:%.*]], [[V8:%.*]]) = ([[C0]], [[C0]]) to ([[V5]], [[V6]]) step ([[ARG5]], [[ARG6]]) {
-// CHECK: [[V9:%.*]] = addi [[V7]], [[V3]] : index
-// CHECK: [[V10:%.*]] = addi [[V8]], [[V4]] : index
+// CHECK: [[V9:%.*]] = arith.addi [[V7]], [[V3]] : index
+// CHECK: [[V10:%.*]] = arith.addi [[V8]], [[V4]] : index
// CHECK: [[V11:%.*]] = memref.load [[ARG8]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
// CHECK: [[V12:%.*]] = memref.load [[ARG9]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
-// CHECK: [[V13:%.*]] = addf [[V11]], [[V12]] : f32
+// CHECK: [[V13:%.*]] = arith.addf [[V11]], [[V12]] : f32
// CHECK: memref.store [[V13]], [[ARG10]]{{\[}}[[V9]], [[V10]]] : memref<?x?xf32>
// CHECK: }
// CHECK: }
// -----
func @static_loop_with_step() {
- %c0 = constant 0 : index
- %c3 = constant 3 : index
- %c22 = constant 22 : index
- %c24 = constant 24 : index
+ %c0 = arith.constant 0 : index
+ %c3 = arith.constant 3 : index
+ %c22 = arith.constant 22 : index
+ %c24 = arith.constant 24 : index
scf.parallel (%i0, %i1) = (%c0, %c0) to (%c22, %c24) step (%c3, %c3) {
}
return
}
// CHECK-LABEL: func @static_loop_with_step() {
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C3:%.*]] = constant 3 : index
-// CHECK: [[C22:%.*]] = constant 22 : index
-// CHECK: [[C24:%.*]] = constant 24 : index
-// CHECK: [[C0_1:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V1:%.*]] = muli [[C3]], [[C1]] : index
-// CHECK: [[V2:%.*]] = muli [[C3]], [[C4]] : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C3:%.*]] = arith.constant 3 : index
+// CHECK: [[C22:%.*]] = arith.constant 22 : index
+// CHECK: [[C24:%.*]] = arith.constant 24 : index
+// CHECK: [[C0_1:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V1:%.*]] = arith.muli [[C3]], [[C1]] : index
+// CHECK: [[V2:%.*]] = arith.muli [[C3]], [[C4]] : index
// CHECK: scf.parallel ([[V3:%.*]], [[V4:%.*]]) = ([[C0]], [[C0]]) to ([[C22]], [[C24]]) step ([[V1]], [[V2]]) {
// CHECK: scf.parallel ([[V5:%.*]], [[V6:%.*]]) = ([[C0_1]], [[C0_1]]) to ([[V1]], [[V2]]) step ([[C3]], [[C3]]) {
-// CHECK: = addi [[V5]], [[V3]] : index
-// CHECK: = addi [[V6]], [[V4]] : index
+// CHECK: = arith.addi [[V5]], [[V3]] : index
+// CHECK: = arith.addi [[V6]], [[V4]] : index
// CHECK: }
// CHECK: }
// CHECK: return
// -----
func @tile_nested_innermost() {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
scf.parallel (%i, %j) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
scf.parallel (%k, %l) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
}
}
// CHECK-LABEL: func @tile_nested_innermost() {
-// CHECK: [[C2:%.*]] = constant 2 : index
-// CHECK: [[C0:%.*]] = constant 0 : index
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C2:%.*]] = arith.constant 2 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: scf.parallel ([[V1:%.*]], [[V2:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[C1]], [[C1]]) {
-// CHECK: [[C0_1:%.*]] = constant 0 : index
-// CHECK: [[C1_1:%.*]] = constant 1 : index
-// CHECK: [[C4:%.*]] = constant 4 : index
-// CHECK: [[V3:%.*]] = muli [[C1]], [[C1_1]] : index
-// CHECK: [[V4:%.*]] = muli [[C1]], [[C4]] : index
+// CHECK: [[C0_1:%.*]] = arith.constant 0 : index
+// CHECK: [[C1_1:%.*]] = arith.constant 1 : index
+// CHECK: [[C4:%.*]] = arith.constant 4 : index
+// CHECK: [[V3:%.*]] = arith.muli [[C1]], [[C1_1]] : index
+// CHECK: [[V4:%.*]] = arith.muli [[C1]], [[C4]] : index
// CHECK: scf.parallel ([[V5:%.*]], [[V6:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[V3]], [[V4]]) {
// CHECK: [[V7:%.*]] = affine.min #map([[V4]], [[C2]], [[V6]])
// CHECK: scf.parallel ([[V8:%.*]], [[V9:%.*]]) = ([[C0_1]], [[C0_1]]) to ([[V3]], [[V7]]) step ([[C1]], [[C1]]) {
-// CHECK: = addi [[V8]], [[V5]] : index
-// CHECK: = addi [[V9]], [[V6]] : index
+// CHECK: = arith.addi [[V8]], [[V5]] : index
+// CHECK: = arith.addi [[V9]], [[V6]] : index
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: [[C0_2:%.*]] = constant 0 : index
-// CHECK: [[C1_2:%.*]] = constant 1 : index
-// CHECK: [[C4_1:%.*]] = constant 4 : index
-// CHECK: [[V10:%.*]] = muli [[C1]], [[C1_2]] : index
-// CHECK: [[V11:%.*]] = muli [[C1]], [[C4_1]] : index
+// CHECK: [[C0_2:%.*]] = arith.constant 0 : index
+// CHECK: [[C1_2:%.*]] = arith.constant 1 : index
+// CHECK: [[C4_1:%.*]] = arith.constant 4 : index
+// CHECK: [[V10:%.*]] = arith.muli [[C1]], [[C1_2]] : index
+// CHECK: [[V11:%.*]] = arith.muli [[C1]], [[C4_1]] : index
// CHECK: scf.parallel ([[V12:%.*]], [[V13:%.*]]) = ([[C0]], [[C0]]) to ([[C2]], [[C2]]) step ([[V10]], [[V11]]) {
// CHECK: [[V14:%.*]] = affine.min #map([[V11]], [[C2]], [[V13]])
// CHECK: scf.parallel ([[V15:%.*]], [[V16:%.*]]) = ([[C0_2]], [[C0_2]]) to ([[V10]], [[V14]]) step ([[C1]], [[C1]]) {
-// CHECK: = addi [[V15]], [[V12]] : index
-// CHECK: = addi [[V16]], [[V13]] : index
+// CHECK: = arith.addi [[V15]], [[V12]] : index
+// CHECK: = arith.addi [[V16]], [[V13]] : index
// CHECK: }
// CHECK: }
// CHECK: return
// -----
func @tile_nested_in_non_ploop() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
scf.for %i = %c0 to %c2 step %c1 {
scf.for %j = %c0 to %c2 step %c1 {
scf.parallel (%k, %l) = (%c0, %c0) to (%c2, %c2) step (%c1, %c1) {
// -----
func @access_chain_invalid_constant_type_1() -> () {
- %0 = std.constant 1: i32
+ %0 = arith.constant 1: i32
%1 = spv.Variable : !spv.ptr<!spv.struct<(f32, !spv.array<4xf32>)>, Function>
- // expected-error @+1 {{index must be an integer spv.Constant to access element of spv.struct, but provided std.constant}}
+ // expected-error @+1 {{index must be an integer spv.Constant to access element of spv.struct, but provided arith.constant}}
%2 = spv.AccessChain %1[%0, %0] : !spv.ptr<!spv.struct<(f32, !spv.array<4xf32>)>, Function>, i32, i32
return
}
// expected-error @+1 {{cannot attach SPIR-V attributes to region result}}
func @unknown_attr_on_region() -> (i32 {spv.something}) {
- %0 = constant 10.0 : f32
+ %0 = arith.constant 10.0 : f32
return %0: f32
}
func @f() -> (!shape.shape, !shape.shape) {
// CHECK-DAG: shape.const_shape [2, 3] : !shape.shape
// CHECK-DAG: shape.const_shape [4, 5] : !shape.shape
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%0 = shape.const_shape [2, 3, 4, 5] : !shape.shape
%head, %tail = "shape.split_at"(%0, %c2) : (!shape.shape, index) -> (!shape.shape, !shape.shape)
return %head, %tail : !shape.shape, !shape.shape
func @f() -> (!shape.shape, !shape.shape) {
// CHECK-DAG: shape.const_shape [2, 3, 4] : !shape.shape
// CHECK-DAG: shape.const_shape [5] : !shape.shape
- %c-1 = constant -1 : index
+ %c-1 = arith.constant -1 : index
%0 = shape.const_shape [2, 3, 4, 5] : !shape.shape
%head, %tail = "shape.split_at"(%0, %c-1) : (!shape.shape, index) -> (!shape.shape, !shape.shape)
return %head, %tail : !shape.shape, !shape.shape
// CHECK-LABEL: func @f
func @f() -> (!shape.shape, !shape.shape) {
// CHECK: shape.split_at
- %c5 = constant 5 : index
+ %c5 = arith.constant 5 : index
%0 = shape.const_shape [2, 3, 4, 5] : !shape.shape
%head, %tail = "shape.split_at"(%0, %c5) : (!shape.shape, index) -> (!shape.shape, !shape.shape)
return %head, %tail : !shape.shape, !shape.shape
// CHECK-LABEL: func @f()
func @f() -> !shape.shape {
// CHECK: shape.const_shape [3, 5, 11] : !shape.shape
- %e0 = constant 3 : index
- %e1 = constant 5 : index
- %e2 = constant 11 : index
+ %e0 = arith.constant 3 : index
+ %e1 = arith.constant 5 : index
+ %e2 = arith.constant 11 : index
%ret = shape.from_extents %e0, %e1, %e2 : index, index, index
return %ret : !shape.shape
}
// CHECK-LABEL: func @no_fold
func @no_fold(%arg0: index) -> !shape.shape {
// CHECK-NOT: shape.const_shape
- %e0 = constant 3 : index
+ %e0 = arith.constant 3 : index
%ret = shape.from_extents %e0, %arg0 : index, index
return %ret : !shape.shape
}
func @const_size_to_index() -> index {
// CHECK-NOT: shape.index_cast
%cs = shape.const_size 123
- // CHECK: constant 123 : index
+ // CHECK: arith.constant 123 : index
%ci = shape.size_to_index %cs : !shape.size
return %ci : index
}
// Cast constant index to size and fold it away.
// CHECK-LABEL: func @const_index_to_size
func @const_index_to_size() -> !shape.size {
- // CHECK-NOT: index_cast
- %ci = constant 123 : index
+ // CHECK-NOT: arith.index_cast
+ %ci = arith.constant 123 : index
// CHECK: shape.const_size 123
%cs = shape.index_to_size %ci
return %cs : !shape.size
// CHECK-LABEL: func @const_index_to_size_to_index
func @const_index_to_size_to_index() -> index {
// CHECK-NOT: shape.index_cast
- %ci0 = constant 123 : index
+ %ci0 = arith.constant 123 : index
%cs0 = shape.index_to_size %ci0
- // CHECK: %[[CI:.*]] = constant 123 : index
+ // CHECK: %[[CI:.*]] = arith.constant 123 : index
// CHECK-NEXT: return %[[CI]] : index
%ci1 = shape.size_to_index %cs0 : !shape.size
return %ci1 : index
func @basic() -> index {
// CHECK: constant 2 : index
%0 = shape.const_shape [0, 1, 2] : tensor<3xindex>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%1 = shape.get_extent %0, %c2 : tensor<3xindex>, index -> index
return %1 : index
}
// CHECK: shape.const_shape
// CHECK: shape.get_extent
%0 = shape.const_shape [0, 1, 2] : tensor<3xindex>
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%1 = shape.get_extent %0, %c3 : tensor<3xindex>, index -> index
return %1 : index
}
// CHECK-LABEL: func @not_const
func @not_const(%arg0: tensor<?xindex>) -> index {
// CHECK: shape.get_extent
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%0 = shape.get_extent %arg0, %c3 : tensor<?xindex>, index -> index
return %0 : index
}
// CHECK-NEXT: shape.const_witness true
// CHECK-NEXT: consume.witness
// CHECK-NEXT: return
- %true = constant true
+ %true = arith.constant true
%0 = shape.cstr_require %true, "msg"
"consume.witness"(%0) : (!shape.witness) -> ()
return
// Fold `rank` based on constant extent tensor.
// CHECK-LABEL: @fold_rank
func @fold_rank() -> index {
- // CHECK: %[[RESULT:.*]] = constant 5 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant 5 : index
// CHECK: return %[[RESULT]] : index
%shape = shape.const_shape [3, 4, 5, 6, 7] : tensor<5xindex>
%rank = shape.rank %shape : tensor<5xindex> -> index
// Canonicalize `rank` when shape is derived from ranked tensor.
// CHECK-LABEL: @canonicalize_rank
func @canonicalize_rank(%arg : tensor<1x2x?xf32>) -> index {
- // CHECK: %[[RESULT:.*]] = constant 3 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant 3 : index
// CHECK: return %[[RESULT]] : index
%shape = shape.shape_of %arg : tensor<1x2x?xf32> -> tensor<?xindex>
%rank = shape.rank %shape : tensor<?xindex> -> index
// Fold `shape_eq` for equal and constant shapes.
// CHECK-LABEL: @shape_eq_fold_1
func @shape_eq_fold_1() -> i1 {
- // CHECK: %[[RESULT:.*]] = constant true
+ // CHECK: %[[RESULT:.*]] = arith.constant true
// CHECK: return %[[RESULT]] : i1
%a = shape.const_shape [1, 2, 3] : !shape.shape
%b = shape.const_shape [1, 2, 3] : tensor<3xindex>
// Fold `shape_eq` for different but constant shapes of same length.
// CHECK-LABEL: @shape_eq_fold_0
func @shape_eq_fold_0() -> i1 {
- // CHECK: %[[RESULT:.*]] = constant false
+ // CHECK: %[[RESULT:.*]] = arith.constant false
// CHECK: return %[[RESULT]] : i1
%a = shape.const_shape [1, 2, 3] : tensor<3xindex>
%b = shape.const_shape [4, 5, 6] : tensor<3xindex>
// Fold `shape_eq` for different but constant shapes of different length.
// CHECK-LABEL: @shape_eq_fold_0
func @shape_eq_fold_0() -> i1 {
- // CHECK: %[[RESULT:.*]] = constant false
+ // CHECK: %[[RESULT:.*]] = arith.constant false
// CHECK: return %[[RESULT]] : i1
%a = shape.const_shape [1, 2, 3, 4, 5, 6] : !shape.shape
%b = shape.const_shape [1, 2, 3] : !shape.shape
// Fold `mul` for constant indices.
// CHECK-LABEL: @fold_mul_index
func @fold_mul_index() -> index {
- // CHECK: %[[RESULT:.*]] = constant 6 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant 6 : index
// CHECK: return %[[RESULT]] : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
%result = shape.mul %c2, %c3 : index, index -> index
return %result : index
}
// CHECK: %[[RESULT:.*]] = shape.const_size 6
// CHECK: return %[[RESULT]] : !shape.size
%c2 = shape.const_size 2
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%result = shape.mul %c2, %c3 : !shape.size, index -> !shape.size
return %result : !shape.size
}
// Fold `div` for constant indices.
// CHECK-LABEL: @fold_div_index
func @fold_div_index() -> index {
- // CHECK: %[[RESULT:.*]] = constant 2 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant 2 : index
// CHECK: return %[[RESULT]] : index
- %c2 = constant 10 : index
- %c3 = constant 4 : index
+ %c2 = arith.constant 10 : index
+ %c3 = arith.constant 4 : index
%result = shape.div %c2, %c3 : index, index -> index
return %result : index
}
// Fold `div` for constant indices and lhs is negative.
// CHECK-LABEL: @fold_div_index_neg_lhs
func @fold_div_index_neg_lhs() -> index {
- // CHECK: %[[RESULT:.*]] = constant -3 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant -3 : index
// CHECK: return %[[RESULT]] : index
- %c2 = constant -10 : index
- %c3 = constant 4 : index
+ %c2 = arith.constant -10 : index
+ %c3 = arith.constant 4 : index
%result = shape.div %c2, %c3 : index, index -> index
return %result : index
}
// Fold `div` for constant indices and rhs is negative.
// CHECK-LABEL: @fold_div_index_neg_rhs
func @fold_div_index_neg_rhs() -> index {
- // CHECK: %[[RESULT:.*]] = constant -3 : index
+ // CHECK: %[[RESULT:.*]] = arith.constant -3 : index
// CHECK: return %[[RESULT]] : index
- %c2 = constant 10 : index
- %c3 = constant -4 : index
+ %c2 = arith.constant 10 : index
+ %c3 = arith.constant -4 : index
%result = shape.div %c2, %c3 : index, index -> index
return %result : index
}
// CHECK: %[[RESULT:.*]] = shape.const_size 4
// CHECK: return %[[RESULT]] : !shape.size
%c2 = shape.const_size 12
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%result = shape.div %c2, %c3 : !shape.size, index -> !shape.size
return %result : !shape.size
}
// CHECK-LABEL: @is_broadcastable_on_same_shape
func @is_broadcastable_on_same_shape(%shape : !shape.shape) -> i1 {
// CHECK-NOT: is_broadcastable
- // CHECK: %[[RES:.*]] = constant true
+ // CHECK: %[[RES:.*]] = arith.constant true
// CHECK: return %[[RES]]
%0 = shape.is_broadcastable %shape, %shape, %shape
: !shape.shape, !shape.shape, !shape.shape
// CHECK-LABEL: func @extract_shapeof
// CHECK-SAME: %[[ARG0:.*]]: tensor<?x?xf64>
func @extract_shapeof(%arg0 : tensor<?x?xf64>) -> index {
- %c1 = constant 1 : index
-// CHECK: %[[C1:.*]] = constant 1
+ %c1 = arith.constant 1 : index
+// CHECK: %[[C1:.*]] = arith.constant 1
%shape = shape.shape_of %arg0 : tensor<?x?xf64> -> tensor<2xindex>
// CHECK: %[[DIM:.*]] = tensor.dim %[[ARG0]], %[[C1]]
%result = tensor.extract %shape[%c1] : tensor<2xindex>
// expected-error@+4 {{types mismatch between yield op and its parent}}
%num_elements = shape.reduce(%shape, %init) : !shape.shape -> !shape.size {
^bb0(%index: index, %dim: !shape.size, %lci: !shape.size):
- %c0 = constant 1 : index
+ %c0 = arith.constant 1 : index
shape.yield %c0 : index
}
return
// CHECK-LABEL: extent_tensor_num_elements
func @extent_tensor_num_elements(%shape : tensor<?xindex>) -> index {
- %init = constant 1 : index
+ %init = arith.constant 1 : index
%num_elements = shape.reduce(%shape, %init) : tensor<?xindex> -> index {
^bb0(%index : index, %extent : index, %acc : index):
%acc_next = shape.mul %acc, %extent : index, index -> index
func @test_constraints() {
%0 = shape.const_shape [] : !shape.shape
%1 = shape.const_shape [1, 2, 3] : !shape.shape
- %true = constant true
+ %true = arith.constant true
%w0 = shape.cstr_broadcastable %0, %1 : !shape.shape, !shape.shape
%w1 = shape.cstr_eq %0, %1 : !shape.shape, !shape.shape
%w2 = shape.const_witness true
}
func @get_extent_on_extent_tensor(%arg : tensor<?xindex>) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%result = shape.get_extent %arg, %c0 : tensor<?xindex>, index -> index
return %result : index
}
%num_elements = shape.num_elements %shape : tensor<?xindex> -> index
return %num_elements : index
}
-// CHECK: [[C1:%.*]] = constant 1 : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
// CHECK: [[NUM_ELEMENTS:%.*]] = shape.reduce([[ARG]], [[C1]]) : tensor<?xindex> -> index
// CHECK: ^bb0({{.*}}: index, [[DIM:%.*]]: index, [[ACC:%.*]]: index
// CHECK: [[NEW_ACC:%.*]] = shape.mul [[DIM]], [[ACC]]
// CHECK-LABEL: func @sparse_dim1d(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[D:.*]] = call @sparseDimSize(%[[A]], %[[C]])
// CHECK: return %[[D]] : index
func @sparse_dim1d(%arg0: tensor<?xf64, #SparseVector>) -> index {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = tensor.dim %arg0, %c : tensor<?xf64, #SparseVector>
return %0 : index
}
// CHECK-LABEL: func @sparse_dim3d(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 2 : index
+// CHECK: %[[C:.*]] = arith.constant 2 : index
// CHECK: %[[D:.*]] = call @sparseDimSize(%[[A]], %[[C]])
// CHECK: return %[[D]] : index
func @sparse_dim3d(%arg0: tensor<?x?x?xf64, #SparseTensor>) -> index {
// Querying for dimension 1 in the tensor type needs to be
// permuted into querying for dimension 2 in the stored sparse
// tensor scheme, since the latter honors the dimOrdering.
- %c = constant 1 : index
+ %c = arith.constant 1 : index
%0 = tensor.dim %arg0, %c : tensor<?x?x?xf64, #SparseTensor>
return %0 : index
}
// CHECK-LABEL: func @sparse_dim3d_const(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 20 : index
+// CHECK: %[[C:.*]] = arith.constant 20 : index
// CHECK: return %[[C]] : index
func @sparse_dim3d_const(%arg0: tensor<10x20x30xf64, #SparseTensor>) -> index {
// Querying for dimension 1 in the tensor type can be directly
// folded into the right value (even though it corresponds
// to dimension 2 in the stored sparse tensor scheme).
- %c = constant 1 : index
+ %c = arith.constant 1 : index
%0 = tensor.dim %arg0, %c : tensor<10x20x30xf64, #SparseTensor>
return %0 : index
}
// CHECK-LABEL: func @sparse_new1d(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[U:.*]] = constant dense<1> : tensor<1xi8>
-// CHECK-DAG: %[[V:.*]] = constant dense<128> : tensor<1xi64>
-// CHECK-DAG: %[[W:.*]] = constant dense<0> : tensor<1xi64>
+// CHECK-DAG: %[[U:.*]] = arith.constant dense<1> : tensor<1xi8>
+// CHECK-DAG: %[[V:.*]] = arith.constant dense<128> : tensor<1xi64>
+// CHECK-DAG: %[[W:.*]] = arith.constant dense<0> : tensor<1xi64>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[U]] : tensor<1xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[V]] : tensor<1xi64> to tensor<?xi64>
// CHECK-DAG: %[[Z:.*]] = tensor.cast %[[W]] : tensor<1xi64> to tensor<?xi64>
// CHECK-LABEL: func @sparse_new2d(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[U:.*]] = constant dense<[0, 1]> : tensor<2xi8>
-// CHECK-DAG: %[[V:.*]] = constant dense<0> : tensor<2xi64>
-// CHECK-DAG: %[[W:.*]] = constant dense<[0, 1]> : tensor<2xi64>
+// CHECK-DAG: %[[U:.*]] = arith.constant dense<[0, 1]> : tensor<2xi8>
+// CHECK-DAG: %[[V:.*]] = arith.constant dense<0> : tensor<2xi64>
+// CHECK-DAG: %[[W:.*]] = arith.constant dense<[0, 1]> : tensor<2xi64>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[U]] : tensor<2xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[V]] : tensor<2xi64> to tensor<?xi64>
// CHECK-DAG: %[[Z:.*]] = tensor.cast %[[W]] : tensor<2xi64> to tensor<?xi64>
// CHECK-LABEL: func @sparse_new3d(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[U:.*]] = constant dense<[0, 1, 1]> : tensor<3xi8>
-// CHECK-DAG: %[[V:.*]] = constant dense<0> : tensor<3xi64>
-// CHECK-DAG: %[[W:.*]] = constant dense<[1, 2, 0]> : tensor<3xi64>
+// CHECK-DAG: %[[U:.*]] = arith.constant dense<[0, 1, 1]> : tensor<3xi8>
+// CHECK-DAG: %[[V:.*]] = arith.constant dense<0> : tensor<3xi64>
+// CHECK-DAG: %[[W:.*]] = arith.constant dense<[1, 2, 0]> : tensor<3xi64>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[U]] : tensor<3xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[V]] : tensor<3xi64> to tensor<?xi64>
// CHECK-DAG: %[[Z:.*]] = tensor.cast %[[W]] : tensor<3xi64> to tensor<?xi64>
// CHECK-LABEL: func @sparse_convert_1d(
// CHECK-SAME: %[[A:.*]]: tensor<?xi32>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[D0:.*]] = constant dense<0> : tensor<1xi64>
-// CHECK-DAG: %[[D1:.*]] = constant dense<1> : tensor<1xi8>
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[D0:.*]] = arith.constant dense<0> : tensor<1xi64>
+// CHECK-DAG: %[[D1:.*]] = arith.constant dense<1> : tensor<1xi8>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[D1]] : tensor<1xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[D0]] : tensor<1xi64> to tensor<?xi64>
// CHECK: %[[C:.*]] = call @newSparseTensor(%[[X]], %[[Y]], %[[Y]], %{{.*}}, %{{.*}}, %{{.*}}, %{{.*}}, %{{.}})
// CHECK-LABEL: func @sparse_convert_2d(
// CHECK-SAME: %[[A:.*]]: tensor<2x4xf64>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[U:.*]] = constant dense<[0, 1]> : tensor<2xi8>
-// CHECK-DAG: %[[V:.*]] = constant dense<[2, 4]> : tensor<2xi64>
-// CHECK-DAG: %[[W:.*]] = constant dense<[0, 1]> : tensor<2xi64>
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[U:.*]] = arith.constant dense<[0, 1]> : tensor<2xi8>
+// CHECK-DAG: %[[V:.*]] = arith.constant dense<[2, 4]> : tensor<2xi64>
+// CHECK-DAG: %[[W:.*]] = arith.constant dense<[0, 1]> : tensor<2xi64>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[U]] : tensor<2xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[V]] : tensor<2xi64> to tensor<?xi64>
// CHECK-DAG: %[[Z:.*]] = tensor.cast %[[W]] : tensor<2xi64> to tensor<?xi64>
#CSR = #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ] }>
// CHECK-LABEL: func @entry() -> !llvm.ptr<i8> {
-// CHECK: %[[C1:.*]] = constant 1 : i32
-// CHECK: %[[Offset:.*]] = constant dense<[0, 1]> : tensor<2xi64>
-// CHECK: %[[Dims:.*]] = constant dense<[8, 7]> : tensor<2xi64>
-// CHECK: %[[Base:.*]] = constant dense<[0, 1]> : tensor<2xi8>
-// CHECK: %[[I2:.*]] = constant 2 : index
-// CHECK: %[[SparseV:.*]] = constant dense<[1.000000e+00, 5.000000e+00]> : tensor<2xf32>
-// CHECK: %[[SparseI:.*]] = constant dense<{{\[\[}}0, 0], [1, 6]]> : tensor<2x2xi64>
-// CHECK: %[[I1:.*]] = constant 1 : index
-// CHECK: %[[I0:.*]] = constant 0 : index
-// CHECK: %[[C2:.*]] = constant 2 : i32
+// CHECK: %[[C1:.*]] = arith.constant 1 : i32
+// CHECK: %[[Offset:.*]] = arith.constant dense<[0, 1]> : tensor<2xi64>
+// CHECK: %[[Dims:.*]] = arith.constant dense<[8, 7]> : tensor<2xi64>
+// CHECK: %[[Base:.*]] = arith.constant dense<[0, 1]> : tensor<2xi8>
+// CHECK: %[[I2:.*]] = arith.constant 2 : index
+// CHECK: %[[SparseV:.*]] = arith.constant dense<[1.000000e+00, 5.000000e+00]> : tensor<2xf32>
+// CHECK: %[[SparseI:.*]] = arith.constant dense<{{\[\[}}0, 0], [1, 6]]> : tensor<2x2xi64>
+// CHECK: %[[I1:.*]] = arith.constant 1 : index
+// CHECK: %[[I0:.*]] = arith.constant 0 : index
+// CHECK: %[[C2:.*]] = arith.constant 2 : i32
// CHECK: %[[BaseD:.*]] = tensor.cast %[[Base]] : tensor<2xi8> to tensor<?xi8>
// CHECK: %[[DimsD:.*]] = tensor.cast %[[Dims]] : tensor<2xi64> to tensor<?xi64>
// CHECK: %[[OffsetD:.*]] = tensor.cast %[[Offset]] : tensor<2xi64> to tensor<?xi64>
// CHECK: %[[IndexD:.*]] = memref.cast %[[Index]] : memref<2xindex> to memref<?xindex>
// CHECK: scf.for %[[IV:.*]] = %[[I0]] to %[[I2]] step %[[I1]] {
// CHECK: %[[VAL0:.*]] = tensor.extract %[[SparseI]]{{\[}}%[[IV]], %[[I0]]] : tensor<2x2xi64>
-// CHECK: %[[VAL1:.*]] = index_cast %[[VAL0]] : i64 to index
+// CHECK: %[[VAL1:.*]] = arith.index_cast %[[VAL0]] : i64 to index
// CHECK: memref.store %[[VAL1]], %[[Index]]{{\[}}%[[I0]]] : memref<2xindex>
// CHECK: %[[VAL2:.*]] = tensor.extract %[[SparseI]]{{\[}}%[[IV]], %[[I1]]] : tensor<2x2xi64>
-// CHECK: %[[VAL3:.*]] = index_cast %[[VAL2]] : i64 to index
+// CHECK: %[[VAL3:.*]] = arith.index_cast %[[VAL2]] : i64 to index
// CHECK: memref.store %[[VAL3]], %[[Index]]{{\[}}%[[I1]]] : memref<2xindex>
// CHECK: %[[VAL4:.*]] = tensor.extract %[[SparseV]]{{\[}}%[[IV]]] : tensor<2xf32>
// CHECK: call @addEltF32(%[[TCOO]], %[[VAL4]], %[[IndexD]], %[[OffsetD]])
// CHECK: return %[[T]] : !llvm.ptr<i8>
func @entry() -> tensor<8x7xf32, #CSR>{
// Initialize a tensor.
- %0 = constant sparse<[[0, 0], [1, 6]], [1.0, 5.0]> : tensor<8x7xf32>
+ %0 = arith.constant sparse<[[0, 0], [1, 6]], [1.0, 5.0]> : tensor<8x7xf32>
// Convert the tensor to a sparse tensor.
%1 = sparse_tensor.convert %0 : tensor<8x7xf32> to tensor<8x7xf32, #CSR>
return %1 : tensor<8x7xf32, #CSR>
// CHECK-LABEL: func @sparse_convert_3d(
// CHECK-SAME: %[[A:.*]]: tensor<?x?x?xf64>) -> !llvm.ptr<i8>
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[U:.*]] = constant dense<[0, 1, 1]> : tensor<3xi8>
-// CHECK-DAG: %[[V:.*]] = constant dense<0> : tensor<3xi64>
-// CHECK-DAG: %[[W:.*]] = constant dense<[1, 2, 0]> : tensor<3xi64>
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[U:.*]] = arith.constant dense<[0, 1, 1]> : tensor<3xi8>
+// CHECK-DAG: %[[V:.*]] = arith.constant dense<0> : tensor<3xi64>
+// CHECK-DAG: %[[W:.*]] = arith.constant dense<[1, 2, 0]> : tensor<3xi64>
// CHECK-DAG: %[[X:.*]] = tensor.cast %[[U]] : tensor<3xi8> to tensor<?xi8>
// CHECK-DAG: %[[Y:.*]] = tensor.cast %[[V]] : tensor<3xi64> to tensor<?xi64>
// CHECK-DAG: %[[Z:.*]] = tensor.cast %[[W]] : tensor<3xi64> to tensor<?xi64>
// CHECK-LABEL: func @sparse_pointers(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparsePointers(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK: return %[[T]] : memref<?xindex>
func @sparse_pointers(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
}
// CHECK-LABEL: func @sparse_pointers64(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparsePointers64(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xi64>
// CHECK: return %[[T]] : memref<?xi64>
func @sparse_pointers64(%arg0: tensor<128xf64, #SparseVector64>) -> memref<?xi64> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector64> to memref<?xi64>
return %0 : memref<?xi64>
}
// CHECK-LABEL: func @sparse_pointers32(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparsePointers32(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xi32>
// CHECK: return %[[T]] : memref<?xi32>
func @sparse_pointers32(%arg0: tensor<128xf64, #SparseVector32>) -> memref<?xi32> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector32> to memref<?xi32>
return %0 : memref<?xi32>
}
// CHECK-LABEL: func @sparse_indices(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparseIndices(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK: return %[[T]] : memref<?xindex>
func @sparse_indices(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.indices %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
}
// CHECK-LABEL: func @sparse_indices64(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparseIndices64(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xi64>
// CHECK: return %[[T]] : memref<?xi64>
func @sparse_indices64(%arg0: tensor<128xf64, #SparseVector64>) -> memref<?xi64> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.indices %arg0, %c : tensor<128xf64, #SparseVector64> to memref<?xi64>
return %0 : memref<?xi64>
}
// CHECK-LABEL: func @sparse_indices32(
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = call @sparseIndices32(%[[A]], %[[C]]) : (!llvm.ptr<i8>, index) -> memref<?xi32>
// CHECK: return %[[T]] : memref<?xi32>
func @sparse_indices32(%arg0: tensor<128xf64, #SparseVector32>) -> memref<?xi32> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.indices %arg0, %c : tensor<128xf64, #SparseVector32> to memref<?xi32>
return %0 : memref<?xi32>
}
// CHECK-SAME: %[[A:.*]]: !llvm.ptr<i8>
// CHECK: return %[[A]] : !llvm.ptr<i8>
func @sparse_reconstruct_n(%arg0: tensor<128xf32, #SparseVector> {linalg.inplaceable = true}) -> tensor<128xf32, #SparseVector> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf32, #SparseVector> to memref<?xindex>
%1 = sparse_tensor.indices %arg0, %c : tensor<128xf32, #SparseVector> to memref<?xindex>
%2 = sparse_tensor.values %arg0 : tensor<128xf32, #SparseVector> to memref<?xf32>
// CHECK-LABEL: func @dense1(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32> {linalg.inplaceable = false}) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_2:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16xf32>
// CHECK: %[[VAL_9:.*]] = memref.alloc() : memref<32x16xf32>
// CHECK: memref.copy %[[VAL_8]], %[[VAL_9]] : memref<32x16xf32> to memref<32x16xf32>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_12:.*]] = muli %[[VAL_10]], %[[VAL_4]] : index
-// CHECK: %[[VAL_13:.*]] = addi %[[VAL_12]], %[[VAL_11]] : index
+// CHECK: %[[VAL_12:.*]] = arith.muli %[[VAL_10]], %[[VAL_4]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_12]], %[[VAL_11]] : index
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_13]]] : memref<?xf32>
-// CHECK: %[[VAL_15:.*]] = addf %[[VAL_14]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_15:.*]] = arith.addf %[[VAL_14]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_15]], %[[VAL_9]]{{\[}}%[[VAL_10]], %[[VAL_11]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
func @dense1(%arga: tensor<32x16xf32, #DenseMatrix>,
%argx: tensor<32x16xf32> {linalg.inplaceable = false})
-> tensor<32x16xf32> {
- %c = constant 1.0 : f32
+ %c = arith.constant 1.0 : f32
%0 = linalg.generic #trait_2d
ins(%arga: tensor<32x16xf32, #DenseMatrix>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %x: f32):
- %1 = addf %a, %c : f32
+ %1 = arith.addf %a, %c : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-LABEL: func @dense2(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32> {linalg.inplaceable = true}) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_2:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16xf32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_11:.*]] = muli %[[VAL_9]], %[[VAL_4]] : index
-// CHECK: %[[VAL_12:.*]] = addi %[[VAL_11]], %[[VAL_10]] : index
+// CHECK: %[[VAL_11:.*]] = arith.muli %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_11]], %[[VAL_10]] : index
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_12]]] : memref<?xf32>
-// CHECK: %[[VAL_14:.*]] = addf %[[VAL_13]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_14:.*]] = arith.addf %[[VAL_13]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_9]], %[[VAL_10]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
func @dense2(%arga: tensor<32x16xf32, #DenseMatrix>,
%argx: tensor<32x16xf32> {linalg.inplaceable = true})
-> tensor<32x16xf32> {
- %c = constant 1.0 : f32
+ %c = arith.constant 1.0 : f32
%0 = linalg.generic #trait_2d
ins(%arga: tensor<32x16xf32, #DenseMatrix>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %x: f32):
- %1 = addf %a, %c : f32
+ %1 = arith.addf %a, %c : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-LABEL: func @dense3(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {linalg.inplaceable = true}) -> tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {
-// CHECK: %[[VAL_2:.*]] = constant 1.000000e+00 : f32
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 1.000000e+00 : f32
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_0]] : memref<32x16xf32>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_1]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xf32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_11:.*]] = muli %[[VAL_9]], %[[VAL_4]] : index
-// CHECK: %[[VAL_12:.*]] = addi %[[VAL_11]], %[[VAL_10]] : index
+// CHECK: %[[VAL_11:.*]] = arith.muli %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_11]], %[[VAL_10]] : index
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_9]], %[[VAL_10]]] : memref<32x16xf32>
-// CHECK: %[[VAL_14:.*]] = addf %[[VAL_13]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_14:.*]] = arith.addf %[[VAL_13]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<?xf32>
// CHECK: }
// CHECK: }
func @dense3(%arga: tensor<32x16xf32>,
%argx: tensor<32x16xf32, #DenseMatrix> {linalg.inplaceable = true})
-> tensor<32x16xf32, #DenseMatrix> {
- %c = constant 1.0 : f32
+ %c = arith.constant 1.0 : f32
%0 = linalg.generic #trait_2d
ins(%arga: tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32, #DenseMatrix>) {
^bb(%a: f32, %x: f32):
- %1 = addf %a, %c : f32
+ %1 = arith.addf %a, %c : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32, #DenseMatrix>
return %0 : tensor<32x16xf32, #DenseMatrix>
// CHECK-LABEL: func @dense4(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {linalg.inplaceable = true}) -> tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {
-// CHECK: %[[VAL_2:.*]] = constant 8 : index
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 8 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_0]] : memref<32x16x8xf32>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_1]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}}>> to memref<?xf32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_11:.*]] = muli %[[VAL_9]], %[[VAL_4]] : index
-// CHECK: %[[VAL_12:.*]] = addi %[[VAL_11]], %[[VAL_10]] : index
+// CHECK: %[[VAL_11:.*]] = arith.muli %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_11]], %[[VAL_10]] : index
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<?xf32>
// CHECK: %[[VAL_14:.*]] = scf.for %[[VAL_15:.*]] = %[[VAL_5]] to %[[VAL_2]] step %[[VAL_6]] iter_args(%[[VAL_16:.*]] = %[[VAL_13]]) -> (f32) {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_9]], %[[VAL_10]], %[[VAL_15]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_18:.*]] = addf %[[VAL_16]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_18:.*]] = arith.addf %[[VAL_16]], %[[VAL_17]] : f32
// CHECK: scf.yield %[[VAL_18]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_19:.*]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<?xf32>
ins(%arga: tensor<32x16x8xf32>)
outs(%argx: tensor<32x16xf32, #DenseMatrix>) {
^bb(%a: f32, %x: f32):
- %1 = addf %x, %a : f32
+ %1 = arith.addf %x, %a : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32, #DenseMatrix>
return %0 : tensor<32x16xf32, #DenseMatrix>
// CHECK-NOT: sparse_tensor.values
// CHECK: return
func @sparse_dce_getters(%arg0: tensor<64xf32, #SparseVector>) {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<64xf32, #SparseVector> to memref<?xindex>
%1 = sparse_tensor.indices %arg0, %c : tensor<64xf32, #SparseVector> to memref<?xindex>
%2 = sparse_tensor.values %arg0 : tensor<64xf32, #SparseVector> to memref<?xf32>
// -----
func @invalid_pointers_dense(%arg0: tensor<128xf64>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
// expected-error@+1 {{expected a sparse tensor to get pointers}}
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64> to memref<?xindex>
return %0 : memref<?xindex>
// -----
func @invalid_pointers_unranked(%arg0: tensor<*xf64>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
// expected-error@+1 {{expected a sparse tensor to get pointers}}
%0 = sparse_tensor.pointers %arg0, %c : tensor<*xf64> to memref<?xindex>
return %0 : memref<?xindex>
#SparseVector = #sparse_tensor.encoding<{dimLevelType = ["compressed"], pointerBitWidth=32}>
func @mismatch_pointers_types(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
// expected-error@+1 {{unexpected type for pointers}}
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
#SparseVector = #sparse_tensor.encoding<{dimLevelType = ["compressed"]}>
func @pointers_oob(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// expected-error@+1 {{requested pointers dimension out of bounds}}
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
// -----
func @invalid_indices_dense(%arg0: tensor<10x10xi32>) -> memref<?xindex> {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// expected-error@+1 {{expected a sparse tensor to get indices}}
%0 = sparse_tensor.indices %arg0, %c : tensor<10x10xi32> to memref<?xindex>
return %0 : memref<?xindex>
// -----
func @invalid_indices_unranked(%arg0: tensor<*xf64>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
// expected-error@+1 {{expected a sparse tensor to get indices}}
%0 = sparse_tensor.indices %arg0, %c : tensor<*xf64> to memref<?xindex>
return %0 : memref<?xindex>
#SparseVector = #sparse_tensor.encoding<{dimLevelType = ["compressed"]}>
func @mismatch_indices_types(%arg0: tensor<?xf64, #SparseVector>) -> memref<?xi32> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
// expected-error@+1 {{unexpected type for indices}}
%0 = sparse_tensor.indices %arg0, %c : tensor<?xf64, #SparseVector> to memref<?xi32>
return %0 : memref<?xi32>
#SparseVector = #sparse_tensor.encoding<{dimLevelType = ["compressed"]}>
func @indices_oob(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 1 : index
+ %c = arith.constant 1 : index
// expected-error@+1 {{requested indices dimension out of bounds}}
%0 = sparse_tensor.indices %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
// CHECK-LABEL: func @sparse_pointers(
// CHECK-SAME: %[[A:.*]]: tensor<128xf64, #{{.*}}>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = sparse_tensor.pointers %[[A]], %[[C]] : tensor<128xf64, #{{.*}}> to memref<?xindex>
// CHECK: return %[[T]] : memref<?xindex>
func @sparse_pointers(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.pointers %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
}
// CHECK-LABEL: func @sparse_indices(
// CHECK-SAME: %[[A:.*]]: tensor<128xf64, #{{.*}}>)
-// CHECK: %[[C:.*]] = constant 0 : index
+// CHECK: %[[C:.*]] = arith.constant 0 : index
// CHECK: %[[T:.*]] = sparse_tensor.indices %[[A]], %[[C]] : tensor<128xf64, #{{.*}}> to memref<?xindex>
// CHECK: return %[[T]] : memref<?xindex>
func @sparse_indices(%arg0: tensor<128xf64, #SparseVector>) -> memref<?xindex> {
- %c = constant 0 : index
+ %c = arith.constant 0 : index
%0 = sparse_tensor.indices %arg0, %c : tensor<128xf64, #SparseVector> to memref<?xindex>
return %0 : memref<?xindex>
}
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: f32,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf32>
// CHECK: %[[VAL_8:.*]] = memref.alloc() : memref<32xf32>
// CHECK: memref.copy %[[VAL_7]], %[[VAL_8]] : memref<32xf32> to memref<32xf32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_10:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_9]]] : memref<?xf32>
-// CHECK: %[[VAL_11:.*]] = addf %[[VAL_10]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_11:.*]] = arith.addf %[[VAL_10]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_11]], %[[VAL_8]]{{\[}}%[[VAL_9]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_12:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xf32>
ins(%arga: tensor<32xf32, #DV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %a, %argb : f32
+ %0 = arith.addf %a, %argb : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-LABEL: func @add_d_init(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: f32) -> tensor<32xf32> {
-// CHECK: %[[VAL_2:.*]] = constant 32 : index
-// CHECK: %[[VAL_3:.*]] = constant 0.000000e+00 : f32
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.alloc() : memref<32xf32>
// CHECK: linalg.fill(%[[VAL_3]], %[[VAL_7]]) : f32, memref<32xf32>
// CHECK: scf.for %[[VAL_8:.*]] = %[[VAL_4]] to %[[VAL_2]] step %[[VAL_5]] {
// CHECK: %[[VAL_9:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_8]]] : memref<?xf32>
-// CHECK: %[[VAL_10:.*]] = addf %[[VAL_9]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_10:.*]] = arith.addf %[[VAL_9]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_10]], %[[VAL_7]]{{\[}}%[[VAL_8]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_11:.*]] = memref.tensor_load %[[VAL_7]] : memref<32xf32>
ins(%arga: tensor<32xf32, #DV>)
outs(%u: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %a, %argb : f32
+ %0 = arith.addf %a, %argb : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: f32,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf32>
// CHECK: %[[VAL_8:.*]] = memref.alloc() : memref<32xf32>
// CHECK: memref.copy %[[VAL_7]], %[[VAL_8]] : memref<32xf32> to memref<32xf32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_10:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_9]]] : memref<?xf32>
-// CHECK: %[[VAL_11:.*]] = mulf %[[VAL_10]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_11:.*]] = arith.mulf %[[VAL_10]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_11]], %[[VAL_8]]{{\[}}%[[VAL_9]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_12:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xf32>
ins(%arga: tensor<32xf32, #DV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %a, %argb : f32
+ %0 = arith.mulf %a, %argb : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: f32,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf32>
-// CHECK: %[[VAL_23:.*]] = addf %[[VAL_22]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_23:.*]] = arith.addf %[[VAL_22]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_23]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_24:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_25:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_24:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_25:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_26:.*]] = select %[[VAL_24]], %[[VAL_25]], %[[VAL_18]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_26]], %[[VAL_27]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_28:.*]] = %[[VAL_29:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga: tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %a, %argb : f32
+ %0 = arith.addf %a, %argb : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-LABEL: func @repeated_add_s(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xf32>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xf32>
-// CHECK: %[[VAL_15:.*]] = addf %[[VAL_13]], %[[VAL_14]] : f32
+// CHECK: %[[VAL_15:.*]] = arith.addf %[[VAL_13]], %[[VAL_14]] : f32
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xf32>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xf32>
-// CHECK: %[[VAL_18:.*]] = addf %[[VAL_16]], %[[VAL_17]] : f32
-// CHECK: %[[VAL_19:.*]] = addf %[[VAL_15]], %[[VAL_18]] : f32
+// CHECK: %[[VAL_18:.*]] = arith.addf %[[VAL_16]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_19:.*]] = arith.addf %[[VAL_15]], %[[VAL_18]] : f32
// CHECK: memref.store %[[VAL_19]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_20:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xf32>
ins(%arga: tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %a, %a : f32 // same tensor
- %1 = addf %a, %a : f32 // should yield
- %2 = addf %0, %1 : f32 // one guard
+ %0 = arith.addf %a, %a : f32 // same tensor
+ %1 = arith.addf %a, %a : f32 // should yield
+ %2 = arith.addf %0, %1 : f32 // one guard
linalg.yield %2 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: f32,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_10]] to %[[VAL_11]] step %[[VAL_4]] {
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_12]]] : memref<?xf32>
-// CHECK: %[[VAL_15:.*]] = mulf %[[VAL_14]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_15:.*]] = arith.mulf %[[VAL_14]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_15]], %[[VAL_9]]{{\[}}%[[VAL_13]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_16:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xf32>
ins(%arga: tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %a, %argb : f32
+ %0 = arith.mulf %a, %argb : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf32>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf32>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_10]]] : memref<32xf32>
-// CHECK: %[[VAL_13:.*]] = addf %[[VAL_11]], %[[VAL_12]] : f32
+// CHECK: %[[VAL_13:.*]] = arith.addf %[[VAL_11]], %[[VAL_12]] : f32
// CHECK: memref.store %[[VAL_13]], %[[VAL_9]]{{\[}}%[[VAL_10]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xf32>
ins(%arga, %argb: tensor<32xf32, #DV>, tensor<32xf32>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf32>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf32>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_10]]] : memref<32xf32>
-// CHECK: %[[VAL_13:.*]] = mulf %[[VAL_11]], %[[VAL_12]] : f32
+// CHECK: %[[VAL_13:.*]] = arith.mulf %[[VAL_11]], %[[VAL_12]] : f32
// CHECK: memref.store %[[VAL_13]], %[[VAL_9]]{{\[}}%[[VAL_10]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xf32>
ins(%arga, %argb: tensor<32xf32, #DV>, tensor<32xf32>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_0]] : memref<32xf32>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]]:2 = scf.while (%[[VAL_16:.*]] = %[[VAL_13]], %[[VAL_17:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_18:.*]] = cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
+// CHECK: %[[VAL_18:.*]] = arith.cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
// CHECK: scf.condition(%[[VAL_18]]) %[[VAL_16]], %[[VAL_17]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_19:.*]]: index, %[[VAL_20:.*]]: index):
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
// CHECK: scf.if %[[VAL_22]] {
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_20]]] : memref<32xf32>
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<?xf32>
-// CHECK: %[[VAL_25:.*]] = addf %[[VAL_23]], %[[VAL_24]] : f32
+// CHECK: %[[VAL_25:.*]] = arith.addf %[[VAL_23]], %[[VAL_24]] : f32
// CHECK: memref.store %[[VAL_25]], %[[VAL_12]]{{\[}}%[[VAL_20]]] : memref<32xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_27:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
-// CHECK: %[[VAL_28:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_28:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: %[[VAL_29:.*]] = select %[[VAL_27]], %[[VAL_28]], %[[VAL_19]] : index
-// CHECK: %[[VAL_30:.*]] = addi %[[VAL_20]], %[[VAL_6]] : index
+// CHECK: %[[VAL_30:.*]] = arith.addi %[[VAL_20]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_29]], %[[VAL_30]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_31:.*]] = %[[VAL_32:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xf32>, tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = memref.buffer_cast %[[VAL_0]] : memref<32xf32>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_13]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_14]]] : memref<32xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_13]]] : memref<?xf32>
-// CHECK: %[[VAL_17:.*]] = mulf %[[VAL_15]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.mulf %[[VAL_15]], %[[VAL_16]] : f32
// CHECK: memref.store %[[VAL_17]], %[[VAL_10]]{{\[}}%[[VAL_14]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_18:.*]] = memref.tensor_load %[[VAL_10]] : memref<32xf32>
ins(%arga, %argb: tensor<32xf32>, tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]]:2 = scf.while (%[[VAL_16:.*]] = %[[VAL_13]], %[[VAL_17:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_18:.*]] = cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
+// CHECK: %[[VAL_18:.*]] = arith.cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
// CHECK: scf.condition(%[[VAL_18]]) %[[VAL_16]], %[[VAL_17]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_19:.*]]: index, %[[VAL_20:.*]]: index):
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
// CHECK: scf.if %[[VAL_22]] {
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xf32>
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_20]]] : memref<32xf32>
-// CHECK: %[[VAL_25:.*]] = addf %[[VAL_23]], %[[VAL_24]] : f32
+// CHECK: %[[VAL_25:.*]] = arith.addf %[[VAL_23]], %[[VAL_24]] : f32
// CHECK: memref.store %[[VAL_25]], %[[VAL_12]]{{\[}}%[[VAL_20]]] : memref<32xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_27:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
-// CHECK: %[[VAL_28:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_28:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: %[[VAL_29:.*]] = select %[[VAL_27]], %[[VAL_28]], %[[VAL_19]] : index
-// CHECK: %[[VAL_30:.*]] = addi %[[VAL_20]], %[[VAL_6]] : index
+// CHECK: %[[VAL_30:.*]] = arith.addi %[[VAL_20]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_29]], %[[VAL_30]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_31:.*]] = %[[VAL_32:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xf32, #SV>, tensor<32xf32>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_13]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_13]]] : memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_14]]] : memref<32xf32>
-// CHECK: %[[VAL_17:.*]] = mulf %[[VAL_15]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.mulf %[[VAL_15]], %[[VAL_16]] : f32
// CHECK: memref.store %[[VAL_17]], %[[VAL_10]]{{\[}}%[[VAL_14]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_18:.*]] = memref.tensor_load %[[VAL_10]] : memref<32xf32>
ins(%arga, %argb: tensor<32xf32, #SV>, tensor<32xf32>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*0]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]]:2 = scf.while (%[[VAL_18:.*]] = %[[VAL_13]], %[[VAL_19:.*]] = %[[VAL_15]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_20:.*]] = cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
-// CHECK: %[[VAL_22:.*]] = and %[[VAL_20]], %[[VAL_21]] : i1
+// CHECK: %[[VAL_20:.*]] = arith.cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
+// CHECK: %[[VAL_22:.*]] = arith.andi %[[VAL_20]], %[[VAL_21]] : i1
// CHECK: scf.condition(%[[VAL_22]]) %[[VAL_18]], %[[VAL_19]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_23:.*]]: index, %[[VAL_24:.*]]: index):
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_24]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_27]], %[[VAL_26]], %[[VAL_25]] : index
-// CHECK: %[[VAL_29:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_31:.*]] = and %[[VAL_29]], %[[VAL_30]] : i1
+// CHECK: %[[VAL_29:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_31:.*]] = arith.andi %[[VAL_29]], %[[VAL_30]] : i1
// CHECK: scf.if %[[VAL_31]] {
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_23]]] : memref<?xf32>
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_34:.*]] = addf %[[VAL_32]], %[[VAL_33]] : f32
+// CHECK: %[[VAL_34:.*]] = arith.addf %[[VAL_32]], %[[VAL_33]] : f32
// CHECK: memref.store %[[VAL_34]], %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<32xf32>
// CHECK: } else {
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
// CHECK: scf.if %[[VAL_35]] {
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_23]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_36]], %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<32xf32>
// CHECK: } else {
-// CHECK: %[[VAL_37:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
// CHECK: scf.if %[[VAL_37]] {
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_38]], %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<32xf32>
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_39:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_23]], %[[VAL_4]] : index
+// CHECK: %[[VAL_39:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_23]], %[[VAL_4]] : index
// CHECK: %[[VAL_41:.*]] = select %[[VAL_39]], %[[VAL_40]], %[[VAL_23]] : index
-// CHECK: %[[VAL_42:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_43:.*]] = addi %[[VAL_24]], %[[VAL_4]] : index
+// CHECK: %[[VAL_42:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_43:.*]] = arith.addi %[[VAL_24]], %[[VAL_4]] : index
// CHECK: %[[VAL_44:.*]] = select %[[VAL_42]], %[[VAL_43]], %[[VAL_24]] : index
// CHECK: scf.yield %[[VAL_41]], %[[VAL_44]] : index, index
// CHECK: }
ins(%arga, %argb: tensor<32xf32, #SV>, tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*0]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]]:2 = scf.while (%[[VAL_18:.*]] = %[[VAL_13]], %[[VAL_19:.*]] = %[[VAL_15]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_20:.*]] = cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
-// CHECK: %[[VAL_22:.*]] = and %[[VAL_20]], %[[VAL_21]] : i1
+// CHECK: %[[VAL_20:.*]] = arith.cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
+// CHECK: %[[VAL_22:.*]] = arith.andi %[[VAL_20]], %[[VAL_21]] : i1
// CHECK: scf.condition(%[[VAL_22]]) %[[VAL_18]], %[[VAL_19]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_23:.*]]: index, %[[VAL_24:.*]]: index):
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_24]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_27]], %[[VAL_26]], %[[VAL_25]] : index
-// CHECK: %[[VAL_29:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_31:.*]] = and %[[VAL_29]], %[[VAL_30]] : i1
+// CHECK: %[[VAL_29:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_31:.*]] = arith.andi %[[VAL_29]], %[[VAL_30]] : i1
// CHECK: scf.if %[[VAL_31]] {
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_23]]] : memref<?xf32>
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_34:.*]] = mulf %[[VAL_32]], %[[VAL_33]] : f32
+// CHECK: %[[VAL_34:.*]] = arith.mulf %[[VAL_32]], %[[VAL_33]] : f32
// CHECK: memref.store %[[VAL_34]], %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<32xf32>
// CHECK: } else {
// CHECK: }
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_36:.*]] = addi %[[VAL_23]], %[[VAL_4]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_36:.*]] = arith.addi %[[VAL_23]], %[[VAL_4]] : index
// CHECK: %[[VAL_37:.*]] = select %[[VAL_35]], %[[VAL_36]], %[[VAL_23]] : index
-// CHECK: %[[VAL_38:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_39:.*]] = addi %[[VAL_24]], %[[VAL_4]] : index
+// CHECK: %[[VAL_38:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_39:.*]] = arith.addi %[[VAL_24]], %[[VAL_4]] : index
// CHECK: %[[VAL_40:.*]] = select %[[VAL_38]], %[[VAL_39]], %[[VAL_24]] : index
// CHECK: scf.yield %[[VAL_37]], %[[VAL_40]] : index, index
// CHECK: }
ins(%arga, %argb: tensor<32xf32, #SV>, tensor<32xf32, #SV>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: f32,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<16xf32>) -> tensor<16xf32> {
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]]:2 = scf.while (%[[VAL_19:.*]] = %[[VAL_14]], %[[VAL_20:.*]] = %[[VAL_16]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_15]] : index
-// CHECK: %[[VAL_22:.*]] = cmpi ult, %[[VAL_20]], %[[VAL_17]] : index
-// CHECK: %[[VAL_23:.*]] = and %[[VAL_21]], %[[VAL_22]] : i1
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_15]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi ult, %[[VAL_20]], %[[VAL_17]] : index
+// CHECK: %[[VAL_23:.*]] = arith.andi %[[VAL_21]], %[[VAL_22]] : i1
// CHECK: scf.condition(%[[VAL_23]]) %[[VAL_19]], %[[VAL_20]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_24:.*]]: index, %[[VAL_25:.*]]: index):
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_24]]] : memref<?xindex>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_25]]] : memref<?xindex>
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[VAL_27]], %[[VAL_26]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[VAL_27]], %[[VAL_26]] : index
// CHECK: %[[VAL_29:.*]] = select %[[VAL_28]], %[[VAL_27]], %[[VAL_26]] : index
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
-// CHECK: %[[VAL_31:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
-// CHECK: %[[VAL_32:.*]] = and %[[VAL_30]], %[[VAL_31]] : i1
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_31:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_32:.*]] = arith.andi %[[VAL_30]], %[[VAL_31]] : i1
// CHECK: scf.if %[[VAL_32]] {
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_34:.*]] = mulf %[[VAL_33]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_34:.*]] = arith.mulf %[[VAL_33]], %[[VAL_2]] : f32
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_25]]] : memref<?xf32>
-// CHECK: %[[VAL_36:.*]] = mulf %[[VAL_35]], %[[VAL_2]] : f32
-// CHECK: %[[VAL_37:.*]] = addf %[[VAL_34]], %[[VAL_36]] : f32
+// CHECK: %[[VAL_36:.*]] = arith.mulf %[[VAL_35]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_37:.*]] = arith.addf %[[VAL_34]], %[[VAL_36]] : f32
// CHECK: memref.store %[[VAL_37]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_38:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_38:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
// CHECK: scf.if %[[VAL_38]] {
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_40:.*]] = mulf %[[VAL_39]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_40:.*]] = arith.mulf %[[VAL_39]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_40]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_41:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_41:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
// CHECK: scf.if %[[VAL_41]] {
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_25]]] : memref<?xf32>
-// CHECK: %[[VAL_43:.*]] = mulf %[[VAL_42]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_43:.*]] = arith.mulf %[[VAL_42]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_43]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_44:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
-// CHECK: %[[VAL_45:.*]] = addi %[[VAL_24]], %[[VAL_5]] : index
+// CHECK: %[[VAL_44:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_45:.*]] = arith.addi %[[VAL_24]], %[[VAL_5]] : index
// CHECK: %[[VAL_46:.*]] = select %[[VAL_44]], %[[VAL_45]], %[[VAL_24]] : index
-// CHECK: %[[VAL_47:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
-// CHECK: %[[VAL_48:.*]] = addi %[[VAL_25]], %[[VAL_5]] : index
+// CHECK: %[[VAL_47:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_48:.*]] = arith.addi %[[VAL_25]], %[[VAL_5]] : index
// CHECK: %[[VAL_49:.*]] = select %[[VAL_47]], %[[VAL_48]], %[[VAL_25]] : index
// CHECK: scf.yield %[[VAL_46]], %[[VAL_49]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_50:.*]] = %[[VAL_51:.*]]#0 to %[[VAL_15]] step %[[VAL_5]] {
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_50]]] : memref<?xindex>
// CHECK: %[[VAL_53:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_50]]] : memref<?xf32>
-// CHECK: %[[VAL_54:.*]] = mulf %[[VAL_53]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_54:.*]] = arith.mulf %[[VAL_53]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_54]], %[[VAL_13]]{{\[}}%[[VAL_52]]] : memref<16xf32>
// CHECK: }
// CHECK: scf.for %[[VAL_55:.*]] = %[[VAL_56:.*]]#1 to %[[VAL_17]] step %[[VAL_5]] {
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_55]]] : memref<?xindex>
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_55]]] : memref<?xf32>
-// CHECK: %[[VAL_59:.*]] = mulf %[[VAL_58]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_59:.*]] = arith.mulf %[[VAL_58]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_59]], %[[VAL_13]]{{\[}}%[[VAL_57]]] : memref<16xf32>
// CHECK: }
// CHECK: %[[VAL_60:.*]] = memref.tensor_load %[[VAL_13]] : memref<16xf32>
ins(%arga, %argb: tensor<16xf32, #SV>, tensor<16xf32, #SV>)
outs(%argx: tensor<16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %argc : f32
- %1 = mulf %b, %argc : f32
- %2 = addf %0, %1 : f32
+ %0 = arith.mulf %a, %argc : f32
+ %1 = arith.mulf %b, %argc : f32
+ %2 = arith.addf %0, %1 : f32
linalg.yield %2 : f32
} -> tensor<16xf32>
return %0 : tensor<16xf32>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: f32,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<16xf32>) -> tensor<16xf32> {
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]]:2 = scf.while (%[[VAL_19:.*]] = %[[VAL_14]], %[[VAL_20:.*]] = %[[VAL_16]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_15]] : index
-// CHECK: %[[VAL_22:.*]] = cmpi ult, %[[VAL_20]], %[[VAL_17]] : index
-// CHECK: %[[VAL_23:.*]] = and %[[VAL_21]], %[[VAL_22]] : i1
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_15]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi ult, %[[VAL_20]], %[[VAL_17]] : index
+// CHECK: %[[VAL_23:.*]] = arith.andi %[[VAL_21]], %[[VAL_22]] : i1
// CHECK: scf.condition(%[[VAL_23]]) %[[VAL_19]], %[[VAL_20]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_24:.*]]: index, %[[VAL_25:.*]]: index):
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_24]]] : memref<?xindex>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_25]]] : memref<?xindex>
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[VAL_27]], %[[VAL_26]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[VAL_27]], %[[VAL_26]] : index
// CHECK: %[[VAL_29:.*]] = select %[[VAL_28]], %[[VAL_27]], %[[VAL_26]] : index
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
-// CHECK: %[[VAL_31:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
-// CHECK: %[[VAL_32:.*]] = and %[[VAL_30]], %[[VAL_31]] : i1
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_31:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_32:.*]] = arith.andi %[[VAL_30]], %[[VAL_31]] : i1
// CHECK: scf.if %[[VAL_32]] {
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xf32>
// CHECK: %[[VAL_34:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_25]]] : memref<?xf32>
-// CHECK: %[[VAL_35:.*]] = addf %[[VAL_33]], %[[VAL_34]] : f32
-// CHECK: %[[VAL_36:.*]] = mulf %[[VAL_35]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_35:.*]] = arith.addf %[[VAL_33]], %[[VAL_34]] : f32
+// CHECK: %[[VAL_36:.*]] = arith.mulf %[[VAL_35]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_36]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_37:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
// CHECK: scf.if %[[VAL_37]] {
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_39:.*]] = mulf %[[VAL_38]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_39:.*]] = arith.mulf %[[VAL_38]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_39]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_40:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_40:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
// CHECK: scf.if %[[VAL_40]] {
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_25]]] : memref<?xf32>
-// CHECK: %[[VAL_42:.*]] = mulf %[[VAL_41]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_42:.*]] = arith.mulf %[[VAL_41]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_42]], %[[VAL_13]]{{\[}}%[[VAL_29]]] : memref<16xf32>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_43:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
-// CHECK: %[[VAL_44:.*]] = addi %[[VAL_24]], %[[VAL_5]] : index
+// CHECK: %[[VAL_43:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_29]] : index
+// CHECK: %[[VAL_44:.*]] = arith.addi %[[VAL_24]], %[[VAL_5]] : index
// CHECK: %[[VAL_45:.*]] = select %[[VAL_43]], %[[VAL_44]], %[[VAL_24]] : index
-// CHECK: %[[VAL_46:.*]] = cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
-// CHECK: %[[VAL_47:.*]] = addi %[[VAL_25]], %[[VAL_5]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi eq, %[[VAL_27]], %[[VAL_29]] : index
+// CHECK: %[[VAL_47:.*]] = arith.addi %[[VAL_25]], %[[VAL_5]] : index
// CHECK: %[[VAL_48:.*]] = select %[[VAL_46]], %[[VAL_47]], %[[VAL_25]] : index
// CHECK: scf.yield %[[VAL_45]], %[[VAL_48]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_49:.*]] = %[[VAL_50:.*]]#0 to %[[VAL_15]] step %[[VAL_5]] {
// CHECK: %[[VAL_51:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_49]]] : memref<?xindex>
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_49]]] : memref<?xf32>
-// CHECK: %[[VAL_53:.*]] = mulf %[[VAL_52]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_53:.*]] = arith.mulf %[[VAL_52]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_53]], %[[VAL_13]]{{\[}}%[[VAL_51]]] : memref<16xf32>
// CHECK: }
// CHECK: scf.for %[[VAL_54:.*]] = %[[VAL_55:.*]]#1 to %[[VAL_17]] step %[[VAL_5]] {
// CHECK: %[[VAL_56:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_54]]] : memref<?xindex>
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_54]]] : memref<?xf32>
-// CHECK: %[[VAL_58:.*]] = mulf %[[VAL_57]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_58:.*]] = arith.mulf %[[VAL_57]], %[[VAL_2]] : f32
// CHECK: memref.store %[[VAL_58]], %[[VAL_13]]{{\[}}%[[VAL_56]]] : memref<16xf32>
// CHECK: }
// CHECK: %[[VAL_59:.*]] = memref.tensor_load %[[VAL_13]] : memref<16xf32>
ins(%arga, %argb: tensor<16xf32, #SV>, tensor<16xf32, #SV>)
outs(%argx: tensor<16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
- %1 = mulf %0, %argc : f32
+ %0 = arith.addf %a, %b : f32
+ %1 = arith.mulf %0, %argc : f32
linalg.yield %1 : f32
} -> tensor<16xf32>
return %0 : tensor<16xf32>
// CHECK-LABEL: func @sum_reduction(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_6:.*]] = memref.buffer_cast %[[VAL_1]] : memref<f32>
// CHECK: %[[VAL_10:.*]] = memref.load %[[VAL_7]][] : memref<f32>
// CHECK: %[[VAL_11:.*]] = scf.for %[[VAL_12:.*]] = %[[VAL_8]] to %[[VAL_9]] step %[[VAL_3]] iter_args(%[[VAL_13:.*]] = %[[VAL_10]]) -> (f32) {
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_12]]] : memref<?xf32>
-// CHECK: %[[VAL_15:.*]] = addf %[[VAL_13]], %[[VAL_14]] : f32
+// CHECK: %[[VAL_15:.*]] = arith.addf %[[VAL_13]], %[[VAL_14]] : f32
// CHECK: scf.yield %[[VAL_15]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_16:.*]], %[[VAL_7]][] : memref<f32>
ins(%arga: tensor<?xf32, #SV>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %x, %a : f32
+ %0 = arith.addf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_0:.*0]]: tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<f32>) -> tensor<f32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]]:2 = scf.while (%[[VAL_18:.*]] = %[[VAL_13]], %[[VAL_19:.*]] = %[[VAL_15]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_20:.*]] = cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
-// CHECK: %[[VAL_22:.*]] = and %[[VAL_20]], %[[VAL_21]] : i1
+// CHECK: %[[VAL_20:.*]] = arith.cmpi ult, %[[VAL_18]], %[[VAL_14]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_16]] : index
+// CHECK: %[[VAL_22:.*]] = arith.andi %[[VAL_20]], %[[VAL_21]] : i1
// CHECK: scf.condition(%[[VAL_22]]) %[[VAL_18]], %[[VAL_19]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_23:.*]]: index, %[[VAL_24:.*]]: index):
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_24]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi ult, %[[VAL_26]], %[[VAL_25]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_27]], %[[VAL_26]], %[[VAL_25]] : index
-// CHECK: %[[VAL_29:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_31:.*]] = and %[[VAL_29]], %[[VAL_30]] : i1
+// CHECK: %[[VAL_29:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_31:.*]] = arith.andi %[[VAL_29]], %[[VAL_30]] : i1
// CHECK: scf.if %[[VAL_31]] {
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_12]][] : memref<f32>
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_23]]] : memref<?xf32>
// CHECK: %[[VAL_34:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_35:.*]] = addf %[[VAL_33]], %[[VAL_34]] : f32
-// CHECK: %[[VAL_36:.*]] = addf %[[VAL_32]], %[[VAL_35]] : f32
+// CHECK: %[[VAL_35:.*]] = arith.addf %[[VAL_33]], %[[VAL_34]] : f32
+// CHECK: %[[VAL_36:.*]] = arith.addf %[[VAL_32]], %[[VAL_35]] : f32
// CHECK: memref.store %[[VAL_36]], %[[VAL_12]][] : memref<f32>
// CHECK: } else {
-// CHECK: %[[VAL_37:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
// CHECK: scf.if %[[VAL_37]] {
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_12]][] : memref<f32>
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_23]]] : memref<?xf32>
-// CHECK: %[[VAL_40:.*]] = addf %[[VAL_38]], %[[VAL_39]] : f32
+// CHECK: %[[VAL_40:.*]] = arith.addf %[[VAL_38]], %[[VAL_39]] : f32
// CHECK: memref.store %[[VAL_40]], %[[VAL_12]][] : memref<f32>
// CHECK: } else {
-// CHECK: %[[VAL_41:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_41:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
// CHECK: scf.if %[[VAL_41]] {
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_12]][] : memref<f32>
// CHECK: %[[VAL_43:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_44:.*]] = addf %[[VAL_42]], %[[VAL_43]] : f32
+// CHECK: %[[VAL_44:.*]] = arith.addf %[[VAL_42]], %[[VAL_43]] : f32
// CHECK: memref.store %[[VAL_44]], %[[VAL_12]][] : memref<f32>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_45:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
-// CHECK: %[[VAL_46:.*]] = addi %[[VAL_23]], %[[VAL_4]] : index
+// CHECK: %[[VAL_45:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_28]] : index
+// CHECK: %[[VAL_46:.*]] = arith.addi %[[VAL_23]], %[[VAL_4]] : index
// CHECK: %[[VAL_47:.*]] = select %[[VAL_45]], %[[VAL_46]], %[[VAL_23]] : index
-// CHECK: %[[VAL_48:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
-// CHECK: %[[VAL_49:.*]] = addi %[[VAL_24]], %[[VAL_4]] : index
+// CHECK: %[[VAL_48:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_28]] : index
+// CHECK: %[[VAL_49:.*]] = arith.addi %[[VAL_24]], %[[VAL_4]] : index
// CHECK: %[[VAL_50:.*]] = select %[[VAL_48]], %[[VAL_49]], %[[VAL_24]] : index
// CHECK: scf.yield %[[VAL_47]], %[[VAL_50]] : index, index
// CHECK: }
// CHECK: %[[VAL_51:.*]] = memref.load %[[VAL_12]][] : memref<f32>
// CHECK: %[[VAL_52:.*]] = scf.for %[[VAL_53:.*]] = %[[VAL_54:.*]]#0 to %[[VAL_14]] step %[[VAL_4]] iter_args(%[[VAL_55:.*]] = %[[VAL_51]]) -> (f32) {
// CHECK: %[[VAL_56:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_53]]] : memref<?xf32>
-// CHECK: %[[VAL_57:.*]] = addf %[[VAL_55]], %[[VAL_56]] : f32
+// CHECK: %[[VAL_57:.*]] = arith.addf %[[VAL_55]], %[[VAL_56]] : f32
// CHECK: scf.yield %[[VAL_57]] : f32
// CHECK: }
// CHECK: %[[VAL_58:.*]] = scf.for %[[VAL_59:.*]] = %[[VAL_60:.*]]#1 to %[[VAL_16]] step %[[VAL_4]] iter_args(%[[VAL_61:.*]] = %[[VAL_62:.*]]) -> (f32) {
// CHECK: %[[VAL_63:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_59]]] : memref<?xf32>
-// CHECK: %[[VAL_64:.*]] = addf %[[VAL_61]], %[[VAL_63]] : f32
+// CHECK: %[[VAL_64:.*]] = arith.addf %[[VAL_61]], %[[VAL_63]] : f32
// CHECK: scf.yield %[[VAL_64]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_65:.*]], %[[VAL_12]][] : memref<f32>
ins(%arga, %argb: tensor<16xf32, #SV>, tensor<16xf32, #SV>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
- %1 = addf %x, %0 : f32
+ %0 = arith.addf %a, %b : f32
+ %1 = arith.addf %x, %0 : f32
linalg.yield %1 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<f32>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<f32>) -> tensor<f32> {
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]]:2 = scf.while (%[[VAL_21:.*]] = %[[VAL_16]], %[[VAL_22:.*]] = %[[VAL_18]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_23:.*]] = cmpi ult, %[[VAL_21]], %[[VAL_17]] : index
-// CHECK: %[[VAL_24:.*]] = cmpi ult, %[[VAL_22]], %[[VAL_19]] : index
-// CHECK: %[[VAL_25:.*]] = and %[[VAL_23]], %[[VAL_24]] : i1
+// CHECK: %[[VAL_23:.*]] = arith.cmpi ult, %[[VAL_21]], %[[VAL_17]] : index
+// CHECK: %[[VAL_24:.*]] = arith.cmpi ult, %[[VAL_22]], %[[VAL_19]] : index
+// CHECK: %[[VAL_25:.*]] = arith.andi %[[VAL_23]], %[[VAL_24]] : i1
// CHECK: scf.condition(%[[VAL_25]]) %[[VAL_21]], %[[VAL_22]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_26:.*]]: index, %[[VAL_27:.*]]: index):
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_26]]] : memref<?xindex>
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_30:.*]] = cmpi ult, %[[VAL_29]], %[[VAL_28]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi ult, %[[VAL_29]], %[[VAL_28]] : index
// CHECK: %[[VAL_31:.*]] = select %[[VAL_30]], %[[VAL_29]], %[[VAL_28]] : index
-// CHECK: %[[VAL_32:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
-// CHECK: %[[VAL_33:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
-// CHECK: %[[VAL_34:.*]] = and %[[VAL_32]], %[[VAL_33]] : i1
+// CHECK: %[[VAL_32:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
+// CHECK: %[[VAL_33:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
+// CHECK: %[[VAL_34:.*]] = arith.andi %[[VAL_32]], %[[VAL_33]] : i1
// CHECK: scf.if %[[VAL_34]] {
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_14]][] : memref<f32>
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_26]]] : memref<?xf32>
-// CHECK: %[[VAL_37:.*]] = mulf %[[VAL_36]], %[[VAL_15]] : f32
+// CHECK: %[[VAL_37:.*]] = arith.mulf %[[VAL_36]], %[[VAL_15]] : f32
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_27]]] : memref<?xf32>
-// CHECK: %[[VAL_39:.*]] = addf %[[VAL_37]], %[[VAL_38]] : f32
-// CHECK: %[[VAL_40:.*]] = addf %[[VAL_35]], %[[VAL_39]] : f32
+// CHECK: %[[VAL_39:.*]] = arith.addf %[[VAL_37]], %[[VAL_38]] : f32
+// CHECK: %[[VAL_40:.*]] = arith.addf %[[VAL_35]], %[[VAL_39]] : f32
// CHECK: memref.store %[[VAL_40]], %[[VAL_14]][] : memref<f32>
// CHECK: } else {
-// CHECK: %[[VAL_41:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
+// CHECK: %[[VAL_41:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
// CHECK: scf.if %[[VAL_41]] {
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_14]][] : memref<f32>
// CHECK: %[[VAL_43:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_26]]] : memref<?xf32>
-// CHECK: %[[VAL_44:.*]] = mulf %[[VAL_43]], %[[VAL_15]] : f32
-// CHECK: %[[VAL_45:.*]] = addf %[[VAL_42]], %[[VAL_44]] : f32
+// CHECK: %[[VAL_44:.*]] = arith.mulf %[[VAL_43]], %[[VAL_15]] : f32
+// CHECK: %[[VAL_45:.*]] = arith.addf %[[VAL_42]], %[[VAL_44]] : f32
// CHECK: memref.store %[[VAL_45]], %[[VAL_14]][] : memref<f32>
// CHECK: } else {
-// CHECK: %[[VAL_46:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
// CHECK: scf.if %[[VAL_46]] {
// CHECK: %[[VAL_47:.*]] = memref.load %[[VAL_14]][] : memref<f32>
// CHECK: %[[VAL_48:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_27]]] : memref<?xf32>
-// CHECK: %[[VAL_49:.*]] = addf %[[VAL_47]], %[[VAL_48]] : f32
+// CHECK: %[[VAL_49:.*]] = arith.addf %[[VAL_47]], %[[VAL_48]] : f32
// CHECK: memref.store %[[VAL_49]], %[[VAL_14]][] : memref<f32>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_50:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
-// CHECK: %[[VAL_51:.*]] = addi %[[VAL_26]], %[[VAL_5]] : index
+// CHECK: %[[VAL_50:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_31]] : index
+// CHECK: %[[VAL_51:.*]] = arith.addi %[[VAL_26]], %[[VAL_5]] : index
// CHECK: %[[VAL_52:.*]] = select %[[VAL_50]], %[[VAL_51]], %[[VAL_26]] : index
-// CHECK: %[[VAL_53:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
-// CHECK: %[[VAL_54:.*]] = addi %[[VAL_27]], %[[VAL_5]] : index
+// CHECK: %[[VAL_53:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_31]] : index
+// CHECK: %[[VAL_54:.*]] = arith.addi %[[VAL_27]], %[[VAL_5]] : index
// CHECK: %[[VAL_55:.*]] = select %[[VAL_53]], %[[VAL_54]], %[[VAL_27]] : index
// CHECK: scf.yield %[[VAL_52]], %[[VAL_55]] : index, index
// CHECK: }
// CHECK: %[[VAL_56:.*]] = memref.load %[[VAL_14]][] : memref<f32>
// CHECK: %[[VAL_57:.*]] = scf.for %[[VAL_58:.*]] = %[[VAL_59:.*]]#0 to %[[VAL_17]] step %[[VAL_5]] iter_args(%[[VAL_60:.*]] = %[[VAL_56]]) -> (f32) {
// CHECK: %[[VAL_61:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_58]]] : memref<?xf32>
-// CHECK: %[[VAL_62:.*]] = mulf %[[VAL_61]], %[[VAL_15]] : f32
-// CHECK: %[[VAL_63:.*]] = addf %[[VAL_60]], %[[VAL_62]] : f32
+// CHECK: %[[VAL_62:.*]] = arith.mulf %[[VAL_61]], %[[VAL_15]] : f32
+// CHECK: %[[VAL_63:.*]] = arith.addf %[[VAL_60]], %[[VAL_62]] : f32
// CHECK: scf.yield %[[VAL_63]] : f32
// CHECK: }
// CHECK: %[[VAL_64:.*]] = scf.for %[[VAL_65:.*]] = %[[VAL_66:.*]]#1 to %[[VAL_19]] step %[[VAL_5]] iter_args(%[[VAL_67:.*]] = %[[VAL_68:.*]]) -> (f32) {
// CHECK: %[[VAL_69:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_65]]] : memref<?xf32>
-// CHECK: %[[VAL_70:.*]] = addf %[[VAL_67]], %[[VAL_69]] : f32
+// CHECK: %[[VAL_70:.*]] = arith.addf %[[VAL_67]], %[[VAL_69]] : f32
// CHECK: scf.yield %[[VAL_70]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_71:.*]], %[[VAL_14]][] : memref<f32>
ins(%arga, %argb, %argc : tensor<16xf32, #SV>, tensor<f32>, tensor<16xf32, #SV>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %b: f32, %c: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = addf %0, %c : f32
- %2 = addf %x, %1 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.addf %0, %c : f32
+ %2 = arith.addf %x, %1 : f32
linalg.yield %2 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<?xf64>,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_4:.*]]: tensor<?xf64>) -> tensor<?xf64> {
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_0]] : memref<?xf64>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_5]] : tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_5]] : tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_23:.*]]:3 = scf.while (%[[VAL_24:.*]] = %[[VAL_19]], %[[VAL_25:.*]] = %[[VAL_21]], %[[VAL_26:.*]] = %[[VAL_5]]) : (index, index, index) -> (index, index, index) {
-// CHECK: %[[VAL_27:.*]] = cmpi ult, %[[VAL_24]], %[[VAL_20]] : index
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[VAL_25]], %[[VAL_22]] : index
-// CHECK: %[[VAL_29:.*]] = and %[[VAL_27]], %[[VAL_28]] : i1
+// CHECK: %[[VAL_27:.*]] = arith.cmpi ult, %[[VAL_24]], %[[VAL_20]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[VAL_25]], %[[VAL_22]] : index
+// CHECK: %[[VAL_29:.*]] = arith.andi %[[VAL_27]], %[[VAL_28]] : i1
// CHECK: scf.condition(%[[VAL_29]]) %[[VAL_24]], %[[VAL_25]], %[[VAL_26]] : index, index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_30:.*]]: index, %[[VAL_31:.*]]: index, %[[VAL_32:.*]]: index):
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_30]]] : memref<?xindex>
// CHECK: %[[VAL_34:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_31]]] : memref<?xindex>
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
-// CHECK: %[[VAL_36:.*]] = cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
-// CHECK: %[[VAL_37:.*]] = and %[[VAL_35]], %[[VAL_36]] : i1
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
+// CHECK: %[[VAL_37:.*]] = arith.andi %[[VAL_35]], %[[VAL_36]] : i1
// CHECK: scf.if %[[VAL_37]] {
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_30]]] : memref<?xf64>
-// CHECK: %[[VAL_40:.*]] = addf %[[VAL_38]], %[[VAL_39]] : f64
+// CHECK: %[[VAL_40:.*]] = arith.addf %[[VAL_38]], %[[VAL_39]] : f64
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_31]]] : memref<?xf64>
-// CHECK: %[[VAL_43:.*]] = addf %[[VAL_41]], %[[VAL_42]] : f64
-// CHECK: %[[VAL_44:.*]] = addf %[[VAL_40]], %[[VAL_43]] : f64
+// CHECK: %[[VAL_43:.*]] = arith.addf %[[VAL_41]], %[[VAL_42]] : f64
+// CHECK: %[[VAL_44:.*]] = arith.addf %[[VAL_40]], %[[VAL_43]] : f64
// CHECK: memref.store %[[VAL_44]], %[[VAL_18]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: } else {
-// CHECK: %[[VAL_45:.*]] = cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
+// CHECK: %[[VAL_45:.*]] = arith.cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
// CHECK: scf.if %[[VAL_45]] {
// CHECK: %[[VAL_46:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_47:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_30]]] : memref<?xf64>
-// CHECK: %[[VAL_48:.*]] = addf %[[VAL_46]], %[[VAL_47]] : f64
+// CHECK: %[[VAL_48:.*]] = arith.addf %[[VAL_46]], %[[VAL_47]] : f64
// CHECK: %[[VAL_49:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_50:.*]] = addf %[[VAL_48]], %[[VAL_49]] : f64
+// CHECK: %[[VAL_50:.*]] = arith.addf %[[VAL_48]], %[[VAL_49]] : f64
// CHECK: memref.store %[[VAL_50]], %[[VAL_18]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: } else {
-// CHECK: %[[VAL_51:.*]] = cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
+// CHECK: %[[VAL_51:.*]] = arith.cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
// CHECK: scf.if %[[VAL_51]] {
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_53:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_54:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_31]]] : memref<?xf64>
-// CHECK: %[[VAL_55:.*]] = addf %[[VAL_53]], %[[VAL_54]] : f64
-// CHECK: %[[VAL_56:.*]] = addf %[[VAL_52]], %[[VAL_55]] : f64
+// CHECK: %[[VAL_55:.*]] = arith.addf %[[VAL_53]], %[[VAL_54]] : f64
+// CHECK: %[[VAL_56:.*]] = arith.addf %[[VAL_52]], %[[VAL_55]] : f64
// CHECK: memref.store %[[VAL_56]], %[[VAL_18]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_59:.*]] = addf %[[VAL_57]], %[[VAL_58]] : f64
+// CHECK: %[[VAL_59:.*]] = arith.addf %[[VAL_57]], %[[VAL_58]] : f64
// CHECK: memref.store %[[VAL_59]], %[[VAL_18]]{{\[}}%[[VAL_32]]] : memref<?xf64>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_60:.*]] = cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
-// CHECK: %[[VAL_61:.*]] = addi %[[VAL_30]], %[[VAL_7]] : index
+// CHECK: %[[VAL_60:.*]] = arith.cmpi eq, %[[VAL_33]], %[[VAL_32]] : index
+// CHECK: %[[VAL_61:.*]] = arith.addi %[[VAL_30]], %[[VAL_7]] : index
// CHECK: %[[VAL_62:.*]] = select %[[VAL_60]], %[[VAL_61]], %[[VAL_30]] : index
-// CHECK: %[[VAL_63:.*]] = cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
-// CHECK: %[[VAL_64:.*]] = addi %[[VAL_31]], %[[VAL_7]] : index
+// CHECK: %[[VAL_63:.*]] = arith.cmpi eq, %[[VAL_34]], %[[VAL_32]] : index
+// CHECK: %[[VAL_64:.*]] = arith.addi %[[VAL_31]], %[[VAL_7]] : index
// CHECK: %[[VAL_65:.*]] = select %[[VAL_63]], %[[VAL_64]], %[[VAL_31]] : index
-// CHECK: %[[VAL_66:.*]] = addi %[[VAL_32]], %[[VAL_7]] : index
+// CHECK: %[[VAL_66:.*]] = arith.addi %[[VAL_32]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_62]], %[[VAL_65]], %[[VAL_66]] : index, index, index
// CHECK: }
// CHECK: %[[VAL_67:.*]]:2 = scf.while (%[[VAL_68:.*]] = %[[VAL_69:.*]]#0, %[[VAL_70:.*]] = %[[VAL_69]]#2) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_71:.*]] = cmpi ult, %[[VAL_68]], %[[VAL_20]] : index
+// CHECK: %[[VAL_71:.*]] = arith.cmpi ult, %[[VAL_68]], %[[VAL_20]] : index
// CHECK: scf.condition(%[[VAL_71]]) %[[VAL_68]], %[[VAL_70]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_72:.*]]: index, %[[VAL_73:.*]]: index):
// CHECK: %[[VAL_74:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_72]]] : memref<?xindex>
-// CHECK: %[[VAL_75:.*]] = cmpi eq, %[[VAL_74]], %[[VAL_73]] : index
+// CHECK: %[[VAL_75:.*]] = arith.cmpi eq, %[[VAL_74]], %[[VAL_73]] : index
// CHECK: scf.if %[[VAL_75]] {
// CHECK: %[[VAL_76:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_73]]] : memref<?xf64>
// CHECK: %[[VAL_77:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_72]]] : memref<?xf64>
-// CHECK: %[[VAL_78:.*]] = addf %[[VAL_76]], %[[VAL_77]] : f64
+// CHECK: %[[VAL_78:.*]] = arith.addf %[[VAL_76]], %[[VAL_77]] : f64
// CHECK: %[[VAL_79:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_73]]] : memref<?xf64>
-// CHECK: %[[VAL_80:.*]] = addf %[[VAL_78]], %[[VAL_79]] : f64
+// CHECK: %[[VAL_80:.*]] = arith.addf %[[VAL_78]], %[[VAL_79]] : f64
// CHECK: memref.store %[[VAL_80]], %[[VAL_18]]{{\[}}%[[VAL_73]]] : memref<?xf64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: %[[VAL_81:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_73]]] : memref<?xf64>
// CHECK: %[[VAL_82:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_73]]] : memref<?xf64>
-// CHECK: %[[VAL_83:.*]] = addf %[[VAL_81]], %[[VAL_82]] : f64
+// CHECK: %[[VAL_83:.*]] = arith.addf %[[VAL_81]], %[[VAL_82]] : f64
// CHECK: memref.store %[[VAL_83]], %[[VAL_18]]{{\[}}%[[VAL_73]]] : memref<?xf64>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_84:.*]] = cmpi eq, %[[VAL_74]], %[[VAL_73]] : index
-// CHECK: %[[VAL_85:.*]] = addi %[[VAL_72]], %[[VAL_7]] : index
+// CHECK: %[[VAL_84:.*]] = arith.cmpi eq, %[[VAL_74]], %[[VAL_73]] : index
+// CHECK: %[[VAL_85:.*]] = arith.addi %[[VAL_72]], %[[VAL_7]] : index
// CHECK: %[[VAL_86:.*]] = select %[[VAL_84]], %[[VAL_85]], %[[VAL_72]] : index
-// CHECK: %[[VAL_87:.*]] = addi %[[VAL_73]], %[[VAL_7]] : index
+// CHECK: %[[VAL_87:.*]] = arith.addi %[[VAL_73]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_86]], %[[VAL_87]] : index, index
// CHECK: }
// CHECK: %[[VAL_88:.*]]:2 = scf.while (%[[VAL_89:.*]] = %[[VAL_90:.*]]#1, %[[VAL_91:.*]] = %[[VAL_92:.*]]#1) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_93:.*]] = cmpi ult, %[[VAL_89]], %[[VAL_22]] : index
+// CHECK: %[[VAL_93:.*]] = arith.cmpi ult, %[[VAL_89]], %[[VAL_22]] : index
// CHECK: scf.condition(%[[VAL_93]]) %[[VAL_89]], %[[VAL_91]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_94:.*]]: index, %[[VAL_95:.*]]: index):
// CHECK: %[[VAL_96:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_94]]] : memref<?xindex>
-// CHECK: %[[VAL_97:.*]] = cmpi eq, %[[VAL_96]], %[[VAL_95]] : index
+// CHECK: %[[VAL_97:.*]] = arith.cmpi eq, %[[VAL_96]], %[[VAL_95]] : index
// CHECK: scf.if %[[VAL_97]] {
// CHECK: %[[VAL_98:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_95]]] : memref<?xf64>
// CHECK: %[[VAL_99:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_95]]] : memref<?xf64>
// CHECK: %[[VAL_100:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_94]]] : memref<?xf64>
-// CHECK: %[[VAL_101:.*]] = addf %[[VAL_99]], %[[VAL_100]] : f64
-// CHECK: %[[VAL_102:.*]] = addf %[[VAL_98]], %[[VAL_101]] : f64
+// CHECK: %[[VAL_101:.*]] = arith.addf %[[VAL_99]], %[[VAL_100]] : f64
+// CHECK: %[[VAL_102:.*]] = arith.addf %[[VAL_98]], %[[VAL_101]] : f64
// CHECK: memref.store %[[VAL_102]], %[[VAL_18]]{{\[}}%[[VAL_95]]] : memref<?xf64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: %[[VAL_103:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_95]]] : memref<?xf64>
// CHECK: %[[VAL_104:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_95]]] : memref<?xf64>
-// CHECK: %[[VAL_105:.*]] = addf %[[VAL_103]], %[[VAL_104]] : f64
+// CHECK: %[[VAL_105:.*]] = arith.addf %[[VAL_103]], %[[VAL_104]] : f64
// CHECK: memref.store %[[VAL_105]], %[[VAL_18]]{{\[}}%[[VAL_95]]] : memref<?xf64>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_106:.*]] = cmpi eq, %[[VAL_96]], %[[VAL_95]] : index
-// CHECK: %[[VAL_107:.*]] = addi %[[VAL_94]], %[[VAL_7]] : index
+// CHECK: %[[VAL_106:.*]] = arith.cmpi eq, %[[VAL_96]], %[[VAL_95]] : index
+// CHECK: %[[VAL_107:.*]] = arith.addi %[[VAL_94]], %[[VAL_7]] : index
// CHECK: %[[VAL_108:.*]] = select %[[VAL_106]], %[[VAL_107]], %[[VAL_94]] : index
-// CHECK: %[[VAL_109:.*]] = addi %[[VAL_95]], %[[VAL_7]] : index
+// CHECK: %[[VAL_109:.*]] = arith.addi %[[VAL_95]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_108]], %[[VAL_109]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_110:.*]] = %[[VAL_111:.*]]#1 to %[[VAL_16]] step %[[VAL_7]] {
// CHECK: %[[VAL_112:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_110]]] : memref<?xf64>
// CHECK: %[[VAL_113:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_110]]] : memref<?xf64>
-// CHECK: %[[VAL_114:.*]] = addf %[[VAL_112]], %[[VAL_113]] : f64
+// CHECK: %[[VAL_114:.*]] = arith.addf %[[VAL_112]], %[[VAL_113]] : f64
// CHECK: memref.store %[[VAL_114]], %[[VAL_18]]{{\[}}%[[VAL_110]]] : memref<?xf64>
// CHECK: }
// CHECK: %[[VAL_115:.*]] = memref.tensor_load %[[VAL_18]] : memref<?xf64>
ins(%arga, %argb, %argc, %argd: tensor<?xf64>, tensor<?xf64, #SV>, tensor<?xf64>, tensor<?xf64, #SV>)
outs(%argx: tensor<?xf64>) {
^bb(%a: f64, %b: f64, %c: f64, %d: f64, %x: f64):
- %0 = addf %a, %b : f64
- %1 = addf %c, %d : f64
- %2 = addf %0, %1 : f64
+ %0 = arith.addf %a, %b : f64
+ %1 = arith.addf %c, %d : f64
+ %2 = arith.addf %0, %1 : f64
linalg.yield %2 : f64
} -> tensor<?xf64>
return %r : tensor<?xf64>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<f64>) -> tensor<f64> {
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf64>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_23:.*]]:3 = scf.while (%[[VAL_24:.*]] = %[[VAL_17]], %[[VAL_25:.*]] = %[[VAL_19]], %[[VAL_26:.*]] = %[[VAL_21]]) : (index, index, index) -> (index, index, index) {
-// CHECK: %[[VAL_27:.*]] = cmpi ult, %[[VAL_24]], %[[VAL_18]] : index
-// CHECK: %[[VAL_28:.*]] = cmpi ult, %[[VAL_25]], %[[VAL_20]] : index
-// CHECK: %[[VAL_29:.*]] = and %[[VAL_27]], %[[VAL_28]] : i1
-// CHECK: %[[VAL_30:.*]] = cmpi ult, %[[VAL_26]], %[[VAL_22]] : index
-// CHECK: %[[VAL_31:.*]] = and %[[VAL_29]], %[[VAL_30]] : i1
+// CHECK: %[[VAL_27:.*]] = arith.cmpi ult, %[[VAL_24]], %[[VAL_18]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi ult, %[[VAL_25]], %[[VAL_20]] : index
+// CHECK: %[[VAL_29:.*]] = arith.andi %[[VAL_27]], %[[VAL_28]] : i1
+// CHECK: %[[VAL_30:.*]] = arith.cmpi ult, %[[VAL_26]], %[[VAL_22]] : index
+// CHECK: %[[VAL_31:.*]] = arith.andi %[[VAL_29]], %[[VAL_30]] : i1
// CHECK: scf.condition(%[[VAL_31]]) %[[VAL_24]], %[[VAL_25]], %[[VAL_26]] : index, index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_32:.*]]: index, %[[VAL_33:.*]]: index, %[[VAL_34:.*]]: index):
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_32]]] : memref<?xindex>
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_37:.*]] = cmpi ult, %[[VAL_36]], %[[VAL_35]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi ult, %[[VAL_36]], %[[VAL_35]] : index
// CHECK: %[[VAL_38:.*]] = select %[[VAL_37]], %[[VAL_36]], %[[VAL_35]] : index
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_34]]] : memref<?xindex>
-// CHECK: %[[VAL_40:.*]] = cmpi ult, %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_40:.*]] = arith.cmpi ult, %[[VAL_39]], %[[VAL_38]] : index
// CHECK: %[[VAL_41:.*]] = select %[[VAL_40]], %[[VAL_39]], %[[VAL_38]] : index
-// CHECK: %[[VAL_42:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
-// CHECK: %[[VAL_43:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
-// CHECK: %[[VAL_44:.*]] = and %[[VAL_42]], %[[VAL_43]] : i1
-// CHECK: %[[VAL_45:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
-// CHECK: %[[VAL_46:.*]] = and %[[VAL_44]], %[[VAL_45]] : i1
+// CHECK: %[[VAL_42:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
+// CHECK: %[[VAL_43:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
+// CHECK: %[[VAL_44:.*]] = arith.andi %[[VAL_42]], %[[VAL_43]] : i1
+// CHECK: %[[VAL_45:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
+// CHECK: %[[VAL_46:.*]] = arith.andi %[[VAL_44]], %[[VAL_45]] : i1
// CHECK: scf.if %[[VAL_46]] {
// CHECK: %[[VAL_47:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_48:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_49:.*]] = addf %[[VAL_47]], %[[VAL_48]] : f64
+// CHECK: %[[VAL_49:.*]] = arith.addf %[[VAL_47]], %[[VAL_48]] : f64
// CHECK: %[[VAL_50:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_33]]] : memref<?xf64>
-// CHECK: %[[VAL_51:.*]] = addf %[[VAL_49]], %[[VAL_50]] : f64
+// CHECK: %[[VAL_51:.*]] = arith.addf %[[VAL_49]], %[[VAL_50]] : f64
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_34]]] : memref<?xf64>
-// CHECK: %[[VAL_53:.*]] = addf %[[VAL_51]], %[[VAL_52]] : f64
+// CHECK: %[[VAL_53:.*]] = arith.addf %[[VAL_51]], %[[VAL_52]] : f64
// CHECK: memref.store %[[VAL_53]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_54:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
-// CHECK: %[[VAL_55:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
-// CHECK: %[[VAL_56:.*]] = and %[[VAL_54]], %[[VAL_55]] : i1
+// CHECK: %[[VAL_54:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
+// CHECK: %[[VAL_55:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
+// CHECK: %[[VAL_56:.*]] = arith.andi %[[VAL_54]], %[[VAL_55]] : i1
// CHECK: scf.if %[[VAL_56]] {
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_33]]] : memref<?xf64>
-// CHECK: %[[VAL_59:.*]] = addf %[[VAL_57]], %[[VAL_58]] : f64
+// CHECK: %[[VAL_59:.*]] = arith.addf %[[VAL_57]], %[[VAL_58]] : f64
// CHECK: %[[VAL_60:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_34]]] : memref<?xf64>
-// CHECK: %[[VAL_61:.*]] = addf %[[VAL_59]], %[[VAL_60]] : f64
+// CHECK: %[[VAL_61:.*]] = arith.addf %[[VAL_59]], %[[VAL_60]] : f64
// CHECK: memref.store %[[VAL_61]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_62:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
-// CHECK: %[[VAL_63:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
-// CHECK: %[[VAL_64:.*]] = and %[[VAL_62]], %[[VAL_63]] : i1
+// CHECK: %[[VAL_62:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
+// CHECK: %[[VAL_63:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
+// CHECK: %[[VAL_64:.*]] = arith.andi %[[VAL_62]], %[[VAL_63]] : i1
// CHECK: scf.if %[[VAL_64]] {
// CHECK: %[[VAL_65:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_66:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_67:.*]] = addf %[[VAL_65]], %[[VAL_66]] : f64
+// CHECK: %[[VAL_67:.*]] = arith.addf %[[VAL_65]], %[[VAL_66]] : f64
// CHECK: %[[VAL_68:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_34]]] : memref<?xf64>
-// CHECK: %[[VAL_69:.*]] = addf %[[VAL_67]], %[[VAL_68]] : f64
+// CHECK: %[[VAL_69:.*]] = arith.addf %[[VAL_67]], %[[VAL_68]] : f64
// CHECK: memref.store %[[VAL_69]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_70:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
+// CHECK: %[[VAL_70:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
// CHECK: scf.if %[[VAL_70]] {
// CHECK: %[[VAL_71:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_72:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_34]]] : memref<?xf64>
-// CHECK: %[[VAL_73:.*]] = addf %[[VAL_71]], %[[VAL_72]] : f64
+// CHECK: %[[VAL_73:.*]] = arith.addf %[[VAL_71]], %[[VAL_72]] : f64
// CHECK: memref.store %[[VAL_73]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_74:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
-// CHECK: %[[VAL_75:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
-// CHECK: %[[VAL_76:.*]] = and %[[VAL_74]], %[[VAL_75]] : i1
+// CHECK: %[[VAL_74:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
+// CHECK: %[[VAL_75:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
+// CHECK: %[[VAL_76:.*]] = arith.andi %[[VAL_74]], %[[VAL_75]] : i1
// CHECK: scf.if %[[VAL_76]] {
// CHECK: %[[VAL_77:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_78:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_79:.*]] = addf %[[VAL_77]], %[[VAL_78]] : f64
+// CHECK: %[[VAL_79:.*]] = arith.addf %[[VAL_77]], %[[VAL_78]] : f64
// CHECK: %[[VAL_80:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_33]]] : memref<?xf64>
-// CHECK: %[[VAL_81:.*]] = addf %[[VAL_79]], %[[VAL_80]] : f64
+// CHECK: %[[VAL_81:.*]] = arith.addf %[[VAL_79]], %[[VAL_80]] : f64
// CHECK: memref.store %[[VAL_81]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_82:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
+// CHECK: %[[VAL_82:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
// CHECK: scf.if %[[VAL_82]] {
// CHECK: %[[VAL_83:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_84:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_33]]] : memref<?xf64>
-// CHECK: %[[VAL_85:.*]] = addf %[[VAL_83]], %[[VAL_84]] : f64
+// CHECK: %[[VAL_85:.*]] = arith.addf %[[VAL_83]], %[[VAL_84]] : f64
// CHECK: memref.store %[[VAL_85]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_86:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
+// CHECK: %[[VAL_86:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
// CHECK: scf.if %[[VAL_86]] {
// CHECK: %[[VAL_87:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_88:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_32]]] : memref<?xf64>
-// CHECK: %[[VAL_89:.*]] = addf %[[VAL_87]], %[[VAL_88]] : f64
+// CHECK: %[[VAL_89:.*]] = arith.addf %[[VAL_87]], %[[VAL_88]] : f64
// CHECK: memref.store %[[VAL_89]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_90:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
-// CHECK: %[[VAL_91:.*]] = addi %[[VAL_32]], %[[VAL_5]] : index
+// CHECK: %[[VAL_90:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_41]] : index
+// CHECK: %[[VAL_91:.*]] = arith.addi %[[VAL_32]], %[[VAL_5]] : index
// CHECK: %[[VAL_92:.*]] = select %[[VAL_90]], %[[VAL_91]], %[[VAL_32]] : index
-// CHECK: %[[VAL_93:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
-// CHECK: %[[VAL_94:.*]] = addi %[[VAL_33]], %[[VAL_5]] : index
+// CHECK: %[[VAL_93:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_41]] : index
+// CHECK: %[[VAL_94:.*]] = arith.addi %[[VAL_33]], %[[VAL_5]] : index
// CHECK: %[[VAL_95:.*]] = select %[[VAL_93]], %[[VAL_94]], %[[VAL_33]] : index
-// CHECK: %[[VAL_96:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
-// CHECK: %[[VAL_97:.*]] = addi %[[VAL_34]], %[[VAL_5]] : index
+// CHECK: %[[VAL_96:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_41]] : index
+// CHECK: %[[VAL_97:.*]] = arith.addi %[[VAL_34]], %[[VAL_5]] : index
// CHECK: %[[VAL_98:.*]] = select %[[VAL_96]], %[[VAL_97]], %[[VAL_34]] : index
// CHECK: scf.yield %[[VAL_92]], %[[VAL_95]], %[[VAL_98]] : index, index, index
// CHECK: }
// CHECK: %[[VAL_99:.*]]:2 = scf.while (%[[VAL_100:.*]] = %[[VAL_101:.*]]#1, %[[VAL_102:.*]] = %[[VAL_101]]#2) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_103:.*]] = cmpi ult, %[[VAL_100]], %[[VAL_20]] : index
-// CHECK: %[[VAL_104:.*]] = cmpi ult, %[[VAL_102]], %[[VAL_22]] : index
-// CHECK: %[[VAL_105:.*]] = and %[[VAL_103]], %[[VAL_104]] : i1
+// CHECK: %[[VAL_103:.*]] = arith.cmpi ult, %[[VAL_100]], %[[VAL_20]] : index
+// CHECK: %[[VAL_104:.*]] = arith.cmpi ult, %[[VAL_102]], %[[VAL_22]] : index
+// CHECK: %[[VAL_105:.*]] = arith.andi %[[VAL_103]], %[[VAL_104]] : i1
// CHECK: scf.condition(%[[VAL_105]]) %[[VAL_100]], %[[VAL_102]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_106:.*]]: index, %[[VAL_107:.*]]: index):
// CHECK: %[[VAL_108:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_106]]] : memref<?xindex>
// CHECK: %[[VAL_109:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_107]]] : memref<?xindex>
-// CHECK: %[[VAL_110:.*]] = cmpi ult, %[[VAL_109]], %[[VAL_108]] : index
+// CHECK: %[[VAL_110:.*]] = arith.cmpi ult, %[[VAL_109]], %[[VAL_108]] : index
// CHECK: %[[VAL_111:.*]] = select %[[VAL_110]], %[[VAL_109]], %[[VAL_108]] : index
-// CHECK: %[[VAL_112:.*]] = cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
-// CHECK: %[[VAL_113:.*]] = cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
-// CHECK: %[[VAL_114:.*]] = and %[[VAL_112]], %[[VAL_113]] : i1
+// CHECK: %[[VAL_112:.*]] = arith.cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
+// CHECK: %[[VAL_113:.*]] = arith.cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
+// CHECK: %[[VAL_114:.*]] = arith.andi %[[VAL_112]], %[[VAL_113]] : i1
// CHECK: scf.if %[[VAL_114]] {
// CHECK: %[[VAL_115:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_116:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_106]]] : memref<?xf64>
-// CHECK: %[[VAL_117:.*]] = addf %[[VAL_115]], %[[VAL_116]] : f64
+// CHECK: %[[VAL_117:.*]] = arith.addf %[[VAL_115]], %[[VAL_116]] : f64
// CHECK: %[[VAL_118:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_107]]] : memref<?xf64>
-// CHECK: %[[VAL_119:.*]] = addf %[[VAL_117]], %[[VAL_118]] : f64
+// CHECK: %[[VAL_119:.*]] = arith.addf %[[VAL_117]], %[[VAL_118]] : f64
// CHECK: memref.store %[[VAL_119]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_120:.*]] = cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
+// CHECK: %[[VAL_120:.*]] = arith.cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
// CHECK: scf.if %[[VAL_120]] {
// CHECK: %[[VAL_121:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_122:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_107]]] : memref<?xf64>
-// CHECK: %[[VAL_123:.*]] = addf %[[VAL_121]], %[[VAL_122]] : f64
+// CHECK: %[[VAL_123:.*]] = arith.addf %[[VAL_121]], %[[VAL_122]] : f64
// CHECK: memref.store %[[VAL_123]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_124:.*]] = cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
+// CHECK: %[[VAL_124:.*]] = arith.cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
// CHECK: scf.if %[[VAL_124]] {
// CHECK: %[[VAL_125:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_126:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_106]]] : memref<?xf64>
-// CHECK: %[[VAL_127:.*]] = addf %[[VAL_125]], %[[VAL_126]] : f64
+// CHECK: %[[VAL_127:.*]] = arith.addf %[[VAL_125]], %[[VAL_126]] : f64
// CHECK: memref.store %[[VAL_127]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_128:.*]] = cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
-// CHECK: %[[VAL_129:.*]] = addi %[[VAL_106]], %[[VAL_5]] : index
+// CHECK: %[[VAL_128:.*]] = arith.cmpi eq, %[[VAL_108]], %[[VAL_111]] : index
+// CHECK: %[[VAL_129:.*]] = arith.addi %[[VAL_106]], %[[VAL_5]] : index
// CHECK: %[[VAL_130:.*]] = select %[[VAL_128]], %[[VAL_129]], %[[VAL_106]] : index
-// CHECK: %[[VAL_131:.*]] = cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
-// CHECK: %[[VAL_132:.*]] = addi %[[VAL_107]], %[[VAL_5]] : index
+// CHECK: %[[VAL_131:.*]] = arith.cmpi eq, %[[VAL_109]], %[[VAL_111]] : index
+// CHECK: %[[VAL_132:.*]] = arith.addi %[[VAL_107]], %[[VAL_5]] : index
// CHECK: %[[VAL_133:.*]] = select %[[VAL_131]], %[[VAL_132]], %[[VAL_107]] : index
// CHECK: scf.yield %[[VAL_130]], %[[VAL_133]] : index, index
// CHECK: }
// CHECK: %[[VAL_134:.*]]:2 = scf.while (%[[VAL_135:.*]] = %[[VAL_136:.*]]#0, %[[VAL_137:.*]] = %[[VAL_138:.*]]#1) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_139:.*]] = cmpi ult, %[[VAL_135]], %[[VAL_18]] : index
-// CHECK: %[[VAL_140:.*]] = cmpi ult, %[[VAL_137]], %[[VAL_22]] : index
-// CHECK: %[[VAL_141:.*]] = and %[[VAL_139]], %[[VAL_140]] : i1
+// CHECK: %[[VAL_139:.*]] = arith.cmpi ult, %[[VAL_135]], %[[VAL_18]] : index
+// CHECK: %[[VAL_140:.*]] = arith.cmpi ult, %[[VAL_137]], %[[VAL_22]] : index
+// CHECK: %[[VAL_141:.*]] = arith.andi %[[VAL_139]], %[[VAL_140]] : i1
// CHECK: scf.condition(%[[VAL_141]]) %[[VAL_135]], %[[VAL_137]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_142:.*]]: index, %[[VAL_143:.*]]: index):
// CHECK: %[[VAL_144:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_142]]] : memref<?xindex>
// CHECK: %[[VAL_145:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_143]]] : memref<?xindex>
-// CHECK: %[[VAL_146:.*]] = cmpi ult, %[[VAL_145]], %[[VAL_144]] : index
+// CHECK: %[[VAL_146:.*]] = arith.cmpi ult, %[[VAL_145]], %[[VAL_144]] : index
// CHECK: %[[VAL_147:.*]] = select %[[VAL_146]], %[[VAL_145]], %[[VAL_144]] : index
-// CHECK: %[[VAL_148:.*]] = cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
-// CHECK: %[[VAL_149:.*]] = cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
-// CHECK: %[[VAL_150:.*]] = and %[[VAL_148]], %[[VAL_149]] : i1
+// CHECK: %[[VAL_148:.*]] = arith.cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
+// CHECK: %[[VAL_149:.*]] = arith.cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
+// CHECK: %[[VAL_150:.*]] = arith.andi %[[VAL_148]], %[[VAL_149]] : i1
// CHECK: scf.if %[[VAL_150]] {
// CHECK: %[[VAL_151:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_152:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_142]]] : memref<?xf64>
-// CHECK: %[[VAL_153:.*]] = addf %[[VAL_151]], %[[VAL_152]] : f64
+// CHECK: %[[VAL_153:.*]] = arith.addf %[[VAL_151]], %[[VAL_152]] : f64
// CHECK: %[[VAL_154:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_143]]] : memref<?xf64>
-// CHECK: %[[VAL_155:.*]] = addf %[[VAL_153]], %[[VAL_154]] : f64
+// CHECK: %[[VAL_155:.*]] = arith.addf %[[VAL_153]], %[[VAL_154]] : f64
// CHECK: memref.store %[[VAL_155]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_156:.*]] = cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
+// CHECK: %[[VAL_156:.*]] = arith.cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
// CHECK: scf.if %[[VAL_156]] {
// CHECK: %[[VAL_157:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_158:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_143]]] : memref<?xf64>
-// CHECK: %[[VAL_159:.*]] = addf %[[VAL_157]], %[[VAL_158]] : f64
+// CHECK: %[[VAL_159:.*]] = arith.addf %[[VAL_157]], %[[VAL_158]] : f64
// CHECK: memref.store %[[VAL_159]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_160:.*]] = cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
+// CHECK: %[[VAL_160:.*]] = arith.cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
// CHECK: scf.if %[[VAL_160]] {
// CHECK: %[[VAL_161:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_162:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_142]]] : memref<?xf64>
-// CHECK: %[[VAL_163:.*]] = addf %[[VAL_161]], %[[VAL_162]] : f64
+// CHECK: %[[VAL_163:.*]] = arith.addf %[[VAL_161]], %[[VAL_162]] : f64
// CHECK: memref.store %[[VAL_163]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_164:.*]] = cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
-// CHECK: %[[VAL_165:.*]] = addi %[[VAL_142]], %[[VAL_5]] : index
+// CHECK: %[[VAL_164:.*]] = arith.cmpi eq, %[[VAL_144]], %[[VAL_147]] : index
+// CHECK: %[[VAL_165:.*]] = arith.addi %[[VAL_142]], %[[VAL_5]] : index
// CHECK: %[[VAL_166:.*]] = select %[[VAL_164]], %[[VAL_165]], %[[VAL_142]] : index
-// CHECK: %[[VAL_167:.*]] = cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
-// CHECK: %[[VAL_168:.*]] = addi %[[VAL_143]], %[[VAL_5]] : index
+// CHECK: %[[VAL_167:.*]] = arith.cmpi eq, %[[VAL_145]], %[[VAL_147]] : index
+// CHECK: %[[VAL_168:.*]] = arith.addi %[[VAL_143]], %[[VAL_5]] : index
// CHECK: %[[VAL_169:.*]] = select %[[VAL_167]], %[[VAL_168]], %[[VAL_143]] : index
// CHECK: scf.yield %[[VAL_166]], %[[VAL_169]] : index, index
// CHECK: }
// CHECK: %[[VAL_170:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_171:.*]] = scf.for %[[VAL_172:.*]] = %[[VAL_173:.*]]#1 to %[[VAL_22]] step %[[VAL_5]] iter_args(%[[VAL_174:.*]] = %[[VAL_170]]) -> (f64) {
// CHECK: %[[VAL_175:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_172]]] : memref<?xf64>
-// CHECK: %[[VAL_176:.*]] = addf %[[VAL_174]], %[[VAL_175]] : f64
+// CHECK: %[[VAL_176:.*]] = arith.addf %[[VAL_174]], %[[VAL_175]] : f64
// CHECK: scf.yield %[[VAL_176]] : f64
// CHECK: }
// CHECK: memref.store %[[VAL_177:.*]], %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_178:.*]]:2 = scf.while (%[[VAL_179:.*]] = %[[VAL_180:.*]]#0, %[[VAL_181:.*]] = %[[VAL_182:.*]]#0) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_183:.*]] = cmpi ult, %[[VAL_179]], %[[VAL_18]] : index
-// CHECK: %[[VAL_184:.*]] = cmpi ult, %[[VAL_181]], %[[VAL_20]] : index
-// CHECK: %[[VAL_185:.*]] = and %[[VAL_183]], %[[VAL_184]] : i1
+// CHECK: %[[VAL_183:.*]] = arith.cmpi ult, %[[VAL_179]], %[[VAL_18]] : index
+// CHECK: %[[VAL_184:.*]] = arith.cmpi ult, %[[VAL_181]], %[[VAL_20]] : index
+// CHECK: %[[VAL_185:.*]] = arith.andi %[[VAL_183]], %[[VAL_184]] : i1
// CHECK: scf.condition(%[[VAL_185]]) %[[VAL_179]], %[[VAL_181]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_186:.*]]: index, %[[VAL_187:.*]]: index):
// CHECK: %[[VAL_188:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_186]]] : memref<?xindex>
// CHECK: %[[VAL_189:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_187]]] : memref<?xindex>
-// CHECK: %[[VAL_190:.*]] = cmpi ult, %[[VAL_189]], %[[VAL_188]] : index
+// CHECK: %[[VAL_190:.*]] = arith.cmpi ult, %[[VAL_189]], %[[VAL_188]] : index
// CHECK: %[[VAL_191:.*]] = select %[[VAL_190]], %[[VAL_189]], %[[VAL_188]] : index
-// CHECK: %[[VAL_192:.*]] = cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
-// CHECK: %[[VAL_193:.*]] = cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
-// CHECK: %[[VAL_194:.*]] = and %[[VAL_192]], %[[VAL_193]] : i1
+// CHECK: %[[VAL_192:.*]] = arith.cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
+// CHECK: %[[VAL_193:.*]] = arith.cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
+// CHECK: %[[VAL_194:.*]] = arith.andi %[[VAL_192]], %[[VAL_193]] : i1
// CHECK: scf.if %[[VAL_194]] {
// CHECK: %[[VAL_195:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_196:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_186]]] : memref<?xf64>
-// CHECK: %[[VAL_197:.*]] = addf %[[VAL_195]], %[[VAL_196]] : f64
+// CHECK: %[[VAL_197:.*]] = arith.addf %[[VAL_195]], %[[VAL_196]] : f64
// CHECK: %[[VAL_198:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_187]]] : memref<?xf64>
-// CHECK: %[[VAL_199:.*]] = addf %[[VAL_197]], %[[VAL_198]] : f64
+// CHECK: %[[VAL_199:.*]] = arith.addf %[[VAL_197]], %[[VAL_198]] : f64
// CHECK: memref.store %[[VAL_199]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_200:.*]] = cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
+// CHECK: %[[VAL_200:.*]] = arith.cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
// CHECK: scf.if %[[VAL_200]] {
// CHECK: %[[VAL_201:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_202:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_187]]] : memref<?xf64>
-// CHECK: %[[VAL_203:.*]] = addf %[[VAL_201]], %[[VAL_202]] : f64
+// CHECK: %[[VAL_203:.*]] = arith.addf %[[VAL_201]], %[[VAL_202]] : f64
// CHECK: memref.store %[[VAL_203]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
-// CHECK: %[[VAL_204:.*]] = cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
+// CHECK: %[[VAL_204:.*]] = arith.cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
// CHECK: scf.if %[[VAL_204]] {
// CHECK: %[[VAL_205:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_206:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_186]]] : memref<?xf64>
-// CHECK: %[[VAL_207:.*]] = addf %[[VAL_205]], %[[VAL_206]] : f64
+// CHECK: %[[VAL_207:.*]] = arith.addf %[[VAL_205]], %[[VAL_206]] : f64
// CHECK: memref.store %[[VAL_207]], %[[VAL_16]][] : memref<f64>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_208:.*]] = cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
-// CHECK: %[[VAL_209:.*]] = addi %[[VAL_186]], %[[VAL_5]] : index
+// CHECK: %[[VAL_208:.*]] = arith.cmpi eq, %[[VAL_188]], %[[VAL_191]] : index
+// CHECK: %[[VAL_209:.*]] = arith.addi %[[VAL_186]], %[[VAL_5]] : index
// CHECK: %[[VAL_210:.*]] = select %[[VAL_208]], %[[VAL_209]], %[[VAL_186]] : index
-// CHECK: %[[VAL_211:.*]] = cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
-// CHECK: %[[VAL_212:.*]] = addi %[[VAL_187]], %[[VAL_5]] : index
+// CHECK: %[[VAL_211:.*]] = arith.cmpi eq, %[[VAL_189]], %[[VAL_191]] : index
+// CHECK: %[[VAL_212:.*]] = arith.addi %[[VAL_187]], %[[VAL_5]] : index
// CHECK: %[[VAL_213:.*]] = select %[[VAL_211]], %[[VAL_212]], %[[VAL_187]] : index
// CHECK: scf.yield %[[VAL_210]], %[[VAL_213]] : index, index
// CHECK: }
// CHECK: %[[VAL_214:.*]] = memref.load %[[VAL_16]][] : memref<f64>
// CHECK: %[[VAL_215:.*]] = scf.for %[[VAL_216:.*]] = %[[VAL_217:.*]]#1 to %[[VAL_20]] step %[[VAL_5]] iter_args(%[[VAL_218:.*]] = %[[VAL_214]]) -> (f64) {
// CHECK: %[[VAL_219:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_216]]] : memref<?xf64>
-// CHECK: %[[VAL_220:.*]] = addf %[[VAL_218]], %[[VAL_219]] : f64
+// CHECK: %[[VAL_220:.*]] = arith.addf %[[VAL_218]], %[[VAL_219]] : f64
// CHECK: scf.yield %[[VAL_220]] : f64
// CHECK: }
// CHECK: %[[VAL_221:.*]] = scf.for %[[VAL_222:.*]] = %[[VAL_223:.*]]#0 to %[[VAL_18]] step %[[VAL_5]] iter_args(%[[VAL_224:.*]] = %[[VAL_225:.*]]) -> (f64) {
// CHECK: %[[VAL_226:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_222]]] : memref<?xf64>
-// CHECK: %[[VAL_227:.*]] = addf %[[VAL_224]], %[[VAL_226]] : f64
+// CHECK: %[[VAL_227:.*]] = arith.addf %[[VAL_224]], %[[VAL_226]] : f64
// CHECK: scf.yield %[[VAL_227]] : f64
// CHECK: }
// CHECK: memref.store %[[VAL_228:.*]], %[[VAL_16]][] : memref<f64>
ins(%arga, %argb, %argc: tensor<?xf64, #SV>, tensor<?xf64, #SV>, tensor<?xf64, #SV>)
outs(%argx: tensor<f64>) {
^bb(%a: f64,%b: f64,%c: f64,%x: f64):
- %0 = addf %x, %a : f64
- %1 = addf %0, %b : f64
- %2 = addf %1, %c : f64
+ %0 = arith.addf %x, %a : f64
+ %1 = arith.addf %0, %b : f64
+ %2 = arith.addf %1, %c : f64
linalg.yield %2 : f64
} -> tensor<f64>
return %0 : tensor<f64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16xf32>
// CHECK: %[[VAL_9:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32x16xf32>
// CHECK: memref.copy %[[VAL_9]], %[[VAL_10]] : memref<32x16xf32> to memref<32x16xf32>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_13:.*]] = muli %[[VAL_11]], %[[VAL_4]] : index
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_12]] : index
+// CHECK: %[[VAL_13:.*]] = arith.muli %[[VAL_11]], %[[VAL_4]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_12]] : index
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_11]], %[[VAL_12]]] : memref<32x16xf32>
-// CHECK: %[[VAL_17:.*]] = addf %[[VAL_15]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.addf %[[VAL_15]], %[[VAL_16]] : f32
// CHECK: memref.store %[[VAL_17]], %[[VAL_10]]{{\[}}%[[VAL_11]], %[[VAL_12]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tdd>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 32 : index
-// CHECK: %[[VAL_4:.*]] = constant 16 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16xf32>
// CHECK: %[[VAL_9:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32x16xf32>
// CHECK: memref.copy %[[VAL_9]], %[[VAL_10]] : memref<32x16xf32> to memref<32x16xf32>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_13:.*]] = muli %[[VAL_11]], %[[VAL_4]] : index
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_12]] : index
+// CHECK: %[[VAL_13:.*]] = arith.muli %[[VAL_11]], %[[VAL_4]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_12]] : index
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_11]], %[[VAL_12]]] : memref<32x16xf32>
-// CHECK: %[[VAL_17:.*]] = mulf %[[VAL_15]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.mulf %[[VAL_15]], %[[VAL_16]] : f32
// CHECK: memref.store %[[VAL_17]], %[[VAL_10]]{{\[}}%[[VAL_11]], %[[VAL_12]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tdd>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_7]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_7]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_12]], %[[VAL_13]] : memref<32x16xf32> to memref<32x16xf32>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_7]] {
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_14]]] : memref<?xindex>
-// CHECK: %[[VAL_16:.*]] = addi %[[VAL_14]], %[[VAL_7]] : index
+// CHECK: %[[VAL_16:.*]] = arith.addi %[[VAL_14]], %[[VAL_7]] : index
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]]:2 = scf.while (%[[VAL_19:.*]] = %[[VAL_15]], %[[VAL_20:.*]] = %[[VAL_5]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
// CHECK: scf.condition(%[[VAL_21]]) %[[VAL_19]], %[[VAL_20]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_22:.*]]: index, %[[VAL_23:.*]]: index):
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<?xindex>
-// CHECK: %[[VAL_25:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
// CHECK: scf.if %[[VAL_25]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_22]]] : memref<?xf32>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_14]], %[[VAL_23]]] : memref<32x16xf32>
-// CHECK: %[[VAL_28:.*]] = addf %[[VAL_26]], %[[VAL_27]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.addf %[[VAL_26]], %[[VAL_27]] : f32
// CHECK: memref.store %[[VAL_28]], %[[VAL_13]]{{\[}}%[[VAL_14]], %[[VAL_23]]] : memref<32x16xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
-// CHECK: %[[VAL_31:.*]] = addi %[[VAL_22]], %[[VAL_7]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_31:.*]] = arith.addi %[[VAL_22]], %[[VAL_7]] : index
// CHECK: %[[VAL_32:.*]] = select %[[VAL_30]], %[[VAL_31]], %[[VAL_22]] : index
-// CHECK: %[[VAL_33:.*]] = addi %[[VAL_23]], %[[VAL_7]] : index
+// CHECK: %[[VAL_33:.*]] = arith.addi %[[VAL_23]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_32]], %[[VAL_33]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_34:.*]] = %[[VAL_35:.*]]#1 to %[[VAL_4]] step %[[VAL_7]] {
ins(%arga, %argb: tensor<32x16xf32, #Tds>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<32x16xf32> to memref<32x16xf32>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_12]], %[[VAL_5]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_12]], %[[VAL_5]] : index
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_13]] to %[[VAL_15]] step %[[VAL_5]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xf32>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_12]], %[[VAL_17]]] : memref<32x16xf32>
-// CHECK: %[[VAL_20:.*]] = mulf %[[VAL_18]], %[[VAL_19]] : f32
+// CHECK: %[[VAL_20:.*]] = arith.mulf %[[VAL_18]], %[[VAL_19]] : f32
// CHECK: memref.store %[[VAL_20]], %[[VAL_11]]{{\[}}%[[VAL_12]], %[[VAL_17]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tds>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]]:2 = scf.while (%[[VAL_17:.*]] = %[[VAL_14]], %[[VAL_18:.*]] = %[[VAL_6]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_19:.*]] = cmpi ult, %[[VAL_17]], %[[VAL_15]] : index
+// CHECK: %[[VAL_19:.*]] = arith.cmpi ult, %[[VAL_17]], %[[VAL_15]] : index
// CHECK: scf.condition(%[[VAL_19]]) %[[VAL_17]], %[[VAL_18]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_20:.*]]: index, %[[VAL_21:.*]]: index):
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<?xindex>
-// CHECK: %[[VAL_23:.*]] = cmpi eq, %[[VAL_22]], %[[VAL_21]] : index
+// CHECK: %[[VAL_23:.*]] = arith.cmpi eq, %[[VAL_22]], %[[VAL_21]] : index
// CHECK: scf.if %[[VAL_23]] {
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_6]] to %[[VAL_4]] step %[[VAL_7]] {
-// CHECK: %[[VAL_25:.*]] = muli %[[VAL_20]], %[[VAL_4]] : index
-// CHECK: %[[VAL_26:.*]] = addi %[[VAL_25]], %[[VAL_24]] : index
+// CHECK: %[[VAL_25:.*]] = arith.muli %[[VAL_20]], %[[VAL_4]] : index
+// CHECK: %[[VAL_26:.*]] = arith.addi %[[VAL_25]], %[[VAL_24]] : index
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_26]]] : memref<?xf32>
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_21]], %[[VAL_24]]] : memref<32x16xf32>
-// CHECK: %[[VAL_29:.*]] = addf %[[VAL_27]], %[[VAL_28]] : f32
+// CHECK: %[[VAL_29:.*]] = arith.addf %[[VAL_27]], %[[VAL_28]] : f32
// CHECK: memref.store %[[VAL_29]], %[[VAL_13]]{{\[}}%[[VAL_21]], %[[VAL_24]]] : memref<32x16xf32>
// CHECK: }
// CHECK: } else {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_32:.*]] = cmpi eq, %[[VAL_22]], %[[VAL_21]] : index
-// CHECK: %[[VAL_33:.*]] = addi %[[VAL_20]], %[[VAL_7]] : index
+// CHECK: %[[VAL_32:.*]] = arith.cmpi eq, %[[VAL_22]], %[[VAL_21]] : index
+// CHECK: %[[VAL_33:.*]] = arith.addi %[[VAL_20]], %[[VAL_7]] : index
// CHECK: %[[VAL_34:.*]] = select %[[VAL_32]], %[[VAL_33]], %[[VAL_20]] : index
-// CHECK: %[[VAL_35:.*]] = addi %[[VAL_21]], %[[VAL_7]] : index
+// CHECK: %[[VAL_35:.*]] = arith.addi %[[VAL_21]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_34]], %[[VAL_35]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_36:.*]] = %[[VAL_37:.*]]#1 to %[[VAL_3]] step %[[VAL_7]] {
ins(%arga, %argb: tensor<32x16xf32, #Tsd>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_12]] to %[[VAL_13]] step %[[VAL_5]] {
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
-// CHECK: %[[VAL_17:.*]] = muli %[[VAL_14]], %[[VAL_3]] : index
-// CHECK: %[[VAL_18:.*]] = addi %[[VAL_17]], %[[VAL_16]] : index
+// CHECK: %[[VAL_17:.*]] = arith.muli %[[VAL_14]], %[[VAL_3]] : index
+// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_17]], %[[VAL_16]] : index
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_15]], %[[VAL_16]]] : memref<32x16xf32>
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_19]], %[[VAL_20]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_19]], %[[VAL_20]] : f32
// CHECK: memref.store %[[VAL_21]], %[[VAL_11]]{{\[}}%[[VAL_15]], %[[VAL_16]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tsd>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_7]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]]:2 = scf.while (%[[VAL_19:.*]] = %[[VAL_16]], %[[VAL_20:.*]] = %[[VAL_6]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
// CHECK: scf.condition(%[[VAL_21]]) %[[VAL_19]], %[[VAL_20]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_22:.*]]: index, %[[VAL_23:.*]]: index):
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<?xindex>
-// CHECK: %[[VAL_25:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
// CHECK: scf.if %[[VAL_25]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_22]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_22]], %[[VAL_7]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_22]], %[[VAL_7]] : index
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_27]]] : memref<?xindex>
// CHECK: %[[VAL_29:.*]]:2 = scf.while (%[[VAL_30:.*]] = %[[VAL_26]], %[[VAL_31:.*]] = %[[VAL_6]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_32:.*]] = cmpi ult, %[[VAL_30]], %[[VAL_28]] : index
+// CHECK: %[[VAL_32:.*]] = arith.cmpi ult, %[[VAL_30]], %[[VAL_28]] : index
// CHECK: scf.condition(%[[VAL_32]]) %[[VAL_30]], %[[VAL_31]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_33:.*]]: index, %[[VAL_34:.*]]: index):
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_36:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
// CHECK: scf.if %[[VAL_36]] {
// CHECK: %[[VAL_37:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_23]], %[[VAL_34]]] : memref<32x16xf32>
-// CHECK: %[[VAL_39:.*]] = addf %[[VAL_37]], %[[VAL_38]] : f32
+// CHECK: %[[VAL_39:.*]] = arith.addf %[[VAL_37]], %[[VAL_38]] : f32
// CHECK: memref.store %[[VAL_39]], %[[VAL_15]]{{\[}}%[[VAL_23]], %[[VAL_34]]] : memref<32x16xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_41:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
-// CHECK: %[[VAL_42:.*]] = addi %[[VAL_33]], %[[VAL_7]] : index
+// CHECK: %[[VAL_41:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
+// CHECK: %[[VAL_42:.*]] = arith.addi %[[VAL_33]], %[[VAL_7]] : index
// CHECK: %[[VAL_43:.*]] = select %[[VAL_41]], %[[VAL_42]], %[[VAL_33]] : index
-// CHECK: %[[VAL_44:.*]] = addi %[[VAL_34]], %[[VAL_7]] : index
+// CHECK: %[[VAL_44:.*]] = arith.addi %[[VAL_34]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_43]], %[[VAL_44]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_45:.*]] = %[[VAL_46:.*]]#1 to %[[VAL_4]] step %[[VAL_7]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_50:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
-// CHECK: %[[VAL_51:.*]] = addi %[[VAL_22]], %[[VAL_7]] : index
+// CHECK: %[[VAL_50:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_51:.*]] = arith.addi %[[VAL_22]], %[[VAL_7]] : index
// CHECK: %[[VAL_52:.*]] = select %[[VAL_50]], %[[VAL_51]], %[[VAL_22]] : index
-// CHECK: %[[VAL_53:.*]] = addi %[[VAL_23]], %[[VAL_7]] : index
+// CHECK: %[[VAL_53:.*]] = arith.addi %[[VAL_23]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_52]], %[[VAL_53]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_54:.*]] = %[[VAL_55:.*]]#1 to %[[VAL_3]] step %[[VAL_7]] {
ins(%arga, %argb: tensor<32x16xf32, #Tss>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_13]] to %[[VAL_14]] step %[[VAL_4]] {
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
-// CHECK: %[[VAL_18:.*]] = addi %[[VAL_15]], %[[VAL_4]] : index
+// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_15]], %[[VAL_4]] : index
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_20:.*]] = %[[VAL_17]] to %[[VAL_19]] step %[[VAL_4]] {
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<?xf32>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_16]], %[[VAL_21]]] : memref<32x16xf32>
-// CHECK: %[[VAL_24:.*]] = mulf %[[VAL_22]], %[[VAL_23]] : f32
+// CHECK: %[[VAL_24:.*]] = arith.mulf %[[VAL_22]], %[[VAL_23]] : f32
// CHECK: memref.store %[[VAL_24]], %[[VAL_12]]{{\[}}%[[VAL_16]], %[[VAL_21]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tss>, tensor<32x16xf32>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*0]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]]:2 = scf.while (%[[VAL_22:.*]] = %[[VAL_17]], %[[VAL_23:.*]] = %[[VAL_19]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_24:.*]] = cmpi ult, %[[VAL_22]], %[[VAL_18]] : index
-// CHECK: %[[VAL_25:.*]] = cmpi ult, %[[VAL_23]], %[[VAL_20]] : index
-// CHECK: %[[VAL_26:.*]] = and %[[VAL_24]], %[[VAL_25]] : i1
+// CHECK: %[[VAL_24:.*]] = arith.cmpi ult, %[[VAL_22]], %[[VAL_18]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi ult, %[[VAL_23]], %[[VAL_20]] : index
+// CHECK: %[[VAL_26:.*]] = arith.andi %[[VAL_24]], %[[VAL_25]] : i1
// CHECK: scf.condition(%[[VAL_26]]) %[[VAL_22]], %[[VAL_23]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_27:.*]]: index, %[[VAL_28:.*]]: index):
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_27]]] : memref<?xindex>
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_28]]] : memref<?xindex>
-// CHECK: %[[VAL_31:.*]] = cmpi ult, %[[VAL_30]], %[[VAL_29]] : index
+// CHECK: %[[VAL_31:.*]] = arith.cmpi ult, %[[VAL_30]], %[[VAL_29]] : index
// CHECK: %[[VAL_32:.*]] = select %[[VAL_31]], %[[VAL_30]], %[[VAL_29]] : index
-// CHECK: %[[VAL_33:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
-// CHECK: %[[VAL_34:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
-// CHECK: %[[VAL_35:.*]] = and %[[VAL_33]], %[[VAL_34]] : i1
+// CHECK: %[[VAL_33:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
+// CHECK: %[[VAL_34:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
+// CHECK: %[[VAL_35:.*]] = arith.andi %[[VAL_33]], %[[VAL_34]] : i1
// CHECK: scf.if %[[VAL_35]] {
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_37:.*]] = addi %[[VAL_27]], %[[VAL_4]] : index
+// CHECK: %[[VAL_37:.*]] = arith.addi %[[VAL_27]], %[[VAL_4]] : index
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_37]]] : memref<?xindex>
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<?xindex>
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_28]], %[[VAL_4]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_28]], %[[VAL_4]] : index
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_40]]] : memref<?xindex>
// CHECK: %[[VAL_42:.*]]:2 = scf.while (%[[VAL_43:.*]] = %[[VAL_36]], %[[VAL_44:.*]] = %[[VAL_39]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_45:.*]] = cmpi ult, %[[VAL_43]], %[[VAL_38]] : index
-// CHECK: %[[VAL_46:.*]] = cmpi ult, %[[VAL_44]], %[[VAL_41]] : index
-// CHECK: %[[VAL_47:.*]] = and %[[VAL_45]], %[[VAL_46]] : i1
+// CHECK: %[[VAL_45:.*]] = arith.cmpi ult, %[[VAL_43]], %[[VAL_38]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi ult, %[[VAL_44]], %[[VAL_41]] : index
+// CHECK: %[[VAL_47:.*]] = arith.andi %[[VAL_45]], %[[VAL_46]] : i1
// CHECK: scf.condition(%[[VAL_47]]) %[[VAL_43]], %[[VAL_44]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_48:.*]]: index, %[[VAL_49:.*]]: index):
// CHECK: %[[VAL_50:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_48]]] : memref<?xindex>
// CHECK: %[[VAL_51:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_49]]] : memref<?xindex>
-// CHECK: %[[VAL_52:.*]] = cmpi ult, %[[VAL_51]], %[[VAL_50]] : index
+// CHECK: %[[VAL_52:.*]] = arith.cmpi ult, %[[VAL_51]], %[[VAL_50]] : index
// CHECK: %[[VAL_53:.*]] = select %[[VAL_52]], %[[VAL_51]], %[[VAL_50]] : index
-// CHECK: %[[VAL_54:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
-// CHECK: %[[VAL_55:.*]] = cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
-// CHECK: %[[VAL_56:.*]] = and %[[VAL_54]], %[[VAL_55]] : i1
+// CHECK: %[[VAL_54:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
+// CHECK: %[[VAL_55:.*]] = arith.cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
+// CHECK: %[[VAL_56:.*]] = arith.andi %[[VAL_54]], %[[VAL_55]] : i1
// CHECK: scf.if %[[VAL_56]] {
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_48]]] : memref<?xf32>
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_49]]] : memref<?xf32>
-// CHECK: %[[VAL_59:.*]] = addf %[[VAL_57]], %[[VAL_58]] : f32
+// CHECK: %[[VAL_59:.*]] = arith.addf %[[VAL_57]], %[[VAL_58]] : f32
// CHECK: memref.store %[[VAL_59]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_53]]] : memref<32x16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_60:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
+// CHECK: %[[VAL_60:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
// CHECK: scf.if %[[VAL_60]] {
// CHECK: %[[VAL_61:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_48]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_61]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_53]]] : memref<32x16xf32>
// CHECK: } else {
-// CHECK: %[[VAL_62:.*]] = cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
+// CHECK: %[[VAL_62:.*]] = arith.cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
// CHECK: scf.if %[[VAL_62]] {
// CHECK: %[[VAL_63:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_49]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_63]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_53]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_64:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
-// CHECK: %[[VAL_65:.*]] = addi %[[VAL_48]], %[[VAL_4]] : index
+// CHECK: %[[VAL_64:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
+// CHECK: %[[VAL_65:.*]] = arith.addi %[[VAL_48]], %[[VAL_4]] : index
// CHECK: %[[VAL_66:.*]] = select %[[VAL_64]], %[[VAL_65]], %[[VAL_48]] : index
-// CHECK: %[[VAL_67:.*]] = cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
-// CHECK: %[[VAL_68:.*]] = addi %[[VAL_49]], %[[VAL_4]] : index
+// CHECK: %[[VAL_67:.*]] = arith.cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
+// CHECK: %[[VAL_68:.*]] = arith.addi %[[VAL_49]], %[[VAL_4]] : index
// CHECK: %[[VAL_69:.*]] = select %[[VAL_67]], %[[VAL_68]], %[[VAL_49]] : index
// CHECK: scf.yield %[[VAL_66]], %[[VAL_69]] : index, index
// CHECK: }
// CHECK: memref.store %[[VAL_77]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_76]]] : memref<32x16xf32>
// CHECK: }
// CHECK: } else {
-// CHECK: %[[VAL_78:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
+// CHECK: %[[VAL_78:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
// CHECK: scf.if %[[VAL_78]] {
// CHECK: %[[VAL_79:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_80:.*]] = addi %[[VAL_27]], %[[VAL_4]] : index
+// CHECK: %[[VAL_80:.*]] = arith.addi %[[VAL_27]], %[[VAL_4]] : index
// CHECK: %[[VAL_81:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_80]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_82:.*]] = %[[VAL_79]] to %[[VAL_81]] step %[[VAL_4]] {
// CHECK: %[[VAL_83:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_82]]] : memref<?xindex>
// CHECK: memref.store %[[VAL_84]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_83]]] : memref<32x16xf32>
// CHECK: }
// CHECK: } else {
-// CHECK: %[[VAL_85:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
+// CHECK: %[[VAL_85:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
// CHECK: scf.if %[[VAL_85]] {
// CHECK: %[[VAL_86:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<?xindex>
-// CHECK: %[[VAL_87:.*]] = addi %[[VAL_28]], %[[VAL_4]] : index
+// CHECK: %[[VAL_87:.*]] = arith.addi %[[VAL_28]], %[[VAL_4]] : index
// CHECK: %[[VAL_88:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_87]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_89:.*]] = %[[VAL_86]] to %[[VAL_88]] step %[[VAL_4]] {
// CHECK: %[[VAL_90:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_89]]] : memref<?xindex>
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_92:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
-// CHECK: %[[VAL_93:.*]] = addi %[[VAL_27]], %[[VAL_4]] : index
+// CHECK: %[[VAL_92:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
+// CHECK: %[[VAL_93:.*]] = arith.addi %[[VAL_27]], %[[VAL_4]] : index
// CHECK: %[[VAL_94:.*]] = select %[[VAL_92]], %[[VAL_93]], %[[VAL_27]] : index
-// CHECK: %[[VAL_95:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
-// CHECK: %[[VAL_96:.*]] = addi %[[VAL_28]], %[[VAL_4]] : index
+// CHECK: %[[VAL_95:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
+// CHECK: %[[VAL_96:.*]] = arith.addi %[[VAL_28]], %[[VAL_4]] : index
// CHECK: %[[VAL_97:.*]] = select %[[VAL_95]], %[[VAL_96]], %[[VAL_28]] : index
// CHECK: scf.yield %[[VAL_94]], %[[VAL_97]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_98:.*]] = %[[VAL_99:.*]]#0 to %[[VAL_18]] step %[[VAL_4]] {
// CHECK: %[[VAL_100:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_98]]] : memref<?xindex>
// CHECK: %[[VAL_101:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_98]]] : memref<?xindex>
-// CHECK: %[[VAL_102:.*]] = addi %[[VAL_98]], %[[VAL_4]] : index
+// CHECK: %[[VAL_102:.*]] = arith.addi %[[VAL_98]], %[[VAL_4]] : index
// CHECK: %[[VAL_103:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_102]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_104:.*]] = %[[VAL_101]] to %[[VAL_103]] step %[[VAL_4]] {
// CHECK: %[[VAL_105:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_104]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_107:.*]] = %[[VAL_108:.*]]#1 to %[[VAL_20]] step %[[VAL_4]] {
// CHECK: %[[VAL_109:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_107]]] : memref<?xindex>
// CHECK: %[[VAL_110:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_107]]] : memref<?xindex>
-// CHECK: %[[VAL_111:.*]] = addi %[[VAL_107]], %[[VAL_4]] : index
+// CHECK: %[[VAL_111:.*]] = arith.addi %[[VAL_107]], %[[VAL_4]] : index
// CHECK: %[[VAL_112:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_111]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_113:.*]] = %[[VAL_110]] to %[[VAL_112]] step %[[VAL_4]] {
// CHECK: %[[VAL_114:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_113]]] : memref<?xindex>
ins(%arga, %argb: tensor<32x16xf32, #Tss>, tensor<32x16xf32, #Tss>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*0]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 0 : index
-// CHECK: %[[VAL_4:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]]:2 = scf.while (%[[VAL_22:.*]] = %[[VAL_17]], %[[VAL_23:.*]] = %[[VAL_19]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_24:.*]] = cmpi ult, %[[VAL_22]], %[[VAL_18]] : index
-// CHECK: %[[VAL_25:.*]] = cmpi ult, %[[VAL_23]], %[[VAL_20]] : index
-// CHECK: %[[VAL_26:.*]] = and %[[VAL_24]], %[[VAL_25]] : i1
+// CHECK: %[[VAL_24:.*]] = arith.cmpi ult, %[[VAL_22]], %[[VAL_18]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi ult, %[[VAL_23]], %[[VAL_20]] : index
+// CHECK: %[[VAL_26:.*]] = arith.andi %[[VAL_24]], %[[VAL_25]] : i1
// CHECK: scf.condition(%[[VAL_26]]) %[[VAL_22]], %[[VAL_23]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_27:.*]]: index, %[[VAL_28:.*]]: index):
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_27]]] : memref<?xindex>
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_28]]] : memref<?xindex>
-// CHECK: %[[VAL_31:.*]] = cmpi ult, %[[VAL_30]], %[[VAL_29]] : index
+// CHECK: %[[VAL_31:.*]] = arith.cmpi ult, %[[VAL_30]], %[[VAL_29]] : index
// CHECK: %[[VAL_32:.*]] = select %[[VAL_31]], %[[VAL_30]], %[[VAL_29]] : index
-// CHECK: %[[VAL_33:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
-// CHECK: %[[VAL_34:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
-// CHECK: %[[VAL_35:.*]] = and %[[VAL_33]], %[[VAL_34]] : i1
+// CHECK: %[[VAL_33:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
+// CHECK: %[[VAL_34:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
+// CHECK: %[[VAL_35:.*]] = arith.andi %[[VAL_33]], %[[VAL_34]] : i1
// CHECK: scf.if %[[VAL_35]] {
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_37:.*]] = addi %[[VAL_27]], %[[VAL_4]] : index
+// CHECK: %[[VAL_37:.*]] = arith.addi %[[VAL_27]], %[[VAL_4]] : index
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_37]]] : memref<?xindex>
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<?xindex>
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_28]], %[[VAL_4]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_28]], %[[VAL_4]] : index
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_40]]] : memref<?xindex>
// CHECK: %[[VAL_42:.*]]:2 = scf.while (%[[VAL_43:.*]] = %[[VAL_36]], %[[VAL_44:.*]] = %[[VAL_39]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_45:.*]] = cmpi ult, %[[VAL_43]], %[[VAL_38]] : index
-// CHECK: %[[VAL_46:.*]] = cmpi ult, %[[VAL_44]], %[[VAL_41]] : index
-// CHECK: %[[VAL_47:.*]] = and %[[VAL_45]], %[[VAL_46]] : i1
+// CHECK: %[[VAL_45:.*]] = arith.cmpi ult, %[[VAL_43]], %[[VAL_38]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi ult, %[[VAL_44]], %[[VAL_41]] : index
+// CHECK: %[[VAL_47:.*]] = arith.andi %[[VAL_45]], %[[VAL_46]] : i1
// CHECK: scf.condition(%[[VAL_47]]) %[[VAL_43]], %[[VAL_44]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_48:.*]]: index, %[[VAL_49:.*]]: index):
// CHECK: %[[VAL_50:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_48]]] : memref<?xindex>
// CHECK: %[[VAL_51:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_49]]] : memref<?xindex>
-// CHECK: %[[VAL_52:.*]] = cmpi ult, %[[VAL_51]], %[[VAL_50]] : index
+// CHECK: %[[VAL_52:.*]] = arith.cmpi ult, %[[VAL_51]], %[[VAL_50]] : index
// CHECK: %[[VAL_53:.*]] = select %[[VAL_52]], %[[VAL_51]], %[[VAL_50]] : index
-// CHECK: %[[VAL_54:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
-// CHECK: %[[VAL_55:.*]] = cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
-// CHECK: %[[VAL_56:.*]] = and %[[VAL_54]], %[[VAL_55]] : i1
+// CHECK: %[[VAL_54:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
+// CHECK: %[[VAL_55:.*]] = arith.cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
+// CHECK: %[[VAL_56:.*]] = arith.andi %[[VAL_54]], %[[VAL_55]] : i1
// CHECK: scf.if %[[VAL_56]] {
// CHECK: %[[VAL_57:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_48]]] : memref<?xf32>
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_49]]] : memref<?xf32>
-// CHECK: %[[VAL_59:.*]] = mulf %[[VAL_57]], %[[VAL_58]] : f32
+// CHECK: %[[VAL_59:.*]] = arith.mulf %[[VAL_57]], %[[VAL_58]] : f32
// CHECK: memref.store %[[VAL_59]], %[[VAL_16]]{{\[}}%[[VAL_32]], %[[VAL_53]]] : memref<32x16xf32>
// CHECK: } else {
// CHECK: }
-// CHECK: %[[VAL_60:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
-// CHECK: %[[VAL_61:.*]] = addi %[[VAL_48]], %[[VAL_4]] : index
+// CHECK: %[[VAL_60:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_53]] : index
+// CHECK: %[[VAL_61:.*]] = arith.addi %[[VAL_48]], %[[VAL_4]] : index
// CHECK: %[[VAL_62:.*]] = select %[[VAL_60]], %[[VAL_61]], %[[VAL_48]] : index
-// CHECK: %[[VAL_63:.*]] = cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
-// CHECK: %[[VAL_64:.*]] = addi %[[VAL_49]], %[[VAL_4]] : index
+// CHECK: %[[VAL_63:.*]] = arith.cmpi eq, %[[VAL_51]], %[[VAL_53]] : index
+// CHECK: %[[VAL_64:.*]] = arith.addi %[[VAL_49]], %[[VAL_4]] : index
// CHECK: %[[VAL_65:.*]] = select %[[VAL_63]], %[[VAL_64]], %[[VAL_49]] : index
// CHECK: scf.yield %[[VAL_62]], %[[VAL_65]] : index, index
// CHECK: }
// CHECK: } else {
// CHECK: }
-// CHECK: %[[VAL_66:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
-// CHECK: %[[VAL_67:.*]] = addi %[[VAL_27]], %[[VAL_4]] : index
+// CHECK: %[[VAL_66:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_32]] : index
+// CHECK: %[[VAL_67:.*]] = arith.addi %[[VAL_27]], %[[VAL_4]] : index
// CHECK: %[[VAL_68:.*]] = select %[[VAL_66]], %[[VAL_67]], %[[VAL_27]] : index
-// CHECK: %[[VAL_69:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
-// CHECK: %[[VAL_70:.*]] = addi %[[VAL_28]], %[[VAL_4]] : index
+// CHECK: %[[VAL_69:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_32]] : index
+// CHECK: %[[VAL_70:.*]] = arith.addi %[[VAL_28]], %[[VAL_4]] : index
// CHECK: %[[VAL_71:.*]] = select %[[VAL_69]], %[[VAL_70]], %[[VAL_28]] : index
// CHECK: scf.yield %[[VAL_68]], %[[VAL_71]] : index, index
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tss>, tensor<32x16xf32, #Tss>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_5]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]]:2 = scf.while (%[[VAL_19:.*]] = %[[VAL_16]], %[[VAL_20:.*]] = %[[VAL_5]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_21:.*]] = cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi ult, %[[VAL_19]], %[[VAL_17]] : index
// CHECK: scf.condition(%[[VAL_21]]) %[[VAL_19]], %[[VAL_20]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_22:.*]]: index, %[[VAL_23:.*]]: index):
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<?xindex>
-// CHECK: %[[VAL_25:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
// CHECK: scf.if %[[VAL_25]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_23]], %[[VAL_7]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_23]], %[[VAL_7]] : index
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_27]]] : memref<?xindex>
// CHECK: %[[VAL_29:.*]]:2 = scf.while (%[[VAL_30:.*]] = %[[VAL_26]], %[[VAL_31:.*]] = %[[VAL_5]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_32:.*]] = cmpi ult, %[[VAL_30]], %[[VAL_28]] : index
+// CHECK: %[[VAL_32:.*]] = arith.cmpi ult, %[[VAL_30]], %[[VAL_28]] : index
// CHECK: scf.condition(%[[VAL_32]]) %[[VAL_30]], %[[VAL_31]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_33:.*]]: index, %[[VAL_34:.*]]: index):
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_36:.*]] = muli %[[VAL_22]], %[[VAL_4]] : index
-// CHECK: %[[VAL_37:.*]] = addi %[[VAL_36]], %[[VAL_34]] : index
-// CHECK: %[[VAL_38:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
+// CHECK: %[[VAL_36:.*]] = arith.muli %[[VAL_22]], %[[VAL_4]] : index
+// CHECK: %[[VAL_37:.*]] = arith.addi %[[VAL_36]], %[[VAL_34]] : index
+// CHECK: %[[VAL_38:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
// CHECK: scf.if %[[VAL_38]] {
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_37]]] : memref<?xf32>
// CHECK: %[[VAL_40:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_33]]] : memref<?xf32>
-// CHECK: %[[VAL_41:.*]] = addf %[[VAL_39]], %[[VAL_40]] : f32
+// CHECK: %[[VAL_41:.*]] = arith.addf %[[VAL_39]], %[[VAL_40]] : f32
// CHECK: memref.store %[[VAL_41]], %[[VAL_15]]{{\[}}%[[VAL_23]], %[[VAL_34]]] : memref<32x16xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_43:.*]] = cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
-// CHECK: %[[VAL_44:.*]] = addi %[[VAL_33]], %[[VAL_7]] : index
+// CHECK: %[[VAL_43:.*]] = arith.cmpi eq, %[[VAL_35]], %[[VAL_34]] : index
+// CHECK: %[[VAL_44:.*]] = arith.addi %[[VAL_33]], %[[VAL_7]] : index
// CHECK: %[[VAL_45:.*]] = select %[[VAL_43]], %[[VAL_44]], %[[VAL_33]] : index
-// CHECK: %[[VAL_46:.*]] = addi %[[VAL_34]], %[[VAL_7]] : index
+// CHECK: %[[VAL_46:.*]] = arith.addi %[[VAL_34]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_45]], %[[VAL_46]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_47:.*]] = %[[VAL_48:.*]]#1 to %[[VAL_4]] step %[[VAL_7]] {
-// CHECK: %[[VAL_49:.*]] = muli %[[VAL_22]], %[[VAL_4]] : index
-// CHECK: %[[VAL_50:.*]] = addi %[[VAL_49]], %[[VAL_47]] : index
+// CHECK: %[[VAL_49:.*]] = arith.muli %[[VAL_22]], %[[VAL_4]] : index
+// CHECK: %[[VAL_50:.*]] = arith.addi %[[VAL_49]], %[[VAL_47]] : index
// CHECK: %[[VAL_51:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_50]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_51]], %[[VAL_15]]{{\[}}%[[VAL_23]], %[[VAL_47]]] : memref<32x16xf32>
// CHECK: }
// CHECK: } else {
// CHECK: scf.if %[[VAL_6]] {
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_53:.*]] = addi %[[VAL_23]], %[[VAL_7]] : index
+// CHECK: %[[VAL_53:.*]] = arith.addi %[[VAL_23]], %[[VAL_7]] : index
// CHECK: %[[VAL_54:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_53]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_55:.*]] = %[[VAL_52]] to %[[VAL_54]] step %[[VAL_7]] {
// CHECK: %[[VAL_56:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_55]]] : memref<?xindex>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_58:.*]] = cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
-// CHECK: %[[VAL_59:.*]] = addi %[[VAL_22]], %[[VAL_7]] : index
+// CHECK: %[[VAL_58:.*]] = arith.cmpi eq, %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_59:.*]] = arith.addi %[[VAL_22]], %[[VAL_7]] : index
// CHECK: %[[VAL_60:.*]] = select %[[VAL_58]], %[[VAL_59]], %[[VAL_22]] : index
-// CHECK: %[[VAL_61:.*]] = addi %[[VAL_23]], %[[VAL_7]] : index
+// CHECK: %[[VAL_61:.*]] = arith.addi %[[VAL_23]], %[[VAL_7]] : index
// CHECK: scf.yield %[[VAL_60]], %[[VAL_61]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_62:.*]] = %[[VAL_63:.*]]#1 to %[[VAL_3]] step %[[VAL_7]] {
// CHECK: %[[VAL_64:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_62]]] : memref<?xindex>
-// CHECK: %[[VAL_65:.*]] = addi %[[VAL_62]], %[[VAL_7]] : index
+// CHECK: %[[VAL_65:.*]] = arith.addi %[[VAL_62]], %[[VAL_7]] : index
// CHECK: %[[VAL_66:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_65]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_67:.*]] = %[[VAL_64]] to %[[VAL_66]] step %[[VAL_7]] {
// CHECK: %[[VAL_68:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_67]]] : memref<?xindex>
ins(%arga, %argb: tensor<32x16xf32, #Tsd>, tensor<32x16xf32, #Tds>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf32>) -> tensor<32x16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_14]] to %[[VAL_15]] step %[[VAL_5]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_17]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_17]], %[[VAL_5]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_17]], %[[VAL_5]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_5]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_21]]] : memref<?xindex>
-// CHECK: %[[VAL_23:.*]] = muli %[[VAL_16]], %[[VAL_3]] : index
-// CHECK: %[[VAL_24:.*]] = addi %[[VAL_23]], %[[VAL_22]] : index
+// CHECK: %[[VAL_23:.*]] = arith.muli %[[VAL_16]], %[[VAL_3]] : index
+// CHECK: %[[VAL_24:.*]] = arith.addi %[[VAL_23]], %[[VAL_22]] : index
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xf32>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_21]]] : memref<?xf32>
-// CHECK: %[[VAL_27:.*]] = mulf %[[VAL_25]], %[[VAL_26]] : f32
+// CHECK: %[[VAL_27:.*]] = arith.mulf %[[VAL_25]], %[[VAL_26]] : f32
// CHECK: memref.store %[[VAL_27]], %[[VAL_13]]{{\[}}%[[VAL_17]], %[[VAL_22]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf32, #Tsd>, tensor<32x16xf32, #Tds>)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16xf32>
return %0 : tensor<32x16xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<16x32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<16xf32>) -> tensor<16xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<16x32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<16x32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<16x32xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<16xf32> to memref<16xf32>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_12]], %[[VAL_5]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_12]], %[[VAL_5]] : index
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_12]]] : memref<16xf32>
// CHECK: %[[VAL_17:.*]] = scf.for %[[VAL_18:.*]] = %[[VAL_13]] to %[[VAL_15]] step %[[VAL_5]] iter_args(%[[VAL_19:.*]] = %[[VAL_16]]) -> (f32) {
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<32xf32>
-// CHECK: %[[VAL_23:.*]] = mulf %[[VAL_21]], %[[VAL_22]] : f32
-// CHECK: %[[VAL_24:.*]] = addf %[[VAL_23]], %[[VAL_19]] : f32
+// CHECK: %[[VAL_23:.*]] = arith.mulf %[[VAL_21]], %[[VAL_22]] : f32
+// CHECK: %[[VAL_24:.*]] = arith.addf %[[VAL_23]], %[[VAL_19]] : f32
// CHECK: scf.yield %[[VAL_24]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_25:.*]], %[[VAL_11]]{{\[}}%[[VAL_12]]] : memref<16xf32>
ins(%argA, %argb: tensor<16x32xf32, #Tds>, tensor<32xf32>)
outs(%argx: tensor<16xf32>) {
^bb(%A: f32, %b: f32, %x: f32):
- %0 = mulf %A, %b : f32
- %1 = addf %0, %x : f32
+ %0 = arith.mulf %A, %b : f32
+ %1 = arith.addf %0, %x : f32
linalg.yield %1 : f32
} -> tensor<16xf32>
return %0 : tensor<16xf32>
// CHECK-LABEL: func @sum_reduction(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 10 : index
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 10 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<10x20xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<10x20xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_1]] : memref<f32>
// CHECK: memref.copy %[[VAL_7]], %[[VAL_8]] : memref<f32> to memref<f32>
// CHECK: scf.for %[[VAL_9:.*]] = %[[VAL_3]] to %[[VAL_2]] step %[[VAL_4]] {
// CHECK: %[[VAL_10:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_9]]] : memref<?xindex>
-// CHECK: %[[VAL_11:.*]] = addi %[[VAL_9]], %[[VAL_4]] : index
+// CHECK: %[[VAL_11:.*]] = arith.addi %[[VAL_9]], %[[VAL_4]] : index
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_8]][] : memref<f32>
// CHECK: %[[VAL_14:.*]] = scf.for %[[VAL_15:.*]] = %[[VAL_10]] to %[[VAL_12]] step %[[VAL_4]] iter_args(%[[VAL_16:.*]] = %[[VAL_13]]) -> (f32) {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_15]]] : memref<?xf32>
-// CHECK: %[[VAL_18:.*]] = addf %[[VAL_16]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_18:.*]] = arith.addf %[[VAL_16]], %[[VAL_17]] : f32
// CHECK: scf.yield %[[VAL_18]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_19:.*]], %[[VAL_8]][] : memref<f32>
ins(%arga: tensor<10x20xf32, #Tds>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %x, %a : f32
+ %0 = arith.addf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-LABEL: func @scale(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<?x?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<?x?xf64>) -> tensor<?x?xf64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2.000000e+00 : f64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2.000000e+00 : f64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<?x?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<?x?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<?x?xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf64>
// CHECK: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<?x?xf64> to memref<?x?xf64>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_3]] to %[[VAL_8]] step %[[VAL_4]] {
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_12]], %[[VAL_4]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_12]], %[[VAL_4]] : index
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_13]] to %[[VAL_15]] step %[[VAL_4]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xf64>
-// CHECK: %[[VAL_19:.*]] = mulf %[[VAL_18]], %[[VAL_2]] : f64
+// CHECK: %[[VAL_19:.*]] = arith.mulf %[[VAL_18]], %[[VAL_2]] : f64
// CHECK: memref.store %[[VAL_19]], %[[VAL_11]]{{\[}}%[[VAL_12]], %[[VAL_17]]] : memref<?x?xf64>
// CHECK: }
// CHECK: }
// CHECK: return %[[VAL_20]] : tensor<?x?xf64>
// CHECK: }
func @scale(%arga: tensor<?x?xf64, #Tds>, %argx: tensor<?x?xf64>) -> tensor<?x?xf64> {
- %0 = constant 2.0 : f64
+ %0 = arith.constant 2.0 : f64
%1 = linalg.generic #trait_scale
ins(%arga: tensor<?x?xf64, #Tds>)
outs(%argx: tensor<?x?xf64>) {
^bb(%a: f64, %x: f64):
- %2 = mulf %a, %0 : f64
+ %2 = arith.mulf %a, %0 : f64
linalg.yield %2 : f64
} -> tensor<?x?xf64>
return %1 : tensor<?x?xf64>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<?x?xf32>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<?x?xf32>,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<?x?xf32>) -> tensor<?x?xf32> {
-// CHECK: %[[VAL_4:.*]] = constant 0 : index
-// CHECK: %[[VAL_5:.*]] = constant 1 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: scf.for %[[VAL_20:.*]] = %[[VAL_18]] to %[[VAL_19]] step %[[VAL_5]] {
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xindex>
-// CHECK: %[[VAL_23:.*]] = addi %[[VAL_20]], %[[VAL_5]] : index
+// CHECK: %[[VAL_23:.*]] = arith.addi %[[VAL_20]], %[[VAL_5]] : index
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_22]] to %[[VAL_24]] step %[[VAL_5]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_25]]] : memref<?xindex>
// CHECK: %[[VAL_29:.*]] = scf.for %[[VAL_30:.*]] = %[[VAL_4]] to %[[VAL_12]] step %[[VAL_5]] iter_args(%[[VAL_31:.*]] = %[[VAL_28]]) -> (f32) {
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_21]], %[[VAL_30]]] : memref<?x?xf32>
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_30]], %[[VAL_26]]] : memref<?x?xf32>
-// CHECK: %[[VAL_34:.*]] = mulf %[[VAL_32]], %[[VAL_33]] : f32
-// CHECK: %[[VAL_35:.*]] = mulf %[[VAL_27]], %[[VAL_34]] : f32
-// CHECK: %[[VAL_36:.*]] = addf %[[VAL_31]], %[[VAL_35]] : f32
+// CHECK: %[[VAL_34:.*]] = arith.mulf %[[VAL_32]], %[[VAL_33]] : f32
+// CHECK: %[[VAL_35:.*]] = arith.mulf %[[VAL_27]], %[[VAL_34]] : f32
+// CHECK: %[[VAL_36:.*]] = arith.addf %[[VAL_31]], %[[VAL_35]] : f32
// CHECK: scf.yield %[[VAL_36]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_37:.*]], %[[VAL_17]]{{\[}}%[[VAL_21]], %[[VAL_26]]] : memref<?x?xf32>
ins(%args, %arga, %argb: tensor<?x?xf32, #Tss>, tensor<?x?xf32>, tensor<?x?xf32>)
outs(%argx: tensor<?x?xf32>) {
^bb(%s: f32, %a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = mulf %s, %0 : f32
- %2 = addf %x, %1 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.mulf %s, %0 : f32
+ %2 = arith.addf %x, %1 : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<?xf32>,
// CHECK-SAME: %[[VAL_4:.*4]]: tensor<f32>,
// CHECK-SAME: %[[VAL_5:.*5]]: tensor<?xf32>) -> tensor<?xf32> {
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant true
-// CHECK-DAG: %[[VAL_8:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_8]] : tensor<?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_8]]] : memref<?xindex>
// CHECK: %[[VAL_28:.*]]:2 = scf.while (%[[VAL_29:.*]] = %[[VAL_26]], %[[VAL_30:.*]] = %[[VAL_6]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_31:.*]] = cmpi ult, %[[VAL_29]], %[[VAL_27]] : index
+// CHECK: %[[VAL_31:.*]] = arith.cmpi ult, %[[VAL_29]], %[[VAL_27]] : index
// CHECK: scf.condition(%[[VAL_31]]) %[[VAL_29]], %[[VAL_30]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_32:.*]]: index, %[[VAL_33:.*]]: index):
// CHECK: %[[VAL_34:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_32]]] : memref<?xindex>
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_34]], %[[VAL_33]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_34]], %[[VAL_33]] : index
// CHECK: scf.if %[[VAL_35]] {
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_20]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_37:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_32]]] : memref<?xindex>
-// CHECK: %[[VAL_38:.*]] = addi %[[VAL_32]], %[[VAL_8]] : index
+// CHECK: %[[VAL_38:.*]] = arith.addi %[[VAL_32]], %[[VAL_8]] : index
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_38]]] : memref<?xindex>
// CHECK: %[[VAL_40:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_41:.*]] = addi %[[VAL_33]], %[[VAL_8]] : index
+// CHECK: %[[VAL_41:.*]] = arith.addi %[[VAL_33]], %[[VAL_8]] : index
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_41]]] : memref<?xindex>
// CHECK: %[[VAL_43:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_44:.*]] = addi %[[VAL_33]], %[[VAL_8]] : index
+// CHECK: %[[VAL_44:.*]] = arith.addi %[[VAL_33]], %[[VAL_8]] : index
// CHECK: %[[VAL_45:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_44]]] : memref<?xindex>
// CHECK: %[[VAL_46:.*]]:3 = scf.while (%[[VAL_47:.*]] = %[[VAL_37]], %[[VAL_48:.*]] = %[[VAL_40]], %[[VAL_49:.*]] = %[[VAL_43]]) : (index, index, index) -> (index, index, index) {
-// CHECK: %[[VAL_50:.*]] = cmpi ult, %[[VAL_47]], %[[VAL_39]] : index
-// CHECK: %[[VAL_51:.*]] = cmpi ult, %[[VAL_48]], %[[VAL_42]] : index
-// CHECK: %[[VAL_52:.*]] = and %[[VAL_50]], %[[VAL_51]] : i1
-// CHECK: %[[VAL_53:.*]] = cmpi ult, %[[VAL_49]], %[[VAL_45]] : index
-// CHECK: %[[VAL_54:.*]] = and %[[VAL_52]], %[[VAL_53]] : i1
+// CHECK: %[[VAL_50:.*]] = arith.cmpi ult, %[[VAL_47]], %[[VAL_39]] : index
+// CHECK: %[[VAL_51:.*]] = arith.cmpi ult, %[[VAL_48]], %[[VAL_42]] : index
+// CHECK: %[[VAL_52:.*]] = arith.andi %[[VAL_50]], %[[VAL_51]] : i1
+// CHECK: %[[VAL_53:.*]] = arith.cmpi ult, %[[VAL_49]], %[[VAL_45]] : index
+// CHECK: %[[VAL_54:.*]] = arith.andi %[[VAL_52]], %[[VAL_53]] : i1
// CHECK: scf.condition(%[[VAL_54]]) %[[VAL_47]], %[[VAL_48]], %[[VAL_49]] : index, index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_55:.*]]: index, %[[VAL_56:.*]]: index, %[[VAL_57:.*]]: index):
// CHECK: %[[VAL_58:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_55]]] : memref<?xindex>
// CHECK: %[[VAL_59:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_56]]] : memref<?xindex>
-// CHECK: %[[VAL_60:.*]] = cmpi ult, %[[VAL_59]], %[[VAL_58]] : index
+// CHECK: %[[VAL_60:.*]] = arith.cmpi ult, %[[VAL_59]], %[[VAL_58]] : index
// CHECK: %[[VAL_61:.*]] = select %[[VAL_60]], %[[VAL_59]], %[[VAL_58]] : index
// CHECK: %[[VAL_62:.*]] = memref.load %[[VAL_18]]{{\[}}%[[VAL_57]]] : memref<?xindex>
-// CHECK: %[[VAL_63:.*]] = cmpi ult, %[[VAL_62]], %[[VAL_61]] : index
+// CHECK: %[[VAL_63:.*]] = arith.cmpi ult, %[[VAL_62]], %[[VAL_61]] : index
// CHECK: %[[VAL_64:.*]] = select %[[VAL_63]], %[[VAL_62]], %[[VAL_61]] : index
-// CHECK: %[[VAL_65:.*]] = cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
-// CHECK: %[[VAL_66:.*]] = cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
-// CHECK: %[[VAL_67:.*]] = and %[[VAL_65]], %[[VAL_66]] : i1
-// CHECK: %[[VAL_68:.*]] = cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
-// CHECK: %[[VAL_69:.*]] = and %[[VAL_67]], %[[VAL_68]] : i1
+// CHECK: %[[VAL_65:.*]] = arith.cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
+// CHECK: %[[VAL_66:.*]] = arith.cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
+// CHECK: %[[VAL_67:.*]] = arith.andi %[[VAL_65]], %[[VAL_66]] : i1
+// CHECK: %[[VAL_68:.*]] = arith.cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
+// CHECK: %[[VAL_69:.*]] = arith.andi %[[VAL_67]], %[[VAL_68]] : i1
// CHECK: scf.if %[[VAL_69]] {
// CHECK: %[[VAL_70:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_71:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_55]]] : memref<?xf32>
// CHECK: %[[VAL_72:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_56]]] : memref<?xf32>
-// CHECK: %[[VAL_73:.*]] = mulf %[[VAL_71]], %[[VAL_72]] : f32
-// CHECK: %[[VAL_74:.*]] = mulf %[[VAL_73]], %[[VAL_36]] : f32
-// CHECK: %[[VAL_75:.*]] = mulf %[[VAL_74]], %[[VAL_25]] : f32
+// CHECK: %[[VAL_73:.*]] = arith.mulf %[[VAL_71]], %[[VAL_72]] : f32
+// CHECK: %[[VAL_74:.*]] = arith.mulf %[[VAL_73]], %[[VAL_36]] : f32
+// CHECK: %[[VAL_75:.*]] = arith.mulf %[[VAL_74]], %[[VAL_25]] : f32
// CHECK: %[[VAL_76:.*]] = memref.load %[[VAL_19]]{{\[}}%[[VAL_57]]] : memref<?xf32>
-// CHECK: %[[VAL_77:.*]] = addf %[[VAL_75]], %[[VAL_76]] : f32
-// CHECK: %[[VAL_78:.*]] = addf %[[VAL_70]], %[[VAL_77]] : f32
+// CHECK: %[[VAL_77:.*]] = arith.addf %[[VAL_75]], %[[VAL_76]] : f32
+// CHECK: %[[VAL_78:.*]] = arith.addf %[[VAL_70]], %[[VAL_77]] : f32
// CHECK: memref.store %[[VAL_78]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
-// CHECK: %[[VAL_79:.*]] = cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
-// CHECK: %[[VAL_80:.*]] = cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
-// CHECK: %[[VAL_81:.*]] = and %[[VAL_79]], %[[VAL_80]] : i1
+// CHECK: %[[VAL_79:.*]] = arith.cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
+// CHECK: %[[VAL_80:.*]] = arith.cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
+// CHECK: %[[VAL_81:.*]] = arith.andi %[[VAL_79]], %[[VAL_80]] : i1
// CHECK: scf.if %[[VAL_81]] {
// CHECK: %[[VAL_82:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_83:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_55]]] : memref<?xf32>
// CHECK: %[[VAL_84:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_56]]] : memref<?xf32>
-// CHECK: %[[VAL_85:.*]] = mulf %[[VAL_83]], %[[VAL_84]] : f32
-// CHECK: %[[VAL_86:.*]] = mulf %[[VAL_85]], %[[VAL_36]] : f32
-// CHECK: %[[VAL_87:.*]] = mulf %[[VAL_86]], %[[VAL_25]] : f32
-// CHECK: %[[VAL_88:.*]] = addf %[[VAL_82]], %[[VAL_87]] : f32
+// CHECK: %[[VAL_85:.*]] = arith.mulf %[[VAL_83]], %[[VAL_84]] : f32
+// CHECK: %[[VAL_86:.*]] = arith.mulf %[[VAL_85]], %[[VAL_36]] : f32
+// CHECK: %[[VAL_87:.*]] = arith.mulf %[[VAL_86]], %[[VAL_25]] : f32
+// CHECK: %[[VAL_88:.*]] = arith.addf %[[VAL_82]], %[[VAL_87]] : f32
// CHECK: memref.store %[[VAL_88]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
-// CHECK: %[[VAL_89:.*]] = cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
+// CHECK: %[[VAL_89:.*]] = arith.cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
// CHECK: scf.if %[[VAL_89]] {
// CHECK: %[[VAL_90:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_91:.*]] = memref.load %[[VAL_19]]{{\[}}%[[VAL_57]]] : memref<?xf32>
-// CHECK: %[[VAL_92:.*]] = addf %[[VAL_90]], %[[VAL_91]] : f32
+// CHECK: %[[VAL_92:.*]] = arith.addf %[[VAL_90]], %[[VAL_91]] : f32
// CHECK: memref.store %[[VAL_92]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
// CHECK: }
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_93:.*]] = cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
-// CHECK: %[[VAL_94:.*]] = addi %[[VAL_55]], %[[VAL_8]] : index
+// CHECK: %[[VAL_93:.*]] = arith.cmpi eq, %[[VAL_58]], %[[VAL_64]] : index
+// CHECK: %[[VAL_94:.*]] = arith.addi %[[VAL_55]], %[[VAL_8]] : index
// CHECK: %[[VAL_95:.*]] = select %[[VAL_93]], %[[VAL_94]], %[[VAL_55]] : index
-// CHECK: %[[VAL_96:.*]] = cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
-// CHECK: %[[VAL_97:.*]] = addi %[[VAL_56]], %[[VAL_8]] : index
+// CHECK: %[[VAL_96:.*]] = arith.cmpi eq, %[[VAL_59]], %[[VAL_64]] : index
+// CHECK: %[[VAL_97:.*]] = arith.addi %[[VAL_56]], %[[VAL_8]] : index
// CHECK: %[[VAL_98:.*]] = select %[[VAL_96]], %[[VAL_97]], %[[VAL_56]] : index
-// CHECK: %[[VAL_99:.*]] = cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
-// CHECK: %[[VAL_100:.*]] = addi %[[VAL_57]], %[[VAL_8]] : index
+// CHECK: %[[VAL_99:.*]] = arith.cmpi eq, %[[VAL_62]], %[[VAL_64]] : index
+// CHECK: %[[VAL_100:.*]] = arith.addi %[[VAL_57]], %[[VAL_8]] : index
// CHECK: %[[VAL_101:.*]] = select %[[VAL_99]], %[[VAL_100]], %[[VAL_57]] : index
// CHECK: scf.yield %[[VAL_95]], %[[VAL_98]], %[[VAL_101]] : index, index, index
// CHECK: }
// CHECK: %[[VAL_102:.*]]:2 = scf.while (%[[VAL_103:.*]] = %[[VAL_104:.*]]#0, %[[VAL_105:.*]] = %[[VAL_104]]#1) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_106:.*]] = cmpi ult, %[[VAL_103]], %[[VAL_39]] : index
-// CHECK: %[[VAL_107:.*]] = cmpi ult, %[[VAL_105]], %[[VAL_42]] : index
-// CHECK: %[[VAL_108:.*]] = and %[[VAL_106]], %[[VAL_107]] : i1
+// CHECK: %[[VAL_106:.*]] = arith.cmpi ult, %[[VAL_103]], %[[VAL_39]] : index
+// CHECK: %[[VAL_107:.*]] = arith.cmpi ult, %[[VAL_105]], %[[VAL_42]] : index
+// CHECK: %[[VAL_108:.*]] = arith.andi %[[VAL_106]], %[[VAL_107]] : i1
// CHECK: scf.condition(%[[VAL_108]]) %[[VAL_103]], %[[VAL_105]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_109:.*]]: index, %[[VAL_110:.*]]: index):
// CHECK: %[[VAL_111:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_109]]] : memref<?xindex>
// CHECK: %[[VAL_112:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_110]]] : memref<?xindex>
-// CHECK: %[[VAL_113:.*]] = cmpi ult, %[[VAL_112]], %[[VAL_111]] : index
+// CHECK: %[[VAL_113:.*]] = arith.cmpi ult, %[[VAL_112]], %[[VAL_111]] : index
// CHECK: %[[VAL_114:.*]] = select %[[VAL_113]], %[[VAL_112]], %[[VAL_111]] : index
-// CHECK: %[[VAL_115:.*]] = cmpi eq, %[[VAL_111]], %[[VAL_114]] : index
-// CHECK: %[[VAL_116:.*]] = cmpi eq, %[[VAL_112]], %[[VAL_114]] : index
-// CHECK: %[[VAL_117:.*]] = and %[[VAL_115]], %[[VAL_116]] : i1
+// CHECK: %[[VAL_115:.*]] = arith.cmpi eq, %[[VAL_111]], %[[VAL_114]] : index
+// CHECK: %[[VAL_116:.*]] = arith.cmpi eq, %[[VAL_112]], %[[VAL_114]] : index
+// CHECK: %[[VAL_117:.*]] = arith.andi %[[VAL_115]], %[[VAL_116]] : i1
// CHECK: scf.if %[[VAL_117]] {
// CHECK: %[[VAL_118:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_119:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_109]]] : memref<?xf32>
// CHECK: %[[VAL_120:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_110]]] : memref<?xf32>
-// CHECK: %[[VAL_121:.*]] = mulf %[[VAL_119]], %[[VAL_120]] : f32
-// CHECK: %[[VAL_122:.*]] = mulf %[[VAL_121]], %[[VAL_36]] : f32
-// CHECK: %[[VAL_123:.*]] = mulf %[[VAL_122]], %[[VAL_25]] : f32
-// CHECK: %[[VAL_124:.*]] = addf %[[VAL_118]], %[[VAL_123]] : f32
+// CHECK: %[[VAL_121:.*]] = arith.mulf %[[VAL_119]], %[[VAL_120]] : f32
+// CHECK: %[[VAL_122:.*]] = arith.mulf %[[VAL_121]], %[[VAL_36]] : f32
+// CHECK: %[[VAL_123:.*]] = arith.mulf %[[VAL_122]], %[[VAL_25]] : f32
+// CHECK: %[[VAL_124:.*]] = arith.addf %[[VAL_118]], %[[VAL_123]] : f32
// CHECK: memref.store %[[VAL_124]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
// CHECK: }
-// CHECK: %[[VAL_125:.*]] = cmpi eq, %[[VAL_111]], %[[VAL_114]] : index
-// CHECK: %[[VAL_126:.*]] = addi %[[VAL_109]], %[[VAL_8]] : index
+// CHECK: %[[VAL_125:.*]] = arith.cmpi eq, %[[VAL_111]], %[[VAL_114]] : index
+// CHECK: %[[VAL_126:.*]] = arith.addi %[[VAL_109]], %[[VAL_8]] : index
// CHECK: %[[VAL_127:.*]] = select %[[VAL_125]], %[[VAL_126]], %[[VAL_109]] : index
-// CHECK: %[[VAL_128:.*]] = cmpi eq, %[[VAL_112]], %[[VAL_114]] : index
-// CHECK: %[[VAL_129:.*]] = addi %[[VAL_110]], %[[VAL_8]] : index
+// CHECK: %[[VAL_128:.*]] = arith.cmpi eq, %[[VAL_112]], %[[VAL_114]] : index
+// CHECK: %[[VAL_129:.*]] = arith.addi %[[VAL_110]], %[[VAL_8]] : index
// CHECK: %[[VAL_130:.*]] = select %[[VAL_128]], %[[VAL_129]], %[[VAL_110]] : index
// CHECK: scf.yield %[[VAL_127]], %[[VAL_130]] : index, index
// CHECK: }
// CHECK: %[[VAL_131:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_132:.*]] = scf.for %[[VAL_133:.*]] = %[[VAL_134:.*]]#2 to %[[VAL_45]] step %[[VAL_8]] iter_args(%[[VAL_135:.*]] = %[[VAL_131]]) -> (f32) {
// CHECK: %[[VAL_136:.*]] = memref.load %[[VAL_19]]{{\[}}%[[VAL_133]]] : memref<?xf32>
-// CHECK: %[[VAL_137:.*]] = addf %[[VAL_135]], %[[VAL_136]] : f32
+// CHECK: %[[VAL_137:.*]] = arith.addf %[[VAL_135]], %[[VAL_136]] : f32
// CHECK: scf.yield %[[VAL_137]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_138:.*]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_7]] {
// CHECK: %[[VAL_139:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_33]]] : memref<?xindex>
-// CHECK: %[[VAL_140:.*]] = addi %[[VAL_33]], %[[VAL_8]] : index
+// CHECK: %[[VAL_140:.*]] = arith.addi %[[VAL_33]], %[[VAL_8]] : index
// CHECK: %[[VAL_141:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_140]]] : memref<?xindex>
// CHECK: %[[VAL_142:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: %[[VAL_143:.*]] = scf.for %[[VAL_144:.*]] = %[[VAL_139]] to %[[VAL_141]] step %[[VAL_8]] iter_args(%[[VAL_145:.*]] = %[[VAL_142]]) -> (f32) {
// CHECK: %[[VAL_146:.*]] = memref.load %[[VAL_19]]{{\[}}%[[VAL_144]]] : memref<?xf32>
-// CHECK: %[[VAL_147:.*]] = addf %[[VAL_145]], %[[VAL_146]] : f32
+// CHECK: %[[VAL_147:.*]] = arith.addf %[[VAL_145]], %[[VAL_146]] : f32
// CHECK: scf.yield %[[VAL_147]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_148:.*]], %[[VAL_24]]{{\[}}%[[VAL_33]]] : memref<?xf32>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_149:.*]] = cmpi eq, %[[VAL_34]], %[[VAL_33]] : index
-// CHECK: %[[VAL_150:.*]] = addi %[[VAL_32]], %[[VAL_8]] : index
+// CHECK: %[[VAL_149:.*]] = arith.cmpi eq, %[[VAL_34]], %[[VAL_33]] : index
+// CHECK: %[[VAL_150:.*]] = arith.addi %[[VAL_32]], %[[VAL_8]] : index
// CHECK: %[[VAL_151:.*]] = select %[[VAL_149]], %[[VAL_150]], %[[VAL_32]] : index
-// CHECK: %[[VAL_152:.*]] = addi %[[VAL_33]], %[[VAL_8]] : index
+// CHECK: %[[VAL_152:.*]] = arith.addi %[[VAL_33]], %[[VAL_8]] : index
// CHECK: scf.yield %[[VAL_151]], %[[VAL_152]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_153:.*]] = %[[VAL_154:.*]]#1 to %[[VAL_22]] step %[[VAL_8]] {
// CHECK: %[[VAL_155:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_153]]] : memref<?xindex>
-// CHECK: %[[VAL_156:.*]] = addi %[[VAL_153]], %[[VAL_8]] : index
+// CHECK: %[[VAL_156:.*]] = arith.addi %[[VAL_153]], %[[VAL_8]] : index
// CHECK: %[[VAL_157:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_156]]] : memref<?xindex>
// CHECK: %[[VAL_158:.*]] = memref.load %[[VAL_24]]{{\[}}%[[VAL_153]]] : memref<?xf32>
// CHECK: %[[VAL_159:.*]] = scf.for %[[VAL_160:.*]] = %[[VAL_155]] to %[[VAL_157]] step %[[VAL_8]] iter_args(%[[VAL_161:.*]] = %[[VAL_158]]) -> (f32) {
// CHECK: %[[VAL_162:.*]] = memref.load %[[VAL_19]]{{\[}}%[[VAL_160]]] : memref<?xf32>
-// CHECK: %[[VAL_163:.*]] = addf %[[VAL_161]], %[[VAL_162]] : f32
+// CHECK: %[[VAL_163:.*]] = arith.addf %[[VAL_161]], %[[VAL_162]] : f32
// CHECK: scf.yield %[[VAL_163]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_164:.*]], %[[VAL_24]]{{\[}}%[[VAL_153]]] : memref<?xf32>
tensor<f32>)
outs(%argx: tensor<?xf32>) {
^bb(%a: f32, %b: f32, %c: f32, %d: f32, %e: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = mulf %0, %d : f32
- %2 = mulf %1, %e : f32
- %3 = addf %2, %c : f32
- %4 = addf %x, %3 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.mulf %0, %d : f32
+ %2 = arith.mulf %1, %e : f32
+ %3 = arith.addf %2, %c : f32
+ %4 = arith.addf %x, %3 : f32
linalg.yield %4 : f32
} -> tensor<?xf32>
return %0 : tensor<?xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_9:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16x8xf32>
// CHECK: %[[VAL_10:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32x16x8xf32>
// CHECK: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_6]] to %[[VAL_3]] step %[[VAL_7]] {
// CHECK: scf.for %[[VAL_13:.*]] = %[[VAL_6]] to %[[VAL_4]] step %[[VAL_7]] {
-// CHECK: %[[VAL_14:.*]] = muli %[[VAL_12]], %[[VAL_4]] : index
-// CHECK: %[[VAL_15:.*]] = addi %[[VAL_14]], %[[VAL_13]] : index
+// CHECK: %[[VAL_14:.*]] = arith.muli %[[VAL_12]], %[[VAL_4]] : index
+// CHECK: %[[VAL_15:.*]] = arith.addi %[[VAL_14]], %[[VAL_13]] : index
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_6]] to %[[VAL_5]] step %[[VAL_7]] {
-// CHECK: %[[VAL_17:.*]] = muli %[[VAL_15]], %[[VAL_5]] : index
-// CHECK: %[[VAL_18:.*]] = addi %[[VAL_17]], %[[VAL_16]] : index
+// CHECK: %[[VAL_17:.*]] = arith.muli %[[VAL_15]], %[[VAL_5]] : index
+// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_17]], %[[VAL_16]] : index
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_12]], %[[VAL_13]], %[[VAL_16]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_21:.*]] = addf %[[VAL_19]], %[[VAL_20]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.addf %[[VAL_19]], %[[VAL_20]] : f32
// CHECK: memref.store %[[VAL_21]], %[[VAL_11]]{{\[}}%[[VAL_12]], %[[VAL_13]], %[[VAL_16]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tddd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_9:.*]] = memref.buffer_cast %[[VAL_1]] : memref<32x16x8xf32>
// CHECK: %[[VAL_10:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32x16x8xf32>
// CHECK: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_6]] to %[[VAL_3]] step %[[VAL_7]] {
// CHECK: scf.for %[[VAL_13:.*]] = %[[VAL_6]] to %[[VAL_4]] step %[[VAL_7]] {
-// CHECK: %[[VAL_14:.*]] = muli %[[VAL_12]], %[[VAL_4]] : index
-// CHECK: %[[VAL_15:.*]] = addi %[[VAL_14]], %[[VAL_13]] : index
+// CHECK: %[[VAL_14:.*]] = arith.muli %[[VAL_12]], %[[VAL_4]] : index
+// CHECK: %[[VAL_15:.*]] = arith.addi %[[VAL_14]], %[[VAL_13]] : index
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_6]] to %[[VAL_5]] step %[[VAL_7]] {
-// CHECK: %[[VAL_17:.*]] = muli %[[VAL_15]], %[[VAL_5]] : index
-// CHECK: %[[VAL_18:.*]] = addi %[[VAL_17]], %[[VAL_16]] : index
+// CHECK: %[[VAL_17:.*]] = arith.muli %[[VAL_15]], %[[VAL_5]] : index
+// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_17]], %[[VAL_16]] : index
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf32>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_12]], %[[VAL_13]], %[[VAL_16]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_19]], %[[VAL_20]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_19]], %[[VAL_20]] : f32
// CHECK: memref.store %[[VAL_21]], %[[VAL_11]]{{\[}}%[[VAL_12]], %[[VAL_13]], %[[VAL_16]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tddd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_8:.*]] = constant true
-// CHECK-DAG: %[[VAL_9:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_9:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_10:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_12:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_14]], %[[VAL_15]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_7]] to %[[VAL_4]] step %[[VAL_9]] {
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_7]] to %[[VAL_5]] step %[[VAL_9]] {
-// CHECK: %[[VAL_18:.*]] = muli %[[VAL_16]], %[[VAL_5]] : index
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_18]], %[[VAL_17]] : index
+// CHECK: %[[VAL_18:.*]] = arith.muli %[[VAL_16]], %[[VAL_5]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_18]], %[[VAL_17]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = addi %[[VAL_19]], %[[VAL_9]] : index
+// CHECK: %[[VAL_21:.*]] = arith.addi %[[VAL_19]], %[[VAL_9]] : index
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: %[[VAL_23:.*]]:2 = scf.while (%[[VAL_24:.*]] = %[[VAL_20]], %[[VAL_25:.*]] = %[[VAL_7]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_26:.*]] = cmpi ult, %[[VAL_24]], %[[VAL_22]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi ult, %[[VAL_24]], %[[VAL_22]] : index
// CHECK: scf.condition(%[[VAL_26]]) %[[VAL_24]], %[[VAL_25]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_27:.*]]: index, %[[VAL_28:.*]]: index):
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_30:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_28]] : index
+// CHECK: %[[VAL_30:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_28]] : index
// CHECK: scf.if %[[VAL_30]] {
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_27]]] : memref<?xf32>
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_16]], %[[VAL_17]], %[[VAL_28]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_33:.*]] = addf %[[VAL_31]], %[[VAL_32]] : f32
+// CHECK: %[[VAL_33:.*]] = arith.addf %[[VAL_31]], %[[VAL_32]] : f32
// CHECK: memref.store %[[VAL_33]], %[[VAL_15]]{{\[}}%[[VAL_16]], %[[VAL_17]], %[[VAL_28]]] : memref<32x16x8xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_8]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_29]], %[[VAL_28]] : index
-// CHECK: %[[VAL_36:.*]] = addi %[[VAL_27]], %[[VAL_9]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_29]], %[[VAL_28]] : index
+// CHECK: %[[VAL_36:.*]] = arith.addi %[[VAL_27]], %[[VAL_9]] : index
// CHECK: %[[VAL_37:.*]] = select %[[VAL_35]], %[[VAL_36]], %[[VAL_27]] : index
-// CHECK: %[[VAL_38:.*]] = addi %[[VAL_28]], %[[VAL_9]] : index
+// CHECK: %[[VAL_38:.*]] = arith.addi %[[VAL_28]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_37]], %[[VAL_38]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_39:.*]] = %[[VAL_40:.*]]#1 to %[[VAL_6]] step %[[VAL_9]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tdds>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 2 : index
-// CHECK: %[[VAL_4:.*]] = constant 32 : index
-// CHECK: %[[VAL_5:.*]] = constant 16 : index
-// CHECK: %[[VAL_6:.*]] = constant 0 : index
-// CHECK: %[[VAL_7:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 16 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_7:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_12]], %[[VAL_13]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_6]] to %[[VAL_4]] step %[[VAL_7]] {
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_6]] to %[[VAL_5]] step %[[VAL_7]] {
-// CHECK: %[[VAL_16:.*]] = muli %[[VAL_14]], %[[VAL_5]] : index
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_16]], %[[VAL_15]] : index
+// CHECK: %[[VAL_16:.*]] = arith.muli %[[VAL_14]], %[[VAL_5]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_16]], %[[VAL_15]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_17]], %[[VAL_7]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_17]], %[[VAL_7]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_7]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_21]]] : memref<?xf32>
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_14]], %[[VAL_15]], %[[VAL_22]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_25:.*]] = mulf %[[VAL_23]], %[[VAL_24]] : f32
+// CHECK: %[[VAL_25:.*]] = arith.mulf %[[VAL_23]], %[[VAL_24]] : f32
// CHECK: memref.store %[[VAL_25]], %[[VAL_13]]{{\[}}%[[VAL_14]], %[[VAL_15]], %[[VAL_22]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tdds>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_8:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_13]], %[[VAL_14]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_7]] to %[[VAL_3]] step %[[VAL_8]] {
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_15]]] : memref<?xindex>
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_15]], %[[VAL_8]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_15]], %[[VAL_8]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]]:2 = scf.while (%[[VAL_20:.*]] = %[[VAL_16]], %[[VAL_21:.*]] = %[[VAL_7]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_22:.*]] = cmpi ult, %[[VAL_20]], %[[VAL_18]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi ult, %[[VAL_20]], %[[VAL_18]] : index
// CHECK: scf.condition(%[[VAL_22]]) %[[VAL_20]], %[[VAL_21]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_23:.*]]: index, %[[VAL_24:.*]]: index):
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
// CHECK: scf.if %[[VAL_26]] {
// CHECK: scf.for %[[VAL_27:.*]] = %[[VAL_7]] to %[[VAL_5]] step %[[VAL_8]] {
-// CHECK: %[[VAL_28:.*]] = muli %[[VAL_23]], %[[VAL_5]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_28]], %[[VAL_27]] : index
+// CHECK: %[[VAL_28:.*]] = arith.muli %[[VAL_23]], %[[VAL_5]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_28]], %[[VAL_27]] : index
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_29]]] : memref<?xf32>
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_15]], %[[VAL_24]], %[[VAL_27]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_32:.*]] = addf %[[VAL_30]], %[[VAL_31]] : f32
+// CHECK: %[[VAL_32:.*]] = arith.addf %[[VAL_30]], %[[VAL_31]] : f32
// CHECK: memref.store %[[VAL_32]], %[[VAL_14]]{{\[}}%[[VAL_15]], %[[VAL_24]], %[[VAL_27]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: } else {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
-// CHECK: %[[VAL_36:.*]] = addi %[[VAL_23]], %[[VAL_8]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
+// CHECK: %[[VAL_36:.*]] = arith.addi %[[VAL_23]], %[[VAL_8]] : index
// CHECK: %[[VAL_37:.*]] = select %[[VAL_35]], %[[VAL_36]], %[[VAL_23]] : index
-// CHECK: %[[VAL_38:.*]] = addi %[[VAL_24]], %[[VAL_8]] : index
+// CHECK: %[[VAL_38:.*]] = arith.addi %[[VAL_24]], %[[VAL_8]] : index
// CHECK: scf.yield %[[VAL_37]], %[[VAL_38]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_39:.*]] = %[[VAL_40:.*]]#1 to %[[VAL_4]] step %[[VAL_8]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tdsd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_11]], %[[VAL_12]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_13:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_13]]] : memref<?xindex>
-// CHECK: %[[VAL_15:.*]] = addi %[[VAL_13]], %[[VAL_6]] : index
+// CHECK: %[[VAL_15:.*]] = arith.addi %[[VAL_13]], %[[VAL_6]] : index
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_14]] to %[[VAL_16]] step %[[VAL_6]] {
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_19:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_20:.*]] = muli %[[VAL_17]], %[[VAL_4]] : index
-// CHECK: %[[VAL_21:.*]] = addi %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_20:.*]] = arith.muli %[[VAL_17]], %[[VAL_4]] : index
+// CHECK: %[[VAL_21:.*]] = arith.addi %[[VAL_20]], %[[VAL_19]] : index
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_21]]] : memref<?xf32>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_13]], %[[VAL_18]], %[[VAL_19]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_24:.*]] = mulf %[[VAL_22]], %[[VAL_23]] : f32
+// CHECK: %[[VAL_24:.*]] = arith.mulf %[[VAL_22]], %[[VAL_23]] : f32
// CHECK: memref.store %[[VAL_24]], %[[VAL_12]]{{\[}}%[[VAL_13]], %[[VAL_18]], %[[VAL_19]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tdsd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant true
-// CHECK-DAG: %[[VAL_8:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_9:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_9:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_10:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_9]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_9]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_12:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: memref.copy %[[VAL_16]], %[[VAL_17]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_18:.*]] = %[[VAL_8]] to %[[VAL_4]] step %[[VAL_9]] {
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_20:.*]] = addi %[[VAL_18]], %[[VAL_9]] : index
+// CHECK: %[[VAL_20:.*]] = arith.addi %[[VAL_18]], %[[VAL_9]] : index
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]]:2 = scf.while (%[[VAL_23:.*]] = %[[VAL_19]], %[[VAL_24:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_25:.*]] = cmpi ult, %[[VAL_23]], %[[VAL_21]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi ult, %[[VAL_23]], %[[VAL_21]] : index
// CHECK: scf.condition(%[[VAL_25]]) %[[VAL_23]], %[[VAL_24]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_26:.*]]: index, %[[VAL_27:.*]]: index):
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_26]]] : memref<?xindex>
-// CHECK: %[[VAL_29:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
+// CHECK: %[[VAL_29:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
// CHECK: scf.if %[[VAL_29]] {
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_26]]] : memref<?xindex>
-// CHECK: %[[VAL_31:.*]] = addi %[[VAL_26]], %[[VAL_9]] : index
+// CHECK: %[[VAL_31:.*]] = arith.addi %[[VAL_26]], %[[VAL_9]] : index
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_31]]] : memref<?xindex>
// CHECK: %[[VAL_33:.*]]:2 = scf.while (%[[VAL_34:.*]] = %[[VAL_30]], %[[VAL_35:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_36:.*]] = cmpi ult, %[[VAL_34]], %[[VAL_32]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi ult, %[[VAL_34]], %[[VAL_32]] : index
// CHECK: scf.condition(%[[VAL_36]]) %[[VAL_34]], %[[VAL_35]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_37:.*]]: index, %[[VAL_38:.*]]: index):
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_37]]] : memref<?xindex>
-// CHECK: %[[VAL_40:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_40:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
// CHECK: scf.if %[[VAL_40]] {
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_37]]] : memref<?xf32>
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_18]], %[[VAL_27]], %[[VAL_38]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_43:.*]] = addf %[[VAL_41]], %[[VAL_42]] : f32
+// CHECK: %[[VAL_43:.*]] = arith.addf %[[VAL_41]], %[[VAL_42]] : f32
// CHECK: memref.store %[[VAL_43]], %[[VAL_17]]{{\[}}%[[VAL_18]], %[[VAL_27]], %[[VAL_38]]] : memref<32x16x8xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_7]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_45:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
-// CHECK: %[[VAL_46:.*]] = addi %[[VAL_37]], %[[VAL_9]] : index
+// CHECK: %[[VAL_45:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_46:.*]] = arith.addi %[[VAL_37]], %[[VAL_9]] : index
// CHECK: %[[VAL_47:.*]] = select %[[VAL_45]], %[[VAL_46]], %[[VAL_37]] : index
-// CHECK: %[[VAL_48:.*]] = addi %[[VAL_38]], %[[VAL_9]] : index
+// CHECK: %[[VAL_48:.*]] = arith.addi %[[VAL_38]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_47]], %[[VAL_48]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_49:.*]] = %[[VAL_50:.*]]#1 to %[[VAL_6]] step %[[VAL_9]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_54:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
-// CHECK: %[[VAL_55:.*]] = addi %[[VAL_26]], %[[VAL_9]] : index
+// CHECK: %[[VAL_54:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
+// CHECK: %[[VAL_55:.*]] = arith.addi %[[VAL_26]], %[[VAL_9]] : index
// CHECK: %[[VAL_56:.*]] = select %[[VAL_54]], %[[VAL_55]], %[[VAL_26]] : index
-// CHECK: %[[VAL_57:.*]] = addi %[[VAL_27]], %[[VAL_9]] : index
+// CHECK: %[[VAL_57:.*]] = arith.addi %[[VAL_27]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_56]], %[[VAL_57]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_58:.*]] = %[[VAL_59:.*]]#1 to %[[VAL_5]] step %[[VAL_9]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tdss>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: memref.copy %[[VAL_13]], %[[VAL_14]] : memref<32x16x8xf32> to memref<32x16x8xf32>
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_15]], %[[VAL_6]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_15]], %[[VAL_6]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_19:.*]] = %[[VAL_16]] to %[[VAL_18]] step %[[VAL_6]] {
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_22:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_21]] to %[[VAL_23]] step %[[VAL_6]] {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_24]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_24]]] : memref<?xf32>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_15]], %[[VAL_20]], %[[VAL_25]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_28:.*]] = mulf %[[VAL_26]], %[[VAL_27]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.mulf %[[VAL_26]], %[[VAL_27]] : f32
// CHECK: memref.store %[[VAL_28]], %[[VAL_14]]{{\[}}%[[VAL_15]], %[[VAL_20]], %[[VAL_25]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tdss>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_8:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_7]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_7]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_8]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]]:2 = scf.while (%[[VAL_18:.*]] = %[[VAL_15]], %[[VAL_19:.*]] = %[[VAL_7]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_20:.*]] = cmpi ult, %[[VAL_18]], %[[VAL_16]] : index
+// CHECK: %[[VAL_20:.*]] = arith.cmpi ult, %[[VAL_18]], %[[VAL_16]] : index
// CHECK: scf.condition(%[[VAL_20]]) %[[VAL_18]], %[[VAL_19]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_21:.*]]: index, %[[VAL_22:.*]]: index):
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_21]]] : memref<?xindex>
-// CHECK: %[[VAL_24:.*]] = cmpi eq, %[[VAL_23]], %[[VAL_22]] : index
+// CHECK: %[[VAL_24:.*]] = arith.cmpi eq, %[[VAL_23]], %[[VAL_22]] : index
// CHECK: scf.if %[[VAL_24]] {
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_7]] to %[[VAL_4]] step %[[VAL_8]] {
-// CHECK: %[[VAL_26:.*]] = muli %[[VAL_21]], %[[VAL_4]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_26:.*]] = arith.muli %[[VAL_21]], %[[VAL_4]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_26]], %[[VAL_25]] : index
// CHECK: scf.for %[[VAL_28:.*]] = %[[VAL_7]] to %[[VAL_5]] step %[[VAL_8]] {
-// CHECK: %[[VAL_29:.*]] = muli %[[VAL_27]], %[[VAL_5]] : index
-// CHECK: %[[VAL_30:.*]] = addi %[[VAL_29]], %[[VAL_28]] : index
+// CHECK: %[[VAL_29:.*]] = arith.muli %[[VAL_27]], %[[VAL_5]] : index
+// CHECK: %[[VAL_30:.*]] = arith.addi %[[VAL_29]], %[[VAL_28]] : index
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_30]]] : memref<?xf32>
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_22]], %[[VAL_25]], %[[VAL_28]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_33:.*]] = addf %[[VAL_31]], %[[VAL_32]] : f32
+// CHECK: %[[VAL_33:.*]] = arith.addf %[[VAL_31]], %[[VAL_32]] : f32
// CHECK: memref.store %[[VAL_33]], %[[VAL_14]]{{\[}}%[[VAL_22]], %[[VAL_25]], %[[VAL_28]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_37:.*]] = cmpi eq, %[[VAL_23]], %[[VAL_22]] : index
-// CHECK: %[[VAL_38:.*]] = addi %[[VAL_21]], %[[VAL_8]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi eq, %[[VAL_23]], %[[VAL_22]] : index
+// CHECK: %[[VAL_38:.*]] = arith.addi %[[VAL_21]], %[[VAL_8]] : index
// CHECK: %[[VAL_39:.*]] = select %[[VAL_37]], %[[VAL_38]], %[[VAL_21]] : index
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_22]], %[[VAL_8]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_22]], %[[VAL_8]] : index
// CHECK: scf.yield %[[VAL_39]], %[[VAL_40]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_41:.*]] = %[[VAL_42:.*]]#1 to %[[VAL_3]] step %[[VAL_8]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tsdd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_13]] to %[[VAL_14]] step %[[VAL_6]] {
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
-// CHECK: %[[VAL_18:.*]] = muli %[[VAL_15]], %[[VAL_3]] : index
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_18]], %[[VAL_17]] : index
+// CHECK: %[[VAL_18:.*]] = arith.muli %[[VAL_15]], %[[VAL_3]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_18]], %[[VAL_17]] : index
// CHECK: scf.for %[[VAL_20:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_21:.*]] = muli %[[VAL_19]], %[[VAL_4]] : index
-// CHECK: %[[VAL_22:.*]] = addi %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_21:.*]] = arith.muli %[[VAL_19]], %[[VAL_4]] : index
+// CHECK: %[[VAL_22:.*]] = arith.addi %[[VAL_21]], %[[VAL_20]] : index
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<?xf32>
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_16]], %[[VAL_17]], %[[VAL_20]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_25:.*]] = mulf %[[VAL_23]], %[[VAL_24]] : f32
+// CHECK: %[[VAL_25:.*]] = arith.mulf %[[VAL_23]], %[[VAL_24]] : f32
// CHECK: memref.store %[[VAL_25]], %[[VAL_12]]{{\[}}%[[VAL_16]], %[[VAL_17]], %[[VAL_20]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tsdd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant true
-// CHECK-DAG: %[[VAL_8:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_9:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_9:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_10:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_12:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_8]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_9]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]]:2 = scf.while (%[[VAL_21:.*]] = %[[VAL_18]], %[[VAL_22:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_23:.*]] = cmpi ult, %[[VAL_21]], %[[VAL_19]] : index
+// CHECK: %[[VAL_23:.*]] = arith.cmpi ult, %[[VAL_21]], %[[VAL_19]] : index
// CHECK: scf.condition(%[[VAL_23]]) %[[VAL_21]], %[[VAL_22]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_24:.*]]: index, %[[VAL_25:.*]]: index):
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_24]]] : memref<?xindex>
-// CHECK: %[[VAL_27:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_25]] : index
// CHECK: scf.if %[[VAL_27]] {
// CHECK: scf.for %[[VAL_28:.*]] = %[[VAL_8]] to %[[VAL_5]] step %[[VAL_9]] {
-// CHECK: %[[VAL_29:.*]] = muli %[[VAL_24]], %[[VAL_5]] : index
-// CHECK: %[[VAL_30:.*]] = addi %[[VAL_29]], %[[VAL_28]] : index
+// CHECK: %[[VAL_29:.*]] = arith.muli %[[VAL_24]], %[[VAL_5]] : index
+// CHECK: %[[VAL_30:.*]] = arith.addi %[[VAL_29]], %[[VAL_28]] : index
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_30]]] : memref<?xindex>
-// CHECK: %[[VAL_32:.*]] = addi %[[VAL_30]], %[[VAL_9]] : index
+// CHECK: %[[VAL_32:.*]] = arith.addi %[[VAL_30]], %[[VAL_9]] : index
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<?xindex>
// CHECK: %[[VAL_34:.*]]:2 = scf.while (%[[VAL_35:.*]] = %[[VAL_31]], %[[VAL_36:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_37:.*]] = cmpi ult, %[[VAL_35]], %[[VAL_33]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi ult, %[[VAL_35]], %[[VAL_33]] : index
// CHECK: scf.condition(%[[VAL_37]]) %[[VAL_35]], %[[VAL_36]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_38:.*]]: index, %[[VAL_39:.*]]: index):
// CHECK: %[[VAL_40:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_38]]] : memref<?xindex>
-// CHECK: %[[VAL_41:.*]] = cmpi eq, %[[VAL_40]], %[[VAL_39]] : index
+// CHECK: %[[VAL_41:.*]] = arith.cmpi eq, %[[VAL_40]], %[[VAL_39]] : index
// CHECK: scf.if %[[VAL_41]] {
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_38]]] : memref<?xf32>
// CHECK: %[[VAL_43:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_25]], %[[VAL_28]], %[[VAL_39]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_44:.*]] = addf %[[VAL_42]], %[[VAL_43]] : f32
+// CHECK: %[[VAL_44:.*]] = arith.addf %[[VAL_42]], %[[VAL_43]] : f32
// CHECK: memref.store %[[VAL_44]], %[[VAL_17]]{{\[}}%[[VAL_25]], %[[VAL_28]], %[[VAL_39]]] : memref<32x16x8xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_7]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_46:.*]] = cmpi eq, %[[VAL_40]], %[[VAL_39]] : index
-// CHECK: %[[VAL_47:.*]] = addi %[[VAL_38]], %[[VAL_9]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi eq, %[[VAL_40]], %[[VAL_39]] : index
+// CHECK: %[[VAL_47:.*]] = arith.addi %[[VAL_38]], %[[VAL_9]] : index
// CHECK: %[[VAL_48:.*]] = select %[[VAL_46]], %[[VAL_47]], %[[VAL_38]] : index
-// CHECK: %[[VAL_49:.*]] = addi %[[VAL_39]], %[[VAL_9]] : index
+// CHECK: %[[VAL_49:.*]] = arith.addi %[[VAL_39]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_48]], %[[VAL_49]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_50:.*]] = %[[VAL_51:.*]]#1 to %[[VAL_6]] step %[[VAL_9]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_56:.*]] = cmpi eq, %[[VAL_26]], %[[VAL_25]] : index
-// CHECK: %[[VAL_57:.*]] = addi %[[VAL_24]], %[[VAL_9]] : index
+// CHECK: %[[VAL_56:.*]] = arith.cmpi eq, %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_57:.*]] = arith.addi %[[VAL_24]], %[[VAL_9]] : index
// CHECK: %[[VAL_58:.*]] = select %[[VAL_56]], %[[VAL_57]], %[[VAL_24]] : index
-// CHECK: %[[VAL_59:.*]] = addi %[[VAL_25]], %[[VAL_9]] : index
+// CHECK: %[[VAL_59:.*]] = arith.addi %[[VAL_25]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_58]], %[[VAL_59]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_60:.*]] = %[[VAL_61:.*]]#1 to %[[VAL_4]] step %[[VAL_9]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tsds>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_15]] to %[[VAL_16]] step %[[VAL_6]] {
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_19:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_20:.*]] = muli %[[VAL_17]], %[[VAL_4]] : index
-// CHECK: %[[VAL_21:.*]] = addi %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_20:.*]] = arith.muli %[[VAL_17]], %[[VAL_4]] : index
+// CHECK: %[[VAL_21:.*]] = arith.addi %[[VAL_20]], %[[VAL_19]] : index
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_21]]] : memref<?xindex>
-// CHECK: %[[VAL_23:.*]] = addi %[[VAL_21]], %[[VAL_6]] : index
+// CHECK: %[[VAL_23:.*]] = arith.addi %[[VAL_21]], %[[VAL_6]] : index
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_22]] to %[[VAL_24]] step %[[VAL_6]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_25]]] : memref<?xindex>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_25]]] : memref<?xf32>
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_18]], %[[VAL_19]], %[[VAL_26]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_29:.*]] = mulf %[[VAL_27]], %[[VAL_28]] : f32
+// CHECK: %[[VAL_29:.*]] = arith.mulf %[[VAL_27]], %[[VAL_28]] : f32
// CHECK: memref.store %[[VAL_29]], %[[VAL_14]]{{\[}}%[[VAL_18]], %[[VAL_19]], %[[VAL_26]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tsds>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant true
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_8:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_7]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_7]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_7]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_8]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]]:2 = scf.while (%[[VAL_20:.*]] = %[[VAL_17]], %[[VAL_21:.*]] = %[[VAL_7]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_22:.*]] = cmpi ult, %[[VAL_20]], %[[VAL_18]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi ult, %[[VAL_20]], %[[VAL_18]] : index
// CHECK: scf.condition(%[[VAL_22]]) %[[VAL_20]], %[[VAL_21]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_23:.*]]: index, %[[VAL_24:.*]]: index):
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
// CHECK: scf.if %[[VAL_26]] {
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_28:.*]] = addi %[[VAL_23]], %[[VAL_8]] : index
+// CHECK: %[[VAL_28:.*]] = arith.addi %[[VAL_23]], %[[VAL_8]] : index
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_28]]] : memref<?xindex>
// CHECK: %[[VAL_30:.*]]:2 = scf.while (%[[VAL_31:.*]] = %[[VAL_27]], %[[VAL_32:.*]] = %[[VAL_7]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_33:.*]] = cmpi ult, %[[VAL_31]], %[[VAL_29]] : index
+// CHECK: %[[VAL_33:.*]] = arith.cmpi ult, %[[VAL_31]], %[[VAL_29]] : index
// CHECK: scf.condition(%[[VAL_33]]) %[[VAL_31]], %[[VAL_32]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_34:.*]]: index, %[[VAL_35:.*]]: index):
// CHECK: %[[VAL_36:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_34]]] : memref<?xindex>
-// CHECK: %[[VAL_37:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_35]] : index
+// CHECK: %[[VAL_37:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_35]] : index
// CHECK: scf.if %[[VAL_37]] {
// CHECK: scf.for %[[VAL_38:.*]] = %[[VAL_7]] to %[[VAL_5]] step %[[VAL_8]] {
-// CHECK: %[[VAL_39:.*]] = muli %[[VAL_34]], %[[VAL_5]] : index
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_39:.*]] = arith.muli %[[VAL_34]], %[[VAL_5]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_39]], %[[VAL_38]] : index
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_40]]] : memref<?xf32>
// CHECK: %[[VAL_42:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_24]], %[[VAL_35]], %[[VAL_38]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_43:.*]] = addf %[[VAL_41]], %[[VAL_42]] : f32
+// CHECK: %[[VAL_43:.*]] = arith.addf %[[VAL_41]], %[[VAL_42]] : f32
// CHECK: memref.store %[[VAL_43]], %[[VAL_16]]{{\[}}%[[VAL_24]], %[[VAL_35]], %[[VAL_38]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: } else {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_46:.*]] = cmpi eq, %[[VAL_36]], %[[VAL_35]] : index
-// CHECK: %[[VAL_47:.*]] = addi %[[VAL_34]], %[[VAL_8]] : index
+// CHECK: %[[VAL_46:.*]] = arith.cmpi eq, %[[VAL_36]], %[[VAL_35]] : index
+// CHECK: %[[VAL_47:.*]] = arith.addi %[[VAL_34]], %[[VAL_8]] : index
// CHECK: %[[VAL_48:.*]] = select %[[VAL_46]], %[[VAL_47]], %[[VAL_34]] : index
-// CHECK: %[[VAL_49:.*]] = addi %[[VAL_35]], %[[VAL_8]] : index
+// CHECK: %[[VAL_49:.*]] = arith.addi %[[VAL_35]], %[[VAL_8]] : index
// CHECK: scf.yield %[[VAL_48]], %[[VAL_49]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_50:.*]] = %[[VAL_51:.*]]#1 to %[[VAL_4]] step %[[VAL_8]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_57:.*]] = cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
-// CHECK: %[[VAL_58:.*]] = addi %[[VAL_23]], %[[VAL_8]] : index
+// CHECK: %[[VAL_57:.*]] = arith.cmpi eq, %[[VAL_25]], %[[VAL_24]] : index
+// CHECK: %[[VAL_58:.*]] = arith.addi %[[VAL_23]], %[[VAL_8]] : index
// CHECK: %[[VAL_59:.*]] = select %[[VAL_57]], %[[VAL_58]], %[[VAL_23]] : index
-// CHECK: %[[VAL_60:.*]] = addi %[[VAL_24]], %[[VAL_8]] : index
+// CHECK: %[[VAL_60:.*]] = arith.addi %[[VAL_24]], %[[VAL_8]] : index
// CHECK: scf.yield %[[VAL_59]], %[[VAL_60]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_61:.*]] = %[[VAL_62:.*]]#1 to %[[VAL_3]] step %[[VAL_8]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tssd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_14]] to %[[VAL_15]] step %[[VAL_5]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_16]], %[[VAL_5]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_16]], %[[VAL_5]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_5]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_23:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
-// CHECK: %[[VAL_24:.*]] = muli %[[VAL_21]], %[[VAL_3]] : index
-// CHECK: %[[VAL_25:.*]] = addi %[[VAL_24]], %[[VAL_23]] : index
+// CHECK: %[[VAL_24:.*]] = arith.muli %[[VAL_21]], %[[VAL_3]] : index
+// CHECK: %[[VAL_25:.*]] = arith.addi %[[VAL_24]], %[[VAL_23]] : index
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_25]]] : memref<?xf32>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_17]], %[[VAL_22]], %[[VAL_23]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_28:.*]] = mulf %[[VAL_26]], %[[VAL_27]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.mulf %[[VAL_26]], %[[VAL_27]] : f32
// CHECK: memref.store %[[VAL_28]], %[[VAL_13]]{{\[}}%[[VAL_17]], %[[VAL_22]], %[[VAL_23]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tssd>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 16 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 8 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant true
-// CHECK-DAG: %[[VAL_8:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_9:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 16 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_9:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_10:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_8]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_12:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_9]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_8]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_9]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]]:2 = scf.while (%[[VAL_23:.*]] = %[[VAL_20]], %[[VAL_24:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_25:.*]] = cmpi ult, %[[VAL_23]], %[[VAL_21]] : index
+// CHECK: %[[VAL_25:.*]] = arith.cmpi ult, %[[VAL_23]], %[[VAL_21]] : index
// CHECK: scf.condition(%[[VAL_25]]) %[[VAL_23]], %[[VAL_24]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_26:.*]]: index, %[[VAL_27:.*]]: index):
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_26]]] : memref<?xindex>
-// CHECK: %[[VAL_29:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
+// CHECK: %[[VAL_29:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
// CHECK: scf.if %[[VAL_29]] {
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_26]]] : memref<?xindex>
-// CHECK: %[[VAL_31:.*]] = addi %[[VAL_26]], %[[VAL_9]] : index
+// CHECK: %[[VAL_31:.*]] = arith.addi %[[VAL_26]], %[[VAL_9]] : index
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_31]]] : memref<?xindex>
// CHECK: %[[VAL_33:.*]]:2 = scf.while (%[[VAL_34:.*]] = %[[VAL_30]], %[[VAL_35:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_36:.*]] = cmpi ult, %[[VAL_34]], %[[VAL_32]] : index
+// CHECK: %[[VAL_36:.*]] = arith.cmpi ult, %[[VAL_34]], %[[VAL_32]] : index
// CHECK: scf.condition(%[[VAL_36]]) %[[VAL_34]], %[[VAL_35]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_37:.*]]: index, %[[VAL_38:.*]]: index):
// CHECK: %[[VAL_39:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_37]]] : memref<?xindex>
-// CHECK: %[[VAL_40:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_40:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
// CHECK: scf.if %[[VAL_40]] {
// CHECK: %[[VAL_41:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_37]]] : memref<?xindex>
-// CHECK: %[[VAL_42:.*]] = addi %[[VAL_37]], %[[VAL_9]] : index
+// CHECK: %[[VAL_42:.*]] = arith.addi %[[VAL_37]], %[[VAL_9]] : index
// CHECK: %[[VAL_43:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_42]]] : memref<?xindex>
// CHECK: %[[VAL_44:.*]]:2 = scf.while (%[[VAL_45:.*]] = %[[VAL_41]], %[[VAL_46:.*]] = %[[VAL_8]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_47:.*]] = cmpi ult, %[[VAL_45]], %[[VAL_43]] : index
+// CHECK: %[[VAL_47:.*]] = arith.cmpi ult, %[[VAL_45]], %[[VAL_43]] : index
// CHECK: scf.condition(%[[VAL_47]]) %[[VAL_45]], %[[VAL_46]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_48:.*]]: index, %[[VAL_49:.*]]: index):
// CHECK: %[[VAL_50:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_48]]] : memref<?xindex>
-// CHECK: %[[VAL_51:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_49]] : index
+// CHECK: %[[VAL_51:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_49]] : index
// CHECK: scf.if %[[VAL_51]] {
// CHECK: %[[VAL_52:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_48]]] : memref<?xf32>
// CHECK: %[[VAL_53:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_27]], %[[VAL_38]], %[[VAL_49]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_54:.*]] = addf %[[VAL_52]], %[[VAL_53]] : f32
+// CHECK: %[[VAL_54:.*]] = arith.addf %[[VAL_52]], %[[VAL_53]] : f32
// CHECK: memref.store %[[VAL_54]], %[[VAL_19]]{{\[}}%[[VAL_27]], %[[VAL_38]], %[[VAL_49]]] : memref<32x16x8xf32>
// CHECK: } else {
// CHECK: scf.if %[[VAL_7]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_56:.*]] = cmpi eq, %[[VAL_50]], %[[VAL_49]] : index
-// CHECK: %[[VAL_57:.*]] = addi %[[VAL_48]], %[[VAL_9]] : index
+// CHECK: %[[VAL_56:.*]] = arith.cmpi eq, %[[VAL_50]], %[[VAL_49]] : index
+// CHECK: %[[VAL_57:.*]] = arith.addi %[[VAL_48]], %[[VAL_9]] : index
// CHECK: %[[VAL_58:.*]] = select %[[VAL_56]], %[[VAL_57]], %[[VAL_48]] : index
-// CHECK: %[[VAL_59:.*]] = addi %[[VAL_49]], %[[VAL_9]] : index
+// CHECK: %[[VAL_59:.*]] = arith.addi %[[VAL_49]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_58]], %[[VAL_59]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_60:.*]] = %[[VAL_61:.*]]#1 to %[[VAL_6]] step %[[VAL_9]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_65:.*]] = cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
-// CHECK: %[[VAL_66:.*]] = addi %[[VAL_37]], %[[VAL_9]] : index
+// CHECK: %[[VAL_65:.*]] = arith.cmpi eq, %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_66:.*]] = arith.addi %[[VAL_37]], %[[VAL_9]] : index
// CHECK: %[[VAL_67:.*]] = select %[[VAL_65]], %[[VAL_66]], %[[VAL_37]] : index
-// CHECK: %[[VAL_68:.*]] = addi %[[VAL_38]], %[[VAL_9]] : index
+// CHECK: %[[VAL_68:.*]] = arith.addi %[[VAL_38]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_67]], %[[VAL_68]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_69:.*]] = %[[VAL_70:.*]]#1 to %[[VAL_5]] step %[[VAL_9]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_76:.*]] = cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
-// CHECK: %[[VAL_77:.*]] = addi %[[VAL_26]], %[[VAL_9]] : index
+// CHECK: %[[VAL_76:.*]] = arith.cmpi eq, %[[VAL_28]], %[[VAL_27]] : index
+// CHECK: %[[VAL_77:.*]] = arith.addi %[[VAL_26]], %[[VAL_9]] : index
// CHECK: %[[VAL_78:.*]] = select %[[VAL_76]], %[[VAL_77]], %[[VAL_26]] : index
-// CHECK: %[[VAL_79:.*]] = addi %[[VAL_27]], %[[VAL_9]] : index
+// CHECK: %[[VAL_79:.*]] = arith.addi %[[VAL_27]], %[[VAL_9]] : index
// CHECK: scf.yield %[[VAL_78]], %[[VAL_79]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_80:.*]] = %[[VAL_81:.*]]#1 to %[[VAL_4]] step %[[VAL_9]] {
ins(%arga, %argb: tensor<32x16x8xf32, #Tsss>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = addf %a, %b : f32
+ %0 = arith.addf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16x8xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16x8xf32>) -> tensor<32x16x8xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x16x8xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: scf.for %[[VAL_18:.*]] = %[[VAL_16]] to %[[VAL_17]] step %[[VAL_5]] {
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = addi %[[VAL_18]], %[[VAL_5]] : index
+// CHECK: %[[VAL_21:.*]] = arith.addi %[[VAL_18]], %[[VAL_5]] : index
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_23:.*]] = %[[VAL_20]] to %[[VAL_22]] step %[[VAL_5]] {
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_23]]] : memref<?xindex>
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_23]]] : memref<?xindex>
-// CHECK: %[[VAL_26:.*]] = addi %[[VAL_23]], %[[VAL_5]] : index
+// CHECK: %[[VAL_26:.*]] = arith.addi %[[VAL_23]], %[[VAL_5]] : index
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_26]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_28:.*]] = %[[VAL_25]] to %[[VAL_27]] step %[[VAL_5]] {
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_28]]] : memref<?xindex>
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_28]]] : memref<?xf32>
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_19]], %[[VAL_24]], %[[VAL_29]]] : memref<32x16x8xf32>
-// CHECK: %[[VAL_32:.*]] = mulf %[[VAL_30]], %[[VAL_31]] : f32
+// CHECK: %[[VAL_32:.*]] = arith.mulf %[[VAL_30]], %[[VAL_31]] : f32
// CHECK: memref.store %[[VAL_32]], %[[VAL_15]]{{\[}}%[[VAL_19]], %[[VAL_24]], %[[VAL_29]]] : memref<32x16x8xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16x8xf32, #Tsss>, tensor<32x16x8xf32>)
outs(%argx: tensor<32x16x8xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<32x16x8xf32>
return %0 : tensor<32x16x8xf32>
// CHECK-SAME: %[[VAL_1:.*1]]: tensor<?x?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*2]]: tensor<?x?xf32>,
// CHECK-SAME: %[[VAL_3:.*3]]: tensor<?x?xf32>) -> tensor<?x?xf32> {
-// CHECK-DAG: %[[VAL_4:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_4]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_4]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_1]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: memref.copy %[[VAL_15]], %[[VAL_16]] : memref<?x?xf32> to memref<?x?xf32>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_5]] to %[[VAL_13]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_18:.*]] = %[[VAL_5]] to %[[VAL_10]] step %[[VAL_6]] {
-// CHECK: %[[VAL_19:.*]] = muli %[[VAL_10]], %[[VAL_17]] : index
-// CHECK: %[[VAL_20:.*]] = addi %[[VAL_19]], %[[VAL_18]] : index
+// CHECK: %[[VAL_19:.*]] = arith.muli %[[VAL_10]], %[[VAL_17]] : index
+// CHECK: %[[VAL_20:.*]] = arith.addi %[[VAL_19]], %[[VAL_18]] : index
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_20]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = addi %[[VAL_20]], %[[VAL_6]] : index
+// CHECK: %[[VAL_22:.*]] = arith.addi %[[VAL_20]], %[[VAL_6]] : index
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_22]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_21]] to %[[VAL_23]] step %[[VAL_6]] {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_24]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_24]]] : memref<?xf32>
// CHECK: scf.for %[[VAL_27:.*]] = %[[VAL_5]] to %[[VAL_14]] step %[[VAL_6]] {
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_18]], %[[VAL_27]]] : memref<?x?xf32>
-// CHECK: %[[VAL_29:.*]] = mulf %[[VAL_26]], %[[VAL_28]] : f32
+// CHECK: %[[VAL_29:.*]] = arith.mulf %[[VAL_26]], %[[VAL_28]] : f32
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_25]], %[[VAL_27]]] : memref<?x?xf32>
-// CHECK: %[[VAL_31:.*]] = mulf %[[VAL_29]], %[[VAL_30]] : f32
+// CHECK: %[[VAL_31:.*]] = arith.mulf %[[VAL_29]], %[[VAL_30]] : f32
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_17]], %[[VAL_27]]] : memref<?x?xf32>
-// CHECK: %[[VAL_33:.*]] = addf %[[VAL_31]], %[[VAL_32]] : f32
+// CHECK: %[[VAL_33:.*]] = arith.addf %[[VAL_31]], %[[VAL_32]] : f32
// CHECK: memref.store %[[VAL_33]], %[[VAL_16]]{{\[}}%[[VAL_17]], %[[VAL_27]]] : memref<?x?xf32>
// CHECK: }
// CHECK: }
ins(%argb, %argc, %argd: tensor<?x?x?xf32, #Tdds>, tensor<?x?xf32>, tensor<?x?xf32>)
outs(%arga: tensor<?x?xf32>) {
^bb(%b: f32, %c: f32, %d: f32, %a: f32):
- %0 = mulf %b, %c : f32
- %1 = mulf %0, %d : f32
- %2 = addf %1, %a : f32
+ %0 = arith.mulf %b, %c : f32
+ %1 = arith.mulf %0, %d : f32
+ %2 = arith.addf %1, %a : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
// CHECK-LABEL: func @sum_reduction(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20x30xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<10x20x30xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<10x20x30xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<10x20x30xf32, #sparse_tensor.encoding<{ dimLevelType = [ "compressed", "compressed", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_13:.*]] = %[[VAL_11]] to %[[VAL_12]] step %[[VAL_4]] {
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_13]]] : memref<?xindex>
-// CHECK: %[[VAL_15:.*]] = addi %[[VAL_13]], %[[VAL_4]] : index
+// CHECK: %[[VAL_15:.*]] = arith.addi %[[VAL_13]], %[[VAL_4]] : index
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_14]] to %[[VAL_16]] step %[[VAL_4]] {
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_17]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_17]], %[[VAL_4]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_17]], %[[VAL_4]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_10]][] : memref<f32>
// CHECK: %[[VAL_22:.*]] = scf.for %[[VAL_23:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_4]] iter_args(%[[VAL_24:.*]] = %[[VAL_21]]) -> (f32) {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_23]]] : memref<?xf32>
-// CHECK: %[[VAL_26:.*]] = addf %[[VAL_24]], %[[VAL_25]] : f32
+// CHECK: %[[VAL_26:.*]] = arith.addf %[[VAL_24]], %[[VAL_25]] : f32
// CHECK: scf.yield %[[VAL_26]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_27:.*]], %[[VAL_10]][] : memref<f32>
ins(%arga: tensor<10x20x30xf32, #Tsss>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %x, %a : f32
+ %0 = arith.addf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<?x?x?xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<?xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = tensor.dim %[[VAL_0]], %[[VAL_5]] : tensor<?x?x?xf32>
// CHECK: %[[VAL_7:.*]] = tensor.dim %[[VAL_0]], %[[VAL_3]] : tensor<?x?x?xf32>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_0]] : memref<?x?x?xf32>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_12]][] : memref<f32>
// CHECK: %[[VAL_17:.*]] = scf.for %[[VAL_18:.*]] = %[[VAL_4]] to %[[VAL_7]] step %[[VAL_5]] iter_args(%[[VAL_19:.*]] = %[[VAL_16]]) -> (f32) {
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_13]], %[[VAL_15]], %[[VAL_18]]] : memref<?x?x?xf32>
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_20]], %[[VAL_14]] : f32
-// CHECK: %[[VAL_22:.*]] = addf %[[VAL_19]], %[[VAL_21]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_20]], %[[VAL_14]] : f32
+// CHECK: %[[VAL_22:.*]] = arith.addf %[[VAL_19]], %[[VAL_21]] : f32
// CHECK: scf.yield %[[VAL_22]] : f32
// CHECK: }
// CHECK: memref.store %[[VAL_23:.*]], %[[VAL_12]][] : memref<f32>
ins(%arga, %argb: tensor<?x?x?xf32>, tensor<?xf32, #Td>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = addf %x, %0 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.addf %x, %0 : f32
linalg.yield %1 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_1:.*]]: tensor<20xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<30xf32>,
// CHECK-SAME: %[[VAL_3:.*]]: tensor<10x20x30xf32>) -> tensor<10x20x30xf32> {
-// CHECK-DAG: %[[VAL_4:.*]] = constant 10 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 20 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 30 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_8:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 10 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 20 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 30 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_8:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<10xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf32>
// CHECK: %[[VAL_10:.*]] = memref.buffer_cast %[[VAL_1]] : memref<20xf32>
// CHECK: %[[VAL_11:.*]] = memref.buffer_cast %[[VAL_2]] : memref<30xf32>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_7]] to %[[VAL_5]] step %[[VAL_8]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_16]]] : memref<20xf32>
// CHECK: scf.for %[[VAL_18:.*]] = %[[VAL_7]] to %[[VAL_6]] step %[[VAL_8]] {
-// CHECK: %[[VAL_19:.*]] = mulf %[[VAL_15]], %[[VAL_17]] : f32
+// CHECK: %[[VAL_19:.*]] = arith.mulf %[[VAL_15]], %[[VAL_17]] : f32
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_18]]] : memref<30xf32>
-// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_19]], %[[VAL_20]] : f32
+// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_19]], %[[VAL_20]] : f32
// CHECK: memref.store %[[VAL_21]], %[[VAL_13]]{{\[}}%[[VAL_14]], %[[VAL_16]], %[[VAL_18]]] : memref<10x20x30xf32>
// CHECK: }
// CHECK: }
ins(%arga, %argb, %argc : tensor<10xf32, #Td>, tensor<20xf32>, tensor<30xf32>)
outs(%argx: tensor<10x20x30xf32>) {
^bb(%a: f32, %b: f32, %c: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = mulf %0, %c : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.mulf %0, %c : f32
linalg.yield %1 : f32
} -> tensor<10x20x30xf32>
return %0 : tensor<10x20x30xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<4xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf32>) -> tensor<32xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 3 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_16]]] : memref<32xf32>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_15]]] : memref<?xf32>
-// CHECK: %[[VAL_19:.*]] = mulf %[[VAL_18]], %[[VAL_12]] : f32
-// CHECK: %[[VAL_20:.*]] = addf %[[VAL_17]], %[[VAL_19]] : f32
+// CHECK: %[[VAL_19:.*]] = arith.mulf %[[VAL_18]], %[[VAL_12]] : f32
+// CHECK: %[[VAL_20:.*]] = arith.addf %[[VAL_17]], %[[VAL_19]] : f32
// CHECK: memref.store %[[VAL_20]], %[[VAL_11]]{{\[}}%[[VAL_16]]] : memref<32xf32>
// CHECK: }
// CHECK: %[[VAL_21:.*]] = memref.tensor_load %[[VAL_11]] : memref<32xf32>
ins(%arga, %argb: tensor<32xf32, #SpVec>, tensor<4xf32>)
outs(%argx: tensor<32xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = addf %x, %0 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.addf %x, %0 : f32
linalg.yield %1 : f32
} -> tensor<32xf32>
return %0 : tensor<32xf32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<34xi32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi32>) -> tensor<32xi32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 2 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 2 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_12]] to %[[VAL_13]] step %[[VAL_4]] {
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_14]]] : memref<?xi32>
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_15]], %[[VAL_5]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_15]], %[[VAL_5]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_17]]] : memref<34xi32>
-// CHECK: %[[VAL_19:.*]] = and %[[VAL_16]], %[[VAL_18]] : i32
+// CHECK: %[[VAL_19:.*]] = arith.andi %[[VAL_16]], %[[VAL_18]] : i32
// CHECK: memref.store %[[VAL_19]], %[[VAL_11]]{{\[}}%[[VAL_15]]] : memref<32xi32>
// CHECK: }
// CHECK: %[[VAL_20:.*]] = memref.tensor_load %[[VAL_11]] : memref<32xi32>
ins(%arga, %argb: tensor<32xi32, #SpVec>, tensor<34xi32>)
outs(%argx: tensor<32xi32>) {
^bb(%a: i32, %b: i32, %x: i32):
- %0 = and %a, %b : i32
+ %0 = arith.andi %a, %b : i32
linalg.yield %0 : i32
} -> tensor<32xi32>
return %0 : tensor<32xi32>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<34x19xf64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32x16xf64>) -> tensor<32x16xf64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 3 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 3 : index
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: memref.copy %[[VAL_12]], %[[VAL_13]] : memref<32x16xf64> to memref<32x16xf64>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_3]] {
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_14]]] : memref<?xindex>
-// CHECK: %[[VAL_16:.*]] = addi %[[VAL_14]], %[[VAL_3]] : index
+// CHECK: %[[VAL_16:.*]] = arith.addi %[[VAL_14]], %[[VAL_3]] : index
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_18:.*]] = %[[VAL_15]] to %[[VAL_17]] step %[[VAL_3]] {
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_14]], %[[VAL_19]]] : memref<32x16xf64>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_18]]] : memref<?xf64>
-// CHECK: %[[VAL_22:.*]] = addi %[[VAL_14]], %[[VAL_6]] : index
-// CHECK: %[[VAL_23:.*]] = addi %[[VAL_19]], %[[VAL_7]] : index
+// CHECK: %[[VAL_22:.*]] = arith.addi %[[VAL_14]], %[[VAL_6]] : index
+// CHECK: %[[VAL_23:.*]] = arith.addi %[[VAL_19]], %[[VAL_7]] : index
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_22]], %[[VAL_23]]] : memref<34x19xf64>
-// CHECK: %[[VAL_25:.*]] = mulf %[[VAL_21]], %[[VAL_24]] : f64
-// CHECK: %[[VAL_26:.*]] = addf %[[VAL_20]], %[[VAL_25]] : f64
+// CHECK: %[[VAL_25:.*]] = arith.mulf %[[VAL_21]], %[[VAL_24]] : f64
+// CHECK: %[[VAL_26:.*]] = arith.addf %[[VAL_20]], %[[VAL_25]] : f64
// CHECK: memref.store %[[VAL_26]], %[[VAL_13]]{{\[}}%[[VAL_14]], %[[VAL_19]]] : memref<32x16xf64>
// CHECK: }
// CHECK: }
ins(%arga, %argb: tensor<32x16xf64, #CSR>, tensor<34x19xf64>)
outs(%argx: tensor<32x16xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %a, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<32x16xf64>
return %0 : tensor<32x16xf64>
// CHECK-LABEL: func @abs(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xf64>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_8]] to %[[VAL_9]] step %[[VAL_3]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_10]]] : memref<?xindex>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf64>
-// CHECK: %[[VAL_13:.*]] = absf %[[VAL_12]] : f64
+// CHECK: %[[VAL_13:.*]] = math.abs %[[VAL_12]] : f64
// CHECK: memref.store %[[VAL_13]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_7]] : memref<32xf64>
ins(%arga: tensor<32xf64, #SV>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %x: f64):
- %0 = absf %a : f64
+ %0 = math.abs %a : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-LABEL: func @ceil(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xf64>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_8]] to %[[VAL_9]] step %[[VAL_3]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_10]]] : memref<?xindex>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf64>
-// CHECK: %[[VAL_13:.*]] = ceilf %[[VAL_12]] : f64
+// CHECK: %[[VAL_13:.*]] = math.ceil %[[VAL_12]] : f64
// CHECK: memref.store %[[VAL_13]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_7]] : memref<32xf64>
ins(%arga: tensor<32xf64, #SV>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %x: f64):
- %0 = ceilf %a : f64
+ %0 = math.ceil %a : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-LABEL: func @floor(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xf64>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_8]] to %[[VAL_9]] step %[[VAL_3]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_10]]] : memref<?xindex>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf64>
-// CHECK: %[[VAL_13:.*]] = floorf %[[VAL_12]] : f64
+// CHECK: %[[VAL_13:.*]] = math.floor %[[VAL_12]] : f64
// CHECK: memref.store %[[VAL_13]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_7]] : memref<32xf64>
ins(%arga: tensor<32xf64, #SV>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %x: f64):
- %0 = floorf %a : f64
+ %0 = math.floor %a : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-LABEL: func @neg(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK: %[[VAL_2:.*]] = constant 0 : index
-// CHECK: %[[VAL_3:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xf64>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_8]] to %[[VAL_9]] step %[[VAL_3]] {
// CHECK: %[[VAL_11:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_10]]] : memref<?xindex>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_10]]] : memref<?xf64>
-// CHECK: %[[VAL_13:.*]] = negf %[[VAL_12]] : f64
+// CHECK: %[[VAL_13:.*]] = arith.negf %[[VAL_12]] : f64
// CHECK: memref.store %[[VAL_13]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_14:.*]] = memref.tensor_load %[[VAL_7]] : memref<32xf64>
ins(%arga: tensor<32xf64, #SV>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %x: f64):
- %0 = negf %a : f64
+ %0 = arith.negf %a : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf64>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xf64>
-// CHECK: %[[VAL_24:.*]] = addf %[[VAL_22]], %[[VAL_23]] : f64
+// CHECK: %[[VAL_24:.*]] = arith.addf %[[VAL_22]], %[[VAL_23]] : f64
// CHECK: memref.store %[[VAL_24]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xf64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_26]], %[[VAL_27]], %[[VAL_18]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_28]], %[[VAL_29]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_30:.*]] = %[[VAL_31:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xf64, #SV>, tensor<32xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = addf %a, %b : f64
+ %0 = arith.addf %a, %b : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xf64>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf64>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xf64>
-// CHECK: %[[VAL_24:.*]] = subf %[[VAL_22]], %[[VAL_23]] : f64
+// CHECK: %[[VAL_24:.*]] = arith.subf %[[VAL_22]], %[[VAL_23]] : f64
// CHECK: memref.store %[[VAL_24]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xf64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xf64>
-// CHECK: %[[VAL_26:.*]] = negf %[[VAL_25]] : f64
+// CHECK: %[[VAL_26:.*]] = arith.negf %[[VAL_25]] : f64
// CHECK: memref.store %[[VAL_26]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xf64>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_27:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_28:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_27:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_28:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_29:.*]] = select %[[VAL_27]], %[[VAL_28]], %[[VAL_18]] : index
-// CHECK: %[[VAL_30:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_30:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_29]], %[[VAL_30]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_31:.*]] = %[[VAL_32:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_31]]] : memref<32xf64>
-// CHECK: %[[VAL_34:.*]] = negf %[[VAL_33]] : f64
+// CHECK: %[[VAL_34:.*]] = arith.negf %[[VAL_33]] : f64
// CHECK: memref.store %[[VAL_34]], %[[VAL_11]]{{\[}}%[[VAL_31]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_35:.*]] = memref.tensor_load %[[VAL_11]] : memref<32xf64>
ins(%arga, %argb: tensor<32xf64, #SV>, tensor<32xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = subf %a, %b : f64
+ %0 = arith.subf %a, %b : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_12]]] : memref<?xf64>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_13]]] : memref<32xf64>
-// CHECK: %[[VAL_16:.*]] = mulf %[[VAL_14]], %[[VAL_15]] : f64
+// CHECK: %[[VAL_16:.*]] = arith.mulf %[[VAL_14]], %[[VAL_15]] : f64
// CHECK: memref.store %[[VAL_16]], %[[VAL_9]]{{\[}}%[[VAL_13]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_17:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xf64>
ins(%arga, %argb: tensor<32xf64, #SV>, tensor<32xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
+ %0 = arith.mulf %a, %b : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-LABEL: func @divbyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2.000000e+00 : f64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2.000000e+00 : f64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xf64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xf64>
-// CHECK: %[[VAL_14:.*]] = divf %[[VAL_13]], %[[VAL_2]] : f64
+// CHECK: %[[VAL_14:.*]] = arith.divf %[[VAL_13]], %[[VAL_2]] : f64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xf64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xf64>
// CHECK: }
func @divbyc(%arga: tensor<32xf64, #SV>,
%argx: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
- %c = constant 2.0 : f64
+ %c = arith.constant 2.0 : f64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xf64, #SV>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %x: f64):
- %0 = divf %a, %c : f64
+ %0 = arith.divf %a, %c : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xi64>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xi64>
-// CHECK: %[[VAL_24:.*]] = addi %[[VAL_22]], %[[VAL_23]] : i64
+// CHECK: %[[VAL_24:.*]] = arith.addi %[[VAL_22]], %[[VAL_23]] : i64
// CHECK: memref.store %[[VAL_24]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xi64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_26]], %[[VAL_27]], %[[VAL_18]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_28]], %[[VAL_29]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_30:.*]] = %[[VAL_31:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = addi %a, %b : i64
+ %0 = arith.addi %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_7:.*]] = constant 0 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_7:.*]] = arith.constant 0 : i64
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_15:.*]]:2 = scf.while (%[[VAL_16:.*]] = %[[VAL_13]], %[[VAL_17:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_18:.*]] = cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
+// CHECK: %[[VAL_18:.*]] = arith.cmpi ult, %[[VAL_16]], %[[VAL_14]] : index
// CHECK: scf.condition(%[[VAL_18]]) %[[VAL_16]], %[[VAL_17]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_19:.*]]: index, %[[VAL_20:.*]]: index):
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_22:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
// CHECK: scf.if %[[VAL_22]] {
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<?xi64>
// CHECK: %[[VAL_24:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_20]]] : memref<32xi64>
-// CHECK: %[[VAL_25:.*]] = subi %[[VAL_23]], %[[VAL_24]] : i64
+// CHECK: %[[VAL_25:.*]] = arith.subi %[[VAL_23]], %[[VAL_24]] : i64
// CHECK: memref.store %[[VAL_25]], %[[VAL_12]]{{\[}}%[[VAL_20]]] : memref<32xi64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_20]]] : memref<32xi64>
-// CHECK: %[[VAL_27:.*]] = subi %[[VAL_7]], %[[VAL_26]] : i64
+// CHECK: %[[VAL_27:.*]] = arith.subi %[[VAL_7]], %[[VAL_26]] : i64
// CHECK: memref.store %[[VAL_27]], %[[VAL_12]]{{\[}}%[[VAL_20]]] : memref<32xi64>
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_28:.*]] = cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_28:.*]] = arith.cmpi eq, %[[VAL_21]], %[[VAL_20]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: %[[VAL_30:.*]] = select %[[VAL_28]], %[[VAL_29]], %[[VAL_19]] : index
-// CHECK: %[[VAL_31:.*]] = addi %[[VAL_20]], %[[VAL_6]] : index
+// CHECK: %[[VAL_31:.*]] = arith.addi %[[VAL_20]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_30]], %[[VAL_31]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_32:.*]] = %[[VAL_33:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: %[[VAL_34:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_32]]] : memref<32xi64>
-// CHECK: %[[VAL_35:.*]] = subi %[[VAL_7]], %[[VAL_34]] : i64
+// CHECK: %[[VAL_35:.*]] = arith.subi %[[VAL_7]], %[[VAL_34]] : i64
// CHECK: memref.store %[[VAL_35]], %[[VAL_12]]{{\[}}%[[VAL_32]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_36:.*]] = memref.tensor_load %[[VAL_12]] : memref<32xi64>
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = subi %a, %b : i64
+ %0 = arith.subi %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_12]]] : memref<?xi64>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_13]]] : memref<32xi64>
-// CHECK: %[[VAL_16:.*]] = muli %[[VAL_14]], %[[VAL_15]] : i64
+// CHECK: %[[VAL_16:.*]] = arith.muli %[[VAL_14]], %[[VAL_15]] : i64
// CHECK: memref.store %[[VAL_16]], %[[VAL_9]]{{\[}}%[[VAL_13]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_17:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xi64>
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = muli %a, %b : i64
+ %0 = arith.muli %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-LABEL: func @divsbyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xi64>
-// CHECK: %[[VAL_14:.*]] = divi_signed %[[VAL_13]], %[[VAL_2]] : i64
+// CHECK: %[[VAL_14:.*]] = arith.divsi %[[VAL_13]], %[[VAL_2]] : i64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xi64>
// CHECK: }
func @divsbyc(%arga: tensor<32xi64, #SV>,
%argx: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
- %c = constant 2 : i64
+ %c = arith.constant 2 : i64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xi64, #SV>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %x: i64):
- %0 = divi_signed %a, %c : i64
+ %0 = arith.divsi %a, %c : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-LABEL: func @divubyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xi64>
-// CHECK: %[[VAL_14:.*]] = divi_unsigned %[[VAL_13]], %[[VAL_2]] : i64
+// CHECK: %[[VAL_14:.*]] = arith.divui %[[VAL_13]], %[[VAL_2]] : i64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xi64>
// CHECK: }
func @divubyc(%arga: tensor<32xi64, #SV>,
%argx: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
- %c = constant 2 : i64
+ %c = arith.constant 2 : i64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xi64, #SV>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %x: i64):
- %0 = divi_unsigned %a, %c : i64
+ %0 = arith.divui %a, %c : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_12]]] : memref<?xi64>
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_13]]] : memref<32xi64>
-// CHECK: %[[VAL_16:.*]] = and %[[VAL_14]], %[[VAL_15]] : i64
+// CHECK: %[[VAL_16:.*]] = arith.andi %[[VAL_14]], %[[VAL_15]] : i64
// CHECK: memref.store %[[VAL_16]], %[[VAL_9]]{{\[}}%[[VAL_13]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_17:.*]] = memref.tensor_load %[[VAL_9]] : memref<32xi64>
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = and %a, %b : i64
+ %0 = arith.andi %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xi64>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xi64>
-// CHECK: %[[VAL_24:.*]] = or %[[VAL_22]], %[[VAL_23]] : i64
+// CHECK: %[[VAL_24:.*]] = arith.ori %[[VAL_22]], %[[VAL_23]] : i64
// CHECK: memref.store %[[VAL_24]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xi64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_26]], %[[VAL_27]], %[[VAL_18]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_28]], %[[VAL_29]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_30:.*]] = %[[VAL_31:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = or %a, %b : i64
+ %0 = arith.ori %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant true
-// CHECK-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant true
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_4]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_4]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_6]]] : memref<?xindex>
// CHECK: %[[VAL_14:.*]]:2 = scf.while (%[[VAL_15:.*]] = %[[VAL_12]], %[[VAL_16:.*]] = %[[VAL_4]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_17:.*]] = cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
+// CHECK: %[[VAL_17:.*]] = arith.cmpi ult, %[[VAL_15]], %[[VAL_13]] : index
// CHECK: scf.condition(%[[VAL_17]]) %[[VAL_15]], %[[VAL_16]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_18:.*]]: index, %[[VAL_19:.*]]: index):
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
-// CHECK: %[[VAL_21:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_21:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
// CHECK: scf.if %[[VAL_21]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xi64>
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xi64>
-// CHECK: %[[VAL_24:.*]] = xor %[[VAL_22]], %[[VAL_23]] : i64
+// CHECK: %[[VAL_24:.*]] = arith.xori %[[VAL_22]], %[[VAL_23]] : i64
// CHECK: memref.store %[[VAL_24]], %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<32xi64>
// CHECK: } else {
// CHECK: scf.if %[[VAL_5]] {
// CHECK: } else {
// CHECK: }
// CHECK: }
-// CHECK: %[[VAL_26:.*]] = cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_18]], %[[VAL_6]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi eq, %[[VAL_20]], %[[VAL_19]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_18]], %[[VAL_6]] : index
// CHECK: %[[VAL_28:.*]] = select %[[VAL_26]], %[[VAL_27]], %[[VAL_18]] : index
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_19]], %[[VAL_6]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_19]], %[[VAL_6]] : index
// CHECK: scf.yield %[[VAL_28]], %[[VAL_29]] : index, index
// CHECK: }
// CHECK: scf.for %[[VAL_30:.*]] = %[[VAL_31:.*]]#1 to %[[VAL_3]] step %[[VAL_6]] {
ins(%arga, %argb: tensor<32xi64, #SV>, tensor<32xi64>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %b: i64, %x: i64):
- %0 = xor %a, %b : i64
+ %0 = arith.xori %a, %b : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-LABEL: func @ashrbyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xi64>
-// CHECK: %[[VAL_14:.*]] = shift_right_signed %[[VAL_13]], %[[VAL_2]] : i64
+// CHECK: %[[VAL_14:.*]] = arith.shrsi %[[VAL_13]], %[[VAL_2]] : i64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xi64>
// CHECK: }
func @ashrbyc(%arga: tensor<32xi64, #SV>,
%argx: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
- %c = constant 2 : i64
+ %c = arith.constant 2 : i64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xi64, #SV>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %x: i64):
- %0 = shift_right_signed %a, %c : i64
+ %0 = arith.shrsi %a, %c : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-LABEL: func @lsrbyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xi64>
-// CHECK: %[[VAL_14:.*]] = shift_right_unsigned %[[VAL_13]], %[[VAL_2]] : i64
+// CHECK: %[[VAL_14:.*]] = arith.shrui %[[VAL_13]], %[[VAL_2]] : i64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xi64>
// CHECK: }
func @lsrbyc(%arga: tensor<32xi64, #SV>,
%argx: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
- %c = constant 2 : i64
+ %c = arith.constant 2 : i64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xi64, #SV>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %x: i64):
- %0 = shift_right_unsigned %a, %c : i64
+ %0 = arith.shrui %a, %c : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-LABEL: func @lslbyc(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xindex>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32xi64, #sparse_tensor.encoding<{{{.*}}}>> to memref<?xi64>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_4]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK: %[[VAL_13:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xi64>
-// CHECK: %[[VAL_14:.*]] = shift_left %[[VAL_13]], %[[VAL_2]] : i64
+// CHECK: %[[VAL_14:.*]] = arith.shli %[[VAL_13]], %[[VAL_2]] : i64
// CHECK: memref.store %[[VAL_14]], %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<32xi64>
// CHECK: }
// CHECK: %[[VAL_15:.*]] = memref.tensor_load %[[VAL_8]] : memref<32xi64>
// CHECK: }
func @lslbyc(%arga: tensor<32xi64, #SV>,
%argx: tensor<32xi64> {linalg.inplaceable = true}) -> tensor<32xi64> {
- %c = constant 2 : i64
+ %c = arith.constant 2 : i64
%0 = linalg.generic #traitc
ins(%arga: tensor<32xi64, #SV>)
outs(%argx: tensor<32xi64>) {
^bb(%a: i64, %x: i64):
- %0 = shift_left %a, %c : i64
+ %0 = arith.shli %a, %c : i64
linalg.yield %0 : i64
} -> tensor<32xi64>
return %0 : tensor<32xi64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20xf32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<20x30xf32>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<10x30xf32>) -> tensor<10x30xf32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 30 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 30 : index
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<10x20xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<10x20xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_4]] : tensor<10x20xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_14]] to %[[VAL_15]] step %[[VAL_4]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_16]], %[[VAL_4]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_16]], %[[VAL_4]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_4]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_3]] to %[[VAL_5]] step %[[VAL_4]] {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_17]], %[[VAL_24]]] : memref<10x30xf32>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_22]], %[[VAL_24]]] : memref<20x30xf32>
-// CHECK: %[[VAL_27:.*]] = mulf %[[VAL_23]], %[[VAL_26]] : f32
-// CHECK: %[[VAL_28:.*]] = addf %[[VAL_25]], %[[VAL_27]] : f32
+// CHECK: %[[VAL_27:.*]] = arith.mulf %[[VAL_23]], %[[VAL_26]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.addf %[[VAL_25]], %[[VAL_27]] : f32
// CHECK: memref.store %[[VAL_28]], %[[VAL_13]]{{\[}}%[[VAL_17]], %[[VAL_24]]] : memref<10x30xf32>
// CHECK: }
// CHECK: }
// CHECK-SAME: %[[VAL_0:.*]]: tensor<8x8xi32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<3x3xi32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<6x6xi32>) -> tensor<6x6xi32> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 6 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 6 : index
// CHECK: %[[VAL_6:.*]] = memref.buffer_cast %[[VAL_0]] : memref<8x8xi32>
// CHECK: %[[VAL_7:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_3]] : tensor<3x3xi32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_3]] : tensor<3x3xi32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_16:.*]] = %[[VAL_14]] to %[[VAL_15]] step %[[VAL_4]] {
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_16]]] : memref<?xindex>
-// CHECK: %[[VAL_19:.*]] = addi %[[VAL_16]], %[[VAL_4]] : index
+// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_16]], %[[VAL_4]] : index
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_18]] to %[[VAL_20]] step %[[VAL_4]] {
// CHECK: %[[VAL_22:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_21]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_3]] to %[[VAL_5]] step %[[VAL_4]] {
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_3]] to %[[VAL_5]] step %[[VAL_4]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_25]], %[[VAL_24]]] : memref<6x6xi32>
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_25]], %[[VAL_17]] : index
-// CHECK: %[[VAL_28:.*]] = addi %[[VAL_24]], %[[VAL_22]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_25]], %[[VAL_17]] : index
+// CHECK: %[[VAL_28:.*]] = arith.addi %[[VAL_24]], %[[VAL_22]] : index
// CHECK: %[[VAL_29:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_27]], %[[VAL_28]]] : memref<8x8xi32>
-// CHECK: %[[VAL_30:.*]] = muli %[[VAL_29]], %[[VAL_23]] : i32
-// CHECK: %[[VAL_31:.*]] = addi %[[VAL_26]], %[[VAL_30]] : i32
+// CHECK: %[[VAL_30:.*]] = arith.muli %[[VAL_29]], %[[VAL_23]] : i32
+// CHECK: %[[VAL_31:.*]] = arith.addi %[[VAL_26]], %[[VAL_30]] : i32
// CHECK: memref.store %[[VAL_31]], %[[VAL_13]]{{\[}}%[[VAL_25]], %[[VAL_24]]] : memref<6x6xi32>
// CHECK: }
// CHECK: }
// CHECK-SAME: %[[VAL_0:.*]]: tensor<5x3xi8>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<3x6xi8, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<5x6xi64>) -> tensor<5x6xi64> {
-// CHECK-DAG: %[[VAL_3:.*]] = constant 2 : i64
-// CHECK-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_5:.*]] = constant 1 : index
-// CHECK-DAG: %[[VAL_6:.*]] = constant 5 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 2 : i64
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[VAL_6:.*]] = arith.constant 5 : index
// CHECK: %[[VAL_7:.*]] = memref.buffer_cast %[[VAL_0]] : memref<5x3xi8>
// CHECK: %[[VAL_8:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_4]] : tensor<3x6xi8, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_9:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_4]] : tensor<3x6xi8, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: scf.for %[[VAL_17:.*]] = %[[VAL_15]] to %[[VAL_16]] step %[[VAL_5]] {
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_17]]] : memref<?xindex>
-// CHECK: %[[VAL_20:.*]] = addi %[[VAL_17]], %[[VAL_5]] : index
+// CHECK: %[[VAL_20:.*]] = arith.addi %[[VAL_17]], %[[VAL_5]] : index
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_22:.*]] = %[[VAL_19]] to %[[VAL_21]] step %[[VAL_5]] {
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_22]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_4]] to %[[VAL_6]] step %[[VAL_5]] {
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_25]], %[[VAL_23]]] : memref<5x6xi64>
// CHECK: %[[VAL_27:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_25]], %[[VAL_18]]] : memref<5x3xi8>
-// CHECK: %[[VAL_28:.*]] = sexti %[[VAL_27]] : i8 to i64
-// CHECK: %[[VAL_29:.*]] = subi %[[VAL_28]], %[[VAL_3]] : i64
-// CHECK: %[[VAL_30:.*]] = sexti %[[VAL_24]] : i8 to i64
-// CHECK: %[[VAL_31:.*]] = muli %[[VAL_29]], %[[VAL_30]] : i64
-// CHECK: %[[VAL_32:.*]] = addi %[[VAL_26]], %[[VAL_31]] : i64
+// CHECK: %[[VAL_28:.*]] = arith.extsi %[[VAL_27]] : i8 to i64
+// CHECK: %[[VAL_29:.*]] = arith.subi %[[VAL_28]], %[[VAL_3]] : i64
+// CHECK: %[[VAL_30:.*]] = arith.extsi %[[VAL_24]] : i8 to i64
+// CHECK: %[[VAL_31:.*]] = arith.muli %[[VAL_29]], %[[VAL_30]] : i64
+// CHECK: %[[VAL_32:.*]] = arith.addi %[[VAL_26]], %[[VAL_31]] : i64
// CHECK: memref.store %[[VAL_32]], %[[VAL_14]]{{\[}}%[[VAL_25]], %[[VAL_23]]] : memref<5x6xi64>
// CHECK: }
// CHECK: }
func @quantized_matmul(%input1: tensor<5x3xi8>,
%input2: tensor<3x6xi8, #DCSR>,
%output: tensor<5x6xi64>) -> tensor<5x6xi64> {
- %c0 = constant 0 : i32
- %c2 = constant 2 : i32
+ %c0 = arith.constant 0 : i32
+ %c2 = arith.constant 2 : i32
%0 = linalg.quantized_matmul
ins(%input1, %input2, %c2, %c0 : tensor<5x3xi8>, tensor<3x6xi8, #DCSR>, i32, i32)
outs(%output : tensor<5x6xi64>) -> tensor<5x6xi64>
// CHECK-HIR-SAME: %[[VAL_0:.*]]: tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-HIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-HIR-SAME: %[[VAL_2:.*]]: tensor<32xf64>) -> tensor<32xf64> {
-// CHECK-HIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-HIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-HIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-HIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-HIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-HIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-HIR: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf64>
// CHECK-HIR: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<32xf64> to memref<32xf64>
// CHECK-HIR: scf.for %[[VAL_12:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-HIR: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK-HIR: %[[VAL_14:.*]] = addi %[[VAL_12]], %[[VAL_5]] : index
+// CHECK-HIR: %[[VAL_14:.*]] = arith.addi %[[VAL_12]], %[[VAL_5]] : index
// CHECK-HIR: %[[VAL_15:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK-HIR: %[[VAL_16:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_12]]] : memref<32xf64>
// CHECK-HIR: %[[VAL_17:.*]] = scf.for %[[VAL_18:.*]] = %[[VAL_13]] to %[[VAL_15]] step %[[VAL_5]] iter_args(%[[VAL_19:.*]] = %[[VAL_16]]) -> (f64) {
// CHECK-HIR: %[[VAL_20:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK-HIR: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf64>
// CHECK-HIR: %[[VAL_22:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<64xf64>
-// CHECK-HIR: %[[VAL_23:.*]] = mulf %[[VAL_21]], %[[VAL_22]] : f64
-// CHECK-HIR: %[[VAL_24:.*]] = addf %[[VAL_19]], %[[VAL_23]] : f64
+// CHECK-HIR: %[[VAL_23:.*]] = arith.mulf %[[VAL_21]], %[[VAL_22]] : f64
+// CHECK-HIR: %[[VAL_24:.*]] = arith.addf %[[VAL_19]], %[[VAL_23]] : f64
// CHECK-HIR: scf.yield %[[VAL_24]] : f64
// CHECK-HIR: }
// CHECK-HIR: memref.store %[[VAL_25:.*]], %[[VAL_11]]{{\[}}%[[VAL_12]]] : memref<32xf64>
// CHECK-MIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-MIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-MIR-SAME: %[[VAL_2:.*]]: tensor<32xf64>) -> tensor<32xf64> {
-// CHECK-MIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-MIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-MIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-MIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-MIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-MIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-MIR: %[[VAL_6:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_7:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_8:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-MIR: memref.copy %[[VAL_10]], %[[VAL_11]] : memref<32xf64> to memref<32xf64>
// CHECK-MIR: scf.for %[[VAL_14:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-MIR: %[[VAL_15:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_14]]] : memref<?xindex>
-// CHECK-MIR: %[[VAL_16:.*]] = addi %[[VAL_14]], %[[VAL_5]] : index
+// CHECK-MIR: %[[VAL_16:.*]] = arith.addi %[[VAL_14]], %[[VAL_5]] : index
// CHECK-MIR: %[[VAL_17:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK-MIR: %[[VAL_18:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_14]]] : memref<32xf64>
// CHECK-MIR: %[[VAL_19:.*]] = scf.for %[[VAL_20:.*]] = %[[VAL_15]] to %[[VAL_17]] step %[[VAL_5]] iter_args(%[[VAL_21:.*]] = %[[VAL_18]]) -> (f64) {
// CHECK-MIR: %[[VAL_22:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK-MIR: %[[VAL_23:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xf64>
// CHECK-MIR: %[[VAL_24:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_22]]] : memref<64xf64>
-// CHECK-MIR: %[[VAL_25:.*]] = mulf %[[VAL_23]], %[[VAL_24]] : f64
-// CHECK-MIR: %[[VAL_26:.*]] = addf %[[VAL_21]], %[[VAL_25]] : f64
+// CHECK-MIR: %[[VAL_25:.*]] = arith.mulf %[[VAL_23]], %[[VAL_24]] : f64
+// CHECK-MIR: %[[VAL_26:.*]] = arith.addf %[[VAL_21]], %[[VAL_25]] : f64
// CHECK-MIR: scf.yield %[[VAL_26]] : f64
// CHECK-MIR: }
// CHECK-MIR: memref.store %[[VAL_27:.*]], %[[VAL_11]]{{\[}}%[[VAL_14]]] : memref<32xf64>
// CHECK-LIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-LIR-SAME: %[[VAL_1:.*]]: memref<64xf64>,
// CHECK-LIR-SAME: %[[VAL_2:.*]]: memref<32xf64>) -> memref<32xf64> {
-// CHECK-LIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-LIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-LIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-LIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-LIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-LIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-LIR: %[[VAL_6:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_7:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_8:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-LIR: memref.copy %[[VAL_2]], %[[VAL_9]] : memref<32xf64> to memref<32xf64>
// CHECK-LIR: scf.for %[[VAL_12:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-LIR: %[[VAL_13:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK-LIR: %[[VAL_14:.*]] = addi %[[VAL_12]], %[[VAL_5]] : index
+// CHECK-LIR: %[[VAL_14:.*]] = arith.addi %[[VAL_12]], %[[VAL_5]] : index
// CHECK-LIR: %[[VAL_15:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK-LIR: %[[VAL_16:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_12]]] : memref<32xf64>
// CHECK-LIR: %[[VAL_17:.*]] = scf.for %[[VAL_18:.*]] = %[[VAL_13]] to %[[VAL_15]] step %[[VAL_5]] iter_args(%[[VAL_19:.*]] = %[[VAL_16]]) -> (f64) {
// CHECK-LIR: %[[VAL_20:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK-LIR: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xf64>
// CHECK-LIR: %[[VAL_22:.*]] = memref.load %[[VAL_1]]{{\[}}%[[VAL_20]]] : memref<64xf64>
-// CHECK-LIR: %[[VAL_23:.*]] = mulf %[[VAL_21]], %[[VAL_22]] : f64
-// CHECK-LIR: %[[VAL_24:.*]] = addf %[[VAL_19]], %[[VAL_23]] : f64
+// CHECK-LIR: %[[VAL_23:.*]] = arith.mulf %[[VAL_21]], %[[VAL_22]] : f64
+// CHECK-LIR: %[[VAL_24:.*]] = arith.addf %[[VAL_19]], %[[VAL_23]] : f64
// CHECK-LIR: scf.yield %[[VAL_24]] : f64
// CHECK-LIR: }
// CHECK-LIR: memref.store %[[VAL_25:.*]], %[[VAL_9]]{{\[}}%[[VAL_12]]] : memref<32xf64>
ins(%arga, %argb : tensor<32x64xf64, #CSR>, tensor<64xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%A: f64, %b: f64, %x: f64):
- %0 = mulf %A, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %A, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-HIR-SAME: %[[VAL_0:.*]]: tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], dimOrdering = affine_map<(d0, d1) -> (d1, d0)>, pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-HIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-HIR-SAME: %[[VAL_2:.*]]: tensor<32xf64>) -> tensor<32xf64> {
-// CHECK-HIR-DAG: %[[VAL_3:.*]] = constant 64 : index
-// CHECK-HIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-HIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-HIR-DAG: %[[VAL_3:.*]] = arith.constant 64 : index
+// CHECK-HIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-HIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-HIR: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], dimOrdering = affine_map<(d0, d1) -> (d1, d0)>, pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], dimOrdering = affine_map<(d0, d1) -> (d1, d0)>, pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], dimOrdering = affine_map<(d0, d1) -> (d1, d0)>, pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf64>
// CHECK-HIR: scf.for %[[VAL_12:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-HIR: %[[VAL_13:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_12]]] : memref<64xf64>
// CHECK-HIR: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_12]]] : memref<?xindex>
-// CHECK-HIR: %[[VAL_15:.*]] = addi %[[VAL_12]], %[[VAL_5]] : index
+// CHECK-HIR: %[[VAL_15:.*]] = arith.addi %[[VAL_12]], %[[VAL_5]] : index
// CHECK-HIR: %[[VAL_16:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK-HIR: scf.for %[[VAL_17:.*]] = %[[VAL_14]] to %[[VAL_16]] step %[[VAL_5]] {
// CHECK-HIR: %[[VAL_18:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK-HIR: %[[VAL_19:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_18]]] : memref<32xf64>
// CHECK-HIR: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xf64>
-// CHECK-HIR: %[[VAL_21:.*]] = mulf %[[VAL_20]], %[[VAL_13]] : f64
-// CHECK-HIR: %[[VAL_22:.*]] = addf %[[VAL_19]], %[[VAL_21]] : f64
+// CHECK-HIR: %[[VAL_21:.*]] = arith.mulf %[[VAL_20]], %[[VAL_13]] : f64
+// CHECK-HIR: %[[VAL_22:.*]] = arith.addf %[[VAL_19]], %[[VAL_21]] : f64
// CHECK-HIR: memref.store %[[VAL_22]], %[[VAL_11]]{{\[}}%[[VAL_18]]] : memref<32xf64>
// CHECK-HIR: }
// CHECK-HIR: }
// CHECK-MIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-MIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-MIR-SAME: %[[VAL_2:.*]]: tensor<32xf64>) -> tensor<32xf64> {
-// CHECK-MIR-DAG: %[[VAL_3:.*]] = constant 64 : index
-// CHECK-MIR-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-MIR-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-MIR-DAG: %[[VAL_3:.*]] = arith.constant 64 : index
+// CHECK-MIR-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-MIR-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK-MIR: %[[VAL_7:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_6]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_8:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_6]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_9:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-MIR: scf.for %[[VAL_15:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK-MIR: %[[VAL_16:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_15]]] : memref<64xf64>
// CHECK-MIR: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
-// CHECK-MIR: %[[VAL_18:.*]] = addi %[[VAL_15]], %[[VAL_6]] : index
+// CHECK-MIR: %[[VAL_18:.*]] = arith.addi %[[VAL_15]], %[[VAL_6]] : index
// CHECK-MIR: %[[VAL_19:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK-MIR: scf.for %[[VAL_20:.*]] = %[[VAL_17]] to %[[VAL_19]] step %[[VAL_6]] {
// CHECK-MIR: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK-MIR: %[[VAL_22:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_21]]] : memref<32xf64>
// CHECK-MIR: %[[VAL_23:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<?xf64>
-// CHECK-MIR: %[[VAL_24:.*]] = mulf %[[VAL_23]], %[[VAL_16]] : f64
-// CHECK-MIR: %[[VAL_25:.*]] = addf %[[VAL_22]], %[[VAL_24]] : f64
+// CHECK-MIR: %[[VAL_24:.*]] = arith.mulf %[[VAL_23]], %[[VAL_16]] : f64
+// CHECK-MIR: %[[VAL_25:.*]] = arith.addf %[[VAL_22]], %[[VAL_24]] : f64
// CHECK-MIR: memref.store %[[VAL_25]], %[[VAL_12]]{{\[}}%[[VAL_21]]] : memref<32xf64>
// CHECK-MIR: }
// CHECK-MIR: }
// CHECK-LIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-LIR-SAME: %[[VAL_1:.*]]: memref<64xf64>,
// CHECK-LIR-SAME: %[[VAL_2:.*]]: memref<32xf64>) -> memref<32xf64> {
-// CHECK-LIR-DAG: %[[VAL_3:.*]] = constant 64 : index
-// CHECK-LIR-DAG: %[[VAL_5:.*]] = constant 0 : index
-// CHECK-LIR-DAG: %[[VAL_6:.*]] = constant 1 : index
+// CHECK-LIR-DAG: %[[VAL_3:.*]] = arith.constant 64 : index
+// CHECK-LIR-DAG: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK-LIR-DAG: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK-LIR: %[[VAL_7:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_6]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_8:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_6]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_9:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-LIR: scf.for %[[VAL_13:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK-LIR: %[[VAL_14:.*]] = memref.load %[[VAL_1]]{{\[}}%[[VAL_13]]] : memref<64xf64>
// CHECK-LIR: %[[VAL_15:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_13]]] : memref<?xindex>
-// CHECK-LIR: %[[VAL_16:.*]] = addi %[[VAL_13]], %[[VAL_6]] : index
+// CHECK-LIR: %[[VAL_16:.*]] = arith.addi %[[VAL_13]], %[[VAL_6]] : index
// CHECK-LIR: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xindex>
// CHECK-LIR: scf.for %[[VAL_18:.*]] = %[[VAL_15]] to %[[VAL_17]] step %[[VAL_6]] {
// CHECK-LIR: %[[VAL_19:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_18]]] : memref<?xindex>
// CHECK-LIR: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xf64>
// CHECK-LIR: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf64>
-// CHECK-LIR: %[[VAL_22:.*]] = mulf %[[VAL_21]], %[[VAL_14]] : f64
-// CHECK-LIR: %[[VAL_23:.*]] = addf %[[VAL_20]], %[[VAL_22]] : f64
+// CHECK-LIR: %[[VAL_22:.*]] = arith.mulf %[[VAL_21]], %[[VAL_14]] : f64
+// CHECK-LIR: %[[VAL_23:.*]] = arith.addf %[[VAL_20]], %[[VAL_22]] : f64
// CHECK-LIR: memref.store %[[VAL_23]], %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<32xf64>
// CHECK-LIR: }
// CHECK-LIR: }
ins(%arga, %argb : tensor<32x64xf64, #CSC>, tensor<64xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%A: f64, %b: f64, %x: f64):
- %0 = mulf %A, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %A, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-HIR-SAME: %[[VAL_0:.*]]: tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-HIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-HIR-SAME: %[[VAL_2:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-HIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-HIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-HIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-HIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-HIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-HIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-HIR: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_7:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_5]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK-HIR: %[[VAL_8:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x64xf64, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "compressed" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xf64>
// CHECK-HIR: %[[VAL_10:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf64>
// CHECK-HIR: scf.for %[[VAL_11:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-HIR: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
-// CHECK-HIR: %[[VAL_13:.*]] = addi %[[VAL_11]], %[[VAL_5]] : index
+// CHECK-HIR: %[[VAL_13:.*]] = arith.addi %[[VAL_11]], %[[VAL_5]] : index
// CHECK-HIR: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_13]]] : memref<?xindex>
// CHECK-HIR: %[[VAL_15:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK-HIR: %[[VAL_16:.*]] = scf.for %[[VAL_17:.*]] = %[[VAL_12]] to %[[VAL_14]] step %[[VAL_5]] iter_args(%[[VAL_18:.*]] = %[[VAL_15]]) -> (f64) {
// CHECK-HIR: %[[VAL_19:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK-HIR: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xf64>
// CHECK-HIR: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<64xf64>
-// CHECK-HIR: %[[VAL_22:.*]] = mulf %[[VAL_20]], %[[VAL_21]] : f64
-// CHECK-HIR: %[[VAL_23:.*]] = addf %[[VAL_18]], %[[VAL_22]] : f64
+// CHECK-HIR: %[[VAL_22:.*]] = arith.mulf %[[VAL_20]], %[[VAL_21]] : f64
+// CHECK-HIR: %[[VAL_23:.*]] = arith.addf %[[VAL_18]], %[[VAL_22]] : f64
// CHECK-HIR: scf.yield %[[VAL_23]] : f64
// CHECK-HIR: }
// CHECK-HIR: memref.store %[[VAL_24:.*]], %[[VAL_10]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK-MIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-MIR-SAME: %[[VAL_1:.*]]: tensor<64xf64>,
// CHECK-MIR-SAME: %[[VAL_2:.*]]: tensor<32xf64> {linalg.inplaceable = true}) -> tensor<32xf64> {
-// CHECK-MIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-MIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-MIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-MIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-MIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-MIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-MIR: %[[VAL_6:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_7:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-MIR: %[[VAL_8:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-MIR: %[[VAL_10:.*]] = memref.buffer_cast %[[VAL_2]] : memref<32xf64>
// CHECK-MIR: scf.for %[[VAL_11:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-MIR: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
-// CHECK-MIR: %[[VAL_13:.*]] = addi %[[VAL_11]], %[[VAL_5]] : index
+// CHECK-MIR: %[[VAL_13:.*]] = arith.addi %[[VAL_11]], %[[VAL_5]] : index
// CHECK-MIR: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_13]]] : memref<?xindex>
// CHECK-MIR: %[[VAL_15:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK-MIR: %[[VAL_16:.*]] = scf.for %[[VAL_17:.*]] = %[[VAL_12]] to %[[VAL_14]] step %[[VAL_5]] iter_args(%[[VAL_18:.*]] = %[[VAL_15]]) -> (f64) {
// CHECK-MIR: %[[VAL_19:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK-MIR: %[[VAL_20:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_17]]] : memref<?xf64>
// CHECK-MIR: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_19]]] : memref<64xf64>
-// CHECK-MIR: %[[VAL_22:.*]] = mulf %[[VAL_20]], %[[VAL_21]] : f64
-// CHECK-MIR: %[[VAL_23:.*]] = addf %[[VAL_18]], %[[VAL_22]] : f64
+// CHECK-MIR: %[[VAL_22:.*]] = arith.mulf %[[VAL_20]], %[[VAL_21]] : f64
+// CHECK-MIR: %[[VAL_23:.*]] = arith.addf %[[VAL_18]], %[[VAL_22]] : f64
// CHECK-MIR: scf.yield %[[VAL_23]] : f64
// CHECK-MIR: }
// CHECK-MIR: memref.store %[[VAL_24:.*]], %[[VAL_10]]{{\[}}%[[VAL_11]]] : memref<32xf64>
// CHECK-LIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-LIR-SAME: %[[VAL_1:.*]]: memref<64xf64>,
// CHECK-LIR-SAME: %[[VAL_2:.*]]: memref<32xf64> {linalg.inplaceable = true}) -> memref<32xf64> {
-// CHECK-LIR-DAG: %[[VAL_3:.*]] = constant 32 : index
-// CHECK-LIR-DAG: %[[VAL_4:.*]] = constant 0 : index
-// CHECK-LIR-DAG: %[[VAL_5:.*]] = constant 1 : index
+// CHECK-LIR-DAG: %[[VAL_3:.*]] = arith.constant 32 : index
+// CHECK-LIR-DAG: %[[VAL_4:.*]] = arith.constant 0 : index
+// CHECK-LIR-DAG: %[[VAL_5:.*]] = arith.constant 1 : index
// CHECK-LIR: %[[VAL_6:.*]] = call @sparsePointers(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_7:.*]] = call @sparseIndices(%[[VAL_0]], %[[VAL_5]]) : (!llvm.ptr<i8>, index) -> memref<?xindex>
// CHECK-LIR: %[[VAL_8:.*]] = call @sparseValuesF64(%[[VAL_0]]) : (!llvm.ptr<i8>) -> memref<?xf64>
// CHECK-LIR: scf.for %[[VAL_9:.*]] = %[[VAL_4]] to %[[VAL_3]] step %[[VAL_5]] {
// CHECK-LIR: %[[VAL_10:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_9]]] : memref<?xindex>
-// CHECK-LIR: %[[VAL_11:.*]] = addi %[[VAL_9]], %[[VAL_5]] : index
+// CHECK-LIR: %[[VAL_11:.*]] = arith.addi %[[VAL_9]], %[[VAL_5]] : index
// CHECK-LIR: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
// CHECK-LIR: %[[VAL_13:.*]] = memref.load %[[VAL_2]]{{\[}}%[[VAL_9]]] : memref<32xf64>
// CHECK-LIR: %[[VAL_14:.*]] = scf.for %[[VAL_15:.*]] = %[[VAL_10]] to %[[VAL_12]] step %[[VAL_5]] iter_args(%[[VAL_16:.*]] = %[[VAL_13]]) -> (f64) {
// CHECK-LIR: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_15]]] : memref<?xindex>
// CHECK-LIR: %[[VAL_18:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_15]]] : memref<?xf64>
// CHECK-LIR: %[[VAL_19:.*]] = memref.load %[[VAL_1]]{{\[}}%[[VAL_17]]] : memref<64xf64>
-// CHECK-LIR: %[[VAL_20:.*]] = mulf %[[VAL_18]], %[[VAL_19]] : f64
-// CHECK-LIR: %[[VAL_21:.*]] = addf %[[VAL_16]], %[[VAL_20]] : f64
+// CHECK-LIR: %[[VAL_20:.*]] = arith.mulf %[[VAL_18]], %[[VAL_19]] : f64
+// CHECK-LIR: %[[VAL_21:.*]] = arith.addf %[[VAL_16]], %[[VAL_20]] : f64
// CHECK-LIR: scf.yield %[[VAL_21]] : f64
// CHECK-LIR: }
// CHECK-LIR: memref.store %[[VAL_22:.*]], %[[VAL_2]]{{\[}}%[[VAL_9]]] : memref<32xf64>
ins(%arga, %argb : tensor<32x64xf64, #CSR>, tensor<64xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%A: f64, %b: f64, %x: f64):
- %0 = mulf %A, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %A, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20x30x40x50x60x70x80xf32>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<80x70x60x50x40x30x20x10xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense", "compressed", "compressed", "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>>,
// CHECK-SAME: %[[VAL_2:.*]]: tensor<10x20x30x40x50x60x70x80xf32>) -> tensor<10x20x30x40x50x60x70x80xf32> {
-// CHECK: %[[VAL_3:.*]] = constant 3 : index
-// CHECK: %[[VAL_4:.*]] = constant 4 : index
-// CHECK: %[[VAL_5:.*]] = constant 10 : index
-// CHECK: %[[VAL_6:.*]] = constant 20 : index
-// CHECK: %[[VAL_7:.*]] = constant 30 : index
-// CHECK: %[[VAL_8:.*]] = constant 60 : index
-// CHECK: %[[VAL_9:.*]] = constant 70 : index
-// CHECK: %[[VAL_10:.*]] = constant 80 : index
-// CHECK: %[[VAL_11:.*]] = constant 0 : index
-// CHECK: %[[VAL_12:.*]] = constant 1 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 3 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 4 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 10 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 20 : index
+// CHECK: %[[VAL_7:.*]] = arith.constant 30 : index
+// CHECK: %[[VAL_8:.*]] = arith.constant 60 : index
+// CHECK: %[[VAL_9:.*]] = arith.constant 70 : index
+// CHECK: %[[VAL_10:.*]] = arith.constant 80 : index
+// CHECK: %[[VAL_11:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_12:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_13:.*]] = memref.buffer_cast %[[VAL_0]] : memref<10x20x30x40x50x60x70x80xf32>
// CHECK: %[[VAL_14:.*]] = sparse_tensor.pointers %[[VAL_1]], %[[VAL_3]] : tensor<80x70x60x50x40x30x20x10xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense", "compressed", "compressed", "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: %[[VAL_15:.*]] = sparse_tensor.indices %[[VAL_1]], %[[VAL_3]] : tensor<80x70x60x50x40x30x20x10xf32, #sparse_tensor.encoding<{ dimLevelType = [ "dense", "dense", "dense", "compressed", "compressed", "dense", "dense", "dense" ], pointerBitWidth = 0, indexBitWidth = 0 }>> to memref<?xindex>
// CHECK: memref.copy %[[VAL_19]], %[[VAL_20]] : memref<10x20x30x40x50x60x70x80xf32> to memref<10x20x30x40x50x60x70x80xf32>
// CHECK: scf.for %[[VAL_21:.*]] = %[[VAL_11]] to %[[VAL_10]] step %[[VAL_12]] {
// CHECK: scf.for %[[VAL_22:.*]] = %[[VAL_11]] to %[[VAL_9]] step %[[VAL_12]] {
-// CHECK: %[[VAL_23:.*]] = muli %[[VAL_21]], %[[VAL_9]] : index
-// CHECK: %[[VAL_24:.*]] = addi %[[VAL_23]], %[[VAL_22]] : index
+// CHECK: %[[VAL_23:.*]] = arith.muli %[[VAL_21]], %[[VAL_9]] : index
+// CHECK: %[[VAL_24:.*]] = arith.addi %[[VAL_23]], %[[VAL_22]] : index
// CHECK: scf.for %[[VAL_25:.*]] = %[[VAL_11]] to %[[VAL_8]] step %[[VAL_12]] {
-// CHECK: %[[VAL_26:.*]] = muli %[[VAL_24]], %[[VAL_8]] : index
-// CHECK: %[[VAL_27:.*]] = addi %[[VAL_26]], %[[VAL_25]] : index
+// CHECK: %[[VAL_26:.*]] = arith.muli %[[VAL_24]], %[[VAL_8]] : index
+// CHECK: %[[VAL_27:.*]] = arith.addi %[[VAL_26]], %[[VAL_25]] : index
// CHECK: %[[VAL_28:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_27]]] : memref<?xindex>
-// CHECK: %[[VAL_29:.*]] = addi %[[VAL_27]], %[[VAL_12]] : index
+// CHECK: %[[VAL_29:.*]] = arith.addi %[[VAL_27]], %[[VAL_12]] : index
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_14]]{{\[}}%[[VAL_29]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_31:.*]] = %[[VAL_28]] to %[[VAL_30]] step %[[VAL_12]] {
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_31]]] : memref<?xindex>
// CHECK: %[[VAL_33:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_31]]] : memref<?xindex>
-// CHECK: %[[VAL_34:.*]] = addi %[[VAL_31]], %[[VAL_12]] : index
+// CHECK: %[[VAL_34:.*]] = arith.addi %[[VAL_31]], %[[VAL_12]] : index
// CHECK: %[[VAL_35:.*]] = memref.load %[[VAL_16]]{{\[}}%[[VAL_34]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_36:.*]] = %[[VAL_33]] to %[[VAL_35]] step %[[VAL_12]] {
// CHECK: %[[VAL_37:.*]] = memref.load %[[VAL_17]]{{\[}}%[[VAL_36]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_38:.*]] = %[[VAL_11]] to %[[VAL_7]] step %[[VAL_12]] {
-// CHECK: %[[VAL_39:.*]] = muli %[[VAL_36]], %[[VAL_7]] : index
-// CHECK: %[[VAL_40:.*]] = addi %[[VAL_39]], %[[VAL_38]] : index
+// CHECK: %[[VAL_39:.*]] = arith.muli %[[VAL_36]], %[[VAL_7]] : index
+// CHECK: %[[VAL_40:.*]] = arith.addi %[[VAL_39]], %[[VAL_38]] : index
// CHECK: scf.for %[[VAL_41:.*]] = %[[VAL_11]] to %[[VAL_6]] step %[[VAL_12]] {
-// CHECK: %[[VAL_42:.*]] = muli %[[VAL_40]], %[[VAL_6]] : index
-// CHECK: %[[VAL_43:.*]] = addi %[[VAL_42]], %[[VAL_41]] : index
+// CHECK: %[[VAL_42:.*]] = arith.muli %[[VAL_40]], %[[VAL_6]] : index
+// CHECK: %[[VAL_43:.*]] = arith.addi %[[VAL_42]], %[[VAL_41]] : index
// CHECK: scf.for %[[VAL_44:.*]] = %[[VAL_11]] to %[[VAL_5]] step %[[VAL_12]] {
-// CHECK: %[[VAL_45:.*]] = muli %[[VAL_43]], %[[VAL_5]] : index
-// CHECK: %[[VAL_46:.*]] = addi %[[VAL_45]], %[[VAL_44]] : index
+// CHECK: %[[VAL_45:.*]] = arith.muli %[[VAL_43]], %[[VAL_5]] : index
+// CHECK: %[[VAL_46:.*]] = arith.addi %[[VAL_45]], %[[VAL_44]] : index
// CHECK: %[[VAL_47:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_44]], %[[VAL_41]], %[[VAL_38]], %[[VAL_37]], %[[VAL_32]], %[[VAL_25]], %[[VAL_22]], %[[VAL_21]]] : memref<10x20x30x40x50x60x70x80xf32>
// CHECK: %[[VAL_48:.*]] = memref.load %[[VAL_18]]{{\[}}%[[VAL_46]]] : memref<?xf32>
-// CHECK: %[[VAL_49:.*]] = mulf %[[VAL_47]], %[[VAL_48]] : f32
+// CHECK: %[[VAL_49:.*]] = arith.mulf %[[VAL_47]], %[[VAL_48]] : f32
// CHECK: memref.store %[[VAL_49]], %[[VAL_20]]{{\[}}%[[VAL_44]], %[[VAL_41]], %[[VAL_38]], %[[VAL_37]], %[[VAL_32]], %[[VAL_25]], %[[VAL_22]], %[[VAL_21]]] : memref<10x20x30x40x50x60x70x80xf32>
// CHECK: }
// CHECK: }
tensor<80x70x60x50x40x30x20x10xf32, #SparseTensor>)
outs(%argx: tensor<10x20x30x40x50x60x70x80xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<10x20x30x40x50x60x70x80xf32>
return %0 : tensor<10x20x30x40x50x60x70x80xf32>
// CHECK-LABEL: func @sparse_simply_dynamic1(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {
-// CHECK-DAG: %[[VAL_1:.*]] = constant 2.000000e+00 : f32
-// CHECK-DAG: %[[VAL_2:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_3:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_1:.*]] = arith.constant 2.000000e+00 : f32
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_2]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_2]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = memref.load %[[VAL_4]]{{\[}}%[[VAL_3]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_9]] to %[[VAL_10]] step %[[VAL_3]] {
// CHECK: %[[VAL_12:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_11]]] : memref<?xindex>
-// CHECK: %[[VAL_13:.*]] = addi %[[VAL_11]], %[[VAL_3]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_11]], %[[VAL_3]] : index
// CHECK: %[[VAL_14:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_13]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_12]] to %[[VAL_14]] step %[[VAL_3]] {
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_15]]] : memref<?xf32>
-// CHECK: %[[VAL_17:.*]] = mulf %[[VAL_16]], %[[VAL_1]] : f32
+// CHECK: %[[VAL_17:.*]] = arith.mulf %[[VAL_16]], %[[VAL_1]] : f32
// CHECK: memref.store %[[VAL_17]], %[[VAL_8]]{{\[}}%[[VAL_15]]] : memref<?xf32>
// CHECK: }
// CHECK: }
// CHECK: return %[[VAL_18]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>>
// CHECK: }
func @sparse_simply_dynamic1(%argx: tensor<32x16xf32, #DCSR> {linalg.inplaceable = true}) -> tensor<32x16xf32, #DCSR> {
- %c = constant 2.0 : f32
+ %c = arith.constant 2.0 : f32
%0 = linalg.generic #trait_scale
outs(%argx: tensor<32x16xf32, #DCSR>) {
^bb(%x: f32):
- %1 = mulf %x, %c : f32
+ %1 = arith.mulf %x, %c : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32, #DCSR>
return %0 : tensor<32x16xf32, #DCSR>
// CHECK-LABEL: func @sparse_simply_dynamic2(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_3:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_4:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_5:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_3]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_6:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xf32>
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_12]] to %[[VAL_13]] step %[[VAL_3]] {
// CHECK: %[[VAL_15:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_14]]] : memref<?xindex>
// CHECK: %[[VAL_16:.*]] = memref.load %[[VAL_4]]{{\[}}%[[VAL_15]]] : memref<?xindex>
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_15]], %[[VAL_3]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_15]], %[[VAL_3]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_4]]{{\[}}%[[VAL_17]]] : memref<?xindex>
// CHECK: %[[VAL_19:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_14]]] : memref<?xindex>
-// CHECK: %[[VAL_20:.*]] = addi %[[VAL_14]], %[[VAL_3]] : index
+// CHECK: %[[VAL_20:.*]] = arith.addi %[[VAL_14]], %[[VAL_3]] : index
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_9]]{{\[}}%[[VAL_20]]] : memref<?xindex>
// CHECK: %[[VAL_22:.*]]:2 = scf.while (%[[VAL_23:.*]] = %[[VAL_16]], %[[VAL_24:.*]] = %[[VAL_19]]) : (index, index) -> (index, index) {
-// CHECK: %[[VAL_25:.*]] = cmpi ult, %[[VAL_23]], %[[VAL_18]] : index
-// CHECK: %[[VAL_26:.*]] = cmpi ult, %[[VAL_24]], %[[VAL_21]] : index
-// CHECK: %[[VAL_27:.*]] = and %[[VAL_25]], %[[VAL_26]] : i1
+// CHECK: %[[VAL_25:.*]] = arith.cmpi ult, %[[VAL_23]], %[[VAL_18]] : index
+// CHECK: %[[VAL_26:.*]] = arith.cmpi ult, %[[VAL_24]], %[[VAL_21]] : index
+// CHECK: %[[VAL_27:.*]] = arith.andi %[[VAL_25]], %[[VAL_26]] : i1
// CHECK: scf.condition(%[[VAL_27]]) %[[VAL_23]], %[[VAL_24]] : index, index
// CHECK: } do {
// CHECK: ^bb0(%[[VAL_28:.*]]: index, %[[VAL_29:.*]]: index):
// CHECK: %[[VAL_30:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_28]]] : memref<?xindex>
// CHECK: %[[VAL_31:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_29]]] : memref<?xindex>
-// CHECK: %[[VAL_32:.*]] = cmpi ult, %[[VAL_31]], %[[VAL_30]] : index
+// CHECK: %[[VAL_32:.*]] = arith.cmpi ult, %[[VAL_31]], %[[VAL_30]] : index
// CHECK: %[[VAL_33:.*]] = select %[[VAL_32]], %[[VAL_31]], %[[VAL_30]] : index
-// CHECK: %[[VAL_34:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_33]] : index
-// CHECK: %[[VAL_35:.*]] = cmpi eq, %[[VAL_31]], %[[VAL_33]] : index
-// CHECK: %[[VAL_36:.*]] = and %[[VAL_34]], %[[VAL_35]] : i1
+// CHECK: %[[VAL_34:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_33]] : index
+// CHECK: %[[VAL_35:.*]] = arith.cmpi eq, %[[VAL_31]], %[[VAL_33]] : index
+// CHECK: %[[VAL_36:.*]] = arith.andi %[[VAL_34]], %[[VAL_35]] : i1
// CHECK: scf.if %[[VAL_36]] {
// CHECK: %[[VAL_37:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_29]]] : memref<?xf32>
// CHECK: %[[VAL_38:.*]] = memref.load %[[VAL_6]]{{\[}}%[[VAL_28]]] : memref<?xf32>
-// CHECK: %[[VAL_39:.*]] = mulf %[[VAL_37]], %[[VAL_38]] : f32
+// CHECK: %[[VAL_39:.*]] = arith.mulf %[[VAL_37]], %[[VAL_38]] : f32
// CHECK: memref.store %[[VAL_39]], %[[VAL_11]]{{\[}}%[[VAL_29]]] : memref<?xf32>
// CHECK: } else {
// CHECK: }
-// CHECK: %[[VAL_40:.*]] = cmpi eq, %[[VAL_30]], %[[VAL_33]] : index
-// CHECK: %[[VAL_41:.*]] = addi %[[VAL_28]], %[[VAL_3]] : index
+// CHECK: %[[VAL_40:.*]] = arith.cmpi eq, %[[VAL_30]], %[[VAL_33]] : index
+// CHECK: %[[VAL_41:.*]] = arith.addi %[[VAL_28]], %[[VAL_3]] : index
// CHECK: %[[VAL_42:.*]] = select %[[VAL_40]], %[[VAL_41]], %[[VAL_28]] : index
-// CHECK: %[[VAL_43:.*]] = cmpi eq, %[[VAL_31]], %[[VAL_33]] : index
-// CHECK: %[[VAL_44:.*]] = addi %[[VAL_29]], %[[VAL_3]] : index
+// CHECK: %[[VAL_43:.*]] = arith.cmpi eq, %[[VAL_31]], %[[VAL_33]] : index
+// CHECK: %[[VAL_44:.*]] = arith.addi %[[VAL_29]], %[[VAL_3]] : index
// CHECK: %[[VAL_45:.*]] = select %[[VAL_43]], %[[VAL_44]], %[[VAL_29]] : index
// CHECK: scf.yield %[[VAL_42]], %[[VAL_45]] : index, index
// CHECK: }
ins(%arga: tensor<32x16xf32, #CSR>)
outs(%argx: tensor<32x16xf32, #DCSR>) {
^bb(%a: f32, %x: f32):
- %1 = mulf %x, %a : f32
+ %1 = arith.mulf %x, %a : f32
linalg.yield %1 : f32
} -> tensor<32x16xf32, #DCSR>
return %0 : tensor<32x16xf32, #DCSR>
ins(%arga: tensor<?x?xf32, #DenseMatrix>)
outs(%argx: tensor<?x?xf32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %a, %scale : f32
+ %0 = arith.mulf %a, %scale : f32
linalg.yield %0 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
ins(%arga: tensor<?x?xf32, #SparseMatrix>)
outs(%argx: tensor<?x?xf32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %a, %scale : f32
+ %0 = arith.mulf %a, %scale : f32
linalg.yield %0 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
ins(%arga, %argb : tensor<16x32xf32, #CSR>, tensor<32xf32>)
outs(%argx: tensor<16xf32>) {
^bb(%A: f32, %b: f32, %x: f32):
- %0 = mulf %A, %b : f32
- %1 = addf %0, %x : f32
+ %0 = arith.mulf %A, %b : f32
+ %1 = arith.addf %0, %x : f32
linalg.yield %1 : f32
} -> tensor<16xf32>
return %0 : tensor<16xf32>
// CHECK-LABEL: func @sparse_static_dims(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20x30xf32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<20x30x10xf32>) -> tensor<20x30x10xf32> {
-// CHECK: %[[VAL_2:.*]] = constant 20 : index
-// CHECK: %[[VAL_3:.*]] = constant 30 : index
-// CHECK: %[[VAL_4:.*]] = constant 10 : index
-// CHECK: %[[VAL_5:.*]] = constant 0 : index
-// CHECK: %[[VAL_6:.*]] = constant 1 : index
+// CHECK: %[[VAL_2:.*]] = arith.constant 20 : index
+// CHECK: %[[VAL_3:.*]] = arith.constant 30 : index
+// CHECK: %[[VAL_4:.*]] = arith.constant 10 : index
+// CHECK: %[[VAL_5:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_6:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_7:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<10x20x30xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_8:.*]] = memref.buffer_cast %[[VAL_1]] : memref<20x30x10xf32>
// CHECK: %[[VAL_9:.*]] = memref.alloc() : memref<20x30x10xf32>
// CHECK: memref.copy %[[VAL_8]], %[[VAL_9]] : memref<20x30x10xf32> to memref<20x30x10xf32>
// CHECK: scf.for %[[VAL_10:.*]] = %[[VAL_5]] to %[[VAL_3]] step %[[VAL_6]] {
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_5]] to %[[VAL_4]] step %[[VAL_6]] {
-// CHECK: %[[VAL_12:.*]] = muli %[[VAL_10]], %[[VAL_4]] : index
-// CHECK: %[[VAL_13:.*]] = addi %[[VAL_12]], %[[VAL_11]] : index
+// CHECK: %[[VAL_12:.*]] = arith.muli %[[VAL_10]], %[[VAL_4]] : index
+// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_12]], %[[VAL_11]] : index
// CHECK: scf.for %[[VAL_14:.*]] = %[[VAL_5]] to %[[VAL_2]] step %[[VAL_6]] {
-// CHECK: %[[VAL_15:.*]] = muli %[[VAL_13]], %[[VAL_2]] : index
-// CHECK: %[[VAL_16:.*]] = addi %[[VAL_15]], %[[VAL_14]] : index
+// CHECK: %[[VAL_15:.*]] = arith.muli %[[VAL_13]], %[[VAL_2]] : index
+// CHECK: %[[VAL_16:.*]] = arith.addi %[[VAL_15]], %[[VAL_14]] : index
// CHECK: %[[VAL_17:.*]] = memref.load %[[VAL_7]]{{\[}}%[[VAL_16]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_17]], %[[VAL_9]]{{\[}}%[[VAL_14]], %[[VAL_10]], %[[VAL_11]]] : memref<20x30x10xf32>
// CHECK: }
// CHECK-LABEL: func @sparse_dynamic_dims(
// CHECK-SAME: %[[VAL_0:.*]]: tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-SAME: %[[VAL_1:.*]]: tensor<?x?x?xf32>) -> tensor<?x?x?xf32> {
-// CHECK-DAG: %[[VAL_2:.*]] = constant 2 : index
-// CHECK-DAG: %[[VAL_3:.*]] = constant 0 : index
-// CHECK-DAG: %[[VAL_4:.*]] = constant 1 : index
+// CHECK-DAG: %[[VAL_2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[VAL_3:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[VAL_4:.*]] = arith.constant 1 : index
// CHECK: %[[VAL_5:.*]] = sparse_tensor.values %[[VAL_0]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK: %[[VAL_6:.*]] = tensor.dim %[[VAL_1]], %[[VAL_3]] : tensor<?x?x?xf32>
// CHECK: %[[VAL_7:.*]] = tensor.dim %[[VAL_1]], %[[VAL_4]] : tensor<?x?x?xf32>
// CHECK: memref.copy %[[VAL_9]], %[[VAL_10]] : memref<?x?x?xf32> to memref<?x?x?xf32>
// CHECK: scf.for %[[VAL_11:.*]] = %[[VAL_3]] to %[[VAL_7]] step %[[VAL_4]] {
// CHECK: scf.for %[[VAL_12:.*]] = %[[VAL_3]] to %[[VAL_8]] step %[[VAL_4]] {
-// CHECK: %[[VAL_13:.*]] = muli %[[VAL_8]], %[[VAL_11]] : index
-// CHECK: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_12]] : index
+// CHECK: %[[VAL_13:.*]] = arith.muli %[[VAL_8]], %[[VAL_11]] : index
+// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_12]] : index
// CHECK: scf.for %[[VAL_15:.*]] = %[[VAL_3]] to %[[VAL_6]] step %[[VAL_4]] {
-// CHECK: %[[VAL_16:.*]] = muli %[[VAL_6]], %[[VAL_14]] : index
-// CHECK: %[[VAL_17:.*]] = addi %[[VAL_16]], %[[VAL_15]] : index
+// CHECK: %[[VAL_16:.*]] = arith.muli %[[VAL_6]], %[[VAL_14]] : index
+// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_16]], %[[VAL_15]] : index
// CHECK: %[[VAL_18:.*]] = memref.load %[[VAL_5]]{{\[}}%[[VAL_17]]] : memref<?xf32>
// CHECK: memref.store %[[VAL_18]], %[[VAL_10]]{{\[}}%[[VAL_15]], %[[VAL_11]], %[[VAL_12]]] : memref<?x?x?xf32>
// CHECK: }
// CHECK-HIR-LABEL: func @sparse_dynamic_dims(
// CHECK-HIR-SAME: %[[VAL_0:.*]]: tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>,
// CHECK-HIR-SAME: %[[VAL_1:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK-HIR-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-HIR-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-HIR-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-HIR-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-HIR-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-HIR-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-HIR: %[[VAL_5:.*]] = tensor.dim %[[VAL_0]], %[[C2]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK-HIR: %[[VAL_6:.*]] = tensor.dim %[[VAL_0]], %[[C0]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK-HIR: %[[VAL_7:.*]] = tensor.dim %[[VAL_0]], %[[C1]] : tensor<?x?x?xf32, #sparse_tensor.encoding<{{{.*}}}>>
// CHECK-HIR: memref.copy %[[VAL_9]], %[[VAL_10]] : memref<f32> to memref<f32>
// CHECK-HIR: scf.for %[[VAL_11:.*]] = %[[C0]] to %[[VAL_5]] step %[[C1]] {
// CHECK-HIR: scf.for %[[VAL_12:.*]] = %[[C0]] to %[[VAL_6]] step %[[C1]] {
-// CHECK-HIR: %[[VAL_13:.*]] = muli %[[VAL_6]], %[[VAL_11]] : index
-// CHECK-HIR: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_12]] : index
+// CHECK-HIR: %[[VAL_13:.*]] = arith.muli %[[VAL_6]], %[[VAL_11]] : index
+// CHECK-HIR: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_12]] : index
// CHECK-HIR: %[[VAL_15:.*]] = memref.load %[[VAL_10]][] : memref<f32>
// CHECK-HIR: %[[VAL_16:.*]] = scf.for %[[VAL_17:.*]] = %[[C0]] to %[[VAL_7]] step %[[C1]] iter_args(%[[VAL_18:.*]] = %[[VAL_15]]) -> (f32) {
-// CHECK-HIR: %[[VAL_19:.*]] = muli %[[VAL_7]], %[[VAL_14]] : index
-// CHECK-HIR: %[[VAL_20:.*]] = addi %[[VAL_19]], %[[VAL_17]] : index
+// CHECK-HIR: %[[VAL_19:.*]] = arith.muli %[[VAL_7]], %[[VAL_14]] : index
+// CHECK-HIR: %[[VAL_20:.*]] = arith.addi %[[VAL_19]], %[[VAL_17]] : index
// CHECK-HIR: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xf32>
-// CHECK-HIR: %[[VAL_22:.*]] = addf %[[VAL_18]], %[[VAL_21]] : f32
+// CHECK-HIR: %[[VAL_22:.*]] = arith.addf %[[VAL_18]], %[[VAL_21]] : f32
// CHECK-HIR: scf.yield %[[VAL_22]] : f32
// CHECK-HIR: }
// CHECK-HIR: memref.store %[[VAL_23:.*]], %[[VAL_10]][] : memref<f32>
// CHECK-MIR-LABEL: func @sparse_dynamic_dims(
// CHECK-MIR-SAME: %[[VAL_0:.*]]: !llvm.ptr<i8>,
// CHECK-MIR-SAME: %[[VAL_1:.*]]: tensor<f32>) -> tensor<f32> {
-// CHECK-MIR-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-MIR-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-MIR-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-MIR-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-MIR-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-MIR-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-MIR: %[[VAL_5:.*]] = call @sparseDimSize(%[[VAL_0]], %[[C0]]) : (!llvm.ptr<i8>, index) -> index
// CHECK-MIR: %[[VAL_6:.*]] = call @sparseDimSize(%[[VAL_0]], %[[C1]]) : (!llvm.ptr<i8>, index) -> index
// CHECK-MIR: %[[VAL_7:.*]] = call @sparseDimSize(%[[VAL_0]], %[[C2]]) : (!llvm.ptr<i8>, index) -> index
// CHECK-MIR: memref.copy %[[VAL_9]], %[[VAL_10]] : memref<f32> to memref<f32>
// CHECK-MIR: scf.for %[[VAL_11:.*]] = %[[C0]] to %[[VAL_5]] step %[[C1]] {
// CHECK-MIR: scf.for %[[VAL_12:.*]] = %[[C0]] to %[[VAL_6]] step %[[C1]] {
-// CHECK-MIR: %[[VAL_13:.*]] = muli %[[VAL_6]], %[[VAL_11]] : index
-// CHECK-MIR: %[[VAL_14:.*]] = addi %[[VAL_13]], %[[VAL_12]] : index
+// CHECK-MIR: %[[VAL_13:.*]] = arith.muli %[[VAL_6]], %[[VAL_11]] : index
+// CHECK-MIR: %[[VAL_14:.*]] = arith.addi %[[VAL_13]], %[[VAL_12]] : index
// CHECK-MIR: %[[VAL_15:.*]] = memref.load %[[VAL_10]][] : memref<f32>
// CHECK-MIR: %[[VAL_16:.*]] = scf.for %[[VAL_17:.*]] = %[[C0]] to %[[VAL_7]] step %[[C1]] iter_args(%[[VAL_18:.*]] = %[[VAL_15]]) -> (f32) {
-// CHECK-MIR: %[[VAL_19:.*]] = muli %[[VAL_7]], %[[VAL_14]] : index
-// CHECK-MIR: %[[VAL_20:.*]] = addi %[[VAL_19]], %[[VAL_17]] : index
+// CHECK-MIR: %[[VAL_19:.*]] = arith.muli %[[VAL_7]], %[[VAL_14]] : index
+// CHECK-MIR: %[[VAL_20:.*]] = arith.addi %[[VAL_19]], %[[VAL_17]] : index
// CHECK-MIR: %[[VAL_21:.*]] = memref.load %[[VAL_8]]{{\[}}%[[VAL_20]]] : memref<?xf32>
-// CHECK-MIR: %[[VAL_22:.*]] = addf %[[VAL_18]], %[[VAL_21]] : f32
+// CHECK-MIR: %[[VAL_22:.*]] = arith.addf %[[VAL_18]], %[[VAL_21]] : f32
// CHECK-MIR: scf.yield %[[VAL_22]] : f32
// CHECK-MIR: }
// CHECK-MIR: memref.store %[[VAL_23:.*]], %[[VAL_10]][] : memref<f32>
ins(%arga: tensor<?x?x?xf32, #X>)
outs(%argx: tensor<f32>) {
^bb(%a : f32, %x: f32):
- %0 = addf %x, %a : f32
+ %0 = arith.addf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
// CHECK-SAME: %[[VAL_2:.*2]]: f32,
// CHECK-SAME: %[[VAL_3:.*3]]: f32,
// CHECK-SAME: %[[VAL_4:.*4]]: tensor<32x16xf32> {linalg.inplaceable = true}) -> tensor<32x16xf32> {
-// CHECK: %[[VAL_5:.*]] = constant 2.200000e+00 : f32
-// CHECK: %[[VAL_6:.*]] = constant 0 : index
-// CHECK: %[[VAL_7:.*]] = constant 1 : index
-// CHECK: %[[VAL_8:.*]] = addf %[[VAL_2]], %[[VAL_3]] : f32
+// CHECK: %[[VAL_5:.*]] = arith.constant 2.200000e+00 : f32
+// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
+// CHECK: %[[VAL_7:.*]] = arith.constant 1 : index
+// CHECK: %[[VAL_8:.*]] = arith.addf %[[VAL_2]], %[[VAL_3]] : f32
// CHECK: %[[VAL_9:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_10:.*]] = sparse_tensor.indices %[[VAL_0]], %[[VAL_6]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: %[[VAL_11:.*]] = sparse_tensor.pointers %[[VAL_0]], %[[VAL_7]] : tensor<32x16xf32, #sparse_tensor.encoding<{{.*}}>> to memref<?xindex>
// CHECK: scf.for %[[VAL_19:.*]] = %[[VAL_17]] to %[[VAL_18]] step %[[VAL_7]] {
// CHECK: %[[VAL_20:.*]] = memref.load %[[VAL_10]]{{\[}}%[[VAL_19]]] : memref<?xindex>
// CHECK: %[[VAL_21:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_19]]] : memref<?xindex>
-// CHECK: %[[VAL_22:.*]] = addi %[[VAL_19]], %[[VAL_7]] : index
+// CHECK: %[[VAL_22:.*]] = arith.addi %[[VAL_19]], %[[VAL_7]] : index
// CHECK: %[[VAL_23:.*]] = memref.load %[[VAL_11]]{{\[}}%[[VAL_22]]] : memref<?xindex>
// CHECK: scf.for %[[VAL_24:.*]] = %[[VAL_21]] to %[[VAL_23]] step %[[VAL_7]] {
// CHECK: %[[VAL_25:.*]] = memref.load %[[VAL_12]]{{\[}}%[[VAL_24]]] : memref<?xindex>
// CHECK: %[[VAL_26:.*]] = memref.load %[[VAL_13]]{{\[}}%[[VAL_24]]] : memref<?xf32>
-// CHECK: %[[VAL_27:.*]] = mulf %[[VAL_26]], %[[VAL_16]] : f32
-// CHECK: %[[VAL_28:.*]] = mulf %[[VAL_27]], %[[VAL_2]] : f32
-// CHECK: %[[VAL_29:.*]] = mulf %[[VAL_28]], %[[VAL_3]] : f32
-// CHECK: %[[VAL_30:.*]] = mulf %[[VAL_29]], %[[VAL_8]] : f32
-// CHECK: %[[VAL_31:.*]] = mulf %[[VAL_30]], %[[VAL_5]] : f32
+// CHECK: %[[VAL_27:.*]] = arith.mulf %[[VAL_26]], %[[VAL_16]] : f32
+// CHECK: %[[VAL_28:.*]] = arith.mulf %[[VAL_27]], %[[VAL_2]] : f32
+// CHECK: %[[VAL_29:.*]] = arith.mulf %[[VAL_28]], %[[VAL_3]] : f32
+// CHECK: %[[VAL_30:.*]] = arith.mulf %[[VAL_29]], %[[VAL_8]] : f32
+// CHECK: %[[VAL_31:.*]] = arith.mulf %[[VAL_30]], %[[VAL_5]] : f32
// CHECK: %[[VAL_32:.*]] = memref.load %[[VAL_15]]{{\[}}%[[VAL_20]], %[[VAL_25]]] : memref<32x16xf32>
-// CHECK: %[[VAL_33:.*]] = addf %[[VAL_31]], %[[VAL_32]] : f32
+// CHECK: %[[VAL_33:.*]] = arith.addf %[[VAL_31]], %[[VAL_32]] : f32
// CHECK: memref.store %[[VAL_33]], %[[VAL_15]]{{\[}}%[[VAL_20]], %[[VAL_25]]] : memref<32x16xf32>
// CHECK: }
// CHECK: }
%argq: f32,
%argr: f32,
%argx: tensor<32x16xf32> {linalg.inplaceable = true}) -> tensor<32x16xf32> {
- %s = addf %argq, %argr : f32
- %c = constant 2.2 : f32
+ %s = arith.addf %argq, %argr : f32
+ %c = arith.constant 2.2 : f32
%0 = linalg.generic #trait
ins(%arga, %argp, %argq: tensor<32x16xf32, #SparseMatrix>, tensor<f32>, f32)
outs(%argx: tensor<32x16xf32>) {
^bb(%a: f32, %p: f32, %q: f32, %x: f32):
- %0 = mulf %a, %p : f32 // scalar tensor argument
- %1 = mulf %0, %q : f32 // scalar argument
- %2 = mulf %1, %argr : f32 // scalar argument from outside block
- %3 = mulf %2, %s : f32 // scalar value from outside block
- %4 = mulf %3, %c : f32 // direct constant from outside block
- %5 = addf %4, %x : f32
+ %0 = arith.mulf %a, %p : f32 // scalar tensor argument
+ %1 = arith.mulf %0, %q : f32 // scalar argument
+ %2 = arith.mulf %1, %argr : f32 // scalar argument from outside block
+ %3 = arith.mulf %2, %s : f32 // scalar value from outside block
+ %4 = arith.mulf %3, %c : f32 // direct constant from outside block
+ %5 = arith.addf %4, %x : f32
linalg.yield %5 : f32
} -> tensor<32x16xf32>
}
// CHECK-LABEL: func @mul64(
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[P0:.*]] = memref.load %{{.*}}[%[[C0]]] : memref<?xi64>
-// CHECK: %[[B0:.*]] = index_cast %[[P0]] : i64 to index
+// CHECK: %[[B0:.*]] = arith.index_cast %[[P0]] : i64 to index
// CHECK: %[[P1:.*]] = memref.load %{{.*}}[%[[C1]]] : memref<?xi64>
-// CHECK: %[[B1:.*]] = index_cast %[[P1]] : i64 to index
+// CHECK: %[[B1:.*]] = arith.index_cast %[[P1]] : i64 to index
// CHECK: scf.for %[[I:.*]] = %[[B0]] to %[[B1]] step %[[C1]] {
// CHECK: %[[IND0:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xi64>
-// CHECK: %[[INDC:.*]] = index_cast %[[IND0]] : i64 to index
+// CHECK: %[[INDC:.*]] = arith.index_cast %[[IND0]] : i64 to index
// CHECK: %[[VAL0:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xf64>
// CHECK: %[[VAL1:.*]] = memref.load %{{.*}}[%[[INDC]]] : memref<32xf64>
-// CHECK: %[[MUL:.*]] = mulf %[[VAL0]], %[[VAL1]] : f64
+// CHECK: %[[MUL:.*]] = arith.mulf %[[VAL0]], %[[VAL1]] : f64
// CHECK: store %[[MUL]], %{{.*}}[%[[INDC]]] : memref<32xf64>
// CHECK: }
func @mul64(%arga: tensor<32xf64, #SparseVector64>, %argb: tensor<32xf64>, %argx: tensor<32xf64>) -> tensor<32xf64> {
ins(%arga, %argb: tensor<32xf64, #SparseVector64>, tensor<32xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
+ %0 = arith.mulf %a, %b : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
}
// CHECK-LABEL: func @mul32(
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: %[[P0:.*]] = memref.load %{{.*}}[%[[C0]]] : memref<?xi32>
-// CHECK: %[[Z0:.*]] = zexti %[[P0]] : i32 to i64
-// CHECK: %[[B0:.*]] = index_cast %[[Z0]] : i64 to index
+// CHECK: %[[Z0:.*]] = arith.extui %[[P0]] : i32 to i64
+// CHECK: %[[B0:.*]] = arith.index_cast %[[Z0]] : i64 to index
// CHECK: %[[P1:.*]] = memref.load %{{.*}}[%[[C1]]] : memref<?xi32>
-// CHECK: %[[Z1:.*]] = zexti %[[P1]] : i32 to i64
-// CHECK: %[[B1:.*]] = index_cast %[[Z1]] : i64 to index
+// CHECK: %[[Z1:.*]] = arith.extui %[[P1]] : i32 to i64
+// CHECK: %[[B1:.*]] = arith.index_cast %[[Z1]] : i64 to index
// CHECK: scf.for %[[I:.*]] = %[[B0]] to %[[B1]] step %[[C1]] {
// CHECK: %[[IND0:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xi32>
-// CHECK: %[[ZEXT:.*]] = zexti %[[IND0]] : i32 to i64
-// CHECK: %[[INDC:.*]] = index_cast %[[ZEXT]] : i64 to index
+// CHECK: %[[ZEXT:.*]] = arith.extui %[[IND0]] : i32 to i64
+// CHECK: %[[INDC:.*]] = arith.index_cast %[[ZEXT]] : i64 to index
// CHECK: %[[VAL0:.*]] = memref.load %{{.*}}[%[[I]]] : memref<?xf64>
// CHECK: %[[VAL1:.*]] = memref.load %{{.*}}[%[[INDC]]] : memref<32xf64>
-// CHECK: %[[MUL:.*]] = mulf %[[VAL0]], %[[VAL1]] : f64
+// CHECK: %[[MUL:.*]] = arith.mulf %[[VAL0]], %[[VAL1]] : f64
// CHECK: store %[[MUL]], %{{.*}}[%[[INDC]]] : memref<32xf64>
// CHECK: }
func @mul32(%arga: tensor<32xf64, #SparseVector32>, %argb: tensor<32xf64>, %argx: tensor<32xf64>) -> tensor<32xf64> {
ins(%arga, %argb: tensor<32xf64, #SparseVector32>, tensor<32xf64>)
outs(%argx: tensor<32xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
+ %0 = arith.mulf %a, %b : f64
linalg.yield %0 : f64
} -> tensor<32xf64>
return %0 : tensor<32xf64>
//
// CHECK-VEC0-LABEL: func @scale_d
-// CHECK-VEC0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC0-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC0-DAG: %[[c1024:.*]] = constant 1024 : index
+// CHECK-VEC0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC0-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC0-DAG: %[[c1024:.*]] = arith.constant 1024 : index
// CHECK-VEC0: scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c1]] {
// CHECK-VEC0: %[[l:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xf32>
-// CHECK-VEC0: %[[m:.*]] = mulf %[[l]], %{{.*}} : f32
+// CHECK-VEC0: %[[m:.*]] = arith.mulf %[[l]], %{{.*}} : f32
// CHECK-VEC0: store %[[m]], %{{.*}}[%[[i]]] : memref<1024xf32>
// CHECK-VEC0: }
// CHECK-VEC0: return
//
// CHECK-VEC1-LABEL: func @scale_d
-// CHECK-VEC1-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC1-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC1-DAG: %[[c1024:.*]] = constant 1024 : index
+// CHECK-VEC1-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC1-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC1-DAG: %[[c1024:.*]] = arith.constant 1024 : index
// CHECK-VEC1: scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c16]] {
// CHECK-VEC1: %[[r:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xf32>, vector<16xf32>
// CHECK-VEC1: %[[b:.*]] = vector.broadcast %{{.*}} : f32 to vector<16xf32>
-// CHECK-VEC1: %[[m:.*]] = mulf %[[r]], %[[b]] : vector<16xf32>
+// CHECK-VEC1: %[[m:.*]] = arith.mulf %[[r]], %[[b]] : vector<16xf32>
// CHECK-VEC1: vector.store %[[m]], %{{.*}}[%[[i]]] : memref<1024xf32>, vector<16xf32>
// CHECK-VEC1: }
// CHECK-VEC1: return
//
// CHECK-VEC2-LABEL: func @scale_d
-// CHECK-VEC2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC2-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC2-DAG: %[[c1024:.*]] = constant 1024 : index
+// CHECK-VEC2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC2-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC2-DAG: %[[c1024:.*]] = arith.constant 1024 : index
// CHECK-VEC2: scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c16]] {
// CHECK-VEC2: %[[r:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xf32>, vector<16xf32>
// CHECK-VEC2: %[[b:.*]] = vector.broadcast %{{.*}} : f32 to vector<16xf32>
-// CHECK-VEC2: %[[m:.*]] = mulf %[[r]], %[[b]] : vector<16xf32>
+// CHECK-VEC2: %[[m:.*]] = arith.mulf %[[r]], %[[b]] : vector<16xf32>
// CHECK-VEC2: vector.store %[[m]], %{{.*}}[%[[i]]] : memref<1024xf32>, vector<16xf32>
// CHECK-VEC2: }
// CHECK-VEC2: return
ins(%arga: tensor<1024xf32, #DenseVector>)
outs(%argx: tensor<1024xf32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<1024xf32>
return %0 : tensor<1024xf32>
//
// CHECK-VEC0-LABEL: func @mul_s
-// CHECK-VEC0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC0-DAG: %[[c1:.*]] = constant 1 : index
+// CHECK-VEC0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC0-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECK-VEC0: %[[p:.*]] = memref.load %{{.*}}[%[[c0]]] : memref<?xi32>
-// CHECK-VEC0: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC0: %[[q:.*]] = index_cast %[[a]] : i64 to index
+// CHECK-VEC0: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC0: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
// CHECK-VEC0: %[[r:.*]] = memref.load %{{.*}}[%[[c1]]] : memref<?xi32>
-// CHECK-VEC0: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC0: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC0: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC0: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC0: scf.for %[[i:.*]] = %[[q]] to %[[s]] step %[[c1]] {
// CHECK-VEC0: %[[li:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC0: %[[zi:.*]] = zexti %[[li]] : i32 to i64
-// CHECK-VEC0: %[[ci:.*]] = index_cast %[[zi]] : i64 to index
+// CHECK-VEC0: %[[zi:.*]] = arith.extui %[[li]] : i32 to i64
+// CHECK-VEC0: %[[ci:.*]] = arith.index_cast %[[zi]] : i64 to index
// CHECK-VEC0: %[[la:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xf32>
// CHECK-VEC0: %[[lb:.*]] = memref.load %{{.*}}[%[[ci]]] : memref<1024xf32>
-// CHECK-VEC0: %[[m:.*]] = mulf %[[la]], %[[lb]] : f32
+// CHECK-VEC0: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : f32
// CHECK-VEC0: store %[[m]], %{{.*}}[%[[ci]]] : memref<1024xf32>
// CHECK-VEC0: }
// CHECK-VEC0: return
//
// CHECK-VEC1-LABEL: func @mul_s
-// CHECK-VEC1-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC1-DAG: %[[c1:.*]] = constant 1 : index
+// CHECK-VEC1-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC1-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECK-VEC1: %[[p:.*]] = memref.load %{{.*}}[%[[c0]]] : memref<?xi32>
-// CHECK-VEC1: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC1: %[[q:.*]] = index_cast %[[a]] : i64 to index
+// CHECK-VEC1: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC1: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
// CHECK-VEC1: %[[r:.*]] = memref.load %{{.*}}[%[[c1]]] : memref<?xi32>
-// CHECK-VEC1: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC1: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC1: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC1: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC1: scf.for %[[i:.*]] = %[[q]] to %[[s]] step %[[c1]] {
// CHECK-VEC1: %[[li:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC1: %[[zi:.*]] = zexti %[[li]] : i32 to i64
-// CHECK-VEC1: %[[ci:.*]] = index_cast %[[zi]] : i64 to index
+// CHECK-VEC1: %[[zi:.*]] = arith.extui %[[li]] : i32 to i64
+// CHECK-VEC1: %[[ci:.*]] = arith.index_cast %[[zi]] : i64 to index
// CHECK-VEC1: %[[la:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xf32>
// CHECK-VEC1: %[[lb:.*]] = memref.load %{{.*}}[%[[ci]]] : memref<1024xf32>
-// CHECK-VEC1: %[[m:.*]] = mulf %[[la]], %[[lb]] : f32
+// CHECK-VEC1: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : f32
// CHECK-VEC1: store %[[m]], %{{.*}}[%[[ci]]] : memref<1024xf32>
// CHECK-VEC1: }
// CHECK-VEC1: return
//
// CHECK-VEC2: #[[$map:.*]] = affine_map<(d0, d1)[s0] -> (16, d0 - d1)
// CHECK-VEC2-LABEL: func @mul_s
-// CHECK-VEC2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC2-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC2-DAG: %[[c16:.*]] = constant 16 : index
+// CHECK-VEC2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC2-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC2-DAG: %[[c16:.*]] = arith.constant 16 : index
// CHECK-VEC2: %[[p:.*]] = memref.load %{{.*}}[%[[c0]]] : memref<?xi32>
-// CHECK-VEC2: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC2: %[[q:.*]] = index_cast %[[a]] : i64 to index
+// CHECK-VEC2: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC2: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
// CHECK-VEC2: %[[r:.*]] = memref.load %{{.*}}[%[[c1]]] : memref<?xi32>
-// CHECK-VEC2: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC2: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC2: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC2: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC2: scf.for %[[i:.*]] = %[[q]] to %[[s]] step %[[c16]] {
// CHECK-VEC2: %[[sub:.*]] = affine.min #[[$map]](%[[s]], %[[i]])[%[[c16]]]
// CHECK-VEC2: %[[mask:.*]] = vector.create_mask %[[sub]] : vector<16xi1>
// CHECK-VEC2: %[[li:.*]] = vector.maskedload %{{.*}}[%[[i]]], %[[mask]], %{{.*}} : memref<?xi32>, vector<16xi1>, vector<16xi32> into vector<16xi32>
-// CHECK-VEC2: %[[zi:.*]] = zexti %[[li]] : vector<16xi32> to vector<16xi64>
+// CHECK-VEC2: %[[zi:.*]] = arith.extui %[[li]] : vector<16xi32> to vector<16xi64>
// CHECK-VEC2: %[[la:.*]] = vector.maskedload %{{.*}}[%[[i]]], %[[mask]], %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-VEC2: %[[lb:.*]] = vector.gather %{{.*}}[%[[c0]]] [%[[zi]]], %[[mask]], %{{.*}} : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK-VEC2: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC2: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
// CHECK-VEC2: vector.scatter %{{.*}}[%[[c0]]] [%[[zi]]], %[[mask]], %[[m]] : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32>
// CHECK-VEC2: }
// CHECK-VEC2: return
//
// CHECK-VEC3: #[[$map:.*]] = affine_map<(d0, d1)[s0] -> (16, d0 - d1)
// CHECK-VEC3-LABEL: func @mul_s
-// CHECK-VEC3-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC3-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC3-DAG: %[[c16:.*]] = constant 16 : index
+// CHECK-VEC3-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC3-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC3-DAG: %[[c16:.*]] = arith.constant 16 : index
// CHECK-VEC3: %[[p:.*]] = memref.load %{{.*}}[%[[c0]]] : memref<?xi32>
-// CHECK-VEC3: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC3: %[[q:.*]] = index_cast %[[a]] : i64 to index
+// CHECK-VEC3: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC3: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
// CHECK-VEC3: %[[r:.*]] = memref.load %{{.*}}[%[[c1]]] : memref<?xi32>
-// CHECK-VEC3: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC3: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC3: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC3: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC3: scf.for %[[i:.*]] = %[[q]] to %[[s]] step %[[c16]] {
// CHECK-VEC3: %[[sub:.*]] = affine.min #[[$map]](%[[s]], %[[i]])[%[[c16]]]
// CHECK-VEC3: %[[mask:.*]] = vector.create_mask %[[sub]] : vector<16xi1>
// CHECK-VEC3: %[[li:.*]] = vector.maskedload %{{.*}}[%[[i]]], %[[mask]], %{{.*}} : memref<?xi32>, vector<16xi1>, vector<16xi32> into vector<16xi32>
// CHECK-VEC3: %[[la:.*]] = vector.maskedload %{{.*}}[%[[i]]], %[[mask]], %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-VEC3: %[[lb:.*]] = vector.gather %{{.*}}[%[[c0]]] [%[[li]]], %[[mask]], %{{.*}} : memref<1024xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK-VEC3: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC3: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
// CHECK-VEC3: vector.scatter %{{.*}}[%[[c0]]] [%[[li]]], %[[mask]], %[[m]] : memref<1024xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-VEC3: }
// CHECK-VEC3: return
ins(%arga, %argb: tensor<1024xf32, #SparseVector>, tensor<1024xf32>)
outs(%argx: tensor<1024xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<1024xf32>
return %0 : tensor<1024xf32>
//
// CHECK-VEC0-LABEL: func @reduction_d
-// CHECK-VEC0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC0-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC0-DAG: %[[c1024:.*]] = constant 1024 : index
+// CHECK-VEC0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC0-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC0-DAG: %[[c1024:.*]] = arith.constant 1024 : index
// CHECK-VEC0: %[[red:.*]] = scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c1]] iter_args(%[[red_in:.*]] = %{{.*}}) -> (f32) {
// CHECK-VEC0: %[[la:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xf32>
// CHECK-VEC0: %[[lb:.*]] = memref.load %{{.*}}[%[[i]]] : memref<1024xf32>
-// CHECK-VEC0: %[[m:.*]] = mulf %[[la]], %[[lb]] : f32
-// CHECK-VEC0: %[[a:.*]] = addf %[[red_in]], %[[m]] : f32
+// CHECK-VEC0: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : f32
+// CHECK-VEC0: %[[a:.*]] = arith.addf %[[red_in]], %[[m]] : f32
// CHECK-VEC0: scf.yield %[[a]] : f32
// CHECK-VEC0: }
// CHECK-VEC0: return
//
// CHECK-VEC1-LABEL: func @reduction_d
-// CHECK-VEC1-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC1-DAG: %[[i0:.*]] = constant 0 : i32
-// CHECK-VEC1-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC1-DAG: %[[c1024:.*]] = constant 1024 : index
-// CHECK-VEC1-DAG: %[[v0:.*]] = constant dense<0.000000e+00> : vector<16xf32>
+// CHECK-VEC1-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC1-DAG: %[[i0:.*]] = arith.constant 0 : i32
+// CHECK-VEC1-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC1-DAG: %[[c1024:.*]] = arith.constant 1024 : index
+// CHECK-VEC1-DAG: %[[v0:.*]] = arith.constant dense<0.000000e+00> : vector<16xf32>
// CHECK-VEC1: %[[l:.*]] = memref.load %{{.*}}[] : memref<f32>
// CHECK-VEC1: %[[r:.*]] = vector.insertelement %[[l]], %[[v0]][%[[i0]] : i32] : vector<16xf32>
// CHECK-VEC1: %[[red:.*]] = scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c16]] iter_args(%[[red_in:.*]] = %[[r]]) -> (vector<16xf32>) {
// CHECK-VEC1: %[[la:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xf32>, vector<16xf32>
// CHECK-VEC1: %[[lb:.*]] = vector.load %{{.*}}[%[[i]]] : memref<1024xf32>, vector<16xf32>
-// CHECK-VEC1: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
-// CHECK-VEC1: %[[a:.*]] = addf %[[red_in]], %[[m]] : vector<16xf32>
+// CHECK-VEC1: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC1: %[[a:.*]] = arith.addf %[[red_in]], %[[m]] : vector<16xf32>
// CHECK-VEC1: scf.yield %[[a]] : vector<16xf32>
// CHECK-VEC1: }
// CHECK-VEC1: %{{.*}} = vector.reduction "add", %[[red]] : vector<16xf32> into f32
// CHECK-VEC1: return
//
// CHECK-VEC2-LABEL: func @reduction_d
-// CHECK-VEC2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC2-DAG: %[[i0:.*]] = constant 0 : i32
-// CHECK-VEC2-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC2-DAG: %[[c1024:.*]] = constant 1024 : index
-// CHECK-VEC2-DAG: %[[v0:.*]] = constant dense<0.000000e+00> : vector<16xf32>
+// CHECK-VEC2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC2-DAG: %[[i0:.*]] = arith.constant 0 : i32
+// CHECK-VEC2-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC2-DAG: %[[c1024:.*]] = arith.constant 1024 : index
+// CHECK-VEC2-DAG: %[[v0:.*]] = arith.constant dense<0.000000e+00> : vector<16xf32>
// CHECK-VEC2: %[[l:.*]] = memref.load %{{.*}}[] : memref<f32>
// CHECK-VEC2: %[[r:.*]] = vector.insertelement %[[l]], %[[v0]][%[[i0]] : i32] : vector<16xf32>
// CHECK-VEC2: %[[red:.*]] = scf.for %[[i:.*]] = %[[c0]] to %[[c1024]] step %[[c16]] iter_args(%[[red_in:.*]] = %[[r]]) -> (vector<16xf32>) {
// CHECK-VEC2: %[[la:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xf32>, vector<16xf32>
// CHECK-VEC2: %[[lb:.*]] = vector.load %{{.*}}[%[[i]]] : memref<1024xf32>, vector<16xf32>
-// CHECK-VEC2: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
-// CHECK-VEC2: %[[a:.*]] = addf %[[red_in]], %[[m]] : vector<16xf32>
+// CHECK-VEC2: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC2: %[[a:.*]] = arith.addf %[[red_in]], %[[m]] : vector<16xf32>
// CHECK-VEC2: scf.yield %[[a]] : vector<16xf32>
// CHECK-VEC2: }
// CHECK-VEC2: %{{.*}} = vector.reduction "add", %[[red]] : vector<16xf32> into f32
ins(%arga, %argb: tensor<1024xf32, #DenseVector>, tensor<1024xf32>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = addf %x, %0 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.addf %x, %0 : f32
linalg.yield %1 : f32
} -> tensor<f32>
return %0 : tensor<f32>
//
// CHECK-VEC0-LABEL: func @mul_ds
-// CHECK-VEC0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC0-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC0-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-VEC0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC0-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC0-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-VEC0: scf.for %[[i:.*]] = %[[c0]] to %[[c512]] step %[[c1]] {
// CHECK-VEC0: %[[p:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC0: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC0: %[[q:.*]] = index_cast %[[a]] : i64 to index
-// CHECK-VEC0: %[[a:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC0: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC0: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
+// CHECK-VEC0: %[[a:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC0: %[[r:.*]] = memref.load %{{.*}}[%[[a]]] : memref<?xi32>
-// CHECK-VEC0: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC0: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC0: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC0: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC0: scf.for %[[j:.*]] = %[[q]] to %[[s]] step %[[c1]] {
// CHECK-VEC0: %[[lj:.*]] = memref.load %{{.*}}[%[[j]]] : memref<?xi32>
-// CHECK-VEC0: %[[zj:.*]] = zexti %[[lj]] : i32 to i64
-// CHECK-VEC0: %[[cj:.*]] = index_cast %[[zj]] : i64 to index
+// CHECK-VEC0: %[[zj:.*]] = arith.extui %[[lj]] : i32 to i64
+// CHECK-VEC0: %[[cj:.*]] = arith.index_cast %[[zj]] : i64 to index
// CHECK-VEC0: %[[la:.*]] = memref.load %{{.*}}[%[[j]]] : memref<?xf32>
// CHECK-VEC0: %[[lb:.*]] = memref.load %{{.*}}[%[[i]], %[[cj]]] : memref<512x1024xf32>
-// CHECK-VEC0: %[[m:.*]] = mulf %[[la]], %[[lb]] : f32
+// CHECK-VEC0: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : f32
// CHECK-VEC0: store %[[m]], %{{.*}}[%[[i]], %[[cj]]] : memref<512x1024xf32>
// CHECK-VEC0: }
// CHECK-VEC0: }
// CHECK-VEC0: return
//
// CHECK-VEC1-LABEL: func @mul_ds
-// CHECK-VEC1-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC1-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC1-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-VEC1-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC1-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC1-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-VEC1: scf.for %[[i:.*]] = %[[c0]] to %[[c512]] step %[[c1]] {
// CHECK-VEC1: %[[p:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC1: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC1: %[[q:.*]] = index_cast %[[a]] : i64 to index
-// CHECK-VEC1: %[[a:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC1: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC1: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
+// CHECK-VEC1: %[[a:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC1: %[[r:.*]] = memref.load %{{.*}}[%[[a]]] : memref<?xi32>
-// CHECK-VEC1: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC1: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC1: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC1: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC1: scf.for %[[j:.*]] = %[[q]] to %[[s]] step %[[c1]] {
// CHECK-VEC1: %[[lj:.*]] = memref.load %{{.*}}[%[[j]]] : memref<?xi32>
-// CHECK-VEC1: %[[zj:.*]] = zexti %[[lj]] : i32 to i64
-// CHECK-VEC1: %[[cj:.*]] = index_cast %[[zj]] : i64 to index
+// CHECK-VEC1: %[[zj:.*]] = arith.extui %[[lj]] : i32 to i64
+// CHECK-VEC1: %[[cj:.*]] = arith.index_cast %[[zj]] : i64 to index
// CHECK-VEC1: %[[la:.*]] = memref.load %{{.*}}[%[[j]]] : memref<?xf32>
// CHECK-VEC1: %[[lb:.*]] = memref.load %{{.*}}[%[[i]], %[[cj]]] : memref<512x1024xf32>
-// CHECK-VEC1: %[[m:.*]] = mulf %[[la]], %[[lb]] : f32
+// CHECK-VEC1: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : f32
// CHECK-VEC1: store %[[m]], %{{.*}}[%[[i]], %[[cj]]] : memref<512x1024xf32>
// CHECK-VEC1: }
// CHECK-VEC1: }
//
// CHECK-VEC2: #[[$map:.*]] = affine_map<(d0, d1)[s0] -> (16, d0 - d1)
// CHECK-VEC2-LABEL: func @mul_ds
-// CHECK-VEC2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC2-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC2-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC2-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-VEC2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC2-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC2-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC2-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-VEC2: scf.for %[[i:.*]] = %[[c0]] to %[[c512]] step %[[c1]] {
// CHECK-VEC2: %[[p:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC2: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC2: %[[q:.*]] = index_cast %[[a]] : i64 to index
-// CHECK-VEC2: %[[a:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC2: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC2: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
+// CHECK-VEC2: %[[a:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC2: %[[r:.*]] = memref.load %{{.*}}[%[[a]]] : memref<?xi32>
-// CHECK-VEC2: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC2: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC2: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC2: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC2: scf.for %[[j:.*]] = %[[q]] to %[[s]] step %[[c16]] {
// CHECK-VEC2: %[[sub:.*]] = affine.min #[[$map]](%[[s]], %[[j]])[%[[c16]]]
// CHECK-VEC2: %[[mask:.*]] = vector.create_mask %[[sub]] : vector<16xi1>
// CHECK-VEC2: %[[lj:.*]] = vector.maskedload %{{.*}}[%[[j]]], %[[mask]], %{{.*}} : memref<?xi32>, vector<16xi1>, vector<16xi32> into vector<16xi32>
-// CHECK-VEC2: %[[zj:.*]] = zexti %[[lj]] : vector<16xi32> to vector<16xi64>
+// CHECK-VEC2: %[[zj:.*]] = arith.extui %[[lj]] : vector<16xi32> to vector<16xi64>
// CHECK-VEC2: %[[la:.*]] = vector.maskedload %{{.*}}[%[[j]]], %[[mask]], %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-VEC2: %[[lb:.*]] = vector.gather %{{.*}}[%[[i]], %[[c0]]] [%[[zj]]], %[[mask]], %{{.*}} : memref<512x1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK-VEC2: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC2: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
// CHECK-VEC2: vector.scatter %{{.*}}[%[[i]], %[[c0]]] [%[[zj]]], %[[mask]], %[[m]] : memref<512x1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32>
// CHECK-VEC2: }
// CHECK-VEC2: }
//
// CHECK-VEC3: #[[$map:.*]] = affine_map<(d0, d1)[s0] -> (16, d0 - d1)
// CHECK-VEC3-LABEL: func @mul_ds
-// CHECK-VEC3-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC3-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC3-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC3-DAG: %[[c512:.*]] = constant 512 : index
+// CHECK-VEC3-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC3-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC3-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC3-DAG: %[[c512:.*]] = arith.constant 512 : index
// CHECK-VEC3: scf.for %[[i:.*]] = %[[c0]] to %[[c512]] step %[[c1]] {
// CHECK-VEC3: %[[p:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xi32>
-// CHECK-VEC3: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK-VEC3: %[[q:.*]] = index_cast %[[a]] : i64 to index
-// CHECK-VEC3: %[[a:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC3: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK-VEC3: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
+// CHECK-VEC3: %[[a:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC3: %[[r:.*]] = memref.load %{{.*}}[%[[a]]] : memref<?xi32>
-// CHECK-VEC3: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK-VEC3: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK-VEC3: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK-VEC3: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK-VEC3: scf.for %[[j:.*]] = %[[q]] to %[[s]] step %[[c16]] {
// CHECK-VEC3: %[[sub:.*]] = affine.min #[[$map]](%[[s]], %[[j]])[%[[c16]]]
// CHECK-VEC3: %[[mask:.*]] = vector.create_mask %[[sub]] : vector<16xi1>
// CHECK-VEC3: %[[lj:.*]] = vector.maskedload %{{.*}}[%[[j]]], %[[mask]], %{{.*}} : memref<?xi32>, vector<16xi1>, vector<16xi32> into vector<16xi32>
// CHECK-VEC3: %[[la:.*]] = vector.maskedload %{{.*}}[%[[j]]], %[[mask]], %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-VEC3: %[[lb:.*]] = vector.gather %{{.*}}[%[[i]], %[[c0]]] [%[[lj]]], %[[mask]], %{{.*}} : memref<512x1024xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK-VEC3: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK-VEC3: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
// CHECK-VEC3: vector.scatter %{{.*}}[%[[i]], %[[c0]]] [%[[lj]]], %[[mask]], %[[m]] : memref<512x1024xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-VEC3: }
// CHECK-VEC3: }
ins(%arga, %argb: tensor<512x1024xf32, #SparseMatrix>, tensor<512x1024xf32>)
outs(%argx: tensor<512x1024xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<512x1024xf32>
return %0 : tensor<512x1024xf32>
//
// CHECK-VEC0-LABEL: func @add_dense
-// CHECK-VEC0-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC0-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC0-DAG: %[[c32:.*]] = constant 32 : index
+// CHECK-VEC0-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC0-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC0-DAG: %[[c32:.*]] = arith.constant 32 : index
// CHECK-VEC0: scf.for %[[i:.*]] = %[[c0]] to %[[c32]] step %[[c1]] {
// CHECK-VEC0: %[[lo:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xindex>
-// CHECK-VEC0: %[[i1:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC0: %[[i1:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC0: %[[hi:.*]] = memref.load %{{.*}}[%[[i1]]] : memref<?xindex>
// CHECK-VEC0: scf.for %[[jj:.*]] = %[[lo]] to %[[hi]] step %[[c1]] {
// CHECK-VEC0: %[[j:.*]] = memref.load %{{.*}}[%[[jj]]] : memref<?xindex>
// CHECK-VEC0: %[[x:.*]] = memref.load %{{.*}}[%[[i1]], %[[j]]] : memref<33x64xf64>
// CHECK-VEC0: %[[a:.*]] = memref.load %{{.*}}[%[[jj]]] : memref<?xf64>
-// CHECK-VEC0: %[[s:.*]] = addf %[[x]], %[[a]] : f64
+// CHECK-VEC0: %[[s:.*]] = arith.addf %[[x]], %[[a]] : f64
// CHECK-VEC0: memref.store %[[s]], %{{.*}}[%[[i1]], %[[j]]] : memref<33x64xf64>
// CHECK-VEC0: }
// CHECK-VEC0: }
// CHECK-VEC0: return
//
// CHECK-VEC1-LABEL: func @add_dense
-// CHECK-VEC1-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC1-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC1-DAG: %[[c32:.*]] = constant 32 : index
+// CHECK-VEC1-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC1-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC1-DAG: %[[c32:.*]] = arith.constant 32 : index
// CHECK-VEC1: scf.for %[[i:.*]] = %[[c0]] to %[[c32]] step %[[c1]] {
// CHECK-VEC1: %[[lo:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xindex>
-// CHECK-VEC1: %[[i1:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC1: %[[i1:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC1: %[[hi:.*]] = memref.load %{{.*}}[%[[i1]]] : memref<?xindex>
// CHECK-VEC1: scf.for %[[jj:.*]] = %[[lo]] to %[[hi]] step %[[c1]] {
// CHECK-VEC1: %[[j:.*]] = memref.load %{{.*}}[%[[jj]]] : memref<?xindex>
// CHECK-VEC1: %[[x:.*]] = memref.load %{{.*}}[%[[i1]], %[[j]]] : memref<33x64xf64>
// CHECK-VEC1: %[[a:.*]] = memref.load %{{.*}}[%[[jj]]] : memref<?xf64>
-// CHECK-VEC1: %[[s:.*]] = addf %[[x]], %[[a]] : f64
+// CHECK-VEC1: %[[s:.*]] = arith.addf %[[x]], %[[a]] : f64
// CHECK-VEC1: memref.store %[[s]], %{{.*}}[%[[i1]], %[[j]]] : memref<33x64xf64>
// CHECK-VEC1: }
// CHECK-VEC1: }
//
// CHECK-VEC2: #[[$map:.*]] = affine_map<(d0, d1)[s0] -> (16, d0 - d1)
// CHECK-VEC2-LABEL: func @add_dense
-// CHECK-VEC2-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-VEC2-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-VEC2-DAG: %[[c16:.*]] = constant 16 : index
-// CHECK-VEC2-DAG: %[[c32:.*]] = constant 32 : index
+// CHECK-VEC2-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-VEC2-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-VEC2-DAG: %[[c16:.*]] = arith.constant 16 : index
+// CHECK-VEC2-DAG: %[[c32:.*]] = arith.constant 32 : index
// CHECK-VEC2: scf.for %[[i:.*]] = %[[c0]] to %[[c32]] step %[[c1]] {
// CHECK-VEC2: %[[lo:.*]] = memref.load %{{.*}}[%[[i]]] : memref<?xindex>
-// CHECK-VEC2: %[[i1:.*]] = addi %[[i]], %[[c1]] : index
+// CHECK-VEC2: %[[i1:.*]] = arith.addi %[[i]], %[[c1]] : index
// CHECK-VEC2: %[[hi:.*]] = memref.load %{{.*}}[%[[i1]]] : memref<?xindex>
// CHECK-VEC2: scf.for %[[jj:.*]] = %[[lo]] to %[[hi]] step %[[c16]] {
// CHECK-VEC2: %[[sub:.*]] = affine.min #[[$map]](%[[hi]], %[[jj]])[%[[c16]]]
// CHECK-VEC2: %[[j:.*]] = vector.maskedload %{{.*}}[%[[jj]]], %[[mask]], %{{.*}} : memref<?xindex>
// CHECK-VEC2: %[[x:.*]] = vector.gather %{{.*}}[%[[i1]], %[[c0]]] [%[[j]]], %[[mask]], %{{.*}} : memref<33x64xf64>
// CHECK-VEC2: %[[a:.*]] = vector.maskedload %{{.*}}[%[[jj]]], %[[mask]], %{{.*}} : memref<?xf64>
-// CHECK-VEC2: %[[s:.*]] = addf %[[x]], %[[a]] : vector<16xf64>
+// CHECK-VEC2: %[[s:.*]] = arith.addf %[[x]], %[[a]] : vector<16xf64>
// CHECK-VEC2: vector.scatter %{{.*}}[%[[i1]], %[[c0]]] [%[[j]]], %[[mask]], %[[s]] : memref<33x64xf64>
// CHECK-VEC2: }
// CHECK-VEC2: }
ins(%arga: tensor<32x64xf64, #SparseMatrix>)
outs(%argx: tensor<33x64xf64>) {
^bb(%a: f64, %x: f64):
- %0 = addf %x, %a : f64
+ %0 = arith.addf %x, %a : f64
linalg.yield %0 : f64
} -> tensor<33x64xf64>
return %0 : tensor<33x64xf64>
// CHECK-DAG: #[[$map0:.*]] = affine_map<()[s0, s1] -> (s0 + ((-s0 + s1) floordiv 16) * 16)>
// CHECK-DAG: #[[$map1:.*]] = affine_map<(d0)[s0] -> (-d0 + s0)>
// CHECK-LABEL: func @mul_s
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
-// CHECK-DAG: %[[c16:.*]] = constant 16 : index
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[c16:.*]] = arith.constant 16 : index
// CHECK: %[[p:.*]] = memref.load %{{.*}}[%[[c0]]] : memref<?xi32>
-// CHECK: %[[a:.*]] = zexti %[[p]] : i32 to i64
-// CHECK: %[[q:.*]] = index_cast %[[a]] : i64 to index
+// CHECK: %[[a:.*]] = arith.extui %[[p]] : i32 to i64
+// CHECK: %[[q:.*]] = arith.index_cast %[[a]] : i64 to index
// CHECK: %[[r:.*]] = memref.load %{{.*}}[%[[c1]]] : memref<?xi32>
-// CHECK: %[[b:.*]] = zexti %[[r]] : i32 to i64
-// CHECK: %[[s:.*]] = index_cast %[[b]] : i64 to index
+// CHECK: %[[b:.*]] = arith.extui %[[r]] : i32 to i64
+// CHECK: %[[s:.*]] = arith.index_cast %[[b]] : i64 to index
// CHECK: %[[boundary:.*]] = affine.apply #[[$map0]]()[%[[q]], %[[s]]]
// CHECK: scf.for %[[i:.*]] = %[[q]] to %[[boundary]] step %[[c16]] {
// CHECK: %[[mask:.*]] = vector.constant_mask [16] : vector<16xi1>
// CHECK: %[[li:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xi32>, vector<16xi32>
-// CHECK: %[[zi:.*]] = zexti %[[li]] : vector<16xi32> to vector<16xi64>
+// CHECK: %[[zi:.*]] = arith.extui %[[li]] : vector<16xi32> to vector<16xi64>
// CHECK: %[[la:.*]] = vector.load %{{.*}}[%[[i]]] : memref<?xf32>, vector<16xf32>
// CHECK: %[[lb:.*]] = vector.gather %{{.*}}[%[[c0]]] [%[[zi]]], %[[mask]], %{{.*}} : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK: %[[m:.*]] = mulf %[[la]], %[[lb]] : vector<16xf32>
+// CHECK: %[[m:.*]] = arith.mulf %[[la]], %[[lb]] : vector<16xf32>
// CHECK: vector.scatter %{{.*}}[%[[c0]]] [%[[zi]]], %[[mask]], %[[m]] : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32>
// CHECK: }
// CHECK: scf.for %[[i2:.*]] = %[[boundary]] to %[[s]] step %[[c16]] {
// CHECK: %[[sub:.*]] = affine.apply #[[$map1]](%[[i2]])[%[[s]]]
// CHECK: %[[mask2:.*]] = vector.create_mask %[[sub]] : vector<16xi1>
// CHECK: %[[li2:.*]] = vector.maskedload %{{.*}}[%[[i2]]], %[[mask2]], %{{.*}} : memref<?xi32>, vector<16xi1>, vector<16xi32> into vector<16xi32>
-// CHECK: %[[zi2:.*]] = zexti %[[li2]] : vector<16xi32> to vector<16xi64>
+// CHECK: %[[zi2:.*]] = arith.extui %[[li2]] : vector<16xi32> to vector<16xi64>
// CHECK: %[[la2:.*]] = vector.maskedload %{{.*}}[%[[i2]]], %[[mask2]], %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: %[[lb2:.*]] = vector.gather %{{.*}}[%[[c0]]] [%[[zi2]]], %[[mask2]], %{{.*}} : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
-// CHECK: %[[m2:.*]] = mulf %[[la2]], %[[lb2]] : vector<16xf32>
+// CHECK: %[[m2:.*]] = arith.mulf %[[la2]], %[[lb2]] : vector<16xf32>
// CHECK: vector.scatter %{{.*}}[%[[c0]]] [%[[zi2]]], %[[mask2]], %[[m2]] : memref<1024xf32>, vector<16xi64>, vector<16xi1>, vector<16xf32>
// CHECK: }
// CHECK: return
ins(%arga, %argb: tensor<1024xf32, #SparseVector>, tensor<1024xf32>)
outs(%argx: tensor<1024xf32>) {
^bb(%a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
+ %0 = arith.mulf %a, %b : f32
linalg.yield %0 : f32
} -> tensor<1024xf32>
return %0 : tensor<1024xf32>
%0 = select %arg0, %arg1, %arg2 : tensor<f32>
return %0 : tensor<f32>
}
-
-// CHECK-LABEL: func @index_cast(
-// CHECK-SAME: %[[TENSOR:.*]]: tensor<i32>, %[[SCALAR:.*]]: i32
-func @index_cast(%tensor: tensor<i32>, %scalar: i32) -> (tensor<index>, index) {
- %index_tensor = index_cast %tensor : tensor<i32> to tensor<index>
- %index_scalar = index_cast %scalar : i32 to index
- return %index_tensor, %index_scalar : tensor<index>, index
-}
-// CHECK: %[[MEMREF:.*]] = memref.buffer_cast %[[TENSOR]] : memref<i32>
-// CHECK-NEXT: %[[INDEX_MEMREF:.*]] = index_cast %[[MEMREF]]
-// CHECK-SAME: memref<i32> to memref<index>
-// CHECK-NEXT: %[[INDEX_TENSOR:.*]] = memref.tensor_load %[[INDEX_MEMREF]]
-// CHECK: return %[[INDEX_TENSOR]]
// CHECK-LABEL: func @br_folding(
func @br_folding() -> i32 {
- // CHECK-NEXT: %[[CST:.*]] = constant 0 : i32
+ // CHECK-NEXT: %[[CST:.*]] = arith.constant 0 : i32
// CHECK-NEXT: return %[[CST]] : i32
- %c0_i32 = constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
br ^bb1(%c0_i32 : i32)
^bb1(%x : i32):
return %x : i32
func @cond_br_folding(%cond : i1, %a : i32) {
// CHECK-NEXT: return
- %false_cond = constant false
- %true_cond = constant true
+ %false_cond = arith.constant false
+ %true_cond = arith.constant true
cond_br %cond, ^bb1, ^bb2(%a : i32)
^bb1:
func @cond_br_and_br_folding(%a : i32) {
// CHECK-NEXT: return
- %false_cond = constant false
- %true_cond = constant true
+ %false_cond = arith.constant false
+ %true_cond = arith.constant true
cond_br %true_cond, ^bb2, ^bb1(%a : i32)
^bb1(%x : i32):
^bb1:
// CHECK-NOT: switch
// CHECK: br ^[[BB2:[a-zA-Z0-9_]+]](%[[CASE_OPERAND_0]]
- %c0_i32 = constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
switch %c0_i32 : i32, [
default: ^bb2(%caseOperand0 : f32),
-1: ^bb3(%caseOperand1 : f32),
^bb1:
// CHECK-NOT: switch
// CHECK: br ^[[BB4:[a-zA-Z0-9_]+]](%[[CASE_OPERAND_2]]
- %c0_i32 = constant 1 : i32
+ %c0_i32 = arith.constant 1 : i32
switch %c0_i32 : i32, [
default: ^bb2(%caseOperand0 : f32),
-1: ^bb3(%caseOperand1 : f32),
// CHECK-LABEL: @assert_true
func @assert_true() {
// CHECK-NOT: assert
- %true = constant true
+ %true = arith.constant true
assert %true, "Computer says no"
return
}
// RUN: mlir-opt %s -canonicalize --split-input-file | FileCheck %s
-// Test case: Folding of comparisons with equal operands.
-// CHECK-LABEL: @cmpi_equal_operands
-// CHECK-DAG: %[[T:.*]] = constant true
-// CHECK-DAG: %[[F:.*]] = constant false
-// CHECK: return %[[T]], %[[T]], %[[T]], %[[T]], %[[T]],
-// CHECK-SAME: %[[F]], %[[F]], %[[F]], %[[F]], %[[F]]
-func @cmpi_equal_operands(%arg0: i64)
- -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
- %0 = cmpi eq, %arg0, %arg0 : i64
- %1 = cmpi sle, %arg0, %arg0 : i64
- %2 = cmpi sge, %arg0, %arg0 : i64
- %3 = cmpi ule, %arg0, %arg0 : i64
- %4 = cmpi uge, %arg0, %arg0 : i64
- %5 = cmpi ne, %arg0, %arg0 : i64
- %6 = cmpi slt, %arg0, %arg0 : i64
- %7 = cmpi sgt, %arg0, %arg0 : i64
- %8 = cmpi ult, %arg0, %arg0 : i64
- %9 = cmpi ugt, %arg0, %arg0 : i64
- return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9
- : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
-}
-
-// -----
-
// CHECK-LABEL: @select_same_val
// CHECK: return %arg1
func @select_same_val(%arg0: i1, %arg1: i64) -> i64 {
// CHECK-LABEL: @select_cmp_eq_select
// CHECK: return %arg1
func @select_cmp_eq_select(%arg0: i64, %arg1: i64) -> i64 {
- %0 = cmpi eq, %arg0, %arg1 : i64
+ %0 = arith.cmpi eq, %arg0, %arg1 : i64
%1 = select %0, %arg0, %arg1 : i64
return %1 : i64
}
// CHECK-LABEL: @select_cmp_ne_select
// CHECK: return %arg0
func @select_cmp_ne_select(%arg0: i64, %arg1: i64) -> i64 {
- %0 = cmpi ne, %arg0, %arg1 : i64
+ %0 = arith.cmpi ne, %arg0, %arg1 : i64
%1 = select %0, %arg0, %arg1 : i64
return %1 : i64
}
// -----
-// CHECK-LABEL: @indexCastOfSignExtend
-// CHECK: %[[res:.+]] = index_cast %arg0 : i8 to index
-// CHECK: return %[[res]]
-func @indexCastOfSignExtend(%arg0: i8) -> index {
- %ext = sexti %arg0 : i8 to i16
- %idx = index_cast %ext : i16 to index
- return %idx : index
-}
-
-// CHECK-LABEL: @signExtendConstant
-// CHECK: %[[cres:.+]] = constant -2 : i16
-// CHECK: return %[[cres]]
-func @signExtendConstant() -> i16 {
- %c-2 = constant -2 : i8
- %ext = sexti %c-2 : i8 to i16
- return %ext : i16
-}
-
-// CHECK-LABEL: @truncConstant
-// CHECK: %[[cres:.+]] = constant -2 : i16
-// CHECK: return %[[cres]]
-func @truncConstant(%arg0: i8) -> i16 {
- %c-2 = constant -2 : i32
- %tr = trunci %c-2 : i32 to i16
- return %tr : i16
-}
-
-// CHECK-LABEL: @truncFPConstant
-// CHECK: %[[cres:.+]] = constant 1.000000e+00 : bf16
-// CHECK: return %[[cres]]
-func @truncFPConstant() -> bf16 {
- %cst = constant 1.000000e+00 : f32
- %0 = fptrunc %cst : f32 to bf16
- return %0 : bf16
-}
-
-// Test that cases with rounding are NOT propagated
-// CHECK-LABEL: @truncFPConstantRounding
-// CHECK: constant 1.444000e+25 : f32
-// CHECK: fptrunc
-func @truncFPConstantRounding() -> bf16 {
- %cst = constant 1.444000e+25 : f32
- %0 = fptrunc %cst : f32 to bf16
- return %0 : bf16
-}
-
-// CHECK-LABEL: @tripleAddAdd
-// CHECK: %[[cres:.+]] = constant 59 : index
-// CHECK: %[[add:.+]] = addi %arg0, %[[cres]] : index
-// CHECK: return %[[add]]
-func @tripleAddAdd(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = addi %c17, %arg0 : index
- %add2 = addi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleAddSub0
-// CHECK: %[[cres:.+]] = constant 59 : index
-// CHECK: %[[add:.+]] = subi %[[cres]], %arg0 : index
-// CHECK: return %[[add]]
-func @tripleAddSub0(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %c17, %arg0 : index
- %add2 = addi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleAddSub1
-// CHECK: %[[cres:.+]] = constant 25 : index
-// CHECK: %[[add:.+]] = addi %arg0, %[[cres]] : index
-// CHECK: return %[[add]]
-func @tripleAddSub1(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %arg0, %c17 : index
- %add2 = addi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubAdd0
-// CHECK: %[[cres:.+]] = constant 25 : index
-// CHECK: %[[add:.+]] = subi %[[cres]], %arg0 : index
-// CHECK: return %[[add]]
-func @tripleSubAdd0(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = addi %c17, %arg0 : index
- %add2 = subi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubAdd1
-// CHECK: %[[cres:.+]] = constant -25 : index
-// CHECK: %[[add:.+]] = addi %arg0, %[[cres]] : index
-// CHECK: return %[[add]]
-func @tripleSubAdd1(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = addi %c17, %arg0 : index
- %add2 = subi %add1, %c42 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubSub0
-// CHECK: %[[cres:.+]] = constant 25 : index
-// CHECK: %[[add:.+]] = addi %arg0, %[[cres]] : index
-// CHECK: return %[[add]]
-func @tripleSubSub0(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %c17, %arg0 : index
- %add2 = subi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubSub1
-// CHECK: %[[cres:.+]] = constant -25 : index
-// CHECK: %[[add:.+]] = subi %[[cres]], %arg0 : index
-// CHECK: return %[[add]]
-func @tripleSubSub1(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %c17, %arg0 : index
- %add2 = subi %add1, %c42 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubSub2
-// CHECK: %[[cres:.+]] = constant 59 : index
-// CHECK: %[[add:.+]] = subi %[[cres]], %arg0 : index
-// CHECK: return %[[add]]
-func @tripleSubSub2(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %arg0, %c17 : index
- %add2 = subi %c42, %add1 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @tripleSubSub3
-// CHECK: %[[cres:.+]] = constant 59 : index
-// CHECK: %[[add:.+]] = subi %arg0, %[[cres]] : index
-// CHECK: return %[[add]]
-func @tripleSubSub3(%arg0: index) -> index {
- %c17 = constant 17 : index
- %c42 = constant 42 : index
- %add1 = subi %arg0, %c17 : index
- %add2 = subi %add1, %c42 : index
- return %add2 : index
-}
-
-// CHECK-LABEL: @notCmpEQ
-// CHECK: %[[cres:.+]] = cmpi ne, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpEQ(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "eq", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpEQ2
-// CHECK: %[[cres:.+]] = cmpi ne, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpEQ2(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "eq", %arg0, %arg1 : i8
- %ncmp = xor %true, %cmp : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpNE
-// CHECK: %[[cres:.+]] = cmpi eq, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpNE(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "ne", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpSLT
-// CHECK: %[[cres:.+]] = cmpi sge, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpSLT(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "slt", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpSLE
-// CHECK: %[[cres:.+]] = cmpi sgt, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpSLE(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "sle", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpSGT
-// CHECK: %[[cres:.+]] = cmpi sle, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpSGT(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "sgt", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpSGE
-// CHECK: %[[cres:.+]] = cmpi slt, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpSGE(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "sge", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpULT
-// CHECK: %[[cres:.+]] = cmpi uge, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpULT(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "ult", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpULE
-// CHECK: %[[cres:.+]] = cmpi ugt, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpULE(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "ule", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpUGT
-// CHECK: %[[cres:.+]] = cmpi ule, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpUGT(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "ugt", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// CHECK-LABEL: @notCmpUGE
-// CHECK: %[[cres:.+]] = cmpi ult, %arg0, %arg1 : i8
-// CHECK: return %[[cres]]
-func @notCmpUGE(%arg0: i8, %arg1: i8) -> i1 {
- %true = constant true
- %cmp = cmpi "uge", %arg0, %arg1 : i8
- %ncmp = xor %cmp, %true : i1
- return %ncmp : i1
-}
-
-// -----
-
// CHECK-LABEL: @branchCondProp
-// CHECK: %[[trueval:.+]] = constant true
-// CHECK: %[[falseval:.+]] = constant false
+// CHECK: %[[trueval:.+]] = arith.constant true
+// CHECK: %[[falseval:.+]] = arith.constant false
// CHECK: "test.consumer1"(%[[trueval]]) : (i1) -> ()
// CHECK: "test.consumer2"(%[[falseval]]) : (i1) -> ()
func @branchCondProp(%arg0: i1) {
// -----
// CHECK-LABEL: @selToNot
-// CHECK: %[[trueval:.+]] = constant true
-// CHECK: %{{.+}} = xor %arg0, %[[trueval]] : i1
+// CHECK: %[[trueval:.+]] = arith.constant true
+// CHECK: %{{.+}} = arith.xori %arg0, %[[trueval]] : i1
func @selToNot(%arg0: i1) -> i1 {
- %true = constant true
- %false = constant false
+ %true = arith.constant true
+ %false = arith.constant false
%res = select %arg0, %false, %true : i1
return %res : i1
}
-
-// -----
-
-// CHECK-LABEL: @bitcastSameType(
-// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
-func @bitcastSameType(%arg : f32) -> f32 {
- // CHECK: return %[[ARG]]
- %res = bitcast %arg : f32 to f32
- return %res : f32
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantFPtoI(
-func @bitcastConstantFPtoI() -> i32 {
- // CHECK: %[[C0:.+]] = constant 0 : i32
- // CHECK: return %[[C0]]
- %c0 = constant 0.0 : f32
- %res = bitcast %c0 : f32 to i32
- return %res : i32
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantItoFP(
-func @bitcastConstantItoFP() -> f32 {
- // CHECK: %[[C0:.+]] = constant 0.0{{.*}} : f32
- // CHECK: return %[[C0]]
- %c0 = constant 0 : i32
- %res = bitcast %c0 : i32 to f32
- return %res : f32
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantFPtoFP(
-func @bitcastConstantFPtoFP() -> f16 {
- // CHECK: %[[C0:.+]] = constant 0.0{{.*}} : f16
- // CHECK: return %[[C0]]
- %c0 = constant 0.0 : bf16
- %res = bitcast %c0 : bf16 to f16
- return %res : f16
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantVecFPtoI(
-func @bitcastConstantVecFPtoI() -> vector<3xf32> {
- // CHECK: %[[C0:.+]] = constant dense<0.0{{.*}}> : vector<3xf32>
- // CHECK: return %[[C0]]
- %c0 = constant dense<0> : vector<3xi32>
- %res = bitcast %c0 : vector<3xi32> to vector<3xf32>
- return %res : vector<3xf32>
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantVecItoFP(
-func @bitcastConstantVecItoFP() -> vector<3xi32> {
- // CHECK: %[[C0:.+]] = constant dense<0> : vector<3xi32>
- // CHECK: return %[[C0]]
- %c0 = constant dense<0.0> : vector<3xf32>
- %res = bitcast %c0 : vector<3xf32> to vector<3xi32>
- return %res : vector<3xi32>
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastConstantVecFPtoFP(
-func @bitcastConstantVecFPtoFP() -> vector<3xbf16> {
- // CHECK: %[[C0:.+]] = constant dense<0.0{{.*}}> : vector<3xbf16>
- // CHECK: return %[[C0]]
- %c0 = constant dense<0.0> : vector<3xf16>
- %res = bitcast %c0 : vector<3xf16> to vector<3xbf16>
- return %res : vector<3xbf16>
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastBackAndForth(
-// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
-func @bitcastBackAndForth(%arg : i32) -> i32 {
- // CHECK: return %[[ARG]]
- %f = bitcast %arg : i32 to f32
- %res = bitcast %f : f32 to i32
- return %res : i32
-}
-
-// -----
-
-// CHECK-LABEL: @bitcastOfBitcast(
-// CHECK-SAME: %[[ARG:[a-zA-Z0-9_]*]]
-func @bitcastOfBitcast(%arg : i16) -> i16 {
- // CHECK: return %[[ARG]]
- %f = bitcast %arg : i16 to f16
- %bf = bitcast %f : f16 to bf16
- %res = bitcast %bf : bf16 to i16
- return %res : i16
-}
}
// CHECK: %0 = generic_atomic_rmw %arg0[%arg2] : memref<10xf32> {
// CHECK: ^bb0([[CUR_VAL:%.*]]: f32):
-// CHECK: [[CMP:%.*]] = cmpf ogt, [[CUR_VAL]], [[f]] : f32
+// CHECK: [[CMP:%.*]] = arith.cmpf ogt, [[CUR_VAL]], [[f]] : f32
// CHECK: [[SELECT:%.*]] = select [[CMP]], [[CUR_VAL]], [[f]] : f32
// CHECK: atomic_yield [[SELECT]] : f32
// CHECK: }
// -----
-// Test ceil divide with signed integer
-// CHECK-LABEL: func @ceildivi
-// CHECK-SAME: ([[ARG0:%.+]]: i32, [[ARG1:%.+]]: i32) -> i32 {
-func @ceildivi(%arg0: i32, %arg1: i32) -> (i32) {
- %res = ceildivi_signed %arg0, %arg1 : i32
- return %res : i32
-
-// CHECK: [[ONE:%.+]] = constant 1 : i32
-// CHECK: [[ZERO:%.+]] = constant 0 : i32
-// CHECK: [[MINONE:%.+]] = constant -1 : i32
-// CHECK: [[CMP1:%.+]] = cmpi sgt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[X:%.+]] = select [[CMP1]], [[MINONE]], [[ONE]] : i32
-// CHECK: [[TRUE1:%.+]] = addi [[X]], [[ARG0]] : i32
-// CHECK: [[TRUE2:%.+]] = divi_signed [[TRUE1]], [[ARG1]] : i32
-// CHECK: [[TRUE3:%.+]] = addi [[ONE]], [[TRUE2]] : i32
-// CHECK: [[FALSE1:%.+]] = subi [[ZERO]], [[ARG0]] : i32
-// CHECK: [[FALSE2:%.+]] = divi_signed [[FALSE1]], [[ARG1]] : i32
-// CHECK: [[FALSE3:%.+]] = subi [[ZERO]], [[FALSE2]] : i32
-// CHECK: [[NNEG:%.+]] = cmpi slt, [[ARG0]], [[ZERO]] : i32
-// CHECK: [[NPOS:%.+]] = cmpi sgt, [[ARG0]], [[ZERO]] : i32
-// CHECK: [[MNEG:%.+]] = cmpi slt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[MPOS:%.+]] = cmpi sgt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[TERM1:%.+]] = and [[NNEG]], [[MNEG]] : i1
-// CHECK: [[TERM2:%.+]] = and [[NPOS]], [[MPOS]] : i1
-// CHECK: [[CMP2:%.+]] = or [[TERM1]], [[TERM2]] : i1
-// CHECK: [[RES:%.+]] = select [[CMP2]], [[TRUE3]], [[FALSE3]] : i32
-}
-
-// -----
-
-// Test floor divide with signed integer
-// CHECK-LABEL: func @floordivi
-// CHECK-SAME: ([[ARG0:%.+]]: i32, [[ARG1:%.+]]: i32) -> i32 {
-func @floordivi(%arg0: i32, %arg1: i32) -> (i32) {
- %res = floordivi_signed %arg0, %arg1 : i32
- return %res : i32
-// CHECK: [[ONE:%.+]] = constant 1 : i32
-// CHECK: [[ZERO:%.+]] = constant 0 : i32
-// CHECK: [[MIN1:%.+]] = constant -1 : i32
-// CHECK: [[CMP1:%.+]] = cmpi slt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[X:%.+]] = select [[CMP1]], [[ONE]], [[MIN1]] : i32
-// CHECK: [[TRUE1:%.+]] = subi [[X]], [[ARG0]] : i32
-// CHECK: [[TRUE2:%.+]] = divi_signed [[TRUE1]], [[ARG1]] : i32
-// CHECK: [[TRUE3:%.+]] = subi [[MIN1]], [[TRUE2]] : i32
-// CHECK: [[FALSE:%.+]] = divi_signed [[ARG0]], [[ARG1]] : i32
-// CHECK: [[NNEG:%.+]] = cmpi slt, [[ARG0]], [[ZERO]] : i32
-// CHECK: [[NPOS:%.+]] = cmpi sgt, [[ARG0]], [[ZERO]] : i32
-// CHECK: [[MNEG:%.+]] = cmpi slt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[MPOS:%.+]] = cmpi sgt, [[ARG1]], [[ZERO]] : i32
-// CHECK: [[TERM1:%.+]] = and [[NNEG]], [[MPOS]] : i1
-// CHECK: [[TERM2:%.+]] = and [[NPOS]], [[MNEG]] : i1
-// CHECK: [[CMP2:%.+]] = or [[TERM1]], [[TERM2]] : i1
-// CHECK: [[RES:%.+]] = select [[CMP2]], [[TRUE3]], [[FALSE]] : i32
-}
-
-// -----
-
// CHECK-LABEL: func @memref_reshape(
func @memref_reshape(%input: memref<*xf32>,
%shape: memref<3xi32>) -> memref<?x?x8xf32> {
// CHECK-SAME: [[SRC:%.*]]: memref<*xf32>,
// CHECK-SAME: [[SHAPE:%.*]]: memref<3xi32>) -> memref<?x?x8xf32> {
-// CHECK: [[C1:%.*]] = constant 1 : index
-// CHECK: [[C8:%.*]] = constant 8 : index
-// CHECK: [[STRIDE_1:%.*]] = muli [[C1]], [[C8]] : index
+// CHECK: [[C1:%.*]] = arith.constant 1 : index
+// CHECK: [[C8:%.*]] = arith.constant 8 : index
+// CHECK: [[STRIDE_1:%.*]] = arith.muli [[C1]], [[C8]] : index
-// CHECK: [[C1_:%.*]] = constant 1 : index
+// CHECK: [[C1_:%.*]] = arith.constant 1 : index
// CHECK: [[DIM_1:%.*]] = memref.load [[SHAPE]]{{\[}}[[C1_]]] : memref<3xi32>
-// CHECK: [[SIZE_1:%.*]] = index_cast [[DIM_1]] : i32 to index
-// CHECK: [[STRIDE_0:%.*]] = muli [[STRIDE_1]], [[SIZE_1]] : index
+// CHECK: [[SIZE_1:%.*]] = arith.index_cast [[DIM_1]] : i32 to index
+// CHECK: [[STRIDE_0:%.*]] = arith.muli [[STRIDE_1]], [[SIZE_1]] : index
-// CHECK: [[C0:%.*]] = constant 0 : index
+// CHECK: [[C0:%.*]] = arith.constant 0 : index
// CHECK: [[DIM_0:%.*]] = memref.load [[SHAPE]]{{\[}}[[C0]]] : memref<3xi32>
-// CHECK: [[SIZE_0:%.*]] = index_cast [[DIM_0]] : i32 to index
+// CHECK: [[SIZE_0:%.*]] = arith.index_cast [[DIM_0]] : i32 to index
// CHECK: [[RESULT:%.*]] = memref.reinterpret_cast [[SRC]]
// CHECK-SAME: to offset: [0], sizes: {{\[}}[[SIZE_0]], [[SIZE_1]], 8],
return %result : f32
}
// CHECK-SAME: %[[LHS:.*]]: f32, %[[RHS:.*]]: f32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpf ogt, %[[LHS]], %[[RHS]] : f32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpf ogt, %[[LHS]], %[[RHS]] : f32
// CHECK-NEXT: %[[SELECT:.*]] = select %[[CMP]], %[[LHS]], %[[RHS]] : f32
-// CHECK-NEXT: %[[IS_NAN:.*]] = cmpf uno, %[[LHS]], %[[RHS]] : f32
-// CHECK-NEXT: %[[NAN:.*]] = constant 0x7FC00000 : f32
+// CHECK-NEXT: %[[IS_NAN:.*]] = arith.cmpf uno, %[[LHS]], %[[RHS]] : f32
+// CHECK-NEXT: %[[NAN:.*]] = arith.constant 0x7FC00000 : f32
// CHECK-NEXT: %[[RESULT:.*]] = select %[[IS_NAN]], %[[NAN]], %[[SELECT]] : f32
// CHECK-NEXT: return %[[RESULT]] : f32
return %result : vector<4xf16>
}
// CHECK-SAME: %[[LHS:.*]]: vector<4xf16>, %[[RHS:.*]]: vector<4xf16>)
-// CHECK-NEXT: %[[CMP:.*]] = cmpf ogt, %[[LHS]], %[[RHS]] : vector<4xf16>
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpf ogt, %[[LHS]], %[[RHS]] : vector<4xf16>
// CHECK-NEXT: %[[SELECT:.*]] = select %[[CMP]], %[[LHS]], %[[RHS]]
-// CHECK-NEXT: %[[IS_NAN:.*]] = cmpf uno, %[[LHS]], %[[RHS]] : vector<4xf16>
-// CHECK-NEXT: %[[NAN:.*]] = constant 0x7E00 : f16
+// CHECK-NEXT: %[[IS_NAN:.*]] = arith.cmpf uno, %[[LHS]], %[[RHS]] : vector<4xf16>
+// CHECK-NEXT: %[[NAN:.*]] = arith.constant 0x7E00 : f16
// CHECK-NEXT: %[[SPLAT_NAN:.*]] = splat %[[NAN]] : vector<4xf16>
// CHECK-NEXT: %[[RESULT:.*]] = select %[[IS_NAN]], %[[SPLAT_NAN]], %[[SELECT]]
// CHECK-NEXT: return %[[RESULT]] : vector<4xf16>
return %result : f32
}
// CHECK-SAME: %[[LHS:.*]]: f32, %[[RHS:.*]]: f32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpf olt, %[[LHS]], %[[RHS]] : f32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpf olt, %[[LHS]], %[[RHS]] : f32
// CHECK-NEXT: %[[SELECT:.*]] = select %[[CMP]], %[[LHS]], %[[RHS]] : f32
-// CHECK-NEXT: %[[IS_NAN:.*]] = cmpf uno, %[[LHS]], %[[RHS]] : f32
-// CHECK-NEXT: %[[NAN:.*]] = constant 0x7FC00000 : f32
+// CHECK-NEXT: %[[IS_NAN:.*]] = arith.cmpf uno, %[[LHS]], %[[RHS]] : f32
+// CHECK-NEXT: %[[NAN:.*]] = arith.constant 0x7FC00000 : f32
// CHECK-NEXT: %[[RESULT:.*]] = select %[[IS_NAN]], %[[NAN]], %[[SELECT]] : f32
// CHECK-NEXT: return %[[RESULT]] : f32
return %result : i32
}
// CHECK-SAME: %[[LHS:.*]]: i32, %[[RHS:.*]]: i32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpi sgt, %[[LHS]], %[[RHS]] : i32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpi sgt, %[[LHS]], %[[RHS]] : i32
// -----
return %result : i32
}
// CHECK-SAME: %[[LHS:.*]]: i32, %[[RHS:.*]]: i32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpi slt, %[[LHS]], %[[RHS]] : i32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpi slt, %[[LHS]], %[[RHS]] : i32
// -----
return %result : i32
}
// CHECK-SAME: %[[LHS:.*]]: i32, %[[RHS:.*]]: i32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpi ugt, %[[LHS]], %[[RHS]] : i32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpi ugt, %[[LHS]], %[[RHS]] : i32
// -----
return %result : i32
}
// CHECK-SAME: %[[LHS:.*]]: i32, %[[RHS:.*]]: i32)
-// CHECK-NEXT: %[[CMP:.*]] = cmpi ult, %[[LHS]], %[[RHS]] : i32
+// CHECK-NEXT: %[[CMP:.*]] = arith.cmpi ult, %[[LHS]], %[[RHS]] : i32
%res = math.tanh %arg : f32
return %res : f32
}
-// CHECK-DAG: %[[ZERO:.+]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[ONE:.+]] = constant 1.000000e+00 : f32
-// CHECK-DAG: %[[TWO:.+]] = constant 2.000000e+00 : f32
-// CHECK: %[[DOUBLEDX:.+]] = mulf %arg0, %[[TWO]] : f32
-// CHECK: %[[NEGDOUBLEDX:.+]] = negf %[[DOUBLEDX]] : f32
+// CHECK-DAG: %[[ZERO:.+]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[ONE:.+]] = arith.constant 1.000000e+00 : f32
+// CHECK-DAG: %[[TWO:.+]] = arith.constant 2.000000e+00 : f32
+// CHECK: %[[DOUBLEDX:.+]] = arith.mulf %arg0, %[[TWO]] : f32
+// CHECK: %[[NEGDOUBLEDX:.+]] = arith.negf %[[DOUBLEDX]] : f32
// CHECK: %[[EXP1:.+]] = math.exp %[[NEGDOUBLEDX]] : f32
-// CHECK: %[[DIVIDEND1:.+]] = subf %[[ONE]], %[[EXP1]] : f32
-// CHECK: %[[DIVISOR1:.+]] = addf %[[ONE]], %[[EXP1]] : f32
-// CHECK: %[[RES1:.+]] = divf %[[DIVIDEND1]], %[[DIVISOR1]] : f32
+// CHECK: %[[DIVIDEND1:.+]] = arith.subf %[[ONE]], %[[EXP1]] : f32
+// CHECK: %[[DIVISOR1:.+]] = arith.addf %[[ONE]], %[[EXP1]] : f32
+// CHECK: %[[RES1:.+]] = arith.divf %[[DIVIDEND1]], %[[DIVISOR1]] : f32
// CHECK: %[[EXP2:.+]] = math.exp %[[DOUBLEDX]] : f32
-// CHECK: %[[DIVIDEND2:.+]] = subf %[[EXP2]], %[[ONE]] : f32
-// CHECK: %[[DIVISOR2:.+]] = addf %[[EXP2]], %[[ONE]] : f32
-// CHECK: %[[RES2:.+]] = divf %[[DIVIDEND2]], %[[DIVISOR2]] : f32
-// CHECK: %[[COND:.+]] = cmpf oge, %arg0, %[[ZERO]] : f32
+// CHECK: %[[DIVIDEND2:.+]] = arith.subf %[[EXP2]], %[[ONE]] : f32
+// CHECK: %[[DIVISOR2:.+]] = arith.addf %[[EXP2]], %[[ONE]] : f32
+// CHECK: %[[RES2:.+]] = arith.divf %[[DIVIDEND2]], %[[DIVISOR2]] : f32
+// CHECK: %[[COND:.+]] = arith.cmpf oge, %arg0, %[[ZERO]] : f32
// CHECK: %[[RESULT:.+]] = select %[[COND]], %[[RES1]], %[[RES2]] : f32
// CHECK: return %[[RESULT]]
// Because this pass updates block arguments, it needs to also atomically
// update all terminators and issue an error if that is not possible.
func @unable_to_update_terminator(%arg0: tensor<f32>) -> tensor<f32> {
- %0 = constant true
+ %0 = arith.constant true
cond_br %0, ^bb1(%arg0: tensor<f32>), ^bb2(%arg0: tensor<f32>)
^bb1(%bbarg0: tensor<f32>):
// expected-error @+1 {{failed to legalize operation 'test.terminator'}}
// CHECK: scf.while
// CHECK: scf.condition
func @bufferize_while(%arg0: i64, %arg1: i64) -> i64 {
- %c2_i64 = constant 2 : i64
+ %c2_i64 = arith.constant 2 : i64
%0:2 = scf.while (%arg2 = %arg0) : (i64) -> (i64, i64) {
- %1 = cmpi slt, %arg2, %arg1 : i64
+ %1 = arith.cmpi slt, %arg2, %arg1 : i64
scf.condition(%1) %arg2, %arg2 : i64, i64
} do {
^bb0(%arg2: i64, %arg3: i64):
- %1 = muli %arg3, %c2_i64 : i64
+ %1 = arith.muli %arg3, %c2_i64 : i64
scf.yield %1 : i64
}
return %0#1 : i64
// RUN: mlir-opt -split-input-file %s -verify-diagnostics
-func @test_index_cast_shape_error(%arg0 : tensor<index>) -> tensor<2xi64> {
- // expected-error @+1 {{all non-scalar operands/results must have the same shape and base type}}
- %0 = index_cast %arg0 : tensor<index> to tensor<2xi64>
- return %0 : tensor<2xi64>
-}
-
-// -----
-
-func @test_index_cast_tensor_error(%arg0 : tensor<index>) -> i64 {
- // expected-error @+1 {{if an operand is non-scalar, then there must be at least one non-scalar result}}
- %0 = index_cast %arg0 : tensor<index> to i64
- return %0 : i64
-}
-
-// -----
-
-func @non_signless_constant() {
- // expected-error @+1 {{requires integer result types to be signless}}
- %0 = constant 0 : ui32
- return
-}
-
-// -----
-
-func @non_signless_constant() {
- // expected-error @+1 {{requires integer result types to be signless}}
- %0 = constant 0 : si32
- return
-}
-
-// -----
-
func @unsupported_attribute() {
// expected-error @+1 {{unsupported 'value' attribute: "" : index}}
%0 = constant "" : index
// -----
-func @complex_constant_wrong_attribute_type() {
- // expected-error @+1 {{requires attribute's type ('f32') to match op's return type ('complex<f32>')}}
- %0 = "std.constant" () {value = 1.0 : f32} : () -> complex<f32>
- return
-}
-
-// -----
-
func @complex_constant_wrong_element_types() {
// expected-error @+1 {{requires attribute's element types ('f32', 'f32') to match the element type of the op's return type ('f64')}}
%0 = constant [1.0 : f32, -1.0 : f32] : complex<f64>
// -----
func @return_i32_f32() -> (i32, f32) {
- %0 = constant 1 : i32
- %1 = constant 1. : f32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 1. : f32
return %0, %1 : i32, f32
}
%0:2 = call @return_i32_f32() : () -> (f32, i32)
return
}
-
-// -----
-
-func @bitcast_different_bit_widths(%arg : f16) -> f32 {
- // expected-error@+1 {{are cast incompatible}}
- %res = bitcast %arg : f16 to f32
- return %res : f32
-}
// RUN: mlir-opt %s | mlir-opt | FileCheck %s
// RUN: mlir-opt %s --mlir-print-op-generic | mlir-opt | FileCheck %s
-// CHECK-LABEL: test_index_cast
-func @test_index_cast(%arg0 : index) -> i64 {
- %0 = index_cast %arg0 : index to i64
- return %0 : i64
-}
-
-// CHECK-LABEL: test_index_cast_tensor
-func @test_index_cast_tensor(%arg0 : tensor<index>) -> tensor<i64> {
- %0 = index_cast %arg0 : tensor<index> to tensor<i64>
- return %0 : tensor<i64>
-}
-
-// CHECK-LABEL: test_index_cast_tensor_reverse
-func @test_index_cast_tensor_reverse(%arg0 : tensor<i64>) -> tensor<index> {
- %0 = index_cast %arg0 : tensor<i64> to tensor<index>
- return %0 : tensor<index>
-}
-
// CHECK-LABEL: @assert
func @assert(%arg : i1) {
assert %arg, "Some message in case this assertion fails."
return %result : complex<f64>
}
-// CHECK-LABEL: func @bitcast(
-func @bitcast(%arg : f32) -> i32 {
- %res = bitcast %arg : f32 to i32
- return %res : i32
-}
-
// CHECK-LABEL: func @maximum
func @maximum(%v1: vector<4xf32>, %v2: vector<4xf32>,
%f1: f32, %f2: f32,
func @basic() -> tensor<3x4xf32> {
// CHECK: %[[MEMREF:.*]] = memref.get_global @__constant_3x4xf32 : memref<3x4xf32>
// CHECK: %[[TENSOR:.*]] = memref.tensor_load %[[MEMREF]]
- %0 = constant dense<7.0> : tensor<3x4xf32>
+ %0 = arith.constant dense<7.0> : tensor<3x4xf32>
// CHECK: return %[[TENSOR]]
return %0 : tensor<3x4xf32>
}
// CHECK: memref.global
// CHECK-NOT: memref.global
func @duplicate_constants() -> (tensor<3x4xf32>, tensor<3x4xf32>) {
- %0 = constant dense<7.0> : tensor<3x4xf32>
- %1 = constant dense<7.0> : tensor<3x4xf32>
+ %0 = arith.constant dense<7.0> : tensor<3x4xf32>
+ %1 = arith.constant dense<7.0> : tensor<3x4xf32>
return %0, %1 : tensor<3x4xf32>, tensor<3x4xf32>
}
// CHECK: memref.global
// CHECK-NOT: memref.global
func @multiple_constants() -> (tensor<3x4xf32>, tensor<3x4xf32>) {
- %0 = constant dense<7.0> : tensor<3x4xf32>
- %1 = constant dense<8.0> : tensor<3x4xf32>
+ %0 = arith.constant dense<7.0> : tensor<3x4xf32>
+ %1 = arith.constant dense<8.0> : tensor<3x4xf32>
return %0, %1 : tensor<3x4xf32>, tensor<3x4xf32>
}
// We don't convert non-tensor globals.
// CHECK-NOT: memref.global
func @non_tensor() {
- %0 = constant 7 : i32
+ %0 = arith.constant 7 : i32
return
}
// CHECK-SAME: %[[ELEM0:.*]]: index,
// CHECK-SAME: %[[ELEM1:.*]]: index) -> tensor<2xindex> {
// CHECK: %[[MEMREF:.*]] = memref.alloc()
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: store %[[ELEM0]], %[[MEMREF]][%[[C0]]]
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: store %[[ELEM1]], %[[MEMREF]][%[[C1]]]
// CHECK: %[[RET:.*]] = memref.tensor_load %[[MEMREF]]
// CHECK: return %[[RET]] : tensor<2xindex>
// CHECK-SAME: %[[ARG:.*]]: tensor<*xf32>,
// CHECK-SAME: %[[DYNAMIC_EXTENT:.*]]: index) -> tensor<?xindex> {
// CHECK: %[[MEMREF:.*]] = memref.alloc(%[[DYNAMIC_EXTENT]]) : memref<?xindex>
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
// CHECK: scf.parallel (%[[I:.*]]) = (%[[C0]]) to (%[[DYNAMIC_EXTENT]]) step (%[[C1]]) {
// CHECK: %[[CASTED:.*]] = memref.buffer_cast %[[ARG]] : memref<*xf32>
// CHECK: %[[ELEM:.*]] = memref.dim %[[CASTED]], %[[I]] : memref<*xf32>
// CHECK-LABEL: func @tensor.generate_static_and_dynamic(
// CHECK-SAME: %[[DYNAMIC_EXTENT:.*]]: index) -> tensor<16x?xindex> {
// CHECK: %[[MEMREF:.*]] = memref.alloc(%[[DYNAMIC_EXTENT]]) : memref<16x?xindex>
-// CHECK: %[[C0:.*]] = constant 0 : index
-// CHECK: %[[C1:.*]] = constant 1 : index
-// CHECK: %[[C16:.*]] = constant 16 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[C1:.*]] = arith.constant 1 : index
+// CHECK: %[[C16:.*]] = arith.constant 16 : index
// CHECK: scf.parallel (%[[I:.*]], %[[J:.*]]) = (%[[C0]], %[[C0]]) to (%[[C16]], %[[DYNAMIC_EXTENT]]) step (%[[C1]], %[[C1]]) {
-// CHECK: %[[VAL_7:.*]] = addi %[[I]], %[[J]] : index
+// CHECK: %[[VAL_7:.*]] = arith.addi %[[I]], %[[J]] : index
// CHECK: store %[[VAL_7]], %[[MEMREF]][%[[I]], %[[J]]] : memref<16x?xindex>
// CHECK: scf.yield
// CHECK: }
func @tensor.generate_static_and_dynamic(%arg0: index) -> tensor<16x?xindex> {
%result = tensor.generate %arg0 {
^bb0(%i: index, %j: index):
- %sum = addi %i, %j : index
+ %sum = arith.addi %i, %j : index
tensor.yield %sum : index
} : tensor<16x?xindex>
return %result : tensor<16x?xindex>
// CHECK-LABEL: func @fold_extract
func @fold_extract(%arg0 : index) -> (f32, f16, f16, i32) {
- %const_0 = constant 0 : index
- %const_1 = constant 1 : index
- %const_3 = constant 3 : index
- // CHECK-DAG: [[C64:%.+]] = constant 64 : i32
- // CHECK-DAG: [[C0:%.+]] = constant 0.{{0*}}e+00 : f16
- // CHECK-DAG: [[CM2:%.+]] = constant -2.{{0*}}e+00 : f16
+ %const_0 = arith.constant 0 : index
+ %const_1 = arith.constant 1 : index
+ %const_3 = arith.constant 3 : index
+ // CHECK-DAG: [[C64:%.+]] = arith.constant 64 : i32
+ // CHECK-DAG: [[C0:%.+]] = arith.constant 0.{{0*}}e+00 : f16
+ // CHECK-DAG: [[CM2:%.+]] = arith.constant -2.{{0*}}e+00 : f16
// Fold an extract into a splat.
- // CHECK-DAG: [[C4:%.+]] = constant 4.{{0*}}e+00 : f32
- %0 = constant dense<4.0> : tensor<4xf32>
+ // CHECK-DAG: [[C4:%.+]] = arith.constant 4.{{0*}}e+00 : f32
+ %0 = arith.constant dense<4.0> : tensor<4xf32>
%ext_1 = tensor.extract %0[%arg0] : tensor<4xf32>
// Fold an extract into a sparse with a sparse index.
- %1 = constant sparse<[[0, 0, 0], [1, 1, 1]], [-5.0, -2.0]> : tensor<4x4x4xf16>
+ %1 = arith.constant sparse<[[0, 0, 0], [1, 1, 1]], [-5.0, -2.0]> : tensor<4x4x4xf16>
%ext_2 = tensor.extract %1[%const_1, %const_1, %const_1] : tensor<4x4x4xf16>
// Fold an extract into a sparse with a non sparse index.
- %2 = constant sparse<[[1, 1, 1]], [-2.0]> : tensor<2x2x2xf16>
+ %2 = arith.constant sparse<[[1, 1, 1]], [-2.0]> : tensor<2x2x2xf16>
%ext_3 = tensor.extract %2[%const_0, %const_0, %const_0] : tensor<2x2x2xf16>
// Fold an extract into a dense tensor.
- %3 = constant dense<[[[1, -2, 1, 36]], [[0, 2, -1, 64]]]> : tensor<2x1x4xi32>
+ %3 = arith.constant dense<[[[1, -2, 1, 36]], [[0, 2, -1, 64]]]> : tensor<2x1x4xi32>
%ext_4 = tensor.extract %3[%const_1, %const_0, %const_3] : tensor<2x1x4xi32>
// CHECK-NEXT: return [[C4]], [[CM2]], [[C0]], [[C64]]
// CHECK-LABEL: func @fold_insert
func @fold_insert(%arg0 : index) -> (tensor<4xf32>) {
// Fold an insert into a splat.
- // CHECK-DAG: %[[C4:.+]] = constant dense<4.{{0*}}e+00> : tensor<4xf32>
- %0 = constant dense<4.0> : tensor<4xf32>
- %1 = constant 4.0 : f32
+ // CHECK-DAG: %[[C4:.+]] = arith.constant dense<4.{{0*}}e+00> : tensor<4xf32>
+ %0 = arith.constant dense<4.0> : tensor<4xf32>
+ %1 = arith.constant 4.0 : f32
%ins_1 = tensor.insert %1 into %0[%arg0] : tensor<4xf32>
// CHECK-NEXT: return %[[C4]]
return %ins_1 : tensor<4xf32>
// CHECK-LABEL: func @extract_from_tensor.cast
// CHECK-SAME: %[[TENSOR:.*]]: tensor<*xf32>
func @extract_from_tensor.cast(%tensor: tensor<*xf32>) -> f32 {
- // CHECK-NEXT: %[[C0:.*]] = constant 0 : index
- %c0 = constant 0 : index
+ // CHECK-NEXT: %[[C0:.*]] = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK-NOT: tensor.cast
%casted = tensor.cast %tensor : tensor<*xf32> to tensor<?xf32>
// CHECK-NEXT: tensor.extract %[[TENSOR]][%[[C0]]]
// CHECK-LABEL: func @extract_from_tensor.from_elements
func @extract_from_tensor.from_elements(%element : index) -> index {
// CHECK-SAME: ([[ARG:%.*]]: index)
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%tensor = tensor.from_elements %element : tensor<1xindex>
%extracted_element = tensor.extract %tensor[%c0] : tensor<1xindex>
// CHECK: [[ARG]] : index
// CHECK-LABEL: func @extract_negative_from_tensor.from_elements
func @extract_negative_from_tensor.from_elements(%element : index) -> index {
// CHECK-SAME: ([[ARG:%.*]]: index)
- %c-1 = constant -1 : index
+ %c-1 = arith.constant -1 : index
%tensor = tensor.from_elements %element : tensor<1xindex>
%extracted_element = tensor.extract %tensor[%c-1] : tensor<1xindex>
// CHECK: tensor.from_elements
// CHECK-LABEL: func @extract_oob_from_tensor.from_elements
func @extract_oob_from_tensor.from_elements(%element : index) -> index {
// CHECK-SAME: ([[ARG:%.*]]: index)
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%tensor = tensor.from_elements %element : tensor<1xindex>
%extracted_element = tensor.extract %tensor[%c1] : tensor<1xindex>
// CHECK: tensor.from_elements
// CHECK-LABEL: func @extract_oob_from_tensor.from_elements
func @extract_oob_from_tensor.from_elements(%element : index) -> index {
// CHECK-SAME: ([[ARG:%.*]]: index)
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%tensor = tensor.from_elements %element : tensor<1xindex>
%extracted_element = tensor.extract %tensor[%c2] : tensor<1xindex>
// CHECK: tensor.from_elements
%size = rank %tensor : tensor<*xf32>
// CHECK-NEXT: %[[DIM0:.*]] = tensor.dim %[[TENSOR]], %[[IDX0]]
// CHECK-NEXT: %[[DIM1:.*]] = tensor.dim %[[TENSOR]], %[[IDX1]]
- // CHECK-NEXT: %[[RES:.*]] = addi %[[DIM0]], %[[DIM1]]
+ // CHECK-NEXT: %[[RES:.*]] = arith.addi %[[DIM0]], %[[DIM1]]
%0 = tensor.generate %size, %size {
^bb0(%arg0: index, %arg1: index):
%1 = tensor.dim %tensor, %arg0 : tensor<*xf32>
%2 = tensor.dim %tensor, %arg1 : tensor<*xf32>
- %3 = addi %1, %2 : index
+ %3 = arith.addi %1, %2 : index
tensor.yield %3 : index
} : tensor<?x?xindex>
%4 = tensor.extract %0[%idx0, %idx1] : tensor<?x?xindex>
// CHECK-LABEL: @static_tensor.generate
// CHECK-SAME: %[[SIZE1:.*]]: index, %[[SIZE4:.*]]: index)
func @static_tensor.generate(%size1: index, %size4: index) -> tensor<3x?x?x7x?xindex> {
- %c5 = constant 5 : index
+ %c5 = arith.constant 5 : index
// CHECK: tensor.generate %[[SIZE1]], %[[SIZE4]]
%0 = tensor.generate %size1, %c5, %size4 {
^bb0(%arg0: index, %arg1: index, %arg2: index, %arg3: index, %arg4: index):
- %1 = constant 32 : index
+ %1 = arith.constant 32 : index
tensor.yield %1 : index
// CHECK: : tensor<3x?x5x7x?xindex>
} : tensor<3x?x?x7x?xindex>
// CHECK-LABEL: @from_elements.constant
func @from_elements.constant() -> tensor<3xindex> {
- // CHECK: %[[CST:.*]] = constant dense<[1, 2, 1]> : tensor<3xindex>
+ // CHECK: %[[CST:.*]] = arith.constant dense<[1, 2, 1]> : tensor<3xindex>
// CHECK: return %[[CST]]
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%tensor = tensor.from_elements %c1, %c2, %c1 : tensor<3xindex>
return %tensor : tensor<3xindex>
}
func @slice_canonicalize(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.extract_slice %arg0[%c0, %arg1, %c1] [%c4, %c1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> to tensor<?x?x?xf32>
return %0 : tensor<?x?x?xf32>
}
func @rank_reducing_slice_canonicalize(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> tensor<?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.extract_slice %arg0[%c0, %arg1, %c1] [%c4, 1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> to tensor<?x?xf32>
return %0 : tensor<?x?xf32>
}
func @insert_slice_canonicalize(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index, %arg3 : tensor<?x?x?xf32>) -> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.insert_slice %arg0 into %arg3[%c0, %arg1, %c1] [%c4, %c1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> into tensor<?x?x?xf32>
return %0 : tensor<?x?x?xf32>
}
func @slice_to_insert_slice_canonicalize(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index, %arg3 : tensor<?x?x?xf32>) -> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.extract_slice %arg0[%c0, %arg1, %c1] [%c4, %c1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> to tensor<?x?x?xf32>
%1 = tensor.insert_slice %0 into %arg3[%c0, %arg1, %c1] [%c4, %c1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> into tensor<?x?x?xf32>
return %1 : tensor<?x?x?xf32>
func @rank_reducing_insert_slice_canonicalize(%arg0 : tensor<?x?xf32>, %arg1 : index,
%arg2 : index, %arg3 : tensor<?x?x?xf32>) -> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.insert_slice %arg0 into %arg3[%c0, %arg1, %c1] [%c4, 1, %arg2] [%c1, %c1, %c1] : tensor<?x?xf32> into tensor<?x?x?xf32>
return %0 : tensor<?x?x?xf32>
}
func @rank_reducing_slice_to_insert_slice_canonicalize(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index, %arg3 : tensor<?x?x?xf32>) -> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
%0 = tensor.extract_slice %arg0[%c0, %arg1, %c1] [%c4, 1, %arg2] [%c1, %c1, %c1] : tensor<?x?x?xf32> to tensor<?x?xf32>
%1 = tensor.insert_slice %0 into %arg3[%c0, %arg1, %c1] [%c4, 1, %arg2] [%c1, %c1, %c1] : tensor<?x?xf32> into tensor<?x?x?xf32>
return %1 : tensor<?x?x?xf32>
func @insert_slice_propagate_dest_cast(%arg0 : tensor<2x?xi32>, %arg1 : tensor<i32>,
%arg2 : index, %arg3 : index) -> tensor<?x?xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
%0 = tensor.dim %arg0, %c1 : tensor<2x?xi32>
%1 = tensor.extract %arg1[] : tensor<i32>
%2 = tensor.generate %arg2, %c8 {
// -----
func @insert_slice_output_dest_canonicalize(%arg0 : tensor<2x3xi32>, %arg1 : tensor<i32>) -> tensor<3x9xi32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c9 = constant 9 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c9 = arith.constant 9 : index
+ %c3 = arith.constant 3 : index
%2 = tensor.extract %arg1[] : tensor<i32>
%4 = tensor.generate %c3, %c9 {
^bb0(%arg2: index, %arg3: index):
// CHECK-NOT: tensor.dim
// CHECK: return %[[IDX1]] : index
func @dim_of_tensor.generate(%arg0: index, %arg1: index) -> index {
- %c3 = constant 3 : index
+ %c3 = arith.constant 3 : index
%0 = tensor.generate %arg0, %arg1 {
^bb0(%arg2: index, %arg3: index, %arg4: index, %arg5: index, %arg6: index):
tensor.yield %c3 : index
// Test case: Folding tensor.dim(tensor.cast %0, %idx) -> tensor.dim %0, %idx
// CHECK-LABEL: func @fold_dim_of_tensor.cast
// CHECK-SAME: %[[ARG0:.[a-z0-9A-Z_]+]]: tensor<4x?xf32>
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C4:.+]] = constant 4 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C4:.+]] = arith.constant 4 : index
// CHECK: %[[T0:.+]] = tensor.dim %[[ARG0]], %[[C1]]
// CHECK-NEXT: return %[[C4]], %[[T0]]
func @fold_dim_of_tensor.cast(%arg0 : tensor<4x?xf32>) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.cast %arg0 : tensor<4x?xf32> to tensor<?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?xf32>
%2 = tensor.dim %0, %c1 : tensor<?x?xf32>
// CHECK-LABEL: func @fold_extract_insert
// CHECK-SAME: %{{.+}}: tensor<?x?x?xf32>, %[[SLICE:.+]]: tensor<4x?x8xf32>
func @fold_extract_insert(%input : tensor<?x?x?xf32>, %slice: tensor<4x?x8xf32>, %i: index, %size: index) -> (tensor<4x?x8xf32>) {
- %c0 = constant 0: index
- %c1 = constant 1: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
%0 = tensor.insert_slice %slice into %input[%c0, %i, 0] [4, %size, 8] [1, 1, %c1] : tensor<4x?x8xf32> into tensor<?x?x?xf32>
%1 = tensor.extract_slice %0[%c0, %i, 0] [4, %size, 8] [1, 1, %c1] : tensor<?x?x?xf32> to tensor<4x?x8xf32>
// CHECK: return %[[SLICE]]
// CHECK-LABEL: func @fold_overlapping_insert
// CHECK-SAME: %[[INPUT:.+]]: tensor<?x?x?xf32>, %{{.+}}: tensor<4x?x8xf32>, %[[SLICE2:.+]]: tensor<4x?x8xf32>
func @fold_overlapping_insert(%input : tensor<?x?x?xf32>, %slice1: tensor<4x?x8xf32>, %slice2: tensor<4x?x8xf32>, %i: index, %size: index) -> (tensor<?x?x?xf32>) {
- %c0 = constant 0: index
- %c1 = constant 1: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
%0 = tensor.insert_slice %slice1 into %input[%c0, %i, 0] [4, %size, 8] [1, 1, %c1] : tensor<4x?x8xf32> into tensor<?x?x?xf32>
// CHECK: %[[INSERT:.+]] = tensor.insert_slice %[[SLICE2]] into %[[INPUT]]
%1 = tensor.insert_slice %slice2 into %0[%c0, %i, 0] [4, %size, 8] [1, 1, %c1] : tensor<4x?x8xf32> into tensor<?x?x?xf32>
func @tensor.from_elements_wrong_result_type() {
// expected-error@+2 {{'result' must be 1D tensor of any type values, but got 'tensor<*xi32>'}}
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
%0 = tensor.from_elements %c0 : tensor<*xi32>
return
}
func @tensor.from_elements_wrong_elements_count() {
// expected-error@+2 {{1 operands present, but expected 2}}
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = tensor.from_elements %c0 : tensor<2xindex>
return
}
// expected-error @+1 {{must have as many index operands as dynamic extents in the result type}}
%tnsr = tensor.generate %m {
^bb0(%i : index, %j : index, %k : index):
- %elem = constant 8.0 : f32
+ %elem = arith.constant 8.0 : f32
tensor.yield %elem : f32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
// expected-error @+1 {{must have one body argument per input dimension}}
%tnsr = tensor.generate %m, %n {
^bb0(%i : index, %j : index):
- %elem = constant 8.0 : f32
+ %elem = arith.constant 8.0 : f32
tensor.yield %elem : f32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
// expected-error @+1 {{all body arguments must be index}}
%tnsr = tensor.generate %m, %n {
^bb0(%i : index, %j : index, %k : i64):
- %elem = constant 8.0 : f32
+ %elem = arith.constant 8.0 : f32
tensor.yield %elem : f32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
// expected-note @+1 {{in custom textual format, the absence of terminator implies 'tensor.yield'}}
%tnsr = tensor.generate %m, %n {
^bb0(%i : index, %j : index, %k : index):
- %elem = constant 8.0 : f32
+ %elem = arith.constant 8.0 : f32
return %elem : f32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
// expected-error @+1 {{body must be terminated with a `yield` operation of the tensor element type}}
%tnsr = tensor.generate %m, %n {
^bb0(%i : index, %j : index, %k : index):
- %elem = constant 8 : i32
+ %elem = arith.constant 8 : i32
tensor.yield %elem : i32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
// CHECK-LABEL: func @tensor.from_elements() {
func @tensor.from_elements() {
- %c0 = "std.constant"() {value = 0: index} : () -> index
+ %c0 = "arith.constant"() {value = 0: index} : () -> index
// CHECK: %0 = tensor.from_elements %c0 : tensor<1xindex>
%0 = tensor.from_elements %c0 : tensor<1xindex>
- %c1 = "std.constant"() {value = 1: index} : () -> index
+ %c1 = "arith.constant"() {value = 1: index} : () -> index
// CHECK: %1 = tensor.from_elements %c0, %c1 : tensor<2xindex>
%1 = tensor.from_elements %c0, %c1 : tensor<2xindex>
- %c0_f32 = "std.constant"() {value = 0.0: f32} : () -> f32
- // CHECK: [[C0_F32:%.*]] = constant
+ %c0_f32 = "arith.constant"() {value = 0.0: f32} : () -> f32
+ // CHECK: [[C0_F32:%.*]] = arith.constant
// CHECK: %2 = tensor.from_elements [[C0_F32]] : tensor<1xf32>
%2 = tensor.from_elements %c0_f32 : tensor<1xf32>
-> tensor<?x3x?xf32> {
%tnsr = tensor.generate %m, %n {
^bb0(%i : index, %j : index, %k : index):
- %elem = constant 8.0 : f32
+ %elem = arith.constant 8.0 : f32
tensor.yield %elem : f32
} : tensor<?x3x?xf32>
return %tnsr : tensor<?x3x?xf32>
func @insert_slice(
%arg0 : tensor<?x?x?xf32>, %arg1 : tensor<?x?x?xf32>,
%arg2 : index, %arg3 : index, %arg4 : index) -> (index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%d0 = tensor.dim %arg0, %c0 : tensor<?x?x?xf32>
%d1 = tensor.dim %arg0, %c1 : tensor<?x?x?xf32>
%d2 = tensor.dim %arg0, %c2 : tensor<?x?x?xf32>
// CHECK-LABEL: func @insert_slice(
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?x?xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?x?xf32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C1:.+]] = constant 1 : index
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
// CHECK-DAG: %[[D0:.+]] = tensor.dim %[[ARG1]], %[[C0]]
// CHECK-DAG: %[[D1:.+]] = tensor.dim %[[ARG1]], %[[C1]]
// CHECK-DAG: %[[D2:.+]] = tensor.dim %[[ARG1]], %[[C2]]
func @extract_slice(%arg0 : tensor<?x?x?xf32>, %arg1 : index, %arg2 : index,
%arg3 : index) -> (index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [%arg1, %arg2, %arg3] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<?x?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?x?xf32>
func @extract_slice_rank_reduced_1(%arg0 : tensor<?x?x?xf32>,
%arg1 : index) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [1, %arg1, 1] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<?xf32>
%1 = tensor.dim %0, %c0 : tensor<?xf32>
func @extract_slice_rank_reduced_2(%arg0 : tensor<?x?x?xf32>,
%arg1 : index) -> index {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [1, %arg1, 1] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<?x1xf32>
%1 = tensor.dim %0, %c0 : tensor<?x1xf32>
func @extract_slice_rank_reduced_3(%arg0 : tensor<?x?x?xf32>,
%arg1 : index) -> index {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [1, %arg1, 1] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<1x?xf32>
%1 = tensor.dim %0, %c1 : tensor<1x?xf32>
func @extract_slice_rank_reduced_4(%arg0 : tensor<?x?x?xf32>,
%arg1 : index) -> index {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [1, %arg1, 1] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<1x?x1xf32>
%1 = tensor.dim %0, %c1 : tensor<1x?x1xf32>
func @extract_slice_rank_reduced_5(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> (index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [%arg1, 1, %arg2] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<?x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x?xf32>
func @extract_slice_rank_reduced_6(%arg0 : tensor<?x?x?xf32>, %arg1 : index,
%arg2 : index) -> (index, index) {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
%0 = tensor.extract_slice %arg0[0, 0, 0] [%arg1, 1, %arg2] [1, 1, 1] :
tensor<?x?x?xf32> to tensor<?x1x?xf32>
%1 = tensor.dim %0, %c0 : tensor<?x1x?xf32>
// CHECK-LABEL: @transpose_fold
func @transpose_fold(%arg0: tensor<3x4xf32>) -> tensor<3x4xf32> {
// CHECK: return %arg0
- %0 = constant dense<[0, 1]> : tensor<2xi32>
+ %0 = arith.constant dense<[0, 1]> : tensor<2xi32>
%1 = "tosa.transpose"(%arg0, %0) { perms = [1, 0] }: (tensor<3x4xf32>, tensor<2xi32>) -> tensor<3x4xf32>
return %1 : tensor<3x4xf32>
}
// CHECK-LABEL: @transpose_nofold
func @transpose_nofold(%arg0: tensor<3x3xf32>) -> tensor<3x3xf32> {
// CHECK: "tosa.transpose"
- %0 = constant dense<[1, 0]> : tensor<2xi32>
+ %0 = arith.constant dense<[1, 0]> : tensor<2xi32>
%1 = "tosa.transpose"(%arg0, %0) { perms = [1, 0] }: (tensor<3x3xf32>, tensor<2xi32>) -> tensor<3x3xf32>
return %1 : tensor<3x3xf32>
}
// CHECK-LABEL: @transpose_nofold_shape
func @transpose_nofold_shape(%arg0: tensor<3x4xf32>) -> tensor<?x?xf32> {
// CHECK: "tosa.transpose"
- %0 = constant dense<[0, 1]> : tensor<2xi32>
+ %0 = arith.constant dense<[0, 1]> : tensor<2xi32>
%1 = "tosa.transpose"(%arg0, %0) { perms = [1, 0] }: (tensor<3x4xf32>, tensor<2xi32>) -> tensor<?x?xf32>
return %1 : tensor<?x?xf32>
}
// CHECK-LABEL:@test_padding_dynamic_input
func @test_padding_dynamic_input(%arg0 : tensor<1x?xf32>) -> () {
- %0 = constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
+ %0 = arith.constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
// CHECK: "tosa.pad"(%arg0, %cst) : (tensor<1x?xf32>, tensor<2x2xi32>) -> tensor<4x?xf32>
%1 = "tosa.pad"(%arg0, %0) : (tensor<1x?xf32>, tensor<2x2xi32>) -> (tensor<?x?xf32>)
return
// CHECK-LABEL: @test_padding_simple
func @test_padding_simple(%arg0 : tensor<1x2xf32>) -> () {
- %0 = constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
+ %0 = arith.constant dense<[[1, 2], [3, 4]]> : tensor<2x2xi32>
// CHECK: "tosa.pad"(%arg0, %cst) : (tensor<1x2xf32>, tensor<2x2xi32>) -> tensor<4x9xf32>
%1 = "tosa.pad"(%arg0, %0) : (tensor<1x2xf32>, tensor<2x2xi32>) -> (tensor<?x?xf32>)
return
// CHECK-LABEL: @test_transpose_static
func @test_transpose_static(%arg0 : tensor<3x4x5xi32>) -> () {
- %0 = constant dense<[2, 1, 0]> : tensor<3xi32>
+ %0 = arith.constant dense<[2, 1, 0]> : tensor<3xi32>
// CHECK: "tosa.transpose"(%arg0, %cst) : (tensor<3x4x5xi32>, tensor<3xi32>) -> tensor<5x4x3xi32>
%1 = "tosa.transpose"(%arg0, %0) : (tensor<3x4x5xi32>, tensor<3xi32>) -> (tensor<?x?x?xi32>)
return
// CHECK-LABEL: create_vector_mask_to_constant_mask
func @create_vector_mask_to_constant_mask() -> (vector<4x3xi1>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
// CHECK: vector.constant_mask [3, 2] : vector<4x3xi1>
%0 = vector.create_mask %c3, %c2 : vector<4x3xi1>
return %0 : vector<4x3xi1>
%1 = vector.transpose %0, [0, 1] : vector<3x4xf32> to vector<3x4xf32>
%2 = vector.transpose %1, [1, 0] : vector<3x4xf32> to vector<4x3xf32>
%3 = vector.transpose %2, [0, 1] : vector<4x3xf32> to vector<4x3xf32>
- // CHECK: [[ADD:%.*]] = addf [[ARG]], [[ARG]]
- %4 = addf %2, %3 : vector<4x3xf32>
+ // CHECK: [[ADD:%.*]] = arith.addf [[ARG]], [[ARG]]
+ %4 = arith.addf %2, %3 : vector<4x3xf32>
// CHECK-NEXT: return [[ADD]]
return %4 : vector<4x3xf32>
}
// CHECK: [[T1:%.*]] = vector.transpose %arg0, [2, 1, 0]
%2 = vector.transpose %1, [2, 1, 0] : vector<2x3x4xf32> to vector<4x3x2xf32>
%3 = vector.transpose %2, [2, 1, 0] : vector<4x3x2xf32> to vector<2x3x4xf32>
- // CHECK: [[MUL:%.*]] = mulf [[T0]], [[T1]]
- %4 = mulf %1, %3 : vector<2x3x4xf32>
+ // CHECK: [[MUL:%.*]] = arith.mulf [[T0]], [[T1]]
+ %4 = arith.mulf %1, %3 : vector<2x3x4xf32>
// CHECK: [[T5:%.*]] = vector.transpose [[MUL]], [2, 1, 0]
%5 = vector.transpose %4, [2, 1, 0] : vector<2x3x4xf32> to vector<4x3x2xf32>
// CHECK-NOT: transpose
%6 = vector.transpose %3, [2, 1, 0] : vector<2x3x4xf32> to vector<4x3x2xf32>
- // CHECK: [[ADD:%.*]] = addf [[T5]], [[ARG]]
- %7 = addf %5, %6 : vector<4x3x2xf32>
+ // CHECK: [[ADD:%.*]] = arith.addf [[T5]], [[ARG]]
+ %7 = arith.addf %5, %6 : vector<4x3x2xf32>
// CHECK-NEXT: return [[ADD]]
return %7 : vector<4x3x2xf32>
}
// CHECK-LABEL: cast_transfers
func @cast_transfers(%A: memref<4x8xf32>) -> (vector<4x8xf32>) {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
%0 = memref.cast %A : memref<4x8xf32> to memref<?x?xf32>
// CHECK: vector.transfer_read %{{.*}} {in_bounds = [true, true]} : memref<4x8xf32>, vector<4x8xf32>
// CHECK-LABEL: cast_transfers
func @cast_transfers(%A: tensor<4x8xf32>) -> (vector<4x8xf32>) {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
%0 = tensor.cast %A : tensor<4x8xf32> to tensor<?x?xf32>
// CHECK: vector.transfer_read %{{.*}} {in_bounds = [true, true]} : tensor<4x8xf32>, vector<4x8xf32>
// CHECK-LABEL: fold_vector_transfers
func @fold_vector_transfers(%A: memref<?x8xf32>) -> (vector<4x8xf32>, vector<4x9xf32>) {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
// CHECK: vector.transfer_read %{{.*}} {in_bounds = [false, true]}
%1 = vector.transfer_read %A[%c0, %c0], %f0 : memref<?x8xf32>, vector<4x8xf32>
// CHECK-LABEL: func @bitcast_f16_to_f32
// bit pattern: 0x40004000
-// CHECK-DAG: %[[CST1:.+]] = constant dense<2.00390625> : vector<4xf32>
+// CHECK-DAG: %[[CST1:.+]] = arith.constant dense<2.00390625> : vector<4xf32>
// bit pattern: 0x00000000
-// CHECK-DAG: %[[CST0:.+]] = constant dense<0.000000e+00> : vector<4xf32>
+// CHECK-DAG: %[[CST0:.+]] = arith.constant dense<0.000000e+00> : vector<4xf32>
// CHECK: return %[[CST0]], %[[CST1]]
func @bitcast_f16_to_f32() -> (vector<4xf32>, vector<4xf32>) {
- %cst0 = constant dense<0.0> : vector<8xf16> // bit pattern: 0x0000
- %cst1 = constant dense<2.0> : vector<8xf16> // bit pattern: 0x4000
+ %cst0 = arith.constant dense<0.0> : vector<8xf16> // bit pattern: 0x0000
+ %cst1 = arith.constant dense<2.0> : vector<8xf16> // bit pattern: 0x4000
%cast0 = vector.bitcast %cst0: vector<8xf16> to vector<4xf32>
%cast1 = vector.bitcast %cst1: vector<8xf16> to vector<4xf32>
return %cast0, %cast1: vector<4xf32>, vector<4xf32>
// -----
// CHECK-LABEL: broadcast_folding1
-// CHECK: %[[CST:.*]] = constant dense<42> : vector<4xi32>
+// CHECK: %[[CST:.*]] = arith.constant dense<42> : vector<4xi32>
// CHECK-NOT: vector.broadcast
// CHECK: return %[[CST]]
func @broadcast_folding1() -> vector<4xi32> {
- %0 = constant 42 : i32
+ %0 = arith.constant 42 : i32
%1 = vector.broadcast %0 : i32 to vector<4xi32>
return %1 : vector<4xi32>
}
// -----
// CHECK-LABEL: @broadcast_folding2
-// CHECK: %[[CST:.*]] = constant dense<42> : vector<4x16xi32>
+// CHECK: %[[CST:.*]] = arith.constant dense<42> : vector<4x16xi32>
// CHECK-NOT: vector.broadcast
// CHECK: return %[[CST]]
func @broadcast_folding2() -> vector<4x16xi32> {
- %0 = constant 42 : i32
+ %0 = arith.constant 42 : i32
%1 = vector.broadcast %0 : i32 to vector<16xi32>
%2 = vector.broadcast %1 : vector<16xi32> to vector<4x16xi32>
return %2 : vector<4x16xi32>
// -----
// CHECK-LABEL: shape_cast_constant
-// CHECK-DAG: %[[CST1:.*]] = constant dense<1> : vector<3x4x2xi32>
-// CHECK-DAG: %[[CST0:.*]] = constant dense<2.000000e+00> : vector<20x2xf32>
+// CHECK-DAG: %[[CST1:.*]] = arith.constant dense<1> : vector<3x4x2xi32>
+// CHECK-DAG: %[[CST0:.*]] = arith.constant dense<2.000000e+00> : vector<20x2xf32>
// CHECK: return %[[CST0]], %[[CST1]] : vector<20x2xf32>, vector<3x4x2xi32>
func @shape_cast_constant() -> (vector<20x2xf32>, vector<3x4x2xi32>) {
- %cst = constant dense<2.000000e+00> : vector<5x4x2xf32>
- %cst_1 = constant dense<1> : vector<12x2xi32>
+ %cst = arith.constant dense<2.000000e+00> : vector<5x4x2xf32>
+ %cst_1 = arith.constant dense<1> : vector<12x2xi32>
%0 = vector.shape_cast %cst : vector<5x4x2xf32> to vector<20x2xf32>
%1 = vector.shape_cast %cst_1 : vector<12x2xi32> to vector<3x4x2xi32>
return %0, %1 : vector<20x2xf32>, vector<3x4x2xi32>
// -----
// CHECK-LABEL: extract_strided_constant
-// CHECK-DAG: %[[CST1:.*]] = constant dense<1> : vector<2x13x3xi32>
-// CHECK-DAG: %[[CST0:.*]] = constant dense<2.000000e+00> : vector<12x2xf32>
+// CHECK-DAG: %[[CST1:.*]] = arith.constant dense<1> : vector<2x13x3xi32>
+// CHECK-DAG: %[[CST0:.*]] = arith.constant dense<2.000000e+00> : vector<12x2xf32>
// CHECK: return %[[CST0]], %[[CST1]] : vector<12x2xf32>, vector<2x13x3xi32>
func @extract_strided_constant() -> (vector<12x2xf32>, vector<2x13x3xi32>) {
- %cst = constant dense<2.000000e+00> : vector<29x7xf32>
- %cst_1 = constant dense<1> : vector<4x37x9xi32>
+ %cst = arith.constant dense<2.000000e+00> : vector<29x7xf32>
+ %cst_1 = arith.constant dense<1> : vector<4x37x9xi32>
%0 = vector.extract_strided_slice %cst
{offsets = [2, 3], sizes = [12, 2], strides = [1, 1]}
: vector<29x7xf32> to vector<12x2xf32>
// CHECK: return
func @dead_transfer_op(%arg0 : tensor<4x4xf32>, %arg1 : memref<4x4xf32>,
%v0 : vector<1x4xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%r = vector.transfer_read %arg1[%c0, %c0], %cf0 :
memref<4x4xf32>, vector<1x4xf32>
%w = vector.transfer_write %v0, %arg0[%c0, %c0] :
// CHECK: return
func @dead_load(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %passthru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = vector.maskedload %base[%c0], %mask, %passthru :
memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%1 = vector.gather %base[%c0][%indices], %mask, %passthru :
%a_i8: vector<2x3xi8>, %b_i8: vector<3x4xi8>, %c_i8: vector<2x4xi8>)
-> (vector<2x4xf32>, vector<2x4xi8>)
{
- // CHECK-NOT: constant
- %vf_0 = constant dense <0.0>: vector<2x4xf32>
- // CHECK-NOT: addf
+ // CHECK-NOT: arith.constant
+ %vf_0 = arith.constant dense <0.0>: vector<2x4xf32>
+ // CHECK-NOT: arith.addf
// CHECK: %[[D:.*]] = vector.contract {{.*}} %[[A]], %[[B]], %[[C]]
%0 = vector.contract #contraction_trait0 %a, %b, %vf_0:
vector<2x3xf32>, vector<3x4xf32> into vector<2x4xf32>
- // CHECK-NOT: addf
- %1 = addf %0, %c: vector<2x4xf32>
+ // CHECK-NOT: arith.addf
+ %1 = arith.addf %0, %c: vector<2x4xf32>
- // CHECK-NOT: constant
- %vi8_0 = constant dense <0>: vector<2x4xi8>
- // CHECK-NOT: addi
+ // CHECK-NOT: arith.constant
+ %vi8_0 = arith.constant dense <0>: vector<2x4xi8>
+ // CHECK-NOT: arith.addi
// CHECK: %[[D_I8:.*]] = vector.contract {{.*}} %[[A_I8]], %[[B_I8]], %[[C_I8]]
%i8_0 = vector.contract #contraction_trait0 %a_i8, %b_i8, %vi8_0:
vector<2x3xi8>, vector<3x4xi8> into vector<2x4xi8>
- // CHECK-NOT: addi
- %i8_1 = addi %i8_0, %c_i8: vector<2x4xi8>
+ // CHECK-NOT: arith.addi
+ %i8_1 = arith.addi %i8_0, %c_i8: vector<2x4xi8>
// CHECK: return %[[D]], %[[D_I8]]
return %1, %i8_1: vector<2x4xf32>, vector<2x4xi8>
func @transfer_folding_1(%t0: tensor<2x3x4xf32>, %t1: tensor<2x3x4xf32>)
-> (tensor<2x3x4xf32>, tensor<2x3x4xf32>, tensor<2x3x4xf32>)
{
- %c0 = constant 0 : index
- %pad = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %pad = arith.constant 0.0 : f32
%v = vector.transfer_read %t0[%c0, %c0, %c0], %pad {in_bounds = [true, true, true]} :
tensor<2x3x4xf32>, vector<2x3x4xf32>
// CHECK-NOT: vector.transfer_write
// CHECK: return %[[ARG]] : tensor<4x4xf32>
func @store_after_load_tensor(%arg0 : tensor<4x4xf32>) -> tensor<4x4xf32> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c1, %c0], %cf0 :
tensor<4x4xf32>, vector<1x4xf32>
%w0 = vector.transfer_write %0, %arg0[%c1, %c0] :
// CHECK: vector.transfer_write
// CHECK: return
func @store_after_load_tensor_negative(%arg0 : tensor<4x4xf32>) -> tensor<4x4xf32> {
- %c1 = constant 1 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c1, %c0], %cf0 :
tensor<4x4xf32>, vector<1x4xf32>
%w0 = vector.transfer_write %0, %arg0[%c0, %c0] :
// CHECK: return %[[V0]] : vector<1x4xf32>
func @store_to_load_tensor(%arg0 : tensor<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>) -> vector<1x4xf32> {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%w0 = vector.transfer_write %v0, %arg0[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
%w1 = vector.transfer_write %v1, %w0[%c2, %c0] {in_bounds = [true, true]} :
// CHECK: return %[[V]] : vector<1x4xf32>
func @store_to_load_negative_tensor(%arg0 : tensor<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) -> vector<1x4xf32> {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%w0 = vector.transfer_write %v0, %arg0[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
%w1 = vector.transfer_write %v0, %w0[%i, %i] {in_bounds = [true, true]} :
// CHECK-LABEL: func @dead_store_tensor
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
// CHECK-NOT: vector.transfer_write {{.*}}, {{.*}}[%[[C1]], %[[C0]]
// CHECK: vector.transfer_write {{.*}}, {{.*}}[%[[C2]], %[[C0]]
// CHECK: %[[VTW:.*]] = vector.transfer_write {{.*}}, {{.*}}[%[[C1]], %[[C0]]
// CHECK: return %[[VTW]] : tensor<4x4xf32>
func @dead_store_tensor(%arg0 : tensor<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) -> tensor<4x4xf32> {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%w0 = vector.transfer_write %v0, %arg0[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
%w1 = vector.transfer_write %v0, %w0[%c2, %c0] {in_bounds = [true, true]} :
// -----
// CHECK-LABEL: func @dead_store_tensor_negative
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[C1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
// CHECK: vector.transfer_write
// CHECK: vector.transfer_write
// CHECK: vector.transfer_read
// CHECK: return %[[VTW]] : tensor<4x4xf32>
func @dead_store_tensor_negative(%arg0 : tensor<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) -> tensor<4x4xf32> {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%w0 = vector.transfer_write %v0, %arg0[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
%w1 = vector.transfer_write %v0, %w0[%c2, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
%0 = vector.transfer_read %w1[%i, %i], %cf0 {in_bounds = [true, true]} :
tensor<4x4xf32>, vector<1x4xf32>
- %x = addf %0, %0 : vector<1x4xf32>
+ %x = arith.addf %0, %0 : vector<1x4xf32>
%w2 = vector.transfer_write %x, %w0[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, tensor<4x4xf32>
return %w2 : tensor<4x4xf32>
// CHECK-LABEL: func @transfer_read_of_extract_slice(
// CHECK-SAME: %[[t:.*]]: tensor<?x?xf32>, %[[s1:.*]]: index, %[[s2:.*]]: index
-// CHECK-DAG: %[[c4:.*]] = constant 4 : index
-// CHECK-DAG: %[[c8:.*]] = constant 8 : index
-// CHECK: %[[add:.*]] = addi %[[s1]], %[[c4]]
+// CHECK-DAG: %[[c4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[c8:.*]] = arith.constant 8 : index
+// CHECK: %[[add:.*]] = arith.addi %[[s1]], %[[c4]]
// CHECK: %[[r:.*]] = vector.transfer_read %[[t]][%[[c8]], %[[add]]], %{{.*}} {in_bounds = [true, true]} : tensor<?x?xf32>, vector<5x6xf32>
// CHECK: return %[[r]]
func @transfer_read_of_extract_slice(%t : tensor<?x?xf32>, %s1 : index, %s2 : index) -> vector<5x6xf32> {
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %cst = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.0 : f32
%0 = tensor.extract_slice %t[5, %s1] [10, %s2] [1, 1] : tensor<?x?xf32> to tensor<10x?xf32>
%1 = vector.transfer_read %0[%c3, %c4], %cst {in_bounds = [true, true]} : tensor<10x?xf32>, vector<5x6xf32>
return %1 : vector<5x6xf32>
// CHECK-LABEL: func @transfer_read_of_extract_slice_rank_reducing(
// CHECK-SAME: %[[t:.*]]: tensor<?x?x?xf32>, %[[s1:.*]]: index, %[[s2:.*]]: index
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
-// CHECK-DAG: %[[c5:.*]] = constant 5 : index
-// CHECK-DAG: %[[c10:.*]] = constant 10 : index
-// CHECK: %[[add:.*]] = addi %[[s1]], %[[c3]]
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[c5:.*]] = arith.constant 5 : index
+// CHECK-DAG: %[[c10:.*]] = arith.constant 10 : index
+// CHECK: %[[add:.*]] = arith.addi %[[s1]], %[[c3]]
// CHECK: %[[r:.*]] = vector.transfer_read %[[t]][%[[c5]], %[[add]], %[[c10]]], %{{.*}} {in_bounds = [true, true]} : tensor<?x?x?xf32>, vector<5x6xf32>
// CHECK: return %[[r]]
func @transfer_read_of_extract_slice_rank_reducing(%t : tensor<?x?x?xf32>, %s1 : index, %s2 : index) -> vector<5x6xf32> {
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %cst = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %cst = arith.constant 0.0 : f32
%0 = tensor.extract_slice %t[5, %s1, 6] [1, %s2, 12] [1, 1, 1] : tensor<?x?x?xf32> to tensor<?x12xf32>
%1 = vector.transfer_read %0[%c3, %c4], %cst {in_bounds = [true, true]} : tensor<?x12xf32>, vector<5x6xf32>
return %1 : vector<5x6xf32>
// CHECK-LABEL: func @insert_slice_of_transfer_write(
// CHECK-SAME: %[[t1:.*]]: tensor<?x12xf32>, %[[v:.*]]: vector<5x6xf32>, %[[s:.*]]: index
-// CHECK: %[[c3:.*]] = constant 3 : index
+// CHECK: %[[c3:.*]] = arith.constant 3 : index
// CHECK: %[[r:.*]] = vector.transfer_write %[[v]], %[[t1]][%[[c3]], %[[s]]] {in_bounds = [true, true]} : vector<5x6xf32>, tensor<?x12xf32>
// CHECK: return %[[r]]
func @insert_slice_of_transfer_write(%t1 : tensor<?x12xf32>, %v : vector<5x6xf32>, %s : index, %t2 : tensor<5x6xf32>) -> tensor<?x12xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = vector.transfer_write %v, %t2[%c0, %c0] {in_bounds = [true, true]} : vector<5x6xf32>, tensor<5x6xf32>
%1 = tensor.insert_slice %0 into %t1[3, %s] [5, 6] [1, 1] : tensor<5x6xf32> into tensor<?x12xf32>
return %1 : tensor<?x12xf32>
// CHECK-LABEL: func @insert_slice_of_transfer_write_rank_extending(
// CHECK-SAME: %[[t1:.*]]: tensor<?x?x12xf32>, %[[v:.*]]: vector<5x6xf32>, %[[s:.*]]: index
-// CHECK-DAG: %[[c3:.*]] = constant 3 : index
-// CHECK-DAG: %[[c4:.*]] = constant 4 : index
+// CHECK-DAG: %[[c3:.*]] = arith.constant 3 : index
+// CHECK-DAG: %[[c4:.*]] = arith.constant 4 : index
// CHECK: %[[r:.*]] = vector.transfer_write %[[v]], %[[t1]][%[[c4]], %[[c3]], %[[s]]] {in_bounds = [true, true]} : vector<5x6xf32>, tensor<?x?x12xf32>
// CHECK: return %[[r]]
func @insert_slice_of_transfer_write_rank_extending(%t1 : tensor<?x?x12xf32>, %v : vector<5x6xf32>, %s : index, %t2 : tensor<5x6xf32>) -> tensor<?x?x12xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = vector.transfer_write %v, %t2[%c0, %c0] {in_bounds = [true, true]} : vector<5x6xf32>, tensor<5x6xf32>
%1 = tensor.insert_slice %0 into %t1[4, 3, %s] [1, 5, 6] [1, 1, 1] : tensor<5x6xf32> into tensor<?x?x12xf32>
return %1 : tensor<?x?x12xf32>
// -----
func @extract_element(%arg0: vector<4x4xf32>) {
- %c = constant 3 : i32
+ %c = arith.constant 3 : i32
// expected-error@+1 {{'vector.extractelement' op expected 1-D vector}}
%1 = vector.extractelement %arg0[%c : i32] : vector<4x4xf32>
}
// -----
func @insert_element(%arg0: f32, %arg1: vector<4x4xf32>) {
- %c = constant 3 : i32
+ %c = arith.constant 3 : i32
// expected-error@+1 {{'vector.insertelement' op expected 1-D vector}}
%0 = vector.insertelement %arg0, %arg1[%c : i32] : vector<4x4xf32>
}
// -----
func @insert_element_wrong_type(%arg0: i32, %arg1: vector<4xf32>) {
- %c = constant 3 : i32
+ %c = arith.constant 3 : i32
// expected-error@+1 {{'vector.insertelement' op failed to verify that source operand type matches element type of result}}
%0 = "vector.insertelement" (%arg0, %arg1, %c) : (i32, vector<4xf32>, i32) -> (vector<4xf32>)
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires two types}}
%0 = vector.transfer_read %arg0[%c3, %c3], %cst { permutation_map = affine_map<()->(0)> } : memref<?x?xf32>
}
// -----
func @test_vector.transfer_read(%arg0: vector<4x3xf32>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4x3xf32>
// expected-error@+1 {{ requires memref or ranked tensor type}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 : vector<4x3xf32>, vector<1x1x2x3xf32>
// -----
func @test_vector.transfer_read(%arg0: memref<4x3xf32>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4x3xf32>
// expected-error@+1 {{ requires vector type}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 : memref<4x3xf32>, f32
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires 2 indices}}
%0 = vector.transfer_read %arg0[%c3, %c3, %c3], %cst { permutation_map = affine_map<()->(0)> } : memref<?x?xf32>, vector<128xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires a permutation_map with input dims of the same rank as the source type}}
%0 = vector.transfer_read %arg0[%c3, %c3], %cst {permutation_map = affine_map<(d0)->(d0)>} : memref<?x?xf32>, vector<128xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires a permutation_map with result dims of the same rank as the vector type}}
%0 = vector.transfer_read %arg0[%c3, %c3], %cst {permutation_map = affine_map<(d0, d1)->(d0, d1)>} : memref<?x?xf32>, vector<128xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires a projected permutation_map (at most one dim or the zero constant can appear in each result)}}
%0 = vector.transfer_read %arg0[%c3, %c3], %cst {permutation_map = affine_map<(d0, d1)->(d0 + d1)>} : memref<?x?xf32>, vector<128xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires a projected permutation_map (at most one dim or the zero constant can appear in each result)}}
%0 = vector.transfer_read %arg0[%c3, %c3], %cst {permutation_map = affine_map<(d0, d1)->(d0 + 1)>} : memref<?x?xf32>, vector<128xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires a permutation_map that is a permutation (found one dim used more than once)}}
%0 = vector.transfer_read %arg0[%c3, %c3, %c3], %cst {permutation_map = affine_map<(d0, d1, d2)->(d0, d0)>} : memref<?x?x?xf32>, vector<3x7xf32>
}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?x?xf32>) {
- %c1 = constant 1 : i1
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c1 = arith.constant 1 : i1
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-note@+1 {{prior use here}}
%mask = splat %c1 : vector<3x8x7xi1>
// expected-error@+1 {{expects different type than prior uses: 'vector<3x7xi1>' vs 'vector<3x8x7xi1>'}}
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xvector<4x3xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4x3xf32>
// expected-error@+1 {{requires source vector element and vector result ranks to match}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 {permutation_map = affine_map<(d0, d1)->(d0, d1)>} : memref<?x?xvector<4x3xf32>>, vector<3xf32>
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xvector<6xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<6xf32>
// expected-error@+1 {{requires the bitwidth of the minor 1-D vector to be an integral multiple of the bitwidth of the minor 1-D vector of the source}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 : memref<?x?xvector<6xf32>>, vector<3xf32>
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xvector<2x3xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<2x3xf32>
// expected-error@+1 {{ expects the optional in_bounds attr of same rank as permutation_map results: affine_map<(d0, d1) -> (d0, d1)>}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 {in_bounds = [true], permutation_map = affine_map<(d0, d1)->(d0, d1)>} : memref<?x?xvector<2x3xf32>>, vector<1x1x2x3xf32>
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xvector<2x3xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<2x3xf32>
// expected-error@+1 {{requires broadcast dimensions to be in-bounds}}
%0 = vector.transfer_read %arg0[%c3, %c3], %vf0 {in_bounds = [false, true], permutation_map = affine_map<(d0, d1)->(0, d1)>} : memref<?x?xvector<2x3xf32>>, vector<1x1x2x3xf32>
// -----
func @test_vector.transfer_read(%arg0: memref<?x?xvector<2x3xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<2x3xf32>
%mask = splat %c1 : vector<2x3xi1>
// expected-error@+1 {{does not support masks with vector element type}}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{requires two types}}
vector.transfer_write %arg0, %arg0[%c3, %c3] : memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<vector<4x3xf32>>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4x3xf32>
// expected-error@+1 {{ requires vector type}}
vector.transfer_write %arg0, %arg0[%c3, %c3] : memref<vector<4x3xf32>>, vector<4x3xf32>
// -----
func @test_vector.transfer_write(%arg0: vector<4x3xf32>) {
- %c3 = constant 3 : index
- %f0 = constant 0.0 : f32
+ %c3 = arith.constant 3 : index
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4x3xf32>
// expected-error@+1 {{ requires memref or ranked tensor type}}
vector.transfer_write %arg0, %arg0[%c3, %c3] : vector<4x3xf32>, f32
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{expected 5 operand types but had 4}}
%0 = "vector.transfer_write"(%cst, %arg0, %c3, %c3, %c3) {permutation_map = affine_map<()->(0)>} : (vector<128xf32>, memref<?x?xf32>, index, index) -> ()
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{requires 2 indices}}
vector.transfer_write %cst, %arg0[%c3, %c3, %c3] {permutation_map = affine_map<()->(0)>} : vector<128xf32>, memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{requires a permutation_map with input dims of the same rank as the source type}}
vector.transfer_write %cst, %arg0[%c3, %c3] {permutation_map = affine_map<(d0)->(d0)>} : vector<128xf32>, memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{requires a permutation_map with result dims of the same rank as the vector type}}
vector.transfer_write %cst, %arg0[%c3, %c3] {permutation_map = affine_map<(d0, d1)->(d0, d1)>} : vector<128xf32>, memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{requires a projected permutation_map (at most one dim or the zero constant can appear in each result)}}
vector.transfer_write %cst, %arg0[%c3, %c3] {permutation_map = affine_map<(d0, d1)->(d0 + d1)>} : vector<128xf32>, memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<128 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<128 x f32>
// expected-error@+1 {{requires a projected permutation_map (at most one dim or the zero constant can appear in each result)}}
vector.transfer_write %cst, %arg0[%c3, %c3] {permutation_map = affine_map<(d0, d1)->(d0 + 1)>} : vector<128xf32>, memref<?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?x?x?xf32>) {
- %c3 = constant 3 : index
- %cst = constant dense<3.0> : vector<3 x 7 x f32>
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant dense<3.0> : vector<3 x 7 x f32>
// expected-error@+1 {{requires a permutation_map that is a permutation (found one dim used more than once)}}
vector.transfer_write %cst, %arg0[%c3, %c3, %c3] {permutation_map = affine_map<(d0, d1, d2)->(d0, d0)>} : vector<3x7xf32>, memref<?x?x?xf32>
}
// -----
func @test_vector.transfer_write(%arg0: memref<?xf32>, %arg1: vector<7xf32>) {
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
// expected-error@+1 {{should not have broadcast dimensions}}
vector.transfer_write %arg1, %arg0[%c3]
{permutation_map = affine_map<(d0) -> (0)>}
// -----
func @create_mask() {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
// expected-error@+1 {{must specify an operand for each result vector dimension}}
%0 = vector.create_mask %c3, %c2 : vector<4x3x7xi1>
}
// -----
func @reshape_bad_input_shape(%arg0 : vector<3x2x4xf32>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c9 = constant 9 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c9 = arith.constant 9 : index
// expected-error@+1 {{invalid input shape for vector type}}
%1 = vector.reshape %arg0, [%c3, %c6, %c3], [%c2, %c9], [4]
: vector<3x2x4xf32> to vector<2x3x4xf32>
// -----
func @reshape_bad_output_shape(%arg0 : vector<3x2x4xf32>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c9 = constant 9 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c9 = arith.constant 9 : index
// expected-error@+1 {{invalid output shape for vector type}}
%1 = vector.reshape %arg0, [%c3, %c6], [%c2, %c9, %c3], [4]
: vector<3x2x4xf32> to vector<2x3x4xf32>
// -----
func @reshape_bad_input_output_shape_product(%arg0 : vector<3x2x4xf32>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c9 = constant 9 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c9 = arith.constant 9 : index
// expected-error@+1 {{product of input and output shape sizes must match}}
%1 = vector.reshape %arg0, [%c3, %c6], [%c2, %c6], [4]
: vector<3x2x4xf32> to vector<2x3x4xf32>
// -----
func @reshape_bad_input_fixed_size(%arg0 : vector<3x2x5xf32>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c9 = constant 9 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c9 = arith.constant 9 : index
// expected-error@+1 {{fixed vector size must match input vector for dim 0}}
%1 = vector.reshape %arg0, [%c3, %c6], [%c2, %c9], [4]
: vector<3x2x5xf32> to vector<2x3x4xf32>
// -----
func @reshape_bad_output_fixed_size(%arg0 : vector<3x2x4xf32>) {
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c9 = constant 9 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c9 = arith.constant 9 : index
// expected-error@+1 {{fixed vector size must match output vector for dim 0}}
%1 = vector.reshape %arg0, [%c3, %c6], [%c2, %c9], [4]
: vector<3x2x4xf32> to vector<2x3x5xf32>
// -----
func @store_base_type_mismatch(%base : memref<?xf64>, %value : vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.store' op base and valueToStore element type should match}}
vector.store %value, %base[%c0] : memref<?xf64>, vector<16xf32>
}
// -----
func @maskedload_base_type_mismatch(%base: memref<?xf64>, %mask: vector<16xi1>, %pass: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedload' op base and result element type should match}}
%0 = vector.maskedload %base[%c0], %mask, %pass : memref<?xf64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
}
// -----
func @maskedload_dim_mask_mismatch(%base: memref<?xf32>, %mask: vector<15xi1>, %pass: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedload' op expected result dim to match mask dim}}
%0 = vector.maskedload %base[%c0], %mask, %pass : memref<?xf32>, vector<15xi1>, vector<16xf32> into vector<16xf32>
}
// -----
func @maskedload_pass_thru_type_mask_mismatch(%base: memref<?xf32>, %mask: vector<16xi1>, %pass: vector<16xi32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedload' op expected pass_thru of same type as result type}}
%0 = vector.maskedload %base[%c0], %mask, %pass : memref<?xf32>, vector<16xi1>, vector<16xi32> into vector<16xf32>
}
// -----
func @maskedstore_base_type_mismatch(%base: memref<?xf64>, %mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedstore' op base and valueToStore element type should match}}
vector.maskedstore %base[%c0], %mask, %value : memref<?xf64>, vector<16xi1>, vector<16xf32>
}
// -----
func @maskedstore_dim_mask_mismatch(%base: memref<?xf32>, %mask: vector<15xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedstore' op expected valueToStore dim to match mask dim}}
vector.maskedstore %base[%c0], %mask, %value : memref<?xf32>, vector<15xi1>, vector<16xf32>
}
// -----
func @maskedstore_memref_mismatch(%base: memref<?xf32>, %mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.maskedstore' op requires 1 indices}}
vector.maskedstore %base[%c0, %c0], %mask, %value : memref<?xf32>, vector<16xi1>, vector<16xf32>
}
func @gather_base_type_mismatch(%base: memref<?xf64>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op base and result element type should match}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf64>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
func @gather_memref_mismatch(%base: memref<?x?xf64>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %pass_thru: vector<16xf64>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op requires 2 indices}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?x?xf64>, vector<16xi32>, vector<16xi1>, vector<16xf64> into vector<16xf64>
func @gather_rank_mismatch(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op result #0 must be of ranks 1, but got 'vector<2x16xf32>'}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<2x16xf32>
func @gather_dim_indices_mismatch(%base: memref<?xf32>, %indices: vector<17xi32>,
%mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op expected result dim to match indices dim}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf32>, vector<17xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
func @gather_dim_mask_mismatch(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<17xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op expected result dim to match mask dim}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf32>, vector<16xi32>, vector<17xi1>, vector<16xf32> into vector<16xf32>
func @gather_pass_thru_type_mismatch(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %pass_thru: vector<16xf64>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.gather' op expected pass_thru of same type as result type}}
%0 = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf64> into vector<16xf32>
func @scatter_base_type_mismatch(%base: memref<?xf64>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.scatter' op base and valueToStore element type should match}}
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?xf64>, vector<16xi32>, vector<16xi1>, vector<16xf32>
func @scatter_memref_mismatch(%base: memref<?x?xf64>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %value: vector<16xf64>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.scatter' op requires 2 indices}}
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?x?xf64>, vector<16xi32>, vector<16xi1>, vector<16xf64>
func @scatter_rank_mismatch(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<16xi1>, %value: vector<2x16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.scatter' op operand #4 must be of ranks 1, but got 'vector<2x16xf32>'}}
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<2x16xf32>
func @scatter_dim_indices_mismatch(%base: memref<?xf32>, %indices: vector<17xi32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.scatter' op expected valueToStore dim to match indices dim}}
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?xf32>, vector<17xi32>, vector<16xi1>, vector<16xf32>
func @scatter_dim_mask_mismatch(%base: memref<?xf32>, %indices: vector<16xi32>,
%mask: vector<17xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.scatter' op expected valueToStore dim to match mask dim}}
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?xf32>, vector<16xi32>, vector<17xi1>, vector<16xf32>
// -----
func @expand_base_type_mismatch(%base: memref<?xf64>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.expandload' op base and result element type should match}}
%0 = vector.expandload %base[%c0], %mask, %pass_thru : memref<?xf64>, vector<16xi1>, vector<16xf32> into vector<16xf32>
}
// -----
func @expand_dim_mask_mismatch(%base: memref<?xf32>, %mask: vector<17xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.expandload' op expected result dim to match mask dim}}
%0 = vector.expandload %base[%c0], %mask, %pass_thru : memref<?xf32>, vector<17xi1>, vector<16xf32> into vector<16xf32>
}
// -----
func @expand_pass_thru_mismatch(%base: memref<?xf32>, %mask: vector<16xi1>, %pass_thru: vector<17xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.expandload' op expected pass_thru of same type as result type}}
%0 = vector.expandload %base[%c0], %mask, %pass_thru : memref<?xf32>, vector<16xi1>, vector<17xf32> into vector<16xf32>
}
// -----
func @expand_memref_mismatch(%base: memref<?x?xf32>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.expandload' op requires 2 indices}}
%0 = vector.expandload %base[%c0], %mask, %pass_thru : memref<?x?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
}
// -----
func @compress_base_type_mismatch(%base: memref<?xf64>, %mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.compressstore' op base and valueToStore element type should match}}
vector.compressstore %base[%c0], %mask, %value : memref<?xf64>, vector<16xi1>, vector<16xf32>
}
// -----
func @compress_dim_mask_mismatch(%base: memref<?xf32>, %mask: vector<17xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.compressstore' op expected valueToStore dim to match mask dim}}
vector.compressstore %base[%c0], %mask, %value : memref<?xf32>, vector<17xi1>, vector<16xf32>
}
// -----
func @compress_memref_mismatch(%base: memref<?x?xf32>, %mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// expected-error@+1 {{'vector.compressstore' op requires 2 indices}}
vector.compressstore %base[%c0, %c0, %c0], %mask, %value : memref<?x?xf32>, vector<16xi1>, vector<16xf32>
}
func @vector_transfer_ops_0d(%arg0: tensor<f32>)
-> tensor<f32> {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
// expected-error@+1 {{0-d transfer requires vector<1xt> shape and () -> (0) permutation_map}}
%0 = vector.transfer_read %arg0[], %f0 {permutation_map = affine_map<(d0)->(d0)>} :
tensor<f32>, vector<1xf32>
// CHECK-LABEL: func @vector_transfer_ops_0d(
func @vector_transfer_ops_0d(%arg0: tensor<f32>, %arg1: memref<f32>)
-> tensor<f32> {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[], %f0 {permutation_map = affine_map<()->(0)>} :
tensor<f32>, vector<1xf32>
%1 = vector.transfer_write %0, %arg0[] {permutation_map = affine_map<()->(0)>} :
%arg2 : memref<?x?xvector<4x3xi32>>,
%arg3 : memref<?x?xvector<4x3xindex>>,
%arg4 : memref<?x?x?xf32>) {
- // CHECK: %[[C3:.*]] = constant 3 : index
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
- %f0 = constant 0.0 : f32
- %c0 = constant 0 : i32
- %i0 = constant 0 : index
- %i1 = constant 1 : i1
+ // CHECK: %[[C3:.*]] = arith.constant 3 : index
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
+ %f0 = arith.constant 0.0 : f32
+ %c0 = arith.constant 0 : i32
+ %i0 = arith.constant 0 : index
+ %i1 = arith.constant 1 : i1
%vf0 = splat %f0 : vector<4x3xf32>
%v0 = splat %c0 : vector<4x3xi32>
%vi0 = splat %i0 : vector<4x3xindex>
- %m = constant dense<[0, 0, 1, 0, 1]> : vector<5xi1>
+ %m = arith.constant dense<[0, 0, 1, 0, 1]> : vector<5xi1>
%m2 = splat %i1 : vector<5x4xi1>
//
// CHECK: vector.transfer_read
(tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xvector<4x3xf32>>,
tensor<?x?xvector<4x3xf32>>, tensor<?x?xvector<4x3xi32>>,
tensor<?x?xvector<4x3xindex>>){
- // CHECK: %[[C3:.*]] = constant 3 : index
- %c3 = constant 3 : index
- %cst = constant 3.0 : f32
- %f0 = constant 0.0 : f32
- %c0 = constant 0 : i32
- %i0 = constant 0 : index
+ // CHECK: %[[C3:.*]] = arith.constant 3 : index
+ %c3 = arith.constant 3 : index
+ %cst = arith.constant 3.0 : f32
+ %f0 = arith.constant 0.0 : f32
+ %c0 = arith.constant 0 : i32
+ %i0 = arith.constant 0 : index
%vf0 = splat %f0 : vector<4x3xf32>
%v0 = splat %c0 : vector<4x3xi32>
// CHECK-LABEL: @extract_element
func @extract_element(%a: vector<16xf32>) -> f32 {
- // CHECK: %[[C15:.*]] = constant 15 : i32
- %c = constant 15 : i32
+ // CHECK: %[[C15:.*]] = arith.constant 15 : i32
+ %c = arith.constant 15 : i32
// CHECK-NEXT: vector.extractelement %{{.*}}[%[[C15]] : i32] : vector<16xf32>
%1 = vector.extractelement %a[%c : i32] : vector<16xf32>
return %1 : f32
// CHECK-LABEL: @insert_element
func @insert_element(%a: f32, %b: vector<16xf32>) -> vector<16xf32> {
- // CHECK: %[[C15:.*]] = constant 15 : i32
- %c = constant 15 : i32
+ // CHECK: %[[C15:.*]] = arith.constant 15 : i32
+ %c = arith.constant 15 : i32
// CHECK-NEXT: vector.insertelement %{{.*}}, %{{.*}}[%[[C15]] : i32] : vector<16xf32>
%1 = vector.insertelement %a, %b[%c : i32] : vector<16xf32>
return %1 : vector<16xf32>
}
// CHECK-LABEL: @contraction_to_scalar
func @contraction_to_scalar(%arg0: vector<10xf32>, %arg1: vector<10xf32>) -> f32 {
- // CHECK: %[[C0:.*]] = constant 0.000000e+00 : f32
- %f0 = constant 0.0: f32
+ // CHECK: %[[C0:.*]] = arith.constant 0.000000e+00 : f32
+ %f0 = arith.constant 0.0: f32
// CHECK: %[[X:.*]] = vector.contract {indexing_maps = [#{{.*}}, #{{.*}}, #{{.*}}], iterator_types = ["reduction"], kind = #vector.kind<add>} %{{.*}}, %{{.*}}, %[[C0]] : vector<10xf32>, vector<10xf32> into f32
%0 = vector.contract #contraction_to_scalar_trait %arg0, %arg1, %f0
: vector<10xf32>, vector<10xf32> into f32
}
// CHECK-LABEL: @contraction_to_scalar_with_max
func @contraction_to_scalar_with_max(%arg0: vector<10xf32>, %arg1: vector<10xf32>) -> f32 {
- // CHECK: %[[C0:.*]] = constant 0.000000e+00 : f32
- %f0 = constant 0.0: f32
+ // CHECK: %[[C0:.*]] = arith.constant 0.000000e+00 : f32
+ %f0 = arith.constant 0.0: f32
// CHECK: %[[X:.*]] = vector.contract {indexing_maps = [#{{.*}}, #{{.*}}, #{{.*}}], iterator_types = ["reduction"], kind = #vector.kind<maxf>} %{{.*}}, %{{.*}}, %[[C0]] : vector<10xf32>, vector<10xf32> into f32
%0 = vector.contract #contraction_to_scalar_max_trait %arg0, %arg1, %f0
: vector<10xf32>, vector<10xf32> into f32
// CHECK-LABEL: @create_vector_mask
func @create_vector_mask() {
- // CHECK: %[[C2:.*]] = constant 2 : index
- %c2 = constant 2 : index
- // CHECK-NEXT: %[[C3:.*]] = constant 3 : index
- %c3 = constant 3 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
+ %c2 = arith.constant 2 : index
+ // CHECK-NEXT: %[[C3:.*]] = arith.constant 3 : index
+ %c3 = arith.constant 3 : index
// CHECK-NEXT: vector.create_mask %[[C3]], %[[C2]] : vector<4x3xi1>
%0 = vector.create_mask %c3, %c2 : vector<4x3xi1>
// CHECK-LABEL: @reshape
func @reshape(%arg0 : vector<3x2x4xf32>) -> (vector<2x3x4xf32>) {
- // CHECK: %[[C2:.*]] = constant 2 : index
- %c2 = constant 2 : index
- // CHECK: %[[C3:.*]] = constant 3 : index
- %c3 = constant 3 : index
- // CHECK: %[[C6:.*]] = constant 6 : index
- %c6 = constant 6 : index
- // CHECK: %[[C9:.*]] = constant 9 : index
- %c9 = constant 9 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
+ %c2 = arith.constant 2 : index
+ // CHECK: %[[C3:.*]] = arith.constant 3 : index
+ %c3 = arith.constant 3 : index
+ // CHECK: %[[C6:.*]] = arith.constant 6 : index
+ %c6 = arith.constant 6 : index
+ // CHECK: %[[C9:.*]] = arith.constant 9 : index
+ %c9 = arith.constant 9 : index
// CHECK: vector.reshape %{{.*}}, [%[[C3]], %[[C6]]], [%[[C2]], %[[C9]]], [4] : vector<3x2x4xf32> to vector<2x3x4xf32>
%1 = vector.reshape %arg0, [%c3, %c6], [%c2, %c9], [4]
: vector<3x2x4xf32> to vector<2x3x4xf32>
// CHECK-LABEL: @vector_load_and_store_out_of_bounds
func @vector_load_and_store_out_of_bounds(%memref : memref<7xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[ld:.*]] = vector.load %{{.*}}[%{{.*}}] : memref<7xf32>, vector<8xf32>
%0 = vector.load %memref[%c0] : memref<7xf32>, vector<8xf32>
// CHECK: vector.store %[[ld]], %{{.*}}[%{{.*}}] : memref<7xf32>, vector<8xf32>
// CHECK-LABEL: @masked_load_and_store
func @masked_load_and_store(%base: memref<?xf32>, %mask: vector<16xi1>, %passthru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.maskedload %{{.*}}[%{{.*}}], %{{.*}}, %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.maskedload %base[%c0], %mask, %passthru : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.maskedstore %{{.*}}[%{{.*}}], %{{.*}}, %[[X]] : memref<?xf32>, vector<16xi1>, vector<16xf32>
// CHECK-LABEL: @masked_load_and_store2d
func @masked_load_and_store2d(%base: memref<?x?xf32>, %mask: vector<16xi1>, %passthru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.maskedload %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}}, %{{.*}} : memref<?x?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.maskedload %base[%c0, %c0], %mask, %passthru : memref<?x?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.maskedstore %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}}, %[[X]] : memref<?x?xf32>, vector<16xi1>, vector<16xf32>
// CHECK-LABEL: @gather_and_scatter
func @gather_and_scatter(%base: memref<?xf32>, %v: vector<16xi32>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.gather %{{.*}}[%{{.*}}] [%{{.*}}], %{{.*}}, %{{.*}} : memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.gather %base[%c0][%v], %mask, %pass_thru : memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.scatter %{{.*}}[%{{.*}}] [%{{.*}}], %{{.*}}, %[[X]] : memref<?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-LABEL: @gather_and_scatter2d
func @gather_and_scatter2d(%base: memref<?x?xf32>, %v: vector<16xi32>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.gather %{{.*}}[%{{.*}}, %{{.*}}] [%{{.*}}], %{{.*}}, %{{.*}} : memref<?x?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.gather %base[%c0, %c0][%v], %mask, %pass_thru : memref<?x?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.scatter %{{.*}}[%{{.*}}] [%{{.*}}], %{{.*}}, %[[X]] : memref<?x?xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-LABEL: @expand_and_compress
func @expand_and_compress(%base: memref<?xf32>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.expandload %{{.*}}[%{{.*}}], %{{.*}}, %{{.*}} : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.expandload %base[%c0], %mask, %pass_thru : memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.compressstore %{{.*}}[%{{.*}}], %{{.*}}, %[[X]] : memref<?xf32>, vector<16xi1>, vector<16xf32>
// CHECK-LABEL: @expand_and_compress2d
func @expand_and_compress2d(%base: memref<?x?xf32>, %mask: vector<16xi1>, %pass_thru: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[X:.*]] = vector.expandload %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}}, %{{.*}} : memref<?x?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
%0 = vector.expandload %base[%c0, %c0], %mask, %pass_thru : memref<?x?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK: vector.compressstore %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}}, %[[X]] : memref<?x?xf32>, vector<16xi1>, vector<16xf32>
// CHECK-SAME: %[[A:.*0]]: vector<4xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<4xf32>,
// CHECK-SAME: %[[C:.*2]]: f32
-// CHECK: %[[F:.*]] = mulf %[[A]], %[[B]] : vector<4xf32>
+// CHECK: %[[F:.*]] = arith.mulf %[[A]], %[[B]] : vector<4xf32>
// CHECK: %[[R:.*]] = vector.reduction "add", %[[F]] : vector<4xf32> into f32
-// CHECK: %[[ACC:.*]] = addf %[[R]], %[[C]] : f32
+// CHECK: %[[ACC:.*]] = arith.addf %[[R]], %[[C]] : f32
// CHECK: return %[[ACC]] : f32
func @extract_contract1(%arg0: vector<4xf32>, %arg1: vector<4xf32>, %arg2: f32) -> f32 {
// CHECK-SAME: %[[A:.*0]]: vector<4xi32>,
// CHECK-SAME: %[[B:.*1]]: vector<4xi32>,
// CHECK-SAME: %[[C:.*2]]: i32
-// CHECK: %[[F:.*]] = muli %[[A]], %[[B]] : vector<4xi32>
+// CHECK: %[[F:.*]] = arith.muli %[[A]], %[[B]] : vector<4xi32>
// CHECK: %[[R:.*]] = vector.reduction "add", %[[F]] : vector<4xi32> into i32
-// CHECK: %[[ACC:.*]] = addi %[[R]], %[[C]] : i32
+// CHECK: %[[ACC:.*]] = arith.addi %[[R]], %[[C]] : i32
// CHECK: return %[[ACC]] : i32
func @extract_contract1_int(%arg0: vector<4xi32>, %arg1: vector<4xi32>, %arg2: i32) -> i32 {
// CHECK-SAME: %[[A:.*0]]: vector<2x3xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xf32>,
// CHECK-SAME: %[[C:.*2]]: vector<2xf32>
-// CHECK: %[[R:.*]] = constant dense<0.000000e+00> : vector<2xf32>
+// CHECK: %[[R:.*]] = arith.constant dense<0.000000e+00> : vector<2xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2x3xf32>
-// CHECK: %[[T2:.*]] = mulf %[[T0]], %[[B]] : vector<3xf32>
+// CHECK: %[[T2:.*]] = arith.mulf %[[T0]], %[[B]] : vector<3xf32>
// CHECK: %[[T3:.*]] = vector.reduction "add", %[[T2]] : vector<3xf32> into f32
// CHECK: %[[T4:.*]] = vector.insert %[[T3]], %[[R]] [0] : f32 into vector<2xf32>
// CHECK: %[[T5:.*]] = vector.extract %[[A]][1] : vector<2x3xf32>
-// CHECK: %[[T7:.*]] = mulf %[[T5]], %[[B]] : vector<3xf32>
+// CHECK: %[[T7:.*]] = arith.mulf %[[T5]], %[[B]] : vector<3xf32>
// CHECK: %[[T8:.*]] = vector.reduction "add", %[[T7]] : vector<3xf32> into f32
// CHECK: %[[T9:.*]] = vector.insert %[[T8]], %[[T4]] [1] : f32 into vector<2xf32>
-// CHECK: %[[T10:.*]] = addf %[[T9]], %[[C]] : vector<2xf32>
+// CHECK: %[[T10:.*]] = arith.addf %[[T9]], %[[C]] : vector<2xf32>
// CHECK: return %[[T10]] : vector<2xf32>
func @extract_contract2(%arg0: vector<2x3xf32>,
// CHECK-SAME: %[[A:.*0]]: vector<2x3xi32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xi32>,
// CHECK-SAME: %[[C:.*2]]: vector<2xi32>
-// CHECK: %[[R:.*]] = constant dense<0> : vector<2xi32>
+// CHECK: %[[R:.*]] = arith.constant dense<0> : vector<2xi32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2x3xi32>
-// CHECK: %[[T2:.*]] = muli %[[T0]], %[[B]] : vector<3xi32>
+// CHECK: %[[T2:.*]] = arith.muli %[[T0]], %[[B]] : vector<3xi32>
// CHECK: %[[T3:.*]] = vector.reduction "add", %[[T2]] : vector<3xi32> into i32
// CHECK: %[[T4:.*]] = vector.insert %[[T3]], %[[R]] [0] : i32 into vector<2xi32>
// CHECK: %[[T5:.*]] = vector.extract %[[A]][1] : vector<2x3xi32>
-// CHECK: %[[T7:.*]] = muli %[[T5]], %[[B]] : vector<3xi32>
+// CHECK: %[[T7:.*]] = arith.muli %[[T5]], %[[B]] : vector<3xi32>
// CHECK: %[[T8:.*]] = vector.reduction "add", %[[T7]] : vector<3xi32> into i32
// CHECK: %[[T9:.*]] = vector.insert %[[T8]], %[[T4]] [1] : i32 into vector<2xi32>
-// CHECK: %[[T10:.*]] = addi %[[T9]], %[[C]] : vector<2xi32>
+// CHECK: %[[T10:.*]] = arith.addi %[[T9]], %[[C]] : vector<2xi32>
// CHECK: return %[[T10]] : vector<2xi32>
func @extract_contract2_int(%arg0: vector<2x3xi32>,
%arg1: vector<3xi32>,
// CHECK-SAME: %[[A:.*0]]: vector<3xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<2x3xf32>,
// CHECK-SAME: %[[C:.*2]]: vector<2xf32>
-// CHECK: %[[R:.*]] = constant dense<0.000000e+00> : vector<2xf32>
+// CHECK: %[[R:.*]] = arith.constant dense<0.000000e+00> : vector<2xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[B]][0] : vector<2x3xf32>
-// CHECK: %[[T2:.*]] = mulf %[[T0]], %[[A]] : vector<3xf32>
+// CHECK: %[[T2:.*]] = arith.mulf %[[T0]], %[[A]] : vector<3xf32>
// CHECK: %[[T3:.*]] = vector.reduction "add", %[[T2]] : vector<3xf32> into f32
// CHECK: %[[T4:.*]] = vector.insert %[[T3]], %[[R]] [0] : f32 into vector<2xf32>
// CHECK: %[[T5:.*]] = vector.extract %[[B]][1] : vector<2x3xf32>
-// CHECK: %[[T7:.*]] = mulf %[[T5]], %[[A]] : vector<3xf32>
+// CHECK: %[[T7:.*]] = arith.mulf %[[T5]], %[[A]] : vector<3xf32>
// CHECK: %[[T8:.*]] = vector.reduction "add", %[[T7]] : vector<3xf32> into f32
// CHECK: %[[T9:.*]] = vector.insert %[[T8]], %[[T4]] [1] : f32 into vector<2xf32>
-// CHECK: %[[T10:.*]] = addf %[[T9]], %[[C]] : vector<2xf32>
+// CHECK: %[[T10:.*]] = arith.addf %[[T9]], %[[C]] : vector<2xf32>
// CHECK: return %[[T10]] : vector<2xf32>
func @extract_contract3(%arg0: vector<3xf32>,
// CHECK-SAME: %[[A:.*0]]: vector<2x2xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<2x2xf32>,
// CHECK-SAME: %[[C:.*2]]: vector<2x2xf32>
-// CHECK: %[[R:.*]] = constant dense<0.000000e+00> : vector<2x2xf32>
+// CHECK: %[[R:.*]] = arith.constant dense<0.000000e+00> : vector<2x2xf32>
// ... bunch of extract insert to transpose B into Bt
// CHECK: %[[Bt:.*]] = vector.insert %{{.*}}, %{{.*}} [1, 1] : f32 into vector<2x2xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2x2xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[Bt]][0] : vector<2x2xf32>
-// CHECK: %[[T9:.*]] = mulf %[[T0]], %[[T2]] : vector<2xf32>
+// CHECK: %[[T9:.*]] = arith.mulf %[[T0]], %[[T2]] : vector<2xf32>
// CHECK: %[[T10:.*]] = vector.reduction "add", %[[T9]] : vector<2xf32> into f32
// CHECK: %[[T11:.*]] = vector.insert %[[T10]], %[[R]] [0, 0] : f32 into vector<2x2xf32>
//
// CHECK: %[[T12:.*]] = vector.extract %[[Bt]][1] : vector<2x2xf32>
-// CHECK: %[[T19:.*]] = mulf %[[T0]], %[[T12]] : vector<2xf32>
+// CHECK: %[[T19:.*]] = arith.mulf %[[T0]], %[[T12]] : vector<2xf32>
// CHECK: %[[T20:.*]] = vector.reduction "add", %[[T19]] : vector<2xf32> into f32
// CHECK: %[[T21:.*]] = vector.insert %[[T20]], %[[T11]] [0, 1] : f32 into vector<2x2xf32>
//
// CHECK: %[[T23:.*]] = vector.extract %[[A]][1] : vector<2x2xf32>
// CHECK: %[[T24:.*]] = vector.extract %[[Bt]][0] : vector<2x2xf32>
-// CHECK: %[[T32:.*]] = mulf %[[T23]], %[[T24]] : vector<2xf32>
+// CHECK: %[[T32:.*]] = arith.mulf %[[T23]], %[[T24]] : vector<2xf32>
// CHECK: %[[T33:.*]] = vector.reduction "add", %[[T32]] : vector<2xf32> into f32
// CHECK: %[[T34:.*]] = vector.insert %[[T33]], %[[T21]] [1, 0] : f32 into vector<2x2xf32>
//
// CHECK: %[[T40:.*]] = vector.extract %[[Bt]][1] : vector<2x2xf32>
-// CHECK: %[[T41:.*]] = mulf %[[T23]], %[[T40]] : vector<2xf32>
+// CHECK: %[[T41:.*]] = arith.mulf %[[T23]], %[[T40]] : vector<2xf32>
// CHECK: %[[T42:.*]] = vector.reduction "add", %[[T41]] : vector<2xf32> into f32
// CHECK: %[[T43:.*]] = vector.insert %[[T42]], %[[T34]] [1, 1] : f32 into vector<2x2xf32>
//
-// CHECK: %[[T52:.*]] = addf %[[T43]], %[[C]] : vector<2x2xf32>
+// CHECK: %[[T52:.*]] = arith.addf %[[T43]], %[[C]] : vector<2x2xf32>
// CHECK: return %[[T52]] : vector<2x2xf32>
func @extract_contract4(%arg0: vector<2x2xf32>,
// CHECK-SAME: %[[C:.*2]]: f32
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2x3xf32>
// CHECK: %[[T1:.*]] = vector.extract %[[B]][0] : vector<2x3xf32>
-// CHECK: %[[T2:.*]] = mulf %[[T0]], %[[T1]] : vector<3xf32>
+// CHECK: %[[T2:.*]] = arith.mulf %[[T0]], %[[T1]] : vector<3xf32>
// CHECK: %[[T3:.*]] = vector.reduction "add", %[[T2]] : vector<3xf32> into f32
-// CHECK: %[[T4:.*]] = addf %[[T3]], %[[C]] : f32
+// CHECK: %[[T4:.*]] = arith.addf %[[T3]], %[[C]] : f32
// CHECK: %[[T5:.*]] = vector.extract %[[A]][1] : vector<2x3xf32>
// CHECK: %[[T6:.*]] = vector.extract %[[B]][1] : vector<2x3xf32>
-// CHECK: %[[T7:.*]] = mulf %[[T5]], %[[T6]] : vector<3xf32>
+// CHECK: %[[T7:.*]] = arith.mulf %[[T5]], %[[T6]] : vector<3xf32>
// CHECK: %[[T8:.*]] = vector.reduction "add", %[[T7]] : vector<3xf32> into f32
-// CHECK: %[[T9:.*]] = addf %[[T8]], %[[T4]] : f32
+// CHECK: %[[T9:.*]] = arith.addf %[[T8]], %[[T4]] : f32
// CHECK: return %[[T9]] : f32
func @full_contract1(%arg0: vector<2x3xf32>,
// CHECK-SAME: %[[A:.*0]]: vector<2x3xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<3x2xf32>,
// CHECK-SAME: %[[C:.*2]]: f32
-// CHECK: %[[Z:.*]] = constant dense<0.000000e+00> : vector<3xf32>
+// CHECK: %[[Z:.*]] = arith.constant dense<0.000000e+00> : vector<3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2x3xf32>
// CHECK: %[[T1:.*]] = vector.extract %[[B]][0, 0] : vector<3x2xf32>
// CHECK: %[[T3:.*]] = vector.insert %[[T1]], %[[Z]] [0] : f32 into vector<3xf32>
// CHECK: %[[T6:.*]] = vector.insert %[[T4]], %[[T3]] [1] : f32 into vector<3xf32>
// CHECK: %[[T7:.*]] = vector.extract %[[B]][2, 0] : vector<3x2xf32>
// CHECK: %[[T9:.*]] = vector.insert %[[T7]], %[[T6]] [2] : f32 into vector<3xf32>
-// CHECK: %[[T10:.*]] = mulf %[[T0]], %[[T9]] : vector<3xf32>
+// CHECK: %[[T10:.*]] = arith.mulf %[[T0]], %[[T9]] : vector<3xf32>
// CHECK: %[[T11:.*]] = vector.reduction "add", %[[T10]] : vector<3xf32> into f32
-// CHECK: %[[ACC0:.*]] = addf %[[T11]], %[[C]] : f32
+// CHECK: %[[ACC0:.*]] = arith.addf %[[T11]], %[[C]] : f32
//
// CHECK: %[[T12:.*]] = vector.extract %[[A]][1] : vector<2x3xf32>
// CHECK: %[[T13:.*]] = vector.extract %[[B]][0, 1] : vector<3x2xf
// CHECK: %[[T18:.*]] = vector.insert %[[T16]], %[[T15]] [1] : f32 into vector<3xf32>
// CHECK: %[[T19:.*]] = vector.extract %[[B]][2, 1] : vector<3x2xf32>
// CHECK: %[[T21:.*]] = vector.insert %[[T19]], %[[T18]] [2] : f32 into vector<3xf32>
-// CHECK: %[[T22:.*]] = mulf %[[T12]], %[[T21]] : vector<3xf32>
+// CHECK: %[[T22:.*]] = arith.mulf %[[T12]], %[[T21]] : vector<3xf32>
// CHECK: %[[T23:.*]] = vector.reduction "add", %[[T22]] : vector<3xf32> into f32
-// CHECK: %[[ACC1:.*]] = addf %[[T23]], %[[ACC0]] : f32
+// CHECK: %[[ACC1:.*]] = arith.addf %[[T23]], %[[ACC0]] : f32
// CHECK: return %[[ACC1]] : f32
func @full_contract2(%arg0: vector<2x3xf32>,
// CHECK-LABEL: func @outerproduct_noacc
// CHECK-SAME: %[[A:.*0]]: vector<2xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2xf32>
// CHECK: %[[T1:.*]] = splat %[[T0]] : vector<3xf32>
-// CHECK: %[[T2:.*]] = mulf %[[T1]], %[[B]] : vector<3xf32>
+// CHECK: %[[T2:.*]] = arith.mulf %[[T1]], %[[B]] : vector<3xf32>
// CHECK: %[[T3:.*]] = vector.insert %[[T2]], %[[C0]] [0] : vector<3xf32> into vector<2x3xf32>
// CHECK: %[[T4:.*]] = vector.extract %[[A]][1] : vector<2xf32>
// CHECK: %[[T5:.*]] = splat %[[T4]] : vector<3xf32>
-// CHECK: %[[T6:.*]] = mulf %[[T5]], %[[B]] : vector<3xf32>
+// CHECK: %[[T6:.*]] = arith.mulf %[[T5]], %[[B]] : vector<3xf32>
// CHECK: %[[T7:.*]] = vector.insert %[[T6]], %[[T3]] [1] : vector<3xf32> into vector<2x3xf32>
// CHECK: return %[[T7]] : vector<2x3xf32>
// CHECK-SAME: %[[A:.*0]]: vector<2xf32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xf32>,
// CHECK-SAME: %[[C:.*2]]: vector<2x3xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2xf32>
// CHECK: %[[T1:.*]] = splat %[[T0]] : vector<3xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[C]][0] : vector<2x3xf32>
// CHECK-LABEL: func @outerproduct_noacc_int
// CHECK-SAME: %[[A:.*0]]: vector<2xi32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xi32>
-// CHECK: %[[C0:.*]] = constant dense<0> : vector<2x3xi32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0> : vector<2x3xi32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2xi32>
// CHECK: %[[T1:.*]] = splat %[[T0]] : vector<3xi32>
-// CHECK: %[[T2:.*]] = muli %[[T1]], %[[B]] : vector<3xi32>
+// CHECK: %[[T2:.*]] = arith.muli %[[T1]], %[[B]] : vector<3xi32>
// CHECK: %[[T3:.*]] = vector.insert %[[T2]], %[[C0]] [0] : vector<3xi32> into vector<2x3xi32>
// CHECK: %[[T4:.*]] = vector.extract %[[A]][1] : vector<2xi32>
// CHECK: %[[T5:.*]] = splat %[[T4]] : vector<3xi32>
-// CHECK: %[[T6:.*]] = muli %[[T5]], %[[B]] : vector<3xi32>
+// CHECK: %[[T6:.*]] = arith.muli %[[T5]], %[[B]] : vector<3xi32>
// CHECK: %[[T7:.*]] = vector.insert %[[T6]], %[[T3]] [1] : vector<3xi32> into vector<2x3xi32>
// CHECK: return %[[T7]] : vector<2x3xi32>
func @outerproduct_noacc_int(%arg0: vector<2xi32>,
// CHECK-SAME: %[[A:.*0]]: vector<2xi32>,
// CHECK-SAME: %[[B:.*1]]: vector<3xi32>,
// CHECK-SAME: %[[C:.*2]]: vector<2x3xi32>
-// CHECK: %[[C0:.*]] = constant dense<0> : vector<2x3xi32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0> : vector<2x3xi32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<2xi32>
// CHECK: %[[T1:.*]] = splat %[[T0]] : vector<3xi32>
// CHECK: %[[T2:.*]] = vector.extract %[[C]][0] : vector<2x3xi32>
-// CHECK: %[[T3:.*]] = muli %[[T1]], %[[B]] : vector<3xi32>
-// CHECK: %[[T4:.*]] = addi %[[T3]], %[[T2]] : vector<3xi32>
+// CHECK: %[[T3:.*]] = arith.muli %[[T1]], %[[B]] : vector<3xi32>
+// CHECK: %[[T4:.*]] = arith.addi %[[T3]], %[[T2]] : vector<3xi32>
// CHECK: %[[T5:.*]] = vector.insert %[[T4]], %[[C0]] [0] : vector<3xi32> into vector<2x3xi32>
// CHECK: %[[T6:.*]] = vector.extract %[[A]][1] : vector<2xi32>
// CHECK: %[[T7:.*]] = splat %[[T6]] : vector<3xi32>
// CHECK: %[[T8:.*]] = vector.extract %[[C]][1] : vector<2x3xi32>
-// CHECK: %[[T9:.*]] = muli %[[T7]], %[[B]] : vector<3xi32>
-// CHECK: %[[T10:.*]] = addi %[[T9]], %[[T8]] : vector<3xi32>
+// CHECK: %[[T9:.*]] = arith.muli %[[T7]], %[[B]] : vector<3xi32>
+// CHECK: %[[T10:.*]] = arith.addi %[[T9]], %[[T8]] : vector<3xi32>
// CHECK: %[[T11:.*]] = vector.insert %[[T10]], %[[T5]] [1] : vector<3xi32> into vector<2x3xi32>
// CHECK: return %[[T11]] : vector<2x3xi32>
func @outerproduct_acc_int(%arg0: vector<2xi32>,
// CHECK-SAME: %[[A:.*0]]: vector<16xf32>,
// CHECK-SAME: %[[B:.*1]]: f32)
// CHECK: %[[T0:.*]] = splat %[[B]] : vector<16xf32>
-// CHECK: %[[T1:.*]] = mulf %[[A]], %[[T0]] : vector<16xf32>
+// CHECK: %[[T1:.*]] = arith.mulf %[[A]], %[[T0]] : vector<16xf32>
// CHECK: return %[[T1]] : vector<16xf32>
func @axpy_fp(%arg0: vector<16xf32>, %arg1: f32) -> vector<16xf32> {
%0 = vector.outerproduct %arg0, %arg1: vector<16xf32>, f32
// CHECK-SAME: %[[A:.*0]]: vector<16xi32>,
// CHECK-SAME: %[[B:.*1]]: i32)
// CHECK: %[[T0:.*]] = splat %[[B]] : vector<16xi32>
-// CHECK: %[[T1:.*]] = muli %[[A]], %[[T0]] : vector<16xi32>
+// CHECK: %[[T1:.*]] = arith.muli %[[A]], %[[T0]] : vector<16xi32>
// CHECK: return %[[T1]] : vector<16xi32>
func @axpy_int(%arg0: vector<16xi32>, %arg1: i32) -> vector<16xi32> {
%0 = vector.outerproduct %arg0, %arg1: vector<16xi32>, i32
// CHECK-SAME: %[[B:.*1]]: i32,
// CHECK-SAME: %[[C:.*2]]: vector<16xi32>)
// CHECK: %[[T0:.*]] = splat %[[B]] : vector<16xi32>
-// CHECK: %[[T1:.*]] = muli %[[A]], %[[T0]] : vector<16xi32>
-// CHECK: %[[T2:.*]] = addi %[[T1]], %[[C]] : vector<16xi32>
+// CHECK: %[[T1:.*]] = arith.muli %[[A]], %[[T0]] : vector<16xi32>
+// CHECK: %[[T2:.*]] = arith.addi %[[T1]], %[[C]] : vector<16xi32>
// CHECK: return %[[T2]] : vector<16xi32>
func @axpy_int_add(%arg0: vector<16xi32>, %arg1: i32, %arg2: vector<16xi32>) -> vector<16xi32> {
%0 = vector.outerproduct %arg0, %arg1, %arg2: vector<16xi32>, i32
// CHECK-LABEL: func @transpose23
// CHECK-SAME: %[[A:.*]]: vector<2x3xf32>
-// CHECK: %[[Z:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[Z:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0, 0] : vector<2x3xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[Z]] [0, 0] : f32 into vector<3x2xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[A]][1, 0] : vector<2x3xf32>
// llvm.matrix operations
// CHECK-LABEL: func @shape_casts
func @shape_casts(%a: vector<2x2xf32>) -> (vector<4xf32>, vector<2x2xf32>) {
- // CHECK-DAG: %[[cst22:.*]] = constant dense<0.000000e+00> : vector<2x2xf32>
- // CHECK-DAG: %[[cst:.*]] = constant dense<0.000000e+00> : vector<4xf32>
+ // CHECK-DAG: %[[cst22:.*]] = arith.constant dense<0.000000e+00> : vector<2x2xf32>
+ // CHECK-DAG: %[[cst:.*]] = arith.constant dense<0.000000e+00> : vector<4xf32>
// CHECK: %[[ex0:.*]] = vector.extract %{{.*}}[0] : vector<2x2xf32>
//
// CHECK: %[[in0:.*]] = vector.insert_strided_slice %[[ex0]], %[[cst]]
// CHECK-SAME: {offsets = [2], strides = [1]} : vector<2xf32> into vector<4xf32>
//
%0 = vector.shape_cast %a : vector<2x2xf32> to vector<4xf32>
- // CHECK: %[[add:.*]] = addf %[[in2]], %[[in2]] : vector<4xf32>
- %r0 = addf %0, %0: vector<4xf32>
+ // CHECK: %[[add:.*]] = arith.addf %[[in2]], %[[in2]] : vector<4xf32>
+ %r0 = arith.addf %0, %0: vector<4xf32>
//
// CHECK: %[[ss0:.*]] = vector.extract_strided_slice %[[add]]
// CHECK-SAME: {offsets = [0], sizes = [2], strides = [1]} :
// CHECK-LABEL: func @shape_cast_2d2d
// CHECK-SAME: %[[A:.*]]: vector<3x2xf32>
-// CHECK: %[[C:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// CHECK: %[[C:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0, 0] : vector<3x2xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[C]] [0, 0] : f32 into vector<2x3xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[A]][0, 1] : vector<3x2xf32>
// CHECK-LABEL: func @shape_cast_3d1d
// CHECK-SAME: %[[A:.*]]: vector<1x3x2xf32>
-// CHECK: %[[C:.*]] = constant dense<0.000000e+00> : vector<6xf32>
+// CHECK: %[[C:.*]] = arith.constant dense<0.000000e+00> : vector<6xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0, 0, 0] : vector<1x3x2xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[C]] [0] : f32 into vector<6xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[A]][0, 0, 1] : vector<1x3x2xf32>
// CHECK-LABEL: func @shape_cast_1d3d
// CHECK-SAME: %[[A:.*]]: vector<6xf32>
-// CHECK: %[[C:.*]] = constant dense<0.000000e+00> : vector<2x1x3xf32>
+// CHECK: %[[C:.*]] = arith.constant dense<0.000000e+00> : vector<2x1x3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<6xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[C]] [0, 0, 0] : f32 into vector<2x1x3xf32>
// CHECK: %[[T2:.*]] = vector.extract %[[A]][1] : vector<6xf32>
// MATRIX-SAME: %[[A:[a-zA-Z0-9]*]]: vector<2x4xf32>,
// MATRIX-SAME: %[[B:[a-zA-Z0-9]*]]: vector<4x3xf32>,
// MATRIX-SAME: %[[C:[a-zA-Z0-9]*]]: vector<2x3xf32>
-// MATRIX: %[[vcst:.*]] = constant dense<0.000000e+00> : vector<8xf32>
-// MATRIX: %[[vcst_0:.*]] = constant dense<0.000000e+00> : vector<12xf32>
-// MATRIX: %[[vcst_1:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// MATRIX: %[[vcst:.*]] = arith.constant dense<0.000000e+00> : vector<8xf32>
+// MATRIX: %[[vcst_0:.*]] = arith.constant dense<0.000000e+00> : vector<12xf32>
+// MATRIX: %[[vcst_1:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// MATRIX: %[[a0:.*]] = vector.extract %[[A]][0] : vector<2x4xf32>
// MATRIX: %[[a1:.*]] = vector.insert_strided_slice %[[a0]], %[[vcst]] {offsets = [0], strides = [1]} : vector<4xf32> into vector<8xf32>
// MATRIX: %[[a2:.*]] = vector.extract %[[A]][1] : vector<2x4xf32>
// MATRIX: %[[mm3:.*]] = vector.insert %[[mm2]], %[[vcst_1]] [0] : vector<3xf32> into vector<2x3xf32>
// MATRIX: %[[mm4:.*]] = vector.extract_strided_slice %[[mm1]] {offsets = [3], sizes = [3], strides = [1]} : vector<6xf32> to vector<3xf32>
// MATRIX: %[[mm5:.*]] = vector.insert %[[mm4]], %[[mm3]] [1] : vector<3xf32> into vector<2x3xf32>
-// MATRIX: %[[mm6:.*]] = addf %[[C]], %[[mm5]] : vector<2x3xf32>
+// MATRIX: %[[mm6:.*]] = arith.addf %[[C]], %[[mm5]] : vector<2x3xf32>
// OUTERPRODUCT-LABEL: func @matmul
// OUTERPRODUCT-SAME: %[[A:[a-zA-Z0-9]*]]: vector<2x4xf32>,
// REDUCE-SAME: %[[B:[a-zA-Z0-9]*]]: vector<4x3xf32>,
// REDUCE-SAME: %[[C:[a-zA-Z0-9]*]]: vector<2x3xf32>
//
-// REDUCE: %[[RES:.*]] = constant dense<0.000000e+00> : vector<2x3xf32>
+// REDUCE: %[[RES:.*]] = arith.constant dense<0.000000e+00> : vector<2x3xf32>
// REDUCE: %[[Bt:.*]] = vector.transpose %[[B]], [1, 0]
// REDUCE-SAME: : vector<4x3f32> to vector<3x4xf32>
//
// CHECK-LABEL: func @broadcast_vec2d_from_vec1d
// CHECK-SAME: %[[A:.*0]]: vector<2xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
// CHECK: %[[T0:.*]] = vector.insert %[[A]], %[[C0]] [0] : vector<2xf32> into vector<3x2xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[A]], %[[T0]] [1] : vector<2xf32> into vector<3x2xf32>
// CHECK: %[[T2:.*]] = vector.insert %[[A]], %[[T1]] [2] : vector<2xf32> into vector<3x2xf32>
// CHECK-LABEL: func @broadcast_vec3d_from_vec1d
// CHECK-SAME: %[[A:.*0]]: vector<2xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
-// CHECK: %[[C1:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[C1:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
// CHECK: %[[T0:.*]] = vector.insert %[[A]], %[[C0]] [0] : vector<2xf32> into vector<3x2xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[A]], %[[T0]] [1] : vector<2xf32> into vector<3x2xf32>
// CHECK: %[[T2:.*]] = vector.insert %[[A]], %[[T1]] [2] : vector<2xf32> into vector<3x2xf32>
// CHECK-LABEL: func @broadcast_vec3d_from_vec2d
// CHECK-SAME: %[[A:.*0]]: vector<3x2xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
// CHECK: %[[T0:.*]] = vector.insert %[[A]], %[[C0]] [0] : vector<3x2xf32> into vector<4x3x2xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[A]], %[[T0]] [1] : vector<3x2xf32> into vector<4x3x2xf32>
// CHECK: %[[T2:.*]] = vector.insert %[[A]], %[[T1]] [2] : vector<3x2xf32> into vector<4x3x2xf32>
// CHECK-LABEL: func @broadcast_stretch_at_start
// CHECK-SAME: %[[A:.*0]]: vector<1x4xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<3x4xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<3x4xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0] : vector<1x4xf32>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[C0]] [0] : vector<4xf32> into vector<3x4xf32>
// CHECK: %[[T2:.*]] = vector.insert %[[T0]], %[[T1]] [1] : vector<4xf32> into vector<3x4xf32>
// CHECK-LABEL: func @broadcast_stretch_at_end
// CHECK-SAME: %[[A:.*0]]: vector<4x1xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<4x3xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<4x3xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0, 0] : vector<4x1xf32>
// CHECK: %[[T2:.*]] = splat %[[T0]] : vector<3xf32>
// CHECK: %[[T3:.*]] = vector.insert %[[T2]], %[[C0]] [0] : vector<3xf32> into vector<4x3xf32>
// CHECK-LABEL: func @broadcast_stretch_in_middle
// CHECK-SAME: %[[A:.*0]]: vector<4x1x2xf32>
-// CHECK: %[[C0:.*]] = constant dense<0.000000e+00> : vector<4x3x2xf32>
-// CHECK: %[[C1:.*]] = constant dense<0.000000e+00> : vector<3x2xf32>
+// CHECK: %[[C0:.*]] = arith.constant dense<0.000000e+00> : vector<4x3x2xf32>
+// CHECK: %[[C1:.*]] = arith.constant dense<0.000000e+00> : vector<3x2xf32>
// CHECK: %[[T0:.*]] = vector.extract %[[A]][0, 0] : vector<4x1x2xf32>
// CHECK: %[[T2:.*]] = vector.insert %[[T0]], %[[C1]] [0] : vector<2xf32> into vector<3x2xf32>
// CHECK: %[[T3:.*]] = vector.insert %[[T0]], %[[T2]] [1] : vector<2xf32> into vector<3x2xf32>
}
// CHECK-LABEL: func @genbool_1d
-// CHECK: %[[T0:.*]] = constant dense<[true, true, true, true, false, false, false, false]> : vector<8xi1>
+// CHECK: %[[T0:.*]] = arith.constant dense<[true, true, true, true, false, false, false, false]> : vector<8xi1>
// CHECK: return %[[T0]] : vector<8xi1>
func @genbool_1d() -> vector<8xi1> {
}
// CHECK-LABEL: func @genbool_2d
-// CHECK: %[[C1:.*]] = constant dense<[true, true, false, false]> : vector<4xi1>
-// CHECK: %[[C2:.*]] = constant dense<false> : vector<4x4xi1>
+// CHECK: %[[C1:.*]] = arith.constant dense<[true, true, false, false]> : vector<4xi1>
+// CHECK: %[[C2:.*]] = arith.constant dense<false> : vector<4x4xi1>
// CHECK: %[[T0:.*]] = vector.insert %[[C1]], %[[C2]] [0] : vector<4xi1> into vector<4x4xi1>
// CHECK: %[[T1:.*]] = vector.insert %[[C1]], %[[T0]] [1] : vector<4xi1> into vector<4x4xi1>
// CHECK: return %[[T1]] : vector<4x4xi1>
}
// CHECK-LABEL: func @genbool_3d
-// CHECK: %[[C1:.*]] = constant dense<[true, true, true, false]> : vector<4xi1>
-// CHECK: %[[C2:.*]] = constant dense<false> : vector<3x4xi1>
-// CHECK: %[[C3:.*]] = constant dense<false> : vector<2x3x4xi1>
+// CHECK: %[[C1:.*]] = arith.constant dense<[true, true, true, false]> : vector<4xi1>
+// CHECK: %[[C2:.*]] = arith.constant dense<false> : vector<3x4xi1>
+// CHECK: %[[C3:.*]] = arith.constant dense<false> : vector<2x3x4xi1>
// CHECK: %[[T0:.*]] = vector.insert %[[C1]], %[[C2]] [0] : vector<4xi1> into vector<3x4xi1>
// CHECK: %[[T1:.*]] = vector.insert %[[T0]], %[[C3]] [0] : vector<3x4xi1> into vector<2x3x4xi1>
// CHECK: return %[[T1]] : vector<2x3x4xi1>
// CHECK-LABEL: func @genbool_var_2d(
// CHECK-SAME: %[[A:.*0]]: index,
// CHECK-SAME: %[[B:.*1]]: index)
-// CHECK: %[[C1:.*]] = constant dense<false> : vector<3xi1>
-// CHECK: %[[C2:.*]] = constant dense<false> : vector<2x3xi1>
-// CHECK: %[[c0:.*]] = constant 0 : index
-// CHECK: %[[c1:.*]] = constant 1 : index
+// CHECK: %[[C1:.*]] = arith.constant dense<false> : vector<3xi1>
+// CHECK: %[[C2:.*]] = arith.constant dense<false> : vector<2x3xi1>
+// CHECK: %[[c0:.*]] = arith.constant 0 : index
+// CHECK: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[T0:.*]] = vector.create_mask %[[B]] : vector<3xi1>
-// CHECK: %[[T1:.*]] = cmpi slt, %[[c0]], %[[A]] : index
+// CHECK: %[[T1:.*]] = arith.cmpi slt, %[[c0]], %[[A]] : index
// CHECK: %[[T2:.*]] = select %[[T1]], %[[T0]], %[[C1]] : vector<3xi1>
// CHECK: %[[T3:.*]] = vector.insert %[[T2]], %[[C2]] [0] : vector<3xi1> into vector<2x3xi1>
-// CHECK: %[[T4:.*]] = cmpi slt, %[[c1]], %[[A]] : index
+// CHECK: %[[T4:.*]] = arith.cmpi slt, %[[c1]], %[[A]] : index
// CHECK: %[[T5:.*]] = select %[[T4]], %[[T0]], %[[C1]] : vector<3xi1>
// CHECK: %[[T6:.*]] = vector.insert %[[T5]], %[[T3]] [1] : vector<3xi1> into vector<2x3xi1>
// CHECK: return %[[T6]] : vector<2x3xi1>
// CHECK-SAME: %[[A:.*0]]: index,
// CHECK-SAME: %[[B:.*1]]: index,
// CHECK-SAME: %[[C:.*2]]: index)
-// CHECK-DAG: %[[C1:.*]] = constant dense<false> : vector<7xi1>
-// CHECK-DAG: %[[C2:.*]] = constant dense<false> : vector<1x7xi1>
-// CHECK-DAG: %[[C3:.*]] = constant dense<false> : vector<2x1x7xi1>
-// CHECK-DAG: %[[c0:.*]] = constant 0 : index
-// CHECK-DAG: %[[c1:.*]] = constant 1 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant dense<false> : vector<7xi1>
+// CHECK-DAG: %[[C2:.*]] = arith.constant dense<false> : vector<1x7xi1>
+// CHECK-DAG: %[[C3:.*]] = arith.constant dense<false> : vector<2x1x7xi1>
+// CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[c1:.*]] = arith.constant 1 : index
// CHECK: %[[T0:.*]] = vector.create_mask %[[C]] : vector<7xi1>
-// CHECK: %[[T1:.*]] = cmpi slt, %[[c0]], %[[B]] : index
+// CHECK: %[[T1:.*]] = arith.cmpi slt, %[[c0]], %[[B]] : index
// CHECK: %[[T2:.*]] = select %[[T1]], %[[T0]], %[[C1]] : vector<7xi1>
// CHECK: %[[T3:.*]] = vector.insert %[[T2]], %[[C2]] [0] : vector<7xi1> into vector<1x7xi1>
-// CHECK: %[[T4:.*]] = cmpi slt, %[[c0]], %[[A]] : index
+// CHECK: %[[T4:.*]] = arith.cmpi slt, %[[c0]], %[[A]] : index
// CHECK: %[[T5:.*]] = select %[[T4]], %[[T3]], %[[C2]] : vector<1x7xi1>
// CHECK: %[[T6:.*]] = vector.insert %[[T5]], %[[C3]] [0] : vector<1x7xi1> into vector<2x1x7xi1>
-// CHECK: %[[T7:.*]] = cmpi slt, %[[c1]], %[[A]] : index
+// CHECK: %[[T7:.*]] = arith.cmpi slt, %[[c1]], %[[A]] : index
// CHECK: %[[T8:.*]] = select %[[T7]], %[[T3]], %[[C2]] : vector<1x7xi1>
// CHECK: %[[T9:.*]] = vector.insert %[[T8]], %[[T6]] [1] : vector<1x7xi1> into vector<2x1x7xi1>
// CHECK: return %[[T9]] : vector<2x1x7xi1>
// CHECK-LABEL: func @distribute_vector_add
// CHECK-SAME: (%[[ID:.*]]: index
-// CHECK-NEXT: %[[ADDV:.*]] = addf %{{.*}}, %{{.*}} : vector<32xf32>
+// CHECK-NEXT: %[[ADDV:.*]] = arith.addf %{{.*}}, %{{.*}} : vector<32xf32>
// CHECK-NEXT: %[[EXA:.*]] = vector.extract_map %{{.*}}[%[[ID]]] : vector<32xf32> to vector<1xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.extract_map %{{.*}}[%[[ID]]] : vector<32xf32> to vector<1xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<1xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<1xf32>
// CHECK-NEXT: %[[INS:.*]] = vector.insert_map %[[ADD]], %[[ADDV]][%[[ID]]] : vector<1xf32> into vector<32xf32>
// CHECK-NEXT: return %[[INS]] : vector<32xf32>
func @distribute_vector_add(%id : index, %A: vector<32xf32>, %B: vector<32xf32>) -> vector<32xf32> {
- %0 = addf %A, %B : vector<32xf32>
+ %0 = arith.addf %A, %B : vector<32xf32>
return %0: vector<32xf32>
}
// CHECK-LABEL: func @distribute_vector_add_exp
// CHECK-SAME: (%[[ID:.*]]: index
// CHECK-NEXT: %[[EXPV:.*]] = math.exp %{{.*}} : vector<32xf32>
-// CHECK-NEXT: %[[ADDV:.*]] = addf %[[EXPV]], %{{.*}} : vector<32xf32>
+// CHECK-NEXT: %[[ADDV:.*]] = arith.addf %[[EXPV]], %{{.*}} : vector<32xf32>
// CHECK-NEXT: %[[EXA:.*]] = vector.extract_map %{{.*}}[%[[ID]]] : vector<32xf32> to vector<1xf32>
// CHECK-NEXT: %[[EXC:.*]] = math.exp %[[EXA]] : vector<1xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.extract_map %{{.*}}[%[[ID]]] : vector<32xf32> to vector<1xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXC]], %[[EXB]] : vector<1xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXC]], %[[EXB]] : vector<1xf32>
// CHECK-NEXT: %[[INS:.*]] = vector.insert_map %[[ADD]], %[[ADDV]][%[[ID]]] : vector<1xf32> into vector<32xf32>
// CHECK-NEXT: return %[[INS]] : vector<32xf32>
func @distribute_vector_add_exp(%id : index, %A: vector<32xf32>, %B: vector<32xf32>) -> vector<32xf32> {
%C = math.exp %A : vector<32xf32>
- %0 = addf %C, %B : vector<32xf32>
+ %0 = arith.addf %C, %B : vector<32xf32>
return %0: vector<32xf32>
}
// CHECK-SAME: (%[[ID:.*]]: index
// CHECK: %[[EXA:.*]] = vector.transfer_read %{{.*}}[%[[ID]]], %{{.*}} : memref<32xf32>, vector<1xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.transfer_read %{{.*}}[%[[ID]]], %{{.*}} : memref<32xf32>, vector<1xf32>
-// CHECK-NEXT: %[[ADD1:.*]] = addf %[[EXA]], %[[EXB]] : vector<1xf32>
+// CHECK-NEXT: %[[ADD1:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<1xf32>
// CHECK-NEXT: %[[EXC:.*]] = vector.transfer_read %{{.*}}[%[[ID]]], %{{.*}} : memref<32xf32>, vector<1xf32>
-// CHECK-NEXT: %[[ADD2:.*]] = addf %[[ADD1]], %[[EXC]] : vector<1xf32>
+// CHECK-NEXT: %[[ADD2:.*]] = arith.addf %[[ADD1]], %[[EXC]] : vector<1xf32>
// CHECK-NEXT: vector.transfer_write %[[ADD2]], %{{.*}}[%[[ID]]] {{.*}} : vector<1xf32>, memref<32xf32>
// CHECK-NEXT: return
func @vector_add_read_write(%id : index, %A: memref<32xf32>, %B: memref<32xf32>, %C: memref<32xf32>, %D: memref<32xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0], %cf0: memref<32xf32>, vector<32xf32>
%b = vector.transfer_read %B[%c0], %cf0: memref<32xf32>, vector<32xf32>
- %acc = addf %a, %b: vector<32xf32>
+ %acc = arith.addf %a, %b: vector<32xf32>
%c = vector.transfer_read %C[%c0], %cf0: memref<32xf32>, vector<32xf32>
- %d = addf %acc, %c: vector<32xf32>
+ %d = arith.addf %acc, %c: vector<32xf32>
vector.transfer_write %d, %D[%c0]: vector<32xf32>, memref<32xf32>
return
}
// CHECK-NEXT: %[[EXA:.*]] = vector.transfer_read %{{.*}}[%[[ID1]]], %{{.*}} : memref<64xf32>, vector<2xf32>
// CHECK-NEXT: %[[ID2:.*]] = affine.apply #[[MAP0]]()[%[[ID]]]
// CHECK-NEXT: %[[EXB:.*]] = vector.transfer_read %{{.*}}[%[[ID2]]], %{{.*}} : memref<64xf32>, vector<2xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<2xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<2xf32>
// CHECK-NEXT: %[[ID3:.*]] = affine.apply #[[MAP0]]()[%[[ID]]]
// CHECK-NEXT: vector.transfer_write %[[ADD]], %{{.*}}[%[[ID3]]] {{.*}} : vector<2xf32>, memref<64xf32>
// CHECK-NEXT: return
func @vector_add_cycle(%id : index, %A: memref<64xf32>, %B: memref<64xf32>, %C: memref<64xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0], %cf0: memref<64xf32>, vector<64xf32>
%b = vector.transfer_read %B[%c0], %cf0: memref<64xf32>, vector<64xf32>
- %acc = addf %a, %b: vector<64xf32>
+ %acc = arith.addf %a, %b: vector<64xf32>
vector.transfer_write %acc, %C[%c0]: vector<64xf32>, memref<64xf32>
return
}
// Negative test to make sure nothing is done in case the vector size is not a
// multiple of multiplicity.
// CHECK-LABEL: func @vector_negative_test
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[EXA:.*]] = vector.transfer_read %{{.*}}[%[[C0]]], %{{.*}} : memref<64xf32>, vector<16xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.transfer_read %{{.*}}[%[[C0]]], %{{.*}} : memref<64xf32>, vector<16xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<16xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<16xf32>
// CHECK-NEXT: vector.transfer_write %[[ADD]], %{{.*}}[%[[C0]]] {{.*}} : vector<16xf32>, memref<64xf32>
// CHECK-NEXT: return
func @vector_negative_test(%id : index, %A: memref<64xf32>, %B: memref<64xf32>, %C: memref<64xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0], %cf0: memref<64xf32>, vector<16xf32>
%b = vector.transfer_read %B[%c0], %cf0: memref<64xf32>, vector<16xf32>
- %acc = addf %a, %b: vector<16xf32>
+ %acc = arith.addf %a, %b: vector<16xf32>
vector.transfer_write %acc, %C[%c0]: vector<16xf32>, memref<64xf32>
return
}
// CHECK-LABEL: func @distribute_vector_add_3d
// CHECK-SAME: (%[[ID0:.*]]: index, %[[ID1:.*]]: index
-// CHECK-NEXT: %[[ADDV:.*]] = addf %{{.*}}, %{{.*}} : vector<64x4x32xf32>
+// CHECK-NEXT: %[[ADDV:.*]] = arith.addf %{{.*}}, %{{.*}} : vector<64x4x32xf32>
// CHECK-NEXT: %[[EXA:.*]] = vector.extract_map %{{.*}}[%[[ID0]], %[[ID1]]] : vector<64x4x32xf32> to vector<2x4x1xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.extract_map %{{.*}}[%[[ID0]], %[[ID1]]] : vector<64x4x32xf32> to vector<2x4x1xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
// CHECK-NEXT: %[[INS:.*]] = vector.insert_map %[[ADD]], %[[ADDV]][%[[ID0]], %[[ID1]]] : vector<2x4x1xf32> into vector<64x4x32xf32>
// CHECK-NEXT: return %[[INS]] : vector<64x4x32xf32>
func @distribute_vector_add_3d(%id0 : index, %id1 : index,
%A: vector<64x4x32xf32>, %B: vector<64x4x32xf32>) -> vector<64x4x32xf32> {
- %0 = addf %A, %B : vector<64x4x32xf32>
+ %0 = arith.addf %A, %B : vector<64x4x32xf32>
return %0: vector<64x4x32xf32>
}
// CHECK: func @vector_add_transfer_3d
// CHECK-SAME: (%[[ID_0:.*]]: index, %[[ID_1:.*]]: index
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[ID1:.*]] = affine.apply #[[MAP0]]()[%[[ID_0]]]
// CHECK-NEXT: %[[EXA:.*]] = vector.transfer_read %{{.*}}[%[[ID1]], %[[C0]], %[[ID_1]]], %{{.*}} : memref<64x64x64xf32>, vector<2x4x1xf32>
// CHECK-NEXT: %[[ID2:.*]] = affine.apply #[[MAP0]]()[%[[ID_0]]]
// CHECK-NEXT: %[[EXB:.*]] = vector.transfer_read %{{.*}}[%[[ID2]], %[[C0]], %[[ID_1]]], %{{.*}} : memref<64x64x64xf32>, vector<2x4x1xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
// CHECK-NEXT: %[[ID3:.*]] = affine.apply #[[MAP0]]()[%[[ID_0]]]
// CHECK-NEXT: vector.transfer_write %[[ADD]], %{{.*}}[%[[ID3]], %[[C0]], %[[ID_1]]] {{.*}} : vector<2x4x1xf32>, memref<64x64x64xf32>
// CHECK-NEXT: return
func @vector_add_transfer_3d(%id0 : index, %id1 : index, %A: memref<64x64x64xf32>,
%B: memref<64x64x64xf32>, %C: memref<64x64x64xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0, %c0, %c0], %cf0: memref<64x64x64xf32>, vector<64x4x32xf32>
%b = vector.transfer_read %B[%c0, %c0, %c0], %cf0: memref<64x64x64xf32>, vector<64x4x32xf32>
- %acc = addf %a, %b: vector<64x4x32xf32>
+ %acc = arith.addf %a, %b: vector<64x4x32xf32>
vector.transfer_write %acc, %C[%c0, %c0, %c0]: vector<64x4x32xf32>, memref<64x64x64xf32>
return
}
// CHECK: func @vector_add_transfer_permutation
// CHECK-SAME: (%[[ID_0:.*]]: index, %[[ID_1:.*]]: index
-// CHECK: %[[C0:.*]] = constant 0 : index
+// CHECK: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[ID2:.*]] = affine.apply #[[MAP0]]()[%[[ID_0]]]
// CHECK-NEXT: %[[EXA:.*]] = vector.transfer_read %{{.*}}[%[[C0]], %[[C0]], %[[C0]], %[[ID2]]], %{{.*}} {permutation_map = #[[MAP1]]} : memref<?x?x?x?xf32>, vector<2x4x1xf32>
// CHECK-NEXT: %[[EXB:.*]] = vector.transfer_read %{{.*}}[%[[ID_0]], %[[C0]], %[[C0]], %[[C0]]], %{{.*}} {permutation_map = #[[MAP2]]} : memref<?x?x?x?xf32>, vector<2x4x1xf32>
-// CHECK-NEXT: %[[ADD:.*]] = addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
+// CHECK-NEXT: %[[ADD:.*]] = arith.addf %[[EXA]], %[[EXB]] : vector<2x4x1xf32>
// CHECK-NEXT: %[[ID3:.*]] = affine.apply #[[MAP0]]()[%[[ID_0]]]
// CHECK-NEXT: vector.transfer_write %[[ADD]], %{{.*}}[%[[C0]], %[[ID_1]], %[[C0]], %[[ID3]]] {permutation_map = #[[MAP3]]} : vector<2x4x1xf32>, memref<?x?x?x?xf32>
// CHECK-NEXT: return
func @vector_add_transfer_permutation(%id0 : index, %id1 : index, %A: memref<?x?x?x?xf32>,
%B: memref<?x?x?x?xf32>, %C: memref<?x?x?x?xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0, %c0, %c0, %c0], %cf0 {permutation_map = #map0} : memref<?x?x?x?xf32>, vector<64x4x32xf32>
%b = vector.transfer_read %B[%c0, %c0, %c0, %c0], %cf0 {permutation_map = #map1}: memref<?x?x?x?xf32>, vector<64x4x32xf32>
- %acc = addf %a, %b: vector<64x4x32xf32>
+ %acc = arith.addf %a, %b: vector<64x4x32xf32>
vector.transfer_write %acc, %C[%c0, %c0, %c0, %c0] {permutation_map = #map2}: vector<64x4x32xf32>, memref<?x?x?x?xf32>
return
}
// CHECK2D: %[[C:.+]] = vector.transfer_read %arg4[%4, %5], %cst : memref<?x?xf32>, vector<2x16xf32>
// CHECK2D: %[[E:.+]] = vector.transfer_read %arg5[%7, %8], %cst : memref<?x?xf32>, vector<2x16xf32>
// CHECK2D: %[[D:.+]] = vector.contract {{.*}} %[[A]], %[[B]], %[[C]] : vector<2x4xf32>, vector<16x4xf32> into vector<2x16xf32>
-// CHECK2D: %[[R:.+]] = addf %[[D]], %[[E]] : vector<2x16xf32>
+// CHECK2D: %[[R:.+]] = arith.addf %[[D]], %[[E]] : vector<2x16xf32>
// CHECK2D: vector.transfer_write %[[R]], {{.*}} : vector<2x16xf32>, memref<?x?xf32>
func @vector_add_contract(%id0 : index, %id1 : index, %A: memref<?x?xf32>,
%B: memref<?x?xf32>, %C: memref<?x?xf32>, %D: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%a = vector.transfer_read %A[%c0, %c0], %cf0 : memref<?x?xf32>, vector<64x4xf32>
%b = vector.transfer_read %B[%c0, %c0], %cf0 : memref<?x?xf32>, vector<64x4xf32>
%c = vector.transfer_read %C[%c0, %c0], %cf0 : memref<?x?xf32>, vector<64x64xf32>
kind = #vector.kind<add>}
%a, %b, %c : vector<64x4xf32>, vector<64x4xf32> into vector<64x64xf32>
%e = vector.transfer_read %D[%c0, %c0], %cf0 : memref<?x?xf32>, vector<64x64xf32>
- %r = addf %d, %e : vector<64x64xf32>
+ %r = arith.addf %d, %e : vector<64x64xf32>
vector.transfer_write %r, %C[%c0, %c0] : vector<64x64xf32>, memref<?x?xf32>
return
}
// CHECK-LABEL: func @maskedload0(
// CHECK-SAME: %[[A0:.*]]: memref<?xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
-// CHECK-DAG: %[[C:.*]] = constant 0 : index
+// CHECK-DAG: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[T:.*]] = vector.load %[[A0]][%[[C]]] : memref<?xf32>, vector<16xf32>
// CHECK-NEXT: return %[[T]] : vector<16xf32>
func @maskedload0(%base: memref<?xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
%ld = vector.maskedload %base[%c0], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-LABEL: func @maskedload1(
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
-// CHECK-DAG: %[[C:.*]] = constant 0 : index
+// CHECK-DAG: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[T:.*]] = vector.load %[[A0]][%[[C]]] : memref<16xf32>, vector<16xf32>
// CHECK-NEXT: return %[[T]] : vector<16xf32>
func @maskedload1(%base: memref<16xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
%ld = vector.maskedload %base[%c0], %mask, %pass_thru
: memref<16xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
// CHECK-NEXT: return %[[A1]] : vector<16xf32>
func @maskedload2(%base: memref<16xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [0] : vector<16xi1>
%ld = vector.maskedload %base[%c0], %mask, %pass_thru
: memref<16xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-LABEL: func @maskedload3(
// CHECK-SAME: %[[A0:.*]]: memref<?xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
-// CHECK-DAG: %[[C:.*]] = constant 8 : index
+// CHECK-DAG: %[[C:.*]] = arith.constant 8 : index
// CHECK-NEXT: %[[T:.*]] = vector.load %[[A0]][%[[C]]] : memref<?xf32>, vector<16xf32>
// CHECK-NEXT: return %[[T]] : vector<16xf32>
func @maskedload3(%base: memref<?xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c8 = constant 8 : index
+ %c8 = arith.constant 8 : index
%mask = vector.constant_mask [16] : vector<16xi1>
%ld = vector.maskedload %base[%c8], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-LABEL: func @maskedstore1(
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) {
-// CHECK-NEXT: %[[C:.*]] = constant 0 : index
+// CHECK-NEXT: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: vector.store %[[A1]], %[[A0]][%[[C]]] : memref<16xf32>, vector<16xf32>
// CHECK-NEXT: return
func @maskedstore1(%base: memref<16xf32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
vector.maskedstore %base[%c0], %mask, %value : memref<16xf32>, vector<16xi1>, vector<16xf32>
return
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) {
// CHECK-NEXT: return
func @maskedstore2(%base: memref<16xf32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [0] : vector<16xi1>
vector.maskedstore %base[%c0], %mask, %value : memref<16xf32>, vector<16xi1>, vector<16xf32>
return
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xi32>,
// CHECK-SAME: %[[A2:.*]]: vector<16xf32>) -> vector<16xf32> {
-// CHECK-NEXT: %[[C:.*]] = constant 0 : index
+// CHECK-NEXT: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[M:.*]] = vector.constant_mask [16] : vector<16xi1>
// CHECK-NEXT: %[[G:.*]] = vector.gather %[[A0]][%[[C]]] [%[[A1]]], %[[M]], %[[A2]] : memref<16xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-NEXT: return %[[G]] : vector<16xf32>
func @gather1(%base: memref<16xf32>, %indices: vector<16xi32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
%ld = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<16xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-SAME: %[[A2:.*]]: vector<16xf32>) -> vector<16xf32> {
// CHECK-NEXT: return %[[A2]] : vector<16xf32>
func @gather2(%base: memref<16xf32>, %indices: vector<16xi32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [0] : vector<16xi1>
%ld = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<16xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xi32>,
// CHECK-SAME: %[[A2:.*]]: vector<16xf32>) {
-// CHECK-NEXT: %[[C:.*]] = constant 0 : index
+// CHECK-NEXT: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[M:.*]] = vector.constant_mask [16] : vector<16xi1>
// CHECK-NEXT: vector.scatter %[[A0]][%[[C]]] [%[[A1]]], %[[M]], %[[A2]] : memref<16xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-NEXT: return
func @scatter1(%base: memref<16xf32>, %indices: vector<16xi32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
vector.scatter %base[%c0][%indices], %mask, %value
: memref<16xf32>, vector<16xi32>, vector<16xi1>, vector<16xf32>
// CHECK-SAME: %[[A2:.*]]: vector<16xf32>) {
// CHECK-NEXT: return
func @scatter2(%base: memref<16xf32>, %indices: vector<16xi32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = vector.type_cast %base : memref<16xf32> to memref<vector<16xf32>>
%mask = vector.constant_mask [0] : vector<16xi1>
vector.scatter %base[%c0][%indices], %mask, %value
// CHECK-LABEL: func @expand1(
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
-// CHECK-DAG: %[[C:.*]] = constant 0 : index
+// CHECK-DAG: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: %[[T:.*]] = vector.load %[[A0]][%[[C]]] : memref<16xf32>, vector<16xf32>
// CHECK-NEXT: return %[[T]] : vector<16xf32>
func @expand1(%base: memref<16xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
%ld = vector.expandload %base[%c0], %mask, %pass_thru
: memref<16xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) -> vector<16xf32> {
// CHECK-NEXT: return %[[A1]] : vector<16xf32>
func @expand2(%base: memref<16xf32>, %pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [0] : vector<16xi1>
%ld = vector.expandload %base[%c0], %mask, %pass_thru
: memref<16xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
// CHECK-LABEL: func @compress1(
// CHECK-SAME: %[[A0:.*]]: memref<16xf32>,
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) {
-// CHECK-NEXT: %[[C:.*]] = constant 0 : index
+// CHECK-NEXT: %[[C:.*]] = arith.constant 0 : index
// CHECK-NEXT: vector.store %[[A1]], %[[A0]][%[[C]]] : memref<16xf32>, vector<16xf32>
// CHECK-NEXT: return
func @compress1(%base: memref<16xf32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [16] : vector<16xi1>
vector.compressstore %base[%c0], %mask, %value : memref<16xf32>, vector<16xi1>, vector<16xf32>
return
// CHECK-SAME: %[[A1:.*]]: vector<16xf32>) {
// CHECK-NEXT: return
func @compress2(%base: memref<16xf32>, %value: vector<16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%mask = vector.constant_mask [0] : vector<16xi1>
vector.compressstore %base[%c0], %mask, %value : memref<16xf32>, vector<16xi1>, vector<16xf32>
return
}
// CHECK-LABEL: func @vector_multi_reduction
// CHECK-SAME: %[[INPUT:.+]]: vector<2x4xf32>
-// CHECK: %[[RESULT_VEC_0:.+]] = constant dense<{{.*}}> : vector<2xf32>
-// CHECK: %[[C0:.+]] = constant 0 : i32
-// CHECK: %[[C1:.+]] = constant 1 : i32
+// CHECK: %[[RESULT_VEC_0:.+]] = arith.constant dense<{{.*}}> : vector<2xf32>
+// CHECK: %[[C0:.+]] = arith.constant 0 : i32
+// CHECK: %[[C1:.+]] = arith.constant 1 : i32
// CHECK: %[[V0:.+]] = vector.extract %[[INPUT]][0]
// CHECK: %[[RV0:.+]] = vector.reduction "mul", %[[V0]] : vector<4xf32> into f32
// CHECK: %[[RESULT_VEC_1:.+]] = vector.insertelement %[[RV0:.+]], %[[RESULT_VEC_0]][%[[C0]] : i32] : vector<2xf32>
}
// CHECK-LABEL: func @vector_reduction_inner
// CHECK-SAME: %[[INPUT:.+]]: vector<2x3x4x5xi32>
-// CHECK: %[[FLAT_RESULT_VEC_0:.+]] = constant dense<0> : vector<6xi32>
-// CHECK-DAG: %[[C0:.+]] = constant 0 : i32
-// CHECK-DAG: %[[C1:.+]] = constant 1 : i32
-// CHECK-DAG: %[[C2:.+]] = constant 2 : i32
-// CHECK-DAG: %[[C3:.+]] = constant 3 : i32
-// CHECK-DAG: %[[C4:.+]] = constant 4 : i32
-// CHECK-DAG: %[[C5:.+]] = constant 5 : i32
+// CHECK: %[[FLAT_RESULT_VEC_0:.+]] = arith.constant dense<0> : vector<6xi32>
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : i32
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : i32
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : i32
+// CHECK-DAG: %[[C3:.+]] = arith.constant 3 : i32
+// CHECK-DAG: %[[C4:.+]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C5:.+]] = arith.constant 5 : i32
// CHECK: %[[RESHAPED_INPUT:.+]] = vector.shape_cast %[[INPUT]] : vector<2x3x4x5xi32> to vector<6x20xi32>
// CHECK: %[[V0:.+]] = vector.extract %[[RESHAPED_INPUT]][0] : vector<6x20xi32>
// CHECK: %[[V0R:.+]] = vector.reduction "add", %[[V0]] : vector<20xi32> into i32
}
// CHECK-LABEL: func @vector_multi_reduction_ordering
// CHECK-SAME: %[[INPUT:.+]]: vector<3x2x4xf32>
-// CHECK: %[[RESULT_VEC_0:.+]] = constant dense<{{.*}}> : vector<8xf32>
-// CHECK: %[[C0:.+]] = constant 0 : i32
-// CHECK: %[[C1:.+]] = constant 1 : i32
-// CHECK: %[[C2:.+]] = constant 2 : i32
-// CHECK: %[[C3:.+]] = constant 3 : i32
-// CHECK: %[[C4:.+]] = constant 4 : i32
-// CHECK: %[[C5:.+]] = constant 5 : i32
-// CHECK: %[[C6:.+]] = constant 6 : i32
-// CHECK: %[[C7:.+]] = constant 7 : i32
+// CHECK: %[[RESULT_VEC_0:.+]] = arith.constant dense<{{.*}}> : vector<8xf32>
+// CHECK: %[[C0:.+]] = arith.constant 0 : i32
+// CHECK: %[[C1:.+]] = arith.constant 1 : i32
+// CHECK: %[[C2:.+]] = arith.constant 2 : i32
+// CHECK: %[[C3:.+]] = arith.constant 3 : i32
+// CHECK: %[[C4:.+]] = arith.constant 4 : i32
+// CHECK: %[[C5:.+]] = arith.constant 5 : i32
+// CHECK: %[[C6:.+]] = arith.constant 6 : i32
+// CHECK: %[[C7:.+]] = arith.constant 7 : i32
// CHECK: %[[TRANSPOSED_INPUT:.+]] = vector.transpose %[[INPUT]], [1, 2, 0] : vector<3x2x4xf32> to vector<2x4x3xf32>
// CHECK: %[[V0:.+]] = vector.extract %[[TRANSPOSED_INPUT]][0, 0]
// CHECK: %[[RV0:.+]] = vector.reduction "mul", %[[V0]] : vector<3xf32> into f32
// CHECK: %[[TRANSPOSED:.+]] = vector.transpose %[[INPUT]], [1, 0] : vector<2x4xf32> to vector<4x2xf32>
// CHECK: %[[V0:.+]] = vector.extract %[[TRANSPOSED]][0] : vector<4x2xf32>
// CHECK: %[[V1:.+]] = vector.extract %[[TRANSPOSED]][1] : vector<4x2xf32>
-// CHECK: %[[RV01:.+]] = mulf %[[V1]], %[[V0]] : vector<2xf32>
+// CHECK: %[[RV01:.+]] = arith.mulf %[[V1]], %[[V0]] : vector<2xf32>
// CHECK: %[[V2:.+]] = vector.extract %[[TRANSPOSED]][2] : vector<4x2xf32>
-// CHECK: %[[RV012:.+]] = mulf %[[V2]], %[[RV01]] : vector<2xf32>
+// CHECK: %[[RV012:.+]] = arith.mulf %[[V2]], %[[RV01]] : vector<2xf32>
// CHECK: %[[V3:.+]] = vector.extract %[[TRANSPOSED]][3] : vector<4x2xf32>
-// CHECK: %[[RESULT_VEC:.+]] = mulf %[[V3]], %[[RV012]] : vector<2xf32>
+// CHECK: %[[RESULT_VEC:.+]] = arith.mulf %[[V3]], %[[RV012]] : vector<2xf32>
// CHECK: return %[[RESULT_VEC]] : vector<2xf32>
func @vector_multi_reduction_min(%arg0: vector<2x4xf32>) -> vector<2xf32> {
// CHECK: %[[TRANSPOSED:.+]] = vector.transpose %[[INPUT]], [1, 0] : vector<2x4xi32> to vector<4x2xi32>
// CHECK: %[[V0:.+]] = vector.extract %[[TRANSPOSED]][0] : vector<4x2xi32>
// CHECK: %[[V1:.+]] = vector.extract %[[TRANSPOSED]][1] : vector<4x2xi32>
-// CHECK: %[[RV01:.+]] = and %[[V1]], %[[V0]] : vector<2xi32>
+// CHECK: %[[RV01:.+]] = arith.andi %[[V1]], %[[V0]] : vector<2xi32>
// CHECK: %[[V2:.+]] = vector.extract %[[TRANSPOSED]][2] : vector<4x2xi32>
-// CHECK: %[[RV012:.+]] = and %[[V2]], %[[RV01]] : vector<2xi32>
+// CHECK: %[[RV012:.+]] = arith.andi %[[V2]], %[[RV01]] : vector<2xi32>
// CHECK: %[[V3:.+]] = vector.extract %[[TRANSPOSED]][3] : vector<4x2xi32>
-// CHECK: %[[RESULT_VEC:.+]] = and %[[V3]], %[[RV012]] : vector<2xi32>
+// CHECK: %[[RESULT_VEC:.+]] = arith.andi %[[V3]], %[[RV012]] : vector<2xi32>
// CHECK: return %[[RESULT_VEC]] : vector<2xi32>
func @vector_multi_reduction_or(%arg0: vector<2x4xi32>) -> vector<2xi32> {
// CHECK: %[[TRANSPOSED:.+]] = vector.transpose %[[INPUT]], [1, 0] : vector<2x4xi32> to vector<4x2xi32>
// CHECK: %[[V0:.+]] = vector.extract %[[TRANSPOSED]][0] : vector<4x2xi32>
// CHECK: %[[V1:.+]] = vector.extract %[[TRANSPOSED]][1] : vector<4x2xi32>
-// CHECK: %[[RV01:.+]] = or %[[V1]], %[[V0]] : vector<2xi32>
+// CHECK: %[[RV01:.+]] = arith.ori %[[V1]], %[[V0]] : vector<2xi32>
// CHECK: %[[V2:.+]] = vector.extract %[[TRANSPOSED]][2] : vector<4x2xi32>
-// CHECK: %[[RV012:.+]] = or %[[V2]], %[[RV01]] : vector<2xi32>
+// CHECK: %[[RV012:.+]] = arith.ori %[[V2]], %[[RV01]] : vector<2xi32>
// CHECK: %[[V3:.+]] = vector.extract %[[TRANSPOSED]][3] : vector<4x2xi32>
-// CHECK: %[[RESULT_VEC:.+]] = or %[[V3]], %[[RV012]] : vector<2xi32>
+// CHECK: %[[RESULT_VEC:.+]] = arith.ori %[[V3]], %[[RV012]] : vector<2xi32>
// CHECK: return %[[RESULT_VEC]] : vector<2xi32>
func @vector_multi_reduction_xor(%arg0: vector<2x4xi32>) -> vector<2xi32> {
// CHECK: %[[TRANSPOSED:.+]] = vector.transpose %[[INPUT]], [1, 0] : vector<2x4xi32> to vector<4x2xi32>
// CHECK: %[[V0:.+]] = vector.extract %[[TRANSPOSED]][0] : vector<4x2xi32>
// CHECK: %[[V1:.+]] = vector.extract %[[TRANSPOSED]][1] : vector<4x2xi32>
-// CHECK: %[[RV01:.+]] = xor %[[V1]], %[[V0]] : vector<2xi32>
+// CHECK: %[[RV01:.+]] = arith.xori %[[V1]], %[[V0]] : vector<2xi32>
// CHECK: %[[V2:.+]] = vector.extract %[[TRANSPOSED]][2] : vector<4x2xi32>
-// CHECK: %[[RV012:.+]] = xor %[[V2]], %[[RV01]] : vector<2xi32>
+// CHECK: %[[RV012:.+]] = arith.xori %[[V2]], %[[RV01]] : vector<2xi32>
// CHECK: %[[V3:.+]] = vector.extract %[[TRANSPOSED]][3] : vector<4x2xi32>
-// CHECK: %[[RESULT_VEC:.+]] = xor %[[V3]], %[[RV012]] : vector<2xi32>
+// CHECK: %[[RESULT_VEC:.+]] = arith.xori %[[V3]], %[[RV012]] : vector<2xi32>
// CHECK: return %[[RESULT_VEC]] : vector<2xi32>
// CHECK: %[[RESHAPED:.+]] = vector.shape_cast %[[TRANSPOSED]] : vector<4x5x2x3xi32> to vector<20x6xi32>
// CHECK: %[[V0:.+]] = vector.extract %[[RESHAPED]][0] : vector<20x6xi32>
// CHECK: %[[V1:.+]] = vector.extract %[[RESHAPED]][1] : vector<20x6xi32>
-// CHECK: %[[R0:.+]] = addi %[[V1]], %[[V0]] : vector<6xi32>
+// CHECK: %[[R0:.+]] = arith.addi %[[V1]], %[[V0]] : vector<6xi32>
// CHECK: %[[V2:.+]] = vector.extract %[[RESHAPED]][2] : vector<20x6xi32>
-// CHECK: %[[R1:.+]] = addi %[[V2]], %[[R0]] : vector<6xi32>
+// CHECK: %[[R1:.+]] = arith.addi %[[V2]], %[[R0]] : vector<6xi32>
// CHECK: %[[V3:.+]] = vector.extract %[[RESHAPED]][3] : vector<20x6xi32>
-// CHECK: %[[R2:.+]] = addi %[[V3]], %[[R1]] : vector<6xi32>
+// CHECK: %[[R2:.+]] = arith.addi %[[V3]], %[[R1]] : vector<6xi32>
// CHECK: %[[V4:.+]] = vector.extract %[[RESHAPED]][4] : vector<20x6xi32>
-// CHECK: %[[R3:.+]] = addi %[[V4]], %[[R2]] : vector<6xi32>
+// CHECK: %[[R3:.+]] = arith.addi %[[V4]], %[[R2]] : vector<6xi32>
// CHECK: %[[V5:.+]] = vector.extract %[[RESHAPED]][5] : vector<20x6xi32>
-// CHECK: %[[R4:.+]] = addi %[[V5]], %[[R3]] : vector<6xi32>
+// CHECK: %[[R4:.+]] = arith.addi %[[V5]], %[[R3]] : vector<6xi32>
// CHECK: %[[V6:.+]] = vector.extract %[[RESHAPED]][6] : vector<20x6xi32>
-// CHECK: %[[R5:.+]] = addi %[[V6]], %[[R4]] : vector<6xi32>
+// CHECK: %[[R5:.+]] = arith.addi %[[V6]], %[[R4]] : vector<6xi32>
// CHECK: %[[V7:.+]] = vector.extract %[[RESHAPED]][7] : vector<20x6xi32>
-// CHECK: %[[R6:.+]] = addi %[[V7]], %[[R5]] : vector<6xi32>
+// CHECK: %[[R6:.+]] = arith.addi %[[V7]], %[[R5]] : vector<6xi32>
// CHECK: %[[V8:.+]] = vector.extract %[[RESHAPED]][8] : vector<20x6xi32>
-// CHECK: %[[R7:.+]] = addi %[[V8]], %[[R6]] : vector<6xi32>
+// CHECK: %[[R7:.+]] = arith.addi %[[V8]], %[[R6]] : vector<6xi32>
// CHECK: %[[V9:.+]] = vector.extract %[[RESHAPED]][9] : vector<20x6xi32>
-// CHECK: %[[R8:.+]] = addi %[[V9]], %[[R7]] : vector<6xi32>
+// CHECK: %[[R8:.+]] = arith.addi %[[V9]], %[[R7]] : vector<6xi32>
// CHECK: %[[V10:.+]] = vector.extract %[[RESHAPED]][10] : vector<20x6xi32>
-// CHECK: %[[R9:.+]] = addi %[[V10]], %[[R8]] : vector<6xi32>
+// CHECK: %[[R9:.+]] = arith.addi %[[V10]], %[[R8]] : vector<6xi32>
// CHECK: %[[V11:.+]] = vector.extract %[[RESHAPED]][11] : vector<20x6xi32>
-// CHECK: %[[R10:.+]] = addi %[[V11]], %[[R9]] : vector<6xi32>
+// CHECK: %[[R10:.+]] = arith.addi %[[V11]], %[[R9]] : vector<6xi32>
// CHECK: %[[V12:.+]] = vector.extract %[[RESHAPED]][12] : vector<20x6xi32>
-// CHECK: %[[R11:.+]] = addi %[[V12]], %[[R10]] : vector<6xi32>
+// CHECK: %[[R11:.+]] = arith.addi %[[V12]], %[[R10]] : vector<6xi32>
// CHECK: %[[V13:.+]] = vector.extract %[[RESHAPED]][13] : vector<20x6xi32>
-// CHECK: %[[R12:.+]] = addi %[[V13]], %[[R11]] : vector<6xi32>
+// CHECK: %[[R12:.+]] = arith.addi %[[V13]], %[[R11]] : vector<6xi32>
// CHECK: %[[V14:.+]] = vector.extract %[[RESHAPED]][14] : vector<20x6xi32>
-// CHECK: %[[R13:.+]] = addi %[[V14]], %[[R12]] : vector<6xi32>
+// CHECK: %[[R13:.+]] = arith.addi %[[V14]], %[[R12]] : vector<6xi32>
// CHECK: %[[V15:.+]] = vector.extract %[[RESHAPED]][15] : vector<20x6xi32>
-// CHECK: %[[R14:.+]] = addi %[[V15]], %[[R13]] : vector<6xi32>
+// CHECK: %[[R14:.+]] = arith.addi %[[V15]], %[[R13]] : vector<6xi32>
// CHECK: %[[V16:.+]] = vector.extract %[[RESHAPED]][16] : vector<20x6xi32>
-// CHECK: %[[R15:.+]] = addi %[[V16]], %[[R14]] : vector<6xi32>
+// CHECK: %[[R15:.+]] = arith.addi %[[V16]], %[[R14]] : vector<6xi32>
// CHECK: %[[V17:.+]] = vector.extract %[[RESHAPED]][17] : vector<20x6xi32>
-// CHECK: %[[R16:.+]] = addi %[[V17]], %[[R15]] : vector<6xi32>
+// CHECK: %[[R16:.+]] = arith.addi %[[V17]], %[[R15]] : vector<6xi32>
// CHECK: %[[V18:.+]] = vector.extract %[[RESHAPED]][18] : vector<20x6xi32>
-// CHECK: %[[R17:.+]] = addi %[[V18]], %[[R16]] : vector<6xi32>
+// CHECK: %[[R17:.+]] = arith.addi %[[V18]], %[[R16]] : vector<6xi32>
// CHECK: %[[V19:.+]] = vector.extract %[[RESHAPED]][19] : vector<20x6xi32>
-// CHECK: %[[R18:.+]] = addi %[[V19]], %[[R17]] : vector<6xi32>
+// CHECK: %[[R18:.+]] = arith.addi %[[V19]], %[[R17]] : vector<6xi32>
// CHECK: %[[RESULT_VEC:.+]] = vector.shape_cast %[[R18]] : vector<6xi32> to vector<2x3xi32>
// CHECK: return %[[RESULT_VEC]] : vector<2x3xi32>
// LINALG-SAME: %[[i:[a-zA-Z0-9]*]]: index
// LINALG-SAME: %[[j:[a-zA-Z0-9]*]]: index
func @split_vector_transfer_read_2d(%A: memref<?x8xf32>, %i: index, %j: index) -> vector<4x8xf32> {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
- // CHECK-DAG: %[[c8:.*]] = constant 8 : index
- // CHECK-DAG: %[[c0:.*]] = constant 0 : index
+ // CHECK-DAG: %[[c8:.*]] = arith.constant 8 : index
+ // CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
// alloca for boundary full tile
// CHECK: %[[alloc:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// %i + 4 <= dim(%A, 0)
// CHECK: %[[idx0:.*]] = affine.apply #[[$map_p4]]()[%[[i]]]
// CHECK: %[[d0:.*]] = memref.dim %[[A]], %[[c0]] : memref<?x8xf32>
- // CHECK: %[[cmp0:.*]] = cmpi sle, %[[idx0]], %[[d0]] : index
+ // CHECK: %[[cmp0:.*]] = arith.cmpi sle, %[[idx0]], %[[d0]] : index
// %j + 8 <= dim(%A, 1)
// CHECK: %[[idx1:.*]] = affine.apply #[[$map_p8]]()[%[[j]]]
- // CHECK: %[[cmp1:.*]] = cmpi sle, %[[idx1]], %[[c8]] : index
+ // CHECK: %[[cmp1:.*]] = arith.cmpi sle, %[[idx1]], %[[c8]] : index
// are both conds true
- // CHECK: %[[cond:.*]] = and %[[cmp0]], %[[cmp1]] : i1
+ // CHECK: %[[cond:.*]] = arith.andi %[[cmp0]], %[[cmp1]] : i1
// CHECK: %[[ifres:.*]]:3 = scf.if %[[cond]] -> (memref<?x8xf32>, index, index) {
// inBounds, just yield %A
// CHECK: scf.yield %[[A]], %[[i]], %[[j]] : memref<?x8xf32>, index, index
// CHECK: %[[res:.*]] = vector.transfer_read %[[ifres]]#0[%[[ifres]]#1, %[[ifres]]#2], %cst
// CHECK_SAME: {in_bounds = [true, true]} : memref<?x8xf32>, vector<4x8xf32>
- // LINALG-DAG: %[[c0:.*]] = constant 0 : index
- // LINALG-DAG: %[[c4:.*]] = constant 4 : index
- // LINALG-DAG: %[[c8:.*]] = constant 8 : index
+ // LINALG-DAG: %[[c0:.*]] = arith.constant 0 : index
+ // LINALG-DAG: %[[c4:.*]] = arith.constant 4 : index
+ // LINALG-DAG: %[[c8:.*]] = arith.constant 8 : index
// alloca for boundary full tile
// LINALG: %[[alloc:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// %i + 4 <= dim(%A, 0)
// LINALG: %[[idx0:.*]] = affine.apply #[[$map_p4]]()[%[[i]]]
// LINALG: %[[d0:.*]] = memref.dim %[[A]], %[[c0]] : memref<?x8xf32>
- // LINALG: %[[cmp0:.*]] = cmpi sle, %[[idx0]], %[[d0]] : index
+ // LINALG: %[[cmp0:.*]] = arith.cmpi sle, %[[idx0]], %[[d0]] : index
// %j + 8 <= dim(%A, 1)
// LINALG: %[[idx1:.*]] = affine.apply #[[$map_p8]]()[%[[j]]]
- // LINALG: %[[cmp1:.*]] = cmpi sle, %[[idx1]], %[[c8]] : index
+ // LINALG: %[[cmp1:.*]] = arith.cmpi sle, %[[idx1]], %[[c8]] : index
// are both conds true
- // LINALG: %[[cond:.*]] = and %[[cmp0]], %[[cmp1]] : i1
+ // LINALG: %[[cond:.*]] = arith.andi %[[cmp0]], %[[cmp1]] : i1
// LINALG: %[[ifres:.*]]:3 = scf.if %[[cond]] -> (memref<?x8xf32>, index, index) {
// inBounds, just yield %A
// LINALG: scf.yield %[[A]], %[[i]], %[[j]] : memref<?x8xf32>, index, index
func @split_vector_transfer_read_strided_2d(
%A: memref<7x8xf32, offset:?, strides:[?, 1]>,
%i: index, %j: index) -> vector<4x8xf32> {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
- // CHECK-DAG: %[[c7:.*]] = constant 7 : index
- // CHECK-DAG: %[[c8:.*]] = constant 8 : index
- // CHECK-DAG: %[[c0:.*]] = constant 0 : index
+ // CHECK-DAG: %[[c7:.*]] = arith.constant 7 : index
+ // CHECK-DAG: %[[c8:.*]] = arith.constant 8 : index
+ // CHECK-DAG: %[[c0:.*]] = arith.constant 0 : index
// alloca for boundary full tile
// CHECK: %[[alloc:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// %i + 4 <= dim(%A, 0)
// CHECK: %[[idx0:.*]] = affine.apply #[[$map_p4]]()[%[[i]]]
- // CHECK: %[[cmp0:.*]] = cmpi sle, %[[idx0]], %[[c7]] : index
+ // CHECK: %[[cmp0:.*]] = arith.cmpi sle, %[[idx0]], %[[c7]] : index
// %j + 8 <= dim(%A, 1)
// CHECK: %[[idx1:.*]] = affine.apply #[[$map_p8]]()[%[[j]]]
- // CHECK: %[[cmp1:.*]] = cmpi sle, %[[idx1]], %[[c8]] : index
+ // CHECK: %[[cmp1:.*]] = arith.cmpi sle, %[[idx1]], %[[c8]] : index
// are both conds true
- // CHECK: %[[cond:.*]] = and %[[cmp0]], %[[cmp1]] : i1
+ // CHECK: %[[cond:.*]] = arith.andi %[[cmp0]], %[[cmp1]] : i1
// CHECK: %[[ifres:.*]]:3 = scf.if %[[cond]] -> (memref<?x8xf32, #[[$map_2d_stride_1]]>, index, index) {
// inBounds but not cast-compatible: yield a memref_casted form of %A
// CHECK: %[[casted:.*]] = memref.cast %arg0 :
// CHECK: %[[res:.*]] = vector.transfer_read {{.*}} {in_bounds = [true, true]} :
// CHECK-SAME: memref<?x8xf32, #[[$map_2d_stride_1]]>, vector<4x8xf32>
- // LINALG-DAG: %[[c0:.*]] = constant 0 : index
- // LINALG-DAG: %[[c4:.*]] = constant 4 : index
- // LINALG-DAG: %[[c7:.*]] = constant 7 : index
- // LINALG-DAG: %[[c8:.*]] = constant 8 : index
+ // LINALG-DAG: %[[c0:.*]] = arith.constant 0 : index
+ // LINALG-DAG: %[[c4:.*]] = arith.constant 4 : index
+ // LINALG-DAG: %[[c7:.*]] = arith.constant 7 : index
+ // LINALG-DAG: %[[c8:.*]] = arith.constant 8 : index
// alloca for boundary full tile
// LINALG: %[[alloc:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// %i + 4 <= dim(%A, 0)
// LINALG: %[[idx0:.*]] = affine.apply #[[$map_p4]]()[%[[i]]]
- // LINALG: %[[cmp0:.*]] = cmpi sle, %[[idx0]], %[[c7]] : index
+ // LINALG: %[[cmp0:.*]] = arith.cmpi sle, %[[idx0]], %[[c7]] : index
// %j + 8 <= dim(%A, 1)
// LINALG: %[[idx1:.*]] = affine.apply #[[$map_p8]]()[%[[j]]]
- // LINALG: %[[cmp1:.*]] = cmpi sle, %[[idx1]], %[[c8]] : index
+ // LINALG: %[[cmp1:.*]] = arith.cmpi sle, %[[idx1]], %[[c8]] : index
// are both conds true
- // LINALG: %[[cond:.*]] = and %[[cmp0]], %[[cmp1]] : i1
+ // LINALG: %[[cond:.*]] = arith.andi %[[cmp0]], %[[cmp1]] : i1
// LINALG: %[[ifres:.*]]:3 = scf.if %[[cond]] -> (memref<?x8xf32, #[[$map_2d_stride_1]]>, index, index) {
// inBounds but not cast-compatible: yield a memref_casted form of %A
// LINALG: %[[casted:.*]] = memref.cast %arg0 :
// CHECK-SAME: %[[DEST:.*]]: memref<?x8xf32>,
// CHECK-SAME: %[[I:.*]]: index,
// CHECK-SAME: %[[J:.*]]: index) {
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[CT:.*]] = constant true
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[CT:.*]] = arith.constant true
// CHECK: %[[TEMP:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// CHECK: %[[VAL_8:.*]] = affine.apply #[[MAP0]]()[%[[I]]]
// CHECK: %[[DIM0:.*]] = memref.dim %[[DEST]], %[[C0]] : memref<?x8xf32>
-// CHECK: %[[DIM0_IN:.*]] = cmpi sle, %[[VAL_8]], %[[DIM0]] : index
+// CHECK: %[[DIM0_IN:.*]] = arith.cmpi sle, %[[VAL_8]], %[[DIM0]] : index
// CHECK: %[[DIM1:.*]] = affine.apply #[[MAP1]]()[%[[J]]]
-// CHECK: %[[DIM1_IN:.*]] = cmpi sle, %[[DIM1]], %[[C8]] : index
-// CHECK: %[[IN_BOUNDS:.*]] = and %[[DIM0_IN]], %[[DIM1_IN]] : i1
+// CHECK: %[[DIM1_IN:.*]] = arith.cmpi sle, %[[DIM1]], %[[C8]] : index
+// CHECK: %[[IN_BOUNDS:.*]] = arith.andi %[[DIM0_IN]], %[[DIM1_IN]] : i1
// CHECK: %[[IN_BOUND_DEST:.*]]:3 = scf.if %[[IN_BOUNDS]] ->
// CHECK-SAME: (memref<?x8xf32>, index, index) {
// CHECK: scf.yield %[[DEST]], %[[I]], %[[J]] : memref<?x8xf32>, index, index
// CHECK: vector.transfer_write %[[VEC]],
// CHECK-SAME: %[[IN_BOUND_DEST:.*]]#0[%[[IN_BOUND_DEST]]#1, %[[IN_BOUND_DEST]]#2]
// CHECK-SAME: {in_bounds = [true, true]} : vector<4x8xf32>, memref<?x8xf32>
-// CHECK: %[[OUT_BOUNDS:.*]] = xor %[[IN_BOUNDS]], %[[CT]] : i1
+// CHECK: %[[OUT_BOUNDS:.*]] = arith.xori %[[IN_BOUNDS]], %[[CT]] : i1
// CHECK: scf.if %[[OUT_BOUNDS]] {
// CHECK: %[[CASTED:.*]] = vector.type_cast %[[TEMP]]
// CHECK-SAME: : memref<4x8xf32> to memref<vector<4x8xf32>>
// LINALG-SAME: %[[DEST:.*]]: memref<?x8xf32>,
// LINALG-SAME: %[[I:.*]]: index,
// LINALG-SAME: %[[J:.*]]: index) {
-// LINALG-DAG: %[[CT:.*]] = constant true
-// LINALG-DAG: %[[C0:.*]] = constant 0 : index
-// LINALG-DAG: %[[C4:.*]] = constant 4 : index
-// LINALG-DAG: %[[C8:.*]] = constant 8 : index
+// LINALG-DAG: %[[CT:.*]] = arith.constant true
+// LINALG-DAG: %[[C0:.*]] = arith.constant 0 : index
+// LINALG-DAG: %[[C4:.*]] = arith.constant 4 : index
+// LINALG-DAG: %[[C8:.*]] = arith.constant 8 : index
// LINALG: %[[TEMP:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// LINALG: %[[IDX0:.*]] = affine.apply #[[MAP0]]()[%[[I]]]
// LINALG: %[[DIM0:.*]] = memref.dim %[[DEST]], %[[C0]] : memref<?x8xf32>
-// LINALG: %[[DIM0_IN:.*]] = cmpi sle, %[[IDX0]], %[[DIM0]] : index
+// LINALG: %[[DIM0_IN:.*]] = arith.cmpi sle, %[[IDX0]], %[[DIM0]] : index
// LINALG: %[[DIM1:.*]] = affine.apply #[[MAP1]]()[%[[J]]]
-// LINALG: %[[DIM1_IN:.*]] = cmpi sle, %[[DIM1]], %[[C8]] : index
-// LINALG: %[[IN_BOUNDS:.*]] = and %[[DIM0_IN]], %[[DIM1_IN]] : i1
+// LINALG: %[[DIM1_IN:.*]] = arith.cmpi sle, %[[DIM1]], %[[C8]] : index
+// LINALG: %[[IN_BOUNDS:.*]] = arith.andi %[[DIM0_IN]], %[[DIM1_IN]] : i1
// LINALG: %[[IN_BOUND_DEST:.*]]:3 = scf.if %[[IN_BOUNDS]]
// LINALG-SAME: -> (memref<?x8xf32>, index, index) {
// LINALG: scf.yield %[[DEST]], %[[I]], %[[J]] : memref<?x8xf32>, index, index
// LINALG: vector.transfer_write %[[VEC]],
// LINALG-SAME: %[[IN_BOUND_DEST:.*]]#0[%[[IN_BOUND_DEST]]#1, %[[IN_BOUND_DEST]]#2]
// LINALG-SAME: {in_bounds = [true, true]} : vector<4x8xf32>, memref<?x8xf32>
-// LINALG: %[[OUT_BOUNDS:.*]] = xor %[[IN_BOUNDS]], %[[CT]] : i1
+// LINALG: %[[OUT_BOUNDS:.*]] = arith.xori %[[IN_BOUNDS]], %[[CT]] : i1
// LINALG: scf.if %[[OUT_BOUNDS]] {
// LINALG: %[[VAL_19:.*]] = memref.dim %[[DEST]], %[[C0]] : memref<?x8xf32>
// LINALG-DAG: %[[VAL_20:.*]] = affine.min #[[MAP2]](%[[VAL_19]], %[[I]], %[[C4]])
// CHECK-SAME: %[[DEST:.*]]: memref<7x8xf32, #[[MAP0]]>,
// CHECK-SAME: %[[I:.*]]: index,
// CHECK-SAME: %[[J:.*]]: index) {
-// CHECK-DAG: %[[C7:.*]] = constant 7 : index
-// CHECK-DAG: %[[C8:.*]] = constant 8 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
-// CHECK-DAG: %[[CT:.*]] = constant true
+// CHECK-DAG: %[[C7:.*]] = arith.constant 7 : index
+// CHECK-DAG: %[[C8:.*]] = arith.constant 8 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[CT:.*]] = arith.constant true
// CHECK: %[[TEMP:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// CHECK: %[[DIM0:.*]] = affine.apply #[[MAP1]]()[%[[I]]]
-// CHECK: %[[DIM0_IN:.*]] = cmpi sle, %[[DIM0]], %[[C7]] : index
+// CHECK: %[[DIM0_IN:.*]] = arith.cmpi sle, %[[DIM0]], %[[C7]] : index
// CHECK: %[[DIM1:.*]] = affine.apply #[[MAP2]]()[%[[J]]]
-// CHECK: %[[DIM1_IN:.*]] = cmpi sle, %[[DIM1]], %[[C8]] : index
-// CHECK: %[[IN_BOUNDS:.*]] = and %[[DIM0_IN]], %[[DIM1_IN]] : i1
+// CHECK: %[[DIM1_IN:.*]] = arith.cmpi sle, %[[DIM1]], %[[C8]] : index
+// CHECK: %[[IN_BOUNDS:.*]] = arith.andi %[[DIM0_IN]], %[[DIM1_IN]] : i1
// CHECK: %[[IN_BOUND_DEST:.*]]:3 = scf.if %[[IN_BOUNDS]]
// CHECK-SAME: -> (memref<?x8xf32, #[[MAP0]]>, index, index) {
// CHECK: %[[VAL_15:.*]] = memref.cast %[[DEST]]
// CHECK-SAME: %[[IN_BOUND_DEST:.*]]#0
// CHECK-SAME: [%[[IN_BOUND_DEST]]#1, %[[IN_BOUND_DEST]]#2]
// CHECK-SAME: {in_bounds = [true, true]} : vector<4x8xf32>, memref<?x8xf32, #[[MAP0]]>
-// CHECK: %[[OUT_BOUNDS:.*]] = xor %[[IN_BOUNDS]], %[[CT]] : i1
+// CHECK: %[[OUT_BOUNDS:.*]] = arith.xori %[[IN_BOUNDS]], %[[CT]] : i1
// CHECK: scf.if %[[OUT_BOUNDS]] {
// CHECK: %[[VAL_19:.*]] = vector.type_cast %[[TEMP]]
// CHECK-SAME: : memref<4x8xf32> to memref<vector<4x8xf32>>
// LINALG-SAME: %[[DEST:.*]]: memref<7x8xf32, #[[MAP0]]>,
// LINALG-SAME: %[[I:.*]]: index,
// LINALG-SAME: %[[J:.*]]: index) {
-// LINALG-DAG: %[[C0:.*]] = constant 0 : index
-// LINALG-DAG: %[[CT:.*]] = constant true
-// LINALG-DAG: %[[C7:.*]] = constant 7 : index
-// LINALG-DAG: %[[C4:.*]] = constant 4 : index
-// LINALG-DAG: %[[C8:.*]] = constant 8 : index
+// LINALG-DAG: %[[C0:.*]] = arith.constant 0 : index
+// LINALG-DAG: %[[CT:.*]] = arith.constant true
+// LINALG-DAG: %[[C7:.*]] = arith.constant 7 : index
+// LINALG-DAG: %[[C4:.*]] = arith.constant 4 : index
+// LINALG-DAG: %[[C8:.*]] = arith.constant 8 : index
// LINALG: %[[TEMP:.*]] = memref.alloca() {alignment = 32 : i64} : memref<4x8xf32>
// LINALG: %[[DIM0:.*]] = affine.apply #[[MAP1]]()[%[[I]]]
-// LINALG: %[[DIM0_IN:.*]] = cmpi sle, %[[DIM0]], %[[C7]] : index
+// LINALG: %[[DIM0_IN:.*]] = arith.cmpi sle, %[[DIM0]], %[[C7]] : index
// LINALG: %[[DIM1:.*]] = affine.apply #[[MAP2]]()[%[[J]]]
-// LINALG: %[[DIM1_IN:.*]] = cmpi sle, %[[DIM1]], %[[C8]] : index
-// LINALG: %[[IN_BOUNDS:.*]] = and %[[DIM0_IN]], %[[DIM1_IN]] : i1
+// LINALG: %[[DIM1_IN:.*]] = arith.cmpi sle, %[[DIM1]], %[[C8]] : index
+// LINALG: %[[IN_BOUNDS:.*]] = arith.andi %[[DIM0_IN]], %[[DIM1_IN]] : i1
// LINALG: %[[IN_BOUND_DEST:.*]]:3 = scf.if %[[IN_BOUNDS]]
// LINALG-SAME: -> (memref<?x8xf32, #[[MAP0]]>, index, index) {
// LINALG: %[[VAL_16:.*]] = memref.cast %[[DEST]]
// LINALG-SAME: [%[[IN_BOUND_DEST]]#1, %[[IN_BOUND_DEST]]#2]
// LINALG-SAME: {in_bounds = [true, true]}
// LINALG-SAME: : vector<4x8xf32>, memref<?x8xf32, #[[MAP0]]>
-// LINALG: %[[OUT_BOUNDS:.*]] = xor %[[IN_BOUNDS]], %[[CT]] : i1
+// LINALG: %[[OUT_BOUNDS:.*]] = arith.xori %[[IN_BOUNDS]], %[[CT]] : i1
// LINALG: scf.if %[[OUT_BOUNDS]] {
// LINALG-DAG: %[[VAL_20:.*]] = affine.min #[[MAP3]](%[[C7]], %[[I]], %[[C4]])
// LINALG-DAG: %[[VAL_21:.*]] = affine.min #[[MAP4]](%[[C8]], %[[J]], %[[C8]])
// CHECK-SAME: %[[MEM:.*]]: memref<f32>
// CHECK-SAME: %[[VV:.*]]: vector<1x1x1xf32>
func @vector_transfer_ops_0d(%M: memref<f32>, %v: vector<1x1x1xf32>) {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
// CHECK-NEXT: %[[V:.*]] = memref.load %[[MEM]][] : memref<f32>
%0 = vector.transfer_read %M[], %f0 {permutation_map = affine_map<()->(0)>} :
// CHECK-NEXT: }
func @transfer_to_load(%mem : memref<8x8xf32>, %i : index) -> vector<4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true]} : memref<8x8xf32>, vector<4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [true]} : vector<4xf32>, memref<8x8xf32>
return %res : vector<4xf32>
// CHECK-NEXT: }
func @transfer_2D(%mem : memref<8x8xf32>, %i : index) -> vector<2x4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true, true]} : memref<8x8xf32>, vector<2x4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [true, true]} : vector<2x4xf32>, memref<8x8xf32>
return %res : vector<2x4xf32>
// CHECK-NEXT: }
func @transfer_vector_element(%mem : memref<8x8xvector<2x4xf32>>, %i : index) -> vector<2x4xf32> {
- %cf0 = constant dense<0.0> : vector<2x4xf32>
+ %cf0 = arith.constant dense<0.0> : vector<2x4xf32>
%res = vector.transfer_read %mem[%i, %i], %cf0 : memref<8x8xvector<2x4xf32>>, vector<2x4xf32>
vector.transfer_write %res, %mem[%i, %i] : vector<2x4xf32>, memref<8x8xvector<2x4xf32>>
return %res : vector<2x4xf32>
// CHECK-LABEL: func @transfer_vector_element_different_types(
// CHECK-SAME: %[[MEM:.*]]: memref<8x8xvector<2x4xf32>>,
// CHECK-SAME: %[[IDX:.*]]: index) -> vector<1x2x4xf32> {
-// CHECK-NEXT: %[[CF0:.*]] = constant dense<0.000000e+00> : vector<2x4xf32>
+// CHECK-NEXT: %[[CF0:.*]] = arith.constant dense<0.000000e+00> : vector<2x4xf32>
// CHECK-NEXT: %[[RES:.*]] = vector.transfer_read %[[MEM]][%[[IDX]], %[[IDX]]], %[[CF0]] {in_bounds = [true]} : memref<8x8xvector<2x4xf32>>, vector<1x2x4xf32>
// CHECK-NEXT: vector.transfer_write %[[RES:.*]], %[[MEM]][%[[IDX]], %[[IDX]]] {in_bounds = [true]} : vector<1x2x4xf32>, memref<8x8xvector<2x4xf32>>
// CHECK-NEXT: return %[[RES]] : vector<1x2x4xf32>
// CHECK-NEXT: }
func @transfer_vector_element_different_types(%mem : memref<8x8xvector<2x4xf32>>, %i : index) -> vector<1x2x4xf32> {
- %cf0 = constant dense<0.0> : vector<2x4xf32>
+ %cf0 = arith.constant dense<0.0> : vector<2x4xf32>
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true]} : memref<8x8xvector<2x4xf32>>, vector<1x2x4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [true]} : vector<1x2x4xf32>, memref<8x8xvector<2x4xf32>>
return %res : vector<1x2x4xf32>
// CHECK-LABEL: func @transfer_2D_not_inbounds(
// CHECK-SAME: %[[MEM:.*]]: memref<8x8xf32>,
// CHECK-SAME: %[[IDX:.*]]: index) -> vector<2x4xf32> {
-// CHECK-NEXT: %[[CF0:.*]] = constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[CF0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: %[[RES:.*]] = vector.transfer_read %[[MEM]][%[[IDX]], %[[IDX]]], %[[CF0]] {in_bounds = [true, false]} : memref<8x8xf32>, vector<2x4xf32>
// CHECK-NEXT: vector.transfer_write %[[RES]], %[[MEM]][%[[IDX]], %[[IDX]]] {in_bounds = [false, true]} : vector<2x4xf32>, memref<8x8xf32>
// CHECK-NEXT: return %[[RES]] : vector<2x4xf32>
// CHECK-NEXT: }
func @transfer_2D_not_inbounds(%mem : memref<8x8xf32>, %i : index) -> vector<2x4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true, false]} : memref<8x8xf32>, vector<2x4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [false, true]} : vector<2x4xf32>, memref<8x8xf32>
return %res : vector<2x4xf32>
// CHECK-LABEL: func @transfer_not_inbounds(
// CHECK-SAME: %[[MEM:.*]]: memref<8x8xf32>,
// CHECK-SAME: %[[IDX:.*]]: index) -> vector<4xf32> {
-// CHECK-NEXT: %[[CF0:.*]] = constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[CF0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: %[[RES:.*]] = vector.transfer_read %[[MEM]][%[[IDX]], %[[IDX]]], %[[CF0]] : memref<8x8xf32>, vector<4xf32>
// CHECK-NEXT: vector.transfer_write %[[RES]], %[[MEM]][%[[IDX]], %[[IDX]]] : vector<4xf32>, memref<8x8xf32>
// CHECK-NEXT: return %[[RES]] : vector<4xf32>
// CHECK-NEXT: }
func @transfer_not_inbounds(%mem : memref<8x8xf32>, %i : index) -> vector<4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 : memref<8x8xf32>, vector<4xf32>
vector.transfer_write %res, %mem[%i, %i] : vector<4xf32>, memref<8x8xf32>
return %res : vector<4xf32>
#layout = affine_map<(d0, d1) -> (d0*16 + d1)>
func @transfer_nondefault_layout(%mem : memref<8x8xf32, #layout>, %i : index) -> vector<4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true]} : memref<8x8xf32, #layout>, vector<4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [true]} : vector<4xf32>, memref<8x8xf32, #layout>
return %res : vector<4xf32>
// CHECK-LABEL: func @transfer_perm_map(
// CHECK-SAME: %[[MEM:.*]]: memref<8x8xf32>,
// CHECK-SAME: %[[IDX:.*]]: index) -> vector<4xf32> {
-// CHECK-NEXT: %[[CF0:.*]] = constant 0.000000e+00 : f32
+// CHECK-NEXT: %[[CF0:.*]] = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: %[[RES:.*]] = vector.transfer_read %[[MEM]][%[[IDX]], %[[IDX]]], %[[CF0]] {in_bounds = [true], permutation_map = #{{.*}}} : memref<8x8xf32>, vector<4xf32>
// CHECK-NEXT: vector.transfer_write %[[RES]], %[[MEM]][%[[IDX]], %[[IDX]]] {in_bounds = [true], permutation_map = #{{.*}}} : vector<4xf32>, memref<8x8xf32>
// CHECK-NEXT: return %[[RES]] : vector<4xf32>
// CHECK-NEXT: }
func @transfer_perm_map(%mem : memref<8x8xf32>, %i : index) -> vector<4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true], permutation_map = affine_map<(d0, d1) -> (d0)>} : memref<8x8xf32>, vector<4xf32>
vector.transfer_write %res, %mem[%i, %i] {in_bounds = [true], permutation_map = affine_map<(d0, d1) -> (d0)>} : vector<4xf32>, memref<8x8xf32>
return %res : vector<4xf32>
#broadcast = affine_map<(d0, d1) -> (0)>
func @transfer_broadcasting(%mem : memref<8x8xf32>, %i : index) -> vector<4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true], permutation_map = #broadcast} : memref<8x8xf32>, vector<4xf32>
return %res : vector<4xf32>
}
// CHECK-NEXT: return %[[RES]] : vector<1xf32>
// CHECK-NEXT: }
func @transfer_scalar(%mem : memref<?x?xf32>, %i : index) -> vector<1xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true]} : memref<?x?xf32>, vector<1xf32>
return %res : vector<1xf32>
}
#broadcast = affine_map<(d0, d1) -> (0, 0)>
func @transfer_broadcasting_2D(%mem : memref<8x8xf32>, %i : index) -> vector<4x4xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i], %cf0 {in_bounds = [true, true], permutation_map = #broadcast} : memref<8x8xf32>, vector<4x4xf32>
return %res : vector<4x4xf32>
}
#broadcast = affine_map<(d0, d1, d2, d3, d4) -> (d1, 0, 0, d4)>
func @transfer_broadcasting_complex(%mem : memref<10x20x30x8x8xf32>, %i : index) -> vector<3x2x4x5xf32> {
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
%res = vector.transfer_read %mem[%i, %i, %i, %i, %i], %cf0 {in_bounds = [true, true, true, true], permutation_map = #broadcast} : memref<10x20x30x8x8xf32>, vector<3x2x4x5xf32>
return %res : vector<3x2x4x5xf32>
}
func @transfer_read_permutations(%arg0 : memref<?x?xf32>, %arg1 : memref<?x?x?x?xf32>)
-> (vector<7x14x8x16xf32>, vector<7x14x8x16xf32>, vector<7x14x8x16xf32>,
vector<7x14x8x16xf32>, vector<7x14x8x16xf32>, vector<7x14x8x16xf32>, vector<8xf32>) {
-// CHECK-DAG: %[[CF0:.*]] = constant 0.000000e+00 : f32
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
- %cst = constant 0.000000e+00 : f32
- %c0 = constant 0 : index
- %m = constant 1 : i1
+// CHECK-DAG: %[[CF0:.*]] = arith.constant 0.000000e+00 : f32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %m = arith.constant 1 : i1
%mask0 = splat %m : vector<7x14xi1>
%0 = vector.transfer_read %arg1[%c0, %c0, %c0, %c0], %cst, %mask0 {in_bounds = [true, false, true, true], permutation_map = #map0} : memref<?x?x?x?xf32>, vector<7x14x8x16xf32>
// CHECK-LABEL: func @transfer_write_permutations
func @transfer_write_permutations(%arg0 : memref<?x?x?x?xf32>,
%v1 : vector<7x14x8x16xf32>, %v2 : vector<8x16xf32>) -> () {
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- %c0 = constant 0 : index
- %m = constant 1 : i1
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
+ %m = arith.constant 1 : i1
%mask0 = splat %m : vector<7x14x8x16xi1>
vector.transfer_write %v1, %arg0[%c0, %c0, %c0, %c0], %mask0 {in_bounds = [true, false, false, true], permutation_map = affine_map<(d0, d1, d2, d3) -> (d2, d1, d3, d0)>} : vector<7x14x8x16xf32>, memref<?x?x?x?xf32>
// RUN: mlir-opt %s -test-vector-transfer-unrolling-patterns --split-input-file | FileCheck %s
// CHECK-LABEL: func @transfer_read_unroll
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C2]]], %{{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC3]] : vector<4x4xf32>
func @transfer_read_unroll(%arg0 : memref<4x4xf32>) -> vector<4x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
return %0 : vector<4x4xf32>
}
// CHECK-LABEL: func @transfer_write_unroll
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[S0:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: vector.transfer_write %[[S0]], {{.*}}[%[[C0]], %[[C0]]] {{.*}} : vector<2x2xf32>, memref<4x4xf32>
// CHECK-NEXT: %[[S1:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: return
func @transfer_write_unroll(%arg0 : memref<4x4xf32>, %arg1 : vector<4x4xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
vector.transfer_write %arg1, %arg0[%c0, %c0] : vector<4x4xf32>, memref<4x4xf32>
return
}
// CHECK-LABEL: func @transfer_readwrite_unroll
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C2]]], %{{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VTR2:.*]] = vector.transfer_read {{.*}}[%[[C2]], %[[C0]]], %{{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return
func @transfer_readwrite_unroll(%arg0 : memref<4x4xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
vector.transfer_write %0, %arg0[%c0, %c0] : vector<4x4xf32>, memref<4x4xf32>
return
}
// CHECK-LABEL: func @transfer_read_unroll_tensor
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : tensor<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C2]]], %{{.*}} : tensor<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC3]] : vector<4x4xf32>
func @transfer_read_unroll_tensor(%arg0 : tensor<4x4xf32>) -> vector<4x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 : tensor<4x4xf32>, vector<4x4xf32>
return %0 : vector<4x4xf32>
}
// CHECK-LABEL: func @transfer_write_unroll_tensor
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[S0:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[VTW0:.*]] = vector.transfer_write %[[S0]], {{.*}}[%[[C0]], %[[C0]]] {{.*}} : vector<2x2xf32>, tensor<4x4xf32>
// CHECK-NEXT: %[[S1:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
func @transfer_write_unroll_tensor(%arg0 : tensor<4x4xf32>,
%arg1 : vector<4x4xf32>) -> tensor<4x4xf32> {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%r = vector.transfer_write %arg1, %arg0[%c0, %c0] :
vector<4x4xf32>, tensor<4x4xf32>
return %r: tensor<4x4xf32>
}
// CHECK-LABEL: func @transfer_readwrite_unroll_tensor
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : tensor<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C2]]], %{{.*}} : tensor<4x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VTR2:.*]] = vector.transfer_read {{.*}}[%[[C2]], %[[C0]]], %{{.*}} : tensor<4x4xf32>, vector<2x2xf32>
func @transfer_readwrite_unroll_tensor(%arg0 : tensor<4x4xf32>, %arg1 : tensor<4x4xf32>) ->
tensor<4x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 : tensor<4x4xf32>, vector<4x4xf32>
%r = vector.transfer_write %0, %arg1[%c0, %c0] : vector<4x4xf32>, tensor<4x4xf32>
return %r: tensor<4x4xf32>
// -----
// CHECK-LABEL: func @transfer_read_unroll_permutation
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x6xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C2]], %[[C0]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC5]] : vector<4x6xf32>
#map0 = affine_map<(d0, d1) -> (d1, d0)>
func @transfer_read_unroll_permutation(%arg0 : memref<6x4xf32>) -> vector<4x6xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 {permutation_map = #map0} : memref<6x4xf32>, vector<4x6xf32>
return %0 : vector<4x6xf32>
}
// -----
// CHECK-LABEL: func @transfer_read_unroll_broadcast
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<6x4xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C2]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC5]] : vector<6x4xf32>
#map0 = affine_map<(d0, d1) -> (0, d1)>
func @transfer_read_unroll_broadcast(%arg0 : memref<6x4xf32>) -> vector<6x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 {permutation_map = #map0} : memref<6x4xf32>, vector<6x4xf32>
return %0 : vector<6x4xf32>
}
// -----
// CHECK-LABEL: func @transfer_read_unroll_broadcast_permuation
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x6xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C2]], %[[C0]]], %{{.*}} : memref<6x4xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC5]] : vector<4x6xf32>
#map0 = affine_map<(d0, d1) -> (0, d0)>
func @transfer_read_unroll_broadcast_permuation(%arg0 : memref<6x4xf32>) -> vector<4x6xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 {permutation_map = #map0} : memref<6x4xf32>, vector<4x6xf32>
return %0 : vector<4x6xf32>
}
// -----
// CHECK-LABEL: func @transfer_read_unroll_different_rank
-// CHECK-DAG: %[[C4:.*]] = constant 4 : index
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VTR0:.*]] = vector.transfer_read {{.*}}[%[[C0]], %[[C0]], %[[C0]]], %{{.*}} : memref<?x?x?xf32>, vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[VTR0]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<6x4xf32>
// CHECK-NEXT: %[[VTR1:.*]] = vector.transfer_read {{.*}}[%[[C2]], %[[C0]], %[[C0]]], %{{.*}} : memref<?x?x?xf32>, vector<2x2xf32>
// CHECK-NEXT: return %[[VEC5]] : vector<6x4xf32>
#map0 = affine_map<(d0, d1, d2) -> (d2, d0)>
func @transfer_read_unroll_different_rank(%arg0 : memref<?x?x?xf32>) -> vector<6x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0, %c0], %cf0 {permutation_map = #map0} : memref<?x?x?xf32>, vector<6x4xf32>
return %0 : vector<6x4xf32>
}
// CHECK: return
func @forward_dead_store(%arg0: i1, %arg1 : memref<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) {
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
vector.transfer_write %v0, %arg1[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, memref<4x4xf32>
%0 = vector.transfer_read %arg1[%c1, %c0], %cf0 {in_bounds = [true, true]} :
memref<4x4xf32>, vector<1x4xf32>
%x = scf.for %i0 = %c0 to %c4 step %c1 iter_args(%acc = %0)
-> (vector<1x4xf32>) {
- %1 = addf %acc, %acc : vector<1x4xf32>
+ %1 = arith.addf %acc, %acc : vector<1x4xf32>
scf.yield %1 : vector<1x4xf32>
}
vector.transfer_write %x, %arg1[%c1, %c0] {in_bounds = [true, true]} :
// CHECK: return
func @forward_nested(%arg0: i1, %arg1 : memref<4x4xf32>, %v0 : vector<1x4xf32>,
%v1 : vector<1x4xf32>, %i : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf0 = arith.constant 0.0 : f32
vector.transfer_write %v1, %arg1[%i, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, memref<4x4xf32>
vector.transfer_write %v0, %arg1[%c1, %c0] {in_bounds = [true, true]} :
// CHECK: return
func @forward_nested_negative(%arg0: i1, %arg1 : memref<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf0 = arith.constant 0.0 : f32
vector.transfer_write %v0, %arg1[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, memref<4x4xf32>
%x = scf.if %arg0 -> (vector<1x4xf32>) {
func @dead_store_region(%arg0: i1, %arg1 : memref<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index)
-> (vector<1x4xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf0 = arith.constant 0.0 : f32
vector.transfer_write %v0, %arg1[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, memref<4x4xf32>
%x = scf.if %arg0 -> (vector<1x4xf32>) {
// CHECK: return
func @dead_store_negative(%arg0: i1, %arg1 : memref<4x4xf32>,
%v0 :vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf0 = arith.constant 0.0 : f32
%x = scf.if %arg0 -> (vector<1x4xf32>) {
vector.transfer_write %v0, %arg1[%c1, %c0] {in_bounds = [true, true]} :
vector<1x4xf32>, memref<4x4xf32>
// CHECK: return
func @dead_store_nested_region(%arg0: i1, %arg1: i1, %arg2 : memref<4x4xf32>,
%v0 : vector<1x4xf32>, %v1 : vector<1x4xf32>, %i : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cf0 = arith.constant 0.0 : f32
scf.if %arg0 {
%0 = vector.transfer_read %arg2[%i, %c0], %cf0 {in_bounds = [true, true]} :
memref<4x4xf32>, vector<1x4xf32>
// CHECK-LABEL: func @add4x2
// CHECK: %[[S1:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x2xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S2:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x2xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A1:.*]] = addf %[[S1]], %[[S2]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A1:.*]] = arith.addf %[[S1]], %[[S2]] : vector<2x2xf32>
// CHECK-NEXT: %[[VEC0:.*]] = vector.insert_strided_slice %[[A1]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x2xf32>
// CHECK-NEXT: %[[S3:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x2xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S4:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x2xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A2:.*]] = addf %[[S3]], %[[S4]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A2:.*]] = arith.addf %[[S3]], %[[S4]] : vector<2x2xf32>
// CHECK-NEXT: %[[VEC1:.*]] = vector.insert_strided_slice %[[A2]], %[[VEC0]] {offsets = [2, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x2xf32>
// CHECK-NEXT: return %[[VEC1:.*]] : vector<4x2xf32>
func @add4x2(%0: vector<4x2xf32>) -> vector<4x2xf32> {
- %1 = addf %0, %0: vector<4x2xf32>
+ %1 = arith.addf %0, %0: vector<4x2xf32>
return %1: vector<4x2xf32>
}
// CHECK: %[[S1:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S2:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A1:.*]] = addf %[[S1]], %[[S2]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A1:.*]] = arith.addf %[[S1]], %[[S2]] : vector<2x2xf32>
// CHECK-NEXT: %[[S3:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S4:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A2:.*]] = addf %[[S3]], %[[S4]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A2:.*]] = arith.addf %[[S3]], %[[S4]] : vector<2x2xf32>
// CHECK-NEXT: %[[S5:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S6:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A3:.*]] = addf %[[S5]], %[[S6]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A3:.*]] = arith.addf %[[S5]], %[[S6]] : vector<2x2xf32>
// CHECK-NEXT: %[[S7:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
// CHECK-NEXT: %[[S8:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A4:.*]] = addf %[[S7]], %[[S8]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A4:.*]] = arith.addf %[[S7]], %[[S8]] : vector<2x2xf32>
// CHECK-NEXT: %[[S9:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A5:.*]] = addf %[[S9]], %[[A1]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A5:.*]] = arith.addf %[[S9]], %[[A1]] : vector<2x2xf32>
// CHECK-NEXT: %[[R1:.*]] = vector.insert_strided_slice %[[A5]], %{{.*}} {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: %[[S11:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [0, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A6:.*]] = addf %[[S11]], %[[A2]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A6:.*]] = arith.addf %[[S11]], %[[A2]] : vector<2x2xf32>
// CHECK-NEXT: %[[R2:.*]] = vector.insert_strided_slice %[[A6]], %[[R1]] {offsets = [0, 2], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: %[[S13:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 0], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A7:.*]] = addf %[[S13]], %[[A3]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A7:.*]] = arith.addf %[[S13]], %[[A3]] : vector<2x2xf32>
// CHECK-NEXT: %[[R3:.*]] = vector.insert_strided_slice %[[A7]], %[[R2]] {offsets = [2, 0], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: %[[S15:.*]] = vector.extract_strided_slice %{{.*}} {offsets = [2, 2], sizes = [2, 2], strides = [1, 1]} : vector<4x4xf32> to vector<2x2xf32>
-// CHECK-NEXT: %[[A8:.*]] = addf %[[S15]], %[[A4]] : vector<2x2xf32>
+// CHECK-NEXT: %[[A8:.*]] = arith.addf %[[S15]], %[[A4]] : vector<2x2xf32>
// CHECK-NEXT: %[[R4:.*]] = vector.insert_strided_slice %[[A8]], %[[R3]] {offsets = [2, 2], strides = [1, 1]} : vector<2x2xf32> into vector<4x4xf32>
// CHECK-NEXT: return %[[R4]] : vector<4x4xf32>
func @add4x4(%0: vector<4x4xf32>, %1: vector<4x4xf32>) -> vector<4x4xf32> {
- %2 = addf %0, %1: vector<4x4xf32>
- %3 = addf %1, %2: vector<4x4xf32>
+ %2 = arith.addf %0, %1: vector<4x4xf32>
+ %3 = arith.addf %1, %2: vector<4x4xf32>
return %3: vector<4x4xf32>
}
// CHECK-LABEL: func @contraction4x4_ikj_xfer_read
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// Check LHS vector.transfer read is split for each user.
func @contraction4x4_ikj_xfer_read(%arg0 : memref<4x2xf32>,
%arg1 : memref<2x4xf32>,
%arg2 : memref<4x4xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0
{ permutation_map = affine_map<(d0, d1) -> (d0, d1)> }
// TODO: Update test with VTR split transform.
// CHECK-LABEL: func @vector_transfers
// CHECK-COUNT-8: vector.transfer_read
-// CHECK-COUNT-4: addf
+// CHECK-COUNT-4: arith.addf
// CHECK-COUNT-4: vector.transfer_write
func @vector_transfers(%arg0: index, %arg1: index) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
%1 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
%2 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
- %cst_0 = constant 1.000000e+00 : f32
- %cst_1 = constant 2.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
+ %cst_1 = arith.constant 2.000000e+00 : f32
affine.for %arg2 = 0 to %arg0 step 4 {
affine.for %arg3 = 0 to %arg1 step 4 {
%4 = vector.transfer_read %0[%arg2, %arg3], %cst {permutation_map = affine_map<(d0, d1) -> (d0, d1)>} : memref<?x?xf32>, vector<4x4xf32>
%5 = vector.transfer_read %1[%arg2, %arg3], %cst {permutation_map = affine_map<(d0, d1) -> (d0, d1)>} : memref<?x?xf32>, vector<4x4xf32>
- %6 = addf %4, %5 : vector<4x4xf32>
+ %6 = arith.addf %4, %5 : vector<4x4xf32>
vector.transfer_write %6, %2[%arg2, %arg3] {permutation_map = affine_map<(d0, d1) -> (d0, d1)>} : vector<4x4xf32>, memref<?x?xf32>
}
}
// CHECK-LABEL: func @elementwise_unroll
// CHECK-SAME: (%[[ARG0:.*]]: memref<4x4xf32>, %[[ARG1:.*]]: memref<4x4xf32>)
-// CHECK-DAG: %[[C2:.*]] = constant 2 : index
-// CHECK-DAG: %[[C0:.*]] = constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
// CHECK: %[[VT0:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT1:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C2]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT2:.*]] = vector.transfer_read %[[ARG0]][%[[C2]], %[[C0]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT5:.*]] = vector.transfer_read %[[ARG1]][%[[C0]], %[[C2]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT6:.*]] = vector.transfer_read %[[ARG1]][%[[C2]], %[[C0]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT7:.*]] = vector.transfer_read %[[ARG1]][%[[C2]], %[[C2]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
-// CHECK: %[[CMP0:.*]] = cmpf ult, %[[VT0]], %[[VT4]] : vector<2x2xf32>
-// CHECK: %[[CMP1:.*]] = cmpf ult, %[[VT1]], %[[VT5]] : vector<2x2xf32>
-// CHECK: %[[CMP2:.*]] = cmpf ult, %[[VT2]], %[[VT6]] : vector<2x2xf32>
-// CHECK: %[[CMP3:.*]] = cmpf ult, %[[VT3]], %[[VT7]] : vector<2x2xf32>
+// CHECK: %[[CMP0:.*]] = arith.cmpf ult, %[[VT0]], %[[VT4]] : vector<2x2xf32>
+// CHECK: %[[CMP1:.*]] = arith.cmpf ult, %[[VT1]], %[[VT5]] : vector<2x2xf32>
+// CHECK: %[[CMP2:.*]] = arith.cmpf ult, %[[VT2]], %[[VT6]] : vector<2x2xf32>
+// CHECK: %[[CMP3:.*]] = arith.cmpf ult, %[[VT3]], %[[VT7]] : vector<2x2xf32>
// CHECK: %[[VT0:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C0]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT1:.*]] = vector.transfer_read %[[ARG0]][%[[C0]], %[[C2]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: %[[VT2:.*]] = vector.transfer_read %[[ARG0]][%[[C2]], %[[C0]]], {{.*}} : memref<4x4xf32>, vector<2x2xf32>
// CHECK: vector.transfer_write %[[SEL2]], %[[ARG0]][%[[C2]], %[[C0]]] {{.*}} : vector<2x2xf32>, memref<4x4xf32>
// CHECK: vector.transfer_write %[[SEL3]], %[[ARG0]][%[[C2]], %[[C2]]] {{.*}} : vector<2x2xf32>, memref<4x4xf32>
func @elementwise_unroll(%arg0 : memref<4x4xf32>, %arg1 : memref<4x4xf32>) {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
%1 = vector.transfer_read %arg1[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
- %cond = cmpf ult, %0, %1 : vector<4x4xf32>
+ %cond = arith.cmpf ult, %0, %1 : vector<4x4xf32>
// Vector transfer split pattern only support single user right now.
%2 = vector.transfer_read %arg0[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
%3 = vector.transfer_read %arg1[%c0, %c0], %cf0 : memref<4x4xf32>, vector<4x4xf32>
%arg1 : tensor<2x4xf32>,
%arg2 : tensor<4x4xf32>) ->
tensor<4x4xf32> {
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
%0 = vector.transfer_read %arg0[%c0, %c0], %cf0 :
tensor<4x2xf32>, vector<4x2xf32>
%1 = vector.transfer_read %arg1[%c0, %c0], %cf0 :
// CHECK-LABEL: func @cast_away_transfer_read_leading_one_dims
func @cast_away_transfer_read_leading_one_dims(%arg0: memref<1x4x8x16xf16>) -> vector<1x4xf16> {
- // CHECK: %[[C0:.+]] = constant 0 : index
- %c0 = constant 0 : index
- // CHECK: %[[F0:.+]] = constant 0.000000e+00 : f16
- %f0 = constant 0. : f16
+ // CHECK: %[[C0:.+]] = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
+ // CHECK: %[[F0:.+]] = arith.constant 0.000000e+00 : f16
+ %f0 = arith.constant 0. : f16
// CHECK: %[[READ:.+]] = vector.transfer_read %{{.*}}[%[[C0]], %[[C0]], %[[C0]], %[[C0]]], %[[F0]] {in_bounds = [true]} : memref<1x4x8x16xf16>, vector<4xf16>
// CHECK: %[[CAST:.+]] = vector.shape_cast %[[READ]] : vector<4xf16> to vector<1x4xf16>
%0 = vector.transfer_read %arg0[%c0, %c0, %c0, %c0], %f0 {in_bounds = [true, true]} : memref<1x4x8x16xf16>, vector<1x4xf16>
// CHECK-LABEL: func @cast_away_transfer_read_leading_one_dims_one_element
func @cast_away_transfer_read_leading_one_dims_one_element(%arg0: memref<1x1x1x1xf16>) -> vector<1x1xf16> {
- %c0 = constant 0 : index
- %f0 = constant 0. : f16
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0. : f16
// CHECK: vector.shape_cast %{{.+}} : vector<1xf16> to vector<1x1xf16>
%0 = vector.transfer_read %arg0[%c0, %c0, %c0, %c0], %f0 {in_bounds = [true, true]} : memref<1x1x1x1xf16>, vector<1x1xf16>
return %0: vector<1x1xf16>
// CHECK-LABEL: func @cast_away_transfer_write_leading_one_dims
func @cast_away_transfer_write_leading_one_dims(%arg0: memref<1x4x8x16xf16>, %arg1: vector<1x4xf16>) {
- // CHECK: %[[C0:.+]] = constant 0 : index
- %c0 = constant 0 : index
+ // CHECK: %[[C0:.+]] = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: %[[CAST:.+]] = vector.shape_cast %{{.*}} : vector<1x4xf16> to vector<4xf16>
// CHECK: vector.transfer_write %[[CAST]], %{{.*}}[%[[C0]], %[[C0]], %[[C0]], %[[C0]]] {in_bounds = [true]} : vector<4xf16>, memref<1x4x8x16xf16>
// CHECK-LABEL: func @cast_away_transfer_write_leading_one_dims_one_element
func @cast_away_transfer_write_leading_one_dims_one_element(%arg0: memref<1x1x1x1xf16>, %arg1: vector<1x1xf16>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
// CHECK: vector.shape_cast %{{.+}} : vector<1x1xf16> to vector<1xf16>
vector.transfer_write %arg1, %arg0[%c0, %c0, %c0, %c0] {in_bounds = [true, true]} : vector<1x1xf16>, memref<1x1x1x1xf16>
return
(vector<1x1x8xf32>, vector<1x4xi1>, vector<1x4xf32>, vector<1x4xf32>) {
// CHECK: vector.shape_cast %{{.*}} : vector<1x1x8xf32> to vector<8xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<1x1x8xf32> to vector<8xf32>
- // CHECK: addf %{{.*}}, %{{.*}} : vector<8xf32>
+ // CHECK: arith.addf %{{.*}}, %{{.*}} : vector<8xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<8xf32> to vector<1x1x8xf32>
- %0 = addf %arg0, %arg0 : vector<1x1x8xf32>
+ %0 = arith.addf %arg0, %arg0 : vector<1x1x8xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<1x4xf32> to vector<4xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<1x4xf32> to vector<4xf32>
- // CHECK: cmpf ogt, %{{.*}}, %{{.*}} : vector<4xf32>
+ // CHECK: arith.cmpf ogt, %{{.*}}, %{{.*}} : vector<4xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<4xi1> to vector<1x4xi1>
- %1 = cmpf ogt, %arg2, %arg3 : vector<1x4xf32>
+ %1 = arith.cmpf ogt, %arg2, %arg3 : vector<1x4xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<1x4xf32> to vector<4xf32>
// CHECK: vector.shape_cast %{{.*}} : vector<1x4xf32> to vector<4xf32>
// CHECK: select %{{.*}}, %{{.*}}, %{{.*}} : vector<4xi1>, vector<4xf32>
}
// CHECK-LABEL: func @main()
-// CHECK-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// CHECK-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// CHECK-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// CHECK-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// CHECK-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// CHECK-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// CHECK-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// CHECK-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// CHECK-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// CHECK-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// CHECK-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// CHECK-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// CHECK: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_7:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_8:%.*]] = memref.alloc() : memref<2x3xf64>
// CHECK: affine.for [[VAL_13:%.*]] = 0 to 2 {
// CHECK: [[VAL_14:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: [[VAL_15:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
-// CHECK: [[VAL_16:%.*]] = mulf [[VAL_14]], [[VAL_15]] : f64
+// CHECK: [[VAL_16:%.*]] = arith.mulf [[VAL_14]], [[VAL_15]] : f64
// CHECK: affine.store [[VAL_16]], [[VAL_6]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: toy.print [[VAL_6]] : memref<3x2xf64>
// CHECK: memref.dealloc [[VAL_8]] : memref<2x3xf64>
// CHECK: memref.dealloc [[VAL_6]] : memref<3x2xf64>
// OPT-LABEL: func @main()
-// OPT-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// OPT-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// OPT-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// OPT-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// OPT-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// OPT-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// OPT-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// OPT-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// OPT-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// OPT-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// OPT-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// OPT-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// OPT: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// OPT: [[VAL_7:%.*]] = memref.alloc() : memref<2x3xf64>
// OPT: affine.store [[VAL_0]], [[VAL_7]][0, 0] : memref<2x3xf64>
// OPT: affine.for [[VAL_8:%.*]] = 0 to 3 {
// OPT: affine.for [[VAL_9:%.*]] = 0 to 2 {
// OPT: [[VAL_10:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_9]], [[VAL_8]]] : memref<2x3xf64>
-// OPT: [[VAL_11:%.*]] = mulf [[VAL_10]], [[VAL_10]] : f64
+// OPT: [[VAL_11:%.*]] = arith.mulf [[VAL_10]], [[VAL_10]] : f64
// OPT: affine.store [[VAL_11]], [[VAL_6]]{{\[}}[[VAL_8]], [[VAL_9]]] : memref<3x2xf64>
// OPT: toy.print [[VAL_6]] : memref<3x2xf64>
// OPT: memref.dealloc [[VAL_7]] : memref<2x3xf64>
}
// CHECK-LABEL: func @main()
-// CHECK-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// CHECK-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// CHECK-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// CHECK-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// CHECK-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// CHECK-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// CHECK-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// CHECK-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// CHECK-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// CHECK-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// CHECK-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// CHECK-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// CHECK: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_7:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_8:%.*]] = memref.alloc() : memref<2x3xf64>
// CHECK: affine.for [[VAL_13:%.*]] = 0 to 2 {
// CHECK: [[VAL_14:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: [[VAL_15:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
-// CHECK: [[VAL_16:%.*]] = mulf [[VAL_14]], [[VAL_15]] : f64
+// CHECK: [[VAL_16:%.*]] = arith.mulf [[VAL_14]], [[VAL_15]] : f64
// CHECK: affine.store [[VAL_16]], [[VAL_6]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: toy.print [[VAL_6]] : memref<3x2xf64>
// CHECK: memref.dealloc [[VAL_8]] : memref<2x3xf64>
// CHECK: memref.dealloc [[VAL_6]] : memref<3x2xf64>
// OPT-LABEL: func @main()
-// OPT-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// OPT-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// OPT-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// OPT-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// OPT-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// OPT-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// OPT-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// OPT-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// OPT-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// OPT-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// OPT-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// OPT-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// OPT: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// OPT: [[VAL_7:%.*]] = memref.alloc() : memref<2x3xf64>
// OPT: affine.store [[VAL_0]], [[VAL_7]][0, 0] : memref<2x3xf64>
// OPT: affine.for [[VAL_8:%.*]] = 0 to 3 {
// OPT: affine.for [[VAL_9:%.*]] = 0 to 2 {
// OPT: [[VAL_10:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_9]], [[VAL_8]]] : memref<2x3xf64>
-// OPT: [[VAL_11:%.*]] = mulf [[VAL_10]], [[VAL_10]] : f64
+// OPT: [[VAL_11:%.*]] = arith.mulf [[VAL_10]], [[VAL_10]] : f64
// OPT: affine.store [[VAL_11]], [[VAL_6]]{{\[}}[[VAL_8]], [[VAL_9]]] : memref<3x2xf64>
// OPT: toy.print [[VAL_6]] : memref<3x2xf64>
// OPT: memref.dealloc [[VAL_7]] : memref<2x3xf64>
}
// CHECK-LABEL: func @main()
-// CHECK-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// CHECK-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// CHECK-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// CHECK-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// CHECK-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// CHECK-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// CHECK-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// CHECK-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// CHECK-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// CHECK-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// CHECK-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// CHECK-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// CHECK: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_7:%.*]] = memref.alloc() : memref<3x2xf64>
// CHECK: [[VAL_8:%.*]] = memref.alloc() : memref<2x3xf64>
// CHECK: affine.for [[VAL_13:%.*]] = 0 to 2 {
// CHECK: [[VAL_14:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: [[VAL_15:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
-// CHECK: [[VAL_16:%.*]] = mulf [[VAL_14]], [[VAL_15]] : f64
+// CHECK: [[VAL_16:%.*]] = arith.mulf [[VAL_14]], [[VAL_15]] : f64
// CHECK: affine.store [[VAL_16]], [[VAL_6]]{{\[}}[[VAL_12]], [[VAL_13]]] : memref<3x2xf64>
// CHECK: toy.print [[VAL_6]] : memref<3x2xf64>
// CHECK: memref.dealloc [[VAL_8]] : memref<2x3xf64>
// CHECK: memref.dealloc [[VAL_6]] : memref<3x2xf64>
// OPT-LABEL: func @main()
-// OPT-DAG: [[VAL_0:%.*]] = constant 1.000000e+00 : f64
-// OPT-DAG: [[VAL_1:%.*]] = constant 2.000000e+00 : f64
-// OPT-DAG: [[VAL_2:%.*]] = constant 3.000000e+00 : f64
-// OPT-DAG: [[VAL_3:%.*]] = constant 4.000000e+00 : f64
-// OPT-DAG: [[VAL_4:%.*]] = constant 5.000000e+00 : f64
-// OPT-DAG: [[VAL_5:%.*]] = constant 6.000000e+00 : f64
+// OPT-DAG: [[VAL_0:%.*]] = arith.constant 1.000000e+00 : f64
+// OPT-DAG: [[VAL_1:%.*]] = arith.constant 2.000000e+00 : f64
+// OPT-DAG: [[VAL_2:%.*]] = arith.constant 3.000000e+00 : f64
+// OPT-DAG: [[VAL_3:%.*]] = arith.constant 4.000000e+00 : f64
+// OPT-DAG: [[VAL_4:%.*]] = arith.constant 5.000000e+00 : f64
+// OPT-DAG: [[VAL_5:%.*]] = arith.constant 6.000000e+00 : f64
// OPT: [[VAL_6:%.*]] = memref.alloc() : memref<3x2xf64>
// OPT: [[VAL_7:%.*]] = memref.alloc() : memref<2x3xf64>
// OPT: affine.store [[VAL_0]], [[VAL_7]][0, 0] : memref<2x3xf64>
// OPT: affine.for [[VAL_8:%.*]] = 0 to 3 {
// OPT: affine.for [[VAL_9:%.*]] = 0 to 2 {
// OPT: [[VAL_10:%.*]] = affine.load [[VAL_7]]{{\[}}[[VAL_9]], [[VAL_8]]] : memref<2x3xf64>
-// OPT: [[VAL_11:%.*]] = mulf [[VAL_10]], [[VAL_10]] : f64
+// OPT: [[VAL_11:%.*]] = arith.mulf [[VAL_10]], [[VAL_10]] : f64
// OPT: affine.store [[VAL_11]], [[VAL_6]]{{\[}}[[VAL_8]], [[VAL_9]]] : memref<3x2xf64>
// OPT: toy.print [[VAL_6]] : memref<3x2xf64>
// OPT: memref.dealloc [[VAL_7]] : memref<2x3xf64>
// CHECK: %[[T:.*]] = "getTensor"() : () -> tensor<4x4x?xf32>
%t = "getTensor"() : () -> tensor<4x4x?xf32>
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK-NEXT: %{{.*}} = tensor.dim %[[T]], %[[C2]] : tensor<4x4x?xf32>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%t2 = "tensor.dim"(%t, %c2) : (tensor<4x4x?xf32>, index) -> index
- // CHECK: %{{.*}} = addf %[[ARG]], %[[ARG]] : f32
- %x = "std.addf"(%a, %a) : (f32,f32) -> (f32)
+ // CHECK: %{{.*}} = arith.addf %[[ARG]], %[[ARG]] : f32
+ %x = "arith.addf"(%a, %a) : (f32,f32) -> (f32)
// CHECK: return
return
// CHECK-LABEL: func @standard_instrs(%arg0: tensor<4x4x?xf32>, %arg1: f32, %arg2: i32, %arg3: index, %arg4: i64, %arg5: f16) {
func @standard_instrs(tensor<4x4x?xf32>, f32, i32, index, i64, f16) {
^bb42(%t: tensor<4x4x?xf32>, %f: f32, %i: i32, %idx : index, %j: i64, %half: f16):
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: %[[A2:.*]] = tensor.dim %arg0, %[[C2]] : tensor<4x4x?xf32>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%a2 = tensor.dim %t, %c2 : tensor<4x4x?xf32>
- // CHECK: %[[F2:.*]] = addf %arg1, %arg1 : f32
- %f2 = "std.addf"(%f, %f) : (f32,f32) -> f32
-
- // CHECK: %[[F3:.*]] = addf %[[F2]], %[[F2]] : f32
- %f3 = addf %f2, %f2 : f32
-
- // CHECK: %[[I2:.*]] = addi %arg2, %arg2 : i32
- %i2 = "std.addi"(%i, %i) : (i32,i32) -> i32
-
- // CHECK: %[[I3:.*]] = addi %[[I2]], %[[I2]] : i32
- %i3 = addi %i2, %i2 : i32
-
- // CHECK: %[[IDX1:.*]] = addi %arg3, %arg3 : index
- %idx1 = addi %idx, %idx : index
-
- // CHECK: %[[IDX2:.*]] = addi %arg3, %[[IDX1]] : index
- %idx2 = "std.addi"(%idx, %idx1) : (index, index) -> index
-
- // CHECK: %[[F4:.*]] = subf %arg1, %arg1 : f32
- %f4 = "std.subf"(%f, %f) : (f32,f32) -> f32
-
- // CHECK: %[[F5:.*]] = subf %[[F4]], %[[F4]] : f32
- %f5 = subf %f4, %f4 : f32
-
- // CHECK: %[[I4:.*]] = subi %arg2, %arg2 : i32
- %i4 = "std.subi"(%i, %i) : (i32,i32) -> i32
-
- // CHECK: %[[I5:.*]] = subi %[[I4]], %[[I4]] : i32
- %i5 = subi %i4, %i4 : i32
-
- // CHECK: %[[F6:.*]] = mulf %[[F2]], %[[F2]] : f32
- %f6 = mulf %f2, %f2 : f32
-
- // CHECK: %[[I6:.*]] = muli %[[I2]], %[[I2]] : i32
- %i6 = muli %i2, %i2 : i32
-
- // CHECK: %c42_i32 = constant 42 : i32
- %x = "std.constant"(){value = 42 : i32} : () -> i32
-
- // CHECK: %c42_i32_0 = constant 42 : i32
- %7 = constant 42 : i32
-
- // CHECK: %c43 = constant {crazy = "std.foo"} 43 : index
- %8 = constant {crazy = "std.foo"} 43: index
-
- // CHECK: %cst = constant 4.300000e+01 : bf16
- %9 = constant 43.0 : bf16
-
// CHECK: %f = constant @func_with_ops : (f32) -> ()
%10 = constant @func_with_ops : (f32) -> ()
- // CHECK: %f_1 = constant @affine_apply : () -> ()
+ // CHECK: %f_0 = constant @affine_apply : () -> ()
%11 = constant @affine_apply : () -> ()
- // CHECK: %f_2 = constant @affine_apply : () -> ()
- %12 = constant @affine_apply : () -> ()
-
- // CHECK: %cst_3 = constant dense<0> : vector<4xi32>
- %13 = constant dense<0> : vector<4 x i32>
-
- // CHECK: %cst_4 = constant dense<0> : tensor<42xi32>
- %tci32 = constant dense<0> : tensor<42 x i32>
-
- // CHECK: %cst_5 = constant dense<0> : vector<42xi32>
- %vci32 = constant dense<0> : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = cmpi eq, %{{[0-9]+}}, %{{[0-9]+}} : i32
- %14 = cmpi eq, %i3, %i4 : i32
-
- // Predicate 1 means inequality comparison.
- // CHECK: %{{[0-9]+}} = cmpi ne, %{{[0-9]+}}, %{{[0-9]+}} : i32
- %15 = "std.cmpi"(%i3, %i4) {predicate = 1} : (i32, i32) -> i1
-
- // CHECK: %{{[0-9]+}} = cmpi slt, %cst_3, %cst_3 : vector<4xi32>
- %16 = cmpi slt, %13, %13 : vector<4 x i32>
-
- // CHECK: %{{[0-9]+}} = cmpi ne, %cst_3, %cst_3 : vector<4xi32>
- %17 = "std.cmpi"(%13, %13) {predicate = 1} : (vector<4 x i32>, vector<4 x i32>) -> vector<4 x i1>
-
- // CHECK: %{{[0-9]+}} = cmpi slt, %arg3, %arg3 : index
- %18 = cmpi slt, %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = cmpi eq, %cst_4, %cst_4 : tensor<42xi32>
- %19 = cmpi eq, %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = cmpi eq, %cst_5, %cst_5 : vector<42xi32>
- %20 = cmpi eq, %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = select %{{[0-9]+}}, %arg3, %arg3 : index
- %21 = select %18, %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = select %{{[0-9]+}}, %cst_4, %cst_4 : tensor<42xi1>, tensor<42xi32>
- %22 = select %19, %tci32, %tci32 : tensor<42 x i1>, tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = select %{{[0-9]+}}, %cst_5, %cst_5 : vector<42xi1>, vector<42xi32>
- %23 = select %20, %vci32, %vci32 : vector<42 x i1>, vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = select %{{[0-9]+}}, %arg3, %arg3 : index
- %24 = "std.select"(%18, %idx, %idx) : (i1, index, index) -> index
-
- // CHECK: %{{[0-9]+}} = select %{{[0-9]+}}, %cst_4, %cst_4 : tensor<42xi32>
- %25 = std.select %18, %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = divi_signed %arg2, %arg2 : i32
- %26 = divi_signed %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = divi_signed %arg3, %arg3 : index
- %27 = divi_signed %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = divi_signed %cst_5, %cst_5 : vector<42xi32>
- %28 = divi_signed %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = divi_signed %cst_4, %cst_4 : tensor<42xi32>
- %29 = divi_signed %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = divi_signed %arg2, %arg2 : i32
- %30 = "std.divi_signed"(%i, %i) : (i32, i32) -> i32
-
- // CHECK: %{{[0-9]+}} = divi_unsigned %arg2, %arg2 : i32
- %31 = divi_unsigned %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = divi_unsigned %arg3, %arg3 : index
- %32 = divi_unsigned %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = divi_unsigned %cst_5, %cst_5 : vector<42xi32>
- %33 = divi_unsigned %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = divi_unsigned %cst_4, %cst_4 : tensor<42xi32>
- %34 = divi_unsigned %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = divi_unsigned %arg2, %arg2 : i32
- %35 = "std.divi_unsigned"(%i, %i) : (i32, i32) -> i32
-
- // CHECK: %{{[0-9]+}} = remi_signed %arg2, %arg2 : i32
- %36 = remi_signed %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = remi_signed %arg3, %arg3 : index
- %37 = remi_signed %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = remi_signed %cst_5, %cst_5 : vector<42xi32>
- %38 = remi_signed %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = remi_signed %cst_4, %cst_4 : tensor<42xi32>
- %39 = remi_signed %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = remi_signed %arg2, %arg2 : i32
- %40 = "std.remi_signed"(%i, %i) : (i32, i32) -> i32
-
- // CHECK: %{{[0-9]+}} = remi_unsigned %arg2, %arg2 : i32
- %41 = remi_unsigned %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = remi_unsigned %arg3, %arg3 : index
- %42 = remi_unsigned %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = remi_unsigned %cst_5, %cst_5 : vector<42xi32>
- %43 = remi_unsigned %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = remi_unsigned %cst_4, %cst_4 : tensor<42xi32>
- %44 = remi_unsigned %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = remi_unsigned %arg2, %arg2 : i32
- %45 = "std.remi_unsigned"(%i, %i) : (i32, i32) -> i32
-
- // CHECK: %{{[0-9]+}} = divf %arg1, %arg1 : f32
- %46 = "std.divf"(%f, %f) : (f32,f32) -> f32
-
- // CHECK: %{{[0-9]+}} = divf %arg1, %arg1 : f32
- %47 = divf %f, %f : f32
-
- // CHECK: %{{[0-9]+}} = divf %arg0, %arg0 : tensor<4x4x?xf32>
- %48 = divf %t, %t : tensor<4x4x?xf32>
-
- // CHECK: %{{[0-9]+}} = remf %arg1, %arg1 : f32
- %49 = "std.remf"(%f, %f) : (f32,f32) -> f32
-
- // CHECK: %{{[0-9]+}} = remf %arg1, %arg1 : f32
- %50 = remf %f, %f : f32
-
- // CHECK: %{{[0-9]+}} = remf %arg0, %arg0 : tensor<4x4x?xf32>
- %51 = remf %t, %t : tensor<4x4x?xf32>
-
- // CHECK: %{{[0-9]+}} = and %arg2, %arg2 : i32
- %52 = "std.and"(%i, %i) : (i32,i32) -> i32
+ // CHECK: %[[I2:.*]] = arith.addi
+ %i2 = arith.addi %i, %i: i32
+ // CHECK: %[[I3:.*]] = arith.addi
+ %i3 = arith.addi %i2, %i : i32
+ // CHECK: %[[I4:.*]] = arith.addi
+ %i4 = arith.addi %i2, %i3 : i32
+ // CHECK: %[[F3:.*]] = arith.addf
+ %f3 = arith.addf %f, %f : f32
+ // CHECK: %[[F4:.*]] = arith.addf
+ %f4 = arith.addf %f, %f3 : f32
- // CHECK: %{{[0-9]+}} = and %arg2, %arg2 : i32
- %53 = and %i, %i : i32
+ %true = arith.constant true
+ %tci32 = arith.constant dense<0> : tensor<42xi32>
+ %vci32 = arith.constant dense<0> : vector<42xi32>
+ %tci1 = arith.constant dense<1> : tensor<42xi1>
+ %vci1 = arith.constant dense<1> : vector<42xi1>
- // CHECK: %{{[0-9]+}} = and %cst_5, %cst_5 : vector<42xi32>
- %54 = std.and %vci32, %vci32 : vector<42 x i32>
+ // CHECK: %{{.*}} = select %{{.*}}, %arg3, %arg3 : index
+ %21 = select %true, %idx, %idx : index
- // CHECK: %{{[0-9]+}} = and %cst_4, %cst_4 : tensor<42xi32>
- %55 = and %tci32, %tci32 : tensor<42 x i32>
+ // CHECK: %{{.*}} = select %{{.*}}, %{{.*}}, %{{.*}} : tensor<42xi1>, tensor<42xi32>
+ %22 = select %tci1, %tci32, %tci32 : tensor<42 x i1>, tensor<42 x i32>
- // CHECK: %{{[0-9]+}} = or %arg2, %arg2 : i32
- %56 = "std.or"(%i, %i) : (i32,i32) -> i32
+ // CHECK: %{{.*}} = select %{{.*}}, %{{.*}}, %{{.*}} : vector<42xi1>, vector<42xi32>
+ %23 = select %vci1, %vci32, %vci32 : vector<42 x i1>, vector<42 x i32>
- // CHECK: %{{[0-9]+}} = or %arg2, %arg2 : i32
- %57 = or %i, %i : i32
+ // CHECK: %{{.*}} = select %{{.*}}, %arg3, %arg3 : index
+ %24 = "std.select"(%true, %idx, %idx) : (i1, index, index) -> index
- // CHECK: %{{[0-9]+}} = or %cst_5, %cst_5 : vector<42xi32>
- %58 = std.or %vci32, %vci32 : vector<42 x i32>
+ // CHECK: %{{.*}} = select %{{.*}}, %{{.*}}, %{{.*}} : tensor<42xi32>
+ %25 = std.select %true, %tci32, %tci32 : tensor<42 x i32>
- // CHECK: %{{[0-9]+}} = or %cst_4, %cst_4 : tensor<42xi32>
- %59 = or %tci32, %tci32 : tensor<42 x i32>
+ %64 = arith.constant dense<0.> : vector<4 x f32>
+ %tcf32 = arith.constant dense<0.> : tensor<42 x f32>
+ %vcf32 = arith.constant dense<0.> : vector<4 x f32>
- // CHECK: %{{[0-9]+}} = xor %arg2, %arg2 : i32
- %60 = "std.xor"(%i, %i) : (i32,i32) -> i32
-
- // CHECK: %{{[0-9]+}} = xor %arg2, %arg2 : i32
- %61 = xor %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = xor %cst_5, %cst_5 : vector<42xi32>
- %62 = std.xor %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = xor %cst_4, %cst_4 : tensor<42xi32>
- %63 = xor %tci32, %tci32 : tensor<42 x i32>
-
- %64 = constant dense<0.> : vector<4 x f32>
- %tcf32 = constant dense<0.> : tensor<42 x f32>
- %vcf32 = constant dense<0.> : vector<4 x f32>
-
- // CHECK: %{{[0-9]+}} = cmpf ogt, %{{[0-9]+}}, %{{[0-9]+}} : f32
- %65 = cmpf ogt, %f3, %f4 : f32
+ // CHECK: %{{.*}} = arith.cmpf ogt, %{{.*}}, %{{.*}} : f32
+ %65 = arith.cmpf ogt, %f3, %f4 : f32
// Predicate 0 means ordered equality comparison.
- // CHECK: %{{[0-9]+}} = cmpf oeq, %{{[0-9]+}}, %{{[0-9]+}} : f32
- %66 = "std.cmpf"(%f3, %f4) {predicate = 1} : (f32, f32) -> i1
+ // CHECK: %{{.*}} = arith.cmpf oeq, %{{.*}}, %{{.*}} : f32
+ %66 = "arith.cmpf"(%f3, %f4) {predicate = 1} : (f32, f32) -> i1
- // CHECK: %{{[0-9]+}} = cmpf olt, %cst_8, %cst_8 : vector<4xf32>
- %67 = cmpf olt, %vcf32, %vcf32 : vector<4 x f32>
+ // CHECK: %{{.*}} = arith.cmpf olt, %{{.*}}, %{{.*}}: vector<4xf32>
+ %67 = arith.cmpf olt, %vcf32, %vcf32 : vector<4 x f32>
- // CHECK: %{{[0-9]+}} = cmpf oeq, %cst_8, %cst_8 : vector<4xf32>
- %68 = "std.cmpf"(%vcf32, %vcf32) {predicate = 1} : (vector<4 x f32>, vector<4 x f32>) -> vector<4 x i1>
+ // CHECK: %{{.*}} = arith.cmpf oeq, %{{.*}}, %{{.*}}: vector<4xf32>
+ %68 = "arith.cmpf"(%vcf32, %vcf32) {predicate = 1} : (vector<4 x f32>, vector<4 x f32>) -> vector<4 x i1>
- // CHECK: %{{[0-9]+}} = cmpf oeq, %cst_7, %cst_7 : tensor<42xf32>
- %69 = cmpf oeq, %tcf32, %tcf32 : tensor<42 x f32>
+ // CHECK: %{{.*}} = arith.cmpf oeq, %{{.*}}, %{{.*}}: tensor<42xf32>
+ %69 = arith.cmpf oeq, %tcf32, %tcf32 : tensor<42 x f32>
- // CHECK: %{{[0-9]+}} = cmpf oeq, %cst_8, %cst_8 : vector<4xf32>
- %70 = cmpf oeq, %vcf32, %vcf32 : vector<4 x f32>
+ // CHECK: %{{.*}} = arith.cmpf oeq, %{{.*}}, %{{.*}}: vector<4xf32>
+ %70 = arith.cmpf oeq, %vcf32, %vcf32 : vector<4 x f32>
- // CHECK: %{{[0-9]+}} = rank %arg0 : tensor<4x4x?xf32>
+ // CHECK: %{{.*}} = rank %arg0 : tensor<4x4x?xf32>
%71 = "std.rank"(%t) : (tensor<4x4x?xf32>) -> index
- // CHECK: %{{[0-9]+}} = rank %arg0 : tensor<4x4x?xf32>
+ // CHECK: %{{.*}} = rank %arg0 : tensor<4x4x?xf32>
%72 = rank %t : tensor<4x4x?xf32>
// CHECK: = constant unit
%73 = constant unit
- // CHECK: constant true
- %74 = constant true
-
- // CHECK: constant false
- %75 = constant false
-
- // CHECK: = index_cast {{.*}} : index to i64
- %76 = index_cast %idx : index to i64
-
- // CHECK: = index_cast {{.*}} : i32 to index
- %77 = index_cast %i : i32 to index
-
- // CHECK: = sitofp {{.*}} : i32 to f32
- %78 = sitofp %i : i32 to f32
-
- // CHECK: = sitofp {{.*}} : i32 to f64
- %79 = sitofp %i : i32 to f64
-
- // CHECK: = sitofp {{.*}} : i64 to f32
- %80 = sitofp %j : i64 to f32
-
- // CHECK: = sitofp {{.*}} : i64 to f64
- %81 = sitofp %j : i64 to f64
-
- // CHECK: = sexti %arg2 : i32 to i64
- %82 = "std.sexti"(%i) : (i32) -> i64
-
- // CHECK: = sexti %arg2 : i32 to i64
- %83 = sexti %i : i32 to i64
-
- // CHECK: %{{[0-9]+}} = sexti %cst_5 : vector<42xi32>
- %84 = sexti %vci32 : vector<42 x i32> to vector<42 x i64>
-
- // CHECK: %{{[0-9]+}} = sexti %cst_4 : tensor<42xi32>
- %85 = sexti %tci32 : tensor<42 x i32> to tensor<42 x i64>
-
- // CHECK: = zexti %arg2 : i32 to i64
- %86 = "std.zexti"(%i) : (i32) -> i64
-
- // CHECK: = zexti %arg2 : i32 to i64
- %87 = zexti %i : i32 to i64
-
- // CHECK: %{{[0-9]+}} = zexti %cst_5 : vector<42xi32>
- %88 = zexti %vci32 : vector<42 x i32> to vector<42 x i64>
-
- // CHECK: %{{[0-9]+}} = zexti %cst_4 : tensor<42xi32>
- %89 = zexti %tci32 : tensor<42 x i32> to tensor<42 x i64>
-
- // CHECK: = trunci %arg2 : i32 to i16
- %90 = "std.trunci"(%i) : (i32) -> i16
-
- // CHECK: = trunci %arg2 : i32 to i16
- %91 = trunci %i : i32 to i16
-
- // CHECK: %{{[0-9]+}} = trunci %cst_5 : vector<42xi32>
- %92 = trunci %vci32 : vector<42 x i32> to vector<42 x i16>
-
- // CHECK: %{{[0-9]+}} = trunci %cst_4 : tensor<42xi32>
- %93 = trunci %tci32 : tensor<42 x i32> to tensor<42 x i16>
-
- // CHECK: = fpext {{.*}} : f16 to f32
- %94 = fpext %half : f16 to f32
-
- // CHECK: = fptrunc {{.*}} : f32 to f16
- %95 = fptrunc %f : f32 to f16
-
- // CHECK: %{{[0-9]+}} = absf %arg1 : f32
- %100 = "std.absf"(%f) : (f32) -> f32
-
- // CHECK: %{{[0-9]+}} = absf %arg1 : f32
- %101 = absf %f : f32
-
- // CHECK: %{{[0-9]+}} = absf %cst_8 : vector<4xf32>
- %102 = absf %vcf32 : vector<4xf32>
+ // CHECK: arith.constant true
+ %74 = arith.constant true
- // CHECK: %{{[0-9]+}} = absf %arg0 : tensor<4x4x?xf32>
- %103 = absf %t : tensor<4x4x?xf32>
+ // CHECK: arith.constant false
+ %75 = arith.constant false
- // CHECK: %{{[0-9]+}} = ceilf %arg1 : f32
- %104 = "std.ceilf"(%f) : (f32) -> f32
+ // CHECK: %{{.*}} = math.abs %arg1 : f32
+ %100 = "math.abs"(%f) : (f32) -> f32
- // CHECK: %{{[0-9]+}} = ceilf %arg1 : f32
- %105 = ceilf %f : f32
+ // CHECK: %{{.*}} = math.abs %arg1 : f32
+ %101 = math.abs %f : f32
- // CHECK: %{{[0-9]+}} = ceilf %cst_8 : vector<4xf32>
- %106 = ceilf %vcf32 : vector<4xf32>
+ // CHECK: %{{.*}} = math.abs %{{.*}}: vector<4xf32>
+ %102 = math.abs %vcf32 : vector<4xf32>
- // CHECK: %{{[0-9]+}} = ceilf %arg0 : tensor<4x4x?xf32>
- %107 = ceilf %t : tensor<4x4x?xf32>
+ // CHECK: %{{.*}} = math.abs %arg0 : tensor<4x4x?xf32>
+ %103 = math.abs %t : tensor<4x4x?xf32>
- // CHECK: %{{[0-9]+}} = negf %arg1 : f32
- %112 = "std.negf"(%f) : (f32) -> f32
+ // CHECK: %{{.*}} = math.ceil %arg1 : f32
+ %104 = "math.ceil"(%f) : (f32) -> f32
- // CHECK: %{{[0-9]+}} = negf %arg1 : f32
- %113 = negf %f : f32
+ // CHECK: %{{.*}} = math.ceil %arg1 : f32
+ %105 = math.ceil %f : f32
- // CHECK: %{{[0-9]+}} = negf %cst_8 : vector<4xf32>
- %114 = negf %vcf32 : vector<4xf32>
+ // CHECK: %{{.*}} = math.ceil %{{.*}}: vector<4xf32>
+ %106 = math.ceil %vcf32 : vector<4xf32>
- // CHECK: %{{[0-9]+}} = negf %arg0 : tensor<4x4x?xf32>
- %115 = negf %t : tensor<4x4x?xf32>
+ // CHECK: %{{.*}} = math.ceil %arg0 : tensor<4x4x?xf32>
+ %107 = math.ceil %t : tensor<4x4x?xf32>
- // CHECK: %{{[0-9]+}} = copysign %arg1, %arg1 : f32
- %116 = "std.copysign"(%f, %f) : (f32, f32) -> f32
+ // CHECK: %{{.*}} = math.copysign %arg1, %arg1 : f32
+ %116 = "math.copysign"(%f, %f) : (f32, f32) -> f32
- // CHECK: %{{[0-9]+}} = copysign %arg1, %arg1 : f32
- %117 = copysign %f, %f : f32
+ // CHECK: %{{.*}} = math.copysign %arg1, %arg1 : f32
+ %117 = math.copysign %f, %f : f32
- // CHECK: %{{[0-9]+}} = copysign %cst_8, %cst_8 : vector<4xf32>
- %118 = copysign %vcf32, %vcf32 : vector<4xf32>
+ // CHECK: %{{.*}} = math.copysign %{{.*}}, %{{.*}}: vector<4xf32>
+ %118 = math.copysign %vcf32, %vcf32 : vector<4xf32>
- // CHECK: %{{[0-9]+}} = copysign %arg0, %arg0 : tensor<4x4x?xf32>
- %119 = copysign %t, %t : tensor<4x4x?xf32>
+ // CHECK: %{{.*}} = math.copysign %arg0, %arg0 : tensor<4x4x?xf32>
+ %119 = math.copysign %t, %t : tensor<4x4x?xf32>
- // CHECK: %{{[0-9]+}} = shift_left %arg2, %arg2 : i32
- %124 = "std.shift_left"(%i, %i) : (i32, i32) -> i32
-
- // CHECK:%{{[0-9]+}} = shift_left %[[I2]], %[[I2]] : i32
- %125 = shift_left %i2, %i2 : i32
-
- // CHECK: %{{[0-9]+}} = shift_left %arg3, %arg3 : index
- %126 = shift_left %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = shift_left %cst_5, %cst_5 : vector<42xi32>
- %127 = shift_left %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = shift_left %cst_4, %cst_4 : tensor<42xi32>
- %128 = shift_left %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = shift_right_signed %arg2, %arg2 : i32
- %129 = "std.shift_right_signed"(%i, %i) : (i32, i32) -> i32
-
- // CHECK:%{{[0-9]+}} = shift_right_signed %[[I2]], %[[I2]] : i32
- %130 = shift_right_signed %i2, %i2 : i32
-
- // CHECK: %{{[0-9]+}} = shift_right_signed %arg3, %arg3 : index
- %131 = shift_right_signed %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = shift_right_signed %cst_5, %cst_5 : vector<42xi32>
- %132 = shift_right_signed %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = shift_right_signed %cst_4, %cst_4 : tensor<42xi32>
- %133 = shift_right_signed %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = shift_right_unsigned %arg2, %arg2 : i32
- %134 = "std.shift_right_unsigned"(%i, %i) : (i32, i32) -> i32
-
- // CHECK:%{{[0-9]+}} = shift_right_unsigned %[[I2]], %[[I2]] : i32
- %135 = shift_right_unsigned %i2, %i2 : i32
-
- // CHECK: %{{[0-9]+}} = shift_right_unsigned %arg3, %arg3 : index
- %136 = shift_right_unsigned %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = shift_right_unsigned %cst_5, %cst_5 : vector<42xi32>
- %137 = shift_right_unsigned %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = shift_right_unsigned %cst_4, %cst_4 : tensor<42xi32>
- %138 = shift_right_unsigned %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: = fpext {{.*}} : vector<4xf32> to vector<4xf64>
- %143 = fpext %vcf32 : vector<4xf32> to vector<4xf64>
-
- // CHECK: = fptrunc {{.*}} : vector<4xf32> to vector<4xf16>
- %144 = fptrunc %vcf32 : vector<4xf32> to vector<4xf16>
-
- // CHECK: %{{[0-9]+}} = math.rsqrt %arg1 : f32
+ // CHECK: %{{.*}} = math.rsqrt %arg1 : f32
%145 = math.rsqrt %f : f32
- // CHECK: = fptosi {{.*}} : f32 to i32
- %159 = fptosi %f : f32 to i32
-
- // CHECK: = fptosi {{.*}} : f32 to i64
- %160 = fptosi %f : f32 to i64
-
- // CHECK: = fptosi {{.*}} : f16 to i32
- %161 = fptosi %half : f16 to i32
-
- // CHECK: = fptosi {{.*}} : f16 to i64
- %162 = fptosi %half : f16 to i64
-
- // CHECK: floorf %arg1 : f32
- %163 = "std.floorf"(%f) : (f32) -> f32
-
- // CHECK: %{{[0-9]+}} = floorf %arg1 : f32
- %164 = floorf %f : f32
-
- // CHECK: %{{[0-9]+}} = floorf %cst_8 : vector<4xf32>
- %165 = floorf %vcf32 : vector<4xf32>
-
- // CHECK: %{{[0-9]+}} = floorf %arg0 : tensor<4x4x?xf32>
- %166 = floorf %t : tensor<4x4x?xf32>
-
- // CHECK: %{{[0-9]+}} = floordivi_signed %arg2, %arg2 : i32
- %167 = floordivi_signed %i, %i : i32
-
- // CHECK: %{{[0-9]+}} = floordivi_signed %arg3, %arg3 : index
- %168 = floordivi_signed %idx, %idx : index
-
- // CHECK: %{{[0-9]+}} = floordivi_signed %cst_5, %cst_5 : vector<42xi32>
- %169 = floordivi_signed %vci32, %vci32 : vector<42 x i32>
-
- // CHECK: %{{[0-9]+}} = floordivi_signed %cst_4, %cst_4 : tensor<42xi32>
- %170 = floordivi_signed %tci32, %tci32 : tensor<42 x i32>
-
- // CHECK: %{{[0-9]+}} = ceildivi_signed %arg2, %arg2 : i32
- %171 = ceildivi_signed %i, %i : i32
+ // CHECK: math.floor %arg1 : f32
+ %163 = "math.floor"(%f) : (f32) -> f32
- // CHECK: %{{[0-9]+}} = ceildivi_signed %arg3, %arg3 : index
- %172 = ceildivi_signed %idx, %idx : index
+ // CHECK: %{{.*}} = math.floor %arg1 : f32
+ %164 = math.floor %f : f32
- // CHECK: %{{[0-9]+}} = ceildivi_signed %cst_5, %cst_5 : vector<42xi32>
- %173 = ceildivi_signed %vci32, %vci32 : vector<42 x i32>
+ // CHECK: %{{.*}} = math.floor %{{.*}}: vector<4xf32>
+ %165 = math.floor %vcf32 : vector<4xf32>
- // CHECK: %{{[0-9]+}} = ceildivi_signed %cst_4, %cst_4 : tensor<42xi32>
- %174 = ceildivi_signed %tci32, %tci32 : tensor<42 x i32>
+ // CHECK: %{{.*}} = math.floor %arg0 : tensor<4x4x?xf32>
+ %166 = math.floor %t : tensor<4x4x?xf32>
return
}
// CHECK-LABEL: func @affine_apply() {
func @affine_apply() {
- %i = "std.constant"() {value = 0: index} : () -> index
- %j = "std.constant"() {value = 1: index} : () -> index
+ %i = "arith.constant"() {value = 0: index} : () -> index
+ %j = "arith.constant"() {value = 1: index} : () -> index
// CHECK: affine.apply #map0(%c0)
%a = "affine.apply" (%i) { map = affine_map<(d0) -> (d0 + 1)> } :
// Test static sizes and static offset.
// CHECK: %{{.*}} = memref.view %0[{{.*}}][] : memref<2048xi8> to memref<64x4xf32>
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%5 = memref.view %0[%c0][] : memref<2048xi8> to memref<64x4xf32>
return
}
// CHECK-LABEL: func @memref_subview(%arg0
func @memref_subview(%arg0 : index, %arg1 : index, %arg2 : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc() : memref<8x16x4xf32, affine_map<(d0, d1, d2) -> (d0 * 64 + d1 * 4 + d2)>>
// CHECK: subview %0[%c0, %c0, %c0] [%arg0, %arg1, %arg2] [%c1, %c1, %c1] :
// CHECK-LABEL: func @test_dimop
// CHECK-SAME: %[[ARG:.*]]: tensor<4x4x?xf32>
func @test_dimop(%arg0: tensor<4x4x?xf32>) {
- // CHECK: %[[C2:.*]] = constant 2 : index
+ // CHECK: %[[C2:.*]] = arith.constant 2 : index
// CHECK: %{{.*}} = tensor.dim %[[ARG]], %[[C2]] : tensor<4x4x?xf32>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%0 = tensor.dim %arg0, %c2 : tensor<4x4x?xf32>
// use dim as an index to ensure type correctness
%1 = affine.apply affine_map<(d0) -> (d0)>(%0)
%x = generic_atomic_rmw %I[%i, %j] : memref<1x2xf32> {
// CHECK-NEXT: generic_atomic_rmw [[BUF]]{{\[}}[[I]], [[J]]] : memref
^bb0(%old_value : f32):
- %c1 = constant 1.0 : f32
- %out = addf %c1, %old_value : f32
+ %c1 = arith.constant 1.0 : f32
+ %out = arith.addf %c1, %old_value : f32
atomic_yield %out : f32
// CHECK: index_attr = 8 : index
} { index_attr = 8 : index }
// CHECK-LABEL: func @slice({{.*}}) {
func @slice(%t: tensor<8x16x4xf32>, %idx : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// CHECK: tensor.extract_slice
// CHECK-SAME: tensor<8x16x4xf32> to tensor<?x?x?xf32>
%t2: tensor<16x32x8xf32>,
%t3: tensor<4x4xf32>,
%idx : index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// CHECK: tensor.insert_slice
// CHECK-SAME: tensor<8x16x4xf32> into tensor<16x32x8xf32>
// Emit the first available call stack in the fused location.
func @constant_out_of_range() {
- // CHECK: mysource1:0:0: error: 'std.constant' op requires attribute's type ('i64') to match op's return type ('i1')
+ // CHECK: mysource1:0:0: error: 'arith.constant' op failed to verify that result and attribute have the same type
// CHECK-NEXT: mysource2:1:0: note: called from
// CHECK-NEXT: mysource3:2:0: note: called from
- %x = "std.constant"() {value = 100} : () -> i1 loc(fused["bar", callsite("foo"("mysource1":0:0) at callsite("mysource2":1:0 at "mysource3":2:0))])
+ %x = "arith.constant"() {value = 100} : () -> i1 loc(fused["bar", callsite("foo"("mysource1":0:0) at callsite("mysource2":1:0 at "mysource3":2:0))])
return
}
// expected-error@below {{Test iterating `uint64_t`: 10, 11, 12, 13, 14}}
// expected-error@below {{Test iterating `APInt`: 10, 11, 12, 13, 14}}
// expected-error@below {{Test iterating `IntegerAttr`: 10 : i64, 11 : i64, 12 : i64, 13 : i64, 14 : i64}}
-std.constant #test.i64_elements<[10, 11, 12, 13, 14]> : tensor<5xi64>
+arith.constant #test.i64_elements<[10, 11, 12, 13, 14]> : tensor<5xi64>
// expected-error@below {{Test iterating `uint64_t`: 10, 11, 12, 13, 14}}
// expected-error@below {{Test iterating `APInt`: 10, 11, 12, 13, 14}}
// expected-error@below {{Test iterating `IntegerAttr`: 10 : i64, 11 : i64, 12 : i64, 13 : i64, 14 : i64}}
-std.constant dense<[10, 11, 12, 13, 14]> : tensor<5xi64>
+arith.constant dense<[10, 11, 12, 13, 14]> : tensor<5xi64>
// expected-error@below {{Test iterating `uint64_t`: unable to iterate type}}
// expected-error@below {{Test iterating `APInt`: unable to iterate type}}
// expected-error@below {{Test iterating `IntegerAttr`: unable to iterate type}}
-std.constant opaque<"_", "0xDEADBEEF"> : tensor<5xi64>
+arith.constant opaque<"_", "0xDEADBEEF"> : tensor<5xi64>
// Check that we don't crash on empty element attributes.
// expected-error@below {{Test iterating `uint64_t`: }}
// expected-error@below {{Test iterating `APInt`: }}
// expected-error@below {{Test iterating `IntegerAttr`: }}
-std.constant dense<> : tensor<0xi64>
+arith.constant dense<> : tensor<0xi64>
// RUN: mlir-opt -allow-unregistered-dialect %s -split-input-file -verify-diagnostics
func @dim(%arg : tensor<1x?xf32>) {
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
tensor.dim %arg, %c2 : tensor<1x?xf32> // expected-error {{'tensor.dim' op index is out of range}}
return
}
}
// -----
-
-func @constant() {
-^bb:
- %x = "std.constant"(){value = "xyz"} : () -> i32 // expected-error {{unsupported 'value' attribute}}
- return
-}
-
-// -----
-
-func @constant_out_of_range() {
-^bb:
- %x = "std.constant"(){value = 100} : () -> i1 // expected-error {{requires attribute's type ('i64') to match op's return type ('i1')}}
- return
-}
-
-// -----
-
-func @constant_wrong_type() {
-^bb:
- %x = "std.constant"(){value = 10.} : () -> f32 // expected-error {{requires attribute's type ('f64') to match op's return type ('f32')}}
- return
-}
-
-// -----
func @affine_apply_no_map() {
^bb0:
- %i = constant 0 : index
+ %i = arith.constant 0 : index
%x = "affine.apply" (%i) { } : (index) -> (index) // expected-error {{requires attribute 'map'}}
return
}
func @affine_apply_wrong_operand_count() {
^bb0:
- %i = constant 0 : index
+ %i = arith.constant 0 : index
%x = "affine.apply" (%i) {map = affine_map<(d0, d1) -> ((d0 + 1), (d1 + 2))>} : (index) -> (index) // expected-error {{'affine.apply' op operand count and affine map dimension and symbol count must match}}
return
}
func @affine_apply_wrong_result_count() {
^bb0:
- %i = constant 0 : index
- %j = constant 1 : index
+ %i = arith.constant 0 : index
+ %j = arith.constant 1 : index
%x = "affine.apply" (%i, %j) {map = affine_map<(d0, d1) -> ((d0 + 1), (d1 + 2))>} : (index,index) -> (index) // expected-error {{'affine.apply' op mapping must produce one value}}
return
}
func @bad_alloc_wrong_dynamic_dim_count() {
^bb0:
- %0 = constant 7 : index
+ %0 = arith.constant 7 : index
// Test alloc with wrong number of dynamic dimensions.
// expected-error@+1 {{dimension operand count does not equal memref dynamic dimension count}}
%1 = memref.alloc(%0)[%0] : memref<2x4xf32, affine_map<(d0, d1)[s0] -> ((d0 + s0), d1)>, 1>
func @bad_alloc_wrong_symbol_count() {
^bb0:
- %0 = constant 7 : index
+ %0 = arith.constant 7 : index
// Test alloc with wrong number of symbols
// expected-error@+1 {{symbol operand count does not equal memref symbol count}}
%1 = memref.alloc(%0) : memref<2x?xf32, affine_map<(d0, d1)[s0] -> ((d0 + s0), d1)>, 1>
func @test_store_zero_results() {
^bb0:
%0 = memref.alloc() : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
- %1 = constant 0 : index
- %2 = constant 1 : index
+ %1 = arith.constant 0 : index
+ %2 = arith.constant 1 : index
%3 = memref.load %0[%1, %2] : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
// Test that store returns zero results.
%4 = memref.store %3, %0[%1, %2] : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1> // expected-error {{cannot name an operation with no results}}
// -----
-func @intlimit2() {
-^bb:
- %0 = "std.constant"() {value = 0} : () -> i16777215
- %1 = "std.constant"() {value = 1} : () -> i16777216 // expected-error {{integer bitwidth is limited to 16777215 bits}}
- return
-}
-
-// -----
-
func @calls(%arg0: i32) {
%x = call @calls() : () -> i32 // expected-error {{incorrect number of operands for callee}}
return
// -----
-func @func_with_ops(f32) {
-^bb0(%a : f32):
- %sf = addf %a, %a, %a : f32 // expected-error {{'std.addf' op expected 2 operands}}
-}
-
-// -----
-
-func @func_with_ops(f32) {
-^bb0(%a : f32):
- %sf = addf(%a, %a) : f32 // expected-error {{'std.addf' expected function type}}
-}
-
-// -----
-
-func @func_with_ops(f32) {
-^bb0(%a : f32):
- %sf = addf{%a, %a} : f32 // expected-error {{expected attribute name}}
-}
-
-// -----
-
-func @func_with_ops(f32) {
-^bb0(%a : f32):
- // expected-error@+1 {{'std.addi' op operand #0 must be signless-integer-like}}
- %sf = addi %a, %a : f32
-}
-
-// -----
-
-func @func_with_ops(i32) {
-^bb0(%a : i32):
- %sf = addf %a, %a : i32 // expected-error {{'std.addf' op operand #0 must be floating-point-like}}
-}
-
-// -----
-
-func @func_with_ops(i32) {
-^bb0(%a : i32):
- // expected-error@+1 {{failed to satisfy constraint: allowed 64-bit signless integer cases: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9}}
- %r = "std.cmpi"(%a, %a) {predicate = 42} : (i32, i32) -> i1
-}
-
-// -----
-
-// Comparison are defined for arguments of the same type.
-func @func_with_ops(i32, i64) {
-^bb0(%a : i32, %b : i64): // expected-note {{prior use here}}
- %r = cmpi eq, %a, %b : i32 // expected-error {{use of value '%b' expects different type than prior uses}}
-}
-
-// -----
-
-// Comparisons must have the "predicate" attribute.
-func @func_with_ops(i32, i32) {
-^bb0(%a : i32, %b : i32):
- %r = cmpi %a, %b : i32 // expected-error {{expected string or keyword containing one of the following enum values}}
-}
-
-// -----
-
-// Integer comparisons are not recognized for float types.
-func @func_with_ops(f32, f32) {
-^bb0(%a : f32, %b : f32):
- %r = cmpi eq, %a, %b : f32 // expected-error {{'lhs' must be signless-integer-like, but got 'f32'}}
-}
-
-// -----
-
-// Result type must be boolean like.
-func @func_with_ops(i32, i32) {
-^bb0(%a : i32, %b : i32):
- %r = "std.cmpi"(%a, %b) {predicate = 0} : (i32, i32) -> i32 // expected-error {{op result #0 must be bool-like}}
-}
-
-// -----
-
-func @func_with_ops(i32, i32) {
-^bb0(%a : i32, %b : i32):
- // expected-error@+1 {{requires attribute 'predicate'}}
- %r = "std.cmpi"(%a, %b) {foo = 1} : (i32, i32) -> i1
-}
-
-// -----
-
-func @func_with_ops() {
-^bb0:
- %c = constant dense<0> : vector<42 x i32>
- // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
- %r = "std.cmpi"(%c, %c) {predicate = 0} : (vector<42 x i32>, vector<42 x i32>) -> vector<41 x i1>
-}
-
-// -----
-
func @func_with_ops(i32, i32, i32) {
^bb0(%cond : i32, %t : i32, %f : i32):
// expected-error@+2 {{different type than prior uses}}
// -----
-func @invalid_cmp_shape(%idx : () -> ()) {
- // expected-error@+1 {{'lhs' must be signless-integer-like, but got '() -> ()'}}
- %cmp = cmpi eq, %idx, %idx : () -> ()
-
-// -----
-
-func @invalid_cmp_attr(%idx : i32) {
- // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
- %cmp = cmpi i1, %idx, %idx : i32
-
-// -----
-
-func @cmpf_generic_invalid_predicate_value(%a : f32) {
- // expected-error@+1 {{attribute 'predicate' failed to satisfy constraint: allowed 64-bit signless integer cases}}
- %r = "std.cmpf"(%a, %a) {predicate = 42} : (f32, f32) -> i1
-}
-
-// -----
-
-func @cmpf_canonical_invalid_predicate_value(%a : f32) {
- // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
- %r = cmpf foo, %a, %a : f32
-}
-
-// -----
-
-func @cmpf_canonical_invalid_predicate_value_signed(%a : f32) {
- // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
- %r = cmpf sge, %a, %a : f32
-}
-
-// -----
-
-func @cmpf_canonical_invalid_predicate_value_no_order(%a : f32) {
- // expected-error@+1 {{expected string or keyword containing one of the following enum values}}
- %r = cmpf eq, %a, %a : f32
-}
-
-// -----
-
-func @cmpf_canonical_no_predicate_attr(%a : f32, %b : f32) {
- %r = cmpf %a, %b : f32 // expected-error {{}}
-}
-
-// -----
-
-func @cmpf_generic_no_predicate_attr(%a : f32, %b : f32) {
- // expected-error@+1 {{requires attribute 'predicate'}}
- %r = "std.cmpf"(%a, %b) {foo = 1} : (f32, f32) -> i1
-}
-
-// -----
-
-func @cmpf_wrong_type(%a : i32, %b : i32) {
- %r = cmpf oeq, %a, %b : i32 // expected-error {{must be floating-point-like}}
-}
-
-// -----
-
-func @cmpf_generic_wrong_result_type(%a : f32, %b : f32) {
- // expected-error@+1 {{result #0 must be bool-like}}
- %r = "std.cmpf"(%a, %b) {predicate = 0} : (f32, f32) -> f32
-}
-
-// -----
-
-func @cmpf_canonical_wrong_result_type(%a : f32, %b : f32) -> f32 {
- %r = cmpf oeq, %a, %b : f32 // expected-note {{prior use here}}
- // expected-error@+1 {{use of value '%r' expects different type than prior uses}}
- return %r : f32
-}
-
-// -----
-
-func @cmpf_result_shape_mismatch(%a : vector<42xf32>) {
- // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
- %r = "std.cmpf"(%a, %a) {predicate = 0} : (vector<42 x f32>, vector<42 x f32>) -> vector<41 x i1>
-}
-
-// -----
-
-func @cmpf_operand_shape_mismatch(%a : vector<42xf32>, %b : vector<41xf32>) {
- // expected-error@+1 {{op requires all operands to have the same type}}
- %r = "std.cmpf"(%a, %b) {predicate = 0} : (vector<42 x f32>, vector<41 x f32>) -> vector<42 x i1>
-}
-
-// -----
-
-func @cmpf_generic_operand_type_mismatch(%a : f32, %b : f64) {
- // expected-error@+1 {{op requires all operands to have the same type}}
- %r = "std.cmpf"(%a, %b) {predicate = 0} : (f32, f64) -> i1
-}
-
-// -----
-
-func @cmpf_canonical_type_mismatch(%a : f32, %b : f64) { // expected-note {{prior use here}}
- // expected-error@+1 {{use of value '%b' expects different type than prior uses}}
- %r = cmpf oeq, %a, %b : f32
-}
-
-// -----
-
-func @index_cast_index_to_index(%arg0: index) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = index_cast %arg0: index to index
- return
-}
-
-// -----
-
-func @index_cast_float(%arg0: index, %arg1: f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = index_cast %arg0 : index to f32
- return
-}
-
-// -----
-
-func @index_cast_float_to_index(%arg0: f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = index_cast %arg0 : f32 to index
- return
-}
-
-// -----
-
-func @sitofp_i32_to_i64(%arg0 : i32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = sitofp %arg0 : i32 to i64
- return
-}
-
-// -----
-
-func @sitofp_f32_to_i32(%arg0 : f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = sitofp %arg0 : f32 to i32
- return
-}
-
-// -----
-
-func @fpext_f32_to_f16(%arg0 : f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : f32 to f16
- return
-}
-
-// -----
-
-func @fpext_f16_to_f16(%arg0 : f16) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : f16 to f16
- return
-}
-
-// -----
-
-func @fpext_i32_to_f32(%arg0 : i32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : i32 to f32
- return
-}
-
-// -----
-
-func @fpext_f32_to_i32(%arg0 : f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : f32 to i32
- return
-}
-
-// -----
-
-func @fpext_vec(%arg0 : vector<2xf16>) {
- // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
- %0 = fpext %arg0 : vector<2xf16> to vector<3xf32>
- return
-}
-
-// -----
-
-func @fpext_vec_f32_to_f16(%arg0 : vector<2xf32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : vector<2xf32> to vector<2xf16>
- return
-}
-
-// -----
-
-func @fpext_vec_f16_to_f16(%arg0 : vector<2xf16>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : vector<2xf16> to vector<2xf16>
- return
-}
-
-// -----
-
-func @fpext_vec_i32_to_f32(%arg0 : vector<2xi32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : vector<2xi32> to vector<2xf32>
- return
-}
-
-// -----
-
-func @fpext_vec_f32_to_i32(%arg0 : vector<2xf32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fpext %arg0 : vector<2xf32> to vector<2xi32>
- return
-}
-
-// -----
-
-func @fptrunc_f16_to_f32(%arg0 : f16) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : f16 to f32
- return
-}
-
-// -----
-
-func @fptrunc_f32_to_f32(%arg0 : f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : f32 to f32
- return
-}
-
-// -----
-
-func @fptrunc_i32_to_f32(%arg0 : i32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : i32 to f32
- return
-}
-
-// -----
-
-func @fptrunc_f32_to_i32(%arg0 : f32) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : f32 to i32
- return
-}
-
-// -----
-
-func @fptrunc_vec(%arg0 : vector<2xf16>) {
- // expected-error@+1 {{all non-scalar operands/results must have the same shape and base type}}
- %0 = fptrunc %arg0 : vector<2xf16> to vector<3xf32>
- return
-}
-
-// -----
-
-func @fptrunc_vec_f16_to_f32(%arg0 : vector<2xf16>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : vector<2xf16> to vector<2xf32>
- return
-}
-
-// -----
-
-func @fptrunc_vec_f32_to_f32(%arg0 : vector<2xf32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : vector<2xf32> to vector<2xf32>
- return
-}
-
-// -----
-
-func @fptrunc_vec_i32_to_f32(%arg0 : vector<2xi32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : vector<2xi32> to vector<2xf32>
- return
-}
-
-// -----
-
-func @fptrunc_vec_f32_to_i32(%arg0 : vector<2xf32>) {
- // expected-error@+1 {{are cast incompatible}}
- %0 = fptrunc %arg0 : vector<2xf32> to vector<2xi32>
- return
-}
-
-// -----
-
-func @sexti_index_as_operand(%arg0 : index) {
- // expected-error@+1 {{'index' is not a valid operand type}}
- %0 = sexti %arg0 : index to i128
- return
-}
-
-// -----
-
-func @zexti_index_as_operand(%arg0 : index) {
- // expected-error@+1 {{'index' is not a valid operand type}}
- %0 = zexti %arg0 : index to i128
- return
-}
-
-// -----
-
-func @trunci_index_as_operand(%arg0 : index) {
- // expected-error@+1 {{'index' is not a valid operand type}}
- %2 = trunci %arg0 : index to i128
- return
-}
-
-// -----
-
-func @sexti_index_as_result(%arg0 : i1) {
- // expected-error@+1 {{'index' is not a valid result type}}
- %0 = sexti %arg0 : i1 to index
- return
-}
-
-// -----
-
-func @zexti_index_as_operand(%arg0 : i1) {
- // expected-error@+1 {{'index' is not a valid result type}}
- %0 = zexti %arg0 : i1 to index
- return
-}
-
-// -----
-
-func @trunci_index_as_result(%arg0 : i128) {
- // expected-error@+1 {{'index' is not a valid result type}}
- %2 = trunci %arg0 : i128 to index
- return
-}
-
-// -----
-
-func @sexti_cast_to_narrower(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = sexti %arg0 : i16 to i15
- return
-}
-
-// -----
-
-func @zexti_cast_to_narrower(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = zexti %arg0 : i16 to i15
- return
-}
-
-// -----
-
-func @trunci_cast_to_wider(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = trunci %arg0 : i16 to i17
- return
-}
-
-// -----
-
-func @sexti_cast_to_same_width(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = sexti %arg0 : i16 to i16
- return
-}
-
-// -----
-
-func @zexti_cast_to_same_width(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = zexti %arg0 : i16 to i16
- return
-}
-
-// -----
-
-func @trunci_cast_to_same_width(%arg0 : i16) {
- // expected-error@+1 {{must be wider}}
- %0 = trunci %arg0 : i16 to i16
- return
-}
-
-// -----
-
func @return_not_in_function() {
"foo.region"() ({
// expected-error@+1 {{'std.return' op expects parent op 'builtin.func'}}
// expected-error@+1 {{expected single number of entry block arguments}}
%x = generic_atomic_rmw %I[%i] : memref<10xf32> {
^bb0(%arg0 : f32, %arg1 : f32):
- %c1 = constant 1.0 : f32
+ %c1 = arith.constant 1.0 : f32
atomic_yield %c1 : f32
}
return
// expected-error@+1 {{expected block argument of the same type result type}}
%x = generic_atomic_rmw %I[%i] : memref<10xf32> {
^bb0(%old_value : i32):
- %c1 = constant 1.0 : f32
+ %c1 = arith.constant 1.0 : f32
atomic_yield %c1 : f32
}
return
// expected-error@+1 {{failed to verify that result type matches element type of memref}}
%0 = "std.generic_atomic_rmw"(%I, %i) ( {
^bb0(%old_value: f32):
- %c1 = constant 1.0 : f32
+ %c1 = arith.constant 1.0 : f32
atomic_yield %c1 : f32
}) : (memref<10xf32>, index) -> i32
return
// expected-error@+4 {{should contain only operations with no side effects}}
%x = generic_atomic_rmw %I[%i] : memref<10xf32> {
^bb0(%old_value : f32):
- %c1 = constant 1.0 : f32
+ %c1 = arith.constant 1.0 : f32
%buf = memref.alloc() : memref<2048xf32>
atomic_yield %c1 : f32
}
// expected-error@+4 {{op types mismatch between yield op: 'i32' and its parent: 'f32'}}
%x = generic_atomic_rmw %I[%i] : memref<10xf32> {
^bb0(%old_value : f32):
- %c1 = constant 1 : i32
+ %c1 = arith.constant 1 : i32
atomic_yield %c1 : i32
}
return
// -----
func @illegaltype() {
- %0 = constant dense<0> : <vector 4 x f32> : vector<4 x f32> // expected-error {{expected non-function type}}
+ %0 = arith.constant dense<0> : <vector 4 x f32> : vector<4 x f32> // expected-error {{expected non-function type}}
}
// -----
// -----
func @no_return() {
- %x = constant 0 : i32
- %y = constant 1 : i32 // expected-error {{block with no terminator}}
+ %x = arith.constant 0 : i32
+ %y = arith.constant 1 : i32 // expected-error {{block with no terminator}}
}
// -----
func @no_terminator() {
br ^bb1
^bb1:
- %x = constant 0 : i32
- %y = constant 1 : i32 // expected-error {{block with no terminator}}
+ %x = arith.constant 0 : i32
+ %y = arith.constant 1 : i32 // expected-error {{block with no terminator}}
}
// -----
func @successors_in_non_terminator(%a : i32, %b : i32) {
- %c = "std.addi"(%a, %b)[^bb1] : () -> () // expected-error {{successors in non-terminator}}
+ %c = "arith.addi"(%a, %b)[^bb1] : () -> () // expected-error {{successors in non-terminator}}
^bb1:
return
}
// `tensor` as operator rather than as a type.
func @f(f32) {
^bb0(%a : f32):
- %18 = cmpi slt, %idx, %idx : index
+ %18 = arith.cmpi slt, %idx, %idx : index
tensor<42 x index // expected-error {{custom op 'tensor' is unknown}}
return
}
// -----
func @invalid_affine_structure() {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%idx = affine.apply affine_map<(d0, d1)> (%c0, %c0) // expected-error {{expected '->' or ':'}}
return
}
^bb2:
// expected-note @+1 {{operand defined here}}
- %1 = constant 0 : i32
+ %1 = arith.constant 0 : i32
"foo.yield" () : () -> ()
}) : () -> ()
return
func @invalid_region_dominance() {
"foo.use" (%1) : (i32) -> ()
"foo.region"() ({
- %1 = constant 0 : i32 // This value is used outside of the region.
+ %1 = arith.constant 0 : i32 // This value is used outside of the region.
"foo.yield" () : () -> ()
}, {
// expected-error @+1 {{expected operation name in quotes}}
- %2 = constant 1 i32 // Syntax error causes region deletion.
+ %2 = arith.constant 1 i32 // Syntax error causes region deletion.
}) : () -> ()
return
}
"foo.yield"() : () -> ()
}, {
// expected-error @+1 {{expected operation name in quotes}}
- %2 = constant 1 i32 // Syntax error causes region deletion.
+ %2 = arith.constant 1 i32 // Syntax error causes region deletion.
}) : () -> ()
}
"foo.use" (%1) : (i32) -> ()
"foo.region"() ({
"foo.region"() ({
- %1 = constant 0 : i32 // This value is used outside of the region.
+ %1 = arith.constant 0 : i32 // This value is used outside of the region.
"foo.yield" () : () -> ()
}) : () -> ()
}, {
// expected-error @+1 {{expected operation name in quotes}}
- %2 = constant 1 i32 // Syntax error causes region deletion.
+ %2 = arith.constant 1 i32 // Syntax error causes region deletion.
}) : () -> ()
return
}
// -----
func @dominance_error_in_unreachable_op() -> i1 {
- %c = constant false
+ %c = arith.constant false
return %c : i1
^bb0:
"test.ssacfg_region" () ({ // unreachable
test.graph_region {
"foo.use" (%1) : (i32) -> ()
"foo.region"() ({
- %1 = constant 0 : i32 // This value is used outside of the region.
+ %1 = arith.constant 0 : i32 // This value is used outside of the region.
"foo.yield" () : () -> ()
}, {
// expected-error @+1 {{expected operation name in quotes}}
- %2 = constant 1 i32 // Syntax error causes region deletion.
+ %2 = arith.constant 1 i32 // Syntax error causes region deletion.
}) : () -> ()
}
return
// CHECK: -> i32 loc("foo")
%1 = "foo"() : () -> i32 loc("foo")
- // CHECK: constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
- %2 = constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ // CHECK: arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ %2 = arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
// CHECK: } loc(fused["foo", "mysource.cc":10:8])
affine.for %i0 = 0 to 8 {
// CHECK-SAME: %arg2: i32 loc("out_of_line_location2")):
// CHECK-ALIAS-SAME: %arg2: i32 loc("out_of_line_location2")):
%z: i32 loc("out_of_line_location2")):
- %1 = addi %x, %y : i32
+ %1 = arith.addi %x, %y : i32
"foo.yield"(%1) : (i32) -> ()
}) : () -> ()
// CHECK: %0 = memref.alloc() : memref<1024x64xf32, 1>
%0 = memref.alloc() : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
- %c0 = "std.constant"() {value = 0: index} : () -> index
- %c1 = "std.constant"() {value = 1: index} : () -> index
+ %c0 = "arith.constant"() {value = 0: index} : () -> index
+ %c1 = "arith.constant"() {value = 1: index} : () -> index
// Test alloc with dynamic dimensions.
// CHECK: %1 = memref.alloc(%c0, %c1) : memref<?x?xf32, 1>
// CHECK: %0 = memref.alloca() : memref<1024x64xf32, 1>
%0 = memref.alloca() : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
- %c0 = "std.constant"() {value = 0: index} : () -> index
- %c1 = "std.constant"() {value = 1: index} : () -> index
+ %c0 = "arith.constant"() {value = 0: index} : () -> index
+ %c1 = "arith.constant"() {value = 1: index} : () -> index
// Test alloca with dynamic dimensions.
// CHECK: %1 = memref.alloca(%c0, %c1) : memref<?x?xf32, 1>
// CHECK: %0 = memref.alloc() : memref<1024x64xf32, 1>
%0 = memref.alloc() : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
- %1 = constant 0 : index
- %2 = constant 1 : index
+ %1 = arith.constant 0 : index
+ %2 = arith.constant 1 : index
// CHECK: %1 = memref.load %0[%c0, %c1] : memref<1024x64xf32, 1>
%3 = memref.load %0[%1, %2] : memref<1024x64xf32, affine_map<(d0, d1) -> (d0, d1)>, 1>
// CHECK-LABEL: func @dma_ops()
func @dma_ops() {
- %c0 = constant 0 : index
- %stride = constant 32 : index
- %elt_per_stride = constant 16 : index
+ %c0 = arith.constant 0 : index
+ %stride = arith.constant 32 : index
+ %elt_per_stride = arith.constant 16 : index
%A = memref.alloc() : memref<256 x f32, affine_map<(d0) -> (d0)>, 0>
%Ah = memref.alloc() : memref<256 x f32, affine_map<(d0) -> (d0)>, 1>
%tag = memref.alloc() : memref<1 x f32>
- %num_elements = constant 256 : index
+ %num_elements = arith.constant 256 : index
memref.dma_start %A[%c0], %Ah[%c0], %num_elements, %tag[%c0] : memref<256 x f32>, memref<256 x f32, 1>, memref<1 x f32>
memref.dma_wait %tag[%c0], %num_elements : memref<1 x f32>
func @main(tensor<4xf32>, tensor<4xf32>) -> tensor<4xf32> {
^bb0(%arg0: tensor<4xf32>, %arg1: tensor<4xf32>):
- %0 = addf %arg0, %arg1 : tensor<4xf32>
- %1 = addf %arg0, %arg1 : tensor<4xf32>
- %2 = addf %arg0, %arg1 : tensor<4xf32>
- %3 = addf %arg0, %arg1 : tensor<4xf32>
- %4 = addf %arg0, %arg1 : tensor<4xf32>
- %5 = addf %arg0, %arg1 : tensor<4xf32>
+ %0 = arith.addf %arg0, %arg1 : tensor<4xf32>
+ %1 = arith.addf %arg0, %arg1 : tensor<4xf32>
+ %2 = arith.addf %arg0, %arg1 : tensor<4xf32>
+ %3 = arith.addf %arg0, %arg1 : tensor<4xf32>
+ %4 = arith.addf %arg0, %arg1 : tensor<4xf32>
+ %5 = arith.addf %arg0, %arg1 : tensor<4xf32>
%10 = "xla.add"(%0, %arg1) : (tensor<4xf32>,tensor<4xf32>)-> tensor<4xf32>
%11 = "xla.add"(%0, %arg1) : (tensor<4xf32>,tensor<4xf32>)-> tensor<4xf32>
%12 = "xla.add"(%0, %arg1) : (tensor<4xf32>,tensor<4xf32>)-> tensor<4xf32>
}
// CHECK-LABEL: Operations encountered
+// CHECK: arith.addf , 6
// CHECK: long_op_name , 1
-// CHECK: std.addf , 6
// CHECK: std.return , 1
// CHECK: xla.add , 17
// CHECK: MyLocation: 0: 'test.foo' op
// CHECK: nullptr: 'test.foo' op
// CHECK: MyLocation: 0: 'test.foo' op
-// CHECK: MyLocation: 1: 'std.constant' op
-// CHECK: nullptr: 'std.constant' op
-// CHECK: MyLocation: 1: 'std.constant' op
+// CHECK: MyLocation: 1: 'arith.constant' op
+// CHECK: nullptr: 'arith.constant' op
+// CHECK: MyLocation: 1: 'arith.constant' op
// CHECK-LABEL: func @inline_notation
func @inline_notation() -> i32 {
// CHECK: -> i32 loc(unknown)
%1 = "test.foo"() : () -> i32 loc("foo")
- // CHECK: constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
- // CHECK: constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
- // CHECK: constant 4 : index loc(unknown)
- %2 = constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ // CHECK: arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ // CHECK: arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ // CHECK: arith.constant 4 : index loc(unknown)
+ %2 = arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
// CHECK: } loc(unknown)
affine.for %i0 = 0 to 8 {
return
}
func @invalid_call_operandtype() {
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
// expected-error @+1 {{operand type mismatch: expected operand type 'i32', but provided 'f32' for operand number 0}}
call @testfunc(%0) : (f32) -> ()
return
// CHECK: func @triang_loop(%{{.*}}: index, %{{.*}}: memref<?x?xi32>) {
func @triang_loop(%arg0: index, %arg1: memref<?x?xi32>) {
- %c = constant 0 : i32 // CHECK: %{{.*}} = constant 0 : i32
+ %c = arith.constant 0 : i32 // CHECK: %{{.*}} = arith.constant 0 : i32
affine.for %i0 = 1 to %arg0 { // CHECK: affine.for %{{.*}} = 1 to %{{.*}} {
affine.for %i1 = affine_map<(d0)[]->(d0)>(%i0)[] to %arg0 { // CHECK: affine.for %{{.*}} = #map{{[0-9]+}}(%{{.*}}) to %{{.*}} {
memref.store %c, %arg1[%i0, %i1] : memref<?x?xi32> // CHECK: memref.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}]
affine.for %k = #bound_map1 (%w1, %i)[%N] to affine_map<(i, j)[s] -> (i + j + s)> (%w2, %j)[%s] {
// CHECK: "foo"(%{{.*}}, %{{.*}}, %{{.*}}) : (index, index, index) -> ()
"foo"(%i, %j, %k) : (index, index, index)->()
- // CHECK: %{{.*}} = constant 30 : index
- %c = constant 30 : index
+ // CHECK: %{{.*}} = arith.constant 30 : index
+ %c = arith.constant 30 : index
// CHECK: %{{.*}} = affine.apply #map{{.*}}(%{{.*}}, %{{.*}})
%u = affine.apply affine_map<(d0, d1)->(d0+d1)> (%N, %c)
// CHECK: affine.for %{{.*}} = max #map{{.*}}(%{{.*}})[%{{.*}}] to min #map{{.*}}(%{{.*}})[%{{.*}}] {
// CHECK-LABEL: func @ifinst(%{{.*}}: index) {
func @ifinst(%N: index) {
- %c = constant 200 : index // CHECK %{{.*}} = constant 200
+ %c = arith.constant 200 : index // CHECK %{{.*}} = arith.constant 200
affine.for %i = 1 to 10 { // CHECK affine.for %{{.*}} = 1 to 10 {
affine.if #set0(%i)[%N, %c] { // CHECK affine.if #set0(%{{.*}})[%{{.*}}, %{{.*}}] {
- %x = constant 1 : i32
- // CHECK: %{{.*}} = constant 1 : i32
+ %x = arith.constant 1 : i32
+ // CHECK: %{{.*}} = arith.constant 1 : i32
%y = "add"(%x, %i) : (i32, index) -> i32 // CHECK: %{{.*}} = "add"(%{{.*}}, %{{.*}}) : (i32, index) -> i32
%z = "mul"(%y, %y) : (i32, i32) -> i32 // CHECK: %{{.*}} = "mul"(%{{.*}}, %{{.*}}) : (i32, i32) -> i32
} else { // CHECK } else {
affine.if affine_set<(i)[N] : (i - 2 >= 0, 4 - i >= 0)>(%i)[%N] { // CHECK affine.if (#set1(%{{.*}})[%{{.*}}]) {
- // CHECK: %{{.*}} = constant 1 : index
- %u = constant 1 : index
+ // CHECK: %{{.*}} = arith.constant 1 : index
+ %u = arith.constant 1 : index
// CHECK: %{{.*}} = affine.apply #map{{.*}}(%{{.*}}, %{{.*}})[%{{.*}}]
%w = affine.apply affine_map<(d0,d1)[s0] -> (d0+d1+s0)> (%i, %i) [%u]
} else { // CHECK } else {
- %v = constant 3 : i32 // %c3_i32 = constant 3 : i32
+ %v = arith.constant 3 : i32 // %c3_i32 = arith.constant 3 : i32
}
} // CHECK }
} // CHECK }
// CHECK-LABEL: func @simple_ifinst(%{{.*}}: index) {
func @simple_ifinst(%N: index) {
- %c = constant 200 : index // CHECK %{{.*}} = constant 200
+ %c = arith.constant 200 : index // CHECK %{{.*}} = arith.constant 200
affine.for %i = 1 to 10 { // CHECK affine.for %{{.*}} = 1 to 10 {
affine.if #set0(%i)[%N, %c] { // CHECK affine.if #set0(%{{.*}})[%{{.*}}, %{{.*}}] {
- %x = constant 1 : i32
- // CHECK: %{{.*}} = constant 1 : i32
+ %x = arith.constant 1 : i32
+ // CHECK: %{{.*}} = arith.constant 1 : i32
%y = "add"(%x, %i) : (i32, index) -> i32 // CHECK: %{{.*}} = "add"(%{{.*}}, %{{.*}}) : (i32, index) -> i32
%z = "mul"(%y, %y) : (i32, i32) -> i32 // CHECK: %{{.*}} = "mul"(%{{.*}}, %{{.*}}) : (i32, i32) -> i32
} // CHECK }
"std.cond_br"(%x, %y, %x, %y) [^bb2, ^bb3] {operand_segment_sizes = dense<[1, 1, 2]>: vector<3xi32>} : (i1, i17, i1, i17) -> ()
^bb2(%a : i17):
- %true = constant true
+ %true = arith.constant true
// CHECK: return %{{.*}}, %{{.*}} : i1, i17
"std.return"(%true, %a) : (i1, i17) -> ()
// Test pretty printing of constant names.
// CHECK-LABEL: func @constants
func @constants() -> (i32, i23, i23, i1, i1) {
- // CHECK: %{{.*}} = constant 42 : i32
- %x = constant 42 : i32
- // CHECK: %{{.*}} = constant 17 : i23
- %y = constant 17 : i23
+ // CHECK: %{{.*}} = arith.constant 42 : i32
+ %x = arith.constant 42 : i32
+ // CHECK: %{{.*}} = arith.constant 17 : i23
+ %y = arith.constant 17 : i23
// This is a redundant definition of 17, the asmprinter gives it a unique name
- // CHECK: %{{.*}} = constant 17 : i23
- %z = constant 17 : i23
+ // CHECK: %{{.*}} = arith.constant 17 : i23
+ %z = arith.constant 17 : i23
- // CHECK: %{{.*}} = constant true
- %t = constant true
- // CHECK: %{{.*}} = constant false
- %f = constant false
+ // CHECK: %{{.*}} = arith.constant true
+ %t = arith.constant true
+ // CHECK: %{{.*}} = arith.constant false
+ %f = arith.constant false
// The trick to parse type declarations should not interfere with hex
// literals.
- // CHECK: %{{.*}} = constant 3890 : i32
- %h = constant 0xf32 : i32
+ // CHECK: %{{.*}} = arith.constant 3890 : i32
+ %h = arith.constant 0xf32 : i32
// CHECK: return %{{.*}}, %{{.*}}, %{{.*}}, %{{.*}}, %{{.*}}
return %x, %y, %z, %t, %f : i32, i23, i23, i1, i1
// CHECK: affine.for %{{.*}} = 0 to #map{{[a-z_0-9]*}}()[%{{.*}}, %{{.*}}] {
affine.for %i5 = 0 to #map_non_simple3()[%arg0] {
// CHECK: affine.for %{{.*}} = 0 to #map{{[a-z_0-9]*}}()[%{{.*}}] {
- %c42_i32 = constant 42 : i32
+ %c42_i32 = arith.constant 42 : i32
}
}
}
// CHECK-LABEL: func @verbose_if(
func @verbose_if(%N: index) {
- %c = constant 200 : index
+ %c = arith.constant 200 : index
// CHECK: affine.if #set{{.*}}(%{{.*}})[%{{.*}}, %{{.*}}] {
"affine.if"(%c, %N, %c) ({
// CHECK-LABEL: @f16_special_values
func @f16_special_values() {
// F16 NaNs.
- // CHECK: constant 0x7C01 : f16
- %0 = constant 0x7C01 : f16
- // CHECK: constant 0x7FFF : f16
- %1 = constant 0x7FFF : f16
- // CHECK: constant 0xFFFF : f16
- %2 = constant 0xFFFF : f16
+ // CHECK: arith.constant 0x7C01 : f16
+ %0 = arith.constant 0x7C01 : f16
+ // CHECK: arith.constant 0x7FFF : f16
+ %1 = arith.constant 0x7FFF : f16
+ // CHECK: arith.constant 0xFFFF : f16
+ %2 = arith.constant 0xFFFF : f16
// F16 positive infinity.
- // CHECK: constant 0x7C00 : f16
- %3 = constant 0x7C00 : f16
+ // CHECK: arith.constant 0x7C00 : f16
+ %3 = arith.constant 0x7C00 : f16
// F16 negative infinity.
- // CHECK: constant 0xFC00 : f16
- %4 = constant 0xFC00 : f16
+ // CHECK: arith.constant 0xFC00 : f16
+ %4 = arith.constant 0xFC00 : f16
return
}
// CHECK-LABEL: @f32_special_values
func @f32_special_values() {
// F32 signaling NaNs.
- // CHECK: constant 0x7F800001 : f32
- %0 = constant 0x7F800001 : f32
- // CHECK: constant 0x7FBFFFFF : f32
- %1 = constant 0x7FBFFFFF : f32
+ // CHECK: arith.constant 0x7F800001 : f32
+ %0 = arith.constant 0x7F800001 : f32
+ // CHECK: arith.constant 0x7FBFFFFF : f32
+ %1 = arith.constant 0x7FBFFFFF : f32
// F32 quiet NaNs.
- // CHECK: constant 0x7FC00000 : f32
- %2 = constant 0x7FC00000 : f32
- // CHECK: constant 0xFFFFFFFF : f32
- %3 = constant 0xFFFFFFFF : f32
+ // CHECK: arith.constant 0x7FC00000 : f32
+ %2 = arith.constant 0x7FC00000 : f32
+ // CHECK: arith.constant 0xFFFFFFFF : f32
+ %3 = arith.constant 0xFFFFFFFF : f32
// F32 positive infinity.
- // CHECK: constant 0x7F800000 : f32
- %4 = constant 0x7F800000 : f32
+ // CHECK: arith.constant 0x7F800000 : f32
+ %4 = arith.constant 0x7F800000 : f32
// F32 negative infinity.
- // CHECK: constant 0xFF800000 : f32
- %5 = constant 0xFF800000 : f32
+ // CHECK: arith.constant 0xFF800000 : f32
+ %5 = arith.constant 0xFF800000 : f32
return
}
// CHECK-LABEL: @f64_special_values
func @f64_special_values() {
// F64 signaling NaNs.
- // CHECK: constant 0x7FF0000000000001 : f64
- %0 = constant 0x7FF0000000000001 : f64
- // CHECK: constant 0x7FF8000000000000 : f64
- %1 = constant 0x7FF8000000000000 : f64
+ // CHECK: arith.constant 0x7FF0000000000001 : f64
+ %0 = arith.constant 0x7FF0000000000001 : f64
+ // CHECK: arith.constant 0x7FF8000000000000 : f64
+ %1 = arith.constant 0x7FF8000000000000 : f64
// F64 quiet NaNs.
- // CHECK: constant 0x7FF0000001000000 : f64
- %2 = constant 0x7FF0000001000000 : f64
- // CHECK: constant 0xFFF0000001000000 : f64
- %3 = constant 0xFFF0000001000000 : f64
+ // CHECK: arith.constant 0x7FF0000001000000 : f64
+ %2 = arith.constant 0x7FF0000001000000 : f64
+ // CHECK: arith.constant 0xFFF0000001000000 : f64
+ %3 = arith.constant 0xFFF0000001000000 : f64
// F64 positive infinity.
- // CHECK: constant 0x7FF0000000000000 : f64
- %4 = constant 0x7FF0000000000000 : f64
+ // CHECK: arith.constant 0x7FF0000000000000 : f64
+ %4 = arith.constant 0x7FF0000000000000 : f64
// F64 negative infinity.
- // CHECK: constant 0xFFF0000000000000 : f64
- %5 = constant 0xFFF0000000000000 : f64
+ // CHECK: arith.constant 0xFFF0000000000000 : f64
+ %5 = arith.constant 0xFFF0000000000000 : f64
// Check that values that can't be represented with the default format, use
// hex instead.
- // CHECK: constant 0xC1CDC00000000000 : f64
- %6 = constant 0xC1CDC00000000000 : f64
+ // CHECK: arith.constant 0xC1CDC00000000000 : f64
+ %6 = arith.constant 0xC1CDC00000000000 : f64
return
}
// CHECK-LABEL: @bfloat16_special_values
func @bfloat16_special_values() {
// bfloat16 signaling NaNs.
- // CHECK: constant 0x7F81 : bf16
- %0 = constant 0x7F81 : bf16
- // CHECK: constant 0xFF81 : bf16
- %1 = constant 0xFF81 : bf16
+ // CHECK: arith.constant 0x7F81 : bf16
+ %0 = arith.constant 0x7F81 : bf16
+ // CHECK: arith.constant 0xFF81 : bf16
+ %1 = arith.constant 0xFF81 : bf16
// bfloat16 quiet NaNs.
- // CHECK: constant 0x7FC0 : bf16
- %2 = constant 0x7FC0 : bf16
- // CHECK: constant 0xFFC0 : bf16
- %3 = constant 0xFFC0 : bf16
+ // CHECK: arith.constant 0x7FC0 : bf16
+ %2 = arith.constant 0x7FC0 : bf16
+ // CHECK: arith.constant 0xFFC0 : bf16
+ %3 = arith.constant 0xFFC0 : bf16
// bfloat16 positive infinity.
- // CHECK: constant 0x7F80 : bf16
- %4 = constant 0x7F80 : bf16
+ // CHECK: arith.constant 0x7F80 : bf16
+ %4 = arith.constant 0x7F80 : bf16
// bfloat16 negative infinity.
- // CHECK: constant 0xFF80 : bf16
- %5 = constant 0xFF80 : bf16
+ // CHECK: arith.constant 0xFF80 : bf16
+ %5 = arith.constant 0xFF80 : bf16
return
}
// the decimal form instead.
// CHECK-LABEL: @f32_potential_precision_loss()
func @f32_potential_precision_loss() {
- // CHECK: constant -1.23697901 : f32
- %0 = constant -1.23697901 : f32
+ // CHECK: arith.constant -1.23697901 : f32
+ %0 = arith.constant -1.23697901 : f32
return
}
// CHECK-LABEL: func @op_with_passthrough_region_args
func @op_with_passthrough_region_args() {
- // CHECK: [[VAL:%.*]] = constant
- %0 = constant 10 : index
+ // CHECK: [[VAL:%.*]] = arith.constant
+ %0 = arith.constant 10 : index
// CHECK: test.isolated_region [[VAL]] {
// CHECK-NEXT: "foo.consumer"([[VAL]]) : (index)
// CHECK-LABEL: func @unreachable_dominance_violation_ok
func @unreachable_dominance_violation_ok() -> i1 {
-// CHECK: [[VAL:%.*]] = constant false
+// CHECK: [[VAL:%.*]] = arith.constant false
// CHECK: return [[VAL]] : i1
// CHECK: ^bb1: // no predecessors
// CHECK: [[VAL2:%.*]]:3 = "bar"([[VAL3:%.*]]) : (i64) -> (i1, i1, i1)
// CHECK: [[VAL3]] = "foo"() : () -> i64
// CHECK: return [[VAL2]]#1 : i1
// CHECK: }
- %c = constant false
+ %c = arith.constant false
return %c : i1
^bb1:
// %1 is not dominated by it's definition, but block is not reachable.
// CHECK: -> i32 "foo"
%1 = "foo"() : () -> i32 loc("foo")
- // CHECK: constant 4 : index "foo" at mysource.cc:10:8
- %2 = constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
+ // CHECK: arith.constant 4 : index "foo" at mysource.cc:10:8
+ %2 = arith.constant 4 : index loc(callsite("foo" at "mysource.cc":10:8))
- // CHECK: constant 4 : index "foo"
+ // CHECK: arith.constant 4 : index "foo"
// CHECK-NEXT: at mysource1.cc:10:8
// CHECK-NEXT: at mysource2.cc:13:8
// CHECK-NEXT: at mysource3.cc:100:10
- %3 = constant 4 : index loc(callsite("foo" at callsite("mysource1.cc":10:8 at callsite("mysource2.cc":13:8 at "mysource3.cc":100:10))))
+ %3 = arith.constant 4 : index loc(callsite("foo" at callsite("mysource1.cc":10:8 at callsite("mysource2.cc":13:8 at "mysource3.cc":100:10))))
// CHECK: } ["foo", mysource.cc:10:8]
affine.for %i0 = 0 to 8 {
func @testType(tensor<1x224x224x3xf32>) -> tensor<96xf32> {
^bb0(%arg0: tensor<1x224x224x3xf32>):
- %1 = "std.constant"() {value = dense<0.1> : tensor<1xf32>} : () -> (tensor<1xf32>)
- %2 = "std.constant"() {value = dense<0.1> : tensor<2xf32>} : () -> (tensor<2xf32>)
- %3 = "std.constant"() {value = dense<0.1> : tensor<3xf32>} : () -> (tensor<3xf32>)
- %4 = "std.constant"() {value = dense<0.1> : tensor<4xf32>} : () -> (tensor<4xf32>)
- %5 = "std.constant"() {value = dense<0.1> : tensor<5xf32>} : () -> (tensor<5xf32>)
- %6 = "std.constant"() {value = dense<0.1> : tensor<6xf32>} : () -> (tensor<6xf32>)
- %7 = "std.constant"() {value = dense<0.1> : tensor<7xf32>} : () -> (tensor<7xf32>)
- %8 = "std.constant"() {value = dense<0.1> : tensor<8xf32>} : () -> (tensor<8xf32>)
- %9 = "std.constant"() {value = dense<0.1> : tensor<9xf32>} : () -> (tensor<9xf32>)
- %10 = "std.constant"() {value = dense<0.1> : tensor<10xf32>} : () -> (tensor<10xf32>)
- %11 = "std.constant"() {value = dense<0.1> : tensor<11xf32>} : () -> (tensor<11xf32>)
- %12 = "std.constant"() {value = dense<0.1> : tensor<12xf32>} : () -> (tensor<12xf32>)
- %13 = "std.constant"() {value = dense<0.1> : tensor<13xf32>} : () -> (tensor<13xf32>)
- %14 = "std.constant"() {value = dense<0.1> : tensor<14xf32>} : () -> (tensor<14xf32>)
- %15 = "std.constant"() {value = dense<0.1> : tensor<15xf32>} : () -> (tensor<15xf32>)
- %16 = "std.constant"() {value = dense<0.1> : tensor<16xf32>} : () -> (tensor<16xf32>)
- %17 = "std.constant"() {value = dense<0.1> : tensor<17xf32>} : () -> (tensor<17xf32>)
- %18 = "std.constant"() {value = dense<0.1> : tensor<18xf32>} : () -> (tensor<18xf32>)
- %19 = "std.constant"() {value = dense<0.1> : tensor<19xf32>} : () -> (tensor<19xf32>)
- %20 = "std.constant"() {value = dense<0.1> : tensor<20xf32>} : () -> (tensor<20xf32>)
- %21 = "std.constant"() {value = dense<0.1> : tensor<21xf32>} : () -> (tensor<21xf32>)
- %22 = "std.constant"() {value = dense<0.1> : tensor<22xf32>} : () -> (tensor<22xf32>)
- %23 = "std.constant"() {value = dense<0.1> : tensor<23xf32>} : () -> (tensor<23xf32>)
- %24 = "std.constant"() {value = dense<0.1> : tensor<24xf32>} : () -> (tensor<24xf32>)
- %25 = "std.constant"() {value = dense<0.1> : tensor<25xf32>} : () -> (tensor<25xf32>)
- %26 = "std.constant"() {value = dense<0.1> : tensor<26xf32>} : () -> (tensor<26xf32>)
- %27 = "std.constant"() {value = dense<0.1> : tensor<27xf32>} : () -> (tensor<27xf32>)
- %28 = "std.constant"() {value = dense<0.1> : tensor<28xf32>} : () -> (tensor<28xf32>)
- %29 = "std.constant"() {value = dense<0.1> : tensor<29xf32>} : () -> (tensor<29xf32>)
- %30 = "std.constant"() {value = dense<0.1> : tensor<30xf32>} : () -> (tensor<30xf32>)
- %31 = "std.constant"() {value = dense<0.1> : tensor<31xf32>} : () -> (tensor<31xf32>)
- %32 = "std.constant"() {value = dense<0.1> : tensor<32xf32>} : () -> (tensor<32xf32>)
- %33 = "std.constant"() {value = dense<0.1> : tensor<33xf32>} : () -> (tensor<33xf32>)
- %34 = "std.constant"() {value = dense<0.1> : tensor<34xf32>} : () -> (tensor<34xf32>)
- %35 = "std.constant"() {value = dense<0.1> : tensor<35xf32>} : () -> (tensor<35xf32>)
- %36 = "std.constant"() {value = dense<0.1> : tensor<36xf32>} : () -> (tensor<36xf32>)
- %37 = "std.constant"() {value = dense<0.1> : tensor<37xf32>} : () -> (tensor<37xf32>)
- %38 = "std.constant"() {value = dense<0.1> : tensor<38xf32>} : () -> (tensor<38xf32>)
- %39 = "std.constant"() {value = dense<0.1> : tensor<39xf32>} : () -> (tensor<39xf32>)
- %40 = "std.constant"() {value = dense<0.1> : tensor<40xf32>} : () -> (tensor<40xf32>)
- %41 = "std.constant"() {value = dense<0.1> : tensor<41xf32>} : () -> (tensor<41xf32>)
- %42 = "std.constant"() {value = dense<0.1> : tensor<42xf32>} : () -> (tensor<42xf32>)
- %43 = "std.constant"() {value = dense<0.1> : tensor<43xf32>} : () -> (tensor<43xf32>)
- %44 = "std.constant"() {value = dense<0.1> : tensor<44xf32>} : () -> (tensor<44xf32>)
- %45 = "std.constant"() {value = dense<0.1> : tensor<45xf32>} : () -> (tensor<45xf32>)
- %46 = "std.constant"() {value = dense<0.1> : tensor<46xf32>} : () -> (tensor<46xf32>)
- %47 = "std.constant"() {value = dense<0.1> : tensor<47xf32>} : () -> (tensor<47xf32>)
- %48 = "std.constant"() {value = dense<0.1> : tensor<48xf32>} : () -> (tensor<48xf32>)
- %49 = "std.constant"() {value = dense<0.1> : tensor<49xf32>} : () -> (tensor<49xf32>)
- %50 = "std.constant"() {value = dense<0.1> : tensor<50xf32>} : () -> (tensor<50xf32>)
- %51 = "std.constant"() {value = dense<0.1> : tensor<51xf32>} : () -> (tensor<51xf32>)
- %52 = "std.constant"() {value = dense<0.1> : tensor<52xf32>} : () -> (tensor<52xf32>)
- %53 = "std.constant"() {value = dense<0.1> : tensor<53xf32>} : () -> (tensor<53xf32>)
- %54 = "std.constant"() {value = dense<0.1> : tensor<54xf32>} : () -> (tensor<54xf32>)
- %55 = "std.constant"() {value = dense<0.1> : tensor<55xf32>} : () -> (tensor<55xf32>)
- %56 = "std.constant"() {value = dense<0.1> : tensor<56xf32>} : () -> (tensor<56xf32>)
- %57 = "std.constant"() {value = dense<0.1> : tensor<57xf32>} : () -> (tensor<57xf32>)
- %58 = "std.constant"() {value = dense<0.1> : tensor<58xf32>} : () -> (tensor<58xf32>)
- %59 = "std.constant"() {value = dense<0.1> : tensor<59xf32>} : () -> (tensor<59xf32>)
- %60 = "std.constant"() {value = dense<0.1> : tensor<60xf32>} : () -> (tensor<60xf32>)
- %61 = "std.constant"() {value = dense<0.1> : tensor<61xf32>} : () -> (tensor<61xf32>)
- %62 = "std.constant"() {value = dense<0.1> : tensor<62xf32>} : () -> (tensor<62xf32>)
- %63 = "std.constant"() {value = dense<0.1> : tensor<63xf32>} : () -> (tensor<63xf32>)
- %64 = "std.constant"() {value = dense<0.1> : tensor<64xf32>} : () -> (tensor<64xf32>)
- %65 = "std.constant"() {value = dense<0.1> : tensor<65xf32>} : () -> (tensor<65xf32>)
- %66 = "std.constant"() {value = dense<0.1> : tensor<66xf32>} : () -> (tensor<66xf32>)
- %67 = "std.constant"() {value = dense<0.1> : tensor<67xf32>} : () -> (tensor<67xf32>)
- %68 = "std.constant"() {value = dense<0.1> : tensor<68xf32>} : () -> (tensor<68xf32>)
- %69 = "std.constant"() {value = dense<0.1> : tensor<69xf32>} : () -> (tensor<69xf32>)
- %70 = "std.constant"() {value = dense<0.1> : tensor<70xf32>} : () -> (tensor<70xf32>)
- %71 = "std.constant"() {value = dense<0.1> : tensor<71xf32>} : () -> (tensor<71xf32>)
- %72 = "std.constant"() {value = dense<0.1> : tensor<72xf32>} : () -> (tensor<72xf32>)
- %73 = "std.constant"() {value = dense<0.1> : tensor<73xf32>} : () -> (tensor<73xf32>)
- %74 = "std.constant"() {value = dense<0.1> : tensor<74xf32>} : () -> (tensor<74xf32>)
- %75 = "std.constant"() {value = dense<0.1> : tensor<75xf32>} : () -> (tensor<75xf32>)
- %76 = "std.constant"() {value = dense<0.1> : tensor<76xf32>} : () -> (tensor<76xf32>)
- %77 = "std.constant"() {value = dense<0.1> : tensor<77xf32>} : () -> (tensor<77xf32>)
- %78 = "std.constant"() {value = dense<0.1> : tensor<78xf32>} : () -> (tensor<78xf32>)
- %79 = "std.constant"() {value = dense<0.1> : tensor<79xf32>} : () -> (tensor<79xf32>)
- %80 = "std.constant"() {value = dense<0.1> : tensor<80xf32>} : () -> (tensor<80xf32>)
- %81 = "std.constant"() {value = dense<0.1> : tensor<81xf32>} : () -> (tensor<81xf32>)
- %82 = "std.constant"() {value = dense<0.1> : tensor<82xf32>} : () -> (tensor<82xf32>)
- %83 = "std.constant"() {value = dense<0.1> : tensor<83xf32>} : () -> (tensor<83xf32>)
- %84 = "std.constant"() {value = dense<0.1> : tensor<84xf32>} : () -> (tensor<84xf32>)
- %85 = "std.constant"() {value = dense<0.1> : tensor<85xf32>} : () -> (tensor<85xf32>)
- %86 = "std.constant"() {value = dense<0.1> : tensor<86xf32>} : () -> (tensor<86xf32>)
- %87 = "std.constant"() {value = dense<0.1> : tensor<87xf32>} : () -> (tensor<87xf32>)
- %88 = "std.constant"() {value = dense<0.1> : tensor<88xf32>} : () -> (tensor<88xf32>)
- %89 = "std.constant"() {value = dense<0.1> : tensor<89xf32>} : () -> (tensor<89xf32>)
- %90 = "std.constant"() {value = dense<0.1> : tensor<90xf32>} : () -> (tensor<90xf32>)
- %91 = "std.constant"() {value = dense<0.1> : tensor<91xf32>} : () -> (tensor<91xf32>)
- %92 = "std.constant"() {value = dense<0.1> : tensor<92xf32>} : () -> (tensor<92xf32>)
- %93 = "std.constant"() {value = dense<0.1> : tensor<93xf32>} : () -> (tensor<93xf32>)
- %94 = "std.constant"() {value = dense<0.1> : tensor<94xf32>} : () -> (tensor<94xf32>)
- %95 = "std.constant"() {value = dense<0.1> : tensor<95xf32>} : () -> (tensor<95xf32>)
- %96 = "std.constant"() {value = dense<0.1> : tensor<96xf32>} : () -> (tensor<96xf32>)
- %97 = "std.constant"() {value = dense<0.1> : tensor<97xf32>} : () -> (tensor<97xf32>)
- %98 = "std.constant"() {value = dense<0.1> : tensor<98xf32>} : () -> (tensor<98xf32>)
- %99 = "std.constant"() {value = dense<0.1> : tensor<99xf32>} : () -> (tensor<99xf32>)
- %100 = "std.constant"() {value = dense<0.1> : tensor<100xf32>} : () -> (tensor<100xf32>)
- %101 = "std.constant"() {value = dense<0.1> : tensor<101xf32>} : () -> (tensor<101xf32>)
- %102 = "std.constant"() {value = dense<0.1> : tensor<102xf32>} : () -> (tensor<102xf32>)
+ %1 = "arith.constant"() {value = dense<0.1> : tensor<1xf32>} : () -> (tensor<1xf32>)
+ %2 = "arith.constant"() {value = dense<0.1> : tensor<2xf32>} : () -> (tensor<2xf32>)
+ %3 = "arith.constant"() {value = dense<0.1> : tensor<3xf32>} : () -> (tensor<3xf32>)
+ %4 = "arith.constant"() {value = dense<0.1> : tensor<4xf32>} : () -> (tensor<4xf32>)
+ %5 = "arith.constant"() {value = dense<0.1> : tensor<5xf32>} : () -> (tensor<5xf32>)
+ %6 = "arith.constant"() {value = dense<0.1> : tensor<6xf32>} : () -> (tensor<6xf32>)
+ %7 = "arith.constant"() {value = dense<0.1> : tensor<7xf32>} : () -> (tensor<7xf32>)
+ %8 = "arith.constant"() {value = dense<0.1> : tensor<8xf32>} : () -> (tensor<8xf32>)
+ %9 = "arith.constant"() {value = dense<0.1> : tensor<9xf32>} : () -> (tensor<9xf32>)
+ %10 = "arith.constant"() {value = dense<0.1> : tensor<10xf32>} : () -> (tensor<10xf32>)
+ %11 = "arith.constant"() {value = dense<0.1> : tensor<11xf32>} : () -> (tensor<11xf32>)
+ %12 = "arith.constant"() {value = dense<0.1> : tensor<12xf32>} : () -> (tensor<12xf32>)
+ %13 = "arith.constant"() {value = dense<0.1> : tensor<13xf32>} : () -> (tensor<13xf32>)
+ %14 = "arith.constant"() {value = dense<0.1> : tensor<14xf32>} : () -> (tensor<14xf32>)
+ %15 = "arith.constant"() {value = dense<0.1> : tensor<15xf32>} : () -> (tensor<15xf32>)
+ %16 = "arith.constant"() {value = dense<0.1> : tensor<16xf32>} : () -> (tensor<16xf32>)
+ %17 = "arith.constant"() {value = dense<0.1> : tensor<17xf32>} : () -> (tensor<17xf32>)
+ %18 = "arith.constant"() {value = dense<0.1> : tensor<18xf32>} : () -> (tensor<18xf32>)
+ %19 = "arith.constant"() {value = dense<0.1> : tensor<19xf32>} : () -> (tensor<19xf32>)
+ %20 = "arith.constant"() {value = dense<0.1> : tensor<20xf32>} : () -> (tensor<20xf32>)
+ %21 = "arith.constant"() {value = dense<0.1> : tensor<21xf32>} : () -> (tensor<21xf32>)
+ %22 = "arith.constant"() {value = dense<0.1> : tensor<22xf32>} : () -> (tensor<22xf32>)
+ %23 = "arith.constant"() {value = dense<0.1> : tensor<23xf32>} : () -> (tensor<23xf32>)
+ %24 = "arith.constant"() {value = dense<0.1> : tensor<24xf32>} : () -> (tensor<24xf32>)
+ %25 = "arith.constant"() {value = dense<0.1> : tensor<25xf32>} : () -> (tensor<25xf32>)
+ %26 = "arith.constant"() {value = dense<0.1> : tensor<26xf32>} : () -> (tensor<26xf32>)
+ %27 = "arith.constant"() {value = dense<0.1> : tensor<27xf32>} : () -> (tensor<27xf32>)
+ %28 = "arith.constant"() {value = dense<0.1> : tensor<28xf32>} : () -> (tensor<28xf32>)
+ %29 = "arith.constant"() {value = dense<0.1> : tensor<29xf32>} : () -> (tensor<29xf32>)
+ %30 = "arith.constant"() {value = dense<0.1> : tensor<30xf32>} : () -> (tensor<30xf32>)
+ %31 = "arith.constant"() {value = dense<0.1> : tensor<31xf32>} : () -> (tensor<31xf32>)
+ %32 = "arith.constant"() {value = dense<0.1> : tensor<32xf32>} : () -> (tensor<32xf32>)
+ %33 = "arith.constant"() {value = dense<0.1> : tensor<33xf32>} : () -> (tensor<33xf32>)
+ %34 = "arith.constant"() {value = dense<0.1> : tensor<34xf32>} : () -> (tensor<34xf32>)
+ %35 = "arith.constant"() {value = dense<0.1> : tensor<35xf32>} : () -> (tensor<35xf32>)
+ %36 = "arith.constant"() {value = dense<0.1> : tensor<36xf32>} : () -> (tensor<36xf32>)
+ %37 = "arith.constant"() {value = dense<0.1> : tensor<37xf32>} : () -> (tensor<37xf32>)
+ %38 = "arith.constant"() {value = dense<0.1> : tensor<38xf32>} : () -> (tensor<38xf32>)
+ %39 = "arith.constant"() {value = dense<0.1> : tensor<39xf32>} : () -> (tensor<39xf32>)
+ %40 = "arith.constant"() {value = dense<0.1> : tensor<40xf32>} : () -> (tensor<40xf32>)
+ %41 = "arith.constant"() {value = dense<0.1> : tensor<41xf32>} : () -> (tensor<41xf32>)
+ %42 = "arith.constant"() {value = dense<0.1> : tensor<42xf32>} : () -> (tensor<42xf32>)
+ %43 = "arith.constant"() {value = dense<0.1> : tensor<43xf32>} : () -> (tensor<43xf32>)
+ %44 = "arith.constant"() {value = dense<0.1> : tensor<44xf32>} : () -> (tensor<44xf32>)
+ %45 = "arith.constant"() {value = dense<0.1> : tensor<45xf32>} : () -> (tensor<45xf32>)
+ %46 = "arith.constant"() {value = dense<0.1> : tensor<46xf32>} : () -> (tensor<46xf32>)
+ %47 = "arith.constant"() {value = dense<0.1> : tensor<47xf32>} : () -> (tensor<47xf32>)
+ %48 = "arith.constant"() {value = dense<0.1> : tensor<48xf32>} : () -> (tensor<48xf32>)
+ %49 = "arith.constant"() {value = dense<0.1> : tensor<49xf32>} : () -> (tensor<49xf32>)
+ %50 = "arith.constant"() {value = dense<0.1> : tensor<50xf32>} : () -> (tensor<50xf32>)
+ %51 = "arith.constant"() {value = dense<0.1> : tensor<51xf32>} : () -> (tensor<51xf32>)
+ %52 = "arith.constant"() {value = dense<0.1> : tensor<52xf32>} : () -> (tensor<52xf32>)
+ %53 = "arith.constant"() {value = dense<0.1> : tensor<53xf32>} : () -> (tensor<53xf32>)
+ %54 = "arith.constant"() {value = dense<0.1> : tensor<54xf32>} : () -> (tensor<54xf32>)
+ %55 = "arith.constant"() {value = dense<0.1> : tensor<55xf32>} : () -> (tensor<55xf32>)
+ %56 = "arith.constant"() {value = dense<0.1> : tensor<56xf32>} : () -> (tensor<56xf32>)
+ %57 = "arith.constant"() {value = dense<0.1> : tensor<57xf32>} : () -> (tensor<57xf32>)
+ %58 = "arith.constant"() {value = dense<0.1> : tensor<58xf32>} : () -> (tensor<58xf32>)
+ %59 = "arith.constant"() {value = dense<0.1> : tensor<59xf32>} : () -> (tensor<59xf32>)
+ %60 = "arith.constant"() {value = dense<0.1> : tensor<60xf32>} : () -> (tensor<60xf32>)
+ %61 = "arith.constant"() {value = dense<0.1> : tensor<61xf32>} : () -> (tensor<61xf32>)
+ %62 = "arith.constant"() {value = dense<0.1> : tensor<62xf32>} : () -> (tensor<62xf32>)
+ %63 = "arith.constant"() {value = dense<0.1> : tensor<63xf32>} : () -> (tensor<63xf32>)
+ %64 = "arith.constant"() {value = dense<0.1> : tensor<64xf32>} : () -> (tensor<64xf32>)
+ %65 = "arith.constant"() {value = dense<0.1> : tensor<65xf32>} : () -> (tensor<65xf32>)
+ %66 = "arith.constant"() {value = dense<0.1> : tensor<66xf32>} : () -> (tensor<66xf32>)
+ %67 = "arith.constant"() {value = dense<0.1> : tensor<67xf32>} : () -> (tensor<67xf32>)
+ %68 = "arith.constant"() {value = dense<0.1> : tensor<68xf32>} : () -> (tensor<68xf32>)
+ %69 = "arith.constant"() {value = dense<0.1> : tensor<69xf32>} : () -> (tensor<69xf32>)
+ %70 = "arith.constant"() {value = dense<0.1> : tensor<70xf32>} : () -> (tensor<70xf32>)
+ %71 = "arith.constant"() {value = dense<0.1> : tensor<71xf32>} : () -> (tensor<71xf32>)
+ %72 = "arith.constant"() {value = dense<0.1> : tensor<72xf32>} : () -> (tensor<72xf32>)
+ %73 = "arith.constant"() {value = dense<0.1> : tensor<73xf32>} : () -> (tensor<73xf32>)
+ %74 = "arith.constant"() {value = dense<0.1> : tensor<74xf32>} : () -> (tensor<74xf32>)
+ %75 = "arith.constant"() {value = dense<0.1> : tensor<75xf32>} : () -> (tensor<75xf32>)
+ %76 = "arith.constant"() {value = dense<0.1> : tensor<76xf32>} : () -> (tensor<76xf32>)
+ %77 = "arith.constant"() {value = dense<0.1> : tensor<77xf32>} : () -> (tensor<77xf32>)
+ %78 = "arith.constant"() {value = dense<0.1> : tensor<78xf32>} : () -> (tensor<78xf32>)
+ %79 = "arith.constant"() {value = dense<0.1> : tensor<79xf32>} : () -> (tensor<79xf32>)
+ %80 = "arith.constant"() {value = dense<0.1> : tensor<80xf32>} : () -> (tensor<80xf32>)
+ %81 = "arith.constant"() {value = dense<0.1> : tensor<81xf32>} : () -> (tensor<81xf32>)
+ %82 = "arith.constant"() {value = dense<0.1> : tensor<82xf32>} : () -> (tensor<82xf32>)
+ %83 = "arith.constant"() {value = dense<0.1> : tensor<83xf32>} : () -> (tensor<83xf32>)
+ %84 = "arith.constant"() {value = dense<0.1> : tensor<84xf32>} : () -> (tensor<84xf32>)
+ %85 = "arith.constant"() {value = dense<0.1> : tensor<85xf32>} : () -> (tensor<85xf32>)
+ %86 = "arith.constant"() {value = dense<0.1> : tensor<86xf32>} : () -> (tensor<86xf32>)
+ %87 = "arith.constant"() {value = dense<0.1> : tensor<87xf32>} : () -> (tensor<87xf32>)
+ %88 = "arith.constant"() {value = dense<0.1> : tensor<88xf32>} : () -> (tensor<88xf32>)
+ %89 = "arith.constant"() {value = dense<0.1> : tensor<89xf32>} : () -> (tensor<89xf32>)
+ %90 = "arith.constant"() {value = dense<0.1> : tensor<90xf32>} : () -> (tensor<90xf32>)
+ %91 = "arith.constant"() {value = dense<0.1> : tensor<91xf32>} : () -> (tensor<91xf32>)
+ %92 = "arith.constant"() {value = dense<0.1> : tensor<92xf32>} : () -> (tensor<92xf32>)
+ %93 = "arith.constant"() {value = dense<0.1> : tensor<93xf32>} : () -> (tensor<93xf32>)
+ %94 = "arith.constant"() {value = dense<0.1> : tensor<94xf32>} : () -> (tensor<94xf32>)
+ %95 = "arith.constant"() {value = dense<0.1> : tensor<95xf32>} : () -> (tensor<95xf32>)
+ %96 = "arith.constant"() {value = dense<0.1> : tensor<96xf32>} : () -> (tensor<96xf32>)
+ %97 = "arith.constant"() {value = dense<0.1> : tensor<97xf32>} : () -> (tensor<97xf32>)
+ %98 = "arith.constant"() {value = dense<0.1> : tensor<98xf32>} : () -> (tensor<98xf32>)
+ %99 = "arith.constant"() {value = dense<0.1> : tensor<99xf32>} : () -> (tensor<99xf32>)
+ %100 = "arith.constant"() {value = dense<0.1> : tensor<100xf32>} : () -> (tensor<100xf32>)
+ %101 = "arith.constant"() {value = dense<0.1> : tensor<101xf32>} : () -> (tensor<101xf32>)
+ %102 = "arith.constant"() {value = dense<0.1> : tensor<102xf32>} : () -> (tensor<102xf32>)
return %96 : tensor<96xf32>
}
// CHECK: testType
// RUN: mlir-opt %s -mlir-disable-threading=true -test-matchers -o /dev/null 2>&1 | FileCheck %s
func @test1(%a: f32, %b: f32, %c: f32) {
- %0 = addf %a, %b: f32
- %1 = addf %a, %c: f32
- %2 = addf %c, %b: f32
- %3 = mulf %a, %2: f32
- %4 = mulf %3, %1: f32
- %5 = mulf %4, %4: f32
- %6 = mulf %5, %5: f32
+ %0 = arith.addf %a, %b: f32
+ %1 = arith.addf %a, %c: f32
+ %2 = arith.addf %c, %b: f32
+ %3 = arith.mulf %a, %2: f32
+ %4 = arith.mulf %3, %1: f32
+ %5 = arith.mulf %4, %4: f32
+ %6 = arith.mulf %5, %5: f32
return
}
// CHECK: Pattern mul(mul(a, *), add(c, b)) matched 0 times
func @test2(%a: f32) -> f32 {
- %0 = constant 1.0: f32
- %1 = addf %a, %0: f32
- %2 = mulf %a, %1: f32
+ %0 = arith.constant 1.0: f32
+ %1 = arith.addf %a, %0: f32
+ %2 = arith.mulf %a, %1: f32
return %2: f32
}
// callbacks with return so that the output includes more cases in pre-order.
func @structured_cfg() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
scf.for %i = %c1 to %c10 step %c1 {
%cond = "use0"(%i) : (index) -> (i1)
scf.if %cond {
outs(%sum : memref<?x?xf32>)
{
^bb0(%lhs_in: f32, %rhs_in: f32, %sum_out: f32):
- %0 = addf %lhs_in, %rhs_in : f32
+ %0 = arith.addf %lhs_in, %rhs_in : f32
linalg.yield %0 : f32
}
}
func @entry() {
- %f1 = constant 1.0 : f32
- %f4 = constant 4.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cM = constant 1000 : index
+ %f1 = arith.constant 1.0 : f32
+ %f4 = arith.constant 4.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cM = arith.constant 1000 : index
//
// Sanity check for the function under test.
: (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32>) -> ()
}
%t1 = call @rtclock() : () -> f64
- %t1024 = subf %t1, %t0 : f64
+ %t1024 = arith.subf %t1, %t0 : f64
// Print timings.
vector.print %t1024 : f64
func @scf_parallel(%lhs: memref<?x?xf32>,
%rhs: memref<?x?xf32>,
%sum: memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%d0 = memref.dim %lhs, %c0 : memref<?x?xf32>
%d1 = memref.dim %lhs, %c1 : memref<?x?xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%d0, %d1) step (%c1, %c1) {
%lv = memref.load %lhs[%i, %j] : memref<?x?xf32>
%rv = memref.load %lhs[%i, %j] : memref<?x?xf32>
- %r = addf %lv, %rv : f32
+ %r = arith.addf %lv, %rv : f32
memref.store %r, %sum[%i, %j] : memref<?x?xf32>
}
}
func @entry() {
- %f1 = constant 1.0 : f32
- %f4 = constant 4.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cM = constant 1000 : index
+ %f1 = arith.constant 1.0 : f32
+ %f4 = arith.constant 4.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cM = arith.constant 1000 : index
//
// Sanity check for the function under test.
: (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32>) -> ()
}
%t1 = call @rtclock() : () -> f64
- %t1024 = subf %t1, %t0 : f64
+ %t1024 = arith.subf %t1, %t0 : f64
// Print timings.
vector.print %t1024 : f64
// Suppress constant folding by introducing "dynamic" zero value at runtime.
func private @zero() -> index {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
return %0 : index
}
func @entry() {
- %c0 = constant 0.0 : f32
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
- %lb = constant 0 : index
- %ub = constant 9 : index
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 9 : index
%A = memref.alloc() : memref<9xf32>
%U = memref.cast %A : memref<9xf32> to memref<*xf32>
// 1. %i = (0) to (9) step (1)
scf.parallel (%i) = (%lb) to (%ub) step (%c1) {
- %0 = index_cast %i : index to i32
- %1 = sitofp %0 : i32 to f32
+ %0 = arith.index_cast %i : index to i32
+ %1 = arith.sitofp %0 : i32 to f32
memref.store %1, %A[%i] : memref<9xf32>
}
// CHECK: [0, 1, 2, 3, 4, 5, 6, 7, 8]
// 2. %i = (0) to (9) step (2)
scf.parallel (%i) = (%lb) to (%ub) step (%c2) {
- %0 = index_cast %i : index to i32
- %1 = sitofp %0 : i32 to f32
+ %0 = arith.index_cast %i : index to i32
+ %1 = arith.sitofp %0 : i32 to f32
memref.store %1, %A[%i] : memref<9xf32>
}
// CHECK: [0, 0, 2, 0, 4, 0, 6, 0, 8]
}
// 3. %i = (-20) to (-11) step (3)
- %lb0 = constant -20 : index
- %ub0 = constant -11 : index
+ %lb0 = arith.constant -20 : index
+ %ub0 = arith.constant -11 : index
scf.parallel (%i) = (%lb0) to (%ub0) step (%c3) {
- %0 = index_cast %i : index to i32
- %1 = sitofp %0 : i32 to f32
- %2 = constant 20 : index
- %3 = addi %i, %2 : index
+ %0 = arith.index_cast %i : index to i32
+ %1 = arith.sitofp %0 : i32 to f32
+ %2 = arith.constant 20 : index
+ %3 = arith.addi %i, %2 : index
memref.store %1, %A[%3] : memref<9xf32>
}
// CHECK: [-20, 0, 0, -17, 0, 0, -14, 0, 0]
%ub1 = call @zero(): () -> (index)
scf.parallel (%i) = (%lb1) to (%ub1) step (%c1) {
- %false = constant 0 : i1
+ %false = arith.constant 0 : i1
assert %false, "should never be executed"
}
// RUN: | FileCheck %s --dump-input=always
func @entry() {
- %c0 = constant 0.0 : f32
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c8 = constant 8 : index
+ %c0 = arith.constant 0.0 : f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c8 = arith.constant 8 : index
- %lb = constant 0 : index
- %ub = constant 8 : index
+ %lb = arith.constant 0 : index
+ %ub = arith.constant 8 : index
%A = memref.alloc() : memref<8x8xf32>
%U = memref.cast %A : memref<8x8xf32> to memref<*xf32>
// 1. (%i, %i) = (0, 8) to (8, 8) step (1, 1)
scf.parallel (%i, %j) = (%lb, %lb) to (%ub, %ub) step (%c1, %c1) {
- %0 = muli %i, %c8 : index
- %1 = addi %j, %0 : index
- %2 = index_cast %1 : index to i32
- %3 = sitofp %2 : i32 to f32
+ %0 = arith.muli %i, %c8 : index
+ %1 = arith.addi %j, %0 : index
+ %2 = arith.index_cast %1 : index to i32
+ %3 = arith.sitofp %2 : i32 to f32
memref.store %3, %A[%i, %j] : memref<8x8xf32>
}
// 2. (%i, %i) = (0, 8) to (8, 8) step (2, 1)
scf.parallel (%i, %j) = (%lb, %lb) to (%ub, %ub) step (%c2, %c1) {
- %0 = muli %i, %c8 : index
- %1 = addi %j, %0 : index
- %2 = index_cast %1 : index to i32
- %3 = sitofp %2 : i32 to f32
+ %0 = arith.muli %i, %c8 : index
+ %1 = arith.addi %j, %0 : index
+ %2 = arith.index_cast %1 : index to i32
+ %3 = arith.sitofp %2 : i32 to f32
memref.store %3, %A[%i, %j] : memref<8x8xf32>
}
// 3. (%i, %i) = (0, 8) to (8, 8) step (1, 2)
scf.parallel (%i, %j) = (%lb, %lb) to (%ub, %ub) step (%c1, %c2) {
- %0 = muli %i, %c8 : index
- %1 = addi %j, %0 : index
- %2 = index_cast %1 : index to i32
- %3 = sitofp %2 : i32 to f32
+ %0 = arith.muli %i, %c8 : index
+ %1 = arith.addi %j, %0 : index
+ %2 = arith.index_cast %1 : index to i32
+ %3 = arith.sitofp %2 : i32 to f32
memref.store %3, %A[%i, %j] : memref<8x8xf32>
}
}
func @print_perf(%iters: index, %total_time: f64) {
- %c2 = constant 2 : index
- %cM = constant ${M} : index
- %cN = constant ${N} : index
- %cK = constant ${K} : index
+ %c2 = arith.constant 2 : index
+ %cM = arith.constant ${M} : index
+ %cN = arith.constant ${N} : index
+ %cK = arith.constant ${K} : index
- %mn = muli %cM, %cN : index
- %mnk = muli %mn, %cK : index
+ %mn = arith.muli %cM, %cN : index
+ %mnk = arith.muli %mn, %cK : index
// 2*M*N*K.
- %flops_per_iter = muli %c2, %mnk : index
- %flops = muli %iters, %flops_per_iter : index
- %flops_i64 = index_cast %flops : index to i64
- %flops_f = sitofp %flops_i64 : i64 to f64
- %flops_per_s = divf %flops_f, %total_time : f64
+ %flops_per_iter = arith.muli %c2, %mnk : index
+ %flops = arith.muli %iters, %flops_per_iter : index
+ %flops_i64 = arith.index_cast %flops : index to i64
+ %flops_f = arith.sitofp %flops_i64 : i64 to f64
+ %flops_per_s = arith.divf %flops_f, %total_time : f64
vector.print %flops_per_s : f64
return
}
func @main() {
- %v0 = constant 0.0 : !elem_type_a
- %v1 = constant 1.0 : !elem_type_a
+ %v0 = arith.constant 0.0 : !elem_type_a
+ %v1 = arith.constant 1.0 : !elem_type_a
%A = memref.alloc() : !row_major_A
%B = memref.alloc() : !row_major_B
linalg.fill(%v1, %B) : !elem_type_b, !row_major_B
linalg.fill(%v0, %C) : !elem_type_c, !row_major_C
- %c0 = constant 0: index
- %c1 = constant 1: index
- %iters = constant ${ITERS}: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %iters = arith.constant ${ITERS}: index
/// Run and dump performance for matmul.
/// Preheating run:
scf.for %arg0 = %c0 to %iters step %c1 {
- %z = constant 0.0 : !elem_type_c
+ %z = arith.constant 0.0 : !elem_type_c
linalg.fill(%z, %C) : !elem_type_c, !row_major_C
call @matmul(%A, %B, %C) : (!row_major_A, !row_major_B, !row_major_C) -> ()
}
// This is accounts for about 10-15% perf hit on small sizes.
// Once linalg on tensors is ready, fusing fill at the register level will
// be easy.
- %z = constant 0.0 : !elem_type_c
+ %z = arith.constant 0.0 : !elem_type_c
linalg.fill(%z, %C) : !elem_type_c, !row_major_C
call @matmul(%A, %B, %C) : (!row_major_A, !row_major_B, !row_major_C) -> ()
}
%t_end_matmul = call @rtclock() : () -> f64
- %tmatmul = subf %t_end_matmul, %t_start_matmul: f64
+ %tmatmul = arith.subf %t_end_matmul, %t_start_matmul: f64
call @print_perf(%iters, %tmatmul) : (index, f64) -> ()
// CHECK: {{^0$}}
func private @print_memref_f32(memref<*xf32>)
func @matmul(%A: memref<?x?xf32>, %B: memref<?x?xf32>) -> (memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %f0 = arith.constant 0.0 : f32
%x = memref.dim %A, %c0 : memref<?x?xf32>
%y = memref.dim %B, %c1 : memref<?x?xf32>
%C = memref.alloc(%x, %y) : memref<?x?xf32>
}
func @matvec(%A: memref<?x?xf32>, %B: memref<?x?xf32>) -> (memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %f0 = arith.constant 0.0 : f32
%m = memref.dim %A, %c0 : memref<?x?xf32>
%x = memref.dim %A, %c1 : memref<?x?xf32>
%n = memref.dim %B, %c1 : memref<?x?xf32>
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %m = constant 5 : index
- %x = constant 3 : index
- %n = constant 2 : index
- %val1 = constant 13.0 : f32
- %val2 = constant 17.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %m = arith.constant 5 : index
+ %x = arith.constant 3 : index
+ %n = arith.constant 2 : index
+ %val1 = arith.constant 13.0 : f32
+ %val2 = arith.constant 17.0 : f32
%A = memref.alloc(%m, %x) : memref<?x?xf32>
%B = memref.alloc(%x, %n) : memref<?x?xf32>
linalg.fill(%val1, %A) : f32, memref<?x?xf32>
scf.for %j = %c0 to %n step %c1 {
%e1 = memref.load %C1[%i, %j] : memref<?x?xf32>
%e2 = memref.load %C2[%i, %j] : memref<?x?xf32>
- %c = cmpf oeq, %e1, %e2 : f32
+ %c = arith.cmpf oeq, %e1, %e2 : f32
assert %c, "Matmul does not produce same output as matvec"
}
}
func private @print_memref_f32(memref<*xf32>)
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %f0 = constant 0.0 : f32
- %f1 = constant 1.0 : f32
- %f2 = constant 2.0 : f32
- %f3 = constant 3.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %f0 = arith.constant 0.0 : f32
+ %f1 = arith.constant 1.0 : f32
+ %f2 = arith.constant 2.0 : f32
+ %f3 = arith.constant 3.0 : f32
%A = memref.alloc(%c2, %c2) : memref<?x?xf32>
memref.store %f0, %A[%c0, %c0] : memref<?x?xf32>
memref.store %f1, %A[%c0, %c1] : memref<?x?xf32>
func @main() {
- %const = constant dense<[[[[-3.9058,0.9072],[-2.9470,-2.2055],[18.3946,8.2997]],[[3.4700,5.9006],[-17.2267,4.9777],[1.0450,-0.8201]]],[[[17.6996,-11.1763],[26.7775,-3.8823],[-4.2492,-5.8966]],[[2.1259,13.1794],[-10.7136,0.8428],[16.4233,9.4589]]]]> : tensor<2x2x3x2xf32>
+ %const = arith.constant dense<[[[[-3.9058,0.9072],[-2.9470,-2.2055],[18.3946,8.2997]],[[3.4700,5.9006],[-17.2267,4.9777],[1.0450,-0.8201]]],[[[17.6996,-11.1763],[26.7775,-3.8823],[-4.2492,-5.8966]],[[2.1259,13.1794],[-10.7136,0.8428],[16.4233,9.4589]]]]> : tensor<2x2x3x2xf32>
%dynamic = tensor.cast %const: tensor<2x2x3x2xf32> to tensor<2x?x?x?xf32>
%collapsed = call @collapse_dynamic_shape(%dynamic) : (tensor<2x?x?x?xf32>) -> (tensor<2x?x?xf32>)
%unranked = tensor.cast %collapsed: tensor<2x?x?xf32> to tensor<*xf32>
#map1 = affine_map<(d0, d1)[s0] -> ((d0 - d1) ceildiv s0)>
func @init_and_dot(%arg0: tensor<64xf32>, %arg1: tensor<64xf32>, %arg2: tensor<f32> {linalg.inplaceable = true}) -> tensor<f32> {
- %c64 = constant 64 : index
- %cst = constant 0.000000e+00 : f32
- %c2 = constant 2 : index
- %c0 = constant 0 : index
+ %c64 = arith.constant 64 : index
+ %cst = arith.constant 0.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
%0 = linalg.fill(%cst, %arg2) : f32, tensor<f32> -> tensor<f32>
%1 = affine.apply #map0(%c0, %c64)[%c2]
%2 = linalg.init_tensor [%1, 2] : tensor<?x2xf32>
}
func @main() {
- %v0 = constant 0.0 : f32
- %v1 = constant 1.0 : f32
- %v2 = constant 2.0 : f32
+ %v0 = arith.constant 0.0 : f32
+ %v1 = arith.constant 1.0 : f32
+ %v2 = arith.constant 2.0 : f32
%A = linalg.init_tensor [64] : tensor<64xf32>
%B = linalg.init_tensor [64] : tensor<64xf32>
}
func @main() {
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter1D = call @alloc_1d_filled_f32(%c3, %val) : (index, f32) -> (memref<?xf32>)
%in1D = call @alloc_1d_filled_f32(%c8, %val) : (index, f32) -> (memref<?xf32>)
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter1D_nwc = call @alloc_3d_filled_f32(%c3, %c1, %c1, %val) : (index, index, index, f32) -> (memref<?x?x?xf32>)
%in1D_nwc = call @alloc_3d_filled_f32(%c3, %c8, %c1, %val) : (index, index, index, f32) -> (memref<?x?x?xf32>)
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter2D = call @alloc_2d_filled_f32(%c3, %c3, %val) : (index, index, f32) -> (memref<?x?xf32>)
%in2D = call @alloc_2d_filled_f32(%c8, %c8, %val) : (index, index, f32) -> (memref<?x?xf32>)
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter2D_nhwc = call @alloc_4d_filled_f32(%c3, %c3, %c3, %c1, %val) :(index, index, index, index, f32) -> (memref<?x?x?x?xf32>)
%in2D_nhwc = call @alloc_4d_filled_f32(%c3, %c8, %c8, %c3, %val) : (index, index, index, index, f32) -> (memref<?x?x?x?xf32>)
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter3D = call @alloc_3d_filled_f32(%c3, %c3, %c3, %val) : (index, index, index, f32) -> (memref<?x?x?xf32>)
%in3D = call @alloc_3d_filled_f32(%c8, %c8, %c8, %val) : (index, index, index, f32) -> (memref<?x?x?xf32>)
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %c8 = constant 8 : index
- %f10 = constant 10.00000e+00 : f32
- %val = constant 2.00000e+00 : f32
- %zero = constant 0.00000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %c8 = arith.constant 8 : index
+ %f10 = arith.constant 10.00000e+00 : f32
+ %val = arith.constant 2.00000e+00 : f32
+ %zero = arith.constant 0.00000e+00 : f32
%filter3D_ndhwc = call @alloc_5d_filled_f32(%c3, %c3, %c3, %c1, %c1, %val) : (index, index, index, index, index, f32) -> (memref<?x?x?x?x?xf32>)
%in3D_ndhwc = call @alloc_5d_filled_f32(%c1, %c8, %c8, %c8, %c1, %val) : (index, index, index, index, index, f32) -> (memref<?x?x?x?x?xf32>)
// RUN: | FileCheck %s
func @main() {
- %a = constant dense<[1.0, 2.0, 3.0]> : tensor<3xf32>
- %b = constant dense<[10.0, 20.0, 30.0]> : tensor<3xf32>
+ %a = arith.constant dense<[1.0, 2.0, 3.0]> : tensor<3xf32>
+ %b = arith.constant dense<[10.0, 20.0, 30.0]> : tensor<3xf32>
- %addf = addf %a, %b : tensor<3xf32>
+ %addf = arith.addf %a, %b : tensor<3xf32>
%addf_unranked = tensor.cast %addf : tensor<3xf32> to tensor<*xf32>
call @print_memref_f32(%addf_unranked) : (tensor<*xf32>) -> ()
// CHECK: Unranked Memref base@ = {{.*}} rank = 1 offset = 0 sizes = [3] strides = [1] data =
func @main() {
- %const = constant dense<[[[-3.9058,0.9072],[-2.9470,-2.2055],[18.3946,8.2997],[3.4700,5.9006],[-17.2267,4.9777],[1.0450,-0.8201]],[[17.6996,-11.1763],[26.7775,-3.8823],[-4.2492,-5.8966],[2.1259,13.1794],[-10.7136,0.8428],[16.4233,9.4589]]]> : tensor<2x6x2xf32>
+ %const = arith.constant dense<[[[-3.9058,0.9072],[-2.9470,-2.2055],[18.3946,8.2997],[3.4700,5.9006],[-17.2267,4.9777],[1.0450,-0.8201]],[[17.6996,-11.1763],[26.7775,-3.8823],[-4.2492,-5.8966],[2.1259,13.1794],[-10.7136,0.8428],[16.4233,9.4589]]]> : tensor<2x6x2xf32>
%dynamic = tensor.cast %const: tensor<2x6x2xf32> to tensor<2x?x?xf32>
%expanded = call @expand_dynamic_shape(%dynamic) : (tensor<2x?x?xf32>) -> (tensor<2x2x?x1x?xf32>)
%unranked = tensor.cast %expanded: tensor<2x2x?x1x?xf32> to tensor<*xf32>
func @main() {
- %const = constant dense<[[[1.0, 2.0, 3.0], [2.0, 3.0, 4.0]]]> : tensor<1x2x3xf32>
+ %const = arith.constant dense<[[[1.0, 2.0, 3.0], [2.0, 3.0, 4.0]]]> : tensor<1x2x3xf32>
%dynamic = tensor.cast %const: tensor<1x2x3xf32> to tensor<1x?x3xf32>
- %offset = constant 2 : index
- %cst = constant 2.3 : f32
- %c0 = constant 0 : index
+ %offset = arith.constant 2 : index
+ %cst = arith.constant 2.3 : f32
+ %c0 = arith.constant 0 : index
%out = linalg.pad_tensor %dynamic low[%c0, %offset, %c0] high[%c0, %c0, %offset] {
^bb0(%gen_arg1: index, %gen_arg2: index, %gen_arg3: index): // no predecessors
linalg.yield %cst : f32
// RUN: | FileCheck %s
func @main() {
- %const = constant dense<10.0> : tensor<2xf32>
- %insert_val = constant dense<20.0> : tensor<1xf32>
+ %const = arith.constant dense<10.0> : tensor<2xf32>
+ %insert_val = arith.constant dense<20.0> : tensor<1xf32>
// Both of these insert_slice ops insert into the same original tensor
// value `%const`. This can easily cause bugs if at the memref level
// RUN: | FileCheck %s
func @main() {
- %const = constant dense<10.0> : tensor<2xf32>
- %insert_val = constant dense<20.0> : tensor<1xf32>
+ %const = arith.constant dense<10.0> : tensor<2xf32>
+ %insert_val = arith.constant dense<20.0> : tensor<1xf32>
%inserted = tensor.insert_slice %insert_val into %const[0][1][1] : tensor<1xf32> into tensor<2xf32>
%unranked = tensor.cast %inserted : tensor<2xf32> to tensor<*xf32>
// RUN: | FileCheck %s
func @foo() -> tensor<4xf32> {
- %0 = constant dense<[1.0, 2.0, 3.0, 4.0]> : tensor<4xf32>
+ %0 = arith.constant dense<[1.0, 2.0, 3.0, 4.0]> : tensor<4xf32>
return %0 : tensor<4xf32>
}
// RUN: | FileCheck %s
func @main() {
- %A = constant dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf32>
- %B = constant dense<[[1.0, 2.0, 3.0, 4.0],
+ %A = arith.constant dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf32>
+ %B = arith.constant dense<[[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0],
[9.0, 10.0, 11.0, 12.0]]> : tensor<3x4xf32>
- %C = constant dense<1000.0> : tensor<2x4xf32>
+ %C = arith.constant dense<1000.0> : tensor<2x4xf32>
%D = linalg.matmul ins(%A, %B: tensor<2x3xf32>, tensor<3x4xf32>)
outs(%C: tensor<2x4xf32>) -> tensor<2x4xf32>
// Main driver that reads matrix from file and calls the kernel.
//
func @entry() {
- %d0 = constant 0.0 : f64
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %d0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Read the sparse matrix from file, construct sparse storage.
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
module {
//
// Various kernels that cast a sparse vector from one type to another.
- // Standard supports the following casts.
+ // Arithmetic supports the following casts.
// sitofp
// uitofp
// fptosi
// fptoui
- // fpext
- // fptrunc
- // sexti
- // zexti
+ // extf
+ // truncf
+ // extsi
+ // extui
// trunci
// bitcast
// Since all casts are "zero preserving" unary operations, lattice computation
// and conversion to sparse code is straightforward.
//
func @sparse_cast_s32_to_f32(%arga: tensor<10xi32, #SV>) -> tensor<10xf32> {
- %argx = constant dense<0.0> : tensor<10xf32>
+ %argx = arith.constant dense<0.0> : tensor<10xf32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xi32, #SV>)
outs(%argx: tensor<10xf32>) {
^bb(%a: i32, %x : f32):
- %cst = sitofp %a : i32 to f32
+ %cst = arith.sitofp %a : i32 to f32
linalg.yield %cst : f32
} -> tensor<10xf32>
return %0 : tensor<10xf32>
}
func @sparse_cast_u32_to_f32(%arga: tensor<10xi32, #SV>) -> tensor<10xf32> {
- %argx = constant dense<0.0> : tensor<10xf32>
+ %argx = arith.constant dense<0.0> : tensor<10xf32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xi32, #SV>)
outs(%argx: tensor<10xf32>) {
^bb(%a: i32, %x : f32):
- %cst = uitofp %a : i32 to f32
+ %cst = arith.uitofp %a : i32 to f32
linalg.yield %cst : f32
} -> tensor<10xf32>
return %0 : tensor<10xf32>
}
func @sparse_cast_f32_to_s32(%arga: tensor<10xf32, #SV>) -> tensor<10xi32> {
- %argx = constant dense<0> : tensor<10xi32>
+ %argx = arith.constant dense<0> : tensor<10xi32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xf32, #SV>)
outs(%argx: tensor<10xi32>) {
^bb(%a: f32, %x : i32):
- %cst = fptosi %a : f32 to i32
+ %cst = arith.fptosi %a : f32 to i32
linalg.yield %cst : i32
} -> tensor<10xi32>
return %0 : tensor<10xi32>
}
func @sparse_cast_f64_to_u32(%arga: tensor<10xf64, #SV>) -> tensor<10xi32> {
- %argx = constant dense<0> : tensor<10xi32>
+ %argx = arith.constant dense<0> : tensor<10xi32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xf64, #SV>)
outs(%argx: tensor<10xi32>) {
^bb(%a: f64, %x : i32):
- %cst = fptoui %a : f64 to i32
+ %cst = arith.fptoui %a : f64 to i32
linalg.yield %cst : i32
} -> tensor<10xi32>
return %0 : tensor<10xi32>
}
func @sparse_cast_f32_to_f64(%arga: tensor<10xf32, #SV>) -> tensor<10xf64> {
- %argx = constant dense<0.0> : tensor<10xf64>
+ %argx = arith.constant dense<0.0> : tensor<10xf64>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xf32, #SV>)
outs(%argx: tensor<10xf64>) {
^bb(%a: f32, %x : f64):
- %cst = fpext %a : f32 to f64
+ %cst = arith.extf %a : f32 to f64
linalg.yield %cst : f64
} -> tensor<10xf64>
return %0 : tensor<10xf64>
}
func @sparse_cast_f64_to_f32(%arga: tensor<10xf64, #SV>) -> tensor<10xf32> {
- %argx = constant dense<0.0> : tensor<10xf32>
+ %argx = arith.constant dense<0.0> : tensor<10xf32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xf64, #SV>)
outs(%argx: tensor<10xf32>) {
^bb(%a: f64, %x : f32):
- %cst = fptrunc %a : f64 to f32
+ %cst = arith.truncf %a : f64 to f32
linalg.yield %cst : f32
} -> tensor<10xf32>
return %0 : tensor<10xf32>
}
func @sparse_cast_s32_to_u64(%arga: tensor<10xi32, #SV>) -> tensor<10xi64> {
- %argx = constant dense<0> : tensor<10xi64>
+ %argx = arith.constant dense<0> : tensor<10xi64>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xi32, #SV>)
outs(%argx: tensor<10xi64>) {
^bb(%a: i32, %x : i64):
- %cst = sexti %a : i32 to i64
+ %cst = arith.extsi %a : i32 to i64
linalg.yield %cst : i64
} -> tensor<10xi64>
return %0 : tensor<10xi64>
}
func @sparse_cast_u32_to_s64(%arga: tensor<10xi32, #SV>) -> tensor<10xi64> {
- %argx = constant dense<0> : tensor<10xi64>
+ %argx = arith.constant dense<0> : tensor<10xi64>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xi32, #SV>)
outs(%argx: tensor<10xi64>) {
^bb(%a: i32, %x : i64):
- %cst = zexti %a : i32 to i64
+ %cst = arith.extui %a : i32 to i64
linalg.yield %cst : i64
} -> tensor<10xi64>
return %0 : tensor<10xi64>
}
func @sparse_cast_i32_to_i8(%arga: tensor<10xi32, #SV>) -> tensor<10xi8> {
- %argx = constant dense<0> : tensor<10xi8>
+ %argx = arith.constant dense<0> : tensor<10xi8>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xi32, #SV>)
outs(%argx: tensor<10xi8>) {
^bb(%a: i32, %x : i8):
- %cst = trunci %a : i32 to i8
+ %cst = arith.trunci %a : i32 to i8
linalg.yield %cst : i8
} -> tensor<10xi8>
return %0 : tensor<10xi8>
}
func @sparse_cast_f32_as_s32(%arga: tensor<10xf32, #SV>) -> tensor<10xi32> {
- %argx = constant dense<0> : tensor<10xi32>
+ %argx = arith.constant dense<0> : tensor<10xi32>
%0 = linalg.generic #trait_cast
ins(%arga: tensor<10xf32, #SV>)
outs(%argx: tensor<10xi32>) {
^bb(%a: f32, %x : i32):
- %cst = bitcast %a : f32 to i32
+ %cst = arith.bitcast %a : f32 to i32
linalg.yield %cst : i32
} -> tensor<10xi32>
return %0 : tensor<10xi32>
// and then calls the sparse casting kernel.
//
func @entry() {
- %z = constant 0 : index
- %b = constant 0 : i8
- %i = constant 0 : i32
- %l = constant 0 : i64
- %f = constant 0.0 : f32
- %d = constant 0.0 : f64
+ %z = arith.constant 0 : index
+ %b = arith.constant 0 : i8
+ %i = arith.constant 0 : i32
+ %l = arith.constant 0 : i64
+ %f = arith.constant 0.0 : f32
+ %d = arith.constant 0.0 : f64
// Initialize dense tensors, convert to a sparse vectors.
- %0 = constant dense<[ -4, -3, -2, -1, 0, 1, 2, 3, 4, 305 ]> : tensor<10xi32>
+ %0 = arith.constant dense<[ -4, -3, -2, -1, 0, 1, 2, 3, 4, 305 ]> : tensor<10xi32>
%1 = sparse_tensor.convert %0 : tensor<10xi32> to tensor<10xi32, #SV>
- %2 = constant dense<[ -4.4, -3.3, -2.2, -1.1, 0.0, 1.1, 2.2, 3.3, 4.4, 305.5 ]> : tensor<10xf32>
+ %2 = arith.constant dense<[ -4.4, -3.3, -2.2, -1.1, 0.0, 1.1, 2.2, 3.3, 4.4, 305.5 ]> : tensor<10xf32>
%3 = sparse_tensor.convert %2 : tensor<10xf32> to tensor<10xf32, #SV>
- %4 = constant dense<[ -4.4, -3.3, -2.2, -1.1, 0.0, 1.1, 2.2, 3.3, 4.4, 305.5 ]> : tensor<10xf64>
+ %4 = arith.constant dense<[ -4.4, -3.3, -2.2, -1.1, 0.0, 1.1, 2.2, 3.3, 4.4, 305.5 ]> : tensor<10xf64>
%5 = sparse_tensor.convert %4 : tensor<10xf64> to tensor<10xf64, #SV>
- %6 = constant dense<[ 4294967295.0, 4294967294.0, 4294967293.0, 4294967292.0,
+ %6 = arith.constant dense<[ 4294967295.0, 4294967294.0, 4294967293.0, 4294967292.0,
0.0, 1.1, 2.2, 3.3, 4.4, 305.5 ]> : tensor<10xf64>
%7 = sparse_tensor.convert %6 : tensor<10xf64> to tensor<10xf64, #SV>
//
module {
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %d0 = constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %d0 = arith.constant 0.0 : f64
// A tensor in COO format.
- %ti = constant sparse<[[0, 0], [0, 7], [1, 2], [4, 2], [5, 3], [6, 4], [6, 6], [9, 7]],
+ %ti = arith.constant sparse<[[0, 0], [0, 7], [1, 2], [4, 2], [5, 3], [6, 4], [6, 6], [9, 7]],
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]> : tensor<10x8xf64>
// Convert the tensor in COO format to a sparse tensor with annotation #Tensor1.
// Verify utilities.
//
func @checkf64(%arg0: memref<?xf64>, %arg1: memref<?xf64>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Same lengths?
%0 = memref.dim %arg0, %c0 : memref<?xf64>
%1 = memref.dim %arg1, %c0 : memref<?xf64>
- %2 = cmpi ne, %0, %1 : index
+ %2 = arith.cmpi ne, %0, %1 : index
scf.if %2 {
call @exit(%c1) : (index) -> ()
}
scf.for %i = %c0 to %0 step %c1 {
%a = memref.load %arg0[%i] : memref<?xf64>
%b = memref.load %arg1[%i] : memref<?xf64>
- %c = cmpf une, %a, %b : f64
+ %c = arith.cmpf une, %a, %b : f64
scf.if %c {
call @exit(%c1) : (index) -> ()
}
return
}
func @check(%arg0: memref<?xindex>, %arg1: memref<?xindex>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Same lengths?
%0 = memref.dim %arg0, %c0 : memref<?xindex>
%1 = memref.dim %arg1, %c0 : memref<?xindex>
- %2 = cmpi ne, %0, %1 : index
+ %2 = arith.cmpi ne, %0, %1 : index
scf.if %2 {
call @exit(%c1) : (index) -> ()
}
scf.for %i = %c0 to %0 step %c1 {
%a = memref.load %arg0[%i] : memref<?xindex>
%b = memref.load %arg1[%i] : memref<?xindex>
- %c = cmpi ne, %a, %b : index
+ %c = arith.cmpi ne, %a, %b : index
scf.if %c {
call @exit(%c1) : (index) -> ()
}
// Output utility.
//
func @dumpf64(%arg0: memref<?xf64>) {
- %c0 = constant 0 : index
- %d0 = constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %d0 = arith.constant 0.0 : f64
%0 = vector.transfer_read %arg0[%c0], %d0: memref<?xf64>, vector<24xf64>
vector.print %0 : vector<24xf64>
return
// Main driver.
//
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
//
// Initialize a 3-dim dense tensor.
//
- %t = constant dense<[
+ %t = arith.constant dense<[
[ [ 1.0, 2.0, 3.0, 4.0 ],
[ 5.0, 6.0, 7.0, 8.0 ],
[ 9.0, 10.0, 11.0, 12.0 ] ],
}
func @entry() {
- %c0 = constant 0 : index
- %i0 = constant 0 : i32
+ %c0 = arith.constant 0 : index
+ %i0 = arith.constant 0 : i32
// A typical edge detection filter.
- %filter = constant dense<[
+ %filter = arith.constant dense<[
[ 1, 0, -1 ],
[ 0, 0, 0 ],
[ -1, 0, 1 ]
%sparse_filter = sparse_tensor.convert %filter
: tensor<3x3xi32> to tensor<3x3xi32, #DCSR>
- %input = constant dense<[
+ %input = arith.constant dense<[
[ 1, 2, 3, 4, 0, 6, 7, 8 ],
[ 2, 2, 4, 4, 0, 0, 6, 8 ],
[ 2, 2, 4, 4, 0, 0, 6, 8 ],
]> : tensor<8x8xi32>
// Call the kernel.
- %output = constant dense<0> : tensor<6x6xi32>
+ %output = arith.constant dense<0> : tensor<6x6xi32>
%0 = call @conv2d(%input, %sparse_filter, %output)
: (tensor<8x8xi32>,
tensor<3x3xi32, #DCSR>, tensor<6x6xi32>) -> tensor<6x6xi32>
ins(%arga: tensor<7x3x3x3x3x3x5x3xf64, #SparseTensor>)
outs(%argx: tensor<7x3xf64>) {
^bb(%a: f64, %x: f64):
- %0 = addf %x, %a : f64
+ %0 = arith.addf %x, %a : f64
linalg.yield %0 : f64
} -> tensor<7x3xf64>
return %0 : tensor<7x3xf64>
// Main driver that reads tensor from file and calls the sparse kernel.
//
func @entry() {
- %d0 = constant 0.0 : f64
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c3 = constant 3 : index
- %c7 = constant 7 : index
+ %d0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c3 = arith.constant 3 : index
+ %c7 = arith.constant 7 : index
// Setup matrix memory that is initialized to zero.
%xdata = memref.alloc() : memref<7x3xf64>
ins(%arga, %argb: tensor<?x?xi32, #SparseMatrix>, tensor<?xi32>)
outs(%argx: tensor<?xi32>) {
^bb(%a: i32, %b: i32, %x: i32):
- %0 = muli %a, %b : i32
- %1 = addi %x, %0 : i32
+ %0 = arith.muli %a, %b : i32
+ %1 = arith.addi %x, %0 : i32
linalg.yield %1 : i32
} -> tensor<?xi32>
return %0 : tensor<?xi32>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %i0 = constant 0 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c256 = constant 256 : index
+ %i0 = arith.constant 0 : i32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c256 = arith.constant 256 : index
// Read the sparse matrix from file, construct sparse storage.
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
%bdata = memref.alloc(%c256) : memref<?xi32>
%xdata = memref.alloc(%c4) : memref<?xi32>
scf.for %i = %c0 to %c256 step %c1 {
- %k = addi %i, %c1 : index
- %j = index_cast %k : index to i32
+ %k = arith.addi %i, %c1 : index
+ %j = arith.index_cast %k : index to i32
memref.store %j, %bdata[%i] : memref<?xi32>
}
scf.for %i = %c0 to %c4 step %c1 {
tensor<?x?x?xf64, #SparseMatrix>, tensor<?x?xf64>, tensor<?x?xf64>)
outs(%arga: tensor<?x?xf64>) {
^bb(%b: f64, %c: f64, %d: f64, %a: f64):
- %0 = mulf %b, %c : f64
- %1 = mulf %d, %0 : f64
- %2 = addf %a, %1 : f64
+ %0 = arith.mulf %b, %c : f64
+ %1 = arith.mulf %d, %0 : f64
+ %2 = arith.addf %a, %1 : f64
linalg.yield %2 : f64
} -> tensor<?x?xf64>
return %0 : tensor<?x?xf64>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %i0 = constant 0. : f64
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c256 = constant 256 : index
+ %i0 = arith.constant 0. : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c256 = arith.constant 256 : index
// Read the sparse B input from a file.
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
%cdata = memref.alloc(%c3, %c5) : memref<?x?xf64>
scf.for %i = %c0 to %c3 step %c1 {
scf.for %j = %c0 to %c5 step %c1 {
- %k0 = muli %i, %c5 : index
- %k1 = addi %k0, %j : index
- %k2 = index_cast %k1 : index to i32
- %k = sitofp %k2 : i32 to f64
+ %k0 = arith.muli %i, %c5 : index
+ %k1 = arith.addi %k0, %j : index
+ %k2 = arith.index_cast %k1 : index to i32
+ %k = arith.sitofp %k2 : i32 to f64
memref.store %k, %cdata[%i, %j] : memref<?x?xf64>
}
}
%ddata = memref.alloc(%c4, %c5) : memref<?x?xf64>
scf.for %i = %c0 to %c4 step %c1 {
scf.for %j = %c0 to %c5 step %c1 {
- %k0 = muli %i, %c5 : index
- %k1 = addi %k0, %j : index
- %k2 = index_cast %k1 : index to i32
- %k = sitofp %k2 : i32 to f64
+ %k0 = arith.muli %i, %c5 : index
+ %k1 = arith.addi %k0, %j : index
+ %k2 = arith.index_cast %k1 : index to i32
+ %k = arith.sitofp %k2 : i32 to f64
memref.store %k, %ddata[%i, %j] : memref<?x?xf64>
}
}
%0 = linalg.generic #eltwise_mult
outs(%argx: tensor<?x?xf64, #DCSR>) {
^bb(%x: f64):
- %0 = mulf %x, %x : f64
+ %0 = arith.mulf %x, %x : f64
linalg.yield %0 : f64
} -> tensor<?x?xf64, #DCSR>
return %0 : tensor<?x?xf64, #DCSR>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %d0 = constant 0.0 : f64
- %c0 = constant 0 : index
+ %d0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
// Read the sparse matrix from file, construct sparse storage.
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
func @quantized_matmul(%input1: tensor<5x3xi8>,
%input2: tensor<3x6xi8, #DCSR>,
%output: tensor<5x6xi32>) -> tensor<5x6xi32> {
- %c0 = constant 0 : i32
- %c2 = constant 2 : i32
+ %c0 = arith.constant 0 : i32
+ %c2 = arith.constant 2 : i32
%0 = linalg.quantized_matmul
ins(%input1, %input2, %c2, %c0 : tensor<5x3xi8>, tensor<3x6xi8, #DCSR>, i32, i32)
outs(%output : tensor<5x6xi32>) -> tensor<5x6xi32>
}
func @entry() {
- %c0 = constant 0 : index
- %i0 = constant 0 : i32
+ %c0 = arith.constant 0 : index
+ %i0 = arith.constant 0 : i32
- %input1 = constant dense<[
+ %input1 = arith.constant dense<[
[ -128, 3, 127 ],
[ 0, 0, 0 ],
[ 11, 1, 0 ],
[ 13, 0, 3 ]
]> : tensor<5x3xi8>
- %input2 = constant dense<[
+ %input2 = arith.constant dense<[
[ 127, 0, -128, 0, 0, 3 ],
[ 0, 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 100, 10, 0 ]
%sparse_input2 = sparse_tensor.convert %input2 : tensor<3x6xi8> to tensor<3x6xi8, #DCSR>
// Call the kernel.
- %output = constant dense<0> : tensor<5x6xi32>
+ %output = arith.constant dense<0> : tensor<5x6xi32>
%0 = call @quantized_matmul(%input1, %sparse_input2, %output)
: (tensor<5x3xi8>,
tensor<3x6xi8, #DCSR>,
ins(%arga: tensor<32xi32, #SV>)
outs(%argx: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %0 = addi %x, %a : i32
+ %0 = arith.addi %x, %a : i32
linalg.yield %0 : i32
} -> tensor<i32>
return %0 : tensor<i32>
ins(%arga: tensor<32xf32, #SV>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %x: f32):
- %0 = addf %x, %a : f32
+ %0 = arith.addf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
ins(%arga: tensor<32xi32, #DV>)
outs(%argx: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %0 = muli %x, %a : i32
+ %0 = arith.muli %x, %a : i32
linalg.yield %0 : i32
} -> tensor<i32>
return %0 : tensor<i32>
ins(%arga: tensor<32xf32, #DV>)
outs(%argx: tensor<f32>) {
^bb(%a: f32, %x: f32):
- %0 = mulf %x, %a : f32
+ %0 = arith.mulf %x, %a : f32
linalg.yield %0 : f32
} -> tensor<f32>
return %0 : tensor<f32>
ins(%arga: tensor<32xi32, #DV>)
outs(%argx: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %0 = and %x, %a : i32
+ %0 = arith.andi %x, %a : i32
linalg.yield %0 : i32
} -> tensor<i32>
return %0 : tensor<i32>
ins(%arga: tensor<32xi32, #SV>)
outs(%argx: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %0 = or %x, %a : i32
+ %0 = arith.ori %x, %a : i32
linalg.yield %0 : i32
} -> tensor<i32>
return %0 : tensor<i32>
ins(%arga: tensor<32xi32, #SV>)
outs(%argx: tensor<i32>) {
^bb(%a: i32, %x: i32):
- %0 = xor %x, %a : i32
+ %0 = arith.xori %x, %a : i32
linalg.yield %0 : i32
} -> tensor<i32>
return %0 : tensor<i32>
}
func @entry() {
- %ri = constant dense< 7 > : tensor<i32>
- %rf = constant dense< 2.0 > : tensor<f32>
+ %ri = arith.constant dense< 7 > : tensor<i32>
+ %rf = arith.constant dense< 2.0 > : tensor<f32>
- %c_0_i32 = constant dense<[
+ %c_0_i32 = arith.constant dense<[
0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 4, 0, 0, 0,
0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9, 0
]> : tensor<32xi32>
- %c_0_f32 = constant dense<[
+ %c_0_f32 = arith.constant dense<[
0.0, 1.0, 0.0, 0.0, 4.0, 0.0, 0.0, 0.0,
0.0, 0.0, 3.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 2.5, 0.0, 0.0, 0.0,
2.0, 0.0, 0.0, 0.0, 0.0, 4.0, 0.0, 9.0
]> : tensor<32xf32>
- %c_1_i32 = constant dense<[
+ %c_1_i32 = arith.constant dense<[
1, 1, 7, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 7, 3
]> : tensor<32xi32>
- %c_1_f32 = constant dense<[
+ %c_1_f32 = arith.constant dense<[
1.0, 1.0, 1.0, 3.5, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 2.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 3.0, 1.0, 1.0, 1.0,
ins(%args, %arga, %argb: tensor<?x?xf32, #SparseMatrix>, tensor<?x?xf32>, tensor<?x?xf32>)
outs(%argx: tensor<?x?xf32>) {
^bb(%s: f32, %a: f32, %b: f32, %x: f32):
- %0 = mulf %a, %b : f32
- %1 = mulf %s, %0 : f32
- %2 = addf %x, %1 : f32
+ %0 = arith.mulf %a, %b : f32
+ %1 = arith.mulf %s, %0 : f32
+ %2 = arith.addf %x, %1 : f32
linalg.yield %2 : f32
} -> tensor<?x?xf32>
return %0 : tensor<?x?xf32>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %d0 = constant 0.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c5 = constant 5 : index
- %c10 = constant 10 : index
+ %d0 = arith.constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c5 = arith.constant 5 : index
+ %c10 = arith.constant 10 : index
// Setup memory for the dense matrices and initialize.
%adata = memref.alloc(%c5, %c10) : memref<?x?xf32>
scf.for %j = %c0 to %c5 step %c1 {
memref.store %d0, %xdata[%i, %j] : memref<?x?xf32>
}
- %p = addi %i, %c1 : index
- %q = index_cast %p : index to i32
- %d = sitofp %q : i32 to f32
+ %p = arith.addi %i, %c1 : index
+ %q = arith.index_cast %p : index to i32
+ %d = arith.sitofp %q : i32 to f32
scf.for %j = %c0 to %c10 step %c1 {
memref.store %d, %adata[%i, %j] : memref<?x?xf32>
memref.store %d, %bdata[%j, %i] : memref<?x?xf32>
func @sampled_dd(%args: tensor<8x8xf64, #SM>,
%arga: tensor<8x8xf64>,
%argb: tensor<8x8xf64>) -> tensor<8x8xf64> {
- %d = constant 0.0 : f64
+ %d = arith.constant 0.0 : f64
%0 = linalg.init_tensor [8, 8] : tensor<8x8xf64>
%1 = linalg.fill(%d, %0) : f64, tensor<8x8xf64> -> tensor<8x8xf64>
tensor<8x8xf64>, tensor<8x8xf64>)
outs(%1: tensor<8x8xf64>) {
^bb(%s: f64, %a: f64, %b: f64, %x: f64):
- %p = mulf %a, %b : f64
- %q = mulf %s, %p : f64
- %r = addf %x, %q : f64
+ %p = arith.mulf %a, %b : f64
+ %q = arith.mulf %s, %p : f64
+ %r = arith.addf %x, %q : f64
linalg.yield %r : f64
} -> tensor<8x8xf64>
return %2 : tensor<8x8xf64>
func @sampled_dd_unfused(%args: tensor<8x8xf64, #SM>,
%arga: tensor<8x8xf64>,
%argb: tensor<8x8xf64>) -> tensor<8x8xf64> {
- %d = constant 0.0 : f64
+ %d = arith.constant 0.0 : f64
%0 = linalg.init_tensor [8, 8] : tensor<8x8xf64>
%1 = linalg.fill(%d, %0) : f64, tensor<8x8xf64> -> tensor<8x8xf64>
ins(%arga, %argb : tensor<8x8xf64>, tensor<8x8xf64>)
outs(%1 : tensor<8x8xf64>) {
^bb0(%a: f64, %b: f64, %x: f64):
- %p = mulf %a, %b : f64
- %q = addf %x, %p : f64
+ %p = arith.mulf %a, %b : f64
+ %q = arith.addf %x, %p : f64
linalg.yield %q : f64
} -> tensor<8x8xf64>
ins(%2, %args : tensor<8x8xf64>, tensor<8x8xf64, #SM>)
outs(%4 : tensor<8x8xf64>) {
^bb0(%t: f64, %s: f64, %x: f64):
- %r = mulf %t, %s : f64
+ %r = arith.mulf %t, %s : f64
linalg.yield %r : f64
} -> tensor<8x8xf64>
// Main driver.
//
func @entry() {
- %d0 = constant 0.0 : f64
- %c0 = constant 0 : index
+ %d0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
- %t = constant sparse<[[0, 0], [7,7]], [1.0, 2.0]>
+ %t = arith.constant sparse<[[0, 0], [7,7]], [1.0, 2.0]>
: tensor<8x8xf64>
%s = sparse_tensor.convert %t
: tensor<8x8xf64> to tensor<8x8xf64, #SM>
- %a = constant dense<3.0> : tensor<8x8xf64>
- %b = constant dense<4.0> : tensor<8x8xf64>
+ %a = arith.constant dense<3.0> : tensor<8x8xf64>
+ %b = arith.constant dense<4.0> : tensor<8x8xf64>
// Call the kernels.
%0 = call @sampled_dd(%s, %a, %b)
//
func @sparse_scale(%argx: tensor<8x8xf32, #CSR>
{linalg.inplaceable = true}) -> tensor<8x8xf32, #CSR> {
- %c = constant 2.0 : f32
+ %c = arith.constant 2.0 : f32
%0 = linalg.generic #trait_scale
outs(%argx: tensor<8x8xf32, #CSR>) {
^bb(%x: f32):
- %1 = mulf %x, %c : f32
+ %1 = arith.mulf %x, %c : f32
linalg.yield %1 : f32
} -> tensor<8x8xf32, #CSR>
return %0 : tensor<8x8xf32, #CSR>
// as input argument.
//
func @entry() {
- %c0 = constant 0 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %f0 = arith.constant 0.0 : f32
// Initialize a dense tensor.
- %0 = constant dense<[
+ %0 = arith.constant dense<[
[1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0],
[0.0, 2.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 3.0, 0.0, 0.0, 0.0, 0.0, 0.0],
ins(%arga, %argb: tensor<?x?xf64, #SparseMatrix>, tensor<?x?xf64>)
outs(%argx: tensor<?x?xf64>) {
^bb(%a: f64, %b: f64, %x: f64):
- %0 = mulf %a, %b : f64
- %1 = addf %x, %0 : f64
+ %0 = arith.mulf %a, %b : f64
+ %1 = arith.addf %x, %0 : f64
linalg.yield %1 : f64
} -> tensor<?x?xf64>
return %0 : tensor<?x?xf64>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %i0 = constant 0.0 : f64
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %c256 = constant 256 : index
+ %i0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %c256 = arith.constant 256 : index
// Read the sparse matrix from file, construct sparse storage.
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
%xdata = memref.alloc(%c4, %c4) : memref<?x?xf64>
scf.for %i = %c0 to %c256 step %c1 {
scf.for %j = %c0 to %c4 step %c1 {
- %k0 = muli %i, %c4 : index
- %k1 = addi %j, %k0 : index
- %k2 = index_cast %k1 : index to i32
- %k = sitofp %k2 : i32 to f64
+ %k0 = arith.muli %i, %c4 : index
+ %k1 = arith.addi %j, %k0 : index
+ %k2 = arith.index_cast %k1 : index to i32
+ %k = arith.sitofp %k2 : i32 to f64
memref.store %k, %bdata[%i, %j] : memref<?x?xf64>
}
}
// everything is working "under the hood".
//
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %d0 = constant 0.0 : f64
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %d0 = arith.constant 0.0 : f64
//
// Initialize a dense tensor.
//
- %t = constant dense<[
+ %t = arith.constant dense<[
[ 1.0, 0.0, 2.0, 0.0, 0.0, 0.0, 0.0, 3.0],
[ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 4.0, 0.0, 0.0, 0.0, 0.0, 0.0],
ins(%arga: tensor<?x?xf64, #SparseMatrix>)
outs(%argx: tensor<f64>) {
^bb(%a: f64, %x: f64):
- %0 = addf %x, %a : f64
+ %0 = arith.addf %x, %a : f64
linalg.yield %0 : f64
} -> tensor<f64>
return %0 : tensor<f64>
// Main driver that reads matrix from file and calls the sparse kernel.
//
func @entry() {
- %d0 = constant 0.0 : f64
- %c0 = constant 0 : index
+ %d0 = arith.constant 0.0 : f64
+ %c0 = arith.constant 0 : index
// Setup memory for a single reduction scalar,
// initialized to zero.
// RUN: FileCheck %s
func @transfer_read_2d(%A : memref<40xi32>, %base1: index) {
- %i42 = constant -42: i32
+ %i42 = arith.constant -42: i32
%f = vector.transfer_read %A[%base1], %i42
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<40xi32>, vector<40xi32>
}
func @entry() {
- %c0 = constant 0: index
- %c20 = constant 20: i32
- %c10 = constant 10: i32
- %cmin10 = constant -10: i32
+ %c0 = arith.constant 0: index
+ %c20 = arith.constant 20: i32
+ %c10 = arith.constant 10: i32
+ %cmin10 = arith.constant -10: i32
%A = memref.alloc() : memref<40xi32>
// print numerator
affine.for %i = 0 to 40 {
- %ii = index_cast %i: index to i32
- %ii30 = subi %ii, %c20 : i32
+ %ii = arith.index_cast %i: index to i32
+ %ii30 = arith.subi %ii, %c20 : i32
memref.store %ii30, %A[%i] : memref<40xi32>
}
call @transfer_read_2d(%A, %c0) : (memref<40xi32>, index) -> ()
// test with ceil(*, 10)
affine.for %i = 0 to 40 {
- %ii = index_cast %i: index to i32
- %ii30 = subi %ii, %c20 : i32
- %val = ceildivi_signed %ii30, %c10 : i32
+ %ii = arith.index_cast %i: index to i32
+ %ii30 = arith.subi %ii, %c20 : i32
+ %val = arith.ceildivsi %ii30, %c10 : i32
memref.store %val, %A[%i] : memref<40xi32>
}
call @transfer_read_2d(%A, %c0) : (memref<40xi32>, index) -> ()
// test with floor(*, 10)
affine.for %i = 0 to 40 {
- %ii = index_cast %i: index to i32
- %ii30 = subi %ii, %c20 : i32
- %val = floordivi_signed %ii30, %c10 : i32
+ %ii = arith.index_cast %i: index to i32
+ %ii30 = arith.subi %ii, %c20 : i32
+ %val = arith.floordivsi %ii30, %c10 : i32
memref.store %val, %A[%i] : memref<40xi32>
}
call @transfer_read_2d(%A, %c0) : (memref<40xi32>, index) -> ()
// test with ceil(*, -10)
affine.for %i = 0 to 40 {
- %ii = index_cast %i: index to i32
- %ii30 = subi %ii, %c20 : i32
- %val = ceildivi_signed %ii30, %cmin10 : i32
+ %ii = arith.index_cast %i: index to i32
+ %ii30 = arith.subi %ii, %c20 : i32
+ %val = arith.ceildivsi %ii30, %cmin10 : i32
memref.store %val, %A[%i] : memref<40xi32>
}
call @transfer_read_2d(%A, %c0) : (memref<40xi32>, index) -> ()
// test with floor(*, -10)
affine.for %i = 0 to 40 {
- %ii = index_cast %i: index to i32
- %ii30 = subi %ii, %c20 : i32
- %val = floordivi_signed %ii30, %cmin10 : i32
+ %ii = arith.index_cast %i: index to i32
+ %ii30 = arith.subi %ii, %c20 : i32
+ %val = arith.floordivsi %ii30, %cmin10 : i32
memref.store %val, %A[%i] : memref<40xi32>
}
call @transfer_read_2d(%A, %c0) : (memref<40xi32>, index) -> ()
func @kernel1(%arg0: memref<2x4xbf16>,
%arg1: memref<2x4xbf16>,
%arg2: memref<2x2xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<2x4xbf16> into vector<2x4xbf16>
%2 = amx.tile_load %arg1[%0, %0] : memref<2x4xbf16> into vector<2x4xbf16>
%3 = amx.tile_zero : vector<2x2xf32>
func @kernel2(%arg0: memref<2x4xbf16>,
%arg1: memref<2x4xbf16>,
%arg2: memref<2x2xf32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<2x4xbf16> into vector<2x4xbf16>
%2 = amx.tile_load %arg1[%0, %0] : memref<2x4xbf16> into vector<2x4xbf16>
%3 = amx.tile_load %arg2[%0, %0] : memref<2x2xf32> into vector<2x2xf32>
}
func @entry() -> i32 {
- %f0 = constant 0.0: f32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
+ %f0 = arith.constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
// Set up memory.
%a = memref.alloc() : memref<2x4xbf16>
%b = memref.alloc() : memref<2x4xbf16>
%c = memref.alloc() : memref<2x2xf32>
- %0 = std.constant dense<[[1.0, 2.0, 3.0, 4.0 ],
- [5.0, 6.0, 7.0, 8.0 ]]> : vector<2x4xbf16>
+ %0 = arith.constant dense<[[1.0, 2.0, 3.0, 4.0 ],
+ [5.0, 6.0, 7.0, 8.0 ]]> : vector<2x4xbf16>
vector.transfer_write %0, %a[%c0, %c0] : vector<2x4xbf16>, memref<2x4xbf16>
- %1 = std.constant dense<[[ 9.0, 10.0, 11.0, 12.0 ],
- [13.0, 14.0, 15.0, 16.0 ]]> : vector<2x4xbf16>
+ %1 = arith.constant dense<[[ 9.0, 10.0, 11.0, 12.0 ],
+ [13.0, 14.0, 15.0, 16.0 ]]> : vector<2x4xbf16>
vector.transfer_write %1, %b[%c0, %c0] : vector<2x4xbf16>, memref<2x4xbf16>
// Call kernel.
memref.dealloc %b : memref<2x4xbf16>
memref.dealloc %c : memref<2x2xf32>
- %i0 = constant 0 : i32
+ %i0 = arith.constant 0 : i32
return %i0 : i32
}
// Note: To run this test, your CPU must support AMX.
func @print(%arg0: memref<16x4xi32>) {
- %iu = constant -1: i32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
+ %iu = arith.constant -1: i32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
scf.for %i = %c0 to %c16 step %c1 {
%0 = vector.transfer_read %arg0[%i, %c0], %iu: memref<16x4xi32>, vector<4xi32>
vector.print %0 : vector<4xi32>
func @kernel1(%arg0: memref<16x16xi8>,
%arg1: memref<4x16xi8>,
%arg2: memref<16x4xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<16x16xi8> into vector<16x16xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<4x16xi8> into vector<4x16xi8>
%3 = amx.tile_zero : vector<16x4xi32>
func @kernel2(%arg0: memref<16x16xi8>,
%arg1: memref<4x16xi8>,
%arg2: memref<16x4xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<16x16xi8> into vector<16x16xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<4x16xi8> into vector<4x16xi8>
%3 = amx.tile_zero : vector<16x4xi32>
func @kernel3(%arg0: memref<16x16xi8>,
%arg1: memref<4x16xi8>,
%arg2: memref<16x4xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<16x16xi8> into vector<16x16xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<4x16xi8> into vector<4x16xi8>
%3 = amx.tile_zero : vector<16x4xi32>
func @kernel4(%arg0: memref<16x16xi8>,
%arg1: memref<4x16xi8>,
%arg2: memref<16x4xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<16x16xi8> into vector<16x16xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<4x16xi8> into vector<4x16xi8>
%3 = amx.tile_zero : vector<16x4xi32>
}
func @entry() -> i32 {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
// Set up memory.
%a = memref.alloc() : memref<16x16xi8>
%b = memref.alloc() : memref<4x16xi8>
%c = memref.alloc() : memref<16x4xi32>
- %0 = std.constant dense<
+ %0 = arith.constant dense<
[ [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ],
[ 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 ],
[ 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47 ],
[224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239 ],
[240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255 ] ]> : vector<16x16xi8>
- %1 = std.constant dense<
+ %1 = arith.constant dense<
[ [192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207 ],
[208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223 ],
[224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239 ],
memref.dealloc %b : memref<4x16xi8>
memref.dealloc %c : memref<16x4xi32>
- %i0 = constant 0 : i32
+ %i0 = arith.constant 0 : i32
return %i0 : i32
}
func @kernel1(%arg0: memref<2x8xi8>,
%arg1: memref<2x8xi8>,
%arg2: memref<2x2xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<2x8xi8> into vector<2x8xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<2x8xi8> into vector<2x8xi8>
%3 = amx.tile_zero : vector<2x2xi32>
func @kernel2(%arg0: memref<2x8xi8>,
%arg1: memref<2x8xi8>,
%arg2: memref<2x2xi32>) {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = amx.tile_load %arg0[%0, %0] : memref<2x8xi8> into vector<2x8xi8>
%2 = amx.tile_load %arg1[%0, %0] : memref<2x8xi8> into vector<2x8xi8>
%3 = amx.tile_load %arg2[%0, %0] : memref<2x2xi32> into vector<2x2xi32>
}
func @entry() -> i32 {
- %i0 = constant 0: i32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
+ %i0 = arith.constant 0: i32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
// Set up memory.
%a = memref.alloc() : memref<2x8xi8>
%b = memref.alloc() : memref<2x8xi8>
%c = memref.alloc() : memref<2x2xi32>
- %0 = std.constant dense<[[1 , 2, 3 , 4 , 5, 6, 7, 8],
+ %0 = arith.constant dense<[[1 , 2, 3 , 4 , 5, 6, 7, 8],
[9, 10, 11, 12, 13, 14, 15, 16]]> : vector<2x8xi8>
vector.transfer_write %0, %a[%c0, %c0] : vector<2x8xi8>, memref<2x8xi8>
- %1 = std.constant dense<[[17, 18, 19, 20, 21, 22, 23, 24],
+ %1 = arith.constant dense<[[17, 18, 19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30, 31, 32]]> : vector<2x8xi8>
vector.transfer_write %1, %b[%c0, %c0] : vector<2x8xi8>, memref<2x8xi8>
// Note: To run this test, your CPU must support AMX.
func @print(%arg0: memref<4x32xf32>) {
- %fu = constant -1.0: f32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c4 = constant 4: index
+ %fu = arith.constant -1.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c4 = arith.constant 4: index
scf.for %i = %c0 to %c4 step %c1 {
%0 = vector.transfer_read %arg0[%i, %c0], %fu: memref<4x32xf32>, vector<32xf32>
vector.print %0 : vector<32xf32>
}
func @kernel(%arg0: memref<4x32xf32>) {
- %c0 = constant 0: index
- %c2 = constant 2 : index
- %c4 = constant 4 : index
- %c16 = constant 16 : index
- %c32 = constant 32 : index
+ %c0 = arith.constant 0: index
+ %c2 = arith.constant 2 : index
+ %c4 = arith.constant 4 : index
+ %c16 = arith.constant 16 : index
+ %c32 = arith.constant 32 : index
scf.for %i = %c0 to %c4 step %c2 {
scf.for %j = %c0 to %c32 step %c16 {
%0 = amx.tile_zero : vector<2x16xf32>
}
func @entry() -> i32 {
- %f1 = constant 1.0: f32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c4 = constant 4 : index
- %c32 = constant 32 : index
+ %f1 = arith.constant 1.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c4 = arith.constant 4 : index
+ %c32 = arith.constant 32 : index
// Set up memory.
%a = memref.alloc() : memref<4x32xf32>
// Release resources.
memref.dealloc %a : memref<4x32xf32>
- %i0 = constant 0 : i32
+ %i0 = arith.constant 0 : i32
return %i0 : i32
}
}
func @entry() -> i32 {
- %i0 = constant 0: i32
- %i1 = constant 1: i32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c3 = constant 3: index
- %c19 = constant 19: index
+ %i0 = arith.constant 0: i32
+ %i1 = arith.constant 1: i32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c3 = arith.constant 3: index
+ %c19 = arith.constant 19: index
// Set up memory.
%a = memref.alloc(%c19, %c19) : memref<?x?xi32>
// RUN: FileCheck %s
func @entry() -> i32 {
- %i0 = constant 0 : i32
- %i4 = constant 4 : i32
+ %i0 = arith.constant 0 : i32
+ %i4 = arith.constant 4 : i32
- %a = std.constant dense<[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]> : vector<8xf32>
- %b = std.constant dense<[9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0]> : vector<8xf32>
+ %a = arith.constant dense<[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]> : vector<8xf32>
+ %b = arith.constant dense<[9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0]> : vector<8xf32>
%r = x86vector.avx.intr.dot %a, %b : vector<8xf32>
%1 = vector.extractelement %r[%i0 : i32]: vector<8xf32>
%2 = vector.extractelement %r[%i4 : i32]: vector<8xf32>
- %d = addf %1, %2 : f32
+ %d = arith.addf %1, %2 : f32
// CHECK: ( 110, 110, 110, 110, 382, 382, 382, 382 )
// CHECK: 492
// RUN: FileCheck %s
func @entry() -> i32 {
- %i0 = constant 0 : i32
+ %i0 = arith.constant 0 : i32
- %a = std.constant dense<[1., 0., 0., 2., 4., 3., 5., 7., 8., 1., 5., 5., 3., 1., 0., 7.]> : vector<16xf32>
- %k = std.constant dense<[1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0]> : vector<16xi1>
+ %a = arith.constant dense<[1., 0., 0., 2., 4., 3., 5., 7., 8., 1., 5., 5., 3., 1., 0., 7.]> : vector<16xf32>
+ %k = arith.constant dense<[1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0]> : vector<16xi1>
%r1 = x86vector.avx512.mask.compress %k, %a : vector<16xf32>
%r2 = x86vector.avx512.mask.compress %k, %a {constant_src = dense<5.0> : vector<16xf32>} : vector<16xf32>
vector.print %r2 : vector<16xf32>
// CHECK: ( 1, 0, 2, 4, 5, 5, 3, 1, 0, 5, 5, 5, 5, 5, 5, 5 )
- %src = std.constant dense<[0., 2., 1., 8., 6., 4., 4., 3., 2., 8., 5., 6., 3., 7., 6., 9.]> : vector<16xf32>
+ %src = arith.constant dense<[0., 2., 1., 8., 6., 4., 4., 3., 2., 8., 5., 6., 3., 7., 6., 9.]> : vector<16xf32>
%r3 = x86vector.avx512.mask.compress %k, %a, %src : vector<16xf32>, vector<16xf32>
vector.print %r3 : vector<16xf32>
// RUN: FileCheck %s
func @entry() -> i32 {
- %i0 = constant 0 : i32
+ %i0 = arith.constant 0 : i32
- %v = std.constant dense<[0.125, 0.25, 0.5, 1.0, 2.0, 4.0, 8.0, 16.0]> : vector<8xf32>
+ %v = arith.constant dense<[0.125, 0.25, 0.5, 1.0, 2.0, 4.0, 8.0, 16.0]> : vector<8xf32>
%r = x86vector.avx.rsqrt %v : vector<8xf32>
// `rsqrt` may produce slightly different results on Intel and AMD machines: accept both results here.
// CHECK: {{( 2.82[0-9]*, 1.99[0-9]*, 1.41[0-9]*, 0.99[0-9]*, 0.70[0-9]*, 0.49[0-9]*, 0.35[0-9]*, 0.24[0-9]* )}}
%p1 = x86vector.avx512.mask.compress %k1, %v_D : vector<8xf64>
// Dense vector dot product.
- %acc = std.constant 0.0 : f64
+ %acc = arith.constant 0.0 : f64
%r = vector.contract #contraction_trait %p0, %p1, %acc
: vector<8xf64>, vector<8xf64> into f64
// input sizes up to 128 elements per sparse vector.
func @init_input(%m_A : memref<?xi64>, %m_B : memref<?xf64>,
%m_C : memref<?xi64>, %m_D : memref<?xf64>) {
- %c0 = constant 0 : index
- %v_data = constant dense<0.0> : vector<128xf64>
- %v_index = constant dense<9223372036854775807> : vector<128xi64>
+ %c0 = arith.constant 0 : index
+ %v_data = arith.constant dense<0.0> : vector<128xf64>
+ %v_index = arith.constant dense<9223372036854775807> : vector<128xi64>
vector.transfer_write %v_index, %m_A[%c0] : vector<128xi64>, memref<?xi64>
vector.transfer_write %v_data, %m_B[%c0] : vector<128xf64>, memref<?xf64>
call @init_input(%m_A, %m_B, %m_C, %m_D)
: (memref<?xi64>, memref<?xf64>, memref<?xi64>, memref<?xf64>) -> ()
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
- %v_A = std.constant dense<[0, 1, 10, 12, 13, 17, 18, 21,
- 51, 52, 57, 61, 62, 82, 98, 99]> : vector<16xi64>
- %v_B = std.constant dense<[1., 5., 8., 3., 2., 1., 0., 9.,
- 6., 7., 7., 3., 5., 2., 9., 1.]> : vector<16xf64>
- %v_C = std.constant dense<[1, 2, 5, 10, 11, 12, 47, 48,
- 67, 68, 69, 70, 71, 72, 77, 78,
- 79, 82, 83, 84, 85, 90, 91, 98]> : vector<24xi64>
- %v_D = std.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
- 6., 7., 7., 3., 5., 2., 9., 1.,
- 2., 9., 8., 7., 2., 0., 0., 4.]> : vector<24xf64>
+ %v_A = arith.constant dense<[0, 1, 10, 12, 13, 17, 18, 21,
+ 51, 52, 57, 61, 62, 82, 98, 99]> : vector<16xi64>
+ %v_B = arith.constant dense<[1., 5., 8., 3., 2., 1., 0., 9.,
+ 6., 7., 7., 3., 5., 2., 9., 1.]> : vector<16xf64>
+ %v_C = arith.constant dense<[1, 2, 5, 10, 11, 12, 47, 48,
+ 67, 68, 69, 70, 71, 72, 77, 78,
+ 79, 82, 83, 84, 85, 90, 91, 98]> : vector<24xi64>
+ %v_D = arith.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
+ 6., 7., 7., 3., 5., 2., 9., 1.,
+ 2., 9., 8., 7., 2., 0., 0., 4.]> : vector<24xf64>
vector.transfer_write %v_A, %m_A[%c0] : vector<16xi64>, memref<?xi64>
vector.transfer_write %v_B, %m_B[%c0] : vector<16xf64>, memref<?xf64>
vector.transfer_write %v_C, %m_C[%c0] : vector<24xi64>, memref<?xi64>
vector.transfer_write %v_D, %m_D[%c0] : vector<24xf64>, memref<?xf64>
- %M = std.constant 16 : index
- %N = std.constant 24 : index
+ %M = arith.constant 16 : index
+ %N = arith.constant 24 : index
return %M, %N : index, index
}
call @init_input(%m_A, %m_B, %m_C, %m_D)
: (memref<?xi64>, memref<?xf64>, memref<?xi64>, memref<?xf64>) -> ()
- %c0 = constant 0 : index
-
- %v_A = std.constant dense<[0, 1, 3, 5, 6, 7, 8, 9,
- 51, 52, 57, 61, 62, 63, 65, 66]> : vector<16xi64>
- %v_B = std.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
- 6., 7., 7., 3., 5., 2., 9., 1.]> : vector<16xf64>
- %v_C = std.constant dense<[6, 7, 11, 12, 15, 17, 19, 21,
- 30, 31, 33, 34, 37, 39, 40, 41,
- 42, 44, 45, 46, 47, 48, 49, 50,
- 62, 63, 64, 65, 66, 67, 68, 69,
- 70, 77, 78, 79, 81, 82, 89, 99]> : vector<40xi64>
- %v_D = std.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
- 6., 7., 7., 3., 5., 2., 9., 1.,
- 2., 9., 8., 7., 2., 1., 2., 4.,
- 4., 5., 8., 8., 2., 3., 5., 1.,
- 8., 6., 6., 4., 3., 8., 9., 2.]> : vector<40xf64>
+ %c0 = arith.constant 0 : index
+
+ %v_A = arith.constant dense<[0, 1, 3, 5, 6, 7, 8, 9,
+ 51, 52, 57, 61, 62, 63, 65, 66]> : vector<16xi64>
+ %v_B = arith.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
+ 6., 7., 7., 3., 5., 2., 9., 1.]> : vector<16xf64>
+ %v_C = arith.constant dense<[6, 7, 11, 12, 15, 17, 19, 21,
+ 30, 31, 33, 34, 37, 39, 40, 41,
+ 42, 44, 45, 46, 47, 48, 49, 50,
+ 62, 63, 64, 65, 66, 67, 68, 69,
+ 70, 77, 78, 79, 81, 82, 89, 99]> : vector<40xi64>
+ %v_D = arith.constant dense<[1., 5., 8., 3., 2., 1., 2., 9.,
+ 6., 7., 7., 3., 5., 2., 9., 1.,
+ 2., 9., 8., 7., 2., 1., 2., 4.,
+ 4., 5., 8., 8., 2., 3., 5., 1.,
+ 8., 6., 6., 4., 3., 8., 9., 2.]> : vector<40xf64>
vector.transfer_write %v_A, %m_A[%c0] : vector<16xi64>, memref<?xi64>
vector.transfer_write %v_B, %m_B[%c0] : vector<16xf64>, memref<?xf64>
vector.transfer_write %v_C, %m_C[%c0] : vector<40xi64>, memref<?xi64>
vector.transfer_write %v_D, %m_D[%c0] : vector<40xf64>, memref<?xf64>
- %M = std.constant 16 : index
- %N = std.constant 40 : index
+ %M = arith.constant 16 : index
+ %N = arith.constant 40 : index
return %M, %N : index, index
}
%M : index, %N : index)
-> f64 {
// Helper constants for loops.
- %c0 = constant 0 : index
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %c8 = arith.constant 8 : index
- %data_zero = constant 0.0 : f64
- %index_padding = constant 9223372036854775807 : i64
+ %data_zero = arith.constant 0.0 : f64
+ %index_padding = arith.constant 9223372036854775807 : i64
// Notation: %sum is the current (partial) aggregated dot product sum.
%subresult = call @vector_dot(%v_A, %v_B, %v_C, %v_D)
: (vector<8xi64>, vector<8xf64>, vector<8xi64>, vector<8xf64>) -> f64
- %r2 = addf %sum1, %subresult : f64
+ %r2 = arith.addf %sum1, %subresult : f64
scf.yield %r2 : f64
}
%M : index, %N : index)
-> f64 {
// Helper constants for loops.
- %c0 = constant 0 : index
- %i0 = constant 0 : i32
- %i7 = constant 7 : i32
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %i0 = arith.constant 0 : i32
+ %i7 = arith.constant 7 : i32
+ %c8 = arith.constant 8 : index
- %data_zero = constant 0.0 : f64
- %index_padding = constant 9223372036854775807 : i64
+ %data_zero = arith.constant 0.0 : f64
+ %index_padding = arith.constant 9223372036854775807 : i64
// Notation: %sum is the current (partial) aggregated dot product sum.
// %j_start is the value from which the inner for loop starts iterating. This
%v_C = vector.transfer_read %m_C[%b], %index_padding
: memref<?xi64>, vector<8xi64>
%segB_max = vector.extractelement %v_C[%i7 : i32] : vector<8xi64>
- %seg1_done = cmpi "slt", %segB_max, %segA_min : i64
+ %seg1_done = arith.cmpi "slt", %segB_max, %segA_min : i64
%r2, %next_b_start1 = scf.if %seg1_done -> (f64, index) {
// %v_C segment is done, no need to examine this one again (ever).
- %next_b_start2 = addi %b_start1, %c8 : index
+ %next_b_start2 = arith.addi %b_start1, %c8 : index
scf.yield %sum1, %next_b_start2 : f64, index
} else {
%v_B = vector.transfer_read %m_B[%a], %data_zero
%subresult = call @vector_dot(%v_A, %v_B, %v_C, %v_D)
: (vector<8xi64>, vector<8xf64>, vector<8xi64>, vector<8xf64>)
-> f64
- %r3 = addf %sum1, %subresult : f64
+ %r3 = arith.addf %sum1, %subresult : f64
scf.yield %r3, %b_start1 : f64, index
}
%M : index, %N : index)
-> f64 {
// Helper constants for loops.
- %c0 = constant 0 : index
- %i0 = constant 0 : i32
- %i7 = constant 7 : i32
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %i0 = arith.constant 0 : i32
+ %i7 = arith.constant 7 : i32
+ %c8 = arith.constant 8 : index
- %data_zero = constant 0.0 : f64
- %index_padding = constant 9223372036854775807 : i64
+ %data_zero = arith.constant 0.0 : f64
+ %index_padding = arith.constant 9223372036854775807 : i64
%r0, %a0, %b0 = scf.while (%r1 = %data_zero, %a1 = %c0, %b1 = %c0)
: (f64, index, index) -> (f64, index, index) {
- %cond_i = cmpi "slt", %a1, %M : index
- %cond_j = cmpi "slt", %b1, %N : index
- %cond = and %cond_i, %cond_j : i1
+ %cond_i = arith.cmpi "slt", %a1, %M : index
+ %cond_j = arith.cmpi "slt", %b1, %N : index
+ %cond = arith.andi %cond_i, %cond_j : i1
scf.condition(%cond) %r1, %a1, %b1 : f64, index, index
} do {
^bb0(%r1 : f64, %a1 : index, %b1 : index):
%segB_min = vector.extractelement %v_C[%i0 : i32] : vector<8xi64>
%segB_max = vector.extractelement %v_C[%i7 : i32] : vector<8xi64>
- %seg1_done = cmpi "slt", %segB_max, %segA_min : i64
+ %seg1_done = arith.cmpi "slt", %segB_max, %segA_min : i64
%r2, %a2, %b2 = scf.if %seg1_done -> (f64, index, index) {
- %b3 = addi %b1, %c8 : index
+ %b3 = arith.addi %b1, %c8 : index
scf.yield %r1, %a1, %b3 : f64, index, index
} else {
- %seg0_done = cmpi "slt", %segA_max, %segB_min : i64
+ %seg0_done = arith.cmpi "slt", %segA_max, %segB_min : i64
%r4, %a4, %b4 = scf.if %seg0_done -> (f64, index, index) {
- %a5 = addi %a1, %c8 : index
+ %a5 = arith.addi %a1, %c8 : index
scf.yield %r1, %a5, %b1 : f64, index, index
} else {
%v_B = vector.transfer_read %m_B[%a1], %data_zero
%subresult = call @vector_dot(%v_A, %v_B, %v_C, %v_D)
: (vector<8xi64>, vector<8xf64>, vector<8xi64>, vector<8xf64>)
-> f64
- %r6 = addf %r1, %subresult : f64
+ %r6 = arith.addf %r1, %subresult : f64
- %incr_a = cmpi "slt", %segA_max, %segB_max : i64
+ %incr_a = arith.cmpi "slt", %segA_max, %segB_max : i64
%a6, %b6 = scf.if %incr_a -> (index, index) {
- %a7 = addi %a1, %c8 : index
+ %a7 = arith.addi %a1, %c8 : index
scf.yield %a7, %b1 : index, index
} else {
- %incr_b = cmpi "slt", %segB_max, %segA_max : i64
+ %incr_b = arith.cmpi "slt", %segB_max, %segA_max : i64
%a8, %b8 = scf.if %incr_b -> (index, index) {
- %b9 = addi %b1, %c8 : index
+ %b9 = arith.addi %b1, %c8 : index
scf.yield %a1, %b9 : index, index
} else {
- %a10 = addi %a1, %c8 : index
- %b10 = addi %b1, %c8 : index
+ %a10 = arith.addi %a1, %c8 : index
+ %b10 = arith.addi %b1, %c8 : index
scf.yield %a10, %b10 : index, index
}
scf.yield %a8, %b8 : index, index
%M : index, %N : index)
-> f64 {
// Helper constants for loops.
- %c0 = constant 0 : index
- %i7 = constant 7 : i32
- %c8 = constant 8 : index
+ %c0 = arith.constant 0 : index
+ %i7 = arith.constant 7 : i32
+ %c8 = arith.constant 8 : index
- %data_zero = constant 0.0 : f64
- %index_padding = constant 9223372036854775807 : i64
+ %data_zero = arith.constant 0.0 : f64
+ %index_padding = arith.constant 9223372036854775807 : i64
%r0, %a0, %b0 = scf.while (%r1 = %data_zero, %a1 = %c0, %b1 = %c0)
: (f64, index, index) -> (f64, index, index) {
- %cond_i = cmpi "slt", %a1, %M : index
- %cond_j = cmpi "slt", %b1, %N : index
- %cond = and %cond_i, %cond_j : i1
+ %cond_i = arith.cmpi "slt", %a1, %M : index
+ %cond_j = arith.cmpi "slt", %b1, %N : index
+ %cond = arith.andi %cond_i, %cond_j : i1
scf.condition(%cond) %r1, %a1, %b1 : f64, index, index
} do {
^bb0(%r1 : f64, %a1 : index, %b1 : index):
%subresult = call @vector_dot(%v_A, %v_B, %v_C, %v_D)
: (vector<8xi64>, vector<8xf64>, vector<8xi64>, vector<8xf64>)
-> f64
- %r2 = addf %r1, %subresult : f64
+ %r2 = arith.addf %r1, %subresult : f64
%segA_max = vector.extractelement %v_A[%i7 : i32] : vector<8xi64>
%segB_max = vector.extractelement %v_C[%i7 : i32] : vector<8xi64>
- %cond_a = cmpi "sle", %segA_max, %segB_max : i64
- %cond_a_i64 = zexti %cond_a : i1 to i64
- %cond_a_idx = index_cast %cond_a_i64 : i64 to index
- %incr_a = muli %cond_a_idx, %c8 : index
- %a2 = addi %a1, %incr_a : index
+ %cond_a = arith.cmpi "sle", %segA_max, %segB_max : i64
+ %cond_a_i64 = arith.extui %cond_a : i1 to i64
+ %cond_a_idx = arith.index_cast %cond_a_i64 : i64 to index
+ %incr_a = arith.muli %cond_a_idx, %c8 : index
+ %a2 = arith.addi %a1, %incr_a : index
- %cond_b = cmpi "sle", %segB_max, %segA_max : i64
- %cond_b_i64 = zexti %cond_b : i1 to i64
- %cond_b_idx = index_cast %cond_b_i64 : i64 to index
- %incr_b = muli %cond_b_idx, %c8 : index
- %b2 = addi %b1, %incr_b : index
+ %cond_b = arith.cmpi "sle", %segB_max, %segA_max : i64
+ %cond_b_i64 = arith.extui %cond_b : i1 to i64
+ %cond_b_idx = arith.index_cast %cond_b_i64 : i64 to index
+ %incr_b = arith.muli %cond_b_idx, %c8 : index
+ %b2 = arith.addi %b1, %incr_b : index
scf.yield %r2, %a2, %b2 : f64, index, index
}
memref.dealloc %b_C : memref<128xi64>
memref.dealloc %b_D : memref<128xf64>
- %r = constant 0 : i32
+ %r = arith.constant 0 : i32
return %r : i32
}
// Note: To run this test, your CPU must support AVX512 vp2intersect.
func @entry() -> i32 {
- %i0 = constant 0 : i32
- %i1 = constant 1: i32
- %i2 = constant 2: i32
- %i3 = constant 7: i32
- %i4 = constant 12: i32
- %i5 = constant -10: i32
- %i6 = constant -219: i32
+ %i0 = arith.constant 0 : i32
+ %i1 = arith.constant 1: i32
+ %i2 = arith.constant 2: i32
+ %i3 = arith.constant 7: i32
+ %i4 = arith.constant 12: i32
+ %i5 = arith.constant -10: i32
+ %i6 = arith.constant -219: i32
%v0 = vector.broadcast %i1 : i32 to vector<16xi32>
%v1 = vector.insert %i2, %v0[1] : i32 into vector<16xi32>
// RUN: FileCheck %s
func @entry() {
- %i = constant 2147483647: i32
- %l = constant 9223372036854775807 : i64
+ %i = arith.constant 2147483647: i32
+ %l = arith.constant 9223372036854775807 : i64
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
// Test simple broadcasts.
%vi = vector.broadcast %i : i32 to vector<2xi32>
func @compress16(%base: memref<?xf32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.compressstore %base[%c0], %mask, %value
: memref<?xf32>, vector<16xi1>, vector<16xf32>
return
func @compress16_at8(%base: memref<?xf32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c8 = constant 8: index
+ %c8 = arith.constant 8: index
vector.compressstore %base[%c8], %mask, %value
: memref<?xf32>, vector<16xi1>, vector<16xf32>
return
}
func @printmem16(%A: memref<?xf32>) {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
- %z = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
+ %z = arith.constant 0.0: f32
%m = vector.broadcast %z : f32 to vector<16xf32>
%mem = scf.for %i = %c0 to %c16 step %c1
iter_args(%m_iter = %m) -> (vector<16xf32>) {
%c = memref.load %A[%i] : memref<?xf32>
- %i32 = index_cast %i : index to i32
+ %i32 = arith.index_cast %i : index to i32
%m_new = vector.insertelement %c, %m_iter[%i32 : i32] : vector<16xf32>
scf.yield %m_new : vector<16xf32>
}
func @entry() {
// Set up memory.
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
%A = memref.alloc(%c16) : memref<?xf32>
- %z = constant 0.0: f32
+ %z = arith.constant 0.0: f32
%v = vector.broadcast %z : f32 to vector<16xf32>
%value = scf.for %i = %c0 to %c16 step %c1
iter_args(%v_iter = %v) -> (vector<16xf32>) {
memref.store %z, %A[%i] : memref<?xf32>
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
%v_new = vector.insertelement %fi, %v_iter[%i32 : i32] : vector<16xf32>
scf.yield %v_new : vector<16xf32>
}
// Set up masks.
- %f = constant 0: i1
- %t = constant 1: i1
+ %f = arith.constant 0: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<16xi1>
%all = vector.constant_mask [16] : vector<16xi1>
%some1 = vector.constant_mask [4] : vector<16xi1>
}
func @entry() {
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f6 = constant 6.0: f32
- %f7 = constant 7.0: f32
- %f8 = constant 8.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f6 = arith.constant 6.0: f32
+ %f7 = arith.constant 7.0: f32
+ %f8 = arith.constant 8.0: f32
// Zero vectors.
%z1 = vector.broadcast %f0 : f32 to vector<2xf32>
%9 = vector.insert %a, %8[0] : vector<2xf32> into vector<3x2xf32>
%10 = vector.insert %b, %9[1] : vector<2xf32> into vector<3x2xf32>
%C = vector.insert %c, %10[2] : vector<2xf32> into vector<3x2xf32>
- %cst = constant dense<0.000000e+00> : vector<2x4xf32>
+ %cst = arith.constant dense<0.000000e+00> : vector<2x4xf32>
%11 = vector.insert_strided_slice %A, %cst {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<2x4xf32>
%D = vector.insert_strided_slice %B, %11 {offsets = [0, 2], strides = [1, 1]} : vector<2x2xf32> into vector<2x4xf32>
// because the v4i1 vector specifically exposed bugs in the LLVM backend.
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c5 = constant 5 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c5 = arith.constant 5 : index
//
// 1-D.
// RUN: FileCheck %s
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
//
// 1-D.
func @expand16(%base: memref<?xf32>,
%mask: vector<16xi1>,
%pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%e = vector.expandload %base[%c0], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
return %e : vector<16xf32>
func @expand16_at8(%base: memref<?xf32>,
%mask: vector<16xi1>,
%pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c8 = constant 8: index
+ %c8 = arith.constant 8: index
%e = vector.expandload %base[%c8], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
return %e : vector<16xf32>
func @entry() {
// Set up memory.
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
%A = memref.alloc(%c16) : memref<?xf32>
scf.for %i = %c0 to %c16 step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
memref.store %fi, %A[%i] : memref<?xf32>
}
// Set up pass thru vector.
- %u = constant -7.0: f32
- %v = constant 7.7: f32
+ %u = arith.constant -7.0: f32
+ %v = arith.constant 7.7: f32
%pass = vector.broadcast %u : f32 to vector<16xf32>
// Set up masks.
- %f = constant 0: i1
- %t = constant 1: i1
+ %f = arith.constant 0: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<16xi1>
%all = vector.constant_mask [16] : vector<16xi1>
%some1 = vector.constant_mask [4] : vector<16xi1>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
%v1 = vector.broadcast %f1 : f32 to vector<8xf32>
%v2 = vector.broadcast %f2 : f32 to vector<8xf32>
%v3 = vector.broadcast %f3 : f32 to vector<8xf32>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f64
- %f1 = constant 1.0: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
- %f4 = constant 4.0: f64
- %f5 = constant 5.0: f64
- %f6 = constant 6.0: f64
- %f7 = constant 7.0: f64
+ %f0 = arith.constant 0.0: f64
+ %f1 = arith.constant 1.0: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
+ %f4 = arith.constant 4.0: f64
+ %f5 = arith.constant 5.0: f64
+ %f6 = arith.constant 6.0: f64
+ %f7 = arith.constant 7.0: f64
// Construct test vectors.
%0 = vector.broadcast %f0 : f64 to vector<4xf64>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f64
- %f1 = constant 1.0: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
- %f4 = constant 4.0: f64
- %f5 = constant 5.0: f64
- %f6 = constant 6.0: f64
- %f7 = constant 7.0: f64
+ %f0 = arith.constant 0.0: f64
+ %f1 = arith.constant 1.0: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
+ %f4 = arith.constant 4.0: f64
+ %f5 = arith.constant 5.0: f64
+ %f6 = arith.constant 6.0: f64
+ %f7 = arith.constant 7.0: f64
// Construct test vectors.
%0 = vector.broadcast %f0 : f64 to vector<4xf64>
// RUN: FileCheck %s
func @entry() {
- %f1 = constant 1.0: f32
- %f3 = constant 3.0: f32
- %f7 = constant 7.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f7 = arith.constant 7.0: f32
%v1 = vector.broadcast %f1 : f32 to vector<8xf32>
%v3 = vector.broadcast %f3 : f32 to vector<8xf32>
%v7 = vector.broadcast %f7 : f32 to vector<8xf32>
func @gather8(%base: memref<?xf32>, %indices: vector<8xi32>,
%mask: vector<8xi1>, %pass_thru: vector<8xf32>) -> vector<8xf32> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%g = vector.gather %base[%c0][%indices], %mask, %pass_thru
: memref<?xf32>, vector<8xi32>, vector<8xi1>, vector<8xf32> into vector<8xf32>
return %g : vector<8xf32>
func @entry() {
// Set up memory.
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c10 = constant 10: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c10 = arith.constant 10: index
%A = memref.alloc(%c10) : memref<?xf32>
scf.for %i = %c0 to %c10 step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
memref.store %fi, %A[%i] : memref<?xf32>
}
// Set up idx vector.
- %i0 = constant 0: i32
- %i1 = constant 1: i32
- %i2 = constant 2: i32
- %i3 = constant 3: i32
- %i4 = constant 4: i32
- %i5 = constant 5: i32
- %i6 = constant 6: i32
- %i9 = constant 9: i32
+ %i0 = arith.constant 0: i32
+ %i1 = arith.constant 1: i32
+ %i2 = arith.constant 2: i32
+ %i3 = arith.constant 3: i32
+ %i4 = arith.constant 4: i32
+ %i5 = arith.constant 5: i32
+ %i6 = arith.constant 6: i32
+ %i9 = arith.constant 9: i32
%0 = vector.broadcast %i0 : i32 to vector<8xi32>
%1 = vector.insert %i6, %0[1] : i32 into vector<8xi32>
%2 = vector.insert %i1, %1[2] : i32 into vector<8xi32>
%idx = vector.insert %i2, %6[7] : i32 into vector<8xi32>
// Set up pass thru vector.
- %u = constant -7.0: f32
+ %u = arith.constant -7.0: f32
%pass = vector.broadcast %u : f32 to vector<8xf32>
// Set up masks.
- %t = constant 1: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<8xi1>
%all = vector.constant_mask [8] : vector<8xi1>
%some = vector.constant_mask [4] : vector<8xi1>
// RUN: FileCheck %s
func @entry() {
- %c0 = constant dense<[0, 1, 2, 3]>: vector<4xindex>
- %c1 = constant dense<[0, 1]>: vector<2xindex>
- %c2 = constant 2 : index
+ %c0 = arith.constant dense<[0, 1, 2, 3]>: vector<4xindex>
+ %c1 = arith.constant dense<[0, 1]>: vector<2xindex>
+ %c2 = arith.constant 2 : index
%v1 = vector.broadcast %c0 : vector<4xindex> to vector<2x4xindex>
%v2 = vector.broadcast %c1 : vector<2xindex> to vector<4x2xindex>
%v3 = vector.transpose %v2, [1, 0] : vector<4x2xindex> to vector<2x4xindex>
%v4 = vector.broadcast %c2 : index to vector<2x4xindex>
- %v5 = addi %v1, %v3 : vector<2x4xindex>
+ %v5 = arith.addi %v1, %v3 : vector<2x4xindex>
vector.print %v1 : vector<2x4xindex>
vector.print %v3 : vector<2x4xindex>
// RUN: FileCheck %s
func @entry() {
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
%v1 = vector.broadcast %f1 : f32 to vector<4xf32>
%v2 = vector.broadcast %f2 : f32 to vector<3xf32>
%v3 = vector.broadcast %f3 : f32 to vector<4x4xf32>
func @maskedload16(%base: memref<?xf32>, %mask: vector<16xi1>,
%pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
%ld = vector.maskedload %base[%c0], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
return %ld : vector<16xf32>
func @maskedload16_at8(%base: memref<?xf32>, %mask: vector<16xi1>,
%pass_thru: vector<16xf32>) -> vector<16xf32> {
- %c8 = constant 8: index
+ %c8 = arith.constant 8: index
%ld = vector.maskedload %base[%c8], %mask, %pass_thru
: memref<?xf32>, vector<16xi1>, vector<16xf32> into vector<16xf32>
return %ld : vector<16xf32>
func @entry() {
// Set up memory.
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
%A = memref.alloc(%c16) : memref<?xf32>
scf.for %i = %c0 to %c16 step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
memref.store %fi, %A[%i] : memref<?xf32>
}
// Set up pass thru vector.
- %u = constant -7.0: f32
+ %u = arith.constant -7.0: f32
%pass = vector.broadcast %u : f32 to vector<16xf32>
// Set up masks.
- %f = constant 0: i1
- %t = constant 1: i1
+ %f = arith.constant 0: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<16xi1>
%all = vector.constant_mask [16] : vector<16xi1>
%some = vector.constant_mask [8] : vector<16xi1>
func @maskedstore16(%base: memref<?xf32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.maskedstore %base[%c0], %mask, %value
: memref<?xf32>, vector<16xi1>, vector<16xf32>
return
func @maskedstore16_at8(%base: memref<?xf32>,
%mask: vector<16xi1>, %value: vector<16xf32>) {
- %c8 = constant 8: index
+ %c8 = arith.constant 8: index
vector.maskedstore %base[%c8], %mask, %value
: memref<?xf32>, vector<16xi1>, vector<16xf32>
return
}
func @printmem16(%A: memref<?xf32>) {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
- %z = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
+ %z = arith.constant 0.0: f32
%m = vector.broadcast %z : f32 to vector<16xf32>
%mem = scf.for %i = %c0 to %c16 step %c1
iter_args(%m_iter = %m) -> (vector<16xf32>) {
%c = memref.load %A[%i] : memref<?xf32>
- %i32 = index_cast %i : index to i32
+ %i32 = arith.index_cast %i : index to i32
%m_new = vector.insertelement %c, %m_iter[%i32 : i32] : vector<16xf32>
scf.yield %m_new : vector<16xf32>
}
func @entry() {
// Set up memory.
- %f0 = constant 0.0: f32
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c16 = constant 16: index
+ %f0 = arith.constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c16 = arith.constant 16: index
%A = memref.alloc(%c16) : memref<?xf32>
scf.for %i = %c0 to %c16 step %c1 {
memref.store %f0, %A[%i] : memref<?xf32>
%v = vector.broadcast %f0 : f32 to vector<16xf32>
%val = scf.for %i = %c0 to %c16 step %c1
iter_args(%v_iter = %v) -> (vector<16xf32>) {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
%v_new = vector.insertelement %fi, %v_iter[%i32 : i32] : vector<16xf32>
scf.yield %v_new : vector<16xf32>
}
// Set up masks.
- %t = constant 1: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<16xi1>
%some = vector.constant_mask [8] : vector<16xi1>
%more = vector.insert %t, %some[13] : i1 into vector<16xi1>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f64
- %f1 = constant 1.0: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
- %f4 = constant 4.0: f64
- %f5 = constant 5.0: f64
- %f6 = constant 6.0: f64
- %f7 = constant 7.0: f64
+ %f0 = arith.constant 0.0: f64
+ %f1 = arith.constant 1.0: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
+ %f4 = arith.constant 4.0: f64
+ %f5 = arith.constant 5.0: f64
+ %f6 = arith.constant 6.0: f64
+ %f7 = arith.constant 7.0: f64
// Construct test vectors.
%0 = vector.broadcast %f0 : f64 to vector<4xf64>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f64
- %f1 = constant 1.0: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
- %f4 = constant 4.0: f64
- %f5 = constant 5.0: f64
- %f6 = constant 6.0: f64
- %f7 = constant 7.0: f64
+ %f0 = arith.constant 0.0: f64
+ %f1 = arith.constant 1.0: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
+ %f4 = arith.constant 4.0: f64
+ %f5 = arith.constant 5.0: f64
+ %f6 = arith.constant 6.0: f64
+ %f7 = arith.constant 7.0: f64
// Construct test vectors.
%0 = vector.broadcast %f0 : f64 to vector<4xf64>
}
func @entry() {
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f10 = constant 10.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f10 = arith.constant 10.0: f32
// Simple case, splat scalars into vectors, then take outer product.
%v = call @vector_outerproduct_splat_8x8(%f1, %f2, %f10)
}
func @entry() {
- %i0 = constant 0: i64
- %i1 = constant 1: i64
- %i2 = constant 2: i64
- %i3 = constant 3: i64
- %i4 = constant 4: i64
- %i5 = constant 5: i64
- %i10 = constant 10: i64
+ %i0 = arith.constant 0: i64
+ %i1 = arith.constant 1: i64
+ %i2 = arith.constant 2: i64
+ %i3 = arith.constant 3: i64
+ %i4 = arith.constant 4: i64
+ %i5 = arith.constant 5: i64
+ %i10 = arith.constant 10: i64
// Simple case, splat scalars into vectors, then take outer product.
%v = call @vector_outerproduct_splat_8x8(%i1, %i2, %i10)
// Test various signless, signed, unsigned integer types.
//
func @entry() {
- %0 = std.constant dense<[true, false, -1, 0, 1]> : vector<5xi1>
+ %0 = arith.constant dense<[true, false, -1, 0, 1]> : vector<5xi1>
vector.print %0 : vector<5xi1>
// CHECK: ( 1, 0, 1, 0, 1 )
- %1 = std.constant dense<[true, false, -1, 0]> : vector<4xsi1>
- vector.print %1 : vector<4xsi1>
+ %1 = arith.constant dense<[true, false, -1, 0]> : vector<4xi1>
+ %cast_1 = vector.bitcast %1 : vector<4xi1> to vector<4xsi1>
+ vector.print %cast_1 : vector<4xsi1>
// CHECK: ( 1, 0, 1, 0 )
- %2 = std.constant dense<[true, false, 0, 1]> : vector<4xui1>
- vector.print %2 : vector<4xui1>
+ %2 = arith.constant dense<[true, false, 0, 1]> : vector<4xi1>
+ %cast_2 = vector.bitcast %2 : vector<4xi1> to vector<4xui1>
+ vector.print %cast_2 : vector<4xui1>
// CHECK: ( 1, 0, 0, 1 )
- %3 = std.constant dense<[-128, -127, -1, 0, 1, 127, 128, 254, 255]> : vector<9xi8>
+ %3 = arith.constant dense<[-128, -127, -1, 0, 1, 127, 128, 254, 255]> : vector<9xi8>
vector.print %3 : vector<9xi8>
// CHECK: ( -128, -127, -1, 0, 1, 127, -128, -2, -1 )
- %4 = std.constant dense<[-128, -127, -1, 0, 1, 127]> : vector<6xsi8>
- vector.print %4 : vector<6xsi8>
+ %4 = arith.constant dense<[-128, -127, -1, 0, 1, 127]> : vector<6xi8>
+ %cast_4 = vector.bitcast %4 : vector<6xi8> to vector<6xsi8>
+ vector.print %cast_4 : vector<6xsi8>
// CHECK: ( -128, -127, -1, 0, 1, 127 )
- %5 = std.constant dense<[0, 1, 127, 128, 254, 255]> : vector<6xui8>
- vector.print %5 : vector<6xui8>
+ %5 = arith.constant dense<[0, 1, 127, 128, 254, 255]> : vector<6xi8>
+ %cast_5 = vector.bitcast %5 : vector<6xi8> to vector<6xui8>
+ vector.print %cast_5 : vector<6xui8>
// CHECK: ( 0, 1, 127, 128, 254, 255 )
- %6 = std.constant dense<[-32768, -32767, -1, 0, 1, 32767, 32768, 65534, 65535]> : vector<9xi16>
+ %6 = arith.constant dense<[-32768, -32767, -1, 0, 1, 32767, 32768, 65534, 65535]> : vector<9xi16>
vector.print %6 : vector<9xi16>
// CHECK: ( -32768, -32767, -1, 0, 1, 32767, -32768, -2, -1 )
- %7 = std.constant dense<[-32768, -32767, -1, 0, 1, 32767]> : vector<6xsi16>
- vector.print %7 : vector<6xsi16>
+ %7 = arith.constant dense<[-32768, -32767, -1, 0, 1, 32767]> : vector<6xi16>
+ %cast_7 = vector.bitcast %7 : vector<6xi16> to vector<6xsi16>
+ vector.print %cast_7 : vector<6xsi16>
// CHECK: ( -32768, -32767, -1, 0, 1, 32767 )
- %8 = std.constant dense<[0, 1, 32767, 32768, 65534, 65535]> : vector<6xui16>
- vector.print %8 : vector<6xui16>
+ %8 = arith.constant dense<[0, 1, 32767, 32768, 65534, 65535]> : vector<6xi16>
+ %cast_8 = vector.bitcast %8 : vector<6xi16> to vector<6xui16>
+ vector.print %cast_8 : vector<6xui16>
// CHECK: ( 0, 1, 32767, 32768, 65534, 65535 )
- %9 = std.constant dense<[-2147483648, -2147483647, -1, 0, 1,
- 2147483647, 2147483648, 4294967294, 4294967295]> : vector<9xi32>
+ %9 = arith.constant dense<[-2147483648, -2147483647, -1, 0, 1,
+ 2147483647, 2147483648, 4294967294, 4294967295]> : vector<9xi32>
vector.print %9 : vector<9xi32>
// CHECK: ( -2147483648, -2147483647, -1, 0, 1, 2147483647, -2147483648, -2, -1 )
- %10 = std.constant dense<[-2147483648, -2147483647, -1, 0, 1, 2147483647]> : vector<6xsi32>
- vector.print %10 : vector<6xsi32>
+ %10 = arith.constant dense<[-2147483648, -2147483647, -1, 0, 1, 2147483647]> : vector<6xi32>
+ %cast_10 = vector.bitcast %10 : vector<6xi32> to vector<6xsi32>
+ vector.print %cast_10 : vector<6xsi32>
// CHECK: ( -2147483648, -2147483647, -1, 0, 1, 2147483647 )
- %11 = std.constant dense<[0, 1, 2147483647, 2147483648, 4294967294, 4294967295]> : vector<6xui32>
- vector.print %11 : vector<6xui32>
+ %11 = arith.constant dense<[0, 1, 2147483647, 2147483648, 4294967294, 4294967295]> : vector<6xi32>
+ %cast_11 = vector.bitcast %11 : vector<6xi32> to vector<6xui32>
+ vector.print %cast_11 : vector<6xui32>
// CHECK: ( 0, 1, 2147483647, 2147483648, 4294967294, 4294967295 )
- %12 = std.constant dense<[-9223372036854775808, -9223372036854775807, -1, 0, 1,
- 9223372036854775807, 9223372036854775808,
- 18446744073709551614, 18446744073709551615]> : vector<9xi64>
+ %12 = arith.constant dense<[-9223372036854775808, -9223372036854775807, -1, 0, 1,
+ 9223372036854775807, 9223372036854775808,
+ 18446744073709551614, 18446744073709551615]> : vector<9xi64>
vector.print %12 : vector<9xi64>
// CHECK: ( -9223372036854775808, -9223372036854775807, -1, 0, 1, 9223372036854775807, -9223372036854775808, -2, -1 )
- %13 = std.constant dense<[-9223372036854775808, -9223372036854775807, -1, 0, 1,
- 9223372036854775807]> : vector<6xsi64>
- vector.print %13 : vector<6xsi64>
+ %13 = arith.constant dense<[-9223372036854775808, -9223372036854775807, -1, 0, 1,
+ 9223372036854775807]> : vector<6xi64>
+ %cast_13 = vector.bitcast %13 : vector<6xi64> to vector<6xsi64>
+ vector.print %cast_13 : vector<6xsi64>
// CHECK: ( -9223372036854775808, -9223372036854775807, -1, 0, 1, 9223372036854775807 )
- %14 = std.constant dense<[0, 1, 9223372036854775807, 9223372036854775808,
- 18446744073709551614, 18446744073709551615]> : vector<6xui64>
- vector.print %14 : vector<6xui64>
+ %14 = arith.constant dense<[0, 1, 9223372036854775807, 9223372036854775808,
+ 18446744073709551614, 18446744073709551615]> : vector<6xi64>
+ %cast_14 = vector.bitcast %14 : vector<6xi64> to vector<6xui64>
+ vector.print %cast_14 : vector<6xui64>
// CHECK: ( 0, 1, 9223372036854775807, 9223372036854775808, 18446744073709551614, 18446744073709551615 )
return
func @entry() {
// Construct test vector, numerically very stable.
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
%v0 = vector.broadcast %f1 : f32 to vector<64xf32>
%v1 = vector.insert %f2, %v0[11] : f32 into vector<64xf32>
%v2 = vector.insert %f3, %v1[52] : f32 into vector<64xf32>
func @entry() {
// Construct test vector.
- %f1 = constant 1.5: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f6 = constant -1.0: f32
- %f7 = constant -2.0: f32
- %f8 = constant -4.0: f32
- %f9 = constant -0.25: f32
- %f10 = constant -16.0: f32
+ %f1 = arith.constant 1.5: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f6 = arith.constant -1.0: f32
+ %f7 = arith.constant -2.0: f32
+ %f8 = arith.constant -4.0: f32
+ %f9 = arith.constant -0.25: f32
+ %f10 = arith.constant -16.0: f32
%v0 = vector.broadcast %f1 : f32 to vector<10xf32>
%v1 = vector.insert %f2, %v0[1] : f32 into vector<10xf32>
%v2 = vector.insert %f3, %v1[2] : f32 into vector<10xf32>
func @entry() {
// Construct test vector, numerically very stable.
- %f1 = constant 1.0: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
+ %f1 = arith.constant 1.0: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
%v0 = vector.broadcast %f1 : f64 to vector<64xf64>
%v1 = vector.insert %f2, %v0[11] : f64 into vector<64xf64>
%v2 = vector.insert %f3, %v1[52] : f64 into vector<64xf64>
func @entry() {
// Construct test vector.
- %f1 = constant 1.5: f64
- %f2 = constant 2.0: f64
- %f3 = constant 3.0: f64
- %f4 = constant 4.0: f64
- %f5 = constant 5.0: f64
- %f6 = constant -1.0: f64
- %f7 = constant -2.0: f64
- %f8 = constant -4.0: f64
- %f9 = constant -0.25: f64
- %f10 = constant -16.0: f64
+ %f1 = arith.constant 1.5: f64
+ %f2 = arith.constant 2.0: f64
+ %f3 = arith.constant 3.0: f64
+ %f4 = arith.constant 4.0: f64
+ %f5 = arith.constant 5.0: f64
+ %f6 = arith.constant -1.0: f64
+ %f7 = arith.constant -2.0: f64
+ %f8 = arith.constant -4.0: f64
+ %f9 = arith.constant -0.25: f64
+ %f10 = arith.constant -16.0: f64
%v0 = vector.broadcast %f1 : f64 to vector<10xf64>
%v1 = vector.insert %f2, %v0[1] : f64 into vector<10xf64>
%v2 = vector.insert %f3, %v1[2] : f64 into vector<10xf64>
func @entry() {
// Construct test vector.
- %i1 = constant 1: i32
- %i2 = constant 2: i32
- %i3 = constant 3: i32
- %i4 = constant 4: i32
- %i5 = constant 5: i32
- %i6 = constant -1: i32
- %i7 = constant -2: i32
- %i8 = constant -4: i32
- %i9 = constant -80: i32
- %i10 = constant -16: i32
+ %i1 = arith.constant 1: i32
+ %i2 = arith.constant 2: i32
+ %i3 = arith.constant 3: i32
+ %i4 = arith.constant 4: i32
+ %i5 = arith.constant 5: i32
+ %i6 = arith.constant -1: i32
+ %i7 = arith.constant -2: i32
+ %i8 = arith.constant -4: i32
+ %i9 = arith.constant -80: i32
+ %i10 = arith.constant -16: i32
%v0 = vector.broadcast %i1 : i32 to vector<10xi32>
%v1 = vector.insert %i2, %v0[1] : i32 into vector<10xi32>
%v2 = vector.insert %i3, %v1[2] : i32 into vector<10xi32>
// RUN: FileCheck %s
func @entry() {
- %v = std.constant dense<[-8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<24xi4>
+ %v = arith.constant dense<[-8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<24xi4>
vector.print %v : vector<24xi4>
//
// Test vector:
func @entry() {
// Construct test vector.
- %i1 = constant 1: i64
- %i2 = constant 2: i64
- %i3 = constant 3: i64
- %i4 = constant 4: i64
- %i5 = constant 5: i64
- %i6 = constant -1: i64
- %i7 = constant -2: i64
- %i8 = constant -4: i64
- %i9 = constant -80: i64
- %i10 = constant -16: i64
+ %i1 = arith.constant 1: i64
+ %i2 = arith.constant 2: i64
+ %i3 = arith.constant 3: i64
+ %i4 = arith.constant 4: i64
+ %i5 = arith.constant 5: i64
+ %i6 = arith.constant -1: i64
+ %i7 = arith.constant -2: i64
+ %i8 = arith.constant -4: i64
+ %i9 = arith.constant -80: i64
+ %i10 = arith.constant -16: i64
%v0 = vector.broadcast %i1 : i64 to vector<10xi64>
%v1 = vector.insert %i2, %v0[1] : i64 into vector<10xi64>
%v2 = vector.insert %i3, %v1[2] : i64 into vector<10xi64>
// RUN: FileCheck %s
func @entry() {
- %v = std.constant dense<[-8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7]> : vector<16xsi4>
+ %v0 = arith.constant dense<[-8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7]> : vector<16xi4>
+ %v = vector.bitcast %v0 : vector<16xi4> to vector<16xsi4>
vector.print %v : vector<16xsi4>
//
// Test vector:
// RUN: FileCheck %s
func @entry() {
- %v = std.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xui4>
+ %v0 = arith.constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]> : vector<16xi4>
+ %v = vector.bitcast %v0 : vector<16xi4> to vector<16xui4>
vector.print %v : vector<16xui4>
//
// Test vector:
func @scatter8(%base: memref<?xf32>,
%indices: vector<8xi32>,
%mask: vector<8xi1>, %value: vector<8xf32>) {
- %c0 = constant 0: index
+ %c0 = arith.constant 0: index
vector.scatter %base[%c0][%indices], %mask, %value
: memref<?xf32>, vector<8xi32>, vector<8xi1>, vector<8xf32>
return
}
func @printmem8(%A: memref<?xf32>) {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c8 = constant 8: index
- %z = constant 0.0: f32
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c8 = arith.constant 8: index
+ %z = arith.constant 0.0: f32
%m = vector.broadcast %z : f32 to vector<8xf32>
%mem = scf.for %i = %c0 to %c8 step %c1
iter_args(%m_iter = %m) -> (vector<8xf32>) {
%c = memref.load %A[%i] : memref<?xf32>
- %i32 = index_cast %i : index to i32
+ %i32 = arith.index_cast %i : index to i32
%m_new = vector.insertelement %c, %m_iter[%i32 : i32] : vector<8xf32>
scf.yield %m_new : vector<8xf32>
}
func @entry() {
// Set up memory.
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c8 = constant 8: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c8 = arith.constant 8: index
%A = memref.alloc(%c8) : memref<?xf32>
scf.for %i = %c0 to %c8 step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
memref.store %fi, %A[%i] : memref<?xf32>
}
// Set up idx vector.
- %i0 = constant 0: i32
- %i1 = constant 1: i32
- %i2 = constant 2: i32
- %i3 = constant 3: i32
- %i4 = constant 4: i32
- %i5 = constant 5: i32
- %i6 = constant 6: i32
- %i7 = constant 7: i32
+ %i0 = arith.constant 0: i32
+ %i1 = arith.constant 1: i32
+ %i2 = arith.constant 2: i32
+ %i3 = arith.constant 3: i32
+ %i4 = arith.constant 4: i32
+ %i5 = arith.constant 5: i32
+ %i6 = arith.constant 6: i32
+ %i7 = arith.constant 7: i32
%0 = vector.broadcast %i7 : i32 to vector<8xi32>
%1 = vector.insert %i0, %0[1] : i32 into vector<8xi32>
%2 = vector.insert %i1, %1[2] : i32 into vector<8xi32>
%idx = vector.insert %i3, %6[7] : i32 into vector<8xi32>
// Set up value vector.
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f6 = constant 6.0: f32
- %f7 = constant 7.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f6 = arith.constant 6.0: f32
+ %f7 = arith.constant 7.0: f32
%7 = vector.broadcast %f0 : f32 to vector<8xf32>
%8 = vector.insert %f1, %7[1] : f32 into vector<8xf32>
%9 = vector.insert %f2, %8[2] : f32 into vector<8xf32>
%val = vector.insert %f7, %13[7] : f32 into vector<8xf32>
// Set up masks.
- %t = constant 1: i1
+ %t = arith.constant 1: i1
%none = vector.constant_mask [0] : vector<8xi1>
%some = vector.constant_mask [4] : vector<8xi1>
%more = vector.insert %t, %some[7] : i1 into vector<8xi1>
// RUN: FileCheck %s
func @entry() {
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f6 = constant 6.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f6 = arith.constant 6.0: f32
// Construct test vector.
%0 = vector.broadcast %f1 : f32 to vector<3x2xf32>
// RUN: FileCheck %s
func @entry() {
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
%v1 = vector.broadcast %f1 : f32 to vector<2x4xf32>
%v2 = vector.broadcast %f2 : f32 to vector<2x4xf32>
vector.print %v1 : vector<2x4xf32>
func @spmv8x8(%AVAL: memref<8xvector<4xf32>>,
%AIDX: memref<8xvector<4xi32>>, %X: memref<?xf32>, %B: memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cn = constant 8 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cn = arith.constant 8 : index
+ %f0 = arith.constant 0.0 : f32
%mask = vector.constant_mask [4] : vector<4xi1>
%pass = vector.broadcast %f0 : f32 to vector<4xf32>
scf.for %i = %c0 to %cn step %c1 {
}
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c8 = constant 8 : index
-
- %f0 = constant 0.0 : f32
- %f1 = constant 1.0 : f32
- %f2 = constant 2.0 : f32
- %f3 = constant 3.0 : f32
- %f4 = constant 4.0 : f32
- %f5 = constant 5.0 : f32
- %f6 = constant 6.0 : f32
- %f7 = constant 7.0 : f32
- %f8 = constant 8.0 : f32
-
- %i0 = constant 0 : i32
- %i1 = constant 1 : i32
- %i2 = constant 2 : i32
- %i3 = constant 3 : i32
- %i4 = constant 4 : i32
- %i5 = constant 5 : i32
- %i6 = constant 6 : i32
- %i7 = constant 7 : i32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c8 = arith.constant 8 : index
+
+ %f0 = arith.constant 0.0 : f32
+ %f1 = arith.constant 1.0 : f32
+ %f2 = arith.constant 2.0 : f32
+ %f3 = arith.constant 3.0 : f32
+ %f4 = arith.constant 4.0 : f32
+ %f5 = arith.constant 5.0 : f32
+ %f6 = arith.constant 6.0 : f32
+ %f7 = arith.constant 7.0 : f32
+ %f8 = arith.constant 8.0 : f32
+
+ %i0 = arith.constant 0 : i32
+ %i1 = arith.constant 1 : i32
+ %i2 = arith.constant 2 : i32
+ %i3 = arith.constant 3 : i32
+ %i4 = arith.constant 4 : i32
+ %i5 = arith.constant 5 : i32
+ %i6 = arith.constant 6 : i32
+ %i7 = arith.constant 7 : i32
//
// Allocate.
memref.store %47, %AIDX[%c7] : memref<8xvector<4xi32>>
scf.for %i = %c0 to %c8 step %c1 {
- %ix = addi %i, %c1 : index
- %kx = index_cast %ix : index to i32
- %fx = sitofp %kx : i32 to f32
+ %ix = arith.addi %i, %c1 : index
+ %kx = arith.index_cast %ix : index to i32
+ %fx = arith.sitofp %kx : i32 to f32
memref.store %fx, %X[%i] : memref<?xf32>
memref.store %f0, %B[%i] : memref<?xf32>
}
func @spmv8x8(%AVAL: memref<4xvector<8xf32>>,
%AIDX: memref<4xvector<8xi32>>,
%X: memref<?xf32>, %B: memref<1xvector<8xf32>>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cn = constant 4 : index
- %f0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cn = arith.constant 4 : index
+ %f0 = arith.constant 0.0 : f32
%mask = vector.constant_mask [8] : vector<8xi1>
%pass = vector.broadcast %f0 : f32 to vector<8xf32>
%b = memref.load %B[%c0] : memref<1xvector<8xf32>>
}
func @entry() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c8 = constant 8 : index
-
- %f0 = constant 0.0 : f32
- %f1 = constant 1.0 : f32
- %f2 = constant 2.0 : f32
- %f3 = constant 3.0 : f32
- %f4 = constant 4.0 : f32
- %f5 = constant 5.0 : f32
- %f6 = constant 6.0 : f32
- %f7 = constant 7.0 : f32
- %f8 = constant 8.0 : f32
-
- %i0 = constant 0 : i32
- %i1 = constant 1 : i32
- %i2 = constant 2 : i32
- %i3 = constant 3 : i32
- %i4 = constant 4 : i32
- %i5 = constant 5 : i32
- %i6 = constant 6 : i32
- %i7 = constant 7 : i32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c8 = arith.constant 8 : index
+
+ %f0 = arith.constant 0.0 : f32
+ %f1 = arith.constant 1.0 : f32
+ %f2 = arith.constant 2.0 : f32
+ %f3 = arith.constant 3.0 : f32
+ %f4 = arith.constant 4.0 : f32
+ %f5 = arith.constant 5.0 : f32
+ %f6 = arith.constant 6.0 : f32
+ %f7 = arith.constant 7.0 : f32
+ %f8 = arith.constant 8.0 : f32
+
+ %i0 = arith.constant 0 : i32
+ %i1 = arith.constant 1 : i32
+ %i2 = arith.constant 2 : i32
+ %i3 = arith.constant 3 : i32
+ %i4 = arith.constant 4 : i32
+ %i5 = arith.constant 5 : i32
+ %i6 = arith.constant 6 : i32
+ %i7 = arith.constant 7 : i32
//
// Allocate.
memref.store %vf0, %B[%c0] : memref<1xvector<8xf32>>
scf.for %i = %c0 to %c8 step %c1 {
- %ix = addi %i, %c1 : index
- %kx = index_cast %ix : index to i32
- %fx = sitofp %kx : i32 to f32
+ %ix = arith.addi %i, %c1 : index
+ %kx = arith.index_cast %ix : index to i32
+ %fx = arith.sitofp %kx : i32 to f32
memref.store %fx, %X[%i] : memref<?xf32>
}
// Non-contiguous, strided load.
func @transfer_read_1d(%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (d0)>}
: memref<?x?xf32>, vector<9xf32>
// Vector load with unit stride only on last dim.
func @transfer_read_1d_unit_stride(%A : memref<?x?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %fm42 = constant -42.0: f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %fm42 = arith.constant -42.0: f32
scf.for %arg2 = %c1 to %c5 step %c2 {
scf.for %arg3 = %c0 to %c6 step %c3 {
%0 = memref.subview %A[%arg2, %arg3] [1, 2] [1, 1]
// Vector load with unit stride only on last dim. Strides are not static, so
// codegen must go through VectorToSCF 1D lowering.
func @transfer_read_1d_non_static_unit_stride(%A : memref<?x?xf32>) {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c6 = constant 6 : index
- %fm42 = constant -42.0: f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c6 = arith.constant 6 : index
+ %fm42 = arith.constant -42.0: f32
%1 = memref.reinterpret_cast %A to offset: [%c6], sizes: [%c1, %c2], strides: [%c6, %c1]
: memref<?x?xf32> to memref<?x?xf32, offset: ?, strides: [?, ?]>
%2 = vector.transfer_read %1[%c2, %c1], %fm42 {in_bounds=[true]}
func @transfer_read_1d_non_unit_stride(%A : memref<?x?xf32>) {
%B = memref.reinterpret_cast %A to offset: [0], sizes: [4, 3], strides: [6, 2]
: memref<?x?xf32> to memref<4x3xf32, #map1>
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %fm42 = constant -42.0: f32
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %fm42 = arith.constant -42.0: f32
%vec = vector.transfer_read %B[%c2, %c1], %fm42 {in_bounds=[false]} : memref<4x3xf32, #map1>, vector<3xf32>
vector.print %vec : vector<3xf32>
return
// Broadcast.
func @transfer_read_1d_broadcast(
%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (0)>}
: memref<?x?xf32>, vector<9xf32>
// Non-contiguous, strided load.
func @transfer_read_1d_in_bounds(
%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (d0)>, in_bounds = [true]}
: memref<?x?xf32>, vector<3xf32>
// Non-contiguous, strided load.
func @transfer_read_1d_mask(
%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[1, 0, 1, 0, 1, 1, 1, 0, 1]> : vector<9xi1>
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[1, 0, 1, 0, 1, 1, 1, 0, 1]> : vector<9xi1>
%f = vector.transfer_read %A[%base1, %base2], %fm42, %mask
{permutation_map = affine_map<(d0, d1) -> (d0)>}
: memref<?x?xf32>, vector<9xf32>
// Non-contiguous, strided load.
func @transfer_read_1d_mask_in_bounds(
%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[1, 0, 1]> : vector<3xi1>
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[1, 0, 1]> : vector<3xi1>
%f = vector.transfer_read %A[%base1, %base2], %fm42, %mask
{permutation_map = affine_map<(d0, d1) -> (d0)>, in_bounds = [true]}
: memref<?x?xf32>, vector<3xf32>
// Non-contiguous, strided store.
func @transfer_write_1d(%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fn1 = constant -1.0 : f32
+ %fn1 = arith.constant -1.0 : f32
%vf0 = splat %fn1 : vector<7xf32>
vector.transfer_write %vf0, %A[%base1, %base2]
{permutation_map = affine_map<(d0, d1) -> (d0)>}
// Non-contiguous, strided store.
func @transfer_write_1d_mask(%A : memref<?x?xf32>, %base1 : index, %base2 : index) {
- %fn1 = constant -2.0 : f32
+ %fn1 = arith.constant -2.0 : f32
%vf0 = splat %fn1 : vector<7xf32>
- %mask = constant dense<[1, 0, 1, 0, 1, 1, 1]> : vector<7xi1>
+ %mask = arith.constant dense<[1, 0, 1, 0, 1, 1, 1]> : vector<7xi1>
vector.transfer_write %vf0, %A[%base1, %base2], %mask
{permutation_map = affine_map<(d0, d1) -> (d0)>}
: vector<7xf32>, memref<?x?xf32>
}
func @entry() {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
- %c3 = constant 3: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
+ %c3 = arith.constant 3: index
%0 = memref.get_global @gv : memref<5x6xf32>
%A = memref.cast %0 : memref<5x6xf32> to memref<?x?xf32>
// Vector load.
func @transfer_read_2d(%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (d0, d1)>} :
memref<?x?xf32>, vector<4x9xf32>
// Vector load with mask.
func @transfer_read_2d_mask(%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[[1, 0, 1, 0, 1, 1, 1, 0, 1],
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[[1, 0, 1, 0, 1, 1, 1, 0, 1],
[0, 0, 1, 1, 1, 1, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[0, 0, 1, 0, 1, 1, 1, 0, 1]]> : vector<4x9xi1>
// Vector load with mask + transpose.
func @transfer_read_2d_mask_transposed(
%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[[1, 0, 1, 0], [0, 0, 1, 0],
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[[1, 0, 1, 0], [0, 0, 1, 0],
[1, 1, 1, 1], [0, 1, 1, 0],
[1, 1, 1, 1], [1, 1, 1, 1],
[1, 1, 1, 1], [0, 0, 0, 0],
// Vector load with mask + broadcast.
func @transfer_read_2d_mask_broadcast(
%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[1, 0, 1, 0, 1, 1, 1, 0, 1]> : vector<9xi1>
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[1, 0, 1, 0, 1, 1, 1, 0, 1]> : vector<9xi1>
%f = vector.transfer_read %A[%base1, %base2], %fm42, %mask
{permutation_map = affine_map<(d0, d1) -> (0, d1)>} :
memref<?x?xf32>, vector<4x9xf32>
// Transpose + vector load with mask + broadcast.
func @transfer_read_2d_mask_transpose_broadcast_last_dim(
%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[1, 0, 1, 1]> : vector<4xi1>
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[1, 0, 1, 1]> : vector<4xi1>
%f = vector.transfer_read %A[%base1, %base2], %fm42, %mask
{permutation_map = affine_map<(d0, d1) -> (d1, 0)>} :
memref<?x?xf32>, vector<4x9xf32>
// Load + transpose.
func @transfer_read_2d_transposed(
%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (d1, d0)>} :
memref<?x?xf32>, vector<4x9xf32>
// Load 1D + broadcast to 2D.
func @transfer_read_2d_broadcast(
%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base1, %base2], %fm42
{permutation_map = affine_map<(d0, d1) -> (d1, 0)>} :
memref<?x?xf32>, vector<4x9xf32>
// Vector store.
func @transfer_write_2d(%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fn1 = constant -1.0 : f32
+ %fn1 = arith.constant -1.0 : f32
%vf0 = splat %fn1 : vector<1x4xf32>
vector.transfer_write %vf0, %A[%base1, %base2]
{permutation_map = affine_map<(d0, d1) -> (d0, d1)>} :
// Vector store with mask.
func @transfer_write_2d_mask(%A : memref<?x?xf32>, %base1: index, %base2: index) {
- %fn1 = constant -2.0 : f32
- %mask = constant dense<[[1, 0, 1, 0]]> : vector<1x4xi1>
+ %fn1 = arith.constant -2.0 : f32
+ %mask = arith.constant dense<[[1, 0, 1, 0]]> : vector<1x4xi1>
%vf0 = splat %fn1 : vector<1x4xf32>
vector.transfer_write %vf0, %A[%base1, %base2], %mask
{permutation_map = affine_map<(d0, d1) -> (d0, d1)>} :
}
func @entry() {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
- %c3 = constant 3: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
+ %c3 = arith.constant 3: index
%0 = memref.get_global @gv : memref<3x4xf32>
%A = memref.cast %0 : memref<3x4xf32> to memref<?x?xf32>
func @transfer_read_3d(%A : memref<?x?x?x?xf32>,
%o: index, %a: index, %b: index, %c: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%o, %a, %b, %c], %fm42
: memref<?x?x?x?xf32>, vector<2x5x3xf32>
vector.print %f: vector<2x5x3xf32>
func @transfer_read_3d_and_extract(%A : memref<?x?x?x?xf32>,
%o: index, %a: index, %b: index, %c: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%o, %a, %b, %c], %fm42
{in_bounds = [true, true, true]}
: memref<?x?x?x?xf32>, vector<2x5x3xf32>
func @transfer_read_3d_broadcast(%A : memref<?x?x?x?xf32>,
%o: index, %a: index, %b: index, %c: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%o, %a, %b, %c], %fm42
{permutation_map = affine_map<(d0, d1, d2, d3) -> (d1, 0, d3)>}
: memref<?x?x?x?xf32>, vector<2x5x3xf32>
func @transfer_read_3d_mask_broadcast(
%A : memref<?x?x?x?xf32>, %o: index, %a: index, %b: index, %c: index) {
- %fm42 = constant -42.0: f32
- %mask = constant dense<[0, 1]> : vector<2xi1>
+ %fm42 = arith.constant -42.0: f32
+ %mask = arith.constant dense<[0, 1]> : vector<2xi1>
%f = vector.transfer_read %A[%o, %a, %b, %c], %fm42, %mask
{permutation_map = affine_map<(d0, d1, d2, d3) -> (d1, 0, 0)>}
: memref<?x?x?x?xf32>, vector<2x5x3xf32>
func @transfer_read_3d_transposed(%A : memref<?x?x?x?xf32>,
%o: index, %a: index, %b: index, %c: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%o, %a, %b, %c], %fm42
{permutation_map = affine_map<(d0, d1, d2, d3) -> (d3, d0, d1)>}
: memref<?x?x?x?xf32>, vector<3x5x3xf32>
func @transfer_write_3d(%A : memref<?x?x?x?xf32>,
%o: index, %a: index, %b: index, %c: index) {
- %fn1 = constant -1.0 : f32
+ %fn1 = arith.constant -1.0 : f32
%vf0 = splat %fn1 : vector<2x9x3xf32>
vector.transfer_write %vf0, %A[%o, %a, %b, %c]
: vector<2x9x3xf32>, memref<?x?x?x?xf32>
}
func @entry() {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
- %c3 = constant 3: index
- %f2 = constant 2.0: f32
- %f10 = constant 10.0: f32
- %first = constant 5: index
- %second = constant 4: index
- %third = constant 2 : index
- %outer = constant 10 : index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
+ %c3 = arith.constant 3: index
+ %f2 = arith.constant 2.0: f32
+ %f10 = arith.constant 10.0: f32
+ %first = arith.constant 5: index
+ %second = arith.constant 4: index
+ %third = arith.constant 2 : index
+ %outer = arith.constant 10 : index
%A = memref.alloc(%outer, %first, %second, %third) : memref<?x?x?x?xf32>
scf.for %o = %c0 to %outer step %c1 {
scf.for %i = %c0 to %first step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
- %fi10 = mulf %fi, %f10 : f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
+ %fi10 = arith.mulf %fi, %f10 : f32
scf.for %j = %c0 to %second step %c1 {
- %j32 = index_cast %j : index to i32
- %fj = sitofp %j32 : i32 to f32
- %fadded = addf %fi10, %fj : f32
+ %j32 = arith.index_cast %j : index to i32
+ %fj = arith.sitofp %j32 : i32 to f32
+ %fadded = arith.addf %fi10, %fj : f32
scf.for %k = %c0 to %third step %c1 {
- %k32 = index_cast %k : index to i32
- %fk = sitofp %k32 : i32 to f32
- %fk1 = addf %f2, %fk : f32
- %fmul = mulf %fadded, %fk1 : f32
+ %k32 = arith.index_cast %k : index to i32
+ %fk = arith.sitofp %k32 : i32 to f32
+ %fk1 = arith.addf %f2, %fk : f32
+ %fmul = arith.mulf %fadded, %fk1 : f32
memref.store %fmul, %A[%o, %i, %j, %k] : memref<?x?x?x?xf32>
}
}
// RUN: FileCheck %s
func @transfer_read_1d(%A : memref<?xf32>, %base: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base], %fm42
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<13xf32>
}
func @transfer_read_mask_1d(%A : memref<?xf32>, %base: index) {
- %fm42 = constant -42.0: f32
- %m = constant dense<[0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]> : vector<13xi1>
+ %fm42 = arith.constant -42.0: f32
+ %m = arith.constant dense<[0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]> : vector<13xi1>
%f = vector.transfer_read %A[%base], %fm42, %m : memref<?xf32>, vector<13xf32>
vector.print %f: vector<13xf32>
return
}
func @transfer_read_inbounds_4(%A : memref<?xf32>, %base: index) {
- %fm42 = constant -42.0: f32
+ %fm42 = arith.constant -42.0: f32
%f = vector.transfer_read %A[%base], %fm42
{permutation_map = affine_map<(d0) -> (d0)>, in_bounds = [true]} :
memref<?xf32>, vector<4xf32>
}
func @transfer_read_mask_inbounds_4(%A : memref<?xf32>, %base: index) {
- %fm42 = constant -42.0: f32
- %m = constant dense<[0, 1, 0, 1]> : vector<4xi1>
+ %fm42 = arith.constant -42.0: f32
+ %m = arith.constant dense<[0, 1, 0, 1]> : vector<4xi1>
%f = vector.transfer_read %A[%base], %fm42, %m {in_bounds = [true]}
: memref<?xf32>, vector<4xf32>
vector.print %f: vector<4xf32>
}
func @transfer_write_1d(%A : memref<?xf32>, %base: index) {
- %f0 = constant 0.0 : f32
+ %f0 = arith.constant 0.0 : f32
%vf0 = splat %f0 : vector<4xf32>
vector.transfer_write %vf0, %A[%base]
{permutation_map = affine_map<(d0) -> (d0)>} :
}
func @entry() {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c2 = constant 2: index
- %c3 = constant 3: index
- %c4 = constant 4: index
- %c5 = constant 5: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c2 = arith.constant 2: index
+ %c3 = arith.constant 3: index
+ %c4 = arith.constant 4: index
+ %c5 = arith.constant 5: index
%A = memref.alloc(%c5) : memref<?xf32>
scf.for %i = %c0 to %c5 step %c1 {
- %i32 = index_cast %i : index to i32
- %fi = sitofp %i32 : i32 to f32
+ %i32 = arith.index_cast %i : index to i32
+ %fi = arith.sitofp %i32 : i32 to f32
memref.store %fi, %A[%i] : memref<?xf32>
}
// On input, memory contains [[ 0, 1, 2, 3, 4, xxx garbage xxx ]]
func private @print_memref_f32(memref<*xf32>)
func @alloc_2d_filled_f32(%arg0: index, %arg1: index) -> memref<?x?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- %c100 = constant 100 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ %c100 = arith.constant 100 : index
%0 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
scf.for %arg5 = %c0 to %arg0 step %c1 {
scf.for %arg6 = %c0 to %arg1 step %c1 {
- %arg66 = muli %arg6, %c100 : index
- %tmp1 = addi %arg5, %arg66 : index
- %tmp2 = index_cast %tmp1 : index to i32
- %tmp3 = sitofp %tmp2 : i32 to f32
+ %arg66 = arith.muli %arg6, %c100 : index
+ %tmp1 = arith.addi %arg5, %arg66 : index
+ %tmp2 = arith.index_cast %tmp1 : index to i32
+ %tmp3 = arith.sitofp %tmp2 : i32 to f32
memref.store %tmp3, %0[%arg5, %arg6] : memref<?x?xf32>
}
}
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c6 = constant 6 : index
- %cst = constant -4.2e+01 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c6 = arith.constant 6 : index
+ %cst = arith.constant -4.2e+01 : f32
%0 = call @alloc_2d_filled_f32(%c6, %c6) : (index, index) -> memref<?x?xf32>
%converted = memref.cast %0 : memref<?x?xf32> to memref<*xf32>
call @print_memref_f32(%converted): (memref<*xf32>) -> ()
// RUN: FileCheck %s
func @transfer_write16_inbounds_1d(%A : memref<?xf32>, %base: index) {
- %f = constant 16.0 : f32
+ %f = arith.constant 16.0 : f32
%v = splat %f : vector<16xf32>
vector.transfer_write %v, %A[%base]
{permutation_map = affine_map<(d0) -> (d0)>, in_bounds = [true]}
}
func @transfer_write13_1d(%A : memref<?xf32>, %base: index) {
- %f = constant 13.0 : f32
+ %f = arith.constant 13.0 : f32
%v = splat %f : vector<13xf32>
vector.transfer_write %v, %A[%base]
{permutation_map = affine_map<(d0) -> (d0)>}
}
func @transfer_write17_1d(%A : memref<?xf32>, %base: index) {
- %f = constant 17.0 : f32
+ %f = arith.constant 17.0 : f32
%v = splat %f : vector<17xf32>
vector.transfer_write %v, %A[%base]
{permutation_map = affine_map<(d0) -> (d0)>}
}
func @transfer_read_1d(%A : memref<?xf32>) -> vector<32xf32> {
- %z = constant 0: index
- %f = constant 0.0: f32
+ %z = arith.constant 0: index
+ %f = arith.constant 0.0: f32
%r = vector.transfer_read %A[%z], %f
{permutation_map = affine_map<(d0) -> (d0)>}
: memref<?xf32>, vector<32xf32>
}
func @entry() {
- %c0 = constant 0: index
- %c1 = constant 1: index
- %c32 = constant 32: index
+ %c0 = arith.constant 0: index
+ %c1 = arith.constant 1: index
+ %c32 = arith.constant 32: index
%A = memref.alloc(%c32) {alignment=64} : memref<?xf32>
scf.for %i = %c0 to %c32 step %c1 {
- %f = constant 0.0: f32
+ %f = arith.constant 0.0: f32
memref.store %f, %A[%i] : memref<?xf32>
}
// Overwrite with 16 values of 16 at base 3.
// Statically guaranteed to be in-bounds. Exercises proper alignment.
- %c3 = constant 3: index
+ %c3 = arith.constant 3: index
call @transfer_write16_inbounds_1d(%A, %c3) : (memref<?xf32>, index) -> ()
%1 = call @transfer_read_1d(%A) : (memref<?xf32>) -> (vector<32xf32>)
vector.print %1 : vector<32xf32>
vector.print %2 : vector<32xf32>
// Overwrite with 17 values of 17 at base 7.
- %c7 = constant 7: index
+ %c7 = arith.constant 7: index
call @transfer_write17_1d(%A, %c3) : (memref<?xf32>, index) -> ()
%3 = call @transfer_read_1d(%A) : (memref<?xf32>) -> (vector<32xf32>)
vector.print %3 : vector<32xf32>
// Overwrite with 13 values of 13 at base 8.
- %c8 = constant 8: index
+ %c8 = arith.constant 8: index
call @transfer_write13_1d(%A, %c8) : (memref<?xf32>, index) -> ()
%4 = call @transfer_read_1d(%A) : (memref<?xf32>) -> (vector<32xf32>)
vector.print %4 : vector<32xf32>
// Overwrite with 17 values of 17 at base 14.
- %c14 = constant 14: index
+ %c14 = arith.constant 14: index
call @transfer_write17_1d(%A, %c14) : (memref<?xf32>, index) -> ()
%5 = call @transfer_read_1d(%A) : (memref<?xf32>) -> (vector<32xf32>)
vector.print %5 : vector<32xf32>
// Overwrite with 13 values of 13 at base 19.
- %c19 = constant 19: index
+ %c19 = arith.constant 19: index
call @transfer_write13_1d(%A, %c19) : (memref<?xf32>, index) -> ()
%6 = call @transfer_read_1d(%A) : (memref<?xf32>) -> (vector<32xf32>)
vector.print %6 : vector<32xf32>
// RUN: FileCheck %s
func @entry() {
- %f0 = constant 0.0: f32
- %f1 = constant 1.0: f32
- %f2 = constant 2.0: f32
- %f3 = constant 3.0: f32
- %f4 = constant 4.0: f32
- %f5 = constant 5.0: f32
- %f6 = constant 6.0: f32
- %f7 = constant 7.0: f32
- %f8 = constant 8.0: f32
+ %f0 = arith.constant 0.0: f32
+ %f1 = arith.constant 1.0: f32
+ %f2 = arith.constant 2.0: f32
+ %f3 = arith.constant 3.0: f32
+ %f4 = arith.constant 4.0: f32
+ %f5 = arith.constant 5.0: f32
+ %f6 = arith.constant 6.0: f32
+ %f7 = arith.constant 7.0: f32
+ %f8 = arith.constant 8.0: f32
// Construct test vectors and matrices.
%0 = vector.broadcast %f1 : f32 to vector<2xf32>
%9 = vector.insert %a, %8[0] : vector<2xf32> into vector<3x2xf32>
%10 = vector.insert %b, %9[1] : vector<2xf32> into vector<3x2xf32>
%C = vector.insert %c, %10[2] : vector<2xf32> into vector<3x2xf32>
- %cst = constant dense<0.000000e+00> : vector<2x4xf32>
+ %cst = arith.constant dense<0.000000e+00> : vector<2x4xf32>
%11 = vector.insert_strided_slice %A, %cst {offsets = [0, 0], strides = [1, 1]} : vector<2x2xf32> into vector<2x4xf32>
%D = vector.insert_strided_slice %B, %11 {offsets = [0, 2], strides = [1, 1]} : vector<2x2xf32> into vector<2x4xf32>
func private @print_memref_f32(memref<*xf32>)
func @alloc_1d_filled_inc_f32(%arg0: index, %arg1: f32) -> memref<?xf32> {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%0 = memref.alloc(%arg0) : memref<?xf32>
scf.for %arg2 = %c0 to %arg0 step %c1 {
- %tmp = index_cast %arg2 : index to i32
- %tmp1 = sitofp %tmp : i32 to f32
- %tmp2 = addf %tmp1, %arg1 : f32
+ %tmp = arith.index_cast %arg2 : index to i32
+ %tmp1 = arith.sitofp %tmp : i32 to f32
+ %tmp2 = arith.addf %tmp1, %arg1 : f32
memref.store %tmp2, %0[%arg2] : memref<?xf32>
}
return %0 : memref<?xf32>
// Large vector addf that can be broken down into a loop of smaller vector addf.
func @main() {
- %cf0 = constant 0.0 : f32
- %cf1 = constant 1.0 : f32
- %cf2 = constant 2.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c32 = constant 32 : index
- %c64 = constant 64 : index
+ %cf0 = arith.constant 0.0 : f32
+ %cf1 = arith.constant 1.0 : f32
+ %cf2 = arith.constant 2.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c32 = arith.constant 32 : index
+ %c64 = arith.constant 64 : index
%out = memref.alloc(%c64) : memref<?xf32>
%in1 = call @alloc_1d_filled_inc_f32(%c64, %cf1) : (index, f32) -> memref<?xf32>
%in2 = call @alloc_1d_filled_inc_f32(%c64, %cf2) : (index, f32) -> memref<?xf32>
// TRANSFORM: scf.for
// TRANSFORM: vector.transfer_read {{.*}} : memref<?xf32>, vector<2xf32>
// TRANSFORM: vector.transfer_read {{.*}} : memref<?xf32>, vector<2xf32>
- // TRANSFORM: %{{.*}} = addf %{{.*}}, %{{.*}} : vector<2xf32>
+ // TRANSFORM: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : vector<2xf32>
// TRANSFORM: vector.transfer_write {{.*}} : vector<2xf32>, memref<?xf32>
// TRANSFORM: }
%a = vector.transfer_read %in1[%c0], %cf0: memref<?xf32>, vector<64xf32>
%b = vector.transfer_read %in2[%c0], %cf0: memref<?xf32>, vector<64xf32>
- %acc = addf %a, %b: vector<64xf32>
+ %acc = arith.addf %a, %b: vector<64xf32>
vector.transfer_write %acc, %out[%c0]: vector<64xf32>, memref<?xf32>
%converted = memref.cast %out : memref<?xf32> to memref<*xf32>
call @print_memref_f32(%converted): (memref<*xf32>) -> ()
%22 = memref.alloc() : memref<16x16xf16>
%1 = memref.alloc() : memref<16x16xf32>
- %f1 = constant 1.0e+00 : f16
- %f0 = constant 0.0e+00 : f16
- %c0 = constant 0 : index
- %c16 = constant 16 : index
- %c32 = constant 32 : index
- %c1 = constant 1 : index
+ %f1 = arith.constant 1.0e+00 : f16
+ %f0 = arith.constant 0.0e+00 : f16
+ %c0 = arith.constant 0 : index
+ %c16 = arith.constant 16 : index
+ %c32 = arith.constant 32 : index
+ %c1 = arith.constant 1 : index
// Intialize the Input matrix with ones.
scf.for %arg0 = %c0 to %c16 step %c1 {
scf.for %arg0 = %c0 to %c16 step %c1 {
scf.for %arg1 = %c0 to %c16 step %c1 {
%6 = memref.load %0[%arg0, %arg1] : memref<16x16xf16>
- %7 = fpext %6 : f16 to f32
+ %7 = arith.extf %6 : f16 to f32
memref.store %7, %1[%arg0, %arg1] : memref<16x16xf32>
}
}
%22 = memref.alloc() : memref<16x16xf32>
%1 = memref.alloc() : memref<16x16xf32>
- %f1 = constant 1.0e+00 : f16
- %f0 = constant 0.0e+00 : f32
- %c0 = constant 0 : index
- %c16 = constant 16 : index
- %c32 = constant 32 : index
- %c1 = constant 1 : index
+ %f1 = arith.constant 1.0e+00 : f16
+ %f0 = arith.constant 0.0e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c16 = arith.constant 16 : index
+ %c32 = arith.constant 32 : index
+ %c1 = arith.constant 1 : index
// Intialize the Input matrix with ones.
scf.for %arg0 = %c0 to %c16 step %c1 {
func @main() {
%data = memref.alloc() : memref<2x6xi32>
%sum = memref.alloc() : memref<2xi32>
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
- %cst2 = constant 2 : i32
- %cst4 = constant 4 : i32
- %cst8 = constant 8 : i32
- %cst16 = constant 16 : i32
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
+ %cst2 = arith.constant 2 : i32
+ %cst4 = arith.constant 4 : i32
+ %cst8 = arith.constant 8 : i32
+ %cst16 = arith.constant 16 : i32
- %cst3 = constant 3 : i32
- %cst6 = constant 6 : i32
- %cst7 = constant 7 : i32
- %cst10 = constant 10 : i32
- %cst11 = constant 11 : i32
+ %cst3 = arith.constant 3 : i32
+ %cst6 = arith.constant 6 : i32
+ %cst7 = arith.constant 7 : i32
+ %cst10 = arith.constant 10 : i32
+ %cst11 = arith.constant 11 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xi32> to memref<*xi32>
gpu.host_register %cast_data : memref<*xi32>
func @main() {
%data = memref.alloc() : memref<2x6xi32>
%sum = memref.alloc() : memref<2xi32>
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
- %cst2 = constant 2 : i32
- %cst4 = constant 4 : i32
- %cst8 = constant 8 : i32
- %cst16 = constant 16 : i32
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
+ %cst2 = arith.constant 2 : i32
+ %cst4 = arith.constant 4 : i32
+ %cst8 = arith.constant 8 : i32
+ %cst16 = arith.constant 16 : i32
- %cst3 = constant 3 : i32
- %cst6 = constant 6 : i32
- %cst7 = constant 7 : i32
- %cst10 = constant 10 : i32
- %cst11 = constant 11 : i32
+ %cst3 = arith.constant 3 : i32
+ %cst6 = arith.constant 6 : i32
+ %cst7 = arith.constant 7 : i32
+ %cst10 = arith.constant 10 : i32
+ %cst11 = arith.constant 11 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xi32> to memref<*xi32>
gpu.host_register %cast_data : memref<*xi32>
func @main() {
%data = memref.alloc() : memref<2x6xi32>
%sum = memref.alloc() : memref<2xi32>
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
- %cst2 = constant 2 : i32
- %cst4 = constant 4 : i32
- %cst8 = constant 8 : i32
- %cst16 = constant 16 : i32
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
+ %cst2 = arith.constant 2 : i32
+ %cst4 = arith.constant 4 : i32
+ %cst8 = arith.constant 8 : i32
+ %cst16 = arith.constant 16 : i32
- %cst3 = constant 3 : i32
- %cst6 = constant 6 : i32
- %cst7 = constant 7 : i32
- %cst10 = constant 10 : i32
- %cst11 = constant 11 : i32
+ %cst3 = arith.constant 3 : i32
+ %cst6 = arith.constant 6 : i32
+ %cst7 = arith.constant 7 : i32
+ %cst10 = arith.constant 10 : i32
+ %cst11 = arith.constant 11 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xi32> to memref<*xi32>
gpu.host_register %cast_data : memref<*xi32>
func @main() {
%arg = memref.alloc() : memref<2x4x13xf32>
%dst = memref.cast %arg : memref<2x4x13xf32> to memref<?x?x?xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%sx = memref.dim %dst, %c2 : memref<?x?x?xf32>
%sy = memref.dim %dst, %c1 : memref<?x?x?xf32>
%sz = memref.dim %dst, %c0 : memref<?x?x?xf32>
gpu.host_register %cast_dst : memref<*xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %sy, %block_z = %sz) {
- %t0 = muli %tz, %block_y : index
- %t1 = addi %ty, %t0 : index
- %t2 = muli %t1, %block_x : index
- %idx = addi %tx, %t2 : index
- %t3 = index_cast %idx : index to i32
- %val = sitofp %t3 : i32 to f32
+ %t0 = arith.muli %tz, %block_y : index
+ %t1 = arith.addi %ty, %t0 : index
+ %t2 = arith.muli %t1, %block_x : index
+ %idx = arith.addi %tx, %t2 : index
+ %t3 = arith.index_cast %idx : index to i32
+ %val = arith.sitofp %t3 : i32 to f32
%sum = "gpu.all_reduce"(%val) ({}) { op = "add" } : (f32) -> (f32)
memref.store %sum, %dst[%tz, %ty, %tx] : memref<?x?x?xf32>
gpu.terminator
func @main() {
%data = memref.alloc() : memref<2x6xi32>
%sum = memref.alloc() : memref<2xi32>
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
- %cst2 = constant 2 : i32
- %cst4 = constant 4 : i32
- %cst8 = constant 8 : i32
- %cst16 = constant 16 : i32
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
+ %cst2 = arith.constant 2 : i32
+ %cst4 = arith.constant 4 : i32
+ %cst8 = arith.constant 8 : i32
+ %cst16 = arith.constant 16 : i32
- %cst3 = constant 3 : i32
- %cst6 = constant 6 : i32
- %cst7 = constant 7 : i32
- %cst10 = constant 10 : i32
- %cst11 = constant 11 : i32
+ %cst3 = arith.constant 3 : i32
+ %cst6 = arith.constant 6 : i32
+ %cst7 = arith.constant 7 : i32
+ %cst10 = arith.constant 10 : i32
+ %cst11 = arith.constant 11 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xi32> to memref<*xi32>
gpu.host_register %cast_data : memref<*xi32>
func @main() {
%arg = memref.alloc() : memref<35xf32>
%dst = memref.cast %arg : memref<35xf32> to memref<?xf32>
- %one = constant 1 : index
- %c0 = constant 0 : index
+ %one = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
%sx = memref.dim %dst, %c0 : memref<?xf32>
%cast_dst = memref.cast %dst : memref<?xf32> to memref<*xf32>
gpu.host_register %cast_dst : memref<*xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %one, %grid_y = %one, %grid_z = %one)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %one, %block_z = %one) {
- %val = index_cast %tx : index to i32
+ %val = arith.index_cast %tx : index to i32
%xor = "gpu.all_reduce"(%val) ({
^bb(%lhs : i32, %rhs : i32):
- %xor = xor %lhs, %rhs : i32
+ %xor = arith.xori %lhs, %rhs : i32
"gpu.yield"(%xor) : (i32) -> ()
}) : (i32) -> (i32)
- %res = sitofp %xor : i32 to f32
+ %res = arith.sitofp %xor : i32 to f32
memref.store %res, %dst[%tx] : memref<?xf32>
gpu.terminator
}
func @main() {
%data = memref.alloc() : memref<2x6xi32>
%sum = memref.alloc() : memref<2xi32>
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
- %cst2 = constant 2 : i32
- %cst4 = constant 4 : i32
- %cst8 = constant 8 : i32
- %cst16 = constant 16 : i32
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
+ %cst2 = arith.constant 2 : i32
+ %cst4 = arith.constant 4 : i32
+ %cst8 = arith.constant 8 : i32
+ %cst16 = arith.constant 16 : i32
- %cst3 = constant 3 : i32
- %cst6 = constant 6 : i32
- %cst7 = constant 7 : i32
- %cst10 = constant 10 : i32
- %cst11 = constant 11 : i32
+ %cst3 = arith.constant 3 : i32
+ %cst6 = arith.constant 6 : i32
+ %cst7 = arith.constant 7 : i32
+ %cst10 = arith.constant 10 : i32
+ %cst11 = arith.constant 11 : i32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xi32> to memref<*xi32>
gpu.host_register %cast_data : memref<*xi32>
// RUN: | FileCheck %s
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %count = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %count = arith.constant 2 : index
// initialize h0 on host
%h0 = memref.alloc(%count) : memref<?xi32>
%h0_unranked = memref.cast %h0 : memref<?xi32> to memref<*xi32>
gpu.host_register %h0_unranked : memref<*xi32>
- %v0 = constant 42 : i32
+ %v0 = arith.constant 42 : i32
memref.store %v0, %h0[%c0] : memref<?xi32>
memref.store %v0, %h0[%c1] : memref<?xi32>
threads(%tx, %ty, %tz) in (%block_x = %count, %block_y = %c1, %block_z = %c1) {
%v1 = memref.load %b1[%tx] : memref<?xi32>
%v2 = memref.load %b2[%tx] : memref<?xi32>
- %sum = addi %v1, %v2 : i32
+ %sum = arith.addi %v1, %v2 : i32
memref.store %sum, %h0[%tx] : memref<?xi32>
gpu.terminator
}
// RUN: | FileCheck %s
func @other_func(%arg0 : f32, %arg1 : memref<?xf32>) {
- %cst = constant 1 : index
- %c0 = constant 0 : index
+ %cst = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
%cst2 = memref.dim %arg1, %c0 : memref<?xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst, %grid_z = %cst)
threads(%tx, %ty, %tz) in (%block_x = %cst2, %block_y = %cst, %block_z = %cst) {
// CHECK: [1, 1, 1, 1, 1]
// CHECK: ( 1, 1 )
func @main() {
- %v0 = constant 0.0 : f32
- %c0 = constant 0: index
+ %v0 = arith.constant 0.0 : f32
+ %c0 = arith.constant 0: index
%arg0 = memref.alloc() : memref<5xf32>
- %21 = constant 5 : i32
+ %21 = arith.constant 5 : i32
%22 = memref.cast %arg0 : memref<5xf32> to memref<?xf32>
%23 = memref.cast %22 : memref<?xf32> to memref<*xf32>
gpu.host_register %23 : memref<*xf32>
call @print_memref_f32(%23) : (memref<*xf32>) -> ()
- %24 = constant 1.0 : f32
+ %24 = arith.constant 1.0 : f32
call @other_func(%24, %22) : (f32, memref<?xf32>) -> ()
call @print_memref_f32(%23) : (memref<*xf32>) -> ()
%val1 = vector.transfer_read %arg0[%c0], %v0: memref<5xf32>, vector<2xf32>
%data = memref.alloc() : memref<2x6xf32>
%sum = memref.alloc() : memref<2xf32>
%mul = memref.alloc() : memref<2xf32>
- %cst0 = constant 0.0 : f32
- %cst1 = constant 1.0 : f32
- %cst2 = constant 2.0 : f32
- %cst4 = constant 4.0 : f32
- %cst8 = constant 8.0 : f32
- %cst16 = constant 16.0 : f32
+ %cst0 = arith.constant 0.0 : f32
+ %cst1 = arith.constant 1.0 : f32
+ %cst2 = arith.constant 2.0 : f32
+ %cst4 = arith.constant 4.0 : f32
+ %cst8 = arith.constant 8.0 : f32
+ %cst16 = arith.constant 16.0 : f32
- %cst3 = constant 3.0 : f32
- %cst6 = constant 6.0 : f32
- %cst7 = constant 7.0 : f32
- %cst10 = constant 10.0 : f32
- %cst11 = constant 11.0 : f32
+ %cst3 = arith.constant 3.0 : f32
+ %cst6 = arith.constant 6.0 : f32
+ %cst7 = arith.constant 7.0 : f32
+ %cst10 = arith.constant 10.0 : f32
+ %cst11 = arith.constant 11.0 : f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
%cast_data = memref.cast %data : memref<2x6xf32> to memref<*xf32>
gpu.host_register %cast_data : memref<*xf32>
func @main() {
%arg = memref.alloc() : memref<13xf32>
%dst = memref.cast %arg : memref<13xf32> to memref<?xf32>
- %one = constant 1 : index
- %c0 = constant 0 : index
+ %one = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
%sx = memref.dim %dst, %c0 : memref<?xf32>
%cast_dst = memref.cast %dst : memref<?xf32> to memref<*xf32>
gpu.host_register %cast_dst : memref<*xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %one, %grid_y = %one, %grid_z = %one)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %one, %block_z = %one) {
- %t0 = index_cast %tx : index to i32
- %val = sitofp %t0 : i32 to f32
- %width = index_cast %block_x : index to i32
- %offset = constant 4 : i32
+ %t0 = arith.index_cast %tx : index to i32
+ %val = arith.sitofp %t0 : i32 to f32
+ %width = arith.index_cast %block_x : index to i32
+ %offset = arith.constant 4 : i32
%shfl, %valid = gpu.shuffle %val, %offset, %width xor : f32
cond_br %valid, ^bb1(%shfl : f32), ^bb0
^bb0:
- %m1 = constant -1.0 : f32
+ %m1 = arith.constant -1.0 : f32
br ^bb1(%m1 : f32)
^bb1(%value : f32):
memref.store %value, %dst[%tx] : memref<?xf32>
func @main() {
%arg = memref.alloc() : memref<13xi32>
%dst = memref.cast %arg : memref<13xi32> to memref<?xi32>
- %one = constant 1 : index
- %c0 = constant 0 : index
+ %one = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
%sx = memref.dim %dst, %c0 : memref<?xi32>
%cast_dst = memref.cast %dst : memref<?xi32> to memref<*xi32>
gpu.host_register %cast_dst : memref<*xi32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %one, %grid_y = %one, %grid_z = %one)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %one, %block_z = %one) {
- %t0 = index_cast %tx : index to i32
+ %t0 = arith.index_cast %tx : index to i32
memref.store %t0, %dst[%tx] : memref<?xi32>
gpu.terminator
}
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %one, %grid_y = %one, %grid_z = %one)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %one, %block_z = %one) {
- %t0 = index_cast %tx : index to i32
+ %t0 = arith.index_cast %tx : index to i32
memref.store %t0, %dst[%tx] : memref<?xi32>
gpu.terminator
}
// RUN: | FileCheck %s
func @other_func(%arg0 : f32, %arg1 : memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%block_dim = dim %arg1, %c0 : memref<?xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
threads(%tx, %ty, %tz) in (%block_x = %block_dim, %block_y = %c1, %block_z = %c1) {
// CHECK: [1, 1, 1, 1, 1]
func @main() {
%arg0 = alloc() : memref<5xf32>
- %21 = constant 5 : i32
+ %21 = arith.constant 5 : i32
%22 = memref_cast %arg0 : memref<5xf32> to memref<?xf32>
%cast = memref_cast %22 : memref<?xf32> to memref<*xf32>
gpu.host_register %cast : memref<*xf32>
%23 = memref_cast %22 : memref<?xf32> to memref<*xf32>
call @print_memref_f32(%23) : (memref<*xf32>) -> ()
- %24 = constant 1.0 : f32
+ %24 = arith.constant 1.0 : f32
%25 = call @mgpuMemGetDeviceMemRef1dFloat(%22) : (memref<?xf32>) -> (memref<?xf32>)
call @other_func(%24, %25) : (f32, memref<?xf32>) -> ()
call @print_memref_f32(%23) : (memref<*xf32>) -> ()
func @main() {
%arg = alloc() : memref<13xi32>
%dst = memref_cast %arg : memref<13xi32> to memref<?xi32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%sx = dim %dst, %c0 : memref<?xi32>
%cast_dst = memref_cast %dst : memref<?xi32> to memref<*xi32>
gpu.host_register %cast_dst : memref<*xi32>
%dst_device = call @mgpuMemGetDeviceMemRef1dInt32(%dst) : (memref<?xi32>) -> (memref<?xi32>)
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %c1, %block_z = %c1) {
- %t0 = index_cast %tx : index to i32
+ %t0 = arith.index_cast %tx : index to i32
store %t0, %dst_device[%tx] : memref<?xi32>
gpu.terminator
}
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
threads(%tx, %ty, %tz) in (%block_x = %sx, %block_y = %c1, %block_z = %c1) {
- %t0 = index_cast %tx : index to i32
+ %t0 = arith.index_cast %tx : index to i32
store %t0, %dst_device[%tx] : memref<?xi32>
gpu.terminator
}
// RUN: | FileCheck %s
func @vecadd(%arg0 : memref<?xf32>, %arg1 : memref<?xf32>, %arg2 : memref<?xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
%block_dim = dim %arg0, %c0 : memref<?xf32>
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %c1, %grid_y = %c1, %grid_z = %c1)
threads(%tx, %ty, %tz) in (%block_x = %block_dim, %block_y = %c1, %block_z = %c1) {
%a = load %arg0[%tx] : memref<?xf32>
%b = load %arg1[%tx] : memref<?xf32>
- %c = addf %a, %b : f32
+ %c = arith.addf %a, %b : f32
store %c, %arg2[%tx] : memref<?xf32>
gpu.terminator
}
// CHECK: [2.46, 2.46, 2.46, 2.46, 2.46]
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c5 = constant 5 : index
- %cf1dot23 = constant 1.23 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c5 = arith.constant 5 : index
+ %cf1dot23 = arith.constant 1.23 : f32
%0 = alloc() : memref<5xf32>
%1 = alloc() : memref<5xf32>
%2 = alloc() : memref<5xf32>
// RUN: | FileCheck %s
func @vectransferx2(%arg0 : memref<?xf32>, %arg1 : memref<?xf32>) {
- %cst = constant 1 : index
+ %cst = arith.constant 1 : index
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst, %grid_z = %cst)
threads(%tx, %ty, %tz) in (%block_x = %cst, %block_y = %cst, %block_z = %cst) {
- %f0 = constant 0.0: f32
- %base = constant 0 : index
+ %f0 = arith.constant 0.0: f32
+ %base = arith.constant 0 : index
%f = vector.transfer_read %arg0[%base], %f0
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<2xf32>
- %c = addf %f, %f : vector<2xf32>
+ %c = arith.addf %f, %f : vector<2xf32>
- %base1 = constant 1 : index
+ %base1 = arith.constant 1 : index
vector.transfer_write %c, %arg1[%base1]
{permutation_map = affine_map<(d0) -> (d0)>} :
vector<2xf32>, memref<?xf32>
}
func @vectransferx4(%arg0 : memref<?xf32>, %arg1 : memref<?xf32>) {
- %cst = constant 1 : index
+ %cst = arith.constant 1 : index
gpu.launch blocks(%bx, %by, %bz) in (%grid_x = %cst, %grid_y = %cst, %grid_z = %cst)
threads(%tx, %ty, %tz) in (%block_x = %cst, %block_y = %cst, %block_z = %cst) {
- %f0 = constant 0.0: f32
- %base = constant 0 : index
+ %f0 = arith.constant 0.0: f32
+ %base = arith.constant 0 : index
%f = vector.transfer_read %arg0[%base], %f0
{permutation_map = affine_map<(d0) -> (d0)>} :
memref<?xf32>, vector<4xf32>
- %c = addf %f, %f : vector<4xf32>
+ %c = arith.addf %f, %f : vector<4xf32>
vector.transfer_write %c, %arg1[%base]
{permutation_map = affine_map<(d0) -> (d0)>} :
}
func @main() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c4 = constant 4 : index
- %cf1 = constant 1.0 : f32
- %cf1dot23 = constant 1.23 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c4 = arith.constant 4 : index
+ %cf1 = arith.constant 1.0 : f32
+ %cf1dot23 = arith.constant 1.23 : f32
%arg0 = alloc() : memref<4xf32>
%arg1 = alloc() : memref<4xf32>
func @result_shape(%arg0 : tensor<2x3x?xf32>, %arg1 : tensor<?x5xf32>)
-> (index, index, index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0:2 = "test.op_with_result_shape_interface"(%arg0, %arg1)
: (tensor<2x3x?xf32>, tensor<?x5xf32>) -> (tensor<?x5xf32>, tensor<2x3x?xf32>)
%1 = tensor.dim %0#0, %c0 : tensor<?x5xf32>
// CHECK-LABEL: func @result_shape(
// CHECK-SAME: %[[ARG_0:[a-z0-9]*]]: tensor<2x3x?xf32>
// CHECK-SAME: %[[ARG_1:[a-z0-9]*]]: tensor<?x5xf32>)
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
-// CHECK-DAG: %[[C3:.+]] = constant 3 : index
-// CHECK-DAG: %[[C5:.+]] = constant 5 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.+]] = arith.constant 3 : index
+// CHECK-DAG: %[[C5:.+]] = arith.constant 5 : index
// CHECK-DAG: %[[D0:.+]] = tensor.dim %[[ARG_1]], %[[C0]]
// CHECK-DAG: %[[S0:.+]] = tensor.from_elements %[[D0]], %[[C5]]
// CHECK-DAG: %[[D0_OUT:.+]] = tensor.extract %[[S0]][%[[C0]]]
func @result_shape_per_dim(%arg0 : tensor<2x3x?xf32>, %arg1 : tensor<?x5xf32>)
-> (index, index, index, index, index) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0:2 = "test.op_with_result_shape_per_dim_interface"(%arg0, %arg1)
: (tensor<2x3x?xf32>, tensor<?x5xf32>) -> (tensor<?x5xf32>, tensor<2x3x?xf32>)
%1 = tensor.dim %0#0, %c0 : tensor<?x5xf32>
// CHECK-LABEL: func @result_shape_per_dim(
// CHECK-SAME: %[[ARG_0:[a-z0-9]*]]: tensor<2x3x?xf32>
// CHECK-SAME: %[[ARG_1:[a-z0-9]*]]: tensor<?x5xf32>)
-// CHECK-DAG: %[[C0:.+]] = constant 0 : index
-// CHECK-DAG: %[[C2:.+]] = constant 2 : index
-// CHECK-DAG: %[[C3:.+]] = constant 3 : index
-// CHECK-DAG: %[[C5:.+]] = constant 5 : index
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.+]] = arith.constant 2 : index
+// CHECK-DAG: %[[C3:.+]] = arith.constant 3 : index
+// CHECK-DAG: %[[C5:.+]] = arith.constant 5 : index
// CHECK-DAG: %[[D0:.+]] = tensor.dim %[[ARG_1]], %[[C0]]
// CHECK-DAG: %[[D1:.+]] = tensor.dim %[[ARG_0]], %[[C2]]
// CHECK: return %[[D0]], %[[C5]], %[[C2]], %[[C3]], %[[D1]]
// RUN: not mlir-opt %s -mlir-disable-threading=true -pass-pipeline='builtin.func(cse,test-pass-failure)' -print-ir-after-failure -o /dev/null 2>&1 | FileCheck -check-prefix=AFTER_FAILURE %s
func @foo() {
- %0 = constant 0 : i32
+ %0 = arith.constant 0 : i32
return
}
// RUN: mlir-opt %s -run-reproducer 2>&1 | FileCheck -check-prefix=BEFORE %s
func @foo() {
- %0 = constant 0 : i32
+ %0 = arith.constant 0 : i32
return
}
func @emitc_call_two_results() {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1:2 = emitc.call "two_results" () : () -> (i32, i32)
return
}
// CPP-DECLTOP-NEXT: return;
func @test_for_yield() {
- %start = constant 0 : index
- %stop = constant 10 : index
- %step = constant 1 : index
+ %start = arith.constant 0 : index
+ %stop = arith.constant 10 : index
+ %step = arith.constant 1 : index
- %s0 = constant 0 : i32
- %p0 = constant 1.0 : f32
+ %s0 = arith.constant 0 : i32
+ %p0 = arith.constant 1.0 : f32
%result:2 = scf.for %iter = %start to %stop step %step iter_args(%si = %s0, %pi = %p0) -> (i32, f32) {
%sn = emitc.call "add"(%si, %iter) : (i32, index) -> i32
func @test_if_yield(%arg0: i1, %arg1: f32) {
- %0 = constant 0 : i8
+ %0 = arith.constant 0 : i8
%x, %y = scf.if %arg0 -> (i32, f64) {
%1 = emitc.call "func_true_1"(%arg1) : (f32) -> i32
%2 = emitc.call "func_true_2"(%arg1) : (f32) -> f64
// -----
func @unsupported_std_op(%arg0: f64) -> f64 {
- // expected-error@+1 {{'std.absf' op unable to find printer for op}}
- %0 = absf %arg0 : f64
+ // expected-error@+1 {{'math.abs' op unable to find printer for op}}
+ %0 = math.abs %arg0 : f64
return %0 : f64
}
// RUN: mlir-translate -mlir-to-cpp -declare-variables-at-top %s | FileCheck %s -check-prefix=CPP-DECLTOP
func @std_constant() {
- %c0 = constant 0 : i32
- %c1 = constant 2 : index
- %c2 = constant 2.0 : f32
- %c3 = constant dense<0> : tensor<i32>
- %c4 = constant dense<[0, 1]> : tensor<2xindex>
- %c5 = constant dense<[[0.0, 1.0], [2.0, 3.0]]> : tensor<2x2xf32>
+ %c0 = arith.constant 0 : i32
+ %c1 = arith.constant 2 : index
+ %c2 = arith.constant 2.0 : f32
+ %c3 = arith.constant dense<0> : tensor<i32>
+ %c4 = arith.constant dense<[0, 1]> : tensor<2xindex>
+ %c5 = arith.constant dense<[[0.0, 1.0], [2.0, 3.0]]> : tensor<2x2xf32>
return
}
// CPP-DEFAULT: void std_constant() {
func @std_call_two_results() {
- %c = constant 0 : i8
+ %c = arith.constant 0 : i8
%0:2 = call @two_results () : () -> (i32, f32)
%1:2 = call @two_results () : () -> (i32, f32)
return
func @one_result() -> i32 {
- %0 = constant 0 : i32
+ %0 = arith.constant 0 : i32
return %0 : i32
}
// CPP-DEFAULT: int32_t one_result() {
func @two_results() -> (i32, f32) {
- %0 = constant 0 : i32
- %1 = constant 1.0 : f32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1.0 : f32
return %0, %1 : i32, f32
}
// CPP-DEFAULT: std::tuple<int32_t, float> two_results() {
-// RUN: mlir-opt %s -convert-vector-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-translate -mlir-to-llvmir | FileCheck %s
+// RUN: mlir-opt %s -convert-vector-to-llvm -convert-arith-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-translate -mlir-to-llvmir | FileCheck %s
func @genbool_1d() -> vector<8xi1> {
%0 = vector.constant_mask [4] : vector<8xi1>
// note: awkward syntax to match [[
func @genbool_1d_var_but_constant() -> vector<8xi1> {
- %i = constant 0 : index
+ %i = arith.constant 0 : index
%v = vector.create_mask %i : vector<8xi1>
return %v : vector<8xi1>
}
func @nested_region_control_flow(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
func @nested_region_control_flow_div(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
func @nestedRegionControlFlowAlloca(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = memref.alloc() : memref<2xf32>
scf.yield %3 : memref<2xf32>
}
// CHECK-NEXT: %[[ALLOC1:.*]] = memref.clone %arg3
// CHECK: %[[ALLOC2:.*]] = scf.for {{.*}} iter_args
// CHECK-SAME: (%[[IALLOC:.*]] = %[[ALLOC1]]
-// CHECK: cmpi
+// CHECK: arith.cmpi
// CHECK: memref.dealloc %[[IALLOC]]
// CHECK: %[[ALLOC3:.*]] = memref.alloc()
// CHECK: %[[ALLOC4:.*]] = memref.clone %[[ALLOC3]]
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
scf.yield %0 : memref<2xf32>
} else {
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
%4 = memref.alloc() : memref<2xf32>
scf.yield %4 : memref<2xf32>
%3 = scf.for %i3 = %lb to %ub step %step
iter_args(%iterBuf3 = %iterBuf2) -> memref<2xf32> {
%4 = memref.alloc() : memref<2xf32>
- %5 = cmpi eq, %i, %ub : index
+ %5 = arith.cmpi eq, %i, %ub : index
%6 = scf.if %5 -> (memref<2xf32>) {
%7 = memref.alloc() : memref<2xf32>
scf.yield %7 : memref<2xf32>
%arg1 : i32,
%arg2: memref<?xf32>,
%arg3: memref<?xf32>) {
- %const0 = constant 0 : i32
+ %const0 = arith.constant 0 : i32
br ^loopHeader(%const0, %arg2 : i32, memref<?xf32>)
^loopHeader(%i : i32, %buff : memref<?xf32>):
- %lessThan = cmpi slt, %i, %arg1 : i32
+ %lessThan = arith.cmpi slt, %i, %arg1 : i32
cond_br %lessThan,
^loopBody(%i, %buff : i32, memref<?xf32>),
^exit(%buff : memref<?xf32>)
^loopBody(%val : i32, %buff2: memref<?xf32>):
- %const1 = constant 1 : i32
- %inc = addi %val, %const1 : i32
- %size = std.index_cast %inc : i32 to index
+ %const1 = arith.constant 1 : i32
+ %inc = arith.addi %val, %const1 : i32
+ %size = arith.index_cast %inc : i32 to index
%alloc1 = memref.alloc(%size) : memref<?xf32>
br ^loopHeader(%inc, %alloc1 : i32, memref<?xf32>)
%arg1 : i32,
%arg2: memref<2xf32>,
%arg3: memref<2xf32>) {
- %const0 = constant 0 : i32
+ %const0 = arith.constant 0 : i32
br ^loopBody(%const0, %arg2 : i32, memref<2xf32>)
^loopBody(%val : i32, %buff2: memref<2xf32>):
- %const1 = constant 1 : i32
- %inc = addi %val, %const1 : i32
+ %const1 = arith.constant 1 : i32
+ %inc = arith.addi %val, %const1 : i32
%alloc1 = memref.alloc() : memref<2xf32>
br ^loopHeader(%inc, %alloc1 : i32, memref<2xf32>)
^loopHeader(%i : i32, %buff : memref<2xf32>):
- %lessThan = cmpi slt, %i, %arg1 : i32
+ %lessThan = arith.cmpi slt, %i, %arg1 : i32
cond_br %lessThan,
^loopBody(%i, %buff : i32, memref<2xf32>),
^exit(%buff : memref<2xf32>)
func @nested_region_control_flow(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
func @nested_region_control_flow_div(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
func @nested_region_control_flow_div_nested(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
%3 = scf.if %0 -> (memref<?x?xf32>) {
%arg1: i1,
%arg2: index) -> memref<?x?xf32> {
%0 = scf.if %arg1 -> (memref<?x?xf32>) {
- %1 = constant 1 : i32
- %2 = addi %arg0, %1 : i32
- %3 = index_cast %2 : i32 to index
+ %1 = arith.constant 1 : i32
+ %2 = arith.addi %arg0, %1 : i32
+ %3 = arith.index_cast %2 : i32 to index
%4 = memref.alloc(%arg2, %3) : memref<?x?xf32>
scf.yield %4 : memref<?x?xf32>
} else {
- %1 = constant 2 : i32
- %2 = addi %arg0, %1 : i32
- %3 = index_cast %2 : i32 to index
+ %1 = arith.constant 2 : i32
+ %2 = arith.addi %arg0, %1 : i32
+ %3 = arith.index_cast %2 : i32 to index
%4 = memref.alloc(%arg2, %3) : memref<?x?xf32>
scf.yield %4 : memref<?x?xf32>
}
// CHECK: (%[[ARG0:.*]]: {{.*}}
// CHECK-NEXT: %{{.*}} = scf.if
-// CHECK-NEXT: %{{.*}} = constant
-// CHECK-NEXT: %{{.*}} = addi
-// CHECK-NEXT: %[[FUNC:.*]] = index_cast
+// CHECK-NEXT: %{{.*}} = arith.constant
+// CHECK-NEXT: %{{.*}} = arith.addi
+// CHECK-NEXT: %[[FUNC:.*]] = arith.index_cast
// CHECK-NEXT: alloc(%arg2, %[[FUNC]])
// CHECK-NEXT: scf.yield
// CHECK-NEXT: } else {
-// CHECK-NEXT: %{{.*}} = constant
-// CHECK-NEXT: %{{.*}} = addi
-// CHECK-NEXT: %[[FUNC:.*]] = index_cast
+// CHECK-NEXT: %{{.*}} = arith.constant
+// CHECK-NEXT: %{{.*}} = arith.addi
+// CHECK-NEXT: %[[FUNC:.*]] = arith.index_cast
// CHECK-NEXT: alloc(%arg2, %[[FUNC]])
// -----
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = memref.alloc() : memref<2xf32>
scf.yield %3 : memref<2xf32>
}
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
%4 = memref.alloc() : memref<2xf32>
scf.yield %4 : memref<2xf32>
%3 = scf.for %i3 = %lb to %ub step %step
iter_args(%iterBuf3 = %iterBuf2) -> memref<2xf32> {
%4 = memref.alloc() : memref<2xf32>
- %5 = cmpi eq, %i, %ub : index
+ %5 = arith.cmpi eq, %i, %ub : index
%6 = scf.if %5 -> (memref<2xf32>) {
%7 = memref.alloc() : memref<2xf32>
scf.yield %7 : memref<2xf32>
iter_args(%iterBuf2 = %iterBuf) -> memref<?xf32> {
%3 = scf.for %i3 = %lb to %ub step %step
iter_args(%iterBuf3 = %iterBuf2) -> memref<?xf32> {
- %5 = cmpi eq, %i, %ub : index
+ %5 = arith.cmpi eq, %i, %ub : index
%6 = scf.if %5 -> (memref<?xf32>) {
%7 = memref.alloc(%i3) : memref<?xf32>
scf.yield %7 : memref<?xf32>
func @nested_region_control_flow(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = memref.alloc() : memref<2xf32>
scf.yield %3 : memref<2xf32>
}
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
%4 = memref.alloc() : memref<2xf32>
scf.yield %4 : memref<2xf32>
%3 = scf.for %i3 = %lb to %ub step %step
iter_args(%iterBuf3 = %iterBuf2) -> memref<2xf32> {
%4 = memref.alloc() : memref<2xf32>
- %5 = cmpi eq, %i, %ub : index
+ %5 = arith.cmpi eq, %i, %ub : index
%6 = scf.if %5 -> (memref<2xf32>) {
%7 = memref.alloc() : memref<2xf32>
%8 = memref.alloc() : memref<2xf32>
%3 = scf.for %i3 = %lb to %ub step %step
iter_args(%iterBuf3 = %iterBuf2) -> memref<?xf32> {
%4 = memref.alloc(%i3) : memref<?xf32>
- %5 = cmpi eq, %i, %ub : index
+ %5 = arith.cmpi eq, %i, %ub : index
%6 = scf.if %5 -> (memref<?xf32>) {
%7 = memref.alloc(%i3) : memref<?xf32>
scf.yield %7 : memref<?xf32>
%res: memref<2xf32>) {
%0 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %1 = cmpi eq, %i, %ub : index
+ %1 = arith.cmpi eq, %i, %ub : index
%2 = scf.if %1 -> (memref<2xf32>) {
%3 = memref.alloc() : memref<2xf32>
scf.yield %3 : memref<2xf32>
%buf: memref<2xf32>,
%res: memref<2xf32>) {
%0 = memref.alloc() : memref<2xf32>
- %1 = cmpi eq, %lb, %ub : index
+ %1 = arith.cmpi eq, %lb, %ub : index
%2 = scf.if %1 -> (memref<2xf32>) {
%3 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
// CHECK-LABEL: func @mismatch_operand_types(
func @mismatch_operand_types(%arg0 : i1, %arg1 : memref<i32>, %arg2 : memref<i1>) {
- %c0_i32 = constant 0 : i32
- %true = constant true
+ %c0_i32 = arith.constant 0 : i32
+ %true = arith.constant true
br ^bb1
^bb1:
func private @print(%arg0: i32, %arg1: i32)
// CHECK-LABEL: @nomerge
func @nomerge(%arg0: i32, %i: i32) {
- %c1_i32 = constant 1 : i32
- %icmp = cmpi slt, %i, %arg0 : i32
+ %c1_i32 = arith.constant 1 : i32
+ %icmp = arith.cmpi slt, %i, %arg0 : i32
cond_br %icmp, ^bb2, ^bb3
^bb2: // pred: ^bb1
- %ip1 = addi %i, %c1_i32 : i32
+ %ip1 = arith.addi %i, %c1_i32 : i32
br ^bb4(%ip1 : i32)
^bb7: // pred: ^bb5
- %jp1 = addi %j, %c1_i32 : i32
+ %jp1 = arith.addi %j, %c1_i32 : i32
br ^bb4(%jp1 : i32)
^bb4(%j: i32): // 2 preds: ^bb2, ^bb7
- %jcmp = cmpi slt, %j, %arg0 : i32
+ %jcmp = arith.cmpi slt, %j, %arg0 : i32
// CHECK-NOT: call @print(%[[arg1:.+]], %[[arg1]])
call @print(%j, %ip1) : (i32, i32) -> ()
cond_br %jcmp, ^bb7, ^bb3
// CHECK-NEXT: return
func @f(%arg0: f32) {
- %0 = "std.addf"(%arg0, %arg0) : (f32, f32) -> f32
+ %0 = "arith.addf"(%arg0, %arg0) : (f32, f32) -> f32
return
}
func @f(%arg0: f32) {
builtin.func @g(%arg1: f32) {
- %0 = "std.addf"(%arg1, %arg1) : (f32, f32) -> f32
+ %0 = "arith.addf"(%arg1, %arg1) : (f32, f32) -> f32
return
}
return
// Test case: Don't delete pure ops that feed into returns.
// CHECK: func @f(%arg0: f32) -> f32
-// CHECK-NEXT: [[VAL0:%.+]] = addf %arg0, %arg0 : f32
+// CHECK-NEXT: [[VAL0:%.+]] = arith.addf %arg0, %arg0 : f32
// CHECK-NEXT: return [[VAL0]] : f32
func @f(%arg0: f32) -> f32 {
- %0 = "std.addf"(%arg0, %arg0) : (f32, f32) -> f32
+ %0 = "arith.addf"(%arg0, %arg0) : (f32, f32) -> f32
return %0 : f32
}
func @default_insertion_position(%cond: i1) {
// Constant should be folded into the entry block.
- // BU: constant 2
+ // BU: arith.constant 2
// BU-NEXT: scf.if
- // TD: constant 2
+ // TD: arith.constant 2
// TD-NEXT: scf.if
scf.if %cond {
- %0 = constant 1 : i32
- %2 = addi %0, %0 : i32
+ %0 = arith.constant 1 : i32
+ %2 = arith.addi %0, %0 : i32
"foo.yield"(%2) : (i32) -> ()
}
return
// TD-LABEL: func @custom_insertion_position
func @custom_insertion_position() {
// BU: test.one_region_op
- // BU-NEXT: constant 2
+ // BU-NEXT: arith.constant 2
// TD: test.one_region_op
- // TD-NEXT: constant 2
+ // TD-NEXT: arith.constant 2
"test.one_region_op"() ({
- %0 = constant 1 : i32
- %2 = addi %0, %0 : i32
+ %0 = arith.constant 1 : i32
+ %2 = arith.addi %0, %0 : i32
"foo.yield"(%2) : (i32) -> ()
}) : () -> ()
return
// CHECK-LABEL: func @test_subi_zero
func @test_subi_zero(%arg0: i32) -> i32 {
- // CHECK-NEXT: %c0_i32 = constant 0 : i32
+ // CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
// CHECK-NEXT: return %c0
- %y = subi %arg0, %arg0 : i32
+ %y = arith.subi %arg0, %arg0 : i32
return %y: i32
}
// CHECK-LABEL: func @test_subi_zero_vector
func @test_subi_zero_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
- //CHECK-NEXT: %cst = constant dense<0> : vector<4xi32>
- %y = subi %arg0, %arg0 : vector<4xi32>
+ //CHECK-NEXT: %cst = arith.constant dense<0> : vector<4xi32>
+ %y = arith.subi %arg0, %arg0 : vector<4xi32>
// CHECK-NEXT: return %cst
return %y: vector<4xi32>
}
// CHECK-LABEL: func @test_subi_zero_tensor
func @test_subi_zero_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- //CHECK-NEXT: %cst = constant dense<0> : tensor<4x5xi32>
- %y = subi %arg0, %arg0 : tensor<4x5xi32>
+ //CHECK-NEXT: %cst = arith.constant dense<0> : tensor<4x5xi32>
+ %y = arith.subi %arg0, %arg0 : tensor<4x5xi32>
// CHECK-NEXT: return %cst
return %y: tensor<4x5xi32>
}
// CHECK-LABEL: func @dim
func @dim(%arg0: tensor<8x4xf32>) -> index {
- // CHECK: %c4 = constant 4 : index
- %c1 = constant 1 : index
+ // CHECK: %c4 = arith.constant 4 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c1 : tensor<8x4xf32>
// CHECK-NEXT: return %c4
// CHECK-LABEL: func @test_commutative
func @test_commutative(%arg0: i32) -> (i32, i32) {
- // CHECK: %c42_i32 = constant 42 : i32
- %c42_i32 = constant 42 : i32
- // CHECK-NEXT: %0 = addi %arg0, %c42_i32 : i32
- %y = addi %c42_i32, %arg0 : i32
+ // CHECK: %c42_i32 = arith.constant 42 : i32
+ %c42_i32 = arith.constant 42 : i32
+ // CHECK-NEXT: %0 = arith.addi %arg0, %c42_i32 : i32
+ %y = arith.addi %c42_i32, %arg0 : i32
// This should not be swapped.
- // CHECK-NEXT: %1 = subi %c42_i32, %arg0 : i32
- %z = subi %c42_i32, %arg0 : i32
+ // CHECK-NEXT: %1 = arith.subi %c42_i32, %arg0 : i32
+ %z = arith.subi %c42_i32, %arg0 : i32
// CHECK-NEXT: return %0, %1
return %y, %z: i32, i32
// CHECK-LABEL: func @trivial_dce
func @trivial_dce(%arg0: tensor<8x4xf32>) {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %arg0, %c1 : tensor<8x4xf32>
// CHECK-NEXT: return
return
// CHECK-LABEL: func @load_dce
func @load_dce(%arg0: index) {
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloc(%c4) : memref<?xf32>
%2 = memref.load %a[%arg0] : memref<?xf32>
memref.dealloc %a: memref<?xf32>
// CHECK-LABEL: func @addi_zero
func @addi_zero(%arg0: i32) -> i32 {
// CHECK-NEXT: return %arg0
- %c0_i32 = constant 0 : i32
- %y = addi %c0_i32, %arg0 : i32
+ %c0_i32 = arith.constant 0 : i32
+ %y = arith.addi %c0_i32, %arg0 : i32
return %y: i32
}
// CHECK-LABEL: func @addi_zero_index
func @addi_zero_index(%arg0: index) -> index {
// CHECK-NEXT: return %arg0
- %c0_index = constant 0 : index
- %y = addi %c0_index, %arg0 : index
+ %c0_index = arith.constant 0 : index
+ %y = arith.addi %c0_index, %arg0 : index
return %y: index
}
// CHECK-LABEL: func @addi_zero_vector
func @addi_zero_vector(%arg0: vector<4 x i32>) -> vector<4 x i32> {
// CHECK-NEXT: return %arg0
- %c0_v4i32 = constant dense<0> : vector<4 x i32>
- %y = addi %c0_v4i32, %arg0 : vector<4 x i32>
+ %c0_v4i32 = arith.constant dense<0> : vector<4 x i32>
+ %y = arith.addi %c0_v4i32, %arg0 : vector<4 x i32>
return %y: vector<4 x i32>
}
// CHECK-LABEL: func @addi_zero_tensor
func @addi_zero_tensor(%arg0: tensor<4 x 5 x i32>) -> tensor<4 x 5 x i32> {
// CHECK-NEXT: return %arg0
- %c0_t45i32 = constant dense<0> : tensor<4 x 5 x i32>
- %y = addi %arg0, %c0_t45i32 : tensor<4 x 5 x i32>
+ %c0_t45i32 = arith.constant dense<0> : tensor<4 x 5 x i32>
+ %y = arith.addi %arg0, %c0_t45i32 : tensor<4 x 5 x i32>
return %y: tensor<4 x 5 x i32>
}
// CHECK-LABEL: func @muli_zero
func @muli_zero(%arg0: i32) -> i32 {
- // CHECK-NEXT: %c0_i32 = constant 0 : i32
- %c0_i32 = constant 0 : i32
+ // CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
- %y = muli %c0_i32, %arg0 : i32
+ %y = arith.muli %c0_i32, %arg0 : i32
// CHECK-NEXT: return %c0_i32
return %y: i32
// CHECK-LABEL: func @muli_zero_index
func @muli_zero_index(%arg0: index) -> index {
- // CHECK-NEXT: %[[CST:.*]] = constant 0 : index
- %c0_index = constant 0 : index
+ // CHECK-NEXT: %[[CST:.*]] = arith.constant 0 : index
+ %c0_index = arith.constant 0 : index
- %y = muli %c0_index, %arg0 : index
+ %y = arith.muli %c0_index, %arg0 : index
// CHECK-NEXT: return %[[CST]]
return %y: index
// CHECK-LABEL: func @muli_zero_vector
func @muli_zero_vector(%arg0: vector<4 x i32>) -> vector<4 x i32> {
- // CHECK-NEXT: %cst = constant dense<0> : vector<4xi32>
- %cst = constant dense<0> : vector<4 x i32>
+ // CHECK-NEXT: %cst = arith.constant dense<0> : vector<4xi32>
+ %cst = arith.constant dense<0> : vector<4 x i32>
- %y = muli %cst, %arg0 : vector<4 x i32>
+ %y = arith.muli %cst, %arg0 : vector<4 x i32>
// CHECK-NEXT: return %cst
return %y: vector<4 x i32>
// CHECK-LABEL: func @muli_zero_tensor
func @muli_zero_tensor(%arg0: tensor<4 x 5 x i32>) -> tensor<4 x 5 x i32> {
- // CHECK-NEXT: %cst = constant dense<0> : tensor<4x5xi32>
- %cst = constant dense<0> : tensor<4 x 5 x i32>
+ // CHECK-NEXT: %cst = arith.constant dense<0> : tensor<4x5xi32>
+ %cst = arith.constant dense<0> : tensor<4 x 5 x i32>
- %y = muli %arg0, %cst : tensor<4 x 5 x i32>
+ %y = arith.muli %arg0, %cst : tensor<4 x 5 x i32>
// CHECK-NEXT: return %cst
return %y: tensor<4 x 5 x i32>
// CHECK-LABEL: func @muli_one
func @muli_one(%arg0: i32) -> i32 {
// CHECK-NEXT: return %arg0
- %c0_i32 = constant 1 : i32
- %y = muli %c0_i32, %arg0 : i32
+ %c0_i32 = arith.constant 1 : i32
+ %y = arith.muli %c0_i32, %arg0 : i32
return %y: i32
}
// CHECK-LABEL: func @muli_one_index
func @muli_one_index(%arg0: index) -> index {
// CHECK-NEXT: return %arg0
- %c0_index = constant 1 : index
- %y = muli %c0_index, %arg0 : index
+ %c0_index = arith.constant 1 : index
+ %y = arith.muli %c0_index, %arg0 : index
return %y: index
}
// CHECK-LABEL: func @muli_one_vector
func @muli_one_vector(%arg0: vector<4 x i32>) -> vector<4 x i32> {
// CHECK-NEXT: return %arg0
- %c1_v4i32 = constant dense<1> : vector<4 x i32>
- %y = muli %c1_v4i32, %arg0 : vector<4 x i32>
+ %c1_v4i32 = arith.constant dense<1> : vector<4 x i32>
+ %y = arith.muli %c1_v4i32, %arg0 : vector<4 x i32>
return %y: vector<4 x i32>
}
// CHECK-LABEL: func @muli_one_tensor
func @muli_one_tensor(%arg0: tensor<4 x 5 x i32>) -> tensor<4 x 5 x i32> {
// CHECK-NEXT: return %arg0
- %c1_t45i32 = constant dense<1> : tensor<4 x 5 x i32>
- %y = muli %arg0, %c1_t45i32 : tensor<4 x 5 x i32>
+ %c1_t45i32 = arith.constant dense<1> : tensor<4 x 5 x i32>
+ %y = arith.muli %arg0, %c1_t45i32 : tensor<4 x 5 x i32>
return %y: tensor<4 x 5 x i32>
}
//CHECK-LABEL: func @and_self
func @and_self(%arg0: i32) -> i32 {
//CHECK-NEXT: return %arg0
- %1 = and %arg0, %arg0 : i32
+ %1 = arith.andi %arg0, %arg0 : i32
return %1 : i32
}
//CHECK-LABEL: func @and_self_vector
func @and_self_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
//CHECK-NEXT: return %arg0
- %1 = and %arg0, %arg0 : vector<4xi32>
+ %1 = arith.andi %arg0, %arg0 : vector<4xi32>
return %1 : vector<4xi32>
}
//CHECK-LABEL: func @and_self_tensor
func @and_self_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
//CHECK-NEXT: return %arg0
- %1 = and %arg0, %arg0 : tensor<4x5xi32>
+ %1 = arith.andi %arg0, %arg0 : tensor<4x5xi32>
return %1 : tensor<4x5xi32>
}
//CHECK-LABEL: func @and_zero
func @and_zero(%arg0: i32) -> i32 {
- // CHECK-NEXT: %c0_i32 = constant 0 : i32
- %c0_i32 = constant 0 : i32
+ // CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
// CHECK-NEXT: return %c0_i32
- %1 = and %arg0, %c0_i32 : i32
+ %1 = arith.andi %arg0, %c0_i32 : i32
return %1 : i32
}
//CHECK-LABEL: func @and_zero_index
func @and_zero_index(%arg0: index) -> index {
- // CHECK-NEXT: %[[CST:.*]] = constant 0 : index
- %c0_index = constant 0 : index
+ // CHECK-NEXT: %[[CST:.*]] = arith.constant 0 : index
+ %c0_index = arith.constant 0 : index
// CHECK-NEXT: return %[[CST]]
- %1 = and %arg0, %c0_index : index
+ %1 = arith.andi %arg0, %c0_index : index
return %1 : index
}
//CHECK-LABEL: func @and_zero_vector
func @and_zero_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
- // CHECK-NEXT: %cst = constant dense<0> : vector<4xi32>
- %cst = constant dense<0> : vector<4xi32>
+ // CHECK-NEXT: %cst = arith.constant dense<0> : vector<4xi32>
+ %cst = arith.constant dense<0> : vector<4xi32>
// CHECK-NEXT: return %cst
- %1 = and %arg0, %cst : vector<4xi32>
+ %1 = arith.andi %arg0, %cst : vector<4xi32>
return %1 : vector<4xi32>
}
//CHECK-LABEL: func @and_zero_tensor
func @and_zero_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- // CHECK-NEXT: %cst = constant dense<0> : tensor<4x5xi32>
- %cst = constant dense<0> : tensor<4x5xi32>
+ // CHECK-NEXT: %cst = arith.constant dense<0> : tensor<4x5xi32>
+ %cst = arith.constant dense<0> : tensor<4x5xi32>
// CHECK-NEXT: return %cst
- %1 = and %arg0, %cst : tensor<4x5xi32>
+ %1 = arith.andi %arg0, %cst : tensor<4x5xi32>
return %1 : tensor<4x5xi32>
}
//CHECK-LABEL: func @or_self
func @or_self(%arg0: i32) -> i32 {
//CHECK-NEXT: return %arg0
- %1 = or %arg0, %arg0 : i32
+ %1 = arith.ori %arg0, %arg0 : i32
return %1 : i32
}
//CHECK-LABEL: func @or_self_vector
func @or_self_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
//CHECK-NEXT: return %arg0
- %1 = or %arg0, %arg0 : vector<4xi32>
+ %1 = arith.ori %arg0, %arg0 : vector<4xi32>
return %1 : vector<4xi32>
}
//CHECK-LABEL: func @or_self_tensor
func @or_self_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
//CHECK-NEXT: return %arg0
- %1 = or %arg0, %arg0 : tensor<4x5xi32>
+ %1 = arith.ori %arg0, %arg0 : tensor<4x5xi32>
return %1 : tensor<4x5xi32>
}
//CHECK-LABEL: func @or_zero
func @or_zero(%arg0: i32) -> i32 {
- %c0_i32 = constant 0 : i32
+ %c0_i32 = arith.constant 0 : i32
// CHECK-NEXT: return %arg0
- %1 = or %arg0, %c0_i32 : i32
+ %1 = arith.ori %arg0, %c0_i32 : i32
return %1 : i32
}
//CHECK-LABEL: func @or_zero_index
func @or_zero_index(%arg0: index) -> index {
- %c0_index = constant 0 : index
+ %c0_index = arith.constant 0 : index
// CHECK-NEXT: return %arg0
- %1 = or %arg0, %c0_index : index
+ %1 = arith.ori %arg0, %c0_index : index
return %1 : index
}
//CHECK-LABEL: func @or_zero_vector
func @or_zero_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
// CHECK-NEXT: return %arg0
- %cst = constant dense<0> : vector<4xi32>
- %1 = or %arg0, %cst : vector<4xi32>
+ %cst = arith.constant dense<0> : vector<4xi32>
+ %1 = arith.ori %arg0, %cst : vector<4xi32>
return %1 : vector<4xi32>
}
//CHECK-LABEL: func @or_zero_tensor
func @or_zero_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
// CHECK-NEXT: return %arg0
- %cst = constant dense<0> : tensor<4x5xi32>
- %1 = or %arg0, %cst : tensor<4x5xi32>
+ %cst = arith.constant dense<0> : tensor<4x5xi32>
+ %1 = arith.ori %arg0, %cst : tensor<4x5xi32>
return %1 : tensor<4x5xi32>
}
// CHECK-LABEL: func @or_all_ones
func @or_all_ones(%arg0: i1, %arg1: i4) -> (i1, i4) {
- // CHECK-DAG: %c-1_i4 = constant -1 : i4
- // CHECK-DAG: %true = constant true
- %c1_i1 = constant 1 : i1
- %c15 = constant 15 : i4
+ // CHECK-DAG: %c-1_i4 = arith.constant -1 : i4
+ // CHECK-DAG: %true = arith.constant true
+ %c1_i1 = arith.constant 1 : i1
+ %c15 = arith.constant 15 : i4
// CHECK-NEXT: return %true
- %1 = or %arg0, %c1_i1 : i1
- %2 = or %arg1, %c15 : i4
+ %1 = arith.ori %arg0, %c1_i1 : i1
+ %2 = arith.ori %arg1, %c15 : i4
return %1, %2 : i1, i4
}
//CHECK-LABEL: func @xor_self
func @xor_self(%arg0: i32) -> i32 {
- //CHECK-NEXT: %c0_i32 = constant 0
- %1 = xor %arg0, %arg0 : i32
+ //CHECK-NEXT: %c0_i32 = arith.constant 0
+ %1 = arith.xori %arg0, %arg0 : i32
//CHECK-NEXT: return %c0_i32
return %1 : i32
}
//CHECK-LABEL: func @xor_self_vector
func @xor_self_vector(%arg0: vector<4xi32>) -> vector<4xi32> {
- //CHECK-NEXT: %cst = constant dense<0> : vector<4xi32>
- %1 = xor %arg0, %arg0 : vector<4xi32>
+ //CHECK-NEXT: %cst = arith.constant dense<0> : vector<4xi32>
+ %1 = arith.xori %arg0, %arg0 : vector<4xi32>
//CHECK-NEXT: return %cst
return %1 : vector<4xi32>
}
//CHECK-LABEL: func @xor_self_tensor
func @xor_self_tensor(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- //CHECK-NEXT: %cst = constant dense<0> : tensor<4x5xi32>
- %1 = xor %arg0, %arg0 : tensor<4x5xi32>
+ //CHECK-NEXT: %cst = arith.constant dense<0> : tensor<4x5xi32>
+ %1 = arith.xori %arg0, %arg0 : tensor<4x5xi32>
//CHECK-NEXT: return %cst
return %1 : tensor<4x5xi32>
}
// CHECK-LABEL: func @memref_cast_folding
func @memref_cast_folding(%arg0: memref<4 x f32>, %arg1: f32) -> (f32, f32) {
%0 = memref.cast %arg0 : memref<4xf32> to memref<?xf32>
- // CHECK-NEXT: %c0 = constant 0 : index
- %c0 = constant 0 : index
+ // CHECK-NEXT: %c0 = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
%dim = memref.dim %0, %c0 : memref<? x f32>
// CHECK-NEXT: affine.load %arg0[3]
// CHECK-LABEL: func @dead_alloc_fold
func @dead_alloc_fold() {
// CHECK-NEXT: return
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloc(%c4) : memref<?xf32>
return
}
// CHECK-LABEL: func @write_only_alloc_fold
func @write_only_alloc_fold(%v: f32) {
// CHECK-NEXT: return
- %c0 = constant 0 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloc(%c4) : memref<?xf32>
memref.store %v, %a[%c0] : memref<?xf32>
memref.dealloc %a: memref<?xf32>
// CHECK-LABEL: func @write_only_alloca_fold
func @write_only_alloca_fold(%v: f32) {
// CHECK-NEXT: return
- %c0 = constant 0 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
%a = memref.alloca(%c4) : memref<?xf32>
memref.store %v, %a[%c0] : memref<?xf32>
return
// CHECK-LABEL: func @dyn_shape_fold(%arg0: index, %arg1: index)
func @dyn_shape_fold(%L : index, %M : index) -> (memref<4 x ? x 8 x ? x ? x f32>, memref<? x ? x i32>, memref<? x ? x f32>, memref<4 x ? x 8 x ? x ? x f32>) {
- // CHECK: %c0 = constant 0 : index
- %zero = constant 0 : index
+ // CHECK: %c0 = arith.constant 0 : index
+ %zero = arith.constant 0 : index
// The constants below disappear after they propagate into shapes.
- %nine = constant 9 : index
- %N = constant 1024 : index
- %K = constant 512 : index
+ %nine = arith.constant 9 : index
+ %N = arith.constant 1024 : index
+ %K = arith.constant 512 : index
// CHECK: memref.alloc(%arg0) : memref<?x1024xf32>
%a = memref.alloc(%L, %N) : memref<? x ? x f32>
// CHECK-SAME: [[M:arg[0-9]+]]: index
// CHECK-SAME: [[N:arg[0-9]+]]: index
// CHECK-SAME: [[K:arg[0-9]+]]: index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.alloc(%arg0, %arg1) : memref<?x?xf32>
%1 = memref.alloc(%arg1, %arg2) : memref<?x8x?xf32>
%2 = memref.dim %1, %c2 : memref<?x8x?xf32>
// CHECK-LABEL: func @merge_constants
func @merge_constants() -> (index, index) {
- // CHECK-NEXT: %c42 = constant 42 : index
- %0 = constant 42 : index
- %1 = constant 42 : index
+ // CHECK-NEXT: %c42 = arith.constant 42 : index
+ %0 = arith.constant 42 : index
+ %1 = arith.constant 42 : index
// CHECK-NEXT: return %c42, %c42
return %0, %1: index, index
}
// CHECK-LABEL: func @hoist_constant
func @hoist_constant(%arg0: memref<8xi32>) {
- // CHECK-NEXT: %c42_i32 = constant 42 : i32
+ // CHECK-NEXT: %c42_i32 = arith.constant 42 : i32
// CHECK-NEXT: affine.for %arg1 = 0 to 8 {
affine.for %arg1 = 0 to 8 {
// CHECK-NEXT: memref.store %c42_i32, %arg0[%arg1]
- %c42_i32 = constant 42 : i32
+ %c42_i32 = arith.constant 42 : i32
memref.store %c42_i32, %arg0[%arg1] : memref<8xi32>
}
return
// CHECK-LABEL: func @const_fold_propagate
func @const_fold_propagate() -> memref<?x?xf32> {
- %VT_i = constant 512 : index
+ %VT_i = arith.constant 512 : index
%VT_i_s = affine.apply affine_map<(d0) -> (d0 floordiv 8)> (%VT_i)
%VT_k_l = affine.apply affine_map<(d0) -> (d0 floordiv 16)> (%VT_i)
//
// CHECK-LABEL: @lowered_affine_mod
func @lowered_affine_mod() -> (index, index) {
-// CHECK-DAG: {{.*}} = constant 1 : index
-// CHECK-DAG: {{.*}} = constant 41 : index
- %c-43 = constant -43 : index
- %c42 = constant 42 : index
- %0 = remi_signed %c-43, %c42 : index
- %c0 = constant 0 : index
- %1 = cmpi slt, %0, %c0 : index
- %2 = addi %0, %c42 : index
+// CHECK-DAG: {{.*}} = arith.constant 1 : index
+// CHECK-DAG: {{.*}} = arith.constant 41 : index
+ %c-43 = arith.constant -43 : index
+ %c42 = arith.constant 42 : index
+ %0 = arith.remsi %c-43, %c42 : index
+ %c0 = arith.constant 0 : index
+ %1 = arith.cmpi slt, %0, %c0 : index
+ %2 = arith.addi %0, %c42 : index
%3 = select %1, %2, %0 : index
- %c43 = constant 43 : index
- %c42_0 = constant 42 : index
- %4 = remi_signed %c43, %c42_0 : index
- %c0_1 = constant 0 : index
- %5 = cmpi slt, %4, %c0_1 : index
- %6 = addi %4, %c42_0 : index
+ %c43 = arith.constant 43 : index
+ %c42_0 = arith.constant 42 : index
+ %4 = arith.remsi %c43, %c42_0 : index
+ %c0_1 = arith.constant 0 : index
+ %5 = arith.cmpi slt, %4, %c0_1 : index
+ %6 = arith.addi %4, %c42_0 : index
%7 = select %5, %6, %4 : index
return %3, %7 : index, index
}
//
// CHECK-LABEL: func @lowered_affine_floordiv
func @lowered_affine_floordiv() -> (index, index) {
-// CHECK-DAG: %c1 = constant 1 : index
-// CHECK-DAG: %c-2 = constant -2 : index
- %c-43 = constant -43 : index
- %c42 = constant 42 : index
- %c0 = constant 0 : index
- %c-1 = constant -1 : index
- %0 = cmpi slt, %c-43, %c0 : index
- %1 = subi %c-1, %c-43 : index
+// CHECK-DAG: %c1 = arith.constant 1 : index
+// CHECK-DAG: %c-2 = arith.constant -2 : index
+ %c-43 = arith.constant -43 : index
+ %c42 = arith.constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c-1 = arith.constant -1 : index
+ %0 = arith.cmpi slt, %c-43, %c0 : index
+ %1 = arith.subi %c-1, %c-43 : index
%2 = select %0, %1, %c-43 : index
- %3 = divi_signed %2, %c42 : index
- %4 = subi %c-1, %3 : index
+ %3 = arith.divsi %2, %c42 : index
+ %4 = arith.subi %c-1, %3 : index
%5 = select %0, %4, %3 : index
- %c43 = constant 43 : index
- %c42_0 = constant 42 : index
- %c0_1 = constant 0 : index
- %c-1_2 = constant -1 : index
- %6 = cmpi slt, %c43, %c0_1 : index
- %7 = subi %c-1_2, %c43 : index
+ %c43 = arith.constant 43 : index
+ %c42_0 = arith.constant 42 : index
+ %c0_1 = arith.constant 0 : index
+ %c-1_2 = arith.constant -1 : index
+ %6 = arith.cmpi slt, %c43, %c0_1 : index
+ %7 = arith.subi %c-1_2, %c43 : index
%8 = select %6, %7, %c43 : index
- %9 = divi_signed %8, %c42_0 : index
- %10 = subi %c-1_2, %9 : index
+ %9 = arith.divsi %8, %c42_0 : index
+ %10 = arith.subi %c-1_2, %9 : index
%11 = select %6, %10, %9 : index
return %5, %11 : index, index
}
//
// CHECK-LABEL: func @lowered_affine_ceildiv
func @lowered_affine_ceildiv() -> (index, index) {
-// CHECK-DAG: %c-1 = constant -1 : index
- %c-43 = constant -43 : index
- %c42 = constant 42 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %0 = cmpi sle, %c-43, %c0 : index
- %1 = subi %c0, %c-43 : index
- %2 = subi %c-43, %c1 : index
+// CHECK-DAG: %c-1 = arith.constant -1 : index
+ %c-43 = arith.constant -43 : index
+ %c42 = arith.constant 42 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %0 = arith.cmpi sle, %c-43, %c0 : index
+ %1 = arith.subi %c0, %c-43 : index
+ %2 = arith.subi %c-43, %c1 : index
%3 = select %0, %1, %2 : index
- %4 = divi_signed %3, %c42 : index
- %5 = subi %c0, %4 : index
- %6 = addi %4, %c1 : index
+ %4 = arith.divsi %3, %c42 : index
+ %5 = arith.subi %c0, %4 : index
+ %6 = arith.addi %4, %c1 : index
%7 = select %0, %5, %6 : index
-// CHECK-DAG: %c2 = constant 2 : index
- %c43 = constant 43 : index
- %c42_0 = constant 42 : index
- %c0_1 = constant 0 : index
- %c1_2 = constant 1 : index
- %8 = cmpi sle, %c43, %c0_1 : index
- %9 = subi %c0_1, %c43 : index
- %10 = subi %c43, %c1_2 : index
+// CHECK-DAG: %c2 = arith.constant 2 : index
+ %c43 = arith.constant 43 : index
+ %c42_0 = arith.constant 42 : index
+ %c0_1 = arith.constant 0 : index
+ %c1_2 = arith.constant 1 : index
+ %8 = arith.cmpi sle, %c43, %c0_1 : index
+ %9 = arith.subi %c0_1, %c43 : index
+ %10 = arith.subi %c43, %c1_2 : index
%11 = select %8, %9, %10 : index
- %12 = divi_signed %11, %c42_0 : index
- %13 = subi %c0_1, %12 : index
- %14 = addi %12, %c1_2 : index
+ %12 = arith.divsi %11, %c42_0 : index
+ %13 = arith.subi %c0_1, %12 : index
+ %14 = arith.addi %12, %c1_2 : index
%15 = select %8, %13, %14 : index
// CHECK-NEXT: return %c-1, %c2
// CHECK-LABEL: func @view
func @view(%arg0 : index) -> (f32, f32, f32, f32) {
- // CHECK: %[[C15:.*]] = constant 15 : index
+ // CHECK: %[[C15:.*]] = arith.constant 15 : index
// CHECK: %[[ALLOC_MEM:.*]] = memref.alloc() : memref<2048xi8>
%0 = memref.alloc() : memref<2048xi8>
- %c0 = constant 0 : index
- %c7 = constant 7 : index
- %c11 = constant 11 : index
- %c15 = constant 15 : index
+ %c0 = arith.constant 0 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
+ %c15 = arith.constant 15 : index
// Test: fold constant sizes.
// CHECK: memref.view %[[ALLOC_MEM]][%[[C15]]][] : memref<2048xi8> to memref<7x11xf32>
// CHECK-SAME: %[[ARG0:.*]]: index, %[[ARG1:.*]]: index
func @subview(%arg0 : index, %arg1 : index) -> (index, index) {
// Folded but reappears after subview folding into dim.
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C7:.*]] = constant 7 : index
- // CHECK-DAG: %[[C11:.*]] = constant 11 : index
- %c0 = constant 0 : index
- // CHECK-NOT: constant 1 : index
- %c1 = constant 1 : index
- // CHECK-NOT: constant 2 : index
- %c2 = constant 2 : index
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C7:.*]] = arith.constant 7 : index
+ // CHECK-DAG: %[[C11:.*]] = arith.constant 11 : index
+ %c0 = arith.constant 0 : index
+ // CHECK-NOT: arith.constant 1 : index
+ %c1 = arith.constant 1 : index
+ // CHECK-NOT: arith.constant 2 : index
+ %c2 = arith.constant 2 : index
// Folded but reappears after subview folding into dim.
- %c7 = constant 7 : index
- %c11 = constant 11 : index
- // CHECK-NOT: constant 15 : index
- %c15 = constant 15 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
+ // CHECK-NOT: arith.constant 15 : index
+ %c15 = arith.constant 15 : index
// CHECK: %[[ALLOC0:.*]] = memref.alloc()
%0 = memref.alloc() : memref<8x16x4xf32, offset : 0, strides : [64, 4, 1]>
// CHECK: %[[ALLOC3:.*]] = memref.alloc() : memref<12x4xf32>
%18 = memref.alloc() : memref<12x4xf32>
- %c4 = constant 4 : index
+ %c4 = arith.constant 4 : index
// TEST: subview strides are maintained when sizes are folded
// CHECK: memref.subview %[[ALLOC3]][%arg1, %arg1] [2, 4] [1, 1] :
// CHECK-LABEL: func @index_cast
// CHECK-SAME: %[[ARG_0:arg[0-9]+]]: i16
func @index_cast(%arg0: i16) -> (i16) {
- %11 = index_cast %arg0 : i16 to index
- %12 = index_cast %11 : index to i16
+ %11 = arith.index_cast %arg0 : i16 to index
+ %12 = arith.index_cast %11 : index to i16
// CHECK: return %[[ARG_0]] : i16
return %12 : i16
}
// CHECK-LABEL: func @index_cast_fold
func @index_cast_fold() -> (i16, index) {
- %c4 = constant 4 : index
- %1 = index_cast %c4 : index to i16
- %c4_i16 = constant 4 : i16
- %2 = index_cast %c4_i16 : i16 to index
- // CHECK-DAG: %[[C4:.*]] = constant 4 : index
- // CHECK-DAG: %[[C4_I16:.*]] = constant 4 : i16
+ %c4 = arith.constant 4 : index
+ %1 = arith.index_cast %c4 : index to i16
+ %c4_i16 = arith.constant 4 : i16
+ %2 = arith.index_cast %c4_i16 : i16 to index
+ // CHECK-DAG: %[[C4:.*]] = arith.constant 4 : index
+ // CHECK-DAG: %[[C4_I16:.*]] = arith.constant 4 : i16
// CHECK: return %[[C4_I16]], %[[C4]] : i16, index
return %1, %2 : i16, index
}
// CHECK-LABEL: func @divi_signed_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
func @divi_signed_by_one(%arg0: i32) -> (i32) {
- %c1 = constant 1 : i32
- %res = divi_signed %arg0, %c1 : i32
+ %c1 = arith.constant 1 : i32
+ %res = arith.divsi %arg0, %c1 : i32
// CHECK: return %[[ARG]]
return %res : i32
}
// CHECK-LABEL: func @divi_unsigned_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
func @divi_unsigned_by_one(%arg0: i32) -> (i32) {
- %c1 = constant 1 : i32
- %res = divi_unsigned %arg0, %c1 : i32
+ %c1 = arith.constant 1 : i32
+ %res = arith.divui %arg0, %c1 : i32
// CHECK: return %[[ARG]]
return %res : i32
}
// CHECK-LABEL: func @tensor_divi_signed_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
func @tensor_divi_signed_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- %c1 = constant dense<1> : tensor<4x5xi32>
- %res = divi_signed %arg0, %c1 : tensor<4x5xi32>
+ %c1 = arith.constant dense<1> : tensor<4x5xi32>
+ %res = arith.divsi %arg0, %c1 : tensor<4x5xi32>
// CHECK: return %[[ARG]]
return %res : tensor<4x5xi32>
}
// CHECK-LABEL: func @tensor_divi_unsigned_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
func @tensor_divi_unsigned_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- %c1 = constant dense<1> : tensor<4x5xi32>
- %res = divi_unsigned %arg0, %c1 : tensor<4x5xi32>
+ %c1 = arith.constant dense<1> : tensor<4x5xi32>
+ %res = arith.divui %arg0, %c1 : tensor<4x5xi32>
// CHECK: return %[[ARG]]
return %res : tensor<4x5xi32>
}
// -----
-// CHECK-LABEL: func @floordivi_signed_by_one
+// CHECK-LABEL: func @arith.floordivsi_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
-func @floordivi_signed_by_one(%arg0: i32) -> (i32) {
- %c1 = constant 1 : i32
- %res = floordivi_signed %arg0, %c1 : i32
+func @arith.floordivsi_by_one(%arg0: i32) -> (i32) {
+ %c1 = arith.constant 1 : i32
+ %res = arith.floordivsi %arg0, %c1 : i32
// CHECK: return %[[ARG]]
return %res : i32
}
-// CHECK-LABEL: func @tensor_floordivi_signed_by_one
+// CHECK-LABEL: func @tensor_arith.floordivsi_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
-func @tensor_floordivi_signed_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- %c1 = constant dense<1> : tensor<4x5xi32>
- %res = floordivi_signed %arg0, %c1 : tensor<4x5xi32>
+func @tensor_arith.floordivsi_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
+ %c1 = arith.constant dense<1> : tensor<4x5xi32>
+ %res = arith.floordivsi %arg0, %c1 : tensor<4x5xi32>
// CHECK: return %[[ARG]]
return %res : tensor<4x5xi32>
}
// -----
-// CHECK-LABEL: func @ceildivi_signed_by_one
+// CHECK-LABEL: func @arith.ceildivsi_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
-func @ceildivi_signed_by_one(%arg0: i32) -> (i32) {
- %c1 = constant 1 : i32
- %res = ceildivi_signed %arg0, %c1 : i32
+func @arith.ceildivsi_by_one(%arg0: i32) -> (i32) {
+ %c1 = arith.constant 1 : i32
+ %res = arith.ceildivsi %arg0, %c1 : i32
// CHECK: return %[[ARG]]
return %res : i32
}
-// CHECK-LABEL: func @tensor_ceildivi_signed_by_one
+// CHECK-LABEL: func @tensor_arith.ceildivsi_by_one
// CHECK-SAME: %[[ARG:[a-zA-Z0-9]+]]
-func @tensor_ceildivi_signed_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
- %c1 = constant dense<1> : tensor<4x5xi32>
- %res = ceildivi_signed %arg0, %c1 : tensor<4x5xi32>
+func @tensor_arith.ceildivsi_by_one(%arg0: tensor<4x5xi32>) -> tensor<4x5xi32> {
+ %c1 = arith.constant dense<1> : tensor<4x5xi32>
+ %res = arith.ceildivsi %arg0, %c1 : tensor<4x5xi32>
// CHECK: return %[[ARG]]
return %res : tensor<4x5xi32>
}
func @slice(%t: tensor<8x16x4xf32>, %arg0 : index, %arg1 : index)
-> tensor<?x?x?xf32>
{
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c7 = constant 7 : index
- %c11 = constant 11 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c7 = arith.constant 7 : index
+ %c11 = arith.constant 11 : index
// CHECK: tensor.extract_slice %{{.*}}[0, 0, 0] [7, 11, 2] [1, 1, 1] :
// CHECK-SAME: tensor<8x16x4xf32> to tensor<7x11x2xf32>
// CHECK-SAME: (%[[ARG0:[0-9a-z]*]]: i1)
func @fold_trunci(%arg0: i1) -> i1 attributes {} {
// CHECK-NEXT: return %[[ARG0]] : i1
- %0 = zexti %arg0 : i1 to i8
- %1 = trunci %0 : i8 to i1
+ %0 = arith.extui %arg0 : i1 to i8
+ %1 = arith.trunci %0 : i8 to i1
return %1 : i1
}
// CHECK-SAME: (%[[ARG0:[0-9a-z]*]]: vector<4xi1>)
func @fold_trunci_vector(%arg0: vector<4xi1>) -> vector<4xi1> attributes {} {
// CHECK-NEXT: return %[[ARG0]] : vector<4xi1>
- %0 = zexti %arg0 : vector<4xi1> to vector<4xi8>
- %1 = trunci %0 : vector<4xi8> to vector<4xi1>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi8>
+ %1 = arith.trunci %0 : vector<4xi8> to vector<4xi1>
return %1 : vector<4xi1>
}
// -----
// TODO Canonicalize this into:
-// zexti %arg0 : i1 to i2
+// arith.extui %arg0 : i1 to i2
// CHECK-LABEL: func @do_not_fold_trunci
// CHECK-SAME: (%[[ARG0:[0-9a-z]*]]: i1)
func @do_not_fold_trunci(%arg0: i1) -> i2 attributes {} {
- // CHECK-NEXT: zexti %[[ARG0]] : i1 to i8
- // CHECK-NEXT: %[[RES:[0-9a-z]*]] = trunci %{{.*}} : i8 to i2
+ // CHECK-NEXT: arith.extui %[[ARG0]] : i1 to i8
+ // CHECK-NEXT: %[[RES:[0-9a-z]*]] = arith.trunci %{{.*}} : i8 to i2
// CHECK-NEXT: return %[[RES]] : i2
- %0 = zexti %arg0 : i1 to i8
- %1 = trunci %0 : i8 to i2
+ %0 = arith.extui %arg0 : i1 to i8
+ %1 = arith.trunci %0 : i8 to i2
return %1 : i2
}
// CHECK-LABEL: func @do_not_fold_trunci_vector
// CHECK-SAME: (%[[ARG0:[0-9a-z]*]]: vector<4xi1>)
func @do_not_fold_trunci_vector(%arg0: vector<4xi1>) -> vector<4xi2> attributes {} {
- // CHECK-NEXT: zexti %[[ARG0]] : vector<4xi1> to vector<4xi8>
- // CHECK-NEXT: %[[RES:[0-9a-z]*]] = trunci %{{.*}} : vector<4xi8> to vector<4xi2>
+ // CHECK-NEXT: arith.extui %[[ARG0]] : vector<4xi1> to vector<4xi8>
+ // CHECK-NEXT: %[[RES:[0-9a-z]*]] = arith.trunci %{{.*}} : vector<4xi8> to vector<4xi2>
// CHECK-NEXT: return %[[RES]] : vector<4xi2>
- %0 = zexti %arg0 : vector<4xi1> to vector<4xi8>
- %1 = trunci %0 : vector<4xi8> to vector<4xi2>
+ %0 = arith.extui %arg0 : vector<4xi1> to vector<4xi8>
+ %1 = arith.trunci %0 : vector<4xi8> to vector<4xi2>
return %1 : vector<4xi2>
}
// CHECK-SAME: (%[[ARG0:[0-9a-z]*]]: i1)
func @fold_trunci_sexti(%arg0: i1) -> i1 attributes {} {
// CHECK-NEXT: return %[[ARG0]] : i1
- %0 = sexti %arg0 : i1 to i8
- %1 = trunci %0 : i8 to i1
+ %0 = arith.extsi %arg0 : i1 to i8
+ %1 = arith.trunci %0 : i8 to i1
return %1 : i1
}
memref.dealloc %0 : memref<2xf32>
%1 = memref.clone %arg3 : memref<2xf32> to memref<2xf32>
%2 = scf.for %arg5 = %arg0 to %arg1 step %arg2 iter_args(%arg6 = %1) -> (memref<2xf32>) {
- %3 = cmpi eq, %arg5, %arg1 : index
+ %3 = arith.cmpi eq, %arg5, %arg1 : index
memref.dealloc %arg6 : memref<2xf32>
%4 = memref.alloc() : memref<2xf32>
%5 = memref.clone %4 : memref<2xf32> to memref<2xf32>
// CHECK-LABEL: func @clone_nested_region
func @clone_nested_region(%arg0: index, %arg1: index, %arg2: index) -> memref<?x?xf32> {
- %cmp = cmpi eq, %arg0, %arg1 : index
- %0 = cmpi eq, %arg0, %arg1 : index
+ %cmp = arith.cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
%3 = scf.if %cmp -> (memref<?x?xf32>) {
#map = affine_map<(d0, d1)[s0] -> (d0 * 1024 + s0 + d1)>
func @main(%input: memref<4x1024xf32>) -> memref<1x128xf32, #map> {
- // CHECK: [[CST_3:%.*]] = constant 3 : index
- %cst_1 = constant 1 : index
- %cst_2 = constant 2 : index
+ // CHECK: [[CST_3:%.*]] = arith.constant 3 : index
+ %cst_1 = arith.constant 1 : index
+ %cst_2 = arith.constant 2 : index
// CHECK: subview %arg0{{\[}}[[CST_3]], 384] [1, 128] [1, 1]
// CHECK-SAME: memref<4x1024xf32> to memref<1x128xf32, [[MAP]]>
%0 = memref.subview %input[%cst_2, 256] [2, 256] [1, 1] : memref<4x1024xf32> to memref<2x256xf32, #map>
#map = affine_map<(d0, d1)[s0] -> (d0 * 1024 + s0 + d1)>
func @main(%input: memref<4x1024xf32>) -> memref<1x128xf32, #map> {
- // CHECK: [[CST_3:%.*]] = constant 3 : index
- %cst_2 = constant 2 : index
- // CHECK: [[CST_384:%.*]] = constant 384 : index
- %cst_128 = constant 128 : index
+ // CHECK: [[CST_3:%.*]] = arith.constant 3 : index
+ %cst_2 = arith.constant 2 : index
+ // CHECK: [[CST_384:%.*]] = arith.constant 384 : index
+ %cst_128 = arith.constant 128 : index
// CHECK: subview %arg0{{\[}}[[CST_3]], [[CST_384]]] [1, 128] [1, 1]
// CHECK-SAME: memref<4x1024xf32> to memref<1x128xf32, [[MAP]]>
%0 = memref.subview %input[%cst_2, 256] [2, 256] [1, 1] : memref<4x1024xf32> to memref<2x256xf32, #map>
// CHECK-LABEL: @affine_for
// CHECK-SAME: [[ARG:%[a-zA-Z0-9]+]]
func @affine_for(%p : memref<f32>) {
- // CHECK: [[C:%.+]] = constant 6.{{0*}}e+00 : f32
+ // CHECK: [[C:%.+]] = arith.constant 6.{{0*}}e+00 : f32
affine.for %arg1 = 0 to 128 {
affine.for %arg2 = 0 to 8 { // CHECK: affine.for %{{.*}} = 0 to 8 {
- %0 = constant 4.5 : f32
- %1 = constant 1.5 : f32
+ %0 = arith.constant 4.5 : f32
+ %1 = arith.constant 1.5 : f32
- %2 = addf %0, %1 : f32
+ %2 = arith.addf %0, %1 : f32
// CHECK-NEXT: memref.store [[C]], [[ARG]][]
memref.store %2, %p[] : memref<f32>
// CHECK-LABEL: func @simple_addf
func @simple_addf() -> f32 {
- %0 = constant 4.5 : f32
- %1 = constant 1.5 : f32
+ %0 = arith.constant 4.5 : f32
+ %1 = arith.constant 1.5 : f32
- // CHECK-NEXT: [[C:%.+]] = constant 6.{{0*}}e+00 : f32
- %2 = addf %0, %1 : f32
+ // CHECK-NEXT: [[C:%.+]] = arith.constant 6.{{0*}}e+00 : f32
+ %2 = arith.addf %0, %1 : f32
// CHECK-NEXT: return [[C]]
return %2 : f32
// CHECK-LABEL: func @addf_splat_tensor
func @addf_splat_tensor() -> tensor<4xf32> {
- %0 = constant dense<4.5> : tensor<4xf32>
- %1 = constant dense<1.5> : tensor<4xf32>
+ %0 = arith.constant dense<4.5> : tensor<4xf32>
+ %1 = arith.constant dense<1.5> : tensor<4xf32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<6.{{0*}}e+00> : tensor<4xf32>
- %2 = addf %0, %1 : tensor<4xf32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<6.{{0*}}e+00> : tensor<4xf32>
+ %2 = arith.addf %0, %1 : tensor<4xf32>
// CHECK-NEXT: return [[C]]
return %2 : tensor<4xf32>
// CHECK-LABEL: func @addf_dense_tensor
func @addf_dense_tensor() -> tensor<4xf32> {
- %0 = constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
- %1 = constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
+ %0 = arith.constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
+ %1 = arith.constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<[3.{{0*}}e+00, 5.{{0*}}e+00, 7.{{0*}}e+00, 9.{{0*}}e+00]> : tensor<4xf32>
- %2 = addf %0, %1 : tensor<4xf32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<[3.{{0*}}e+00, 5.{{0*}}e+00, 7.{{0*}}e+00, 9.{{0*}}e+00]> : tensor<4xf32>
+ %2 = arith.addf %0, %1 : tensor<4xf32>
// CHECK-NEXT: return [[C]]
return %2 : tensor<4xf32>
// CHECK-LABEL: func @addf_dense_and_splat_tensors
func @addf_dense_and_splat_tensors() -> tensor<4xf32> {
- %0 = constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
- %1 = constant dense<1.5> : tensor<4xf32>
+ %0 = arith.constant dense<[1.5, 2.5, 3.5, 4.5]> : tensor<4xf32>
+ %1 = arith.constant dense<1.5> : tensor<4xf32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<[3.{{0*}}e+00, 4.{{0*}}e+00, 5.{{0*}}e+00, 6.{{0*}}e+00]> : tensor<4xf32>
- %2 = addf %0, %1 : tensor<4xf32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<[3.{{0*}}e+00, 4.{{0*}}e+00, 5.{{0*}}e+00, 6.{{0*}}e+00]> : tensor<4xf32>
+ %2 = arith.addf %0, %1 : tensor<4xf32>
// CHECK-NEXT: return [[C]]
return %2 : tensor<4xf32>
// CHECK-LABEL: func @simple_addi
func @simple_addi() -> i32 {
- %0 = constant 1 : i32
- %1 = constant 5 : i32
+ %0 = arith.constant 1 : i32
+ %1 = arith.constant 5 : i32
- // CHECK-NEXT: [[C:%.+]] = constant 6 : i32
- %2 = addi %0, %1 : i32
+ // CHECK-NEXT: [[C:%.+]] = arith.constant 6 : i32
+ %2 = arith.addi %0, %1 : i32
// CHECK-NEXT: return [[C]]
return %2 : i32
// CHECK-SAME: [[ARG0:%[a-zA-Z0-9]+]]: i1
// CHECK-SAME: [[ARG1:%[a-zA-Z0-9]+]]: i32)
func @simple_and(%arg0 : i1, %arg1 : i32) -> (i1, i32) {
- %c1 = constant 1 : i1
- %cAllOnes_32 = constant 4294967295 : i32
+ %c1 = arith.constant 1 : i1
+ %cAllOnes_32 = arith.constant 4294967295 : i32
- // CHECK: [[C31:%.*]] = constant 31 : i32
- %c31 = constant 31 : i32
- %1 = and %arg0, %c1 : i1
- %2 = and %arg1, %cAllOnes_32 : i32
+ // CHECK: [[C31:%.*]] = arith.constant 31 : i32
+ %c31 = arith.constant 31 : i32
+ %1 = arith.andi %arg0, %c1 : i1
+ %2 = arith.andi %arg1, %cAllOnes_32 : i32
- // CHECK: [[VAL:%.*]] = and [[ARG1]], [[C31]]
- %3 = and %2, %c31 : i32
+ // CHECK: [[VAL:%.*]] = arith.andi [[ARG1]], [[C31]]
+ %3 = arith.andi %2, %c31 : i32
// CHECK: return [[ARG0]], [[VAL]]
return %1, %3 : i1, i32
// CHECK-LABEL: func @and_index
// CHECK-SAME: [[ARG:%[a-zA-Z0-9]+]]
func @and_index(%arg0 : index) -> (index) {
- // CHECK: [[C31:%.*]] = constant 31 : index
- %c31 = constant 31 : index
- %c_AllOnes = constant -1 : index
- %1 = and %arg0, %c31 : index
+ // CHECK: [[C31:%.*]] = arith.constant 31 : index
+ %c31 = arith.constant 31 : index
+ %c_AllOnes = arith.constant -1 : index
+ %1 = arith.andi %arg0, %c31 : index
- // CHECK: and [[ARG]], [[C31]]
- %2 = and %1, %c_AllOnes : index
+ // CHECK: arith.andi [[ARG]], [[C31]]
+ %2 = arith.andi %1, %c_AllOnes : index
return %2 : index
}
// CHECK: func @tensor_and
// CHECK-SAME: [[ARG0:%[a-zA-Z0-9]+]]: tensor<2xi32>
func @tensor_and(%arg0 : tensor<2xi32>) -> tensor<2xi32> {
- %cAllOnes_32 = constant dense<4294967295> : tensor<2xi32>
+ %cAllOnes_32 = arith.constant dense<4294967295> : tensor<2xi32>
- // CHECK: [[C31:%.*]] = constant dense<31> : tensor<2xi32>
- %c31 = constant dense<31> : tensor<2xi32>
+ // CHECK: [[C31:%.*]] = arith.constant dense<31> : tensor<2xi32>
+ %c31 = arith.constant dense<31> : tensor<2xi32>
- // CHECK: [[CMIXED:%.*]] = constant dense<[31, -1]> : tensor<2xi32>
- %c_mixed = constant dense<[31, 4294967295]> : tensor<2xi32>
+ // CHECK: [[CMIXED:%.*]] = arith.constant dense<[31, -1]> : tensor<2xi32>
+ %c_mixed = arith.constant dense<[31, 4294967295]> : tensor<2xi32>
- %0 = and %arg0, %cAllOnes_32 : tensor<2xi32>
+ %0 = arith.andi %arg0, %cAllOnes_32 : tensor<2xi32>
- // CHECK: [[T1:%.*]] = and [[ARG0]], [[C31]]
- %1 = and %0, %c31 : tensor<2xi32>
+ // CHECK: [[T1:%.*]] = arith.andi [[ARG0]], [[C31]]
+ %1 = arith.andi %0, %c31 : tensor<2xi32>
- // CHECK: [[T2:%.*]] = and [[T1]], [[CMIXED]]
- %2 = and %1, %c_mixed : tensor<2xi32>
+ // CHECK: [[T2:%.*]] = arith.andi [[T1]], [[CMIXED]]
+ %2 = arith.andi %1, %c_mixed : tensor<2xi32>
// CHECK: return [[T2]]
return %2 : tensor<2xi32>
// CHECK: func @vector_and
// CHECK-SAME: [[ARG0:%[a-zA-Z0-9]+]]: vector<2xi32>
func @vector_and(%arg0 : vector<2xi32>) -> vector<2xi32> {
- %cAllOnes_32 = constant dense<4294967295> : vector<2xi32>
+ %cAllOnes_32 = arith.constant dense<4294967295> : vector<2xi32>
- // CHECK: [[C31:%.*]] = constant dense<31> : vector<2xi32>
- %c31 = constant dense<31> : vector<2xi32>
+ // CHECK: [[C31:%.*]] = arith.constant dense<31> : vector<2xi32>
+ %c31 = arith.constant dense<31> : vector<2xi32>
- // CHECK: [[CMIXED:%.*]] = constant dense<[31, -1]> : vector<2xi32>
- %c_mixed = constant dense<[31, 4294967295]> : vector<2xi32>
+ // CHECK: [[CMIXED:%.*]] = arith.constant dense<[31, -1]> : vector<2xi32>
+ %c_mixed = arith.constant dense<[31, 4294967295]> : vector<2xi32>
- %0 = and %arg0, %cAllOnes_32 : vector<2xi32>
+ %0 = arith.andi %arg0, %cAllOnes_32 : vector<2xi32>
- // CHECK: [[T1:%.*]] = and [[ARG0]], [[C31]]
- %1 = and %0, %c31 : vector<2xi32>
+ // CHECK: [[T1:%.*]] = arith.andi [[ARG0]], [[C31]]
+ %1 = arith.andi %0, %c31 : vector<2xi32>
- // CHECK: [[T2:%.*]] = and [[T1]], [[CMIXED]]
- %2 = and %1, %c_mixed : vector<2xi32>
+ // CHECK: [[T2:%.*]] = arith.andi [[T1]], [[CMIXED]]
+ %2 = arith.andi %1, %c_mixed : vector<2xi32>
// CHECK: return [[T2]]
return %2 : vector<2xi32>
// CHECK-LABEL: func @addi_splat_vector
func @addi_splat_vector() -> vector<8xi32> {
- %0 = constant dense<1> : vector<8xi32>
- %1 = constant dense<5> : vector<8xi32>
+ %0 = arith.constant dense<1> : vector<8xi32>
+ %1 = arith.constant dense<5> : vector<8xi32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<6> : vector<8xi32>
- %2 = addi %0, %1 : vector<8xi32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<6> : vector<8xi32>
+ %2 = arith.addi %0, %1 : vector<8xi32>
// CHECK-NEXT: return [[C]]
return %2 : vector<8xi32>
// CHECK-LABEL: func @simple_subf
func @simple_subf() -> f32 {
- %0 = constant 4.5 : f32
- %1 = constant 1.5 : f32
+ %0 = arith.constant 4.5 : f32
+ %1 = arith.constant 1.5 : f32
- // CHECK-NEXT: [[C:%.+]] = constant 3.{{0*}}e+00 : f32
- %2 = subf %0, %1 : f32
+ // CHECK-NEXT: [[C:%.+]] = arith.constant 3.{{0*}}e+00 : f32
+ %2 = arith.subf %0, %1 : f32
// CHECK-NEXT: return [[C]]
return %2 : f32
// CHECK-LABEL: func @subf_splat_vector
func @subf_splat_vector() -> vector<4xf32> {
- %0 = constant dense<4.5> : vector<4xf32>
- %1 = constant dense<1.5> : vector<4xf32>
+ %0 = arith.constant dense<4.5> : vector<4xf32>
+ %1 = arith.constant dense<1.5> : vector<4xf32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<3.{{0*}}e+00> : vector<4xf32>
- %2 = subf %0, %1 : vector<4xf32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<3.{{0*}}e+00> : vector<4xf32>
+ %2 = arith.subf %0, %1 : vector<4xf32>
// CHECK-NEXT: return [[C]]
return %2 : vector<4xf32>
// CHECK: func @simple_subi
// CHECK-SAME: [[ARG0:%[a-zA-Z0-9]+]]
func @simple_subi(%arg0 : i32) -> (i32, i32) {
- %0 = constant 4 : i32
- %1 = constant 1 : i32
- %2 = constant 0 : i32
+ %0 = arith.constant 4 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 0 : i32
- // CHECK-NEXT:[[C3:%.+]] = constant 3 : i32
- %3 = subi %0, %1 : i32
- %4 = subi %arg0, %2 : i32
+ // CHECK-NEXT:[[C3:%.+]] = arith.constant 3 : i32
+ %3 = arith.subi %0, %1 : i32
+ %4 = arith.subi %arg0, %2 : i32
// CHECK-NEXT: return [[C3]], [[ARG0]]
return %3, %4 : i32, i32
// CHECK-LABEL: func @subi_splat_tensor
func @subi_splat_tensor() -> tensor<4xi32> {
- %0 = constant dense<4> : tensor<4xi32>
- %1 = constant dense<1> : tensor<4xi32>
+ %0 = arith.constant dense<4> : tensor<4xi32>
+ %1 = arith.constant dense<1> : tensor<4xi32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<3> : tensor<4xi32>
- %2 = subi %0, %1 : tensor<4xi32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<3> : tensor<4xi32>
+ %2 = arith.subi %0, %1 : tensor<4xi32>
// CHECK-NEXT: return [[C]]
return %2 : tensor<4xi32>
// CHECK-LABEL: func @affine_apply
func @affine_apply(%variable : index) -> (index, index, index) {
- %c177 = constant 177 : index
- %c211 = constant 211 : index
- %N = constant 1075 : index
+ %c177 = arith.constant 177 : index
+ %c211 = arith.constant 211 : index
+ %N = arith.constant 1075 : index
- // CHECK:[[C1159:%.+]] = constant 1159 : index
- // CHECK:[[C1152:%.+]] = constant 1152 : index
+ // CHECK:[[C1159:%.+]] = arith.constant 1159 : index
+ // CHECK:[[C1152:%.+]] = arith.constant 1152 : index
%x0 = affine.apply affine_map<(d0, d1)[S0] -> ( (d0 + 128 * S0) floordiv 128 + d1 mod 128)>
(%c177, %c211)[%N]
%x1 = affine.apply affine_map<(d0, d1)[S0] -> (128 * (S0 ceildiv 128))>
(%c177, %c211)[%N]
- // CHECK:[[C42:%.+]] = constant 42 : index
+ // CHECK:[[C42:%.+]] = arith.constant 42 : index
%y = affine.apply affine_map<(d0) -> (42)> (%variable)
// CHECK: return [[C1159]], [[C1152]], [[C42]]
// CHECK-LABEL: func @simple_mulf
func @simple_mulf() -> f32 {
- %0 = constant 4.5 : f32
- %1 = constant 1.5 : f32
+ %0 = arith.constant 4.5 : f32
+ %1 = arith.constant 1.5 : f32
- // CHECK-NEXT: [[C:%.+]] = constant 6.75{{0*}}e+00 : f32
- %2 = mulf %0, %1 : f32
+ // CHECK-NEXT: [[C:%.+]] = arith.constant 6.75{{0*}}e+00 : f32
+ %2 = arith.mulf %0, %1 : f32
// CHECK-NEXT: return [[C]]
return %2 : f32
// CHECK-LABEL: func @mulf_splat_tensor
func @mulf_splat_tensor() -> tensor<4xf32> {
- %0 = constant dense<4.5> : tensor<4xf32>
- %1 = constant dense<1.5> : tensor<4xf32>
+ %0 = arith.constant dense<4.5> : tensor<4xf32>
+ %1 = arith.constant dense<1.5> : tensor<4xf32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<6.75{{0*}}e+00> : tensor<4xf32>
- %2 = mulf %0, %1 : tensor<4xf32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<6.75{{0*}}e+00> : tensor<4xf32>
+ %2 = arith.mulf %0, %1 : tensor<4xf32>
// CHECK-NEXT: return [[C]]
return %2 : tensor<4xf32>
// CHECK-LABEL: func @simple_divi_signed
func @simple_divi_signed() -> (i32, i32, i32) {
- // CHECK-DAG: [[C0:%.+]] = constant 0
- %z = constant 0 : i32
- // CHECK-DAG: [[C6:%.+]] = constant 6
- %0 = constant 6 : i32
- %1 = constant 2 : i32
+ // CHECK-DAG: [[C0:%.+]] = arith.constant 0
+ %z = arith.constant 0 : i32
+ // CHECK-DAG: [[C6:%.+]] = arith.constant 6
+ %0 = arith.constant 6 : i32
+ %1 = arith.constant 2 : i32
- // CHECK-NEXT: [[C3:%.+]] = constant 3 : i32
- %2 = divi_signed %0, %1 : i32
+ // CHECK-NEXT: [[C3:%.+]] = arith.constant 3 : i32
+ %2 = arith.divsi %0, %1 : i32
- %3 = constant -2 : i32
+ %3 = arith.constant -2 : i32
- // CHECK-NEXT: [[CM3:%.+]] = constant -3 : i32
- %4 = divi_signed %0, %3 : i32
+ // CHECK-NEXT: [[CM3:%.+]] = arith.constant -3 : i32
+ %4 = arith.divsi %0, %3 : i32
- // CHECK-NEXT: [[XZ:%.+]] = divi_signed [[C6]], [[C0]]
- %5 = divi_signed %0, %z : i32
+ // CHECK-NEXT: [[XZ:%.+]] = arith.divsi [[C6]], [[C0]]
+ %5 = arith.divsi %0, %z : i32
// CHECK-NEXT: return [[C3]], [[CM3]], [[XZ]]
return %2, %4, %5 : i32, i32, i32
// CHECK-LABEL: func @divi_signed_splat_tensor
func @divi_signed_splat_tensor() -> (tensor<4xi32>, tensor<4xi32>, tensor<4xi32>) {
- // CHECK-DAG: [[C0:%.+]] = constant dense<0>
- %z = constant dense<0> : tensor<4xi32>
- // CHECK-DAG: [[C6:%.+]] = constant dense<6>
- %0 = constant dense<6> : tensor<4xi32>
- %1 = constant dense<2> : tensor<4xi32>
+ // CHECK-DAG: [[C0:%.+]] = arith.constant dense<0>
+ %z = arith.constant dense<0> : tensor<4xi32>
+ // CHECK-DAG: [[C6:%.+]] = arith.constant dense<6>
+ %0 = arith.constant dense<6> : tensor<4xi32>
+ %1 = arith.constant dense<2> : tensor<4xi32>
- // CHECK-NEXT: [[C3:%.+]] = constant dense<3> : tensor<4xi32>
- %2 = divi_signed %0, %1 : tensor<4xi32>
+ // CHECK-NEXT: [[C3:%.+]] = arith.constant dense<3> : tensor<4xi32>
+ %2 = arith.divsi %0, %1 : tensor<4xi32>
- %3 = constant dense<-2> : tensor<4xi32>
+ %3 = arith.constant dense<-2> : tensor<4xi32>
- // CHECK-NEXT: [[CM3:%.+]] = constant dense<-3> : tensor<4xi32>
- %4 = divi_signed %0, %3 : tensor<4xi32>
+ // CHECK-NEXT: [[CM3:%.+]] = arith.constant dense<-3> : tensor<4xi32>
+ %4 = arith.divsi %0, %3 : tensor<4xi32>
- // CHECK-NEXT: [[XZ:%.+]] = divi_signed [[C6]], [[C0]]
- %5 = divi_signed %0, %z : tensor<4xi32>
+ // CHECK-NEXT: [[XZ:%.+]] = arith.divsi [[C6]], [[C0]]
+ %5 = arith.divsi %0, %z : tensor<4xi32>
// CHECK-NEXT: return [[C3]], [[CM3]], [[XZ]]
return %2, %4, %5 : tensor<4xi32>, tensor<4xi32>, tensor<4xi32>
// CHECK-LABEL: func @simple_divi_unsigned
func @simple_divi_unsigned() -> (i32, i32, i32) {
- %z = constant 0 : i32
- // CHECK-DAG: [[C6:%.+]] = constant 6
- %0 = constant 6 : i32
- %1 = constant 2 : i32
+ %z = arith.constant 0 : i32
+ // CHECK-DAG: [[C6:%.+]] = arith.constant 6
+ %0 = arith.constant 6 : i32
+ %1 = arith.constant 2 : i32
- // CHECK-DAG: [[C3:%.+]] = constant 3 : i32
- %2 = divi_unsigned %0, %1 : i32
+ // CHECK-DAG: [[C3:%.+]] = arith.constant 3 : i32
+ %2 = arith.divui %0, %1 : i32
- %3 = constant -2 : i32
+ %3 = arith.constant -2 : i32
// Unsigned division interprets -2 as 2^32-2, so the result is 0.
- // CHECK-DAG: [[C0:%.+]] = constant 0 : i32
- %4 = divi_unsigned %0, %3 : i32
+ // CHECK-DAG: [[C0:%.+]] = arith.constant 0 : i32
+ %4 = arith.divui %0, %3 : i32
- // CHECK-NEXT: [[XZ:%.+]] = divi_unsigned [[C6]], [[C0]]
- %5 = divi_unsigned %0, %z : i32
+ // CHECK-NEXT: [[XZ:%.+]] = arith.divui [[C6]], [[C0]]
+ %5 = arith.divui %0, %z : i32
// CHECK-NEXT: return [[C3]], [[C0]], [[XZ]]
return %2, %4, %5 : i32, i32, i32
// CHECK-LABEL: func @divi_unsigned_splat_tensor
func @divi_unsigned_splat_tensor() -> (tensor<4xi32>, tensor<4xi32>, tensor<4xi32>) {
- %z = constant dense<0> : tensor<4xi32>
- // CHECK-DAG: [[C6:%.+]] = constant dense<6>
- %0 = constant dense<6> : tensor<4xi32>
- %1 = constant dense<2> : tensor<4xi32>
+ %z = arith.constant dense<0> : tensor<4xi32>
+ // CHECK-DAG: [[C6:%.+]] = arith.constant dense<6>
+ %0 = arith.constant dense<6> : tensor<4xi32>
+ %1 = arith.constant dense<2> : tensor<4xi32>
- // CHECK-DAG: [[C3:%.+]] = constant dense<3> : tensor<4xi32>
- %2 = divi_unsigned %0, %1 : tensor<4xi32>
+ // CHECK-DAG: [[C3:%.+]] = arith.constant dense<3> : tensor<4xi32>
+ %2 = arith.divui %0, %1 : tensor<4xi32>
- %3 = constant dense<-2> : tensor<4xi32>
+ %3 = arith.constant dense<-2> : tensor<4xi32>
// Unsigned division interprets -2 as 2^32-2, so the result is 0.
- // CHECK-DAG: [[C0:%.+]] = constant dense<0> : tensor<4xi32>
- %4 = divi_unsigned %0, %3 : tensor<4xi32>
+ // CHECK-DAG: [[C0:%.+]] = arith.constant dense<0> : tensor<4xi32>
+ %4 = arith.divui %0, %3 : tensor<4xi32>
- // CHECK-NEXT: [[XZ:%.+]] = divi_unsigned [[C6]], [[C0]]
- %5 = divi_unsigned %0, %z : tensor<4xi32>
+ // CHECK-NEXT: [[XZ:%.+]] = arith.divui [[C6]], [[C0]]
+ %5 = arith.divui %0, %z : tensor<4xi32>
// CHECK-NEXT: return [[C3]], [[C0]], [[XZ]]
return %2, %4, %5 : tensor<4xi32>, tensor<4xi32>, tensor<4xi32>
// -----
-// CHECK-LABEL: func @simple_floordivi_signed
-func @simple_floordivi_signed() -> (i32, i32, i32, i32, i32) {
- // CHECK-DAG: [[C0:%.+]] = constant 0
- %z = constant 0 : i32
- // CHECK-DAG: [[C6:%.+]] = constant 7
- %0 = constant 7 : i32
- %1 = constant 2 : i32
+// CHECK-LABEL: func @simple_arith.floordivsi
+func @simple_arith.floordivsi() -> (i32, i32, i32, i32, i32) {
+ // CHECK-DAG: [[C0:%.+]] = arith.constant 0
+ %z = arith.constant 0 : i32
+ // CHECK-DAG: [[C6:%.+]] = arith.constant 7
+ %0 = arith.constant 7 : i32
+ %1 = arith.constant 2 : i32
// floor(7, 2) = 3
- // CHECK-NEXT: [[C3:%.+]] = constant 3 : i32
- %2 = floordivi_signed %0, %1 : i32
+ // CHECK-NEXT: [[C3:%.+]] = arith.constant 3 : i32
+ %2 = arith.floordivsi %0, %1 : i32
- %3 = constant -2 : i32
+ %3 = arith.constant -2 : i32
// floor(7, -2) = -4
- // CHECK-NEXT: [[CM3:%.+]] = constant -4 : i32
- %4 = floordivi_signed %0, %3 : i32
+ // CHECK-NEXT: [[CM3:%.+]] = arith.constant -4 : i32
+ %4 = arith.floordivsi %0, %3 : i32
- %5 = constant -9 : i32
+ %5 = arith.constant -9 : i32
// floor(-9, 2) = -5
- // CHECK-NEXT: [[CM4:%.+]] = constant -5 : i32
- %6 = floordivi_signed %5, %1 : i32
+ // CHECK-NEXT: [[CM4:%.+]] = arith.constant -5 : i32
+ %6 = arith.floordivsi %5, %1 : i32
- %7 = constant -13 : i32
+ %7 = arith.constant -13 : i32
// floor(-13, -2) = 6
- // CHECK-NEXT: [[CM5:%.+]] = constant 6 : i32
- %8 = floordivi_signed %7, %3 : i32
+ // CHECK-NEXT: [[CM5:%.+]] = arith.constant 6 : i32
+ %8 = arith.floordivsi %7, %3 : i32
- // CHECK-NEXT: [[XZ:%.+]] = floordivi_signed [[C6]], [[C0]]
- %9 = floordivi_signed %0, %z : i32
+ // CHECK-NEXT: [[XZ:%.+]] = arith.floordivsi [[C6]], [[C0]]
+ %9 = arith.floordivsi %0, %z : i32
return %2, %4, %6, %8, %9 : i32, i32, i32, i32, i32
}
// -----
-// CHECK-LABEL: func @simple_ceildivi_signed
-func @simple_ceildivi_signed() -> (i32, i32, i32, i32, i32) {
- // CHECK-DAG: [[C0:%.+]] = constant 0
- %z = constant 0 : i32
- // CHECK-DAG: [[C6:%.+]] = constant 7
- %0 = constant 7 : i32
- %1 = constant 2 : i32
+// CHECK-LABEL: func @simple_arith.ceildivsi
+func @simple_arith.ceildivsi() -> (i32, i32, i32, i32, i32) {
+ // CHECK-DAG: [[C0:%.+]] = arith.constant 0
+ %z = arith.constant 0 : i32
+ // CHECK-DAG: [[C6:%.+]] = arith.constant 7
+ %0 = arith.constant 7 : i32
+ %1 = arith.constant 2 : i32
// ceil(7, 2) = 4
- // CHECK-NEXT: [[C3:%.+]] = constant 4 : i32
- %2 = ceildivi_signed %0, %1 : i32
+ // CHECK-NEXT: [[C3:%.+]] = arith.constant 4 : i32
+ %2 = arith.ceildivsi %0, %1 : i32
- %3 = constant -2 : i32
+ %3 = arith.constant -2 : i32
// ceil(7, -2) = -3
- // CHECK-NEXT: [[CM3:%.+]] = constant -3 : i32
- %4 = ceildivi_signed %0, %3 : i32
+ // CHECK-NEXT: [[CM3:%.+]] = arith.constant -3 : i32
+ %4 = arith.ceildivsi %0, %3 : i32
- %5 = constant -9 : i32
+ %5 = arith.constant -9 : i32
// ceil(-9, 2) = -4
- // CHECK-NEXT: [[CM4:%.+]] = constant -4 : i32
- %6 = ceildivi_signed %5, %1 : i32
+ // CHECK-NEXT: [[CM4:%.+]] = arith.constant -4 : i32
+ %6 = arith.ceildivsi %5, %1 : i32
- %7 = constant -15 : i32
+ %7 = arith.constant -15 : i32
// ceil(-15, -2) = 8
- // CHECK-NEXT: [[CM5:%.+]] = constant 8 : i32
- %8 = ceildivi_signed %7, %3 : i32
+ // CHECK-NEXT: [[CM5:%.+]] = arith.constant 8 : i32
+ %8 = arith.ceildivsi %7, %3 : i32
- // CHECK-NEXT: [[XZ:%.+]] = ceildivi_signed [[C6]], [[C0]]
- %9 = ceildivi_signed %0, %z : i32
+ // CHECK-NEXT: [[XZ:%.+]] = arith.ceildivsi [[C6]], [[C0]]
+ %9 = arith.ceildivsi %0, %z : i32
return %2, %4, %6, %8, %9 : i32, i32, i32, i32, i32
}
// -----
-// CHECK-LABEL: func @simple_remi_signed
-func @simple_remi_signed(%a : i32) -> (i32, i32, i32) {
- %0 = constant 5 : i32
- %1 = constant 2 : i32
- %2 = constant 1 : i32
- %3 = constant -2 : i32
+// CHECK-LABEL: func @simple_arith.remsi
+func @simple_arith.remsi(%a : i32) -> (i32, i32, i32) {
+ %0 = arith.constant 5 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 1 : i32
+ %3 = arith.constant -2 : i32
- // CHECK-NEXT:[[C1:%.+]] = constant 1 : i32
- %4 = remi_signed %0, %1 : i32
- %5 = remi_signed %0, %3 : i32
- // CHECK-NEXT:[[C0:%.+]] = constant 0 : i32
- %6 = remi_signed %a, %2 : i32
+ // CHECK-NEXT:[[C1:%.+]] = arith.constant 1 : i32
+ %4 = arith.remsi %0, %1 : i32
+ %5 = arith.remsi %0, %3 : i32
+ // CHECK-NEXT:[[C0:%.+]] = arith.constant 0 : i32
+ %6 = arith.remsi %a, %2 : i32
// CHECK-NEXT: return [[C1]], [[C1]], [[C0]] : i32, i32, i32
return %4, %5, %6 : i32, i32, i32
// -----
-// CHECK-LABEL: func @simple_remi_unsigned
-func @simple_remi_unsigned(%a : i32) -> (i32, i32, i32) {
- %0 = constant 5 : i32
- %1 = constant 2 : i32
- %2 = constant 1 : i32
- %3 = constant -2 : i32
+// CHECK-LABEL: func @simple_arith.remui
+func @simple_arith.remui(%a : i32) -> (i32, i32, i32) {
+ %0 = arith.constant 5 : i32
+ %1 = arith.constant 2 : i32
+ %2 = arith.constant 1 : i32
+ %3 = arith.constant -2 : i32
- // CHECK-DAG:[[C1:%.+]] = constant 1 : i32
- %4 = remi_unsigned %0, %1 : i32
- // CHECK-DAG:[[C5:%.+]] = constant 5 : i32
- %5 = remi_unsigned %0, %3 : i32
- // CHECK-DAG:[[C0:%.+]] = constant 0 : i32
- %6 = remi_unsigned %a, %2 : i32
+ // CHECK-DAG:[[C1:%.+]] = arith.constant 1 : i32
+ %4 = arith.remui %0, %1 : i32
+ // CHECK-DAG:[[C5:%.+]] = arith.constant 5 : i32
+ %5 = arith.remui %0, %3 : i32
+ // CHECK-DAG:[[C0:%.+]] = arith.constant 0 : i32
+ %6 = arith.remui %a, %2 : i32
// CHECK-NEXT: return [[C1]], [[C5]], [[C0]] : i32, i32, i32
return %4, %5, %6 : i32, i32, i32
// CHECK-LABEL: func @muli
func @muli() -> i32 {
- %0 = constant 4 : i32
- %1 = constant 2 : i32
+ %0 = arith.constant 4 : i32
+ %1 = arith.constant 2 : i32
- // CHECK-NEXT:[[C8:%.+]] = constant 8 : i32
- %2 = muli %0, %1 : i32
+ // CHECK-NEXT:[[C8:%.+]] = arith.constant 8 : i32
+ %2 = arith.muli %0, %1 : i32
// CHECK-NEXT: return [[C8]]
return %2 : i32
// CHECK-LABEL: func @muli_splat_vector
func @muli_splat_vector() -> vector<4xi32> {
- %0 = constant dense<4> : vector<4xi32>
- %1 = constant dense<2> : vector<4xi32>
+ %0 = arith.constant dense<4> : vector<4xi32>
+ %1 = arith.constant dense<2> : vector<4xi32>
- // CHECK-NEXT: [[C:%.+]] = constant dense<8> : vector<4xi32>
- %2 = muli %0, %1 : vector<4xi32>
+ // CHECK-NEXT: [[C:%.+]] = arith.constant dense<8> : vector<4xi32>
+ %2 = arith.muli %0, %1 : vector<4xi32>
// CHECK-NEXT: return [[C]]
return %2 : vector<4xi32>
// CHECK-LABEL: func @dim
func @dim(%x : tensor<8x4xf32>) -> index {
- // CHECK:[[C4:%.+]] = constant 4 : index
- %c1 = constant 1 : index
+ // CHECK:[[C4:%.+]] = arith.constant 4 : index
+ %c1 = arith.constant 1 : index
%0 = tensor.dim %x, %c1 : tensor<8x4xf32>
// CHECK-NEXT: return [[C4]]
// CHECK-LABEL: func @cmpi
func @cmpi() -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
- %c42 = constant 42 : i32
- %cm1 = constant -1 : i32
- // CHECK-DAG: [[F:%.+]] = constant false
- // CHECK-DAG: [[T:%.+]] = constant true
+ %c42 = arith.constant 42 : i32
+ %cm1 = arith.constant -1 : i32
+ // CHECK-DAG: [[F:%.+]] = arith.constant false
+ // CHECK-DAG: [[T:%.+]] = arith.constant true
// CHECK-NEXT: return [[F]],
- %0 = cmpi eq, %c42, %cm1 : i32
+ %0 = arith.cmpi eq, %c42, %cm1 : i32
// CHECK-SAME: [[T]],
- %1 = cmpi ne, %c42, %cm1 : i32
+ %1 = arith.cmpi ne, %c42, %cm1 : i32
// CHECK-SAME: [[F]],
- %2 = cmpi slt, %c42, %cm1 : i32
+ %2 = arith.cmpi slt, %c42, %cm1 : i32
// CHECK-SAME: [[F]],
- %3 = cmpi sle, %c42, %cm1 : i32
+ %3 = arith.cmpi sle, %c42, %cm1 : i32
// CHECK-SAME: [[T]],
- %4 = cmpi sgt, %c42, %cm1 : i32
+ %4 = arith.cmpi sgt, %c42, %cm1 : i32
// CHECK-SAME: [[T]],
- %5 = cmpi sge, %c42, %cm1 : i32
+ %5 = arith.cmpi sge, %c42, %cm1 : i32
// CHECK-SAME: [[T]],
- %6 = cmpi ult, %c42, %cm1 : i32
+ %6 = arith.cmpi ult, %c42, %cm1 : i32
// CHECK-SAME: [[T]],
- %7 = cmpi ule, %c42, %cm1 : i32
+ %7 = arith.cmpi ule, %c42, %cm1 : i32
// CHECK-SAME: [[F]],
- %8 = cmpi ugt, %c42, %cm1 : i32
+ %8 = arith.cmpi ugt, %c42, %cm1 : i32
// CHECK-SAME: [[F]]
- %9 = cmpi uge, %c42, %cm1 : i32
+ %9 = arith.cmpi uge, %c42, %cm1 : i32
return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9 : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
}
// CHECK-LABEL: func @cmpf_normal_numbers
func @cmpf_normal_numbers() -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
- %c42 = constant 42. : f32
- %cm1 = constant -1. : f32
- // CHECK-DAG: [[F:%.+]] = constant false
- // CHECK-DAG: [[T:%.+]] = constant true
+ %c42 = arith.constant 42. : f32
+ %cm1 = arith.constant -1. : f32
+ // CHECK-DAG: [[F:%.+]] = arith.constant false
+ // CHECK-DAG: [[T:%.+]] = arith.constant true
// CHECK-NEXT: return [[F]],
- %0 = cmpf false, %c42, %cm1 : f32
+ %0 = arith.cmpf false, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %1 = cmpf oeq, %c42, %cm1 : f32
+ %1 = arith.cmpf oeq, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %2 = cmpf ogt, %c42, %cm1 : f32
+ %2 = arith.cmpf ogt, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %3 = cmpf oge, %c42, %cm1 : f32
+ %3 = arith.cmpf oge, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %4 = cmpf olt, %c42, %cm1 : f32
+ %4 = arith.cmpf olt, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %5 = cmpf ole, %c42, %cm1 : f32
+ %5 = arith.cmpf ole, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %6 = cmpf one, %c42, %cm1 : f32
+ %6 = arith.cmpf one, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %7 = cmpf ord, %c42, %cm1 : f32
+ %7 = arith.cmpf ord, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %8 = cmpf ueq, %c42, %cm1 : f32
+ %8 = arith.cmpf ueq, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %9 = cmpf ugt, %c42, %cm1 : f32
+ %9 = arith.cmpf ugt, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %10 = cmpf uge, %c42, %cm1 : f32
+ %10 = arith.cmpf uge, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %11 = cmpf ult, %c42, %cm1 : f32
+ %11 = arith.cmpf ult, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %12 = cmpf ule, %c42, %cm1 : f32
+ %12 = arith.cmpf ule, %c42, %cm1 : f32
// CHECK-SAME: [[T]],
- %13 = cmpf une, %c42, %cm1 : f32
+ %13 = arith.cmpf une, %c42, %cm1 : f32
// CHECK-SAME: [[F]],
- %14 = cmpf uno, %c42, %cm1 : f32
+ %14 = arith.cmpf uno, %c42, %cm1 : f32
// CHECK-SAME: [[T]]
- %15 = cmpf true, %c42, %cm1 : f32
+ %15 = arith.cmpf true, %c42, %cm1 : f32
return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9, %10, %11, %12, %13, %14, %15 : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
}
// CHECK-LABEL: func @cmpf_nan
func @cmpf_nan() -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
- %c42 = constant 42. : f32
- %cqnan = constant 0xFFFFFFFF : f32
- // CHECK-DAG: [[F:%.+]] = constant false
- // CHECK-DAG: [[T:%.+]] = constant true
+ %c42 = arith.constant 42. : f32
+ %cqnan = arith.constant 0xFFFFFFFF : f32
+ // CHECK-DAG: [[F:%.+]] = arith.constant false
+ // CHECK-DAG: [[T:%.+]] = arith.constant true
// CHECK-NEXT: return [[F]],
- %0 = cmpf false, %c42, %cqnan : f32
+ %0 = arith.cmpf false, %c42, %cqnan : f32
// CHECK-SAME: [[F]]
- %1 = cmpf oeq, %c42, %cqnan : f32
+ %1 = arith.cmpf oeq, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %2 = cmpf ogt, %c42, %cqnan : f32
+ %2 = arith.cmpf ogt, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %3 = cmpf oge, %c42, %cqnan : f32
+ %3 = arith.cmpf oge, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %4 = cmpf olt, %c42, %cqnan : f32
+ %4 = arith.cmpf olt, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %5 = cmpf ole, %c42, %cqnan : f32
+ %5 = arith.cmpf ole, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %6 = cmpf one, %c42, %cqnan : f32
+ %6 = arith.cmpf one, %c42, %cqnan : f32
// CHECK-SAME: [[F]],
- %7 = cmpf ord, %c42, %cqnan : f32
+ %7 = arith.cmpf ord, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %8 = cmpf ueq, %c42, %cqnan : f32
+ %8 = arith.cmpf ueq, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %9 = cmpf ugt, %c42, %cqnan : f32
+ %9 = arith.cmpf ugt, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %10 = cmpf uge, %c42, %cqnan : f32
+ %10 = arith.cmpf uge, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %11 = cmpf ult, %c42, %cqnan : f32
+ %11 = arith.cmpf ult, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %12 = cmpf ule, %c42, %cqnan : f32
+ %12 = arith.cmpf ule, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %13 = cmpf une, %c42, %cqnan : f32
+ %13 = arith.cmpf une, %c42, %cqnan : f32
// CHECK-SAME: [[T]],
- %14 = cmpf uno, %c42, %cqnan : f32
+ %14 = arith.cmpf uno, %c42, %cqnan : f32
// CHECK-SAME: [[T]]
- %15 = cmpf true, %c42, %cqnan : f32
+ %15 = arith.cmpf true, %c42, %cqnan : f32
return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9, %10, %11, %12, %13, %14, %15 : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
}
// CHECK-LABEL: func @cmpf_inf
func @cmpf_inf() -> (i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1) {
- %c42 = constant 42. : f32
- %cpinf = constant 0x7F800000 : f32
- // CHECK-DAG: [[F:%.+]] = constant false
- // CHECK-DAG: [[T:%.+]] = constant true
+ %c42 = arith.constant 42. : f32
+ %cpinf = arith.constant 0x7F800000 : f32
+ // CHECK-DAG: [[F:%.+]] = arith.constant false
+ // CHECK-DAG: [[T:%.+]] = arith.constant true
// CHECK-NEXT: return [[F]],
- %0 = cmpf false, %c42, %cpinf: f32
+ %0 = arith.cmpf false, %c42, %cpinf: f32
// CHECK-SAME: [[F]]
- %1 = cmpf oeq, %c42, %cpinf: f32
+ %1 = arith.cmpf oeq, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %2 = cmpf ogt, %c42, %cpinf: f32
+ %2 = arith.cmpf ogt, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %3 = cmpf oge, %c42, %cpinf: f32
+ %3 = arith.cmpf oge, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %4 = cmpf olt, %c42, %cpinf: f32
+ %4 = arith.cmpf olt, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %5 = cmpf ole, %c42, %cpinf: f32
+ %5 = arith.cmpf ole, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %6 = cmpf one, %c42, %cpinf: f32
+ %6 = arith.cmpf one, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %7 = cmpf ord, %c42, %cpinf: f32
+ %7 = arith.cmpf ord, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %8 = cmpf ueq, %c42, %cpinf: f32
+ %8 = arith.cmpf ueq, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %9 = cmpf ugt, %c42, %cpinf: f32
+ %9 = arith.cmpf ugt, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %10 = cmpf uge, %c42, %cpinf: f32
+ %10 = arith.cmpf uge, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %11 = cmpf ult, %c42, %cpinf: f32
+ %11 = arith.cmpf ult, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %12 = cmpf ule, %c42, %cpinf: f32
+ %12 = arith.cmpf ule, %c42, %cpinf: f32
// CHECK-SAME: [[T]],
- %13 = cmpf une, %c42, %cpinf: f32
+ %13 = arith.cmpf une, %c42, %cpinf: f32
// CHECK-SAME: [[F]],
- %14 = cmpf uno, %c42, %cpinf: f32
+ %14 = arith.cmpf uno, %c42, %cpinf: f32
// CHECK-SAME: [[T]]
- %15 = cmpf true, %c42, %cpinf: f32
+ %15 = arith.cmpf true, %c42, %cpinf: f32
return %0, %1, %2, %3, %4, %5, %6, %7, %8, %9, %10, %11, %12, %13, %14, %15 : i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1, i1
}
// CHECK-LABEL: func @fold_rank
func @fold_rank() -> (index) {
- %const_0 = constant dense<[[[1, -2, 1, 36]], [[0, 2, -1, 64]]]> : tensor<2x1x4xi32>
+ %const_0 = arith.constant dense<[[[1, -2, 1, 36]], [[0, 2, -1, 64]]]> : tensor<2x1x4xi32>
// Fold a rank into a constant
- // CHECK-NEXT: [[C3:%.+]] = constant 3 : index
+ // CHECK-NEXT: [[C3:%.+]] = arith.constant 3 : index
%rank_0 = rank %const_0 : tensor<2x1x4xi32>
// CHECK-NEXT: return [[C3]]
// CHECK-LABEL: func @fold_rank_memref
func @fold_rank_memref(%arg0 : memref<?x?xf32>) -> (index) {
// Fold a rank into a constant
- // CHECK-NEXT: [[C2:%.+]] = constant 2 : index
+ // CHECK-NEXT: [[C2:%.+]] = arith.constant 2 : index
%rank_0 = rank %arg0 : memref<?x?xf32>
// CHECK-NEXT: return [[C2]]
// CHECK-LABEL: func @nested_isolated_region
func @nested_isolated_region() {
// CHECK-NEXT: func @isolated_op
- // CHECK-NEXT: constant 2
+ // CHECK-NEXT: arith.constant 2
builtin.func @isolated_op() {
- %0 = constant 1 : i32
- %2 = addi %0, %0 : i32
+ %0 = arith.constant 1 : i32
+ %2 = arith.addi %0, %0 : i32
"foo.yield"(%2) : (i32) -> ()
}
// CHECK: "foo.unknown_region"
- // CHECK-NEXT: constant 2
+ // CHECK-NEXT: arith.constant 2
"foo.unknown_region"() ({
- %0 = constant 1 : i32
- %2 = addi %0, %0 : i32
+ %0 = arith.constant 1 : i32
+ %2 = arith.addi %0, %0 : i32
"foo.yield"(%2) : (i32) -> ()
}) : () -> ()
return
// CHECK-LABEL: func @custom_insertion_position
func @custom_insertion_position() {
// CHECK: test.one_region_op
- // CHECK-NEXT: constant 2
+ // CHECK-NEXT: arith.constant 2
"test.one_region_op"() ({
- %0 = constant 1 : i32
- %2 = addi %0, %0 : i32
+ %0 = arith.constant 1 : i32
+ %2 = arith.addi %0, %0 : i32
"foo.yield"(%2) : (i32) -> ()
}) : () -> ()
return
// CHECK-LABEL: func @splat_fold
func @splat_fold() -> (vector<4xf32>, tensor<4xf32>) {
- %c = constant 1.0 : f32
+ %c = arith.constant 1.0 : f32
%v = splat %c : vector<4xf32>
%t = splat %c : tensor<4xf32>
return %v, %t : vector<4xf32>, tensor<4xf32>
- // CHECK-NEXT: [[V:%.*]] = constant dense<1.000000e+00> : vector<4xf32>
- // CHECK-NEXT: [[T:%.*]] = constant dense<1.000000e+00> : tensor<4xf32>
+ // CHECK-NEXT: [[V:%.*]] = arith.constant dense<1.000000e+00> : vector<4xf32>
+ // CHECK-NEXT: [[T:%.*]] = arith.constant dense<1.000000e+00> : tensor<4xf32>
// CHECK-NEXT: return [[V]], [[T]] : vector<4xf32>, tensor<4xf32>
}
// CHECK-LABEL: @simple_constant
func @simple_constant() -> (i32, i32) {
- // CHECK-NEXT: %c1_i32 = constant 1 : i32
- %0 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
+ %0 = arith.constant 1 : i32
// CHECK-NEXT: return %c1_i32, %c1_i32 : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
return %0, %1 : i32, i32
}
// CHECK-LABEL: @basic
func @basic() -> (index, index) {
- // CHECK: %c0 = constant 0 : index
- %c0 = constant 0 : index
- %c1 = constant 0 : index
+ // CHECK: %c0 = arith.constant 0 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 0 : index
// CHECK-NEXT: %0 = affine.apply #[[$MAP]](%c0)
%0 = affine.apply #map0(%c0)
// CHECK-LABEL: @many
func @many(f32, f32) -> (f32) {
^bb0(%a : f32, %b : f32):
- // CHECK-NEXT: %0 = addf %arg0, %arg1 : f32
- %c = addf %a, %b : f32
- %d = addf %a, %b : f32
- %e = addf %a, %b : f32
- %f = addf %a, %b : f32
+ // CHECK-NEXT: %0 = arith.addf %arg0, %arg1 : f32
+ %c = arith.addf %a, %b : f32
+ %d = arith.addf %a, %b : f32
+ %e = arith.addf %a, %b : f32
+ %f = arith.addf %a, %b : f32
- // CHECK-NEXT: %1 = addf %0, %0 : f32
- %g = addf %c, %d : f32
- %h = addf %e, %f : f32
- %i = addf %c, %e : f32
+ // CHECK-NEXT: %1 = arith.addf %0, %0 : f32
+ %g = arith.addf %c, %d : f32
+ %h = arith.addf %e, %f : f32
+ %i = arith.addf %c, %e : f32
- // CHECK-NEXT: %2 = addf %1, %1 : f32
- %j = addf %g, %h : f32
- %k = addf %h, %i : f32
+ // CHECK-NEXT: %2 = arith.addf %1, %1 : f32
+ %j = arith.addf %g, %h : f32
+ %k = arith.addf %h, %i : f32
- // CHECK-NEXT: %3 = addf %2, %2 : f32
- %l = addf %j, %k : f32
+ // CHECK-NEXT: %3 = arith.addf %2, %2 : f32
+ %l = arith.addf %j, %k : f32
// CHECK-NEXT: return %3 : f32
return %l : f32
/// Check that operations are not eliminated if they have different operands.
// CHECK-LABEL: @different_ops
func @different_ops() -> (i32, i32) {
- // CHECK: %c0_i32 = constant 0 : i32
- // CHECK: %c1_i32 = constant 1 : i32
- %0 = constant 0 : i32
- %1 = constant 1 : i32
+ // CHECK: %c0_i32 = arith.constant 0 : i32
+ // CHECK: %c1_i32 = arith.constant 1 : i32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1 : i32
// CHECK-NEXT: return %c0_i32, %c1_i32 : i32, i32
return %0, %1 : i32, i32
// CHECK-LABEL: @different_attributes
func @different_attributes(index, index) -> (i1, i1, i1) {
^bb0(%a : index, %b : index):
- // CHECK: %0 = cmpi slt, %arg0, %arg1 : index
- %0 = cmpi slt, %a, %b : index
+ // CHECK: %0 = arith.cmpi slt, %arg0, %arg1 : index
+ %0 = arith.cmpi slt, %a, %b : index
- // CHECK-NEXT: %1 = cmpi ne, %arg0, %arg1 : index
+ // CHECK-NEXT: %1 = arith.cmpi ne, %arg0, %arg1 : index
/// Predicate 1 means inequality comparison.
- %1 = cmpi ne, %a, %b : index
- %2 = "std.cmpi"(%a, %b) {predicate = 1} : (index, index) -> i1
+ %1 = arith.cmpi ne, %a, %b : index
+ %2 = "arith.cmpi"(%a, %b) {predicate = 1} : (index, index) -> i1
// CHECK-NEXT: return %0, %1, %1 : i1, i1, i1
return %0, %1, %2 : i1, i1, i1
/// tree.
// CHECK-LABEL: @down_propagate_for
func @down_propagate_for() {
- // CHECK: %c1_i32 = constant 1 : i32
- %0 = constant 1 : i32
+ // CHECK: %c1_i32 = arith.constant 1 : i32
+ %0 = arith.constant 1 : i32
// CHECK-NEXT: affine.for {{.*}} = 0 to 4 {
affine.for %i = 0 to 4 {
// CHECK-NEXT: "foo"(%c1_i32, %c1_i32) : (i32, i32) -> ()
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
"foo"(%0, %1) : (i32, i32) -> ()
}
return
// CHECK-LABEL: @down_propagate
func @down_propagate() -> i32 {
- // CHECK-NEXT: %c1_i32 = constant 1 : i32
- %0 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
+ %0 = arith.constant 1 : i32
- // CHECK-NEXT: %true = constant true
- %cond = constant true
+ // CHECK-NEXT: %true = arith.constant true
+ %cond = arith.constant true
// CHECK-NEXT: cond_br %true, ^bb1, ^bb2(%c1_i32 : i32)
cond_br %cond, ^bb1, ^bb2(%0 : i32)
^bb1: // CHECK: ^bb1:
// CHECK-NEXT: br ^bb2(%c1_i32 : i32)
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
br ^bb2(%1 : i32)
^bb2(%arg : i32):
func @up_propagate_for() -> i32 {
// CHECK: affine.for {{.*}} = 0 to 4 {
affine.for %i = 0 to 4 {
- // CHECK-NEXT: %c1_i32_0 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32_0 = arith.constant 1 : i32
// CHECK-NEXT: "foo"(%c1_i32_0) : (i32) -> ()
- %0 = constant 1 : i32
+ %0 = arith.constant 1 : i32
"foo"(%0) : (i32) -> ()
}
- // CHECK: %c1_i32 = constant 1 : i32
+ // CHECK: %c1_i32 = arith.constant 1 : i32
// CHECK-NEXT: return %c1_i32 : i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
return %1 : i32
}
// CHECK-LABEL: func @up_propagate
func @up_propagate() -> i32 {
- // CHECK-NEXT: %c0_i32 = constant 0 : i32
- %0 = constant 0 : i32
+ // CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
+ %0 = arith.constant 0 : i32
- // CHECK-NEXT: %true = constant true
- %cond = constant true
+ // CHECK-NEXT: %true = arith.constant true
+ %cond = arith.constant true
// CHECK-NEXT: cond_br %true, ^bb1, ^bb2(%c0_i32 : i32)
cond_br %cond, ^bb1, ^bb2(%0 : i32)
^bb1: // CHECK: ^bb1:
- // CHECK-NEXT: %c1_i32 = constant 1 : i32
- %1 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
+ %1 = arith.constant 1 : i32
// CHECK-NEXT: br ^bb2(%c1_i32 : i32)
br ^bb2(%1 : i32)
^bb2(%arg : i32): // CHECK: ^bb2
- // CHECK-NEXT: %c1_i32_0 = constant 1 : i32
- %2 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32_0 = arith.constant 1 : i32
+ %2 = arith.constant 1 : i32
- // CHECK-NEXT: %1 = addi %0, %c1_i32_0 : i32
- %add = addi %arg, %2 : i32
+ // CHECK-NEXT: %1 = arith.addi %0, %c1_i32_0 : i32
+ %add = arith.addi %arg, %2 : i32
// CHECK-NEXT: return %1 : i32
return %add : i32
func @up_propagate_region() -> i32 {
// CHECK-NEXT: %0 = "foo.region"
%0 = "foo.region"() ({
- // CHECK-NEXT: %c0_i32 = constant 0 : i32
- // CHECK-NEXT: %true = constant true
+ // CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
+ // CHECK-NEXT: %true = arith.constant true
// CHECK-NEXT: cond_br
- %1 = constant 0 : i32
- %true = constant true
+ %1 = arith.constant 0 : i32
+ %true = arith.constant true
cond_br %true, ^bb1, ^bb2(%1 : i32)
^bb1: // CHECK: ^bb1:
- // CHECK-NEXT: %c1_i32 = constant 1 : i32
+ // CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
// CHECK-NEXT: br
- %c1_i32 = constant 1 : i32
+ %c1_i32 = arith.constant 1 : i32
br ^bb2(%c1_i32 : i32)
^bb2(%arg : i32): // CHECK: ^bb2(%1: i32):
- // CHECK-NEXT: %c1_i32_0 = constant 1 : i32
- // CHECK-NEXT: %2 = addi %1, %c1_i32_0 : i32
+ // CHECK-NEXT: %c1_i32_0 = arith.constant 1 : i32
+ // CHECK-NEXT: %2 = arith.addi %1, %c1_i32_0 : i32
// CHECK-NEXT: "foo.yield"(%2) : (i32) -> ()
- %c1_i32_0 = constant 1 : i32
- %2 = addi %arg, %c1_i32_0 : i32
+ %c1_i32_0 = arith.constant 1 : i32
+ %2 = arith.addi %arg, %c1_i32_0 : i32
"foo.yield" (%2) : (i32) -> ()
}) : () -> (i32)
return %0 : i32
/// properly handled.
// CHECK-LABEL: @nested_isolated
func @nested_isolated() -> i32 {
- // CHECK-NEXT: constant 1
- %0 = constant 1 : i32
+ // CHECK-NEXT: arith.constant 1
+ %0 = arith.constant 1 : i32
// CHECK-NEXT: @nested_func
builtin.func @nested_func() {
- // CHECK-NEXT: constant 1
- %foo = constant 1 : i32
+ // CHECK-NEXT: arith.constant 1
+ %foo = arith.constant 1 : i32
"foo.yield"(%foo) : (i32) -> ()
}
// CHECK: "foo.region"
"foo.region"() ({
- // CHECK-NEXT: constant 1
- %foo = constant 1 : i32
+ // CHECK-NEXT: arith.constant 1
+ %foo = arith.constant 1 : i32
"foo.yield"(%foo) : (i32) -> ()
}) : () -> ()
func @use_before_def() {
// CHECK-NEXT: test.graph_region
test.graph_region {
- // CHECK-NEXT: addi %c1_i32, %c1_i32_0
- %0 = addi %1, %2 : i32
+ // CHECK-NEXT: arith.addi %c1_i32, %c1_i32_0
+ %0 = arith.addi %1, %2 : i32
- // CHECK-NEXT: constant 1
- // CHECK-NEXT: constant 1
- %1 = constant 1 : i32
- %2 = constant 1 : i32
+ // CHECK-NEXT: arith.constant 1
+ // CHECK-NEXT: arith.constant 1
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 1 : i32
// CHECK-NEXT: "foo.yield"(%0) : (i32) -> ()
"foo.yield"(%0) : (i32) -> ()
// Inline a function that takes an argument.
func @func_with_arg(%c : i32) -> i32 {
- %b = addi %c, %c : i32
+ %b = arith.addi %c, %c : i32
return %b : i32
}
// CHECK-LABEL: func @inline_with_arg
func @inline_with_arg(%arg0 : i32) -> i32 {
- // CHECK-NEXT: addi
+ // CHECK-NEXT: arith.addi
// CHECK-NEXT: return
%0 = call @func_with_arg(%arg0) : (i32) -> i32
cond_br %a, ^bb1, ^bb2
^bb1:
- %const_0 = constant 0 : i32
+ %const_0 = arith.constant 0 : i32
return %const_0 : i32
^bb2:
- %const_55 = constant 55 : i32
+ %const_55 = arith.constant 55 : i32
return %const_55 : i32
}
// CHECK-LABEL: func @inline_with_multi_return() -> i32
func @inline_with_multi_return() -> i32 {
-// CHECK-NEXT: [[VAL_7:%.*]] = constant false
+// CHECK-NEXT: [[VAL_7:%.*]] = arith.constant false
// CHECK-NEXT: cond_br [[VAL_7]], ^bb1, ^bb2
// CHECK: ^bb1:
-// CHECK-NEXT: [[VAL_8:%.*]] = constant 0 : i32
+// CHECK-NEXT: [[VAL_8:%.*]] = arith.constant 0 : i32
// CHECK-NEXT: br ^bb3([[VAL_8]] : i32)
// CHECK: ^bb2:
-// CHECK-NEXT: [[VAL_9:%.*]] = constant 55 : i32
+// CHECK-NEXT: [[VAL_9:%.*]] = arith.constant 55 : i32
// CHECK-NEXT: br ^bb3([[VAL_9]] : i32)
// CHECK: ^bb3([[VAL_10:%.*]]: i32):
// CHECK-NEXT: return [[VAL_10]] : i32
- %false = constant false
+ %false = arith.constant false
%x = call @func_with_multi_return(%false) : (i1) -> i32
return %x : i32
}
// Check that location information is updated for inlined instructions.
func @func_with_locations(%c : i32) -> i32 {
- %b = addi %c, %c : i32 loc("mysource.cc":10:8)
+ %b = arith.addi %c, %c : i32 loc("mysource.cc":10:8)
return %b : i32 loc("mysource.cc":11:2)
}
// INLINE-LOC-LABEL: func @inline_with_locations
func @inline_with_locations(%arg0 : i32) -> i32 {
- // INLINE-LOC-NEXT: addi %{{.*}}, %{{.*}} : i32 loc(callsite("mysource.cc":10:8 at "mysource.cc":55:14))
+ // INLINE-LOC-NEXT: arith.addi %{{.*}}, %{{.*}} : i32 loc(callsite("mysource.cc":10:8 at "mysource.cc":55:14))
// INLINE-LOC-NEXT: return
%0 = call @func_with_locations(%arg0) : (i32) -> i32 loc("mysource.cc":55:14)
return
}
func @convert_callee_fn_multi_res() -> (i32, i32) {
- %res = constant 0 : i32
+ %res = arith.constant 0 : i32
return %res, %res : i32, i32
}
// CHECK-LABEL: func @inline_convert_call
func @inline_convert_call() -> i16 {
- // CHECK: %[[INPUT:.*]] = constant
- %test_input = constant 0 : i16
+ // CHECK: %[[INPUT:.*]] = arith.constant
+ %test_input = arith.constant 0 : i16
// CHECK: %[[CAST_INPUT:.*]] = "test.cast"(%[[INPUT]]) : (i16) -> i32
// CHECK: %[[CAST_RESULT:.*]] = "test.cast"(%[[CAST_INPUT]]) : (i32) -> i16
func @convert_callee_fn_multiblock() -> i32 {
br ^bb0
^bb0:
- %0 = constant 0 : i32
+ %0 = arith.constant 0 : i32
return %0 : i32
}
func @inline_convert_result_multiblock() -> i16 {
// CHECK: br ^bb1 {inlined_conversion}
// CHECK: ^bb1:
-// CHECK: %[[C:.+]] = constant {inlined_conversion} 0 : i32
+// CHECK: %[[C:.+]] = arith.constant {inlined_conversion} 0 : i32
// CHECK: br ^bb2(%[[C]] : i32)
// CHECK: ^bb2(%[[BBARG:.+]]: i32):
// CHECK: %[[CAST_RESULT:.+]] = "test.cast"(%[[BBARG]]) : (i32) -> i16
// CHECK-LABEL: func @no_inline_convert_call
func @no_inline_convert_call() {
// CHECK: "test.conversion_call_op"
- %test_input_i16 = constant 0 : i16
- %test_input_i64 = constant 0 : i64
+ %test_input_i16 = arith.constant 0 : i16
+ %test_input_i64 = arith.constant 0 : i64
"test.conversion_call_op"(%test_input_i16, %test_input_i64) { callee=@convert_callee_fn_multi_arg } : (i16, i64) -> ()
// CHECK: "test.conversion_call_op"
// Check that we properly simplify when inlining.
func @simplify_return_constant() -> i32 {
- %res = constant 0 : i32
+ %res = arith.constant 0 : i32
return %res : i32
}
// INLINE_SIMPLIFY-LABEL: func @inline_simplify
func @inline_simplify() -> i32 {
- // INLINE_SIMPLIFY-NEXT: %[[CST:.*]] = constant 0 : i32
+ // INLINE_SIMPLIFY-NEXT: %[[CST:.*]] = arith.constant 0 : i32
// INLINE_SIMPLIFY-NEXT: return %[[CST]]
%fn = call @simplify_return_reference() : () -> (() -> i32)
%res = call_indirect %fn() : () -> i32
func @one_3d_nest() {
// Capture original bounds. Note that for zero-based step-one loops, the
// upper bound is also the number of iterations.
- // CHECK: %[[orig_lb:.*]] = constant 0
- // CHECK: %[[orig_step:.*]] = constant 1
- // CHECK: %[[orig_ub_k:.*]] = constant 3
- // CHECK: %[[orig_ub_i:.*]] = constant 42
- // CHECK: %[[orig_ub_j:.*]] = constant 56
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c42 = constant 42 : index
- %c56 = constant 56 : index
+ // CHECK: %[[orig_lb:.*]] = arith.constant 0
+ // CHECK: %[[orig_step:.*]] = arith.constant 1
+ // CHECK: %[[orig_ub_k:.*]] = arith.constant 3
+ // CHECK: %[[orig_ub_i:.*]] = arith.constant 42
+ // CHECK: %[[orig_ub_j:.*]] = arith.constant 56
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c42 = arith.constant 42 : index
+ %c56 = arith.constant 56 : index
// The range of the new scf.
- // CHECK: %[[partial_range:.*]] = muli %[[orig_ub_i]], %[[orig_ub_j]]
- // CHECK-NEXT:%[[range:.*]] = muli %[[partial_range]], %[[orig_ub_k]]
+ // CHECK: %[[partial_range:.*]] = arith.muli %[[orig_ub_i]], %[[orig_ub_j]]
+ // CHECK-NEXT:%[[range:.*]] = arith.muli %[[partial_range]], %[[orig_ub_k]]
// Updated loop bounds.
// CHECK: scf.for %[[i:.*]] = %[[orig_lb]] to %[[range]] step %[[orig_step]]
// CHECK-NOT: scf.for
// Reconstruct original IVs from the linearized one.
- // CHECK: %[[orig_k:.*]] = remi_signed %[[i]], %[[orig_ub_k]]
- // CHECK: %[[div:.*]] = divi_signed %[[i]], %[[orig_ub_k]]
- // CHECK: %[[orig_j:.*]] = remi_signed %[[div]], %[[orig_ub_j]]
- // CHECK: %[[orig_i:.*]] = divi_signed %[[div]], %[[orig_ub_j]]
+ // CHECK: %[[orig_k:.*]] = arith.remsi %[[i]], %[[orig_ub_k]]
+ // CHECK: %[[div:.*]] = arith.divsi %[[i]], %[[orig_ub_k]]
+ // CHECK: %[[orig_j:.*]] = arith.remsi %[[div]], %[[orig_ub_j]]
+ // CHECK: %[[orig_i:.*]] = arith.divsi %[[div]], %[[orig_ub_j]]
scf.for %j = %c0 to %c56 step %c1 {
scf.for %k = %c0 to %c3 step %c1 {
// CHECK: "use"(%[[orig_i]], %[[orig_j]], %[[orig_k]])
// CHECK-LABEL: @multi_use
func @multi_use() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
// CHECK: scf.for %[[iv:.*]] =
scf.for %i = %c1 to %c10 step %c1 {
scf.for %j = %c1 to %c10 step %c1 {
scf.for %k = %c1 to %c10 step %c1 {
- // CHECK: %[[k_unshifted:.*]] = remi_signed %[[iv]], %[[k_extent:.*]]
- // CHECK: %[[ij:.*]] = divi_signed %[[iv]], %[[k_extent]]
- // CHECK: %[[j_unshifted:.*]] = remi_signed %[[ij]], %[[j_extent:.*]]
- // CHECK: %[[i_unshifted:.*]] = divi_signed %[[ij]], %[[j_extent]]
- // CHECK: %[[k:.*]] = addi %[[k_unshifted]]
- // CHECK: %[[j:.*]] = addi %[[j_unshifted]]
- // CHECK: %[[i:.*]] = addi %[[i_unshifted]]
+ // CHECK: %[[k_unshifted:.*]] = arith.remsi %[[iv]], %[[k_extent:.*]]
+ // CHECK: %[[ij:.*]] = arith.divsi %[[iv]], %[[k_extent]]
+ // CHECK: %[[j_unshifted:.*]] = arith.remsi %[[ij]], %[[j_extent:.*]]
+ // CHECK: %[[i_unshifted:.*]] = arith.divsi %[[ij]], %[[j_extent]]
+ // CHECK: %[[k:.*]] = arith.addi %[[k_unshifted]]
+ // CHECK: %[[j:.*]] = arith.addi %[[j_unshifted]]
+ // CHECK: %[[i:.*]] = arith.addi %[[i_unshifted]]
// CHECK: "use1"(%[[i]], %[[j]], %[[k]])
"use1"(%i,%j,%k) : (index,index,index) -> ()
}
func @unnormalized_loops() {
- // CHECK: %[[orig_step_i:.*]] = constant 2
- // CHECK: %[[orig_step_j:.*]] = constant 3
- // CHECK: %[[orig_lb_i:.*]] = constant 5
- // CHECK: %[[orig_lb_j:.*]] = constant 7
- // CHECK: %[[orig_ub_i:.*]] = constant 10
- // CHECK: %[[orig_ub_j:.*]] = constant 17
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c5 = constant 5 : index
- %c7 = constant 7 : index
- %c10 = constant 10 : index
- %c17 = constant 17 : index
+ // CHECK: %[[orig_step_i:.*]] = arith.constant 2
+ // CHECK: %[[orig_step_j:.*]] = arith.constant 3
+ // CHECK: %[[orig_lb_i:.*]] = arith.constant 5
+ // CHECK: %[[orig_lb_j:.*]] = arith.constant 7
+ // CHECK: %[[orig_ub_i:.*]] = arith.constant 10
+ // CHECK: %[[orig_ub_j:.*]] = arith.constant 17
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c5 = arith.constant 5 : index
+ %c7 = arith.constant 7 : index
+ %c10 = arith.constant 10 : index
+ %c17 = arith.constant 17 : index
// Number of iterations in the outer scf.
- // CHECK: %[[diff_i:.*]] = subi %[[orig_ub_i]], %[[orig_lb_i]]
- // CHECK: %[[c1:.*]] = constant 1
- // CHECK: %[[step_minus_c1:.*]] = subi %[[orig_step_i]], %[[c1]]
- // CHECK: %[[dividend:.*]] = addi %[[diff_i]], %[[step_minus_c1]]
- // CHECK: %[[numiter_i:.*]] = divi_signed %[[dividend]], %[[orig_step_i]]
+ // CHECK: %[[diff_i:.*]] = arith.subi %[[orig_ub_i]], %[[orig_lb_i]]
+ // CHECK: %[[c1:.*]] = arith.constant 1
+ // CHECK: %[[step_minus_c1:.*]] = arith.subi %[[orig_step_i]], %[[c1]]
+ // CHECK: %[[dividend:.*]] = arith.addi %[[diff_i]], %[[step_minus_c1]]
+ // CHECK: %[[numiter_i:.*]] = arith.divsi %[[dividend]], %[[orig_step_i]]
// Normalized lower bound and step for the outer scf.
- // CHECK: %[[lb_i:.*]] = constant 0
- // CHECK: %[[step_i:.*]] = constant 1
+ // CHECK: %[[lb_i:.*]] = arith.constant 0
+ // CHECK: %[[step_i:.*]] = arith.constant 1
// Number of iterations in the inner loop, the pattern is the same as above,
// only capture the final result.
- // CHECK: %[[numiter_j:.*]] = divi_signed {{.*}}, %[[orig_step_j]]
+ // CHECK: %[[numiter_j:.*]] = arith.divsi {{.*}}, %[[orig_step_j]]
// New bounds of the outer scf.
- // CHECK: %[[range:.*]] = muli %[[numiter_i]], %[[numiter_j]]
+ // CHECK: %[[range:.*]] = arith.muli %[[numiter_i]], %[[numiter_j]]
// CHECK: scf.for %[[i:.*]] = %[[lb_i]] to %[[range]] step %[[step_i]]
scf.for %i = %c5 to %c10 step %c2 {
// The inner loop has been removed.
// CHECK-NOT: scf.for
scf.for %j = %c7 to %c17 step %c3 {
// The IVs are rewritten.
- // CHECK: %[[normalized_j:.*]] = remi_signed %[[i]], %[[numiter_j]]
- // CHECK: %[[normalized_i:.*]] = divi_signed %[[i]], %[[numiter_j]]
- // CHECK: %[[scaled_j:.*]] = muli %[[normalized_j]], %[[orig_step_j]]
- // CHECK: %[[orig_j:.*]] = addi %[[scaled_j]], %[[orig_lb_j]]
- // CHECK: %[[scaled_i:.*]] = muli %[[normalized_i]], %[[orig_step_i]]
- // CHECK: %[[orig_i:.*]] = addi %[[scaled_i]], %[[orig_lb_i]]
+ // CHECK: %[[normalized_j:.*]] = arith.remsi %[[i]], %[[numiter_j]]
+ // CHECK: %[[normalized_i:.*]] = arith.divsi %[[i]], %[[numiter_j]]
+ // CHECK: %[[scaled_j:.*]] = arith.muli %[[normalized_j]], %[[orig_step_j]]
+ // CHECK: %[[orig_j:.*]] = arith.addi %[[scaled_j]], %[[orig_lb_j]]
+ // CHECK: %[[scaled_i:.*]] = arith.muli %[[normalized_i]], %[[orig_step_i]]
+ // CHECK: %[[orig_i:.*]] = arith.addi %[[scaled_i]], %[[orig_lb_i]]
// CHECK: "use"(%[[orig_i]], %[[orig_j]])
"use"(%i, %j) : (index, index) -> ()
}
%lb2 : index, %ub2 : index, %step2 : index) {
// Compute the number of iterations for each of the loops and the total
// number of iterations.
- // CHECK: %[[range1:.*]] = subi %[[orig_ub1]], %[[orig_lb1]]
- // CHECK: %[[orig_step1_minus_1:.*]] = subi %[[orig_step1]], %c1
- // CHECK: %[[dividend1:.*]] = addi %[[range1]], %[[orig_step1_minus_1]]
- // CHECK: %[[numiter1:.*]] = divi_signed %[[dividend1]], %[[orig_step1]]
- // CHECK: %[[range2:.*]] = subi %[[orig_ub2]], %[[orig_lb2]]
- // CHECK: %[[orig_step2_minus_1:.*]] = subi %arg5, %c1
- // CHECK: %[[dividend2:.*]] = addi %[[range2]], %[[orig_step2_minus_1]]
- // CHECK: %[[numiter2:.*]] = divi_signed %[[dividend2]], %[[orig_step2]]
- // CHECK: %[[range:.*]] = muli %[[numiter1]], %[[numiter2]] : index
+ // CHECK: %[[range1:.*]] = arith.subi %[[orig_ub1]], %[[orig_lb1]]
+ // CHECK: %[[orig_step1_minus_1:.*]] = arith.subi %[[orig_step1]], %c1
+ // CHECK: %[[dividend1:.*]] = arith.addi %[[range1]], %[[orig_step1_minus_1]]
+ // CHECK: %[[numiter1:.*]] = arith.divsi %[[dividend1]], %[[orig_step1]]
+ // CHECK: %[[range2:.*]] = arith.subi %[[orig_ub2]], %[[orig_lb2]]
+ // CHECK: %[[orig_step2_minus_1:.*]] = arith.subi %arg5, %c1
+ // CHECK: %[[dividend2:.*]] = arith.addi %[[range2]], %[[orig_step2_minus_1]]
+ // CHECK: %[[numiter2:.*]] = arith.divsi %[[dividend2]], %[[orig_step2]]
+ // CHECK: %[[range:.*]] = arith.muli %[[numiter1]], %[[numiter2]] : index
// Check that the outer loop is updated.
// CHECK: scf.for %[[i:.*]] = %c0{{.*}} to %[[range]] step %c1
// CHECK-NOT: scf.for
scf.for %j = %lb2 to %ub2 step %step2 {
// Remapping of the induction variables.
- // CHECK: %[[normalized_j:.*]] = remi_signed %[[i]], %[[numiter2]] : index
- // CHECK: %[[normalized_i:.*]] = divi_signed %[[i]], %[[numiter2]] : index
- // CHECK: %[[scaled_j:.*]] = muli %[[normalized_j]], %[[orig_step2]]
- // CHECK: %[[orig_j:.*]] = addi %[[scaled_j]], %[[orig_lb2]]
- // CHECK: %[[scaled_i:.*]] = muli %[[normalized_i]], %[[orig_step1]]
- // CHECK: %[[orig_i:.*]] = addi %[[scaled_i]], %[[orig_lb1]]
+ // CHECK: %[[normalized_j:.*]] = arith.remsi %[[i]], %[[numiter2]] : index
+ // CHECK: %[[normalized_i:.*]] = arith.divsi %[[i]], %[[numiter2]] : index
+ // CHECK: %[[scaled_j:.*]] = arith.muli %[[normalized_j]], %[[orig_step2]]
+ // CHECK: %[[orig_j:.*]] = arith.addi %[[scaled_j]], %[[orig_lb2]]
+ // CHECK: %[[scaled_i:.*]] = arith.muli %[[normalized_i]], %[[orig_step1]]
+ // CHECK: %[[orig_i:.*]] = arith.addi %[[scaled_i]], %[[orig_lb1]]
// CHECK: "foo"(%[[orig_i]], %[[orig_j]])
"foo"(%i, %j) : (index, index) -> ()
// CHECK-LABEL: @two_bands
func @two_bands() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c10 = constant 10 : index
- // CHECK: %[[outer_range:.*]] = muli
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c10 = arith.constant 10 : index
+ // CHECK: %[[outer_range:.*]] = arith.muli
// CHECK: scf.for %{{.*}} = %{{.*}} to %[[outer_range]]
scf.for %i = %c0 to %c10 step %c1 {
// Check that the "j" loop was removed and that the inner loops were
// coalesced as well. The preparation step for coalescing will inject the
// subtraction operation unlike the IV remapping.
// CHECK-NOT: scf.for
- // CHECK: subi
+ // CHECK: arith.subi
scf.for %j = %c0 to %c10 step %c1 {
// The inner pair of loops is coalesced separately.
// CHECK: scf.for
// CHECK-DAG: #[[MOD:.*]] = affine_map<(d0)[s0] -> (d0 mod s0)>
// CHECK-DAG: #[[FLOOR:.*]] = affine_map<(d0)[s0] -> (d0 floordiv s0)>
func @coalesce_affine_for(%arg0: memref<?x?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %arg0, %c0 : memref<?x?xf32>
%N = memref.dim %arg0, %c0 : memref<?x?xf32>
%K = memref.dim %arg0, %c0 : memref<?x?xf32>
// CHECK-DAG: #[[MOD:.*]] = affine_map<(d0)[s0] -> (d0 mod s0)>
// CHECK-DAG: #[[DIV:.*]] = affine_map<(d0)[s0] -> (d0 floordiv s0)>
func @coalesce_affine_for(%arg0: memref<?x?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %arg0, %c0 : memref<?x?xf32>
%N = memref.dim %arg0, %c0 : memref<?x?xf32>
affine.for %i = 0 to %M {
// CHECK-DAG: #[[DIV:.*]] = affine_map<(d0)[s0] -> (d0 floordiv s0)>
#myMap = affine_map<()[s1] -> (s1, -s1)>
func @coalesce_affine_for(%arg0: memref<?x?xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%M = memref.dim %arg0, %c0 : memref<?x?xf32>
%N = memref.dim %arg0, %c0 : memref<?x?xf32>
%K = memref.dim %arg0, %c0 : memref<?x?xf32>
// CHECK-LABEL: func @should_fuse_at_depth_above_loop_carried_dependence(%{{.*}}: memref<64x4xf32>, %{{.*}}: memref<64x4xf32>) {
func @should_fuse_at_depth_above_loop_carried_dependence(%arg0: memref<64x4xf32>, %arg1: memref<64x4xf32>) {
%out = memref.alloc() : memref<64x4xf32>
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 64 {
affine.for %i1 = 0 to 4 {
affine.store %0, %out[%i0, %i1] : memref<64x4xf32>
affine.for %i7 = 0 to 16 {
%r = "op2"() : () -> (f32)
%v = affine.load %out[16 * %i5 + %i7, %i2] : memref<64x4xf32>
- %s = addf %v, %r : f32
+ %s = arith.addf %v, %r : f32
affine.store %s, %out[16 * %i5 + %i7, %i2] : memref<64x4xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 16 {
// CHECK-NEXT: %{{.*}} = "op2"() : () -> f32
// CHECK: affine.load %{{.*}}[%{{.*}} * 16 + %{{.*}}, 0] : memref<64x1xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK: affine.store %{{.*}}, %{{.*}}[%{{.*}} * 16 + %{{.*}}, 0] : memref<64x1xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %a[%i0] : memref<10xf32>
func @should_fuse_after_one_loop_interchange() {
%a = memref.alloc() : memref<10xf32>
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf0, %a[%i0] : memref<10xf32>
}
func @should_fuse_after_two_loop_interchanges() {
%a = memref.alloc() : memref<6x8xf32>
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 6 {
affine.for %i1 = 0 to 8 {
affine.store %cf0, %a[%i0, %i1] : memref<6x8xf32>
affine.for %i4 = 0 to 2 {
affine.for %i5 = 0 to 8 {
%v0 = affine.load %a[%i3, %i5] : memref<6x8xf32>
- %v1 = addf %v0, %v0 : f32
+ %v1 = arith.addf %v0, %v0 : f32
affine.store %v1, %a[%i3, %i5] : memref<6x8xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 4 {
// CHECK-NEXT: affine.for %{{.*}} = 0 to 2 {
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// -----
func @should_fuse_live_out_writer(%arg0 : memref<10xf32>) -> memref<10xf32> {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %arg0[%i0] : memref<10xf32>
}
}
return %arg0 : memref<10xf32>
- // CHECK: %{{.*}} = constant 0.000000e+00 : f32
+ // CHECK: %{{.*}} = arith.constant 0.000000e+00 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
}
affine.for %ii = 0 to 16 {
%v = affine.load %arg1[16 * %i + %ii, %j] : memref<32x8xf32>
- %s = addf %v, %v : f32
+ %s = arith.addf %v, %v : f32
affine.store %s, %arg1[16 * %i + %ii, %j] : memref<32x8xf32>
}
}
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 16 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}} * 16 + %{{.*}}, %{{.*}}] : memref<32x8xf32>
-// CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}} * 16 + %{{.*}}, %{{.*}}] : memref<32x8xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
func @test_add_slice_bounds() {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %c0 = constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
+ %c0 = arith.constant 0 : index
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
func @should_fuse_init_loops_siblings_then_shared_producer(%arg0: memref<10x10xf32>, %arg1: memref<10x10xf32>) {
%0 = memref.alloc() : memref<10x10xf32>
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
- %cst_1 = constant 7.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
+ %cst_1 = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
affine.store %cst_1, %0[%i0, %i1] : memref<10x10xf32>
affine.for %i5 = 0 to 3 {
%1 = affine.load %0[%i4, %i5] : memref<10x10xf32>
%2 = affine.load %arg0[%i4, %i5] : memref<10x10xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
affine.store %3, %arg0[%i4, %i5] : memref<10x10xf32>
}
}
affine.for %i9 = 0 to 3 {
%4 = affine.load %0[%i8, %i9] : memref<10x10xf32>
%5 = affine.load %arg1[%i8, %i9] : memref<10x10xf32>
- %6 = addf %4, %5 : f32
+ %6 = arith.addf %4, %5 : f32
affine.store %6, %arg1[%i8, %i9] : memref<10x10xf32>
}
}
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
-// CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
%in_vec1 = memref.alloc() : memref<10xf32>
%out_vec0 = memref.alloc() : memref<10xf32>
%out_vec1 = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Populate input matrix.
affine.for %i0 = 0 to 10 {
affine.for %i3 = 0 to 10 {
%v0 = affine.load %in_matrix[%i2, %i3] : memref<10x10xf32>
%v1 = affine.load %in_vec0[%i3] : memref<10xf32>
- %v2 = mulf %v0, %v1 : f32
+ %v2 = arith.mulf %v0, %v1 : f32
%v3 = affine.load %out_vec0[%i3] : memref<10xf32>
- %v4 = addf %v2, %v3 : f32
+ %v4 = arith.addf %v2, %v3 : f32
affine.store %v4, %out_vec0[%i3] : memref<10xf32>
}
}
affine.for %i5 = 0 to 10 {
%v5 = affine.load %in_matrix[%i4, %i5] : memref<10x10xf32>
%v6 = affine.load %in_vec1[%i5] : memref<10xf32>
- %v7 = mulf %v5, %v6 : f32
+ %v7 = arith.mulf %v5, %v6 : f32
%v8 = affine.load %out_vec1[%i5] : memref<10xf32>
- %v9 = addf %v7, %v8 : f32
+ %v9 = arith.addf %v7, %v8 : f32
affine.store %v9, %out_vec1[%i5] : memref<10xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, 0] : memref<10x1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
-// CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
-// CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, 0] : memref<10x1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
-// CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
-// CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+// CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
#map0 = affine_map<(d0, d1) -> (d0 * 16 + d1)>
func @fuse_across_dim_mismatch(%arg0: memref<4x4x16x1xf32>, %arg1: memref<144x9xf32>, %arg2: memref<9xf32>) {
%1 = memref.alloc() : memref<144x4xf32>
- %2 = constant 0.0 : f32
+ %2 = arith.constant 0.0 : f32
affine.for %i2 = 0 to 9 {
affine.for %i3 = 0 to 4 {
affine.for %i5 = 0 to 16 {
#map11 = affine_map<(d0, d1) -> (d0 * 16 + d1)>
#map12 = affine_map<(d0, d1) -> (d0 * 16 - d1 + 15)>
func @fuse_across_varying_dims_complex(%arg0: f32) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<2x2x3x3x16x1xf32>
%1 = memref.alloc() : memref<64x9xf32>
%2 = memref.alloc() : memref<144x4xf32>
// MAXIMAL-DAG: [[$MAP8:#map[0-9]+]] = affine_map<(d0, d1) -> (d0 * 16 - d1 + 15)>
// MAXIMAL-LABEL: func @fuse_across_varying_dims_complex
// MAXIMAL-NEXT: memref.alloc() : memref<64x1xf32>
-// MAXIMAL-NEXT: constant 0 : index
+// MAXIMAL-NEXT: arith.constant 0 : index
// MAXIMAL-NEXT: memref.alloc() : memref<2x2x3x3x16x1xf32>
// MAXIMAL-NEXT: memref.alloc() : memref<144x4xf32>
// MAXIMAL-NEXT: affine.for %{{.*}} = 0 to 9 {
func @should_fuse_with_slice_union() {
%a = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %cf0, %a[%i0]: memref<100xf32>
affine.for %i3 = 0 to 1024 {
%0 = affine.load %arg3[%i2, %i3] : memref<1024x1024xf32>
%1 = affine.load %arg2[%i2, %i3] : memref<1024x1024xf32>
- %2 = addf %1, %0 : f32
+ %2 = arith.addf %1, %0 : f32
affine.store %2, %arg2[%i2, %i3] : memref<1024x1024xf32>
}
}
affine.for %i6 = 0 to 1024 {
%3 = affine.load %arg1[%i6, %i5] : memref<1024x1024xf32>
%4 = affine.load %arg0[%i4, %i6] : memref<1024x1024xf32>
- %5 = mulf %4, %3 : f32
+ %5 = arith.mulf %4, %3 : f32
%6 = affine.load %arg2[%i4, %i5] : memref<1024x1024xf32>
- %7 = addf %6, %5 : f32
+ %7 = arith.addf %6, %5 : f32
affine.store %7, %arg2[%i4, %i5] : memref<1024x1024xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// -----
func @affine_2mm_fused(%arg0: memref<1024x1024xf32>, %arg1: memref<1024x1024xf32>, %arg2: memref<1024x1024xf32>, %arg3: memref<1024x1024xf32>, %arg4: memref<1024x1024xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 1024 {
affine.for %i1 = 0 to 1024 {
affine.store %cst, %arg2[%i0, %i1] : memref<1024x1024xf32>
affine.for %i6 = 0 to 1024 {
%0 = affine.load %arg1[%i6, %i5] : memref<1024x1024xf32>
%1 = affine.load %arg0[%i4, %i6] : memref<1024x1024xf32>
- %2 = mulf %1, %0 : f32
+ %2 = arith.mulf %1, %0 : f32
%3 = affine.load %arg2[%i4, %i5] : memref<1024x1024xf32>
- %4 = addf %3, %2 : f32
+ %4 = arith.addf %3, %2 : f32
affine.store %4, %arg2[%i4, %i5] : memref<1024x1024xf32>
}
}
affine.for %i9 = 0 to 1024 {
%5 = affine.load %arg1[%i9, %i8] : memref<1024x1024xf32>
%6 = affine.load %arg0[%i7, %i9] : memref<1024x1024xf32>
- %7 = mulf %6, %5 : f32
+ %7 = arith.mulf %6, %5 : f32
%8 = affine.load %arg4[%i7, %i8] : memref<1024x1024xf32>
- %9 = addf %8, %7 : f32
+ %9 = arith.addf %8, %7 : f32
affine.store %9, %arg4[%i7, %i8] : memref<1024x1024xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
affine.for %i2 = 0 to 1024 {
%0 = affine.load %arg1[%i2, %i1] : memref<1024x1024xf32>
%1 = affine.load %arg0[%i0, %i2] : memref<1024x1024xf32>
- %2 = mulf %1, %0 : f32
+ %2 = arith.mulf %1, %0 : f32
%3 = affine.load %arg2[%i0, %i1] : memref<1024x1024xf32>
- %4 = addf %3, %2 : f32
+ %4 = arith.addf %3, %2 : f32
affine.store %4, %arg2[%i0, %i1] : memref<1024x1024xf32>
}
}
affine.for %i5 = 0 to 1024 {
%5 = affine.load %arg3[%i5, %i4] : memref<1024x1024xf32>
%6 = affine.load %arg2[%i3, %i5] : memref<1024x1024xf32>
- %7 = mulf %6, %5 : f32
+ %7 = arith.mulf %6, %5 : f32
%8 = affine.load %arg4[%i3, %i4] : memref<1024x1024xf32>
- %9 = addf %8, %7 : f32
+ %9 = arith.addf %8, %7 : f32
affine.store %9, %arg4[%i3, %i4] : memref<1024x1024xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %{{.*}} = 0 to 1024 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<1024x1024xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
func @should_fuse_self_dependence_multi_store_producer() {
%m = memref.alloc() : memref<10xf32>
%local_m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %local_m[%i0] : memref<10xf32>
func @should_fuse_dead_multi_store_producer() {
%m = memref.alloc() : memref<10xf32>
%dead_m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %dead_m[%i0] : memref<10xf32>
// CHECK-LABEL: func @should_fuse_function_live_out_multi_store_producer
func @should_fuse_function_live_out_multi_store_producer(%live_in_out_m : memref<10xf32>) {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %live_in_out_m[%i0] : memref<10xf32>
// Test case from github bug 777.
// CHECK-LABEL: func @mul_add_0
func @mul_add_0(%arg0: memref<3x4xf32>, %arg1: memref<4x3xf32>, %arg2: memref<3x3xf32>, %arg3: memref<3x3xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
%0 = memref.alloc() : memref<3x3xf32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
affine.for %arg6 = 0 to 4 {
%1 = affine.load %arg1[%arg6, %arg5] : memref<4x3xf32>
%2 = affine.load %arg0[%arg4, %arg6] : memref<3x4xf32>
- %3 = mulf %2, %1 : f32
+ %3 = arith.mulf %2, %1 : f32
%4 = affine.load %0[%arg4, %arg5] : memref<3x3xf32>
- %5 = addf %4, %3 : f32
+ %5 = arith.addf %4, %3 : f32
affine.store %5, %0[%arg4, %arg5] : memref<3x3xf32>
}
}
affine.for %arg5 = 0 to 3 {
%6 = affine.load %arg2[%arg4, %arg5] : memref<3x3xf32>
%7 = affine.load %0[%arg4, %arg5] : memref<3x3xf32>
- %8 = addf %7, %6 : f32
+ %8 = arith.addf %7, %6 : f32
affine.store %8, %arg3[%arg4, %arg5] : memref<3x3xf32>
}
}
// CHECK-NEXT: affine.for %[[i2:.*]] = 0 to 4 {
// CHECK-NEXT: affine.load %{{.*}}[%[[i2]], %[[i1]]] : memref<4x3xf32>
// CHECK-NEXT: affine.load %{{.*}}[%[[i0]], %[[i2]]] : memref<3x4xf32>
- // CHECK-NEXT: mulf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.mulf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0, 0] : memref<1x1xf32>
// CHECK-NEXT: }
// CHECK-NEXT: affine.load %{{.*}}[%[[i0]], %[[i1]]] : memref<3x3xf32>
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%[[i0]], %[[i1]]] : memref<3x3xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-LABEL: func @should_fuse_multi_outgoing_edge_store_producer
func @should_fuse_multi_outgoing_edge_store_producer(%a : memref<1xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %arg0 = 0 to 1 {
affine.store %cst, %a[%arg0] : memref<1xf32>
}
// CHECK-LABEL: func @should_fuse_producer_with_multi_outgoing_edges
func @should_fuse_producer_with_multi_outgoing_edges(%a : memref<1xf32>, %b : memref<1xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %arg0 = 0 to 1 {
%0 = affine.load %a[%arg0] : memref<1xf32>
affine.store %cst, %b[%arg0] : memref<1xf32>
affine.for %k = 0 to 1024 {
%0 = affine.load %rhs[%k, %j] : memref<1024x1024xf32>
%1 = affine.load %lhs[%i, %k] : memref<1024x1024xf32>
- %2 = mulf %1, %0 : f32
+ %2 = arith.mulf %1, %0 : f32
%3 = affine.load %out[%i, %j] : memref<1024x1024xf32>
- %4 = addf %3, %2 : f32
+ %4 = arith.addf %3, %2 : f32
affine.store %4, %out[%i, %j] : memref<1024x1024xf32>
}
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = addf %lhs, %rhs : f32
+ %add = arith.addf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = subf %lhs, %rhs : f32
+ %add = arith.subf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = mulf %lhs, %rhs : f32
+ %add = arith.mulf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = divf %lhs, %rhs : f32
+ %add = arith.divf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
return
// CHECK: affine.for
// CHECK-NOT: affine.for
-// CHECK: addf
+// CHECK: arith.addf
// CHECK-NOT: affine.for
-// CHECK: subf
+// CHECK: arith.subf
// CHECK-NOT: affine.for
-// CHECK: mulf
+// CHECK: arith.mulf
// CHECK-NOT: affine.for
-// CHECK: divf
+// CHECK: arith.divf
// -----
// CHECK-LABEL: func @calc
func @calc(%arg0: memref<?xf32>, %arg1: memref<?xf32>, %arg2: memref<?xf32>, %len: index) {
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%1 = memref.alloc(%len) : memref<?xf32>
affine.for %arg4 = 1 to 10 {
%7 = affine.load %arg0[%arg4] : memref<?xf32>
%8 = affine.load %arg1[%arg4] : memref<?xf32>
- %9 = addf %7, %8 : f32
+ %9 = arith.addf %7, %8 : f32
affine.store %9, %1[%arg4] : memref<?xf32>
}
affine.for %arg4 = 1 to 10 {
%7 = affine.load %1[%arg4] : memref<?xf32>
%8 = affine.load %arg1[%arg4] : memref<?xf32>
- %9 = mulf %7, %8 : f32
+ %9 = arith.mulf %7, %8 : f32
affine.store %9, %arg2[%arg4] : memref<?xf32>
}
return
// CHECK: affine.for %arg{{.*}} = 1 to 10 {
// CHECK-NEXT: affine.load %arg{{.*}}
// CHECK-NEXT: affine.load %arg{{.*}}
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: affine.load %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: affine.load %arg{{.*}}[%arg{{.*}}] : memref<?xf32>
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.store %{{.*}}, %arg{{.*}}[%arg{{.*}}] : memref<?xf32>
// CHECK-NEXT: }
// CHECK-NEXT: return
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = addf %lhs, %rhs : f32
+ %add = arith.addf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = memref.load %in0[%d] : memref<32xf32>
%rhs = memref.load %in1[%d] : memref<32xf32>
- %add = subf %lhs, %rhs : f32
+ %add = arith.subf %lhs, %rhs : f32
memref.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = mulf %lhs, %rhs : f32
+ %add = arith.mulf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
return
}
// CHECK: affine.for
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: affine.for
-// CHECK: subf
+// CHECK: arith.subf
// CHECK: affine.for
-// CHECK: mulf
+// CHECK: arith.mulf
// -----
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = addf %lhs, %rhs : f32
+ %add = arith.addf %lhs, %rhs : f32
memref.store %add, %sum[] : memref<f32>
affine.store %add, %in0[%d] : memref<32xf32>
}
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = mulf %lhs, %rhs : f32
- %sub = subf %add, %load_sum: f32
+ %add = arith.mulf %lhs, %rhs : f32
+ %sub = arith.subf %add, %load_sum: f32
affine.store %sub, %in0[%d] : memref<32xf32>
}
memref.dealloc %sum : memref<f32>
}
// CHECK: affine.for
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: affine.for
-// CHECK: mulf
-// CHECK: subf
+// CHECK: arith.mulf
+// CHECK: arith.subf
// -----
// CHECK-LABEL: func @should_not_fuse_since_top_level_non_affine_mem_write_users
func @should_not_fuse_since_top_level_non_affine_mem_write_users(
%in0 : memref<32xf32>, %in1 : memref<32xf32>) {
- %c0 = constant 0 : index
- %cst_0 = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst_0 = arith.constant 0.000000e+00 : f32
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = addf %lhs, %rhs : f32
+ %add = arith.addf %lhs, %rhs : f32
affine.store %add, %in0[%d] : memref<32xf32>
}
memref.store %cst_0, %in0[%c0] : memref<32xf32>
affine.for %d = 0 to 32 {
%lhs = affine.load %in0[%d] : memref<32xf32>
%rhs = affine.load %in1[%d] : memref<32xf32>
- %add = addf %lhs, %rhs: f32
+ %add = arith.addf %lhs, %rhs: f32
affine.store %add, %in0[%d] : memref<32xf32>
}
return
}
// CHECK: affine.for
-// CHECK: addf
+// CHECK: arith.addf
// CHECK: affine.for
-// CHECK: addf
+// CHECK: arith.addf
// -----
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %arg0 = 0 to 10 {
affine.store %cst, %a[%arg0] : memref<10xf32>
affine.store %cst, %b[%arg0] : memref<10xf32>
func @should_fuse_multi_store_producer_with_escaping_memrefs_and_remove_src(
%a : memref<10xf32>, %b : memref<10xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %a[%i0] : memref<10xf32>
affine.store %cst, %b[%i0] : memref<10xf32>
func @should_fuse_multi_store_producer_with_escaping_memrefs_and_preserve_src(
%a : memref<10xf32>, %b : memref<10xf32>) {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %a[%i0] : memref<10xf32>
affine.store %cst, %b[%i0] : memref<10xf32>
func @should_not_fuse_due_to_dealloc(%arg0: memref<16xf32>){
%A = memref.alloc() : memref<16xf32>
%C = memref.alloc() : memref<16xf32>
- %cst_1 = constant 1.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
affine.for %arg1 = 0 to 16 {
%a = affine.load %arg0[%arg1] : memref<16xf32>
affine.store %a, %A[%arg1] : memref<16xf32>
%B = memref.alloc() : memref<16xf32>
affine.for %arg1 = 0 to 16 {
%a = affine.load %A[%arg1] : memref<16xf32>
- %b = addf %cst_1, %a : f32
+ %b = arith.addf %cst_1, %a : f32
affine.store %b, %B[%arg1] : memref<16xf32>
}
memref.dealloc %A : memref<16xf32>
// CHECK: memref.dealloc
// CHECK: affine.for
// CHECK-NEXT: affine.load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// -----
%0 = affine.load %b[] : memref<f32>
affine.for %i1 = 0 to 10 {
%1 = affine.load %a[%i1] : memref<10xf32>
- %2 = divf %0, %1 : f32
+ %2 = arith.divf %0, %1 : f32
}
// Loops '%i0' and '%i1' should be fused even though there is a defining
// CHECK-NEXT: affine.load %{{.*}}[] : memref<f32>
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
- // CHECK-NEXT: divf
+ // CHECK-NEXT: arith.divf
// CHECK-NEXT: }
// CHECK-NOT: affine.for
return
// CHECK-LABEL: func @should_not_fuse_defining_node_has_dependence_from_source_loop
func @should_not_fuse_defining_node_has_dependence_from_source_loop(
%a : memref<10xf32>, %b : memref<f32>) -> () {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %b[] : memref<f32>
affine.store %cst, %a[%i0] : memref<10xf32>
%0 = affine.load %b[] : memref<f32>
affine.for %i1 = 0 to 10 {
%1 = affine.load %a[%i1] : memref<10xf32>
- %2 = divf %0, %1 : f32
+ %2 = arith.divf %0, %1 : f32
}
// Loops '%i0' and '%i1' should not be fused because the defining node
// CHECK-NEXT: affine.load %{{.*}}[] : memref<f32>
// CHECK: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
- // CHECK-NEXT: divf
+ // CHECK-NEXT: arith.divf
// CHECK-NEXT: }
return
}
// CHECK-LABEL: func @should_not_fuse_defining_node_has_transitive_dependence_from_source_loop
func @should_not_fuse_defining_node_has_transitive_dependence_from_source_loop(
%a : memref<10xf32>, %b : memref<10xf32>, %c : memref<f32>) -> () {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %a[%i0] : memref<10xf32>
affine.store %cst, %b[%i0] : memref<10xf32>
%0 = affine.load %c[] : memref<f32>
affine.for %i2 = 0 to 10 {
%1 = affine.load %a[%i2] : memref<10xf32>
- %2 = divf %0, %1 : f32
+ %2 = arith.divf %0, %1 : f32
}
// When loops '%i0' and '%i2' are evaluated first, they should not be
// CHECK-NEXT: affine.load %{{.*}}[] : memref<f32>
// CHECK: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
- // CHECK-NEXT: divf
+ // CHECK-NEXT: arith.divf
// CHECK-NEXT: }
// CHECK-NOT: affine.for
return
// CHECK-LABEL: func @should_not_fuse_dest_loop_nest_return_value
func @should_not_fuse_dest_loop_nest_return_value(
%a : memref<10xf32>) -> () {
- %cst = constant 0.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %a[%i0] : memref<10xf32>
}
// CHECK-LABEL: func @should_not_fuse_src_loop_nest_return_value
func @should_not_fuse_src_loop_nest_return_value(
%a : memref<10xf32>) -> () {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
%b = affine.for %i = 0 to 10 step 2 iter_args(%b_iter = %cst) -> f32 {
- %c = addf %b_iter, %b_iter : f32
+ %c = arith.addf %b_iter, %b_iter : f32
affine.store %c, %a[%i] : memref<10xf32>
affine.yield %c: f32
}
}
// CHECK: %{{.*}} = affine.for %{{.*}} = 0 to 10 step 2 iter_args(%{{.*}} = %{{.*}}) -> (f32) {
- // CHECK-NEXT: %{{.*}} = addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: %{{.*}} = arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.yield %{{.*}} : f32
// CHECK-NEXT: }
func private @some_function(memref<16xf32>)
func @call_op_prevents_fusion(%arg0: memref<16xf32>){
%A = memref.alloc() : memref<16xf32>
- %cst_1 = constant 1.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
affine.for %arg1 = 0 to 16 {
%a = affine.load %arg0[%arg1] : memref<16xf32>
affine.store %a, %A[%arg1] : memref<16xf32>
%B = memref.alloc() : memref<16xf32>
affine.for %arg1 = 0 to 16 {
%a = affine.load %A[%arg1] : memref<16xf32>
- %b = addf %cst_1, %a : f32
+ %b = arith.addf %cst_1, %a : f32
affine.store %b, %B[%arg1] : memref<16xf32>
}
return
// CHECK: call
// CHECK: affine.for
// CHECK-NEXT: affine.load
-// CHECK-NEXT: addf
+// CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// -----
func private @some_function()
func @call_op_does_not_prevent_fusion(%arg0: memref<16xf32>){
%A = memref.alloc() : memref<16xf32>
- %cst_1 = constant 1.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
affine.for %arg1 = 0 to 16 {
%a = affine.load %arg0[%arg1] : memref<16xf32>
affine.store %a, %A[%arg1] : memref<16xf32>
%B = memref.alloc() : memref<16xf32>
affine.for %arg1 = 0 to 16 {
%a = affine.load %A[%arg1] : memref<16xf32>
- %b = addf %cst_1, %a : f32
+ %b = arith.addf %cst_1, %a : f32
affine.store %b, %B[%arg1] : memref<16xf32>
}
return
// This should enable both the consumers to benefit from fusion, which would not
// be possible if private memrefs were not created.
func @should_fuse_with_both_consumers_separately(%arg0: memref<10xf32>) {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %arg0[%i0] : memref<10xf32>
}
%A = memref.alloc() : memref<5xf32>
%B = memref.alloc() : memref<6xf32>
%C = memref.alloc() : memref<5xf32>
- %cst = constant 0. : f32
+ %cst = arith.constant 0. : f32
affine.for %arg0 = 0 to 5 {
%a = affine.load %A[%arg0] : memref<5xf32>
// }
%a = affine.load %B[%arg0] : memref<6xf32>
- %b = mulf %a, %cst : f32
+ %b = arith.mulf %a, %cst : f32
affine.store %b, %C[%arg0] : memref<5xf32>
}
return
// CHECK-NEXT: affine.store
// CHECK: affine.for
// CHECK-NEXT: affine.load
-// CHECK-NEXT: mulf
+// CHECK-NEXT: arith.mulf
// CHECK-NEXT: affine.store
// MAXIMAL-LABEL: func @reduce_add_f32_f32(
func @reduce_add_f32_f32(%arg0: memref<64x64xf32, 1>, %arg1: memref<1x64xf32, 1>, %arg2: memref<1x64xf32, 1>) {
- %cst_0 = constant 0.000000e+00 : f32
- %cst_1 = constant 1.000000e+00 : f32
+ %cst_0 = arith.constant 0.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
%0 = memref.alloca() : memref<f32, 1>
%1 = memref.alloca() : memref<f32, 1>
affine.for %arg3 = 0 to 1 {
affine.for %arg4 = 0 to 64 {
%accum = affine.for %arg5 = 0 to 64 iter_args (%prevAccum = %cst_0) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = addf %prevAccum, %4 : f32
+ %5 = arith.addf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_dbl = addf %accum, %accum : f32
+ %accum_dbl = arith.addf %accum, %accum : f32
affine.store %accum_dbl, %arg1[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
affine.for %arg4 = 0 to 64 {
%accum = affine.for %arg5 = 0 to 64 iter_args (%prevAccum = %cst_1) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = mulf %prevAccum, %4 : f32
+ %5 = arith.mulf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_sqr = mulf %accum, %accum : f32
+ %accum_sqr = arith.mulf %accum, %accum : f32
affine.store %accum_sqr, %arg2[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
// MAXIMAL-SAME: %[[arg_0:.*]]: memref<64x64xf32, 1>,
// MAXIMAL-SAME: %[[arg_1:.*]]: memref<1x64xf32, 1>,
// MAXIMAL-SAME: %[[arg_2:.*]]: memref<1x64xf32, 1>) {
-// MAXIMAL: %[[cst:.*]] = constant 0 : index
-// MAXIMAL-NEXT: %[[cst_0:.*]] = constant 0.000000e+00 : f32
-// MAXIMAL-NEXT: %[[cst_1:.*]] = constant 1.000000e+00 : f32
+// MAXIMAL: %[[cst:.*]] = arith.constant 0 : index
+// MAXIMAL-NEXT: %[[cst_0:.*]] = arith.constant 0.000000e+00 : f32
+// MAXIMAL-NEXT: %[[cst_1:.*]] = arith.constant 1.000000e+00 : f32
// MAXIMAL: affine.for %[[idx_0:.*]] = 0 to 1 {
// MAXIMAL-NEXT: affine.for %[[idx_1:.*]] = 0 to 64 {
// MAXIMAL-NEXT: %[[results:.*]]:2 = affine.for %[[idx_2:.*]] = 0 to 64 iter_args(%[[iter_0:.*]] = %[[cst_1]], %[[iter_1:.*]] = %[[cst_0]]) -> (f32, f32) {
// MAXIMAL-NEXT: %[[val_0:.*]] = affine.load %[[arg_0]][%[[idx_2]], %[[idx_1]]] : memref<64x64xf32, 1>
-// MAXIMAL-NEXT: %[[reduc_0:.*]] = addf %[[iter_1]], %[[val_0]] : f32
+// MAXIMAL-NEXT: %[[reduc_0:.*]] = arith.addf %[[iter_1]], %[[val_0]] : f32
// MAXIMAL-NEXT: %[[val_1:.*]] = affine.load %[[arg_0]][%[[idx_2]], %[[idx_1]]] : memref<64x64xf32, 1>
-// MAXIMAL-NEXT: %[[reduc_1:.*]] = mulf %[[iter_0]], %[[val_1]] : f32
+// MAXIMAL-NEXT: %[[reduc_1:.*]] = arith.mulf %[[iter_0]], %[[val_1]] : f32
// MAXIMAL-NEXT: affine.yield %[[reduc_1]], %[[reduc_0]] : f32, f32
// MAXIMAL-NEXT: }
-// MAXIMAL-NEXT: %[[reduc_0_dbl:.*]] = addf %[[results:.*]]#1, %[[results]]#1 : f32
+// MAXIMAL-NEXT: %[[reduc_0_dbl:.*]] = arith.addf %[[results:.*]]#1, %[[results]]#1 : f32
// MAXIMAL-NEXT: affine.store %[[reduc_0_dbl]], %[[arg_1]][%[[cst]], %[[idx_1]]] : memref<1x64xf32, 1>
-// MAXIMAL-NEXT: %[[reduc_1_sqr:.*]] = mulf %[[results]]#0, %[[results]]#0 : f32
+// MAXIMAL-NEXT: %[[reduc_1_sqr:.*]] = arith.mulf %[[results]]#0, %[[results]]#0 : f32
// MAXIMAL-NEXT: affine.store %[[reduc_1_sqr]], %[[arg_2]][%[[idx_0]], %[[idx_1]]] : memref<1x64xf32, 1>
// MAXIMAL-NEXT: }
// MAXIMAL-NEXT: }
// CHECK-LABEL: func @reduce_add_non_innermost
func @reduce_add_non_innermost(%arg0: memref<64x64xf32, 1>, %arg1: memref<1x64xf32, 1>, %arg2: memref<1x64xf32, 1>) {
- %cst = constant 0.000000e+00 : f32
- %cst_0 = constant 1.000000e+00 : f32
+ %cst = arith.constant 0.000000e+00 : f32
+ %cst_0 = arith.constant 1.000000e+00 : f32
%0 = memref.alloca() : memref<f32, 1>
%1 = memref.alloca() : memref<f32, 1>
affine.for %arg3 = 0 to 1 {
affine.for %arg4 = 0 to 64 {
%accum = affine.for %arg5 = 0 to 64 iter_args (%prevAccum = %cst) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = addf %prevAccum, %4 : f32
+ %5 = arith.addf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_dbl = addf %accum, %accum : f32
+ %accum_dbl = arith.addf %accum, %accum : f32
affine.store %accum_dbl, %arg1[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
affine.for %arg4 = 0 to 64 {
%accum = affine.for %arg5 = 0 to 64 iter_args (%prevAccum = %cst_0) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = mulf %prevAccum, %4 : f32
+ %5 = arith.mulf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_sqr = mulf %accum, %accum : f32
+ %accum_sqr = arith.mulf %accum, %accum : f32
affine.store %accum_sqr, %arg2[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
// CHECK-LABEL: func @fuse_large_number_of_loops
func @fuse_large_number_of_loops(%arg0: memref<20x10xf32, 1>, %arg1: memref<20x10xf32, 1>, %arg2: memref<20x10xf32, 1>, %arg3: memref<20x10xf32, 1>, %arg4: memref<20x10xf32, 1>, %arg5: memref<f32, 1>, %arg6: memref<f32, 1>, %arg7: memref<f32, 1>, %arg8: memref<f32, 1>, %arg9: memref<20x10xf32, 1>, %arg10: memref<20x10xf32, 1>, %arg11: memref<20x10xf32, 1>, %arg12: memref<20x10xf32, 1>) {
- %cst = constant 1.000000e+00 : f32
+ %cst = arith.constant 1.000000e+00 : f32
%0 = memref.alloc() : memref<f32, 1>
affine.store %cst, %0[] : memref<f32, 1>
%1 = memref.alloc() : memref<20x10xf32, 1>
affine.for %arg14 = 0 to 10 {
%21 = affine.load %1[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %arg3[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %2[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
%3 = memref.alloc() : memref<f32, 1>
%4 = affine.load %arg6[] : memref<f32, 1>
%5 = affine.load %0[] : memref<f32, 1>
- %6 = subf %5, %4 : f32
+ %6 = arith.subf %5, %4 : f32
affine.store %6, %3[] : memref<f32, 1>
%7 = memref.alloc() : memref<20x10xf32, 1>
affine.for %arg13 = 0 to 20 {
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg1[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %7[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %8[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg1[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %8[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %9[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %9[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %2[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = addf %22, %21 : f32
+ %23 = arith.addf %22, %21 : f32
affine.store %23, %arg11[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %1[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %arg2[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %10[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %8[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %10[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = addf %22, %21 : f32
+ %23 = arith.addf %22, %21 : f32
affine.store %23, %arg10[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg10[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %arg10[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %11[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %11[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %arg11[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = subf %22, %21 : f32
+ %23 = arith.subf %22, %21 : f32
affine.store %23, %12[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg4[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %13[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %14[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %15[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %12[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = addf %22, %21 : f32
+ %23 = arith.addf %22, %21 : f32
affine.store %23, %16[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg1[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %18[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = mulf %22, %21 : f32
+ %23 = arith.mulf %22, %21 : f32
affine.store %23, %19[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %17[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %19[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = divf %22, %21 : f32
+ %23 = arith.divf %22, %21 : f32
affine.store %23, %20[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %20[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %14[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = addf %22, %21 : f32
+ %23 = arith.addf %22, %21 : f32
affine.store %23, %arg12[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
affine.for %arg14 = 0 to 10 {
%21 = affine.load %arg12[%arg13, %arg14] : memref<20x10xf32, 1>
%22 = affine.load %arg0[%arg13, %arg14] : memref<20x10xf32, 1>
- %23 = subf %22, %21 : f32
+ %23 = arith.subf %22, %21 : f32
affine.store %23, %arg9[%arg13, %arg14] : memref<20x10xf32, 1>
}
}
// PRODUCER-CONSUMER-LABEL: func @unflatten4d
func @unflatten4d(%arg1: memref<7x8x9x10xf32>) {
%m = memref.alloc() : memref<5040xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 7 {
affine.for %i1 = 0 to 8 {
// PRODUCER-CONSUMER-LABEL: func @unflatten2d_with_transpose
func @unflatten2d_with_transpose(%arg1: memref<8x7xf32>) {
%m = memref.alloc() : memref<56xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 7 {
affine.for %i1 = 0 to 8 {
// SIBLING-MAXIMAL-LABEL: func @reduce_add_non_maximal_f32_f32(
func @reduce_add_non_maximal_f32_f32(%arg0: memref<64x64xf32, 1>, %arg1 : memref<1x64xf32, 1>, %arg2 : memref<1x64xf32, 1>) {
- %cst_0 = constant 0.000000e+00 : f32
- %cst_1 = constant 1.000000e+00 : f32
+ %cst_0 = arith.constant 0.000000e+00 : f32
+ %cst_1 = arith.constant 1.000000e+00 : f32
affine.for %arg3 = 0 to 1 {
affine.for %arg4 = 0 to 64 {
%accum = affine.for %arg5 = 0 to 64 iter_args (%prevAccum = %cst_0) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = addf %prevAccum, %4 : f32
+ %5 = arith.addf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_dbl = addf %accum, %accum : f32
+ %accum_dbl = arith.addf %accum, %accum : f32
affine.store %accum_dbl, %arg1[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
// Following loop trip count does not match the corresponding source trip count.
%accum = affine.for %arg5 = 0 to 32 iter_args (%prevAccum = %cst_1) -> f32 {
%4 = affine.load %arg0[%arg5, %arg4] : memref<64x64xf32, 1>
- %5 = mulf %prevAccum, %4 : f32
+ %5 = arith.mulf %prevAccum, %4 : f32
affine.yield %5 : f32
}
- %accum_sqr = mulf %accum, %accum : f32
+ %accum_sqr = arith.mulf %accum, %accum : f32
affine.store %accum_sqr, %arg2[%arg3, %arg4] : memref<1x64xf32, 1>
}
}
// Test checks the loop structure is preserved after sibling fusion
// since the destination loop and source loop trip counts do not
// match.
-// SIBLING-MAXIMAL: %[[cst_0:.*]] = constant 0.000000e+00 : f32
-// SIBLING-MAXIMAL-NEXT: %[[cst_1:.*]] = constant 1.000000e+00 : f32
+// SIBLING-MAXIMAL: %[[cst_0:.*]] = arith.constant 0.000000e+00 : f32
+// SIBLING-MAXIMAL-NEXT: %[[cst_1:.*]] = arith.constant 1.000000e+00 : f32
// SIBLING-MAXIMAL-NEXT: affine.for %[[idx_0:.*]]= 0 to 1 {
// SIBLING-MAXIMAL-NEXT: affine.for %[[idx_1:.*]] = 0 to 64 {
// SIBLING-MAXIMAL-NEXT: %[[result_1:.*]] = affine.for %[[idx_2:.*]] = 0 to 32 iter_args(%[[iter_0:.*]] = %[[cst_1]]) -> (f32) {
-// SIBLING-MAXIMAL-NEXT: %[[result_0:.*]] = affine.for %[[idx_3:.*]] = 0 to 64 iter_args(%[[iter_1:.*]] = %[[cst_0]]) -> (f32) {
\ No newline at end of file
+// SIBLING-MAXIMAL-NEXT: %[[result_0:.*]] = affine.for %[[idx_3:.*]] = 0 to 64 iter_args(%[[iter_1:.*]] = %[[cst_0]]) -> (f32) {
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up the following dependences:
// 1) loop0 -> loop1 on memref '%a'
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up the following dependences:
// Make dependence from 0 to 1 on '%a' read-after-read.
%c = memref.alloc() : memref<10xf32>
%d = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up the following dependences:
// Make dependence from 0 to 1 on unrelated memref '%d'.
// CHECK-LABEL: func @should_not_fuse_across_intermediate_store() {
func @should_not_fuse_across_intermediate_store() {
%0 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 0 into loop nest 1 at depth 0}}
// CHECK-LABEL: func @should_not_fuse_across_intermediate_load() {
func @should_not_fuse_across_intermediate_load() {
%0 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 0 into loop nest 1 at depth 0}}
func @should_not_fuse_across_ssa_value_def() {
%0 = memref.alloc() : memref<10xf32>
%1 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 0 into loop nest 1 at depth 0}}
"op0"(%v1) : (f32) -> ()
// Loop nest '%i1' cannot be fused past SSA value def '%c2' which it uses.
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
affine.for %i1 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 1 into loop nest 0 at depth 0}}
// CHECK-LABEL: func @should_not_fuse_store_before_load() {
func @should_not_fuse_store_before_load() {
%0 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 0 into loop nest 2 at depth 0}}
// CHECK-LABEL: func @should_not_fuse_across_load_at_depth1() {
func @should_not_fuse_across_load_at_depth1() {
%0 = memref.alloc() : memref<10x10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
// CHECK-LABEL: func @should_not_fuse_across_load_in_loop_at_depth1() {
func @should_not_fuse_across_load_in_loop_at_depth1() {
%0 = memref.alloc() : memref<10x10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
// CHECK-LABEL: func @should_not_fuse_across_store_at_depth1() {
func @should_not_fuse_across_store_at_depth1() {
%0 = memref.alloc() : memref<10x10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
// CHECK-LABEL: func @should_not_fuse_across_store_in_loop_at_depth1() {
func @should_not_fuse_across_store_in_loop_at_depth1() {
%0 = memref.alloc() : memref<10x10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
func @should_not_fuse_across_ssa_value_def_at_depth1() {
%0 = memref.alloc() : memref<10x10xf32>
%1 = memref.alloc() : memref<10x10xf32>
- %c0 = constant 0 : index
- %cf7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
"op0"(%v1) : (f32) -> ()
// Loop nest '%i2' cannot be fused past SSA value def '%c2' which it uses.
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
affine.for %i2 = 0 to 10 {
// expected-remark@-1 {{block-level dependence preventing fusion of loop nest 1 into loop nest 0 at depth 1}}
// CHECK-LABEL: func @slice_depth1_loop_nest() {
func @slice_depth1_loop_nest() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 1) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] )}}
affine.store %cst, %0[%i0] : memref<100xf32>
// CHECK-LABEL: func @forward_slice_slice_depth1_loop_nest() {
func @forward_slice_slice_depth1_loop_nest() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 5 {
// expected-remark@-1 {{slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 1) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] )}}
affine.store %cst, %0[%i0] : memref<100xf32>
// CHECK-LABEL: func @slice_depth1_loop_nest_with_offsets() {
func @slice_depth1_loop_nest_with_offsets() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 2) loop bounds: [(d0) -> (d0 + 3), (d0) -> (d0 + 4)] )}}
%a0 = affine.apply affine_map<(d0) -> (d0 + 2)>(%i0)
// CHECK-LABEL: func @slice_depth2_loop_nest() {
func @slice_depth2_loop_nest() {
%0 = memref.alloc() : memref<100x100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 1) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] [(d0) -> (0), (d0) -> (8)] )}}
// expected-remark@-2 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 2 : insert point: (2, 1) loop bounds: [(d0, d1) -> (d0), (d0, d1) -> (d0 + 1)] [(d0, d1) -> (d1), (d0, d1) -> (d1 + 1)] )}}
// CHECK-LABEL: func @slice_depth2_loop_nest_two_loads() {
func @slice_depth2_loop_nest_two_loads() {
%0 = memref.alloc() : memref<100x100xf32>
- %c0 = constant 0 : index
- %cst = constant 7.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 1) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] [(d0) -> (0), (d0) -> (8)] )}}
// expected-remark@-2 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 2 : insert point: (2, 1) loop bounds: [(d0, d1) -> (d0), (d0, d1) -> (d0 + 1)] [(d0, d1) -> (0), (d0, d1) -> (16)] )}}
// CHECK-LABEL: func @slice_depth2_loop_nest_two_stores() {
func @slice_depth2_loop_nest_two_stores() {
%0 = memref.alloc() : memref<100x100xf32>
- %c0 = constant 0 : index
- %cst = constant 7.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 2) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] [(d0) -> (0), (d0) -> (8)] )}}
affine.for %i1 = 0 to 16 {
// CHECK-LABEL: func @slice_loop_nest_with_smaller_outer_trip_count() {
func @slice_loop_nest_with_smaller_outer_trip_count() {
%0 = memref.alloc() : memref<100x100xf32>
- %c0 = constant 0 : index
- %cst = constant 7.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
// expected-remark@-1 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 1 : insert point: (1, 1) loop bounds: [(d0) -> (d0), (d0) -> (d0 + 1)] [(d0) -> (0), (d0) -> (10)] )}}
// expected-remark@-2 {{Incorrect slice ( src loop: 1, dst loop: 0, depth: 2 : insert point: (2, 1) loop bounds: [(d0, d1) -> (d0), (d0, d1) -> (d0 + 1)] [(d0, d1) -> (d1), (d0, d1) -> (d1 + 1)] )}}
// CHECK-LABEL: func @slice_depth1_loop_nest() {
func @slice_depth1_loop_nest() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 16 {
affine.store %cst, %0[%i0] : memref<100xf32>
}
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
%v0 = affine.load %b[%i0] : memref<10xf32>
%v1 = affine.load %a[%i0, %i1] : memref<10x10xf32>
- %v3 = addf %v0, %v1 : f32
+ %v3 = arith.addf %v0, %v1 : f32
affine.store %v3, %b[%i0] : memref<10xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up the following dependences:
// 1) loop0 -> loop1 on memref '%{{.*}}'
// CHECK-LABEL: func @should_fuse_raw_dep_for_locality() {
func @should_fuse_raw_dep_for_locality() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
%v0 = affine.load %b[%i0] : memref<10xf32>
%v1 = affine.load %a[%i0, %i1] : memref<10x10xf32>
- %v3 = addf %v0, %v1 : f32
+ %v3 = arith.addf %v0, %v1 : f32
affine.store %v3, %b[%i0] : memref<10xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x10xf32>
- // CHECK-NEXT: addf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.addf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: }
// CHECK-NEXT: affine.load %{{.*}}[0] : memref<1xf32>
// CHECK-LABEL: func @should_fuse_loop_nests_with_shifts() {
func @should_fuse_loop_nests_with_shifts() {
%a = memref.alloc() : memref<10x10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 9 {
affine.for %i1 = 0 to 9 {
func @should_fuse_loop_nest() {
%a = memref.alloc() : memref<10x10xf32>
%b = memref.alloc() : memref<10x10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %a[%i0] : memref<10xf32>
func @should_fuse_all_loops() {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up flow dependences from first and second loops to third.
affine.for %i0 = 0 to 10 {
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %a[%i0] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
// Set up the following dependences:
// 1) loop0 -> loop1 on memref '%{{.*}}'
// CHECK-LABEL: func @should_fuse_producer_consumer() {
func @should_fuse_producer_consumer() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
func @should_fuse_and_move_to_preserve_war_dep() {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %a[%i0] : memref<10xf32>
// CHECK-LABEL: func @should_fuse_if_top_level_access() {
func @should_fuse_if_top_level_access() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
%v0 = affine.load %m[%i1] : memref<10xf32>
}
- %c0 = constant 4 : index
+ %c0 = arith.constant 4 : index
%v1 = affine.load %m[%c0] : memref<10xf32>
// Top-level load to '%m' should prevent creating a private memref but
// loop nests should be fused and '%i0' should be removed.
// CHECK-LABEL: func @should_fuse_but_not_remove_src() {
func @should_fuse_but_not_remove_src() {
%m = memref.alloc() : memref<100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %cf7, %m[%i0] : memref<100xf32>
// CHECK-LABEL: func @should_fuse_no_top_level_access() {
func @should_fuse_no_top_level_access() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
// CHECK-LABEL: func @should_not_fuse_if_op_at_top_level() {
func @should_not_fuse_if_op_at_top_level() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
affine.for %i1 = 0 to 10 {
%v0 = affine.load %m[%i1] : memref<10xf32>
}
- %c0 = constant 4 : index
+ %c0 = arith.constant 4 : index
affine.if #set0(%c0) {
}
// Top-level IfOp should prevent fusion.
// CHECK-LABEL: func @should_not_fuse_if_op_in_loop_nest() {
func @should_not_fuse_if_op_in_loop_nest() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %c4 = constant 4 : index
+ %cf7 = arith.constant 7.0 : f32
+ %c4 = arith.constant 4 : index
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
func @should_fuse_if_op_in_loop_nest_not_sandwiched() -> memref<10xf32> {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %a[%i0] : memref<10xf32>
func @should_not_fuse_if_op_in_loop_nest_between_src_and_dest() -> memref<10xf32> {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %a[%i0] : memref<10xf32>
func @permute_and_fuse() {
%m = memref.alloc() : memref<10x20x30xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 20 {
affine.for %i2 = 0 to 30 {
affine.for %i = 0 to 64 {
affine.for %j = 0 to 9 {
%a = affine.load %out[%i, %j] : memref<64x9xi32>
- %b = muli %a, %a : i32
+ %b = arith.muli %a, %a : i32
affine.store %b, %live_out[%i, %j] : memref<64x9xi32>
}
}
// CHECK-NEXT: affine.load %{{.*}}[0, ((%{{.*}} * 9 + %{{.*}}) mod 288) floordiv 144, ((%{{.*}} * 9 + %{{.*}}) mod 144) floordiv 48, ((%{{.*}} * 9 + %{{.*}}) mod 48) floordiv 16, (%{{.*}} * 9 + %{{.*}}) mod 16, 0] : memref<1x2x3x3x16x1xi32>
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0, 0] : memref<1x1xi32>
// CHECK-NEXT: affine.load %{{.*}}[0, 0] : memref<1x1xi32>
-// CHECK-NEXT: muli %{{.*}}, %{{.*}} : i32
+// CHECK-NEXT: arith.muli %{{.*}}, %{{.*}} : i32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}, %{{.*}}] : memref<64x9xi32>
// CHECK-NEXT: }
// CHECK-NEXT: }
%N_plus_5 = affine.apply affine_map<(d0) -> (d0 + 5)>(%N)
%m = memref.alloc(%M, %N_plus_5) : memref<? x ? x f32>
- %c0 = constant 0.0 : f32
- %s = constant 5 : index
+ %c0 = arith.constant 0.0 : f32
+ %s = arith.constant 5 : index
affine.for %i0 = 0 to %M {
affine.for %i1 = 0 to affine_map<(d0) -> (d0 + 5)> (%N) {
affine.for %i3 = 0 to 100 {
%v3 = affine.load %b[%i2] : memref<10xf32>
%v4 = affine.load %a[%i2, %i3] : memref<10x100xf32>
- %v5 = subf %v4, %v3 : f32
+ %v5 = arith.subf %v4, %v3 : f32
affine.store %v5, %b[%i2] : memref<10xf32>
}
}
// CHECK-NEXT: affine.for %{{.*}} = 0 to 100 {
// CHECK-NEXT: affine.load %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}, %{{.*}}] : memref<10x100xf32>
- // CHECK-NEXT: subf %{{.*}}, %{{.*}} : f32
+ // CHECK-NEXT: arith.subf %{{.*}}, %{{.*}} : f32
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0] : memref<1xf32>
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-LABEL: func @should_fuse_src_depth1_at_dst_depth2
func @should_fuse_src_depth1_at_dst_depth2() {
%a = memref.alloc() : memref<100xf32>
- %c0 = constant 0.0 : f32
+ %c0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %c0, %a[%i0] : memref<100xf32>
// CHECK-LABEL: func @fusion_at_depth0_not_currently_supported
func @fusion_at_depth0_not_currently_supported() {
%0 = memref.alloc() : memref<10xf32>
- %c0 = constant 0 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.store %cst, %0[%i0] : memref<10xf32>
}
%0 = memref.alloc() : memref<2x2x3x3x16x10xf32, 2>
%1 = memref.alloc() : memref<2x2x3x3x16x10xf32, 2>
%2 = memref.alloc() : memref<3x3x3x3x16x10xf32, 2>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c1_0 = constant 1 : index
- %cst = constant 0.000000e+00 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c1_0 = arith.constant 1 : index
+ %cst = arith.constant 0.000000e+00 : f32
affine.for %i0 = 0 to 2 {
affine.for %i1 = 0 to 2 {
affine.for %i2 = 0 to 3 {
%a = memref.alloc() : memref<4x256xf32>
%b = memref.alloc() : memref<4x256xf32>
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 4 {
affine.for %i1 = 0 to 256 {
// CHECK-LABEL: func @should_fuse_at_depth1_with_trip_count_20
func @should_fuse_at_depth1_with_trip_count_20() {
%a = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %cf0, %a[%i0]: memref<100xf32>
// CHECK-LABEL: func @should_fuse_at_depth1_with_trip_count_19
func @should_fuse_at_depth1_with_trip_count_19() {
%a = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %cf0 = constant 0.0 : f32
+ %c0 = arith.constant 0 : index
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %cf0, %a[%i0]: memref<100xf32>
// CHECK-LABEL: func @should_fuse_with_private_memrefs_with_diff_shapes() {
func @should_fuse_with_private_memrefs_with_diff_shapes() {
%m = memref.alloc() : memref<100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 100 {
affine.store %cf7, %m[%i0] : memref<100xf32>
// CHECK-LABEL: func @should_fuse_live_out_arg_but_preserve_src_loop(%{{.*}}: memref<10xf32>) {
func @should_fuse_live_out_arg_but_preserve_src_loop(%arg0: memref<10xf32>) {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %arg0[%i0] : memref<10xf32>
// CHECK-LABEL: func @should_fuse_live_out_arg(%{{.*}}: memref<10xf32>) {
func @should_fuse_live_out_arg(%arg0: memref<10xf32>) {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %arg0[%i0] : memref<10xf32>
// CHECK-LABEL: func @should_fuse_escaping_memref_but_preserve_src_loop() -> memref<10xf32>
func @should_fuse_escaping_memref_but_preserve_src_loop() -> memref<10xf32> {
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
%m = memref.alloc() : memref<10xf32>
affine.for %i0 = 0 to 10 {
affine.store %cf7, %m[%i0] : memref<10xf32>
func @R3_to_R2_reshape() {
%in = memref.alloc() : memref<2x3x16xi32>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
affine.for %i0 = 0 to 2 {
affine.for %i1 = 0 to 3 {
%a = memref.alloc() : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.store %cf7, %a[%i0] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %a[%i0] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %b[%i0] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %b[%i0] : memref<10xf32>
affine.for %i1 = 0 to 10 {
affine.store %cf7, %b[%i1] : memref<10xf32>
}
- %cf11 = constant 11.0 : f32
+ %cf11 = arith.constant 11.0 : f32
affine.for %i2 = 0 to 10 {
%v2 = affine.load %a[%i2] : memref<10xf32>
affine.store %cf11, %c[%i2] : memref<10xf32>
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: }
- // CHECK-NEXT: %{{.*}} = constant 1.100000e+01 : f32
+ // CHECK-NEXT: %{{.*}} = arith.constant 1.100000e+01 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[%{{.*}}] : memref<10xf32>
%b = memref.alloc() : memref<10xf32>
%c = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf11 = constant 11.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf11 = arith.constant 11.0 : f32
affine.for %i0 = 0 to 10 {
%v0 = affine.load %b[%i0] : memref<10xf32>
affine.store %cf7, %a[%i0] : memref<10xf32>
// '%a', and preserve the WAR dep from '%i0' to '%i1' on memref '%b', and
// the SSA value dep from '%cf11' def to use in '%i2'.
- // CHECK: constant 1.100000e+01 : f32
+ // CHECK: arith.constant 1.100000e+01 : f32
// CHECK-NEXT: affine.for %{{.*}} = 0 to 10 {
// CHECK-NEXT: affine.load %{{.*}}[%{{.*}}] : memref<10xf32>
// CHECK-NEXT: affine.store %{{.*}}, %{{.*}}[0] : memref<1xf32>
func @nested_loops_both_having_invariant_code() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
affine.for %arg1 = 0 to 10 {
- %v1 = addf %v0, %cf8 : f32
+ %v1 = arith.addf %v0, %cf8 : f32
affine.store %v0, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %[[CST0:.*]] = constant 7.000000e+00 : f32
- // CHECK-NEXT: %[[CST1:.*]] = constant 8.000000e+00 : f32
- // CHECK-NEXT: %[[ADD0:.*]] = addf %[[CST0]], %[[CST1]] : f32
- // CHECK-NEXT: addf %[[ADD0]], %[[CST1]] : f32
+ // CHECK-NEXT: %[[CST0:.*]] = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %[[CST1:.*]] = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %[[ADD0:.*]] = arith.addf %[[CST0]], %[[CST1]] : f32
+ // CHECK-NEXT: arith.addf %[[ADD0]], %[[CST1]] : f32
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.store
func @nested_loops_code_invariant_to_both() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
return
}
affine.for %arg0 = 0 to 10 {
%v0 = affine.load %m1[%arg0] : memref<10xf32>
%v1 = affine.load %m2[%arg0] : memref<10xf32>
- %v2 = addf %v0, %v1 : f32
+ %v2 = arith.addf %v0, %v1 : f32
affine.store %v2, %m1[%arg0] : memref<10xf32>
}
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %2 = affine.load %0[%arg0] : memref<10xf32>
// CHECK-NEXT: %3 = affine.load %1[%arg0] : memref<10xf32>
- // CHECK-NEXT: %4 = addf %2, %3 : f32
+ // CHECK-NEXT: %4 = arith.addf %2, %3 : f32
// CHECK-NEXT: affine.store %4, %0[%arg0] : memref<10xf32>
return
func @invariant_code_inside_affine_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
%t0 = affine.apply affine_map<(d1) -> (d1 + 1)>(%arg0)
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %t0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %cst = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %arg0 = 0 to 10 {
// CHECK-NEXT: %1 = affine.apply #map(%arg0)
// CHECK-NEXT: affine.if #set(%arg0, %1) {
- // CHECK-NEXT: %2 = addf %cst, %cst : f32
+ // CHECK-NEXT: %2 = arith.addf %cst, %cst : f32
// CHECK-NEXT: affine.store %2, %0[%arg0] : memref<10xf32>
// CHECK-NEXT: }
func @invariant_affine_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
}
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %[[CST:.*]] = constant 8.000000e+00 : f32
+ // CHECK-NEXT: %[[CST:.*]] = arith.constant 8.000000e+00 : f32
// CHECK-NEXT: affine.for %[[ARG:.*]] = 0 to 10 {
// CHECK-NEXT: }
// CHECK-NEXT: affine.for %[[ARG:.*]] = 0 to 10 {
// CHECK-NEXT: affine.if #set(%[[ARG]], %[[ARG]]) {
- // CHECK-NEXT: addf %[[CST]], %[[CST]] : f32
+ // CHECK-NEXT: arith.addf %[[CST]], %[[CST]] : f32
// CHECK-NEXT: }
return
func @invariant_affine_if2() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg1] : memref<10xf32>
}
}
}
// CHECK: memref.alloc
- // CHECK-NEXT: constant
+ // CHECK-NEXT: arith.constant
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.if
- // CHECK-NEXT: addf
+ // CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// CHECK-NEXT: }
// CHECK-NEXT: }
func @invariant_affine_nested_if() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf10 = addf %cf9, %cf9 : f32
+ %cf10 = arith.addf %cf9, %cf9 : f32
}
}
}
}
// CHECK: memref.alloc
- // CHECK-NEXT: constant
+ // CHECK-NEXT: arith.constant
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.if
- // CHECK-NEXT: addf
+ // CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.if
- // CHECK-NEXT: addf
+ // CHECK-NEXT: arith.addf
// CHECK-NEXT: }
// CHECK-NEXT: }
// CHECK-NEXT: }
func @invariant_affine_nested_if_else() {
%m = memref.alloc() : memref<10xf32>
- %cf8 = constant 8.0 : f32
+ %cf8 = arith.constant 8.0 : f32
affine.for %arg0 = 0 to 10 {
affine.for %arg1 = 0 to 10 {
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf9 = addf %cf8, %cf8 : f32
+ %cf9 = arith.addf %cf8, %cf8 : f32
affine.store %cf9, %m[%arg0] : memref<10xf32>
affine.if affine_set<(d0, d1) : (d1 - d0 >= 0)> (%arg0, %arg0) {
- %cf10 = addf %cf9, %cf9 : f32
+ %cf10 = arith.addf %cf9, %cf9 : f32
} else {
affine.store %cf9, %m[%arg1] : memref<10xf32>
}
}
// CHECK: memref.alloc
- // CHECK-NEXT: constant
+ // CHECK-NEXT: arith.constant
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.for
// CHECK-NEXT: affine.if
- // CHECK-NEXT: addf
+ // CHECK-NEXT: arith.addf
// CHECK-NEXT: affine.store
// CHECK-NEXT: affine.if
- // CHECK-NEXT: addf
+ // CHECK-NEXT: arith.addf
// CHECK-NEXT: } else {
// CHECK-NEXT: affine.store
// CHECK-NEXT: }
// -----
func @invariant_loop_dialect() {
- %ci0 = constant 0 : index
- %ci10 = constant 10 : index
- %ci1 = constant 1 : index
+ %ci0 = arith.constant 0 : index
+ %ci10 = arith.constant 10 : index
+ %ci1 = arith.constant 1 : index
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %cf8 = constant 8.0 : f32
+ %cf7 = arith.constant 7.0 : f32
+ %cf8 = arith.constant 8.0 : f32
scf.for %arg0 = %ci0 to %ci10 step %ci1 {
scf.for %arg1 = %ci0 to %ci10 step %ci1 {
- %v0 = addf %cf7, %cf8 : f32
+ %v0 = arith.addf %cf7, %cf8 : f32
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
- // CHECK-NEXT: %cst = constant 7.000000e+00 : f32
- // CHECK-NEXT: %cst_0 = constant 8.000000e+00 : f32
- // CHECK-NEXT: %1 = addf %cst, %cst_0 : f32
+ // CHECK-NEXT: %cst = arith.constant 7.000000e+00 : f32
+ // CHECK-NEXT: %cst_0 = arith.constant 8.000000e+00 : f32
+ // CHECK-NEXT: %1 = arith.addf %cst, %cst_0 : f32
return
}
// -----
func @variant_loop_dialect() {
- %ci0 = constant 0 : index
- %ci10 = constant 10 : index
- %ci1 = constant 1 : index
+ %ci0 = arith.constant 0 : index
+ %ci10 = arith.constant 10 : index
+ %ci1 = arith.constant 1 : index
%m = memref.alloc() : memref<10xf32>
scf.for %arg0 = %ci0 to %ci10 step %ci1 {
scf.for %arg1 = %ci0 to %ci10 step %ci1 {
- %v0 = addi %arg0, %arg1 : index
+ %v0 = arith.addi %arg0, %arg1 : index
}
}
// CHECK: %0 = memref.alloc() : memref<10xf32>
// CHECK-NEXT: scf.for
// CHECK-NEXT: scf.for
- // CHECK-NEXT: addi
+ // CHECK-NEXT: arith.addi
return
}
// -----
func @parallel_loop_with_invariant() {
- %c0 = constant 0 : index
- %c10 = constant 10 : index
- %c1 = constant 1 : index
- %c7 = constant 7 : i32
- %c8 = constant 8 : i32
+ %c0 = arith.constant 0 : index
+ %c10 = arith.constant 10 : index
+ %c1 = arith.constant 1 : index
+ %c7 = arith.constant 7 : i32
+ %c8 = arith.constant 8 : i32
scf.parallel (%arg0, %arg1) = (%c0, %c0) to (%c10, %c10) step (%c1, %c1) {
- %v0 = addi %c7, %c8 : i32
- %v3 = addi %arg0, %arg1 : index
+ %v0 = arith.addi %c7, %c8 : i32
+ %v3 = arith.addi %arg0, %arg1 : index
}
// CHECK-LABEL: func @parallel_loop_with_invariant
- // CHECK: %c0 = constant 0 : index
- // CHECK-NEXT: %c10 = constant 10 : index
- // CHECK-NEXT: %c1 = constant 1 : index
- // CHECK-NEXT: %c7_i32 = constant 7 : i32
- // CHECK-NEXT: %c8_i32 = constant 8 : i32
- // CHECK-NEXT: addi %c7_i32, %c8_i32 : i32
+ // CHECK: %c0 = arith.constant 0 : index
+ // CHECK-NEXT: %c10 = arith.constant 10 : index
+ // CHECK-NEXT: %c1 = arith.constant 1 : index
+ // CHECK-NEXT: %c7_i32 = arith.constant 7 : i32
+ // CHECK-NEXT: %c8_i32 = arith.constant 8 : i32
+ // CHECK-NEXT: arith.addi %c7_i32, %c8_i32 : i32
// CHECK-NEXT: scf.parallel (%arg0, %arg1) = (%c0, %c0) to (%c10, %c10) step (%c1, %c1)
- // CHECK-NEXT: addi %arg0, %arg1 : index
+ // CHECK-NEXT: arith.addi %arg0, %arg1 : index
// CHECK-NEXT: yield
// CHECK-NEXT: }
// CHECK-NEXT: return
// CHECK-LABEL: func @test() {
func @test() {
- %zero = constant 0 : index
- %minusone = constant -1 : index
- %sym = constant 111 : index
+ %zero = arith.constant 0 : index
+ %minusone = arith.constant -1 : index
+ %sym = arith.constant 111 : index
%A = memref.alloc() : memref<9 x 9 x i32>
%B = memref.alloc() : memref<111 x i32>
// CHECK-LABEL: func @test_mod_floordiv_ceildiv
func @test_mod_floordiv_ceildiv() {
- %zero = constant 0 : index
+ %zero = arith.constant 0 : index
%A = memref.alloc() : memref<128 x 64 x 64 x i32>
affine.for %i = 0 to 256 {
// CHECK-LABEL: func @test_no_out_of_bounds()
func @test_no_out_of_bounds() {
- %zero = constant 0 : index
+ %zero = arith.constant 0 : index
%A = memref.alloc() : memref<257 x 256 x i32>
%C = memref.alloc() : memref<257 x i32>
%B = memref.alloc() : memref<1 x i32>
// CHECK-LABEL: func @mod_div
func @mod_div() {
- %zero = constant 0 : index
+ %zero = arith.constant 0 : index
%A = memref.alloc() : memref<128 x 64 x 64 x i32>
affine.for %i = 0 to 256 {
// CHECK-LABEL: func @delinearize_mod_floordiv
func @delinearize_mod_floordiv() {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%in = memref.alloc() : memref<2x2x3x3x16x1xi32>
%out = memref.alloc() : memref<64x9xi32>
// CHECK-LABEL: func @zero_d_memref
func @zero_d_memref(%arg0: memref<i32>) {
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
// A 0-d memref always has in-bound accesses!
affine.store %c0, %arg0[] : memref<i32>
return
// CHECK-LABEL: func @out_of_bounds
func @out_of_bounds() {
%in = memref.alloc() : memref<1xi32>
- %c9 = constant 9 : i32
+ %c9 = arith.constant 9 : i32
affine.for %i0 = 10 to 11 {
%idy = affine.apply affine_map<(d0) -> (100 * d0 floordiv 1000)> (%i0)
#map5 = affine_map<(d0, d1) -> (((((d0 * 72 + d1) mod 2304) mod 1152) floordiv 9) floordiv 8)>
// CHECK-LABEL: func @test_complex_mod_floordiv
func @test_complex_mod_floordiv(%arg0: memref<4x4x16x1xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<1x2x3x3x16x1xf32>
affine.for %i0 = 0 to 64 {
affine.for %i1 = 0 to 9 {
%0 = memref.alloc() : memref<1027 x f32>
%1 = memref.alloc() : memref<1026 x f32>
%2 = memref.alloc() : memref<4096 x f32>
- %N = constant 2048 : index
+ %N = arith.constant 2048 : index
affine.for %i0 = 0 to 4096 {
affine.for %i1 = #map0(%i0) to #map1(%i0) {
affine.load %0[%i1] : memref<1027 x f32>
// CHECK-LABEL: func @store_may_execute_before_load() {
func @store_may_execute_before_load() {
%m = memref.alloc() : memref<10xf32>
- %cf7 = constant 7.0 : f32
- %c0 = constant 4 : index
+ %cf7 = arith.constant 7.0 : f32
+ %c0 = arith.constant 4 : index
// There is no dependence from store 0 to load 1 at depth if we take into account
// the constraint introduced by the following `affine.if`, which indicates that
// the store 0 will never be executed.
// CHECK-LABEL: func @dependent_loops() {
func @dependent_loops() {
%0 = memref.alloc() : memref<10xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
// There is a dependence from 0 to 1 at depth 1 (common surrounding loops 0)
// because the first loop with the store dominates the second scf.
affine.for %i0 = 0 to 10 {
func @different_memrefs() {
%m.a = memref.alloc() : memref<100xf32>
%m.b = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %c1 = constant 1.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1.0 : f32
affine.store %c1, %m.a[%c0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = false}}
// CHECK-LABEL: func @store_load_different_elements() {
func @store_load_different_elements() {
%m = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c7 = arith.constant 7.0 : f32
affine.store %c7, %m[%c0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = false}}
// CHECK-LABEL: func @load_store_different_elements() {
func @load_store_different_elements() {
%m = memref.alloc() : memref<100xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c7 = constant 7.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c7 = arith.constant 7.0 : f32
%v0 = affine.load %m[%c1] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = false}}
// CHECK-LABEL: func @store_load_same_element() {
func @store_load_same_element() {
%m = memref.alloc() : memref<100xf32>
- %c11 = constant 11 : index
- %c7 = constant 7.0 : f32
+ %c11 = arith.constant 11 : index
+ %c7 = arith.constant 7.0 : f32
affine.store %c7, %m[%c11] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = true}}
// CHECK-LABEL: func @load_load_same_element() {
func @load_load_same_element() {
%m = memref.alloc() : memref<100xf32>
- %c11 = constant 11 : index
- %c7 = constant 7.0 : f32
+ %c11 = arith.constant 11 : index
+ %c7 = arith.constant 7.0 : f32
%v0 = affine.load %m[%c11] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = false}}
// CHECK-LABEL: func @store_load_same_symbol(%arg0: index) {
func @store_load_same_symbol(%arg0: index) {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.store %c7, %m[%arg0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = true}}
// CHECK-LABEL: func @store_load_different_symbols(%arg0: index, %arg1: index) {
func @store_load_different_symbols(%arg0: index, %arg1: index) {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.store %c7, %m[%arg0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// expected-remark@above {{dependence from 0 to 1 at depth 1 = true}}
// CHECK-LABEL: func @store_load_diff_element_affine_apply_const() {
func @store_load_diff_element_affine_apply_const() {
%m = memref.alloc() : memref<100xf32>
- %c1 = constant 1 : index
- %c8 = constant 8.0 : f32
+ %c1 = arith.constant 1 : index
+ %c8 = arith.constant 8.0 : f32
%a0 = affine.apply affine_map<(d0) -> (d0)> (%c1)
affine.store %c8, %m[%a0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// CHECK-LABEL: func @store_load_same_element_affine_apply_const() {
func @store_load_same_element_affine_apply_const() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c9 = constant 9 : index
- %c11 = constant 11 : index
+ %c7 = arith.constant 7.0 : f32
+ %c9 = arith.constant 9 : index
+ %c11 = arith.constant 11 : index
%a0 = affine.apply affine_map<(d0) -> (d0 + 1)> (%c9)
affine.store %c7, %m[%a0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// CHECK-LABEL: func @store_load_affine_apply_symbol(%arg0: index) {
func @store_load_affine_apply_symbol(%arg0: index) {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
%a0 = affine.apply affine_map<(d0) -> (d0)> (%arg0)
affine.store %c7, %m[%a0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// CHECK-LABEL: func @store_load_affine_apply_symbol_offset(%arg0: index) {
func @store_load_affine_apply_symbol_offset(%arg0: index) {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
%a0 = affine.apply affine_map<(d0) -> (d0)> (%arg0)
affine.store %c7, %m[%a0] : memref<100xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// CHECK-LABEL: func @store_range_load_after_range() {
func @store_range_load_after_range() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c10 = constant 10 : index
+ %c7 = arith.constant 7.0 : f32
+ %c10 = arith.constant 10 : index
affine.for %i0 = 0 to 10 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%i0)
affine.store %c7, %m[%a0] : memref<100xf32>
// CHECK-LABEL: func @store_load_func_symbol(%arg0: index, %arg1: index) {
func @store_load_func_symbol(%arg0: index, %arg1: index) {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c10 = constant 10 : index
+ %c7 = arith.constant 7.0 : f32
+ %c10 = arith.constant 10 : index
affine.for %i0 = 0 to %arg1 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%arg0)
affine.store %c7, %m[%a0] : memref<100xf32>
// CHECK-LABEL: func @store_range_load_last_in_range() {
func @store_range_load_last_in_range() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c10 = constant 10 : index
+ %c7 = arith.constant 7.0 : f32
+ %c10 = arith.constant 10 : index
affine.for %i0 = 0 to 10 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%i0)
// For dependence from 0 to 1, we do not have a loop carried dependence
// CHECK-LABEL: func @store_range_load_before_range() {
func @store_range_load_before_range() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c0 = constant 0 : index
+ %c7 = arith.constant 7.0 : f32
+ %c0 = arith.constant 0 : index
affine.for %i0 = 1 to 11 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%i0)
affine.store %c7, %m[%a0] : memref<100xf32>
// CHECK-LABEL: func @store_range_load_first_in_range() {
func @store_range_load_first_in_range() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
- %c0 = constant 0 : index
+ %c7 = arith.constant 7.0 : f32
+ %c0 = arith.constant 0 : index
affine.for %i0 = 1 to 11 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%i0)
// Dependence from 0 to 1 at depth 1 is a range because all loads at
// CHECK-LABEL: func @store_plus_3() {
func @store_plus_3() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 1 to 11 {
%a0 = affine.apply affine_map<(d0) -> (d0 + 3)> (%i0)
affine.store %c7, %m[%a0] : memref<100xf32>
// CHECK-LABEL: func @load_minus_2() {
func @load_minus_2() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 2 to 11 {
%a0 = affine.apply affine_map<(d0) -> (d0)> (%i0)
affine.store %c7, %m[%a0] : memref<100xf32>
// CHECK-LABEL: func @perfectly_nested_loops_loop_independent() {
func @perfectly_nested_loops_loop_independent() {
%m = memref.alloc() : memref<10x10xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 11 {
affine.for %i1 = 0 to 11 {
// Dependence from access 0 to 1 is loop independent at depth = 3.
// CHECK-LABEL: func @perfectly_nested_loops_loop_carried_at_depth1() {
func @perfectly_nested_loops_loop_carried_at_depth1() {
%m = memref.alloc() : memref<10x10xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 9 {
affine.for %i1 = 0 to 9 {
// Dependence from access 0 to 1 is loop carried at depth 1.
// CHECK-LABEL: func @perfectly_nested_loops_loop_carried_at_depth2() {
func @perfectly_nested_loops_loop_carried_at_depth2() {
%m = memref.alloc() : memref<10x10xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
// Dependence from access 0 to 1 is loop carried at depth 2.
// CHECK-LABEL: func @one_common_loop() {
func @one_common_loop() {
%m = memref.alloc() : memref<10x10xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
// There is a loop-independent dependence from access 0 to 1 at depth 2.
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
// CHECK-LABEL: func @negative_and_positive_direction_vectors(%arg0: index, %arg1: index) {
func @negative_and_positive_direction_vectors(%arg0: index, %arg1: index) {
%m = memref.alloc() : memref<10x10xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to %arg0 {
affine.for %i1 = 0 to %arg1 {
%a00 = affine.apply affine_map<(d0, d1) -> (d0 - 1)> (%i0, %i1)
// CHECK-LABEL: func @war_raw_waw_deps() {
func @war_raw_waw_deps() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = 0 to 10 {
%a0 = affine.apply affine_map<(d0) -> (d0 + 1)> (%i1)
// CHECK-LABEL: func @mod_deps() {
func @mod_deps() {
%m = memref.alloc() : memref<100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
%a0 = affine.apply affine_map<(d0) -> (d0 mod 2)> (%i0)
// Results are conservative here since we currently don't have a way to
// CHECK-LABEL: func @loop_nest_depth() {
func @loop_nest_depth() {
%0 = memref.alloc() : memref<100x100xf32>
- %c7 = constant 7.0 : f32
+ %c7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 128 {
affine.for %i1 = 0 to 8 {
// CHECK-LABEL: func @mod_div_3d() {
func @mod_div_3d() {
%M = memref.alloc() : memref<2x2x2xi32>
- %c0 = constant 0 : i32
+ %c0 = arith.constant 0 : i32
affine.for %i0 = 0 to 8 {
affine.for %i1 = 0 to 8 {
affine.for %i2 = 0 to 8 {
// This test case arises in the context of a 6-d to 2-d reshape.
// CHECK-LABEL: func @delinearize_mod_floordiv
func @delinearize_mod_floordiv() {
- %c0 = constant 0 : index
- %val = constant 0 : i32
+ %c0 = arith.constant 0 : index
+ %val = arith.constant 0 : i32
%in = memref.alloc() : memref<2x2x3x3x16x1xi32>
%out = memref.alloc() : memref<64x9xi32>
// CHECK-LABEL: func @strided_loop_with_dependence_at_depth2
func @strided_loop_with_dependence_at_depth2() {
%0 = memref.alloc() : memref<10xf32>
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 8 step 2 {
affine.store %cf0, %0[%i0] : memref<10xf32>
// expected-remark@above {{dependence from 0 to 0 at depth 1 = false}}
// CHECK-LABEL: func @strided_loop_with_no_dependence
func @strided_loop_with_no_dependence() {
%0 = memref.alloc() : memref<10xf32>
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 8 step 2 {
%a0 = affine.apply affine_map<(d0) -> (d0 + 1)>(%i0)
affine.store %cf0, %0[%a0] : memref<10xf32>
// CHECK-LABEL: func @strided_loop_with_loop_carried_dependence_at_depth1
func @strided_loop_with_loop_carried_dependence_at_depth1() {
%0 = memref.alloc() : memref<10xf32>
- %cf0 = constant 0.0 : f32
+ %cf0 = arith.constant 0.0 : f32
affine.for %i0 = 0 to 8 step 2 {
%a0 = affine.apply affine_map<(d0) -> (d0 + 4)>(%i0)
affine.store %cf0, %0[%a0] : memref<10xf32>
// CHECK-LABEL: func @test_dep_store_depth1_load_depth2
func @test_dep_store_depth1_load_depth2() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 10 {
%a0 = affine.apply affine_map<(d0) -> (d0 - 1)>(%i0)
affine.store %cst, %0[%a0] : memref<100xf32>
// CHECK-LABEL: func @test_dep_store_depth2_load_depth1
func @test_dep_store_depth2_load_depth1() {
%0 = memref.alloc() : memref<100xf32>
- %cst = constant 7.000000e+00 : f32
+ %cst = arith.constant 7.000000e+00 : f32
affine.for %i0 = 0 to 10 {
affine.for %i1 = affine_map<(d0) -> (d0)>(%i0) to affine_map<(d0) -> (d0 + 1)>(%i0) {
affine.store %cst, %0[%i1] : memref<100xf32>
// CHECK-LABEL: func @test_affine_for_if_same_block() {
func @test_affine_for_if_same_block() {
%0 = memref.alloc() : memref<100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 100 {
affine.if #set(%i0) {
// CHECK-LABEL: func @test_affine_for_if_separated() {
func @test_affine_for_if_separated() {
%0 = memref.alloc() : memref<100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 10 {
affine.if #set(%i0) {
// CHECK-LABEL: func @test_affine_for_if_partially_joined() {
func @test_affine_for_if_partially_joined() {
%0 = memref.alloc() : memref<100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 100 {
affine.if #set1(%i0) {
// CHECK-LABEL: func @test_interleaved_affine_for_if() {
func @test_interleaved_affine_for_if() {
%0 = memref.alloc() : memref<100x100xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 100 {
affine.if #set1(%i0) {
// CHECK-LABEL: func @test_interleaved_affine_for_if() {
func @test_interleaved_affine_for_if() {
%0 = memref.alloc() : memref<101xf32>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%N = memref.dim %0, %c0 : memref<101xf32>
- %cf7 = constant 7.0 : f32
+ %cf7 = arith.constant 7.0 : f32
affine.for %i0 = 0 to 101 {
affine.if #set1(%i0)[%N] {
// CHECK-LABEL: test_norm_dynamic12
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x1x?x64xf32>) {
func @test_norm_dynamic12(%arg0 : memref<1x?x?x14xf32, #map_tiled>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_tiled>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_tiled>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_tiled>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_tiled>, memref<1x?x?x14xf32, #map_tiled>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_tiled>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x1x?x64xf32>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x1x?x64xf32>
- // CHECK-DAG: [[CST_1_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_14_:%.+]] = constant 14 : index
+ // CHECK-DAG: [[CST_1_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_14_:%.+]] = arith.constant 14 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[VAR_2_:%.+]] = affine.apply #[[$MAP0]]([[CST_1_1_]], [[DIM_0_]], [[DIM_1_]], [[CST_14_]])
// CHECK-DAG: [[VAR_3_:%.+]] = affine.apply #[[$MAP1]]([[CST_1_1_]], [[DIM_0_]], [[DIM_1_]], [[CST_14_]])
// CHECK-LABEL: test_norm_dynamic1234
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<?x?x?x?x?x?xf32>) {
func @test_norm_dynamic1234(%arg0 : memref<?x?x?x?xf32, #map_tiled1>) -> () {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
%0 = memref.dim %arg0, %c0 :memref<?x?x?x?xf32, #map_tiled1>
%1 = memref.dim %arg0, %c1 :memref<?x?x?x?xf32, #map_tiled1>
%2 = memref.dim %arg0, %c2 :memref<?x?x?x?xf32, #map_tiled1>
"test.op_norm"(%arg0, %4) : (memref<?x?x?x?xf32, #map_tiled1>, memref<?x?x?x?xf32, #map_tiled1>) -> ()
memref.dealloc %4 : memref<?x?x?x?xf32, #map_tiled1>
return
- // CHECK-DAG: [[CST_0_:%.+]] = constant 0 : index
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
- // CHECK-DAG: [[CST_3_:%.+]] = constant 3 : index
+ // CHECK-DAG: [[CST_0_:%.+]] = arith.constant 0 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
+ // CHECK-DAG: [[CST_3_:%.+]] = arith.constant 3 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_0_]] : memref<?x?x?x?x?x?xf32>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<?x?x?x?x?x?xf32>
// CHECK-LABEL: func @test_norm_dynamic_not_tiled0
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x14xf32, #[[$MAP6]]>) {
func @test_norm_dynamic_not_tiled0(%arg0 : memref<1x?x?x14xf32, #map_not_tiled0>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_not_tiled0>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_not_tiled0>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_not_tiled0>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_not_tiled0>, memref<1x?x?x14xf32, #map_not_tiled0>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_not_tiled0>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x14xf32, #[[$MAP6]]>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x14xf32, #[[$MAP6]]>
// CHECK-LABEL: func @test_norm_dynamic_not_tiled1
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x14xf32, #[[$MAP6]]>) {
func @test_norm_dynamic_not_tiled1(%arg0 : memref<1x?x?x14xf32, #map_not_tiled1>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_not_tiled1>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_not_tiled1>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_not_tiled1>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_not_tiled1>, memref<1x?x?x14xf32, #map_not_tiled1>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_not_tiled1>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x14xf32, #[[$MAP6]]>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x14xf32, #[[$MAP6]]>
// CHECK-LABEL: func @test_norm_dynamic_not_tiled2
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x14xf32, #[[$MAP7]]>) {
func @test_norm_dynamic_not_tiled2(%arg0 : memref<1x?x?x14xf32, #map_not_tiled2>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_not_tiled2>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_not_tiled2>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_not_tiled2>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_not_tiled2>, memref<1x?x?x14xf32, #map_not_tiled2>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_not_tiled2>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x14xf32, #[[$MAP7]]>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x14xf32, #[[$MAP7]]>
// CHECK-LABEL: func @test_norm_dynamic_not_tiled3
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x14xf32, #[[$MAP8]]>) {
func @test_norm_dynamic_not_tiled3(%arg0 : memref<1x?x?x14xf32, #map_not_tiled3>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_not_tiled3>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_not_tiled3>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_not_tiled3>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_not_tiled3>, memref<1x?x?x14xf32, #map_not_tiled3>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_not_tiled3>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x14xf32, #[[$MAP8]]>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x14xf32, #[[$MAP8]]>
// CHECK-LABEL: func @test_norm_dynamic_not_tiled4
// CHECK-SAME: ([[ARG_0_:%.+]]: memref<1x?x?x14xf32, #[[$MAP9]]>) {
func @test_norm_dynamic_not_tiled4(%arg0 : memref<1x?x?x14xf32, #map_not_tiled4>) -> () {
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%0 = memref.dim %arg0, %c1 :memref<1x?x?x14xf32, #map_not_tiled4>
%1 = memref.dim %arg0, %c2 :memref<1x?x?x14xf32, #map_not_tiled4>
%2 = memref.alloc(%0, %1) : memref<1x?x?x14xf32, #map_not_tiled4>
"test.op_norm"(%arg0, %2) : (memref<1x?x?x14xf32, #map_not_tiled4>, memref<1x?x?x14xf32, #map_not_tiled4>) -> ()
memref.dealloc %2 : memref<1x?x?x14xf32, #map_not_tiled4>
return
- // CHECK-DAG: [[CST_1_:%.+]] = constant 1 : index
- // CHECK-DAG: [[CST_2_:%.+]] = constant 2 : index
+ // CHECK-DAG: [[CST_1_:%.+]] = arith.constant 1 : index
+ // CHECK-DAG: [[CST_2_:%.+]] = arith.constant 2 : index
// CHECK-NOT: separator of consecutive DAGs
// CHECK-DAG: [[DIM_0_:%.+]] = memref.dim [[ARG_0_]], [[CST_1_]] : memref<1x?x?x14xf32, #[[$MAP9]]>
// CHECK-DAG: [[DIM_1_:%.+]] = memref.dim [[ARG_0_]], [[CST_2_]] : memref<1x?x?x14xf32, #[[$MAP9]]>
// CHECK: %[[v1:.*]] = memref.alloc() : memref<1x16x14x14xf32>
"test.op_norm"(%0, %1) : (memref<1x16x14x14xf32, #map_tile>, memref<1x16x14x14xf32>) -> ()
// CHECK: "test.op_norm"(%[[v0]], %[[v1]]) : (memref<1x16x1x1x32x32xf32>, memref<1x16x14x14xf32>) -> ()
- %cst = constant 3.0 : f32
+ %cst = arith.constant 3.0 : f32
affine.for %i = 0 to 1 {
affine.for %j = 0 to 16 {
affine.for %k = 0 to 14 {
affine.for %l = 0 to 14 {
%2 = memref.load %1[%i, %j, %k, %l] : memref<1x16x14x14xf32>
// CHECK: memref<1x16x14x14xf32>
- %3 = addf %2, %cst : f32
+ %3 = arith.addf %2, %cst : f32
memref.store %3, %arg0[%i, %j, %k, %l] : memref<1x16x14x14xf32>
// CHECK: memref<1x16x14x14xf32>
}
// CHECK-SAME: (%[[A:arg[0-9]+]]: memref<4x4xf64>, %[[B:arg[0-9]+]]: f64, %[[C:arg[0-9]+]]: memref<2x4xf64>, %[[D:arg[0-9]+]]: memref<24xf64>) -> f64
func @multiple_argument_type(%A: memref<16xf64, #tile>, %B: f64, %C: memref<8xf64, #tile>, %D: memref<24xf64>) -> f64 {
%a = affine.load %A[0] : memref<16xf64, #tile>
- %p = mulf %a, %a : f64
+ %p = arith.mulf %a, %a : f64
affine.store %p, %A[10] : memref<16xf64, #tile>
call @single_argument_type(%C): (memref<8xf64, #tile>) -> ()
return %B : f64
}
// CHECK: %[[a:[0-9]+]] = affine.load %[[A]][0, 0] : memref<4x4xf64>
-// CHECK: %[[p:[0-9]+]] = mulf %[[a]], %[[a]] : f64
+// CHECK: %[[p:[0-9]+]] = arith.mulf %[[a]], %[[a]] : f64
// CHECK: affine.store %[[p]], %[[A]][2, 2] : memref<4x4xf64>
// CHECK: call @single_argument_type(%[[C]]) : (memref<2x4xf64>) -> ()
// CHECK: return %[[B]] : f64
func @single_argument_type(%C : memref<8xf64, #tile>) {
%a = memref.alloc(): memref<8xf64, #tile>
%b = memref.alloc(): memref<16xf64, #tile>
- %d = constant 23.0 : f64
+ %d = arith.constant 23.0 : f64
%e = memref.alloc(): memref<24xf64>
call @single_argument_type(%a): (memref<8xf64, #tile>) -> ()
call @single_argument_type(%C): (memref<8xf64, #tile>) -> ()
// CHECK: %[[a:[0-9]+]] = memref.alloc() : memref<2x4xf64>
// CHECK: %[[b:[0-9]+]] = memref.alloc() : memref<4x4xf64>
-// CHECK: %cst = constant 2.300000e+01 : f64
+// CHECK: %cst = arith.constant 2.300000e+01 : f64
// CHECK: %[[e:[0-9]+]] = memref.alloc() : memref<24xf64>
// CHECK: call @single_argument_type(%[[a]]) : (memref<2x4xf64>) -> ()
// CHECK: call @single_argument_type(%[[C]]) : (memref<2x4xf64>) -> ()
// CHECK-LABEL: func @non_memref_ret
// CHECK-SAME: (%[[C:arg[0-9]+]]: memref<2x4xf64>) -> i1
func @non_memref_ret(%A: memref<8xf64, #tile>) -> i1 {
- %d = constant 1 : i1
+ %d = arith.constant 1 : i1
return %d : i1
}
// CHECK-SAME: (%[[A:arg[0-9]+]]: memref<4x4xf64>, %[[B:arg[0-9]+]]: f64, %[[C:arg[0-9]+]]: memref<2x4xf64>) -> (memref<2x4xf64>, f64)
func @ret_multiple_argument_type(%A: memref<16xf64, #tile>, %B: f64, %C: memref<8xf64, #tile>) -> (memref<8xf64, #tile>, f64) {
%a = affine.load %A[0] : memref<16xf64, #tile>
- %p = mulf %a, %a : f64
- %cond = constant 1 : i1
+ %p = arith.mulf %a, %a : f64
+ %cond = arith.constant 1 : i1
cond_br %cond, ^bb1, ^bb2
^bb1:
%res1, %res2 = call @ret_single_argument_type(%C) : (memref<8xf64, #tile>) -> (memref<16xf64, #tile>, memref<8xf64, #tile>)
}
// CHECK: %[[a:[0-9]+]] = affine.load %[[A]][0, 0] : memref<4x4xf64>
-// CHECK: %[[p:[0-9]+]] = mulf %[[a]], %[[a]] : f64
-// CHECK: %true = constant true
+// CHECK: %[[p:[0-9]+]] = arith.mulf %[[a]], %[[a]] : f64
+// CHECK: %true = arith.constant true
// CHECK: cond_br %true, ^bb1, ^bb2
// CHECK: ^bb1: // pred: ^bb0
// CHECK: %[[res:[0-9]+]]:2 = call @ret_single_argument_type(%[[C]]) : (memref<2x4xf64>) -> (memref<4x4xf64>, memref<2x4xf64>)
func @ret_single_argument_type(%C: memref<8xf64, #tile>) -> (memref<16xf64, #tile>, memref<8xf64, #tile>){
%a = memref.alloc() : memref<8xf64, #tile>
%b = memref.alloc() : memref<16xf64, #tile>
- %d = constant 23.0 : f64
+ %d = arith.constant 23.0 : f64
call @ret_single_argument_type(%a) : (memref<8xf64, #tile>) -> (memref<16xf64, #tile>, memref<8xf64, #tile>)
call @ret_single_argument_type(%C) : (memref<8xf64, #tile>) -> (memref<16xf64, #tile>, memref<8xf64, #tile>)
%res1, %res2 = call @ret_multiple_argument_type(%b, %d, %a) : (memref<16xf64, #tile>, f64, memref<8xf64, #tile>) -> (memref<8xf64, #tile>, f64)
// CHECK: %[[a:[0-9]+]] = memref.alloc() : memref<2x4xf64>
// CHECK: %[[b:[0-9]+]] = memref.alloc() : memref<4x4xf64>
-// CHECK: %cst = constant 2.300000e+01 : f64
+// CHECK: %cst = arith.constant 2.300000e+01 : f64
// CHECK: %[[resA:[0-9]+]]:2 = call @ret_single_argument_type(%[[a]]) : (memref<2x4xf64>) -> (memref<4x4xf64>, memref<2x4xf64>)
// CHECK: %[[resB:[0-9]+]]:2 = call @ret_single_argument_type(%[[C]]) : (memref<2x4xf64>) -> (memref<4x4xf64>, memref<2x4xf64>)
// CHECK: %[[resC:[0-9]+]]:2 = call @ret_multiple_argument_type(%[[b]], %cst, %[[a]]) : (memref<4x4xf64>, f64, memref<2x4xf64>) -> (memref<2x4xf64>, f64)
// CHECK-LABEL: func @affine_parallel_norm
func @affine_parallel_norm() -> memref<8xf32, #tile> {
- %c = constant 23.0 : f32
+ %c = arith.constant 23.0 : f32
%a = memref.alloc() : memref<8xf32, #tile>
// CHECK: affine.parallel (%{{.*}}) = (0) to (8) reduce ("assign") -> (memref<2x4xf32>)
%1 = affine.parallel (%i) = (0) to (8) reduce ("assign") -> memref<8xf32, #tile> {
// CHECK-LABEL: func @parallel_many_dims() {
func @parallel_many_dims() {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
- %c3 = constant 3 : index
- %c4 = constant 4 : index
- %c5 = constant 5 : index
- %c6 = constant 6 : index
- %c7 = constant 7 : index
- %c8 = constant 8 : index
- %c9 = constant 9 : index
- %c10 = constant 10 : index
- %c11 = constant 11 : index
- %c12 = constant 12 : index
- %c13 = constant 13 : index
- %c14 = constant 14 : index
- %c15 = constant 15 : index
- %c26 = constant 26 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
+ %c4 = arith.constant 4 : index
+ %c5 = arith.constant 5 : index
+ %c6 = arith.constant 6 : index
+ %c7 = arith.constant 7 : index
+ %c8 = arith.constant 8 : index
+ %c9 = arith.constant 9 : index
+ %c10 = arith.constant 10 : index
+ %c11 = arith.constant 11 : index
+ %c12 = arith.constant 12 : index
+ %c13 = arith.constant 13 : index
+ %c14 = arith.constant 14 : index
+ %c15 = arith.constant 15 : index
+ %c26 = arith.constant 26 : index
scf.parallel (%i0, %i1, %i2, %i3, %i4) = (%c0, %c3, %c6, %c9, %c12)
to (%c2, %c5, %c8, %c26, %c14) step (%c1, %c4, %c7, %c10, %c13) {
return
}
-// CHECK-DAG: [[C12:%.*]] = constant 12 : index
-// CHECK-DAG: [[C10:%.*]] = constant 10 : index
-// CHECK-DAG: [[C9:%.*]] = constant 9 : index
-// CHECK-DAG: [[C6:%.*]] = constant 6 : index
-// CHECK-DAG: [[C4:%.*]] = constant 4 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
-// CHECK-DAG: [[C2:%.*]] = constant 2 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
+// CHECK-DAG: [[C12:%.*]] = arith.constant 12 : index
+// CHECK-DAG: [[C10:%.*]] = arith.constant 10 : index
+// CHECK-DAG: [[C9:%.*]] = arith.constant 9 : index
+// CHECK-DAG: [[C6:%.*]] = arith.constant 6 : index
+// CHECK-DAG: [[C4:%.*]] = arith.constant 4 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
+// CHECK-DAG: [[C2:%.*]] = arith.constant 2 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
// CHECK: scf.parallel ([[NEW_I0:%.*]]) = ([[C0]]) to ([[C4]]) step ([[C1]]) {
-// CHECK: [[V0:%.*]] = remi_signed [[NEW_I0]], [[C2]] : index
-// CHECK: [[I0:%.*]] = divi_signed [[NEW_I0]], [[C2]] : index
-// CHECK: [[V2:%.*]] = muli [[V0]], [[C10]] : index
-// CHECK: [[I3:%.*]] = addi [[V2]], [[C9]] : index
+// CHECK: [[V0:%.*]] = arith.remsi [[NEW_I0]], [[C2]] : index
+// CHECK: [[I0:%.*]] = arith.divsi [[NEW_I0]], [[C2]] : index
+// CHECK: [[V2:%.*]] = arith.muli [[V0]], [[C10]] : index
+// CHECK: [[I3:%.*]] = arith.addi [[V2]], [[C9]] : index
// CHECK: "magic.op"([[I0]], [[C3]], [[C6]], [[I3]], [[C12]]) : (index, index, index, index, index) -> index
// CHECK: scf.yield
// COMMON-LABEL: @rectangular
func @rectangular(%arg0: memref<?x?xf32>) {
- %c2 = constant 2 : index
- %c44 = constant 44 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c44 = arith.constant 44 : index
+ %c1 = arith.constant 1 : index
// Range of the original loop:
// (upper - lower + step - 1) / step
// where step is known to be %c1.
- // COMMON: %[[diff:.*]] = subi %c44, %c2
- // COMMON: %[[adjustment:.*]] = subi %c1, %c1_{{.*}}
- // COMMON-NEXT: %[[diff_adj:.*]] = addi %[[diff]], %[[adjustment]]
- // COMMON-NEXT: %[[range:.*]] = divi_signed %[[diff_adj]], %c1
+ // COMMON: %[[diff:.*]] = arith.subi %c44, %c2
+ // COMMON: %[[adjustment:.*]] = arith.subi %c1, %c1_{{.*}}
+ // COMMON-NEXT: %[[diff_adj:.*]] = arith.addi %[[diff]], %[[adjustment]]
+ // COMMON-NEXT: %[[range:.*]] = arith.divsi %[[diff_adj]], %c1
// Ceildiv to get the parametric tile size.
- // COMMON: %[[sum:.*]] = addi %[[range]], %c6
- // COMMON-NEXT: %[[size:.*]] = divi_signed %[[sum]], %c7
+ // COMMON: %[[sum:.*]] = arith.addi %[[range]], %c6
+ // COMMON-NEXT: %[[size:.*]] = arith.divsi %[[sum]], %c7
// New outer step (original is %c1).
- // COMMON-NEXT: %[[step:.*]] = muli %c1, %[[size]]
+ // COMMON-NEXT: %[[step:.*]] = arith.muli %c1, %[[size]]
// Range of the second original loop
// (upper - lower + step - 1) / step
// where step is known to be %c2.
- // TILE_74: %[[diff2:.*]] = subi %c44, %c1
- // TILE_74: %[[adjustment2:.*]] = subi %c2, %c1_{{.*}}
- // TILE_74-NEXT: %[[diff2_adj:.*]] = addi %[[diff2]], %[[adjustment2]]
- // TILE_74-NEXT: %[[range2:.*]] = divi_signed %[[diff2_adj]], %c2
+ // TILE_74: %[[diff2:.*]] = arith.subi %c44, %c1
+ // TILE_74: %[[adjustment2:.*]] = arith.subi %c2, %c1_{{.*}}
+ // TILE_74-NEXT: %[[diff2_adj:.*]] = arith.addi %[[diff2]], %[[adjustment2]]
+ // TILE_74-NEXT: %[[range2:.*]] = arith.divsi %[[diff2_adj]], %c2
// Ceildiv to get the parametric tile size for the second original scf.
- // TILE_74: %[[sum2:.*]] = addi %[[range2]], %c3
- // TILE_74-NEXT: %[[size2:.*]] = divi_signed %[[sum2]], %c4
+ // TILE_74: %[[sum2:.*]] = arith.addi %[[range2]], %c3
+ // TILE_74-NEXT: %[[size2:.*]] = arith.divsi %[[sum2]], %c4
// New inner step (original is %c2).
- // TILE_74-NEXT: %[[step2:.*]] = muli %c2, %[[size2]]
+ // TILE_74-NEXT: %[[step2:.*]] = arith.muli %c2, %[[size2]]
// Updated outer loop(s) use new steps.
// COMMON: scf.for %[[i:.*]] = %c2 to %c44 step %[[step]]
// TILE_74:scf.for %[[j:.*]] = %c1 to %c44 step %[[step2]]
scf.for %i = %c2 to %c44 step %c1 {
// Upper bound for the inner loop min(%i + %step, %c44).
- // COMMON: %[[stepped:.*]] = addi %[[i]], %[[step]]
- // COMMON-NEXT: cmpi slt, %c44, %[[stepped]]
+ // COMMON: %[[stepped:.*]] = arith.addi %[[i]], %[[step]]
+ // COMMON-NEXT: arith.cmpi slt, %c44, %[[stepped]]
// COMMON-NEXT: %[[ub:.*]] = select {{.*}}, %c44, %[[stepped]]
//
- // TILE_74: %[[stepped2:.*]] = addi %[[j]], %[[step2]]
- // TILE_74-NEXT: cmpi slt, %c44, %[[stepped2]]
+ // TILE_74: %[[stepped2:.*]] = arith.addi %[[j]], %[[step2]]
+ // TILE_74-NEXT: arith.cmpi slt, %c44, %[[stepped2]]
// TILE_74-NEXT: %[[ub2:.*]] = select {{.*}}, %c44, %[[stepped2]]
// Created inner scf.
// COMMON-LABEL: @triangular
func @triangular(%arg0: memref<?x?xf32>) {
- %c2 = constant 2 : index
- %c44 = constant 44 : index
- %c1 = constant 1 : index
+ %c2 = arith.constant 2 : index
+ %c44 = arith.constant 44 : index
+ %c1 = arith.constant 1 : index
// Range of the original outer loop:
// (upper - lower + step - 1) / step
// where step is known to be %c1.
- // COMMON: %[[diff:.*]] = subi %c44, %c2
- // COMMON: %[[adjustment:.*]] = subi %c1, %c1_{{.*}}
- // COMMON-NEXT: %[[diff_adj:.*]] = addi %[[diff]], %[[adjustment]]
- // COMMON-NEXT: %[[range:.*]] = divi_signed %[[diff_adj]], %c1
+ // COMMON: %[[diff:.*]] = arith.subi %c44, %c2
+ // COMMON: %[[adjustment:.*]] = arith.subi %c1, %c1_{{.*}}
+ // COMMON-NEXT: %[[diff_adj:.*]] = arith.addi %[[diff]], %[[adjustment]]
+ // COMMON-NEXT: %[[range:.*]] = arith.divsi %[[diff_adj]], %c1
// Ceildiv to get the parametric tile size.
- // COMMON: %[[sum:.*]] = addi %[[range]], %c6
- // COMMON-NEXT: %[[size:.*]] = divi_signed %[[sum]], %c7
+ // COMMON: %[[sum:.*]] = arith.addi %[[range]], %c6
+ // COMMON-NEXT: %[[size:.*]] = arith.divsi %[[sum]], %c7
// New outer step (original is %c1).
- // COMMON-NEXT: %[[step:.*]] = muli %c1, %[[size]]
+ // COMMON-NEXT: %[[step:.*]] = arith.muli %c1, %[[size]]
// Constant adjustment for inner loop has been hoisted out.
- // TILE_74: %[[adjustment2:.*]] = subi %c2, %c1_{{.*}}
+ // TILE_74: %[[adjustment2:.*]] = arith.subi %c2, %c1_{{.*}}
// New outer scf.
// COMMON: scf.for %[[i:.*]] = %c2 to %c44 step %[[step]]
// Range of the original inner loop
// (upper - lower + step - 1) / step
// where step is known to be %c2.
- // TILE_74: %[[diff2:.*]] = subi %[[i]], %c1
- // TILE_74-NEXT: %[[diff2_adj:.*]] = addi %[[diff2]], %[[adjustment2]]
- // TILE_74-NEXT: %[[range2:.*]] = divi_signed %[[diff2_adj]], %c2
+ // TILE_74: %[[diff2:.*]] = arith.subi %[[i]], %c1
+ // TILE_74-NEXT: %[[diff2_adj:.*]] = arith.addi %[[diff2]], %[[adjustment2]]
+ // TILE_74-NEXT: %[[range2:.*]] = arith.divsi %[[diff2_adj]], %c2
// Ceildiv to get the parametric tile size for the second original scf.
- // TILE_74: %[[sum2:.*]] = addi %[[range2]], %c3
- // TILE_74-NEXT: %[[size2:.*]] = divi_signed %[[sum2]], %c4
+ // TILE_74: %[[sum2:.*]] = arith.addi %[[range2]], %c3
+ // TILE_74-NEXT: %[[size2:.*]] = arith.divsi %[[sum2]], %c4
// New inner step (original is %c2).
- // TILE_74-NEXT: %[[step2:.*]] = muli %c2, %[[size2]]
+ // TILE_74-NEXT: %[[step2:.*]] = arith.muli %c2, %[[size2]]
// New inner scf.
// TILE_74:scf.for %[[j:.*]] = %c1 to %[[i]] step %[[step2]]
scf.for %i = %c2 to %c44 step %c1 {
// Upper bound for the inner loop min(%i + %step, %c44).
- // COMMON: %[[stepped:.*]] = addi %[[i]], %[[step]]
- // COMMON-NEXT: cmpi slt, %c44, %[[stepped]]
+ // COMMON: %[[stepped:.*]] = arith.addi %[[i]], %[[step]]
+ // COMMON-NEXT: arith.cmpi slt, %c44, %[[stepped]]
// COMMON-NEXT: %[[ub:.*]] = select {{.*}}, %c44, %[[stepped]]
- // TILE_74: %[[stepped2:.*]] = addi %[[j]], %[[step2]]
- // TILE_74-NEXT: cmpi slt, %[[i]], %[[stepped2]]
+ // TILE_74: %[[stepped2:.*]] = arith.addi %[[j]], %[[step2]]
+ // TILE_74-NEXT: arith.cmpi slt, %[[i]], %[[stepped2]]
// TILE_74-NEXT: %[[ub2:.*]] = select {{.*}}, %[[i]], %[[stepped2]]
//
// Created inner scf.
%tag = memref.alloc() : memref<1 x f32>
- %zero = constant 0 : index
- %num_elts = constant 32 : index
+ %zero = arith.constant 0 : index
+ %num_elts = arith.constant 32 : index
affine.for %i = 0 to 8 {
affine.dma_start %A[%i], %Ah[%i], %tag[%zero], %num_elts : memref<256 x f32>, memref<32 x f32, 1>, memref<1 x f32>
// CHECK-LABEL: @loop_step
func @loop_step(%arg0: memref<512xf32>,
%arg1: memref<512xf32>) {
- %c0 = constant 0 : index
- %c4 = constant 4 : index
+ %c0 = arith.constant 0 : index
+ %c4 = arith.constant 4 : index
affine.for %i0 = 0 to 512 step 4 {
%1 = memref.alloc() : memref<4xf32, 1>
%2 = memref.alloc() : memref<1xi32>
#map2 = affine_map<(d0) -> ((d0 * 2048) floordiv 32)>
// CHECK-LABEL: func @loop_dma_nested(%{{.*}}: memref<512x32xvector<8xf32>
func @loop_dma_nested(%arg0: memref<512x32xvector<8xf32>>, %arg1: memref<512x32xvector<8xf32>>, %arg2: memref<512x32xvector<8xf32>>) {
- %num_elts = constant 256 : index
- %c0 = constant 0 : index
+ %num_elts = arith.constant 256 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
%1 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
%2 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
// CHECK: func @loop_dma_dependent
func @loop_dma_dependent(%arg2: memref<512x32xvector<8xf32>>) {
- %num_elts = constant 256 : index
- %c0 = constant 0 : index
+ %num_elts = arith.constant 256 : index
+ %c0 = arith.constant 0 : index
%0 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
%1 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
%2 = memref.alloc() : memref<64x4xvector<8xf32>, 2>
// CHECK-LABEL: func @escaping_use
func @escaping_use(%arg0: memref<512 x 32 x f32>) {
- %c32 = constant 32 : index
- %num_elt = constant 512 : index
- %zero = constant 0 : index
+ %c32 = arith.constant 32 : index
+ %num_elt = arith.constant 512 : index
+ %zero = arith.constant 0 : index
%Av = memref.alloc() : memref<32 x 32 x f32, 2>
%tag = memref.alloc() : memref<1 x i32>
// CHECK-LABEL: func @escaping_tag
func @escaping_tag(%arg0: memref<512 x 32 x f32>) {
- %c32 = constant 32 : index
- %num_elt = constant 512 : index
- %zero = constant 0 : index
+ %c32 = arith.constant 32 : index
+ %num_elt = arith.constant 512 : index
+ %zero = arith.constant 0 : index
%Av = memref.alloc() : memref<32 x 32 x f32, 2>
%tag = memref.alloc() : memref<1 x i32>
// CHECK-LABEL: func @live_out_use
func @live_out_use(%arg0: memref<512 x 32 x f32>) -> f32 {
- %c32 = constant 32 : index
- %num_elt = constant 512 : index
- %zero = constant 0 : index
+ %c32 = arith.constant 32 : index
+ %num_elt = arith.constant 512 : index
+ %zero = arith.constant 0 : index
%Av = memref.alloc() : memref<32 x 32 x f32, 2>
%tag = memref.alloc() : memref<1 x i32>
// CHECK-LABEL: func @dynamic_shape_dma_buffer
func @dynamic_shape_dma_buffer(%arg0: memref<512 x 32 x f32>, %Av: memref<? x ? x f32, 2>) {
- %num_elt = constant 512 : index
- %zero = constant 0 : index
+ %num_elt = arith.constant 512 : index
+ %zero = arith.constant 0 : index
%tag = memref.alloc() : memref<1 x i32>
// Double buffering for dynamic shaped buffer.
// Note: Cannot capture C0 because there are multiple C0 constants in the IR.
// CHECK: memref.dim %{{.*}}, %{{.*}} : memref<?x?xf32, 2>
-// CHECK-NEXT: %[[C1:.*]] = constant 1 : index
+// CHECK-NEXT: %[[C1:.*]] = arith.constant 1 : index
// CHECK-NEXT: memref.dim %{{.*}}, %[[C1]] : memref<?x?xf32, 2>
// CHECK-NEXT: memref.alloc(%{{.*}}, %{{.*}}) : memref<2x?x?xf32, 2>
// CHECK: affine.dma_start %{{.*}}[%{{.*}}, %{{.*}}], %{{.*}}[%{{.*}} mod 2, 0, 0], %{{.*}}[%{{.*}} mod 2, 0], %{{.*}}
%A = memref.alloc() : memref<256 x f32, affine_map<(d0) -> (d0)>, 0>
%Ah = memref.alloc() : memref<32 x f32, affine_map<(d0) -> (d0)>, 1>
%tag = memref.alloc() : memref<1 x f32>
- %zero = constant 0 : index
- %num_elts = constant 32 : index
+ %zero = arith.constant 0 : index
+ %num_elts = arith.constant 32 : index
// alloc for the buffer is created but no replacement should happen.
affine.for %i = 0 to 8 {
// CFG: subgraph {{.*}}
// CFG: label = "builtin.func{{.*}}merge_blocks
// CFG: subgraph {{.*}} {
-// CFG: v[[C1:.*]] [label = "std.constant
-// CFG: v[[C2:.*]] [label = "std.constant
-// CFG: v[[C3:.*]] [label = "std.constant
-// CFG: v[[C4:.*]] [label = "std.constant
+// CFG: v[[C1:.*]] [label = "arith.constant
+// CFG: v[[C2:.*]] [label = "arith.constant
+// CFG: v[[C3:.*]] [label = "arith.constant
+// CFG: v[[C4:.*]] [label = "arith.constant
// CFG: v[[TEST_FUNC:.*]] [label = "test.func
// CFG: subgraph [[CLUSTER_MERGE_BLOCKS:.*]] {
// CFG: v[[ANCHOR:.*]] [label = " ", shape = plain]
// CFG: v[[ANCHOR]] -> v[[TEST_RET]] [{{.*}}, ltail = [[CLUSTER_MERGE_BLOCKS]]]
func @merge_blocks(%arg0: i32, %arg1 : i32) -> () {
- %0 = constant dense<[[0, 1], [2, 3]]> : tensor<2x2xi32>
- %1 = constant dense<1> : tensor<5xi32>
- %2 = constant dense<[[0, 1]]> : tensor<1x2xi32>
- %a = constant 10 : i32
+ %0 = arith.constant dense<[[0, 1], [2, 3]]> : tensor<2x2xi32>
+ %1 = arith.constant dense<1> : tensor<5xi32>
+ %2 = arith.constant dense<[[0, 1]]> : tensor<1x2xi32>
+ %a = arith.constant 10 : i32
%b = "test.func"() : () -> i32
%3:2 = "test.merge_blocks"() ({
^bb0:
func @nested_region_control_flow(
%arg0 : index,
%arg1 : index) -> memref<?x?xf32> {
- %0 = cmpi eq, %arg0, %arg1 : index
+ %0 = arith.cmpi eq, %arg0, %arg1 : index
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
%2 = scf.if %0 -> (memref<?x?xf32>) {
scf.yield %1 : memref<?x?xf32>
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = memref.alloc() : memref<2xf32>
scf.yield %3 : memref<2xf32>
}
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
scf.yield %0 : memref<2xf32>
} else {
%0 = memref.alloc() : memref<2xf32>
%1 = scf.for %i = %lb to %ub step %step
iter_args(%iterBuf = %buf) -> memref<2xf32> {
- %2 = cmpi eq, %i, %ub : index
+ %2 = arith.cmpi eq, %i, %ub : index
%3 = scf.if %2 -> (memref<2xf32>) {
%4 = memref.alloc() : memref<2xf32>
scf.yield %4 : memref<2xf32>
// CHECK-LABEL: func private @private(
func private @private(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
return %arg0 : i32
// CHECK-LABEL: func @simple_private(
func @simple_private() -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result = call @private(%1) : (i32) -> i32
return %result : i32
}
// CHECK: func nested @nested(
func nested @nested(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
return %arg0 : i32
// CHECK-LABEL: func @simple_nested(
func @simple_nested() -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result = call @nested(%1) : (i32) -> i32
return %result : i32
}
// NESTED: func nested @nested(
func nested @nested(%arg0 : i32) -> (i32, i32) {
- // NESTED: %[[CST:.*]] = constant 1 : i32
+ // NESTED: %[[CST:.*]] = arith.constant 1 : i32
// NESTED: return %[[CST]], %arg0 : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
return %1, %arg0 : i32, i32
}
// NESTED: func @nested_not_all_uses_visible(
func @nested_not_all_uses_visible() -> (i32, i32) {
- // NESTED: %[[CST:.*]] = constant 1 : i32
+ // NESTED: %[[CST:.*]] = arith.constant 1 : i32
// NESTED: %[[CALL:.*]]:2 = call @nested
// NESTED: return %[[CST]], %[[CALL]]#1 : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result:2 = call @nested(%1) : (i32) -> (i32, i32)
return %result#0, %result#1 : i32, i32
}
// CHECK-LABEL: func @public(
func @public(%arg0 : i32) -> (i32, i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
return %1, %arg0 : i32, i32
}
// CHECK-LABEL: func @simple_public(
func @simple_public() -> (i32, i32) {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: %[[CALL:.*]]:2 = call @public
// CHECK: return %[[CST]], %[[CALL]]#1 : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result:2 = call @public(%1) : (i32) -> (i32, i32)
return %result#0, %result#1 : i32, i32
}
/// Check that functions with non-call users don't have arguments tracked.
func private @callable(%arg0 : i32) -> (i32, i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
return %1, %arg0 : i32, i32
}
// CHECK-LABEL: func @non_call_users(
func @non_call_users() -> (i32, i32) {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: %[[CALL:.*]]:2 = call @callable
// CHECK: return %[[CST]], %[[CALL]]#1 : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result:2 = call @callable(%1) : (i32) -> (i32, i32)
return %result#0, %result#1 : i32, i32
}
// CHECK: %[[CALL:.*]] = call @callable
// CHECK: return %[[CALL]] : i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result = call @callable(%1) : (i32) -> i32
return %result : i32
}
// CHECK: %[[CALL2:.*]] = call @callable
// CHECK: return %[[CALL1]], %[[CALL2]] : i32, i32
- %1 = constant 1 : i32
- %2 = constant 2 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
%result = call @callable(%1) : (i32) -> i32
%result2 = call @callable(%2) : (i32) -> i32
return %result, %result2 : i32, i32
// CHECK: %[[CALL2:.*]] = call @callable
// CHECK: return %[[CALL1]], %[[CALL2]] : i32, i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result = call @callable(%1) : (i32) -> i32
%result2 = call @callable(%arg0) : (i32) -> i32
return %result, %result2 : i32, i32
// CHECK-LABEL: func private @complex_inner_if(
func private @complex_inner_if(%arg0 : i32) -> i32 {
- // CHECK-DAG: %[[TRUE:.*]] = constant true
- // CHECK-DAG: %[[CST:.*]] = constant 1 : i32
+ // CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+ // CHECK-DAG: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: cond_br %[[TRUE]], ^bb1
- %cst_20 = constant 20 : i32
- %cond = cmpi ult, %arg0, %cst_20 : i32
+ %cst_20 = arith.constant 20 : i32
+ %cond = arith.cmpi ult, %arg0, %cst_20 : i32
cond_br %cond, ^bb1, ^bb2
^bb1:
// CHECK: ^bb1:
// CHECK: return %[[CST]] : i32
- %cst_1 = constant 1 : i32
+ %cst_1 = arith.constant 1 : i32
return %cst_1 : i32
^bb2:
- %cst_1_2 = constant 1 : i32
- %arg_inc = addi %arg0, %cst_1_2 : i32
+ %cst_1_2 = arith.constant 1 : i32
+ %arg_inc = arith.addi %arg0, %cst_1_2 : i32
return %arg_inc : i32
}
// CHECK-LABEL: func private @complex_callee(
func private @complex_callee(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
%loop_cond = call @complex_cond() : () -> i1
cond_br %loop_cond, ^bb1, ^bb2
// CHECK-LABEL: func @complex_caller(
func @complex_caller(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
%result = call @complex_callee(%1) : (i32) -> i32
return %result : i32
}
// CHECK: return %[[RES]] : i32
%fn = "test.functional_region_op"() ({
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
"test.return"(%1) : (i32) -> ()
}) : () -> (() -> i32)
%res = call_indirect %fn() : () -> (i32)
func private @unreferenced_private_function() -> i32 {
// CHECK: %[[RES:.*]] = select
// CHECK: return %[[RES]] : i32
- %true = constant true
- %cst0 = constant 0 : i32
- %cst1 = constant 1 : i32
+ %true = arith.constant true
+ %cst0 = arith.constant 0 : i32
+ %cst1 = arith.constant 1 : i32
%result = select %true, %cst0, %cst1 : i32
return %result : i32
}
// CHECK-LABEL: func @simple(
func @simple(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK-NOT: scf.if
// CHECK: return %[[CST]] : i32
- %cond = constant true
+ %cond = arith.constant true
%res = scf.if %cond -> (i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
scf.yield %1 : i32
} else {
scf.yield %arg0 : i32
// CHECK-LABEL: func @simple_both_same(
func @simple_both_same(%cond : i1) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK-NOT: scf.if
// CHECK: return %[[CST]] : i32
%res = scf.if %cond -> (i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
scf.yield %1 : i32
} else {
- %2 = constant 1 : i32
+ %2 = arith.constant 1 : i32
scf.yield %2 : i32
}
return %res : i32
// CHECK: return %[[RES]] : i32
%res = scf.if %cond -> (i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
scf.yield %1 : i32
} else {
scf.yield %arg0 : i32
// CHECK: return %[[RES]] : i32
%res = scf.if %cond -> (i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
scf.yield %1 : i32
} else {
- %2 = constant 2 : i32
+ %2 = arith.constant 2 : i32
scf.yield %2 : i32
}
return %res : i32
// CHECK-LABEL: func @simple_loop(
func @simple_loop(%arg0 : index, %arg1 : index, %arg2 : index) -> i32 {
- // CHECK: %[[CST:.*]] = constant 0 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 0 : i32
// CHECK-NOT: scf.for
// CHECK: return %[[CST]] : i32
- %s0 = constant 0 : i32
+ %s0 = arith.constant 0 : i32
%result = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %s0) -> (i32) {
- %sn = addi %si, %si : i32
+ %sn = arith.addi %si, %si : i32
scf.yield %sn : i32
}
return %result : i32
// CHECK: %[[RES:.*]] = scf.for
// CHECK: return %[[RES]] : i32
- %s0 = constant 1 : i32
+ %s0 = arith.constant 1 : i32
%result = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %s0) -> (i32) {
- %sn = addi %si, %si : i32
+ %sn = arith.addi %si, %si : i32
scf.yield %sn : i32
}
return %result : i32
// CHECK-LABEL: func @loop_inner_control_flow(
func @loop_inner_control_flow(%arg0 : index, %arg1 : index, %arg2 : index) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK-NOT: scf.for
// CHECK-NOT: scf.if
// CHECK: return %[[CST]] : i32
- %cst_1 = constant 1 : i32
+ %cst_1 = arith.constant 1 : i32
%result = scf.for %i0 = %arg0 to %arg1 step %arg2 iter_args(%si = %cst_1) -> (i32) {
- %cst_20 = constant 20 : i32
- %cond = cmpi ult, %si, %cst_20 : i32
+ %cst_20 = arith.constant 20 : i32
+ %cond = arith.cmpi ult, %si, %cst_20 : i32
%inner_res = scf.if %cond -> (i32) {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
scf.yield %1 : i32
} else {
- %si_inc = addi %si, %cst_1 : i32
+ %si_inc = arith.addi %si, %cst_1 : i32
scf.yield %si_inc : i32
}
scf.yield %inner_res : i32
// CHECK-LABEL: func @loop_region_branch_terminator_op(
func @loop_region_branch_terminator_op(%arg1 : i32) {
- // CHECK: %c2_i32 = constant 2 : i32
+ // CHECK: %c2_i32 = arith.constant 2 : i32
// CHECK-NEXT: return
- %c2_i32 = constant 2 : i32
+ %c2_i32 = arith.constant 2 : i32
%0 = scf.while (%arg2 = %c2_i32) : (i32) -> (i32) {
- %1 = cmpi slt, %arg2, %arg1 : i32
+ %1 = arith.cmpi slt, %arg2, %arg1 : i32
scf.condition(%1) %arg2 : i32
} do {
^bb0(%arg2: i32):
// CHECK-LABEL: func @no_control_flow
func @no_control_flow(%arg0: i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
// CHECK: return %[[CST]] : i32
- %cond = constant true
- %cst_1 = constant 1 : i32
+ %cond = arith.constant true
+ %cst_1 = arith.constant 1 : i32
%select = select %cond, %cst_1, %arg0 : i32
return %select : i32
}
// CHECK-LABEL: func @simple_control_flow
func @simple_control_flow(%arg0 : i32) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
- %cond = constant true
- %1 = constant 1 : i32
+ %cond = arith.constant true
+ %1 = arith.constant 1 : i32
cond_br %cond, ^bb1, ^bb2(%arg0 : i32)
^bb1:
// CHECK-LABEL: func @simple_control_flow_overdefined
func @simple_control_flow_overdefined(%arg0 : i32, %arg1 : i1) -> i32 {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
cond_br %arg1, ^bb1, ^bb2(%arg0 : i32)
^bb1:
// CHECK-LABEL: func @simple_control_flow_constant_overdefined
func @simple_control_flow_constant_overdefined(%arg0 : i32, %arg1 : i1) -> i32 {
- %1 = constant 1 : i32
- %2 = constant 2 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
cond_br %arg1, ^bb1, ^bb2(%arg0 : i32)
^bb1:
// CHECK-LABEL: func @unknown_terminator
func @unknown_terminator(%arg0 : i32, %arg1 : i1) -> i32 {
- %1 = constant 1 : i32
+ %1 = arith.constant 1 : i32
"foo.cond_br"() [^bb1, ^bb2] : () -> ()
^bb1:
// CHECK-LABEL: func @simple_loop
func @simple_loop(%arg0 : i32, %cond1 : i1) -> i32 {
- // CHECK: %[[CST:.*]] = constant 1 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 1 : i32
- %cst_1 = constant 1 : i32
+ %cst_1 = arith.constant 1 : i32
cond_br %cond1, ^bb1(%cst_1 : i32), ^bb2(%cst_1 : i32)
^bb1(%iv: i32):
// CHECK-NEXT: %[[COND:.*]] = call @ext_cond_fn()
// CHECK-NEXT: cond_br %[[COND]], ^bb1(%[[CST]] : i32), ^bb2(%[[CST]] : i32)
- %cst_0 = constant 0 : i32
- %res = addi %iv, %cst_0 : i32
+ %cst_0 = arith.constant 0 : i32
+ %res = arith.addi %iv, %cst_0 : i32
%cond2 = call @ext_cond_fn() : () -> i1
cond_br %cond2, ^bb1(%res : i32), ^bb2(%res : i32)
// CHECK-LABEL: func @simple_loop_inner_control_flow
func @simple_loop_inner_control_flow(%arg0 : i32) -> i32 {
- // CHECK-DAG: %[[CST:.*]] = constant 1 : i32
- // CHECK-DAG: %[[TRUE:.*]] = constant true
+ // CHECK-DAG: %[[CST:.*]] = arith.constant 1 : i32
+ // CHECK-DAG: %[[TRUE:.*]] = arith.constant true
- %cst_1 = constant 1 : i32
+ %cst_1 = arith.constant 1 : i32
br ^bb1(%cst_1 : i32)
^bb1(%iv: i32):
// CHECK: ^bb2:
// CHECK: cond_br %[[TRUE]], ^bb3, ^bb4
- %cst_20 = constant 20 : i32
- %cond = cmpi ult, %iv, %cst_20 : i32
+ %cst_20 = arith.constant 20 : i32
+ %cond = arith.cmpi ult, %iv, %cst_20 : i32
cond_br %cond, ^bb3, ^bb4
^bb3:
// CHECK: ^bb3:
// CHECK: br ^bb1(%[[CST]] : i32)
- %cst_1_2 = constant 1 : i32
+ %cst_1_2 = arith.constant 1 : i32
br ^bb1(%cst_1_2 : i32)
^bb4:
- %iv_inc = addi %iv, %cst_1 : i32
+ %iv_inc = arith.addi %iv, %cst_1 : i32
br ^bb1(%iv_inc : i32)
^bb5(%result: i32):
// CHECK-LABEL: func @simple_loop_overdefined
func @simple_loop_overdefined(%arg0 : i32, %cond1 : i1) -> i32 {
- %cst_1 = constant 1 : i32
+ %cst_1 = arith.constant 1 : i32
cond_br %cond1, ^bb1(%cst_1 : i32), ^bb2(%cst_1 : i32)
^bb1(%iv: i32):
// CHECK-LABEL: func @recheck_executable_edge
func @recheck_executable_edge(%cond0: i1) -> (i1, i1) {
- %true = constant true
- %false = constant false
+ %true = arith.constant true
+ %false = arith.constant false
cond_br %cond0, ^bb_1a, ^bb2(%false : i1)
^bb_1a:
br ^bb2(%true : i1)
// CHECK-LABEL: scf_loop_unroll_single
func @scf_loop_unroll_single(%arg0 : f32, %arg1 : f32) -> f32 {
- %from = constant 0 : index
- %to = constant 10 : index
- %step = constant 1 : index
+ %from = arith.constant 0 : index
+ %to = arith.constant 10 : index
+ %step = arith.constant 1 : index
%sum = scf.for %iv = %from to %to step %step iter_args(%sum_iter = %arg0) -> (f32) {
- %next = addf %sum_iter, %arg1 : f32
+ %next = arith.addf %sum_iter, %arg1 : f32
scf.yield %next : f32
}
// CHECK: %[[SUM:.*]] = scf.for %{{.*}} = %{{.*}} to %{{.*}} step %{{.*}} iter_args(%[[V0:.*]] =
- // CHECK-NEXT: %[[V1:.*]] = addf %[[V0]]
- // CHECK-NEXT: %[[V2:.*]] = addf %[[V1]]
- // CHECK-NEXT: %[[V3:.*]] = addf %[[V2]]
+ // CHECK-NEXT: %[[V1:.*]] = arith.addf %[[V0]]
+ // CHECK-NEXT: %[[V2:.*]] = arith.addf %[[V1]]
+ // CHECK-NEXT: %[[V3:.*]] = arith.addf %[[V2]]
// CHECK-NEXT: scf.yield %[[V3]]
// CHECK-NEXT: }
- // CHECK-NEXT: %[[RES:.*]] = addf %[[SUM]],
+ // CHECK-NEXT: %[[RES:.*]] = arith.addf %[[SUM]],
// CHECK-NEXT: return %[[RES]]
return %sum : f32
}
// CHECK-LABEL: scf_loop_unroll_double_symbolic_ub
// CHECK-SAME: (%{{.*}}: f32, %{{.*}}: f32, %[[N:.*]]: index)
func @scf_loop_unroll_double_symbolic_ub(%arg0 : f32, %arg1 : f32, %n : index) -> (f32,f32) {
- %from = constant 0 : index
- %step = constant 1 : index
+ %from = arith.constant 0 : index
+ %step = arith.constant 1 : index
%sum:2 = scf.for %iv = %from to %n step %step iter_args(%i0 = %arg0, %i1 = %arg1) -> (f32, f32) {
- %sum0 = addf %i0, %arg0 : f32
- %sum1 = addf %i1, %arg1 : f32
+ %sum0 = arith.addf %i0, %arg0 : f32
+ %sum1 = arith.addf %i1, %arg1 : f32
scf.yield %sum0, %sum1 : f32, f32
}
return %sum#0, %sum#1 : f32, f32
- // CHECK-DAG: %[[C0:.*]] = constant 0 : index
- // CHECK-DAG: %[[C1:.*]] = constant 1 : index
- // CHECK-DAG: %[[C3:.*]] = constant 3 : index
- // CHECK-NEXT: %[[REM:.*]] = remi_signed %[[N]], %[[C3]]
- // CHECK-NEXT: %[[UB:.*]] = subi %[[N]], %[[REM]]
+ // CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+ // CHECK-DAG: %[[C1:.*]] = arith.constant 1 : index
+ // CHECK-DAG: %[[C3:.*]] = arith.constant 3 : index
+ // CHECK-NEXT: %[[REM:.*]] = arith.remsi %[[N]], %[[C3]]
+ // CHECK-NEXT: %[[UB:.*]] = arith.subi %[[N]], %[[REM]]
// CHECK-NEXT: %[[SUM:.*]]:2 = scf.for {{.*}} = %[[C0]] to %[[UB]] step %[[C3]] iter_args
// CHECK: }
// CHECK-NEXT: %[[SUM1:.*]]:2 = scf.for {{.*}} = %[[UB]] to %[[N]] step %[[C1]] iter_args(%[[V1:.*]] = %[[SUM]]#0, %[[V2:.*]] = %[[SUM]]#1)
// RUN: mlir-opt -allow-unregistered-dialect %s -pass-pipeline='builtin.func(parallel-loop-collapsing{collapsed-indices-0=0,1}, canonicalize)' | FileCheck %s
func @collapse_to_single() {
- %c0 = constant 3 : index
- %c1 = constant 7 : index
- %c2 = constant 11 : index
- %c3 = constant 29 : index
- %c4 = constant 3 : index
- %c5 = constant 4 : index
+ %c0 = arith.constant 3 : index
+ %c1 = arith.constant 7 : index
+ %c2 = arith.constant 11 : index
+ %c3 = arith.constant 29 : index
+ %c4 = arith.constant 3 : index
+ %c5 = arith.constant 4 : index
scf.parallel (%i0, %i1) = (%c0, %c1) to (%c2, %c3) step (%c4, %c5) {
%result = "magic.op"(%i0, %i1): (index, index) -> index
}
}
// CHECK-LABEL: func @collapse_to_single() {
-// CHECK-DAG: [[C18:%.*]] = constant 18 : index
-// CHECK-DAG: [[C6:%.*]] = constant 6 : index
-// CHECK-DAG: [[C3:%.*]] = constant 3 : index
-// CHECK-DAG: [[C7:%.*]] = constant 7 : index
-// CHECK-DAG: [[C4:%.*]] = constant 4 : index
-// CHECK-DAG: [[C1:%.*]] = constant 1 : index
-// CHECK-DAG: [[C0:%.*]] = constant 0 : index
+// CHECK-DAG: [[C18:%.*]] = arith.constant 18 : index
+// CHECK-DAG: [[C6:%.*]] = arith.constant 6 : index
+// CHECK-DAG: [[C3:%.*]] = arith.constant 3 : index
+// CHECK-DAG: [[C7:%.*]] = arith.constant 7 : index
+// CHECK-DAG: [[C4:%.*]] = arith.constant 4 : index
+// CHECK-DAG: [[C1:%.*]] = arith.constant 1 : index
+// CHECK-DAG: [[C0:%.*]] = arith.constant 0 : index
// CHECK: scf.parallel ([[NEW_I:%.*]]) = ([[C0]]) to ([[C18]]) step ([[C1]]) {
-// CHECK: [[I0_COUNT:%.*]] = remi_signed [[NEW_I]], [[C6]] : index
-// CHECK: [[I1_COUNT:%.*]] = divi_signed [[NEW_I]], [[C6]] : index
-// CHECK: [[V0:%.*]] = muli [[I0_COUNT]], [[C4]] : index
-// CHECK: [[I1:%.*]] = addi [[V0]], [[C7]] : index
-// CHECK: [[V1:%.*]] = muli [[I1_COUNT]], [[C3]] : index
-// CHECK: [[I0:%.*]] = addi [[V1]], [[C3]] : index
+// CHECK: [[I0_COUNT:%.*]] = arith.remsi [[NEW_I]], [[C6]] : index
+// CHECK: [[I1_COUNT:%.*]] = arith.divsi [[NEW_I]], [[C6]] : index
+// CHECK: [[V0:%.*]] = arith.muli [[I0_COUNT]], [[C4]] : index
+// CHECK: [[I1:%.*]] = arith.addi [[V0]], [[C7]] : index
+// CHECK: [[V1:%.*]] = arith.muli [[I1_COUNT]], [[C3]] : index
+// CHECK: [[I0:%.*]] = arith.addi [[V1]], [[C3]] : index
// CHECK: "magic.op"([[I0]], [[I1]]) : (index, index) -> index
// CHECK: scf.yield
// CHECK-NEXT: }
} loc(fused["foo", "mysource.cc":10:8])
// CHECK: } loc(unknown)
- %2 = constant 4 : index
+ %2 = arith.constant 4 : index
affine.if #set0(%2) {
} loc(fused<"myPass">["foo", "foo2"])
"foo.region"() ({
// CHECK: ^bb0(%{{.*}}: i32 loc(unknown), %{{.*}}: i32 loc(unknown)):
^bb0(%a0: i32 loc("argloc"), %z: i32 loc("argloc2")):
- %s = addi %a0, %a0 : i32
+ %s = arith.addi %a0, %a0 : i32
"foo.yield"(%s) : (i32) -> ()
}) : () -> ()
// CHECK-LABEL: func @test_commutative_multi
// CHECK-SAME: (%[[ARG_0:[a-z0-9]*]]: i32, %[[ARG_1:[a-z0-9]*]]: i32)
func @test_commutative_multi(%arg0: i32, %arg1: i32) -> (i32, i32) {
- // CHECK-DAG: %[[C42:.*]] = constant 42 : i32
- %c42_i32 = constant 42 : i32
- // CHECK-DAG: %[[C43:.*]] = constant 43 : i32
- %c43_i32 = constant 43 : i32
+ // CHECK-DAG: %[[C42:.*]] = arith.constant 42 : i32
+ %c42_i32 = arith.constant 42 : i32
+ // CHECK-DAG: %[[C43:.*]] = arith.constant 43 : i32
+ %c43_i32 = arith.constant 43 : i32
// CHECK-NEXT: %[[O0:.*]] = "test.op_commutative"(%[[ARG_0]], %[[ARG_1]], %[[C42]], %[[C43]]) : (i32, i32, i32, i32) -> i32
%y = "test.op_commutative"(%c42_i32, %arg0, %arg1, %c43_i32) : (i32, i32, i32, i32) -> i32
// CHECK-LABEL: func @test_commutative_multi_cst
func @test_commutative_multi_cst(%arg0: i32, %arg1: i32) -> (i32, i32) {
- // CHECK-NEXT: %c42_i32 = constant 42 : i32
- %c42_i32 = constant 42 : i32
- %c42_i32_2 = constant 42 : i32
+ // CHECK-NEXT: %c42_i32 = arith.constant 42 : i32
+ %c42_i32 = arith.constant 42 : i32
+ %c42_i32_2 = arith.constant 42 : i32
// CHECK-NEXT: %[[O0:.*]] = "test.op_commutative"(%arg0, %arg1, %c42_i32, %c42_i32) : (i32, i32, i32, i32) -> i32
%y = "test.op_commutative"(%c42_i32, %arg0, %arg1, %c42_i32_2) : (i32, i32, i32, i32) -> i32
- %c42_i32_3 = constant 42 : i32
+ %c42_i32_3 = arith.constant 42 : i32
// CHECK-NEXT: %[[O1:.*]] = "test.op_commutative"(%arg0, %arg1, %c42_i32, %c42_i32) : (i32, i32, i32, i32) -> i32
%z = "test.op_commutative"(%arg0, %c42_i32_3, %c42_i32_2, %arg1): (i32, i32, i32, i32) -> i32
// CHECK-LABEL: func @typemismatch
func @typemismatch() -> i32 {
- %c42 = constant 42.0 : f32
+ %c42 = arith.constant 42.0 : f32
// The "passthrough_fold" folder will naively return its operand, but we don't
// want to fold here because of the type mismatch.
// CHECK-LABEL: test_dialect_canonicalizer
func @test_dialect_canonicalizer() -> (i32) {
%0 = "test.dialect_canonicalizable"() : () -> (i32)
- // CHECK: %[[CST:.*]] = constant 42 : i32
+ // CHECK: %[[CST:.*]] = arith.constant 42 : i32
// CHECK: return %[[CST]]
return %0 : i32
}
// CHECK-LABEL: func @inline_with_arg
func @inline_with_arg(%arg0 : i32) -> i32 {
- // CHECK-NEXT: %[[ADD:.*]] = addi %{{.*}}, %{{.*}} : i32
+ // CHECK-NEXT: %[[ADD:.*]] = arith.addi %{{.*}}, %{{.*}} : i32
// CHECK-NEXT: return %[[ADD]] : i32
%fn = "test.functional_region_op"() ({
^bb0(%a : i32):
- %b = addi %a, %a : i32
+ %b = arith.addi %a, %a : i32
"test.return"(%b) : (i32) -> ()
}) : () -> ((i32) -> i32)
// RUN: mlir-opt -test-patterns %s | FileCheck %s
func @foo() -> i32 {
- %c42 = constant 42 : i32
+ %c42 = arith.constant 42 : i32
// The new operation should be present in the output and contain an attribute
// with value "42" that results from folding.
func @test_fold_before_previously_folded_op() -> (i32, i32) {
// When folding two constants will be generated and uniqued. Check that the
// uniqued constant properly dominates both uses.
- // CHECK: %[[CST:.+]] = constant true
+ // CHECK: %[[CST:.+]] = arith.constant true
// CHECK-NEXT: "test.cast"(%[[CST]]) : (i1) -> i32
// CHECK-NEXT: "test.cast"(%[[CST]]) : (i1) -> i32
// CHECK-LABEL: @test1
// CHECK-SAME: %[[ARG0:.*]]: i32, %[[ARG1:.*]]: i32
func @test1(%arg0: i32, %arg1 : i32) -> () {
- // CHECK: addi %[[ARG1]], %[[ARG1]]
+ // CHECK: arith.addi %[[ARG1]], %[[ARG1]]
// CHECK-NEXT: "test.return"(%[[ARG0]]
%cast = "test.cast"(%arg0, %arg1) : (i32, i32) -> (i32)
- %non_terminator = addi %cast, %cast : i32
+ %non_terminator = arith.addi %cast, %cast : i32
"test.return"(%cast, %non_terminator) : (i32, i32) -> ()
}
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
struct TestGpuRewritePass
: public PassWrapper<TestGpuRewritePass, OperationPass<ModuleOp>> {
void getDependentDialects(DialectRegistry ®istry) const override {
- registry.insert<StandardOpsDialect, memref::MemRefDialect>();
+ registry.insert<arith::ArithmeticDialect, StandardOpsDialect,
+ memref::MemRefDialect>();
}
StringRef getArgument() const final { return "test-gpu-rewrite"; }
StringRef getDescription() const final {
//===----------------------------------------------------------------------===//
#include "mlir/Dialect/Affine/IR/AffineOps.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/Linalg/IR/LinalgOps.h"
#include "mlir/Dialect/Linalg/Transforms/HoistPadding.h"
if (!floatType.isa<FloatType>())
return failure();
if (!isOutput) {
- Value cst =
- b.create<ConstantOp>(src.getLoc(), FloatAttr::get(floatType, 42.0));
+ Value cst = b.create<arith::ConstantOp>(src.getLoc(),
+ FloatAttr::get(floatType, 42.0));
b.create<FillOp>(src.getLoc(), cst, dst);
}
b.create<CopyOp>(src.getLoc(), src, dst);
// In the future, it should be the zero of type + op.
static Value getNeutralOfLinalgOp(OpBuilder &b, OpOperand &op) {
auto t = getElementTypeOrSelf(op.get());
- return b.create<ConstantOp>(op.getOwner()->getLoc(), t, b.getZeroAttr(t));
+ return b.create<arith::ConstantOp>(op.getOwner()->getLoc(), t,
+ b.getZeroAttr(t));
}
static void applyTilePattern(FuncOp funcOp, std::string loopType,
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/Math/Transforms/Passes.h"
#include "mlir/Dialect/Vector/VectorOps.h"
: public PassWrapper<TestMathPolynomialApproximationPass, FunctionPass> {
void runOnFunction() override;
void getDependentDialects(DialectRegistry ®istry) const override {
- registry.insert<vector::VectorDialect, math::MathDialect>();
+ registry.insert<arith::ArithmeticDialect, math::MathDialect,
+ vector::VectorDialect>();
}
StringRef getArgument() const final {
return "test-math-polynomial-approximation";
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
#include "mlir/Dialect/SCF/Transforms.h"
#include "mlir/Dialect/SCF/Utils.h"
+#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/PatternMatch.h"
#include "mlir/Pass/Pass.h"
});
}
+ void getDependentDialects(DialectRegistry ®istry) const override {
+ registry.insert<arith::ArithmeticDialect, StandardOpsDialect>();
+ }
+
void runOnFunction() override {
RewritePatternSet patterns(&getContext());
mlir::scf::PipeliningOption options;
#include "TestAttributes.h"
#include "TestInterfaces.h"
#include "TestTypes.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/DLTI/DLTI.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
static LogicalResult
dialectCanonicalizationPattern(TestDialectCanonicalizerOp op,
PatternRewriter &rewriter) {
- rewriter.replaceOpWithNewOp<ConstantOp>(op, rewriter.getI32Type(),
- rewriter.getI32IntegerAttr(42));
+ rewriter.replaceOpWithNewOp<arith::ConstantOp>(
+ op, rewriter.getI32IntegerAttr(42));
return success();
}
//===----------------------------------------------------------------------===//
#include "TestDialect.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/Dialect/StandardOps/Transforms/FuncConversions.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
return failure();
rewriter.setInsertionPointToStart(op->getBlock());
- auto constOp =
- rewriter.create<ConstantOp>(op.getLoc(), rewriter.getBoolAttr(true));
+ auto constOp = rewriter.create<arith::ConstantOp>(
+ op.getLoc(), rewriter.getBoolAttr(true));
rewriter.replaceOpWithNewOp<TestCastOp>(op, rewriter.getI32Type(),
Value(constOp));
return success();
converter.isLegal(&op.getBody());
});
- // TestCreateUnregisteredOp creates `std.constant` operation,
+ // TestCreateUnregisteredOp creates `arith.constant` operation,
// which was not added to target intentionally to test
// correct error code from conversion driver.
target.addDynamicallyLegalOp<ILLegalOpG>([](ILLegalOpG) { return false; });
private:
// Return the target shape based on op type.
static Optional<SmallVector<int64_t, 4>> getShape(Operation *op) {
- if (isa<AddFOp, SelectOp, CmpFOp>(op))
+ if (isa<arith::AddFOp, SelectOp, arith::CmpFOp>(op))
return SmallVector<int64_t, 4>(2, 2);
if (isa<vector::ContractionOp>(op))
return SmallVector<int64_t, 4>(3, 2);
}
static LogicalResult filter(Operation *op) {
- return success(isa<AddFOp, SelectOp, CmpFOp, ContractionOp, TransferReadOp,
- TransferWriteOp>(op));
+ return success(isa<arith::AddFOp, SelectOp, arith::CmpFOp, ContractionOp,
+ TransferReadOp, TransferWriteOp>(op));
}
};
patterns, UnrollVectorOptions()
.setNativeShape(ArrayRef<int64_t>{2, 2})
.setFilterConstraint([](Operation *op) {
- return success(isa<AddFOp, vector::FMAOp>(op));
+ return success(isa<arith::AddFOp, vector::FMAOp>(op));
}));
if (unrollBasedOnType) {
MLIRContext *ctx = &getContext();
RewritePatternSet patterns(ctx);
FuncOp func = getFunction();
- func.walk([&](AddFOp op) {
+ func.walk([&](arith::AddFOp op) {
OpBuilder builder(op);
if (auto vecType = op.getType().dyn_cast<VectorType>()) {
SmallVector<int64_t, 2> mul;
MLIRContext *ctx = &getContext();
RewritePatternSet patterns(ctx);
FuncOp func = getFunction();
- func.walk([&](AddFOp op) {
+ func.walk([&](arith::AddFOp op) {
// Check that the operation type can be broken down into a loop.
VectorType type = op.getType().dyn_cast<VectorType>();
if (!type || type.getRank() != 1 ||
type.getNumElements() % multiplicity != 0)
return mlir::WalkResult::advance();
auto filterAlloc = [](Operation *op) {
- if (isa<ConstantOp, memref::AllocOp, CallOp>(op))
+ if (isa<arith::ConstantOp, memref::AllocOp, CallOp>(op))
return false;
return true;
};
auto dependentOps = getSlice(op, filterAlloc);
// Create a loop and move instructions from the Op slice into the loop.
OpBuilder builder(op);
- auto zero = builder.create<ConstantOp>(
- op.getLoc(), builder.getIndexType(),
- builder.getIntegerAttr(builder.getIndexType(), 0));
- auto one = builder.create<ConstantOp>(
- op.getLoc(), builder.getIndexType(),
- builder.getIntegerAttr(builder.getIndexType(), 1));
- auto numIter = builder.create<ConstantOp>(
- op.getLoc(), builder.getIndexType(),
- builder.getIntegerAttr(builder.getIndexType(), multiplicity));
+ auto zero = builder.create<arith::ConstantIndexOp>(op.getLoc(), 0);
+ auto one = builder.create<arith::ConstantIndexOp>(op.getLoc(), 1);
+ auto numIter =
+ builder.create<arith::ConstantIndexOp>(op.getLoc(), multiplicity);
auto forOp = builder.create<scf::ForOp>(op.getLoc(), zero, numIter, one);
for (Operation *it : dependentOps) {
it->moveBefore(forOp.getBody()->getTerminator());
auto b = m_Val(f.getArgument(1));
auto c = m_Val(f.getArgument(2));
- auto p0 = m_Op<AddFOp>(); // using 0-arity matcher
+ auto p0 = m_Op<arith::AddFOp>(); // using 0-arity matcher
llvm::outs() << "Pattern add(*) matched " << countMatches(f, p0)
<< " times\n";
- auto p1 = m_Op<MulFOp>(); // using 0-arity matcher
+ auto p1 = m_Op<arith::MulFOp>(); // using 0-arity matcher
llvm::outs() << "Pattern mul(*) matched " << countMatches(f, p1)
<< " times\n";
- auto p2 = m_Op<AddFOp>(m_Op<AddFOp>(), m_Any());
+ auto p2 = m_Op<arith::AddFOp>(m_Op<arith::AddFOp>(), m_Any());
llvm::outs() << "Pattern add(add(*), *) matched " << countMatches(f, p2)
<< " times\n";
- auto p3 = m_Op<AddFOp>(m_Any(), m_Op<AddFOp>());
+ auto p3 = m_Op<arith::AddFOp>(m_Any(), m_Op<arith::AddFOp>());
llvm::outs() << "Pattern add(*, add(*)) matched " << countMatches(f, p3)
<< " times\n";
- auto p4 = m_Op<MulFOp>(m_Op<AddFOp>(), m_Any());
+ auto p4 = m_Op<arith::MulFOp>(m_Op<arith::AddFOp>(), m_Any());
llvm::outs() << "Pattern mul(add(*), *) matched " << countMatches(f, p4)
<< " times\n";
- auto p5 = m_Op<MulFOp>(m_Any(), m_Op<AddFOp>());
+ auto p5 = m_Op<arith::MulFOp>(m_Any(), m_Op<arith::AddFOp>());
llvm::outs() << "Pattern mul(*, add(*)) matched " << countMatches(f, p5)
<< " times\n";
- auto p6 = m_Op<MulFOp>(m_Op<MulFOp>(), m_Any());
+ auto p6 = m_Op<arith::MulFOp>(m_Op<arith::MulFOp>(), m_Any());
llvm::outs() << "Pattern mul(mul(*), *) matched " << countMatches(f, p6)
<< " times\n";
- auto p7 = m_Op<MulFOp>(m_Op<MulFOp>(), m_Op<MulFOp>());
+ auto p7 = m_Op<arith::MulFOp>(m_Op<arith::MulFOp>(), m_Op<arith::MulFOp>());
llvm::outs() << "Pattern mul(mul(*), mul(*)) matched " << countMatches(f, p7)
<< " times\n";
- auto mul_of_mulmul = m_Op<MulFOp>(m_Op<MulFOp>(), m_Op<MulFOp>());
- auto p8 = m_Op<MulFOp>(mul_of_mulmul, mul_of_mulmul);
+ auto mul_of_mulmul =
+ m_Op<arith::MulFOp>(m_Op<arith::MulFOp>(), m_Op<arith::MulFOp>());
+ auto p8 = m_Op<arith::MulFOp>(mul_of_mulmul, mul_of_mulmul);
llvm::outs()
<< "Pattern mul(mul(mul(*), mul(*)), mul(mul(*), mul(*))) matched "
<< countMatches(f, p8) << " times\n";
// clang-format off
- auto mul_of_muladd = m_Op<MulFOp>(m_Op<MulFOp>(), m_Op<AddFOp>());
- auto mul_of_anyadd = m_Op<MulFOp>(m_Any(), m_Op<AddFOp>());
- auto p9 = m_Op<MulFOp>(m_Op<MulFOp>(
- mul_of_muladd, m_Op<MulFOp>()),
- m_Op<MulFOp>(mul_of_anyadd, mul_of_anyadd));
+ auto mul_of_muladd = m_Op<arith::MulFOp>(m_Op<arith::MulFOp>(), m_Op<arith::AddFOp>());
+ auto mul_of_anyadd = m_Op<arith::MulFOp>(m_Any(), m_Op<arith::AddFOp>());
+ auto p9 = m_Op<arith::MulFOp>(m_Op<arith::MulFOp>(
+ mul_of_muladd, m_Op<arith::MulFOp>()),
+ m_Op<arith::MulFOp>(mul_of_anyadd, mul_of_anyadd));
// clang-format on
llvm::outs() << "Pattern mul(mul(mul(mul(*), add(*)), mul(*)), mul(mul(*, "
"add(*)), mul(*, add(*)))) matched "
<< countMatches(f, p9) << " times\n";
- auto p10 = m_Op<AddFOp>(a, b);
+ auto p10 = m_Op<arith::AddFOp>(a, b);
llvm::outs() << "Pattern add(a, b) matched " << countMatches(f, p10)
<< " times\n";
- auto p11 = m_Op<AddFOp>(a, c);
+ auto p11 = m_Op<arith::AddFOp>(a, c);
llvm::outs() << "Pattern add(a, c) matched " << countMatches(f, p11)
<< " times\n";
- auto p12 = m_Op<AddFOp>(b, a);
+ auto p12 = m_Op<arith::AddFOp>(b, a);
llvm::outs() << "Pattern add(b, a) matched " << countMatches(f, p12)
<< " times\n";
- auto p13 = m_Op<AddFOp>(c, a);
+ auto p13 = m_Op<arith::AddFOp>(c, a);
llvm::outs() << "Pattern add(c, a) matched " << countMatches(f, p13)
<< " times\n";
- auto p14 = m_Op<MulFOp>(a, m_Op<AddFOp>(c, b));
+ auto p14 = m_Op<arith::MulFOp>(a, m_Op<arith::AddFOp>(c, b));
llvm::outs() << "Pattern mul(a, add(c, b)) matched " << countMatches(f, p14)
<< " times\n";
- auto p15 = m_Op<MulFOp>(a, m_Op<AddFOp>(b, c));
+ auto p15 = m_Op<arith::MulFOp>(a, m_Op<arith::AddFOp>(b, c));
llvm::outs() << "Pattern mul(a, add(b, c)) matched " << countMatches(f, p15)
<< " times\n";
- auto mul_of_aany = m_Op<MulFOp>(a, m_Any());
- auto p16 = m_Op<MulFOp>(mul_of_aany, m_Op<AddFOp>(a, c));
+ auto mul_of_aany = m_Op<arith::MulFOp>(a, m_Any());
+ auto p16 = m_Op<arith::MulFOp>(mul_of_aany, m_Op<arith::AddFOp>(a, c));
llvm::outs() << "Pattern mul(mul(a, *), add(a, c)) matched "
<< countMatches(f, p16) << " times\n";
- auto p17 = m_Op<MulFOp>(mul_of_aany, m_Op<AddFOp>(c, b));
+ auto p17 = m_Op<arith::MulFOp>(mul_of_aany, m_Op<arith::AddFOp>(c, b));
llvm::outs() << "Pattern mul(mul(a, *), add(c, b)) matched "
<< countMatches(f, p17) << " times\n";
}
void test2(FuncOp f) {
auto a = m_Val(f.getArgument(0));
FloatAttr floatAttr;
- auto p = m_Op<MulFOp>(a, m_Op<AddFOp>(a, m_Constant(&floatAttr)));
- auto p1 = m_Op<MulFOp>(a, m_Op<AddFOp>(a, m_Constant()));
+ auto p =
+ m_Op<arith::MulFOp>(a, m_Op<arith::AddFOp>(a, m_Constant(&floatAttr)));
+ auto p1 = m_Op<arith::MulFOp>(a, m_Op<arith::AddFOp>(a, m_Constant()));
// Last operation that is not the terminator.
Operation *lastOp = f.getBody().front().back().getPrevNode();
if (p.match(lastOp))
//
//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/SCF/SCF.h"
+#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/Pass/Pass.h"
#include "mlir/Transforms/LoopUtils.h"
annotateLoop = annotateLoopParam;
}
+ void getDependentDialects(DialectRegistry ®istry) const override {
+ registry.insert<arith::ArithmeticDialect, StandardOpsDialect>();
+ }
+
void runOnFunction() override {
FuncOp func = getFunction();
SmallVector<scf::ForOp, 4> loops;
// RUN: -convert-scf-to-std \
// RUN: -convert-linalg-to-llvm \
// RUN: -convert-vector-to-llvm \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-std-to-llvm \
// RUN: -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner \
// RUN: | FileCheck %s --dump-input=always
func @main() {
- %false = constant 0 : i1
+ %false = arith.constant 0 : i1
// ------------------------------------------------------------------------ //
// Check that simple async region completes without errors.
%token3, %value3 = async.execute -> !async.value<f32> {
%token, %value = async.execute -> !async.value<f32> {
assert %false, "error"
- %0 = constant 123.45 : f32
+ %0 = arith.constant 123.45 : f32
async.yield %0 : f32
}
%ret = async.await %value : !async.value<f32>
// Check error propagation from a token to the group.
// ------------------------------------------------------------------------ //
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
%group0 = async.create_group %c2 : !async.group
%token4 = async.execute {
// RUN: -async-runtime-ref-counting \
// RUN: -async-runtime-ref-counting-opt \
// RUN: -convert-async-to-llvm \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-std-to-llvm \
// RUN: -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner \
// UNSUPPORTED: asan
func @main() {
- %c1 = constant 1 : index
- %c5 = constant 5 : index
+ %c1 = arith.constant 1 : index
+ %c5 = arith.constant 5 : index
%group = async.create_group %c5 : !async.group
// RUN: -async-runtime-ref-counting \
// RUN: -async-runtime-ref-counting-opt \
// RUN: -convert-async-to-llvm \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-vector-to-llvm \
// RUN: -convert-memref-to-llvm \
// RUN: -convert-std-to-llvm \
// Blocking async.await outside of the async.execute.
// ------------------------------------------------------------------------ //
%token, %result = async.execute -> !async.value<f32> {
- %0 = constant 123.456 : f32
+ %0 = arith.constant 123.456 : f32
async.yield %0 : f32
}
%1 = async.await %result : !async.value<f32>
// ------------------------------------------------------------------------ //
%token0, %result0 = async.execute -> !async.value<f32> {
%token1, %result2 = async.execute -> !async.value<f32> {
- %2 = constant 456.789 : f32
+ %2 = arith.constant 456.789 : f32
async.yield %2 : f32
}
%3 = async.await %result2 : !async.value<f32>
// ------------------------------------------------------------------------ //
%token2, %result2 = async.execute[%token0] -> !async.value<memref<f32>> {
%5 = memref.alloc() : memref<f32>
- %c0 = constant 0.25 : f32
+ %c0 = arith.constant 0.25 : f32
memref.store %c0, %5[]: memref<f32>
async.yield %5 : memref<f32>
}
// ------------------------------------------------------------------------ //
%token3 = async.execute(%result2 as %unwrapped : !async.value<memref<f32>>) {
%8 = memref.load %unwrapped[]: memref<f32>
- %9 = addf %8, %8 : f32
+ %9 = arith.addf %8, %8 : f32
memref.store %9, %unwrapped[]: memref<f32>
async.yield
}
// RUN: -convert-scf-to-std \
// RUN: -convert-linalg-to-llvm \
// RUN: -convert-memref-to-llvm \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-std-to-llvm \
// RUN: -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner \
// RUN: | FileCheck %s
func @main() {
- %i0 = constant 0 : index
- %i1 = constant 1 : index
- %i2 = constant 2 : index
- %i3 = constant 3 : index
-
- %c0 = constant 0.0 : f32
- %c1 = constant 1.0 : f32
- %c2 = constant 2.0 : f32
- %c3 = constant 3.0 : f32
- %c4 = constant 4.0 : f32
+ %i0 = arith.constant 0 : index
+ %i1 = arith.constant 1 : index
+ %i2 = arith.constant 2 : index
+ %i3 = arith.constant 3 : index
+
+ %c0 = arith.constant 0.0 : f32
+ %c1 = arith.constant 1.0 : f32
+ %c2 = arith.constant 2.0 : f32
+ %c3 = arith.constant 3.0 : f32
+ %c4 = arith.constant 4.0 : f32
%A = memref.alloc() : memref<4xf32>
linalg.fill(%c0, %A) : f32, memref<4xf32>
-// RUN: mlir-opt %s -convert-scf-to-std -convert-memref-to-llvm -convert-std-to-llvm='use-bare-ptr-memref-call-conv=1' -reconcile-unrealized-casts | mlir-cpu-runner -shared-libs=%linalg_test_lib_dir/libmlir_c_runner_utils%shlibext -entry-point-result=void | FileCheck %s
+// RUN: mlir-opt %s -convert-scf-to-std -convert-arith-to-llvm -convert-memref-to-llvm -convert-std-to-llvm='use-bare-ptr-memref-call-conv=1' -reconcile-unrealized-casts | mlir-cpu-runner -shared-libs=%linalg_test_lib_dir/libmlir_c_runner_utils%shlibext -entry-point-result=void | FileCheck %s
// Verify bare pointer memref calling convention. `simple_add1_add2_test`
// gets two 2xf32 memrefs, adds 1.0f to the first one and 2.0f to the second
// and {4, 4} are the expected outputs.
func @simple_add1_add2_test(%arg0: memref<2xf32>, %arg1: memref<2xf32>) {
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cst = constant 1.000000e+00 : f32
- %cst_0 = constant 2.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ %cst_0 = arith.constant 2.000000e+00 : f32
scf.for %arg2 = %c0 to %c2 step %c1 {
%0 = memref.load %arg0[%arg2] : memref<2xf32>
- %1 = addf %0, %cst : f32
+ %1 = arith.addf %0, %cst : f32
memref.store %1, %arg0[%arg2] : memref<2xf32>
// CHECK: 2, 2
%2 = memref.load %arg1[%arg2] : memref<2xf32>
- %3 = addf %1, %cst_0 : f32
+ %3 = arith.addf %1, %cst_0 : f32
memref.store %3, %arg1[%arg2] : memref<2xf32>
// CHECK-NEXT: 4, 4
}
func @main()
{
- %c2 = constant 2 : index
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %cst = constant 1.000000e+00 : f32
- %cst_0 = constant 2.000000e+00 : f32
+ %c2 = arith.constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %cst = arith.constant 1.000000e+00 : f32
+ %cst_0 = arith.constant 2.000000e+00 : f32
%a = memref.alloc() : memref<2xf32>
%b = memref.alloc() : memref<2xf32>
scf.for %i = %c0 to %c2 step %c1 {
-// RUN: mlir-opt %s -convert-scf-to-std -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
+// RUN: mlir-opt %s -convert-scf-to-std -convert-arith-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner -e main -entry-point-result=void \
// RUN: -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext \
// RUN: | FileCheck %s
func private @print_memref_f32(memref<*xf32>) attributes { llvm.emit_c_interface }
func @main() -> () {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Initialize input.
%input = memref.alloc() : memref<2x3xf32>
%dim_x = memref.dim %input, %c0 : memref<2x3xf32>
%dim_y = memref.dim %input, %c1 : memref<2x3xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%dim_x, %dim_y) step (%c1, %c1) {
- %prod = muli %i, %dim_y : index
- %val = addi %prod, %j : index
- %val_i64 = index_cast %val : index to i64
- %val_f32 = sitofp %val_i64 : i64 to f32
+ %prod = arith.muli %i, %dim_y : index
+ %val = arith.addi %prod, %j : index
+ %val_i64 = arith.index_cast %val : index to i64
+ %val_f32 = arith.sitofp %val_i64 : i64 to f32
memref.store %val_f32, %input[%i, %j] : memref<2x3xf32>
}
%unranked_input = memref.cast %input : memref<2x3xf32> to memref<*xf32>
-// RUN: mlir-opt %s -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e main -entry-point-result=void -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext | FileCheck %s
+// RUN: mlir-opt %s -convert-arith-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e main -entry-point-result=void -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext | FileCheck %s
func private @print_memref_f32(memref<*xf32>) attributes { llvm.emit_c_interface }
func private @print_memref_i32(memref<*xi32>) attributes { llvm.emit_c_interface }
call @printNewline() : () -> ()
// Overwrite some of the elements.
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %fp0 = constant 4.0 : f32
- %fp1 = constant 5.0 : f32
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %fp0 = arith.constant 4.0 : f32
+ %fp1 = arith.constant 5.0 : f32
memref.store %fp0, %0[%c0] : memref<4xf32>
memref.store %fp1, %0[%c2] : memref<4xf32>
// CHECK: rank = 1
call @printNewline() : () -> ()
// Overwrite the 1.0 (at index [0, 1]) with 10.0
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %fp10 = constant 10.0 : f32
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %fp10 = arith.constant 10.0 : f32
memref.store %fp10, %0[%c0, %c1] : memref<4x2xf32>
// CHECK: rank = 2
// CHECK: offset = 0
// RUN: mlir-opt %s -test-math-polynomial-approximation \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-vector-to-llvm \
+// RUN: -convert-math-to-llvm \
// RUN: -convert-std-to-llvm \
// RUN: -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner \
// -------------------------------------------------------------------------- //
func @tanh() {
// CHECK: 0.848284
- %0 = constant 1.25 : f32
+ %0 = arith.constant 1.25 : f32
%1 = math.tanh %0 : f32
vector.print %1 : f32
// CHECK: 0.244919, 0.635149, 0.761594, 0.848284
- %2 = constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
+ %2 = arith.constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
%3 = math.tanh %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: 0.099668, 0.197375, 0.291313, 0.379949, 0.462117, 0.53705, 0.604368, 0.664037
- %4 = constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
+ %4 = arith.constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
%5 = math.tanh %4 : vector<8xf32>
vector.print %5 : vector<8xf32>
// -------------------------------------------------------------------------- //
func @log() {
// CHECK: 2.64704
- %0 = constant 14.112233 : f32
+ %0 = arith.constant 14.112233 : f32
%1 = math.log %0 : f32
vector.print %1 : f32
// CHECK: -1.38629, -0.287682, 0, 0.223144
- %2 = constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
+ %2 = arith.constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
%3 = math.log %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: -2.30259, -1.60944, -1.20397, -0.916291, -0.693147, -0.510826, -0.356675, -0.223144
- %4 = constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
+ %4 = arith.constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
%5 = math.log %4 : vector<8xf32>
vector.print %5 : vector<8xf32>
// CHECK: -inf
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%log_zero = math.log %zero : f32
vector.print %log_zero : f32
// CHECK: nan
- %neg_one = constant -1.0 : f32
+ %neg_one = arith.constant -1.0 : f32
%log_neg_one = math.log %neg_one : f32
vector.print %log_neg_one : f32
// CHECK: inf
- %inf = constant 0x7f800000 : f32
+ %inf = arith.constant 0x7f800000 : f32
%log_inf = math.log %inf : f32
vector.print %log_inf : f32
// CHECK: -inf, nan, inf, 0.693147
- %special_vec = constant dense<[0.0, -1.0, 0x7f800000, 2.0]> : vector<4xf32>
+ %special_vec = arith.constant dense<[0.0, -1.0, 0x7f800000, 2.0]> : vector<4xf32>
%log_special_vec = math.log %special_vec : vector<4xf32>
vector.print %log_special_vec : vector<4xf32>
func @log2() {
// CHECK: 3.81887
- %0 = constant 14.112233 : f32
+ %0 = arith.constant 14.112233 : f32
%1 = math.log2 %0 : f32
vector.print %1 : f32
// CHECK: -2, -0.415037, 0, 0.321928
- %2 = constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
+ %2 = arith.constant dense<[0.25, 0.75, 1.0, 1.25]> : vector<4xf32>
%3 = math.log2 %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: -3.32193, -2.32193, -1.73697, -1.32193, -1, -0.736966, -0.514573, -0.321928
- %4 = constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
+ %4 = arith.constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
%5 = math.log2 %4 : vector<8xf32>
vector.print %5 : vector<8xf32>
// CHECK: -inf
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%log_zero = math.log2 %zero : f32
vector.print %log_zero : f32
// CHECK: nan
- %neg_one = constant -1.0 : f32
+ %neg_one = arith.constant -1.0 : f32
%log_neg_one = math.log2 %neg_one : f32
vector.print %log_neg_one : f32
// CHECK: inf
- %inf = constant 0x7f800000 : f32
+ %inf = arith.constant 0x7f800000 : f32
%log_inf = math.log2 %inf : f32
vector.print %log_inf : f32
// CHECK: -inf, nan, inf, 1.58496
- %special_vec = constant dense<[0.0, -1.0, 0x7f800000, 3.0]> : vector<4xf32>
+ %special_vec = arith.constant dense<[0.0, -1.0, 0x7f800000, 3.0]> : vector<4xf32>
%log_special_vec = math.log2 %special_vec : vector<4xf32>
vector.print %log_special_vec : vector<4xf32>
func @log1p() {
// CHECK: 0.00995033
- %0 = constant 0.01 : f32
+ %0 = arith.constant 0.01 : f32
%1 = math.log1p %0 : f32
vector.print %1 : f32
// CHECK: -4.60517, -0.693147, 0, 1.38629
- %2 = constant dense<[-0.99, -0.5, 0.0, 3.0]> : vector<4xf32>
+ %2 = arith.constant dense<[-0.99, -0.5, 0.0, 3.0]> : vector<4xf32>
%3 = math.log1p %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: 0.0953102, 0.182322, 0.262364, 0.336472, 0.405465, 0.470004, 0.530628, 0.587787
- %4 = constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
+ %4 = arith.constant dense<[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]> : vector<8xf32>
%5 = math.log1p %4 : vector<8xf32>
vector.print %5 : vector<8xf32>
// CHECK: -inf
- %neg_one = constant -1.0 : f32
+ %neg_one = arith.constant -1.0 : f32
%log_neg_one = math.log1p %neg_one : f32
vector.print %log_neg_one : f32
// CHECK: nan
- %neg_two = constant -2.0 : f32
+ %neg_two = arith.constant -2.0 : f32
%log_neg_two = math.log1p %neg_two : f32
vector.print %log_neg_two : f32
// CHECK: inf
- %inf = constant 0x7f800000 : f32
+ %inf = arith.constant 0x7f800000 : f32
%log_inf = math.log1p %inf : f32
vector.print %log_inf : f32
// CHECK: -inf, nan, inf, 9.99995e-06
- %special_vec = constant dense<[-1.0, -1.1, 0x7f800000, 0.00001]> : vector<4xf32>
+ %special_vec = arith.constant dense<[-1.0, -1.1, 0x7f800000, 0.00001]> : vector<4xf32>
%log_special_vec = math.log1p %special_vec : vector<4xf32>
vector.print %log_special_vec : vector<4xf32>
// -------------------------------------------------------------------------- //
func @exp() {
// CHECK: 2.71828
- %0 = constant 1.0 : f32
+ %0 = arith.constant 1.0 : f32
%1 = math.exp %0 : f32
vector.print %1 : f32
// CHECK: 0.778802, 2.117, 2.71828, 3.85742
- %2 = constant dense<[-0.25, 0.75, 1.0, 1.35]> : vector<4xf32>
+ %2 = arith.constant dense<[-0.25, 0.75, 1.0, 1.35]> : vector<4xf32>
%3 = math.exp %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: 1
- %zero = constant 0.0 : f32
+ %zero = arith.constant 0.0 : f32
%exp_zero = math.exp %zero : f32
vector.print %exp_zero : f32
// CHECK: 1.17549e-38, 1.38879e-11, 7.20049e+10, inf
- %special_vec = constant dense<[-89.0, -25.0, 25.0, 89.0]> : vector<4xf32>
+ %special_vec = arith.constant dense<[-89.0, -25.0, 25.0, 89.0]> : vector<4xf32>
%exp_special_vec = math.exp %special_vec : vector<4xf32>
vector.print %exp_special_vec : vector<4xf32>
// CHECK: inf
- %inf = constant 0x7f800000 : f32
+ %inf = arith.constant 0x7f800000 : f32
%exp_inf = math.exp %inf : f32
vector.print %exp_inf : f32
// CHECK: 0
- %negative_inf = constant 0xff800000 : f32
+ %negative_inf = arith.constant 0xff800000 : f32
%exp_negative_inf = math.exp %negative_inf : f32
vector.print %exp_negative_inf : f32
func @expm1() {
// CHECK: 1e-10
- %0 = constant 1.0e-10 : f32
+ %0 = arith.constant 1.0e-10 : f32
%1 = math.expm1 %0 : f32
vector.print %1 : f32
// CHECK: -0.00995016, 0.0100502, 0.648721, 6.38905
- %2 = constant dense<[-0.01, 0.01, 0.5, 2.0]> : vector<4xf32>
+ %2 = arith.constant dense<[-0.01, 0.01, 0.5, 2.0]> : vector<4xf32>
%3 = math.expm1 %2 : vector<4xf32>
vector.print %3 : vector<4xf32>
// CHECK: -0.181269, 0, 0.221403, 0.491825, 0.822119, 1.22554, 1.71828, 2.32012
- %4 = constant dense<[-0.2, 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2]> : vector<8xf32>
+ %4 = arith.constant dense<[-0.2, 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2]> : vector<8xf32>
%5 = math.expm1 %4 : vector<8xf32>
vector.print %5 : vector<8xf32>
// CHECK: -1
- %neg_inf = constant 0xff800000 : f32
+ %neg_inf = arith.constant 0xff800000 : f32
%expm1_neg_inf = math.expm1 %neg_inf : f32
vector.print %expm1_neg_inf : f32
// CHECK: inf
- %inf = constant 0x7f800000 : f32
+ %inf = arith.constant 0x7f800000 : f32
%expm1_inf = math.expm1 %inf : f32
vector.print %expm1_inf : f32
// CHECK: -1, inf, 1e-10
- %special_vec = constant dense<[0xff800000, 0x7f800000, 1.0e-10]> : vector<3xf32>
+ %special_vec = arith.constant dense<[0xff800000, 0x7f800000, 1.0e-10]> : vector<3xf32>
%log_special_vec = math.expm1 %special_vec : vector<3xf32>
vector.print %log_special_vec : vector<3xf32>
// -------------------------------------------------------------------------- //
func @sin() {
// CHECK: 0
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
%sin_0 = math.sin %0 : f32
vector.print %sin_0 : f32
// CHECK: 0.707107
- %pi_over_4 = constant 0.78539816339 : f32
+ %pi_over_4 = arith.constant 0.78539816339 : f32
%sin_pi_over_4 = math.sin %pi_over_4 : f32
vector.print %sin_pi_over_4 : f32
// CHECK: 1
- %pi_over_2 = constant 1.57079632679 : f32
+ %pi_over_2 = arith.constant 1.57079632679 : f32
%sin_pi_over_2 = math.sin %pi_over_2 : f32
vector.print %sin_pi_over_2 : f32
// CHECK: 0
- %pi = constant 3.14159265359 : f32
+ %pi = arith.constant 3.14159265359 : f32
%sin_pi = math.sin %pi : f32
vector.print %sin_pi : f32
// CHECK: -1
- %pi_3_over_2 = constant 4.71238898038 : f32
+ %pi_3_over_2 = arith.constant 4.71238898038 : f32
%sin_pi_3_over_2 = math.sin %pi_3_over_2 : f32
vector.print %sin_pi_3_over_2 : f32
// CHECK: 0, 0.866025, -1
- %vec_x = constant dense<[9.42477796077, 2.09439510239, -1.57079632679]> : vector<3xf32>
+ %vec_x = arith.constant dense<[9.42477796077, 2.09439510239, -1.57079632679]> : vector<3xf32>
%sin_vec_x = math.sin %vec_x : vector<3xf32>
vector.print %sin_vec_x : vector<3xf32>
func @cos() {
// CHECK: 1
- %0 = constant 0.0 : f32
+ %0 = arith.constant 0.0 : f32
%cos_0 = math.cos %0 : f32
vector.print %cos_0 : f32
// CHECK: 0.707107
- %pi_over_4 = constant 0.78539816339 : f32
+ %pi_over_4 = arith.constant 0.78539816339 : f32
%cos_pi_over_4 = math.cos %pi_over_4 : f32
vector.print %cos_pi_over_4 : f32
//// CHECK: 0
- %pi_over_2 = constant 1.57079632679 : f32
+ %pi_over_2 = arith.constant 1.57079632679 : f32
%cos_pi_over_2 = math.cos %pi_over_2 : f32
vector.print %cos_pi_over_2 : f32
/// CHECK: -1
- %pi = constant 3.14159265359 : f32
+ %pi = arith.constant 3.14159265359 : f32
%cos_pi = math.cos %pi : f32
vector.print %cos_pi : f32
// CHECK: 0
- %pi_3_over_2 = constant 4.71238898038 : f32
+ %pi_3_over_2 = arith.constant 4.71238898038 : f32
%cos_pi_3_over_2 = math.cos %pi_3_over_2 : f32
vector.print %cos_pi_3_over_2 : f32
// CHECK: -1, -0.5, 0
- %vec_x = constant dense<[9.42477796077, 2.09439510239, -1.57079632679]> : vector<3xf32>
+ %vec_x = arith.constant dense<[9.42477796077, 2.09439510239, -1.57079632679]> : vector<3xf32>
%cos_vec_x = math.cos %vec_x : vector<3xf32>
vector.print %cos_vec_x : vector<3xf32>
-// RUN: mlir-opt %s -convert-scf-to-std -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
+// RUN: mlir-opt %s -convert-scf-to-std -convert-memref-to-llvm -convert-arith-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner -e main -entry-point-result=void \
// RUN: -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext \
// RUN: | FileCheck %s
func private @print_memref_f32(memref<*xf32>) attributes { llvm.emit_c_interface }
func @main() -> () {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Initialize input.
%input = memref.alloc() : memref<2x3xf32>
%dim_x = memref.dim %input, %c0 : memref<2x3xf32>
%dim_y = memref.dim %input, %c1 : memref<2x3xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%dim_x, %dim_y) step (%c1, %c1) {
- %prod = muli %i, %dim_y : index
- %val = addi %prod, %j : index
- %val_i64 = index_cast %val : index to i64
- %val_f32 = sitofp %val_i64 : i64 to f32
+ %prod = arith.muli %i, %dim_y : index
+ %val = arith.addi %prod, %j : index
+ %val_i64 = arith.index_cast %val : index to i64
+ %val_f32 = arith.sitofp %val_i64 : i64 to f32
memref.store %val_f32, %input[%i, %j] : memref<2x3xf32>
}
%unranked_input = memref.cast %input : memref<2x3xf32> to memref<*xf32>
}
func @cast_ranked_memref_to_dynamic_shape(%input : memref<2x3xf32>) {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c6 = arith.constant 6 : index
%output = memref.reinterpret_cast %input to
offset: [%c0], sizes: [%c1, %c6], strides: [%c6, %c1]
: memref<2x3xf32> to memref<?x?xf32, offset: ?, strides: [?, ?]>
func @cast_unranked_memref_to_dynamic_shape(%input : memref<2x3xf32>) {
%unranked_input = memref.cast %input : memref<2x3xf32> to memref<*xf32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c6 = constant 6 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c6 = arith.constant 6 : index
%output = memref.reinterpret_cast %unranked_input to
offset: [%c0], sizes: [%c1, %c6], strides: [%c6, %c1]
: memref<*xf32> to memref<?x?xf32, offset: ?, strides: [?, ?]>
-// RUN: mlir-opt %s -convert-scf-to-std -std-expand -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
+// RUN: mlir-opt %s -convert-scf-to-std -std-expand -convert-arith-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts \
// RUN: | mlir-cpu-runner -e main -entry-point-result=void \
// RUN: -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext \
// RUN: | FileCheck %s
func private @print_memref_f32(memref<*xf32>) attributes { llvm.emit_c_interface }
func @main() -> () {
- %c0 = constant 0 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
// Initialize input.
%input = memref.alloc() : memref<2x3xf32>
%dim_x = memref.dim %input, %c0 : memref<2x3xf32>
%dim_y = memref.dim %input, %c1 : memref<2x3xf32>
scf.parallel (%i, %j) = (%c0, %c0) to (%dim_x, %dim_y) step (%c1, %c1) {
- %prod = muli %i, %dim_y : index
- %val = addi %prod, %j : index
- %val_i64 = index_cast %val : index to i64
- %val_f32 = sitofp %val_i64 : i64 to f32
+ %prod = arith.muli %i, %dim_y : index
+ %val = arith.addi %prod, %j : index
+ %val_i64 = arith.index_cast %val : index to i64
+ %val_f32 = arith.sitofp %val_i64 : i64 to f32
memref.store %val_f32, %input[%i, %j] : memref<2x3xf32>
}
%unranked_input = memref.cast %input : memref<2x3xf32> to memref<*xf32>
// Initialize shape.
%shape = memref.alloc() : memref<2xindex>
- %c2 = constant 2 : index
- %c3 = constant 3 : index
+ %c2 = arith.constant 2 : index
+ %c3 = arith.constant 3 : index
memref.store %c3, %shape[%c0] : memref<2xindex>
memref.store %c2, %shape[%c1] : memref<2xindex>
-// RUN: mlir-opt -convert-linalg-to-loops -lower-affine -convert-scf-to-std -convert-vector-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts %s | mlir-cpu-runner -O3 -e main -entry-point-result=void -shared-libs=%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext | FileCheck %s
+// RUN: mlir-opt -convert-linalg-to-loops -lower-affine -convert-scf-to-std -convert-arith-to-llvm -convert-vector-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts %s | mlir-cpu-runner -O3 -e main -entry-point-result=void -shared-libs=%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext | FileCheck %s
func @main() {
%A = memref.alloc() : memref<16x16xf32>
%B = memref.alloc() : memref<16x16xf32>
%C = memref.alloc() : memref<16x16xf32>
- %cf1 = constant 1.00000e+00 : f32
+ %cf1 = arith.constant 1.00000e+00 : f32
linalg.fill(%cf1, %A) : f32, memref<16x16xf32>
linalg.fill(%cf1, %B) : f32, memref<16x16xf32>
- %reps = constant 1 : index
+ %reps = arith.constant 1 : index
%t_start = call @rtclock() : () -> f64
affine.for %arg0 = 0 to 5 {
call @sgemm_naive(%A, %B, %C) : (memref<16x16xf32>, memref<16x16xf32>, memref<16x16xf32>) -> ()
}
%t_end = call @rtclock() : () -> f64
- %t = subf %t_end, %t_start : f64
+ %t = arith.subf %t_end, %t_start : f64
%res = affine.load %C[0, 0]: memref<16x16xf32>
vector.print %res: f32
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
%M = memref.dim %C, %c0 : memref<16x16xf32>
%N = memref.dim %C, %c1 : memref<16x16xf32>
%K = memref.dim %A, %c1 : memref<16x16xf32>
- %f1 = muli %M, %N : index
- %f2 = muli %f1, %K : index
+ %f1 = arith.muli %M, %N : index
+ %f2 = arith.muli %f1, %K : index
// 2*M*N*K.
- %f3 = muli %c2, %f2 : index
- %num_flops = muli %reps, %f3 : index
- %num_flops_i = index_cast %num_flops : index to i16
- %num_flops_f = sitofp %num_flops_i : i16 to f64
- %flops = divf %num_flops_f, %t : f64
+ %f3 = arith.muli %c2, %f2 : index
+ %num_flops = arith.muli %reps, %f3 : index
+ %num_flops_i = arith.index_cast %num_flops : index to i16
+ %num_flops_f = arith.sitofp %num_flops_i : i16 to f64
+ %flops = arith.divf %num_flops_f, %t : f64
call @print_flops(%flops) : (f64) -> ()
memref.dealloc %A : memref<16x16xf32>
// CHECK: 17
func @sgemm_naive(%arg0: memref<16x16xf32>, %arg1: memref<16x16xf32>, %arg2: memref<16x16xf32>) {
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
affine.for %arg3 = 0 to 16 {
affine.for %arg4 = 0 to 16 {
%m = memref.alloc() : memref<1xf32>
%3 = affine.load %arg0[%arg3, %arg5] : memref<16x16xf32>
%4 = affine.load %arg1[%arg5, %arg4] : memref<16x16xf32>
%5 = affine.load %m[0] : memref<1xf32>
- %6 = mulf %3, %4 : f32
- %7 = addf %6, %5 : f32
+ %6 = arith.mulf %3, %4 : f32
+ %7 = arith.addf %6, %5 : f32
affine.store %7, %m[0] : memref<1xf32>
}
%s = affine.load %m[%c0] : memref<1xf32>
// RUN: mlir-opt %s -convert-linalg-to-loops \
// RUN: -convert-scf-to-std \
+// RUN: -convert-arith-to-llvm \
// RUN: -convert-linalg-to-llvm \
// RUN: -convert-memref-to-llvm \
// RUN: -convert-std-to-llvm \
-// RUN: -reconcile-unrealized-casts | \
+// RUN: -reconcile-unrealized-casts | \
// RUN: mlir-cpu-runner -e main -entry-point-result=void \
// RUN: -shared-libs=%mlir_runner_utils_dir/libmlir_runner_utils%shlibext,%mlir_runner_utils_dir/libmlir_c_runner_utils%shlibext | FileCheck %s
// CHECK-COUNT-4: [1, 1, 1]
func @main() -> () {
%A = memref.alloc() : memref<10x3xf32, 0>
- %f2 = constant 2.00000e+00 : f32
- %f5 = constant 5.00000e+00 : f32
- %f10 = constant 10.00000e+00 : f32
+ %f2 = arith.constant 2.00000e+00 : f32
+ %f5 = arith.constant 5.00000e+00 : f32
+ %f10 = arith.constant 10.00000e+00 : f32
%V = memref.cast %A : memref<10x3xf32, 0> to memref<?x?xf32>
linalg.fill(%f10, %V) : f32, memref<?x?xf32, 0>
call @print_memref_f32(%U3) : (memref<*xf32>) -> ()
// 122 is ASCII for 'z'.
- %i8_z = constant 122 : i8
+ %i8_z = arith.constant 122 : i8
%I8 = memref.alloc() : memref<i8>
memref.store %i8_z, %I8[]: memref<i8>
%U4 = memref.cast %I8 : memref<i8> to memref<*xi8>
func @return_two_var_memref_caller() {
%0 = memref.alloca() : memref<4x3xf32>
- %c0f32 = constant 1.0 : f32
+ %c0f32 = arith.constant 1.0 : f32
linalg.fill(%c0f32, %0) : f32, memref<4x3xf32>
%1:2 = call @return_two_var_memref(%0) : (memref<4x3xf32>) -> (memref<*xf32>, memref<*xf32>)
call @print_memref_f32(%1#0) : (memref<*xf32>) -> ()
func @return_var_memref_caller() {
%0 = memref.alloca() : memref<4x3xf32>
- %c0f32 = constant 1.0 : f32
+ %c0f32 = arith.constant 1.0 : f32
linalg.fill(%c0f32, %0) : f32, memref<4x3xf32>
%1 = call @return_var_memref(%0) : (memref<4x3xf32>) -> memref<*xf32>
call @print_memref_f32(%1) : (memref<*xf32>) -> ()
%ranked = memref.alloca() : memref<4x3xf32>
%unranked = memref.cast %ranked: memref<4x3xf32> to memref<*xf32>
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%dim_0 = memref.dim %unranked, %c0 : memref<*xf32>
call @printU64(%dim_0) : (index) -> ()
call @printNewline() : () -> ()
// CHECK: 4
- %c1 = constant 1 : index
+ %c1 = arith.constant 1 : index
%dim_1 = memref.dim %unranked, %c1 : memref<*xf32>
call @printU64(%dim_1) : (index) -> ()
call @printNewline() : () -> ()
-// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_0d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-0D
-// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_1d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-1D
-// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_3d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-3D
-// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e vector_splat_2d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-VECTOR-SPLAT-2D
+// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-arith-to-llvm -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_0d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-0D
+// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-arith-to-llvm -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_1d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-1D
+// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-arith-to-llvm -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e print_3d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-3D
+// RUN: mlir-opt %s -convert-linalg-to-loops -convert-scf-to-std -convert-arith-to-llvm -convert-linalg-to-llvm -convert-memref-to-llvm -convert-std-to-llvm -reconcile-unrealized-casts | mlir-cpu-runner -e vector_splat_2d -entry-point-result=void -shared-libs=%linalg_test_lib_dir/libmlir_runner_utils%shlibext | FileCheck %s --check-prefix=PRINT-VECTOR-SPLAT-2D
func @print_0d() {
- %f = constant 2.00000e+00 : f32
+ %f = arith.constant 2.00000e+00 : f32
%A = memref.alloc() : memref<f32>
memref.store %f, %A[]: memref<f32>
%U = memref.cast %A : memref<f32> to memref<*xf32>
// PRINT-0D: [2]
func @print_1d() {
- %f = constant 2.00000e+00 : f32
+ %f = arith.constant 2.00000e+00 : f32
%A = memref.alloc() : memref<16xf32>
%B = memref.cast %A: memref<16xf32> to memref<?xf32>
linalg.fill(%f, %B) : f32, memref<?xf32>
// PRINT-1D-NEXT: [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
func @print_3d() {
- %f = constant 2.00000e+00 : f32
- %f4 = constant 4.00000e+00 : f32
+ %f = arith.constant 2.00000e+00 : f32
+ %f4 = arith.constant 4.00000e+00 : f32
%A = memref.alloc() : memref<3x4x5xf32>
%B = memref.cast %A: memref<3x4x5xf32> to memref<?x?x?xf32>
linalg.fill(%f, %B) : f32, memref<?x?x?xf32>
- %c2 = constant 2 : index
+ %c2 = arith.constant 2 : index
memref.store %f4, %B[%c2, %c2, %c2]: memref<?x?x?xf32>
%U = memref.cast %B : memref<?x?x?xf32> to memref<*xf32>
call @print_memref_f32(%U): (memref<*xf32>) -> ()
!vector_type_C = type vector<4x4xf32>
!matrix_type_CC = type memref<1x1x!vector_type_C>
func @vector_splat_2d() {
- %c0 = constant 0 : index
- %f10 = constant 10.0 : f32
+ %c0 = arith.constant 0 : index
+ %f10 = arith.constant 10.0 : f32
%vf10 = splat %f10: !vector_type_C
%C = memref.alloc() : !matrix_type_CC
memref.store %vf10, %C[%c0, %c0]: !matrix_type_CC
"uri":"test:///foo.mlir",
"languageId":"mlir",
"version":1,
- "text":"func @foo() -> {}\n// -----\nfunc @foo() -> i1 {\n%value = constant true\nreturn %value : i1\n}"
+ "text":"func @foo() -> {}\n// -----\nfunc @foo() -> i1 {\n%value = arith.constant true\nreturn %value : i1\n}"
}}}
// -----
{"jsonrpc":"2.0","id":1,"method":"textDocument/definition","params":{
"uri":"test:///foo.mlir",
"languageId":"mlir",
"version":1,
- "text":"func @foo() -> i1 {\n%value = constant true\nreturn %value : i1\n}"
+ "text":"func @foo() -> i1 {\n%value = arith.constant true\nreturn %value : i1\n}"
}}}
// -----
{"jsonrpc":"2.0","id":1,"method":"textDocument/definition","params":{
"uri":"test:///foo.mlir",
"languageId":"mlir",
"version":1,
- "text":"func @foo(%arg: i1) {\n%value = constant true\nbr ^bb2\n^bb2:\nreturn\n}"
+ "text":"func @foo(%arg: i1) {\n%value = arith.constant true\nbr ^bb2\n^bb2:\nreturn\n}"
}}}
// -----
// Hover on an operation.
// CHECK-NEXT: "result": {
// CHECK-NEXT: "contents": {
// CHECK-NEXT: "kind": "markdown",
-// CHECK-NEXT: "value": "\"std.constant\"\n\nGeneric Form:\n\n```mlir\n%0 = \"std.constant\"() {value = true} : () -> i1\n```\n"
+// CHECK-NEXT: "value": "\"arith.constant\"\n\nGeneric Form:\n\n```mlir\n%0 = \"arith.constant\"() {value = true} : () -> i1\n```\n"
// CHECK-NEXT: },
// CHECK-NEXT: "range": {
// CHECK-NEXT: "end": {
-// CHECK-NEXT: "character": 17,
+// CHECK-NEXT: "character": 23,
// CHECK-NEXT: "line": 1
// CHECK-NEXT: },
// CHECK-NEXT: "start": {
// CHECK-NEXT: "result": {
// CHECK-NEXT: "contents": {
// CHECK-NEXT: "kind": "markdown",
-// CHECK-NEXT: "value": "Operation: \"std.constant\"\n\nResult #0\n\nType: `i1`\n\n"
+// CHECK-NEXT: "value": "Operation: \"arith.constant\"\n\nResult #0\n\nType: `i1`\n\n"
// CHECK-NEXT: },
// CHECK-NEXT: "range": {
// CHECK-NEXT: "end": {
"uri":"test:///foo.mlir",
"languageId":"mlir",
"version":1,
- "text":"func @foo() -> i1 {\n%value = constant true\n%result = call @foo() : () -> i1\nreturn %value : i1\n}"
+ "text":"func @foo() -> i1 {\n%value = arith.constant true\n%result = call @foo() : () -> i1\nreturn %value : i1\n}"
}}}
// -----
{"jsonrpc":"2.0","id":1,"method":"textDocument/references","params":{
// CHECK-NEXT: acc
// CHECK-NEXT: affine
// CHECK-NEXT: amx
+// CHECK-NEXT: arith
// CHECK-NEXT: arm_neon
// CHECK-NEXT: arm_sve
// CHECK-NEXT: async
gpu.module @kernels {
gpu.func @double(%arg0 : memref<6xi32>, %arg1 : memref<6xi32>)
kernel attributes { spv.entry_point_abi = {local_size = dense<[1, 1, 1]>: vector<3xi32>}} {
- %factor = constant 2 : i32
+ %factor = arith.constant 2 : i32
- %i0 = constant 0 : index
- %i1 = constant 1 : index
- %i2 = constant 2 : index
- %i3 = constant 3 : index
- %i4 = constant 4 : index
- %i5 = constant 5 : index
+ %i0 = arith.constant 0 : index
+ %i1 = arith.constant 1 : index
+ %i2 = arith.constant 2 : index
+ %i3 = arith.constant 3 : index
+ %i4 = arith.constant 4 : index
+ %i5 = arith.constant 5 : index
%x0 = memref.load %arg0[%i0] : memref<6xi32>
%x1 = memref.load %arg0[%i1] : memref<6xi32>
%x4 = memref.load %arg0[%i4] : memref<6xi32>
%x5 = memref.load %arg0[%i5] : memref<6xi32>
- %y0 = muli %x0, %factor : i32
- %y1 = muli %x1, %factor : i32
- %y2 = muli %x2, %factor : i32
- %y3 = muli %x3, %factor : i32
- %y4 = muli %x4, %factor : i32
- %y5 = muli %x5, %factor : i32
+ %y0 = arith.muli %x0, %factor : i32
+ %y1 = arith.muli %x1, %factor : i32
+ %y2 = arith.muli %x2, %factor : i32
+ %y3 = arith.muli %x3, %factor : i32
+ %y4 = arith.muli %x4, %factor : i32
+ %y5 = arith.muli %x5, %factor : i32
memref.store %y0, %arg1[%i0] : memref<6xi32>
memref.store %y1, %arg1[%i1] : memref<6xi32>
func @main() {
%input = memref.alloc() : memref<6xi32>
%output = memref.alloc() : memref<6xi32>
- %four = constant 4 : i32
- %zero = constant 0 : i32
+ %four = arith.constant 4 : i32
+ %zero = arith.constant 0 : i32
%input_casted = memref.cast %input : memref<6xi32> to memref<?xi32>
%output_casted = memref.cast %output : memref<6xi32> to memref<?xi32>
call @fillI32Buffer(%input_casted, %four) : (memref<?xi32>, i32) -> ()
call @fillI32Buffer(%output_casted, %zero) : (memref<?xi32>, i32) -> ()
- %one = constant 1 : index
+ %one = arith.constant 1 : index
gpu.launch_func @kernels::@double
blocks in (%one, %one, %one) threads in (%one, %one, %one)
args(%input : memref<6xi32>, %output : memref<6xi32>)
gpu.module @kernels {
gpu.func @sum(%arg0 : memref<3xf32>, %arg1 : memref<3x3xf32>, %arg2 : memref<3x3x3xf32>)
kernel attributes { spv.entry_point_abi = {local_size = dense<[1, 1, 1]>: vector<3xi32>}} {
- %i0 = constant 0 : index
- %i1 = constant 1 : index
- %i2 = constant 2 : index
+ %i0 = arith.constant 0 : index
+ %i1 = arith.constant 1 : index
+ %i2 = arith.constant 2 : index
%x = memref.load %arg0[%i0] : memref<3xf32>
%y = memref.load %arg1[%i0, %i0] : memref<3x3xf32>
- %sum = addf %x, %y : f32
+ %sum = arith.addf %x, %y : f32
memref.store %sum, %arg2[%i0, %i0, %i0] : memref<3x3x3xf32>
memref.store %sum, %arg2[%i0, %i1, %i0] : memref<3x3x3xf32>
%input1 = memref.alloc() : memref<3xf32>
%input2 = memref.alloc() : memref<3x3xf32>
%output = memref.alloc() : memref<3x3x3xf32>
- %0 = constant 0.0 : f32
- %3 = constant 3.4 : f32
- %4 = constant 4.3 : f32
+ %0 = arith.constant 0.0 : f32
+ %3 = arith.constant 3.4 : f32
+ %4 = arith.constant 4.3 : f32
%input1_casted = memref.cast %input1 : memref<3xf32> to memref<?xf32>
%input2_casted = memref.cast %input2 : memref<3x3xf32> to memref<?x?xf32>
%output_casted = memref.cast %output : memref<3x3x3xf32> to memref<?x?x?xf32>
call @fillF32Buffer2D(%input2_casted, %4) : (memref<?x?xf32>, f32) -> ()
call @fillF32Buffer3D(%output_casted, %0) : (memref<?x?x?xf32>, f32) -> ()
- %one = constant 1 : index
+ %one = arith.constant 1 : index
gpu.launch_func @kernels::@sum
blocks in (%one, %one, %one) threads in (%one, %one, %one)
args(%input1 : memref<3xf32>, %input2 : memref<3x3xf32>, %output : memref<3x3x3xf32>)
// CHECK-LABEL: testReifyFunctions
func @testReifyFunctions(%arg0 : tensor<10xf32>, %arg1 : tensor<20xf32>) {
- // expected-remark@+1 {{constant 10}}
+ // expected-remark@+1 {{arith.constant 10}}
%0 = "test.op_with_shaped_type_infer_type_if"(%arg0, %arg1) : (tensor<10xf32>, tensor<20xf32>) -> tensor<10xi17>
- // expected-remark@+1 {{constant 20}}
+ // expected-remark@+1 {{arith.constant 20}}
%1 = "test.op_with_shaped_type_infer_type_if"(%arg1, %arg0) : (tensor<20xf32>, tensor<10xf32>) -> tensor<20xi17>
return
}
%0 = "gpu.block_id"() {dimension = "x"} : () -> index
%1 = memref.load %arg0[%0] : memref<8xf32>
%2 = memref.load %arg1[%0] : memref<8xf32>
- %3 = addf %1, %2 : f32
+ %3 = arith.addf %1, %2 : f32
memref.store %3, %arg2[%0] : memref<8xf32>
gpu.return
}
%arg0 = memref.alloc() : memref<8xf32>
%arg1 = memref.alloc() : memref<8xf32>
%arg2 = memref.alloc() : memref<8xf32>
- %0 = constant 0 : i32
- %1 = constant 1 : i32
- %2 = constant 2 : i32
- %value0 = constant 0.0 : f32
- %value1 = constant 1.1 : f32
- %value2 = constant 2.2 : f32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
+ %value0 = arith.constant 0.0 : f32
+ %value1 = arith.constant 1.1 : f32
+ %value2 = arith.constant 2.2 : f32
%arg3 = memref.cast %arg0 : memref<8xf32> to memref<?xf32>
%arg4 = memref.cast %arg1 : memref<8xf32> to memref<?xf32>
%arg5 = memref.cast %arg2 : memref<8xf32> to memref<?xf32>
call @fillResource1DFloat(%arg4, %value2) : (memref<?xf32>, f32) -> ()
call @fillResource1DFloat(%arg5, %value0) : (memref<?xf32>, f32) -> ()
- %cst1 = constant 1 : index
- %cst8 = constant 8 : index
+ %cst1 = arith.constant 1 : index
+ %cst8 = arith.constant 8 : index
gpu.launch_func @kernels::@kernel_add
blocks in (%cst8, %cst1, %cst1) threads in (%cst1, %cst1, %cst1)
args(%arg0 : memref<8xf32>, %arg1 : memref<8xf32>, %arg2 : memref<8xf32>)
%z = "gpu.block_id"() {dimension = "z"} : () -> index
%0 = memref.load %arg0[%x] : memref<8xi32>
%1 = memref.load %arg1[%y, %x] : memref<8x8xi32>
- %2 = addi %0, %1 : i32
+ %2 = arith.addi %0, %1 : i32
memref.store %2, %arg2[%z, %y, %x] : memref<8x8x8xi32>
gpu.return
}
%arg0 = memref.alloc() : memref<8xi32>
%arg1 = memref.alloc() : memref<8x8xi32>
%arg2 = memref.alloc() : memref<8x8x8xi32>
- %value0 = constant 0 : i32
- %value1 = constant 1 : i32
- %value2 = constant 2 : i32
+ %value0 = arith.constant 0 : i32
+ %value1 = arith.constant 1 : i32
+ %value2 = arith.constant 2 : i32
%arg3 = memref.cast %arg0 : memref<8xi32> to memref<?xi32>
%arg4 = memref.cast %arg1 : memref<8x8xi32> to memref<?x?xi32>
%arg5 = memref.cast %arg2 : memref<8x8x8xi32> to memref<?x?x?xi32>
call @fillResource2DInt(%arg4, %value2) : (memref<?x?xi32>, i32) -> ()
call @fillResource3DInt(%arg5, %value0) : (memref<?x?x?xi32>, i32) -> ()
- %cst1 = constant 1 : index
- %cst8 = constant 8 : index
+ %cst1 = arith.constant 1 : index
+ %cst8 = arith.constant 8 : index
gpu.launch_func @kernels::@kernel_addi
blocks in (%cst8, %cst8, %cst8) threads in (%cst1, %cst1, %cst1)
args(%arg0 : memref<8xi32>, %arg1 : memref<8x8xi32>, %arg2 : memref<8x8x8xi32>)
%z = "gpu.block_id"() {dimension = "z"} : () -> index
%0 = memref.load %arg0[%x] : memref<8xi8>
%1 = memref.load %arg1[%y, %x] : memref<8x8xi8>
- %2 = addi %0, %1 : i8
- %3 = zexti %2 : i8 to i32
+ %2 = arith.addi %0, %1 : i8
+ %3 = arith.extui %2 : i8 to i32
memref.store %3, %arg2[%z, %y, %x] : memref<8x8x8xi32>
gpu.return
}
%arg0 = memref.alloc() : memref<8xi8>
%arg1 = memref.alloc() : memref<8x8xi8>
%arg2 = memref.alloc() : memref<8x8x8xi32>
- %value0 = constant 0 : i32
- %value1 = constant 1 : i8
- %value2 = constant 2 : i8
+ %value0 = arith.constant 0 : i32
+ %value1 = arith.constant 1 : i8
+ %value2 = arith.constant 2 : i8
%arg3 = memref.cast %arg0 : memref<8xi8> to memref<?xi8>
%arg4 = memref.cast %arg1 : memref<8x8xi8> to memref<?x?xi8>
%arg5 = memref.cast %arg2 : memref<8x8x8xi32> to memref<?x?x?xi32>
call @fillResource2DInt8(%arg4, %value2) : (memref<?x?xi8>, i8) -> ()
call @fillResource3DInt(%arg5, %value0) : (memref<?x?x?xi32>, i32) -> ()
- %cst1 = constant 1 : index
- %cst8 = constant 8 : index
+ %cst1 = arith.constant 1 : index
+ %cst8 = arith.constant 8 : index
gpu.launch_func @kernels::@kernel_addi
blocks in (%cst8, %cst8, %cst8) threads in (%cst1, %cst1, %cst1)
args(%arg0 : memref<8xi8>, %arg1 : memref<8x8xi8>, %arg2 : memref<8x8x8xi32>)
%y = "gpu.block_id"() {dimension = "y"} : () -> index
%1 = memref.load %arg0[%x, %y] : memref<4x4xf32>
%2 = memref.load %arg1[%x, %y] : memref<4x4xf32>
- %3 = mulf %1, %2 : f32
+ %3 = arith.mulf %1, %2 : f32
memref.store %3, %arg2[%x, %y] : memref<4x4xf32>
gpu.return
}
%arg0 = memref.alloc() : memref<4x4xf32>
%arg1 = memref.alloc() : memref<4x4xf32>
%arg2 = memref.alloc() : memref<4x4xf32>
- %0 = constant 0 : i32
- %1 = constant 1 : i32
- %2 = constant 2 : i32
- %value0 = constant 0.0 : f32
- %value1 = constant 2.0 : f32
- %value2 = constant 3.0 : f32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
+ %value0 = arith.constant 0.0 : f32
+ %value1 = arith.constant 2.0 : f32
+ %value2 = arith.constant 3.0 : f32
%arg3 = memref.cast %arg0 : memref<4x4xf32> to memref<?x?xf32>
%arg4 = memref.cast %arg1 : memref<4x4xf32> to memref<?x?xf32>
%arg5 = memref.cast %arg2 : memref<4x4xf32> to memref<?x?xf32>
call @fillResource2DFloat(%arg4, %value2) : (memref<?x?xf32>, f32) -> ()
call @fillResource2DFloat(%arg5, %value0) : (memref<?x?xf32>, f32) -> ()
- %cst1 = constant 1 : index
- %cst4 = constant 4 : index
+ %cst1 = arith.constant 1 : index
+ %cst4 = arith.constant 4 : index
gpu.launch_func @kernels::@kernel_mul
blocks in (%cst4, %cst4, %cst1) threads in(%cst1, %cst1, %cst1)
args(%arg0 : memref<4x4xf32>, %arg1 : memref<4x4xf32>, %arg2 : memref<4x4xf32>)
%z = "gpu.block_id"() {dimension = "z"} : () -> index
%1 = memref.load %arg0[%x, %y, %z] : memref<8x4x4xf32>
%2 = memref.load %arg1[%y, %z] : memref<4x4xf32>
- %3 = subf %1, %2 : f32
+ %3 = arith.subf %1, %2 : f32
memref.store %3, %arg2[%x, %y, %z] : memref<8x4x4xf32>
gpu.return
}
%arg0 = memref.alloc() : memref<8x4x4xf32>
%arg1 = memref.alloc() : memref<4x4xf32>
%arg2 = memref.alloc() : memref<8x4x4xf32>
- %0 = constant 0 : i32
- %1 = constant 1 : i32
- %2 = constant 2 : i32
- %value0 = constant 0.0 : f32
- %value1 = constant 3.3 : f32
- %value2 = constant 1.1 : f32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
+ %value0 = arith.constant 0.0 : f32
+ %value1 = arith.constant 3.3 : f32
+ %value2 = arith.constant 1.1 : f32
%arg3 = memref.cast %arg0 : memref<8x4x4xf32> to memref<?x?x?xf32>
%arg4 = memref.cast %arg1 : memref<4x4xf32> to memref<?x?xf32>
%arg5 = memref.cast %arg2 : memref<8x4x4xf32> to memref<?x?x?xf32>
call @fillResource2DFloat(%arg4, %value2) : (memref<?x?xf32>, f32) -> ()
call @fillResource3DFloat(%arg5, %value0) : (memref<?x?x?xf32>, f32) -> ()
- %cst1 = constant 1 : index
- %cst4 = constant 4 : index
- %cst8 = constant 8 : index
+ %cst1 = arith.constant 1 : index
+ %cst4 = arith.constant 4 : index
+ %cst8 = arith.constant 8 : index
gpu.launch_func @kernels::@kernel_sub
blocks in (%cst8, %cst4, %cst4) threads in (%cst1, %cst1, %cst1)
args(%arg0 : memref<8x4x4xf32>, %arg1 : memref<4x4xf32>, %arg2 : memref<8x4x4xf32>)
kernel attributes { spv.entry_point_abi = {local_size = dense<[128, 1, 1]>: vector<3xi32> }} {
%bid = "gpu.block_id"() {dimension = "x"} : () -> index
%tid = "gpu.thread_id"() {dimension = "x"} : () -> index
- %cst = constant 128 : index
- %b = muli %bid, %cst : index
- %0 = addi %b, %tid : index
+ %cst = arith.constant 128 : index
+ %b = arith.muli %bid, %cst : index
+ %0 = arith.addi %b, %tid : index
%1 = memref.load %arg0[%0] : memref<16384xf32>
%2 = memref.load %arg1[%0] : memref<16384xf32>
- %3 = addf %1, %2 : f32
+ %3 = arith.addf %1, %2 : f32
memref.store %3, %arg2[%0] : memref<16384xf32>
gpu.return
}
%arg0 = memref.alloc() : memref<16384xf32>
%arg1 = memref.alloc() : memref<16384xf32>
%arg2 = memref.alloc() : memref<16384xf32>
- %0 = constant 0 : i32
- %1 = constant 1 : i32
- %2 = constant 2 : i32
- %value0 = constant 0.0 : f32
- %value1 = constant 1.1 : f32
- %value2 = constant 2.2 : f32
+ %0 = arith.constant 0 : i32
+ %1 = arith.constant 1 : i32
+ %2 = arith.constant 2 : i32
+ %value0 = arith.constant 0.0 : f32
+ %value1 = arith.constant 1.1 : f32
+ %value2 = arith.constant 2.2 : f32
%arg3 = memref.cast %arg0 : memref<16384xf32> to memref<?xf32>
%arg4 = memref.cast %arg1 : memref<16384xf32> to memref<?xf32>
%arg5 = memref.cast %arg2 : memref<16384xf32> to memref<?xf32>
call @fillResource1DFloat(%arg4, %value2) : (memref<?xf32>, f32) -> ()
call @fillResource1DFloat(%arg5, %value0) : (memref<?xf32>, f32) -> ()
- %cst1 = constant 1 : index
- %cst128 = constant 128 : index
+ %cst1 = arith.constant 1 : index
+ %cst128 = arith.constant 128 : index
gpu.launch_func @kernels::@kernel_add
blocks in (%cst128, %cst1, %cst1) threads in (%cst128, %cst1, %cst1)
args(%arg0 : memref<16384xf32>, %arg1 : memref<16384xf32>, %arg2 : memref<16384xf32>)
cast(U, I[D.n, D.oh * S.SH + D.kh * S.DH, D.ow * S.SW + D.kw * S.DW,
D.c]))
+
@linalg_structured_op
def pooling_max_unsigned_poly(
I=TensorDef(T1, S.N, S.H, S.W, S.C),
cast_unsigned(
U, I[D.n, D.oh * S.SH + D.kh * S.DH, D.ow * S.SW + D.kw * S.DW, D.c]))
+
@linalg_structured_op
def pooling_min_poly(
I=TensorDef(T1, S.N, S.H, S.W, S.C),
cast(U, I[D.n, D.oh * S.SH + D.kh * S.DH, D.ow * S.SW + D.kw * S.DW,
D.c]))
+
@linalg_structured_op
def pooling_min_unsigned_poly(
I=TensorDef(T1, S.N, S.H, S.W, S.C),
cast_unsigned(
U, I[D.n, D.oh * S.SH + D.kh * S.DH, D.ow * S.SW + D.kw * S.DW, D.c]))
+
@linalg_structured_op
def fill_rng_poly(
min=ScalarDef(F64),
# CHECK-LABEL: @test_i8i8i32_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: i8, %[[B_ARG:.+]]: i8, %[[C_ARG:.+]]: i32)
- # CHECK-NEXT: %[[A_CAST:.+]] = sexti %[[A_ARG]] : i8 to i32
- # CHECK-NEXT: %[[B_CAST:.+]] = sexti %[[B_ARG]] : i8 to i32
- # CHECK-NEXT: %[[MUL:.+]] = muli %[[A_CAST]], %[[B_CAST]] : i32
- # CHECK-NEXT: %[[ADD:.+]] = addi %[[C_ARG]], %[[MUL]] : i32
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.extsi %[[A_ARG]] : i8 to i32
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.extsi %[[B_ARG]] : i8 to i32
+ # CHECK-NEXT: %[[MUL:.+]] = arith.muli %[[A_CAST]], %[[B_CAST]] : i32
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addi %[[C_ARG]], %[[MUL]] : i32
# CHECK-NEXT: linalg.yield %[[ADD]] : i32
# CHECK-NEXT: -> tensor<4x8xi32>
@builtin.FuncOp.from_py_func(
return matmul_poly(lhs, rhs, outs=[init_result])
# CHECK-LABEL: @test_i8i8i32_matmul_unsigned
- # CHECK: = zexti
- # CHECK: = zexti
+ # CHECK: = arith.extui
+ # CHECK: = arith.extui
@builtin.FuncOp.from_py_func(
RankedTensorType.get((4, 16), i8), RankedTensorType.get((16, 8), i8),
RankedTensorType.get((4, 8), i32))
# CHECK-LABEL: @test_i8i16i32_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: i8, %[[B_ARG:.+]]: i16, %[[C_ARG:.+]]: i32)
- # CHECK-NEXT: %[[A_CAST:.+]] = sexti %[[A_ARG]] : i8 to i32
- # CHECK-NEXT: %[[B_CAST:.+]] = sexti %[[B_ARG]] : i16 to i32
- # CHECK-NEXT: %[[MUL:.+]] = muli %[[A_CAST]], %[[B_CAST]] : i32
- # CHECK-NEXT: %[[ADD:.+]] = addi %[[C_ARG]], %[[MUL]] : i32
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.extsi %[[A_ARG]] : i8 to i32
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.extsi %[[B_ARG]] : i16 to i32
+ # CHECK-NEXT: %[[MUL:.+]] = arith.muli %[[A_CAST]], %[[B_CAST]] : i32
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addi %[[C_ARG]], %[[MUL]] : i32
# CHECK-NEXT: linalg.yield %[[ADD]] : i32
# CHECK-NEXT: -> tensor<4x8xi32>
@builtin.FuncOp.from_py_func(
# CHECK-LABEL: @test_i32i32i16_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: i32, %[[B_ARG:.+]]: i32, %[[C_ARG:.+]]: i16)
- # CHECK-NEXT: %[[A_CAST:.+]] = trunci %[[A_ARG]] : i32 to i16
- # CHECK-NEXT: %[[B_CAST:.+]] = trunci %[[B_ARG]] : i32 to i16
- # CHECK-NEXT: %[[MUL:.+]] = muli %[[A_CAST]], %[[B_CAST]] : i16
- # CHECK-NEXT: %[[ADD:.+]] = addi %[[C_ARG]], %[[MUL]] : i16
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.trunci %[[A_ARG]] : i32 to i16
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.trunci %[[B_ARG]] : i32 to i16
+ # CHECK-NEXT: %[[MUL:.+]] = arith.muli %[[A_CAST]], %[[B_CAST]] : i16
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addi %[[C_ARG]], %[[MUL]] : i16
# CHECK-NEXT: linalg.yield %[[ADD]] : i16
# CHECK-NEXT: -> tensor<4x8xi16>
@builtin.FuncOp.from_py_func(
# CHECK-LABEL: @test_i8i8f32_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: i8, %[[B_ARG:.+]]: i8, %[[C_ARG:.+]]: f32)
- # CHECK-NEXT: %[[A_CAST:.+]] = sitofp %[[A_ARG]] : i8 to f32
- # CHECK-NEXT: %[[B_CAST:.+]] = sitofp %[[B_ARG]] : i8 to f32
- # CHECK-NEXT: %[[MUL:.+]] = mulf %[[A_CAST]], %[[B_CAST]] : f32
- # CHECK-NEXT: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.sitofp %[[A_ARG]] : i8 to f32
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.sitofp %[[B_ARG]] : i8 to f32
+ # CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[A_CAST]], %[[B_CAST]] : f32
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
# CHECK-NEXT: linalg.yield %[[ADD]] : f32
# CHECK-NEXT: -> tensor<4x8xf32>
@builtin.FuncOp.from_py_func(
return matmul_poly(lhs, rhs, outs=[init_result])
# CHECK-LABEL: @test_i8i8f32_matmul_unsigned
- # CHECK: = uitofp
- # CHECK: = uitofp
+ # CHECK: = arith.uitofp
+ # CHECK: = arith.uitofp
@builtin.FuncOp.from_py_func(
RankedTensorType.get((4, 16), i8), RankedTensorType.get((16, 8), i8),
RankedTensorType.get((4, 8), f32))
# CHECK-LABEL: @test_f16f16f32_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: f16, %[[B_ARG:.+]]: f16, %[[C_ARG:.+]]: f32)
- # CHECK-NEXT: %[[A_CAST:.+]] = fpext %[[A_ARG]] : f16 to f32
- # CHECK-NEXT: %[[B_CAST:.+]] = fpext %[[B_ARG]] : f16 to f32
- # CHECK-NEXT: %[[MUL:.+]] = mulf %[[A_CAST]], %[[B_CAST]] : f32
- # CHECK-NEXT: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.extf %[[A_ARG]] : f16 to f32
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.extf %[[B_ARG]] : f16 to f32
+ # CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[A_CAST]], %[[B_CAST]] : f32
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
# CHECK-NEXT: linalg.yield %[[ADD]] : f32
# CHECK-NEXT: -> tensor<4x8xf32>
@builtin.FuncOp.from_py_func(
# CHECK-LABEL: @test_f64f64f32_matmul
# CHECK: ^{{.*}}(%[[A_ARG:.+]]: f64, %[[B_ARG:.+]]: f64, %[[C_ARG:.+]]: f32)
- # CHECK-NEXT: %[[A_CAST:.+]] = fptrunc %[[A_ARG]] : f64 to f32
- # CHECK-NEXT: %[[B_CAST:.+]] = fptrunc %[[B_ARG]] : f64 to f32
- # CHECK-NEXT: %[[MUL:.+]] = mulf %[[A_CAST]], %[[B_CAST]] : f32
- # CHECK-NEXT: %[[ADD:.+]] = addf %[[C_ARG]], %[[MUL]] : f32
+ # CHECK-NEXT: %[[A_CAST:.+]] = arith.truncf %[[A_ARG]] : f64 to f32
+ # CHECK-NEXT: %[[B_CAST:.+]] = arith.truncf %[[B_ARG]] : f64 to f32
+ # CHECK-NEXT: %[[MUL:.+]] = arith.mulf %[[A_CAST]], %[[B_CAST]] : f32
+ # CHECK-NEXT: %[[ADD:.+]] = arith.addf %[[C_ARG]], %[[MUL]] : f32
# CHECK-NEXT: linalg.yield %[[ADD]] : f32
# CHECK-NEXT: -> tensor<4x8xf32>
@builtin.FuncOp.from_py_func(
# CHECK-SAME: indexing_maps = [#[[$CONV_MAP_I]], #[[$CONV_MAP_K]], #[[$CONV_MAP_O]]]
# CHECK-SAME: iterator_types = ["parallel", "parallel", "parallel", "reduction", "reduction", "parallel"]
# CHECK: ^{{.*}}(%[[IN:.+]]: f32, %[[FILTER:.+]]: f32, %[[OUT:.+]]: i32)
- # CHECK-NEXT: %[[IN_CAST:.+]] = fptosi %[[IN:.+]] : f32 to i32
- # CHECK-NEXT: %[[FILTER_CAST:.+]] = fptosi %[[FILTER:.+]] : f32 to i32
- # CHECK-NEXT: %[[PROD:.+]] = muli %[[IN_CAST]], %[[FILTER_CAST]] : i32
- # CHECK-NEXT: %[[SUM:.+]] = addi %[[OUT]], %[[PROD]] : i32
+ # CHECK-NEXT: %[[IN_CAST:.+]] = arith.fptosi %[[IN:.+]] : f32 to i32
+ # CHECK-NEXT: %[[FILTER_CAST:.+]] = arith.fptosi %[[FILTER:.+]] : f32 to i32
+ # CHECK-NEXT: %[[PROD:.+]] = arith.muli %[[IN_CAST]], %[[FILTER_CAST]] : i32
+ # CHECK-NEXT: %[[SUM:.+]] = arith.addi %[[OUT]], %[[PROD]] : i32
# CHECK-NEXT: linalg.yield %[[SUM]] : i32
# CHECK-NEXT: -> tensor<2x4xi32>
@builtin.FuncOp.from_py_func(
# CHECK-SAME: indexing_maps = [#[[$CONV_MAP_I]], #[[$POOL_MAP_K]], #[[$CONV_MAP_O]]]
# CHECK-SAME: iterator_types = ["parallel", "parallel", "parallel", "reduction", "reduction", "parallel"]
# CHECK: ^{{.*}}(%[[IN:.+]]: f32, %[[SHAPE:.+]]: f32, %[[OUT:.+]]: i32)
- # CHECK-NEXT: %[[IN_CAST:.+]] = fptosi %[[IN:.+]] : f32 to i32
+ # CHECK-NEXT: %[[IN_CAST:.+]] = arith.fptosi %[[IN:.+]] : f32 to i32
# CHECK-NEXT: %[[MAX:.+]] = maxsi %[[OUT]], %[[IN_CAST:.+]] : i32
# CHECK-NEXT: linalg.yield %[[MAX]] : i32
# CHECK-NEXT: -> tensor<2x4xi32>
input, shape, outs=[init_result], strides=[2, 4], dilations=[1, 2])
# CHECK-LABEL: @test_f32i32_max_unsigned_pooling
- # CHECK: = fptoui
+ # CHECK: = arith.fptoui
# CHECK: = maxui
@builtin.FuncOp.from_py_func(
RankedTensorType.get((4, 16), f32), RankedTensorType.get((2, 2), f32),
input, shape, outs=[init_result], strides=[2, 4], dilations=[1, 2])
# CHECK-LABEL: @test_f32i32_min_pooling
- # CHECK: = fptosi
+ # CHECK: = arith.fptosi
# CHECK: = minsi
@builtin.FuncOp.from_py_func(
RankedTensorType.get((4, 16), f32), RankedTensorType.get((2, 2), f32),
input, shape, outs=[init_result], strides=[2, 4], dilations=[1, 2])
# CHECK-LABEL: @test_f32i32_min_unsigned_pooling
- # CHECK: = fptoui
+ # CHECK: = arith.fptoui
# CHECK: = minui
@builtin.FuncOp.from_py_func(
RankedTensorType.get((4, 16), f32), RankedTensorType.get((2, 2), f32),
# CHECK-LABEL: @test_i32_fill_rng
# CHECK: ^{{.*}}(%[[MIN:.+]]: f64, %[[MAX:.+]]: f64, %[[SEED:.+]]: i32, %{{.*}}
# CHECK-DAG: %[[IDX0:.+]] = linalg.index 0 : index
- # CHECK-DAG: %[[IDX0_CAST:.+]] = index_cast %[[IDX0]] : index to i32
- # CHECK-DAG: %[[RND0:.+]] = addi %[[IDX0_CAST]], %[[SEED]] : i32
- # CHECK-DAG: %[[CST0:.+]] = constant 1103515245 : i64
- # CHECK-DAG: %[[CST0_CAST:.+]] = trunci %[[CST0]] : i64 to i32
+ # CHECK-DAG: %[[IDX0_CAST:.+]] = arith.index_cast %[[IDX0]] : index to i32
+ # CHECK-DAG: %[[RND0:.+]] = arith.addi %[[IDX0_CAST]], %[[SEED]] : i32
+ # CHECK-DAG: %[[CST0:.+]] = arith.constant 1103515245 : i64
+ # CHECK-DAG: %[[CST0_CAST:.+]] = arith.trunci %[[CST0]] : i64 to i32
# Skip the remaining random number computation and match the scaling logic.
- # CHECK-DAG: %[[DIFF:.+]] = subf %[[MAX]], %[[MIN]] : f64
- # CHECK-DAG: %[[CST3:.+]] = constant 2.3283063999999999E-10 : f64
- # CHECK-DAG: %[[FACT:.+]] = mulf %[[DIFF]], %[[CST3]] : f64
- # CHECK-DAG: %[[RND4:.+]] = mulf %{{.+}}, %[[FACT]] : f64
- # CHECK-DAG: %[[RND5:.+]] = addf %[[RND4]], %[[MIN]] : f64
- # CHECK-DAG: %{{.*}} = fptosi %[[RND5]] : f64 to i32
+ # CHECK-DAG: %[[DIFF:.+]] = arith.subf %[[MAX]], %[[MIN]] : f64
+ # CHECK-DAG: %[[CST3:.+]] = arith.constant 2.3283063999999999E-10 : f64
+ # CHECK-DAG: %[[FACT:.+]] = arith.mulf %[[DIFF]], %[[CST3]] : f64
+ # CHECK-DAG: %[[RND4:.+]] = arith.mulf %{{.+}}, %[[FACT]] : f64
+ # CHECK-DAG: %[[RND5:.+]] = arith.addf %[[RND4]], %[[MIN]] : f64
+ # CHECK-DAG: %{{.*}} = arith.fptosi %[[RND5]] : f64 to i32
@builtin.FuncOp.from_py_func(f64, f64, i32,
RankedTensorType.get((4, 16), i32))
def test_i32_fill_rng(min, max, seed, init_result):
# CHECK-LABEL: @test_f32_soft_plus
# CHECK: ^{{.*}}(%[[IN:.+]]: f32, %[[OUT:.+]]: f32)
- # CHECK-NEXT: %[[C1:.+]] = constant 1.000000e+00 : f64
- # CHECK-NEXT: %[[C1_CAST:.+]] = fptrunc %[[C1]] : f64 to f32
+ # CHECK-NEXT: %[[C1:.+]] = arith.constant 1.000000e+00 : f64
+ # CHECK-NEXT: %[[C1_CAST:.+]] = arith.truncf %[[C1]] : f64 to f32
# CHECK-NEXT: %[[EXP:.+]] = math.exp %[[IN]] : f32
- # CHECK-NEXT: %[[SUM:.+]] = addf %[[C1_CAST]], %[[EXP]] : f32
+ # CHECK-NEXT: %[[SUM:.+]] = arith.addf %[[C1_CAST]], %[[EXP]] : f32
# CHECK-NEXT: %[[LOG:.+]] = math.log %[[SUM]] : f32
# CHECK-NEXT: linalg.yield %[[LOG]] : f32
# CHECK-NEXT: -> tensor<4x16xf32>
from mlir.dialects import builtin
from mlir.dialects import linalg
from mlir.dialects import std
+from mlir.dialects import arith
+
def run(f):
print("\nTEST:", f.__name__)
print(module)
+
# CHECK-LABEL: TEST: testInitTensorStaticSizesAttribute
@run
def testInitTensorStaticSizesAttribute():
with InsertionPoint(module.body):
op = linalg.InitTensorOp([3, 4], f32)
# CHECK: [3, 4]
- print(op.attributes['static_sizes'])
+ print(op.attributes["static_sizes"])
+
# CHECK-LABEL: TEST: testFill
@run
with InsertionPoint(module.body):
# CHECK-LABEL: func @fill_tensor
# CHECK-SAME: %[[OUT:[0-9a-z]+]]: tensor<12x?xf32>
- # CHECK-NEXT: %[[CST:.*]] = constant 0.0{{.*}} : f32
+ # CHECK-NEXT: %[[CST:.*]] = arith.constant 0.0{{.*}} : f32
# CHECK-NEXT: %[[RES:.*]] = linalg.fill(%[[CST]], %[[OUT]]) : f32, tensor<12x?xf32> -> tensor<12x?xf32>
# CHECK-NEXT: return %[[RES]] : tensor<12x?xf32>
- @builtin.FuncOp.from_py_func(
- RankedTensorType.get((12, -1), f32))
+ @builtin.FuncOp.from_py_func(RankedTensorType.get((12, -1), f32))
def fill_tensor(out):
- zero = std.ConstantOp(value=FloatAttr.get(f32, 0.), result=f32).result
+ zero = arith.ConstantOp(value=FloatAttr.get(f32, 0.), result=f32).result
# TODO: FillOp.result is None. When len(results) == 1 we expect it to
# be results[0] as per _linalg_ops_gen.py. This seems like an
# orthogonal bug in the generator of _linalg_ops_gen.py.
# CHECK-LABEL: func @fill_buffer
# CHECK-SAME: %[[OUT:[0-9a-z]+]]: memref<12x?xf32>
- # CHECK-NEXT: %[[CST:.*]] = constant 0.0{{.*}} : f32
+ # CHECK-NEXT: %[[CST:.*]] = arith.constant 0.0{{.*}} : f32
# CHECK-NEXT: linalg.fill(%[[CST]], %[[OUT]]) : f32, memref<12x?xf32>
# CHECK-NEXT: return
- @builtin.FuncOp.from_py_func(
- MemRefType.get((12, -1), f32))
+ @builtin.FuncOp.from_py_func(MemRefType.get((12, -1), f32))
def fill_buffer(out):
- zero = std.ConstantOp(value=FloatAttr.get(f32, 0.), result=f32).result
+ zero = arith.ConstantOp(value=FloatAttr.get(f32, 0.), result=f32).result
linalg.FillOp(output=out, value=zero)
print(module)
f32 = F32Type.get()
tensor_type = RankedTensorType.get((2, 3, 4), f32)
with InsertionPoint(module.body):
- func = builtin.FuncOp(name="matmul_test",
- type=FunctionType.get(
- inputs=[tensor_type, tensor_type],
- results=[tensor_type]))
+ func = builtin.FuncOp(
+ name="matmul_test",
+ type=FunctionType.get(
+ inputs=[tensor_type, tensor_type], results=[tensor_type]))
with InsertionPoint(func.add_entry_block()):
lhs, rhs = func.entry_block.arguments
result = linalg.MatmulOp([lhs, rhs], results=[tensor_type]).result
f32 = F32Type.get()
memref_type = MemRefType.get((2, 3, 4), f32)
with InsertionPoint(module.body):
- func = builtin.FuncOp(name="matmul_test",
- type=FunctionType.get(
- inputs=[memref_type, memref_type, memref_type],
- results=[]))
+ func = builtin.FuncOp(
+ name="matmul_test",
+ type=FunctionType.get(
+ inputs=[memref_type, memref_type, memref_type], results=[]))
with InsertionPoint(func.add_entry_block()):
lhs, rhs, result = func.entry_block.arguments
# TODO: prperly hook up the region.
# CHECK: linalg.matmul ins(%arg0, %arg1 : memref<2x3x4xf32>, memref<2x3x4xf32>) outs(%arg2 : memref<2x3x4xf32>)
print(module)
+
# CHECK-LABEL: TEST: testNamedStructuredOpCustomForm
@run
def testNamedStructuredOpCustomForm():
module = Module.create()
f32 = F32Type.get()
with InsertionPoint(module.body):
- @builtin.FuncOp.from_py_func(RankedTensorType.get((4, 16), f32),
- RankedTensorType.get((16, 8), f32))
+
+ @builtin.FuncOp.from_py_func(
+ RankedTensorType.get((4, 16), f32), RankedTensorType.get((16, 8),
+ f32))
def named_form(lhs, rhs):
init_result = linalg.InitTensorOp([4, 8], f32)
# First check the named form with custom format
print(module)
+
# CHECK-LABEL: TEST: testNamedStructuredOpGenericForm
@run
def testNamedStructuredOpGenericForm():
module = Module.create()
f32 = F32Type.get()
with InsertionPoint(module.body):
- @builtin.FuncOp.from_py_func(RankedTensorType.get((4, 16), f32),
- RankedTensorType.get((16, 8), f32))
+
+ @builtin.FuncOp.from_py_func(
+ RankedTensorType.get((4, 16), f32), RankedTensorType.get((16, 8),
+ f32))
def named_form(lhs, rhs):
init_result = linalg.InitTensorOp([4, 8], f32)
# CHECK: "linalg.matmul"(%{{.*}})
# CHECK-NEXT: ^bb0(%{{.*}}: f32, %{{.*}}: f32, %{{.*}}: f32):
- # CHECK-NEXT: std.mulf{{.*}} (f32, f32) -> f32
- # CHECK-NEXT: std.addf{{.*}} (f32, f32) -> f32
+ # CHECK-NEXT: arith.mulf{{.*}} (f32, f32) -> f32
+ # CHECK-NEXT: arith.addf{{.*}} (f32, f32) -> f32
# CHECK-NEXT: linalg.yield{{.*}} (f32) -> ()
# CHECK-NEXT: {linalg.memoized_indexing_maps{{.*}}operand_segment_sizes = dense<[2, 1]> : vector<2xi32>} :
# CHECK-SAME: (tensor<4x16xf32>, tensor<16x8xf32>, tensor<4x8xf32>) -> tensor<4x8xf32>
module.operation.print(print_generic_op_form=True)
+
# CHECK-LABEL: TEST: testNamedStructuredAsGenericOp
@run
def testNamedStructuredAsGenericOp():
module = Module.create()
f32 = F32Type.get()
with InsertionPoint(module.body):
- @builtin.FuncOp.from_py_func(RankedTensorType.get((4, 16), f32),
- RankedTensorType.get((16, 8), f32))
+
+ @builtin.FuncOp.from_py_func(
+ RankedTensorType.get((4, 16), f32), RankedTensorType.get((16, 8),
+ f32))
def generic_form(lhs, rhs):
init_result = linalg.InitTensorOp([4, 8], f32)
# CHECK: linalg.generic
- return linalg.matmul(lhs, rhs, outs=[init_result.result], emit_generic=True)
+ return linalg.matmul(
+ lhs, rhs, outs=[init_result.result], emit_generic=True)
print(module)
RankedTensorType.get((4, 16), f32), RankedTensorType.get((16, 8),
f32))
def pass_an_op_directly(arg0, arg1):
- one = std.ConstantOp(F32Type.get(), 1.0)
+ one = arith.ConstantOp(F32Type.get(), 1.0)
# CHECK: %[[LHS:.*]] = linalg.fill
lhs = linalg.FillOp(arg0, one)
# CHECK: %[[RHS:.*]] = linalg.fill
import mlir.dialects.std as std
import mlir.dialects.memref as memref
+
def run(f):
print("\nTEST:", f.__name__)
f()
+
# CHECK-LABEL: TEST: testSubViewAccessors
def testSubViewAccessors():
ctx = Context()
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: memref<?x?xf32>) {
- %0 = constant 0 : index
- %1 = constant 1 : index
- %2 = constant 2 : index
- %3 = constant 3 : index
- %4 = constant 4 : index
- %5 = constant 5 : index
+ %0 = arith.constant 0 : index
+ %1 = arith.constant 1 : index
+ %2 = arith.constant 2 : index
+ %3 = arith.constant 3 : index
+ %4 = arith.constant 4 : index
+ %5 = arith.constant 5 : index
memref.subview %arg0[%0, %1][%2, %3][%4, %5] : memref<?x?xf32> to memref<?x?xf32, offset: ?, strides: [?, ?]>
return
}
run(testSubViewAccessors)
-
# RUN: %PYTHON %s | FileCheck %s
from mlir.ir import *
+from mlir.dialects import arith
from mlir.dialects import scf
from mlir.dialects import std
from mlir.dialects import builtin
"callee", ([], [index_type, index_type]), visibility="private")
func = builtin.FuncOp("ops_as_arguments", ([], []))
with InsertionPoint(func.add_entry_block()):
- lb = std.ConstantOp.create_index(0)
- ub = std.ConstantOp.create_index(42)
- step = std.ConstantOp.create_index(2)
+ lb = arith.ConstantOp.create_index(0)
+ ub = arith.ConstantOp.create_index(42)
+ step = arith.ConstantOp.create_index(2)
iter_args = std.CallOp(callee, [])
loop = scf.ForOp(lb, ub, step, iter_args)
with InsertionPoint(loop.body):
# CHECK-LABEL: TEST: testOpsAsArguments
# CHECK: func private @callee() -> (index, index)
# CHECK: func @ops_as_arguments() {
-# CHECK: %[[LB:.*]] = constant 0
-# CHECK: %[[UB:.*]] = constant 42
-# CHECK: %[[STEP:.*]] = constant 2
+# CHECK: %[[LB:.*]] = arith.constant 0
+# CHECK: %[[UB:.*]] = arith.constant 42
+# CHECK: %[[STEP:.*]] = arith.constant 2
# CHECK: %[[ARGS:.*]]:2 = call @callee()
# CHECK: scf.for %arg0 = %c0 to %c42 step %c2
# CHECK: iter_args(%{{.*}} = %[[ARGS]]#0, %{{.*}} = %[[ARGS]]#1)
# RUN: %PYTHON %s | FileCheck %s
from mlir.ir import *
+from mlir.dialects import arith
from mlir.dialects import builtin
from mlir.dialects import std
print(module)
return f
+
# CHECK-LABEL: TEST: testConstantOp
+
@constructAndPrintInModule
def testConstantOp():
- c1 = std.ConstantOp(IntegerType.get_signless(32), 42)
- c2 = std.ConstantOp(IntegerType.get_signless(64), 100)
- c3 = std.ConstantOp(F32Type.get(), 3.14)
- c4 = std.ConstantOp(F64Type.get(), 1.23)
+ c1 = arith.ConstantOp(IntegerType.get_signless(32), 42)
+ c2 = arith.ConstantOp(IntegerType.get_signless(64), 100)
+ c3 = arith.ConstantOp(F32Type.get(), 3.14)
+ c4 = arith.ConstantOp(F64Type.get(), 1.23)
# CHECK: 42
print(c1.literal_value)
# CHECK: 1.23
print(c4.literal_value)
-# CHECK: = constant 42 : i32
-# CHECK: = constant 100 : i64
-# CHECK: = constant 3.140000e+00 : f32
-# CHECK: = constant 1.230000e+00 : f64
+
+# CHECK: = arith.constant 42 : i32
+# CHECK: = arith.constant 100 : i64
+# CHECK: = arith.constant 3.140000e+00 : f32
+# CHECK: = arith.constant 1.230000e+00 : f64
+
# CHECK-LABEL: TEST: testVectorConstantOp
@constructAndPrintInModule
def testVectorConstantOp():
int_type = IntegerType.get_signless(32)
vec_type = VectorType.get([2, 2], int_type)
- c1 = std.ConstantOp(vec_type,
- DenseElementsAttr.get_splat(vec_type, IntegerAttr.get(int_type, 42)))
+ c1 = arith.ConstantOp(
+ vec_type,
+ DenseElementsAttr.get_splat(vec_type, IntegerAttr.get(int_type, 42)))
try:
print(c1.literal_value)
except ValueError as e:
else:
assert False
-# CHECK: = constant dense<42> : vector<2x2xi32>
+
+# CHECK: = arith.constant dense<42> : vector<2x2xi32>
+
# CHECK-LABEL: TEST: testConstantIndexOp
@constructAndPrintInModule
def testConstantIndexOp():
- c1 = std.ConstantOp.create_index(10)
+ c1 = arith.ConstantOp.create_index(10)
# CHECK: 10
print(c1.literal_value)
-# CHECK: = constant 10 : index
+
+# CHECK: = arith.constant 10 : index
+
# CHECK-LABEL: TEST: testFunctionCalls
@constructAndPrintInModule
std.CallOp([F32Type.get()], FlatSymbolRefAttr.get("qux"), [])
std.ReturnOp([])
+
# CHECK: func @foo()
# CHECK: func @bar() -> index
# CHECK: func @qux() -> f32
# CHECK: %1 = call @qux() : () -> f32
# CHECK: return
# CHECK: }
-
from mlir.execution_engine import *
from mlir.runtime import *
+
# Log everything to stderr and flush so that we have a unified stream to match
# errors/info emitted by MLIR to stderr.
def log(*args):
print(*args, file=sys.stderr)
sys.stderr.flush()
+
def run(f):
log("\nTEST:", f.__name__)
f()
gc.collect()
assert Context._get_live_count() == 0
+
# Verify capsule interop.
# CHECK-LABEL: TEST: testCapsule
def testCapsule():
# CHECK: _mlirExecutionEngine.ExecutionEngine
log(repr(execution_engine1))
+
run(testCapsule)
+
# Test invalid ExecutionEngine creation
# CHECK-LABEL: TEST: testInvalidModule
def testInvalidModule():
except RuntimeError as e:
log("Got RuntimeError: ", e)
+
run(testInvalidModule)
+
def lowerToLLVM(module):
import mlir.conversions
- pm = PassManager.parse("convert-memref-to-llvm,convert-std-to-llvm,reconcile-unrealized-casts")
+ pm = PassManager.parse(
+ "convert-memref-to-llvm,convert-std-to-llvm,reconcile-unrealized-casts")
pm.run(module)
return module
+
# Test simple ExecutionEngine execution
# CHECK-LABEL: TEST: testInvokeVoid
def testInvokeVoid():
# Nothing to check other than no exception thrown here.
execution_engine.invoke("void")
+
run(testInvokeVoid)
with Context():
module = Module.parse(r"""
func @add(%arg0: f32, %arg1: f32) -> f32 attributes { llvm.emit_c_interface } {
- %add = std.addf %arg0, %arg1 : f32
+ %add = arith.addf %arg0, %arg1 : f32
return %add : f32
}
""")
# CHECK: 42.0 + 2.0 = 44.0
log("{0} + {1} = {2}".format(arg0[0], arg1[0], res[0]))
+
run(testInvokeFloatAdd)
# Define a callback function that takes a float and an integer and returns a float.
@ctypes.CFUNCTYPE(ctypes.c_float, ctypes.c_float, ctypes.c_int)
def callback(a, b):
- return a/2 + b/2
+ return a / 2 + b / 2
with Context():
# The module just forwards to a runtime function known as "some_callback_into_python".
res = c_float_p(-1.)
execution_engine.invoke("add", arg0, arg1, res)
# CHECK: 42.0 + 2 = 44.0
- log("{0} + {1} = {2}".format(arg0[0], arg1[0], res[0]*2))
+ log("{0} + {1} = {2}".format(arg0[0], arg1[0], res[0] * 2))
+
run(testBasicCallback)
+
# Test callback with an unranked memref
# CHECK-LABEL: TEST: testUnrankedMemRefCallback
def testUnrankedMemRefCallback():
- # Define a callback function that takes an unranked memref, converts it to a numpy array and prints it.
- @ctypes.CFUNCTYPE(None, ctypes.POINTER(UnrankedMemRefDescriptor))
- def callback(a):
- arr = unranked_memref_to_numpy(a, np.float32)
- log("Inside callback: ")
- log(arr)
-
- with Context():
- # The module just forwards to a runtime function known as "some_callback_into_python".
- module = Module.parse(
- r"""
+ # Define a callback function that takes an unranked memref, converts it to a numpy array and prints it.
+ @ctypes.CFUNCTYPE(None, ctypes.POINTER(UnrankedMemRefDescriptor))
+ def callback(a):
+ arr = unranked_memref_to_numpy(a, np.float32)
+ log("Inside callback: ")
+ log(arr)
+
+ with Context():
+ # The module just forwards to a runtime function known as "some_callback_into_python".
+ module = Module.parse(r"""
func @callback_memref(%arg0: memref<*xf32>) attributes { llvm.emit_c_interface } {
call @some_callback_into_python(%arg0) : (memref<*xf32>) -> ()
return
}
func private @some_callback_into_python(memref<*xf32>) -> () attributes { llvm.emit_c_interface }
-"""
- )
- execution_engine = ExecutionEngine(lowerToLLVM(module))
- execution_engine.register_runtime("some_callback_into_python", callback)
- inp_arr = np.array([[1.0, 2.0], [3.0, 4.0]], np.float32)
- # CHECK: Inside callback:
- # CHECK{LITERAL}: [[1. 2.]
- # CHECK{LITERAL}: [3. 4.]]
- execution_engine.invoke(
- "callback_memref",
- ctypes.pointer(ctypes.pointer(get_unranked_memref_descriptor(inp_arr))),
- )
- inp_arr_1 = np.array([5, 6, 7], dtype=np.float32)
- strided_arr = np.lib.stride_tricks.as_strided(
- inp_arr_1, strides=(4, 0), shape=(3, 4)
- )
- # CHECK: Inside callback:
- # CHECK{LITERAL}: [[5. 5. 5. 5.]
- # CHECK{LITERAL}: [6. 6. 6. 6.]
- # CHECK{LITERAL}: [7. 7. 7. 7.]]
- execution_engine.invoke(
- "callback_memref",
- ctypes.pointer(
- ctypes.pointer(get_unranked_memref_descriptor(strided_arr))
- ),
- )
+""")
+ execution_engine = ExecutionEngine(lowerToLLVM(module))
+ execution_engine.register_runtime("some_callback_into_python", callback)
+ inp_arr = np.array([[1.0, 2.0], [3.0, 4.0]], np.float32)
+ # CHECK: Inside callback:
+ # CHECK{LITERAL}: [[1. 2.]
+ # CHECK{LITERAL}: [3. 4.]]
+ execution_engine.invoke(
+ "callback_memref",
+ ctypes.pointer(ctypes.pointer(get_unranked_memref_descriptor(inp_arr))),
+ )
+ inp_arr_1 = np.array([5, 6, 7], dtype=np.float32)
+ strided_arr = np.lib.stride_tricks.as_strided(
+ inp_arr_1, strides=(4, 0), shape=(3, 4))
+ # CHECK: Inside callback:
+ # CHECK{LITERAL}: [[5. 5. 5. 5.]
+ # CHECK{LITERAL}: [6. 6. 6. 6.]
+ # CHECK{LITERAL}: [7. 7. 7. 7.]]
+ execution_engine.invoke(
+ "callback_memref",
+ ctypes.pointer(
+ ctypes.pointer(get_unranked_memref_descriptor(strided_arr))),
+ )
+
run(testUnrankedMemRefCallback)
+
# Test callback with a ranked memref.
# CHECK-LABEL: TEST: testRankedMemRefCallback
def testRankedMemRefCallback():
- # Define a callback function that takes a ranked memref, converts it to a numpy array and prints it.
- @ctypes.CFUNCTYPE(
- None,
- ctypes.POINTER(
- make_nd_memref_descriptor(2, np.ctypeslib.as_ctypes_type(np.float32))
- ),
- )
- def callback(a):
- arr = ranked_memref_to_numpy(a)
- log("Inside Callback: ")
- log(arr)
-
- with Context():
- # The module just forwards to a runtime function known as "some_callback_into_python".
- module = Module.parse(
- r"""
+ # Define a callback function that takes a ranked memref, converts it to a numpy array and prints it.
+ @ctypes.CFUNCTYPE(
+ None,
+ ctypes.POINTER(
+ make_nd_memref_descriptor(2,
+ np.ctypeslib.as_ctypes_type(np.float32))),
+ )
+ def callback(a):
+ arr = ranked_memref_to_numpy(a)
+ log("Inside Callback: ")
+ log(arr)
+
+ with Context():
+ # The module just forwards to a runtime function known as "some_callback_into_python".
+ module = Module.parse(r"""
func @callback_memref(%arg0: memref<2x2xf32>) attributes { llvm.emit_c_interface } {
call @some_callback_into_python(%arg0) : (memref<2x2xf32>) -> ()
return
}
func private @some_callback_into_python(memref<2x2xf32>) -> () attributes { llvm.emit_c_interface }
-"""
- )
- execution_engine = ExecutionEngine(lowerToLLVM(module))
- execution_engine.register_runtime("some_callback_into_python", callback)
- inp_arr = np.array([[1.0, 5.0], [6.0, 7.0]], np.float32)
- # CHECK: Inside Callback:
- # CHECK{LITERAL}: [[1. 5.]
- # CHECK{LITERAL}: [6. 7.]]
- execution_engine.invoke(
- "callback_memref", ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(inp_arr)))
- )
+""")
+ execution_engine = ExecutionEngine(lowerToLLVM(module))
+ execution_engine.register_runtime("some_callback_into_python", callback)
+ inp_arr = np.array([[1.0, 5.0], [6.0, 7.0]], np.float32)
+ # CHECK: Inside Callback:
+ # CHECK{LITERAL}: [[1. 5.]
+ # CHECK{LITERAL}: [6. 7.]]
+ execution_engine.invoke(
+ "callback_memref",
+ ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(inp_arr))))
+
run(testRankedMemRefCallback)
+
# Test addition of two memrefs.
# CHECK-LABEL: TEST: testMemrefAdd
def testMemrefAdd():
- with Context():
- module = Module.parse(
- """
+ with Context():
+ module = Module.parse("""
module {
func @main(%arg0: memref<1xf32>, %arg1: memref<f32>, %arg2: memref<1xf32>) attributes { llvm.emit_c_interface } {
- %0 = constant 0 : index
+ %0 = arith.constant 0 : index
%1 = memref.load %arg0[%0] : memref<1xf32>
%2 = memref.load %arg1[] : memref<f32>
- %3 = addf %1, %2 : f32
+ %3 = arith.addf %1, %2 : f32
memref.store %3, %arg2[%0] : memref<1xf32>
return
}
- } """
- )
- arg1 = np.array([32.5]).astype(np.float32)
- arg2 = np.array(6).astype(np.float32)
- res = np.array([0]).astype(np.float32)
-
- arg1_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(arg1)))
- arg2_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(arg2)))
- res_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(res)))
-
- execution_engine = ExecutionEngine(lowerToLLVM(module))
- execution_engine.invoke(
- "main", arg1_memref_ptr, arg2_memref_ptr, res_memref_ptr
- )
- # CHECK: [32.5] + 6.0 = [38.5]
- log("{0} + {1} = {2}".format(arg1, arg2, res))
+ } """)
+ arg1 = np.array([32.5]).astype(np.float32)
+ arg2 = np.array(6).astype(np.float32)
+ res = np.array([0]).astype(np.float32)
+
+ arg1_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(arg1)))
+ arg2_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(arg2)))
+ res_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(res)))
+
+ execution_engine = ExecutionEngine(lowerToLLVM(module))
+ execution_engine.invoke("main", arg1_memref_ptr, arg2_memref_ptr,
+ res_memref_ptr)
+ # CHECK: [32.5] + 6.0 = [38.5]
+ log("{0} + {1} = {2}".format(arg1, arg2, res))
+
run(testMemrefAdd)
+
# Test addition of two 2d_memref
# CHECK-LABEL: TEST: testDynamicMemrefAdd2D
def testDynamicMemrefAdd2D():
- with Context():
- module = Module.parse(
- """
+ with Context():
+ module = Module.parse("""
module {
func @memref_add_2d(%arg0: memref<2x2xf32>, %arg1: memref<?x?xf32>, %arg2: memref<2x2xf32>) attributes {llvm.emit_c_interface} {
- %c0 = constant 0 : index
- %c2 = constant 2 : index
- %c1 = constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %c1 = arith.constant 1 : index
br ^bb1(%c0 : index)
^bb1(%0: index): // 2 preds: ^bb0, ^bb5
- %1 = cmpi slt, %0, %c2 : index
+ %1 = arith.cmpi slt, %0, %c2 : index
cond_br %1, ^bb2, ^bb6
^bb2: // pred: ^bb1
- %c0_0 = constant 0 : index
- %c2_1 = constant 2 : index
- %c1_2 = constant 1 : index
+ %c0_0 = arith.constant 0 : index
+ %c2_1 = arith.constant 2 : index
+ %c1_2 = arith.constant 1 : index
br ^bb3(%c0_0 : index)
^bb3(%2: index): // 2 preds: ^bb2, ^bb4
- %3 = cmpi slt, %2, %c2_1 : index
+ %3 = arith.cmpi slt, %2, %c2_1 : index
cond_br %3, ^bb4, ^bb5
^bb4: // pred: ^bb3
%4 = memref.load %arg0[%0, %2] : memref<2x2xf32>
%5 = memref.load %arg1[%0, %2] : memref<?x?xf32>
- %6 = addf %4, %5 : f32
+ %6 = arith.addf %4, %5 : f32
memref.store %6, %arg2[%0, %2] : memref<2x2xf32>
- %7 = addi %2, %c1_2 : index
+ %7 = arith.addi %2, %c1_2 : index
br ^bb3(%7 : index)
^bb5: // pred: ^bb3
- %8 = addi %0, %c1 : index
+ %8 = arith.addi %0, %c1 : index
br ^bb1(%8 : index)
^bb6: // pred: ^bb1
return
}
}
- """
- )
- arg1 = np.random.randn(2,2).astype(np.float32)
- arg2 = np.random.randn(2,2).astype(np.float32)
- res = np.random.randn(2,2).astype(np.float32)
-
- arg1_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(arg1)))
- arg2_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(arg2)))
- res_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(res)))
-
- execution_engine = ExecutionEngine(lowerToLLVM(module))
- execution_engine.invoke(
- "memref_add_2d", arg1_memref_ptr, arg2_memref_ptr, res_memref_ptr
- )
- # CHECK: True
- log(np.allclose(arg1+arg2, res))
+ """)
+ arg1 = np.random.randn(2, 2).astype(np.float32)
+ arg2 = np.random.randn(2, 2).astype(np.float32)
+ res = np.random.randn(2, 2).astype(np.float32)
+
+ arg1_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(arg1)))
+ arg2_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(arg2)))
+ res_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(res)))
+
+ execution_engine = ExecutionEngine(lowerToLLVM(module))
+ execution_engine.invoke("memref_add_2d", arg1_memref_ptr, arg2_memref_ptr,
+ res_memref_ptr)
+ # CHECK: True
+ log(np.allclose(arg1 + arg2, res))
+
run(testDynamicMemrefAdd2D)
+
# Test loading of shared libraries.
# CHECK-LABEL: TEST: testSharedLibLoad
def testSharedLibLoad():
- with Context():
- module = Module.parse(
- """
+ with Context():
+ module = Module.parse("""
module {
func @main(%arg0: memref<1xf32>) attributes { llvm.emit_c_interface } {
- %c0 = constant 0 : index
- %cst42 = constant 42.0 : f32
+ %c0 = arith.constant 0 : index
+ %cst42 = arith.constant 42.0 : f32
memref.store %cst42, %arg0[%c0] : memref<1xf32>
%u_memref = memref.cast %arg0 : memref<1xf32> to memref<*xf32>
call @print_memref_f32(%u_memref) : (memref<*xf32>) -> ()
return
}
func private @print_memref_f32(memref<*xf32>) attributes { llvm.emit_c_interface }
- } """
- )
- arg0 = np.array([0.0]).astype(np.float32)
-
- arg0_memref_ptr = ctypes.pointer(ctypes.pointer(get_ranked_memref_descriptor(arg0)))
-
- execution_engine = ExecutionEngine(lowerToLLVM(module), opt_level=3,
- shared_libs=["../../../../lib/libmlir_runner_utils.so",
- "../../../../lib/libmlir_c_runner_utils.so"])
- execution_engine.invoke("main", arg0_memref_ptr)
- # CHECK: Unranked Memref
- # CHECK-NEXT: [42]
+ } """)
+ arg0 = np.array([0.0]).astype(np.float32)
+
+ arg0_memref_ptr = ctypes.pointer(
+ ctypes.pointer(get_ranked_memref_descriptor(arg0)))
+
+ execution_engine = ExecutionEngine(
+ lowerToLLVM(module),
+ opt_level=3,
+ shared_libs=[
+ "../../../../lib/libmlir_runner_utils.so",
+ "../../../../lib/libmlir_c_runner_utils.so"
+ ])
+ execution_engine.invoke("main", arg0_memref_ptr)
+ # CHECK: Unranked Memref
+ # CHECK-NEXT: [42]
+
run(testSharedLibLoad)
matmul_boiler = """
func @main() -> f32 attributes {llvm.emit_c_interface} {
- %v0 = constant 0.0 : f32
- %v1 = constant 1.0 : f32
- %v2 = constant 2.0 : f32
+ %v0 = arith.constant 0.0 : f32
+ %v1 = arith.constant 1.0 : f32
+ %v2 = arith.constant 2.0 : f32
%A = memref.alloc() : memref<4x16xf32>
%B = memref.alloc() : memref<16x8xf32>
call @matmul_on_buffers(%A, %B, %C) :
(memref<4x16xf32>, memref<16x8xf32>, memref<4x8xf32>) -> ()
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.load %C[%c0, %c0] : memref<4x8xf32>
// TODO: FFI-based solution to allow testing and printing with python code.
fill_boiler = """
func @main() -> i32 attributes {llvm.emit_c_interface} {
%O = memref.alloc() : memref<4x16xi32>
- %min = constant -1000.0 : f64
- %max = constant 1000.0 : f64
- %seed = constant 42 : i32
+ %min = arith.constant -1000.0 : f64
+ %max = arith.constant 1000.0 : f64
+ %seed = arith.constant 42 : i32
call @fill_on_buffers(%min, %max, %seed, %O) :
(f64, f64, i32, memref<4x16xi32>) -> ()
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.load %O[%c0, %c0] : memref<4x16xi32>
// TODO: FFI-based solution to allow testing and printing with python code.
conv_boiler = """
func @main() -> i32 attributes {llvm.emit_c_interface} {
- %v0 = constant 0 : i32
- %v1 = constant 1.0 : f64
- %v2 = constant 2.0 : f64
+ %v0 = arith.constant 0 : i32
+ %v1 = arith.constant 1.0 : f64
+ %v2 = arith.constant 2.0 : f64
%input = memref.alloc() : memref<1x4x16x1xf64>
%filter = memref.alloc() : memref<2x2x1xf64>
call @conv_on_buffers(%input, %filter, %output) :
(memref<1x4x16x1xf64>, memref<2x2x1xf64>, memref<1x2x4x1xi32>) -> ()
- %c0 = constant 0 : index
+ %c0 = arith.constant 0 : index
%0 = memref.load %output[%c0, %c0, %c0, %c0] : memref<1x2x4x1xi32>
// TODO: FFI-based solution to allow testing and printing with python code.
pooling_boiler = """
func @main() -> i32 attributes {llvm.emit_c_interface} {
- %v0 = constant 0 : i32
- %v42 = constant 42.0 : f64
- %v77 = constant 77.0 : f64
- %v-13 = constant -13.0 : f64
- %v1 = constant 1.0 : f64
+ %v0 = arith.constant 0 : i32
+ %v42 = arith.constant 42.0 : f64
+ %v77 = arith.constant 77.0 : f64
+ %v-13 = arith.constant -13.0 : f64
+ %v1 = arith.constant 1.0 : f64
%input = memref.alloc() : memref<1x4x16x1xf64>
%shape = memref.alloc() : memref<2x2xf64>
linalg.fill(%v1, %shape) : f64, memref<2x2xf64>
linalg.fill(%v0, %output) : i32, memref<1x2x4x1xi32>
- %c0 = constant 0 : index
- %c1 = constant 1 : index
- %c2 = constant 2 : index
+ %c0 = arith.constant 0 : index
+ %c1 = arith.constant 1 : index
+ %c2 = arith.constant 2 : index
memref.store %v42, %input[%c0, %c0, %c0, %c0] : memref<1x4x16x1xf64>
memref.store %v77, %input[%c0, %c0, %c1, %c0] : memref<1x4x16x1xf64>
memref.store %v-13, %input[%c0, %c0, %c2, %c0] : memref<1x4x16x1xf64>
# Create via dialects context collection.
input1 = createInput()
input2 = createInput()
- op1 = ctx.dialects.std.AddFOp(input1.type, input1, input2)
+ op1 = ctx.dialects.arith.AddFOp(input1.type, input1, input2)
# Create via an import
- from mlir.dialects.std import AddFOp
+ from mlir.dialects.arith import AddFOp
AddFOp(input1.type, input1, op1.result)
# CHECK: %[[INPUT0:.*]] = "pytest_dummy.intinput"
# CHECK: %[[INPUT1:.*]] = "pytest_dummy.intinput"
- # CHECK: %[[R0:.*]] = addf %[[INPUT0]], %[[INPUT1]] : f32
- # CHECK: %[[R1:.*]] = addf %[[INPUT0]], %[[R0]] : f32
+ # CHECK: %[[R0:.*]] = arith.addf %[[INPUT0]], %[[INPUT1]] : f32
+ # CHECK: %[[R1:.*]] = arith.addf %[[INPUT0]], %[[R0]] : f32
m.operation.print()
import itertools
from mlir.ir import *
+
def run(f):
print("\nTEST:", f.__name__)
f()
def testTraverseOpRegionBlockIterators():
ctx = Context()
ctx.allow_unregistered_dialects = True
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: i32) -> i32 {
%1 = "custom.addi"(%arg0, %arg0) : (i32, i32) -> i32
return %1 : i32
# CHECK: OP 1: return
walk_operations("", op)
+
run(testTraverseOpRegionBlockIterators)
def testTraverseOpRegionBlockIndices():
ctx = Context()
ctx.allow_unregistered_dialects = True
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: i32) -> i32 {
%1 = "custom.addi"(%arg0, %arg0) : (i32, i32) -> i32
return %1 : i32
# CHECK: OP 1: parent builtin.func
walk_operations("", module.operation)
+
run(testTraverseOpRegionBlockIndices)
# CHECK-LABEL: TEST: testBlockArgumentList
def testBlockArgumentList():
with Context() as ctx:
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: i32, %arg1: f64, %arg2: index) {
return
}
with Location.unknown(ctx):
i32 = IntegerType.get_signed(32)
op1 = Operation.create(
- "custom.op1", results=[i32, i32], regions=1, attributes={
+ "custom.op1",
+ results=[i32, i32],
+ regions=1,
+ attributes={
"foo": StringAttr.get("foo_value"),
"bar": StringAttr.get("bar_value"),
})
# TODO: Check successors once enough infra exists to do it properly.
+
run(testDetachedOperation)
def testOperationInsertionPoint():
ctx = Context()
ctx.allow_unregistered_dialects = True
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: i32) -> i32 {
%1 = "custom.addi"(%arg0, %arg0) : (i32, i32) -> i32
return %1 : i32
else:
assert False, "expected insert of attached op to raise"
+
run(testOperationInsertionPoint)
# CHECK: %0 = "custom.addi"
print(module)
+
run(testOperationWithRegion)
# CHECK-LABEL: TEST: testOperationResultList
def testOperationResultList():
ctx = Context()
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1() {
%0:3 = call @f2() : () -> (i32, f64, index)
return
def testOperationAttributes():
ctx = Context()
ctx.allow_unregistered_dialects = True
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
"some.op"() { some.attribute = 1 : i8,
other.attribute = 3.0,
dependent = "text" } : () -> ()
# CHECK-LABEL: TEST: testOperationPrint
def testOperationPrint():
ctx = Context()
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
func @f1(%arg0: i32) -> i32 {
- %0 = constant dense<[1, 2, 3, 4]> : tensor<4xi32>
+ %0 = arith.constant dense<[1, 2, 3, 4]> : tensor<4xi32>
return %arg0 : i32
}
""", ctx)
# Test get_asm with options.
# CHECK: value = opaque<"_", "0xDEADBEEF"> : tensor<4xi32>
# CHECK: "std.return"(%arg0) : (i32) -> () -:4:7
- module.operation.print(large_elements_limit=2, enable_debug_info=True,
- pretty_debug_info=True, print_generic_op_form=True, use_local_scope=True)
+ module.operation.print(
+ large_elements_limit=2,
+ enable_debug_info=True,
+ pretty_debug_info=True,
+ print_generic_op_form=True,
+ use_local_scope=True)
+
run(testOperationPrint)
module = Module.parse(r"""
%1 = "custom.f32"() : () -> f32
%2 = "custom.f32"() : () -> f32
- %3 = addf %1, %2 : f32
+ %3 = arith.addf %1, %2 : f32
""")
print(module)
# addf should map to a known OpView class in the std dialect.
# We know the OpView for it defines an 'lhs' attribute.
addf = module.body.operations[2]
- # CHECK: <mlir.dialects._std_ops_gen._AddFOp object
+ # CHECK: <mlir.dialects._arith_ops_gen._AddFOp object
print(repr(addf))
# CHECK: "custom.f32"()
print(addf.lhs)
# CHECK: OpView object
print(repr(custom))
+
run(testKnownOpView)
# CHECK: %1 = "custom.one_result"() : () -> f32
print(module.body.operations[2])
+
run(testSingleResultProperty)
+
# CHECK-LABEL: TEST: testPrintInvalidOperation
def testPrintInvalidOperation():
ctx = Context()
print(module)
# CHECK: .verify = False
print(f".verify = {module.operation.verify()}")
+
+
run(testPrintInvalidOperation)
except Exception as e:
# CHECK: Found an invalid (`None`?) attribute value for the key "some_key" when attempting to create the operation "builtin.module"
print(e)
+
+
run(testCreateWithInvalidAttributes)
def testOperationName():
ctx = Context()
ctx.allow_unregistered_dialects = True
- module = Module.parse(r"""
+ module = Module.parse(
+ r"""
%0 = "custom.op1"() : () -> f32
%1 = "custom.op2"() : () -> i32
%2 = "custom.op1"() : () -> f32
for op in module.body.operations:
print(op.operation.name)
+
run(testOperationName)
+
# CHECK-LABEL: TEST: testCapsuleConversions
def testCapsuleConversions():
ctx = Context()
m2 = Operation._CAPICreate(m_capsule)
assert m2 is m
+
run(testCapsuleConversions)
+
# CHECK-LABEL: TEST: testOperationErase
def testOperationErase():
ctx = Context()
# Ensure we can create another operation
Operation.create("custom.op2")
+
run(testOperationErase)
target_link_libraries(mlir-spirv-cpu-runner PRIVATE
${conversion_libs}
MLIRAnalysis
+ MLIRArithmetic
MLIRExecutionEngine
MLIRGPUOps
MLIRIR
#include "mlir/Conversion/GPUToSPIRV/GPUToSPIRVPass.h"
#include "mlir/Conversion/SPIRVToLLVM/SPIRVToLLVMPass.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
jitRunnerConfig.llvmModuleBuilder = convertMLIRModule;
mlir::DialectRegistry registry;
- registry.insert<mlir::LLVM::LLVMDialect, mlir::gpu::GPUDialect,
- mlir::spirv::SPIRVDialect, mlir::StandardOpsDialect,
- mlir::memref::MemRefDialect>();
+ registry.insert<mlir::arith::ArithmeticDialect, mlir::LLVM::LLVMDialect,
+ mlir::gpu::GPUDialect, mlir::spirv::SPIRVDialect,
+ mlir::StandardOpsDialect, mlir::memref::MemRefDialect>();
mlir::registerLLVMDialectTranslation(registry);
return mlir::JitRunnerMain(argc, argv, registry, jitRunnerConfig);
set(LIBS
${conversion_libs}
MLIRAnalysis
+ MLIRArithmetic
MLIRExecutionEngine
MLIRGPUOps
MLIRIR
#include "mlir/Conversion/ReconcileUnrealizedCasts/ReconcileUnrealizedCasts.h"
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
#include "mlir/Conversion/StandardToSPIRV/StandardToSPIRVPass.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/GPU/GPUDialect.h"
#include "mlir/Dialect/GPU/Passes.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
jitRunnerConfig.mlirTransformer = runMLIRPasses;
mlir::DialectRegistry registry;
- registry.insert<mlir::LLVM::LLVMDialect, mlir::gpu::GPUDialect,
- mlir::spirv::SPIRVDialect, mlir::StandardOpsDialect,
- mlir::memref::MemRefDialect>();
+ registry.insert<mlir::arith::ArithmeticDialect, mlir::LLVM::LLVMDialect,
+ mlir::gpu::GPUDialect, mlir::spirv::SPIRVDialect,
+ mlir::StandardOpsDialect, mlir::memref::MemRefDialect>();
mlir::registerLLVMDialectTranslation(registry);
return mlir::JitRunnerMain(argc, argv, registry, jitRunnerConfig);
target_link_libraries(MLIRExecutionEngineTests
PRIVATE
+ MLIRArithmeticToLLVM
MLIRExecutionEngine
MLIRLinalgToLLVM
MLIRMemRefToLLVM
//
//===----------------------------------------------------------------------===//
+#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
#include "mlir/Conversion/LinalgToLLVM/LinalgToLLVM.h"
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
#include "mlir/Conversion/ReconcileUnrealizedCasts/ReconcileUnrealizedCasts.h"
static LogicalResult lowerToLLVMDialect(ModuleOp module) {
PassManager pm(module.getContext());
pm.addPass(mlir::createMemRefToLLVMPass());
+ pm.addNestedPass<FuncOp>(mlir::arith::createConvertArithmeticToLLVMPass());
pm.addPass(mlir::createLowerToLLVMPass());
pm.addPass(mlir::createReconcileUnrealizedCastsPass());
return pm.run(module);
TEST(MLIRExecutionEngine, AddInteger) {
std::string moduleStr = R"mlir(
func @foo(%arg0 : i32) -> i32 attributes { llvm.emit_c_interface } {
- %res = std.addi %arg0, %arg0 : i32
+ %res = arith.addi %arg0, %arg0 : i32
return %res : i32
}
)mlir";
TEST(MLIRExecutionEngine, SubtractFloat) {
std::string moduleStr = R"mlir(
func @foo(%arg0 : f32, %arg1 : f32) -> f32 attributes { llvm.emit_c_interface } {
- %res = std.subf %arg0, %arg1 : f32
+ %res = arith.subf %arg0, %arg1 : f32
return %res : f32
}
)mlir";
A[{}] = 0;
std::string moduleStr = R"mlir(
func @zero_ranked(%arg0 : memref<f32>) attributes { llvm.emit_c_interface } {
- %cst42 = constant 42.0 : f32
+ %cst42 = arith.constant 42.0 : f32
memref.store %cst42, %arg0[] : memref<f32>
return
}
std::string moduleStr = R"mlir(
func @one_ranked(%arg0 : memref<?xf32>) attributes { llvm.emit_c_interface } {
- %cst42 = constant 42.0 : f32
- %cst5 = constant 5 : index
+ %cst42 = arith.constant 42.0 : f32
+ %cst5 = arith.constant 5 : index
memref.store %cst42, %arg0[%cst5] : memref<?xf32>
return
}
}
std::string moduleStr = R"mlir(
func @rank2_memref(%arg0 : memref<?x?xf32>, %arg1 : memref<?x?xf32>) attributes { llvm.emit_c_interface } {
- %x = constant 2 : index
- %y = constant 1 : index
- %cst42 = constant 42.0 : f32
+ %x = arith.constant 2 : index
+ %y = arith.constant 1 : index
+ %cst42 = arith.constant 42.0 : f32
memref.store %cst42, %arg0[%y, %x] : memref<?x?xf32>
memref.store %cst42, %arg1[%x, %y] : memref<?x?xf32>
return
//===----------------------------------------------------------------------===//
#include "mlir/Interfaces/InferTypeOpInterface.h"
+#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
#include "mlir/Dialect/StandardOps/IR/Ops.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinOps.h"
void SetUp() override {
const char *ir = R"MLIR(
func @map(%arg : tensor<1xi64>) {
- %0 = constant dense<[10]> : tensor<1xi64>
- %1 = addi %arg, %0 : tensor<1xi64>
+ %0 = arith.constant dense<[10]> : tensor<1xi64>
+ %1 = arith.addi %arg, %0 : tensor<1xi64>
return
}
)MLIR";
- registry.insert<StandardOpsDialect>();
+ registry.insert<StandardOpsDialect, arith::ArithmeticDialect>();
ctx.appendDialectRegistry(registry);
module = parseSourceString(ir, &ctx);
mapFn = cast<FuncOp>(module->front());
}
- // Create ValueShapeRange on the addi operation.
+ // Create ValueShapeRange on the arith.addi operation.
ValueShapeRange addiRange() {
auto &fnBody = mapFn.body();
return std::next(fnBody.front().begin())->getOperands();
]),
hdrs = glob(["include/mlir/Target/Cpp/*.h"]),
deps = [
+ ":ArithmeticDialect",
":EmitC",
":IR",
+ ":MathDialect",
":SCFDialect",
":StandardOps",
":Support",
],
includes = ["include"],
deps = [
+ ":ArithmeticOpsTdFiles",
":LLVMOpsTdFiles",
":OpBaseTdFiles",
":SideEffectInterfacesTdFiles",
hdrs = ["include/mlir/Dialect/X86Vector/Transforms.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":LLVMCommonConversion",
":LLVMDialect",
deps = [
":Affine",
":Analysis",
+ ":ArithmeticDialect",
":DialectUtils",
":IR",
":MemRefDialect",
hdrs = ["include/mlir/Dialect/SparseTensor/IR/SparseTensor.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":SideEffectInterfaces",
":SparseTensorAttrDefsIncGen",
hdrs = glob(["include/mlir/Dialect/SparseTensor/Utils/*.h"]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":LinalgOps",
":SideEffectInterfaces",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":IR",
":LLVMDialect",
":LinalgOps",
deps = [
":AffineMemoryOpInterfacesIncGen",
":AffineOpsIncGen",
+ ":ArithmeticDialect",
":IR",
":LoopLikeInterface",
":MemRefDialect",
includes = ["include"],
deps = [
":Analysis",
+ ":ArithmeticDialect",
":Async",
":AsyncPassIncGen",
":IR",
":AffinePassIncGen",
":AffineUtils",
":Analysis",
+ ":ArithmeticDialect",
":IR",
":MemRefDialect",
":Pass",
includes = ["include"],
deps = [
":AffineToStandard",
+ ":ArithmeticToLLVM",
+ ":ArithmeticToSPIRV",
":ArmNeon2dToIntr",
":AsyncToLLVM",
":ComplexToLLVM",
hdrs = glob(["include/mlir/Conversion/AsyncToLLVM/*.h"]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":Async",
":ConversionPassIncGen",
":IR",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":MemRefDialect",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ControlFlowInterfaces",
":IR",
":LoopLikeInterface",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":DialectUtils",
":IR",
":InferTypeOpInterface",
hdrs = ["include/mlir/Dialect/Shape/IR/Shape.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":CallOpInterfaces",
":CommonFolders",
":ControlFlowInterfaces",
hdrs = ["include/mlir/Conversion/ShapeToStandard/ShapeToStandard.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":MemRefDialect",
hdrs = ["include/mlir/Dialect/Shape/Transforms/Passes.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":MemRefDialect",
":Pass",
]) + ["include/mlir/Transforms/InliningUtils.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":CallOpInterfaces",
":CastOpInterfaces",
":CommonFolders",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
+ ":ArithmeticTransforms",
":IR",
":MemRefDialect", # TODO: Remove dependency on MemRef dialect
":Pass",
":Affine",
":AffineUtils",
":Analysis",
+ ":ArithmeticDialect",
":DataLayoutInterfaces",
":DialectUtils",
":IR",
hdrs = ["include/mlir/Dialect/GPU/GPUDialect.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":DLTIDialect",
":GPUBaseIncGen",
":GPUOpsIncGen",
defines = if_cuda_available(["MLIR_GPU_TO_CUBIN_PASS_ENABLE"]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":Async",
":GPUDialect",
":GPUPassIncGen",
":IR",
":ParallelLoopMapperAttrGen",
":Pass",
+ ":ROCDLToLLVMIRTranslation",
":SCFDialect",
":StandardOps",
":Support",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
+ ":ArithmeticToLLVM",
":ConversionPassIncGen",
":GPUCommonTransforms",
":GPUDialect",
hdrs = ["include/mlir/Conversion/GPUToROCDL/GPUToROCDLPass.h"],
includes = ["include"],
deps = [
+ ":ArithmeticToLLVM",
":ConversionPassIncGen",
":GPUCommonTransforms",
":GPUDialect",
hdrs = ["include/mlir/Conversion/GPUCommon/GPUCommonPass.h"],
includes = ["include"],
deps = [
+ ":ArithmeticToLLVM",
":Async",
":AsyncToLLVM",
":ConversionPassIncGen",
"lib/Conversions/GPUToSPIRV",
],
deps = [
+ ":ArithmeticToSPIRV",
":ConversionPassIncGen",
":GPUDialect",
":IR",
]),
includes = ["include"],
deps = [
+ ":ArithmeticToLLVM",
":ConversionPassIncGen",
":GPUDialect",
":IR",
)
cc_library(
+ name = "SPIRVCommonConversion",
+ hdrs = ["lib/Conversion/SPIRVCommon/Pattern.h"],
+ includes = ["include"],
+ deps = [
+ ":IR",
+ ":SPIRVDialect",
+ ":Support",
+ ":Transforms",
+ ],
+)
+
+cc_library(
name = "MathToSPIRV",
srcs = glob([
"lib/Conversion/MathToSPIRV/*.cpp",
":IR",
":MathDialect",
":Pass",
+ ":SPIRVCommonConversion",
":SPIRVConversion",
":SPIRVDialect",
":Support",
"lib/Conversion/StandardToSPIRV",
],
deps = [
+ ":ArithmeticToSPIRV",
":ConversionPassIncGen",
":IR",
+ ":MathToSPIRV",
":Pass",
+ ":SPIRVCommonConversion",
":SPIRVConversion",
":SPIRVDialect",
":SPIRVUtils",
hdrs = ["include/mlir/Dialect/Tensor/IR/Tensor.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":CastOpInterfaces",
":ControlFlowInterfaces",
":DialectUtils",
hdrs = ["include/mlir/Dialect/Tensor/Transforms/Passes.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":Async",
":IR",
":MemRefDialect",
deps = [
":Affine",
":Analysis",
+ ":ArithmeticDialect",
":ControlFlowInterfaces",
":IR",
":MemRefDialect",
deps = [
":Affine",
":Analysis",
+ ":ArithmeticDialect",
":ControlFlowInterfaces",
":CopyOpInterface",
":IR",
deps = [
":Affine",
":AffineToStandard",
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":GPUDialect",
":GPUTransforms",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":ComplexDialect",
":ConversionPassIncGen",
":GPUDialect",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticToSPIRV",
":ConversionPassIncGen",
":IR",
":MemRefToSPIRV",
includes = ["include"],
deps = [
":Analysis",
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":LLVMDialect",
hdrs = ["include/mlir/Conversion/SCFToStandard/SCFToStandard.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":LLVMDialect",
includes = ["include"],
deps = [
":Analysis",
+ ":ArithmeticToLLVM",
":ConversionPassIncGen",
":DataLayoutInterfaces",
":DialectUtils",
)
cc_library(
+ name = "ArithmeticToLLVM",
+ srcs = glob(["lib/Conversion/ArithmeticToLLVM/*.cpp"]) + ["lib/Conversion/PassDetail.h"],
+ hdrs = glob(["include/mlir/Conversion/ArithmeticToLLVM/*.h"]),
+ includes = ["include"],
+ deps = [
+ ":Analysis",
+ ":ArithmeticDialect",
+ ":ConversionPassIncGen",
+ ":IR",
+ ":LLVMCommonConversion",
+ ":LLVMDialect",
+ ":Pass",
+ ":Support",
+ ":Transforms",
+ ],
+)
+
+cc_library(
+ name = "ArithmeticToSPIRV",
+ srcs = glob(["lib/Conversion/ArithmeticToSPIRV/*.cpp"]) + ["lib/Conversion/PassDetail.h"],
+ hdrs = glob(["include/mlir/Conversion/ArithmeticToSPIRV/*.h"]),
+ includes = ["include"],
+ deps = [
+ ":ArithmeticDialect",
+ ":ConversionPassIncGen",
+ ":IR",
+ ":Pass",
+ ":SPIRVCommonConversion",
+ ":SPIRVConversion",
+ ":SPIRVDialect",
+ ":Support",
+ ":Transforms",
+ "//llvm:Support",
+ ],
+)
+
+cc_library(
name = "MathToLLVM",
srcs = glob(["lib/Conversion/MathToLLVM/*.cpp"]) + ["lib/Conversion/PassDetail.h"],
hdrs = glob(["include/mlir/Conversion/MathToLLVM/*.h"]),
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":CallOpInterfaces",
":ControlFlowInterfaces",
":DataLayoutInterfaces",
":AffinePassIncGen",
":AffineToStandard",
":AffineTransforms",
+ ":ArithmeticDialect",
+ ":ArithmeticToLLVM",
+ ":ArithmeticToSPIRV",
+ ":ArithmeticTransforms",
":ArmNeon",
":ArmSVE",
":ArmSVETransforms",
name = "mlir-vulkan-runner",
srcs = ["tools/mlir-vulkan-runner/mlir-vulkan-runner.cpp"],
deps = [
+ ":ArithmeticDialect",
":ExecutionEngineUtils",
":GPUDialect",
":GPUToSPIRV",
name = "mlir-spirv-cpu-runner",
srcs = ["tools/mlir-spirv-cpu-runner/mlir-spirv-cpu-runner.cpp"],
deps = [
+ ":ArithmeticDialect",
":ExecutionEngineUtils",
":GPUDialect",
":GPUToSPIRV",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":OpenACCOpsIncGen",
":StandardOps",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":OpenACCDialect",
]),
includes = ["include"],
deps = [
+ ":ArithmeticToLLVM",
":ConversionPassIncGen",
":IR",
":LLVMCommonConversion",
],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":Pass",
":QuantOpsIncGen",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":CopyOpInterface",
":DialectUtils",
":IR",
":Affine",
":AffineUtils",
":Analysis",
+ ":ArithmeticDialect",
":ComplexDialect",
":DialectUtils",
":IR",
deps = [
":AMX",
":AMXTransforms",
+ ":ArithmeticDialect",
":ArmNeon",
":ArmSVE",
":ArmSVETransforms",
deps = [
":Affine",
":Analysis",
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":DialectUtils",
":GPUDialect",
deps = [
":Affine",
":AffineUtils",
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":LLVMDialect",
"lib/Conversion/TosaToLinalg",
],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":DialectUtils",
":IR",
"lib/Conversion/TosaToStandard",
],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":Pass",
hdrs = ["include/mlir/Dialect/Complex/IR/Complex.h"],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ComplexBaseIncGen",
":ComplexOpsIncGen",
":IR",
":SideEffectInterfaces",
+ ":StandardOps",
":Support",
":VectorInterfaces",
"//llvm:Support",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ComplexDialect",
":ConversionPassIncGen",
":IR",
":LLVMCommonConversion",
":LLVMDialect",
":Pass",
+ ":StandardOps",
":Support",
":Transforms",
"//llvm:Core",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ComplexDialect",
":ConversionPassIncGen",
":IR",
],
includes = ["include"],
deps = [
+ ":CastInterfacesTdFiles",
":OpBaseTdFiles",
":SideEffectInterfacesTdFiles",
":VectorInterfacesTdFiles",
td_file = "include/mlir/Dialect/Arithmetic/IR/ArithmeticOps.td",
deps = [
":ArithmeticOpsTdFiles",
- ":CastInterfacesTdFiles",
],
)
":CommonFolders",
":IR",
":SideEffectInterfaces",
- ":StandardOps",
":Support",
":VectorInterfaces",
"//llvm:Support",
],
)
+gentbl_cc_library(
+ name = "ArithmeticPassIncGen",
+ strip_include_prefix = "include",
+ tbl_outs = [
+ (
+ [
+ "-gen-pass-decls",
+ "-name=Arithmetic",
+ ],
+ "include/mlir/Dialect/Arithmetic/Transforms/Passes.h.inc",
+ ),
+ ],
+ tblgen = ":mlir-tblgen",
+ td_file = "include/mlir/Dialect/Arithmetic/Transforms/Passes.td",
+ deps = [":PassBaseTdFiles"],
+)
+
+cc_library(
+ name = "ArithmeticTransforms",
+ srcs = glob([
+ "lib/Dialect/Arithmetic/Transforms/*.cpp",
+ "lib/Dialect/Arithmetic/Transforms/*.h",
+ ]),
+ hdrs = ["include/mlir/Dialect/Arithmetic/Transforms/Passes.h"],
+ includes = ["include"],
+ deps = [
+ ":ArithmeticDialect",
+ ":ArithmeticPassIncGen",
+ ":IR",
+ ":MemRefDialect",
+ ":Pass",
+ ":Transforms",
+ ],
+)
+
td_library(
name = "MathOpsTdFiles",
srcs = [
hdrs = glob(["include/mlir/Dialect/Math/Transforms/*.h"]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":IR",
":MathDialect",
":Pass",
]),
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ConversionPassIncGen",
":IR",
":LLVMDialect",
],
includes = ["include"],
deps = [
+ ":ArithmeticDialect",
":ControlFlowInterfaces",
":CopyOpInterface",
":DialectUtils",
includes = ["include"],
deps = [
":Affine",
+ ":ArithmeticDialect",
":IR",
":InferTypeOpInterface",
":MemRefDialect",
":TestOpsIncGen",
":TestTypeDefsIncGen",
"//llvm:Support",
+ "//mlir:ArithmeticDialect",
"//mlir:ControlFlowInterfaces",
"//mlir:CopyOpInterface",
"//mlir:DLTIDialect",
"//llvm:Support",
"//mlir:Affine",
"//mlir:Analysis",
+ "//mlir:ArithmeticDialect",
"//mlir:IR",
"//mlir:MathDialect",
"//mlir:Pass",
"//llvm:NVPTXCodeGen",
"//llvm:Support",
"//mlir:Affine",
+ "//mlir:ArithmeticDialect",
"//mlir:GPUDialect",
"//mlir:GPUTransforms",
"//mlir:IR",
deps = [
"//llvm:Support",
"//mlir:Affine",
+ "//mlir:ArithmeticDialect",
"//mlir:GPUDialect",
"//mlir:IR",
"//mlir:LinalgOps",
defines = ["MLIR_CUDA_CONVERSIONS_ENABLED"],
includes = ["lib/Dialect/Test"],
deps = [
+ "//mlir:ArithmeticDialect",
"//mlir:MathDialect",
"//mlir:MathTransforms",
"//mlir:Pass",
includes = ["lib/Dialect/Test"],
deps = [
"//llvm:Support",
+ "//mlir:ArithmeticDialect",
"//mlir:IR",
+ "//mlir:MathDialect",
"//mlir:Pass",
"//mlir:SCFDialect",
"//mlir:SCFTransforms",
+ "//mlir:StandardOps",
"//mlir:TransformUtils",
],
)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}